
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SQRDL-NID1 (FusionGDB2 ID:86195) |
Fusion Gene Summary for SQRDL-NID1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SQRDL-NID1 | Fusion gene ID: 86195 | Hgene | Tgene | Gene symbol | SQRDL | NID1 | Gene ID | 58472 | 4811 |
| Gene name | sulfide quinone oxidoreductase | nidogen 1 | |
| Synonyms | CGI-44|PRO1975|SQR|SQRDL | NID | |
| Cytomap | 15q21.1 | 1q42.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sulfide:quinone oxidoreductase, mitochondrialsulfide dehydrogenase likesulfide quinone reductase-like | nidogen-1NID-1enactinentactinepididymis secretory sperm binding protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | P14543 | |
| Ensembl transtripts involved in fusion gene | ENST00000260324, ENST00000568606, | ENST00000264187, ENST00000366595, | |
| Fusion gene scores | * DoF score | 5 X 4 X 5=100 | 4 X 6 X 4=96 |
| # samples | 5 | 7 | |
| ** MAII score | log2(5/100*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/96*10)=-0.45567948377619 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SQRDL [Title/Abstract] AND NID1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NID1(236143879)-SQRDL(45981354), # samples:1 SQRDL(45981354)-NID1(236143879), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SQRDL | GO:0070221 | sulfide oxidation, using sulfide:quinone oxidoreductase | 22852582 |
| Hgene | SQRDL | GO:0070813 | hydrogen sulfide metabolic process | 22852582 |
| Fusion gene breakpoints across SQRDL (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NID1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | BU075210 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + |
Top |
Fusion Gene ORF analysis for SQRDL-NID1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000260324 | ENST00000264187 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + |
| In-frame | ENST00000260324 | ENST00000366595 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + |
| In-frame | ENST00000568606 | ENST00000264187 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + |
| In-frame | ENST00000568606 | ENST00000366595 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000568606 | SQRDL | chr15 | 45981354 | - | ENST00000366595 | NID1 | chr1 | 236143879 | + | 3846 | 1366 | 183 | 1322 | 379 |
| ENST00000568606 | SQRDL | chr15 | 45981354 | - | ENST00000264187 | NID1 | chr1 | 236143879 | + | 3846 | 1366 | 183 | 1322 | 379 |
| ENST00000260324 | SQRDL | chr15 | 45981354 | - | ENST00000366595 | NID1 | chr1 | 236143879 | + | 4043 | 1563 | 380 | 1519 | 379 |
| ENST00000260324 | SQRDL | chr15 | 45981354 | - | ENST00000264187 | NID1 | chr1 | 236143879 | + | 4043 | 1563 | 380 | 1519 | 379 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000568606 | ENST00000366595 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + | 0.000814067 | 0.999186 |
| ENST00000568606 | ENST00000264187 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + | 0.000814067 | 0.999186 |
| ENST00000260324 | ENST00000366595 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + | 0.001028329 | 0.9989717 |
| ENST00000260324 | ENST00000264187 | SQRDL | chr15 | 45981354 | - | NID1 | chr1 | 236143879 | + | 0.001028329 | 0.9989717 |
Top |
Fusion Genomic Features for SQRDL-NID1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
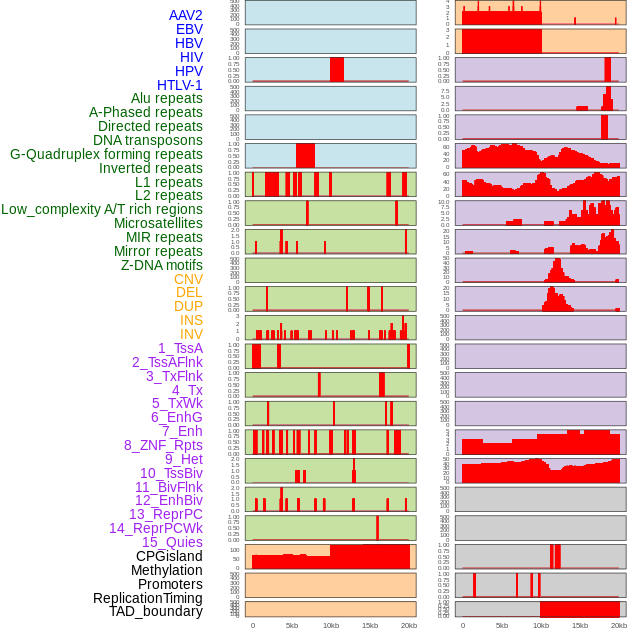 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SQRDL-NID1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:236143879/chr1:45981354) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NID1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Sulfated glycoprotein widely distributed in basement membranes and tightly associated with laminin. Also binds to collagen IV and perlecan. It probably has a role in cell-extracellular matrix interactions. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 106_268 | 0 | 1248.0 | Domain | NIDO | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 1208_1244 | 0 | 1248.0 | Domain | EGF-like 6 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 386_426 | 0 | 1248.0 | Domain | EGF-like 1 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 430_667 | 0 | 1248.0 | Domain | Nidogen G2 beta-barrel | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 668_709 | 0 | 1248.0 | Domain | EGF-like 2 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 710_751 | 0 | 1248.0 | Domain | EGF-like 3%3B calcium-binding | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 758_801 | 0 | 1248.0 | Domain | EGF-like 4 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 802_840 | 0 | 1248.0 | Domain | EGF-like 5%3B calcium-binding | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 846_919 | 0 | 1248.0 | Domain | Thyroglobulin type-1 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 106_268 | 0 | 1115.0 | Domain | NIDO | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 1208_1244 | 0 | 1115.0 | Domain | EGF-like 6 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 386_426 | 0 | 1115.0 | Domain | EGF-like 1 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 430_667 | 0 | 1115.0 | Domain | Nidogen G2 beta-barrel | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 668_709 | 0 | 1115.0 | Domain | EGF-like 2 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 710_751 | 0 | 1115.0 | Domain | EGF-like 3%3B calcium-binding | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 758_801 | 0 | 1115.0 | Domain | EGF-like 4 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 802_840 | 0 | 1115.0 | Domain | EGF-like 5%3B calcium-binding | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 846_919 | 0 | 1115.0 | Domain | Thyroglobulin type-1 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 702_704 | 0 | 1248.0 | Motif | Note=Cell attachment site | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 702_704 | 0 | 1115.0 | Motif | Note=Cell attachment site | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 1033_1075 | 0 | 1248.0 | Repeat | Note=LDL-receptor class B 2 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 1076_1120 | 0 | 1248.0 | Repeat | Note=LDL-receptor class B 3 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 1121_1162 | 0 | 1248.0 | Repeat | Note=LDL-receptor class B 4 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000264187 | 0 | 20 | 990_1032 | 0 | 1248.0 | Repeat | Note=LDL-receptor class B 1 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 1033_1075 | 0 | 1115.0 | Repeat | Note=LDL-receptor class B 2 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 1076_1120 | 0 | 1115.0 | Repeat | Note=LDL-receptor class B 3 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 1121_1162 | 0 | 1115.0 | Repeat | Note=LDL-receptor class B 4 | |
| Tgene | NID1 | chr15:45981354 | chr1:236143879 | ENST00000366595 | 0 | 17 | 990_1032 | 0 | 1115.0 | Repeat | Note=LDL-receptor class B 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SQRDL | chr15:45981354 | chr1:236143879 | ENST00000260324 | - | 1 | 10 | 344_347 | 0 | 451.0 | Nucleotide binding | FAD |
| Hgene | SQRDL | chr15:45981354 | chr1:236143879 | ENST00000260324 | - | 1 | 10 | 53_54 | 0 | 451.0 | Nucleotide binding | FAD |
| Hgene | SQRDL | chr15:45981354 | chr1:236143879 | ENST00000568606 | - | 1 | 11 | 344_347 | 0 | 451.0 | Nucleotide binding | FAD |
| Hgene | SQRDL | chr15:45981354 | chr1:236143879 | ENST00000568606 | - | 1 | 11 | 53_54 | 0 | 451.0 | Nucleotide binding | FAD |
Top |
Fusion Gene Sequence for SQRDL-NID1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >86195_86195_1_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000260324_NID1_chr1_236143879_ENST00000264187_length(transcript)=4043nt_BP=1563nt AGCGTCAGGTGGCCTCGGTGTCCTCCGCCTGTGCGCCCCAGCCTGCGGGGCCGCCCTTCAGGGCGCGCAAGGGGCGAGTCTGTCCAGCCG GCAGCACCCCAGGCCGGATGGACGCTTGTTCCTGGTTCTGTGCCCCGTGAGCGCTCAACGCCCTGGTGTGTTCACTGACCATGGTGCCTG GGCTGCGGCGCCGGGCGGGGCACGGCGGGACTTTTCGGGACCTTTCCTGGGGGGAGCCTCGCTTTCCCCGCCTCCAGCCTCCGCCCGGAT GGCAGGCGGGCGGGGCCCCAGTCCAGGCCTTGAGACCCAGAAGGGAGCGAAGGTTTTTGCTGCGCCAACGCAGTGACCGAAGGCTCCGCT CACGCCCGGCCTGATCCTGCCTGAAGATGGTGCCACTGGTGGCTGTGGTATCAGGGCCCCGTGCCCAGCTCTTTGCCTGCCTGCTCAGGC TGGGCACTCAGCAGGTCGGCCCCCTTCAGCTGCACACCGGGGCCAGCCATGCGGCCAGGAACCATTATGAGGTGCTGGTGCTGGGTGGGG GCAGTGGCGGAATCACCATGGCTGCCCGCATGAAGAGGAAAGTGGGTGCAGAGAATGTGGCCATTGTTGAGCCCAGTGAGAGACATTTCT ACCAGCCAATCTGGACACTGGTGGGTGCTGGTGCCAAACAATTGTCCTCATCTGGTCGTCCCACGGCAAGTGTGATTCCATCTGGTGTAG AATGGATCAAAGCTAGAGTGACTGAGTTGAACCCAGACAAGAACTGCATTCACACAGATGACGACGAGAAGATCTCCTACCGATATCTTA TTATTGCTCTCGGAATCCAGCTGGACTATGAGAAGATTAAAGGCCTACCTGAAGGTTTCGCTCATCCCAAAATAGGGTCGAATTATTCAG TTAAGACTGTAGAGAAGACATGGAAAGCTCTGCAGGACTTCAAAGAGGGCAATGCCATCTTCACCTTCCCAAATACTCCAGTGAAGTGTG CTGGAGCCCCTCAGAAGATCATGTACTTATCAGAAGCCTACTTCAGGAAGACAGGGAAGCGATCCAAGGCCAATATCATTTTCAACACTT CTCTTGGAGCCATTTTCGGGGTTAAGAAGTATGCAGATGCCCTGCAGGAGATCATCCAGGAGCGGAACCTCACTGTTAACTACAAGAAAA ACCTCATTGAAGTCCGAGCCGATAAACAAGAGGCTGTATTTGAGAACCTGGACAAACCAGGAGAGACCCAAGTGATTTCATATGAAATGC TTCATGTCACACCTCCAATGAGCCCACCAGATGTCCTCAAGACCAGTCCTGTGGCTGATGCTGCTGGTTGGGTGGATGTGGATAAAGAAA CTCTGCAACACAGGAGGTACCCAAATGTGTTTGGGATTGGGGACTGCACCAACCTTCCTACGTCAAAGACCGCTGCTGCAGTAGCTGCCC AGTCAGGAATACTTGATAGGACAATTTCTGTAATTATGAAGAATCAAACACCAACAAAGAAGTTTCCATGTATCTCATGAAAGCTGACCT GATGCCTTTCCTGTATTGGAATATGATGCTAAGGCCATAACTACTGCTCAGTGAACAATGGCGGCTGCACCCACCTATGCTTGGCCACCC CAGGGAGCAGGACCTGCCGTTGCCCTGACAACACCTTGGGAGTTGACTGTATCGAACAGAAATGAAGACAAGAGTGCCTTATTTCCTTTC CAAGTATTTCACAGCAACACTCTACTTGAAGCAACTTGGTCCAGATTGAAAAGTGTCCTCTGGCTGAGTGGCCACTAGGCCCAGACCCAG CCCAGCCTGAGCCCCAACAACTTTTCCCTCACTGTTCCCCAAAACATGCACCCTGGACTTCTCTAATAGAAAAGTCTCCACCCCTACACA AGGACAGAACCCTCCACCCCTACCCCCAACCCTCAGACAGACTTATACACCCCTGAGTGAGGATTACATGCCCATCCCAGTGTCCTAGGA CCTTTTCCCAATACTAGCCCCCCAGTGGTGAACAGAACCTCCCAAATTTGAGTTGCACCCTTCCCTGTGGCCTTATGAGCTCAGCCTCGC TTTGAGGTACCCACCGTCCTGTCAGCTCCTTGACCTATGAGCCGGGGCCTGACTAGGAAAAGTTGGGAGTTAAGGAGGAAATTAGCATTC CTTAATGTTTTGTTTTGGTGCTCTGAATTTCTTCTTTATTATAGTCCTATAGTTTTACTCCTCAGTTCCTCACCATCATCATCTTGTCTA AGACCCCCATTATAATATTCATGCGCTGCTTTTTCATCAAAACCTACCCTGTCCTAGAGATCTATGGGCATTTGGTGGATGATAATGAGC AGCCCCTCCCAGATAGAATGTCAATATTTGAGCAGTAGGATATTGGCATTTGTTAGTTAAAGGCTTAAATCAAAAGAATGTCCAATGGTA GGAATTTCAAGGTGTAGGTCAGATATTTGAGAATAGGGGATTTTTTTGATGTGCCTTAAATTATACCAAAGATTACTAATTATTCCTCTT TGCCCAAAATACTTGCATCCAAGGTTCTAGTCTCTGTTGCTGTGCTGGTCTTTAGCCCCACTGCTTGCACTGATGTCCCTCCTTTTCACG GAGACCTATCTGAGGTACAGGATGGGGCTGGCACCAGATGATGTCCCACCACAGTCCCTCACCTCCGGCCTCCACATGACAGAACCAATT TACACTCAACCATGACCTCACCCCTCCTTGGTTTCTCCCTCGATCTGTGGCCCTTTTTGGATGTATTCTTATCTAACAACACAATCCGGA AAGACTGAATTGAATATTTATACTAATGGTTCATATCCTTTATTGCTCAATGATCTAATTAAAGGGATCATTGCCACATTTCATGTTTAT ATTTCTACAATTTGTTTAGAAAACATCTCCTGACCATATCAGTAGCTCGTGTTATCTTTTTATCAACTGCTTCCCAGAGTCCTAAAACAA TAGAAATTTTGGATTGAAAAGTTCAGCATAAGGAGTTTGAGTCAGTAAAGGATGGGATAAAGGAGTCGAGATGATTCAATGAAAAGTATC ACAAAAAAGAGATTGATCAACAAGAGAAATAAAAAAGCCCAAGAGGAAGTGGTAGGGGAAGGAATTTAAGAACAGCAATAAGTAAAACTC TTAAGTAACTCCAAAAAGAAAATGGTACATTTTGCCAAAGACCACTTATACTTGAGAACATGGAAGAATTTGCCTGATACTCTCTTTGGG GAAAAGAGTCTCTCCTCTTTTCCTCAAACCCCAGTACACTCAGCCTCTCTGCCCCACCTTCTCCTGACTTTGTCCTCACTTGCTTCTGCA GTACATTGGAACCTGAATTGAAAGAAAGTCTTCCTTGAATAATTGGAGTTTGTCTTGAGAGGCAAATATAGCCCCAAGAATCACAAGATT CGAGGACCATGTAGGTCTTTTACGTAGCCCAAATCCATAAATTAGTCTCACTTTTTGTATTTATCGTTTCATATTAAACCCTCTATATCA AATGTTCATCATGATTTTGTATGATTTTTATAACTATTTTATTCATTTTATTAGATTTATTCTAAAATTTTTTAATGGTAAATTCTTAAA CTGTGGAAACCACTGAAGGTGCTTATTAACTGTTCTCCCAGATTTGTACAAGTATTGGATGATTCCTTGAGTTTACAGCTGTACAAATAG TGTGGAAAATAAACTTTTTTTAAAAAAGAAAAGAATTCCGTGGTTGCTCTCGATCTTGCAATTTCCAAGGAGACGGATGCTTTCCAACCC CACAAGCAGACCCGGCTGTATGGCATCACCACGGCCCTGTCTCAGTGTCCGCAAGGCACCAATCGGGCGGAATGCCTGAACCCCAGTCAG CCCAGCAGACGCAAGGCTCTCGAAGGGCTCCAGTATCCTTTTGCTGTGACGAGCTACGGGAAGAATCTGTATTTCACAGACTGGAAGATG >86195_86195_1_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000260324_NID1_chr1_236143879_ENST00000264187_length(amino acids)=379AA_BP= MKMVPLVAVVSGPRAQLFACLLRLGTQQVGPLQLHTGASHAARNHYEVLVLGGGSGGITMAARMKRKVGAENVAIVEPSERHFYQPIWTL VGAGAKQLSSSGRPTASVIPSGVEWIKARVTELNPDKNCIHTDDDEKISYRYLIIALGIQLDYEKIKGLPEGFAHPKIGSNYSVKTVEKT WKALQDFKEGNAIFTFPNTPVKCAGAPQKIMYLSEAYFRKTGKRSKANIIFNTSLGAIFGVKKYADALQEIIQERNLTVNYKKNLIEVRA DKQEAVFENLDKPGETQVISYEMLHVTPPMSPPDVLKTSPVADAAGWVDVDKETLQHRRYPNVFGIGDCTNLPTSKTAAAVAAQSGILDR -------------------------------------------------------------- >86195_86195_2_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000260324_NID1_chr1_236143879_ENST00000366595_length(transcript)=4043nt_BP=1563nt AGCGTCAGGTGGCCTCGGTGTCCTCCGCCTGTGCGCCCCAGCCTGCGGGGCCGCCCTTCAGGGCGCGCAAGGGGCGAGTCTGTCCAGCCG GCAGCACCCCAGGCCGGATGGACGCTTGTTCCTGGTTCTGTGCCCCGTGAGCGCTCAACGCCCTGGTGTGTTCACTGACCATGGTGCCTG GGCTGCGGCGCCGGGCGGGGCACGGCGGGACTTTTCGGGACCTTTCCTGGGGGGAGCCTCGCTTTCCCCGCCTCCAGCCTCCGCCCGGAT GGCAGGCGGGCGGGGCCCCAGTCCAGGCCTTGAGACCCAGAAGGGAGCGAAGGTTTTTGCTGCGCCAACGCAGTGACCGAAGGCTCCGCT CACGCCCGGCCTGATCCTGCCTGAAGATGGTGCCACTGGTGGCTGTGGTATCAGGGCCCCGTGCCCAGCTCTTTGCCTGCCTGCTCAGGC TGGGCACTCAGCAGGTCGGCCCCCTTCAGCTGCACACCGGGGCCAGCCATGCGGCCAGGAACCATTATGAGGTGCTGGTGCTGGGTGGGG GCAGTGGCGGAATCACCATGGCTGCCCGCATGAAGAGGAAAGTGGGTGCAGAGAATGTGGCCATTGTTGAGCCCAGTGAGAGACATTTCT ACCAGCCAATCTGGACACTGGTGGGTGCTGGTGCCAAACAATTGTCCTCATCTGGTCGTCCCACGGCAAGTGTGATTCCATCTGGTGTAG AATGGATCAAAGCTAGAGTGACTGAGTTGAACCCAGACAAGAACTGCATTCACACAGATGACGACGAGAAGATCTCCTACCGATATCTTA TTATTGCTCTCGGAATCCAGCTGGACTATGAGAAGATTAAAGGCCTACCTGAAGGTTTCGCTCATCCCAAAATAGGGTCGAATTATTCAG TTAAGACTGTAGAGAAGACATGGAAAGCTCTGCAGGACTTCAAAGAGGGCAATGCCATCTTCACCTTCCCAAATACTCCAGTGAAGTGTG CTGGAGCCCCTCAGAAGATCATGTACTTATCAGAAGCCTACTTCAGGAAGACAGGGAAGCGATCCAAGGCCAATATCATTTTCAACACTT CTCTTGGAGCCATTTTCGGGGTTAAGAAGTATGCAGATGCCCTGCAGGAGATCATCCAGGAGCGGAACCTCACTGTTAACTACAAGAAAA ACCTCATTGAAGTCCGAGCCGATAAACAAGAGGCTGTATTTGAGAACCTGGACAAACCAGGAGAGACCCAAGTGATTTCATATGAAATGC TTCATGTCACACCTCCAATGAGCCCACCAGATGTCCTCAAGACCAGTCCTGTGGCTGATGCTGCTGGTTGGGTGGATGTGGATAAAGAAA CTCTGCAACACAGGAGGTACCCAAATGTGTTTGGGATTGGGGACTGCACCAACCTTCCTACGTCAAAGACCGCTGCTGCAGTAGCTGCCC AGTCAGGAATACTTGATAGGACAATTTCTGTAATTATGAAGAATCAAACACCAACAAAGAAGTTTCCATGTATCTCATGAAAGCTGACCT GATGCCTTTCCTGTATTGGAATATGATGCTAAGGCCATAACTACTGCTCAGTGAACAATGGCGGCTGCACCCACCTATGCTTGGCCACCC CAGGGAGCAGGACCTGCCGTTGCCCTGACAACACCTTGGGAGTTGACTGTATCGAACAGAAATGAAGACAAGAGTGCCTTATTTCCTTTC CAAGTATTTCACAGCAACACTCTACTTGAAGCAACTTGGTCCAGATTGAAAAGTGTCCTCTGGCTGAGTGGCCACTAGGCCCAGACCCAG CCCAGCCTGAGCCCCAACAACTTTTCCCTCACTGTTCCCCAAAACATGCACCCTGGACTTCTCTAATAGAAAAGTCTCCACCCCTACACA AGGACAGAACCCTCCACCCCTACCCCCAACCCTCAGACAGACTTATACACCCCTGAGTGAGGATTACATGCCCATCCCAGTGTCCTAGGA CCTTTTCCCAATACTAGCCCCCCAGTGGTGAACAGAACCTCCCAAATTTGAGTTGCACCCTTCCCTGTGGCCTTATGAGCTCAGCCTCGC TTTGAGGTACCCACCGTCCTGTCAGCTCCTTGACCTATGAGCCGGGGCCTGACTAGGAAAAGTTGGGAGTTAAGGAGGAAATTAGCATTC CTTAATGTTTTGTTTTGGTGCTCTGAATTTCTTCTTTATTATAGTCCTATAGTTTTACTCCTCAGTTCCTCACCATCATCATCTTGTCTA AGACCCCCATTATAATATTCATGCGCTGCTTTTTCATCAAAACCTACCCTGTCCTAGAGATCTATGGGCATTTGGTGGATGATAATGAGC AGCCCCTCCCAGATAGAATGTCAATATTTGAGCAGTAGGATATTGGCATTTGTTAGTTAAAGGCTTAAATCAAAAGAATGTCCAATGGTA GGAATTTCAAGGTGTAGGTCAGATATTTGAGAATAGGGGATTTTTTTGATGTGCCTTAAATTATACCAAAGATTACTAATTATTCCTCTT TGCCCAAAATACTTGCATCCAAGGTTCTAGTCTCTGTTGCTGTGCTGGTCTTTAGCCCCACTGCTTGCACTGATGTCCCTCCTTTTCACG GAGACCTATCTGAGGTACAGGATGGGGCTGGCACCAGATGATGTCCCACCACAGTCCCTCACCTCCGGCCTCCACATGACAGAACCAATT TACACTCAACCATGACCTCACCCCTCCTTGGTTTCTCCCTCGATCTGTGGCCCTTTTTGGATGTATTCTTATCTAACAACACAATCCGGA AAGACTGAATTGAATATTTATACTAATGGTTCATATCCTTTATTGCTCAATGATCTAATTAAAGGGATCATTGCCACATTTCATGTTTAT ATTTCTACAATTTGTTTAGAAAACATCTCCTGACCATATCAGTAGCTCGTGTTATCTTTTTATCAACTGCTTCCCAGAGTCCTAAAACAA TAGAAATTTTGGATTGAAAAGTTCAGCATAAGGAGTTTGAGTCAGTAAAGGATGGGATAAAGGAGTCGAGATGATTCAATGAAAAGTATC ACAAAAAAGAGATTGATCAACAAGAGAAATAAAAAAGCCCAAGAGGAAGTGGTAGGGGAAGGAATTTAAGAACAGCAATAAGTAAAACTC TTAAGTAACTCCAAAAAGAAAATGGTACATTTTGCCAAAGACCACTTATACTTGAGAACATGGAAGAATTTGCCTGATACTCTCTTTGGG GAAAAGAGTCTCTCCTCTTTTCCTCAAACCCCAGTACACTCAGCCTCTCTGCCCCACCTTCTCCTGACTTTGTCCTCACTTGCTTCTGCA GTACATTGGAACCTGAATTGAAAGAAAGTCTTCCTTGAATAATTGGAGTTTGTCTTGAGAGGCAAATATAGCCCCAAGAATCACAAGATT CGAGGACCATGTAGGTCTTTTACGTAGCCCAAATCCATAAATTAGTCTCACTTTTTGTATTTATCGTTTCATATTAAACCCTCTATATCA AATGTTCATCATGATTTTGTATGATTTTTATAACTATTTTATTCATTTTATTAGATTTATTCTAAAATTTTTTAATGGTAAATTCTTAAA CTGTGGAAACCACTGAAGGTGCTTATTAACTGTTCTCCCAGATTTGTACAAGTATTGGATGATTCCTTGAGTTTACAGCTGTACAAATAG TGTGGAAAATAAACTTTTTTTAAAAAAGAAAAGAATTCCGTGGTTGCTCTCGATCTTGCAATTTCCAAGGAGACGGATGCTTTCCAACCC CACAAGCAGACCCGGCTGTATGGCATCACCACGGCCCTGTCTCAGTGTCCGCAAGGCACCAATCGGGCGGAATGCCTGAACCCCAGTCAG CCCAGCAGACGCAAGGCTCTCGAAGGGCTCCAGTATCCTTTTGCTGTGACGAGCTACGGGAAGAATCTGTATTTCACAGACTGGAAGATG >86195_86195_2_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000260324_NID1_chr1_236143879_ENST00000366595_length(amino acids)=379AA_BP= MKMVPLVAVVSGPRAQLFACLLRLGTQQVGPLQLHTGASHAARNHYEVLVLGGGSGGITMAARMKRKVGAENVAIVEPSERHFYQPIWTL VGAGAKQLSSSGRPTASVIPSGVEWIKARVTELNPDKNCIHTDDDEKISYRYLIIALGIQLDYEKIKGLPEGFAHPKIGSNYSVKTVEKT WKALQDFKEGNAIFTFPNTPVKCAGAPQKIMYLSEAYFRKTGKRSKANIIFNTSLGAIFGVKKYADALQEIIQERNLTVNYKKNLIEVRA DKQEAVFENLDKPGETQVISYEMLHVTPPMSPPDVLKTSPVADAAGWVDVDKETLQHRRYPNVFGIGDCTNLPTSKTAAAVAAQSGILDR -------------------------------------------------------------- >86195_86195_3_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000568606_NID1_chr1_236143879_ENST00000264187_length(transcript)=3846nt_BP=1366nt CTCATTTTCTCTTGCCGCCACCATGTAAGAAGCGCCTTTCGCCTCCCTCCATGATTCTGAGGCCTCCCCAGCCACATGGTACTTGTATGC CTAGACAGCGGGCACAGGGCTTGCTGGACACAGAAGGCAAGGACTCAGAGAATATCCACCAGATGAAAGAATGACTGCATGACCTGATCC TGCCTGAAGATGGTGCCACTGGTGGCTGTGGTATCAGGGCCCCGTGCCCAGCTCTTTGCCTGCCTGCTCAGGCTGGGCACTCAGCAGGTC GGCCCCCTTCAGCTGCACACCGGGGCCAGCCATGCGGCCAGGAACCATTATGAGGTGCTGGTGCTGGGTGGGGGCAGTGGCGGAATCACC ATGGCTGCCCGCATGAAGAGGAAAGTGGGTGCAGAGAATGTGGCCATTGTTGAGCCCAGTGAGAGACATTTCTACCAGCCAATCTGGACA CTGGTGGGTGCTGGTGCCAAACAATTGTCCTCATCTGGTCGTCCCACGGCAAGTGTGATTCCATCTGGTGTAGAATGGATCAAAGCTAGA GTGACTGAGTTGAACCCAGACAAGAACTGCATTCACACAGATGACGACGAGAAGATCTCCTACCGATATCTTATTATTGCTCTCGGAATC CAGCTGGACTATGAGAAGATTAAAGGCCTACCTGAAGGTTTCGCTCATCCCAAAATAGGGTCGAATTATTCAGTTAAGACTGTAGAGAAG ACATGGAAAGCTCTGCAGGACTTCAAAGAGGGCAATGCCATCTTCACCTTCCCAAATACTCCAGTGAAGTGTGCTGGAGCCCCTCAGAAG ATCATGTACTTATCAGAAGCCTACTTCAGGAAGACAGGGAAGCGATCCAAGGCCAATATCATTTTCAACACTTCTCTTGGAGCCATTTTC GGGGTTAAGAAGTATGCAGATGCCCTGCAGGAGATCATCCAGGAGCGGAACCTCACTGTTAACTACAAGAAAAACCTCATTGAAGTCCGA GCCGATAAACAAGAGGCTGTATTTGAGAACCTGGACAAACCAGGAGAGACCCAAGTGATTTCATATGAAATGCTTCATGTCACACCTCCA ATGAGCCCACCAGATGTCCTCAAGACCAGTCCTGTGGCTGATGCTGCTGGTTGGGTGGATGTGGATAAAGAAACTCTGCAACACAGGAGG TACCCAAATGTGTTTGGGATTGGGGACTGCACCAACCTTCCTACGTCAAAGACCGCTGCTGCAGTAGCTGCCCAGTCAGGAATACTTGAT AGGACAATTTCTGTAATTATGAAGAATCAAACACCAACAAAGAAGTTTCCATGTATCTCATGAAAGCTGACCTGATGCCTTTCCTGTATT GGAATATGATGCTAAGGCCATAACTACTGCTCAGTGAACAATGGCGGCTGCACCCACCTATGCTTGGCCACCCCAGGGAGCAGGACCTGC CGTTGCCCTGACAACACCTTGGGAGTTGACTGTATCGAACAGAAATGAAGACAAGAGTGCCTTATTTCCTTTCCAAGTATTTCACAGCAA CACTCTACTTGAAGCAACTTGGTCCAGATTGAAAAGTGTCCTCTGGCTGAGTGGCCACTAGGCCCAGACCCAGCCCAGCCTGAGCCCCAA CAACTTTTCCCTCACTGTTCCCCAAAACATGCACCCTGGACTTCTCTAATAGAAAAGTCTCCACCCCTACACAAGGACAGAACCCTCCAC CCCTACCCCCAACCCTCAGACAGACTTATACACCCCTGAGTGAGGATTACATGCCCATCCCAGTGTCCTAGGACCTTTTCCCAATACTAG CCCCCCAGTGGTGAACAGAACCTCCCAAATTTGAGTTGCACCCTTCCCTGTGGCCTTATGAGCTCAGCCTCGCTTTGAGGTACCCACCGT CCTGTCAGCTCCTTGACCTATGAGCCGGGGCCTGACTAGGAAAAGTTGGGAGTTAAGGAGGAAATTAGCATTCCTTAATGTTTTGTTTTG GTGCTCTGAATTTCTTCTTTATTATAGTCCTATAGTTTTACTCCTCAGTTCCTCACCATCATCATCTTGTCTAAGACCCCCATTATAATA TTCATGCGCTGCTTTTTCATCAAAACCTACCCTGTCCTAGAGATCTATGGGCATTTGGTGGATGATAATGAGCAGCCCCTCCCAGATAGA ATGTCAATATTTGAGCAGTAGGATATTGGCATTTGTTAGTTAAAGGCTTAAATCAAAAGAATGTCCAATGGTAGGAATTTCAAGGTGTAG GTCAGATATTTGAGAATAGGGGATTTTTTTGATGTGCCTTAAATTATACCAAAGATTACTAATTATTCCTCTTTGCCCAAAATACTTGCA TCCAAGGTTCTAGTCTCTGTTGCTGTGCTGGTCTTTAGCCCCACTGCTTGCACTGATGTCCCTCCTTTTCACGGAGACCTATCTGAGGTA CAGGATGGGGCTGGCACCAGATGATGTCCCACCACAGTCCCTCACCTCCGGCCTCCACATGACAGAACCAATTTACACTCAACCATGACC TCACCCCTCCTTGGTTTCTCCCTCGATCTGTGGCCCTTTTTGGATGTATTCTTATCTAACAACACAATCCGGAAAGACTGAATTGAATAT TTATACTAATGGTTCATATCCTTTATTGCTCAATGATCTAATTAAAGGGATCATTGCCACATTTCATGTTTATATTTCTACAATTTGTTT AGAAAACATCTCCTGACCATATCAGTAGCTCGTGTTATCTTTTTATCAACTGCTTCCCAGAGTCCTAAAACAATAGAAATTTTGGATTGA AAAGTTCAGCATAAGGAGTTTGAGTCAGTAAAGGATGGGATAAAGGAGTCGAGATGATTCAATGAAAAGTATCACAAAAAAGAGATTGAT CAACAAGAGAAATAAAAAAGCCCAAGAGGAAGTGGTAGGGGAAGGAATTTAAGAACAGCAATAAGTAAAACTCTTAAGTAACTCCAAAAA GAAAATGGTACATTTTGCCAAAGACCACTTATACTTGAGAACATGGAAGAATTTGCCTGATACTCTCTTTGGGGAAAAGAGTCTCTCCTC TTTTCCTCAAACCCCAGTACACTCAGCCTCTCTGCCCCACCTTCTCCTGACTTTGTCCTCACTTGCTTCTGCAGTACATTGGAACCTGAA TTGAAAGAAAGTCTTCCTTGAATAATTGGAGTTTGTCTTGAGAGGCAAATATAGCCCCAAGAATCACAAGATTCGAGGACCATGTAGGTC TTTTACGTAGCCCAAATCCATAAATTAGTCTCACTTTTTGTATTTATCGTTTCATATTAAACCCTCTATATCAAATGTTCATCATGATTT TGTATGATTTTTATAACTATTTTATTCATTTTATTAGATTTATTCTAAAATTTTTTAATGGTAAATTCTTAAACTGTGGAAACCACTGAA GGTGCTTATTAACTGTTCTCCCAGATTTGTACAAGTATTGGATGATTCCTTGAGTTTACAGCTGTACAAATAGTGTGGAAAATAAACTTT TTTTAAAAAAGAAAAGAATTCCGTGGTTGCTCTCGATCTTGCAATTTCCAAGGAGACGGATGCTTTCCAACCCCACAAGCAGACCCGGCT GTATGGCATCACCACGGCCCTGTCTCAGTGTCCGCAAGGCACCAATCGGGCGGAATGCCTGAACCCCAGTCAGCCCAGCAGACGCAAGGC TCTCGAAGGGCTCCAGTATCCTTTTGCTGTGACGAGCTACGGGAAGAATCTGTATTTCACAGACTGGAAGATGGATCCTTGTGCAGGATG >86195_86195_3_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000568606_NID1_chr1_236143879_ENST00000264187_length(amino acids)=379AA_BP= MKMVPLVAVVSGPRAQLFACLLRLGTQQVGPLQLHTGASHAARNHYEVLVLGGGSGGITMAARMKRKVGAENVAIVEPSERHFYQPIWTL VGAGAKQLSSSGRPTASVIPSGVEWIKARVTELNPDKNCIHTDDDEKISYRYLIIALGIQLDYEKIKGLPEGFAHPKIGSNYSVKTVEKT WKALQDFKEGNAIFTFPNTPVKCAGAPQKIMYLSEAYFRKTGKRSKANIIFNTSLGAIFGVKKYADALQEIIQERNLTVNYKKNLIEVRA DKQEAVFENLDKPGETQVISYEMLHVTPPMSPPDVLKTSPVADAAGWVDVDKETLQHRRYPNVFGIGDCTNLPTSKTAAAVAAQSGILDR -------------------------------------------------------------- >86195_86195_4_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000568606_NID1_chr1_236143879_ENST00000366595_length(transcript)=3846nt_BP=1366nt CTCATTTTCTCTTGCCGCCACCATGTAAGAAGCGCCTTTCGCCTCCCTCCATGATTCTGAGGCCTCCCCAGCCACATGGTACTTGTATGC CTAGACAGCGGGCACAGGGCTTGCTGGACACAGAAGGCAAGGACTCAGAGAATATCCACCAGATGAAAGAATGACTGCATGACCTGATCC TGCCTGAAGATGGTGCCACTGGTGGCTGTGGTATCAGGGCCCCGTGCCCAGCTCTTTGCCTGCCTGCTCAGGCTGGGCACTCAGCAGGTC GGCCCCCTTCAGCTGCACACCGGGGCCAGCCATGCGGCCAGGAACCATTATGAGGTGCTGGTGCTGGGTGGGGGCAGTGGCGGAATCACC ATGGCTGCCCGCATGAAGAGGAAAGTGGGTGCAGAGAATGTGGCCATTGTTGAGCCCAGTGAGAGACATTTCTACCAGCCAATCTGGACA CTGGTGGGTGCTGGTGCCAAACAATTGTCCTCATCTGGTCGTCCCACGGCAAGTGTGATTCCATCTGGTGTAGAATGGATCAAAGCTAGA GTGACTGAGTTGAACCCAGACAAGAACTGCATTCACACAGATGACGACGAGAAGATCTCCTACCGATATCTTATTATTGCTCTCGGAATC CAGCTGGACTATGAGAAGATTAAAGGCCTACCTGAAGGTTTCGCTCATCCCAAAATAGGGTCGAATTATTCAGTTAAGACTGTAGAGAAG ACATGGAAAGCTCTGCAGGACTTCAAAGAGGGCAATGCCATCTTCACCTTCCCAAATACTCCAGTGAAGTGTGCTGGAGCCCCTCAGAAG ATCATGTACTTATCAGAAGCCTACTTCAGGAAGACAGGGAAGCGATCCAAGGCCAATATCATTTTCAACACTTCTCTTGGAGCCATTTTC GGGGTTAAGAAGTATGCAGATGCCCTGCAGGAGATCATCCAGGAGCGGAACCTCACTGTTAACTACAAGAAAAACCTCATTGAAGTCCGA GCCGATAAACAAGAGGCTGTATTTGAGAACCTGGACAAACCAGGAGAGACCCAAGTGATTTCATATGAAATGCTTCATGTCACACCTCCA ATGAGCCCACCAGATGTCCTCAAGACCAGTCCTGTGGCTGATGCTGCTGGTTGGGTGGATGTGGATAAAGAAACTCTGCAACACAGGAGG TACCCAAATGTGTTTGGGATTGGGGACTGCACCAACCTTCCTACGTCAAAGACCGCTGCTGCAGTAGCTGCCCAGTCAGGAATACTTGAT AGGACAATTTCTGTAATTATGAAGAATCAAACACCAACAAAGAAGTTTCCATGTATCTCATGAAAGCTGACCTGATGCCTTTCCTGTATT GGAATATGATGCTAAGGCCATAACTACTGCTCAGTGAACAATGGCGGCTGCACCCACCTATGCTTGGCCACCCCAGGGAGCAGGACCTGC CGTTGCCCTGACAACACCTTGGGAGTTGACTGTATCGAACAGAAATGAAGACAAGAGTGCCTTATTTCCTTTCCAAGTATTTCACAGCAA CACTCTACTTGAAGCAACTTGGTCCAGATTGAAAAGTGTCCTCTGGCTGAGTGGCCACTAGGCCCAGACCCAGCCCAGCCTGAGCCCCAA CAACTTTTCCCTCACTGTTCCCCAAAACATGCACCCTGGACTTCTCTAATAGAAAAGTCTCCACCCCTACACAAGGACAGAACCCTCCAC CCCTACCCCCAACCCTCAGACAGACTTATACACCCCTGAGTGAGGATTACATGCCCATCCCAGTGTCCTAGGACCTTTTCCCAATACTAG CCCCCCAGTGGTGAACAGAACCTCCCAAATTTGAGTTGCACCCTTCCCTGTGGCCTTATGAGCTCAGCCTCGCTTTGAGGTACCCACCGT CCTGTCAGCTCCTTGACCTATGAGCCGGGGCCTGACTAGGAAAAGTTGGGAGTTAAGGAGGAAATTAGCATTCCTTAATGTTTTGTTTTG GTGCTCTGAATTTCTTCTTTATTATAGTCCTATAGTTTTACTCCTCAGTTCCTCACCATCATCATCTTGTCTAAGACCCCCATTATAATA TTCATGCGCTGCTTTTTCATCAAAACCTACCCTGTCCTAGAGATCTATGGGCATTTGGTGGATGATAATGAGCAGCCCCTCCCAGATAGA ATGTCAATATTTGAGCAGTAGGATATTGGCATTTGTTAGTTAAAGGCTTAAATCAAAAGAATGTCCAATGGTAGGAATTTCAAGGTGTAG GTCAGATATTTGAGAATAGGGGATTTTTTTGATGTGCCTTAAATTATACCAAAGATTACTAATTATTCCTCTTTGCCCAAAATACTTGCA TCCAAGGTTCTAGTCTCTGTTGCTGTGCTGGTCTTTAGCCCCACTGCTTGCACTGATGTCCCTCCTTTTCACGGAGACCTATCTGAGGTA CAGGATGGGGCTGGCACCAGATGATGTCCCACCACAGTCCCTCACCTCCGGCCTCCACATGACAGAACCAATTTACACTCAACCATGACC TCACCCCTCCTTGGTTTCTCCCTCGATCTGTGGCCCTTTTTGGATGTATTCTTATCTAACAACACAATCCGGAAAGACTGAATTGAATAT TTATACTAATGGTTCATATCCTTTATTGCTCAATGATCTAATTAAAGGGATCATTGCCACATTTCATGTTTATATTTCTACAATTTGTTT AGAAAACATCTCCTGACCATATCAGTAGCTCGTGTTATCTTTTTATCAACTGCTTCCCAGAGTCCTAAAACAATAGAAATTTTGGATTGA AAAGTTCAGCATAAGGAGTTTGAGTCAGTAAAGGATGGGATAAAGGAGTCGAGATGATTCAATGAAAAGTATCACAAAAAAGAGATTGAT CAACAAGAGAAATAAAAAAGCCCAAGAGGAAGTGGTAGGGGAAGGAATTTAAGAACAGCAATAAGTAAAACTCTTAAGTAACTCCAAAAA GAAAATGGTACATTTTGCCAAAGACCACTTATACTTGAGAACATGGAAGAATTTGCCTGATACTCTCTTTGGGGAAAAGAGTCTCTCCTC TTTTCCTCAAACCCCAGTACACTCAGCCTCTCTGCCCCACCTTCTCCTGACTTTGTCCTCACTTGCTTCTGCAGTACATTGGAACCTGAA TTGAAAGAAAGTCTTCCTTGAATAATTGGAGTTTGTCTTGAGAGGCAAATATAGCCCCAAGAATCACAAGATTCGAGGACCATGTAGGTC TTTTACGTAGCCCAAATCCATAAATTAGTCTCACTTTTTGTATTTATCGTTTCATATTAAACCCTCTATATCAAATGTTCATCATGATTT TGTATGATTTTTATAACTATTTTATTCATTTTATTAGATTTATTCTAAAATTTTTTAATGGTAAATTCTTAAACTGTGGAAACCACTGAA GGTGCTTATTAACTGTTCTCCCAGATTTGTACAAGTATTGGATGATTCCTTGAGTTTACAGCTGTACAAATAGTGTGGAAAATAAACTTT TTTTAAAAAAGAAAAGAATTCCGTGGTTGCTCTCGATCTTGCAATTTCCAAGGAGACGGATGCTTTCCAACCCCACAAGCAGACCCGGCT GTATGGCATCACCACGGCCCTGTCTCAGTGTCCGCAAGGCACCAATCGGGCGGAATGCCTGAACCCCAGTCAGCCCAGCAGACGCAAGGC TCTCGAAGGGCTCCAGTATCCTTTTGCTGTGACGAGCTACGGGAAGAATCTGTATTTCACAGACTGGAAGATGGATCCTTGTGCAGGATG >86195_86195_4_SQRDL-NID1_SQRDL_chr15_45981354_ENST00000568606_NID1_chr1_236143879_ENST00000366595_length(amino acids)=379AA_BP= MKMVPLVAVVSGPRAQLFACLLRLGTQQVGPLQLHTGASHAARNHYEVLVLGGGSGGITMAARMKRKVGAENVAIVEPSERHFYQPIWTL VGAGAKQLSSSGRPTASVIPSGVEWIKARVTELNPDKNCIHTDDDEKISYRYLIIALGIQLDYEKIKGLPEGFAHPKIGSNYSVKTVEKT WKALQDFKEGNAIFTFPNTPVKCAGAPQKIMYLSEAYFRKTGKRSKANIIFNTSLGAIFGVKKYADALQEIIQERNLTVNYKKNLIEVRA DKQEAVFENLDKPGETQVISYEMLHVTPPMSPPDVLKTSPVADAAGWVDVDKETLQHRRYPNVFGIGDCTNLPTSKTAAAVAAQSGILDR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SQRDL-NID1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SQRDL-NID1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SQRDL-NID1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies