
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SGCD-LCP2 (FusionGDB2 ID:81250) |
Fusion Gene Summary for SGCD-LCP2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SGCD-LCP2 | Fusion gene ID: 81250 | Hgene | Tgene | Gene symbol | SGCD | LCP2 | Gene ID | 6444 | 3937 |
| Gene name | sarcoglycan delta | lymphocyte cytosolic protein 2 | |
| Synonyms | 35DAG|CMD1L|DAGD|LGMDR6|SG-delta|SGCDP|SGD | SLP-76|SLP76 | |
| Cytomap | 5q33.2-q33.3 | 5q35.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | delta-sarcoglycan35 kDa dystrophin-associated glycoproteindelta-SGdystrophin associated glycoprotein, delta sarcoglycanplacental delta sarcoglycansarcoglycan, delta (35kDa dystrophin-associated glycoprotein) | lymphocyte cytosolic protein 276 kDa tyrosine phosphoproteinSH2 domain-containing leukocyte protein of 76 kDaSLP-76 tyrosine phosphoprotein | |
| Modification date | 20200328 | 20200327 | |
| UniProtAcc | . | Q13094 | |
| Ensembl transtripts involved in fusion gene | ENST00000337851, ENST00000435422, ENST00000447401, ENST00000517913, | ENST00000046794, ENST00000521416, | |
| Fusion gene scores | * DoF score | 12 X 10 X 6=720 | 2 X 3 X 2=12 |
| # samples | 13 | 3 | |
| ** MAII score | log2(13/720*10)=-2.46948528330122 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/12*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: SGCD [Title/Abstract] AND LCP2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SGCD(155771687)-LCP2(169724729), # samples:2 SGCD(155771687)-LCP2(169720376), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | LCP2 | GO:0050852 | T cell receptor signaling pathway | 20551903 |
| Fusion gene breakpoints across SGCD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across LCP2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CQ-6221-01A | SGCD | chr5 | 155771687 | - | LCP2 | chr5 | 169720376 | - |
| ChimerDB4 | HNSC | TCGA-CQ-6221-01A | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| ChimerDB4 | HNSC | TCGA-CQ-6221 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| ChimerDB4 | HNSC | TCGA-CQ-6221 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
Top |
Fusion Gene ORF analysis for SGCD-LCP2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000337851 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-5UTR | ENST00000435422 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-5UTR | ENST00000447401 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-5UTR | ENST00000517913 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-intron | ENST00000337851 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-intron | ENST00000337851 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| 5CDS-intron | ENST00000435422 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-intron | ENST00000435422 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| 5CDS-intron | ENST00000447401 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-intron | ENST00000447401 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| 5CDS-intron | ENST00000517913 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169724729 | - |
| 5CDS-intron | ENST00000517913 | ENST00000521416 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| In-frame | ENST00000337851 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| In-frame | ENST00000435422 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| In-frame | ENST00000447401 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| In-frame | ENST00000517913 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000517913 | SGCD | chr5 | 155771687 | + | ENST00000046794 | LCP2 | chr5 | 169720376 | - | 4538 | 554 | 362 | 2077 | 571 |
| ENST00000435422 | SGCD | chr5 | 155771687 | + | ENST00000046794 | LCP2 | chr5 | 169720376 | - | 4660 | 676 | 352 | 2199 | 615 |
| ENST00000447401 | SGCD | chr5 | 155771687 | + | ENST00000046794 | LCP2 | chr5 | 169720376 | - | 4695 | 711 | 519 | 2234 | 571 |
| ENST00000337851 | SGCD | chr5 | 155771687 | + | ENST00000046794 | LCP2 | chr5 | 169720376 | - | 4695 | 711 | 519 | 2234 | 571 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000517913 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - | 0.000928296 | 0.9990717 |
| ENST00000435422 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - | 0.000659697 | 0.99934024 |
| ENST00000447401 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - | 0.001215825 | 0.99878424 |
| ENST00000337851 | ENST00000046794 | SGCD | chr5 | 155771687 | + | LCP2 | chr5 | 169720376 | - | 0.001215825 | 0.99878424 |
Top |
Fusion Genomic Features for SGCD-LCP2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
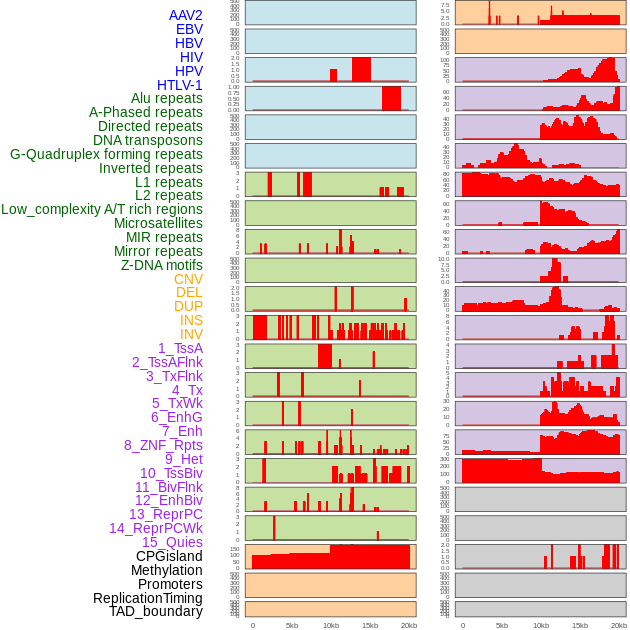
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SGCD-LCP2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:155771687/chr5:169724729) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | LCP2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Involved in T-cell antigen receptor mediated signaling. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000337851 | + | 3 | 9 | 1_35 | 64 | 291.0 | Topological domain | Cytoplasmic |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000435422 | + | 2 | 8 | 1_35 | 63 | 290.0 | Topological domain | Cytoplasmic |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000447401 | + | 3 | 8 | 1_35 | 64 | 257.0 | Topological domain | Cytoplasmic |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000517913 | + | 5 | 10 | 1_35 | 64 | 257.0 | Topological domain | Cytoplasmic |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000337851 | + | 3 | 9 | 36_56 | 64 | 291.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000435422 | + | 2 | 8 | 36_56 | 63 | 290.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000447401 | + | 3 | 8 | 36_56 | 64 | 257.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000517913 | + | 5 | 10 | 36_56 | 64 | 257.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | LCP2 | chr5:155771687 | chr5:169720376 | ENST00000046794 | 0 | 21 | 133_136 | 26 | 534.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | LCP2 | chr5:155771687 | chr5:169720376 | ENST00000046794 | 0 | 21 | 198_201 | 26 | 534.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | LCP2 | chr5:155771687 | chr5:169720376 | ENST00000046794 | 0 | 21 | 422_530 | 26 | 534.0 | Domain | SH2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000337851 | + | 3 | 9 | 57_289 | 64 | 291.0 | Topological domain | Extracellular |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000435422 | + | 2 | 8 | 57_289 | 63 | 290.0 | Topological domain | Extracellular |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000447401 | + | 3 | 8 | 57_289 | 64 | 257.0 | Topological domain | Extracellular |
| Hgene | SGCD | chr5:155771687 | chr5:169720376 | ENST00000517913 | + | 5 | 10 | 57_289 | 64 | 257.0 | Topological domain | Extracellular |
| Tgene | LCP2 | chr5:155771687 | chr5:169720376 | ENST00000046794 | 0 | 21 | 15_81 | 26 | 534.0 | Domain | Note=SAM |
Top |
Fusion Gene Sequence for SGCD-LCP2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >81250_81250_1_SGCD-LCP2_SGCD_chr5_155771687_ENST00000337851_LCP2_chr5_169720376_ENST00000046794_length(transcript)=4695nt_BP=711nt AGAGAGGACTTATCTCCAGCATCTAGCACTACAGAGCAGAGGCTGTGTGGAGAATGGCTGAAAAATCAGAATTGGTTGTAGAAGCAGTTT TCTTTCTGGTTGTGAGTATGAGCCCGGCAGACACCATGAGCGCTGTTGCAGGGGAGTCGGCCTGTGCTTGACACATGTGTTTCCCATTGA TAGCTGGAGACAGCCCAGTAGCTGTGAGTCGGTCTGACAAAGCCATATTGAAGTACGGAGTACGGTTTCAAAGCAGTCAGAAAAAGAACG GGAATGCTGTTCAGGAAATTCTTCAGGCATGGGCAGGGACTTGGCTGCAGTTCTGCAGTTGGAAAATCTGACTGGGGCAGCTTCTGAGCG CAGGCTGGGCCTGCACACACTCAGCGGGCCGAGTGGCCACCTCCTTCAGAGCTGCTCAGCACGCCCTGGGATCGCGGGCGGTTTTCATCG GCCGGTTTGTGAAACGGACAAGAGAGAGACATTACTGCCGGGAGTGTTGAGTGAAGGGACCAGGTGGAGATGATGCCTCAGGAGCAGTAC ACTCACCACCGGAGCACCATGCCTGGCTCTGTGGGGCCACAGGTATACAAGGTGGGGATTTATGGCTGGCGGAAACGATGCCTGTATTTC TTTGTCCTGCTCCTCATGATTTTAATACTGGTGAACTTGGCCATGACCATCTGGATTCTCAAAGTCATGAACTTCACAATTCTCAACTAT AAGGACTGTGAGAAGGCAGTGAAGAAGTACCACATCGATGGGGCTCGCTTCTTGAACCTGACAGAAAATGACATCCAGAAGTTCCCCAAG CTCCGGGTGCCGATTCTCAGTAAGTTAAGTCAGGAAATCAACAAGAACGAAGAGAGGAGGAGCATCTTCACACGCAAACCCCAAGTCCCG CGGTTTCCTGAAGAGACAGAAAGCCACGAAGAGGACAATGGGGGCTGGTCGTCCTTTGAAGAAGACGATTATGAAAGTCCCAATGATGAC CAGGATGGGGAGGATGATGGAGACTATGAGTCCCCCAATGAGGAGGAAGAGGCACCCGTGGAAGATGACGCGGATTATGAGCCGCCACCC TCCAATGACGAGGAAGCTCTGCAGAACTCCATCCTGCCTGCCAAGCCTTTCCCCAACTCCAACTCCATGTACATCGACCGGCCCCCCTCT GGGAAAACCCCCCAGCAGCCTCCTGTGCCCCCCCAGAGACCGATGGCCGCCCTCCCGCCCCCACCAGCCGGCCGGAATCACTCGCCACTG CCCCCACCCCAGACCAACCACGAAGAACCCAGCAGAAGCAGAAACCACAAAACGGCAAAGCTCCCTGCTCCTTCAATAGACAGAAGCACG AAACCTCCCCTAGATCGTTCATTAGCTCCGTTTGATAGAGAACCCTTCACACTAGGAAAGAAACCACCATTTTCTGACAAGCCCTCGATT CCAGCGGGAAGGTCACTCGGGGAGCATTTACCCAAGATTCAAAAGCCTCCTTTACCACCGACCACGGAAAGACATGAAAGGAGCAGCCCC CTGCCAGGGAAGAAGCCACCTGTGCCAAAGCATGGATGGGGACCAGACAGAAGAGAGAATGATGAAGATGATGTGCATCAGAGACCTTTG CCCCAGCCAGCACTACTTCCTATGAGCTCCAACACTTTCCCTTCAAGATCTACTAAGCCAAGTCCCATGAACCCTCTCCCATCCTCTCAC ATGCCTGGAGCATTCTCAGAAAGTAACAGCAGTTTTCCACAGAGTGCCTCCCTGCCACCATACTTCTCTCAAGGCCCTAGCAACAGACCA CCTATCAGAGCCGAAGGCAGAAACTTCCCCTTGCCACTTCCAAACAAACCTCGGCCCCCATCCCCCGCGGAGGAAGAGAATTCATTAAAT GAAGAGTGGTACGTTTCTTATATTACCCGACCAGAGGCAGAAGCTGCTCTTAGAAAGATAAACCAGGATGGCACATTTCTGGTCAGAGAC AGCTCTAAAAAAACAACAACCAATCCATATGTCCTCATGGTGTTGTACAAAGATAAAGTTTACAACATCCAGATCCGTTATCAGAAGGAA AGTCAAGTTTACTTGTTGGGAACTGGACTCCGAGGGAAAGAGGACTTTCTGTCTGTGTCAGATATTATTGACTACTTCAGGAAAATGCCA CTTCTGCTCATTGATGGGAAAAACCGAGGTTCCAGATACCAGTGCACATTAACGCATGCTGCAGGGTACCCATAGCAAGTTATAGCCGAG CAAATGAACCGTCCTCCTGCCTCTGTTGCCAACACGAGATCAATCAGCCTTGGTCAATGGACAAACACTTAGGACTGAACTGAACCCCTC CCCATGAACACAAGGGTTTTATCCTTTCCTTTAAAAACAGTGTTTGAAATGAAGACTGTCAACTATCCCATAATTTATTTATTCTTCTTC AATGTTTGTAAAGTGCATGAGTCATGTTCACACTTGAAGTCTAGTAGTGCACTGTAATAATTCATTTTTTAAAAGATTATTTAATGCCCA TTTCAAAATACAGTAGTTTACACAGCTACAGAAACAATTTGGGGCAAGTTTTAAAACACTGAAACAGTAATAGTTATTGGTGTCACATAA AACTGATTTGTTTTTTACAGCCAAACCTCTGTCAGTCAGAGGCATTCATTAGTTTTATACATGTAATTTGAAAATCACTAAACCTCGTTT TCTCAGCAGCAATAATTTAAGAGGCTTCAAAAATATAATTTCACTCTTATTTAGTATTTTTTCCTGGGGGCATTTTTACGTAATTTTTTT ATGAAAAGACAAATGCATGTTGAGATAACTTCTGGGATTAAAATAGTCTTTTGCTTTACTTTTTTGGTTTCCTAAAACAACTTTATTGAC TTTTAGTCCATACTGTTATATTTTTGTCTTAAAGAAAATTTAAACTACAAATACCAAAAGAAAACATTTTAAATTTAGGGATGAGACTTT GGTGTATCGTGGGTCTAGGTTTAATGAACACATCTGGGGTTAAGTTGGCATTTCTTCACATCTCCACACCCACACCAACCATCACAGCCC CCCACCAACCTTCTCCCAACCCCAAAAGCATTGTCCAGGGATATAGATTTTACCAAAGGCTTCCTGGGAAGACGAGGGAGCAACACTTTA GATTAAATGTGATCAGACTTTCCTATTAGATATGGCTCTTCTGTCTCTTGTTATCCCCCTGACAGCTCTGCCATAAAGTCCCTTCTCCTC ATCCTTCCCAAACAGGCTGTATAAGTGCTTTGAGGTAATTAAACTCTTTCCTCCAGTTTACAAATATCACTTAACAAAAAATATAGGCAT TCAGCCAGATTAAAAAACTGGTATTCAGCCAAATAGTGACAATCAGTTGTTCTTCAAGTTTTTCCCTTTGGGACCTTGGTTGTTATTGCA CAACTTTTATTAGCAACAATTTTTGGCGTCTCTGCTTAATCTACAAGTTTTCGAAATGGAAAAGAGTATCTTGCAGCTTCATTTTCATGA GCTAATAAAAGGGGTATTGGAAGGAATCTAAGAAGTCACCATTTTAAAACTGATGATATGTTAAAATAAGGAGTATGCAGAAGGTAGAGA CTTTTAACTGATGATAAAAATGGTGTTTCACAAAATCTCATCCTTAACAACCAGAAGTTCTCAGTTTAGGGTCCAAAACTTGGGAGTTTA AGGCTGAAAACCCTGCATTCATTTACACGTCTACACAACGGGCTATTCAGCAAGTATTTACTTAGTGGCTCTTCTGTGTTAAACAAGTGA GCTAGGTACAAGGTAGTAAGGATAGCATACACCATAGGTTCTAGTATCGAGTAAGCTCCACTTGTCTTGCTTTGCCGTATTCTATCTTTA CAATTCAAAAATATCTAAAATGAAGGACCTGATAGATTTCAAAGCAACTATTTGGTAGCGAATCATGTTTATAAAACAAACCAAAGCTCA TTTTAAGTCTATTAGTGGAAAGTGCCATCAGGATTAAGATGTTCTGTTCCATGGCTATGACTGAAATCAATGTTGGGAAGCTAATGTTTT CATGACTAGCATTCTCTCTCTGTTCAAGCACCGACAACTCCTTTTGGCTGGGCCTTGCCTCTTTTGGCCACAGACCTTCTATATGACCCC AGGTGCATCAGTCACAGTTGCTCAGAACCCTGCTCAGTGATAAACATCTTACTAAAGCTGGGTCAATCAGGGTCACTCTCTGGAATGTTA AACATGAAGCCTGAGACAAGATCTCTCTTTTATCTGGGGTCCCCAAAGGCAATGCTGTACACTTGGAGCTGCCTGCTGCCCTGCAACTAC TCCCATTTACCAATTATCTGGAAGAACCAGTCTACAATAGAAGACAACGAGGCCAACACACAAAAACACAGTAAAAGTATGGACAAATTA GTGGGATCCCTGAAATCTATTCCAACTATGTGCTTCCAAGTCACATGACTCAATAAATGCTTCAGCTGGTTGAGTTGTGCTTGGCGTTCA CTACCAGGAGAGTTCTGATTAATAAAAACTCATTCCATCAATTAATAATTTAGTAGCTCTCTTTCAACCTGAGCCAAATTCAAGCATAAG CTAAAGGATAAGCAGTGACCCATGGCCAATTTCCTATGTCATACACTTGCCATTAGTGACGTAAGTTAAGCCATTCTTCAAAACATTAAA >81250_81250_1_SGCD-LCP2_SGCD_chr5_155771687_ENST00000337851_LCP2_chr5_169720376_ENST00000046794_length(amino acids)=571AA_BP=64 MMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTILNYKDCEKAVKKYHIDGARFLNLTEN DIQKFPKLRVPILSKLSQEINKNEERRSIFTRKPQVPRFPEETESHEEDNGGWSSFEEDDYESPNDDQDGEDDGDYESPNEEEEAPVEDD ADYEPPPSNDEEALQNSILPAKPFPNSNSMYIDRPPSGKTPQQPPVPPQRPMAALPPPPAGRNHSPLPPPQTNHEEPSRSRNHKTAKLPA PSIDRSTKPPLDRSLAPFDREPFTLGKKPPFSDKPSIPAGRSLGEHLPKIQKPPLPPTTERHERSSPLPGKKPPVPKHGWGPDRRENDED DVHQRPLPQPALLPMSSNTFPSRSTKPSPMNPLPSSHMPGAFSESNSSFPQSASLPPYFSQGPSNRPPIRAEGRNFPLPLPNKPRPPSPA EEENSLNEEWYVSYITRPEAEAALRKINQDGTFLVRDSSKKTTTNPYVLMVLYKDKVYNIQIRYQKESQVYLLGTGLRGKEDFLSVSDII -------------------------------------------------------------- >81250_81250_2_SGCD-LCP2_SGCD_chr5_155771687_ENST00000435422_LCP2_chr5_169720376_ENST00000046794_length(transcript)=4660nt_BP=676nt GAGCAGAAGAAAGAGAGGACTTATCTCCAGCATCTAGCACTACAGAGCAGAGGCTGTGTGGAGAATGGCTGAAAAATCAGAATTGGTTGT AGAAGCAGTTTTCTTTCTGGTTGTGAGTATGAGCCCGGCAGACACCATGAGCGCTGTTGCAGGGGAGTCGGCCTGTGCTTGACACATGTG TTTCCCATTGATAGCTGGAGACAGCCCAGTAGCTGTGAGTCGGTCTGACAAAGCCATATTGAAGTACGGAGTACGGTTTCAAAGCAGTCA GAAAAAGAACGGGAATGCTGTTCAGGAAATTCTTCAGGCATGGGCAGGGACTTGGCTGCAGTTCTGCAGTTGGAAAATCTGACTGGGGCA GCTTCTGAGCGCAGGCTGGGCCTGCACACACTCAGCGGGCCGAGTGGCCACCTCCTTCAGAGCTGCTCAGCACGCCCTGGGATCGCGGGC GGTTTTCATCGGCCGGTTTGTGAAACGGACAAGAGAGATGCCTCAGGAGCAGTACACTCACCACCGGAGCACCATGCCTGGCTCTGTGGG GCCACAGGTATACAAGGTGGGGATTTATGGCTGGCGGAAACGATGCCTGTATTTCTTTGTCCTGCTCCTCATGATTTTAATACTGGTGAA CTTGGCCATGACCATCTGGATTCTCAAAGTCATGAACTTCACAATTCTCAACTATAAGGACTGTGAGAAGGCAGTGAAGAAGTACCACAT CGATGGGGCTCGCTTCTTGAACCTGACAGAAAATGACATCCAGAAGTTCCCCAAGCTCCGGGTGCCGATTCTCAGTAAGTTAAGTCAGGA AATCAACAAGAACGAAGAGAGGAGGAGCATCTTCACACGCAAACCCCAAGTCCCGCGGTTTCCTGAAGAGACAGAAAGCCACGAAGAGGA CAATGGGGGCTGGTCGTCCTTTGAAGAAGACGATTATGAAAGTCCCAATGATGACCAGGATGGGGAGGATGATGGAGACTATGAGTCCCC CAATGAGGAGGAAGAGGCACCCGTGGAAGATGACGCGGATTATGAGCCGCCACCCTCCAATGACGAGGAAGCTCTGCAGAACTCCATCCT GCCTGCCAAGCCTTTCCCCAACTCCAACTCCATGTACATCGACCGGCCCCCCTCTGGGAAAACCCCCCAGCAGCCTCCTGTGCCCCCCCA GAGACCGATGGCCGCCCTCCCGCCCCCACCAGCCGGCCGGAATCACTCGCCACTGCCCCCACCCCAGACCAACCACGAAGAACCCAGCAG AAGCAGAAACCACAAAACGGCAAAGCTCCCTGCTCCTTCAATAGACAGAAGCACGAAACCTCCCCTAGATCGTTCATTAGCTCCGTTTGA TAGAGAACCCTTCACACTAGGAAAGAAACCACCATTTTCTGACAAGCCCTCGATTCCAGCGGGAAGGTCACTCGGGGAGCATTTACCCAA GATTCAAAAGCCTCCTTTACCACCGACCACGGAAAGACATGAAAGGAGCAGCCCCCTGCCAGGGAAGAAGCCACCTGTGCCAAAGCATGG ATGGGGACCAGACAGAAGAGAGAATGATGAAGATGATGTGCATCAGAGACCTTTGCCCCAGCCAGCACTACTTCCTATGAGCTCCAACAC TTTCCCTTCAAGATCTACTAAGCCAAGTCCCATGAACCCTCTCCCATCCTCTCACATGCCTGGAGCATTCTCAGAAAGTAACAGCAGTTT TCCACAGAGTGCCTCCCTGCCACCATACTTCTCTCAAGGCCCTAGCAACAGACCACCTATCAGAGCCGAAGGCAGAAACTTCCCCTTGCC ACTTCCAAACAAACCTCGGCCCCCATCCCCCGCGGAGGAAGAGAATTCATTAAATGAAGAGTGGTACGTTTCTTATATTACCCGACCAGA GGCAGAAGCTGCTCTTAGAAAGATAAACCAGGATGGCACATTTCTGGTCAGAGACAGCTCTAAAAAAACAACAACCAATCCATATGTCCT CATGGTGTTGTACAAAGATAAAGTTTACAACATCCAGATCCGTTATCAGAAGGAAAGTCAAGTTTACTTGTTGGGAACTGGACTCCGAGG GAAAGAGGACTTTCTGTCTGTGTCAGATATTATTGACTACTTCAGGAAAATGCCACTTCTGCTCATTGATGGGAAAAACCGAGGTTCCAG ATACCAGTGCACATTAACGCATGCTGCAGGGTACCCATAGCAAGTTATAGCCGAGCAAATGAACCGTCCTCCTGCCTCTGTTGCCAACAC GAGATCAATCAGCCTTGGTCAATGGACAAACACTTAGGACTGAACTGAACCCCTCCCCATGAACACAAGGGTTTTATCCTTTCCTTTAAA AACAGTGTTTGAAATGAAGACTGTCAACTATCCCATAATTTATTTATTCTTCTTCAATGTTTGTAAAGTGCATGAGTCATGTTCACACTT GAAGTCTAGTAGTGCACTGTAATAATTCATTTTTTAAAAGATTATTTAATGCCCATTTCAAAATACAGTAGTTTACACAGCTACAGAAAC AATTTGGGGCAAGTTTTAAAACACTGAAACAGTAATAGTTATTGGTGTCACATAAAACTGATTTGTTTTTTACAGCCAAACCTCTGTCAG TCAGAGGCATTCATTAGTTTTATACATGTAATTTGAAAATCACTAAACCTCGTTTTCTCAGCAGCAATAATTTAAGAGGCTTCAAAAATA TAATTTCACTCTTATTTAGTATTTTTTCCTGGGGGCATTTTTACGTAATTTTTTTATGAAAAGACAAATGCATGTTGAGATAACTTCTGG GATTAAAATAGTCTTTTGCTTTACTTTTTTGGTTTCCTAAAACAACTTTATTGACTTTTAGTCCATACTGTTATATTTTTGTCTTAAAGA AAATTTAAACTACAAATACCAAAAGAAAACATTTTAAATTTAGGGATGAGACTTTGGTGTATCGTGGGTCTAGGTTTAATGAACACATCT GGGGTTAAGTTGGCATTTCTTCACATCTCCACACCCACACCAACCATCACAGCCCCCCACCAACCTTCTCCCAACCCCAAAAGCATTGTC CAGGGATATAGATTTTACCAAAGGCTTCCTGGGAAGACGAGGGAGCAACACTTTAGATTAAATGTGATCAGACTTTCCTATTAGATATGG CTCTTCTGTCTCTTGTTATCCCCCTGACAGCTCTGCCATAAAGTCCCTTCTCCTCATCCTTCCCAAACAGGCTGTATAAGTGCTTTGAGG TAATTAAACTCTTTCCTCCAGTTTACAAATATCACTTAACAAAAAATATAGGCATTCAGCCAGATTAAAAAACTGGTATTCAGCCAAATA GTGACAATCAGTTGTTCTTCAAGTTTTTCCCTTTGGGACCTTGGTTGTTATTGCACAACTTTTATTAGCAACAATTTTTGGCGTCTCTGC TTAATCTACAAGTTTTCGAAATGGAAAAGAGTATCTTGCAGCTTCATTTTCATGAGCTAATAAAAGGGGTATTGGAAGGAATCTAAGAAG TCACCATTTTAAAACTGATGATATGTTAAAATAAGGAGTATGCAGAAGGTAGAGACTTTTAACTGATGATAAAAATGGTGTTTCACAAAA TCTCATCCTTAACAACCAGAAGTTCTCAGTTTAGGGTCCAAAACTTGGGAGTTTAAGGCTGAAAACCCTGCATTCATTTACACGTCTACA CAACGGGCTATTCAGCAAGTATTTACTTAGTGGCTCTTCTGTGTTAAACAAGTGAGCTAGGTACAAGGTAGTAAGGATAGCATACACCAT AGGTTCTAGTATCGAGTAAGCTCCACTTGTCTTGCTTTGCCGTATTCTATCTTTACAATTCAAAAATATCTAAAATGAAGGACCTGATAG ATTTCAAAGCAACTATTTGGTAGCGAATCATGTTTATAAAACAAACCAAAGCTCATTTTAAGTCTATTAGTGGAAAGTGCCATCAGGATT AAGATGTTCTGTTCCATGGCTATGACTGAAATCAATGTTGGGAAGCTAATGTTTTCATGACTAGCATTCTCTCTCTGTTCAAGCACCGAC AACTCCTTTTGGCTGGGCCTTGCCTCTTTTGGCCACAGACCTTCTATATGACCCCAGGTGCATCAGTCACAGTTGCTCAGAACCCTGCTC AGTGATAAACATCTTACTAAAGCTGGGTCAATCAGGGTCACTCTCTGGAATGTTAAACATGAAGCCTGAGACAAGATCTCTCTTTTATCT GGGGTCCCCAAAGGCAATGCTGTACACTTGGAGCTGCCTGCTGCCCTGCAACTACTCCCATTTACCAATTATCTGGAAGAACCAGTCTAC AATAGAAGACAACGAGGCCAACACACAAAAACACAGTAAAAGTATGGACAAATTAGTGGGATCCCTGAAATCTATTCCAACTATGTGCTT CCAAGTCACATGACTCAATAAATGCTTCAGCTGGTTGAGTTGTGCTTGGCGTTCACTACCAGGAGAGTTCTGATTAATAAAAACTCATTC CATCAATTAATAATTTAGTAGCTCTCTTTCAACCTGAGCCAAATTCAAGCATAAGCTAAAGGATAAGCAGTGACCCATGGCCAATTTCCT >81250_81250_2_SGCD-LCP2_SGCD_chr5_155771687_ENST00000435422_LCP2_chr5_169720376_ENST00000046794_length(amino acids)=615AA_BP=108 MGQLLSAGWACTHSAGRVATSFRAAQHALGSRAVFIGRFVKRTREMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILI LVNLAMTIWILKVMNFTILNYKDCEKAVKKYHIDGARFLNLTENDIQKFPKLRVPILSKLSQEINKNEERRSIFTRKPQVPRFPEETESH EEDNGGWSSFEEDDYESPNDDQDGEDDGDYESPNEEEEAPVEDDADYEPPPSNDEEALQNSILPAKPFPNSNSMYIDRPPSGKTPQQPPV PPQRPMAALPPPPAGRNHSPLPPPQTNHEEPSRSRNHKTAKLPAPSIDRSTKPPLDRSLAPFDREPFTLGKKPPFSDKPSIPAGRSLGEH LPKIQKPPLPPTTERHERSSPLPGKKPPVPKHGWGPDRRENDEDDVHQRPLPQPALLPMSSNTFPSRSTKPSPMNPLPSSHMPGAFSESN SSFPQSASLPPYFSQGPSNRPPIRAEGRNFPLPLPNKPRPPSPAEEENSLNEEWYVSYITRPEAEAALRKINQDGTFLVRDSSKKTTTNP -------------------------------------------------------------- >81250_81250_3_SGCD-LCP2_SGCD_chr5_155771687_ENST00000447401_LCP2_chr5_169720376_ENST00000046794_length(transcript)=4695nt_BP=711nt AGAGAGGACTTATCTCCAGCATCTAGCACTACAGAGCAGAGGCTGTGTGGAGAATGGCTGAAAAATCAGAATTGGTTGTAGAAGCAGTTT TCTTTCTGGTTGTGAGTATGAGCCCGGCAGACACCATGAGCGCTGTTGCAGGGGAGTCGGCCTGTGCTTGACACATGTGTTTCCCATTGA TAGCTGGAGACAGCCCAGTAGCTGTGAGTCGGTCTGACAAAGCCATATTGAAGTACGGAGTACGGTTTCAAAGCAGTCAGAAAAAGAACG GGAATGCTGTTCAGGAAATTCTTCAGGCATGGGCAGGGACTTGGCTGCAGTTCTGCAGTTGGAAAATCTGACTGGGGCAGCTTCTGAGCG CAGGCTGGGCCTGCACACACTCAGCGGGCCGAGTGGCCACCTCCTTCAGAGCTGCTCAGCACGCCCTGGGATCGCGGGCGGTTTTCATCG GCCGGTTTGTGAAACGGACAAGAGAGAGACATTACTGCCGGGAGTGTTGAGTGAAGGGACCAGGTGGAGATGATGCCTCAGGAGCAGTAC ACTCACCACCGGAGCACCATGCCTGGCTCTGTGGGGCCACAGGTATACAAGGTGGGGATTTATGGCTGGCGGAAACGATGCCTGTATTTC TTTGTCCTGCTCCTCATGATTTTAATACTGGTGAACTTGGCCATGACCATCTGGATTCTCAAAGTCATGAACTTCACAATTCTCAACTAT AAGGACTGTGAGAAGGCAGTGAAGAAGTACCACATCGATGGGGCTCGCTTCTTGAACCTGACAGAAAATGACATCCAGAAGTTCCCCAAG CTCCGGGTGCCGATTCTCAGTAAGTTAAGTCAGGAAATCAACAAGAACGAAGAGAGGAGGAGCATCTTCACACGCAAACCCCAAGTCCCG CGGTTTCCTGAAGAGACAGAAAGCCACGAAGAGGACAATGGGGGCTGGTCGTCCTTTGAAGAAGACGATTATGAAAGTCCCAATGATGAC CAGGATGGGGAGGATGATGGAGACTATGAGTCCCCCAATGAGGAGGAAGAGGCACCCGTGGAAGATGACGCGGATTATGAGCCGCCACCC TCCAATGACGAGGAAGCTCTGCAGAACTCCATCCTGCCTGCCAAGCCTTTCCCCAACTCCAACTCCATGTACATCGACCGGCCCCCCTCT GGGAAAACCCCCCAGCAGCCTCCTGTGCCCCCCCAGAGACCGATGGCCGCCCTCCCGCCCCCACCAGCCGGCCGGAATCACTCGCCACTG CCCCCACCCCAGACCAACCACGAAGAACCCAGCAGAAGCAGAAACCACAAAACGGCAAAGCTCCCTGCTCCTTCAATAGACAGAAGCACG AAACCTCCCCTAGATCGTTCATTAGCTCCGTTTGATAGAGAACCCTTCACACTAGGAAAGAAACCACCATTTTCTGACAAGCCCTCGATT CCAGCGGGAAGGTCACTCGGGGAGCATTTACCCAAGATTCAAAAGCCTCCTTTACCACCGACCACGGAAAGACATGAAAGGAGCAGCCCC CTGCCAGGGAAGAAGCCACCTGTGCCAAAGCATGGATGGGGACCAGACAGAAGAGAGAATGATGAAGATGATGTGCATCAGAGACCTTTG CCCCAGCCAGCACTACTTCCTATGAGCTCCAACACTTTCCCTTCAAGATCTACTAAGCCAAGTCCCATGAACCCTCTCCCATCCTCTCAC ATGCCTGGAGCATTCTCAGAAAGTAACAGCAGTTTTCCACAGAGTGCCTCCCTGCCACCATACTTCTCTCAAGGCCCTAGCAACAGACCA CCTATCAGAGCCGAAGGCAGAAACTTCCCCTTGCCACTTCCAAACAAACCTCGGCCCCCATCCCCCGCGGAGGAAGAGAATTCATTAAAT GAAGAGTGGTACGTTTCTTATATTACCCGACCAGAGGCAGAAGCTGCTCTTAGAAAGATAAACCAGGATGGCACATTTCTGGTCAGAGAC AGCTCTAAAAAAACAACAACCAATCCATATGTCCTCATGGTGTTGTACAAAGATAAAGTTTACAACATCCAGATCCGTTATCAGAAGGAA AGTCAAGTTTACTTGTTGGGAACTGGACTCCGAGGGAAAGAGGACTTTCTGTCTGTGTCAGATATTATTGACTACTTCAGGAAAATGCCA CTTCTGCTCATTGATGGGAAAAACCGAGGTTCCAGATACCAGTGCACATTAACGCATGCTGCAGGGTACCCATAGCAAGTTATAGCCGAG CAAATGAACCGTCCTCCTGCCTCTGTTGCCAACACGAGATCAATCAGCCTTGGTCAATGGACAAACACTTAGGACTGAACTGAACCCCTC CCCATGAACACAAGGGTTTTATCCTTTCCTTTAAAAACAGTGTTTGAAATGAAGACTGTCAACTATCCCATAATTTATTTATTCTTCTTC AATGTTTGTAAAGTGCATGAGTCATGTTCACACTTGAAGTCTAGTAGTGCACTGTAATAATTCATTTTTTAAAAGATTATTTAATGCCCA TTTCAAAATACAGTAGTTTACACAGCTACAGAAACAATTTGGGGCAAGTTTTAAAACACTGAAACAGTAATAGTTATTGGTGTCACATAA AACTGATTTGTTTTTTACAGCCAAACCTCTGTCAGTCAGAGGCATTCATTAGTTTTATACATGTAATTTGAAAATCACTAAACCTCGTTT TCTCAGCAGCAATAATTTAAGAGGCTTCAAAAATATAATTTCACTCTTATTTAGTATTTTTTCCTGGGGGCATTTTTACGTAATTTTTTT ATGAAAAGACAAATGCATGTTGAGATAACTTCTGGGATTAAAATAGTCTTTTGCTTTACTTTTTTGGTTTCCTAAAACAACTTTATTGAC TTTTAGTCCATACTGTTATATTTTTGTCTTAAAGAAAATTTAAACTACAAATACCAAAAGAAAACATTTTAAATTTAGGGATGAGACTTT GGTGTATCGTGGGTCTAGGTTTAATGAACACATCTGGGGTTAAGTTGGCATTTCTTCACATCTCCACACCCACACCAACCATCACAGCCC CCCACCAACCTTCTCCCAACCCCAAAAGCATTGTCCAGGGATATAGATTTTACCAAAGGCTTCCTGGGAAGACGAGGGAGCAACACTTTA GATTAAATGTGATCAGACTTTCCTATTAGATATGGCTCTTCTGTCTCTTGTTATCCCCCTGACAGCTCTGCCATAAAGTCCCTTCTCCTC ATCCTTCCCAAACAGGCTGTATAAGTGCTTTGAGGTAATTAAACTCTTTCCTCCAGTTTACAAATATCACTTAACAAAAAATATAGGCAT TCAGCCAGATTAAAAAACTGGTATTCAGCCAAATAGTGACAATCAGTTGTTCTTCAAGTTTTTCCCTTTGGGACCTTGGTTGTTATTGCA CAACTTTTATTAGCAACAATTTTTGGCGTCTCTGCTTAATCTACAAGTTTTCGAAATGGAAAAGAGTATCTTGCAGCTTCATTTTCATGA GCTAATAAAAGGGGTATTGGAAGGAATCTAAGAAGTCACCATTTTAAAACTGATGATATGTTAAAATAAGGAGTATGCAGAAGGTAGAGA CTTTTAACTGATGATAAAAATGGTGTTTCACAAAATCTCATCCTTAACAACCAGAAGTTCTCAGTTTAGGGTCCAAAACTTGGGAGTTTA AGGCTGAAAACCCTGCATTCATTTACACGTCTACACAACGGGCTATTCAGCAAGTATTTACTTAGTGGCTCTTCTGTGTTAAACAAGTGA GCTAGGTACAAGGTAGTAAGGATAGCATACACCATAGGTTCTAGTATCGAGTAAGCTCCACTTGTCTTGCTTTGCCGTATTCTATCTTTA CAATTCAAAAATATCTAAAATGAAGGACCTGATAGATTTCAAAGCAACTATTTGGTAGCGAATCATGTTTATAAAACAAACCAAAGCTCA TTTTAAGTCTATTAGTGGAAAGTGCCATCAGGATTAAGATGTTCTGTTCCATGGCTATGACTGAAATCAATGTTGGGAAGCTAATGTTTT CATGACTAGCATTCTCTCTCTGTTCAAGCACCGACAACTCCTTTTGGCTGGGCCTTGCCTCTTTTGGCCACAGACCTTCTATATGACCCC AGGTGCATCAGTCACAGTTGCTCAGAACCCTGCTCAGTGATAAACATCTTACTAAAGCTGGGTCAATCAGGGTCACTCTCTGGAATGTTA AACATGAAGCCTGAGACAAGATCTCTCTTTTATCTGGGGTCCCCAAAGGCAATGCTGTACACTTGGAGCTGCCTGCTGCCCTGCAACTAC TCCCATTTACCAATTATCTGGAAGAACCAGTCTACAATAGAAGACAACGAGGCCAACACACAAAAACACAGTAAAAGTATGGACAAATTA GTGGGATCCCTGAAATCTATTCCAACTATGTGCTTCCAAGTCACATGACTCAATAAATGCTTCAGCTGGTTGAGTTGTGCTTGGCGTTCA CTACCAGGAGAGTTCTGATTAATAAAAACTCATTCCATCAATTAATAATTTAGTAGCTCTCTTTCAACCTGAGCCAAATTCAAGCATAAG CTAAAGGATAAGCAGTGACCCATGGCCAATTTCCTATGTCATACACTTGCCATTAGTGACGTAAGTTAAGCCATTCTTCAAAACATTAAA >81250_81250_3_SGCD-LCP2_SGCD_chr5_155771687_ENST00000447401_LCP2_chr5_169720376_ENST00000046794_length(amino acids)=571AA_BP=64 MMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTILNYKDCEKAVKKYHIDGARFLNLTEN DIQKFPKLRVPILSKLSQEINKNEERRSIFTRKPQVPRFPEETESHEEDNGGWSSFEEDDYESPNDDQDGEDDGDYESPNEEEEAPVEDD ADYEPPPSNDEEALQNSILPAKPFPNSNSMYIDRPPSGKTPQQPPVPPQRPMAALPPPPAGRNHSPLPPPQTNHEEPSRSRNHKTAKLPA PSIDRSTKPPLDRSLAPFDREPFTLGKKPPFSDKPSIPAGRSLGEHLPKIQKPPLPPTTERHERSSPLPGKKPPVPKHGWGPDRRENDED DVHQRPLPQPALLPMSSNTFPSRSTKPSPMNPLPSSHMPGAFSESNSSFPQSASLPPYFSQGPSNRPPIRAEGRNFPLPLPNKPRPPSPA EEENSLNEEWYVSYITRPEAEAALRKINQDGTFLVRDSSKKTTTNPYVLMVLYKDKVYNIQIRYQKESQVYLLGTGLRGKEDFLSVSDII -------------------------------------------------------------- >81250_81250_4_SGCD-LCP2_SGCD_chr5_155771687_ENST00000517913_LCP2_chr5_169720376_ENST00000046794_length(transcript)=4538nt_BP=554nt GTGATATCTATTGAAGCTGGGAGGGTCACAGTATCAGTGAGTGGTCCCCCAATTTCTTCTTGAGCATCGATGAATTAGCAGTGGTGTAAT ATTGTGGATCTGACTTCATGTGTCACTAAGAACAGGAGATCCAAGACTGCTCTTCTGGGGATGAGACTTGGAAGAAACCTCCATCCTCAG GGATTTGAAGAAGGTTATACTGGAACCTGTGTGAAGGCTGAGACAACCGTCCCTTTTGTGGTGGCCTGAGGGGATTTTCTTAATCCCAAT GTTGCCCTGAAATTTATGTCCAGGATTCAAAAAGTTTAGGACTGCTAAGAGACATTACTGCCGGGAGTGTTGAGTGAAGGGACCAGGTGG AGATGATGCCTCAGGAGCAGTACACTCACCACCGGAGCACCATGCCTGGCTCTGTGGGGCCACAGGTATACAAGGTGGGGATTTATGGCT GGCGGAAACGATGCCTGTATTTCTTTGTCCTGCTCCTCATGATTTTAATACTGGTGAACTTGGCCATGACCATCTGGATTCTCAAAGTCA TGAACTTCACAATTCTCAACTATAAGGACTGTGAGAAGGCAGTGAAGAAGTACCACATCGATGGGGCTCGCTTCTTGAACCTGACAGAAA ATGACATCCAGAAGTTCCCCAAGCTCCGGGTGCCGATTCTCAGTAAGTTAAGTCAGGAAATCAACAAGAACGAAGAGAGGAGGAGCATCT TCACACGCAAACCCCAAGTCCCGCGGTTTCCTGAAGAGACAGAAAGCCACGAAGAGGACAATGGGGGCTGGTCGTCCTTTGAAGAAGACG ATTATGAAAGTCCCAATGATGACCAGGATGGGGAGGATGATGGAGACTATGAGTCCCCCAATGAGGAGGAAGAGGCACCCGTGGAAGATG ACGCGGATTATGAGCCGCCACCCTCCAATGACGAGGAAGCTCTGCAGAACTCCATCCTGCCTGCCAAGCCTTTCCCCAACTCCAACTCCA TGTACATCGACCGGCCCCCCTCTGGGAAAACCCCCCAGCAGCCTCCTGTGCCCCCCCAGAGACCGATGGCCGCCCTCCCGCCCCCACCAG CCGGCCGGAATCACTCGCCACTGCCCCCACCCCAGACCAACCACGAAGAACCCAGCAGAAGCAGAAACCACAAAACGGCAAAGCTCCCTG CTCCTTCAATAGACAGAAGCACGAAACCTCCCCTAGATCGTTCATTAGCTCCGTTTGATAGAGAACCCTTCACACTAGGAAAGAAACCAC CATTTTCTGACAAGCCCTCGATTCCAGCGGGAAGGTCACTCGGGGAGCATTTACCCAAGATTCAAAAGCCTCCTTTACCACCGACCACGG AAAGACATGAAAGGAGCAGCCCCCTGCCAGGGAAGAAGCCACCTGTGCCAAAGCATGGATGGGGACCAGACAGAAGAGAGAATGATGAAG ATGATGTGCATCAGAGACCTTTGCCCCAGCCAGCACTACTTCCTATGAGCTCCAACACTTTCCCTTCAAGATCTACTAAGCCAAGTCCCA TGAACCCTCTCCCATCCTCTCACATGCCTGGAGCATTCTCAGAAAGTAACAGCAGTTTTCCACAGAGTGCCTCCCTGCCACCATACTTCT CTCAAGGCCCTAGCAACAGACCACCTATCAGAGCCGAAGGCAGAAACTTCCCCTTGCCACTTCCAAACAAACCTCGGCCCCCATCCCCCG CGGAGGAAGAGAATTCATTAAATGAAGAGTGGTACGTTTCTTATATTACCCGACCAGAGGCAGAAGCTGCTCTTAGAAAGATAAACCAGG ATGGCACATTTCTGGTCAGAGACAGCTCTAAAAAAACAACAACCAATCCATATGTCCTCATGGTGTTGTACAAAGATAAAGTTTACAACA TCCAGATCCGTTATCAGAAGGAAAGTCAAGTTTACTTGTTGGGAACTGGACTCCGAGGGAAAGAGGACTTTCTGTCTGTGTCAGATATTA TTGACTACTTCAGGAAAATGCCACTTCTGCTCATTGATGGGAAAAACCGAGGTTCCAGATACCAGTGCACATTAACGCATGCTGCAGGGT ACCCATAGCAAGTTATAGCCGAGCAAATGAACCGTCCTCCTGCCTCTGTTGCCAACACGAGATCAATCAGCCTTGGTCAATGGACAAACA CTTAGGACTGAACTGAACCCCTCCCCATGAACACAAGGGTTTTATCCTTTCCTTTAAAAACAGTGTTTGAAATGAAGACTGTCAACTATC CCATAATTTATTTATTCTTCTTCAATGTTTGTAAAGTGCATGAGTCATGTTCACACTTGAAGTCTAGTAGTGCACTGTAATAATTCATTT TTTAAAAGATTATTTAATGCCCATTTCAAAATACAGTAGTTTACACAGCTACAGAAACAATTTGGGGCAAGTTTTAAAACACTGAAACAG TAATAGTTATTGGTGTCACATAAAACTGATTTGTTTTTTACAGCCAAACCTCTGTCAGTCAGAGGCATTCATTAGTTTTATACATGTAAT TTGAAAATCACTAAACCTCGTTTTCTCAGCAGCAATAATTTAAGAGGCTTCAAAAATATAATTTCACTCTTATTTAGTATTTTTTCCTGG GGGCATTTTTACGTAATTTTTTTATGAAAAGACAAATGCATGTTGAGATAACTTCTGGGATTAAAATAGTCTTTTGCTTTACTTTTTTGG TTTCCTAAAACAACTTTATTGACTTTTAGTCCATACTGTTATATTTTTGTCTTAAAGAAAATTTAAACTACAAATACCAAAAGAAAACAT TTTAAATTTAGGGATGAGACTTTGGTGTATCGTGGGTCTAGGTTTAATGAACACATCTGGGGTTAAGTTGGCATTTCTTCACATCTCCAC ACCCACACCAACCATCACAGCCCCCCACCAACCTTCTCCCAACCCCAAAAGCATTGTCCAGGGATATAGATTTTACCAAAGGCTTCCTGG GAAGACGAGGGAGCAACACTTTAGATTAAATGTGATCAGACTTTCCTATTAGATATGGCTCTTCTGTCTCTTGTTATCCCCCTGACAGCT CTGCCATAAAGTCCCTTCTCCTCATCCTTCCCAAACAGGCTGTATAAGTGCTTTGAGGTAATTAAACTCTTTCCTCCAGTTTACAAATAT CACTTAACAAAAAATATAGGCATTCAGCCAGATTAAAAAACTGGTATTCAGCCAAATAGTGACAATCAGTTGTTCTTCAAGTTTTTCCCT TTGGGACCTTGGTTGTTATTGCACAACTTTTATTAGCAACAATTTTTGGCGTCTCTGCTTAATCTACAAGTTTTCGAAATGGAAAAGAGT ATCTTGCAGCTTCATTTTCATGAGCTAATAAAAGGGGTATTGGAAGGAATCTAAGAAGTCACCATTTTAAAACTGATGATATGTTAAAAT AAGGAGTATGCAGAAGGTAGAGACTTTTAACTGATGATAAAAATGGTGTTTCACAAAATCTCATCCTTAACAACCAGAAGTTCTCAGTTT AGGGTCCAAAACTTGGGAGTTTAAGGCTGAAAACCCTGCATTCATTTACACGTCTACACAACGGGCTATTCAGCAAGTATTTACTTAGTG GCTCTTCTGTGTTAAACAAGTGAGCTAGGTACAAGGTAGTAAGGATAGCATACACCATAGGTTCTAGTATCGAGTAAGCTCCACTTGTCT TGCTTTGCCGTATTCTATCTTTACAATTCAAAAATATCTAAAATGAAGGACCTGATAGATTTCAAAGCAACTATTTGGTAGCGAATCATG TTTATAAAACAAACCAAAGCTCATTTTAAGTCTATTAGTGGAAAGTGCCATCAGGATTAAGATGTTCTGTTCCATGGCTATGACTGAAAT CAATGTTGGGAAGCTAATGTTTTCATGACTAGCATTCTCTCTCTGTTCAAGCACCGACAACTCCTTTTGGCTGGGCCTTGCCTCTTTTGG CCACAGACCTTCTATATGACCCCAGGTGCATCAGTCACAGTTGCTCAGAACCCTGCTCAGTGATAAACATCTTACTAAAGCTGGGTCAAT CAGGGTCACTCTCTGGAATGTTAAACATGAAGCCTGAGACAAGATCTCTCTTTTATCTGGGGTCCCCAAAGGCAATGCTGTACACTTGGA GCTGCCTGCTGCCCTGCAACTACTCCCATTTACCAATTATCTGGAAGAACCAGTCTACAATAGAAGACAACGAGGCCAACACACAAAAAC ACAGTAAAAGTATGGACAAATTAGTGGGATCCCTGAAATCTATTCCAACTATGTGCTTCCAAGTCACATGACTCAATAAATGCTTCAGCT GGTTGAGTTGTGCTTGGCGTTCACTACCAGGAGAGTTCTGATTAATAAAAACTCATTCCATCAATTAATAATTTAGTAGCTCTCTTTCAA CCTGAGCCAAATTCAAGCATAAGCTAAAGGATAAGCAGTGACCCATGGCCAATTTCCTATGTCATACACTTGCCATTAGTGACGTAAGTT >81250_81250_4_SGCD-LCP2_SGCD_chr5_155771687_ENST00000517913_LCP2_chr5_169720376_ENST00000046794_length(amino acids)=571AA_BP=64 MMPQEQYTHHRSTMPGSVGPQVYKVGIYGWRKRCLYFFVLLLMILILVNLAMTIWILKVMNFTILNYKDCEKAVKKYHIDGARFLNLTEN DIQKFPKLRVPILSKLSQEINKNEERRSIFTRKPQVPRFPEETESHEEDNGGWSSFEEDDYESPNDDQDGEDDGDYESPNEEEEAPVEDD ADYEPPPSNDEEALQNSILPAKPFPNSNSMYIDRPPSGKTPQQPPVPPQRPMAALPPPPAGRNHSPLPPPQTNHEEPSRSRNHKTAKLPA PSIDRSTKPPLDRSLAPFDREPFTLGKKPPFSDKPSIPAGRSLGEHLPKIQKPPLPPTTERHERSSPLPGKKPPVPKHGWGPDRRENDED DVHQRPLPQPALLPMSSNTFPSRSTKPSPMNPLPSSHMPGAFSESNSSFPQSASLPPYFSQGPSNRPPIRAEGRNFPLPLPNKPRPPSPA EEENSLNEEWYVSYITRPEAEAALRKINQDGTFLVRDSSKKTTTNPYVLMVLYKDKVYNIQIRYQKESQVYLLGTGLRGKEDFLSVSDII -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SGCD-LCP2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SGCD-LCP2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SGCD-LCP2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies