
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TSC2-RBP1 (FusionGDB2 ID:94521) |
Fusion Gene Summary for TSC2-RBP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TSC2-RBP1 | Fusion gene ID: 94521 | Hgene | Tgene | Gene symbol | TSC2 | RBP1 | Gene ID | 7249 | 5947 |
| Gene name | TSC complex subunit 2 | retinol binding protein 1 | |
| Synonyms | LAM|PPP1R160|TSC4 | CRABP-I|CRBP|CRBP1|CRBPI|RBPC | |
| Cytomap | 16p13.3 | 3q23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tuberinprotein phosphatase 1, regulatory subunit 160tuberous sclerosis 2 protein | retinol-binding protein 1CRBP-Icellular retinol binding protein 1cellular retinol-binding protein Iretinol-binding protein 1, cellular | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000219476, ENST00000350773, ENST00000353929, ENST00000382538, ENST00000401874, ENST00000439673, ENST00000568454, ENST00000568366, | ENST00000483943, ENST00000492918, ENST00000232219, | |
| Fusion gene scores | * DoF score | 10 X 12 X 6=720 | 4 X 3 X 3=36 |
| # samples | 12 | 6 | |
| ** MAII score | log2(12/720*10)=-2.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/36*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: TSC2 [Title/Abstract] AND RBP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TSC2(2108874)-RBP1(139258671), # samples:1 TSC2(2108874)-RBP1(139258674), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across TSC2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RBP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1552-01A | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| ChimerDB4 | OV | TCGA-24-1552 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
Top |
Fusion Gene ORF analysis for TSC2-RBP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000219476 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000219476 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000219476 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000219476 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000350773 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000350773 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000350773 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000350773 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000353929 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000353929 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000353929 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000353929 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000382538 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000382538 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000382538 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000382538 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000401874 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000401874 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000401874 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000401874 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000439673 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000439673 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000439673 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000439673 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000568454 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000568454 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| 5CDS-intron | ENST00000568454 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| 5CDS-intron | ENST00000568454 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000219476 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000219476 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000350773 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000350773 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000353929 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000353929 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000382538 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000382538 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000401874 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000401874 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000439673 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000439673 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| In-frame | ENST00000568454 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| In-frame | ENST00000568454 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| intron-3CDS | ENST00000568366 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| intron-3CDS | ENST00000568366 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| intron-intron | ENST00000568366 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| intron-intron | ENST00000568366 | ENST00000483943 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| intron-intron | ENST00000568366 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - |
| intron-intron | ENST00000568366 | ENST00000492918 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000219476 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 2503 | 1605 | 57 | 2309 | 750 |
| ENST00000382538 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1821 | 923 | 89 | 1627 | 512 |
| ENST00000401874 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1979 | 1081 | 106 | 1785 | 559 |
| ENST00000353929 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1979 | 1081 | 106 | 1785 | 559 |
| ENST00000439673 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1843 | 945 | 81 | 1649 | 522 |
| ENST00000350773 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1948 | 1050 | 75 | 1754 | 559 |
| ENST00000568454 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258671 | - | 1974 | 1076 | 59 | 1780 | 573 |
| ENST00000219476 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 2503 | 1605 | 57 | 2309 | 750 |
| ENST00000382538 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1821 | 923 | 89 | 1627 | 512 |
| ENST00000401874 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1979 | 1081 | 106 | 1785 | 559 |
| ENST00000353929 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1979 | 1081 | 106 | 1785 | 559 |
| ENST00000439673 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1843 | 945 | 81 | 1649 | 522 |
| ENST00000350773 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1948 | 1050 | 75 | 1754 | 559 |
| ENST00000568454 | TSC2 | chr16 | 2108874 | + | ENST00000232219 | RBP1 | chr3 | 139258674 | - | 1974 | 1076 | 59 | 1780 | 573 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000219476 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.02965212 | 0.9703479 |
| ENST00000382538 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.00579462 | 0.9942054 |
| ENST00000401874 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.008398738 | 0.9916013 |
| ENST00000353929 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.008398738 | 0.9916013 |
| ENST00000439673 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.008126396 | 0.99187356 |
| ENST00000350773 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.008988096 | 0.991012 |
| ENST00000568454 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258671 | - | 0.007446096 | 0.9925539 |
| ENST00000219476 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.02965212 | 0.9703479 |
| ENST00000382538 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.00579462 | 0.9942054 |
| ENST00000401874 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.008398738 | 0.9916013 |
| ENST00000353929 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.008398738 | 0.9916013 |
| ENST00000439673 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.008126396 | 0.99187356 |
| ENST00000350773 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.008988096 | 0.991012 |
| ENST00000568454 | ENST00000232219 | TSC2 | chr16 | 2108874 | + | RBP1 | chr3 | 139258674 | - | 0.007446096 | 0.9925539 |
Top |
Fusion Genomic Features for TSC2-RBP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
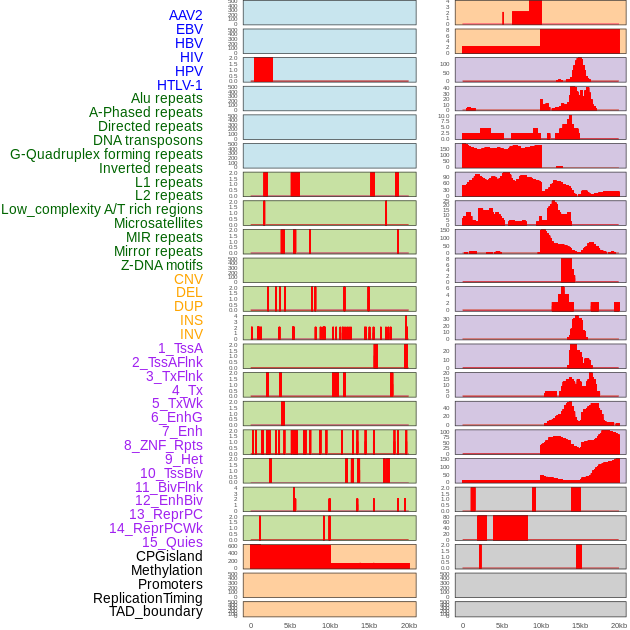 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for TSC2-RBP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr16:2108874/chr3:139258671) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TSC2 | chr16:2108874 | chr3:139258671 | ENST00000219476 | + | 10 | 42 | 1531_1758 | 325 | 1808.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258671 | ENST00000350773 | + | 10 | 41 | 1531_1758 | 325 | 1785.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258671 | ENST00000353929 | + | 10 | 41 | 1531_1758 | 325 | 1765.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258671 | ENST00000401874 | + | 10 | 40 | 1531_1758 | 325 | 1741.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258671 | ENST00000439673 | + | 9 | 39 | 1531_1758 | 288 | 1705.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258674 | ENST00000219476 | + | 10 | 42 | 1531_1758 | 325 | 1808.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258674 | ENST00000350773 | + | 10 | 41 | 1531_1758 | 325 | 1785.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258674 | ENST00000353929 | + | 10 | 41 | 1531_1758 | 325 | 1765.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258674 | ENST00000401874 | + | 10 | 40 | 1531_1758 | 325 | 1741.0 | Domain | Rap-GAP |
| Hgene | TSC2 | chr16:2108874 | chr3:139258674 | ENST00000439673 | + | 9 | 39 | 1531_1758 | 288 | 1705.0 | Domain | Rap-GAP |
Top |
Fusion Gene Sequence for TSC2-RBP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >94521_94521_1_TSC2-RBP1_TSC2_chr16_2108874_ENST00000219476_RBP1_chr3_139258671_ENST00000232219_length(transcript)=2503nt_BP=1605nt CGTTTTCTTGCTTGGGGCGAAAGGGGGCAGCGGAGCGGAGCGCCCGAAACCCAGCCCCTGCGGACCGCAATCTTTGGGAAAAAGGCGCAA GGTGGGAACGCAGGGCCGCACGTGGGAACCGTTCGCGGCTGCCGGGTTTGCAGCCCCTGCCCGCGCAGCTGGGAGCCGCAGGAGGCGGCC CGGGACTCCAGCCTGCAGCCCCTATCCCGCCTCCTCCCACGCTCCAGCCACGGCGCGGCGCTACCTGCTGCAGCCTCTCTTCTCCGGAGA GGCCCGGGCTCCTCCCTACACCCCCGCGGCCCAGCCCCGGGTCCCAGGCTCCGGCTCCGGGTCAGCATCCTCGCGCTCAAGGCGGTCATG CCGGACTCCTGCGGACTACACATCCCGGCGGCCCATGCGGCCCCGTCACGTGATGCAAGGATCGCCGGCCTTTCCGCCAGAGGGCGGCAC AGAACTACAACTCCCAGCAAGCTCCCAAGGCGGCCCTCCGCGCAATGCCGCTACCGGAAGTGCGGGTCGCGCTTCCGGCGGCGTCCCGGG GCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACC ATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCT GCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATG ATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAG CCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGA GCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGG AGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTG GTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCG TCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATC GTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCAC AGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGC ATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGT CTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACC GCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCAT TTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAG TCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTC AATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGC ACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACA GTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTG CACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAA TCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTG >94521_94521_1_TSC2-RBP1_TSC2_chr16_2108874_ENST00000219476_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=750AA_BP=516 MRTAIFGKKAQGGNAGPHVGTVRGCRVCSPCPRSWEPQEAARDSSLQPLSRLLPRSSHGAALPAAASLLRRGPGSSLHPRGPAPGPRLRL RVSILALKAVMPDSCGLHIPAAHAAPSRDARIAGLSARGRHRTTTPSKLPRRPSAQCRYRKCGSRFRRRPGARGVRLSPRRGGPERGGAA REGFSGASWSTMAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVE ALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMD VGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKL MRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAP APALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNE NFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGR -------------------------------------------------------------- >94521_94521_2_TSC2-RBP1_TSC2_chr16_2108874_ENST00000219476_RBP1_chr3_139258674_ENST00000232219_length(transcript)=2503nt_BP=1605nt CGTTTTCTTGCTTGGGGCGAAAGGGGGCAGCGGAGCGGAGCGCCCGAAACCCAGCCCCTGCGGACCGCAATCTTTGGGAAAAAGGCGCAA GGTGGGAACGCAGGGCCGCACGTGGGAACCGTTCGCGGCTGCCGGGTTTGCAGCCCCTGCCCGCGCAGCTGGGAGCCGCAGGAGGCGGCC CGGGACTCCAGCCTGCAGCCCCTATCCCGCCTCCTCCCACGCTCCAGCCACGGCGCGGCGCTACCTGCTGCAGCCTCTCTTCTCCGGAGA GGCCCGGGCTCCTCCCTACACCCCCGCGGCCCAGCCCCGGGTCCCAGGCTCCGGCTCCGGGTCAGCATCCTCGCGCTCAAGGCGGTCATG CCGGACTCCTGCGGACTACACATCCCGGCGGCCCATGCGGCCCCGTCACGTGATGCAAGGATCGCCGGCCTTTCCGCCAGAGGGCGGCAC AGAACTACAACTCCCAGCAAGCTCCCAAGGCGGCCCTCCGCGCAATGCCGCTACCGGAAGTGCGGGTCGCGCTTCCGGCGGCGTCCCGGG GCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACC ATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCT GCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATG ATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAG CCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGA GCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGG AGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTG GTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCG TCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATC GTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCAC AGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGC ATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGT CTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACC GCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCAT TTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAG TCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTC AATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGC ACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACA GTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTG CACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAA TCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTG >94521_94521_2_TSC2-RBP1_TSC2_chr16_2108874_ENST00000219476_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=750AA_BP=516 MRTAIFGKKAQGGNAGPHVGTVRGCRVCSPCPRSWEPQEAARDSSLQPLSRLLPRSSHGAALPAAASLLRRGPGSSLHPRGPAPGPRLRL RVSILALKAVMPDSCGLHIPAAHAAPSRDARIAGLSARGRHRTTTPSKLPRRPSAQCRYRKCGSRFRRRPGARGVRLSPRRGGPERGGAA REGFSGASWSTMAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVE ALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMD VGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKL MRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAP APALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNE NFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGR -------------------------------------------------------------- >94521_94521_3_TSC2-RBP1_TSC2_chr16_2108874_ENST00000350773_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1948nt_BP=1050nt CTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACCATGGCCAAACCAACA AGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCTGCAGAGGGTAAACAG ACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAGATTTGT GAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAGCCGGAGCGGCCGCTG GAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAG GTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTAC TTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAA TTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATA GAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGC ACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAAC ATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGA GCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGG CGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCT CCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCAC CACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATG CCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGC AAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTAC ATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGA GACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGA GTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTG GGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTC >94521_94521_3_TSC2-RBP1_TSC2_chr16_2108874_ENST00000350773_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_4_TSC2-RBP1_TSC2_chr16_2108874_ENST00000350773_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1948nt_BP=1050nt CTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACCATGGCCAAACCAACA AGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCTGCAGAGGGTAAACAG ACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAGATTTGT GAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAGCCGGAGCGGCCGCTG GAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAG GTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTAC TTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAA TTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATA GAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGC ACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAAC ATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGA GCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGG CGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCT CCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCAC CACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATG CCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGC AAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTAC ATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGA GACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGA GTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTG GGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTC >94521_94521_4_TSC2-RBP1_TSC2_chr16_2108874_ENST00000350773_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_5_TSC2-RBP1_TSC2_chr16_2108874_ENST00000353929_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1979nt_BP=1081nt CCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGG TGCGTCCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAG GCCAAATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAA CAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGT CGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCG TTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGC CCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGA ATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCT GTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAG CCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGG CACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGC CGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCA GAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAA GCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTC CCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGT GGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCT GCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGAT CATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCG CAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGAT CGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACA ACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCAT >94521_94521_5_TSC2-RBP1_TSC2_chr16_2108874_ENST00000353929_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_6_TSC2-RBP1_TSC2_chr16_2108874_ENST00000353929_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1979nt_BP=1081nt CCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGG TGCGTCCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAG GCCAAATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAA CAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGT CGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCG TTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGC CCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGA ATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCT GTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAG CCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGG CACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGC CGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCA GAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAA GCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTC CCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGT GGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCT GCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGAT CATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCG CAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGAT CGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACA ACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCAT >94521_94521_6_TSC2-RBP1_TSC2_chr16_2108874_ENST00000353929_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_7_TSC2-RBP1_TSC2_chr16_2108874_ENST00000382538_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1821nt_BP=923nt GTCGCGCTTCCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGGAAC TGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAG TGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCA TCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACG AAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGA TGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGA TGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCT ACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGA AGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGG ACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACAT CTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCG CCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCG CCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTC TCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCA ACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCG TGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGG ATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGG GGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGG TGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAA ATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTCACTTTTCCTTTTCTTAAAACAAAGCCATGCCAATAAA >94521_94521_7_TSC2-RBP1_TSC2_chr16_2108874_ENST00000382538_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=512AA_BP=278 MSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLH ERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVC YNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPT SVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGS LQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEE -------------------------------------------------------------- >94521_94521_8_TSC2-RBP1_TSC2_chr16_2108874_ENST00000382538_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1821nt_BP=923nt GTCGCGCTTCCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGGAAC TGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAG TGGAAGCACTCTGGAAGGCGGTCGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCA TCGTGCAGGGGCAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACG AAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGA TGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGA TGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCT ACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGA AGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGG ACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACAT CTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCG CCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCG CCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTC TCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCA ACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCG TGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGG ATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGG GGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGG TGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAA ATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTCACTTTTCCTTTTCTTAAAACAAAGCCATGCCAATAAA >94521_94521_8_TSC2-RBP1_TSC2_chr16_2108874_ENST00000382538_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=512AA_BP=278 MSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLH ERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVC YNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPT SVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGS LQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEE -------------------------------------------------------------- >94521_94521_9_TSC2-RBP1_TSC2_chr16_2108874_ENST00000401874_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1979nt_BP=1081nt CCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGG TGCGTCCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAG GCCAAATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAA CAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGT CGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCG TTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGC CCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGA ATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCT GTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAG CCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGG CACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGC CGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCA GAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAA GCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTC CCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGT GGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCT GCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGAT CATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCG CAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGAT CGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACA ACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCAT >94521_94521_9_TSC2-RBP1_TSC2_chr16_2108874_ENST00000401874_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_10_TSC2-RBP1_TSC2_chr16_2108874_ENST00000401874_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1979nt_BP=1081nt CCGGCGGCGTCCCGGGGCCAGGGGGGTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGG TGCGTCCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAG GCCAAATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAA CAATCGCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGT CGCGGATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCG TTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGC CCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGA ATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCT GTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAG CCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGG CACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGC CGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCA GAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAA GCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTC CCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGT GGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCT GCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGAT CATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCG CAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGAT CGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACA ACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCAT >94521_94521_10_TSC2-RBP1_TSC2_chr16_2108874_ENST00000401874_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=559AA_BP=325 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEHAVEALWKAVADLLQ PERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVL VNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGH SAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGAT ATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDV NVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEKEGRGWTQWIEGDEL -------------------------------------------------------------- >94521_94521_11_TSC2-RBP1_TSC2_chr16_2108874_ENST00000439673_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1843nt_BP=945nt GTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACCATGGCCAAA CCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCTGCAGAGGGT AAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAG ATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTAC CCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTG GCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTAC CTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAG GTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAG GAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATG GAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTAT TCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAA CCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTG CGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACC GGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACT GGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTG CTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAG GTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGT GTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTC TGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCT CTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTCACTTTTCCTTTTCTT >94521_94521_11_TSC2-RBP1_TSC2_chr16_2108874_ENST00000439673_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=522AA_BP=288 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEGERLGVLRALFFKVI KDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEV SLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAH RLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHP RSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIM -------------------------------------------------------------- >94521_94521_12_TSC2-RBP1_TSC2_chr16_2108874_ENST00000439673_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1843nt_BP=945nt GTGCGCCTTTCTCCGCGTCGGGGCGGCCCGGAGCGCGGTGGCGCGGCGCGGGAGGGGTTTTCTGGTGCGTCCTGGTCCACCATGGCCAAA CCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAAATCCCAGGTCTGCAGAGGGT AAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATCGCATCCGGATGATAGGGCAG ATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGGGCGAGCGTTTGGGGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTAC CCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCACAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTG GCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCCTTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTAC CTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCGTCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAG GTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCCCGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAG GAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCCACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATG GAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGTTTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTAT TCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAACGAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAA CCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGGGAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTG CGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGGAGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACC GGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCAACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACT GGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCGCCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTG CTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCCGCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAG GTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGTGCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGT GTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGGGTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTC TGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTTGTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCT CTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTTAGCAGAGTCTGTCTCTTGGCTTTGTCACTTTTCCTTTTCTT >94521_94521_12_TSC2-RBP1_TSC2_chr16_2108874_ENST00000439673_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=522AA_BP=288 MAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEGERLGVLRALFFKVI KDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQWMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEV SLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPCWKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAH RLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTSPAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHP RSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKMLVNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIM -------------------------------------------------------------- >94521_94521_13_TSC2-RBP1_TSC2_chr16_2108874_ENST00000568454_RBP1_chr3_139258671_ENST00000232219_length(transcript)=1974nt_BP=1076nt AGTTTTAAGTCATGGCGGGTGCGAACGGGTCTCTGCTGCAGGCGGCTCCGTGACAGCTCCTGCTTCACATGGAGGGGTTTTCTGGTGCGT CCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAA ATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATC GCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGG ATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGG GGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCA CAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCC TTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCG TCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCC CGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCC ACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGT TTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAAC GAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGG GAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGG AGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCA ACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCG CCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCC GCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGT GCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGG GTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTT GTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTT >94521_94521_13_TSC2-RBP1_TSC2_chr16_2108874_ENST00000568454_RBP1_chr3_139258671_ENST00000232219_length(amino acids)=573AA_BP=339 MLHMEGFSGASWSTMAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEH AVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQ WMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPC WKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTS PAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKML VNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEK -------------------------------------------------------------- >94521_94521_14_TSC2-RBP1_TSC2_chr16_2108874_ENST00000568454_RBP1_chr3_139258674_ENST00000232219_length(transcript)=1974nt_BP=1076nt AGTTTTAAGTCATGGCGGGTGCGAACGGGTCTCTGCTGCAGGCGGCTCCGTGACAGCTCCTGCTTCACATGGAGGGGTTTTCTGGTGCGT CCTGGTCCACCATGGCCAAACCAACAAGCAAAGATTCAGGCTTGAAGGAGAAGTTTAAGATTCTGTTGGGACTGGGAACACCGAGGCCAA ATCCCAGGTCTGCAGAGGGTAAACAGACGGAGTTTATCATCACCGCGGAAATACTGAGAGAACTGAGCATGGAATGTGGCCTCAACAATC GCATCCGGATGATAGGGCAGATTTGTGAAGTCGCAAAAACCAAGAAATTTGAAGAGCACGCAGTGGAAGCACTCTGGAAGGCGGTCGCGG ATCTGTTGCAGCCGGAGCGGCCGCTGGAGGCCCGGCACGCGGTGCTGGCTCTGCTGAAGGCCATCGTGCAGGGGCAGGGCGAGCGTTTGG GGGTCCTCAGAGCCCTCTTCTTTAAGGTCATCAAGGATTACCCTTCCAACGAAGACCTTCACGAAAGGCTGGAGGTTTTCAAGGCCCTCA CAGACAATGGGAGACACATCACCTACTTGGAGGAAGAGCTGGCTGACTTTGTCCTGCAGTGGATGGATGTTGGCTTGTCCTCGGAATTCC TTCTGGTGCTGGTGAACTTGGTCAAATTCAATAGCTGTTACCTCGACGAGTACATCGCAAGGATGGTTCAGATGATCTGTCTGCTGTGCG TCCGGACCGCGTCCTCTGTGGACATAGAGGTCTCCCTGCAGGTGCTGGACGCCGTGGTCTGCTACAACTGCCTGCCGGCTGAGAGCCTCC CGCTGTTCATCGTTACCCTCTGTCGCACCATCAACGTCAAGGAGCTCTGCGAGCCTTGCTGGAAGCTGATGCGGAACCTCCTTGGCACCC ACCTGGGCCACAGCGCCATCTACAACATGTGCCACCTCATGGAGGACAGAGCCTACATGGAGGACGCGCCCCTGCTGAGAGGAGCCGTGT TTTTTGTGGGCATGGCTCTCTGGGGAGCCCACCGGCTCTATTCTCTCAGGAACTCGCCGACATCTGTGTTGCCATCATTTTACCAGAAAC GAACTGAACGTCTGAAACGAAGGTGGCGCGGCCTGGACAAACCTGACCCTTCGACATCCCCCGCCCCTGCGCCCGCCCTCGCTAAGCGGG GAGGAGCGACCGCTACAATGGATCCTCCCGCAGGCTTTGTGCGCGCTGGGAATCCAGCTGTCGCCGCCCCGCAGAGCCCCCTGTCCCCGG AGGGCGCTCATTTCCGGGCCGCCCACCACCCGCGTAGCACCGGCAGCCGCTGTCCCGGCAGTCTCCAGCCGTCCCGCCCGCTTGTGGCCA ACTGGCTCCAGTCACTCCCCGAAATGCCAGTCGACTTCACTGGGTACTGGAAGATGTTGGTCAACGAGAATTTCGAGGAGTACCTGCGCG CCCTCGACGTCAATGTGGCCTTGCGCAAAATCGCCAACTTGCTGAAGCCAGACAAAGAGATCGTGCAGGACGGTGACCATATGATCATCC GCACGCTGAGCACTTTTAGGAACTACATCATGGACTTCCAGGTTGGGAAGGAGTTTGAGGAGGATCTGACAGGCATAGATGACCGCAAGT GCATGACAACAGTGAGCTGGGACGGAGACAAGCTCCAGTGTGTGCAGAAGGGTGAGAAGGAGGGGCGTGGCTGGACCCAGTGGATCGAGG GTGATGAGCTGCACCTGGAGATGAGAGTGGAAGGTGTGGTCTGCAAGCAAGTATTCAAGAAGGTGCAGTGAGGCCCAGGCAGACAACCTT GTCCCAAGGAATCAGCAGGATGTGTGGGCCAGGATCCCCCTCTTTGCACAGCATGAGGCAAAAATGTCCAGCCACCCCCAGGCATCTGTT >94521_94521_14_TSC2-RBP1_TSC2_chr16_2108874_ENST00000568454_RBP1_chr3_139258674_ENST00000232219_length(amino acids)=573AA_BP=339 MLHMEGFSGASWSTMAKPTSKDSGLKEKFKILLGLGTPRPNPRSAEGKQTEFIITAEILRELSMECGLNNRIRMIGQICEVAKTKKFEEH AVEALWKAVADLLQPERPLEARHAVLALLKAIVQGQGERLGVLRALFFKVIKDYPSNEDLHERLEVFKALTDNGRHITYLEEELADFVLQ WMDVGLSSEFLLVLVNLVKFNSCYLDEYIARMVQMICLLCVRTASSVDIEVSLQVLDAVVCYNCLPAESLPLFIVTLCRTINVKELCEPC WKLMRNLLGTHLGHSAIYNMCHLMEDRAYMEDAPLLRGAVFFVGMALWGAHRLYSLRNSPTSVLPSFYQKRTERLKRRWRGLDKPDPSTS PAPAPALAKRGGATATMDPPAGFVRAGNPAVAAPQSPLSPEGAHFRAAHHPRSTGSRCPGSLQPSRPLVANWLQSLPEMPVDFTGYWKML VNENFEEYLRALDVNVALRKIANLLKPDKEIVQDGDHMIIRTLSTFRNYIMDFQVGKEFEEDLTGIDDRKCMTTVSWDGDKLQCVQKGEK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TSC2-RBP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TSC2-RBP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TSC2-RBP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies