
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SFXN5-M1AP (FusionGDB2 ID:81231) |
Fusion Gene Summary for SFXN5-M1AP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SFXN5-M1AP | Fusion gene ID: 81231 | Hgene | Tgene | Gene symbol | SFXN5 | M1AP | Gene ID | 94097 | 130951 |
| Gene name | sideroflexin 5 | meiosis 1 associated protein | |
| Synonyms | BBG-TCC|SLC56A5 | C2orf65|D6Mm5e|SPATA37 | |
| Cytomap | 2p13.2 | 2p13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sideroflexin-5 | meiosis 1 arrest proteinmeiosis 1 arresting proteinspermatogenesis associated 37 | |
| Modification date | 20200320 | 20200320 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000272433, ENST00000410065, ENST00000474528, | ENST00000464686, ENST00000358434, ENST00000290536, ENST00000409585, ENST00000536235, | |
| Fusion gene scores | * DoF score | 10 X 10 X 6=600 | 6 X 6 X 5=180 |
| # samples | 11 | 7 | |
| ** MAII score | log2(11/600*10)=-2.44745897697122 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SFXN5 [Title/Abstract] AND M1AP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SFXN5(73226078)-M1AP(74789550), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SFXN5 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across M1AP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-61-1740-01A | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| ChimerDB4 | OV | TCGA-61-1740-01A | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
Top |
Fusion Gene ORF analysis for SFXN5-M1AP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000272433 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5CDS-5UTR | ENST00000272433 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5CDS-5UTR | ENST00000410065 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5CDS-5UTR | ENST00000410065 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5CDS-intron | ENST00000272433 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5CDS-intron | ENST00000410065 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5UTR-3CDS | ENST00000474528 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5UTR-5UTR | ENST00000474528 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| 5UTR-5UTR | ENST00000474528 | ENST00000464686 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| 5UTR-intron | ENST00000474528 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000272433 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000272433 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000272433 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000272433 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000272433 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000272433 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000272433 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000410065 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000410065 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000410065 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000410065 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000410065 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| In-frame | ENST00000410065 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - |
| In-frame | ENST00000410065 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000290536 | M1AP | chr2 | 74789550 | - | 2017 | 665 | 113 | 1183 | 356 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000409585 | M1AP | chr2 | 74789550 | - | 1996 | 665 | 113 | 1171 | 352 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000536235 | M1AP | chr2 | 74789550 | - | 1550 | 665 | 113 | 1171 | 352 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000290536 | M1AP | chr2 | 74789550 | - | 1905 | 553 | 1 | 1071 | 356 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000409585 | M1AP | chr2 | 74789550 | - | 1884 | 553 | 1 | 1059 | 352 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000536235 | M1AP | chr2 | 74789550 | - | 1438 | 553 | 1 | 1059 | 352 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000290536 | M1AP | chr2 | 74787418 | - | 1810 | 665 | 113 | 976 | 287 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000409585 | M1AP | chr2 | 74787418 | - | 1789 | 665 | 113 | 964 | 283 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000536235 | M1AP | chr2 | 74787418 | - | 1343 | 665 | 113 | 964 | 283 |
| ENST00000272433 | SFXN5 | chr2 | 73226078 | - | ENST00000358434 | M1AP | chr2 | 74787418 | - | 977 | 665 | 113 | 976 | 288 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000290536 | M1AP | chr2 | 74787418 | - | 1698 | 553 | 1 | 864 | 287 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000409585 | M1AP | chr2 | 74787418 | - | 1677 | 553 | 1 | 852 | 283 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000536235 | M1AP | chr2 | 74787418 | - | 1231 | 553 | 1 | 852 | 283 |
| ENST00000410065 | SFXN5 | chr2 | 73226078 | - | ENST00000358434 | M1AP | chr2 | 74787418 | - | 865 | 553 | 1 | 864 | 288 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000272433 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.06372754 | 0.93627244 |
| ENST00000272433 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.055148084 | 0.94485193 |
| ENST00000272433 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.091501154 | 0.9084989 |
| ENST00000410065 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.06907164 | 0.9309283 |
| ENST00000410065 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.05970704 | 0.9402929 |
| ENST00000410065 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74789550 | - | 0.10229201 | 0.897708 |
| ENST00000272433 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.12239026 | 0.8776097 |
| ENST00000272433 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.06905878 | 0.9309412 |
| ENST00000272433 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.08701527 | 0.9129847 |
| ENST00000272433 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.07790374 | 0.9220962 |
| ENST00000410065 | ENST00000290536 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.13870744 | 0.86129254 |
| ENST00000410065 | ENST00000409585 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.08001347 | 0.9199865 |
| ENST00000410065 | ENST00000536235 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.09513126 | 0.9048687 |
| ENST00000410065 | ENST00000358434 | SFXN5 | chr2 | 73226078 | - | M1AP | chr2 | 74787418 | - | 0.053612027 | 0.946388 |
Top |
Fusion Genomic Features for SFXN5-M1AP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
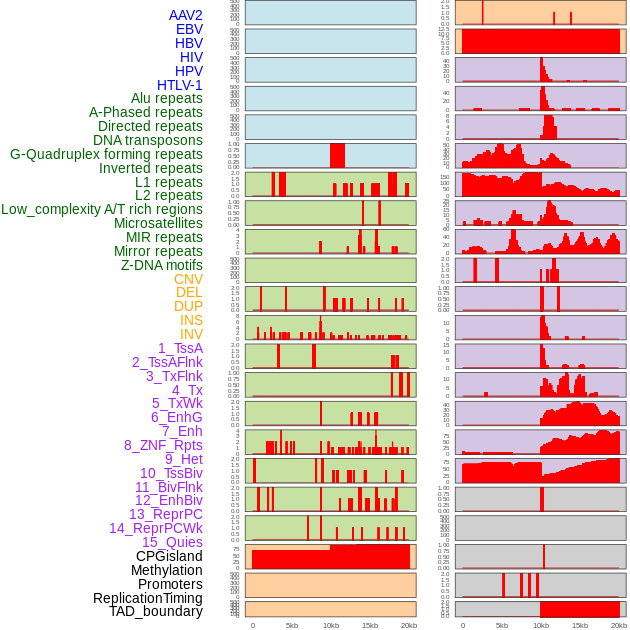 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SFXN5-M1AP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:73226078/chr2:74789550) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SFXN5 | chr2:73226078 | chr2:74787418 | ENST00000272433 | - | 9 | 14 | 103_123 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74789550 | ENST00000272433 | - | 9 | 14 | 103_123 | 178 | 341.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SFXN5 | chr2:73226078 | chr2:74787418 | ENST00000272433 | - | 9 | 14 | 163_183 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74787418 | ENST00000272433 | - | 9 | 14 | 254_274 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74787418 | ENST00000272433 | - | 9 | 14 | 287_307 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74789550 | ENST00000272433 | - | 9 | 14 | 163_183 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74789550 | ENST00000272433 | - | 9 | 14 | 254_274 | 178 | 341.0 | Transmembrane | Helical |
| Hgene | SFXN5 | chr2:73226078 | chr2:74789550 | ENST00000272433 | - | 9 | 14 | 287_307 | 178 | 341.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for SFXN5-M1AP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >81231_81231_1_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000290536_length(transcript)=1810nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAA GCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATC CCTGCAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGA TGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCA GAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTC TGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGC CTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTA CCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGA CCTCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCAC TACACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAA CAGGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCA CAGAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGT GGGATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACACTGTGAGACCCCCCCGCCATCTCTACATAAATAATAAAAACTTT >81231_81231_1_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000290536_length(amino acids)=287AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPCKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSS -------------------------------------------------------------- >81231_81231_2_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000358434_length(transcript)=977nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAA GCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATC CCTGCAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGA >81231_81231_2_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000358434_length(amino acids)=288AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPCKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSS -------------------------------------------------------------- >81231_81231_3_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000409585_length(transcript)=1789nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAA GCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTG GGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCA GCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGC CCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGG CTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTC CAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGA GCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAA GGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGG CTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGA TGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGC TACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACT >81231_81231_3_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000409585_length(amino acids)=283AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSSSDAF -------------------------------------------------------------- >81231_81231_4_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000536235_length(transcript)=1343nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAA GCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTG GGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCA GCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGC CCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGG CTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTC CAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGA >81231_81231_4_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74787418_ENST00000536235_length(amino acids)=283AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSSSDAF -------------------------------------------------------------- >81231_81231_5_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000290536_length(transcript)=2017nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCC AGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGC TGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGC CCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACT GGGAGAGCCGAGCTCCGAGAAAGCATCCCTGCAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGA CTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATC CCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCA GACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCC TCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGT GAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATG AGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCC TCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGT GCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTAC CAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGT AATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACACTGTGAGACCCCCCCGC >81231_81231_5_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000290536_length(amino acids)=356AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- >81231_81231_6_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000409585_length(transcript)=1996nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCC AGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGC TGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGC CCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACT GGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAG GCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCT AAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCT ATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAA GCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACA CCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCAC CTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGC CTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGG GAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGT TGCTCCCTCCATCCACAGAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACT TTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACACTGTGAGACCCCCCCGCCATCTCTACATA >81231_81231_6_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000409585_length(amino acids)=352AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- >81231_81231_7_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000536235_length(transcript)=1550nt_BP=665nt AACTACACTCCCCACAACGCCTTGCGCCTCCCGCTCGCTGCGGTTGATTAGGGCCAATCGGGAGAGGCAGCTGTGGCGGGGGCCGAGGAG GGACATTTTAAAAGGGCCGGAGATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTA GCGCCTCGAGCGATGCACCTCCTTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATA TCATCGACCCTCGCACACTCTTTGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCC CGGGGGTCACCAATGAACAGCTCTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCAT TTAGAATGTCAGGTTATATTCCTTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGC AGTGGCTGAACCAGAGCCACAATGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGAT ACCTGGGAGCTGTCATCAGCGCCGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCC AGAGAATTCCTGCCAGCACCTTCTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGC TGCCCAGCACCTTCCCCCTGCTACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGC CCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACT GGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAG GCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCT AAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCT ATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAA GCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACA CCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCAC >81231_81231_7_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000272433_M1AP_chr2_74789550_ENST00000536235_length(amino acids)=352AA_BP=184 MRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- >81231_81231_8_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000290536_length(transcript)=1698nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAG CAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATCCCTGCAAGACTGGGCAGTTGCA GACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTC CTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAAC CATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGA AACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGAC TTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAA CTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTT TTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTC CAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAA AAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTACCATTTAT AAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGG >81231_81231_8_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000290536_length(amino acids)=287AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPCKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSS -------------------------------------------------------------- >81231_81231_9_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000358434_length(transcript)=865nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAG CAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGCATCCCTGCAAGACTGGGCAGTTGCA GACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTC >81231_81231_9_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000358434_length(amino acids)=288AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKHPCKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSS -------------------------------------------------------------- >81231_81231_10_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000409585_length(transcript)=1677nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAG CAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGC TCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTT CTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCT CAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTT CCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTT TAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCT TCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCAT AAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAG TGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTC CTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATAATAGCTACCATTTATAAAATGTTTACT CTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCA >81231_81231_10_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000409585_length(amino acids)=283AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSSSDAF -------------------------------------------------------------- >81231_81231_11_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000536235_length(transcript)=1231nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGTTCAAAGCCACCTGTACTCACACCTGAG CAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAAGACTGGGCAGTTGCAGACCAACCGAGC TCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTT CTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCT CAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTT CCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTT TAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCT >81231_81231_11_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74787418_ENST00000536235_length(amino acids)=283AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIASMLDSLELEPTYNPLHVQSHLYSHLSSIYAKPQGRLHPHWESRAPRKTGQLQTNRARATVAPLPMTPVPGRASKMPAASKSSSDAF -------------------------------------------------------------- >81231_81231_12_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000290536_length(transcript)=1905nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTT CTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCT ACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGT TCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAA GCATCCCTGCAAGACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTC CAAGATGCCAGCAGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAG CACCAGAGCCCAGCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGA GCCTCTGTGAGTGAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACC CGAGCCTGTCCTTTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGC TTCTACCATTGTTAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAA CTGGACCTCAGGAACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTT CCCACTACACCACCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCC CAGAACAGGGGAGAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCC ATCCACAGAATAATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCT GAGGTGGGATGATCACTTGAGGCCAGGAGTTCGAGACCAGCCTGAGCAACACTGTGAGACCCCCCCGCCATCTCTACATAAATAATAAAA >81231_81231_12_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000290536_length(amino acids)=356AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- >81231_81231_13_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000409585_length(transcript)=1884nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTT CTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCT ACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGT TCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAA GACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGC AGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCA GCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGT GAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCT TTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGT TAGGAGCATTCATAACTCAGAATTTCTTCTTGTAGCTCTGTGTAAGCAGGTGGATGAGGTCAGATCACCTTTGGTAAACTGGACCTCAGG AACAAGGATGAGGTTTTGAAAGCTCATAAAAGACAAGTAAGATTGAAATCCAAGCCTCATTTCAGAGCCTGTGCCCTTCCCACTACACCA CCAGGCTTCAGCCTCCAAAGAGACAAGTGCTTGGTACCTACATGCAAAGTGTGTGTGCTGGGGGGTGGGAGGGCTGCCCAGAACAGGGGA GAGGATGGTGTAAAAAAAGACCTACTCCTTTCCTGTTACCCTCTCCCCACATGTACCAACCTTCCTGTTGCTCCCTCCATCCACAGAATA ATAGCTACCATTTATAAAATGTTTACTCTGGGCTGGGAGCAGTGGCTCACACCTGTAATCCCAACACTTTGAGAGGCTGAGGTGGGATGA >81231_81231_13_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000409585_length(amino acids)=352AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- >81231_81231_14_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000536235_length(transcript)=1438nt_BP=553nt ATTGCGGGCGTCAGTGGCCATGGCGGATACAGCGACTACAGCATCGGCGGCGGCGGCTAGTGCCGCTAGCGCCTCGAGCGATGCACCTCC TTTCCAACTGGGCAAACCCCGCTTCCAGCAGACGTCCTTCTATGGCCGCTTCAGGCACTTCTTGGATATCATCGACCCTCGCACACTCTT TGTCACTGAGAGACGTCTCAGAGAGGCTGTGCAGCTGCTGGAGGACTATAAGCATGGGACCCTGCGCCCGGGGGTCACCAATGAACAGCT CTGGAGTGCACAGAAAATCAAGCAGGCTATTCTACATCCGGACACCAATGAGAAGATCTTCATGCCATTTAGAATGTCAGGTTATATTCC TTTTGGGACGCCAATTGTAGTCGGTCTTCTCTTGCCCAACCAGACACTGGCATCCACTGTCTTCTGGCAGTGGCTGAACCAGAGCCACAA TGCCTGTGTCAACTATGCAAACCGCAATGCGACCAAGCCTTCACCTGCATCCAAGTTCATCCAGGGATACCTGGGAGCTGTCATCAGCGC CGTCTCCATTGCTAAAAGGGAATGGCTGCTGTTAGCCAAGGGGGAACCACCGGGCCCAGGACACAGCCAGAGAATTCCTGCCAGCACCTT CTATGTGATCATGCCGTCACACTCCCTCACACTGCTGGTAAAGGCGGTGGCCACGCGGGAACTGATGCTGCCCAGCACCTTCCCCCTGCT ACCTGAGGACCCACATGATGATAGCCTTAAGAATGTGGAGAGCATGCTGGACAGCCTGGAGCTGGAGCCCACCTACAACCCCTTGCATGT TCAAAGCCACCTGTACTCACACCTGAGCAGCATCTATGCCAAGCCTCAGGGGCGGCTCCACCCACACTGGGAGAGCCGAGCTCCGAGAAA GACTGGGCAGTTGCAGACCAACCGAGCTCGAGCTACTGTGGCCCCCCTGCCTATGACTCCTGTCCCAGGCAGAGCCTCCAAGATGCCAGC AGCCAGCAAATCTTCCTCAGATGCCTTCTTCCTGCCTTCAGAGTGGGAGAAGGATCCCTCAAGGCCCTAAGTCACCAGCACCAGAGCCCA GCTGCCCAGCTTAACCATATCCATGCTCAGGTTCACATAATGGCTATCTGTGGTCAGACTTGCTCTCTATCCGCCTGAGCCTCTGTGAGT GAGGGCTGACTGGGAAACAACAGCCTTCCTGTCCTGTTTCAGTGCTGTCCCACTCCTCAAGTCTGGAAGCGACACACCCGAGCCTGTCCT TTCTCCAGCAAGGACTTTCATTTTCTTTAGAATCATTTGCTACTGTTTACACAGGTGAAGATTAAACACCCAGTAAGCTTCTACCATTGT >81231_81231_14_SFXN5-M1AP_SFXN5_chr2_73226078_ENST00000410065_M1AP_chr2_74789550_ENST00000536235_length(amino acids)=352AA_BP=184 LRASVAMADTATTASAAAASAASASSDAPPFQLGKPRFQQTSFYGRFRHFLDIIDPRTLFVTERRLREAVQLLEDYKHGTLRPGVTNEQL WSAQKIKQAILHPDTNEKIFMPFRMSGYIPFGTPIVVGLLLPNQTLASTVFWQWLNQSHNACVNYANRNATKPSPASKFIQGYLGAVISA VSIAKREWLLLAKGEPPGPGHSQRIPASTFYVIMPSHSLTLLVKAVATRELMLPSTFPLLPEDPHDDSLKNVESMLDSLELEPTYNPLHV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SFXN5-M1AP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SFXN5-M1AP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SFXN5-M1AP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies