
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TGFBRAP1-RQCD1 (FusionGDB2 ID:90494) |
Fusion Gene Summary for TGFBRAP1-RQCD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TGFBRAP1-RQCD1 | Fusion gene ID: 90494 | Hgene | Tgene | Gene symbol | TGFBRAP1 | RQCD1 | Gene ID | 9392 | 9125 |
| Gene name | transforming growth factor beta receptor associated protein 1 | CCR4-NOT transcription complex subunit 9 | |
| Synonyms | TRAP-1|TRAP1|VPS3 | CAF40|CT129|RCD-1|RCD1|RQCD1 | |
| Cytomap | 2q12.1-q12.2 | 2q35 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transforming growth factor-beta receptor-associated protein 1TGF-beta receptor-associated protein 1VPS3 CORVET complex subunit | CCR4-NOT transcription complex subunit 9RCD1 required for cell differentiation1 homologcancer/testis antigen 129cell differentiation protein RCD1 homologcell differentiation protein RQCD1 homologprotein involved in sexual development | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000258449, ENST00000393359, | ENST00000489687, ENST00000273064, ENST00000295701, ENST00000509807, ENST00000542068, | |
| Fusion gene scores | * DoF score | 8 X 6 X 5=240 | 2 X 2 X 2=8 |
| # samples | 10 | 2 | |
| ** MAII score | log2(10/240*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: TGFBRAP1 [Title/Abstract] AND RQCD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TGFBRAP1(105912813)-RQCD1(219447694), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TGFBRAP1 | GO:0006355 | regulation of transcription, DNA-templated | 11278302 |
| Hgene | TGFBRAP1 | GO:0007165 | signal transduction | 11278302 |
| Tgene | RQCD1 | GO:2000327 | positive regulation of nuclear receptor transcription coactivator activity | 18180299 |
| Fusion gene breakpoints across TGFBRAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RQCD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-13-1505-01A | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
Top |
Fusion Gene ORF analysis for TGFBRAP1-RQCD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000258449 | ENST00000489687 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| 5CDS-intron | ENST00000393359 | ENST00000489687 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000258449 | ENST00000273064 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000258449 | ENST00000295701 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000258449 | ENST00000509807 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000258449 | ENST00000542068 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000393359 | ENST00000273064 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000393359 | ENST00000295701 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000393359 | ENST00000509807 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| In-frame | ENST00000393359 | ENST00000542068 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393359 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000509807 | RQCD1 | chr2 | 219447694 | + | 2507 | 1465 | 283 | 2256 | 657 |
| ENST00000393359 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000273064 | RQCD1 | chr2 | 219447694 | + | 4965 | 1465 | 283 | 2160 | 625 |
| ENST00000393359 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000542068 | RQCD1 | chr2 | 219447694 | + | 4273 | 1465 | 283 | 2160 | 625 |
| ENST00000393359 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000295701 | RQCD1 | chr2 | 219447694 | + | 2310 | 1465 | 283 | 2037 | 584 |
| ENST00000258449 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000509807 | RQCD1 | chr2 | 219447694 | + | 2100 | 1058 | 20 | 1849 | 609 |
| ENST00000258449 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000273064 | RQCD1 | chr2 | 219447694 | + | 4558 | 1058 | 20 | 1753 | 577 |
| ENST00000258449 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000542068 | RQCD1 | chr2 | 219447694 | + | 3866 | 1058 | 20 | 1753 | 577 |
| ENST00000258449 | TGFBRAP1 | chr2 | 105912813 | - | ENST00000295701 | RQCD1 | chr2 | 219447694 | + | 1903 | 1058 | 20 | 1630 | 536 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393359 | ENST00000509807 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.00628484 | 0.9937151 |
| ENST00000393359 | ENST00000273064 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.002177955 | 0.99782205 |
| ENST00000393359 | ENST00000542068 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.002981674 | 0.99701834 |
| ENST00000393359 | ENST00000295701 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.002349796 | 0.9976502 |
| ENST00000258449 | ENST00000509807 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.004359695 | 0.9956403 |
| ENST00000258449 | ENST00000273064 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.001658056 | 0.9983419 |
| ENST00000258449 | ENST00000542068 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.002123684 | 0.9978763 |
| ENST00000258449 | ENST00000295701 | TGFBRAP1 | chr2 | 105912813 | - | RQCD1 | chr2 | 219447694 | + | 0.001644583 | 0.99835545 |
Top |
Fusion Genomic Features for TGFBRAP1-RQCD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TGFBRAP1 | chr2 | 105912812 | - | RQCD1 | chr2 | 219447693 | + | 2.67E-06 | 0.9999974 |
| TGFBRAP1 | chr2 | 105912812 | - | RQCD1 | chr2 | 219447693 | + | 2.67E-06 | 0.9999974 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
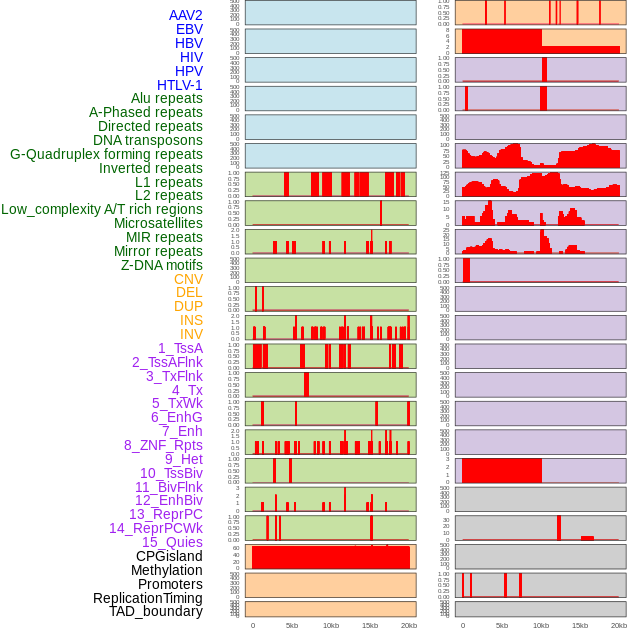 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
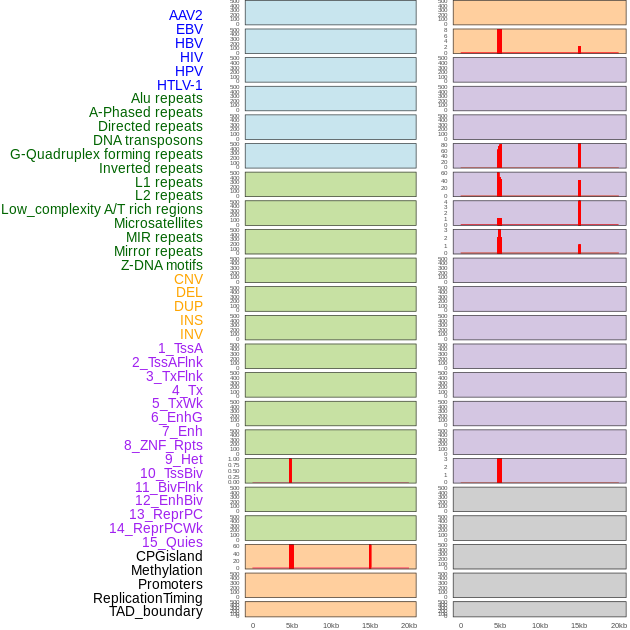 |
Top |
Fusion Protein Features for TGFBRAP1-RQCD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:105912813/chr2:219447694) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TGFBRAP1 | chr2:105912813 | chr2:219447694 | ENST00000258449 | - | 3 | 11 | 24_297 | 346 | 861.0 | Domain | CNH |
| Hgene | TGFBRAP1 | chr2:105912813 | chr2:219447694 | ENST00000393359 | - | 4 | 12 | 24_297 | 346 | 861.0 | Domain | CNH |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TGFBRAP1 | chr2:105912813 | chr2:219447694 | ENST00000258449 | - | 3 | 11 | 564_728 | 346 | 861.0 | Repeat | Note=CHCR |
| Hgene | TGFBRAP1 | chr2:105912813 | chr2:219447694 | ENST00000393359 | - | 4 | 12 | 564_728 | 346 | 861.0 | Repeat | Note=CHCR |
Top |
Fusion Gene Sequence for TGFBRAP1-RQCD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >90494_90494_1_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000273064_length(transcript)=4558nt_BP=1058nt CAGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTACGCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGC GCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTACGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGA GGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACAGCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTG CGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTCCATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGG CCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCCTGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCA AACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGTGCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGG CTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTACATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCT ACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAGACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCA CAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGAGAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCG ATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACAGAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTG AAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTTGGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCC GCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAGGAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCAT CTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGTTTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAA CCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTACCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCC GGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGATGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTT TATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAACAGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTT TGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGCCATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTG CCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTCAGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCCCTGACC AGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGATGACACCACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGCAAGAGG GCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCCTCAGTGATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGAAAGGAG GGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCACCGACTGGGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGGGGCAAG GTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGCTGTCTTGAGGACCTGGGCTCCCTCTGCTACTCCCAGGAAATGGGCTCCTGACA CAGCAGTCTGCCACCACAGCCCCAGGAGGGTGTCAACACCAGCAAATGCTGTATTTGCAGCATGTCCAAGATGACCCTTCTCCCCTACCT CTACCTAGCCACTGGCAGGGAGGGGAGACAGTGGTGATAGCAGCAGCACTCTAGGCATGGTGAACGCCTGGGACCAAGCCATGTGGCGTT TTTTATTTTGCCTTTCTGGAAGACTCAAGATATGTCTCTTCATTCTCTCTCAGTATTTGTTTACTTTGGTTTTTTTGTTTTTAATCTCAG AGAGAGGTGTGTTTAGTGGGCACAAGCTGTAATATTCAGCAAAACTTTGTCGACTGGCACTGTTTACAAGTCTGTTAGCTGCATAAGCTC AATAAAAAGTTGGTCTGGGCATTACATCCCCTCTGGCAGGCCAATAGCTGCATCAAGCTGTTGGGAGAAATGGGAGGGCAGGGGAAAGAT GTAAAGCCAAAGTACAGCAGGAACCCACCACCTGTTTCCCTTCCTTCTCCCATTCTACTCCCAGTCCGGAATGCCACGAGGACCTTAACC TTGTTTCTGGCTTTAGCTGCTAGTTTTCCCAAATCTCAGTGCTTTCCCTTTTTGAACTTCCCTTCTATTAAACTTAAAACAGATGTCTTA ATTAATCAGGCTGTCTTGGAAGGGTATTGTATTGGGAGACAAGGGGCGGTGGTGGACCTCACCTTCAATCCAAGTTTTCAAAGATATTTT CTCAATAACTCTAAAAGGGAGGTGCTTGGGATTAAGGTGACAGTCCACTTGATCCTTTTCTTTGTTTTAGTGTGAATTTCAGCAGCTCCA TCTGTCTTCATGATTGTACTTGAGCAGTATTAGCTGTATGAGTTAATTTTATTCAGATTGAAGATGGAGGGCTGGGTTCTGCTCACTCAG TCTTTTTTTTTTTTTTTTTTTTTTTTTTTTGACCATTCTCTTTTAGTCTATGGGAATTACAGGGTTGCCGCTAAAATATTCACTTGTTCA TATCGTGTCAGAGATTTCCTCTTCTCTGGAGCTTAGGTGGCTCTTCACAATCCATAGGCTTGAATCTGCAACCTAGTGTAAACTGCCTTG CTTTCCCCGGTTCTTTCCCCTGCTAGCACCTGCTTTCTCATCCCTATCTCCAGTCAAAGATGGGATTGCTTAATCCAACTCTGGAGAGGG ACCAAGTCTTTTCTGCCCACATCTCACACAATTGAGGTGTCTGAACAAGCTTGGGGAGGGTCTATAAGGGGTAGGCTCAAAAAAAAAAAA ACCCATTTGCAGAGGCAGTTTTGCCAACACAAGGGCTCTTTCAAGCCGACTTTCACAAAGAGAGCCGGACTTGTTAGTTGGCTTCTGTCT CTTTAGAGCCAAGAAAATAGTAATTAAGTGGCCTAGATATAGGAAGGGCAGAATAAGCACTTACTCCCCCTGCCTTCCAAGATGAAGAGG AGAAGCAGGCCAACCCTCAATAATTGCAAGCCTGAAGAGAAGTGATCTTAGAGAAAGCAGAGAACAGAATGGACTGGATAGACATCTTGA CTCTATTCAGCCCGTAGTCTGTGATCTGGAGAGTCCAGTTAAGGTAACCCAGATTTTTGACAACCGCCTTCCTGCTGAGCCAAAGTTTTC TCATTACCCCTCCACTGGGGAAGCAGCTGAGGCCCAGGGCCTTGCTCCCTGGGAAATTCTCTTCTCTCCATCTTTCGGTGCATTGGCCAT GTTACTGTGCCAAAGTGTCTTAATTCTTGTCCCATCTATTCTCAGCTGGCCTTGGAACCCACATAGGAGTTGGTGGGGGAGGGATGGAAT GGGTATTATTCATTGTAGTTGATCCTGGTGTGTGTATTATATAAAGAGACCCCTCCCCTTATTTTGTGTTTTCCATCCCTCTCCCTTAAC AGGATTGAAATAAAACATGCTTCTGTTTTTGTAAAAATAATTTTTCCTTTACACTGGAGATTTTATTCTATCAGTATATGGGTAACTAGG CACTTTGGTCAGGTGATCCTTGTCATGCCTGCTTCTCCCCTCTGTCTACCTACACAACACACACACACACACACACACAGCCCTGCTAAG ATGGCAGTAGTGGTTCTTTTGTGAACATGTTTTTTGGGGAGACTCCATCTGAGGTACAAAAGCTGTTTGGGAGGCTGGGAGGGGGATGAT GCCCCTTACCTGATAAAAGTATGTTTTACTGGGACAGAACTTCACTCCTGGCCATATTGGCCAGAACTTAGTGCCAGTGTAGGGAGAGAC TTCCATAGTGACAAGGTAATGCTTGAAACATCTTACGAACTTTGATGTTCATTTCCTCAAGTTCAAGGCTTGGAGCACATCTCCAGGATT GTTTCCATGCCTGGCTGTCAGTGGGACACAGCTGCCCTATGCTTCCACGTTCTTTTTTCAAGAGCCTTAGAGGGCCTGTGGCCTGTTTCA CTGGTGGAACAGGAGCAGCATTGGTAGCCTTCAGAGCATGCCTTGCTTACTAACTACATATTATTCCTCTGCTCATTGTTCCTGCTGCTT >90494_90494_1_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000273064_length(amino acids)=577AA_BP=344 MMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTNDCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNR LLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGDPFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFL CLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFLLAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITV HSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLPLEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTL TAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIME SGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRAREALRQCLPDQLKDTTF -------------------------------------------------------------- >90494_90494_2_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000295701_length(transcript)=1903nt_BP=1058nt CAGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTACGCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGC GCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTACGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGA GGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACAGCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTG CGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTCCATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGG CCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCCTGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCA AACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGTGCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGG CTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTACATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCT ACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAGACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCA CAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGAGAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCG ATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACAGAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTG AAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTTGGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCC GCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAGGAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCAT CTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGTTTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAA CCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTACCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCC GGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGATGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTT TATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAACAGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTT TGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGCCATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTG CCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTCAGATAACCCCAGGTTTTCAGATTTGACTTTCTGCTGGTCATCTTTTC AAAGAAAATGAAACGTTTAAAAGTTCATCTGATAATACTGCTACCATAGTTTTGTTTTCACTGCTCATCTCTTATTAAGGTTTTTAACCA TAAAACTGAAGCAATTTCTGTAAAGACACAAATTGATAACTTAGTATAGAATTAAAATTCATTAAGTTATCATAAGTTTGATGATATCCT TGTTAATGTACTGATTTTTGAATTATTTTATTTGCCATAATCCATATATTTCTAACATGAGTATTTTGACAGTATTTAATAAATCAGAAA >90494_90494_2_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000295701_length(amino acids)=536AA_BP=344 MMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTNDCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNR LLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGDPFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFL CLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFLLAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITV HSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLPLEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTL TAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIME -------------------------------------------------------------- >90494_90494_3_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000509807_length(transcript)=2100nt_BP=1058nt CAGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTACGCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGC GCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTACGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGA GGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACAGCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTG CGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTCCATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGG CCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCCTGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCA AACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGTGCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGG CTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTACATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCT ACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAGACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCA CAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGAGAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCG ATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACAGAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTG AAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTTGGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCC GCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAGGAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCAT CTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGTTTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAA CCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTACCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCC GGCTCACCAGCCTTGGAGTTATTGTAGAGACGGGGTTTCACCATGTTGGCCAGGCTGATCTTGAACTCCCGACCTCAAGTGATCTGCCCG CCTCGGCCTCCCAAAGTGCTGGGATTACAGGGGCCCTGGTGAAAACAGATGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTA TCCCTTTATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAACAGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACA CTGGTTTGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGCCATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGC CTTCTGCCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTCAGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCC CTGACCAGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGATGACACCACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGC AAGAGGGCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCCTCAGTGATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGA AAGGAGGGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCACCGACTGGGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGG GGCAAGGTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGCTGTCTTGAGGACCTGGGCTCCCTCTGCTACTCCCAGGAAATGGGCTC >90494_90494_3_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000509807_length(amino acids)=609AA_BP=344 MMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTNDCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNR LLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGDPFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFL CLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFLLAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITV HSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLPLEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTL TAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIVETGFHHVGQADLELPTSSDLPASASQSA GITGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLK -------------------------------------------------------------- >90494_90494_4_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000542068_length(transcript)=3866nt_BP=1058nt CAGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTACGCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGC GCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTACGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGA GGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACAGCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTG CGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTCCATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGG CCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCCTGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCA AACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGTGCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGG CTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTACATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCT ACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAGACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCA CAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGAGAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCG ATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACAGAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTG AAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTTGGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCC GCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAGGAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCAT CTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGTTTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAA CCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTACCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCC GGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGATGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTT TATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAACAGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTT TGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGCCATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTG CCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTCAGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCCCTGACC AGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGATGACACCACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGCAAGAGG GCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCCTCAGTGATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGAAAGGAG GGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCACCGACTGGGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGGGGCAAG GTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGCTGTCTTGAGGACCTGGGCTCCCTCTGCTACTCCCAGGAAATGGGCTCCTGACA CAGCAGTCTGCCACCACAGCCCCAGGAGGGTGTCAACACCAGCAAATGCTGTATTTGCAGCATGTCCAAGATGACCCTTCTCCCCTACCT CTACCTAGCCACTGGCAGGGAGGGGAGACAGTGGTGATAGCAGCAGCACTCTAGGCATGGTGAACGCCTGGGACCAAGCCATGTGGCGTT TTTTATTTTGCCTTTCTGGAAGACTCAAGATATGTCTCTTCATTCTCTCTCAGTATTTGTTTACTTTGGTTTTTTTGTTTTTAATCTCAG AGAGAGGTGTGTTTAGTGGGCACAAGCTGTAATATTCAGCAAAACTTTGTCGACTGGCACTGTTTACAAGTCTGTTAGCTGCATAAGCTC AATAAAAAGTTGGTCTGGGCATTACATCCCCTCTGGCAGGCCAATAGCTGCATCAAGCTGTTGGGAGAAATGGGAGGGCAGGGGAAAGAT GTAAAGCCAAAGTACAGCAGGAACCCACCACCTGTTTCCCTTCCTTCTCCCATTCTACTCCCAGTCCGGAATGCCACGAGGACCTTAACC TTGTTTCTGGCTTTAGCTGCTAGTTTTCCCAAATCTCAGTGCTTTCCCTTTTTGAACTTCCCTTCTATTAAACTTAAAACAGATGTCTTA ATTAATCAGGCTGTCTTGGAAGGGTATTGTATTGGGAGACAAGGGGCGGTGGTGGACCTCACCTTCAATCCAAGTTTTCAAAGATATTTT CTCAATAACTCTAAAAGGGAGGTGCTTGGGATTAAGGTGACAGTCCACTTGATCCTTTTCTTTGTTTTAGTGTGAATTTCAGCAGCTCCA TCTGTCTTCATGATTGTACTTGAGCAGTATTAGCTGTATGAGTTAATTTTATTCAGATTGAAGATGGAGGGCTGGGTTCTGCTCACTCAG TCTTTTTTTTTTTTTTTTTTTTTTTTTTTTGACCATTCTCTTTTAGTCTATGGGAATTACAGGGTTGCCGCTAAAATATTCACTTGTTCA TATCGTGTCAGAGATTTCCTCTTCTCTGGAGCTTAGGTGGCTCTTCACAATCCATAGGCTTGAATCTGCAACCTAGTGTAAACTGCCTTG CTTTCCCCGGTTCTTTCCCCTGCTAGCACCTGCTTTCTCATCCCTATCTCCAGTCAAAGATGGGATTGCTTAATCCAACTCTGGAGAGGG ACCAAGTCTTTTCTGCCCACATCTCACACAATTGAGGTGTCTGAACAAGCTTGGGGAGGGTCTATAAGGGGTAGGCTCAAAAAAAAAAAA ACCCATTTGCAGAGGCAGTTTTGCCAACACAAGGGCTCTTTCAAGCCGACTTTCACAAAGAGAGCCGGACTTGTTAGTTGGCTTCTGTCT CTTTAGAGCCAAGAAAATAGTAATTAAGTGGCCTAGATATAGGAAGGGCAGAATAAGCACTTACTCCCCCTGCCTTCCAAGATGAAGAGG AGAAGCAGGCCAACCCTCAATAATTGCAAGCCTGAAGAGAAGTGATCTTAGAGAAAGCAGAGAACAGAATGGACTGGATAGACATCTTGA CTCTATTCAGCCCGTAGTCTGTGATCTGGAGAGTCCAGTTAAGGTAACCCAGATTTTTGACAACCGCCTTCCTGCTGAGCCAAAGTTTTC TCATTACCCCTCCACTGGGGAAGCAGCTGAGGCCCAGGGCCTTGCTCCCTGGGAAATTCTCTTCTCTCCATCTTTCGGTGCATTGGCCAT GTTACTGTGCCAAAGTGTCTTAATTCTTGTCCCATCTATTCTCAGCTGGCCTTGGAACCCACATAGGAGTTGGTGGGGGAGGGATGTGTA >90494_90494_4_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000258449_RQCD1_chr2_219447694_ENST00000542068_length(amino acids)=577AA_BP=344 MMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTNDCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNR LLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGDPFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFL CLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFLLAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITV HSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLPLEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTL TAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLHTVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIME SGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRAREALRQCLPDQLKDTTF -------------------------------------------------------------- >90494_90494_5_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000273064_length(transcript)=4965nt_BP=1465nt CCCGCAGCGGCGGGGGCGGAGAAGAGACCTCAGCCCCGCGGGCTCGCACAGCTGGCGCGGACCACGCTCTCGCCCGGGGCCGGCGGCCTC AGCGCCCCCCGAATGAACACCTTCCGCCCGCTGGCCGCCCCGCGAGGCGGGCCGTGTCGTGGCCCCGGTGCACGGAGGGGGACGCCGAGG CCCGGAGCAGGGCCCGTCTCGGCCTGTGCTCGGAGCCAGGCGGCAGGGCCCGCGGGCCGGCGGGCGGCGCGGAGACGGCTGCGCTCCCGC CCTCCGCCAGCGCCTGGCGGCCGCCCCACGTGACGGGAAGCGGCGGCTGCGGGGTCGGGCCAGCCCAGGAGCCGCGGGCCGGAGCGGGGC GGCGGGGCCCCAGGCCGCGGGGCGGCGCGGGACGGCGGGCGCCGGCGCCGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTAC GCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGCGCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTA CGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGAGGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACA GCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTGCGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTC CATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGGCCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCC TGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCAAACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGT GCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGGCTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTA CATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCTACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAG ACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCACAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGA GAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCGATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACA GAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTGAAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTT GGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCCGCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAG GAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCATCTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGT TTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAACCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTA CCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCCGGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGA TGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTTTATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAAC AGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTTTGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGC CATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTGCCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTC AGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCCCTGACCAGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGATGACAC CACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGCAAGAGGGCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCCTCAGTG ATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGAAAGGAGGGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCACCGACTG GGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGGGGCAAGGTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGCTGTCTT GAGGACCTGGGCTCCCTCTGCTACTCCCAGGAAATGGGCTCCTGACACAGCAGTCTGCCACCACAGCCCCAGGAGGGTGTCAACACCAGC AAATGCTGTATTTGCAGCATGTCCAAGATGACCCTTCTCCCCTACCTCTACCTAGCCACTGGCAGGGAGGGGAGACAGTGGTGATAGCAG CAGCACTCTAGGCATGGTGAACGCCTGGGACCAAGCCATGTGGCGTTTTTTATTTTGCCTTTCTGGAAGACTCAAGATATGTCTCTTCAT TCTCTCTCAGTATTTGTTTACTTTGGTTTTTTTGTTTTTAATCTCAGAGAGAGGTGTGTTTAGTGGGCACAAGCTGTAATATTCAGCAAA ACTTTGTCGACTGGCACTGTTTACAAGTCTGTTAGCTGCATAAGCTCAATAAAAAGTTGGTCTGGGCATTACATCCCCTCTGGCAGGCCA ATAGCTGCATCAAGCTGTTGGGAGAAATGGGAGGGCAGGGGAAAGATGTAAAGCCAAAGTACAGCAGGAACCCACCACCTGTTTCCCTTC CTTCTCCCATTCTACTCCCAGTCCGGAATGCCACGAGGACCTTAACCTTGTTTCTGGCTTTAGCTGCTAGTTTTCCCAAATCTCAGTGCT TTCCCTTTTTGAACTTCCCTTCTATTAAACTTAAAACAGATGTCTTAATTAATCAGGCTGTCTTGGAAGGGTATTGTATTGGGAGACAAG GGGCGGTGGTGGACCTCACCTTCAATCCAAGTTTTCAAAGATATTTTCTCAATAACTCTAAAAGGGAGGTGCTTGGGATTAAGGTGACAG TCCACTTGATCCTTTTCTTTGTTTTAGTGTGAATTTCAGCAGCTCCATCTGTCTTCATGATTGTACTTGAGCAGTATTAGCTGTATGAGT TAATTTTATTCAGATTGAAGATGGAGGGCTGGGTTCTGCTCACTCAGTCTTTTTTTTTTTTTTTTTTTTTTTTTTTTGACCATTCTCTTT TAGTCTATGGGAATTACAGGGTTGCCGCTAAAATATTCACTTGTTCATATCGTGTCAGAGATTTCCTCTTCTCTGGAGCTTAGGTGGCTC TTCACAATCCATAGGCTTGAATCTGCAACCTAGTGTAAACTGCCTTGCTTTCCCCGGTTCTTTCCCCTGCTAGCACCTGCTTTCTCATCC CTATCTCCAGTCAAAGATGGGATTGCTTAATCCAACTCTGGAGAGGGACCAAGTCTTTTCTGCCCACATCTCACACAATTGAGGTGTCTG AACAAGCTTGGGGAGGGTCTATAAGGGGTAGGCTCAAAAAAAAAAAAACCCATTTGCAGAGGCAGTTTTGCCAACACAAGGGCTCTTTCA AGCCGACTTTCACAAAGAGAGCCGGACTTGTTAGTTGGCTTCTGTCTCTTTAGAGCCAAGAAAATAGTAATTAAGTGGCCTAGATATAGG AAGGGCAGAATAAGCACTTACTCCCCCTGCCTTCCAAGATGAAGAGGAGAAGCAGGCCAACCCTCAATAATTGCAAGCCTGAAGAGAAGT GATCTTAGAGAAAGCAGAGAACAGAATGGACTGGATAGACATCTTGACTCTATTCAGCCCGTAGTCTGTGATCTGGAGAGTCCAGTTAAG GTAACCCAGATTTTTGACAACCGCCTTCCTGCTGAGCCAAAGTTTTCTCATTACCCCTCCACTGGGGAAGCAGCTGAGGCCCAGGGCCTT GCTCCCTGGGAAATTCTCTTCTCTCCATCTTTCGGTGCATTGGCCATGTTACTGTGCCAAAGTGTCTTAATTCTTGTCCCATCTATTCTC AGCTGGCCTTGGAACCCACATAGGAGTTGGTGGGGGAGGGATGGAATGGGTATTATTCATTGTAGTTGATCCTGGTGTGTGTATTATATA AAGAGACCCCTCCCCTTATTTTGTGTTTTCCATCCCTCTCCCTTAACAGGATTGAAATAAAACATGCTTCTGTTTTTGTAAAAATAATTT TTCCTTTACACTGGAGATTTTATTCTATCAGTATATGGGTAACTAGGCACTTTGGTCAGGTGATCCTTGTCATGCCTGCTTCTCCCCTCT GTCTACCTACACAACACACACACACACACACACACAGCCCTGCTAAGATGGCAGTAGTGGTTCTTTTGTGAACATGTTTTTTGGGGAGAC TCCATCTGAGGTACAAAAGCTGTTTGGGAGGCTGGGAGGGGGATGATGCCCCTTACCTGATAAAAGTATGTTTTACTGGGACAGAACTTC ACTCCTGGCCATATTGGCCAGAACTTAGTGCCAGTGTAGGGAGAGACTTCCATAGTGACAAGGTAATGCTTGAAACATCTTACGAACTTT GATGTTCATTTCCTCAAGTTCAAGGCTTGGAGCACATCTCCAGGATTGTTTCCATGCCTGGCTGTCAGTGGGACACAGCTGCCCTATGCT TCCACGTTCTTTTTTCAAGAGCCTTAGAGGGCCTGTGGCCTGTTTCACTGGTGGAACAGGAGCAGCATTGGTAGCCTTCAGAGCATGCCT TGCTTACTAACTACATATTATTCCTCTGCTCATTGTTCCTGCTGCTTAAAGGCTAGGAAAAGGGGGATATACAAAGTTGTTGCTTTCAAA >90494_90494_5_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000273064_length(amino acids)=625AA_BP=392 MAAAPRDGKRRLRGRASPGAAGRSGAAGPQAAGRRGTAGAGAADQPVDMMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTN DCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNRLLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGD PFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFLCLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFL LAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITVHSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLP LEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLH TVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILG -------------------------------------------------------------- >90494_90494_6_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000295701_length(transcript)=2310nt_BP=1465nt CCCGCAGCGGCGGGGGCGGAGAAGAGACCTCAGCCCCGCGGGCTCGCACAGCTGGCGCGGACCACGCTCTCGCCCGGGGCCGGCGGCCTC AGCGCCCCCCGAATGAACACCTTCCGCCCGCTGGCCGCCCCGCGAGGCGGGCCGTGTCGTGGCCCCGGTGCACGGAGGGGGACGCCGAGG CCCGGAGCAGGGCCCGTCTCGGCCTGTGCTCGGAGCCAGGCGGCAGGGCCCGCGGGCCGGCGGGCGGCGCGGAGACGGCTGCGCTCCCGC CCTCCGCCAGCGCCTGGCGGCCGCCCCACGTGACGGGAAGCGGCGGCTGCGGGGTCGGGCCAGCCCAGGAGCCGCGGGCCGGAGCGGGGC GGCGGGGCCCCAGGCCGCGGGGCGGCGCGGGACGGCGGGCGCCGGCGCCGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTAC GCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGCGCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTA CGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGAGGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACA GCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTGCGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTC CATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGGCCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCC TGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCAAACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGT GCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGGCTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTA CATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCTACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAG ACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCACAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGA GAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCGATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACA GAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTGAAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTT GGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCCGCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAG GAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCATCTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGT TTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAACCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTA CCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCCGGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGA TGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTTTATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAAC AGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTTTGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGC CATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTGCCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTC AGATAACCCCAGGTTTTCAGATTTGACTTTCTGCTGGTCATCTTTTCAAAGAAAATGAAACGTTTAAAAGTTCATCTGATAATACTGCTA CCATAGTTTTGTTTTCACTGCTCATCTCTTATTAAGGTTTTTAACCATAAAACTGAAGCAATTTCTGTAAAGACACAAATTGATAACTTA GTATAGAATTAAAATTCATTAAGTTATCATAAGTTTGATGATATCCTTGTTAATGTACTGATTTTTGAATTATTTTATTTGCCATAATCC >90494_90494_6_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000295701_length(amino acids)=584AA_BP=392 MAAAPRDGKRRLRGRASPGAAGRSGAAGPQAAGRRGTAGAGAADQPVDMMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTN DCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNRLLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGD PFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFLCLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFL LAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITVHSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLP LEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLH TVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILG -------------------------------------------------------------- >90494_90494_7_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000509807_length(transcript)=2507nt_BP=1465nt CCCGCAGCGGCGGGGGCGGAGAAGAGACCTCAGCCCCGCGGGCTCGCACAGCTGGCGCGGACCACGCTCTCGCCCGGGGCCGGCGGCCTC AGCGCCCCCCGAATGAACACCTTCCGCCCGCTGGCCGCCCCGCGAGGCGGGCCGTGTCGTGGCCCCGGTGCACGGAGGGGGACGCCGAGG CCCGGAGCAGGGCCCGTCTCGGCCTGTGCTCGGAGCCAGGCGGCAGGGCCCGCGGGCCGGCGGGCGGCGCGGAGACGGCTGCGCTCCCGC CCTCCGCCAGCGCCTGGCGGCCGCCCCACGTGACGGGAAGCGGCGGCTGCGGGGTCGGGCCAGCCCAGGAGCCGCGGGCCGGAGCGGGGC GGCGGGGCCCCAGGCCGCGGGGCGGCGCGGGACGGCGGGCGCCGGCGCCGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTAC GCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGCGCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTA CGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGAGGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACA GCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTGCGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTC CATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGGCCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCC TGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCAAACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGT GCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGGCTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTA CATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCTACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAG ACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCACAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGA GAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCGATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACA GAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTGAAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTT GGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCCGCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAG GAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCATCTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGT TTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAACCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTA CCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCCGGCTCACCAGCCTTGGAGTTATTGTAGAGACGGGGTTTCACCA TGTTGGCCAGGCTGATCTTGAACTCCCGACCTCAAGTGATCTGCCCGCCTCGGCCTCCCAAAGTGCTGGGATTACAGGGGCCCTGGTGAA AACAGATGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTTTATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTC TAAAACAGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTTTGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCA TGTTGCCATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTGCCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCG ACTTTCAGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCCCTGACCAGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGA TGACACCACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGCAAGAGGGCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCC TCAGTGATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGAAAGGAGGGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCAC CGACTGGGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGGGGCAAGGTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGC >90494_90494_7_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000509807_length(amino acids)=657AA_BP=392 MAAAPRDGKRRLRGRASPGAAGRSGAAGPQAAGRRGTAGAGAADQPVDMMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTN DCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNRLLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGD PFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFLCLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFL LAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITVHSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLP LEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLH TVSKTRPFEYLRLTSLGVIVETGFHHVGQADLELPTSSDLPASASQSAGITGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVA TFILQKILLDDTGLAYICQTYERFSHVAMILGKMVLQLSKEPSARLLKHVVRCYLRLSDNPRAREALRQCLPDQLKDTTFAQVLKDDTTT -------------------------------------------------------------- >90494_90494_8_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000542068_length(transcript)=4273nt_BP=1465nt CCCGCAGCGGCGGGGGCGGAGAAGAGACCTCAGCCCCGCGGGCTCGCACAGCTGGCGCGGACCACGCTCTCGCCCGGGGCCGGCGGCCTC AGCGCCCCCCGAATGAACACCTTCCGCCCGCTGGCCGCCCCGCGAGGCGGGCCGTGTCGTGGCCCCGGTGCACGGAGGGGGACGCCGAGG CCCGGAGCAGGGCCCGTCTCGGCCTGTGCTCGGAGCCAGGCGGCAGGGCCCGCGGGCCGGCGGGCGGCGCGGAGACGGCTGCGCTCCCGC CCTCCGCCAGCGCCTGGCGGCCGCCCCACGTGACGGGAAGCGGCGGCTGCGGGGTCGGGCCAGCCCAGGAGCCGCGGGCCGGAGCGGGGC GGCGGGGCCCCAGGCCGCGGGGCGGCGCGGGACGGCGGGCGCCGGCGCCGCAGATCAGCCAGTAGACATGATGAGCATCAAAGCCTTTAC GCTTGTCTCTGCTGTGGAGCGGGAGCTGCTGATGGGCGACAAGGAGCGCGTCAACATAGAGTGCGTGGAGTGCTGCGGCAGGGACCTCTA CGTGGGCACCAACGACTGCTTCGTCTACCACTTCCTGTTGGAGGAGAGGCCAGTGCCTGCTGGGCCAGCCACGTTCACTGCCACCAAACA GCTGCAGAGACACTTGGGCTTCAAGAAGCCCGTGAACGAGCTGCGTGCGGCCTCAGCACTCAACAGGCTGCTGGTGCTGTGTGACAACTC CATCAGCCTGGTCAACATGCTGAACCTCGAGCCAGTGCCTTCGGGGGCCCGCATCAAGGGGGCAGCCACGTTTGCACTGAACGAGAACCC TGTGAGTGGGGACCCCTTCTGTGTAGAAGTTTGCATCATCTCTGTCAAACGCAGAACCATCCAGATGTTTCTGGTGTACGAGGACCGGGT GCAGATCGTCAAGGAGGTGTCGACTGCCGAGCAGCCCCTCGCTGTGGCTGTGGACGGCCACTTCCTGTGTCTGGCTCTGACCACTCAGTA CATCATCCACAATTACAGCACAGGCGTCTCCCAGGACCTGTTTCCCTACTGCAGTGAGGAGAGGCCGCCGATCGTCAAGAGGATAGGGAG ACAGGAGTTCCTGCTGGCGGGCCCCGGAGGGCTGGGCATGTTTGCCACAGTCGCAGGGATATCCCAGCGCGCCCCCGTGCACTGGTCGGA GAATGTGATTGGGGCGGCTGTGTCCTTTCCATACGTCATAGCGCTCGATGACGAATTCATCACAGTCCACAGCATGTTGGATCAGCAACA GAAGCAGACGCTGCCCTTTAAGGAGGGCCATATCCTACAGGACTTTGAAGGAAGAGTGATCGTTGCCACAAGTAAAGGAGTTTACATCTT GGTTCCATTACCTTTGGAAAAACAAATACAGGATCTTCTAGCAAGCCGCAGAGTAGAAGAGGCTTTGGTTTTAGCAAAAGGAGCCCGGAG GAACATTCCAAAGGAAAAATTTCAGGAAATTGTAAATATTTATCCATCTATCAACCCACCCACCTTGACAGCACACCAGTCTAACAGAGT TTGCAATGCTCTGGCATTACTGCAATGTGTAGCATCACATCCAGAAACCAGGTCAGCGTTTCTCGCAGCACACATCCCACTTTTTTTGTA CCCCTTTTTGCACACTGTCAGCAAAACACGTCCCTTTGAGTATCTCCGGCTCACCAGCCTTGGAGTTATTGGGGCCCTGGTGAAAACAGA TGAACAAGAAGTAATCAACTTTTTATTAACAACAGAAATTATCCCTTTATGTTTGCGAATTATGGAATCTGGAAGTGAACTTTCTAAAAC AGTTGCCACATTCATCCTCCAGAAGATCTTGTTAGATGACACTGGTTTGGCTTATATATGTCAGACGTATGAGCGTTTCTCCCATGTTGC CATGATCTTGGGTAAGATGGTCCTGCAGCTATCCAAAGAGCCTTCTGCCCGTCTGCTGAAGCATGTAGTGAGATGTTACCTTCGACTTTC AGATAACCCCAGGGCACGTGAAGCACTCAGACAGTGCCTCCCTGACCAGCTGAAAGACACAACCTTCGCCCAGGTGCTAAAAGATGACAC CACCACGAAACGCTGGCTTGCACAACTGGTGAAGAACCTGCAAGAGGGCCAGGTCACCGATCCCCGGGGTATCCCCCTGCCCCCTCAGTG ATCCTTCCCTGTTCCCTCCCACTACTCCCCCAAGTTGGGGAAAGGAGGGGGAACCTACGAGAAAAACAGCTCAGGTTTTATCACCGACTG GGAATAGACAACCTCAATGCTGAACCGCACTGGAGAAAAGGGGCAAGGTACCCCTGCTGAGGTGTATGGGCTGCCATCTCAGGCTGTCTT GAGGACCTGGGCTCCCTCTGCTACTCCCAGGAAATGGGCTCCTGACACAGCAGTCTGCCACCACAGCCCCAGGAGGGTGTCAACACCAGC AAATGCTGTATTTGCAGCATGTCCAAGATGACCCTTCTCCCCTACCTCTACCTAGCCACTGGCAGGGAGGGGAGACAGTGGTGATAGCAG CAGCACTCTAGGCATGGTGAACGCCTGGGACCAAGCCATGTGGCGTTTTTTATTTTGCCTTTCTGGAAGACTCAAGATATGTCTCTTCAT TCTCTCTCAGTATTTGTTTACTTTGGTTTTTTTGTTTTTAATCTCAGAGAGAGGTGTGTTTAGTGGGCACAAGCTGTAATATTCAGCAAA ACTTTGTCGACTGGCACTGTTTACAAGTCTGTTAGCTGCATAAGCTCAATAAAAAGTTGGTCTGGGCATTACATCCCCTCTGGCAGGCCA ATAGCTGCATCAAGCTGTTGGGAGAAATGGGAGGGCAGGGGAAAGATGTAAAGCCAAAGTACAGCAGGAACCCACCACCTGTTTCCCTTC CTTCTCCCATTCTACTCCCAGTCCGGAATGCCACGAGGACCTTAACCTTGTTTCTGGCTTTAGCTGCTAGTTTTCCCAAATCTCAGTGCT TTCCCTTTTTGAACTTCCCTTCTATTAAACTTAAAACAGATGTCTTAATTAATCAGGCTGTCTTGGAAGGGTATTGTATTGGGAGACAAG GGGCGGTGGTGGACCTCACCTTCAATCCAAGTTTTCAAAGATATTTTCTCAATAACTCTAAAAGGGAGGTGCTTGGGATTAAGGTGACAG TCCACTTGATCCTTTTCTTTGTTTTAGTGTGAATTTCAGCAGCTCCATCTGTCTTCATGATTGTACTTGAGCAGTATTAGCTGTATGAGT TAATTTTATTCAGATTGAAGATGGAGGGCTGGGTTCTGCTCACTCAGTCTTTTTTTTTTTTTTTTTTTTTTTTTTTTGACCATTCTCTTT TAGTCTATGGGAATTACAGGGTTGCCGCTAAAATATTCACTTGTTCATATCGTGTCAGAGATTTCCTCTTCTCTGGAGCTTAGGTGGCTC TTCACAATCCATAGGCTTGAATCTGCAACCTAGTGTAAACTGCCTTGCTTTCCCCGGTTCTTTCCCCTGCTAGCACCTGCTTTCTCATCC CTATCTCCAGTCAAAGATGGGATTGCTTAATCCAACTCTGGAGAGGGACCAAGTCTTTTCTGCCCACATCTCACACAATTGAGGTGTCTG AACAAGCTTGGGGAGGGTCTATAAGGGGTAGGCTCAAAAAAAAAAAAACCCATTTGCAGAGGCAGTTTTGCCAACACAAGGGCTCTTTCA AGCCGACTTTCACAAAGAGAGCCGGACTTGTTAGTTGGCTTCTGTCTCTTTAGAGCCAAGAAAATAGTAATTAAGTGGCCTAGATATAGG AAGGGCAGAATAAGCACTTACTCCCCCTGCCTTCCAAGATGAAGAGGAGAAGCAGGCCAACCCTCAATAATTGCAAGCCTGAAGAGAAGT GATCTTAGAGAAAGCAGAGAACAGAATGGACTGGATAGACATCTTGACTCTATTCAGCCCGTAGTCTGTGATCTGGAGAGTCCAGTTAAG GTAACCCAGATTTTTGACAACCGCCTTCCTGCTGAGCCAAAGTTTTCTCATTACCCCTCCACTGGGGAAGCAGCTGAGGCCCAGGGCCTT GCTCCCTGGGAAATTCTCTTCTCTCCATCTTTCGGTGCATTGGCCATGTTACTGTGCCAAAGTGTCTTAATTCTTGTCCCATCTATTCTC AGCTGGCCTTGGAACCCACATAGGAGTTGGTGGGGGAGGGATGTGTATTATATAAAGAGACCCCTCCCCTTATTTTGTGTTTTCCATCCC >90494_90494_8_TGFBRAP1-RQCD1_TGFBRAP1_chr2_105912813_ENST00000393359_RQCD1_chr2_219447694_ENST00000542068_length(amino acids)=625AA_BP=392 MAAAPRDGKRRLRGRASPGAAGRSGAAGPQAAGRRGTAGAGAADQPVDMMSIKAFTLVSAVERELLMGDKERVNIECVECCGRDLYVGTN DCFVYHFLLEERPVPAGPATFTATKQLQRHLGFKKPVNELRAASALNRLLVLCDNSISLVNMLNLEPVPSGARIKGAATFALNENPVSGD PFCVEVCIISVKRRTIQMFLVYEDRVQIVKEVSTAEQPLAVAVDGHFLCLALTTQYIIHNYSTGVSQDLFPYCSEERPPIVKRIGRQEFL LAGPGGLGMFATVAGISQRAPVHWSENVIGAAVSFPYVIALDDEFITVHSMLDQQQKQTLPFKEGHILQDFEGRVIVATSKGVYILVPLP LEKQIQDLLASRRVEEALVLAKGARRNIPKEKFQEIVNIYPSINPPTLTAHQSNRVCNALALLQCVASHPETRSAFLAAHIPLFLYPFLH TVSKTRPFEYLRLTSLGVIGALVKTDEQEVINFLLTTEIIPLCLRIMESGSELSKTVATFILQKILLDDTGLAYICQTYERFSHVAMILG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TGFBRAP1-RQCD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TGFBRAP1-RQCD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TGFBRAP1-RQCD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies