
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:XRCC6-ACO2 (FusionGDB2 ID:99774) |
Fusion Gene Summary for XRCC6-ACO2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: XRCC6-ACO2 | Fusion gene ID: 99774 | Hgene | Tgene | Gene symbol | XRCC6 | ACO2 | Gene ID | 2547 | 50 |
| Gene name | X-ray repair cross complementing 6 | aconitase 2 | |
| Synonyms | CTC75|CTCBF|G22P1|KU70|ML8|TLAA | ACONM|HEL-S-284|ICRD|OCA8|OPA9 | |
| Cytomap | 22q13.2 | 22q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | X-ray repair cross-complementing protein 65'-dRP lyase Ku705'-deoxyribose-5-phosphate lyase Ku7070 kDa subunit of Ku antigenATP-dependent DNA helicase 2 subunit 1ATP-dependent DNA helicase II, 70 kDa subunitCTC box binding factor 75 kDa subunitDNA | aconitate hydratase, mitochondrialaconitase 2, mitochondrialcitrate hydro-lyaseepididymis secretory sperm binding protein Li 284mitochondrial aconitase | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | Q99798 | |
| Ensembl transtripts involved in fusion gene | ENST00000359308, ENST00000360079, ENST00000402580, ENST00000405878, ENST00000405506, ENST00000428575, | ENST00000466237, ENST00000216254, ENST00000396512, | |
| Fusion gene scores | * DoF score | 12 X 10 X 8=960 | 13 X 16 X 8=1664 |
| # samples | 15 | 18 | |
| ** MAII score | log2(15/960*10)=-2.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1664*10)=-3.20858662181142 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: XRCC6 [Title/Abstract] AND ACO2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | XRCC6(42024234)-ACO2(41916175), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | XRCC6 | GO:0002218 | activation of innate immune response | 28712728 |
| Hgene | XRCC6 | GO:0045860 | positive regulation of protein kinase activity | 22504299 |
| Hgene | XRCC6 | GO:0045893 | positive regulation of transcription, DNA-templated | 12145306 |
| Hgene | XRCC6 | GO:0071480 | cellular response to gamma radiation | 26359349 |
| Hgene | XRCC6 | GO:0097680 | double-strand break repair via classical nonhomologous end joining | 24095731 |
| Tgene | ACO2 | GO:0006099 | tricarboxylic acid cycle | 9630632 |
| Tgene | ACO2 | GO:0006101 | citrate metabolic process | 9630632 |
| Fusion gene breakpoints across XRCC6 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ACO2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-DD-A11C-01A | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
Top |
Fusion Gene ORF analysis for XRCC6-ACO2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000359308 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| 5CDS-3UTR | ENST00000360079 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| 5CDS-3UTR | ENST00000402580 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| 5CDS-3UTR | ENST00000405878 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000359308 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000359308 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000360079 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000360079 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000402580 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000402580 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000405878 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| In-frame | ENST00000405878 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3CDS | ENST00000405506 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3CDS | ENST00000405506 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3CDS | ENST00000428575 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3CDS | ENST00000428575 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3UTR | ENST00000405506 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| intron-3UTR | ENST00000428575 | ENST00000466237 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000360079 | XRCC6 | chr22 | 42024234 | + | ENST00000216254 | ACO2 | chr22 | 41916175 | + | 2124 | 437 | 242 | 1747 | 501 |
| ENST00000360079 | XRCC6 | chr22 | 42024234 | + | ENST00000396512 | ACO2 | chr22 | 41916175 | + | 2124 | 437 | 242 | 1747 | 501 |
| ENST00000402580 | XRCC6 | chr22 | 42024234 | + | ENST00000216254 | ACO2 | chr22 | 41916175 | + | 1948 | 261 | 66 | 1571 | 501 |
| ENST00000402580 | XRCC6 | chr22 | 42024234 | + | ENST00000396512 | ACO2 | chr22 | 41916175 | + | 1948 | 261 | 66 | 1571 | 501 |
| ENST00000359308 | XRCC6 | chr22 | 42024234 | + | ENST00000216254 | ACO2 | chr22 | 41916175 | + | 2537 | 850 | 655 | 2160 | 501 |
| ENST00000359308 | XRCC6 | chr22 | 42024234 | + | ENST00000396512 | ACO2 | chr22 | 41916175 | + | 2537 | 850 | 655 | 2160 | 501 |
| ENST00000405878 | XRCC6 | chr22 | 42024234 | + | ENST00000216254 | ACO2 | chr22 | 41916175 | + | 2028 | 341 | 146 | 1651 | 501 |
| ENST00000405878 | XRCC6 | chr22 | 42024234 | + | ENST00000396512 | ACO2 | chr22 | 41916175 | + | 2028 | 341 | 146 | 1651 | 501 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000360079 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.007762413 | 0.9922376 |
| ENST00000360079 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.007762413 | 0.9922376 |
| ENST00000402580 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.00736227 | 0.99263775 |
| ENST00000402580 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.00736227 | 0.99263775 |
| ENST00000359308 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.008674827 | 0.99132526 |
| ENST00000359308 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.008674827 | 0.99132526 |
| ENST00000405878 | ENST00000216254 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.008140617 | 0.9918594 |
| ENST00000405878 | ENST00000396512 | XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916175 | + | 0.008140617 | 0.9918594 |
Top |
Fusion Genomic Features for XRCC6-ACO2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916174 | + | 3.90E-11 | 1 |
| XRCC6 | chr22 | 42024234 | + | ACO2 | chr22 | 41916174 | + | 3.90E-11 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
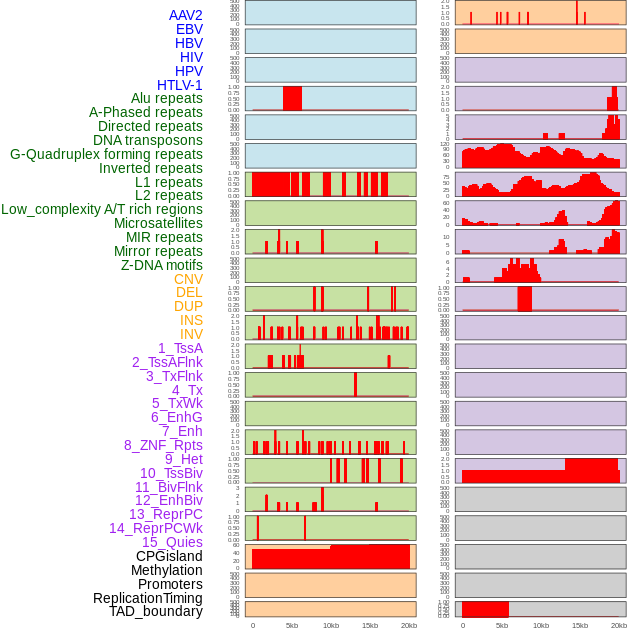 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
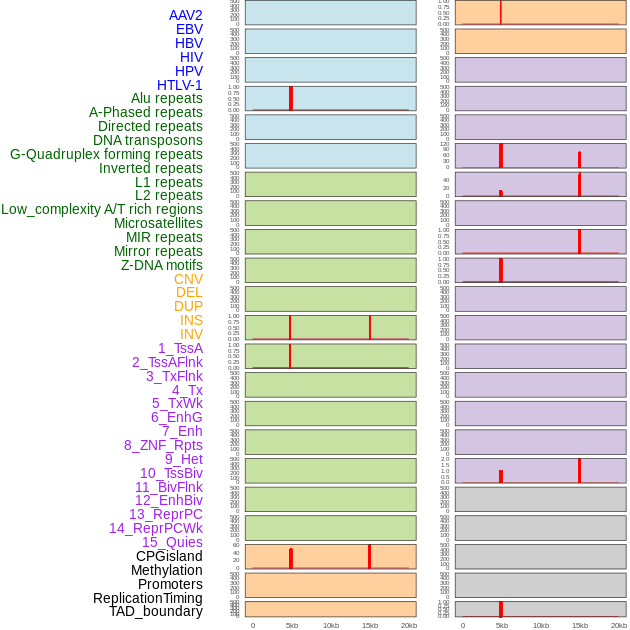 |
Top |
Fusion Protein Features for XRCC6-ACO2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:42024234/chr22:41916175) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ACO2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Catalyzes the isomerization of citrate to isocitrate via cis-aconitate. {ECO:0000250|UniProtKB:P16276}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 11_29 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 2_61 | 65 | 610.0 | Compositional bias | Note=Ser-rich (potentially targets for phosphorylation) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 11_29 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 2_61 | 65 | 610.0 | Compositional bias | Note=Ser-rich (potentially targets for phosphorylation) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 11_29 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 2_61 | 65 | 610.0 | Compositional bias | Note=Ser-rich (potentially targets for phosphorylation) |
| Tgene | ACO2 | chr22:42024234 | chr22:41916175 | ENST00000216254 | 7 | 18 | 670_671 | 344 | 781.0 | Region | Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 330_342 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 330_342 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 330_342 | 65 | 610.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 261_468 | 65 | 610.0 | Domain | Note=Ku |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 573_607 | 65 | 610.0 | Domain | SAP |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 261_468 | 65 | 610.0 | Domain | Note=Ku |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 573_607 | 65 | 610.0 | Domain | SAP |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 261_468 | 65 | 610.0 | Domain | Note=Ku |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 573_607 | 65 | 610.0 | Domain | SAP |
| Tgene | ACO2 | chr22:42024234 | chr22:41916175 | ENST00000216254 | 7 | 18 | 192_194 | 344 | 781.0 | Region | Substrate binding |
Top |
Fusion Gene Sequence for XRCC6-ACO2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >99774_99774_1_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000359308_ACO2_chr22_41916175_ENST00000216254_length(transcript)=2537nt_BP=850nt GCGGGCCGTTATCCATTTGTGTTGTTCGCCAGCTAGGCCTGGCCTCGTCCCGCTTCGCTCGGTCGGTCTCGCGCGCCCCCATAGCCTTGC TAGAGGGTTAGCGTTAGCCTTAAGTGTGCGAATCCGAGGAGCAGCGACAGACTCGAGACCACGCTCCTTCCTCGGGAAGGAGGCGGCACC TCGCGTTTGAGGCCCGCCTGCGTTTGAGGCCCGCCTGCGCTTGCGGCCCGCCTGCGCTTGAGGCCTGTCTGCGTTTGAGATCTCATTGGG CGTGATTGAGGAATTTGGGGAGGTTTTTGGGCGGTATTGAGGACGAGGGGGTCCGTTAGTCAGCATAGAATCCTGGAGCGGGAATCCCTC ACCGTCTAAATGGCGTCGGGGGCGGGACCTCCGGGATCTGGCTTCCGCGGGCCGCCGCCGGCCCTGAAACGTGAGGGATAGCTGAGATGA GGCAGCTACTGGGATGGCCCCCATGCGCATTTACATGCAGTCCGACTGCCGAGCTTTCGAGGCAGCAGGATTTACCGTCCACATTCCTCA CTACTAACCAAGCTTTTAGAACAGATCTCACAAGAACCTAGAGGTCGGTATTTTTTCGATTTAAATTTGCCTGTTACTGACGTTAACGTC TTTCGCCTAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAACCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGA GAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTTTTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCA GAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACATCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGT GGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAGTGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGA AGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCAAGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGA GCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATCTGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTG CATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCGTCACCTCCTACAACAGGAACTTCACGGGCCGCAACGA CGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCCTGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGAC CGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATGCAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCA GGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGAGCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTT TGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCAAAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGG CCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCATTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTC CGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCTACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGG AGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTCGCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTT TGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCTTCGCTGACCCGGCTGACTACAACAAGATTCACCCTGT GGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGAAGTGCATCATCAAGCACCCCAACGGGACCCAGGAGAC CATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTGGCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTG AGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGCCATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTA TTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAGTGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACT TTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCATGCAACTGTATTTATTTTTGATGACAAGACTCCCATC TAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGAACCTTTTGTTCTTGCAAGGAAAACAAGAATCCAAAAC >99774_99774_1_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000359308_ACO2_chr22_41916175_ENST00000216254_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_2_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000359308_ACO2_chr22_41916175_ENST00000396512_length(transcript)=2537nt_BP=850nt GCGGGCCGTTATCCATTTGTGTTGTTCGCCAGCTAGGCCTGGCCTCGTCCCGCTTCGCTCGGTCGGTCTCGCGCGCCCCCATAGCCTTGC TAGAGGGTTAGCGTTAGCCTTAAGTGTGCGAATCCGAGGAGCAGCGACAGACTCGAGACCACGCTCCTTCCTCGGGAAGGAGGCGGCACC TCGCGTTTGAGGCCCGCCTGCGTTTGAGGCCCGCCTGCGCTTGCGGCCCGCCTGCGCTTGAGGCCTGTCTGCGTTTGAGATCTCATTGGG CGTGATTGAGGAATTTGGGGAGGTTTTTGGGCGGTATTGAGGACGAGGGGGTCCGTTAGTCAGCATAGAATCCTGGAGCGGGAATCCCTC ACCGTCTAAATGGCGTCGGGGGCGGGACCTCCGGGATCTGGCTTCCGCGGGCCGCCGCCGGCCCTGAAACGTGAGGGATAGCTGAGATGA GGCAGCTACTGGGATGGCCCCCATGCGCATTTACATGCAGTCCGACTGCCGAGCTTTCGAGGCAGCAGGATTTACCGTCCACATTCCTCA CTACTAACCAAGCTTTTAGAACAGATCTCACAAGAACCTAGAGGTCGGTATTTTTTCGATTTAAATTTGCCTGTTACTGACGTTAACGTC TTTCGCCTAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAACCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGA GAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTTTTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCA GAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACATCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGT GGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAGTGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGA AGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCAAGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGA GCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATCTGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTG CATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCGTCACCTCCTACAACAGGAACTTCACGGGCCGCAACGA CGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCCTGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGAC CGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATGCAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCA GGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGAGCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTT TGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCAAAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGG CCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCATTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTC CGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCTACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGG AGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTCGCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTT TGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCTTCGCTGACCCGGCTGACTACAACAAGATTCACCCTGT GGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGAAGTGCATCATCAAGCACCCCAACGGGACCCAGGAGAC CATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTGGCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTG AGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGCCATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTA TTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAGTGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACT TTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCATGCAACTGTATTTATTTTTGATGACAAGACTCCCATC TAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGAACCTTTTGTTCTTGCAAGGAAAACAAGAATCCAAAAC >99774_99774_2_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000359308_ACO2_chr22_41916175_ENST00000396512_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_3_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000360079_ACO2_chr22_41916175_ENST00000216254_length(transcript)=2124nt_BP=437nt GTAGGAAGGGGCGGGGCTTTGCCGAAGGGGGCGGGGCTCTCGCTGATGGGTTGGCTTTCGTCAGGGACATAGGTAGAAGCTGGTTGGGGA GTGTGCGTGCCAGCCTGACGCGATATAGTGCGCACATGCGTGATGACGTAGAGGGCGTTGATTGGGACCGAGTACAGGGCCCGCGCATGC GTGGATTGTCGTCTTCTGTCCAAGTTGGTCGCTTCCCTGCGCCAAAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAA CCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTT TTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACA TCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAG TGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCA AGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATC TGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCG TCACCTCCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCC TGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATG CAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGA GCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCA AAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCA TTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCT ACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTC GCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCT TCGCTGACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGA AGTGCATCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTG GCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGC CATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAG TGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCA TGCAACTGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGA >99774_99774_3_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000360079_ACO2_chr22_41916175_ENST00000216254_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_4_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000360079_ACO2_chr22_41916175_ENST00000396512_length(transcript)=2124nt_BP=437nt GTAGGAAGGGGCGGGGCTTTGCCGAAGGGGGCGGGGCTCTCGCTGATGGGTTGGCTTTCGTCAGGGACATAGGTAGAAGCTGGTTGGGGA GTGTGCGTGCCAGCCTGACGCGATATAGTGCGCACATGCGTGATGACGTAGAGGGCGTTGATTGGGACCGAGTACAGGGCCCGCGCATGC GTGGATTGTCGTCTTCTGTCCAAGTTGGTCGCTTCCCTGCGCCAAAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAA CCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTT TTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACA TCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAG TGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCA AGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATC TGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCG TCACCTCCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCC TGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATG CAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGA GCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCA AAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCA TTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCT ACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTC GCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCT TCGCTGACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGA AGTGCATCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTG GCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGC CATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAG TGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCA TGCAACTGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGA >99774_99774_4_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000360079_ACO2_chr22_41916175_ENST00000396512_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_5_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000402580_ACO2_chr22_41916175_ENST00000216254_length(transcript)=1948nt_BP=261nt ATGCGTGGATTGTCGTCTTCTGTCCAAGTTGGTCGCTTCCCTGCGCCAAAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTAC AAAACCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTG ATTTTTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCA CACATCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATC CGAGTGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGC CTCAAGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGG GATCTGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACA ATCGTCACCTCCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACA GCCCTGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCG GATGCAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGAC GTGAGCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAG GTCAAAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTG CTCATTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCC CGCTACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAG CCTCGCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTG ACCTTCGCTGACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCC CTGAAGTGCATCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGC GCTGGCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGT GTGCCATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCAC GGAGTGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGC TCCATGCAACTGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTA >99774_99774_5_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000402580_ACO2_chr22_41916175_ENST00000216254_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_6_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000402580_ACO2_chr22_41916175_ENST00000396512_length(transcript)=1948nt_BP=261nt ATGCGTGGATTGTCGTCTTCTGTCCAAGTTGGTCGCTTCCCTGCGCCAAAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTAC AAAACCGAGGGCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTG ATTTTTTTGGTTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCA CACATCAATGGGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATC CGAGTGGGTCTAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGC CTCAAGTGCAAGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGG GATCTGGGTGGCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACA ATCGTCACCTCCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACA GCCCTGGCCATTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCG GATGCAGATGAGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGAC GTGAGCCCCACCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAG GTCAAAGGGAAGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTG CTCATTGGTGCCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCC CGCTACTACAAGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAG CCTCGCCACCTTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTG ACCTTCGCTGACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCC CTGAAGTGCATCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGC GCTGGCAGTGCCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGT GTGCCATCAGTGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCAC GGAGTGACTGTGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGC TCCATGCAACTGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTA >99774_99774_6_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000402580_ACO2_chr22_41916175_ENST00000396512_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_7_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000405878_ACO2_chr22_41916175_ENST00000216254_length(transcript)=2028nt_BP=341nt AAGTGTGCGAATCCGAGGAGCAGCGACAGACTCGAGACCACGCTCCTTCCTCGGGAAGGAGGCGGCACCTCGCGTTTGAGGCCCGCCTGC GTTTGAGGCCCGCCTGCGCTTGCGGCCCGCCTGCGCTTGAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAACCGAGG GCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTTTTTTGG TTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACATCAATG GGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAGTGGGTC TAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCAAGTGCA AGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATCTGGGTG GCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCGTCACCT CCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCCTGGCCA TTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATGCAGATG AGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGAGCCCCA CCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCAAAGGGA AGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCATTGGTG CCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCTACTACA AGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTCGCCACC TTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCTTCGCTG ACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGAAGTGCA TCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTGGCAGTG CCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGCCATCAG TGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAGTGACTG TGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCATGCAAC TGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGAACCTTT >99774_99774_7_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000405878_ACO2_chr22_41916175_ENST00000216254_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- >99774_99774_8_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000405878_ACO2_chr22_41916175_ENST00000396512_length(transcript)=2028nt_BP=341nt AAGTGTGCGAATCCGAGGAGCAGCGACAGACTCGAGACCACGCTCCTTCCTCGGGAAGGAGGCGGCACCTCGCGTTTGAGGCCCGCCTGC GTTTGAGGCCCGCCTGCGCTTGCGGCCCGCCTGCGCTTGAGTGAGCAGTAGCCAACATGTCAGGGTGGGAGTCATATTACAAAACCGAGG GCGATGAAGAAGCAGAGGAAGAACAAGAAGAGAACCTTGAAGCAAGTGGAGACTATAAATATTCAGGAAGAGATAGTTTGATTTTTTTGG TTGATGCCTCCAAGGCTATGTTTGAATCTCAGAGTGAAGATGAGTTGACACCTTTTGACATGAGCATCCAGCTGAAGCCACACATCAATG GGCCCTTCACCCCTGACCTGGCTCACCCTGTGGCAGAAGTGGGCAAGGTGGCAGAGAAGGAAGGATGGCCTCTGGACATCCGAGTGGGTC TAATTGGTAGCTGCACCAATTCAAGCTATGAAGATATGGGGCGCTCAGCAGCTGTGGCCAAGCAGGCACTGGCCCATGGCCTCAAGTGCA AGTCCCAGTTCACCATCACTCCAGGTTCCGAGCAGATCCGCGCCACCATTGAGCGGGACGGCTATGCACAGATCTTGAGGGATCTGGGTG GCATTGTCCTGGCCAATGCTTGTGGCCCCTGCATTGGCCAGTGGGACAGGAAGGACATCAAGAAGGGGGAGAAGAACACAATCGTCACCT CCTACAACAGGAACTTCACGGGCCGCAACGACGCAAACCCCGAGACCCATGCCTTTGTCACGTCCCCAGAGATTGTCACAGCCCTGGCCA TTGCGGGAACCCTCAAGTTCAACCCAGAGACCGACTACCTGACGGGCACGGATGGCAAGAAGTTCAGGCTGGAGGCTCCGGATGCAGATG AGCTTCCCAAAGGGGAGTTTGACCCAGGGCAGGACACCTACCAGCACCCACCCAAGGACAGCAGCGGGCAGCATGTGGACGTGAGCCCCA CCAGCCAGCGCCTGCAGCTCCTGGAGCCTTTTGACAAGTGGGATGGCAAGGACCTGGAGGACCTGCAGATCCTCATCAAGGTCAAAGGGA AGTGTACCACTGACCACATCTCAGCTGCTGGCCCCTGGCTCAAGTTCCGTGGGCACTTGGATAACATCTCCAACAACCTGCTCATTGGTG CCATCAACATTGAAAACGGCAAGGCCAACTCCGTGCGCAATGCCGTCACTCAGGAGTTTGGCCCCGTCCCTGACACTGCCCGCTACTACA AGAAACATGGCATCAGGTGGGTGGTGATCGGAGACGAGAACTACGGCGAGGGCTCGAGCCGGGAGCATGCAGCTCTGGAGCCTCGCCACC TTGGGGGCCGGGCCATCATCACCAAGAGCTTTGCCAGGATCCACGAGACCAACCTGAAGAAACAGGGCCTGCTGCCTCTGACCTTCGCTG ACCCGGCTGACTACAACAAGATTCACCCTGTGGACAAGCTGACCATTCAGGGCCTGAAGGACTTCACCCCTGGCAAGCCCCTGAAGTGCA TCATCAAGCACCCCAACGGGACCCAGGAGACCATCCTCCTGAACCACACCTTCAACGAGACGCAGATTGAGTGGTTCCGCGCTGGCAGTG CCCTCAACAGAATGAAGGAACTGCAACAGTGAGGGCAGTGCCTCCCCGCCCCGCCGCTGGCGTCAAGTTCAGCTCCACGTGTGCCATCAG TGGATCCGATCCGTCCAGCCATGGCTTCCTATTCCAAGATGGTGTGACCAGACATGCTTCCTGCTCCCCGCTTAGCCCACGGAGTGACTG TGGTTGTGGTGGGGGGGTTCTTAAAATAACTTTTTAGCCCCCGTCTTCCTATTTTGAGTTTGGTTCAGATCTTAAGCAGCTCCATGCAAC TGTATTTATTTTTGATGACAAGACTCCCATCTAAAGTTTTTCTCCTGCCTGATCATTTCATTGGTGGCTGAAGGATTCTAGAGAACCTTT >99774_99774_8_XRCC6-ACO2_XRCC6_chr22_42024234_ENST00000405878_ACO2_chr22_41916175_ENST00000396512_length(amino acids)=501AA_BP=64 MSGWESYYKTEGDEEAEEEQEENLEASGDYKYSGRDSLIFLVDASKAMFESQSEDELTPFDMSIQLKPHINGPFTPDLAHPVAEVGKVAE KEGWPLDIRVGLIGSCTNSSYEDMGRSAAVAKQALAHGLKCKSQFTITPGSEQIRATIERDGYAQILRDLGGIVLANACGPCIGQWDRKD IKKGEKNTIVTSYNRNFTGRNDANPETHAFVTSPEIVTALAIAGTLKFNPETDYLTGTDGKKFRLEAPDADELPKGEFDPGQDTYQHPPK DSSGQHVDVSPTSQRLQLLEPFDKWDGKDLEDLQILIKVKGKCTTDHISAAGPWLKFRGHLDNISNNLLIGAINIENGKANSVRNAVTQE FGPVPDTARYYKKHGIRWVVIGDENYGEGSSREHAALEPRHLGGRAIITKSFARIHETNLKKQGLLPLTFADPADYNKIHPVDKLTIQGL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for XRCC6-ACO2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000359308 | + | 2 | 12 | 550_609 | 65.0 | 610.0 | DEAF1 |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000360079 | + | 3 | 13 | 550_609 | 65.0 | 610.0 | DEAF1 |
| Hgene | XRCC6 | chr22:42024234 | chr22:41916175 | ENST00000405878 | + | 3 | 13 | 550_609 | 65.0 | 610.0 | DEAF1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for XRCC6-ACO2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for XRCC6-ACO2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies