
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SLC37A1-MTA1 (FusionGDB2 ID:83051) |
Fusion Gene Summary for SLC37A1-MTA1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SLC37A1-MTA1 | Fusion gene ID: 83051 | Hgene | Tgene | Gene symbol | SLC37A1 | MTA1 | Gene ID | 54020 | 9112 |
| Gene name | solute carrier family 37 member 1 | metastasis associated 1 | |
| Synonyms | G3PP | - | |
| Cytomap | 21q22.3 | 14q32.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | glucose-6-phosphate exchanger SLC37A1G-3-P permeaseG-3-P transporterglycerol-3-phosphate permeaseglycerol-3-phosphate transportersolute carrier family 37 (glucose-6-phosphate transporter), member 1solute carrier family 37 (glycerol-3-phosphate trans | metastasis-associated protein MTA1metastasis associated gene 1 protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q13330 | |
| Ensembl transtripts involved in fusion gene | ENST00000352133, ENST00000398341, ENST00000454800, | ENST00000331320, ENST00000405646, ENST00000406191, ENST00000435036, | |
| Fusion gene scores | * DoF score | 7 X 6 X 3=126 | 6 X 9 X 5=270 |
| # samples | 8 | 10 | |
| ** MAII score | log2(8/126*10)=-0.655351828612554 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/270*10)=-1.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SLC37A1 [Title/Abstract] AND MTA1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SLC37A1(43988548)-MTA1(105932763), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SLC37A1 | GO:0015760 | glucose-6-phosphate transport | 21949678 |
| Hgene | SLC37A1 | GO:0035435 | phosphate ion transmembrane transport | 21949678 |
| Tgene | MTA1 | GO:0010212 | response to ionizing radiation | 19805145 |
| Tgene | MTA1 | GO:1902499 | positive regulation of protein autoubiquitination | 19805145 |
| Fusion gene breakpoints across SLC37A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MTA1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-EJ-5504-01A | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
Top |
Fusion Gene ORF analysis for SLC37A1-MTA1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000352133 | ENST00000331320 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000352133 | ENST00000405646 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000352133 | ENST00000406191 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000352133 | ENST00000435036 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000398341 | ENST00000331320 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000398341 | ENST00000405646 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000398341 | ENST00000406191 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| In-frame | ENST00000398341 | ENST00000435036 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| intron-3CDS | ENST00000454800 | ENST00000331320 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| intron-3CDS | ENST00000454800 | ENST00000405646 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| intron-3CDS | ENST00000454800 | ENST00000406191 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| intron-3CDS | ENST00000454800 | ENST00000435036 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000398341 | SLC37A1 | chr21 | 43988548 | - | ENST00000331320 | MTA1 | chr14 | 105932763 | + | 2873 | 1835 | 412 | 2358 | 648 |
| ENST00000398341 | SLC37A1 | chr21 | 43988548 | - | ENST00000406191 | MTA1 | chr14 | 105932763 | + | 2837 | 1835 | 412 | 2322 | 636 |
| ENST00000398341 | SLC37A1 | chr21 | 43988548 | - | ENST00000405646 | MTA1 | chr14 | 105932763 | + | 2873 | 1835 | 412 | 2358 | 648 |
| ENST00000398341 | SLC37A1 | chr21 | 43988548 | - | ENST00000435036 | MTA1 | chr14 | 105932763 | + | 2839 | 1835 | 412 | 2370 | 652 |
| ENST00000352133 | SLC37A1 | chr21 | 43988548 | - | ENST00000331320 | MTA1 | chr14 | 105932763 | + | 3443 | 2405 | 982 | 2928 | 648 |
| ENST00000352133 | SLC37A1 | chr21 | 43988548 | - | ENST00000406191 | MTA1 | chr14 | 105932763 | + | 3407 | 2405 | 982 | 2892 | 636 |
| ENST00000352133 | SLC37A1 | chr21 | 43988548 | - | ENST00000405646 | MTA1 | chr14 | 105932763 | + | 3443 | 2405 | 982 | 2928 | 648 |
| ENST00000352133 | SLC37A1 | chr21 | 43988548 | - | ENST00000435036 | MTA1 | chr14 | 105932763 | + | 3409 | 2405 | 982 | 2940 | 652 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000398341 | ENST00000331320 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.007843455 | 0.9921565 |
| ENST00000398341 | ENST00000406191 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.006301333 | 0.9936986 |
| ENST00000398341 | ENST00000405646 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.007843455 | 0.9921565 |
| ENST00000398341 | ENST00000435036 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.008626649 | 0.99137336 |
| ENST00000352133 | ENST00000331320 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.007908795 | 0.9920912 |
| ENST00000352133 | ENST00000406191 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.006520932 | 0.993479 |
| ENST00000352133 | ENST00000405646 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.007908795 | 0.9920912 |
| ENST00000352133 | ENST00000435036 | SLC37A1 | chr21 | 43988548 | - | MTA1 | chr14 | 105932763 | + | 0.008717786 | 0.9912822 |
Top |
Fusion Genomic Features for SLC37A1-MTA1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
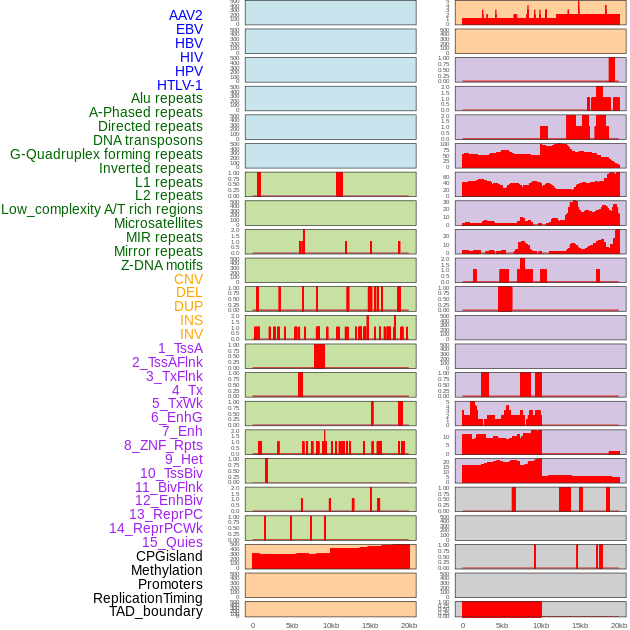
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SLC37A1-MTA1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr21:43988548/chr14:105932763) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | MTA1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional coregulator which can act as both a transcriptional corepressor and coactivator. As a part of the histone-deacetylase multiprotein complex (NuRD), regulates transcription of its targets by modifying the acetylation status of the target chromatin and cofactor accessibility to the target DNA. In conjunction with other components of NuRD, acts as a transcriptional corepressor of BRCA1, ESR1, TFF1 and CDKN1A. Acts as a transcriptional coactivator of BCAS3, PAX5 and SUMO2, independent of the NuRD complex. Stimulates the expression of WNT1 by inhibiting the expression of its transcriptional corepressor SIX3. Regulates p53-dependent and -independent DNA repair processes following genotoxic stress. Regulates the stability and function of p53/TP53 by inhibiting its ubiquitination by COP1 and MDM2 thereby regulating the p53-dependent DNA repair. Plays an important role in tumorigenesis, tumor invasion, and metastasis. Involved in the epigenetic regulation of ESR1 expression in breast cancer in a TFAP2C, IFI16 and HDAC4/5/6-dependent manner. Plays a role in the regulation of the circadian clock and is essential for the generation and maintenance of circadian rhythms under constant light and for normal entrainment of behavior to light-dark (LD) cycles. Positively regulates the CLOCK-ARNTL/BMAL1 heterodimer mediated transcriptional activation of its own transcription and the transcription of CRY1. Regulates deacetylation of ARNTL/BMAL1 by regulating SIRT1 expression, resulting in derepressing CRY1-mediated transcription repression. Isoform Short binds to ESR1 and sequesters it in the cytoplasm and enhances its non-genomic responses. With TFCP2L1, promotes establishment and maintenance of pluripotency in embryonic stem cells (ESCs) and inhibits endoderm differentiation (By similarity). {ECO:0000250|UniProtKB:Q8K4B0, ECO:0000269|PubMed:16617102, ECO:0000269|PubMed:17671180, ECO:0000269|PubMed:17922032, ECO:0000269|PubMed:19837670, ECO:0000269|PubMed:21965678, ECO:0000269|PubMed:24413532}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 100_120 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 129_149 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 157_177 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 18_38 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 222_242 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 304_324 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 334_354 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 366_386 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 394_414 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 423_443 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 100_120 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 129_149 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 157_177 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 18_38 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 222_242 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 304_324 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 334_354 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 366_386 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 394_414 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 423_443 | 474 | 534.0 | Transmembrane | Helical |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 697_705 | 541 | 716.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 697_705 | 524 | 699.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 545_552 | 541 | 716.0 | Motif | SH3-binding | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 696_705 | 541 | 716.0 | Motif | SH3-binding | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 545_552 | 524 | 699.0 | Motif | SH3-binding | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 696_705 | 524 | 699.0 | Motif | SH3-binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 466_486 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000352133 | - | 17 | 20 | 490_510 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 466_486 | 474 | 534.0 | Transmembrane | Helical |
| Hgene | SLC37A1 | chr21:43988548 | chr14:105932763 | ENST00000398341 | - | 18 | 21 | 490_510 | 474 | 534.0 | Transmembrane | Helical |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 165_276 | 541 | 716.0 | Domain | ELM2 | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 1_164 | 541 | 716.0 | Domain | BAH | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 283_335 | 541 | 716.0 | Domain | SANT | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 165_276 | 524 | 699.0 | Domain | ELM2 | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 1_164 | 524 | 699.0 | Domain | BAH | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 283_335 | 524 | 699.0 | Domain | SANT | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000331320 | 15 | 21 | 393_420 | 541 | 716.0 | Zinc finger | Note=GATA-type%3B atypical | |
| Tgene | MTA1 | chr21:43988548 | chr14:105932763 | ENST00000405646 | 14 | 20 | 393_420 | 524 | 699.0 | Zinc finger | Note=GATA-type%3B atypical |
Top |
Fusion Gene Sequence for SLC37A1-MTA1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >83051_83051_1_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000331320_length(transcript)=3443nt_BP=2405nt CGGCGGCGCAGGTGAGGCGCGGGGCCGGGGCCGGACCGGGAGGCGGGGACCCCCCGCCCCCCCGCCCGCACCTGCGGGGCAGCCGGCGCT CAGGCGCCGCAGCCGCTCAGCACCTGCGGCGCCCTCAGGGAGCCGGGCGCGGGGCCCTGCGCACTCGGAGCTCGGCTCCTCTCCTTCCTT TTCTTTTTTTTCGGGGGGAGGTGGGGGCTGGTTTGGATGTTTTCCGAGAGCCGGGGACGGTCTCAAGCTATTTTCGCGGAGGGAAGTCTT TGAAATACGACATCTAGAAGAGTGGCCCTCGGCGACAATGCCGGGCGTTCCCGGACCGGGGCAACGCTGGGATTCCGGGGAAGTGGAGGC AGAGGGAGCGGGCACGGGGCCGGCAGCCGCTCCACGGAGTCCCCGGCAGGGGCGAGCTTAGCTGTCCAGCCGGGTCCCCTGCCCACCCCG GCCCGGGCCGCGGTGACAGCTGAGGGTCCAGAGAGCCGGCAGGAGGGGACCCTGCGCATTGTCTGCCGCGATGGGGACGTGGGCGTGCCC GCGGAATTCACCTCCTCCGGGGACCAGCCGCCCAGGGAGGAGCCGGCACAGAACGCTGGCTCGGAGCGCCGGCACCCTGGGCCTTTGCGT TGTTTGTCGGCTGAGCAGCTGGTTCCCGGAGCCCGTGGGCCTCCTGGCCAATGCGAGTGACAGCGACCTTCTGGGTTTATAATAAAGGGC TTGACGCGCCGGAAAGTCCCCTCGCCGCTGGCCACCAGCCTTCCAGCCCTTACGGCCCACGCCGTAATCCTGGTGACCGAGAAGAGAGCA GAGCCACTGCCAGAAGGAAGGGGACAAGACCCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGA GAGGATCTGGAGCCAGGATTAATGACTCATTTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCG ACTCCCCGCTGGCATTCGCTTCATCATCTCATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGC AAGTTTTCACTTATCTCGAAAGCCTATCAGCATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTT CAGCAGCCAGAACAGGAAGTCTGGGTCCGCTGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAA CAACTATCAGCAGCTGCTTGGGGCCCTGGACTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCG CCTGCCGATTAGGTATTACCTAACTTTCGGGATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCA CAGTTTCGGATTCTACGTGGTAACTCAGGTCATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTG GTTTGGAAAAGGAAGGAGAGGTTTGATTATGGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTA CTGGGTGTCCACATGCTGGGGCCTGTCCTTCGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGA ACATCCGAACGACGTCAGGTGCTCCTCCACCCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCA AATCTTGAAGAGCGAAAAGAACAAGCCTCTGGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCA CGTCGTCATTCTCCCCGGGGACGGTGGGAGTGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTC ACTGTGTCTGCTGTTTGCCAAGCTGGTCAGCTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAA AAAGGCGGGGGAGCTCTCCACCCTGTTTGACGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAG GGCCTCCACCTGCGGCCTGATGCTGCTGCTCGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCAT CGCCATGCTGCTGCTCAGCGGAGCCCTGGTCAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAG TCTGAAAGGCAACGCGCACGCCCTCTCCACCGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCC TGACCCCGTGAAAAGCGTGTCCAGCGTGCTCAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCT GGGCAAGCGCAGCTACGAGCAGCACAACGGGGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGTCTGGCAAACCACGG ACAGGCCAGGCACATGGGACCAAGCCGGAACCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCT GCCCCCAGTCAAGCGGCGGCGGATGAACTGGATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAA GCTGCTCTCATCCTCGGAAACCAAGCGTGCTGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCC ACCGCCACCTGCGCCCGTCAACGACGAGCCCATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGC CCACACGGCCCCTTCCCAGCCAGCCCGCCGCCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCC TTGGCGGACACTGGGGGAGGAGAGGAAGAAGCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTT TTTGGCTGGAGCGGAGATGAGGGGCCACCCCGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTT CTGTTGAAGGTGCCATTTTAAATTTTATTTTTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATC GTGCGGCCGCGGCCGGCCGAGCTGCCTGGCGGGGTTGGCCCTTGTCTTTTCAAGTAATTTTCATATTAAACAAAAACAAAGAAAAAAAAT >83051_83051_1_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000331320_length(amino acids)=648AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGLA NHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALP -------------------------------------------------------------- >83051_83051_2_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000405646_length(transcript)=3443nt_BP=2405nt CGGCGGCGCAGGTGAGGCGCGGGGCCGGGGCCGGACCGGGAGGCGGGGACCCCCCGCCCCCCCGCCCGCACCTGCGGGGCAGCCGGCGCT CAGGCGCCGCAGCCGCTCAGCACCTGCGGCGCCCTCAGGGAGCCGGGCGCGGGGCCCTGCGCACTCGGAGCTCGGCTCCTCTCCTTCCTT TTCTTTTTTTTCGGGGGGAGGTGGGGGCTGGTTTGGATGTTTTCCGAGAGCCGGGGACGGTCTCAAGCTATTTTCGCGGAGGGAAGTCTT TGAAATACGACATCTAGAAGAGTGGCCCTCGGCGACAATGCCGGGCGTTCCCGGACCGGGGCAACGCTGGGATTCCGGGGAAGTGGAGGC AGAGGGAGCGGGCACGGGGCCGGCAGCCGCTCCACGGAGTCCCCGGCAGGGGCGAGCTTAGCTGTCCAGCCGGGTCCCCTGCCCACCCCG GCCCGGGCCGCGGTGACAGCTGAGGGTCCAGAGAGCCGGCAGGAGGGGACCCTGCGCATTGTCTGCCGCGATGGGGACGTGGGCGTGCCC GCGGAATTCACCTCCTCCGGGGACCAGCCGCCCAGGGAGGAGCCGGCACAGAACGCTGGCTCGGAGCGCCGGCACCCTGGGCCTTTGCGT TGTTTGTCGGCTGAGCAGCTGGTTCCCGGAGCCCGTGGGCCTCCTGGCCAATGCGAGTGACAGCGACCTTCTGGGTTTATAATAAAGGGC TTGACGCGCCGGAAAGTCCCCTCGCCGCTGGCCACCAGCCTTCCAGCCCTTACGGCCCACGCCGTAATCCTGGTGACCGAGAAGAGAGCA GAGCCACTGCCAGAAGGAAGGGGACAAGACCCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGA GAGGATCTGGAGCCAGGATTAATGACTCATTTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCG ACTCCCCGCTGGCATTCGCTTCATCATCTCATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGC AAGTTTTCACTTATCTCGAAAGCCTATCAGCATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTT CAGCAGCCAGAACAGGAAGTCTGGGTCCGCTGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAA CAACTATCAGCAGCTGCTTGGGGCCCTGGACTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCG CCTGCCGATTAGGTATTACCTAACTTTCGGGATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCA CAGTTTCGGATTCTACGTGGTAACTCAGGTCATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTG GTTTGGAAAAGGAAGGAGAGGTTTGATTATGGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTA CTGGGTGTCCACATGCTGGGGCCTGTCCTTCGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGA ACATCCGAACGACGTCAGGTGCTCCTCCACCCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCA AATCTTGAAGAGCGAAAAGAACAAGCCTCTGGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCA CGTCGTCATTCTCCCCGGGGACGGTGGGAGTGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTC ACTGTGTCTGCTGTTTGCCAAGCTGGTCAGCTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAA AAAGGCGGGGGAGCTCTCCACCCTGTTTGACGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAG GGCCTCCACCTGCGGCCTGATGCTGCTGCTCGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCAT CGCCATGCTGCTGCTCAGCGGAGCCCTGGTCAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAG TCTGAAAGGCAACGCGCACGCCCTCTCCACCGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCC TGACCCCGTGAAAAGCGTGTCCAGCGTGCTCAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCT GGGCAAGCGCAGCTACGAGCAGCACAACGGGGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGTCTGGCAAACCACGG ACAGGCCAGGCACATGGGACCAAGCCGGAACCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCT GCCCCCAGTCAAGCGGCGGCGGATGAACTGGATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAA GCTGCTCTCATCCTCGGAAACCAAGCGTGCTGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCC ACCGCCACCTGCGCCCGTCAACGACGAGCCCATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGC CCACACGGCCCCTTCCCAGCCAGCCCGCCGCCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCC TTGGCGGACACTGGGGGAGGAGAGGAAGAAGCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTT TTTGGCTGGAGCGGAGATGAGGGGCCACCCCGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTT CTGTTGAAGGTGCCATTTTAAATTTTATTTTTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATC GTGCGGCCGCGGCCGGCCGAGCTGCCTGGCGGGGTTGGCCCTTGTCTTTTCAAGTAATTTTCATATTAAACAAAAACAAAGAAAAAAAAT >83051_83051_2_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000405646_length(amino acids)=648AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGLA NHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALP -------------------------------------------------------------- >83051_83051_3_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000406191_length(transcript)=3407nt_BP=2405nt CGGCGGCGCAGGTGAGGCGCGGGGCCGGGGCCGGACCGGGAGGCGGGGACCCCCCGCCCCCCCGCCCGCACCTGCGGGGCAGCCGGCGCT CAGGCGCCGCAGCCGCTCAGCACCTGCGGCGCCCTCAGGGAGCCGGGCGCGGGGCCCTGCGCACTCGGAGCTCGGCTCCTCTCCTTCCTT TTCTTTTTTTTCGGGGGGAGGTGGGGGCTGGTTTGGATGTTTTCCGAGAGCCGGGGACGGTCTCAAGCTATTTTCGCGGAGGGAAGTCTT TGAAATACGACATCTAGAAGAGTGGCCCTCGGCGACAATGCCGGGCGTTCCCGGACCGGGGCAACGCTGGGATTCCGGGGAAGTGGAGGC AGAGGGAGCGGGCACGGGGCCGGCAGCCGCTCCACGGAGTCCCCGGCAGGGGCGAGCTTAGCTGTCCAGCCGGGTCCCCTGCCCACCCCG GCCCGGGCCGCGGTGACAGCTGAGGGTCCAGAGAGCCGGCAGGAGGGGACCCTGCGCATTGTCTGCCGCGATGGGGACGTGGGCGTGCCC GCGGAATTCACCTCCTCCGGGGACCAGCCGCCCAGGGAGGAGCCGGCACAGAACGCTGGCTCGGAGCGCCGGCACCCTGGGCCTTTGCGT TGTTTGTCGGCTGAGCAGCTGGTTCCCGGAGCCCGTGGGCCTCCTGGCCAATGCGAGTGACAGCGACCTTCTGGGTTTATAATAAAGGGC TTGACGCGCCGGAAAGTCCCCTCGCCGCTGGCCACCAGCCTTCCAGCCCTTACGGCCCACGCCGTAATCCTGGTGACCGAGAAGAGAGCA GAGCCACTGCCAGAAGGAAGGGGACAAGACCCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGA GAGGATCTGGAGCCAGGATTAATGACTCATTTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCG ACTCCCCGCTGGCATTCGCTTCATCATCTCATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGC AAGTTTTCACTTATCTCGAAAGCCTATCAGCATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTT CAGCAGCCAGAACAGGAAGTCTGGGTCCGCTGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAA CAACTATCAGCAGCTGCTTGGGGCCCTGGACTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCG CCTGCCGATTAGGTATTACCTAACTTTCGGGATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCA CAGTTTCGGATTCTACGTGGTAACTCAGGTCATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTG GTTTGGAAAAGGAAGGAGAGGTTTGATTATGGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTA CTGGGTGTCCACATGCTGGGGCCTGTCCTTCGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGA ACATCCGAACGACGTCAGGTGCTCCTCCACCCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCA AATCTTGAAGAGCGAAAAGAACAAGCCTCTGGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCA CGTCGTCATTCTCCCCGGGGACGGTGGGAGTGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTC ACTGTGTCTGCTGTTTGCCAAGCTGGTCAGCTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAA AAAGGCGGGGGAGCTCTCCACCCTGTTTGACGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAG GGCCTCCACCTGCGGCCTGATGCTGCTGCTCGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCAT CGCCATGCTGCTGCTCAGCGGAGCCCTGGTCAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAG TCTGAAAGGCAACGCGCACGCCCTCTCCACCGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCC TGACCCCGTGAAAAGCGTGTCCAGCGTGCTCAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCT GGGCAAGCGCAGCTACGAGCAGCACAACGGGGTGGACGGTCTGGCAAACCACGGACAGGCCAGGCACATGGGACCAAGCCGGAACCTCCT GCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCTGCCCCCAGTCAAGCGGCGGCGGATGAACTGGATCGA CGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAAGCTGCTCTCATCCTCGGAAACCAAGCGTGCTGCCCG CCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCCACCGCCACCTGCGCCCGTCAACGACGAGCCCATCGT CATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGCCCACACGGCCCCTTCCCAGCCAGCCCGCCGCCCGCC CCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCCTTGGCGGACACTGGGGGAGGAGAGGAAGAAGCGCGG CTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTTTTTGGCTGGAGCGGAGATGAGGGGCCACCCCGTGCC CCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTTCTGTTGAAGGTGCCATTTTAAATTTTATTTTTATTA CTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATCGTGCGGCCGCGGCCGGCCGAGCTGCCTGGCGGGGTT >83051_83051_3_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000406191_length(amino acids)=636AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGLANHGQARHMGPSR NLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALPPRPPPPAPVNDE -------------------------------------------------------------- >83051_83051_4_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000435036_length(transcript)=3409nt_BP=2405nt CGGCGGCGCAGGTGAGGCGCGGGGCCGGGGCCGGACCGGGAGGCGGGGACCCCCCGCCCCCCCGCCCGCACCTGCGGGGCAGCCGGCGCT CAGGCGCCGCAGCCGCTCAGCACCTGCGGCGCCCTCAGGGAGCCGGGCGCGGGGCCCTGCGCACTCGGAGCTCGGCTCCTCTCCTTCCTT TTCTTTTTTTTCGGGGGGAGGTGGGGGCTGGTTTGGATGTTTTCCGAGAGCCGGGGACGGTCTCAAGCTATTTTCGCGGAGGGAAGTCTT TGAAATACGACATCTAGAAGAGTGGCCCTCGGCGACAATGCCGGGCGTTCCCGGACCGGGGCAACGCTGGGATTCCGGGGAAGTGGAGGC AGAGGGAGCGGGCACGGGGCCGGCAGCCGCTCCACGGAGTCCCCGGCAGGGGCGAGCTTAGCTGTCCAGCCGGGTCCCCTGCCCACCCCG GCCCGGGCCGCGGTGACAGCTGAGGGTCCAGAGAGCCGGCAGGAGGGGACCCTGCGCATTGTCTGCCGCGATGGGGACGTGGGCGTGCCC GCGGAATTCACCTCCTCCGGGGACCAGCCGCCCAGGGAGGAGCCGGCACAGAACGCTGGCTCGGAGCGCCGGCACCCTGGGCCTTTGCGT TGTTTGTCGGCTGAGCAGCTGGTTCCCGGAGCCCGTGGGCCTCCTGGCCAATGCGAGTGACAGCGACCTTCTGGGTTTATAATAAAGGGC TTGACGCGCCGGAAAGTCCCCTCGCCGCTGGCCACCAGCCTTCCAGCCCTTACGGCCCACGCCGTAATCCTGGTGACCGAGAAGAGAGCA GAGCCACTGCCAGAAGGAAGGGGACAAGACCCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGA GAGGATCTGGAGCCAGGATTAATGACTCATTTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCG ACTCCCCGCTGGCATTCGCTTCATCATCTCATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGC AAGTTTTCACTTATCTCGAAAGCCTATCAGCATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTT CAGCAGCCAGAACAGGAAGTCTGGGTCCGCTGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAA CAACTATCAGCAGCTGCTTGGGGCCCTGGACTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCG CCTGCCGATTAGGTATTACCTAACTTTCGGGATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCA CAGTTTCGGATTCTACGTGGTAACTCAGGTCATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTG GTTTGGAAAAGGAAGGAGAGGTTTGATTATGGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTA CTGGGTGTCCACATGCTGGGGCCTGTCCTTCGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGA ACATCCGAACGACGTCAGGTGCTCCTCCACCCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCA AATCTTGAAGAGCGAAAAGAACAAGCCTCTGGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCA CGTCGTCATTCTCCCCGGGGACGGTGGGAGTGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTC ACTGTGTCTGCTGTTTGCCAAGCTGGTCAGCTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAA AAAGGCGGGGGAGCTCTCCACCCTGTTTGACGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAG GGCCTCCACCTGCGGCCTGATGCTGCTGCTCGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCAT CGCCATGCTGCTGCTCAGCGGAGCCCTGGTCAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAG TCTGAAAGGCAACGCGCACGCCCTCTCCACCGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCC TGACCCCGTGAAAAGCGTGTCCAGCGTGCTCAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCT GGGCAAGCGCAGCTACGAGCAGCACAACGGGGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGCACTTACCTGGGTCT GGCAAACCACGGACAGGCCAGGCACATGGGACCAAGCCGGAACCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCG GGGGGGCTCCCTGCCCCCAGTCAAGCGGCGGCGGATGAACTGGATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAG GAAGATCCGCAAGCTGCTCTCATCCTCGGAAACCAAGCGTGCTGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCT GCCGCCGCGGCCACCGCCACCTGCGCCCGTCAACGACGAGCCCATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCG CCCCTCGCCCGCCCACACGGCCCCTTCCCAGCCAGCCCGCCGCCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGA GAAACGCGCTCCTTGGCGGACACTGGGGGAGGAGAGGAAGAAGCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCT TTGTGTTTACTTTTTGGCTGGAGCGGAGATGAGGGGCCACCCCGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGG TTTTGTTGTGTTCTGTTGAAGGTGCCATTTTAAATTTTATTTTTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGG >83051_83051_4_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000352133_MTA1_chr14_105932763_ENST00000435036_length(amino acids)=652AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGTY LGLANHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQS -------------------------------------------------------------- >83051_83051_5_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000331320_length(transcript)=2873nt_BP=1835nt TGGGAAGTTCGCGCAAGTGCGGCTCTGCAGGGAGGAGGGAGGGCCGAGGGGAAGGCCCTCGAGAGAGTGGAGGGCAACAGTGGCCACGGT TCCTCTGTACTTCGTTTCTTCCCTTTATAGAATTGAGAGATTGCTGAGCCTAAATACATGTTGCTGCATTGCCTCCGAGAATGGCCGGAC CTATCCCCACTCTCACCAAAACAGAGTGTGGGACTCACTGCTCCCTCGCCTACTAGAGCAGAGCCACTGCCAGAAGGAAGGGGACAAGAC CCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGAGAGGATCTGGAGCCAGGATTAATGACTCAT TTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCGACTCCCCGCTGGCATTCGCTTCATCATCTC ATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGCAAGTTTTCACTTATCTCGAAAGCCTATCAG CATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTTCAGCAGCCAGAACAGGAAGTCTGGGTCCGC TGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAACAACTATCAGCAGCTGCTTGGGGCCCTGGA CTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCGCCTGCCGATTAGGTATTACCTAACTTTCGG GATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCACAGTTTCGGATTCTACGTGGTAACTCAGGT CATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTGGTTTGGAAAAGGAAGGAGAGGTTTGATTAT GGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTACTGGGTGTCCACATGCTGGGGCCTGTCCTT CGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGAACATCCGAACGACGTCAGGTGCTCCTCCAC CCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCAAATCTTGAAGAGCGAAAAGAACAAGCCTCT GGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCACGTCGTCATTCTCCCCGGGGACGGTGGGAG TGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTCACTGTGTCTGCTGTTTGCCAAGCTGGTCAG CTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAAAAAGGCGGGGGAGCTCTCCACCCTGTTTGA CGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAGGGCCTCCACCTGCGGCCTGATGCTGCTGCT CGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCATCGCCATGCTGCTGCTCAGCGGAGCCCTGGT CAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAGTCTGAAAGGCAACGCGCACGCCCTCTCCAC CGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCCTGACCCCGTGAAAAGCGTGTCCAGCGTGCT CAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCTGGGCAAGCGCAGCTACGAGCAGCACAACGG GGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGTCTGGCAAACCACGGACAGGCCAGGCACATGGGACCAAGCCGGAA CCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCTGCCCCCAGTCAAGCGGCGGCGGATGAACTG GATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAAGCTGCTCTCATCCTCGGAAACCAAGCGTGC TGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCCACCGCCACCTGCGCCCGTCAACGACGAGCC CATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGCCCACACGGCCCCTTCCCAGCCAGCCCGCCG CCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCCTTGGCGGACACTGGGGGAGGAGAGGAAGAA GCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTTTTTGGCTGGAGCGGAGATGAGGGGCCACCC CGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTTCTGTTGAAGGTGCCATTTTAAATTTTATTT TTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATCGTGCGGCCGCGGCCGGCCGAGCTGCCTGGC >83051_83051_5_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000331320_length(amino acids)=648AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGLA NHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALP -------------------------------------------------------------- >83051_83051_6_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000405646_length(transcript)=2873nt_BP=1835nt TGGGAAGTTCGCGCAAGTGCGGCTCTGCAGGGAGGAGGGAGGGCCGAGGGGAAGGCCCTCGAGAGAGTGGAGGGCAACAGTGGCCACGGT TCCTCTGTACTTCGTTTCTTCCCTTTATAGAATTGAGAGATTGCTGAGCCTAAATACATGTTGCTGCATTGCCTCCGAGAATGGCCGGAC CTATCCCCACTCTCACCAAAACAGAGTGTGGGACTCACTGCTCCCTCGCCTACTAGAGCAGAGCCACTGCCAGAAGGAAGGGGACAAGAC CCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGAGAGGATCTGGAGCCAGGATTAATGACTCAT TTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCGACTCCCCGCTGGCATTCGCTTCATCATCTC ATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGCAAGTTTTCACTTATCTCGAAAGCCTATCAG CATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTTCAGCAGCCAGAACAGGAAGTCTGGGTCCGC TGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAACAACTATCAGCAGCTGCTTGGGGCCCTGGA CTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCGCCTGCCGATTAGGTATTACCTAACTTTCGG GATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCACAGTTTCGGATTCTACGTGGTAACTCAGGT CATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTGGTTTGGAAAAGGAAGGAGAGGTTTGATTAT GGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTACTGGGTGTCCACATGCTGGGGCCTGTCCTT CGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGAACATCCGAACGACGTCAGGTGCTCCTCCAC CCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCAAATCTTGAAGAGCGAAAAGAACAAGCCTCT GGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCACGTCGTCATTCTCCCCGGGGACGGTGGGAG TGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTCACTGTGTCTGCTGTTTGCCAAGCTGGTCAG CTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAAAAAGGCGGGGGAGCTCTCCACCCTGTTTGA CGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAGGGCCTCCACCTGCGGCCTGATGCTGCTGCT CGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCATCGCCATGCTGCTGCTCAGCGGAGCCCTGGT CAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAGTCTGAAAGGCAACGCGCACGCCCTCTCCAC CGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCCTGACCCCGTGAAAAGCGTGTCCAGCGTGCT CAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCTGGGCAAGCGCAGCTACGAGCAGCACAACGG GGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGTCTGGCAAACCACGGACAGGCCAGGCACATGGGACCAAGCCGGAA CCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCTGCCCCCAGTCAAGCGGCGGCGGATGAACTG GATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAAGCTGCTCTCATCCTCGGAAACCAAGCGTGC TGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCCACCGCCACCTGCGCCCGTCAACGACGAGCC CATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGCCCACACGGCCCCTTCCCAGCCAGCCCGCCG CCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCCTTGGCGGACACTGGGGGAGGAGAGGAAGAA GCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTTTTTGGCTGGAGCGGAGATGAGGGGCCACCC CGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTTCTGTTGAAGGTGCCATTTTAAATTTTATTT TTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATCGTGCGGCCGCGGCCGGCCGAGCTGCCTGGC >83051_83051_6_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000405646_length(amino acids)=648AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGLA NHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALP -------------------------------------------------------------- >83051_83051_7_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000406191_length(transcript)=2837nt_BP=1835nt TGGGAAGTTCGCGCAAGTGCGGCTCTGCAGGGAGGAGGGAGGGCCGAGGGGAAGGCCCTCGAGAGAGTGGAGGGCAACAGTGGCCACGGT TCCTCTGTACTTCGTTTCTTCCCTTTATAGAATTGAGAGATTGCTGAGCCTAAATACATGTTGCTGCATTGCCTCCGAGAATGGCCGGAC CTATCCCCACTCTCACCAAAACAGAGTGTGGGACTCACTGCTCCCTCGCCTACTAGAGCAGAGCCACTGCCAGAAGGAAGGGGACAAGAC CCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGAGAGGATCTGGAGCCAGGATTAATGACTCAT TTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCGACTCCCCGCTGGCATTCGCTTCATCATCTC ATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGCAAGTTTTCACTTATCTCGAAAGCCTATCAG CATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTTCAGCAGCCAGAACAGGAAGTCTGGGTCCGC TGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAACAACTATCAGCAGCTGCTTGGGGCCCTGGA CTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCGCCTGCCGATTAGGTATTACCTAACTTTCGG GATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCACAGTTTCGGATTCTACGTGGTAACTCAGGT CATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTGGTTTGGAAAAGGAAGGAGAGGTTTGATTAT GGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTACTGGGTGTCCACATGCTGGGGCCTGTCCTT CGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGAACATCCGAACGACGTCAGGTGCTCCTCCAC CCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCAAATCTTGAAGAGCGAAAAGAACAAGCCTCT GGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCACGTCGTCATTCTCCCCGGGGACGGTGGGAG TGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTCACTGTGTCTGCTGTTTGCCAAGCTGGTCAG CTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAAAAAGGCGGGGGAGCTCTCCACCCTGTTTGA CGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAGGGCCTCCACCTGCGGCCTGATGCTGCTGCT CGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCATCGCCATGCTGCTGCTCAGCGGAGCCCTGGT CAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAGTCTGAAAGGCAACGCGCACGCCCTCTCCAC CGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCCTGACCCCGTGAAAAGCGTGTCCAGCGTGCT CAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCTGGGCAAGCGCAGCTACGAGCAGCACAACGG GGTGGACGGTCTGGCAAACCACGGACAGGCCAGGCACATGGGACCAAGCCGGAACCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGT GCGCCTGATCCGGGGGGGCTCCCTGCCCCCAGTCAAGCGGCGGCGGATGAACTGGATCGACGCCCCGGATGACGTGTTCTACATGGCCAC AGAGGAGACCAGGAAGATCCGCAAGCTGCTCTCATCCTCGGAAACCAAGCGTGCTGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCA GAGCCAGGCCCTGCCGCCGCGGCCACCGCCACCTGCGCCCGTCAACGACGAGCCCATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGC GGCCGCCCCCCGCCCCTCGCCCGCCCACACGGCCCCTTCCCAGCCAGCCCGCCGCCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCC CTCACCTGCAGAGAAACGCGCTCCTTGGCGGACACTGGGGGAGGAGAGGAAGAAGCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTG TCGTTTTTAGCTTTGTGTTTACTTTTTGGCTGGAGCGGAGATGAGGGGCCACCCCGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGC CGGGCCCTAAGGTTTTGTTGTGTTCTGTTGAAGGTGCCATTTTAAATTTTATTTTTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTA ACTTACACCTGGAATGTTAGGATCGTGCGGCCGCGGCCGGCCGAGCTGCCTGGCGGGGTTGGCCCTTGTCTTTTCAAGTAATTTTCATAT >83051_83051_7_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000406191_length(amino acids)=636AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGLANHGQARHMGPSR NLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQSQALPPRPPPPAPVNDE -------------------------------------------------------------- >83051_83051_8_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000435036_length(transcript)=2839nt_BP=1835nt TGGGAAGTTCGCGCAAGTGCGGCTCTGCAGGGAGGAGGGAGGGCCGAGGGGAAGGCCCTCGAGAGAGTGGAGGGCAACAGTGGCCACGGT TCCTCTGTACTTCGTTTCTTCCCTTTATAGAATTGAGAGATTGCTGAGCCTAAATACATGTTGCTGCATTGCCTCCGAGAATGGCCGGAC CTATCCCCACTCTCACCAAAACAGAGTGTGGGACTCACTGCTCCCTCGCCTACTAGAGCAGAGCCACTGCCAGAAGGAAGGGGACAAGAC CCAGCAGGACACCTTCTTTCCACGCTTTCCAGCCTGTGGGAGCGGCAGGGGCAACAGAGAGAGGATCTGGAGCCAGGATTAATGACTCAT TTATGAAGCATCTTATTCTGCGACCGAGGCTCAGTGGTCAGTGGCGACGTAAATGGCTCGACTCCCCGCTGGCATTCGCTTCATCATCTC ATTCTCCAGGGATCAGTGGTACAGAGCCTTCATTTTTATTTTGACATTTCTGCTGTATGCAAGTTTTCACTTATCTCGAAAGCCTATCAG CATAGTTAAGGGTGAGCTCCACAAGTACTGCACTGCTTGGGATGAAGCTGACGTCAGGTTCAGCAGCCAGAACAGGAAGTCTGGGTCCGC TGCCCCCCACCAGCTCCCTGACAATGAGACCGACTGTGGCTGGGCACCGTTTGATAAGAACAACTATCAGCAGCTGCTTGGGGCCCTGGA CTACTCCTTCCTGTGCGCCTATGCCGTGGGGATGTACCTCAGTGGCATCATTGGGGAGCGCCTGCCGATTAGGTATTACCTAACTTTCGG GATGCTCGCCAGCGGAGCCTTCACCGCCCTGTTCGGCTTAGGGTATTTCTACAACATCCACAGTTTCGGATTCTACGTGGTAACTCAGGT CATCAACGGGCTGGTGCAGACCACCGGCTGGCCCAGCGTCGTCACCTGCCTCGGCAACTGGTTTGGAAAAGGAAGGAGAGGTTTGATTAT GGGGGTCTGGAACTCCCACACCTCCGTGGGCAACATCTTGGGGTCATTGATCGCTGGCTACTGGGTGTCCACATGCTGGGGCCTGTCCTT CGTCGTGCCTGGAGCCATCGTGGCAGCCATGGGGATAGTGTGCTTTCTCTTCCTCATTGAACATCCGAACGACGTCAGGTGCTCCTCCAC CCTGGTGACGCACTCAAAAGGCTATGAGAATGGTACAAACAGATTGAGACTCCAGAAGCAAATCTTGAAGAGCGAAAAGAACAAGCCTCT GGACCCAGAGATGCAGTGCCTGCTGCTCTCAGATGGGAAGGGCTCCATCCACCCGAACCACGTCGTCATTCTCCCCGGGGACGGTGGGAG TGGCACGGCCGCCATCAGCTTCACAGGGGCCTTGAAAATTCCAGGCGTGATAGAGTTCTCACTGTGTCTGCTGTTTGCCAAGCTGGTCAG CTATACTTTCCTCTTCTGGCTGCCCCTGTACATCACGAATGTGGATCACCTTGATGCCAAAAAGGCGGGGGAGCTCTCCACCCTGTTTGA CGTGGGCGGAATCTTTGGTGGGATCCTGGCAGGTGTGATCTCAGACCGACTGGAGAAAAGGGCCTCCACCTGCGGCCTGATGCTGCTGCT CGCGGCCCCCACGCTCTACATCTTCTCCACCGTCAGCAAGATGGGGCTTGAGGCCACCATCGCCATGCTGCTGCTCAGCGGAGCCCTGGT CAGTGGGCCCTACACACTCATCACCACCGCCGTCTCCGCCGACCTGGGGACTCATAAAAGTCTGAAAGGCAACGCGCACGCCCTCTCCAC CGTGACGGCCATCATTGACGGGACGGGCTCTGTAGAGACCCACCCCCGCCCCCCCAAGCCTGACCCCGTGAAAAGCGTGTCCAGCGTGCT CAGCAGCCTGACGCCCGCCAAGGTGGCCCCCGTCATCAACAACGGCTCCCCCACCATCCTGGGCAAGCGCAGCTACGAGCAGCACAACGG GGTGGACGGCAACATGAAGAAGCGCCTCTTGATGCCCAGTAGGGGCACTTACCTGGGTCTGGCAAACCACGGACAGGCCAGGCACATGGG ACCAAGCCGGAACCTCCTGCTCAACGGGAAGTCCTACCCCACCAAAGTGCGCCTGATCCGGGGGGGCTCCCTGCCCCCAGTCAAGCGGCG GCGGATGAACTGGATCGACGCCCCGGATGACGTGTTCTACATGGCCACAGAGGAGACCAGGAAGATCCGCAAGCTGCTCTCATCCTCGGA AACCAAGCGTGCTGCCCGCCGGCCCTACAAGCCCATCGCCCTGCGCCAGAGCCAGGCCCTGCCGCCGCGGCCACCGCCACCTGCGCCCGT CAACGACGAGCCCATCGTCATCGAGGACTAGGGGCCGCCCCCACCTGCGGCCGCCCCCCGCCCCTCGCCCGCCCACACGGCCCCTTCCCA GCCAGCCCGCCGCCCGCCCCTCAGTTTGGTAGTGCCCCACCTCCCGCCCTCACCTGCAGAGAAACGCGCTCCTTGGCGGACACTGGGGGA GGAGAGGAAGAAGCGCGGCTAACTTATTCCGAGAATGCCGAGGAGTTGTCGTTTTTAGCTTTGTGTTTACTTTTTGGCTGGAGCGGAGAT GAGGGGCCACCCCGTGCCCCTGTGCTGCGGGGCCTTTTGCCCGGAGGCCGGGCCCTAAGGTTTTGTTGTGTTCTGTTGAAGGTGCCATTT TAAATTTTATTTTTATTACTTTTTTTGTAGATGAACTTGAGCTCTGTAACTTACACCTGGAATGTTAGGATCGTGCGGCCGCGGCCGGCC >83051_83051_8_SLC37A1-MTA1_SLC37A1_chr21_43988548_ENST00000398341_MTA1_chr14_105932763_ENST00000435036_length(amino acids)=652AA_BP=474 MARLPAGIRFIISFSRDQWYRAFIFILTFLLYASFHLSRKPISIVKGELHKYCTAWDEADVRFSSQNRKSGSAAPHQLPDNETDCGWAPF DKNNYQQLLGALDYSFLCAYAVGMYLSGIIGERLPIRYYLTFGMLASGAFTALFGLGYFYNIHSFGFYVVTQVINGLVQTTGWPSVVTCL GNWFGKGRRGLIMGVWNSHTSVGNILGSLIAGYWVSTCWGLSFVVPGAIVAAMGIVCFLFLIEHPNDVRCSSTLVTHSKGYENGTNRLRL QKQILKSEKNKPLDPEMQCLLLSDGKGSIHPNHVVILPGDGGSGTAAISFTGALKIPGVIEFSLCLLFAKLVSYTFLFWLPLYITNVDHL DAKKAGELSTLFDVGGIFGGILAGVISDRLEKRASTCGLMLLLAAPTLYIFSTVSKMGLEATIAMLLLSGALVSGPYTLITTAVSADLGT HKSLKGNAHALSTVTAIIDGTGSVETHPRPPKPDPVKSVSSVLSSLTPAKVAPVINNGSPTILGKRSYEQHNGVDGNMKKRLLMPSRGTY LGLANHGQARHMGPSRNLLLNGKSYPTKVRLIRGGSLPPVKRRRMNWIDAPDDVFYMATEETRKIRKLLSSSETKRAARRPYKPIALRQS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SLC37A1-MTA1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SLC37A1-MTA1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SLC37A1-MTA1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies