
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SOD2-CHMP1A (FusionGDB2 ID:85118) |
Fusion Gene Summary for SOD2-CHMP1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SOD2-CHMP1A | Fusion gene ID: 85118 | Hgene | Tgene | Gene symbol | SOD2 | CHMP1A | Gene ID | 100129518 | 5119 |
| Gene name | SOD2 overlapping transcript 1 | charged multivesicular body protein 1A | |
| Synonyms | SOD2 | CHMP1|PCH8|PCOLN3|PRSM1|VPS46-1|VPS46A | |
| Cytomap | 6q25.3 | 16q24.3 | |
| Type of gene | ncRNA | protein-coding | |
| Description | Superoxide dismutase [Mn], mitochondrial | charged multivesicular body protein 1acharged multivesicular body protein 1/chromatin modifying protein 1chromatin modifying protein 1Aprocollagen (type III) N-endopeptidaseprotease, metallo, 1, 33kDvacuolar protein sorting-associated protein 46-1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9HD42 | |
| Ensembl transtripts involved in fusion gene | ENST00000337404, ENST00000367054, ENST00000367055, ENST00000444946, ENST00000538183, ENST00000546087, ENST00000452684, ENST00000535372, | ENST00000547614, ENST00000397901, ENST00000535997, ENST00000550102, ENST00000253475, | |
| Fusion gene scores | * DoF score | 11 X 13 X 4=572 | 45 X 11 X 21=10395 |
| # samples | 16 | 48 | |
| ** MAII score | log2(16/572*10)=-1.83794324189103 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(48/10395*10)=-4.43671154213721 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SOD2 [Title/Abstract] AND CHMP1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SOD2(160113693)-CHMP1A(89713739), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | SOD2-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CHMP1A | GO:0007076 | mitotic chromosome condensation | 11559747 |
| Tgene | CHMP1A | GO:0016192 | vesicle-mediated transport | 11559748 |
| Tgene | CHMP1A | GO:0016458 | gene silencing | 11559747 |
| Tgene | CHMP1A | GO:0045892 | negative regulation of transcription, DNA-templated | 11559747 |
| Fusion gene breakpoints across SOD2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CHMP1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
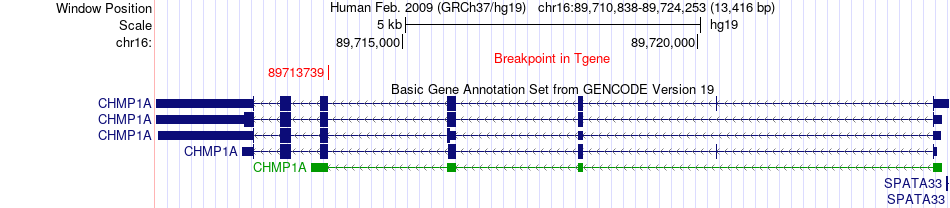 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-VS-A953-01A | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
Top |
Fusion Gene ORF analysis for SOD2-CHMP1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000337404 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000367054 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000367055 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000444946 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000538183 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000546087 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000337404 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000337404 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000337404 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000367054 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000367055 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000444946 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000444946 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000444946 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000538183 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000538183 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000538183 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000546087 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000546087 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000546087 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000546087 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000337404 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367054 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367054 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367054 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367055 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367055 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367055 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000444946 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000538183 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000452684 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000452684 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000452684 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000452684 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000535372 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000535372 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000535372 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-3CDS | ENST00000535372 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-5UTR | ENST00000452684 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| intron-5UTR | ENST00000535372 | ENST00000547614 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000538183 | SOD2 | chr6 | 160113693 | - | ENST00000253475 | CHMP1A | chr16 | 89713739 | - | 2354 | 387 | 95 | 877 | 260 |
| ENST00000367055 | SOD2 | chr6 | 160113693 | - | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2267 | 293 | 1 | 783 | 260 |
| ENST00000367055 | SOD2 | chr6 | 160113693 | - | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2235 | 293 | 1 | 783 | 260 |
| ENST00000367055 | SOD2 | chr6 | 160113693 | - | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 809 | 293 | 1 | 783 | 260 |
| ENST00000367054 | SOD2 | chr6 | 160113693 | - | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2261 | 287 | 61 | 777 | 238 |
| ENST00000367054 | SOD2 | chr6 | 160113693 | - | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2229 | 287 | 61 | 777 | 238 |
| ENST00000367054 | SOD2 | chr6 | 160113693 | - | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 803 | 287 | 61 | 777 | 238 |
| ENST00000444946 | SOD2 | chr6 | 160113693 | - | ENST00000253475 | CHMP1A | chr16 | 89713739 | - | 2267 | 300 | 8 | 790 | 260 |
| ENST00000337404 | SOD2 | chr6 | 160113693 | - | ENST00000253475 | CHMP1A | chr16 | 89713739 | - | 2304 | 337 | 45 | 827 | 260 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000538183 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.20473322 | 0.7952668 |
| ENST00000367055 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.19669642 | 0.80330354 |
| ENST00000367055 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.18685873 | 0.8131413 |
| ENST00000367055 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.0089651 | 0.9910349 |
| ENST00000367054 | ENST00000397901 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.18558654 | 0.8144135 |
| ENST00000367054 | ENST00000535997 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.17482673 | 0.8251733 |
| ENST00000367054 | ENST00000550102 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.008161354 | 0.99183863 |
| ENST00000444946 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.21009488 | 0.7899051 |
| ENST00000337404 | ENST00000253475 | SOD2 | chr6 | 160113693 | - | CHMP1A | chr16 | 89713739 | - | 0.2231694 | 0.77683055 |
Top |
Fusion Genomic Features for SOD2-CHMP1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
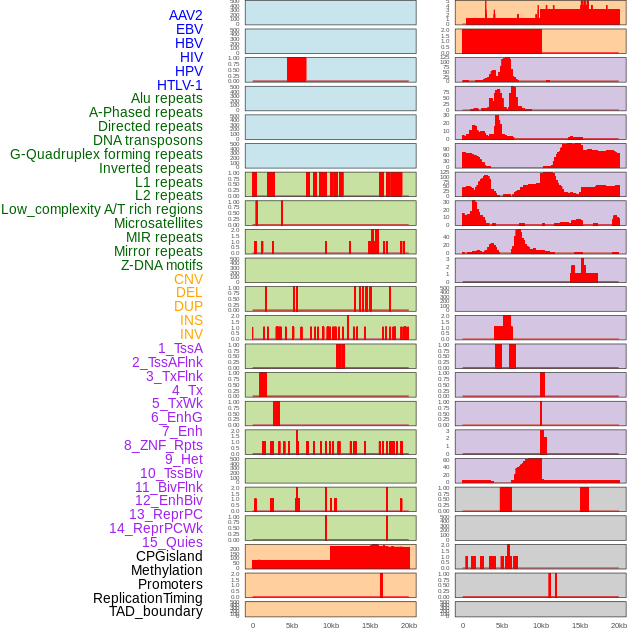 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SOD2-CHMP1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr6:160113693/chr16:89713739) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CHMP1A |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Probable peripherally associated component of the endosomal sorting required for transport complex III (ESCRT-III) which is involved in multivesicular bodies (MVBs) formation and sorting of endosomal cargo proteins into MVBs. MVBs contain intraluminal vesicles (ILVs) that are generated by invagination and scission from the limiting membrane of the endosome and mostly are delivered to lysosomes enabling degradation of membrane proteins, such as stimulated growth factor receptors, lysosomal enzymes and lipids. The MVB pathway appears to require the sequential function of ESCRT-O, -I,-II and -III complexes. ESCRT-III proteins mostly dissociate from the invaginating membrane before the ILV is released. The ESCRT machinery also functions in topologically equivalent membrane fission events, such as the terminal stages of cytokinesis and the budding of enveloped viruses (HIV-1 and other lentiviruses). ESCRT-III proteins are believed to mediate the necessary vesicle extrusion and/or membrane fission activities, possibly in conjunction with the AAA ATPase VPS4. Involved in cytokinesis. Involved in recruiting VPS4A and/or VPS4B to the midbody of dividing cells. May also be involved in chromosome condensation. Targets the Polycomb group (PcG) protein BMI1/PCGF4 to regions of condensed chromatin. May play a role in stable cell cycle progression and in PcG gene silencing. {ECO:0000269|PubMed:11559747, ECO:0000269|PubMed:11559748, ECO:0000269|PubMed:19129479, ECO:0000269|PubMed:23045692}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CHMP1A | chr6:160113693 | chr16:89713739 | ENST00000397901 | 3 | 7 | 102_124 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CHMP1A | chr6:160113693 | chr16:89713739 | ENST00000397901 | 3 | 7 | 185_195 | 84 | 197.0 | Motif | Note=MIT-interacting motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CHMP1A | chr6:160113693 | chr16:89713739 | ENST00000397901 | 3 | 7 | 5_47 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for SOD2-CHMP1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >85118_85118_1_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000337404_CHMP1A_chr16_89713739_ENST00000253475_length(transcript)=2304nt_BP=337nt GCGCTTTCTTAAGGCCCGCGGGCGGCGCAGGAGCGGCACTCGTGGCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGC GGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGGCACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGG CAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCTGGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAG CACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAAGTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGT GACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCT GGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCA GATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAG CCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTG GAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCC AGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGG TGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGG GCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAG CGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACG CTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCT GGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGC CCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAG CCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGG GCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCA GCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCA TTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCAT TTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAG GGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGT CGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGG GCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGG TAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGG >85118_85118_1_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000337404_CHMP1A_chr16_89713739_ENST00000253475_length(amino acids)=260AA_BP=97 MWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- >85118_85118_2_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2261nt_BP=287nt GTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGGCACCAG CAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCTGGAACC TCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAAGTACCA GGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCT CCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCC TGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGC CCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGT GCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGC GGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGG GTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGT GGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTG TTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCAC AGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGG GTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCA TGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTT TGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCC CCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAAC AACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCA GCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAG GCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTT TTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCC TGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCG TTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATC AACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGG GGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGATCC >85118_85118_2_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=238AA_BP=75 MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGDQEYGPGDQSPGQG PEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQPAARGRLCRGRELCAQPGGPAVT -------------------------------------------------------------- >85118_85118_3_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2229nt_BP=287nt GTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGGCACCAG CAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCTGGAACC TCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAAGTACCA GGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCT CCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCC TGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGC CCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGT GCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGC GGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGG GTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGT GGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTG TTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCAC AGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGG GTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCA TGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTT TGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCC CCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAAC AACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCA GCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAG GCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTT TTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCC TGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCG TTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATC AACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGG >85118_85118_3_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=238AA_BP=75 MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGDQEYGPGDQSPGQG PEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQPAARGRLCRGRELCAQPGGPAVT -------------------------------------------------------------- >85118_85118_4_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=803nt_BP=287nt GTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGGCACCAG CAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCTGGAACC TCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAAGTACCA GGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCT CCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCC TGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGC CCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGT GCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGC >85118_85118_4_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367054_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=238AA_BP=75 MLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEKYQEALAKGDQEYGPGDQSPGQG PEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQPAARGRLCRGRELCAQPGGPAVT -------------------------------------------------------------- >85118_85118_5_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2267nt_BP=293nt GCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGG CACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCT GGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAA GTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGA AGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCA CCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCC AGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACT AGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGA CCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGG CGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGG CCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCT GCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGG CACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACT CCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCC AGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGG TGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGC TCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCT GTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCG TCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGC TGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTT TTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCT CAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTC ACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCC AAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCC AGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAAT >85118_85118_5_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=260AA_BP=97 LWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- >85118_85118_6_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2235nt_BP=293nt GCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGG CACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCT GGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAA GTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGA AGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCA CCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCC AGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACT AGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGA CCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGG CGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGG CCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCT GCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGG CACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACT CCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCC AGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGG TGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGC TCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCT GTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCG TCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGC TGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTT TTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCT CAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTC ACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCC AAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCC >85118_85118_6_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=260AA_BP=97 LWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- >85118_85118_7_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=809nt_BP=293nt GCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGTGCGG CACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCGCCCT GGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGGAGAA GTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGA AGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCA CCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCC AGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACT AGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGA >85118_85118_7_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000367055_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=260AA_BP=97 LWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- >85118_85118_8_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000444946_CHMP1A_chr16_89713739_ENST00000253475_length(transcript)=2267nt_BP=300nt ACTCGTGGCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAG TGTGCGGCACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACG GCGCCCTGGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCG AGGAGAAGTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGAC CTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGC TCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAG CTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTG AGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTT GTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTA GGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCA AGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGT CAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCC AAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTC CATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAA GCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCT CTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGT CTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCT ACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGG AGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAG GACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGG TTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTC CCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACG TGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAG CCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCC ATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATA >85118_85118_8_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000444946_CHMP1A_chr16_89713739_ENST00000253475_length(amino acids)=260AA_BP=97 MWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- >85118_85118_9_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000538183_CHMP1A_chr16_89713739_ENST00000253475_length(transcript)=2354nt_BP=387nt CGGGGCGGCGGTGCCCTTGCGGCGCAGCTGGGGTCGCGGCCCTGCTCCCCGCGCTTTCTTAAGGCCCGCGGGCGGCGCAGGAGCGGCACT CGTGGCTGTGGTGGCTTCGGCAGCGGCTTCAGCAGATCGGCGGCATCAGCGGTAGCACCAGCACTAGCAGCATGTTGAGCCGGGCAGTGT GCGGCACCAGCAGGCAGCTGGCTCCGGTTTTGGGGTATCTGGGCTCCAGGCAGAAGCACAGCCTCCCCGACCTGCCCTACGACTACGGCG CCCTGGAACCTCACATCAACGCGCAGATCATGCAGCTGCACCACAGCAAGCACCACGCGGCCTACGTGAACAACCTGAACGTCACCGAGG AGAAGTACCAGGAGGCGTTGGCCAAGGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTG CAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCG GCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTC AGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGG AACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTG CTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGT TGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGA GGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAG GGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAG GAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCAT CACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCT GCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTG GAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTG CAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACC ATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGA GCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGAC TTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTT TGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCC TCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGG GCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCT CCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATG GGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAAC >85118_85118_9_SOD2-CHMP1A_SOD2_chr6_160113693_ENST00000538183_CHMP1A_chr16_89713739_ENST00000253475_length(amino acids)=260AA_BP=97 MWWLRQRLQQIGGISGSTSTSSMLSRAVCGTSRQLAPVLGYLGSRQKHSLPDLPYDYGALEPHINAQIMQLHHSKHHAAYVNNLNVTEEK YQEALAKGDQEYGPGDQSPGQGPEHHGPAEGLLSDGQVRAAGAEPGRPYIGDGGLHELGHHPDHAAGAGGQPHHADRRGEWPGGAGPAQP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SOD2-CHMP1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SOD2-CHMP1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SOD2-CHMP1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies