
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:WDFY1-AP1S3 (FusionGDB2 ID:98821) |
Fusion Gene Summary for WDFY1-AP1S3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: WDFY1-AP1S3 | Fusion gene ID: 98821 | Hgene | Tgene | Gene symbol | WDFY1 | AP1S3 | Gene ID | 57590 | 130340 |
| Gene name | WD repeat and FYVE domain containing 1 | adaptor related protein complex 1 subunit sigma 3 | |
| Synonyms | FENS-1|FENS1|WDF1|ZFYVE17 | PSORS15 | |
| Cytomap | 2q36.1 | 2q36.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | WD repeat and FYVE domain-containing protein 1FYVE domain-containing protein localized to endosomes 1WD40- and FYVE domain-containing protein 1phosphoinositide-binding protein SR1zinc finger FYVE domain-containing protein 17 | AP-1 complex subunit sigma-3adapter-related protein complex 1 subunit sigma-1Cadaptor protein complex AP-1 sigma-1C subunitadaptor related protein complex 1 sigma 3 subunitadaptor-related protein complex 1 subunit sigma-1Cclathrin assembly protein co | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q96PC3 | |
| Ensembl transtripts involved in fusion gene | ENST00000233055, ENST00000462702, | ENST00000396653, ENST00000396654, ENST00000409375, ENST00000423110, ENST00000443700, ENST00000446015, | |
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 4 X 2 X 3=24 |
| # samples | 6 | 5 | |
| ** MAII score | log2(6/48*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(5/24*10)=1.05889368905357 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: WDFY1 [Title/Abstract] AND AP1S3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP1S3(224632653)-WDFY1(224730175), # samples:1 WDFY1(224809865)-AP1S3(224642586), # samples:1 WDFY1(224749365)-AP1S3(224642586), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across WDFY1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across AP1S3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8534-01A | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| ChimerDB4 | STAD | TCGA-HJ-7597-01A | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
Top |
Fusion Gene ORF analysis for WDFY1-AP1S3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000233055 | ENST00000396653 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000396653 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000396654 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000396654 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000409375 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000409375 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000423110 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000423110 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000443700 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000443700 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000446015 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| In-frame | ENST00000233055 | ENST00000446015 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000396653 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000396653 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000396654 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000396654 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000409375 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000409375 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000423110 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000423110 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000443700 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000443700 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000446015 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - |
| intron-3CDS | ENST00000462702 | ENST00000446015 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000443700 | AP1S3 | chr2 | 224642586 | - | 1870 | 240 | 57 | 731 | 224 |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000396654 | AP1S3 | chr2 | 224642586 | - | 935 | 240 | 57 | 701 | 214 |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000396653 | AP1S3 | chr2 | 224642586 | - | 694 | 240 | 57 | 428 | 123 |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000446015 | AP1S3 | chr2 | 224642586 | - | 702 | 240 | 57 | 701 | 214 |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000409375 | AP1S3 | chr2 | 224642586 | - | 698 | 240 | 57 | 650 | 197 |
| ENST00000233055 | WDFY1 | chr2 | 224809865 | - | ENST00000423110 | AP1S3 | chr2 | 224642586 | - | 552 | 240 | 57 | 551 | 164 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000443700 | AP1S3 | chr2 | 224642586 | - | 2666 | 1036 | 103 | 1527 | 474 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000396654 | AP1S3 | chr2 | 224642586 | - | 1731 | 1036 | 103 | 1497 | 464 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000396653 | AP1S3 | chr2 | 224642586 | - | 1490 | 1036 | 103 | 1224 | 373 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000446015 | AP1S3 | chr2 | 224642586 | - | 1498 | 1036 | 103 | 1497 | 465 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000409375 | AP1S3 | chr2 | 224642586 | - | 1494 | 1036 | 103 | 1446 | 447 |
| ENST00000233055 | WDFY1 | chr2 | 224749365 | - | ENST00000423110 | AP1S3 | chr2 | 224642586 | - | 1348 | 1036 | 103 | 1347 | 415 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000233055 | ENST00000443700 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.002630962 | 0.99736905 |
| ENST00000233055 | ENST00000396654 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.001161131 | 0.99883884 |
| ENST00000233055 | ENST00000396653 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.3330897 | 0.66691023 |
| ENST00000233055 | ENST00000446015 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.00506166 | 0.9949384 |
| ENST00000233055 | ENST00000409375 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.033976756 | 0.96602327 |
| ENST00000233055 | ENST00000423110 | WDFY1 | chr2 | 224809865 | - | AP1S3 | chr2 | 224642586 | - | 0.039523736 | 0.96047634 |
| ENST00000233055 | ENST00000443700 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.002146707 | 0.9978532 |
| ENST00000233055 | ENST00000396654 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.003273921 | 0.99672604 |
| ENST00000233055 | ENST00000396653 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.022969224 | 0.97703075 |
| ENST00000233055 | ENST00000446015 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.010826275 | 0.98917377 |
| ENST00000233055 | ENST00000409375 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.03251259 | 0.9674874 |
| ENST00000233055 | ENST00000423110 | WDFY1 | chr2 | 224749365 | - | AP1S3 | chr2 | 224642586 | - | 0.03732555 | 0.9626744 |
Top |
Fusion Genomic Features for WDFY1-AP1S3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
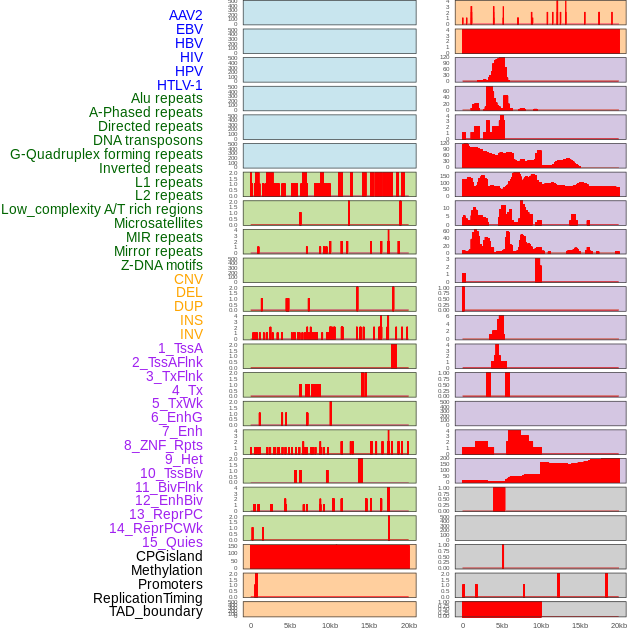 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for WDFY1-AP1S3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:224632653/chr2:224730175) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | AP1S3 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Subunit of clathrin-associated adaptor protein complex 1 that plays a role in protein sorting in the late-Golgi/trans-Golgi network (TGN) and/or endosomes. The AP complexes mediate both the recruitment of clathrin to membranes and the recognition of sorting signals within the cytosolic tails of transmembrane cargo molecules. Involved in TLR3 trafficking (PubMed:24791904). {ECO:0000269|PubMed:24791904}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 112_150 | 311 | 411.0 | Repeat | Note=WD 3 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 153_192 | 311 | 411.0 | Repeat | Note=WD 4 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 197_236 | 311 | 411.0 | Repeat | Note=WD 5 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 22_61 | 311 | 411.0 | Repeat | Note=WD 1 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 240_279 | 311 | 411.0 | Repeat | Note=WD 6 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 66_105 | 311 | 411.0 | Repeat | Note=WD 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 364_403 | 311 | 411.0 | Repeat | Note=WD 7 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 112_150 | 45 | 411.0 | Repeat | Note=WD 3 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 153_192 | 45 | 411.0 | Repeat | Note=WD 4 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 197_236 | 45 | 411.0 | Repeat | Note=WD 5 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 22_61 | 45 | 411.0 | Repeat | Note=WD 1 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 240_279 | 45 | 411.0 | Repeat | Note=WD 6 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 364_403 | 45 | 411.0 | Repeat | Note=WD 7 |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 66_105 | 45 | 411.0 | Repeat | Note=WD 2 |
| Hgene | WDFY1 | chr2:224749365 | chr2:224642586 | ENST00000233055 | - | 9 | 12 | 281_352 | 311 | 411.0 | Zinc finger | FYVE-type |
| Hgene | WDFY1 | chr2:224809865 | chr2:224642586 | ENST00000233055 | - | 1 | 12 | 281_352 | 45 | 411.0 | Zinc finger | FYVE-type |
Top |
Fusion Gene Sequence for WDFY1-AP1S3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >98821_98821_1_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000396653_length(transcript)=1490nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTGTCTGTGAGCTGGATATTATCTTTAATTTTGAAAAGGCTTATT TCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCTGTCAAAGCCATTGAAGACTCTGATATGTTAC AGGAGGTCAGTACGGTTTCCCAAACCATGGGAGAAAGATGATGATGATGATGATGATGGTGTTAATAATTATAATATTAACCAGACTTAC >98821_98821_1_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000396653_length(amino acids)=373AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV -------------------------------------------------------------- >98821_98821_2_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000396654_length(transcript)=1731nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATAGAAAATCAGGACAA TGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTGGATATTATCTTTAA TTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCTGTCAAAGCCATTGA AGACTCTGATATGTTACAGGAGACAATGGAAGAATACATGAACAAGCCTACATTTTAACTGGAAATCTACTTGAAGACTCCAGCACTACA TGTTATGAAGCTGTAAATAAGCAACGCCTCCCATCCGGTTTTTTGATGGAGCCTCAGGCACCATGCCAAAAATAATTTAAAGGGATTCTT TGTTAACTAACAAAGTTAAAGTTGTTTAACATATTTATAATTACTATGTGTCTGTATTATTAAAAAAAATTATGTGTCTGTGTTATACTG >98821_98821_2_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000396654_length(amino acids)=464AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV DWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIGGEIQETSKKIAVKAIEDSDM -------------------------------------------------------------- >98821_98821_3_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000409375_length(transcript)=1494nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATAGAAAATCAGGACAA TGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGAGTTTAATTGCTGGTTTCTCCTAAT GAGGCTCCTGTCTGTCTTGGATTCCTGGTCTACGCCTGCCTTGAACTCCGAGGTTCCTCAGCTTGCTACTATAACTCCTGACTTCTGCCT >98821_98821_3_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000409375_length(amino acids)=447AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV -------------------------------------------------------------- >98821_98821_4_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000423110_length(transcript)=1348nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATAGAAAATCAGGACAA >98821_98821_4_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000423110_length(amino acids)=415AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV -------------------------------------------------------------- >98821_98821_5_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000443700_length(transcript)=2666nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATAGAAAATCAGGACAA TGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTGGATATTATCTTTAA TTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCTGTCAAAGCCATTGA AGACTCTGATATGTTACAGGAGAATCGTTTGAGCCCCAGAGGCAGAGATTGCAGTGAGCCGAGATCATGCCATTGCACTCTAGCCTAGGC AACAAGAGCAAAACTCCATCTAAAAAAAAAAAAAAAGAAAAGAAAAAGGAGAATTATGAAGAACTTGGTTCCACAAGTAAGATAGTCCTC ATACTGCATCAGTAGTGACTTAAACTTTTTTAAAACTTTTATTTTTTGTGGGGGGATCTGTTGAATTTGGGAAGCCTCCAGTTTTAATAA AATTTTTTTATTATGGTGGAAACATGTCTGTAAAACTTAGGACTATAGAAATGCAAAGAATAAAGAACTGAGGGAGTTACACACATTTGT AGTCAGAAATTAAGTTCAAAAAATAATTTAGGTCATTTGCATTTTTTAGTATGCAAAATAAATGGAAAAATTAAAGTGCAATAAAAATAT AATTTGGGAAATGAATGCAGTAAAATTGAAAACATTGAAATATTATAATTTAATAAAATAAACTTCAAAAAATGTATGAAAATATAAGTA TCTTTACTTATATAGGATTAAATATATTTCTGATAATCTGTCCTCTATAATGAATTGGTTTAATTATGTTTTTCTGTTTTTAGAAATGGG CATCTTTTTATTTCTGGAAACAACTTTTTAATGAGATTTTATCAAACATTAGACTATGACTAATTATAATATTCAAAGCCAATACCAAAA CGATGGATAAATAAATGAATAAAACAAGGCACATTAATAGAAAAAAATGAATGAAATCAATTACGGGTTCTACTTGAAACACCTAATCTC ATTATAATAGCAATAATAAAACAATTTGTACATACTTTATTAGTCGAACATTTATTAAAAATATAAGAGCATAGAGCAAATTAATTTGGA AGAAAATTTAAATCTTTTACATACAAATACCCTCAAGAATAATAAATCATGGAGTATTAATAAAATTAAACCAGCTGATAATTTTAGAAA GTGCTTCATGCACAGAGACTTTTATTCAAGTCCTCTTTGCTTTCTGCTAGTGCTTTTTTTTTTTTCTTGAAATGGGATGGGATCTCACTC TGTCACCCAGGCTGGAGTGCAGTAGCACGATAGCAGCGCACTGCAACCTGGACCTCCTGGGCTCAAGCAATCCTCTCACCGCAGCCTCCT >98821_98821_5_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000443700_length(amino acids)=474AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV DWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIGGEIQETSKKIAVKAIEDSDM -------------------------------------------------------------- >98821_98821_6_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000446015_length(transcript)=1498nt_BP=1036nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGAACCATCCGGGTATGGCTGAAAAGAGACAG TGGTCAATACTGGCCCAGCATTTACCACACAATGGCCTCTCCTTGCTCTGCTATGGCTTACCATCATGACAGCAGACGGATATTTGTGGG CCAGGATAATGGAGCTGTAATGGAATTTCACGTTTCTGAAGATTTTAATAAAATGAACTTTATCAAGACCTACCCAGCTCATCAGAACCG GGTGTCTGCGATTATCTTCAGCTTGGCCACAGAGTGGGTGATCAGTACCGGCCACGACAAGTGTGTGAGCTGGATGTGCACGCGGAGCGG GAACATGCTCGGGAGGCACTTCTTCACGTCCTGGGCTTCGTGTCTGCAATATGACTTTGACACTCAGTATGCTTTCGTTGGTGATTATTC TGGGCAGATCACCCTGCTGAAGCTTGAACAGAACACGTGTTCAGTCATCACAACCCTCAAAGGACATGAAGGTAGTGTCGCCTGCCTCTG GTGGGACCCTATTCAGCGGTTACTCTTCTCAGGAGCATCTGACAACAGCATCATCATGTGGGACATCGGAGGAAGGAAAGGCCGGACGCT GTTACTTCAGGGCCATCATGACAAGGTGCAGTCGCTGTGCTACCTTCAGCTCACCAGGCAGCTCGTCTCCTGTTCCTCGGACGGCGGAAT TGCAGTGTGGAACATGGATGTTAGCAGAGAAGAGGCTCCTCAGTGGTTGGAAAGTGATTCTTGTCAGAAATGTGAGCAGCCATTTTTCTG GAACATAAAGCAGATGTGGGACACCAAGACGCTGGGGCTAAGACAAATACATTTCATATTGCTCTTCAGTCGACAAGGGAAATTACGGCT ACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCCCGTGGTCACAGGAC AAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATAGAAAATCAGGACAA TGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTGGATATTATCTTTAA TTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCTGTCAAAGCCATTGA >98821_98821_6_WDFY1-AP1S3_WDFY1_chr2_224749365_ENST00000233055_AP1S3_chr2_224642586_ENST00000446015_length(amino acids)=465AA_BP=0 MAAEIHSRPQSSRPVLLSKIEGHQDAVTAALLIPKEDGVITASEDRTIRVWLKRDSGQYWPSIYHTMASPCSAMAYHHDSRRIFVGQDNG AVMEFHVSEDFNKMNFIKTYPAHQNRVSAIIFSLATEWVISTGHDKCVSWMCTRSGNMLGRHFFTSWASCLQYDFDTQYAFVGDYSGQIT LLKLEQNTCSVITTLKGHEGSVACLWWDPIQRLLFSGASDNSIIMWDIGGRKGRTLLLQGHHDKVQSLCYLQLTRQLVSCSSDGGIAVWN MDVSREEAPQWLESDSCQKCEQPFFWNIKQMWDTKTLGLRQIHFILLFSRQGKLRLQKWYITLPDKERKKITREIVQIILSRGHRTSSFV DWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIGGEIQETSKKIAVKAIEDSDM -------------------------------------------------------------- >98821_98821_7_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000396653_length(transcript)=694nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTGTCTGTGAGCTGGATATTATCTTTAATTT TGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCTGTCAAAGCCATTGAAGA CTCTGATATGTTACAGGAGGTCAGTACGGTTTCCCAAACCATGGGAGAAAGATGATGATGATGATGATGATGGTGTTAATAATTATAATA >98821_98821_7_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000396653_length(amino acids)=123AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK -------------------------------------------------------------- >98821_98821_8_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000396654_length(transcript)=935nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATA GAAAATCAGGACAATGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTG GATATTATCTTTAATTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCT GTCAAAGCCATTGAAGACTCTGATATGTTACAGGAGACAATGGAAGAATACATGAACAAGCCTACATTTTAACTGGAAATCTACTTGAAG ACTCCAGCACTACATGTTATGAAGCTGTAAATAAGCAACGCCTCCCATCCGGTTTTTTGATGGAGCCTCAGGCACCATGCCAAAAATAAT TTAAAGGGATTCTTTGTTAACTAACAAAGTTAAAGTTGTTTAACATATTTATAATTACTATGTGTCTGTATTATTAAAAAAAATTATGTG >98821_98821_8_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000396654_length(amino acids)=214AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK ITREIVQIILSRGHRTSSFVDWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIG -------------------------------------------------------------- >98821_98821_9_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000409375_length(transcript)=698nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATA GAAAATCAGGACAATGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGAGTTTAATTGC TGGTTTCTCCTAATGAGGCTCCTGTCTGTCTTGGATTCCTGGTCTACGCCTGCCTTGAACTCCGAGGTTCCTCAGCTTGCTACTATAACT >98821_98821_9_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000409375_length(amino acids)=197AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK ITREIVQIILSRGHRTSSFVDWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNEFNCWFLLMRLLSVLDSWSTPAL -------------------------------------------------------------- >98821_98821_10_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000423110_length(transcript)=552nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATA GAAAATCAGGACAATGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATACTTGGCCTTTT >98821_98821_10_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000423110_length(amino acids)=164AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK -------------------------------------------------------------- >98821_98821_11_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000443700_length(transcript)=1870nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATA GAAAATCAGGACAATGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTG GATATTATCTTTAATTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCT GTCAAAGCCATTGAAGACTCTGATATGTTACAGGAGAATCGTTTGAGCCCCAGAGGCAGAGATTGCAGTGAGCCGAGATCATGCCATTGC ACTCTAGCCTAGGCAACAAGAGCAAAACTCCATCTAAAAAAAAAAAAAAAGAAAAGAAAAAGGAGAATTATGAAGAACTTGGTTCCACAA GTAAGATAGTCCTCATACTGCATCAGTAGTGACTTAAACTTTTTTAAAACTTTTATTTTTTGTGGGGGGATCTGTTGAATTTGGGAAGCC TCCAGTTTTAATAAAATTTTTTTATTATGGTGGAAACATGTCTGTAAAACTTAGGACTATAGAAATGCAAAGAATAAAGAACTGAGGGAG TTACACACATTTGTAGTCAGAAATTAAGTTCAAAAAATAATTTAGGTCATTTGCATTTTTTAGTATGCAAAATAAATGGAAAAATTAAAG TGCAATAAAAATATAATTTGGGAAATGAATGCAGTAAAATTGAAAACATTGAAATATTATAATTTAATAAAATAAACTTCAAAAAATGTA TGAAAATATAAGTATCTTTACTTATATAGGATTAAATATATTTCTGATAATCTGTCCTCTATAATGAATTGGTTTAATTATGTTTTTCTG TTTTTAGAAATGGGCATCTTTTTATTTCTGGAAACAACTTTTTAATGAGATTTTATCAAACATTAGACTATGACTAATTATAATATTCAA AGCCAATACCAAAACGATGGATAAATAAATGAATAAAACAAGGCACATTAATAGAAAAAAATGAATGAAATCAATTACGGGTTCTACTTG AAACACCTAATCTCATTATAATAGCAATAATAAAACAATTTGTACATACTTTATTAGTCGAACATTTATTAAAAATATAAGAGCATAGAG CAAATTAATTTGGAAGAAAATTTAAATCTTTTACATACAAATACCCTCAAGAATAATAAATCATGGAGTATTAATAAAATTAAACCAGCT GATAATTTTAGAAAGTGCTTCATGCACAGAGACTTTTATTCAAGTCCTCTTTGCTTTCTGCTAGTGCTTTTTTTTTTTTCTTGAAATGGG ATGGGATCTCACTCTGTCACCCAGGCTGGAGTGCAGTAGCACGATAGCAGCGCACTGCAACCTGGACCTCCTGGGCTCAAGCAATCCTCT >98821_98821_11_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000443700_length(amino acids)=224AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK ITREIVQIILSRGHRTSSFVDWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIG -------------------------------------------------------------- >98821_98821_12_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000446015_length(transcript)=702nt_BP=240nt AAGAGGCCCCAGCAGCCGAAGGGAAACCGGCGCGTCCCCCGCCCGCCCAGGCGTCAGCTGATGGGCTGCCTGCCGAGGAGGCCGCAGCAG TCGCCGCGCGAACATGGCGGCCGAAATCCACTCCAGGCCGCAGAGCAGCCGCCCGGTGCTGCTGAGCAAGATCGAGGGGCACCAGGACGC CGTCACGGCCGCGCTGCTCATCCCCAAGGAGGACGGCGTGATCACGGCCAGCGAGGACAGATACATTTCATATTGCTCTTCAGTCGACAA GGGAAATTACGGCTACAGAAATGGTACATCACTCTCCCTGATAAAGAGAGGAAGAAGATCACCCGGGAAATTGTTCAGATTATTCTCTCC CGTGGTCACAGGACAAGCAGTTTTGTTGACTGGAAGGAGCTAAAACTTGTTTATAAAAGGTATGCTAGTTTATATTTTTGCTGTGCAATA GAAAATCAGGACAATGAGCTCTTGACGCTAGAGATTGTGCATCGTTACGTGGAGCTGCTGGACAAATATTTTGGAAATGTCTGTGAGCTG GATATTATCTTTAATTTTGAAAAGGCTTATTTCATCCTGGACGAGTTTATAATAGGTGGGGAAATTCAGGAAACATCCAAGAAAATTGCT >98821_98821_12_WDFY1-AP1S3_WDFY1_chr2_224809865_ENST00000233055_AP1S3_chr2_224642586_ENST00000446015_length(amino acids)=214AA_BP=1 MMGCLPRRPQQSPREHGGRNPLQAAEQPPGAAEQDRGAPGRRHGRAAHPQGGRRDHGQRGQIHFILLFSRQGKLRLQKWYITLPDKERKK ITREIVQIILSRGHRTSSFVDWKELKLVYKRYASLYFCCAIENQDNELLTLEIVHRYVELLDKYFGNVCELDIIFNFEKAYFILDEFIIG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for WDFY1-AP1S3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for WDFY1-AP1S3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for WDFY1-AP1S3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies