
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SIPA1-FRMD8 (FusionGDB2 ID:81933) |
Fusion Gene Summary for SIPA1-FRMD8 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SIPA1-FRMD8 | Fusion gene ID: 81933 | Hgene | Tgene | Gene symbol | SIPA1 | FRMD8 | Gene ID | 6494 | 83786 |
| Gene name | signal-induced proliferation-associated 1 | FERM domain containing 8 | |
| Synonyms | SPA1 | FKSG44|iTAP | |
| Cytomap | 11q13.1 | 11q13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | signal-induced proliferation-associated protein 1GTPase-activating protein Spa-1p130 SPA-1signal-induced proliferation-associated gene 1sipa-1 | FERM domain-containing protein 8band4.1 inhibitor LRP interactorbiliiRhom Tail-Associated Protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9BZ67 | |
| Ensembl transtripts involved in fusion gene | ENST00000394224, ENST00000394227, ENST00000527525, ENST00000534313, | ENST00000355991, ENST00000416776, ENST00000531296, ENST00000317568, | |
| Fusion gene scores | * DoF score | 4 X 4 X 4=64 | 10 X 11 X 10=1100 |
| # samples | 5 | 18 | |
| ** MAII score | log2(5/64*10)=-0.356143810225275 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1100*10)=-2.61143471208235 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SIPA1 [Title/Abstract] AND FRMD8 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SIPA1(65412600)-FRMD8(65178713), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | FRMD8 | GO:1904469 | positive regulation of tumor necrosis factor secretion | 29897333 |
| Fusion gene breakpoints across SIPA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across FRMD8 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-DS-A1O9-01A | SIPA1 | chr11 | 65412600 | - | FRMD8 | chr11 | 65178713 | + |
| ChimerDB4 | CESC | TCGA-DS-A1O9-01A | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| ChimerDB4 | CESC | TCGA-DS-A1O9 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| ChimerDB4 | SKCM | TCGA-FR-A3YO-06A | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
Top |
Fusion Gene ORF analysis for SIPA1-FRMD8 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000394224 | ENST00000355991 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394224 | ENST00000355991 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000394224 | ENST00000416776 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394224 | ENST00000416776 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000394224 | ENST00000531296 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394224 | ENST00000531296 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000394227 | ENST00000355991 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394227 | ENST00000355991 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000394227 | ENST00000416776 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394227 | ENST00000416776 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000394227 | ENST00000531296 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000394227 | ENST00000531296 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000527525 | ENST00000355991 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000527525 | ENST00000355991 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000527525 | ENST00000416776 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000527525 | ENST00000416776 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000527525 | ENST00000531296 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000527525 | ENST00000531296 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000534313 | ENST00000355991 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000534313 | ENST00000355991 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000534313 | ENST00000416776 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000534313 | ENST00000416776 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| 5CDS-intron | ENST00000534313 | ENST00000531296 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| 5CDS-intron | ENST00000534313 | ENST00000531296 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| In-frame | ENST00000394224 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| In-frame | ENST00000394224 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| In-frame | ENST00000394227 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| In-frame | ENST00000394227 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| In-frame | ENST00000527525 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| In-frame | ENST00000527525 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| In-frame | ENST00000534313 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + |
| In-frame | ENST00000534313 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000534313 | SIPA1 | chr11 | 65412600 | + | ENST00000317568 | FRMD8 | chr11 | 65178713 | + | 3620 | 1336 | 177 | 1454 | 425 |
| ENST00000527525 | SIPA1 | chr11 | 65412600 | + | ENST00000317568 | FRMD8 | chr11 | 65178713 | + | 3690 | 1406 | 247 | 1524 | 425 |
| ENST00000394224 | SIPA1 | chr11 | 65412600 | + | ENST00000317568 | FRMD8 | chr11 | 65178713 | + | 3739 | 1455 | 296 | 1573 | 425 |
| ENST00000394227 | SIPA1 | chr11 | 65412600 | + | ENST00000317568 | FRMD8 | chr11 | 65178713 | + | 3537 | 1253 | 94 | 1371 | 425 |
| ENST00000534313 | SIPA1 | chr11 | 65410110 | + | ENST00000317568 | FRMD8 | chr11 | 65172335 | + | 3650 | 1161 | 177 | 1484 | 435 |
| ENST00000527525 | SIPA1 | chr11 | 65410110 | + | ENST00000317568 | FRMD8 | chr11 | 65172335 | + | 3720 | 1231 | 247 | 1554 | 435 |
| ENST00000394224 | SIPA1 | chr11 | 65410110 | + | ENST00000317568 | FRMD8 | chr11 | 65172335 | + | 3769 | 1280 | 296 | 1603 | 435 |
| ENST00000394227 | SIPA1 | chr11 | 65410110 | + | ENST00000317568 | FRMD8 | chr11 | 65172335 | + | 3567 | 1078 | 94 | 1401 | 435 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000534313 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + | 0.13719428 | 0.8628057 |
| ENST00000527525 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + | 0.14396358 | 0.8560364 |
| ENST00000394224 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + | 0.13312648 | 0.86687356 |
| ENST00000394227 | ENST00000317568 | SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178713 | + | 0.1355961 | 0.86440396 |
| ENST00000534313 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + | 0.1516846 | 0.8483154 |
| ENST00000527525 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + | 0.16208725 | 0.8379128 |
| ENST00000394224 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + | 0.14916837 | 0.8508317 |
| ENST00000394227 | ENST00000317568 | SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172335 | + | 0.15203948 | 0.84796053 |
Top |
Fusion Genomic Features for SIPA1-FRMD8 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172334 | + | 0.001376027 | 0.99862397 |
| SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178712 | + | 7.37E-05 | 0.9999263 |
| SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178712 | + | 7.37E-05 | 0.9999263 |
| SIPA1 | chr11 | 65410110 | + | FRMD8 | chr11 | 65172334 | + | 0.001376027 | 0.99862397 |
| SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178712 | + | 7.37E-05 | 0.9999263 |
| SIPA1 | chr11 | 65412600 | + | FRMD8 | chr11 | 65178712 | + | 7.37E-05 | 0.9999263 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
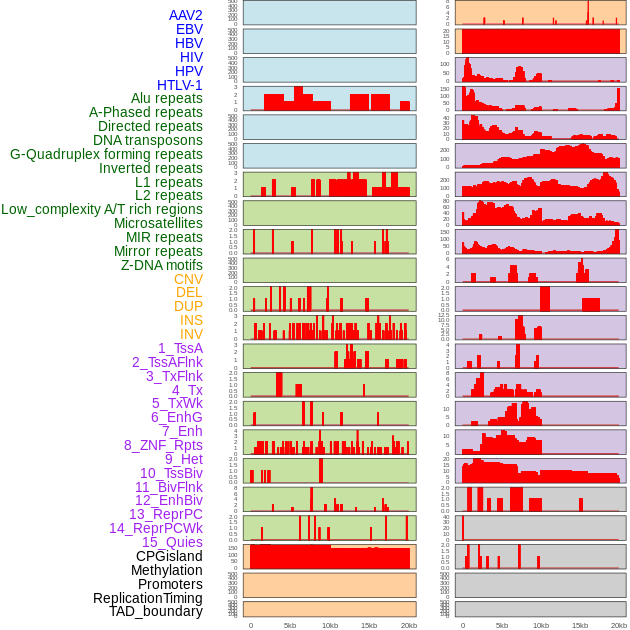 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
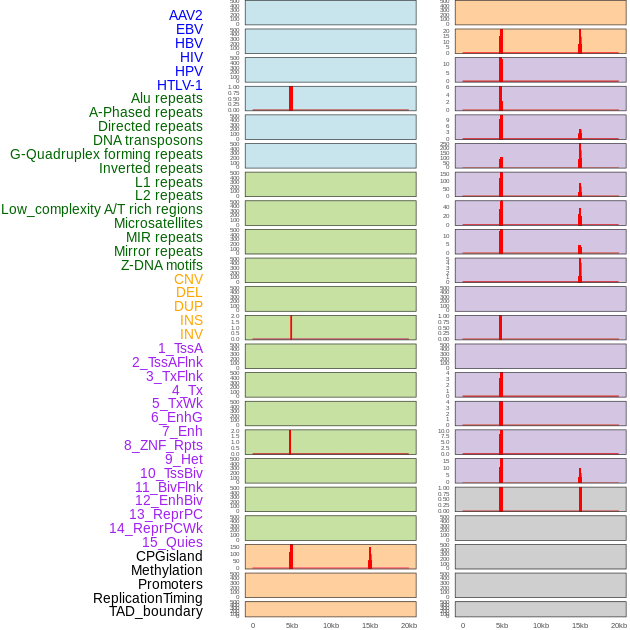 |
Top |
Fusion Protein Features for SIPA1-FRMD8 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:65412600/chr11:65178713) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | FRMD8 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Promotes the cell surface stability of iRhom1/RHBDF1 and iRhom2/RHBDF2 and prevents their degradation via the endolysosomal pathway. By acting on iRhoms, involved in ADAM17-mediated shedding of TNF, amphiregulin/AREG, HBEGF and TGFA from the cell surface (PubMed:29897333, PubMed:29897336). Negatively regulates Wnt signaling, possibly by antagonizing the recruitment of AXIN1 to LRP6 (PubMed:19572019). {ECO:0000269|PubMed:19572019, ECO:0000269|PubMed:29897333, ECO:0000269|PubMed:29897336}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000394224 | + | 4 | 16 | 972_1034 | 328 | 1043.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000534313 | + | 4 | 16 | 972_1034 | 328 | 1043.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000394224 | + | 5 | 16 | 972_1034 | 386 | 1043.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000534313 | + | 5 | 16 | 972_1034 | 386 | 1043.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000394224 | + | 4 | 16 | 321_539 | 328 | 1043.0 | Domain | Rap-GAP |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000394224 | + | 4 | 16 | 687_763 | 328 | 1043.0 | Domain | PDZ |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000534313 | + | 4 | 16 | 321_539 | 328 | 1043.0 | Domain | Rap-GAP |
| Hgene | SIPA1 | chr11:65410110 | chr11:65172335 | ENST00000534313 | + | 4 | 16 | 687_763 | 328 | 1043.0 | Domain | PDZ |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000394224 | + | 5 | 16 | 321_539 | 386 | 1043.0 | Domain | Rap-GAP |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000394224 | + | 5 | 16 | 687_763 | 386 | 1043.0 | Domain | PDZ |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000534313 | + | 5 | 16 | 321_539 | 386 | 1043.0 | Domain | Rap-GAP |
| Hgene | SIPA1 | chr11:65412600 | chr11:65178713 | ENST00000534313 | + | 5 | 16 | 687_763 | 386 | 1043.0 | Domain | PDZ |
| Tgene | FRMD8 | chr11:65410110 | chr11:65172335 | ENST00000317568 | 8 | 11 | 30_376 | 357 | 465.0 | Domain | FERM | |
| Tgene | FRMD8 | chr11:65410110 | chr11:65172335 | ENST00000355991 | 7 | 10 | 30_376 | 301 | 409.0 | Domain | FERM | |
| Tgene | FRMD8 | chr11:65412600 | chr11:65178713 | ENST00000317568 | 9 | 11 | 30_376 | 425 | 465.0 | Domain | FERM | |
| Tgene | FRMD8 | chr11:65412600 | chr11:65178713 | ENST00000355991 | 8 | 10 | 30_376 | 369 | 409.0 | Domain | FERM |
Top |
Fusion Gene Sequence for SIPA1-FRMD8 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >81933_81933_1_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000394224_FRMD8_chr11_65172335_ENST00000317568_length(transcript)=3769nt_BP=1280nt GGCAGGGTGACTGGGGTCCCATGACAGCTGCTGTGACCCCAGCACCTTCCTCAGGATGTGGGGGCCTGGCAGAGGGCTGGGCCCACAGTT GGGGCTACTTCCTGTGCTGAAGGAAGTCCTCTTGCCATTCCTGCTGCCCTGCCGCTGCCTCCCTGGGAACCCATGTGTCCTTGTGGCCCC TCTGAGCAGCCCCCTCCTCCTTCAGGGCAGGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAG CCCCCGGAGAGTCAGGCCCACAGAGCATGCCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATG ACCTCTTTGCCCGCAAGCTGCGCCAGCCAGCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGC GCAGCGGCAGCGATGCAGGCGAGGCCAGGCCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTG CAGCCACTTCCACCCGGCTCTTCACTGACCCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTG AGCCTCGATGGTTTGCCCACTATGACGTGCAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCA GCTCTGGGACCCTGGCTTCAGCCGAGGACCAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTG AGGGTGAGCTAGGCCTGGGTGGACCAGCATCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGA ACCGAACCTCGGCCTACAGCCTGGAGCACGCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCT TCGGGATGGACGAGTCGCTGGGCCCGGTGGCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACC GCGTCATCGTGCGGACCACGCAGCTCCGGACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCC CAAGGAAACTTCTGGAGCACGTGGCGCCGCAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGC TCACACTGGATGAGCAAGTGGCCGAACTGATGAGCAGTCTCATTGAGTACTGCATCGAACTGAGCCAGGCGGCGGAGCCCGCAGGCCCCC AGGACAGTGCGACTGGCTCGCCCTCGGACCCCAGCTCCTCACTGGCTCCTGTTCAGCGCCCCAAGCTGCGGAGGCAGGGCAGTGTGGTGT CCAGCCGGATCCAGCATCTCTCCACCATCGACTACGTGGAGGACGGCAAGGGGATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCT TCAGCCGGCAGCTGTCCTTGGGCCAGGGGAGCTACACCGTGGTGCAGCCCGGCGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGC AGGAGGAGGGCGACTGGGGGCCCTGGCCCGGCACTGTCCTCCTGAGGGGCAGGCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGG AGGGCTGCCTCAGCAGGTTTCTCAGACCACGGAGAAGTGACTTTTGGGCCCGGGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTC CTGTAGGGCTCCTCTGCAGCCTGCCCTCCCTTCCCCCGGATGCTGGGCCCTGCTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCC ACCCTCACCTAGAAACATGCCTTTGTGCCCACCTCAAGATGGGCAGTGTCCCTGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGG ACCAAGGATTGAGGTTTGGGACCTGAAGCTCCAGTGTGTGCCTTTGGCCTCTTCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTG CTAGTGCTCCACCCCCCGGACTTGGATGACCAGTTTCCCACCTTCCTCCTGCTGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACT CTGAGGAGGGTAGGAGGGGCCTCCCTGGATTGAACCGGGACAGAAACACGGTGAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAAT GGAGGGAGCCAGGCAGGGCCCTACCTGGGGTCCTGTGCCCCTCGTTCTGGTCTCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTT TCTGATAGCCTTTGGTGATGTCACTGCTGGGAGGTGGCTATCCTGTGGACCACCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAAC TGAAAATCCCCTGGTGGGCACTCCCTGGAGCCCAAGCAGCTCCCCTAGGGGACTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCT TCAGGTTTTAGTTTGGTCTTTGTTCATCTGAGTTGTGCTGGGGCAACGCCAGGAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCA GGTGGCGCCATGGATTCCTCTGGGGGCTGGCGCATGCCCAGGAAAGCCTGGGCCACACGGGACACTCTCTTCTTTATCGAGGACACTTGG AAAGGTGACTGATATGGGTGCTTGGCTTCTCTGGTCCCAGCTTGCCCTCCGGGGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAG CCCCTGAGAGGAGGGCTTTCCCAGCCCTGGGACCCTCCGAGGTGGGTGTGCGGGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCA CAGGGCTTGGCTTTGTCTTCGTTCCCGGTGGAAAACCGTGGGAGAGGAAGCTTGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTC CTCCCTTTGGTAGCTTGTGAATGTGCCAGGTGTTTCGAGGTAGGCTTGCCTTCTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAG AAGAGGCCTGGGAAGGGCCCCCAGTCTTTTGGAATGTCCTGGTCACAGGGTCATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTG CTCGGTCTTGCGGAGCTGCCCGCCTGCCTGTTCTGGCGGCTCCAGCGCAGGCTGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTT TTATTTTTTTATTTTTTTTGAGACGGAGTCTTGCTCTGTTGCCCAGGCAGGAGTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCT CAAGCGATTCTCCTGCCTCAGCCTCCTGAGTAGCTGGGATTACAGGTGCATGCCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGA TAGGGTTTCACCATGTTGGTCAGGCTGGTCGTGAACTCCTGACCTCATGATCTGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGC GTGAGCCACCGCCCCCAGCTGATTCCAGGCGAATTCTTCTCTGATGGGCGGGCGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGT CTGAGTACACAGATGATGTGTTTTCCCTTCAGCTTCTTACGTTTTCTGAGCATCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGA >81933_81933_1_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000394224_FRMD8_chr11_65172335_ENST00000317568_length(amino acids)=435AA_BP=303 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVAELMSSLIEYCIELSQAAEPAGPQDSATGSPS -------------------------------------------------------------- >81933_81933_2_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000394227_FRMD8_chr11_65172335_ENST00000317568_length(transcript)=3567nt_BP=1078nt CAGGGCAGGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACA GAGCATGCCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCG CCAGCCAGCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGA GGCCAGGCCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTT CACTGACCCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTA TGACGTGCAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGC CGAGGACCAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGG ACCAGCATCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCT GGAGCACGCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGG CCCGGTGGCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCA GCTCCGGACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGT GGCGCCGCAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGGC CGAACTGATGAGCAGTCTCATTGAGTACTGCATCGAACTGAGCCAGGCGGCGGAGCCCGCAGGCCCCCAGGACAGTGCGACTGGCTCGCC CTCGGACCCCAGCTCCTCACTGGCTCCTGTTCAGCGCCCCAAGCTGCGGAGGCAGGGCAGTGTGGTGTCCAGCCGGATCCAGCATCTCTC CACCATCGACTACGTGGAGGACGGCAAGGGGATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGG CCAGGGGAGCTACACCGTGGTGCAGCCCGGCGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCC CTGGCCCGGCACTGTCCTCCTGAGGGGCAGGCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCT CAGACCACGGAGAAGTGACTTTTGGGCCCGGGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCT GCCCTCCCTTCCCCCGGATGCTGGGCCCTGCTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCT TTGTGCCCACCTCAAGATGGGCAGTGTCCCTGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGAC CTGAAGCTCCAGTGTGTGCCTTTGGCCTCTTCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACT TGGATGACCAGTTTCCCACCTTCCTCCTGCTGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCT CCCTGGATTGAACCGGGACAGAAACACGGTGAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCT ACCTGGGGTCCTGTGCCCCTCGTTCTGGTCTCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTC ACTGCTGGGAGGTGGCTATCCTGTGGACCACCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACT CCCTGGAGCCCAAGCAGCTCCCCTAGGGGACTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTG TTCATCTGAGTTGTGCTGGGGCAACGCCAGGAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTG GGGGCTGGCGCATGCCCAGGAAAGCCTGGGCCACACGGGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCT TGGCTTCTCTGGTCCCAGCTTGCCCTCCGGGGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCC AGCCCTGGGACCCTCCGAGGTGGGTGTGCGGGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGT TCCCGGTGGAAAACCGTGGGAGAGGAAGCTTGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAAT GTGCCAGGTGTTTCGAGGTAGGCTTGCCTTCTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCC AGTCTTTTGGAATGTCCTGGTCACAGGGTCATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCG CCTGCCTGTTCTGGCGGCTCCAGCGCAGGCTGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAG ACGGAGTCTTGCTCTGTTGCCCAGGCAGGAGTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGC CTCCTGAGTAGCTGGGATTACAGGTGCATGCCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCA GGCTGGTCGTGAACTCCTGACCTCATGATCTGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGA TTCCAGGCGAATTCTTCTCTGATGGGCGGGCGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTT TTCCCTTCAGCTTCTTACGTTTTCTGAGCATCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTC >81933_81933_2_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000394227_FRMD8_chr11_65172335_ENST00000317568_length(amino acids)=435AA_BP=303 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVAELMSSLIEYCIELSQAAEPAGPQDSATGSPS -------------------------------------------------------------- >81933_81933_3_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000527525_FRMD8_chr11_65172335_ENST00000317568_length(transcript)=3720nt_BP=1231nt AGGTGCAGCCCTGCTTAGGGCCTGGAGATGGGCAGACCCAGGCTCACATCCTAGCTCTGACACGGAATTGCTTCAGGCAAGAGCATCTCC TCTGGACCTCATCTGACCATCTGTCACATGGGGTTCAGACCTCCCTGTCTGCATCAGTGAGACCAGGGCAGGAACTGCTGCCACAACCTC AGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACAGAGCATGCCCATGTGGGCCGGCGGTGT GGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCGCCAGCCAGCAAGGCCCCCGCTGACACC GCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGAGGCCAGGCCCCCCACGCCAGCCAGCCC CCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTTCACTGACCCGCTGGCACTGCTGGGGCT GCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTATGACGTGCAAAGCCTGCTCTTTGATTG GGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGCCGAGGACCAGGCTGCCAGCTCGGACCT GCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGGACCAGCATCCCCACCTGTGCCCCCTGC ACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCTGGAGCACGCAGACCTGGGTGCTGGCTA CTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGGCCCGGTGGCAGTGAGCCTGCGGCGGGA GGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCAGCTCCGGACACTCCGTGGCACCATCTC GGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGTGGCGCCGCAGCTGAGCCCCAGCTGCCT GCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGGCCGAACTGATGAGCAGTCTCATTGAGTA CTGCATCGAACTGAGCCAGGCGGCGGAGCCCGCAGGCCCCCAGGACAGTGCGACTGGCTCGCCCTCGGACCCCAGCTCCTCACTGGCTCC TGTTCAGCGCCCCAAGCTGCGGAGGCAGGGCAGTGTGGTGTCCAGCCGGATCCAGCATCTCTCCACCATCGACTACGTGGAGGACGGCAA GGGGATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGGAGCTACACCGTGGTGCAGCC CGGCGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCCGGCACTGTCCTCCTGAGGGG CAGGCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCACGGAGAAGTGACTTTTGGGC CCGGGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCCCTTCCCCCGGATGCTGGGCC CTGCTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCCCACCTCAAGATGGGCAGTGT CCCTGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGCTCCAGTGTGTGCCTTTGGCC TCTTCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGACCAGTTTCCCACCTTCCTCC TGCTGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGATTGAACCGGGACAGAAACAC GGTGAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGGGTCCTGTGCCCCTCGTTCTG GTCTCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTGGGAGGTGGCTATCCTGTGGA CCACCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGAGCCCAAGCAGCTCCCCTAGG GGACTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCTGAGTTGTGCTGGGGCAACGC CAGGAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTGGCGCATGCCCAGGAAAGCCT GGGCCACACGGGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTCTCTGGTCCCAGCTTGCCCTC CGGGGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTGGGACCCTCCGAGGTGGGTGT GCGGGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGTGGAAAACCGTGGGAGAGGAA GCTTGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAGGTGTTTCGAGGTAGGCTTGC CTTCTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTTTGGAATGTCCTGGTCACAGG GTCATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCTGTTCTGGCGGCTCCAGCGCA GGCTGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGTCTTGCTCTGTTGCCCAGGCA GGAGTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGAGTAGCTGGGATTACAGGTGC ATGCCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGTCGTGAACTCCTGACCTCATG ATCTGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGGCGAATTCTTCTCTGATGGGC GGGCGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTTCAGCTTCTTACGTTTTCTGA GCATCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAATGTTCTCATTCTTTTGTATCA >81933_81933_3_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000527525_FRMD8_chr11_65172335_ENST00000317568_length(amino acids)=435AA_BP=303 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVAELMSSLIEYCIELSQAAEPAGPQDSATGSPS -------------------------------------------------------------- >81933_81933_4_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000534313_FRMD8_chr11_65172335_ENST00000317568_length(transcript)=3650nt_BP=1161nt AGGCGGAGCCGGCGCCGGGAGCGGTAGCGGGAGAGCGGCAGCGGGACCCCAGCGCGGGCGGCGGCGGCTGGGCGGGAGCCCCAGAGGGCA GGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACAGAGCATG CCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCGCCAGCCA GCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGAGGCCAGG CCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTTCACTGAC CCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTATGACGTG CAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGCCGAGGAC CAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGGACCAGCA TCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCTGGAGCAC GCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGGCCCGGTG GCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCAGCTCCGG ACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGTGGCGCCG CAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGGCCGAACTG ATGAGCAGTCTCATTGAGTACTGCATCGAACTGAGCCAGGCGGCGGAGCCCGCAGGCCCCCAGGACAGTGCGACTGGCTCGCCCTCGGAC CCCAGCTCCTCACTGGCTCCTGTTCAGCGCCCCAAGCTGCGGAGGCAGGGCAGTGTGGTGTCCAGCCGGATCCAGCATCTCTCCACCATC GACTACGTGGAGGACGGCAAGGGGATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGG AGCTACACCGTGGTGCAGCCCGGCGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCC GGCACTGTCCTCCTGAGGGGCAGGCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCA CGGAGAAGTGACTTTTGGGCCCGGGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCC CTTCCCCCGGATGCTGGGCCCTGCTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCC CACCTCAAGATGGGCAGTGTCCCTGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGC TCCAGTGTGTGCCTTTGGCCTCTTCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGA CCAGTTTCCCACCTTCCTCCTGCTGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGA TTGAACCGGGACAGAAACACGGTGAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGG GTCCTGTGCCCCTCGTTCTGGTCTCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTG GGAGGTGGCTATCCTGTGGACCACCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGA GCCCAAGCAGCTCCCCTAGGGGACTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCT GAGTTGTGCTGGGGCAACGCCAGGAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTG GCGCATGCCCAGGAAAGCCTGGGCCACACGGGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTC TCTGGTCCCAGCTTGCCCTCCGGGGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTG GGACCCTCCGAGGTGGGTGTGCGGGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGT GGAAAACCGTGGGAGAGGAAGCTTGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAG GTGTTTCGAGGTAGGCTTGCCTTCTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTT TGGAATGTCCTGGTCACAGGGTCATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCT GTTCTGGCGGCTCCAGCGCAGGCTGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGT CTTGCTCTGTTGCCCAGGCAGGAGTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGA GTAGCTGGGATTACAGGTGCATGCCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGT CGTGAACTCCTGACCTCATGATCTGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGG CGAATTCTTCTCTGATGGGCGGGCGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTT CAGCTTCTTACGTTTTCTGAGCATCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAAT >81933_81933_4_SIPA1-FRMD8_SIPA1_chr11_65410110_ENST00000534313_FRMD8_chr11_65172335_ENST00000317568_length(amino acids)=435AA_BP=303 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVAELMSSLIEYCIELSQAAEPAGPQDSATGSPS -------------------------------------------------------------- >81933_81933_5_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000394224_FRMD8_chr11_65178713_ENST00000317568_length(transcript)=3739nt_BP=1455nt GGCAGGGTGACTGGGGTCCCATGACAGCTGCTGTGACCCCAGCACCTTCCTCAGGATGTGGGGGCCTGGCAGAGGGCTGGGCCCACAGTT GGGGCTACTTCCTGTGCTGAAGGAAGTCCTCTTGCCATTCCTGCTGCCCTGCCGCTGCCTCCCTGGGAACCCATGTGTCCTTGTGGCCCC TCTGAGCAGCCCCCTCCTCCTTCAGGGCAGGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAG CCCCCGGAGAGTCAGGCCCACAGAGCATGCCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATG ACCTCTTTGCCCGCAAGCTGCGCCAGCCAGCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGC GCAGCGGCAGCGATGCAGGCGAGGCCAGGCCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTG CAGCCACTTCCACCCGGCTCTTCACTGACCCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTG AGCCTCGATGGTTTGCCCACTATGACGTGCAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCA GCTCTGGGACCCTGGCTTCAGCCGAGGACCAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTG AGGGTGAGCTAGGCCTGGGTGGACCAGCATCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGA ACCGAACCTCGGCCTACAGCCTGGAGCACGCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCT TCGGGATGGACGAGTCGCTGGGCCCGGTGGCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACC GCGTCATCGTGCGGACCACGCAGCTCCGGACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCC CAAGGAAACTTCTGGAGCACGTGGCGCCGCAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGC TCACACTGGATGAGCAAGTGCTGAGCTTCCAACGCAAGGTGGGCATCCTGTACTGCCGGGCGGGCCAGGGCTCGGAGGAGGAGATGTACA ACAACCAGGAGGCGGGACCGGCCTTCATGCAGTTTCTCACCTTGCTGGGCGATGTGGTGCGGCTCAAAGGCTTTGAGAGTTACCGGGCCC AGCTAGACACCAAAAGCAAGGGGATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGGA GCTACACCGTGGTGCAGCCCGGCGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCCG GCACTGTCCTCCTGAGGGGCAGGCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCAC GGAGAAGTGACTTTTGGGCCCGGGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCCC TTCCCCCGGATGCTGGGCCCTGCTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCCC ACCTCAAGATGGGCAGTGTCCCTGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGCT CCAGTGTGTGCCTTTGGCCTCTTCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGAC CAGTTTCCCACCTTCCTCCTGCTGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGAT TGAACCGGGACAGAAACACGGTGAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGGG TCCTGTGCCCCTCGTTCTGGTCTCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTGG GAGGTGGCTATCCTGTGGACCACCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGAG CCCAAGCAGCTCCCCTAGGGGACTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCTG AGTTGTGCTGGGGCAACGCCAGGAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTGG CGCATGCCCAGGAAAGCCTGGGCCACACGGGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTCT CTGGTCCCAGCTTGCCCTCCGGGGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTGG GACCCTCCGAGGTGGGTGTGCGGGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGTG GAAAACCGTGGGAGAGGAAGCTTGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAGG TGTTTCGAGGTAGGCTTGCCTTCTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTTT GGAATGTCCTGGTCACAGGGTCATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCTG TTCTGGCGGCTCCAGCGCAGGCTGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGTC TTGCTCTGTTGCCCAGGCAGGAGTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGAG TAGCTGGGATTACAGGTGCATGCCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGTC GTGAACTCCTGACCTCATGATCTGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGGC GAATTCTTCTCTGATGGGCGGGCGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTTC AGCTTCTTACGTTTTCTGAGCATCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAATG >81933_81933_5_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000394224_FRMD8_chr11_65178713_ENST00000317568_length(amino acids)=425AA_BP=387 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVLSFQRKVGILYCRAGQGSEEEMYNNQEAGPAF -------------------------------------------------------------- >81933_81933_6_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000394227_FRMD8_chr11_65178713_ENST00000317568_length(transcript)=3537nt_BP=1253nt CAGGGCAGGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACA GAGCATGCCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCG CCAGCCAGCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGA GGCCAGGCCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTT CACTGACCCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTA TGACGTGCAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGC CGAGGACCAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGG ACCAGCATCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCT GGAGCACGCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGG CCCGGTGGCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCA GCTCCGGACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGT GGCGCCGCAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGCT GAGCTTCCAACGCAAGGTGGGCATCCTGTACTGCCGGGCGGGCCAGGGCTCGGAGGAGGAGATGTACAACAACCAGGAGGCGGGACCGGC CTTCATGCAGTTTCTCACCTTGCTGGGCGATGTGGTGCGGCTCAAAGGCTTTGAGAGTTACCGGGCCCAGCTAGACACCAAAAGCAAGGG GATCAGGCGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGGAGCTACACCGTGGTGCAGCCCGG CGACAGCCTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCCGGCACTGTCCTCCTGAGGGGCAG GCGCCGGCTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCACGGAGAAGTGACTTTTGGGCCCG GGGCCATGCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCCCTTCCCCCGGATGCTGGGCCCTG CTGCTCTCTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCCCACCTCAAGATGGGCAGTGTCCC TGTTCTGAAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGCTCCAGTGTGTGCCTTTGGCCTCT TCCCTGGACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGACCAGTTTCCCACCTTCCTCCTGC TGGTGCTCCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGATTGAACCGGGACAGAAACACGGT GAGGGCCCCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGGGTCCTGTGCCCCTCGTTCTGGTC TCCTTTGCAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTGGGAGGTGGCTATCCTGTGGACCA CCTGGCCTCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGAGCCCAAGCAGCTCCCCTAGGGGA CTGACCGGACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCTGAGTTGTGCTGGGGCAACGCCAG GAAGTGCCCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTGGCGCATGCCCAGGAAAGCCTGGG CCACACGGGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTCTCTGGTCCCAGCTTGCCCTCCGG GGAGCAGGGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTGGGACCCTCCGAGGTGGGTGTGCG GGTCTCACAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGTGGAAAACCGTGGGAGAGGAAGCT TGGGCCTCTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAGGTGTTTCGAGGTAGGCTTGCCTT CTGGCAGCATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTTTGGAATGTCCTGGTCACAGGGTC ATGTCAGCTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCTGTTCTGGCGGCTCCAGCGCAGGC TGTCCCTGCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGTCTTGCTCTGTTGCCCAGGCAGGA GTGCAGTGGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGAGTAGCTGGGATTACAGGTGCATG CCACCAGGCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGTCGTGAACTCCTGACCTCATGATC TGCCCGCCTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGGCGAATTCTTCTCTGATGGGCGGG CGAGGGTGTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTTCAGCTTCTTACGTTTTCTGAGCA TCCATTGTGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAATGTTCTCATTCTTTTGTATCATGT >81933_81933_6_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000394227_FRMD8_chr11_65178713_ENST00000317568_length(amino acids)=425AA_BP=387 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVLSFQRKVGILYCRAGQGSEEEMYNNQEAGPAF -------------------------------------------------------------- >81933_81933_7_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000527525_FRMD8_chr11_65178713_ENST00000317568_length(transcript)=3690nt_BP=1406nt AGGTGCAGCCCTGCTTAGGGCCTGGAGATGGGCAGACCCAGGCTCACATCCTAGCTCTGACACGGAATTGCTTCAGGCAAGAGCATCTCC TCTGGACCTCATCTGACCATCTGTCACATGGGGTTCAGACCTCCCTGTCTGCATCAGTGAGACCAGGGCAGGAACTGCTGCCACAACCTC AGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACAGAGCATGCCCATGTGGGCCGGCGGTGT GGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCGCCAGCCAGCAAGGCCCCCGCTGACACC GCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGAGGCCAGGCCCCCCACGCCAGCCAGCCC CCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTTCACTGACCCGCTGGCACTGCTGGGGCT GCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTATGACGTGCAAAGCCTGCTCTTTGATTG GGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGCCGAGGACCAGGCTGCCAGCTCGGACCT GCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGGACCAGCATCCCCACCTGTGCCCCCTGC ACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCTGGAGCACGCAGACCTGGGTGCTGGCTA CTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGGCCCGGTGGCAGTGAGCCTGCGGCGGGA GGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCAGCTCCGGACACTCCGTGGCACCATCTC GGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGTGGCGCCGCAGCTGAGCCCCAGCTGCCT GCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGCTGAGCTTCCAACGCAAGGTGGGCATCCT GTACTGCCGGGCGGGCCAGGGCTCGGAGGAGGAGATGTACAACAACCAGGAGGCGGGACCGGCCTTCATGCAGTTTCTCACCTTGCTGGG CGATGTGGTGCGGCTCAAAGGCTTTGAGAGTTACCGGGCCCAGCTAGACACCAAAAGCAAGGGGATCAGGCGAGTGAAGCCGAAGCGCAC CACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGGAGCTACACCGTGGTGCAGCCCGGCGACAGCCTGGAGCAGGGCTGAGGACG CTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCCGGCACTGTCCTCCTGAGGGGCAGGCGCCGGCTGCAACAGTCTCATGGGTC ACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCACGGAGAAGTGACTTTTGGGCCCGGGGCCATGCCCGGGCTGTGCAAAGCTG GCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCCCTTCCCCCGGATGCTGGGCCCTGCTGCTCTCTCAGGACCATCCGATCAAG CTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCCCACCTCAAGATGGGCAGTGTCCCTGTTCTGAAGTGCCCAGTGGCAGCTCC AGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGCTCCAGTGTGTGCCTTTGGCCTCTTCCCTGGACTTGGGTGACCAGTCTCCG TCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGACCAGTTTCCCACCTTCCTCCTGCTGGTGCTCCATCCCCCAATACCAGGCT GGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGATTGAACCGGGACAGAAACACGGTGAGGGCCCCCACCACACCTCCCTGGTT GAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGGGTCCTGTGCCCCTCGTTCTGGTCTCCTTTGCAGGCACGAGATACCAGAAA GAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTGGGAGGTGGCTATCCTGTGGACCACCTGGCCTCCAGACCCACACTCACAGT CTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGAGCCCAAGCAGCTCCCCTAGGGGACTGACCGGACCTGACCTCCCCTCCCTG TGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCTGAGTTGTGCTGGGGCAACGCCAGGAAGTGCCCTGGGTACCTCTGCTGTGC GCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTGGCGCATGCCCAGGAAAGCCTGGGCCACACGGGACACTCTCTTCTTTATCG AGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTCTCTGGTCCCAGCTTGCCCTCCGGGGAGCAGGGGCTCTGTCTTGTCCCAGA TGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTGGGACCCTCCGAGGTGGGTGTGCGGGTCTCACAGGTGCTTCCTGGGACTTC CTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGTGGAAAACCGTGGGAGAGGAAGCTTGGGCCTCTACTCCAAGTATCAGAGCC TGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAGGTGTTTCGAGGTAGGCTTGCCTTCTGGCAGCATGGACTTTGTTAAAATAA TAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTTTGGAATGTCCTGGTCACAGGGTCATGTCAGCTGCCAGTTCTCGTCTCCCG TCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCTGTTCTGGCGGCTCCAGCGCAGGCTGTCCCTGCTGCTTTGATTCCAGGTGA TTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGTCTTGCTCTGTTGCCCAGGCAGGAGTGCAGTGGCGCATCTCGGCTCACTGC AACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGAGTAGCTGGGATTACAGGTGCATGCCACCAGGCCCCGCTGATTTTTGTATT TTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGTCGTGAACTCCTGACCTCATGATCTGCCCGCCTCAACCTCCCAAAGTGCTG GGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGGCGAATTCTTCTCTGATGGGCGGGCGAGGGTGTGTTCGTGTGATGGGTTGG AGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTTCAGCTTCTTACGTTTTCTGAGCATCCATTGTGCCTTAACATTTTCTGCTT GTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAATGTTCTCATTCTTTTGTATCATGTGACTTATTAAAATCAGTTTCTAACAAA >81933_81933_7_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000527525_FRMD8_chr11_65178713_ENST00000317568_length(amino acids)=425AA_BP=387 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVLSFQRKVGILYCRAGQGSEEEMYNNQEAGPAF -------------------------------------------------------------- >81933_81933_8_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000534313_FRMD8_chr11_65178713_ENST00000317568_length(transcript)=3620nt_BP=1336nt AGGCGGAGCCGGCGCCGGGAGCGGTAGCGGGAGAGCGGCAGCGGGACCCCAGCGCGGGCGGCGGCGGCTGGGCGGGAGCCCCAGAGGGCA GGAACTGCTGCCACAACCTCAGGCTGGGCACCAAACACCCGTGCCCGCCAATGCGGCCCAGCCCCCGGAGAGTCAGGCCCACAGAGCATG CCCATGTGGGCCGGCGGTGTGGGGAGCCCTCGGCGGGGCATGGCCCCTGCGTCCACAGATGACCTCTTTGCCCGCAAGCTGCGCCAGCCA GCAAGGCCCCCGCTGACACCGCACACCTTCGAGCCGAGGCCAGTCCGGGGCCCACTCCTGCGCAGCGGCAGCGATGCAGGCGAGGCCAGG CCCCCCACGCCAGCCAGCCCCCGTGCCCGTGCCCACAGCCACGAAGAGGCCAGCCGACCTGCAGCCACTTCCACCCGGCTCTTCACTGAC CCGCTGGCACTGCTGGGGCTGCCAGCAGAGGAACCAGAGCCTGCCTTCCCACCAGTGCTTGAGCCTCGATGGTTTGCCCACTATGACGTG CAAAGCCTGCTCTTTGATTGGGCTCCGAGGTCTCAGGGGATGGGGAGCCACTCAGAGGCCAGCTCTGGGACCCTGGCTTCAGCCGAGGAC CAGGCTGCCAGCTCGGACCTGCTGCATGGGGCACCTGGCTTTGTGTGTGAGCTCGGGGGTGAGGGTGAGCTAGGCCTGGGTGGACCAGCA TCCCCACCTGTGCCCCCTGCACTGCCCAACGCGGCCGTGTCCATCCTGGAGGAGCCACAGAACCGAACCTCGGCCTACAGCCTGGAGCAC GCAGACCTGGGTGCTGGCTACTACCGCAAATACTTCTATGGCAAAGAACATCAGAACTTCTTCGGGATGGACGAGTCGCTGGGCCCGGTG GCAGTGAGCCTGCGGCGGGAGGAGAAGGAGGGCAGCGGAGGGGGCACCCTGCACAGCTACCGCGTCATCGTGCGGACCACGCAGCTCCGG ACACTCCGTGGCACCATCTCGGAGGACGCGCTGCCGCCGGGGCCCCCACGGGGTCTGTCCCCAAGGAAACTTCTGGAGCACGTGGCGCCG CAGCTGAGCCCCAGCTGCCTGCGCCTGGGCTCAGCTTCACCCAAGGTACCACGGACGCTGCTCACACTGGATGAGCAAGTGCTGAGCTTC CAACGCAAGGTGGGCATCCTGTACTGCCGGGCGGGCCAGGGCTCGGAGGAGGAGATGTACAACAACCAGGAGGCGGGACCGGCCTTCATG CAGTTTCTCACCTTGCTGGGCGATGTGGTGCGGCTCAAAGGCTTTGAGAGTTACCGGGCCCAGCTAGACACCAAAAGCAAGGGGATCAGG CGAGTGAAGCCGAAGCGCACCACATCCTTCTTCAGCCGGCAGCTGTCCTTGGGCCAGGGGAGCTACACCGTGGTGCAGCCCGGCGACAGC CTGGAGCAGGGCTGAGGACGCTGCACCCGGCAGGAGGAGGGCGACTGGGGGCCCTGGCCCGGCACTGTCCTCCTGAGGGGCAGGCGCCGG CTGCAACAGTCTCATGGGTCACCACGTGGGGAGGGCTGCCTCAGCAGGTTTCTCAGACCACGGAGAAGTGACTTTTGGGCCCGGGGCCAT GCCCGGGCTGTGCAAAGCTGGCCAGGGCCTCCTGTAGGGCTCCTCTGCAGCCTGCCCTCCCTTCCCCCGGATGCTGGGCCCTGCTGCTCT CTCAGGACCATCCGATCAAGCTGCAGCTGCCACCCTCACCTAGAAACATGCCTTTGTGCCCACCTCAAGATGGGCAGTGTCCCTGTTCTG AAGTGCCCAGTGGCAGCTCCAGTGGTAGAGGACCAAGGATTGAGGTTTGGGACCTGAAGCTCCAGTGTGTGCCTTTGGCCTCTTCCCTGG ACTTGGGTGACCAGTCTCCGTCTTCCTCCTGCTAGTGCTCCACCCCCCGGACTTGGATGACCAGTTTCCCACCTTCCTCCTGCTGGTGCT CCATCCCCCAATACCAGGCTGGGCCACCACTCTGAGGAGGGTAGGAGGGGCCTCCCTGGATTGAACCGGGACAGAAACACGGTGAGGGCC CCCACCACACCTCCCTGGTTGAATCAGGAATGGAGGGAGCCAGGCAGGGCCCTACCTGGGGTCCTGTGCCCCTCGTTCTGGTCTCCTTTG CAGGCACGAGATACCAGAAAGAGCATGCCTTTCTGATAGCCTTTGGTGATGTCACTGCTGGGAGGTGGCTATCCTGTGGACCACCTGGCC TCCAGACCCACACTCACAGTCTGTGAAAAACTGAAAATCCCCTGGTGGGCACTCCCTGGAGCCCAAGCAGCTCCCCTAGGGGACTGACCG GACCTGACCTCCCCTCCCTGTGTCTGGGTCTTCAGGTTTTAGTTTGGTCTTTGTTCATCTGAGTTGTGCTGGGGCAACGCCAGGAAGTGC CCTGGGTACCTCTGCTGTGCGCTCCTTCCCAGGTGGCGCCATGGATTCCTCTGGGGGCTGGCGCATGCCCAGGAAAGCCTGGGCCACACG GGACACTCTCTTCTTTATCGAGGACACTTGGAAAGGTGACTGATATGGGTGCTTGGCTTCTCTGGTCCCAGCTTGCCCTCCGGGGAGCAG GGGCTCTGTCTTGTCCCAGATGAGCTGAGAGCCCCTGAGAGGAGGGCTTTCCCAGCCCTGGGACCCTCCGAGGTGGGTGTGCGGGTCTCA CAGGTGCTTCCTGGGACTTCCTGTGGCTGCACAGGGCTTGGCTTTGTCTTCGTTCCCGGTGGAAAACCGTGGGAGAGGAAGCTTGGGCCT CTACTCCAAGTATCAGAGCCTGTTCACCCTCCTCCCTTTGGTAGCTTGTGAATGTGCCAGGTGTTTCGAGGTAGGCTTGCCTTCTGGCAG CATGGACTTTGTTAAAATAATAGGCGGAAAGAAGAGGCCTGGGAAGGGCCCCCAGTCTTTTGGAATGTCCTGGTCACAGGGTCATGTCAG CTGCCAGTTCTCGTCTCCCGTCCTGGAGTTGCTCGGTCTTGCGGAGCTGCCCGCCTGCCTGTTCTGGCGGCTCCAGCGCAGGCTGTCCCT GCTGCTTTGATTCCAGGTGATTTTATTTTTTTTATTTTTTTATTTTTTTTGAGACGGAGTCTTGCTCTGTTGCCCAGGCAGGAGTGCAGT GGCGCATCTCGGCTCACTGCAACCTCTGTCTCAAGCGATTCTCCTGCCTCAGCCTCCTGAGTAGCTGGGATTACAGGTGCATGCCACCAG GCCCCGCTGATTTTTGTATTTTTAGTAGAGATAGGGTTTCACCATGTTGGTCAGGCTGGTCGTGAACTCCTGACCTCATGATCTGCCCGC CTCAACCTCCCAAAGTGCTGGGATTATAGGCGTGAGCCACCGCCCCCAGCTGATTCCAGGCGAATTCTTCTCTGATGGGCGGGCGAGGGT GTGTTCGTGTGATGGGTTGGAGTGTGTGTGTCTGAGTACACAGATGATGTGTTTTCCCTTCAGCTTCTTACGTTTTCTGAGCATCCATTG TGCCTTAACATTTTCTGCTTGTCCTTTGGGACAAAGCAGTATTTTACTCATTCTTTGAATGTTCTCATTCTTTTGTATCATGTGACTTAT >81933_81933_8_SIPA1-FRMD8_SIPA1_chr11_65412600_ENST00000534313_FRMD8_chr11_65178713_ENST00000317568_length(amino acids)=425AA_BP=387 MPMWAGGVGSPRRGMAPASTDDLFARKLRQPARPPLTPHTFEPRPVRGPLLRSGSDAGEARPPTPASPRARAHSHEEASRPAATSTRLFT DPLALLGLPAEEPEPAFPPVLEPRWFAHYDVQSLLFDWAPRSQGMGSHSEASSGTLASAEDQAASSDLLHGAPGFVCELGGEGELGLGGP ASPPVPPALPNAAVSILEEPQNRTSAYSLEHADLGAGYYRKYFYGKEHQNFFGMDESLGPVAVSLRREEKEGSGGGTLHSYRVIVRTTQL RTLRGTISEDALPPGPPRGLSPRKLLEHVAPQLSPSCLRLGSASPKVPRTLLTLDEQVLSFQRKVGILYCRAGQGSEEEMYNNQEAGPAF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SIPA1-FRMD8 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SIPA1-FRMD8 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SIPA1-FRMD8 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies