
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SDC4-NRG1 (FusionGDB2 ID:79822) |
Fusion Gene Summary for SDC4-NRG1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SDC4-NRG1 | Fusion gene ID: 79822 | Hgene | Tgene | Gene symbol | SDC4 | NRG1 | Gene ID | 6385 | 3084 |
| Gene name | syndecan 4 | neuregulin 1 | |
| Synonyms | SYND4 | ARIA|GGF|GGF2|HGL|HRG|HRG1|HRGA|MST131|MSTP131|NDF|NRG1-IT2|SMDF | |
| Cytomap | 20q13.12 | 8p12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | syndecan-4amphiglycanryudocan amphiglycanryudocan core proteinsyndecan 4 (amphiglycan, ryudocan)syndecan proteoglycan 4 | pro-neuregulin-1, membrane-bound isoformacetylcholine receptor-inducing activityglial growth factor 2heregulin, alpha (45kD, ERBB2 p185-activator)neu differentiation factorpro-NRG1sensory and motor neuron derived factor | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | Q02297 | |
| Ensembl transtripts involved in fusion gene | ENST00000372733, ENST00000537976, | ENST00000523681, ENST00000287842, ENST00000287845, ENST00000338921, ENST00000341377, ENST00000356819, ENST00000405005, ENST00000519301, ENST00000520407, ENST00000520502, ENST00000521670, ENST00000523079, ENST00000539990, | |
| Fusion gene scores | * DoF score | 12 X 12 X 10=1440 | 25 X 17 X 14=5950 |
| # samples | 21 | 27 | |
| ** MAII score | log2(21/1440*10)=-2.77760757866355 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(27/5950*10)=-4.46185835603184 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SDC4 [Title/Abstract] AND NRG1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SDC4(43959006)-NRG1(32585467), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NRG1 | GO:0003222 | ventricular trabecula myocardium morphogenesis | 17336907 |
| Tgene | NRG1 | GO:0031334 | positive regulation of protein complex assembly | 10559227 |
| Tgene | NRG1 | GO:0038127 | ERBB signaling pathway | 11389077 |
| Tgene | NRG1 | GO:0038129 | ERBB3 signaling pathway | 27353365 |
| Tgene | NRG1 | GO:0045892 | negative regulation of transcription, DNA-templated | 15073182 |
| Tgene | NRG1 | GO:0051048 | negative regulation of secretion | 10559227 |
| Tgene | NRG1 | GO:0060379 | cardiac muscle cell myoblast differentiation | 17336907 |
| Tgene | NRG1 | GO:0060956 | endocardial cell differentiation | 17336907 |
| Fusion gene breakpoints across SDC4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NRG1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-86-7954-01A | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| ChimerDB4 | LUAD | TCGA-86-7954 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| ChimerDB4 | LUSC | TCGA-85-7950-01A | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| ChimerKB4 | . | . | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
Top |
Fusion Gene ORF analysis for SDC4-NRG1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000372733 | ENST00000523681 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000372733 | ENST00000523681 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| 5CDS-intron | ENST00000537976 | ENST00000523681 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| 5CDS-intron | ENST00000537976 | ENST00000523681 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000287842 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000287842 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000287845 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000287845 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000338921 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000338921 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000341377 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000341377 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000356819 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000356819 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000405005 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000405005 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000519301 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000519301 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000520407 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000520407 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000520502 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000520502 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000521670 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000521670 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000523079 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000523079 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000372733 | ENST00000539990 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000372733 | ENST00000539990 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000287842 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000287842 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000287845 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000287845 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000338921 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000338921 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000341377 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000341377 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000356819 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000356819 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000405005 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000405005 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000519301 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000519301 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000520407 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000520407 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000520502 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000520502 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000521670 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000521670 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000523079 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000523079 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| In-frame | ENST00000537976 | ENST00000539990 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + |
| In-frame | ENST00000537976 | ENST00000539990 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + |
| intron-intron | ENST00000372733 | ENST00000287842 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000287845 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000338921 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000341377 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000356819 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000405005 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000519301 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000520407 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000520502 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000521670 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000523079 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000523681 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000372733 | ENST00000539990 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000287842 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000287845 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000338921 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000341377 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000356819 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000405005 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000519301 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000520407 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000520502 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000521670 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000523079 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000523681 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| intron-intron | ENST00000537976 | ENST00000539990 | SDC4 | chr20 | 43964560 | - | NRG1 | chr8 | 43964560 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1924 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 1165 | 485 | 40 | 708 | 222 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1825 | 485 | 40 | 1245 | 401 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2558 | 485 | 40 | 1929 | 629 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2549 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2549 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2593 | 485 | 726 | 1964 | 412 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 2006 | 485 | 40 | 1896 | 618 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1644 | 485 | 40 | 1371 | 443 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1975 | 485 | 40 | 1905 | 621 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 1148 | 485 | 40 | 708 | 222 |
| ENST00000372733 | SDC4 | chr20 | 43959006 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 2003 | 485 | 40 | 1896 | 618 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000519301 | NRG1 | chr8 | 32585467 | + | 1785 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000520407 | NRG1 | chr8 | 32585467 | + | 1026 | 346 | 12 | 569 | 185 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000523079 | NRG1 | chr8 | 32585467 | + | 1686 | 346 | 12 | 1106 | 364 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000338921 | NRG1 | chr8 | 32585467 | + | 2419 | 346 | 12 | 1790 | 592 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000356819 | NRG1 | chr8 | 32585467 | + | 2410 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000287845 | NRG1 | chr8 | 32585467 | + | 2410 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000341377 | NRG1 | chr8 | 32585467 | + | 2454 | 346 | 587 | 1825 | 412 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000287842 | NRG1 | chr8 | 32585467 | + | 1867 | 346 | 12 | 1757 | 581 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000521670 | NRG1 | chr8 | 32585467 | + | 1505 | 346 | 12 | 1232 | 406 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000405005 | NRG1 | chr8 | 32585467 | + | 1836 | 346 | 12 | 1766 | 584 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000520502 | NRG1 | chr8 | 32585467 | + | 1009 | 346 | 12 | 569 | 185 |
| ENST00000537976 | SDC4 | chr20 | 43959006 | - | ENST00000539990 | NRG1 | chr8 | 32585467 | + | 1864 | 346 | 12 | 1757 | 581 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000519301 | NRG1 | chr8 | 32585466 | + | 1924 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000520407 | NRG1 | chr8 | 32585466 | + | 1165 | 485 | 40 | 708 | 222 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000523079 | NRG1 | chr8 | 32585466 | + | 1825 | 485 | 40 | 1245 | 401 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000338921 | NRG1 | chr8 | 32585466 | + | 2558 | 485 | 40 | 1929 | 629 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000356819 | NRG1 | chr8 | 32585466 | + | 2549 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000287845 | NRG1 | chr8 | 32585466 | + | 2549 | 485 | 40 | 1920 | 626 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000341377 | NRG1 | chr8 | 32585466 | + | 2593 | 485 | 726 | 1964 | 412 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000287842 | NRG1 | chr8 | 32585466 | + | 2006 | 485 | 40 | 1896 | 618 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000521670 | NRG1 | chr8 | 32585466 | + | 1644 | 485 | 40 | 1371 | 443 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000405005 | NRG1 | chr8 | 32585466 | + | 1975 | 485 | 40 | 1905 | 621 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000520502 | NRG1 | chr8 | 32585466 | + | 1148 | 485 | 40 | 708 | 222 |
| ENST00000372733 | SDC4 | chr20 | 43959005 | - | ENST00000539990 | NRG1 | chr8 | 32585466 | + | 2003 | 485 | 40 | 1896 | 618 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000519301 | NRG1 | chr8 | 32585466 | + | 1785 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000520407 | NRG1 | chr8 | 32585466 | + | 1026 | 346 | 12 | 569 | 185 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000523079 | NRG1 | chr8 | 32585466 | + | 1686 | 346 | 12 | 1106 | 364 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000338921 | NRG1 | chr8 | 32585466 | + | 2419 | 346 | 12 | 1790 | 592 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000356819 | NRG1 | chr8 | 32585466 | + | 2410 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000287845 | NRG1 | chr8 | 32585466 | + | 2410 | 346 | 12 | 1781 | 589 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000341377 | NRG1 | chr8 | 32585466 | + | 2454 | 346 | 587 | 1825 | 412 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000287842 | NRG1 | chr8 | 32585466 | + | 1867 | 346 | 12 | 1757 | 581 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000521670 | NRG1 | chr8 | 32585466 | + | 1505 | 346 | 12 | 1232 | 406 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000405005 | NRG1 | chr8 | 32585466 | + | 1836 | 346 | 12 | 1766 | 584 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000520502 | NRG1 | chr8 | 32585466 | + | 1009 | 346 | 12 | 569 | 185 |
| ENST00000537976 | SDC4 | chr20 | 43959005 | - | ENST00000539990 | NRG1 | chr8 | 32585466 | + | 1864 | 346 | 12 | 1757 | 581 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372733 | ENST00000519301 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.002693056 | 0.99730694 |
| ENST00000372733 | ENST00000520407 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.000566086 | 0.99943393 |
| ENST00000372733 | ENST00000523079 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001002807 | 0.99899715 |
| ENST00000372733 | ENST00000338921 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.000927518 | 0.99907243 |
| ENST00000372733 | ENST00000356819 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.000894542 | 0.9991054 |
| ENST00000372733 | ENST00000287845 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.000894542 | 0.9991054 |
| ENST00000372733 | ENST00000341377 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.003922332 | 0.9960777 |
| ENST00000372733 | ENST00000287842 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001761918 | 0.9982381 |
| ENST00000372733 | ENST00000521670 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.003831241 | 0.9961688 |
| ENST00000372733 | ENST00000405005 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.002274064 | 0.9977259 |
| ENST00000372733 | ENST00000520502 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.000592547 | 0.9994074 |
| ENST00000372733 | ENST00000539990 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001791421 | 0.99820864 |
| ENST00000537976 | ENST00000519301 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.004856348 | 0.99514365 |
| ENST00000537976 | ENST00000520407 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.010107018 | 0.989893 |
| ENST00000537976 | ENST00000523079 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.002841114 | 0.9971589 |
| ENST00000537976 | ENST00000338921 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001772211 | 0.9982278 |
| ENST00000537976 | ENST00000356819 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001381163 | 0.99861884 |
| ENST00000537976 | ENST00000287845 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.001381163 | 0.99861884 |
| ENST00000537976 | ENST00000341377 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.00413066 | 0.99586934 |
| ENST00000537976 | ENST00000287842 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.003605708 | 0.99639434 |
| ENST00000537976 | ENST00000521670 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.02628162 | 0.97371835 |
| ENST00000537976 | ENST00000405005 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.004881383 | 0.9951186 |
| ENST00000537976 | ENST00000520502 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.009548867 | 0.99045116 |
| ENST00000537976 | ENST00000539990 | SDC4 | chr20 | 43959006 | - | NRG1 | chr8 | 32585467 | + | 0.003658911 | 0.99634105 |
| ENST00000372733 | ENST00000519301 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.002693056 | 0.99730694 |
| ENST00000372733 | ENST00000520407 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.000566086 | 0.99943393 |
| ENST00000372733 | ENST00000523079 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001002807 | 0.99899715 |
| ENST00000372733 | ENST00000338921 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.000927518 | 0.99907243 |
| ENST00000372733 | ENST00000356819 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.000894542 | 0.9991054 |
| ENST00000372733 | ENST00000287845 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.000894542 | 0.9991054 |
| ENST00000372733 | ENST00000341377 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.003922332 | 0.9960777 |
| ENST00000372733 | ENST00000287842 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001761918 | 0.9982381 |
| ENST00000372733 | ENST00000521670 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.003831241 | 0.9961688 |
| ENST00000372733 | ENST00000405005 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.002274064 | 0.9977259 |
| ENST00000372733 | ENST00000520502 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.000592547 | 0.9994074 |
| ENST00000372733 | ENST00000539990 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001791421 | 0.99820864 |
| ENST00000537976 | ENST00000519301 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.004856348 | 0.99514365 |
| ENST00000537976 | ENST00000520407 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.010107018 | 0.989893 |
| ENST00000537976 | ENST00000523079 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.002841114 | 0.9971589 |
| ENST00000537976 | ENST00000338921 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001772211 | 0.9982278 |
| ENST00000537976 | ENST00000356819 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001381163 | 0.99861884 |
| ENST00000537976 | ENST00000287845 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.001381163 | 0.99861884 |
| ENST00000537976 | ENST00000341377 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00413066 | 0.99586934 |
| ENST00000537976 | ENST00000287842 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.003605708 | 0.99639434 |
| ENST00000537976 | ENST00000521670 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.02628162 | 0.97371835 |
| ENST00000537976 | ENST00000405005 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.004881383 | 0.9951186 |
| ENST00000537976 | ENST00000520502 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.009548867 | 0.99045116 |
| ENST00000537976 | ENST00000539990 | SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.003658911 | 0.99634105 |
Top |
Fusion Genomic Features for SDC4-NRG1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
| SDC4 | chr20 | 43959005 | - | NRG1 | chr8 | 32585466 | + | 0.00011245 | 0.9998876 |
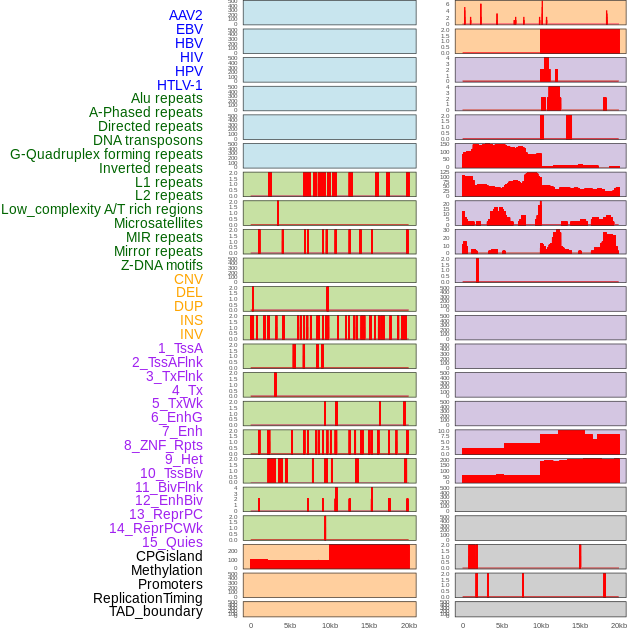
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for SDC4-NRG1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:43959006/chr8:32585467) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NRG1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Direct ligand for ERBB3 and ERBB4 tyrosine kinase receptors. Concomitantly recruits ERBB1 and ERBB2 coreceptors, resulting in ligand-stimulated tyrosine phosphorylation and activation of the ERBB receptors. The multiple isoforms perform diverse functions such as inducing growth and differentiation of epithelial, glial, neuronal, and skeletal muscle cells; inducing expression of acetylcholine receptor in synaptic vesicles during the formation of the neuromuscular junction; stimulating lobuloalveolar budding and milk production in the mammary gland and inducing differentiation of mammary tumor cells; stimulating Schwann cell proliferation; implication in the development of the myocardium such as trabeculation of the developing heart. Isoform 10 may play a role in motor and sensory neuron development. Binds to ERBB4 (PubMed:10867024, PubMed:7902537). Binds to ERBB3 (PubMed:20682778). Acts as a ligand for integrins and binds (via EGF domain) to integrins ITGAV:ITGB3 or ITGA6:ITGB4. Its binding to integrins and subsequent ternary complex formation with integrins and ERRB3 are essential for NRG1-ERBB signaling. Induces the phosphorylation and activation of MAPK3/ERK1, MAPK1/ERK2 and AKT1 (PubMed:20682778). Ligand-dependent ERBB4 endocytosis is essential for the NRG1-mediated activation of these kinases in neurons (By similarity). {ECO:0000250|UniProtKB:P43322, ECO:0000269|PubMed:10867024, ECO:0000269|PubMed:1348215, ECO:0000269|PubMed:20682778, ECO:0000269|PubMed:7902537}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SDC4 | chr20:43959005 | chr8:32585466 | ENST00000372733 | - | 4 | 5 | 19_145 | 148 | 199.0 | Topological domain | Extracellular |
| Hgene | SDC4 | chr20:43959006 | chr8:32585467 | ENST00000372733 | - | 4 | 5 | 19_145 | 148 | 199.0 | Topological domain | Extracellular |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 165_177 | 167 | 638.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 165_177 | 167 | 525.3333333333334 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 165_177 | 167 | 646.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 165_177 | 167 | 641.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 165_177 | 112 | 591.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 165_177 | 167 | 477.3333333333333 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 165_177 | 167 | 421.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 165_177 | 167 | 638.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 165_177 | 167 | 525.3333333333334 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 165_177 | 167 | 646.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 165_177 | 167 | 641.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 165_177 | 112 | 591.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 165_177 | 167 | 477.3333333333333 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 165_177 | 167 | 421.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 178_222 | 167 | 638.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 178_222 | 167 | 525.3333333333334 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 178_222 | 167 | 646.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 178_222 | 167 | 641.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 178_222 | 112 | 591.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 178_222 | 167 | 477.3333333333333 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 178_222 | 167 | 421.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 178_222 | 167 | 638.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 178_222 | 167 | 525.3333333333334 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 178_222 | 167 | 646.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 178_222 | 167 | 641.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 178_222 | 112 | 591.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 178_222 | 167 | 477.3333333333333 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 178_222 | 167 | 421.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 266_640 | 167 | 638.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 266_640 | 167 | 525.3333333333334 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 266_640 | 167 | 646.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 266_640 | 167 | 641.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 266_640 | 112 | 591.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 266_640 | 222 | 297.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 266_640 | 167 | 477.3333333333333 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 266_640 | 167 | 421.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 266_640 | 167 | 638.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 266_640 | 167 | 525.3333333333334 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 266_640 | 167 | 646.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 266_640 | 167 | 641.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 266_640 | 112 | 591.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 266_640 | 222 | 297.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 266_640 | 167 | 477.3333333333333 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 266_640 | 167 | 421.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 243_265 | 167 | 638.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 243_265 | 167 | 525.3333333333334 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 243_265 | 167 | 646.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 243_265 | 167 | 641.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 243_265 | 112 | 591.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 243_265 | 222 | 297.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 243_265 | 167 | 477.3333333333333 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 243_265 | 167 | 421.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 243_265 | 167 | 638.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 243_265 | 167 | 525.3333333333334 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 243_265 | 167 | 646.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 243_265 | 167 | 641.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 243_265 | 112 | 591.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 243_265 | 222 | 297.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 243_265 | 167 | 477.3333333333333 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 243_265 | 167 | 421.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SDC4 | chr20:43959005 | chr8:32585466 | ENST00000372733 | - | 4 | 5 | 171_198 | 148 | 199.0 | Topological domain | Cytoplasmic |
| Hgene | SDC4 | chr20:43959006 | chr8:32585467 | ENST00000372733 | - | 4 | 5 | 171_198 | 148 | 199.0 | Topological domain | Cytoplasmic |
| Hgene | SDC4 | chr20:43959005 | chr8:32585466 | ENST00000372733 | - | 4 | 5 | 146_170 | 148 | 199.0 | Transmembrane | Helical |
| Hgene | SDC4 | chr20:43959006 | chr8:32585467 | ENST00000372733 | - | 4 | 5 | 146_170 | 148 | 199.0 | Transmembrane | Helical |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 165_177 | 348 | 423.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 165_177 | 222 | 297.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 165_177 | 348 | 423.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 165_177 | 222 | 297.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 37_128 | 167 | 638.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 37_128 | 167 | 525.3333333333334 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 37_128 | 167 | 646.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 37_128 | 167 | 641.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 37_128 | 112 | 591.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 178_222 | 348 | 423.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 37_128 | 348 | 423.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 178_222 | 222 | 297.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 37_128 | 222 | 297.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 37_128 | 167 | 477.3333333333333 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 37_128 | 167 | 421.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 37_128 | 167 | 638.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 37_128 | 167 | 525.3333333333334 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 37_128 | 167 | 646.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 37_128 | 167 | 641.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 37_128 | 112 | 591.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 178_222 | 348 | 423.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 37_128 | 348 | 423.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 178_222 | 222 | 297.0 | Domain | EGF-like | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 37_128 | 222 | 297.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 37_128 | 167 | 477.3333333333333 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 37_128 | 167 | 421.0 | Domain | Note=Ig-like C2-type | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000287842 | 4 | 12 | 20_242 | 167 | 638.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000341377 | 4 | 13 | 20_242 | 167 | 525.3333333333334 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000356819 | 4 | 13 | 20_242 | 167 | 646.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000405005 | 4 | 12 | 20_242 | 167 | 641.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000519301 | 2 | 11 | 20_242 | 112 | 591.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 20_242 | 348 | 423.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 266_640 | 348 | 423.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520502 | 0 | 3 | 20_242 | 222 | 297.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000521670 | 4 | 13 | 20_242 | 167 | 477.3333333333333 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000523079 | 4 | 11 | 20_242 | 167 | 421.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000287842 | 4 | 12 | 20_242 | 167 | 638.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000341377 | 4 | 13 | 20_242 | 167 | 525.3333333333334 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000356819 | 4 | 13 | 20_242 | 167 | 646.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000405005 | 4 | 12 | 20_242 | 167 | 641.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000519301 | 2 | 11 | 20_242 | 112 | 591.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 20_242 | 348 | 423.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 266_640 | 348 | 423.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520502 | 0 | 3 | 20_242 | 222 | 297.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000521670 | 4 | 13 | 20_242 | 167 | 477.3333333333333 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000523079 | 4 | 11 | 20_242 | 167 | 421.0 | Topological domain | Extracellular | |
| Tgene | NRG1 | chr20:43959005 | chr8:32585466 | ENST00000520407 | 2 | 5 | 243_265 | 348 | 423.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG1 | chr20:43959006 | chr8:32585467 | ENST00000520407 | 2 | 5 | 243_265 | 348 | 423.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
Top |
Fusion Gene Sequence for SDC4-NRG1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >79822_79822_1_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000287842_length(transcript)=2006nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGAC CACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCAT GACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAA GAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGAT AGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAG AACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGA TGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGA CAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGC TGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTT >79822_79822_1_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000287842_length(amino acids)=618AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS SPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFM EEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEV -------------------------------------------------------------- >79822_79822_2_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000287845_length(transcript)=2549nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT AATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCC ACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAA AATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGA GCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATT GCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTA ATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCA AAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAA >79822_79822_2_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000287845_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_3_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000338921_length(transcript)=2558nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCT GTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAA GAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCA TCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGC AGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGG ACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCC AAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTC TCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCC CCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCT ACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGA CAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGT TAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTC CCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAG TCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCT GTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATA AAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATAT GTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTT ATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTC TTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTA TGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTC TGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAG >79822_79822_3_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000338921_length(amino acids)=629AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQS LRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVI VMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTV SMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTK -------------------------------------------------------------- >79822_79822_4_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000341377_length(transcript)=2593nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAAC TACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTC GGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGA AACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAAC GTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACT GTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTA GAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGG CATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCT GTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATG GCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAG CAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAA ACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATT GCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACG CCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGC CGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACAC ATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAG AAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAA CGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTG CAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTG TCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCT TTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCA >79822_79822_4_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_5_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000356819_length(transcript)=2549nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT AATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCC ACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAA AATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGA GCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATT GCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTA ATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCA AAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAA >79822_79822_5_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000356819_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_6_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000405005_length(transcript)=1975nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCAT AACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGA CCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGT CCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCA CTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGA AAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGG AGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTC AGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGT GTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCT GCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCC CTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCG GGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGA AACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCG CCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGA >79822_79822_6_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000405005_length(amino acids)=621AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNM MNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENS RHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVS PFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANR -------------------------------------------------------------- >79822_79822_7_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000519301_length(transcript)=1924nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT >79822_79822_7_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000519301_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_8_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000520407_length(transcript)=1165nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCA GTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGC CTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCT CCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAA GTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAA >79822_79822_8_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000520407_length(amino acids)=222AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV -------------------------------------------------------------- >79822_79822_9_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000520502_length(transcript)=1148nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCA GTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGC CTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCT CCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAA GTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAA >79822_79822_9_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000520502_length(amino acids)=222AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV -------------------------------------------------------------- >79822_79822_10_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000521670_length(transcript)=1644nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCAT AACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGA CCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGT CCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCA CTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGA AAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGG AGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCT TATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAGATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCC CCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATT TCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCA GCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCA >79822_79822_10_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000521670_length(amino acids)=443AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNM MNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENS -------------------------------------------------------------- >79822_79822_11_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000523079_length(transcript)=1825nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAA GCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCGGTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCG GCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTGTTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCC AGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCGGAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCT CAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATGGCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGC CAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTATCTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAA TCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCTCCACCCTATAGTATCTATTTTATGAAATTCCAAGAAGGGAT >79822_79822_11_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000523079_length(amino acids)=401AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS -------------------------------------------------------------- >79822_79822_12_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000539990_length(transcript)=2003nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGAC CACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCAT GACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAA GAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGAT AGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAG AACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGA TGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGA CAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGC TGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTT >79822_79822_12_SDC4-NRG1_SDC4_chr20_43959005_ENST00000372733_NRG1_chr8_32585466_ENST00000539990_length(amino acids)=618AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS SPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFM EEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEV -------------------------------------------------------------- >79822_79822_13_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000287842_length(transcript)=1867nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCC AAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAG AGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCC GCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAA GAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAAC ACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTG GCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAG GCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTT >79822_79822_13_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000287842_length(amino acids)=581AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP HSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDS NSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASL -------------------------------------------------------------- >79822_79822_14_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000287845_length(transcript)=2410nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC TTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATA GATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAA ACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGA GAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAA AACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCC CTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTG CTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGC >79822_79822_14_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000287845_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_15_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000338921_length(transcript)=2419nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTT GTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCT GAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCT AAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCC ACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCA TCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTC CTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATG TCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCT TCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCAC CCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAG TATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGC CACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAA GATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCA GCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAAT AAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGC AAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATT TCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTA TTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTG CAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAG TTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCA >79822_79822_15_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000338921_length(amino acids)=592AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHS GEPFPEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_16_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000341377_length(transcript)=2454nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAG TGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAA AGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCC CCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTT CCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCA TCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTA ATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAA GGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGT CTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACAC CACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCC CTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCA ATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACT CAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACAC CTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTG CTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTT AAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGT GTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAG TTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATT ATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGC ACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGT TTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAAATATT >79822_79822_16_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_17_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000356819_length(transcript)=2410nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC TTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATA GATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAA ACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGA GAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAA AACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCC CTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTG CTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGC >79822_79822_17_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000356819_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_18_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000405005_length(transcript)=1836nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTG GCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATT GCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCAT ATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGC CACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGC AGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCT GATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCA AGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATG GAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCAC CACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAG CCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTG GACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAG AACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAA GAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAA >79822_79822_18_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000405005_length(amino acids)=584AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAE ELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVER EAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYR DSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPA HDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLA -------------------------------------------------------------- >79822_79822_19_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000519301_length(transcript)=1785nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC >79822_79822_19_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000519301_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_20_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000520407_length(transcript)=1026nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACG TCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGA GCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTC GCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGT CAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATC TTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAG >79822_79822_20_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000520407_length(amino acids)=185AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYSTSTPF -------------------------------------------------------------- >79822_79822_21_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000520502_length(transcript)=1009nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACG TCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGA GCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTC GCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGT CAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATC TTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAG >79822_79822_21_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000520502_length(amino acids)=185AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYSTSTPF -------------------------------------------------------------- >79822_79822_22_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000521670_length(transcript)=1505nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTG GCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATT GCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCAT ATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGC CACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGC AGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCT GATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAG ATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGT GTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACC CGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAG >79822_79822_22_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000521670_length(amino acids)=406AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAE ELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVER EAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYR -------------------------------------------------------------- >79822_79822_23_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000523079_length(transcript)=1686nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCG GTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTG TTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCG GAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATG GCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTAT CTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCT >79822_79822_23_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000523079_length(amino acids)=364AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP -------------------------------------------------------------- >79822_79822_24_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000539990_length(transcript)=1864nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCC AAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAG AGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCC GCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAA GAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAAC ACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTG GCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAG GCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTT >79822_79822_24_SDC4-NRG1_SDC4_chr20_43959005_ENST00000537976_NRG1_chr8_32585466_ENST00000539990_length(amino acids)=581AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP HSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDS NSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASL -------------------------------------------------------------- >79822_79822_25_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000287842_length(transcript)=2006nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGAC CACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCAT GACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAA GAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGAT AGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAG AACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGA TGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGA CAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGC TGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTT >79822_79822_25_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=618AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS SPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFM EEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEV -------------------------------------------------------------- >79822_79822_26_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2549nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT AATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCC ACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAA AATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGA GCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATT GCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTA ATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCA AAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAA >79822_79822_26_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_27_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2558nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCT GTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAA GAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCA TCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGC AGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGG ACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCC AAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTC TCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCC CCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCT ACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGA CAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGT TAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTC CCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAG TCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCT GTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATA AAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATAT GTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTT ATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTC TTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTA TGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTC TGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAG >79822_79822_27_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=629AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHSGEPFPEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQS LRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVI VMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTV SMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTK -------------------------------------------------------------- >79822_79822_28_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2593nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAAC TACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTC GGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGA AACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAAC GTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACT GTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTA GAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGG CATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCT GTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATG GCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAG CAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAA ACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATT GCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACG CCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGC CGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACAC ATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAG AAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAA CGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTG CAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTG TCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCT TTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCA >79822_79822_28_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_29_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2549nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT AATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCC ACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAA AATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGA GCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATT GCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTA ATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCA AAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAA >79822_79822_29_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_30_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1975nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCAT AACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGA CCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGT CCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCA CTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGA AAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGG AGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTC AGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGT GTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCT GCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCC CTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCG GGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGA AACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCG CCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGA >79822_79822_30_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=621AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNM MNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENS RHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVS PFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANR -------------------------------------------------------------- >79822_79822_31_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1924nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCATCTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAA GAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCG GAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCC ACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATC CTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGA AAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACG TCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAG TGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGA AATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGT GACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAG CCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACT CGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAG TAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGC AACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGT >79822_79822_31_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=626AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIEFMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRS ERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMS SVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMP SMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNG -------------------------------------------------------------- >79822_79822_32_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000520407_length(transcript)=1165nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCA GTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGC CTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCT CCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAA GTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAA >79822_79822_32_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=222AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV -------------------------------------------------------------- >79822_79822_33_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000520502_length(transcript)=1148nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACGTCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCA GTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGAGCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGC CTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTCGCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCT CCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGTCAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAA GTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATCTTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAA >79822_79822_33_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=222AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV -------------------------------------------------------------- >79822_79822_34_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1644nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATT CACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAAGAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCAT AACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGA CCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGT CCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCA CTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGA AAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGG AGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCT TATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAGATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCC CCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATT TCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCA GCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCA >79822_79822_34_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=443AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNM MNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENS -------------------------------------------------------------- >79822_79822_35_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1825nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAA GCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCGGTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCG GCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTGTTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCC AGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCGGAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCT CAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATGGCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGC CAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTATCTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAA TCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCTCCACCCTATAGTATCTATTTTATGAAATTCCAAGAAGGGAT >79822_79822_35_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=401AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS -------------------------------------------------------------- >79822_79822_36_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000539990_length(transcript)=2003nt_BP=485nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATCCGAGAGACTGAGGTCATCGACCCCCAGGACCTCCTAGAAGGCCGATACTTCTCCGGAGCCCTACCAGACGATGAGGA TGTAGTGGGGCCCGGGCAGGAATCTGATGACTTTGAGCTGTCTGGCTCTGGAGATCTGGATGACTTGGAAGACTCCATGATCGGCCCTGA AGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCAGGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGA GGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAGGATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGG CAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCCACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGA GAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTTTCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTT TACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCAT CTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCG GCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGT GAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTC CACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTC TGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCG TGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGAC CACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCAT GACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAA GAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGAT AGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAG AACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGA TGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGA CAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGC TGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTT >79822_79822_36_SDC4-NRG1_SDC4_chr20_43959006_ENST00000372733_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=618AA_BP=148 MAPARLFALLLFFVGGVAESIRETEVIDPQDLLEGRYFSGALPDDEDVVGPGQESDDFELSGSGDLDDLEDSMIGPEVVHPLVPLDNHIP ERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSNKVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMV KDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNI ANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHS SPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFM EEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEV -------------------------------------------------------------- >79822_79822_37_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000287842_length(transcript)=1867nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCC AAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAG AGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCC GCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAA GAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAAC ACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTG GCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAG GCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTT >79822_79822_37_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000287842_length(amino acids)=581AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP HSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDS NSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASL -------------------------------------------------------------- >79822_79822_38_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000287845_length(transcript)=2410nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC TTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATA GATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAA ACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGA GAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAA AACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCC CTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTG CTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGC >79822_79822_38_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000287845_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_39_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000338921_length(transcript)=2419nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGCATTCTGGAGAACCCTTTCCAGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTT GTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCT GAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCT AAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCC ACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCA TCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTC CTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATG TCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCT TCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCAC CCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAG TATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGC CACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAA GATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCA GCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAAT AAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGC AAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATT TCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTA TTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTG CAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAG TTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCA >79822_79822_39_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000338921_length(amino acids)=592AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKHS GEPFPEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_40_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000341377_length(transcript)=2454nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCGGAGGAGCTGTACCAGAAGAGAG TGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAA AGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCC CCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTT CCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCA TCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTA ATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAA GGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGT CTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACAC CACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCC CTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCA ATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACT CAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACAC CTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTG CTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTT AAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAAACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGT GTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGAGAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAG TTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAAAACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATT ATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCCCTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGC ACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTGCTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGT TTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGCTACTATTAAATACAGCAAGAAACTGCATTAAGTAATGTTAAATATT >79822_79822_40_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000341377_length(amino acids)=412AA_BP= MASFYKAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVI SSEHIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHA RETPDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQF SSFHHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPF -------------------------------------------------------------- >79822_79822_41_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000356819_length(transcript)=2410nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC TTCTCGACACAGGAAGAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATA GATTCACCTGTAAAACTTTATTTTATATAATAAAGTATTCCACCTTAAATTAAACAATTTATTTTATTTTAGCAGTTCTGCAAATAGAAA ACAGGAAAAAAACTTTTATAAATTAAATATATGTATGTAAAAATGTGTTATGTGCCATATGTAGCAATTTTTTACAGTATTTCAAAACGA GAAAGATATCAATGGTGCCTTTATGTTATGTTATGTCGAGAGCAAGTTTTGTACAGTTACAGTGATTGCTTTTCCACAGTATTTCTGCAA AACCTCTCATAGATTCAGTTTTTGCTGGCTTCTTGTGCATTGCATTATGATGTTGACTGGATGTATGATTTGCAAGACTTGCAACTGTCC CTCTGTTTGCTTGTAGTAGCACCCGATCAGTATGTCTTGTAATGGCACATCCATCCAGATATGCCTCTCTTGTGTATGAAGTTTTCTTTG CTTTCAGAATATGAAATGAGTTGTGTCTACTCTGCCAGCCAAAGGTTTGCCTCATTGGGCTCTGAGATAATAGTAGATCCAACAGCATGC >79822_79822_41_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000356819_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_42_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000405005_length(transcript)=1836nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTG GCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATT GCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCAT ATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGC CACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGC AGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCT GATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCA AGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATG GAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCAC CACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAG CCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTG GACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAG AACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAA GAAATCCAGGCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAA >79822_79822_42_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000405005_length(amino acids)=584AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAE ELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVER EAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYR DSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPA HDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLA -------------------------------------------------------------- >79822_79822_43_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000519301_length(transcript)=1785nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGCAT CTTGGGATTGAATTTATGGAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGC ATCATGTGTGTGGTGGCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAAC AATATGATGAACATTGCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTC ATCTCCAGTGAGCATATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTC ACCCAGACTCCTAGCCACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAA AACAGTAGGCACAGCAGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCAT GCCAGAGAAACCCCTGATTCCTACCGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTA GATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCG GTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAG TTCAGCTCCTTCCACCACAACCCCGCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACG ACCCAAGAGTACGAGCCAGCCCAAGAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCT AACAGATTGGAAGTGGACAGCAACACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCT TTCCTGGGCATACAGAACCCCCTGGCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGC >79822_79822_43_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000519301_length(amino acids)=589AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKHLGIE FMEAEELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSE HIVEREAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARET PDSYRDSPHSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSF HHNPAHDSNSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGI -------------------------------------------------------------- >79822_79822_44_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000520407_length(transcript)=1026nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACG TCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGA GCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTC GCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGT CAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATC TTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAG >79822_79822_44_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000520407_length(amino acids)=185AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYSTSTPF -------------------------------------------------------------- >79822_79822_45_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000520502_length(transcript)=1009nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAGTACG TCCACTCCCTTTCTGTCTCTGCCTGAATAGGAGCATGCTCAGTTGGTGCTGCTTTCTTGTTGCTGCATCTCCCCTCAGATTCCACCTAGA GCTAGATGTGTCTTACCAGATCTAATATTGACTGCCTCTGCCTGTCGCATGAGAACATTAACAAAAGCAATTGTATTACTTCCTCTGTTC GCGACTAGTTGGCTCTGAGATACTAATAGGTGTGTGAGGCTCCGGATGTTTCTGGAATTGATATTGAATGATGTGATACAAATTGATAGT CAATATCAAGCAGTGAAATATGATAATAAAGGCATTTCAAAGTCTCACTTTTATTGATAAAATAAAAATCATTCTACTGAACAGTCCATC TTCTTTATACAATGACCACATCCTGAAAAGGGTGTTGCTAAGCTGTAACCGATATGCACTTGAAATGATGGTAAGTTAATTTTGATTCAG >79822_79822_45_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000520502_length(amino acids)=185AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYSTSTPF -------------------------------------------------------------- >79822_79822_46_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000521670_length(transcript)=1505nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCAACCTGGATTCACTGGAGCAAGATGTACTGAGAATGTGCCCATGAAAGTCCAAAACCAA GAAAAGGCGGAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTG GCCTACTGCAAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATT GCCAATGGGCCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCAT ATTGTTGAGAGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGC CACAGCTGGAGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGC AGCCCAACTGGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCT GATTCCTACCGAGACTCTCCTCATAGTGAAAGACATAACCTTATAGCTGAGCTAAGGAGAAACAAGGCACACAGATCCAAATGCATGCAG ATCCAGCTATCAGCAACTCATCTTAGATCTTCTTCCATTCCCCATTTGGGCTTCATTCTCTAAGACCCCTTGGCCTTTAGGAAGGTATGT GTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCCAAATCGCCCCCTTCGGAAATGTCTCCACC CGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAGAGACCTCTACTTCTCGTGACACCACCAAG >79822_79822_46_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000521670_length(amino acids)=406AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCQPGFTGARCTENVPMKVQNQEKAE ELYQKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVER EAETSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYR -------------------------------------------------------------- >79822_79822_47_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000523079_length(transcript)=1686nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTAAAACCGAAGGGCAAAGCTACTGCAGAGGAGAAACTCAGTCAGAGAATCCCTGTGAGCACCTGCG GTCTCACCTCAGGAAATCTACTCTAATCAGAATAAGGGGCGGCAGTTACCTGTTCTAGGAGTGCTCCTAGTTGATGAAGTCATCTCTTTG TTTGACGGAACTTATTTCTTCTGAGCTTCTCTCGTCGTCCCAGTGACTGACAGGCAACAGACTCTTAAAGAGCTGGGATGCTTTGATGCG GAAGGTGCAGCACATGGAGTTTCCAGCTCTGGCCATGGGCTCAGACCCACTCGGGGTCTCAGTGTCCTCAGTTGTAACATTAGAGAGATG GCATCAATGCTTGATAAGGACCCTTCTATAATTCCAATTGCCAGTTATCCAAACTCTGATTCGGTGGTCGAGCTGGCCTCGTGTTCTTAT CTGCTAACCCTGTCTTACCTTCCAGCCTCAGTTAAGTCAAATCAAGGGCTATGTCATTGCTGAATGTCATGGGGGGCAACTGCTTGCCCT >79822_79822_47_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000523079_length(amino acids)=364AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP -------------------------------------------------------------- >79822_79822_48_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000539990_length(transcript)=1864nt_BP=346nt ACTCGCCGCAGCCTGCGCGCCTTCTCCAGTCCGCGGTGCCATGGCCCCCGCCCGTCTGTTCGCGCTGCTGCTGTTCTTCGTAGGCGGAGT CGCCGAGTCGATGACTTGGAAGACTCCATGATCGGCCCTGAAGTTGTCCATCCCTTGGTGCCTCTAGATAACCATATCCCTGAGAGGGCA GGGTCTGGGAGCCAAGTCCCCACCGAACCCAAGAAACTAGAGGAGAATGAGGTTATCCCCAAGAGAATCTCACCCGTTGAAGAGAGTGAG GATGTGTCCAACAAGGTGTCAATGTCCAGCACTGTGCAGGGCAGCAACATCTTTGAGAGAACGGAGGTCCTGGCAGCTACATCTACATCC ACCACTGGGACAAGCCATCTTGTAAAATGTGCGGAGAAGGAGAAAACTTTCTGTGTGAATGGAGGGGAGTGCTTCATGGTGAAAGACCTT TCAAACCCCTCGAGATACTTGTGCAAGTGCCCAAATGAGTTTACTGGTGATCGCTGCCAAAACTACGTAATGGCCAGCTTCTACAAGGCG GAGGAGCTGTACCAGAAGAGAGTGCTGACCATAACCGGCATCTGCATCGCCCTCCTTGTGGTCGGCATCATGTGTGTGGTGGCCTACTGC AAAACCAAGAAACAGCGGAAAAAGCTGCATGACCGTCTTCGGCAGAGCCTTCGGTCTGAACGAAACAATATGATGAACATTGCCAATGGG CCTCACCATCCTAACCCACCCCCCGAGAATGTCCAGCTGGTGAATCAATACGTATCTAAAAACGTCATCTCCAGTGAGCATATTGTTGAG AGAGAAGCAGAGACATCCTTTTCCACCAGTCACTATACTTCCACAGCCCATCACTCCACTACTGTCACCCAGACTCCTAGCCACAGCTGG AGCAACGGACACACTGAAAGCATCCTTTCCGAAAGCCACTCTGTAATCGTGATGTCATCCGTAGAAAACAGTAGGCACAGCAGCCCAACT GGGGGCCCAAGAGGACGTCTTAATGGCACAGGAGGCCCTCGTGAATGTAACAGCTTCCTCAGGCATGCCAGAGAAACCCCTGATTCCTAC CGAGACTCTCCTCATAGTGAAAGGTATGTGTCAGCCATGACCACCCCGGCTCGTATGTCACCTGTAGATTTCCACACGCCAAGCTCCCCC AAATCGCCCCCTTCGGAAATGTCTCCACCCGTGTCCAGCATGACGGTGTCCATGCCTTCCATGGCGGTCAGCCCCTTCATGGAAGAAGAG AGACCTCTACTTCTCGTGACACCACCAAGGCTGCGGGAGAAGAAGTTTGACCATCACCCTCAGCAGTTCAGCTCCTTCCACCACAACCCC GCGCATGACAGTAACAGCCTCCCTGCTAGCCCCTTGAGGATAGTGGAGGATGAGGAGTATGAAACGACCCAAGAGTACGAGCCAGCCCAA GAGCCTGTTAAGAAACTCGCCAATAGCCGGCGGGCCAAAAGAACCAAGCCCAATGGCCACATTGCTAACAGATTGGAAGTGGACAGCAAC ACAAGCTCCCAGAGCAGTAACTCAGAGAGTGAAACAGAAGATGAAAGAGTAGGTGAAGATACGCCTTTCCTGGGCATACAGAACCCCCTG GCAGCCAGTCTTGAGGCAACACCTGCCTTCCGCCTGGCTGACAGCAGGACTAACCCAGCAGGCCGCTTCTCGACACAGGAAGAAATCCAG GCCAGGCTGTCTAGTGTAATTGCTAACCAAGACCCTATTGCTGTATAAAACCTAAATAAACACATAGATTCACCTGTAAAACTTTATTTT >79822_79822_48_SDC4-NRG1_SDC4_chr20_43959006_ENST00000537976_NRG1_chr8_32585467_ENST00000539990_length(amino acids)=581AA_BP=111 MRAFSSPRCHGPRPSVRAAAVLRRRSRRVDDLEDSMIGPEVVHPLVPLDNHIPERAGSGSQVPTEPKKLEENEVIPKRISPVEESEDVSN KVSMSSTVQGSNIFERTEVLAATSTSTTGTSHLVKCAEKEKTFCVNGGECFMVKDLSNPSRYLCKCPNEFTGDRCQNYVMASFYKAEELY QKRVLTITGICIALLVVGIMCVVAYCKTKKQRKKLHDRLRQSLRSERNNMMNIANGPHHPNPPPENVQLVNQYVSKNVISSEHIVEREAE TSFSTSHYTSTAHHSTTVTQTPSHSWSNGHTESILSESHSVIVMSSVENSRHSSPTGGPRGRLNGTGGPRECNSFLRHARETPDSYRDSP HSERYVSAMTTPARMSPVDFHTPSSPKSPPSEMSPPVSSMTVSMPSMAVSPFMEEERPLLLVTPPRLREKKFDHHPQQFSSFHHNPAHDS NSLPASPLRIVEDEEYETTQEYEPAQEPVKKLANSRRAKRTKPNGHIANRLEVDSNTSSQSSNSESETEDERVGEDTPFLGIQNPLAASL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SDC4-NRG1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SDC4-NRG1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SDC4-NRG1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies