
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SEC14L1-GALK1 (FusionGDB2 ID:79981) |
Fusion Gene Summary for SEC14L1-GALK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SEC14L1-GALK1 | Fusion gene ID: 79981 | Hgene | Tgene | Gene symbol | SEC14L1 | GALK1 | Gene ID | 6397 | 2584 |
| Gene name | SEC14 like lipid binding 1 | galactokinase 1 | |
| Synonyms | PRELID4A|SEC14L | GALK|GK1|HEL-S-19 | |
| Cytomap | 17q25.2-q25.3 | 17q25.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | SEC14-like protein 1 | galactokinaseepididymis secretory protein Li 19galactose kinase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000392476, ENST00000413679, ENST00000430767, ENST00000436233, ENST00000443798, ENST00000585618, ENST00000431431, ENST00000564509, ENST00000591437, | ENST00000225614, ENST00000437911, ENST00000588479, | |
| Fusion gene scores | * DoF score | 14 X 8 X 8=896 | 4 X 2 X 4=32 |
| # samples | 14 | 5 | |
| ** MAII score | log2(14/896*10)=-2.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/32*10)=0.643856189774725 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: SEC14L1 [Title/Abstract] AND GALK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SEC14L1(75139741)-GALK1(73760167), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SEC14L1 | GO:0015871 | choline transport | 17092608 |
| Fusion gene breakpoints across SEC14L1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
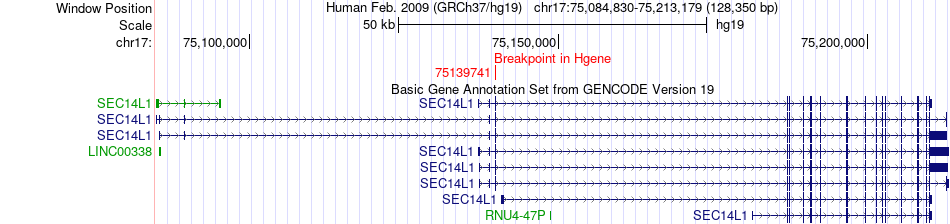 |
| Fusion gene breakpoints across GALK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
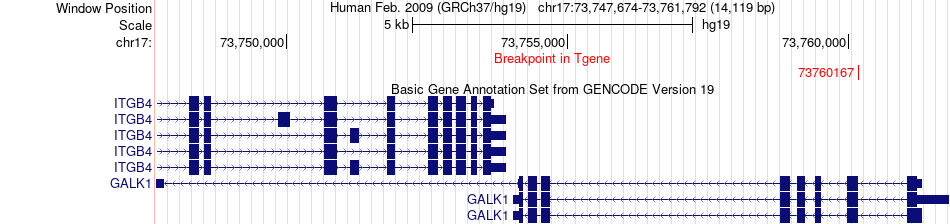 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-50-6590-01A | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
Top |
Fusion Gene ORF analysis for SEC14L1-GALK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000392476 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000392476 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000392476 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000413679 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000413679 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000413679 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000430767 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000430767 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000430767 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000436233 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000436233 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000436233 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000443798 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000443798 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000443798 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000585618 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000585618 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| In-frame | ENST00000585618 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000431431 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000431431 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000431431 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000564509 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000564509 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000564509 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000591437 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000591437 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| intron-3CDS | ENST00000591437 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000392476 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1802 | 622 | 559 | 1635 | 358 |
| ENST00000392476 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1748 | 622 | 559 | 1635 | 358 |
| ENST00000392476 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1746 | 622 | 559 | 1635 | 358 |
| ENST00000430767 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1599 | 419 | 356 | 1432 | 358 |
| ENST00000430767 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1545 | 419 | 356 | 1432 | 358 |
| ENST00000430767 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1543 | 419 | 356 | 1432 | 358 |
| ENST00000585618 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1501 | 321 | 258 | 1334 | 358 |
| ENST00000585618 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1447 | 321 | 258 | 1334 | 358 |
| ENST00000585618 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1445 | 321 | 258 | 1334 | 358 |
| ENST00000413679 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1546 | 366 | 303 | 1379 | 358 |
| ENST00000413679 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1492 | 366 | 303 | 1379 | 358 |
| ENST00000413679 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1490 | 366 | 303 | 1379 | 358 |
| ENST00000436233 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1507 | 327 | 264 | 1340 | 358 |
| ENST00000436233 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1453 | 327 | 264 | 1340 | 358 |
| ENST00000436233 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1451 | 327 | 264 | 1340 | 358 |
| ENST00000443798 | SEC14L1 | chr17 | 75139741 | - | ENST00000225614 | GALK1 | chr17 | 73760167 | - | 1454 | 274 | 211 | 1287 | 358 |
| ENST00000443798 | SEC14L1 | chr17 | 75139741 | - | ENST00000588479 | GALK1 | chr17 | 73760167 | - | 1400 | 274 | 211 | 1287 | 358 |
| ENST00000443798 | SEC14L1 | chr17 | 75139741 | - | ENST00000437911 | GALK1 | chr17 | 73760167 | - | 1398 | 274 | 211 | 1287 | 358 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000392476 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.036197472 | 0.9638026 |
| ENST00000392476 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.030914988 | 0.969085 |
| ENST00000392476 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.03063942 | 0.9693606 |
| ENST00000430767 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.033302188 | 0.9666978 |
| ENST00000430767 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.027132984 | 0.972867 |
| ENST00000430767 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.026788132 | 0.9732118 |
| ENST00000585618 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.035399232 | 0.96460074 |
| ENST00000585618 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.03187891 | 0.9681211 |
| ENST00000585618 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.031359605 | 0.9686404 |
| ENST00000413679 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.036161292 | 0.9638387 |
| ENST00000413679 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.032235473 | 0.9677645 |
| ENST00000413679 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.031802915 | 0.9681971 |
| ENST00000436233 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.035169497 | 0.9648305 |
| ENST00000436233 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.030971507 | 0.9690285 |
| ENST00000436233 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.030528786 | 0.9694713 |
| ENST00000443798 | ENST00000225614 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.03406595 | 0.96593404 |
| ENST00000443798 | ENST00000588479 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.029628756 | 0.97037125 |
| ENST00000443798 | ENST00000437911 | SEC14L1 | chr17 | 75139741 | - | GALK1 | chr17 | 73760167 | - | 0.029075753 | 0.97092426 |
Top |
Fusion Genomic Features for SEC14L1-GALK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
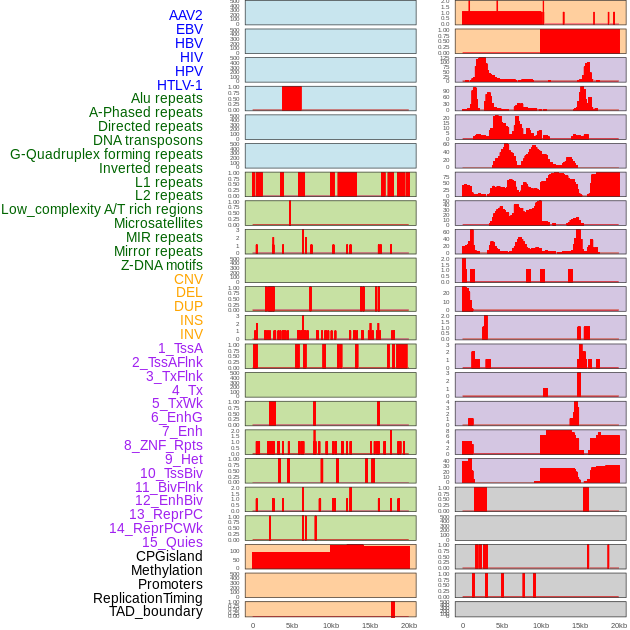 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SEC14L1-GALK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:75139741/chr17:73760167) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000225614 | 0 | 9 | 134_144 | 55 | 320.6666666666667 | Nucleotide binding | Note=ATP | |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000588479 | 0 | 8 | 134_144 | 55 | 393.0 | Nucleotide binding | Note=ATP | |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000225614 | 0 | 9 | 183_186 | 55 | 320.6666666666667 | Region | Note=Substrate binding | |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000588479 | 0 | 8 | 183_186 | 55 | 393.0 | Region | Note=Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000392476 | - | 5 | 20 | 1_175 | 21 | 720.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000392476 | - | 5 | 20 | 319_495 | 21 | 720.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000392476 | - | 5 | 20 | 521_674 | 21 | 720.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000413679 | - | 3 | 18 | 1_175 | 21 | 1018.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000413679 | - | 3 | 18 | 319_495 | 21 | 1018.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000413679 | - | 3 | 18 | 521_674 | 21 | 1018.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000430767 | - | 4 | 18 | 1_175 | 21 | 716.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000430767 | - | 4 | 18 | 319_495 | 21 | 716.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000430767 | - | 4 | 18 | 521_674 | 21 | 716.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000431431 | - | 1 | 15 | 1_175 | 0 | 682.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000431431 | - | 1 | 15 | 319_495 | 0 | 682.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000431431 | - | 1 | 15 | 521_674 | 0 | 682.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000436233 | - | 3 | 17 | 1_175 | 21 | 716.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000436233 | - | 3 | 17 | 319_495 | 21 | 716.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000436233 | - | 3 | 17 | 521_674 | 21 | 716.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000443798 | - | 3 | 18 | 1_175 | 21 | 720.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000443798 | - | 3 | 18 | 319_495 | 21 | 720.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000443798 | - | 3 | 18 | 521_674 | 21 | 720.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000585618 | - | 3 | 17 | 1_175 | 21 | 716.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000585618 | - | 3 | 17 | 319_495 | 21 | 716.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000585618 | - | 3 | 17 | 521_674 | 21 | 716.0 | Domain | GOLD |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000591437 | - | 1 | 15 | 1_175 | 0 | 682.0 | Domain | PRELI/MSF1 |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000591437 | - | 1 | 15 | 319_495 | 0 | 682.0 | Domain | CRAL-TRIO |
| Hgene | SEC14L1 | chr17:75139741 | chr17:73760167 | ENST00000591437 | - | 1 | 15 | 521_674 | 0 | 682.0 | Domain | GOLD |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000225614 | 0 | 9 | 43_46 | 55 | 320.6666666666667 | Region | Note=Substrate binding | |
| Tgene | GALK1 | chr17:75139741 | chr17:73760167 | ENST00000588479 | 0 | 8 | 43_46 | 55 | 393.0 | Region | Note=Substrate binding |
Top |
Fusion Gene Sequence for SEC14L1-GALK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >79981_79981_1_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1802nt_BP=622nt ACTCGCAGTCCGCAGGATGACTCAGGGCAGCCCTGACCACAGTTCCGCCGCCATCGGCCCTAGCCTGCGGAATTGGGCTCGCCCCGGGAC GATAACAGAGCTCTGCCGGGGGCTGGAGGCACTGACCGGGTGACCAGAGACCCAGAGACCAGACCCCCTCCACGGCGCCCGGGATTTCGG GGACGGCTTCTCCCATCGCAAGTTTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTC CTGCCCCTCGTTGATGAGAGCATTCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATAT CTGGTTTTGTCTCTGCTGGGCCTGTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATAT TCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGG TTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGA GCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCT GCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCC AGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGC CACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGC AGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGAC CAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGT GCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGA CCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGG CGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCT GGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGC CTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAA GGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTAACACGATCTCGGTT CACTGCAACCTGCGCCTTCTGGGTTCAAGTGATTCTCCTGCCTCAGCCTCCTGACTAGCTGGGACTACAGGCATGAGCCACCATGCCTGT >79981_79981_1_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_2_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1746nt_BP=622nt ACTCGCAGTCCGCAGGATGACTCAGGGCAGCCCTGACCACAGTTCCGCCGCCATCGGCCCTAGCCTGCGGAATTGGGCTCGCCCCGGGAC GATAACAGAGCTCTGCCGGGGGCTGGAGGCACTGACCGGGTGACCAGAGACCCAGAGACCAGACCCCCTCCACGGCGCCCGGGATTTCGG GGACGGCTTCTCCCATCGCAAGTTTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTC CTGCCCCTCGTTGATGAGAGCATTCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATAT CTGGTTTTGTCTCTGCTGGGCCTGTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATAT TCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGG TTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGA GCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCT GCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCC AGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGC CACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGC AGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGAC CAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGT GCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGA CCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGG CGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCT GGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGC CTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAA GGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCAT >79981_79981_2_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_3_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1748nt_BP=622nt ACTCGCAGTCCGCAGGATGACTCAGGGCAGCCCTGACCACAGTTCCGCCGCCATCGGCCCTAGCCTGCGGAATTGGGCTCGCCCCGGGAC GATAACAGAGCTCTGCCGGGGGCTGGAGGCACTGACCGGGTGACCAGAGACCCAGAGACCAGACCCCCTCCACGGCGCCCGGGATTTCGG GGACGGCTTCTCCCATCGCAAGTTTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTC CTGCCCCTCGTTGATGAGAGCATTCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATAT CTGGTTTTGTCTCTGCTGGGCCTGTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATAT TCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGG TTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGA GCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCT GCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCC AGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGC CACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGC AGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGAC CAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGT GCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGA CCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGG CGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCT GGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGC CTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAA GGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCAT >79981_79981_3_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000392476_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_4_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1546nt_BP=366nt CAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAA CCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGG CTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGA CAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATT ATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGAT GAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTG ATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCA TCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCC GAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGC AGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCC AGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTA GAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCC GCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCA GAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTG ACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCA GCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTA ACACGATCTCGGTTCACTGCAACCTGCGCCTTCTGGGTTCAAGTGATTCTCCTGCCTCAGCCTCCTGACTAGCTGGGACTACAGGCATGA >79981_79981_4_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_5_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1490nt_BP=366nt CAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAA CCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGG CTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGA CAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATT ATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGAT GAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTG ATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCA TCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCC GAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGC AGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCC AGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTA GAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCC GCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCA GAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTG ACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCA GCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCT >79981_79981_5_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_6_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1492nt_BP=366nt CAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAA CCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGG CTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGA CAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATT ATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGAT GAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTG ATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCA TCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCC GAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGC AGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCC AGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTA GAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCC GCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCA GAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTG ACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCA GCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCT >79981_79981_6_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000413679_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_7_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1599nt_BP=419nt TTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTCCTGCCCCTCGTTGATGAGAGCAT TCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATATCTGGTTTTGTCTCTGCTGGGCCT GTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATC CTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGG TGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCA GCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCC AGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCA GTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGC TCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGG ACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACC CCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAG TGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCC GGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCC TCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGC CTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGC GGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCC CCAGGACAGCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTAACACGATCTCGGTTCACTGCAACCTGCGCCTTCTGGG >79981_79981_7_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_8_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1543nt_BP=419nt TTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTCCTGCCCCTCGTTGATGAGAGCAT TCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATATCTGGTTTTGTCTCTGCTGGGCCT GTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATC CTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGG TGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCA GCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCC AGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCA GTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGC TCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGG ACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACC CCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAG TGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCC GGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCC TCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGC CTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGC GGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCC CCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATA >79981_79981_8_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_9_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1545nt_BP=419nt TTCAACAGAAAATGAGAAATATCCCCCGACGATTGGCTGAAAACATGCAGCAACCACTATTTTCTTCCTGCCCCTCGTTGATGAGAGCAT TCGAAGTGACCTCAGCAGGGCATCCAGGTCAGTTTCTGGAAGACTTGTGTGTGTGATGAATGAATATCTGGTTTTGTCTCTGCTGGGCCT GTGTGCCTGGAAAGGAATTGTTTTGGCCTAGGATCATCCAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATC CTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGG TGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCA GCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCC AGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCA GTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGC TCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGG ACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACC CCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAG TGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCC GGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCC TCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGC CTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGC GGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCC CCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATA >79981_79981_9_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000430767_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_10_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1507nt_BP=327nt CGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCT CGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCT CTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTG CAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGC CCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAG CGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGT GCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTC TGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGAC CAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCC AAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTG GCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGG CGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTC ATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCT GGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGG CACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCC AGGACAGCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTAACACGATCTCGGTTCACTGCAACCTGCGCCTTCTGGGTT >79981_79981_10_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_11_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1451nt_BP=327nt CGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCT CGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCT CTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTG CAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGC CCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAG CGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGT GCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTC TGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGAC CAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCC AAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTG GCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGG CGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTC ATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCT GGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGG CACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCC AGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATAAA >79981_79981_11_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_12_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1453nt_BP=327nt CGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAGCAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCT CGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCT CTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTG CAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGC CCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAG CGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGT GCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTC TGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGAC CAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCC AAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTG GCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGG CGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTC ATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCT GGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGG CACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCC AGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATAAA >79981_79981_12_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000436233_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_13_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1454nt_BP=274nt GAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCT CCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACA GGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTAT GGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGA GCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGAT TCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATC CTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGA GCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAG GTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAG CGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGA GGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGC CCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGA GCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGAC ACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGC CGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTAAC ACGATCTCGGTTCACTGCAACCTGCGCCTTCTGGGTTCAAGTGATTCTCCTGCCTCAGCCTCCTGACTAGCTGGGACTACAGGCATGAGC >79981_79981_13_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_14_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1398nt_BP=274nt GAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCT CCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACA GGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTAT GGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGA GCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGAT TCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATC CTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGA GCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAG GTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAG CGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGA GGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGC CCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGA GCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGAC ACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGC CGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGT >79981_79981_14_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_15_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1400nt_BP=274nt GAGACTGCCCCGCGGAGCCGCCGGTATGAGCGCCCCTCGCCACCCCGTGTCCCAGGCCCGGCCTTTCTGACAAGAGCTAGACTTCGGGCT CCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACCATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACA GGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAATACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTAT GGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGCAAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGA GCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCGCTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGAT TCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTGGTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATC CTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCAGACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGA GCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTCATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAG GTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTGGCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAG CGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGGGCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGA GGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCCCGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGC CCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTGGAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGA GCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTTTATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGAC ACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATCCAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGC CGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACAGCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGT >79981_79981_15_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000443798_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_16_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000225614_length(transcript)=1501nt_BP=321nt AACAACCACAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAG CAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACC ATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAA TACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGC AAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCG CTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTG GTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCA GACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTC ATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTG GCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGG GCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCC CGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTG GAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTT TATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATC CAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACA GCACACGACGGAGTCTGGCTCTGTCACCCTGTCTGGAGTGCGGTAACACGATCTCGGTTCACTGCAACCTGCGCCTTCTGGGTTCAAGTG >79981_79981_16_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000225614_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_17_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000437911_length(transcript)=1445nt_BP=321nt AACAACCACAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAG CAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACC ATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAA TACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGC AAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCG CTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTG GTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCA GACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTC ATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTG GCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGG GCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCC CGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTG GAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTT TATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATC CAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACA GCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATAAACTTGTG >79981_79981_17_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000437911_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- >79981_79981_18_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000588479_length(transcript)=1447nt_BP=321nt AACAACCACAAGTGCCGTCGCCGCGCCCCTTCCCCCTCCCGCCTCCCCGGCCCCCTCCCCGGAACCGGCGGTCGAGCTACGGTCGCGGAG CAGTGGAACCGAGACTGCCCCGCGGAGCCGCCGCTAGACTTCGGGCTCCTTGAGGATATTCAGTTTTGTATGTTTGAATATCCTCTCACC ATGTTCAGCATAAAGTACCATTCTTAATGATTATCCTCAACAAGACAGGTGTGAGAGGGTTGCTGTTGTATTGCAATCATGGTGCAGAAA TACCAGTCCCCAGTGAGGGTGTACAAATACCCCTTTGAATTAATTATGGCTGCTCTGGAGCTCATGACGGTGCTGGTGGGCAGCCCCCGC AAGGATGGGCTGGTGTCTCTCCTCACCACCTCTGAGGGTGCCGATGAGCCCCAGCGGCTGCAGTTTCCACTGCCCACAGCCCAGCGCTCG CTGGAGCCTGGGACTCCTCGGTGGGCCAACTATGTCAAGGGAGTGATTCAGTACTACCCAGCTGCCCCCCTCCCTGGCTTCAGTGCAGTG GTGGTCAGCTCAGTGCCCCTGGGGGGTGGCCTGTCCAGCTCAGCATCCTTGGAAGTGGCCACGTACACCTTCCTCCAGCAGCTCTGTCCA GACTCGGGCACAATAGCTGCCCGCGCCCAGGTGTGTCAGCAGGCCGAGCACAGCTTCGCAGGGATGCCCTGTGGCATCATGGACCAGTTC ATCTCACTTATGGGACAGAAAGGCCACGCGCTGCTCATTGACTGCAGGTCCTTGGAGACCAGCCTGGTGCCACTCTCGGACCCCAAGCTG GCCGTGCTCATCACCAACTCTAATGTCCGCCACTCCCTGGCCTCCAGCGAGTACCCTGTGCGGCGGCGCCAATGTGAAGAAGTGGCCCGG GCGCTGGGCAAGGAAAGCCTCCGGGAGGTACAACTGGAAGAGCTAGAGGCTGCCAGGGACCTGGTGAGCAAAGAGGGCTTCCGGCGGGCC CGGCACGTGGTGGGGGAGATTCGGCGCACGGCCCAGGCAGCGGCCGCCCTGAGACGTGGCGACTACAGAGCCTTTGGCCGCCTCATGGTG GAGAGCCACCGCTCACTCAGAGACGACTATGAGGTGAGCTGCCCAGAGCTGGACCAGCTGGTGGAGGCTGCGCTTGCTGTGCCTGGGGTT TATGGCAGCCGCATGACGGGCGGTGGCTTCGGTGGCTGCACGGTGACACTGCTGGAGGCCTCCGCTGCTCCCCACGCCATGCGGCACATC CAGGAGCACTACGGCGGGACTGCCACCTTCTACCTCTCTCAAGCAGCCGATGGAGCCAAGGTGCTGTGCTTGTGAGGCACCCCCAGGACA GCACACGGTGAGGGTGCGGGGCCTGCAGGCCAGTCCCACGGCTCTGTGCCCGGTGCCATCTTCCATATCCGGGTGCTCAATAAACTTGTG >79981_79981_18_SEC14L1-GALK1_SEC14L1_chr17_75139741_ENST00000585618_GALK1_chr17_73760167_ENST00000588479_length(amino acids)=358AA_BP=21 MVQKYQSPVRVYKYPFELIMAALELMTVLVGSPRKDGLVSLLTTSEGADEPQRLQFPLPTAQRSLEPGTPRWANYVKGVIQYYPAAPLPG FSAVVVSSVPLGGGLSSSASLEVATYTFLQQLCPDSGTIAARAQVCQQAEHSFAGMPCGIMDQFISLMGQKGHALLIDCRSLETSLVPLS DPKLAVLITNSNVRHSLASSEYPVRRRQCEEVARALGKESLREVQLEELEAARDLVSKEGFRRARHVVGEIRRTAQAAAALRRGDYRAFG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SEC14L1-GALK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SEC14L1-GALK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SEC14L1-GALK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies