
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SLC39A14-TRMT11 (FusionGDB2 ID:83175) |
Fusion Gene Summary for SLC39A14-TRMT11 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SLC39A14-TRMT11 | Fusion gene ID: 83175 | Hgene | Tgene | Gene symbol | SLC39A14 | TRMT11 | Gene ID | 23516 | 60487 |
| Gene name | solute carrier family 39 member 14 | tRNA methyltransferase 11 homolog | |
| Synonyms | HCIN|HMNDYT2|LZT-Hs4|NET34|ZIP14|cig19 | C6orf75|MDS024|TRM11|TRMT11-1 | |
| Cytomap | 8p21.3 | 6q22.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | zinc transporter ZIP14LIV-1 subfamily of ZIP zinc transporter 4Zrt-, Irt-like protein 14solute carrier family 39 (metal ion transporter), member 14solute carrier family 39 (zinc transporter), member 14zrt- and Irt-like protein 14 | tRNA (guanine(10)-N2)-methyltransferase homologtRNA guanosine-2'-O-methyltransferase TRM11 homolog | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000240095, ENST00000289952, ENST00000359741, ENST00000381237, | ENST00000450358, ENST00000489934, ENST00000334379, ENST00000368332, | |
| Fusion gene scores | * DoF score | 14 X 11 X 9=1386 | 5 X 6 X 3=90 |
| # samples | 15 | 5 | |
| ** MAII score | log2(15/1386*10)=-3.20789285164133 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/90*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SLC39A14 [Title/Abstract] AND TRMT11 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SLC39A14(22266009)-TRMT11(126332399), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SLC39A14 | GO:0006882 | cellular zinc ion homeostasis | 15642354|21917916 |
| Hgene | SLC39A14 | GO:0071577 | zinc ion transmembrane transport | 21917916 |
| Hgene | SLC39A14 | GO:0071578 | zinc ion import across plasma membrane | 15642354|29621230 |
| Fusion gene breakpoints across SLC39A14 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TRMT11 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-BR-7851-11A | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
Top |
Fusion Gene ORF analysis for SLC39A14-TRMT11 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000240095 | ENST00000450358 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000240095 | ENST00000489934 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000289952 | ENST00000450358 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000289952 | ENST00000489934 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000359741 | ENST00000450358 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000359741 | ENST00000489934 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000381237 | ENST00000450358 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| 5CDS-intron | ENST00000381237 | ENST00000489934 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000240095 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000240095 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000289952 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000289952 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000359741 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000359741 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000381237 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| In-frame | ENST00000381237 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000240095 | SLC39A14 | chr8 | 22266009 | + | ENST00000334379 | TRMT11 | chr6 | 126332399 | + | 1662 | 594 | 47 | 1225 | 392 |
| ENST00000240095 | SLC39A14 | chr8 | 22266009 | + | ENST00000368332 | TRMT11 | chr6 | 126332399 | + | 1651 | 594 | 47 | 1210 | 387 |
| ENST00000359741 | SLC39A14 | chr8 | 22266009 | + | ENST00000334379 | TRMT11 | chr6 | 126332399 | + | 1700 | 632 | 85 | 1263 | 392 |
| ENST00000359741 | SLC39A14 | chr8 | 22266009 | + | ENST00000368332 | TRMT11 | chr6 | 126332399 | + | 1689 | 632 | 85 | 1248 | 387 |
| ENST00000381237 | SLC39A14 | chr8 | 22266009 | + | ENST00000334379 | TRMT11 | chr6 | 126332399 | + | 1644 | 576 | 29 | 1207 | 392 |
| ENST00000381237 | SLC39A14 | chr8 | 22266009 | + | ENST00000368332 | TRMT11 | chr6 | 126332399 | + | 1633 | 576 | 29 | 1192 | 387 |
| ENST00000289952 | SLC39A14 | chr8 | 22266009 | + | ENST00000334379 | TRMT11 | chr6 | 126332399 | + | 1741 | 673 | 216 | 1304 | 362 |
| ENST00000289952 | SLC39A14 | chr8 | 22266009 | + | ENST00000368332 | TRMT11 | chr6 | 126332399 | + | 1730 | 673 | 216 | 1289 | 357 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000240095 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000629862 | 0.99937016 |
| ENST00000240095 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000728098 | 0.9992719 |
| ENST00000359741 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000657348 | 0.9993426 |
| ENST00000359741 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000760036 | 0.99924004 |
| ENST00000381237 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000677846 | 0.9993222 |
| ENST00000381237 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000786766 | 0.9992132 |
| ENST00000289952 | ENST00000334379 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.000906401 | 0.99909365 |
| ENST00000289952 | ENST00000368332 | SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332399 | + | 0.001063168 | 0.99893683 |
Top |
Fusion Genomic Features for SLC39A14-TRMT11 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332398 | + | 2.25E-08 | 1 |
| SLC39A14 | chr8 | 22266009 | + | TRMT11 | chr6 | 126332398 | + | 2.25E-08 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
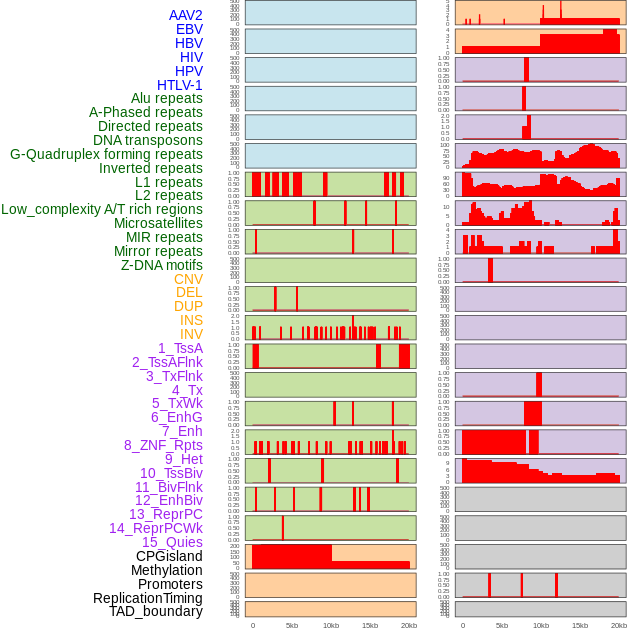 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
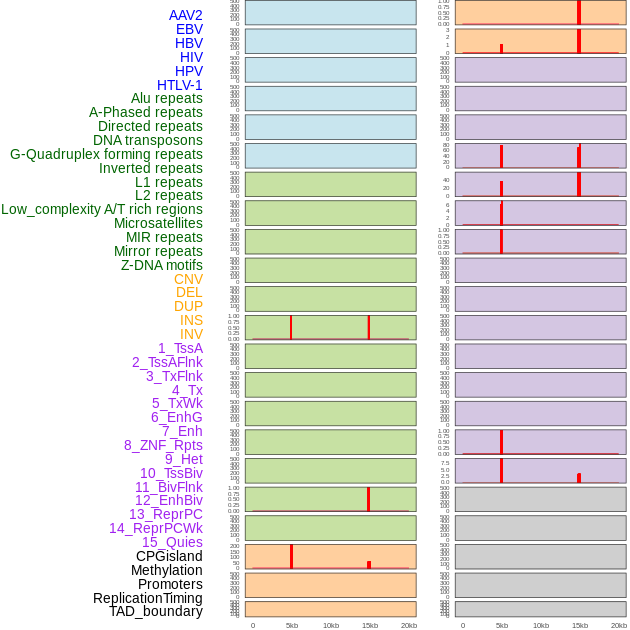 |
Top |
Fusion Protein Features for SLC39A14-TRMT11 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:22266009/chr6:126332399) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 251_258 | 152 | 482.0 | Motif | HHHGHXHX-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 376_381 | 152 | 482.0 | Motif | XEXPHE-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 251_258 | 152 | 493.0 | Motif | HHHGHXHX-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 376_381 | 152 | 493.0 | Motif | XEXPHE-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 251_258 | 152 | 493.0 | Motif | HHHGHXHX-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 376_381 | 152 | 493.0 | Motif | XEXPHE-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 251_258 | 152 | 493.0 | Motif | HHHGHXHX-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 376_381 | 152 | 493.0 | Motif | XEXPHE-motif |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 179_186 | 152 | 482.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 208_224 | 152 | 482.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 246_397 | 152 | 482.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 31_157 | 152 | 482.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 419_424 | 152 | 482.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 446_460 | 152 | 482.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 482_492 | 152 | 482.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 179_186 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 208_224 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 246_397 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 31_157 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 419_424 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 446_460 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 482_492 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 179_186 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 208_224 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 246_397 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 31_157 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 419_424 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 446_460 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 482_492 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 179_186 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 208_224 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 246_397 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 31_157 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 419_424 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 446_460 | 152 | 493.0 | Topological domain | Cytoplasmic |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 482_492 | 152 | 493.0 | Topological domain | Extracellular |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 158_178 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 187_207 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 225_245 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 398_418 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 425_445 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000240095 | + | 3 | 9 | 461_481 | 152 | 482.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 158_178 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 187_207 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 225_245 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 398_418 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 425_445 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000289952 | + | 3 | 9 | 461_481 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 158_178 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 187_207 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 225_245 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 398_418 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 425_445 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000359741 | + | 3 | 9 | 461_481 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 158_178 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 187_207 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 225_245 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 398_418 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 425_445 | 152 | 493.0 | Transmembrane | Helical |
| Hgene | SLC39A14 | chr8:22266009 | chr6:126332399 | ENST00000381237 | + | 3 | 9 | 461_481 | 152 | 493.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for SLC39A14-TRMT11 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >83175_83175_1_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000240095_TRMT11_chr6_126332399_ENST00000334379_length(transcript)=1662nt_BP=594nt CAGTGAGGGGGGTCGGCGCGCGTGTCTACGCGGACGCACCGGCTAAGCTGCTTCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGC TGCGCGGGGCCGAGGCCGCCTCCGAGCGCCAGGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCC TGCTGACCCTGCTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGC AGGATCTAATACATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCC GGGGTAATGTCACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCG AGCAGTCGCGGATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACC AGGAAAACGAGGAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGAC CAGATGAAAACATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCT GGAGGAAGGGCACATATTTTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGA TACCAAAGGGGATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACC TGTTAAACTTCGCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGG TGCCTTGGCACCCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGG TGAAGAAATTTGAGAATCGGGACCAGTATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAAT ATTTTAGTGGGGTAACAAAAAGAATTGCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGA ATTTGATTTAAAAAGACATCTGGATGTGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTAC AAAGTAAATTGAGCAATGCTTTTAAAGTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGT ATATTTGTACTTTCAAGTACTGATGGAGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTT TTAAAACATCTGCTGGATATATTATATGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTC >83175_83175_1_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000240095_TRMT11_chr6_126332399_ENST00000334379_length(amino acids)=392AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKVKKFENRDQYSHLLSD -------------------------------------------------------------- >83175_83175_2_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000240095_TRMT11_chr6_126332399_ENST00000368332_length(transcript)=1651nt_BP=594nt CAGTGAGGGGGGTCGGCGCGCGTGTCTACGCGGACGCACCGGCTAAGCTGCTTCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGC TGCGCGGGGCCGAGGCCGCCTCCGAGCGCCAGGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCC TGCTGACCCTGCTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGC AGGATCTAATACATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCC GGGGTAATGTCACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCG AGCAGTCGCGGATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACC AGGAAAACGAGGAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGAC CAGATGAAAACATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCT GGAGGAAGGGCACATATTTTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGA TACCAAAGGGGATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACC TGTTAAACTTCGCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGG TGCCTTGGCACCCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGA ATCGGGACCAGTATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAA CAAAAAGAATTGCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAG ACATCTGGATGTGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCA ATGCTTTTAAAGTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACTTTCA AGTACTGATGGAGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTG GATATATTATATGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTCATCGATTTACATTGC >83175_83175_2_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000240095_TRMT11_chr6_126332399_ENST00000368332_length(amino acids)=387AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKNRDQYSHLLSDHFLPY -------------------------------------------------------------- >83175_83175_3_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000289952_TRMT11_chr6_126332399_ENST00000334379_length(transcript)=1741nt_BP=673nt CACACGCCCGGACGGCTGGGTGGAGGCTGCACCTGGCCGTGGTGCCGCGCTGGCGAGGGGAGAGGTCAAGGCGCGGCCTGTCCGCCTGGA GGGTGCGGGATGCTAGAGCCGCAGAAGGGTGCCCAGAGCGTGGGTCGCCGCGCCGAAGGCTGAGCCAGGCTCCCGGATTCCCCGCGCGGA CACGGACGCAGAACGCAGACAGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTG CTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATA CATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTC ACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGG ATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAG GAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAAC ATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGC ACATATTTTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGG ATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTC GCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCAC CCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGGTGAAGAAATTT GAGAATCGGGACCAGTATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGG GTAACAAAAAGAATTGCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAA AAAGACATCTGGATGTGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTG AGCAATGCTTTTAAAGTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACT TTCAAGTACTGATGGAGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCT GCTGGATATATTATATGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTCATCGATTTACA >83175_83175_3_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000289952_TRMT11_chr6_126332399_ENST00000334379_length(amino acids)=362AA_BP=152 MKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQQLKALLNHLDVGVGRGNVTQHVQGHRNLST CFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSAVEGKATRKNQKWRGPDENIRANLRQYGLEK YYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHVPVSLSYHLSDMFLDLLNFAAETLVLGGRLV YWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKVKKFENRDQYSHLLSDHFLPYQGHNSFREKYFSGVTKRIAKEEKST -------------------------------------------------------------- >83175_83175_4_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000289952_TRMT11_chr6_126332399_ENST00000368332_length(transcript)=1730nt_BP=673nt CACACGCCCGGACGGCTGGGTGGAGGCTGCACCTGGCCGTGGTGCCGCGCTGGCGAGGGGAGAGGTCAAGGCGCGGCCTGTCCGCCTGGA GGGTGCGGGATGCTAGAGCCGCAGAAGGGTGCCCAGAGCGTGGGTCGCCGCGCCGAAGGCTGAGCCAGGCTCCCGGATTCCCCGCGCGGA CACGGACGCAGAACGCAGACAGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTG CTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATA CATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTC ACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGG ATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAG GAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAAC ATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGC ACATATTTTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGG ATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTC GCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCAC CCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGAATCGGGACCAG TATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAACAAAAAGAATT GCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAGACATCTGGATG TGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCAATGCTTTTAAA GTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACTTTCAAGTACTGATGG AGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTGGATATATTATA TGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTCATCGATTTACATTGCCACTAATAAAC >83175_83175_4_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000289952_TRMT11_chr6_126332399_ENST00000368332_length(amino acids)=357AA_BP=152 MKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQQLKALLNHLDVGVGRGNVTQHVQGHRNLST CFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSAVEGKATRKNQKWRGPDENIRANLRQYGLEK YYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHVPVSLSYHLSDMFLDLLNFAAETLVLGGRLV -------------------------------------------------------------- >83175_83175_5_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000359741_TRMT11_chr6_126332399_ENST00000334379_length(transcript)=1700nt_BP=632nt ATATAGCCGGGCATGCGCGCGGTGCCGGGGCCCGGACGCAGTGAGGGGGGTCGGCGCGCGTGTCTACGCGGACGCACCGGCTAAGCTGCT TCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGCTGCGCGGGGCCGAGGCCGCCTCCGAGCGCCAGGTTTATTCAGTCACCATGAA GCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTGCTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATC CCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATACATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCT GAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTCACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTT TAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGGATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCT CCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAGGAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGA AGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAACATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTA CCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGCACATATTTTGATGCAATCATTACTGATCCTCCATATGGTAT CAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGGATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGT TTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTCGCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTG GTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCACCCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTC CAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGGTGAAGAAATTTGAGAATCGGGACCAGTATTCACATCTGCTAAGTGATCATTT TCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAACAAAAAGAATTGCCAAGGAAGAAAAATCCACCCAGGA ATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAGACATCTGGATGTGAACTTTCATGTATGATCCAGAAAA TAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCAATGCTTTTAAAGTTATCTTTGTTTTATAGACTTTTTT GTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACTTTCAAGTACTGATGGAGATAGACTCAAAACAGTTATTTTTT TACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTGGATATATTATATGCAATTAATAGTAGTTAAGAATTTA >83175_83175_5_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000359741_TRMT11_chr6_126332399_ENST00000334379_length(amino acids)=392AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKVKKFENRDQYSHLLSD -------------------------------------------------------------- >83175_83175_6_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000359741_TRMT11_chr6_126332399_ENST00000368332_length(transcript)=1689nt_BP=632nt ATATAGCCGGGCATGCGCGCGGTGCCGGGGCCCGGACGCAGTGAGGGGGGTCGGCGCGCGTGTCTACGCGGACGCACCGGCTAAGCTGCT TCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGCTGCGCGGGGCCGAGGCCGCCTCCGAGCGCCAGGTTTATTCAGTCACCATGAA GCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTGCTTGGCTTATGGAGAACCACCCCTGAGGCTCACGCTTCATC CCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATACATCGGTATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCT GAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTCACCCAGCACGTGCAAGGACACAGGAACCTCTCCACGTGCTT TAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGGATTGGGAGCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCT CCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAGGAGAATGAGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGA AGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAACATTAGGGCCAATCTTCGTCAATATGGTTTAGAGAAGTATTA CCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGCACATATTTTGATGCAATCATTACTGATCCTCCATATGGTAT CAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGGATAGAAAAATGGGAAAAATGTCCAGAAAGCCATGTTCCTGT TTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTCGCAGCTGAGACCCTCGTTTTAGGTGGAAGACTAGTCTATTG GTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCACCCTTGCCTGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTC CAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGAATCGGGACCAGTATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGG TCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAACAAAAAGAATTGCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATT TTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAGACATCTGGATGTGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAA AATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCAATGCTTTTAAAGTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACA GTCTTTATAATCTTATTTAATGTATATTTGTACTTTCAAGTACTGATGGAGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACA AAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTGGATATATTATATGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATA >83175_83175_6_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000359741_TRMT11_chr6_126332399_ENST00000368332_length(amino acids)=387AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKNRDQYSHLLSDHFLPY -------------------------------------------------------------- >83175_83175_7_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000381237_TRMT11_chr6_126332399_ENST00000334379_length(transcript)=1644nt_BP=576nt CGCGTGTCTACGCGGACGCACCGGCTAAGCTGCTTCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGCTGCGCGGGGCCGAGGCCG CCTCCGAGCGCCAGGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTGCTTGGCT TATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATACATCGGT ATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTCACCCAGC ACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGGATTGGGA GCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAGGAGAATG AGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAACATTAGGG CCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGCACATATT TTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGGATAGAAA AATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTCGCAGCTG AGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCACCCTTGCC TGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGGTGAAGAAATTTGAGAATC GGGACCAGTATTCACATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAACAA AAAGAATTGCCAAGGAAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAGACA TCTGGATGTGAACTTTCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCAATG CTTTTAAAGTTATCTTTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACTTTCAAGT ACTGATGGAGATAGACTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTGGAT ATATTATATGCAATTAATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTCATCGATTTACATTGCCAC >83175_83175_7_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000381237_TRMT11_chr6_126332399_ENST00000334379_length(amino acids)=392AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKVKKFENRDQYSHLLSD -------------------------------------------------------------- >83175_83175_8_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000381237_TRMT11_chr6_126332399_ENST00000368332_length(transcript)=1633nt_BP=576nt CGCGTGTCTACGCGGACGCACCGGCTAAGCTGCTTCTGCCGCCGCCGGCCGCCTGGGACCTTGCGGTGAGGCTGCGCGGGGCCGAGGCCG CCTCCGAGCGCCAGGTTTATTCAGTCACCATGAAGCTGCTGCTGCTGCACCCGGCCTTCCAGAGCTGCCTCCTGCTGACCCTGCTTGGCT TATGGAGAACCACCCCTGAGGCTCACGCTTCATCCCTGGGTGCACCAGCTATCAGCGCTGCCTCCTTCCTGCAGGATCTAATACATCGGT ATGGCGAGGGTGACAGCCTCACTCTGCAGCAGCTGAAGGCCCTACTCAACCACCTGGATGTGGGAGTGGGCCGGGGTAATGTCACCCAGC ACGTGCAAGGACACAGGAACCTCTCCACGTGCTTTAGTTCTGGAGACCTCTTCACTGCCCACAATTTCAGCGAGCAGTCGCGGATTGGGA GCAGCGAGCTCCAGGAGTTCTGCCCCACCATCCTCCAGCAGCTGGATTCCCGGGCCTGCACCTCGGAGAACCAGGAAAACGAGGAGAATG AGCAGACGGAGGAGGGGCGGCCAAGCGCTGTTGAAGGAAAGGCTACTAGGAAAAACCAGAAGTGGAGAGGACCAGATGAAAACATTAGGG CCAATCTTCGTCAATATGGTTTAGAGAAGTATTACCTTGATGTCCTGGTTTCAGATGCATCTAAACCTTCCTGGAGGAAGGGCACATATT TTGATGCAATCATTACTGATCCTCCATATGGTATCAGAGAATCTACAAGAAGAACAGGTTCACAGAAGGAGATACCAAAGGGGATAGAAA AATGGGAAAAATGTCCAGAAAGCCATGTTCCTGTTTCCTTGAGTTATCATCTGAGTGATATGTTTCTTGACCTGTTAAACTTCGCAGCTG AGACCCTCGTTTTAGGTGGAAGACTAGTCTATTGGTTACCGGTGTATACGCCAGAATACACTGAAGAGATGGTGCCTTGGCACCCTTGCC TGGAACTCGTTAGCAACTGCGAGCAGAAGCTTTCCAGTCACACATCAAGGCGCTTGATCACAATGGAAAAGAATCGGGACCAGTATTCAC ATCTGCTAAGTGATCATTTTCTGCCATACCAAGGTCATAATTCCTTCCGTGAGAAATATTTTAGTGGGGTAACAAAAAGAATTGCCAAGG AAGAAAAATCCACCCAGGAATGAAAATTAAGATTTTGACAATGAAGAAAGAATAAGAATTTGATTTAAAAAGACATCTGGATGTGAACTT TCATGTATGATCCAGAAAATAGGTACGGTTTTAAAATATTTTATATAGAAAAGCTACAAAGTAAATTGAGCAATGCTTTTAAAGTTATCT TTGTTTTATAGACTTTTTTGTTGTATGTATTACAGTCTTTATAATCTTATTTAATGTATATTTGTACTTTCAAGTACTGATGGAGATAGA CTCAAAACAGTTATTTTTTTACAATTAATCTACAAAGGGAATTAATATTGTTGACTTTTAAAACATCTGCTGGATATATTATATGCAATT AATAGTAGTTAAGAATTTATTCATTTGGTAGATATGTTTATTTGGTTTTTGGTTGTCATCGATTTACATTGCCACTAATAAACCATATTG >83175_83175_8_SLC39A14-TRMT11_SLC39A14_chr8_22266009_ENST00000381237_TRMT11_chr6_126332399_ENST00000368332_length(amino acids)=387AA_BP=182 MLLPPPAAWDLAVRLRGAEAASERQVYSVTMKLLLLHPAFQSCLLLTLLGLWRTTPEAHASSLGAPAISAASFLQDLIHRYGEGDSLTLQ QLKALLNHLDVGVGRGNVTQHVQGHRNLSTCFSSGDLFTAHNFSEQSRIGSSELQEFCPTILQQLDSRACTSENQENEENEQTEEGRPSA VEGKATRKNQKWRGPDENIRANLRQYGLEKYYLDVLVSDASKPSWRKGTYFDAIITDPPYGIRESTRRTGSQKEIPKGIEKWEKCPESHV PVSLSYHLSDMFLDLLNFAAETLVLGGRLVYWLPVYTPEYTEEMVPWHPCLELVSNCEQKLSSHTSRRLITMEKNRDQYSHLLSDHFLPY -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SLC39A14-TRMT11 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SLC39A14-TRMT11 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SLC39A14-TRMT11 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies