
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TIAL1-PRMT2 (FusionGDB2 ID:90834) |
Fusion Gene Summary for TIAL1-PRMT2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TIAL1-PRMT2 | Fusion gene ID: 90834 | Hgene | Tgene | Gene symbol | TIAL1 | PRMT2 | Gene ID | 7073 | 3275 |
| Gene name | TIA1 cytotoxic granule associated RNA binding protein like 1 | protein arginine methyltransferase 2 | |
| Synonyms | TCBP|TIAR | HRMT1L1 | |
| Cytomap | 10q26.11 | 21q22.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nucleolysin TIART-cluster binding proteinTIA-1-related nucleolysinTIA1 relatedaging-associated gene 7 protein | protein arginine N-methyltransferase 2HMT1 (hnRNP methyltransferase, S. cerevisiae)-like 1HMT1 hnRNP methyltransferase-like 1PRMT2 alphaPRMT2 betaPRMT2 gammahistone-arginine N-methyltransferase PRMT2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000369093, ENST00000436547, ENST00000369092, ENST00000463089, | ENST00000491389, ENST00000291705, ENST00000334494, ENST00000355680, ENST00000397628, ENST00000397637, ENST00000397638, ENST00000440086, ENST00000451211, ENST00000458387, | |
| Fusion gene scores | * DoF score | 9 X 9 X 5=405 | 9 X 8 X 4=288 |
| # samples | 9 | 9 | |
| ** MAII score | log2(9/405*10)=-2.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/288*10)=-1.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TIAL1 [Title/Abstract] AND PRMT2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TIAL1(121347663)-PRMT2(48068369), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PRMT2 | GO:0016571 | histone methylation | 19405910 |
| Tgene | PRMT2 | GO:0032088 | negative regulation of NF-kappaB transcription factor activity | 16648481 |
| Tgene | PRMT2 | GO:0045892 | negative regulation of transcription, DNA-templated | 16648481 |
| Tgene | PRMT2 | GO:0045893 | positive regulation of transcription, DNA-templated | 12039952 |
| Tgene | PRMT2 | GO:0060765 | regulation of androgen receptor signaling pathway | 17587566 |
| Fusion gene breakpoints across TIAL1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PRMT2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-09-1666 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
Top |
Fusion Gene ORF analysis for TIAL1-PRMT2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000369093 | ENST00000491389 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5CDS-3UTR | ENST00000436547 | ENST00000491389 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3CDS | ENST00000369092 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| 5UTR-3UTR | ENST00000369092 | ENST00000491389 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000369093 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| In-frame | ENST00000436547 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3CDS | ENST00000463089 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| intron-3UTR | ENST00000463089 | ENST00000491389 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000355680 | PRMT2 | chr21 | 48068369 | + | 1758 | 159 | 0 | 1133 | 377 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000397638 | PRMT2 | chr21 | 48068369 | + | 1758 | 159 | 0 | 1133 | 377 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000291705 | PRMT2 | chr21 | 48068369 | + | 1137 | 159 | 767 | 60 | 235 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000458387 | PRMT2 | chr21 | 48068369 | + | 1309 | 159 | 0 | 737 | 245 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000451211 | PRMT2 | chr21 | 48068369 | + | 1313 | 159 | 0 | 701 | 233 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000397637 | PRMT2 | chr21 | 48068369 | + | 1758 | 159 | 0 | 1133 | 377 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000334494 | PRMT2 | chr21 | 48068369 | + | 999 | 159 | 0 | 686 | 228 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000397628 | PRMT2 | chr21 | 48068369 | + | 640 | 159 | 0 | 593 | 197 |
| ENST00000369093 | TIAL1 | chr10 | 121347663 | - | ENST00000440086 | PRMT2 | chr21 | 48068369 | + | 1625 | 159 | 0 | 827 | 275 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000355680 | PRMT2 | chr21 | 48068369 | + | 1773 | 174 | 3 | 1148 | 381 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000397638 | PRMT2 | chr21 | 48068369 | + | 1773 | 174 | 3 | 1148 | 381 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000291705 | PRMT2 | chr21 | 48068369 | + | 1152 | 174 | 782 | 75 | 235 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000458387 | PRMT2 | chr21 | 48068369 | + | 1324 | 174 | 3 | 752 | 249 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000451211 | PRMT2 | chr21 | 48068369 | + | 1328 | 174 | 3 | 716 | 237 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000397637 | PRMT2 | chr21 | 48068369 | + | 1773 | 174 | 3 | 1148 | 381 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000334494 | PRMT2 | chr21 | 48068369 | + | 1014 | 174 | 3 | 701 | 232 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000397628 | PRMT2 | chr21 | 48068369 | + | 655 | 174 | 3 | 608 | 201 |
| ENST00000436547 | TIAL1 | chr10 | 121347663 | - | ENST00000440086 | PRMT2 | chr21 | 48068369 | + | 1640 | 174 | 3 | 842 | 279 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000369093 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.00914831 | 0.9908517 |
| ENST00000369093 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.00914831 | 0.9908517 |
| ENST00000369093 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.007296579 | 0.99270344 |
| ENST00000369093 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.007781413 | 0.9922186 |
| ENST00000369093 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.002834313 | 0.9971656 |
| ENST00000369093 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.00914831 | 0.9908517 |
| ENST00000369093 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.04454734 | 0.9554527 |
| ENST00000369093 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.007349388 | 0.99265057 |
| ENST00000369093 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.005301649 | 0.9946984 |
| ENST00000436547 | ENST00000355680 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.009185172 | 0.99081486 |
| ENST00000436547 | ENST00000397638 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.009185172 | 0.99081486 |
| ENST00000436547 | ENST00000291705 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.005861159 | 0.99413884 |
| ENST00000436547 | ENST00000458387 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.007424334 | 0.99257565 |
| ENST00000436547 | ENST00000451211 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.002509768 | 0.9974903 |
| ENST00000436547 | ENST00000397637 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.009185172 | 0.99081486 |
| ENST00000436547 | ENST00000334494 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.04477369 | 0.9552263 |
| ENST00000436547 | ENST00000397628 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.007875238 | 0.99212474 |
| ENST00000436547 | ENST00000440086 | TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 0.005422169 | 0.9945779 |
Top |
Fusion Genomic Features for TIAL1-PRMT2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 1.12E-06 | 0.9999989 |
| TIAL1 | chr10 | 121347663 | - | PRMT2 | chr21 | 48068369 | + | 1.12E-06 | 0.9999989 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
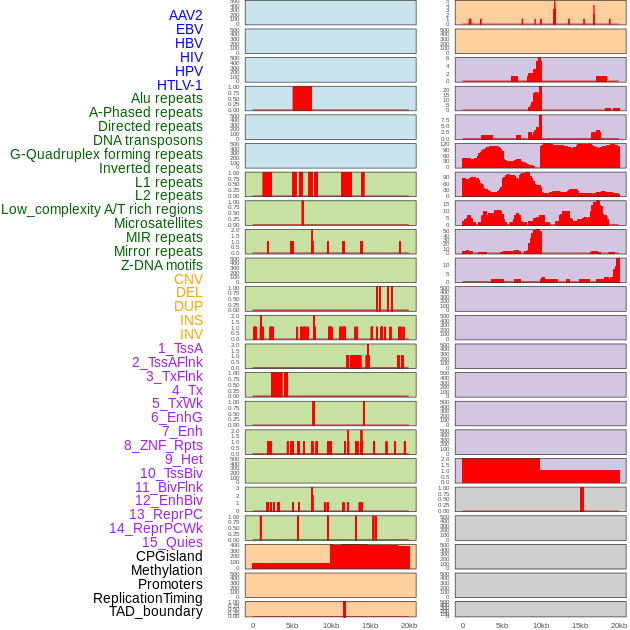 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
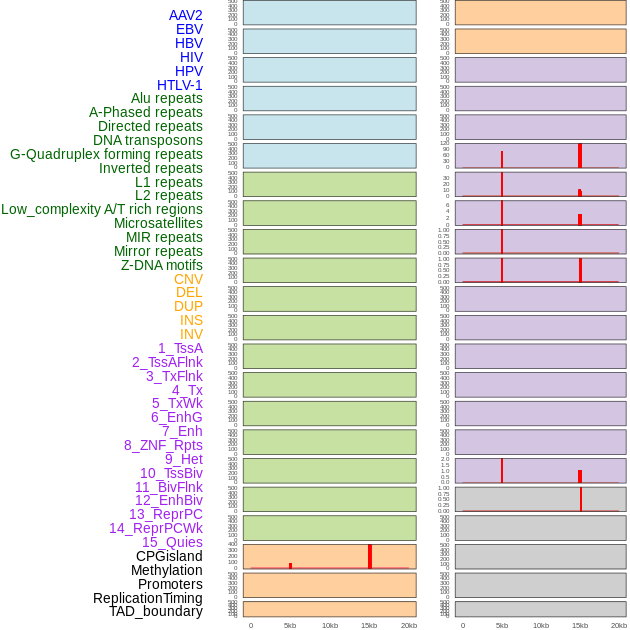 |
Top |
Fusion Protein Features for TIAL1-PRMT2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:121347663/chr21:48068369) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000369093 | - | 2 | 12 | 205_277 | 43 | 393.0 | Domain | RRM 3 |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000369093 | - | 2 | 12 | 97_175 | 43 | 393.0 | Domain | RRM 2 |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000369093 | - | 2 | 12 | 9_85 | 43 | 393.0 | Domain | RRM 1 |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000436547 | - | 2 | 12 | 205_277 | 43 | 376.0 | Domain | RRM 3 |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000436547 | - | 2 | 12 | 97_175 | 43 | 376.0 | Domain | RRM 2 |
| Hgene | TIAL1 | chr10:121347663 | chr21:48068369 | ENST00000436547 | - | 2 | 12 | 9_85 | 43 | 376.0 | Domain | RRM 1 |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000334494 | 3 | 7 | 30_89 | 109 | 285.0 | Domain | SH3 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000334494 | 3 | 7 | 99_432 | 109 | 285.0 | Domain | SAM-dependent MTase PRMT-type | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000355680 | 4 | 12 | 30_89 | 109 | 434.0 | Domain | SH3 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000355680 | 4 | 12 | 99_432 | 109 | 434.0 | Domain | SAM-dependent MTase PRMT-type | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397637 | 3 | 11 | 30_89 | 109 | 434.0 | Domain | SH3 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397637 | 3 | 11 | 99_432 | 109 | 434.0 | Domain | SAM-dependent MTase PRMT-type | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397638 | 3 | 11 | 30_89 | 109 | 434.0 | Domain | SH3 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397638 | 3 | 11 | 99_432 | 109 | 434.0 | Domain | SAM-dependent MTase PRMT-type | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000440086 | 3 | 9 | 30_89 | 109 | 332.0 | Domain | SH3 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000440086 | 3 | 9 | 99_432 | 109 | 332.0 | Domain | SAM-dependent MTase PRMT-type |
Top |
Fusion Gene Sequence for TIAL1-PRMT2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >90834_90834_1_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000291705_length(transcript)=1137nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAA AGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTC ACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCC ACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGT CGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCC ACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGG GAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCC >90834_90834_1_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000291705_length(amino acids)=235AA_BP=1 METQPTSRGQTLGSGGGHGSSCRAQACLSVKDPDVTCQAREGSMWSECSPTFAGVCRSQVQLGLLVFITPQDMHTAFQIKHQLSSPDGED FFSNQQAGPHPLRHQHVHLLGQHHILHLLLVHGDDVSKAVLQDQLPRVLCHLTGLHRVHRSRPRIVCTEETDDPSPTAHVQDDFIRQGFF -------------------------------------------------------------- >90834_90834_2_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000334494_length(transcript)=999nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGCTGCGCCTCTCCTGAGCTGCCGCATTCTCCCCTGCACCTGTGCGTCTGGCCCT CTTCACGTCCTCCTGGCCTGCTGTCTGCCTCTCCCCTGCACCTGTGCGTCTGTCCCTCTTCATGTCCTCCTTGCCTGCTGTCTGCCTGTT CTCAGAGCCCCTCAGCCCTCAGGCCTTCATCTCTCCTGGCCCATCTTCCTACTCTGACGCTGACATGTAGTAAAAGTCTGAAGACAGAGA AGAGTGCATGTGCGTTTAGCATAGGAGGGGCAGCTTTCAGTCAGTGCAGCAAGGGCATGTAGTTGTTCAGAGATGGTGCTGGAACGACTG ATTTGGAGAAAAGAGGCCCTTCTTCACACCATCTGCTAAAATAAACCTCAGATGGGCTCAAGAGTTAAATATTTAAGAAAAGGAGGAAAC AAAAAAATTGCTACAAGTTTATTTGTTGTTAGGATGGGAAAGGTTTTTCTAAGAACCAAGTTCATAATGAAGCTGTCAAATAAAATACTT >90834_90834_2_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000334494_length(amino acids)=228AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLAAPLLSCRILPCTCASGP -------------------------------------------------------------- >90834_90834_3_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000355680_length(transcript)=1758nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGATGCCTGGCTGAAGGAG GACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAGGTGCTCTTCTGGGAC AACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAACCACATTTTGAAACCA GAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACCCTGAGGGGCGAGCTG CGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAGGAGGGGCAGCCGCCG CAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCATACAGGA GACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCACTTCCAGA CAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGTGCATATC TTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACATTGACCC CTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGCTGCCCAG TGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTCCATGTTC CTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTATGTTAGT GGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTGCCCTGGC TCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAATTATGTGT >90834_90834_3_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000355680_length(amino acids)=377AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDAWLKE DGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETLRGEL RFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWAVTSR -------------------------------------------------------------- >90834_90834_4_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397628_length(transcript)=640nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGTGAGGGCGGGCGTGCGGGCAGCTGGGGGCCGGAGCTGGGGGGCTTCTGAGCAC GGGCTCGGCTGGGCCAACCTCAGGATCTCAAGGGTCGTGCGTGATTCATTTTGATGTTTTCCCTAATGTGAGGTCTAATTAATTTCTTGT >90834_90834_4_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397628_length(amino acids)=197AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLVRAGVRAAGGRSWGASEH -------------------------------------------------------------- >90834_90834_5_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397637_length(transcript)=1758nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGATGCCTGGCTGAAGGAG GACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAGGTGCTCTTCTGGGAC AACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAACCACATTTTGAAACCA GAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACCCTGAGGGGCGAGCTG CGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAGGAGGGGCAGCCGCCG CAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCATACAGGA GACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCACTTCCAGA CAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGTGCATATC TTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACATTGACCC CTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGCTGCCCAG TGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTCCATGTTC CTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTATGTTAGT GGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTGCCCTGGC TCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAATTATGTGT >90834_90834_5_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397637_length(amino acids)=377AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDAWLKE DGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETLRGEL RFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWAVTSR -------------------------------------------------------------- >90834_90834_6_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397638_length(transcript)=1758nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGATGCCTGGCTGAAGGAG GACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAGGTGCTCTTCTGGGAC AACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAACCACATTTTGAAACCA GAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACCCTGAGGGGCGAGCTG CGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAGGAGGGGCAGCCGCCG CAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCATACAGGA GACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCACTTCCAGA CAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGTGCATATC TTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACATTGACCC CTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGCTGCCCAG TGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTCCATGTTC CTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTATGTTAGT GGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTGCCCTGGC TCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAATTATGTGT >90834_90834_6_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000397638_length(amino acids)=377AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDAWLKE DGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETLRGEL RFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWAVTSR -------------------------------------------------------------- >90834_90834_7_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000440086_length(transcript)=1625nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGACCCTGAGGGGCGAGCTGCGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGC TTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAGGAGGGGCAGCCGCCGCAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACA CACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAAC CCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCACTTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTC TTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCAC CTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCAC AGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTG TTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCAC GCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGG GACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGG GACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAATTATGTGTTGGTCCATCGCACATGCTCAATAAATATTTTTAAAT GAGTGAATGTCATTGTGTATCCTGTTTTATGCATATATGTTATTTTTTGTAATTACAGGATCATACTATATGCATTGCTTTATAAGTTTT TCTCAATATTGTGAAAAAACTTCCACATCAGTAGATACATGTCCATAATTTTTTTTTGTATTGTTTTGATTTTTATTAAATTTTATTGAA >90834_90834_7_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000440086_length(amino acids)=275AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLTLRGELRFDIRKAGTLHG FTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWAVTSRQDPTSQKVGEKV -------------------------------------------------------------- >90834_90834_8_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000451211_length(transcript)=1313nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGATGCCTGGCTGAAGGAG GACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAGGTGCTCTTCTGGGAC AACGCGTACGAGTTCAACCTCAGCGCTCTGAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCA GTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTC CACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCC CCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGA GCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCT CCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAAC ACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAAT >90834_90834_8_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000451211_length(amino acids)=233AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDAWLKE -------------------------------------------------------------- >90834_90834_9_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000458387_length(transcript)=1309nt_BP=159nt TTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAACCTTTCCAGAGATGTG ACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTCCACTTGGAGATGTTG GCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATCCTGGACGTGGGCTGT GGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAGATGGCACAGCACACG GGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTGCCCGAGAAGGTGGAC GTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCA TACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCAC TTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGT GCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACA TTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGC TGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTC CATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTA TGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTG CCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAAT >90834_90834_9_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000369093_PRMT2_chr21_48068369_ENST00000458387_length(amino acids)=245AA_BP=53 LSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVILDVGC GTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLHHTLEADAVHDGRPSPCP -------------------------------------------------------------- >90834_90834_10_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000291705_length(transcript)=1152nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTG ATGCTTTATTTGGAAAGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAA AGTCGGTGAACATTCACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCA GGAGCTGCCGTGGCCACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCC GACCCGTGGCTGGGTCGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTG ACAGTGACTGTCCCCACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTG CCAGTGGCGTGTAGGGAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTT >90834_90834_10_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000291705_length(amino acids)=235AA_BP=1 METQPTSRGQTLGSGGGHGSSCRAQACLSVKDPDVTCQAREGSMWSECSPTFAGVCRSQVQLGLLVFITPQDMHTAFQIKHQLSSPDGED FFSNQQAGPHPLRHQHVHLLGQHHILHLLLVHGDDVSKAVLQDQLPRVLCHLTGLHRVHRSRPRIVCTEETDDPSPTAHVQDDFIRQGFF -------------------------------------------------------------- >90834_90834_11_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000334494_length(transcript)=1014nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGCTGCGCCTCTCCTGAGCTGCCGCATTCTCCCCTGCACC TGTGCGTCTGGCCCTCTTCACGTCCTCCTGGCCTGCTGTCTGCCTCTCCCCTGCACCTGTGCGTCTGTCCCTCTTCATGTCCTCCTTGCC TGCTGTCTGCCTGTTCTCAGAGCCCCTCAGCCCTCAGGCCTTCATCTCTCCTGGCCCATCTTCCTACTCTGACGCTGACATGTAGTAAAA GTCTGAAGACAGAGAAGAGTGCATGTGCGTTTAGCATAGGAGGGGCAGCTTTCAGTCAGTGCAGCAAGGGCATGTAGTTGTTCAGAGATG GTGCTGGAACGACTGATTTGGAGAAAAGAGGCCCTTCTTCACACCATCTGCTAAAATAAACCTCAGATGGGCTCAAGAGTTAAATATTTA AGAAAAGGAGGAAACAAAAAAATTGCTACAAGTTTATTTGTTGTTAGGATGGGAAAGGTTTTTCTAAGAACCAAGTTCATAATGAAGCTG >90834_90834_11_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000334494_length(amino acids)=232AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLAAPLLSCRILPCTC -------------------------------------------------------------- >90834_90834_12_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000355680_length(transcript)=1773nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGAT GCCTGGCTGAAGGAGGACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAG GTGCTCTTCTGGGACAACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAAC CACATTTTGAAACCAGAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACC CTGAGGGGCGAGCTGCGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAG GAGGGGCAGCCGCCGCAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTC CCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGG GCTGTCACTTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAA AGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTC ACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCC ACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGT CGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCC ACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGG GAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCC >90834_90834_12_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000355680_length(amino acids)=381AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDA WLKEDGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETL RGELRFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWA -------------------------------------------------------------- >90834_90834_13_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397628_length(transcript)=655nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGGTGAGGGCGGGCGTGCGGGCAGCTGGGGGCCGGAGCTGG GGGGCTTCTGAGCACGGGCTCGGCTGGGCCAACCTCAGGATCTCAAGGGTCGTGCGTGATTCATTTTGATGTTTTCCCTAATGTGAGGTC >90834_90834_13_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397628_length(amino acids)=201AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLVRAGVRAAGGRSWG -------------------------------------------------------------- >90834_90834_14_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397637_length(transcript)=1773nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGAT GCCTGGCTGAAGGAGGACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAG GTGCTCTTCTGGGACAACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAAC CACATTTTGAAACCAGAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACC CTGAGGGGCGAGCTGCGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAG GAGGGGCAGCCGCCGCAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTC CCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGG GCTGTCACTTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAA AGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTC ACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCC ACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGT CGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCC ACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGG GAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCC >90834_90834_14_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397637_length(amino acids)=381AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDA WLKEDGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETL RGELRFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWA -------------------------------------------------------------- >90834_90834_15_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397638_length(transcript)=1773nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGAT GCCTGGCTGAAGGAGGACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAG GTGCTCTTCTGGGACAACGCGTACGAGTTCAACCTCAGCGCTCTGAAATCTTTAGCAGTTAAGGAGTTTTTTTCAAAGCCCAAGTATAAC CACATTTTGAAACCAGAAGACTGTCTCTCTGAACCGTGCACTATATTGCAGTTGGACATGAGAACCGTGCAAATTTCTGATCTAGAGACC CTGAGGGGCGAGCTGCGCTTCGACATCAGGAAGGCGGGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAG GAGGGGCAGCCGCCGCAGGTGCTCAGCACCGGGCCCTTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTC CCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGG GCTGTCACTTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAA AGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTC ACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCC ACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGT CGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCC ACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGG GAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCC >90834_90834_15_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000397638_length(amino acids)=381AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDA WLKEDGVIWPTMAALHLVPCSADKDYRSKVLFWDNAYEFNLSALKSLAVKEFFSKPKYNHILKPEDCLSEPCTILQLDMRTVQISDLETL RGELRFDIRKAGTLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWA -------------------------------------------------------------- >90834_90834_16_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000440086_length(transcript)=1640nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGACCCTGAGGGGCGAGCTGCGCTTCGACATCAGGAAGGCG GGGACCCTGCACGGCTTCACGGCCTGGTTTAGCGTCCACTTCCAGAGCCTGCAGGAGGGGCAGCCGCCGCAGGTGCTCAGCACCGGGCCC TTCCACCCCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGACCCAGTCCCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTT GTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCTGAGCTGGGCTGTCACTTCCAGACAAGACCCCACATCTCAAAAA GTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTATTTGGAAAGCAGTGTGCATATCTTGAGGGGTGATGAACACAAG CAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTGAACATTCACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGAC GTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGCCGTGGCCACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGG CTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTGGCTGGGTCGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTAC ACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGACTGTCCCCACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCT CATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGCGTGTAGGGAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGG TGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGACGTCTTCCAAATAAATTATGTGTTGGTCCATCGCACATGCTCAA TAAATATTTTTAAATGAGTGAATGTCATTGTGTATCCTGTTTTATGCATATATGTTATTTTTTGTAATTACAGGATCATACTATATGCAT TGCTTTATAAGTTTTTCTCAATATTGTGAAAAAACTTCCACATCAGTAGATACATGTCCATAATTTTTTTTTGTATTGTTTTGATTTTTA >90834_90834_16_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000440086_length(amino acids)=279AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLTLRGELRFDIRKAG TLHGFTAWFSVHFQSLQEGQPPQVLSTGPFHPTTHWKQTLFMMDDPVPVHTGDVVTGSVVLQRNPVWRRHMSVALSWAVTSRQDPTSQKV -------------------------------------------------------------- >90834_90834_17_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000451211_length(transcript)=1328nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGTTTGAGTTCATGATCGAGTCCATCCTGTATGCCCGGGAT GCCTGGCTGAAGGAGGACGGGGTCATTTGGCCCACCATGGCTGCGTTGCACCTTGTGCCCTGCAGTGCTGATAAGGATTATCGTAGCAAG GTGCTCTTCTGGGACAACGCGTACGAGTTCAACCTCAGCGCTCTGAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGC TTTATTTGGAAAGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTC GGTGAACATTCACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAG CTGCCGTGGCCACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACC CGTGGCTGGGTCGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAG TGACTGTCCCCACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAG TGGCGTGTAGGGAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGT >90834_90834_17_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000451211_length(amino acids)=237AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLFEFMIESILYARDA -------------------------------------------------------------- >90834_90834_18_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000458387_length(transcript)=1324nt_BP=174nt ACCCTGCCCTCCCCCTTGTCCCGGGATCGCTCCGTCGCACCCACCATGATGGAAGACGACGGGCAGCCCCGGACTCTATACGTAGGTAAC CTTTCCAGAGATGTGACAGAAGTCCTTATACTTCAGTTGTTCAGTCAGATTGGACCCTGTAAAAGCTGTAAAATGATAACAGAGAAACTC CACTTGGAGATGTTGGCAGACCAGCCACGAACAACTAAATACCACAGTGTCATCCTGCAGAATAAAGAATCCCTGACGGATAAAGTCATC CTGGACGTGGGCTGTGGGACTGGGATCATCAGTCTCTTCTGTGCACACTATGCGCGGCCTAGAGCGGTGTACGCGGTGGAGGCCAGTGAG ATGGCACAGCACACGGGGCAGCTGGTCCTGCAGAACGGCTTTGCTGACATCATCACCGTGTACCAGCAGAAGGTGGAGGATGTGGTGCTG CCCGAGAAGGTGGACGTGCTGGTGTCTGAGTGGATGGGGACCTGCCTGCTGCACCACACACTGGAAGCAGACGCTGTTCATGATGGACGA CCCAGTCCCTGTCCATACAGGAGACGTGGTCACGGGTTCAGTTGTGTTGCAGAGAAACCCAGTGTGGAGAAGGCACATGTCTGTGGCTCT GAGCTGGGCTGTCACTTCCAGACAAGACCCCACATCTCAAAAAGTTGGAGAAAAAGTCTTCCCCATCTGGAGATGACAGTTGATGCTTTA TTTGGAAAGCAGTGTGCATATCTTGAGGGGTGATGAACACAAGCAAACCAAGTTGCACCTGGCTTCTGCACACTCCTGCGAAAGTCGGTG AACATTCACTCCACATTGACCCCTCCCTAGCCTGGCAGGTGACGTCAGGGTCCTTCACAGACAAACACGCTTGGGCTCGGCAGGAGCTGC CGTGGCCACCCCCGCTGCCCAGTGTCTGCCCTCTAGAAGTAGGCTGTGTTTCCAGGTGTTCACCCGTGGTGCCCACAGTGCCGACCCGTG GCTGGGTCGGAGCTCCATGTTCCTAAGCTAGGTCTAGGTCTACACTCCTAGGACGCACGCATATCAGCCCGTGTACCCTGTGACAGTGAC TGTCCCCACCTCCTATGTTAGTGGTGCCCTTACTGCCGTCGCTCATCCACTCGTGTGGGACGTAGGATTGCACAGGGCTGTGCCAGTGGC GTGTAGGGAACACTGCCCTGGCTCAGCGTGCGAGCTAAGGTGGTGATGTATGCGATGGGACTCTGCATGGGATAGTACAGTTGTGTAGAC >90834_90834_18_TIAL1-PRMT2_TIAL1_chr10_121347663_ENST00000436547_PRMT2_chr21_48068369_ENST00000458387_length(amino acids)=249AA_BP=57 MPSPLSRDRSVAPTMMEDDGQPRTLYVGNLSRDVTEVLILQLFSQIGPCKSCKMITEKLHLEMLADQPRTTKYHSVILQNKESLTDKVIL DVGCGTGIISLFCAHYARPRAVYAVEASEMAQHTGQLVLQNGFADIITVYQQKVEDVVLPEKVDVLVSEWMGTCLLHHTLEADAVHDGRP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TIAL1-PRMT2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000334494 | 3 | 7 | 133_275 | 109.0 | 285.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000355680 | 4 | 12 | 133_275 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397637 | 3 | 11 | 133_275 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397638 | 3 | 11 | 133_275 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000440086 | 3 | 9 | 133_275 | 109.0 | 332.0 | ESR1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000334494 | 3 | 7 | 1_277 | 109.0 | 285.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000355680 | 4 | 12 | 1_277 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397637 | 3 | 11 | 1_277 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397638 | 3 | 11 | 1_277 | 109.0 | 434.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000440086 | 3 | 9 | 1_277 | 109.0 | 332.0 | ESR1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000334494 | 3 | 7 | 83_207 | 109.0 | 285.0 | RB1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000355680 | 4 | 12 | 83_207 | 109.0 | 434.0 | RB1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397637 | 3 | 11 | 83_207 | 109.0 | 434.0 | RB1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000397638 | 3 | 11 | 83_207 | 109.0 | 434.0 | RB1 | |
| Tgene | PRMT2 | chr10:121347663 | chr21:48068369 | ENST00000440086 | 3 | 9 | 83_207 | 109.0 | 332.0 | RB1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TIAL1-PRMT2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TIAL1-PRMT2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies