
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:WAC-C10orf76 (FusionGDB2 ID:98668) |
Fusion Gene Summary for WAC-C10orf76 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: WAC-C10orf76 | Fusion gene ID: 98668 | Hgene | Tgene | Gene symbol | WAC | C10orf76 | Gene ID | 51322 | 79591 |
| Gene name | WW domain containing adaptor with coiled-coil | armadillo like helical domain containing 3 | |
| Synonyms | BM-016|DESSH|PRO1741|Wwp4 | C10orf76 | |
| Cytomap | 10p12.1|10p12.1-p11.2 | 10q24.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | WW domain-containing adapter protein with coiled-coil | armadillo-like helical domain-containing protein 3UPF0668 protein C10orf76 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000532233, ENST00000347934, ENST00000354911, ENST00000375646, ENST00000375664, ENST00000428935, | ENST00000370033, ENST00000311122, ENST00000495001, | |
| Fusion gene scores | * DoF score | 17 X 16 X 8=2176 | 8 X 6 X 5=240 |
| # samples | 22 | 9 | |
| ** MAII score | log2(22/2176*10)=-3.30610312772568 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/240*10)=-1.41503749927884 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: WAC [Title/Abstract] AND C10orf76 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | WAC(28824686)-C10orf76(103699695), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across WAC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
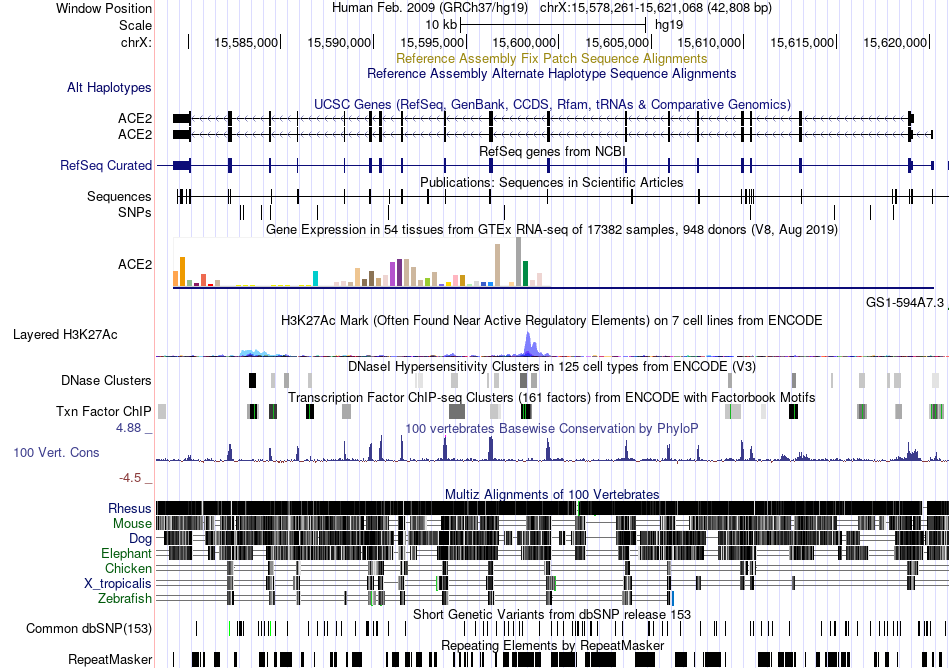 |
| Fusion gene breakpoints across C10orf76 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
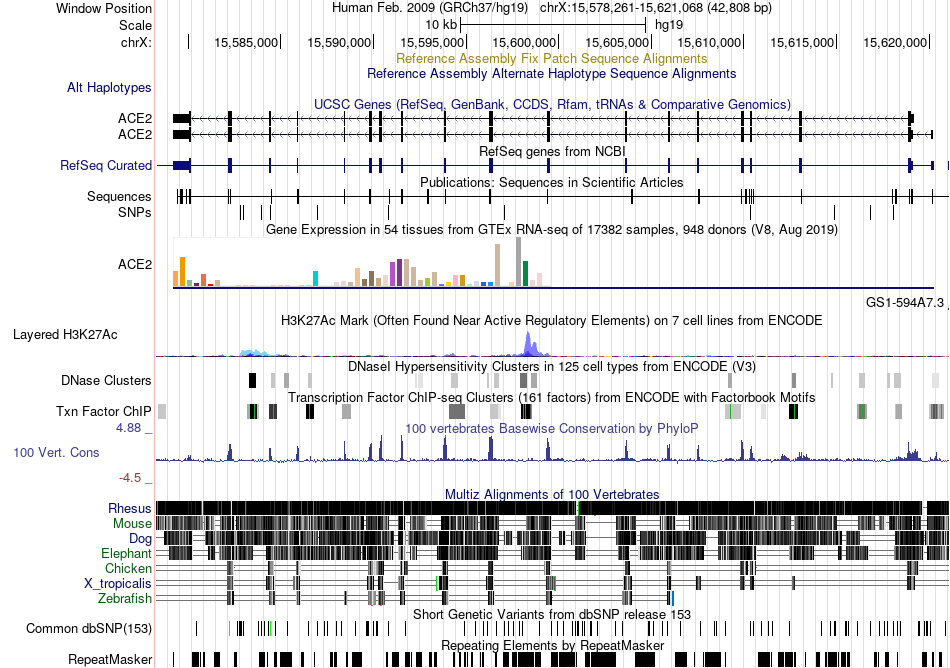 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | READ | TCGA-AG-3887 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
Top |
Fusion Gene ORF analysis for WAC-C10orf76 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000532233 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 3UTR-intron | ENST00000532233 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 3UTR-intron | ENST00000532233 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000347934 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000347934 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000354911 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000354911 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000375646 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000375646 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000375664 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000375664 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000428935 | ENST00000311122 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| 5CDS-intron | ENST00000428935 | ENST00000495001 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| In-frame | ENST00000347934 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| In-frame | ENST00000354911 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| In-frame | ENST00000375646 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| In-frame | ENST00000375664 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| In-frame | ENST00000428935 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000375664 | WAC | chr10 | 28824686 | + | ENST00000370033 | C10orf76 | chr10 | 103699695 | - | 3042 | 748 | 609 | 1112 | 167 |
| ENST00000375646 | WAC | chr10 | 28824686 | + | ENST00000370033 | C10orf76 | chr10 | 103699695 | - | 2751 | 457 | 318 | 821 | 167 |
| ENST00000347934 | WAC | chr10 | 28824686 | + | ENST00000370033 | C10orf76 | chr10 | 103699695 | - | 2835 | 541 | 171 | 905 | 244 |
| ENST00000354911 | WAC | chr10 | 28824686 | + | ENST00000370033 | C10orf76 | chr10 | 103699695 | - | 2729 | 435 | 65 | 799 | 244 |
| ENST00000428935 | WAC | chr10 | 28824686 | + | ENST00000370033 | C10orf76 | chr10 | 103699695 | - | 2653 | 359 | 16 | 723 | 235 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000375664 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - | 0.008837459 | 0.99116254 |
| ENST00000375646 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - | 0.006848722 | 0.9931513 |
| ENST00000347934 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - | 0.007145078 | 0.9928549 |
| ENST00000354911 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - | 0.009692678 | 0.99030733 |
| ENST00000428935 | ENST00000370033 | WAC | chr10 | 28824686 | + | C10orf76 | chr10 | 103699695 | - | 0.009184924 | 0.99081504 |
Top |
Fusion Genomic Features for WAC-C10orf76 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
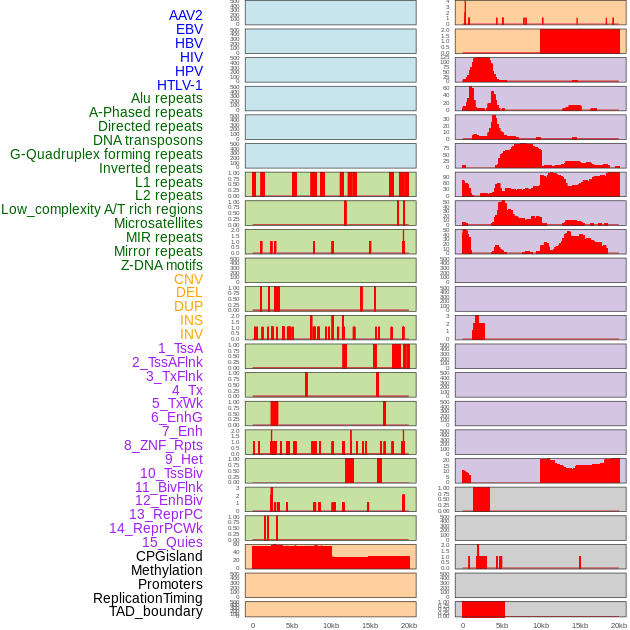 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for WAC-C10orf76 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:28824686/chr10:103699695) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000347934 | + | 3 | 13 | 618_644 | 91 | 545.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000354911 | + | 3 | 14 | 618_644 | 91 | 648.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000375664 | + | 3 | 14 | 618_644 | 46 | 603.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000428935 | + | 3 | 10 | 618_644 | 46 | 437.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000347934 | + | 3 | 13 | 129_162 | 91 | 545.0 | Domain | WW |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000354911 | + | 3 | 14 | 129_162 | 91 | 648.0 | Domain | WW |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000375664 | + | 3 | 14 | 129_162 | 46 | 603.0 | Domain | WW |
| Hgene | WAC | chr10:28824686 | chr10:103699695 | ENST00000428935 | + | 3 | 10 | 129_162 | 46 | 437.0 | Domain | WW |
| Tgene | C10orf76 | chr10:28824686 | chr10:103699695 | ENST00000370033 | 21 | 26 | 520_538 | 568 | 690.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for WAC-C10orf76 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >98668_98668_1_WAC-C10orf76_WAC_chr10_28824686_ENST00000347934_C10orf76_chr10_103699695_ENST00000370033_length(transcript)=2835nt_BP=541nt CGTCGTCTTGCCCCCCTCCCCCCGGTTCGCGGTGCCGCCGTGTAGTTGGCGCCGCTGCCCCGGCTGAGAGTGAGCGTGGTGTCGACGGAG GGAGATGGCCCGGGAGCGCCGGCGCCAGTAACTGGGAGCTGATGAGAGTCGCCGAGGGCGCGCCGGGCCCAGGTGCCGGGGCTGCCCGCC GCCCGCCGCCGCCGCCGCCTGCGCGCCCGCCCGCCTTTCGCGGCCGCTCTCCCCCCTCCCCGACACACACTCACAGGCCGGGCATTGATG GTAATGTATGCGAGGAAACAGCAGAGACTCAGTGATGGCTGTCACGACCGGAGGGGGGACTCGCAGCCTTACCAGGCACTTAAGTATTCA TCGAAGAGTCACCCCAGTAGCGGTGATCACAGACATGAAAAGATGCGAGACGCCGGAGATCCTTCACCACCAAATAAAATGTTGCGGAGA TCTGATAGTCCTGAAAACAAATACAGTGACAGCACAGGTCACAGTAAGGCCAAAAATGTGCATACTCACAGAGTTAGAGAGAGGGATGGT GTCCTGAGGCTTTCTACCAATGCAGGCCAGTGGAAGGAAGCAGCTAGCAAGGTGACCCATGCATTGGTTAATATCAGAGCCATCATCAAC CACTTTAACCCCAAAATTGAGTCCTACGCTGCTGTGAATCACATATCCCAACTGTCAGAGGAGCAGGTGCTGGAGGTGGTGAGAGCCAAC TATGACACGCTCACGCTGAAGCTGCAGGATGGCCTGGACCAGTATGAGCGCTACTCAGAGCAGCACAAGGAAGCTGCCTTCTTCAAAGAG CTGGTTCGATCCATTAGCACCAACGTCCGGAGAAACCTGGCCTTCCACACACTCAGCCAAGAAGTCCTGCTCAAGGAGTTCTCCACTATC TCCTGAGGCCACGCCTACCTGAGCAGCCTCTGACTGCCCTTACCCATGAGGATCATGGGCTGGAGGGGGAGCGAGGGGAGAGGGGGCTGC CCCCGAGGTTGGAGAGAAACACAGATACCAAGTTCTCTTGGTGAAGACCGCACTTCAATGGAGCTTGGGCAGCAGGGGCAGGAGGGTCAA GCCAGGGATAATCTTATTTGGGGAGGAATGGGTGGGCACAGTGGGGAGAGGCCTCCAGGAATGTGGGGACTTCCAGAGTGGGCTCCCTAA ACAGCCCCTCACATTTCCAATCTTGAGGTTACAAGCTGTAGCTACTGACTAATTTTCGGGAGCTGGTGAGGCAAGCCTCAGGGTAATGCC AGCACCCTGAAAGTCAGTGGCTCTGCTCGGCTTCTGAAAACAGATCAACTCTCAGATATAGCTGGAGCTACATCCTGCTTCCTTTGGGCC TGGGGCTGTGCTTGGCTTGAAATCTGTGTCCCCTGCCTGCACTGGCACTTTGTCCAGTCATCGGGACCTTTGGCTCAGATTTAGGGTAAG ATAGGAATAGGGTACCTTTTTCCTTTTTTTTCTGAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAATGCAGTGGCGTGATCTCGGCTTT ACTGCAGCCTCCGCTTCCTGGGTTCAAGCGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGAGCGTGTGCCACGCCCGGCT AATTTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTACCCAGGATGGTCTCAATATCCTGAGTTCATGATCCACCCACCTTGGCC TCCCAAAGTGCTGGGATTACAGGCGTGAGCCACCACACCCAGCCAGTTTTCCTATTTTCTGAATTCAGAATTGACTTCTCTGGGAAAACT GGAGATGAGAATCTGCCCAGTGCTCTGCTGTCCAGTCACCGCCTTTTGAATTTTAGTTTTGGCACCAGGAGTACCGTTAGCTTTCCCCTT CTTCTGGCCCATTTGACTCATCAGCACAATAGGGTCACCACCTTAACTTTTAATTTCTAATCTGCTTTACTGTCTTTAGGGTGTGTATGA AATAAACATTGACAGGCTTTCTGGAGCCCTCAAGGTGCCTACTTTGCTGGTTCCCTTTCCAGCAGCTCCCCCACCTCCCTTAGCCCCCCC TCCTCTGGCAGCCTCTCCTGCCTCTGCTGAGCTCCCCTCCACGTGTTCCACCCCCTTACCCTGCTGTTGTTTACATCCAACCTGCCTGAG AATTTCCTCTGGGGAGGAATCTATTCCTGTCATGGTCTAGTGCCTGGGAGGGAGAGAACTTTCTGGGGGTAGGGTGCCCTCCATCTGAAA CAGGCCAGGTGAGCATCATGCATAAGGCCTCCATTCTGTCCGCTCAGATTCTGGGTGGGGCCACAGGCAAATCTCCTGACTTATGGGGAG TTGGCTTGTGGTTCCTCCCTTGGATAGCCTCCATGGAACCACTATAGGCTTTCCCAACAGCTGCCTCTGAAATAGCTGCTGCTTCGAGAT CCTCCCTTTTTAAAGCACTTTCTAAAGCCCTCAGGATGGCGGGAGCAAACAGCACTGGTATATTCTAGGAGTAAGTGCAGGAATTCAGCA GTGAGAGCATGTCTGGGACCACCTGGACTGCCATCCATTTAACCTCAAATCTCTTTGGGATACTCGCCCTCCCTGGGAACCAGAGTTCTG GCTCTAACATTGAGCAGCTATGCACTAGTTCCAGAGAAGCCACTAACAGGCTGCCATGTGTAGATGTAGGTTCTTAAGAGATCACAGGCT GGGTCATCTGATCACTGGATGGATAGCTCAGCCTGGGGCATTTAGTGTTTTCCCTGGTGATAAATCCCCAAGGCAGCTGGATTTGGAGCT >98668_98668_1_WAC-C10orf76_WAC_chr10_28824686_ENST00000347934_C10orf76_chr10_103699695_ENST00000370033_length(amino acids)=244AA_BP=123 MPAARRRRRLRARPPFAAALPPPRHTLTGRALMVMYARKQQRLSDGCHDRRGDSQPYQALKYSSKSHPSSGDHRHEKMRDAGDPSPPNKM LRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGVLRLSTNAGQWKEAASKVTHALVNIRAIINHFNPKIESYAAVNHISQLSEEQVLEVV -------------------------------------------------------------- >98668_98668_2_WAC-C10orf76_WAC_chr10_28824686_ENST00000354911_C10orf76_chr10_103699695_ENST00000370033_length(transcript)=2729nt_BP=435nt CGCCGGCGCCAGTAACTGGGAGCTGATGAGAGTCGCCGAGGGCGCGCCGGGCCCAGGTGCCGGGGCTGCCCGCCGCCCGCCGCCGCCGCC GCCTGCGCGCCCGCCCGCCTTTCGCGGCCGCTCTCCCCCCTCCCCGACACACACTCACAGGCCGGGCATTGATGGTAATGTATGCGAGGA AACAGCAGAGACTCAGTGATGGCTGTCACGACCGGAGGGGGGACTCGCAGCCTTACCAGGCACTTAAGTATTCATCGAAGAGTCACCCCA GTAGCGGTGATCACAGACATGAAAAGATGCGAGACGCCGGAGATCCTTCACCACCAAATAAAATGTTGCGGAGATCTGATAGTCCTGAAA ACAAATACAGTGACAGCACAGGTCACAGTAAGGCCAAAAATGTGCATACTCACAGAGTTAGAGAGAGGGATGGTGTCCTGAGGCTTTCTA CCAATGCAGGCCAGTGGAAGGAAGCAGCTAGCAAGGTGACCCATGCATTGGTTAATATCAGAGCCATCATCAACCACTTTAACCCCAAAA TTGAGTCCTACGCTGCTGTGAATCACATATCCCAACTGTCAGAGGAGCAGGTGCTGGAGGTGGTGAGAGCCAACTATGACACGCTCACGC TGAAGCTGCAGGATGGCCTGGACCAGTATGAGCGCTACTCAGAGCAGCACAAGGAAGCTGCCTTCTTCAAAGAGCTGGTTCGATCCATTA GCACCAACGTCCGGAGAAACCTGGCCTTCCACACACTCAGCCAAGAAGTCCTGCTCAAGGAGTTCTCCACTATCTCCTGAGGCCACGCCT ACCTGAGCAGCCTCTGACTGCCCTTACCCATGAGGATCATGGGCTGGAGGGGGAGCGAGGGGAGAGGGGGCTGCCCCCGAGGTTGGAGAG AAACACAGATACCAAGTTCTCTTGGTGAAGACCGCACTTCAATGGAGCTTGGGCAGCAGGGGCAGGAGGGTCAAGCCAGGGATAATCTTA TTTGGGGAGGAATGGGTGGGCACAGTGGGGAGAGGCCTCCAGGAATGTGGGGACTTCCAGAGTGGGCTCCCTAAACAGCCCCTCACATTT CCAATCTTGAGGTTACAAGCTGTAGCTACTGACTAATTTTCGGGAGCTGGTGAGGCAAGCCTCAGGGTAATGCCAGCACCCTGAAAGTCA GTGGCTCTGCTCGGCTTCTGAAAACAGATCAACTCTCAGATATAGCTGGAGCTACATCCTGCTTCCTTTGGGCCTGGGGCTGTGCTTGGC TTGAAATCTGTGTCCCCTGCCTGCACTGGCACTTTGTCCAGTCATCGGGACCTTTGGCTCAGATTTAGGGTAAGATAGGAATAGGGTACC TTTTTCCTTTTTTTTCTGAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAATGCAGTGGCGTGATCTCGGCTTTACTGCAGCCTCCGCTT CCTGGGTTCAAGCGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGAGCGTGTGCCACGCCCGGCTAATTTTTTGTATTTTT AGTAGAGATGGGGTTTCACCATGTTACCCAGGATGGTCTCAATATCCTGAGTTCATGATCCACCCACCTTGGCCTCCCAAAGTGCTGGGA TTACAGGCGTGAGCCACCACACCCAGCCAGTTTTCCTATTTTCTGAATTCAGAATTGACTTCTCTGGGAAAACTGGAGATGAGAATCTGC CCAGTGCTCTGCTGTCCAGTCACCGCCTTTTGAATTTTAGTTTTGGCACCAGGAGTACCGTTAGCTTTCCCCTTCTTCTGGCCCATTTGA CTCATCAGCACAATAGGGTCACCACCTTAACTTTTAATTTCTAATCTGCTTTACTGTCTTTAGGGTGTGTATGAAATAAACATTGACAGG CTTTCTGGAGCCCTCAAGGTGCCTACTTTGCTGGTTCCCTTTCCAGCAGCTCCCCCACCTCCCTTAGCCCCCCCTCCTCTGGCAGCCTCT CCTGCCTCTGCTGAGCTCCCCTCCACGTGTTCCACCCCCTTACCCTGCTGTTGTTTACATCCAACCTGCCTGAGAATTTCCTCTGGGGAG GAATCTATTCCTGTCATGGTCTAGTGCCTGGGAGGGAGAGAACTTTCTGGGGGTAGGGTGCCCTCCATCTGAAACAGGCCAGGTGAGCAT CATGCATAAGGCCTCCATTCTGTCCGCTCAGATTCTGGGTGGGGCCACAGGCAAATCTCCTGACTTATGGGGAGTTGGCTTGTGGTTCCT CCCTTGGATAGCCTCCATGGAACCACTATAGGCTTTCCCAACAGCTGCCTCTGAAATAGCTGCTGCTTCGAGATCCTCCCTTTTTAAAGC ACTTTCTAAAGCCCTCAGGATGGCGGGAGCAAACAGCACTGGTATATTCTAGGAGTAAGTGCAGGAATTCAGCAGTGAGAGCATGTCTGG GACCACCTGGACTGCCATCCATTTAACCTCAAATCTCTTTGGGATACTCGCCCTCCCTGGGAACCAGAGTTCTGGCTCTAACATTGAGCA GCTATGCACTAGTTCCAGAGAAGCCACTAACAGGCTGCCATGTGTAGATGTAGGTTCTTAAGAGATCACAGGCTGGGTCATCTGATCACT GGATGGATAGCTCAGCCTGGGGCATTTAGTGTTTTCCCTGGTGATAAATCCCCAAGGCAGCTGGATTTGGAGCTGGTGGCAAGTTGAAAT >98668_98668_2_WAC-C10orf76_WAC_chr10_28824686_ENST00000354911_C10orf76_chr10_103699695_ENST00000370033_length(amino acids)=244AA_BP=123 MPAARRRRRLRARPPFAAALPPPRHTLTGRALMVMYARKQQRLSDGCHDRRGDSQPYQALKYSSKSHPSSGDHRHEKMRDAGDPSPPNKM LRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGVLRLSTNAGQWKEAASKVTHALVNIRAIINHFNPKIESYAAVNHISQLSEEQVLEVV -------------------------------------------------------------- >98668_98668_3_WAC-C10orf76_WAC_chr10_28824686_ENST00000375646_C10orf76_chr10_103699695_ENST00000370033_length(transcript)=2751nt_BP=457nt GCGATGGCTTCCCTCGCGCCCCACCGTCCTCTTCCGGAAGGCGGCTCCCTCCCTGCGCAGCCCGGAGCCCCTGAGATCAGCCTCGAGCAG GCGCCCGAGCGAGACTATCCCTAAACGGGAACGGCGGTGGCCGACTCGCGAGTGAGGAAAAGAAGGAAAGGGCAGACTGGTCGCGAAGAG AAGATCCAGGCCTCAGAGGAGGAGAAAGGCCGGAGCCAGCCGAGCTGTCACGACCGGAGGGGGGACTCGCAGCCTTACCAGGCACTTAAG TATTCATCGAAGAGTCACCCCAGTAGCGGTGATCACAGACATGAAAAGATGCGAGACGCCGGAGATCCTTCACCACCAAATAAAATGTTG CGGAGATCTGATAGTCCTGAAAACAAATACAGTGACAGCACAGGTCACAGTAAGGCCAAAAATGTGCATACTCACAGAGTTAGAGAGAGG GATGGTGTCCTGAGGCTTTCTACCAATGCAGGCCAGTGGAAGGAAGCAGCTAGCAAGGTGACCCATGCATTGGTTAATATCAGAGCCATC ATCAACCACTTTAACCCCAAAATTGAGTCCTACGCTGCTGTGAATCACATATCCCAACTGTCAGAGGAGCAGGTGCTGGAGGTGGTGAGA GCCAACTATGACACGCTCACGCTGAAGCTGCAGGATGGCCTGGACCAGTATGAGCGCTACTCAGAGCAGCACAAGGAAGCTGCCTTCTTC AAAGAGCTGGTTCGATCCATTAGCACCAACGTCCGGAGAAACCTGGCCTTCCACACACTCAGCCAAGAAGTCCTGCTCAAGGAGTTCTCC ACTATCTCCTGAGGCCACGCCTACCTGAGCAGCCTCTGACTGCCCTTACCCATGAGGATCATGGGCTGGAGGGGGAGCGAGGGGAGAGGG GGCTGCCCCCGAGGTTGGAGAGAAACACAGATACCAAGTTCTCTTGGTGAAGACCGCACTTCAATGGAGCTTGGGCAGCAGGGGCAGGAG GGTCAAGCCAGGGATAATCTTATTTGGGGAGGAATGGGTGGGCACAGTGGGGAGAGGCCTCCAGGAATGTGGGGACTTCCAGAGTGGGCT CCCTAAACAGCCCCTCACATTTCCAATCTTGAGGTTACAAGCTGTAGCTACTGACTAATTTTCGGGAGCTGGTGAGGCAAGCCTCAGGGT AATGCCAGCACCCTGAAAGTCAGTGGCTCTGCTCGGCTTCTGAAAACAGATCAACTCTCAGATATAGCTGGAGCTACATCCTGCTTCCTT TGGGCCTGGGGCTGTGCTTGGCTTGAAATCTGTGTCCCCTGCCTGCACTGGCACTTTGTCCAGTCATCGGGACCTTTGGCTCAGATTTAG GGTAAGATAGGAATAGGGTACCTTTTTCCTTTTTTTTCTGAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAATGCAGTGGCGTGATCTC GGCTTTACTGCAGCCTCCGCTTCCTGGGTTCAAGCGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGAGCGTGTGCCACGC CCGGCTAATTTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTACCCAGGATGGTCTCAATATCCTGAGTTCATGATCCACCCACC TTGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACCACACCCAGCCAGTTTTCCTATTTTCTGAATTCAGAATTGACTTCTCTGGG AAAACTGGAGATGAGAATCTGCCCAGTGCTCTGCTGTCCAGTCACCGCCTTTTGAATTTTAGTTTTGGCACCAGGAGTACCGTTAGCTTT CCCCTTCTTCTGGCCCATTTGACTCATCAGCACAATAGGGTCACCACCTTAACTTTTAATTTCTAATCTGCTTTACTGTCTTTAGGGTGT GTATGAAATAAACATTGACAGGCTTTCTGGAGCCCTCAAGGTGCCTACTTTGCTGGTTCCCTTTCCAGCAGCTCCCCCACCTCCCTTAGC CCCCCCTCCTCTGGCAGCCTCTCCTGCCTCTGCTGAGCTCCCCTCCACGTGTTCCACCCCCTTACCCTGCTGTTGTTTACATCCAACCTG CCTGAGAATTTCCTCTGGGGAGGAATCTATTCCTGTCATGGTCTAGTGCCTGGGAGGGAGAGAACTTTCTGGGGGTAGGGTGCCCTCCAT CTGAAACAGGCCAGGTGAGCATCATGCATAAGGCCTCCATTCTGTCCGCTCAGATTCTGGGTGGGGCCACAGGCAAATCTCCTGACTTAT GGGGAGTTGGCTTGTGGTTCCTCCCTTGGATAGCCTCCATGGAACCACTATAGGCTTTCCCAACAGCTGCCTCTGAAATAGCTGCTGCTT CGAGATCCTCCCTTTTTAAAGCACTTTCTAAAGCCCTCAGGATGGCGGGAGCAAACAGCACTGGTATATTCTAGGAGTAAGTGCAGGAAT TCAGCAGTGAGAGCATGTCTGGGACCACCTGGACTGCCATCCATTTAACCTCAAATCTCTTTGGGATACTCGCCCTCCCTGGGAACCAGA GTTCTGGCTCTAACATTGAGCAGCTATGCACTAGTTCCAGAGAAGCCACTAACAGGCTGCCATGTGTAGATGTAGGTTCTTAAGAGATCA CAGGCTGGGTCATCTGATCACTGGATGGATAGCTCAGCCTGGGGCATTTAGTGTTTTCCCTGGTGATAAATCCCCAAGGCAGCTGGATTT >98668_98668_3_WAC-C10orf76_WAC_chr10_28824686_ENST00000375646_C10orf76_chr10_103699695_ENST00000370033_length(amino acids)=167AA_BP=46 MRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGVLRLSTNAGQWKEAASKVTHALVNIRAIINHFNPKIESYAAVNH -------------------------------------------------------------- >98668_98668_4_WAC-C10orf76_WAC_chr10_28824686_ENST00000375664_C10orf76_chr10_103699695_ENST00000370033_length(transcript)=3042nt_BP=748nt GGTGGCGCGCGGCGTCCGGTGAGGGGCAGCGGCCCGGGCTCGGTTCCGGCTTCCAGCAGCGGCCCGAAGGCGCCGGAGCACGCTCCCCGC TCCCCAGAACGCAGCTTCCGCGGCTGCAGCCCAGGCAGCTCTTCGGGAAGCGTCCGCCCGTGGTCTCGCCAGGGGGTTTCCGACCTCCCC GCCCGACAGCGCAGGGGCGGGGGCCGCGGCCGGAGAGCTCGCCCGAGAGCACCCCCTCCCGCTGCGCCTCTGGGCGCACGCGCAGCCGCT GCAGCCTCCCTTATTTAGTCCGCGATGGCTTCCCTCGCGCCCCACCGTCCTCTTCCGGAAGGCGGCTCCCTCCCTGCGCAGCCCGGAGCC CCTGAGATCAGCCTCGAGCAGGCGCCCGAGCGAGACTATCCCTAAACGGGAACGGCGGTGGCCGACTCGCGAGTGAGGAAAAGAAGGAAA GGGCAGACTGGTCGCGAAGAGAAGATCCAGGCCTCAGAGGAGGAGAAAGGCCGGAGCCAGCCGAGCTGTCACGACCGGAGGGGGGACTCG CAGCCTTACCAGGCACTTAAGTATTCATCGAAGAGTCACCCCAGTAGCGGTGATCACAGACATGAAAAGATGCGAGACGCCGGAGATCCT TCACCACCAAATAAAATGTTGCGGAGATCTGATAGTCCTGAAAACAAATACAGTGACAGCACAGGTCACAGTAAGGCCAAAAATGTGCAT ACTCACAGAGTTAGAGAGAGGGATGGTGTCCTGAGGCTTTCTACCAATGCAGGCCAGTGGAAGGAAGCAGCTAGCAAGGTGACCCATGCA TTGGTTAATATCAGAGCCATCATCAACCACTTTAACCCCAAAATTGAGTCCTACGCTGCTGTGAATCACATATCCCAACTGTCAGAGGAG CAGGTGCTGGAGGTGGTGAGAGCCAACTATGACACGCTCACGCTGAAGCTGCAGGATGGCCTGGACCAGTATGAGCGCTACTCAGAGCAG CACAAGGAAGCTGCCTTCTTCAAAGAGCTGGTTCGATCCATTAGCACCAACGTCCGGAGAAACCTGGCCTTCCACACACTCAGCCAAGAA GTCCTGCTCAAGGAGTTCTCCACTATCTCCTGAGGCCACGCCTACCTGAGCAGCCTCTGACTGCCCTTACCCATGAGGATCATGGGCTGG AGGGGGAGCGAGGGGAGAGGGGGCTGCCCCCGAGGTTGGAGAGAAACACAGATACCAAGTTCTCTTGGTGAAGACCGCACTTCAATGGAG CTTGGGCAGCAGGGGCAGGAGGGTCAAGCCAGGGATAATCTTATTTGGGGAGGAATGGGTGGGCACAGTGGGGAGAGGCCTCCAGGAATG TGGGGACTTCCAGAGTGGGCTCCCTAAACAGCCCCTCACATTTCCAATCTTGAGGTTACAAGCTGTAGCTACTGACTAATTTTCGGGAGC TGGTGAGGCAAGCCTCAGGGTAATGCCAGCACCCTGAAAGTCAGTGGCTCTGCTCGGCTTCTGAAAACAGATCAACTCTCAGATATAGCT GGAGCTACATCCTGCTTCCTTTGGGCCTGGGGCTGTGCTTGGCTTGAAATCTGTGTCCCCTGCCTGCACTGGCACTTTGTCCAGTCATCG GGACCTTTGGCTCAGATTTAGGGTAAGATAGGAATAGGGTACCTTTTTCCTTTTTTTTCTGAGACGGAGTCTCACTCTGTCGCCCAGGCT GGAATGCAGTGGCGTGATCTCGGCTTTACTGCAGCCTCCGCTTCCTGGGTTCAAGCGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGA CTACAGGAGCGTGTGCCACGCCCGGCTAATTTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTACCCAGGATGGTCTCAATATCC TGAGTTCATGATCCACCCACCTTGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACCACACCCAGCCAGTTTTCCTATTTTCTGAA TTCAGAATTGACTTCTCTGGGAAAACTGGAGATGAGAATCTGCCCAGTGCTCTGCTGTCCAGTCACCGCCTTTTGAATTTTAGTTTTGGC ACCAGGAGTACCGTTAGCTTTCCCCTTCTTCTGGCCCATTTGACTCATCAGCACAATAGGGTCACCACCTTAACTTTTAATTTCTAATCT GCTTTACTGTCTTTAGGGTGTGTATGAAATAAACATTGACAGGCTTTCTGGAGCCCTCAAGGTGCCTACTTTGCTGGTTCCCTTTCCAGC AGCTCCCCCACCTCCCTTAGCCCCCCCTCCTCTGGCAGCCTCTCCTGCCTCTGCTGAGCTCCCCTCCACGTGTTCCACCCCCTTACCCTG CTGTTGTTTACATCCAACCTGCCTGAGAATTTCCTCTGGGGAGGAATCTATTCCTGTCATGGTCTAGTGCCTGGGAGGGAGAGAACTTTC TGGGGGTAGGGTGCCCTCCATCTGAAACAGGCCAGGTGAGCATCATGCATAAGGCCTCCATTCTGTCCGCTCAGATTCTGGGTGGGGCCA CAGGCAAATCTCCTGACTTATGGGGAGTTGGCTTGTGGTTCCTCCCTTGGATAGCCTCCATGGAACCACTATAGGCTTTCCCAACAGCTG CCTCTGAAATAGCTGCTGCTTCGAGATCCTCCCTTTTTAAAGCACTTTCTAAAGCCCTCAGGATGGCGGGAGCAAACAGCACTGGTATAT TCTAGGAGTAAGTGCAGGAATTCAGCAGTGAGAGCATGTCTGGGACCACCTGGACTGCCATCCATTTAACCTCAAATCTCTTTGGGATAC TCGCCCTCCCTGGGAACCAGAGTTCTGGCTCTAACATTGAGCAGCTATGCACTAGTTCCAGAGAAGCCACTAACAGGCTGCCATGTGTAG ATGTAGGTTCTTAAGAGATCACAGGCTGGGTCATCTGATCACTGGATGGATAGCTCAGCCTGGGGCATTTAGTGTTTTCCCTGGTGATAA >98668_98668_4_WAC-C10orf76_WAC_chr10_28824686_ENST00000375664_C10orf76_chr10_103699695_ENST00000370033_length(amino acids)=167AA_BP=46 MRDAGDPSPPNKMLRRSDSPENKYSDSTGHSKAKNVHTHRVRERDGVLRLSTNAGQWKEAASKVTHALVNIRAIINHFNPKIESYAAVNH -------------------------------------------------------------- >98668_98668_5_WAC-C10orf76_WAC_chr10_28824686_ENST00000428935_C10orf76_chr10_103699695_ENST00000370033_length(transcript)=2653nt_BP=359nt CCGCCGCCGCCGCCGCCTGCGCGCCCGCCCGCCTTTCGCGGCCGCTCTCCCCCCTCCCCGACACACACTCACAGGCCGGGCATTGATGGT AATGTATGCGAGGAAACAGCAGAGACTCAGTGATGGCTGTCACGACCGGAGGGGGGACTCGCAGCCTTACCAGGCACTTAAGTATTCATC GAAGAGTCACCCCAGTAGCGGTGATCACAGACATGAAAAGATGCGAGACGCCGGAGATCCTTCACCACCAAATAAAATGTTGCGGAGATC TGATAGTCCTGAAAACAAATACAGTGACAGCACAGGTCACAGTAAGGCCAAAAATGTGCATACTCACAGAGTTAGAGAGAGGGATGGTGT CCTGAGGCTTTCTACCAATGCAGGCCAGTGGAAGGAAGCAGCTAGCAAGGTGACCCATGCATTGGTTAATATCAGAGCCATCATCAACCA CTTTAACCCCAAAATTGAGTCCTACGCTGCTGTGAATCACATATCCCAACTGTCAGAGGAGCAGGTGCTGGAGGTGGTGAGAGCCAACTA TGACACGCTCACGCTGAAGCTGCAGGATGGCCTGGACCAGTATGAGCGCTACTCAGAGCAGCACAAGGAAGCTGCCTTCTTCAAAGAGCT GGTTCGATCCATTAGCACCAACGTCCGGAGAAACCTGGCCTTCCACACACTCAGCCAAGAAGTCCTGCTCAAGGAGTTCTCCACTATCTC CTGAGGCCACGCCTACCTGAGCAGCCTCTGACTGCCCTTACCCATGAGGATCATGGGCTGGAGGGGGAGCGAGGGGAGAGGGGGCTGCCC CCGAGGTTGGAGAGAAACACAGATACCAAGTTCTCTTGGTGAAGACCGCACTTCAATGGAGCTTGGGCAGCAGGGGCAGGAGGGTCAAGC CAGGGATAATCTTATTTGGGGAGGAATGGGTGGGCACAGTGGGGAGAGGCCTCCAGGAATGTGGGGACTTCCAGAGTGGGCTCCCTAAAC AGCCCCTCACATTTCCAATCTTGAGGTTACAAGCTGTAGCTACTGACTAATTTTCGGGAGCTGGTGAGGCAAGCCTCAGGGTAATGCCAG CACCCTGAAAGTCAGTGGCTCTGCTCGGCTTCTGAAAACAGATCAACTCTCAGATATAGCTGGAGCTACATCCTGCTTCCTTTGGGCCTG GGGCTGTGCTTGGCTTGAAATCTGTGTCCCCTGCCTGCACTGGCACTTTGTCCAGTCATCGGGACCTTTGGCTCAGATTTAGGGTAAGAT AGGAATAGGGTACCTTTTTCCTTTTTTTTCTGAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAATGCAGTGGCGTGATCTCGGCTTTAC TGCAGCCTCCGCTTCCTGGGTTCAAGCGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGAGCGTGTGCCACGCCCGGCTAA TTTTTTGTATTTTTAGTAGAGATGGGGTTTCACCATGTTACCCAGGATGGTCTCAATATCCTGAGTTCATGATCCACCCACCTTGGCCTC CCAAAGTGCTGGGATTACAGGCGTGAGCCACCACACCCAGCCAGTTTTCCTATTTTCTGAATTCAGAATTGACTTCTCTGGGAAAACTGG AGATGAGAATCTGCCCAGTGCTCTGCTGTCCAGTCACCGCCTTTTGAATTTTAGTTTTGGCACCAGGAGTACCGTTAGCTTTCCCCTTCT TCTGGCCCATTTGACTCATCAGCACAATAGGGTCACCACCTTAACTTTTAATTTCTAATCTGCTTTACTGTCTTTAGGGTGTGTATGAAA TAAACATTGACAGGCTTTCTGGAGCCCTCAAGGTGCCTACTTTGCTGGTTCCCTTTCCAGCAGCTCCCCCACCTCCCTTAGCCCCCCCTC CTCTGGCAGCCTCTCCTGCCTCTGCTGAGCTCCCCTCCACGTGTTCCACCCCCTTACCCTGCTGTTGTTTACATCCAACCTGCCTGAGAA TTTCCTCTGGGGAGGAATCTATTCCTGTCATGGTCTAGTGCCTGGGAGGGAGAGAACTTTCTGGGGGTAGGGTGCCCTCCATCTGAAACA GGCCAGGTGAGCATCATGCATAAGGCCTCCATTCTGTCCGCTCAGATTCTGGGTGGGGCCACAGGCAAATCTCCTGACTTATGGGGAGTT GGCTTGTGGTTCCTCCCTTGGATAGCCTCCATGGAACCACTATAGGCTTTCCCAACAGCTGCCTCTGAAATAGCTGCTGCTTCGAGATCC TCCCTTTTTAAAGCACTTTCTAAAGCCCTCAGGATGGCGGGAGCAAACAGCACTGGTATATTCTAGGAGTAAGTGCAGGAATTCAGCAGT GAGAGCATGTCTGGGACCACCTGGACTGCCATCCATTTAACCTCAAATCTCTTTGGGATACTCGCCCTCCCTGGGAACCAGAGTTCTGGC TCTAACATTGAGCAGCTATGCACTAGTTCCAGAGAAGCCACTAACAGGCTGCCATGTGTAGATGTAGGTTCTTAAGAGATCACAGGCTGG GTCATCTGATCACTGGATGGATAGCTCAGCCTGGGGCATTTAGTGTTTTCCCTGGTGATAAATCCCCAAGGCAGCTGGATTTGGAGCTGG >98668_98668_5_WAC-C10orf76_WAC_chr10_28824686_ENST00000428935_C10orf76_chr10_103699695_ENST00000370033_length(amino acids)=235AA_BP=114 MRARPPFAAALPPPRHTLTGRALMVMYARKQQRLSDGCHDRRGDSQPYQALKYSSKSHPSSGDHRHEKMRDAGDPSPPNKMLRRSDSPEN KYSDSTGHSKAKNVHTHRVRERDGVLRLSTNAGQWKEAASKVTHALVNIRAIINHFNPKIESYAAVNHISQLSEEQVLEVVRANYDTLTL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for WAC-C10orf76 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for WAC-C10orf76 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for WAC-C10orf76 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies