
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TRDMT1-NID2 (FusionGDB2 ID:93909) |
Fusion Gene Summary for TRDMT1-NID2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TRDMT1-NID2 | Fusion gene ID: 93909 | Hgene | Tgene | Gene symbol | TRDMT1 | NID2 | Gene ID | 1787 | 22795 |
| Gene name | tRNA aspartic acid methyltransferase 1 | nidogen 2 | |
| Synonyms | DMNT2|DNMT2|MHSAIIP|PUMET|RNMT1 | NID-2 | |
| Cytomap | 10p13 | 14q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tRNA (cytosine(38)-C(5))-methyltransferaseDNA (cytosine-5)-methyltransferase-like protein 2DNA MTase homolog HsaIIPDNA cytosine-5 methyltransferase 2DNA methyltransferase-2tRNA (cytosine-5-)-methyltransferase | nidogen-2osteonidogen | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q14112 | |
| Ensembl transtripts involved in fusion gene | ENST00000358282, ENST00000377766, ENST00000452380, ENST00000351358, ENST00000377799, ENST00000412821, ENST00000457442, ENST00000488990, | ENST00000216286, ENST00000541773, | |
| Fusion gene scores | * DoF score | 4 X 4 X 1=16 | 5 X 5 X 3=75 |
| # samples | 4 | 5 | |
| ** MAII score | log2(4/16*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(5/75*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TRDMT1 [Title/Abstract] AND NID2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TRDMT1(17195506)-NID2(52486897), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TRDMT1 | GO:0030488 | tRNA methylation | 16424344 |
| Fusion gene breakpoints across TRDMT1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
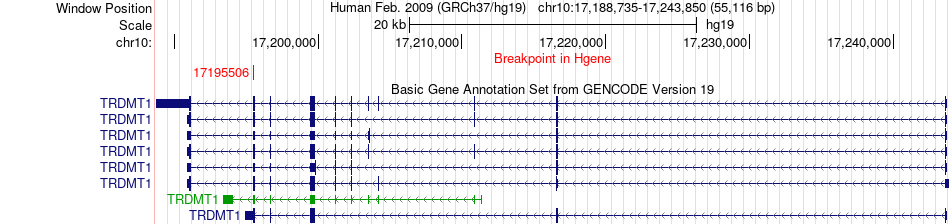 |
| Fusion gene breakpoints across NID2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | DA483206 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
Top |
Fusion Gene ORF analysis for TRDMT1-NID2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000358282 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| 3UTR-3CDS | ENST00000358282 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| 3UTR-3CDS | ENST00000377766 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| 3UTR-3CDS | ENST00000377766 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| 5UTR-3CDS | ENST00000452380 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| 5UTR-3CDS | ENST00000452380 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000351358 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000351358 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000377799 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000377799 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000412821 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000412821 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000457442 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| In-frame | ENST00000457442 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| intron-3CDS | ENST00000488990 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| intron-3CDS | ENST00000488990 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000377799 | TRDMT1 | chr10 | 17195506 | - | ENST00000541773 | NID2 | chr14 | 52486897 | - | 3260 | 1123 | 48 | 2576 | 842 |
| ENST00000377799 | TRDMT1 | chr10 | 17195506 | - | ENST00000216286 | NID2 | chr14 | 52486897 | - | 3260 | 1123 | 48 | 2576 | 842 |
| ENST00000412821 | TRDMT1 | chr10 | 17195506 | - | ENST00000541773 | NID2 | chr14 | 52486897 | - | 3147 | 1010 | 7 | 2463 | 818 |
| ENST00000412821 | TRDMT1 | chr10 | 17195506 | - | ENST00000216286 | NID2 | chr14 | 52486897 | - | 3147 | 1010 | 7 | 2463 | 818 |
| ENST00000351358 | TRDMT1 | chr10 | 17195506 | - | ENST00000541773 | NID2 | chr14 | 52486897 | - | 3081 | 944 | 7 | 2397 | 796 |
| ENST00000351358 | TRDMT1 | chr10 | 17195506 | - | ENST00000216286 | NID2 | chr14 | 52486897 | - | 3081 | 944 | 7 | 2397 | 796 |
| ENST00000457442 | TRDMT1 | chr10 | 17195506 | - | ENST00000541773 | NID2 | chr14 | 52486897 | - | 3286 | 1149 | 293 | 2602 | 769 |
| ENST00000457442 | TRDMT1 | chr10 | 17195506 | - | ENST00000216286 | NID2 | chr14 | 52486897 | - | 3286 | 1149 | 293 | 2602 | 769 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000377799 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.001017758 | 0.99898225 |
| ENST00000377799 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.001017758 | 0.99898225 |
| ENST00000412821 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.000778354 | 0.9992217 |
| ENST00000412821 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.000778354 | 0.9992217 |
| ENST00000351358 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.000515507 | 0.9994844 |
| ENST00000351358 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.000515507 | 0.9994844 |
| ENST00000457442 | ENST00000541773 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.001224008 | 0.998776 |
| ENST00000457442 | ENST00000216286 | TRDMT1 | chr10 | 17195506 | - | NID2 | chr14 | 52486897 | - | 0.001224008 | 0.998776 |
Top |
Fusion Genomic Features for TRDMT1-NID2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
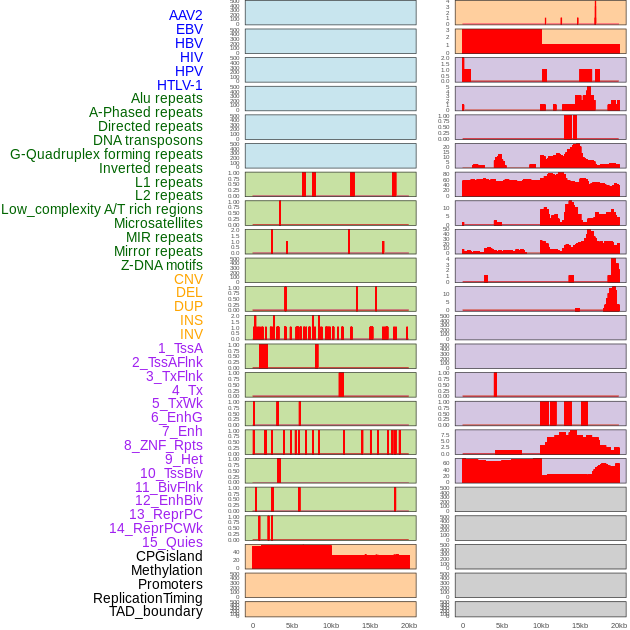 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for TRDMT1-NID2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:17195506/chr14:52486897) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NID2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Cell adhesion glycoprotein which is widely distributed in basement membranes. Binds to collagens I and IV, to perlecan and to laminin 1. Does not bind fibulins. It probably has a role in cell-extracellular matrix interactions. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000358282 | - | 8 | 9 | 4_391 | 308 | 143.0 | Domain | SAM-dependent MTase C5-type |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000351358 | - | 8 | 9 | 13_15 | 312 | 346.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000351358 | - | 8 | 9 | 57_58 | 312 | 346.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000358282 | - | 8 | 9 | 13_15 | 308 | 143.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000358282 | - | 8 | 9 | 57_58 | 308 | 143.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000377799 | - | 10 | 11 | 13_15 | 358 | 392.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000377799 | - | 10 | 11 | 57_58 | 358 | 392.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000412821 | - | 9 | 10 | 13_15 | 334 | 368.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000412821 | - | 9 | 10 | 57_58 | 334 | 368.0 | Region | S-adenosyl-L-methionine binding |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1016_1084 | 891 | 1376.0 | Domain | Thyroglobulin type-1 2 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 892_930 | 891 | 1376.0 | Domain | EGF-like 5%3B calcium-binding | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 937_1005 | 891 | 1376.0 | Domain | Thyroglobulin type-1 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1016_1084 | 790 | 1275.0 | Domain | Thyroglobulin type-1 2 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 801_843 | 790 | 1275.0 | Domain | EGF-like 3%3B calcium-binding | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 848_891 | 790 | 1275.0 | Domain | EGF-like 4 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 892_930 | 790 | 1275.0 | Domain | EGF-like 5%3B calcium-binding | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 937_1005 | 790 | 1275.0 | Domain | Thyroglobulin type-1 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1154_1197 | 891 | 1376.0 | Repeat | Note=LDL-receptor class B 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1198_1240 | 891 | 1376.0 | Repeat | Note=LDL-receptor class B 2 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1241_1285 | 891 | 1376.0 | Repeat | Note=LDL-receptor class B 3 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1286_1327 | 891 | 1376.0 | Repeat | Note=LDL-receptor class B 4 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 1329_1373 | 891 | 1376.0 | Repeat | Note=LDL-receptor class B 5 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1154_1197 | 790 | 1275.0 | Repeat | Note=LDL-receptor class B 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1198_1240 | 790 | 1275.0 | Repeat | Note=LDL-receptor class B 2 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1241_1285 | 790 | 1275.0 | Repeat | Note=LDL-receptor class B 3 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1286_1327 | 790 | 1275.0 | Repeat | Note=LDL-receptor class B 4 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 1329_1373 | 790 | 1275.0 | Repeat | Note=LDL-receptor class B 5 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000351358 | - | 8 | 9 | 4_391 | 312 | 346.0 | Domain | SAM-dependent MTase C5-type |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000377799 | - | 10 | 11 | 4_391 | 358 | 392.0 | Domain | SAM-dependent MTase C5-type |
| Hgene | TRDMT1 | chr10:17195506 | chr14:52486897 | ENST00000412821 | - | 9 | 10 | 4_391 | 334 | 368.0 | Domain | SAM-dependent MTase C5-type |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 108_273 | 891 | 1376.0 | Domain | NIDO | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 484_524 | 891 | 1376.0 | Domain | EGF-like 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 528_758 | 891 | 1376.0 | Domain | Nidogen G2 beta-barrel | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 759_800 | 891 | 1376.0 | Domain | EGF-like 2 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 801_843 | 891 | 1376.0 | Domain | EGF-like 3%3B calcium-binding | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000216286 | 11 | 22 | 848_891 | 891 | 1376.0 | Domain | EGF-like 4 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 108_273 | 790 | 1275.0 | Domain | NIDO | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 484_524 | 790 | 1275.0 | Domain | EGF-like 1 | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 528_758 | 790 | 1275.0 | Domain | Nidogen G2 beta-barrel | |
| Tgene | NID2 | chr10:17195506 | chr14:52486897 | ENST00000541773 | 11 | 22 | 759_800 | 790 | 1275.0 | Domain | EGF-like 2 |
Top |
Fusion Gene Sequence for TRDMT1-NID2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >93909_93909_1_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000351358_NID2_chr14_52486897_ENST00000216286_length(transcript)=3081nt_BP=944nt CGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACA AGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGA AGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTAATGAGCCCTCCCTGCCAGCCATTCACAAGAGACCTCTTGAT ACAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTT TCTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCC ACAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGG AAAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAA AGATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCA GCCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGT GCAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCAC TCCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTG CTACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCT GACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGG CAACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCC ACCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCT GGAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAA GAGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCAC CGTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCA GATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAAT TGATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCC TGAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCT GGATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGA TCCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAAT TCTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAA ACTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCA CTTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACG ATCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTA CAATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAG ATGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGC AAGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCA TTCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATAT AACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTT CTAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGC CTCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTTAAAATTTTCTAGATTACTCCAATAA >93909_93909_1_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000351358_NID2_chr14_52486897_ENST00000216286_length(amino acids)=796AA_BP=312 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRDLLIQT IENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKD AILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQV ENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTP CEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEH YGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIG YLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDK IESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLE -------------------------------------------------------------- >93909_93909_2_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000351358_NID2_chr14_52486897_ENST00000541773_length(transcript)=3081nt_BP=944nt CGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACA AGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGA AGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTAATGAGCCCTCCCTGCCAGCCATTCACAAGAGACCTCTTGAT ACAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTT TCTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCC ACAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGG AAAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAA AGATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCA GCCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGT GCAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCAC TCCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTG CTACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCT GACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGG CAACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCC ACCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCT GGAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAA GAGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCAC CGTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCA GATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAAT TGATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCC TGAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCT GGATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGA TCCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAAT TCTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAA ACTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCA CTTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACG ATCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTA CAATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAG ATGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGC AAGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCA TTCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATAT AACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTT CTAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGC CTCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTTAAAATTTTCTAGATTACTCCAATAA >93909_93909_2_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000351358_NID2_chr14_52486897_ENST00000541773_length(amino acids)=796AA_BP=312 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRDLLIQT IENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKD AILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQV ENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTP CEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEH YGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIG YLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDK IESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLE -------------------------------------------------------------- >93909_93909_3_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000377799_NID2_chr14_52486897_ENST00000216286_length(transcript)=3260nt_BP=1123nt ACGGACCGGCAGGCCTAGCTCCGGGGCTGCGGCGGCTGAGGCGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGC GGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACAAGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAG TATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGAAGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTA ATGAGCCCTCCCTGCCAGCCATTCACAAGGATTGGCCGGCAGGGTGATATGACTGATTCAAGGACGAATAGCTTCTTACATATTCTAGAT ATTCTCCCAAGATTACAAAAATTACCAAAGTATATTCTTTTGGAAAATGTTAAAGGTTTTGAAGTATCTTCTACAAGAGACCTCTTGATA CAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTTT CTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCCA CAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGGA AAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAAA GATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCAG CCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGTG CAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCACT CCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTGC TACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCTG ACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGGC AACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCCA CCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCTG GAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAAG AGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCACC GTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCAG ATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAATT GATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCCT GAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCTG GATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGAT CCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAATT CTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAAA CTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCAC TTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACGA TCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTAC AATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAGA TGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGCA AGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCAT TCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATATA ACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTTC TAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGCC TCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTTAAAATTTTCTAGATTACTCCAATAAA >93909_93909_3_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000377799_NID2_chr14_52486897_ENST00000216286_length(amino acids)=842AA_BP=358 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRIGRQGD MTDSRTNSFLHILDILPRLQKLPKYILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPG QVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPP KSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDV DECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWC VDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQG TRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAG RTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAP KIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYADHFYHTDWRRDGVVSVNK -------------------------------------------------------------- >93909_93909_4_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000377799_NID2_chr14_52486897_ENST00000541773_length(transcript)=3260nt_BP=1123nt ACGGACCGGCAGGCCTAGCTCCGGGGCTGCGGCGGCTGAGGCGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGC GGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACAAGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAG TATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGAAGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTA ATGAGCCCTCCCTGCCAGCCATTCACAAGGATTGGCCGGCAGGGTGATATGACTGATTCAAGGACGAATAGCTTCTTACATATTCTAGAT ATTCTCCCAAGATTACAAAAATTACCAAAGTATATTCTTTTGGAAAATGTTAAAGGTTTTGAAGTATCTTCTACAAGAGACCTCTTGATA CAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTTT CTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCCA CAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGGA AAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAAA GATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCAG CCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGTG CAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCACT CCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTGC TACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCTG ACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGGC AACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCCA CCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCTG GAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAAG AGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCACC GTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCAG ATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAATT GATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCCT GAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCTG GATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGAT CCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAATT CTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAAA CTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCAC TTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACGA TCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTAC AATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAGA TGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGCA AGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCAT TCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATATA ACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTTC TAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGCC TCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTTAAAATTTTCTAGATTACTCCAATAAA >93909_93909_4_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000377799_NID2_chr14_52486897_ENST00000541773_length(amino acids)=842AA_BP=358 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRIGRQGD MTDSRTNSFLHILDILPRLQKLPKYILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPG QVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPP KSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDV DECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWC VDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQG TRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAG RTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAP KIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYADHFYHTDWRRDGVVSVNK -------------------------------------------------------------- >93909_93909_5_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000412821_NID2_chr14_52486897_ENST00000216286_length(transcript)=3147nt_BP=1010nt CGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACA AGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGA AGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTAATGAGCCCTCCCTGCCAGCCATTCACAAGATTACAAAAATT ACCAAAGTATATTCTTTTGGAAAATGTTAAAGGTTTTGAAGTATCTTCTACAAGAGACCTCTTGATACAAACAATAGAAAATTGTGGCTT TCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTTTCTTATTGCAAAGCTTCAGTCAGA GCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCCACAAAAATATGCAATGGATGTAGA AAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGGAAAAGATGCCATTCTTTTTAAGCT TGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAAAGATTTTCTTGAAGATGACACTGA CGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCAGCCCACTTGTAGAAGGTCCGTGTG CTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGTGCAGGTTGAGAATATCTACAAATC CCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCACTCCTAAAGAAATAGCAAATCTCCT TGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTGCTACAATACTCCTGGTTCCTTCTC CTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCTGACACCCTGTGAACAACAGCAGCG CCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGGCAACTTCCTGCCCCTACAGTGTCA TGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCCACCTGGCTCCACCCCGCCTCACTG TGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCTGGAGCACTACGGTGGCACCCCCCG GGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAAGAGCGACTTCTGCTGGTGTGTGGA CAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCACCGTCGCTCCACCCATGGTCCGGCC CACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCAGATTGGCTACTTACCCCTCAATGG CACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAATTGATTACGACTGCCGGGAGAGGAT GGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCCTGAGACGATCGTGAATTCAGGTCT GATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCTGGATAAGATAGAGAGCGCCCTGCT GGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGATCCAATCCGAGGCAACTTGTACTG GACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAATTCTGATCAATACAGACATTGGATT GCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAAACTGGAGTGTACACTACCTGATGG AACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCACTTCTACCACACAGACTGGAGGAG GGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACGATCTCACCTCTACGGGATAACTGC AGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTACAATCAGAACCTGGACCCTAAAGA ACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAGATGAACATTTTGTAGTGCAAAAAG ACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGCAAGTTTAAAAAGGTAACAGAATTT TAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCATTCAACTAAGAATTAGAGTTTAAG ACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATATAACAATATAATCCTAAACCTTGAC AGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTTCTAAGATTTTTTACCTCTGCATCA GTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGCCTCTATAGAAGTACCCACAGAAAG >93909_93909_5_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000412821_NID2_chr14_52486897_ENST00000216286_length(amino acids)=818AA_BP=334 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRLQKLPK YILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENK IQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFT KGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCR CQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGP SPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTP RPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLIS PEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPN GLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYADHFYHTDWRRDGVVSVNKHSGQFTDEYLPEQRSHLYGITAVY -------------------------------------------------------------- >93909_93909_6_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000412821_NID2_chr14_52486897_ENST00000541773_length(transcript)=3147nt_BP=1010nt CGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCACGCGCTGAGAGAAAGCTGTATACCTGCACA AGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCCTCACACACAGTTACTTGCCAAGACGATTGA AGGCATTACACTCGAAGAGTTTGACAGATTATCTTTTGATATGATTTTAATGAGCCCTCCCTGCCAGCCATTCACAAGATTACAAAAATT ACCAAAGTATATTCTTTTGGAAAATGTTAAAGGTTTTGAAGTATCTTCTACAAGAGACCTCTTGATACAAACAATAGAAAATTGTGGCTT TCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCATTCCAAATTCAAGGCTACGATATTTTCTTATTGCAAAGCTTCAGTCAGA GCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGTTCCCCAAAATTGAATCTGTACATCCACAAAAATATGCAATGGATGTAGA AAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCTTTGATGGCAGCATACAGTGTTCTGGAAAAGATGCCATTCTTTTTAAGCT TGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATAGTGATCTCTCTGTGAAAATGCTAAAAGATTTTCTTGAAGATGACACTGA CGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGATATGCTCTTCTGTTAGACATTGTTCAGCCCACTTGTAGAAGGTCCGTGTG CTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGTCTGTGTTACAGACTGCAGAGGATGTGCAGGTTGAGAATATCTACAAATC CCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGTTAATACTTAAACTGCGATATTTCACTCCTAAAGAAATAGCAAATCTCCT TGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAAACAGATGTCACCCTGCAGCTACCTGCTACAATACTCCTGGTTCCTTCTC CTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGTGCATACCTGACTCCACCTCAAGCCTGACACCCTGTGAACAACAGCAGCG CCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCCACATCCCCCAATGCGACGAGCAGGGCAACTTCCTGCCCCTACAGTGTCA TGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTCATGAAGTTCCTGGTACCCAGACTCCACCTGGCTCCACCCCGCCTCACTG TGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCTGTGAGCGCTGGAGGGAAAACCTGCTGGAGCACTACGGTGGCACCCCCCG GGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACTTCATCCCCCTGCAGTGCCACGGAAAGAGCGACTTCTGCTGGTGTGTGGA CAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAGGCACCACCCCTGCGTGTATACCCACCGTCGCTCCACCCATGGTCCGGCC CACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCTTCCTGCTCTATACTCAGGGCCAGCAGATTGGCTACTTACCCCTCAATGG CACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTCTGCATGGCTCCATAATCGTGGGAATTGATTACGACTGCCGGGAGAGGAT GGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTGCTGGTCTGGAACTGGGAGCAGAGCCTGAGACGATCGTGAATTCAGGTCT GATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAACAATGTACTGGACGGACAGTGTCCTGGATAAGATAGAGAGCGCCCTGCT GGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGGTGAATCCCCGTGCCATCGCTGTGGATCCAATCCGAGGCAACTTGTACTG GACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCATCTTTAGATGGAGAAAACAGAAGAATTCTGATCAATACAGACATTGGATT GCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCTGCTGGGCAGATGCAGGAACCAAAAAACTGGAGTGTACACTACCTGATGG AACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCTTCAGCATCGTAAGCTATGCAGATCACTTCTACCACACAGACTGGAGGAG GGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTACTGATGAGTATCTCCCAGAACAACGATCTCACCTCTACGGGATAACTGC AGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGTAATGTAAAGGAAGACTTGGAGTTTACAATCAGAACCTGGACCCTAAAGA ACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGCCATTAGACGTTCCTGAGCATCCAAGATGAACATTTTGTAGTGCAAAAAG ACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTATTTTTAAAAATGAAGGTTGTTATTGCAAGTTTAAAAAGGTAACAGAATTT TAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATCATTAATATTTAAAAGATCAAATTCATTCAACTAAGAATTAGAGTTTAAG ACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAGAAATTAAAGCACATGTGATCAATATAACAATATAATCCTAAACCTTGAC AGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAATTATTTATAGTTTCCCAACAAAAGTTCTAAGATTTTTTACCTCTGCATCA GTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAATTTGCATTTTCTGATCCTGTAGTGCCTCTATAGAAGTACCCACAGAAAG >93909_93909_6_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000412821_NID2_chr14_52486897_ENST00000541773_length(amino acids)=818AA_BP=334 MEPLRVLELYSGVGGMHHALRESCIPAQVVAAIDVNTVANEVYKYNFPHTQLLAKTIEGITLEEFDRLSFDMILMSPPCQPFTRLQKLPK YILLENVKGFEVSSTRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRYFLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENK IQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKMLKDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFT KGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYFTPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCR CQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQGNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGP SPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHGKSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTP RPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVGIDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLIS PEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAVDPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPN GLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYADHFYHTDWRRDGVVSVNKHSGQFTDEYLPEQRSHLYGITAVY -------------------------------------------------------------- >93909_93909_7_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000457442_NID2_chr14_52486897_ENST00000216286_length(transcript)=3286nt_BP=1149nt ATTCGGGAAGCCTTATTGTTTTCCGTCCTTTGTTCCCCTCTAGACCCTTGCCAATCCCCAGGCCGCGAGGCCCTCTGAAGCCCTGAGCCT GGAGCGGTAGGAGACGGGGGAACTGAAACGCCGCGGAACCAGAGGCTGAGGGAGCGGCGCGATGGAGGGAGGAGGAGCGACGGACCGGCA GGCCTAGCTCCGGGGCTGCGGCGGCTGAGGCGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCA CGCGCTGAGAGAAAGCTGTATACCTGCACAAGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCC TCACACACAGTTACTTGCCAAGACGATTGAAGATTGGCCGGCAGGGTGATATGACTGATTCAAGGACGAATAGCTTCTTACATATTCTAG ATATTCTCCCAAGAGACCTCTTGATACAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCA TTCCAAATTCAAGGCTACGATATTTTCTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGT TCCCCAAAATTGAATCTGTACATCCACAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCT TTGATGGCAGCATACAGTGTTCTGGAAAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATA GTGATCTCTCTGTGAAAATGCTAAAAGATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGAT ATGCTCTTCTGTTAGACATTGTTCAGCCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGT CTGTGTTACAGACTGCAGAGGATGTGCAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGT TAATACTTAAACTGCGATATTTCACTCCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAA ACAGATGTCACCCTGCAGCTACCTGCTACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGT GCATACCTGACTCCACCTCAAGCCTGACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCC ACATCCCCCAATGCGACGAGCAGGGCAACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTC ATGAAGTTCCTGGTACCCAGACTCCACCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCT GTGAGCGCTGGAGGGAAAACCTGCTGGAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACT TCATCCCCCTGCAGTGCCACGGAAAGAGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAG GCACCACCCCTGCGTGTATACCCACCGTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCT TCCTGCTCTATACTCAGGGCCAGCAGATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTC TGCATGGCTCCATAATCGTGGGAATTGATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTG CTGGTCTGGAACTGGGAGCAGAGCCTGAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAA CAATGTACTGGACGGACAGTGTCCTGGATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGG TGAATCCCCGTGCCATCGCTGTGGATCCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCAT CTTTAGATGGAGAAAACAGAAGAATTCTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCT GCTGGGCAGATGCAGGAACCAAAAAACTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCT TCAGCATCGTAAGCTATGCAGATCACTTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTA CTGATGAGTATCTCCCAGAACAACGATCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGT AATGTAAAGGAAGACTTGGAGTTTACAATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGC CATTAGACGTTCCTGAGCATCCAAGATGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTAT TTTTAAAAATGAAGGTTGTTATTGCAAGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATC ATTAATATTTAAAAGATCAAATTCATTCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAG AAATTAAAGCACATGTGATCAATATAACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAAT TATTTATAGTTTCCCAACAAAAGTTCTAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAA TTTGCATTTTCTGATCCTGTAGTGCCTCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTT >93909_93909_7_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000457442_NID2_chr14_52486897_ENST00000216286_length(amino acids)=769AA_BP=285 MHKWWLPLMSTLSLMKYTSIIFLTHSYLPRRLKIGRQGDMTDSRTNSFLHILDILPRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRY FLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKML KDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYF TPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQ GNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHG KSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVG IDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAV DPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYAD -------------------------------------------------------------- >93909_93909_8_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000457442_NID2_chr14_52486897_ENST00000541773_length(transcript)=3286nt_BP=1149nt ATTCGGGAAGCCTTATTGTTTTCCGTCCTTTGTTCCCCTCTAGACCCTTGCCAATCCCCAGGCCGCGAGGCCCTCTGAAGCCCTGAGCCT GGAGCGGTAGGAGACGGGGGAACTGAAACGCCGCGGAACCAGAGGCTGAGGGAGCGGCGCGATGGAGGGAGGAGGAGCGACGGACCGGCA GGCCTAGCTCCGGGGCTGCGGCGGCTGAGGCGCGGGGATGGAGCCCCTGCGGGTGCTGGAGCTATACAGCGGCGTGGGCGGCATGCACCA CGCGCTGAGAGAAAGCTGTATACCTGCACAAGTGGTGGCTGCCATTGATGTCAACACTGTCGCTAATGAAGTATACAAGTATAATTTTCC TCACACACAGTTACTTGCCAAGACGATTGAAGATTGGCCGGCAGGGTGATATGACTGATTCAAGGACGAATAGCTTCTTACATATTCTAG ATATTCTCCCAAGAGACCTCTTGATACAAACAATAGAAAATTGTGGCTTTCAGTACCAAGAGTTTCTATTATCTCCAACCTCTCTTGGCA TTCCAAATTCAAGGCTACGATATTTTCTTATTGCAAAGCTTCAGTCAGAGCCATTACCCTTTCAAGCCCCTGGTCAGGTACTGATGGAGT TCCCCAAAATTGAATCTGTACATCCACAAAAATATGCAATGGATGTAGAAAATAAAATTCAAGAAAAGAACGTTGAACCAAATATTAGCT TTGATGGCAGCATACAGTGTTCTGGAAAAGATGCCATTCTTTTTAAGCTTGAAACTGCAGAAGAAATTCACAGGAAAAATCAACAAGATA GTGATCTCTCTGTGAAAATGCTAAAAGATTTTCTTGAAGATGACACTGACGTGAACCAGTATCTTTTACCACCAAAGTCATTGCTGCGAT ATGCTCTTCTGTTAGACATTGTTCAGCCCACTTGTAGAAGGTCCGTGTGCTTTACCAAAGGATATGGAAGCTACATAGAAGGGACAGGGT CTGTGTTACAGACTGCAGAGGATGTGCAGGTTGAGAATATCTACAAATCCCTTACCAATTTGTCACAAGAAGAACAGATAACAAAGCTGT TAATACTTAAACTGCGATATTTCACTCCTAAAGAAATAGCAAATCTCCTTGGATTTCCTCCAGAGTTCGATGTAGATGAATGCTCAGAAA ACAGATGTCACCCTGCAGCTACCTGCTACAATACTCCTGGTTCCTTCTCCTGCCGTTGTCAACCCGGATATTATGGGGATGGATTTCAGT GCATACCTGACTCCACCTCAAGCCTGACACCCTGTGAACAACAGCAGCGCCATGCCCAGGCCCAGTATGCCTACCCTGGGGCCCGGTTCC ACATCCCCCAATGCGACGAGCAGGGCAACTTCCTGCCCCTACAGTGTCATGGCAGCACTGGTTTCTGCTGGTGCGTGGACCCTGATGGTC ATGAAGTTCCTGGTACCCAGACTCCACCTGGCTCCACCCCGCCTCACTGTGGACCATCACCAGAGCCCACCCAGAGGCCCCCGACCATCT GTGAGCGCTGGAGGGAAAACCTGCTGGAGCACTACGGTGGCACCCCCCGGGATGACCAGTACGTGCCCCAGTGCGATGACCTGGGCCACT TCATCCCCCTGCAGTGCCACGGAAAGAGCGACTTCTGCTGGTGTGTGGACAAAGATGGCAGAGAGGTGCAGGGCACCCGCTCCCAGCCAG GCACCACCCCTGCGTGTATACCCACCGTCGCTCCACCCATGGTCCGGCCCACGCCCCGGCCAGATGTGACCCCTCCATCTGTGGGCACCT TCCTGCTCTATACTCAGGGCCAGCAGATTGGCTACTTACCCCTCAATGGCACCAGGCTTCAGAAGGATGCAGCTAAGACCCTGCTGTCTC TGCATGGCTCCATAATCGTGGGAATTGATTACGACTGCCGGGAGAGGATGGTGTACTGGACAGATGTTGCTGGACGGACAATCAGCCGTG CTGGTCTGGAACTGGGAGCAGAGCCTGAGACGATCGTGAATTCAGGTCTGATAAGCCCTGAAGGACTTGCCATAGACCACATCCGCAGAA CAATGTACTGGACGGACAGTGTCCTGGATAAGATAGAGAGCGCCCTGCTGGATGGCTCTGAGCGCAAGGTCCTCTTCTACACAGATCTGG TGAATCCCCGTGCCATCGCTGTGGATCCAATCCGAGGCAACTTGTACTGGACAGACTGGAATAGAGAAGCTCCTAAAATTGAAACGTCAT CTTTAGATGGAGAAAACAGAAGAATTCTGATCAATACAGACATTGGATTGCCCAATGGCTTAACCTTTGACCCTTTCTCTAAACTGCTCT GCTGGGCAGATGCAGGAACCAAAAAACTGGAGTGTACACTACCTGATGGAACTGGACGGCGTGTCATTCAAAACAACCTCAAGTACCCCT TCAGCATCGTAAGCTATGCAGATCACTTCTACCACACAGACTGGAGGAGGGATGGTGTTGTATCAGTAAATAAACATAGTGGCCAGTTTA CTGATGAGTATCTCCCAGAACAACGATCTCACCTCTACGGGATAACTGCAGTCTACCCCTACTGCCCAACAGGAAGAAAGTAAGTACAGT AATGTAAAGGAAGACTTGGAGTTTACAATCAGAACCTGGACCCTAAAGAACAGTGACTGCAAAGGCAAAGAAAGTAAAAAAGGAATTGGC CATTAGACGTTCCTGAGCATCCAAGATGAACATTTTGTAGTGCAAAAAGACTTTTGTGAAAAGCTGATACCTCAATCTTTACTACTGTAT TTTTAAAAATGAAGGTTGTTATTGCAAGTTTAAAAAGGTAACAGAATTTTAACTGTTGCTTATTAAAGCAACTTCTTGTAAACATTTATC ATTAATATTTAAAAGATCAAATTCATTCAACTAAGAATTAGAGTTTAAGACTCTAAACCTGATTTTTGCCATGGATTCCTTCTGGCCAAG AAATTAAAGCACATGTGATCAATATAACAATATAATCCTAAACCTTGACAGTTGGAGAAGCCAATGCAGAACTGATGGGAAAGGACCAAT TATTTATAGTTTCCCAACAAAAGTTCTAAGATTTTTTACCTCTGCATCAGTGCATTTCTATTTATATCAAAAGGTGCTAAAATGATTCAA TTTGCATTTTCTGATCCTGTAGTGCCTCTATAGAAGTACCCACAGAAAGTAAAGTATCACATTTATAAATACCAAAGATGTAACAATTTT >93909_93909_8_TRDMT1-NID2_TRDMT1_chr10_17195506_ENST00000457442_NID2_chr14_52486897_ENST00000541773_length(amino acids)=769AA_BP=285 MHKWWLPLMSTLSLMKYTSIIFLTHSYLPRRLKIGRQGDMTDSRTNSFLHILDILPRDLLIQTIENCGFQYQEFLLSPTSLGIPNSRLRY FLIAKLQSEPLPFQAPGQVLMEFPKIESVHPQKYAMDVENKIQEKNVEPNISFDGSIQCSGKDAILFKLETAEEIHRKNQQDSDLSVKML KDFLEDDTDVNQYLLPPKSLLRYALLLDIVQPTCRRSVCFTKGYGSYIEGTGSVLQTAEDVQVENIYKSLTNLSQEEQITKLLILKLRYF TPKEIANLLGFPPEFDVDECSENRCHPAATCYNTPGSFSCRCQPGYYGDGFQCIPDSTSSLTPCEQQQRHAQAQYAYPGARFHIPQCDEQ GNFLPLQCHGSTGFCWCVDPDGHEVPGTQTPPGSTPPHCGPSPEPTQRPPTICERWRENLLEHYGGTPRDDQYVPQCDDLGHFIPLQCHG KSDFCWCVDKDGREVQGTRSQPGTTPACIPTVAPPMVRPTPRPDVTPPSVGTFLLYTQGQQIGYLPLNGTRLQKDAAKTLLSLHGSIIVG IDYDCRERMVYWTDVAGRTISRAGLELGAEPETIVNSGLISPEGLAIDHIRRTMYWTDSVLDKIESALLDGSERKVLFYTDLVNPRAIAV DPIRGNLYWTDWNREAPKIETSSLDGENRRILINTDIGLPNGLTFDPFSKLLCWADAGTKKLECTLPDGTGRRVIQNNLKYPFSIVSYAD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TRDMT1-NID2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TRDMT1-NID2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TRDMT1-NID2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies