
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SMURF1-PTCD1 (FusionGDB2 ID:84322) |
Fusion Gene Summary for SMURF1-PTCD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SMURF1-PTCD1 | Fusion gene ID: 84322 | Hgene | Tgene | Gene symbol | SMURF1 | PTCD1 | Gene ID | 57154 | 26024 |
| Gene name | SMAD specific E3 ubiquitin protein ligase 1 | pentatricopeptide repeat domain 1 | |
| Synonyms | - | - | |
| Cytomap | 7q22.1 | 7q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | E3 ubiquitin-protein ligase SMURF1E3 ubiquitin ligase SMURF1HECT-type E3 ubiquitin transferase SMURF1Smad ubiquitination regulatory factor 1Smad-specific E3 ubiquitin ligase 1hSMURF1 | pentatricopeptide repeat-containing protein 1, mitochondrial | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000361125, ENST00000361368, ENST00000480055, | ENST00000485746, ENST00000292478, ENST00000555673, | |
| Fusion gene scores | * DoF score | 19 X 8 X 12=1824 | 3 X 2 X 3=18 |
| # samples | 24 | 4 | |
| ** MAII score | log2(24/1824*10)=-2.92599941855622 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/18*10)=1.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: SMURF1 [Title/Abstract] AND PTCD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SMURF1(98741348)-PTCD1(99027429), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SMURF1 | GO:0000209 | protein polyubiquitination | 19937093 |
| Hgene | SMURF1 | GO:0006511 | ubiquitin-dependent protein catabolic process | 10458166|12151385|19937093 |
| Hgene | SMURF1 | GO:0006611 | protein export from nucleus | 11278251 |
| Hgene | SMURF1 | GO:0016567 | protein ubiquitination | 11278251 |
| Hgene | SMURF1 | GO:0030154 | cell differentiation | 10458166 |
| Hgene | SMURF1 | GO:0030509 | BMP signaling pathway | 21572392 |
| Hgene | SMURF1 | GO:0030512 | negative regulation of transforming growth factor beta receptor signaling pathway | 11278251|12151385 |
| Hgene | SMURF1 | GO:0030514 | negative regulation of BMP signaling pathway | 27214554 |
| Hgene | SMURF1 | GO:0030579 | ubiquitin-dependent SMAD protein catabolic process | 11278251|12151385 |
| Hgene | SMURF1 | GO:0032801 | receptor catabolic process | 12151385 |
| Hgene | SMURF1 | GO:0034394 | protein localization to cell surface | 12151385 |
| Hgene | SMURF1 | GO:0043161 | proteasome-mediated ubiquitin-dependent protein catabolic process | 11278251 |
| Hgene | SMURF1 | GO:1903861 | positive regulation of dendrite extension | 23999003 |
| Tgene | PTCD1 | GO:0042780 | tRNA 3'-end processing | 21857155 |
| Fusion gene breakpoints across SMURF1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
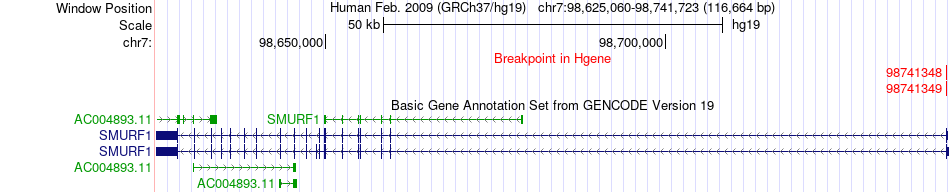 |
| Fusion gene breakpoints across PTCD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
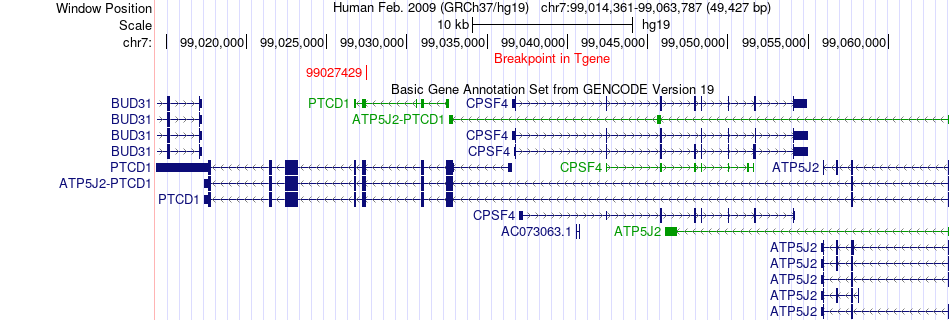 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-L5-A4OQ-01A | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| ChimerDB4 | ESCA | TCGA-L5-A4OQ | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
Top |
Fusion Gene ORF analysis for SMURF1-PTCD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000361125 | ENST00000485746 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| 5CDS-5UTR | ENST00000361125 | ENST00000485746 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| 5CDS-5UTR | ENST00000361368 | ENST00000485746 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| 5CDS-5UTR | ENST00000361368 | ENST00000485746 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361125 | ENST00000292478 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361125 | ENST00000292478 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361125 | ENST00000555673 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361125 | ENST00000555673 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361368 | ENST00000292478 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361368 | ENST00000292478 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361368 | ENST00000555673 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| In-frame | ENST00000361368 | ENST00000555673 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| intron-3CDS | ENST00000480055 | ENST00000292478 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| intron-3CDS | ENST00000480055 | ENST00000292478 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| intron-3CDS | ENST00000480055 | ENST00000555673 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| intron-3CDS | ENST00000480055 | ENST00000555673 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| intron-5UTR | ENST00000480055 | ENST00000485746 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - |
| intron-5UTR | ENST00000480055 | ENST00000485746 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000361368 | SMURF1 | chr7 | 98741348 | - | ENST00000292478 | PTCD1 | chr7 | 99027429 | - | 5031 | 294 | 294 | 1802 | 502 |
| ENST00000361368 | SMURF1 | chr7 | 98741348 | - | ENST00000555673 | PTCD1 | chr7 | 99027429 | - | 2021 | 294 | 294 | 1802 | 502 |
| ENST00000361125 | SMURF1 | chr7 | 98741348 | - | ENST00000292478 | PTCD1 | chr7 | 99027429 | - | 5112 | 375 | 375 | 1883 | 502 |
| ENST00000361125 | SMURF1 | chr7 | 98741348 | - | ENST00000555673 | PTCD1 | chr7 | 99027429 | - | 2102 | 375 | 375 | 1883 | 502 |
| ENST00000361368 | SMURF1 | chr7 | 98741349 | - | ENST00000292478 | PTCD1 | chr7 | 99027429 | - | 5031 | 294 | 294 | 1802 | 502 |
| ENST00000361368 | SMURF1 | chr7 | 98741349 | - | ENST00000555673 | PTCD1 | chr7 | 99027429 | - | 2021 | 294 | 294 | 1802 | 502 |
| ENST00000361125 | SMURF1 | chr7 | 98741349 | - | ENST00000292478 | PTCD1 | chr7 | 99027429 | - | 5112 | 375 | 375 | 1883 | 502 |
| ENST00000361125 | SMURF1 | chr7 | 98741349 | - | ENST00000555673 | PTCD1 | chr7 | 99027429 | - | 2102 | 375 | 375 | 1883 | 502 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000361368 | ENST00000292478 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - | 0.005317466 | 0.9946825 |
| ENST00000361368 | ENST00000555673 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - | 0.017284036 | 0.98271596 |
| ENST00000361125 | ENST00000292478 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - | 0.0055393 | 0.9944607 |
| ENST00000361125 | ENST00000555673 | SMURF1 | chr7 | 98741348 | - | PTCD1 | chr7 | 99027429 | - | 0.015550864 | 0.9844491 |
| ENST00000361368 | ENST00000292478 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - | 0.005317466 | 0.9946825 |
| ENST00000361368 | ENST00000555673 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - | 0.017284036 | 0.98271596 |
| ENST00000361125 | ENST00000292478 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - | 0.0055393 | 0.9944607 |
| ENST00000361125 | ENST00000555673 | SMURF1 | chr7 | 98741349 | - | PTCD1 | chr7 | 99027429 | - | 0.015550864 | 0.9844491 |
Top |
Fusion Genomic Features for SMURF1-PTCD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
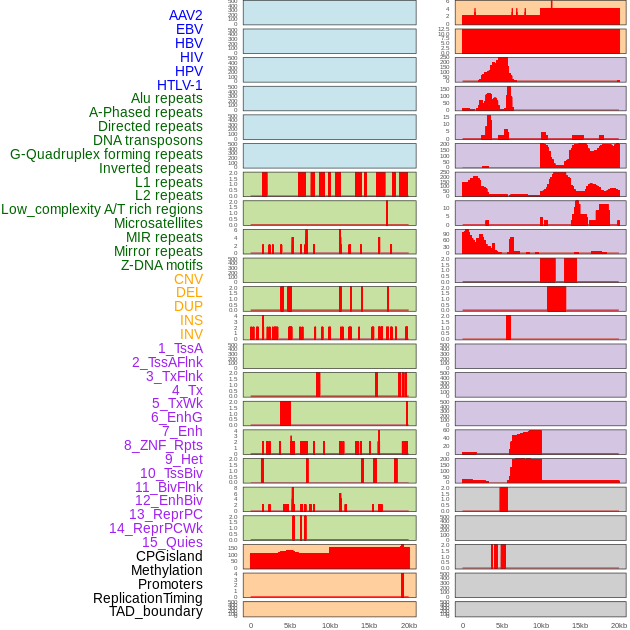 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SMURF1-PTCD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:98741348/chr7:99027429) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 207_245 | 198 | 701.0 | Repeat | Note=PPR 3 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 246_280 | 198 | 701.0 | Repeat | Note=PPR 4 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 281_317 | 198 | 701.0 | Repeat | Note=PPR 5 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 318_354 | 198 | 701.0 | Repeat | Note=PPR 6 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 519_553 | 198 | 701.0 | Repeat | Note=PPR 7 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 554_585 | 198 | 701.0 | Repeat | Note=PPR 8 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 586_620 | 198 | 701.0 | Repeat | Note=PPR 9 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 207_245 | 198 | 701.0 | Repeat | Note=PPR 3 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 246_280 | 198 | 701.0 | Repeat | Note=PPR 4 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 281_317 | 198 | 701.0 | Repeat | Note=PPR 5 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 318_354 | 198 | 701.0 | Repeat | Note=PPR 6 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 519_553 | 198 | 701.0 | Repeat | Note=PPR 7 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 554_585 | 198 | 701.0 | Repeat | Note=PPR 8 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 586_620 | 198 | 701.0 | Repeat | Note=PPR 9 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 1_120 | 18 | 758.0 | Domain | C2 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 234_267 | 18 | 758.0 | Domain | WW 1 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 306_339 | 18 | 758.0 | Domain | WW 2 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 420_757 | 18 | 758.0 | Domain | HECT |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 1_120 | 18 | 732.0 | Domain | C2 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 234_267 | 18 | 732.0 | Domain | WW 1 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 306_339 | 18 | 732.0 | Domain | WW 2 |
| Hgene | SMURF1 | chr7:98741348 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 420_757 | 18 | 732.0 | Domain | HECT |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 1_120 | 18 | 758.0 | Domain | C2 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 234_267 | 18 | 758.0 | Domain | WW 1 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 306_339 | 18 | 758.0 | Domain | WW 2 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361125 | - | 1 | 19 | 420_757 | 18 | 758.0 | Domain | HECT |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 1_120 | 18 | 732.0 | Domain | C2 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 234_267 | 18 | 732.0 | Domain | WW 1 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 306_339 | 18 | 732.0 | Domain | WW 2 |
| Hgene | SMURF1 | chr7:98741349 | chr7:99027429 | ENST00000361368 | - | 1 | 18 | 420_757 | 18 | 732.0 | Domain | HECT |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 135_171 | 198 | 701.0 | Repeat | Note=PPR 1 | |
| Tgene | PTCD1 | chr7:98741348 | chr7:99027429 | ENST00000292478 | 2 | 8 | 172_206 | 198 | 701.0 | Repeat | Note=PPR 2 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 135_171 | 198 | 701.0 | Repeat | Note=PPR 1 | |
| Tgene | PTCD1 | chr7:98741349 | chr7:99027429 | ENST00000292478 | 2 | 8 | 172_206 | 198 | 701.0 | Repeat | Note=PPR 2 |
Top |
Fusion Gene Sequence for SMURF1-PTCD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >84322_84322_1_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361125_PTCD1_chr7_99027429_ENST00000292478_length(transcript)=5112nt_BP=375nt GGCAGCGGCGGAAGCGGCGAGGGCGGCGGGCGTCCGGCTCTGAGGTGGTGGAGGCGGCGGAGGCGGCGGCGGAGGCGGCGGCGGCTCGGG ACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCCGGACGCCTG GGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGGCCGGGCCGG GCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCTCCAGCATCA AGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAGTCCCCCTGG AAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATACCACGCGCTG CTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTCACAGAGGAG ACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATGCTGAGTCTA GGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCCTCAGAGCTG CTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAGGCAGGCAAC CTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAGCCTCCGGAA GCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCCCTGAAGCCA CCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACCCCAGCTGAC CGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTCACGCTACTG GCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTGACATTCTTT AACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGCCTCGTCCCC AACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAGTCCCAGGTG ACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTGAAGGACATG AAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGGTACCAAGGG AAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACCCCGCACCCC TGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGGTGATGGGAG CACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGGGGAAGAGCC AGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAGGTCCAAGTG CAGCTCCAGCCACCTTTGCGTGTCACCTTCACGGGACTTCCAGCTCCAGCTACCTTTGTGTGTCACCTCACACACCACAAGGGGGCTGGG GCATCTGGTCCCTGGGGCCTGGGCCGCCCCGCCGGGTTCCATAGGCCGATGCTCTGAAAGAAGAGACGTGGGGCTCGAGAGATTTAAAGA TTTTATTTTTACAAATCACAGCTGATAGACAGCGAAGCCTTCCCCATAGAGACCGTGCTCCAACTCGGGCCTGGGGCACTGCTCGCTGCT CCCAGGAAGGGGGTGGCGTGACAGGCAGGAACCTGCGAAGTCCAGAGTCCAGGGTGGAGCGCGCCAGCCTCAGCCAGAGCAGCCACGACA GCCACAGTGTGTGCACTCGATGATGCGGCCCTGCAACGGAGGAGGACAGTGAGACGATGCCACTGCGCCACGCTCGCCCCTGCACACTCA CATATGTGGCAACCCTCCCACGAAGGACCTGCCACCATGCCATATAGGGACACACCTCAGAAACCCTTCCTTGACAGCTCTGGACAGGGA AAATTTGGCTCCCTCATGAAGGTAGAACCAGCTGCTGTTGACACCGAGGTTACATCTGTATGTCTATTTATAATATGTTCTGCAAATCCA ACACACGTTTGCCAATCAAGAAAAAGAAATCGGTGTGAATGAGTCTCGTTATTCTGCTAAGTGAGCATGACAGACCCTGCGATGAGCAGA CGTGGCTCTGCTACTGTTTGGGGACTTCAGGGGGGCCTCTGGGCTGGTACACTCTGGTGGGGGAAGAGGGCAGGAGACTATGCACTTGAG TCACACCCTTCTGGCCCAGAGCCCCCCAGAAAGAAGGGTCTTGTCCCCCAGGCCTGGTGCGGCCCAACACTTGGCCAGCCAGAAAGCCCT AGAACAGTGGCTTGTGTTTATTTTACTTTTTCAAGTTCTTTTTTTGGAAGAACAAGACCATAGTTTAAGTAAACAGGATCCTCTGGTGAA ACCCAGGTAAGTCTACAGCGGGCTGTTTTGGCCACAGGGCTGAAGCAGCACCCCAGCCCACCAGCCCCTGACCTGGACTCCTTGTGGAAT CTGGGCACTCAGAGGAAGGGGGCTTCTGCCACTCTGCCACCTGTCCCTGCCTCCATCAGAAAACCAACACCCCAGTCTTCCGTCGGGGAG GCGGCCCTTGCTCGCCCCCACTGCTCAGTACCCAAGTCCTCAGCATCCAGCCACAGCTCTCCATTGTCAGTCTCACTGCAGCATAAAGGG GACTCATGTGAAGAGGCCCCTGTGTGGAGCTGGGGAAAAGAAGGCCAGGCTGGCAGATGGGCGGTGGGGCCAACAACTGTGCTGAGGGGC TGCACTGAGCGGCCACTGCTGTGACTCTGCCTCGGGCCACAGCTGCCTTTCAGAGGGGCTTGGAACCGGATGGAGCTCAGCTCCTGTCCC TCAGCACCACTCCTGAGGCGCCTGGCCTAGGAGTGGTACTTGGAACAGAAAGTTCTGAAAGAAGAAACACAGTGGGCTGGGCGCAGTAGC TCATGCCTGTAATCCCGGCACTTTGGGAGGCTGAGGCGGGTGGATCACCTGAGGTCGGGAGTTCGAGACCAGCCTGAGCAACATTGAGAA ACCCCGTCTCTACTAAAAATACAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGTCCCAGCTACTCAGGAGGATGAGGCAGGAGAACC GCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCAAGATGGCATCACTGCACTCCAGCCTGGGCGACAAAGCAAGACTCCGTCTTGGGGG GGCGGGAAAGATAGTGATGGTAATGTTAAAGTATCACTGTGAGGACTGAAAGGGACAGGAACTCACTGGTTGTCCTTCCCTGATGTCACC CTGCCACCACCTTGGGATTAGGGCTCCCCACCACCATTTCCTAAGTGAGGAAAGGGGTTCAGTAATTTGCCCAAAAGTGGAGTTGAGATT GACCCCAGACCTAACAAACACACAGCCACACGCTGCCTCACATGGATTCCTGAATACAGGGACCCACTCCCACGAGGGAGAGCCAGCAGG ACATCCAGGGACAAAACGACATTCCAGCCCAACCAAATAACATAAGATCCCTTGCAGTCGACTAAGGCAGAATTTTGAGCTGAAAACAAC ACCAAGCTTGAGTGTCAGACATTACCACTTCCAGCTTGCTTTTGGGCACGCGGCAGATGCAGTTCGTCCCGAAGTTGGTGTCCCGTGTCT GAATGCACCGCAGGCAGCACAAGTTCTCATATCCTTGCTTTTTCCATTTTGCAATCAGGTTTTTGTCTGCATAGCCTTCTTTAATACAAT ATTCATAGAGTTCTGTCAAAAAGATGGGGAAAGAGCATCAGGCCATGGTCTAAAAACCTTCCCCACCCTTGATCAAAAAAAGCATTCAGG CCGGGTGCAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCCGAGGCAGGCGGATCACCTGAGGTCAGGAGTTCAGGACCAGCCCG GCCAACATGGTAAAACCCCGTCTCTACTAAAAATACAAAAATTACTCGGGCGTGGTAGCAGCTGTAATCCCAGCTACTTAGGAGGCTGAG GCAGGAGAATCACTTGAACCCAGGAGGCGGAGGTTGTAGTGACCTGAGGTCGTGCCACTGGACTCCAGCCTGGGTGACAGCGAAACTCCA TCTCAAAAAAAAAAAGGCATTCAGTATTGCAACGGGACAGTCCTTGGAGGAGGAACAAAAAAAAAAAGTACTTAGGCCAGGCAAGGTGCC TCACACCTGTAATCCCAGCACTTTTGGAAGCCAACGCCAGAGGATCATTTGAGTTAAGAAACCAGCCTGGGCCAAGGGCCCATCTCCACA AAAAATTTAAAAATTAGCTGGGTGTGGTGGTGCACACCTGTAGTCACAGCTACTCAGGAGGTTGAGGTGAGAGGATCCCTTGAGCCCAGA >84322_84322_1_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361125_PTCD1_chr7_99027429_ENST00000292478_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_2_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361125_PTCD1_chr7_99027429_ENST00000555673_length(transcript)=2102nt_BP=375nt GGCAGCGGCGGAAGCGGCGAGGGCGGCGGGCGTCCGGCTCTGAGGTGGTGGAGGCGGCGGAGGCGGCGGCGGAGGCGGCGGCGGCTCGGG ACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCCGGACGCCTG GGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGGCCGGGCCGG GCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCTCCAGCATCA AGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAGTCCCCCTGG AAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATACCACGCGCTG CTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTCACAGAGGAG ACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATGCTGAGTCTA GGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCCTCAGAGCTG CTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAGGCAGGCAAC CTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAGCCTCCGGAA GCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCCCTGAAGCCA CCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACCCCAGCTGAC CGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTCACGCTACTG GCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTGACATTCTTT AACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGCCTCGTCCCC AACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAGTCCCAGGTG ACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTGAAGGACATG AAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGGTACCAAGGG AAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACCCCGCACCCC TGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGGTGATGGGAG CACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGGGGAAGAGCC AGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAGGTCCAAGTG >84322_84322_2_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361125_PTCD1_chr7_99027429_ENST00000555673_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_3_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361368_PTCD1_chr7_99027429_ENST00000292478_length(transcript)=5031nt_BP=294nt CGGCTCGGGACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCC GGACGCCTGGGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGG CCGGGCCGGGCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCT CCAGCATCAAGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAG TCCCCCTGGAAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATAC CACGCGCTGCTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTC ACAGAGGAGACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATG CTGAGTCTAGGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCC TCAGAGCTGCTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAG GCAGGCAACCTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAG CCTCCGGAAGCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCC CTGAAGCCACCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACC CCAGCTGACCGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTC ACGCTACTGGCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTG ACATTCTTTAACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGC CTCGTCCCCAACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAG TCCCAGGTGACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTG AAGGACATGAAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGG TACCAAGGGAAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACC CCGCACCCCTGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGG TGATGGGAGCACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGG GGAAGAGCCAGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAG GTCCAAGTGCAGCTCCAGCCACCTTTGCGTGTCACCTTCACGGGACTTCCAGCTCCAGCTACCTTTGTGTGTCACCTCACACACCACAAG GGGGCTGGGGCATCTGGTCCCTGGGGCCTGGGCCGCCCCGCCGGGTTCCATAGGCCGATGCTCTGAAAGAAGAGACGTGGGGCTCGAGAG ATTTAAAGATTTTATTTTTACAAATCACAGCTGATAGACAGCGAAGCCTTCCCCATAGAGACCGTGCTCCAACTCGGGCCTGGGGCACTG CTCGCTGCTCCCAGGAAGGGGGTGGCGTGACAGGCAGGAACCTGCGAAGTCCAGAGTCCAGGGTGGAGCGCGCCAGCCTCAGCCAGAGCA GCCACGACAGCCACAGTGTGTGCACTCGATGATGCGGCCCTGCAACGGAGGAGGACAGTGAGACGATGCCACTGCGCCACGCTCGCCCCT GCACACTCACATATGTGGCAACCCTCCCACGAAGGACCTGCCACCATGCCATATAGGGACACACCTCAGAAACCCTTCCTTGACAGCTCT GGACAGGGAAAATTTGGCTCCCTCATGAAGGTAGAACCAGCTGCTGTTGACACCGAGGTTACATCTGTATGTCTATTTATAATATGTTCT GCAAATCCAACACACGTTTGCCAATCAAGAAAAAGAAATCGGTGTGAATGAGTCTCGTTATTCTGCTAAGTGAGCATGACAGACCCTGCG ATGAGCAGACGTGGCTCTGCTACTGTTTGGGGACTTCAGGGGGGCCTCTGGGCTGGTACACTCTGGTGGGGGAAGAGGGCAGGAGACTAT GCACTTGAGTCACACCCTTCTGGCCCAGAGCCCCCCAGAAAGAAGGGTCTTGTCCCCCAGGCCTGGTGCGGCCCAACACTTGGCCAGCCA GAAAGCCCTAGAACAGTGGCTTGTGTTTATTTTACTTTTTCAAGTTCTTTTTTTGGAAGAACAAGACCATAGTTTAAGTAAACAGGATCC TCTGGTGAAACCCAGGTAAGTCTACAGCGGGCTGTTTTGGCCACAGGGCTGAAGCAGCACCCCAGCCCACCAGCCCCTGACCTGGACTCC TTGTGGAATCTGGGCACTCAGAGGAAGGGGGCTTCTGCCACTCTGCCACCTGTCCCTGCCTCCATCAGAAAACCAACACCCCAGTCTTCC GTCGGGGAGGCGGCCCTTGCTCGCCCCCACTGCTCAGTACCCAAGTCCTCAGCATCCAGCCACAGCTCTCCATTGTCAGTCTCACTGCAG CATAAAGGGGACTCATGTGAAGAGGCCCCTGTGTGGAGCTGGGGAAAAGAAGGCCAGGCTGGCAGATGGGCGGTGGGGCCAACAACTGTG CTGAGGGGCTGCACTGAGCGGCCACTGCTGTGACTCTGCCTCGGGCCACAGCTGCCTTTCAGAGGGGCTTGGAACCGGATGGAGCTCAGC TCCTGTCCCTCAGCACCACTCCTGAGGCGCCTGGCCTAGGAGTGGTACTTGGAACAGAAAGTTCTGAAAGAAGAAACACAGTGGGCTGGG CGCAGTAGCTCATGCCTGTAATCCCGGCACTTTGGGAGGCTGAGGCGGGTGGATCACCTGAGGTCGGGAGTTCGAGACCAGCCTGAGCAA CATTGAGAAACCCCGTCTCTACTAAAAATACAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGTCCCAGCTACTCAGGAGGATGAGGC AGGAGAACCGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCAAGATGGCATCACTGCACTCCAGCCTGGGCGACAAAGCAAGACTCCG TCTTGGGGGGGCGGGAAAGATAGTGATGGTAATGTTAAAGTATCACTGTGAGGACTGAAAGGGACAGGAACTCACTGGTTGTCCTTCCCT GATGTCACCCTGCCACCACCTTGGGATTAGGGCTCCCCACCACCATTTCCTAAGTGAGGAAAGGGGTTCAGTAATTTGCCCAAAAGTGGA GTTGAGATTGACCCCAGACCTAACAAACACACAGCCACACGCTGCCTCACATGGATTCCTGAATACAGGGACCCACTCCCACGAGGGAGA GCCAGCAGGACATCCAGGGACAAAACGACATTCCAGCCCAACCAAATAACATAAGATCCCTTGCAGTCGACTAAGGCAGAATTTTGAGCT GAAAACAACACCAAGCTTGAGTGTCAGACATTACCACTTCCAGCTTGCTTTTGGGCACGCGGCAGATGCAGTTCGTCCCGAAGTTGGTGT CCCGTGTCTGAATGCACCGCAGGCAGCACAAGTTCTCATATCCTTGCTTTTTCCATTTTGCAATCAGGTTTTTGTCTGCATAGCCTTCTT TAATACAATATTCATAGAGTTCTGTCAAAAAGATGGGGAAAGAGCATCAGGCCATGGTCTAAAAACCTTCCCCACCCTTGATCAAAAAAA GCATTCAGGCCGGGTGCAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCCGAGGCAGGCGGATCACCTGAGGTCAGGAGTTCAGG ACCAGCCCGGCCAACATGGTAAAACCCCGTCTCTACTAAAAATACAAAAATTACTCGGGCGTGGTAGCAGCTGTAATCCCAGCTACTTAG GAGGCTGAGGCAGGAGAATCACTTGAACCCAGGAGGCGGAGGTTGTAGTGACCTGAGGTCGTGCCACTGGACTCCAGCCTGGGTGACAGC GAAACTCCATCTCAAAAAAAAAAAGGCATTCAGTATTGCAACGGGACAGTCCTTGGAGGAGGAACAAAAAAAAAAAGTACTTAGGCCAGG CAAGGTGCCTCACACCTGTAATCCCAGCACTTTTGGAAGCCAACGCCAGAGGATCATTTGAGTTAAGAAACCAGCCTGGGCCAAGGGCCC ATCTCCACAAAAAATTTAAAAATTAGCTGGGTGTGGTGGTGCACACCTGTAGTCACAGCTACTCAGGAGGTTGAGGTGAGAGGATCCCTT >84322_84322_3_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361368_PTCD1_chr7_99027429_ENST00000292478_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_4_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361368_PTCD1_chr7_99027429_ENST00000555673_length(transcript)=2021nt_BP=294nt CGGCTCGGGACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCC GGACGCCTGGGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGG CCGGGCCGGGCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCT CCAGCATCAAGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAG TCCCCCTGGAAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATAC CACGCGCTGCTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTC ACAGAGGAGACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATG CTGAGTCTAGGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCC TCAGAGCTGCTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAG GCAGGCAACCTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAG CCTCCGGAAGCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCC CTGAAGCCACCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACC CCAGCTGACCGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTC ACGCTACTGGCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTG ACATTCTTTAACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGC CTCGTCCCCAACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAG TCCCAGGTGACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTG AAGGACATGAAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGG TACCAAGGGAAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACC CCGCACCCCTGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGG TGATGGGAGCACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGG GGAAGAGCCAGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAG >84322_84322_4_SMURF1-PTCD1_SMURF1_chr7_98741348_ENST00000361368_PTCD1_chr7_99027429_ENST00000555673_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_5_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361125_PTCD1_chr7_99027429_ENST00000292478_length(transcript)=5112nt_BP=375nt GGCAGCGGCGGAAGCGGCGAGGGCGGCGGGCGTCCGGCTCTGAGGTGGTGGAGGCGGCGGAGGCGGCGGCGGAGGCGGCGGCGGCTCGGG ACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCCGGACGCCTG GGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGGCCGGGCCGG GCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCTCCAGCATCA AGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAGTCCCCCTGG AAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATACCACGCGCTG CTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTCACAGAGGAG ACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATGCTGAGTCTA GGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCCTCAGAGCTG CTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAGGCAGGCAAC CTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAGCCTCCGGAA GCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCCCTGAAGCCA CCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACCCCAGCTGAC CGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTCACGCTACTG GCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTGACATTCTTT AACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGCCTCGTCCCC AACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAGTCCCAGGTG ACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTGAAGGACATG AAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGGTACCAAGGG AAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACCCCGCACCCC TGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGGTGATGGGAG CACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGGGGAAGAGCC AGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAGGTCCAAGTG CAGCTCCAGCCACCTTTGCGTGTCACCTTCACGGGACTTCCAGCTCCAGCTACCTTTGTGTGTCACCTCACACACCACAAGGGGGCTGGG GCATCTGGTCCCTGGGGCCTGGGCCGCCCCGCCGGGTTCCATAGGCCGATGCTCTGAAAGAAGAGACGTGGGGCTCGAGAGATTTAAAGA TTTTATTTTTACAAATCACAGCTGATAGACAGCGAAGCCTTCCCCATAGAGACCGTGCTCCAACTCGGGCCTGGGGCACTGCTCGCTGCT CCCAGGAAGGGGGTGGCGTGACAGGCAGGAACCTGCGAAGTCCAGAGTCCAGGGTGGAGCGCGCCAGCCTCAGCCAGAGCAGCCACGACA GCCACAGTGTGTGCACTCGATGATGCGGCCCTGCAACGGAGGAGGACAGTGAGACGATGCCACTGCGCCACGCTCGCCCCTGCACACTCA CATATGTGGCAACCCTCCCACGAAGGACCTGCCACCATGCCATATAGGGACACACCTCAGAAACCCTTCCTTGACAGCTCTGGACAGGGA AAATTTGGCTCCCTCATGAAGGTAGAACCAGCTGCTGTTGACACCGAGGTTACATCTGTATGTCTATTTATAATATGTTCTGCAAATCCA ACACACGTTTGCCAATCAAGAAAAAGAAATCGGTGTGAATGAGTCTCGTTATTCTGCTAAGTGAGCATGACAGACCCTGCGATGAGCAGA CGTGGCTCTGCTACTGTTTGGGGACTTCAGGGGGGCCTCTGGGCTGGTACACTCTGGTGGGGGAAGAGGGCAGGAGACTATGCACTTGAG TCACACCCTTCTGGCCCAGAGCCCCCCAGAAAGAAGGGTCTTGTCCCCCAGGCCTGGTGCGGCCCAACACTTGGCCAGCCAGAAAGCCCT AGAACAGTGGCTTGTGTTTATTTTACTTTTTCAAGTTCTTTTTTTGGAAGAACAAGACCATAGTTTAAGTAAACAGGATCCTCTGGTGAA ACCCAGGTAAGTCTACAGCGGGCTGTTTTGGCCACAGGGCTGAAGCAGCACCCCAGCCCACCAGCCCCTGACCTGGACTCCTTGTGGAAT CTGGGCACTCAGAGGAAGGGGGCTTCTGCCACTCTGCCACCTGTCCCTGCCTCCATCAGAAAACCAACACCCCAGTCTTCCGTCGGGGAG GCGGCCCTTGCTCGCCCCCACTGCTCAGTACCCAAGTCCTCAGCATCCAGCCACAGCTCTCCATTGTCAGTCTCACTGCAGCATAAAGGG GACTCATGTGAAGAGGCCCCTGTGTGGAGCTGGGGAAAAGAAGGCCAGGCTGGCAGATGGGCGGTGGGGCCAACAACTGTGCTGAGGGGC TGCACTGAGCGGCCACTGCTGTGACTCTGCCTCGGGCCACAGCTGCCTTTCAGAGGGGCTTGGAACCGGATGGAGCTCAGCTCCTGTCCC TCAGCACCACTCCTGAGGCGCCTGGCCTAGGAGTGGTACTTGGAACAGAAAGTTCTGAAAGAAGAAACACAGTGGGCTGGGCGCAGTAGC TCATGCCTGTAATCCCGGCACTTTGGGAGGCTGAGGCGGGTGGATCACCTGAGGTCGGGAGTTCGAGACCAGCCTGAGCAACATTGAGAA ACCCCGTCTCTACTAAAAATACAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGTCCCAGCTACTCAGGAGGATGAGGCAGGAGAACC GCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCAAGATGGCATCACTGCACTCCAGCCTGGGCGACAAAGCAAGACTCCGTCTTGGGGG GGCGGGAAAGATAGTGATGGTAATGTTAAAGTATCACTGTGAGGACTGAAAGGGACAGGAACTCACTGGTTGTCCTTCCCTGATGTCACC CTGCCACCACCTTGGGATTAGGGCTCCCCACCACCATTTCCTAAGTGAGGAAAGGGGTTCAGTAATTTGCCCAAAAGTGGAGTTGAGATT GACCCCAGACCTAACAAACACACAGCCACACGCTGCCTCACATGGATTCCTGAATACAGGGACCCACTCCCACGAGGGAGAGCCAGCAGG ACATCCAGGGACAAAACGACATTCCAGCCCAACCAAATAACATAAGATCCCTTGCAGTCGACTAAGGCAGAATTTTGAGCTGAAAACAAC ACCAAGCTTGAGTGTCAGACATTACCACTTCCAGCTTGCTTTTGGGCACGCGGCAGATGCAGTTCGTCCCGAAGTTGGTGTCCCGTGTCT GAATGCACCGCAGGCAGCACAAGTTCTCATATCCTTGCTTTTTCCATTTTGCAATCAGGTTTTTGTCTGCATAGCCTTCTTTAATACAAT ATTCATAGAGTTCTGTCAAAAAGATGGGGAAAGAGCATCAGGCCATGGTCTAAAAACCTTCCCCACCCTTGATCAAAAAAAGCATTCAGG CCGGGTGCAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCCGAGGCAGGCGGATCACCTGAGGTCAGGAGTTCAGGACCAGCCCG GCCAACATGGTAAAACCCCGTCTCTACTAAAAATACAAAAATTACTCGGGCGTGGTAGCAGCTGTAATCCCAGCTACTTAGGAGGCTGAG GCAGGAGAATCACTTGAACCCAGGAGGCGGAGGTTGTAGTGACCTGAGGTCGTGCCACTGGACTCCAGCCTGGGTGACAGCGAAACTCCA TCTCAAAAAAAAAAAGGCATTCAGTATTGCAACGGGACAGTCCTTGGAGGAGGAACAAAAAAAAAAAGTACTTAGGCCAGGCAAGGTGCC TCACACCTGTAATCCCAGCACTTTTGGAAGCCAACGCCAGAGGATCATTTGAGTTAAGAAACCAGCCTGGGCCAAGGGCCCATCTCCACA AAAAATTTAAAAATTAGCTGGGTGTGGTGGTGCACACCTGTAGTCACAGCTACTCAGGAGGTTGAGGTGAGAGGATCCCTTGAGCCCAGA >84322_84322_5_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361125_PTCD1_chr7_99027429_ENST00000292478_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_6_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361125_PTCD1_chr7_99027429_ENST00000555673_length(transcript)=2102nt_BP=375nt GGCAGCGGCGGAAGCGGCGAGGGCGGCGGGCGTCCGGCTCTGAGGTGGTGGAGGCGGCGGAGGCGGCGGCGGAGGCGGCGGCGGCTCGGG ACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCCGGACGCCTG GGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGGCCGGGCCGG GCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCTCCAGCATCA AGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAGTCCCCCTGG AAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATACCACGCGCTG CTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTCACAGAGGAG ACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATGCTGAGTCTA GGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCCTCAGAGCTG CTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAGGCAGGCAAC CTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAGCCTCCGGAA GCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCCCTGAAGCCA CCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACCCCAGCTGAC CGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTCACGCTACTG GCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTGACATTCTTT AACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGCCTCGTCCCC AACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAGTCCCAGGTG ACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTGAAGGACATG AAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGGTACCAAGGG AAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACCCCGCACCCC TGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGGTGATGGGAG CACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGGGGAAGAGCC AGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAGGTCCAAGTG >84322_84322_6_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361125_PTCD1_chr7_99027429_ENST00000555673_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_7_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361368_PTCD1_chr7_99027429_ENST00000292478_length(transcript)=5031nt_BP=294nt CGGCTCGGGACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCC GGACGCCTGGGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGG CCGGGCCGGGCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCT CCAGCATCAAGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAG TCCCCCTGGAAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATAC CACGCGCTGCTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTC ACAGAGGAGACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATG CTGAGTCTAGGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCC TCAGAGCTGCTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAG GCAGGCAACCTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAG CCTCCGGAAGCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCC CTGAAGCCACCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACC CCAGCTGACCGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTC ACGCTACTGGCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTG ACATTCTTTAACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGC CTCGTCCCCAACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAG TCCCAGGTGACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTG AAGGACATGAAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGG TACCAAGGGAAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACC CCGCACCCCTGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGG TGATGGGAGCACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGG GGAAGAGCCAGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAG GTCCAAGTGCAGCTCCAGCCACCTTTGCGTGTCACCTTCACGGGACTTCCAGCTCCAGCTACCTTTGTGTGTCACCTCACACACCACAAG GGGGCTGGGGCATCTGGTCCCTGGGGCCTGGGCCGCCCCGCCGGGTTCCATAGGCCGATGCTCTGAAAGAAGAGACGTGGGGCTCGAGAG ATTTAAAGATTTTATTTTTACAAATCACAGCTGATAGACAGCGAAGCCTTCCCCATAGAGACCGTGCTCCAACTCGGGCCTGGGGCACTG CTCGCTGCTCCCAGGAAGGGGGTGGCGTGACAGGCAGGAACCTGCGAAGTCCAGAGTCCAGGGTGGAGCGCGCCAGCCTCAGCCAGAGCA GCCACGACAGCCACAGTGTGTGCACTCGATGATGCGGCCCTGCAACGGAGGAGGACAGTGAGACGATGCCACTGCGCCACGCTCGCCCCT GCACACTCACATATGTGGCAACCCTCCCACGAAGGACCTGCCACCATGCCATATAGGGACACACCTCAGAAACCCTTCCTTGACAGCTCT GGACAGGGAAAATTTGGCTCCCTCATGAAGGTAGAACCAGCTGCTGTTGACACCGAGGTTACATCTGTATGTCTATTTATAATATGTTCT GCAAATCCAACACACGTTTGCCAATCAAGAAAAAGAAATCGGTGTGAATGAGTCTCGTTATTCTGCTAAGTGAGCATGACAGACCCTGCG ATGAGCAGACGTGGCTCTGCTACTGTTTGGGGACTTCAGGGGGGCCTCTGGGCTGGTACACTCTGGTGGGGGAAGAGGGCAGGAGACTAT GCACTTGAGTCACACCCTTCTGGCCCAGAGCCCCCCAGAAAGAAGGGTCTTGTCCCCCAGGCCTGGTGCGGCCCAACACTTGGCCAGCCA GAAAGCCCTAGAACAGTGGCTTGTGTTTATTTTACTTTTTCAAGTTCTTTTTTTGGAAGAACAAGACCATAGTTTAAGTAAACAGGATCC TCTGGTGAAACCCAGGTAAGTCTACAGCGGGCTGTTTTGGCCACAGGGCTGAAGCAGCACCCCAGCCCACCAGCCCCTGACCTGGACTCC TTGTGGAATCTGGGCACTCAGAGGAAGGGGGCTTCTGCCACTCTGCCACCTGTCCCTGCCTCCATCAGAAAACCAACACCCCAGTCTTCC GTCGGGGAGGCGGCCCTTGCTCGCCCCCACTGCTCAGTACCCAAGTCCTCAGCATCCAGCCACAGCTCTCCATTGTCAGTCTCACTGCAG CATAAAGGGGACTCATGTGAAGAGGCCCCTGTGTGGAGCTGGGGAAAAGAAGGCCAGGCTGGCAGATGGGCGGTGGGGCCAACAACTGTG CTGAGGGGCTGCACTGAGCGGCCACTGCTGTGACTCTGCCTCGGGCCACAGCTGCCTTTCAGAGGGGCTTGGAACCGGATGGAGCTCAGC TCCTGTCCCTCAGCACCACTCCTGAGGCGCCTGGCCTAGGAGTGGTACTTGGAACAGAAAGTTCTGAAAGAAGAAACACAGTGGGCTGGG CGCAGTAGCTCATGCCTGTAATCCCGGCACTTTGGGAGGCTGAGGCGGGTGGATCACCTGAGGTCGGGAGTTCGAGACCAGCCTGAGCAA CATTGAGAAACCCCGTCTCTACTAAAAATACAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGTCCCAGCTACTCAGGAGGATGAGGC AGGAGAACCGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCAAGATGGCATCACTGCACTCCAGCCTGGGCGACAAAGCAAGACTCCG TCTTGGGGGGGCGGGAAAGATAGTGATGGTAATGTTAAAGTATCACTGTGAGGACTGAAAGGGACAGGAACTCACTGGTTGTCCTTCCCT GATGTCACCCTGCCACCACCTTGGGATTAGGGCTCCCCACCACCATTTCCTAAGTGAGGAAAGGGGTTCAGTAATTTGCCCAAAAGTGGA GTTGAGATTGACCCCAGACCTAACAAACACACAGCCACACGCTGCCTCACATGGATTCCTGAATACAGGGACCCACTCCCACGAGGGAGA GCCAGCAGGACATCCAGGGACAAAACGACATTCCAGCCCAACCAAATAACATAAGATCCCTTGCAGTCGACTAAGGCAGAATTTTGAGCT GAAAACAACACCAAGCTTGAGTGTCAGACATTACCACTTCCAGCTTGCTTTTGGGCACGCGGCAGATGCAGTTCGTCCCGAAGTTGGTGT CCCGTGTCTGAATGCACCGCAGGCAGCACAAGTTCTCATATCCTTGCTTTTTCCATTTTGCAATCAGGTTTTTGTCTGCATAGCCTTCTT TAATACAATATTCATAGAGTTCTGTCAAAAAGATGGGGAAAGAGCATCAGGCCATGGTCTAAAAACCTTCCCCACCCTTGATCAAAAAAA GCATTCAGGCCGGGTGCAGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCCGAGGCAGGCGGATCACCTGAGGTCAGGAGTTCAGG ACCAGCCCGGCCAACATGGTAAAACCCCGTCTCTACTAAAAATACAAAAATTACTCGGGCGTGGTAGCAGCTGTAATCCCAGCTACTTAG GAGGCTGAGGCAGGAGAATCACTTGAACCCAGGAGGCGGAGGTTGTAGTGACCTGAGGTCGTGCCACTGGACTCCAGCCTGGGTGACAGC GAAACTCCATCTCAAAAAAAAAAAGGCATTCAGTATTGCAACGGGACAGTCCTTGGAGGAGGAACAAAAAAAAAAAGTACTTAGGCCAGG CAAGGTGCCTCACACCTGTAATCCCAGCACTTTTGGAAGCCAACGCCAGAGGATCATTTGAGTTAAGAAACCAGCCTGGGCCAAGGGCCC ATCTCCACAAAAAATTTAAAAATTAGCTGGGTGTGGTGGTGCACACCTGTAGTCACAGCTACTCAGGAGGTTGAGGTGAGAGGATCCCTT >84322_84322_7_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361368_PTCD1_chr7_99027429_ENST00000292478_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- >84322_84322_8_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361368_PTCD1_chr7_99027429_ENST00000555673_length(transcript)=2021nt_BP=294nt CGGCTCGGGACTGGGCTCGGCTGGAAGCAGCGAGGGTCAGAGCGCCGCAGCAAGCGCCGATCTCCCGGCTCGACCATCCGCCTGCCGCCC GGACGCCTGGGCCGCGGAGTTTGTGTCCCGGCTCGGACCCCGGCGCCCAGCCCGGAGCCGTAACCTTGAGGCGGCGGCGGCGGGGCCGGG CCGGGCCGGGCTGGGGGGCGGTGGCGCTGGATCCGCGGCTGCCCGATCGTTGGCGGGAGATGTCGAACCCCGGGACACGCAGGAACGGCT CCAGCATCAAGATCCGTCTGACAGATGAAAAAGCGGGACCTGGAGCCCTCGGACGCCACCTACACGGCCCTGTTCAACGTCTGTGCCGAG TCCCCCTGGAAGGACTCAGCTCTACAGAGCGCCCTGAAGCTCCGGCAGCAGCTGCAGGCCAAAAACTTCGAGCTCAACTTGAAAACATAC CACGCGCTGCTGAAGATGGCTGCCAAGTGCGCAGACCTTAGGATGTGCCTCGATGTGTTCAAGGAAATCATCCACAAAGGGCACGTGGTC ACAGAGGAGACCTTCAGTTTCCTGCTCATGGGCTGCATCCAAGACAAGAAGACAGGCTTCCGGTACGCCCTCCAGGTGTGGCGGCTGATG CTGAGTCTAGGGCTACAGCCGAGCCGGGACAGCTACAACCTGCTGTTGGTGGCAGCTCGGGACTGTGGCCTAGGGGACCCCCAGGTGGCC TCAGAGCTGCTTCTGAAGCCCAGGGAGGAGGCGACTGTGCTTCAGCCCCCAGTGAGCAGGCAGCGGCCAAGGAGGACAGCCCAGGCCAAG GCAGGCAACCTCATGTCAGCCATGCTGCATGTGGAGGCCCTGGAGAGGCAGCTGTTTCTGGAACCTTCTCAGGCACTTGGGCCTCCAGAG CCTCCGGAAGCCAGAGTGCCCGGCAAGGCCCAACCAGAGGTGGATACTAAGGCAGAGCCCAGCCACACAGCAGCCCTCACCGCAGTGGCC CTGAAGCCACCTCCCGTGGAGCTGGAAGTCAACCTCCTGACCCCCGGGGCCGTTCCCCCTACAGTGGTCTCCTTTGGAACGGTGACCACC CCAGCTGACCGGCTGGCCTTGATAGGGGGCCTGGAGGGCTTCCTGAGCAAGATGGCAGAGCACAGGCAGCAGCCCGACATCAGGACCCTC ACGCTACTGGCCGAGGTGGTGGAGTCCGGGAGTCCTGCAGAGTCCTTGCTGCTGGCCCTCCTGGATGAGCACCAGGTAGAGGCCGACCTG ACATTCTTTAACACGCTGGTGAGAAAGAAGAGCAAGCTGGGAGACCTGGAGGGGGCCAAGGCGCTGTTGCCGGTCCTGGCAAAGAGGGGC CTCGTCCCCAACCTGCAGACATTCTGCAACCTGGCCATCGGGTGCCACAGGCCGAAGGACGGTCTACAGCTTCTCACAGACATGAAGAAG TCCCAGGTGACCCCCAACACTCACATCTACAGTGCCCTCATCAACGCGGCCATCAGGAAGCTGAACTACACCTATCTCATCAGCATCTTG AAGGACATGAAGCAGAACAGGGTCCCGGTGAACGAAGTGGTCATCCGCCAGCTGGAGTTTGCAGCCCAGTACCCTCCCACCTTTGACCGG TACCAAGGGAAGAACACCTACCTGGAGAAGATTGACGGCTTCCGAGCCTATTACAAGCAGTGGCTGACAGTGATGCCCGCAGAGGAAACC CCGCACCCCTGGCAGAAGTTCCGGACCAAGCCCCAGGGGGACCAGGACACCGGCAAGGAGGCTGATGACGGATGTGCCCTTGGGGGCAGG TGATGGGAGCACAGCTGGAACAATGTGCTCGGCCCCCAGTGCTCTGTGGGAGCCCCAGGACAAGTGAGCTGGTGTCACCTCCTGCCTGGG GGAAGAGCCAGGCCCTGAGGAACAGCCGCAGCGTGTCACAGGTGTTGGTGAGGACACACACTAGGCCCAAGGTGCCTGTGCTCCCAGCAG >84322_84322_8_SMURF1-PTCD1_SMURF1_chr7_98741349_ENST00000361368_PTCD1_chr7_99027429_ENST00000555673_length(amino acids)=502AA_BP=0 MKKRDLEPSDATYTALFNVCAESPWKDSALQSALKLRQQLQAKNFELNLKTYHALLKMAAKCADLRMCLDVFKEIIHKGHVVTEETFSFL LMGCIQDKKTGFRYALQVWRLMLSLGLQPSRDSYNLLLVAARDCGLGDPQVASELLLKPREEATVLQPPVSRQRPRRTAQAKAGNLMSAM LHVEALERQLFLEPSQALGPPEPPEARVPGKAQPEVDTKAEPSHTAALTAVALKPPPVELEVNLLTPGAVPPTVVSFGTVTTPADRLALI GGLEGFLSKMAEHRQQPDIRTLTLLAEVVESGSPAESLLLALLDEHQVEADLTFFNTLVRKKSKLGDLEGAKALLPVLAKRGLVPNLQTF CNLAIGCHRPKDGLQLLTDMKKSQVTPNTHIYSALINAAIRKLNYTYLISILKDMKQNRVPVNEVVIRQLEFAAQYPPTFDRYQGKNTYL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SMURF1-PTCD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SMURF1-PTCD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SMURF1-PTCD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies