
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TTC39C-NPC1 (FusionGDB2 ID:95046) |
Fusion Gene Summary for TTC39C-NPC1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TTC39C-NPC1 | Fusion gene ID: 95046 | Hgene | Tgene | Gene symbol | TTC39C | NPC1 | Gene ID | 125488 | 4864 |
| Gene name | tetratricopeptide repeat domain 39C | NPC intracellular cholesterol transporter 1 | |
| Synonyms | C18orf17|HsT2697 | NPC|POGZ|SLC65A1 | |
| Cytomap | 18q11.2 | 18q11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tetratricopeptide repeat protein 39CTPR repeat protein 39C | NPC intracellular cholesterol transporter 1Niemann-Pick C1 proteintruncated Niemann-Pick C1 | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | . | NPC1L1 | |
| Ensembl transtripts involved in fusion gene | ENST00000304621, ENST00000317571, ENST00000540918, ENST00000577185, ENST00000578150, ENST00000584250, | ENST00000412552, ENST00000540608, ENST00000269228, | |
| Fusion gene scores | * DoF score | 6 X 5 X 5=150 | 12 X 11 X 5=660 |
| # samples | 6 | 13 | |
| ** MAII score | log2(6/150*10)=-1.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/660*10)=-2.34395440121736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TTC39C [Title/Abstract] AND NPC1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TTC39C(21663045)-NPC1(21153538), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NPC1 | GO:0006486 | protein glycosylation | 10821832 |
| Tgene | NPC1 | GO:0030301 | cholesterol transport | 18772377 |
| Tgene | NPC1 | GO:0033344 | cholesterol efflux | 16141411 |
| Tgene | NPC1 | GO:0042632 | cholesterol homeostasis | 12719428 |
| Tgene | NPC1 | GO:0090150 | establishment of protein localization to membrane | 23360953 |
| Fusion gene breakpoints across TTC39C (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NPC1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8526-01A | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
Top |
Fusion Gene ORF analysis for TTC39C-NPC1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000304621 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| 5CDS-intron | ENST00000304621 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| 5CDS-intron | ENST00000317571 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| 5CDS-intron | ENST00000317571 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| In-frame | ENST00000304621 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| In-frame | ENST00000317571 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-3CDS | ENST00000540918 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-3CDS | ENST00000577185 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-3CDS | ENST00000578150 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-3CDS | ENST00000584250 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000540918 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000540918 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000577185 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000577185 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000578150 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000578150 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000584250 | ENST00000412552 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| intron-intron | ENST00000584250 | ENST00000540608 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000304621 | TTC39C | chr18 | 21663045 | - | ENST00000269228 | NPC1 | chr18 | 21153538 | - | 5628 | 1083 | 282 | 4862 | 1526 |
| ENST00000317571 | TTC39C | chr18 | 21663045 | - | ENST00000269228 | NPC1 | chr18 | 21153538 | - | 5765 | 1220 | 191 | 4999 | 1602 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000304621 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - | 0.000227896 | 0.99977213 |
| ENST00000317571 | ENST00000269228 | TTC39C | chr18 | 21663045 | - | NPC1 | chr18 | 21153538 | - | 0.00032372 | 0.99967635 |
Top |
Fusion Genomic Features for TTC39C-NPC1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
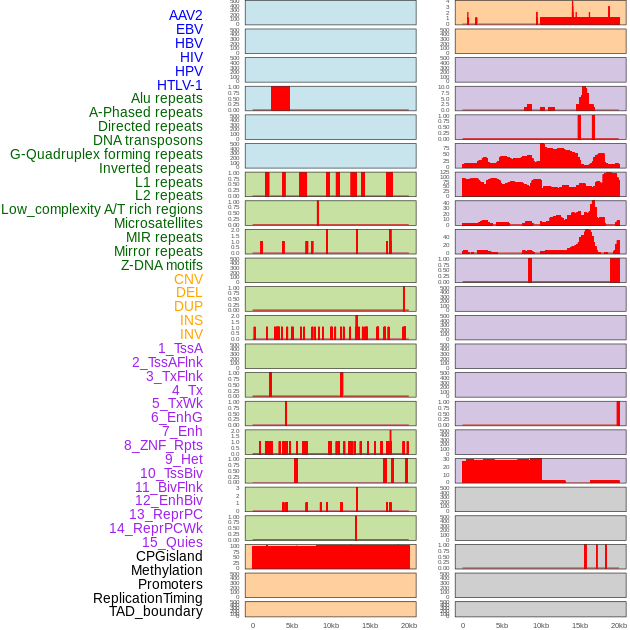 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for TTC39C-NPC1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr18:21663045/chr18:21153538) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NPC1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | 1359 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000304621 | - | 6 | 14 | 19_25 | 267 | 523.0 | Compositional bias | Note=Poly-Ala |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000317571 | - | 6 | 14 | 19_25 | 328 | 584.0 | Compositional bias | Note=Poly-Ala |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 249_259 | 19 | 1279.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 620_785 | 19 | 1279.0 | Domain | SSD | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 175_205 | 19 | 1279.0 | Region | Note=Important for cholesterol binding and cholesterol transfer from NPC1 to liposomes | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1119_1124 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1146_1150 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1172_1194 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1216_1223 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1245_1278 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 23_261 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 283_350 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 372_620 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 642_653 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 676_685 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 707_730 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 752_759 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 784_832 | 19 | 1279.0 | Topological domain | Cytoplasmic | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 854_1097 | 19 | 1279.0 | Topological domain | Lumenal | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1098_1118 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1125_1145 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1151_1171 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1195_1215 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 1224_1244 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 262_282 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 351_371 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 621_641 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 654_675 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 686_706 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 731_751 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 760_783 | 19 | 1279.0 | Transmembrane | Helical | |
| Tgene | NPC1 | chr18:21663045 | chr18:21153538 | ENST00000269228 | 0 | 25 | 833_853 | 19 | 1279.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000584250 | - | 1 | 2 | 19_25 | 0 | 77.0 | Compositional bias | Note=Poly-Ala |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000304621 | - | 6 | 14 | 315_348 | 267 | 523.0 | Repeat | Note=TPR 1 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000304621 | - | 6 | 14 | 353_386 | 267 | 523.0 | Repeat | Note=TPR 2 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000304621 | - | 6 | 14 | 485_518 | 267 | 523.0 | Repeat | Note=TPR 3 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000317571 | - | 6 | 14 | 315_348 | 328 | 584.0 | Repeat | Note=TPR 1 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000317571 | - | 6 | 14 | 353_386 | 328 | 584.0 | Repeat | Note=TPR 2 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000317571 | - | 6 | 14 | 485_518 | 328 | 584.0 | Repeat | Note=TPR 3 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000584250 | - | 1 | 2 | 315_348 | 0 | 77.0 | Repeat | Note=TPR 1 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000584250 | - | 1 | 2 | 353_386 | 0 | 77.0 | Repeat | Note=TPR 2 |
| Hgene | TTC39C | chr18:21663045 | chr18:21153538 | ENST00000584250 | - | 1 | 2 | 485_518 | 0 | 77.0 | Repeat | Note=TPR 3 |
Top |
Fusion Gene Sequence for TTC39C-NPC1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >95046_95046_1_TTC39C-NPC1_TTC39C_chr18_21663045_ENST00000304621_NPC1_chr18_21153538_ENST00000269228_length(transcript)=5628nt_BP=1083nt AATCATGCTTACGCATATAGGTTAACCACAGTTATGTAAGCAGGTTCTGAGAAAAGGTGAGAAAGAGAATGGAGAGTTTTGCTACAACAG AGGCAGGATTCTGAATTTATTTCCAGCTGCCCATCTTGTCCCTCCTGGAGACCTAACCCCTCCAGCACCTACACACACAGCCTCTTTAGA AGCAACTATCCTGCCACTGGCTCAGAAAGGCTGAGTCCTAAGAATTCTAAAATCTTGCTCCTAAGAAATCTCAAGCTTCTTTTGTGAAAT CATAGCCCACTAATGAGTTTTGGAGCCAGCTTTGTCAGTTTTTTGAATGCCATGATGACATTTGAGGAAGAAAAAATGCAGTTGGCATGT GATGACTTAAAAACCACAGAAAAACTGTGTGAAAGTGAAGAGGCTGGAGTAATTGAAACAATCAAGAATAAAATTAAGAAGAACGTTGAT GTCCGAAAATCCGCCCCCTCTATGGTTGATCGGCTTCAGAGGCAGATAATCATAGCTGACTGCCAGGTTTACCTGGCTGTGCTTTCATTT GTAAAACAAGAATTGTCAGCTTATATCAAAGGTGGGTGGATCCTTAGGAAAGCCTGGAAGATTTACAATAAATGCTATCTGGACATCAAT GCCCTTCAGGAGCTGTATCAGAAGAAGCTAACTGAAGAGTCCTTGACTTCTGATGCTGCAAATGATAATCACATTGTGGCTGAAGGGGTG TCTGAGGAGTCTCTGAACAGACTGAAAGGTGCTGTTAGCTTTGGATATGGCCTTTTTCACCTTTGCATATCCATGGTGCCCCCAAACCTG CTCAAAATCATCAACCTGCTGGGTTTTCCTGGAGACCGCCTACAGGGGCTTTCTTCACTGATGTATGCAAGCGAAAGTAAGGACATGAAG GCCCCTTTAGCTACATTAGCTCTGCTCTGGTATCATACTGTAGTCCGCCCGTTTTTTGCCTTGGATGGCAGTGATAACAAGGCAGGCCTG GATGAAGCTAAGGAAATTCTCCTTAAAAAAGAAGCTGCTTATCCAAATTCTTCCCTCTTTATGTTTTTCAAGGGACGGATACAACGACTA GAGGTGTTTTCACAGTCCTGTGTTTGGTATGGAGAGTGTGGAATTGCATATGGGGACAAGAGGTACAATTGCGAATATTCTGGCCCACCA AAACCATTGCCAAAGGATGGATATGACTTAGTGCAGGAACTCTGTCCAGGATTCTTCTTTGGCAATGTCAGTCTCTGTTGTGATGTTCGG CAGCTTCAGACACTAAAAGACAACCTGCAGCTGCCTCTACAGTTTCTGTCCAGATGTCCATCCTGTTTTTATAACCTACTGAACCTGTTT TGTGAGCTGACATGTAGCCCTCGACAGAGTCAGTTTTTGAATGTTACAGCTACTGAAGATTATGTTGATCCTGTTACAAACCAGACGAAA ACAAATGTGAAAGAGTTACAATACTACGTCGGACAGAGTTTTGCCAATGCAATGTACAATGCCTGCCGGGATGTGGAGGCCCCCTCAAGT AATGACAAGGCCCTGGGACTCCTGTGTGGGAAGGACGCTGACGCCTGTAATGCCACCAACTGGATTGAATACATGTTCAATAAGGACAAT GGACAGGCACCTTTTACCATCACTCCTGTGTTTTCAGATTTTCCAGTCCATGGGATGGAGCCCATGAACAATGCCACCAAAGGCTGTGAC GAGTCTGTGGATGAGGTCACAGCACCATGTAGCTGCCAAGACTGCTCTATTGTCTGTGGCCCCAAGCCCCAGCCCCCACCTCCTCCTGCT CCCTGGACGATCCTTGGCTTGGACGCCATGTATGTCATCATGTGGATCACCTACATGGCGTTTTTGCTTGTGTTTTTTGGAGCATTTTTT GCAGTGTGGTGCTACAGAAAACGGTATTTTGTCTCCGAGTACACTCCCATCGATAGCAATATAGCTTTTTCTGTTAATGCAAGTGACAAA GGAGAGGCGTCCTGCTGTGACCCTGTCAGCGCAGCATTTGAGGGCTGCTTGAGGCGGCTGTTCACACGCTGGGGGTCTTTCTGCGTCCGA AACCCTGGCTGTGTCATTTTCTTCTCGCTGGTCTTCATTACTGCGTGTTCGTCAGGCCTGGTGTTTGTCCGGGTCACAACCAATCCAGTT GACCTCTGGTCAGCCCCCAGCAGCCAGGCTCGCCTGGAAAAAGAGTACTTTGACCAGCACTTTGGGCCTTTCTTCCGGACGGAGCAGCTC ATCATCCGGGCCCCTCTCACTGACAAACACATTTACCAGCCATACCCTTCGGGAGCTGATGTACCCTTTGGACCTCCGCTTGACATACAG ATACTGCACCAGGTTCTTGACTTACAAATAGCCATCGAAAACATTACTGCCTCTTATGACAATGAGACTGTGACACTTCAAGACATCTGC TTGGCCCCTCTTTCACCGTATAACACGAACTGCACCATTTTGAGTGTGTTAAATTACTTCCAGAACAGCCATTCCGTGCTGGACCACAAG AAAGGGGACGACTTCTTTGTGTATGCCGATTACCACACGCACTTTCTGTACTGCGTACGGGCTCCTGCCTCTCTGAATGATACAAGTTTG CTCCATGACCCTTGTCTGGGTACGTTTGGTGGACCAGTGTTCCCGTGGCTTGTGTTGGGAGGCTATGATGATCAAAACTACAATAACGCC ACTGCCCTTGTGATTACCTTCCCTGTCAATAATTACTATAATGATACAGAGAAGCTCCAGAGGGCCCAGGCCTGGGAAAAAGAGTTTATT AATTTTGTGAAAAACTACAAGAATCCCAATCTGACCATTTCCTTCACTGCTGAACGAAGTATTGAAGATGAACTAAATCGTGAAAGTGAC AGTGATGTCTTCACCGTTGTAATTAGCTATGCCATCATGTTTCTATATATTTCCCTAGCCTTGGGGCACATGAAAAGCTGTCGCAGGCTT CTGGTGGATTCGAAGGTCTCACTAGGCATCGCGGGCATCTTGATCGTGCTGAGCTCGGTGGCTTGCTCCTTGGGTGTCTTCAGCTACATT GGGTTGCCCTTGACCCTCATTGTGATTGAAGTCATCCCGTTCCTGGTGCTGGCTGTTGGAGTGGACAACATCTTCATTCTGGTGCAGGCC TACCAGAGAGATGAACGTCTTCAAGGGGAAACCCTGGATCAGCAGCTGGGCAGGGTCCTAGGAGAAGTGGCTCCCAGTATGTTCCTGTCA TCCTTTTCTGAGACTGTAGCATTTTTCTTAGGAGCATTGTCCGTGATGCCAGCCGTGCACACCTTCTCTCTCTTTGCGGGATTGGCAGTC TTCATTGACTTTCTTCTGCAGATTACCTGTTTCGTGAGTCTCTTGGGGTTAGACATTAAACGTCAAGAGAAAAATCGGCTAGACATCTTT TGCTGTGTCAGAGGTGCTGAAGATGGAACAAGCGTCCAGGCCTCAGAGAGCTGTTTGTTTCGCTTCTTCAAAAACTCCTATTCTCCACTT CTGCTAAAGGACTGGATGAGACCAATTGTGATAGCAATATTTGTGGGTGTTCTGTCATTCAGCATCGCAGTCCTGAACAAAGTAGATATT GGATTGGATCAGTCTCTTTCGATGCCAGATGACTCCTACATGGTGGATTATTTCAAATCCATCAGTCAGTACCTGCATGCGGGTCCGCCT GTGTACTTTGTCCTGGAGGAAGGGCACGACTACACTTCTTCCAAGGGGCAGAACATGGTGTGCGGCGGCATGGGCTGCAACAATGATTCC CTGGTGCAGCAGATATTTAACGCGGCGCAGCTGGACAACTATACCCGAATAGGCTTCGCCCCCTCGTCCTGGATCGACGATTATTTCGAC TGGGTGAAGCCACAGTCGTCTTGCTGTCGAGTGGACAATATCACTGACCAGTTCTGCAATGCTTCAGTGGTTGACCCTGCCTGCGTTCGC TGCAGGCCTCTGACTCCGGAAGGCAAACAGAGGCCTCAGGGGGGAGACTTCATGAGATTCCTGCCCATGTTCCTTTCGGATAACCCTAAC CCCAAGTGTGGCAAAGGGGGACATGCTGCCTATAGTTCTGCAGTTAACATCCTCCTTGGCCATGGCACCAGGGTCGGAGCCACGTACTTC ATGACCTACCACACCGTGCTGCAGACCTCTGCTGACTTTATTGACGCTCTGAAGAAAGCCCGACTTATAGCCAGTAATGTCACCGAAACC ATGGGCATTAACGGCAGTGCCTACCGAGTATTTCCTTACAGTGTGTTTTATGTCTTCTACGAACAGTACCTGACCATCATTGACGACACT ATCTTCAACCTCGGTGTGTCCCTGGGCGCGATATTTCTGGTGACCATGGTCCTCCTGGGCTGTGAGCTCTGGTCTGCAGTCATCATGTGT GCCACCATCGCCATGGTCTTGGTCAACATGTTTGGAGTTATGTGGCTCTGGGGCATCAGTCTGAACGCTGTATCCTTGGTCAACCTGGTG ATGAGCTGTGGCATCTCCGTGGAGTTCTGCAGCCACATAACCAGAGCGTTCACGGTGAGCATGAAAGGCAGCCGCGTGGAGCGCGCGGAA GAGGCACTTGCCCACATGGGCAGCTCCGTGTTCAGTGGAATCACACTTACAAAATTTGGAGGGATTGTGGTGTTGGCTTTTGCCAAATCT CAAATTTTCCAGATATTCTACTTCAGGATGTATTTGGCCATGGTCTTACTGGGAGCCACTCACGGATTAATATTTCTCCCTGTCTTACTC AGTTACATAGGGCCATCAGTAAATAAAGCCAAAAGTTGTGCCACTGAAGAGCGATACAAAGGAACAGAGCGCGAACGGCTTCTAAATTTC TAGCCCTCTCGCAGGGCATCCTGACTGAACTGTGTCTAAGGGTCGGTCGGTTTACCACTGGACGGGTGCTGCATCGGCAAGGCCAAGTTG AACACCGGATGGTGCCAACCATCGGTTGTTTGGCAGCAGCTTTGAACGTAGCGCCTGTGAACTCAGGAATGCACAGTTGACTTGGGAAGC AGTATTACTAGATCTGGAGGCAACCACAGGACACTAAACTTCTCCCAGCCTCTTCAGGAAAGAAACCTCATTCTTTGGCAAGCAGGAGGT GACACTAGATGGCTGTGAATGTGATCCGCTCACTGACACTCTGTAAAGGCCAATCAATGCACTGTCTGTCTCTCCTTTTAGGAGTAAGCC ATCCCACAAGTTCTATACCATATTTTTAGTGACAGTTGAGGTTGTAGATACACTTTATAACATTTTATAGTTTAAAGAGCTTTATTAATG CAATAAATTAACTTTGTACACATTTTTATATAAAAAAACAGCAAGTGATTTCAGAATGTTGTAGGCCTCATTAGAGCTTGGTCTCCAAAA ATCTGTTTGAAAAAAGCAACATGTTCTTCACAGTGTTCCCCTAGAAAGGAAGAGATTTAATTGCCAGTTAGATGTGGCATGAAATGAGGG ACAAAGAAAGCATCTCGTAGGTGTGTCTACTGGGTTTTAACTTATTTTTCTTTAATAAAATACATTGTTTTCCTAAGTTTTGGGGTTACC >95046_95046_1_TTC39C-NPC1_TTC39C_chr18_21663045_ENST00000304621_NPC1_chr18_21153538_ENST00000269228_length(amino acids)=1526AA_BP=265 MSFGASFVSFLNAMMTFEEEKMQLACDDLKTTEKLCESEEAGVIETIKNKIKKNVDVRKSAPSMVDRLQRQIIIADCQVYLAVLSFVKQE LSAYIKGGWILRKAWKIYNKCYLDINALQELYQKKLTEESLTSDAANDNHIVAEGVSEESLNRLKGAVSFGYGLFHLCISMVPPNLLKII NLLGFPGDRLQGLSSLMYASESKDMKAPLATLALLWYHTVVRPFFALDGSDNKAGLDEAKEILLKKEAAYPNSSLFMFFKGRIQRLEVFS QSCVWYGECGIAYGDKRYNCEYSGPPKPLPKDGYDLVQELCPGFFFGNVSLCCDVRQLQTLKDNLQLPLQFLSRCPSCFYNLLNLFCELT CSPRQSQFLNVTATEDYVDPVTNQTKTNVKELQYYVGQSFANAMYNACRDVEAPSSNDKALGLLCGKDADACNATNWIEYMFNKDNGQAP FTITPVFSDFPVHGMEPMNNATKGCDESVDEVTAPCSCQDCSIVCGPKPQPPPPPAPWTILGLDAMYVIMWITYMAFLLVFFGAFFAVWC YRKRYFVSEYTPIDSNIAFSVNASDKGEASCCDPVSAAFEGCLRRLFTRWGSFCVRNPGCVIFFSLVFITACSSGLVFVRVTTNPVDLWS APSSQARLEKEYFDQHFGPFFRTEQLIIRAPLTDKHIYQPYPSGADVPFGPPLDIQILHQVLDLQIAIENITASYDNETVTLQDICLAPL SPYNTNCTILSVLNYFQNSHSVLDHKKGDDFFVYADYHTHFLYCVRAPASLNDTSLLHDPCLGTFGGPVFPWLVLGGYDDQNYNNATALV ITFPVNNYYNDTEKLQRAQAWEKEFINFVKNYKNPNLTISFTAERSIEDELNRESDSDVFTVVISYAIMFLYISLALGHMKSCRRLLVDS KVSLGIAGILIVLSSVACSLGVFSYIGLPLTLIVIEVIPFLVLAVGVDNIFILVQAYQRDERLQGETLDQQLGRVLGEVAPSMFLSSFSE TVAFFLGALSVMPAVHTFSLFAGLAVFIDFLLQITCFVSLLGLDIKRQEKNRLDIFCCVRGAEDGTSVQASESCLFRFFKNSYSPLLLKD WMRPIVIAIFVGVLSFSIAVLNKVDIGLDQSLSMPDDSYMVDYFKSISQYLHAGPPVYFVLEEGHDYTSSKGQNMVCGGMGCNNDSLVQQ IFNAAQLDNYTRIGFAPSSWIDDYFDWVKPQSSCCRVDNITDQFCNASVVDPACVRCRPLTPEGKQRPQGGDFMRFLPMFLSDNPNPKCG KGGHAAYSSAVNILLGHGTRVGATYFMTYHTVLQTSADFIDALKKARLIASNVTETMGINGSAYRVFPYSVFYVFYEQYLTIIDDTIFNL GVSLGAIFLVTMVLLGCELWSAVIMCATIAMVLVNMFGVMWLWGISLNAVSLVNLVMSCGISVEFCSHITRAFTVSMKGSRVERAEEALA -------------------------------------------------------------- >95046_95046_2_TTC39C-NPC1_TTC39C_chr18_21663045_ENST00000317571_NPC1_chr18_21153538_ENST00000269228_length(transcript)=5765nt_BP=1220nt TGAGTAATCCCCGCGGCGGCGGCCGGACGCCCACCTCCCACGCCGCGCCGCAGCCGGGCCGCGGCTCCTCCCTCCGCGGTCCTTCCCTCC TCTTCCCTCCCGTCTTCTCCCCTCCCCTCCCCTCCCCTCCCGGCTCCGCTTGGCTCCGGGCAGGTAGAGCCGGGCTCCGGGCGCGCGCGG GGCCGCAGCAGCTGCTCCCGATCTCGCCTCGGCCCAGCGCAGGGCCTCGCACGCCCATGGCCGGCTCGGAGCAGCAGCGGCCGCGGCGGC GGGACGACGGAGACTCGGACGCGGCAGCGGCGGCGGCGGCGCCCCTGCAGGACGCGGAGCTGGCCCTGGCCGGCATCAACATGCTGCTCA ACAACGGCTTCAGGGAGTCGGACCAGCTTTTCAAACAATACAGAAATCATAGCCCACTAATGAGTTTTGGAGCCAGCTTTGTCAGTTTTT TGAATGCCATGATGACATTTGAGGAAGAAAAAATGCAGTTGGCATGTGATGACTTAAAAACCACAGAAAAACTGTGTGAAAGTGAAGAGG CTGGAGTAATTGAAACAATCAAGAATAAAATTAAGAAGAACGTTGATGTCCGAAAATCCGCCCCCTCTATGGTTGATCGGCTTCAGAGGC AGATAATCATAGCTGACTGCCAGGTTTACCTGGCTGTGCTTTCATTTGTAAAACAAGAATTGTCAGCTTATATCAAAGGTGGGTGGATCC TTAGGAAAGCCTGGAAGATTTACAATAAATGCTATCTGGACATCAATGCCCTTCAGGAGCTGTATCAGAAGAAGCTAACTGAAGAGTCCT TGACTTCTGATGCTGCAAATGATAATCACATTGTGGCTGAAGGGGTGTCTGAGGAGTCTCTGAACAGACTGAAAGGTGCTGTTAGCTTTG GATATGGCCTTTTTCACCTTTGCATATCCATGGTGCCCCCAAACCTGCTCAAAATCATCAACCTGCTGGGTTTTCCTGGAGACCGCCTAC AGGGGCTTTCTTCACTGATGTATGCAAGCGAAAGTAAGGACATGAAGGCCCCTTTAGCTACATTAGCTCTGCTCTGGTATCATACTGTAG TCCGCCCGTTTTTTGCCTTGGATGGCAGTGATAACAAGGCAGGCCTGGATGAAGCTAAGGAAATTCTCCTTAAAAAAGAAGCTGCTTATC CAAATTCTTCCCTCTTTATGTTTTTCAAGGGACGGATACAACGACTAGAGGTGTTTTCACAGTCCTGTGTTTGGTATGGAGAGTGTGGAA TTGCATATGGGGACAAGAGGTACAATTGCGAATATTCTGGCCCACCAAAACCATTGCCAAAGGATGGATATGACTTAGTGCAGGAACTCT GTCCAGGATTCTTCTTTGGCAATGTCAGTCTCTGTTGTGATGTTCGGCAGCTTCAGACACTAAAAGACAACCTGCAGCTGCCTCTACAGT TTCTGTCCAGATGTCCATCCTGTTTTTATAACCTACTGAACCTGTTTTGTGAGCTGACATGTAGCCCTCGACAGAGTCAGTTTTTGAATG TTACAGCTACTGAAGATTATGTTGATCCTGTTACAAACCAGACGAAAACAAATGTGAAAGAGTTACAATACTACGTCGGACAGAGTTTTG CCAATGCAATGTACAATGCCTGCCGGGATGTGGAGGCCCCCTCAAGTAATGACAAGGCCCTGGGACTCCTGTGTGGGAAGGACGCTGACG CCTGTAATGCCACCAACTGGATTGAATACATGTTCAATAAGGACAATGGACAGGCACCTTTTACCATCACTCCTGTGTTTTCAGATTTTC CAGTCCATGGGATGGAGCCCATGAACAATGCCACCAAAGGCTGTGACGAGTCTGTGGATGAGGTCACAGCACCATGTAGCTGCCAAGACT GCTCTATTGTCTGTGGCCCCAAGCCCCAGCCCCCACCTCCTCCTGCTCCCTGGACGATCCTTGGCTTGGACGCCATGTATGTCATCATGT GGATCACCTACATGGCGTTTTTGCTTGTGTTTTTTGGAGCATTTTTTGCAGTGTGGTGCTACAGAAAACGGTATTTTGTCTCCGAGTACA CTCCCATCGATAGCAATATAGCTTTTTCTGTTAATGCAAGTGACAAAGGAGAGGCGTCCTGCTGTGACCCTGTCAGCGCAGCATTTGAGG GCTGCTTGAGGCGGCTGTTCACACGCTGGGGGTCTTTCTGCGTCCGAAACCCTGGCTGTGTCATTTTCTTCTCGCTGGTCTTCATTACTG CGTGTTCGTCAGGCCTGGTGTTTGTCCGGGTCACAACCAATCCAGTTGACCTCTGGTCAGCCCCCAGCAGCCAGGCTCGCCTGGAAAAAG AGTACTTTGACCAGCACTTTGGGCCTTTCTTCCGGACGGAGCAGCTCATCATCCGGGCCCCTCTCACTGACAAACACATTTACCAGCCAT ACCCTTCGGGAGCTGATGTACCCTTTGGACCTCCGCTTGACATACAGATACTGCACCAGGTTCTTGACTTACAAATAGCCATCGAAAACA TTACTGCCTCTTATGACAATGAGACTGTGACACTTCAAGACATCTGCTTGGCCCCTCTTTCACCGTATAACACGAACTGCACCATTTTGA GTGTGTTAAATTACTTCCAGAACAGCCATTCCGTGCTGGACCACAAGAAAGGGGACGACTTCTTTGTGTATGCCGATTACCACACGCACT TTCTGTACTGCGTACGGGCTCCTGCCTCTCTGAATGATACAAGTTTGCTCCATGACCCTTGTCTGGGTACGTTTGGTGGACCAGTGTTCC CGTGGCTTGTGTTGGGAGGCTATGATGATCAAAACTACAATAACGCCACTGCCCTTGTGATTACCTTCCCTGTCAATAATTACTATAATG ATACAGAGAAGCTCCAGAGGGCCCAGGCCTGGGAAAAAGAGTTTATTAATTTTGTGAAAAACTACAAGAATCCCAATCTGACCATTTCCT TCACTGCTGAACGAAGTATTGAAGATGAACTAAATCGTGAAAGTGACAGTGATGTCTTCACCGTTGTAATTAGCTATGCCATCATGTTTC TATATATTTCCCTAGCCTTGGGGCACATGAAAAGCTGTCGCAGGCTTCTGGTGGATTCGAAGGTCTCACTAGGCATCGCGGGCATCTTGA TCGTGCTGAGCTCGGTGGCTTGCTCCTTGGGTGTCTTCAGCTACATTGGGTTGCCCTTGACCCTCATTGTGATTGAAGTCATCCCGTTCC TGGTGCTGGCTGTTGGAGTGGACAACATCTTCATTCTGGTGCAGGCCTACCAGAGAGATGAACGTCTTCAAGGGGAAACCCTGGATCAGC AGCTGGGCAGGGTCCTAGGAGAAGTGGCTCCCAGTATGTTCCTGTCATCCTTTTCTGAGACTGTAGCATTTTTCTTAGGAGCATTGTCCG TGATGCCAGCCGTGCACACCTTCTCTCTCTTTGCGGGATTGGCAGTCTTCATTGACTTTCTTCTGCAGATTACCTGTTTCGTGAGTCTCT TGGGGTTAGACATTAAACGTCAAGAGAAAAATCGGCTAGACATCTTTTGCTGTGTCAGAGGTGCTGAAGATGGAACAAGCGTCCAGGCCT CAGAGAGCTGTTTGTTTCGCTTCTTCAAAAACTCCTATTCTCCACTTCTGCTAAAGGACTGGATGAGACCAATTGTGATAGCAATATTTG TGGGTGTTCTGTCATTCAGCATCGCAGTCCTGAACAAAGTAGATATTGGATTGGATCAGTCTCTTTCGATGCCAGATGACTCCTACATGG TGGATTATTTCAAATCCATCAGTCAGTACCTGCATGCGGGTCCGCCTGTGTACTTTGTCCTGGAGGAAGGGCACGACTACACTTCTTCCA AGGGGCAGAACATGGTGTGCGGCGGCATGGGCTGCAACAATGATTCCCTGGTGCAGCAGATATTTAACGCGGCGCAGCTGGACAACTATA CCCGAATAGGCTTCGCCCCCTCGTCCTGGATCGACGATTATTTCGACTGGGTGAAGCCACAGTCGTCTTGCTGTCGAGTGGACAATATCA CTGACCAGTTCTGCAATGCTTCAGTGGTTGACCCTGCCTGCGTTCGCTGCAGGCCTCTGACTCCGGAAGGCAAACAGAGGCCTCAGGGGG GAGACTTCATGAGATTCCTGCCCATGTTCCTTTCGGATAACCCTAACCCCAAGTGTGGCAAAGGGGGACATGCTGCCTATAGTTCTGCAG TTAACATCCTCCTTGGCCATGGCACCAGGGTCGGAGCCACGTACTTCATGACCTACCACACCGTGCTGCAGACCTCTGCTGACTTTATTG ACGCTCTGAAGAAAGCCCGACTTATAGCCAGTAATGTCACCGAAACCATGGGCATTAACGGCAGTGCCTACCGAGTATTTCCTTACAGTG TGTTTTATGTCTTCTACGAACAGTACCTGACCATCATTGACGACACTATCTTCAACCTCGGTGTGTCCCTGGGCGCGATATTTCTGGTGA CCATGGTCCTCCTGGGCTGTGAGCTCTGGTCTGCAGTCATCATGTGTGCCACCATCGCCATGGTCTTGGTCAACATGTTTGGAGTTATGT GGCTCTGGGGCATCAGTCTGAACGCTGTATCCTTGGTCAACCTGGTGATGAGCTGTGGCATCTCCGTGGAGTTCTGCAGCCACATAACCA GAGCGTTCACGGTGAGCATGAAAGGCAGCCGCGTGGAGCGCGCGGAAGAGGCACTTGCCCACATGGGCAGCTCCGTGTTCAGTGGAATCA CACTTACAAAATTTGGAGGGATTGTGGTGTTGGCTTTTGCCAAATCTCAAATTTTCCAGATATTCTACTTCAGGATGTATTTGGCCATGG TCTTACTGGGAGCCACTCACGGATTAATATTTCTCCCTGTCTTACTCAGTTACATAGGGCCATCAGTAAATAAAGCCAAAAGTTGTGCCA CTGAAGAGCGATACAAAGGAACAGAGCGCGAACGGCTTCTAAATTTCTAGCCCTCTCGCAGGGCATCCTGACTGAACTGTGTCTAAGGGT CGGTCGGTTTACCACTGGACGGGTGCTGCATCGGCAAGGCCAAGTTGAACACCGGATGGTGCCAACCATCGGTTGTTTGGCAGCAGCTTT GAACGTAGCGCCTGTGAACTCAGGAATGCACAGTTGACTTGGGAAGCAGTATTACTAGATCTGGAGGCAACCACAGGACACTAAACTTCT CCCAGCCTCTTCAGGAAAGAAACCTCATTCTTTGGCAAGCAGGAGGTGACACTAGATGGCTGTGAATGTGATCCGCTCACTGACACTCTG TAAAGGCCAATCAATGCACTGTCTGTCTCTCCTTTTAGGAGTAAGCCATCCCACAAGTTCTATACCATATTTTTAGTGACAGTTGAGGTT GTAGATACACTTTATAACATTTTATAGTTTAAAGAGCTTTATTAATGCAATAAATTAACTTTGTACACATTTTTATATAAAAAAACAGCA AGTGATTTCAGAATGTTGTAGGCCTCATTAGAGCTTGGTCTCCAAAAATCTGTTTGAAAAAAGCAACATGTTCTTCACAGTGTTCCCCTA GAAAGGAAGAGATTTAATTGCCAGTTAGATGTGGCATGAAATGAGGGACAAAGAAAGCATCTCGTAGGTGTGTCTACTGGGTTTTAACTT ATTTTTCTTTAATAAAATACATTGTTTTCCTAAGTTTTGGGGTTACCCTATCTGCTTTGAGAGACAAATACAAAAGCTAAATGGAAGAGA >95046_95046_2_TTC39C-NPC1_TTC39C_chr18_21663045_ENST00000317571_NPC1_chr18_21153538_ENST00000269228_length(amino acids)=1602AA_BP=341 MLPISPRPSAGPRTPMAGSEQQRPRRRDDGDSDAAAAAAAPLQDAELALAGINMLLNNGFRESDQLFKQYRNHSPLMSFGASFVSFLNAM MTFEEEKMQLACDDLKTTEKLCESEEAGVIETIKNKIKKNVDVRKSAPSMVDRLQRQIIIADCQVYLAVLSFVKQELSAYIKGGWILRKA WKIYNKCYLDINALQELYQKKLTEESLTSDAANDNHIVAEGVSEESLNRLKGAVSFGYGLFHLCISMVPPNLLKIINLLGFPGDRLQGLS SLMYASESKDMKAPLATLALLWYHTVVRPFFALDGSDNKAGLDEAKEILLKKEAAYPNSSLFMFFKGRIQRLEVFSQSCVWYGECGIAYG DKRYNCEYSGPPKPLPKDGYDLVQELCPGFFFGNVSLCCDVRQLQTLKDNLQLPLQFLSRCPSCFYNLLNLFCELTCSPRQSQFLNVTAT EDYVDPVTNQTKTNVKELQYYVGQSFANAMYNACRDVEAPSSNDKALGLLCGKDADACNATNWIEYMFNKDNGQAPFTITPVFSDFPVHG MEPMNNATKGCDESVDEVTAPCSCQDCSIVCGPKPQPPPPPAPWTILGLDAMYVIMWITYMAFLLVFFGAFFAVWCYRKRYFVSEYTPID SNIAFSVNASDKGEASCCDPVSAAFEGCLRRLFTRWGSFCVRNPGCVIFFSLVFITACSSGLVFVRVTTNPVDLWSAPSSQARLEKEYFD QHFGPFFRTEQLIIRAPLTDKHIYQPYPSGADVPFGPPLDIQILHQVLDLQIAIENITASYDNETVTLQDICLAPLSPYNTNCTILSVLN YFQNSHSVLDHKKGDDFFVYADYHTHFLYCVRAPASLNDTSLLHDPCLGTFGGPVFPWLVLGGYDDQNYNNATALVITFPVNNYYNDTEK LQRAQAWEKEFINFVKNYKNPNLTISFTAERSIEDELNRESDSDVFTVVISYAIMFLYISLALGHMKSCRRLLVDSKVSLGIAGILIVLS SVACSLGVFSYIGLPLTLIVIEVIPFLVLAVGVDNIFILVQAYQRDERLQGETLDQQLGRVLGEVAPSMFLSSFSETVAFFLGALSVMPA VHTFSLFAGLAVFIDFLLQITCFVSLLGLDIKRQEKNRLDIFCCVRGAEDGTSVQASESCLFRFFKNSYSPLLLKDWMRPIVIAIFVGVL SFSIAVLNKVDIGLDQSLSMPDDSYMVDYFKSISQYLHAGPPVYFVLEEGHDYTSSKGQNMVCGGMGCNNDSLVQQIFNAAQLDNYTRIG FAPSSWIDDYFDWVKPQSSCCRVDNITDQFCNASVVDPACVRCRPLTPEGKQRPQGGDFMRFLPMFLSDNPNPKCGKGGHAAYSSAVNIL LGHGTRVGATYFMTYHTVLQTSADFIDALKKARLIASNVTETMGINGSAYRVFPYSVFYVFYEQYLTIIDDTIFNLGVSLGAIFLVTMVL LGCELWSAVIMCATIAMVLVNMFGVMWLWGISLNAVSLVNLVMSCGISVEFCSHITRAFTVSMKGSRVERAEEALAHMGSSVFSGITLTK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TTC39C-NPC1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TTC39C-NPC1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TTC39C-NPC1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies