
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TFAP2A-CDK5RAP1 (FusionGDB2 ID:90255) |
Fusion Gene Summary for TFAP2A-CDK5RAP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TFAP2A-CDK5RAP1 | Fusion gene ID: 90255 | Hgene | Tgene | Gene symbol | TFAP2A | CDK5RAP1 | Gene ID | 7020 | 51654 |
| Gene name | transcription factor AP-2 alpha | CDK5 regulatory subunit associated protein 1 | |
| Synonyms | AP-2|AP-2alpha|AP2TF|BOFS|TFAP2 | C20orf34|C42|CGI-05|HSPC167 | |
| Cytomap | 6p24.3 | 20q11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transcription factor AP-2-alphaAP-2 transcription factoractivating enhancer-binding protein 2-alphaactivator protein 2transcription factor AP-2 alpha (activating enhancer binding protein 2 alpha) | CDK5 regulatory subunit-associated protein 1CDK5 activator-binding protein C42 | |
| Modification date | 20200328 | 20200313 | |
| UniProtAcc | . | Q96SZ6 | |
| Ensembl transtripts involved in fusion gene | ENST00000319516, ENST00000379604, ENST00000379608, ENST00000379613, ENST00000482890, ENST00000497266, | ENST00000477105, ENST00000544843, ENST00000339269, ENST00000346416, ENST00000357886, ENST00000473997, | |
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 8 X 6 X 7=336 |
| # samples | 4 | 9 | |
| ** MAII score | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/336*10)=-1.90046432644909 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TFAP2A [Title/Abstract] AND CDK5RAP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TFAP2A(10402725)-CDK5RAP1(31958435), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TFAP2A | GO:0000122 | negative regulation of transcription by RNA polymerase II | 8321221|9520389|20066163 |
| Hgene | TFAP2A | GO:0008285 | negative regulation of cell proliferation | 20607706 |
| Hgene | TFAP2A | GO:0030501 | positive regulation of bone mineralization | 19578371 |
| Hgene | TFAP2A | GO:0043066 | negative regulation of apoptotic process | 20066163 |
| Hgene | TFAP2A | GO:0043525 | positive regulation of neuron apoptotic process | 20607706 |
| Hgene | TFAP2A | GO:0045595 | regulation of cell differentiation | 20607706 |
| Hgene | TFAP2A | GO:0045892 | negative regulation of transcription, DNA-templated | 20607706 |
| Hgene | TFAP2A | GO:0045893 | positive regulation of transcription, DNA-templated | 12586840 |
| Hgene | TFAP2A | GO:0045944 | positive regulation of transcription by RNA polymerase II | 7555706|7559606|11278550|20808827 |
| Hgene | TFAP2A | GO:0070172 | positive regulation of tooth mineralization | 19578371 |
| Hgene | TFAP2A | GO:0071281 | cellular response to iron ion | 20808827 |
| Hgene | TFAP2A | GO:2000378 | negative regulation of reactive oxygen species metabolic process | 20066163 |
| Tgene | CDK5RAP1 | GO:0045736 | negative regulation of cyclin-dependent protein serine/threonine kinase activity | 11882646 |
| Fusion gene breakpoints across TFAP2A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CDK5RAP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
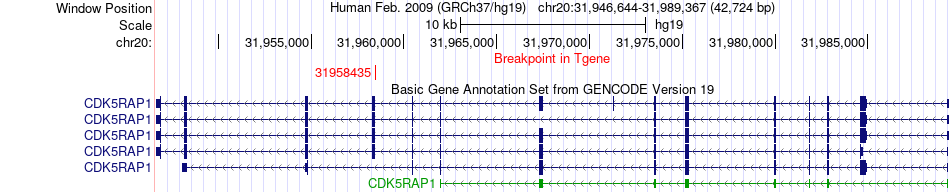 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-ZG-A9L9-01A | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| ChimerDB4 | PRAD | TCGA-ZG-A9L9 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
Top |
Fusion Gene ORF analysis for TFAP2A-CDK5RAP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000319516 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000319516 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379604 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379604 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379608 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379608 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379613 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000379613 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000482890 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5CDS-intron | ENST00000482890 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-3CDS | ENST00000497266 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-3CDS | ENST00000497266 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-3CDS | ENST00000497266 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-3CDS | ENST00000497266 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-intron | ENST00000497266 | ENST00000477105 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| 5UTR-intron | ENST00000497266 | ENST00000544843 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000319516 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000319516 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000319516 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000319516 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379604 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379604 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379604 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379604 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379608 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379608 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379608 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379608 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379613 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379613 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379613 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000379613 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000482890 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000482890 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000482890 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| In-frame | ENST00000482890 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379613 | TFAP2A | chr6 | 10402725 | - | ENST00000473997 | CDK5RAP1 | chr20 | 31958435 | - | 1853 | 1146 | 98 | 1648 | 516 |
| ENST00000379613 | TFAP2A | chr6 | 10402725 | - | ENST00000346416 | CDK5RAP1 | chr20 | 31958435 | - | 1853 | 1146 | 98 | 1648 | 516 |
| ENST00000379613 | TFAP2A | chr6 | 10402725 | - | ENST00000339269 | CDK5RAP1 | chr20 | 31958435 | - | 1853 | 1146 | 98 | 1648 | 516 |
| ENST00000379613 | TFAP2A | chr6 | 10402725 | - | ENST00000357886 | CDK5RAP1 | chr20 | 31958435 | - | 1853 | 1146 | 98 | 1648 | 516 |
| ENST00000379604 | TFAP2A | chr6 | 10402725 | - | ENST00000473997 | CDK5RAP1 | chr20 | 31958435 | - | 1842 | 1135 | 87 | 1637 | 516 |
| ENST00000379604 | TFAP2A | chr6 | 10402725 | - | ENST00000346416 | CDK5RAP1 | chr20 | 31958435 | - | 1842 | 1135 | 87 | 1637 | 516 |
| ENST00000379604 | TFAP2A | chr6 | 10402725 | - | ENST00000339269 | CDK5RAP1 | chr20 | 31958435 | - | 1842 | 1135 | 87 | 1637 | 516 |
| ENST00000379604 | TFAP2A | chr6 | 10402725 | - | ENST00000357886 | CDK5RAP1 | chr20 | 31958435 | - | 1842 | 1135 | 87 | 1637 | 516 |
| ENST00000319516 | TFAP2A | chr6 | 10402725 | - | ENST00000473997 | CDK5RAP1 | chr20 | 31958435 | - | 1766 | 1059 | 101 | 1561 | 486 |
| ENST00000319516 | TFAP2A | chr6 | 10402725 | - | ENST00000346416 | CDK5RAP1 | chr20 | 31958435 | - | 1766 | 1059 | 101 | 1561 | 486 |
| ENST00000319516 | TFAP2A | chr6 | 10402725 | - | ENST00000339269 | CDK5RAP1 | chr20 | 31958435 | - | 1766 | 1059 | 101 | 1561 | 486 |
| ENST00000319516 | TFAP2A | chr6 | 10402725 | - | ENST00000357886 | CDK5RAP1 | chr20 | 31958435 | - | 1766 | 1059 | 101 | 1561 | 486 |
| ENST00000379608 | TFAP2A | chr6 | 10402725 | - | ENST00000473997 | CDK5RAP1 | chr20 | 31958435 | - | 2350 | 1643 | 778 | 2145 | 455 |
| ENST00000379608 | TFAP2A | chr6 | 10402725 | - | ENST00000346416 | CDK5RAP1 | chr20 | 31958435 | - | 2350 | 1643 | 778 | 2145 | 455 |
| ENST00000379608 | TFAP2A | chr6 | 10402725 | - | ENST00000339269 | CDK5RAP1 | chr20 | 31958435 | - | 2350 | 1643 | 778 | 2145 | 455 |
| ENST00000379608 | TFAP2A | chr6 | 10402725 | - | ENST00000357886 | CDK5RAP1 | chr20 | 31958435 | - | 2350 | 1643 | 778 | 2145 | 455 |
| ENST00000482890 | TFAP2A | chr6 | 10402725 | - | ENST00000473997 | CDK5RAP1 | chr20 | 31958435 | - | 1943 | 1236 | 242 | 1738 | 498 |
| ENST00000482890 | TFAP2A | chr6 | 10402725 | - | ENST00000346416 | CDK5RAP1 | chr20 | 31958435 | - | 1943 | 1236 | 242 | 1738 | 498 |
| ENST00000482890 | TFAP2A | chr6 | 10402725 | - | ENST00000339269 | CDK5RAP1 | chr20 | 31958435 | - | 1943 | 1236 | 242 | 1738 | 498 |
| ENST00000482890 | TFAP2A | chr6 | 10402725 | - | ENST00000357886 | CDK5RAP1 | chr20 | 31958435 | - | 1943 | 1236 | 242 | 1738 | 498 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379613 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015695663 | 0.98430437 |
| ENST00000379613 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015695663 | 0.98430437 |
| ENST00000379613 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015695663 | 0.98430437 |
| ENST00000379613 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015695663 | 0.98430437 |
| ENST00000379604 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015709348 | 0.9842906 |
| ENST00000379604 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015709348 | 0.9842906 |
| ENST00000379604 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015709348 | 0.9842906 |
| ENST00000379604 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.015709348 | 0.9842906 |
| ENST00000319516 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.01033155 | 0.9896685 |
| ENST00000319516 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.01033155 | 0.9896685 |
| ENST00000319516 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.01033155 | 0.9896685 |
| ENST00000319516 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.01033155 | 0.9896685 |
| ENST00000379608 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.007233099 | 0.99276686 |
| ENST00000379608 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.007233099 | 0.99276686 |
| ENST00000379608 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.007233099 | 0.99276686 |
| ENST00000379608 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.007233099 | 0.99276686 |
| ENST00000482890 | ENST00000473997 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.008940688 | 0.99105924 |
| ENST00000482890 | ENST00000346416 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.008940688 | 0.99105924 |
| ENST00000482890 | ENST00000339269 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.008940688 | 0.99105924 |
| ENST00000482890 | ENST00000357886 | TFAP2A | chr6 | 10402725 | - | CDK5RAP1 | chr20 | 31958435 | - | 0.008940688 | 0.99105924 |
Top |
Fusion Genomic Features for TFAP2A-CDK5RAP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
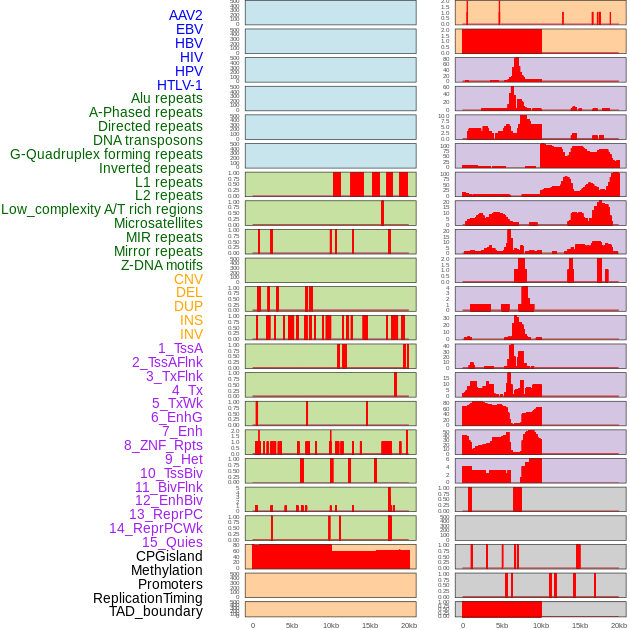 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for TFAP2A-CDK5RAP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr6:10402725/chr20:31958435) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CDK5RAP1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Methylthiotransferase that catalyzes the conversion of N6-(dimethylallyl)adenosine (i(6)A) to 2-methylthio-N6-(dimethylallyl)adenosine (ms(2)i(6)A) at position 37 (adjacent to the 3'-end of the anticodon) of four mitochondrial DNA-encoded tRNAs (Ser(UCN), Phe, Tyr and Trp) (PubMed:22422838, PubMed:25738458, PubMed:28981754). Essential for efficient and highly accurate protein translation by the ribosome (PubMed:22422838, PubMed:25738458, PubMed:28981754). Specifically inhibits CDK5 activation by CDK5R1 (PubMed:11882646). Essential for efficient mitochondrial protein synthesis and respiratory chain; shows pathological consequences in mitochondrial disease (PubMed:25738458). {ECO:0000269|PubMed:11882646, ECO:0000269|PubMed:22422838, ECO:0000269|PubMed:25738458, ECO:0000269|PubMed:28981754}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000319516 | - | 5 | 7 | 29_117 | 290 | 434.0 | Compositional bias | Note=Gln/Pro-rich (transactivation domain) |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379604 | - | 5 | 7 | 29_117 | 294 | 438.0 | Compositional bias | Note=Gln/Pro-rich (transactivation domain) |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379608 | - | 5 | 7 | 29_117 | 288 | 432.0 | Compositional bias | Note=Gln/Pro-rich (transactivation domain) |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000482890 | - | 6 | 8 | 29_117 | 294 | 438.0 | Compositional bias | Note=Gln/Pro-rich (transactivation domain) |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000319516 | - | 5 | 7 | 57_62 | 290 | 434.0 | Motif | Note=PPxY motif |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379604 | - | 5 | 7 | 57_62 | 294 | 438.0 | Motif | Note=PPxY motif |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379608 | - | 5 | 7 | 57_62 | 288 | 432.0 | Motif | Note=PPxY motif |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000482890 | - | 6 | 8 | 57_62 | 294 | 438.0 | Motif | Note=PPxY motif |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000339269 | 8 | 13 | 515_590 | 343 | 511.0 | Domain | TRAM | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000346416 | 9 | 14 | 515_590 | 420 | 588.0 | Domain | TRAM | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000357886 | 10 | 15 | 515_590 | 434 | 602.0 | Domain | TRAM | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000544843 | 0 | 12 | 100_220 | 0 | 427.6666666666667 | Domain | MTTase N-terminal | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000544843 | 0 | 12 | 244_512 | 0 | 427.6666666666667 | Domain | Radical SAM core | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000544843 | 0 | 12 | 515_590 | 0 | 427.6666666666667 | Domain | TRAM |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000319516 | - | 5 | 7 | 280_410 | 290 | 434.0 | Region | Note=H-S-H (helix-span-helix)%2C dimerization |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379604 | - | 5 | 7 | 280_410 | 294 | 438.0 | Region | Note=H-S-H (helix-span-helix)%2C dimerization |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000379608 | - | 5 | 7 | 280_410 | 288 | 432.0 | Region | Note=H-S-H (helix-span-helix)%2C dimerization |
| Hgene | TFAP2A | chr6:10402725 | chr20:31958435 | ENST00000482890 | - | 6 | 8 | 280_410 | 294 | 438.0 | Region | Note=H-S-H (helix-span-helix)%2C dimerization |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000339269 | 8 | 13 | 100_220 | 343 | 511.0 | Domain | MTTase N-terminal | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000339269 | 8 | 13 | 244_512 | 343 | 511.0 | Domain | Radical SAM core | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000346416 | 9 | 14 | 100_220 | 420 | 588.0 | Domain | MTTase N-terminal | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000346416 | 9 | 14 | 244_512 | 420 | 588.0 | Domain | Radical SAM core | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000357886 | 10 | 15 | 100_220 | 434 | 602.0 | Domain | MTTase N-terminal | |
| Tgene | CDK5RAP1 | chr6:10402725 | chr20:31958435 | ENST00000357886 | 10 | 15 | 244_512 | 434 | 602.0 | Domain | Radical SAM core |
Top |
Fusion Gene Sequence for TFAP2A-CDK5RAP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >90255_90255_1_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000339269_length(transcript)=1766nt_BP=1059nt TGGCGGAGTGAATTCCTGGGCCAGCGCGCATGCGTCGGCAGGTAGCAACCCAGCTCTTTATGACCAGGTGAGATGTTGGTGAGCAGGTAA AAAAGGAGGATTTGCCTAAGCGATTCCAGGGAGCTGGCCCGACCGAGCCCTCCAGCCCATGCCCGGCGGGGACCAGTCGCCAGGAGCGCA GAGCCGCGATGTCCATACTTGCCAAAATGGGGGACTGGCAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGG GCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCT ACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGC AGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGG ATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCT TACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCC TGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCT GTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCG AGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAA TAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATT TCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCT TTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAAC TCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAAC GCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGC TCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGA CCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGAC ATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTT >90255_90255_1_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000339269_length(amino acids)=486AA_BP=319 MPKRFQGAGPTEPSSPCPAGTSRQERRAAMSILAKMGDWQDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPI YPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHA IEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLN ASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYS MRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVR -------------------------------------------------------------- >90255_90255_2_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000346416_length(transcript)=1766nt_BP=1059nt TGGCGGAGTGAATTCCTGGGCCAGCGCGCATGCGTCGGCAGGTAGCAACCCAGCTCTTTATGACCAGGTGAGATGTTGGTGAGCAGGTAA AAAAGGAGGATTTGCCTAAGCGATTCCAGGGAGCTGGCCCGACCGAGCCCTCCAGCCCATGCCCGGCGGGGACCAGTCGCCAGGAGCGCA GAGCCGCGATGTCCATACTTGCCAAAATGGGGGACTGGCAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGG GCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCT ACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGC AGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGG ATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCT TACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCC TGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCT GTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCG AGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAA TAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATT TCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCT TTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAAC TCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAAC GCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGC TCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGA CCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGAC ATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTT >90255_90255_2_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000346416_length(amino acids)=486AA_BP=319 MPKRFQGAGPTEPSSPCPAGTSRQERRAAMSILAKMGDWQDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPI YPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHA IEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLN ASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYS MRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVR -------------------------------------------------------------- >90255_90255_3_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000357886_length(transcript)=1766nt_BP=1059nt TGGCGGAGTGAATTCCTGGGCCAGCGCGCATGCGTCGGCAGGTAGCAACCCAGCTCTTTATGACCAGGTGAGATGTTGGTGAGCAGGTAA AAAAGGAGGATTTGCCTAAGCGATTCCAGGGAGCTGGCCCGACCGAGCCCTCCAGCCCATGCCCGGCGGGGACCAGTCGCCAGGAGCGCA GAGCCGCGATGTCCATACTTGCCAAAATGGGGGACTGGCAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGG GCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCT ACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGC AGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGG ATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCT TACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCC TGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCT GTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCG AGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAA TAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATT TCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCT TTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAAC TCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAAC GCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGC TCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGA CCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGAC ATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTT >90255_90255_3_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000357886_length(amino acids)=486AA_BP=319 MPKRFQGAGPTEPSSPCPAGTSRQERRAAMSILAKMGDWQDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPI YPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHA IEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLN ASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYS MRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVR -------------------------------------------------------------- >90255_90255_4_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000473997_length(transcript)=1766nt_BP=1059nt TGGCGGAGTGAATTCCTGGGCCAGCGCGCATGCGTCGGCAGGTAGCAACCCAGCTCTTTATGACCAGGTGAGATGTTGGTGAGCAGGTAA AAAAGGAGGATTTGCCTAAGCGATTCCAGGGAGCTGGCCCGACCGAGCCCTCCAGCCCATGCCCGGCGGGGACCAGTCGCCAGGAGCGCA GAGCCGCGATGTCCATACTTGCCAAAATGGGGGACTGGCAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGG GCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCT ACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGC AGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGG ATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCT TACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCC TGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCT GTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCG AGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAA TAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATT TCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCT TTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAAC TCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAAC GCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGC TCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGA CCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGAC ATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTT >90255_90255_4_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000319516_CDK5RAP1_chr20_31958435_ENST00000473997_length(amino acids)=486AA_BP=319 MPKRFQGAGPTEPSSPCPAGTSRQERRAAMSILAKMGDWQDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPI YPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHA IEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLN ASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYS MRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVR -------------------------------------------------------------- >90255_90255_5_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000339269_length(transcript)=1842nt_BP=1135nt ACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCTCCTCCTCCTTG CCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGCCAGCACTTTGC GCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTTGGAAATTGACG GATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAA TCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTAC CCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGG CCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGAC TACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATC GAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAAC AGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGT CGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCG TCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTG CCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTT TGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATG AGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTC CGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGAC CTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCC CAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGAC TCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTG AGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTG >90255_90255_5_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000339269_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_6_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000346416_length(transcript)=1842nt_BP=1135nt ACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCTCCTCCTCCTTG CCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGCCAGCACTTTGC GCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTTGGAAATTGACG GATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAA TCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTAC CCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGG CCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGAC TACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATC GAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAAC AGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGT CGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCG TCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTG CCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTT TGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATG AGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTC CGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGAC CTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCC CAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGAC TCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTG AGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTG >90255_90255_6_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000346416_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_7_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000357886_length(transcript)=1842nt_BP=1135nt ACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCTCCTCCTCCTTG CCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGCCAGCACTTTGC GCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTTGGAAATTGACG GATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAA TCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTAC CCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGG CCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGAC TACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATC GAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAAC AGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGT CGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCG TCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTG CCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTT TGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATG AGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTC CGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGAC CTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCC CAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGAC TCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTG AGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTG >90255_90255_7_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000357886_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_8_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000473997_length(transcript)=1842nt_BP=1135nt ACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCTCCTCCTCCTTG CCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGCCAGCACTTTGC GCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTTGGAAATTGACG GATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAA TCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTAC CCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGG CCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGAC TACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATC GAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAAC AGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGT CGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCG TCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTG CCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTT TGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATG AGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTC CGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGAC CTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCC CAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGAC TCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTG AGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTG >90255_90255_8_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379604_CDK5RAP1_chr20_31958435_ENST00000473997_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_9_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000339269_length(transcript)=2350nt_BP=1643nt CACGCACGCAGACACATTCTCCCTCTCTGCGCTCTCTCCTTCGGTCTCCCTCTCTGCCTCTTTCTCTTTCACTTTTGCATGCCCTGCAAC CTTTTAAAATGTTGCCCCTTCCCTGTGATTCGCCAGACGCCGCGCCGCGGCCCCCCGCGCGCTCGCCCGCTCCCTCTCTCGCTCGCTTTT TGTCTCTCGCGCTCCCTCTCCCCACTCCGATTTGCTACACTGAGACTCCCGTCAATGGACTGCATTGAGAGCCGGCTCCGGCGCGAGTTG CCTCTCCGCTTCACGCTCGATTTCCAGGCATTCTTCCCTTATTAAGTATTCGTGTAATATTAATAGTCATGAATATCTGCTATTAGGAGG CTCCAGGAACGCTGCCCAGCGCGGTTATTAGAAGCTCAAGCGAAGCCGCCGCTAAGAAAAGAGGGGGAGACACGGATTAAGGAACACGCA CGCACCCACACACTCACACATACTTTTTCCTTTTTCCTTTTTTGGGGTTTTTCATTTTTAAAGAACTTTGAATCATAACCAGTCGCGGCA GGATAGAGACCGTGGGTTCGACCAGCTGAAGGCGCCGCGCGAATCGGTGGTTCAAGTTCGGATGGATCCGAGCCGGGCTCCCGCGCTCCG GGGAGCGTCGGCGCCGTGACTGGAGTCCTGGGTGGCGCGGGGCTCTCGGCGCCTTTTGTGTGGGGCGCGCTCGGGCGGCGGGGCAGCCGG GCGCTCCAGGCTTGCTTGTTTTTTTCCACCCTGACTCGTTACCCCAGACTCTTCGCAGATGTTAGTTCACAGTTTTTCAGCCATGGACCG TCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCA CACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAA CGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCT CCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCC ACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTAT TAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAA GGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTA CAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAA GTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTAC CCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGAC AGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAA GGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTC TGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGT GATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCAC CTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGC CTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTG CAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTGAACAGCTTTTACAGTCATTAAATTTACCTAAA >90255_90255_9_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000339269_length(amino acids)=455AA_BP=288 MLVHSFSAMDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGW PGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSN SNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNL PAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIF REEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVRAQPGDYVLVKITSASSQTLRGHVLCRTTLRD -------------------------------------------------------------- >90255_90255_10_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000346416_length(transcript)=2350nt_BP=1643nt CACGCACGCAGACACATTCTCCCTCTCTGCGCTCTCTCCTTCGGTCTCCCTCTCTGCCTCTTTCTCTTTCACTTTTGCATGCCCTGCAAC CTTTTAAAATGTTGCCCCTTCCCTGTGATTCGCCAGACGCCGCGCCGCGGCCCCCCGCGCGCTCGCCCGCTCCCTCTCTCGCTCGCTTTT TGTCTCTCGCGCTCCCTCTCCCCACTCCGATTTGCTACACTGAGACTCCCGTCAATGGACTGCATTGAGAGCCGGCTCCGGCGCGAGTTG CCTCTCCGCTTCACGCTCGATTTCCAGGCATTCTTCCCTTATTAAGTATTCGTGTAATATTAATAGTCATGAATATCTGCTATTAGGAGG CTCCAGGAACGCTGCCCAGCGCGGTTATTAGAAGCTCAAGCGAAGCCGCCGCTAAGAAAAGAGGGGGAGACACGGATTAAGGAACACGCA CGCACCCACACACTCACACATACTTTTTCCTTTTTCCTTTTTTGGGGTTTTTCATTTTTAAAGAACTTTGAATCATAACCAGTCGCGGCA GGATAGAGACCGTGGGTTCGACCAGCTGAAGGCGCCGCGCGAATCGGTGGTTCAAGTTCGGATGGATCCGAGCCGGGCTCCCGCGCTCCG GGGAGCGTCGGCGCCGTGACTGGAGTCCTGGGTGGCGCGGGGCTCTCGGCGCCTTTTGTGTGGGGCGCGCTCGGGCGGCGGGGCAGCCGG GCGCTCCAGGCTTGCTTGTTTTTTTCCACCCTGACTCGTTACCCCAGACTCTTCGCAGATGTTAGTTCACAGTTTTTCAGCCATGGACCG TCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCA CACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAA CGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCT CCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCC ACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTAT TAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAA GGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTA CAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAA GTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTAC CCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGAC AGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAA GGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTC TGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGT GATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCAC CTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGC CTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTG CAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTGAACAGCTTTTACAGTCATTAAATTTACCTAAA >90255_90255_10_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000346416_length(amino acids)=455AA_BP=288 MLVHSFSAMDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGW PGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSN SNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNL PAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIF REEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVRAQPGDYVLVKITSASSQTLRGHVLCRTTLRD -------------------------------------------------------------- >90255_90255_11_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000357886_length(transcript)=2350nt_BP=1643nt CACGCACGCAGACACATTCTCCCTCTCTGCGCTCTCTCCTTCGGTCTCCCTCTCTGCCTCTTTCTCTTTCACTTTTGCATGCCCTGCAAC CTTTTAAAATGTTGCCCCTTCCCTGTGATTCGCCAGACGCCGCGCCGCGGCCCCCCGCGCGCTCGCCCGCTCCCTCTCTCGCTCGCTTTT TGTCTCTCGCGCTCCCTCTCCCCACTCCGATTTGCTACACTGAGACTCCCGTCAATGGACTGCATTGAGAGCCGGCTCCGGCGCGAGTTG CCTCTCCGCTTCACGCTCGATTTCCAGGCATTCTTCCCTTATTAAGTATTCGTGTAATATTAATAGTCATGAATATCTGCTATTAGGAGG CTCCAGGAACGCTGCCCAGCGCGGTTATTAGAAGCTCAAGCGAAGCCGCCGCTAAGAAAAGAGGGGGAGACACGGATTAAGGAACACGCA CGCACCCACACACTCACACATACTTTTTCCTTTTTCCTTTTTTGGGGTTTTTCATTTTTAAAGAACTTTGAATCATAACCAGTCGCGGCA GGATAGAGACCGTGGGTTCGACCAGCTGAAGGCGCCGCGCGAATCGGTGGTTCAAGTTCGGATGGATCCGAGCCGGGCTCCCGCGCTCCG GGGAGCGTCGGCGCCGTGACTGGAGTCCTGGGTGGCGCGGGGCTCTCGGCGCCTTTTGTGTGGGGCGCGCTCGGGCGGCGGGGCAGCCGG GCGCTCCAGGCTTGCTTGTTTTTTTCCACCCTGACTCGTTACCCCAGACTCTTCGCAGATGTTAGTTCACAGTTTTTCAGCCATGGACCG TCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCA CACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAA CGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCT CCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCC ACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTAT TAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAA GGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTA CAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAA GTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTAC CCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGAC AGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAA GGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTC TGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGT GATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCAC CTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGC CTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTG CAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTGAACAGCTTTTACAGTCATTAAATTTACCTAAA >90255_90255_11_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000357886_length(amino acids)=455AA_BP=288 MLVHSFSAMDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGW PGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSN SNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNL PAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIF REEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVRAQPGDYVLVKITSASSQTLRGHVLCRTTLRD -------------------------------------------------------------- >90255_90255_12_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000473997_length(transcript)=2350nt_BP=1643nt CACGCACGCAGACACATTCTCCCTCTCTGCGCTCTCTCCTTCGGTCTCCCTCTCTGCCTCTTTCTCTTTCACTTTTGCATGCCCTGCAAC CTTTTAAAATGTTGCCCCTTCCCTGTGATTCGCCAGACGCCGCGCCGCGGCCCCCCGCGCGCTCGCCCGCTCCCTCTCTCGCTCGCTTTT TGTCTCTCGCGCTCCCTCTCCCCACTCCGATTTGCTACACTGAGACTCCCGTCAATGGACTGCATTGAGAGCCGGCTCCGGCGCGAGTTG CCTCTCCGCTTCACGCTCGATTTCCAGGCATTCTTCCCTTATTAAGTATTCGTGTAATATTAATAGTCATGAATATCTGCTATTAGGAGG CTCCAGGAACGCTGCCCAGCGCGGTTATTAGAAGCTCAAGCGAAGCCGCCGCTAAGAAAAGAGGGGGAGACACGGATTAAGGAACACGCA CGCACCCACACACTCACACATACTTTTTCCTTTTTCCTTTTTTGGGGTTTTTCATTTTTAAAGAACTTTGAATCATAACCAGTCGCGGCA GGATAGAGACCGTGGGTTCGACCAGCTGAAGGCGCCGCGCGAATCGGTGGTTCAAGTTCGGATGGATCCGAGCCGGGCTCCCGCGCTCCG GGGAGCGTCGGCGCCGTGACTGGAGTCCTGGGTGGCGCGGGGCTCTCGGCGCCTTTTGTGTGGGGCGCGCTCGGGCGGCGGGGCAGCCGG GCGCTCCAGGCTTGCTTGTTTTTTTCCACCCTGACTCGTTACCCCAGACTCTTCGCAGATGTTAGTTCACAGTTTTTCAGCCATGGACCG TCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCACTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCA CACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACCAGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAA CGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGCACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCT CCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATCCTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCC ACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTACCTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTAT TAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGTCCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAA GGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTTCAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTA CAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGTGTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAA GTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAGGATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTAC CCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCATTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGAC AGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTGCCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAA GGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCATCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTC TGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCTCTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGT GATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCAGGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCAC CTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCACTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGC CTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATTGCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTG CAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAAGCTGCTATGTGAACAGCTTTTACAGTCATTAAATTTACCTAAA >90255_90255_12_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379608_CDK5RAP1_chr20_31958435_ENST00000473997_length(amino acids)=455AA_BP=288 MLVHSFSAMDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGW PGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSN SNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNL PAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIF REEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAEMEDVNNPGLRVRAQPGDYVLVKITSASSQTLRGHVLCRTTLRD -------------------------------------------------------------- >90255_90255_13_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000339269_length(transcript)=1853nt_BP=1146nt TCCGAGCGCACACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCT CCTCCTCCTTGCCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_13_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000339269_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_14_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000346416_length(transcript)=1853nt_BP=1146nt TCCGAGCGCACACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCT CCTCCTCCTTGCCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_14_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000346416_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_15_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000357886_length(transcript)=1853nt_BP=1146nt TCCGAGCGCACACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCT CCTCCTCCTTGCCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_15_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000357886_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_16_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000473997_length(transcript)=1853nt_BP=1146nt TCCGAGCGCACACGGGAGCTCTTTCCCTTCTCTCCTCCTCCTCGCCCTTCTCCTCGCCCTCCTCCTCCTCCTCGCCCTCCTCTTCCTCCT CCTCCTCCTTGCCCTCCTCCTCTCCCTCCTCCTTCTCCTCCTCCACCTCCTCTCCCTCCTCCTCCTCCTCCTGCGCTCACCGCCGGCAGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_16_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000379613_CDK5RAP1_chr20_31958435_ENST00000473997_length(amino acids)=516AA_BP=349 MPSSSPSSFSSSTSSPSSSSSCAHRRQPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVG QSPYTSAPPLSHTPNADFQPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRR DYRRHEDLLHGPHALSSGLGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVP GRLSLLSSTSKYKVTVAEVQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAG FCGETEEDHVQTVSLLREVQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSAT -------------------------------------------------------------- >90255_90255_17_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000339269_length(transcript)=1943nt_BP=1236nt GCAGATTAACACAGCTAAAAGTCGGTTCCCGGTGATTTATTTTGATGCACGCACGAGACGGTATCTAGACTTGCAGGCACACACACGTCT GTTTTTAGGCTCAACTTCAGAAGCGGGTGTGCAGTTCCATAGGAGTTCTGTATTCGTGTCCACGTTGCACCCAGGAAACCTTAGCCTGAA CACCAATTTGAACTGTCAGTTGGCCCTAGCTTCACACAAACAGGAGAAAAATTGTTTAACCCCTGGAGCTGTCAAGTAACCTCTTCAGGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_17_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000339269_length(amino acids)=498AA_BP=331 MELSSNLFRPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADF QPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSG LGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAE VQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLRE VQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAE -------------------------------------------------------------- >90255_90255_18_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000346416_length(transcript)=1943nt_BP=1236nt GCAGATTAACACAGCTAAAAGTCGGTTCCCGGTGATTTATTTTGATGCACGCACGAGACGGTATCTAGACTTGCAGGCACACACACGTCT GTTTTTAGGCTCAACTTCAGAAGCGGGTGTGCAGTTCCATAGGAGTTCTGTATTCGTGTCCACGTTGCACCCAGGAAACCTTAGCCTGAA CACCAATTTGAACTGTCAGTTGGCCCTAGCTTCACACAAACAGGAGAAAAATTGTTTAACCCCTGGAGCTGTCAAGTAACCTCTTCAGGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_18_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000346416_length(amino acids)=498AA_BP=331 MELSSNLFRPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADF QPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSG LGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAE VQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLRE VQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAE -------------------------------------------------------------- >90255_90255_19_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000357886_length(transcript)=1943nt_BP=1236nt GCAGATTAACACAGCTAAAAGTCGGTTCCCGGTGATTTATTTTGATGCACGCACGAGACGGTATCTAGACTTGCAGGCACACACACGTCT GTTTTTAGGCTCAACTTCAGAAGCGGGTGTGCAGTTCCATAGGAGTTCTGTATTCGTGTCCACGTTGCACCCAGGAAACCTTAGCCTGAA CACCAATTTGAACTGTCAGTTGGCCCTAGCTTCACACAAACAGGAGAAAAATTGTTTAACCCCTGGAGCTGTCAAGTAACCTCTTCAGGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_19_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000357886_length(amino acids)=498AA_BP=331 MELSSNLFRPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADF QPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSG LGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAE VQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLRE VQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAE -------------------------------------------------------------- >90255_90255_20_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000473997_length(transcript)=1943nt_BP=1236nt GCAGATTAACACAGCTAAAAGTCGGTTCCCGGTGATTTATTTTGATGCACGCACGAGACGGTATCTAGACTTGCAGGCACACACACGTCT GTTTTTAGGCTCAACTTCAGAAGCGGGTGTGCAGTTCCATAGGAGTTCTGTATTCGTGTCCACGTTGCACCCAGGAAACCTTAGCCTGAA CACCAATTTGAACTGTCAGTTGGCCCTAGCTTCACACAAACAGGAGAAAAATTGTTTAACCCCTGGAGCTGTCAAGTAACCTCTTCAGGC CAGCACTTTGCGCTCACCCAGAGAGTAGCTCCACTTGGGTGCGAGACCGAGAGGGGCATATCCGTTCACGCCGATCCATGAAAATGCTTT GGAAATTGACGGATAATATCAAGTACGAGGACTGCGAGGACCGTCACGACGGCACCAGCAACGGGACGGCACGGTTGCCCCAGCTGGGCA CTGTAGGTCAATCTCCCTACACGAGCGCCCCGCCGCTGTCCCACACCCCCAATGCCGACTTCCAGCCCCCATACTTCCCCCCACCCTACC AGCCTATCTACCCCCAGTCGCAAGATCCTTACTCCCACGTCAACGACCCCTACAGCCTGAACCCCCTGCACGCCCAGCCGCAGCCGCAGC ACCCAGGCTGGCCCGGCCAGAGGCAGAGCCAGGAGTCTGGGCTCCTGCACACGCACCGGGGGCTGCCTCACCAGCTGTCGGGCCTGGATC CTCGCAGGGACTACAGGCGGCACGAGGACCTCCTGCACGGCCCACACGCGCTCAGCTCAGGACTCGGAGACCTCTCGATCCACTCCTTAC CTCACGCCATCGAGGAGGTCCCGCATGTAGAAGACCCGGGTATTAACATCCCAGATCAAACTGTAATTAAGAAAGGCCCCGTGTCCCTGT CCAAGTCCAACAGCAATGCCGTCTCCGCCATCCCTATTAACAAGGACAACCTCTTCGGCGGCGTGGTGAACCCCAACGAAGTCTTCTGTT CAGTTCCGGGTCGCCTCTCGCTCCTCAGCTCCACCTCGAAGTACAAGGTCACGGTGGCGGAAGTGCAGCGGCGGCTCTCACCACCCGAGT GTCTCAACGCGTCGCTGCTGGGCGGAGTGCTCCGGAGGGCGAAGTCTAAAAATGGAGGAAGATCTTTAAGAGAAAAACTGGACAAAATAG GATTAAATCTGCCTGCAGGGAGACGTAAAGCTGCCAACGTTACCCTGCTCACATCACTAGTAGAGGGTGTGAGCCTCAGCAGCGATTTCA TTGCTGGCTTTTGTGGTGAGACGGAGGAAGATCACGTCCAGACAGTCTCTTTGCTCCGGGAAGTTCAGTACAACATGGGCTTCCTCTTTG CCTACAGCATGAGACAGAAGACACGGGCATATCATAGGCTGAAGGATGATGTCCCGGAAGAGGTAAAATTAAGGCGTTTGGAGGAACTCA TCACTATCTTCCGAGAAGAAGCAACAAAAGCCAATCAGACCTCTGTGGGCTGTACCCAGTTGGTGCTAGTGGAAGGGCTCAGTAAACGCT CTGCCACTGACCTGTGTGGCAGGAATGATGGAAACCTTAAGGTGATCTTCCCTGATGCAGAGATGGAGGATGTCAATAACCCTGGGCTCA GGGTCAGAGCCCAGCCTGGGGACTATGTGCTGGTGAAGATCACCTCAGCCAGTTCTCAGACACTTAGGGGACATGTTCTCTGCAGGACCA CTCTGAGGGACTCTTCTGCATATTGCTGACCTGAGAGGATGGCCTCAGAGCTGACTTGGGCAATCCTCCCCAACAGGAAGGGGAGACATT GCCTGCCACTGAGGAAACAGGTCATGAAGGTGGAGATAAGCTGCAAGGGGCGAAGCAACTTTATGTCAGTGGAAAACGTGTCTCTTTAAA >90255_90255_20_TFAP2A-CDK5RAP1_TFAP2A_chr6_10402725_ENST00000482890_CDK5RAP1_chr20_31958435_ENST00000473997_length(amino acids)=498AA_BP=331 MELSSNLFRPALCAHPESSSTWVRDREGHIRSRRSMKMLWKLTDNIKYEDCEDRHDGTSNGTARLPQLGTVGQSPYTSAPPLSHTPNADF QPPYFPPPYQPIYPQSQDPYSHVNDPYSLNPLHAQPQPQHPGWPGQRQSQESGLLHTHRGLPHQLSGLDPRRDYRRHEDLLHGPHALSSG LGDLSIHSLPHAIEEVPHVEDPGINIPDQTVIKKGPVSLSKSNSNAVSAIPINKDNLFGGVVNPNEVFCSVPGRLSLLSSTSKYKVTVAE VQRRLSPPECLNASLLGGVLRRAKSKNGGRSLREKLDKIGLNLPAGRRKAANVTLLTSLVEGVSLSSDFIAGFCGETEEDHVQTVSLLRE VQYNMGFLFAYSMRQKTRAYHRLKDDVPEEVKLRRLEELITIFREEATKANQTSVGCTQLVLVEGLSKRSATDLCGRNDGNLKVIFPDAE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TFAP2A-CDK5RAP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TFAP2A-CDK5RAP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TFAP2A-CDK5RAP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies