
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TBC1D22A-DOK7 (FusionGDB2 ID:89288) |
Fusion Gene Summary for TBC1D22A-DOK7 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TBC1D22A-DOK7 | Fusion gene ID: 89288 | Hgene | Tgene | Gene symbol | TBC1D22A | DOK7 | Gene ID | 25771 | 285489 |
| Gene name | TBC1 domain family member 22A | docking protein 7 | |
| Synonyms | C22orf4|HSC79E021 | C4orf25|CMS10|CMS1B|FADS3 | |
| Cytomap | 22q13.31 | 4p16.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | TBC1 domain family member 22Aputative GTPase activator | protein Dok-7downstream of tyrosine kinase 7 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q18PE1 | |
| Ensembl transtripts involved in fusion gene | ENST00000337137, ENST00000355704, ENST00000407381, ENST00000380995, ENST00000406733, ENST00000472791, | ENST00000512714, ENST00000340083, ENST00000389653, ENST00000507039, | |
| Fusion gene scores | * DoF score | 34 X 18 X 14=8568 | 3 X 3 X 2=18 |
| # samples | 37 | 3 | |
| ** MAII score | log2(37/8568*10)=-4.53336130423394 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: TBC1D22A [Title/Abstract] AND DOK7 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TBC1D22A(47158745)-DOK7(3487266), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | TBC1D22A-DOK7 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. TBC1D22A-DOK7 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | DOK7 | GO:0061098 | positive regulation of protein tyrosine kinase activity | 20603078 |
| Fusion gene breakpoints across TBC1D22A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DOK7 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315354 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
Top |
Fusion Gene ORF analysis for TBC1D22A-DOK7 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000337137 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5CDS-intron | ENST00000355704 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5CDS-intron | ENST00000407381 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5UTR-3CDS | ENST00000380995 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5UTR-3CDS | ENST00000380995 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5UTR-3CDS | ENST00000380995 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| 5UTR-intron | ENST00000380995 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000337137 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000337137 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000355704 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000355704 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000407381 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| Frame-shift | ENST00000407381 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| In-frame | ENST00000337137 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| In-frame | ENST00000355704 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| In-frame | ENST00000407381 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000406733 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000406733 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000406733 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000472791 | ENST00000340083 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000472791 | ENST00000389653 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-3CDS | ENST00000472791 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-intron | ENST00000406733 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| intron-intron | ENST00000472791 | ENST00000512714 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000337137 | TBC1D22A | chr22 | 47158745 | + | ENST00000507039 | DOK7 | chr4 | 3487266 | + | 2193 | 228 | 146 | 1210 | 354 |
| ENST00000407381 | TBC1D22A | chr22 | 47158745 | + | ENST00000507039 | DOK7 | chr4 | 3487266 | + | 2142 | 177 | 95 | 1159 | 354 |
| ENST00000355704 | TBC1D22A | chr22 | 47158745 | + | ENST00000507039 | DOK7 | chr4 | 3487266 | + | 2133 | 168 | 86 | 1150 | 354 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000337137 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + | 0.60975355 | 0.3902464 |
| ENST00000407381 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + | 0.705193 | 0.29480702 |
| ENST00000355704 | ENST00000507039 | TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487266 | + | 0.75178087 | 0.24821913 |
Top |
Fusion Genomic Features for TBC1D22A-DOK7 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487265 | + | 1.76E-06 | 0.9999982 |
| TBC1D22A | chr22 | 47158745 | + | DOK7 | chr4 | 3487265 | + | 1.76E-06 | 0.9999982 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
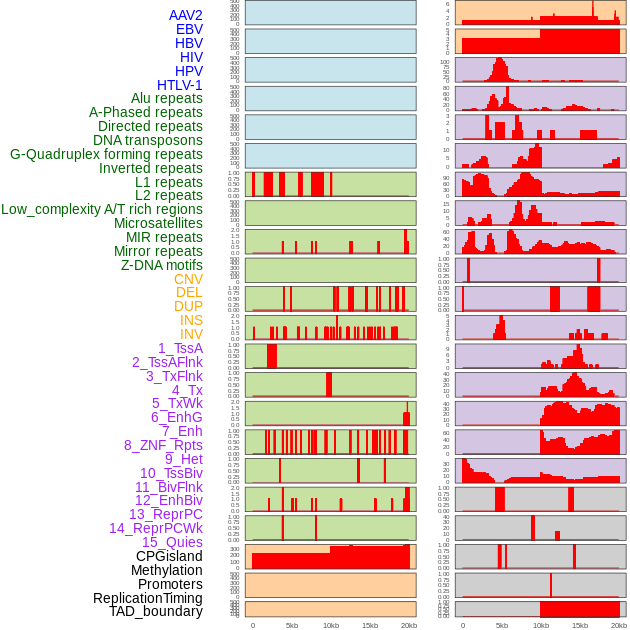 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
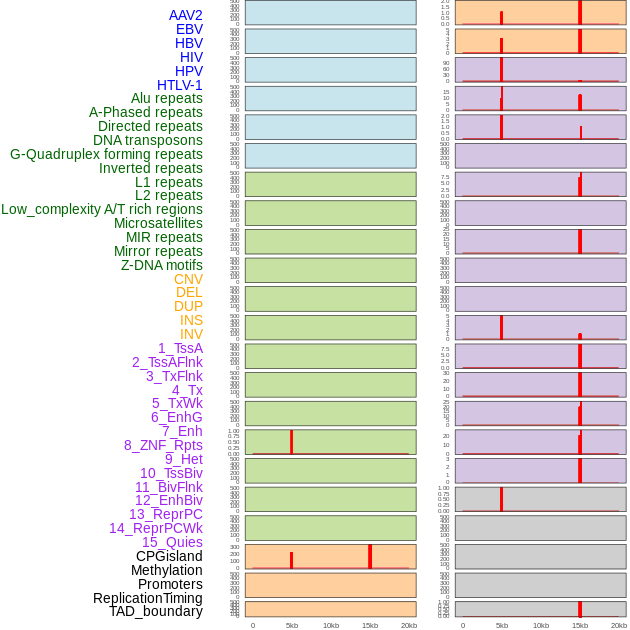 |
Top |
Fusion Protein Features for TBC1D22A-DOK7 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:47158745/chr4:3487266) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | DOK7 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Probable muscle-intrinsic activator of MUSK that plays an essential role in neuromuscular synaptogenesis. Acts in aneural activation of MUSK and subsequent acetylcholine receptor (AchR) clustering in myotubes. Induces autophosphorylation of MUSK. {ECO:0000269|PubMed:20603078}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000340083 | 3 | 7 | 262_359 | 177 | 505.0 | Compositional bias | Note=Ser-rich | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000389653 | 3 | 10 | 262_359 | 177 | 609.0 | Compositional bias | Note=Ser-rich | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000507039 | 3 | 7 | 262_359 | 173 | 256.0 | Compositional bias | Note=Ser-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TBC1D22A | chr22:47158745 | chr4:3487266 | ENST00000337137 | + | 1 | 13 | 222_446 | 20 | 518.0 | Domain | Rab-GAP TBC |
| Hgene | TBC1D22A | chr22:47158745 | chr4:3487266 | ENST00000355704 | + | 1 | 11 | 222_446 | 20 | 440.0 | Domain | Rab-GAP TBC |
| Hgene | TBC1D22A | chr22:47158745 | chr4:3487266 | ENST00000380995 | + | 1 | 9 | 222_446 | 0 | 325.0 | Domain | Rab-GAP TBC |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000340083 | 3 | 7 | 105_210 | 177 | 505.0 | Domain | IRS-type PTB | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000340083 | 3 | 7 | 4_109 | 177 | 505.0 | Domain | PH | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000389653 | 3 | 10 | 105_210 | 177 | 609.0 | Domain | IRS-type PTB | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000389653 | 3 | 10 | 4_109 | 177 | 609.0 | Domain | PH | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000507039 | 3 | 7 | 105_210 | 173 | 256.0 | Domain | IRS-type PTB | |
| Tgene | DOK7 | chr22:47158745 | chr4:3487266 | ENST00000507039 | 3 | 7 | 4_109 | 173 | 256.0 | Domain | PH |
Top |
Fusion Gene Sequence for TBC1D22A-DOK7 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >89288_89288_1_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000337137_DOK7_chr4_3487266_ENST00000507039_length(transcript)=2193nt_BP=228nt GCGCGTAGGCACAACTTCCGGAAGGAGGCGGAAGAGCTTCTCGGCTCTAGGCTCTGGAGTCCCGGGAGCAGTGAGGGGCCACCCGGGGCA CAGGAAAGGGCCGCTAGGGGAGGGCCGGGTGCACTCGGGGTGTCTGGGCCGCGGGTCTGAGGGATGAGGAGGGGCCATGGCCAGCGACGG GGCCAGGAAGCAATTCTGGAAGCGCAGCAACAGCAAGCTCCCGGGCAGGGGCTGGCGTCTTCTTCCTGTCCTCGGCCGAGGGGGAGCAGA TCAGCTTCCTGTTCGACTGCATCGTCCGAGGCATCTCCCCCACCAAGGGCCCCTTTGGGCTGCGGCCGGTTCTACCAGACCCAAGTCCCC CGGGACCCTCGACTGTGGAGGAGCGTGTGGCCCAGGAAGCCCTGGAAACCCTACAGCTGGAGAAGCGGCTGAGCCTCCTCTCACATGCGG GCAGGCCGGGCAGTGGAGGGGATGACCGCAGCCTGTCCAGCTCATCCTCAGAGGCCAGTCACTTGGACGTCAGCGCCAGCAGCCGGCTCA CCGCATGGCCAGAGCAATCCTCGTCGTCAGCCAGCACGTCACAGGAGGGGCCTAGACCAGCAGCTGCCCAGGCCGCCGGGGAAGCCATGG TGGGTGCCTCAAGGCCACCCCCCAAGCCGCTGCGTCCGCGGCAGCTGCAGGAGGTTGGCCGCCAGAGCTCCTCGGACAGCGGCATCGCCA CTGGCAGCCACTCCTCTTACTCCAGCAGCCTCTCGTCCTACGCGGGCAGCAGCCTGGACGTGTGGCGGGCCACAGATGAACTGGGCTCAC TGCTCAGCCTGCCAGCAGCGGGGGCCCCCGAGCCCAGCCTGTGCACCTGCCTGCCCGGGACAGTCGAGTACCAGGTGCCCACCTCCCTGC GGGCCCACTATGACACACCACGCAGCCTTTGCCTGGCTCCTAGAGACCACAGCCCCCCCTCACAGGGCAGCCCCGGCAACAGTGCGGCCA GGGACTCAGGCGGCCAGACGTCCGCCGGGTGTCCCTCTGGCTGGCTGGGCACGAGACGGCGGGGCCTGGTGATGGAGGCCCCCCAGGGCA GCGAGGCCACACTGCCTGGCCCTGCCCCTGGCGAGCCCTGGGAAGCAGGCGGCCCCCACGCGGGGCCACCCCCGGCTTTCTTTTCGGCAT GTCCAGTCTGTGGAGGACTCAAGGTAAACCCCCCTCCTTGAGAGCCGCAGATCCCGCCCCGCGGCTGCAAAGGGGCTGAATTTGCCCCCA GATGGCAGAGGAAGTGGCGCCAGCCTCCTTGCAGACTGGTGCTCTGTGTTCTGTGGGAGGGACCGGGGGTCTCCCGGAGAGGGGAGCTGG AGGGCGCGCCCTGTGGCTGCCACCGGAGGAAGGGGCTGACTTGGGGAGGTGAGTTCTGGAAGGCAGGGGCTCTGGGTCCGGCAGGTCGGG GTCACCAGAGCCCCAATGCTCAGCTGCTTCACTCCGTGTCCCCCACCCCTGAGGATCAGGTGAGTGCTGCACCTCTGTTGGCTCGTGCCT TGCACTGGGGTGCCAAGGGCTGGAGGCCCTGCCGCTGGCCTTGTCCTCCTTGGGCCTCACGCCCCCTTCGGGGGTGGCCGGTTCTCCCCA TCACCTCTCTGGGGCAGTCACACCACCTGTTAAGCATCAAGCTACCACAGAGGCTCCGGCCACCTGGGCTCCACCAGCCCAGCCCCCCTG GGCTCCGTGTGCGCTGGGCCTCATCCCCATCTATGGGAGGAAACTGAAGCTCAGGAGGCTGTGTGGCTTGCGGGGTCTCTGGGTTCTGGG CCCCACTGTTCCCCAGTGAAGCCCTTGTGGGAAGGTTCCGGGAGCAGGTGGTGTCCTCAGAGCAGCCTCGCCTGCTGACCCCACTGGGAG AGGCGCCGTGCCTCGGGCCCCTGGTGGGAGCTCTGCTGGCTCCTGTCTGAACCTCCTCGCAGGGCCAAAGGCTGGCTTGGCCTGTGTTTC CCCTGGCCCAGGCCTCAGCCCCTGCGTCGGAGGTGGGGCTGTGTTGGGCCCATTGTCCCCCGCCCTGGGTGGCTTCCTCTTGCACAGCCT GGAGCCTGCCCTGACCACAGCCCAGCAGCTCCCTGTGAACACCTCTTTGTCCCTTCACTGTCAGCTGTTTCTAAACCCAGACACTGTTTG >89288_89288_1_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000337137_DOK7_chr4_3487266_ENST00000507039_length(amino acids)=354AA_BP=24 MRDEEGPWPATGPGSNSGSAATASSRAGAGVFFLSSAEGEQISFLFDCIVRGISPTKGPFGLRPVLPDPSPPGPSTVEERVAQEALETLQ LEKRLSLLSHAGRPGSGGDDRSLSSSSSEASHLDVSASSRLTAWPEQSSSSASTSQEGPRPAAAQAAGEAMVGASRPPPKPLRPRQLQEV GRQSSSDSGIATGSHSSYSSSLSSYAGSSLDVWRATDELGSLLSLPAAGAPEPSLCTCLPGTVEYQVPTSLRAHYDTPRSLCLAPRDHSP -------------------------------------------------------------- >89288_89288_2_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000355704_DOK7_chr4_3487266_ENST00000507039_length(transcript)=2133nt_BP=168nt CCCGGGAGCAGTGAGGGGCCACCCGGGGCACAGGAAAGGGCCGCTAGGGGAGGGCCGGGTGCACTCGGGGTGTCTGGGCCGCGGGTCTGA GGGATGAGGAGGGGCCATGGCCAGCGACGGGGCCAGGAAGCAATTCTGGAAGCGCAGCAACAGCAAGCTCCCGGGCAGGGGCTGGCGTCT TCTTCCTGTCCTCGGCCGAGGGGGAGCAGATCAGCTTCCTGTTCGACTGCATCGTCCGAGGCATCTCCCCCACCAAGGGCCCCTTTGGGC TGCGGCCGGTTCTACCAGACCCAAGTCCCCCGGGACCCTCGACTGTGGAGGAGCGTGTGGCCCAGGAAGCCCTGGAAACCCTACAGCTGG AGAAGCGGCTGAGCCTCCTCTCACATGCGGGCAGGCCGGGCAGTGGAGGGGATGACCGCAGCCTGTCCAGCTCATCCTCAGAGGCCAGTC ACTTGGACGTCAGCGCCAGCAGCCGGCTCACCGCATGGCCAGAGCAATCCTCGTCGTCAGCCAGCACGTCACAGGAGGGGCCTAGACCAG CAGCTGCCCAGGCCGCCGGGGAAGCCATGGTGGGTGCCTCAAGGCCACCCCCCAAGCCGCTGCGTCCGCGGCAGCTGCAGGAGGTTGGCC GCCAGAGCTCCTCGGACAGCGGCATCGCCACTGGCAGCCACTCCTCTTACTCCAGCAGCCTCTCGTCCTACGCGGGCAGCAGCCTGGACG TGTGGCGGGCCACAGATGAACTGGGCTCACTGCTCAGCCTGCCAGCAGCGGGGGCCCCCGAGCCCAGCCTGTGCACCTGCCTGCCCGGGA CAGTCGAGTACCAGGTGCCCACCTCCCTGCGGGCCCACTATGACACACCACGCAGCCTTTGCCTGGCTCCTAGAGACCACAGCCCCCCCT CACAGGGCAGCCCCGGCAACAGTGCGGCCAGGGACTCAGGCGGCCAGACGTCCGCCGGGTGTCCCTCTGGCTGGCTGGGCACGAGACGGC GGGGCCTGGTGATGGAGGCCCCCCAGGGCAGCGAGGCCACACTGCCTGGCCCTGCCCCTGGCGAGCCCTGGGAAGCAGGCGGCCCCCACG CGGGGCCACCCCCGGCTTTCTTTTCGGCATGTCCAGTCTGTGGAGGACTCAAGGTAAACCCCCCTCCTTGAGAGCCGCAGATCCCGCCCC GCGGCTGCAAAGGGGCTGAATTTGCCCCCAGATGGCAGAGGAAGTGGCGCCAGCCTCCTTGCAGACTGGTGCTCTGTGTTCTGTGGGAGG GACCGGGGGTCTCCCGGAGAGGGGAGCTGGAGGGCGCGCCCTGTGGCTGCCACCGGAGGAAGGGGCTGACTTGGGGAGGTGAGTTCTGGA AGGCAGGGGCTCTGGGTCCGGCAGGTCGGGGTCACCAGAGCCCCAATGCTCAGCTGCTTCACTCCGTGTCCCCCACCCCTGAGGATCAGG TGAGTGCTGCACCTCTGTTGGCTCGTGCCTTGCACTGGGGTGCCAAGGGCTGGAGGCCCTGCCGCTGGCCTTGTCCTCCTTGGGCCTCAC GCCCCCTTCGGGGGTGGCCGGTTCTCCCCATCACCTCTCTGGGGCAGTCACACCACCTGTTAAGCATCAAGCTACCACAGAGGCTCCGGC CACCTGGGCTCCACCAGCCCAGCCCCCCTGGGCTCCGTGTGCGCTGGGCCTCATCCCCATCTATGGGAGGAAACTGAAGCTCAGGAGGCT GTGTGGCTTGCGGGGTCTCTGGGTTCTGGGCCCCACTGTTCCCCAGTGAAGCCCTTGTGGGAAGGTTCCGGGAGCAGGTGGTGTCCTCAG AGCAGCCTCGCCTGCTGACCCCACTGGGAGAGGCGCCGTGCCTCGGGCCCCTGGTGGGAGCTCTGCTGGCTCCTGTCTGAACCTCCTCGC AGGGCCAAAGGCTGGCTTGGCCTGTGTTTCCCCTGGCCCAGGCCTCAGCCCCTGCGTCGGAGGTGGGGCTGTGTTGGGCCCATTGTCCCC CGCCCTGGGTGGCTTCCTCTTGCACAGCCTGGAGCCTGCCCTGACCACAGCCCAGCAGCTCCCTGTGAACACCTCTTTGTCCCTTCACTG >89288_89288_2_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000355704_DOK7_chr4_3487266_ENST00000507039_length(amino acids)=354AA_BP=24 MRDEEGPWPATGPGSNSGSAATASSRAGAGVFFLSSAEGEQISFLFDCIVRGISPTKGPFGLRPVLPDPSPPGPSTVEERVAQEALETLQ LEKRLSLLSHAGRPGSGGDDRSLSSSSSEASHLDVSASSRLTAWPEQSSSSASTSQEGPRPAAAQAAGEAMVGASRPPPKPLRPRQLQEV GRQSSSDSGIATGSHSSYSSSLSSYAGSSLDVWRATDELGSLLSLPAAGAPEPSLCTCLPGTVEYQVPTSLRAHYDTPRSLCLAPRDHSP -------------------------------------------------------------- >89288_89288_3_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000407381_DOK7_chr4_3487266_ENST00000507039_length(transcript)=2142nt_BP=177nt CTCTGGAGTCCCGGGAGCAGTGAGGGGCCACCCGGGGCACAGGAAAGGGCCGCTAGGGGAGGGCCGGGTGCACTCGGGGTGTCTGGGCCG CGGGTCTGAGGGATGAGGAGGGGCCATGGCCAGCGACGGGGCCAGGAAGCAATTCTGGAAGCGCAGCAACAGCAAGCTCCCGGGCAGGGG CTGGCGTCTTCTTCCTGTCCTCGGCCGAGGGGGAGCAGATCAGCTTCCTGTTCGACTGCATCGTCCGAGGCATCTCCCCCACCAAGGGCC CCTTTGGGCTGCGGCCGGTTCTACCAGACCCAAGTCCCCCGGGACCCTCGACTGTGGAGGAGCGTGTGGCCCAGGAAGCCCTGGAAACCC TACAGCTGGAGAAGCGGCTGAGCCTCCTCTCACATGCGGGCAGGCCGGGCAGTGGAGGGGATGACCGCAGCCTGTCCAGCTCATCCTCAG AGGCCAGTCACTTGGACGTCAGCGCCAGCAGCCGGCTCACCGCATGGCCAGAGCAATCCTCGTCGTCAGCCAGCACGTCACAGGAGGGGC CTAGACCAGCAGCTGCCCAGGCCGCCGGGGAAGCCATGGTGGGTGCCTCAAGGCCACCCCCCAAGCCGCTGCGTCCGCGGCAGCTGCAGG AGGTTGGCCGCCAGAGCTCCTCGGACAGCGGCATCGCCACTGGCAGCCACTCCTCTTACTCCAGCAGCCTCTCGTCCTACGCGGGCAGCA GCCTGGACGTGTGGCGGGCCACAGATGAACTGGGCTCACTGCTCAGCCTGCCAGCAGCGGGGGCCCCCGAGCCCAGCCTGTGCACCTGCC TGCCCGGGACAGTCGAGTACCAGGTGCCCACCTCCCTGCGGGCCCACTATGACACACCACGCAGCCTTTGCCTGGCTCCTAGAGACCACA GCCCCCCCTCACAGGGCAGCCCCGGCAACAGTGCGGCCAGGGACTCAGGCGGCCAGACGTCCGCCGGGTGTCCCTCTGGCTGGCTGGGCA CGAGACGGCGGGGCCTGGTGATGGAGGCCCCCCAGGGCAGCGAGGCCACACTGCCTGGCCCTGCCCCTGGCGAGCCCTGGGAAGCAGGCG GCCCCCACGCGGGGCCACCCCCGGCTTTCTTTTCGGCATGTCCAGTCTGTGGAGGACTCAAGGTAAACCCCCCTCCTTGAGAGCCGCAGA TCCCGCCCCGCGGCTGCAAAGGGGCTGAATTTGCCCCCAGATGGCAGAGGAAGTGGCGCCAGCCTCCTTGCAGACTGGTGCTCTGTGTTC TGTGGGAGGGACCGGGGGTCTCCCGGAGAGGGGAGCTGGAGGGCGCGCCCTGTGGCTGCCACCGGAGGAAGGGGCTGACTTGGGGAGGTG AGTTCTGGAAGGCAGGGGCTCTGGGTCCGGCAGGTCGGGGTCACCAGAGCCCCAATGCTCAGCTGCTTCACTCCGTGTCCCCCACCCCTG AGGATCAGGTGAGTGCTGCACCTCTGTTGGCTCGTGCCTTGCACTGGGGTGCCAAGGGCTGGAGGCCCTGCCGCTGGCCTTGTCCTCCTT GGGCCTCACGCCCCCTTCGGGGGTGGCCGGTTCTCCCCATCACCTCTCTGGGGCAGTCACACCACCTGTTAAGCATCAAGCTACCACAGA GGCTCCGGCCACCTGGGCTCCACCAGCCCAGCCCCCCTGGGCTCCGTGTGCGCTGGGCCTCATCCCCATCTATGGGAGGAAACTGAAGCT CAGGAGGCTGTGTGGCTTGCGGGGTCTCTGGGTTCTGGGCCCCACTGTTCCCCAGTGAAGCCCTTGTGGGAAGGTTCCGGGAGCAGGTGG TGTCCTCAGAGCAGCCTCGCCTGCTGACCCCACTGGGAGAGGCGCCGTGCCTCGGGCCCCTGGTGGGAGCTCTGCTGGCTCCTGTCTGAA CCTCCTCGCAGGGCCAAAGGCTGGCTTGGCCTGTGTTTCCCCTGGCCCAGGCCTCAGCCCCTGCGTCGGAGGTGGGGCTGTGTTGGGCCC ATTGTCCCCCGCCCTGGGTGGCTTCCTCTTGCACAGCCTGGAGCCTGCCCTGACCACAGCCCAGCAGCTCCCTGTGAACACCTCTTTGTC >89288_89288_3_TBC1D22A-DOK7_TBC1D22A_chr22_47158745_ENST00000407381_DOK7_chr4_3487266_ENST00000507039_length(amino acids)=354AA_BP=24 MRDEEGPWPATGPGSNSGSAATASSRAGAGVFFLSSAEGEQISFLFDCIVRGISPTKGPFGLRPVLPDPSPPGPSTVEERVAQEALETLQ LEKRLSLLSHAGRPGSGGDDRSLSSSSSEASHLDVSASSRLTAWPEQSSSSASTSQEGPRPAAAQAAGEAMVGASRPPPKPLRPRQLQEV GRQSSSDSGIATGSHSSYSSSLSSYAGSSLDVWRATDELGSLLSLPAAGAPEPSLCTCLPGTVEYQVPTSLRAHYDTPRSLCLAPRDHSP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TBC1D22A-DOK7 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TBC1D22A-DOK7 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TBC1D22A-DOK7 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies