
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:VTI1A-GLUD1 (FusionGDB2 ID:98588) |
Fusion Gene Summary for VTI1A-GLUD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: VTI1A-GLUD1 | Fusion gene ID: 98588 | Hgene | Tgene | Gene symbol | VTI1A | GLUD1 | Gene ID | 143187 | 2746 |
| Gene name | vesicle transport through interaction with t-SNAREs 1A | glutamate dehydrogenase 1 | |
| Synonyms | MMDS3|MVti1|VTI1RP2|Vti1-rp2 | GDH|GDH1|GLUD | |
| Cytomap | 10q25.2 | 10q23.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | vesicle transport through interaction with t-SNAREs homolog 1ASNARE Vti1a-beta proteinvesicle transport v-SNARE protein Vti1-like 2 | glutamate dehydrogenase 1, mitochondrialepididymis secretory sperm binding proteinepididymis tissue sperm binding protein Li 18mPglutamate dehydrogenase (NAD(P)+) | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | P00367 | |
| Ensembl transtripts involved in fusion gene | ENST00000393077, ENST00000432306, ENST00000483122, | ENST00000465164, ENST00000277865, ENST00000537649, ENST00000544149, | |
| Fusion gene scores | * DoF score | 15 X 12 X 12=2160 | 10 X 7 X 8=560 |
| # samples | 24 | 11 | |
| ** MAII score | log2(24/2160*10)=-3.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/560*10)=-2.34792330342031 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: VTI1A [Title/Abstract] AND GLUD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | VTI1A(114298089)-GLUD1(88827914), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | VTI1A | GO:0042147 | retrograde transport, endosome to Golgi | 15215310|18195106 |
| Tgene | GLUD1 | GO:0006537 | glutamate biosynthetic process | 11032875 |
| Tgene | GLUD1 | GO:0006538 | glutamate catabolic process | 6121377|11032875 |
| Fusion gene breakpoints across VTI1A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GLUD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-09-2051 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
Top |
Fusion Gene ORF analysis for VTI1A-GLUD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000393077 | ENST00000465164 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| 5CDS-intron | ENST00000432306 | ENST00000465164 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000393077 | ENST00000277865 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000393077 | ENST00000537649 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000393077 | ENST00000544149 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000432306 | ENST00000277865 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000432306 | ENST00000537649 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| In-frame | ENST00000432306 | ENST00000544149 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000483122 | ENST00000277865 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000483122 | ENST00000537649 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| intron-3CDS | ENST00000483122 | ENST00000544149 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| intron-intron | ENST00000483122 | ENST00000465164 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000432306 | VTI1A | chr10 | 114298089 | + | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2839 | 543 | 86 | 1573 | 495 |
| ENST00000432306 | VTI1A | chr10 | 114298089 | + | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2835 | 543 | 86 | 1573 | 495 |
| ENST00000432306 | VTI1A | chr10 | 114298089 | + | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1724 | 543 | 86 | 1573 | 495 |
| ENST00000393077 | VTI1A | chr10 | 114298089 | + | ENST00000277865 | GLUD1 | chr10 | 88827914 | - | 2839 | 543 | 86 | 1573 | 495 |
| ENST00000393077 | VTI1A | chr10 | 114298089 | + | ENST00000537649 | GLUD1 | chr10 | 88827914 | - | 2835 | 543 | 86 | 1573 | 495 |
| ENST00000393077 | VTI1A | chr10 | 114298089 | + | ENST00000544149 | GLUD1 | chr10 | 88827914 | - | 1724 | 543 | 86 | 1573 | 495 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000432306 | ENST00000277865 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.000418673 | 0.9995813 |
| ENST00000432306 | ENST00000537649 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.000417767 | 0.99958223 |
| ENST00000432306 | ENST00000544149 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.00077806 | 0.9992219 |
| ENST00000393077 | ENST00000277865 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.000418673 | 0.9995813 |
| ENST00000393077 | ENST00000537649 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.000417767 | 0.99958223 |
| ENST00000393077 | ENST00000544149 | VTI1A | chr10 | 114298089 | + | GLUD1 | chr10 | 88827914 | - | 0.00077806 | 0.9992219 |
Top |
Fusion Genomic Features for VTI1A-GLUD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
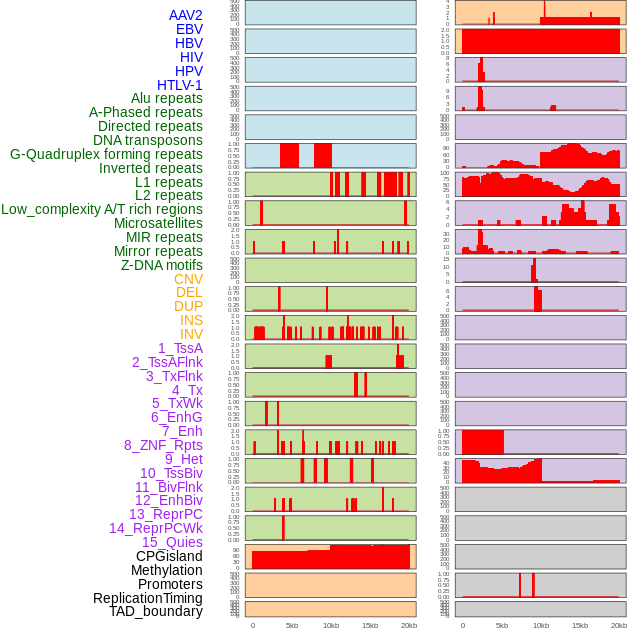 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for VTI1A-GLUD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:114298089/chr10:88827914) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | GLUD1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Mitochondrial glutamate dehydrogenase that catalyzes the conversion of L-glutamate into alpha-ketoglutarate. Plays a key role in glutamine anaplerosis by producing alpha-ketoglutarate, an important intermediate in the tricarboxylic acid cycle (PubMed:11032875, PubMed:16959573, PubMed:11254391, PubMed:16023112). Plays a role in insulin homeostasis (PubMed:9571255, PubMed:11297618). May be involved in learning and memory reactions by increasing the turnover of the excitatory neurotransmitter glutamate (By similarity). {ECO:0000250|UniProtKB:P10860, ECO:0000269|PubMed:11032875, ECO:0000269|PubMed:11254391, ECO:0000269|PubMed:11297618, ECO:0000269|PubMed:16023112, ECO:0000269|PubMed:16959573, ECO:0000269|PubMed:9571255}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000393077 | + | 5 | 8 | 31_92 | 142 | 218.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000432306 | + | 5 | 8 | 31_92 | 142 | 204.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000393077 | + | 5 | 8 | 112_178 | 142 | 218.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000432306 | + | 5 | 8 | 112_178 | 142 | 204.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000393077 | + | 5 | 8 | 1_192 | 142 | 218.0 | Topological domain | Cytoplasmic |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000393077 | + | 5 | 8 | 214_217 | 142 | 218.0 | Topological domain | Extracellular |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000432306 | + | 5 | 8 | 1_192 | 142 | 204.0 | Topological domain | Cytoplasmic |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000432306 | + | 5 | 8 | 214_217 | 142 | 204.0 | Topological domain | Extracellular |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000393077 | + | 5 | 8 | 193_213 | 142 | 218.0 | Transmembrane | Helical |
| Hgene | VTI1A | chr10:114298089 | chr10:88827914 | ENST00000432306 | + | 5 | 8 | 193_213 | 142 | 204.0 | Transmembrane | Helical |
| Tgene | GLUD1 | chr10:114298089 | chr10:88827914 | ENST00000277865 | 3 | 13 | 141_143 | 215 | 559.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for VTI1A-GLUD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >98588_98588_1_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2839nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC CAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCC ATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGT GCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAA GTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTG CAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATC ACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGT CATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAG GCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTG TTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGT CTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCA CTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAG TGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATG >98588_98588_1_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- >98588_98588_2_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2835nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC CAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCC ATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGT GCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAA GTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTG CAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATC ACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGT CATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAG GCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTG TTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGT CTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCA CTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAG TGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATG >98588_98588_2_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- >98588_98588_3_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1724nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC >98588_98588_3_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000393077_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- >98588_98588_4_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000277865_length(transcript)=2839nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC CAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCC ATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGT GCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAA GTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTG CAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATC ACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGT CATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAG GCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTG TTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGT CTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCA CTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAG TGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATG >98588_98588_4_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000277865_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- >98588_98588_5_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000537649_length(transcript)=2835nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC CAAGTCAGCCCGTTAAGGAGAAAGAAATTAAGGTTAGCGGATCATGTACAAGCTGAGTGTGAAAGTAGAAATCACCTACACCAGAGAGCC ATTTTGGTATTTTGCCTTTAAATAAAAAGCCTCCTTTATCTGGCTGTGCAGCCTTGCTCTGTGGCTTTTCCCAACACAATCAGTGCTAGT GCTGGGGAGGAACAGTCAAGAGCAGTCAGTTGCTTGCTTATTTTTTCTGGATGAGTCTGGGACACACTGTAACTTTAACACATTTAAGAA GTAGGTGTGTGGCCTTTTCAGAAGGTGGCATGGTCCTCAAGTGAGTTCTTAGTATTTTATATCAGCAAAATAATTCAATTTTGCAGGTTG CAAACAAATATAAAACCTGTTTCTGTTTATGAATATTATTCTTTTAGAATAGAATAAGTACATGCTGCTGTAATAAAATTGCCTTTAATC ACTTAACAAGCCTAACCTTGACTCAAACAGTGAATGCCTATAGAAATAATAAATGAAAAAAACTAGTATTTTTATATCATAAAACAATGT CATTTATAGCTTATCATTCATGTATTGTCCAGCAGACATTAAAAGCCCTGTGGATAATTAAGTTATCTTCATACCTGCAAAATGGTGGAG GCTATTTTCATTAAAACTGTCAGAATTTGCTTACTATAATTATGATACAGTCCAAAGAATGCAGTCACTTTTTATCATGTTAACTAATTG TTCTCTTTTGAAGATCTATGGTTGACTAATTAAACAATAATTCAAGTAGAGTGTCCCAGAAAAAAACCACTTGGGCTCCCTGTTTGGAGT CTGGCTGGCTCTGAGCATTGCCAATGGCCCCTACTCACCTGACTTTGTATCCTCTCCTTTTAGAGGCTTTGCATTCTGCACCCAGCTTCA CTAACAGTGGGCTGAAAACATCCTTGGGTTGAGTGTTTCATTTGGGAGTTATTTGGCCAGGGCCTTTTGAACAGTAGTGTCCCCATGAAG TGCTAGATAATATATGTGTAAGAGTCAGCTTTTTTTTTTTTTTTAACTCTAACACCCTTCAGAAATTTCTAACTACTTTGTAACTGCATG >98588_98588_5_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000537649_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- >98588_98588_6_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000544149_length(transcript)=1724nt_BP=543nt CCGTTCTGCTCTCGGGGGCACCTTCCGGGGTTCCTAAGCCGCGGGGCCCCTCGCTGCCCCTCGAGGCCCTTTCCCTGACCTAGGCTTTGG CCTGGGCTACTCGTTCCGGAGCCGCCATGTCGTCCGACTTCGAAGGTTACGAGCAGGACTTCGCGGTGCTCACTGCAGAGATCACCAGCA AGATTGCGAGGGTCCCACGACTCCCGCCTGATGAAAAGAAACAGATGGTTGCAAATGTGGAGAAACAGCTTGAAGAAGCGAAAGAACTGC TTGAACAGATGGATTTGGAAGTCCGAGAGATACCACCCCAAAGTCGAGGGATGTACAGCAACAGAATGAGAAGCTACAAACAAGAAATGG GAAAACTCGAAACAGATTTTAAAAGGTCACGGATCGCCTACAGTGACGAAGTACGGAATGAGCTCCTGGGGGATGATGGGAATTCCTCAG AGAACCAGAGGGCACATCTGCTCGATAACACAGAGAGGCTGGAAAGGTCATCTCGGAGACTAGAGGCTGGATACCAAATAGCAGTGGAAA CCGGTCCTGGCATTGATGTGCCTGCTCCAGACATGAGCACAGGTGAGCGGGAGATGTCCTGGATCGCTGATACCTATGCCAGCACCATAG GGCACTATGATATTAATGCACACGCCTGTGTTACTGGTAAACCCATCAGCCAAGGGGGAATCCATGGACGCATCTCTGCTACTGGCCGTG GTGTCTTCCATGGGATTGAAAATTTCATCAATGAAGCTTCTTACATGAGCATTTTAGGAATGACACCAGGGTTTGGAGATAAAACATTTG TTGTTCAGGGATTTGGTAATGTGGGCCTACACTCTATGAGATATTTACATCGTTTTGGTGCTAAATGTATTGCTGTTGGTGAGTCTGATG GGAGTATATGGAATCCAGATGGTATTGACCCAAAGGAACTGGAAGACTTCAAATTGCAACATGGGTCCATTCTGGGCTTCCCCAAGGCAA AGCCCTATGAAGGAAGCATCTTGGAGGCCGACTGTGACATACTGATCCCAGCTGCCAGTGAGAAGCAGTTGACCAAATCCAACGCACCCA GAGTCAAAGCCAAGATCATTGCTGAAGGTGCCAATGGGCCAACAACTCCAGAAGCTGACAAGATCTTCCTGGAGAGAAACATTATGGTTA TTCCAGATCTCTACTTGAATGCTGGAGGAGTGACAGTATCTTACTTTGAGTGGCTGAAGAATCTAAATCATGTCAGCTATGGCCGTTTGA CCTTCAAATATGAAAGGGATTCTAACTACCACTTGCTCATGTCTGTTCAAGAGAGTTTAGAAAGAAAATTTGGAAAGCATGGTGGAACTA TTCCCATTGTACCCACGGCAGAGTTCCAAGACAGGATATCGGGTGCATCTGAGAAAGACATCGTGCACTCTGGCTTGGCATACACAATGG AGCGTTCTGCCAGGCAAATTATGCGCACAGCCATGAAGTATAACCTGGGATTGGACCTGAGAACAGCTGCCTATGTTAATGCCATTGAGA AAGTCTTCAAAGTGTACAATGAAGCTGGTGTGACCTTCACATAGATGGATCATGGCTGACTTCCTCACTATCCTCTTCACATGTAACTTC TGCAGACCTATCACAAGTTTACATGTAACCACAGAAATCCCTTTCTCTCCTGACTCATTAATAATGGATACCATTCTCAACAAGTCAATC >98588_98588_6_VTI1A-GLUD1_VTI1A_chr10_114298089_ENST00000432306_GLUD1_chr10_88827914_ENST00000544149_length(amino acids)=495AA_BP=152 MAWATRSGAAMSSDFEGYEQDFAVLTAEITSKIARVPRLPPDEKKQMVANVEKQLEEAKELLEQMDLEVREIPPQSRGMYSNRMRSYKQE MGKLETDFKRSRIAYSDEVRNELLGDDGNSSENQRAHLLDNTERLERSSRRLEAGYQIAVETGPGIDVPAPDMSTGEREMSWIADTYAST IGHYDINAHACVTGKPISQGGIHGRISATGRGVFHGIENFINEASYMSILGMTPGFGDKTFVVQGFGNVGLHSMRYLHRFGAKCIAVGES DGSIWNPDGIDPKELEDFKLQHGSILGFPKAKPYEGSILEADCDILIPAASEKQLTKSNAPRVKAKIIAEGANGPTTPEADKIFLERNIM VIPDLYLNAGGVTVSYFEWLKNLNHVSYGRLTFKYERDSNYHLLMSVQESLERKFGKHGGTIPIVPTAEFQDRISGASEKDIVHSGLAYT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for VTI1A-GLUD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for VTI1A-GLUD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for VTI1A-GLUD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies