
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SEMA4B-GLUD1 (FusionGDB2 ID:80311) |
Fusion Gene Summary for SEMA4B-GLUD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SEMA4B-GLUD1 | Fusion gene ID: 80311 | Hgene | Tgene | Gene symbol | SEMA4B | GLUD1 | Gene ID | 10509 | 2746 |
| Gene name | semaphorin 4B | glutamate dehydrogenase 1 | |
| Synonyms | SEMAC|SemC | GDH|GDH1|GLUD | |
| Cytomap | 15q26.1 | 10q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | semaphorin-4Bsema domain, immunoglobulin domain (Ig), transmembrane domain (TM) and short cytoplasmic domain, (semaphorin) 4Bsema domain, immunoglobulin domain (Ig), transmembrane domain (TM) and short cytoplasmic domain, 4Bsemaphorin-C | glutamate dehydrogenase 1, mitochondrialepididymis secretory sperm binding proteinepididymis tissue sperm binding protein Li 18mPglutamate dehydrogenase (NAD(P)+) | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | P00367 | |
| Ensembl transtripts involved in fusion gene | ENST00000332496, ENST00000379122, ENST00000411539, ENST00000560263, | ENST00000465164, ENST00000277865, ENST00000537649, ENST00000544149, | |
| Fusion gene scores | * DoF score | 16 X 9 X 11=1584 | 10 X 7 X 8=560 |
| # samples | 21 | 11 | |
| ** MAII score | log2(21/1584*10)=-2.91511110241349 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/560*10)=-2.34792330342031 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SEMA4B [Title/Abstract] AND GLUD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SEMA4B(90744967)-GLUD1(88827914), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GLUD1 | GO:0006537 | glutamate biosynthetic process | 11032875 |
| Tgene | GLUD1 | GO:0006538 | glutamate catabolic process | 6121377|11032875 |
| Fusion gene breakpoints across SEMA4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GLUD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-IG-A5B8 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
Top |
Fusion Gene ORF analysis for SEMA4B-GLUD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000332496 | ENST00000465164 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000379122 | ENST00000465164 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000411539 | ENST00000465164 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000332496 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000332496 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000332496 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000379122 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000379122 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000379122 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000411539 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000411539 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000411539 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000560263 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000560263 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000560263 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| intron-intron | ENST00000560263 | ENST00000465164 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379122 | SEMA4B | chr15 | 90744967 | + | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2736 | 440 | 142 | 1470 | 442 |
| ENST00000379122 | SEMA4B | chr15 | 90744967 | + | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2732 | 440 | 142 | 1470 | 442 |
| ENST00000379122 | SEMA4B | chr15 | 90744967 | + | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1621 | 440 | 142 | 1470 | 442 |
| ENST00000332496 | SEMA4B | chr15 | 90744967 | + | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2693 | 397 | 99 | 1427 | 442 |
| ENST00000332496 | SEMA4B | chr15 | 90744967 | + | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2689 | 397 | 99 | 1427 | 442 |
| ENST00000332496 | SEMA4B | chr15 | 90744967 | + | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1578 | 397 | 99 | 1427 | 442 |
| ENST00000411539 | SEMA4B | chr15 | 90744967 | + | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2713 | 417 | 191 | 1447 | 418 |
| ENST00000411539 | SEMA4B | chr15 | 90744967 | + | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2709 | 417 | 191 | 1447 | 418 |
| ENST00000411539 | SEMA4B | chr15 | 90744967 | + | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1598 | 417 | 191 | 1447 | 418 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379122 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000805687 | 0.9991943 |
| ENST00000379122 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000811604 | 0.99918836 |
| ENST00000379122 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.002292869 | 0.9977071 |
| ENST00000332496 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000784535 | 0.9992155 |
| ENST00000332496 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000789733 | 0.99921024 |
| ENST00000332496 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.00230156 | 0.9976985 |
| ENST00000411539 | ENST00000277865 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000833856 | 0.99916613 |
| ENST00000411539 | ENST00000537649 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.000841342 | 0.9991586 |
| ENST00000411539 | ENST00000544149 | SEMA4B | chr15 | 90744967 | + | GLUD1 | chr10 | 88827914 | - | 0.00252341 | 0.99747664 |
Top |
Fusion Genomic Features for SEMA4B-GLUD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
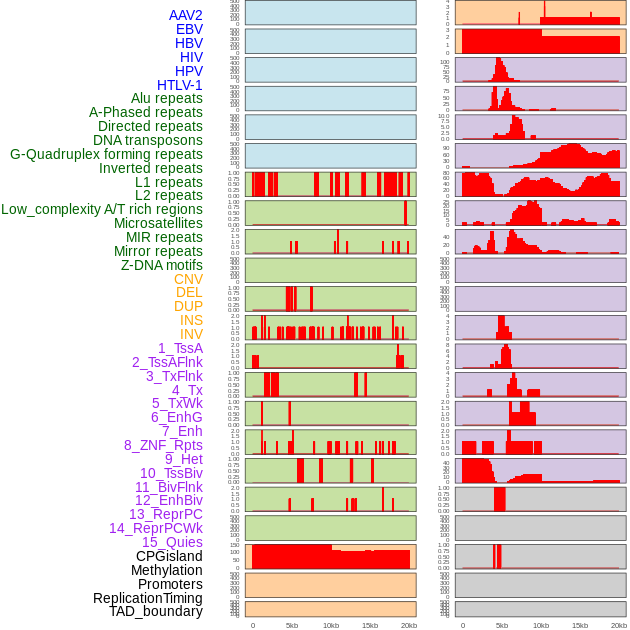
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SEMA4B-GLUD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:90744967/chr10:88827914) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | GLUD1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Mitochondrial glutamate dehydrogenase that catalyzes the conversion of L-glutamate into alpha-ketoglutarate. Plays a key role in glutamine anaplerosis by producing alpha-ketoglutarate, an important intermediate in the tricarboxylic acid cycle (PubMed:11032875, PubMed:16959573, PubMed:11254391, PubMed:16023112). Plays a role in insulin homeostasis (PubMed:9571255, PubMed:11297618). May be involved in learning and memory reactions by increasing the turnover of the excitatory neurotransmitter glutamate (By similarity). {ECO:0000250|UniProtKB:P10860, ECO:0000269|PubMed:11032875, ECO:0000269|PubMed:11254391, ECO:0000269|PubMed:11297618, ECO:0000269|PubMed:16023112, ECO:0000269|PubMed:16959573, ECO:0000269|PubMed:9571255}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 758_781 | 47 | 738.0 | Compositional bias | Note=Pro-rich |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 47_523 | 47 | 738.0 | Domain | Sema |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 525_579 | 47 | 738.0 | Domain | Note=PSI |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 604_663 | 47 | 738.0 | Domain | Note=Ig-like C2-type |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 44_717 | 47 | 738.0 | Topological domain | Extracellular |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 739_837 | 47 | 738.0 | Topological domain | Cytoplasmic |
| Hgene | SEMA4B | chr15:90744967 | chr10:88827914 | ENST00000379122 | + | 2 | 16 | 718_738 | 47 | 738.0 | Transmembrane | Helical |
| Tgene | GLUD1 | chr15:90744967 | chr10:88827914 | ENST00000277865 | 3 | 13 | 141_143 | 215 | 559.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for SEMA4B-GLUD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >80311_80311_1_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2693nt_BP=397nt CTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACGAGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGAT GACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCC GTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGC TGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCG ACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATG TCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGG GGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTA GGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTT GGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTG CAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCC AGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCT GACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTG AAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGT TTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAA GACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGAC CTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGC TGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTC ATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGA GTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTG CTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGT CTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATT TTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATA AGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGA AAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATA ATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAA GAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCC CAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTC CTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGG CCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACC >80311_80311_1_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_2_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2689nt_BP=397nt CTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACGAGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGAT GACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCC GTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGC TGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCG ACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATG TCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGG GGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTA GGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTT GGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTG CAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCC AGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCT GACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTG AAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGT TTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAA GACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGAC CTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGC TGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTC ATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGA GTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTG CTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGT CTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATT TTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATA AGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGA AAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATA ATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAA GAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCC CAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTC CTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGG CCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACC >80311_80311_2_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_3_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1578nt_BP=397nt CTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACGAGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGAT GACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCC GTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGC TGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCG ACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATG TCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGG GGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTA GGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTT GGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTG CAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCC AGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCT GACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTG AAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGT TTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAA GACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGAC CTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGC TGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTC >80311_80311_3_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000332496_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_4_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2736nt_BP=440nt ATTTCCGGGGACGCCGCGCCGGACTGAGGCTGTGCGCCCGAGACTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACG AGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGATGACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCC CCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGC TCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCT GCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCAT TGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATAT TAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGG GATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATT TGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAA TCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGG AAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAA GATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTA CTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGA AAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACC CACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAG GCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGT GTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCA CAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGT TAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTT GCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAAC AGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGC CTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAA AACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCT AACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTA TCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTA AAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAG ATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTG AGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCT GAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATAT ATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTG >80311_80311_4_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_5_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2732nt_BP=440nt ATTTCCGGGGACGCCGCGCCGGACTGAGGCTGTGCGCCCGAGACTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACG AGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGATGACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCC CCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGC TCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCT GCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCAT TGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATAT TAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGG GATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATT TGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAA TCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGG AAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAA GATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTA CTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGA AAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACC CACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAG GCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGT GTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCA CAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGT TAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTT GCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAAC AGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGC CTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAA AACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCT AACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTA TCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTA AAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAG ATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTG AGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCT GAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATAT ATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTG >80311_80311_5_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_6_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1621nt_BP=440nt ATTTCCGGGGACGCCGCGCCGGACTGAGGCTGTGCGCCCGAGACTCCGGGTCCCCAGGGGCTGCGCCGGGCCGGCCTGGCAAGGGGGACG AGTCAGTGGACACTCCAGGAAGAGCGGCCCCGCGGGGGGCGATGACCGTGCGCTGACCCTGACTCACTCCAGGTCCGGAGGCGGGGGCCC CCGGGGCGACTCGGGGGCGGACCGCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGC TCCTGCTCTCCGAATGCTGCGCACCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCT GCTGCTCCTGCTGCTGCTGCTCCTGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCAT TGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATAT TAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGG GATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATT TGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAA TCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGG AAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAA GATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTA CTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGA AAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACC CACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAG GCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGT GTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCA CAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGT >80311_80311_6_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000379122_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=442AA_BP=97 MTLTHSRSGGGGPRGDSGADRGAELPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWA LSPRISLPLGPGIDVPAPDMSTGEREMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMT PGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEK QLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLER -------------------------------------------------------------- >80311_80311_7_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2713nt_BP=417nt CGCCCTCCGCCGCTTGCGGGTGAGCTCTGCCCAAGCCGAGGCTGCGGGGCCGGCGCCGGCGGGAGGACTGCGGTGCCCCGCGGAGGGGCT GAGTTTGCCAGGGCCCACTTGACCCTGTTTCCCACCTCCCGCCCCCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACC GCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCA CCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCC TGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGA GCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTG GTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAG CTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTA TGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGG AACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTG ACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATG GGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAG TATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGC TCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGA TATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGA AGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCT TCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAA ATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTA GCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTT TATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTG CTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCC TCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATAT TATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATG CCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGA CATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTA TAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACA ATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTC ACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGT TTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTT TTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCT >80311_80311_7_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=418AA_BP=73 MPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWALSPRISLPLGPGIDVPAPDMSTGE REMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYL HRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTT PEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGA -------------------------------------------------------------- >80311_80311_8_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2709nt_BP=417nt CGCCCTCCGCCGCTTGCGGGTGAGCTCTGCCCAAGCCGAGGCTGCGGGGCCGGCGCCGGCGGGAGGACTGCGGTGCCCCGCGGAGGGGCT GAGTTTGCCAGGGCCCACTTGACCCTGTTTCCCACCTCCCGCCCCCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACC GCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCA CCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCC TGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGA GCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTG GTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAG CTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTA TGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGG AACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTG ACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATG GGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAG TATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGC TCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGA TATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGA AGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCT TCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAA ATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATCCAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTA GCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCCATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTT TATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGTGCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTG CTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAAGTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCC TCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTGCAAACAAATATAAAACCTGTTTCTGTTTATGAATAT TATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATCACTTAACAAGCCTAACCTTGACTCAAACAGTGAATG CCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGTCATTTATAGCTTATCATTCATGTATTGTCCAGCAGA CATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAGGCTATTTTCATTAAAACTGTCAGAATTTGCTTACTA TAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTGTTCTCTTTTGAAGATCTATGGTTGACTAATTAAACA ATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGTCTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTC ACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCACTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGT TTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAGTGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTT TTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATGGCTTAACCTGGTGATAAAAGCAGTTATTAAAAGTCT >80311_80311_8_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=418AA_BP=73 MPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWALSPRISLPLGPGIDVPAPDMSTGE REMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYL HRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTT PEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGA -------------------------------------------------------------- >80311_80311_9_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1598nt_BP=417nt CGCCCTCCGCCGCTTGCGGGTGAGCTCTGCCCAAGCCGAGGCTGCGGGGCCGGCGCCGGCGGGAGGACTGCGGTGCCCCGCGGAGGGGCT GAGTTTGCCAGGGCCCACTTGACCCTGTTTCCCACCTCCCGCCCCCCAGGTCCGGAGGCGGGGGCCCCCGGGGCGACTCGGGGGCGGACC GCGGGGCGGAGCTGCCGCCCGTGAGTCCGGCCGAGCCACCTGAGCCCGAGCCGCGGGACACCGTCGCTCCTGCTCTCCGAATGCTGCGCA CCGCGATGGGCCTGAGGAGCTGGCTCGCCGCCCCATGGGGCGCGCTGCCGCCTCGGCCACCGCTGCTGCTGCTCCTGCTGCTGCTGCTCC TGCTGCAGCCGCCGCCTCCGACCTGGGCGCTCAGCCCCCGGATCAGCCTGCCTCTGGGTCCTGGCATTGATGTGCCTGCTCCAGACATGA GCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAGGGCACTATGATATTAATGCACACGCCTGTGTTACTG GTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTGGTGTCTTCCATGGGATTGAAAATTTCATCAATGAAG CTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTGTTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTA TGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATGGGAGTATATGGAATCCAGATGGTATTGACCCAAAGG AACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAAAGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTG ACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCAGAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATG GGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTATTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAG TATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGACCTTCAAATATGAAAGGGATTCTAACTACCACTTGC TCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTATTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGA TATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGGAGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGA AGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGAAAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCT TCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTCTGCAGACCTATCACAAGTTTACATGTAACCACAGAA >80311_80311_9_SEMA4B-GLUD1_SEMA4B_chr15_90744967_ENST00000411539_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=418AA_BP=73 MPPVSPAEPPEPEPRDTVAPALRMLRTAMGLRSWLAAPWGALPPRPPLLLLLLLLLLLQPPPPTWALSPRISLPLGPGIDVPAPDMSTGE REMSWIADTYASTIGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYL HRFGAKCIAVGESDGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTT PEADKIFLERNIMVIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SEMA4B-GLUD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SEMA4B-GLUD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SEMA4B-GLUD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies