
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SEPT2-DCTN4 (FusionGDB2 ID:80474) |
Fusion Gene Summary for SEPT2-DCTN4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SEPT2-DCTN4 | Fusion gene ID: 80474 | Hgene | Tgene | Gene symbol | SEPT2 | DCTN4 | Gene ID | 23157 | 51164 |
| Gene name | septin 6 | dynactin subunit 4 | |
| Synonyms | SEP2|SEPT2|SEPT6 | DYN4|P62 | |
| Cytomap | Xq24 | 5q33.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | septin-6septin 2 | dynactin subunit 4dynactin 4 (p62)dynactin p62 subunitdynactin subunit p62 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9UJW0 | |
| Ensembl transtripts involved in fusion gene | ENST00000461048, ENST00000360051, ENST00000391971, ENST00000391973, ENST00000401990, ENST00000402092, ENST00000407971, | ENST00000424236, ENST00000446090, ENST00000447998, ENST00000521093, | |
| Fusion gene scores | * DoF score | 8 X 6 X 5=240 | 5 X 7 X 4=140 |
| # samples | 9 | 7 | |
| ** MAII score | log2(9/240*10)=-1.41503749927884 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/140*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SEPT2 [Title/Abstract] AND DCTN4 [Title/Abstract] AND fusion [Title/Abstract] | ||
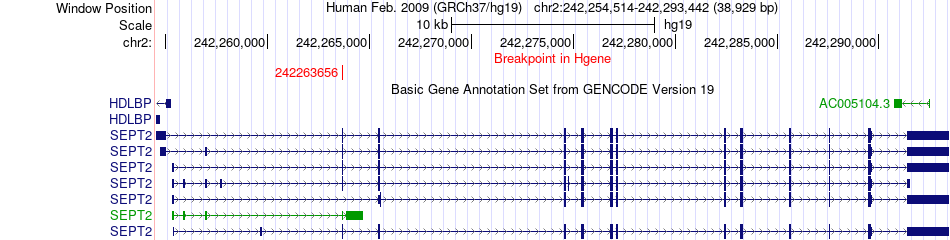
| Most frequent breakpoint | SEPT2(242263656)-DCTN4(150102542), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SEPT2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DCTN4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 257N | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
Top |
Fusion Gene ORF analysis for SEPT2-DCTN4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000461048 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 3UTR-3CDS | ENST00000461048 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 3UTR-3CDS | ENST00000461048 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 3UTR-intron | ENST00000461048 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 5CDS-intron | ENST00000360051 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 5CDS-intron | ENST00000391971 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 5CDS-intron | ENST00000391973 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 5CDS-intron | ENST00000401990 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| 5CDS-intron | ENST00000402092 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000360051 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000360051 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000360051 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391971 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391971 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391971 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391973 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391973 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000391973 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000401990 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000401990 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000401990 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000402092 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000402092 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| In-frame | ENST00000402092 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| intron-3CDS | ENST00000407971 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| intron-3CDS | ENST00000407971 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| intron-3CDS | ENST00000407971 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| intron-intron | ENST00000407971 | ENST00000521093 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000391973 | SEPT2 | chr2 | 242263656 | + | ENST00000447998 | DCTN4 | chr5 | 150102542 | - | 3795 | 537 | 528 | 1085 | 185 |
| ENST00000391973 | SEPT2 | chr2 | 242263656 | + | ENST00000424236 | DCTN4 | chr5 | 150102542 | - | 3487 | 537 | 528 | 1085 | 185 |
| ENST00000391973 | SEPT2 | chr2 | 242263656 | + | ENST00000446090 | DCTN4 | chr5 | 150102542 | - | 1377 | 537 | 528 | 1085 | 185 |
| ENST00000360051 | SEPT2 | chr2 | 242263656 | + | ENST00000447998 | DCTN4 | chr5 | 150102542 | - | 3707 | 449 | 440 | 997 | 185 |
| ENST00000360051 | SEPT2 | chr2 | 242263656 | + | ENST00000424236 | DCTN4 | chr5 | 150102542 | - | 3399 | 449 | 440 | 997 | 185 |
| ENST00000360051 | SEPT2 | chr2 | 242263656 | + | ENST00000446090 | DCTN4 | chr5 | 150102542 | - | 1289 | 449 | 440 | 997 | 185 |
| ENST00000391971 | SEPT2 | chr2 | 242263656 | + | ENST00000447998 | DCTN4 | chr5 | 150102542 | - | 3406 | 148 | 19 | 696 | 225 |
| ENST00000391971 | SEPT2 | chr2 | 242263656 | + | ENST00000424236 | DCTN4 | chr5 | 150102542 | - | 3098 | 148 | 19 | 696 | 225 |
| ENST00000391971 | SEPT2 | chr2 | 242263656 | + | ENST00000446090 | DCTN4 | chr5 | 150102542 | - | 988 | 148 | 19 | 696 | 225 |
| ENST00000401990 | SEPT2 | chr2 | 242263656 | + | ENST00000447998 | DCTN4 | chr5 | 150102542 | - | 3713 | 455 | 446 | 1003 | 185 |
| ENST00000401990 | SEPT2 | chr2 | 242263656 | + | ENST00000424236 | DCTN4 | chr5 | 150102542 | - | 3405 | 455 | 446 | 1003 | 185 |
| ENST00000401990 | SEPT2 | chr2 | 242263656 | + | ENST00000446090 | DCTN4 | chr5 | 150102542 | - | 1295 | 455 | 446 | 1003 | 185 |
| ENST00000402092 | SEPT2 | chr2 | 242263656 | + | ENST00000447998 | DCTN4 | chr5 | 150102542 | - | 3424 | 166 | 124 | 714 | 196 |
| ENST00000402092 | SEPT2 | chr2 | 242263656 | + | ENST00000424236 | DCTN4 | chr5 | 150102542 | - | 3116 | 166 | 124 | 714 | 196 |
| ENST00000402092 | SEPT2 | chr2 | 242263656 | + | ENST00000446090 | DCTN4 | chr5 | 150102542 | - | 1006 | 166 | 124 | 714 | 196 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000391973 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.00133199 | 0.9986681 |
| ENST00000391973 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.000848109 | 0.99915195 |
| ENST00000391973 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.003210581 | 0.9967894 |
| ENST00000360051 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.001288 | 0.99871206 |
| ENST00000360051 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.000809945 | 0.99919003 |
| ENST00000360051 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.002840852 | 0.9971591 |
| ENST00000391971 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.001273843 | 0.9987262 |
| ENST00000391971 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.00079685 | 0.99920315 |
| ENST00000391971 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.002723004 | 0.99727696 |
| ENST00000401990 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.001397443 | 0.99860257 |
| ENST00000401990 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.000866478 | 0.9991335 |
| ENST00000401990 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.002776868 | 0.99722314 |
| ENST00000402092 | ENST00000447998 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.00114999 | 0.99885 |
| ENST00000402092 | ENST00000424236 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.000718189 | 0.9992818 |
| ENST00000402092 | ENST00000446090 | SEPT2 | chr2 | 242263656 | + | DCTN4 | chr5 | 150102542 | - | 0.001406317 | 0.9985936 |
Top |
Fusion Genomic Features for SEPT2-DCTN4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SEPT2-DCTN4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:242263656/chr5:150102542) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | DCTN4 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Could have a dual role in dynein targeting and in ACTR1A/Arp1 subunit of dynactin pointed-end capping. Could be involved in ACTR1A pointed-end binding and in additional roles in linking dynein and dynactin to the cortical cytoskeleton. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 34_306 | 3 | 940.6666666666666 | Domain | Septin-type G |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 34_306 | 3 | 1008.3333333333334 | Domain | Septin-type G |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 34_306 | 3 | 877.6666666666666 | Domain | Septin-type G |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 34_306 | 3 | 386.0 | Domain | Septin-type G |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 34_306 | 3 | 1030.6666666666667 | Domain | Septin-type G |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 183_191 | 3 | 940.6666666666666 | Nucleotide binding | Note=GTP |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 183_191 | 3 | 1008.3333333333334 | Nucleotide binding | Note=GTP |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 183_191 | 3 | 877.6666666666666 | Nucleotide binding | Note=GTP |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 183_191 | 3 | 386.0 | Nucleotide binding | Note=GTP |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 183_191 | 3 | 1030.6666666666667 | Nucleotide binding | Note=GTP |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 101_104 | 3 | 940.6666666666666 | Region | G3 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 182_185 | 3 | 940.6666666666666 | Region | G4 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 260_270 | 3 | 940.6666666666666 | Region | Note=Important for dimerization |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000360051 | + | 3 | 14 | 44_51 | 3 | 940.6666666666666 | Region | G1 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 101_104 | 3 | 1008.3333333333334 | Region | G3 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 182_185 | 3 | 1008.3333333333334 | Region | G4 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 260_270 | 3 | 1008.3333333333334 | Region | Note=Important for dimerization |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391971 | + | 2 | 13 | 44_51 | 3 | 1008.3333333333334 | Region | G1 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 101_104 | 3 | 877.6666666666666 | Region | G3 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 182_185 | 3 | 877.6666666666666 | Region | G4 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 260_270 | 3 | 877.6666666666666 | Region | Note=Important for dimerization |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000391973 | + | 2 | 13 | 44_51 | 3 | 877.6666666666666 | Region | G1 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 101_104 | 3 | 386.0 | Region | G3 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 182_185 | 3 | 386.0 | Region | G4 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 260_270 | 3 | 386.0 | Region | Note=Important for dimerization |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000401990 | + | 5 | 17 | 44_51 | 3 | 386.0 | Region | G1 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 101_104 | 3 | 1030.6666666666667 | Region | G3 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 182_185 | 3 | 1030.6666666666667 | Region | G4 motif |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 260_270 | 3 | 1030.6666666666667 | Region | Note=Important for dimerization |
| Hgene | SEPT2 | chr2:242263656 | chr5:150102542 | ENST00000402092 | + | 3 | 14 | 44_51 | 3 | 1030.6666666666667 | Region | G1 motif |
| Tgene | DCTN4 | chr2:242263656 | chr5:150102542 | ENST00000424236 | 7 | 13 | 152_172 | 221 | 404.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | DCTN4 | chr2:242263656 | chr5:150102542 | ENST00000446090 | 8 | 14 | 152_172 | 285 | 468.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | DCTN4 | chr2:242263656 | chr5:150102542 | ENST00000447998 | 7 | 13 | 152_172 | 278 | 461.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for SEPT2-DCTN4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >80474_80474_1_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000424236_length(transcript)=3399nt_BP=449nt GATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGCCCCAGCTCG GTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCACCTGCCCTC CCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGCAAGGCGAAG ATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTAT TTTTTTTTTTTTTTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGACGAAGCTTCACAAAAGATGTCTAAGA AATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAG TGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATG TGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTG GCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACA AAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGG CAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTC TTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGG CCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCT GCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTC CATCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTA AGGATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTG CTTTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATAT AACTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTT TTTCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAAC AATTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAA TCTTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAA GAAAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCA TTGATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTG TCATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTG CTGTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGC TGCACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTA AGTCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTT AGGAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTC CTACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAG CAGGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTAC CTGCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGT TTGCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCAT TCCCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTA ATGTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTG TATTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCA CTTGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCT TATCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTT >80474_80474_1_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000424236_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_2_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000446090_length(transcript)=1289nt_BP=449nt GATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGCCCCAGCTCG GTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCACCTGCCCTC CCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGCAAGGCGAAG ATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTAT TTTTTTTTTTTTTTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGACGAAGCTTCACAAAAGATGTCTAAGA AATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAG TGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATG TGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTG GCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACA AAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGG CAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTC TTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGG CCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCT GCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTC >80474_80474_2_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000446090_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_3_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000447998_length(transcript)=3707nt_BP=449nt GATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGCCCCAGCTCG GTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCACCTGCCCTC CCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGCAAGGCGAAG ATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTAT TTTTTTTTTTTTTTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGACGAAGCTTCACAAAAGATGTCTAAGA AATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAG TGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATG TGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTG GCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACA AAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGG CAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTC TTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGG CCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCT GCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTC CATCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTA AGGATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTG CTTTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATAT AACTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTT TTTCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAAC AATTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAA TCTTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAA GAAAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCA TTGATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTG TCATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTG CTGTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGC TGCACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTA AGTCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTT AGGAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTC CTACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAG CAGGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTAC CTGCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGT TTGCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCAT TCCCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTA ATGTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTG TATTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCA CTTGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCT TATCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTT ATGAATGACAGGTTACTGTTTTGCCTTATTGCTTAACTTAATGTAGTGAAATAAAGCAGACAAAGCTTGAGCGTGTCTTTTGTTTGCTCT CATGTAGATACTAAGTAGCATGGCTCAGAGCCAAAAGACAAGCGTGAAGTTAAGAGAGTTGGCTAAGAGAGTTGGTGGGGCATGCTCCCT TCCATTCCTTAAATGAAGTAATCTAAAATCTCTTAGCAGGTTAGTTCACCATAATATATAAGTAGATGTTGCTTTGAGCTTCTTATATAC ATATTCACAGAACCATTATATAAATGTTGTTAGACCTCTACCAGTTTTTATCCTGGGTCATTGCTTCTAAAGATATCCTTTACAATATAC >80474_80474_3_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000360051_DCTN4_chr5_150102542_ENST00000447998_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_4_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000424236_length(transcript)=3098nt_BP=148nt GACGCAATCCGCCTGCGCGCTGGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGT CGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATT TAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTA CATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCC TGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTT GGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTTCATCAAAGTTACACCACA GCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGA CCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATC CCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAACGATGTACCCATGCACTAC GGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACA CCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCATCCTAGGAAAGGGGATGGGTGTTCCTTGG AATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAGGATCACAATGTCACAGATGAAACTTAAAT GATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCTTTCTGCATTCCGTTAAATATCATCTAACA GTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAACTGAAAAACTGAATTGTCACTTTATCTTT AGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTTTCTAAGTGAATACAGGACACGTATTAGTT GTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAATTACATGTCATGTCAAGGGGGTAGCAGAT TCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATCTTTATTTGTCTTACTTCCTACCCCTTCCC TGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGAAAACCTGAGTGGACAGGTTCATTTCTGGA ATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATTGATTTGAAGGGGAAATTAACTATTATAAT CTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTCATGTGGTGAGTCAAATAAGACCATTTTGA TTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCTGTTTTCACTTGGTATCCTGGAGTTGGGTT GCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTGCACCGTGTTTTCTGTAAAAGTATTGTTAG TAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAGTCTTAAAAAATTAAAGATAACATTATAAT GTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAGGAAGCTTTTAAAAGACACTAAATTGTACT CTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCTACAGAGTAATATATGTGATGCAGTGTAAG AAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCAGGGGGATGGGTAATTACAGATTTGCAGAC TATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCTGCTAGAGCCTACTGTGAAATCACTGCTCC ATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTTGCATAGACTACACACATGTCATGCGTTTA TGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTCCCATACACAGAAACACAAAACACTTTGAT CATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAATGTTTCCTCAAGATAGGTTTTAGTGTAAGC TAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTATTTGTTGCCTTTTTTATATTAGATGAGGT GCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACTTGAAACTACAGCTTTGGAAACTTAGGCTA AGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTATCAGCATAATGAGCTAAGTGTCATGCATA TTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTATGAATGACAGGTTACTGTTTTGCCTTATTG >80474_80474_4_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000424236_length(amino acids)=225AA_BP=43 MGGAGRAGAGCERTASAGRVRGAVGRRLFSGCLADEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQV LLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEV -------------------------------------------------------------- >80474_80474_5_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000446090_length(transcript)=988nt_BP=148nt GACGCAATCCGCCTGCGCGCTGGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGT CGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATT TAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTA CATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCC TGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTT GGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTTCATCAAAGTTACACCACA GCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGA CCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATC CCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAACGATGTACCCATGCACTAC GGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACA >80474_80474_5_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000446090_length(amino acids)=225AA_BP=43 MGGAGRAGAGCERTASAGRVRGAVGRRLFSGCLADEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQV LLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEV -------------------------------------------------------------- >80474_80474_6_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000447998_length(transcript)=3406nt_BP=148nt GACGCAATCCGCCTGCGCGCTGGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGT CGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATT TAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTA CATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCC TGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTT GGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTTCATCAAAGTTACACCACA GCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGA CCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATC CCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAACGATGTACCCATGCACTAC GGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACA CCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCATCCTAGGAAAGGGGATGGGTGTTCCTTGG AATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAGGATCACAATGTCACAGATGAAACTTAAAT GATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCTTTCTGCATTCCGTTAAATATCATCTAACA GTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAACTGAAAAACTGAATTGTCACTTTATCTTT AGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTTTCTAAGTGAATACAGGACACGTATTAGTT GTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAATTACATGTCATGTCAAGGGGGTAGCAGAT TCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATCTTTATTTGTCTTACTTCCTACCCCTTCCC TGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGAAAACCTGAGTGGACAGGTTCATTTCTGGA ATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATTGATTTGAAGGGGAAATTAACTATTATAAT CTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTCATGTGGTGAGTCAAATAAGACCATTTTGA TTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCTGTTTTCACTTGGTATCCTGGAGTTGGGTT GCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTGCACCGTGTTTTCTGTAAAAGTATTGTTAG TAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAGTCTTAAAAAATTAAAGATAACATTATAAT GTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAGGAAGCTTTTAAAAGACACTAAATTGTACT CTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCTACAGAGTAATATATGTGATGCAGTGTAAG AAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCAGGGGGATGGGTAATTACAGATTTGCAGAC TATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCTGCTAGAGCCTACTGTGAAATCACTGCTCC ATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTTGCATAGACTACACACATGTCATGCGTTTA TGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTCCCATACACAGAAACACAAAACACTTTGAT CATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAATGTTTCCTCAAGATAGGTTTTAGTGTAAGC TAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTATTTGTTGCCTTTTTTATATTAGATGAGGT GCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACTTGAAACTACAGCTTTGGAAACTTAGGCTA AGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTATCAGCATAATGAGCTAAGTGTCATGCATA TTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTATGAATGACAGGTTACTGTTTTGCCTTATTG CTTAACTTAATGTAGTGAAATAAAGCAGACAAAGCTTGAGCGTGTCTTTTGTTTGCTCTCATGTAGATACTAAGTAGCATGGCTCAGAGC CAAAAGACAAGCGTGAAGTTAAGAGAGTTGGCTAAGAGAGTTGGTGGGGCATGCTCCCTTCCATTCCTTAAATGAAGTAATCTAAAATCT CTTAGCAGGTTAGTTCACCATAATATATAAGTAGATGTTGCTTTGAGCTTCTTATATACATATTCACAGAACCATTATATAAATGTTGTT >80474_80474_6_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391971_DCTN4_chr5_150102542_ENST00000447998_length(amino acids)=225AA_BP=43 MGGAGRAGAGCERTASAGRVRGAVGRRLFSGCLADEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQV LLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEV -------------------------------------------------------------- >80474_80474_7_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000424236_length(transcript)=3487nt_BP=537nt ACCTCGGGCCCCACACCAGAAGGAGAAAGCTAGGGGCCGCGCCAGCTCCGCCCTCCCCCGCGGGGCGGCGGGCCCCAGCCCGGGCACAGG AAGGCCACGTCCCCGGGGAGGGACGCCCGACTCGATGGTCTGCGCAGGGCCCGTCGGCCCCACGTGACGTGCGCGCAGCCAATCCCAGAG AGGCCCCCCGATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGC CCCAGCTCGGTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCA CCTGCCCTCCCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGC AAGGCGAAGATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGACGAAGCTTCACAAAAGATGTCTAAGAAA TGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTG AGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTG ACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGC AAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAA GTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCA GCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTT CCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCC TTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGC TGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCA TCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAG GATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCT TTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAA CTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTT TCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAA TTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATC TTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGA AAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATT GATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTC ATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCT GTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTG CACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAG TCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAG GAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCT ACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCA GGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCT GCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTT GCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTC CCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAAT GTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTA TTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACT TGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTA TCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTAT >80474_80474_7_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000424236_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_8_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000446090_length(transcript)=1377nt_BP=537nt ACCTCGGGCCCCACACCAGAAGGAGAAAGCTAGGGGCCGCGCCAGCTCCGCCCTCCCCCGCGGGGCGGCGGGCCCCAGCCCGGGCACAGG AAGGCCACGTCCCCGGGGAGGGACGCCCGACTCGATGGTCTGCGCAGGGCCCGTCGGCCCCACGTGACGTGCGCGCAGCCAATCCCAGAG AGGCCCCCCGATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGC CCCAGCTCGGTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCA CCTGCCCTCCCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGC AAGGCGAAGATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGACGAAGCTTCACAAAAGATGTCTAAGAAA TGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTG AGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTG ACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGC AAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAA GTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCA GCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTT CCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCC TTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGC TGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCA >80474_80474_8_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000446090_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_9_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000447998_length(transcript)=3795nt_BP=537nt ACCTCGGGCCCCACACCAGAAGGAGAAAGCTAGGGGCCGCGCCAGCTCCGCCCTCCCCCGCGGGGCGGCGGGCCCCAGCCCGGGCACAGG AAGGCCACGTCCCCGGGGAGGGACGCCCGACTCGATGGTCTGCGCAGGGCCCGTCGGCCCCACGTGACGTGCGCGCAGCCAATCCCAGAG AGGCCCCCCGATCATCGAGACGGCGGCGGTGGTGGGCTAGACGAGTTTCGCGCGGCCGCTCGCCGTCCCCCGCCCAGTCGTACTCGGCGC CCCAGCTCGGTGCTGCCGCCATCTTCTTGGAGGACAGGAGGAGAGGCGAAGGCTCCCCCTCCCCGTGATCGCTCCGCACTCCCGCCACCA CCTGCCCTCCCGCGACCGCCTCTCTCCTCCTCAGTGGGCACTTGTCTCCTTCTAACAAACGGCCTTCCCCCCACTCCAGTTACCCACCGC AAGGCGAAGATTCTCATTACCTGTTCCACTCTTATAAGCATAAGAAAACCGAGCTCATAAGACGAAGCTTCACAAAAGATGTCTAAGAAA TGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTG AGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTG ACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGC AAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAA GTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCA GCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTT CCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCC TTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGC TGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCA TCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAG GATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCT TTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAA CTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTT TCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAA TTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATC TTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGA AAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATT GATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTC ATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCT GTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTG CACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAG TCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAG GAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCT ACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCA GGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCT GCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTT GCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTC CCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAAT GTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTA TTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACT TGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTA TCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTAT GAATGACAGGTTACTGTTTTGCCTTATTGCTTAACTTAATGTAGTGAAATAAAGCAGACAAAGCTTGAGCGTGTCTTTTGTTTGCTCTCA TGTAGATACTAAGTAGCATGGCTCAGAGCCAAAAGACAAGCGTGAAGTTAAGAGAGTTGGCTAAGAGAGTTGGTGGGGCATGCTCCCTTC CATTCCTTAAATGAAGTAATCTAAAATCTCTTAGCAGGTTAGTTCACCATAATATATAAGTAGATGTTGCTTTGAGCTTCTTATATACAT ATTCACAGAACCATTATATAAATGTTGTTAGACCTCTACCAGTTTTTATCCTGGGTCATTGCTTCTAAAGATATCCTTTACAATATACAC >80474_80474_9_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000391973_DCTN4_chr5_150102542_ENST00000447998_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_10_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000424236_length(transcript)=3405nt_BP=455nt GGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGG CTGTTTGGCGGGCGTGGAGGACTGGCCAGCCCCCAAACCTCCAAGCCCATCGGCTGGATGCCGTGGATAAGCGAGGGGAGAGCGACTAGG CCCTGTCTGCGGGTACCTTCGGCGAGGAGAGGCGACGAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTATTTTTTTTTTTTT TTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGGGTTCAGTGAGGCTGAGGGGTTCTGTGGAGGTGCGGGAG AGGTGCTCTATGGTATTTCTATGTTGCACTGTGTGGGTTTGAAATCAGATACATGTAATAGGTGATAAGACGAAGCTTCACAAAAGATGT CTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTC CAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCA CCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTT TAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGG CCAACAAAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAA ACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCC CACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTC ATTAGGCCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGG GTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCA TAATTCCATCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATC TCACTAAGGATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTAC CAACTGCTTTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTT CCATATAACTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGC CCTCTTTTTCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAA GCAAACAATTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGG GGGCAATCTTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAA CCCAAAGAAAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTC TTTCCATTGATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGA CTTTTGTCATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCA GACTTGCTGTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACC ACCAGCTGCACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTT GTTTTAAGTCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAA ATATTTAGGAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAA ACAGTCCTACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAG TTGGAGCAGGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTT CACTACCTGCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTT ACACGTTTGCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCT CATCATTCCCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACT GGTTTAATGTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAG GAATTGTATTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCA TTAGCACTTGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGA AGTGCTTATCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTG >80474_80474_10_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000424236_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_11_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000446090_length(transcript)=1295nt_BP=455nt GGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGG CTGTTTGGCGGGCGTGGAGGACTGGCCAGCCCCCAAACCTCCAAGCCCATCGGCTGGATGCCGTGGATAAGCGAGGGGAGAGCGACTAGG CCCTGTCTGCGGGTACCTTCGGCGAGGAGAGGCGACGAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTATTTTTTTTTTTTT TTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGGGTTCAGTGAGGCTGAGGGGTTCTGTGGAGGTGCGGGAG AGGTGCTCTATGGTATTTCTATGTTGCACTGTGTGGGTTTGAAATCAGATACATGTAATAGGTGATAAGACGAAGCTTCACAAAAGATGT CTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTC CAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCA CCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTT TAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGG CCAACAAAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAA ACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCC CACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTC ATTAGGCCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGG GTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCA >80474_80474_11_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000446090_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_12_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000447998_length(transcript)=3713nt_BP=455nt GGGCGGGGCGGGGCGGGCTGGGGCGGGCTGTGAGCGGACCGCGAGCGCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGG CTGTTTGGCGGGCGTGGAGGACTGGCCAGCCCCCAAACCTCCAAGCCCATCGGCTGGATGCCGTGGATAAGCGAGGGGAGAGCGACTAGG CCCTGTCTGCGGGTACCTTCGGCGAGGAGAGGCGACGAAGCATACAGAAACTGCTGTAAAAGAAGAAGTTGTGGGTATTTTTTTTTTTTT TTTTGTCTGGAGGAATGGGGACACCAAAACTCATTTGGCAGCAGAGGTGAGGGTTCAGTGAGGCTGAGGGGTTCTGTGGAGGTGCGGGAG AGGTGCTCTATGGTATTTCTATGTTGCACTGTGTGGGTTTGAAATCAGATACATGTAATAGGTGATAAGACGAAGCTTCACAAAAGATGT CTAAGAAATGTGAACATAATTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTC CAGAAGTGAGAATCATGTCAATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCA CCCATGTGACTCTCTTCGAGTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTT TAGCTGGCAAGGATGCAGCAGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGG CCAACAAAGTGGGTATTTTCATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAA ACCTGGCAGCCCCCATTCGCCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCC CACTTCTTCCTTAAAAGGTTCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTC ATTAGGCCTTGTTTATAACGATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGG GTAGCTGCTGTTGCTCTTGCTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCA TAATTCCATCCTAGGAAAGGGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATC TCACTAAGGATCACAATGTCACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTAC CAACTGCTTTCTGCATTCCGTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTT CCATATAACTGAAAAACTGAATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGC CCTCTTTTTCTAAGTGAATACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAA GCAAACAATTACATGTCATGTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGG GGGCAATCTTTATTTGTCTTACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAA CCCAAAGAAAACCTGAGTGGACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTC TTTCCATTGATTTGAAGGGGAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGA CTTTTGTCATGTGGTGAGTCAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCA GACTTGCTGTTTTCACTTGGTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACC ACCAGCTGCACCGTGTTTTCTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTT GTTTTAAGTCTTAAAAAATTAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAA ATATTTAGGAAGCTTTTAAAAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAA ACAGTCCTACAGAGTAATATATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAG TTGGAGCAGGGGGATGGGTAATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTT CACTACCTGCTAGAGCCTACTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTT ACACGTTTGCATAGACTACACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCT CATCATTCCCATACACAGAAACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACT GGTTTAATGTTTCCTCAAGATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAG GAATTGTATTTGTTGCCTTTTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCA TTAGCACTTGAAACTACAGCTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGA AGTGCTTATCAGCATAATGAGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTG ATCTTTATGAATGACAGGTTACTGTTTTGCCTTATTGCTTAACTTAATGTAGTGAAATAAAGCAGACAAAGCTTGAGCGTGTCTTTTGTT TGCTCTCATGTAGATACTAAGTAGCATGGCTCAGAGCCAAAAGACAAGCGTGAAGTTAAGAGAGTTGGCTAAGAGAGTTGGTGGGGCATG CTCCCTTCCATTCCTTAAATGAAGTAATCTAAAATCTCTTAGCAGGTTAGTTCACCATAATATATAAGTAGATGTTGCTTTGAGCTTCTT ATATACATATTCACAGAACCATTATATAAATGTTGTTAGACCTCTACCAGTTTTTATCCTGGGTCATTGCTTCTAAAGATATCCTTTACA >80474_80474_12_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000401990_DCTN4_chr5_150102542_ENST00000447998_length(amino acids)=185AA_BP=3 MSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINSTAKVVVPPKEL VLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEVIWLTQHVELSL -------------------------------------------------------------- >80474_80474_13_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000424236_length(transcript)=3116nt_BP=166nt GCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGAGGCTTGGAATAGTTAAATGACTTTGGTCTTGTCC AAGGTTAGATGGAGTTCAACTCTAACGTCAAGTCTTGGTCCTTTTCATTGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAA TTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTC AATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGA GTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGC AGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTT CATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCG CCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGT TCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAAC GATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTG CTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCATCCTAGGAAAG GGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAGGATCACAATGT CACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCTTTCTGCATTCC GTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAACTGAAAAACTG AATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTTTCTAAGTGAAT ACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAATTACATGTCAT GTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATCTTTATTTGTCT TACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGAAAACCTGAGTG GACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATTGATTTGAAGGG GAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTCATGTGGTGAGT CAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCTGTTTTCACTTG GTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTGCACCGTGTTTT CTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAGTCTTAAAAAAT TAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAGGAAGCTTTTAA AAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCTACAGAGTAATA TATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCAGGGGGATGGGT AATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCTGCTAGAGCCTA CTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTTGCATAGACTAC ACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTCCCATACACAGA AACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAATGTTTCCTCAAG ATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTATTTGTTGCCTT TTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACTTGAAACTACAG CTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTATCAGCATAATG AGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTATGAATGACAGGT >80474_80474_13_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000424236_length(amino acids)=196AA_BP=14 MVLFIDEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINS TAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEV -------------------------------------------------------------- >80474_80474_14_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000446090_length(transcript)=1006nt_BP=166nt GCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGAGGCTTGGAATAGTTAAATGACTTTGGTCTTGTCC AAGGTTAGATGGAGTTCAACTCTAACGTCAAGTCTTGGTCCTTTTCATTGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAA TTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTC AATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGA GTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGC AGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTT CATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCG CCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGT TCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAAC GATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTG CTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCATCCTAGGAAAG >80474_80474_14_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000446090_length(amino acids)=196AA_BP=14 MVLFIDEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINS TAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEV -------------------------------------------------------------- >80474_80474_15_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000447998_length(transcript)=3424nt_BP=166nt GCTGGGCGGGTCCGCGGCGCGGTCGGTCGGCGCCTGTTCTCGGGCTGTTTGGCGGAGGCTTGGAATAGTTAAATGACTTTGGTCTTGTCC AAGGTTAGATGGAGTTCAACTCTAACGTCAAGTCTTGGTCCTTTTCATTGACGAAGCTTCACAAAAGATGTCTAAGAAATGTGAACATAA TTTGAGCAAGCCAGAATTTAACCCAACGTCAATCAAATTCAAAATCCAGCTGGTCGCTGTCAATTATATTCCAGAAGTGAGAATCATGTC AATTCCCAACCTTCGCTACATGAAGGAGAGCCAGGTCCTCCTGACTCTTACAAATCCAGTTGAGAACCTCACCCATGTGACTCTCTTCGA GTGTGAGGAGGGGGACCCTGATGATATCAACAGCACTGCTAAGGTGGTGGTGCCTCCCAAAGAGCTCGTTTTAGCTGGCAAGGATGCAGC AGCAGAGTACGATGAGTTGGCAGAACCTCAAGACTTTCAGGACGATCCTGACATTATAGCCTTCAGAAAGGCCAACAAAGTGGGTATTTT CATCAAAGTTACACCACAGCGTGAGGAGGGTGAAGTGACCGTGTGCTTCAAGATGAAGCATGATTTTAAAAACCTGGCAGCCCCCATTCG CCCCATTGAAGAAAGTGACCAGGGAACAGAAGTCATCTGGCTCACCCAGCATGTGGAACTTAGCTTGGGCCCACTTCTTCCTTAAAAGGT TCCACTGGAGGGCAGATCCCAAAGGACAGTATCACCGTAAACCTGCGTTAAAATGTGGAAGCTGCTGCTTCATTAGGCCTTGTTTATAAC GATGTACCCATGCACTACGGAATTCTATTGCTAAGAAAGTGGGAGCATAGGCAAGGCATTGGGAACACAGGGTAGCTGCTGTTGCTCTTG CTCTCACCCCTGTTGACACCAGTAAGTCTGTGTCTCCCTCACTGAACCCTGCACGTTGAGTAACAGCAGCATAATTCCATCCTAGGAAAG GGGATGGGTGTTCCTTGGAATGGCATTGTATTTACCACCTGAGAAACTCTGTACTGTCTCTTGATCTGATCTCACTAAGGATCACAATGT CACAGATGAAACTTAAATGATAACCCAAAGGTAGACCTGCTGTTAATGATCCAGCATTGGTCACAATGTACCAACTGCTTTCTGCATTCC GTTAAATATCATCTAACAGTCTAAAACATATCCCTTCATTGCCATAATGGCTGCCATTTTGCCATAGATTTCCATATAACTGAAAAACTG AATTGTCACTTTATCTTTAGTATCATGATGATTGGAAAAACCTGTGAAGTTGTTAAGGCACTCTCATTTGCCCTCTTTTTCTAAGTGAAT ACAGGACACGTATTAGTTGTTCTTAATTTTTTTCCCAGTAAAATATGGATCTTTTAAGAAGAATTTGAGAAGCAAACAATTACATGTCAT GTCAAGGGGGTAGCAGATTCCATTCGTTTTCAATATTGCCACAATACCCAGGGATTAATGCTGCCACAGGGGGGCAATCTTTATTTGTCT TACTTCCTACCCCTTCCCTGTTCTGCCTCTTTAACTCAGTTAAGTTGTTCTGTTTGGGACCTGGAAAAGAACCCAAAGAAAACCTGAGTG GACAGGTTCATTTCTGGAATGCAGAAAACATTTTAAAGGCTAGATTTTTAGAATATTCTCAACTAGCATTCTTTCCATTGATTTGAAGGG GAAATTAACTATTATAATCTCTTGAATCCAAAACTGGATATTAAGAACTTTCCCCCTTACTAAGTTTAAGACTTTTGTCATGTGGTGAGT CAAATAAGACCATTTTGATTGTAAACCATAAAATAGTTCAGCAAGTAGCCCACAGTTCTGGCCTAACAGCAGACTTGCTGTTTTCACTTG GTATCCTGGAGTTGGGTTGCTAACCTTAATTTCTATGATGTTTTCTAAAATGAAACTTGATAAAGTAGACCACCAGCTGCACCGTGTTTT CTGTAAAAGTATTGTTAGTAAGTGGCCAAGAGACTTGAGGAAAATACAGATTTTTTGTTTACCTTGGTCTTGTTTTAAGTCTTAAAAAAT TAAAGATAACATTATAATGTAGAATACAGATGGGACATAGTCCTTGTAAGCTTCCCTTGAAAATGTTTTAAATATTTAGGAAGCTTTTAA AAGACACTAAATTGTACTCTAAAAGACACTAAATTGTACTAATTGTACAAAGGTCAAGCCAATTTTATGAAACAGTCCTACAGAGTAATA TATGTGATGCAGTGTAAGAAGGAAAATACTCATCTCTAACATTATGGTAATAACATTTAGCCTCTTAGGAGTTGGAGCAGGGGGATGGGT AATTACAGATTTGCAGACTATAGAAAGAGTTTCATTTTTTTGTGACCCCACAGAGTCTCAAATTTTTATTTCACTACCTGCTAGAGCCTA CTGTGAAATCACTGCTCCATATTTGCCAGTGGAGGAAATGGGCATAGAGTAGAGAATAGCTTCATATGTTTACACGTTTGCATAGACTAC ACACATGTCATGCGTTTATGGCAGGTAGCTGGTATTTATTCCCCAAAGTAATAATGTTGAAGTATGGGTCTCATCATTCCCATACACAGA AACACAAAACACTTTGATCATAAACTTTTTTCTTCAGAAGCCAAACTAACTTGCAGAATAATAGAGCCACTGGTTTAATGTTTCCTCAAG ATAGGTTTTAGTGTAAGCTAGTATTCTGTGTGTTCGTAGAAATGATTCAATACCTGCAGCTGGTGAATTAGGAATTGTATTTGTTGCCTT TTTTATATTAGATGAGGTGCAAAAATTTTAATGCTAGTCAGTATGCACCACCACAGGAAAGTTAGATCCCATTAGCACTTGAAACTACAG CTTTGGAAACTTAGGCTAAGTTAATTTGGATTTGTTACTTGATTCACCTACTGACCTTTTCTTTTGTTTGAAGTGCTTATCAGCATAATG AGCTAAGTGTCATGCATATTTGTGAAGAAACACCCTTTTTGGTCCCTTTTGGGACAGAGAGGTACTCCTTGATCTTTATGAATGACAGGT TACTGTTTTGCCTTATTGCTTAACTTAATGTAGTGAAATAAAGCAGACAAAGCTTGAGCGTGTCTTTTGTTTGCTCTCATGTAGATACTA AGTAGCATGGCTCAGAGCCAAAAGACAAGCGTGAAGTTAAGAGAGTTGGCTAAGAGAGTTGGTGGGGCATGCTCCCTTCCATTCCTTAAA TGAAGTAATCTAAAATCTCTTAGCAGGTTAGTTCACCATAATATATAAGTAGATGTTGCTTTGAGCTTCTTATATACATATTCACAGAAC CATTATATAAATGTTGTTAGACCTCTACCAGTTTTTATCCTGGGTCATTGCTTCTAAAGATATCCTTTACAATATACACAGTGGTCTGAC >80474_80474_15_SEPT2-DCTN4_SEPT2_chr2_242263656_ENST00000402092_DCTN4_chr5_150102542_ENST00000447998_length(amino acids)=196AA_BP=14 MVLFIDEASQKMSKKCEHNLSKPEFNPTSIKFKIQLVAVNYIPEVRIMSIPNLRYMKESQVLLTLTNPVENLTHVTLFECEEGDPDDINS TAKVVVPPKELVLAGKDAAAEYDELAEPQDFQDDPDIIAFRKANKVGIFIKVTPQREEGEVTVCFKMKHDFKNLAAPIRPIEESDQGTEV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SEPT2-DCTN4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SEPT2-DCTN4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SEPT2-DCTN4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies