
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SRRT-GAPDH (FusionGDB2 ID:86572) |
Fusion Gene Summary for SRRT-GAPDH |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SRRT-GAPDH | Fusion gene ID: 86572 | Hgene | Tgene | Gene symbol | SRRT | GAPDH | Gene ID | 51593 | 2597 |
| Gene name | serrate, RNA effector molecule | glyceraldehyde-3-phosphate dehydrogenase | |
| Synonyms | ARS2|ASR2|serrate | G3PD|GAPD|HEL-S-162eP | |
| Cytomap | 7q22.1 | 12p13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | serrate RNA effector molecule homologarsenate resistance protein 2arsenate resistance protein ARS2arsenite resistance proteinarsenite-resistance protein 2 | glyceraldehyde-3-phosphate dehydrogenaseOCAS, p38 componentOct1 coactivator in S phase, 38 Kd componentaging-associated gene 9 proteinepididymis secretory sperm binding protein Li 162ePpeptidyl-cysteine S-nitrosylase GAPDH | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | P04406 | |
| Ensembl transtripts involved in fusion gene | ENST00000347433, ENST00000388793, ENST00000432932, ENST00000457580, | ENST00000396856, ENST00000396858, ENST00000396859, ENST00000229239, ENST00000396861, | |
| Fusion gene scores | * DoF score | 9 X 8 X 3=216 | 27 X 29 X 8=6264 |
| # samples | 10 | 31 | |
| ** MAII score | log2(10/216*10)=-1.11103131238874 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(31/6264*10)=-4.3367440920168 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SRRT [Title/Abstract] AND GAPDH [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SRRT(100484540)-GAPDH(6647322), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | SRRT-GAPDH seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. SRRT-GAPDH seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. SRRT-GAPDH seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GAPDH | GO:0010951 | negative regulation of endopeptidase activity | 22832495 |
| Tgene | GAPDH | GO:0017148 | negative regulation of translation | 23071094 |
| Tgene | GAPDH | GO:0031640 | killing of cells of other organism | 22832495 |
| Tgene | GAPDH | GO:0050715 | positive regulation of cytokine secretion | 22832495 |
| Tgene | GAPDH | GO:0050832 | defense response to fungus | 22832495 |
| Tgene | GAPDH | GO:0051873 | killing by host of symbiont cells | 22832495 |
| Tgene | GAPDH | GO:0052501 | positive regulation by organism of apoptotic process in other organism involved in symbiotic interaction | 22832495 |
| Tgene | GAPDH | GO:0061844 | antimicrobial humoral immune response mediated by antimicrobial peptide | 22832495 |
| Tgene | GAPDH | GO:0071346 | cellular response to interferon-gamma | 15479637 |
| Fusion gene breakpoints across SRRT (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GAPDH (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | BF820683 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
Top |
Fusion Gene ORF analysis for SRRT-GAPDH |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000347433 | ENST00000396856 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000347433 | ENST00000396858 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000347433 | ENST00000396859 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000388793 | ENST00000396856 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000388793 | ENST00000396858 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000388793 | ENST00000396859 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000432932 | ENST00000396856 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000432932 | ENST00000396858 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000432932 | ENST00000396859 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000457580 | ENST00000396856 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000457580 | ENST00000396858 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| Frame-shift | ENST00000457580 | ENST00000396859 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000347433 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000347433 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000388793 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000388793 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000432932 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000432932 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000457580 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| In-frame | ENST00000457580 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000457580 | SRRT | chr7 | 100484540 | + | ENST00000229239 | GAPDH | chr12 | 6647322 | + | 2131 | 1916 | 220 | 1902 | 560 |
| ENST00000457580 | SRRT | chr7 | 100484540 | + | ENST00000396861 | GAPDH | chr12 | 6647322 | + | 2119 | 1916 | 220 | 1902 | 560 |
| ENST00000388793 | SRRT | chr7 | 100484540 | + | ENST00000229239 | GAPDH | chr12 | 6647322 | + | 2128 | 1913 | 220 | 1899 | 559 |
| ENST00000388793 | SRRT | chr7 | 100484540 | + | ENST00000396861 | GAPDH | chr12 | 6647322 | + | 2116 | 1913 | 220 | 1899 | 559 |
| ENST00000432932 | SRRT | chr7 | 100484540 | + | ENST00000229239 | GAPDH | chr12 | 6647322 | + | 2069 | 1854 | 161 | 1840 | 559 |
| ENST00000432932 | SRRT | chr7 | 100484540 | + | ENST00000396861 | GAPDH | chr12 | 6647322 | + | 2057 | 1854 | 161 | 1840 | 559 |
| ENST00000347433 | SRRT | chr7 | 100484540 | + | ENST00000229239 | GAPDH | chr12 | 6647322 | + | 2069 | 1854 | 158 | 1840 | 560 |
| ENST00000347433 | SRRT | chr7 | 100484540 | + | ENST00000396861 | GAPDH | chr12 | 6647322 | + | 2057 | 1854 | 158 | 1840 | 560 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000457580 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.010773321 | 0.9892267 |
| ENST00000457580 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.010904308 | 0.98909575 |
| ENST00000388793 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.010652451 | 0.9893476 |
| ENST00000388793 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.010781937 | 0.9892181 |
| ENST00000432932 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.01158466 | 0.98841536 |
| ENST00000432932 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.011736834 | 0.9882632 |
| ENST00000347433 | ENST00000229239 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.011800337 | 0.9881997 |
| ENST00000347433 | ENST00000396861 | SRRT | chr7 | 100484540 | + | GAPDH | chr12 | 6647322 | + | 0.011955645 | 0.9880443 |
Top |
Fusion Genomic Features for SRRT-GAPDH |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
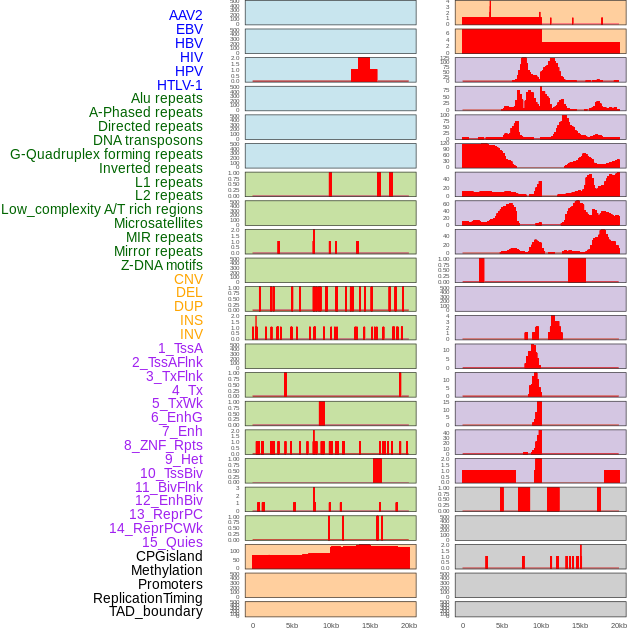 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SRRT-GAPDH |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:100484540/chr12:6647322) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | GAPDH |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Has both glyceraldehyde-3-phosphate dehydrogenase and nitrosylase activities, thereby playing a role in glycolysis and nuclear functions, respectively. Participates in nuclear events including transcription, RNA transport, DNA replication and apoptosis. Nuclear functions are probably due to the nitrosylase activity that mediates cysteine S-nitrosylation of nuclear target proteins such as SIRT1, HDAC2 and PRKDC. Modulates the organization and assembly of the cytoskeleton. Facilitates the CHP1-dependent microtubule and membrane associations through its ability to stimulate the binding of CHP1 to microtubules (By similarity). Glyceraldehyde-3-phosphate dehydrogenase is a key enzyme in glycolysis that catalyzes the first step of the pathway by converting D-glyceraldehyde 3-phosphate (G3P) into 3-phospho-D-glyceroyl phosphate. Component of the GAIT (gamma interferon-activated inhibitor of translation) complex which mediates interferon-gamma-induced transcript-selective translation inhibition in inflammation processes. Upon interferon-gamma treatment assembles into the GAIT complex which binds to stem loop-containing GAIT elements in the 3'-UTR of diverse inflammatory mRNAs (such as ceruplasmin) and suppresses their translation. {ECO:0000250, ECO:0000269|PubMed:11724794, ECO:0000269|PubMed:23071094, ECO:0000269|PubMed:3170585}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000229239 | 0 | 9 | 245_250 | 0 | 336.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396858 | 0 | 8 | 245_250 | 0 | 294.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396859 | 0 | 8 | 245_250 | 0 | 336.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396861 | 0 | 9 | 245_250 | 0 | 336.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000229239 | 0 | 9 | 13_14 | 0 | 336.0 | Nucleotide binding | NAD | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396858 | 0 | 8 | 13_14 | 0 | 294.0 | Nucleotide binding | NAD | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396859 | 0 | 8 | 13_14 | 0 | 336.0 | Nucleotide binding | NAD | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396861 | 0 | 9 | 13_14 | 0 | 336.0 | Nucleotide binding | NAD | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000229239 | 0 | 9 | 151_153 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000229239 | 0 | 9 | 211_212 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396858 | 0 | 8 | 151_153 | 0 | 294.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396858 | 0 | 8 | 211_212 | 0 | 294.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396859 | 0 | 8 | 151_153 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396859 | 0 | 8 | 211_212 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396861 | 0 | 9 | 151_153 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396861 | 0 | 9 | 211_212 | 0 | 336.0 | Region | Glyceraldehyde 3-phosphate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000347433 | + | 1 | 20 | 10_82 | 0 | 877.0 | Compositional bias | Note=Arg-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000347433 | + | 1 | 20 | 258_402 | 0 | 877.0 | Compositional bias | Note=Glu-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000347433 | + | 1 | 20 | 760_828 | 0 | 877.0 | Compositional bias | Note=Pro-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000388793 | + | 1 | 20 | 10_82 | 0 | 876.0 | Compositional bias | Note=Arg-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000388793 | + | 1 | 20 | 258_402 | 0 | 876.0 | Compositional bias | Note=Glu-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000388793 | + | 1 | 20 | 760_828 | 0 | 876.0 | Compositional bias | Note=Pro-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000432932 | + | 1 | 20 | 10_82 | 0 | 872.0 | Compositional bias | Note=Arg-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000432932 | + | 1 | 20 | 258_402 | 0 | 872.0 | Compositional bias | Note=Glu-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000432932 | + | 1 | 20 | 760_828 | 0 | 872.0 | Compositional bias | Note=Pro-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000457580 | + | 1 | 20 | 10_82 | 0 | 873.0 | Compositional bias | Note=Arg-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000457580 | + | 1 | 20 | 258_402 | 0 | 873.0 | Compositional bias | Note=Glu-rich |
| Hgene | SRRT | chr7:100484540 | chr12:6647322 | ENST00000457580 | + | 1 | 20 | 760_828 | 0 | 873.0 | Compositional bias | Note=Pro-rich |
Top |
Fusion Gene Sequence for SRRT-GAPDH |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >86572_86572_1_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000347433_GAPDH_chr12_6647322_ENST00000229239_length(transcript)=2069nt_BP=1854nt GTTCGCCTCTCTTCGGCCCTCTACTCAAGAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCC CTGAAATCTAGCCCGTCCGAGCGCGAGTCCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGT ACGATCGAAGGCGCAGGGACAAGTTCAGAAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATT GGAATGACAGAGAGTGGGACCGTGGCCGTGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGC CACCTCGCCACGAACTCAGCCCGCCACAGAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGA TGCCCTATGCTGGGGGGGGTGGGGGCCCAACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCC TGCCTATCCAGGCCAGGCTGGGCAGCATTGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCT CCCTGGATGACTCGGTGGATGAGACGGAGGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCT TCCTGGCGCACAAAGATGAGGAGTGGTTTCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGC AAAACCGACTGAGGGTCTTCCTGTCCCTCATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCA AGATGCTGGATGCAGCCGTGATTAAGATGGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAG GAAAGCCTGGGGAGCCCAGCAAGAAAGAAGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGA AGAAGGAAGACGGCAAGCAGGCTGAGAATGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGA AAGAAGACTCCGAGAAGGAAGCCAAAAAGAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGT CAGAGTCTGAGTCGGAGTCAGAGAGCGGCCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGG AAGAAGAATGGGAGAAGCCCAAGGACGCCGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACA TCGCGCCCAACATCTCCCGGGCCGAGATCATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAG AGAGGAGGTTTTTCCGTCGTGGCTGGGTGACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCC GGGAGTGTGAGCTGAGCCCTGGTGTGAACAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGC GCAACGACATCAAGCTGGCGGCCAAGCTGATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGC CCACGAGGGAACCCGGCAGAGATCAACGTGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCA GCAAGAGCACAAGAGGAAGAGAGAGACCCTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCAC >86572_86572_1_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000347433_GAPDH_chr12_6647322_ENST00000229239_length(amino acids)=560AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRV ALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWAS -------------------------------------------------------------- >86572_86572_2_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000347433_GAPDH_chr12_6647322_ENST00000396861_length(transcript)=2057nt_BP=1854nt GTTCGCCTCTCTTCGGCCCTCTACTCAAGAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCC CTGAAATCTAGCCCGTCCGAGCGCGAGTCCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGT ACGATCGAAGGCGCAGGGACAAGTTCAGAAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATT GGAATGACAGAGAGTGGGACCGTGGCCGTGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGC CACCTCGCCACGAACTCAGCCCGCCACAGAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGA TGCCCTATGCTGGGGGGGGTGGGGGCCCAACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCC TGCCTATCCAGGCCAGGCTGGGCAGCATTGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCT CCCTGGATGACTCGGTGGATGAGACGGAGGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCT TCCTGGCGCACAAAGATGAGGAGTGGTTTCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGC AAAACCGACTGAGGGTCTTCCTGTCCCTCATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCA AGATGCTGGATGCAGCCGTGATTAAGATGGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAG GAAAGCCTGGGGAGCCCAGCAAGAAAGAAGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGA AGAAGGAAGACGGCAAGCAGGCTGAGAATGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGA AAGAAGACTCCGAGAAGGAAGCCAAAAAGAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGT CAGAGTCTGAGTCGGAGTCAGAGAGCGGCCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGG AAGAAGAATGGGAGAAGCCCAAGGACGCCGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACA TCGCGCCCAACATCTCCCGGGCCGAGATCATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAG AGAGGAGGTTTTTCCGTCGTGGCTGGGTGACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCC GGGAGTGTGAGCTGAGCCCTGGTGTGAACAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGC GCAACGACATCAAGCTGGCGGCCAAGCTGATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGC CCACGAGGGAACCCGGCAGAGATCAACGTGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCA GCAAGAGCACAAGAGGAAGAGAGAGACCCTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCAC >86572_86572_2_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000347433_GAPDH_chr12_6647322_ENST00000396861_length(amino acids)=560AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRV ALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWAS -------------------------------------------------------------- >86572_86572_3_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000388793_GAPDH_chr12_6647322_ENST00000229239_length(transcript)=2128nt_BP=1913nt GGGTGACGCAGGCGCAGCGCGGGCTGCGCGCGCTACTGCCCATCCCCGGTTGTCCCACTTTTGTTCGCCTCTCTTCGGCCCTCTACTCAA GAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCCCTGAAATCTAGCCCGTCCGAGCGCGAGT CCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGTACGATCGAAGGCGCAGGGACAAGTTCAG AAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATTGGAATGACAGAGAGTGGGACCGTGGCCG TGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGCCACCTCGCCACGAACTCAGCCCGCCACA GAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGATGCCCTATGCTGGGGGGGGTGGGGGCCC AACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCCTGCCTATCCAGGCCAGGCTGGGCAGCAT TGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCTCCCTGGATGACTCGGTGGATGAGACGGA GGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCTTCCTGGCGCACAAAGATGAGGAGTGGTT TCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGCAAAACCGACTGAGGGTCTTCCTGTCCCT CATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCAAGATGCTGGATGCAGCCGTGATTAAGAT GGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAGGAAAGCCTGGGGAGCCCAGCAAGAAAGA AGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGAAGAAGGAAGACGGCAAGCAGGCTGAGAA TGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGAAAGAAGACTCCGAGAAGGAAGCCAAAAA GAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGTCAGAGTCTGAGTCGGAGTCAGAGAGCGG CCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGGAAGAAGAATGGGAGAAGCCCAAGGACGCCGC GGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACATCGCGCCCAACATCTCCCGGGCCGAGATCAT CTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAGAGAGGAGGTTTTTCCGTCGTGGCTGGGTGAC CTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCCGGGAGTGTGAGCTGAGCCCTGGTGTGAACAG GGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGCGCAACGACATCAAGCTGGCGGCCAAGCTGAT CCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGCCCACGAGGGAACCCGGCAGAGATCAACGTGG AGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCAGCAAGAGCACAAGAGGAAGAGAGAGACCCTC ACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCACAGTTGCCATGTAGACCCCTTGAAGAGGGGAG >86572_86572_3_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000388793_GAPDH_chr12_6647322_ENST00000229239_length(amino acids)=559AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVA LSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASE -------------------------------------------------------------- >86572_86572_4_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000388793_GAPDH_chr12_6647322_ENST00000396861_length(transcript)=2116nt_BP=1913nt GGGTGACGCAGGCGCAGCGCGGGCTGCGCGCGCTACTGCCCATCCCCGGTTGTCCCACTTTTGTTCGCCTCTCTTCGGCCCTCTACTCAA GAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCCCTGAAATCTAGCCCGTCCGAGCGCGAGT CCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGTACGATCGAAGGCGCAGGGACAAGTTCAG AAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATTGGAATGACAGAGAGTGGGACCGTGGCCG TGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGCCACCTCGCCACGAACTCAGCCCGCCACA GAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGATGCCCTATGCTGGGGGGGGTGGGGGCCC AACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCCTGCCTATCCAGGCCAGGCTGGGCAGCAT TGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCTCCCTGGATGACTCGGTGGATGAGACGGA GGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCTTCCTGGCGCACAAAGATGAGGAGTGGTT TCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGCAAAACCGACTGAGGGTCTTCCTGTCCCT CATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCAAGATGCTGGATGCAGCCGTGATTAAGAT GGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAGGAAAGCCTGGGGAGCCCAGCAAGAAAGA AGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGAAGAAGGAAGACGGCAAGCAGGCTGAGAA TGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGAAAGAAGACTCCGAGAAGGAAGCCAAAAA GAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGTCAGAGTCTGAGTCGGAGTCAGAGAGCGG CCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGGAAGAAGAATGGGAGAAGCCCAAGGACGCCGC GGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACATCGCGCCCAACATCTCCCGGGCCGAGATCAT CTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAGAGAGGAGGTTTTTCCGTCGTGGCTGGGTGAC CTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCCGGGAGTGTGAGCTGAGCCCTGGTGTGAACAG GGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGCGCAACGACATCAAGCTGGCGGCCAAGCTGAT CCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGCCCACGAGGGAACCCGGCAGAGATCAACGTGG AGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCAGCAAGAGCACAAGAGGAAGAGAGAGACCCTC ACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCACAGTTGCCATGTAGACCCCTTGAAGAGGGGAG >86572_86572_4_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000388793_GAPDH_chr12_6647322_ENST00000396861_length(amino acids)=559AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVA LSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASE -------------------------------------------------------------- >86572_86572_5_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000432932_GAPDH_chr12_6647322_ENST00000229239_length(transcript)=2069nt_BP=1854nt TTTGTTCGCCTCTCTTCGGCCCTCTACTCAAGAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTC GCCCTGAAATCTAGCCCGTCCGAGCGCGAGTCCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACG AGTACGATCGAAGGCGCAGGGACAAGTTCAGAAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACG ATTGGAATGACAGAGAGTGGGACCGTGGCCGTGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCT CGCCACCTCGCCACGAACTCAGCCCGCCACAGAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATG AGATGCCCTATGCTGGGGGGGGTGGGGGCCCAACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATG TCCTGCCTATCCAGGCCAGGCTGGGCAGCATTGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCC TCTCCCTGGATGACTCGGTGGATGAGACGGAGGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATT TCTTCCTGGCGCACAAAGATGAGGAGTGGTTTCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCC TGCAAAACCGACTGAGGGTCTTCCTGTCCCTCATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTG TCAAGATGCTGGATGCAGCCGTGATTAAGATGGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGG CAGGAAAGCCTGGGGAGCCCAGCAAGAAAGAAGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATG AGAAGAAGGAAGACGGCAAGCAGGCTGAGAATGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGA AGAAAGAAGACTCCGAGAAGGAAGCCAAAAAGAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCG TGTCAGAGTCTGAGTCGGAGTCAGAGAGCGGCCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGG AAGAAGAATGGGAGAAGCCCAAGGACGCCGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACA TCGCGCCCAACATCTCCCGGGCCGAGATCATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAG AGAGGAGGTTTTTCCGTCGTGGCTGGGTGACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCC GGGAGTGTGAGCTGAGCCCTGGTGTGAACAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGC GCAACGACATCAAGCTGGCGGCCAAGCTGATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGC CCACGAGGGAACCCGGCAGAGATCAACGTGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCA GCAAGAGCACAAGAGGAAGAGAGAGACCCTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCAC >86572_86572_5_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000432932_GAPDH_chr12_6647322_ENST00000229239_length(amino acids)=559AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVA LSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASE -------------------------------------------------------------- >86572_86572_6_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000432932_GAPDH_chr12_6647322_ENST00000396861_length(transcript)=2057nt_BP=1854nt TTTGTTCGCCTCTCTTCGGCCCTCTACTCAAGAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTC GCCCTGAAATCTAGCCCGTCCGAGCGCGAGTCCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACG AGTACGATCGAAGGCGCAGGGACAAGTTCAGAAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACG ATTGGAATGACAGAGAGTGGGACCGTGGCCGTGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCT CGCCACCTCGCCACGAACTCAGCCCGCCACAGAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATG AGATGCCCTATGCTGGGGGGGGTGGGGGCCCAACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATG TCCTGCCTATCCAGGCCAGGCTGGGCAGCATTGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCC TCTCCCTGGATGACTCGGTGGATGAGACGGAGGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATT TCTTCCTGGCGCACAAAGATGAGGAGTGGTTTCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCC TGCAAAACCGACTGAGGGTCTTCCTGTCCCTCATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTG TCAAGATGCTGGATGCAGCCGTGATTAAGATGGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGG CAGGAAAGCCTGGGGAGCCCAGCAAGAAAGAAGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATG AGAAGAAGGAAGACGGCAAGCAGGCTGAGAATGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGA AGAAAGAAGACTCCGAGAAGGAAGCCAAAAAGAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCG TGTCAGAGTCTGAGTCGGAGTCAGAGAGCGGCCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGG AAGAAGAATGGGAGAAGCCCAAGGACGCCGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACA TCGCGCCCAACATCTCCCGGGCCGAGATCATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAG AGAGGAGGTTTTTCCGTCGTGGCTGGGTGACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCC GGGAGTGTGAGCTGAGCCCTGGTGTGAACAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGC GCAACGACATCAAGCTGGCGGCCAAGCTGATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGC CCACGAGGGAACCCGGCAGAGATCAACGTGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCA GCAAGAGCACAAGAGGAAGAGAGAGACCCTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCAC >86572_86572_6_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000432932_GAPDH_chr12_6647322_ENST00000396861_length(amino acids)=559AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRVA LSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWASE -------------------------------------------------------------- >86572_86572_7_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000457580_GAPDH_chr12_6647322_ENST00000229239_length(transcript)=2131nt_BP=1916nt GGGTGACGCAGGCGCAGCGCGGGCTGCGCGCGCTACTGCCCATCCCCGGTTGTCCCACTTTTGTTCGCCTCTCTTCGGCCCTCTACTCAA GAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCCCTGAAATCTAGCCCGTCCGAGCGCGAGT CCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGTACGATCGAAGGCGCAGGGACAAGTTCAG AAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATTGGAATGACAGAGAGTGGGACCGTGGCCG TGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGCCACCTCGCCACGAACTCAGCCCGCCACA GAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGATGCCCTATGCTGGGGGGGGTGGGGGCCC AACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCCTGCCTATCCAGGCCAGGCTGGGCAGCAT TGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCTCCCTGGATGACTCGGTGGATGAGACGGA GGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCTTCCTGGCGCACAAAGATGAGGAGTGGTT TCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGCAAAACCGACTGAGGGTCTTCCTGTCCCT CATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCAAGATGCTGGATGCAGCCGTGATTAAGAT GGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAGGAAAGCCTGGGGAGCCCAGCAAGAAAGA AGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGAAGAAGGAAGACGGCAAGCAGGCTGAGAA TGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGAAAGAAGACTCCGAGAAGGAAGCCAAAAA GAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGTCAGAGTCTGAGTCGGAGTCAGAGAGCGG CCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGGAAGAAGAATGGGAGAAGCCCAAGGACGC CGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACATCGCGCCCAACATCTCCCGGGCCGAGAT CATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAGAGAGGAGGTTTTTCCGTCGTGGCTGGGT GACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCCGGGAGTGTGAGCTGAGCCCTGGTGTGAA CAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGCGCAACGACATCAAGCTGGCGGCCAAGCT GATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGCCCACGAGGGAACCCGGCAGAGATCAACG TGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCAGCAAGAGCACAAGAGGAAGAGAGAGACC CTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCACAGTTGCCATGTAGACCCCTTGAAGAGGG >86572_86572_7_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000457580_GAPDH_chr12_6647322_ENST00000229239_length(amino acids)=560AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRV ALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWAS -------------------------------------------------------------- >86572_86572_8_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000457580_GAPDH_chr12_6647322_ENST00000396861_length(transcript)=2119nt_BP=1916nt GGGTGACGCAGGCGCAGCGCGGGCTGCGCGCGCTACTGCCCATCCCCGGTTGTCCCACTTTTGTTCGCCTCTCTTCGGCCCTCTACTCAA GAGCTCCGTCTCCGTCTCGCCCTCCTCGAAGTCCTCGTCGCGCGCCCGCGACCCAGGTCGCCCTGAAATCTAGCCCGTCCGAGCGCGAGT CCAACGCCGCGGCCGCACCAAGGCCCCCTCAGACCGTGCCATGGGTGACAGTGATGACGAGTACGATCGAAGGCGCAGGGACAAGTTCAG AAGAGAGCGCAGCGACTACGACCGTTCCCGCGAGAGAGATGAAAGACGTCGAGGGGACGATTGGAATGACAGAGAGTGGGACCGTGGCCG TGAGCGCCGTAGTCGGGGTGAATATCGGGACTATGACCGGAATCGGCGAGAGCGCTTCTCGCCACCTCGCCACGAACTCAGCCCGCCACA GAAGCGCATGAGGAGAGACTGGGATGAGCACAGCTCTGACCCATACCACAGTGGCTATGAGATGCCCTATGCTGGGGGGGGTGGGGGCCC AACTTATGGCCCCCCTCAGCCCTGGGGCCACCCTGACGTCCACATCATGCAGCACCATGTCCTGCCTATCCAGGCCAGGCTGGGCAGCAT TGCAGAGATTGACCTGGGTGTGCCGCCGCCCGTGATGAAGACCTTCAAGGAGTTTCTCCTCTCCCTGGATGACTCGGTGGATGAGACGGA GGCCGTCAAGCGCTATAATGACTACAAGCTGGATTTCCGGAGGCAACAGATGCAGGATTTCTTCCTGGCGCACAAAGATGAGGAGTGGTT TCGGTCTAAGTACCACCCAGATGAGGTGGGGAAGCGTCGGCAGGAGGCCCGGGGGGCCCTGCAAAACCGACTGAGGGTCTTCCTGTCCCT CATGGAGACTGGCTGGTTTGATAACCTTCTCCTGGACATAGACAAAGCTGATGCCATTGTCAAGATGCTGGATGCAGCCGTGATTAAGAT GGAAGGAGGCACGGAGAATGATCTTCGCATCCTGGAGCAGGAGGAGGAGGAGGAGCAGGCAGGAAAGCCTGGGGAGCCCAGCAAGAAAGA AGAAGGACGGGCTGGAGCAGGCCTAGGGGACGGGGAGCGCAAAACCAACGACAAGGATGAGAAGAAGGAAGACGGCAAGCAGGCTGAGAA TGACAGTTCTAATGATGACAAAACAAAGAAGTCGGAGGGTGATGGGGACAAGGAAGAGAAGAAAGAAGACTCCGAGAAGGAAGCCAAAAA GAGTAGCAAGAAGCGGAACCGGAAGCACAGTGGTGACGACAGCTTTGACGAGGGCAGCGTGTCAGAGTCTGAGTCGGAGTCAGAGAGCGG CCAGGCTGAGGAGGAGAAGGAGGAGGCCGAAGAAGCGCTCAAGGAGAAGGAGAAGCCCAAGGAAGAAGAATGGGAGAAGCCCAAGGACGC CGCGGGGCTGGAGTGCAAGCCGCGGCCGCTGCATAAGACCTGCTCCCTCTTCATGCGCAACATCGCGCCCAACATCTCCCGGGCCGAGAT CATCTCCCTTTGTAAAAGGTACCCAGGCTTTATGCGGGTGGCGCTCTCAGAGCCCCAGCCAGAGAGGAGGTTTTTCCGTCGTGGCTGGGT GACCTTCGACCGCAGTGTTAACATTAAAGAGATCTGTTGGAACCTGCAGAACATCCGTCTCCGGGAGTGTGAGCTGAGCCCTGGTGTGAA CAGGGACCTGACCCGGCGCGTTCGCAACATCAACGGCATCACCCAGCACAAGCAGATTGTGCGCAACGACATCAAGCTGGCGGCCAAGCT GATCCACACGCTGGATGACAGGACACAGCTTTGGGCCTCAGAACCAGGGACGCCTCCCCTGCCCACGAGGGAACCCGGCAGAGATCAACG TGGAGCGGGATGAGAAGTTGATTAAGCCTCCAAGGAGTAAGACCCCTGGACCACCAGCCCCAGCAAGAGCACAAGAGGAAGAGAGAGACC CTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCACAGTTGCCATGTAGACCCCTTGAAGAGGG >86572_86572_8_SRRT-GAPDH_SRRT_chr7_100484540_ENST00000457580_GAPDH_chr12_6647322_ENST00000396861_length(amino acids)=560AA_BP= MGDSDDEYDRRRRDKFRRERSDYDRSRERDERRRGDDWNDREWDRGRERRSRGEYRDYDRNRRERFSPPRHELSPPQKRMRRDWDEHSSD PYHSGYEMPYAGGGGGPTYGPPQPWGHPDVHIMQHHVLPIQARLGSIAEIDLGVPPPVMKTFKEFLLSLDDSVDETEAVKRYNDYKLDFR RQQMQDFFLAHKDEEWFRSKYHPDEVGKRRQEARGALQNRLRVFLSLMETGWFDNLLLDIDKADAIVKMLDAAVIKMEGGTENDLRILEQ EEEEEQAGKPGEPSKKEEGRAGAGLGDGERKTNDKDEKKEDGKQAENDSSNDDKTKKSEGDGDKEEKKEDSEKEAKKSSKKRNRKHSGDD SFDEGSVSESESESESGQAEEEKEEAEEALKEKEKPKEEEWEKPKDAAGLECKPRPLHKTCSLFMRNIAPNISRAEIISLCKRYPGFMRV ALSEPQPERRFFRRGWVTFDRSVNIKEICWNLQNIRLRECELSPGVNRDLTRRVRNINGITQHKQIVRNDIKLAAKLIHTLDDRTQLWAS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SRRT-GAPDH |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000229239 | 0 | 9 | 2_148 | 0 | 336.0 | WARS1 | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396858 | 0 | 8 | 2_148 | 0 | 294.0 | WARS1 | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396859 | 0 | 8 | 2_148 | 0 | 336.0 | WARS1 | |
| Tgene | GAPDH | chr7:100484540 | chr12:6647322 | ENST00000396861 | 0 | 9 | 2_148 | 0 | 336.0 | WARS1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SRRT-GAPDH |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SRRT-GAPDH |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies