
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TOLLIP-AP2A2 (FusionGDB2 ID:92980) |
Fusion Gene Summary for TOLLIP-AP2A2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TOLLIP-AP2A2 | Fusion gene ID: 92980 | Hgene | Tgene | Gene symbol | TOLLIP | AP2A2 | Gene ID | 54472 | 161 |
| Gene name | toll interacting protein | adaptor related protein complex 2 subunit alpha 2 | |
| Synonyms | IL-1RAcPIP | ADTAB|CLAPA2|HIP-9|HIP9|HYPJ | |
| Cytomap | 11p15.5 | 11p15.5 | |
| Type of gene | protein-coding | protein-coding | |
| Description | toll-interacting proteinadapter protein | AP-2 complex subunit alpha-2100 kDa coated vesicle protein Cadapter-related protein complex 2 subunit alpha-2adaptin, alpha Badaptor related protein complex 2 alpha 2 subunitalpha-adaptin C; Huntingtin interacting protein Jalpha2-adaptinclathrin as | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | . | O94973 | |
| Ensembl transtripts involved in fusion gene | ENST00000317204, ENST00000525159, ENST00000527938, ENST00000542915, ENST00000263646, ENST00000527886, ENST00000528719, | ENST00000525891, ENST00000332231, ENST00000448903, ENST00000534328, | |
| Fusion gene scores | * DoF score | 6 X 5 X 5=150 | 6 X 8 X 4=192 |
| # samples | 7 | 7 | |
| ** MAII score | log2(7/150*10)=-1.09953567355091 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/192*10)=-1.45567948377619 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TOLLIP [Title/Abstract] AND AP2A2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP2A2(926088)-TOLLIP(1298483), # samples:2 TOLLIP(1330696)-AP2A2(972062), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | TOLLIP-AP2A2 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. AP2A2-TOLLIP seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TOLLIP | GO:0016310 | phosphorylation | 1085432 |
| Hgene | TOLLIP | GO:0036010 | protein localization to endosome | 16412388 |
| Tgene | AP2A2 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Fusion gene breakpoints across TOLLIP (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
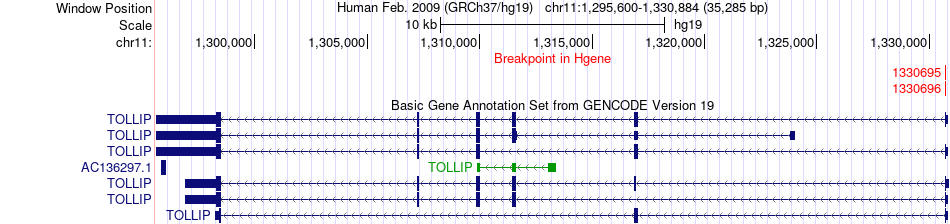 |
| Fusion gene breakpoints across AP2A2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-0970-01B | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| ChimerDB4 | OV | TCGA-24-0970-01B | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| ChimerDB4 | OV | TCGA-24-0970 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
Top |
Fusion Gene ORF analysis for TOLLIP-AP2A2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000317204 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| 5CDS-intron | ENST00000317204 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| 5CDS-intron | ENST00000317204 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| 5CDS-intron | ENST00000525159 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| 5CDS-intron | ENST00000525159 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| 5CDS-intron | ENST00000525159 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| 5CDS-intron | ENST00000527938 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| 5CDS-intron | ENST00000527938 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| 5CDS-intron | ENST00000527938 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| 5CDS-intron | ENST00000542915 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| 5CDS-intron | ENST00000542915 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| 5CDS-intron | ENST00000542915 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000317204 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000317204 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000317204 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000317204 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000317204 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000317204 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000525159 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000525159 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000525159 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000525159 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000525159 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000525159 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000527938 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000527938 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000527938 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000527938 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000527938 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000527938 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000542915 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000542915 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000542915 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000542915 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| Frame-shift | ENST00000542915 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| Frame-shift | ENST00000542915 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| In-frame | ENST00000317204 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000317204 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000317204 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000525159 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000525159 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000525159 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000527938 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000527938 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000527938 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000542915 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000542915 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| In-frame | ENST00000542915 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000263646 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000263646 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000263646 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000263646 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000263646 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000263646 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000263646 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000263646 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000263646 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000527886 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000527886 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000527886 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000527886 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000527886 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000527886 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000527886 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000527886 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000527886 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000528719 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000528719 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000528719 | ENST00000332231 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000528719 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000528719 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000528719 | ENST00000448903 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-3CDS | ENST00000528719 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-3CDS | ENST00000528719 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-3CDS | ENST00000528719 | ENST00000534328 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-intron | ENST00000263646 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-intron | ENST00000263646 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-intron | ENST00000263646 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-intron | ENST00000527886 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-intron | ENST00000527886 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-intron | ENST00000527886 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| intron-intron | ENST00000528719 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 970169 | + |
| intron-intron | ENST00000528719 | ENST00000525891 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + |
| intron-intron | ENST00000528719 | ENST00000525891 | TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000317204 | TOLLIP | chr11 | 1330696 | - | ENST00000534328 | AP2A2 | chr11 | 972062 | + | 1227 | 157 | 34 | 1014 | 326 |
| ENST00000317204 | TOLLIP | chr11 | 1330696 | - | ENST00000332231 | AP2A2 | chr11 | 972062 | + | 2993 | 157 | 34 | 2700 | 888 |
| ENST00000317204 | TOLLIP | chr11 | 1330696 | - | ENST00000448903 | AP2A2 | chr11 | 972062 | + | 4312 | 157 | 34 | 2697 | 887 |
| ENST00000525159 | TOLLIP | chr11 | 1330696 | - | ENST00000534328 | AP2A2 | chr11 | 972062 | + | 1224 | 154 | 31 | 1011 | 326 |
| ENST00000525159 | TOLLIP | chr11 | 1330696 | - | ENST00000332231 | AP2A2 | chr11 | 972062 | + | 2990 | 154 | 31 | 2697 | 888 |
| ENST00000525159 | TOLLIP | chr11 | 1330696 | - | ENST00000448903 | AP2A2 | chr11 | 972062 | + | 4309 | 154 | 31 | 2694 | 887 |
| ENST00000542915 | TOLLIP | chr11 | 1330696 | - | ENST00000534328 | AP2A2 | chr11 | 972062 | + | 1228 | 158 | 35 | 1015 | 326 |
| ENST00000542915 | TOLLIP | chr11 | 1330696 | - | ENST00000332231 | AP2A2 | chr11 | 972062 | + | 2994 | 158 | 35 | 2701 | 888 |
| ENST00000542915 | TOLLIP | chr11 | 1330696 | - | ENST00000448903 | AP2A2 | chr11 | 972062 | + | 4313 | 158 | 35 | 2698 | 887 |
| ENST00000527938 | TOLLIP | chr11 | 1330696 | - | ENST00000534328 | AP2A2 | chr11 | 972062 | + | 1228 | 158 | 35 | 1015 | 326 |
| ENST00000527938 | TOLLIP | chr11 | 1330696 | - | ENST00000332231 | AP2A2 | chr11 | 972062 | + | 2994 | 158 | 35 | 2701 | 888 |
| ENST00000527938 | TOLLIP | chr11 | 1330696 | - | ENST00000448903 | AP2A2 | chr11 | 972062 | + | 4313 | 158 | 35 | 2698 | 887 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000317204 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.099163316 | 0.90083665 |
| ENST00000317204 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.006177702 | 0.99382234 |
| ENST00000317204 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.003343263 | 0.9966568 |
| ENST00000525159 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.096247666 | 0.9037524 |
| ENST00000525159 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.006178714 | 0.99382126 |
| ENST00000525159 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.00334136 | 0.9966587 |
| ENST00000542915 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.10149357 | 0.89850646 |
| ENST00000542915 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.006224289 | 0.9937757 |
| ENST00000542915 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.003358401 | 0.99664164 |
| ENST00000527938 | ENST00000534328 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.10149357 | 0.89850646 |
| ENST00000527938 | ENST00000332231 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.006224289 | 0.9937757 |
| ENST00000527938 | ENST00000448903 | TOLLIP | chr11 | 1330696 | - | AP2A2 | chr11 | 972062 | + | 0.003358401 | 0.99664164 |
Top |
Fusion Genomic Features for TOLLIP-AP2A2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 972061 | + | 2.17E-12 | 1 |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + | 3.37E-08 | 1 |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + | 3.37E-08 | 1 |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 972061 | + | 2.17E-12 | 1 |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + | 3.37E-08 | 1 |
| TOLLIP | chr11 | 1330695 | - | AP2A2 | chr11 | 970168 | + | 3.37E-08 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
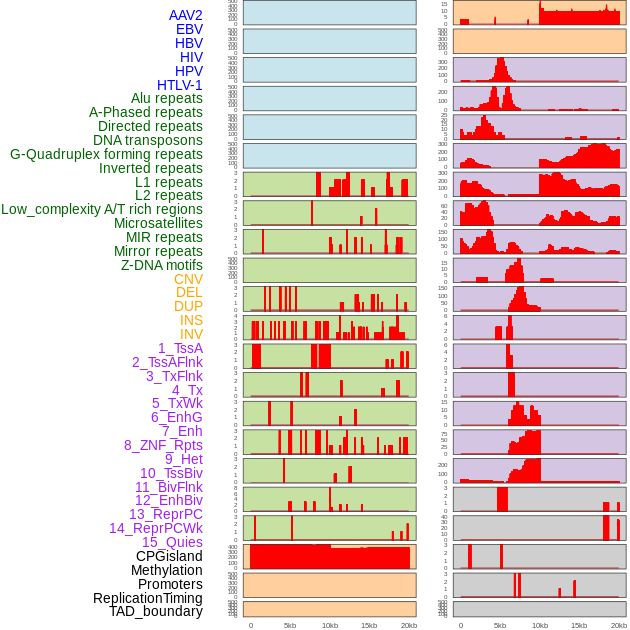 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
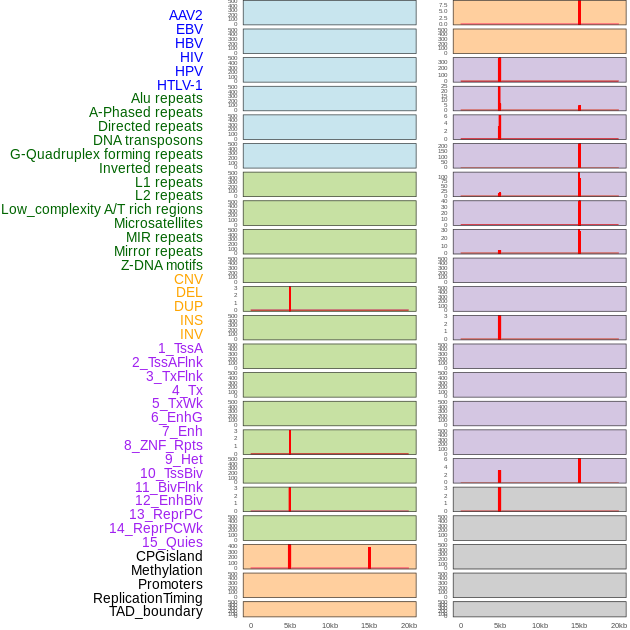 |
Top |
Fusion Protein Features for TOLLIP-AP2A2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:926088/chr11:1298483) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | AP2A2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Component of the adaptor protein complex 2 (AP-2). Adaptor protein complexes function in protein transport via transport vesicles in different membrane traffic pathways. Adaptor protein complexes are vesicle coat components and appear to be involved in cargo selection and vesicle formation. AP-2 is involved in clathrin-dependent endocytosis in which cargo proteins are incorporated into vesicles surrounded by clathrin (clathrin-coated vesicles, CCVs) which are destined for fusion with the early endosome. The clathrin lattice serves as a mechanical scaffold but is itself unable to bind directly to membrane components. Clathrin-associated adaptor protein (AP) complexes which can bind directly to both the clathrin lattice and to the lipid and protein components of membranes are considered to be the major clathrin adaptors contributing the CCV formation. AP-2 also serves as a cargo receptor to selectively sort the membrane proteins involved in receptor-mediated endocytosis. AP-2 seems to play a role in the recycling of synaptic vesicle membranes from the presynaptic surface. AP-2 recognizes Y-X-X-[FILMV] (Y-X-X-Phi) and [ED]-X-X-X-L-[LI] endocytosis signal motifs within the cytosolic tails of transmembrane cargo molecules. AP-2 may also play a role in maintaining normal post-endocytic trafficking through the ARF6-regulated, non-clathrin pathway. During long-term potentiation in hippocampal neurons, AP-2 is responsible for the endocytosis of ADAM10 (PubMed:23676497). The AP-2 alpha subunit binds polyphosphoinositide-containing lipids, positioning AP-2 on the membrane. The AP-2 alpha subunit acts via its C-terminal appendage domain as a scaffolding platform for endocytic accessory proteins. The AP-2 alpha and AP-2 sigma subunits are thought to contribute to the recognition of the [ED]-X-X-X-L-[LI] motif (By similarity). {ECO:0000250, ECO:0000269|PubMed:12960147, ECO:0000269|PubMed:14745134, ECO:0000269|PubMed:15473838, ECO:0000269|PubMed:19033387, ECO:0000269|PubMed:23676497}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TOLLIP | chr11:1330696 | chr11:972062 | ENST00000317204 | - | 1 | 6 | 28_44 | 11 | 275.0 | Compositional bias | Note=Gln-rich |
| Hgene | TOLLIP | chr11:1330696 | chr11:972062 | ENST00000317204 | - | 1 | 6 | 229_272 | 11 | 275.0 | Domain | CUE |
| Hgene | TOLLIP | chr11:1330696 | chr11:972062 | ENST00000317204 | - | 1 | 6 | 35_152 | 11 | 275.0 | Domain | C2 |
| Hgene | TOLLIP | chr11:1330696 | chr11:972062 | ENST00000317204 | - | 1 | 6 | 133_136 | 11 | 275.0 | Motif | Note=AIM1 |
| Hgene | TOLLIP | chr11:1330696 | chr11:972062 | ENST00000317204 | - | 1 | 6 | 151_154 | 11 | 275.0 | Motif | Note=AIM2 |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000332231 | 2 | 22 | 11_12 | 93 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding | |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000332231 | 2 | 22 | 57_61 | 93 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding | |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000332231 | 2 | 22 | 5_80 | 93 | 941.0 | Region | Note=Lipid-binding | |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000448903 | 2 | 22 | 11_12 | 93 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding | |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000448903 | 2 | 22 | 57_61 | 93 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding | |
| Tgene | AP2A2 | chr11:1330696 | chr11:972062 | ENST00000448903 | 2 | 22 | 5_80 | 93 | 940.0 | Region | Note=Lipid-binding |
Top |
Fusion Gene Sequence for TOLLIP-AP2A2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >92980_92980_1_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000332231_length(transcript)=2993nt_BP=157nt GCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGT CGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTT GGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGC CCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTAT GGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCG AGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGA GTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTT TGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGAAGACCCTGCAGTGCGAGGCCGCCTGAC TGAGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTT CGAGGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCG CGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGA GACGGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAA CGCCCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCT GGCTGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGT GTGGTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGC GTGCCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGAT CCAGTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCT CTTCCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGT GGAGTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTC CATCTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGG GGGTCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGC CCCCGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCC TGGCTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGA ATTTCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTC AGACGACCTTCAGCCTAATCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACAT AGAGTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCC CATCACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGA AGTGCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGA AGTTGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAA CCTGCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTA GTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGT GTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAG GAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTA >92980_92980_1_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000332231_length(amino acids)=888AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDS EPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSY LETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGY ILGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVAST DILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGS GLLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQT KPVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPM -------------------------------------------------------------- >92980_92980_2_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000448903_length(transcript)=4312nt_BP=157nt GCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGT CGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTT GGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGC CCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTAT GGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCG AGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGA GTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTT TGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTGA GTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCGA GGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCGCGA GACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGAGAC GGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAACGC CCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCTGGC TGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGTGTG GTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGCGTG CCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGATCCA GTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCTCTT CCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGTGGA GTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTCCAT CTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGGGGG TCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGCCCC CGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCCTGG CTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGAATT TCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTCAGA CGACCTTCAGCCTAACCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACATAGA GTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCCCAT CACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGAAGT GCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGAAGT TGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAACCT GCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTC CTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTC CAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAGGAG GAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTAAAT CTACAAATTAAAGGGAAATTAGAAGTTGGCGTGAACGTGGCGTTTGTGGGAGTGTCACTGAGATGGCCCGTGCTGCCGCCCACCCCGCCT CGGAGCCTCTGGGAGCAGCAGTGCCACTGTGCATGGCGTGGGCTGAGCCTTGGTGTGTGGCCGTCCTGGTGGCTGCACACCTGGCGTCGT CCTGGGCCCTTGGGAGGAGCACAGCTGACCCTGGTTTTGCTGCAGTCCCAGCTGGACTGTTTTCCCAGGCAGGATTTTAATCTAGAATTT AGAAACATTTGTATTTGTAATGACTTCTGGCAAAAGCACGTGTCCTGGCCGGATGTAACTGTTCTCCTTTCCCAGCTCCTGTTTGTGAAG GGCGTCTGTTATGCTCCTGCAGTCGCCGAGGCCTTGGATGTGCAGCCAGGGGAGGAGCGTCCTGCCGGCCCCGCAGGGCCCCCAGGACTC CAGGGTAAAGTGTGGGCCGGTGGCGCAAGACTCAGAGGTGTGCTCGTCTCTTTCCTGTCAGAGTGGGCGTCCCCAGGCCACGGTGCAGGC CTGAGTCCTTCCACCGGCCCCGTCCAGTCGTCCCTGGAGGGGCTGTGGAGGAGGGACGCCTCTGTGTGGTCAGGAAGTGAAGGGGCCATT GGCCGCATGCCATGTGCCACCTGCGGCTTGTGTCTCACCTGTCATCTGGACTCAGCACCCAGGCTGCACGTCTGACACCTGAGAGGCGAG AGAGTGGGGCCGGCCTAGGAGCCAAGGCTGGGGCCTTGCGCTCTGTCCCCAGGATGGTGGCCTTGTTTGTCCTAAACACACCCAGCACAG GTTCTGGCTTCCTGACATGCTGTGGAGGCAGGGAGGGTGGGTGGCCACATGTGCTTGAGGGTTTTCACCCTGGCCCTCAGTTGCCTGCTG TGCGGGTCCCTGGGGCAGCTGCAGGGGCTCATGGACCCATCAGGGTCTCCACAGCTCCCCTGCAGTGTGTGCACCCCACAATGTCTGCGG CTCTTCTTCCGGCGTGTCGGGCTTTGATCACAGCATAGCCACGTCAGTGGCGTGCGCCTCTCGCACAGGCCATTCTGGGTCTGGTGGTGC CAGGTGCCGTGACACGCCGTGCTGGGCTTGTGCTGCAGCTGGGTGGTGTGGCCCTCATTCTCATGTTCCAGCTGCTGGGCAGTGCTCTGC CTGTGTGCTGCGCCTGCAGGCTGCGTGTGCTGCCGTGGATCTCCTGCATCCCTTGACCCCTCCCGCCATCAGAGGAAAGGCTGCTCCCCG >92980_92980_2_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000448903_length(amino acids)=887AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDSE PNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSYL ETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGYI LGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVASTD ILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGSG LLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQTK PVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPMD -------------------------------------------------------------- >92980_92980_3_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000534328_length(transcript)=1227nt_BP=157nt GCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGT CGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTT GGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGC CCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTAT GGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCG AGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGA GTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTT TGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTGA GTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCGA GGCCATCAGCTTAATCATTCACCATGACAGGTGTGTCGGCTGCCTATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAG AGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTT GTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTT GGGCTGGACGGGAACACACGTGTGTGGCTCAGGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAA >92980_92980_3_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000317204_AP2A2_chr11_972062_ENST00000534328_length(amino acids)=326AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDRC -------------------------------------------------------------- >92980_92980_4_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000332231_length(transcript)=2990nt_BP=154nt GACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGTCGG GTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTTGGT GAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCT GCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGA CAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGT GGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGAGTT TAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTTTGT CCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGAAGACCCTGCAGTGCGAGGCCGCCTGACTGA GTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCGA GGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCGCGA GACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGAGAC GGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAACGC CCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCTGGC TGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGTGTG GTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGCGTG CCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGATCCA GTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCTCTT CCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGTGGA GTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTCCAT CTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGGGGG TCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGCCCC CGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCCTGG CTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGAATT TCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTCAGA CGACCTTCAGCCTAATCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACATAGA GTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCCCAT CACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGAAGT GCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGAAGT TGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAACCT GCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTC CTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTC CAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAGGAG GAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTAAAT >92980_92980_4_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000332231_length(amino acids)=888AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDS EPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSY LETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGY ILGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVAST DILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGS GLLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQT KPVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPM -------------------------------------------------------------- >92980_92980_5_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000448903_length(transcript)=4309nt_BP=154nt GACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGTCGG GTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTTGGT GAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCT GCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGA CAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGT GGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGAGTT TAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTTTGT CCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTGAGTG CCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCGAGGC CATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCGCGAGAC CAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGAGACGGT CATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAACGCCCC ACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCTGGCTGA GAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGTGTGGTA CCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGCGTGCCA CGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGATCCAGTT CCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCTCTTCCC GGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGTGGAGTA CCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTCCATCTT GGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGGGGGTCC TGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGCCCCCGC GGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCCTGGCTC CGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGAATTTCG GCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTCAGACGA CCTTCAGCCTAACCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACATAGAGTG CGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCCCATCAC TCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGAAGTGCA GAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGAAGTTGA TCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAACCTGCA AGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTCCTG AGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTCCAG TGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAGGAGGAA AAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTAAATCTA CAAATTAAAGGGAAATTAGAAGTTGGCGTGAACGTGGCGTTTGTGGGAGTGTCACTGAGATGGCCCGTGCTGCCGCCCACCCCGCCTCGG AGCCTCTGGGAGCAGCAGTGCCACTGTGCATGGCGTGGGCTGAGCCTTGGTGTGTGGCCGTCCTGGTGGCTGCACACCTGGCGTCGTCCT GGGCCCTTGGGAGGAGCACAGCTGACCCTGGTTTTGCTGCAGTCCCAGCTGGACTGTTTTCCCAGGCAGGATTTTAATCTAGAATTTAGA AACATTTGTATTTGTAATGACTTCTGGCAAAAGCACGTGTCCTGGCCGGATGTAACTGTTCTCCTTTCCCAGCTCCTGTTTGTGAAGGGC GTCTGTTATGCTCCTGCAGTCGCCGAGGCCTTGGATGTGCAGCCAGGGGAGGAGCGTCCTGCCGGCCCCGCAGGGCCCCCAGGACTCCAG GGTAAAGTGTGGGCCGGTGGCGCAAGACTCAGAGGTGTGCTCGTCTCTTTCCTGTCAGAGTGGGCGTCCCCAGGCCACGGTGCAGGCCTG AGTCCTTCCACCGGCCCCGTCCAGTCGTCCCTGGAGGGGCTGTGGAGGAGGGACGCCTCTGTGTGGTCAGGAAGTGAAGGGGCCATTGGC CGCATGCCATGTGCCACCTGCGGCTTGTGTCTCACCTGTCATCTGGACTCAGCACCCAGGCTGCACGTCTGACACCTGAGAGGCGAGAGA GTGGGGCCGGCCTAGGAGCCAAGGCTGGGGCCTTGCGCTCTGTCCCCAGGATGGTGGCCTTGTTTGTCCTAAACACACCCAGCACAGGTT CTGGCTTCCTGACATGCTGTGGAGGCAGGGAGGGTGGGTGGCCACATGTGCTTGAGGGTTTTCACCCTGGCCCTCAGTTGCCTGCTGTGC GGGTCCCTGGGGCAGCTGCAGGGGCTCATGGACCCATCAGGGTCTCCACAGCTCCCCTGCAGTGTGTGCACCCCACAATGTCTGCGGCTC TTCTTCCGGCGTGTCGGGCTTTGATCACAGCATAGCCACGTCAGTGGCGTGCGCCTCTCGCACAGGCCATTCTGGGTCTGGTGGTGCCAG GTGCCGTGACACGCCGTGCTGGGCTTGTGCTGCAGCTGGGTGGTGTGGCCCTCATTCTCATGTTCCAGCTGCTGGGCAGTGCTCTGCCTG TGTGCTGCGCCTGCAGGCTGCGTGTGCTGCCGTGGATCTCCTGCATCCCTTGACCCCTCCCGCCATCAGAGGAAAGGCTGCTCCCCGAGG >92980_92980_5_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000448903_length(amino acids)=887AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDSE PNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSYL ETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGYI LGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVASTD ILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGSG LLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQTK PVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPMD -------------------------------------------------------------- >92980_92980_6_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000534328_length(transcript)=1224nt_BP=154nt GACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTGTCGG GTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGTTGGT GAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCT GCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGA CAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGT GGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAGAGTT TAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATTTTGT CCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTGAGTG CCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCGAGGC CATCAGCTTAATCATTCACCATGACAGGTGTGTCGGCTGCCTATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGA TTATGTGAATTGCTCTCAGCGCAGTTTTAGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTC TTCGTGGCCATCCTGCAGATGAGCACCGTGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGG CTGGACGGGAACACACGTGTGTGGCTCAGGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTT >92980_92980_6_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000525159_AP2A2_chr11_972062_ENST00000534328_length(amino acids)=326AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDRC -------------------------------------------------------------- >92980_92980_7_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000332231_length(transcript)=2994nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGAAGACCCTGCAGTGCGAGGCCGCCTGA CTGAGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCT TCGAGGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACC GCGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCG AGACGGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCA ACGCCCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCC TGGCTGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGG TGTGGTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCG CGTGCCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGA TCCAGTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACC TCTTCCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTG TGGAGTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCT CCATCTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACG GGGGTCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTG CCCCCGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTC CTGGCTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTG AATTTCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTT CAGACGACCTTCAGCCTAATCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACA TAGAGTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGC CCATCACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGG AAGTGCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAG AAGTTGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGA ACCTGCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTT AGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCG TGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCA GGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTT >92980_92980_7_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000332231_length(amino acids)=888AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDS EPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSY LETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGY ILGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVAST DILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGS GLLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQT KPVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPM -------------------------------------------------------------- >92980_92980_8_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000448903_length(transcript)=4313nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTG AGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCG AGGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCGCG AGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGAGA CGGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAACG CCCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCTGG CTGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGTGT GGTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGCGT GCCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGATCC AGTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCTCT TCCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGTGG AGTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTCCA TCTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGGGG GTCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGCCC CCGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCCTG GCTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGAAT TTCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTCAG ACGACCTTCAGCCTAACCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACATAG AGTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCCCA TCACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGAAG TGCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGAAG TTGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAACC TGCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGT CCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGT CCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAGGA GGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTAAA TCTACAAATTAAAGGGAAATTAGAAGTTGGCGTGAACGTGGCGTTTGTGGGAGTGTCACTGAGATGGCCCGTGCTGCCGCCCACCCCGCC TCGGAGCCTCTGGGAGCAGCAGTGCCACTGTGCATGGCGTGGGCTGAGCCTTGGTGTGTGGCCGTCCTGGTGGCTGCACACCTGGCGTCG TCCTGGGCCCTTGGGAGGAGCACAGCTGACCCTGGTTTTGCTGCAGTCCCAGCTGGACTGTTTTCCCAGGCAGGATTTTAATCTAGAATT TAGAAACATTTGTATTTGTAATGACTTCTGGCAAAAGCACGTGTCCTGGCCGGATGTAACTGTTCTCCTTTCCCAGCTCCTGTTTGTGAA GGGCGTCTGTTATGCTCCTGCAGTCGCCGAGGCCTTGGATGTGCAGCCAGGGGAGGAGCGTCCTGCCGGCCCCGCAGGGCCCCCAGGACT CCAGGGTAAAGTGTGGGCCGGTGGCGCAAGACTCAGAGGTGTGCTCGTCTCTTTCCTGTCAGAGTGGGCGTCCCCAGGCCACGGTGCAGG CCTGAGTCCTTCCACCGGCCCCGTCCAGTCGTCCCTGGAGGGGCTGTGGAGGAGGGACGCCTCTGTGTGGTCAGGAAGTGAAGGGGCCAT TGGCCGCATGCCATGTGCCACCTGCGGCTTGTGTCTCACCTGTCATCTGGACTCAGCACCCAGGCTGCACGTCTGACACCTGAGAGGCGA GAGAGTGGGGCCGGCCTAGGAGCCAAGGCTGGGGCCTTGCGCTCTGTCCCCAGGATGGTGGCCTTGTTTGTCCTAAACACACCCAGCACA GGTTCTGGCTTCCTGACATGCTGTGGAGGCAGGGAGGGTGGGTGGCCACATGTGCTTGAGGGTTTTCACCCTGGCCCTCAGTTGCCTGCT GTGCGGGTCCCTGGGGCAGCTGCAGGGGCTCATGGACCCATCAGGGTCTCCACAGCTCCCCTGCAGTGTGTGCACCCCACAATGTCTGCG GCTCTTCTTCCGGCGTGTCGGGCTTTGATCACAGCATAGCCACGTCAGTGGCGTGCGCCTCTCGCACAGGCCATTCTGGGTCTGGTGGTG CCAGGTGCCGTGACACGCCGTGCTGGGCTTGTGCTGCAGCTGGGTGGTGTGGCCCTCATTCTCATGTTCCAGCTGCTGGGCAGTGCTCTG CCTGTGTGCTGCGCCTGCAGGCTGCGTGTGCTGCCGTGGATCTCCTGCATCCCTTGACCCCTCCCGCCATCAGAGGAAAGGCTGCTCCCC >92980_92980_8_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000448903_length(amino acids)=887AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDSE PNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSYL ETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGYI LGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVASTD ILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGSG LLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQTK PVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPMD -------------------------------------------------------------- >92980_92980_9_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000534328_length(transcript)=1228nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTG AGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCG AGGCCATCAGCTTAATCATTCACCATGACAGGTGTGTCGGCTGCCTATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCA GAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTT TGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTT TGGGCTGGACGGGAACACACGTGTGTGGCTCAGGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCA >92980_92980_9_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000527938_AP2A2_chr11_972062_ENST00000534328_length(amino acids)=326AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDRC -------------------------------------------------------------- >92980_92980_10_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000332231_length(transcript)=2994nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGAAGACCCTGCAGTGCGAGGCCGCCTGA CTGAGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCT TCGAGGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACC GCGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCG AGACGGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCA ACGCCCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCC TGGCTGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGG TGTGGTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCG CGTGCCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGA TCCAGTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACC TCTTCCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTG TGGAGTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCT CCATCTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACG GGGGTCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTG CCCCCGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTC CTGGCTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTG AATTTCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTT CAGACGACCTTCAGCCTAATCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACA TAGAGTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGC CCATCACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGG AAGTGCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAG AAGTTGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGA ACCTGCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTT AGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCG TGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCA GGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTT >92980_92980_10_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000332231_length(amino acids)=888AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDS EPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSY LETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGY ILGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVAST DILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGS GLLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQT KPVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPM -------------------------------------------------------------- >92980_92980_11_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000448903_length(transcript)=4313nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTG AGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCG AGGCCATCAGCTTAATCATTCACCATGACAGTGAGCCGAACCTGCTCGTCCGTGCCTGCAACCAGTTGGGCCAGTTTCTGCAGCACCGCG AGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCTGAGTTCTCCCATGAGGCTGTCAAGACGCACATCGAGA CGGTCATCAACGCCCTGAAGACTGAGCGGGACGTGAGCGTGCGGCAGCGGGCCGTGGACCTCCTCTACGCCATGTGCGACCGCAGCAACG CCCCACAGATCGTGGCCGAGATGCTGAGCTATCTGGAGACAGCTGACTACTCCATCCGAGAAGAGATTGTGCTGAAGGTCGCCATCCTGG CTGAGAAGTACGCGGTGGACTACACCTGGTATGTGGATACCATCTTGAACTTGATCCGAATTGCTGGTGATTACGTGAGTGAAGAGGTGT GGTACCGAGTCATTCAGATCGTCATCAACCGGGACGACGTGCAGGGCTACGCGGCCAAGACTGTGTTCGAGGCTCTTCAGGCTCCCGCGT GCCACGAGAACCTGGTCAAAGTGGGCGGCTACATCCTGGGGGAGTTTGGAAACTTGATAGCTGGAGACCCGAGATCCAGCCCGCTGATCC AGTTCCACCTGCTGCACTCCAAGTTCCACCTGTGCAGCGTCCCCACCCGCGCGCTGCTCCTGTCCACCTACATCAAGTTCGTGAACCTCT TCCCGGAGGTGAAGCCCACCATCCAGGACGTGCTGCGCAGCGACAGCCAGCTCAGGAACGCAGACGTGGAGCTGCAGCAGCGTGCTGTGG AGTACCTGCGGCTCAGCACCGTGGCCAGCACCGACATTCTGGCGACCGTGCTGGAGGAGATGCCCCCATTCCCGGAGCGGGAGTCCTCCA TCTTGGCAAAGCTCAAGAAGAAGAAGGGCCCCAGCACGGTGACAGACCTGGAGGACACCAAGCGGGACAGGAGTGTGGACGTGAACGGGG GTCCTGAGCCTGCCCCAGCCAGTACCAGCGCCGTGTCTACGCCTTCTCCGTCGGCAGACCTGCTGGGTCTCGGGGCTGCCCCCCCTGCCC CCGCGGGCCCCCCACCCTCCTCCGGCGGCAGCGGGCTGCTCGTGGACGTGTTCTCAGACTCGGCCTCTGTGGTCGCGCCTCTCGCTCCTG GCTCCGAAGACAACTTTGCCAGGTTTGTTTGTAAAAACAATGGTGTGTTGTTTGAAAACCAGCTGCTTCAAATTGGACTTAAGTCTGAAT TTCGGCAGAATTTAGGTCGGATGTTTATCTTTTATGGTAATAAGACCTCCACGCAGTTCCTAAACTTTACCCCAACACTAATCTGTTCAG ACGACCTTCAGCCTAACCTGAACCTGCAGACCAAGCCCGTGGACCCGACCGTGGAGGGGGGCGCGCAGGTGCAGCAGGTGGTCAACATAG AGTGCGTGTCCGACTTCACGGAGGCGCCAGTCCTCAACATTCAGTTCAGGTATGGGGGCACCTTCCAGAACGTGTCTGTGCAGCTGCCCA TCACTCTCAACAAATTCTTCCAGCCGACAGAAATGGCTTCTCAGGATTTCTTTCAACGTTGGAAGCAGTTGAGCAATCCACAGCAGGAAG TGCAGAACATCTTCAAAGCAAAGCACCCAATGGACACAGAAGTCACCAAAGCCAAGATCATTGGATTTGGTTCTGCACTTCTTGAAGAAG TTGATCCTAATCCTGCGAATTTCGTGGGAGCTGGAATCATCCACACGAAAACCACCCAGATTGGATGCCTGCTGCGCTTGGAGCCGAACC TGCAAGCCCAGATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCAGAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGT CCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTTTGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGT CCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTTTGGGCTGGACGGGAACACACGTGTGTGGCTCAGGA GGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCAATTTTTATAAAAATCGAGACAGTTCTGTGGTTAAA TCTACAAATTAAAGGGAAATTAGAAGTTGGCGTGAACGTGGCGTTTGTGGGAGTGTCACTGAGATGGCCCGTGCTGCCGCCCACCCCGCC TCGGAGCCTCTGGGAGCAGCAGTGCCACTGTGCATGGCGTGGGCTGAGCCTTGGTGTGTGGCCGTCCTGGTGGCTGCACACCTGGCGTCG TCCTGGGCCCTTGGGAGGAGCACAGCTGACCCTGGTTTTGCTGCAGTCCCAGCTGGACTGTTTTCCCAGGCAGGATTTTAATCTAGAATT TAGAAACATTTGTATTTGTAATGACTTCTGGCAAAAGCACGTGTCCTGGCCGGATGTAACTGTTCTCCTTTCCCAGCTCCTGTTTGTGAA GGGCGTCTGTTATGCTCCTGCAGTCGCCGAGGCCTTGGATGTGCAGCCAGGGGAGGAGCGTCCTGCCGGCCCCGCAGGGCCCCCAGGACT CCAGGGTAAAGTGTGGGCCGGTGGCGCAAGACTCAGAGGTGTGCTCGTCTCTTTCCTGTCAGAGTGGGCGTCCCCAGGCCACGGTGCAGG CCTGAGTCCTTCCACCGGCCCCGTCCAGTCGTCCCTGGAGGGGCTGTGGAGGAGGGACGCCTCTGTGTGGTCAGGAAGTGAAGGGGCCAT TGGCCGCATGCCATGTGCCACCTGCGGCTTGTGTCTCACCTGTCATCTGGACTCAGCACCCAGGCTGCACGTCTGACACCTGAGAGGCGA GAGAGTGGGGCCGGCCTAGGAGCCAAGGCTGGGGCCTTGCGCTCTGTCCCCAGGATGGTGGCCTTGTTTGTCCTAAACACACCCAGCACA GGTTCTGGCTTCCTGACATGCTGTGGAGGCAGGGAGGGTGGGTGGCCACATGTGCTTGAGGGTTTTCACCCTGGCCCTCAGTTGCCTGCT GTGCGGGTCCCTGGGGCAGCTGCAGGGGCTCATGGACCCATCAGGGTCTCCACAGCTCCCCTGCAGTGTGTGCACCCCACAATGTCTGCG GCTCTTCTTCCGGCGTGTCGGGCTTTGATCACAGCATAGCCACGTCAGTGGCGTGCGCCTCTCGCACAGGCCATTCTGGGTCTGGTGGTG CCAGGTGCCGTGACACGCCGTGCTGGGCTTGTGCTGCAGCTGGGTGGTGTGGCCCTCATTCTCATGTTCCAGCTGCTGGGCAGTGCTCTG CCTGTGTGCTGCGCCTGCAGGCTGCGTGTGCTGCCGTGGATCTCCTGCATCCCTTGACCCCTCCCGCCATCAGAGGAAAGGCTGCTCCCC >92980_92980_11_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000448903_length(amino acids)=887AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDSE PNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIETVINALKTERDVSVRQRAVDLLYAMCDRSNAPQIVAEMLSYL ETADYSIREEIVLKVAILAEKYAVDYTWYVDTILNLIRIAGDYVSEEVWYRVIQIVINRDDVQGYAAKTVFEALQAPACHENLVKVGGYI LGEFGNLIAGDPRSSPLIQFHLLHSKFHLCSVPTRALLLSTYIKFVNLFPEVKPTIQDVLRSDSQLRNADVELQQRAVEYLRLSTVASTD ILATVLEEMPPFPERESSILAKLKKKKGPSTVTDLEDTKRDRSVDVNGGPEPAPASTSAVSTPSPSADLLGLGAAPPAPAGPPPSSGGSG LLVDVFSDSASVVAPLAPGSEDNFARFVCKNNGVLFENQLLQIGLKSEFRQNLGRMFIFYGNKTSTQFLNFTPTLICSDDLQPNLNLQTK PVDPTVEGGAQVQQVVNIECVSDFTEAPVLNIQFRYGGTFQNVSVQLPITLNKFFQPTEMASQDFFQRWKQLSNPQQEVQNIFKAKHPMD -------------------------------------------------------------- >92980_92980_12_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000534328_length(transcript)=1228nt_BP=158nt AGCTGACTGTGGCGGCGGCGGCCTCGAGGTGACAACTGTCTCCGTCGCAGGCTCCGGCGGGGGCGCAGGAGGTCGCCCGGCGCGTCACTG TCGGGTCGGCGAGCCACGGGGGCCGCCGCAGCACCATGGCGACCACCGTCAGCACTCAGCGCGGGCCGGGCTACCTTTTCATCTCTGTGT TGGTGAACTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGG CCCTGCACTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTA TGGACAGCGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCC GAGTGGTGCACCTGCTCAATGACCAGCACTTGGGTGTGGTAACTGCAGCCACAAGTCTGATCACCACTTTAGCACAGAAGAACCCAGAAG AGTTTAAAACCTCCGTGTCTCTGGCTGTCTCTAGGCTAAGCAGAATCGTGACGTCTGCATCCACAGATCTCCAGGATTACACTTACTATT TTGTCCCGGCTCCCTGGCTGTCTGTCAAACTGCTGAGACTGCTGCAGTGCTACCCACCCCCAGACCCTGCAGTGCGAGGCCGCCTGACTG AGTGCCTGGAGACCATCCTGAACAAAGCCCAAGAACCGCCCAAGTCGAAGAAGGTCCAGCACTCCAACGCGAAGAATGCCGTGCTCTTCG AGGCCATCAGCTTAATCATTCACCATGACAGGTGTGTCGGCTGCCTATGTACCGGCTCACGCTGCGCACAAGTAAGGAAGCCGTTTCTCA GAGATTATGTGAATTGCTCTCAGCGCAGTTTTAGTCCTGAGGATGGAAGACCAGGCTCGTGTGTCTTGTGTTGTCTTCGTCTGTGCCGTT TGTCTTCGTGGCCATCCTGCAGATGAGCACCGTGTCCAGTGCCACAGCACAAGGCGCCTCCCCGCCCCGCCGCCCCACACCTCTCCCCTT TGGGCTGGACGGGAACACACGTGTGTGGCTCAGGAGGAAAAGCTCAGCCTGGACTGTGGCAGCCACGGCAGAAGGTGGATCTTGGGATCA >92980_92980_12_TOLLIP-AP2A2_TOLLIP_chr11_1330696_ENST00000542915_AP2A2_chr11_972062_ENST00000534328_length(amino acids)=326AA_BP=41 MSPSQAPAGAQEVARRVTVGSASHGGRRSTMATTVSTQRGPGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSRE MAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSPDLVPMGDWTSRVVHLLNDQHLGVVTAATSLITTLAQKNPEEFKTSVSLAVSR LSRIVTSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPDPAVRGRLTECLETILNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHHDRC -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TOLLIP-AP2A2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TOLLIP-AP2A2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TOLLIP-AP2A2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies