
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:BCAT2-PPP1R12C (FusionGDB2 ID:9288) |
Fusion Gene Summary for BCAT2-PPP1R12C |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: BCAT2-PPP1R12C | Fusion gene ID: 9288 | Hgene | Tgene | Gene symbol | BCAT2 | PPP1R12C | Gene ID | 587 | 54776 |
| Gene name | branched chain amino acid transaminase 2 | protein phosphatase 1 regulatory subunit 12C | |
| Synonyms | BCAM|BCATM|BCT2|PP18 | AAVS1|LENG3|MBS85|p84|p85 | |
| Cytomap | 19q13.33 | 19q13.42 | |
| Type of gene | protein-coding | protein-coding | |
| Description | branched-chain-amino-acid aminotransferase, mitochondrialbranched chain amino-acid transaminase 2, mitochondrialbranched chain aminotransferase 2, mitochondrialplacental protein 18 | protein phosphatase 1 regulatory subunit 12Cleukocyte receptor cluster (LRC) encoded novel gene 3leukocyte receptor cluster (LRC) member 3myosin-binding subunit 85protein phosphatase 1 myosin-binding subunit of 85 kDaprotein phosphatase 1 myosin-bind | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O15382 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000402551, ENST00000601496, ENST00000316273, ENST00000545387, ENST00000598162, ENST00000599246, ENST00000597011, | ENST00000263433, ENST00000376393, ENST00000435544, | |
| Fusion gene scores | * DoF score | 10 X 9 X 9=810 | 16 X 6 X 9=864 |
| # samples | 11 | 16 | |
| ** MAII score | log2(11/810*10)=-2.88041838424733 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/864*10)=-2.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: BCAT2 [Title/Abstract] AND PPP1R12C [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | BCAT2(49314240)-PPP1R12C(55607703), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across BCAT2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PPP1R12C (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-FD-A3SL | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
Top |
Fusion Gene ORF analysis for BCAT2-PPP1R12C |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5UTR-3CDS | ENST00000402551 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| 5UTR-3CDS | ENST00000402551 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| 5UTR-3CDS | ENST00000402551 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| 5UTR-3CDS | ENST00000601496 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| 5UTR-3CDS | ENST00000601496 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| 5UTR-3CDS | ENST00000601496 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000316273 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000316273 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000316273 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000545387 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000545387 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000545387 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000598162 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000598162 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000598162 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000599246 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000599246 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| In-frame | ENST00000599246 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000597011 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000597011 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| intron-3CDS | ENST00000597011 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000545387 | BCAT2 | chr19 | 49314240 | - | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 1986 | 29 | 5 | 1426 | 473 |
| ENST00000545387 | BCAT2 | chr19 | 49314240 | - | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 1795 | 29 | 5 | 1237 | 410 |
| ENST00000545387 | BCAT2 | chr19 | 49314240 | - | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1535 | 29 | 5 | 1423 | 472 |
| ENST00000316273 | BCAT2 | chr19 | 49314240 | - | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 1994 | 37 | 13 | 1434 | 473 |
| ENST00000316273 | BCAT2 | chr19 | 49314240 | - | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 1803 | 37 | 13 | 1245 | 410 |
| ENST00000316273 | BCAT2 | chr19 | 49314240 | - | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1543 | 37 | 13 | 1431 | 472 |
| ENST00000599246 | BCAT2 | chr19 | 49314240 | - | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 2003 | 46 | 22 | 1443 | 473 |
| ENST00000599246 | BCAT2 | chr19 | 49314240 | - | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 1812 | 46 | 22 | 1254 | 410 |
| ENST00000599246 | BCAT2 | chr19 | 49314240 | - | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1552 | 46 | 22 | 1440 | 472 |
| ENST00000598162 | BCAT2 | chr19 | 49314240 | - | ENST00000263433 | PPP1R12C | chr19 | 55607703 | - | 2001 | 44 | 20 | 1441 | 473 |
| ENST00000598162 | BCAT2 | chr19 | 49314240 | - | ENST00000376393 | PPP1R12C | chr19 | 55607703 | - | 1810 | 44 | 20 | 1252 | 410 |
| ENST00000598162 | BCAT2 | chr19 | 49314240 | - | ENST00000435544 | PPP1R12C | chr19 | 55607703 | - | 1550 | 44 | 20 | 1438 | 472 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000545387 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.049321603 | 0.95067835 |
| ENST00000545387 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.039440136 | 0.9605599 |
| ENST00000545387 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.06222593 | 0.9377741 |
| ENST00000316273 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.048758004 | 0.95124197 |
| ENST00000316273 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.038338672 | 0.9616613 |
| ENST00000316273 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.06150464 | 0.9384954 |
| ENST00000599246 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.04876436 | 0.9512356 |
| ENST00000599246 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.0387689 | 0.9612311 |
| ENST00000599246 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.060765725 | 0.9392343 |
| ENST00000598162 | ENST00000263433 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.04846785 | 0.9515322 |
| ENST00000598162 | ENST00000376393 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.038284395 | 0.96171564 |
| ENST00000598162 | ENST00000435544 | BCAT2 | chr19 | 49314240 | - | PPP1R12C | chr19 | 55607703 | - | 0.060710058 | 0.93929 |
Top |
Fusion Genomic Features for BCAT2-PPP1R12C |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
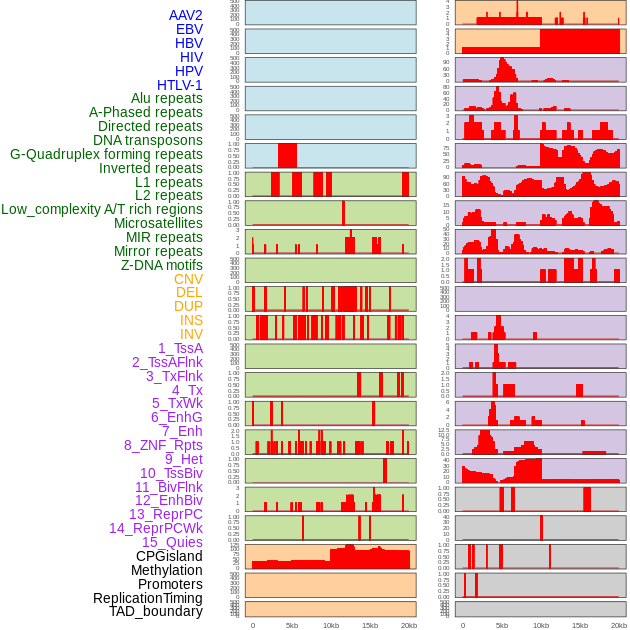 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for BCAT2-PPP1R12C |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:49314240/chr19:55607703) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| BCAT2 | . |
| FUNCTION: Catalyzes the first reaction in the catabolism of the essential branched chain amino acids leucine, isoleucine, and valine. May also function as a transporter of branched chain alpha-keto acids. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 681_782 | 317 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 473_523 | 317 | 783.0 | Compositional bias | Pro-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 297_329 | 317 | 783.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 100_129 | 317 | 783.0 | Repeat | ANK 1 | |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 133_162 | 317 | 783.0 | Repeat | ANK 2 | |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 226_255 | 317 | 783.0 | Repeat | ANK 3 | |
| Tgene | PPP1R12C | chr19:49314240 | chr19:55607703 | ENST00000263433 | 5 | 22 | 259_288 | 317 | 783.0 | Repeat | ANK 4 |
Top |
Fusion Gene Sequence for BCAT2-PPP1R12C |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >9288_9288_1_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=1994nt_BP=37nt CGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCC CTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCC TGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAA TGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGAC AGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTG GCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCT GTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGT CCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCA GAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGC AGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCC TGCCCAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCC TGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCA GCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGA GCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTT CGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGC CCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGG AGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGA AGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGA TGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAG TGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCA GGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTA TTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTG >9288_9288_1_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=473AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLN PEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDL -------------------------------------------------------------- >9288_9288_2_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=1803nt_BP=37nt CGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCC CTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCC TGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAA TGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGAC AGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTG GCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCT GTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGT CCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCA GAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGG GGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCT CAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCG CGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAG GCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGA CCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTT CCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGA GAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGG GAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGAT CAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAA GAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCT GCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTGAAGTTGCCA >9288_9288_2_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=410AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAE PADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALL -------------------------------------------------------------- >9288_9288_3_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1543nt_BP=37nt CGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCC CTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCC TGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAA TGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGAC AGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTG GCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCT GTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGT CCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCA GAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGC AGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCC TGCCCAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGC GGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCG GGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCG GCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGC TGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCT GTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGG GACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGT >9288_9288_3_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000316273_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=472AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNP EPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLR -------------------------------------------------------------- >9288_9288_4_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=1986nt_BP=29nt GGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCA GCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGG CTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCT CCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTT CTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAG GGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGG TCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAG CCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAG CTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGG CCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGA GAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGG GGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACC TCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTC GCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGA GGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTG ACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTT TCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAG AGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTG GGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGA TCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCA AGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGC TGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTGAAGTTGCC >9288_9288_4_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=473AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLN PEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDL -------------------------------------------------------------- >9288_9288_5_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=1795nt_BP=29nt GGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCA GCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGG CTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCT CCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTT CTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAG GGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGG TCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAG CCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAG CTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGGGGAGGAGG CGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCAACCCAG AACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCGAGGCCC TGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGCCAGCCC TCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACCTCCGCG CTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCCCGCACC CGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGAAGCCAT AGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATGGAGGTGGGAGGCCGA GCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTGCAAGGATCAGTAGCC AGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGGGATCCAAGAATGTGC CAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATTTTTTGCTGCCCCCTC >9288_9288_5_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=410AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAE PADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALL -------------------------------------------------------------- >9288_9288_6_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1535nt_BP=29nt GGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCCAAGCGCCCTCTAGCA GCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGCGCCGGCCTGGTGGGG CTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAACCCTCAATGGCGTCT CCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCCTGAAGACAGGGAGTT CTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCTCCTCCTGGCTGGAAG GGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCTCTGTCCTGTCTGAGG TCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGCCAAACGTCCCCACAG CCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGGAATCCCAGAGAAAAG CTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGAAGGCTGCAGGGAAGG CCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTGACAGCCCTGCCCAGA GAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGGGGCCTGCGGAGGGGG AGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGCGGGACCTCA ACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGCGGCTTCGCG AGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCGCTGAGAGGC CAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCCTGTCTGACC TCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAGGGACTTTCC CGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAGTCTCAGAGA >9288_9288_6_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000545387_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=472AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNP EPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLR -------------------------------------------------------------- >9288_9288_7_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=2001nt_BP=44nt AGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCC AAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGC GCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAA CCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCC TGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCT CCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCT CTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGC CAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGG AATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGA AGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTG ACAGCCCTGCCCAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGA GGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGC GGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGG AGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAG AACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGC TGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGT GACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTC CGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAG GCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGAC CAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTC CTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACG TCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAA >9288_9288_7_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=473AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLN PEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDL -------------------------------------------------------------- >9288_9288_8_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=1810nt_BP=44nt AGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCC AAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGC GCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAA CCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCC TGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCT CCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCT CTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGC CAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGG AATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGA AGGCTGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCAGC GGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGAGC GGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTTCG CTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGCCC TGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGGAG GGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGAAG TCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGATG GAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAGTG CAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCAGG GATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTATT TTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTGAA >9288_9288_8_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=410AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAE PADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALL -------------------------------------------------------------- >9288_9288_9_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1550nt_BP=44nt AGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCCCC AAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGAGC GCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAGAA CCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCTCC TGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTCCT CCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCCCT CTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAAGC CAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTCGG AATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGAGA AGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTCTG ACAGCCCTGCCCAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAGGG GGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGT GGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGA ACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAAC GCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGA AGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGAC CCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGG >9288_9288_9_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000598162_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=472AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNP EPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLR -------------------------------------------------------------- >9288_9288_10_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000263433_length(transcript)=2003nt_BP=46nt ACAGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCC CCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGA GCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAG AACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCT CCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTC CTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCC CTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAA GCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTC GGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGA GAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTC TGACAGCCCTGCCCAGAGAGCAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTG GAGGGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCA GCGGTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAG GGAGAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCA AGAACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGA GCTGAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAA GTGACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGC TCCGGGGGAAGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCG AGGCCAGGATGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGG ACCAAGAAGTGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCC TCCTGAGCAGGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGA CGTCTTCTATTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATA >9288_9288_10_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000263433_length(amino acids)=473AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQRAEAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLN PEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDL -------------------------------------------------------------- >9288_9288_11_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000376393_length(transcript)=1812nt_BP=46nt ACAGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCC CCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGA GCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAG AACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCT CCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTC CTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCC CTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAA GCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTC GGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGA GAAGGCTGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCGGTGGCA GCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGAGAACGA GCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGAACGCTT CGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCTGAAGGC CCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTGACCCGG AGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCCGGGGGA AGTCTCAGAGAAGCCATAGCCCCCCTGGGACCTCCGGACTGGGAGGGGAGCAGAGTCCCCAGGAGCCGAGGGGGCCACCCGAGGCCAGGA TGGAGGTGGGAGGCCGAGCCAAGCAGGGGGACGTTGCCAGAGGGGACCAGGGCCAGAGACGGGACCAGGAAGGAACTGAGGACCAAGAAG TGCAAGGATCAGTAGCCAGGACCAGAGTGGCCGCCTGGAGGTCCCCATCTCACGTGTGATGCCACCCCGTCACCCCTCCCCTCCTGAGCA GGGATCCAAGAATGTGCCAAGAGTCCCGCCAGCCTCAGCCAGGTGGGCCTGTATATAGGGTCCATGTGCAATAGGGAGGGACGTCTTCTA TTTTTTGCTGCCCCCTCCCCGCCCACTGTCTGGGGCAGGGGGAGAAGGTATTTTCGAGATAAAGCACAGGCACCACAAATAAAAGTCGTG >9288_9288_11_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000376393_length(amino acids)=410AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAGEEAE PADRSQESSTLEGGPSARRQRWQRDLNPEPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALL -------------------------------------------------------------- >9288_9288_12_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000435544_length(transcript)=1552nt_BP=46nt ACAGTTACGCGCCGCACGGATCATGGCCGCAGCCGCTCTGGGGCAGCTTCGGAACCAAAAAGAAGCTTCCCAGAGCCGGGGCCAGGAGCC CCAAGCGCCCTCTAGCAGCAAACACAGAAGGAGCTCTGTGTGTCGTCTGAGCAGTCGCGAGAAGATTTCCCTCCAGGACTTGTCCAAGGA GCGCCGGCCTGGTGGGGCTGGGGGGCCCCCCATCCAGGACGAGGATGAGGGGGAAGAAGGTCCCACCGAACCACCCCCTGCAGAACCCAG AACCCTCAATGGCGTCTCCTCCCCGCCGCACCCCAGCCCTAAGAGTCCCGTGCAGCTTGAAGAGGCCCCCTTCTCCAGGCGCTTTGGCCT CCTGAAGACAGGGAGTTCTGGTGCCCTGGGTCCCCCTGAAAGGCGGACAGCGGAGGGAGCCCCTGGGGCTGGGCTGCAGCGCTCGGCTTC CTCCTCCTGGCTGGAAGGGACCTCCACTCAGGCCAAGGAGCTCCGTCTTGCCAGAATTACCCCGACCCCCTCCCCGAAGCTGCCGGAGCC CTCTGTCCTGTCTGAGGTCACCAAGCCTCCTCCTTGCTTGGAGAACTCCTCGCCTCCCTCCAGGATTCCGGAGCCTGAATCCCCAGCGAA GCCAAACGTCCCCACAGCCTCCACGGCGCCCCCAGCGGACTCCCGGGACCGACGGAGGTCCTACCAGATGCCTGTGCGGGATGAGGAGTC GGAATCCCAGAGAAAAGCTCGCTCCCGTCTCATGCGCCAGTCTCGGAGGTCCACACAGGGTGTGACTCTTACAGACCTGAAGGAGGCAGA GAAGGCTGCAGGGAAGGCCCCAGAGTCAGAGAAGCCGGCGCAGAGCCTGGACCCTTCCCGAAGGCCCCGCGTCCCTGGAGTGGAGAACTC TGACAGCCCTGCCCAGAGAGAGGCGCCCGACGGGCAGGGTCCGGGACCGCAGGCGGCCAGGGAGCACCGCAAGGTCGGAAAGGAGTGGAG GGGGCCTGCGGAGGGGGAGGAGGCGGAGCCGGCTGACCGCAGCCAGGAGTCCAGCACCCTGGAGGGCGGCCCCTCGGCCCGCAGGCAGCG GTGGCAGCGGGACCTCAACCCAGAACCTGAGCCAGAATCGGAAGAGCCAGACGGAGGCTTTAGGACGCTGTATGCAGAGCTGCGCAGGGA GAACGAGCGGCTTCGCGAGGCCCTGACCGAGACCACGCTGCGGCTGGCGCAGCTCAAGGTGGAGCTGGAGCGGGCCACGCAGAGGCAAGA ACGCTTCGCTGAGAGGCCAGCCCTCCTGGAACTGGAGAGATTCGAGCGCAGGGCCCTGGAACGCAAGGCCGCAGAGCTGGAGGAGGAGCT GAAGGCCCTGTCTGACCTCCGCGCTGACAACCAGCGCCTCAAGGATGAGAATGCAGCGTTGATCCGCGTCATCAGCAAACTCTCCAAGTG ACCCGGAGGGACTTTCCCGCACCCGTATTTATACAGCTGCTTCTGCCACACGCACCCCTTCCCCCGTGTGAACACGAGTGACAGGGCTCC >9288_9288_12_BCAT2-PPP1R12C_BCAT2_chr19_49314240_ENST00000599246_PPP1R12C_chr19_55607703_ENST00000435544_length(amino acids)=472AA_BP=7 MAAAALGQLRNQKEASQSRGQEPQAPSSSKHRRSSVCRLSSREKISLQDLSKERRPGGAGGPPIQDEDEGEEGPTEPPPAEPRTLNGVSS PPHPSPKSPVQLEEAPFSRRFGLLKTGSSGALGPPERRTAEGAPGAGLQRSASSSWLEGTSTQAKELRLARITPTPSPKLPEPSVLSEVT KPPPCLENSSPPSRIPEPESPAKPNVPTASTAPPADSRDRRRSYQMPVRDEESESQRKARSRLMRQSRRSTQGVTLTDLKEAEKAAGKAP ESEKPAQSLDPSRRPRVPGVENSDSPAQREAPDGQGPGPQAAREHRKVGKEWRGPAEGEEAEPADRSQESSTLEGGPSARRQRWQRDLNP EPEPESEEPDGGFRTLYAELRRENERLREALTETTLRLAQLKVELERATQRQERFAERPALLELERFERRALERKAAELEEELKALSDLR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for BCAT2-PPP1R12C |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for BCAT2-PPP1R12C |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for BCAT2-PPP1R12C |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies