
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SAE1-RPA2 (FusionGDB2 ID:79014) |
Fusion Gene Summary for SAE1-RPA2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SAE1-RPA2 | Fusion gene ID: 79014 | Hgene | Tgene | Gene symbol | SAE1 | RPA2 | Gene ID | 10055 | 84172 |
| Gene name | SUMO1 activating enzyme subunit 1 | RNA polymerase I subunit B | |
| Synonyms | AOS1|HSPC140|SUA1|UBLE1A | A135|RPA135|RPA2|Rpo1-2 | |
| Cytomap | 19q13.32 | 2q14.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | SUMO-activating enzyme subunit 1SUMO-1 activating enzyme E1 N subunitSUMO-1 activating enzyme subunit 1activator of SUMO1sentrin/SUMO-activating protein AOS1ubiquitin-like 1-activating enzyme E1Aubiquitin-like protein SUMO-1 activating enzyme | DNA-directed RNA polymerase I subunit RPA2DNA-directed RNA polymerase I 135 kDa polypeptideDNA-directed RNA polymerase I 135kDa polypeptideRNA polymerase I subunit 2polymerase (RNA) I polypeptide B, 128kDapolymerase (RNA) I subunit B | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000270225, ENST00000392776, ENST00000413379, ENST00000540850, ENST00000598840, | ENST00000313433, ENST00000373909, ENST00000373912, | |
| Fusion gene scores | * DoF score | 17 X 10 X 12=2040 | 3 X 3 X 2=18 |
| # samples | 19 | 3 | |
| ** MAII score | log2(19/2040*10)=-3.42449782852791 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: SAE1 [Title/Abstract] AND RPA2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SAE1(47658470)-RPA2(28233793), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SAE1 | GO:0016925 | protein sumoylation | 15660128|20164921 |
| Hgene | SAE1 | GO:0033235 | positive regulation of protein sumoylation | 10187858 |
| Fusion gene breakpoints across SAE1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RPA2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-B5-A3S1-01A | SAE1 | chr19 | 47658470 | - | RPA2 | chr1 | 28233793 | - |
| ChimerDB4 | UCEC | TCGA-B5-A3S1-01A | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
Top |
Fusion Gene ORF analysis for SAE1-RPA2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000270225 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000270225 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000270225 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000392776 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000392776 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000392776 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000413379 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000413379 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000413379 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000540850 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000540850 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| In-frame | ENST00000540850 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| intron-3CDS | ENST00000598840 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| intron-3CDS | ENST00000598840 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| intron-3CDS | ENST00000598840 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000413379 | SAE1 | chr19 | 47658470 | + | ENST00000373912 | RPA2 | chr1 | 28233793 | - | 2064 | 729 | 18 | 1424 | 468 |
| ENST00000413379 | SAE1 | chr19 | 47658470 | + | ENST00000373909 | RPA2 | chr1 | 28233793 | - | 1664 | 729 | 18 | 1424 | 468 |
| ENST00000413379 | SAE1 | chr19 | 47658470 | + | ENST00000313433 | RPA2 | chr1 | 28233793 | - | 1515 | 729 | 18 | 1424 | 468 |
| ENST00000540850 | SAE1 | chr19 | 47658470 | + | ENST00000373912 | RPA2 | chr1 | 28233793 | - | 1745 | 410 | 305 | 1105 | 266 |
| ENST00000540850 | SAE1 | chr19 | 47658470 | + | ENST00000373909 | RPA2 | chr1 | 28233793 | - | 1345 | 410 | 305 | 1105 | 266 |
| ENST00000540850 | SAE1 | chr19 | 47658470 | + | ENST00000313433 | RPA2 | chr1 | 28233793 | - | 1196 | 410 | 305 | 1105 | 266 |
| ENST00000270225 | SAE1 | chr19 | 47658470 | + | ENST00000373912 | RPA2 | chr1 | 28233793 | - | 2030 | 695 | 29 | 1390 | 453 |
| ENST00000270225 | SAE1 | chr19 | 47658470 | + | ENST00000373909 | RPA2 | chr1 | 28233793 | - | 1630 | 695 | 29 | 1390 | 453 |
| ENST00000270225 | SAE1 | chr19 | 47658470 | + | ENST00000313433 | RPA2 | chr1 | 28233793 | - | 1481 | 695 | 29 | 1390 | 453 |
| ENST00000392776 | SAE1 | chr19 | 47658470 | + | ENST00000373912 | RPA2 | chr1 | 28233793 | - | 1998 | 663 | 36 | 1358 | 440 |
| ENST00000392776 | SAE1 | chr19 | 47658470 | + | ENST00000373909 | RPA2 | chr1 | 28233793 | - | 1598 | 663 | 36 | 1358 | 440 |
| ENST00000392776 | SAE1 | chr19 | 47658470 | + | ENST00000313433 | RPA2 | chr1 | 28233793 | - | 1449 | 663 | 36 | 1358 | 440 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000413379 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.002409573 | 0.9975904 |
| ENST00000413379 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.004445408 | 0.9955546 |
| ENST00000413379 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.005987494 | 0.99401253 |
| ENST00000540850 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.001315057 | 0.99868494 |
| ENST00000540850 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.002164626 | 0.99783534 |
| ENST00000540850 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.002945022 | 0.99705493 |
| ENST00000270225 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.002294104 | 0.9977059 |
| ENST00000270225 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.004069914 | 0.99593014 |
| ENST00000270225 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.005508294 | 0.9944917 |
| ENST00000392776 | ENST00000373912 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.002260706 | 0.9977393 |
| ENST00000392776 | ENST00000373909 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.003891969 | 0.996108 |
| ENST00000392776 | ENST00000313433 | SAE1 | chr19 | 47658470 | + | RPA2 | chr1 | 28233793 | - | 0.005402924 | 0.9945971 |
Top |
Fusion Genomic Features for SAE1-RPA2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
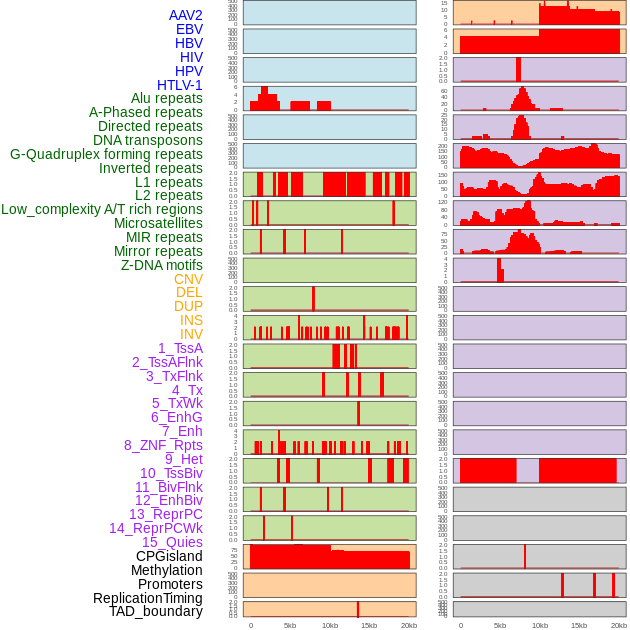 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SAE1-RPA2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:47658470/chr1:28233793) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 127_145 | 127 | 359.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 247_270 | 127 | 359.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 127_145 | 47 | 279.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 247_270 | 47 | 279.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 95_123 | 47 | 279.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 127_145 | 39 | 271.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 247_270 | 39 | 271.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 37_45 | 39 | 271.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 95_123 | 39 | 271.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 74_148 | 47 | 279.0 | DNA binding | Note=OB | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 74_148 | 39 | 271.0 | DNA binding | Note=OB |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 1_29 | 127 | 359.0 | Compositional bias | Note=Gly/Ser-rich | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 37_45 | 127 | 359.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 95_123 | 127 | 359.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 1_29 | 47 | 279.0 | Compositional bias | Note=Gly/Ser-rich | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 37_45 | 47 | 279.0 | Compositional bias | Note=Arg/Lys-rich (basic) | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 1_29 | 39 | 271.0 | Compositional bias | Note=Gly/Ser-rich | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 74_148 | 127 | 359.0 | DNA binding | Note=OB |
Top |
Fusion Gene Sequence for SAE1-RPA2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >79014_79014_1_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000313433_length(transcript)=1481nt_BP=695nt GTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTG GCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTC GGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATC ACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGC GAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATG CTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATG TTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAG TAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGC CCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGG GGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGG TTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACA AAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGG TACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATA GCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTC AGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTA CTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCA >79014_79014_1_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000313433_length(amino acids)=453AA_BP=217 MSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPG AQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFA NLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAP TNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPS AGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNEGHIYSTVDDDHFKST -------------------------------------------------------------- >79014_79014_2_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000373909_length(transcript)=1630nt_BP=695nt GTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTG GCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTC GGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATC ACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGC GAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATG CTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATG TTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAG TAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGC CCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGG GGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGG TTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACA AAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGG TACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATA GCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTC AGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTA CTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCA CAATCTGTTGTCTCCAGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTT TGAAACTTACTGCTCTTCTGTTTTATTTTGTTTTGTTTGAAGCTCAGAGGGAGATGGGCAATTGACAGGGATGCAATCCAGGGTGGGATT >79014_79014_2_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000373909_length(amino acids)=453AA_BP=217 MSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPG AQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFA NLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAP TNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPS AGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNEGHIYSTVDDDHFKST -------------------------------------------------------------- >79014_79014_3_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000373912_length(transcript)=2030nt_BP=695nt GTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTG GCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTC GGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATC ACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGC GAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATG CTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATG TTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAG TAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGC CCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGG GGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGG TTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACA AAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGG TACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATA GCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTC AGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTA CTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCA CAATCTGTTGTCTCCAGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTT TGAAACTTACTGCTCTTCTGTTTTATTTTGTTTTGTTTGAAGCTCAGAGGGAGATGGGCAATTGACAGGGATGCAATCCAGGGTGGGATT TCTTGAGGAAGTTACAAATAAGCTTGTTACAACATCAAGATAGATGGAATTGGAAGGATGCTACCAGGAGAGTACTTACATAGTGCTCAG GAGTTTCTCTTCTTAAAATGTTTACTGCTGAAAGATGAGCAGGACCAGGGCGTTATAGGCAGAGCCCTAGCCGAGAAACCTGCTGGCCTC TGCCTGTTTTCATTTCCCACTTTGGTTGTGTGGCATTACTTTCAGAATTGCACTTTCCTGCTTGTCATGACTTTTTGACACACTTGCCAT GACGTGTGTTTCTGTGAACATGAAGTTCTGCGGTAGTGCCTCCAGGGGCAGAGGAAAAGAAGAAGTGTTACTGCATTTTGTACAAAATAA >79014_79014_3_SAE1-RPA2_SAE1_chr19_47658470_ENST00000270225_RPA2_chr1_28233793_ENST00000373912_length(amino acids)=453AA_BP=217 MSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPG AQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFA NLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAP TNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPS AGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNEGHIYSTVDDDHFKST -------------------------------------------------------------- >79014_79014_4_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000313433_length(transcript)=1449nt_BP=663nt AGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAG TATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGG GCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCT CAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTG AAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTC ATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAAT CTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAA CTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACT TTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACC AACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACT GTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCC CTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCA GGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCC CAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCT GTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGAT GCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCCAGCTCTGCATATGTCTG >79014_79014_4_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000313433_length(amino acids)=440AA_BP=204 MVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPGAQFLIRTGSVGRN RAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFANLGEHEFVEEKTK VAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKIDDMTAA PMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPISNPGMSE -------------------------------------------------------------- >79014_79014_5_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000373909_length(transcript)=1598nt_BP=663nt AGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAG TATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGG GCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCT CAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTG AAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTC ATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAAT CTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAA CTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACT TTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACC AACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACT GTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCC CTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCA GGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCC CAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCT GTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGAT GCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCCAGCTCTGCATATGTCTG GCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTCTTCTGTTTTATTTTGTT >79014_79014_5_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000373909_length(amino acids)=440AA_BP=204 MVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPGAQFLIRTGSVGRN RAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFANLGEHEFVEEKTK VAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKIDDMTAA PMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPISNPGMSE -------------------------------------------------------------- >79014_79014_6_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000373912_length(transcript)=1998nt_BP=663nt AGCGGGACCGGAGCTGAGGCAGGAAGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAG TATGACCGGCAGATCCGCCTGTGGGGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGG GCTGAAATTGCCAAGAATCTCATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCT CAGTTCTTGATTCGTACTGGGTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTG AAGGTGGACACTGAGGATATAGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTC ATAGTTAAAGTTGACCAGATCTGTCACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAAT CTAGGAGAGCATGAGTTTGTAGAGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAA CTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACT TTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACC AACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACT GTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCC CTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCA GGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCC CAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCT GTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGAT GCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCCAGCTCTGCATATGTCTG GCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTCTTCTGTTTTATTTTGTT TTGTTTGAAGCTCAGAGGGAGATGGGCAATTGACAGGGATGCAATCCAGGGTGGGATTTCTTGAGGAAGTTACAAATAAGCTTGTTACAA CATCAAGATAGATGGAATTGGAAGGATGCTACCAGGAGAGTACTTACATAGTGCTCAGGAGTTTCTCTTCTTAAAATGTTTACTGCTGAA AGATGAGCAGGACCAGGGCGTTATAGGCAGAGCCCTAGCCGAGAAACCTGCTGGCCTCTGCCTGTTTTCATTTCCCACTTTGGTTGTGTG GCATTACTTTCAGAATTGCACTTTCCTGCTTGTCATGACTTTTTGACACACTTGCCATGACGTGTGTTTCTGTGAACATGAAGTTCTGCG GTAGTGCCTCCAGGGGCAGAGGAAAAGAAGAAGTGTTACTGCATTTTGTACAAAATAAATACAGTCATATGTTTAATAAAACAGTTCTAT >79014_79014_6_SAE1-RPA2_SAE1_chr19_47658470_ENST00000392776_RPA2_chr1_28233793_ENST00000373912_length(amino acids)=440AA_BP=204 MVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKGLTMLDHEQVTPEDPGAQFLIRTGSVGRN RAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIKFFTGDVFGYHGYTFANLGEHEFVEEKTK VAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKIDDMTAA PMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPISNPGMSE -------------------------------------------------------------- >79014_79014_7_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000313433_length(transcript)=1515nt_BP=729nt AGAAGCACTCCGGGCGTGCTGCCGGCGGCGGTAGGTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGA AGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGG GGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATC TTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCT GTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAG AAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGT CACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAG GAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATG GTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATT GGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGAC ATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTG AAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACC ACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCA GGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATT AAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTG GATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGG >79014_79014_7_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000313433_length(amino acids)=468AA_BP=232 MPAAVGGARVRRAVGLSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKG LTMLDHEQVTPEDPGAQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIK FFTGDVFGYHGYTFANLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEIS QVTIVGIIRHAEKAPTNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEV INAHMVLSKANSQPSAGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNE -------------------------------------------------------------- >79014_79014_8_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000373909_length(transcript)=1664nt_BP=729nt AGAAGCACTCCGGGCGTGCTGCCGGCGGCGGTAGGTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGA AGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGG GGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATC TTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCT GTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAG AAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGT CACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAG GAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATG GTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATT GGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGAC ATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTG AAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACC ACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCA GGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATT AAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTG GATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGG TACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCCAGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGG TTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTCTTCTGTTTTATTTTGTTTTGTTTGAAGCTCAGAGGGAGATG >79014_79014_8_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000373909_length(amino acids)=468AA_BP=232 MPAAVGGARVRRAVGLSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKG LTMLDHEQVTPEDPGAQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIK FFTGDVFGYHGYTFANLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEIS QVTIVGIIRHAEKAPTNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEV INAHMVLSKANSQPSAGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNE -------------------------------------------------------------- >79014_79014_9_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000373912_length(transcript)=2064nt_BP=729nt AGAAGCACTCCGGGCGTGCTGCCGGCGGCGGTAGGTGGCGCGCGGGTCCGGCGGGCGGTTGGCTTGAGCGGGACCGGAGCTGAGGCAGGA AGAGCCGGCGCCATGGTGGAGAAGGAGGAGGCTGGCGGCGGCATTAGCGAGGAGGAGGCGGCACAGTATGACCGGCAGATCCGCCTGTGG GGACTGGAGGCCCAGAAACGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCTCATC TTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGGGTCT GTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATATAGAG AAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGTGTGTCTGACTTGCTGCTCCAGGGATGTCATAGTTAAAGTTGACCAGATCTGT CACAAAAATAGCATCAAGTTCTTTACAGGAGATGTTTTTGGCTACCATGGATACACATTTGCCAATCTAGGAGAGCATGAGTTTGTAGAG GAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCGACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATG GTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTCAGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATT GGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATGCAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGAC ATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACACCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTG AAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAGCCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACC ACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCAACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCA GGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAAATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATT AAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACCAGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTG GATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACCATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGG TACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCCAGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGG TTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTCTTCTGTTTTATTTTGTTTTGTTTGAAGCTCAGAGGGAGATG GGCAATTGACAGGGATGCAATCCAGGGTGGGATTTCTTGAGGAAGTTACAAATAAGCTTGTTACAACATCAAGATAGATGGAATTGGAAG GATGCTACCAGGAGAGTACTTACATAGTGCTCAGGAGTTTCTCTTCTTAAAATGTTTACTGCTGAAAGATGAGCAGGACCAGGGCGTTAT AGGCAGAGCCCTAGCCGAGAAACCTGCTGGCCTCTGCCTGTTTTCATTTCCCACTTTGGTTGTGTGGCATTACTTTCAGAATTGCACTTT CCTGCTTGTCATGACTTTTTGACACACTTGCCATGACGTGTGTTTCTGTGAACATGAAGTTCTGCGGTAGTGCCTCCAGGGGCAGAGGAA >79014_79014_9_SAE1-RPA2_SAE1_chr19_47658470_ENST00000413379_RPA2_chr1_28233793_ENST00000373912_length(amino acids)=468AA_BP=232 MPAAVGGARVRRAVGLSGTGAEAGRAGAMVEKEEAGGGISEEEAAQYDRQIRLWGLEAQKRLRASRVLLVGLKGLGAEIAKNLILAGVKG LTMLDHEQVTPEDPGAQFLIRTGSVGRNRAEASLERAQNLNPMVDVKVDTEDIEKKPESFFTQFDAVCLTCCSRDVIVKVDQICHKNSIK FFTGDVFGYHGYTFANLGEHEFVEEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEIS QVTIVGIIRHAEKAPTNIVYKIDDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEV INAHMVLSKANSQPSAGRAPISNPGMSEAGNFGGNSFMPANGLTVAQNQVLNLIKACPRPEGLNFQDLKNQLKHMSVSSIKQAVDFLSNE -------------------------------------------------------------- >79014_79014_10_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000313433_length(transcript)=1196nt_BP=410nt ACTCCGGGCGTGCTGCCGGCGGCGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCT CATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGG GTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATAT AGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCG ACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTC AGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATG CAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACA CCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAG CCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCA ACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAA ATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACC AGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACC ATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCC >79014_79014_10_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000313433_length(amino acids)=266AA_BP=30 MLEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKI DDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPIS -------------------------------------------------------------- >79014_79014_11_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000373909_length(transcript)=1345nt_BP=410nt ACTCCGGGCGTGCTGCCGGCGGCGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCT CATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGG GTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATAT AGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCG ACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTC AGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATG CAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACA CCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAG CCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCA ACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAA ATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACC AGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACC ATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCC AGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTC >79014_79014_11_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000373909_length(amino acids)=266AA_BP=30 MLEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKI DDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPIS -------------------------------------------------------------- >79014_79014_12_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000373912_length(transcript)=1745nt_BP=410nt ACTCCGGGCGTGCTGCCGGCGGCGGCTGCGGGCCTCTCGGGTGCTTCTTGTCGGCTTGAAAGGACTTGGGGCTGAAATTGCCAAGAATCT CATCTTGGCAGGAGTGAAAGGACTGACCATGCTGGATCACGAACAGGTAACTCCAGAAGATCCCGGAGCTCAGTTCTTGATTCGTACTGG GTCTGTTGGCCGAAATAGGGCTGAAGCCTCTTTGGAGCGAGCTCAGAATCTCAACCCCATGGTGGATGTGAAGGTGGACACTGAGGATAT AGAGAAGAAACCAGAGTCATTTTTCACTCAATTCGATGCTGGAGAAAACTAAAGTTGCCAAAGTTAGCCAAGGAGTAGAAGATGGGCCCG ACACCAAGAGAGCAAAACTTGATTCTTCTGAGACAACGATGGTCAAAAAGAGAGCCCGAGCCCAGCACATTGTGCCCTGTACTATATCTC AGCTGCTTTCTGCCACTTTGGTTGATGAAGTGTTCAGAATTGGGAATGTTGAGATTTCACAGGTCACTATTGTGGGGATCATCAGACATG CAGAGAAGGCTCCAACCAACATTGTTTACAAAATAGATGACATGACAGCTGCACCCATGGACGTTCGCCAGTGGGTTGACACAGATGACA CCAGCAGTGAAAACACTGTGGTTCCTCCAGAAACATATGTGAAAGTGGCAGGCCACCTGAGATCTTTTCAGAACAAAAAGAGCCTGGTAG CCTTTAAGATCATGCCCCTGGAGGATATGAATGAGTTCACCACACATATTCTGGAAGTGATCAATGCACACATGGTACTAAGCAAAGCCA ACAGCCAGCCCTCAGCAGGGAGAGCACCTATCAGCAATCCAGGAATGAGTGAAGCAGGGAACTTTGGTGGGAATAGCTTCATGCCAGCAA ATGGCCTCACTGTGGCCCAAAACCAGGTGTTGAATTTGATTAAGGCTTGTCCAAGACCTGAAGGGTTGAACTTTCAGGATCTCAAGAACC AGCTGAAACACATGTCTGTATCCTCAATCAAGCAAGCTGTGGATTTTCTGAGCAATGAGGGGCACATCTATTCTACTGTGGATGATGACC ATTTTAAATCCACAGATGCAGAATAACTGGATCTAACTGGGTACCTGAGATATTTTACAGCTGGACCTAGTTTCACAATCTGTTGTCTCC AGCTCTGCATATGTCTGGCCAGGGGGCTTCTAGGAAGTAGGTTTCATCTATCAAATGTCTCCTCTGACTTCCTTTTGAAACTTACTGCTC TTCTGTTTTATTTTGTTTTGTTTGAAGCTCAGAGGGAGATGGGCAATTGACAGGGATGCAATCCAGGGTGGGATTTCTTGAGGAAGTTAC AAATAAGCTTGTTACAACATCAAGATAGATGGAATTGGAAGGATGCTACCAGGAGAGTACTTACATAGTGCTCAGGAGTTTCTCTTCTTA AAATGTTTACTGCTGAAAGATGAGCAGGACCAGGGCGTTATAGGCAGAGCCCTAGCCGAGAAACCTGCTGGCCTCTGCCTGTTTTCATTT CCCACTTTGGTTGTGTGGCATTACTTTCAGAATTGCACTTTCCTGCTTGTCATGACTTTTTGACACACTTGCCATGACGTGTGTTTCTGT GAACATGAAGTTCTGCGGTAGTGCCTCCAGGGGCAGAGGAAAAGAAGAAGTGTTACTGCATTTTGTACAAAATAAATACAGTCATATGTT >79014_79014_12_SAE1-RPA2_SAE1_chr19_47658470_ENST00000540850_RPA2_chr1_28233793_ENST00000373912_length(amino acids)=266AA_BP=30 MLEKTKVAKVSQGVEDGPDTKRAKLDSSETTMVKKRARAQHIVPCTISQLLSATLVDEVFRIGNVEISQVTIVGIIRHAEKAPTNIVYKI DDMTAAPMDVRQWVDTDDTSSENTVVPPETYVKVAGHLRSFQNKKSLVAFKIMPLEDMNEFTTHILEVINAHMVLSKANSQPSAGRAPIS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SAE1-RPA2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000313433 | 0 | 8 | 187_270 | 127.0 | 359.0 | RAD52%2C TIPIN%2C UNG and XPA | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373909 | 1 | 9 | 187_270 | 47.0 | 279.0 | RAD52%2C TIPIN%2C UNG and XPA | |
| Tgene | RPA2 | chr19:47658470 | chr1:28233793 | ENST00000373912 | 1 | 9 | 187_270 | 39.0 | 271.0 | RAD52%2C TIPIN%2C UNG and XPA |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SAE1-RPA2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SAE1-RPA2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies