
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SSBP4-PPP1R12C (FusionGDB2 ID:86738) |
Fusion Gene Summary for SSBP4-PPP1R12C |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SSBP4-PPP1R12C | Fusion gene ID: 86738 | Hgene | Tgene | Gene symbol | SSBP4 | PPP1R12C | Gene ID | 170463 | 54776 |
| Gene name | single stranded DNA binding protein 4 | protein phosphatase 1 regulatory subunit 12C | |
| Synonyms | - | AAVS1|LENG3|MBS85|p84|p85 | |
| Cytomap | 19p13.11 | 19q13.42 | |
| Type of gene | protein-coding | protein-coding | |
| Description | single-stranded DNA-binding protein 4 | protein phosphatase 1 regulatory subunit 12Cleukocyte receptor cluster (LRC) encoded novel gene 3leukocyte receptor cluster (LRC) member 3myosin-binding subunit 85protein phosphatase 1 myosin-binding subunit of 85 kDaprotein phosphatase 1 myosin-bind | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000598159, ENST00000270061, ENST00000348495, ENST00000599699, | ENST00000263433, ENST00000376393, ENST00000435544, | |
| Fusion gene scores | * DoF score | 5 X 4 X 4=80 | 16 X 6 X 9=864 |
| # samples | 5 | 16 | |
| ** MAII score | log2(5/80*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/864*10)=-2.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SSBP4 [Title/Abstract] AND PPP1R12C [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SSBP4(18530517)-PPP1R12C(55607546), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SSBP4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PPP1R12C (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8078-01A | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
Top |
Fusion Gene ORF analysis for SSBP4-PPP1R12C |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000598159 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| 3UTR-3CDS | ENST00000598159 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| 3UTR-3CDS | ENST00000598159 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000270061 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000270061 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000270061 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000348495 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000348495 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| In-frame | ENST00000348495 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| intron-3CDS | ENST00000599699 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| intron-3CDS | ENST00000599699 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| intron-3CDS | ENST00000599699 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000348495 | SSBP4 | chr19 | 18530517 | + | ENST00000263433 | PPP1R12C | chr19 | 55607546 | - | 2255 | 372 | 313 | 1695 | 460 |
| ENST00000348495 | SSBP4 | chr19 | 18530517 | + | ENST00000376393 | PPP1R12C | chr19 | 55607546 | - | 2064 | 372 | 313 | 1506 | 397 |
| ENST00000348495 | SSBP4 | chr19 | 18530517 | + | ENST00000435544 | PPP1R12C | chr19 | 55607546 | - | 1804 | 372 | 313 | 1692 | 459 |
| ENST00000270061 | SSBP4 | chr19 | 18530517 | + | ENST00000263433 | PPP1R12C | chr19 | 55607546 | - | 2236 | 353 | 294 | 1676 | 460 |
| ENST00000270061 | SSBP4 | chr19 | 18530517 | + | ENST00000376393 | PPP1R12C | chr19 | 55607546 | - | 2045 | 353 | 294 | 1487 | 397 |
| ENST00000270061 | SSBP4 | chr19 | 18530517 | + | ENST00000435544 | PPP1R12C | chr19 | 55607546 | - | 1785 | 353 | 294 | 1673 | 459 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000348495 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.03978145 | 0.9602186 |
| ENST00000348495 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.02730892 | 0.972691 |
| ENST00000348495 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.047150213 | 0.95284975 |
| ENST00000270061 | ENST00000263433 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.04059287 | 0.95940715 |
| ENST00000270061 | ENST00000376393 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.028170697 | 0.9718293 |
| ENST00000270061 | ENST00000435544 | SSBP4 | chr19 | 18530517 | + | PPP1R12C | chr19 | 55607546 | - | 0.04863226 | 0.95136774 |
Top |
Fusion Genomic Features for SSBP4-PPP1R12C |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
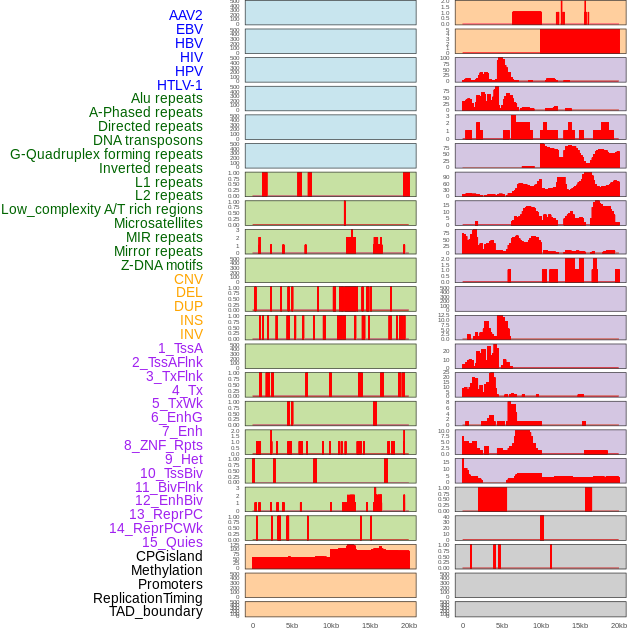 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for SSBP4-PPP1R12C |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:18530517/chr19:55607546) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 681_782 | 341 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 473_523 | 341 | 783.0 | Compositional bias | Pro-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SSBP4 | chr19:18530517 | chr19:55607546 | ENST00000270061 | + | 1 | 18 | 125_279 | 19 | 386.0 | Compositional bias | Note=Pro-rich |
| Hgene | SSBP4 | chr19:18530517 | chr19:55607546 | ENST00000270061 | + | 1 | 18 | 17_49 | 19 | 386.0 | Domain | LisH |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 297_329 | 341 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 100_129 | 341 | 783.0 | Repeat | ANK 1 | |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 133_162 | 341 | 783.0 | Repeat | ANK 2 | |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 226_255 | 341 | 783.0 | Repeat | ANK 3 | |
| Tgene | PPP1R12C | chr19:18530517 | chr19:55607546 | ENST00000263433 | 6 | 22 | 259_288 | 341 | 783.0 | Repeat | ANK 4 |
Top |
Fusion Gene Sequence for SSBP4-PPP1R12C |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >86738_86738_1_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000263433_length(transcript)=2236nt_BP=353nt GGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAAAGGGAGGAAAAAAAGCCAC CCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCGGACGATGCCTGCCGTGCCC GCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGCCGCCTGACAGGTGTGGGCC CCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCAGGCCCGCGAGAAGAGCTCT GTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAG GACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGC CCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCT GAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAG GAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGC TTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCG GACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGC CAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCG GCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGCAGAGGCGCCCGACGGG CAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCT GACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCA GAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACC ACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTG GAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAG CGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATAC AGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGG GACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGG GGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGT GGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCG CCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTG >86738_86738_1_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000263433_length(amino acids)=460AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSR RPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGG FRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAA -------------------------------------------------------------- >86738_86738_2_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000376393_length(transcript)=2045nt_BP=353nt GGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAAAGGGAGGAAAAAAAGCCAC CCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCGGACGATGCCTGCCGTGCCC GCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGCCGCCTGACAGGTGTGGGCC CCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCAGGCCCGCGAGAAGAGCTCT GTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAG GACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGC CCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCT GAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAG GAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGC TTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCG GACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGC CAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGGGGAGGAGGCGGAGCCGGCTGACCGCAGC CAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAA GAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGG CTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTC GAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAG GATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTC TGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGG ACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGC CAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTG GAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCA GCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCA >86738_86738_2_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000376393_length(amino acids)=397AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAEPADRSQESSTLEG GPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERK -------------------------------------------------------------- >86738_86738_3_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000435544_length(transcript)=1785nt_BP=353nt GGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAAAGGGAGGAAAAAAAGCCAC CCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCGGACGATGCCTGCCGTGCCC GCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGCCGCCTGACAGGTGTGGGCC CCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCAGGCCCGCGAGAAGAGCTCT GTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAG GACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGC CCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCT GAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAG GAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGC TTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCG GACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGC CAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCG GCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAGAGAGGCGCCCGACGGGCAG GGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGAC CGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAA TCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACG CTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAG AGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGC CTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGC >86738_86738_3_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000270061_PPP1R12C_chr19_55607546_ENST00000435544_length(amino acids)=459AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSR RPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGF RTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAAL -------------------------------------------------------------- >86738_86738_4_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000263433_length(transcript)=2255nt_BP=372nt CGCCCGCGGGCGGCGTAGAGGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAA AGGGAGGAAAAAAAGCCACCCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCG GACGATGCCTGCCGTGCCCGCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGC CGCCTGACAGGTGTGGGCCCCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCA GGCCCGCGAGAAGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGC TGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTC CTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTC TGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGG GACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGT CACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGC CTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGC TCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGC CCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAG AGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGG GGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCT CAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCG CGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAG GCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGA CCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTT CCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGA GAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGG GAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGAT CAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAA GAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCT GCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTGAAGTTGCCA >86738_86738_4_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000263433_length(amino acids)=460AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSR RPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGG FRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAA -------------------------------------------------------------- >86738_86738_5_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000376393_length(transcript)=2064nt_BP=372nt CGCCCGCGGGCGGCGTAGAGGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAA AGGGAGGAAAAAAAGCCACCCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCG GACGATGCCTGCCGTGCCCGCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGC CGCCTGACAGGTGTGGGCCCCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCA GGCCCGCGAGAAGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGC TGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTC CTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTC TGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGG GACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGT CACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGC CTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGC TCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGGGGAGGAGGC GGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAGA ACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCCT GACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCCT CCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCGC TGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACCC GTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCATA GCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGAG CCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCCA GGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGCC AAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTCC >86738_86738_5_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000376393_length(amino acids)=397AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAEPADRSQESSTLEG GPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERK -------------------------------------------------------------- >86738_86738_6_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000435544_length(transcript)=1804nt_BP=372nt CGCCCGCGGGCGGCGTAGAGGCAGCGGGCGGGGGCGCGCGCGGCGGGAGGAGGGGAGCGCGCGTTTCCCGGAACAGCCCGCGCGGAGGAA AGGGAGGAAAAAAAGCCACCCTGCGGCCGGGGCCGGAGCTGGAGCCGCCGCTGCCGCCGCCGCCGCGGCCGTCTGGAGCTCCCCCGCGCG GACGATGCCTGCCGTGCCCGCCTGGGGCTCGGGGCGGTGAGGCCCGGGGCGCGGGGTAGCTATGGCGACGGCAAGCGCGGCCCGCGGCGC CGCCTGACAGGTGTGGGCCCCGGCGGCGGCGGCGTGGAGCAGCATGTACGCCAAGGGGGGCAAGGGTTCGGCCGTGCCCTCCGACAGCCA GGCCCGCGAGAAGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGGC TGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCTC CTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTTC TGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAGG GACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGGT CACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAGC CTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAGC TCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGGC CCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGAG AGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGGA GGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAA CCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGA GGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCC AGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCT CCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCC GCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAA >86738_86738_6_SSBP4-PPP1R12C_SSBP4_chr19_18530517_ENST00000348495_PPP1R12C_chr19_55607546_ENST00000435544_length(amino acids)=459AA_BP=20 MYAKGGKGSAVPSDSQAREKSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSSPPHPSPKSPVQLE EAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVTKPPPCLENSSPPS RIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAPESEKPAQSLDPSR RPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGF RTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLRADNQRLKDENAAL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SSBP4-PPP1R12C |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SSBP4-PPP1R12C |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SSBP4-PPP1R12C |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies