
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:STIP1-PAK1 (FusionGDB2 ID:87428) |
Fusion Gene Summary for STIP1-PAK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: STIP1-PAK1 | Fusion gene ID: 87428 | Hgene | Tgene | Gene symbol | STIP1 | PAK1 | Gene ID | 10963 | 5585 |
| Gene name | stress induced phosphoprotein 1 | protein kinase N1 | |
| Synonyms | HEL-S-94n|HOP|IEF-SSP-3521|P60|STI1|STI1L | DBK|PAK-1|PAK1|PKN|PKN-ALPHA|PRK1|PRKCL1 | |
| Cytomap | 11q13.1 | 19p13.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | stress-induced-phosphoprotein 1Hsp70/Hsp90-organizing proteinNY-REN-11 antigenepididymis secretory sperm binding protein Li 94nhsc70/Hsp90-organizing proteinrenal carcinoma antigen NY-REN-11transformation-sensitive protein IEF SSP 3521 | serine/threonine-protein kinase N1protease-activated kinase 1protein kinase C-like 1protein kinase C-like PKNprotein kinase C-related kinase 1protein kinase PKN-alphaserine-threonine kinase Nserine/threonine protein kinase N | |
| Modification date | 20200329 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000305218, ENST00000538945, ENST00000543847, ENST00000358794, ENST00000540501, | ENST00000525542, ENST00000278568, ENST00000356341, ENST00000528203, ENST00000530617, | |
| Fusion gene scores | * DoF score | 14 X 8 X 10=1120 | 22 X 17 X 10=3740 |
| # samples | 15 | 26 | |
| ** MAII score | log2(15/1120*10)=-2.90046432644909 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(26/3740*10)=-3.84645474174655 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: STIP1 [Title/Abstract] AND PAK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | STIP1(63953742)-PAK1(77043912), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PAK1 | GO:0006357 | regulation of transcription by RNA polymerase II | 12514133 |
| Tgene | PAK1 | GO:0006468 | protein phosphorylation | 17332740 |
| Tgene | PAK1 | GO:0035407 | histone H3-T11 phosphorylation | 18066052 |
| Fusion gene breakpoints across STIP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PAK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-94-7557-01A | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| ChimerDB4 | LUSC | TCGA-94-7557 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
Top |
Fusion Gene ORF analysis for STIP1-PAK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000305218 | ENST00000525542 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| 5CDS-5UTR | ENST00000538945 | ENST00000525542 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| 5CDS-5UTR | ENST00000543847 | ENST00000525542 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000305218 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000305218 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000305218 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000305218 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000538945 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000538945 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000538945 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000538945 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000543847 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000543847 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000543847 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| In-frame | ENST00000543847 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000358794 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000358794 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000358794 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000358794 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000540501 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000540501 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000540501 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-3CDS | ENST00000540501 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-5UTR | ENST00000358794 | ENST00000525542 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| intron-5UTR | ENST00000540501 | ENST00000525542 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000305218 | STIP1 | chr11 | 63953742 | + | ENST00000356341 | PAK1 | chr11 | 77043912 | - | 1948 | 156 | 1230 | 892 | 112 |
| ENST00000305218 | STIP1 | chr11 | 63953742 | + | ENST00000530617 | PAK1 | chr11 | 77043912 | - | 1432 | 156 | 1024 | 686 | 112 |
| ENST00000305218 | STIP1 | chr11 | 63953742 | + | ENST00000278568 | PAK1 | chr11 | 77043912 | - | 756 | 156 | 147 | 404 | 85 |
| ENST00000305218 | STIP1 | chr11 | 63953742 | + | ENST00000528203 | PAK1 | chr11 | 77043912 | - | 680 | 156 | 606 | 319 | 95 |
| ENST00000538945 | STIP1 | chr11 | 63953742 | + | ENST00000356341 | PAK1 | chr11 | 77043912 | - | 1859 | 67 | 1141 | 803 | 112 |
| ENST00000538945 | STIP1 | chr11 | 63953742 | + | ENST00000530617 | PAK1 | chr11 | 77043912 | - | 1343 | 67 | 935 | 597 | 112 |
| ENST00000538945 | STIP1 | chr11 | 63953742 | + | ENST00000278568 | PAK1 | chr11 | 77043912 | - | 667 | 67 | 58 | 315 | 85 |
| ENST00000538945 | STIP1 | chr11 | 63953742 | + | ENST00000528203 | PAK1 | chr11 | 77043912 | - | 591 | 67 | 517 | 230 | 95 |
| ENST00000543847 | STIP1 | chr11 | 63953742 | + | ENST00000356341 | PAK1 | chr11 | 77043912 | - | 1838 | 46 | 1120 | 782 | 112 |
| ENST00000543847 | STIP1 | chr11 | 63953742 | + | ENST00000530617 | PAK1 | chr11 | 77043912 | - | 1322 | 46 | 914 | 576 | 112 |
| ENST00000543847 | STIP1 | chr11 | 63953742 | + | ENST00000278568 | PAK1 | chr11 | 77043912 | - | 646 | 46 | 37 | 294 | 85 |
| ENST00000543847 | STIP1 | chr11 | 63953742 | + | ENST00000528203 | PAK1 | chr11 | 77043912 | - | 570 | 46 | 496 | 209 | 95 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000305218 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.10166063 | 0.8983394 |
| ENST00000305218 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.30515152 | 0.6948485 |
| ENST00000305218 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.039600857 | 0.9603991 |
| ENST00000305218 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.029192068 | 0.97080797 |
| ENST00000538945 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.16454034 | 0.83545965 |
| ENST00000538945 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.5929421 | 0.40705788 |
| ENST00000538945 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.052714594 | 0.94728535 |
| ENST00000538945 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.024258295 | 0.97574174 |
| ENST00000543847 | ENST00000356341 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.36544713 | 0.63455284 |
| ENST00000543847 | ENST00000530617 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.6595956 | 0.34040433 |
| ENST00000543847 | ENST00000278568 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.050145328 | 0.9498546 |
| ENST00000543847 | ENST00000528203 | STIP1 | chr11 | 63953742 | + | PAK1 | chr11 | 77043912 | - | 0.026046855 | 0.9739532 |
Top |
Fusion Genomic Features for STIP1-PAK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
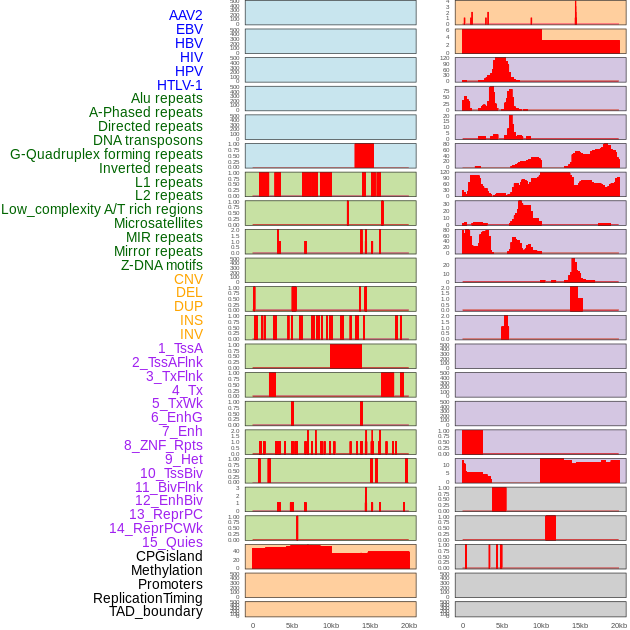 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for STIP1-PAK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:63953742/chr11:77043912) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 130_169 | 3 | 544.0 | Domain | Note=STI1 1 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 492_531 | 3 | 544.0 | Domain | Note=STI1 2 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 222_239 | 3 | 544.0 | Motif | Bipartite nuclear localization signal |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 225_258 | 3 | 544.0 | Repeat | Note=TPR 4 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 259_292 | 3 | 544.0 | Repeat | Note=TPR 5 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 300_333 | 3 | 544.0 | Repeat | Note=TPR 6 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 360_393 | 3 | 544.0 | Repeat | Note=TPR 7 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 38_71 | 3 | 544.0 | Repeat | Note=TPR 2 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 394_427 | 3 | 544.0 | Repeat | Note=TPR 8 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 428_461 | 3 | 544.0 | Repeat | Note=TPR 9 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 4_37 | 3 | 544.0 | Repeat | Note=TPR 1 |
| Hgene | STIP1 | chr11:63953742 | chr11:77043912 | ENST00000305218 | + | 1 | 14 | 72_105 | 3 | 544.0 | Repeat | Note=TPR 3 |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 270_521 | 471 | 554.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 75_88 | 471 | 554.0 | Domain | CRIB | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 270_521 | 471 | 546.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 75_88 | 471 | 546.0 | Domain | CRIB | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 276_284 | 471 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 345_347 | 471 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 276_284 | 471 | 546.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 345_347 | 471 | 546.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 70_140 | 471 | 554.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 75_105 | 471 | 554.0 | Region | Note=GTPase-binding | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 70_140 | 471 | 546.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 75_105 | 471 | 546.0 | Region | Note=GTPase-binding |
Top |
Fusion Gene Sequence for STIP1-PAK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >87428_87428_1_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000278568_length(transcript)=756nt_BP=156nt CTAGAAGAACTCGACCAGTGAGCAGGCGAGGAAGGGGCGGGAGCCGGGGTCCCGGTAGCTTCTAGTAGGTTCCAGAAGGCGGCGCGTGCG GTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAAT GGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGA GGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGAT TGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCT CATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTC CTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGG CCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTC >87428_87428_1_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000278568_length(amino acids)=85AA_BP=2 -------------------------------------------------------------- >87428_87428_2_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000356341_length(transcript)=1948nt_BP=156nt CTAGAAGAACTCGACCAGTGAGCAGGCGAGGAAGGGGCGGGAGCCGGGGTCCCGGTAGCTTCTAGTAGGTTCCAGAAGGCGGCGCGTGCG GTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAAT GGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGA GGTTCAGCTAAAGAGCTGCTACAGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAG GCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAA CTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAG CATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGT TTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATT CTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGC CCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTC CTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGAC CTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGC CCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGA CTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATA AGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTC TGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAA ATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCAT TGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATAA AAGGAGATGAAAATATTCTATTGGAGTATGCCTTTCTTTTTTCTCTTCGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGAG TAGTTTCTTCCTGAACCATTTGAGAGTGGTAAGTTGCAGATAGAATGCCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTTA ACACTTTTATTTTAAATATAAATTAAGAGAAATGGGCCAAAACCATTTGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACCA >87428_87428_2_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000356341_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- >87428_87428_3_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000528203_length(transcript)=680nt_BP=156nt CTAGAAGAACTCGACCAGTGAGCAGGCGAGGAAGGGGCGGGAGCCGGGGTCCCGGTAGCTTCTAGTAGGTTCCAGAAGGCGGCGCGTGCG GTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAAT GGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGA GGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGAT TGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCT CATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTC CTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGG >87428_87428_3_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000528203_length(amino acids)=95AA_BP= MQFSSMLDTRFPRIKVLRSARSGNGRSKARRRGHQELEFLKCAFISQKAWHNEAGVSVVLVIVLCCLLSCSNQWSEAGEGLGNLQELMQL -------------------------------------------------------------- >87428_87428_4_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000530617_length(transcript)=1432nt_BP=156nt CTAGAAGAACTCGACCAGTGAGCAGGCGAGGAAGGGGCGGGAGCCGGGGTCCCGGTAGCTTCTAGTAGGTTCCAGAAGGCGGCGCGTGCG GTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAAT GGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGA GGTTCAGCTAAAGAGCTGCTACAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGA CTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAA ATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGA TAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAAC TGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGA TCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTG TTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACA TTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATC AGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCT TCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGA TACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGT TTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTG >87428_87428_4_STIP1-PAK1_STIP1_chr11_63953742_ENST00000305218_PAK1_chr11_77043912_ENST00000530617_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- >87428_87428_5_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000278568_length(transcript)=667nt_BP=67nt GGTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAA TGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAG AGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGA TTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCC TCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTT CCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATG GCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTT >87428_87428_5_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000278568_length(amino acids)=85AA_BP=2 -------------------------------------------------------------- >87428_87428_6_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000356341_length(transcript)=1859nt_BP=67nt GGTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAA TGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAG AGGTTCAGCTAAAGAGCTGCTACAGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGA GGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCA ACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCA GCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGG TTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAAT TCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTG CCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTT CCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGA CCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTG CCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTG ACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGAT AAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTT CTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGA AATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCA TTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATA AAAGGAGATGAAAATATTCTATTGGAGTATGCCTTTCTTTTTTCTCTTCGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGA GTAGTTTCTTCCTGAACCATTTGAGAGTGGTAAGTTGCAGATAGAATGCCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTT AACACTTTTATTTTAAATATAAATTAAGAGAAATGGGCCAAAACCATTTGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACC >87428_87428_6_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000356341_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- >87428_87428_7_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000528203_length(transcript)=591nt_BP=67nt GGTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAA TGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAG AGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGA TTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCC TCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTT CCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATG >87428_87428_7_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000528203_length(amino acids)=95AA_BP= MQFSSMLDTRFPRIKVLRSARSGNGRSKARRRGHQELEFLKCAFISQKAWHNEAGVSVVLVIVLCCLLSCSNQWSEAGEGLGNLQELMQL -------------------------------------------------------------- >87428_87428_8_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000530617_length(transcript)=1343nt_BP=67nt GGTTGGGAACGCGGAGCGGACGGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAA TGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAG AGGTTCAGCTAAAGAGCTGCTACAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATG ACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATA AATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTG ATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAA CTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTG ATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCT GTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAAC ATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCAT CAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATC TTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATG ATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATG TTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATT >87428_87428_8_STIP1-PAK1_STIP1_chr11_63953742_ENST00000538945_PAK1_chr11_77043912_ENST00000530617_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- >87428_87428_9_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000278568_length(transcript)=646nt_BP=46nt GGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAA CCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCT ACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCC TCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGT GAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAG ACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATT TCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACC >87428_87428_9_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000278568_length(amino acids)=85AA_BP=2 -------------------------------------------------------------- >87428_87428_10_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000356341_length(transcript)=1838nt_BP=46nt GGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAA CCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCT ACAGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTA AAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCC TTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACT GAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATAT AAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATG GTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTT GAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTC AGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCC ATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTT ATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTG GGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTT GGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTG ACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGG GGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCC CCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATAAAAGGAGATGAAAATATTCTA TTGGAGTATGCCTTTCTTTTTTCTCTTCGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGAGTAGTTTCTTCCTGAACCATT TGAGAGTGGTAAGTTGCAGATAGAATGCCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTTAACACTTTTATTTTAAATATA AATTAAGAGAAATGGGCCAAAACCATTTGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACCAAATCAAGAAATGGAACACTG >87428_87428_10_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000356341_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- >87428_87428_11_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000528203_length(transcript)=570nt_BP=46nt GGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAA CCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCT ACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCC TCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGT GAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAG ACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATT >87428_87428_11_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000528203_length(amino acids)=95AA_BP= MQFSSMLDTRFPRIKVLRSARSGNGRSKARRRGHQELEFLKCAFISQKAWHNEAGVSVVLVIVLCCLLSCSNQWSEAGEGLGNLQELMQL -------------------------------------------------------------- >87428_87428_12_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000530617_length(transcript)=1322nt_BP=46nt GGATTCGATTCAACGGGGTTCCGGACCGCGCTGCGCTATGGAGCAGGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAA CCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCT ACAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATT TCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGT GTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAAT CAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCC ATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAAC CACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCG GCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCA CATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACT TGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTT GGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGG GACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTT TGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGA >87428_87428_12_STIP1-PAK1_STIP1_chr11_63953742_ENST00000543847_PAK1_chr11_77043912_ENST00000530617_length(amino acids)=112AA_BP= MKHHTSRAGQVLMPSLALKVVTIFPDFSTLLSLSMCPRKPLNVINKGQDRGSSLGYAGNQKLLHSREHFTRNSMGTLLGQGPPEQLLEAH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for STIP1-PAK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000278568 | 12 | 16 | 132_270 | 471.0 | 554.0 | CRIPAK | |
| Tgene | PAK1 | chr11:63953742 | chr11:77043912 | ENST00000356341 | 12 | 15 | 132_270 | 471.0 | 546.0 | CRIPAK |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for STIP1-PAK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for STIP1-PAK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies