
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:URI1-VSTM2B (FusionGDB2 ID:97090) |
Fusion Gene Summary for URI1-VSTM2B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: URI1-VSTM2B | Fusion gene ID: 97090 | Hgene | Tgene | Gene symbol | URI1 | VSTM2B | Gene ID | 8725 | 342865 |
| Gene name | URI1 prefoldin like chaperone | V-set and transmembrane domain containing 2B | |
| Synonyms | C19orf2|NNX3|PPP1R19|RMP|URI | - | |
| Cytomap | 19q12 | 19q12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | unconventional prefoldin RPB5 interactor 1RNA polymerase II subunit 5-mediating proteinRPB5-mediating proteinprotein phosphatase 1, regulatory subunit 19 | V-set and transmembrane domain-containing protein 2B | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O94763 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000574176, ENST00000312051, ENST00000360605, ENST00000392271, ENST00000542441, | ENST00000335523, | |
| Fusion gene scores | * DoF score | 30 X 13 X 12=4680 | 9 X 4 X 6=216 |
| # samples | 40 | 11 | |
| ** MAII score | log2(40/4680*10)=-3.54843662469604 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/216*10)=-0.973527788638809 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: URI1 [Title/Abstract] AND VSTM2B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | URI1(30477324)-VSTM2B(30054753), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | URI1 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 12737519|15367675|21730289 |
| Hgene | URI1 | GO:0001558 | regulation of cell growth | 21730289 |
| Hgene | URI1 | GO:0071363 | cellular response to growth factor stimulus | 17936702 |
| Hgene | URI1 | GO:0071383 | cellular response to steroid hormone stimulus | 21730289 |
| Fusion gene breakpoints across URI1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VSTM2B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-04-1348-01A | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| ChimerDB4 | OV | TCGA-25-1323-01A | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| ChimerDB4 | OV | TCGA-25-1323-01A | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
Top |
Fusion Gene ORF analysis for URI1-VSTM2B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000574176 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000312051 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000312051 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000360605 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000360605 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000392271 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000392271 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000542441 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| In-frame | ENST00000542441 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + |
| intron-3CDS | ENST00000574176 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000360605 | URI1 | chr19 | 30477324 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 995 | 361 | 30 | 449 | 139 |
| ENST00000542441 | URI1 | chr19 | 30477324 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1298 | 664 | 297 | 752 | 151 |
| ENST00000392271 | URI1 | chr19 | 30477324 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1298 | 664 | 297 | 752 | 151 |
| ENST00000312051 | URI1 | chr19 | 30477324 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 996 | 362 | 10 | 450 | 146 |
| ENST00000360605 | URI1 | chr19 | 30496615 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1145 | 511 | 30 | 599 | 189 |
| ENST00000542441 | URI1 | chr19 | 30496615 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1448 | 814 | 297 | 902 | 201 |
| ENST00000392271 | URI1 | chr19 | 30496615 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1448 | 814 | 297 | 902 | 201 |
| ENST00000312051 | URI1 | chr19 | 30496615 | + | ENST00000335523 | VSTM2B | chr19 | 30054753 | + | 1146 | 512 | 10 | 600 | 196 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000360605 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + | 0.042470105 | 0.95752984 |
| ENST00000542441 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + | 0.018124076 | 0.98187596 |
| ENST00000392271 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + | 0.018124076 | 0.98187596 |
| ENST00000312051 | ENST00000335523 | URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054753 | + | 0.15304305 | 0.84695697 |
| ENST00000360605 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + | 0.001698227 | 0.99830174 |
| ENST00000542441 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + | 0.001982203 | 0.9980178 |
| ENST00000392271 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + | 0.001982203 | 0.9980178 |
| ENST00000312051 | ENST00000335523 | URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054753 | + | 0.003315344 | 0.9966846 |
Top |
Fusion Genomic Features for URI1-VSTM2B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054752 | + | 0.000153736 | 0.9998462 |
| URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054752 | + | 1.77E-06 | 0.9999982 |
| URI1 | chr19 | 30496615 | + | VSTM2B | chr19 | 30054752 | + | 0.000153736 | 0.9998462 |
| URI1 | chr19 | 30477324 | + | VSTM2B | chr19 | 30054752 | + | 1.77E-06 | 0.9999982 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
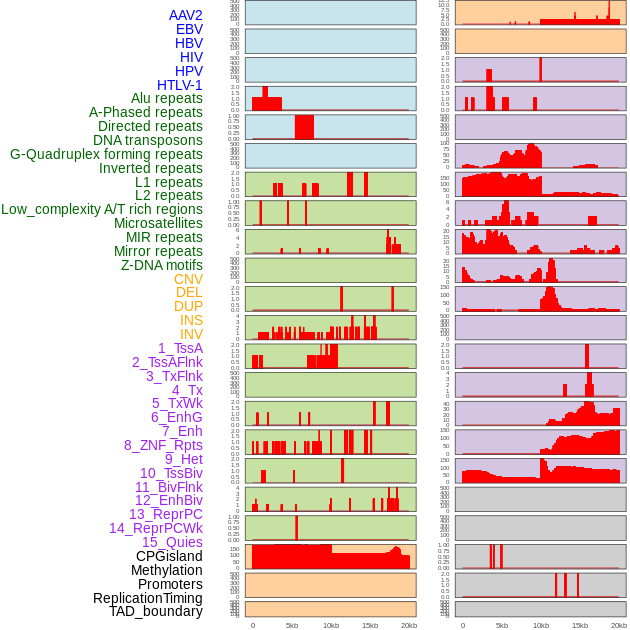 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
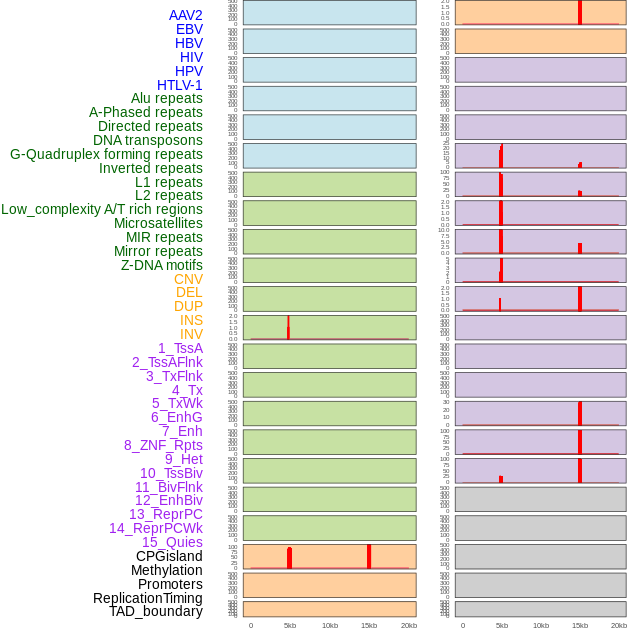 |
Top |
Fusion Protein Features for URI1-VSTM2B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:30477324/chr19:30054753) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| URI1 | . |
| FUNCTION: Involved in gene transcription regulation. Acts as a transcriptional repressor in concert with the corepressor UXT to regulate androgen receptor (AR) transcription. May act as a tumor suppressor to repress AR-mediated gene transcription and to inhibit anchorage-independent growth in prostate cancer cells. Required for cell survival in ovarian cancer cells. Together with UXT, associates with chromatin to the NKX3-1 promoter region. Antagonizes transcriptional modulation via hepatitis B virus X protein.; FUNCTION: Plays a central role in maintaining S6K1 signaling and BAD phosphorylation under normal growth conditions thereby protecting cells from potential deleterious effects of sustained S6K1 signaling. The URI1-PPP1CC complex acts as a central component of a negative feedback mechanism that counteracts excessive S6K1 survival signaling to BAD in response to growth factors. Mediates inhibition of PPP1CC phosphatase activity in mitochondria. Coordinates the regulation of nutrient-sensitive gene expression availability in a mTOR-dependent manner. Seems to be a scaffolding protein able to assemble a prefoldin-like complex that contains PFDs and proteins with roles in transcription and ubiquitination. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VSTM2B | chr19:30477324 | chr19:30054753 | ENST00000335523 | 3 | 5 | 285_285 | 256 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | VSTM2B | chr19:30496615 | chr19:30054753 | ENST00000335523 | 3 | 5 | 285_285 | 256 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | VSTM2B | chr19:30477324 | chr19:30054753 | ENST00000335523 | 3 | 5 | 264_284 | 256 | 286.0 | Transmembrane | Helical | |
| Tgene | VSTM2B | chr19:30496615 | chr19:30054753 | ENST00000335523 | 3 | 5 | 264_284 | 256 | 286.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000360605 | + | 4 | 11 | 299_311 | 104 | 476.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000360605 | + | 4 | 11 | 314_321 | 104 | 476.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000392271 | + | 4 | 11 | 299_311 | 46 | 460.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000392271 | + | 4 | 11 | 314_321 | 46 | 460.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000542441 | + | 4 | 11 | 299_311 | 122 | 536.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30477324 | chr19:30054753 | ENST00000542441 | + | 4 | 11 | 314_321 | 122 | 536.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000360605 | + | 6 | 11 | 299_311 | 154 | 476.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000360605 | + | 6 | 11 | 314_321 | 154 | 476.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000392271 | + | 6 | 11 | 299_311 | 96 | 460.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000392271 | + | 6 | 11 | 314_321 | 96 | 460.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000542441 | + | 6 | 11 | 299_311 | 172 | 536.0 | Compositional bias | Note=Poly-Asp |
| Hgene | URI1 | chr19:30496615 | chr19:30054753 | ENST00000542441 | + | 6 | 11 | 314_321 | 172 | 536.0 | Compositional bias | Note=Poly-Asp |
| Tgene | VSTM2B | chr19:30477324 | chr19:30054753 | ENST00000335523 | 3 | 5 | 29_143 | 256 | 286.0 | Domain | Note=Ig-like V-type | |
| Tgene | VSTM2B | chr19:30496615 | chr19:30054753 | ENST00000335523 | 3 | 5 | 29_143 | 256 | 286.0 | Domain | Note=Ig-like V-type | |
| Tgene | VSTM2B | chr19:30477324 | chr19:30054753 | ENST00000335523 | 3 | 5 | 29_263 | 256 | 286.0 | Topological domain | Extracellular | |
| Tgene | VSTM2B | chr19:30496615 | chr19:30054753 | ENST00000335523 | 3 | 5 | 29_263 | 256 | 286.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for URI1-VSTM2B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >97090_97090_1_URI1-VSTM2B_URI1_chr19_30477324_ENST00000312051_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=996nt_BP=362nt ACACGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCT GCCCTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGAAGAAGGTAGATAATGACTATAATGCCCTTCG AGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGCCCTTTTGCCTTCATGCCAGGAAAACTTGTCCA TACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAGCAGGCTGTAGGTTTAGTTGAGCACCGGAAAGA ACGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACATTG ACAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGAGA GACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAATG CATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCTAC ACTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTGAC AAAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAATTA TTTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTGTCAATAATATTTATTTTTAAATAAAGATTGGA >97090_97090_1_URI1-VSTM2B_URI1_chr19_30477324_ENST00000312051_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=146AA_BP=118 MRPAGPSWRRPPWRRPPTPRPLRPRPLPWFRCAPRMWRGCARSRKRKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNE -------------------------------------------------------------- >97090_97090_2_URI1-VSTM2B_URI1_chr19_30477324_ENST00000360605_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=995nt_BP=361nt AGTGGGTCTTCTCACTCTTTTCCAGGCTCCTTGGAGGTCACTGCCCTGATGACAACATGGTCTTCCCTTCAAGGAAGCCACGTTTCTAAG AGGGCTCTGGCATATGCATTGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGGAAGAAGGTAGATAATGACTATAATGCCCTTCGA GAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGCCCTTTTGCCTTCATGCCAGGAAAACTTGTCCAT ACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAGCAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAA CGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACATTGA CAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGAGAG ACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAATGC ATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCTACA CTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTGACA AAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAATTAT TTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTGTCAATAATATTTATTTTTAAATAAAGATTGGAA >97090_97090_2_URI1-VSTM2B_URI1_chr19_30477324_ENST00000360605_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=139AA_BP=111 MEVTALMTTWSSLQGSHVSKRALAYALVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNEVTVLLGD -------------------------------------------------------------- >97090_97090_3_URI1-VSTM2B_URI1_chr19_30477324_ENST00000392271_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1298nt_BP=664nt GCGGCCGCCACGCGACGCCTGGCTGGGCCCGCACCGGAGAGGCGTCTCGGTACCTGGCAGGCGGCCTGCTACTCGGAGCCCGCTGCGGGG CGGCGGCGGCGGGGACATGCACGTGTGAGATGCGGCAGCGGGCGGCGCGGACGCGAACAGCAGCGGCGGCGGCGGGCGCGGCCTCCTGGG CGCGGGGCGCGCGGTGCCTGAGGGCGGGCGCGCGGGCGCTGGGCAACTGCCGGCCGCGCCGCCTGCGCAGGCGCTGGTTCAGGACTCACA CGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCTGCC CTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGG AAGAAGGTAGATAATGACTATAATGCCCTTCGAGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGC CCTTTTGCCTTCATGCCAGGAAAACTTGTCCATACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAG CAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAACGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTG CATAAGTTCCTGCGCCTGCTCTTGGGACATTGACAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCG GTGAGGACCATGTCGCTGGATGGACACAGAGAGACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAA AGTTACACAAATGTAGAACACCTAAAATAATGCATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGA TTTCTCTACTTCAATGTAGTTTTCTTTTCTACACTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAAT ATGTACAAATGTTGGGGTCAAAGCCTTTTGACAAAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTT TTCTTTGGGGGCTTTTCTTTTTTATTAAATTATTTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTG >97090_97090_3_URI1-VSTM2B_URI1_chr19_30477324_ENST00000392271_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=151AA_BP=123 MEAPTVETPPDPSPPSAPAPALVPLRAPDVARLREEQEKVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKL -------------------------------------------------------------- >97090_97090_4_URI1-VSTM2B_URI1_chr19_30477324_ENST00000542441_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1298nt_BP=664nt GCGGCCGCCACGCGACGCCTGGCTGGGCCCGCACCGGAGAGGCGTCTCGGTACCTGGCAGGCGGCCTGCTACTCGGAGCCCGCTGCGGGG CGGCGGCGGCGGGGACATGCACGTGTGAGATGCGGCAGCGGGCGGCGCGGACGCGAACAGCAGCGGCGGCGGCGGGCGCGGCCTCCTGGG CGCGGGGCGCGCGGTGCCTGAGGGCGGGCGCGCGGGCGCTGGGCAACTGCCGGCCGCGCCGCCTGCGCAGGCGCTGGTTCAGGACTCACA CGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCTGCC CTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGG AAGAAGGTAGATAATGACTATAATGCCCTTCGAGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGC CCTTTTGCCTTCATGCCAGGAAAACTTGTCCATACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAG CAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAACGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTG CATAAGTTCCTGCGCCTGCTCTTGGGACATTGACAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCG GTGAGGACCATGTCGCTGGATGGACACAGAGAGACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAA AGTTACACAAATGTAGAACACCTAAAATAATGCATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGA TTTCTCTACTTCAATGTAGTTTTCTTTTCTACACTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAAT ATGTACAAATGTTGGGGTCAAAGCCTTTTGACAAAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTT TTCTTTGGGGGCTTTTCTTTTTTATTAAATTATTTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTG >97090_97090_4_URI1-VSTM2B_URI1_chr19_30477324_ENST00000542441_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=151AA_BP=123 MEAPTVETPPDPSPPSAPAPALVPLRAPDVARLREEQEKVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKL -------------------------------------------------------------- >97090_97090_5_URI1-VSTM2B_URI1_chr19_30496615_ENST00000312051_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1146nt_BP=512nt ACACGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCT GCCCTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGAAGAAGGTAGATAATGACTATAATGCCCTTCG AGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGCCCTTTTGCCTTCATGCCAGGAAAACTTGTCCA TACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAGCAGGCTGTAGGTTTAGTTGAGCACCGGAAAGA ACATGTAAGAAAAACAATAGATGACTTAAAAAAAGTGATGAAAAATTTTGAATCCAGAGTTGAATTCACAGAAGATTTGCAGAAAATGAG CGATGCTGCAGGTGATATTGTTGACATACGAGAAGAAATTAAATGTGACTTCGAATTTAAAGGCACCGGCCGTAGCTACACCACAGACCC ACTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACATTGACAGACAAGACCAACCCGAGCATCTCAGAG GCCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGAGAGACTGAGAGACGCATGAAAAAGTCCACATG GAAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAATGCATCTAGTTTCCAAATAATTTGGAGTTTGG CCCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCTACACTTTCCCTCCAAGTCTTCATTTTGCACGA ACTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTGACAAAGCAAAATATTTTTAGTAGATTATTGTG TTTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAATTATTTCTTTTGAGGCATTTTGATTAAAAAAGA >97090_97090_5_URI1-VSTM2B_URI1_chr19_30496615_ENST00000312051_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=196AA_BP=167 MRPAGPSWRRPPWRRPPTPRPLRPRPLPWFRCAPRMWRGCARSRKRKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNE VTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKGTGRSYTTDPLLS -------------------------------------------------------------- >97090_97090_6_URI1-VSTM2B_URI1_chr19_30496615_ENST00000360605_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1145nt_BP=511nt AGTGGGTCTTCTCACTCTTTTCCAGGCTCCTTGGAGGTCACTGCCCTGATGACAACATGGTCTTCCCTTCAAGGAAGCCACGTTTCTAAG AGGGCTCTGGCATATGCATTGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGGAAGAAGGTAGATAATGACTATAATGCCCTTCGA GAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGCCCTTTTGCCTTCATGCCAGGAAAACTTGTCCAT ACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAGCAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAA CATGTAAGAAAAACAATAGATGACTTAAAAAAAGTGATGAAAAATTTTGAATCCAGAGTTGAATTCACAGAAGATTTGCAGAAAATGAGC GATGCTGCAGGTGATATTGTTGACATACGAGAAGAAATTAAATGTGACTTCGAATTTAAAGGCACCGGCCGTAGCTACACCACAGACCCA CTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACATTGACAGACAAGACCAACCCGAGCATCTCAGAGG CCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGAGAGACTGAGAGACGCATGAAAAAGTCCACATGG AAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAATGCATCTAGTTTCCAAATAATTTGGAGTTTGGC CCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCTACACTTTCCCTCCAAGTCTTCATTTTGCACGAA CTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTGACAAAGCAAAATATTTTTAGTAGATTATTGTGT TTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAATTATTTCTTTTGAGGCATTTTGATTAAAAAAGAC >97090_97090_6_URI1-VSTM2B_URI1_chr19_30496615_ENST00000360605_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=189AA_BP=160 MEVTALMTTWSSLQGSHVSKRALAYALVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKLVHTNEVTVLLGD NWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKGTGRSYTTDPLLSLLLLALH -------------------------------------------------------------- >97090_97090_7_URI1-VSTM2B_URI1_chr19_30496615_ENST00000392271_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1448nt_BP=814nt GCGGCCGCCACGCGACGCCTGGCTGGGCCCGCACCGGAGAGGCGTCTCGGTACCTGGCAGGCGGCCTGCTACTCGGAGCCCGCTGCGGGG CGGCGGCGGCGGGGACATGCACGTGTGAGATGCGGCAGCGGGCGGCGCGGACGCGAACAGCAGCGGCGGCGGCGGGCGCGGCCTCCTGGG CGCGGGGCGCGCGGTGCCTGAGGGCGGGCGCGCGGGCGCTGGGCAACTGCCGGCCGCGCCGCCTGCGCAGGCGCTGGTTCAGGACTCACA CGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCTGCC CTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGG AAGAAGGTAGATAATGACTATAATGCCCTTCGAGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGC CCTTTTGCCTTCATGCCAGGAAAACTTGTCCATACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAG CAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAACATGTAAGAAAAACAATAGATGACTTAAAAAAAGTGATGAAAAATTTTGAATCCAGA GTTGAATTCACAGAAGATTTGCAGAAAATGAGCGATGCTGCAGGTGATATTGTTGACATACGAGAAGAAATTAAATGTGACTTCGAATTT AAAGGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACAT TGACAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGA GAGACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAA TGCATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCT ACACTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTG ACAAAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAAT TATTTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTGTCAATAATATTTATTTTTAAATAAAGATTG >97090_97090_7_URI1-VSTM2B_URI1_chr19_30496615_ENST00000392271_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=201AA_BP=172 MEAPTVETPPDPSPPSAPAPALVPLRAPDVARLREEQEKVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKL VHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKGTGRSYTT -------------------------------------------------------------- >97090_97090_8_URI1-VSTM2B_URI1_chr19_30496615_ENST00000542441_VSTM2B_chr19_30054753_ENST00000335523_length(transcript)=1448nt_BP=814nt GCGGCCGCCACGCGACGCCTGGCTGGGCCCGCACCGGAGAGGCGTCTCGGTACCTGGCAGGCGGCCTGCTACTCGGAGCCCGCTGCGGGG CGGCGGCGGCGGGGACATGCACGTGTGAGATGCGGCAGCGGGCGGCGCGGACGCGAACAGCAGCGGCGGCGGCGGGCGCGGCCTCCTGGG CGCGGGGCGCGCGGTGCCTGAGGGCGGGCGCGCGGGCGCTGGGCAACTGCCGGCCGCGCCGCCTGCGCAGGCGCTGGTTCAGGACTCACA CGCCGCGCTGAGGCCCGCGGGCCCGTCATGGAGGCGCCCACCGTGGAGACGCCCCCCGACCCCTCGCCCCCTTCGGCCCCGGCCCCTGCC CTGGTTCCGTTGCGCGCCCCGGATGTGGCGCGGCTGCGCGAGGAGCAGGAAAAGGTGGTCACTAACTGCCAAGAGAGAATCCAGCATTGG AAGAAGGTAGATAATGACTATAATGCCCTTCGAGAAAGACTCAGCACCTTGCCTGATAAATTGTCTTATAATATAATGGTACCATTTGGC CCTTTTGCCTTCATGCCAGGAAAACTTGTCCATACTAATGAAGTCACTGTTTTACTGGGGGACAACTGGTTTGCAAAGTGCTCAGCAAAG CAGGCTGTAGGTTTAGTTGAGCACCGGAAAGAACATGTAAGAAAAACAATAGATGACTTAAAAAAAGTGATGAAAAATTTTGAATCCAGA GTTGAATTCACAGAAGATTTGCAGAAAATGAGCGATGCTGCAGGTGATATTGTTGACATACGAGAAGAAATTAAATGTGACTTCGAATTT AAAGGCACCGGCCGTAGCTACACCACAGACCCACTCTTGTCCCTGCTCCTGTTAGCTCTGCATAAGTTCCTGCGCCTGCTCTTGGGACAT TGACAGACAAGACCAACCCGAGCATCTCAGAGGCCGCACATGACCTGCCCGGGGCCCTCGGTGAGGACCATGTCGCTGGATGGACACAGA GAGACTGAGAGACGCATGAAAAAGTCCACATGGAAAATAAATAAATCATATTTTTGGGAAAGTTACACAAATGTAGAACACCTAAAATAA TGCATCTAGTTTCCAAATAATTTGGAGTTTGGCCCATGCAGTCTGCATGGGAATCAATGATTTCTCTACTTCAATGTAGTTTTCTTTTCT ACACTTTCCCTCCAAGTCTTCATTTTGCACGAACTGTTGAGCAGTTATCTTTAGGATAATATGTACAAATGTTGGGGTCAAAGCCTTTTG ACAAAGCAAAATATTTTTAGTAGATTATTGTGTTTAGGATTTTTTTTTAATTTACTTTTTTTCTTTGGGGGCTTTTCTTTTTTATTAAAT TATTTCTTTTGAGGCATTTTGATTAAAAAAGACACATCTTATCATAATTAAAATTCACTGTCAATAATATTTATTTTTAAATAAAGATTG >97090_97090_8_URI1-VSTM2B_URI1_chr19_30496615_ENST00000542441_VSTM2B_chr19_30054753_ENST00000335523_length(amino acids)=201AA_BP=172 MEAPTVETPPDPSPPSAPAPALVPLRAPDVARLREEQEKVVTNCQERIQHWKKVDNDYNALRERLSTLPDKLSYNIMVPFGPFAFMPGKL VHTNEVTVLLGDNWFAKCSAKQAVGLVEHRKEHVRKTIDDLKKVMKNFESRVEFTEDLQKMSDAAGDIVDIREEIKCDFEFKGTGRSYTT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for URI1-VSTM2B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for URI1-VSTM2B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for URI1-VSTM2B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies