
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TCP11L1-SYT9 (FusionGDB2 ID:89874) |
Fusion Gene Summary for TCP11L1-SYT9 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TCP11L1-SYT9 | Fusion gene ID: 89874 | Hgene | Tgene | Gene symbol | TCP11L1 | SYT9 | Gene ID | 55346 | 143425 |
| Gene name | t-complex 11 like 1 | synaptotagmin 9 | |
| Synonyms | dJ85M6.3 | - | |
| Cytomap | 11p13 | 11p15.4 | |
| Type of gene | protein-coding | protein-coding | |
| Description | T-complex protein 11-like protein 1t-complex 11, testis-specific-like 1 | synaptotagmin-9synaptotagmin IXsytIX | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000334274, ENST00000432887, ENST00000324357, ENST00000531632, ENST00000530171, | ENST00000318881, ENST00000396716, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 3 X 3 X 3=27 |
| # samples | 2 | 3 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: TCP11L1 [Title/Abstract] AND SYT9 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TCP11L1(33094199)-SYT9(7324270), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across TCP11L1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SYT9 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-S3-AA17-01A | TCP11L1 | chr11 | 33094199 | - | SYT9 | chr11 | 7324270 | + |
| ChimerDB4 | BRCA | TCGA-S3-AA17-01A | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
Top |
Fusion Gene ORF analysis for TCP11L1-SYT9 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000334274 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| Frame-shift | ENST00000334274 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| Frame-shift | ENST00000432887 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| Frame-shift | ENST00000432887 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| In-frame | ENST00000324357 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| In-frame | ENST00000324357 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| In-frame | ENST00000531632 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| In-frame | ENST00000531632 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| intron-3CDS | ENST00000530171 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| intron-3CDS | ENST00000530171 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000531632 | TCP11L1 | chr11 | 33094199 | + | ENST00000318881 | SYT9 | chr11 | 7324270 | + | 5291 | 1718 | 1687 | 3048 | 453 |
| ENST00000531632 | TCP11L1 | chr11 | 33094199 | + | ENST00000396716 | SYT9 | chr11 | 7324270 | + | 2629 | 1718 | 190 | 1545 | 451 |
| ENST00000324357 | TCP11L1 | chr11 | 33094199 | + | ENST00000318881 | SYT9 | chr11 | 7324270 | + | 4429 | 856 | 3 | 2186 | 727 |
| ENST00000324357 | TCP11L1 | chr11 | 33094199 | + | ENST00000396716 | SYT9 | chr11 | 7324270 | + | 1767 | 856 | 3 | 1766 | 587 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000531632 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + | 0.003361813 | 0.9966382 |
| ENST00000531632 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + | 0.003051465 | 0.99694854 |
| ENST00000324357 | ENST00000318881 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + | 0.006811647 | 0.9931884 |
| ENST00000324357 | ENST00000396716 | TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324270 | + | 0.005976392 | 0.9940236 |
Top |
Fusion Genomic Features for TCP11L1-SYT9 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324269 | + | 9.86E-07 | 0.99999905 |
| TCP11L1 | chr11 | 33094199 | + | SYT9 | chr11 | 7324269 | + | 9.86E-07 | 0.99999905 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
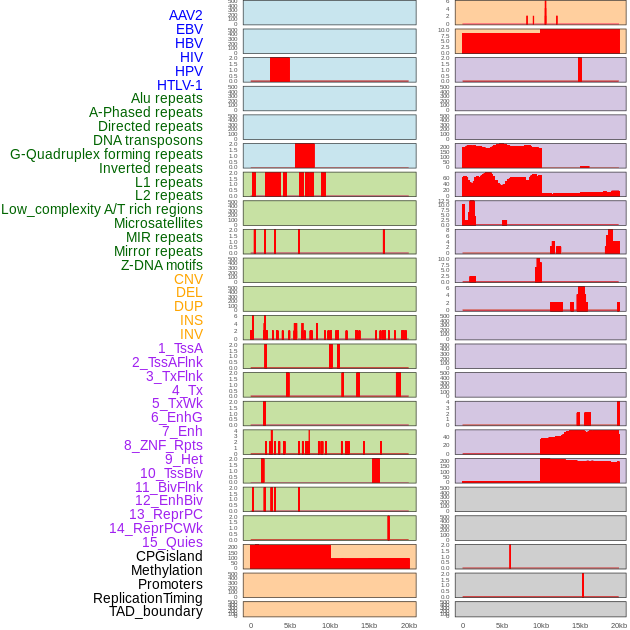 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
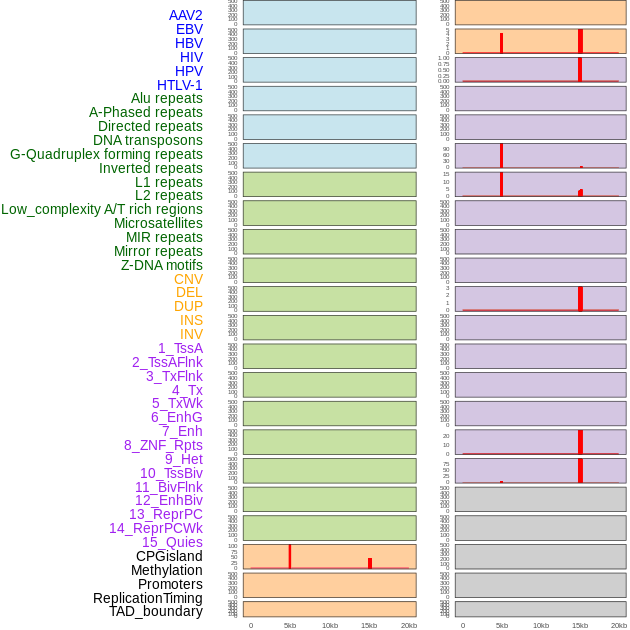 |
Top |
Fusion Protein Features for TCP11L1-SYT9 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:33094199/chr11:7324270) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 220_341 | 48 | 492.0 | Domain | C2 1 | |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 352_485 | 48 | 492.0 | Domain | C2 2 | |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 74_491 | 48 | 492.0 | Topological domain | Cytoplasmic | |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 53_73 | 48 | 492.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 9_31 | 48 | 492.0 | Region | Cysteine motif | |
| Tgene | SYT9 | chr11:33094199 | chr11:7324270 | ENST00000318881 | 0 | 7 | 1_52 | 48 | 492.0 | Topological domain | Vesicular |
Top |
Fusion Gene Sequence for TCP11L1-SYT9 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >89874_89874_1_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000324357_SYT9_chr11_7324270_ENST00000318881_length(transcript)=4429nt_BP=856nt GTGTTGGACCTAATGAAAGTGGACATGGCCAACTTTGCTATCAGTAGCATCAGGCCTCATCTCATGCAGCAGTCAGTTGAATACGAAAGG AAGAAGTTTCAAGAGATTTTGGAGAGGCAACCAAATTCCCTGGACTTTGTCACCCAGTGGCTGGAAGAAGCCTCAGAGGACCTTATGACT CAGAAGTATAAACACGCCCTGCCAGTGGGGGGAATGGCTGCTGGCTCTGGGGACATGCCCAGGCTGAGCCCTGTTGCTGTCCAGAATTAC GCTTACCTGAAGCTTCTGAAGTGGGACCACCTCCAGAGGCCGTTCCCCGAAACAGTTTTAATGGACCAGTCTCGCTTCCACGAGCTCCAG TTGCAGCTGGAACAACTGACCATCCTGGGGGCTGTGTTGCTGGTCACCTTCAGCATGGCAGCGCCAGGAATTTCCAGCCAGGCCGACTTT GCTGAGAAACTCAAGATGATTGTGAAGATTTTGCTAACAGATATGCACCTGCCCTCCTTCCATCTGAAGGACGTCCTCACTACCATCGGG GAGAAGGTGTGCCTGGAGGTGAGCAGCTGCCTCTCCCTGTGTGGGTCCTCTCCCTTCACCACGGACAAGGAGACCGTGCTCAAGGGCCAG ATCCAGGCCGTGGCCAGTCCCGATGACCCCATTCGCAGGATCATGGAATCTCGAATCCTGACCTTCTTAGAAACCTACCTTGCCTCGGGT CATCAGAAGCCATTGCCCACAGTCCCTGGGGGACTCAGTCCAGTTCAGAGAGAGCTGGAGGAAGTTGCTATTAAATTTGCTCGCCTGGTC AACTATAACAAGATGGTCTTCTGTCCCTACTACGATGCAATCCTGAATATCTCAGTGAGCCTGCTGACCCTTGTGGTCACTGCCTGTGGT CTCGCTCTCTTTGGCGTGTCTCTCTTCGTATCTTGGAAACTCTGCTGGGTTCCGTGGCGAGAACGAGGCCTGCCCTCTGGTAGCAAAGAC AACAACCAGGAGCCCCTTAACTACATGGACACAGAGACCAATGAGCAGGAGAACAGTGAGGACTTCCTAGATCCTCCCACGCCCTGCCCT GACTCCTCCATGAAGATCAGCCACACCTCCCCTGACATTCCCCTCTCCACCCAGACGGGGATCCAGGAGAACTGTGCCCATGGCGTCCGC GTGCAGCGCCAAGTCACAGAGCCAACCTCGTCGGCCCGGCATAATTCAATCCGAAGACAACTCAACTTGTCAAACCCGGACTTCAATATC CAGCAGCTTCAAAAACAGGAACAGTTGACTGGAATTGGTAGAATTAAACCAGAGTTATATAAGCAGAGGTCATTGGATAATGATGACGGG AGACGGAGTAACAGCAAGGCTTGTGGGAAACTGAACTTCATTTTAAAATATGACTGTGACTTAGAGCAGCTCATAGTGAAGATTCACAAA GCTGTCAATTTGCCCGCCAAGGACTTTTCTGGGACTTCAGATCCTTATGTCAAGATCTATTTGCTTCCTGATCGGAAAACAAAACACCAG ACTAAAGTTCACAGAAAGACCCTGAACCCTGTGTTTGATGAAGTGTTTTTATTTCCGGTTCCCTACAATGACCTTGAAGCACGGAAGCTT CACTTCTCTGTGTACGACTTTGACAGGTTCTCTCGTCATGACTTAATCGGCCAAGTGGTGGTGGATCACTTCCTAGACTTGGCTGATTTC CCCAGGGAGTGCATCCTTTGGAAGGATATCGAATATGTCACCAATGACAACGTGGATCTGGGAGAGCTGATGTTTTCCCTGTGCTATCTT CCAACGGCTGGCAGGCTGACCATTACCATTATAAAAGCAAGGAATTTAAAGGCAATGGACATAACAGGAGCATCAGATCCCTATGTGAAA GTCTCGCTGATGTGTGATGGCAGACGACTGAAGAAGAGGAAAACATCCACCAAGAGGAACACCTTGAATCCTGTTTACAACGAAGCCATA GTCTTTGATGTCCCTCCCGAGAACATTGACCAAATCCACTTGTCCATAGCAGTCATGGACTATGACCGTGTAGGTCACAATGAGATCATC GGCGTGTGTCAAGTAGGCAACGAGGCTGAGAGGCTGGGCAGAGACCACTGGAGTGAAATGTTGTCATATCCTCGGAAGCCCATTGCACAC TGGCATTCCCTGGTGGAGAAACGATGACCATGGGTAAGAGGACTGCTTGTGCCAAGGACAAAATAGGACAACCATCTCACAAAGATCTTA AGTAACTTTTTCCATCCAGCAACATCCAGACGATTTCAGTGACCAAATGCTCAGCTGTAACCACAGCACTAACTGGCCTTCTTTCCAGAT TGGGTTTGGTGAACCTGAATGGTCCAGCCACCTTCTGCAGGTGGCCCAAGGTGATGTGCTGCAGGGAAGCATGTCTCTCATGCCAAGAAC CAAGATCGGACTATGAACAAAAACAAATGATAGATATAGTGACAGTACCAAGAGTACCAGGACTCAATGTTTCATATGAAGCCCTTGGTG ATGAGGACATAGCATCTGCCCTGGAAATCGTTATTCCAACATAATATTATTTTCTAGAATGCCCTGGAAGGACAGAATATTTAAAAATAT ATCCAGGTGCTAAATAGGCAGCAGATCTCAATTCACACATGACTACCTTTGAGCTAATGACTGTCTCCAGAAAATAACTGTGCCCCAAGA AGTGCTCCAGATTTGCAAGGAATAGCCCCAAGAGAATACCAAGACAAGCAGGCTGTTCCCTGGAAAAAATCTAATGCAAGGAGGGCTAGT TCACAGCAAATTCACTGCCTCCTCCCATGCACGTGGTAGAGAGTACCAGTATCAACATGGCCCTGTTTTCTGCTAAAACCAGATTTTGAG GAATCAGAGACCCCCAACACTACTCACTCAGTAGCTAGCAGCCCCTTCCTTTCAACTGGGAGTGTTATTAGAATGAAAAGTAATTAGTTA GAAGGGCATACATCTCAGTGGCATGAGCATTGTGGAATATCCTTTCCTAGGCACATTCGTCCACTAAGGGAACAGCCTCAGAAACTGGTA CAGCAATGGGTGAGATGAGATCATGGAGAGAGAACACAGCCATCCCCTATAGAAAGGCACAGCTTTTGGGCTTCTCTGGCCTGAATGCCT TCTGGGGTATTTCCATATGCAACAGCCCAGAGTCATAGCCTTGGGCAACCACACATAGAGGTTTCCTTCTCACTTCAGACACATACATCA CTTTCACACCACTTGGGGATGGAAATACCTACAAGAGTGAAGGTCAAGGGCCCTCCCCAGGCATCTCATTCATTACTCAGCTTCCTTCCT GACCAAGTCTGCCAACCAATGGCCAGCTATGCGCCTCATCCTCATTGCTTCTGCCTCCACGTAAATGAAACCAAAGGCCTCAGCATATCC TGGGAGGACTGGGGGCTGTTACCTAATGGTCCTCTCTGTCCCATTATAGGTGCAAGGCACCCCATCCACACATTTGCACCACTACTCCAA GATAGTATTTTTCTTTTCACACAATCTCTTTACAGCAGAATCCAGAGTTGGATTGTAGTTTACCTTCCTGGAAAGCTCATTATCTCTGTT TGAATTAACATTTCAGCATGGAACTAACTGGGCGGAGGAAGGATCGTTATACGTCTTCAGAAAGTTCTCATTGCCCCAGCTGCCTAGTAC TATACAAGAAGCTCTACTTTGATGGCAGATCTAAGAAGGCTATAGGCCTTTGTTTGTAGGAAGCAGTGTCATTACATTCAAGCTTCACTT CTCTGATTGGCTTCCAACCACTGGGATTCAAAGAGAATCCAAGGTTCTGCCTATGTCTGATGACATAAGGAAAACTTGGCTTCCTCTGCT CAAGGTTCCCCTCTGCTCATCCCTCCTCATTCAGACATCCTCCACCATACCAGTGTTTAGAAGCAAAACATGAAGGGCTAGCGCCACCAG GATAGTTAGCAGAAATATTGTCTGTAAAGCTAGGCAGATGAGCCCAGAAGAATGGTCCCAGAGAAAGCAGACTGGCTCCAATAGATATCA GGCAGCAATCCCAATAAATTCTGACATGTCCTTGGCAATGGAAGCCTGGGTTGGAGATCCTGAGGCAGCTGTGCCTACTGTTCCCCACCT CAGAAGCTTCCTGCCCAGAGAGCCAGCAGCCTTGGGATACTAATGAGGATGCAACTGGCTTATTGGTATGAAATAGAAGGTGGCTTTGTA GGGGCAAGCAGGCAAAGAGTACTATCCACATGGCAGGCAGGTGGCTTTGTGTCTGGAAAGCTTTGCCTAGCCAGTACAGCTGTGAGCAGA GGCTGGTTATAAATTTGAACTCCCTCAGCCCATTTGCAACTCTGCCTCTGTTCTCTTGCATTCTGTTTGGTTGCCCTTTAGTTTCCTAGT >89874_89874_1_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000324357_SYT9_chr11_7324270_ENST00000318881_length(amino acids)=727AA_BP=285 MDLMKVDMANFAISSIRPHLMQQSVEYERKKFQEILERQPNSLDFVTQWLEEASEDLMTQKYKHALPVGGMAAGSGDMPRLSPVAVQNYA YLKLLKWDHLQRPFPETVLMDQSRFHELQLQLEQLTILGAVLLVTFSMAAPGISSQADFAEKLKMIVKILLTDMHLPSFHLKDVLTTIGE KVCLEVSSCLSLCGSSPFTTDKETVLKGQIQAVASPDDPIRRIMESRILTFLETYLASGHQKPLPTVPGGLSPVQRELEEVAIKFARLVN YNKMVFCPYYDAILNISVSLLTLVVTACGLALFGVSLFVSWKLCWVPWRERGLPSGSKDNNQEPLNYMDTETNEQENSEDFLDPPTPCPD SSMKISHTSPDIPLSTQTGIQENCAHGVRVQRQVTEPTSSARHNSIRRQLNLSNPDFNIQQLQKQEQLTGIGRIKPELYKQRSLDNDDGR RSNSKACGKLNFILKYDCDLEQLIVKIHKAVNLPAKDFSGTSDPYVKIYLLPDRKTKHQTKVHRKTLNPVFDEVFLFPVPYNDLEARKLH FSVYDFDRFSRHDLIGQVVVDHFLDLADFPRECILWKDIEYVTNDNVDLGELMFSLCYLPTAGRLTITIIKARNLKAMDITGASDPYVKV SLMCDGRRLKKRKTSTKRNTLNPVYNEAIVFDVPPENIDQIHLSIAVMDYDRVGHNEIIGVCQVGNEAERLGRDHWSEMLSYPRKPIAHW -------------------------------------------------------------- >89874_89874_2_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000324357_SYT9_chr11_7324270_ENST00000396716_length(transcript)=1767nt_BP=856nt GTGTTGGACCTAATGAAAGTGGACATGGCCAACTTTGCTATCAGTAGCATCAGGCCTCATCTCATGCAGCAGTCAGTTGAATACGAAAGG AAGAAGTTTCAAGAGATTTTGGAGAGGCAACCAAATTCCCTGGACTTTGTCACCCAGTGGCTGGAAGAAGCCTCAGAGGACCTTATGACT CAGAAGTATAAACACGCCCTGCCAGTGGGGGGAATGGCTGCTGGCTCTGGGGACATGCCCAGGCTGAGCCCTGTTGCTGTCCAGAATTAC GCTTACCTGAAGCTTCTGAAGTGGGACCACCTCCAGAGGCCGTTCCCCGAAACAGTTTTAATGGACCAGTCTCGCTTCCACGAGCTCCAG TTGCAGCTGGAACAACTGACCATCCTGGGGGCTGTGTTGCTGGTCACCTTCAGCATGGCAGCGCCAGGAATTTCCAGCCAGGCCGACTTT GCTGAGAAACTCAAGATGATTGTGAAGATTTTGCTAACAGATATGCACCTGCCCTCCTTCCATCTGAAGGACGTCCTCACTACCATCGGG GAGAAGGTGTGCCTGGAGGTGAGCAGCTGCCTCTCCCTGTGTGGGTCCTCTCCCTTCACCACGGACAAGGAGACCGTGCTCAAGGGCCAG ATCCAGGCCGTGGCCAGTCCCGATGACCCCATTCGCAGGATCATGGAATCTCGAATCCTGACCTTCTTAGAAACCTACCTTGCCTCGGGT CATCAGAAGCCATTGCCCACAGTCCCTGGGGGACTCAGTCCAGTTCAGAGAGAGCTGGAGGAAGTTGCTATTAAATTTGCTCGCCTGGTC AACTATAACAAGATGGTCTTCTGTCCCTACTACGATGCAATCCTGAATATCTCAGTGAGCCTGCTGACCCTTGTGGTCACTGCCTGTGGT CTCGCTCTCTTTGGCGTGTCTCTCTTCGTATCTTGGAAACTCTGCTGGGTTCCGTGGCGAGAACGAGGCCTGCCCTCTGGTAGCAAAGAC AACAACCAGGAGCCCCTTAACTACATGGACACAGAGACCAATGAGCAGGAGAACAGTGAGGACTTCCTAGATCCTCCCACGCCCTGCCCT GACTCCTCCATGAAGATCAGCCACACCTCCCCTGACATTCCCCTCTCCACCCAGACGGGGATCCAGGAGAACTGTGCCCATGGCGTCCGC GTGCAGCGCCAAGTCACAGAGCCAACCTCGTCGGCCCGGCATAATTCAATCCGAAGACAACTCAACTTGTCAAACCCGGACTTCAATATC CAGCAGCTTCAAAAACAGGAACAGTTGACTGGAATTGGTAGAATTAAACCAGAGTTATATAAGCAGAGGTCATTGGATAATGATGACGGG AGACGGAGTAACAGCAAGGCTTGTGGGAAACTGAACTTCATTTTAAAATATGACTGTGACTTAGAGCAGCTCATAGTGAAGATTCACAAA GCTGTCAATTTGCCCGCCAAGGACTTTTCTGGGACTTCAGATCCTTATGTCAAGATCTATTTGCTTCCTGATCGGAAAACAAAACACCAG ACTAAAGTTCACAGAAAGACCCTGAACCCTGTGTTTGATGAAGTGTTTTTATTTCCGGTTCCCTACAATGACCTTGAAGCACGGAAGCTT CACTTCTCTGTGTACGACTTTGACAGGTTCTCTCGTCATGACTTAATCGGCCAAGTGGTGGTGGATCACTTCCTAGACTTGGCTGATTTC >89874_89874_2_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000324357_SYT9_chr11_7324270_ENST00000396716_length(amino acids)=587AA_BP=285 MDLMKVDMANFAISSIRPHLMQQSVEYERKKFQEILERQPNSLDFVTQWLEEASEDLMTQKYKHALPVGGMAAGSGDMPRLSPVAVQNYA YLKLLKWDHLQRPFPETVLMDQSRFHELQLQLEQLTILGAVLLVTFSMAAPGISSQADFAEKLKMIVKILLTDMHLPSFHLKDVLTTIGE KVCLEVSSCLSLCGSSPFTTDKETVLKGQIQAVASPDDPIRRIMESRILTFLETYLASGHQKPLPTVPGGLSPVQRELEEVAIKFARLVN YNKMVFCPYYDAILNISVSLLTLVVTACGLALFGVSLFVSWKLCWVPWRERGLPSGSKDNNQEPLNYMDTETNEQENSEDFLDPPTPCPD SSMKISHTSPDIPLSTQTGIQENCAHGVRVQRQVTEPTSSARHNSIRRQLNLSNPDFNIQQLQKQEQLTGIGRIKPELYKQRSLDNDDGR RSNSKACGKLNFILKYDCDLEQLIVKIHKAVNLPAKDFSGTSDPYVKIYLLPDRKTKHQTKVHRKTLNPVFDEVFLFPVPYNDLEARKLH -------------------------------------------------------------- >89874_89874_3_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000531632_SYT9_chr11_7324270_ENST00000318881_length(transcript)=5291nt_BP=1718nt TACAACGGAATCCGGACGCCGGGCGCGAGTGGAGCTCAGTGCCAGAGGAGGGGATTCCCGGCGCCGGGGGACAGAGCCCCTTTTTTCTTT TGCCGAAAGACCCTTTCTGCTGGGGAGCCTCTTGTGTCCAGCCTAGGCCCGCGTGCAGCGCCGACGGATGACCGTCTTCTTGGAAAGTGA ATAAACTTAATTGAGAATGTCTGAAAACCTTGACAAGTCCAATGTAAATGAAGCAGGAAAATCAAAATCCAATGATTCTGAGGAAGGCCT CGAAGATGCTGTGGAAGGTGCTGATGAAGCCTTACAAAAAGCAATAAAGTCAGACTCCTCCAGCCCCCAAAGAGTGCAGAGACCTCACTC TAGTCCTCCTCGCTTTGTGACAGTAGAAGAACTTCTAGAGACAGCGAGAGGTGTCACCAACATGGCTCTAGCCCATGAAATTGTAGTAAA TGGAGACTTTCAGATTAAACCAGTTGAATTACCAGAAAACAGCTTGAAGAAGAGAGTAAAGGAGATTGTACATAAAGCGTTTTGGGATTG CTTGAGTGTGCAGCTAAGTGAAGATCCCCCAGCATATGACCATGCTATCAAACTTGTAGGAGAAATCAAAGAGACTCTCTTATCTTTCTT GCTGCCTGGTCATACTAGACTGAGAAACCAGATAACAGAAGTCTTGGATCTGGATCTGATAAAGCAGGAAGCAGAGAATGGGGCGCTAGA CATTTCCAAGCTGGCAGAATTCATTATTGGCATGATGGGGACACTGTGTGCACCTGCTCGAGATGAGGAAGTTAAGAAACTAAAGGACAT TAAGGAAATAGTGCCCCTTTTCAGAGAAATTTTTTCTGTGTTGGACCTAATGAAAGTGGACATGGCCAACTTTGCTATCAGTAGCATCAG GCCTCATCTCATGCAGCAGTCAGTTGAATACGAAAGGAAGAAGTTTCAAGAGATTTTGGAGAGGCAACCAAATTCCCTGGACTTTGTCAC CCAGTGGCTGGAAGAAGCCTCAGAGGACCTTATGACTCAGAAGTATAAACACGCCCTGCCAGTGGGGGGAATGGCTGCTGGCTCTGGGGA CATGCCCAGGCTGAGCCCTGTTGCTGTCCAGAATTACGCTTACCTGAAGCTTCTGAAGTGGGACCACCTCCAGAGGCCGTTCCCCGAAAC AGTTTTAATGGACCAGTCTCGCTTCCACGAGCTCCAGTTGCAGCTGGAACAACTGACCATCCTGGGGGCTGTGTTGCTGGTCACCTTCAG CATGGCAGCGCCAGGAATTTCCAGCCAGGCCGACTTTGCTGAGAAACTCAAGATGATTGTGAAGATTTTGCTAACAGATATGCACCTGCC CTCCTTCCATCTGAAGGACGTCCTCACTACCATCGGGGAGAAGGTGTGCCTGGAGGTGAGCAGCTGCCTCTCCCTGTGTGGGTCCTCTCC CTTCACCACGGACAAGGAGACCGTGCTCAAGGGCCAGATCCAGGCCGTGGCCAGTCCCGATGACCCCATTCGCAGGATCATGGGTAAGAT CCTCGTCCGATCCTAACGTGTATGCACCCTACAGCAGCAGTATTACTCACTAGCCACAGAATACCTGTTCTGTACTCTAATGTTGCATTG GAAAATGGCTATATAGTACATGTCTATTTAACAGCACCGATTCCAAAGGGAAGAATATTGTGTATCACTGTTGAAAAGACTTGTTGAGAA ATCCACTGATATCTCAGTGAGCCTGCTGACCCTTGTGGTCACTGCCTGTGGTCTCGCTCTCTTTGGCGTGTCTCTCTTCGTATCTTGGAA ACTCTGCTGGGTTCCGTGGCGAGAACGAGGCCTGCCCTCTGGTAGCAAAGACAACAACCAGGAGCCCCTTAACTACATGGACACAGAGAC CAATGAGCAGGAGAACAGTGAGGACTTCCTAGATCCTCCCACGCCCTGCCCTGACTCCTCCATGAAGATCAGCCACACCTCCCCTGACAT TCCCCTCTCCACCCAGACGGGGATCCAGGAGAACTGTGCCCATGGCGTCCGCGTGCAGCGCCAAGTCACAGAGCCAACCTCGTCGGCCCG GCATAATTCAATCCGAAGACAACTCAACTTGTCAAACCCGGACTTCAATATCCAGCAGCTTCAAAAACAGGAACAGTTGACTGGAATTGG TAGAATTAAACCAGAGTTATATAAGCAGAGGTCATTGGATAATGATGACGGGAGACGGAGTAACAGCAAGGCTTGTGGGAAACTGAACTT CATTTTAAAATATGACTGTGACTTAGAGCAGCTCATAGTGAAGATTCACAAAGCTGTCAATTTGCCCGCCAAGGACTTTTCTGGGACTTC AGATCCTTATGTCAAGATCTATTTGCTTCCTGATCGGAAAACAAAACACCAGACTAAAGTTCACAGAAAGACCCTGAACCCTGTGTTTGA TGAAGTGTTTTTATTTCCGGTTCCCTACAATGACCTTGAAGCACGGAAGCTTCACTTCTCTGTGTACGACTTTGACAGGTTCTCTCGTCA TGACTTAATCGGCCAAGTGGTGGTGGATCACTTCCTAGACTTGGCTGATTTCCCCAGGGAGTGCATCCTTTGGAAGGATATCGAATATGT CACCAATGACAACGTGGATCTGGGAGAGCTGATGTTTTCCCTGTGCTATCTTCCAACGGCTGGCAGGCTGACCATTACCATTATAAAAGC AAGGAATTTAAAGGCAATGGACATAACAGGAGCATCAGATCCCTATGTGAAAGTCTCGCTGATGTGTGATGGCAGACGACTGAAGAAGAG GAAAACATCCACCAAGAGGAACACCTTGAATCCTGTTTACAACGAAGCCATAGTCTTTGATGTCCCTCCCGAGAACATTGACCAAATCCA CTTGTCCATAGCAGTCATGGACTATGACCGTGTAGGTCACAATGAGATCATCGGCGTGTGTCAAGTAGGCAACGAGGCTGAGAGGCTGGG CAGAGACCACTGGAGTGAAATGTTGTCATATCCTCGGAAGCCCATTGCACACTGGCATTCCCTGGTGGAGAAACGATGACCATGGGTAAG AGGACTGCTTGTGCCAAGGACAAAATAGGACAACCATCTCACAAAGATCTTAAGTAACTTTTTCCATCCAGCAACATCCAGACGATTTCA GTGACCAAATGCTCAGCTGTAACCACAGCACTAACTGGCCTTCTTTCCAGATTGGGTTTGGTGAACCTGAATGGTCCAGCCACCTTCTGC AGGTGGCCCAAGGTGATGTGCTGCAGGGAAGCATGTCTCTCATGCCAAGAACCAAGATCGGACTATGAACAAAAACAAATGATAGATATA GTGACAGTACCAAGAGTACCAGGACTCAATGTTTCATATGAAGCCCTTGGTGATGAGGACATAGCATCTGCCCTGGAAATCGTTATTCCA ACATAATATTATTTTCTAGAATGCCCTGGAAGGACAGAATATTTAAAAATATATCCAGGTGCTAAATAGGCAGCAGATCTCAATTCACAC ATGACTACCTTTGAGCTAATGACTGTCTCCAGAAAATAACTGTGCCCCAAGAAGTGCTCCAGATTTGCAAGGAATAGCCCCAAGAGAATA CCAAGACAAGCAGGCTGTTCCCTGGAAAAAATCTAATGCAAGGAGGGCTAGTTCACAGCAAATTCACTGCCTCCTCCCATGCACGTGGTA GAGAGTACCAGTATCAACATGGCCCTGTTTTCTGCTAAAACCAGATTTTGAGGAATCAGAGACCCCCAACACTACTCACTCAGTAGCTAG CAGCCCCTTCCTTTCAACTGGGAGTGTTATTAGAATGAAAAGTAATTAGTTAGAAGGGCATACATCTCAGTGGCATGAGCATTGTGGAAT ATCCTTTCCTAGGCACATTCGTCCACTAAGGGAACAGCCTCAGAAACTGGTACAGCAATGGGTGAGATGAGATCATGGAGAGAGAACACA GCCATCCCCTATAGAAAGGCACAGCTTTTGGGCTTCTCTGGCCTGAATGCCTTCTGGGGTATTTCCATATGCAACAGCCCAGAGTCATAG CCTTGGGCAACCACACATAGAGGTTTCCTTCTCACTTCAGACACATACATCACTTTCACACCACTTGGGGATGGAAATACCTACAAGAGT GAAGGTCAAGGGCCCTCCCCAGGCATCTCATTCATTACTCAGCTTCCTTCCTGACCAAGTCTGCCAACCAATGGCCAGCTATGCGCCTCA TCCTCATTGCTTCTGCCTCCACGTAAATGAAACCAAAGGCCTCAGCATATCCTGGGAGGACTGGGGGCTGTTACCTAATGGTCCTCTCTG TCCCATTATAGGTGCAAGGCACCCCATCCACACATTTGCACCACTACTCCAAGATAGTATTTTTCTTTTCACACAATCTCTTTACAGCAG AATCCAGAGTTGGATTGTAGTTTACCTTCCTGGAAAGCTCATTATCTCTGTTTGAATTAACATTTCAGCATGGAACTAACTGGGCGGAGG AAGGATCGTTATACGTCTTCAGAAAGTTCTCATTGCCCCAGCTGCCTAGTACTATACAAGAAGCTCTACTTTGATGGCAGATCTAAGAAG GCTATAGGCCTTTGTTTGTAGGAAGCAGTGTCATTACATTCAAGCTTCACTTCTCTGATTGGCTTCCAACCACTGGGATTCAAAGAGAAT CCAAGGTTCTGCCTATGTCTGATGACATAAGGAAAACTTGGCTTCCTCTGCTCAAGGTTCCCCTCTGCTCATCCCTCCTCATTCAGACAT CCTCCACCATACCAGTGTTTAGAAGCAAAACATGAAGGGCTAGCGCCACCAGGATAGTTAGCAGAAATATTGTCTGTAAAGCTAGGCAGA TGAGCCCAGAAGAATGGTCCCAGAGAAAGCAGACTGGCTCCAATAGATATCAGGCAGCAATCCCAATAAATTCTGACATGTCCTTGGCAA TGGAAGCCTGGGTTGGAGATCCTGAGGCAGCTGTGCCTACTGTTCCCCACCTCAGAAGCTTCCTGCCCAGAGAGCCAGCAGCCTTGGGAT ACTAATGAGGATGCAACTGGCTTATTGGTATGAAATAGAAGGTGGCTTTGTAGGGGCAAGCAGGCAAAGAGTACTATCCACATGGCAGGC AGGTGGCTTTGTGTCTGGAAAGCTTTGCCTAGCCAGTACAGCTGTGAGCAGAGGCTGGTTATAAATTTGAACTCCCTCAGCCCATTTGCA >89874_89874_3_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000531632_SYT9_chr11_7324270_ENST00000318881_length(amino acids)=453AA_BP=10 MLKRLVEKSTDISVSLLTLVVTACGLALFGVSLFVSWKLCWVPWRERGLPSGSKDNNQEPLNYMDTETNEQENSEDFLDPPTPCPDSSMK ISHTSPDIPLSTQTGIQENCAHGVRVQRQVTEPTSSARHNSIRRQLNLSNPDFNIQQLQKQEQLTGIGRIKPELYKQRSLDNDDGRRSNS KACGKLNFILKYDCDLEQLIVKIHKAVNLPAKDFSGTSDPYVKIYLLPDRKTKHQTKVHRKTLNPVFDEVFLFPVPYNDLEARKLHFSVY DFDRFSRHDLIGQVVVDHFLDLADFPRECILWKDIEYVTNDNVDLGELMFSLCYLPTAGRLTITIIKARNLKAMDITGASDPYVKVSLMC DGRRLKKRKTSTKRNTLNPVYNEAIVFDVPPENIDQIHLSIAVMDYDRVGHNEIIGVCQVGNEAERLGRDHWSEMLSYPRKPIAHWHSLV -------------------------------------------------------------- >89874_89874_4_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000531632_SYT9_chr11_7324270_ENST00000396716_length(transcript)=2629nt_BP=1718nt TACAACGGAATCCGGACGCCGGGCGCGAGTGGAGCTCAGTGCCAGAGGAGGGGATTCCCGGCGCCGGGGGACAGAGCCCCTTTTTTCTTT TGCCGAAAGACCCTTTCTGCTGGGGAGCCTCTTGTGTCCAGCCTAGGCCCGCGTGCAGCGCCGACGGATGACCGTCTTCTTGGAAAGTGA ATAAACTTAATTGAGAATGTCTGAAAACCTTGACAAGTCCAATGTAAATGAAGCAGGAAAATCAAAATCCAATGATTCTGAGGAAGGCCT CGAAGATGCTGTGGAAGGTGCTGATGAAGCCTTACAAAAAGCAATAAAGTCAGACTCCTCCAGCCCCCAAAGAGTGCAGAGACCTCACTC TAGTCCTCCTCGCTTTGTGACAGTAGAAGAACTTCTAGAGACAGCGAGAGGTGTCACCAACATGGCTCTAGCCCATGAAATTGTAGTAAA TGGAGACTTTCAGATTAAACCAGTTGAATTACCAGAAAACAGCTTGAAGAAGAGAGTAAAGGAGATTGTACATAAAGCGTTTTGGGATTG CTTGAGTGTGCAGCTAAGTGAAGATCCCCCAGCATATGACCATGCTATCAAACTTGTAGGAGAAATCAAAGAGACTCTCTTATCTTTCTT GCTGCCTGGTCATACTAGACTGAGAAACCAGATAACAGAAGTCTTGGATCTGGATCTGATAAAGCAGGAAGCAGAGAATGGGGCGCTAGA CATTTCCAAGCTGGCAGAATTCATTATTGGCATGATGGGGACACTGTGTGCACCTGCTCGAGATGAGGAAGTTAAGAAACTAAAGGACAT TAAGGAAATAGTGCCCCTTTTCAGAGAAATTTTTTCTGTGTTGGACCTAATGAAAGTGGACATGGCCAACTTTGCTATCAGTAGCATCAG GCCTCATCTCATGCAGCAGTCAGTTGAATACGAAAGGAAGAAGTTTCAAGAGATTTTGGAGAGGCAACCAAATTCCCTGGACTTTGTCAC CCAGTGGCTGGAAGAAGCCTCAGAGGACCTTATGACTCAGAAGTATAAACACGCCCTGCCAGTGGGGGGAATGGCTGCTGGCTCTGGGGA CATGCCCAGGCTGAGCCCTGTTGCTGTCCAGAATTACGCTTACCTGAAGCTTCTGAAGTGGGACCACCTCCAGAGGCCGTTCCCCGAAAC AGTTTTAATGGACCAGTCTCGCTTCCACGAGCTCCAGTTGCAGCTGGAACAACTGACCATCCTGGGGGCTGTGTTGCTGGTCACCTTCAG CATGGCAGCGCCAGGAATTTCCAGCCAGGCCGACTTTGCTGAGAAACTCAAGATGATTGTGAAGATTTTGCTAACAGATATGCACCTGCC CTCCTTCCATCTGAAGGACGTCCTCACTACCATCGGGGAGAAGGTGTGCCTGGAGGTGAGCAGCTGCCTCTCCCTGTGTGGGTCCTCTCC CTTCACCACGGACAAGGAGACCGTGCTCAAGGGCCAGATCCAGGCCGTGGCCAGTCCCGATGACCCCATTCGCAGGATCATGGGTAAGAT CCTCGTCCGATCCTAACGTGTATGCACCCTACAGCAGCAGTATTACTCACTAGCCACAGAATACCTGTTCTGTACTCTAATGTTGCATTG GAAAATGGCTATATAGTACATGTCTATTTAACAGCACCGATTCCAAAGGGAAGAATATTGTGTATCACTGTTGAAAAGACTTGTTGAGAA ATCCACTGATATCTCAGTGAGCCTGCTGACCCTTGTGGTCACTGCCTGTGGTCTCGCTCTCTTTGGCGTGTCTCTCTTCGTATCTTGGAA ACTCTGCTGGGTTCCGTGGCGAGAACGAGGCCTGCCCTCTGGTAGCAAAGACAACAACCAGGAGCCCCTTAACTACATGGACACAGAGAC CAATGAGCAGGAGAACAGTGAGGACTTCCTAGATCCTCCCACGCCCTGCCCTGACTCCTCCATGAAGATCAGCCACACCTCCCCTGACAT TCCCCTCTCCACCCAGACGGGGATCCAGGAGAACTGTGCCCATGGCGTCCGCGTGCAGCGCCAAGTCACAGAGCCAACCTCGTCGGCCCG GCATAATTCAATCCGAAGACAACTCAACTTGTCAAACCCGGACTTCAATATCCAGCAGCTTCAAAAACAGGAACAGTTGACTGGAATTGG TAGAATTAAACCAGAGTTATATAAGCAGAGGTCATTGGATAATGATGACGGGAGACGGAGTAACAGCAAGGCTTGTGGGAAACTGAACTT CATTTTAAAATATGACTGTGACTTAGAGCAGCTCATAGTGAAGATTCACAAAGCTGTCAATTTGCCCGCCAAGGACTTTTCTGGGACTTC AGATCCTTATGTCAAGATCTATTTGCTTCCTGATCGGAAAACAAAACACCAGACTAAAGTTCACAGAAAGACCCTGAACCCTGTGTTTGA TGAAGTGTTTTTATTTCCGGTTCCCTACAATGACCTTGAAGCACGGAAGCTTCACTTCTCTGTGTACGACTTTGACAGGTTCTCTCGTCA TGACTTAATCGGCCAAGTGGTGGTGGATCACTTCCTAGACTTGGCTGATTTCCCCAGGGAGTGCATCCTTTGGAAGGATATCGAATATGT >89874_89874_4_TCP11L1-SYT9_TCP11L1_chr11_33094199_ENST00000531632_SYT9_chr11_7324270_ENST00000396716_length(amino acids)=451AA_BP= MRMSENLDKSNVNEAGKSKSNDSEEGLEDAVEGADEALQKAIKSDSSSPQRVQRPHSSPPRFVTVEELLETARGVTNMALAHEIVVNGDF QIKPVELPENSLKKRVKEIVHKAFWDCLSVQLSEDPPAYDHAIKLVGEIKETLLSFLLPGHTRLRNQITEVLDLDLIKQEAENGALDISK LAEFIIGMMGTLCAPARDEEVKKLKDIKEIVPLFREIFSVLDLMKVDMANFAISSIRPHLMQQSVEYERKKFQEILERQPNSLDFVTQWL EEASEDLMTQKYKHALPVGGMAAGSGDMPRLSPVAVQNYAYLKLLKWDHLQRPFPETVLMDQSRFHELQLQLEQLTILGAVLLVTFSMAA PGISSQADFAEKLKMIVKILLTDMHLPSFHLKDVLTTIGEKVCLEVSSCLSLCGSSPFTTDKETVLKGQIQAVASPDDPIRRIMGKILVR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TCP11L1-SYT9 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TCP11L1-SYT9 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TCP11L1-SYT9 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies