
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SLC36A1-IFNGR1 (FusionGDB2 ID:83042) |
Fusion Gene Summary for SLC36A1-IFNGR1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SLC36A1-IFNGR1 | Fusion gene ID: 83042 | Hgene | Tgene | Gene symbol | SLC36A1 | IFNGR1 | Gene ID | 206358 | 3459 |
| Gene name | solute carrier family 36 member 1 | interferon gamma receptor 1 | |
| Synonyms | Dct1|LYAAT1|PAT1|TRAMD3 | CD119|IFNGR|IMD27A|IMD27B | |
| Cytomap | 5q33.1 | 6q23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | proton-coupled amino acid transporter 1lysosomal amino acid transporter 1proton/amino acid transporter 1solute carrier family 36 (proton/amino acid symporter), member 1 | interferon gamma receptor 1AVP, type 2CD119 antigenCDw119IFN-gamma receptor 1IFN-gamma-R-alphaIFN-gamma-R1antiviral protein, type 2immune interferon receptor 1interferon-gamma receptor alpha chain | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | P15260 | |
| Ensembl transtripts involved in fusion gene | ENST00000243389, ENST00000520701, ENST00000521925, ENST00000429484, ENST00000521351, | ENST00000478333, ENST00000367735, ENST00000367739, ENST00000543628, | |
| Fusion gene scores | * DoF score | 5 X 4 X 5=100 | 7 X 5 X 4=140 |
| # samples | 5 | 9 | |
| ** MAII score | log2(5/100*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/140*10)=-0.637429920615292 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SLC36A1 [Title/Abstract] AND IFNGR1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SLC36A1(150859050)-IFNGR1(137528214), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SLC36A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across IFNGR1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315488 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
Top |
Fusion Gene ORF analysis for SLC36A1-IFNGR1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000243389 | ENST00000478333 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| 5CDS-5UTR | ENST00000520701 | ENST00000478333 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| 5CDS-5UTR | ENST00000521925 | ENST00000478333 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000243389 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000243389 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000243389 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000520701 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000520701 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000520701 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000521925 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000521925 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| In-frame | ENST00000521925 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000429484 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000429484 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000429484 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000521351 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000521351 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-3CDS | ENST00000521351 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-5UTR | ENST00000429484 | ENST00000478333 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| intron-5UTR | ENST00000521351 | ENST00000478333 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000520701 | SLC36A1 | chr5 | 150859050 | + | ENST00000367739 | IFNGR1 | chr6 | 137528214 | - | 3229 | 1297 | 129 | 2681 | 850 |
| ENST00000520701 | SLC36A1 | chr5 | 150859050 | + | ENST00000543628 | IFNGR1 | chr6 | 137528214 | - | 2881 | 1297 | 129 | 2681 | 850 |
| ENST00000520701 | SLC36A1 | chr5 | 150859050 | + | ENST00000367735 | IFNGR1 | chr6 | 137528214 | - | 1942 | 1297 | 129 | 1802 | 557 |
| ENST00000243389 | SLC36A1 | chr5 | 150859050 | + | ENST00000367739 | IFNGR1 | chr6 | 137528214 | - | 3314 | 1382 | 145 | 2766 | 873 |
| ENST00000243389 | SLC36A1 | chr5 | 150859050 | + | ENST00000543628 | IFNGR1 | chr6 | 137528214 | - | 2966 | 1382 | 145 | 2766 | 873 |
| ENST00000243389 | SLC36A1 | chr5 | 150859050 | + | ENST00000367735 | IFNGR1 | chr6 | 137528214 | - | 2027 | 1382 | 145 | 1887 | 580 |
| ENST00000521925 | SLC36A1 | chr5 | 150859050 | + | ENST00000367739 | IFNGR1 | chr6 | 137528214 | - | 3383 | 1451 | 1417 | 2835 | 472 |
| ENST00000521925 | SLC36A1 | chr5 | 150859050 | + | ENST00000543628 | IFNGR1 | chr6 | 137528214 | - | 3035 | 1451 | 1417 | 2835 | 472 |
| ENST00000521925 | SLC36A1 | chr5 | 150859050 | + | ENST00000367735 | IFNGR1 | chr6 | 137528214 | - | 2096 | 1451 | 114 | 1184 | 356 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000520701 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000574244 | 0.99942577 |
| ENST00000520701 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000742997 | 0.999257 |
| ENST00000520701 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.003363577 | 0.9966364 |
| ENST00000243389 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000663212 | 0.9993368 |
| ENST00000243389 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000855831 | 0.9991442 |
| ENST00000243389 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.00457682 | 0.99542314 |
| ENST00000521925 | ENST00000367739 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000331263 | 0.9996687 |
| ENST00000521925 | ENST00000543628 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.000437787 | 0.9995622 |
| ENST00000521925 | ENST00000367735 | SLC36A1 | chr5 | 150859050 | + | IFNGR1 | chr6 | 137528214 | - | 0.007315898 | 0.9926842 |
Top |
Fusion Genomic Features for SLC36A1-IFNGR1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
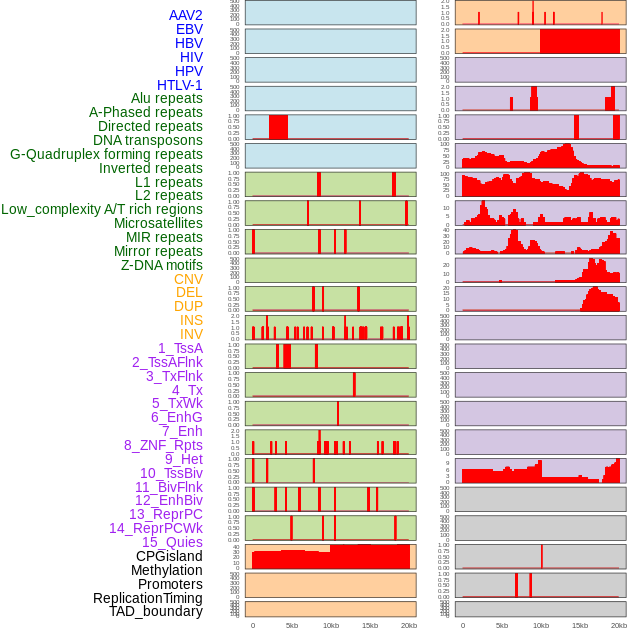 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SLC36A1-IFNGR1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:150859050/chr6:137528214) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | IFNGR1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Associates with IFNGR2 to form a receptor for the cytokine interferon gamma (IFNG) (PubMed:7615558, PubMed:2971451, PubMed:7617032, PubMed:10986460). Ligand binding stimulates activation of the JAK/STAT signaling pathway (PubMed:7673114). Plays an essential role in the IFN-gamma pathway that is required for the cellular response to infectious agents (PubMed:20015550). {ECO:0000269|PubMed:10986460, ECO:0000269|PubMed:20015550, ECO:0000269|PubMed:2971451, ECO:0000269|PubMed:7615558, ECO:0000269|PubMed:7617032, ECO:0000269|PubMed:7673114}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 100_141 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 163_190 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 1_51 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 212_215 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 237_257 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 279_289 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 311_342 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 364_372 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 73_78 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 100_141 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 163_190 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 1_51 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 212_215 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 237_257 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 279_289 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 311_342 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 364_372 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 73_78 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 142_162 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 191_211 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 216_236 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 258_278 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 290_310 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 343_363 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D8 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 52_72 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 79_99 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 142_162 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 191_211 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 216_236 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 258_278 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 290_310 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 343_363 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D8 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 52_72 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 79_99 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D2 |
| Tgene | IFNGR1 | chr5:150859050 | chr6:137528214 | ENST00000367739 | 0 | 7 | 267_489 | 28 | 490.0 | Topological domain | Cytoplasmic | |
| Tgene | IFNGR1 | chr5:150859050 | chr6:137528214 | ENST00000367739 | 0 | 7 | 246_266 | 28 | 490.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 394_397 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 419_439 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 461_476 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 100_141 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 163_190 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 1_51 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 212_215 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 237_257 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 279_289 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 311_342 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 364_372 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 394_397 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 419_439 | 0 | 255.66666666666666 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 461_476 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 73_78 | 0 | 255.66666666666666 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 394_397 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 419_439 | 386 | 477.0 | Topological domain | Cytoplasmic |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 461_476 | 386 | 477.0 | Topological domain | Extracellular |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 373_393 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D9 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 398_418 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D10 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000243389 | + | 10 | 11 | 440_460 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D11 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 142_162 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 191_211 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 216_236 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 258_278 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 290_310 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 343_363 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D8 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 373_393 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D9 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 398_418 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D10 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 440_460 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D11 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 52_72 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000429484 | + | 1 | 9 | 79_99 | 0 | 255.66666666666666 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 373_393 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D9 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 398_418 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D10 |
| Hgene | SLC36A1 | chr5:150859050 | chr6:137528214 | ENST00000520701 | + | 10 | 11 | 440_460 | 386 | 477.0 | Transmembrane | Helical%3B Name%3D11 |
| Tgene | IFNGR1 | chr5:150859050 | chr6:137528214 | ENST00000367739 | 0 | 7 | 18_245 | 28 | 490.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for SLC36A1-IFNGR1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >83042_83042_1_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000367735_length(transcript)=2027nt_BP=1382nt ACGTGATGAGGTCCGGAAGCGGCTGCCGGGCAGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAG CCAGAGCCGGAGCCGGAGCTGGGGCCAGAACCCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGA CCCACCTCGCCTTCCTCCCGGCGTGGCAGATGCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTC CACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAG CACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGG CATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTG CCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGC ACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTT TAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACT CTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACAT CACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAA GACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCG GAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGC TAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTTTTCAC CTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTGGACCT GTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTG GGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCAT CAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACA AAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGA GAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTA CATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATTAAAAGAAGCTGTGCATTTTCACTGTTTTCTTTTTTCATCTAGAT CCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGATTCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTA >83042_83042_1_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000367735_length(amino acids)=580AA_BP=410 MPAGGARRLGQDPPRLPPGVADAPAAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTG LLGLPLAVKNAGIVMGPISLLIIGIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGF CCVYFVFLADNFKQVIEAANGTTNNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIP DPSHLPLVAPWKTYPLFFGTAIFSFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQS VKLLYSIGIFFTYALQFYVPAEIIIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNY GVKNSEWIDACINISHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDE -------------------------------------------------------------- >83042_83042_2_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000367739_length(transcript)=3314nt_BP=1382nt ACGTGATGAGGTCCGGAAGCGGCTGCCGGGCAGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAG CCAGAGCCGGAGCCGGAGCTGGGGCCAGAACCCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGA CCCACCTCGCCTTCCTCCCGGCGTGGCAGATGCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTC CACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAG CACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGG CATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTG CCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGC ACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTT TAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACT CTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACAT CACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAA GACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCG GAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGC TAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTTTTCAC CTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTGGACCT GTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTG GGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCAT CAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACA AAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGA GAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTA CATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGAT TCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTTACAAC TGAAAAGTCAAAAGAAGTTTGTATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTACTCTT TCTAGTGCTTAGCCTGGTATTCATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCCTTGAT CTCTGTGGTAAGAAGTGCTACTTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTAGAAAA GGAGGTGGTCTGTGAAGAGCCGTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACAGAAGA ACTTTCTAGTATAACAGAAGTGGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGAGAGAG TTCTTCACCTTTAAGTAGTAACCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGATCACTC CAGAAATGGTTTTGATACTGATTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGTGAAAT AAAAACAGAAGGACAAGAGCTCATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTACTTGT GGATGATAGCGGTAAAGAGTCCTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACCAACTT TGAAGTCTGATTTTCCTGGACAGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAACCAAA TGGAGTGACTTAGTGTACATGAAAGCGTAAAGAGGATGTGTGGCATTTTCACTTTTGGCTTGTAAAGTACAGACTTTTTTTTTTTTTTAA ACAAAAAAAGCATTGTAACTTATGAACCTTTACATCCAGATAGGTTACCAGTAACGGAACAGTATCCAGTACTCCTGGTTCCTAGGTGAG CAGGTGATGCCCCAGGGACCTTTGTAGCCACTTCACTTTTTTTCTTTTCTCTGCCTTGGTATAGCATATGTTTTTGTAAGTTTATGCATA CAGTAATTTTAAGTAATTTCAGAAGAAATTCTGCAAGCTTTTCAAAATTGGACTTAAAATCTAATTCAAACTAATAGAATTAATGGAATA >83042_83042_2_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000367739_length(amino acids)=873AA_BP=410 MPAGGARRLGQDPPRLPPGVADAPAAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTG LLGLPLAVKNAGIVMGPISLLIIGIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGF CCVYFVFLADNFKQVIEAANGTTNNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIP DPSHLPLVAPWKTYPLFFGTAIFSFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQS VKLLYSIGIFFTYALQFYVPAEIIIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNY GVKNSEWIDACINISHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDE QEVDYDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGS LWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHT EDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLS -------------------------------------------------------------- >83042_83042_3_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000543628_length(transcript)=2966nt_BP=1382nt ACGTGATGAGGTCCGGAAGCGGCTGCCGGGCAGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAG CCAGAGCCGGAGCCGGAGCTGGGGCCAGAACCCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGA CCCACCTCGCCTTCCTCCCGGCGTGGCAGATGCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTC CACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAG CACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGG CATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTG CCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGC ACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTT TAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACT CTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACAT CACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAA GACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCG GAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGC TAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTTTTCAC CTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTGGACCT GTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTG GGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCAT CAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACA AAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGA GAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTA CATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGAT TCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTTACAAC TGAAAAGTCAAAAGAAGTTTGTATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTACTCTT TCTAGTGCTTAGCCTGGTATTCATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCCTTGAT CTCTGTGGTAAGAAGTGCTACTTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTAGAAAA GGAGGTGGTCTGTGAAGAGCCGTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACAGAAGA ACTTTCTAGTATAACAGAAGTGGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGAGAGAG TTCTTCACCTTTAAGTAGTAACCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGATCACTC CAGAAATGGTTTTGATACTGATTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGTGAAAT AAAAACAGAAGGACAAGAGCTCATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTACTTGT GGATGATAGCGGTAAAGAGTCCTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACCAACTT TGAAGTCTGATTTTCCTGGACAGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAACCAAA >83042_83042_3_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000243389_IFNGR1_chr6_137528214_ENST00000543628_length(amino acids)=873AA_BP=410 MPAGGARRLGQDPPRLPPGVADAPAAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTG LLGLPLAVKNAGIVMGPISLLIIGIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGF CCVYFVFLADNFKQVIEAANGTTNNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIP DPSHLPLVAPWKTYPLFFGTAIFSFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQS VKLLYSIGIFFTYALQFYVPAEIIIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNY GVKNSEWIDACINISHHYCNISDHVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDE QEVDYDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGS LWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHT EDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLS -------------------------------------------------------------- >83042_83042_4_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000367735_length(transcript)=1942nt_BP=1297nt GAGCTCTTCATCCGCCTGGGCCCAACCCTGGAACTATTCCTTTCAATGGTGTCTTTTCTTGCCTTGTTTCAGAAGGATCTACTAGTTGGC CCTATCTTGTGCCAAGACTGACAGCAAGGAAGCTGCTGGCTGACTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTAC AGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGC AATAGCACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAAT GCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCAC TTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAAC CACGCACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGAC AACTTTAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCG CGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCC AACATCACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCT TGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGAT CCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTT GGAGCTAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTT TTCACCTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTG GACCTGTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTA TATTGGGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCC TGCATCAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTT GGACAAAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAG GAGGAGAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACC TGTTACATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATTAAAAGAAGCTGTGCATTTTCACTGTTTTCTTTTTTCATC TAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGATTCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCT >83042_83042_4_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000367735_length(amino acids)=557AA_BP=387 MTAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTGLLGLPLAVKNAGIVMGPISLLII GIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGFCCVYFVFLADNFKQVIEAANGTT NNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIPDPSHLPLVAPWKTYPLFFGTAIF SFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQSVKLLYSIGIFFTYALQFYVPAEI IIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINISHHYCNISD HVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVDYDPETTCYIRVYNVYVRMN -------------------------------------------------------------- >83042_83042_5_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000367739_length(transcript)=3229nt_BP=1297nt GAGCTCTTCATCCGCCTGGGCCCAACCCTGGAACTATTCCTTTCAATGGTGTCTTTTCTTGCCTTGTTTCAGAAGGATCTACTAGTTGGC CCTATCTTGTGCCAAGACTGACAGCAAGGAAGCTGCTGGCTGACTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTAC AGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGC AATAGCACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAAT GCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCAC TTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAAC CACGCACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGAC AACTTTAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCG CGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCC AACATCACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCT TGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGAT CCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTT GGAGCTAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTT TTCACCTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTG GACCTGTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTA TATTGGGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCC TGCATCAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTT GGACAAAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAG GAGGAGAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACC TGTTACATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGAC GAGATTCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTT ACAACTGAAAAGTCAAAAGAAGTTTGTATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTA CTCTTTCTAGTGCTTAGCCTGGTATTCATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCC TTGATCTCTGTGGTAAGAAGTGCTACTTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTA GAAAAGGAGGTGGTCTGTGAAGAGCCGTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACA GAAGAACTTTCTAGTATAACAGAAGTGGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGA GAGAGTTCTTCACCTTTAAGTAGTAACCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGAT CACTCCAGAAATGGTTTTGATACTGATTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGT GAAATAAAAACAGAAGGACAAGAGCTCATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTA CTTGTGGATGATAGCGGTAAAGAGTCCTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACC AACTTTGAAGTCTGATTTTCCTGGACAGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAA CCAAATGGAGTGACTTAGTGTACATGAAAGCGTAAAGAGGATGTGTGGCATTTTCACTTTTGGCTTGTAAAGTACAGACTTTTTTTTTTT TTTAAACAAAAAAAGCATTGTAACTTATGAACCTTTACATCCAGATAGGTTACCAGTAACGGAACAGTATCCAGTACTCCTGGTTCCTAG GTGAGCAGGTGATGCCCCAGGGACCTTTGTAGCCACTTCACTTTTTTTCTTTTCTCTGCCTTGGTATAGCATATGTTTTTGTAAGTTTAT GCATACAGTAATTTTAAGTAATTTCAGAAGAAATTCTGCAAGCTTTTCAAAATTGGACTTAAAATCTAATTCAAACTAATAGAATTAATG >83042_83042_5_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000367739_length(amino acids)=850AA_BP=387 MTAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTGLLGLPLAVKNAGIVMGPISLLII GIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGFCCVYFVFLADNFKQVIEAANGTT NNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIPDPSHLPLVAPWKTYPLFFGTAIF SFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQSVKLLYSIGIFFTYALQFYVPAEI IIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINISHHYCNISD HVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVDYDPETTCYIRVYNVYVRMN GSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGSLWIPVVAALLLFLVLSLVFICFY IKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTE ENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVI -------------------------------------------------------------- >83042_83042_6_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000543628_length(transcript)=2881nt_BP=1297nt GAGCTCTTCATCCGCCTGGGCCCAACCCTGGAACTATTCCTTTCAATGGTGTCTTTTCTTGCCTTGTTTCAGAAGGATCTACTAGTTGGC CCTATCTTGTGCCAAGACTGACAGCAAGGAAGCTGCTGGCTGACTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTAC AGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCGGAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGC AATAGCACAACATGGTTCCAGACCTTGATCCACCTGTTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAAT GCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATCATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCAC TTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTATGGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAAC CACGCACACTGGGGAAGACGTGTTGTGGACTTCTTCCTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGAC AACTTTAAACAGGTGATAGAAGCGGCCAATGGGACCACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCG CGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTGCTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCC AACATCACCATGCTGGTCAGCTTGGTCATGATCTACCAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCT TGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATTTTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGAT CCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATGGTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTT GGAGCTAATATCCAAGGCAGCATAACCCTCAACCTGCCCAACTGCTGGTTGTACCAGTCAGTTAAGCTGCTGTACTCCATCGGGATCTTT TTCACCTACGCACTCCAGTTCTACGTCCCGGCTGAGATCATCATCCCCTTCTTTGTGTCCCGAGCGCCCGAGCACTGTGAGTTAGTGGTG GACCTGTTTGTGCGCACAGTGCTGGTCTGCCTGACATTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTA TATTGGGAGTACCAGATCATGCCACAGGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCC TGCATCAATATTTCTCATCATTATTGTAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTT GGACAAAAAGAATCTGCCTATGCAAAGTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAG GAGGAGAAGCAAATCATGATTGACATATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACC TGTTACATTAGGGTGTACAATGTGTATGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGAC GAGATTCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTT ACAACTGAAAAGTCAAAAGAAGTTTGTATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTA CTCTTTCTAGTGCTTAGCCTGGTATTCATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCC TTGATCTCTGTGGTAAGAAGTGCTACTTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTA GAAAAGGAGGTGGTCTGTGAAGAGCCGTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACA GAAGAACTTTCTAGTATAACAGAAGTGGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGA GAGAGTTCTTCACCTTTAAGTAGTAACCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGAT CACTCCAGAAATGGTTTTGATACTGATTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGT GAAATAAAAACAGAAGGACAAGAGCTCATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTA CTTGTGGATGATAGCGGTAAAGAGTCCTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACC AACTTTGAAGTCTGATTTTCCTGGACAGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAA CCAAATGGAGTGACTTAGTGTACATGAAAGCGTAAAGAGGATGTGTGGCATTTTCACTTTTGGCTTGTAAAGTACAGACTTTTTTTTTTT >83042_83042_6_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000520701_IFNGR1_chr6_137528214_ENST00000543628_length(amino acids)=850AA_BP=387 MTAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTGLLGLPLAVKNAGIVMGPISLLII GIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGFCCVYFVFLADNFKQVIEAANGTT NNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIPDPSHLPLVAPWKTYPLFFGTAIF SFEGIGMVLPLENKMKDPRKFPLILYLGMVIVTILYISLGCLGYLQFGANIQGSITLNLPNCWLYQSVKLLYSIGIFFTYALQFYVPAEI IIPFFVSRAPEHCELVVDLFVRTVLVCLTLPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINISHHYCNISD HVGDPSNSLWVRVKARVGQKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVDYDPETTCYIRVYNVYVRMN GSEIQYKILTQKEDDCDEIQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGSLWIPVVAALLLFLVLSLVFICFY IKKINPLKEKSIILPKSLISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTE ENIPDVVPGSHLTPIERESSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVI -------------------------------------------------------------- >83042_83042_7_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000367735_length(transcript)=2096nt_BP=1451nt AGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAGCCAGAGCCGGAGCCGGAGCTGGGGCCAGAAC CCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGACCCACCTCGCCTTCCTCCCGGCGTGGCAGAT GCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCG GAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAGCACAACATGGTTCCAGACCTTGATCCACCTG TTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATC ATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTAT GGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGCACACTGGGGAAGACGTGTTGTGGACTTCTTC CTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTTTAAACAGGTGATAGAAGCGGCCAATGGGACC ACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTG CTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACATCACCATGCTGGTCAGCTTGGTCATGATCTAC CAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATT TTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATG GTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGCTAATATCCAAGGCAGCATAACCCTCAACCTG CCCAACTGCTGGTGAGTAGAAGATGATAATTGCCTTGCTTGTTTTTCCCTAAAGGGCACCCAGTCTGCAGGCTTTCATGAGAAAAGACAA TGTGTGTTGTAGTGAAGCTGGCTATGTTTGTGACAGAGAACCTGGCCCATGGCCTCACTTTCAGAGTTGAGGCACCTCCAGATGGGGAAG TGAATTAATTACATATGTACTGTAAAGAACATGGGAATGAGGACAGTGGTTTATGTATAGATAGGGTATGAAATGCTGTGGAGGTGGTTA TCATTCAGAGTTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTGGGAGTACCAGATCATGCCACA GGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCATCAATATTTCTCATCATTATTG TAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACAAAAAGAATCTGCCTATGCAAA GTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGAGAAGCAAATCATGATTGACAT ATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTACATTAGGGTGTACAATGTGTA TGTGAGAATGAACGGAAGTGAGATTAAAAGAAGCTGTGCATTTTCACTGTTTTCTTTTTTCATCTAGATCCAGTATAAAATACTCACGCA GAAGGAAGATGATTGTGACGAGATTCAGTGCCAGTTAGCGATTCCAGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGT >83042_83042_7_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000367735_length(amino acids)=356AA_BP= MPAGGARRLGQDPPRLPPGVADAPAAMSTQRLRNEDYHDYSSTDVSPEESPSEGLNNLSSPGSYQRFGQSNSTTWFQTLIHLLKGNIGTG LLGLPLAVKNAGIVMGPISLLIIGIVAVHCMGILVKCAHHFCRRLNKSFVDYGDTVMYGLESSPCSWLRNHAHWGRRVVDFFLIVTQLGF CCVYFVFLADNFKQVIEAANGTTNNCHNNETVILTPTMDSRLYMLSFLPFLVLLVFIRNLRALSIFSLLANITMLVSLVMIYQFIVQRIP -------------------------------------------------------------- >83042_83042_8_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000367739_length(transcript)=3383nt_BP=1451nt AGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAGCCAGAGCCGGAGCCGGAGCTGGGGCCAGAAC CCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGACCCACCTCGCCTTCCTCCCGGCGTGGCAGAT GCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCG GAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAGCACAACATGGTTCCAGACCTTGATCCACCTG TTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATC ATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTAT GGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGCACACTGGGGAAGACGTGTTGTGGACTTCTTC CTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTTTAAACAGGTGATAGAAGCGGCCAATGGGACC ACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTG CTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACATCACCATGCTGGTCAGCTTGGTCATGATCTAC CAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATT TTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATG GTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGCTAATATCCAAGGCAGCATAACCCTCAACCTG CCCAACTGCTGGTGAGTAGAAGATGATAATTGCCTTGCTTGTTTTTCCCTAAAGGGCACCCAGTCTGCAGGCTTTCATGAGAAAAGACAA TGTGTGTTGTAGTGAAGCTGGCTATGTTTGTGACAGAGAACCTGGCCCATGGCCTCACTTTCAGAGTTGAGGCACCTCCAGATGGGGAAG TGAATTAATTACATATGTACTGTAAAGAACATGGGAATGAGGACAGTGGTTTATGTATAGATAGGGTATGAAATGCTGTGGAGGTGGTTA TCATTCAGAGTTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTGGGAGTACCAGATCATGCCACA GGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCATCAATATTTCTCATCATTATTG TAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACAAAAAGAATCTGCCTATGCAAA GTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGAGAAGCAAATCATGATTGACAT ATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTACATTAGGGTGTACAATGTGTA TGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGATTCAGTGCCAGTTAGCGATTCC AGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTTACAACTGAAAAGTCAAAAGAAGTTTG TATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTACTCTTTCTAGTGCTTAGCCTGGTATT CATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCCTTGATCTCTGTGGTAAGAAGTGCTAC TTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTAGAAAAGGAGGTGGTCTGTGAAGAGCC GTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACAGAAGAACTTTCTAGTATAACAGAAGT GGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGAGAGAGTTCTTCACCTTTAAGTAGTAA CCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGATCACTCCAGAAATGGTTTTGATACTGA TTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGTGAAATAAAAACAGAAGGACAAGAGCT CATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTACTTGTGGATGATAGCGGTAAAGAGTC CTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACCAACTTTGAAGTCTGATTTTCCTGGAC AGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAACCAAATGGAGTGACTTAGTGTACATG AAAGCGTAAAGAGGATGTGTGGCATTTTCACTTTTGGCTTGTAAAGTACAGACTTTTTTTTTTTTTTAAACAAAAAAAGCATTGTAACTT ATGAACCTTTACATCCAGATAGGTTACCAGTAACGGAACAGTATCCAGTACTCCTGGTTCCTAGGTGAGCAGGTGATGCCCCAGGGACCT TTGTAGCCACTTCACTTTTTTTCTTTTCTCTGCCTTGGTATAGCATATGTTTTTGTAAGTTTATGCATACAGTAATTTTAAGTAATTTCA GAAGAAATTCTGCAAGCTTTTCAAAATTGGACTTAAAATCTAATTCAAACTAATAGAATTAATGGAATATGTAAATAGAAACGTGTATAT >83042_83042_8_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000367739_length(amino acids)=472AA_BP=12 MKCCGGGYHSELPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINISHHYCNISDHVGDPSNSLWVRVKARVG QKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVDYDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDE IQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSL ISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERE SSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSFGYDKPHVLVDLL -------------------------------------------------------------- >83042_83042_9_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000543628_length(transcript)=3035nt_BP=1451nt AGCAAAGGAGGATGGCGAGGGGCTGATACTGAACCCGGGAAGGGTGGGCTGTGCTGAAGCCAGAGCCGGAGCCGGAGCTGGGGCCAGAAC CCGAGCAGTGAGTTCCTCCACTGGCTGCCGGCTGGCGGCGCTCGCCGCCTTGGGCAGGACCCACCTCGCCTTCCTCCCGGCGTGGCAGAT GCTCCAGCTGCCATGTCCACGCAGAGACTTCGGAATGAAGACTACCACGACTACAGCTCCACGGACGTGAGCCCTGAGGAGAGCCCGTCG GAAGGCCTCAACAACCTCTCCTCCCCGGGCTCCTACCAGCGCTTTGGTCAAAGCAATAGCACAACATGGTTCCAGACCTTGATCCACCTG TTAAAAGGCAACATTGGCACAGGACTCCTGGGACTCCCTCTGGCGGTGAAAAATGCAGGCATCGTGATGGGTCCCATCAGCCTGCTGATC ATAGGCATCGTGGCCGTGCACTGCATGGGTATCCTGGTGAAATGTGCTCACCACTTCTGCCGCAGGCTGAATAAATCCTTTGTGGATTAT GGTGATACTGTGATGTATGGACTAGAATCCAGCCCCTGCTCCTGGCTCCGGAACCACGCACACTGGGGAAGACGTGTTGTGGACTTCTTC CTGATTGTCACCCAGCTGGGATTCTGCTGTGTCTATTTTGTGTTTCTGGCTGACAACTTTAAACAGGTGATAGAAGCGGCCAATGGGACC ACCAATAACTGCCACAACAATGAGACGGTGATTCTGACGCCTACCATGGACTCGCGACTCTACATGCTCTCCTTCCTGCCCTTCCTGGTG CTGCTGGTTTTCATCAGGAACCTCCGAGCCCTGTCCATCTTCTCCCTGTTGGCCAACATCACCATGCTGGTCAGCTTGGTCATGATCTAC CAGTTCATTGTTCAGAGGATCCCAGACCCCAGCCACCTCCCCTTGGTGGCCCCTTGGAAGACCTACCCTCTCTTCTTTGGCACAGCGATT TTTTCATTTGAAGGCATTGGAATGGTTCTGCCCCTGGAAAACAAAATGAAGGATCCTCGGAAGTTCCCACTCATCCTGTACCTGGGCATG GTCATCGTCACCATCCTCTACATCAGCCTGGGGTGTCTGGGGTACCTGCAATTTGGAGCTAATATCCAAGGCAGCATAACCCTCAACCTG CCCAACTGCTGGTGAGTAGAAGATGATAATTGCCTTGCTTGTTTTTCCCTAAAGGGCACCCAGTCTGCAGGCTTTCATGAGAAAAGACAA TGTGTGTTGTAGTGAAGCTGGCTATGTTTGTGACAGAGAACCTGGCCCATGGCCTCACTTTCAGAGTTGAGGCACCTCCAGATGGGGAAG TGAATTAATTACATATGTACTGTAAAGAACATGGGAATGAGGACAGTGGTTTATGTATAGATAGGGTATGAAATGCTGTGGAGGTGGTTA TCATTCAGAGTTGCCTACACCAACTAATGTTACAATTGAATCCTATAACATGAACCCTATCGTATATTGGGAGTACCAGATCATGCCACA GGTCCCTGTTTTTACCGTAGAGGTAAAGAACTATGGTGTTAAGAATTCAGAATGGATTGATGCCTGCATCAATATTTCTCATCATTATTG TAATATTTCTGATCATGTTGGTGATCCATCAAATTCTCTTTGGGTCAGAGTTAAAGCCAGGGTTGGACAAAAAGAATCTGCCTATGCAAA GTCAGAAGAATTTGCTGTATGCCGAGATGGAAAAATTGGACCACCTAAACTGGATATCAGAAAGGAGGAGAAGCAAATCATGATTGACAT ATTTCACCCTTCAGTTTTTGTAAATGGAGACGAGCAGGAAGTCGATTATGATCCCGAAACTACCTGTTACATTAGGGTGTACAATGTGTA TGTGAGAATGAACGGAAGTGAGATCCAGTATAAAATACTCACGCAGAAGGAAGATGATTGTGACGAGATTCAGTGCCAGTTAGCGATTCC AGTATCCTCACTGAATTCTCAGTACTGTGTTTCAGCAGAAGGAGTCTTACATGTGTGGGGTGTTACAACTGAAAAGTCAAAAGAAGTTTG TATTACCATTTTCAATAGCAGTATAAAAGGTTCTCTTTGGATTCCAGTTGTTGCTGCTTTACTACTCTTTCTAGTGCTTAGCCTGGTATT CATCTGTTTTTATATTAAGAAAATTAATCCATTGAAGGAAAAAAGCATAATATTACCCAAGTCCTTGATCTCTGTGGTAAGAAGTGCTAC TTTAGAGACAAAACCTGAATCAAAATATGTATCACTCATCACGTCATACCAGCCATTTTCCTTAGAAAAGGAGGTGGTCTGTGAAGAGCC GTTGTCTCCAGCAACAGTTCCAGGCATGCATACCGAAGACAATCCAGGAAAAGTGGAACATACAGAAGAACTTTCTAGTATAACAGAAGT GGTGACTACTGAAGAAAATATTCCTGACGTGGTCCCGGGCAGCCATCTGACTCCAATAGAGAGAGAGAGTTCTTCACCTTTAAGTAGTAA CCAGTCTGAACCTGGCAGCATCGCTTTAAACTCGTATCACTCCAGAAATTGTTCTGAGAGTGATCACTCCAGAAATGGTTTTGATACTGA TTCCAGCTGTCTGGAATCACATAGCTCCTTATCTGACTCAGAATTTCCCCCAAATAATAAAGGTGAAATAAAAACAGAAGGACAAGAGCT CATAACCGTAATAAAAGCCCCCACCTCCTTTGGTTATGATAAACCACATGTGCTAGTGGATCTACTTGTGGATGATAGCGGTAAAGAGTC CTTGATTGGTTATAGACCAACAGAAGATTCCAAAGAATTTTCATGAGATCAGCTAAGTTGCACCAACTTTGAAGTCTGATTTTCCTGGAC AGTTTTCTGCTTTAATTTCATGAAAAGATTATGATCTCAGAAATTGTATCTTAGTTGGTATCAACCAAATGGAGTGACTTAGTGTACATG >83042_83042_9_SLC36A1-IFNGR1_SLC36A1_chr5_150859050_ENST00000521925_IFNGR1_chr6_137528214_ENST00000543628_length(amino acids)=472AA_BP=12 MKCCGGGYHSELPTPTNVTIESYNMNPIVYWEYQIMPQVPVFTVEVKNYGVKNSEWIDACINISHHYCNISDHVGDPSNSLWVRVKARVG QKESAYAKSEEFAVCRDGKIGPPKLDIRKEEKQIMIDIFHPSVFVNGDEQEVDYDPETTCYIRVYNVYVRMNGSEIQYKILTQKEDDCDE IQCQLAIPVSSLNSQYCVSAEGVLHVWGVTTEKSKEVCITIFNSSIKGSLWIPVVAALLLFLVLSLVFICFYIKKINPLKEKSIILPKSL ISVVRSATLETKPESKYVSLITSYQPFSLEKEVVCEEPLSPATVPGMHTEDNPGKVEHTEELSSITEVVTTEENIPDVVPGSHLTPIERE SSSPLSSNQSEPGSIALNSYHSRNCSESDHSRNGFDTDSSCLESHSSLSDSEFPPNNKGEIKTEGQELITVIKAPTSFGYDKPHVLVDLL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SLC36A1-IFNGR1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SLC36A1-IFNGR1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SLC36A1-IFNGR1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies