
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SOGA2-TOM1 (FusionGDB2 ID:85144) |
Fusion Gene Summary for SOGA2-TOM1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SOGA2-TOM1 | Fusion gene ID: 85144 | Hgene | Tgene | Gene symbol | SOGA2 | TOM1 | Gene ID | 23255 | 10043 |
| Gene name | microtubule crosslinking factor 1 | target of myb1 membrane trafficking protein | |
| Synonyms | CCDC165|KIAA0802|SOGA2 | - | |
| Cytomap | 18p11.22 | 22q12.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | microtubule cross-linking factor 1PAR-1-interacting proteinSOGA family member 2coiled-coil domain containing 165coiled-coil domain-containing protein 165 | target of Myb protein 1target of myb 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | TOM1L2 | |
| Ensembl transtripts involved in fusion gene | ENST00000306329, ENST00000359865, ENST00000400050, ENST00000517570, ENST00000306285, ENST00000518815, ENST00000581670, | ENST00000382034, ENST00000411850, ENST00000425375, ENST00000436462, ENST00000447733, ENST00000449058, | |
| Fusion gene scores | * DoF score | 5 X 3 X 4=60 | 12 X 10 X 7=840 |
| # samples | 5 | 15 | |
| ** MAII score | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/840*10)=-2.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SOGA2 [Title/Abstract] AND TOM1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SOGA2(8720494)-TOM1(35729397), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SOGA2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TOM1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
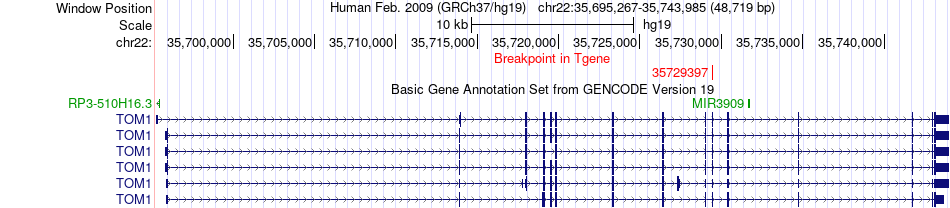 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315469 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
Top |
Fusion Gene ORF analysis for SOGA2-TOM1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000306329 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5CDS-3UTR | ENST00000359865 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5CDS-3UTR | ENST00000400050 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5CDS-3UTR | ENST00000517570 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3CDS | ENST00000306285 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3CDS | ENST00000306285 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3CDS | ENST00000306285 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3CDS | ENST00000306285 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3CDS | ENST00000306285 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| 5UTR-3UTR | ENST00000306285 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000306329 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000306329 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000306329 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000306329 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000306329 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000359865 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000359865 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000359865 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000359865 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000359865 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000400050 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000400050 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000400050 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000400050 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000400050 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000517570 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000517570 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000517570 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000517570 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| In-frame | ENST00000517570 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000518815 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000518815 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000518815 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000518815 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000518815 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000581670 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000581670 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000581670 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000581670 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3CDS | ENST00000581670 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3UTR | ENST00000518815 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| intron-3UTR | ENST00000581670 | ENST00000382034 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000306329 | SOGA2 | chr18 | 8720494 | + | ENST00000447733 | TOM1 | chr22 | 35729397 | + | 2769 | 1437 | 0 | 1985 | 661 |
| ENST00000306329 | SOGA2 | chr18 | 8720494 | + | ENST00000449058 | TOM1 | chr22 | 35729397 | + | 2761 | 1437 | 0 | 1982 | 660 |
| ENST00000306329 | SOGA2 | chr18 | 8720494 | + | ENST00000425375 | TOM1 | chr22 | 35729397 | + | 2766 | 1437 | 0 | 1982 | 660 |
| ENST00000306329 | SOGA2 | chr18 | 8720494 | + | ENST00000411850 | TOM1 | chr22 | 35729397 | + | 2769 | 1437 | 0 | 1985 | 661 |
| ENST00000306329 | SOGA2 | chr18 | 8720494 | + | ENST00000436462 | TOM1 | chr22 | 35729397 | + | 2472 | 1437 | 0 | 1982 | 660 |
| ENST00000517570 | SOGA2 | chr18 | 8720494 | + | ENST00000447733 | TOM1 | chr22 | 35729397 | + | 1871 | 539 | 182 | 1087 | 301 |
| ENST00000517570 | SOGA2 | chr18 | 8720494 | + | ENST00000449058 | TOM1 | chr22 | 35729397 | + | 1863 | 539 | 182 | 1084 | 300 |
| ENST00000517570 | SOGA2 | chr18 | 8720494 | + | ENST00000425375 | TOM1 | chr22 | 35729397 | + | 1868 | 539 | 182 | 1084 | 300 |
| ENST00000517570 | SOGA2 | chr18 | 8720494 | + | ENST00000411850 | TOM1 | chr22 | 35729397 | + | 1871 | 539 | 182 | 1087 | 301 |
| ENST00000517570 | SOGA2 | chr18 | 8720494 | + | ENST00000436462 | TOM1 | chr22 | 35729397 | + | 1574 | 539 | 182 | 1084 | 300 |
| ENST00000400050 | SOGA2 | chr18 | 8720494 | + | ENST00000447733 | TOM1 | chr22 | 35729397 | + | 1831 | 499 | 100 | 1047 | 315 |
| ENST00000400050 | SOGA2 | chr18 | 8720494 | + | ENST00000449058 | TOM1 | chr22 | 35729397 | + | 1823 | 499 | 100 | 1044 | 314 |
| ENST00000400050 | SOGA2 | chr18 | 8720494 | + | ENST00000425375 | TOM1 | chr22 | 35729397 | + | 1828 | 499 | 100 | 1044 | 314 |
| ENST00000400050 | SOGA2 | chr18 | 8720494 | + | ENST00000411850 | TOM1 | chr22 | 35729397 | + | 1831 | 499 | 100 | 1047 | 315 |
| ENST00000400050 | SOGA2 | chr18 | 8720494 | + | ENST00000436462 | TOM1 | chr22 | 35729397 | + | 1534 | 499 | 100 | 1044 | 314 |
| ENST00000359865 | SOGA2 | chr18 | 8720494 | + | ENST00000447733 | TOM1 | chr22 | 35729397 | + | 1831 | 499 | 100 | 1047 | 315 |
| ENST00000359865 | SOGA2 | chr18 | 8720494 | + | ENST00000449058 | TOM1 | chr22 | 35729397 | + | 1823 | 499 | 100 | 1044 | 314 |
| ENST00000359865 | SOGA2 | chr18 | 8720494 | + | ENST00000425375 | TOM1 | chr22 | 35729397 | + | 1828 | 499 | 100 | 1044 | 314 |
| ENST00000359865 | SOGA2 | chr18 | 8720494 | + | ENST00000411850 | TOM1 | chr22 | 35729397 | + | 1831 | 499 | 100 | 1047 | 315 |
| ENST00000359865 | SOGA2 | chr18 | 8720494 | + | ENST00000436462 | TOM1 | chr22 | 35729397 | + | 1534 | 499 | 100 | 1044 | 314 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000306329 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.042942047 | 0.95705795 |
| ENST00000306329 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.042820927 | 0.95717907 |
| ENST00000306329 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.042055365 | 0.95794463 |
| ENST00000306329 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.042942047 | 0.95705795 |
| ENST00000306329 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.04744019 | 0.95255977 |
| ENST00000517570 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.002892715 | 0.9971073 |
| ENST00000517570 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.002851963 | 0.9971481 |
| ENST00000517570 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.002829073 | 0.997171 |
| ENST00000517570 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.002892715 | 0.9971073 |
| ENST00000517570 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003041081 | 0.996959 |
| ENST00000400050 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003378599 | 0.9966214 |
| ENST00000400050 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003189861 | 0.99681014 |
| ENST00000400050 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003165756 | 0.9968342 |
| ENST00000400050 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003378599 | 0.9966214 |
| ENST00000400050 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003399537 | 0.99660045 |
| ENST00000359865 | ENST00000447733 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003378599 | 0.9966214 |
| ENST00000359865 | ENST00000449058 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003189861 | 0.99681014 |
| ENST00000359865 | ENST00000425375 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003165756 | 0.9968342 |
| ENST00000359865 | ENST00000411850 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003378599 | 0.9966214 |
| ENST00000359865 | ENST00000436462 | SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729397 | + | 0.003399537 | 0.99660045 |
Top |
Fusion Genomic Features for SOGA2-TOM1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729396 | + | 7.66E-06 | 0.9999924 |
| SOGA2 | chr18 | 8720494 | + | TOM1 | chr22 | 35729396 | + | 7.66E-06 | 0.9999924 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
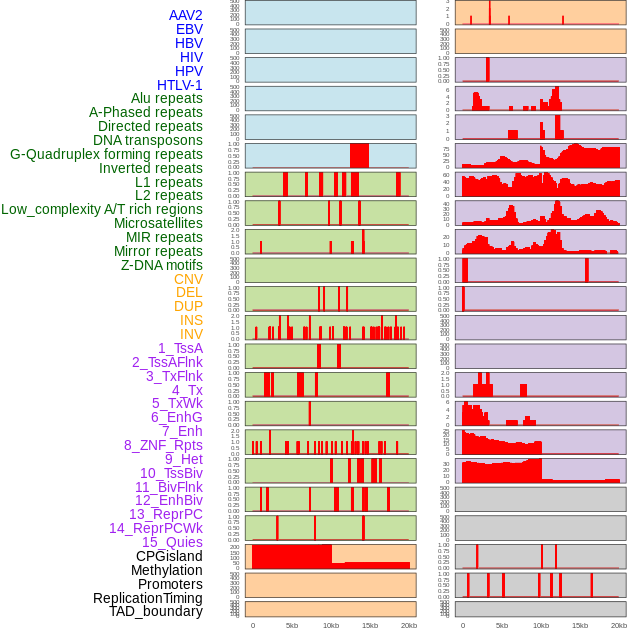 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for SOGA2-TOM1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr18:8720494/chr22:35729397) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | TOM1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | 507 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 330_404 | 479 | 1906.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 42_319 | 479 | 1906.0 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 54_198 | 479 | 1906.0 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 1_249 | 479 | 1906.0 | Region | Necessary for colocalization and binding with microtubules |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 1143_1201 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 1238_1278 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 330_404 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 432_483 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 513_718 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 1143_1201 | 479 | 1906.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 1238_1278 | 479 | 1906.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 432_483 | 479 | 1906.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 513_718 | 479 | 1906.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 1143_1201 | 119 | 1959.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 1238_1278 | 119 | 1959.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 330_404 | 119 | 1959.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 432_483 | 119 | 1959.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 513_718 | 119 | 1959.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 1143_1201 | 119 | 1917.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 1238_1278 | 119 | 1917.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 330_404 | 119 | 1917.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 432_483 | 119 | 1917.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 513_718 | 119 | 1917.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 1143_1201 | 119 | 1884.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 1238_1278 | 119 | 1884.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 330_404 | 119 | 1884.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 432_483 | 119 | 1884.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 513_718 | 119 | 1884.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 1143_1201 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 1238_1278 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 330_404 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 432_483 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 513_718 | 0 | 977.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 42_319 | 0 | 977.0 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 54_198 | 0 | 977.0 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 42_319 | 119 | 1959.0 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 54_198 | 119 | 1959.0 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 42_319 | 119 | 1917.6666666666667 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 54_198 | 119 | 1917.6666666666667 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 42_319 | 119 | 1884.6666666666667 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 54_198 | 119 | 1884.6666666666667 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 42_319 | 0 | 977.0 | Compositional bias | Note=Pro-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 54_198 | 0 | 977.0 | Compositional bias | Note=Ala-rich |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 1678_1773 | 0 | 977.0 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 1_249 | 0 | 977.0 | Region | Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306285 | + | 4 | 17 | 1_508 | 0 | 977.0 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 1678_1773 | 479 | 1906.0 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000306329 | + | 3 | 14 | 1_508 | 479 | 1906.0 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 1678_1773 | 119 | 1959.0 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 1_249 | 119 | 1959.0 | Region | Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000359865 | + | 4 | 17 | 1_508 | 119 | 1959.0 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 1678_1773 | 119 | 1917.6666666666667 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 1_249 | 119 | 1917.6666666666667 | Region | Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000400050 | + | 4 | 16 | 1_508 | 119 | 1917.6666666666667 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 1678_1773 | 119 | 1884.6666666666667 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 1_249 | 119 | 1884.6666666666667 | Region | Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000517570 | + | 3 | 15 | 1_508 | 119 | 1884.6666666666667 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 1678_1773 | 0 | 977.0 | Region | Note=Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 1_249 | 0 | 977.0 | Region | Necessary for colocalization and binding with microtubules |
| Hgene | SOGA2 | chr18:8720494 | chr22:35729397 | ENST00000518815 | + | 1 | 10 | 1_508 | 0 | 977.0 | Region | Necessary for self-assembly%2C microtubule bundling activity and apicobasal microtubule organization |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000411850 | 8 | 15 | 20_152 | 311 | 494.0 | Domain | VHS | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000411850 | 8 | 15 | 215_303 | 311 | 494.0 | Domain | GAT | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000425375 | 7 | 14 | 20_152 | 266 | 448.0 | Domain | VHS | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000425375 | 7 | 14 | 215_303 | 266 | 448.0 | Domain | GAT | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000447733 | 8 | 15 | 20_152 | 278 | 461.0 | Domain | VHS | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000447733 | 8 | 15 | 215_303 | 278 | 461.0 | Domain | GAT | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000449058 | 8 | 15 | 20_152 | 311 | 493.0 | Domain | VHS | |
| Tgene | TOM1 | chr18:8720494 | chr22:35729397 | ENST00000449058 | 8 | 15 | 215_303 | 311 | 493.0 | Domain | GAT |
Top |
Fusion Gene Sequence for SOGA2-TOM1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >85144_85144_1_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000411850_length(transcript)=2769nt_BP=1437nt ATGGAGACACTGAACGGCCCCGCGGGCGGAGGTGCCCCGGACGCGAAGCTGCAGCCGCCCGGCCAGCACCACCGCCACCACCACCTCCAC CCGGTGGCCGAAAGGCGGCGGCTGCACCGTGCGCCCTCGCCCGCCAGACCCTTCCTCAAGGACCTGCACGCCCGGCCCGCCGCGCCCGGC CCGGCCGTCCCCTCCTCGGGCCGAGCCCCGGCTCCCGCCGCCCCGCGCTCGCCCAACCTCGCGGGCAAAGCGCCGCCCTCGCCGGGGTCC CTGGCCGCGCCCGGCCGCCTCTCTCGGCGCAGTGGCGGCGTCCCGGGCGCGAAGGACAAGCCCCCGCCGGGCGCCGGGGCCAGAGCGGCG GGCGGTGCCAAGGCTGCCCTGGGAAGCAGGAGGGCGGCGCGCGTGGCGCCCGCGGAGCCGCTGTCCCGGGCTGGGAAGCCTCCCGGAGCC GAGCCGCCGTCTGCCGCTGCCAAGGGCCGCAAAGCCAAGCGCGGCTCCCGGGCGCCACCCGCCCGCACCGTCGGCCCCCCGACCCCGGCC GCCCGGATCCCTGCCGTGACCCTCGCGGTGACCTCGGTGGCCGGGTCCCCGGCCCGCTGCTCGCGCATCAGCCACACGGACAGCAGCTCC GACCTCTCTGACTGCCCCTCCGAACCCCTGTCCGACGAGCAGCGCCTGCTCCCTGCCGCCAGCAGCGACGCCGAATCCGGCACGGGCTCC AGCGACCGTGAACCCCCACGAGGAGCGCCGACGCCGAGCCCCGCAGCCCGAGGAGCGCCGCCGGGCAGCCCCGAGCCCCCAGCGCTCCTC GCCGCGCCCCTCGCCGCGGGCGCCTGTCCCGGGGGCCGGAGCATCCCGAGCGGGGTTTCGGGGGGTTTCGCGGGGCCCGGCGTGGCGGAG GATGTCCGGGGGCGCTCGCCACCGGAGCGACCAGTCCCCGGGACCCCCAAGGAGCCCAGCCTGGGCGAGCAGTCTCGGCTCGTGCCAGCG GCGGAGGAAGAAGAGCTGCTGCGGGAGATGGAGGAGCTGCGCTCGGAGAACGACTATCTCAAGGATGAGTTAGATGAACTCCGTGCTGAG ATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGC CGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGC CTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAG GATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCC CCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATG AACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACA CGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGG CAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCG GAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCC AGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCC TTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAA GGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGG ATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAG TGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATG CCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTT CCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGG CCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCC ACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTC >85144_85144_1_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000411850_length(amino acids)=661AA_BP=479 METLNGPAGGGAPDAKLQPPGQHHRHHHLHPVAERRRLHRAPSPARPFLKDLHARPAAPGPAVPSSGRAPAPAAPRSPNLAGKAPPSPGS LAAPGRLSRRSGGVPGAKDKPPPGAGARAAGGAKAALGSRRAARVAPAEPLSRAGKPPGAEPPSAAAKGRKAKRGSRAPPARTVGPPTPA ARIPAVTLAVTSVAGSPARCSRISHTDSSSDLSDCPSEPLSDEQRLLPAASSDAESGTGSSDREPPRGAPTPSPAARGAPPGSPEPPALL AAPLAAGACPGGRSIPSGVSGGFAGPGVAEDVRGRSPPERPVPGTPKEPSLGEQSRLVPAAEEEELLREMEELRSENDYLKDELDELRAE MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFLEERAKAADRLPNLS -------------------------------------------------------------- >85144_85144_2_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000425375_length(transcript)=2766nt_BP=1437nt ATGGAGACACTGAACGGCCCCGCGGGCGGAGGTGCCCCGGACGCGAAGCTGCAGCCGCCCGGCCAGCACCACCGCCACCACCACCTCCAC CCGGTGGCCGAAAGGCGGCGGCTGCACCGTGCGCCCTCGCCCGCCAGACCCTTCCTCAAGGACCTGCACGCCCGGCCCGCCGCGCCCGGC CCGGCCGTCCCCTCCTCGGGCCGAGCCCCGGCTCCCGCCGCCCCGCGCTCGCCCAACCTCGCGGGCAAAGCGCCGCCCTCGCCGGGGTCC CTGGCCGCGCCCGGCCGCCTCTCTCGGCGCAGTGGCGGCGTCCCGGGCGCGAAGGACAAGCCCCCGCCGGGCGCCGGGGCCAGAGCGGCG GGCGGTGCCAAGGCTGCCCTGGGAAGCAGGAGGGCGGCGCGCGTGGCGCCCGCGGAGCCGCTGTCCCGGGCTGGGAAGCCTCCCGGAGCC GAGCCGCCGTCTGCCGCTGCCAAGGGCCGCAAAGCCAAGCGCGGCTCCCGGGCGCCACCCGCCCGCACCGTCGGCCCCCCGACCCCGGCC GCCCGGATCCCTGCCGTGACCCTCGCGGTGACCTCGGTGGCCGGGTCCCCGGCCCGCTGCTCGCGCATCAGCCACACGGACAGCAGCTCC GACCTCTCTGACTGCCCCTCCGAACCCCTGTCCGACGAGCAGCGCCTGCTCCCTGCCGCCAGCAGCGACGCCGAATCCGGCACGGGCTCC AGCGACCGTGAACCCCCACGAGGAGCGCCGACGCCGAGCCCCGCAGCCCGAGGAGCGCCGCCGGGCAGCCCCGAGCCCCCAGCGCTCCTC GCCGCGCCCCTCGCCGCGGGCGCCTGTCCCGGGGGCCGGAGCATCCCGAGCGGGGTTTCGGGGGGTTTCGCGGGGCCCGGCGTGGCGGAG GATGTCCGGGGGCGCTCGCCACCGGAGCGACCAGTCCCCGGGACCCCCAAGGAGCCCAGCCTGGGCGAGCAGTCTCGGCTCGTGCCAGCG GCGGAGGAAGAAGAGCTGCTGCGGGAGATGGAGGAGCTGCGCTCGGAGAACGACTATCTCAAGGATGAGTTAGATGAACTCCGTGCTGAG ATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGC CGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGC CTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAG GATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCC CCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATG AACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACA CGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGG CAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCG GAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGC CCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTA TGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGC TGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATG AACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGG AGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCC CAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCC TGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCC AGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACT GCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTG >85144_85144_2_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000425375_length(amino acids)=660AA_BP=479 METLNGPAGGGAPDAKLQPPGQHHRHHHLHPVAERRRLHRAPSPARPFLKDLHARPAAPGPAVPSSGRAPAPAAPRSPNLAGKAPPSPGS LAAPGRLSRRSGGVPGAKDKPPPGAGARAAGGAKAALGSRRAARVAPAEPLSRAGKPPGAEPPSAAAKGRKAKRGSRAPPARTVGPPTPA ARIPAVTLAVTSVAGSPARCSRISHTDSSSDLSDCPSEPLSDEQRLLPAASSDAESGTGSSDREPPRGAPTPSPAARGAPPGSPEPPALL AAPLAAGACPGGRSIPSGVSGGFAGPGVAEDVRGRSPPERPVPGTPKEPSLGEQSRLVPAAEEEELLREMEELRSENDYLKDELDELRAE MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- >85144_85144_3_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000436462_length(transcript)=2472nt_BP=1437nt ATGGAGACACTGAACGGCCCCGCGGGCGGAGGTGCCCCGGACGCGAAGCTGCAGCCGCCCGGCCAGCACCACCGCCACCACCACCTCCAC CCGGTGGCCGAAAGGCGGCGGCTGCACCGTGCGCCCTCGCCCGCCAGACCCTTCCTCAAGGACCTGCACGCCCGGCCCGCCGCGCCCGGC CCGGCCGTCCCCTCCTCGGGCCGAGCCCCGGCTCCCGCCGCCCCGCGCTCGCCCAACCTCGCGGGCAAAGCGCCGCCCTCGCCGGGGTCC CTGGCCGCGCCCGGCCGCCTCTCTCGGCGCAGTGGCGGCGTCCCGGGCGCGAAGGACAAGCCCCCGCCGGGCGCCGGGGCCAGAGCGGCG GGCGGTGCCAAGGCTGCCCTGGGAAGCAGGAGGGCGGCGCGCGTGGCGCCCGCGGAGCCGCTGTCCCGGGCTGGGAAGCCTCCCGGAGCC GAGCCGCCGTCTGCCGCTGCCAAGGGCCGCAAAGCCAAGCGCGGCTCCCGGGCGCCACCCGCCCGCACCGTCGGCCCCCCGACCCCGGCC GCCCGGATCCCTGCCGTGACCCTCGCGGTGACCTCGGTGGCCGGGTCCCCGGCCCGCTGCTCGCGCATCAGCCACACGGACAGCAGCTCC GACCTCTCTGACTGCCCCTCCGAACCCCTGTCCGACGAGCAGCGCCTGCTCCCTGCCGCCAGCAGCGACGCCGAATCCGGCACGGGCTCC AGCGACCGTGAACCCCCACGAGGAGCGCCGACGCCGAGCCCCGCAGCCCGAGGAGCGCCGCCGGGCAGCCCCGAGCCCCCAGCGCTCCTC GCCGCGCCCCTCGCCGCGGGCGCCTGTCCCGGGGGCCGGAGCATCCCGAGCGGGGTTTCGGGGGGTTTCGCGGGGCCCGGCGTGGCGGAG GATGTCCGGGGGCGCTCGCCACCGGAGCGACCAGTCCCCGGGACCCCCAAGGAGCCCAGCCTGGGCGAGCAGTCTCGGCTCGTGCCAGCG GCGGAGGAAGAAGAGCTGCTGCGGGAGATGGAGGAGCTGCGCTCGGAGAACGACTATCTCAAGGATGAGTTAGATGAACTCCGTGCTGAG ATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGC CGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGC CTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAG GATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCC CCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATG AACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACA CGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGG CAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCG GAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGC CCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTA TGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGC TGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATG AACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGG AGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCC CAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCC >85144_85144_3_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000436462_length(amino acids)=660AA_BP=479 METLNGPAGGGAPDAKLQPPGQHHRHHHLHPVAERRRLHRAPSPARPFLKDLHARPAAPGPAVPSSGRAPAPAAPRSPNLAGKAPPSPGS LAAPGRLSRRSGGVPGAKDKPPPGAGARAAGGAKAALGSRRAARVAPAEPLSRAGKPPGAEPPSAAAKGRKAKRGSRAPPARTVGPPTPA ARIPAVTLAVTSVAGSPARCSRISHTDSSSDLSDCPSEPLSDEQRLLPAASSDAESGTGSSDREPPRGAPTPSPAARGAPPGSPEPPALL AAPLAAGACPGGRSIPSGVSGGFAGPGVAEDVRGRSPPERPVPGTPKEPSLGEQSRLVPAAEEEELLREMEELRSENDYLKDELDELRAE MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- >85144_85144_4_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000447733_length(transcript)=2769nt_BP=1437nt ATGGAGACACTGAACGGCCCCGCGGGCGGAGGTGCCCCGGACGCGAAGCTGCAGCCGCCCGGCCAGCACCACCGCCACCACCACCTCCAC CCGGTGGCCGAAAGGCGGCGGCTGCACCGTGCGCCCTCGCCCGCCAGACCCTTCCTCAAGGACCTGCACGCCCGGCCCGCCGCGCCCGGC CCGGCCGTCCCCTCCTCGGGCCGAGCCCCGGCTCCCGCCGCCCCGCGCTCGCCCAACCTCGCGGGCAAAGCGCCGCCCTCGCCGGGGTCC CTGGCCGCGCCCGGCCGCCTCTCTCGGCGCAGTGGCGGCGTCCCGGGCGCGAAGGACAAGCCCCCGCCGGGCGCCGGGGCCAGAGCGGCG GGCGGTGCCAAGGCTGCCCTGGGAAGCAGGAGGGCGGCGCGCGTGGCGCCCGCGGAGCCGCTGTCCCGGGCTGGGAAGCCTCCCGGAGCC GAGCCGCCGTCTGCCGCTGCCAAGGGCCGCAAAGCCAAGCGCGGCTCCCGGGCGCCACCCGCCCGCACCGTCGGCCCCCCGACCCCGGCC GCCCGGATCCCTGCCGTGACCCTCGCGGTGACCTCGGTGGCCGGGTCCCCGGCCCGCTGCTCGCGCATCAGCCACACGGACAGCAGCTCC GACCTCTCTGACTGCCCCTCCGAACCCCTGTCCGACGAGCAGCGCCTGCTCCCTGCCGCCAGCAGCGACGCCGAATCCGGCACGGGCTCC AGCGACCGTGAACCCCCACGAGGAGCGCCGACGCCGAGCCCCGCAGCCCGAGGAGCGCCGCCGGGCAGCCCCGAGCCCCCAGCGCTCCTC GCCGCGCCCCTCGCCGCGGGCGCCTGTCCCGGGGGCCGGAGCATCCCGAGCGGGGTTTCGGGGGGTTTCGCGGGGCCCGGCGTGGCGGAG GATGTCCGGGGGCGCTCGCCACCGGAGCGACCAGTCCCCGGGACCCCCAAGGAGCCCAGCCTGGGCGAGCAGTCTCGGCTCGTGCCAGCG GCGGAGGAAGAAGAGCTGCTGCGGGAGATGGAGGAGCTGCGCTCGGAGAACGACTATCTCAAGGATGAGTTAGATGAACTCCGTGCTGAG ATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGC CGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGC CTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAG GATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCC CCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATG AACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACA CGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGG CAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCG GAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCC AGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCC TTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAA GGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGG ATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAG TGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATG CCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTT CCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGG CCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCC ACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTC >85144_85144_4_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000447733_length(amino acids)=661AA_BP=479 METLNGPAGGGAPDAKLQPPGQHHRHHHLHPVAERRRLHRAPSPARPFLKDLHARPAAPGPAVPSSGRAPAPAAPRSPNLAGKAPPSPGS LAAPGRLSRRSGGVPGAKDKPPPGAGARAAGGAKAALGSRRAARVAPAEPLSRAGKPPGAEPPSAAAKGRKAKRGSRAPPARTVGPPTPA ARIPAVTLAVTSVAGSPARCSRISHTDSSSDLSDCPSEPLSDEQRLLPAASSDAESGTGSSDREPPRGAPTPSPAARGAPPGSPEPPALL AAPLAAGACPGGRSIPSGVSGGFAGPGVAEDVRGRSPPERPVPGTPKEPSLGEQSRLVPAAEEEELLREMEELRSENDYLKDELDELRAE MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFLEERAKAADRLPNLS -------------------------------------------------------------- >85144_85144_5_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000449058_length(transcript)=2761nt_BP=1437nt ATGGAGACACTGAACGGCCCCGCGGGCGGAGGTGCCCCGGACGCGAAGCTGCAGCCGCCCGGCCAGCACCACCGCCACCACCACCTCCAC CCGGTGGCCGAAAGGCGGCGGCTGCACCGTGCGCCCTCGCCCGCCAGACCCTTCCTCAAGGACCTGCACGCCCGGCCCGCCGCGCCCGGC CCGGCCGTCCCCTCCTCGGGCCGAGCCCCGGCTCCCGCCGCCCCGCGCTCGCCCAACCTCGCGGGCAAAGCGCCGCCCTCGCCGGGGTCC CTGGCCGCGCCCGGCCGCCTCTCTCGGCGCAGTGGCGGCGTCCCGGGCGCGAAGGACAAGCCCCCGCCGGGCGCCGGGGCCAGAGCGGCG GGCGGTGCCAAGGCTGCCCTGGGAAGCAGGAGGGCGGCGCGCGTGGCGCCCGCGGAGCCGCTGTCCCGGGCTGGGAAGCCTCCCGGAGCC GAGCCGCCGTCTGCCGCTGCCAAGGGCCGCAAAGCCAAGCGCGGCTCCCGGGCGCCACCCGCCCGCACCGTCGGCCCCCCGACCCCGGCC GCCCGGATCCCTGCCGTGACCCTCGCGGTGACCTCGGTGGCCGGGTCCCCGGCCCGCTGCTCGCGCATCAGCCACACGGACAGCAGCTCC GACCTCTCTGACTGCCCCTCCGAACCCCTGTCCGACGAGCAGCGCCTGCTCCCTGCCGCCAGCAGCGACGCCGAATCCGGCACGGGCTCC AGCGACCGTGAACCCCCACGAGGAGCGCCGACGCCGAGCCCCGCAGCCCGAGGAGCGCCGCCGGGCAGCCCCGAGCCCCCAGCGCTCCTC GCCGCGCCCCTCGCCGCGGGCGCCTGTCCCGGGGGCCGGAGCATCCCGAGCGGGGTTTCGGGGGGTTTCGCGGGGCCCGGCGTGGCGGAG GATGTCCGGGGGCGCTCGCCACCGGAGCGACCAGTCCCCGGGACCCCCAAGGAGCCCAGCCTGGGCGAGCAGTCTCGGCTCGTGCCAGCG GCGGAGGAAGAAGAGCTGCTGCGGGAGATGGAGGAGCTGCGCTCGGAGAACGACTATCTCAAGGATGAGTTAGATGAACTCCGTGCTGAG ATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGC CGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGC CTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAG GATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCC CCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATG AACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACA CGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGG CAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCG GAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGC CCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTA TGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGC TGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATG AACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGG AGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCC CAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCC TGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCC AGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACT GCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTG >85144_85144_5_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000306329_TOM1_chr22_35729397_ENST00000449058_length(amino acids)=660AA_BP=479 METLNGPAGGGAPDAKLQPPGQHHRHHHLHPVAERRRLHRAPSPARPFLKDLHARPAAPGPAVPSSGRAPAPAAPRSPNLAGKAPPSPGS LAAPGRLSRRSGGVPGAKDKPPPGAGARAAGGAKAALGSRRAARVAPAEPLSRAGKPPGAEPPSAAAKGRKAKRGSRAPPARTVGPPTPA ARIPAVTLAVTSVAGSPARCSRISHTDSSSDLSDCPSEPLSDEQRLLPAASSDAESGTGSSDREPPRGAPTPSPAARGAPPGSPEPPALL AAPLAAGACPGGRSIPSGVSGGFAGPGVAEDVRGRSPPERPVPGTPKEPSLGEQSRLVPAAEEEELLREMEELRSENDYLKDELDELRAE MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- >85144_85144_6_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000411850_length(transcript)=1831nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGA CAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGG CCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCC CCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCC TCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTG GCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGC TTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAG GCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGG CCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGA GATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTG TTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAA >85144_85144_6_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000411850_length(amino acids)=315AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFL -------------------------------------------------------------- >85144_85144_7_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000425375_length(transcript)=1828nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA CTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGAT CTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTC CTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAAGGT >85144_85144_7_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000425375_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_8_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000436462_length(transcript)=1534nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA >85144_85144_8_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000436462_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_9_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000447733_length(transcript)=1831nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGA CAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGG CCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCC CCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCC TCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTG GCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGC TTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAG GCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGG CCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGA GATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTG TTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAA >85144_85144_9_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000447733_length(amino acids)=315AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFL -------------------------------------------------------------- >85144_85144_10_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000449058_length(transcript)=1823nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA CTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGAT CTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTC CTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAAGGT >85144_85144_10_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000359865_TOM1_chr22_35729397_ENST00000449058_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_11_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000411850_length(transcript)=1831nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGA CAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGG CCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCC CCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCC TCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTG GCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGC TTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAG GCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGG CCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGA GATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTG TTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAA >85144_85144_11_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000411850_length(amino acids)=315AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFL -------------------------------------------------------------- >85144_85144_12_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000425375_length(transcript)=1828nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA CTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGAT CTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTC CTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAAGGT >85144_85144_12_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000425375_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_13_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000436462_length(transcript)=1534nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA >85144_85144_13_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000436462_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_14_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000447733_length(transcript)=1831nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGA CAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGG CCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCC CCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCC TCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTG GCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGC TTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAG GCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGG CCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGA GATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTG TTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAA >85144_85144_14_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000447733_length(amino acids)=315AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFL -------------------------------------------------------------- >85144_85144_15_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000449058_length(transcript)=1823nt_BP=499nt GAGTGTTTTCAGAAGTGGGAATAGCAGGCGAGGTCTTGAGGCCTGAAGAAGCAAAGCGTCGCTTAGTCAATGCTGAGATGCGTCTTGTGG AACAGAATTTTTGGGACATTTGCAGGATGAGTTAGATGAACTCCGTGCTGAGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGT TTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACTGCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAA AAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAAGCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGT CAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTGAGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGT GGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGGCCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACAT GGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAATGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTC TCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGACACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAA ATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCCGGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTG CCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATGCGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAA ATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCC AGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCA CTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCT TTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCT GCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTG ACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCC TGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCA CTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGAT CTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTC CTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCTTGTACTGGGAGAGGTGCCTTTTGTATCCCCAATTAAAGGT >85144_85144_15_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000400050_TOM1_chr22_35729397_ENST00000449058_length(amino acids)=314AA_BP=133 MGHLQDELDELRAEMEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLH HELKTVEEKRAKAEDENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEA SGRLEDEFDMFALTRGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLE -------------------------------------------------------------- >85144_85144_16_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000411850_length(transcript)=1871nt_BP=539nt CGGCGCCTGCTGCACTCTCTGAGTATTTTCCGGCAGGGCCTGCGGGCAGTGGCGTCTTAGTCGCCTTAGCACTGGGTGCTTAATCCGGCT CCATCTTTTCTCCACGGAGGGGGCCTGGTGCTGCAGACGGGGTTCCCGGGGTCAGGACGATCCAGGATGAGTTAGATGAACTCCGTGCTG AGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACT GCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAA GCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTG AGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGG CCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAA TGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGA CACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCC GGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATG CGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCT CCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTG CCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTT AAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTG GGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGA AGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCA TGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCC TTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGC GGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCC CCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCC >85144_85144_16_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000411850_length(amino acids)=301AA_BP=119 MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFLEERAKAADRLPNLS -------------------------------------------------------------- >85144_85144_17_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000425375_length(transcript)=1868nt_BP=539nt CGGCGCCTGCTGCACTCTCTGAGTATTTTCCGGCAGGGCCTGCGGGCAGTGGCGTCTTAGTCGCCTTAGCACTGGGTGCTTAATCCGGCT CCATCTTTTCTCCACGGAGGGGGCCTGGTGCTGCAGACGGGGTTCCCGGGGTCAGGACGATCCAGGATGAGTTAGATGAACTCCGTGCTG AGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACT GCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAA GCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTG AGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGG CCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAA TGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGA CACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCC GGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATG CGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCA GCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCT TATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAG GCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGA TGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGT GGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGC CCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTC CCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGC CCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCA CTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCT >85144_85144_17_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000425375_length(amino acids)=300AA_BP=119 MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- >85144_85144_18_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000436462_length(transcript)=1574nt_BP=539nt CGGCGCCTGCTGCACTCTCTGAGTATTTTCCGGCAGGGCCTGCGGGCAGTGGCGTCTTAGTCGCCTTAGCACTGGGTGCTTAATCCGGCT CCATCTTTTCTCCACGGAGGGGGCCTGGTGCTGCAGACGGGGTTCCCGGGGTCAGGACGATCCAGGATGAGTTAGATGAACTCCGTGCTG AGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACT GCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAA GCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTG AGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGG CCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAA TGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGA CACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCC GGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATG CGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCA GCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCT TATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAG GCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGA TGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGT GGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGC CCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTC >85144_85144_18_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000436462_length(amino acids)=300AA_BP=119 MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- >85144_85144_19_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000447733_length(transcript)=1871nt_BP=539nt CGGCGCCTGCTGCACTCTCTGAGTATTTTCCGGCAGGGCCTGCGGGCAGTGGCGTCTTAGTCGCCTTAGCACTGGGTGCTTAATCCGGCT CCATCTTTTCTCCACGGAGGGGGCCTGGTGCTGCAGACGGGGTTCCCGGGGTCAGGACGATCCAGGATGAGTTAGATGAACTCCGTGCTG AGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACT GCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAA GCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTG AGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGG CCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAA TGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGA CACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCC GGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATG CGGAAGAGCCTAAGGGGGTCACCAGCGAAGGTAAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCT CCAGCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTG CCTTATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTT AAGGCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTG GGATGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGA AGTGGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCA TGCCCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCC TTCCCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGC GGCCCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCC CCACTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCC >85144_85144_19_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000447733_length(amino acids)=301AA_BP=119 MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEGKFDKFLEERAKAADRLPNLS -------------------------------------------------------------- >85144_85144_20_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000449058_length(transcript)=1863nt_BP=539nt CGGCGCCTGCTGCACTCTCTGAGTATTTTCCGGCAGGGCCTGCGGGCAGTGGCGTCTTAGTCGCCTTAGCACTGGGTGCTTAATCCGGCT CCATCTTTTCTCCACGGAGGGGGCCTGGTGCTGCAGACGGGGTTCCCGGGGTCAGGACGATCCAGGATGAGTTAGATGAACTCCGTGCTG AGATGGAAGAGATGAGAGACAGTTATTTAGAGGAAGATGTTTACCAGCTGCAGGAACTTCGGCGAGAACTGGACCGCGCTAATAAAAACT GCCGAATCCTGCAGTACCGTCTTCGGAAAGCCGAGCAGAAAAGCCTGAAAGTGGCTGAGACGGGTCAGGTGGATGGTGAGCTTATTCGAA GCCTGGAGCAGGACTTGAAGGTAGCCAAAGATGTATCTGTCAGATTGCACCACGAACTTAAGACGGTGGAGGAAAAGCGCGCTAAAGCTG AGGATGAAAACGAAACTCTCCGACAGCAGATGATTGAAGTGGAAATATCCAAACAGGCCCTCCAGAATGAGCTGGAGAGACTGAAAGAGG CCCCAAGTGAGGCCGAGCCGGCAGCTGACCTGATCGACATGGGCCCTGACCCAGCAGCCACCGGCAACCTCTCATCCCAGCTGGCAGGAA TGAACCTGGGCTCCAGCAGTGTGAGAGCTGGCCTGCAGTCTCTGGAGGCCTCTGGTCGACTGGAAGATGAGTTTGACATGTTTGCGCTGA CACGGGGCAGCTCACTGGCTGACCAACGGAAAGAGGTAAAATACGAAGCCCCCCAAGCAACAGACGGCCTGGCTGGAGCCCTGGACGCCC GGCAGCAGAGCACTGGCGCGATCCCAGTCACCCAGGCCTGCCTCATGGAGGACATCGAGCAGTGGCTGTCCACTGACGTGGGTAATGATG CGGAAGAGCCTAAGGGGGTCACCAGCGAAGAATTTGACAAATTCCTGGAAGAACGGGCCAAAGCCGCGGACCGATTGCCCAACCTCTCCA GCCCCTCAGCTGAGGGGCCCCCGGGTCCCCCATCTGGCCCAGCGCCCCGGAAGAAGACCCAGGAGAAAGATGATGACATGCTGTTTGCCT TATGAGTGTGGGGTCTGGCACCCTGCAGCCCAGGTCCCCACTGCTCTCACACCCTTAGGCTGGGACCTCCCTCCCTCCTCTGGTGTTAAG GCTGCTTTGGGGGTGGCTTGTTACCCCCTTTTCCTCCTCTTTGAAGACGGAGCTGCCCCAGCTGTGGCTGGGGGTGTGGAGGCAGTGGGA TGAACTGGGGGACAGGTCTGCGCTGCAGTGGGATCTGGCTGCTCTGCCTCCTTTCCCACCCCAGCTGACCATGAGACTTTGCTGAGAAGT GGAGGCCCCAGGACAGGCTGGCTGGCTGGCTGGCTGCTTGACCCAGTGTGACTCTCCTTCACTGAGTGATACCCTGCTCCGGGCCCATGC CCCAAGGAGCCCTTCAGAGCCCACACTGCCAGTCGAGGCCTGGCTGGAGGCTGGCCACAGTGGAAATTCTGCCGAGCCTCTTGTCCCTTC CCTGCTCTGCTGCATGGGGCCCCATGGCTTTGGCTGGCCACTGAGGGTAGGGTGTGGAGGTGTGGAGGCCCCCTGAGGAGCTGCGGCGGC CCAGGTACGAAGCTGCAACTCTGCGCGCAGTGGGCGAGATCTCATCAGCCCCAGGCTGCAGGTGAGGCTTCAGGGGATGCTGGGGCCCCA CTGCCCCTCCGCTGCCTTGCCCTCCATCCTTCCTCTGTTCCTTCTGGCCGGGCACCACAGCACTGGGGCTCACCTCTTGGTTGATCCTCT >85144_85144_20_SOGA2-TOM1_SOGA2_chr18_8720494_ENST00000517570_TOM1_chr22_35729397_ENST00000449058_length(amino acids)=300AA_BP=119 MEEMRDSYLEEDVYQLQELRRELDRANKNCRILQYRLRKAEQKSLKVAETGQVDGELIRSLEQDLKVAKDVSVRLHHELKTVEEKRAKAE DENETLRQQMIEVEISKQALQNELERLKEAPSEAEPAADLIDMGPDPAATGNLSSQLAGMNLGSSSVRAGLQSLEASGRLEDEFDMFALT RGSSLADQRKEVKYEAPQATDGLAGALDARQQSTGAIPVTQACLMEDIEQWLSTDVGNDAEEPKGVTSEEFDKFLEERAKAADRLPNLSS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SOGA2-TOM1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SOGA2-TOM1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SOGA2-TOM1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies