
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:USF2-CLASRP (FusionGDB2 ID:97120) |
Fusion Gene Summary for USF2-CLASRP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: USF2-CLASRP | Fusion gene ID: 97120 | Hgene | Tgene | Gene symbol | USF2 | CLASRP | Gene ID | 7392 | 11129 |
| Gene name | upstream transcription factor 2, c-fos interacting | CLK4 associating serine/arginine rich protein | |
| Synonyms | FIP|bHLHb12 | CLASP|SFRS16|SWAP2 | |
| Cytomap | 19q13.12 | 19q13.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | upstream stimulatory factor 2c-fos interacting proteinclass B basic helix-loop-helix protein 12major late transcription factor 2 | CLK4-associating serine/arginine rich proteinClk4 associating SR-related proteinsplicing factor, arginine/serine-rich 16 (suppressor-of-white-apricot homolog, Drosophila)suppressor of white apricot homolog 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q8N2M8 | |
| Ensembl transtripts involved in fusion gene | ENST00000600341, ENST00000222305, ENST00000343550, ENST00000379134, ENST00000594064, ENST00000595068, | ENST00000221455, ENST00000391953, ENST00000544944, | |
| Fusion gene scores | * DoF score | 5 X 4 X 5=100 | 8 X 10 X 6=480 |
| # samples | 7 | 12 | |
| ** MAII score | log2(7/100*10)=-0.514573172829758 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/480*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: USF2 [Title/Abstract] AND CLASRP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | USF2(35762044)-CLASRP(45556356), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | USF2-CLASRP seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. USF2-CLASRP seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across USF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CLASRP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-49-AAQV-01A | USF2 | chr19 | 35762044 | - | CLASRP | chr19 | 45556356 | + |
| ChimerDB4 | LUAD | TCGA-49-AAQV-01A | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| ChimerDB4 | LUAD | TCGA-49-AAQV | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| ChimerDB4 | LUAD | TCGA-49-AAQV | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
Top |
Fusion Gene ORF analysis for USF2-CLASRP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000600341 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 3UTR-3CDS | ENST00000600341 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| 3UTR-3CDS | ENST00000600341 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| 3UTR-3CDS | ENST00000600341 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| 3UTR-intron | ENST00000600341 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 3UTR-intron | ENST00000600341 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000222305 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000222305 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000343550 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000343550 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000379134 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000379134 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000594064 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000594064 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000595068 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| 5CDS-intron | ENST00000595068 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| Frame-shift | ENST00000222305 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| Frame-shift | ENST00000343550 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| Frame-shift | ENST00000379134 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| Frame-shift | ENST00000594064 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| Frame-shift | ENST00000595068 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556356 | + |
| In-frame | ENST00000222305 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000222305 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000222305 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000343550 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000343550 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000343550 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000379134 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000379134 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000379134 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000594064 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000594064 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000594064 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000595068 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000595068 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| In-frame | ENST00000595068 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000343550 | USF2 | chr19 | 35762044 | + | ENST00000221455 | CLASRP | chr19 | 45559708 | + | 2407 | 650 | 124 | 2295 | 723 |
| ENST00000343550 | USF2 | chr19 | 35762044 | + | ENST00000391953 | CLASRP | chr19 | 45559708 | + | 2306 | 650 | 124 | 2295 | 723 |
| ENST00000343550 | USF2 | chr19 | 35762044 | + | ENST00000544944 | CLASRP | chr19 | 45559708 | + | 2348 | 650 | 124 | 2238 | 704 |
| ENST00000222305 | USF2 | chr19 | 35762044 | + | ENST00000221455 | CLASRP | chr19 | 45559708 | + | 2521 | 764 | 37 | 2409 | 790 |
| ENST00000222305 | USF2 | chr19 | 35762044 | + | ENST00000391953 | CLASRP | chr19 | 45559708 | + | 2420 | 764 | 37 | 2409 | 790 |
| ENST00000222305 | USF2 | chr19 | 35762044 | + | ENST00000544944 | CLASRP | chr19 | 45559708 | + | 2462 | 764 | 37 | 2352 | 771 |
| ENST00000595068 | USF2 | chr19 | 35762044 | + | ENST00000221455 | CLASRP | chr19 | 45559708 | + | 2521 | 764 | 37 | 2409 | 790 |
| ENST00000595068 | USF2 | chr19 | 35762044 | + | ENST00000391953 | CLASRP | chr19 | 45559708 | + | 2420 | 764 | 37 | 2409 | 790 |
| ENST00000595068 | USF2 | chr19 | 35762044 | + | ENST00000544944 | CLASRP | chr19 | 45559708 | + | 2462 | 764 | 37 | 2352 | 771 |
| ENST00000379134 | USF2 | chr19 | 35762044 | + | ENST00000221455 | CLASRP | chr19 | 45559708 | + | 2091 | 334 | 0 | 1979 | 659 |
| ENST00000379134 | USF2 | chr19 | 35762044 | + | ENST00000391953 | CLASRP | chr19 | 45559708 | + | 1990 | 334 | 0 | 1979 | 659 |
| ENST00000379134 | USF2 | chr19 | 35762044 | + | ENST00000544944 | CLASRP | chr19 | 45559708 | + | 2032 | 334 | 0 | 1922 | 640 |
| ENST00000594064 | USF2 | chr19 | 35762044 | + | ENST00000221455 | CLASRP | chr19 | 45559708 | + | 2478 | 721 | 0 | 2366 | 788 |
| ENST00000594064 | USF2 | chr19 | 35762044 | + | ENST00000391953 | CLASRP | chr19 | 45559708 | + | 2377 | 721 | 0 | 2366 | 788 |
| ENST00000594064 | USF2 | chr19 | 35762044 | + | ENST00000544944 | CLASRP | chr19 | 45559708 | + | 2419 | 721 | 0 | 2309 | 769 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000343550 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.025057336 | 0.9749426 |
| ENST00000343550 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.025193546 | 0.9748064 |
| ENST00000343550 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.023878736 | 0.9761213 |
| ENST00000222305 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.022292836 | 0.97770715 |
| ENST00000222305 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.02479367 | 0.9752064 |
| ENST00000222305 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.022572603 | 0.97742736 |
| ENST00000595068 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.022292836 | 0.97770715 |
| ENST00000595068 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.02479367 | 0.9752064 |
| ENST00000595068 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.022572603 | 0.97742736 |
| ENST00000379134 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.027492547 | 0.9725074 |
| ENST00000379134 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.025747124 | 0.97425294 |
| ENST00000379134 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.027550962 | 0.97244906 |
| ENST00000594064 | ENST00000221455 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.019866146 | 0.9801339 |
| ENST00000594064 | ENST00000391953 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.0232146 | 0.9767854 |
| ENST00000594064 | ENST00000544944 | USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559708 | + | 0.020082323 | 0.9799177 |
Top |
Fusion Genomic Features for USF2-CLASRP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556355 | + | 6.37E-06 | 0.9999937 |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556355 | + | 6.37E-06 | 0.9999937 |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559707 | + | 4.05E-06 | 0.99999595 |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556355 | + | 6.37E-06 | 0.9999937 |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45556355 | + | 6.37E-06 | 0.9999937 |
| USF2 | chr19 | 35762044 | + | CLASRP | chr19 | 45559707 | + | 4.05E-06 | 0.99999595 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
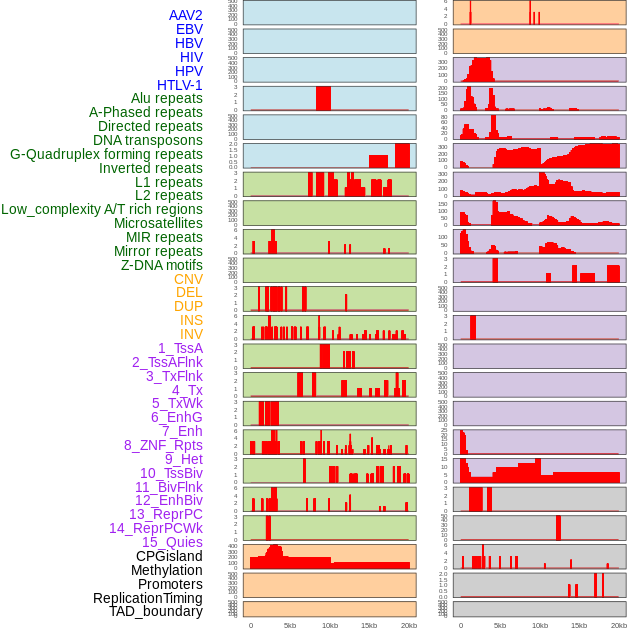 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
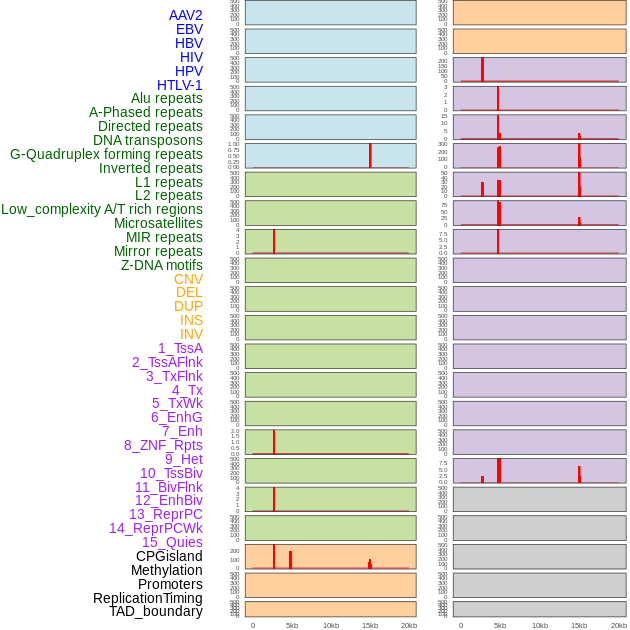 |
Top |
Fusion Protein Features for USF2-CLASRP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:35762044/chr19:45556356) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CLASRP |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Probably functions as an alternative splicing regulator. May regulate the mRNA splicing of genes such as CLK1. May act by regulating members of the CLK kinase family (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000222305 | + | 7 | 10 | 11_20 | 242 | 347.0 | Compositional bias | Note=Poly-Ala |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000343550 | + | 6 | 9 | 11_20 | 175 | 280.0 | Compositional bias | Note=Poly-Ala |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000379134 | + | 5 | 8 | 11_20 | 111 | 216.0 | Compositional bias | Note=Poly-Ala |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000595068 | + | 7 | 10 | 11_20 | 242 | 339.0 | Compositional bias | Note=Poly-Ala |
| Tgene | CLASRP | chr19:35762044 | chr19:45559708 | ENST00000221455 | 4 | 21 | 585_647 | 126 | 675.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CLASRP | chr19:35762044 | chr19:45559708 | ENST00000221455 | 4 | 21 | 369_673 | 126 | 675.0 | Compositional bias | Note=Arg-rich | |
| Tgene | CLASRP | chr19:35762044 | chr19:45559708 | ENST00000221455 | 4 | 21 | 377_535 | 126 | 675.0 | Compositional bias | Note=Ser-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000222305 | + | 7 | 10 | 245_248 | 242 | 347.0 | Compositional bias | Note=Poly-Arg |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000343550 | + | 6 | 9 | 245_248 | 175 | 280.0 | Compositional bias | Note=Poly-Arg |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000379134 | + | 5 | 8 | 245_248 | 111 | 216.0 | Compositional bias | Note=Poly-Arg |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000595068 | + | 7 | 10 | 245_248 | 242 | 339.0 | Compositional bias | Note=Poly-Arg |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000222305 | + | 7 | 10 | 235_290 | 242 | 347.0 | Domain | bHLH |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000343550 | + | 6 | 9 | 235_290 | 175 | 280.0 | Domain | bHLH |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000379134 | + | 5 | 8 | 235_290 | 111 | 216.0 | Domain | bHLH |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000595068 | + | 7 | 10 | 235_290 | 242 | 339.0 | Domain | bHLH |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000222305 | + | 7 | 10 | 307_328 | 242 | 347.0 | Region | Note=Leucine-zipper |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000343550 | + | 6 | 9 | 307_328 | 175 | 280.0 | Region | Note=Leucine-zipper |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000379134 | + | 5 | 8 | 307_328 | 111 | 216.0 | Region | Note=Leucine-zipper |
| Hgene | USF2 | chr19:35762044 | chr19:45559708 | ENST00000595068 | + | 7 | 10 | 307_328 | 242 | 339.0 | Region | Note=Leucine-zipper |
Top |
Fusion Gene Sequence for USF2-CLASRP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >97120_97120_1_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000221455_length(transcript)=2521nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGC GGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGAT CCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATA CAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGG GAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAGTGAAATAAAGTCAAAAGTTATTTAATTCCCGTC >97120_97120_1_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000221455_length(amino acids)=790AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQ -------------------------------------------------------------- >97120_97120_2_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000391953_length(transcript)=2420nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGC GGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGAT CCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATA >97120_97120_2_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000391953_length(amino acids)=790AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQ -------------------------------------------------------------- >97120_97120_3_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000544944_length(transcript)=2462nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAAGTCATCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCG GGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTA CAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCA TTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAG >97120_97120_3_USF2-CLASRP_USF2_chr19_35762044_ENST00000222305_CLASRP_chr19_45559708_ENST00000544944_length(amino acids)=771AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKVIKADKKAAQEKMIQQEHERQEREDELRAMARKIR -------------------------------------------------------------- >97120_97120_4_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000221455_length(transcript)=2407nt_BP=650nt CTCCTGCCGCGCGGCGTGAGCGCCGGGCTCGGGGCCCCCCCGGCCGCCCGCCCCCTCCCCTCCCTCCCTCCCCTCCCCTCCCCTCCCCCC CGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGC CGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGT GGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGCTGTGAT CCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGG AGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCT TCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAG AAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGA AGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGA AAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGT GGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCG GAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCA GCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTA TAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCAC CAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCC CCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTC CAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCG CTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGG ACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAG GCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCG CAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAA GCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACC CAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAA GATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCG AGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCG AAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGG >97120_97120_4_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000221455_length(amino acids)=723AA_BP=175 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQAVIQNPFSNGGSPA AEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQ CLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADL NKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSES RSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSR SRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSS SRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLR MQKALNRQFKADKKAAQEKMIQQEHERQEREDELRAMARKIRMKERERREKEREEWERQYSRQSRSPSPRYSREYSSSRRRSRSRSRSPH -------------------------------------------------------------- >97120_97120_5_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000391953_length(transcript)=2306nt_BP=650nt CTCCTGCCGCGCGGCGTGAGCGCCGGGCTCGGGGCCCCCCCGGCCGCCCGCCCCCTCCCCTCCCTCCCTCCCCTCCCCTCCCCTCCCCCC CGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGC CGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGT GGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGCTGTGAT CCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGG AGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCT TCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAG AAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGA AGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGA AAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGT GGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCG GAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCA GCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTA TAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCAC CAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCC CCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTC CAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCG CTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGG ACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAG GCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCG CAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAA GCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACC CAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAA GATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCG AGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCG >97120_97120_5_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000391953_length(amino acids)=723AA_BP=175 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQAVIQNPFSNGGSPA AEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQ CLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADL NKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSES RSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSR SRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSS SRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLR MQKALNRQFKADKKAAQEKMIQQEHERQEREDELRAMARKIRMKERERREKEREEWERQYSRQSRSPSPRYSREYSSSRRRSRSRSRSPH -------------------------------------------------------------- >97120_97120_6_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000544944_length(transcript)=2348nt_BP=650nt CTCCTGCCGCGCGGCGTGAGCGCCGGGCTCGGGGCCCCCCCGGCCGCCCGCCCCCTCCCCTCCCTCCCTCCCCTCCCCTCCCCTCCCCCC CGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGC CGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGT GGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGCTGTGAT CCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGG AGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCT TCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAG AAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGA AGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGA AAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGT GGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCG GAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCA GCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTA TAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCAC CAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCC CCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTC CAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCG CTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGG ACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAG GCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCG CAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAA GCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAAGT CATCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGC CCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTC CCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTG GGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAGTGAAATAAAGTCAAAAGTTATTTA >97120_97120_6_USF2-CLASRP_USF2_chr19_35762044_ENST00000343550_CLASRP_chr19_45559708_ENST00000544944_length(amino acids)=704AA_BP=175 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQAVIQNPFSNGGSPA AEAVSGEARFAYFPASSVGDTTAVSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQ CLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADL NKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSES RSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSR SRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSS SRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKVIKADKKAAQEK -------------------------------------------------------------- >97120_97120_7_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000221455_length(transcript)=2091nt_BP=334nt ATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAG GGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGC GACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTAC TCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAG ATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTAT ACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCG GACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCC ACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTT GAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGC CCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCC CGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCC GCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGC CGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGT GGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCC CGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCC CGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGC AGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGC CGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAA AAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCG CTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTT CGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGC CGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAG GCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAGTGAAATAAAGTCA >97120_97120_7_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000221455_length(amino acids)=659AA_BP=111 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQTGTQRTIAPRTHPY SPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNS DEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKIS PPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARR RSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGP RRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLK KTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQEHERQEREDELRAMARKIRMKERERREKEREEWERQYSRQS -------------------------------------------------------------- >97120_97120_8_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000391953_length(transcript)=1990nt_BP=334nt ATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAG GGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGC GACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTAC TCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAG ATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTAT ACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCG GACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCC ACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTT GAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGC CCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCC CGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCC GCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGC CGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGT GGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCC CGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCC CGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGC AGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGC CGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAA AAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCG CTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTT CGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGC CGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAG >97120_97120_8_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000391953_length(amino acids)=659AA_BP=111 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQTGTQRTIAPRTHPY SPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNS DEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKIS PPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARR RSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGP RRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLK KTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQEHERQEREDELRAMARKIRMKERERREKEREEWERQYSRQS -------------------------------------------------------------- >97120_97120_9_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000544944_length(transcript)=2032nt_BP=334nt ATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAG GGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGC GACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTAC TCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAG ATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTAT ACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCG GACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCC ACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTT GAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGC CCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCC CGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCC GCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGC CGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGT GGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCC CGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCC CGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGC AGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGC CGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAA AAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAAGTCATCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAG GAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGA GAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGG TCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGAT >97120_97120_9_USF2-CLASRP_USF2_chr19_35762044_ENST00000379134_CLASRP_chr19_45559708_ENST00000544944_length(amino acids)=640AA_BP=111 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQTGTQRTIAPRTHPY SPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNS DEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKIS PPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARR RSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGP RRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLK KTEPAAGKETGAAKVIKADKKAAQEKMIQQEHERQEREDELRAMARKIRMKERERREKEREEWERQYSRQSRSPSPRYSREYSSSRRRSR -------------------------------------------------------------- >97120_97120_10_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000221455_length(transcript)=2478nt_BP=721nt ATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTC GAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCAC AACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGACATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAG GGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGCGGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCA GCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGCAGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAAT GGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCC GTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGG ACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAA GTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTG GCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAG TCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAG CAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCA GAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAG AAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAG TCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGAT GAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCC CCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCT CGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGC TCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCG CCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTC AGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCC AGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCG TCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAG AAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCAT GAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAG TGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGA TCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCT >97120_97120_10_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000221455_length(amino acids)=788AA_BP=240 MLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLDGQ GDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVS VQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKL AEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEA EAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSD EEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSR SRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSP SPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQEH -------------------------------------------------------------- >97120_97120_11_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000391953_length(transcript)=2377nt_BP=721nt ATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTC GAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCAC AACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGACATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAG GGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGCGGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCA GCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGCAGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAAT GGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCC GTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGG ACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAA GTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTG GCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAG TCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAG CAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCA GAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAG AAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAG TCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGAT GAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCC CCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCT CGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGC TCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCG CCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTC AGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCC AGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCG TCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAG AAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCAT GAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAG TGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGA >97120_97120_11_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000391953_length(amino acids)=788AA_BP=240 MLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLDGQ GDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVS VQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKL AEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEA EAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSD EEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSR SRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSP SPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQEH -------------------------------------------------------------- >97120_97120_12_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000544944_length(transcript)=2419nt_BP=721nt ATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGCCGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTC GAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGCGGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCAC AACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGACATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAG GGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGCGGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCA GCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGCAGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAAT GGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGCCTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCC GTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGTCATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGG ACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAACCAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAA GTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTACGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTG GCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGTGGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAG TCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCCCGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAG CAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGACGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCA GAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTACTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAG AAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCGAGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAG TCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCGCGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGAT GAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCACCACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCC CCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTCCTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCT CGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGGCCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGC TCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCACTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCG CCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCGCTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTC AGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCCGTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCC AGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCCCTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCG TCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGGTAAAGAGACAGGAGCTGCCAAAGTCATCAAGGCGGATAAGAAG GCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAG GAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAA TACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGG >97120_97120_12_USF2-CLASRP_USF2_chr19_35762044_ENST00000594064_CLASRP_chr19_45559708_ENST00000544944_length(amino acids)=769AA_BP=240 MLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLDGQ GDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTAVS VQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKKKL AEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKEEA EAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGGSD EEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSRSR SRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSHSP SPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKVIKADKKAAQEKMIQQEHERQEREDELRAMARKIRMK -------------------------------------------------------------- >97120_97120_13_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000221455_length(transcript)=2521nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGC GGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGAT CCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATA CAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCATTACCGACATTAGGCAGAAGAGTGGGGGGTGGG GAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAGTGAAATAAAGTCAAAAGTTATTTAATTCCCGTC >97120_97120_13_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000221455_length(amino acids)=790AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQ -------------------------------------------------------------- >97120_97120_14_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000391953_length(transcript)=2420nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAACCCAAGCTGACGCCTCAGGAGAAGCTGAAACTGAGGATGCAGAAGGCGCTGAACAGGCAGTTCAAGGC GGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCGGGAAGACGAGCTTCGAGCCATGGCCCGCAAGAT CCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTACAGCCGGCAGAGCCGCTCACCCTCCCCCCGATA >97120_97120_14_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000391953_length(amino acids)=790AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKPKLTPQEKLKLRMQKALNRQFKADKKAAQEKMIQQ -------------------------------------------------------------- >97120_97120_15_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000544944_length(transcript)=2462nt_BP=764nt CCCCGGGCCCCGCGCCCCCCCCGCCCCCGCCCCCCCCATGGACATGCTGGACCCGGGTCTGGATCCCGCTGCCTCGGCCACCGCTGCTGC CGCCGCCAGCCACGACAAGGGACCCGAGGCGGAGGAGGGCGTCGAGCTGCAGGAAGGCGGGGACGGCCCAGGAGCGGAGGAGCAGACAGC GGTGGCCATCACCAGCGTCCAGCAGGCGGCGTTCGGCGACCACAACATCCAGTACCAGTTCCGCACAGAGACAAATGGAGGACAGGTGAC ATACCGCGTAGTCCAGGTGACTGATGGTCAGCTGGACGGCCAGGGCGACACAGCTGGCGCCGTCAGCGTCGTGTCCACCGCTGCCTTCGC GGGGGGGCAGCAGGCTGTGACCCAGGTGGGTGTGGACGGGGCAGCCCAGCGCCCGGGCCCCGCCGCTGCCTCTGTGCCCCCAGGTCCTGC AGCGCCCTTCCCGCTGGCTGTGATCCAAAATCCCTTCAGCAATGGTGGCAGTCCGGCGGCCGAGGCTGTCAGCGGGGAGGCACGATTTGC CTATTTCCCAGCGTCCAGTGTGGGAGATACTACGGCTGTGTCCGTACAGACCACAGACCAGAGCTTGCAGGCTGGAGGCCAGTTCTACGT CATGATGACGCCCCAGGATGTGCTTCAGACAGGAACACAGAGGACGATCGCCCCCCGGACACACCCTTACTCTCCAAAAATTGATGGAAC CAGAACACCCCGAGATGAGAGGAGAAGAGCCCAGCACAACGAAGTCTCAGAGGAGCAGTGCCTGTACCAGATCTACATTGATGAGTTGTA CGGAGGCCTCCAGAGACCCAGCGAAGATGAGAAGAAGAAGCTGGCAGAGAAGAAGGCTTCCATCGGTTATACCTACGAGGACAGCACGGT GGCCAAGGTAGAGAAGGCGGCAGAAAAGCCAGAGGAGGAGGAGTCAGCGGCCGAGGAGGAGAGCAACTCGGACGAAGATGAGGTCATCCC CGACATCGACGTGGAGGTGGACGTGGATGAATTGAACCAGGAGCAGGTGGCAGATCTCAACAAACAGGCCACGACTTATGGCATGGCCGA CGGTGACTTCGTCAGGATGCTCCGGAAAGACAAGGAGGAGGCAGAGGCCATCAAGCATGCCAAGGCTCTTGAGGAGGAGAAGGCCATGTA CTCGGGACGCCGCTCTCGACGCCAGCGGAGAGAGTTTCGGGAGAAGCGGCTGAGGGGTCGCAAGATCAGCCCACCCAGCTATGCCCGCCG AGACAGCCCCACCTATGACCCCTATAAGCGGTCACCCTCGGAGTCCAGCTCAGAGTCCCGCTCCCGCTCCCGCTCCCCGACCCCGGGCCG CGAGGAGAAGATCACGTTCATCACCAGTTTTGGGGGCAGCGATGAGGAGGCAGCCGCAGCCGCTGCTGCCGCAGCAGCATCAGGAGTCAC CACAGGGAAGCCCCCCGCACCTCCCCAGCCTGGCGGCCCCGCCCCGGGACGTAATGCCAGCGCCCGCCGCCGCTCCTCCTCCTCCTCCTC CTCCTCTTCTGCCTCGAGGACCTCCAGCTCCCGCTCCAGCTCTCGCTCCAGCTCCCGCTCTCGCCGTGGTGGGGGCTACTACCGTTCCGG CCGCCACGCCCGCTCCCGGTCCCGCTCCTGGTCCCGCTCCCGCTCCCGCTCCCGGCGCTATTCCCGGTCCCGTAGCCGTGGCCGGCGGCA CTCAGGTGGGGGCTCCCGAGACGGACACCGGTACTCCCGCTCGCCCGCCCGGCGTGGTGGTTACGGGCCCCGGCGCAGAAGCAGGAGCCG CTCCCACTCAGGGGACCGCTACAGGCGGGGCGGCCGGGGCCTCAGGCACCACAGCAGTAGCCGCAGCCGCAGCAGCTGGTCCCTCAGCCC GTCCCGCAGTCGCAGCCTGACTCGCAGCCGCAGCCATAGCCCCAGCCCCAGCCAGAGCCGCAGCCGCAGCCGCAGCCGCAGCCAGAGCCC CTCGCCATCACCCGCAAGAGAGAAGCTGACCAGGCCGGCCGCGTCCCCTGCTGTGGGCGAGAAGCTGAAAAAGACCGAACCTGCCGCTGG TAAAGAGACAGGAGCTGCCAAAGTCATCAAGGCGGATAAGAAGGCGGCACAAGAAAAGATGATCCAGCAGGAGCATGAGCGGCAGGAGCG GGAAGACGAGCTTCGAGCCATGGCCCGCAAGATCCGCATGAAGGAGCGGGAACGCCGAGAGAAGGAGAGAGAAGAGTGGGAACGCCAGTA CAGCCGGCAGAGCCGCTCACCCTCCCCCCGATACAGTCGAGAATACAGCTCTTCTCGAAGGCGCTCAAGGTCCCGATCCCGAAGCCCCCA TTACCGACATTAGGCAGAAGAGTGGGGGGTGGGGAGGACAAGGGGGTGGGTAAGGGGCTCAAGCTGTGATGCTGCTGGTTTTATCTCTAG >97120_97120_15_USF2-CLASRP_USF2_chr19_35762044_ENST00000595068_CLASRP_chr19_45559708_ENST00000544944_length(amino acids)=771AA_BP=242 MDMLDPGLDPAASATAAAAASHDKGPEAEEGVELQEGGDGPGAEEQTAVAITSVQQAAFGDHNIQYQFRTETNGGQVTYRVVQVTDGQLD GQGDTAGAVSVVSTAAFAGGQQAVTQVGVDGAAQRPGPAAASVPPGPAAPFPLAVIQNPFSNGGSPAAEAVSGEARFAYFPASSVGDTTA VSVQTTDQSLQAGGQFYVMMTPQDVLQTGTQRTIAPRTHPYSPKIDGTRTPRDERRRAQHNEVSEEQCLYQIYIDELYGGLQRPSEDEKK KLAEKKASIGYTYEDSTVAKVEKAAEKPEEEESAAEEESNSDEDEVIPDIDVEVDVDELNQEQVADLNKQATTYGMADGDFVRMLRKDKE EAEAIKHAKALEEEKAMYSGRRSRRQRREFREKRLRGRKISPPSYARRDSPTYDPYKRSPSESSSESRSRSRSPTPGREEKITFITSFGG SDEEAAAAAAAAAASGVTTGKPPAPPQPGGPAPGRNASARRRSSSSSSSSSASRTSSSRSSSRSSSRSRRGGGYYRSGRHARSRSRSWSR SRSRSRRYSRSRSRGRRHSGGGSRDGHRYSRSPARRGGYGPRRRSRSRSHSGDRYRRGGRGLRHHSSSRSRSSWSLSPSRSRSLTRSRSH SPSPSQSRSRSRSRSQSPSPSPAREKLTRPAASPAVGEKLKKTEPAAGKETGAAKVIKADKKAAQEKMIQQEHERQEREDELRAMARKIR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for USF2-CLASRP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for USF2-CLASRP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for USF2-CLASRP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies