
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SSR1-HADH (FusionGDB2 ID:86825) |
Fusion Gene Summary for SSR1-HADH |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SSR1-HADH | Fusion gene ID: 86825 | Hgene | Tgene | Gene symbol | SSR1 | HADH | Gene ID | 6745 | 3033 |
| Gene name | signal sequence receptor subunit 1 | hydroxyacyl-CoA dehydrogenase | |
| Synonyms | TRAPA | HAD|HADH1|HADHSC|HCDH|HHF4|MSCHAD|SCHAD | |
| Cytomap | 6p24.3 | 4q25 | |
| Type of gene | protein-coding | protein-coding | |
| Description | translocon-associated protein subunit alphaSSR alpha subunitSSR-alphaTRAP alphasignal sequence receptor subunit alphasignal sequence receptor, alphatranslocon-associated protein alpha subunit | hydroxyacyl-coenzyme A dehydrogenase, mitochondrialL-3-hydroxyacyl-Coenzyme A dehydrogenase, short chainmedium and short-chain L-3-hydroxyacyl-coenzyme A dehydrogenaseshort-chain 3-hydroxyacyl-CoA dehydrogenasetestis secretory sperm-binding protein Li | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | P55084 | |
| Ensembl transtripts involved in fusion gene | ENST00000244763, ENST00000397511, ENST00000462112, ENST00000474597, ENST00000479365, ENST00000489567, ENST00000534851, ENST00000488834, | ENST00000510728, ENST00000309522, ENST00000403312, ENST00000454409, ENST00000505878, ENST00000603302, | |
| Fusion gene scores | * DoF score | 15 X 18 X 8=2160 | 5 X 7 X 3=105 |
| # samples | 18 | 5 | |
| ** MAII score | log2(18/2160*10)=-3.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/105*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SSR1 [Title/Abstract] AND HADH [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SSR1(7310149)-HADH(108944629), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across SSR1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
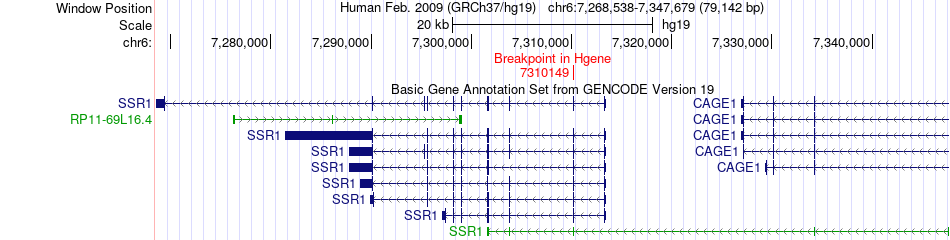 |
| Fusion gene breakpoints across HADH (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
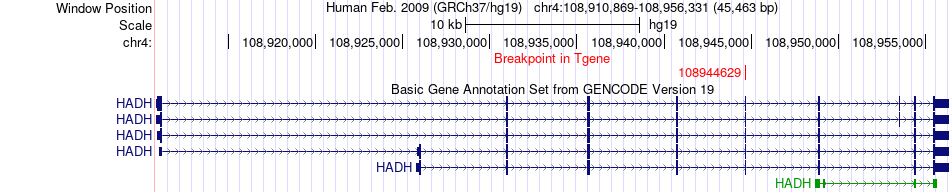 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 123Nd | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
Top |
Fusion Gene ORF analysis for SSR1-HADH |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000244763 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000397511 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000462112 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000474597 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000479365 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000489567 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5CDS-intron | ENST00000534851 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-3CDS | ENST00000488834 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-3CDS | ENST00000488834 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-3CDS | ENST00000488834 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-3CDS | ENST00000488834 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-3CDS | ENST00000488834 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| 5UTR-intron | ENST00000488834 | ENST00000510728 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000244763 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000244763 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000244763 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000244763 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000244763 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000397511 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000397511 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000397511 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000397511 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000397511 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000462112 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000462112 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000462112 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000462112 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000462112 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000474597 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000474597 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000474597 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000474597 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000474597 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000479365 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000479365 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000479365 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000479365 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000479365 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000489567 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000489567 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000489567 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000489567 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000489567 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000534851 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000534851 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000534851 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000534851 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| In-frame | ENST00000534851 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000474597 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1546 | 279 | 87 | 728 | 213 |
| ENST00000474597 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1547 | 279 | 87 | 728 | 213 |
| ENST00000474597 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1496 | 279 | 87 | 677 | 196 |
| ENST00000474597 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1492 | 279 | 87 | 677 | 196 |
| ENST00000474597 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1492 | 279 | 87 | 677 | 196 |
| ENST00000244763 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1546 | 279 | 87 | 728 | 213 |
| ENST00000244763 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1547 | 279 | 87 | 728 | 213 |
| ENST00000244763 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1496 | 279 | 87 | 677 | 196 |
| ENST00000244763 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1492 | 279 | 87 | 677 | 196 |
| ENST00000244763 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1492 | 279 | 87 | 677 | 196 |
| ENST00000397511 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1537 | 270 | 78 | 719 | 213 |
| ENST00000397511 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1538 | 270 | 78 | 719 | 213 |
| ENST00000397511 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1487 | 270 | 78 | 668 | 196 |
| ENST00000397511 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1483 | 270 | 78 | 668 | 196 |
| ENST00000397511 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1483 | 270 | 78 | 668 | 196 |
| ENST00000534851 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1541 | 274 | 82 | 723 | 213 |
| ENST00000534851 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1542 | 274 | 82 | 723 | 213 |
| ENST00000534851 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1491 | 274 | 82 | 672 | 196 |
| ENST00000534851 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1487 | 274 | 82 | 672 | 196 |
| ENST00000534851 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1487 | 274 | 82 | 672 | 196 |
| ENST00000489567 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1513 | 246 | 54 | 695 | 213 |
| ENST00000489567 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1514 | 246 | 54 | 695 | 213 |
| ENST00000489567 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1463 | 246 | 54 | 644 | 196 |
| ENST00000489567 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1459 | 246 | 54 | 644 | 196 |
| ENST00000489567 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1459 | 246 | 54 | 644 | 196 |
| ENST00000479365 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1521 | 254 | 62 | 703 | 213 |
| ENST00000479365 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1522 | 254 | 62 | 703 | 213 |
| ENST00000479365 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1471 | 254 | 62 | 652 | 196 |
| ENST00000479365 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1467 | 254 | 62 | 652 | 196 |
| ENST00000479365 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1467 | 254 | 62 | 652 | 196 |
| ENST00000462112 | SSR1 | chr6 | 7310149 | - | ENST00000603302 | HADH | chr4 | 108944629 | + | 1527 | 260 | 68 | 709 | 213 |
| ENST00000462112 | SSR1 | chr6 | 7310149 | - | ENST00000403312 | HADH | chr4 | 108944629 | + | 1528 | 260 | 68 | 709 | 213 |
| ENST00000462112 | SSR1 | chr6 | 7310149 | - | ENST00000309522 | HADH | chr4 | 108944629 | + | 1477 | 260 | 68 | 658 | 196 |
| ENST00000462112 | SSR1 | chr6 | 7310149 | - | ENST00000505878 | HADH | chr4 | 108944629 | + | 1473 | 260 | 68 | 658 | 196 |
| ENST00000462112 | SSR1 | chr6 | 7310149 | - | ENST00000454409 | HADH | chr4 | 108944629 | + | 1473 | 260 | 68 | 658 | 196 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000474597 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.00027621 | 0.99972373 |
| ENST00000474597 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000280418 | 0.99971956 |
| ENST00000474597 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000234301 | 0.9997657 |
| ENST00000474597 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000225545 | 0.9997745 |
| ENST00000474597 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000225545 | 0.9997745 |
| ENST00000244763 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.00027621 | 0.99972373 |
| ENST00000244763 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000280418 | 0.99971956 |
| ENST00000244763 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000234301 | 0.9997657 |
| ENST00000244763 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000225545 | 0.9997745 |
| ENST00000244763 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000225545 | 0.9997745 |
| ENST00000397511 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000247606 | 0.99975234 |
| ENST00000397511 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000252186 | 0.9997478 |
| ENST00000397511 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000192616 | 0.9998074 |
| ENST00000397511 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000185814 | 0.9998142 |
| ENST00000397511 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000185814 | 0.9998142 |
| ENST00000534851 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000229562 | 0.99977046 |
| ENST00000534851 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.00023243 | 0.9997676 |
| ENST00000534851 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000185988 | 0.9998141 |
| ENST00000534851 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000181493 | 0.9998185 |
| ENST00000534851 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000181493 | 0.9998185 |
| ENST00000489567 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000275528 | 0.99972445 |
| ENST00000489567 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000278265 | 0.9997217 |
| ENST00000489567 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000251814 | 0.9997482 |
| ENST00000489567 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000247083 | 0.99975294 |
| ENST00000489567 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000247083 | 0.99975294 |
| ENST00000479365 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000236753 | 0.9997632 |
| ENST00000479365 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000239514 | 0.99976045 |
| ENST00000479365 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000196611 | 0.99980336 |
| ENST00000479365 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000189351 | 0.99981064 |
| ENST00000479365 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000189351 | 0.99981064 |
| ENST00000462112 | ENST00000603302 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000255597 | 0.99974436 |
| ENST00000462112 | ENST00000403312 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000257511 | 0.99974245 |
| ENST00000462112 | ENST00000309522 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.0002153 | 0.99978477 |
| ENST00000462112 | ENST00000505878 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000203432 | 0.99979657 |
| ENST00000462112 | ENST00000454409 | SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 0.000203432 | 0.99979657 |
Top |
Fusion Genomic Features for SSR1-HADH |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 3.96E-10 | 1 |
| SSR1 | chr6 | 7310149 | - | HADH | chr4 | 108944629 | + | 3.96E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for SSR1-HADH |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr6:7310149/chr4:108944629) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HADH |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Mitochondrial trifunctional enzyme catalyzes the last three of the four reactions of the mitochondrial beta-oxidation pathway (PubMed:8135828, PubMed:29915090, PubMed:30850536). The mitochondrial beta-oxidation pathway is the major energy-producing process in tissues and is performed through four consecutive reactions breaking down fatty acids into acetyl-CoA (PubMed:29915090). Among the enzymes involved in this pathway, the trifunctional enzyme exhibits specificity for long-chain fatty acids (PubMed:30850536). Mitochondrial trifunctional enzyme is a heterotetrameric complex composed of two proteins, the trifunctional enzyme subunit alpha/HADHA carries the 2,3-enoyl-CoA hydratase and the 3-hydroxyacyl-CoA dehydrogenase activities, while the trifunctional enzyme subunit beta/HADHB described here bears the 3-ketoacyl-CoA thiolase activity (PubMed:8135828, PubMed:29915090, PubMed:30850536). {ECO:0000269|PubMed:29915090, ECO:0000269|PubMed:30850536, ECO:0000269|PubMed:8135828, ECO:0000303|PubMed:29915090, ECO:0000303|PubMed:30850536}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SSR1 | chr6:7310149 | chr4:108944629 | ENST00000244763 | - | 2 | 8 | 19_207 | 64 | 287.0 | Topological domain | Lumenal |
| Hgene | SSR1 | chr6:7310149 | chr4:108944629 | ENST00000244763 | - | 2 | 8 | 229_286 | 64 | 287.0 | Topological domain | Cytoplasmic |
| Hgene | SSR1 | chr6:7310149 | chr4:108944629 | ENST00000244763 | - | 2 | 8 | 208_228 | 64 | 287.0 | Transmembrane | Helical |
| Tgene | HADH | chr6:7310149 | chr4:108944629 | ENST00000309522 | 3 | 8 | 34_39 | 182 | 315.0 | Nucleotide binding | NAD | |
| Tgene | HADH | chr6:7310149 | chr4:108944629 | ENST00000603302 | 3 | 9 | 34_39 | 182 | 332.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for SSR1-HADH |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >86825_86825_1_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000309522_length(transcript)=1496nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_1_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_2_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000403312_length(transcript)=1547nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAA ACGTGTGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCC GGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCA GAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAA TACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTT GGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTA ATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAG CAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCG AGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCA CCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATT CAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTT CCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAAT AACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGT >86825_86825_2_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_3_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000454409_length(transcript)=1492nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_3_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_4_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000505878_length(transcript)=1492nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_4_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_5_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000603302_length(transcript)=1546nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAA ACGTGTGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCC GGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCA GAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAA TACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTT GGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTA ATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAG CAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCG AGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCA CCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATT CAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTT CCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAAT AACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGT >86825_86825_5_SSR1-HADH_SSR1_chr6_7310149_ENST00000244763_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_6_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000309522_length(transcript)=1487nt_BP=270nt GATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTC CCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGAT CTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTG GTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAG GACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAA GACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTC ATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTC GGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCA GTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATC GAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCT AAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCAT CAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGT ATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACAT TTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTG CAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGC AAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATAC >86825_86825_6_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_7_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000403312_length(transcript)=1538nt_BP=270nt GATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTC CCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGAT CTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTG GTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAG GACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGT GATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCC ATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCA TTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGA TGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACA TTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCT CCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGT TTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCA TGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCT TGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTC GTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATC TGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTT TCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGTAATTTAGGC >86825_86825_7_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_8_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000454409_length(transcript)=1483nt_BP=270nt GATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTC CCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGAT CTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTG GTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAG GACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAA GACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTC ATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTC GGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCA GTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATC GAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCT AAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCAT CAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGT ATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACAT TTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTG CAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGC AAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATAC >86825_86825_8_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_9_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000505878_length(transcript)=1483nt_BP=270nt GATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTC CCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGAT CTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTG GTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAG GACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAA GACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTC ATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTC GGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCA GTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATC GAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCT AAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCAT CAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGT ATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACAT TTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTG CAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGC AAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATAC >86825_86825_9_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_10_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000603302_length(transcript)=1537nt_BP=270nt GATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTC CCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGAT CTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTG GTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAG GACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGT GATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCC ATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCA TTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGA TGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACA TTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCT CCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGT TTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCA TGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCT TGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTC GTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATC TGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTT TCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGTAATTTAGGC >86825_86825_10_SSR1-HADH_SSR1_chr6_7310149_ENST00000397511_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_11_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000309522_length(transcript)=1477nt_BP=260nt AACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGC TGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGG ATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAA CACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTG GGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACA CTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATG GGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGA CTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAG TGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTA TTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTT ACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAA GTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTG AAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATG ACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCG GTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTA TAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGA >86825_86825_11_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_12_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000403312_length(transcript)=1528nt_BP=260nt AACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGC TGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGG ATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAA CACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTG GGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACT CGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCAT TTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGC CCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTT CTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACA CAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAA ATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACC TTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGT TGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATA AGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGC TGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTA CTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAA >86825_86825_12_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_13_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000454409_length(transcript)=1473nt_BP=260nt AACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGC TGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGG ATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAA CACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTG GGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACA CTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATG GGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGA CTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAG TGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTA TTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTT ACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAA GTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTG AAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATG ACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCG GTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTA TAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGA >86825_86825_13_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_14_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000505878_length(transcript)=1473nt_BP=260nt AACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGC TGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGG ATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAA CACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTG GGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACA CTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATG GGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGA CTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAG TGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTA TTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTT ACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAA GTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTG AAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATG ACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCG GTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTA TAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGA >86825_86825_14_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_15_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000603302_length(transcript)=1527nt_BP=260nt AACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGC TGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGG ATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAA CACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTG GGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACT CGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCAT TTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGC CCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTT CTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACA CAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAA ATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACC TTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGT TGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATA AGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGC TGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTA CTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAA >86825_86825_15_SSR1-HADH_SSR1_chr6_7310149_ENST00000462112_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_16_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000309522_length(transcript)=1496nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_16_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_17_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000403312_length(transcript)=1547nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAA ACGTGTGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCC GGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCA GAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAA TACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTT GGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTA ATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAG CAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCG AGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCA CCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATT CAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTT CCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAAT AACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGT >86825_86825_17_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_18_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000454409_length(transcript)=1492nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_18_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_19_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000505878_length(transcript)=1492nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCA TCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACT ACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAG AACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCT TTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTG TAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGT GTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCC TTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAA GCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTT GCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTG CATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAAT CACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAA >86825_86825_19_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_20_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000603302_length(transcript)=1546nt_BP=279nt CGGAGCCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATG AGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTG GCACAAGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCC ACAGATTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTT TCTTGCAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAA ACGTGTGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCC GGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCA GAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAA TACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTT GGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTA ATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAG CAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCG AGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCA CCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATT CAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTT CCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAAT AACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGT >86825_86825_20_SSR1-HADH_SSR1_chr6_7310149_ENST00000474597_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_21_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000309522_length(transcript)=1471nt_BP=254nt ATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGC TTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAG AAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAA TGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTA TTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTA TGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGC ATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAG AAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTG TGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACAC CAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCC TTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTT CCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCAC TGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAA GATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTC ATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATT GACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAA >86825_86825_21_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_22_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000403312_length(transcript)=1522nt_BP=254nt ATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGC TTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAG AAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAA TGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTA TTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACTCGGGTT TGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGC TTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCC CATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGG CTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTAC AGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATT CCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCA TTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGC GTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACA TTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGC TGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCT GTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTG >86825_86825_22_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_23_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000454409_length(transcript)=1467nt_BP=254nt ATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGC TTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAG AAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAA TGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTA TTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTA TGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGC ATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAG AAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTG TGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACAC CAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCC TTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTT CCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCAC TGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAA GATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTC ATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATT GACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAA >86825_86825_23_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_24_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000505878_length(transcript)=1467nt_BP=254nt ATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGC TTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAG AAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAA TGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTA TTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTA TGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGC ATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAG AAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTG TGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACAC CAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCC TTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTT CCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCAC TGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAA GATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTC ATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATT GACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAA >86825_86825_24_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_25_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000603302_length(transcript)=1521nt_BP=254nt ATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGC TTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAG AAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAA TGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTA TTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACTCGGGTT TGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGC TTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCC CATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGG CTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTAC AGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATT CCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCA TTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGC GTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACA TTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGC TGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCT GTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTG >86825_86825_25_SSR1-HADH_SSR1_chr6_7310149_ENST00000479365_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_26_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000309522_length(transcript)=1463nt_BP=246nt CGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTA CTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAGAAACAGTA GAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAATGACCAGC CAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTATTGTGAAC CGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTA GGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATG GATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTT TACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATG CTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACA GCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCC TTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAG AGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGA GCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTC TTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCAT TCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTAC TAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAA >86825_86825_26_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_27_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000403312_length(transcript)=1514nt_BP=246nt CGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTA CTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAGAAACAGTA GAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAATGACCAGC CAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTATTGTGAAC CGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACTCGGGTTTGGGCTTT TCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGAT TATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTA AATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGA AGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAAT AAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTT TAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTG AAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGA GTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTA CCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGG TCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGT CTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAA >86825_86825_27_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_28_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000454409_length(transcript)=1459nt_BP=246nt CGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTA CTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAGAAACAGTA GAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAATGACCAGC CAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTATTGTGAAC CGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTA GGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATG GATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTT TACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATG CTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACA GCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCC TTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAG AGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGA GCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTC TTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCAT TCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTAC TAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAA >86825_86825_28_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_29_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000505878_length(transcript)=1459nt_BP=246nt CGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTA CTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAGAAACAGTA GAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAATGACCAGC CAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTATTGTGAAC CGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTA GGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATG GATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTT TACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATG CTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACA GCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCC TTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAG AGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGA GCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTC TTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCAT TCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTAC TAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAA >86825_86825_29_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_30_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000603302_length(transcript)=1513nt_BP=246nt CGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACTCCTCCCCCGCTTGCTGCTGCTTCTCTTA CTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACAAGATCTTACAGAGGATGAAGAAACAGTA GAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGATTTGGTCATTAAAACACCAATGACCAGC CAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTGCAAGGACACTCCTGGGTTTATTGTGAAC CGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTGTGGTGATTCTAACTCGGGTTTGGGCTTT TCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGAT TATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTA AATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGA AGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAAT AAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTT TAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTG AAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGA GTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTA CCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGG TCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGT CTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAA >86825_86825_30_SSR1-HADH_SSR1_chr6_7310149_ENST00000489567_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_31_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000309522_length(transcript)=1491nt_BP=274nt CCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACT CCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACA AGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGA TTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTG CAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAA AGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAA GTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAA GTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCA GCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATC TATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATT TTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTC TCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAG TGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCT ACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGG TTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTG TTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTA >86825_86825_31_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000309522_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_32_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000403312_length(transcript)=1542nt_BP=274nt CCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACT CCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACA AGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGA TTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTG CAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTG TGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTA CCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAA CCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAA GTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCA GACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGA TTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAAC ATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGC ACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGG ATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCT CGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACA GATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAA TGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGTAATTT >86825_86825_32_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000403312_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- >86825_86825_33_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000454409_length(transcript)=1487nt_BP=274nt CCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACT CCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACA AGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGA TTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTG CAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAA AGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAA GTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAA GTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCA GCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATC TATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATT TTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTC TCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAG TGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCT ACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGG TTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTG TTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTA >86825_86825_33_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000454409_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_34_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000505878_length(transcript)=1487nt_BP=274nt CCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACT CCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACA AGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGA TTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTG CAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGGTGACGCATCCAA AGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTACCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAA GTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAACCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAA GTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAAGTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCA GCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCAGACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATC TATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGATTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATT TTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAACATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTC TCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGCACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAG TGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGGATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCT ACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCTCGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGG TTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACAGATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTG TTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAATGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTA >86825_86825_34_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000505878_length(amino acids)=196AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMDAENPLHQPSPSLNKLVA -------------------------------------------------------------- >86825_86825_35_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000603302_length(transcript)=1541nt_BP=274nt CCCGGATGAAGAGTAACGCCATTACCGCCGGAGCCGCCGAGAGCCTTAGCCGACGGAAACTGGACACTGGACCGGCAGCGCCATGAGACT CCTCCCCCGCTTGCTGCTGCTTCTCTTACTCGTGTTCCCTGCCACTGTCTTGTTCCGAGGCGGCCCCAGAGGCTTGTTAGCAGTGGCACA AGATCTTACAGAGGATGAAGAAACAGTAGAAGATTCCATAATTGAGGATGAAGATGATGAAGCCGAGGTAGAAGAAGATGAACCCACAGA TTTGGTCATTAAAACACCAATGACCAGCCAGAAGACATTTGAATCTTTGGTAGACTTTAGCAAAGCCCTAGGAAAGCATCCTGTTTCTTG CAAGGACACTCCTGGGTTTATTGTGAACCGCCTCCTGGTTCCATACCTCATGGAAGCAATCAGGCTGTATGAACGAGACTTCCAAACGTG TGGTGATTCTAACTCGGGTTTGGGCTTTTCTTTAAAAGGTGACGCATCCAAAGAAGACATTGACACTGCTATGAAATTAGGAGCCGGTTA CCCCATGGGCCCATTTGAGCTTCTAGATTATGTCGGACTGGATACTACGAAGTTCATCGTGGATGGGTGGCATGAAATGGATGCAGAGAA CCCATTACATCAGCCCAGCCCATCCTTAAATAAGCTGGTAGCAGAGAACAAGTTCGGCAAGAAGACTGGAGAAGGATTTTACAAATACAA GTGATGTGCAGCTTCTCCGGCTCTGAGAAGAACACCTGAGAGCGCTTTCCAGCCAGTGCCCCGAGTGCCTGTGGGAATGCTCTTTGGTCA GACATTCCCTCACACAGTACAGTTTAATAAATGTGCATTTTGATTGTAATCTATCGAAGTGATTATTACACCAGTTACAGCAGTAATAGA TTCTCCATTAAGAAATAATTCCCTTTTTTAGTCTGTTCATTTCTGTGTATTTTCTAAACAGCTTTACACCCTTGGTGCCTTGGAGCAAAC ATGTTTTTTGAACCTTGTCATTTTTGTGAAGAATTGCCTAGATTCCTTCTCTCATCAACGGGAAAGTACTTCCTCTGAGAGTGCGAGTGC ACCATGCTCACTGTTGCTGCGTGGGAGAGTCACAAGCCACTGGCAAGCAAGTGGTATAGTCTGTGAAGCACTGCAGCGAGCAGCACCTGG ATCTTGCCTTTATAAGAACATTTTACTACCTGCAGCTTTGAGTCTTGCCCTACATTTTGGGCATGACATAAGATGTGTCTTTATTCAGCT CGTCGTGAAGATGCTGCTGCTGAATGGGTCAGCATATCTCTGTTTGCATGGTTTGCAGGAGGTCGGTTTTCATGGTCATTCAGTTCCACA GATCTGAATGATTACTGTCTGTCTGTGTCTTTTTTCCATGAGAAATCACTGTTGCAAATTGCCTATAAATTGACTCTACTAAAATAACAA TGTTTCAGTCTGAAAATTTGAATTGAAAAAAATGTATAATATAAAATTGTAATACACTCAAATGATTATAAAAGTAAAAGTTGGTAATTT >86825_86825_35_SSR1-HADH_SSR1_chr6_7310149_ENST00000534851_HADH_chr4_108944629_ENST00000603302_length(amino acids)=213AA_BP=64 MRLLPRLLLLLLLVFPATVLFRGGPRGLLAVAQDLTEDEETVEDSIIEDEDDEAEVEEDEPTDLVIKTPMTSQKTFESLVDFSKALGKHP VSCKDTPGFIVNRLLVPYLMEAIRLYERDFQTCGDSNSGLGFSLKGDASKEDIDTAMKLGAGYPMGPFELLDYVGLDTTKFIVDGWHEMD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SSR1-HADH |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SSR1-HADH |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SSR1-HADH |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies