
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:STXBP1-LRSAM1 (FusionGDB2 ID:87871) |
Fusion Gene Summary for STXBP1-LRSAM1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: STXBP1-LRSAM1 | Fusion gene ID: 87871 | Hgene | Tgene | Gene symbol | STXBP1 | LRSAM1 | Gene ID | 6812 | 90678 |
| Gene name | syntaxin binding protein 1 | leucine rich repeat and sterile alpha motif containing 1 | |
| Synonyms | MUNC18-1|N-Sec1|NSEC1|P67|RBSEC1|UNC18|unc-18A|unc18-1 | CMT2P|RIFLE|TAL | |
| Cytomap | 9q34.11 | 9q33.3-q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | syntaxin-binding protein 1neuronal SEC1protein unc-18 homolog 1protein unc-18 homolog A | E3 ubiquitin-protein ligase LRSAM1RING finger leucine repeat richRING-type E3 ubiquitin transferase LRSAM1Tsg101-associated ligase | |
| Modification date | 20200313 | 20200328 | |
| UniProtAcc | . | Q6UWE0 | |
| Ensembl transtripts involved in fusion gene | ENST00000373299, ENST00000373302, ENST00000481942, | ENST00000483302, ENST00000300417, ENST00000323301, ENST00000373322, ENST00000373324, | |
| Fusion gene scores | * DoF score | 7 X 6 X 3=126 | 10 X 11 X 7=770 |
| # samples | 7 | 10 | |
| ** MAII score | log2(7/126*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/770*10)=-2.94485844580754 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: STXBP1 [Title/Abstract] AND LRSAM1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | STXBP1(130439032)-LRSAM1(130242118), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | STXBP1 | GO:0072659 | protein localization to plasma membrane | 17543282 |
| Tgene | LRSAM1 | GO:0000209 | protein polyubiquitination | 18077552 |
| Tgene | LRSAM1 | GO:0051865 | protein autoubiquitination | 15256501|23245322 |
| Tgene | LRSAM1 | GO:0070086 | ubiquitin-dependent endocytosis | 15256501 |
| Fusion gene breakpoints across STXBP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across LRSAM1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-B5-A5OE-01A | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
Top |
Fusion Gene ORF analysis for STXBP1-LRSAM1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000373299 | ENST00000483302 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| 5CDS-3UTR | ENST00000373302 | ENST00000483302 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373299 | ENST00000300417 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373299 | ENST00000323301 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373299 | ENST00000373322 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373299 | ENST00000373324 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373302 | ENST00000300417 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373302 | ENST00000323301 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373302 | ENST00000373322 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| In-frame | ENST00000373302 | ENST00000373324 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| intron-3CDS | ENST00000481942 | ENST00000300417 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| intron-3CDS | ENST00000481942 | ENST00000323301 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| intron-3CDS | ENST00000481942 | ENST00000373322 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| intron-3CDS | ENST00000481942 | ENST00000373324 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| intron-3UTR | ENST00000481942 | ENST00000483302 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000373302 | STXBP1 | chr9 | 130439032 | + | ENST00000300417 | LRSAM1 | chr9 | 130242118 | + | 3369 | 1498 | 139 | 2766 | 875 |
| ENST00000373302 | STXBP1 | chr9 | 130439032 | + | ENST00000373324 | LRSAM1 | chr9 | 130242118 | + | 3286 | 1498 | 139 | 2685 | 848 |
| ENST00000373302 | STXBP1 | chr9 | 130439032 | + | ENST00000323301 | LRSAM1 | chr9 | 130242118 | + | 3367 | 1498 | 139 | 2766 | 875 |
| ENST00000373302 | STXBP1 | chr9 | 130439032 | + | ENST00000373322 | LRSAM1 | chr9 | 130242118 | + | 3367 | 1498 | 139 | 2766 | 875 |
| ENST00000373299 | STXBP1 | chr9 | 130439032 | + | ENST00000300417 | LRSAM1 | chr9 | 130242118 | + | 3345 | 1474 | 115 | 2742 | 875 |
| ENST00000373299 | STXBP1 | chr9 | 130439032 | + | ENST00000373324 | LRSAM1 | chr9 | 130242118 | + | 3262 | 1474 | 115 | 2661 | 848 |
| ENST00000373299 | STXBP1 | chr9 | 130439032 | + | ENST00000323301 | LRSAM1 | chr9 | 130242118 | + | 3343 | 1474 | 115 | 2742 | 875 |
| ENST00000373299 | STXBP1 | chr9 | 130439032 | + | ENST00000373322 | LRSAM1 | chr9 | 130242118 | + | 3343 | 1474 | 115 | 2742 | 875 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000373302 | ENST00000300417 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.014964928 | 0.98503506 |
| ENST00000373302 | ENST00000373324 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.01544619 | 0.9845538 |
| ENST00000373302 | ENST00000323301 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015015631 | 0.9849844 |
| ENST00000373302 | ENST00000373322 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015015631 | 0.9849844 |
| ENST00000373299 | ENST00000300417 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015262525 | 0.98473746 |
| ENST00000373299 | ENST00000373324 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015665082 | 0.9843349 |
| ENST00000373299 | ENST00000323301 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015300578 | 0.9846994 |
| ENST00000373299 | ENST00000373322 | STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242118 | + | 0.015300578 | 0.9846994 |
Top |
Fusion Genomic Features for STXBP1-LRSAM1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242117 | + | 7.67E-09 | 1 |
| STXBP1 | chr9 | 130439032 | + | LRSAM1 | chr9 | 130242117 | + | 7.67E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
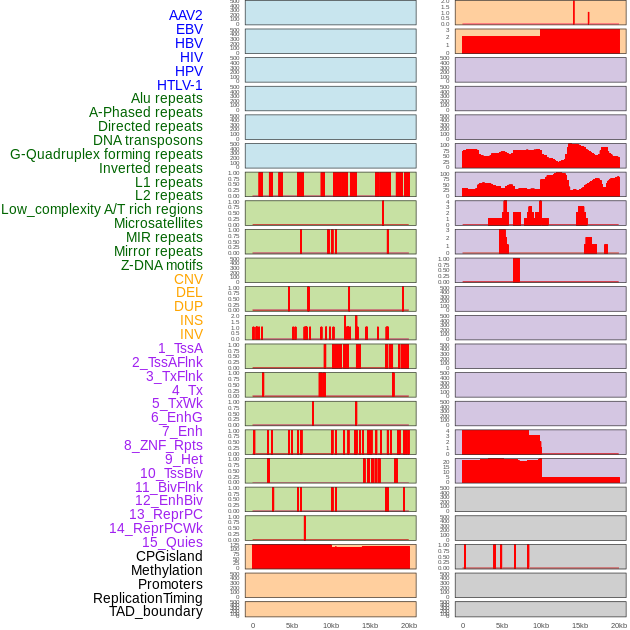 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
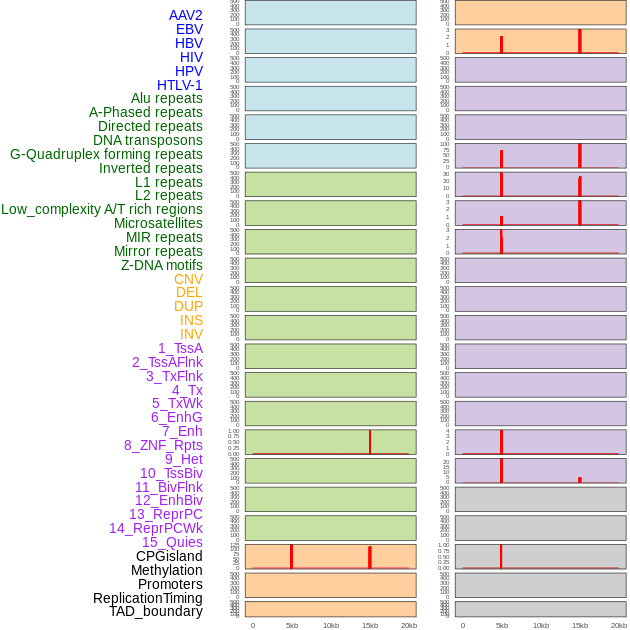 |
Top |
Fusion Protein Features for STXBP1-LRSAM1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:130439032/chr9:130242118) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | LRSAM1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: E3 ubiquitin-protein ligase that mediates monoubiquitination of TSG101 at multiple sites, leading to inactivate the ability of TSG101 to sort endocytic (EGF receptors) and exocytic (HIV-1 viral proteins) cargos (PubMed:15256501). Bacterial recognition protein that defends the cytoplasm from invasive pathogens (PubMed:23245322). Localizes to several intracellular bacterial pathogens and generates the bacteria-associated ubiquitin signal leading to autophagy-mediated intracellular bacteria degradation (xenophagy) (PubMed:23245322, PubMed:25484098). {ECO:0000269|PubMed:15256501, ECO:0000269|PubMed:23245322, ECO:0000269|PubMed:25484098}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 510_562 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 510_562 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 510_562 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 510_562 | 301 | 697.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 569_632 | 301 | 724.0 | Domain | SAM | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 569_632 | 301 | 724.0 | Domain | SAM | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 569_632 | 301 | 724.0 | Domain | SAM | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 569_632 | 301 | 697.0 | Domain | SAM | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 649_652 | 301 | 724.0 | Motif | Note=PTAP motif 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 661_664 | 301 | 724.0 | Motif | Note=PTAP motif 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 649_652 | 301 | 724.0 | Motif | Note=PTAP motif 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 661_664 | 301 | 724.0 | Motif | Note=PTAP motif 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 649_652 | 301 | 724.0 | Motif | Note=PTAP motif 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 661_664 | 301 | 724.0 | Motif | Note=PTAP motif 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 649_652 | 301 | 697.0 | Motif | Note=PTAP motif 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 661_664 | 301 | 697.0 | Motif | Note=PTAP motif 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 675_710 | 301 | 724.0 | Zinc finger | RING-type | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 675_710 | 301 | 724.0 | Zinc finger | RING-type | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 675_710 | 301 | 724.0 | Zinc finger | RING-type | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 675_710 | 301 | 697.0 | Zinc finger | RING-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 254_380 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 254_380 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 254_380 | 301 | 724.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 254_380 | 301 | 697.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 105_127 | 301 | 724.0 | Repeat | Note=LRR 4 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 128_149 | 301 | 724.0 | Repeat | Note=LRR 5 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 151_172 | 301 | 724.0 | Repeat | Note=LRR 6 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 30_51 | 301 | 724.0 | Repeat | Note=LRR 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 56_77 | 301 | 724.0 | Repeat | Note=LRR 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000300417 | 12 | 26 | 82_103 | 301 | 724.0 | Repeat | Note=LRR 3 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 105_127 | 301 | 724.0 | Repeat | Note=LRR 4 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 128_149 | 301 | 724.0 | Repeat | Note=LRR 5 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 151_172 | 301 | 724.0 | Repeat | Note=LRR 6 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 30_51 | 301 | 724.0 | Repeat | Note=LRR 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 56_77 | 301 | 724.0 | Repeat | Note=LRR 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000323301 | 11 | 25 | 82_103 | 301 | 724.0 | Repeat | Note=LRR 3 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 105_127 | 301 | 724.0 | Repeat | Note=LRR 4 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 128_149 | 301 | 724.0 | Repeat | Note=LRR 5 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 151_172 | 301 | 724.0 | Repeat | Note=LRR 6 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 30_51 | 301 | 724.0 | Repeat | Note=LRR 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 56_77 | 301 | 724.0 | Repeat | Note=LRR 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373322 | 11 | 25 | 82_103 | 301 | 724.0 | Repeat | Note=LRR 3 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 105_127 | 301 | 697.0 | Repeat | Note=LRR 4 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 128_149 | 301 | 697.0 | Repeat | Note=LRR 5 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 151_172 | 301 | 697.0 | Repeat | Note=LRR 6 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 30_51 | 301 | 697.0 | Repeat | Note=LRR 1 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 56_77 | 301 | 697.0 | Repeat | Note=LRR 2 | |
| Tgene | LRSAM1 | chr9:130439032 | chr9:130242118 | ENST00000373324 | 12 | 25 | 82_103 | 301 | 697.0 | Repeat | Note=LRR 3 |
Top |
Fusion Gene Sequence for STXBP1-LRSAM1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >87871_87871_1_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000300417_length(transcript)=3345nt_BP=1474nt GCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCGCAGGCGTCGCGGGACGAGGAGATC GGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGATTATGCATGATGTGATAAAGAAGGT CAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTGCTGCAAGATGACAGACATCATGAC CGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGTGTATCTCATCACTCCATCCGAGAA GTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGTCTTCTTCACTGACTCTTGTCCAGA TGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAATATTGCATTTCTCCCGTATGAATC CCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGATGAAGAATCCTATACTGGAGCGCCT GGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGAATACAAGGACAATGCCCTGCTGGC TCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGACAAGGCACGCTCCCAGCTCCTGAT CCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTATGATCTGCTGCCTATCGAAAATGA TGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGACGACGACCTGTGGATAGCACTGCG CCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAAGAGAATGAATACTGGAGAGAAGAC CACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTACTCCACCCACCTGCACCTTGCTGA GGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCATGGGCACAGATGCTGAGGGAGAGAA GATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAAAATCCGCATCATCCTTCTCTACAT CTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCCGGAGGATAGTGAGATCATCACCAA CATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGAGCACCAGCGCCACCTCAACGCAGA GCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCTGCTGCAGGACAATCAGAGACAAAA GAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCATAACCCAGGAGGAGACTGAGAGCCT GCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCATCCAGATGGCCTACGAATCTCAGAG GCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCTGTCGTGGCAGCAAATGGATCAGAA CAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGTGAAGAAAGACCTGATGCATCGGCA GATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAGGAAGTCCCTGGACACAGAGTCACT CCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAAGCAGCAGCGAGAGGAAGAGCTCCG GGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTATCAACGGCTTTTGAACCAGAAGCC CTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTCGGCTGAGCACTACCTGCCCATCTT TGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGGCGTCTCAGAAGCTGGCCTGCAGCA CGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACCAATGGGTGAGGTCGTCACCCCTAC GGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGCCTCAGAGTGTGTCGTGTGCCTGGA ACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCCACTGCGCACCTGCCCGCTGTGCCG CCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCTGGTCCTAGCCCTGCCTCGGCCACT GTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGGGCCCCTTCCCCACTGCCCAGGAGC CCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGTCTGAATGGTCCTGGGGGCTGGGGC TGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCTGCCTCCCAGCTGTCTTGACTGAAG GCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCATGTGGGAAGGGAGCAGGAGGGCCT GGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAGCAACCCTGGGTCTCCCTCTCTGCT GCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGATCCGAAGCAGGAGTGTCAATAAACC >87871_87871_1_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000300417_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_2_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000323301_length(transcript)=3343nt_BP=1474nt GCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCGCAGGCGTCGCGGGACGAGGAGATC GGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGATTATGCATGATGTGATAAAGAAGGT CAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTGCTGCAAGATGACAGACATCATGAC CGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGTGTATCTCATCACTCCATCCGAGAA GTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGTCTTCTTCACTGACTCTTGTCCAGA TGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAATATTGCATTTCTCCCGTATGAATC CCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGATGAAGAATCCTATACTGGAGCGCCT GGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGAATACAAGGACAATGCCCTGCTGGC TCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGACAAGGCACGCTCCCAGCTCCTGAT CCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTATGATCTGCTGCCTATCGAAAATGA TGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGACGACGACCTGTGGATAGCACTGCG CCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAAGAGAATGAATACTGGAGAGAAGAC CACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTACTCCACCCACCTGCACCTTGCTGA GGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCATGGGCACAGATGCTGAGGGAGAGAA GATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAAAATCCGCATCATCCTTCTCTACAT CTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCCGGAGGATAGTGAGATCATCACCAA CATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGAGCACCAGCGCCACCTCAACGCAGA GCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCTGCTGCAGGACAATCAGAGACAAAA GAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCATAACCCAGGAGGAGACTGAGAGCCT GCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCATCCAGATGGCCTACGAATCTCAGAG GCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCTGTCGTGGCAGCAAATGGATCAGAA CAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGTGAAGAAAGACCTGATGCATCGGCA GATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAGGAAGTCCCTGGACACAGAGTCACT CCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAAGCAGCAGCGAGAGGAAGAGCTCCG GGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTATCAACGGCTTTTGAACCAGAAGCC CTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTCGGCTGAGCACTACCTGCCCATCTT TGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGGCGTCTCAGAAGCTGGCCTGCAGCA CGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACCAATGGGTGAGGTCGTCACCCCTAC GGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGCCTCAGAGTGTGTCGTGTGCCTGGA ACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCCACTGCGCACCTGCCCGCTGTGCCG CCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCTGGTCCTAGCCCTGCCTCGGCCACT GTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGGGCCCCTTCCCCACTGCCCAGGAGC CCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGTCTGAATGGTCCTGGGGGCTGGGGC TGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCTGCCTCCCAGCTGTCTTGACTGAAG GCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCATGTGGGAAGGGAGCAGGAGGGCCT GGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAGCAACCCTGGGTCTCCCTCTCTGCT GCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGATCCGAAGCAGGAGTGTCAATAAACC >87871_87871_2_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000323301_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_3_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000373322_length(transcript)=3343nt_BP=1474nt GCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCGCAGGCGTCGCGGGACGAGGAGATC GGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGATTATGCATGATGTGATAAAGAAGGT CAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTGCTGCAAGATGACAGACATCATGAC CGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGTGTATCTCATCACTCCATCCGAGAA GTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGTCTTCTTCACTGACTCTTGTCCAGA TGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAATATTGCATTTCTCCCGTATGAATC CCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGATGAAGAATCCTATACTGGAGCGCCT GGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGAATACAAGGACAATGCCCTGCTGGC TCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGACAAGGCACGCTCCCAGCTCCTGAT CCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTATGATCTGCTGCCTATCGAAAATGA TGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGACGACGACCTGTGGATAGCACTGCG CCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAAGAGAATGAATACTGGAGAGAAGAC CACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTACTCCACCCACCTGCACCTTGCTGA GGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCATGGGCACAGATGCTGAGGGAGAGAA GATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAAAATCCGCATCATCCTTCTCTACAT CTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCCGGAGGATAGTGAGATCATCACCAA CATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGAGCACCAGCGCCACCTCAACGCAGA GCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCTGCTGCAGGACAATCAGAGACAAAA GAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCATAACCCAGGAGGAGACTGAGAGCCT GCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCATCCAGATGGCCTACGAATCTCAGAG GCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCTGTCGTGGCAGCAAATGGATCAGAA CAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGTGAAGAAAGACCTGATGCATCGGCA GATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAGGAAGTCCCTGGACACAGAGTCACT CCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAAGCAGCAGCGAGAGGAAGAGCTCCG GGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTATCAACGGCTTTTGAACCAGAAGCC CTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTCGGCTGAGCACTACCTGCCCATCTT TGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGGCGTCTCAGAAGCTGGCCTGCAGCA CGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACCAATGGGTGAGGTCGTCACCCCTAC GGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGCCTCAGAGTGTGTCGTGTGCCTGGA ACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCCACTGCGCACCTGCCCGCTGTGCCG CCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCTGGTCCTAGCCCTGCCTCGGCCACT GTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGGGCCCCTTCCCCACTGCCCAGGAGC CCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGTCTGAATGGTCCTGGGGGCTGGGGC TGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCTGCCTCCCAGCTGTCTTGACTGAAG GCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCATGTGGGAAGGGAGCAGGAGGGCCT GGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAGCAACCCTGGGTCTCCCTCTCTGCT GCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGATCCGAAGCAGGAGTGTCAATAAACC >87871_87871_3_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000373322_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_4_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000373324_length(transcript)=3262nt_BP=1474nt GCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCGCAGGCGTCGCGGGACGAGGAGATC GGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGATTATGCATGATGTGATAAAGAAGGT CAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTGCTGCAAGATGACAGACATCATGAC CGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGTGTATCTCATCACTCCATCCGAGAA GTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGTCTTCTTCACTGACTCTTGTCCAGA TGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAATATTGCATTTCTCCCGTATGAATC CCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGATGAAGAATCCTATACTGGAGCGCCT GGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGAATACAAGGACAATGCCCTGCTGGC TCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGACAAGGCACGCTCCCAGCTCCTGAT CCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTATGATCTGCTGCCTATCGAAAATGA TGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGACGACGACCTGTGGATAGCACTGCG CCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAAGAGAATGAATACTGGAGAGAAGAC CACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTACTCCACCCACCTGCACCTTGCTGA GGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCATGGGCACAGATGCTGAGGGAGAGAA GATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAAAATCCGCATCATCCTTCTCTACAT CTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCCGGAGGATAGTGAGATCATCACCAA CATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGAGCACCAGCGCCACCTCAACGCAGA GCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCTGCTGCAGGACAATCAGAGACAAAA GAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCATAACCCAGGAGGAGACTGAGAGCCT GCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCATCCAGATGGCCTACGAATCTCAGAG GCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCTGTCGTGGCAGCAAATGGATCAGAA CAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGTGAAGAAAGACCTGATGCATCGGCA GATCAGGAGCCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAAGCAGCAGCGAGAGGA AGAGCTCCGGGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTATCAACGGCTTTTGAA CCAGAAGCCCTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTCGGCTGAGCACTACCT GCCCATCTTTGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGGCGTCTCAGAAGCTGG CCTGCAGCACGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACCAATGGGTGAGGTCGT CACCCCTACGGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGCCTCAGAGTGTGTCGT GTGCCTGGAACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCCACTGCGCACCTGCCC GCTGTGCCGCCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCTGGTCCTAGCCCTGCC TCGGCCACTGTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGGGCCCCTTCCCCACTG CCCAGGAGCCCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGTCTGAATGGTCCTGGG GGCTGGGGCTGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCTGCCTCCCAGCTGTCT TGACTGAAGGCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCATGTGGGAAGGGAGCA GGAGGGCCTGGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAGCAACCCTGGGTCTCC CTCTCTGCTGCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGATCCGAAGCAGGAGTGT >87871_87871_4_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373299_LRSAM1_chr9_130242118_ENST00000373324_length(amino acids)=848AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQEMIS EQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEEGMERQLVALLEELSAEHYLPIFAHHRL SLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPESVRPSAPPAELEVQASECVVCLEREAQM -------------------------------------------------------------- >87871_87871_5_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000300417_length(transcript)=3369nt_BP=1498nt AGTCCGCGCGTCAGTCGGTCCCTAGCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCG CAGGCGTCGCGGGACGAGGAGATCGGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGAT TATGCATGATGTGATAAAGAAGGTCAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTG CTGCAAGATGACAGACATCATGACCGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGT GTATCTCATCACTCCATCCGAGAAGTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGT CTTCTTCACTGACTCTTGTCCAGATGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAA TATTGCATTTCTCCCGTATGAATCCCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGAT GAAGAATCCTATACTGGAGCGCCTGGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGA ATACAAGGACAATGCCCTGCTGGCTCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGA CAAGGCACGCTCCCAGCTCCTGATCCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTA TGATCTGCTGCCTATCGAAAATGATGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGA CGACGACCTGTGGATAGCACTGCGCCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAA GAGAATGAATACTGGAGAGAAGACCACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTA CTCCACCCACCTGCACCTTGCTGAGGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCAT GGGCACAGATGCTGAGGGAGAGAAGATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAA AATCCGCATCATCCTTCTCTACATCTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCC GGAGGATAGTGAGATCATCACCAACATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGA GCACCAGCGCCACCTCAACGCAGAGCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCT GCTGCAGGACAATCAGAGACAAAAGAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCAT AACCCAGGAGGAGACTGAGAGCCTGCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCAT CCAGATGGCCTACGAATCTCAGAGGCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCT GTCGTGGCAGCAAATGGATCAGAACAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGT GAAGAAAGACCTGATGCATCGGCAGATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAG GAAGTCCCTGGACACAGAGTCACTCCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAA GCAGCAGCGAGAGGAAGAGCTCCGGGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTA TCAACGGCTTTTGAACCAGAAGCCCTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTC GGCTGAGCACTACCTGCCCATCTTTGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGG CGTCTCAGAAGCTGGCCTGCAGCACGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACC AATGGGTGAGGTCGTCACCCCTACGGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGC CTCAGAGTGTGTCGTGTGCCTGGAACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCC ACTGCGCACCTGCCCGCTGTGCCGCCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCT GGTCCTAGCCCTGCCTCGGCCACTGTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGG GCCCCTTCCCCACTGCCCAGGAGCCCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGT CTGAATGGTCCTGGGGGCTGGGGCTGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCT GCCTCCCAGCTGTCTTGACTGAAGGCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCA TGTGGGAAGGGAGCAGGAGGGCCTGGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAG CAACCCTGGGTCTCCCTCTCTGCTGCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGAT >87871_87871_5_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000300417_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_6_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000323301_length(transcript)=3367nt_BP=1498nt AGTCCGCGCGTCAGTCGGTCCCTAGCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCG CAGGCGTCGCGGGACGAGGAGATCGGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGAT TATGCATGATGTGATAAAGAAGGTCAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTG CTGCAAGATGACAGACATCATGACCGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGT GTATCTCATCACTCCATCCGAGAAGTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGT CTTCTTCACTGACTCTTGTCCAGATGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAA TATTGCATTTCTCCCGTATGAATCCCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGAT GAAGAATCCTATACTGGAGCGCCTGGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGA ATACAAGGACAATGCCCTGCTGGCTCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGA CAAGGCACGCTCCCAGCTCCTGATCCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTA TGATCTGCTGCCTATCGAAAATGATGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGA CGACGACCTGTGGATAGCACTGCGCCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAA GAGAATGAATACTGGAGAGAAGACCACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTA CTCCACCCACCTGCACCTTGCTGAGGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCAT GGGCACAGATGCTGAGGGAGAGAAGATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAA AATCCGCATCATCCTTCTCTACATCTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCC GGAGGATAGTGAGATCATCACCAACATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGA GCACCAGCGCCACCTCAACGCAGAGCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCT GCTGCAGGACAATCAGAGACAAAAGAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCAT AACCCAGGAGGAGACTGAGAGCCTGCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCAT CCAGATGGCCTACGAATCTCAGAGGCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCT GTCGTGGCAGCAAATGGATCAGAACAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGT GAAGAAAGACCTGATGCATCGGCAGATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAG GAAGTCCCTGGACACAGAGTCACTCCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAA GCAGCAGCGAGAGGAAGAGCTCCGGGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTA TCAACGGCTTTTGAACCAGAAGCCCTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTC GGCTGAGCACTACCTGCCCATCTTTGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGG CGTCTCAGAAGCTGGCCTGCAGCACGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACC AATGGGTGAGGTCGTCACCCCTACGGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGC CTCAGAGTGTGTCGTGTGCCTGGAACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCC ACTGCGCACCTGCCCGCTGTGCCGCCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCT GGTCCTAGCCCTGCCTCGGCCACTGTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGG GCCCCTTCCCCACTGCCCAGGAGCCCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGT CTGAATGGTCCTGGGGGCTGGGGCTGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCT GCCTCCCAGCTGTCTTGACTGAAGGCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCA TGTGGGAAGGGAGCAGGAGGGCCTGGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAG CAACCCTGGGTCTCCCTCTCTGCTGCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGAT >87871_87871_6_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000323301_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_7_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000373322_length(transcript)=3367nt_BP=1498nt AGTCCGCGCGTCAGTCGGTCCCTAGCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCG CAGGCGTCGCGGGACGAGGAGATCGGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGAT TATGCATGATGTGATAAAGAAGGTCAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTG CTGCAAGATGACAGACATCATGACCGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGT GTATCTCATCACTCCATCCGAGAAGTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGT CTTCTTCACTGACTCTTGTCCAGATGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAA TATTGCATTTCTCCCGTATGAATCCCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGAT GAAGAATCCTATACTGGAGCGCCTGGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGA ATACAAGGACAATGCCCTGCTGGCTCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGA CAAGGCACGCTCCCAGCTCCTGATCCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTA TGATCTGCTGCCTATCGAAAATGATGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGA CGACGACCTGTGGATAGCACTGCGCCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAA GAGAATGAATACTGGAGAGAAGACCACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTA CTCCACCCACCTGCACCTTGCTGAGGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCAT GGGCACAGATGCTGAGGGAGAGAAGATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAA AATCCGCATCATCCTTCTCTACATCTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCC GGAGGATAGTGAGATCATCACCAACATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGA GCACCAGCGCCACCTCAACGCAGAGCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCT GCTGCAGGACAATCAGAGACAAAAGAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCAT AACCCAGGAGGAGACTGAGAGCCTGCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCAT CCAGATGGCCTACGAATCTCAGAGGCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCT GTCGTGGCAGCAAATGGATCAGAACAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGT GAAGAAAGACCTGATGCATCGGCAGATCAGGAGCCAGATTAAGTTAATAGAAACTGAGTTATTGCAGCTGACACAGCTGGAGTTAAAGAG GAAGTCCCTGGACACAGAGTCACTCCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCTCAAAGAGAA GCAGCAGCGAGAGGAAGAGCTCCGGGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCTGATTCAGTA TCAACGGCTTTTGAACCAGAAGCCCTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGAGGAGCTGTC GGCTGAGCACTACCTGCCCATCTTTGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGCCAAGGTGGG CGTCTCAGAAGCTGGCCTGCAGCACGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCTGAAACCACC AATGGGTGAGGTCGTCACCCCTACGGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGAGGTGCAGGC CTCAGAGTGTGTCGTGTGCCTGGAACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTGCTGCCAGCC ACTGCGCACCTGCCCGCTGTGCCGCCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCACCTGGGCCT GGTCCTAGCCCTGCCTCGGCCACTGTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCCCTGCCCTGG GCCCCTTCCCCACTGCCCAGGAGCCCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGACACCACCAGT CTGAATGGTCCTGGGGGCTGGGGCTGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCACGGATCTGCT GCCTCCCAGCTGTCTTGACTGAAGGCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCCCACCCTGCA TGTGGGAAGGGAGCAGGAGGGCCTGGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAGTGGCACCAG CAACCCTGGGTCTCCCTCTCTGCTGCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATGTAGCTCGAT >87871_87871_7_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000373322_length(amino acids)=875AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQIKLI ETELLQLTQLELKRKSLDTESLQEMISEQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEE GMERQLVALLEELSAEHYLPIFAHHRLSLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPES -------------------------------------------------------------- >87871_87871_8_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000373324_length(transcript)=3286nt_BP=1498nt AGTCCGCGCGTCAGTCGGTCCCTAGCGCGGCTGCGGGGCGGAGAGCTGCGGCTGGCCCAGCGCGCCCACCTGAGGAGGCGGCGGGGTCCG CAGGCGTCGCGGGACGAGGAGATCGGAGCCGGGAGACTCGCGCAGCGCCATGGCCCCCATTGGCCTCAAAGCTGTTGTCGGAGAGAAGAT TATGCATGATGTGATAAAGAAGGTCAAGAAGAAGGGGGAATGGAAGGTGCTGGTGGTGGATCAGTTAAGCATGAGGATGCTGTCCTCCTG CTGCAAGATGACAGACATCATGACCGAGGGCATAACGATTGTGGAAGATATCAATAAGCGCAGAGAGCCGCTCCCCAGCCTGGAGGCTGT GTATCTCATCACTCCATCCGAGAAGTCCGTCCACTCTCTCATCAGTGACTTTAAGGACCCGCCGACTGCTAAATACCGGGCTGCACACGT CTTCTTCACTGACTCTTGTCCAGATGCCCTGTTTAATGAACTGGTAAAATCCCGAGCAGCCAAAGTCATCAAAACTCTGACGGAAATCAA TATTGCATTTCTCCCGTATGAATCCCAGGTCTATTCCTTGGACTCTGCTGACTCTTTCCAAAGCTTCTACAGTCCCCACAAGGCTCAGAT GAAGAATCCTATACTGGAGCGCCTGGCAGAGCAGATCGCGACCCTTTGTGCCACCCTGAAGGAGTACCCGGCTGTGCGGTATCGGGGGGA ATACAAGGACAATGCCCTGCTGGCTCAGCTAATCCAGGACAAGCTCGATGCCTATAAAGCTGATGATCCAACAATGGGGGAGGGCCCAGA CAAGGCACGCTCCCAGCTCCTGATCCTGGATCGAGGCTTTGACCCCAGCTCCCCTGTGCTCCATGAATTGACTTTTCAGGCTATGAGTTA TGATCTGCTGCCTATCGAAAATGATGTATACAAGTATGAGACCAGCGGCATCGGGGAGGCACGGGTGAAGGAGGTGCTCCTGGACGAGGA CGACGACCTGTGGATAGCACTGCGCCACAAGCACATCGCAGAGGTGTCCCAGGAAGTCACCCGGTCTCTGAAAGATTTTTCTTCTAGCAA GAGAATGAATACTGGAGAGAAGACCACCATGCGGGACCTGTCCCAGATGCTGAAGAAGATGCCTCAGTACCAGAAAGAGCTCAGCAAGTA CTCCACCCACCTGCACCTTGCTGAGGACTGTATGAAGCATTACCAAGGCACCGTAGACAAACTCTGCCGAGTGGAGCAGGACCTGGCCAT GGGCACAGATGCTGAGGGAGAGAAGATCAAGGACCCTATGCGAGCCATCGTCCCCATTCTGCTGGATGCCAATGTCAGCACTTATGACAA AATCCGCATCATCCTTCTCTACATCTTTTTGAAGAATGGCATCACGGAGGAAAACCTGAACAAACTGATCCAGCACGCCCAGATACCCCC GGAGGATAGTGAGATCATCACCAACATGGCTCACCTCGGCGTGCCCATCGTCACCGATGAGCAGTCCCGGCTGGAGCAGGGCCTGAGTGA GCACCAGCGCCACCTCAACGCAGAGCGGCAGCGGCTGCAGGAGCAGCTGAAGCAGACGGAACAGAACATTTCCAGCCGGATCCAGAAGCT GCTGCAGGACAATCAGAGACAAAAGAAAAGCTCCGAGATTTTGAAATCGCTGGAAAATGAAAGAATAAGAATGGAACAGTTGATGTCCAT AACCCAGGAGGAGACTGAGAGCCTGCGGCGACGTGACGTTGCCTCCGCCATGCAGCAGATGCTGACTGAGAGCTGTAAGAACCGGCTCAT CCAGATGGCCTACGAATCTCAGAGGCAGAACTTGGTCCAGCAGGCCTGTTCCAGCATGGCCGAAATGGATGAACGATTCCAGCAGATTCT GTCGTGGCAGCAAATGGATCAGAACAAAGCCATCAGCCAGATCCTGCAGGAGAGCGCGATGCAGAAGGCTGCGTTCGAGGCACTCCAGGT GAAGAAAGACCTGATGCATCGGCAGATCAGGAGCCAGGAGATGATCTCGGAGCAGCGCTGGGCCCTCAGCTCCCTGCTCCAGCAGCTGCT CAAAGAGAAGCAGCAGCGAGAGGAAGAGCTCCGGGAAATCCTGACGGAGTTAGAAGCCAAAAGTGAAACCAGGCAGGAAAATTACTGGCT GATTCAGTATCAACGGCTTTTGAACCAGAAGCCCTTGTCCTTGAAGCTGCAAGAAGAGGGGATGGAGCGCCAGCTGGTGGCCCTCCTGGA GGAGCTGTCGGCTGAGCACTACCTGCCCATCTTTGCGCACCACCGCCTCTCACTGGACCTGCTGAGCCAAATGAGCCCAGGGGACCTGGC CAAGGTGGGCGTCTCAGAAGCTGGCCTGCAGCACGAGATCCTCCGGAGAGTCCAGGAACTGCTGGATGCAGCCAGGATCCAGCCAGAGCT GAAACCACCAATGGGTGAGGTCGTCACCCCTACGGCCCCCCAGGAGCCTCCTGAGTCTGTGAGGCCATCCGCTCCCCCTGCAGAGCTGGA GGTGCAGGCCTCAGAGTGTGTCGTGTGCCTGGAACGGGAGGCCCAGATGATCTTCCTCAACTGTGGCCACGTCTGCTGCTGCCAGCAGTG CTGCCAGCCACTGCGCACCTGCCCGCTGTGCCGCCAGGACATCGCCCAGCGCCTCCGCATCTACCACAGCAGCTGAGTGCTGCCCGCCCA CCTGGGCCTGGTCCTAGCCCTGCCTCGGCCACTGTGAGCCCCGGGCTCCTGCTCAGCCTTGTGCCAGCCAGACTCGTATGAGGCTCCCCC CTGCCCTGGGCCCCTTCCCCACTGCCCAGGAGCCCCCATCCTAAGCTCCAAGCATGTCTGGGCCAGGCAGAGGTGCTCCTCATCCATGAC ACCACCAGTCTGAATGGTCCTGGGGGCTGGGGCTGGAGAGGCCGCTGCACCACCACCCGAGCCTGGGAGCCAGCGTCCCAGCCTAATCAC GGATCTGCTGCCTCCCAGCTGTCTTGACTGAAGGCCACCGCCCCTGCAGGAGCTTGGGTCCTCATCTGGGGGCCATGCACAGGCCCGTCC CACCCTGCATGTGGGAAGGGAGCAGGAGGGCCTGGCTGGGTGAGGGGAGGCCTTCCTGGGAAGGCGTGTGGTGCAGGCCTGTGCTCACAG TGGCACCAGCAACCCTGGGTCTCCCTCTCTGCTGCTCCCCAGAACCCCGGGGCCCTCCTGCTCTCCACAACTGTCCCTCCTTACCCCATG >87871_87871_8_STXBP1-LRSAM1_STXBP1_chr9_130439032_ENST00000373302_LRSAM1_chr9_130242118_ENST00000373324_length(amino acids)=848AA_BP=453 MAPIGLKAVVGEKIMHDVIKKVKKKGEWKVLVVDQLSMRMLSSCCKMTDIMTEGITIVEDINKRREPLPSLEAVYLITPSEKSVHSLISD FKDPPTAKYRAAHVFFTDSCPDALFNELVKSRAAKVIKTLTEINIAFLPYESQVYSLDSADSFQSFYSPHKAQMKNPILERLAEQIATLC ATLKEYPAVRYRGEYKDNALLAQLIQDKLDAYKADDPTMGEGPDKARSQLLILDRGFDPSSPVLHELTFQAMSYDLLPIENDVYKYETSG IGEARVKEVLLDEDDDLWIALRHKHIAEVSQEVTRSLKDFSSSKRMNTGEKTTMRDLSQMLKKMPQYQKELSKYSTHLHLAEDCMKHYQG TVDKLCRVEQDLAMGTDAEGEKIKDPMRAIVPILLDANVSTYDKIRIILLYIFLKNGITEENLNKLIQHAQIPPEDSEIITNMAHLGVPI VTDEQSRLEQGLSEHQRHLNAERQRLQEQLKQTEQNISSRIQKLLQDNQRQKKSSEILKSLENERIRMEQLMSITQEETESLRRRDVASA MQQMLTESCKNRLIQMAYESQRQNLVQQACSSMAEMDERFQQILSWQQMDQNKAISQILQESAMQKAAFEALQVKKDLMHRQIRSQEMIS EQRWALSSLLQQLLKEKQQREEELREILTELEAKSETRQENYWLIQYQRLLNQKPLSLKLQEEGMERQLVALLEELSAEHYLPIFAHHRL SLDLLSQMSPGDLAKVGVSEAGLQHEILRRVQELLDAARIQPELKPPMGEVVTPTAPQEPPESVRPSAPPAELEVQASECVVCLEREAQM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for STXBP1-LRSAM1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for STXBP1-LRSAM1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for STXBP1-LRSAM1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies