
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ATXN10-ARHGAP8 (FusionGDB2 ID:8365) |
Fusion Gene Summary for ATXN10-ARHGAP8 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ATXN10-ARHGAP8 | Fusion gene ID: 8365 | Hgene | Tgene | Gene symbol | ATXN10 | ARHGAP8 | Gene ID | 25814 | 23779 |
| Gene name | ataxin 10 | Rho GTPase activating protein 8 | |
| Synonyms | E46L|HUMEEP|SCA10 | BPGAP1|PP610 | |
| Cytomap | 22q13.31 | 22q13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ataxin-10brain protein E46 homologspinocerebellar ataxia type 10 protein | rho GTPase-activating protein 8BCH domain-containing Cdc42GAP-like proteinBNIP-2 and Cdc42GAP homology domain-containing, proline-rich and Cdc42GAP-like protein subtype-1rho-type GTPase-activating protein 8 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9UBB4 | P85298 | |
| Ensembl transtripts involved in fusion gene | ENST00000498009, ENST00000252934, ENST00000381061, ENST00000402380, | ENST00000336963, ENST00000356099, ENST00000389773, ENST00000389774, ENST00000517296, ENST00000469872, | |
| Fusion gene scores | * DoF score | 16 X 12 X 11=2112 | 6 X 9 X 5=270 |
| # samples | 19 | 7 | |
| ** MAII score | log2(19/2112*10)=-3.47453851102751 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/270*10)=-1.94753258010586 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ATXN10 [Title/Abstract] AND ARHGAP8 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ATXN10(46098727)-ARHGAP8(45221363), # samples:1 ATXN10(46098727)-ARHGAP8(45241149), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ATXN10 | GO:0031175 | neuron projection development | 16498633 |
| Tgene | ARHGAP8 | GO:0070374 | positive regulation of ERK1 and ERK2 cascade | 20179103 |
| Fusion gene breakpoints across ATXN10 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ARHGAP8 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CG-4449-01A | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| ChimerDB4 | STAD | TCGA-CG-4449-01A | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
Top |
Fusion Gene ORF analysis for ATXN10-ARHGAP8 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000498009 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-3CDS | ENST00000498009 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 3UTR-intron | ENST00000498009 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 3UTR-intron | ENST00000498009 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 5CDS-intron | ENST00000252934 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 5CDS-intron | ENST00000252934 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| 5CDS-intron | ENST00000381061 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| 5CDS-intron | ENST00000381061 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000252934 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000252934 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000252934 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000252934 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000252934 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000252934 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000252934 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000252934 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000252934 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000252934 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000381061 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000381061 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000381061 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000381061 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000381061 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000381061 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000381061 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000381061 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| In-frame | ENST00000381061 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| In-frame | ENST00000381061 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-3CDS | ENST00000402380 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-3CDS | ENST00000402380 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-3CDS | ENST00000402380 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-3CDS | ENST00000402380 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-3CDS | ENST00000402380 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-3CDS | ENST00000402380 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-3CDS | ENST00000402380 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-3CDS | ENST00000402380 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-3CDS | ENST00000402380 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-3CDS | ENST00000402380 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| intron-intron | ENST00000402380 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + |
| intron-intron | ENST00000402380 | ENST00000469872 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000517296 | ARHGAP8 | chr22 | 45221363 | + | 1649 | 721 | 266 | 1537 | 423 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000389773 | ARHGAP8 | chr22 | 45221363 | + | 1727 | 721 | 266 | 1537 | 423 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000389774 | ARHGAP8 | chr22 | 45221363 | + | 1727 | 721 | 266 | 1537 | 423 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000336963 | ARHGAP8 | chr22 | 45221363 | + | 1624 | 721 | 266 | 1153 | 295 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000356099 | ARHGAP8 | chr22 | 45221363 | + | 1727 | 721 | 266 | 1537 | 423 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000517296 | ARHGAP8 | chr22 | 45221363 | + | 1840 | 912 | 265 | 1728 | 487 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000389773 | ARHGAP8 | chr22 | 45221363 | + | 1918 | 912 | 265 | 1728 | 487 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000389774 | ARHGAP8 | chr22 | 45221363 | + | 1918 | 912 | 265 | 1728 | 487 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000336963 | ARHGAP8 | chr22 | 45221363 | + | 1815 | 912 | 265 | 1344 | 359 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000356099 | ARHGAP8 | chr22 | 45221363 | + | 1918 | 912 | 265 | 1728 | 487 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000517296 | ARHGAP8 | chr22 | 45241149 | + | 1538 | 721 | 266 | 1426 | 386 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000389773 | ARHGAP8 | chr22 | 45241149 | + | 1616 | 721 | 266 | 1426 | 386 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000389774 | ARHGAP8 | chr22 | 45241149 | + | 1616 | 721 | 266 | 1426 | 386 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000336963 | ARHGAP8 | chr22 | 45241149 | + | 1513 | 721 | 266 | 1042 | 258 |
| ENST00000381061 | ATXN10 | chr22 | 46098727 | + | ENST00000356099 | ARHGAP8 | chr22 | 45241149 | + | 1616 | 721 | 266 | 1426 | 386 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000517296 | ARHGAP8 | chr22 | 45241149 | + | 1729 | 912 | 265 | 1617 | 450 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000389773 | ARHGAP8 | chr22 | 45241149 | + | 1807 | 912 | 265 | 1617 | 450 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000389774 | ARHGAP8 | chr22 | 45241149 | + | 1807 | 912 | 265 | 1617 | 450 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000336963 | ARHGAP8 | chr22 | 45241149 | + | 1704 | 912 | 265 | 1233 | 322 |
| ENST00000252934 | ATXN10 | chr22 | 46098727 | + | ENST00000356099 | ARHGAP8 | chr22 | 45241149 | + | 1807 | 912 | 265 | 1617 | 450 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000381061 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.012014804 | 0.9879852 |
| ENST00000381061 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.011250871 | 0.98874915 |
| ENST00000381061 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.011250871 | 0.98874915 |
| ENST00000381061 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.004906134 | 0.9950938 |
| ENST00000381061 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.011250871 | 0.98874915 |
| ENST00000252934 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.019339532 | 0.9806605 |
| ENST00000252934 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.017781697 | 0.9822183 |
| ENST00000252934 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.017781697 | 0.9822183 |
| ENST00000252934 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.007982896 | 0.99201715 |
| ENST00000252934 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221363 | + | 0.017781697 | 0.9822183 |
| ENST00000381061 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.00714024 | 0.9928598 |
| ENST00000381061 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.006806967 | 0.9931931 |
| ENST00000381061 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.006806967 | 0.9931931 |
| ENST00000381061 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.003609897 | 0.99639004 |
| ENST00000381061 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.006806967 | 0.9931931 |
| ENST00000252934 | ENST00000517296 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.013713081 | 0.98628694 |
| ENST00000252934 | ENST00000389773 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.012699616 | 0.98730046 |
| ENST00000252934 | ENST00000389774 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.012699616 | 0.98730046 |
| ENST00000252934 | ENST00000336963 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.004936072 | 0.99506396 |
| ENST00000252934 | ENST00000356099 | ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241149 | + | 0.012699616 | 0.98730046 |
Top |
Fusion Genomic Features for ATXN10-ARHGAP8 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221362 | + | 0.23358807 | 0.76641196 |
| ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241148 | + | 7.16E-06 | 0.99999285 |
| ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45221362 | + | 0.23358807 | 0.76641196 |
| ATXN10 | chr22 | 46098727 | + | ARHGAP8 | chr22 | 45241148 | + | 7.16E-06 | 0.99999285 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
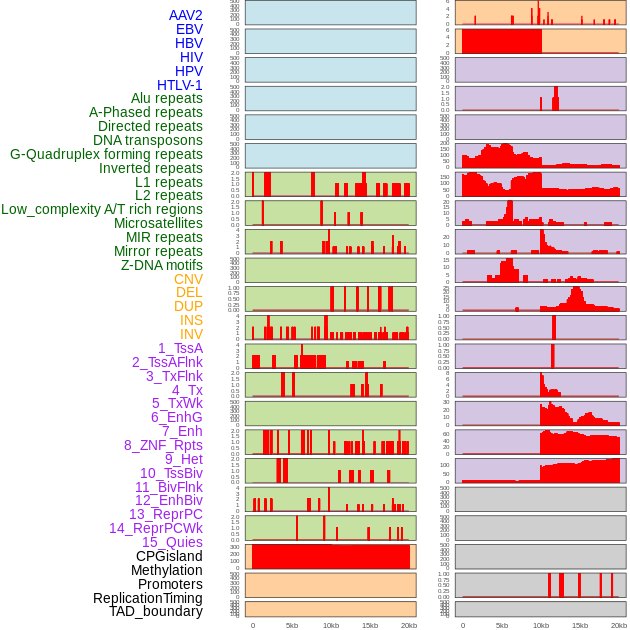 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
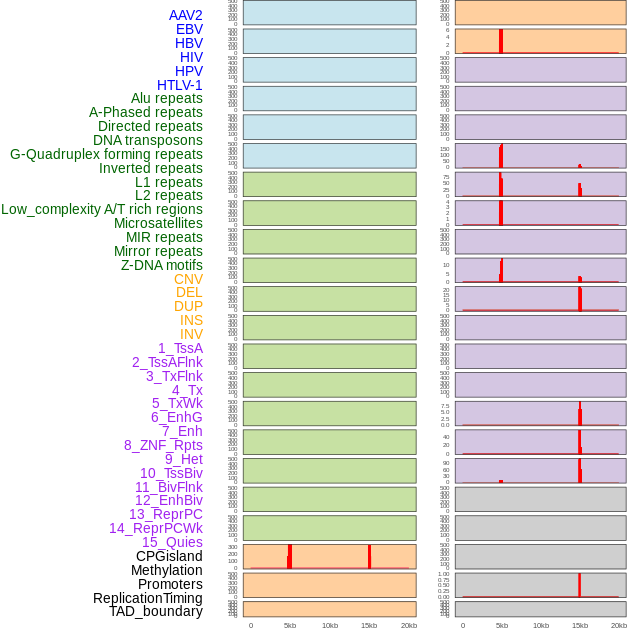 |
Top |
Fusion Protein Features for ATXN10-ARHGAP8 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:46098727/chr22:45221363) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATXN10 | ARHGAP8 |
| FUNCTION: Necessary for the survival of cerebellar neurons. Induces neuritogenesis by activating the Ras-MAP kinase pathway. May play a role in the maintenance of a critical intracellular glycosylation level and homeostasis. {ECO:0000250}. | FUNCTION: GTPase activator for the Rho-type GTPases by converting them to an inactive GDP-bound state. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45221363 | ENST00000356099 | 5 | 12 | 226_412 | 161 | 434.0 | Domain | Rho-GAP | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45221363 | ENST00000389774 | 6 | 13 | 226_412 | 192 | 465.0 | Domain | Rho-GAP | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45241149 | ENST00000356099 | 6 | 12 | 226_412 | 198 | 434.0 | Domain | Rho-GAP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45221363 | ENST00000356099 | 5 | 12 | 13_199 | 161 | 434.0 | Domain | CRAL-TRIO | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45221363 | ENST00000389774 | 6 | 13 | 13_199 | 192 | 465.0 | Domain | CRAL-TRIO | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45241149 | ENST00000356099 | 6 | 12 | 13_199 | 198 | 434.0 | Domain | CRAL-TRIO | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45241149 | ENST00000389774 | 7 | 13 | 13_199 | 229 | 465.0 | Domain | CRAL-TRIO | |
| Tgene | ARHGAP8 | chr22:46098727 | chr22:45241149 | ENST00000389774 | 7 | 13 | 226_412 | 229 | 465.0 | Domain | Rho-GAP |
Top |
Fusion Gene Sequence for ATXN10-ARHGAP8 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >8365_8365_1_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000336963_length(transcript)=1815nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCT GCCCACACAGCAGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGAC GTACCTGAGAGAGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAA CCAAGGGAAGCCCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCC GCTTCTGACCTTCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGG CCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGC TGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCC CTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTC TCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAA TAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGTGGA >8365_8365_1_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000336963_length(amino acids)=359AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFT -------------------------------------------------------------- >8365_8365_2_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000356099_length(transcript)=1918nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCT GCCCACACAGCAGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGAC GTACCTGAGAGAGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAA CCAAGGGAAGCCCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCC GCTTCTGACCTTCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACG GAGCCTCCCAGAGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAA CAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACAT GTTCACTGAACTGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGG GAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGC AGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTT GGCATCTGTAAAAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGT >8365_8365_2_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000356099_length(amino acids)=487AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFT VTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQI LRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWE -------------------------------------------------------------- >8365_8365_3_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000389773_length(transcript)=1918nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCT GCCCACACAGCAGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGAC GTACCTGAGAGAGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAA CCAAGGGAAGCCCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCC GCTTCTGACCTTCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACG GAGCCTCCCAGAGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAA CAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACAT GTTCACTGAACTGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGG GAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGC AGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTT GGCATCTGTAAAAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGT >8365_8365_3_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000389773_length(amino acids)=487AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFT VTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQI LRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWE -------------------------------------------------------------- >8365_8365_4_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000389774_length(transcript)=1918nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCT GCCCACACAGCAGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGAC GTACCTGAGAGAGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAA CCAAGGGAAGCCCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCC GCTTCTGACCTTCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACG GAGCCTCCCAGAGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAA CAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACAT GTTCACTGAACTGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGG GAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGC AGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTT GGCATCTGTAAAAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGT >8365_8365_4_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000389774_length(amino acids)=487AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFT VTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQI LRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWE -------------------------------------------------------------- >8365_8365_5_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000517296_length(transcript)=1840nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCT GCCCACACAGCAGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGAC GTACCTGAGAGAGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAA CCAAGGGAAGCCCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCC GCTTCTGACCTTCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACG GAGCCTCCCAGAGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAA CAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACAT GTTCACTGAACTGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGG GAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGC AGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTT >8365_8365_5_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45221363_ENST00000517296_length(amino acids)=487AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPTQQFGVSLQYLKDKNQGELIPPVLRFT VTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQI LRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWE -------------------------------------------------------------- >8365_8365_6_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000336963_length(transcript)=1704nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCT GCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTT TGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTA CGAGCAGATTCTCGGGATCACCTGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATT TGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAAAGA TCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCAC GGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTG TATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGAATT >8365_8365_6_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000336963_length(amino acids)=322AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPV -------------------------------------------------------------- >8365_8365_7_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000356099_length(transcript)=1807nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCT GCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTT TGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTA CGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTA CGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGT CTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGA GTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCA GGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTG TTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAG CCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGTGGACCGGGAT >8365_8365_7_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000356099_length(amino acids)=450AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPV NFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLA CVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL -------------------------------------------------------------- >8365_8365_8_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000389773_length(transcript)=1807nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCT GCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTT TGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTA CGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTA CGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGT CTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGA GTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCA GGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTG TTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAG CCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGTGGACCGGGAT >8365_8365_8_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000389773_length(amino acids)=450AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPV NFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLA CVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL -------------------------------------------------------------- >8365_8365_9_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000389774_length(transcript)=1807nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCT GCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTT TGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTA CGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTA CGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGT CTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGA GTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCA GGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTG TTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAG CCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGTGGACCGGGAT >8365_8365_9_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000389774_length(amino acids)=450AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPV NFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLA CVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL -------------------------------------------------------------- >8365_8365_10_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000517296_length(transcript)=1729nt_BP=912nt GGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGGC GGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATCC TACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGGC GGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGCT CTTCAAAGAGCAGCGGAACCGAGAAACAGCACCCAGGACTATCTTCCAAAGAGTTCTGGATATCCTAAAGAAATCTTCTCATGCTGTTGA GCTTGCCTGCAGAGATCCATCCCAAGTGGAAAACCTGGCTTCCAGTCTGCAGTTAATAACAGAATGCTTCAGGTGTCTTCGCAATGCTTG CATAGAGTGTTCTGTGAACCAGAATTCAATCAGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCG AGTGGAACAGGAATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTAT TGTTTGGGTGCATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTT TACATCCCTTAATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGA ATCAGAATGGCCCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCT GCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTT TGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTA CGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTA CGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGT CTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGA GTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCA GGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTG TTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAG >8365_8365_10_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000252934_ARHGAP8_chr22_45241149_ENST00000517296_length(amino acids)=450AA_BP=216 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRETAPRTIFQRVLDILKKSSHAVELACRDPSQVENLASSLQLITECFRCLRN ACIECSVNQNSIRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVWVHAFPELFLSCLNHPDKKIVAYSSMI LFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPV NFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLA CVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEAVPRTQATGLTKPTLPPSPLMAARRRL -------------------------------------------------------------- >8365_8365_11_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000336963_length(transcript)=1624nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCTGCCCACACAGC AGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAG AGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGC CCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCT TCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTC GGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTAC TATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAG GCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGC GAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCAT TAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGTGGACCGGGATAGAA >8365_8365_11_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000336963_length(amino acids)=295AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPT QQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLL -------------------------------------------------------------- >8365_8365_12_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000356099_length(transcript)=1727nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCTGCCCACACAGC AGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAG AGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGC CCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCT TCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAG AGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACC TGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAAC TGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAG CCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGAC GTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAA AAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGT >8365_8365_12_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000356099_length(amino acids)=423AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPT QQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLL TFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFT -------------------------------------------------------------- >8365_8365_13_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000389773_length(transcript)=1727nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCTGCCCACACAGC AGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAG AGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGC CCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCT TCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAG AGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACC TGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAAC TGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAG CCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGAC GTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAA AAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGT >8365_8365_13_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000389773_length(amino acids)=423AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPT QQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLL TFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFT -------------------------------------------------------------- >8365_8365_14_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000389774_length(transcript)=1727nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCTGCCCACACAGC AGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAG AGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGC CCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCT TCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAG AGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACC TGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAAC TGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAG CCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGAC GTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAA AAATAACCAGCCATTAGATGAATTCAGAACCTTCTAATGAAAACTCCATGCCTCTGGTCCTTGGACTCTTGTCCATGGTTCCTGAGCTGT >8365_8365_14_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000389774_length(amino acids)=423AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPT QQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLL TFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFT -------------------------------------------------------------- >8365_8365_15_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000517296_length(transcript)=1649nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CGTACGATGAGAAGCTCCAGAGCCTGCACGAGGGCCGGACGCCGCCTCCCACCAAGACACCACCGCCGCGGCCCCCGCTGCCCACACAGC AGTTTGGCGTCAGTCTGCAATACCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAG AGAAAGGCCTGCGCACCGAGGGCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGC CCGTGAACTTTGACGACTACGGGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCT TCCAGGCCTACGAGCAGATTCTCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAG AGCACAACTACGTCGTCCTCCGCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACC TGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAAC TGCTGATCGAGTACTATGAAAAGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAG CCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGAC GTCTCTAGTGTTGCGAACACTCTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAA >8365_8365_15_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45221363_ENST00000517296_length(amino acids)=423AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPYDEKLQSLHEGRTPPPTKTPPPRPPLPT QQFGVSLQYLKDKNQGELIPPVLRFTVTYLREKGLRTEGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLL TFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVVLRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFT -------------------------------------------------------------- >8365_8365_16_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000336963_length(transcript)=1513nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCTGCGCACCGAGG GCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTTTGACGACTACG GGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTACGAGCAGATTC TCGGGATCACCTGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGAATTTGATCTGGCCA TCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAAAGATCTTCAGCACC CCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGCCACGGACACAAGCC ACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACTCTGTATATTTCGAG CTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGAATTCAGAACCTTCT >8365_8365_16_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000336963_length(amino acids)=258AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRT -------------------------------------------------------------- >8365_8365_17_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000356099_length(transcript)=1616nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCTGCGCACCGAGG GCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTTTGACGACTACG GGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTACGAGCAGATTC TCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTACGTCGTCCTCC GCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGA ATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAA AGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGC CACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACT CTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGA >8365_8365_17_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000356099_length(amino acids)=386AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRT EGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVV LRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEA -------------------------------------------------------------- >8365_8365_18_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000389773_length(transcript)=1616nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCTGCGCACCGAGG GCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTTTGACGACTACG GGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTACGAGCAGATTC TCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTACGTCGTCCTCC GCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGA ATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAA AGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGC CACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACT CTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGA >8365_8365_18_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000389773_length(amino acids)=386AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRT EGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVV LRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEA -------------------------------------------------------------- >8365_8365_19_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000389774_length(transcript)=1616nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCTGCGCACCGAGG GCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTTTGACGACTACG GGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTACGAGCAGATTC TCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTACGTCGTCCTCC GCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGA ATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAA AGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGC CACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACT CTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGA >8365_8365_19_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000389774_length(amino acids)=386AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRT EGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVV LRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEA -------------------------------------------------------------- >8365_8365_20_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000517296_length(transcript)=1538nt_BP=721nt AGGCGGGACTTCCGCCGGCGCCCCCTCCCCCGCGGCGCCGTCTCCTCCTCCCGCCTGAGGCGAGTCTGGGCTCAGCCTAGAGCTCTCCGG CGGCGGCGCAGCTTCAGGGCAGCGCGGGCTGCAGCGGCGGCGGCGGTTAGGGCTGTGTAGGGCGAGGCCTCCCCCTTCCTCCTCGCCATC CTACTCCTCCCTCCTCGTCATCCTCCCCCTTCGTCCTCCTCGCCTTCCTCCTCCTCGTCAGGCTCGACCCAGCTGTGAGCGGCAAGATGG CGGCGCCCAGGCCGCCGCCTGCCAGGCTGTCGGGCGTCATGGTGCCGGCGCCCATCCAAGACCTGGAGGCCCTGCGCGCGCTCACGGCGC TCTTCAAAGAGCAGCGGAACCGGAACTTGGATACGATTGGTGTTGCTGTTGATTTGATTCTTCTGTTTCGTGAACTGCGAGTGGAACAGG AATCTCTGTTGACAGCTTTTCGCTGTGGCCTGCAGTTTTTAGGCAACATTGCCTCACGGAATGAAGATTCCCAGTCTATTGTTTGGGTGC ATGCTTTCCCAGAACTGTTTTTGTCTTGCTTAAATCATCCGGACAAAAAAATTGTTGCCTACTCTTCAATGATTTTGTTTACATCCCTTA ATCATGAAAGAATGAAAGAACTGGAGGAGAACCTCAATATTGCAATTGATGTCATAGATGCTTACCAAAAACATCCTGAATCAGAATGGC CCCTCAAAGACAAAAATCAAGGCGAACTCATCCCCCCTGTGCTGAGGTTCACAGTGACGTACCTGAGAGAGAAAGGCCTGCGCACCGAGG GCCTGTTCCGGAGATCCGCCAGCGTGCAGACCGTCCGCGAGATCCAGAGGCTCTACAACCAAGGGAAGCCCGTGAACTTTGACGACTACG GGGACATTCACATCCCTGCCGTGATCCTGAAGACCTTCCTGCGAGAGCTGCCCCAGCCGCTTCTGACCTTCCAGGCCTACGAGCAGATTC TCGGGATCACCTGTGTGGAGAGCAGCCTGCGTGTCACTGGCTGCCGCCAGATCTTACGGAGCCTCCCAGAGCACAACTACGTCGTCCTCC GCTACCTCATGGGCTTCCTGCATGCGGTGTCCCGGGAGAGCATCTTCAACAAAATGAACAGCTCTAACCTGGCCTGTGTCTTCGGGCTGA ATTTGATCTGGCCATCCCAGGGGGTCTCCTCCCTGAGTGCCCTTGTGCCCCTGAACATGTTCACTGAACTGCTGATCGAGTACTATGAAA AGATCTTCAGCACCCCGGAGGCACCTGGGGAGCACGGCCTGGCACCATGGGAACAGGGGAGCAGGGCAGCCCCTTTGCAGGAGGCTGTGC CACGGACACAAGCCACGGGCCTCACCAAGCCTACCCTACCTCCGAGTCCCCTGATGGCAGCCAGAAGACGTCTCTAGTGTTGCGAACACT CTGTATATTTCGAGCTACCTCCCACACCTGTCTGTGCACTTGTATGTTTTGTAAACTTGGCATCTGTAAAAATAACCAGCCATTAGATGA >8365_8365_20_ATXN10-ARHGAP8_ATXN10_chr22_46098727_ENST00000381061_ARHGAP8_chr22_45241149_ENST00000517296_length(amino acids)=386AA_BP=152 MAAPRPPPARLSGVMVPAPIQDLEALRALTALFKEQRNRNLDTIGVAVDLILLFRELRVEQESLLTAFRCGLQFLGNIASRNEDSQSIVW VHAFPELFLSCLNHPDKKIVAYSSMILFTSLNHERMKELEENLNIAIDVIDAYQKHPESEWPLKDKNQGELIPPVLRFTVTYLREKGLRT EGLFRRSASVQTVREIQRLYNQGKPVNFDDYGDIHIPAVILKTFLRELPQPLLTFQAYEQILGITCVESSLRVTGCRQILRSLPEHNYVV LRYLMGFLHAVSRESIFNKMNSSNLACVFGLNLIWPSQGVSSLSALVPLNMFTELLIEYYEKIFSTPEAPGEHGLAPWEQGSRAAPLQEA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ATXN10-ARHGAP8 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ATXN10-ARHGAP8 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ATXN10-ARHGAP8 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies