| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:CDK5RAP2-GRIN1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: CDK5RAP2-GRIN1 | FusionPDB ID: 15271 | FusionGDB2.0 ID: 15271 | Hgene | Tgene | Gene symbol | CDK5RAP2 | GRIN1 | Gene ID | 55755 | 114787 |
| Gene name | CDK5 regulatory subunit associated protein 2 | G protein regulated inducer of neurite outgrowth 1 | |
| Synonyms | C48|Cep215|MCPH3 | GRIN1 | |
| Cytomap | 9q33.2 | 5q35.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | CDK5 regulatory subunit-associated protein 2CDK5 activator-binding protein C48centrosomal protein 215 kDacentrosomin | G protein-regulated inducer of neurite outgrowth 1 | |
| Modification date | 20200328 | 20200313 | |
| UniProtAcc | Q96SN8 | Q05586 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000349780, ENST00000359309, ENST00000360190, ENST00000360822, ENST00000480467, | ENST00000350902, ENST00000371546, ENST00000371550, ENST00000371553, ENST00000371555, ENST00000371559, ENST00000371560, ENST00000471122, ENST00000315048, ENST00000371561, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 12 X 13 X 5=780 | 5 X 5 X 5=125 |
| # samples | 13 | 6 | |
| ** MAII score | log2(13/780*10)=-2.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/125*10)=-1.05889368905357 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: CDK5RAP2 [Title/Abstract] AND GRIN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | CDK5RAP2(123280705)-GRIN1(140036465), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | CDK5RAP2-GRIN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CDK5RAP2-GRIN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CDK5RAP2-GRIN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CDK5RAP2-GRIN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CDK5RAP2 | GO:0000226 | microtubule cytoskeleton organization | 17959831 |
| Hgene | CDK5RAP2 | GO:0001578 | microtubule bundle formation | 19553473 |
| Hgene | CDK5RAP2 | GO:0045893 | positive regulation of transcription, DNA-templated | 19282672 |
| Hgene | CDK5RAP2 | GO:0090266 | regulation of mitotic cell cycle spindle assembly checkpoint | 19282672 |
| Fusion gene breakpoints across CDK5RAP2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GRIN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-HT-7873-01B | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + |
| ChimerDB4 | LGG | TCGA-HT-7873 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000360822 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000371561 | GRIN1 | chr9 | 140036465 | + | 5279 | 1492 | 181 | 4050 | 1289 |
| ENST00000360822 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000315048 | GRIN1 | chr9 | 140036465 | + | 4916 | 1492 | 181 | 4002 | 1273 |
| ENST00000359309 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000371561 | GRIN1 | chr9 | 140036465 | + | 5279 | 1492 | 181 | 4050 | 1289 |
| ENST00000359309 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000315048 | GRIN1 | chr9 | 140036465 | + | 4916 | 1492 | 181 | 4002 | 1273 |
| ENST00000349780 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000371561 | GRIN1 | chr9 | 140036465 | + | 5278 | 1491 | 180 | 4049 | 1289 |
| ENST00000349780 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000315048 | GRIN1 | chr9 | 140036465 | + | 4915 | 1491 | 180 | 4001 | 1273 |
| ENST00000360190 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000371561 | GRIN1 | chr9 | 140036465 | + | 5278 | 1491 | 180 | 4049 | 1289 |
| ENST00000360190 | CDK5RAP2 | chr9 | 123280705 | - | ENST00000315048 | GRIN1 | chr9 | 140036465 | + | 4915 | 1491 | 180 | 4001 | 1273 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000360822 | ENST00000371561 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.005151743 | 0.99484825 |
| ENST00000360822 | ENST00000315048 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.00480265 | 0.99519736 |
| ENST00000359309 | ENST00000371561 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.005151743 | 0.99484825 |
| ENST00000359309 | ENST00000315048 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.00480265 | 0.99519736 |
| ENST00000349780 | ENST00000371561 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.005150917 | 0.994849 |
| ENST00000349780 | ENST00000315048 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.004804057 | 0.9951959 |
| ENST00000360190 | ENST00000371561 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.005150917 | 0.994849 |
| ENST00000360190 | ENST00000315048 | CDK5RAP2 | chr9 | 123280705 | - | GRIN1 | chr9 | 140036465 | + | 0.004804057 | 0.9951959 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >15271_15271_1_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000349780_GRIN1_chr9_140036465_ENST00000315048_length(amino acids)=1273AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTQYHPTDITG -------------------------------------------------------------- >15271_15271_2_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000349780_GRIN1_chr9_140036465_ENST00000371561_length(amino acids)=1289AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTSTGGGRGAL -------------------------------------------------------------- >15271_15271_3_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000359309_GRIN1_chr9_140036465_ENST00000315048_length(amino acids)=1273AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTQYHPTDITG -------------------------------------------------------------- >15271_15271_4_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000359309_GRIN1_chr9_140036465_ENST00000371561_length(amino acids)=1289AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTSTGGGRGAL -------------------------------------------------------------- >15271_15271_5_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000360190_GRIN1_chr9_140036465_ENST00000315048_length(amino acids)=1273AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTQYHPTDITG -------------------------------------------------------------- >15271_15271_6_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000360190_GRIN1_chr9_140036465_ENST00000371561_length(amino acids)=1289AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTSTGGGRGAL -------------------------------------------------------------- >15271_15271_7_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000360822_GRIN1_chr9_140036465_ENST00000315048_length(amino acids)=1273AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTQYHPTDITG -------------------------------------------------------------- >15271_15271_8_CDK5RAP2-GRIN1_CDK5RAP2_chr9_123280705_ENST00000360822_GRIN1_chr9_140036465_ENST00000371561_length(amino acids)=1289AA_BP=437 MMDLVLEEDVTVPGTLSGCSGLVPSVPDDLDGINPNAGLGNGLLPNVSEETVSPTRARNMKDFENQITELKKENFNLKLRIYFLEERMQQ EFHGPTEHIYKTNIELKVEVESLKRELQEREQLLIKASKAVESLAEAGGSEIQRVKEDARKKVQQVEDLLTKRILLLEKDVTAAQAELEK AFAGTETEKALRLRLESKLSEMKKMHEGDLAMALVLDEKDRLIEELKLSLKSKEALIQCLKEEKSQMACPDENVSSGELRGLCAAPREEK ERETEAAQMEHQKERNSFEERIQALEEDLREKEREIATEKKNSLKRDKAIQGLTMALKSKEKKVEELNSEIEKLSAAFAKAREALQKAQT QEFQGSEDYETALSGKEALSAALRSQNLTKSTENHRLRRSIKKITQELSDLQQERERLEKDLEEAHREKSKGDCTIRVYAILVSHPPTPN DHFTPTPVSYTAGFYRIPVLGLTTRMSIYSDKSIHLSFLRTVPPYSHQSSVWFEMMRVYSWNHIILLVSDDHEGRAAQKRLETLLEERES KAEKVLQFDPGTKNVTALLMEAKELEARVIILSASEDDAATVYRAAAMLNMTGSGYVWLVGEREISGNALRYAPDGILGLQLINGKNESA HISDAVGVVAQAVHELLEKENITDPPRGCVGNTNIWKTGPLFKRVLMSSKYADGVTGRVEFNEDGDRKFANYSIMNLQNRKLVQVGIYNG THVIPNDRKIIWPGGETEKPRGYQMSTRLKIVTIHQEPFVYVKPTLSDGTCKEEFTVNGDPVKKVICTGPNDTSPGSPRHTVPQCCYGFC IDLLIKLARTMNFTYEVHLVADGKFGTQERVNNSNKKEWNGMMGELLSGQADMIVAPLTINNERAQYIEFSKPFKYQGLTILVKKEIPRS TLDSFMQPFQSTLWLLVGLSVHVVAVMLYLLDRFSPFGRFKVNSEEEEEDALTLSSAMWFSWGVLLNSGIGEGAPRSFSARILGMVWAGF AMIIVASYTANLAAFLVLDRPEERITGINDPRLRNPSDKFIYATVKQSSVDIYFRRQVELSTMYRHMEKHNYESAAEAIQAVRDNKLHAF IWDSAVLEFEASQKCDLVTTGELFFRSGFGIGMRKDSPWKQNVSLSILKSHENGFMEDLDKTWVRYQECDSRSNAPATLTFENMAGVFML VAGGIVAGIFLIFIEIAYKRHKDARRKQMQLAFAAVNVWRKNLQDRKSGRAEPDPKKKATFRAITSTLASSFKRRRSSKDTSTGGGRGAL -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:123280705/chr9:140036465) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CDK5RAP2 | GRIN1 |
| FUNCTION: Potential regulator of CDK5 activity via its interaction with CDK5R1. Negative regulator of centriole disengagement (licensing) which maintains centriole engagement and cohesion. Involved in regulation of mitotic spindle orientation (By similarity). Plays a role in the spindle checkpoint activation by acting as a transcriptional regulator of both BUBR1 and MAD2 promoter. Together with EB1/MAPRE1, may promote microtubule polymerization, bundle formation, growth and dynamics at the plus ends. Regulates centrosomal maturation by recruitment of the gamma-tubulin ring complex (gamma-TuRC) onto centrosomes (PubMed:26485573). In complex with PDE4DIP isoform 13/MMG8/SMYLE, MAPRE1 and AKAP9, contributes to microtubules nucleation and extension from the centrosome to the cell periphery (PubMed:29162697). Required for the recruitment of AKAP9 to centrosomes (PubMed:29162697). Plays a role in neurogenesis (By similarity). {ECO:0000250|UniProtKB:Q8K389, ECO:0000269|PubMed:17959831, ECO:0000269|PubMed:18042621, ECO:0000269|PubMed:19282672, ECO:0000269|PubMed:19553473, ECO:0000269|PubMed:26485573, ECO:0000269|PubMed:29162697}. | FUNCTION: Component of NMDA receptor complexes that function as heterotetrameric, ligand-gated ion channels with high calcium permeability and voltage-dependent sensitivity to magnesium. Channel activation requires binding of the neurotransmitter glutamate to the epsilon subunit, glycine binding to the zeta subunit, plus membrane depolarization to eliminate channel inhibition by Mg(2+) (PubMed:7685113, PubMed:28126851, PubMed:26919761, PubMed:26875626, PubMed:28105280). Sensitivity to glutamate and channel kinetics depend on the subunit composition (PubMed:26919761). {ECO:0000269|PubMed:26875626, ECO:0000269|PubMed:26919761, ECO:0000269|PubMed:28105280, ECO:0000269|PubMed:28126851, ECO:0000269|PubMed:7685113}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 516_518 | 86.0 | 923.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 603_624 | 86.0 | 923.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 516_518 | 86.0 | 960.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 603_624 | 86.0 | 960.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 516_518 | 86.0 | 902.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 603_624 | 86.0 | 902.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 516_518 | 86.0 | 944.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 603_624 | 86.0 | 944.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 516_518 | 86.0 | 886.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 603_624 | 86.0 | 886.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 516_518 | 86.0 | 907.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 603_624 | 86.0 | 907.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 516_518 | 86.0 | 939.0 | Region | Glycine binding | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 603_624 | 86.0 | 939.0 | Region | Pore-forming | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 581_602 | 86.0 | 923.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 625_630 | 86.0 | 923.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 648_812 | 86.0 | 923.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 834_938 | 86.0 | 923.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 581_602 | 86.0 | 960.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 625_630 | 86.0 | 960.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 648_812 | 86.0 | 960.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 834_938 | 86.0 | 960.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 581_602 | 86.0 | 902.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 625_630 | 86.0 | 902.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 648_812 | 86.0 | 902.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 834_938 | 86.0 | 902.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 581_602 | 86.0 | 944.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 625_630 | 86.0 | 944.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 648_812 | 86.0 | 944.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 834_938 | 86.0 | 944.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 581_602 | 86.0 | 886.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 625_630 | 86.0 | 886.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 648_812 | 86.0 | 886.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 834_938 | 86.0 | 886.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 581_602 | 86.0 | 907.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 625_630 | 86.0 | 907.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 648_812 | 86.0 | 907.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 834_938 | 86.0 | 907.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 581_602 | 86.0 | 939.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 625_630 | 86.0 | 939.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 648_812 | 86.0 | 939.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 834_938 | 86.0 | 939.0 | Topological domain | Cytoplasmic | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 560_580 | 86.0 | 923.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 631_647 | 86.0 | 923.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 813_833 | 86.0 | 923.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 560_580 | 86.0 | 960.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 631_647 | 86.0 | 960.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 813_833 | 86.0 | 960.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 560_580 | 86.0 | 902.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 631_647 | 86.0 | 902.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 813_833 | 86.0 | 902.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 560_580 | 86.0 | 944.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 631_647 | 86.0 | 944.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 813_833 | 86.0 | 944.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 560_580 | 86.0 | 886.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 631_647 | 86.0 | 886.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 813_833 | 86.0 | 886.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 560_580 | 86.0 | 907.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 631_647 | 86.0 | 907.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 813_833 | 86.0 | 907.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 560_580 | 86.0 | 939.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 631_647 | 86.0 | 939.0 | Transmembrane | Helical | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 813_833 | 86.0 | 939.0 | Transmembrane | Helical |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000315048 | 0 | 20 | 19_559 | 86.0 | 923.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371546 | 0 | 21 | 19_559 | 86.0 | 960.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371550 | 0 | 19 | 19_559 | 86.0 | 902.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371553 | 0 | 21 | 19_559 | 86.0 | 944.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371559 | 0 | 19 | 19_559 | 86.0 | 886.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371560 | 0 | 20 | 19_559 | 86.0 | 907.0 | Topological domain | Extracellular | |
| Tgene | GRIN1 | chr9:123280705 | chr9:140036465 | ENST00000371561 | 0 | 20 | 19_559 | 86.0 | 939.0 | Topological domain | Extracellular |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
CDK5RAP2_pLDDT.png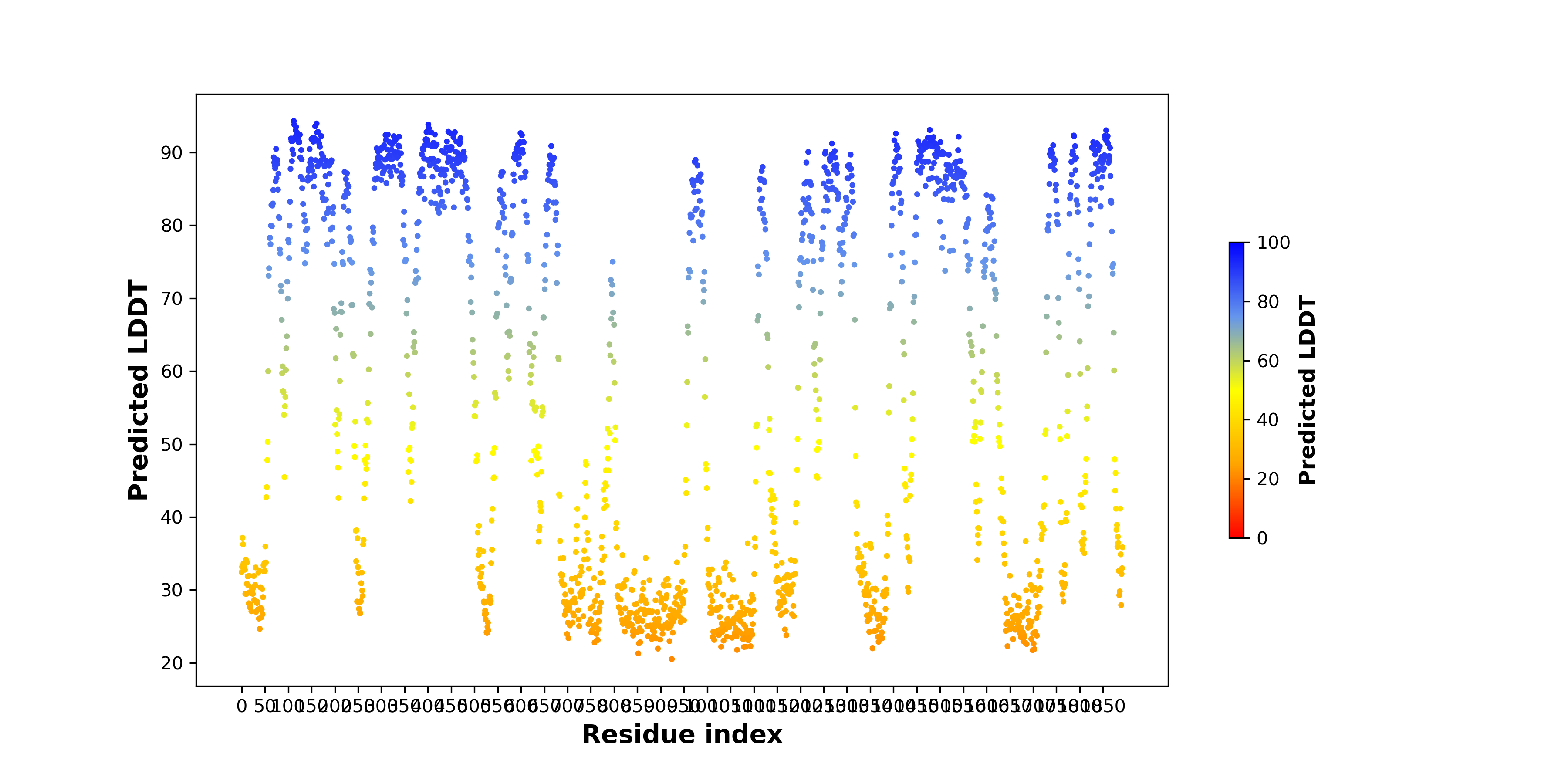  |
GRIN1_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| CDK5RAP2 | |
| GRIN1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000349780 | - | 12 | 38 | 1726_1768 | 437.0 | 1894.0 | CDK5R1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000359309 | - | 12 | 37 | 1726_1768 | 437.0 | 1853.0 | CDK5R1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360190 | - | 12 | 37 | 1726_1768 | 437.0 | 1815.0 | CDK5R1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360822 | - | 12 | 37 | 1726_1768 | 437.0 | 1862.0 | CDK5R1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000349780 | - | 12 | 38 | 926_1208 | 437.0 | 1894.0 | MAPRE1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000359309 | - | 12 | 37 | 926_1208 | 437.0 | 1853.0 | MAPRE1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360190 | - | 12 | 37 | 926_1208 | 437.0 | 1815.0 | MAPRE1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360822 | - | 12 | 37 | 926_1208 | 437.0 | 1862.0 | MAPRE1 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000349780 | - | 12 | 38 | 1726_1893 | 437.0 | 1894.0 | PCNT and AKAP9 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000359309 | - | 12 | 37 | 1726_1893 | 437.0 | 1853.0 | PCNT and AKAP9 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360190 | - | 12 | 37 | 1726_1893 | 437.0 | 1815.0 | PCNT and AKAP9 |
| Hgene | CDK5RAP2 | chr9:123280705 | chr9:140036465 | ENST00000360822 | - | 12 | 37 | 1726_1893 | 437.0 | 1862.0 | PCNT and AKAP9 |
Top |
Related Drugs to CDK5RAP2-GRIN1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to CDK5RAP2-GRIN1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies