
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TP53I3-CENPO (FusionGDB2 ID:93218) |
Fusion Gene Summary for TP53I3-CENPO |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TP53I3-CENPO | Fusion gene ID: 93218 | Hgene | Tgene | Gene symbol | TP53I3 | CENPO | Gene ID | 9540 | 79172 |
| Gene name | tumor protein p53 inducible protein 3 | centromere protein O | |
| Synonyms | PIG3 | CENP-O|ICEN-36|MCM21R | |
| Cytomap | 2p23.3 | 2p23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | quinone oxidoreductase PIG3p53-induced gene 3 proteinquinone oxidoreductase homolog | centromere protein Ocentromeric protein Ointerphase centromere complex protein 36 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9BU64 | |
| Ensembl transtripts involved in fusion gene | ENST00000238721, ENST00000313482, ENST00000335934, ENST00000407482, ENST00000417886, | ENST00000395845, ENST00000260662, ENST00000380834, ENST00000473706, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 4 X 4 X 4=64 |
| # samples | 2 | 4 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(4/64*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TP53I3 [Title/Abstract] AND CENPO [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TP53I3(24305754)-CENPO(25022543), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TP53I3 | GO:0006739 | NADP metabolic process | 19349281 |
| Fusion gene breakpoints across TP53I3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CENPO (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-IN-A6RN | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
Top |
Fusion Gene ORF analysis for TP53I3-CENPO |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000238721 | ENST00000395845 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| 5CDS-intron | ENST00000313482 | ENST00000395845 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| 5CDS-intron | ENST00000335934 | ENST00000395845 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| 5CDS-intron | ENST00000407482 | ENST00000395845 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000238721 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000238721 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000238721 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000313482 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000313482 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000313482 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000335934 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000335934 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000335934 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000407482 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000407482 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| In-frame | ENST00000407482 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| intron-3CDS | ENST00000417886 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| intron-3CDS | ENST00000417886 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| intron-3CDS | ENST00000417886 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| intron-intron | ENST00000417886 | ENST00000395845 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000335934 | TP53I3 | chr2 | 24305754 | - | ENST00000473706 | CENPO | chr2 | 25022543 | + | 4811 | 896 | 391 | 1752 | 453 |
| ENST00000335934 | TP53I3 | chr2 | 24305754 | - | ENST00000380834 | CENPO | chr2 | 25022543 | + | 4811 | 896 | 391 | 1752 | 453 |
| ENST00000335934 | TP53I3 | chr2 | 24305754 | - | ENST00000260662 | CENPO | chr2 | 25022543 | + | 2350 | 896 | 391 | 1752 | 453 |
| ENST00000238721 | TP53I3 | chr2 | 24305754 | - | ENST00000473706 | CENPO | chr2 | 25022543 | + | 5176 | 1261 | 540 | 2117 | 525 |
| ENST00000238721 | TP53I3 | chr2 | 24305754 | - | ENST00000380834 | CENPO | chr2 | 25022543 | + | 5176 | 1261 | 540 | 2117 | 525 |
| ENST00000238721 | TP53I3 | chr2 | 24305754 | - | ENST00000260662 | CENPO | chr2 | 25022543 | + | 2715 | 1261 | 540 | 2117 | 525 |
| ENST00000313482 | TP53I3 | chr2 | 24305754 | - | ENST00000473706 | CENPO | chr2 | 25022543 | + | 4381 | 466 | 60 | 1322 | 420 |
| ENST00000313482 | TP53I3 | chr2 | 24305754 | - | ENST00000380834 | CENPO | chr2 | 25022543 | + | 4381 | 466 | 60 | 1322 | 420 |
| ENST00000313482 | TP53I3 | chr2 | 24305754 | - | ENST00000260662 | CENPO | chr2 | 25022543 | + | 1920 | 466 | 60 | 1322 | 420 |
| ENST00000407482 | TP53I3 | chr2 | 24305754 | - | ENST00000473706 | CENPO | chr2 | 25022543 | + | 4321 | 406 | 0 | 1262 | 420 |
| ENST00000407482 | TP53I3 | chr2 | 24305754 | - | ENST00000380834 | CENPO | chr2 | 25022543 | + | 4321 | 406 | 0 | 1262 | 420 |
| ENST00000407482 | TP53I3 | chr2 | 24305754 | - | ENST00000260662 | CENPO | chr2 | 25022543 | + | 1860 | 406 | 0 | 1262 | 420 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000335934 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005882947 | 0.994117 |
| ENST00000335934 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005882947 | 0.994117 |
| ENST00000335934 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.006772727 | 0.9932273 |
| ENST00000238721 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005436178 | 0.9945639 |
| ENST00000238721 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005436178 | 0.9945639 |
| ENST00000238721 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.00529568 | 0.9947043 |
| ENST00000313482 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005309573 | 0.9946904 |
| ENST00000313482 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005309573 | 0.9946904 |
| ENST00000313482 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.007148426 | 0.99285156 |
| ENST00000407482 | ENST00000473706 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005302765 | 0.9946972 |
| ENST00000407482 | ENST00000380834 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.005302765 | 0.9946972 |
| ENST00000407482 | ENST00000260662 | TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.006563015 | 0.993437 |
Top |
Fusion Genomic Features for TP53I3-CENPO |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.034778234 | 0.96522176 |
| TP53I3 | chr2 | 24305754 | - | CENPO | chr2 | 25022543 | + | 0.034778234 | 0.96522176 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
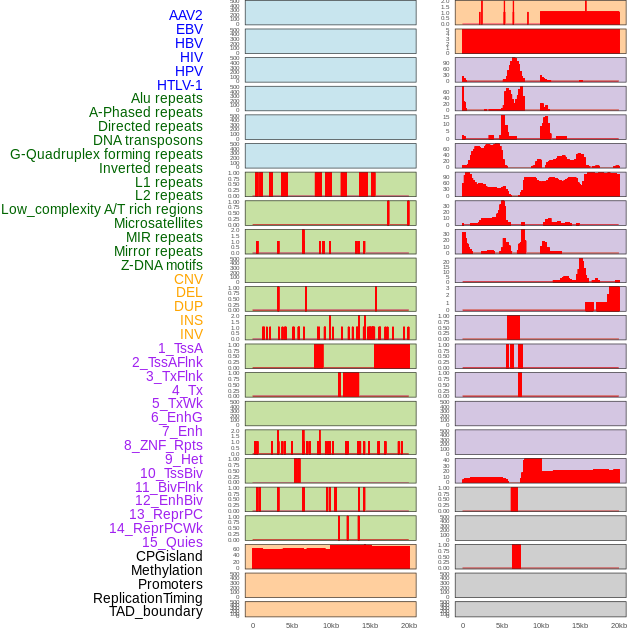 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
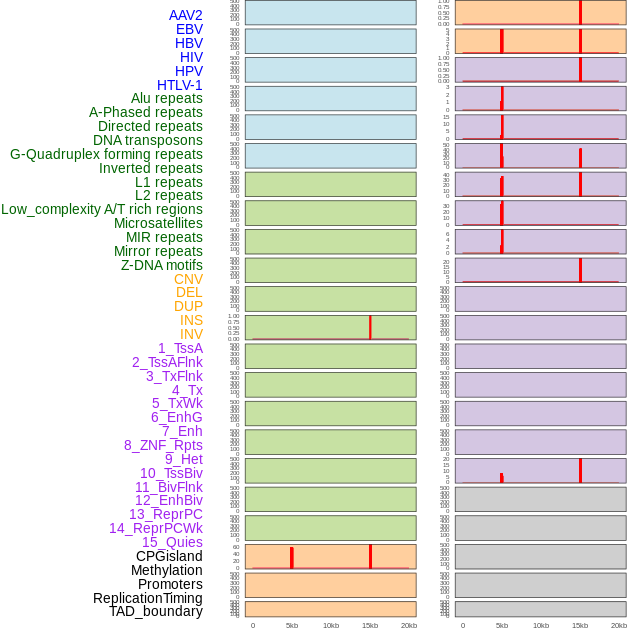 |
Top |
Fusion Protein Features for TP53I3-CENPO |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:24305754/chr2:25022543) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CENPO |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Component of the CENPA-CAD (nucleosome distal) complex, a complex recruited to centromeres which is involved in assembly of kinetochore proteins, mitotic progression and chromosome segregation. May be involved in incorporation of newly synthesized CENPA into centromeres via its interaction with the CENPA-NAC complex. Modulates the kinetochore-bound levels of NDC80 complex. {ECO:0000269|PubMed:16622420, ECO:0000269|PubMed:16716197, ECO:0000269|PubMed:16932742, ECO:0000269|PubMed:18007590}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000260662 | 1 | 8 | 18_42 | 15 | 469.3333333333333 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000260662 | 1 | 8 | 83_109 | 15 | 469.3333333333333 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000380834 | 1 | 8 | 18_42 | 15 | 1189.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000380834 | 1 | 8 | 83_109 | 15 | 1189.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000473706 | 0 | 7 | 18_42 | 9 | 1183.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CENPO | chr2:24305754 | chr2:25022543 | ENST00000473706 | 0 | 7 | 83_109 | 9 | 1183.6666666666667 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000238721 | - | 2 | 5 | 148_154 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000238721 | - | 2 | 5 | 173_177 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000238721 | - | 2 | 5 | 264_266 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000313482 | - | 3 | 5 | 148_154 | 135 | 249.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000313482 | - | 3 | 5 | 173_177 | 135 | 249.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000313482 | - | 3 | 5 | 264_266 | 135 | 249.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000335934 | - | 3 | 6 | 148_154 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000335934 | - | 3 | 6 | 173_177 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000335934 | - | 3 | 6 | 264_266 | 135 | 333.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000407482 | - | 2 | 4 | 148_154 | 135 | 249.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000407482 | - | 2 | 4 | 173_177 | 135 | 249.0 | Nucleotide binding | NADP |
| Hgene | TP53I3 | chr2:24305754 | chr2:25022543 | ENST00000407482 | - | 2 | 4 | 264_266 | 135 | 249.0 | Nucleotide binding | NADP |
Top |
Fusion Gene Sequence for TP53I3-CENPO |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >93218_93218_1_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000260662_length(transcript)=2715nt_BP=1261nt CTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCAAAAGCCTGGCCATGCCTGGAAAATGGACCAATCC GCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGAAGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTG AGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTTCTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAG GAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCAGCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTG GGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGG AGTAAGTAACTCATACGGGCGCCGGGGACCCGGGTCGGGCTGGGGGCTTCCAACTCAGAGGGAGTGTGATTTGCCTGATCCTCTTCGGCG TTGTCCTGCTCTGCCGCATCCAGCCCTGTACCGCCATCCCACTTCCCGCCGTTCCCATCTGTGTTCCGGGTGGGATCGGTCTGGAGGCGG CCGAGGACTTCCCAGGCAGGAGCTCGGGGCGGAGGCCGGGTCCGCGGCAGACCAGGGCAGCGAGGCGCTGGCCGGCAGGGGGCGCTGCGG TGCCAGCCTGAGGCTGGGCTGCTCCGCGAGGATACAGCGGCCCCTGCCCTGTCCTGTCCTGCCCTGCCCTGTCCTGTCCTGCCCTGCCCT GCCCTGTCCTGTCCTGCCCTGCCCTGCCCTGTGTCCTCAGACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTC TACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATG CAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGC TGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTC CTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTG GGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAA GGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCA TGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTG CAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTG GATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCT GCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGAC CGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGAT CCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAA GGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCC TCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAA TCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATG ATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAA GCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCA CCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCC TAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTG AGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTT >93218_93218_1_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000260662_length(amino acids)=525AA_BP=235 MSCSAASSPVPPSHFPPFPSVFRVGSVWRRPRTSQAGARGGGRVRGRPGQRGAGRQGALRCQPEAGLLREDTAAPALSCPALPCPVLPCP ALSCPALPCPVSSDNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPG CQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQE GALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLL DSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLD -------------------------------------------------------------- >93218_93218_2_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000380834_length(transcript)=5176nt_BP=1261nt CTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCAAAAGCCTGGCCATGCCTGGAAAATGGACCAATCC GCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGAAGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTG AGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTTCTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAG GAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCAGCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTG GGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGG AGTAAGTAACTCATACGGGCGCCGGGGACCCGGGTCGGGCTGGGGGCTTCCAACTCAGAGGGAGTGTGATTTGCCTGATCCTCTTCGGCG TTGTCCTGCTCTGCCGCATCCAGCCCTGTACCGCCATCCCACTTCCCGCCGTTCCCATCTGTGTTCCGGGTGGGATCGGTCTGGAGGCGG CCGAGGACTTCCCAGGCAGGAGCTCGGGGCGGAGGCCGGGTCCGCGGCAGACCAGGGCAGCGAGGCGCTGGCCGGCAGGGGGCGCTGCGG TGCCAGCCTGAGGCTGGGCTGCTCCGCGAGGATACAGCGGCCCCTGCCCTGTCCTGTCCTGCCCTGCCCTGTCCTGTCCTGCCCTGCCCT GCCCTGTCCTGTCCTGCCCTGCCCTGCCCTGTGTCCTCAGACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTC TACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATG CAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGC TGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTC CTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTG GGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAA GGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCA TGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTG CAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTG GATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCT GCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGAC CGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGAT CCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAA GGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCC TCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAA TCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATG ATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAA GCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCA CCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCC TAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTG AGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTT CCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGG CTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGT ACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGG CGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCC CTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGA TGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCT GCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTG TGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTAC TGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTG CCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTG GTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACAC CTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCT GTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTA CTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCA GCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACA AACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTA GTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCC TGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTAT GCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTG CTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGC TGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACG CTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCT GACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGG TGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAA GCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTA GCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATG AAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTT >93218_93218_2_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000380834_length(amino acids)=525AA_BP=235 MSCSAASSPVPPSHFPPFPSVFRVGSVWRRPRTSQAGARGGGRVRGRPGQRGAGRQGALRCQPEAGLLREDTAAPALSCPALPCPVLPCP ALSCPALPCPVSSDNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPG CQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQE GALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLL DSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLD -------------------------------------------------------------- >93218_93218_3_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000473706_length(transcript)=5176nt_BP=1261nt CTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCAAAAGCCTGGCCATGCCTGGAAAATGGACCAATCC GCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGAAGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTG AGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTTCTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAG GAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCAGCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTG GGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGG AGTAAGTAACTCATACGGGCGCCGGGGACCCGGGTCGGGCTGGGGGCTTCCAACTCAGAGGGAGTGTGATTTGCCTGATCCTCTTCGGCG TTGTCCTGCTCTGCCGCATCCAGCCCTGTACCGCCATCCCACTTCCCGCCGTTCCCATCTGTGTTCCGGGTGGGATCGGTCTGGAGGCGG CCGAGGACTTCCCAGGCAGGAGCTCGGGGCGGAGGCCGGGTCCGCGGCAGACCAGGGCAGCGAGGCGCTGGCCGGCAGGGGGCGCTGCGG TGCCAGCCTGAGGCTGGGCTGCTCCGCGAGGATACAGCGGCCCCTGCCCTGTCCTGTCCTGCCCTGCCCTGTCCTGTCCTGCCCTGCCCT GCCCTGTCCTGTCCTGCCCTGCCCTGCCCTGTGTCCTCAGACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTC TACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATG CAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGC TGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTC CTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTG GGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAA GGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCA TGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTG CAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTG GATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCT GCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGAC CGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGAT CCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAA GGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCC TCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAA TCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATG ATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAA GCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCA CCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCC TAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTG AGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTT CCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGG CTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGT ACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGG CGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCC CTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGA TGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCT GCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTG TGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTAC TGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTG CCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTG GTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACAC CTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCT GTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTA CTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCA GCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACA AACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTA GTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCC TGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTAT GCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTG CTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGC TGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACG CTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCT GACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGG TGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAA GCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTA GCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATG AAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTT >93218_93218_3_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000238721_CENPO_chr2_25022543_ENST00000473706_length(amino acids)=525AA_BP=235 MSCSAASSPVPPSHFPPFPSVFRVGSVWRRPRTSQAGARGGGRVRGRPGQRGAGRQGALRCQPEAGLLREDTAAPALSCPALPCPVLPCP ALSCPALPCPVSSDNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPG CQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQE GALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLL DSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLD -------------------------------------------------------------- >93218_93218_4_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000260662_length(transcript)=1920nt_BP=466nt AGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGA GGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAAC CGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCA GAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACT GTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAG CTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGC GTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGA GCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAAT GTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTT GAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCC CTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGG AAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTT ACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTC ACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTG CATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCA CATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAA GAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCAT GTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTT GTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACT GTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACG AACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAA >93218_93218_4_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000260662_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- >93218_93218_5_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000380834_length(transcript)=4381nt_BP=466nt AGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGA GGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAAC CGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCA GAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACT GTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAG CTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGC GTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGA GCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAAT GTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTT GAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCC CTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGG AAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTT ACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTC ACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTG CATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCA CATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAA GAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCAT GTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTT GTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACT GTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACG AACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAA AATAAATTCTCCCTTCCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGC CATTGGGGAAGGTGGCTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCA CAAAGCGGAAGCCGTACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGG AGCCTAGACTGAGGGCGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACC TCCCAGGGCCAAGCCCTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAG ACTTCTCTCCTAGGATGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTT TCGTGGAGCTTTTCTGCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACT TCAGCCCAGATTTTGTGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTC TGCCTCTGGACTTACTGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAG CACGTGCCAGCTGTGCCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCC AGATGTCGTAGTGTGGTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCAC AGCCACAGGCCACACCTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCC TCATTCAACTTGGCTGTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCC CCATATGCAGATTTACTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACC CCCTCAGTAGAAGCAGCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTC TGGAAATGGATCACAAACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGC TGGGTTTTTGGTTTAGTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAA TTGCCTCAGTTGTCCTGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTG GGGGTGCTCACCTATGCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGC CAGGTCAGCCAGGTGCTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGC AGCAGCCTGCTCTGCTGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAA GGAGTCGCAGCCACGCTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGA CGGACCTGTGAGTCTGACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTG GATCCCTCAACTAGGTGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGAT GGTTGTAGAGGTAAAGCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAA CAAAGGTCTAAATTAGCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGC TCTCCAGTTCCTATGAAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTG >93218_93218_5_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000380834_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- >93218_93218_6_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000473706_length(transcript)=4381nt_BP=466nt AGGAGCCAGAACCACTCGGCGCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGA GGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAAC CGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCA GAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACT GTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAG CTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGC GTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGA GCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAAT GTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTT GAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCC CTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGG AAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTT ACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTC ACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTG CATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCA CATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAA GAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCAT GTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTT GTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACT GTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACG AACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAA AATAAATTCTCCCTTCCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGC CATTGGGGAAGGTGGCTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCA CAAAGCGGAAGCCGTACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGG AGCCTAGACTGAGGGCGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACC TCCCAGGGCCAAGCCCTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAG ACTTCTCTCCTAGGATGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTT TCGTGGAGCTTTTCTGCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACT TCAGCCCAGATTTTGTGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTC TGCCTCTGGACTTACTGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAG CACGTGCCAGCTGTGCCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCC AGATGTCGTAGTGTGGTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCAC AGCCACAGGCCACACCTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCC TCATTCAACTTGGCTGTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCC CCATATGCAGATTTACTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACC CCCTCAGTAGAAGCAGCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTC TGGAAATGGATCACAAACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGC TGGGTTTTTGGTTTAGTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAA TTGCCTCAGTTGTCCTGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTG GGGGTGCTCACCTATGCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGC CAGGTCAGCCAGGTGCTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGC AGCAGCCTGCTCTGCTGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAA GGAGTCGCAGCCACGCTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGA CGGACCTGTGAGTCTGACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTG GATCCCTCAACTAGGTGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGAT GGTTGTAGAGGTAAAGCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAA CAAAGGTCTAAATTAGCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGC TCTCCAGTTCCTATGAAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTG >93218_93218_6_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000313482_CENPO_chr2_25022543_ENST00000473706_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- >93218_93218_7_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000260662_length(transcript)=2350nt_BP=896nt AACGGCTCCTTTCTCTTCTCTTAGCAGCACCCAGCTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCA AAAGCCTGGCCATGCCTGGAAAATGGACCAATCCGCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGA AGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTGAGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTT CTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAGGAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCA GCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTGGGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGC GCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGT GAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAG ACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCA GGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCAT GCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGT TTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGC TCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTAT TGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGC ATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTC CTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAA ATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCT TCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGG GGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGT GGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATT TACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCC CCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAG GAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCT GTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTC CTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGA CCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAG GTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTTCCGGT >93218_93218_7_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000260662_length(amino acids)=453AA_BP=163 MGLWGSGFVTGTRRSQNHSAPPGAWEGSRARNNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGA SNILGLEASGHVAELGPGCQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQ VSRSRKQSEELQSVQAQEGALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKL TSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTG PLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYKDLTATLPTDVTVTCQGVEVLSTSWEEQRASHETLFCTKPLHQVFASFTRKGEKLDMS -------------------------------------------------------------- >93218_93218_8_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000380834_length(transcript)=4811nt_BP=896nt AACGGCTCCTTTCTCTTCTCTTAGCAGCACCCAGCTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCA AAAGCCTGGCCATGCCTGGAAAATGGACCAATCCGCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGA AGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTGAGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTT CTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAGGAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCA GCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTGGGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGC GCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGT GAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAG ACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCA GGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCAT GCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGT TTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGC TCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTAT TGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGC ATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTC CTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAA ATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCT TCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGG GGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGT GGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATT TACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCC CCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAG GAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCT GTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTC CTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGA CCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAG GTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTTCCGGT TTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGGCTAGC TTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGTACTCT CGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGGCGGGT GGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCCCTTCC ACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGATGGCC ATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCTGCCAG ACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTGTGGAT GGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTACTGTTC AGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTGCCACT GGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTGGTTTC CGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACACCTTGT TATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCTGTATG CTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTACTCGG CATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCAGCAGG TGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACAAACTC ACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTAGTCAT CTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCCTGAGC CTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTATGCGCA GCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTGCTGCC AGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGCTGCCT TCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACGCTAGC TCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCTGACCA CGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGGTGATA AGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAAGCAGG ATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTAGCTTA ACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATGAAAGC ACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTTTCTCT >93218_93218_8_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000380834_length(amino acids)=453AA_BP=163 MGLWGSGFVTGTRRSQNHSAPPGAWEGSRARNNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGA SNILGLEASGHVAELGPGCQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQ VSRSRKQSEELQSVQAQEGALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKL TSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTG PLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYKDLTATLPTDVTVTCQGVEVLSTSWEEQRASHETLFCTKPLHQVFASFTRKGEKLDMS -------------------------------------------------------------- >93218_93218_9_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000473706_length(transcript)=4811nt_BP=896nt AACGGCTCCTTTCTCTTCTCTTAGCAGCACCCAGCTTGCCCACCCATGCTCAAGATGGGCGGGATGCCAGCCTGTTACATAAATGTGCCA AAAGCCTGGCCATGCCTGGAAAATGGACCAATCCGCCCGCCAAGAGGTTGGGTCTCGTTCCCTAGAGAGAAGGAAGTTTCCTCTCCTTGA AGTGAGAGCTAGAATCGCACTTTCTGTCAAGCTGAGAGAAAGACTCTTTTCCAGAGGCTAAAAGGACAAGAAAATCTGATTTGCTTGCTT CTAACTTTGCGTTTTAAAGGGGGAAGGAGGAAAGGAAAGAGGGGGAGGGTGGTTCTGCTTAGCCCCACCCCTCCGGCTACCCCAGGTCCA GCCGTCCATTCCGGTGGAGGCAGAGGCAGTCCTGGGGCTCTGGGGCTCGGGCTTTGTCACCGGGACCCGCAGGAGCCAGAACCACTCGGC GCCGCCTGGTGCATGGGAGGGGAGCCGGGCCAGGAACAATATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGT GAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTCCTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAG ACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATTTTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCA GGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTCCCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCAT GCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCCATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGT TTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGATCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGC TCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGATGAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTAT TGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAGCAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGC ATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGAGGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTC CTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATACATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAA ATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTCTGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCT TCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAGAGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGG GGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAGGACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGT GGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCTCATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATT TACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCCTAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCC CCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTTCTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAG GAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCACATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCT GTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGTCCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTC CTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGCAGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGA CCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGCAGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAG GTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCAGGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTTCCGGT TTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCACCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGGCTAGC TTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCTTCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGTACTCT CGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGAGGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGGCGGGT GGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGGTCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCCCTTCC ACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGTGACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGATGGCC ATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCCACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCTGCCAG ACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATACCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTGTGGAT GGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGCAGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTACTGTTC AGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTGTTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTGCCACT GGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCATCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTGGTTTC CGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCATGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACACCTTGT TATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCACAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCTGTATG CTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGTGCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTACTCGG CATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAGTCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCAGCAGG TGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAGCCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACAAACTC ACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTAGGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTAGTCAT CTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGCCCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCCTGAGC CTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGGAAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTATGCGCA GCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAGCGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTGCTGCC AGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACCGTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGCTGCCT TCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGATGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACGCTAGC TCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTAGGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCTGACCA CGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGTCCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGGTGATA AGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTTAACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAAGCAGG ATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCCTACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTAGCTTA ACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCCATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATGAAAGC ACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCTTAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTTTCTCT >93218_93218_9_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000335934_CENPO_chr2_25022543_ENST00000473706_length(amino acids)=453AA_BP=163 MGLWGSGFVTGTRRSQNHSAPPGAWEGSRARNNMLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGA SNILGLEASGHVAELGPGCQGHWKIGDTAMALLPGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQ VSRSRKQSEELQSVQAQEGALGTKIHKLRRLRDELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKL TSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRIHHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTG PLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYKDLTATLPTDVTVTCQGVEVLSTSWEEQRASHETLFCTKPLHQVFASFTRKGEKLDMS -------------------------------------------------------------- >93218_93218_10_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000260662_length(transcript)=1860nt_BP=406nt ATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTC CTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATT TTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTC CCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCC ATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGA TCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGAT GAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAG CAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGA GGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATA CATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTC TGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAG AGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAG GACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCT CATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCC TAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTT CTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCAC ATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGT CCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGC AGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGC AGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCA >93218_93218_10_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000260662_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- >93218_93218_11_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000380834_length(transcript)=4321nt_BP=406nt ATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTC CTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATT TTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTC CCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCC ATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGA TCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGAT GAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAG CAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGA GGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATA CATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTC TGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAG AGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAG GACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCT CATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCC TAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTT CTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCAC ATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGT CCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGC AGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGC AGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCA GGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTTCCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCA CCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGGCTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCT TCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGTACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGA GGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGGCGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGG TCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCCCTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGT GACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGATGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCC ACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCTGCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATA CCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTGTGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGC AGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTACTGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTG TTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTGCCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCA TCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTGGTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCA TGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACACCTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCA CAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCTGTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGT GCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTACTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAG TCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCAGCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAG CCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACAAACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTA GGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTAGTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGC CCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCCTGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGG AAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTATGCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAG CGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTGCTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACC GTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGCTGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGA TGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACGCTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTA GGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCTGACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGT CCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGGTGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTT AACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAAGCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCC TACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTAGCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCC ATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATGAAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCT TAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTTTCTCTGCTTGCCGAACTTTCTCAATAAACCCTATTTCTTATTTAT >93218_93218_11_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000380834_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- >93218_93218_12_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000473706_length(transcript)=4321nt_BP=406nt ATGTTAGCCGTGCACTTTGACAAGCCGGGAGGACCGGAAAACCTCTACGTGAAGGAGGTGGCCAAGCCGAGCCCGGGGGAGGGTGAAGTC CTCCTGAAGGTGGCGGCCAGCGCCCTGAACCGGGCGGACTTAATGCAGAGACAAGGCCAGTATGACCCACCTCCAGGAGCCAGCAACATT TTGGGACTTGAGGCATCTGGACATGTGGCAGAGCTGGGGCCTGGCTGCCAGGGACACTGGAAGATCGGGGACACAGCCATGGCTCTGCTC CCCGGTGGGGGCCAGGCTCAGTACGTCACTGTCCCCGAAGGGCTCCTCATGCCTATCCCAGAGGGATTGACCCTGACCCAGGCTGCAGCC ATCCCAGAGGCCTGGCTCACCGCCTTCCAGCTGTTACATCTTGTGGGTGTTTTAGCTCACTTGGAAAGGCTAGAGACCCAAGTGAGCAGA TCCCGTAAACAGTCTGAAGAGCTGCAGAGCGTGCAGGCCCAGGAAGGTGCTCTTGGAACCAAGATTCATAAACTAAGGCGTCTGCGAGAT GAGCTGAGGGCTGTGGTGCGGCACCGGCGAGCCAGCGTGAAAGCATGTATTGCCAATGTAGAACCCAACCAAACAGTGGAGATCAATGAG CAAGAAGCATTGGAAGAGAAATTGGAAAATGTGAAAGCCATTCTGCAGGCATATCATTTTACAGGCCTCAGTGGTAAACTGACCAGCCGA GGAGTTTGTGTCTGCATCAGTACTGCTTTTGAGGGGAACCTATTGGATTCCTATTTTGTGGACCTTGTCATACAGAAACCACTCCGGATA CATCACCATTCAGTCCCAGTCTTCATTCCCCTGGAAGAGATAGCTGCAAAATATTTACAGACCAACATCCAGCACTTCCTGTTCAGTCTC TGCGAGTACCTGAATGCTTACTCTGGGAGGAAGTACCAGGCAGACCGGCTTCAGAGTGACTTTGCAGCCCTCCTGACTGGGCCCTTGCAG AGAAACCCACTGTGTAACTTGCTGTCATTTACTTACAAACTGGATCCAGGGGGTCAGTCCTTCCCGTTCTGTGCTAGATTGCTGTATAAG GACCTCACAGCAACTCTTCCCACTGACGTCACCGTGACATGTCAAGGAGTGGAAGTATTATCCACTTCATGGGAGGAGCAACGAGCATCT CATGAAACTCTGTTCTGTACGAAGCCCTTGCATCAAGTGTTTGCCTCATTTACAAGAAAAGGAGAAAAGTTGGATATGAGTCTGGTCTCC TAATAGATTGTTTTCACTGCACTGGGAGCACATCAGAGAAATAAATCCCCCCTCCCCTGCCAGGTGAAAGGAAATATTGCACTTTCTGTT CTCATGACTAAGGGGACAGGAGTTCCAGAAGAACCTTTCAAGATGATCAGGAACACCAGGACGAGGGCCGTCTCACCTCACTCGGACCAC ATGGAGACCTCCCTTCAAAATGGGAGCCATGTCCTGCCCCACCAAGCCCTGTCTGAAGTGGAGCTTCCCCGCCTGTGCTCCCTCCACAGT CCCGGAAAGCCCAGCGGCAAAGGCAGCTTTGTCCCAGCTCTGCCACCCTCCTGCTCACAGTGGTCAGGGCCCCTCAGGGGCAAGGACGGC AGGGATTGGAACGAGGGCTCTGGAAGGACTGTTCAGCCCTATGCCTAAGACCCCTATGCTGGGGACACTACAGGCACACACAGGAATAGC AGGGCCACCCTCAGAGCTCACACATCCACGAACAAATGAAGGCTGAGGAGGTTTCTAAACCTAAAGTCCATGAGTGTGCACTTCAATCCA GGAAGGTCGGGACTTCCTTCAGTTTCAAAAAATAAATTCTCCCTTCCGGTTTGGACTGTTGCAGGCTCGAGGCCATTCAGGAGTTGTCCA CCACCTGGTGGGGCAGTGTGACAGAGGGGCCATTGGGGAAGGTGGCTAGCTTATCCCGCCCCTTCAAGAAGAAGGTCAGCAGCTCCCCCT TCCCCTTCACAAAGATGGGGCCTCGCCTCACAAAGCGGAAGCCGTACTCTCGGAGGATGACTTGGGTTTCTTCTACCACCTGGAGAGGGA GGGGGAGCAAGAACGTGGCGTTACGGGGGGAGCCTAGACTGAGGGCGGGTGGGGGCTTTGGGTGGTTGGAGCCGAGCACTGATCCATGGG TCCCAAGCAGTACGGGACACTCCCCAAACCTCCCAGGGCCAAGCCCTTCCACCCGTGGCGAGCAGCGGGTGGGAAGGAGAACCCTGGAGT GACTGGCTGGGGGCCTCCTCTCATCCAGAGACTTCTCTCCTAGGATGGCCATGGTCACCTGGGTGGCAGCACTGTTACCTGGAAACTGCC ACTGCCTGCTCTTCTGTCCCTTTGCCCCTTTCGTGGAGCTTTTCTGCCAGACGCCACTGAGACAGATCACAAGGTATTAGAAGGTTCATA CCCAAAGGTAGGCCATATGCATCTAGAACTTCAGCCCAGATTTTGTGGATGGGTGGAAGTGTTTCTTCCTGTGCTGAGGCTAGCTATTGC AGAGATTCTTTTCCACTTGCCCCACGTCTCTGCCTCTGGACTTACTGTTCAGGGCCAGGGTGGGAGGCAGGGGCACGTGGGAAAGCACTG TTCCGGTTTTGTTCTCATGCCGAGTCTGAGCACGTGCCAGCTGTGCCACTGGACATACCTGAATGTTGCCCATGACCCCCGTGGACTCCA TCCTGCTGGCTACATTGACTGTATTGCCCCAGATGTCGTAGTGTGGTTTCCGGGCTCCGATGACCCCAGCCAGAACCCCGCCTTTGTTCA TGCCTAGGGTAGAGGCATAAAGTTCAGCACAGCCACAGGCCACACCTTGTTATGGGCCTCAGAAGCCATCTCCTCTCCAGACCTGTACCA CAAAGCTCCTAATGTAACACATCATTGTCCTCATTCAACTTGGCTGTATGCTATTGGAGGGTGGAAATCACATCTCCTGTTTATCCGTGT GCTTGTTAGGTGTCAGCCGCCACCCCCCCCCCATATGCAGATTTACTCGGCATGGTAGTGGCCAGCTTCTAACACAGCTGGTATTTCAAG TCTCCTGGGACCTCACTCAGGAATGATACCCCCTCAGTAGAAGCAGCAGGTGATCTTAACTCCTTTCAAAGAGCAGGCCTGTCTGGGAAG CCATGTCCTCAGCAGGCACAGCAACCCCTCTGGAAATGGATCACAAACTCACTTCTCAGCCAGGCAGGCCAAGCTTCTATTGTAACAGTA GGCACAGTATAGTCGGATCATCACATCAGCTGGGTTTTTGGTTTAGTCATCTAGAGTCGTCTGGACTAAAGGTCTTTCAGGTCTCCTTGC CCTGTGAGTGCGTGAACCTCCCCACCCGAATTGCCTCAGTTGTCCTGAGCCTCATGTCTCTCCTGGTGGTGGGCCAGGCCCCTGCATGGG AAGGGAGCCTGCTGCGGGGCAGGCCAGCTGGGGGTGCTCACCTATGCGCAGCATGAAGTTATTGAAGGACTGGTTGTTGATGTTGGTGAG CGTATCCTTCATGGCCAGCGCGAAGTCGGCCAGGTCAGCCAGGTGCTGCCAGCGCTCTCTCTCGGACTTGTCTTCCTGTGCCAGGGGACC GTGGAGAAAGTGTCAGGGGCCGCTCACTGCAGCAGCCTGCTCTGCTGCCTTCCCTGGCAGTGTTCTGGGGGTGGATTCCCTACACCTAGA TGTTCAAGGCCTTACTTTTCCTCCCACAAAGGAGTCGCAGCCACGCTAGCTCTGACTTGCCACTGTGACAAAGTTCACGTAGCAGGTCTA GGCAAAGACTGGGCAATTGAGCAGAGGAGACGGACCTGTGAGTCTGACCACGAGGCGGACCCCTTCACCTTGGCTGGGCCTGGTCCTGGT CCTTAGGTTTTGTCAGGTTGTCCTTGTTTGGATCCCTCAACTAGGTGATAAGCACTGGAGGGGGATGACCCGCCTTGGACGTGTTTCTTT AACCTCATCCATATAATAGGGCCGTGGGATGGTTGTAGAGGTAAAGCAGGATGATGGTGTTTTAAGACCAGAGCTTGGGACCAGGGCTCC TACACCTAATTTTCTCTCCTGGTAGCTGAACAAAGGTCTAAATTAGCTTAACAAAAGAACAGGCTGCCGTCAGCCAGAGTTCTGAAGGCC ATGCTTTCAGTTTCCCTTGTTGACAATTGCTCTCCAGTTCCTATGAAAGCACAGAGCCTTAGGGGGCCTGGCCACAGAACACAACCATCT TAGGCCTGAGCTGTGAACAGCAGGGGGTTGTGTGTCTGTTCTGTTTCTCTGCTTGCCGAACTTTCTCAATAAACCCTATTTCTTATTTAT >93218_93218_12_TP53I3-CENPO_TP53I3_chr2_24305754_ENST00000407482_CENPO_chr2_25022543_ENST00000473706_length(amino acids)=420AA_BP=130 MLAVHFDKPGGPENLYVKEVAKPSPGEGEVLLKVAASALNRADLMQRQGQYDPPPGASNILGLEASGHVAELGPGCQGHWKIGDTAMALL PGGGQAQYVTVPEGLLMPIPEGLTLTQAAAIPEAWLTAFQLLHLVGVLAHLERLETQVSRSRKQSEELQSVQAQEGALGTKIHKLRRLRD ELRAVVRHRRASVKACIANVEPNQTVEINEQEALEEKLENVKAILQAYHFTGLSGKLTSRGVCVCISTAFEGNLLDSYFVDLVIQKPLRI HHHSVPVFIPLEEIAAKYLQTNIQHFLFSLCEYLNAYSGRKYQADRLQSDFAALLTGPLQRNPLCNLLSFTYKLDPGGQSFPFCARLLYK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TP53I3-CENPO |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TP53I3-CENPO |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TP53I3-CENPO |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies