
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SF1-TC2N (FusionGDB2 ID:81021) |
Fusion Gene Summary for SF1-TC2N |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SF1-TC2N | Fusion gene ID: 81021 | Hgene | Tgene | Gene symbol | SF1 | TC2N | Gene ID | 7536 | 123036 |
| Gene name | splicing factor 1 | tandem C2 domains, nuclear | |
| Synonyms | BBP|D11S636|MBBP|ZCCHC25|ZFM1|ZNF162 | C14orf47|C2CD1|MTAC2D1|Tac2-N | |
| Cytomap | 11q13.1 | 14q32.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | splicing factor 1mammalian branch point-binding proteintranscription factor ZFM1zinc finger gene in MEN1 locuszinc finger protein 162 | tandem C2 domains nuclear proteinC2 calcium-dependent domain containing 1membrane targeting (tandem) C2 domain containing 1tandem C2 protein in nucleus | |
| Modification date | 20200318 | 20200315 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000227503, ENST00000334944, ENST00000377387, ENST00000377390, ENST00000377394, ENST00000433274, ENST00000422298, ENST00000489544, | ENST00000555302, ENST00000340892, ENST00000360594, ENST00000435962, ENST00000556018, | |
| Fusion gene scores | * DoF score | 21 X 11 X 13=3003 | 5 X 4 X 5=100 |
| # samples | 26 | 6 | |
| ** MAII score | log2(26/3003*10)=-3.52982094652869 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/100*10)=-0.736965594166206 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SF1 [Title/Abstract] AND TC2N [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SF1(64543969)-TC2N(92249554), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | SF1-TC2N seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SF1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TC2N (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-13-1507 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
Top |
Fusion Gene ORF analysis for SF1-TC2N |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000227503 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5CDS-intron | ENST00000334944 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5CDS-intron | ENST00000377387 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5CDS-intron | ENST00000377390 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5CDS-intron | ENST00000377394 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5CDS-intron | ENST00000433274 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5UTR-3CDS | ENST00000422298 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5UTR-3CDS | ENST00000422298 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5UTR-3CDS | ENST00000422298 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5UTR-3CDS | ENST00000422298 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| 5UTR-intron | ENST00000422298 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000227503 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000227503 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000227503 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000334944 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000334944 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000334944 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377387 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377387 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377387 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377390 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377390 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377390 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377394 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377394 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000377394 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000433274 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| Frame-shift | ENST00000433274 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000227503 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000334944 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000377387 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000377390 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000377394 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000433274 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| In-frame | ENST00000433274 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| intron-3CDS | ENST00000489544 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| intron-3CDS | ENST00000489544 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| intron-3CDS | ENST00000489544 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| intron-3CDS | ENST00000489544 | ENST00000556018 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| intron-intron | ENST00000489544 | ENST00000555302 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000377387 | SF1 | chr11 | 64543969 | - | ENST00000360594 | TC2N | chr14 | 92249554 | - | 2868 | 612 | 706 | 2 | 235 |
| ENST00000377390 | SF1 | chr11 | 64543969 | - | ENST00000360594 | TC2N | chr14 | 92249554 | - | 2754 | 498 | 592 | 59 | 177 |
| ENST00000377394 | SF1 | chr11 | 64543969 | - | ENST00000360594 | TC2N | chr14 | 92249554 | - | 2771 | 515 | 609 | 76 | 177 |
| ENST00000227503 | SF1 | chr11 | 64543969 | - | ENST00000360594 | TC2N | chr14 | 92249554 | - | 2771 | 515 | 609 | 76 | 177 |
| ENST00000334944 | SF1 | chr11 | 64543969 | - | ENST00000360594 | TC2N | chr14 | 92249554 | - | 2810 | 554 | 648 | 115 | 177 |
| ENST00000433274 | SF1 | chr11 | 64543969 | - | ENST00000435962 | TC2N | chr14 | 92249554 | - | 3851 | 391 | 485 | 249 | 78 |
| ENST00000433274 | SF1 | chr11 | 64543969 | - | ENST00000340892 | TC2N | chr14 | 92249554 | - | 3423 | 391 | 485 | 249 | 78 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000377387 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.008741958 | 0.99125797 |
| ENST00000377390 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.79002506 | 0.20997494 |
| ENST00000377394 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.94063425 | 0.05936579 |
| ENST00000227503 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.94063425 | 0.05936579 |
| ENST00000334944 | ENST00000360594 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.93002677 | 0.06997321 |
| ENST00000433274 | ENST00000435962 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.9342587 | 0.06574133 |
| ENST00000433274 | ENST00000340892 | SF1 | chr11 | 64543969 | - | TC2N | chr14 | 92249554 | - | 0.83634996 | 0.16365005 |
Top |
Fusion Genomic Features for SF1-TC2N |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
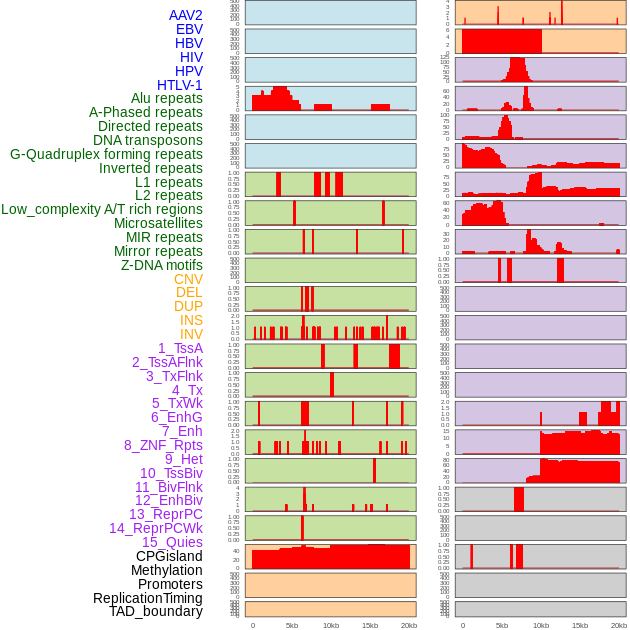 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SF1-TC2N |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:64543969/chr14:92249554) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000227503 | - | 2 | 13 | 15_19 | 53 | 549.0 | Motif | Nuclear localization signal |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000334944 | - | 2 | 14 | 15_19 | 53 | 639.0 | Motif | Nuclear localization signal |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377387 | - | 2 | 13 | 15_19 | 178 | 674.0 | Motif | Nuclear localization signal |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377390 | - | 2 | 13 | 15_19 | 53 | 640.0 | Motif | Nuclear localization signal |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377394 | - | 2 | 13 | 15_19 | 53 | 572.0 | Motif | Nuclear localization signal |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000433274 | - | 2 | 13 | 15_19 | 27 | 614.0 | Motif | Nuclear localization signal |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000556018 | 9 | 11 | 447_449 | 390 | 427.0 | Motif | Nuclear localization signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000227503 | - | 2 | 13 | 324_637 | 53 | 549.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000334944 | - | 2 | 14 | 324_637 | 53 | 639.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377387 | - | 2 | 13 | 324_637 | 178 | 674.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377390 | - | 2 | 13 | 324_637 | 53 | 640.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377394 | - | 2 | 13 | 324_637 | 53 | 572.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000433274 | - | 2 | 13 | 324_637 | 27 | 614.0 | Compositional bias | Note=Pro-rich |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000227503 | - | 2 | 13 | 141_222 | 53 | 549.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000334944 | - | 2 | 14 | 141_222 | 53 | 639.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377387 | - | 2 | 13 | 141_222 | 178 | 674.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377390 | - | 2 | 13 | 141_222 | 53 | 640.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377394 | - | 2 | 13 | 141_222 | 53 | 572.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000433274 | - | 2 | 13 | 141_222 | 27 | 614.0 | Domain | KH |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000227503 | - | 2 | 13 | 277_296 | 53 | 549.0 | Zinc finger | CCHC-type |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000334944 | - | 2 | 14 | 277_296 | 53 | 639.0 | Zinc finger | CCHC-type |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377387 | - | 2 | 13 | 277_296 | 178 | 674.0 | Zinc finger | CCHC-type |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377390 | - | 2 | 13 | 277_296 | 53 | 640.0 | Zinc finger | CCHC-type |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000377394 | - | 2 | 13 | 277_296 | 53 | 572.0 | Zinc finger | CCHC-type |
| Hgene | SF1 | chr11:64543969 | chr14:92249554 | ENST00000433274 | - | 2 | 13 | 277_296 | 27 | 614.0 | Zinc finger | CCHC-type |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000340892 | 10 | 12 | 223_342 | 454 | 491.0 | Domain | C2 1 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000340892 | 10 | 12 | 344_471 | 454 | 491.0 | Domain | C2 2 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000360594 | 10 | 12 | 223_342 | 454 | 491.0 | Domain | C2 1 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000360594 | 10 | 12 | 344_471 | 454 | 491.0 | Domain | C2 2 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000435962 | 10 | 12 | 223_342 | 454 | 491.0 | Domain | C2 1 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000435962 | 10 | 12 | 344_471 | 454 | 491.0 | Domain | C2 2 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000556018 | 9 | 11 | 223_342 | 390 | 427.0 | Domain | C2 1 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000556018 | 9 | 11 | 344_471 | 390 | 427.0 | Domain | C2 2 | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000340892 | 10 | 12 | 447_449 | 454 | 491.0 | Motif | Nuclear localization signal | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000360594 | 10 | 12 | 447_449 | 454 | 491.0 | Motif | Nuclear localization signal | |
| Tgene | TC2N | chr11:64543969 | chr14:92249554 | ENST00000435962 | 10 | 12 | 447_449 | 454 | 491.0 | Motif | Nuclear localization signal |
Top |
Fusion Gene Sequence for SF1-TC2N |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >81021_81021_1_SF1-TC2N_SF1_chr11_64543969_ENST00000227503_TC2N_chr14_92249554_ENST00000360594_length(transcript)=2771nt_BP=515nt GCGACACCTCCCAGCCCACCGAACTCCGCCGCCATTTCCTCGCTTGGCCTAACGGTTCGGCCAATCCCAGCGCGCATCAAGAAGGACTGA GGCTCCGCCAATCGGAGGCCGCCGATTTCGACCCTTCGCCTCGGCCCGGCCCAATCCAGGCCCCGGCCCCGCCGCCCCCGGCCCGCCCCC GCGGTGCCCTCTCTCCTCCCTCTTTGTGCGTCTCGCGCCGCCGCCGCCCGCCGCGTGAGAGGACGGGCTCCGCGCGCTCCGGCAGCGCAT TCGGGTCCCCTCCCCCCGGGAGGCTTGCGAAGGAGAAGCCGCCGCAGAGGAAAAGCAGGTGCCGGTGCCTGTCCCCGGGGGCGCCATGGC GACCGGAGCGAACGCCACGCCGTTGGACTTCCCAAGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGT GATTCCAGGAATGCCTACAGTTATTCCCCCTGGACTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATA ACATTGAAGCAGTGAACCAGTGGAAAGAGACAGTAATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGAC TTCACACATTAATTTGGTGAAGAACTTGACATTCTTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAA TTTGTCAATTTATGGGGGCTATAATTATGGTATATAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCAGATATCC AAAGTAAAGGAAATGTTTTAAAACTGCAACAAGAGACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCT GTGAGAATATCAACCATAGATAGTTCTTTCTATATTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATAT CAAGTCTCTGTTAGTACTATTGGCATTTAGAAGACTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTA CCTCTTGCTATGTATTTTCTCCCGGTAAAAATGAATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTA TAATTTTTTTACCCATAAGACATCACATTATCCCTTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAG GAATAATTGAAAACACCAGAAGGTTGAAGTTTAATTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTAT TTGTTTTATTTGGAGTTAAAATAAGAGTATCATCCATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTAT TTTATGATAATCACTTCGTTTTTAGTTTTTAAAATTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACC ATACCTGATTATACTGTGTAACAAATATTTTCTATTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCT TAATTGACCATAAGAACTGTGGCCAAAAAGAACAGTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCACTTTATTT TTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTCAGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAG ATGGTGATATTTTAGGCCAGGAGTATACCTTGCTATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAAC ATTTTCCCAAATAAACACTTAATTCTCTTTTCCCTAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCT ACTGCTCTGATTTTGTGGTACCAGTACTCTCTGCCACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTC AGTACTCACATGGATTTTTAAGATAAATCACCTGTGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAA TAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAACAGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACA GCCTCCCAGGCTATCAGTATCCTGCACCACAATGGTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCCAAAGTTC ATGGTTTACATTAGAGTCCCCTCTTGGTGTTATACATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATAGTATAGT TTCGCTGCCCTAAACATCCTCTGCAAATGCAACTATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAA CGGGCTTTATTGTTTATTTTAAAAGCTACAATTTGTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATG TAGTCATGCATTTAACTTAATATTTAATTATTTGATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTTAAGGGAA >81021_81021_1_SF1-TC2N_SF1_chr11_64543969_ENST00000227503_TC2N_chr14_92249554_ENST00000360594_length(amino acids)=177AA_BP=1 MCHLITTFSGFITVSFHWFTASMLLLSSLIQIYISSFLFSSKSRGNNCRHSWNHCLLFHCVLVPAAPLPLLTWEVQRRGVRSGRHGAPGD -------------------------------------------------------------- >81021_81021_2_SF1-TC2N_SF1_chr11_64543969_ENST00000334944_TC2N_chr14_92249554_ENST00000360594_length(transcript)=2810nt_BP=554nt CGGAGCTCAGTTCACGCAGTAACAAATGAAGTGCGCGCTGCGACACCTCCCAGCCCACCGAACTCCGCCGCCATTTCCTCGCTTGGCCTA ACGGTTCGGCCAATCCCAGCGCGCATCAAGAAGGACTGAGGCTCCGCCAATCGGAGGCCGCCGATTTCGACCCTTCGCCTCGGCCCGGCC CAATCCAGGCCCCGGCCCCGCCGCCCCCGGCCCGCCCCCGCGGTGCCCTCTCTCCTCCCTCTTTGTGCGTCTCGCGCCGCCGCCGCCCGC CGCGTGAGAGGACGGGCTCCGCGCGCTCCGGCAGCGCATTCGGGTCCCCTCCCCCCGGGAGGCTTGCGAAGGAGAAGCCGCCGCAGAGGA AAAGCAGGTGCCGGTGCCTGTCCCCGGGGGCGCCATGGCGACCGGAGCGAACGCCACGCCGTTGGACTTCCCAAGTAAGAAGCGGAAGAG GAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGTGATTCCAGGAATGCCTACAGTTATTCCCCCTGGACTTACTCGAGAACAAGA AAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATAACATTGAAGCAGTGAACCAGTGGAAAGAGACAGTAATAAATCCAGAAAAGG TTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGACTTCACACATTAATTTGGTGAAGAACTTGACATTCTTTTAGAAGACTTATGA TTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAATTTGTCAATTTATGGGGGCTATAATTATGGTATATAATGTATCTGATAGAA AATTTGATAAGAAAATGTAATGAATTTTATCAGATATCCAAAGTAAAGGAAATGTTTTAAAACTGCAACAAGAGACACAGACAGTAAAAT CAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCTGTGAGAATATCAACCATAGATAGTTCTTTCTATATTATGTTTTCGCTTTTG TATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATATCAAGTCTCTGTTAGTACTATTGGCATTTAGAAGACTTTACCATTATTTCAG TGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTACCTCTTGCTATGTATTTTCTCCCGGTAAAAATGAATTGAACCATTTCAACT ATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTATAATTTTTTTACCCATAAGACATCACATTATCCCTTTGTAAGCTACTTATC TCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAGGAATAATTGAAAACACCAGAAGGTTGAAGTTTAATTGGAAACCCAGAATAT ACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTATTTGTTTTATTTGGAGTTAAAATAAGAGTATCATCCATATGGTCCATCCTAA TTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTATTTTATGATAATCACTTCGTTTTTAGTTTTTAAAATTTAGATTATTCTATAA TTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACCATACCTGATTATACTGTGTAACAAATATTTTCTATTGCAGTTTTCTTTCCA GTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCTTAATTGACCATAAGAACTGTGGCCAAAAAGAACAGTTTTTTGGAGAGGCAG ATGACATTATACCTGATTTTAGAAAATCTCACTTTATTTTTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTCAGTCTTCCCTTTTTTTC TGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAGATGGTGATATTTTAGGCCAGGAGTATACCTTGCTATAACCTAAGCATGCCT TCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAACATTTTCCCAAATAAACACTTAATTCTCTTTTCCCTAGGTGCCATCTCCTCA AGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCTACTGCTCTGATTTTGTGGTACCAGTACTCTCTGCCACTGAACATTTTGAAA TATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTCAGTACTCACATGGATTTTTAAGATAAATCACCTGTGTGATAATATTTTGAA TCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAATAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAACAGAAAAATTGAGAGGAA GATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACAGCCTCCCAGGCTATCAGTATCCTGCACCACAATGGTACATTTGTTACAATC AATGAACCTACTCTGAAACATCATTATCATCCAAAGTTCATGGTTTACATTAGAGTCCCCTCTTGGTGTTATACATGCTAGAGGACAAAT ATATGATGATATGTATGCATCATTATAATATAGTATAGTTTCGCTGCCCTAAACATCCTCTGCAAATGCAACTATTTTAATGGGTACCAA AGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAACGGGCTTTATTGTTTATTTTAAAAGCTACAATTTGTTTTAGCTGGTTTCTC TGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATGTAGTCATGCATTTAACTTAATATTTAATTATTTGATTTATTTAATTTTCTA TATTCTTACAATGTATGTATGATGTATAATTTAAGGGAAAGCTATGACTTCTCAGTTTCTTAGAATCCTAGGTAAATAAAACAATAAAAA >81021_81021_2_SF1-TC2N_SF1_chr11_64543969_ENST00000334944_TC2N_chr14_92249554_ENST00000360594_length(amino acids)=177AA_BP=1 MCHLITTFSGFITVSFHWFTASMLLLSSLIQIYISSFLFSSKSRGNNCRHSWNHCLLFHCVLVPAAPLPLLTWEVQRRGVRSGRHGAPGD -------------------------------------------------------------- >81021_81021_3_SF1-TC2N_SF1_chr11_64543969_ENST00000377387_TC2N_chr14_92249554_ENST00000360594_length(transcript)=2868nt_BP=612nt CCTCCCCCCGGGAGGCTTGCGAAGGAGAAGCCGCCGCAGAGGAAAAGCAGGTGCCGGTGCCTGTCCCCGGGGGCGCCATGGCGACCGGAG CGAACGCCACGCCGTTGGGTAAGCTGGGCCCCCCCGGGCTGCCCCCGCTCCCCGGGCCCAAAGGAGGCTTCGAGCCGGGCCCTCCGCCTG CACCCGGGCCTGGGGCGGGGCTGCTGGCTCCCGGGCCGCCGCCGCCCCCGCCCGTGGGCTCGATGGGGGCCCTGACCGCGGCCTTCCCCT TCGCGGCGCTGCCTCCGCCGCCTCCGCCGCCGCCCCCTCCGCCTCCCCAGCAGCCGCCGCCGCCTCCACCGCCACCGTCCCCCGGCGCCT CGTACCCGCCGCCGCAGCCGCCCCCTCCGCCGCCGCTCTACCAGCGCGTGTCGCCGCCGCAGCCGCCGCCACCCCAGCCGCCGCGTAAGG ACCAGCAGCCGGGCCCGGCCGGCGGCGGAGGAGACTTCCCAAGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGA AGACAGTGATTCCAGGAATGCCTACAGTTATTCCCCCTGGACTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGAC AGTAATAACATTGAAGCAGTGAACCAGTGGAAAGAGACAGTAATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCT TGAAGACTTCACACATTAATTTGGTGAAGAACTTGACATTCTTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAAT CAACAAATTTGTCAATTTATGGGGGCTATAATTATGGTATATAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCA GATATCCAAAGTAAAGGAAATGTTTTAAAACTGCAACAAGAGACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTAT AAAGTCTGTGAGAATATCAACCATAGATAGTTCTTTCTATATTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCT GGTATATCAAGTCTCTGTTAGTACTATTGGCATTTAGAAGACTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCA CTGTTTACCTCTTGCTATGTATTTTCTCCCGGTAAAAATGAATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTG TGTTTTATAATTTTTTTACCCATAAGACATCACATTATCCCTTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATT TTGGCAGGAATAATTGAAAACACCAGAAGGTTGAAGTTTAATTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATT TTACTATTTGTTTTATTTGGAGTTAAAATAAGAGTATCATCCATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAAT TCAGTATTTTATGATAATCACTTCGTTTTTAGTTTTTAAAATTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTT CATAACCATACCTGATTATACTGTGTAACAAATATTTTCTATTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAAT TTCAGCTTAATTGACCATAAGAACTGTGGCCAAAAAGAACAGTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCAC TTTATTTTTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTCAGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCA GAGAAAGATGGTGATATTTTAGGCCAGGAGTATACCTTGCTATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATAT CATTAACATTTTCCCAAATAAACACTTAATTCTCTTTTCCCTAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTT TGCTTCTACTGCTCTGATTTTGTGGTACCAGTACTCTCTGCCACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACAT ATAGGTCAGTACTCACATGGATTTTTAAGATAAATCACCTGTGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTT TTAAAAATAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAACAGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCC CTCAACAGCCTCCCAGGCTATCAGTATCCTGCACCACAATGGTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCC AAAGTTCATGGTTTACATTAGAGTCCCCTCTTGGTGTTATACATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATA GTATAGTTTCGCTGCCCTAAACATCCTCTGCAAATGCAACTATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAA TAAATAACGGGCTTTATTGTTTATTTTAAAAGCTACAATTTGTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTA ATATATGTAGTCATGCATTTAACTTAATATTTAATTATTTGATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTT >81021_81021_3_SF1-TC2N_SF1_chr11_64543969_ENST00000377387_TC2N_chr14_92249554_ENST00000360594_length(amino acids)=235AA_BP=1 MCHLITTFSGFITVSFHWFTASMLLLSSLIQIYISSFLFSSKSRGNNCRHSWNHCLLFHCVLVPAAPLPLLTWEVSSAAGRARLLVLTRR LGWRRLRRRHALVERRRRGRLRRRVRGAGGRWRWRRRRLLGRRRGRRRRRRRQRREGEGRGQGPHRAHGRGRRRPGSQQPRPRPGCRRRA -------------------------------------------------------------- >81021_81021_4_SF1-TC2N_SF1_chr11_64543969_ENST00000377390_TC2N_chr14_92249554_ENST00000360594_length(transcript)=2754nt_BP=498nt ACCGAACTCCGCCGCCATTTCCTCGCTTGGCCTAACGGTTCGGCCAATCCCAGCGCGCATCAAGAAGGACTGAGGCTCCGCCAATCGGAG GCCGCCGATTTCGACCCTTCGCCTCGGCCCGGCCCAATCCAGGCCCCGGCCCCGCCGCCCCCGGCCCGCCCCCGCGGTGCCCTCTCTCCT CCCTCTTTGTGCGTCTCGCGCCGCCGCCGCCCGCCGCGTGAGAGGACGGGCTCCGCGCGCTCCGGCAGCGCATTCGGGTCCCCTCCCCCC GGGAGGCTTGCGAAGGAGAAGCCGCCGCAGAGGAAAAGCAGGTGCCGGTGCCTGTCCCCGGGGGCGCCATGGCGACCGGAGCGAACGCCA CGCCGTTGGACTTCCCAAGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGTGATTCCAGGAATGCCTA CAGTTATTCCCCCTGGACTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATAACATTGAAGCAGTGAAC CAGTGGAAAGAGACAGTAATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGACTTCACACATTAATTTGG TGAAGAACTTGACATTCTTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAATTTGTCAATTTATGGGG GCTATAATTATGGTATATAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCAGATATCCAAAGTAAAGGAAATGTT TTAAAACTGCAACAAGAGACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCTGTGAGAATATCAACCAT AGATAGTTCTTTCTATATTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATATCAAGTCTCTGTTAGTAC TATTGGCATTTAGAAGACTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTACCTCTTGCTATGTATTT TCTCCCGGTAAAAATGAATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTATAATTTTTTTACCCATA AGACATCACATTATCCCTTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAGGAATAATTGAAAACACC AGAAGGTTGAAGTTTAATTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTATTTGTTTTATTTGGAGTT AAAATAAGAGTATCATCCATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTATTTTATGATAATCACTTC GTTTTTAGTTTTTAAAATTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACCATACCTGATTATACTGT GTAACAAATATTTTCTATTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCTTAATTGACCATAAGAAC TGTGGCCAAAAAGAACAGTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCACTTTATTTTTGCTAATAAGTAGACT AAGTGCTCTGTGTTCTCAGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAGATGGTGATATTTTAGGC CAGGAGTATACCTTGCTATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAACATTTTCCCAAATAAACA CTTAATTCTCTTTTCCCTAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCTACTGCTCTGATTTTGTG GTACCAGTACTCTCTGCCACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTCAGTACTCACATGGATTT TTAAGATAAATCACCTGTGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAATAGACTTTTTTTTTTAG AGCAGTTGTAGGTTAACAGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACAGCCTCCCAGGCTATCAG TATCCTGCACCACAATGGTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCCAAAGTTCATGGTTTACATTAGAGT CCCCTCTTGGTGTTATACATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATAGTATAGTTTCGCTGCCCTAAACAT CCTCTGCAAATGCAACTATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAACGGGCTTTATTGTTTAT TTTAAAAGCTACAATTTGTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATGTAGTCATGCATTTAACT TAATATTTAATTATTTGATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTTAAGGGAAAGCTATGACTTCTCAGT >81021_81021_4_SF1-TC2N_SF1_chr11_64543969_ENST00000377390_TC2N_chr14_92249554_ENST00000360594_length(amino acids)=177AA_BP=1 MCHLITTFSGFITVSFHWFTASMLLLSSLIQIYISSFLFSSKSRGNNCRHSWNHCLLFHCVLVPAAPLPLLTWEVQRRGVRSGRHGAPGD -------------------------------------------------------------- >81021_81021_5_SF1-TC2N_SF1_chr11_64543969_ENST00000377394_TC2N_chr14_92249554_ENST00000360594_length(transcript)=2771nt_BP=515nt GCGACACCTCCCAGCCCACCGAACTCCGCCGCCATTTCCTCGCTTGGCCTAACGGTTCGGCCAATCCCAGCGCGCATCAAGAAGGACTGA GGCTCCGCCAATCGGAGGCCGCCGATTTCGACCCTTCGCCTCGGCCCGGCCCAATCCAGGCCCCGGCCCCGCCGCCCCCGGCCCGCCCCC GCGGTGCCCTCTCTCCTCCCTCTTTGTGCGTCTCGCGCCGCCGCCGCCCGCCGCGTGAGAGGACGGGCTCCGCGCGCTCCGGCAGCGCAT TCGGGTCCCCTCCCCCCGGGAGGCTTGCGAAGGAGAAGCCGCCGCAGAGGAAAAGCAGGTGCCGGTGCCTGTCCCCGGGGGCGCCATGGC GACCGGAGCGAACGCCACGCCGTTGGACTTCCCAAGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGT GATTCCAGGAATGCCTACAGTTATTCCCCCTGGACTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATA ACATTGAAGCAGTGAACCAGTGGAAAGAGACAGTAATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGAC TTCACACATTAATTTGGTGAAGAACTTGACATTCTTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAA TTTGTCAATTTATGGGGGCTATAATTATGGTATATAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCAGATATCC AAAGTAAAGGAAATGTTTTAAAACTGCAACAAGAGACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCT GTGAGAATATCAACCATAGATAGTTCTTTCTATATTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATAT CAAGTCTCTGTTAGTACTATTGGCATTTAGAAGACTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTA CCTCTTGCTATGTATTTTCTCCCGGTAAAAATGAATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTA TAATTTTTTTACCCATAAGACATCACATTATCCCTTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAG GAATAATTGAAAACACCAGAAGGTTGAAGTTTAATTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTAT TTGTTTTATTTGGAGTTAAAATAAGAGTATCATCCATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTAT TTTATGATAATCACTTCGTTTTTAGTTTTTAAAATTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACC ATACCTGATTATACTGTGTAACAAATATTTTCTATTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCT TAATTGACCATAAGAACTGTGGCCAAAAAGAACAGTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCACTTTATTT TTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTCAGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAG ATGGTGATATTTTAGGCCAGGAGTATACCTTGCTATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAAC ATTTTCCCAAATAAACACTTAATTCTCTTTTCCCTAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCT ACTGCTCTGATTTTGTGGTACCAGTACTCTCTGCCACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTC AGTACTCACATGGATTTTTAAGATAAATCACCTGTGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAA TAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAACAGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACA GCCTCCCAGGCTATCAGTATCCTGCACCACAATGGTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCCAAAGTTC ATGGTTTACATTAGAGTCCCCTCTTGGTGTTATACATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATAGTATAGT TTCGCTGCCCTAAACATCCTCTGCAAATGCAACTATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAA CGGGCTTTATTGTTTATTTTAAAAGCTACAATTTGTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATG TAGTCATGCATTTAACTTAATATTTAATTATTTGATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTTAAGGGAA >81021_81021_5_SF1-TC2N_SF1_chr11_64543969_ENST00000377394_TC2N_chr14_92249554_ENST00000360594_length(amino acids)=177AA_BP=1 MCHLITTFSGFITVSFHWFTASMLLLSSLIQIYISSFLFSSKSRGNNCRHSWNHCLLFHCVLVPAAPLPLLTWEVQRRGVRSGRHGAPGD -------------------------------------------------------------- >81021_81021_6_SF1-TC2N_SF1_chr11_64543969_ENST00000433274_TC2N_chr14_92249554_ENST00000340892_length(transcript)=3423nt_BP=391nt GACGCAGTGAGGTGGCCGGGCTGTGCGGCGCAACTGTATAGACTGGGGGCCCACTATTGCTGTCCAGTCCGCTGGTGTCGGGAACAGGGG TGGCGGGTGTTCAGCGCTGGACGGGGTGCTAGCTGTGAATGCCAGCAGGGCGTGAAAGCCTCACCTGATGACGTGCAGCGACTCCCTTCT GGTCTTGAGGAACCAGAATGGGAACCGTACCAAGGATAGCTCCTCTGCTTCTACAGCAAGGCAGGGTTTTCATCCGGGAGAGACTTCCCA AGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGTGATTCCAGGAATGCCTACAGTTATTCCCCCTGGA CTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATAACATTGAAGCAGTGAACCAGTGGAAAGAGACAGT AATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGACTTCACACATTAATTTGGTGAAGAACTTGACATTC TTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAATTTGTCAATTTATGGGGGCTATAATTATGGTATA TAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCAGATATCCAAAGTAAAGGAAATGTTTTAAAACTGCAACAAGA GACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCTGTGAGAATATCAACCATAGATAGTTCTTTCTATA TTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATATCAAGTCTCTGTTAGTACTATTGGCATTTAGAAGA CTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTACCTCTTGCTATGTATTTTCTCCCGGTAAAAATGA ATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTATAATTTTTTTACCCATAAGACATCACATTATCCC TTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAGGAATAATTGAAAACACCAGAAGGTTGAAGTTTAA TTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTATTTGTTTTATTTGGAGTTAAAATAAGAGTATCATC CATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTATTTTATGATAATCACTTCGTTTTTAGTTTTTAAAA TTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACCATACCTGATTATACTGTGTAACAAATATTTTCTA TTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCTTAATTGACCATAAGAACTGTGGCCAAAAAGAACA GTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCACTTTATTTTTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTC AGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAGATGGTGATATTTTAGGCCAGGAGTATACCTTGCT ATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAACATTTTCCCAAATAAACACTTAATTCTCTTTTCCC TAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCTACTGCTCTGATTTTGTGGTACCAGTACTCTCTGC CACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTCAGTACTCACATGGATTTTTAAGATAAATCACCTG TGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAATAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAAC AGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACAGCCTCCCAGGCTATCAGTATCCTGCACCACAATG GTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCCAAAGTTCATGGTTTACATTAGAGTCCCCTCTTGGTGTTATA CATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATAGTATAGTTTCGCTGCCCTAAACATCCTCTGCAAATGCAACT ATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAACGGGCTTTATTGTTTATTTTAAAAGCTACAATTT GTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATGTAGTCATGCATTTAACTTAATATTTAATTATTTG ATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTTAAGGGAAAGCTATGACTTCTCAGTTTCTTAGAATCCTAGGT AAATAAAACAATAAAAAGAAAACCCTTACATTTAAAAGAGCTTTCAGGTACAGAAGTATTGATACAACTAAGATCCTAAATGTTTTAATT AGTGTTTACTTAAGCCTTTTTCAGGTGAGGAGGTACTAATGCTGGTTATTTCCTTGAAGCTTTATGTGGACCTATAAATAAAAATCCAAT CTCCTGCTAATAGGTATGCATATTGTGAGAAAAACGTTAGGAGCTGGTAGTAAAAAATGAGATTCTATGCCAAAATAACTTCTCTTCATA TTTGCCTAGGCATTTCTTGACCTTTACCCACTTACGCAAGGAGAAGGAAATCATAATGATGTCATGTGATCAAAGGAAACCATGGAAGGG TTCACGCTGATAGCTGATAGCTTTTACAGTGCTCATTCCTAACAGTGGATTTACTTGTAAGCTTTCAGATCAACACAAATAGCTGCAGCC TGGGTTAAAATATAACATCACTATTTGGCTTTTGTTTTGCATGATTTTTAAAAGCAGTACTCCTAGGGAAATGGCCTCTGAAGTATATCA GTTTCATCTCTTACCAAGACTGTTAAGAAGAAACTAGTGGGATTTTGAACAAGTTATATAATTGTGGTCTGAAAAGACCCTAAACTGAAG TTCTGTTTAAATATAGTTACATGAATTTCTCTGATACTAATGTACTCAACAGCCAGGTATAAACTATATCTCCTAGTAACATTTTCCATT TTTGTTTAATCAAATACTTGCTTATGAAGGATTTCAGAAATTTGTAATAAATGTCAGCTTTTGATAGCATAGCAGTAATTGACATTTCAA >81021_81021_6_SF1-TC2N_SF1_chr11_64543969_ENST00000433274_TC2N_chr14_92249554_ENST00000340892_length(amino acids)=78AA_BP=1 -------------------------------------------------------------- >81021_81021_7_SF1-TC2N_SF1_chr11_64543969_ENST00000433274_TC2N_chr14_92249554_ENST00000435962_length(transcript)=3851nt_BP=391nt GACGCAGTGAGGTGGCCGGGCTGTGCGGCGCAACTGTATAGACTGGGGGCCCACTATTGCTGTCCAGTCCGCTGGTGTCGGGAACAGGGG TGGCGGGTGTTCAGCGCTGGACGGGGTGCTAGCTGTGAATGCCAGCAGGGCGTGAAAGCCTCACCTGATGACGTGCAGCGACTCCCTTCT GGTCTTGAGGAACCAGAATGGGAACCGTACCAAGGATAGCTCCTCTGCTTCTACAGCAAGGCAGGGTTTTCATCCGGGAGAGACTTCCCA AGTAAGAAGCGGAAGAGGAGCCGCTGGAACCAAGACACAATGGAACAGAAGACAGTGATTCCAGGAATGCCTACAGTTATTCCCCCTGGA CTTACTCGAGAACAAGAAAGAGCTTATATAGATTTGGATAAGTGAAGACAGTAATAACATTGAAGCAGTGAACCAGTGGAAAGAGACAGT AATAAATCCAGAAAAGGTTGTTATCAGGTGGCACAAATTAAATCCATCTTGAAGACTTCACACATTAATTTGGTGAAGAACTTGACATTC TTTTAGAAGACTTATGATTTCAATTTGCTACCAATGAGAAGAGGCAAATCAACAAATTTGTCAATTTATGGGGGCTATAATTATGGTATA TAATGTATCTGATAGAAAATTTGATAAGAAAATGTAATGAATTTTATCAGATATCCAAAGTAAAGGAAATGTTTTAAAACTGCAACAAGA GACACAGACAGTAAAATCAAAGTATTATTAGGATGACTAAATAAATTATAAAGTCTGTGAGAATATCAACCATAGATAGTTCTTTCTATA TTATGTTTTCGCTTTTGTATTTTAAGCTTTACTTAGATATTCAAAACCTGGTATATCAAGTCTCTGTTAGTACTATTGGCATTTAGAAGA CTTTACCATTATTTCAGTGCTAGGCATTATTGATTAGGTCTTGGCTCCACTGTTTACCTCTTGCTATGTATTTTCTCCCGGTAAAAATGA ATTGAACCATTTCAACTATTTTCTATATTTGGAGAAAGTTTGTGCCCTGTGTTTTATAATTTTTTTACCCATAAGACATCACATTATCCC TTTGTAAGCTACTTATCTCCAAAAAACTTCAGAAATAGAAAACTACATTTTGGCAGGAATAATTGAAAACACCAGAAGGTTGAAGTTTAA TTGGAAACCCAGAATATACATACTTTGCTGTTTTCTTCCCTCAAATATTTTACTATTTGTTTTATTTGGAGTTAAAATAAGAGTATCATC CATATGGTCCATCCTAATTCACAGAATTAAATGAGCTTAAATAGAAAATTCAGTATTTTATGATAATCACTTCGTTTTTAGTTTTTAAAA TTTAGATTATTCTATAATTTACCGTGTTTGAGTATTTTCTCATTTTTTTCATAACCATACCTGATTATACTGTGTAACAAATATTTTCTA TTGCAGTTTTCTTTCCAGTACTTATTAGAACTCAGTATTTGGAAATAATTTCAGCTTAATTGACCATAAGAACTGTGGCCAAAAAGAACA GTTTTTTGGAGAGGCAGATGACATTATACCTGATTTTAGAAAATCTCACTTTATTTTTGCTAATAAGTAGACTAAGTGCTCTGTGTTCTC AGTCTTCCCTTTTTTTCTGCCCCCATTCTTACTTTGTCCCAGGCATGCAGAGAAAGATGGTGATATTTTAGGCCAGGAGTATACCTTGCT ATAACCTAAGCATGCCTTCTTTATTCCAGCTCCTATGTTCTGTGTATATCATTAACATTTTCCCAAATAAACACTTAATTCTCTTTTCCC TAGGTGCCATCTCCTCAAGCTACAAAATGTCCACATCTTATATCCCCTTTGCTTCTACTGCTCTGATTTTGTGGTACCAGTACTCTCTGC CACTGAACATTTTGAAATATTTTTGTTTTAGATTTGCAAAAAATGACATATAGGTCAGTACTCACATGGATTTTTAAGATAAATCACCTG TGTGATAATATTTTGAATCTGAGACGAATACAACTTTTAAAAATTGTTTTTAAAAATAGACTTTTTTTTTTAGAGCAGTTGTAGGTTAAC AGAAAAATTGAGAGGAAGATAGAGATTTCCTTTCTCCCCTGACAAAGCCCTCAACAGCCTCCCAGGCTATCAGTATCCTGCACCACAATG GTACATTTGTTACAATCAATGAACCTACTCTGAAACATCATTATCATCCAAAGTTCATGGTTTACATTAGAGTCCCCTCTTGGTGTTATA CATGCTAGAGGACAAATATATGATGATATGTATGCATCATTATAATATAGTATAGTTTCGCTGCCCTAAACATCCTCTGCAAATGCAACT ATTTTAATGGGTACCAAAGAAGTAAATGTATTTACTGGCTTTTAGATAATAAATAACGGGCTTTATTGTTTATTTTAAAAGCTACAATTT GTTTTAGCTGGTTTCTCTGTTCTATTAATGCTTTGAATTTCCAAATTTAATATATGTAGTCATGCATTTAACTTAATATTTAATTATTTG ATTTATTTAATTTTCTATATTCTTACAATGTATGTATGATGTATAATTTAAGGGAAAGCTATGACTTCTCAGTTTCTTAGAATCCTAGGT AAATAAAACAATAAAAAGAAAACCCTTACATTTAAAAGAGCTTTCAGGTACAGAAGTATTGATACAACTAAGATCCTAAATGTTTTAATT AGTGTTTACTTAAGCCTTTTTCAGGTGAGGAGGTACTAATGCTGGTTATTTCCTTGAAGCTTTATGTGGACCTATAAATAAAAATCCAAT CTCCTGCTAATAGGTATGCATATTGTGAGAAAAACGTTAGGAGCTGGTAGTAAAAAATGAGATTCTATGCCAAAATAACTTCTCTTCATA TTTGCCTAGGCATTTCTTGACCTTTACCCACTTACGCAAGGAGAAGGAAATCATAATGATGTCATGTGATCAAAGGAAACCATGGAAGGG TTCACGCTGATAGCTGATAGCTTTTACAGTGCTCATTCCTAACAGTGGATTTACTTGTAAGCTTTCAGATCAACACAAATAGCTGCAGCC TGGGTTAAAATATAACATCACTATTTGGCTTTTGTTTTGCATGATTTTTAAAAGCAGTACTCCTAGGGAAATGGCCTCTGAAGTATATCA GTTTCATCTCTTACCAAGACTGTTAAGAAGAAACTAGTGGGATTTTGAACAAGTTATATAATTGTGGTCTGAAAAGACCCTAAACTGAAG TTCTGTTTAAATATAGTTACATGAATTTCTCTGATACTAATGTACTCAACAGCCAGGTATAAACTATATCTCCTAGTAACATTTTCCATT TTTGTTTAATCAAATACTTGCTTATGAAGGATTTCAGAAATTTGTAATAAATGTCAGCTTTTGATAGCATAGCAGTAATTGACATTTCAA AAATATATATTTCTTTCTGTGTTTGGTTGGGTGTAATGAGGAAAATACCTGATAAAATGTCTGAAGACACTTTCTAATGTTATCTTGGTG CATAAGCTGTAATTTTTATTCAAAATTAAATTTCAAATGTTTGCAGTTTTGGCTAAAACATTGAGTTGAAAGAATTATGAAAAGTGGGCC CATATGAAGTACCATGTTCATTTTGAAATATAGATTTAAGATTTAGAAATATATTAAAAGAGTTAATGGAGCCTCCTAAATTGGATTTTA TTTTGTGGGTGAAGAATTGTAGGAAGATGAATGTGGCCTACAGTTTTAGTAATCTCCTAGTGGAGTTTTTTTTAACTTAGTACTTTTTTA >81021_81021_7_SF1-TC2N_SF1_chr11_64543969_ENST00000433274_TC2N_chr14_92249554_ENST00000435962_length(amino acids)=78AA_BP=1 -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SF1-TC2N |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SF1-TC2N |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SF1-TC2N |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies