
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SS18-SSX4B (FusionGDB2 ID:86686) |
Fusion Gene Summary for SS18-SSX4B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SS18-SSX4B | Fusion gene ID: 86686 | Hgene | Tgene | Gene symbol | SS18 | SSX4B | Gene ID | 6760 | 548313 |
| Gene name | SS18 subunit of BAF chromatin remodeling complex | SSX family member 4B | |
| Synonyms | SSXT|SYT | CT5.4 | |
| Cytomap | 18q11.2 | Xp11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein SSXTSS18, nBAF chromatin remodeling complex subunitsynovial sarcoma translocated to X chromosome proteinsynovial sarcoma translocation, chromosome 18synovial sarcoma, translocated to X chromosome | protein SSX4cancer/testis antigen 5.4synovial sarcoma, X breakpoint 4B | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000269137, ENST00000415083, ENST00000539849, ENST00000542420, ENST00000542743, ENST00000545952, ENST00000585241, | ENST00000376884, ENST00000396928, | |
| Fusion gene scores | * DoF score | 24 X 33 X 8=6336 | 1 X 1 X 1=1 |
| # samples | 38 | 1 | |
| ** MAII score | log2(38/6336*10)=-4.05950101174866 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: SS18 [Title/Abstract] AND SSX4B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SS18(23612362)-SSX4B(48263000), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | SS18-SSX4B seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SS18 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 15919756 |
| Fusion gene breakpoints across SS18 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SSX4B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | AF257501 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
Top |
Fusion Gene ORF analysis for SS18-SSX4B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000269137 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000415083 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000539849 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000542420 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000542743 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000542743 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| Frame-shift | ENST00000545952 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| In-frame | ENST00000269137 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| In-frame | ENST00000415083 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| In-frame | ENST00000539849 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| In-frame | ENST00000542420 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| In-frame | ENST00000545952 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| intron-3CDS | ENST00000585241 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| intron-3CDS | ENST00000585241 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000415083 | SS18 | chr18 | 23612362 | - | ENST00000396928 | SSX4B | chrX | 48263000 | - | 1979 | 1286 | 56 | 1417 | 453 |
| ENST00000542420 | SS18 | chr18 | 23612362 | - | ENST00000376884 | SSX4B | chrX | 48263000 | - | 1976 | 1283 | 59 | 1414 | 451 |
| ENST00000539849 | SS18 | chr18 | 23612362 | - | ENST00000376884 | SSX4B | chrX | 48263000 | - | 1867 | 1174 | 190 | 1305 | 371 |
| ENST00000269137 | SS18 | chr18 | 23612362 | - | ENST00000396928 | SSX4B | chrX | 48263000 | - | 2162 | 1469 | 161 | 1600 | 479 |
| ENST00000545952 | SS18 | chr18 | 23612362 | - | ENST00000396928 | SSX4B | chrX | 48263000 | - | 1977 | 1284 | 303 | 1415 | 370 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000415083 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - | 0.00179495 | 0.99820507 |
| ENST00000542420 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - | 0.001043028 | 0.9989569 |
| ENST00000539849 | ENST00000376884 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - | 0.001335108 | 0.99866486 |
| ENST00000269137 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - | 0.002188063 | 0.9978119 |
| ENST00000545952 | ENST00000396928 | SS18 | chr18 | 23612362 | - | SSX4B | chrX | 48263000 | - | 0.000949589 | 0.99905044 |
Top |
Fusion Genomic Features for SS18-SSX4B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
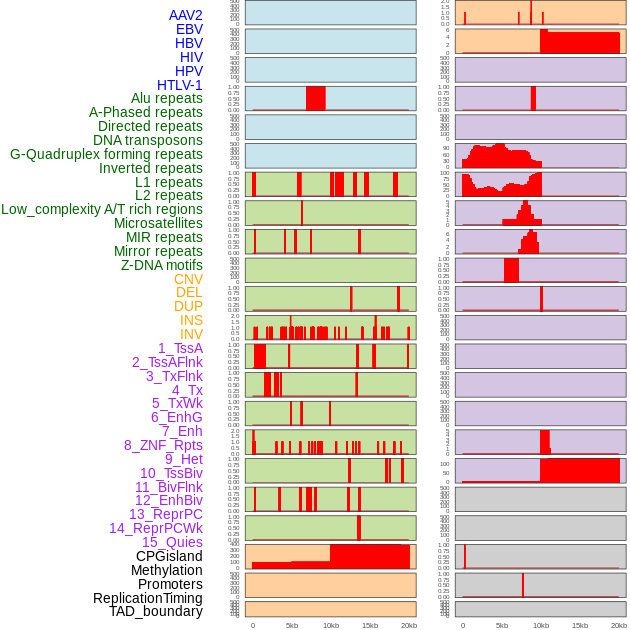 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SS18-SSX4B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr18:23612362/chrX:48263000) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 95_99 | 379 | 388.0 | Compositional bias | Note=Poly-Pro |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 95_99 | 410 | 419.0 | Compositional bias | Note=Poly-Pro |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 374_377 | 379 | 388.0 | Motif | SH2-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 50_53 | 379 | 388.0 | Motif | SH2-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 374_377 | 410 | 419.0 | Motif | SH2-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 392_401 | 410 | 419.0 | Motif | SH3-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 50_53 | 410 | 419.0 | Motif | SH2-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 2_186 | 379 | 388.0 | Region | Note=Transcriptional activation |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 344_369 | 379 | 388.0 | Region | Note=2 X 13 AA imperfect tandem repeats |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 2_186 | 410 | 419.0 | Region | Note=Transcriptional activation |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 344_369 | 410 | 419.0 | Region | Note=2 X 13 AA imperfect tandem repeats |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 344_356 | 379 | 388.0 | Repeat | Note=1 |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 357_369 | 379 | 388.0 | Repeat | Note=2 |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 344_356 | 410 | 419.0 | Repeat | Note=1 |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 357_369 | 410 | 419.0 | Repeat | Note=2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 175_418 | 379 | 388.0 | Compositional bias | Note=Gln-rich |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 175_418 | 410 | 419.0 | Compositional bias | Note=Gln-rich |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 392_401 | 379 | 388.0 | Motif | SH3-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000269137 | - | 9 | 10 | 413_416 | 379 | 388.0 | Motif | SH2-binding |
| Hgene | SS18 | chr18:23612362 | chrX:48263000 | ENST00000415083 | - | 10 | 11 | 413_416 | 410 | 419.0 | Motif | SH2-binding |
| Tgene | SSX4B | chr18:23612362 | chrX:48263000 | ENST00000376884 | 5 | 8 | 20_83 | 155 | 377.6666666666667 | Domain | KRAB-related |
Top |
Fusion Gene Sequence for SS18-SSX4B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >86686_86686_1_SS18-SSX4B_SS18_chr18_23612362_ENST00000269137_SSX4B_chrX_48263000_ENST00000396928_length(transcript)=2162nt_BP=1469nt TTTCCTGAATCGCTGAAGCGGAGGGAGGACTAGGGCGCGACTCTACCATTAGCGCAAAGGGCCAGGGGGTGCCCATAAGGAGAGCTCGGG GGATGCAGGGACGGTCAAGAAAGTTCGGCCAGGGCTAGGGGTCCCCCAGAGTGCGCAGAAGCGAGACATCCCTGGCCAGAGTGCCTCCTT CAGGCCTGCCCCGCCGCCCGTCCGCTTGGCCCCGGAGCATCCCCCCTCCCCGCATTCCCGAGGTGGTTCAGCCCGAGAGGCCGGCGTCTC TCCCCCAGTTTGCCGTTCACCCGGAGCGCTCGGGACTTGCCGATAGTGGTGACGGCGGCAACATGTCTGTGGCTTTCGCGGCCCCGAGGC AGCGAGGCAAGGGGGAGATCACTCCCGCTGCGATTCAGAAGATGTTGGATGACAATAACCATCTTATTCAGTGTATAATGGACTCTCAGA ATAAAGGAAAGACCTCAGAGTGTTCTCAGTATCAGCAGATGTTGCACACAAACTTGGTATACCTTGCTACAATAGCAGATTCTAATCAAA ATATGCAGTCTCTTTTACCAGCACCACCCACACAGAATATGCCTATGGGTCCTGGAGGGATGAATCAGAGCGGCCCTCCCCCACCTCCAC GCTCTCACAACATGCCTTCAGATGGAATGGTAGGTGGGGGTCCTCCTGCACCGCACATGCAGAACCAGATGAACGGCCAGATGCCTGGGC CTAACCATATGCCTATGCAGGGACCTGGACCCAATCAACTCAATATGACAAACAGTTCCATGAATATGCCTTCAAGTAGCCATGGATCCA TGGGAGGTTACAACCATTCTGTGCCATCATCACAGAGCATGCCAGTACAGAATCAGATGACAATGAGTCAGGGACAACCAATGGGAAACT ATGGTCCCAGACCAAATATGAGTATGCAGCCAAACCAAGGTCCAATGATGCATCAGCAGCCTCCTTCTCAGCAATACAATATGCCACAGG GAGGCGGACAGCATTACCAAGGACAGCAGCCACCTATGGGAATGATGGGTCAAGTTAACCAAGGCAATCATATGATGGGTCAGAGACAGA TTCCTCCCTATAGACCTCCTCAACAGGGCCCACCACAGCAGTACTCAGGCCAGGAAGACTATTACGGGGACCAATACAGTCATGGTGGAC AAGGTCCTCCAGAAGGCATGAACCAGCAATATTACCCTGATGGAAATTCACAGTATGGCCAACAGCAAGATGCATACCAGGGACCACCTC CACAACAGGGATATCCACCCCAGCAGCAGCAGTACCCAGGGCAGCAAGGTTACCCAGGACAGCAGCAGGGCTACGGTCCTTCACAGGGTG GTCCAGGTCCTCAGTATCCTAACTACCCACAGGGACAAGGTCAGCAGTATGGAGGATATAGACCAACACAGCCTGGACCACCACAGCCAC CCCAGCAGAGGCCTTATGGATATGACCAGGACCCAAAAGGGGGAAACATGCCTGGACCCACAGACTGCGTGAGAGAAAGCAGCTGGTGGT TTATGAAGAGATCAGCGACCCTGAGGAAGATGACGAGTAACTCCCCTCGGGGATATGACACATGCCCATGATGAGAAGCAGAACGTGGTG ACCTTTCACGAACATGGGCATGGCTGCGGACCCCTCGTCATCAGGTGCATAGCAAGTGAAAGCAAGTGTTCACAACAGTGAAAAGTTGAG CGTCATTTTTCTTAGTGTGCCAAGAGTTCGATGTTGGCGTTTCCGCTGTATTTTCTTGCAGTGTGCCATTCTGTTAGACATTAGCGTTTT CGTTGATGAGCAAGACATGCTTAATGCATATTTCGGCTTGTGTATCCATGCACCTACCTCAGAAAACAAGTATTGTCAGGTATTCTCTCC ATAGAACAGCACTACCCTCCTCTCTCCCCAGATGTGACTACTGAGGGGAGGTCTGAGTGTTTAATTTCCGATTTTTTCCTCTGCATTTAC ACACACACCACACACGCACACACACACACCAAGTACCAGTATAAGCATCTCCCATCTGCTTTTCTCCATTGCCATGCGACCTGGTCAAGC CCCCCTCACTCTGTTTCCTGTTCAGCATGTACTCCCCTCATCCGATTCCGTTGTATCAGTCACTGACAGTTAATAAACCTTTGCAAACGT >86686_86686_1_SS18-SSX4B_SS18_chr18_23612362_ENST00000269137_SSX4B_chrX_48263000_ENST00000396928_length(amino acids)=479AA_BP=421 MARVPPSGLPRRPSAWPRSIPPPRIPEVVQPERPASLPQFAVHPERSGLADSGDGGNMSVAFAAPRQRGKGEITPAAIQKMLDDNNHLIQ CIMDSQNKGKTSECSQYQQMLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGMNQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQM NGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMTMSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQ QYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDYYGDQYSHGGQGPPEGMNQQYYPDGNSQYGQQQD AYQGPPPQQGYPPQQQQYPGQQGYPGQQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQDPKGGNMPGPTDCV -------------------------------------------------------------- >86686_86686_2_SS18-SSX4B_SS18_chr18_23612362_ENST00000415083_SSX4B_chrX_48263000_ENST00000396928_length(transcript)=1979nt_BP=1286nt AGTTTGCCGTTCACCCGGAGCGCTCGGGACTTGCCGATAGTGGTGACGGCGGCAACATGTCTGTGGCTTTCGCGGCCCCGAGGCAGCGAG GCAAGGGGGAGATCACTCCCGCTGCGATTCAGAAGATGTTGGATGACAATAACCATCTTATTCAGTGTATAATGGACTCTCAGAATAAAG GAAAGACCTCAGAGTGTTCTCAGTATCAGCAGATGTTGCACACAAACTTGGTATACCTTGCTACAATAGCAGATTCTAATCAAAATATGC AGTCTCTTTTACCAGCACCACCCACACAGAATATGCCTATGGGTCCTGGAGGGATGAATCAGAGCGGCCCTCCCCCACCTCCACGCTCTC ACAACATGCCTTCAGATGGAATGGTAGGTGGGGGTCCTCCTGCACCGCACATGCAGAACCAGATGAACGGCCAGATGCCTGGGCCTAACC ATATGCCTATGCAGGGACCTGGACCCAATCAACTCAATATGACAAACAGTTCCATGAATATGCCTTCAAGTAGCCATGGATCCATGGGAG GTTACAACCATTCTGTGCCATCATCACAGAGCATGCCAGTACAGAATCAGATGACAATGAGTCAGGGACAACCAATGGGAAACTATGGTC CCAGACCAAATATGAGTATGCAGCCAAACCAAGGTCCAATGATGCATCAGCAGCCTCCTTCTCAGCAATACAATATGCCACAGGGAGGCG GACAGCATTACCAAGGACAGCAGCCACCTATGGGAATGATGGGTCAAGTTAACCAAGGCAATCATATGATGGGTCAGAGACAGATTCCTC CCTATAGACCTCCTCAACAGGGCCCACCACAGCAGTACTCAGGCCAGGAAGACTATTACGGGGACCAATACAGTCATGGTGGACAAGGTC CTCCAGAAGGCATGAACCAGCAATATTACCCTGATGGTCATAATGATTACGGTTATCAGCAACCGTCGTATCCTGAACAAGGCTACGATA GGCCTTATGAGGATTCCTCACAACATTACTACGAAGGAGGAAATTCACAGTATGGCCAACAGCAAGATGCATACCAGGGACCACCTCCAC AACAGGGATATCCACCCCAGCAGCAGCAGTACCCAGGGCAGCAAGGTTACCCAGGACAGCAGCAGGGCTACGGTCCTTCACAGGGTGGTC CAGGTCCTCAGTATCCTAACTACCCACAGGGACAAGGTCAGCAGTATGGAGGATATAGACCAACACAGCCTGGACCACCACAGCCACCCC AGCAGAGGCCTTATGGATATGACCAGGACCCAAAAGGGGGAAACATGCCTGGACCCACAGACTGCGTGAGAGAAAGCAGCTGGTGGTTTA TGAAGAGATCAGCGACCCTGAGGAAGATGACGAGTAACTCCCCTCGGGGATATGACACATGCCCATGATGAGAAGCAGAACGTGGTGACC TTTCACGAACATGGGCATGGCTGCGGACCCCTCGTCATCAGGTGCATAGCAAGTGAAAGCAAGTGTTCACAACAGTGAAAAGTTGAGCGT CATTTTTCTTAGTGTGCCAAGAGTTCGATGTTGGCGTTTCCGCTGTATTTTCTTGCAGTGTGCCATTCTGTTAGACATTAGCGTTTTCGT TGATGAGCAAGACATGCTTAATGCATATTTCGGCTTGTGTATCCATGCACCTACCTCAGAAAACAAGTATTGTCAGGTATTCTCTCCATA GAACAGCACTACCCTCCTCTCTCCCCAGATGTGACTACTGAGGGGAGGTCTGAGTGTTTAATTTCCGATTTTTTCCTCTGCATTTACACA CACACCACACACGCACACACACACACCAAGTACCAGTATAAGCATCTCCCATCTGCTTTTCTCCATTGCCATGCGACCTGGTCAAGCCCC >86686_86686_2_SS18-SSX4B_SS18_chr18_23612362_ENST00000415083_SSX4B_chrX_48263000_ENST00000396928_length(amino acids)=453AA_BP=395 MSVAFAAPRQRGKGEITPAAIQKMLDDNNHLIQCIMDSQNKGKTSECSQYQQMLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGM NQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMT MSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDY YGDQYSHGGQGPPEGMNQQYYPDGHNDYGYQQPSYPEQGYDRPYEDSSQHYYEGGNSQYGQQQDAYQGPPPQQGYPPQQQQYPGQQGYPG QQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQDPKGGNMPGPTDCVRESSWWFMKRSATLRKMTSNSPRGYD -------------------------------------------------------------- >86686_86686_3_SS18-SSX4B_SS18_chr18_23612362_ENST00000539849_SSX4B_chrX_48263000_ENST00000376884_length(transcript)=1867nt_BP=1174nt GACTTGCCGATAGTGGTGACGGCGGCAACATGTCTGTGGCTTTCGCGGCCCCGAGGCAGCGAGGCAAGGGGGAGATCACTCCCGCTGCGA TTCAGAAGATGTTGGATGACAATAACCATCTTATTCAGTGTATAATGGACTCTCAGAATAAAGGAAAGACCTCAGAGTGTTCTCACCACC CACACAGAATATGCCTATGGGTCCTGGAGGGATGAATCAGAGCGGCCCTCCCCCACCTCCACGCTCTCACAACATGCCTTCAGATGGAAT GGTAGGTGGGGGTCCTCCTGCACCGCACATGCAGAACCAGATGAACGGCCAGATGCCTGGGCCTAACCATATGCCTATGCAGGGACCTGG ACCCAATCAACTCAATATGACAAACAGTTCCATGAATATGCCTTCAAGTAGCCATGGATCCATGGGAGGTTACAACCATTCTGTGCCATC ATCACAGAGCATGCCAGTACAGAATCAGATGACAATGAGTCAGGGACAACCAATGGGAAACTATGGTCCCAGACCAAATATGAGTATGCA GCCAAACCAAGGTCCAATGATGCATCAGCAGCCTCCTTCTCAGCAATACAATATGCCACAGGGAGGCGGACAGCATTACCAAGGACAGCA GCCACCTATGGGAATGATGGGTCAAGTTAACCAAGGCAATCATATGATGGGTCAGAGACAGATTCCTCCCTATAGACCTCCTCAACAGGG CCCACCACAGCAGTACTCAGGCCAGGAAGACTATTACGGGGACCAATACAGTCATGGTGGACAAGGTCCTCCAGAAGGCATGAACCAGCA ATATTACCCTGATGGTCATAATGATTACGGTTATCAGCAACCGTCGTATCCTGAACAAGGCTACGATAGGCCTTATGAGGATTCCTCACA ACATTACTACGAAGGAGGAAATTCACAGTATGGCCAACAGCAAGATGCATACCAGGGACCACCTCCACAACAGGGATATCCACCCCAGCA GCAGCAGTACCCAGGGCAGCAAGGTTACCCAGGACAGCAGCAGGGCTACGGTCCTTCACAGGGTGGTCCAGGTCCTCAGTATCCTAACTA CCCACAGGGACAAGGTCAGCAGTATGGAGGATATAGACCAACACAGCCTGGACCACCACAGCCACCCCAGCAGAGGCCTTATGGATATGA CCAGGACCCAAAAGGGGGAAACATGCCTGGACCCACAGACTGCGTGAGAGAAAGCAGCTGGTGGTTTATGAAGAGATCAGCGACCCTGAG GAAGATGACGAGTAACTCCCCTCGGGGATATGACACATGCCCATGATGAGAAGCAGAACGTGGTGACCTTTCACGAACATGGGCATGGCT GCGGACCCCTCGTCATCAGGTGCATAGCAAGTGAAAGCAAGTGTTCACAACAGTGAAAAGTTGAGCGTCATTTTTCTTAGTGTGCCAAGA GTTCGATGTTGGCGTTTCCGCTGTATTTTCTTGCAGTGTGCCATTCTGTTAGACATTAGCGTTTTCGTTGATGAGCAAGACATGCTTAAT GCATATTTCGGCTTGTGTATCCATGCACCTACCTCAGAAAACAAGTATTGTCAGGTATTCTCTCCATAGAACAGCACTACCCTCCTCTCT CCCCAGATGTGACTACTGAGGGGAGGTCTGAGTGTTTAATTTCCGATTTTTTCCTCTGCATTTACACACACACCACACACGCACACACAC ACACCAAGTACCAGTATAAGCATCTCCCATCTGCTTTTCTCCATTGCCATGCGACCTGGTCAAGCCCCCCTCACTCTGTTTCCTGTTCAG >86686_86686_3_SS18-SSX4B_SS18_chr18_23612362_ENST00000539849_SSX4B_chrX_48263000_ENST00000376884_length(amino acids)=371AA_BP=313 MPMGPGGMNQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQS MPVQNQMTMSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQ QYSGQEDYYGDQYSHGGQGPPEGMNQQYYPDGHNDYGYQQPSYPEQGYDRPYEDSSQHYYEGGNSQYGQQQDAYQGPPPQQGYPPQQQQY PGQQGYPGQQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQDPKGGNMPGPTDCVRESSWWFMKRSATLRKMT -------------------------------------------------------------- >86686_86686_4_SS18-SSX4B_SS18_chr18_23612362_ENST00000542420_SSX4B_chrX_48263000_ENST00000376884_length(transcript)=1976nt_BP=1283nt CCTTCCACCTCTGCCCTATCTCGGCAGATGCTCCACGGATTTGCACGAACTCCCGAGTCTTGACCTCCCTCCCCTCTCCGGGCTGCCGGG ACAACTCGGGGCGGCCACTCTTGCCAGGAGGCATGTTGGATGACAATAACCATCTTATTCAGTGTATAATGGACTCTCAGAATAAAGGAA AGACCTCAGAGTGTTCTCAGTATCAGCAGATGTTGCACACAAACTTGGTATACCTTGCTACAATAGCAGATTCTAATCAAAATATGCAGT CTCTTTTACCAGCACCACCCACACAGAATATGCCTATGGGTCCTGGAGGGATGAATCAGAGCGGCCCTCCCCCACCTCCACGCTCTCACA ACATGCCTTCAGATGGAATGGTAGGTGGGGGTCCTCCTGCACCGCACATGCAGAACCAGATGAACGGCCAGATGCCTGGGCCTAACCATA TGCCTATGCAGGGACCTGGACCCAATCAACTCAATATGACAAACAGTTCCATGAATATGCCTTCAAGTAGCCATGGATCCATGGGAGGTT ACAACCATTCTGTGCCATCATCACAGAGCATGCCAGTACAGAATCAGATGACAATGAGTCAGGGACAACCAATGGGAAACTATGGTCCCA GACCAAATATGAGTATGCAGCCAAACCAAGGTCCAATGATGCATCAGCAGCCTCCTTCTCAGCAATACAATATGCCACAGGGAGGCGGAC AGCATTACCAAGGACAGCAGCCACCTATGGGAATGATGGGTCAAGTTAACCAAGGCAATCATATGATGGGTCAGAGACAGATTCCTCCCT ATAGACCTCCTCAACAGGGCCCACCACAGCAGTACTCAGGCCAGGAAGACTATTACGGGGACCAATACAGTCATGGTGGACAAGGTCCTC CAGAAGGCATGAACCAGCAATATTACCCTGATGGTCATAATGATTACGGTTATCAGCAACCGTCGTATCCTGAACAAGGCTACGATAGGC CTTATGAGGATTCCTCACAACATTACTACGAAGGAGGAAATTCACAGTATGGCCAACAGCAAGATGCATACCAGGGACCACCTCCACAAC AGGGATATCCACCCCAGCAGCAGCAGTACCCAGGGCAGCAAGGTTACCCAGGACAGCAGCAGGGCTACGGTCCTTCACAGGGTGGTCCAG GTCCTCAGTATCCTAACTACCCACAGGGACAAGGTCAGCAGTATGGAGGATATAGACCAACACAGCCTGGACCACCACAGCCACCCCAGC AGAGGCCTTATGGATATGACCAGGACCCAAAAGGGGGAAACATGCCTGGACCCACAGACTGCGTGAGAGAAAGCAGCTGGTGGTTTATGA AGAGATCAGCGACCCTGAGGAAGATGACGAGTAACTCCCCTCGGGGATATGACACATGCCCATGATGAGAAGCAGAACGTGGTGACCTTT CACGAACATGGGCATGGCTGCGGACCCCTCGTCATCAGGTGCATAGCAAGTGAAAGCAAGTGTTCACAACAGTGAAAAGTTGAGCGTCAT TTTTCTTAGTGTGCCAAGAGTTCGATGTTGGCGTTTCCGCTGTATTTTCTTGCAGTGTGCCATTCTGTTAGACATTAGCGTTTTCGTTGA TGAGCAAGACATGCTTAATGCATATTTCGGCTTGTGTATCCATGCACCTACCTCAGAAAACAAGTATTGTCAGGTATTCTCTCCATAGAA CAGCACTACCCTCCTCTCTCCCCAGATGTGACTACTGAGGGGAGGTCTGAGTGTTTAATTTCCGATTTTTTCCTCTGCATTTACACACAC ACCACACACGCACACACACACACCAAGTACCAGTATAAGCATCTCCCATCTGCTTTTCTCCATTGCCATGCGACCTGGTCAAGCCCCCCT >86686_86686_4_SS18-SSX4B_SS18_chr18_23612362_ENST00000542420_SSX4B_chrX_48263000_ENST00000376884_length(amino acids)=451AA_BP=393 MTSLPSPGCRDNSGRPLLPGGMLDDNNHLIQCIMDSQNKGKTSECSQYQQMLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGMNQ SGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQLNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMTMS QGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPMGMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDYYG DQYSHGGQGPPEGMNQQYYPDGHNDYGYQQPSYPEQGYDRPYEDSSQHYYEGGNSQYGQQQDAYQGPPPQQGYPPQQQQYPGQQGYPGQQ QGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQDPKGGNMPGPTDCVRESSWWFMKRSATLRKMTSNSPRGYDTC -------------------------------------------------------------- >86686_86686_5_SS18-SSX4B_SS18_chr18_23612362_ENST00000545952_SSX4B_chrX_48263000_ENST00000396928_length(transcript)=1977nt_BP=1284nt ACTTGCCGATAGTGGTGACGGCGGCAACATGTCTGTGGCTTTCGCGGCCCCGAGGCAGCGAGGCAAGGGGGAGATCACTCCCGCTGCGAT TCAGAAGATGTTGGATGACAATAACCATCTTATTCAGTGTATAATGGACTCTCAGAATAAAGGAAAGACCTCAGAGTGTTCTCAGGTCAT GAATAAACCACATCTGTTAGTATGGTTTGGTCAGTGGTCCTCAGAAAATCTCATGTCGTGCAACCATACTAATACTCAAGCAAAGGAAAA CTTGAAGGCCTAGACTGAAACAGGTATCAGCAGATGTTGCACACAAACTTGGTATACCTTGCTACAATAGCAGATTCTAATCAAAATATG CAGTCTCTTTTACCAGCACCACCCACACAGAATATGCCTATGGGTCCTGGAGGGATGAATCAGAGCGGCCCTCCCCCACCTCCACGCTCT CACAACATGCCTTCAGATGGAATGGTAGGTGGGGGTCCTCCTGCACCGCACATGCAGAACCAGATGAACGGCCAGATGCCTGGGCCTAAC CATATGCCTATGCAGGGACCTGGACCCAATCAACTCAATATGACAAACAGTTCCATGAATATGCCTTCAAGTAGCCATGGATCCATGGGA GGTTACAACCATTCTGTGCCATCATCACAGAGCATGCCAGTACAGAATCAGATGACAATGAGTCAGGGACAACCAATGGGAAACTATGGT CCCAGACCAAATATGAGTATGCAGCCAAACCAAGGTCCAATGATGCATCAGCAGCCTCCTTCTCAGCAATACAATATGCCACAGGGAGGC GGACAGCATTACCAAGGACAGCAGCCACCTATGGGAATGATGGGTCAAGTTAACCAAGGCAATCATATGATGGGTCAGAGACAGATTCCT CCCTATAGACCTCCTCAACAGGGCCCACCACAGCAGTACTCAGGCCAGGAAGACTATTACGGGGACCAATACAGTCATGGTGGACAAGGT CCTCCAGAAGGCATGAACCAGCAATATTACCCTGATGGAAATTCACAGTATGGCCAACAGCAAGATGCATACCAGGGACCACCTCCACAA CAGGGATATCCACCCCAGCAGCAGCAGTACCCAGGGCAGCAAGGTTACCCAGGACAGCAGCAGGGCTACGGTCCTTCACAGGGTGGTCCA GGTCCTCAGTATCCTAACTACCCACAGGGACAAGGTCAGCAGTATGGAGGATATAGACCAACACAGCCTGGACCACCACAGCCACCCCAG CAGAGGCCTTATGGATATGACCAGGACCCAAAAGGGGGAAACATGCCTGGACCCACAGACTGCGTGAGAGAAAGCAGCTGGTGGTTTATG AAGAGATCAGCGACCCTGAGGAAGATGACGAGTAACTCCCCTCGGGGATATGACACATGCCCATGATGAGAAGCAGAACGTGGTGACCTT TCACGAACATGGGCATGGCTGCGGACCCCTCGTCATCAGGTGCATAGCAAGTGAAAGCAAGTGTTCACAACAGTGAAAAGTTGAGCGTCA TTTTTCTTAGTGTGCCAAGAGTTCGATGTTGGCGTTTCCGCTGTATTTTCTTGCAGTGTGCCATTCTGTTAGACATTAGCGTTTTCGTTG ATGAGCAAGACATGCTTAATGCATATTTCGGCTTGTGTATCCATGCACCTACCTCAGAAAACAAGTATTGTCAGGTATTCTCTCCATAGA ACAGCACTACCCTCCTCTCTCCCCAGATGTGACTACTGAGGGGAGGTCTGAGTGTTTAATTTCCGATTTTTTCCTCTGCATTTACACACA CACCACACACGCACACACACACACCAAGTACCAGTATAAGCATCTCCCATCTGCTTTTCTCCATTGCCATGCGACCTGGTCAAGCCCCCC >86686_86686_5_SS18-SSX4B_SS18_chr18_23612362_ENST00000545952_SSX4B_chrX_48263000_ENST00000396928_length(amino acids)=370AA_BP=312 MLHTNLVYLATIADSNQNMQSLLPAPPTQNMPMGPGGMNQSGPPPPPRSHNMPSDGMVGGGPPAPHMQNQMNGQMPGPNHMPMQGPGPNQ LNMTNSSMNMPSSSHGSMGGYNHSVPSSQSMPVQNQMTMSQGQPMGNYGPRPNMSMQPNQGPMMHQQPPSQQYNMPQGGGQHYQGQQPPM GMMGQVNQGNHMMGQRQIPPYRPPQQGPPQQYSGQEDYYGDQYSHGGQGPPEGMNQQYYPDGNSQYGQQQDAYQGPPPQQGYPPQQQQYP GQQGYPGQQQGYGPSQGGPGPQYPNYPQGQGQQYGGYRPTQPGPPQPPQQRPYGYDQDPKGGNMPGPTDCVRESSWWFMKRSATLRKMTS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SS18-SSX4B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SS18-SSX4B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SS18-SSX4B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies