
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TENC1-ACVR1B (FusionGDB2 ID:90039) |
Fusion Gene Summary for TENC1-ACVR1B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TENC1-ACVR1B | Fusion gene ID: 90039 | Hgene | Tgene | Gene symbol | TENC1 | ACVR1B | Gene ID | 23371 | 91 |
| Gene name | tensin 2 | activin A receptor type 1B | |
| Synonyms | C1-TEN|C1TEN|TENC1 | ACTRIB|ACVRLK4|ALK4|SKR2 | |
| Cytomap | 12q13.13 | 12q13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tensin-2C1 domain-containing phosphatase and tensin homologtensin like C1 domain containing phosphatase (tensin 2)tensin-like C1 domain-containing phosphatase | activin receptor type-1Bactivin A receptor, type IBactivin A receptor, type II-like kinase 4activin receptor-like kinase 4serine/threonine-protein kinase receptor R2 | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | P36896 | |
| Ensembl transtripts involved in fusion gene | ENST00000314250, ENST00000314276, ENST00000451358, ENST00000546602, ENST00000549700, ENST00000552570, ENST00000379902, | ENST00000563121, ENST00000257963, ENST00000415850, ENST00000426655, ENST00000541224, ENST00000542485, | |
| Fusion gene scores | * DoF score | 1 X 1 X 1=1 | 6 X 5 X 6=180 |
| # samples | 1 | 6 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(6/180*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TENC1 [Title/Abstract] AND ACVR1B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TENC1(53445747)-ACVR1B(52378976), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TENC1 | GO:0035335 | peptidyl-tyrosine dephosphorylation | 23401856 |
| Hgene | TENC1 | GO:0046627 | negative regulation of insulin receptor signaling pathway | 23401856 |
| Tgene | ACVR1B | GO:0000082 | G1/S transition of mitotic cell cycle | 11117535 |
| Tgene | ACVR1B | GO:0006355 | regulation of transcription, DNA-templated | 8622651|12665502 |
| Tgene | ACVR1B | GO:0006468 | protein phosphorylation | 12065756 |
| Tgene | ACVR1B | GO:0007165 | signal transduction | 8622651|12665502 |
| Tgene | ACVR1B | GO:0018107 | peptidyl-threonine phosphorylation | 18039968 |
| Tgene | ACVR1B | GO:0030308 | negative regulation of cell growth | 11117535 |
| Tgene | ACVR1B | GO:0032924 | activin receptor signaling pathway | 9892009 |
| Tgene | ACVR1B | GO:0032927 | positive regulation of activin receptor signaling pathway | 16720724 |
| Tgene | ACVR1B | GO:0045648 | positive regulation of erythrocyte differentiation | 9032295 |
| Tgene | ACVR1B | GO:0046777 | protein autophosphorylation | 18039968 |
| Tgene | ACVR1B | GO:1901165 | positive regulation of trophoblast cell migration | 21356369 |
| Fusion gene breakpoints across TENC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ACVR1B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-C8-A12V-01A | TENC1 | chr12 | 53445747 | - | ACVR1B | chr12 | 52378976 | + |
| ChimerDB4 | BRCA | TCGA-C8-A12V-01A | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
Top |
Fusion Gene ORF analysis for TENC1-ACVR1B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000314250 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5CDS-3UTR | ENST00000314276 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5CDS-3UTR | ENST00000451358 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5CDS-3UTR | ENST00000546602 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5CDS-3UTR | ENST00000549700 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5CDS-3UTR | ENST00000552570 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3CDS | ENST00000379902 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3CDS | ENST00000379902 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3CDS | ENST00000379902 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3CDS | ENST00000379902 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3CDS | ENST00000379902 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| 5UTR-3UTR | ENST00000379902 | ENST00000563121 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314250 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314250 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314250 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314250 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314250 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314276 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314276 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314276 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314276 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000314276 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000451358 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000451358 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000451358 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000451358 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000451358 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000546602 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000546602 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000546602 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000546602 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000546602 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000549700 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000549700 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000549700 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000549700 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000549700 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000552570 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000552570 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000552570 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000552570 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| In-frame | ENST00000552570 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000314276 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3916 | 409 | 141 | 947 | 268 |
| ENST00000314276 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 1055 | 409 | 141 | 947 | 268 |
| ENST00000314276 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 1170 | 409 | 141 | 860 | 239 |
| ENST00000314276 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 1095 | 409 | 141 | 893 | 250 |
| ENST00000314276 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1763 | 409 | 141 | 947 | 268 |
| ENST00000451358 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3981 | 474 | 53 | 1012 | 319 |
| ENST00000451358 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 1120 | 474 | 53 | 1012 | 319 |
| ENST00000451358 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 1235 | 474 | 53 | 925 | 290 |
| ENST00000451358 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 1160 | 474 | 53 | 958 | 301 |
| ENST00000451358 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1828 | 474 | 53 | 1012 | 319 |
| ENST00000314250 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3981 | 474 | 53 | 1012 | 319 |
| ENST00000314250 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 1120 | 474 | 53 | 1012 | 319 |
| ENST00000314250 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 1235 | 474 | 53 | 925 | 290 |
| ENST00000314250 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 1160 | 474 | 53 | 958 | 301 |
| ENST00000314250 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1828 | 474 | 53 | 1012 | 319 |
| ENST00000546602 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3691 | 184 | 0 | 722 | 240 |
| ENST00000546602 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 830 | 184 | 0 | 722 | 240 |
| ENST00000546602 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 945 | 184 | 0 | 635 | 211 |
| ENST00000546602 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 870 | 184 | 0 | 668 | 222 |
| ENST00000546602 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1538 | 184 | 0 | 722 | 240 |
| ENST00000552570 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3691 | 184 | 0 | 722 | 240 |
| ENST00000552570 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 830 | 184 | 0 | 722 | 240 |
| ENST00000552570 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 945 | 184 | 0 | 635 | 211 |
| ENST00000552570 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 870 | 184 | 0 | 668 | 222 |
| ENST00000552570 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1538 | 184 | 0 | 722 | 240 |
| ENST00000549700 | TENC1 | chr12 | 53445747 | + | ENST00000257963 | ACVR1B | chr12 | 52378976 | + | 3691 | 184 | 0 | 722 | 240 |
| ENST00000549700 | TENC1 | chr12 | 53445747 | + | ENST00000541224 | ACVR1B | chr12 | 52378976 | + | 830 | 184 | 0 | 722 | 240 |
| ENST00000549700 | TENC1 | chr12 | 53445747 | + | ENST00000426655 | ACVR1B | chr12 | 52378976 | + | 945 | 184 | 0 | 635 | 211 |
| ENST00000549700 | TENC1 | chr12 | 53445747 | + | ENST00000415850 | ACVR1B | chr12 | 52378976 | + | 870 | 184 | 0 | 668 | 222 |
| ENST00000549700 | TENC1 | chr12 | 53445747 | + | ENST00000542485 | ACVR1B | chr12 | 52378976 | + | 1538 | 184 | 0 | 722 | 240 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000314276 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003816231 | 0.9961838 |
| ENST00000314276 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003501836 | 0.9964981 |
| ENST00000314276 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.004701908 | 0.9952981 |
| ENST00000314276 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.001566793 | 0.9984332 |
| ENST00000314276 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005967381 | 0.99403256 |
| ENST00000451358 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002401625 | 0.99759835 |
| ENST00000451358 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.004143198 | 0.9958568 |
| ENST00000451358 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.009314834 | 0.99068516 |
| ENST00000451358 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002204075 | 0.99779594 |
| ENST00000451358 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005967313 | 0.9940327 |
| ENST00000314250 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002401625 | 0.99759835 |
| ENST00000314250 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.004143198 | 0.9958568 |
| ENST00000314250 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.009314834 | 0.99068516 |
| ENST00000314250 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002204075 | 0.99779594 |
| ENST00000314250 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005967313 | 0.9940327 |
| ENST00000546602 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002103053 | 0.9978969 |
| ENST00000546602 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003547533 | 0.99645245 |
| ENST00000546602 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005511336 | 0.9944886 |
| ENST00000546602 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.001566048 | 0.9984339 |
| ENST00000546602 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003955383 | 0.99604464 |
| ENST00000552570 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002103053 | 0.9978969 |
| ENST00000552570 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003547533 | 0.99645245 |
| ENST00000552570 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005511336 | 0.9944886 |
| ENST00000552570 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.001566048 | 0.9984339 |
| ENST00000552570 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003955383 | 0.99604464 |
| ENST00000549700 | ENST00000257963 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.002103053 | 0.9978969 |
| ENST00000549700 | ENST00000541224 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003547533 | 0.99645245 |
| ENST00000549700 | ENST00000426655 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.005511336 | 0.9944886 |
| ENST00000549700 | ENST00000415850 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.001566048 | 0.9984339 |
| ENST00000549700 | ENST00000542485 | TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378976 | + | 0.003955383 | 0.99604464 |
Top |
Fusion Genomic Features for TENC1-ACVR1B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378975 | + | 0.5609124 | 0.43908763 |
| TENC1 | chr12 | 53445747 | + | ACVR1B | chr12 | 52378975 | + | 0.5609124 | 0.43908763 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
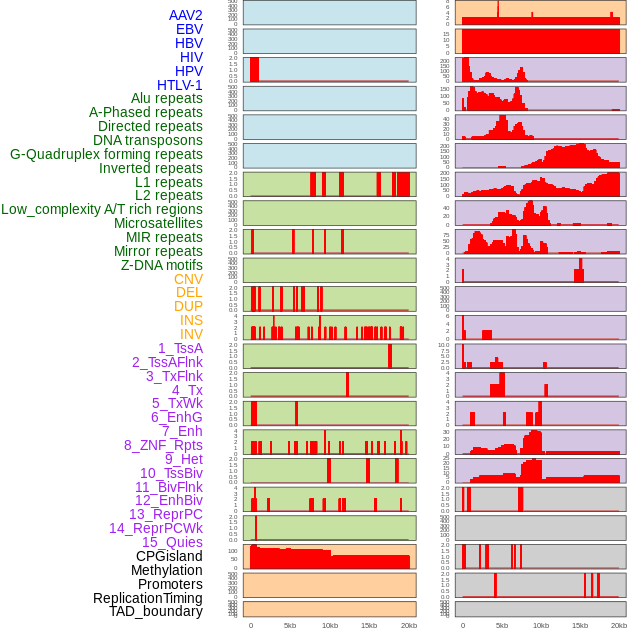 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
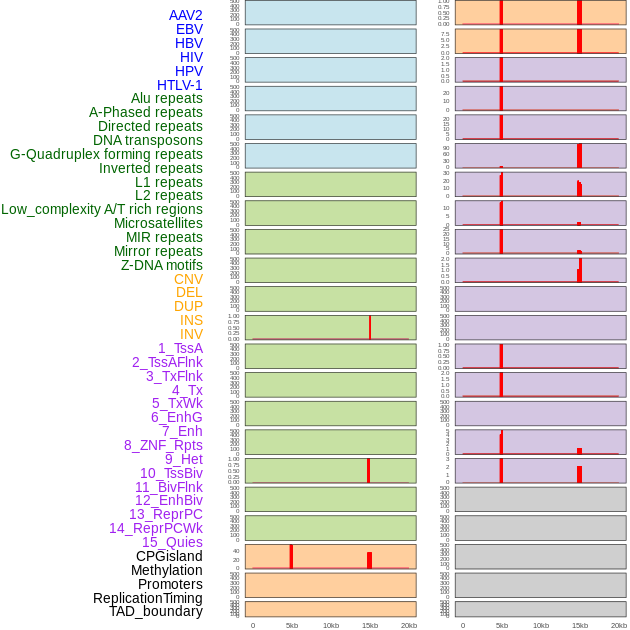 |
Top |
Fusion Protein Features for TENC1-ACVR1B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:53445747/chr12:52378976) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ACVR1B |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transmembrane serine/threonine kinase activin type-1 receptor forming an activin receptor complex with activin receptor type-2 (ACVR2A or ACVR2B). Transduces the activin signal from the cell surface to the cytoplasm and is thus regulating a many physiological and pathological processes including neuronal differentiation and neuronal survival, hair follicle development and cycling, FSH production by the pituitary gland, wound healing, extracellular matrix production, immunosuppression and carcinogenesis. Activin is also thought to have a paracrine or autocrine role in follicular development in the ovary. Within the receptor complex, type-2 receptors (ACVR2A and/or ACVR2B) act as a primary activin receptors whereas the type-1 receptors like ACVR1B act as downstream transducers of activin signals. Activin binds to type-2 receptor at the plasma membrane and activates its serine-threonine kinase. The activated receptor type-2 then phosphorylates and activates the type-1 receptor such as ACVR1B. Once activated, the type-1 receptor binds and phosphorylates the SMAD proteins SMAD2 and SMAD3, on serine residues of the C-terminal tail. Soon after their association with the activin receptor and subsequent phosphorylation, SMAD2 and SMAD3 are released into the cytoplasm where they interact with the common partner SMAD4. This SMAD complex translocates into the nucleus where it mediates activin-induced transcription. Inhibitory SMAD7, which is recruited to ACVR1B through FKBP1A, can prevent the association of SMAD2 and SMAD3 with the activin receptor complex, thereby blocking the activin signal. Activin signal transduction is also antagonized by the binding to the receptor of inhibin-B via the IGSF1 inhibin coreceptor. ACVR1B also phosphorylates TDP2. {ECO:0000269|PubMed:12364468, ECO:0000269|PubMed:12639945, ECO:0000269|PubMed:18039968, ECO:0000269|PubMed:20226172, ECO:0000269|PubMed:8196624, ECO:0000269|PubMed:9032295, ECO:0000269|PubMed:9892009}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 489_533 | 61 | 1410.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 724_1122 | 61 | 1410.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 489_533 | 71 | 1420.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 724_1122 | 71 | 1420.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 489_533 | 0 | 1286.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 724_1122 | 0 | 1286.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 489_533 | 61 | 1313.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 724_1122 | 61 | 1313.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 489_533 | 61 | 1408.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 724_1122 | 61 | 1408.0 | Compositional bias | Note=Pro-rich |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 1140_1247 | 61 | 1410.0 | Domain | SH2 |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 122_294 | 61 | 1410.0 | Domain | Phosphatase tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 299_425 | 61 | 1410.0 | Domain | C2 tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 1140_1247 | 71 | 1420.0 | Domain | SH2 |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 122_294 | 71 | 1420.0 | Domain | Phosphatase tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 299_425 | 71 | 1420.0 | Domain | C2 tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 1140_1247 | 0 | 1286.0 | Domain | SH2 |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 122_294 | 0 | 1286.0 | Domain | Phosphatase tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 299_425 | 0 | 1286.0 | Domain | C2 tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 1140_1247 | 61 | 1313.0 | Domain | SH2 |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 122_294 | 61 | 1313.0 | Domain | Phosphatase tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 299_425 | 61 | 1313.0 | Domain | C2 tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 1140_1247 | 61 | 1408.0 | Domain | SH2 |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 122_294 | 61 | 1408.0 | Domain | Phosphatase tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 299_425 | 61 | 1408.0 | Domain | C2 tensin-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314250 | + | 2 | 29 | 31_79 | 61 | 1410.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000314276 | + | 2 | 29 | 31_79 | 71 | 1420.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000379902 | + | 2 | 29 | 31_79 | 0 | 1286.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000546602 | + | 2 | 29 | 31_79 | 61 | 1313.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | TENC1 | chr12:53445747 | chr12:52378976 | ENST00000552570 | + | 2 | 29 | 31_79 | 61 | 1408.0 | Zinc finger | Phorbol-ester/DAG-type |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 177_206 | 326 | 506.0 | Domain | GS | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 207_497 | 326 | 506.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 177_206 | 326 | 488.0 | Domain | GS | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 207_497 | 326 | 488.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 177_206 | 326 | 477.0 | Domain | GS | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 207_497 | 326 | 477.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 177_206 | 367 | 547.0 | Domain | GS | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 207_497 | 367 | 547.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 177_206 | 274 | 454.0 | Domain | GS | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 207_497 | 274 | 454.0 | Domain | Protein kinase | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 213_221 | 326 | 506.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 213_221 | 326 | 488.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 213_221 | 326 | 477.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 213_221 | 367 | 547.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 213_221 | 274 | 454.0 | Nucleotide binding | ATP | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 150_505 | 326 | 506.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 24_126 | 326 | 506.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 150_505 | 326 | 488.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 24_126 | 326 | 488.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 150_505 | 326 | 477.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 24_126 | 326 | 477.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 150_505 | 367 | 547.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 24_126 | 367 | 547.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 150_505 | 274 | 454.0 | Topological domain | Cytoplasmic | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 24_126 | 274 | 454.0 | Topological domain | Extracellular | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000257963 | 4 | 9 | 127_149 | 326 | 506.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000415850 | 4 | 7 | 127_149 | 326 | 488.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000426655 | 4 | 8 | 127_149 | 326 | 477.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000541224 | 5 | 10 | 127_149 | 367 | 547.0 | Transmembrane | Helical | |
| Tgene | ACVR1B | chr12:53445747 | chr12:52378976 | ENST00000542485 | 4 | 9 | 127_149 | 274 | 454.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for TENC1-ACVR1B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >90039_90039_1_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3981nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC GATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCA CTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTG CCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGG GGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAG AACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGA GACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACAC GTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATG CTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAG CCCCTCATGCCACAGTGGTACTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTG GAACCAAAGCTGGCCCAGTTGTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCT GGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAAT GTGAAGCCAGATCTCGGGACTCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGT GGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTA CTGGACTGTCTGATCAGGGTGGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGT TATTTAACCTGAGTATAGTATTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTT GAAGCCATAACTTTTAACTGGAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAA TATTAAGTTTTTGTAAAAGGAAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCA ATTGAACGCACATAGCTCAATCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCT GAGGCTCAGTCTCTCTCGTATTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTT GTACCCTCTCCAGGCATTTATTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCT TGGGTCCTACTCCTGGAGCACTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTAC GACCCTTTTGAGCCTAGAATTATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGC GGGTGATGAGACCTGGGGTTTAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGT ATTGTGTATGTAGCCTTAGAGCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCT CAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGG GCCAATTTACTGGCCACTAATTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCC TGCAGCAGAACCTTGGCGGTTTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACA CGTCCACTCCCAAGCCACTAGCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGAT GGAGCAGGTCTTTGGGAAGCTCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGC CCCCCGAGGCTAACCCTGATCCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCAT AAAGGCCCCCGAACGGCATTCTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTAC CTCTTCAGTATGCAAATGTAAATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTGTCCAATTTCTGCTGTACATT >90039_90039_1_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_2_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=1160nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCAC CCAAAGCTGTTTTACTGCCCCCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAG GTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGC TCGTTTGGCTTTATAAACAAACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGT >90039_90039_2_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=301AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLPPFFLQPVGCLL -------------------------------------------------------------- >90039_90039_3_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=1235nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGC CTCCTGCGGCTTTCCCATCAGCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAG TGTCAGTTATTATTTACTATTACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCA TTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCA >90039_90039_3_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=290AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_4_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=1120nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC >90039_90039_4_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_5_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1828nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC GATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCA CTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTG CCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGG GGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAG AACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGA GACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACAC GTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATG CTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAG >90039_90039_5_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314250_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_6_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3916nt_BP=409nt GCACATTCTTTCAAGTGACAGCTATAGCCTGTCCCAGGGGCTGCTGTCCACAGCTTGGGGCTGAAGACTCCCAGGCCATTAACCCCTTAG CTTTTAGGAAGATTACTCCCCCTTTTTCAAGGCCCCATCCACCTCCCTCCCTTGACTCCCAGGACGGGAAGTTGGCCATGTTCCCAGGAG GGAGGCCGGAGGCCCATGGATGGGGGTGGAGTATGTGTTGGGAGGGGGGACCTCCTGTCCAGTCCTCAGGCCCTGGGACAGCTGCTGAGG AAGGAGAGCAGACCCAGGAGAGCCATGAAGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTC TGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAAC ATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCC CCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGT GCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATAT TACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGG CAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATC AAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTA CGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGG ACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAG AGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGG AGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCC ACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGG ACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTG CCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGT GCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCC CTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTACTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAG CTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTTGTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGG GTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAG CAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGACTCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGA AACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGG AGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGTGGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGA AGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTATTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAG CATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTGGAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGAT TTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGGAAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGA AATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAATCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTC AGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTATTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGC CCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTATTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGG AATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCACTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGAC CAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAATTATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAA CCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTTTAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCC CCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGAGCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGA GGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTA AAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAATTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCC CTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGTTTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAA GTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTAGCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTC CAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGCTCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGG GAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGATCCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAG TCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATTCTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTG TAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTAAATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGA >90039_90039_6_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=268AA_BP=89 MTPRTGSWPCSQEGGRRPMDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRG KPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRC -------------------------------------------------------------- >90039_90039_7_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=1095nt_BP=409nt GCACATTCTTTCAAGTGACAGCTATAGCCTGTCCCAGGGGCTGCTGTCCACAGCTTGGGGCTGAAGACTCCCAGGCCATTAACCCCTTAG CTTTTAGGAAGATTACTCCCCCTTTTTCAAGGCCCCATCCACCTCCCTCCCTTGACTCCCAGGACGGGAAGTTGGCCATGTTCCCAGGAG GGAGGCCGGAGGCCCATGGATGGGGGTGGAGTATGTGTTGGGAGGGGGGACCTCCTGTCCAGTCCTCAGGCCCTGGGACAGCTGCTGAGG AAGGAGAGCAGACCCAGGAGAGCCATGAAGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTC TGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAAC ATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCC CCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGT GCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTAC CTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCCCCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAA TCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGT GTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAAACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCG CATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAGTATATTCTAACGCGGTGGCTCCCAAGCCACATTCATGGGAAACCC >90039_90039_7_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=250AA_BP=89 MTPRTGSWPCSQEGGRRPMDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRG KPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRC -------------------------------------------------------------- >90039_90039_8_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=1170nt_BP=409nt GCACATTCTTTCAAGTGACAGCTATAGCCTGTCCCAGGGGCTGCTGTCCACAGCTTGGGGCTGAAGACTCCCAGGCCATTAACCCCTTAG CTTTTAGGAAGATTACTCCCCCTTTTTCAAGGCCCCATCCACCTCCCTCCCTTGACTCCCAGGACGGGAAGTTGGCCATGTTCCCAGGAG GGAGGCCGGAGGCCCATGGATGGGGGTGGAGTATGTGTTGGGAGGGGGGACCTCCTGTCCAGTCCTCAGGCCCTGGGACAGCTGCTGAGG AAGGAGAGCAGACCCAGGAGAGCCATGAAGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTC TGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAAC ATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCC CCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGT GCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATAT TACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGG CAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCAGCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTC AGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTATTACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTC TTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAAT CGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAGAAGTTCGAGACAAACCTGGGCAATGTGGGGAGACCCCATCTCTAC >90039_90039_8_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=239AA_BP=89 MTPRTGSWPCSQEGGRRPMDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRG KPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRC -------------------------------------------------------------- >90039_90039_9_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=1055nt_BP=409nt GCACATTCTTTCAAGTGACAGCTATAGCCTGTCCCAGGGGCTGCTGTCCACAGCTTGGGGCTGAAGACTCCCAGGCCATTAACCCCTTAG CTTTTAGGAAGATTACTCCCCCTTTTTCAAGGCCCCATCCACCTCCCTCCCTTGACTCCCAGGACGGGAAGTTGGCCATGTTCCCAGGAG GGAGGCCGGAGGCCCATGGATGGGGGTGGAGTATGTGTTGGGAGGGGGGACCTCCTGTCCAGTCCTCAGGCCCTGGGACAGCTGCTGAGG AAGGAGAGCAGACCCAGGAGAGCCATGAAGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTC TGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAAC ATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCC CCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGT GCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATAT TACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGG CAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATC AAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTA >90039_90039_9_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=268AA_BP=89 MTPRTGSWPCSQEGGRRPMDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRG KPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRC -------------------------------------------------------------- >90039_90039_10_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1763nt_BP=409nt GCACATTCTTTCAAGTGACAGCTATAGCCTGTCCCAGGGGCTGCTGTCCACAGCTTGGGGCTGAAGACTCCCAGGCCATTAACCCCTTAG CTTTTAGGAAGATTACTCCCCCTTTTTCAAGGCCCCATCCACCTCCCTCCCTTGACTCCCAGGACGGGAAGTTGGCCATGTTCCCAGGAG GGAGGCCGGAGGCCCATGGATGGGGGTGGAGTATGTGTTGGGAGGGGGGACCTCCTGTCCAGTCCTCAGGCCCTGGGACAGCTGCTGAGG AAGGAGAGCAGACCCAGGAGAGCCATGAAGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTC TGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAAC ATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCC CCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGT GCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATAT TACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGG CAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATC AAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTA CGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGG ACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAG AGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGG AGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCC ACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGG ACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTG CCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGT GCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCC >90039_90039_10_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000314276_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=268AA_BP=89 MTPRTGSWPCSQEGGRRPMDGGGVCVGRGDLLSSPQALGQLLRKESRPRRAMKPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRG KPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRC -------------------------------------------------------------- >90039_90039_11_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3981nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC GATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCA CTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTG CCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGG GGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAG AACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGA GACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACAC GTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATG CTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAG CCCCTCATGCCACAGTGGTACTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTG GAACCAAAGCTGGCCCAGTTGTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCT GGTGGAAGTCTTGGGTGTTAGTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAAT GTGAAGCCAGATCTCGGGACTCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGT GGTGGGTTTGGGGTGGGGAAGGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTA CTGGACTGTCTGATCAGGGTGGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGT TATTTAACCTGAGTATAGTATTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTT GAAGCCATAACTTTTAACTGGAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAA TATTAAGTTTTTGTAAAAGGAAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCA ATTGAACGCACATAGCTCAATCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCT GAGGCTCAGTCTCTCTCGTATTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTT GTACCCTCTCCAGGCATTTATTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCT TGGGTCCTACTCCTGGAGCACTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTAC GACCCTTTTGAGCCTAGAATTATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGC GGGTGATGAGACCTGGGGTTTAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGT ATTGTGTATGTAGCCTTAGAGCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCT CAGGCTCCCCAGTGCTCCTGGCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGG GCCAATTTACTGGCCACTAATTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCC TGCAGCAGAACCTTGGCGGTTTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACA CGTCCACTCCCAAGCCACTAGCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGAT GGAGCAGGTCTTTGGGAAGCTCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGC CCCCCGAGGCTAACCCTGATCCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCAT AAAGGCCCCCGAACGGCATTCTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTAC CTCTTCAGTATGCAAATGTAAATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTGTCCAATTTCTGCTGTACATT >90039_90039_11_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_12_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=1160nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCAC CCAAAGCTGTTTTACTGCCCCCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAG GTGTGGAGGTAGCTGTGCTTAGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGC TCGTTTGGCTTTATAAACAAACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGT >90039_90039_12_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=301AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLPPFFLQPVGCLL -------------------------------------------------------------- >90039_90039_13_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=1235nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGC CTCCTGCGGCTTTCCCATCAGCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAG TGTCAGTTATTATTTACTATTACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCA TTTGGAGTTCACAGCCTAGAAGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCA >90039_90039_13_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=290AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_14_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=1120nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC >90039_90039_14_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_15_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1828nt_BP=474nt GGGGGAGCAAAAGATCACAGGCTGACACTCCCAGCAGGGTAGATCCTGGGAATCTGATCTCCTGGCCTCCCCCACATCCTCCCCCCTCCA CTTCCTGGAGCAGCGACCTGCCCCCTTCCCGCCTGCACTTCCCTCCACTTCCAGGGCCGGGCTTCTCCTCACACCAGCCAGACAGCCTAC CCTCCGCCCAGGGGAAGCGGCTGCCTCCGCCAGGCCGCTTCCAGGAAGCCCCGGGCCAGGCCCCAGCATTGTTCAGGCCCTGGGGCCAGC ACCCCAGCCAGCCGAACACCATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAA GCAGGCCTAGGAAAGCTGAGCCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCG ATGGGACAGGCGTTTCGTGCAGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGT GTGCCATAGCAGACCTGGGCCTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAAC GATACATGGCCCCTGAAGTACTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTG TATATTGGGAGATTGCTCGAAGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTT CCATTGAGGAAATGCGAAAGGTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGA TGGGGAAGATGATGCGAGAGTGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCG TGCAGGAAGACGTGAAGATCTAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTAC GATGGAGGCCTACCTCTCGTTTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCA CTCCCATGTTGGGTTTGAGACAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTG CCACACCTCGAACTGGTTGTAGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGG GGCCGGAGGAACCGAGGTGTTGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAG AACCAGAAGTGCAGCCCCTCTCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGA GACGGAATCTGCCGCTTTGTCTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACAC GTGCGTGTGAGTGTGTGTGTGTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATG CTGTCCGTGCTTGCTGGTGCCTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAG >90039_90039_15_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000451358_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=319AA_BP=140 MISWPPPHPPPSTSWSSDLPPSRLHFPPLPGPGFSSHQPDSLPSAQGKRLPPPGRFQEAPGQAPALFRPWGQHPSQPNTMKSSGPVERLL RALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLGLAVRHDAVTDT IDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRKVVCDQKLRPNI -------------------------------------------------------------- >90039_90039_16_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3691nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA CTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTT GTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTA GTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGAC TCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAA GGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGT GGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTA TTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTG GAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGG AAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAA TCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTA TTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTA TTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCA CTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAAT TATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTT TAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGA GCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTG GCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAA TTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGT TTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTA GCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGC TCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGAT CCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATT CTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTA AATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTGTCCAATTTCTGCTGTACATTATTAAAAGTTTTATTCACAG >90039_90039_16_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_17_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=870nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCC CCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTT AGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAA ACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAG >90039_90039_17_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=222AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLP -------------------------------------------------------------- >90039_90039_18_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=945nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCA GCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTAT TACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGA AGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAG >90039_90039_18_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=211AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_19_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=830nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT >90039_90039_19_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_20_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1538nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA >90039_90039_20_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000546602_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_21_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3691nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA CTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTT GTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTA GTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGAC TCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAA GGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGT GGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTA TTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTG GAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGG AAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAA TCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTA TTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTA TTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCA CTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAAT TATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTT TAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGA GCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTG GCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAA TTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGT TTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTA GCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGC TCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGAT CCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATT CTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTA AATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTGTCCAATTTCTGCTGTACATTATTAAAAGTTTTATTCACAG >90039_90039_21_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_22_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=870nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCC CCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTT AGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAA ACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAG >90039_90039_22_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=222AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLP -------------------------------------------------------------- >90039_90039_23_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=945nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCA GCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTAT TACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGA AGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAG >90039_90039_23_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=211AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_24_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=830nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT >90039_90039_24_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_25_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1538nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA >90039_90039_25_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000549700_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_26_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000257963_length(transcript)=3691nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA CTCTGTGTCTGGCAGGCTACTCTGCCCACCCCAGCATCAGCACAGCTCTCCTCCTCCATCTCAGACTGTGGAACCAAAGCTGGCCCAGTT GTCCATGACAAAAGAGGCTTTTGGGCCAAAATGTGAGGGTGGTGGGTGGGATGGGCAGGGAAGGAATCCTGGTGGAAGTCTTGGGTGTTA GTGTCAGCCATGGGAAATGAGCCAGCCCAAGGGCATCATCCTCAGCAGCATCGAGGAAGGGCCGAGGAATGTGAAGCCAGATCTCGGGAC TCAGATTGGAATGTTACATCTGTCTTTCATCTCCCAGATCCTGGAAACAGCAGTGTATATTTTTGGTGGTGGTGGGTTTGGGGTGGGGAA GGGAAGGGCGGGCAAGGAGTGGGGAGGGAGTCTGGGGTGGGAGGGAGGCATCTGCATGGGTCTTCTTTTACTGGACTGTCTGATCAGGGT GGAGGGAAGGTGAGAGGTTTGCATCCACTTCAGGAGCCCTACTGAAGGGAACAGCCTGAGCCGAACATGTTATTTAACCTGAGTATAGTA TTTAACGAAGCCTAGAAGCACGGCTGTGGGTGGTGATTTGGTCAGCATATCTTAGGTATATAATAACTTTGAAGCCATAACTTTTAACTG GAGTGGTTTGATTTCTTTTTTTAATTTTATTGGGAGGGTTTGGATTTTAACTTTTTTTAATGTTGTTAAATATTAAGTTTTTGTAAAAGG AAAACCATCTCTGTGATTACCTCTCAATCTATTTGTTTTTAAAGAAATCCCTAAAAAAAAAAATTATCCAATTGAACGCACATAGCTCAA TCACACTGGAAATGTTTGTCCTTGCACCTGAGCCTGTTCCCACTCAGCAGTGAGAGTTCCTCTTTGCCCTGAGGCTCAGTCTCTCTCGTA TTTTGTCCCCACCCCCAATTCCTTGAGTGGTTTTTGCTCTAGGGCCCTTTCTTGCACTGTCCAGCTGGTTGTACCCTCTCCAGGCATTTA TTCAACAAATGTGGGTGAAGTGCCTGCTGGGTGCCAGGTGCTGGGAATACATCTGTGGACAAGACATGCTTGGGTCCTACTCCTGGAGCA CTGTAAAAAGAGCTGATTCAAGTAAGTAGATGCCTGTTTTGAGACCAGAAGGTTTCATAATTGGTTCTACGACCCTTTTGAGCCTAGAAT TATTGTTCTTATATAAGATCACTGAAGAAAGAGGAACCCCCACAACCCCCTCCACAAAGAGACCAGGGGCGGGTGATGAGACCTGGGGTT TAGAACCCCAGGTGAGACCTCAAATCACTGCATTCATTCTGAGCCCCCTTCCTGTCCCCAGGGGAGGTGTATTGTGTATGTAGCCTTAGA GCATCTCTGCCTCCAACCCAGCAGTTCTCTGCCAAAGCTTGTGGAGGAGGGAGAGCCCTGTCCCTGCCCTCAGGCTCCCCAGTGCTCCTG GCCCTTCTATTTATTTGACTGATTATTGCTTCTTTCCTTGCATTAAAGGAGATCTTCCCCTAACCTTTGGGCCAATTTACTGGCCACTAA TTTCGTTTAAATACCATTGTGTCATTGGGGGGACCGTCTTTACCCCTGCTGACCTCCCACCTATCCGCCCTGCAGCAGAACCTTGGCGGT TTATAGGTAATGATGGAACTTAGACTCCTCTTCCCAGAGTCACAAGTAGCCTCTGGGATCTGCCAACACACGTCCACTCCCAAGCCACTA GCCCACTCCCCAGTTGGCCCTTCTGCCCTTACCCCACACACAGTCCAACTCTTCCACCTCTGGGGAAGATGGAGCAGGTCTTTGGGAAGC TCCCACACCCACCTCTGCCACTCTTAACACTAAGTGAGAGTTGGGGAGAAACTGAAGCCGTGTTTTTGGCCCCCCGAGGCTAACCCTGAT CCATAGTGCTACCTGCACCTCTGGATTCTGGATTCACAGACCAAGTCCAAGCCCGTTCTTACGTCGCCATAAAGGCCCCCGAACGGCATT CTCGGTACTTCTGTTTGTTTTTGTACATTTTATTAGAAAGGACTGTAAAATAGCCACTTAGACACTTTACCTCTTCAGTATGCAAATGTA AATAAATTGTAATATAGGAAATCTTTTGTTTTAATATAAGAATGAGCCTGTCCAATTTCTGCTGTACATTATTAAAAGTTTTATTCACAG >90039_90039_26_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000257963_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_27_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000415850_length(transcript)=870nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGTACCTTTCTTTTTTGCCTTTGCTCCTACCTCCCATTCCAGGATGCTGGATCACCCAAAGCTGTTTTACTGCCC CCTTTCTTTTTACAACCTGTTGGATGCCTGTTGCCAGAGCCTGAATCATCGTTTAAGGTTGCCATCAAAGGTGTGGAGGTAGCTGTGCTT AGGGTGCGTTTATTCTTCAGGGATCAGTTTGTTGAATAGCGTTGTGTGTTATGGTAACCATTCTGAAGGCTCGTTTGGCTTTATAAACAA ACAAACATTGTTTTATTAGTCCGTGGCGGGGAGTGCCCCGGTGCGCATAGCACGGGATTCATGCAGTGGTCTCCTTCACATCAGAAGCAG >90039_90039_27_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000415850_length(amino acids)=222AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGTFLFCLCSYLPFQDAGSPKAVLLP -------------------------------------------------------------- >90039_90039_28_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000426655_length(transcript)=945nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGTAAGAAGCTGGCCTCCTGCGGCTTTCCCATCA GCCTGATTTCTCCACCTTAGAAAAGGGTTTCTTGACAATGGGGTCAGGCCCCAGAGGAGCCCCCTGAGAGTGTCAGTTATTATTTACTAT TACGTGCTATTTTACATATCCCAAGCCCTTTAGGGCTACAGTCTCTTGTCCTGGACCCTGTAGGGTGCCATTTGGAGTTCACAGCCTAGA AGAAGAAAAGGCTTTGGGCCTGGTGTGGTGGCATAGGCCTGTAATCGTAGCGCTTTGAGAGGCTGAGGCAGGAAGATAGCTTGAGCTCAG >90039_90039_28_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000426655_length(amino acids)=211AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_29_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000541224_length(transcript)=830nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT >90039_90039_29_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000541224_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- >90039_90039_30_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000542485_length(transcript)=1538nt_BP=184nt ATGAAGTCCAGCGGCCCTGTGGAGAGGCTGCTCAGAGCCCTGGGGAGGAGGGACAGCAGCCGGGCCGCAAGCAGGCCTAGGAAAGCTGAG CCTCATAGCTTCCGGGAGAAGGTTTTCCGGAAGAAACCTCCAGTCTGTGCAGTATGTAAGGTGACCATCGATGGGACAGGCGTTTCGTGC AGAGGGAAGCCTGGAATTGCTCATCGAGACTTAAAGTCAAAGAACATTCTGGTGAAGAAAAATGGCATGTGTGCCATAGCAGACCTGGGC CTGGCTGTCCGTCATGATGCAGTCACTGACACCATTGACATTGCCCCGAATCAGAGGGTGGGGACCAAACGATACATGGCCCCTGAAGTA CTTGATGAAACCATTAATATGAAACACTTTGACTCCTTTAAATGTGCTGATATTTATGCCCTCGGGCTTGTATATTGGGAGATTGCTCGA AGATGCAATTCTGGAGGAGTCCATGAAGAATATCAGCTGCCATATTACGACTTAGTGCCCTCTGACCCTTCCATTGAGGAAATGCGAAAG GTTGTATGTGATCAGAAGCTGCGTCCCAACATCCCCAACTGGTGGCAGAGTTATGAGGCACTGCGGGTGATGGGGAAGATGATGCGAGAG TGTTGGTATGCCAACGGCGCAGCCCGCCTGACGGCCCTGCGCATCAAGAAGACCCTCTCCCAGCTCAGCGTGCAGGAAGACGTGAAGATC TAACTGCTCCCTCTCTCCACACGGAGCTCCTGGCAGCGAGAACTACGCACAGCTGCCGCGTTGAGCGTACGATGGAGGCCTACCTCTCGT TTCTGCCCAGCCCTCTGTGGCCAGGAGCCCTGGCCCGCAAGAGGGACAGAGCCCGGGAGAGACTCGCTCACTCCCATGTTGGGTTTGAGA CAGACACCTTTTCTATTTACCTCCTAATGGCATGGAGACTCTGAGAGCGAATTGTGTGGAGAACTCAGTGCCACACCTCGAACTGGTTGT AGTGGGAAGTCCCGCGAAACCCGGTGCATCTGGCACGTGGCCAGGAGCCATGACAGGGGCGCTTGGGAGGGGCCGGAGGAACCGAGGTGT TGCCAGTGCTAAGCTGCCCTGAGGGTTTCCTTCGGGGACCAGCCCACAGCACACCAAGGTGGCCCGGAAGAACCAGAAGTGCAGCCCCTC TCACAGGCAGCTCTGAGCCGCGCTTTCCCCTCCTCCCTGGGATGGACGCTGCCGGGAGACTGCCAGTGGAGACGGAATCTGCCGCTTTGT CTGTCCAGCCGTGTGTGCATGTGCCGAGGTGCGTCCCCCGTTGTGCCTGGTTCGTGCCATGCCCTTACACGTGCGTGTGAGTGTGTGTGT GTGTCTGTAGGTGCGCACTTACCTGCTTGAGCTTTCTGTGCATGTGCAGGTCGGGGGTGTGGTCGTCATGCTGTCCGTGCTTGCTGGTGC CTCTTTTCAGTAGTGAGCAGCATCTAGTTTCCCTGGTGCCCTTCCCTGGAGGTCTCTCCCTCCCCCAGAGCCCCTCATGCCACAGTGGTA >90039_90039_30_TENC1-ACVR1B_TENC1_chr12_53445747_ENST00000552570_ACVR1B_chr12_52378976_ENST00000542485_length(amino acids)=240AA_BP=61 MKSSGPVERLLRALGRRDSSRAASRPRKAEPHSFREKVFRKKPPVCAVCKVTIDGTGVSCRGKPGIAHRDLKSKNILVKKNGMCAIADLG LAVRHDAVTDTIDIAPNQRVGTKRYMAPEVLDETINMKHFDSFKCADIYALGLVYWEIARRCNSGGVHEEYQLPYYDLVPSDPSIEEMRK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TENC1-ACVR1B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TENC1-ACVR1B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TENC1-ACVR1B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies