
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SCYL1-ASNA1 (FusionGDB2 ID:79767) |
Fusion Gene Summary for SCYL1-ASNA1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SCYL1-ASNA1 | Fusion gene ID: 79767 | Hgene | Tgene | Gene symbol | SCYL1 | ASNA1 | Gene ID | 57410 | 439 |
| Gene name | SCY1 like pseudokinase 1 | guided entry of tail-anchored proteins factor 3, ATPase | |
| Synonyms | GKLP|HT019|NKTL|NTKL|P105|SCAR21|TAPK|TEIF|TRAP | ARSA-I|ARSA1|ASNA-I|ASNA1|TRC40 | |
| Cytomap | 11q13.1 | 19p13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | N-terminal kinase-like proteinSCY1-like protein 1SCY1-like, kinase-like 1coated vesicle-associated kinase of 90 kDalikely ortholog of mouse N-terminal kinase-like proteintelomerase regulation-associated proteintelomerase transcriptional elements-int | ATPase ASNA1arsA arsenite transporter, ATP-binding, homolog 1golgi to ER traffic 3 homologtransmembrane domain recognition complex 40 kDa ATPase subunit | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000270176, ENST00000279270, ENST00000420247, ENST00000524944, ENST00000525364, ENST00000527009, ENST00000533862, ENST00000534462, | ENST00000357332, ENST00000591090, | |
| Fusion gene scores | * DoF score | 8 X 8 X 7=448 | 8 X 8 X 4=256 |
| # samples | 14 | 10 | |
| ** MAII score | log2(14/448*10)=-1.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/256*10)=-1.35614381022528 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SCYL1 [Title/Abstract] AND ASNA1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SCYL1(65299154)-ASNA1(12856190), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SCYL1 | GO:0006890 | retrograde vesicle-mediated transport, Golgi to ER | 18556652 |
| Tgene | ASNA1 | GO:0071816 | tail-anchored membrane protein insertion into ER membrane | 25535373 |
| Fusion gene breakpoints across SCYL1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ASNA1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-13-0801 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
Top |
Fusion Gene ORF analysis for SCYL1-ASNA1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000270176 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000270176 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000279270 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000279270 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000420247 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000420247 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000524944 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000524944 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000525364 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000525364 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000527009 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000527009 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000533862 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| In-frame | ENST00000533862 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| intron-3CDS | ENST00000534462 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| intron-3CDS | ENST00000534462 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000525364 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2150 | 1193 | 77 | 1930 | 617 |
| ENST00000525364 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2150 | 1193 | 77 | 1930 | 617 |
| ENST00000270176 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2150 | 1193 | 77 | 1930 | 617 |
| ENST00000270176 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2150 | 1193 | 77 | 1930 | 617 |
| ENST00000420247 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2142 | 1185 | 69 | 1922 | 617 |
| ENST00000420247 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2142 | 1185 | 69 | 1922 | 617 |
| ENST00000533862 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2115 | 1158 | 42 | 1895 | 617 |
| ENST00000533862 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2115 | 1158 | 42 | 1895 | 617 |
| ENST00000279270 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2114 | 1157 | 41 | 1894 | 617 |
| ENST00000279270 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2114 | 1157 | 41 | 1894 | 617 |
| ENST00000524944 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2106 | 1149 | 33 | 1886 | 617 |
| ENST00000524944 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2106 | 1149 | 33 | 1886 | 617 |
| ENST00000527009 | SCYL1 | chr11 | 65299154 | + | ENST00000591090 | ASNA1 | chr19 | 12856190 | + | 2123 | 1166 | 278 | 1903 | 541 |
| ENST00000527009 | SCYL1 | chr11 | 65299154 | + | ENST00000357332 | ASNA1 | chr19 | 12856190 | + | 2123 | 1166 | 278 | 1903 | 541 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000525364 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.01145062 | 0.9885494 |
| ENST00000525364 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.01145062 | 0.9885494 |
| ENST00000270176 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.01145062 | 0.9885494 |
| ENST00000270176 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.01145062 | 0.9885494 |
| ENST00000420247 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011278546 | 0.98872143 |
| ENST00000420247 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011278546 | 0.98872143 |
| ENST00000533862 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011236977 | 0.98876303 |
| ENST00000533862 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011236977 | 0.98876303 |
| ENST00000279270 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011311387 | 0.98868865 |
| ENST00000279270 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011311387 | 0.98868865 |
| ENST00000524944 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011244512 | 0.9887554 |
| ENST00000524944 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.011244512 | 0.9887554 |
| ENST00000527009 | ENST00000591090 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.012783952 | 0.98721606 |
| ENST00000527009 | ENST00000357332 | SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 0.012783952 | 0.98721606 |
Top |
Fusion Genomic Features for SCYL1-ASNA1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 4.78E-10 | 1 |
| SCYL1 | chr11 | 65299154 | + | ASNA1 | chr19 | 12856190 | + | 4.78E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
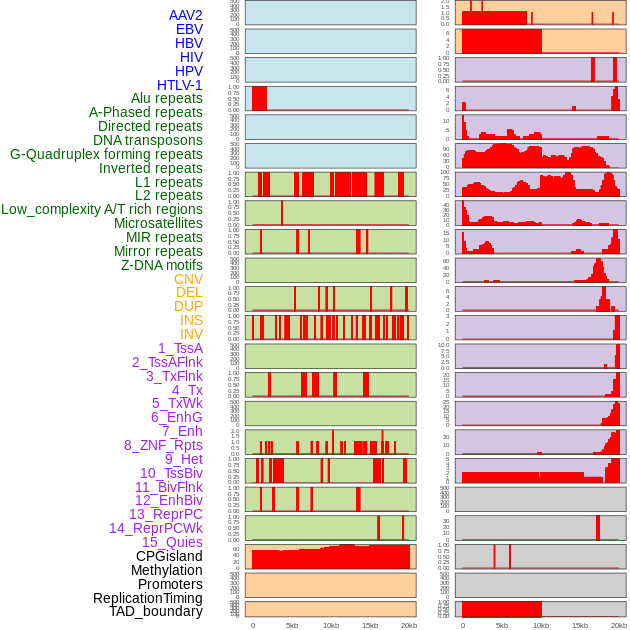 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
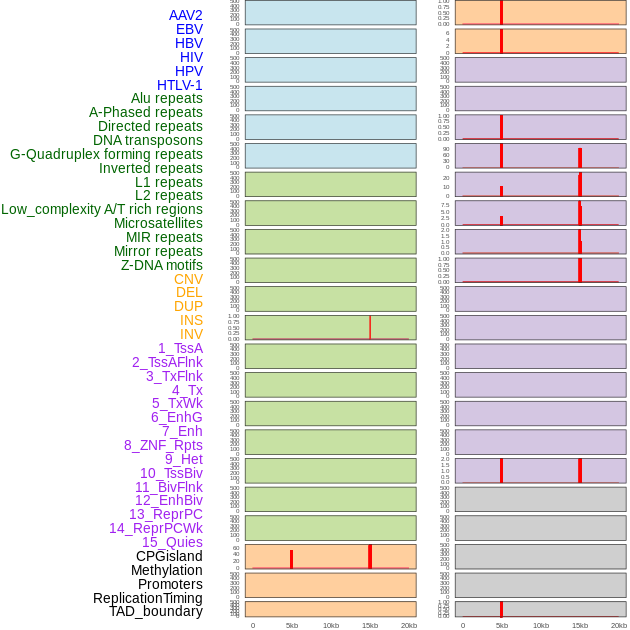 |
Top |
Fusion Protein Features for SCYL1-ASNA1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:65299154/chr19:12856190) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 14_314 | 372 | 809.0 | Domain | Protein kinase |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 14_314 | 372 | 782.0 | Domain | Protein kinase |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 14_314 | 372 | 792.0 | Domain | Protein kinase |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 14_314 | 372 | 788.0 | Domain | Protein kinase |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 761_797 | 372 | 809.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 761_797 | 372 | 782.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 761_797 | 372 | 792.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 761_797 | 372 | 788.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 589_619 | 372 | 809.0 | Compositional bias | Note=Pro-rich |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 589_619 | 372 | 782.0 | Compositional bias | Note=Pro-rich |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 589_619 | 372 | 792.0 | Compositional bias | Note=Pro-rich |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 589_619 | 372 | 788.0 | Compositional bias | Note=Pro-rich |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 350_388 | 372 | 809.0 | Repeat | Note=HEAT 1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 389_427 | 372 | 809.0 | Repeat | Note=HEAT 2 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 507_545 | 372 | 809.0 | Repeat | Note=HEAT 3 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 350_388 | 372 | 782.0 | Repeat | Note=HEAT 1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 389_427 | 372 | 782.0 | Repeat | Note=HEAT 2 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 507_545 | 372 | 782.0 | Repeat | Note=HEAT 3 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 350_388 | 372 | 792.0 | Repeat | Note=HEAT 1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 389_427 | 372 | 792.0 | Repeat | Note=HEAT 2 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 507_545 | 372 | 792.0 | Repeat | Note=HEAT 3 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 350_388 | 372 | 788.0 | Repeat | Note=HEAT 1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 389_427 | 372 | 788.0 | Repeat | Note=HEAT 2 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 507_545 | 372 | 788.0 | Repeat | Note=HEAT 3 |
| Tgene | ASNA1 | chr11:65299154 | chr19:12856190 | ENST00000357332 | 1 | 7 | 45_52 | 103 | 349.0 | Nucleotide binding | ATP | |
| Tgene | ASNA1 | chr11:65299154 | chr19:12856190 | ENST00000591090 | 2 | 8 | 45_52 | 103 | 349.0 | Nucleotide binding | ATP |
Top |
Fusion Gene Sequence for SCYL1-ASNA1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >79767_79767_1_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000270176_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2150nt_BP=1193nt CTCTCCGCCCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTG CCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCC GCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCT TCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGG CTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCG TGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGT GGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATG ACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAG TCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGG GAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAA CCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCC CTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCT TCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCA TGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGA GCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGA AGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGG GCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAG ACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCT GCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAA TTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGA TGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGG CCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCT CCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCC >79767_79767_1_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000270176_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_2_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000270176_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2150nt_BP=1193nt CTCTCCGCCCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTG CCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCC GCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCT TCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGG CTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCG TGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGT GGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATG ACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAG TCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGG GAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAA CCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCC CTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCT TCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCA TGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGA GCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGA AGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGG GCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAG ACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCT GCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAA TTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGA TGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGG CCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCT CCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCC >79767_79767_2_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000270176_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_3_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000279270_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2114nt_BP=1157nt CCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCA TCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCG TCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATCC TGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAG TGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCC TCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCC AGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGG TCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTAC GCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCT TCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGC CAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGC TGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATC AGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCA GCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCG CATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACGG CACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCA GCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCG TCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGA CAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGC CCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAGC TGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCC AGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCC CCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCCT >79767_79767_3_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000279270_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_4_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000279270_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2114nt_BP=1157nt CCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCA TCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCG TCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATCC TGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAG TGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCC TCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCC AGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGG TCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTAC GCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCT TCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGC CAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGC TGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATC AGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCA GCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCG CATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACGG CACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCA GCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCG TCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGA CAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGC CCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAGC TGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCC AGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCC CCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCCT >79767_79767_4_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000279270_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_5_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000420247_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2142nt_BP=1185nt CCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGAC CCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAG GCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGC TTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACC CCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCC CTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTT GGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCG GAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAAT GGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAAC CCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTC TTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGAT TTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTG GGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATC CGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGC AAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATG AACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGC CGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTG GCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGC ATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAAC CAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGAC CTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTC CTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCC CCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGG >79767_79767_5_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000420247_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_6_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000420247_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2142nt_BP=1185nt CCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGAC CCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAG GCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGC TTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACC CCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCC CTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTT GGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCG GAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAAT GGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAAC CCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTC TTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGAT TTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTG GGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATC CGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGC AAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATG AACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGC CGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTG GCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGC ATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAAC CAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGAC CTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTC CTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCC CCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGG >79767_79767_6_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000420247_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_7_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000524944_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2106nt_BP=1149nt AAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAG CCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGAT GTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTAC ATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCT GGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCAC AACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAAC GGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAG AAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCT GGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAG AACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAG AAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACC GCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAG ATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGC GTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCC GGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACG GGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTC ATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGC TCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGG CTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAG ATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTG TTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCAC AGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAA TACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCCTACCTCTCC >79767_79767_7_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000524944_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_8_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000524944_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2106nt_BP=1149nt AAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAG CCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGAT GTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTAC ATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCT GGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCAC AACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAAC GGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAG AAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCT GGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAG AACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAG AAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACC GCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAG ATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGC GTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCC GGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACG GGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTC ATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGC TCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGG CTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAG ATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTG TTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCAC AGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAA TACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCCTACCTCTCC >79767_79767_8_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000524944_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_9_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000525364_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2150nt_BP=1193nt CTCTCCGCCCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTG CCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCC GCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCT TCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGG CTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCG TGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGT GGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATG ACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAG TCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGG GAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAA CCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCC CTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCT TCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCA TGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGA GCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGA AGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGG GCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAG ACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCT GCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAA TTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGA TGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGG CCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCT CCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCC >79767_79767_9_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000525364_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_10_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000525364_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2150nt_BP=1193nt CTCTCCGCCCCGCCCCGGCTCGGGCGGCCGGAGGACCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTG CCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTCATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCC GCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCT TCAAGCGCTTCAAAACTCTACGGCACCCCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGG CTGTGACCCCGTTGGGAATATACCTCAAGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCG TGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGT GGAAGCTTGGGGGCCTGGACTACATGTATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATG ACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAG TCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGG GAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAA CCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCC CTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCT TCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCA TGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGA GCATGGGCAAGAAGATGATGCAGGAGGCCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGA AGGGCATGAACTTCTCGGTGGTGGTATTTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGG GCCTGGGCCGGCTTATGCAGATCAAGAACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAG ACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCT GCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAA TTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGA TGGAGGACCTGTATGAAGACTTCCACATCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGG CCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCT CCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCC >79767_79767_10_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000525364_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_11_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000527009_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2123nt_BP=1166nt GGCGGAGGGACCGAGGGACCGACAGGCGGACAGGGCCGGGGTCACGTGGGCCCGGCGAAGTGTCCCTAAGGCTGACCTGGGGAGAGACCT GGCTGCGGGCCCTTGTCTTCCGGCCACACAACAGCTCTGGGACCATCTCAGGCCCCGCTGCCCTCCCCTAGGCCACAGGCAGCCCCGTGT CCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACC CCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCA AGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACG ACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGT ATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTG GCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAG CAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACC CAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGA TCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGC TGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTG AGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGA TTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGG CCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTAT TTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGA ACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGA CGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCC TGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACC CCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACA TCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCC CCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCA CAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAG >79767_79767_11_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000527009_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=541AA_BP=295 MAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSA QGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPAR FLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEY QQKIIPVVVKMFSSTDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDT APTGHTLRLLNFPTIVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYE TERLIQELAKCKIDTHNIIVNQLVFPDPEKPCKMCEARHKIQAKYLDQMEDLYEDFHIVKLPLLPHEVRGADKVNTFSALLLEPYKPPSA -------------------------------------------------------------- >79767_79767_12_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000527009_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2123nt_BP=1166nt GGCGGAGGGACCGAGGGACCGACAGGCGGACAGGGCCGGGGTCACGTGGGCCCGGCGAAGTGTCCCTAAGGCTGACCTGGGGAGAGACCT GGCTGCGGGCCCTTGTCTTCCGGCCACACAACAGCTCTGGGACCATCTCAGGCCCCGCTGCCCTCCCCTAGGCCACAGGCAGCCCCGTGT CCATCTTCGTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACC CCAACATCCTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCA AGGCGAGAGTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACG ACTGCAGCCTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGT ATTCGGCCCAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTG GCAGAGTGGTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAG CAGCCCTACGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACC CAGCCCGCTTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGA TCAAAGAGCCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGC TGCCCCAGCTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTG AGGAGTATCAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGA TTGACCCCAGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGG CCATGAGCGCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTAT TTGACACGGCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGA ACCAGATCAGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGA CGCTGCCCGTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCC TGTATGAGACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACC CCGAGAAGCCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACA TCGTGAAGCTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCC CCAGTGCCCAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCA CAAAGTCCCCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAG >79767_79767_12_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000527009_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=541AA_BP=295 MAYIDGLETEKCLHVVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSA QGNGGGPPRKGIPELEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPAR FLQNCRAPGGFMSNRFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEY QQKIIPVVVKMFSSTDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDT APTGHTLRLLNFPTIVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYE TERLIQELAKCKIDTHNIIVNQLVFPDPEKPCKMCEARHKIQAKYLDQMEDLYEDFHIVKLPLLPHEVRGADKVNTFSALLLEPYKPPSA -------------------------------------------------------------- >79767_79767_13_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000533862_ASNA1_chr19_12856190_ENST00000357332_length(transcript)=2115nt_BP=1158nt CCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTC ATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTC GTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATC CTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGA GTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGC CTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCC CAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTG GTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTA CGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGC TTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAG CCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAG CTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTAT CAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCC AGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGC GCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACG GCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATC AGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCC GTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAG ACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAG CCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAG CTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCC CAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCC CCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCC >79767_79767_13_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000533862_ASNA1_chr19_12856190_ENST00000357332_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- >79767_79767_14_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000533862_ASNA1_chr19_12856190_ENST00000591090_length(transcript)=2115nt_BP=1158nt CCCGGAGCTAAGGCGCCCGAACCCGCGGCGGCGGTGGGGACGATGTGGTTCTTTGCCCGGGACCCGGTCCGGGACTTTCCGTTCGAGCTC ATCCCGGAGCCCCCAGAGGGCGGCCTGCCCGGGCCCTGGGCCCTGCACCGCGGCCGCAAGAAGGCCACAGGCAGCCCCGTGTCCATCTTC GTCTATGATGTGAAGCCTGGCGCGGAAGAGCAGACCCAGGTGGCCAAAGCTGCCTTCAAGCGCTTCAAAACTCTACGGCACCCCAACATC CTGGCTTACATCGATGGACTGGAGACAGAAAAATGCCTCCACGTCGTGACAGAGGCTGTGACCCCGTTGGGAATATACCTCAAGGCGAGA GTGGAGGCTGGTGGCCTGAAGGAGCTGGAGATCTCCTGGGGGCTACACCAGATCGTGAAAGCCCTCAGCTTCCTGGTCAACGACTGCAGC CTCATCCACAACAATGTCTGCATGGCCGCCGTGTTCGTGGACCGAGCTGGCGAGTGGAAGCTTGGGGGCCTGGACTACATGTATTCGGCC CAGGGCAACGGTGGGGGACCTCCCCGCAAGGGGATCCCCGAGCTTGAGCAGTATGACCCCCCGGAGTTGGCTGACAGCAGTGGCAGAGTG GTCAGAGAGAAGTGGTCAGCAGACATGTGGCGCTTGGGCTGCCTCATTTGGGAAGTCTTCAATGGGCCCCTACCTCGGGCAGCAGCCCTA CGCAACCCTGGGAAGATCCCCAAAACGCTGGTGCCCCATTACTGTGAGCTGGTGGGAGCAAACCCCAAGGTGCGTCCCAACCCAGCCCGC TTCCTGCAGAACTGCCGGGCACCTGGTGGCTTCATGAGCAACCGCTTTGTAGAAACCAACCTCTTCCTGGAGGAGATTCAGATCAAAGAG CCAGCCGAGAAGCAAAAATTCTTCCAGGAGCTGAGCAAGAGCCTGGACGCATTCCCTGAGGATTTCTGTCGGCACAAGGTGCTGCCCCAG CTGCTGACCGCCTTCGAGTTCGGCAATGCTGGGGCCGTTGTCCTCACGCCCCTCTTCAAGGTGGGCAAGTTCCTGAGCGCTGAGGAGTAT CAGCAGAAGATCATCCCTGTGGTGGTCAAGATGTTCTCATCCACTGACCGGGCCATGCGCATCCGCCTCCTGCAGCAGGAGATTGACCCC AGCCTGGGCGTGGCGGAGCTGCCTGACGAGTTCTTCGAGGAGGACAACATGCTGAGCATGGGCAAGAAGATGATGCAGGAGGCCATGAGC GCATTTCCCGGCATCGATGAGGCCATGAGCTATGCCGAGGTCATGAGGCTGGTGAAGGGCATGAACTTCTCGGTGGTGGTATTTGACACG GCACCCACGGGCCACACCCTGAGGCTGCTCAACTTCCCCACCATCGTGGAGCGGGGCCTGGGCCGGCTTATGCAGATCAAGAACCAGATC AGCCCTTTCATCTCACAGATGTGCAACATGCTGGGCCTGGGGGACATGAACGCAGACCAGCTGGCCTCCAAGCTGGAGGAGACGCTGCCC GTCATCCGCTCAGTCAGCGAACAGTTCAAGGACCCTGAGCAGACAACTTTCATCTGCGTATGCATTGCTGAGTTCCTGTCCCTGTATGAG ACAGAGAGGCTGATCCAGGAGCTGGCCAAGTGCAAGATTGACACACACAATATAATTGTCAACCAGCTCGTCTTCCCCGACCCCGAGAAG CCCTGCAAGATGTGTGAGGCCCGTCACAAGATCCAGGCCAAGTATCTGGACCAGATGGAGGACCTGTATGAAGACTTCCACATCGTGAAG CTGCCGCTGTTACCCCATGAGGTGCGGGGGGCAGACAAGGTCAACACCTTCTCGGCCCTCCTCCTGGAGCCCTACAAGCCCCCCAGTGCC CAGTAGCACAGCTGCCAGCCCCAACCGCTGCCATTTCACACTCACCCTCCACCCTCCCCACCCCCTCGGGGCAGAGTTTGCACAAAGTCC CCCCCATAATACAGGGGGAGCCACTTGGGCAGGAGGCAGGGAGGGGTCCATTCCCCCTGGTGGGGCTGGTGGGGAGCTGTAGTTGCCCCC >79767_79767_14_SCYL1-ASNA1_SCYL1_chr11_65299154_ENST00000533862_ASNA1_chr19_12856190_ENST00000591090_length(amino acids)=617AA_BP=371 MWFFARDPVRDFPFELIPEPPEGGLPGPWALHRGRKKATGSPVSIFVYDVKPGAEEQTQVAKAAFKRFKTLRHPNILAYIDGLETEKCLH VVTEAVTPLGIYLKARVEAGGLKELEISWGLHQIVKALSFLVNDCSLIHNNVCMAAVFVDRAGEWKLGGLDYMYSAQGNGGGPPRKGIPE LEQYDPPELADSSGRVVREKWSADMWRLGCLIWEVFNGPLPRAAALRNPGKIPKTLVPHYCELVGANPKVRPNPARFLQNCRAPGGFMSN RFVETNLFLEEIQIKEPAEKQKFFQELSKSLDAFPEDFCRHKVLPQLLTAFEFGNAGAVVLTPLFKVGKFLSAEEYQQKIIPVVVKMFSS TDRAMRIRLLQQEIDPSLGVAELPDEFFEEDNMLSMGKKMMQEAMSAFPGIDEAMSYAEVMRLVKGMNFSVVVFDTAPTGHTLRLLNFPT IVERGLGRLMQIKNQISPFISQMCNMLGLGDMNADQLASKLEETLPVIRSVSEQFKDPEQTTFICVCIAEFLSLYETERLIQELAKCKID -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SCYL1-ASNA1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000270176 | + | 8 | 18 | 793_808 | 372.0 | 809.0 | COPB1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000279270 | + | 8 | 17 | 793_808 | 372.0 | 782.0 | COPB1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000420247 | + | 8 | 18 | 793_808 | 372.0 | 792.0 | COPB1 |
| Hgene | SCYL1 | chr11:65299154 | chr19:12856190 | ENST00000533862 | + | 8 | 18 | 793_808 | 372.0 | 788.0 | COPB1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SCYL1-ASNA1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SCYL1-ASNA1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies