
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SLC35E4-HSCB (FusionGDB2 ID:82999) |
Fusion Gene Summary for SLC35E4-HSCB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SLC35E4-HSCB | Fusion gene ID: 82999 | Hgene | Tgene | Gene symbol | SLC35E4 | HSCB | Gene ID | 339665 | 150274 |
| Gene name | solute carrier family 35 member E4 | HscB mitochondrial iron-sulfur cluster cochaperone | |
| Synonyms | - | DNAJC20|HSC20|JAC1 | |
| Cytomap | 22q12.2 | 22q12.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | solute carrier family 35 member E4 | iron-sulfur cluster co-chaperone protein HscBDnaJ (Hsp40) homolog, subfamily C, member 20HscB iron-sulfur cluster co-chaperone homologHscB mitochondrial iron-sulfur cluster co-chaperoneJ-type co-chaperone HSC20epididymis secretory sperm binding prote | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | Q8IWL3 | |
| Ensembl transtripts involved in fusion gene | ENST00000300385, ENST00000343605, ENST00000406566, | ENST00000495977, ENST00000216027, ENST00000398941, | |
| Fusion gene scores | * DoF score | 4 X 3 X 3=36 | 12 X 9 X 8=864 |
| # samples | 4 | 18 | |
| ** MAII score | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(18/864*10)=-2.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SLC35E4 [Title/Abstract] AND HSCB [Title/Abstract] AND fusion [Title/Abstract] | ||
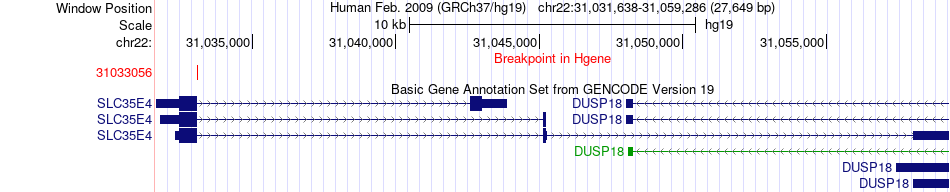
| Most frequent breakpoint | SLC35E4(31033056)-HSCB(29147229), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SLC35E4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HSCB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-EW-A423-01A | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
Top |
Fusion Gene ORF analysis for SLC35E4-HSCB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000300385 | ENST00000495977 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| 5CDS-3UTR | ENST00000343605 | ENST00000495977 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| 5CDS-3UTR | ENST00000406566 | ENST00000495977 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000300385 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000300385 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000343605 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000343605 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000406566 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| In-frame | ENST00000406566 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000343605 | SLC35E4 | chr22 | 31033056 | + | ENST00000216027 | HSCB | chr22 | 29147229 | + | 1899 | 1418 | 739 | 1557 | 272 |
| ENST00000343605 | SLC35E4 | chr22 | 31033056 | + | ENST00000398941 | HSCB | chr22 | 29147229 | + | 1904 | 1418 | 739 | 1557 | 272 |
| ENST00000300385 | SLC35E4 | chr22 | 31033056 | + | ENST00000216027 | HSCB | chr22 | 29147229 | + | 1745 | 1264 | 585 | 1403 | 272 |
| ENST00000300385 | SLC35E4 | chr22 | 31033056 | + | ENST00000398941 | HSCB | chr22 | 29147229 | + | 1750 | 1264 | 585 | 1403 | 272 |
| ENST00000406566 | SLC35E4 | chr22 | 31033056 | + | ENST00000216027 | HSCB | chr22 | 29147229 | + | 1228 | 747 | 68 | 886 | 272 |
| ENST00000406566 | SLC35E4 | chr22 | 31033056 | + | ENST00000398941 | HSCB | chr22 | 29147229 | + | 1233 | 747 | 68 | 886 | 272 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000343605 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.40302888 | 0.5969711 |
| ENST00000343605 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.40767306 | 0.59232694 |
| ENST00000300385 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.3879244 | 0.6120756 |
| ENST00000300385 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.39399534 | 0.6060046 |
| ENST00000406566 | ENST00000216027 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.33268654 | 0.66731346 |
| ENST00000406566 | ENST00000398941 | SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147229 | + | 0.33687365 | 0.66312635 |
Top |
Fusion Genomic Features for SLC35E4-HSCB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147228 | + | 2.49E-05 | 0.9999751 |
| SLC35E4 | chr22 | 31033056 | + | HSCB | chr22 | 29147228 | + | 2.49E-05 | 0.9999751 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for SLC35E4-HSCB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:31033056/chr22:29147229) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HSCB |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Acts as a co-chaperone in iron-sulfur cluster assembly in both mitochondria and the cytoplasm (PubMed:20668094, PubMed:29309586). Required for incorporation of iron-sulfur clusters into SDHB, the iron-sulfur protein subunit of succinate dehydrogenase that is involved in complex II of the mitochondrial electron transport chain (PubMed:26749241). Recruited to SDHB by interaction with SDHAF1 which first binds SDHB and then recruits the iron-sulfur transfer complex formed by HSC20, HSPA9 and ISCU through direct binding to HSC20 (PubMed:26749241). Also mediates complex formation between components of the cytosolic iron-sulfur biogenesis pathway and the CIA targeting complex composed of CIAO1, DIPK1B/FAM69B and MMS19 by binding directly to the scaffold protein ISCU and to CIAO1 (PubMed:29309586). This facilitates iron-sulfur cluster insertion into a number of cytoplasmic and nuclear proteins including POLD1, ELP3, DPYD and PPAT (PubMed:29309586). {ECO:0000269|PubMed:20668094, ECO:0000269|PubMed:26749241, ECO:0000269|PubMed:29309586}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 125_179 | 206 | 235.0 | Domain | Note=EamA |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 125_179 | 206 | 351.0 | Domain | Note=EamA |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 125_179 | 206 | 399.3333333333333 | Domain | Note=EamA |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 110_132 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 135_155 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 51_71 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 73_93 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 110_132 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 135_155 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 51_71 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 73_93 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 110_132 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 135_155 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 51_71 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 73_93 | 206 | 399.3333333333333 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 111_319 | 206 | 235.0 | Compositional bias | Note=Leu-rich |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 111_319 | 206 | 351.0 | Compositional bias | Note=Leu-rich |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 111_319 | 206 | 399.3333333333333 | Compositional bias | Note=Leu-rich |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 218_238 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 258_278 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 279_299 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000300385 | + | 1 | 2 | 312_332 | 206 | 235.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 218_238 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 258_278 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 279_299 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000343605 | + | 1 | 2 | 312_332 | 206 | 351.0 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 218_238 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 258_278 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 279_299 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Hgene | SLC35E4 | chr22:31033056 | chr22:29147229 | ENST00000406566 | + | 1 | 3 | 312_332 | 206 | 399.3333333333333 | Transmembrane | Helical |
| Tgene | HSCB | chr22:31033056 | chr22:29147229 | ENST00000216027 | 3 | 6 | 72_144 | 189 | 236.0 | Domain | Note=J |
Top |
Fusion Gene Sequence for SLC35E4-HSCB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >82999_82999_1_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000300385_HSCB_chr22_29147229_ENST00000216027_length(transcript)=1745nt_BP=1264nt GGAGTCACAGCCGCAGCCAGAGCCGCAGCCAAAGCCTCAGAGAGCAGGAGTTGGAGCGCAGGCCCTGCTGGATCCGCGCCTAGCTCGCCG CCAGGCACCGGCCGGAGGACGGGCCGTGGTGTCAGCTCACTGCCCGGGCGCTGTGGGAGGCAGCGAGCCCGCGACCCCCCGGGCCGGGCA CCGCCAGGCGCGGAGCCCAGATCGCCCCCCTGCCAGGCCTGGTCACGGCCAGAGCACGCAGGAGTTCCCAGGGTCTGGATCTGCGCGCAC CCTAATGACCTGGGGACTGAAGAGAAAAAAGGAACGAGGATTTCATCTAAAAGCATAACGTGGGCACTAGGCGAGGAGGAAAGTGGAGAC CACCTGGCACGGGGCAGAGGTGCCTGGAGCCCACGCTTGAGCATCGGAGACCCTGGCATCCTAGCAGCCGCGACCTTGGCTCTGCCCTGT CTGAGCTGGAAACACAGCTTAGCTTCTAGACATCGCTGGCACAGGCCTGGCACAAGTAAGCAGTGTCCTCACCTGTCTGAAACGGGACAC GGGGTCGGAGGAACCAGGATCTAGCCTGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCACTGGGGAGCCCGCCTCCTGCCCTA GCCTCACTGGTGCGGATGTGCCGCTGCCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAGTAGGAGCAGCAGCTGGTGGTGCT CAGGCGGCTGGGCCCCCCGAGTGGCCCCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCCGAGTGGCCATGGCAGCACTGGTG TGGCTGCTGGCGGGAGCCAGCATGTCAAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGCGGCCCCTGCTGCTGTCGGCCCTG CACATGCTGGTGGCAGCCCTGGCATGCCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCTGCCGAGTCCTACTGCTCAGTCTC ACCTTTGGCACGTCCATGGCCTGCGGCAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAACTGGTTACTACCACCACACCTCTG TTCACCCTGGCCCTGTCGGCGCTGCTGCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGGGTCCGCTCTGCCTGGGGGCCGCC TGCAGCCTGGCTGGAGAGTTCCGGACACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCCTCCGCGGACTCAAGTCGGTTCAG CAAACTAAACAGAAAGAATTTACTGACAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAGCCAAGGAAATTTTGACAAAGATG AGATACTTTTCAAATATAGAAGAAAAGATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTTAAAGTTTAAAAAATAAAGTTCTT GCTGGGCACAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGGTCAGGAGTTCAAGACCAGCTTGG CCAACATAGTGAAACCCCGTCTCTGCTGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTGTAATCCCAGCTACTTGGTAGGCC GAGGCAGGAGAATCGCTTAAACCCGTGAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACTCCAGCTTGGGCAACAGAGTGAGA >82999_82999_1_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000300385_HSCB_chr22_29147229_ENST00000216027_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- >82999_82999_2_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000300385_HSCB_chr22_29147229_ENST00000398941_length(transcript)=1750nt_BP=1264nt GGAGTCACAGCCGCAGCCAGAGCCGCAGCCAAAGCCTCAGAGAGCAGGAGTTGGAGCGCAGGCCCTGCTGGATCCGCGCCTAGCTCGCCG CCAGGCACCGGCCGGAGGACGGGCCGTGGTGTCAGCTCACTGCCCGGGCGCTGTGGGAGGCAGCGAGCCCGCGACCCCCCGGGCCGGGCA CCGCCAGGCGCGGAGCCCAGATCGCCCCCCTGCCAGGCCTGGTCACGGCCAGAGCACGCAGGAGTTCCCAGGGTCTGGATCTGCGCGCAC CCTAATGACCTGGGGACTGAAGAGAAAAAAGGAACGAGGATTTCATCTAAAAGCATAACGTGGGCACTAGGCGAGGAGGAAAGTGGAGAC CACCTGGCACGGGGCAGAGGTGCCTGGAGCCCACGCTTGAGCATCGGAGACCCTGGCATCCTAGCAGCCGCGACCTTGGCTCTGCCCTGT CTGAGCTGGAAACACAGCTTAGCTTCTAGACATCGCTGGCACAGGCCTGGCACAAGTAAGCAGTGTCCTCACCTGTCTGAAACGGGACAC GGGGTCGGAGGAACCAGGATCTAGCCTGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCACTGGGGAGCCCGCCTCCTGCCCTA GCCTCACTGGTGCGGATGTGCCGCTGCCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAGTAGGAGCAGCAGCTGGTGGTGCT CAGGCGGCTGGGCCCCCCGAGTGGCCCCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCCGAGTGGCCATGGCAGCACTGGTG TGGCTGCTGGCGGGAGCCAGCATGTCAAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGCGGCCCCTGCTGCTGTCGGCCCTG CACATGCTGGTGGCAGCCCTGGCATGCCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCTGCCGAGTCCTACTGCTCAGTCTC ACCTTTGGCACGTCCATGGCCTGCGGCAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAACTGGTTACTACCACCACACCTCTG TTCACCCTGGCCCTGTCGGCGCTGCTGCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGGGTCCGCTCTGCCTGGGGGCCGCC TGCAGCCTGGCTGGAGAGTTCCGGACACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCCTCCGCGGACTCAAGTCGGTTCAG CAAACTAAACAGAAAGAATTTACTGACAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAGCCAAGGAAATTTTGACAAAGATG AGATACTTTTCAAATATAGAAGAAAAGATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTTAAAGTTTAAAAAATAAAGTTCTT GCTGGGCACAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGGTCAGGAGTTCAAGACCAGCTTGG CCAACATAGTGAAACCCCGTCTCTGCTGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTGTAATCCCAGCTACTTGGTAGGCC GAGGCAGGAGAATCGCTTAAACCCGTGAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACTCCAGCTTGGGCAACAGAGTGAGA >82999_82999_2_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000300385_HSCB_chr22_29147229_ENST00000398941_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- >82999_82999_3_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000343605_HSCB_chr22_29147229_ENST00000216027_length(transcript)=1899nt_BP=1418nt GGGCTTGGCTGGGGTGCTCAGCCCAATTTTCCGTGTAGGGAGCGGGCGGCGGCGGGGGAGGCAGAGGCGGAGGCGGAGTCAAGAGCGCAC CGCCGCGCCCGCCGTGCCGGGCCTGAGCTGGAGCCGGGCGTGAGTCGCAGCAGGAGCCGCAGCCGGAGTCACAGCCGCAGCCAGAGCCGC AGCCAAAGCCTCAGAGAGCAGGAGTTGGAGCGCAGGCCCTGCTGGATCCGCGCCTAGCTCGCCGCCAGGCACCGGCCGGAGGACGGGCCG TGGTGTCAGCTCACTGCCCGGGCGCTGTGGGAGGCAGCGAGCCCGCGACCCCCCGGGCCGGGCACCGCCAGGCGCGGAGCCCAGATCGCC CCCCTGCCAGGCCTGGTCACGGCCAGAGCACGCAGGAGTTCCCAGGGTCTGGATCTGCGCGCACCCTAATGACCTGGGGACTGAAGAGAA AAAAGGAACGAGGATTTCATCTAAAAGCATAACGTGGGCACTAGGCGAGGAGGAAAGTGGAGACCACCTGGCACGGGGCAGAGGTGCCTG GAGCCCACGCTTGAGCATCGGAGACCCTGGCATCCTAGCAGCCGCGACCTTGGCTCTGCCCTGTCTGAGCTGGAAACACAGCTTAGCTTC TAGACATCGCTGGCACAGGCCTGGCACAAGTAAGCAGTGTCCTCACCTGTCTGAAACGGGACACGGGGTCGGAGGAACCAGGATCTAGCC TGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCACTGGGGAGCCCGCCTCCTGCCCTAGCCTCACTGGTGCGGATGTGCCGCTG CCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAGTAGGAGCAGCAGCTGGTGGTGCTCAGGCGGCTGGGCCCCCCGAGTGGCC CCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCCGAGTGGCCATGGCAGCACTGGTGTGGCTGCTGGCGGGAGCCAGCATGTC AAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGCGGCCCCTGCTGCTGTCGGCCCTGCACATGCTGGTGGCAGCCCTGGCATG CCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCTGCCGAGTCCTACTGCTCAGTCTCACCTTTGGCACGTCCATGGCCTGCGG CAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAACTGGTTACTACCACCACACCTCTGTTCACCCTGGCCCTGTCGGCGCTGCT GCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGGGTCCGCTCTGCCTGGGGGCCGCCTGCAGCCTGGCTGGAGAGTTCCGGAC ACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCCTCCGCGGACTCAAGTCGGTTCAGCAAACTAAACAGAAAGAATTTACTGA CAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAGCCAAGGAAATTTTGACAAAGATGAGATACTTTTCAAATATAGAAGAAAA GATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTTAAAGTTTAAAAAATAAAGTTCTTGCTGGGCACAGTGGCTCACACCTGTA ATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGGTCAGGAGTTCAAGACCAGCTTGGCCAACATAGTGAAACCCCGTCTCTGC TGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTGTAATCCCAGCTACTTGGTAGGCCGAGGCAGGAGAATCGCTTAAACCCGT GAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACTCCAGCTTGGGCAACAGAGTGAGACTTAATCTTGAAAAATAAATAAATGA >82999_82999_3_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000343605_HSCB_chr22_29147229_ENST00000216027_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- >82999_82999_4_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000343605_HSCB_chr22_29147229_ENST00000398941_length(transcript)=1904nt_BP=1418nt GGGCTTGGCTGGGGTGCTCAGCCCAATTTTCCGTGTAGGGAGCGGGCGGCGGCGGGGGAGGCAGAGGCGGAGGCGGAGTCAAGAGCGCAC CGCCGCGCCCGCCGTGCCGGGCCTGAGCTGGAGCCGGGCGTGAGTCGCAGCAGGAGCCGCAGCCGGAGTCACAGCCGCAGCCAGAGCCGC AGCCAAAGCCTCAGAGAGCAGGAGTTGGAGCGCAGGCCCTGCTGGATCCGCGCCTAGCTCGCCGCCAGGCACCGGCCGGAGGACGGGCCG TGGTGTCAGCTCACTGCCCGGGCGCTGTGGGAGGCAGCGAGCCCGCGACCCCCCGGGCCGGGCACCGCCAGGCGCGGAGCCCAGATCGCC CCCCTGCCAGGCCTGGTCACGGCCAGAGCACGCAGGAGTTCCCAGGGTCTGGATCTGCGCGCACCCTAATGACCTGGGGACTGAAGAGAA AAAAGGAACGAGGATTTCATCTAAAAGCATAACGTGGGCACTAGGCGAGGAGGAAAGTGGAGACCACCTGGCACGGGGCAGAGGTGCCTG GAGCCCACGCTTGAGCATCGGAGACCCTGGCATCCTAGCAGCCGCGACCTTGGCTCTGCCCTGTCTGAGCTGGAAACACAGCTTAGCTTC TAGACATCGCTGGCACAGGCCTGGCACAAGTAAGCAGTGTCCTCACCTGTCTGAAACGGGACACGGGGTCGGAGGAACCAGGATCTAGCC TGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCACTGGGGAGCCCGCCTCCTGCCCTAGCCTCACTGGTGCGGATGTGCCGCTG CCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAGTAGGAGCAGCAGCTGGTGGTGCTCAGGCGGCTGGGCCCCCCGAGTGGCC CCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCCGAGTGGCCATGGCAGCACTGGTGTGGCTGCTGGCGGGAGCCAGCATGTC AAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGCGGCCCCTGCTGCTGTCGGCCCTGCACATGCTGGTGGCAGCCCTGGCATG CCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCTGCCGAGTCCTACTGCTCAGTCTCACCTTTGGCACGTCCATGGCCTGCGG CAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAACTGGTTACTACCACCACACCTCTGTTCACCCTGGCCCTGTCGGCGCTGCT GCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGGGTCCGCTCTGCCTGGGGGCCGCCTGCAGCCTGGCTGGAGAGTTCCGGAC ACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCCTCCGCGGACTCAAGTCGGTTCAGCAAACTAAACAGAAAGAATTTACTGA CAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAGCCAAGGAAATTTTGACAAAGATGAGATACTTTTCAAATATAGAAGAAAA GATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTTAAAGTTTAAAAAATAAAGTTCTTGCTGGGCACAGTGGCTCACACCTGTA ATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGGTCAGGAGTTCAAGACCAGCTTGGCCAACATAGTGAAACCCCGTCTCTGC TGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTGTAATCCCAGCTACTTGGTAGGCCGAGGCAGGAGAATCGCTTAAACCCGT GAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACTCCAGCTTGGGCAACAGAGTGAGACTTAATCTTGAAAAATAAATAAATGA >82999_82999_4_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000343605_HSCB_chr22_29147229_ENST00000398941_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- >82999_82999_5_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000406566_HSCB_chr22_29147229_ENST00000216027_length(transcript)=1228nt_BP=747nt CTCACCTGTCTGAAACGGGACACGGGGTCGGAGGAACCAGGATCTAGCCTGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCAC TGGGGAGCCCGCCTCCTGCCCTAGCCTCACTGGTGCGGATGTGCCGCTGCCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAG TAGGAGCAGCAGCTGGTGGTGCTCAGGCGGCTGGGCCCCCCGAGTGGCCCCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCC GAGTGGCCATGGCAGCACTGGTGTGGCTGCTGGCGGGAGCCAGCATGTCAAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGC GGCCCCTGCTGCTGTCGGCCCTGCACATGCTGGTGGCAGCCCTGGCATGCCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCT GCCGAGTCCTACTGCTCAGTCTCACCTTTGGCACGTCCATGGCCTGCGGCAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAAC TGGTTACTACCACCACACCTCTGTTCACCCTGGCCCTGTCGGCGCTGCTGCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGG GTCCGCTCTGCCTGGGGGCCGCCTGCAGCCTGGCTGGAGAGTTCCGGACACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCC TCCGCGGACTCAAGTCGGTTCAGCAAACTAAACAGAAAGAATTTACTGACAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAG CCAAGGAAATTTTGACAAAGATGAGATACTTTTCAAATATAGAAGAAAAGATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTT AAAGTTTAAAAAATAAAGTTCTTGCTGGGCACAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGG TCAGGAGTTCAAGACCAGCTTGGCCAACATAGTGAAACCCCGTCTCTGCTGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTG TAATCCCAGCTACTTGGTAGGCCGAGGCAGGAGAATCGCTTAAACCCGTGAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACT >82999_82999_5_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000406566_HSCB_chr22_29147229_ENST00000216027_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- >82999_82999_6_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000406566_HSCB_chr22_29147229_ENST00000398941_length(transcript)=1233nt_BP=747nt CTCACCTGTCTGAAACGGGACACGGGGTCGGAGGAACCAGGATCTAGCCTGGCCCCAAGCGGAACTCTCTGGTGGCCCAGAGGTCGTCAC TGGGGAGCCCGCCTCCTGCCCTAGCCTCACTGGTGCGGATGTGCCGCTGCCCGCCGGAGCACCATGATGGCAGGATGACCTCAGCCGAAG TAGGAGCAGCAGCTGGTGGTGCTCAGGCGGCTGGGCCCCCCGAGTGGCCCCCTGGCAGCCCTCAGGCCCTCCGGCAGCCTGGCCGGGCCC GAGTGGCCATGGCAGCACTGGTGTGGCTGCTGGCGGGAGCCAGCATGTCAAGCCTCAACAAGTGGATCTTCACAGTGCACGGCTTTGGGC GGCCCCTGCTGCTGTCGGCCCTGCACATGCTGGTGGCAGCCCTGGCATGCCACCGGGGGGCACGGCGCCCCATGCCAGGCGGCACTCGCT GCCGAGTCCTACTGCTCAGTCTCACCTTTGGCACGTCCATGGCCTGCGGCAACGTGGGCCTAAGGGCTGTGCCCCTGGACCTGGCACAAC TGGTTACTACCACCACACCTCTGTTCACCCTGGCCCTGTCGGCGCTGCTGCTGGGCCGCCGCCACCACCCACTTCAGTTGGCCGCCATGG GTCCGCTCTGCCTGGGGGCCGCCTGCAGCCTGGCTGGAGAGTTCCGGACACCCCCTACCGGCTGTGGCTTCCTGCTCGCAGCCACCTGCC TCCGCGGACTCAAGTCGGTTCAGCAAACTAAACAGAAAGAATTTACTGACAATGTGAGCAGTGCTTTTGAACAAGATGACTTTGAAGAAG CCAAGGAAATTTTGACAAAGATGAGATACTTTTCAAATATAGAAGAAAAGATCAAGTTAAAGAAGATTCCCCTTTAATTGTGGATAGTTT AAAGTTTAAAAAATAAAGTTCTTGCTGGGCACAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCTGAGGTGGGTGGATGACAAGG TCAGGAGTTCAAGACCAGCTTGGCCAACATAGTGAAACCCCGTCTCTGCTGAAAATACAAAAATTAGCCGGGCATGGTGGCGCGTGCCTG TAATCCCAGCTACTTGGTAGGCCGAGGCAGGAGAATCGCTTAAACCCGTGAGGTGGAGGTTGCAGTGAGCAGAGATCACGCAACTGCACT >82999_82999_6_SLC35E4-HSCB_SLC35E4_chr22_31033056_ENST00000406566_HSCB_chr22_29147229_ENST00000398941_length(amino acids)=272AA_BP=227 MVAQRSSLGSPPPALASLVRMCRCPPEHHDGRMTSAEVGAAAGGAQAAGPPEWPPGSPQALRQPGRARVAMAALVWLLAGASMSSLNKWI FTVHGFGRPLLLSALHMLVAALACHRGARRPMPGGTRCRVLLLSLTFGTSMACGNVGLRAVPLDLAQLVTTTTPLFTLALSALLLGRRHH PLQLAAMGPLCLGAACSLAGEFRTPPTGCGFLLAATCLRGLKSVQQTKQKEFTDNVSSAFEQDDFEEAKEILTKMRYFSNIEEKIKLKKI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SLC35E4-HSCB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SLC35E4-HSCB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SLC35E4-HSCB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies