
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:WHSC1-NUP210L (FusionGDB2 ID:99231) |
Fusion Gene Summary for WHSC1-NUP210L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: WHSC1-NUP210L | Fusion gene ID: 99231 | Hgene | Tgene | Gene symbol | WHSC1 | NUP210L | Gene ID | 7468 | 91181 |
| Gene name | nuclear receptor binding SET domain protein 2 | nucleoporin 210 like | |
| Synonyms | KMT3F|KMT3G|MMSET|REIIBP|TRX5|WHS|WHSC1 | - | |
| Cytomap | 4p16.3 | 1q21.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | histone-lysine N-methyltransferase NSD2IL5 promoter REII region-binding proteinWolf-Hirschhorn syndrome candidate 1multiple myeloma SET domain containing protein type IIInuclear SET domain-containing protein 2probable histone-lysine N-methyltransfera | nuclear pore membrane glycoprotein 210-likenuclear pore membrane glycoprotein 210-like (LOC91181)nucleoporin 210kDa likenucleoporin Nup210-like | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000382891, ENST00000382892, ENST00000382895, ENST00000398261, ENST00000420906, ENST00000436793, ENST00000503128, ENST00000508803, ENST00000514045, ENST00000382888, ENST00000482415, | ENST00000271854, ENST00000368553, ENST00000368559, | |
| Fusion gene scores | * DoF score | 22 X 18 X 13=5148 | 14 X 14 X 7=1372 |
| # samples | 27 | 18 | |
| ** MAII score | log2(27/5148*10)=-4.25298074116987 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1372*10)=-2.93021166984314 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: WHSC1 [Title/Abstract] AND NUP210L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | WHSC1(1902978)-NUP210L(153984846), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across WHSC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NUP210L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCS | TCGA-N5-A4RA-01A | WHSC1 | chr4 | 1902978 | - | NUP210L | chr1 | 153984846 | - |
| ChimerDB4 | UCS | TCGA-N5-A4RA | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
Top |
Fusion Gene ORF analysis for WHSC1-NUP210L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000382891 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382891 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382891 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382892 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382892 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382892 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382895 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382895 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000382895 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000398261 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000398261 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000398261 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000420906 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000420906 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000420906 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000436793 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000436793 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000436793 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000503128 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000503128 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000503128 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000508803 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000508803 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000508803 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000514045 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000514045 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| In-frame | ENST00000514045 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000382888 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000382888 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000382888 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000482415 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000482415 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| intron-3CDS | ENST00000482415 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000508803 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 1909 | 745 | 139 | 1758 | 539 |
| ENST00000508803 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1448 | 745 | 139 | 1302 | 387 |
| ENST00000508803 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1444 | 745 | 139 | 1302 | 387 |
| ENST00000382892 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 2075 | 911 | 305 | 1924 | 539 |
| ENST00000382892 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1614 | 911 | 305 | 1468 | 387 |
| ENST00000382892 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1610 | 911 | 305 | 1468 | 387 |
| ENST00000382891 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 1900 | 736 | 130 | 1749 | 539 |
| ENST00000382891 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1439 | 736 | 130 | 1293 | 387 |
| ENST00000382891 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1435 | 736 | 130 | 1293 | 387 |
| ENST00000382895 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 2192 | 1028 | 422 | 2041 | 539 |
| ENST00000382895 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1731 | 1028 | 422 | 1585 | 387 |
| ENST00000382895 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1727 | 1028 | 422 | 1585 | 387 |
| ENST00000514045 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 1872 | 708 | 102 | 1721 | 539 |
| ENST00000514045 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1411 | 708 | 102 | 1265 | 387 |
| ENST00000514045 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1407 | 708 | 102 | 1265 | 387 |
| ENST00000436793 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 2255 | 1091 | 485 | 2104 | 539 |
| ENST00000436793 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1794 | 1091 | 485 | 1648 | 387 |
| ENST00000436793 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1790 | 1091 | 485 | 1648 | 387 |
| ENST00000420906 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 2192 | 1028 | 422 | 2041 | 539 |
| ENST00000420906 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1731 | 1028 | 422 | 1585 | 387 |
| ENST00000420906 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1727 | 1028 | 422 | 1585 | 387 |
| ENST00000503128 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 1968 | 804 | 198 | 1817 | 539 |
| ENST00000503128 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1507 | 804 | 198 | 1361 | 387 |
| ENST00000503128 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1503 | 804 | 198 | 1361 | 387 |
| ENST00000398261 | WHSC1 | chr4 | 1902978 | + | ENST00000368559 | NUP210L | chr1 | 153984846 | - | 1790 | 626 | 20 | 1639 | 539 |
| ENST00000398261 | WHSC1 | chr4 | 1902978 | + | ENST00000368553 | NUP210L | chr1 | 153984846 | - | 1329 | 626 | 20 | 1183 | 387 |
| ENST00000398261 | WHSC1 | chr4 | 1902978 | + | ENST00000271854 | NUP210L | chr1 | 153984846 | - | 1325 | 626 | 20 | 1183 | 387 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000508803 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004039486 | 0.99596053 |
| ENST00000508803 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003061323 | 0.9969387 |
| ENST00000508803 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003141051 | 0.99685895 |
| ENST00000382892 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004740323 | 0.9952597 |
| ENST00000382892 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.00302718 | 0.9969728 |
| ENST00000382892 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003096194 | 0.99690384 |
| ENST00000382891 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003291422 | 0.9967085 |
| ENST00000382891 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002865162 | 0.9971348 |
| ENST00000382891 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002964557 | 0.9970355 |
| ENST00000382895 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004560561 | 0.99543947 |
| ENST00000382895 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002882281 | 0.99711776 |
| ENST00000382895 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002939462 | 0.9970605 |
| ENST00000514045 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003848797 | 0.99615115 |
| ENST00000514045 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002927038 | 0.99707294 |
| ENST00000514045 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003018922 | 0.9969811 |
| ENST00000436793 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004692897 | 0.99530715 |
| ENST00000436793 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.0031508 | 0.99684924 |
| ENST00000436793 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003233086 | 0.9967669 |
| ENST00000420906 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004560561 | 0.99543947 |
| ENST00000420906 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002882281 | 0.99711776 |
| ENST00000420906 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002939462 | 0.9970605 |
| ENST00000503128 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.004603754 | 0.9953962 |
| ENST00000503128 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002810539 | 0.99718946 |
| ENST00000503128 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002858949 | 0.9971411 |
| ENST00000398261 | ENST00000368559 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.003364174 | 0.99663585 |
| ENST00000398261 | ENST00000368553 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002722408 | 0.99727756 |
| ENST00000398261 | ENST00000271854 | WHSC1 | chr4 | 1902978 | + | NUP210L | chr1 | 153984846 | - | 0.002802026 | 0.997198 |
Top |
Fusion Genomic Features for WHSC1-NUP210L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
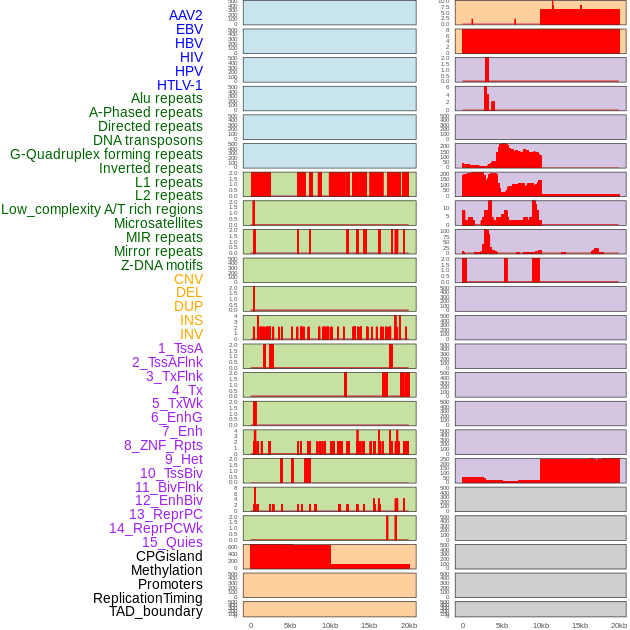 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for WHSC1-NUP210L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:1902978/chr1:153984846) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NUP210L | chr4:1902978 | chr1:153984846 | ENST00000368559 | 32 | 40 | 1813_1833 | 1551 | 1889.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 453_521 | 0 | 714.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 453_521 | 199 | 1366.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 453_521 | 199 | 1366.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 453_521 | 199 | 1366.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 453_521 | 199 | 648.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 453_521 | 199 | 630.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 453_521 | 199 | 274.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 453_521 | 199 | 648.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 453_521 | 199 | 1366.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 453_521 | 199 | 630.0 | DNA binding | HMG box |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1011_1061 | 0 | 714.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1063_1180 | 0 | 714.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1187_1203 | 0 | 714.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 222_286 | 0 | 714.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 880_942 | 0 | 714.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1011_1061 | 199 | 1366.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1063_1180 | 199 | 1366.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1187_1203 | 199 | 1366.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 222_286 | 199 | 1366.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 880_942 | 199 | 1366.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1011_1061 | 199 | 1366.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1063_1180 | 199 | 1366.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1187_1203 | 199 | 1366.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 222_286 | 199 | 1366.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 880_942 | 199 | 1366.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1011_1061 | 199 | 1366.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1063_1180 | 199 | 1366.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1187_1203 | 199 | 1366.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 222_286 | 199 | 1366.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 880_942 | 199 | 1366.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1011_1061 | 199 | 648.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1063_1180 | 199 | 648.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1187_1203 | 199 | 648.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 222_286 | 199 | 648.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 880_942 | 199 | 648.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1011_1061 | 199 | 630.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1063_1180 | 199 | 630.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1187_1203 | 199 | 630.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 222_286 | 199 | 630.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 880_942 | 199 | 630.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1011_1061 | 199 | 274.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1063_1180 | 199 | 274.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1187_1203 | 199 | 274.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 222_286 | 199 | 274.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 880_942 | 199 | 274.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1011_1061 | 199 | 648.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1063_1180 | 199 | 648.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1187_1203 | 199 | 648.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 222_286 | 199 | 648.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 880_942 | 199 | 648.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1011_1061 | 199 | 1366.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1063_1180 | 199 | 1366.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1187_1203 | 199 | 1366.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 222_286 | 199 | 1366.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 880_942 | 199 | 1366.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1011_1061 | 199 | 630.0 | Domain | AWS |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1063_1180 | 199 | 630.0 | Domain | SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1187_1203 | 199 | 630.0 | Domain | Post-SET |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 222_286 | 199 | 630.0 | Domain | PWWP 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 880_942 | 199 | 630.0 | Domain | PWWP 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1115_1118 | 0 | 714.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1141_1142 | 0 | 714.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1115_1118 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1141_1142 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1115_1118 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1141_1142 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1115_1118 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1141_1142 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1115_1118 | 199 | 648.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1141_1142 | 199 | 648.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1115_1118 | 199 | 630.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1141_1142 | 199 | 630.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1115_1118 | 199 | 274.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1141_1142 | 199 | 274.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1115_1118 | 199 | 648.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1141_1142 | 199 | 648.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1115_1118 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1141_1142 | 199 | 1366.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1115_1118 | 199 | 630.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1141_1142 | 199 | 630.0 | Region | S-adenosyl-L-methionine binding |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 1239_1286 | 0 | 714.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 667_713 | 0 | 714.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 714_770 | 0 | 714.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382888 | + | 1 | 12 | 831_875 | 0 | 714.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 1239_1286 | 199 | 1366.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 667_713 | 199 | 1366.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 714_770 | 199 | 1366.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382891 | + | 2 | 22 | 831_875 | 199 | 1366.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 1239_1286 | 199 | 1366.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 667_713 | 199 | 1366.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 714_770 | 199 | 1366.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382892 | + | 3 | 23 | 831_875 | 199 | 1366.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 1239_1286 | 199 | 1366.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 667_713 | 199 | 1366.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 714_770 | 199 | 1366.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000382895 | + | 4 | 24 | 831_875 | 199 | 1366.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 1239_1286 | 199 | 648.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 667_713 | 199 | 648.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 714_770 | 199 | 648.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000398261 | + | 1 | 9 | 831_875 | 199 | 648.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 1239_1286 | 199 | 630.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 667_713 | 199 | 630.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 714_770 | 199 | 630.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000420906 | + | 4 | 11 | 831_875 | 199 | 630.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 1239_1286 | 199 | 274.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 667_713 | 199 | 274.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 714_770 | 199 | 274.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000436793 | + | 4 | 6 | 831_875 | 199 | 274.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 1239_1286 | 199 | 648.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 667_713 | 199 | 648.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 714_770 | 199 | 648.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000503128 | + | 2 | 10 | 831_875 | 199 | 648.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 1239_1286 | 199 | 1366.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 667_713 | 199 | 1366.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 714_770 | 199 | 1366.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000508803 | + | 2 | 22 | 831_875 | 199 | 1366.0 | Zinc finger | PHD-type 3 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 1239_1286 | 199 | 630.0 | Zinc finger | PHD-type 4%3B atypical |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 667_713 | 199 | 630.0 | Zinc finger | PHD-type 1 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 714_770 | 199 | 630.0 | Zinc finger | PHD-type 2 |
| Hgene | WHSC1 | chr4:1902978 | chr1:153984846 | ENST00000514045 | + | 2 | 9 | 831_875 | 199 | 630.0 | Zinc finger | PHD-type 3 |
| Tgene | NUP210L | chr4:1902978 | chr1:153984846 | ENST00000368559 | 32 | 40 | 1082_1154 | 1551 | 1889.0 | Domain | BIG2 |
Top |
Fusion Gene Sequence for WHSC1-NUP210L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >99231_99231_1_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1435nt_BP=736nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAG TGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTG TTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTAT TCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGA AATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAA TGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAA GGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAG TCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTC AACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAA AGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCA TTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCT CTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACC AACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCG GCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCG >99231_99231_1_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_2_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1439nt_BP=736nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAG TGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTG TTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTAT TCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGA AATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAA TGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAA GGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAG TCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTC AACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAA AGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCA TTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCT CTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACC AACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCG GCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCG >99231_99231_2_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_3_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=1900nt_BP=736nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAG TGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTG TTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTAT TCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGA AATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAA TGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAA GGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAG TCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTC AACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAA AGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCA TTCAGATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGC TGACACCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTT TTATATTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCT AGAGGTCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGT GGTCAACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGT GAGGGCTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTT GACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTA TGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCA AAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAG TCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAAGCTGTTTCT >99231_99231_3_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382891_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_4_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1610nt_BP=911nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTG CAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTC TAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGC AACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAG >99231_99231_4_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_5_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1614nt_BP=911nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTG CAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTC TAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGC AACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAG >99231_99231_5_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_6_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=2075nt_BP=911nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGCTGACA CCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTTTTATA TTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCTAGAGG TCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGTGGTCA ACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGTGAGGG CTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCC TCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTAC CAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTC GGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTC GACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAAGCTGTTTCTTAAAA >99231_99231_6_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382892_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_7_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1727nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTT ACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAA CAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTAC AACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGG GAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGC >99231_99231_7_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_8_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1731nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTT ACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAA CAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTAC AACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGG GAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGC >99231_99231_8_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_9_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=2192nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGC TGCTACAGGCCCTCAGTGTGGCTGACACCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCC TCATTCCTTTCATCCCAGCCTTTTATATTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAG TGGACAGAGTTCTTAGGAAGCTAGAGGTCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCC TGGCCATTTACTCTGTAAGAGTGGTCAACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCA GTCAAAGTGAGGCAGTGGTAGTGAGGGCTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTG GCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGA TACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGA GTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACT GCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAA >99231_99231_9_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000382895_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_10_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1325nt_BP=626nt TGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGA TGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAG CCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAG ATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACAC CCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAAT CTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGA GGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGG TGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCA TCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCC TCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGA AAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAA CAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGC CAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGA GTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAAC >99231_99231_10_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_11_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1329nt_BP=626nt TGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGA TGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAG CCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAG ATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACAC CCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAAT CTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGA GGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGG TGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCA TCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCC TCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGA AAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAA CAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGC CAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGA GTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAAC >99231_99231_11_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_12_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=1790nt_BP=626nt TGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGA TGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAG CCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAG ATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACAC CCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAAT CTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGA GGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGG TGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCA TCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCC TCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGA AAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGCTGACACCTCAGTCTATGGGT GGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTTTTATATTAACCAGTCAGAAT TGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCTAGAGGTCATCTCCAGCTCCC CAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGTGGTCAACTTCACTTCCTTCC AGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGTGAGGGCTATGAAAGATAAGT TGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGG CATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACAC CACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGT TATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAAC >99231_99231_12_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000398261_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_13_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1727nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTT ACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAA CAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTAC AACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGG GAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGC >99231_99231_13_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_14_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1731nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTT ACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAA CAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTAC AACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGG GAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGC >99231_99231_14_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_15_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=2192nt_BP=1028nt GCATGAGCCACCGTGCCTGTCCTAGAACCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCT GAGCTCAAGCGATCTACCTGCCTCGTCCTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAAT GATAATTTACCTGGGCATAAAATTCTGGACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCA GCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGT TGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGC AGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGA GCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACG GCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCA AACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGA AAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAA ATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAG CTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTT ATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAA ACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAG CAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGC TGCTACAGGCCCTCAGTGTGGCTGACACCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCC TCATTCCTTTCATCCCAGCCTTTTATATTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAG TGGACAGAGTTCTTAGGAAGCTAGAGGTCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCC TGGCCATTTACTCTGTAAGAGTGGTCAACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCA GTCAAAGTGAGGCAGTGGTAGTGAGGGCTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTG GCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGA TACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGA GTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACT GCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAA >99231_99231_15_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000420906_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_16_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1790nt_BP=1091nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCTGAGCTCAAGCGATCTACCTGCCTCGTC CTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAATGATAATTTACCTGGGCATAAAATTCTG GACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTG CAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTC TAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGC AACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAG >99231_99231_16_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_17_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1794nt_BP=1091nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCTGAGCTCAAGCGATCTACCTGCCTCGTC CTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAATGATAATTTACCTGGGCATAAAATTCTG GACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTG CAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTC TAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGC AACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAG >99231_99231_17_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_18_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=2255nt_BP=1091nt TGGTCTTGAACTCCTGACCTTGTGATCCGCTCGCCTCAGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCACCGTGCCTGTCCTAGAA CCACTGGTAACTCTTAACTGAGACAAGATTTCGCCATGTTGCCCAGGCTGGTCTCGAACTTCTGAGCTCAAGCGATCTACCTGCCTCGTC CTCCCAAAGTGTTGGAATTGCAGGTGTGAGCCACTGCACCCGGCCCTTGCCTCATGTTTGAATGATAATTTACCTGGGCATAAAATTCTG GACACTTGTGGTGGCACGAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTC CTCCACCTCAGTACTGTGGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGAC CGCAACCCATCAGAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTG TAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTG TGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAG CCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGA AAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGA AGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGA GAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTT CAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTG TATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTAC TTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAG ATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGCTGACA CCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTTTTATA TTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCTAGAGG TCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGTGGTCA ACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGTGAGGG CTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCC TCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTAC CAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTC GGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTC GACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAAGCTGTTTCTTAAAA >99231_99231_18_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000436793_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_19_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1503nt_BP=804nt CAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGT GGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTG TTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATG AAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCC CAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGAT CTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCC CCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCT TCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGG AGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTG GTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATC ACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTC ATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAA GATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACA GCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCA GGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGT ATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTT >99231_99231_19_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_20_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1507nt_BP=804nt CAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGT GGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTG TTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATG AAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCC CAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGAT CTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCC CCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCT TCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGG AGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTG GTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATC ACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTC ATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAA GATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACA GCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCA GGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGT ATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTT >99231_99231_20_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_21_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=1968nt_BP=804nt CAGCTGTCTGCTTTTCTGTGGAGACTGCGGGTTGCAGACACCAGCAGCCCCCTATTGCTGCACGTCAGGTGTCCTCCACCTCAGTACTGT GGACATCTCGGGCCGCATAGCCCTGTTGCGCGGGCATCCTGTGCGTTGCAGGAGATGCAGCAGCATCCATGACCGCAACCCATCAGAGTG TTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATG AAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCC CAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGAT CTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCC CCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCT TCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGG AGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTG GTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATC ACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTC ATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAA GGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGCTGACACCTCAGTCTATGGGTGG GCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTTTTATATTAACCAGTCAGAATTG GTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCTAGAGGTCATCTCCAGCTCCCCA GTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGTGGTCAACTTCACTTCCTTCCAG CAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGTGAGGGCTATGAAAGATAAGTTG GGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCA TCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCA CAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTA TGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAG >99231_99231_21_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000503128_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_22_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1444nt_BP=745nt CGCTGCGCCCGCCGCCGCCGCCGCCCCCTCCCCGCCTGGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAG CCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTC TGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAA CCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCT GCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGA GTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAAC ATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACC AGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAA GATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATAC CCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGC CATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTT TCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCT CTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGT GTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGC CCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTC TAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAAGCTGTT >99231_99231_22_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_23_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1448nt_BP=745nt CGCTGCGCCCGCCGCCGCCGCCGCCCCCTCCCCGCCTGGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAG CCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTC TGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAA CCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCT GCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGA GTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAAC ATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACC AGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAA GATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATAC CCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGC CATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTT TCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCT CTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGT GTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGC CCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTC TAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAAGCTGTT >99231_99231_23_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_24_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=1909nt_BP=745nt CGCTGCGCCCGCCGCCGCCGCCGCCCCCTCCCCGCCTGGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAG CCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAAGAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTC TGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAGGCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAA CCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTCTCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCT GCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACTTCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGA GTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAACACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAAC ATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATTTGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACC AGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATAAAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAA GATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAATGCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATAC CCTCAATTCAACTGTATTCAAGCTCTTCATCACCACTGGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGC CATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTGTGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTT TCAGGTCCATTCAGATTTCAGTATGGAGAAAGGGGTTTATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCT CAGTGTGGCTGACACCTCAGTCTATGGGTGGGCTACACTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCAT CCCAGCCTTTTATATTAACCAGTCAGAATTGGTTCTTAGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCT TAGGAAGCTAGAGGTCATCTCCAGCTCCCCAGTTCTAGTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTC TGTAAGAGTGGTCAACTTCACTTCCTTCCAGCAAATGGCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGC AGTGGTAGTGAGGGCTATGAAAGATAAGTTGGGTGCAGATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGAT CCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCC AGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCC ATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAA GATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACATTAAGTTTCCAGATAAGGCTTCTGAGAACTATAAATAAAGCATCCTAA >99231_99231_24_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000508803_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- >99231_99231_25_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000271854_length(transcript)=1407nt_BP=708nt GGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAGCCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAA GAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAG GCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTC TCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACT TCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAAC ACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATT TGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATA AAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAAT GCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACT GGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTG TGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCAC TGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCC ATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTT TTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGG CACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACAT >99231_99231_25_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000271854_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_26_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000368553_length(transcript)=1411nt_BP=708nt GGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAGCCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAA GAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAG GCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTC TCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACT TCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAAC ACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATT TGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATA AAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAAT GCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACT GGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTG TGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGATCAC TGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACAGCTTCC ATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCAGGTTTT TTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGTATAAGG CACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTTCTACAT >99231_99231_26_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000368553_length(amino acids)=387AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKDHCEDSAILKRFTGSYQILLLTLFAVLASTASIFLAYNAFLNKIQTVPVVYVPTLGTPQPGFFNST -------------------------------------------------------------- >99231_99231_27_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000368559_length(transcript)=1872nt_BP=708nt GGGCCCTACCGCCGCACGGCCCCGGCCCCCTCCCAGCCTGCCGCTCCGGAGAGCCGCCCGCCGAGGATGCGACGCACCGCAGTGTTCTAA GAACGGAAGCATCTGGGCTGGATGGAATTTAGCATCAAGCAGAGTCCCCTTTCTGTTCAGAGTGTTGTAAAGTGCATAAAGATGAAGCAG GCACCAGAAATCCTCGGCAGTGCCAACGGGAAGACTCCGAGCTGCGAGGTGAACCGCGAGTGTTCTGTGTTCCTCAGCAAAGCCCAGCTC TCCAGTAGCCTGCAGGAGGGGGTCATGCAGAAGTTTAACGGCCACGACGCCCTGCCCTTTATTCCAGCCGACAAGCTGAAAGATCTTACT TCCCGGGTGTTTAATGGAGAACCCGGCGCACACGATGCCAAACTGCGTTTTGAGTCCCAGGAAATGAAAGGGATTGGGACACCCCCTAAC ACTACCCCTATCAAAAATGGCTCTCCAGAAATTAAGCTGAAAATCACCAAAACATACATGAATGGGAAGCCTCTCTTTGAATCTTCCATT TGTGGTGACAGTGCTGCTGATGTGTCTCAGTCAGAAGAAAATGGACAAAAACCAGAAAACAAGGCGAGAAGGAACAGGAAGAGGAGCATA AAATATGACTCCTTGCTGGAGCAGGGCCTTGTCGAAGCAGCTCTTGTGTCTAAGATCTCAAGTCCTTCAGATAAAAAGGTGGTGGTCAAT GCATCATCAAGATTAATGCTCAGTTATGACCTCAAGACTTATCTCACCAATACCCTCAATTCAACTGTATTCAAGCTCTTCATCACCACT GGCAGAAATGGTGTCAATCTTAAAGGATTCTGTACCCCAAACCAGGCCTTGGCCATTACAAAAGTACTTCTTCCAGCGACCCTCATGCTG TGCCATGTACAGTTCAGTAATACTTTGCTAGACATTCCAGCAAGTAAAGTCTTTCAGGTCCATTCAGATTTCAGTATGGAGAAAGGGGTT TATGTCTGCATAATCAAGGTTCGACCGCAGTCAGAGGAGCTGCTACAGGCCCTCAGTGTGGCTGACACCTCAGTCTATGGGTGGGCTACA CTGGTCAGTGAACGTAGCAAGAATGGAATGCAACGAATCCTCATTCCTTTCATCCCAGCCTTTTATATTAACCAGTCAGAATTGGTTCTT AGCCACAAACAAGATATCGGGGAGATAAGAGTACTGGGAGTGGACAGAGTTCTTAGGAAGCTAGAGGTCATCTCCAGCTCCCCAGTTCTA GTGGTCGCTGGCCATAGCCACTCTCCCCTCACTCCTGGCCTGGCCATTTACTCTGTAAGAGTGGTCAACTTCACTTCCTTCCAGCAAATG GCATCACCTGTTTTCATCAATATTTCCTGTGTACTCACCAGTCAAAGTGAGGCAGTGGTAGTGAGGGCTATGAAAGATAAGTTGGGTGCA GATCACTGTGAAGATTCCGCCATCCTCAAGCGGTTCACTGGCTCTTACCAGATCCTGCTCTTGACCCTCTTTGCAGTGCTGGCATCAACA GCTTCCATCTTCCTAGCATACAATGCCTTCCTAAACAAGATACAAACAGTTCCAGTTGTGTATGTACCAACTCTAGGAACACCACAGCCA GGTTTTTTTAACTCCACAAGTTCTCCCCCTCACTTCATGAGTCTACAACCTCCATTGGCCCAAAGTCGGCTGCAACATTGGTTATGGAGT ATAAGGCACTAACCTCTGCTTGGACAAGTTTCTCTTAACTGCAGGGGAATGAAGATTTCTAGTCCTCGACAAGAAGCCTAACAGCAACTT >99231_99231_27_WHSC1-NUP210L_WHSC1_chr4_1902978_ENST00000514045_NUP210L_chr1_153984846_ENST00000368559_length(amino acids)=539AA_BP=202 MGWMEFSIKQSPLSVQSVVKCIKMKQAPEILGSANGKTPSCEVNRECSVFLSKAQLSSSLQEGVMQKFNGHDALPFIPADKLKDLTSRVF NGEPGAHDAKLRFESQEMKGIGTPPNTTPIKNGSPEIKLKITKTYMNGKPLFESSICGDSAADVSQSEENGQKPENKARRNRKRSIKYDS LLEQGLVEAALVSKISSPSDKKVVVNASSRLMLSYDLKTYLTNTLNSTVFKLFITTGRNGVNLKGFCTPNQALAITKVLLPATLMLCHVQ FSNTLLDIPASKVFQVHSDFSMEKGVYVCIIKVRPQSEELLQALSVADTSVYGWATLVSERSKNGMQRILIPFIPAFYINQSELVLSHKQ DIGEIRVLGVDRVLRKLEVISSSPVLVVAGHSHSPLTPGLAIYSVRVVNFTSFQQMASPVFINISCVLTSQSEAVVVRAMKDKLGADHCE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for WHSC1-NUP210L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for WHSC1-NUP210L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for WHSC1-NUP210L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies