
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TMX2-ARHGAP4 (FusionGDB2 ID:92556) |
Fusion Gene Summary for TMX2-ARHGAP4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TMX2-ARHGAP4 | Fusion gene ID: 92556 | Hgene | Tgene | Gene symbol | TMX2 | ARHGAP4 | Gene ID | 51075 | 393 |
| Gene name | thioredoxin related transmembrane protein 2 | Rho GTPase activating protein 4 | |
| Synonyms | CGI-31|NEDMCMS|PDIA12|PIG26|TXNDC14 | C1|RGC1|RhoGAP4|SrGAP4|p115 | |
| Cytomap | 11q12.1 | Xq28 | |
| Type of gene | protein-coding | protein-coding | |
| Description | thioredoxin-related transmembrane protein 2cell proliferation-inducing gene 26 proteingrowth-inhibiting gene 11protein disulfide isomerase family A, member 12thioredoxin domain-containing protein 14 | rho GTPase-activating protein 4Rho-GAP hematopoietic protein C1rho-type GTPase-activating protein 4 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | Q92619 | |
| Ensembl transtripts involved in fusion gene | ENST00000278422, ENST00000378312, | ENST00000467421, ENST00000350060, ENST00000370016, ENST00000370028, ENST00000393721, ENST00000537206, | |
| Fusion gene scores | * DoF score | 9 X 3 X 9=243 | 4 X 6 X 3=72 |
| # samples | 16 | 7 | |
| ** MAII score | log2(16/243*10)=-0.602884408718418 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/72*10)=-0.0406419844973459 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TMX2 [Title/Abstract] AND ARHGAP4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TMX2(57480279)-ARHGAP4(153179333), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across TMX2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ARHGAP4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1426 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
Top |
Fusion Gene ORF analysis for TMX2-ARHGAP4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000278422 | ENST00000467421 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| 5CDS-intron | ENST00000378312 | ENST00000467421 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000278422 | ENST00000350060 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000278422 | ENST00000370016 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000278422 | ENST00000370028 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000278422 | ENST00000393721 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000278422 | ENST00000537206 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000378312 | ENST00000350060 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000378312 | ENST00000370016 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000378312 | ENST00000370028 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000378312 | ENST00000393721 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| In-frame | ENST00000378312 | ENST00000537206 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000378312 | TMX2 | chr11 | 57480279 | + | ENST00000393721 | ARHGAP4 | chrX | 153179333 | - | 2376 | 205 | 16 | 2013 | 665 |
| ENST00000378312 | TMX2 | chr11 | 57480279 | + | ENST00000370028 | ARHGAP4 | chrX | 153179333 | - | 2367 | 205 | 16 | 2013 | 665 |
| ENST00000378312 | TMX2 | chr11 | 57480279 | + | ENST00000350060 | ARHGAP4 | chrX | 153179333 | - | 2366 | 205 | 16 | 2013 | 665 |
| ENST00000378312 | TMX2 | chr11 | 57480279 | + | ENST00000370016 | ARHGAP4 | chrX | 153179333 | - | 2289 | 205 | 16 | 2013 | 665 |
| ENST00000378312 | TMX2 | chr11 | 57480279 | + | ENST00000537206 | ARHGAP4 | chrX | 153179333 | - | 2177 | 205 | 16 | 2013 | 665 |
| ENST00000278422 | TMX2 | chr11 | 57480279 | + | ENST00000393721 | ARHGAP4 | chrX | 153179333 | - | 2372 | 201 | 12 | 2009 | 665 |
| ENST00000278422 | TMX2 | chr11 | 57480279 | + | ENST00000370028 | ARHGAP4 | chrX | 153179333 | - | 2363 | 201 | 12 | 2009 | 665 |
| ENST00000278422 | TMX2 | chr11 | 57480279 | + | ENST00000350060 | ARHGAP4 | chrX | 153179333 | - | 2362 | 201 | 12 | 2009 | 665 |
| ENST00000278422 | TMX2 | chr11 | 57480279 | + | ENST00000370016 | ARHGAP4 | chrX | 153179333 | - | 2285 | 201 | 12 | 2009 | 665 |
| ENST00000278422 | TMX2 | chr11 | 57480279 | + | ENST00000537206 | ARHGAP4 | chrX | 153179333 | - | 2173 | 201 | 12 | 2009 | 665 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000378312 | ENST00000393721 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.014845506 | 0.98515445 |
| ENST00000378312 | ENST00000370028 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.014598012 | 0.985402 |
| ENST00000378312 | ENST00000350060 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.014607501 | 0.9853925 |
| ENST00000378312 | ENST00000370016 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.015132527 | 0.9848675 |
| ENST00000378312 | ENST00000537206 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.01326629 | 0.9867337 |
| ENST00000278422 | ENST00000393721 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.015628068 | 0.98437196 |
| ENST00000278422 | ENST00000370028 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.015395418 | 0.98460466 |
| ENST00000278422 | ENST00000350060 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.015406299 | 0.98459363 |
| ENST00000278422 | ENST00000370016 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.016050175 | 0.9839498 |
| ENST00000278422 | ENST00000537206 | TMX2 | chr11 | 57480279 | + | ARHGAP4 | chrX | 153179333 | - | 0.014061929 | 0.98593813 |
Top |
Fusion Genomic Features for TMX2-ARHGAP4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
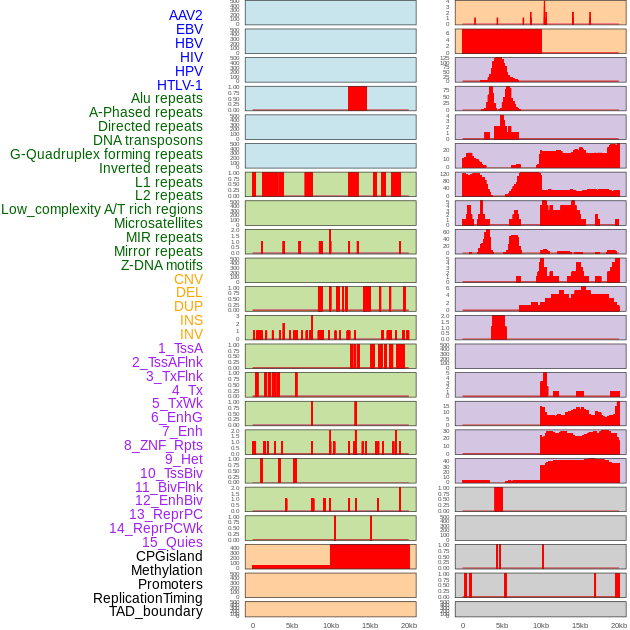 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for TMX2-ARHGAP4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:57480279/chrX:153179333) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ARHGAP4 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Contains a GTPase activator for the Rho-type GTPases (RhoGAP) domain that would be able to negatively regulate the actin cytoskeleton as well as cell spreading. However, also contains N-terminally a BAR-domin which is able to play an autoinhibitory effect on this RhoGAP activity. {ECO:0000269|PubMed:24086303}.; FUNCTION: Precursor of the histocompatibility antigen HA-1. More generally, minor histocompatibility antigens (mHags) refer to immunogenic peptide which, when complexed with MHC, can generate an immune response after recognition by specific T-cells. The peptides are derived from polymorphic intracellular proteins, which are cleaved by normal pathways of antigen processing. The binding of these peptides to MHC class I or class II molecules and its expression on the cell surface can stimulate T-cell responses and thereby trigger graft rejection or graft-versus-host disease (GVHD) after hematopoietic stem cell transplantation from HLA-identical sibling donor. GVHD is a frequent complication after bone marrow transplantation (BMT), due to mismatch of minor histocompatibility antigen in HLA-matched sibling marrow transplants. Specifically, mismatching for mHag HA-1 which is recognized as immunodominant, is shown to be associated with the development of severe GVHD after HLA-identical BMT. HA-1 is presented to the cell surface by MHC class I HLA-A*0201, but also by other HLA-A alleles. This complex specifically elicits donor-cytotoxic T-lymphocyte (CTL) reactivity against hematologic malignancies after treatment by HLA-identical allogenic BMT. It induces cell recognition and lysis by CTL. {ECO:0000269|PubMed:12601144, ECO:0000269|PubMed:8260714, ECO:0000269|PubMed:8532022, ECO:0000269|PubMed:9798702}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000350060 | 6 | 22 | 507_695 | 344 | 947.0 | Domain | Rho-GAP | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000350060 | 6 | 22 | 746_805 | 344 | 947.0 | Domain | SH3 | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000370028 | 7 | 23 | 507_695 | 384 | 987.0 | Domain | Rho-GAP | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000370028 | 7 | 23 | 746_805 | 384 | 987.0 | Domain | SH3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000278422 | + | 1 | 8 | 114_269 | 63 | 297.0 | Domain | Thioredoxin |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000378312 | + | 1 | 7 | 114_269 | 63 | 259.0 | Domain | Thioredoxin |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000278422 | + | 1 | 8 | 293_296 | 63 | 297.0 | Motif | Di-lysine motif |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000378312 | + | 1 | 7 | 293_296 | 63 | 259.0 | Motif | Di-lysine motif |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000278422 | + | 1 | 8 | 126_296 | 63 | 297.0 | Topological domain | Cytoplasmic |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000278422 | + | 1 | 8 | 49_102 | 63 | 297.0 | Topological domain | Extracellular |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000378312 | + | 1 | 7 | 126_296 | 63 | 259.0 | Topological domain | Cytoplasmic |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000378312 | + | 1 | 7 | 49_102 | 63 | 259.0 | Topological domain | Extracellular |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000278422 | + | 1 | 8 | 103_125 | 63 | 297.0 | Transmembrane | Helical |
| Hgene | TMX2 | chr11:57480279 | chrX:153179333 | ENST00000378312 | + | 1 | 7 | 103_125 | 63 | 259.0 | Transmembrane | Helical |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000350060 | 6 | 22 | 128_195 | 344 | 947.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000370028 | 7 | 23 | 128_195 | 384 | 987.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000350060 | 6 | 22 | 19_317 | 344 | 947.0 | Domain | F-BAR | |
| Tgene | ARHGAP4 | chr11:57480279 | chrX:153179333 | ENST00000370028 | 7 | 23 | 19_317 | 384 | 987.0 | Domain | F-BAR |
Top |
Fusion Gene Sequence for TMX2-ARHGAP4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >92556_92556_1_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000350060_length(transcript)=2362nt_BP=201nt ACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTACTAC CTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGACGGT AACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCAGAGC CGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGAT GACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGCGGGC CGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTG CAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAGAAAA TTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGC CAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGGTGCC CAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTCGGTG GCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGAGCTG GAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACC TTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACCGGTG CCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCC CTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCTGGGG GCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTAC ACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGGGGAG CACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACT GCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCATGGGA CCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCT GTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAGCCCA AAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAG GGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCTCCCC AGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGCACAC AGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAGCCCT CTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATTCATA >92556_92556_1_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000350060_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_2_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000370016_length(transcript)=2285nt_BP=201nt ACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTACTAC CTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGACGGT AACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCAGAGC CGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGAT GACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGCGGGC CGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTG CAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAGAAAA TTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGC CAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGGTGCC CAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTCGGTG GCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGAGCTG GAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACC TTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACCGGTG CCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCC CTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCTGGGG GCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTAC ACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGGGGAG CACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACT GCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCATGGGA CCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCT GTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAGCCCA AAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAG GGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCTCCCC AGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGCACAC AGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAGCCCT >92556_92556_2_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000370016_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_3_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000370028_length(transcript)=2363nt_BP=201nt ACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTACTAC CTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGACGGT AACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCAGAGC CGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGAT GACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGCGGGC CGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTG CAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAGAAAA TTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGC CAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGGTGCC CAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTCGGTG GCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGAGCTG GAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACC TTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACCGGTG CCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCC CTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCTGGGG GCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTAC ACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGGGGAG CACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACT GCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCATGGGA CCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCT GTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAGCCCA AAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAG GGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCTCCCC AGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGCACAC AGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAGCCCT CTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATTCATA >92556_92556_3_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000370028_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_4_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000393721_length(transcript)=2372nt_BP=201nt ACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTACTAC CTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGACGGT AACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCAGAGC CGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGAT GACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGCGGGC CGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTG CAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAGAAAA TTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGC CAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGGTGCC CAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTCGGTG GCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGAGCTG GAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACC TTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACCGGTG CCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCC CTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCTGGGG GCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTAC ACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGGGGAG CACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACT GCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCATGGGA CCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCT GTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAGCCCA AAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAG GGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCTCCCC AGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGCACAC AGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAGCCCT CTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATTCATA >92556_92556_4_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000393721_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_5_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000537206_length(transcript)=2173nt_BP=201nt ACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTACTAC CTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGACGGT AACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCAGAGC CGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTCGGAT GACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGCGGGC CGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAAGCTG CAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAGAAAA TTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTCAGGC CAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGGTGCC CAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTCGGTG GCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGAGCTG GAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTTCACC TTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACCGGTG CCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCCGCCC CTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCTGGGG GCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGCCTAC ACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGGGGAG CACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCAGACT GCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCATGGGA CCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGACTCT GTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAGCCCA AAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCCCCAG GGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCTCCCC AGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGCACAC >92556_92556_5_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000278422_ARHGAP4_chrX_153179333_ENST00000537206_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_6_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000350060_length(transcript)=2366nt_BP=205nt CGTTACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTA CTACCTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGA CGGTAACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCA GAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTC GGATGACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGC GGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAA GCTGCAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAG AAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTC AGGCCAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGG TGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTC GGTGGCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGA GCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTT CACCTTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACC GGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCC GCCCCTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCT GGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGC CTACACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGG GGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCA GACTGCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCAT GGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGA CTCTGTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAG CCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCC CCAGGGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCT CCCCAGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGC ACACAGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAG CCCTCTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATT >92556_92556_6_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000350060_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_7_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000370016_length(transcript)=2289nt_BP=205nt CGTTACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTA CTACCTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGA CGGTAACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCA GAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTC GGATGACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGC GGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAA GCTGCAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAG AAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTC AGGCCAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGG TGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTC GGTGGCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGA GCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTT CACCTTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACC GGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCC GCCCCTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCT GGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGC CTACACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGG GGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCA GACTGCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCAT GGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGA CTCTGTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAG CCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCC CCAGGGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCT CCCCAGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGC ACACAGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAG >92556_92556_7_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000370016_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_8_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000370028_length(transcript)=2367nt_BP=205nt CGTTACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTA CTACCTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGA CGGTAACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCA GAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTC GGATGACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGC GGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAA GCTGCAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAG AAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTC AGGCCAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGG TGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTC GGTGGCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGA GCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTT CACCTTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACC GGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCC GCCCCTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCT GGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGC CTACACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGG GGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCA GACTGCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCAT GGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGA CTCTGTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAG CCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCC CCAGGGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCT CCCCAGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGC ACACAGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAG CCCTCTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATT >92556_92556_8_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000370028_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_9_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000393721_length(transcript)=2376nt_BP=205nt CGTTACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTA CTACCTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGA CGGTAACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCA GAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTC GGATGACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGC GGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAA GCTGCAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAG AAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTC AGGCCAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGG TGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTC GGTGGCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGA GCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTT CACCTTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACC GGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCC GCCCCTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCT GGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGC CTACACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGG GGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCA GACTGCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCAT GGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGA CTCTGTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAG CCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCC CCAGGGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCT CCCCAGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGC ACACAGGGATGCCCGCTCCACATCCTGCCTGCCCCTCAGCCCTGGCCCAGGCCCCTTTTGGAGGCAGCTGAGGAAGGATGCTGGGGAAAG CCCTCTTCTGCAGCTTTGTGGAAGGCTGATCAGTGGCTGCTGGGTGGCGGGTACCCTTGCTCAGATGCCTGGCAGGGCTGGGTGGCGATT >92556_92556_9_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000393721_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- >92556_92556_10_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000537206_length(transcript)=2177nt_BP=205nt CGTTACGGCCGAAAAGATGGCGGTCTTGGCACCTCTAATTGCTCTCGTGTATTCGGTGCCGCGACTTTCACGATGGCTCGCCCAACCTTA CTACCTTCTGTCGGCCCTGCTCTCTGCTGCCTTCCTACTCGTGAGGAAACTGCCGCCGCTCTGCCACGGTCTGCCCACCCAACGCGAAGA CGGTAACCCGTGTGACTTTGACTGGGTGGCTGAGATCTGCGTTGAAATGGAGCTGCGGGACGAGATTCTGCCCAGAGCCCAGAACATCCA GAGCCGCCTGGACCGACAGACCATTGAGACAGAGGAGGTGAACAAGACTCTGAAGGCGACACTGCAGGCCCTGCTGGAGGTGGTGGCCTC GGATGACGGGGATGTGCTTGATTCCTTCCAGACCAGCCCCTCCACCGAGTCCCTCAAGTCCACCAGCTCAGACCCAGGCAGCCGGCAGGC GGGCCGGAGGCGCGGCCAGCAGCAGGAGACCGAAACCTTCTACCTCACGAAGCTCCAGGAGTATCTGAGTGGACGGAGCATCCTCGCCAA GCTGCAGGCCAAGCACGAGAAGCTGCAGGAGGCCCTTCAGCGAGGTGACAAGGAGGAGCAGGAGGTGTCTTGGACCCAGTACACACAGAG AAAATTCCAGAAGAGCCGCCAGCCCCGCCCCAGCTCCCAGTATAACCAGAGACTCTTTGGGGGAGACATGGAGAAGTTTATCCAGAGCTC AGGCCAGCCTGTGCCCCTGGTGGTGGAGAGCTGCATTCGCTTCATCAACCTCAATGGCCTGCAGCATGAAGGCATCTTCCGGGTATCGGG TGCCCAGCTCCGGGTCTCAGAGATCCGTGATGCCTTCGAGAGAGGGGAGGACCCACTGGTGGAGGGCTGCACTGCCCATGACCTGGACTC GGTGGCCGGGGTGCTGAAGCTCTACTTCCGGAGCCTGGAGCCCCCACTCTTCCCCCCAGACCTGTTCGGCGAGCTGCTGGCTTCTTCGGA GCTGGAGGCCACAGCGGAGAGGGTGGAGCACGTGAGCCGCCTGCTGTGGCGGCTGCCCGCGCCGGTGCTGGTGGTTCTGCGCTACCTCTT CACCTTCCTCAACCACCTGGCCCAGTACAGCGATGAGAACATGATGGACCCCTACAACCTGGCCGTGTGCTTCGGGCCCACGCTGCTACC GGTGCCCGCTGGGCAGGACCCGGTGGCGCTGCAGGGCCGGGTGAACCAGCTGGTGCAGACGCTCATAGTGCAGCCCGATCGGGTCTTCCC GCCCCTGACCTCGCTGCCTGGCCCCGTCTACGAGAAGTGCATGGCACCGCCTTCCGCCAGCTGCCTGGGGGACGCCCAGCTGGAGAGCCT GGGGGCGGACAATGAGCCGGAGCTGGAAGCCGAGATGCCCGCACAGGAGGATGACCTGGAGGGGGTCGTGGAGGCTGTGGCCTGCTTTGC CTACACGGGCCGCACAGCCCAGGAGCTGAGCTTCCGGCGGGGGGACGTACTGCGGCTGCACGAGAGGGCCTCGAGCGACTGGTGGCGGGG GGAGCACAACGGCATGCGGGGCCTCATCCCCCACAAGTATATCACGCTGCCCGCCGGGACGGAGAAGCAGGTGGTGGGCGCAGGGCTGCA GACTGCAGGGGAGTCTGGGAGCAGTCCCGAGGGCCTCCTGGCATCGGAGCTGGTCCACCGGCCAGAGCCATGCACCTCACCTGAGGCCAT GGGACCCTCTGGACACAGACGACGCTGCTTGGTCCCAGCCTCCCCAGAGCAACACGTGGAGGTGGATAAGGCTGTGGCACAGAACATGGA CTCTGTGTTTAAGGAGCTCTTGGGAAAGACCTCTGTCCGCCAGGGCCTTGGGCCAGCATCTACCACCTCTCCCAGTCCTGGGCCCCGAAG CCCAAAGGCCCCGCCCAGCAGCCGCCTGGGCAGGAACAAAGGCTTCTCCCGGGGCCCTGGGGCCCCAGCCTCACCCTCAGCTTCCCACCC CCAGGGCCTAGACACGACCCCCAAGCCACACTGAGGTGCCGCTGCTGGAGATGCGTGCCCCCGGCGGCTACCCGCTGGACCGGCCACTCT CCCCAGCCCCCTTGCTTCTCTCCAGCCCTGTCCAGCAAGTGCAGGGTGCCTGCACTTCACCCTGTGCAGAGAGGTGGGATGGGGCCGTGC >92556_92556_10_TMX2-ARHGAP4_TMX2_chr11_57480279_ENST00000378312_ARHGAP4_chrX_153179333_ENST00000537206_length(amino acids)=665AA_BP=63 MAVLAPLIALVYSVPRLSRWLAQPYYLLSALLSAAFLLVRKLPPLCHGLPTQREDGNPCDFDWVAEICVEMELRDEILPRAQNIQSRLDR QTIETEEVNKTLKATLQALLEVVASDDGDVLDSFQTSPSTESLKSTSSDPGSRQAGRRRGQQQETETFYLTKLQEYLSGRSILAKLQAKH EKLQEALQRGDKEEQEVSWTQYTQRKFQKSRQPRPSSQYNQRLFGGDMEKFIQSSGQPVPLVVESCIRFINLNGLQHEGIFRVSGAQLRV SEIRDAFERGEDPLVEGCTAHDLDSVAGVLKLYFRSLEPPLFPPDLFGELLASSELEATAERVEHVSRLLWRLPAPVLVVLRYLFTFLNH LAQYSDENMMDPYNLAVCFGPTLLPVPAGQDPVALQGRVNQLVQTLIVQPDRVFPPLTSLPGPVYEKCMAPPSASCLGDAQLESLGADNE PELEAEMPAQEDDLEGVVEAVACFAYTGRTAQELSFRRGDVLRLHERASSDWWRGEHNGMRGLIPHKYITLPAGTEKQVVGAGLQTAGES GSSPEGLLASELVHRPEPCTSPEAMGPSGHRRRCLVPASPEQHVEVDKAVAQNMDSVFKELLGKTSVRQGLGPASTTSPSPGPRSPKAPP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TMX2-ARHGAP4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TMX2-ARHGAP4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TMX2-ARHGAP4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies