| PDB file | PAE analysis | pLDDT distribution with InterPro domain align | Ramachandran plot | RMSD with the known PDB, Superimpose |
 Fusion_PDB_File superimposed PDB: Known_PDB_ID of partner (Partner_Gene). RMSD:Core_RMSD
Å Fusion_PDB_File superimposed PDB: Known_PDB_ID of partner (Partner_Gene). RMSD:Core_RMSD
Å |
 |  |  |  |  |
| A1BG_FGA_ENST00000263100_ENST00000403106_58864657_155508809 superimposed PDB: 3GHG of partner (FGA). RMSD:1.2639
Å |
 |  | 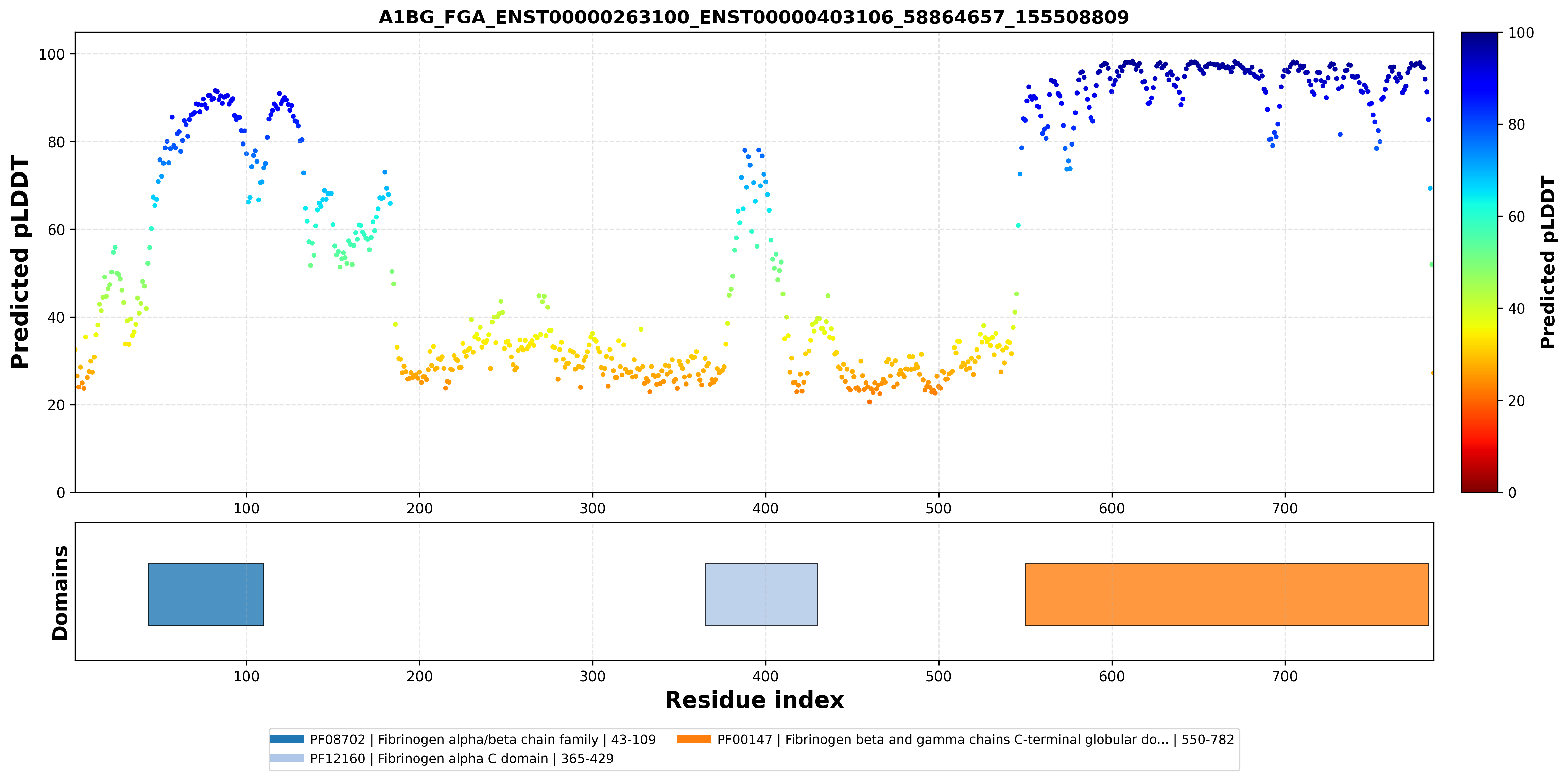 |  |  |
| A2ML1_RBM39_ENST00000299698_ENST00000253363_8988262_34301018 superimposed PDB: 7Q61 of partner (A2ML1). RMSD:2.0216
Å |
 |  |  |  |  |
| A2ML1_RBM39_ENST00000299698_ENST00000361162_8988262_34301018 superimposed PDB: 7Q61 of partner (A2ML1). RMSD:2.593
Å |
 |  |  |  |  |
| A2ML1_RBM39_ENST00000299698_ENST00000361162_8988262_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7186
Å |
| | | |  |
| A2ML1_RBM39_ENST00000299698_ENST00000528062_8988262_34301018 superimposed PDB: 7Q61 of partner (A2ML1). RMSD:2.676
Å |
 |  |  |  |  |
| A2ML1_RBM39_ENST00000299698_ENST00000528062_8988262_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7177
Å |
| | | |  |
| A2M_FN1_ENST00000318602_ENST00000323926_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.5287
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000345488_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8534
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000346544_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9484
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000354785_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1674
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000357009_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7249
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000357867_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:3.033
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000359671_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1995
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000432072_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1309
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000443816_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7718
Å |
 |  |  |  |  |
| A2M_FN1_ENST00000318602_ENST00000446046_9247568_216261946 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7363
Å |
 |  |  |  |  |
| AAK1_FNTA_ENST00000406297_ENST00000302279_69732700_42919243 superimposed PDB: 5TE0 of partner (AAK1). RMSD:0.4408
Å |
 |  |  |  |  |
| AAK1_FNTA_ENST00000406297_ENST00000302279_69732700_42919243 superimposed PDB: 2H6F of partner (FNTA). RMSD:0.8977
Å |
| | | |  |
| AAK1_KCMF1_ENST00000409085_ENST00000409785_69870009_85255011 superimposed PDB: 9QWS of partner (KCMF1). RMSD:0.7161
Å |
 |  |  |  |  |
| AAK1_NFU1_ENST00000409085_ENST00000410022_69870009_69650849 superimposed PDB: 2LTM of partner (NFU1). RMSD:0.6224
Å |
 |  |  |  |  |
| AAK1_NOP58_ENST00000406297_ENST00000264279_69732700_203160396 superimposed PDB: 5TE0 of partner (AAK1). RMSD:0.4339
Å |
 |  |  |  |  |
| AAK1_RFWD2_ENST00000409068_ENST00000308769_69870009_175996824 superimposed PDB: 9LTR of partner (RFWD2). RMSD:0.946
Å |
 |  |  |  |  |
| AAK1_RFWD2_ENST00000409085_ENST00000367669_69870009_175996824 superimposed PDB: 9LTR of partner (RFWD2). RMSD:0.9197
Å |
 |  |  |  |  |
| AAK1_WFDC13_ENST00000406297_ENST00000305479_69732700_44333082 superimposed PDB: 5TE0 of partner (AAK1). RMSD:0.4398
Å |
 |  |  |  |  |
| AARS_ST3GAL2_ENST00000261772_ENST00000342907_70303520_70415765 superimposed PDB: 4XEM of partner (AARS). RMSD:0.6973
Å |
 |  | 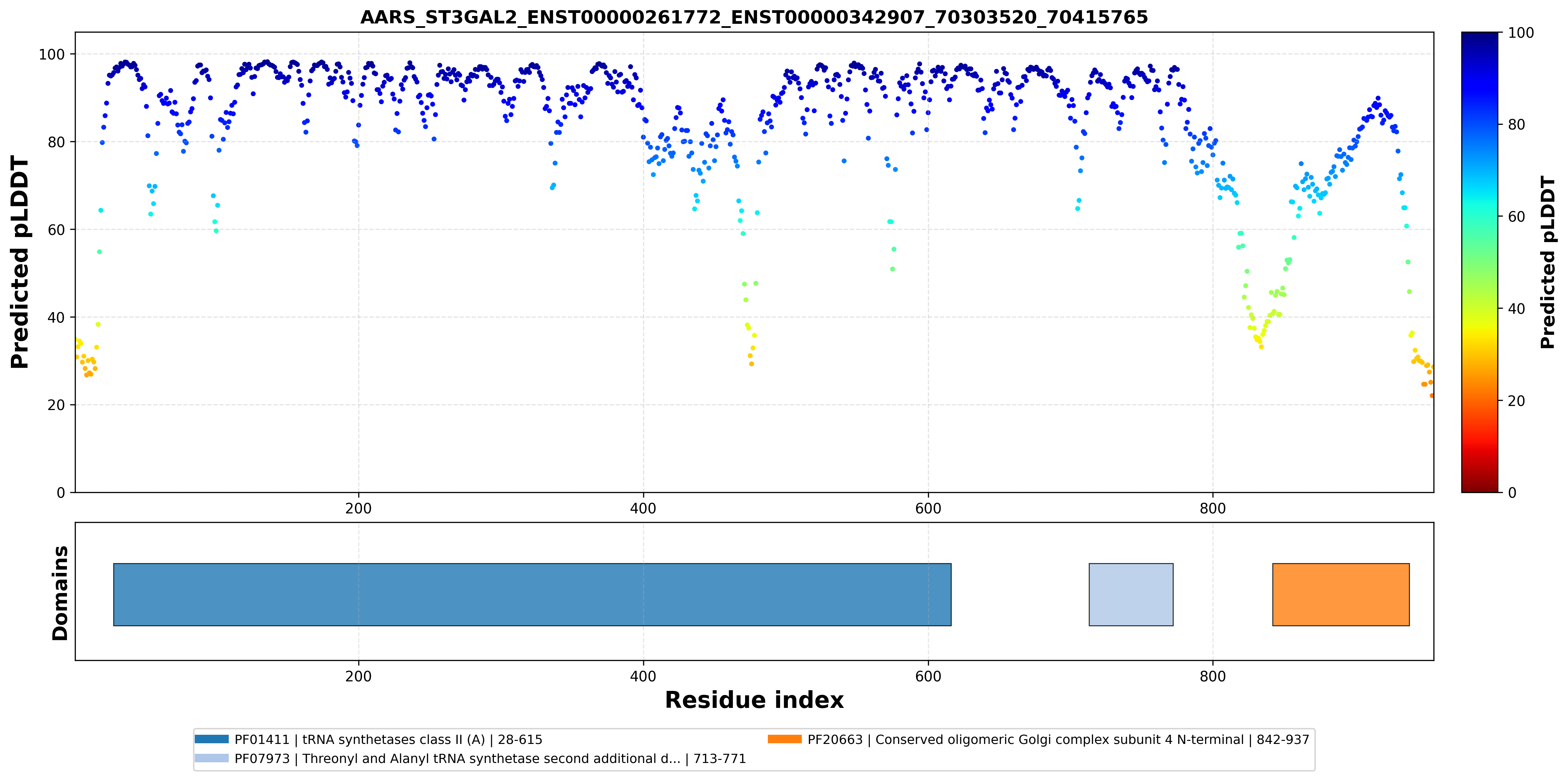 |  |  |
| AASDHPPT_ABTB2_ENST00000278618_ENST00000435224_105950419_34226237 superimposed PDB: 2C43 of partner (AASDHPPT). RMSD:0.4622
Å |
 |  |  |  |  |
| ABCA1_RAB5C_ENST00000374736_ENST00000393860_107645319_40278866 superimposed PDB: 4KYI of partner (RAB5C). RMSD:2.1694
Å |
 |  |  |  |  |
| ABCA1_RAB5C_ENST00000423487_ENST00000346213_107645319_40278866 superimposed PDB: 7TBW of partner (ABCA1). RMSD:2.7619
Å |
 |  |  |  |  |
| ABCA7_COL5A3_ENST00000433129_ENST00000264828_1059084_10114821 superimposed PDB: 8Y1P of partner (ABCA7). RMSD:2.9221
Å |
 |  |  |  |  |
| ABCA7_COL5A3_ENST00000435683_ENST00000264828_1059084_10114821 superimposed PDB: 8Y1P of partner (ABCA7). RMSD:3.0041
Å |
 |  |  |  |  |
| ABCC10_PPP2R5D_ENST00000244533_ENST00000394110_43401098_42974200 superimposed PDB: 8U1X of partner (PPP2R5D). RMSD:0.7877
Å |
 |  |  |  |  |
| ABCC10_PPP2R5D_ENST00000244533_ENST00000485511_43401098_42974200 superimposed PDB: 8U1X of partner (PPP2R5D). RMSD:0.7239
Å |
 |  |  |  |  |
| ABCC10_PPP2R5D_ENST00000372530_ENST00000394110_43401098_42974200 superimposed PDB: 8U1X of partner (PPP2R5D). RMSD:0.8247
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000346370_ENST00000300006_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2603
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000346370_ENST00000452191_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0924
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000346370_ENST00000566490_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0447
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000349029_ENST00000300006_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.245
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000349029_ENST00000452191_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9479
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000349029_ENST00000566490_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9972
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000351154_ENST00000300006_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0264
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000351154_ENST00000452191_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.1316
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000351154_ENST00000566490_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.1323
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000399408_ENST00000300006_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.1666
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000399408_ENST00000452191_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2566
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000399408_ENST00000566490_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2352
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000399410_ENST00000452191_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2512
Å |
 |  |  |  |  |
| ABCC1_C16orf45_ENST00000399410_ENST00000566490_16232415_15661839 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2421
Å |
 |  |  |  |  |
| ABCC1_PRKCB_ENST00000346370_ENST00000303531_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0897
Å |
 |  | 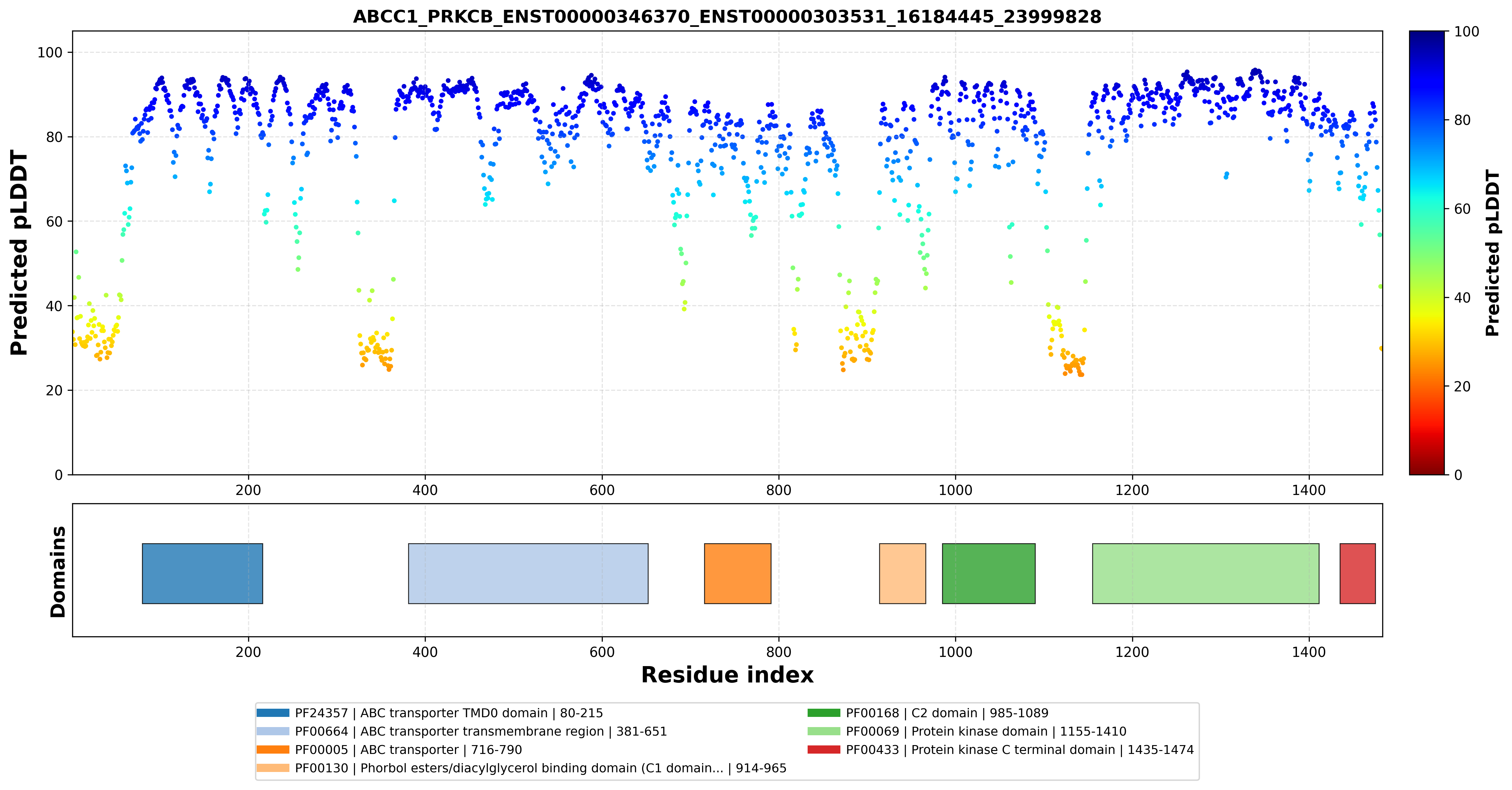 |  |  |
| ABCC1_PRKCB_ENST00000346370_ENST00000303531_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.4795
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000349029_ENST00000303531_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.995
Å |
 |  | 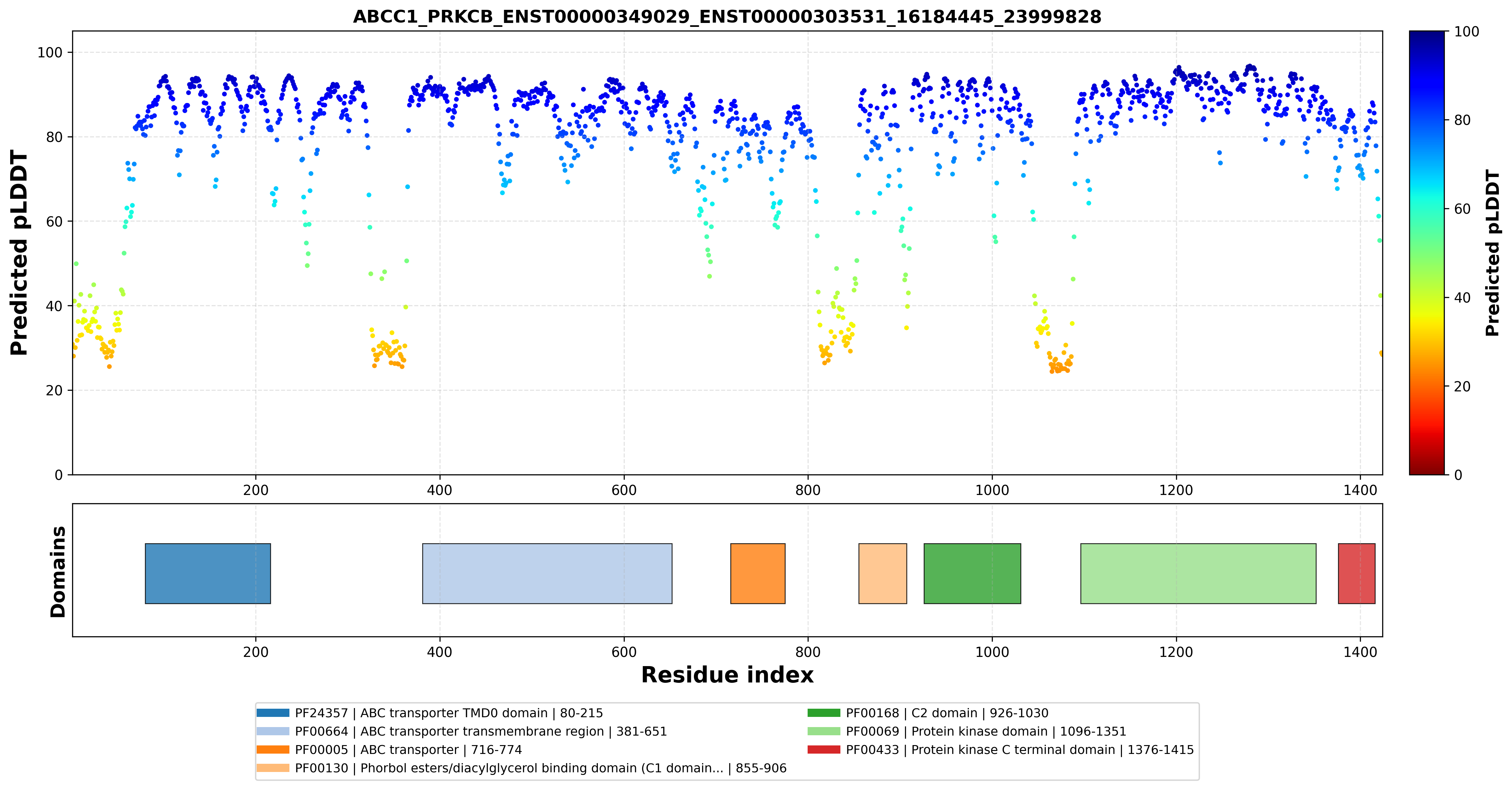 |  |  |
| ABCC1_PRKCB_ENST00000349029_ENST00000303531_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.5419
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000349029_ENST00000321728_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.7802
Å |
 |  | 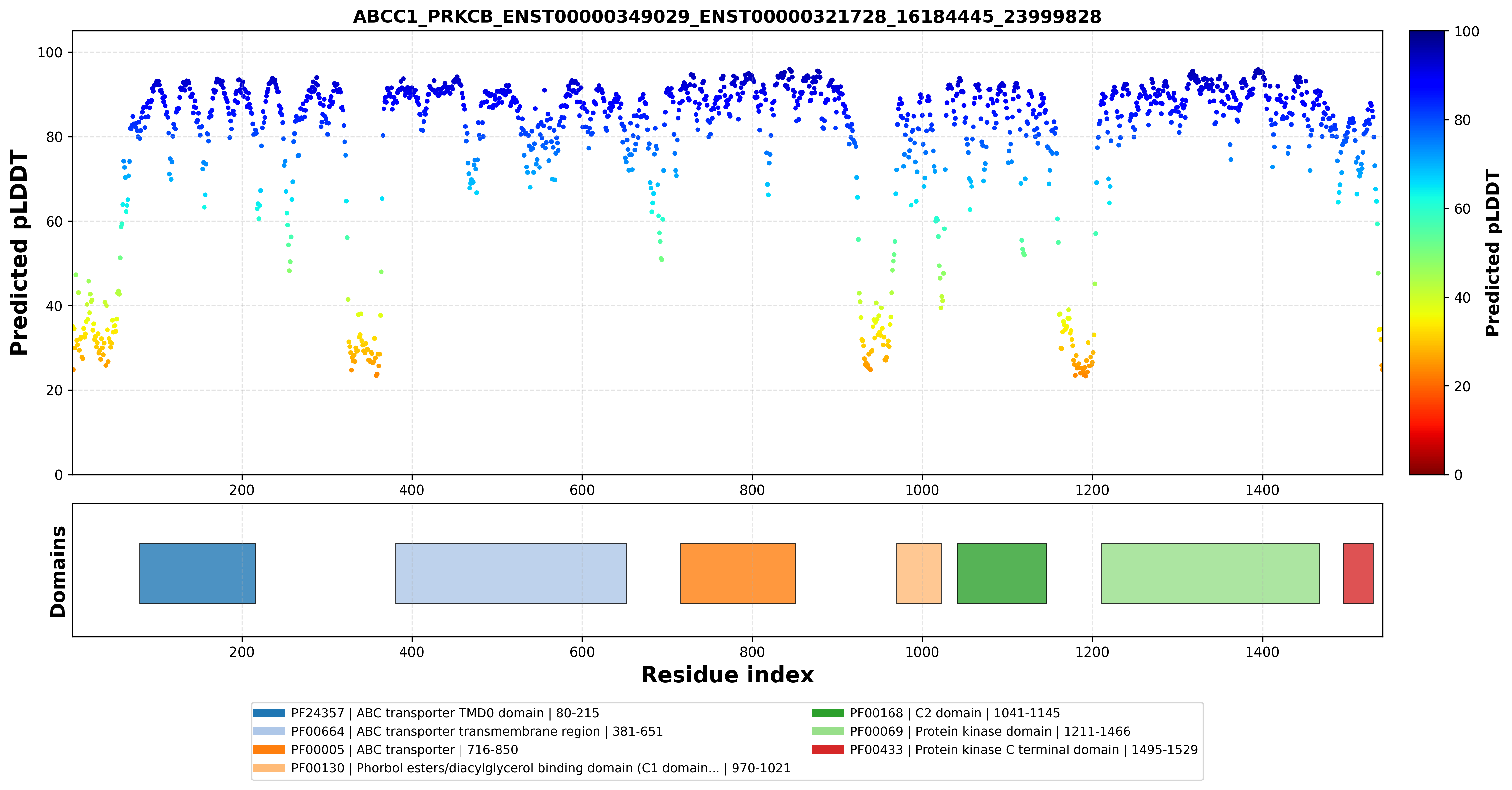 |  |  |
| ABCC1_PRKCB_ENST00000349029_ENST00000321728_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.8016
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000351154_ENST00000303531_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.353
Å |
 |  | 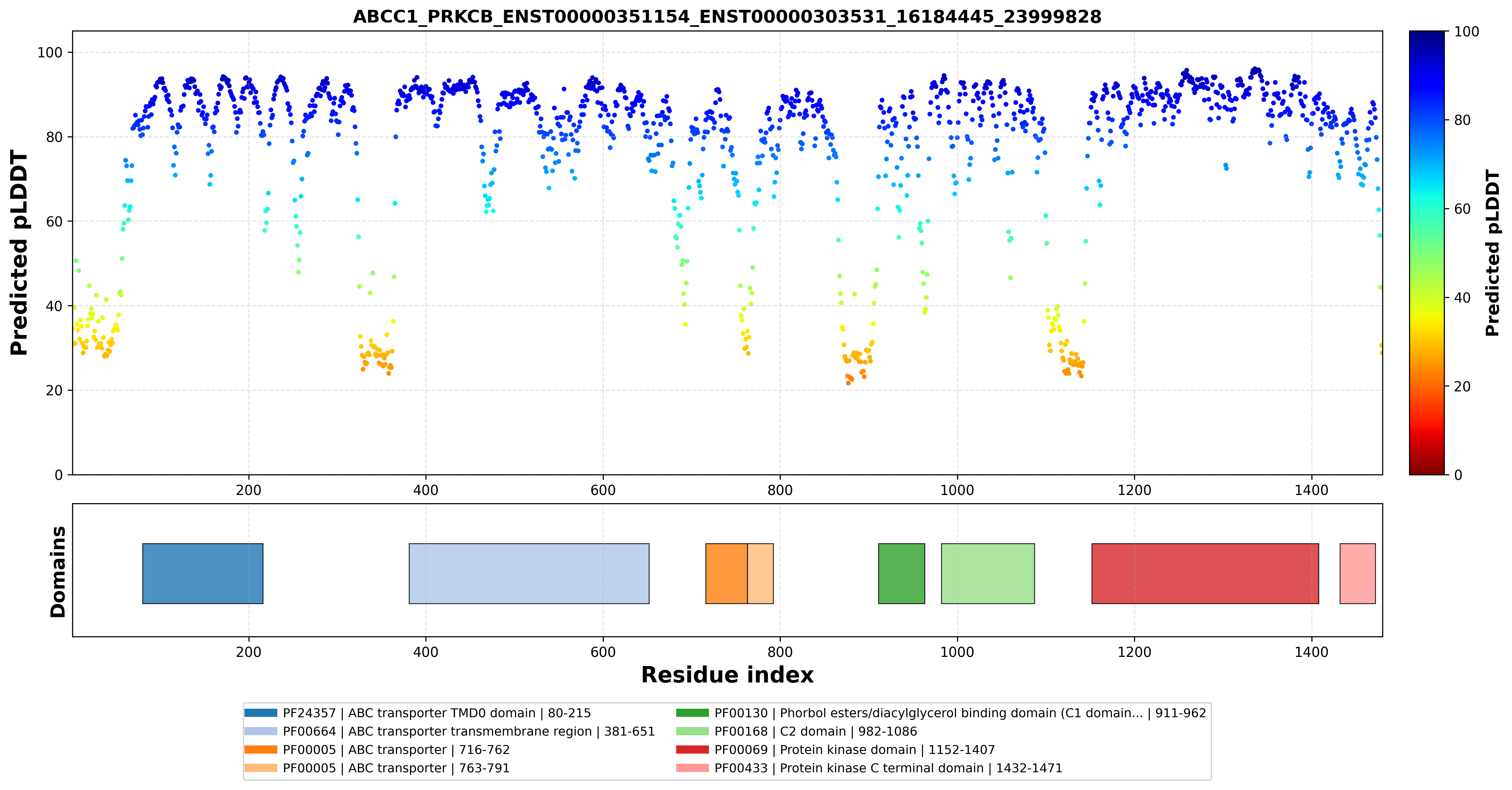 |  |  |
| ABCC1_PRKCB_ENST00000351154_ENST00000303531_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.5134
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000351154_ENST00000321728_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0724
Å |
 |  |  |  |  |
| ABCC1_PRKCB_ENST00000351154_ENST00000321728_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.5718
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000399408_ENST00000321728_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3781
Å |
 |  | 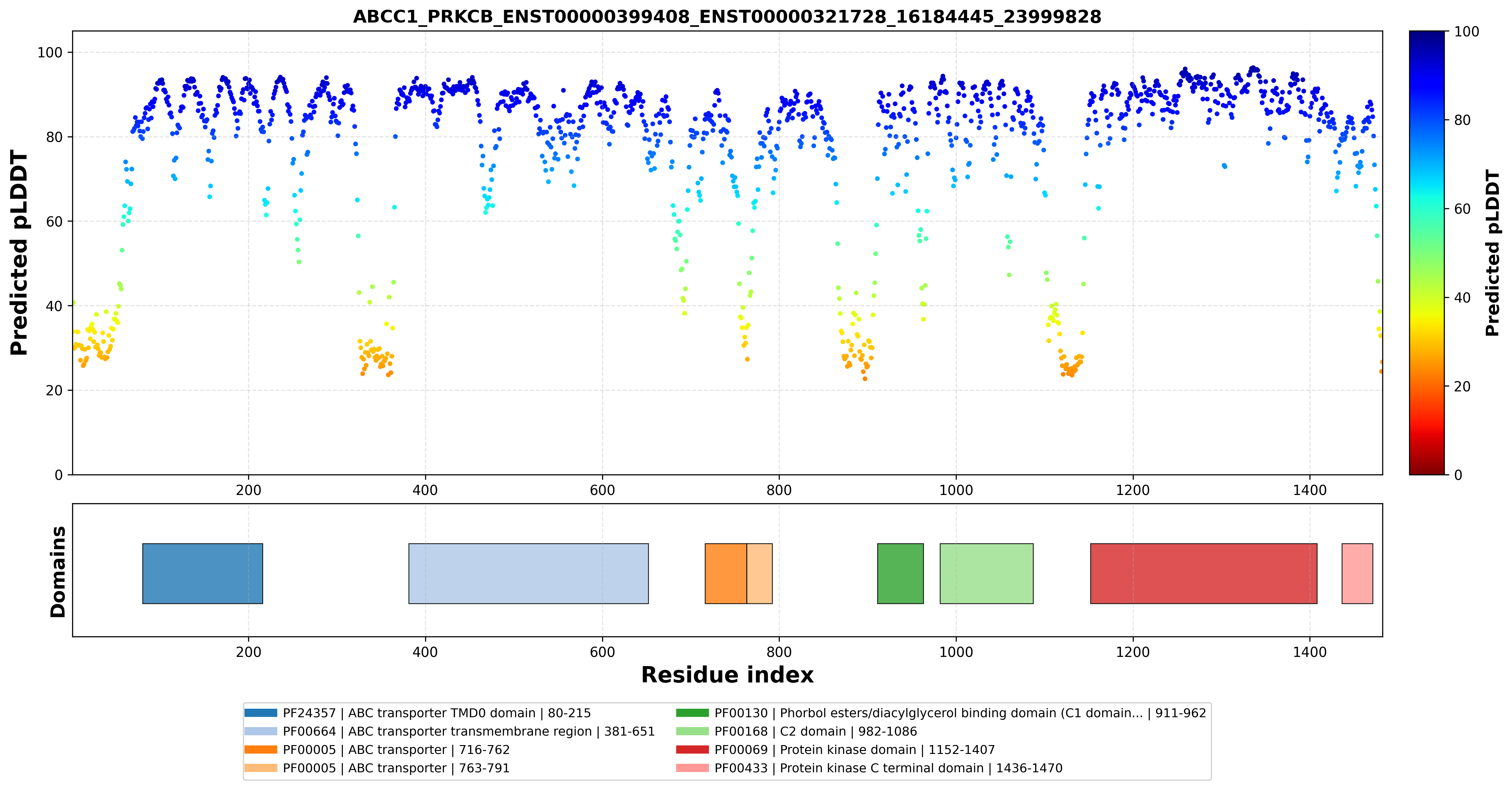 |  |  |
| ABCC1_PRKCB_ENST00000399408_ENST00000321728_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.5353
Å |
| | | |  |
| ABCC1_PRKCB_ENST00000399410_ENST00000303531_16184445_23999828 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.8385
Å |
 |  | 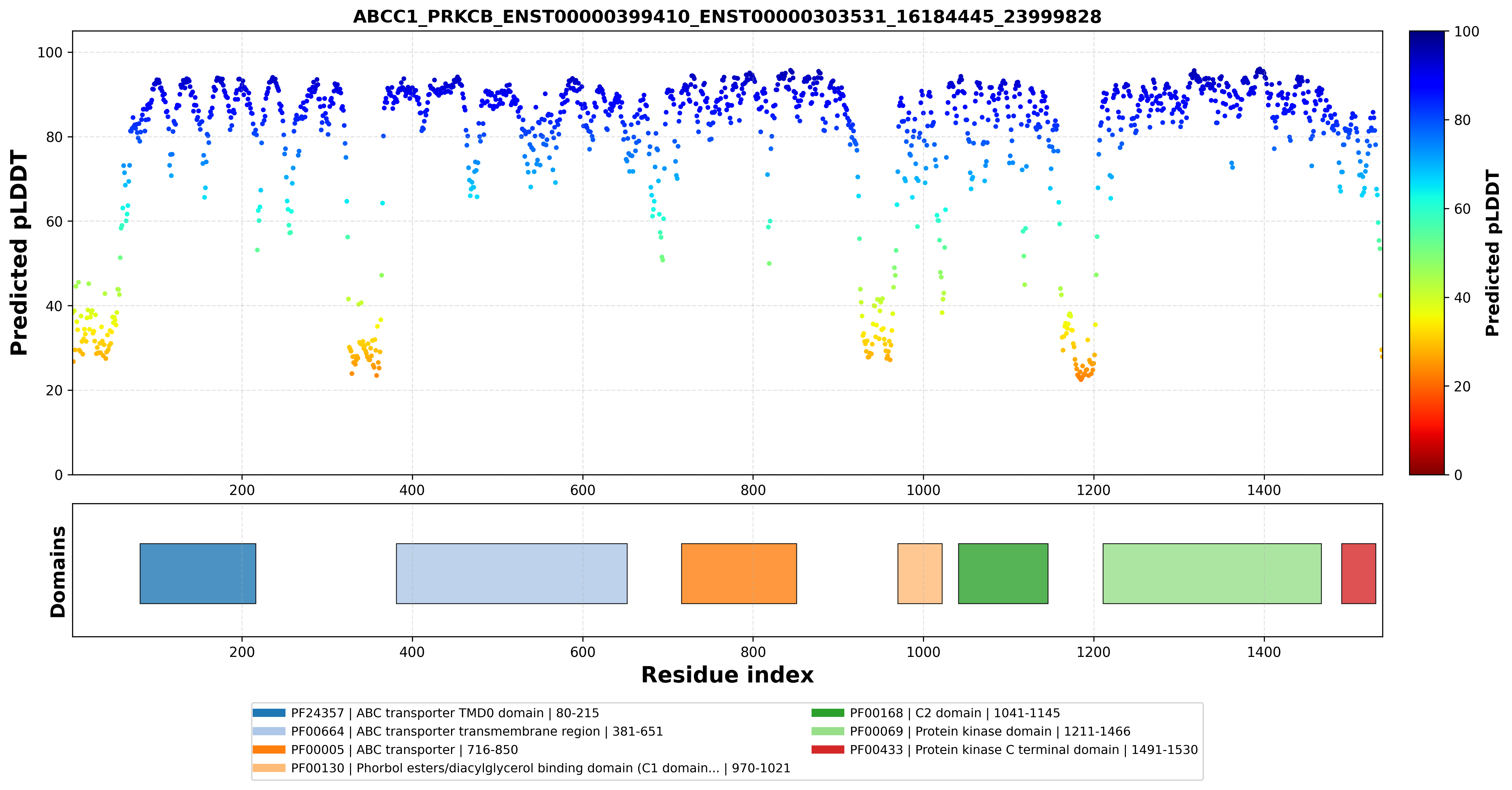 |  |  |
| ABCC1_PRKCB_ENST00000399410_ENST00000303531_16184445_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.6257
Å |
| | | |  |
| ABCC2_CTNNA3_ENST00000370434_ENST00000373744_101544538_67680375 superimposed PDB: 9C12 of partner (ABCC2). RMSD:2.9491
Å |
 |  |  |  |  |
| ABCC2_CTNNA3_ENST00000370449_ENST00000373744_101544538_67680375 superimposed PDB: 9C12 of partner (ABCC2). RMSD:2.544
Å |
 |  |  |  |  |
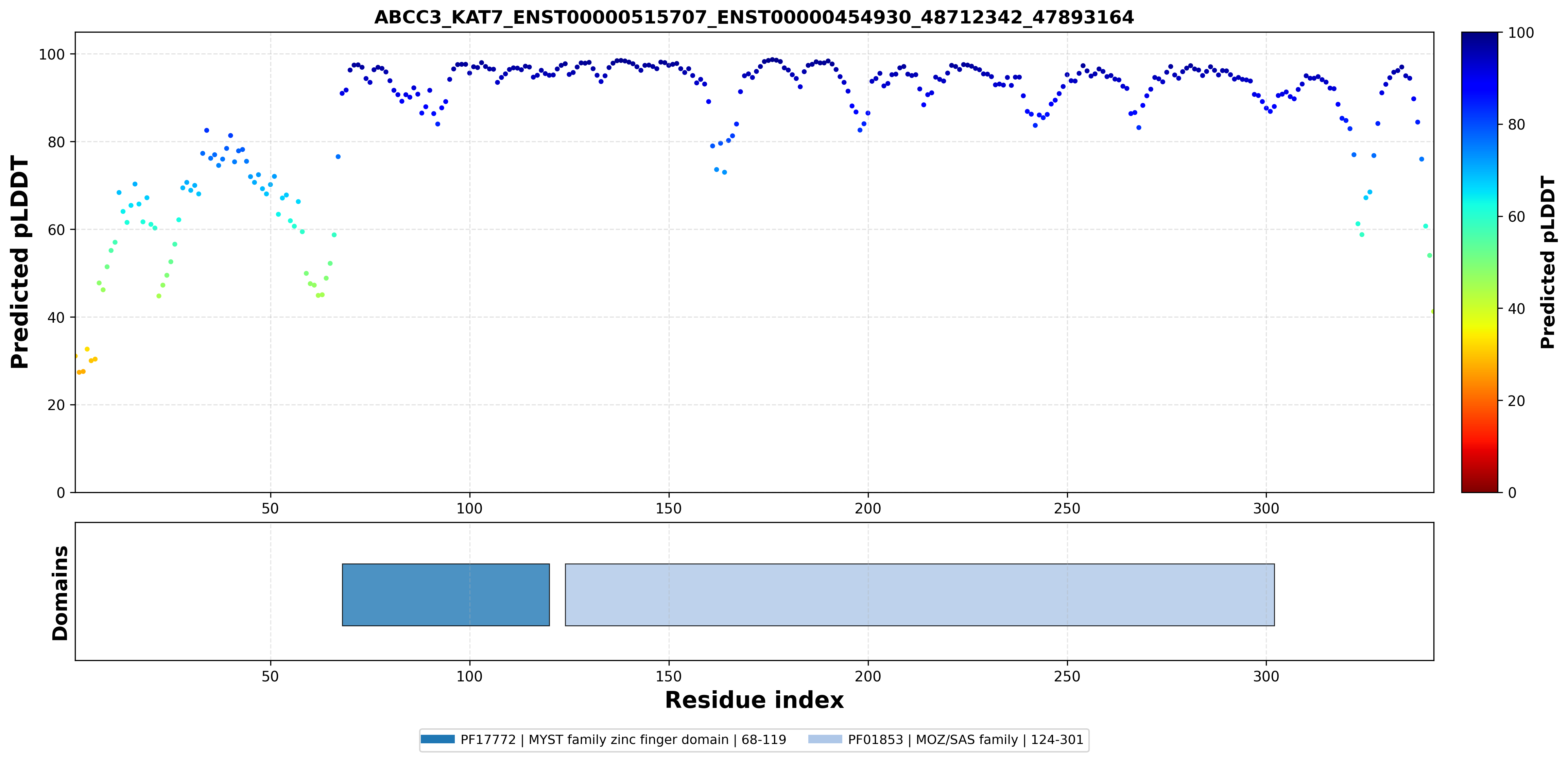
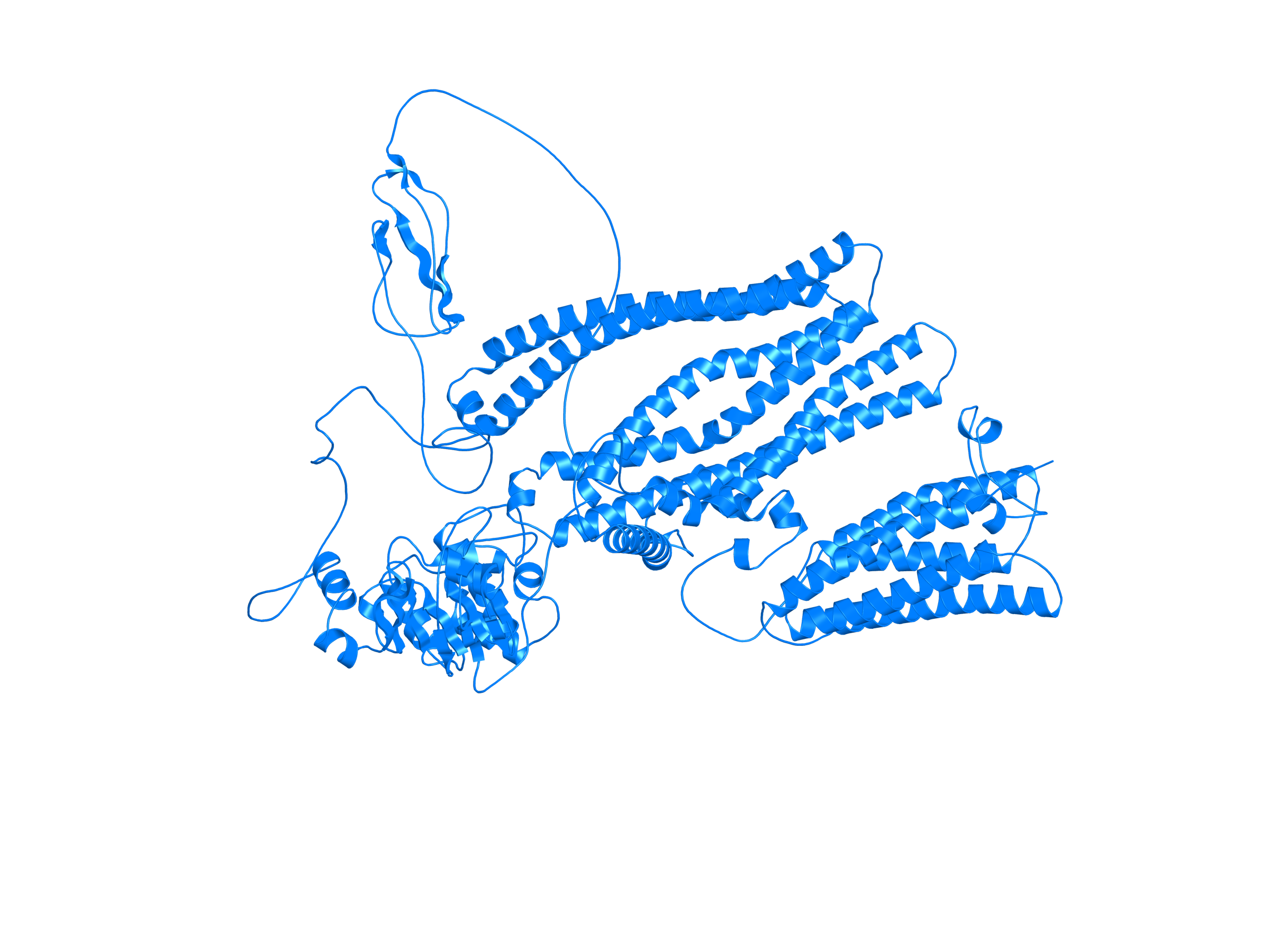
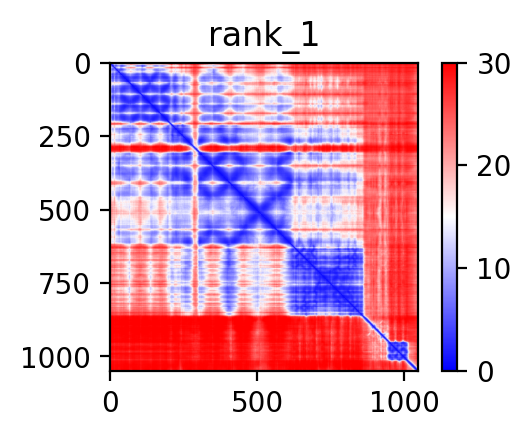
| ABCC3_KAT7_ENST00000285238_ENST00000454930_48712342_47893164 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.3975
Å |
 |  |  |  |  |
| ABCC3_KAT7_ENST00000515707_ENST00000454930_48712342_47893164 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.3943
Å |
 |  |  |  |  |
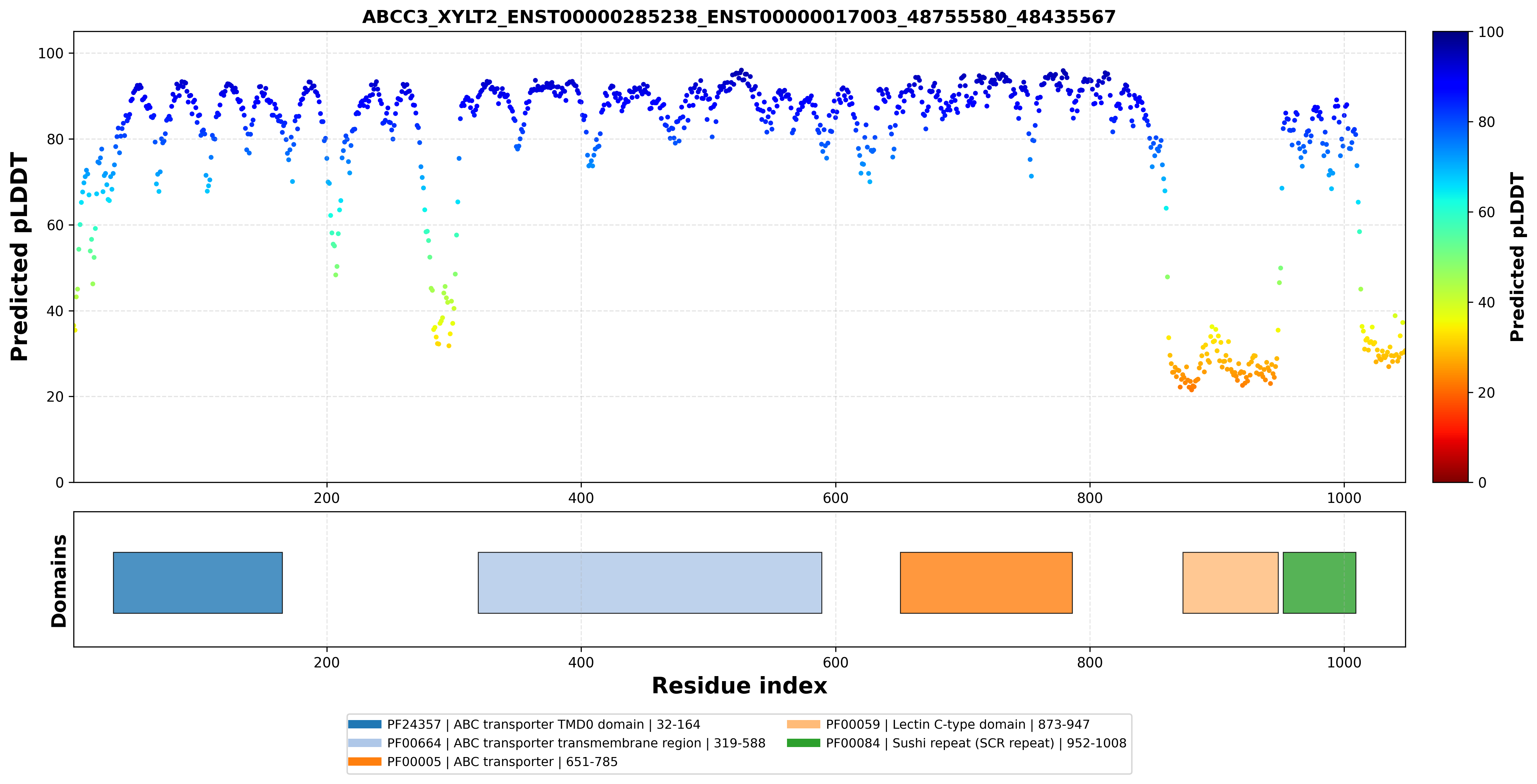
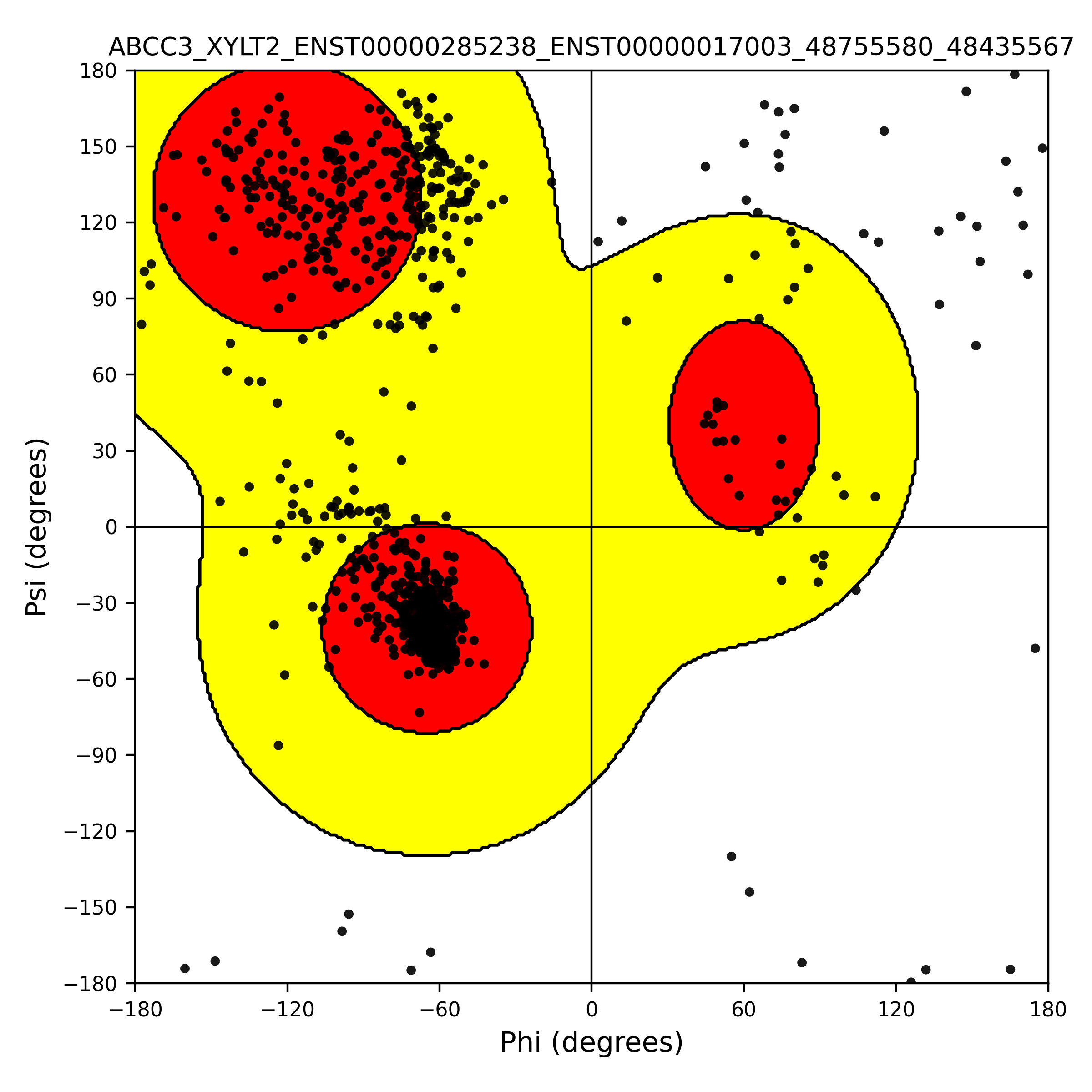
| ABCC3_XYLT2_ENST00000285238_ENST00000017003_48755580_48435567 superimposed PDB: 8HVH of partner (ABCC3). RMSD:1.7763
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000358400_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.8319
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000358400_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.4558
Å |
| | | |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000453593_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.8812
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000453593_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.3665
Å |
| | | |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000545634_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.863
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000412704_ENST00000545634_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.3733
Å |
| | | |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000358400_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.9541
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000358400_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.1286
Å |
| | | |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000453593_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.9305
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000453593_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0889
Å |
| | | |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000545634_95829960_87038708 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.9581
Å |
 |  |  |  |  |
| ABCC4_ABCB4_ENST00000536256_ENST00000545634_95829960_87038708 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0783
Å |
| | | |  |
| ABCC4_COL4A2_ENST00000376887_ENST00000360467_95822785_111077080 superimposed PDB: 8XOK of partner (ABCC4). RMSD:1.8531
Å |
 |  |  |  |  |
| ABCC4_COL4A2_ENST00000376887_ENST00000360467_95822785_111077080 superimposed PDB: 1LI1 of partner (COL4A2). RMSD:0.5743
Å |
| | | |  |
| ABCC4_COL4A2_ENST00000431522_ENST00000360467_95822785_111077080 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.5094
Å |
 |  |  |  |  |
| ABCC4_COL4A2_ENST00000431522_ENST00000360467_95822785_111077080 superimposed PDB: 1LI1 of partner (COL4A2). RMSD:0.5961
Å |
| | | |  |
| ABCC4_UGGT2_ENST00000376887_ENST00000376747_95813442_96454066 superimposed PDB: 8XOK of partner (ABCC4). RMSD:1.8744
Å |
 |  |  |  |  |
| ABCC4_UGGT2_ENST00000412704_ENST00000376747_95813442_96454066 superimposed PDB: 8XOK of partner (ABCC4). RMSD:1.9951
Å |
 |  |  |  |  |
| ABCC4_UGGT2_ENST00000431522_ENST00000376747_95813442_96454066 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.4697
Å |
 |  |  |  |  |
| ABCC4_UGGT2_ENST00000536256_ENST00000376747_95813442_96454066 superimposed PDB: 8XOK of partner (ABCC4). RMSD:1.9926
Å |
 |  |  |  |  |
| ABCC6_C16orf70_ENST00000205557_ENST00000219139_16253338_67165188 superimposed PDB: 6BZR of partner (ABCC6). RMSD:1.6597
Å |
 |  |  |  |  |
| ABCC6_LTA4H_ENST00000205557_ENST00000552789_16276268_96397698 superimposed PDB: 6BZR of partner (ABCC6). RMSD:2.1761
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000370214_ENST00000344720_94965170_77876665 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.2891
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000370214_ENST00000344720_94965170_77876665 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.9023
Å |
| | | |  |
| ABCD3_AK5_ENST00000394233_ENST00000344720_94965170_77876665 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.4903
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000394233_ENST00000344720_94965170_77876665 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.926
Å |
| | | |  |
| ABCD3_AK5_ENST00000394233_ENST00000354567_94965170_77876665 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.6127
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000454898_ENST00000344720_94965170_77876665 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.2632
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000454898_ENST00000344720_94965170_77876665 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.9699
Å |
| | | |  |
| ABCD3_AK5_ENST00000536817_ENST00000344720_94965170_77876665 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.2868
Å |
 |  |  |  |  |
| ABCD3_AK5_ENST00000536817_ENST00000344720_94965170_77876665 superimposed PDB: 2BWJ of partner (AK5). RMSD:1.0268
Å |
| | | |  |
| ABCD3_DPYD_ENST00000370214_ENST00000370192_94956803_97981497 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.7185
Å |
 |  |  |  |  |
| ABCD3_DPYD_ENST00000454898_ENST00000370192_94956803_97981497 superimposed PDB: 9W65 of partner (ABCD3). RMSD:2.2946
Å |
 |  |  |  |  |
| ABCD3_DPYD_ENST00000536817_ENST00000370192_94956803_97981497 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.9851
Å |
 |  |  |  |  |
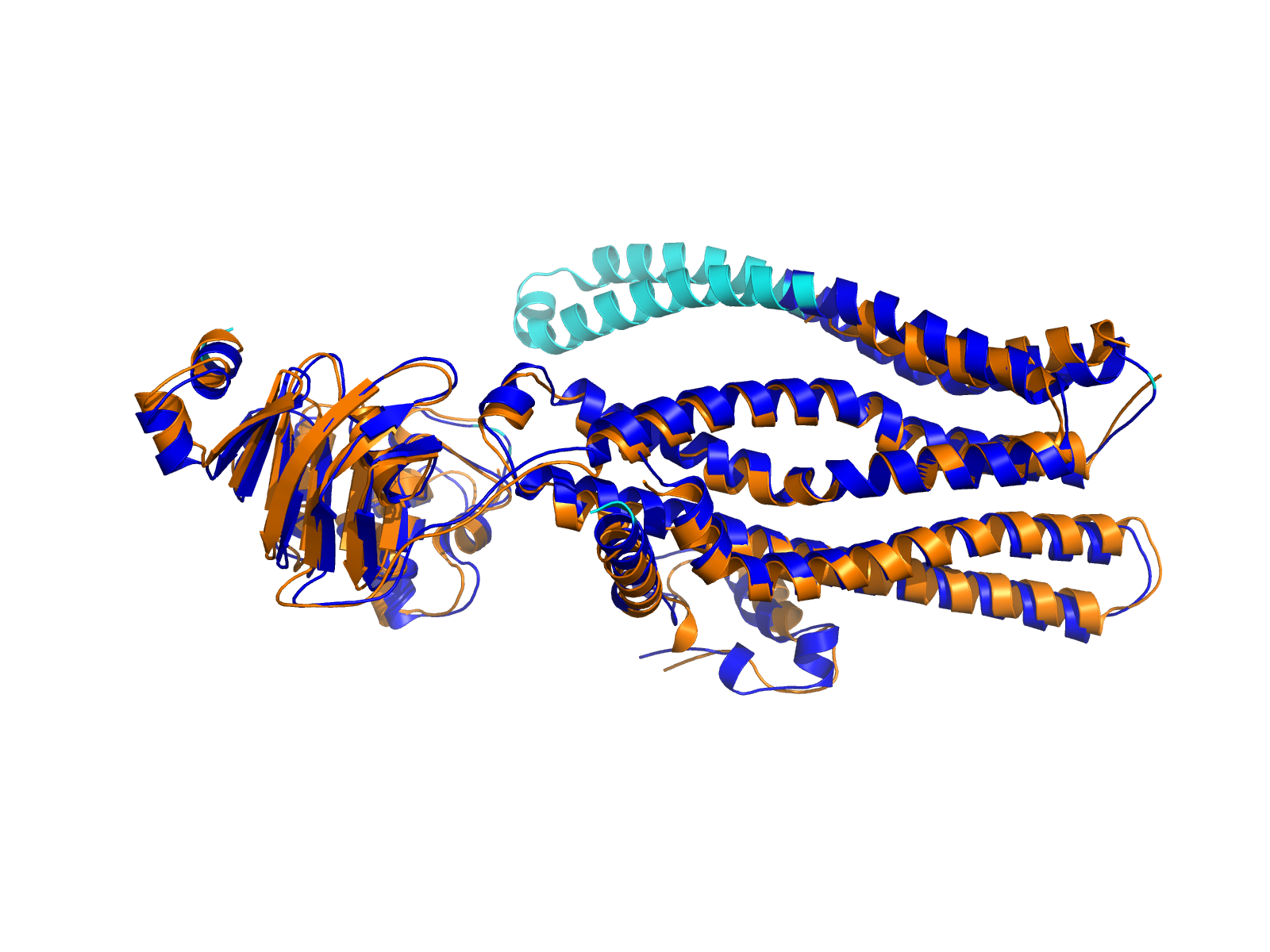
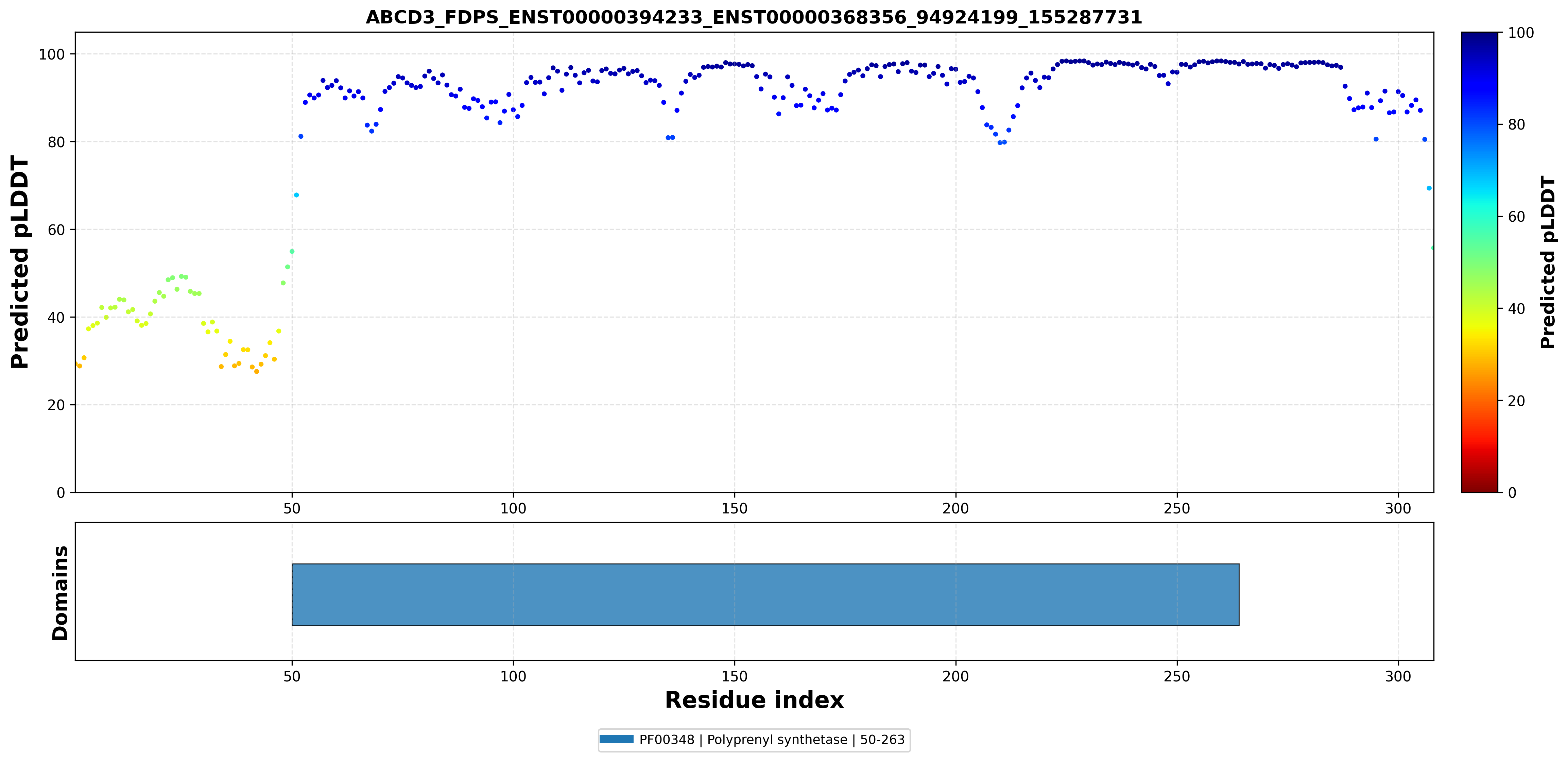
| ABCD3_FDPS_ENST00000394233_ENST00000368356_94924199_155287731 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.7865
Å |
 |  |  |  |  |
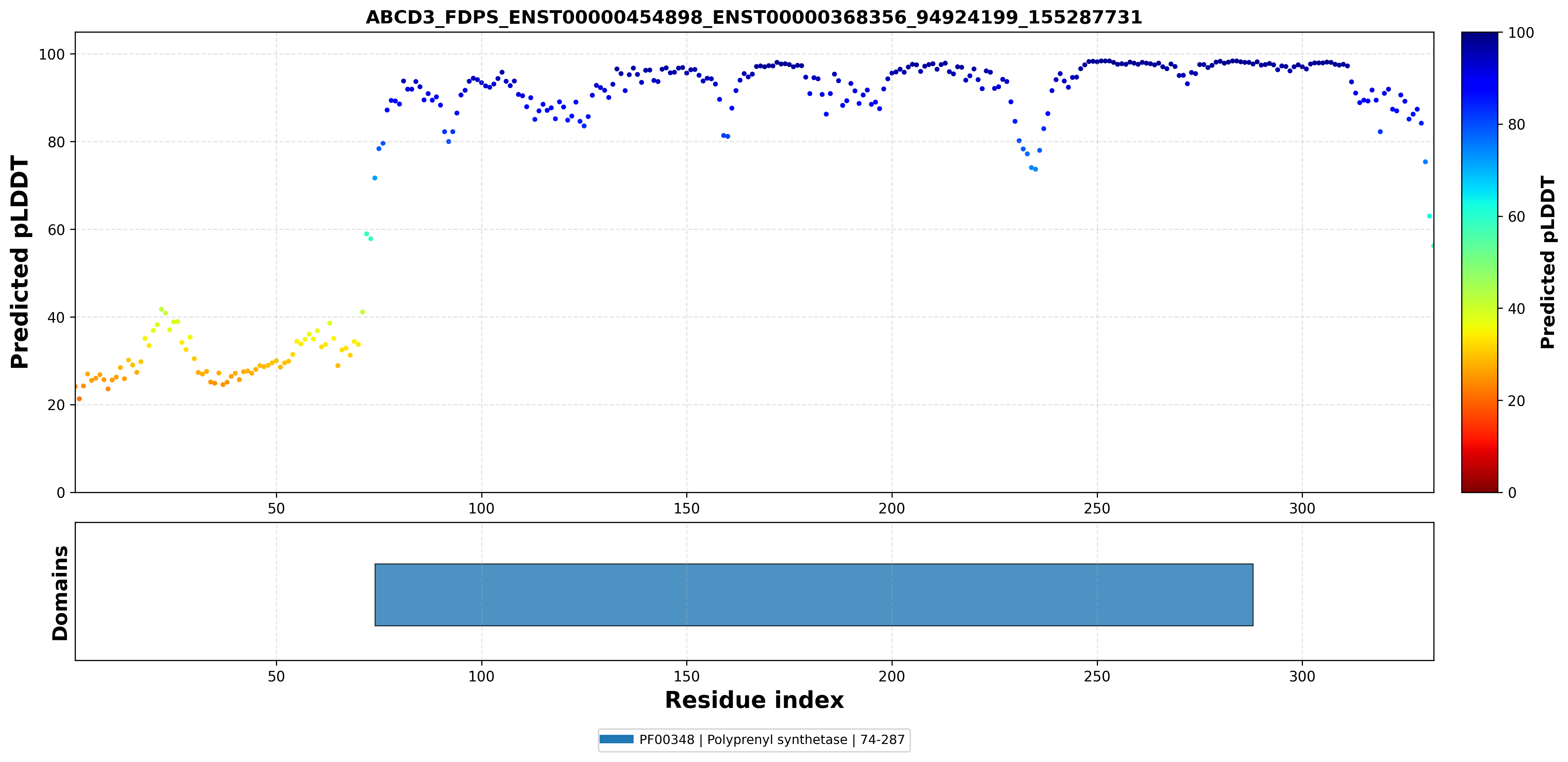
| ABCD3_FDPS_ENST00000454898_ENST00000368356_94924199_155287731 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.7512
Å |
 |  |  |  |  |
| ABCG1_BACE2_ENST00000340588_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7576
Å |
 |  | 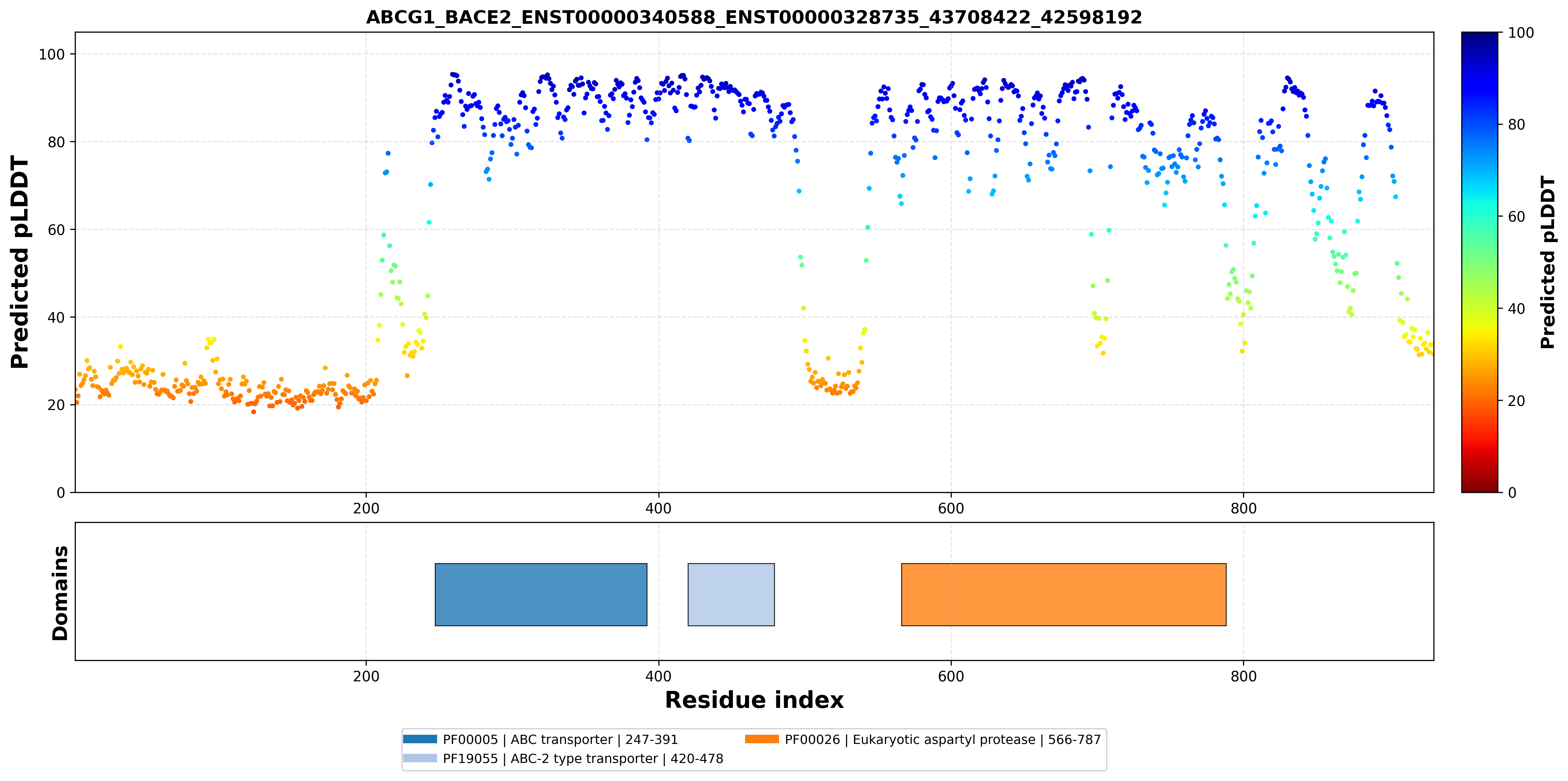 |  |  |
| ABCG1_BACE2_ENST00000340588_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.7194
Å |
| | | |  |
| ABCG1_BACE2_ENST00000340588_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7019
Å |
 |  | 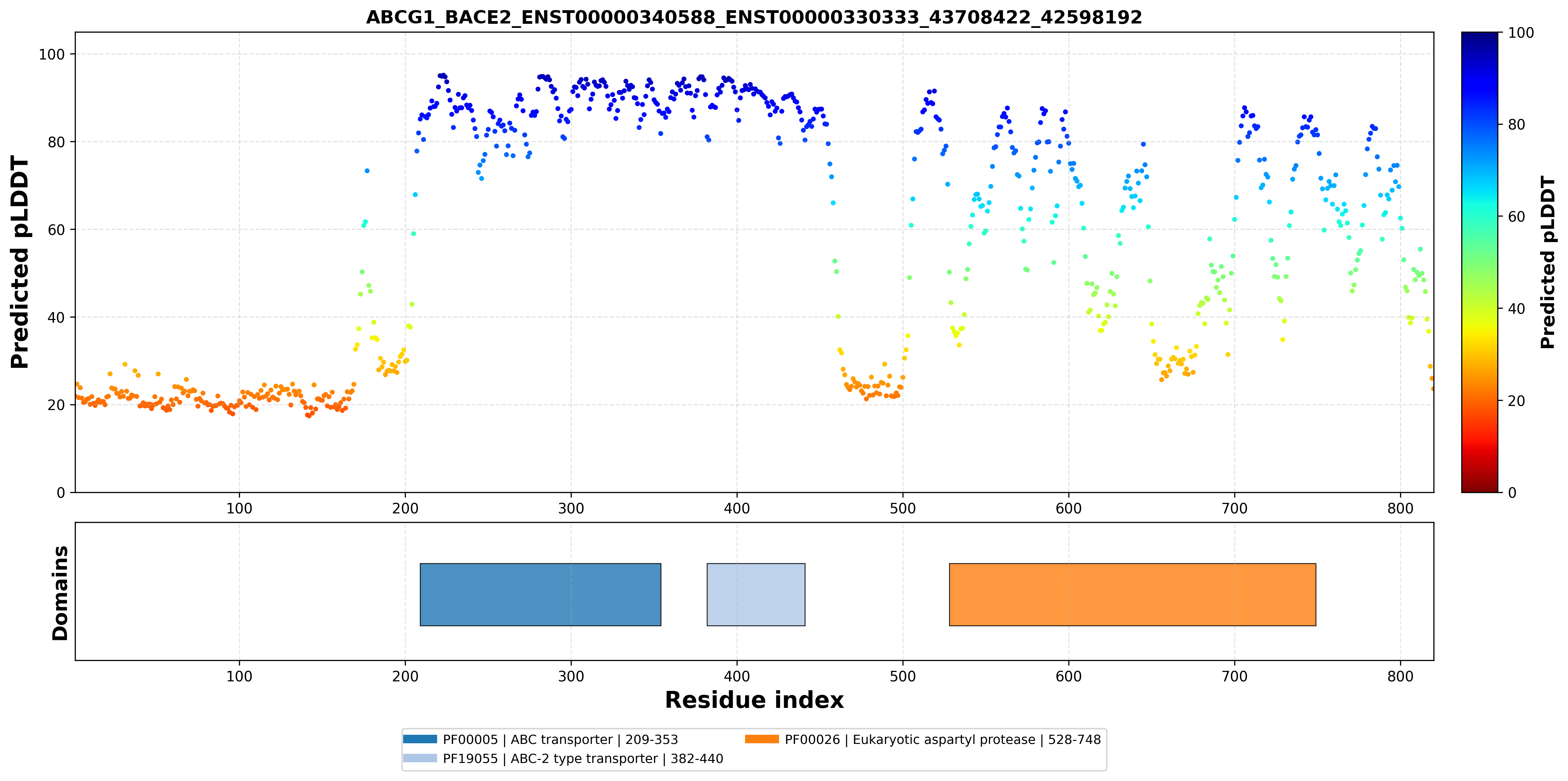 |  |  |
| ABCG1_BACE2_ENST00000340588_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.5426
Å |
| | | |  |
| ABCG1_BACE2_ENST00000340588_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7524
Å |
 |  | 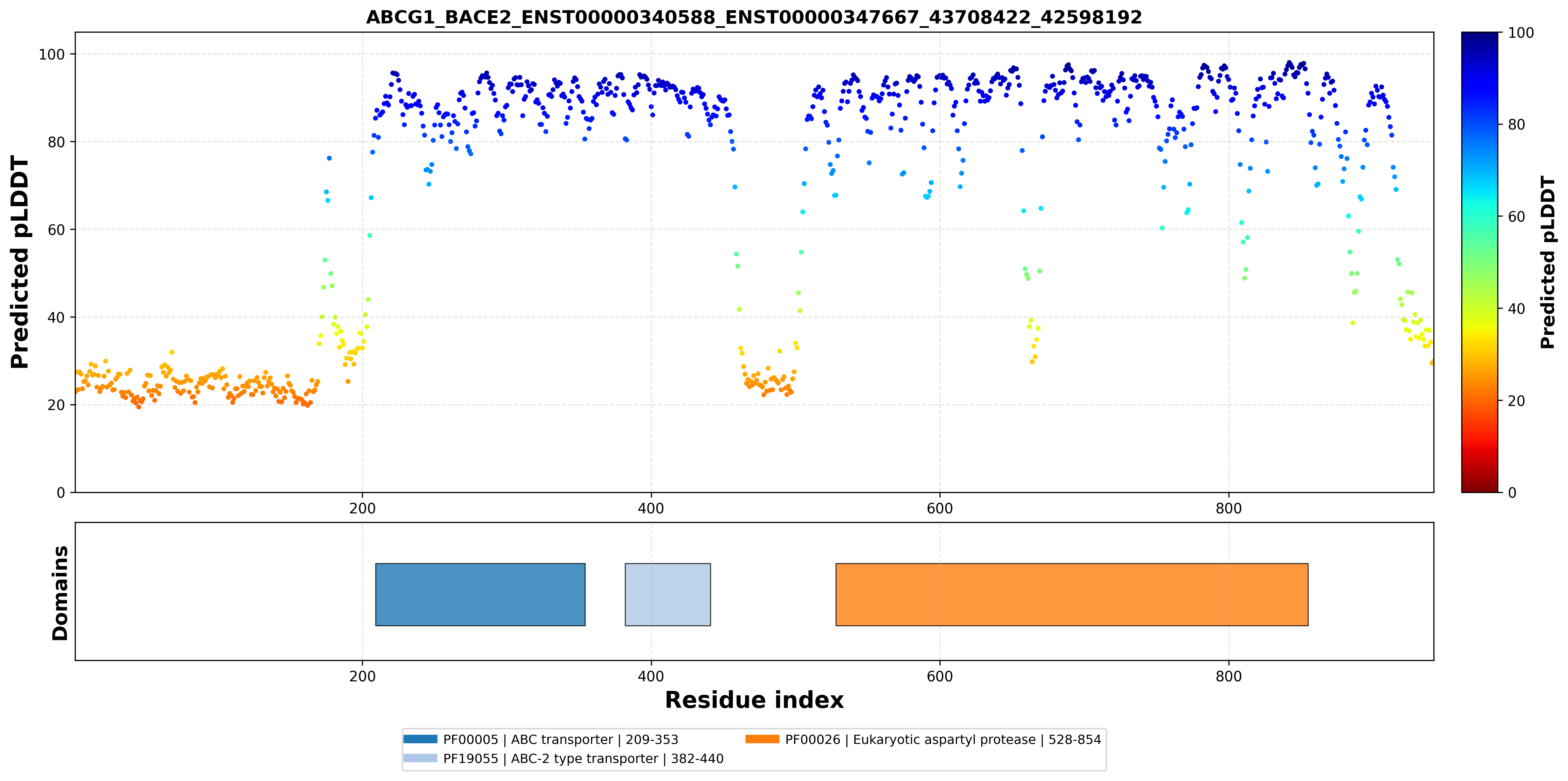 |  |  |
| ABCG1_BACE2_ENST00000340588_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.5022
Å |
| | | |  |
| ABCG1_BACE2_ENST00000343687_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7273
Å |
 |  | 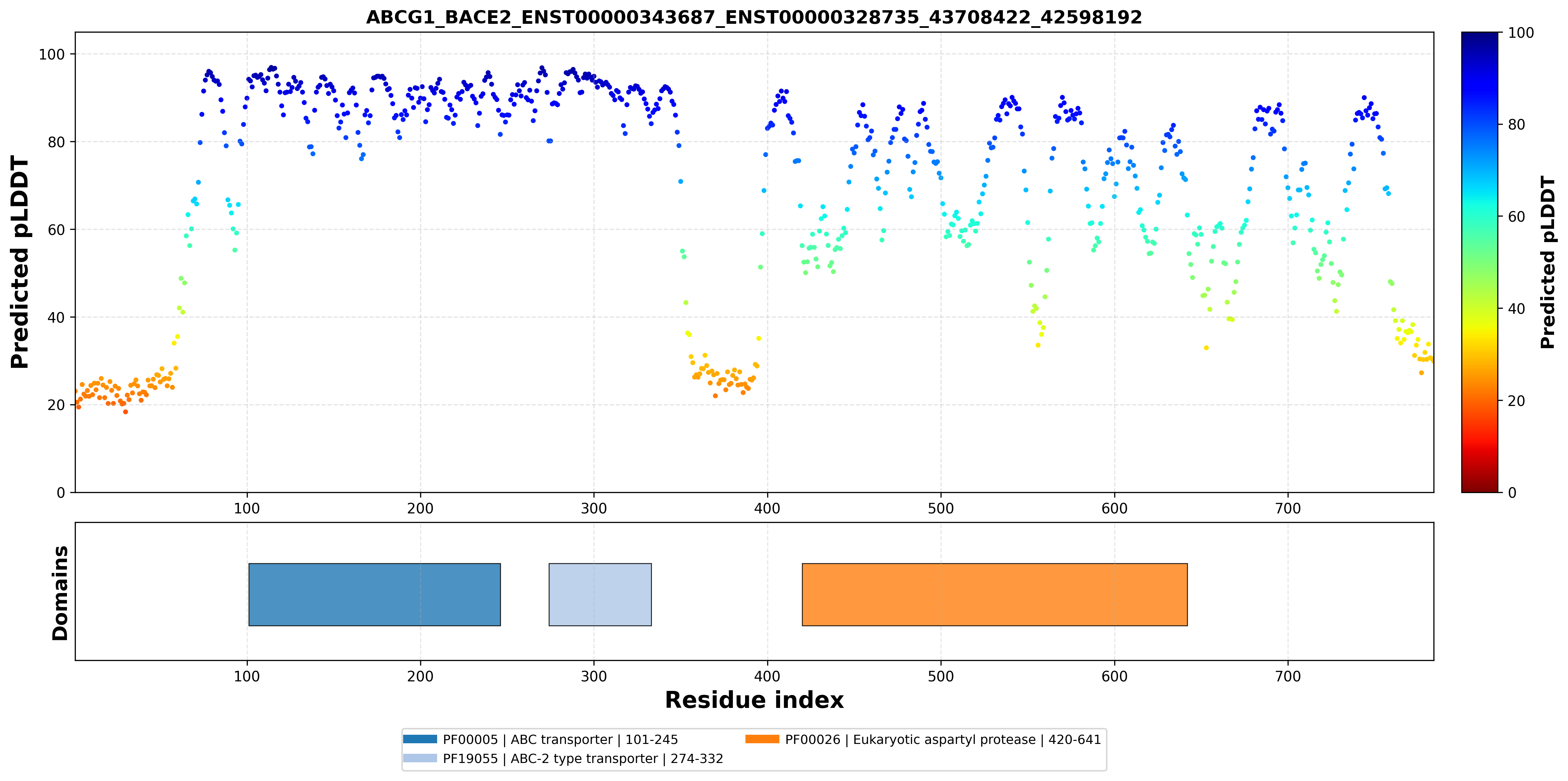 |  |  |
| ABCG1_BACE2_ENST00000343687_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.0495
Å |
| | | |  |
| ABCG1_BACE2_ENST00000343687_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6995
Å |
 |  | 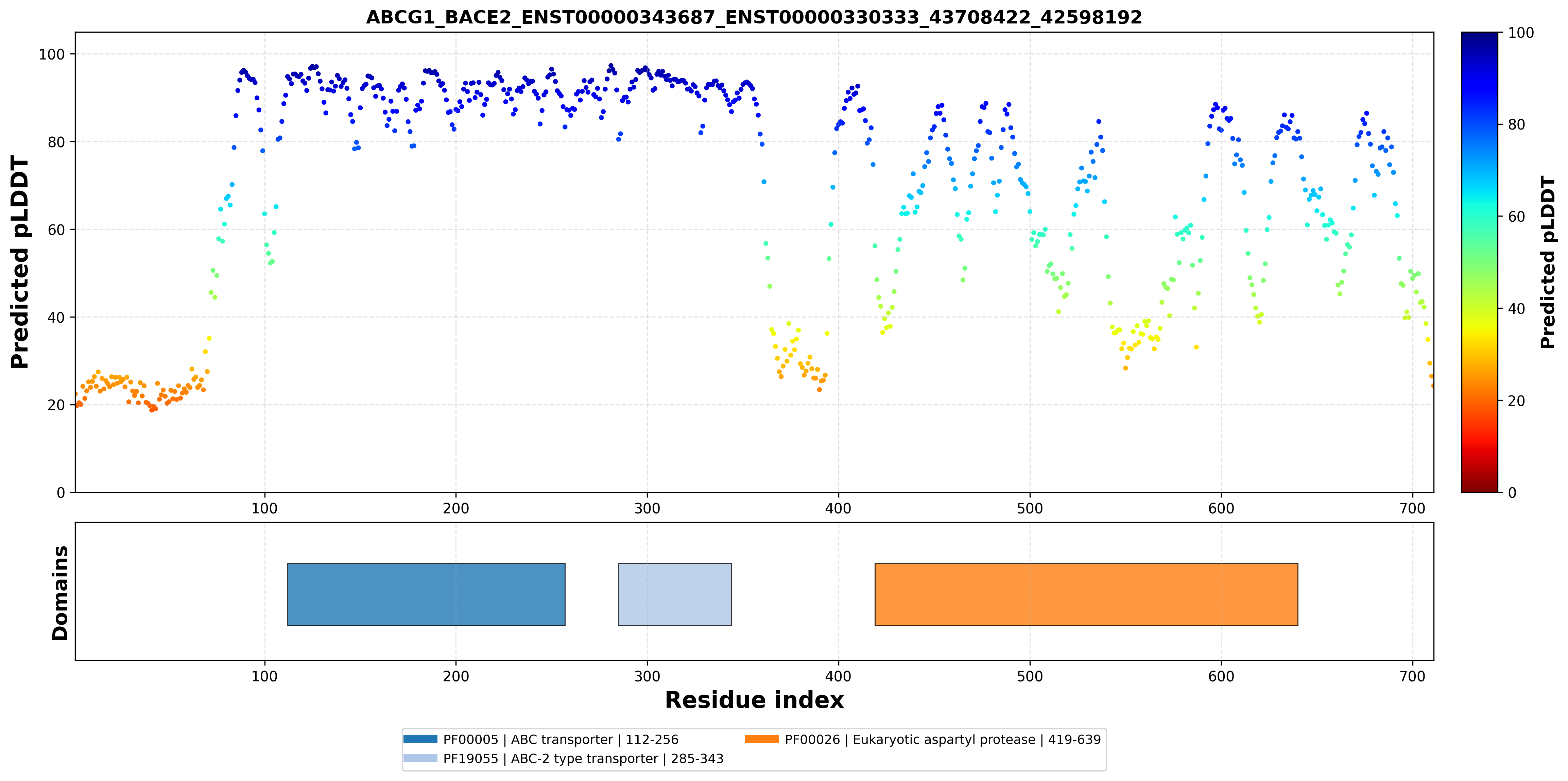 |  |  |
| ABCG1_BACE2_ENST00000343687_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.2409
Å |
| | | |  |
| ABCG1_BACE2_ENST00000343687_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6743
Å |
 |  | 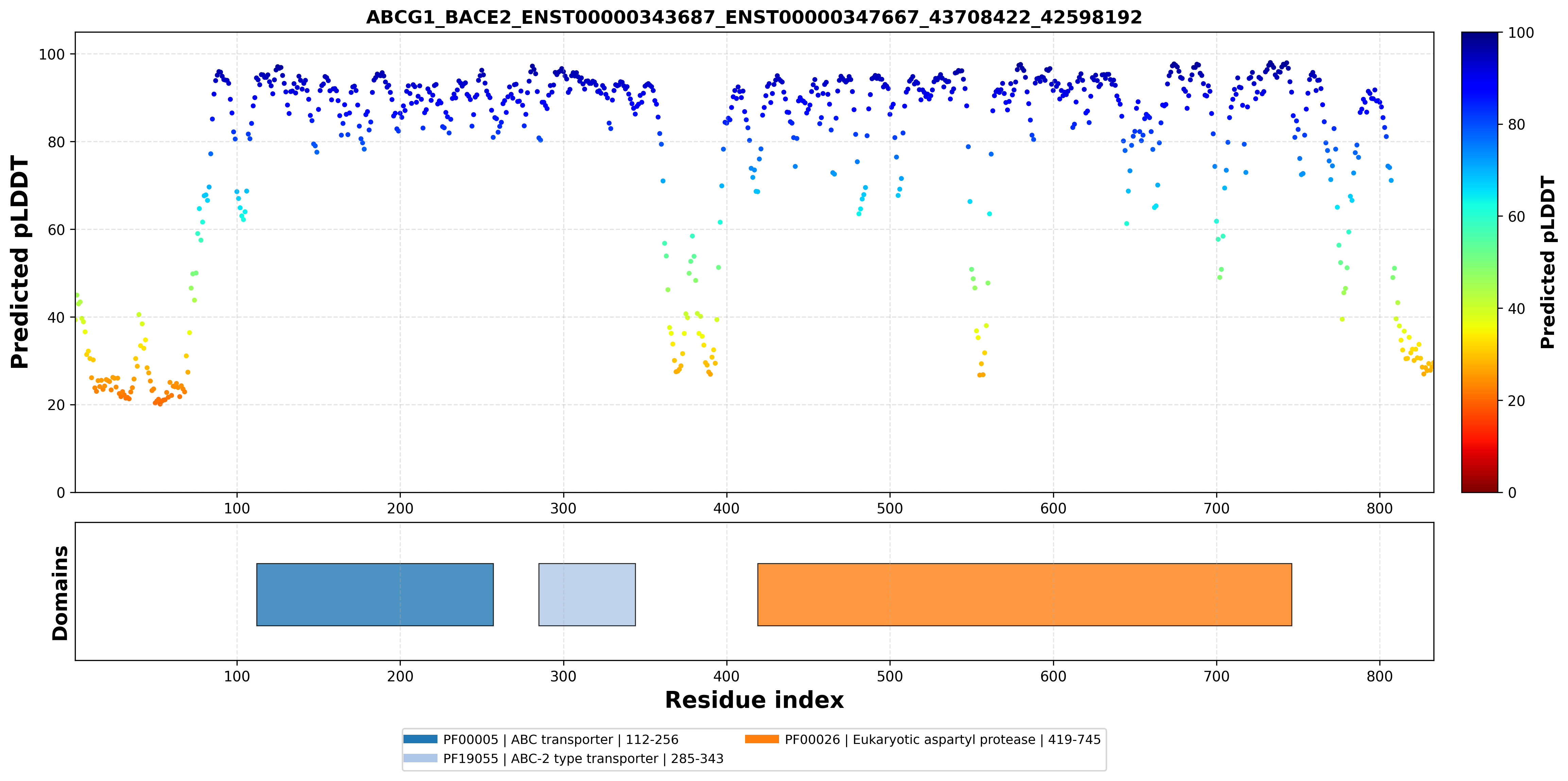 |  |  |
| ABCG1_BACE2_ENST00000343687_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.5543
Å |
| | | |  |
| ABCG1_BACE2_ENST00000347800_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6944
Å |
 |  | 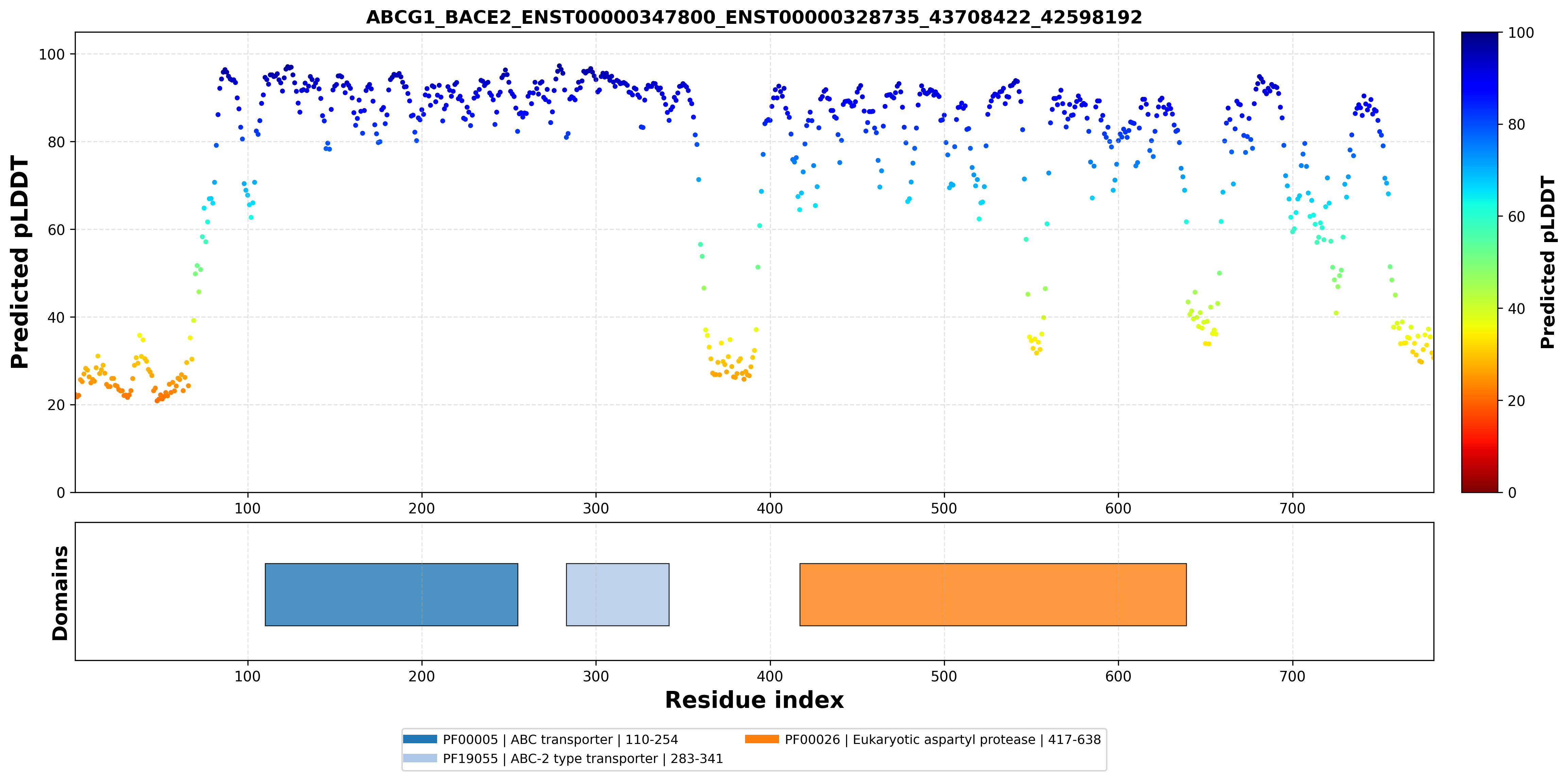 |  |  |
| ABCG1_BACE2_ENST00000347800_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.5797
Å |
| | | |  |
| ABCG1_BACE2_ENST00000347800_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6732
Å |
 |  | 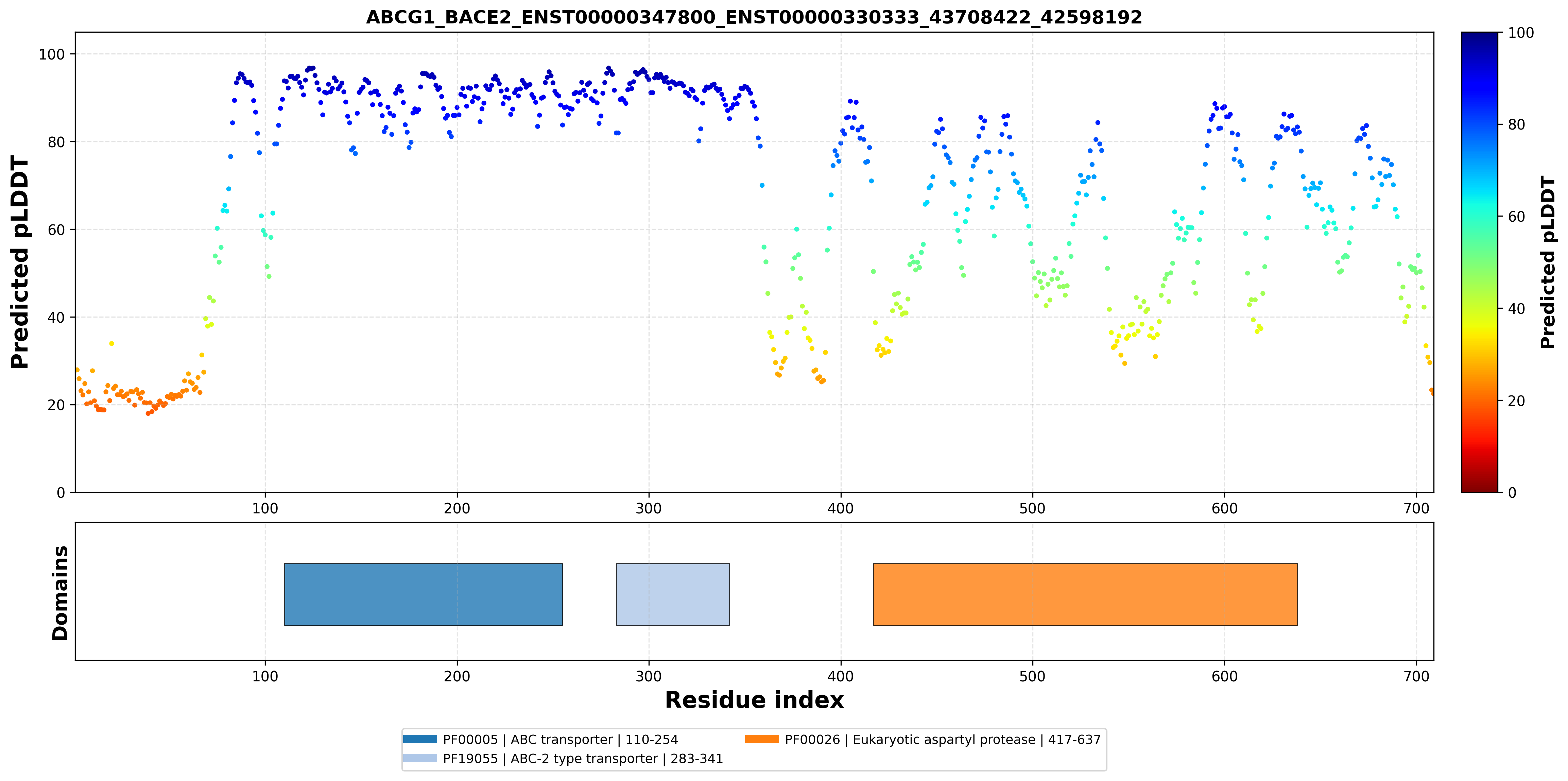 |  |  |
| ABCG1_BACE2_ENST00000347800_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.644
Å |
| | | |  |
| ABCG1_BACE2_ENST00000347800_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6642
Å |
 |  | 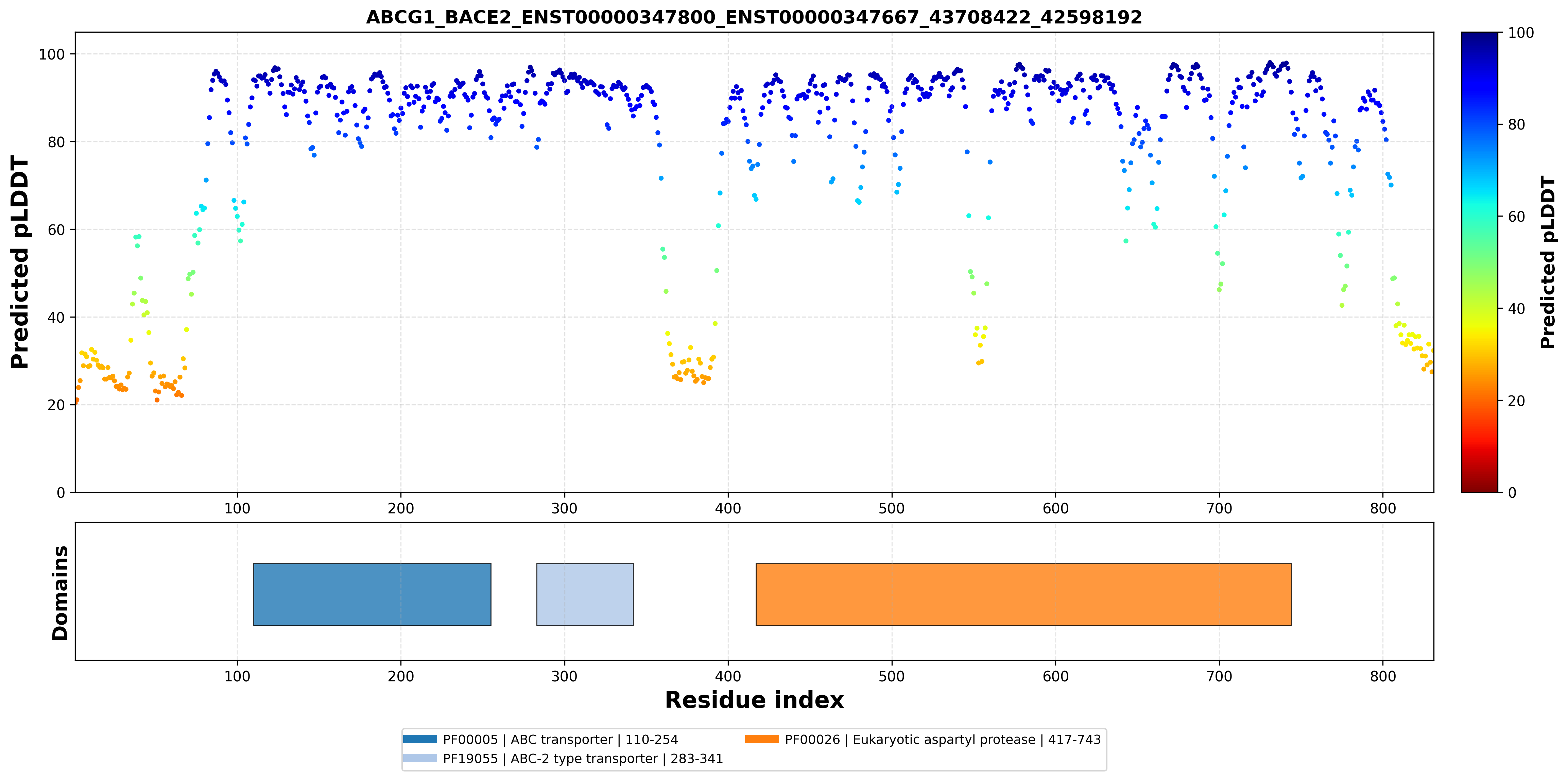 |  |  |
| ABCG1_BACE2_ENST00000347800_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.4833
Å |
| | | |  |
| ABCG1_BACE2_ENST00000361802_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7336
Å |
 |  | 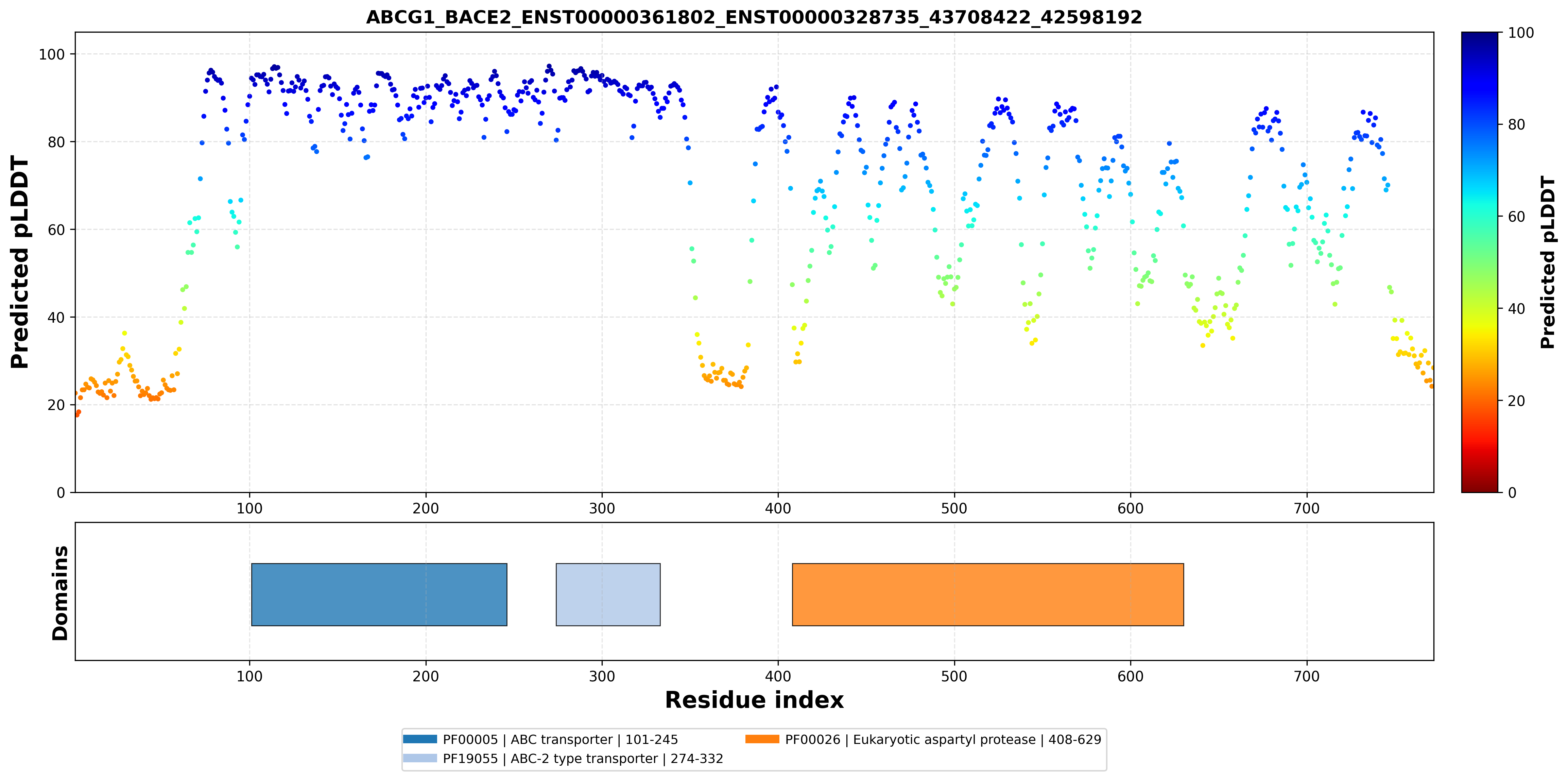 |  |  |
| ABCG1_BACE2_ENST00000361802_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.2544
Å |
| | | |  |
| ABCG1_BACE2_ENST00000361802_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6968
Å |
 |  | 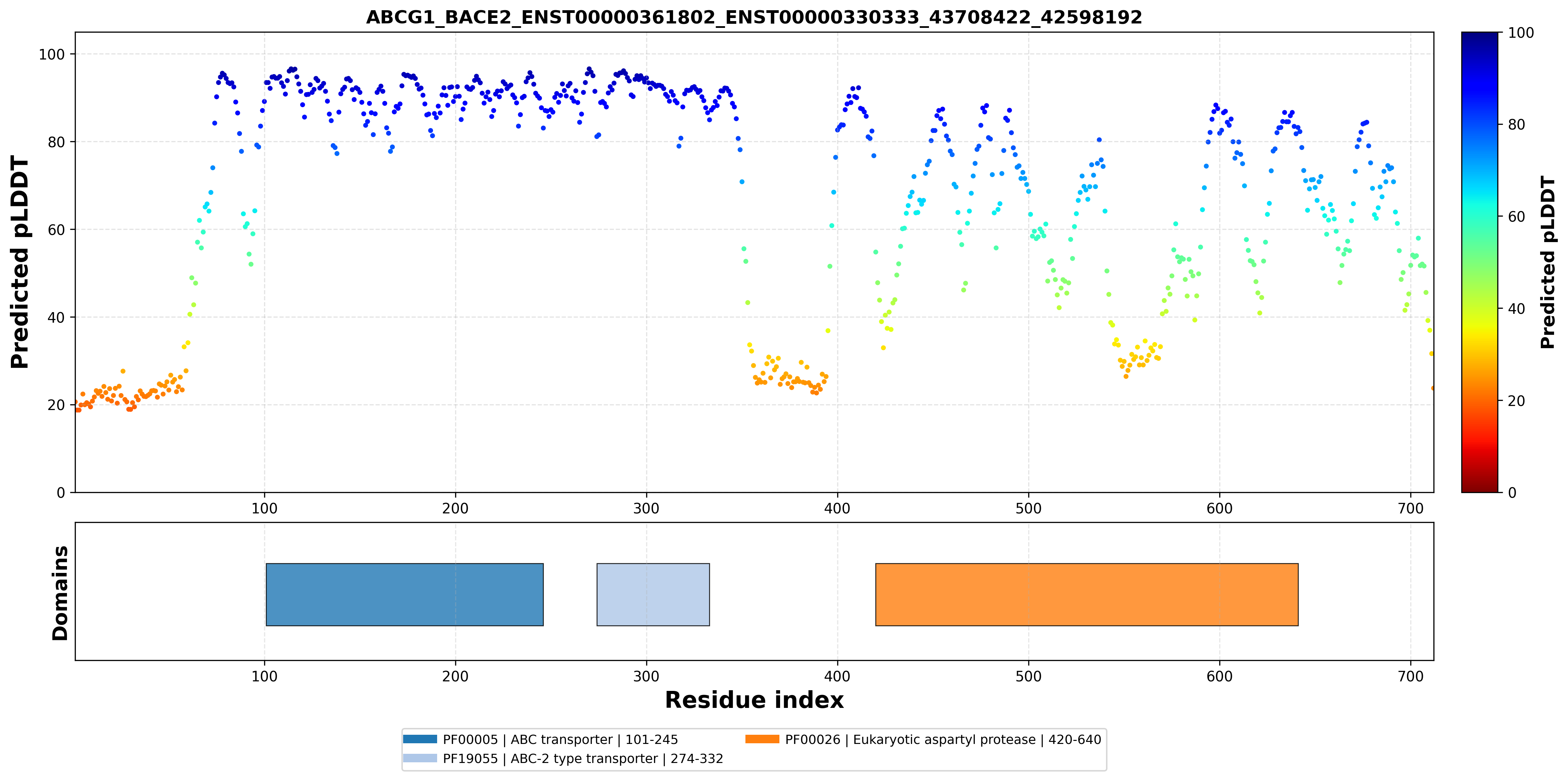 |  |  |
| ABCG1_BACE2_ENST00000361802_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.8382
Å |
| | | |  |
| ABCG1_BACE2_ENST00000361802_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.674
Å |
 |  | 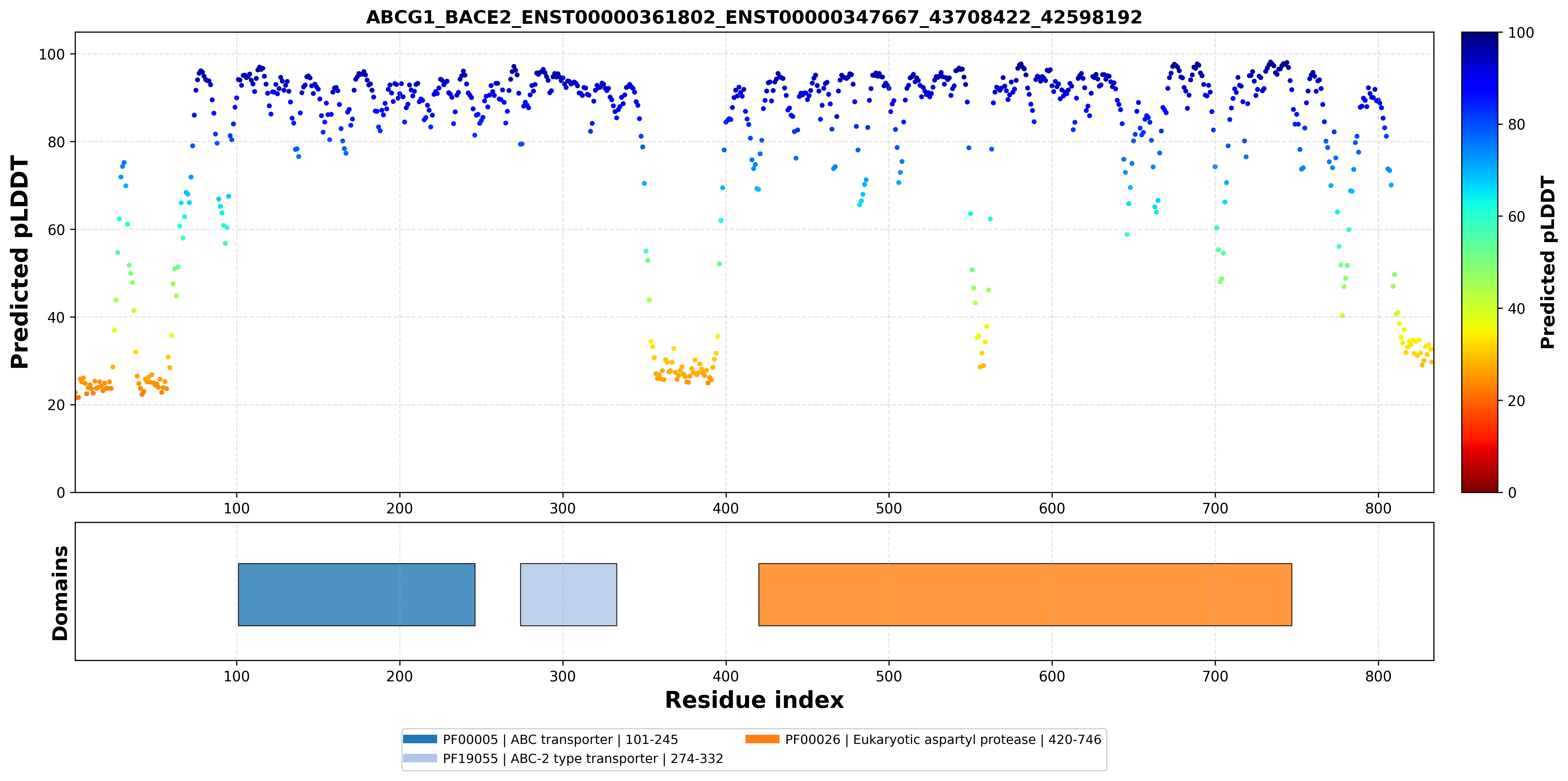 |  |  |
| ABCG1_BACE2_ENST00000361802_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.4714
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398437_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.719
Å |
 |  | 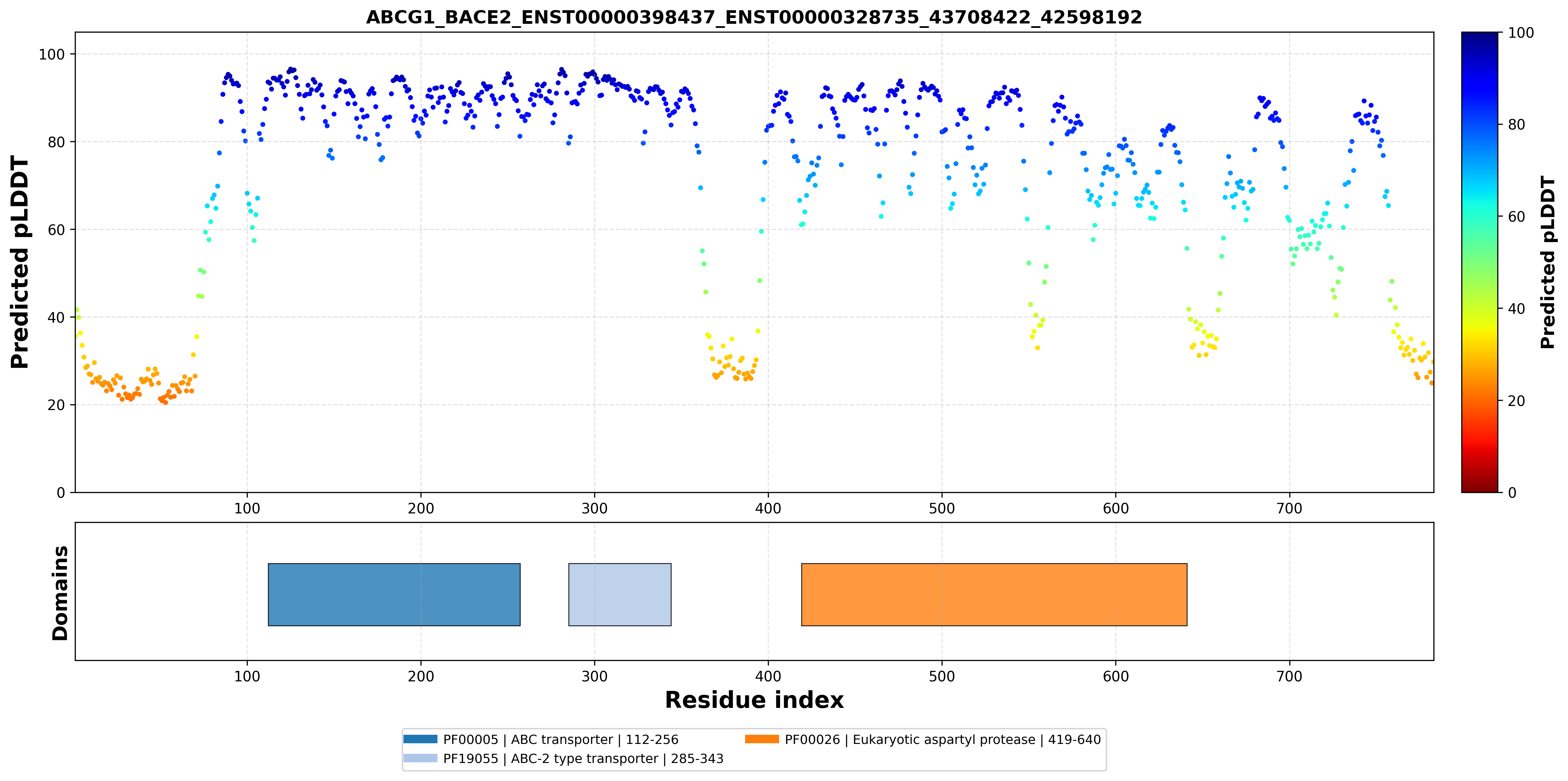 |  |  |
| ABCG1_BACE2_ENST00000398437_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:1.2984
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398437_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7189
Å |
 |  | 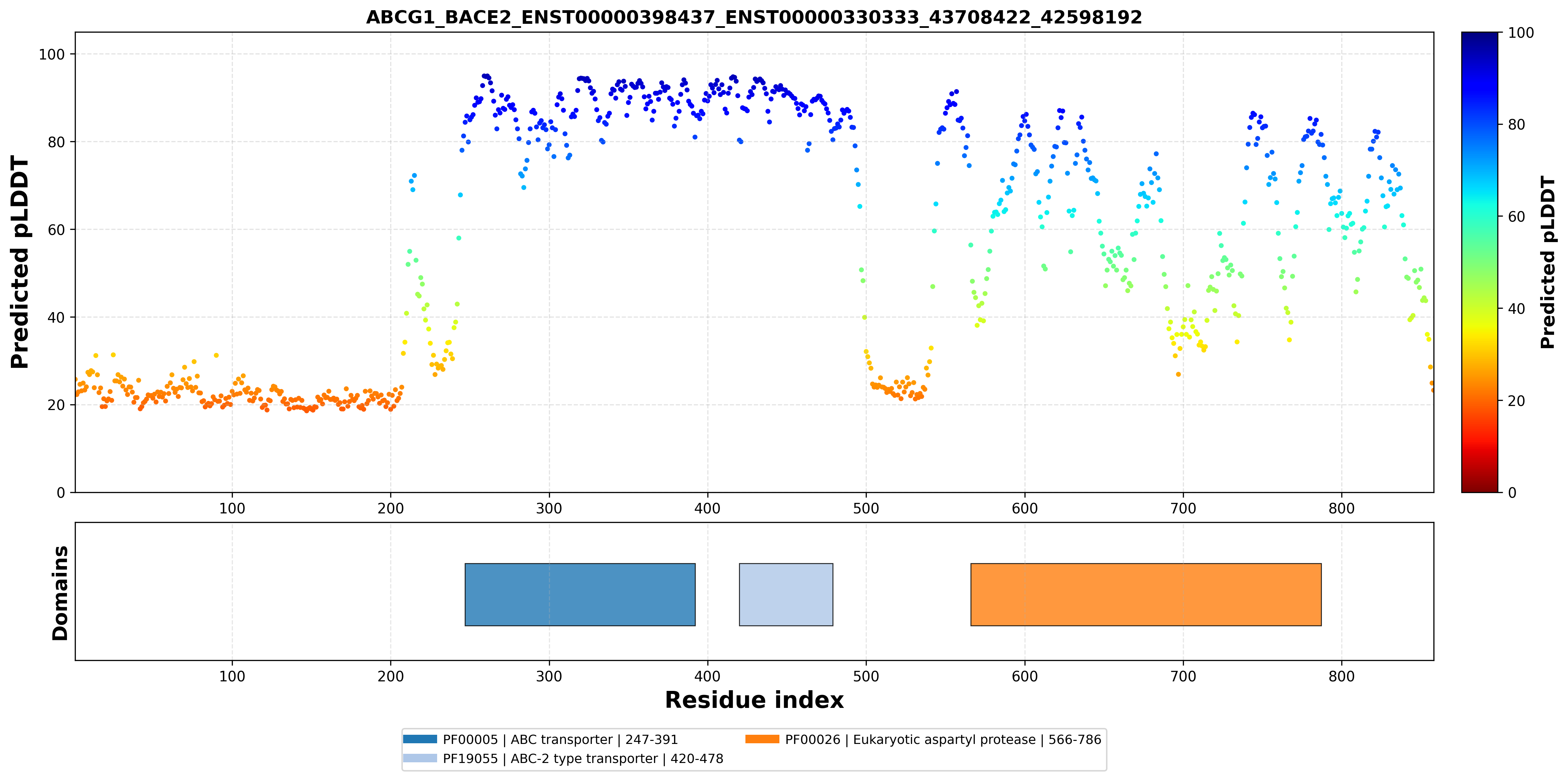 |  |  |
| ABCG1_BACE2_ENST00000398437_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.7244
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398437_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7409
Å |
 |  | 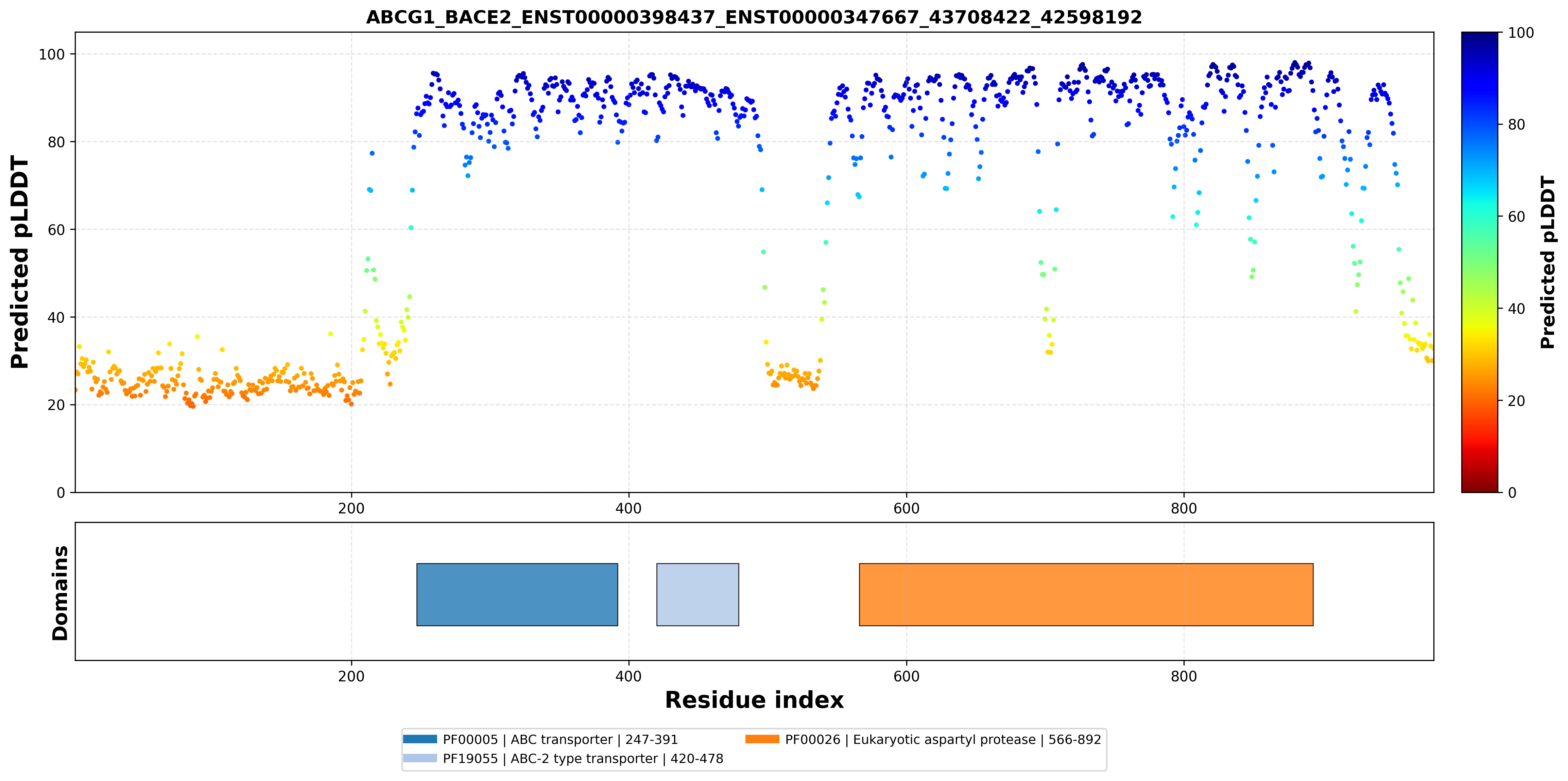 |  |  |
| ABCG1_BACE2_ENST00000398437_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.5401
Å |
| | | |  |
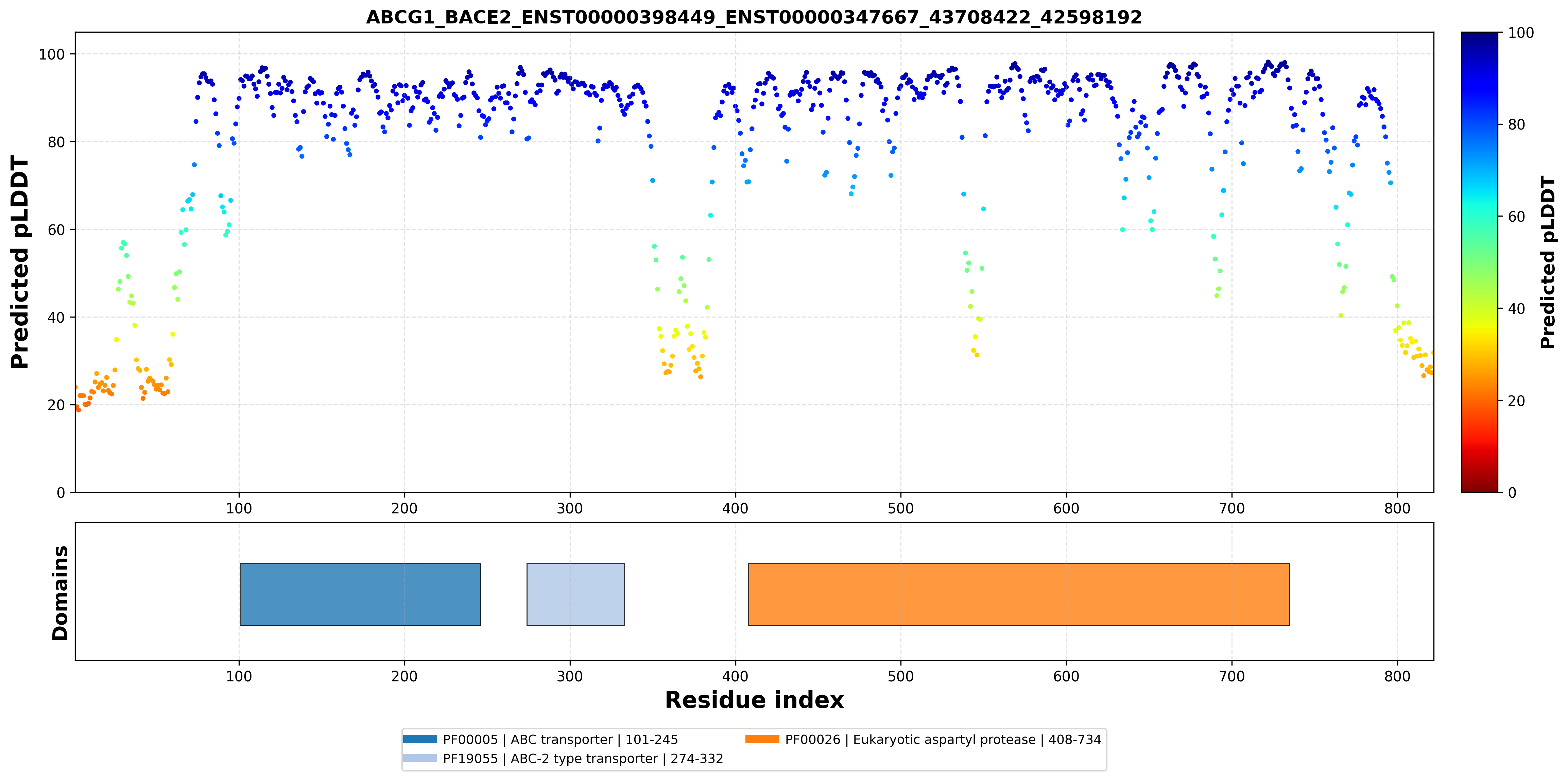
| ABCG1_BACE2_ENST00000398449_ENST00000328735_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.709
Å |
 |  | 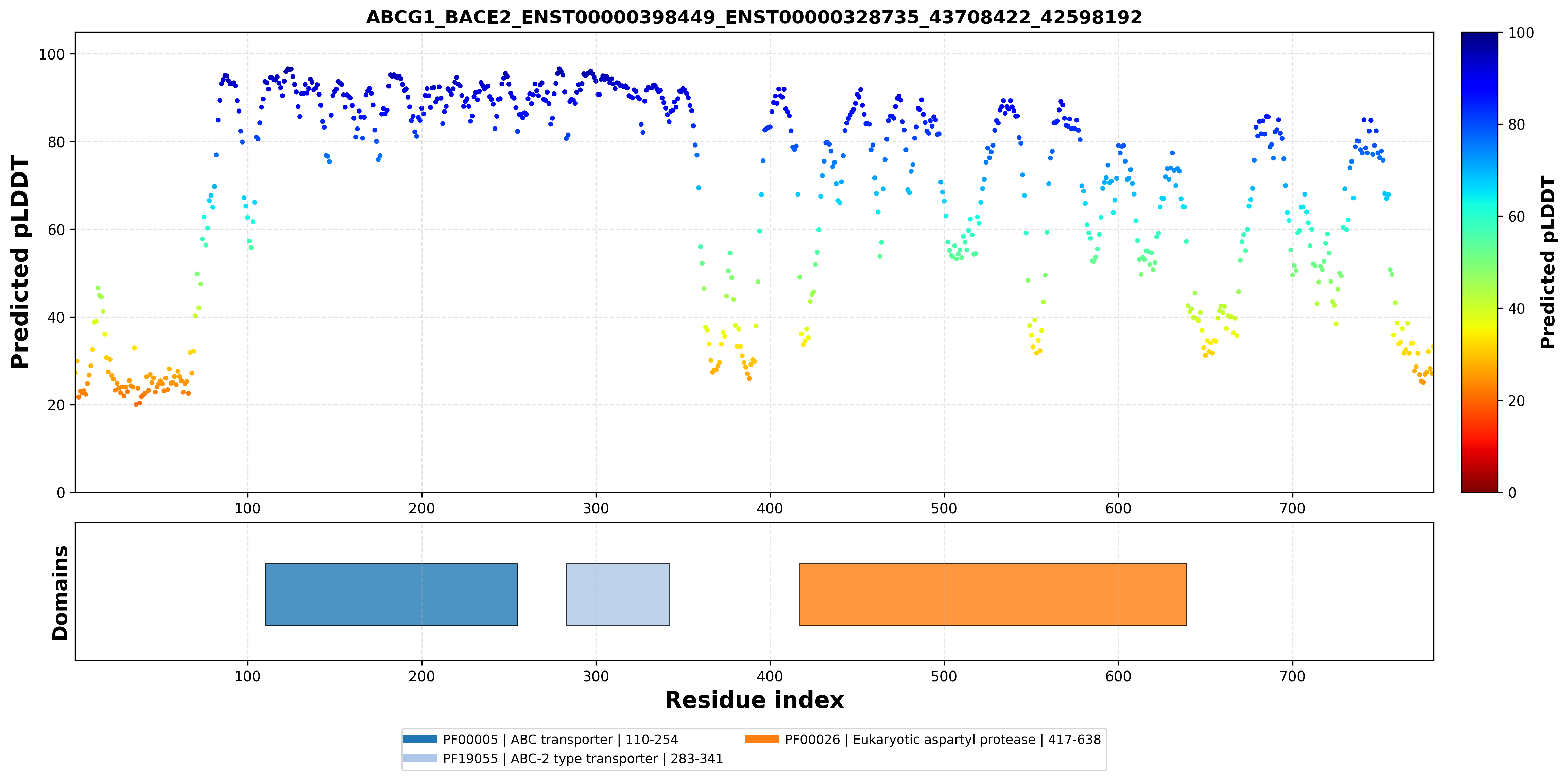 |  |  |
| ABCG1_BACE2_ENST00000398449_ENST00000328735_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:1.887
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398449_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6781
Å |
 |  | 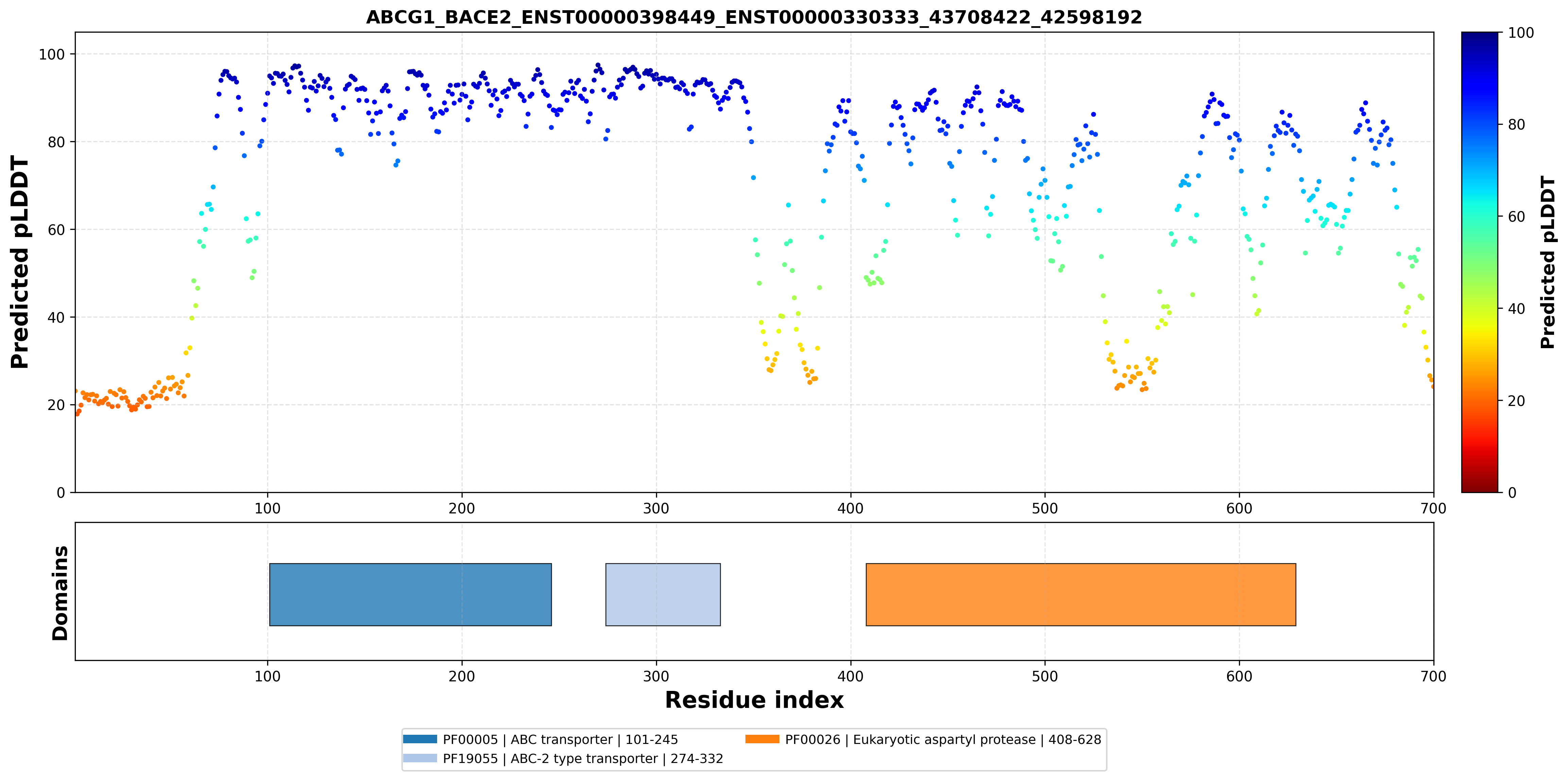 |  |  |
| ABCG1_BACE2_ENST00000398449_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.9408
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398449_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7001
Å |
 |  |  |  |  |
| ABCG1_BACE2_ENST00000398449_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.4794
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398457_ENST00000330333_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.6799
Å |
 |  | 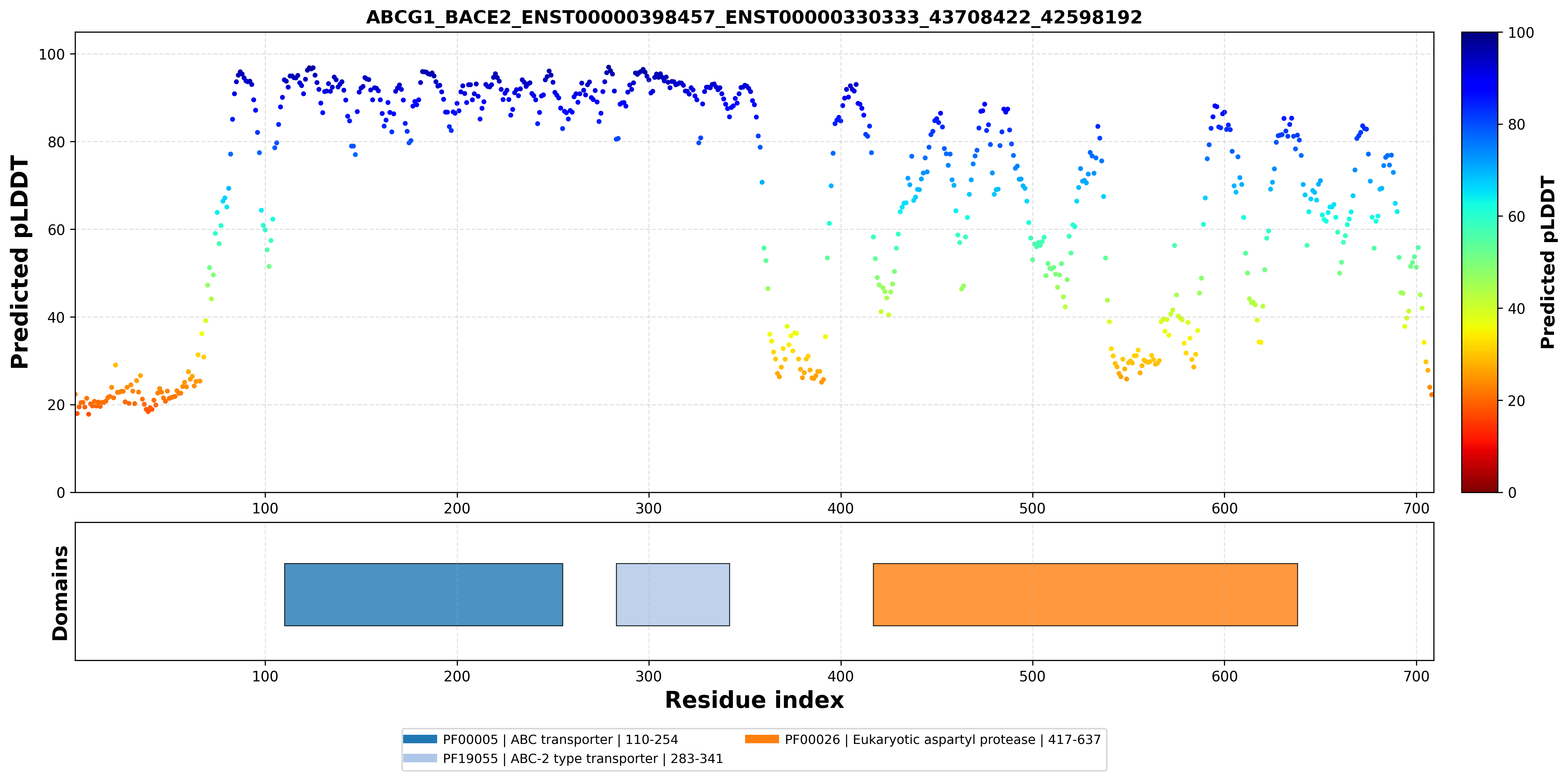 |  |  |
| ABCG1_BACE2_ENST00000398457_ENST00000330333_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.8827
Å |
| | | |  |
| ABCG1_BACE2_ENST00000398457_ENST00000347667_43708422_42598192 superimposed PDB: 7FDV of partner (ABCG1). RMSD:0.7192
Å |
 | 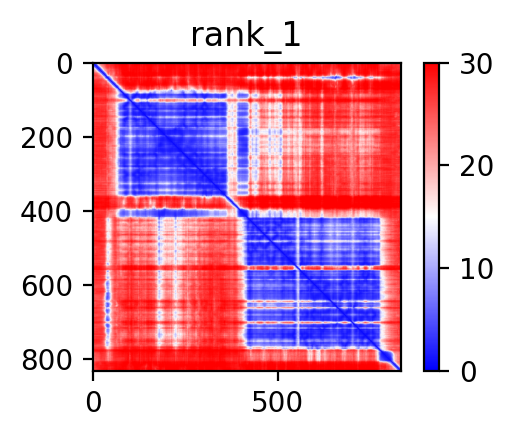 | 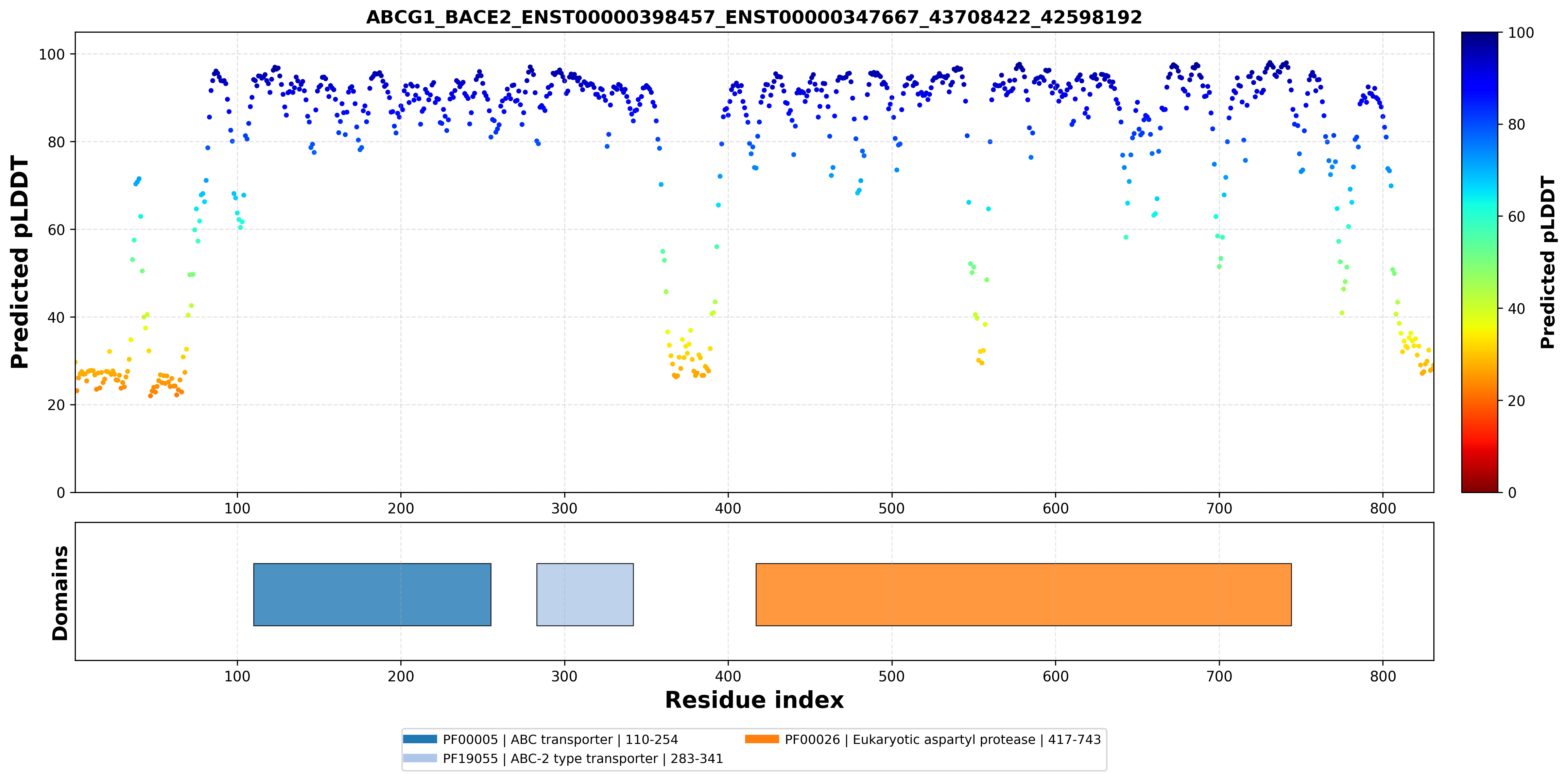 |  |  |
| ABCG1_BACE2_ENST00000398457_ENST00000347667_43708422_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.596
Å |
| | | |  |
| ABHD12_KIF16B_ENST00000339157_ENST00000354981_25282854_16509085 superimposed PDB: 2V14 of partner (KIF16B). RMSD:0.6689
Å |
 |  |  |  |  |
| ABHD12_PPP2R2A_ENST00000376542_ENST00000315985_25295560_26196405 superimposed PDB: 3DW8 of partner (PPP2R2A). RMSD:0.4167
Å |
 |  |  |  |  |
| ABHD17A_TCF3_ENST00000590661_ENST00000262965_1881233_1646426 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6363
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000359188_ENST00000261233_27054146_66597490 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5849
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000359188_ENST00000261233_27054146_66603235 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5809
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000376137_ENST00000261233_27054146_66597490 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5612
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000376137_ENST00000261233_27054146_66603235 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5681
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000376160_ENST00000261233_27054146_66597490 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5787
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000376160_ENST00000261233_27054146_66603235 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5525
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000490841_ENST00000261233_27054146_66597490 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5648
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000490841_ENST00000261233_27054146_66603235 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5591
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000536334_ENST00000261233_27054146_66597490 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5836
Å |
 |  |  |  |  |
| ABI1_IRAK3_ENST00000536334_ENST00000261233_27054146_66603235 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.5646
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000261016_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:1.258
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000261016_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6138
Å |
| | | |  |
| ABI2_MLLT3_ENST00000261017_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:1.1193
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000261017_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6833
Å |
| | | |  |
| ABI2_MLLT3_ENST00000261018_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:0.9875
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000261018_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6388
Å |
| | | |  |
| ABI2_MLLT3_ENST00000295851_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:0.617
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000422511_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:2.953
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000422511_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.5465
Å |
| | | |  |
| ABI2_MLLT3_ENST00000424558_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:1.144
Å |
 |  | 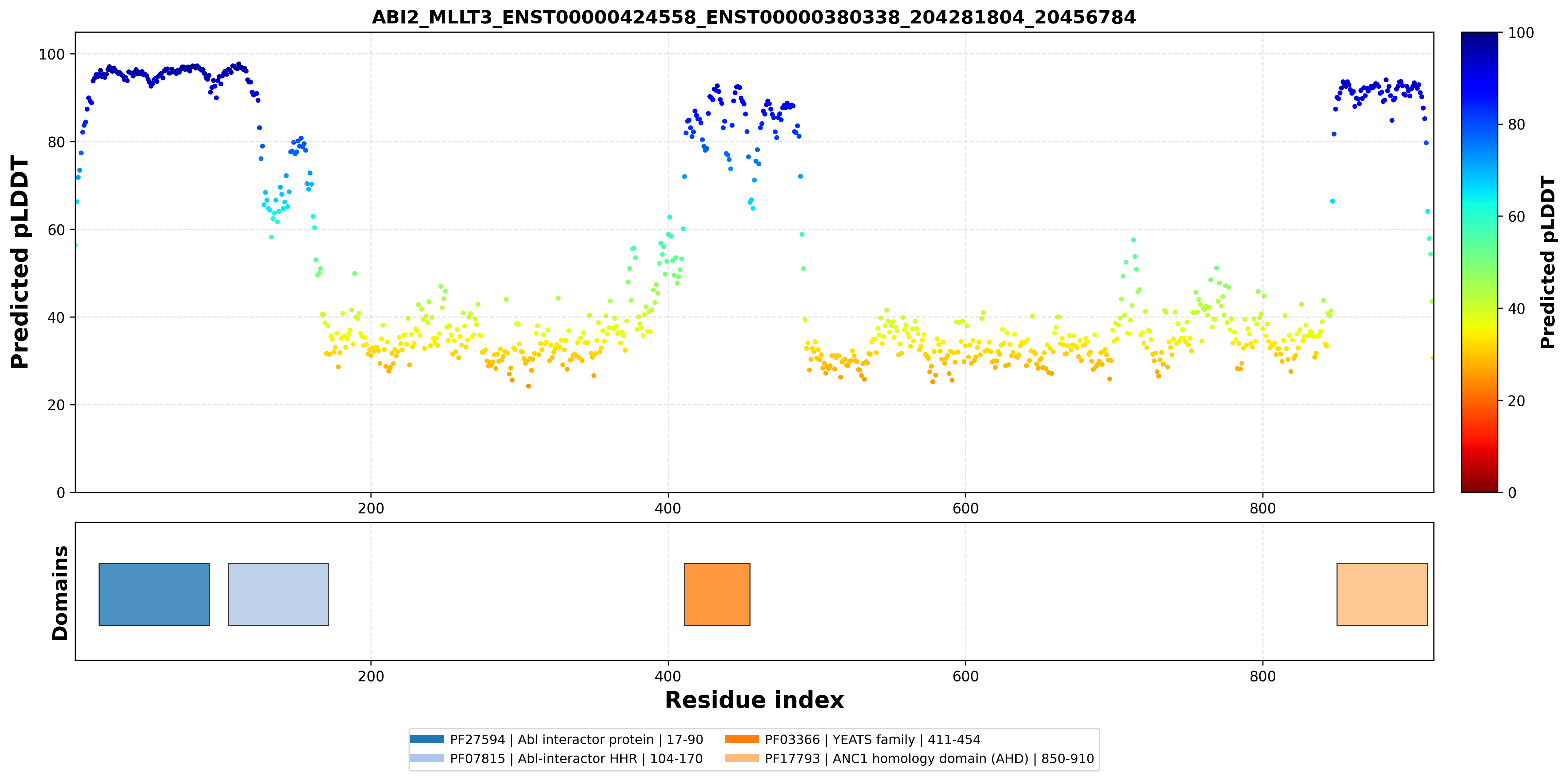 |  |  |
| ABI2_MLLT3_ENST00000424558_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.5593
Å |
| | | |  |
| ABI2_MLLT3_ENST00000430418_ENST00000380338_204281804_20456784 superimposed PDB: 4N78 of partner (ABI2). RMSD:1.1982
Å |
 |  |  |  |  |
| ABI2_MLLT3_ENST00000430418_ENST00000380338_204281804_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.7003
Å |
| | | |  |
| ABL1_BCR_ENST00000318560_ENST00000305877_133710912_23634727 superimposed PDB: 5N7E of partner (BCR). RMSD:0.5127
Å |
 |  |  |  |  |
| ABL1_BCR_ENST00000318560_ENST00000359540_133710912_23595985 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4119
Å |
 |  |  |  |  |
| ABL1_NTRK2_ENST00000318560_ENST00000376213_133710912_87338487 superimposed PDB: 1OPL of partner (ABL1). RMSD:3.2975
Å |
 |  |  |  |  |
| ABL1_NTRK2_ENST00000318560_ENST00000376213_133710912_87338487 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.6833
Å |
| | | |  |
| ABL1_NTRK2_ENST00000318560_ENST00000395882_133710912_87338487 superimposed PDB: 1OPL of partner (ABL1). RMSD:2.9361
Å |
 |  |  |  |  |
| ABL1_NTRK2_ENST00000318560_ENST00000395882_133710912_87338487 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7606
Å |
| | | |  |
| ABLIM2_PPP2R2C_ENST00000361581_ENST00000515571_8079354_6380299 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.5162
Å |
 |  |  |  |  |
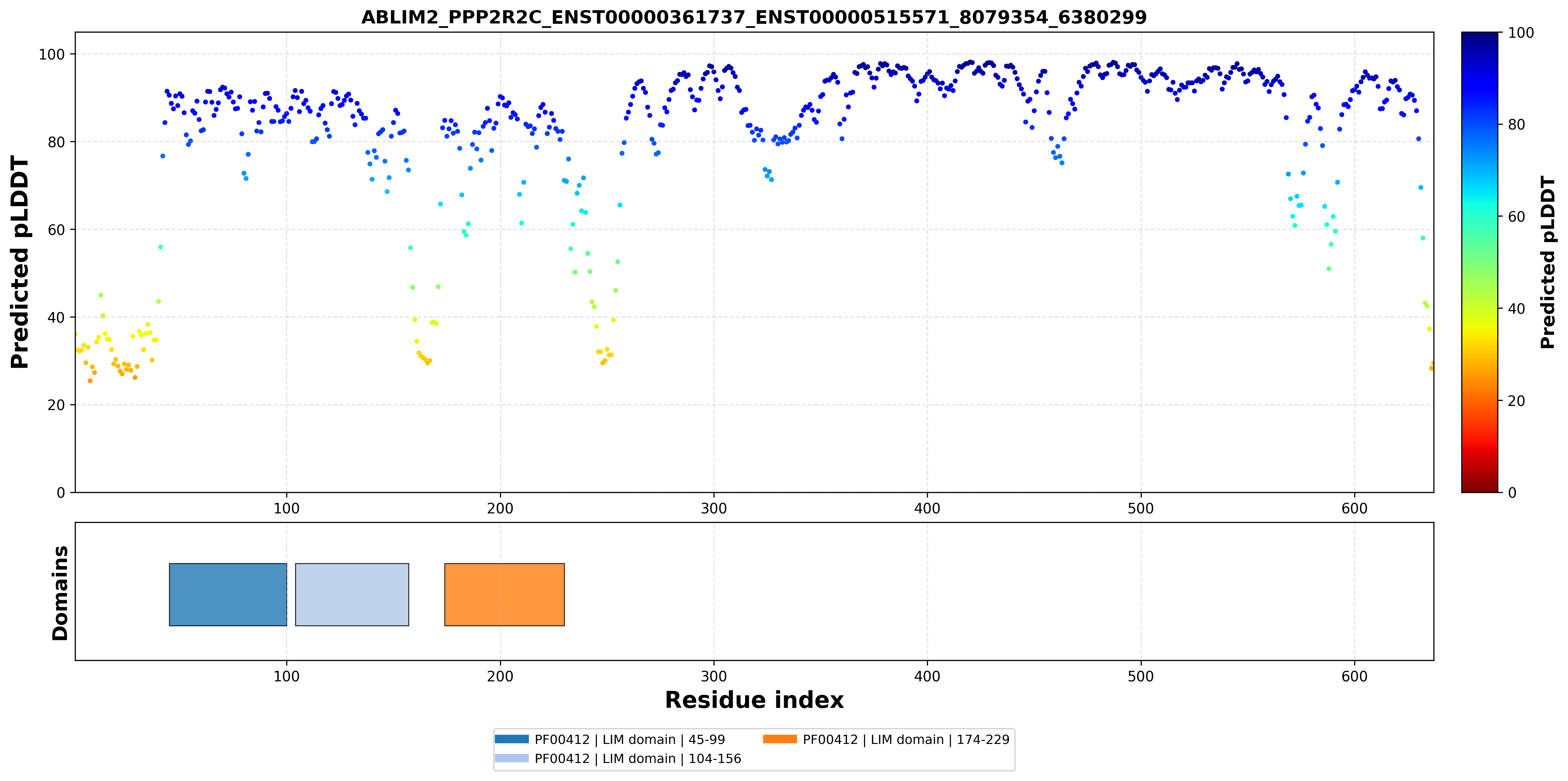
| ABLIM2_PPP2R2C_ENST00000361737_ENST00000515571_8079354_6380299 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.5998
Å |
 |  |  |  |  |
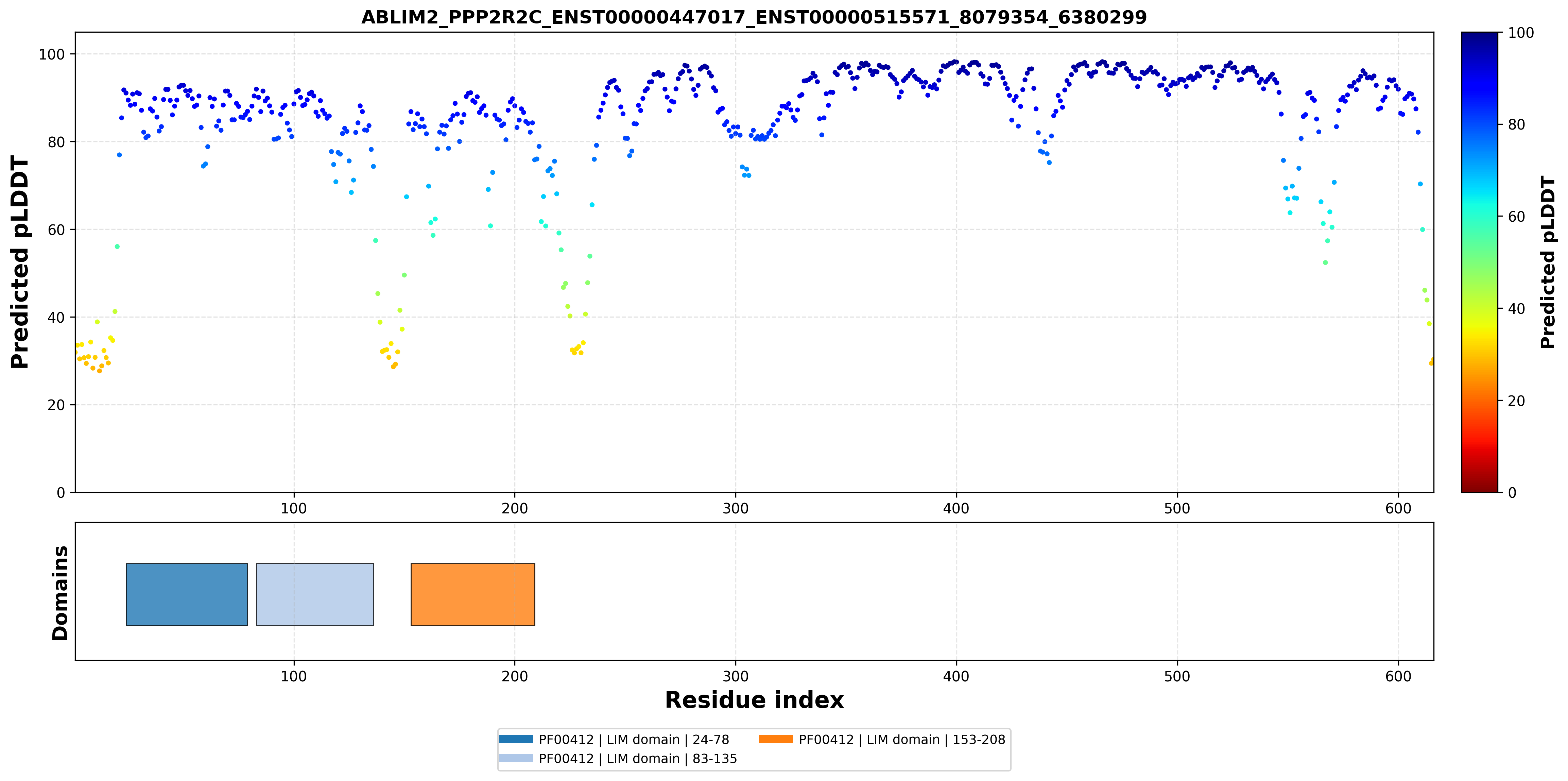
| ABLIM2_PPP2R2C_ENST00000447017_ENST00000515571_8079354_6380299 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.522
Å |
 |  |  |  |  |
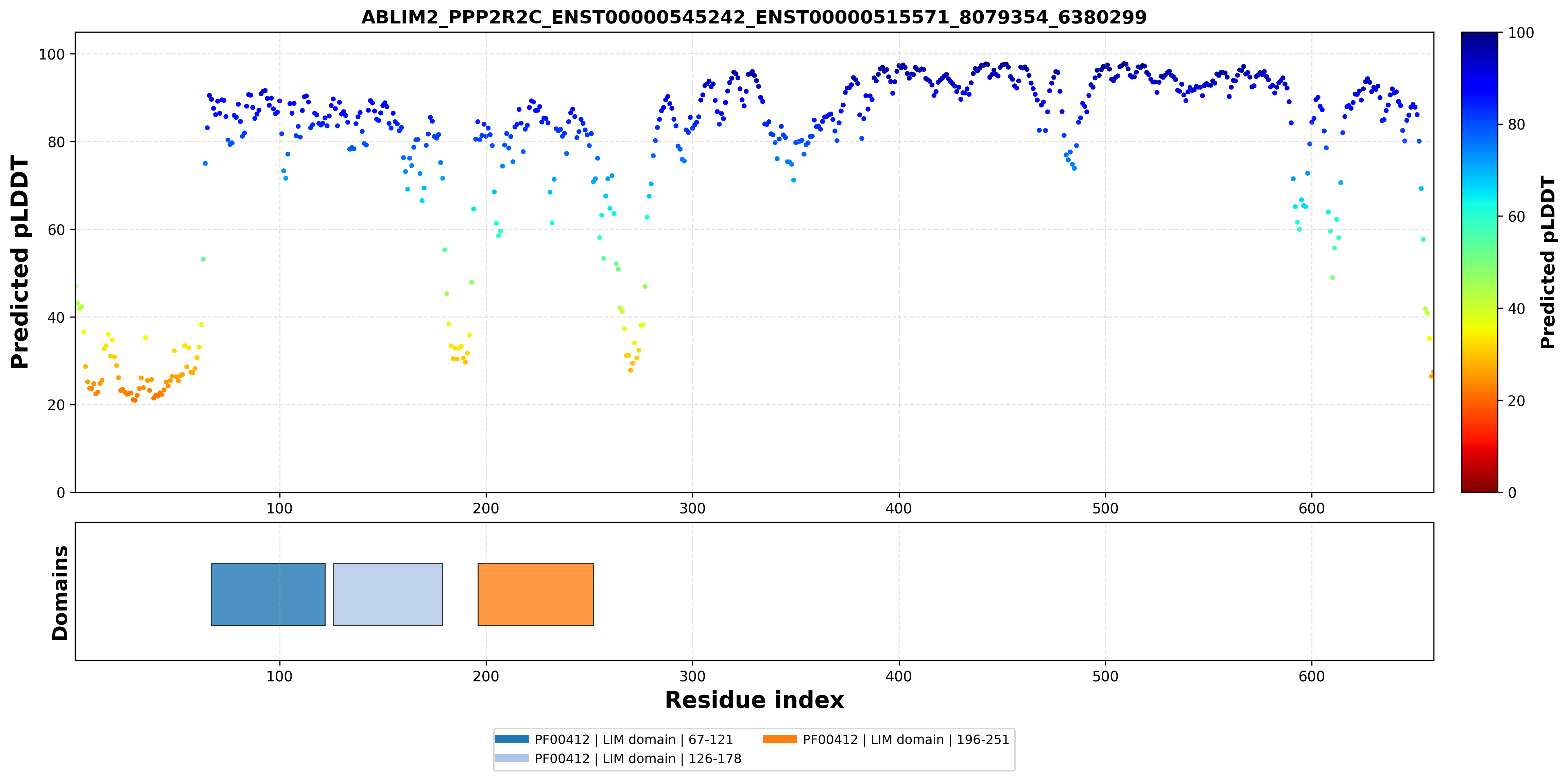
| ABLIM2_PPP2R2C_ENST00000545242_ENST00000515571_8079354_6380299 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.3965
Å |
 |  |  |  |  |
| ABR_MYO1C_ENST00000291107_ENST00000438665_953289_1387597 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9515
Å |
 |  |  |  |  |
| ABR_MYO1C_ENST00000302538_ENST00000438665_953289_1387597 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9644
Å |
 |  |  |  |  |
| ABR_MYO1C_ENST00000536794_ENST00000438665_953289_1387597 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0425
Å |
 |  |  |  |  |
| ABR_MYO1C_ENST00000574437_ENST00000438665_953289_1387597 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0315
Å |
 |  |  |  |  |
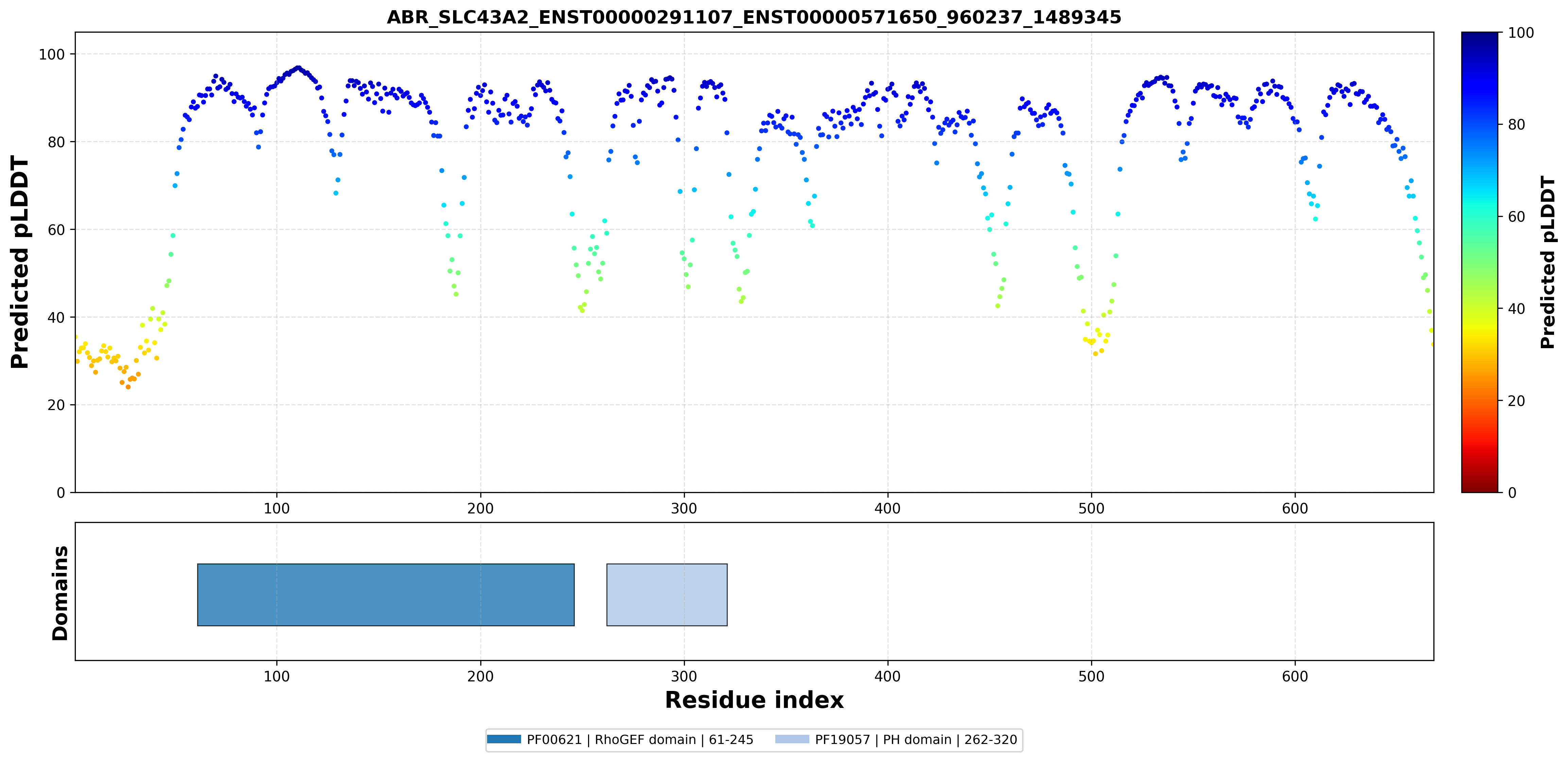
| ABR_SLC43A2_ENST00000291107_ENST00000571650_960237_1489345 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.0488
Å |
 |  |  |  |  |
| ABR_SLC43A2_ENST00000302538_ENST00000571650_960237_1489345 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.0544
Å |
 |  | 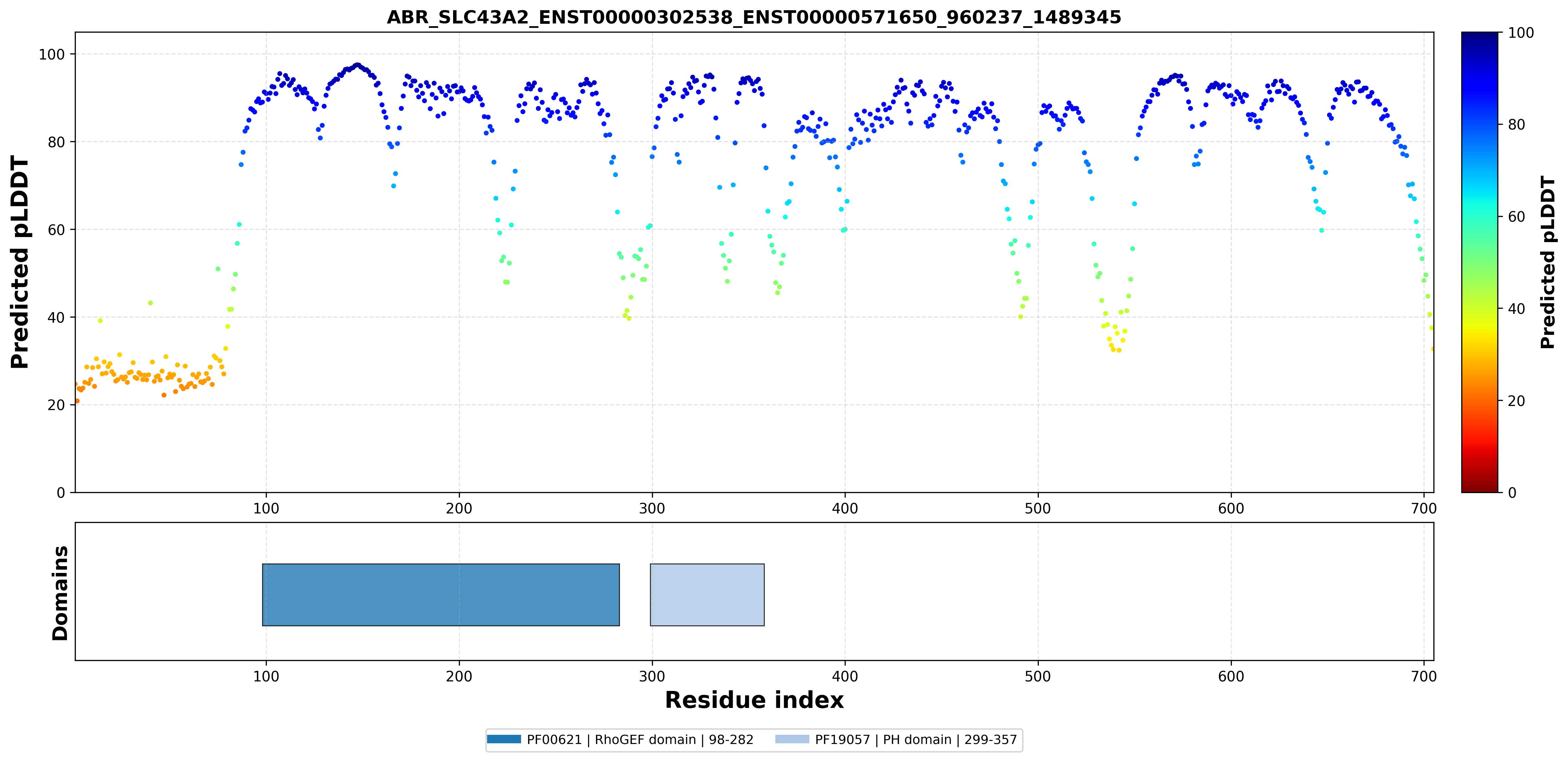 |  |  |
| ABR_SLC43A2_ENST00000536794_ENST00000571650_960237_1489345 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.1936
Å |
 |  | 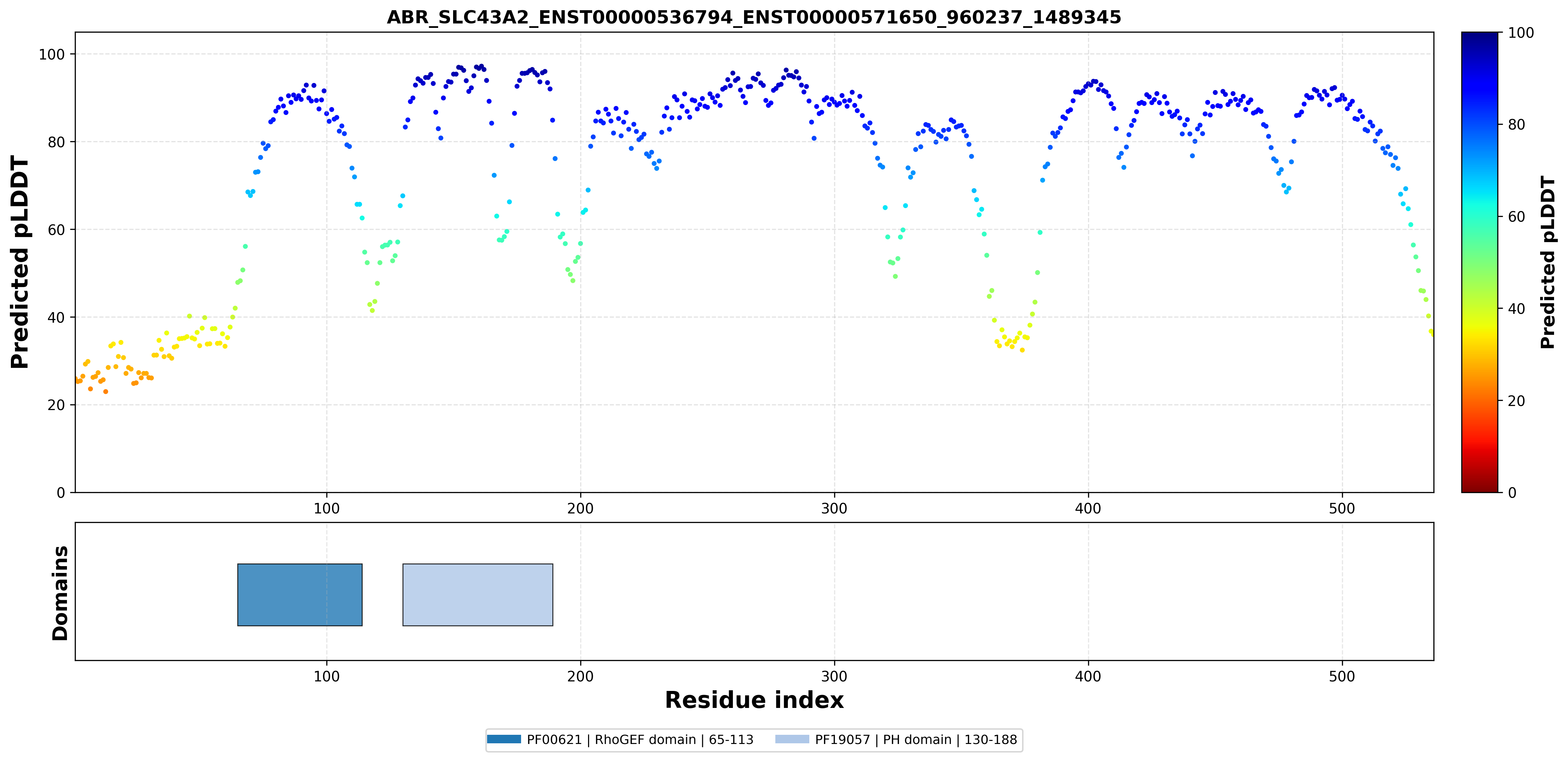 |  |  |
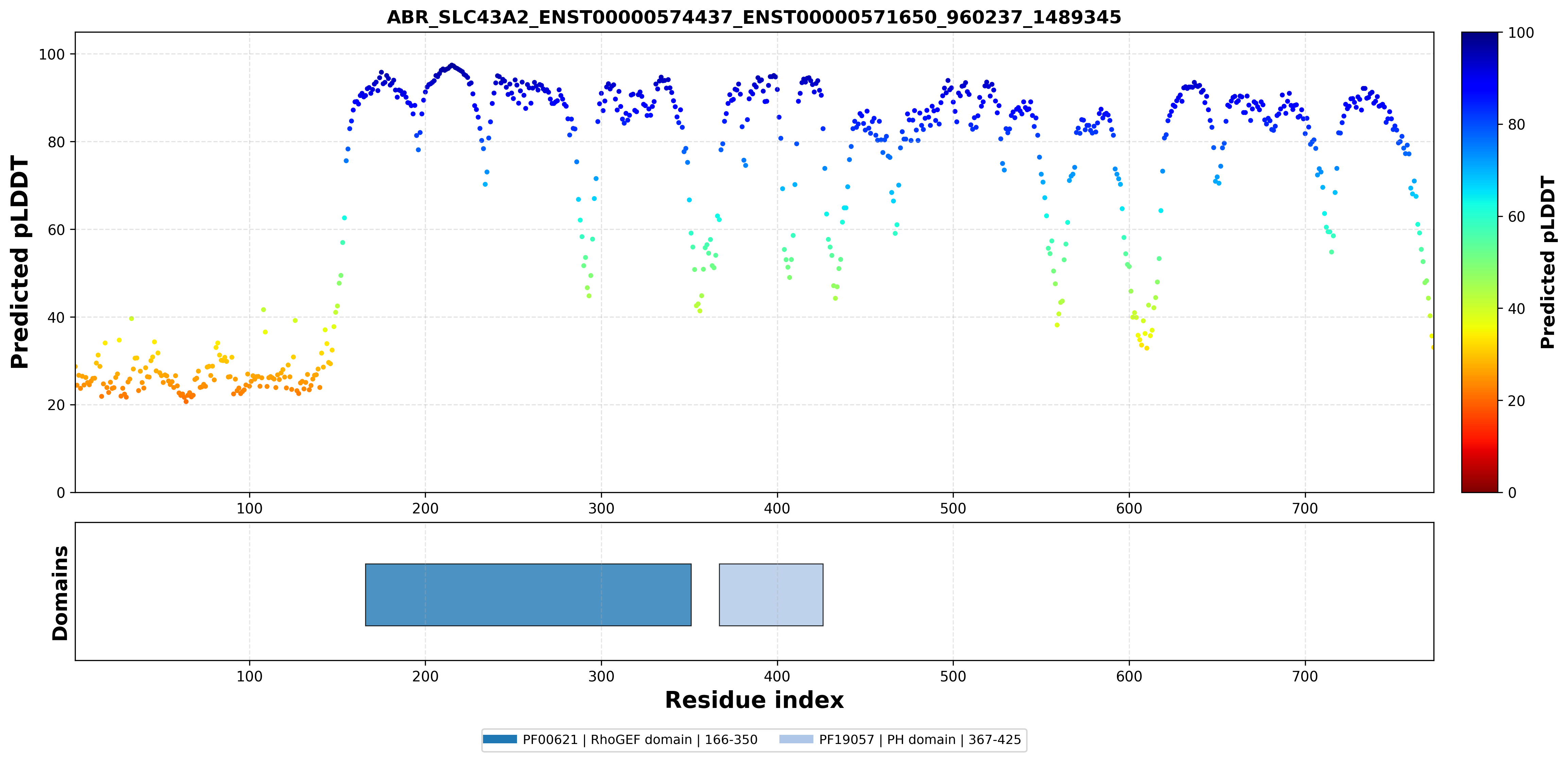
| ABR_SLC43A2_ENST00000574437_ENST00000571650_960237_1489345 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.1021
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000291107_ENST00000264335_982569_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.2728
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000291107_ENST00000573026_953289_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.7636
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000302538_ENST00000573026_953289_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.7596
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000536794_ENST00000573026_953289_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.9006
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000574437_ENST00000264335_982569_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.2795
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000574437_ENST00000571732_953289_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.7583
Å |
 |  |  |  |  |
| ABR_YWHAE_ENST00000574437_ENST00000573026_953289_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.7495
Å |
 |  |  |  |  |
| ABTB2_APIP_ENST00000298992_ENST00000395787_34378247_34916657 superimposed PDB: 4M6R of partner (APIP). RMSD:0.2926
Å |
 |  |  |  |  |
| ABTB2_ELF5_ENST00000298992_ENST00000312319_34218871_34501861 superimposed PDB: 1WWX of partner (ELF5). RMSD:0.6227
Å |
 |  |  |  |  |
| ABTB2_ELF5_ENST00000298992_ENST00000312319_34226090_34504046 superimposed PDB: 1WWX of partner (ELF5). RMSD:0.652
Å |
 |  |  |  |  |
| ABTB2_ELF5_ENST00000435224_ENST00000312319_34218871_34501861 superimposed PDB: 1WWX of partner (ELF5). RMSD:0.8211
Å |
 |  |  |  |  |
| ABTB2_ELF5_ENST00000435224_ENST00000312319_34226090_34504046 superimposed PDB: 1WWX of partner (ELF5). RMSD:0.6941
Å |
 |  |  |  |  |
| ACACA_CCL5_ENST00000353139_ENST00000293272_35478276_34199468 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.7373
Å |
 |  |  |  |  |
| ACACA_CCL5_ENST00000353139_ENST00000293272_35478276_34199468 superimposed PDB: 7O7F of partner (CCL5). RMSD:1.5693
Å |
| | | |  |
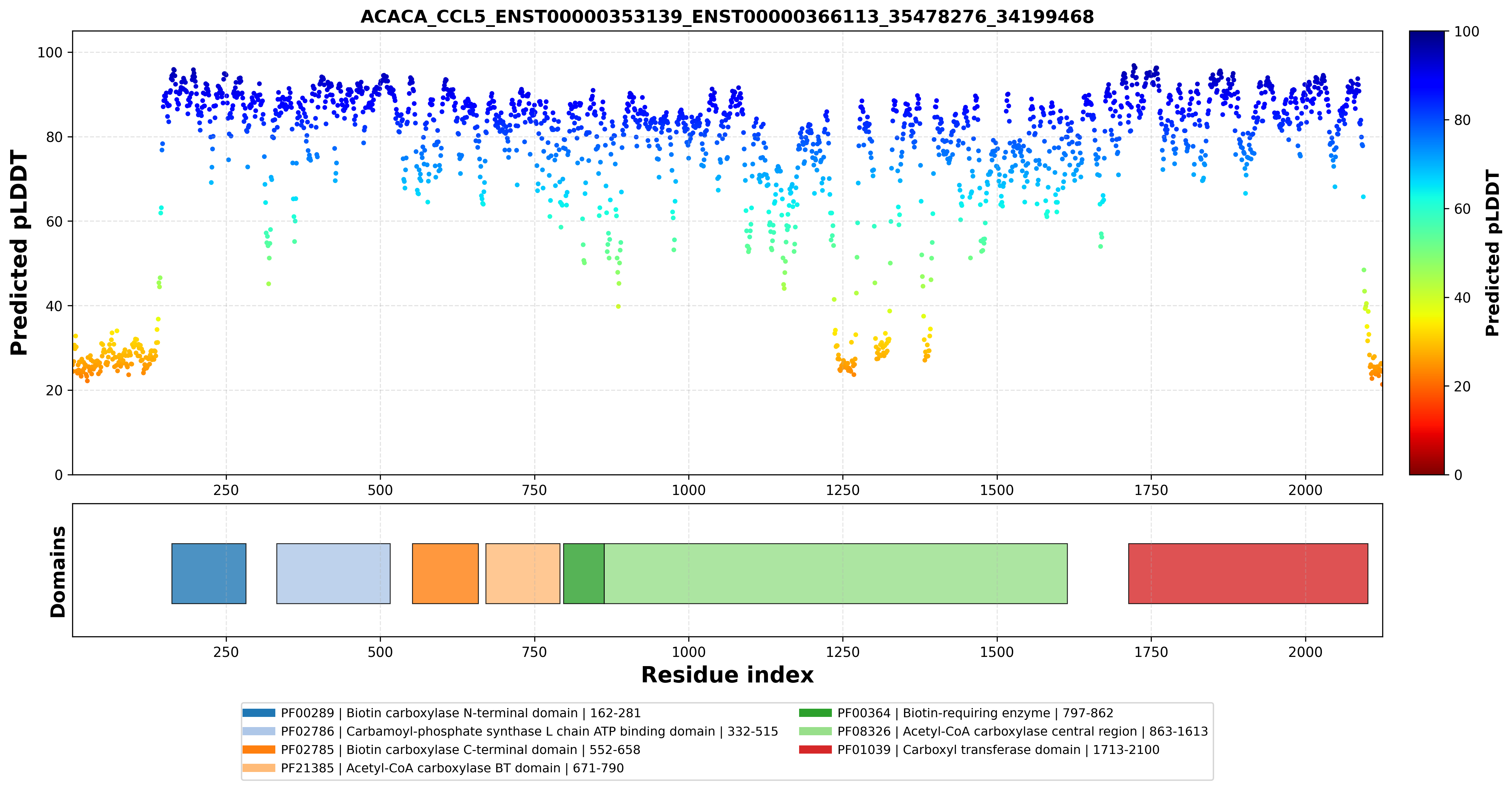
| ACACA_CCL5_ENST00000353139_ENST00000366113_35478276_34199468 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.568
Å |
 |  |  |  |  |
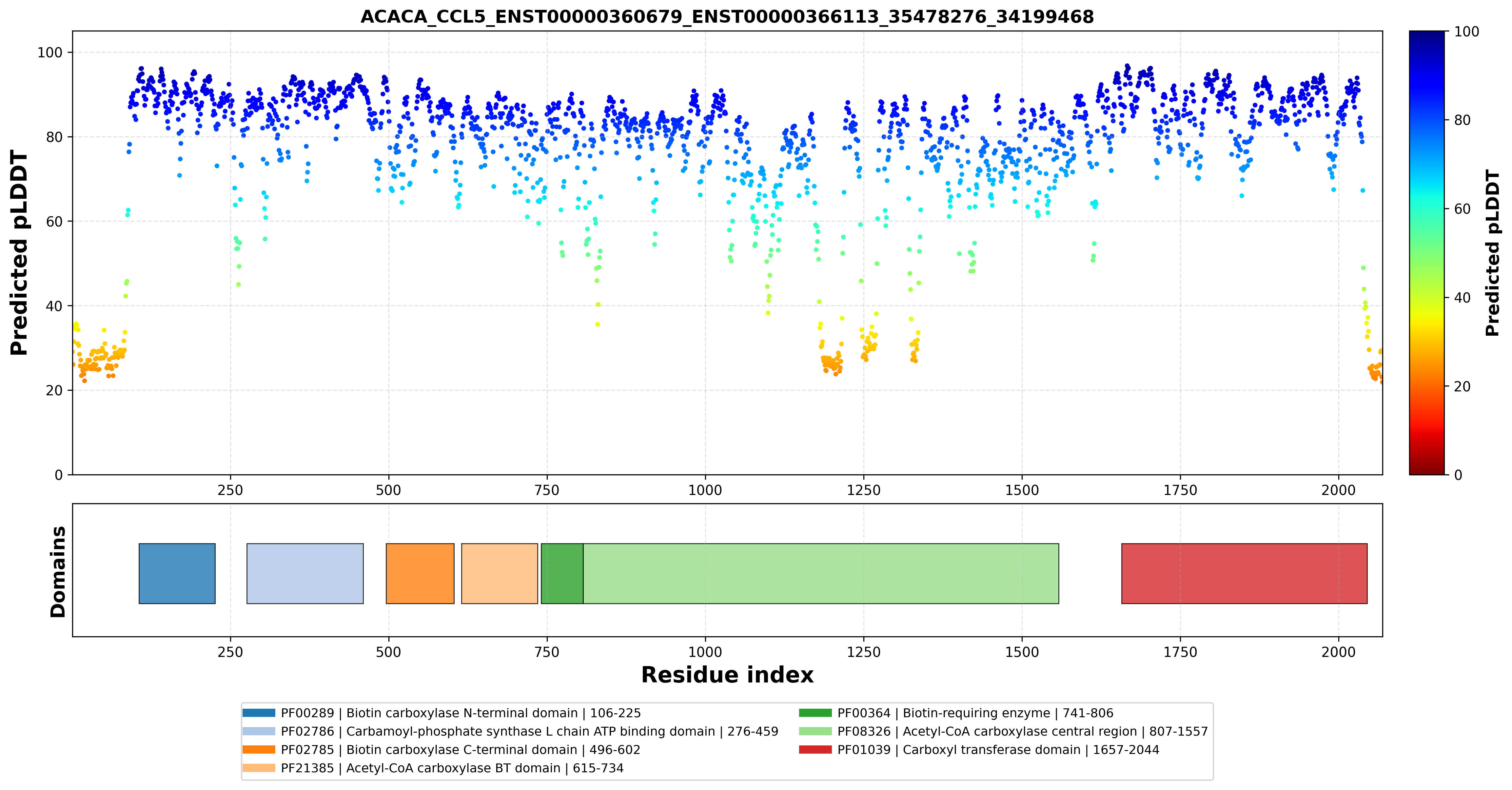
| ACACA_CCL5_ENST00000360679_ENST00000366113_35478276_34199468 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.6342
Å |
 |  |  |  |  |
| ACACA_CCL5_ENST00000361253_ENST00000366113_35478276_34199468 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.6639
Å |
 | 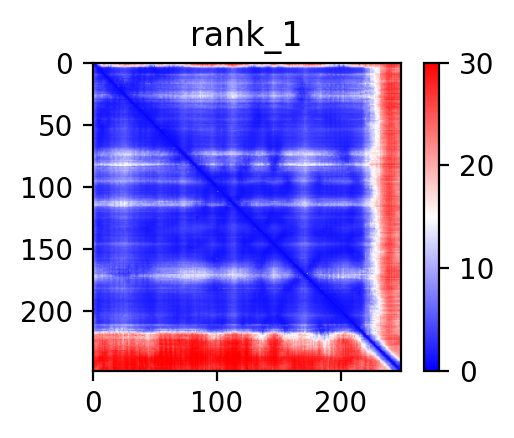 | 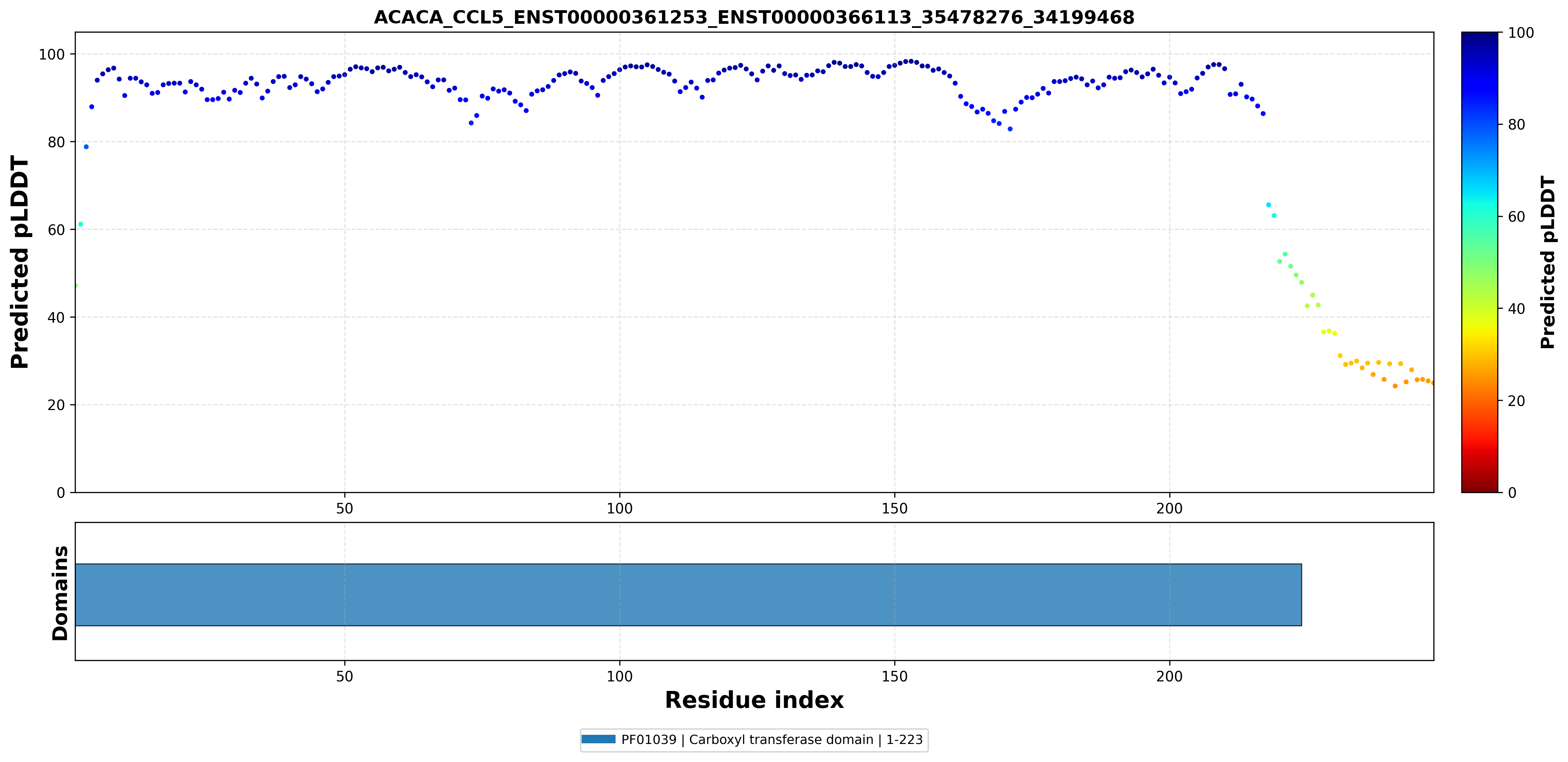 |  | 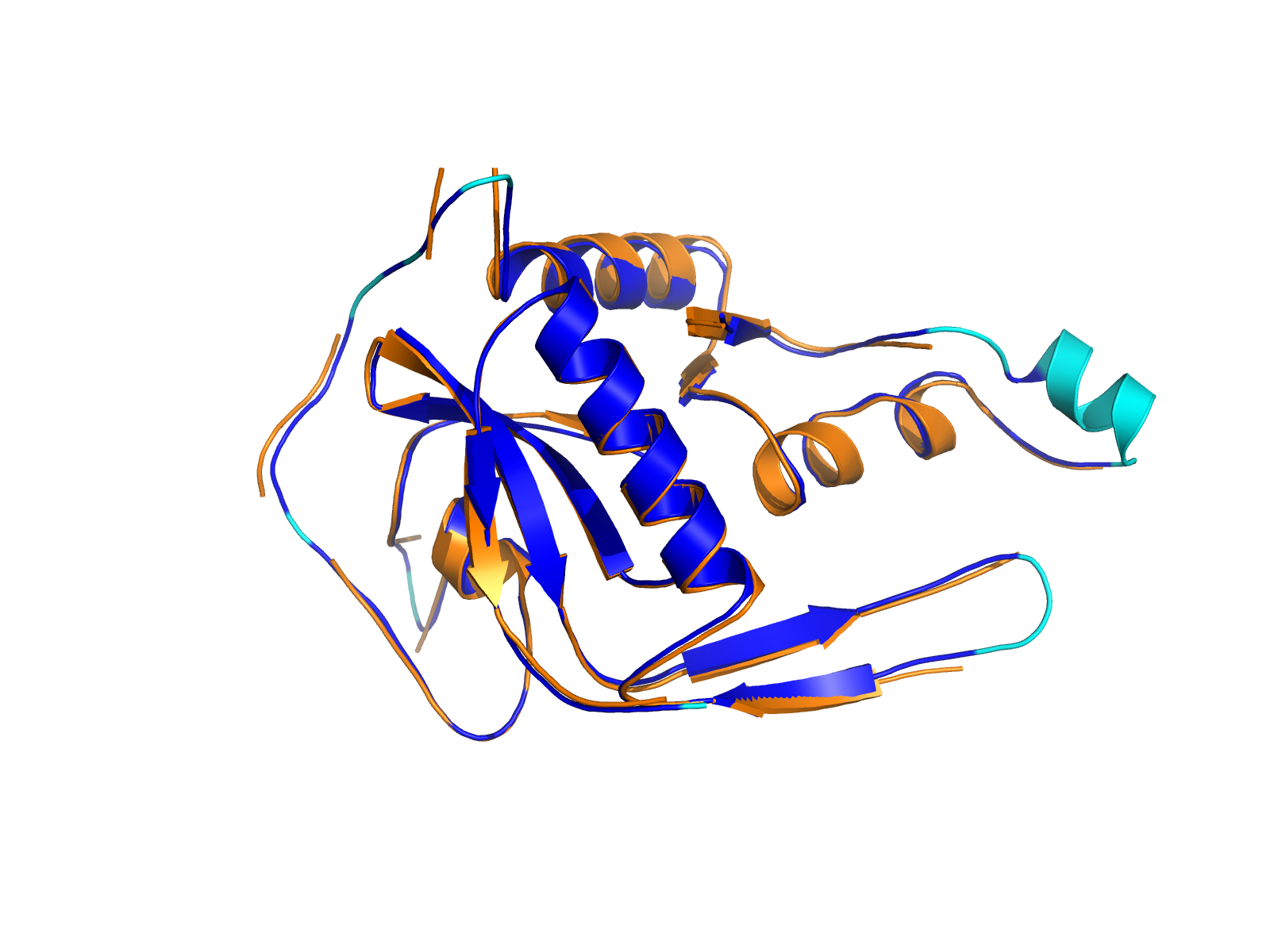 |
| ACACA_ERC1_ENST00000394406_ENST00000543086_35687112_1553727 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.5872
Å |
 |  |  |  |  |
| ACACA_GSDMB_ENST00000335166_ENST00000309481_35627641_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.922
Å |
 |  |  |  |  |
| ACACA_GSDMB_ENST00000335166_ENST00000394175_35627641_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.8844
Å |
 |  |  |  |  |
| ACACA_GSDMB_ENST00000335166_ENST00000418519_35627641_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.98
Å |
 |  |  |  |  |
| ACACA_GSDMB_ENST00000335166_ENST00000520542_35627641_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.8834
Å |
 |  |  |  |  |
| ACACA_GSDMB_ENST00000394406_ENST00000360317_35627641_38068750 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.581
Å |
 |  |  |  |  |
| ACACA_LASP1_ENST00000360679_ENST00000318008_35536200_37034338 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7267
Å |
 |  | 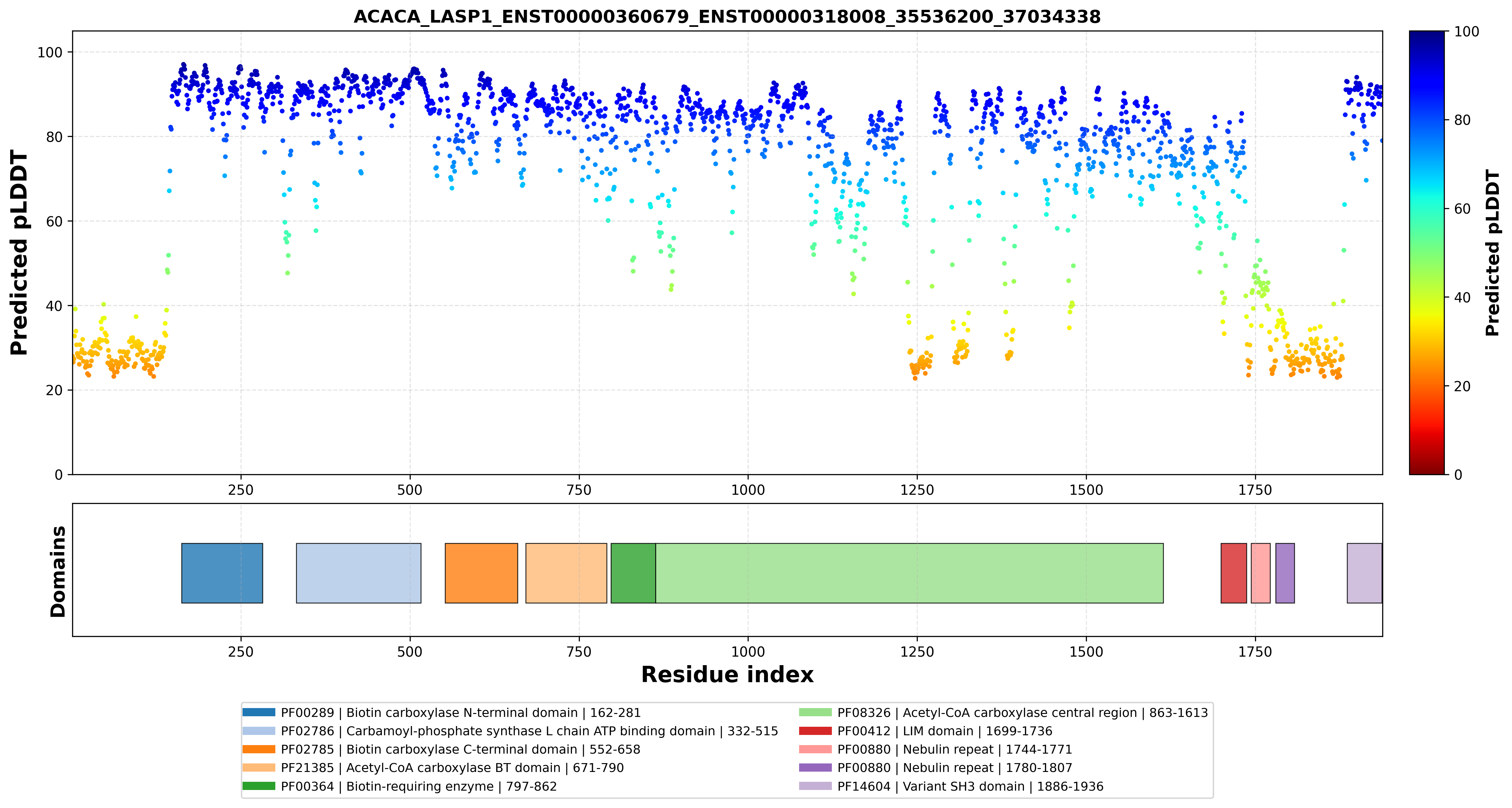 |  |  |
| ACACA_LASP1_ENST00000360679_ENST00000318008_35536200_37034338 superimposed PDB: 3I35 of partner (LASP1). RMSD:0.3651
Å |
| | | |  |
| ACACA_LGALS9_ENST00000353139_ENST00000302228_35627641_25965288 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:3.4669
Å |
 |  |  |  |  |
| ACACA_LGALS9_ENST00000353139_ENST00000313648_35627641_25965288 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:3.061
Å |
 |  |  |  |  |
| ACACA_LGALS9_ENST00000360679_ENST00000310394_35627641_25965288 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:0.4276
Å |
 |  |  |  |  |
| ACACA_LGALS9_ENST00000360679_ENST00000313648_35627641_25965288 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:3.2812
Å |
 |  |  |  |  |
| ACACA_LGALS9_ENST00000360679_ENST00000395473_35627641_25965288 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:3.0066
Å |
 |  |  |  |  |
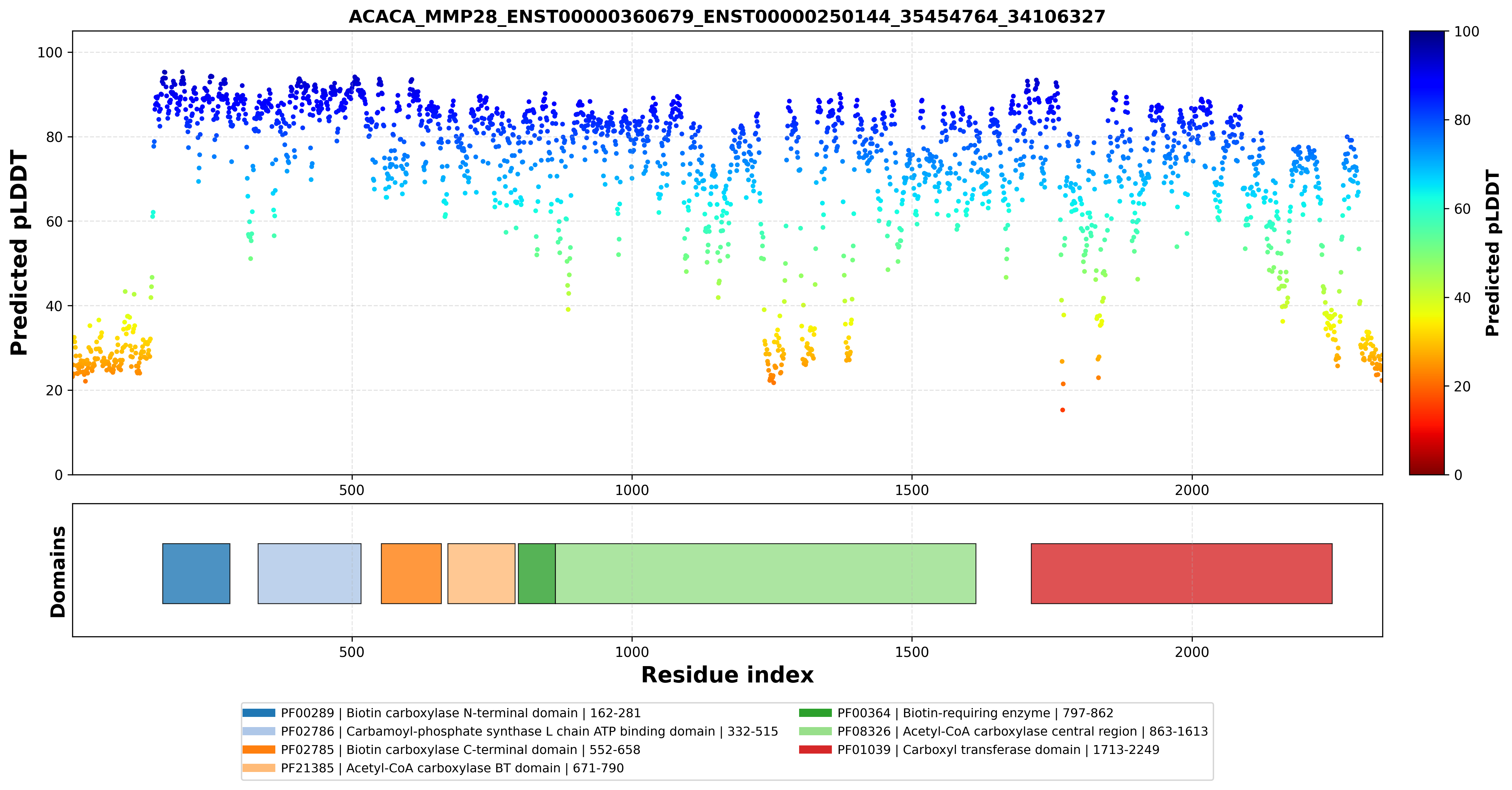
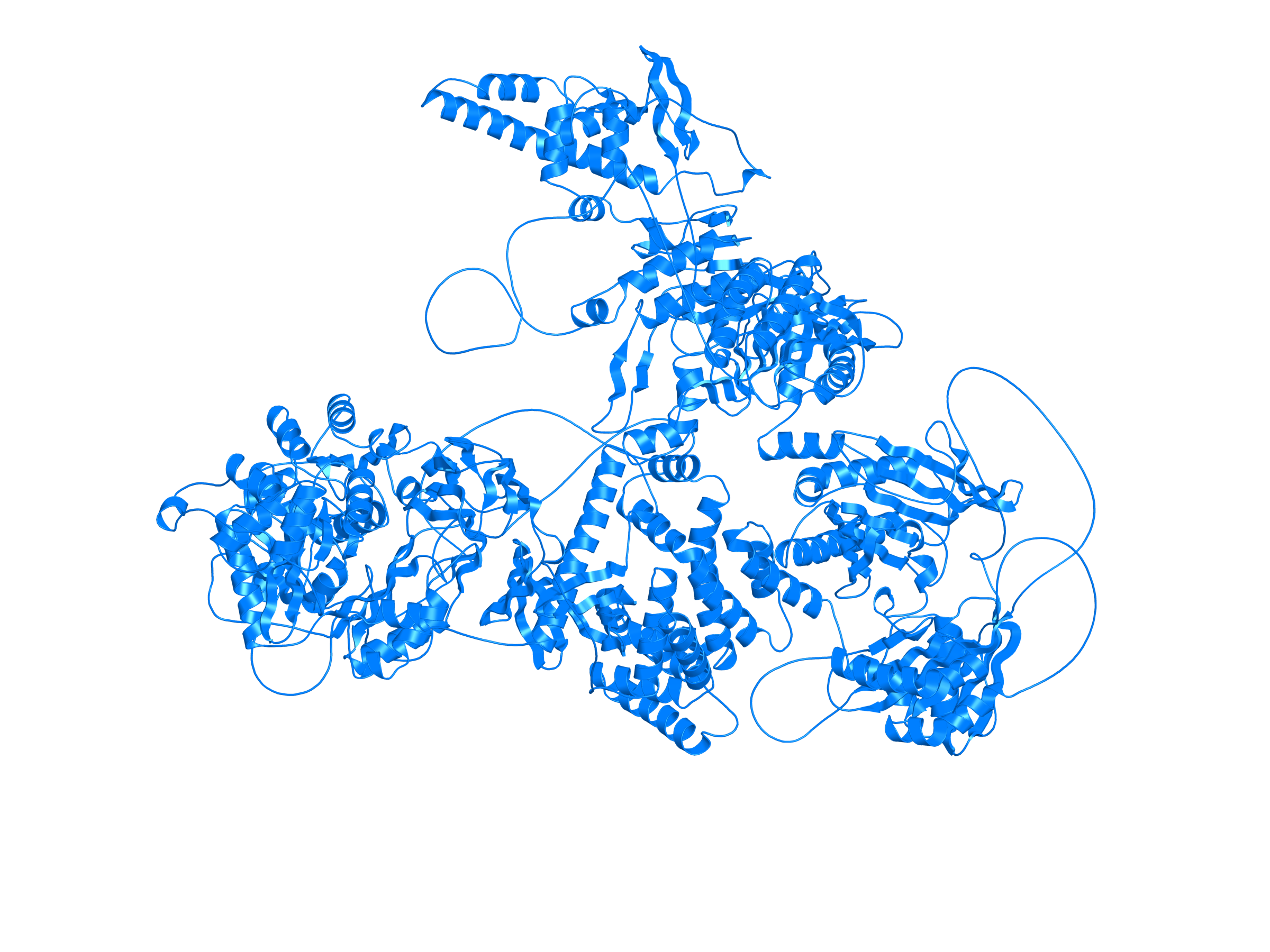
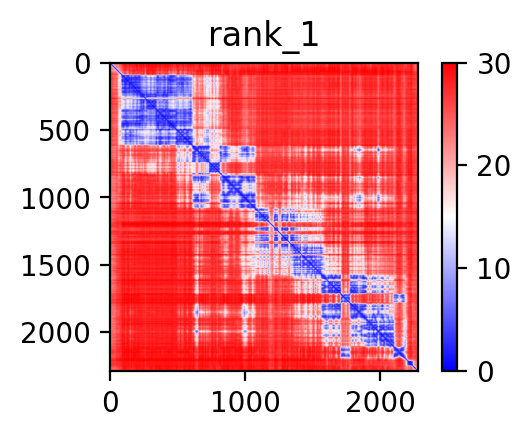
| ACACA_MMP28_ENST00000360679_ENST00000250144_35454764_34106327 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.9619
Å |
 |  |  |  |  |
| ACACA_MMP28_ENST00000361253_ENST00000250144_35454764_34106327 superimposed PDB: 8XL1 of partner (ACACA). RMSD:3.0065
Å |
 |  | 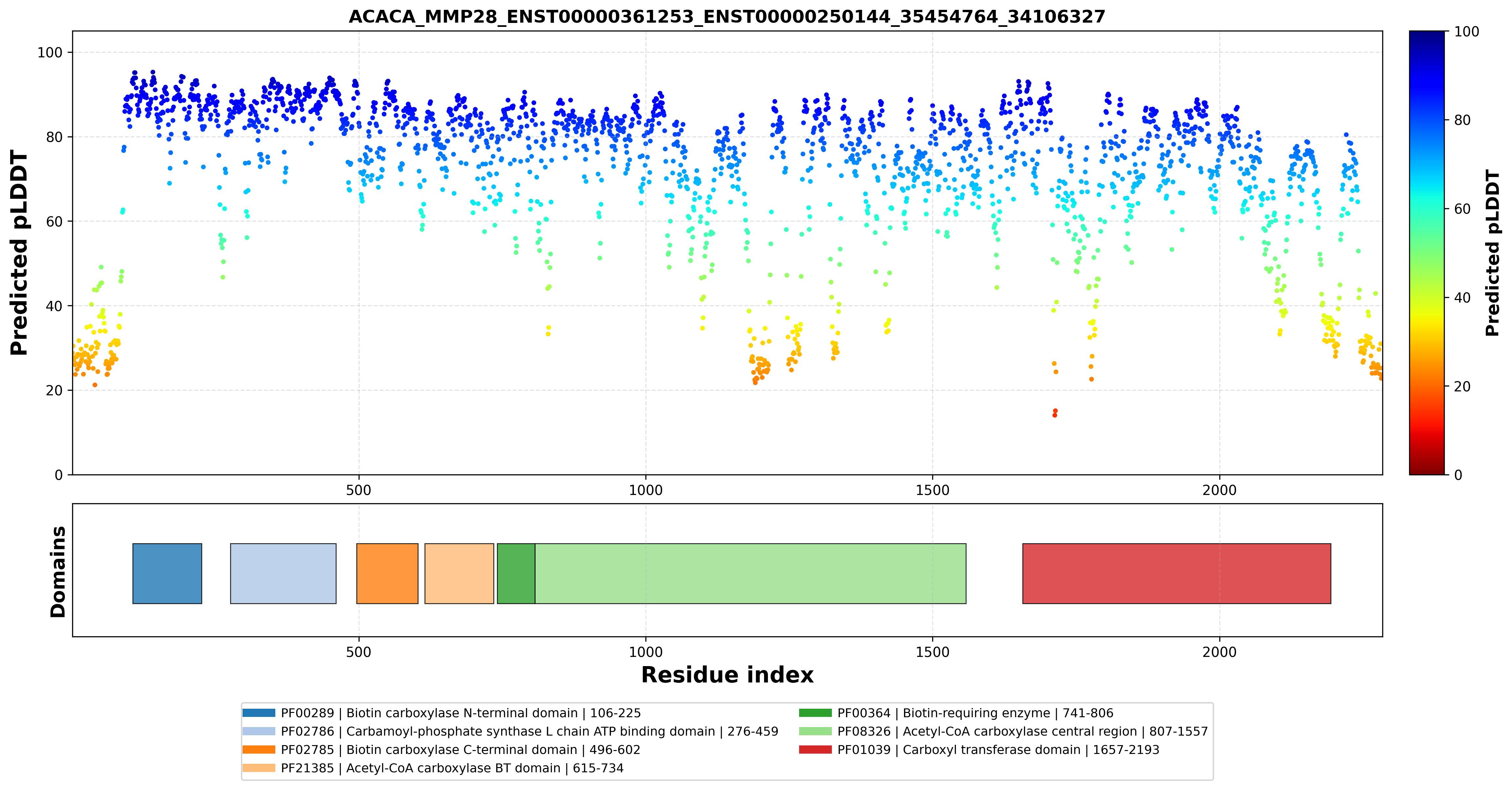 | 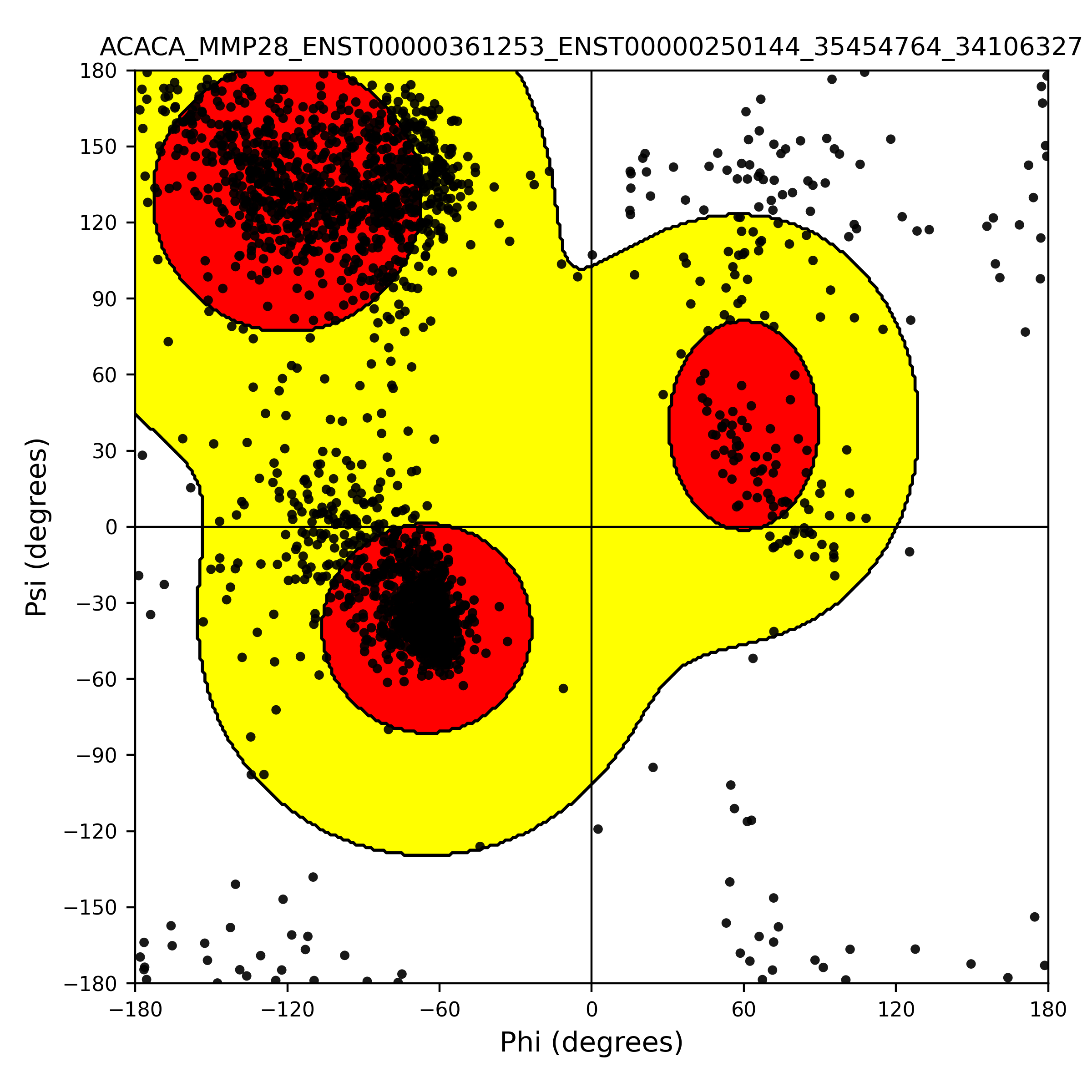 |  |
| ACACA_MRPL45_ENST00000353139_ENST00000312513_35766351_36478008 superimposed PDB: 7OF0 of partner (MRPL45). RMSD:0.9302
Å |
 |  |  |  |  |
| ACACA_MXRA7_ENST00000353139_ENST00000375036_35506787_74684258 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.5349
Å |
 |  |  |  |  |
| ACACA_MXRA7_ENST00000353139_ENST00000449428_35506787_74684258 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7497
Å |
 |  |  |  |  |
| ACACA_MXRA7_ENST00000360679_ENST00000355797_35506787_74684258 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.6039
Å |
 |  |  |  |  |
| ACACA_MXRA7_ENST00000360679_ENST00000375036_35506787_74684258 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.4901
Å |
 |  |  |  |  |
| ACACA_MXRA7_ENST00000360679_ENST00000449428_35506787_74684258 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.6649
Å |
 |  |  |  |  |
| ACACA_SRCIN1_ENST00000353139_ENST00000264659_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.842
Å |
 |  |  |  |  |
| ACACA_SRCIN1_ENST00000353139_ENST00000578925_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.8512
Å |
 |  |  |  |  |
| ACACA_SRCIN1_ENST00000360679_ENST00000264659_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.8307
Å |
 |  |  |  |  |
| ACACA_SRCIN1_ENST00000360679_ENST00000578925_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7754
Å |
 |  |  |  |  |
| ACACA_SRCIN1_ENST00000361253_ENST00000264659_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.8374
Å |
 | 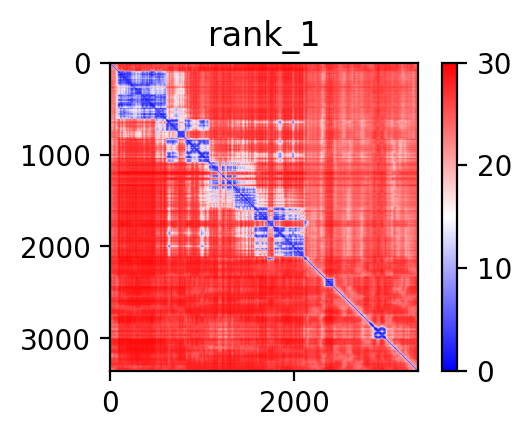 | 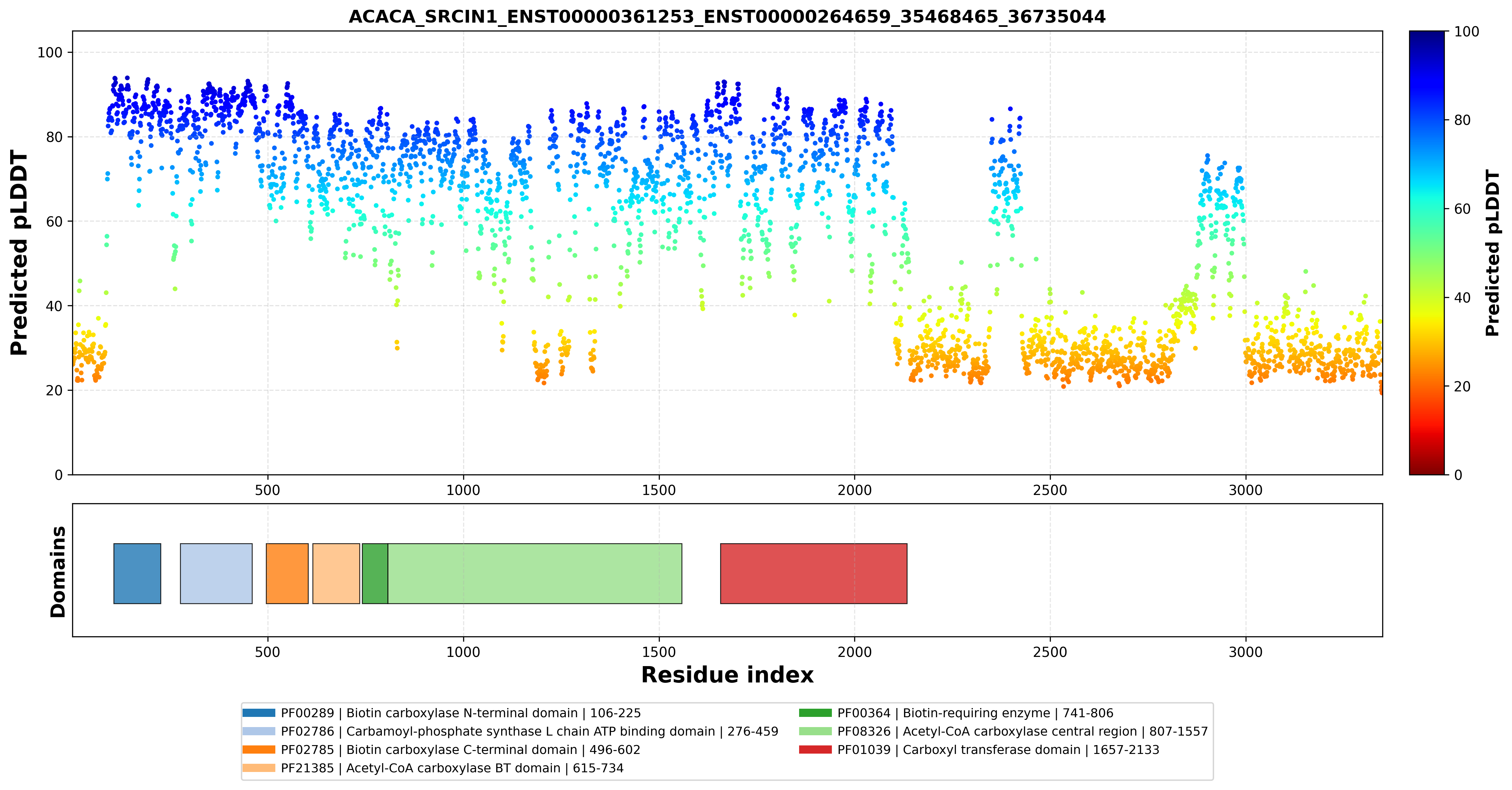 |  |  |
| ACACA_SRCIN1_ENST00000361253_ENST00000578925_35468465_36735044 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.7481
Å |
 |  | 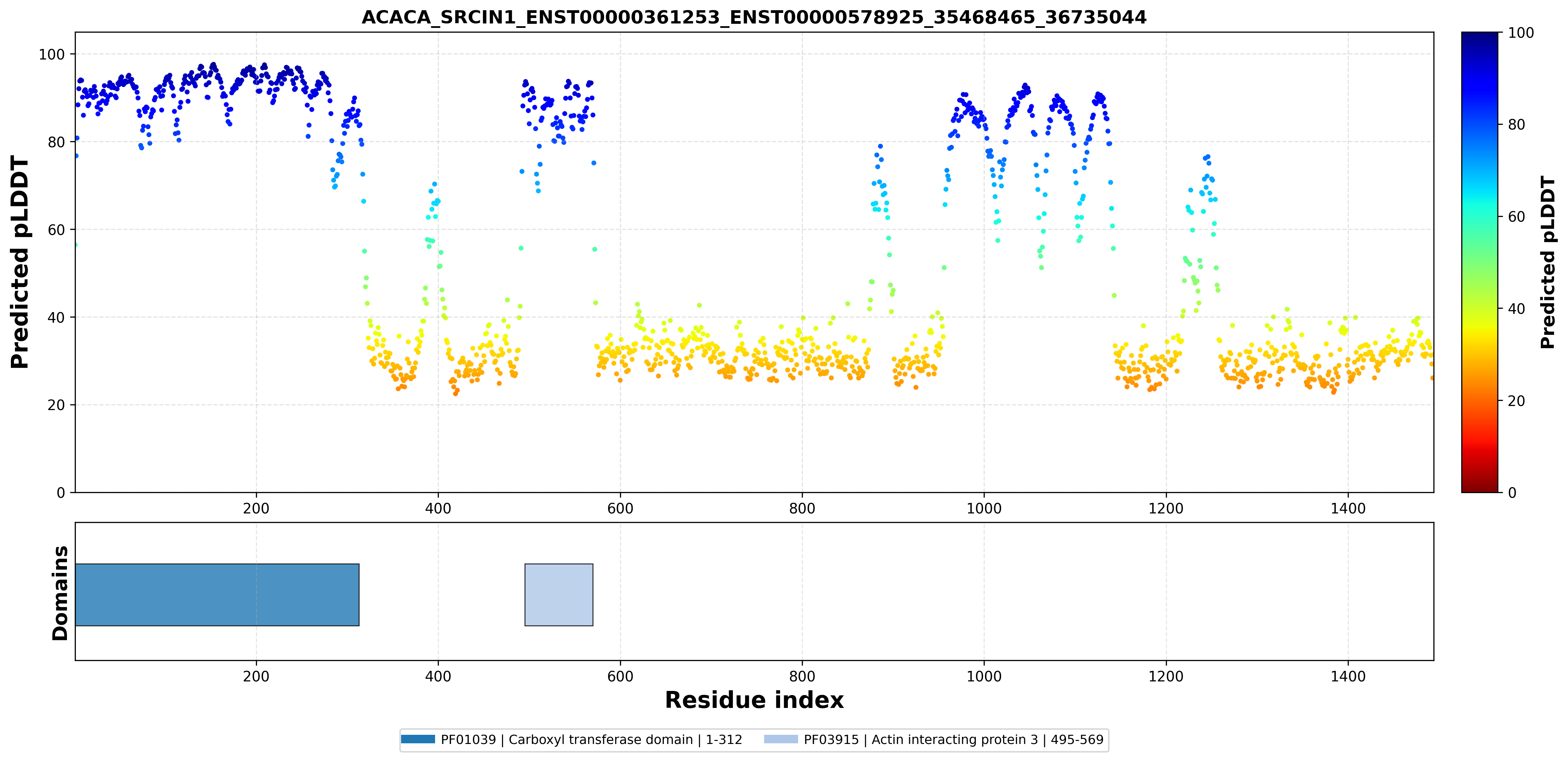 |  |  |
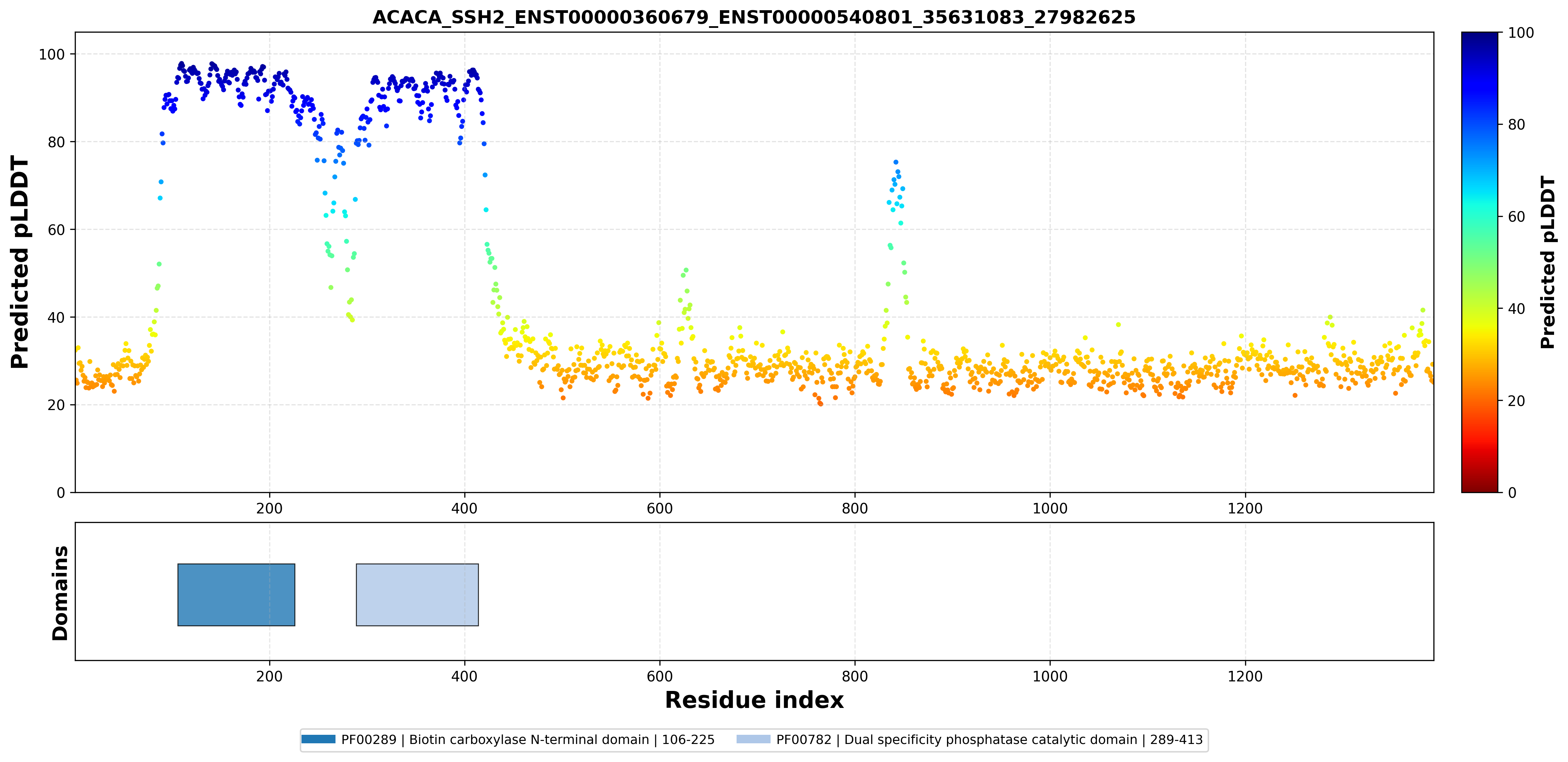
| ACACA_SSH2_ENST00000353139_ENST00000540801_35631083_27982625 superimposed PDB: 2NT2 of partner (SSH2). RMSD:0.3906
Å |
 |  |  |  |  |
| ACACA_SSH2_ENST00000360679_ENST00000540801_35631083_27982625 superimposed PDB: 2NT2 of partner (SSH2). RMSD:0.3921
Å |
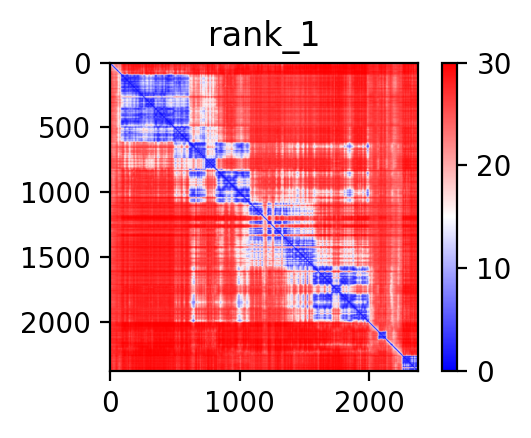
 |  |  |  |  |
| ACACA_STAC2_ENST00000360679_ENST00000333461_35479452_37374426 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.8304
Å |
 |  | 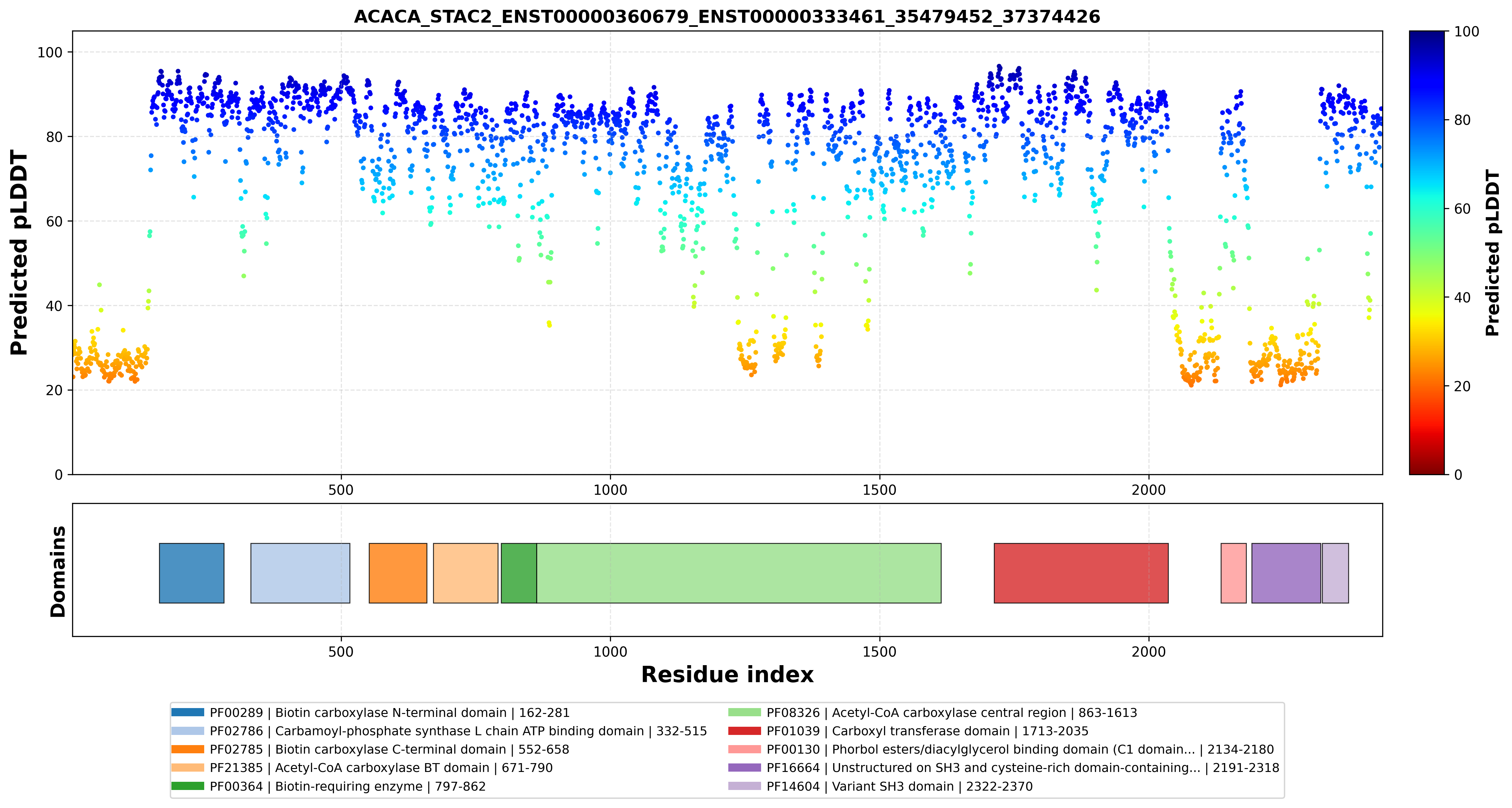 |  |  |
| ACACA_STAC2_ENST00000360679_ENST00000333461_35479452_37374426 superimposed PDB: 6B26 of partner (STAC2). RMSD:0.8233
Å |
| | | |  |
| ACACA_STAC2_ENST00000361253_ENST00000333461_35479452_37374426 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.6788
Å |
 |  | 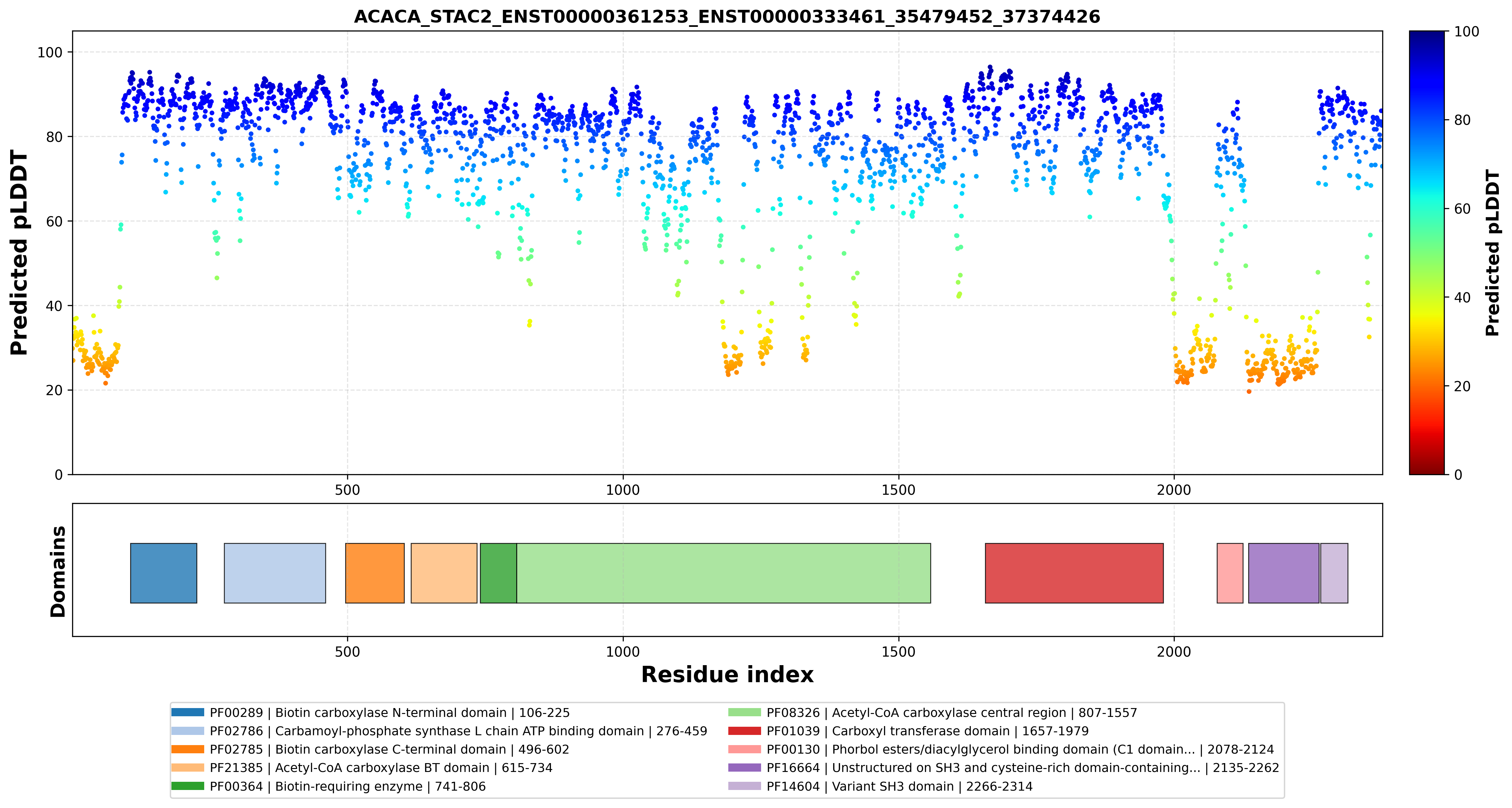 | 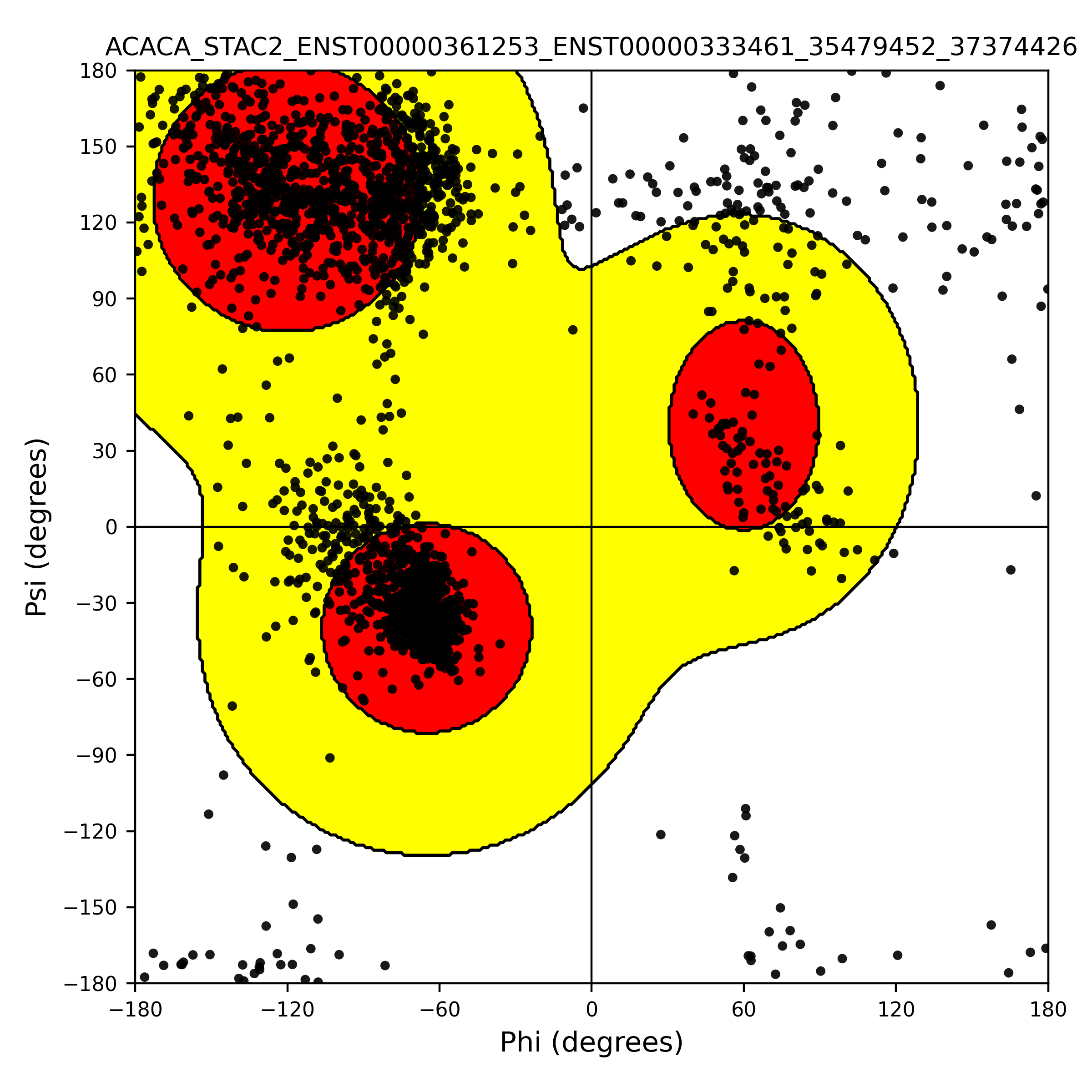 |  |
| ACACA_STAC2_ENST00000361253_ENST00000333461_35479452_37374426 superimposed PDB: 6B26 of partner (STAC2). RMSD:0.8116
Å |
| | | |  |
| ACADSB_PHEX_ENST00000358776_ENST00000535894_124804001_22186428 superimposed PDB: 2JIF of partner (ACADSB). RMSD:0.2943
Å |
 |  |  |  |  |
| ACADSB_PHEX_ENST00000358776_ENST00000537599_124804001_22186428 superimposed PDB: 2JIF of partner (ACADSB). RMSD:0.2961
Å |
 |  |  |  |  |
| ACADSB_PHEX_ENST00000368869_ENST00000535894_124804001_22186428 superimposed PDB: 2JIF of partner (ACADSB). RMSD:0.3373
Å |
 |  |  |  |  |
| ACADSB_PHEX_ENST00000368869_ENST00000537599_124804001_22186428 superimposed PDB: 2JIF of partner (ACADSB). RMSD:0.3658
Å |
 |  |  |  |  |
| ACAP2_TTBK1_ENST00000326793_ENST00000259750_195163523_43220476 superimposed PDB: 6IF3 of partner (ACAP2). RMSD:0.3296
Å |
 |  |  |  |  |
| ACBD4_LRRC37A_ENST00000398322_ENST00000320254_43216527_44412910 superimposed PDB: 2WH5 of partner (ACBD4). RMSD:0.3842
Å |
 |  |  |  |  |
| ACBD4_LRRC37A_ENST00000398322_ENST00000393465_43216527_44412910 superimposed PDB: 2WH5 of partner (ACBD4). RMSD:0.3727
Å |
 |  |  |  |  |
| ACE2_GPR143_ENST00000427411_ENST00000467482_15596211_9693880 superimposed PDB: 8XSF of partner (ACE2). RMSD:2.5212
Å |
 |  |  |  |  |
| ACER3_PC_ENST00000532485_ENST00000393960_76670075_66620854 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.8979
Å |
 |  | 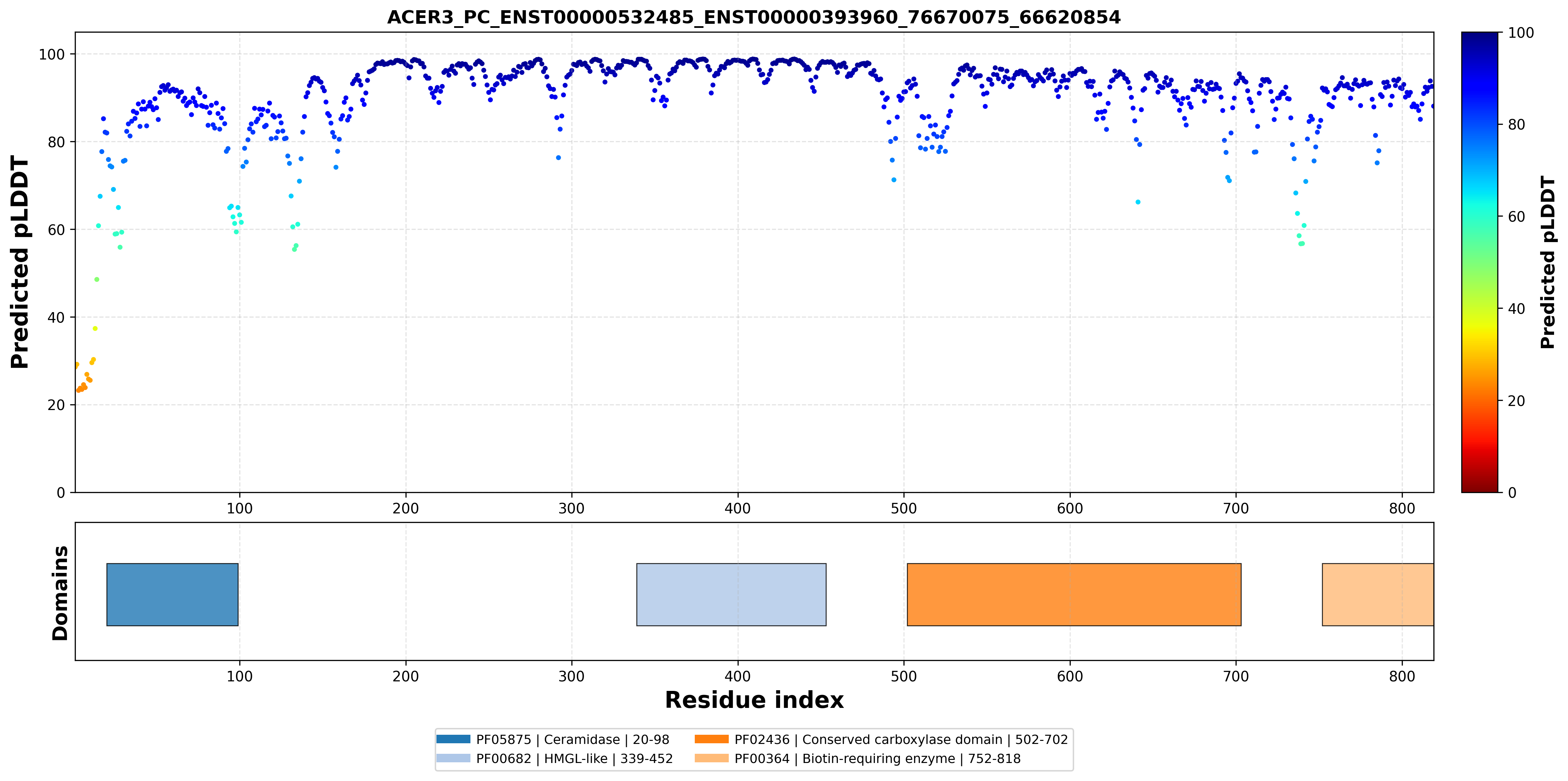 |  |  |
| ACER3_PC_ENST00000532485_ENST00000393960_76670075_66620854 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7571
Å |
| | | |  |
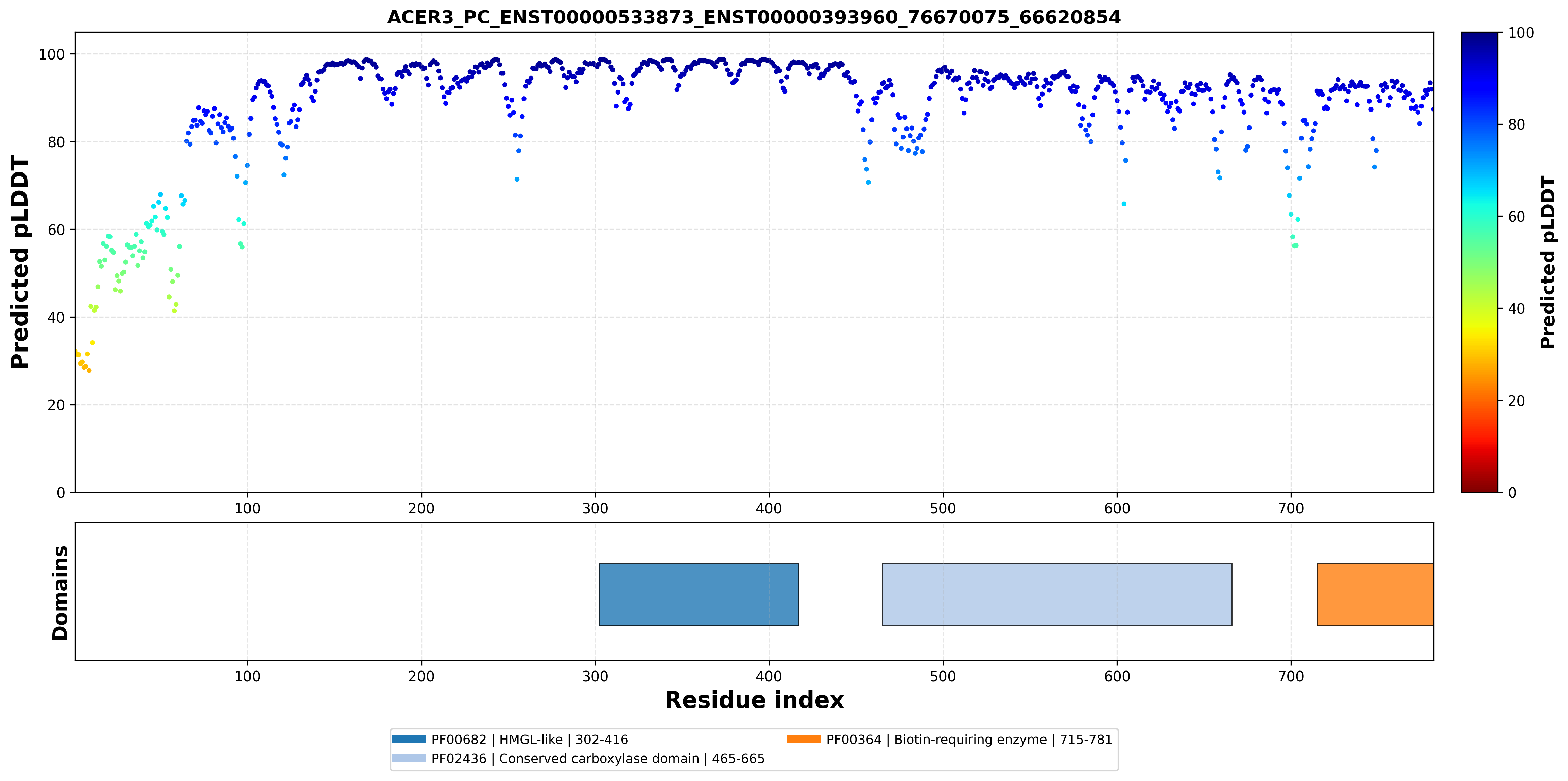
| ACER3_PC_ENST00000533873_ENST00000393960_76670075_66620854 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7634
Å |
 |  |  |  |  |
| ACER3_PC_ENST00000538157_ENST00000393960_76670075_66620854 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.464
Å |
 |  | 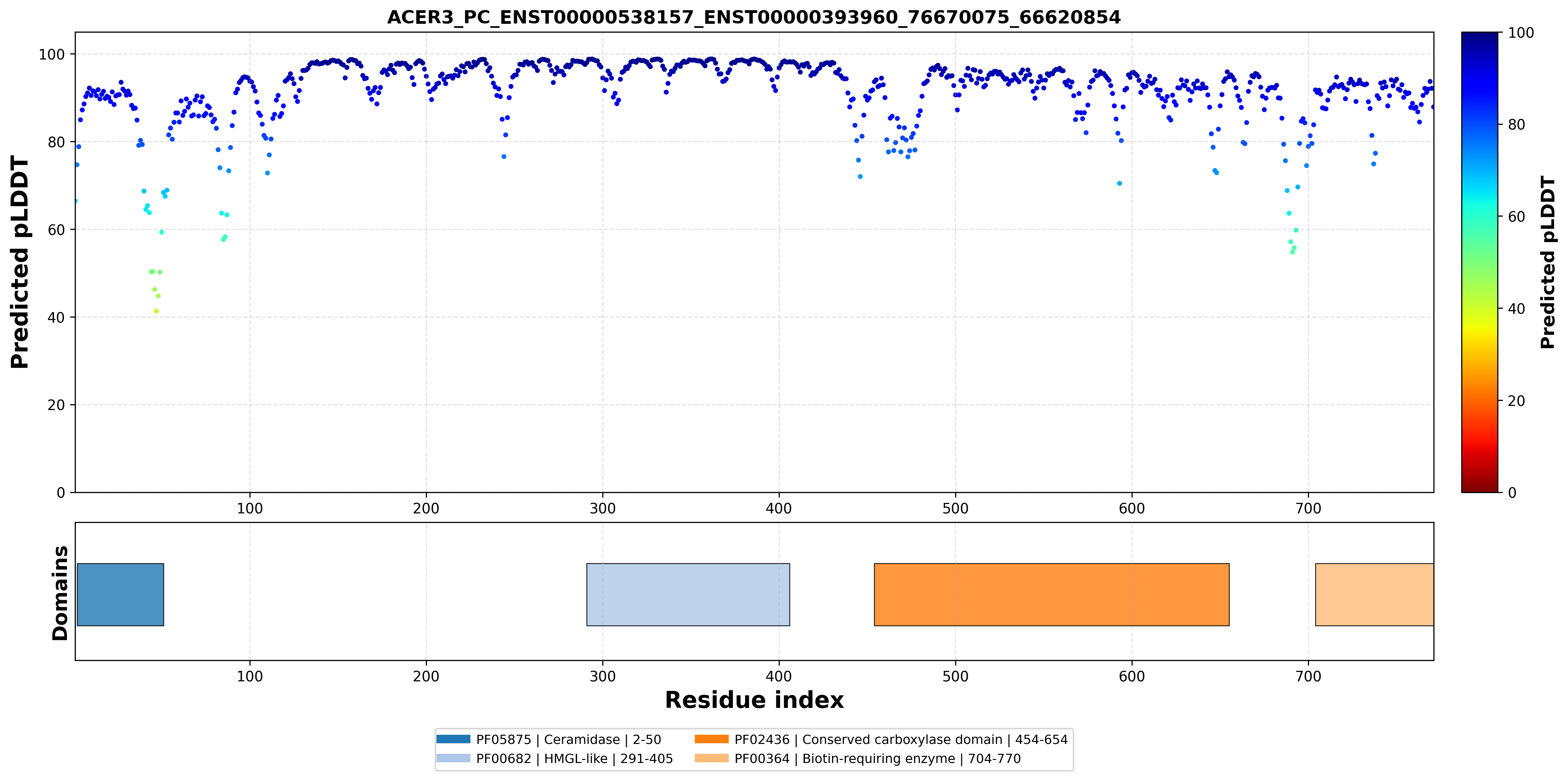 |  |  |
| ACER3_PC_ENST00000538157_ENST00000393960_76670075_66620854 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7468
Å |
| | | |  |
| ACER3_PPME1_ENST00000532485_ENST00000398427_76670075_73933356 superimposed PDB: 6YXH of partner (ACER3). RMSD:1.0041
Å |
 |  |  |  |  |
| ACER3_PPME1_ENST00000532485_ENST00000398427_76670075_73933356 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.0617
Å |
| | | |  |
| ACER3_PPME1_ENST00000533873_ENST00000328257_76670075_73933356 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.9559
Å |
 |  |  |  |  |
| ACER3_PPME1_ENST00000533873_ENST00000328257_76670075_73933356 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.0786
Å |
| | | |  |
| ACER3_PPME1_ENST00000533873_ENST00000398427_76670075_73933356 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.1366
Å |
 |  |  |  |  |
| ACER3_PPME1_ENST00000538157_ENST00000328257_76670075_73933356 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.1171
Å |
 |  |  |  |  |
| ACER3_PPME1_ENST00000538157_ENST00000398427_76670075_73933356 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.0498
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000526597_ENST00000528420_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:1.5701
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000532485_ENST00000356136_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:3.4337
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000532485_ENST00000528420_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.4141
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000533873_ENST00000528420_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.6665
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000538157_ENST00000528420_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.5387
Å |
 |  |  |  |  |
| ACER3_UVRAG_ENST00000544113_ENST00000528420_76730820_75826967 superimposed PDB: 6YXH of partner (ACER3). RMSD:1.7742
Å |
 |  |  |  |  |
| ACIN1_NUTM1_ENST00000262710_ENST00000438749_23559190_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7001
Å |
 |  |  |  |  |
| ACIN1_NUTM1_ENST00000457657_ENST00000438749_23559730_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7099
Å |
 |  |  |  |  |
| ACIN1_NUTM1_ENST00000605057_ENST00000438749_23559190_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7836
Å |
 |  |  |  |  |
| ACIN1_NUTM1_ENST00000605057_ENST00000438749_23559730_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7171
Å |
 |  |  |  |  |
| ACLY_FAM117A_ENST00000393896_ENST00000240364_40060981_47810082 superimposed PDB: 7RIG of partner (ACLY). RMSD:0.9657
Å |
 |  |  |  |  |
| ACLY_TAF15_ENST00000352035_ENST00000311979_40054001_34163135 superimposed PDB: 7RIG of partner (ACLY). RMSD:1.7622
Å |
 |  |  |  |  |
| ACLY_TAF15_ENST00000352035_ENST00000592237_40054001_34163135 superimposed PDB: 7RIG of partner (ACLY). RMSD:1.7535
Å |
 |  |  |  |  |
| ACO1_ARL3_ENST00000379923_ENST00000260746_32436395_104445758 superimposed PDB: 2B3Y of partner (ACO1). RMSD:0.8578
Å |
 |  |  |  |  |
| ACO2_AHRR_ENST00000216254_ENST00000316418_41865186_422843 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.9424
Å |
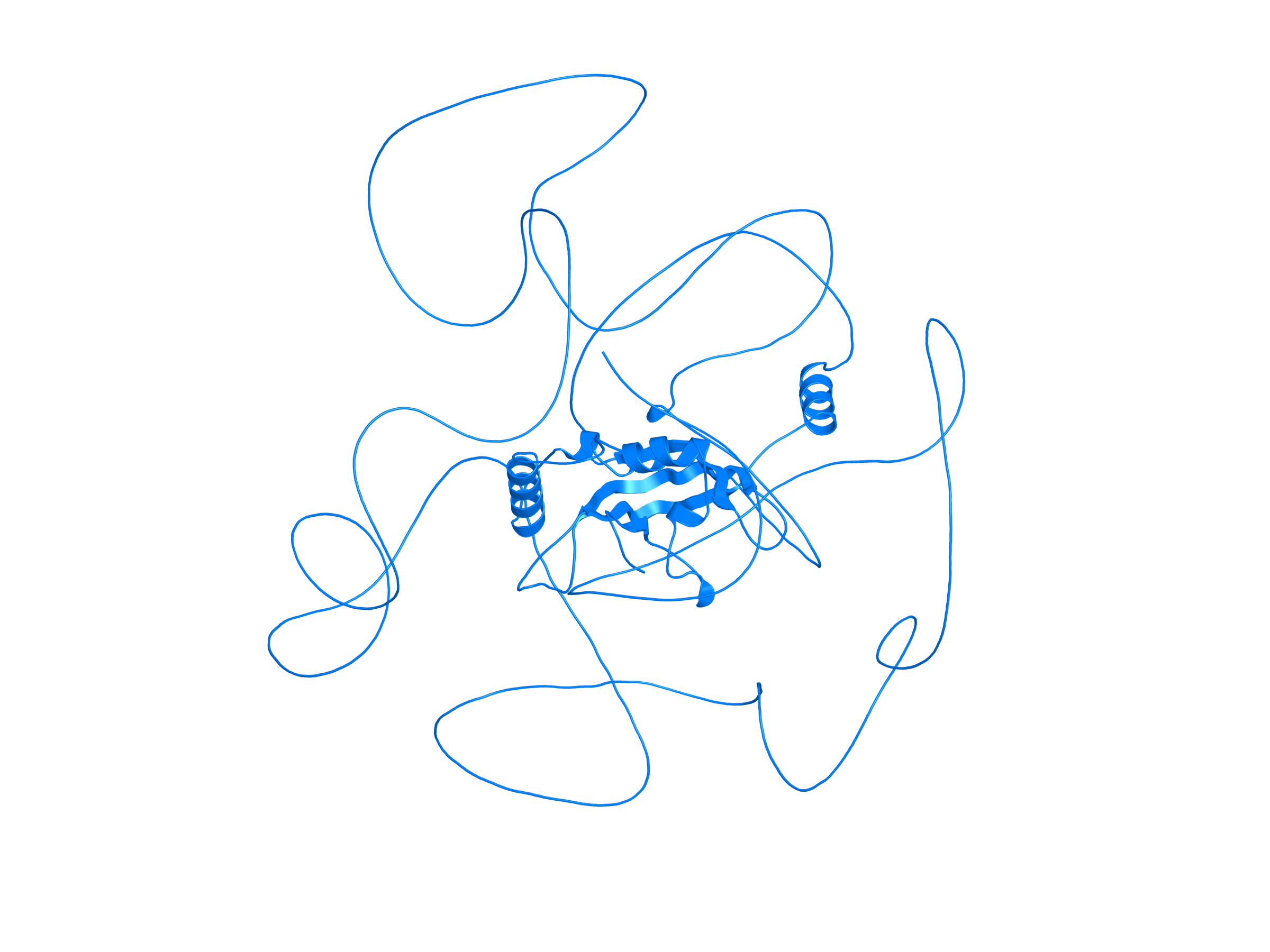 | 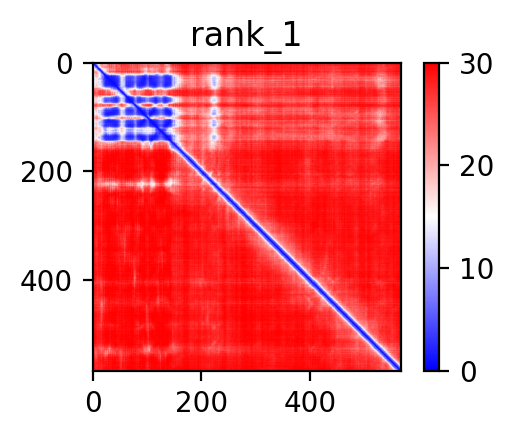 | 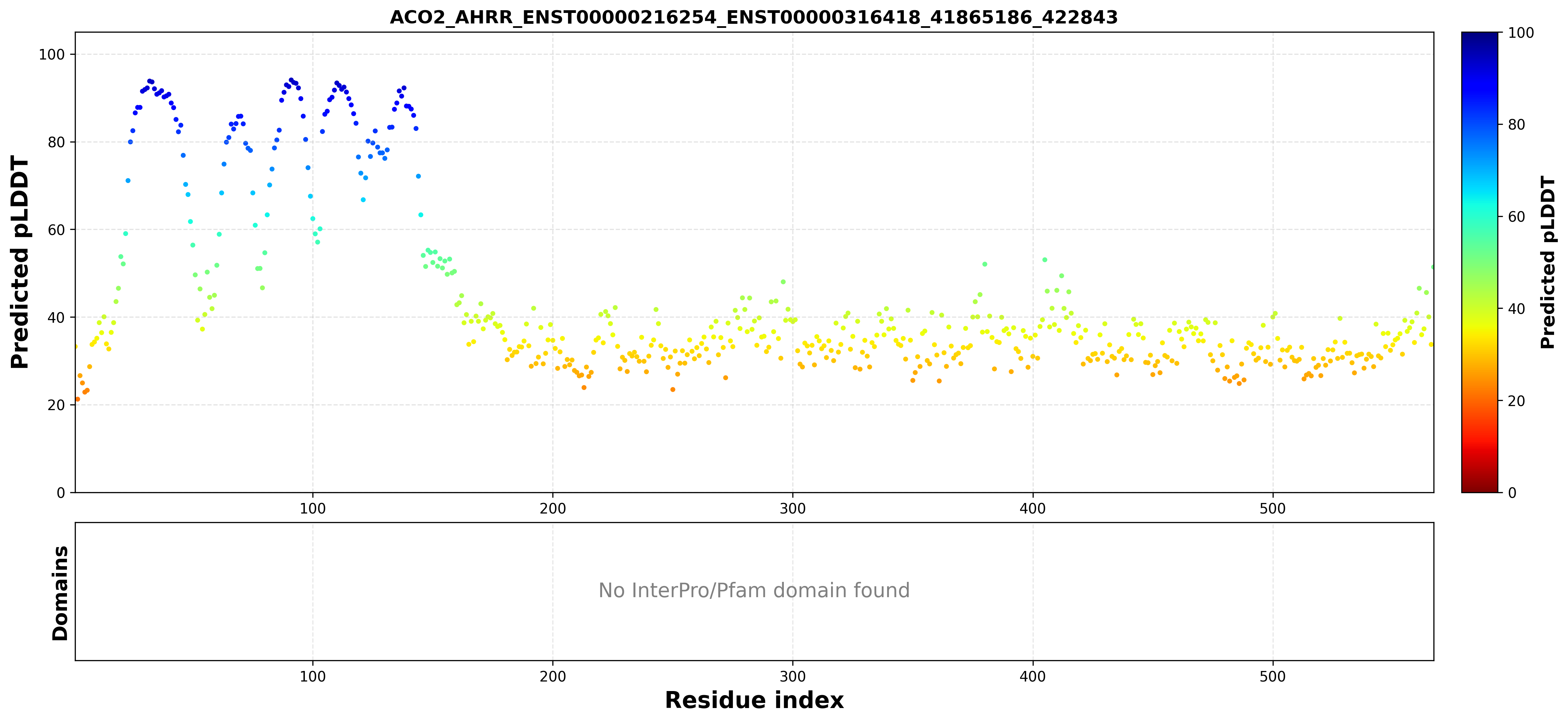 |  |  |
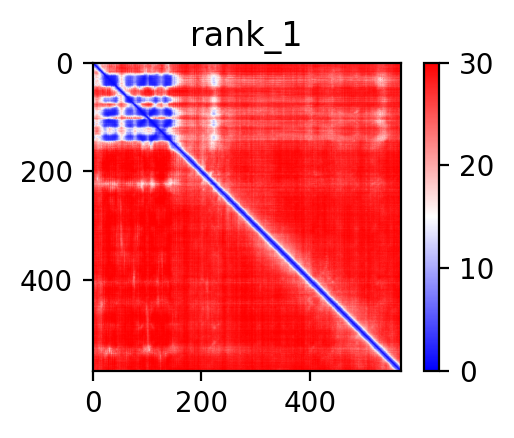
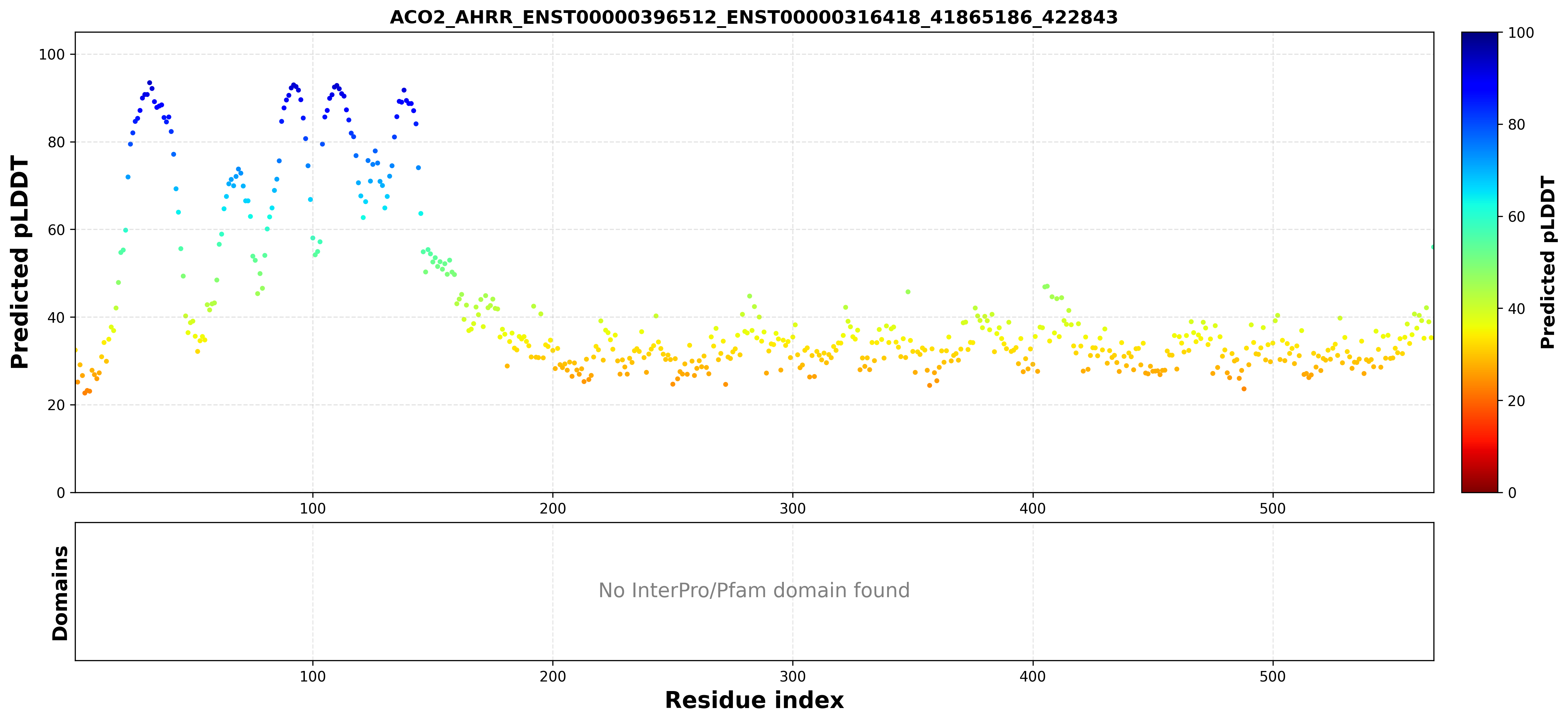
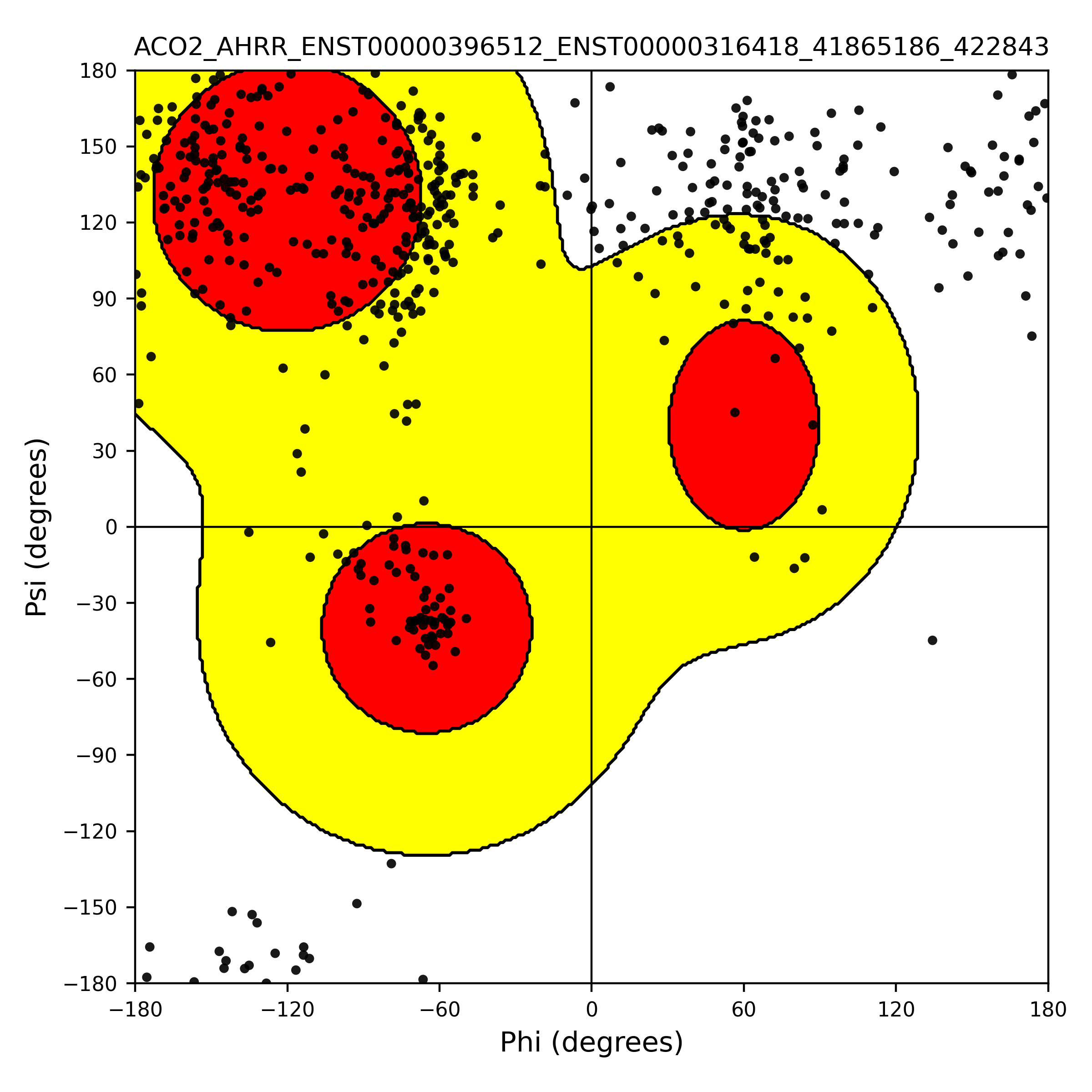
| ACO2_AHRR_ENST00000396512_ENST00000316418_41865186_422843 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.5507
Å |
 |  |  |  |  |
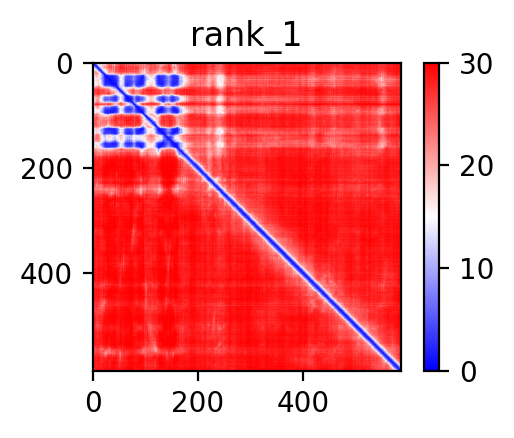
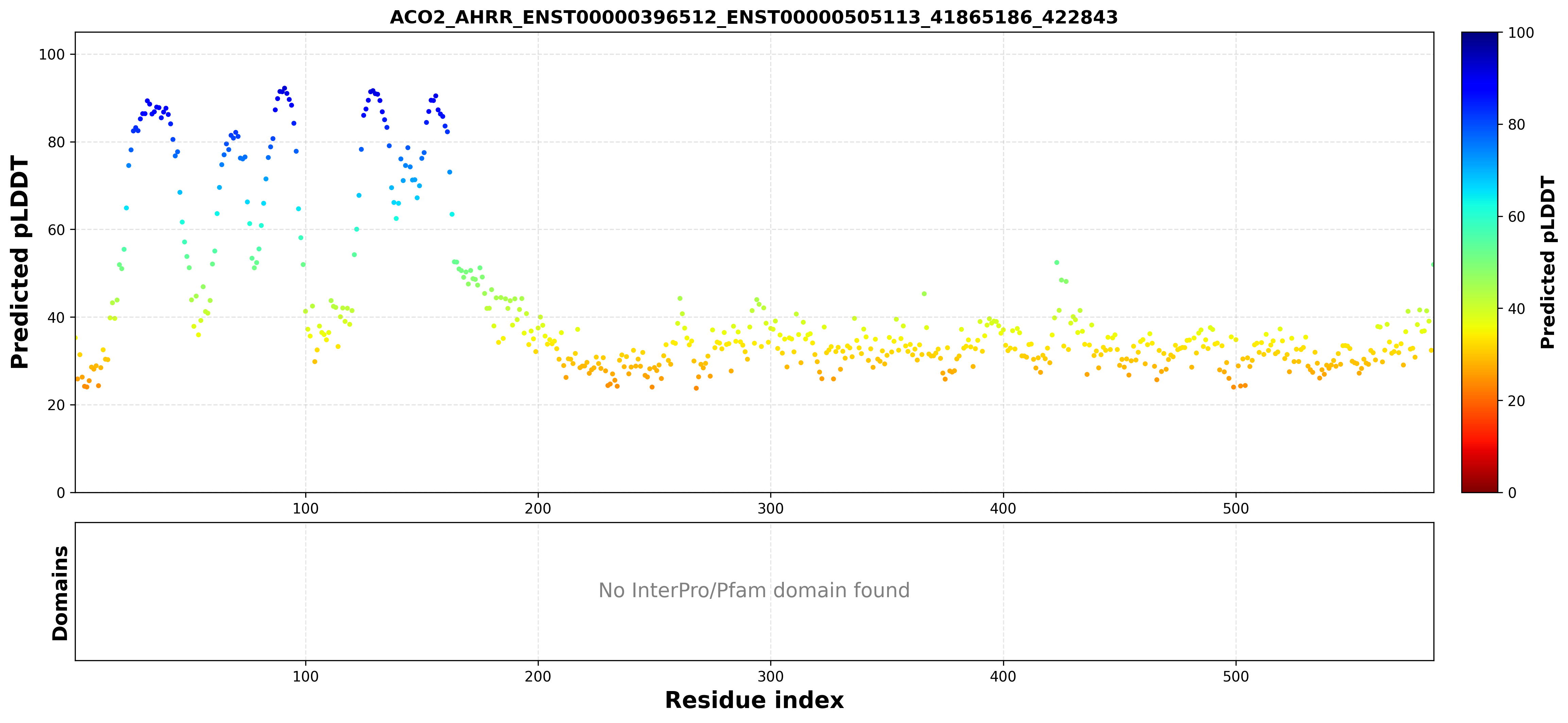
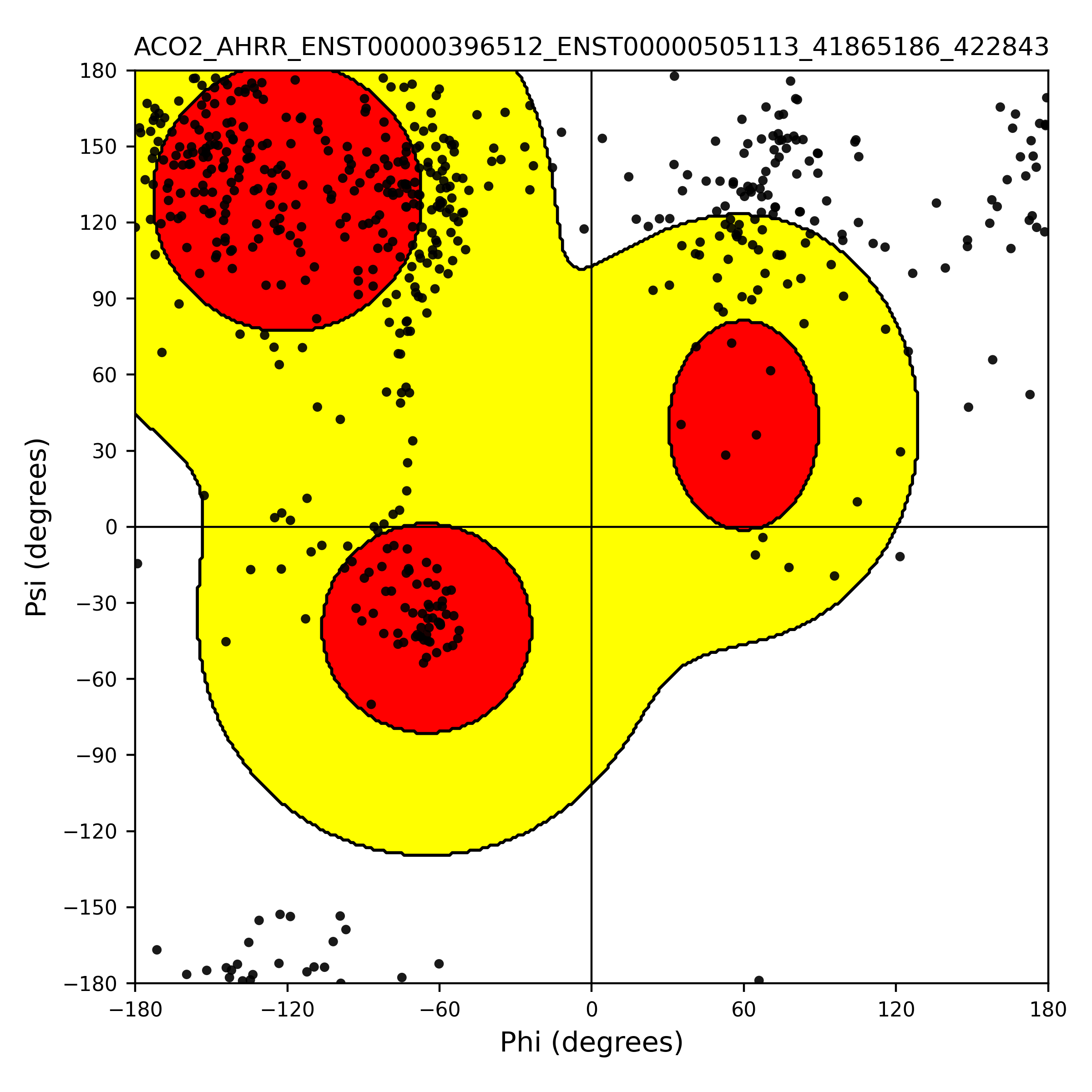
| ACO2_AHRR_ENST00000396512_ENST00000505113_41865186_422843 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.9169
Å |
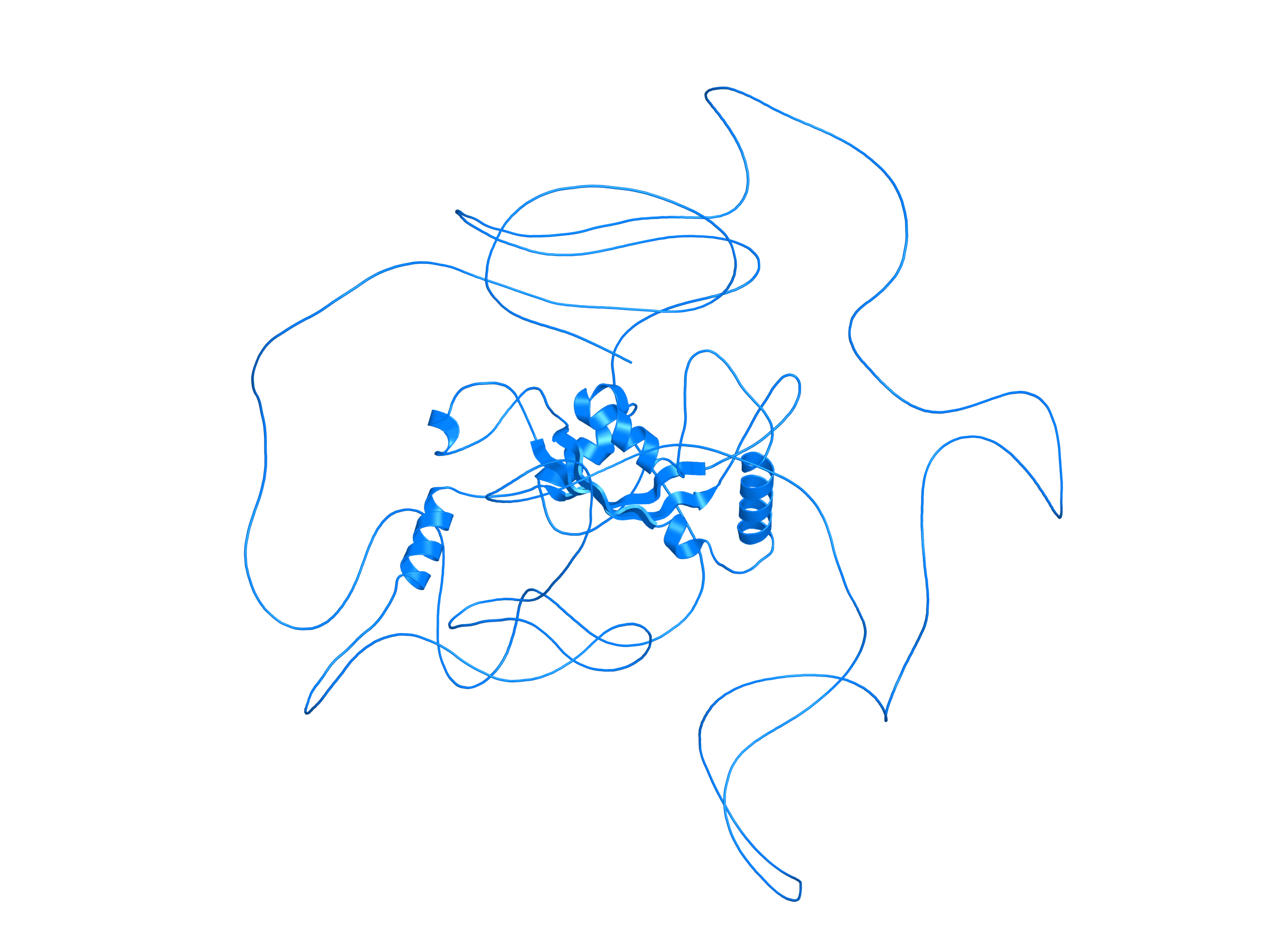 |  |  |  |  |
| ACOT7_CHD5_ENST00000545482_ENST00000262450_6378551_6228337 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.335
Å |
 |  |  |  |  |
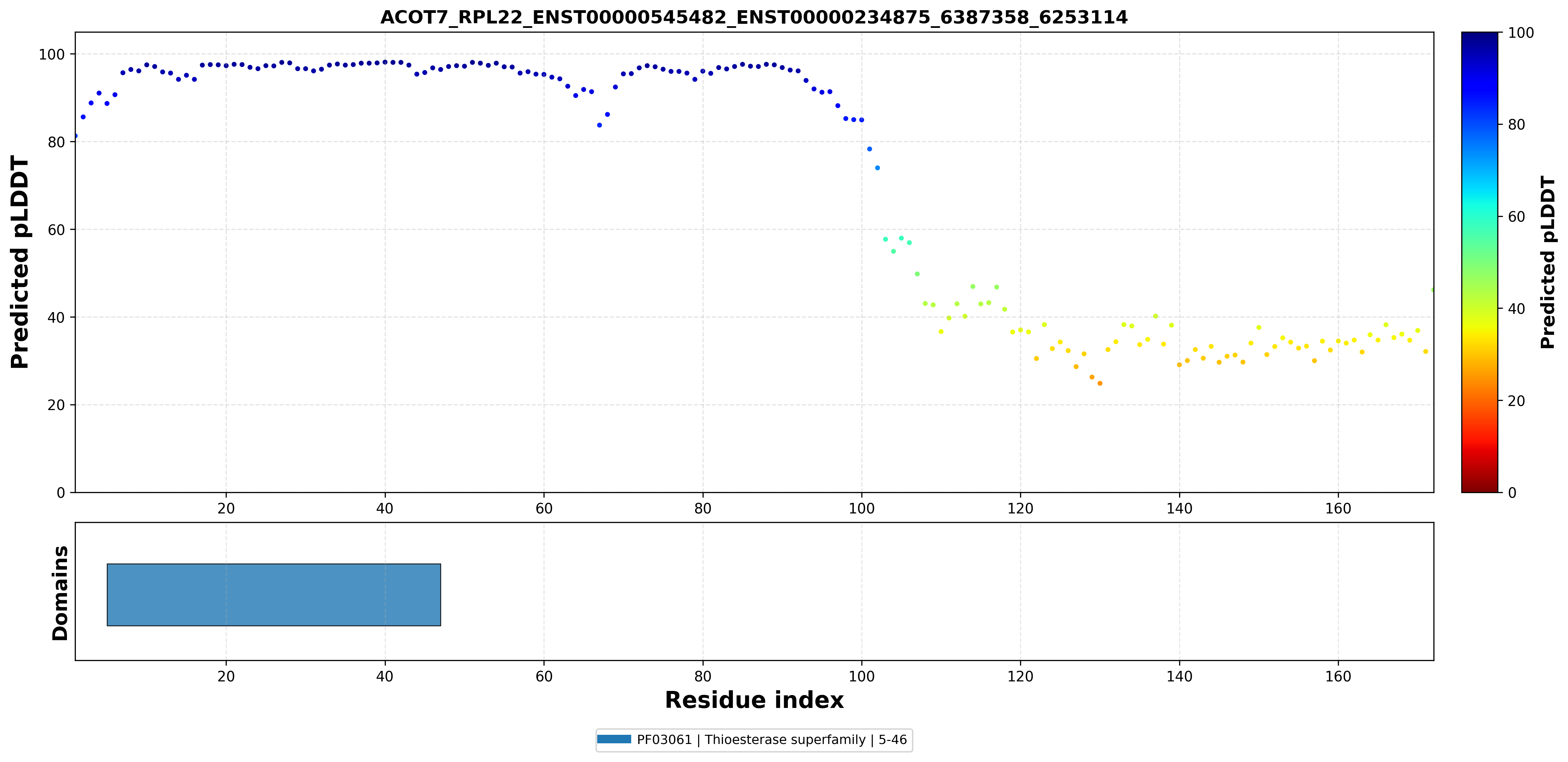
| ACOT7_RPL22_ENST00000545482_ENST00000234875_6387358_6253114 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.9085
Å |
 |  |  |  |  |
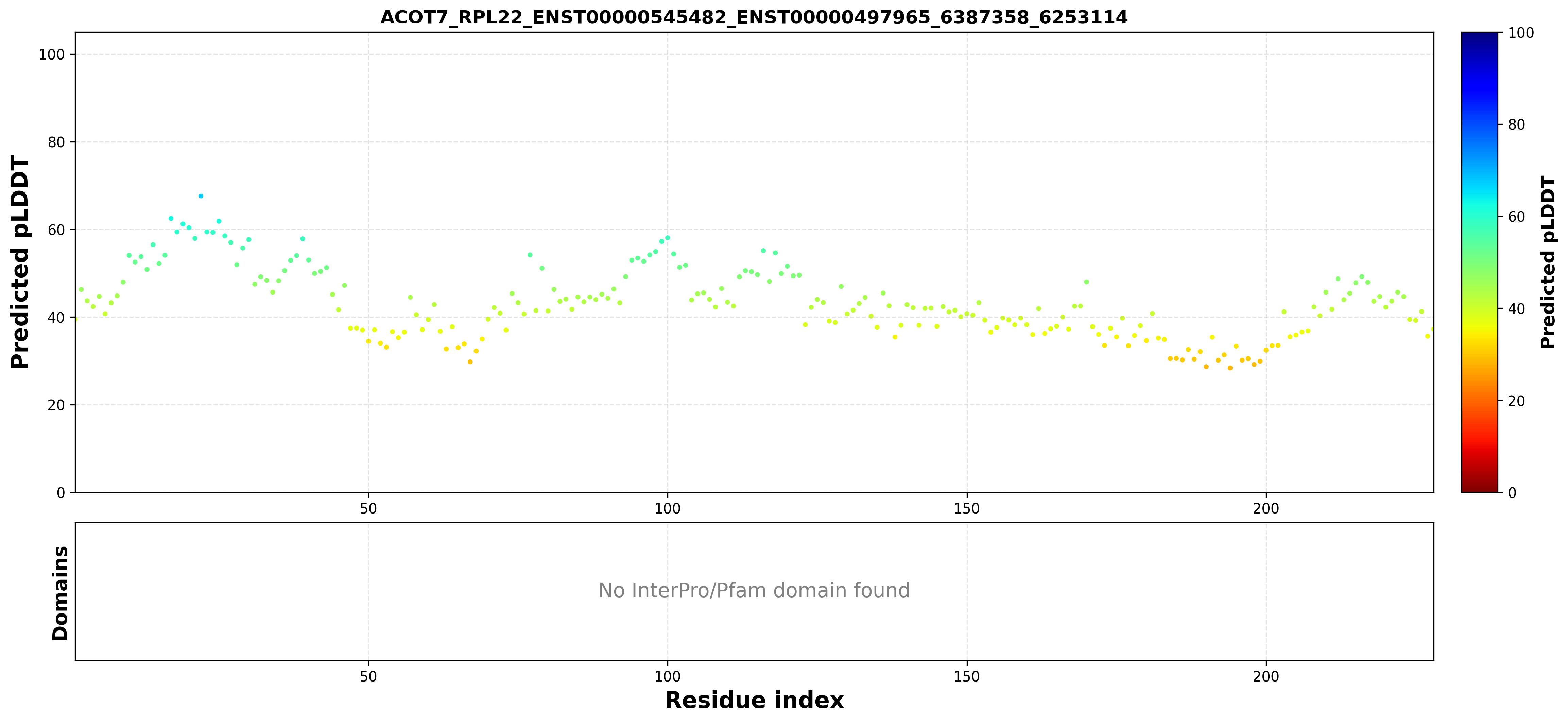
| ACOT7_RPL22_ENST00000545482_ENST00000497965_6387358_6253114 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:2.8554
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000361521_ENST00000348333_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6478
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000361521_ENST00000351748_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6968
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000361521_ENST00000356876_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.7183
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377842_ENST00000348333_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6368
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377842_ENST00000351748_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.676
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377842_ENST00000356876_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.635
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377842_ENST00000356876_6378551_6522726 superimposed PDB: 5YEV of partner (TNFRSF25). RMSD:2.8554
Å |
| | | |  |
| ACOT7_TNFRSF25_ENST00000377842_ENST00000377782_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.7092
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377845_ENST00000348333_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6714
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377845_ENST00000351748_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6337
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377845_ENST00000356876_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6538
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377845_ENST00000377782_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6035
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377855_ENST00000351748_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6765
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377855_ENST00000356876_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6537
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000377855_ENST00000377782_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6853
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000541130_ENST00000377782_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.7115
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000608083_ENST00000348333_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6751
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000608083_ENST00000351748_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.7184
Å |
 |  |  |  |  |
| ACOT7_TNFRSF25_ENST00000608083_ENST00000356876_6378551_6522726 superimposed PDB: 2QQ2 of partner (ACOT7). RMSD:0.6926
Å |
 |  |  |  |  |
| ACOT8_ANGPT1_ENST00000217455_ENST00000520734_44485826_108306265 superimposed PDB: 4JYO of partner (ANGPT1). RMSD:0.2981
Å |
 |  |  |  |  |
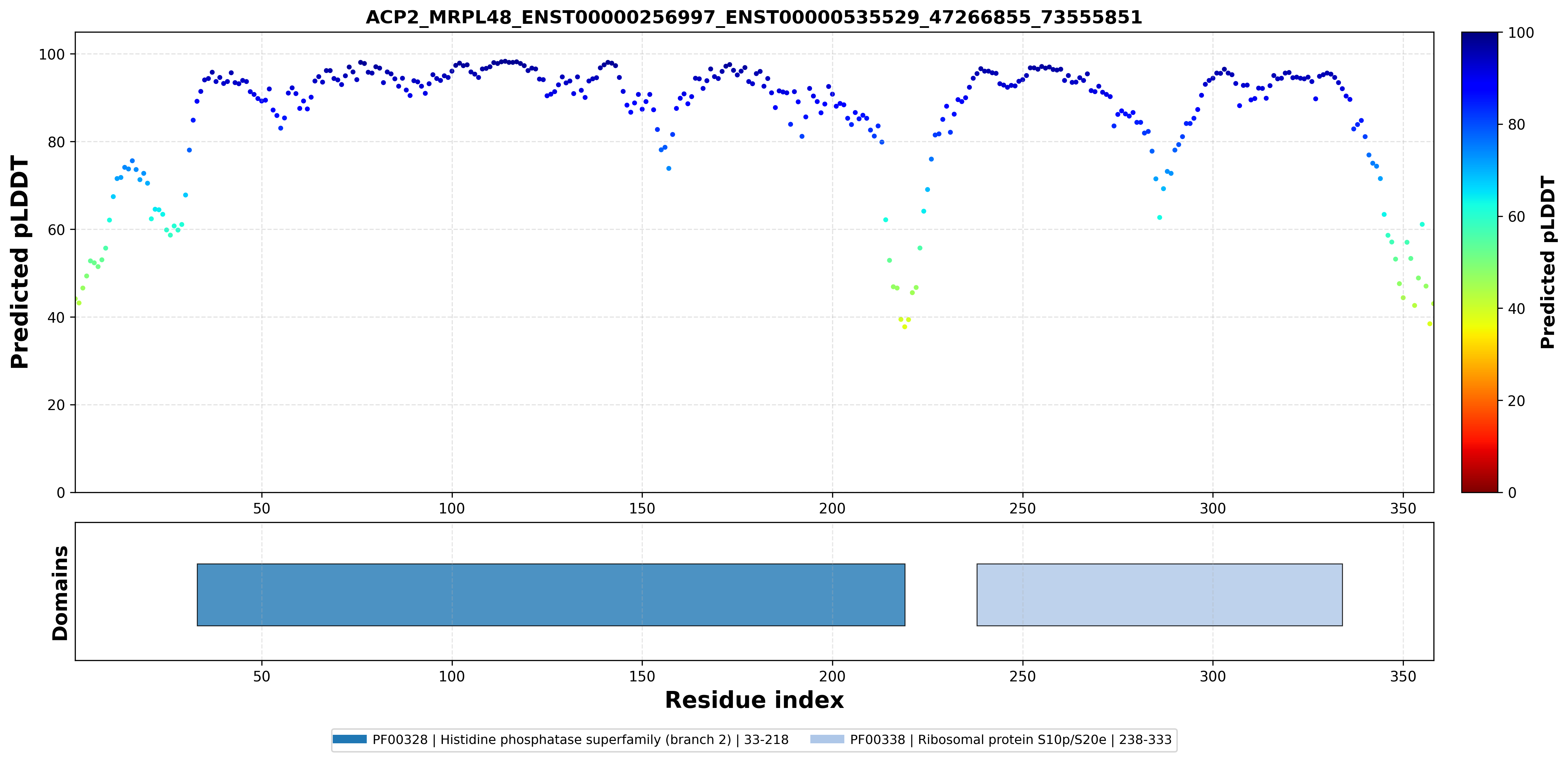
| ACP2_MRPL48_ENST00000256997_ENST00000535529_47266855_73555851 superimposed PDB: 7OF0 of partner (MRPL48). RMSD:0.863
Å |
 |  |  |  |  |
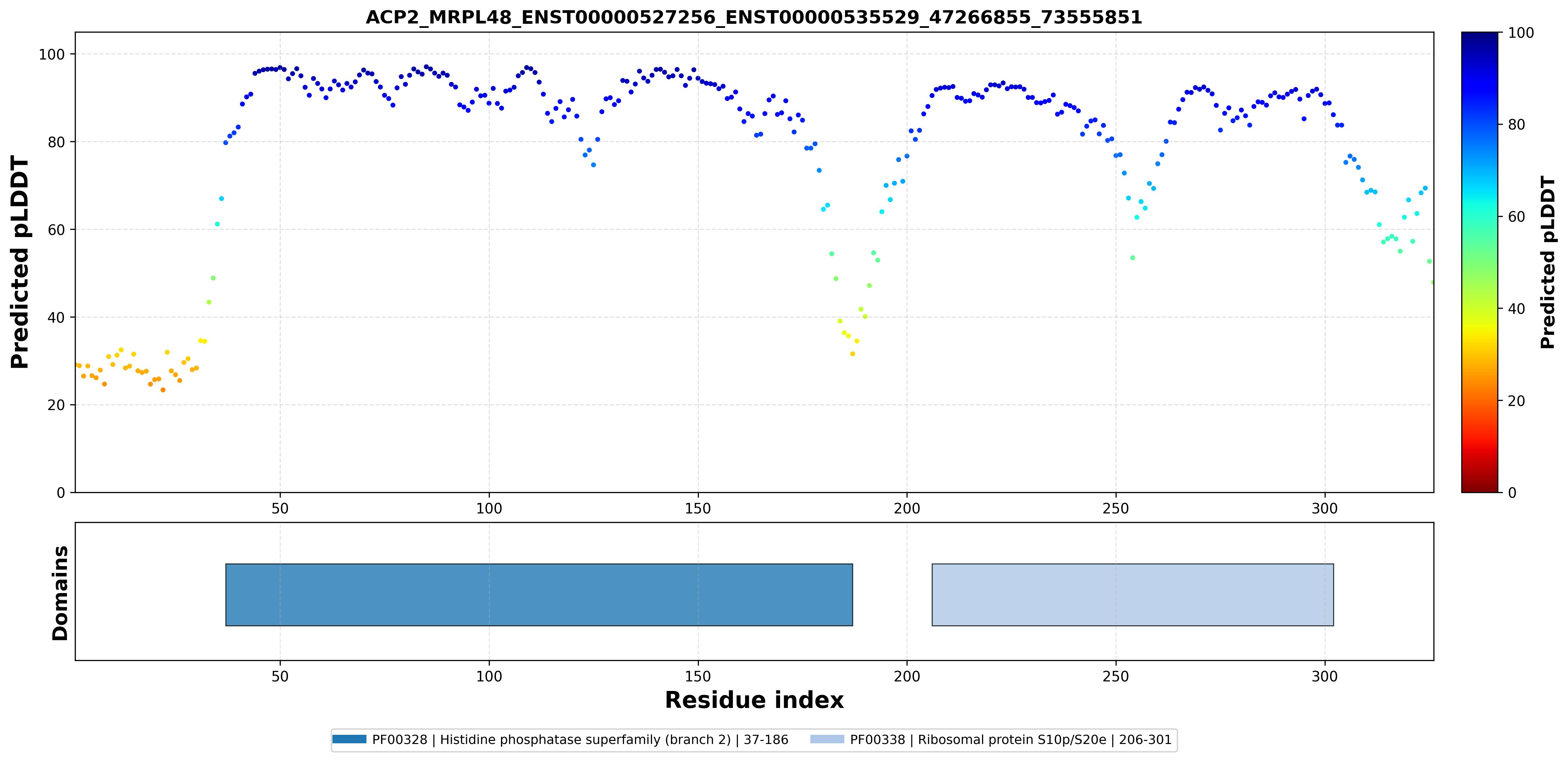
| ACP2_MRPL48_ENST00000527256_ENST00000535529_47266855_73555851 superimposed PDB: 7OF0 of partner (MRPL48). RMSD:0.8208
Å |
 |  |  |  |  |
| ACP2_MRPL48_ENST00000533929_ENST00000535529_47266855_73555851 superimposed PDB: 7OF0 of partner (MRPL48). RMSD:0.8597
Å |
 |  |  |  |  |
| ACPP_AMACR_ENST00000351273_ENST00000382072_132075699_34006004 superimposed PDB: 1ND6 of partner (ACPP). RMSD:0.4672
Å |
 |  |  |  |  |
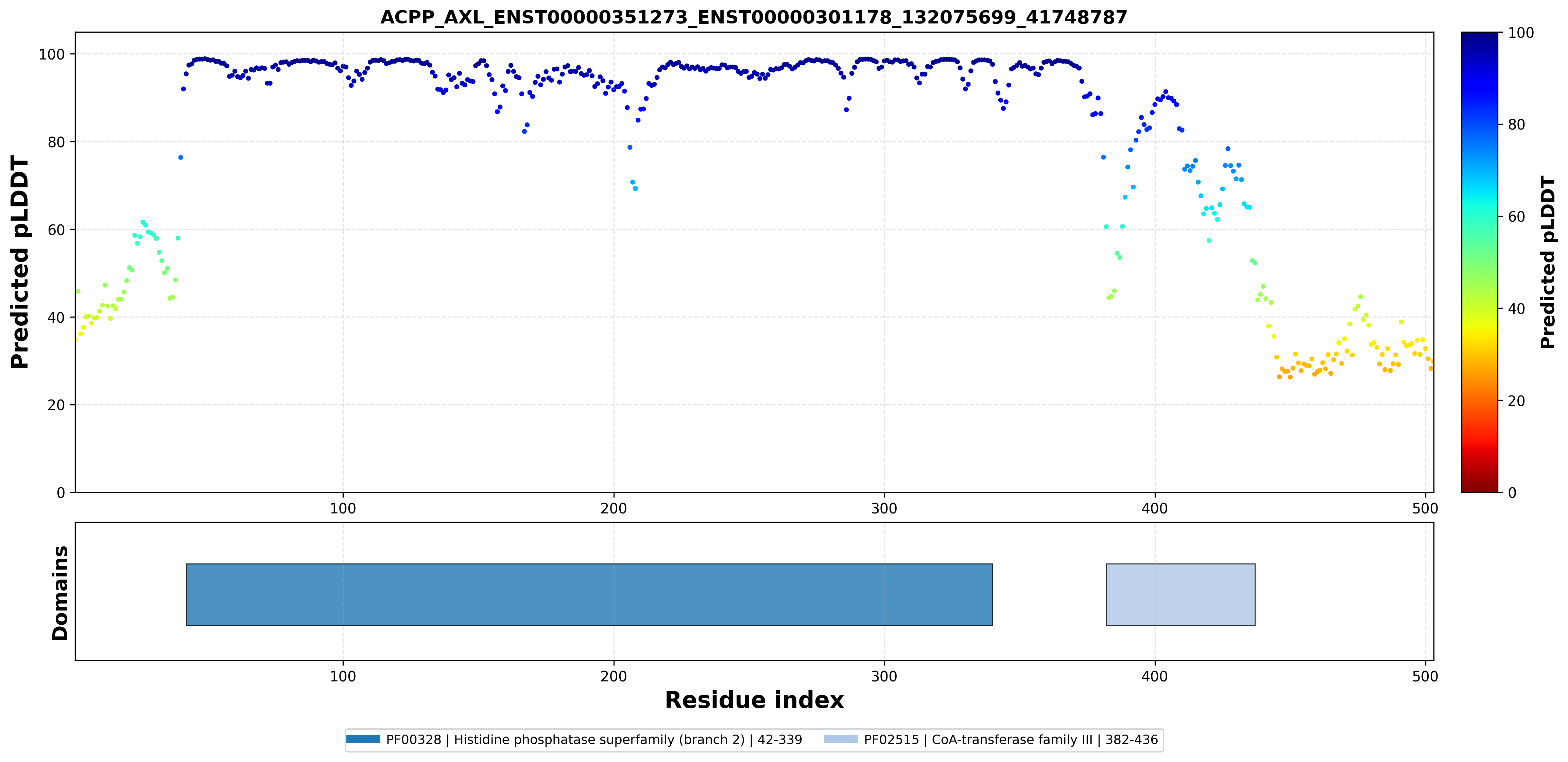
| ACPP_AXL_ENST00000351273_ENST00000301178_132075699_41748787 superimposed PDB: 1ND6 of partner (ACPP). RMSD:0.4693
Å |
 |  |  |  |  |
| ACPP_AXL_ENST00000351273_ENST00000359092_132075699_41748787 superimposed PDB: 1ND6 of partner (ACPP). RMSD:0.4975
Å |
 |  | 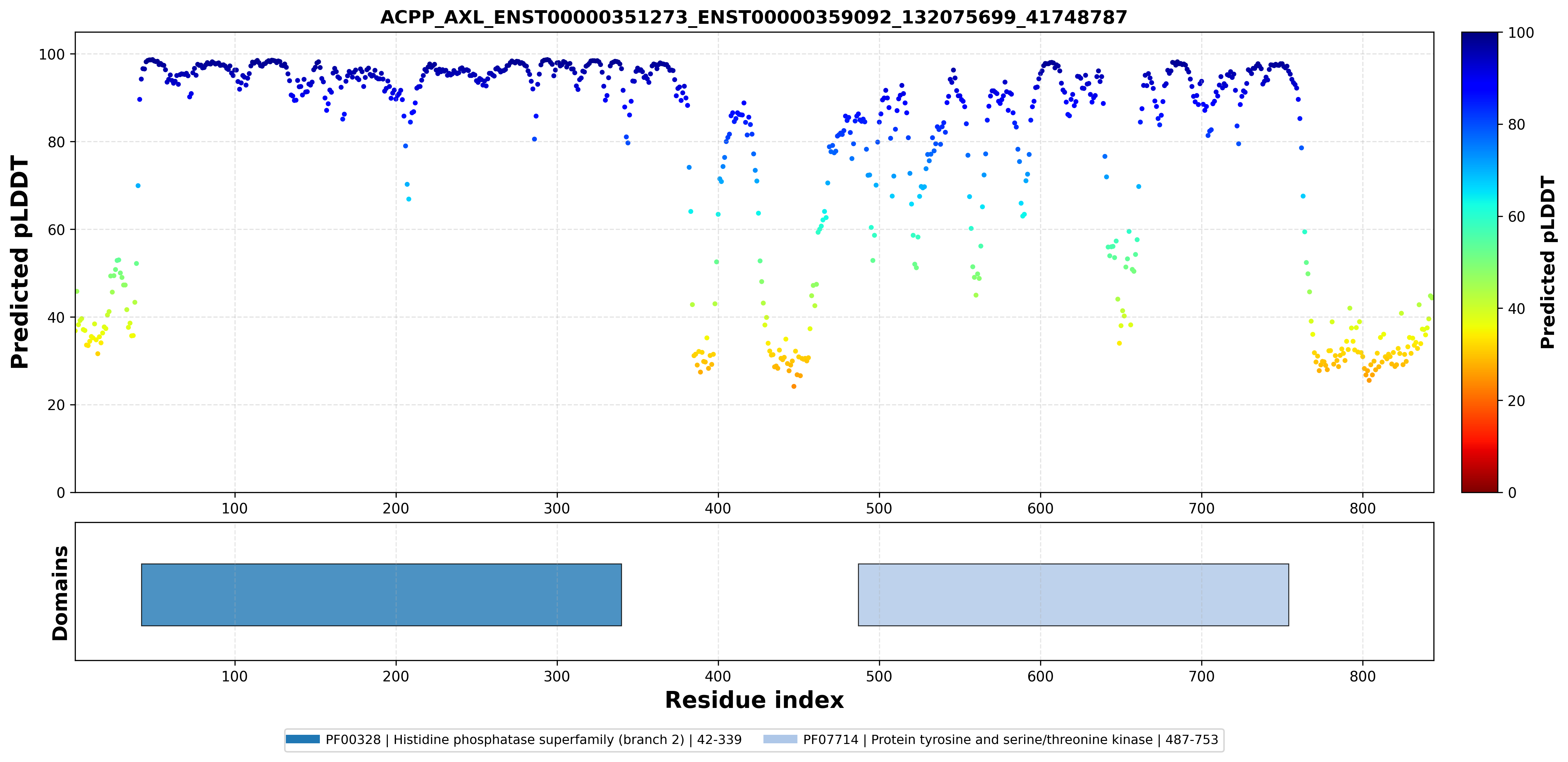 |  |  |
| ACPP_AXL_ENST00000351273_ENST00000359092_132075699_41748787 superimposed PDB: 5U6B of partner (AXL). RMSD:1.0167
Å |
| | | |  |
| ACPP_RDH11_ENST00000351273_ENST00000553384_132075699_68157138 superimposed PDB: 1ND6 of partner (ACPP). RMSD:0.5298
Å |
 |  |  |  |  |
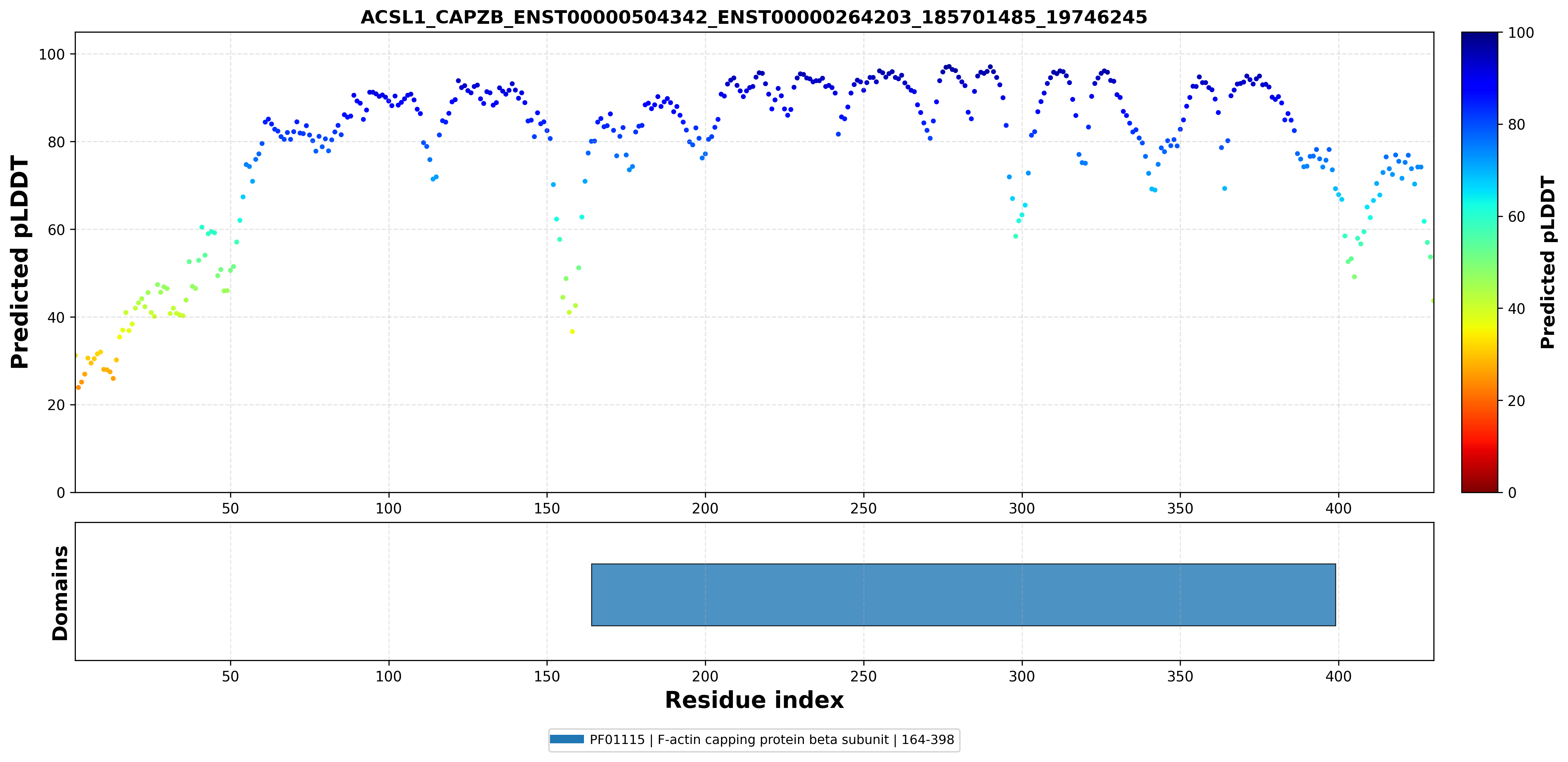
| ACSL1_CAPZB_ENST00000504342_ENST00000264203_185701485_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.5472
Å |
 |  |  |  |  |
| ACSL1_CAPZB_ENST00000504342_ENST00000375142_185701485_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.4603
Å |
 |  |  |  |  |
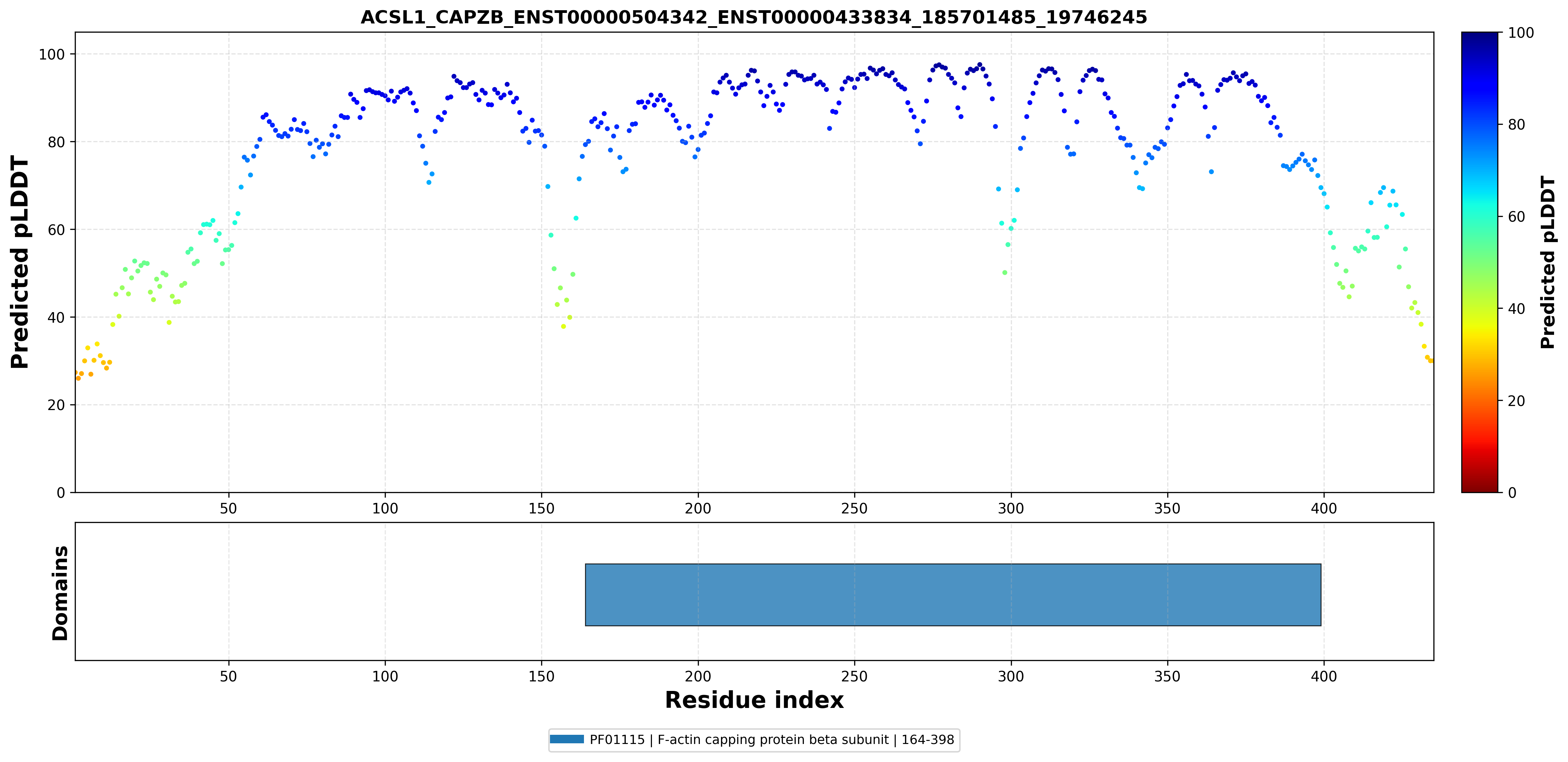
| ACSL1_CAPZB_ENST00000504342_ENST00000433834_185701485_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.5268
Å |
 |  |  |  |  |
| ACSL1_HERC5_ENST00000515030_ENST00000508159_185698037_89407265 superimposed PDB: 8Y4Z of partner (HERC5). RMSD:0.7294
Å |
 |  |  |  |  |
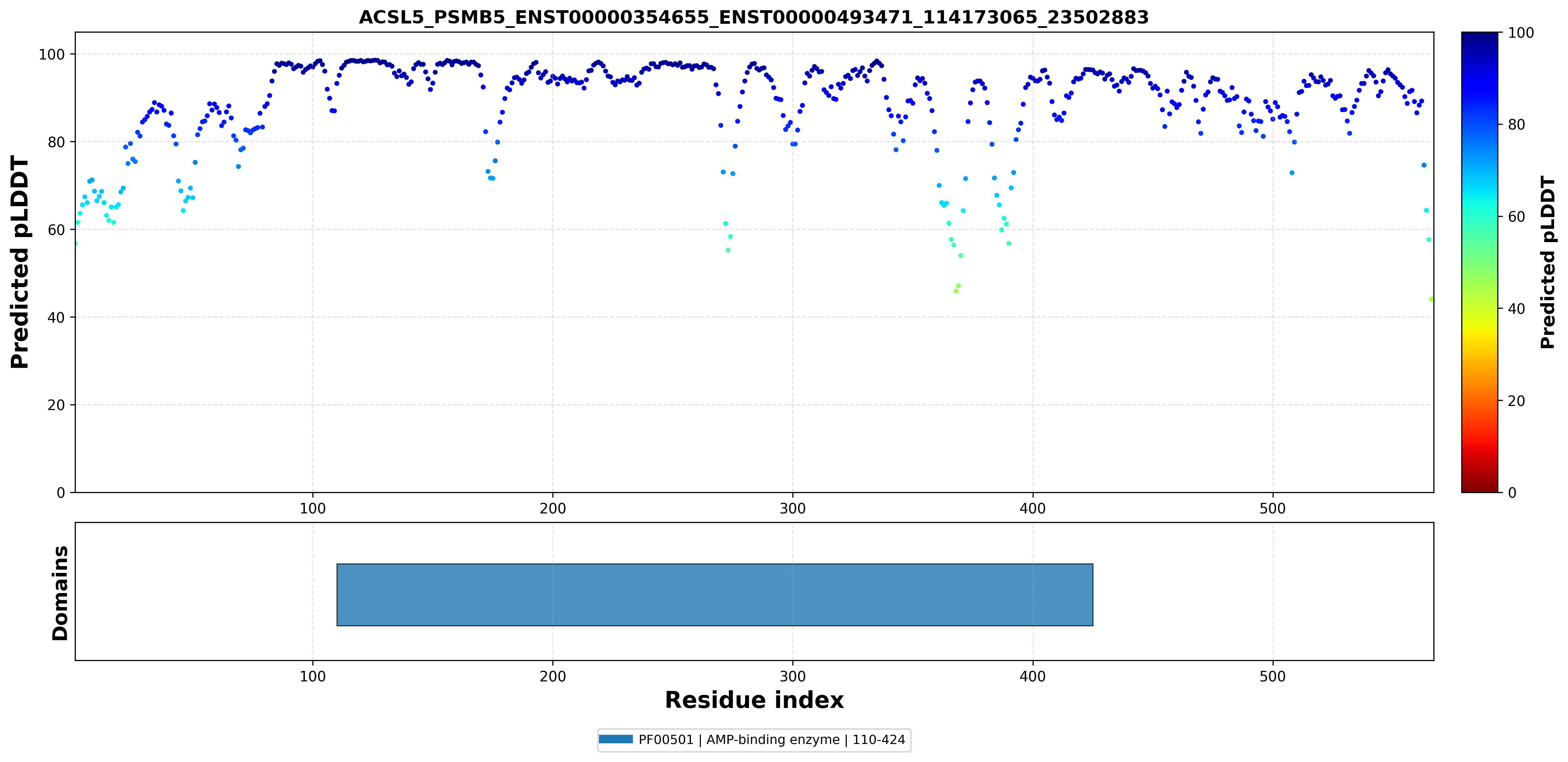
| ACSL5_PSMB5_ENST00000354655_ENST00000493471_114173065_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.4083
Å |
 |  |  |  |  |
| ACSL5_PSMB5_ENST00000356116_ENST00000361611_114173065_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.6775
Å |
 |  |  |  |  |
| ACSL5_PSMB5_ENST00000369410_ENST00000493471_114173065_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.4079
Å |
 |  |  |  |  |
| ACSL5_PSMB5_ENST00000393081_ENST00000361611_114173065_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.6032
Å |
 |  |  |  |  |
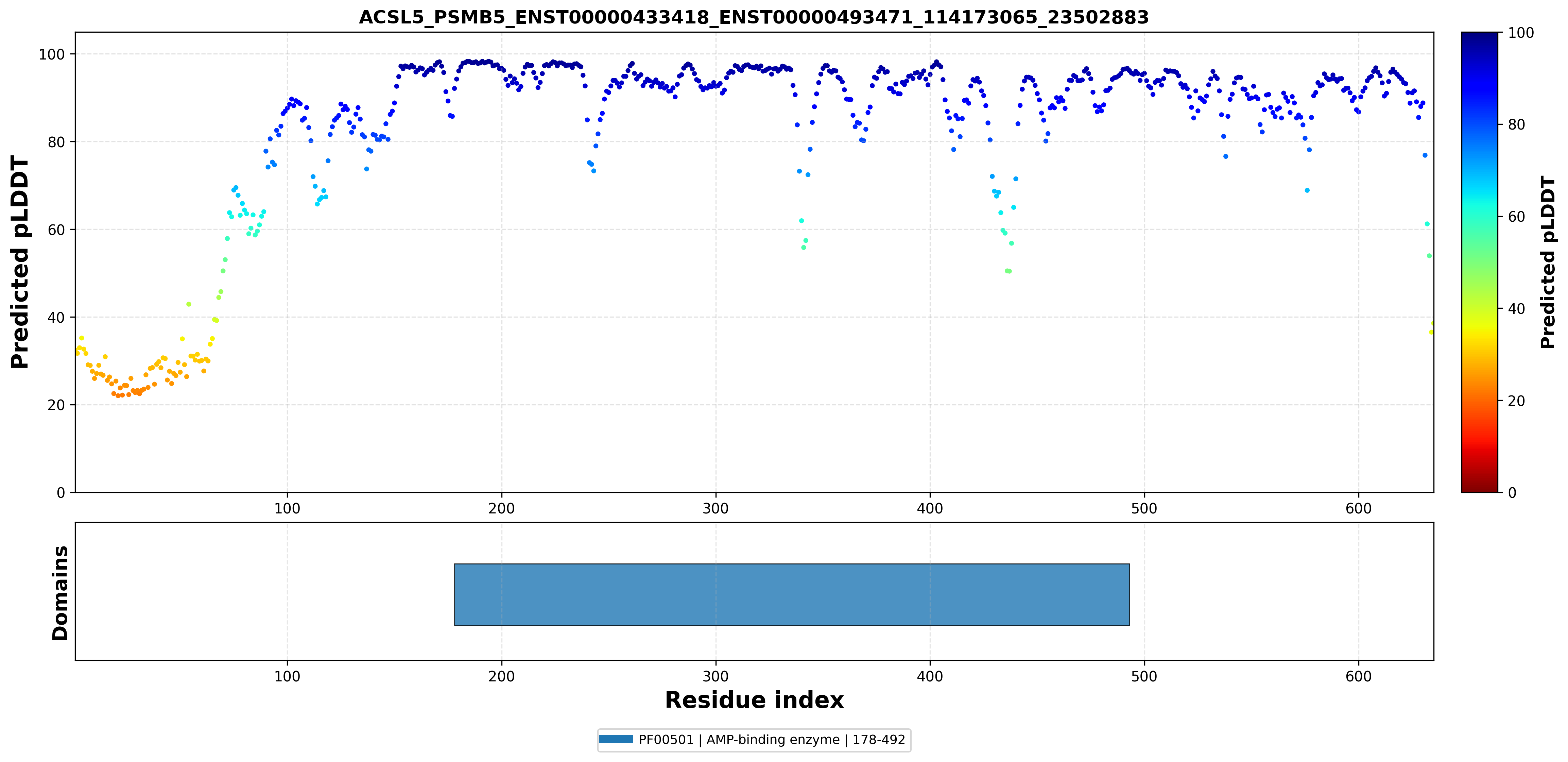
| ACSL5_PSMB5_ENST00000433418_ENST00000493471_114173065_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.4086
Å |
 |  |  |  |  |
| ACSM2A_ABCC6_ENST00000219054_ENST00000205557_20492243_16263710 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.637
Å |
 |  |  |  |  |
| ACSM2A_ABCC6_ENST00000219054_ENST00000205557_20492243_16263710 superimposed PDB: 6BZR of partner (ABCC6). RMSD:0.9421
Å |
| | | |  |
| ACSM2A_ABCC6_ENST00000536134_ENST00000205557_20492243_16263710 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.5287
Å |
 |  |  |  |  |
| ACSM2A_ABCC6_ENST00000536134_ENST00000205557_20492243_16263710 superimposed PDB: 6BZR of partner (ABCC6). RMSD:0.9366
Å |
| | | |  |
| ACSM2A_ABCC6_ENST00000573854_ENST00000205557_20492243_16263710 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.6102
Å |
 |  |  |  |  |
| ACSM2A_ABCC6_ENST00000573854_ENST00000205557_20492243_16263710 superimposed PDB: 6BZR of partner (ABCC6). RMSD:0.942
Å |
| | | |  |
| ACSM2A_ABCC6_ENST00000575690_ENST00000205557_20492243_16263710 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.6701
Å |
 |  |  |  |  |
| ACSM2A_ABCC6_ENST00000575690_ENST00000205557_20492243_16263710 superimposed PDB: 6BZR of partner (ABCC6). RMSD:0.9215
Å |
| | | |  |
| ACSM2A_ACSM1_ENST00000219054_ENST00000307493_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.4989
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000396104_ENST00000219151_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.5264
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000417235_ENST00000307493_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.4871
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000536134_ENST00000219151_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.4949
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000536134_ENST00000307493_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.6645
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000573854_ENST00000219151_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.6263
Å |
 |  |  |  |  |
| ACSM2A_ACSM1_ENST00000573854_ENST00000307493_20494499_20635537 superimposed PDB: 2WD9 of partner (ACSM2A). RMSD:0.5128
Å |
 |  |  |  |  |
| ACSS1_BCAT1_ENST00000323482_ENST00000538118_24994596_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:2.9898
Å |
 |  |  |  |  |
| ACSS1_BCAT1_ENST00000537502_ENST00000538118_24994596_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.0527
Å |
 |  |  |  |  |
| ACSS1_BCAT1_ENST00000542618_ENST00000538118_24994596_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.1448
Å |
 |  |  |  |  |
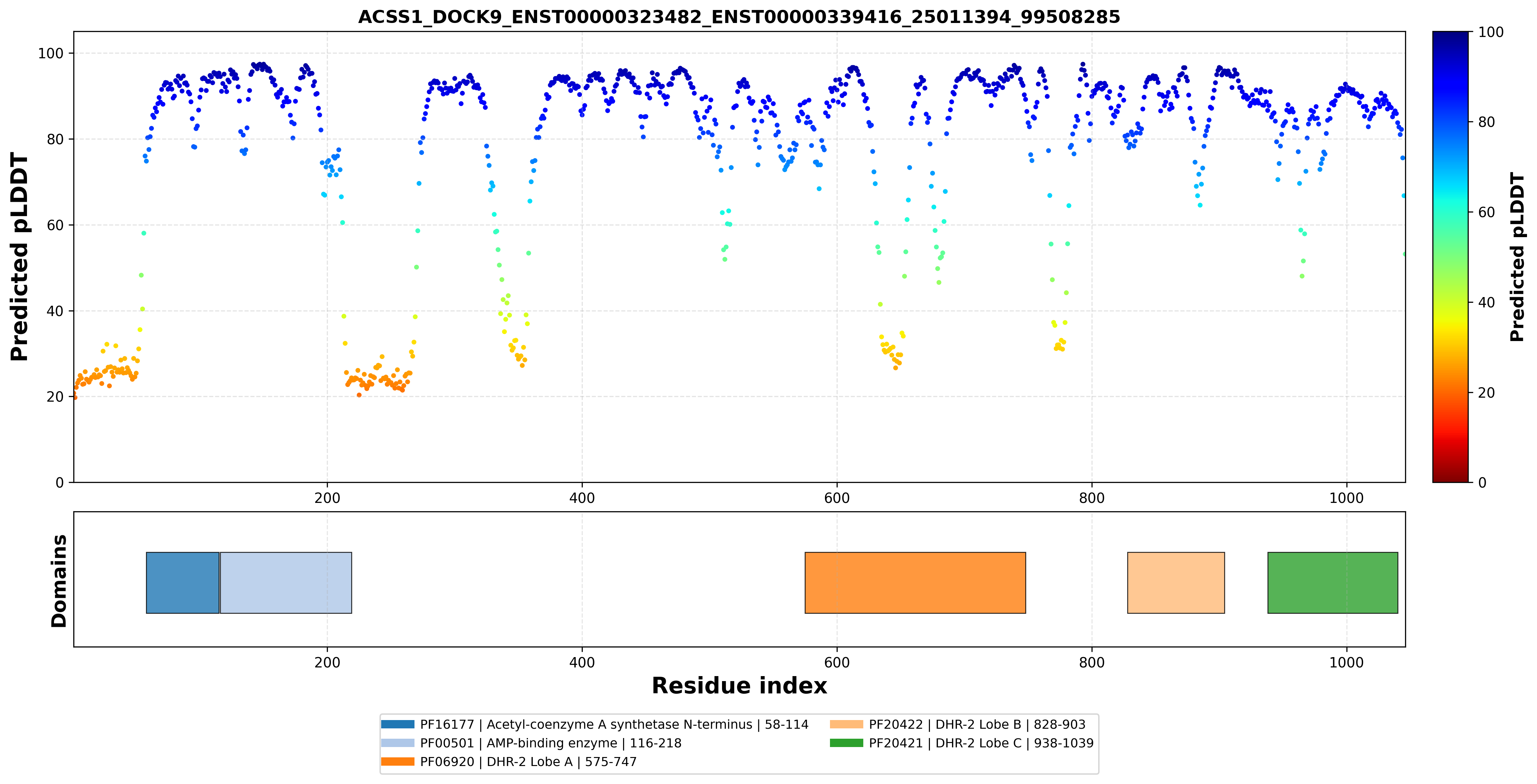
| ACSS1_DOCK9_ENST00000323482_ENST00000339416_25011394_99508285 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8677
Å |
 |  |  |  |  |
| ACSS1_DOCK9_ENST00000323482_ENST00000448493_25011394_99508285 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8138
Å |
 |  |  |  |  |
| ACSS1_DOCK9_ENST00000432802_ENST00000376460_25011394_99508285 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.4874
Å |
 |  |  |  |  |
| ACSS1_DOCK9_ENST00000542618_ENST00000339416_25011394_99508285 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.9166
Å |
 |  |  |  |  |
| ACSS1_DOCK9_ENST00000542618_ENST00000448493_25011394_99508285 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8688
Å |
 |  |  |  |  |
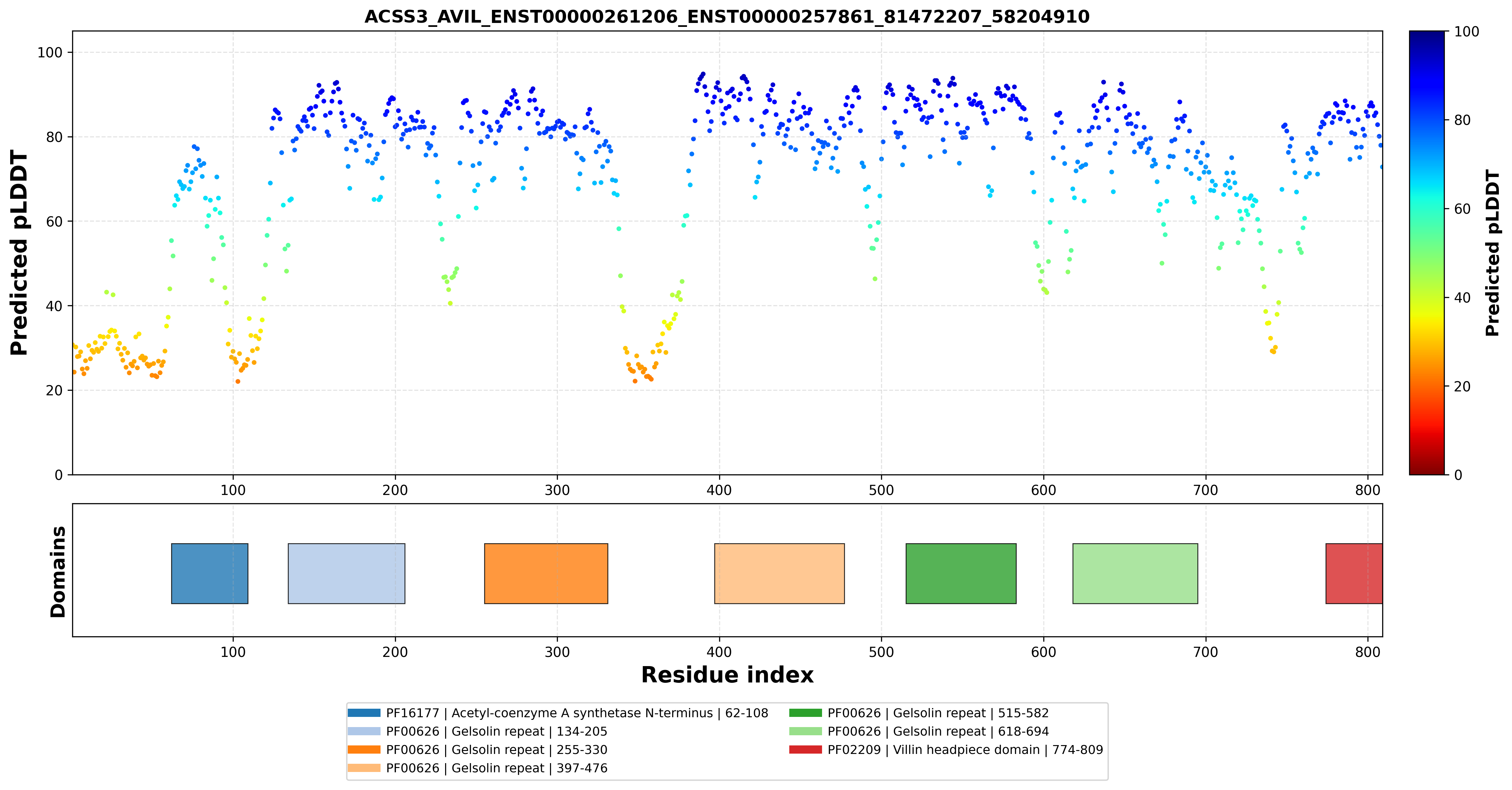
| ACSS3_AVIL_ENST00000261206_ENST00000257861_81472207_58204910 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7906
Å |
 |  |  |  |  |
| ACSS3_AVIL_ENST00000261206_ENST00000537081_81472207_58204910 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7785
Å |
 |  |  |  |  |
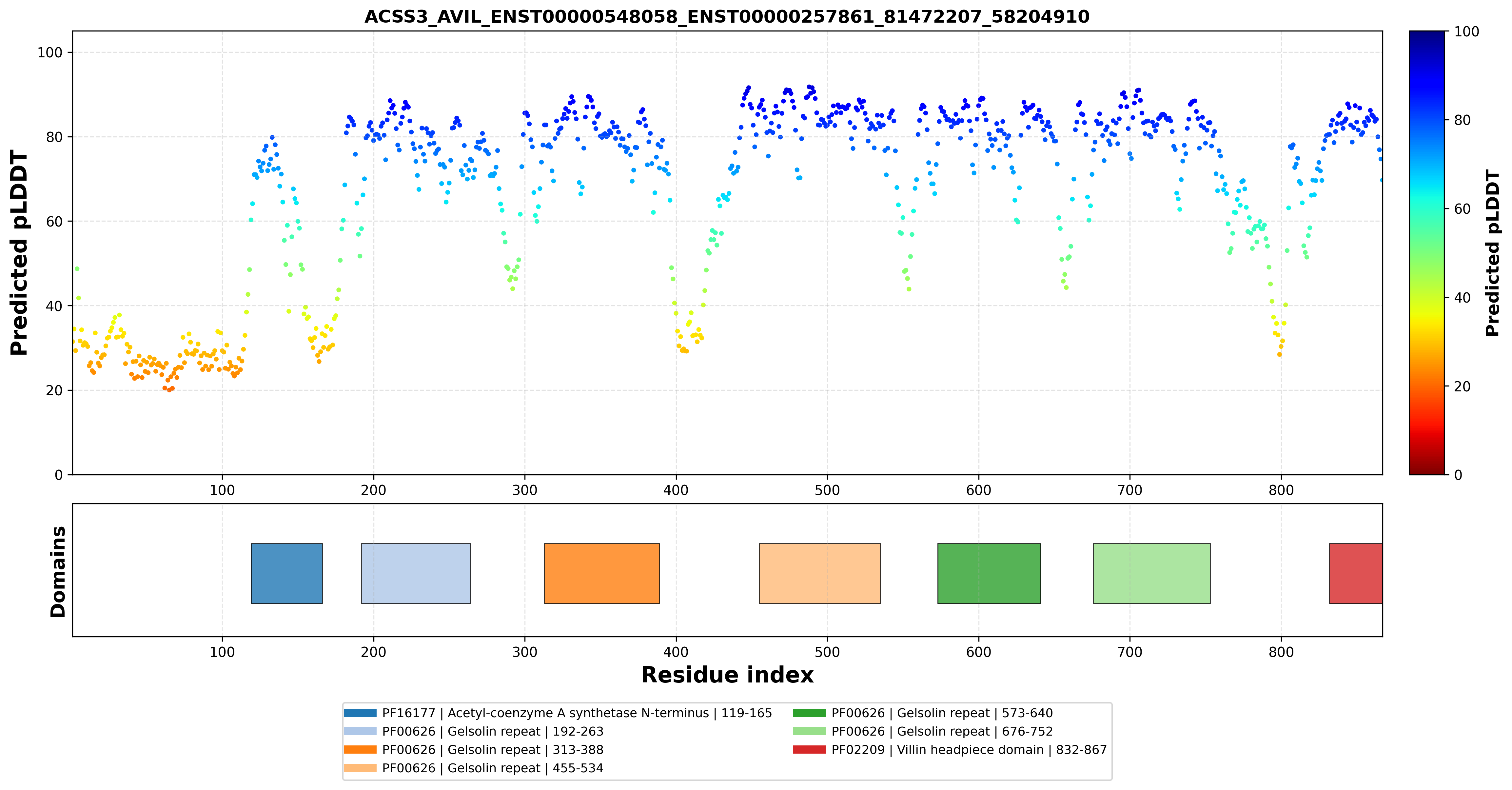
| ACSS3_AVIL_ENST00000548058_ENST00000257861_81472207_58204910 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7591
Å |
 |  |  |  |  |
| ACSS3_METTL21B_ENST00000261206_ENST00000548256_81503483_58166799 superimposed PDB: 4QPN of partner (METTL21B). RMSD:0.8222
Å |
 |  |  |  |  |
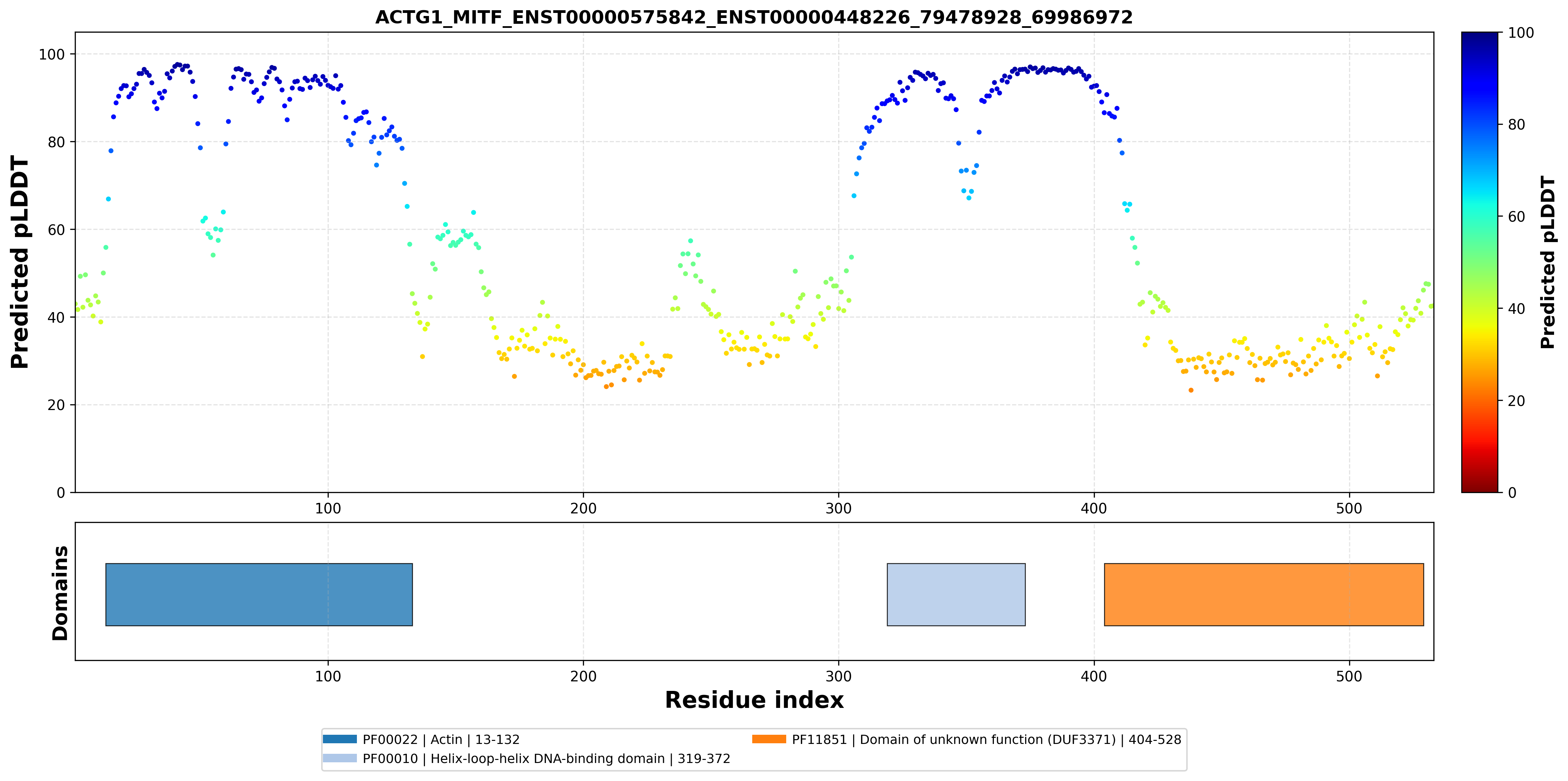
| ACTG1_MITF_ENST00000575842_ENST00000448226_79478928_69986972 superimposed PDB: 7D8S of partner (MITF). RMSD:0.6219
Å |
 |  |  |  |  |
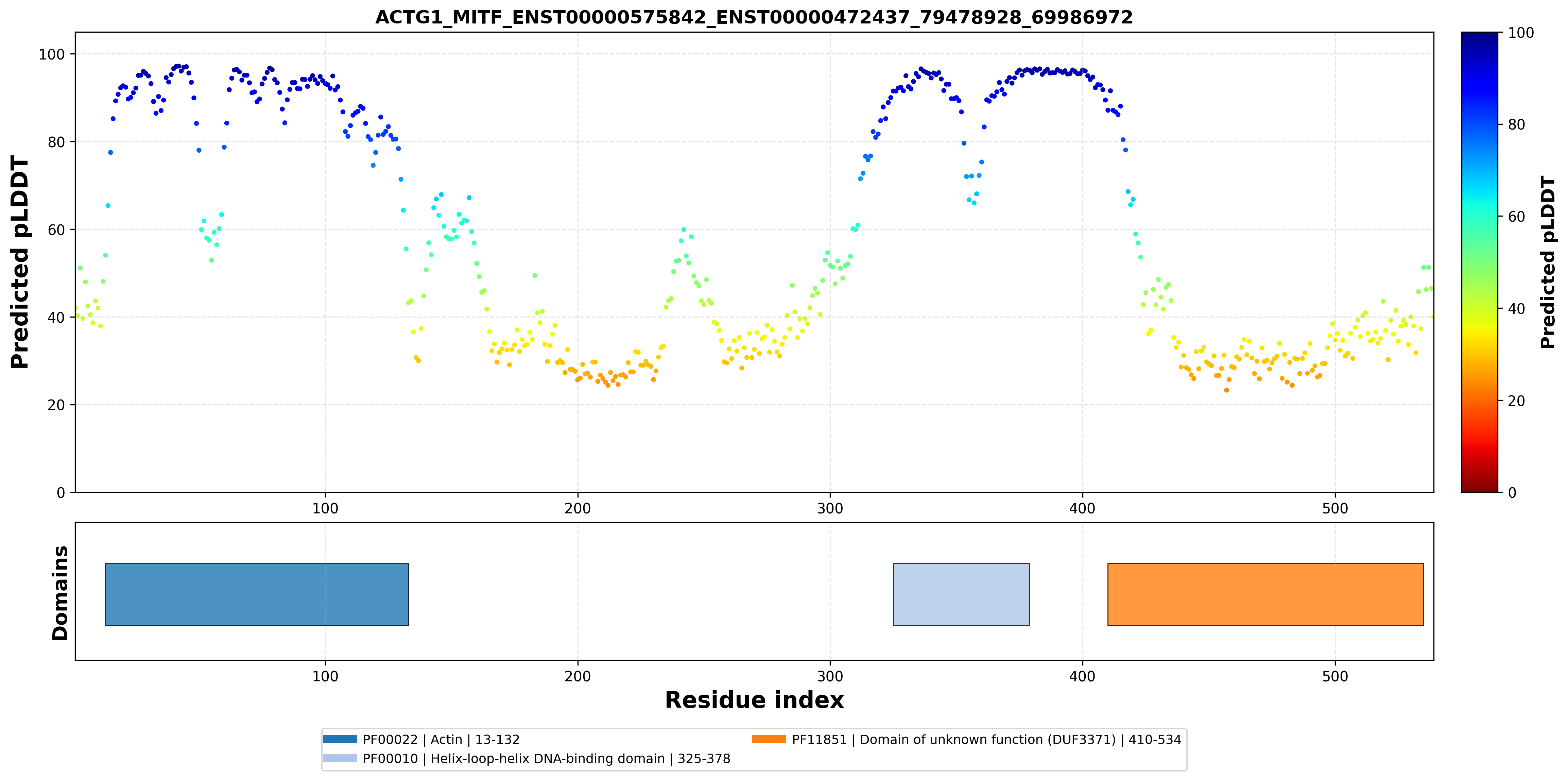
| ACTG1_MITF_ENST00000575842_ENST00000472437_79478928_69986972 superimposed PDB: 7D8S of partner (MITF). RMSD:0.6362
Å |
 |  |  |  |  |
| ACTN3_KMT2A_ENST00000513398_ENST00000354520_66314555_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.838
Å |
 |  |  |  |  |
| ACTN3_KMT2A_ENST00000513398_ENST00000389506_66314555_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9988
Å |
 |  |  |  |  |
| ACTN4_APLP1_ENST00000252699_ENST00000221891_39138547_36360568 superimposed PDB: 3PMR of partner (APLP1). RMSD:0.8329
Å |
 |  |  |  |  |
| ACTN4_APLP1_ENST00000252699_ENST00000537454_39138547_36360568 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.5346
Å |
 |  |  |  |  |
| ACTN4_APLP1_ENST00000424234_ENST00000537454_39138547_36360568 superimposed PDB: 3PMR of partner (APLP1). RMSD:0.7781
Å |
 |  |  |  |  |
| ACTN4_CDH13_ENST00000252699_ENST00000268613_39138547_83158989 superimposed PDB: 2V37 of partner (CDH13). RMSD:0.8841
Å |
 |  |  |  |  |
| ACTN4_CDH13_ENST00000252699_ENST00000431540_39138547_83158989 superimposed PDB: 2V37 of partner (CDH13). RMSD:1.2046
Å |
 |  |  |  |  |
| ACTN4_CDH13_ENST00000252699_ENST00000566620_39138547_83158989 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:1.7752
Å |
 |  |  |  |  |
| ACTN4_FTO_ENST00000424234_ENST00000471389_39138547_53844051 superimposed PDB: 4IE5 of partner (FTO). RMSD:0.8229
Å |
 |  |  |  |  |
| ACTN4_KMT2A_ENST00000252699_ENST00000354520_39138547_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8607
Å |
 |  |  |  |  |
| ACTN4_KMT2A_ENST00000252699_ENST00000389506_39138547_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:2.0808
Å |
 |  |  |  |  |
| ACTN4_KMT2A_ENST00000252699_ENST00000534358_39138547_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.5734
Å |
 |  |  |  |  |
| ACTN4_KMT2A_ENST00000424234_ENST00000534358_39138547_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8292
Å |
 |  |  |  |  |
| ACTN4_RPS16_ENST00000252699_ENST00000601655_39138547_39926348 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:3.0551
Å |
 |  |  |  |  |
| ACTN4_RPS16_ENST00000424234_ENST00000599539_39138547_39926348 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:3.0314
Å |
 |  |  |  |  |
| ACTN4_RYR1_ENST00000252699_ENST00000355481_39205201_39051752 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:3.091
Å |
 |  |  |  |  |
| ACTN4_RYR1_ENST00000252699_ENST00000360985_39205201_39051752 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.5398
Å |
 |  |  |  |  |
| ACTN4_RYR1_ENST00000390009_ENST00000355481_39205201_39051752 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.5702
Å |
 |  |  |  |  |
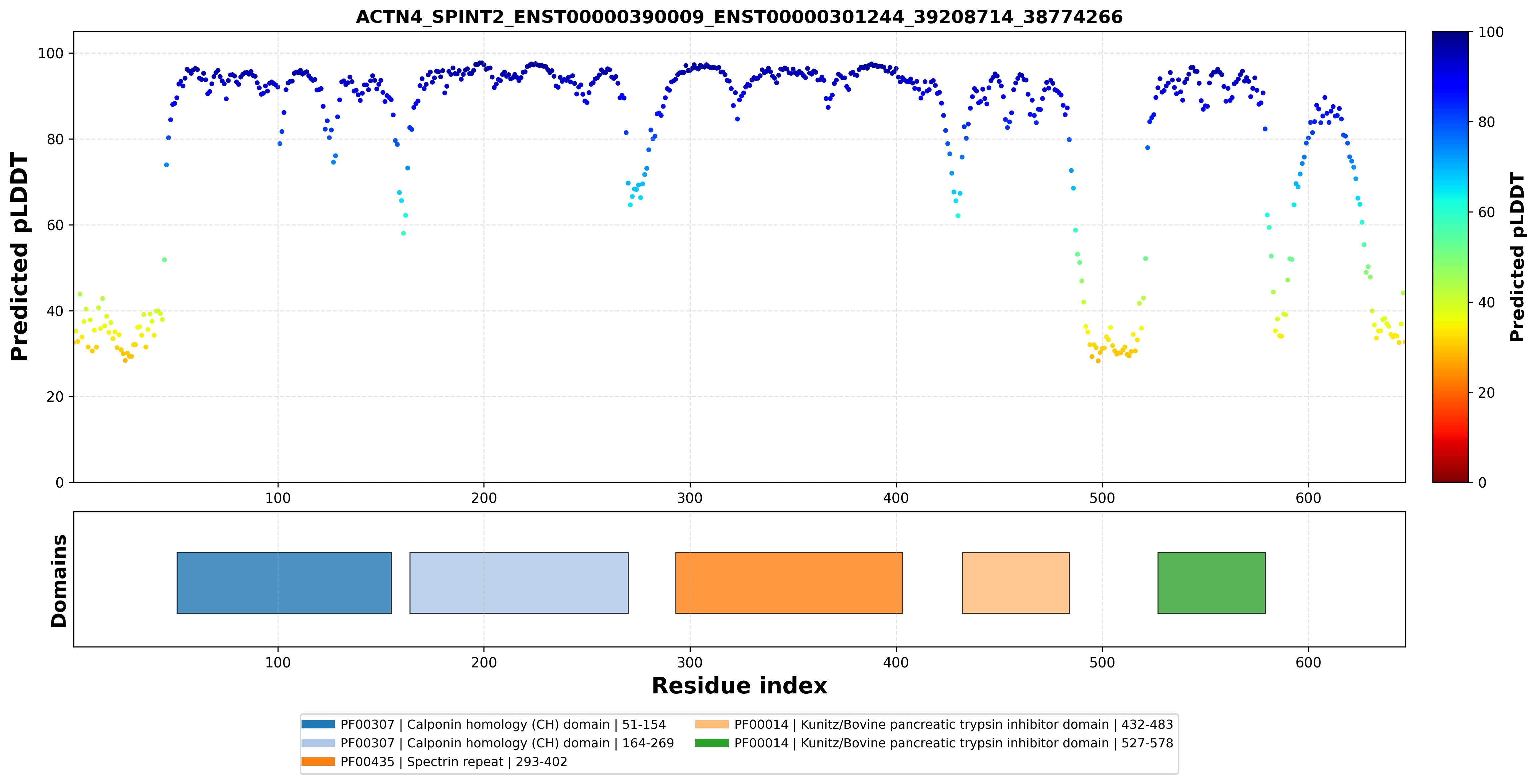
| ACTN4_SPINT2_ENST00000390009_ENST00000301244_39208714_38774266 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.4838
Å |
 |  |  |  |  |
| ACTN4_SPINT2_ENST00000390009_ENST00000301244_39208714_38774266 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2345
Å |
| | | |  |
| ACTR3B_JMJD1C_ENST00000256001_ENST00000399262_152522207_65140242 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.6553
Å |
 |  |  |  |  |
| ACTR3B_JMJD1C_ENST00000537264_ENST00000399262_152522207_65140242 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.6395
Å |
 |  |  |  |  |
| ACTR3B_PARK7_ENST00000377776_ENST00000493678_152497740_8030953 superimposed PDB: 9YFR of partner (PARK7). RMSD:0.505
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000243349_ENST00000415850_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.2439
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000243349_ENST00000426655_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.192
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000243349_ENST00000542485_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.2262
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000335450_ENST00000415850_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.1052
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000335450_ENST00000541224_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.1002
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000335450_ENST00000542485_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.149
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000409680_ENST00000415850_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.2019
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000409680_ENST00000541224_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.151
Å |
 |  |  |  |  |
| ACVR1C_ACVR1B_ENST00000409680_ENST00000542485_158406673_52377782 superimposed PDB: 7MRZ of partner (ACVR1B). RMSD:1.1696
Å |
 |  |  |  |  |
| ACVR2A_CPQ_ENST00000241416_ENST00000220763_148602776_97847200 superimposed PDB: 3SOC of partner (ACVR2A). RMSD:2.6487
Å |
 |  |  |  |  |
| ACVRL1_SLC43A2_ENST00000388922_ENST00000571650_52312899_1481617 superimposed PDB: 3MY0 of partner (ACVRL1). RMSD:0.4867
Å |
 |  |  |  |  |
| ACVRL1_SLC43A2_ENST00000419526_ENST00000571650_52312899_1481617 superimposed PDB: 3MY0 of partner (ACVRL1). RMSD:0.5489
Å |
 |  |  |  |  |
| ACVRL1_SLC43A2_ENST00000550683_ENST00000571650_52312899_1481617 superimposed PDB: 3MY0 of partner (ACVRL1). RMSD:0.5111
Å |
 |  |  |  |  |
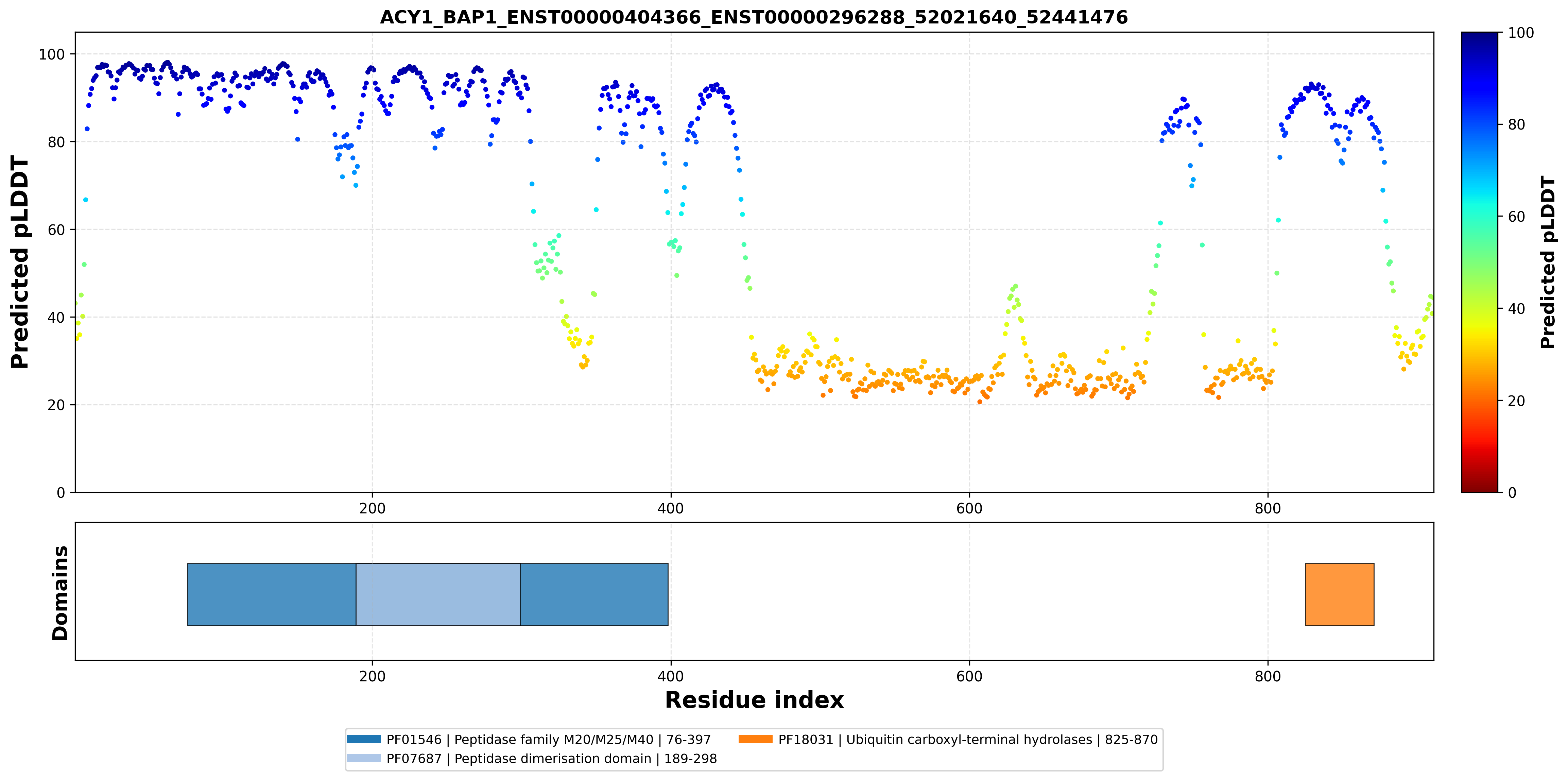
| ACY1_BAP1_ENST00000404366_ENST00000296288_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.5055
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000404366_ENST00000296288_52021640_52441476 superimposed PDB: 8H1T of partner (BAP1). RMSD:2.5723
Å |
| | | |  |
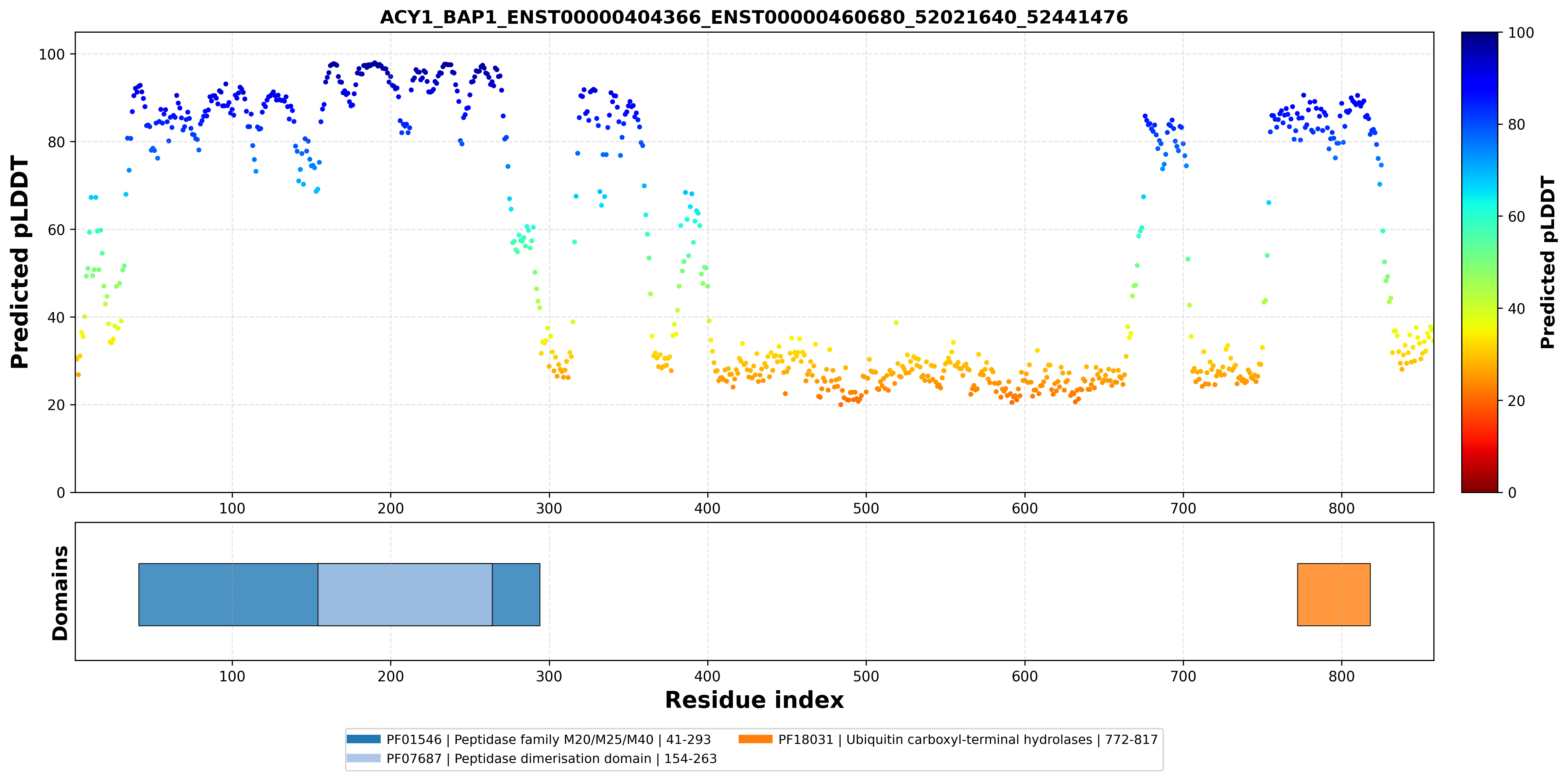
| ACY1_BAP1_ENST00000404366_ENST00000460680_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.77
Å |
 |  |  |  |  |
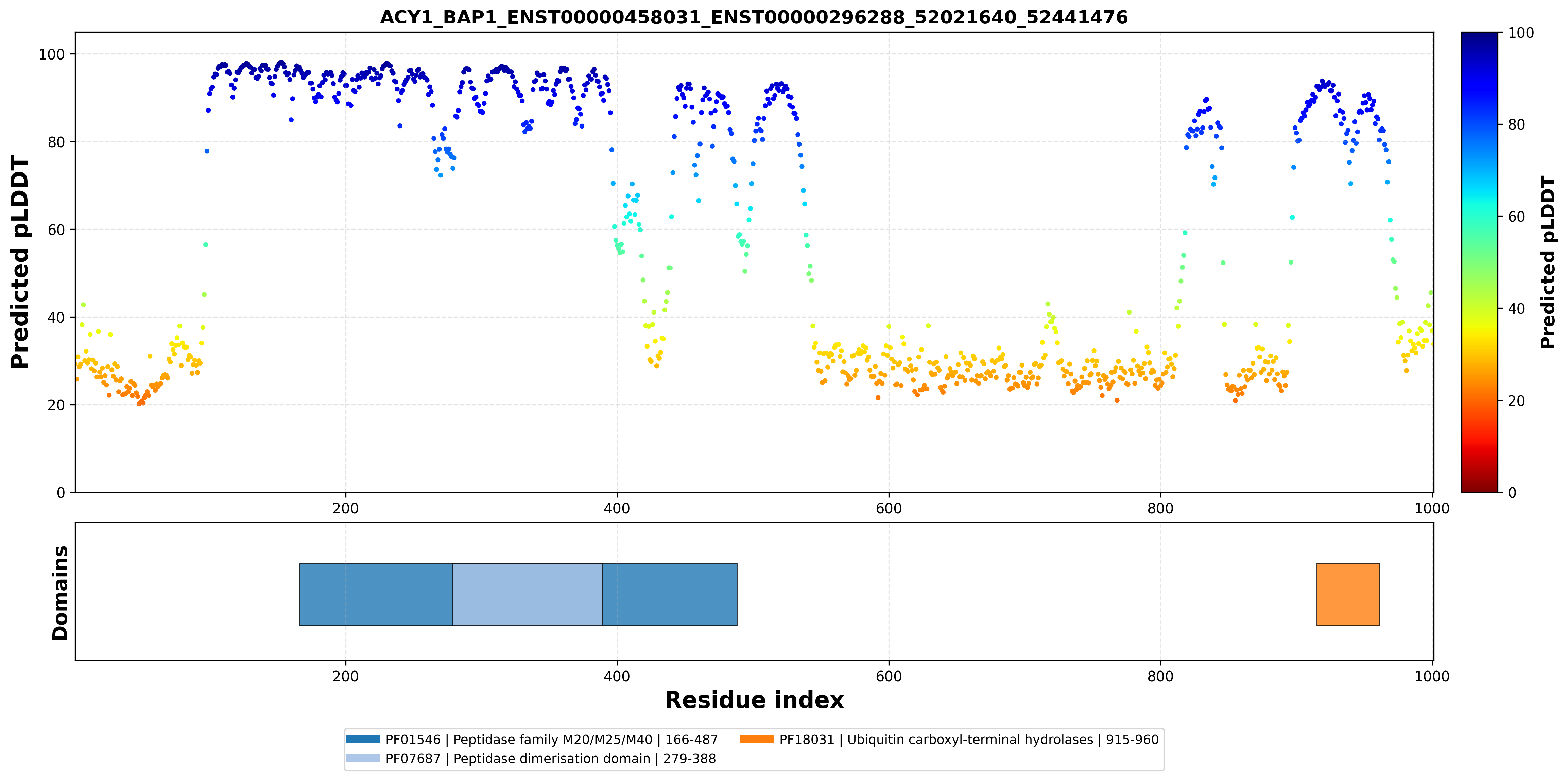
| ACY1_BAP1_ENST00000458031_ENST00000296288_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.5304
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000458031_ENST00000296288_52021640_52441476 superimposed PDB: 8H1T of partner (BAP1). RMSD:2.4409
Å |
| | | |  |
| ACY1_BAP1_ENST00000476351_ENST00000296288_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.7716
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000476351_ENST00000296288_52021640_52441476 superimposed PDB: 8H1T of partner (BAP1). RMSD:2.4494
Å |
| | | |  |
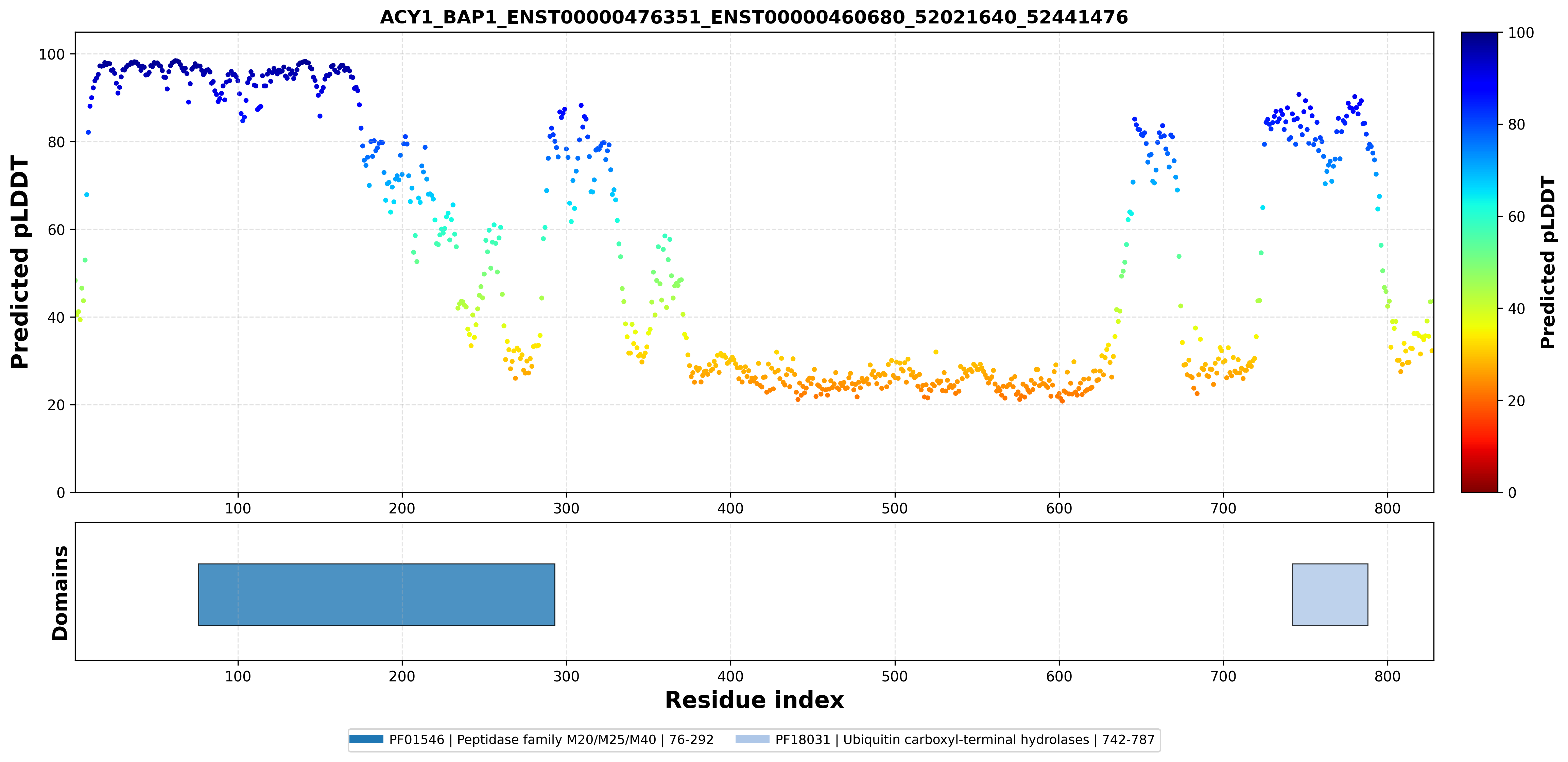
| ACY1_BAP1_ENST00000476351_ENST00000460680_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.5128
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000476854_ENST00000296288_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.5286
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000476854_ENST00000296288_52021640_52441476 superimposed PDB: 8H1T of partner (BAP1). RMSD:2.6136
Å |
| | | |  |
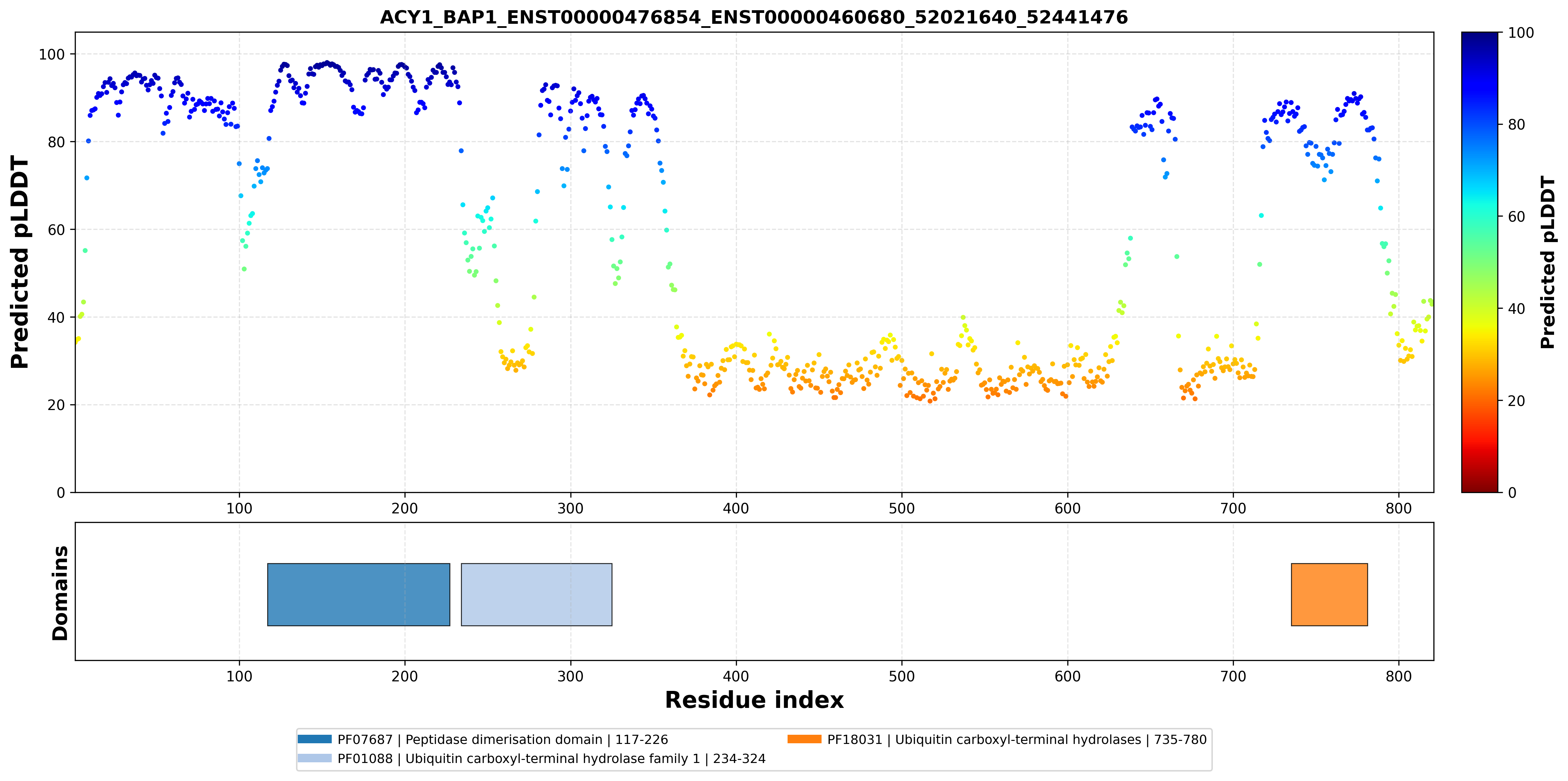
| ACY1_BAP1_ENST00000476854_ENST00000460680_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.7404
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000494103_ENST00000296288_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.772
Å |
 |  |  |  |  |
| ACY1_BAP1_ENST00000494103_ENST00000296288_52021640_52441476 superimposed PDB: 8H1T of partner (BAP1). RMSD:2.4341
Å |
| | | |  |
| ACY1_BAP1_ENST00000494103_ENST00000460680_52021640_52441476 superimposed PDB: 1Q7L of partner (ACY1). RMSD:0.5084
Å |
 |  | 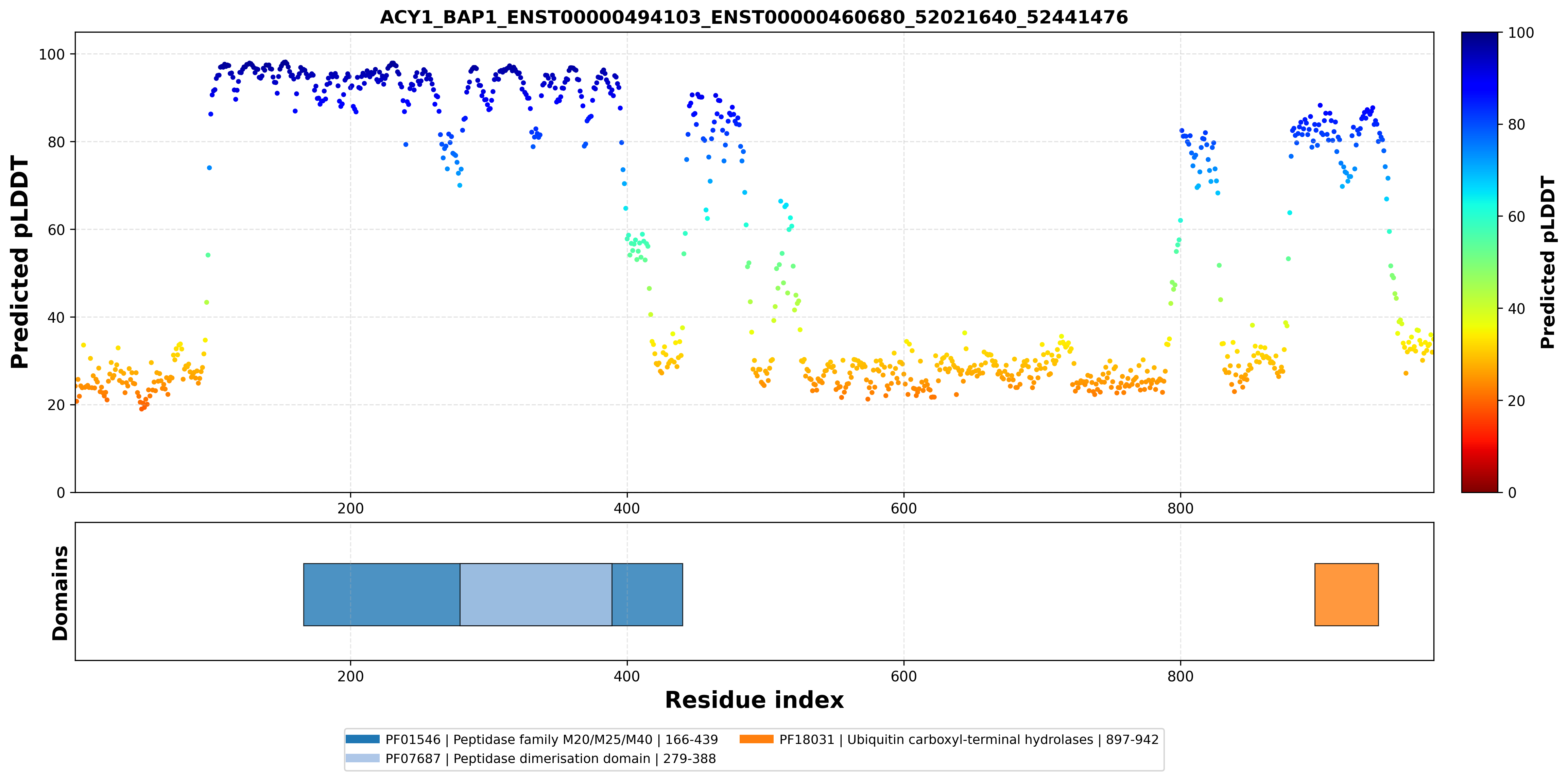 |  |  |
| ADAM10_PAK2_ENST00000396140_ENST00000327134_58904006_196534652 superimposed PDB: 8ESV of partner (ADAM10). RMSD:1.7682
Å |
 |  |  |  |  |
| ADAM10_PAK2_ENST00000396140_ENST00000327134_58904006_196534652 superimposed PDB: 9M41 of partner (PAK2). RMSD:1.0533
Å |
| | | |  |
| ADAM17_ITGB1BP1_ENST00000310823_ENST00000238091_9675962_9548334 superimposed PDB: 8SNL of partner (ADAM17). RMSD:0.6811
Å |
 |  |  |  |  |
| ADAM17_ITGB1BP1_ENST00000310823_ENST00000238091_9675962_9548334 superimposed PDB: 4JIF of partner (ITGB1BP1). RMSD:0.5721
Å |
| | | |  |
| ADAM17_ITGB1BP1_ENST00000310823_ENST00000355346_9675962_9548334 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.6723
Å |
 |  |  |  |  |
| ADAM17_ITGB1BP1_ENST00000310823_ENST00000355346_9675962_9548334 superimposed PDB: 4JIF of partner (ITGB1BP1). RMSD:2.8205
Å |
| | | |  |
| ADAM17_ITGB1BP1_ENST00000310823_ENST00000360635_9675962_9548334 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.142
Å |
 |  |  |  |  |
| ADAM17_SEC31A_ENST00000310823_ENST00000311785_9634765_83765662 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.2424
Å |
 |  |  |  |  |
| ADAM17_SEC31A_ENST00000310823_ENST00000395310_9634765_83765662 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.1689
Å |
 |  |  |  |  |
| ADAM17_SEC31A_ENST00000310823_ENST00000509142_9634765_83765662 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.1688
Å |
 |  | 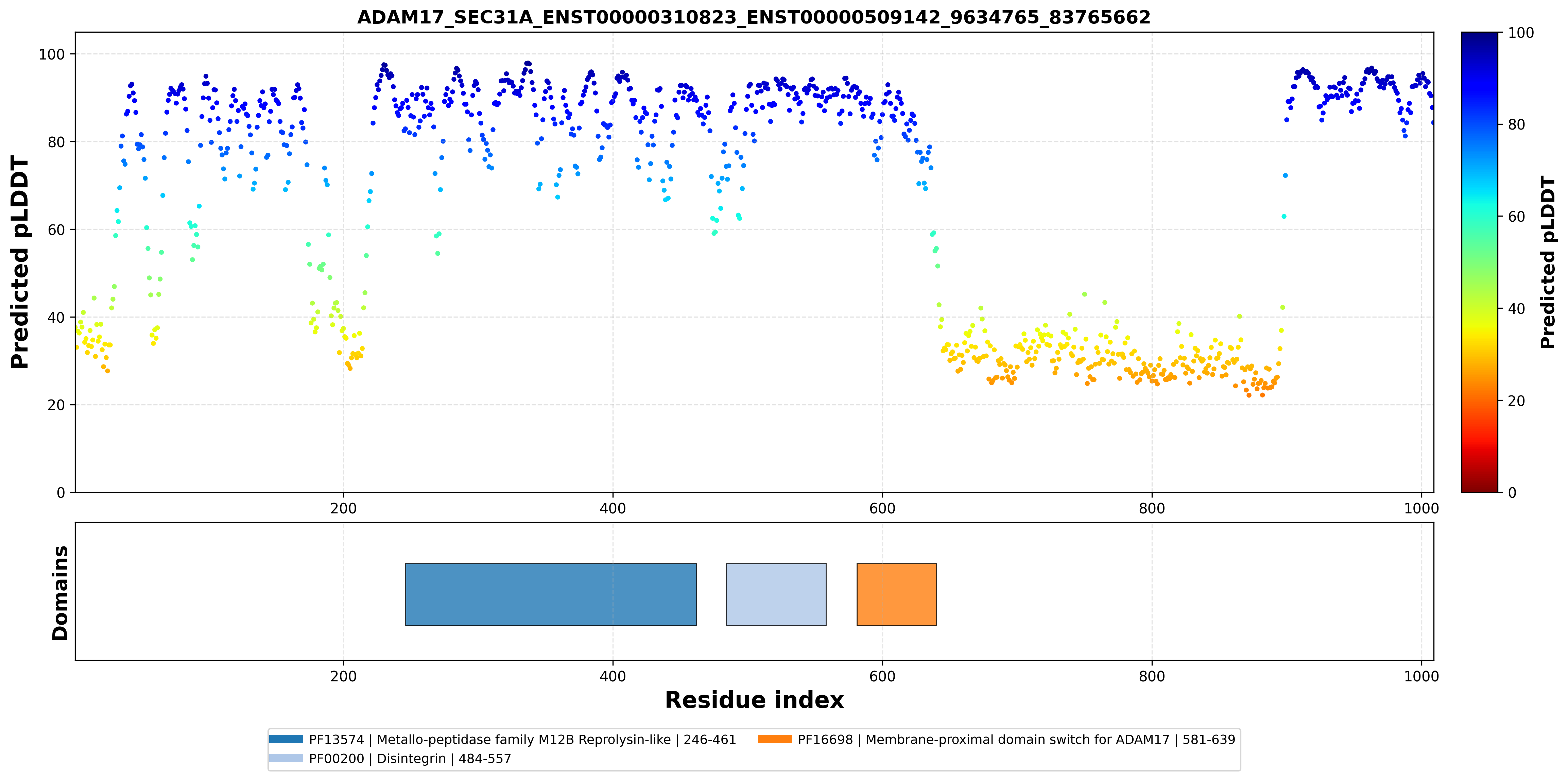 |  |  |
| ADAM17_SEC31A_ENST00000310823_ENST00000513858_9634765_83765662 superimposed PDB: 8SNL of partner (ADAM17). RMSD:1.2293
Å |
 |  |  |  |  |
| ADAM28_UBL7_ENST00000265769_ENST00000565335_24208823_74741694 superimposed PDB: 2CWB of partner (UBL7). RMSD:0.85
Å |
 |  |  |  |  |
| ADAMTS16_ETV6_ENST00000511368_ENST00000396373_5209359_11905383 superimposed PDB: 9O0H of partner (ETV6). RMSD:1.0447
Å |
 |  |  |  |  |
| ADAP1_MAD1L1_ENST00000265846_ENST00000399654_966188_2108973 superimposed PDB: 3FM8 of partner (ADAP1). RMSD:2.9505
Å |
 |  |  |  |  |
| ADAP1_MAD1L1_ENST00000265846_ENST00000399654_966188_2108973 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.0696
Å |
| | | |  |
| ADAP1_MAD1L1_ENST00000449296_ENST00000399654_966188_2108973 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.0745
Å |
 |  |  |  |  |
| ADAP1_MAD1L1_ENST00000539900_ENST00000399654_966188_2108973 superimposed PDB: 3FM8 of partner (ADAP1). RMSD:3.098
Å |
 |  |  |  |  |
| ADAP1_MAD1L1_ENST00000539900_ENST00000399654_966188_2108973 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.2165
Å |
| | | |  |
| ADAR_SUMO3_ENST00000292205_ENST00000332859_154600330_46229033 superimposed PDB: 7ZJU of partner (SUMO3). RMSD:2.3026
Å |
 |  |  |  |  |
| ADCY9_CREBBP_ENST00000294016_ENST00000382070_4163750_3901010 superimposed PDB: 9U3P of partner (ADCY9). RMSD:1.6011
Å |
 |  |  |  |  |
| ADCY9_CREBBP_ENST00000294016_ENST00000382070_4163750_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.7754
Å |
| | | |  |
| ADCY9_GLYR1_ENST00000294016_ENST00000321919_4038994_4862249 superimposed PDB: 9U3P of partner (ADCY9). RMSD:3.0388
Å |
 |  |  |  |  |
| ADCY9_GLYR1_ENST00000294016_ENST00000321919_4038994_4862249 superimposed PDB: 2UYY of partner (GLYR1). RMSD:0.6185
Å |
| | | |  |
| ADCY9_NMRAL1_ENST00000294016_ENST00000574733_4163750_4519466 superimposed PDB: 9U3P of partner (ADCY9). RMSD:1.1439
Å |
 |  |  |  |  |
| ADCY9_NMRAL1_ENST00000294016_ENST00000574733_4163750_4519466 superimposed PDB: 3DXF of partner (NMRAL1). RMSD:0.5547
Å |
| | | |  |
| ADCY9_PRKCB_ENST00000294016_ENST00000303531_4163750_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.3025
Å |
 |  |  |  |  |
| ADCY9_ZSCAN32_ENST00000294016_ENST00000304926_4163750_3434941 superimposed PDB: 9U3P of partner (ADCY9). RMSD:1.3606
Å |
 |  |  |  |  |
| ADCY9_ZSCAN32_ENST00000294016_ENST00000396852_4163750_3434941 superimposed PDB: 9U3P of partner (ADCY9). RMSD:1.399
Å |
 |  |  |  |  |
| ADCYAP1R1_GHRHR_ENST00000396211_ENST00000409904_31139824_31014585 superimposed PDB: 8E3X of partner (ADCYAP1R1). RMSD:2.1546
Å |
 |  |  |  |  |
| ADCYAP1R1_GHRHR_ENST00000396211_ENST00000409904_31139824_31014585 superimposed PDB: 7CZ5 of partner (GHRHR). RMSD:1.0966
Å |
| | | |  |
| ADCYAP1R1_GHRHR_ENST00000409489_ENST00000409904_31139824_31014585 superimposed PDB: 8E3X of partner (ADCYAP1R1). RMSD:2.22
Å |
 |  |  |  |  |
| ADCYAP1R1_GHRHR_ENST00000409489_ENST00000409904_31139824_31014585 superimposed PDB: 7CZ5 of partner (GHRHR). RMSD:1.0991
Å |
| | | |  |
| ADC_PHIP_ENST00000294517_ENST00000275034_33563780_79713575 superimposed PDB: 3MB3 of partner (PHIP). RMSD:0.4222
Å |
 |  | 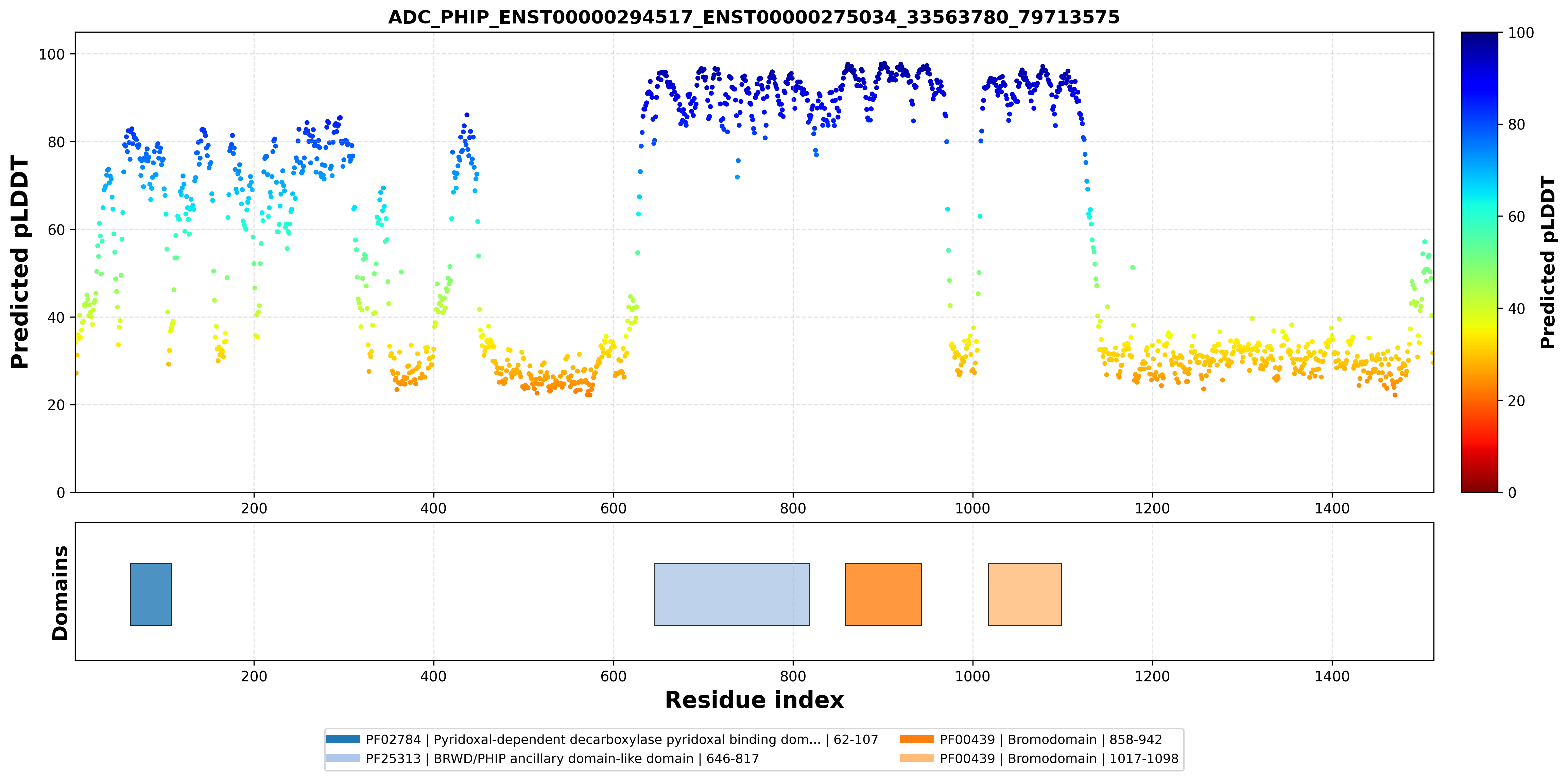 |  |  |
| ADC_PHIP_ENST00000373440_ENST00000275034_33563780_79713575 superimposed PDB: 3MB3 of partner (PHIP). RMSD:0.4023
Å |
 |  | 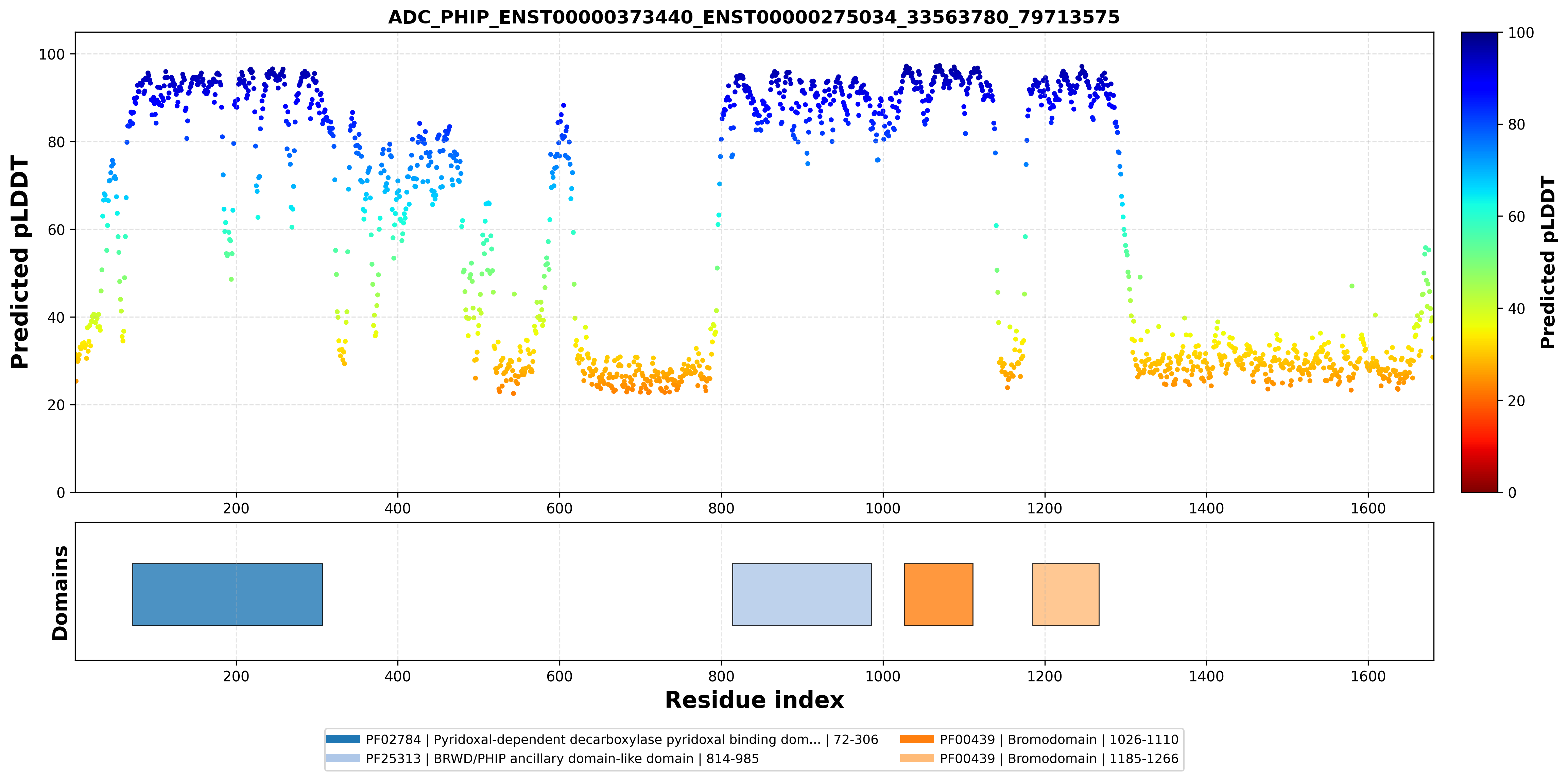 |  |  |
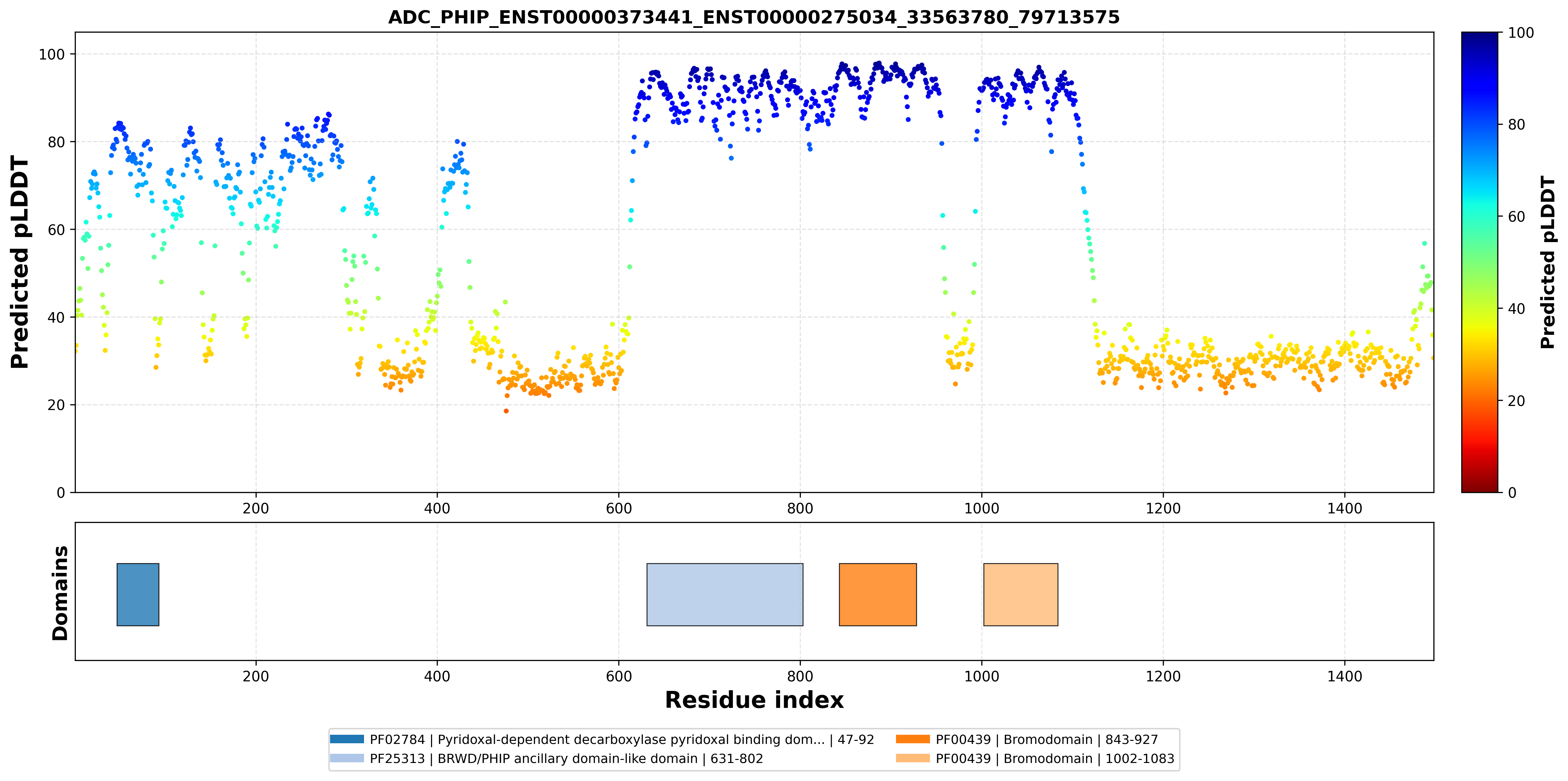
| ADC_PHIP_ENST00000373441_ENST00000275034_33563780_79713575 superimposed PDB: 3MB3 of partner (PHIP). RMSD:0.4459
Å |
 |  |  |  |  |
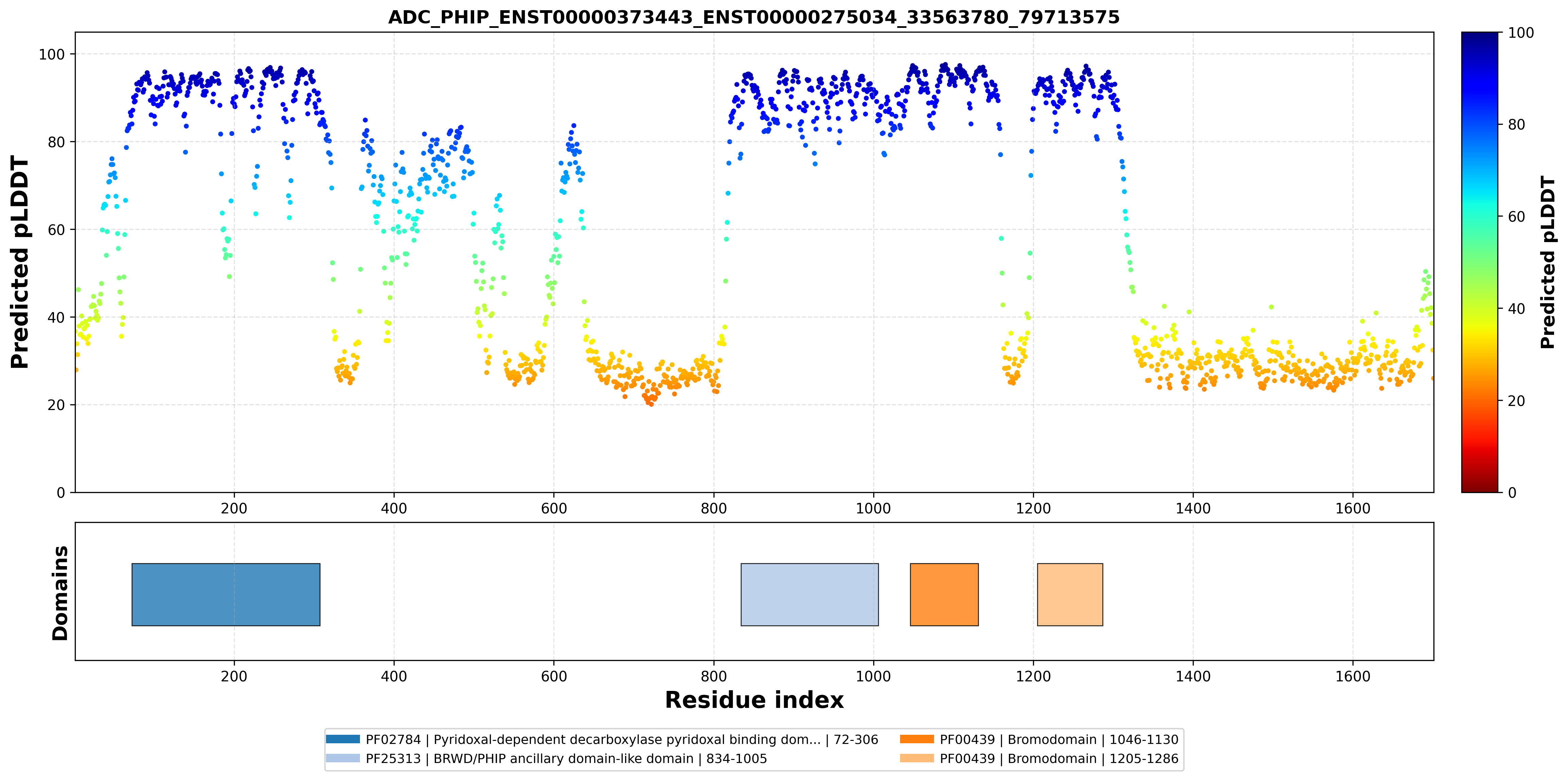
| ADC_PHIP_ENST00000373443_ENST00000275034_33563780_79713575 superimposed PDB: 3MB3 of partner (PHIP). RMSD:0.4577
Å |
 |  |  |  |  |
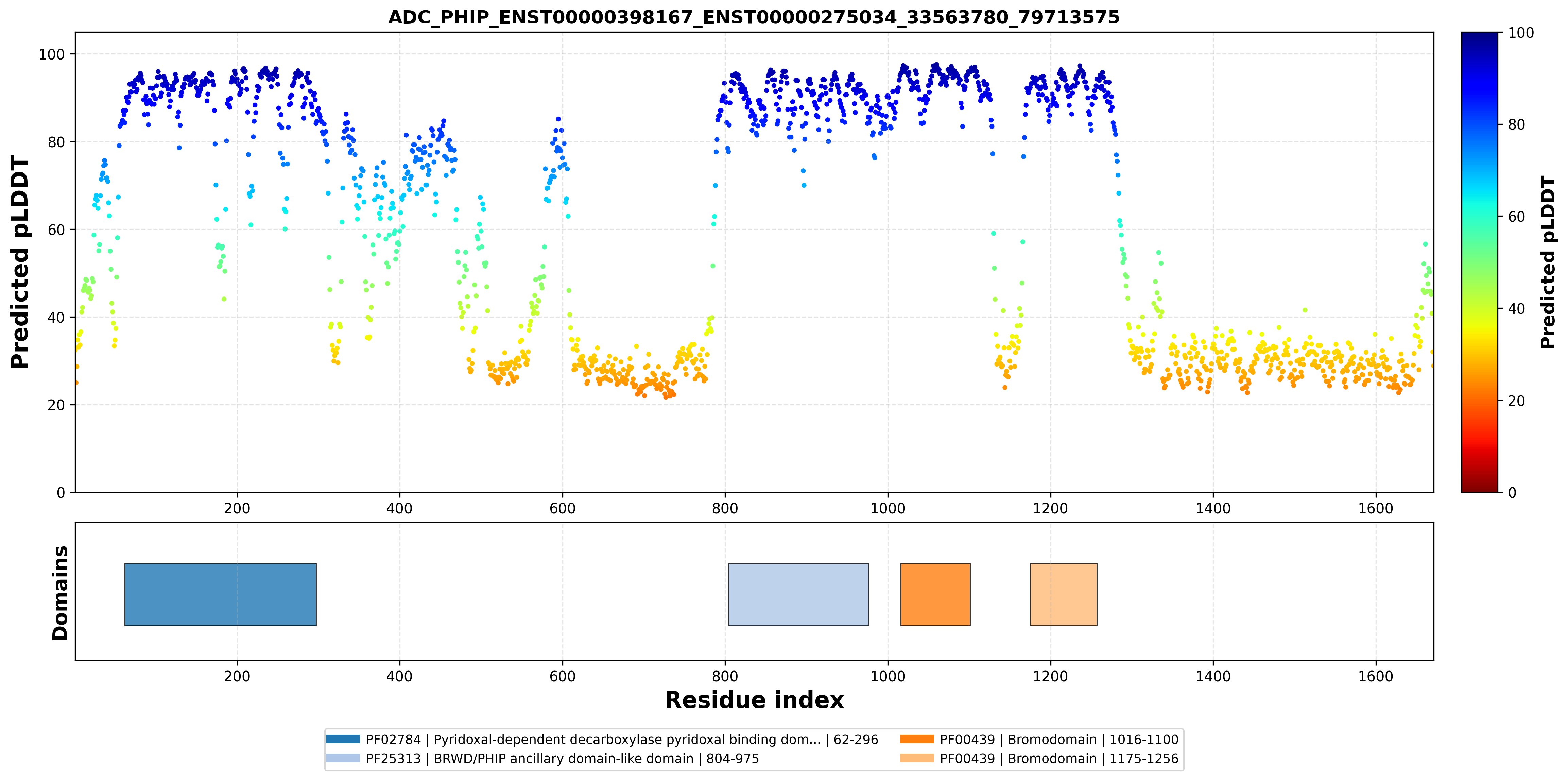
| ADC_PHIP_ENST00000398167_ENST00000275034_33563780_79713575 superimposed PDB: 3MB3 of partner (PHIP). RMSD:0.391
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000264758_ENST00000357681_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.6466
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000355842_ENST00000357681_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.5303
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000398125_ENST00000367218_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.3978
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000398125_ENST00000391954_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.5427
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000446856_ENST00000367218_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.4039
Å |
 |  |  |  |  |
| ADD1_ATP2B4_ENST00000446856_ENST00000391954_2931789_203671171 superimposed PDB: 2KNE of partner (ATP2B4). RMSD:1.6866
Å |
 |  |  |  |  |
| ADI1_KHDRBS3_ENST00000327435_ENST00000520981_3517627_136619197 superimposed PDB: 4QGN of partner (ADI1). RMSD:1.9826
Å |
 |  |  |  |  |
| ADI1_KHDRBS3_ENST00000382093_ENST00000520981_3517627_136619197 superimposed PDB: 4QGN of partner (ADI1). RMSD:2.6868
Å |
 |  |  |  |  |
| ADIPOR1_DAD1_ENST00000340990_ENST00000250498_202915566_23044133 superimposed PDB: 5LXG of partner (ADIPOR1). RMSD:0.8194
Å |
 |  |  |  |  |
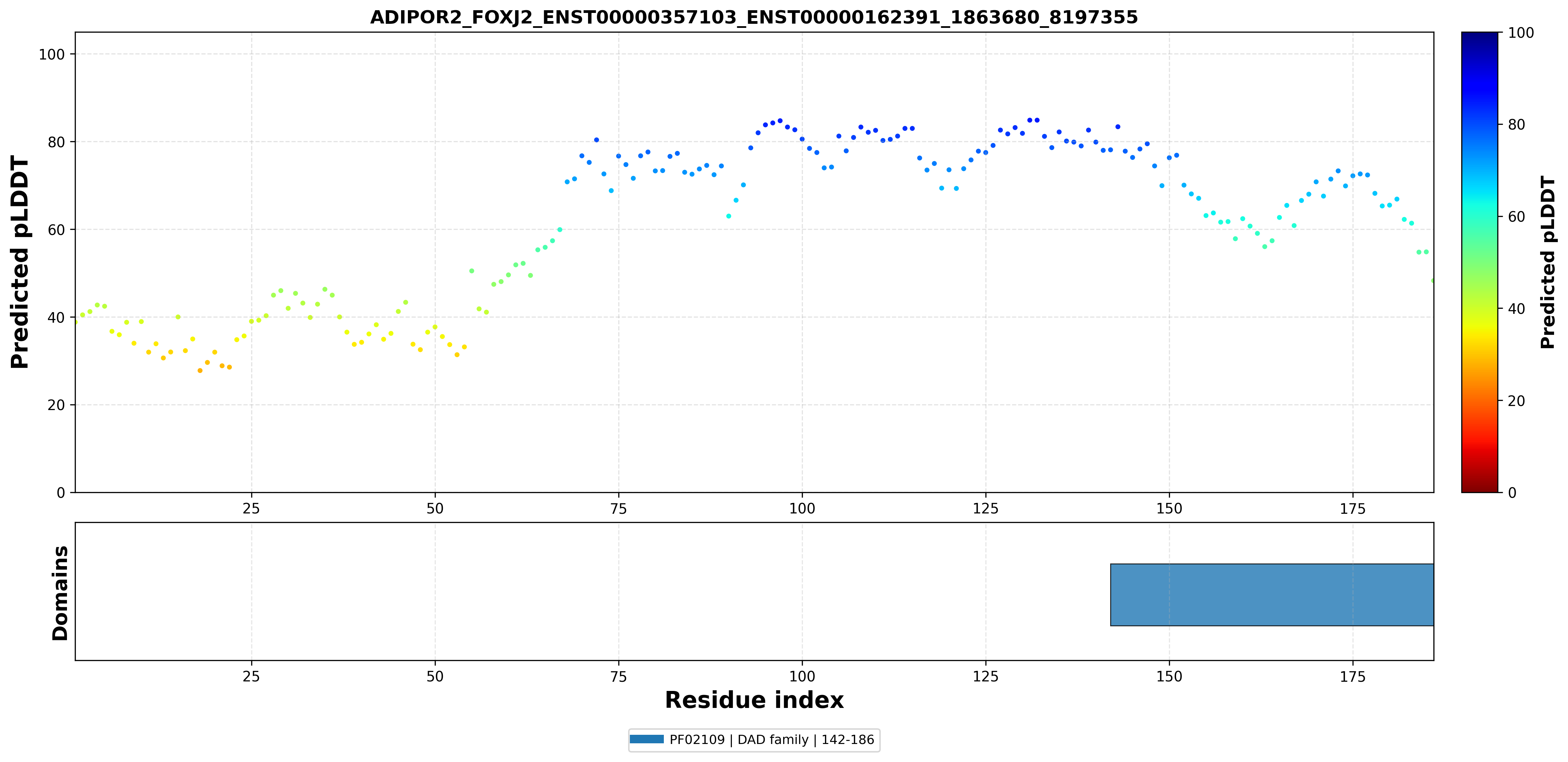
| ADIPOR2_FOXJ2_ENST00000357103_ENST00000162391_1863680_8197355 superimposed PDB: 5LX9 of partner (ADIPOR2). RMSD:2.7769
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000286621_ENST00000373867_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.1376
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000277705_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.8794
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000373868_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.6144
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000419214_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.8526
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000422313_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.8277
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000442566_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:2.1344
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000372734_ENST00000468840_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.9811
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000277705_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:2.09
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000373868_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:2.0763
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000419214_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.0759
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000422313_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.1014
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000442566_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:1.797
Å |
 |  |  |  |  |
| ADK_FAM13C_ENST00000539909_ENST00000468840_75984349_61062624 superimposed PDB: 4O1L of partner (ADK). RMSD:2.0194
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000286621_ENST00000372725_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3838
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000372734_ENST00000372714_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4314
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000372734_ENST00000372724_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4716
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000539909_ENST00000372714_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.402
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000539909_ENST00000372724_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4519
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000539909_ENST00000372725_76074503_76719727 superimposed PDB: 4O1L of partner (ADK). RMSD:3.2016
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000541550_ENST00000372714_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4201
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000541550_ENST00000372724_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4759
Å |
 |  |  |  |  |
| ADK_KAT6B_ENST00000541550_ENST00000372725_76074503_76719727 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.4769
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000286621_ENST00000404771_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:2.6612
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000372734_ENST00000286627_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:2.5321
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000372734_ENST00000372440_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:2.1004
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000372734_ENST00000406533_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:2.2451
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000539909_ENST00000286627_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:1.8472
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000539909_ENST00000372440_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:1.7463
Å |
 |  |  |  |  |
| ADK_KCNMA1_ENST00000539909_ENST00000406533_75984349_78778860 superimposed PDB: 4O1L of partner (ADK). RMSD:1.9756
Å |
 |  |  |  |  |
| ADK_VCL_ENST00000286621_ENST00000211998_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:2.4329
Å |
 |  | 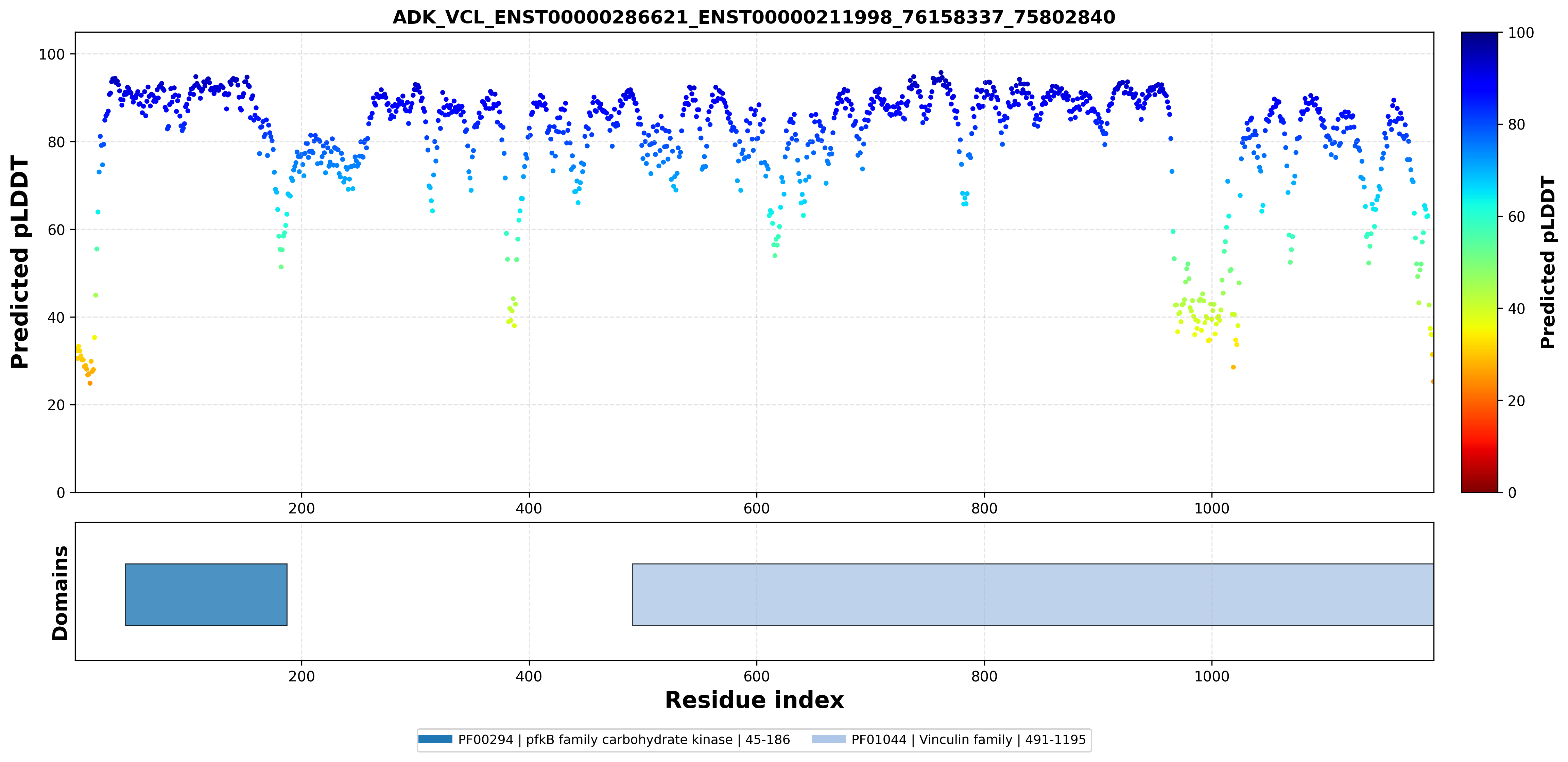 |  |  |
| ADK_VCL_ENST00000286621_ENST00000211998_76158337_75802840 superimposed PDB: 6UPW of partner (VCL). RMSD:1.662
Å |
| | | |  |
| ADK_VCL_ENST00000372734_ENST00000372755_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:2.4523
Å |
 |  | 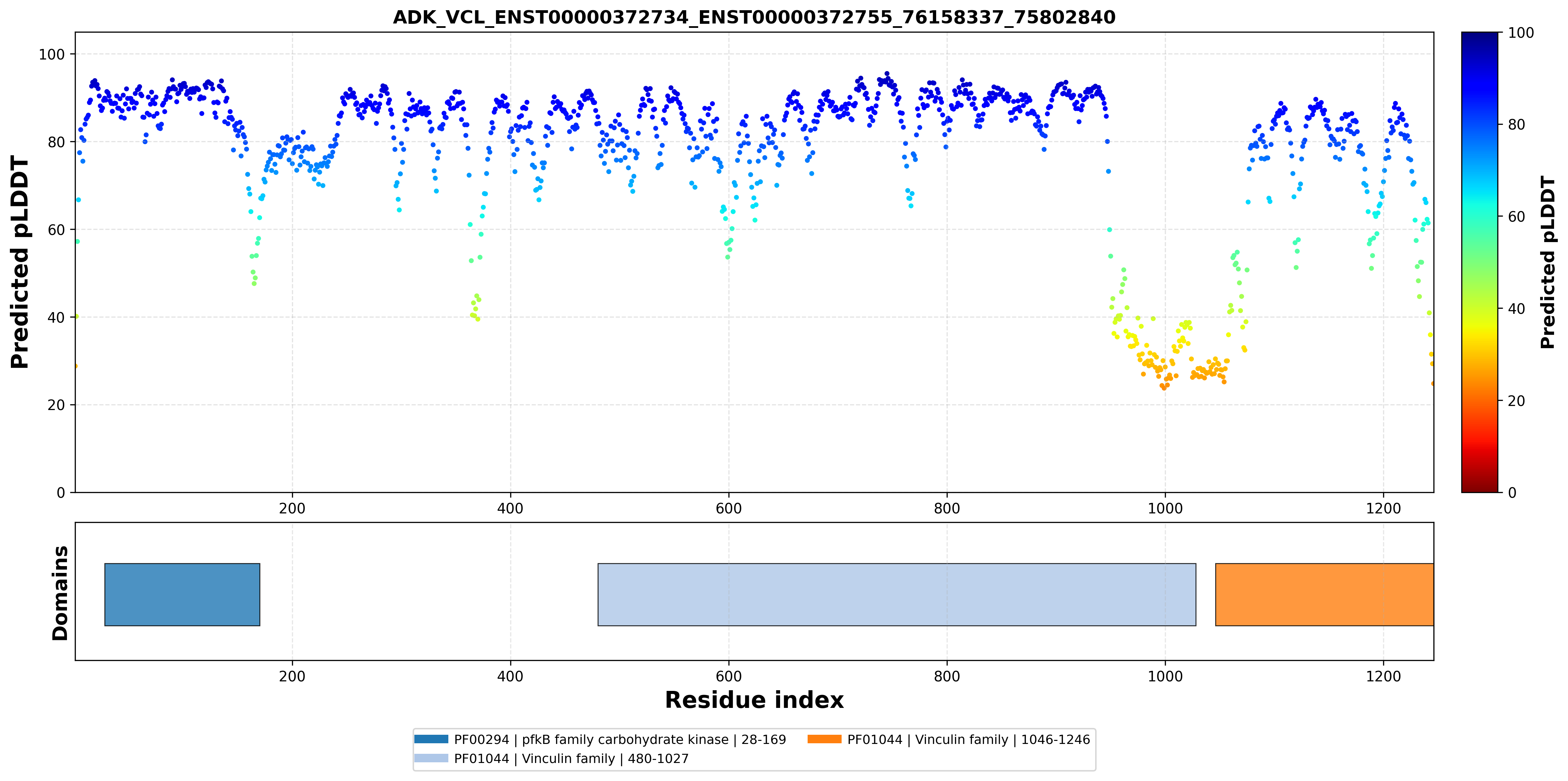 |  |  |
| ADK_VCL_ENST00000372734_ENST00000372755_76158337_75802840 superimposed PDB: 6UPW of partner (VCL). RMSD:1.8088
Å |
| | | |  |
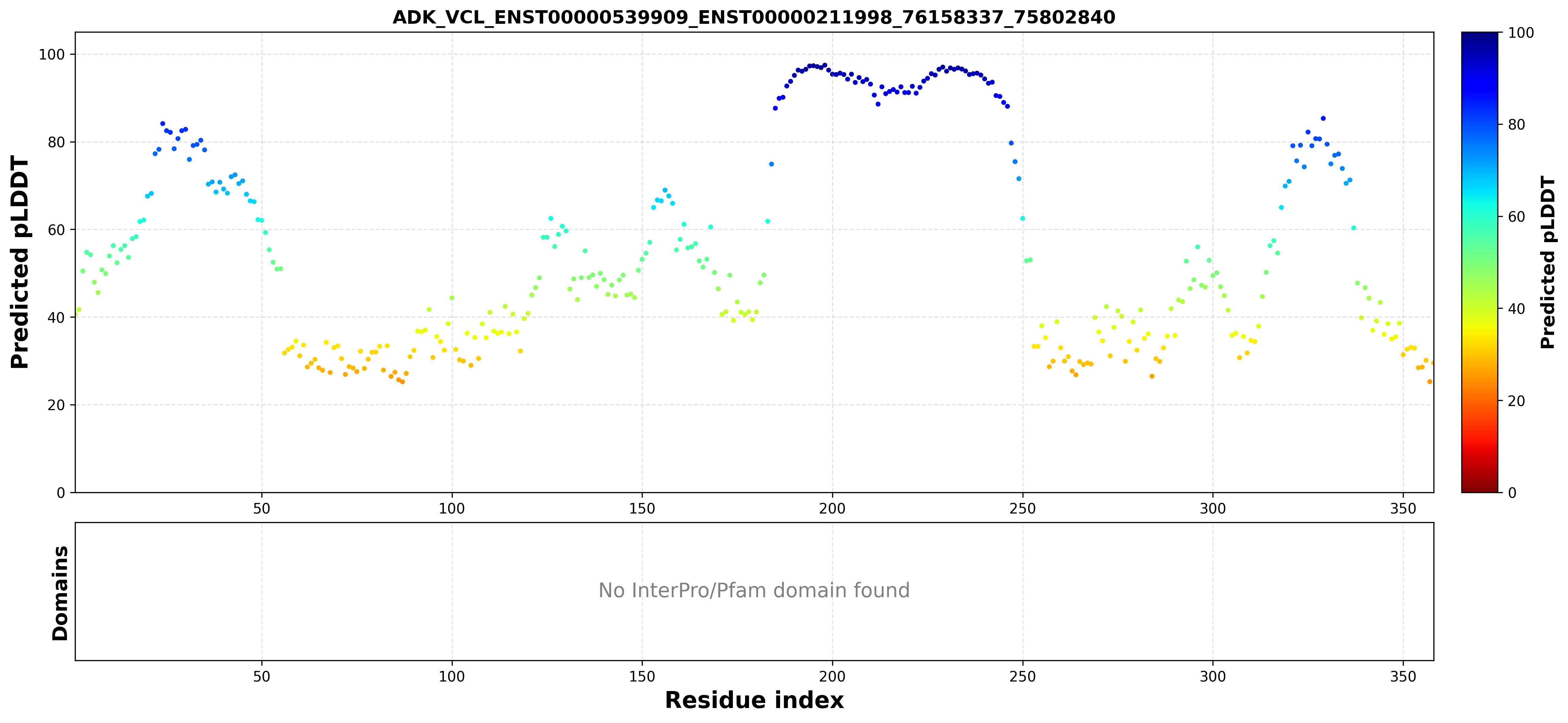
| ADK_VCL_ENST00000539909_ENST00000211998_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:1.824
Å |
 |  |  |  |  |
| ADK_VCL_ENST00000539909_ENST00000372755_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:2.5293
Å |
 |  | 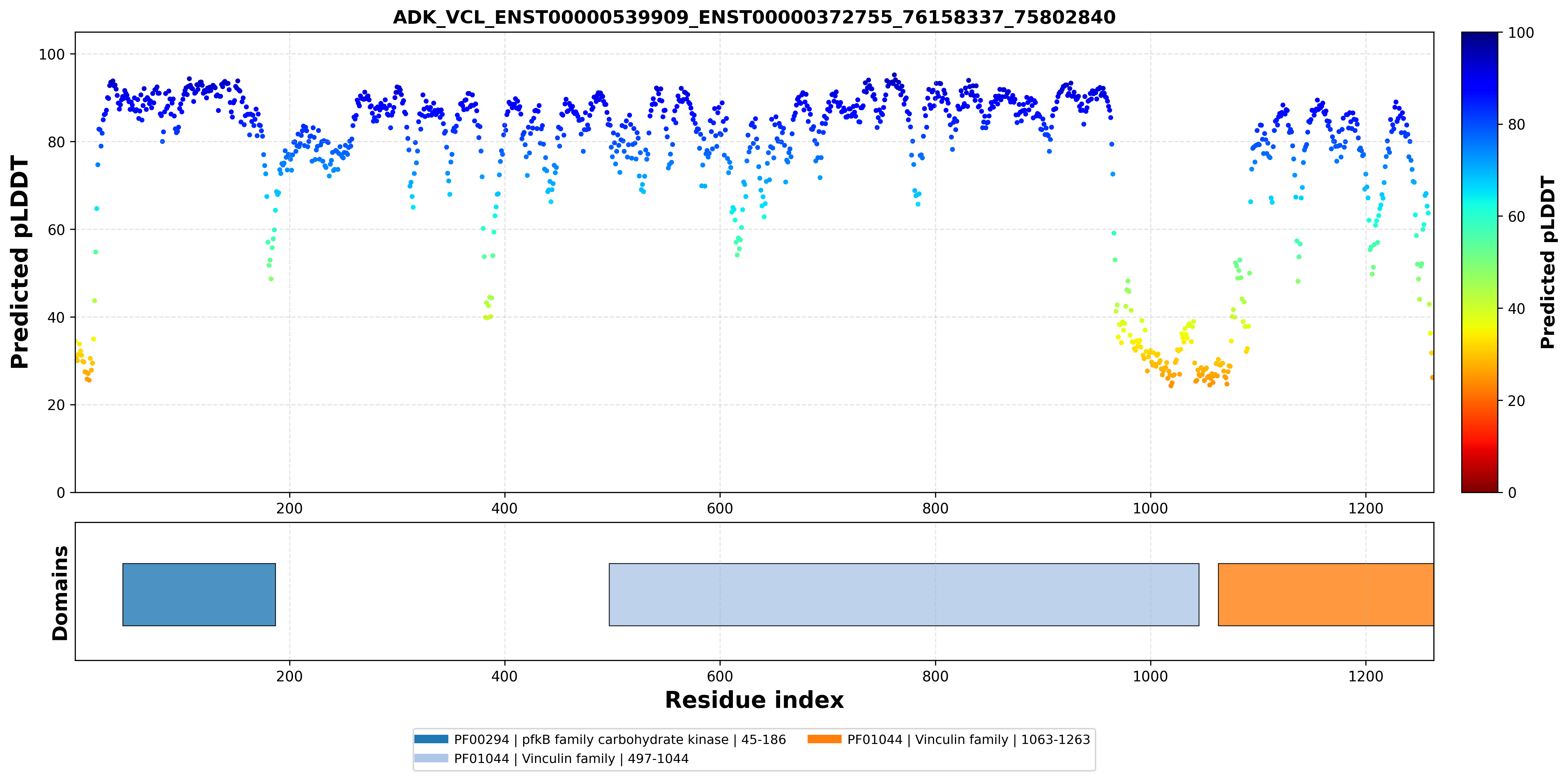 |  |  |
| ADK_VCL_ENST00000539909_ENST00000372755_76158337_75802840 superimposed PDB: 6UPW of partner (VCL). RMSD:1.7987
Å |
| | | |  |
| ADK_VCL_ENST00000541550_ENST00000211998_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:2.5337
Å |
 |  | 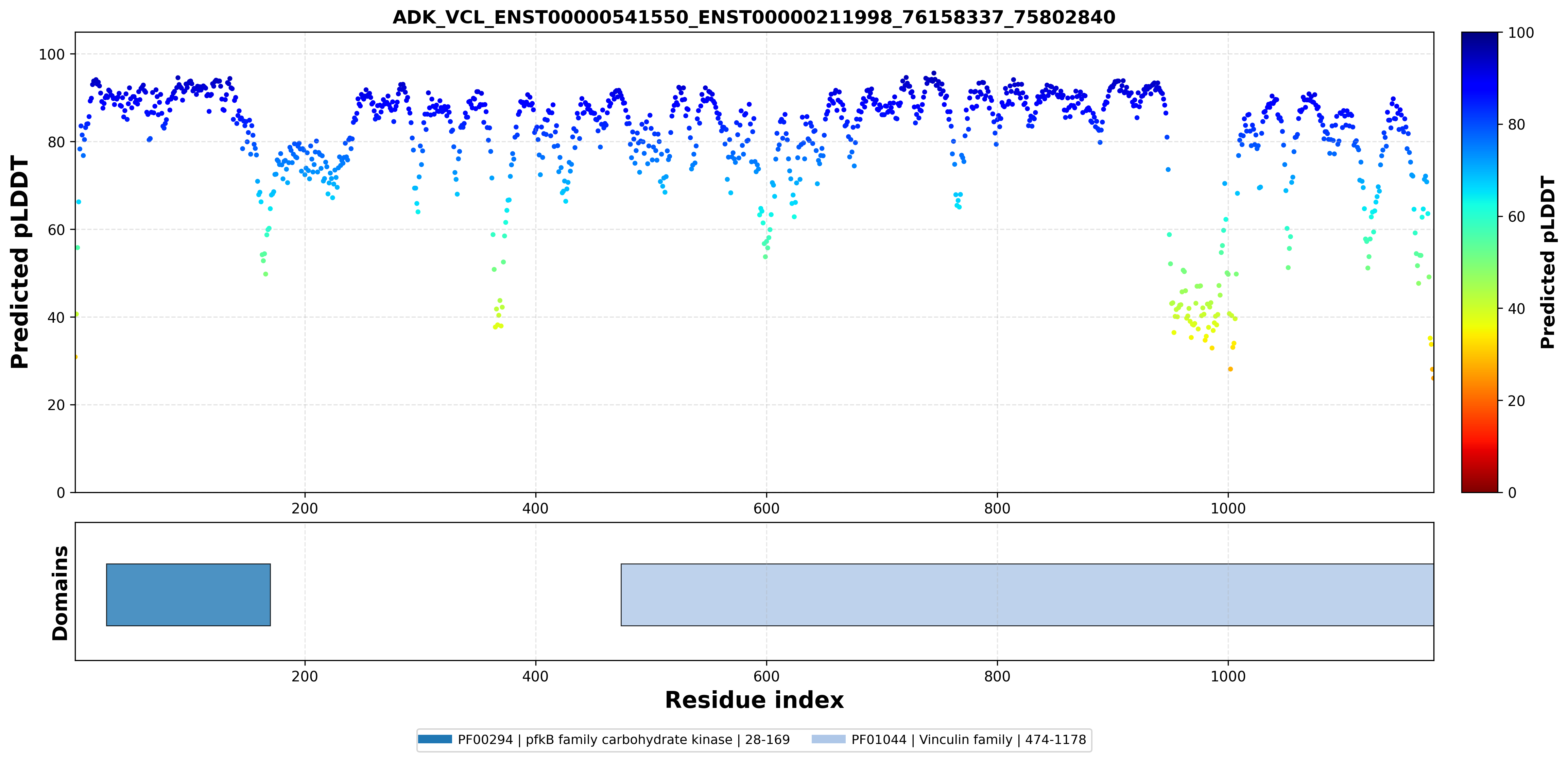 |  |  |
| ADK_VCL_ENST00000541550_ENST00000211998_76158337_75802840 superimposed PDB: 6UPW of partner (VCL). RMSD:1.6724
Å |
| | | |  |
| ADK_VCL_ENST00000541550_ENST00000372755_76158337_75802840 superimposed PDB: 4O1L of partner (ADK). RMSD:3.0385
Å |
 |  | 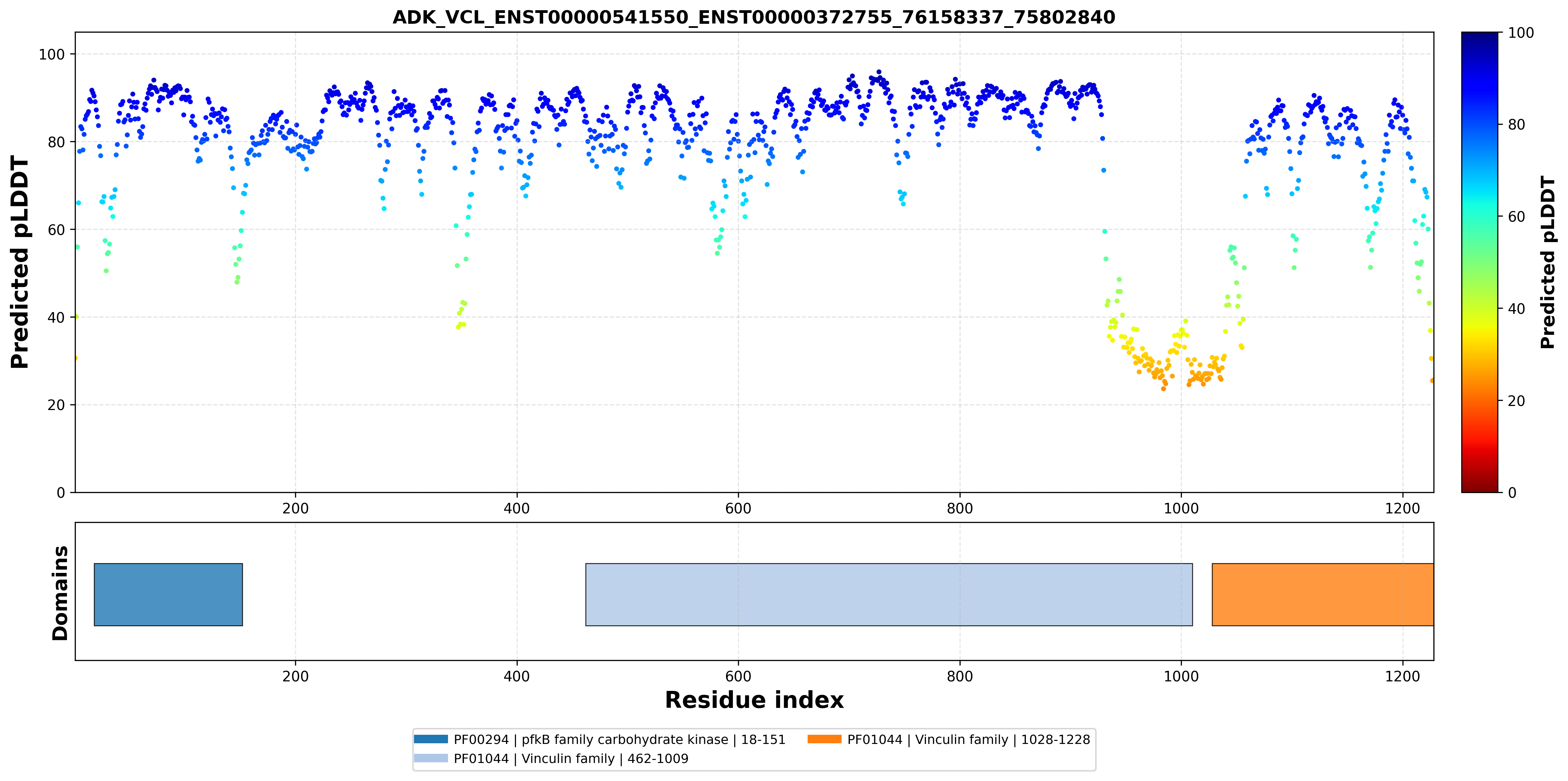 |  |  |
| ADK_VCL_ENST00000541550_ENST00000372755_76158337_75802840 superimposed PDB: 6UPW of partner (VCL). RMSD:1.8047
Å |
| | | |  |
| ADORA2B_PIGL_ENST00000304222_ENST00000225609_15848897_16203201 superimposed PDB: 8HDO of partner (ADORA2B). RMSD:1.0815
Å |
 |  |  |  |  |
| ADORA2B_PIGL_ENST00000304222_ENST00000395844_15848897_16203201 superimposed PDB: 8HDO of partner (ADORA2B). RMSD:0.6051
Å |
 |  |  |  |  |
| ADRBK1_IQGAP1_ENST00000526285_ENST00000268182_67034283_90969341 superimposed PDB: 3FAY of partner (IQGAP1). RMSD:1.2015
Å |
 |  | 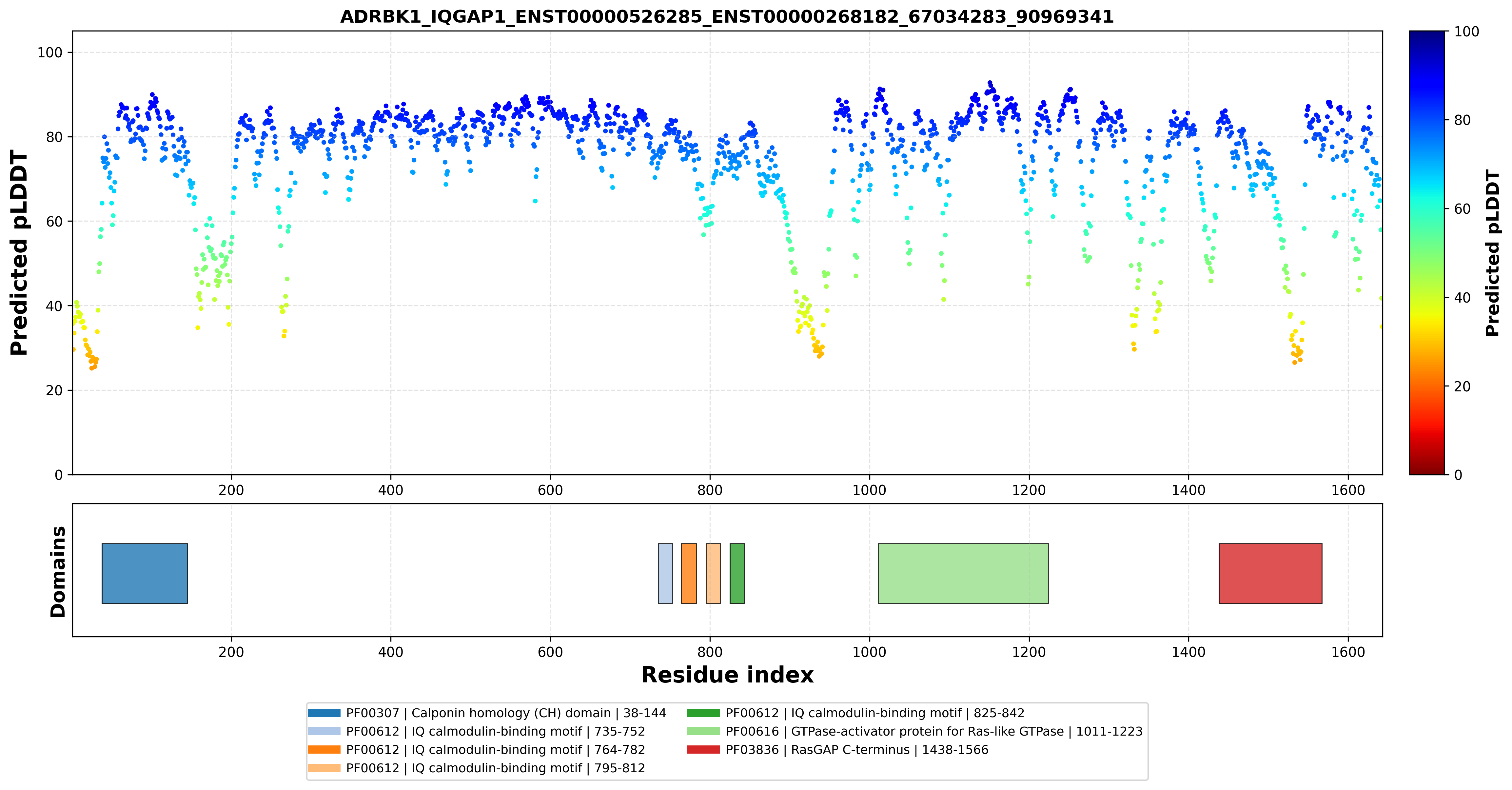 |  |  |
| ADRBK2_SF3A1_ENST00000324198_ENST00000439242_26040632_30749061 superimposed PDB: 7EVO of partner (SF3A1). RMSD:1.8947
Å |
 |  |  |  |  |
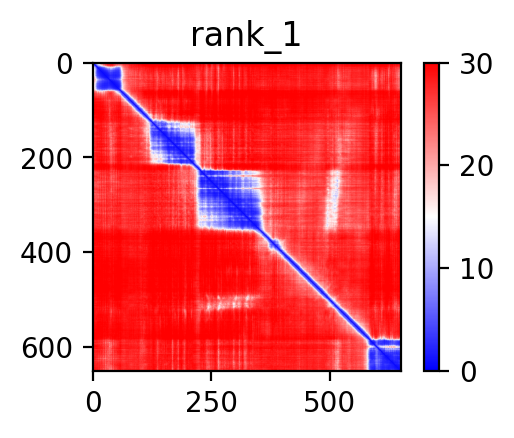
| AFAP1_ABLIM2_ENST00000358461_ENST00000296372_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.3275
Å |
 | 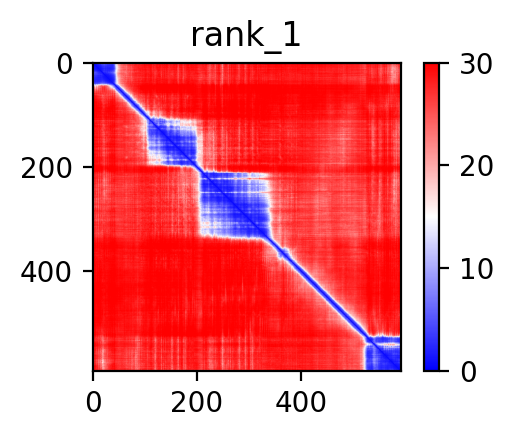 | 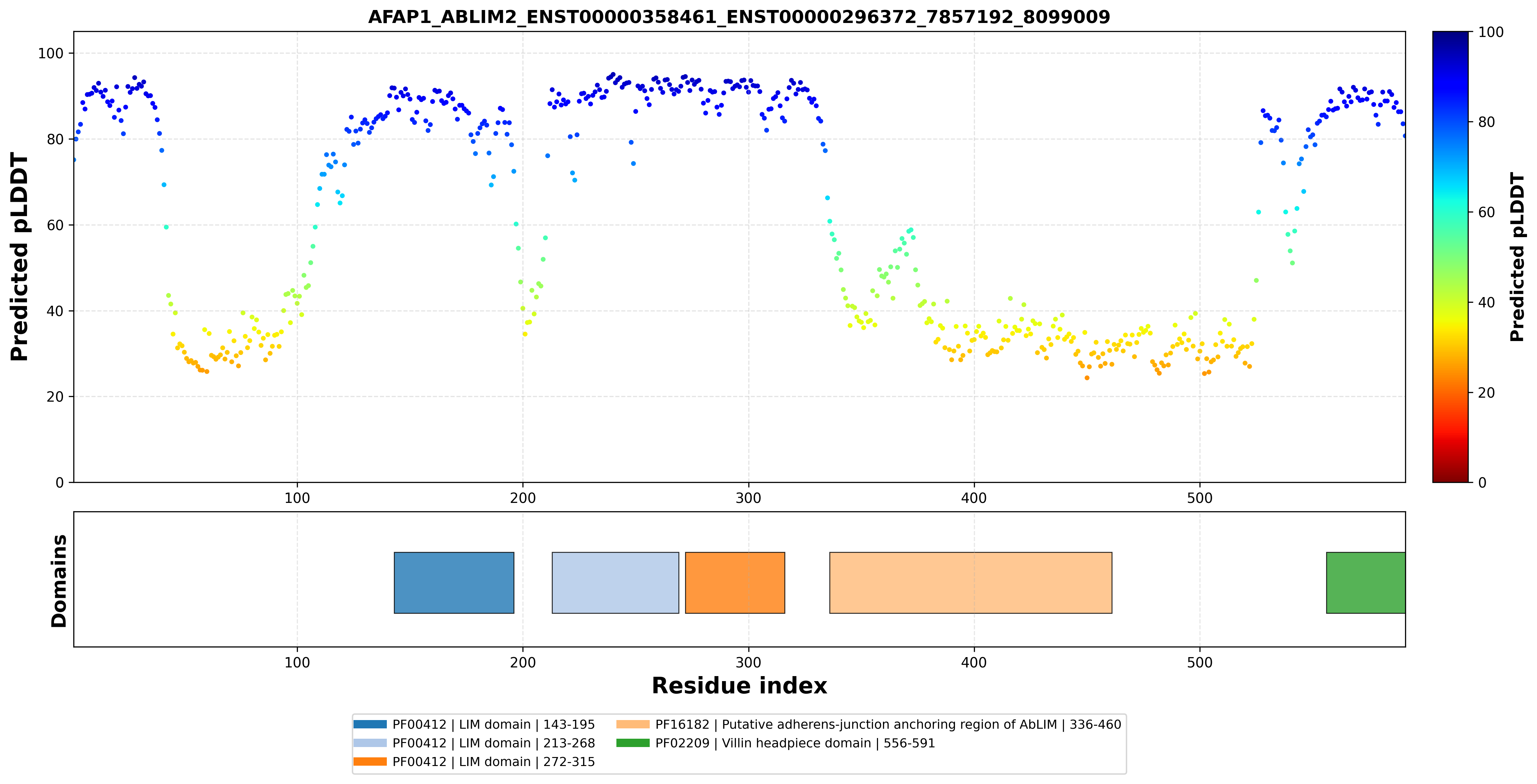 |  |  |
| AFAP1_ABLIM2_ENST00000358461_ENST00000361737_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.4161
Å |
 |  | 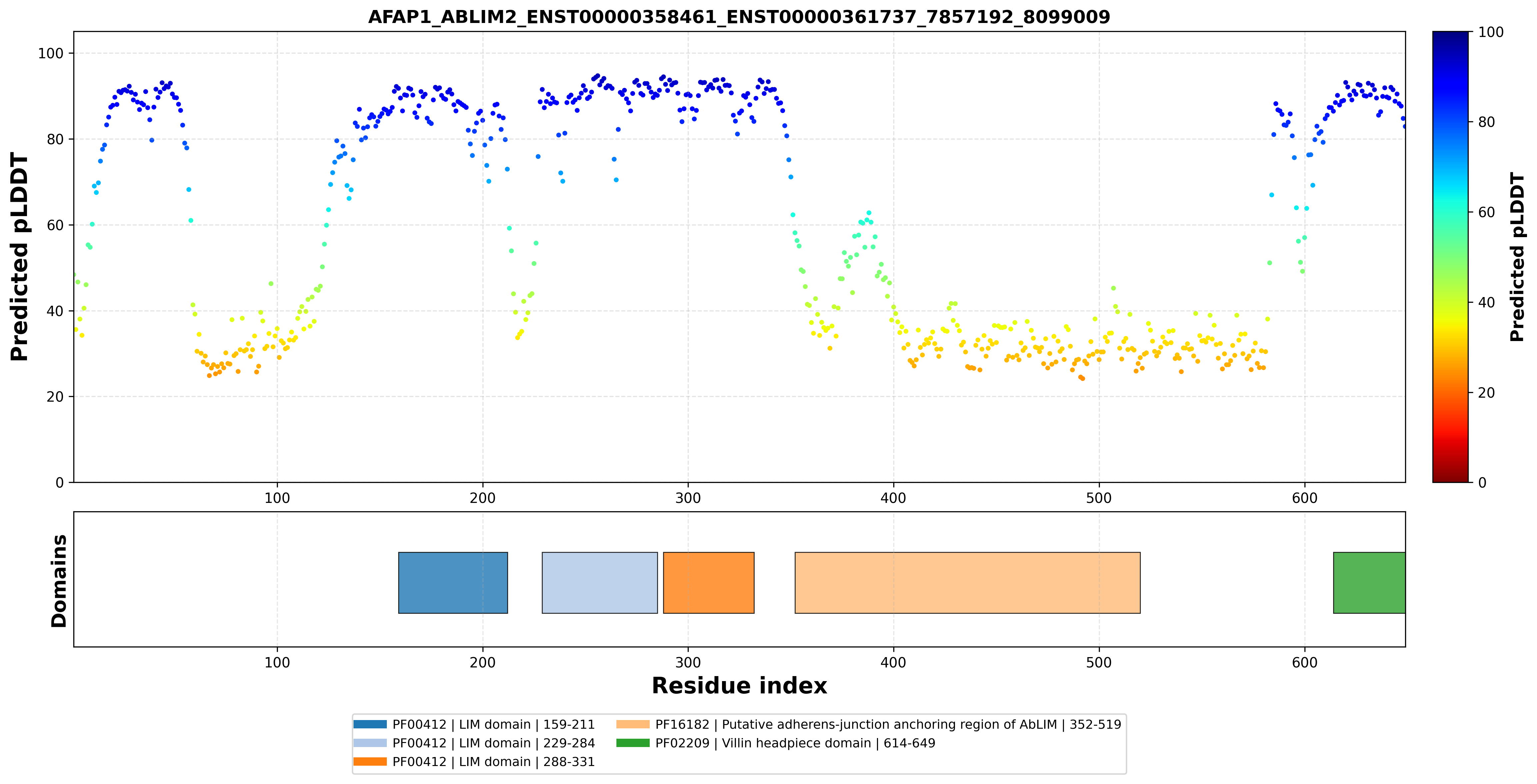 |  |  |
| AFAP1_ABLIM2_ENST00000358461_ENST00000545242_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.2664
Å |
 | 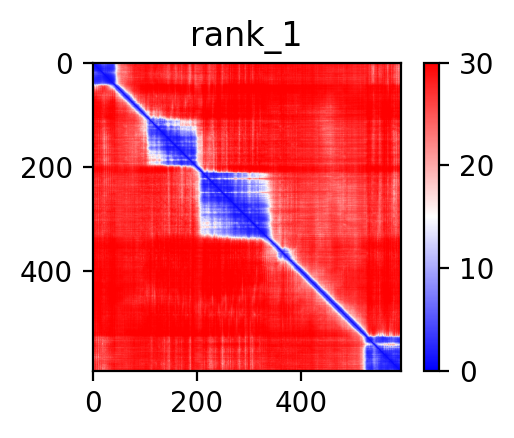 | 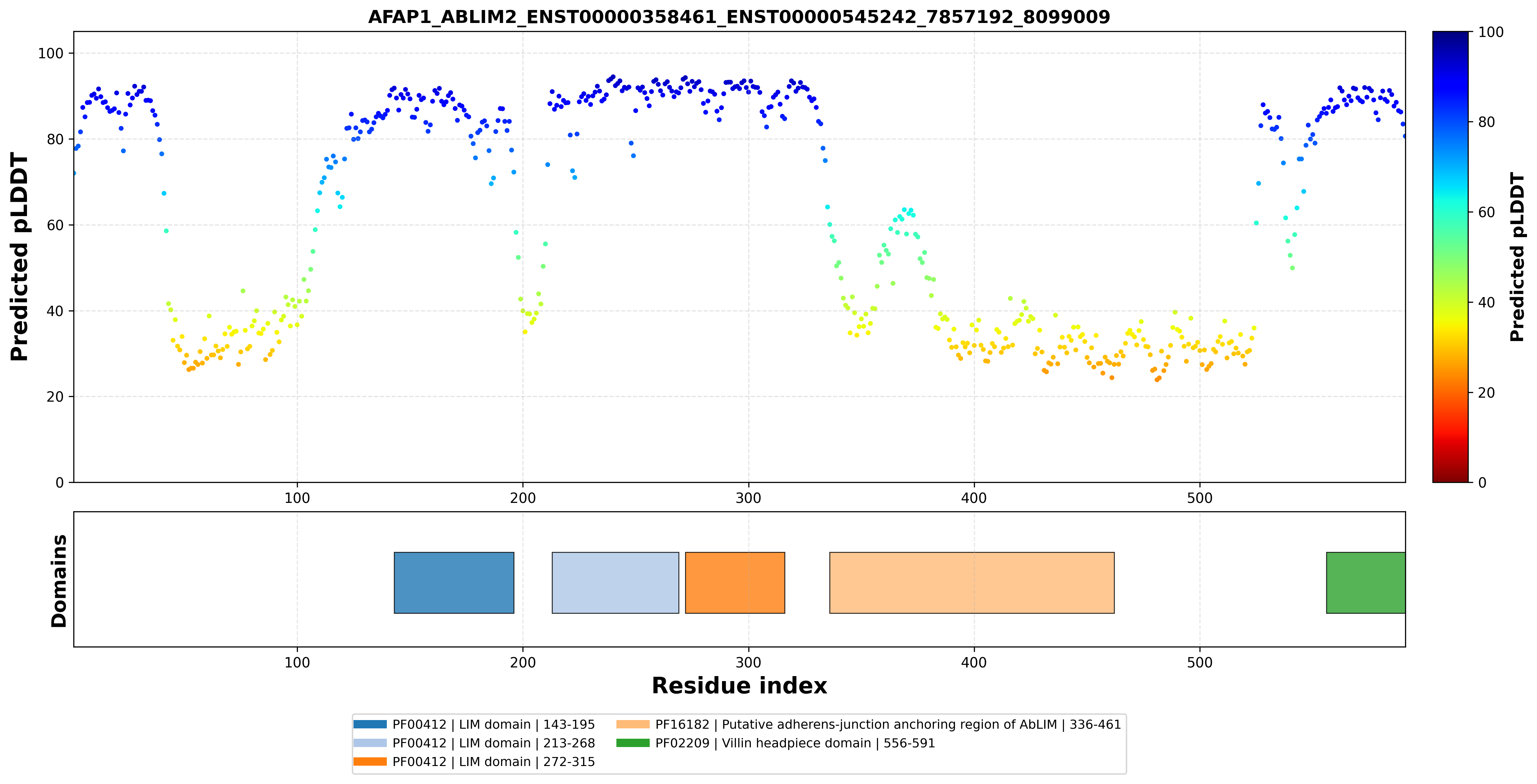 |  |  |
| AFAP1_ABLIM2_ENST00000358461_ENST00000546334_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.383
Å |
 | 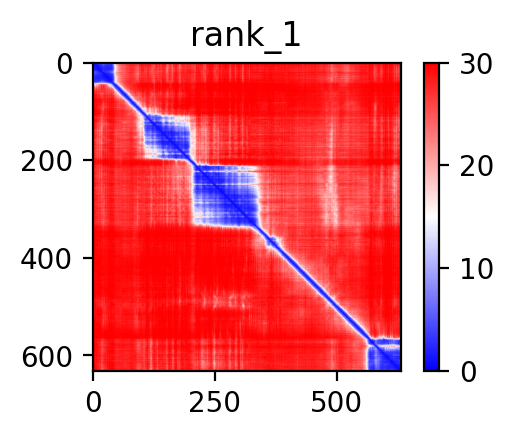 | 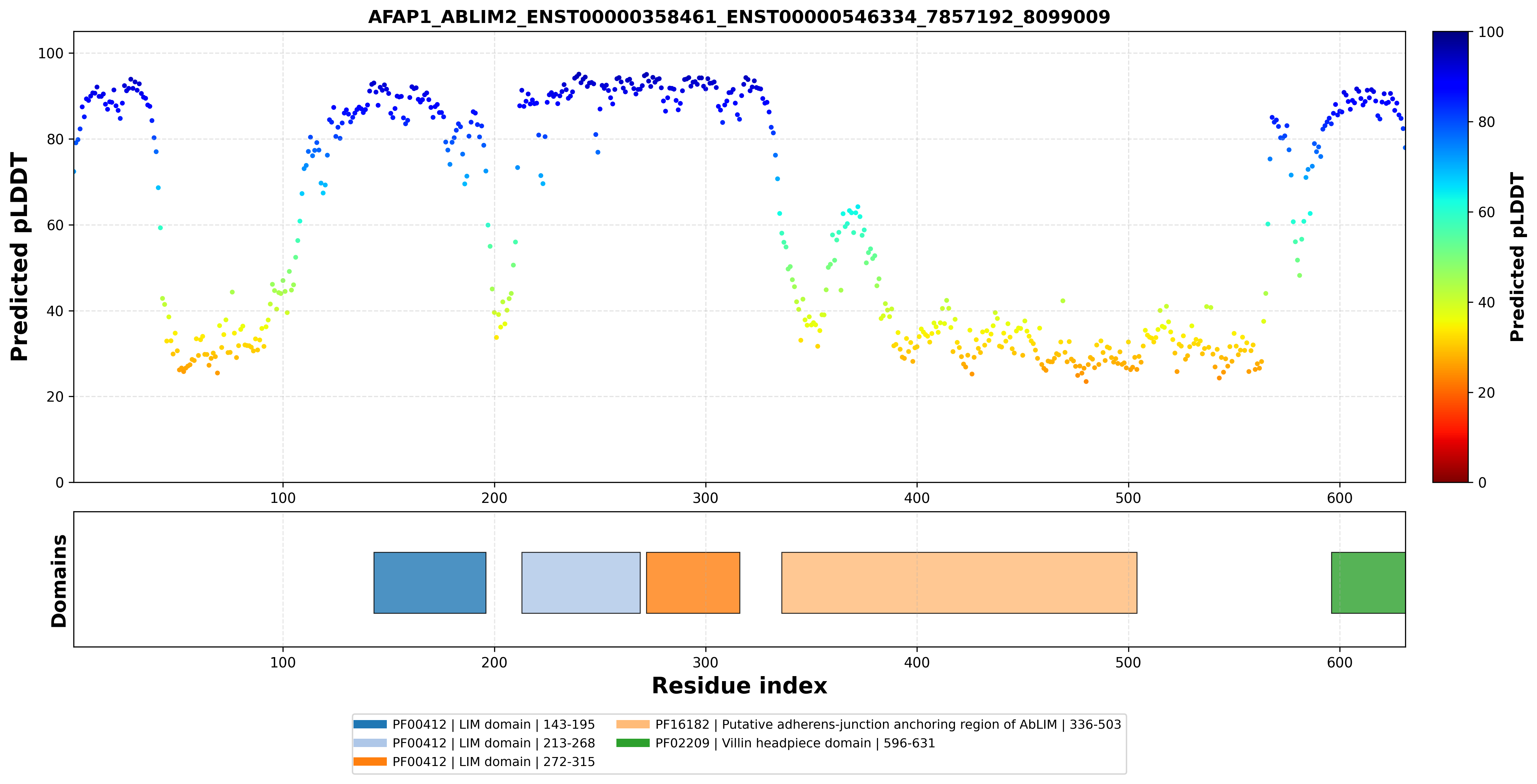 |  |  |
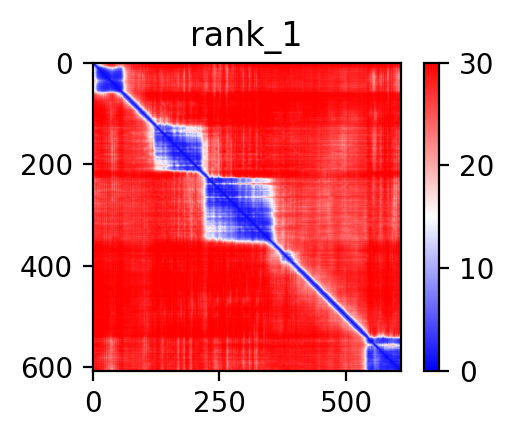
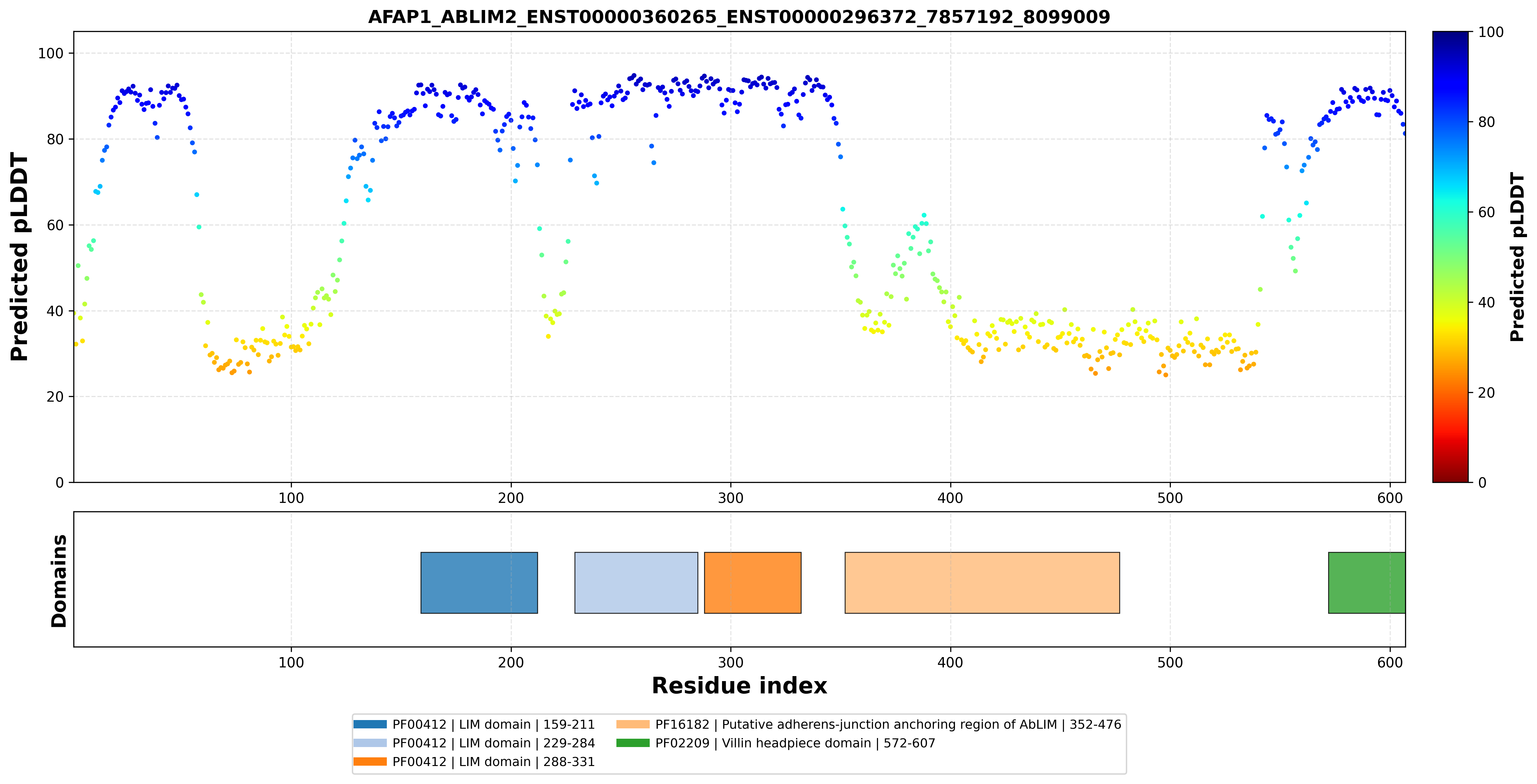
| AFAP1_ABLIM2_ENST00000360265_ENST00000296372_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.2531
Å |
 |  |  |  |  |
| AFAP1_ABLIM2_ENST00000360265_ENST00000545242_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.3131
Å |
 | 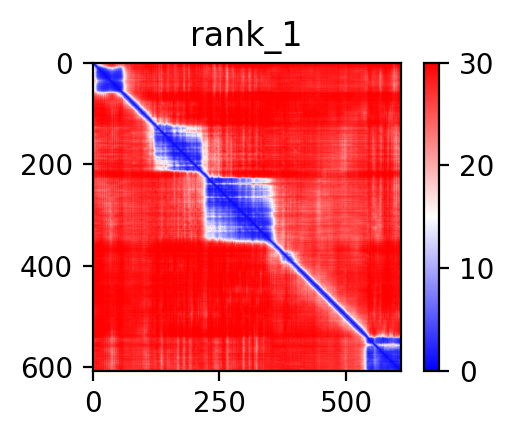 | 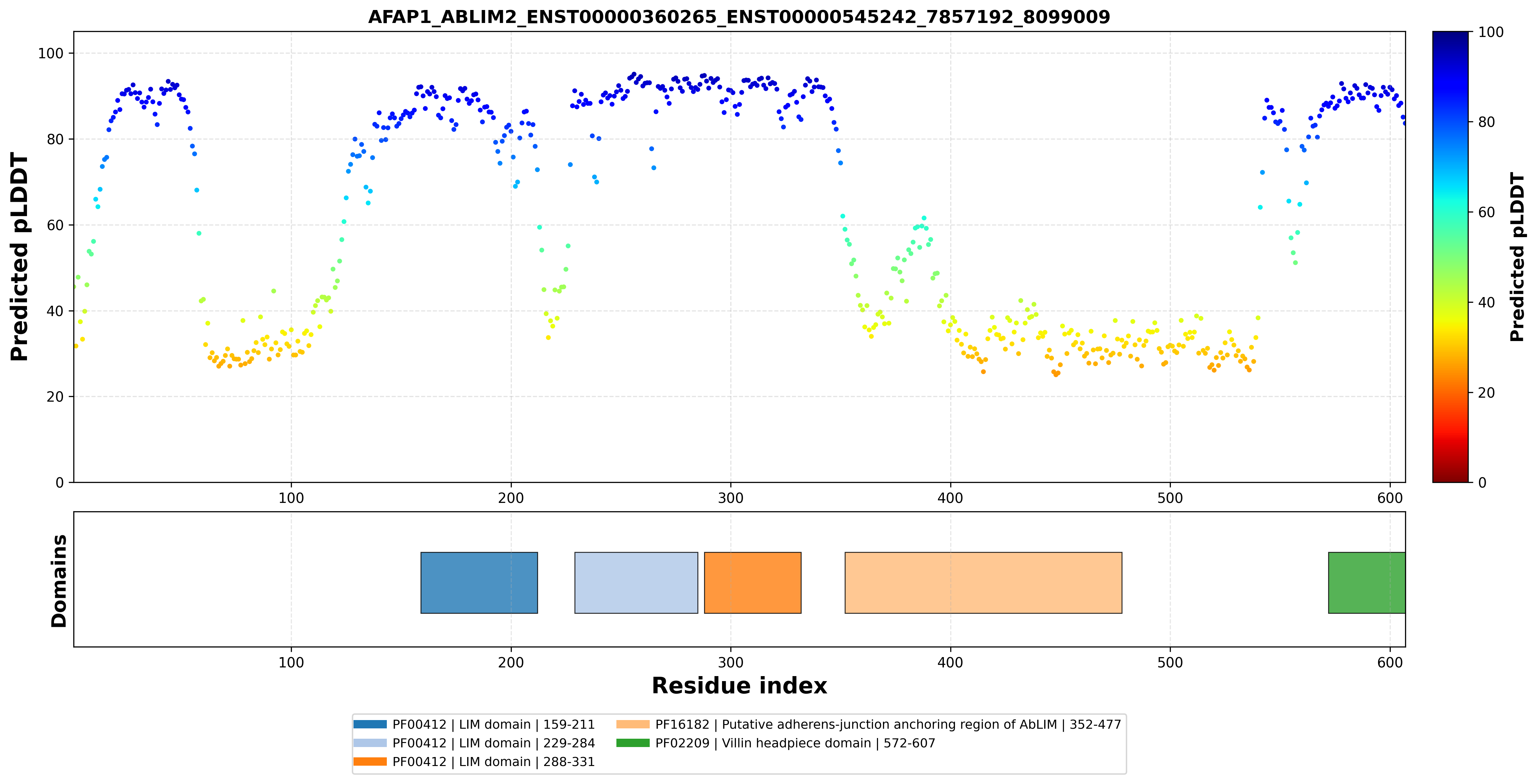 |  |  |
| AFAP1_ABLIM2_ENST00000360265_ENST00000546334_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.4248
Å |
 | 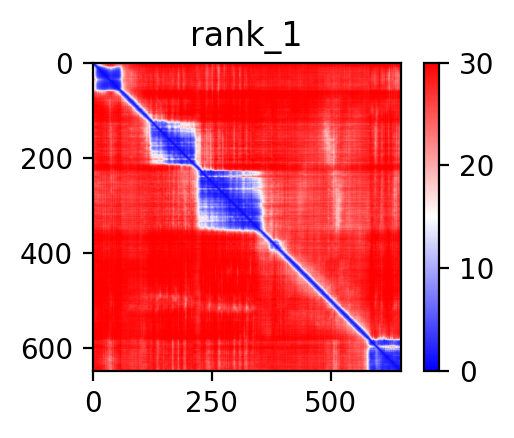 | 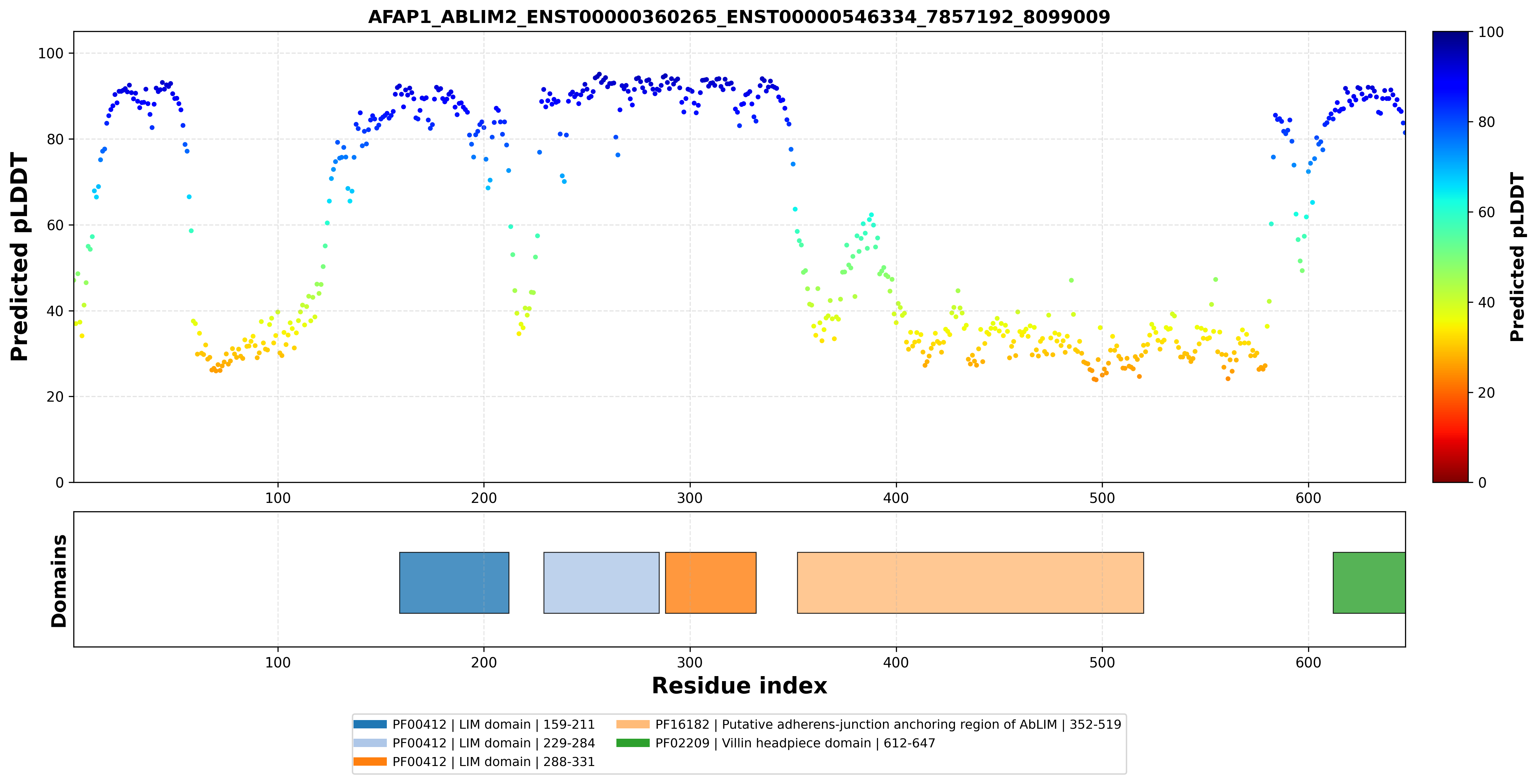 |  |  |
| AFAP1_ABLIM2_ENST00000420658_ENST00000361737_7857192_8099009 superimposed PDB: 1V6G of partner (ABLIM2). RMSD:1.4012
Å |
 |  | 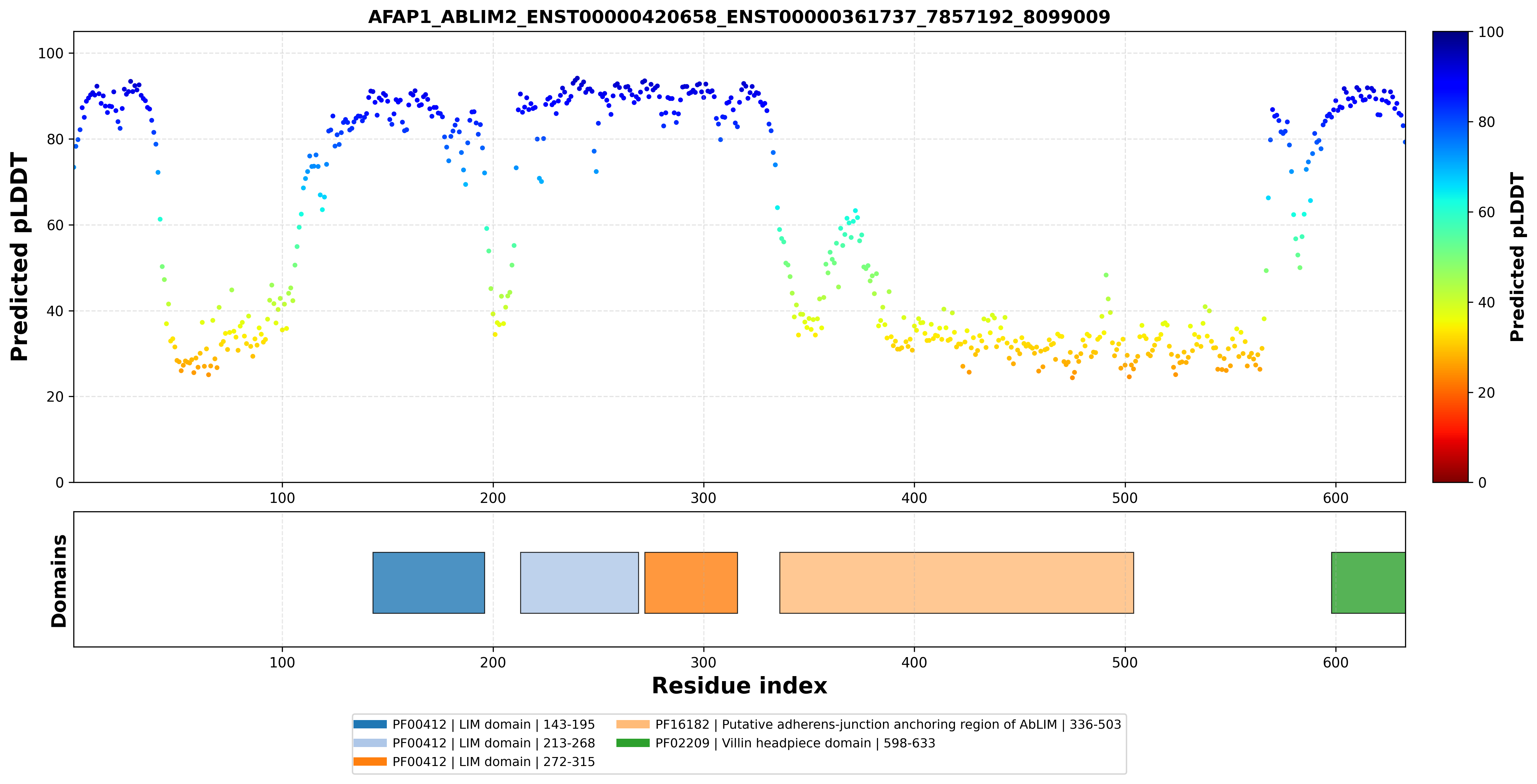 |  |  |
| AFAP1_NTRK2_ENST00000358461_ENST00000376213_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8119
Å |
 |  | 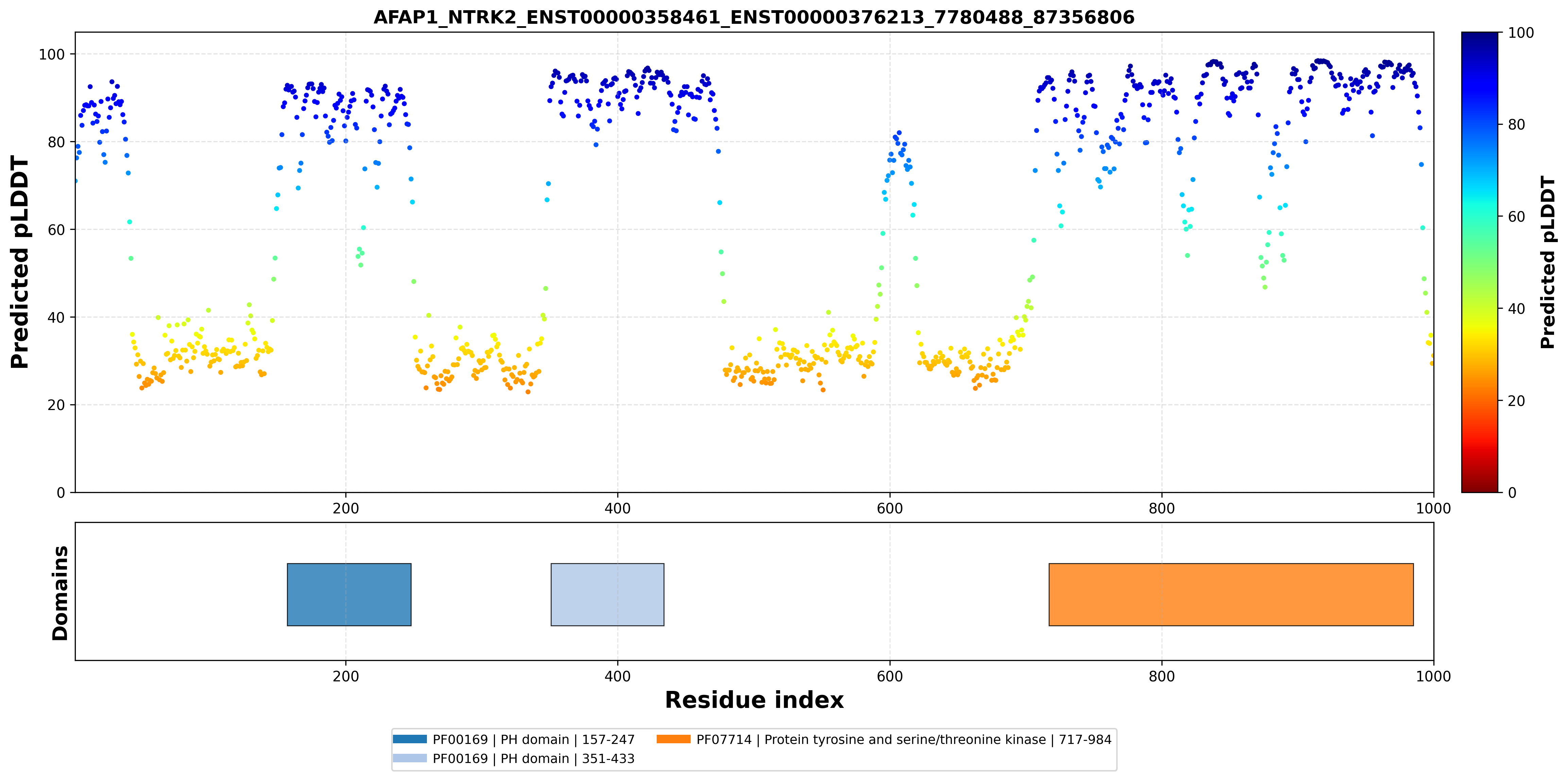 |  |  |
| AFAP1_NTRK2_ENST00000358461_ENST00000376213_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8124
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000358461_ENST00000395882_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7736
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000358461_ENST00000395882_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8122
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000360265_ENST00000376213_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8123
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000360265_ENST00000376213_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8204
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000360265_ENST00000395882_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8113
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000360265_ENST00000395882_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8048
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000420658_ENST00000376213_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.783
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000420658_ENST00000376213_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8421
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000420658_ENST00000395882_7780488_87356806 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8049
Å |
 |  |  |  |  |
| AFAP1_NTRK2_ENST00000420658_ENST00000395882_7780488_87359887 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8135
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000354520_87968746_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:2.0485
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000354520_87968746_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.6742
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000354520_88005316_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8422
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000389506_87968746_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8643
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000389506_87968746_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9757
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000389506_87968746_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.4303
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000389506_88005316_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9717
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000534358_87968746_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9282
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000534358_87968746_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7976
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000307808_ENST00000534358_88005316_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8292
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000354520_87968746_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7093
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000354520_87968746_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7031
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000354520_88005316_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8882
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000389506_87968746_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9114
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000389506_87968746_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9548
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000389506_87968746_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.634
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000389506_88005316_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:2.1498
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000534358_87968746_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8012
Å |
 |  |  |  |  |
| AFF1_KMT2A_ENST00000395146_ENST00000534358_87968746_118359328__from_GenBank_48 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8615
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000307808_ENST00000427191_88048855_87666118 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5987
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000307808_ENST00000436978_88046295_87701554 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5094
Å |
 |  | 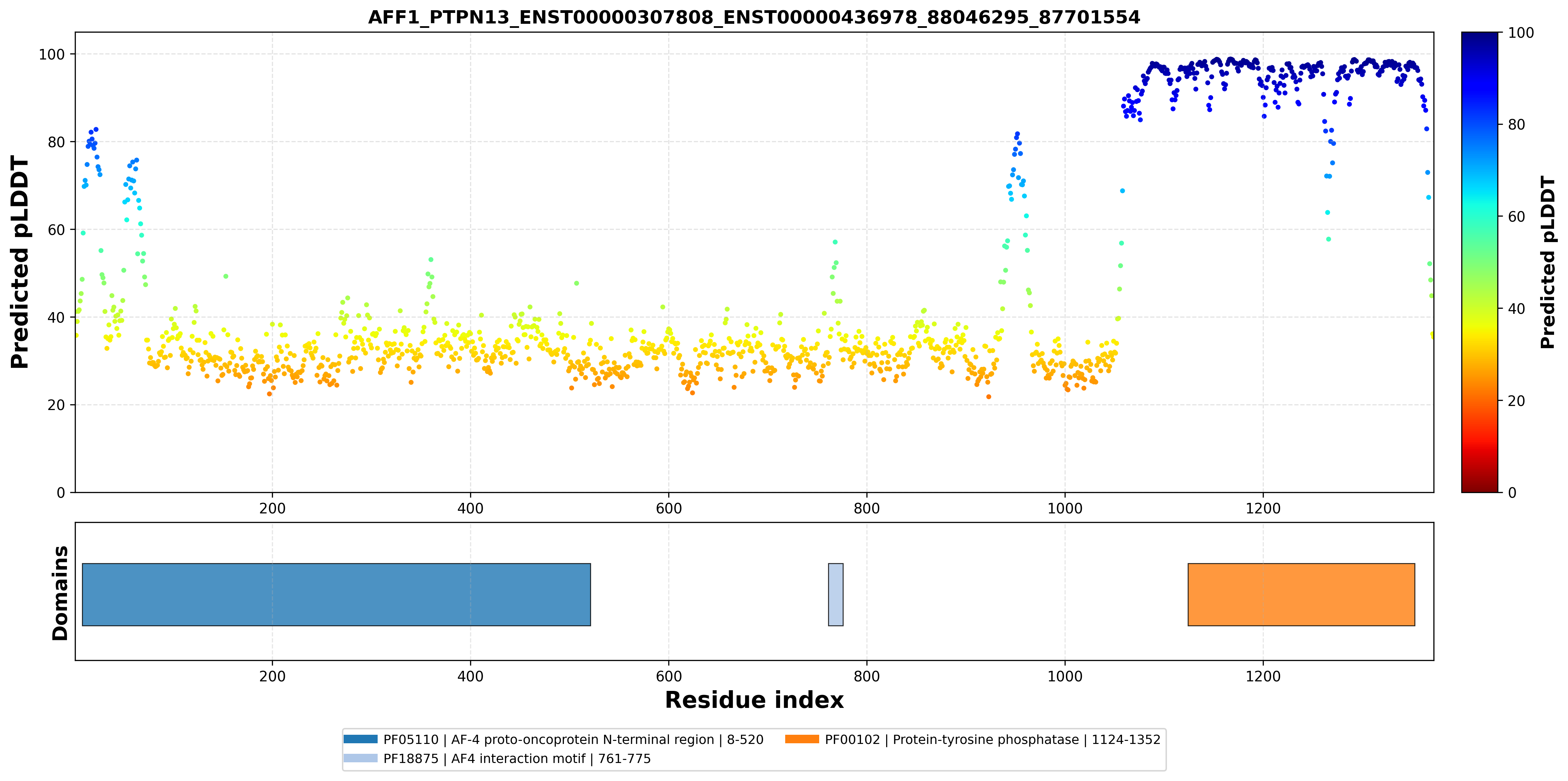 |  |  |
| AFF1_PTPN13_ENST00000307808_ENST00000436978_88048855_87666118 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5731
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000395146_ENST00000436978_88046295_87701554 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5104
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000395146_ENST00000436978_88048855_87666118 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.6299
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000544085_ENST00000427191_88048855_87666118 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5754
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000544085_ENST00000436978_88046295_87701554 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.5019
Å |
 |  |  |  |  |
| AFF1_PTPN13_ENST00000544085_ENST00000436978_88048855_87666118 superimposed PDB: 1WCH of partner (PTPN13). RMSD:0.6143
Å |
 |  |  |  |  |
| AFF1_UBR5_ENST00000307808_ENST00000220959_87928576_103373854 superimposed PDB: 8E0Q of partner (UBR5). RMSD:2.9667
Å |
 |  |  |  |  |
| AFF3_HDAC5_ENST00000409236_ENST00000393622_100623093_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.274
Å |
 |  |  |  |  |
| AFF3_HDAC5_ENST00000409236_ENST00000586802_100623093_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2684
Å |
 |  |  |  |  |
| AFG3L2_TUBB2A_ENST00000269143_ENST00000489942_12328942_3157760 superimposed PDB: 6NYY of partner (AFG3L2). RMSD:2.6982
Å |
 |  |  |  |  |
| AFTPH_THRB_ENST00000487769_ENST00000356447_64812679_24193981 superimposed PDB: 7WMH of partner (THRB). RMSD:0.4817
Å |
 |  | 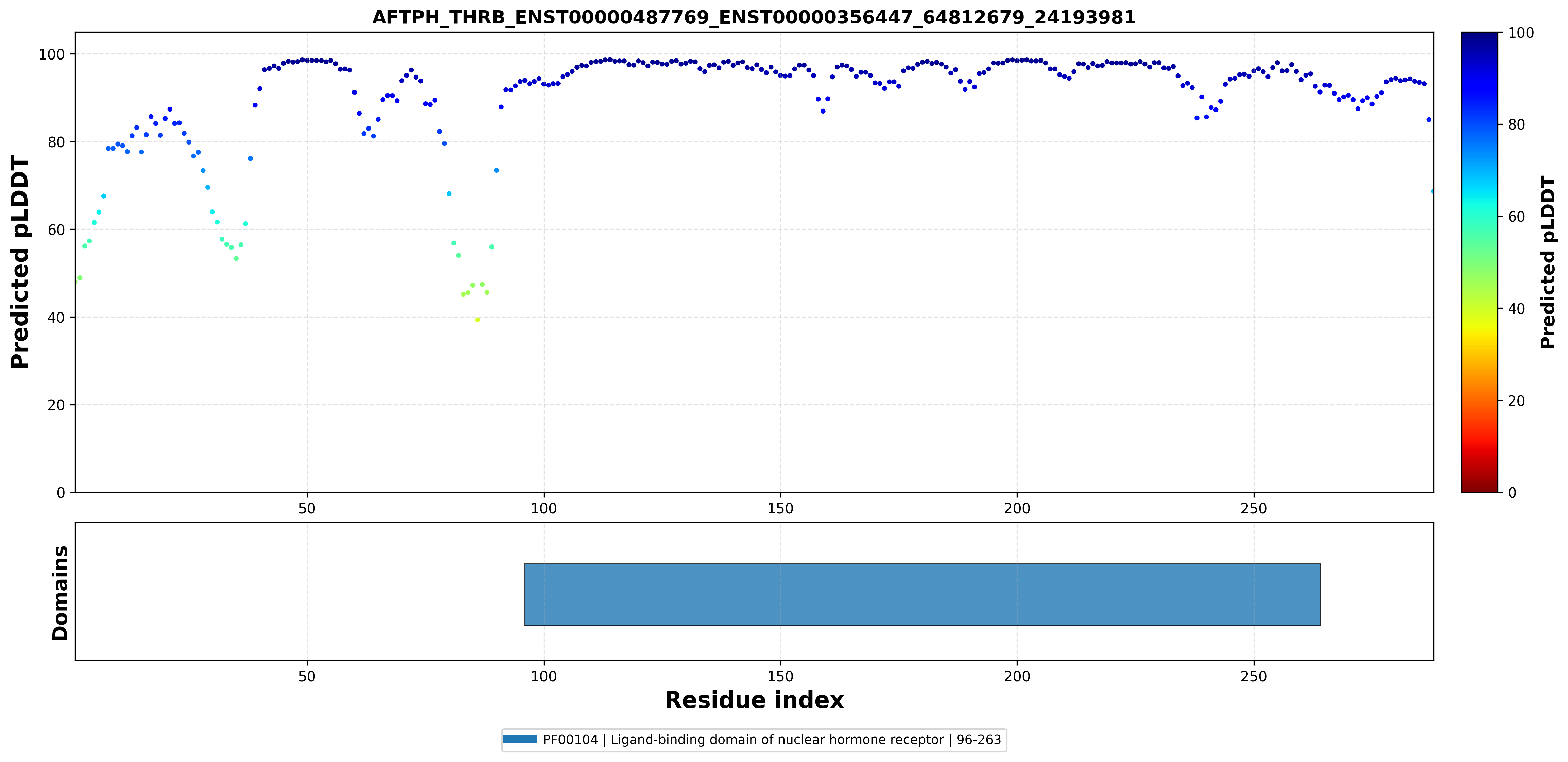 |  |  |
| AGAP1_HMGN1_ENST00000336665_ENST00000380748_236715975_40717200 superimposed PDB: 9UVL of partner (AGAP1). RMSD:0.3629
Å |
 |  |  |  |  |
| AGAP1_HMGN1_ENST00000336665_ENST00000380749_236715975_40717200 superimposed PDB: 9UVL of partner (AGAP1). RMSD:0.389
Å |
 |  |  |  |  |
| AGAP1_HMGN1_ENST00000409538_ENST00000380748_236715975_40717200 superimposed PDB: 9UVL of partner (AGAP1). RMSD:0.4152
Å |
 |  |  |  |  |
| AGAP1_HMGN1_ENST00000428334_ENST00000380748_236715975_40717200 superimposed PDB: 9UVL of partner (AGAP1). RMSD:0.6396
Å |
 |  |  |  |  |
| AGAP2_RAB21_ENST00000257897_ENST00000261263_58123421_72179310 superimposed PDB: 1Z08 of partner (RAB21). RMSD:2.3117
Å |
 |  |  |  |  |
| AGAP2_RAB21_ENST00000547588_ENST00000261263_58123421_72179310 superimposed PDB: 2RLO of partner (AGAP2). RMSD:1.4094
Å |
 |  |  |  |  |
| AGAP2_RAB21_ENST00000547588_ENST00000261263_58123421_72179310 superimposed PDB: 1Z08 of partner (RAB21). RMSD:1.1046
Å |
| | | |  |
| AGBL4_SMYD3_ENST00000371839_ENST00000490107_49511255_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8358
Å |
 |  |  |  |  |
| AGFG1_CCDC169_ENST00000409315_ENST00000239860_228356356_36822819 superimposed PDB: 2OLM of partner (AGFG1). RMSD:0.4249
Å |
 |  |  |  |  |
| AGFG1_CCDC169_ENST00000409315_ENST00000379862_228356356_36822819 superimposed PDB: 2OLM of partner (AGFG1). RMSD:0.5402
Å |
 |  |  |  |  |
| AGFG1_CCDC169_ENST00000409979_ENST00000239860_228356356_36822819 superimposed PDB: 2OLM of partner (AGFG1). RMSD:0.5121
Å |
 |  |  |  |  |
| AGFG1_CCDC169_ENST00000409979_ENST00000379862_228356356_36822819 superimposed PDB: 2OLM of partner (AGFG1). RMSD:0.5984
Å |
 |  |  |  |  |
| AGGF1_RAF1_ENST00000312916_ENST00000442415_76335544_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.056
Å |
 |  |  |  |  |
| AGO2_DDX5_ENST00000220592_ENST00000450599_141595217_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.6819
Å |
 | 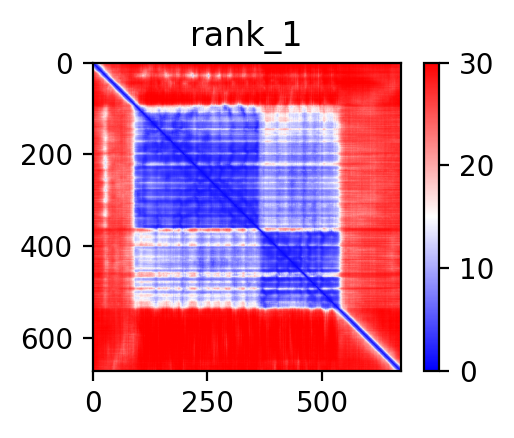 | 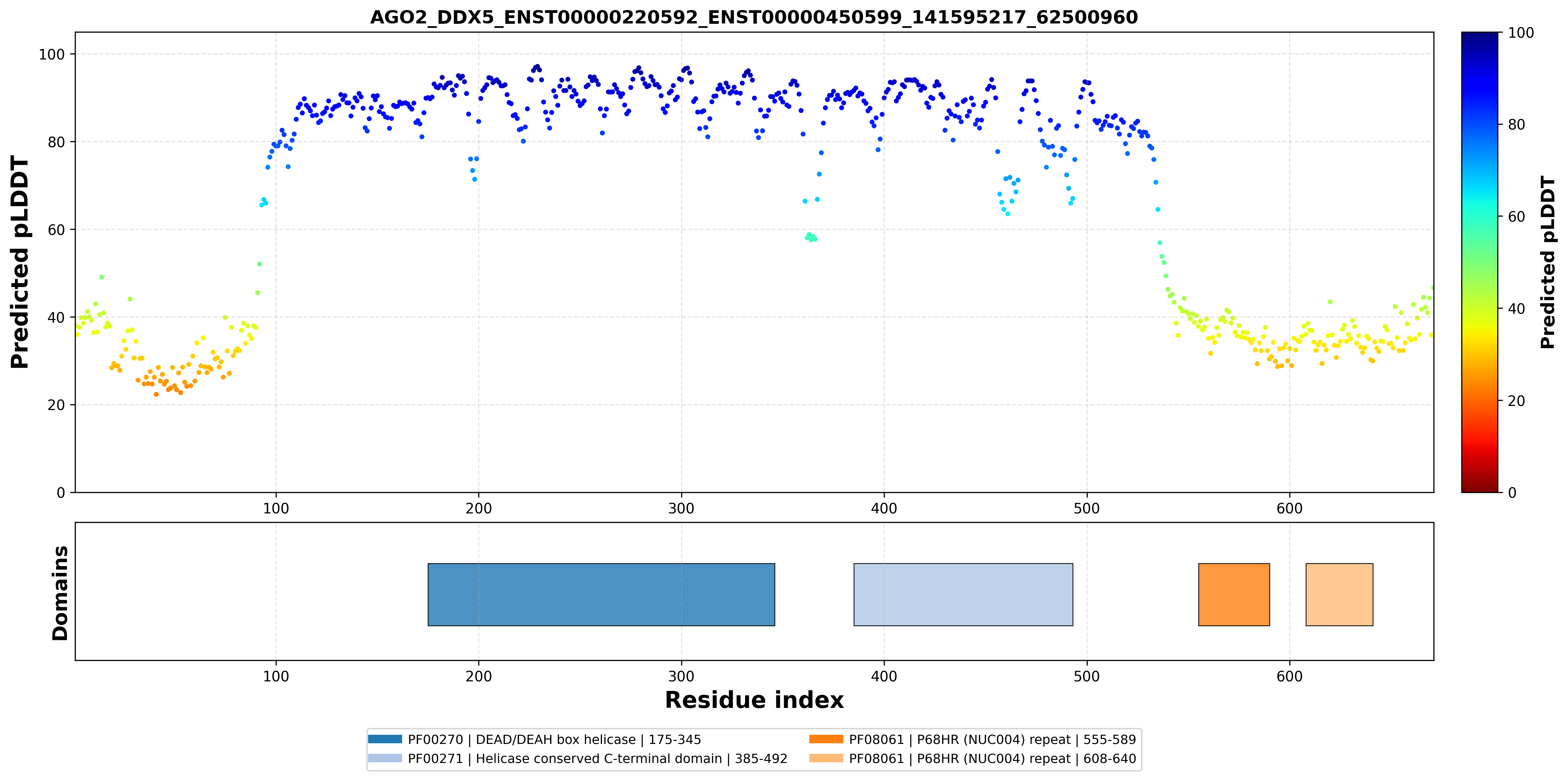 | 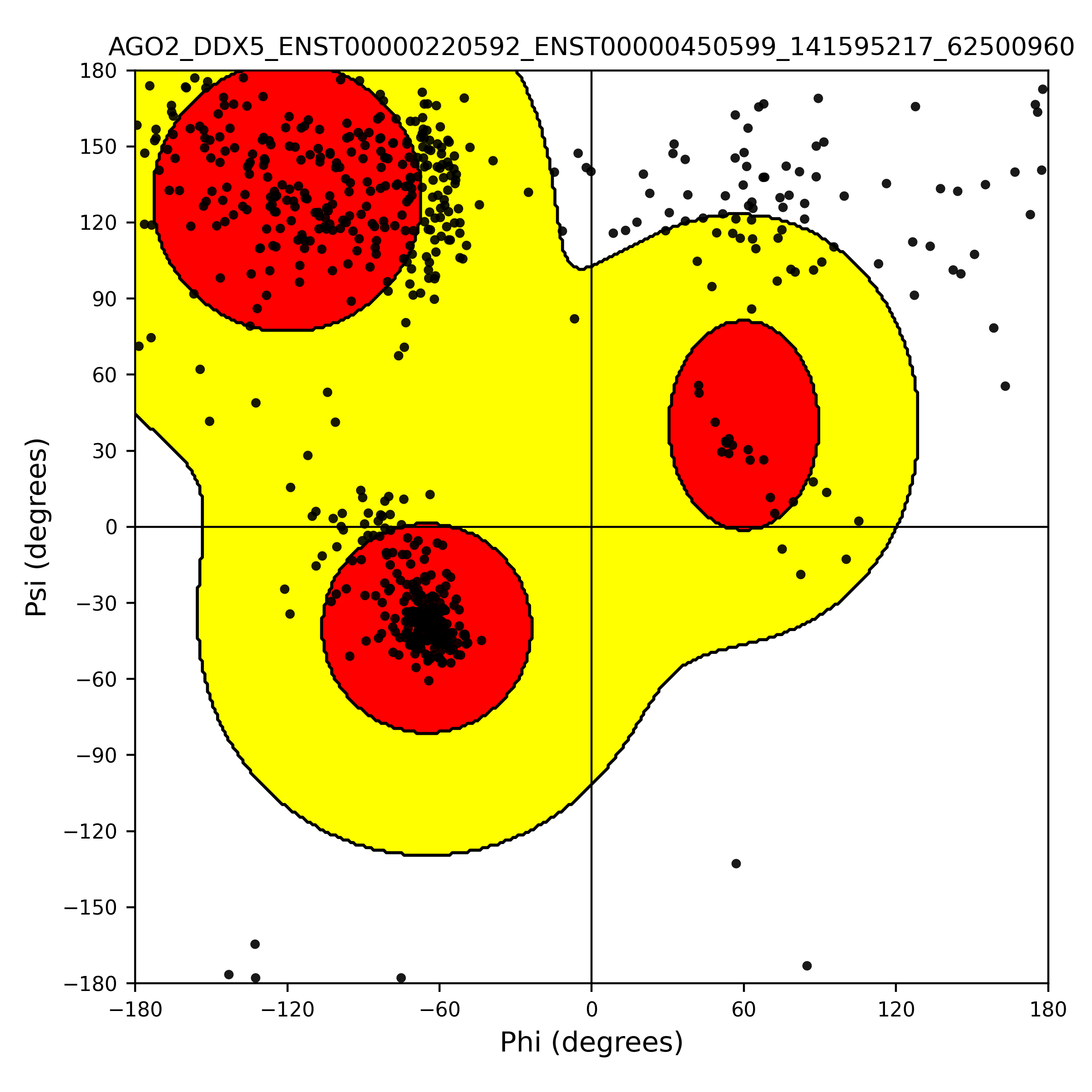 |  |
| AGO2_DDX5_ENST00000220592_ENST00000578804_141595217_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.5412
Å |
 | 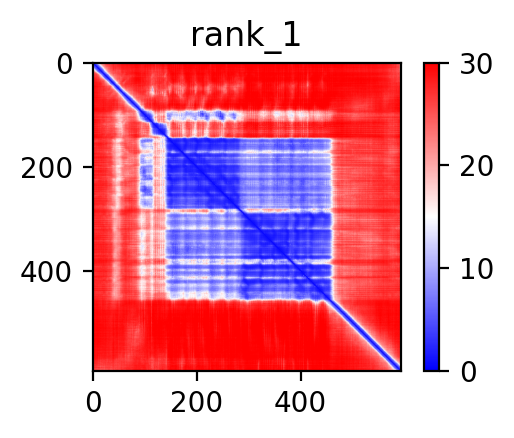 | 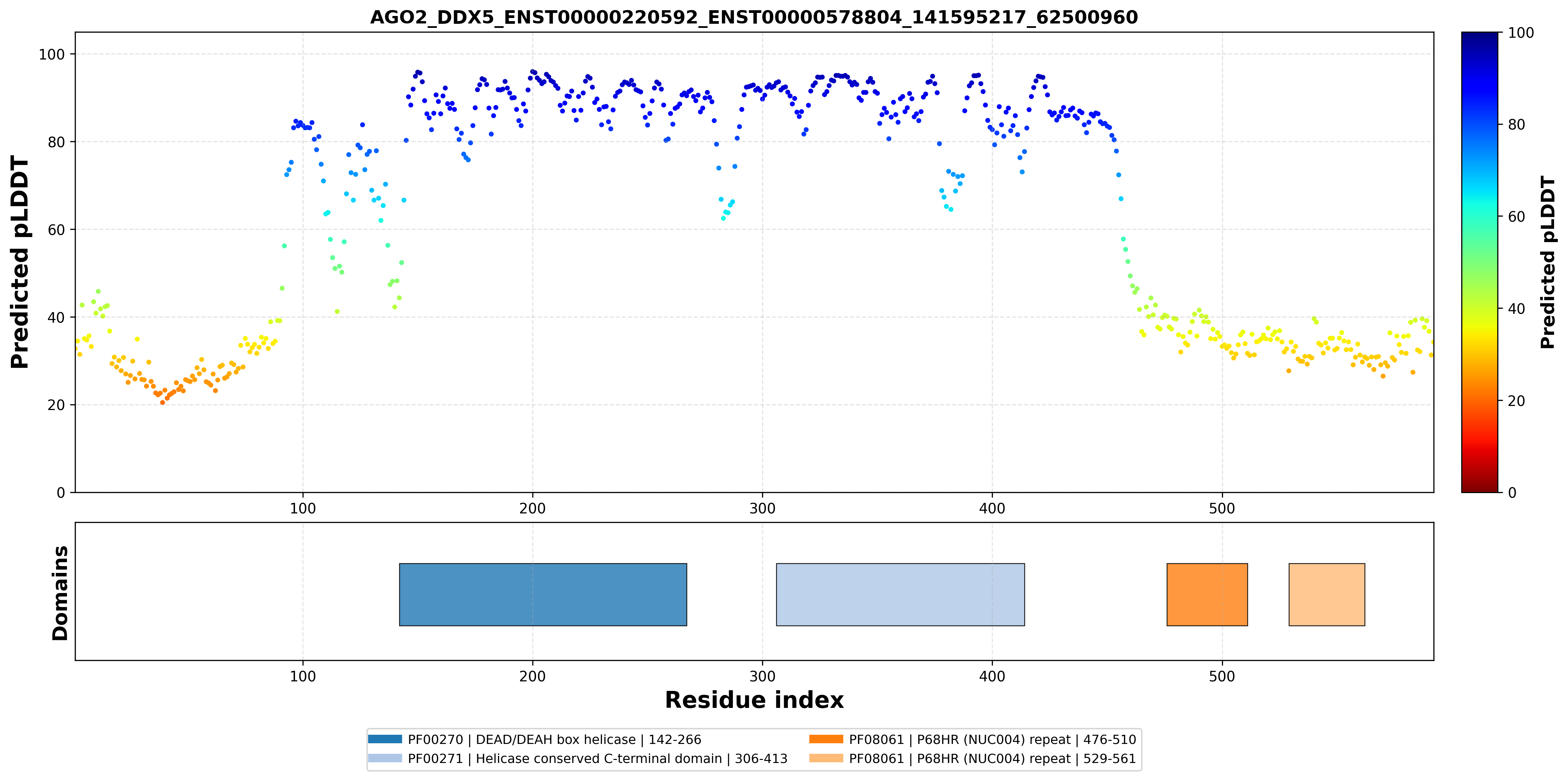 | 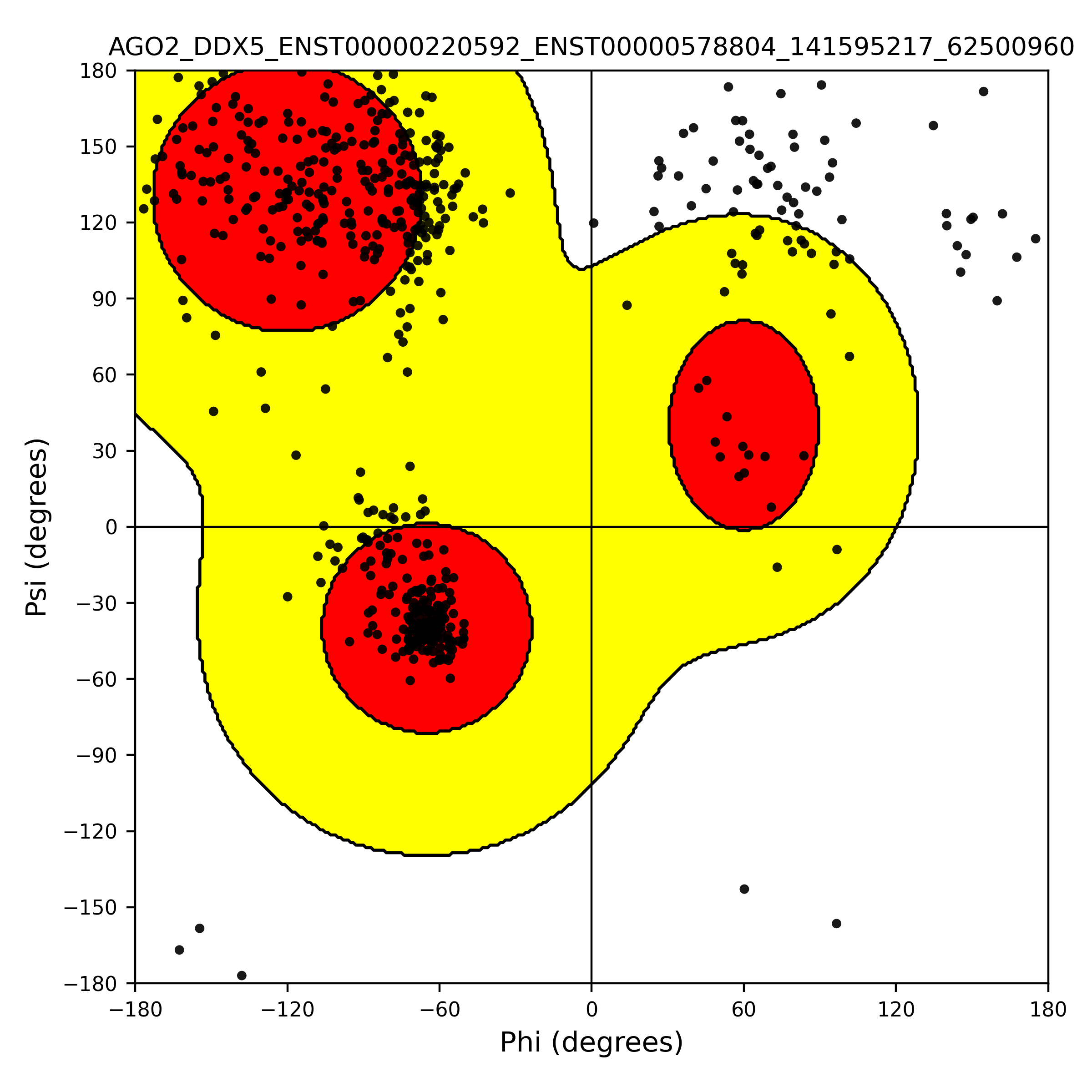 |  |
| AGO2_PCMTD1_ENST00000220592_ENST00000544451_141595217_52746249 superimposed PDB: 9OMA of partner (PCMTD1). RMSD:2.2073
Å |
 | 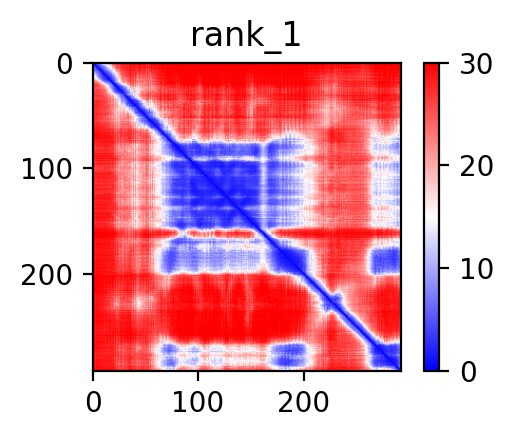 | 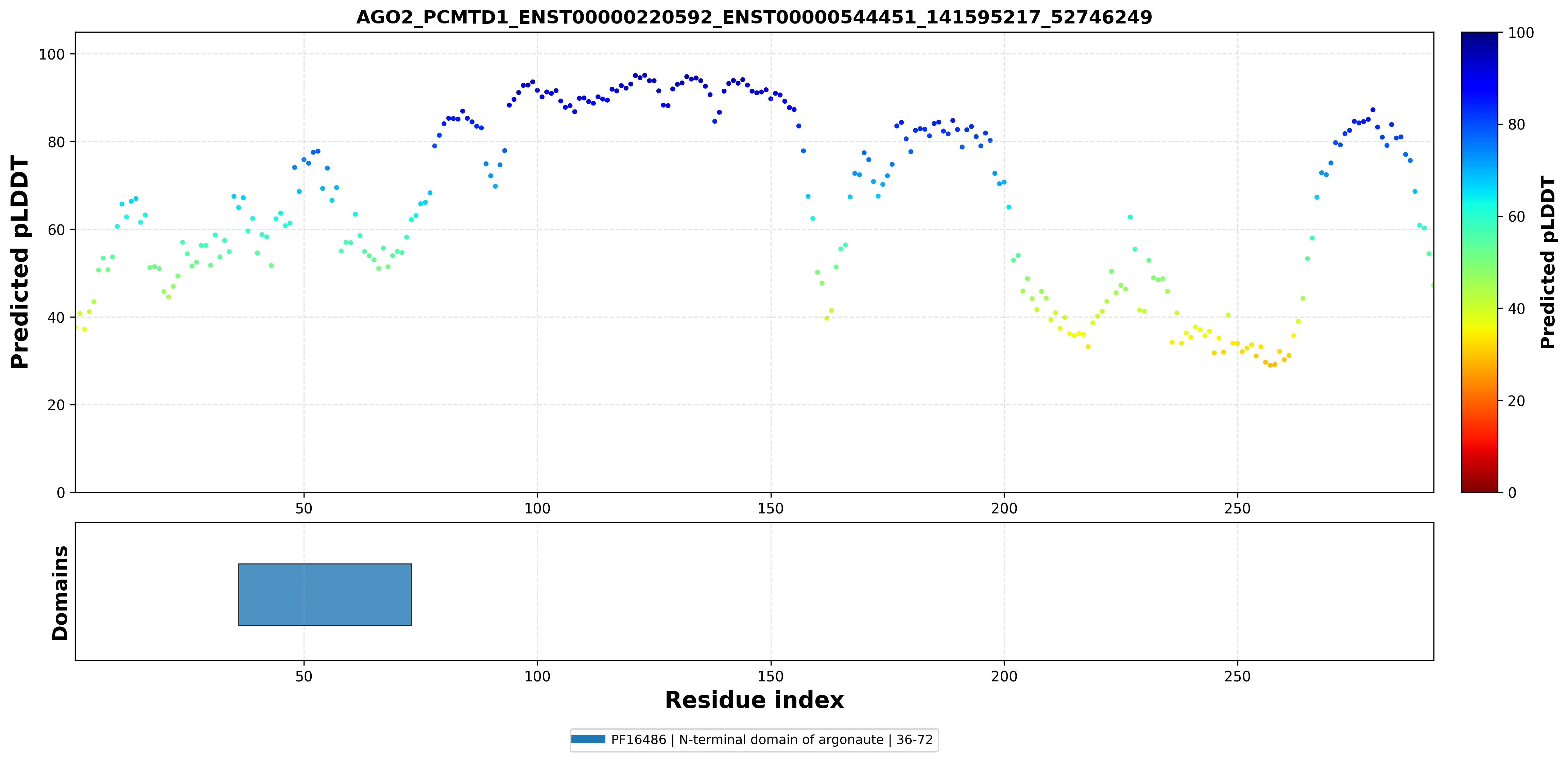 | 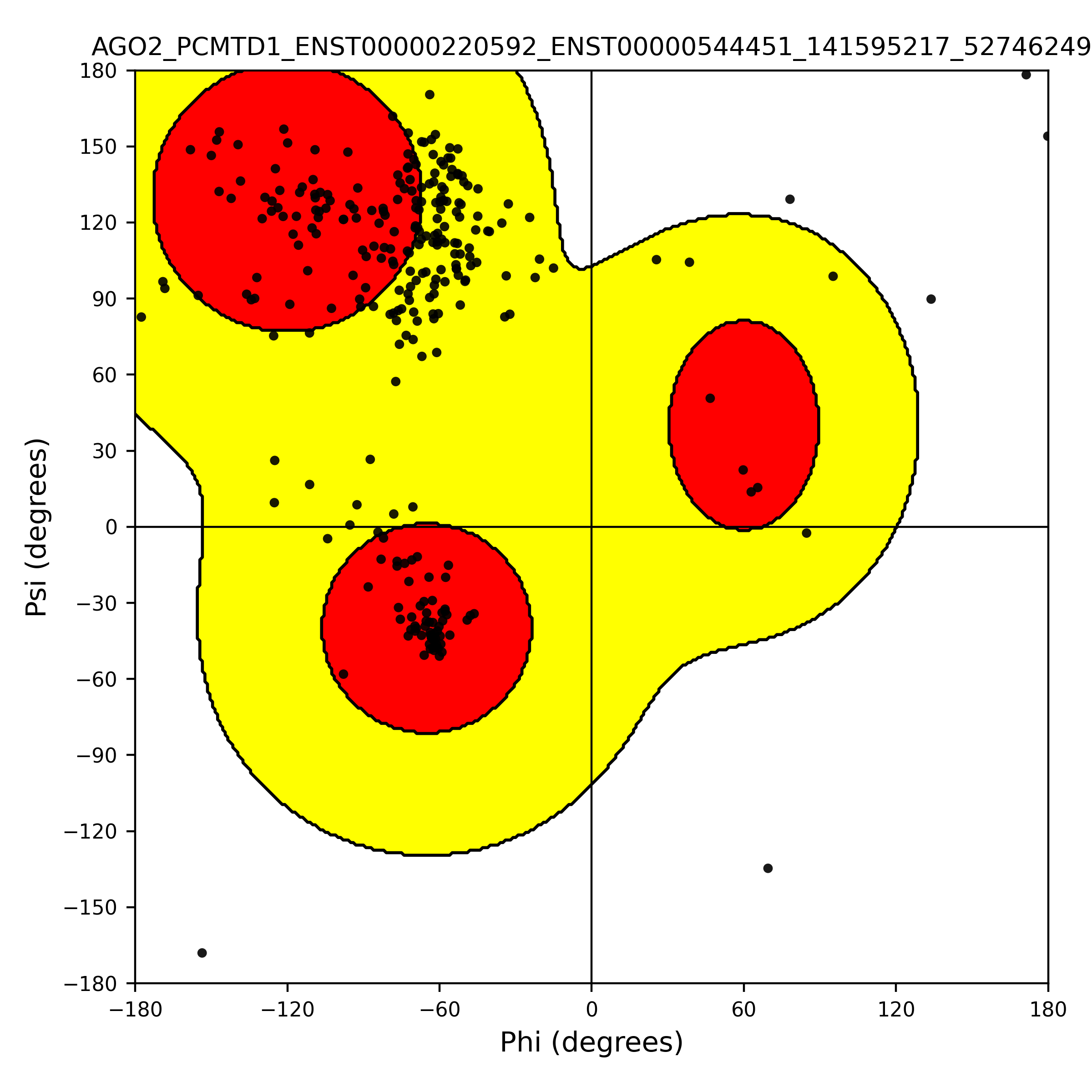 | 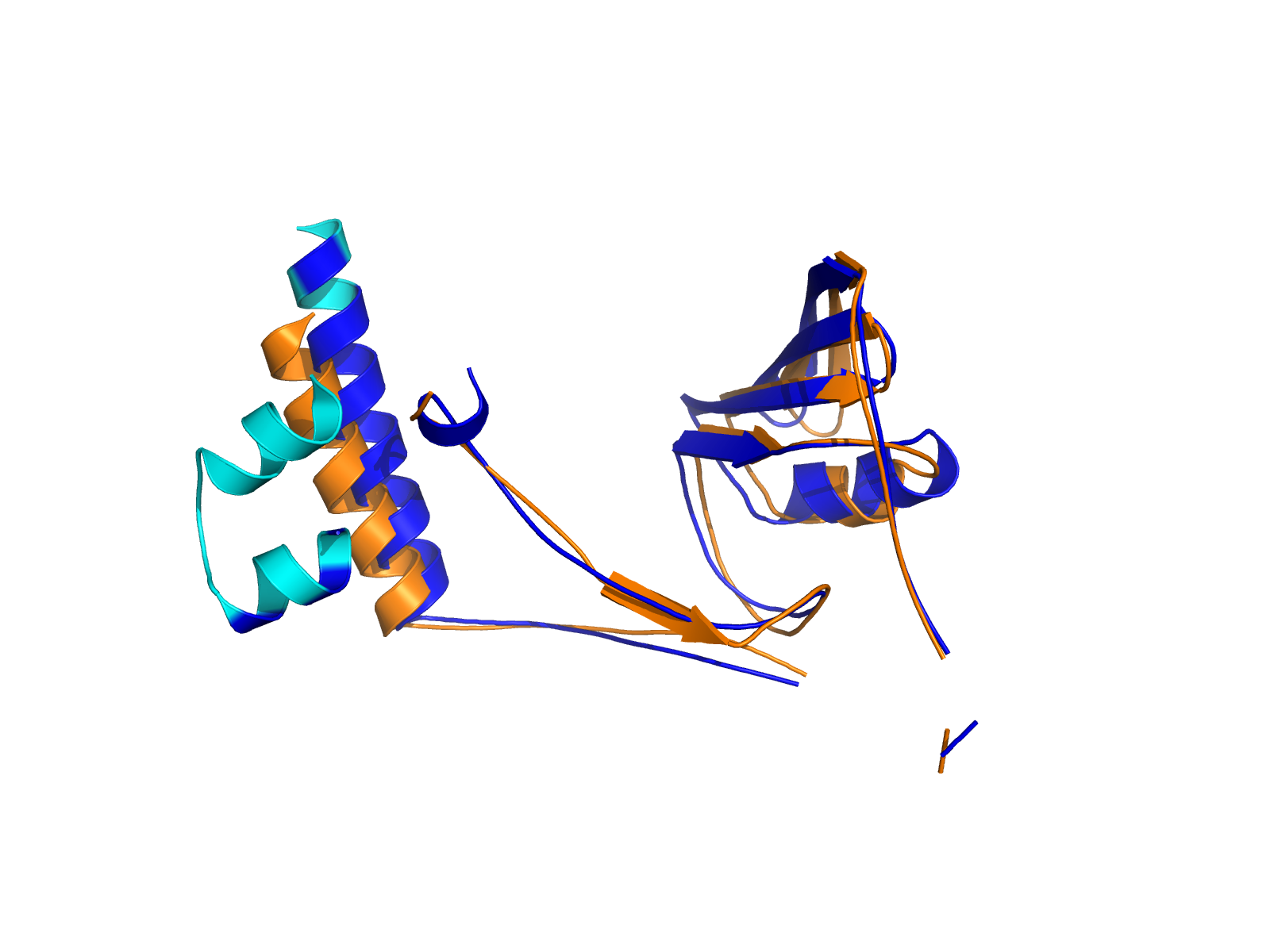 |
| AGO2_STRN3_ENST00000220592_ENST00000357479_141554311_31381388 superimposed PDB: 4Z4D of partner (AGO2). RMSD:2.1293
Å |
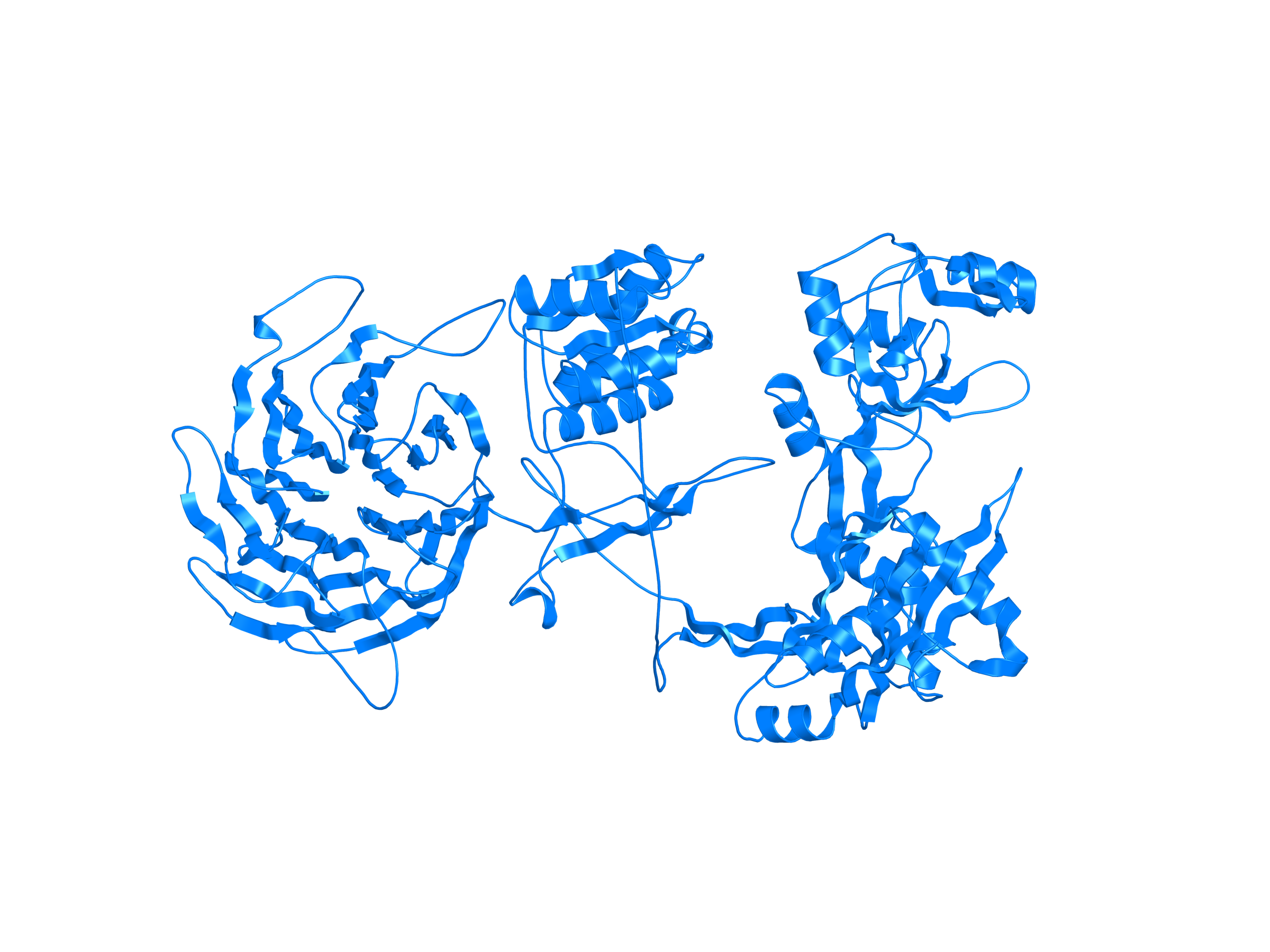 | 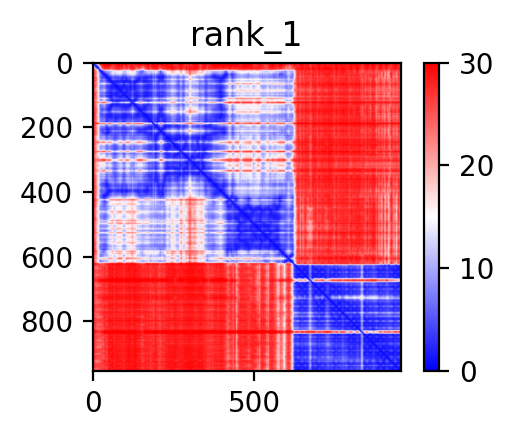 | 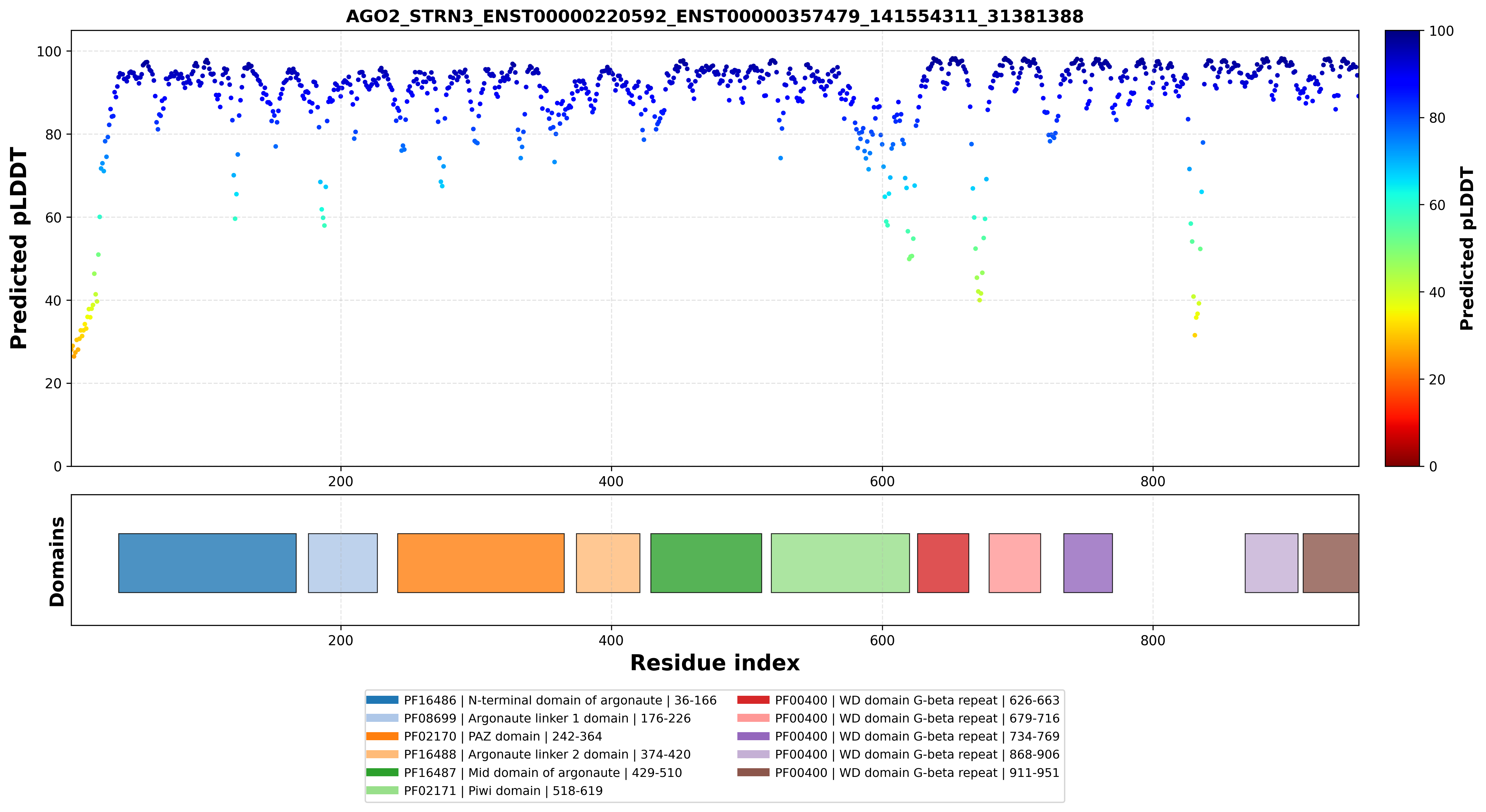 | 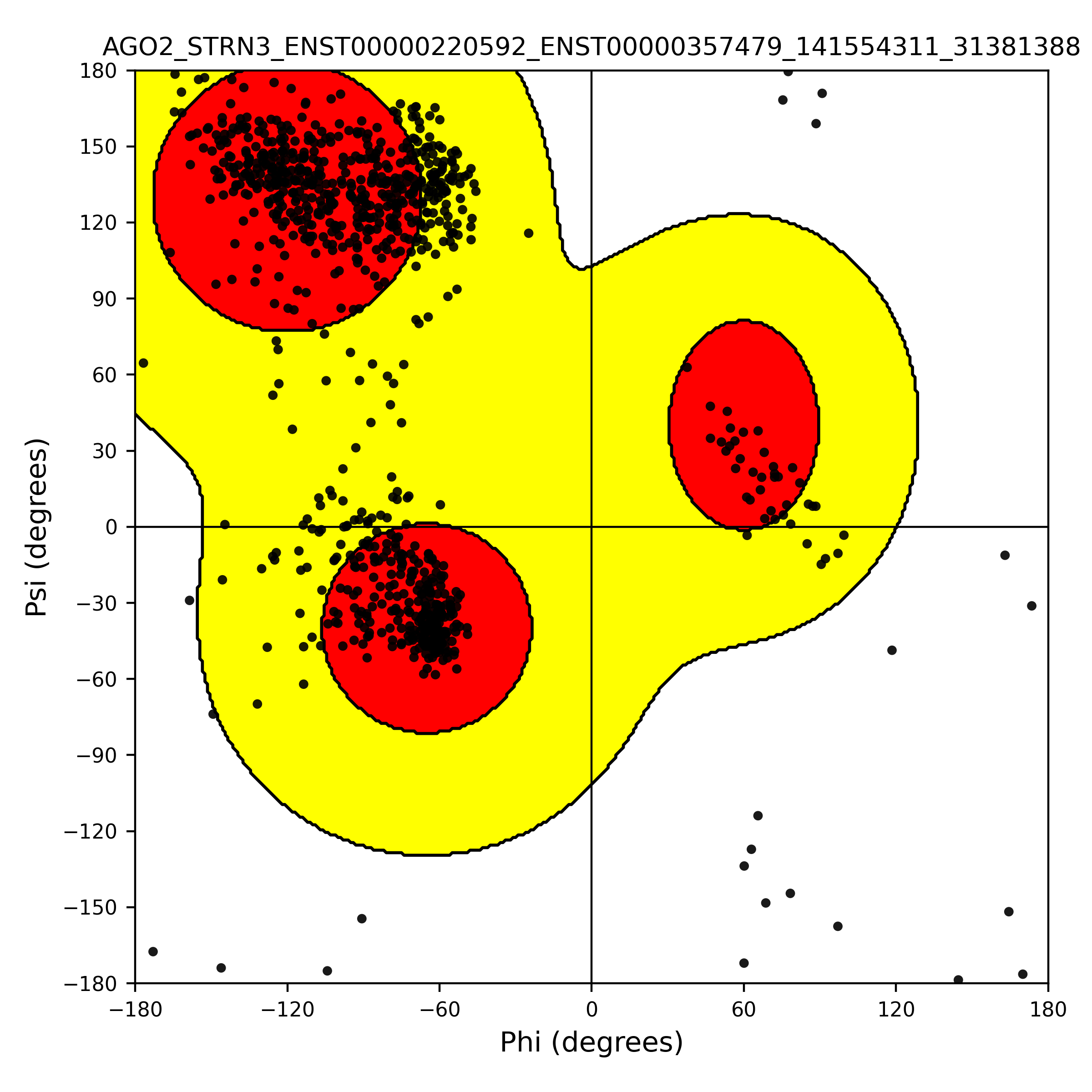 | 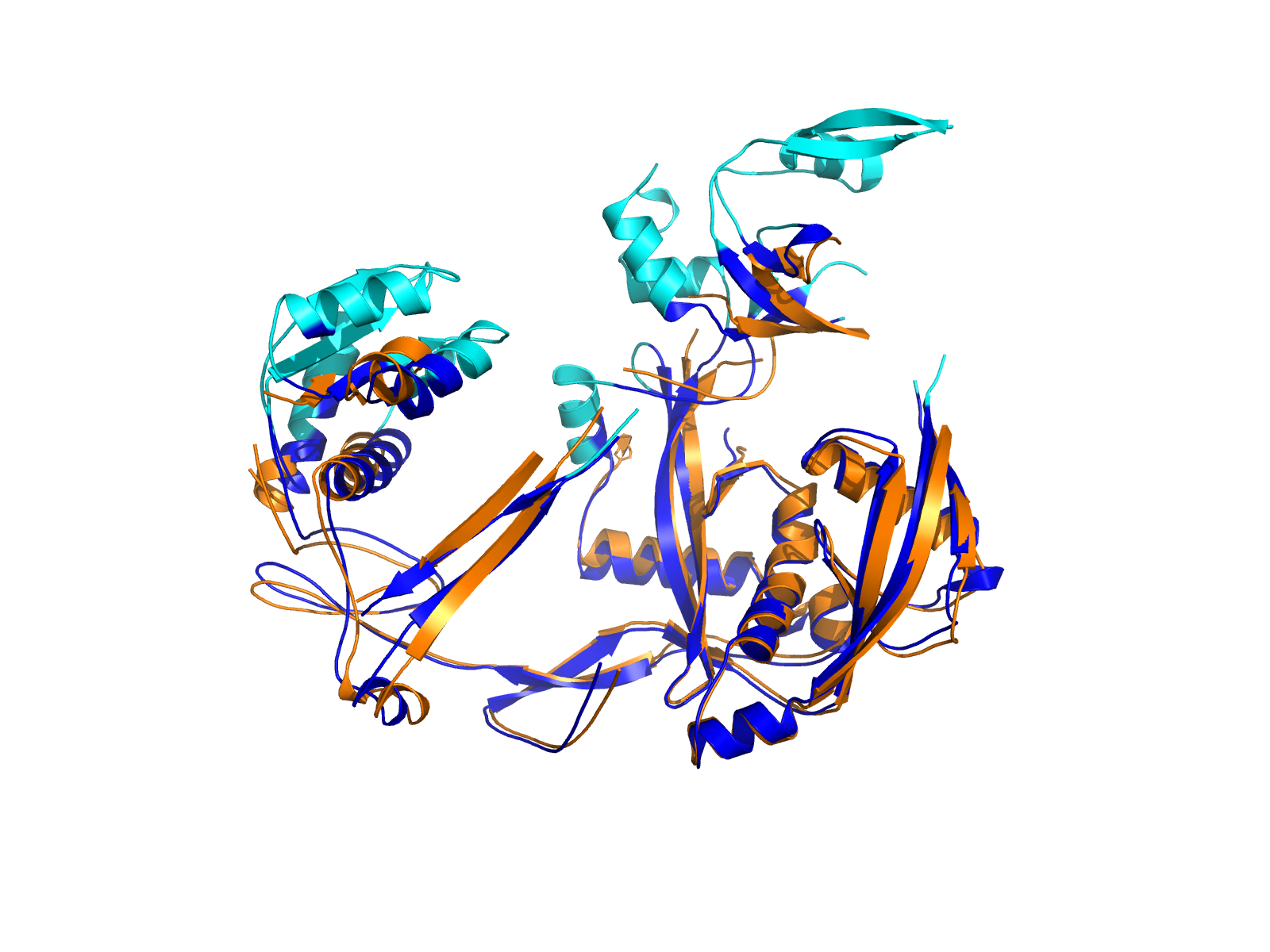 |
| AGO2_STRN3_ENST00000220592_ENST00000357479_141554311_31381388 superimposed PDB: 7K36 of partner (STRN3). RMSD:0.6907
Å |
| | | | 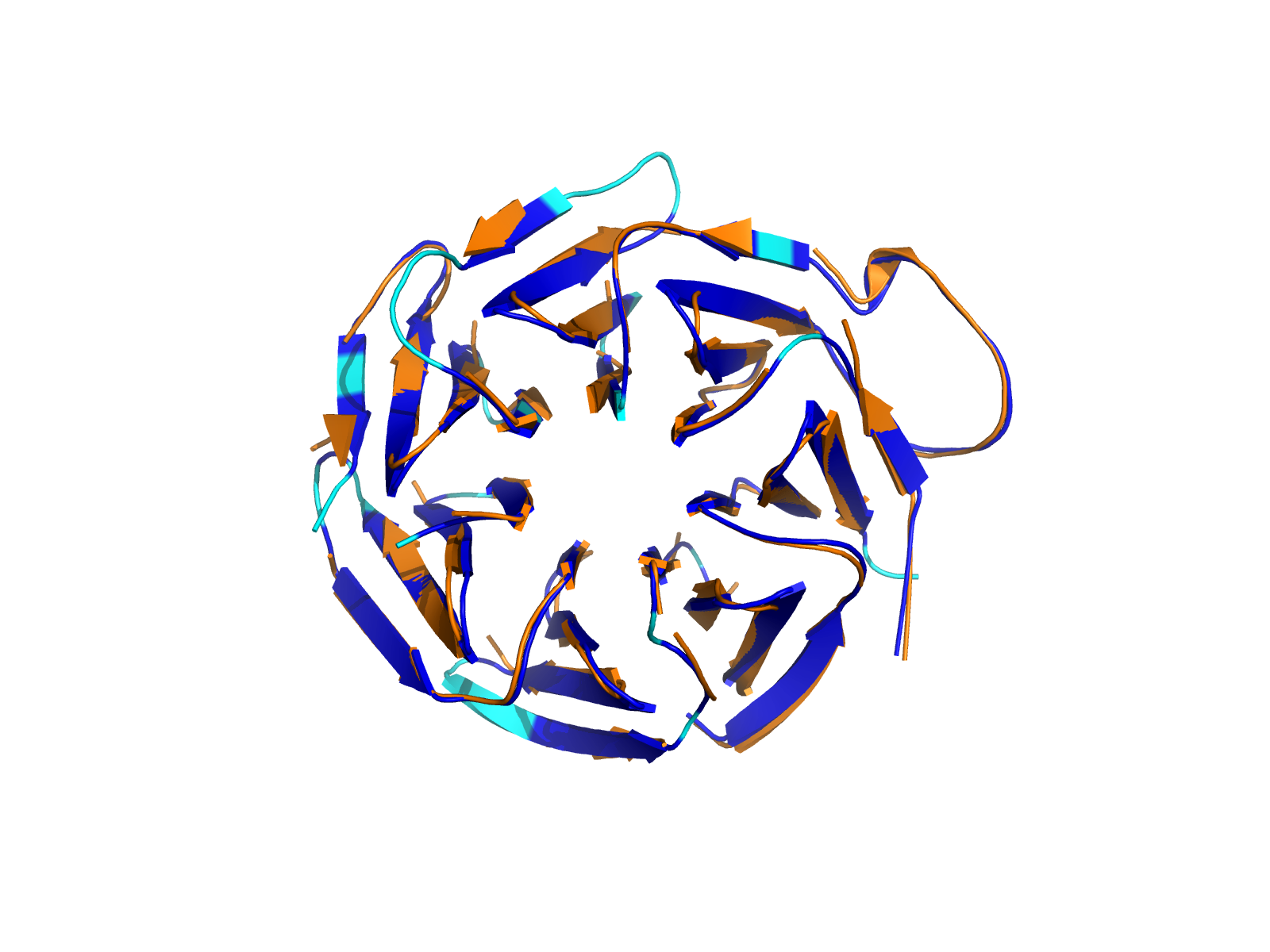 |
| AGPAT9_COPS4_ENST00000264409_ENST00000503682_84465755_83987590 superimposed PDB: 9QO4 of partner (COPS4). RMSD:2.9514
Å |
 |  |  |  |  |
| AGPAT9_COPS4_ENST00000264409_ENST00000509093_84465755_83987590 superimposed PDB: 9QO4 of partner (COPS4). RMSD:0.4525
Å |
 |  |  |  |  |
| AGPAT9_COPS4_ENST00000395226_ENST00000503682_84465755_83987590 superimposed PDB: 9QO4 of partner (COPS4). RMSD:2.9389
Å |
 |  |  |  |  |
| AGRN_FLNA_ENST00000379370_ENST00000360319_989931_153582095 superimposed PDB: 8S9P of partner (AGRN). RMSD:1.2381
Å |
 |  |  |  |  |
| AGRN_FLNA_ENST00000379370_ENST00000422373_987025_153586936 superimposed PDB: 8S9P of partner (AGRN). RMSD:1.3617
Å |
 |  |  |  |  |
| AGRN_FLNA_ENST00000379370_ENST00000422373_989931_153582095 superimposed PDB: 8S9P of partner (AGRN). RMSD:0.8295
Å |
 |  |  |  |  |
| AGRN_ZC3H18_ENST00000379370_ENST00000452588_970704_88664585 superimposed PDB: 9T3X of partner (ZC3H18). RMSD:1.4978
Å |
 |  |  |  |  |
| AHCY_PIGU_ENST00000217426_ENST00000374820_32881886_33245048 superimposed PDB: 1LI4 of partner (AHCY). RMSD:0.4155
Å |
 |  |  |  |  |
| AHCY_PIGU_ENST00000217426_ENST00000374820_32881886_33245048 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9271
Å |
| | | |  |
| AHI1_RPL22_ENST00000457866_ENST00000234875_135811760_6257816 superimposed PDB: 4ESR of partner (AHI1). RMSD:2.8035
Å |
 |  |  |  |  |
| AHI1_RPL22_ENST00000457866_ENST00000484532_135811760_6257816 superimposed PDB: 4ESR of partner (AHI1). RMSD:2.7152
Å |
 |  |  |  |  |
| AHRR_AVIL_ENST00000316418_ENST00000537081_376831_58193703 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7638
Å |
 |  |  |  |  |
| AHRR_AVIL_ENST00000505113_ENST00000257861_376831_58193703 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:1.2209
Å |
 |  |  |  |  |
| AHRR_AVIL_ENST00000505113_ENST00000257861_376831_58193703 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7924
Å |
| | | |  |
| AHRR_HSP90AB1_ENST00000505113_ENST00000371554_376831_44216366 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.7996
Å |
 |  |  |  |  |
| AHRR_HSP90AB1_ENST00000505113_ENST00000371554_376831_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.6209
Å |
| | | |  |
| AHRR_HSP90AB1_ENST00000505113_ENST00000371646_376831_44216366 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:2.8743
Å |
 |  |  |  |  |
| AK4_NDC1_ENST00000327299_ENST00000540001_65656512_54293846 superimposed PDB: 2BBW of partner (AK4). RMSD:0.9444
Å |
 |  |  |  |  |
| AK4_NDC1_ENST00000545314_ENST00000540001_65656512_54293846 superimposed PDB: 2BBW of partner (AK4). RMSD:1.0198
Å |
 |  |  |  |  |
| AK4_NDC1_ENST00000546702_ENST00000371429_65656512_54293846 superimposed PDB: 2BBW of partner (AK4). RMSD:0.9961
Å |
 |  |  |  |  |
| AK4_WLS_ENST00000327299_ENST00000354777_65614235_68624930 superimposed PDB: 7DRT of partner (WLS). RMSD:1.769
Å |
 |  |  |  |  |
| AK4_WLS_ENST00000327299_ENST00000370976_65614235_68624930 superimposed PDB: 7DRT of partner (WLS). RMSD:1.9749
Å |
 |  |  |  |  |
| AK4_WLS_ENST00000545314_ENST00000354777_65614235_68624930 superimposed PDB: 7DRT of partner (WLS). RMSD:1.6833
Å |
 |  | 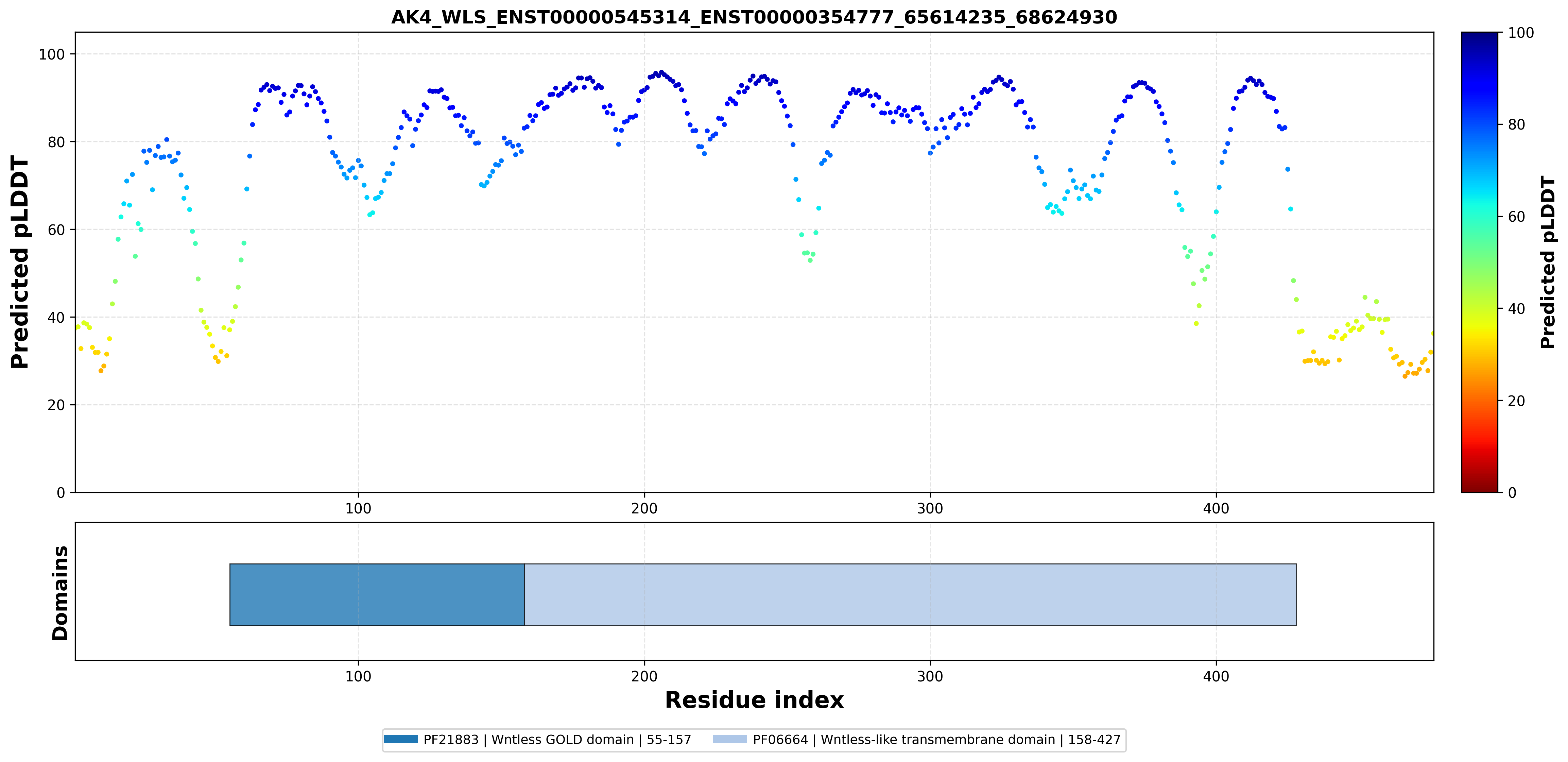 |  |  |
| AK4_WLS_ENST00000545314_ENST00000370976_65614235_68624930 superimposed PDB: 7DRT of partner (WLS). RMSD:1.7406
Å |
 |  | 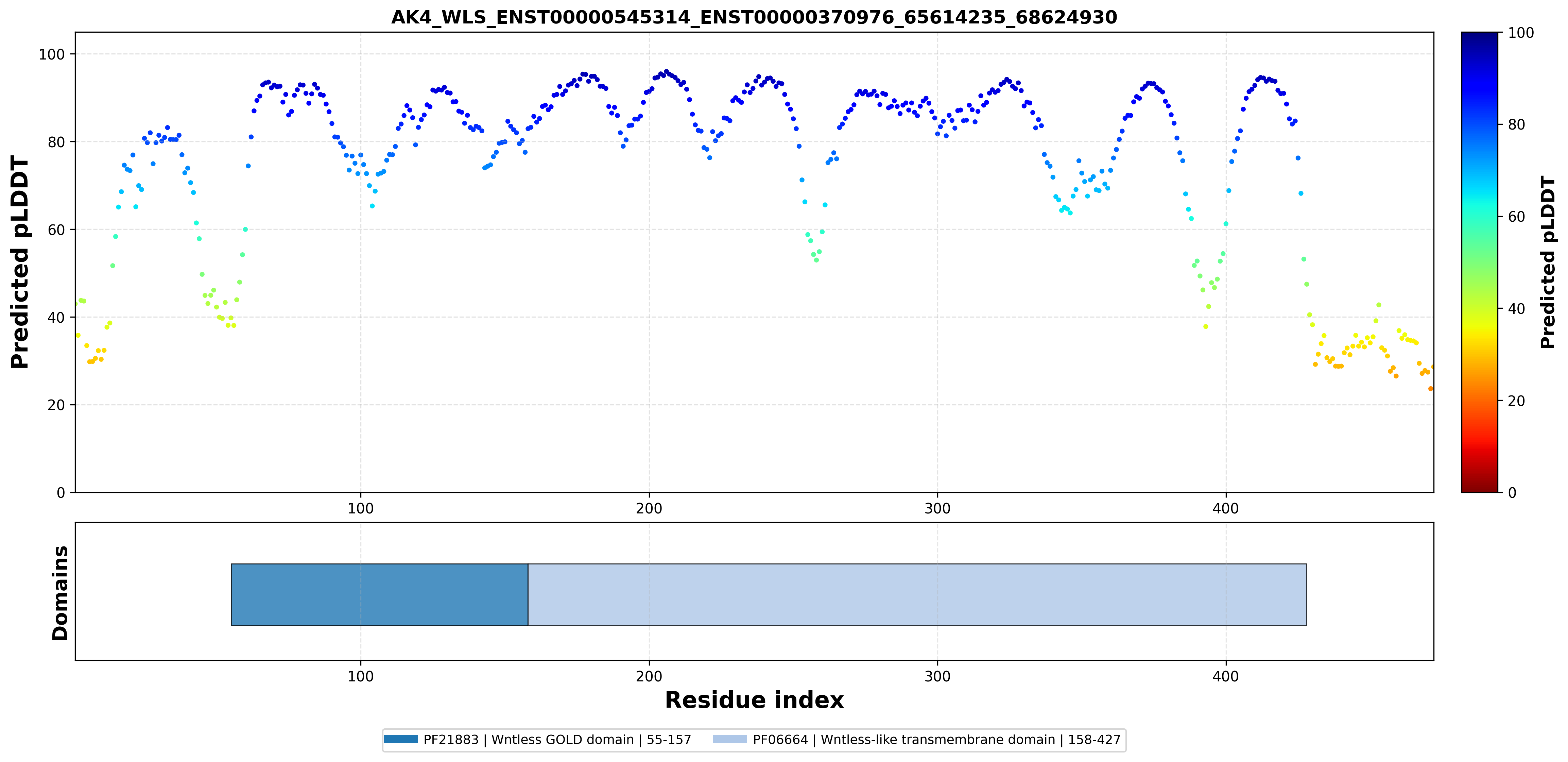 |  |  |
| AK4_WLS_ENST00000545314_ENST00000540432_65614235_68624930 superimposed PDB: 2BBW of partner (AK4). RMSD:1.0331
Å |
 |  | 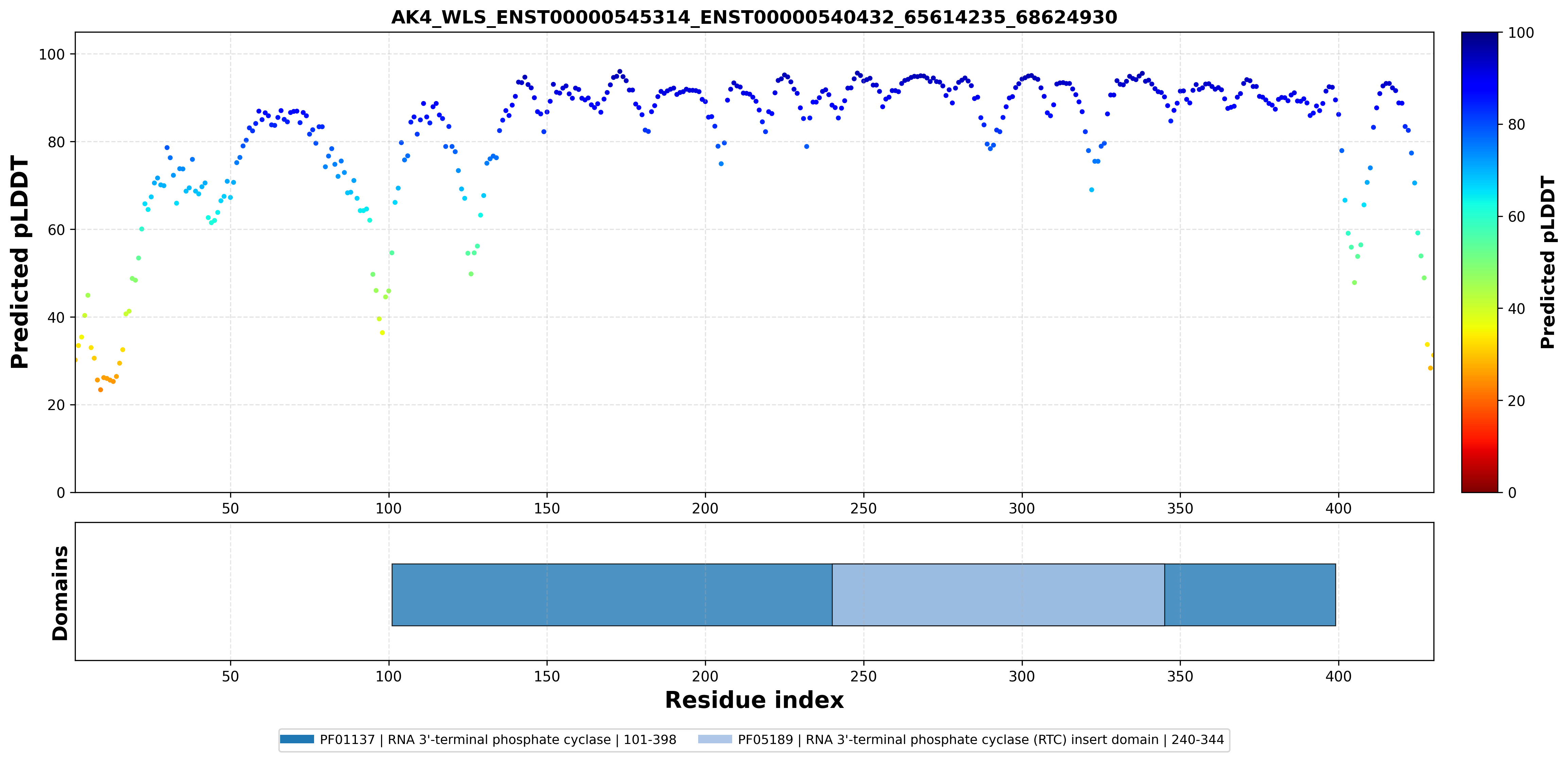 |  |  |
| AK4_WLS_ENST00000545314_ENST00000540432_65614235_68624930 superimposed PDB: 7DRT of partner (WLS). RMSD:2.7201
Å |
| | | |  |
| AK5_USP33_ENST00000344720_ENST00000357428_78001723_78167156 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.9718
Å |
 |  |  |  |  |
| AK5_USP33_ENST00000354567_ENST00000357428_78001723_78167156 superimposed PDB: 2BWJ of partner (AK5). RMSD:1.1666
Å |
 |  |  |  |  |
| AK5_USP33_ENST00000478255_ENST00000357428_78001723_78167156 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.7981
Å |
 |  |  |  |  |
| AKAP10_GID4_ENST00000395536_ENST00000268719_19839598_17962181 superimposed PDB: 3IM4 of partner (AKAP10). RMSD:0.3283
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000361243_ENST00000317501_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6853
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000361243_ENST00000355254_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.736
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000361243_ENST00000557856_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7668
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000361243_ENST00000558676_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.733
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000394518_ENST00000317501_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.702
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000394518_ENST00000355254_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6671
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000394518_ENST00000557856_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.707
Å |
 |  |  |  |  |
| AKAP13_NTRK3_ENST00000394518_ENST00000558676_86213061_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7047
Å |
 |  |  |  |  |
| AKAP13_RET_ENST00000394510_ENST00000340058_86284726_43612031 superimposed PDB: 4D0N of partner (AKAP13). RMSD:0.9183
Å |
 |  |  |  |  |
| AKAP13_SPI1_ENST00000394518_ENST00000227163_86129054_47380557 superimposed PDB: 8EE9 of partner (SPI1). RMSD:0.3084
Å |
 |  |  |  |  |
| AKAP9_PPP2R3B_ENST00000358100_ENST00000390665_91570461_272325 superimposed PDB: 4I5L of partner (PPP2R3B). RMSD:0.8373
Å |
 |  |  |  |  |
| AKR1C1_CCT5_ENST00000380872_ENST00000280326_5005720_10254256 superimposed PDB: 7NVL of partner (CCT5). RMSD:2.2149
Å |
 |  |  |  |  |
| AKR1C1_CCT5_ENST00000434459_ENST00000503026_5005720_10254256 superimposed PDB: 3C3U of partner (AKR1C1). RMSD:2.7648
Å |
 |  |  |  |  |
| AKR1C1_CCT5_ENST00000434459_ENST00000503026_5005720_10254256 superimposed PDB: 7NVL of partner (CCT5). RMSD:1.3035
Å |
| | | |  |
| AKR1C2_ATP1A1_ENST00000380753_ENST00000537345_5045943_116939219 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:2.5683
Å |
 |  |  |  |  |
| AKR1C2_ATP1A1_ENST00000421196_ENST00000537345_5045943_116939219 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:2.5208
Å |
 |  |  |  |  |
| AKR1C3_AKR1E2_ENST00000439082_ENST00000298375_5139742_4872866 superimposed PDB: 1S1P of partner (AKR1C3). RMSD:2.7959
Å |
 |  |  |  |  |
| AKR1C3_AKR1E2_ENST00000605149_ENST00000298375_5139742_4872866 superimposed PDB: 1S1P of partner (AKR1C3). RMSD:0.6038
Å |
 |  |  |  |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000264203_19610489_19746245 superimposed PDB: 2CLP of partner (AKR7A3). RMSD:0.5112
Å |
 |  |  |  |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000264203_19610489_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7654
Å |
| | | |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000375142_19610489_19746245 superimposed PDB: 2CLP of partner (AKR7A3). RMSD:0.4288
Å |
 |  |  |  |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000375142_19610489_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8048
Å |
| | | |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000433834_19610489_19746245 superimposed PDB: 2CLP of partner (AKR7A3). RMSD:0.4522
Å |
 |  |  |  |  |
| AKR7A3_CAPZB_ENST00000361640_ENST00000433834_19610489_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8738
Å |
| | | |  |
| AKT1_ITPK1_ENST00000402615_ENST00000354313_105258934_93542964 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.7451
Å |
 |  |  |  |  |
| AKT1_ITPK1_ENST00000555528_ENST00000556603_105258934_93542964 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.6256
Å |
 |  |  |  |  |
| AKT2_NSMAF_ENST00000579047_ENST00000427130_40741796_59508218 superimposed PDB: 8Q61 of partner (AKT2). RMSD:2.9844
Å |
 |  |  |  |  |
| AKT3_MYCL_ENST00000263826_ENST00000397332_243708811_40367115 superimposed PDB: 2X18 of partner (AKT3). RMSD:0.431
Å |
 |  |  |  |  |
| AKT3_MYCL_ENST00000336199_ENST00000397332_243708811_40363642 superimposed PDB: 2X18 of partner (AKT3). RMSD:1.1699
Å |
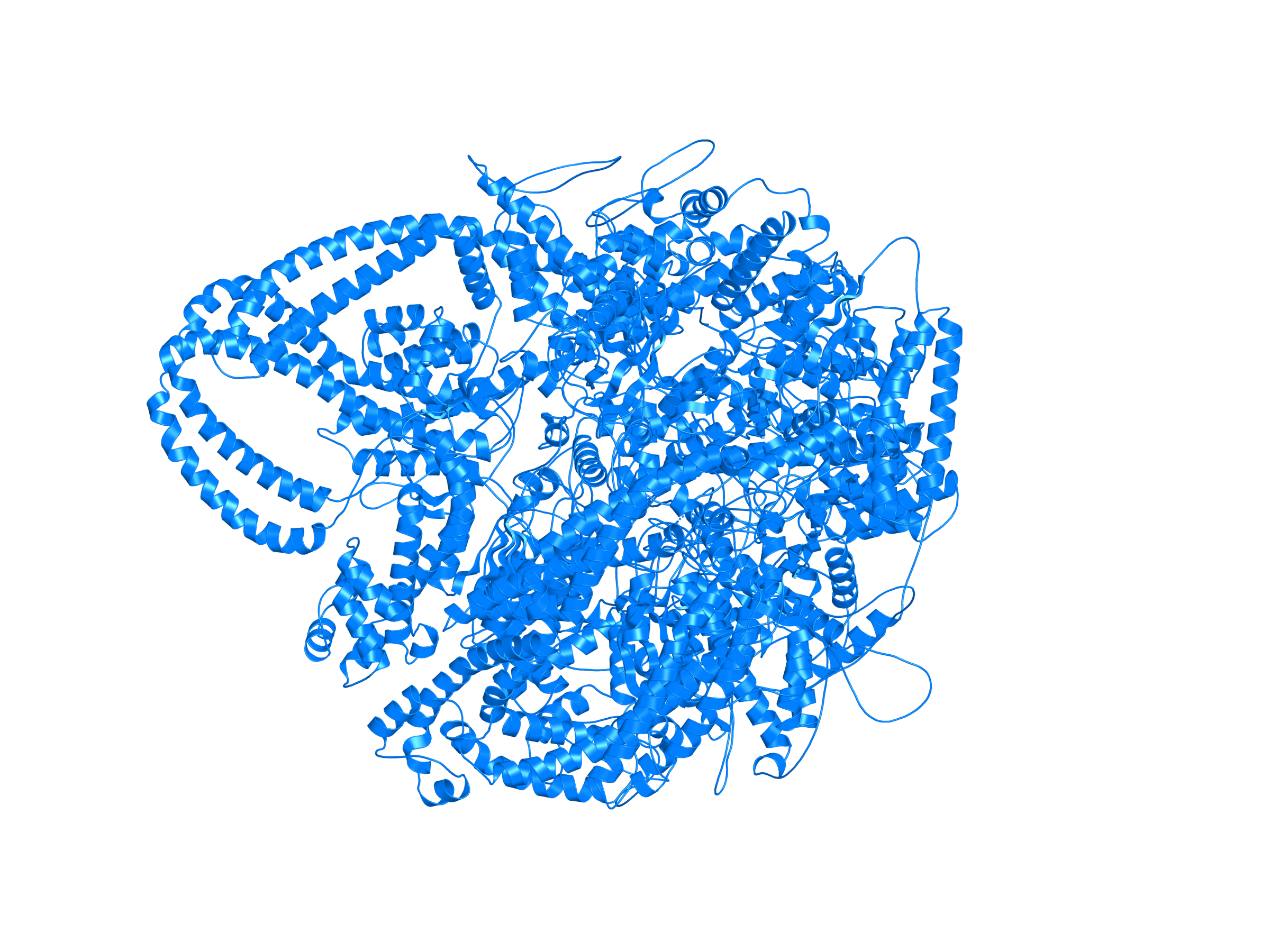 | 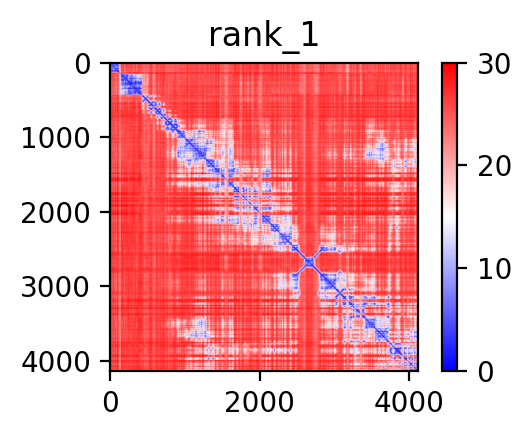 | 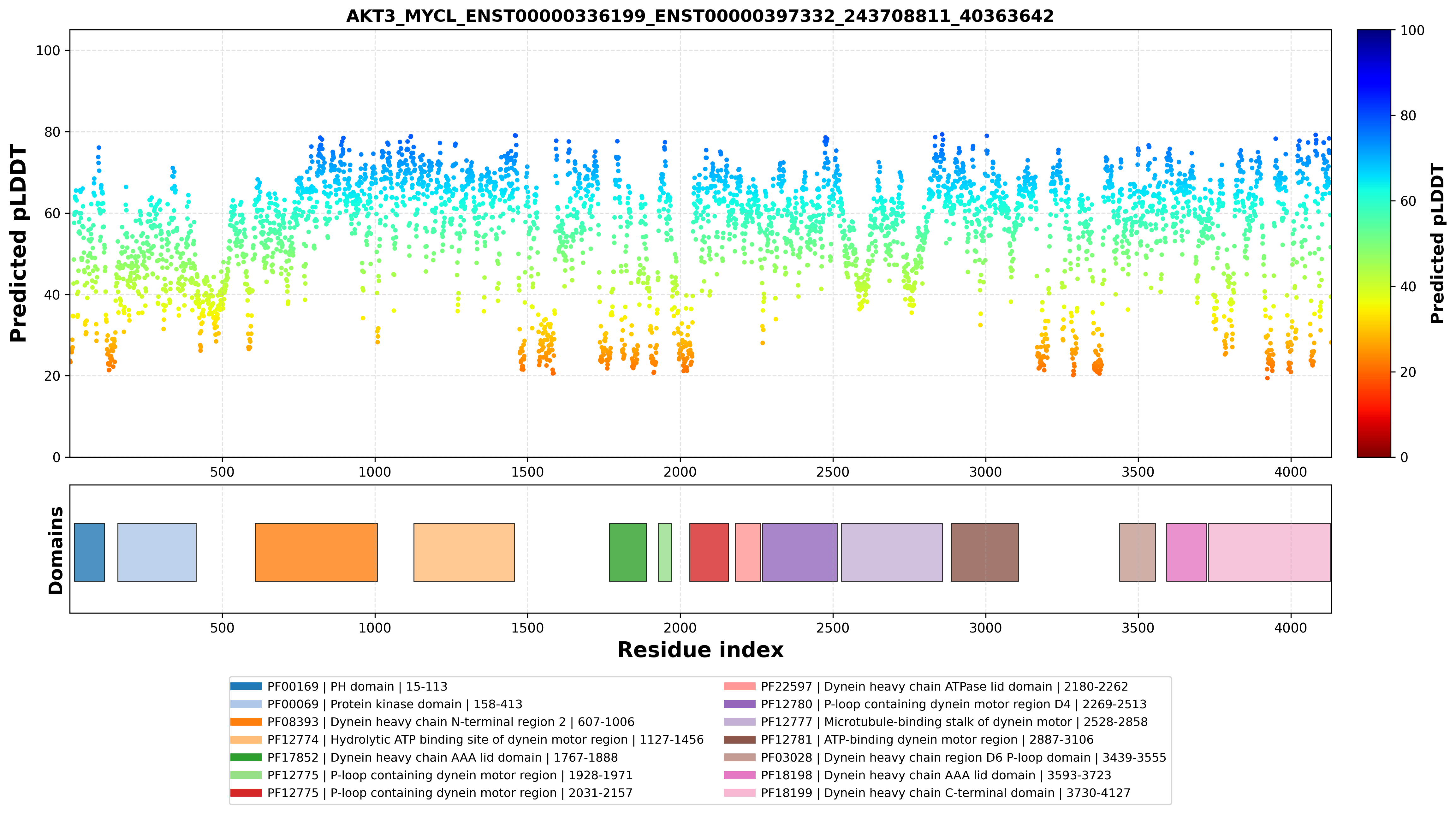 |  |  |
| AKT3_MYCL_ENST00000366539_ENST00000397332_243708811_40363642 superimposed PDB: 2X18 of partner (AKT3). RMSD:0.4458
Å |
 |  | 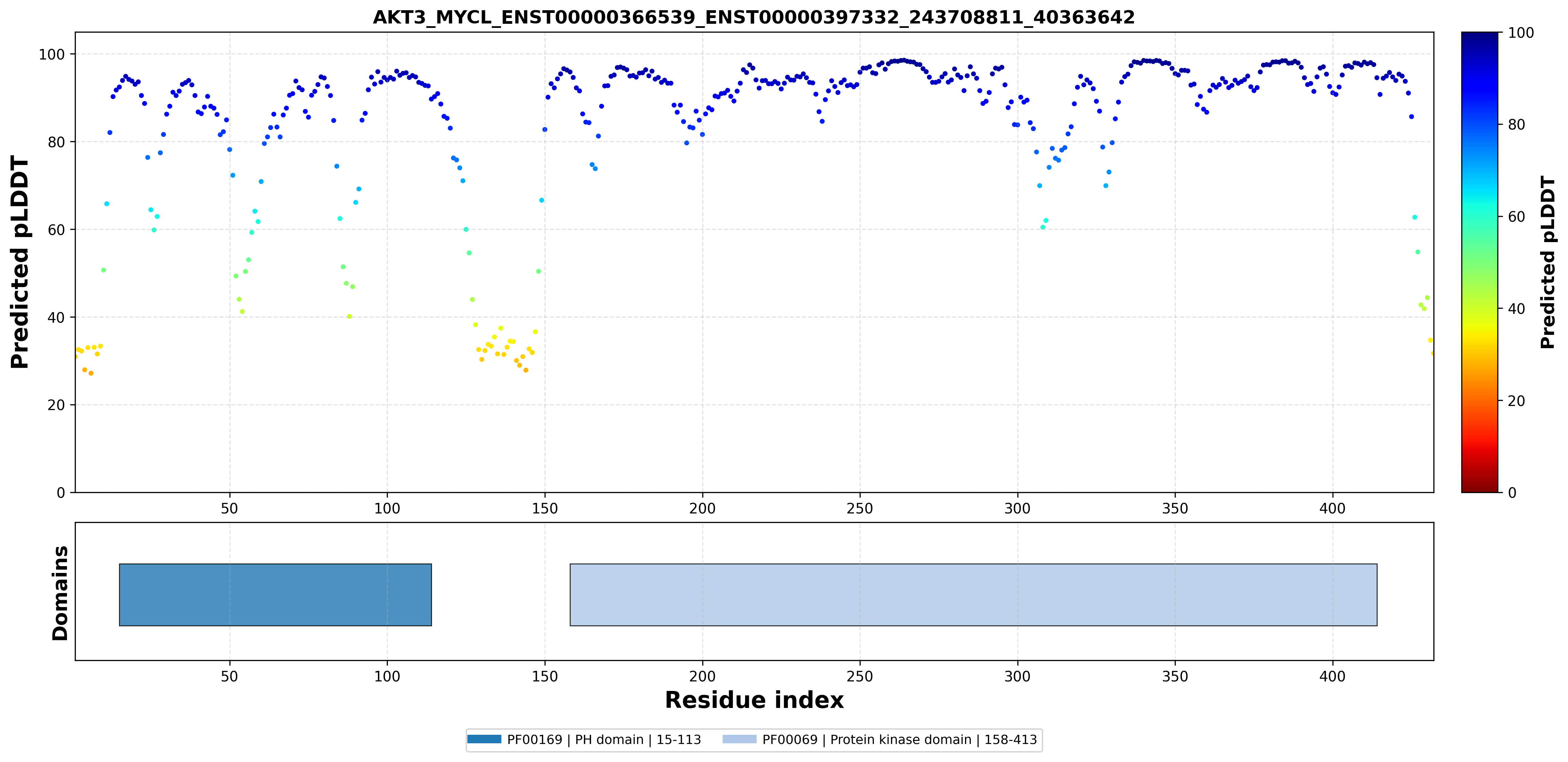 |  |  |
| AKT3_PPP2R2A_ENST00000336199_ENST00000315985_244006426_26211983 superimposed PDB: 3DW8 of partner (PPP2R2A). RMSD:0.5921
Å |
 |  |  |  |  |
| AKT3_PTPRR_ENST00000336199_ENST00000283228_243776972_71078044 superimposed PDB: 2X18 of partner (AKT3). RMSD:0.4358
Å |
 |  | 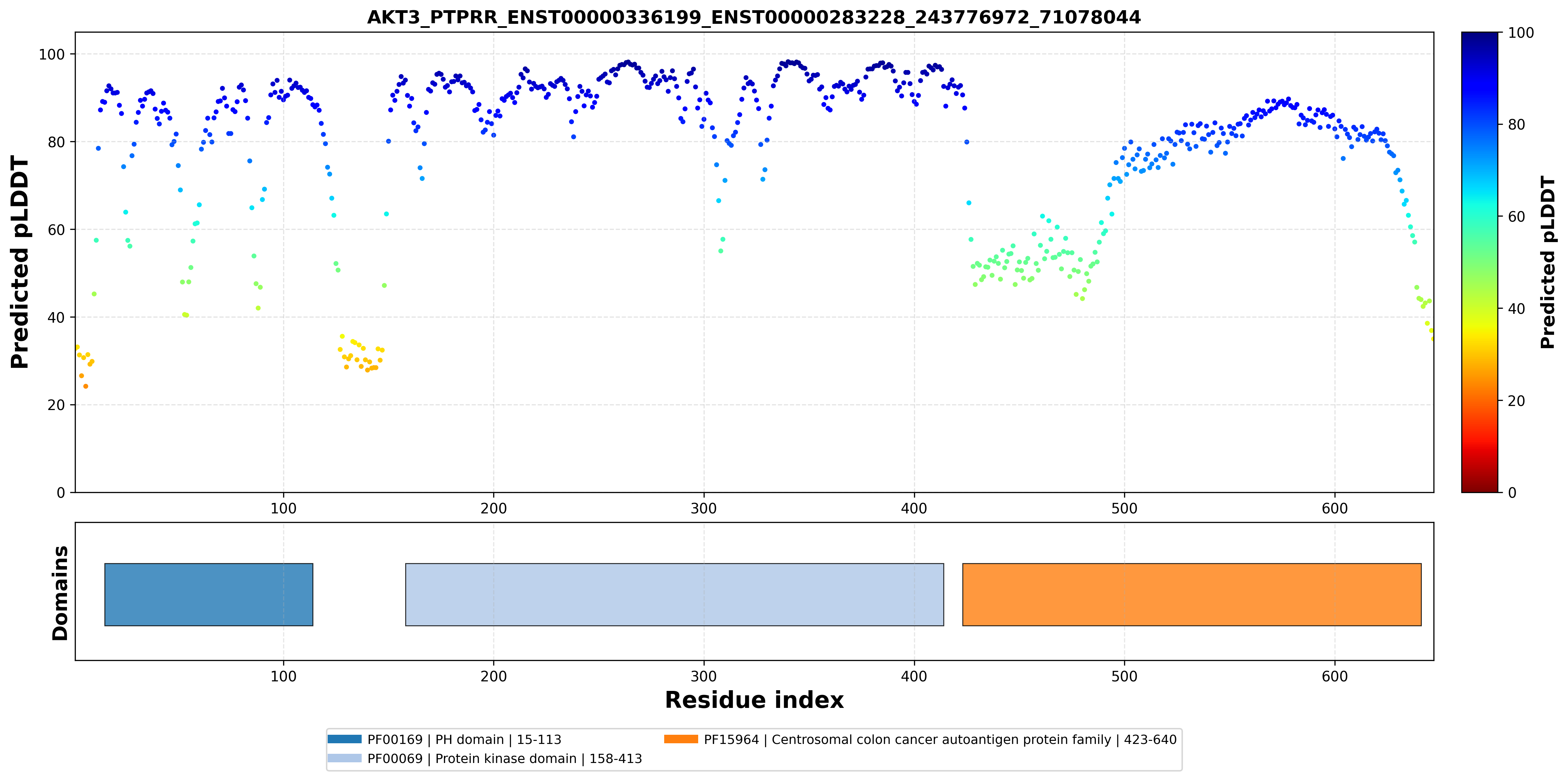 |  |  |
| AKT3_PTPRR_ENST00000336199_ENST00000440835_243776972_71078044 superimposed PDB: 2X18 of partner (AKT3). RMSD:0.4602
Å |
 |  | 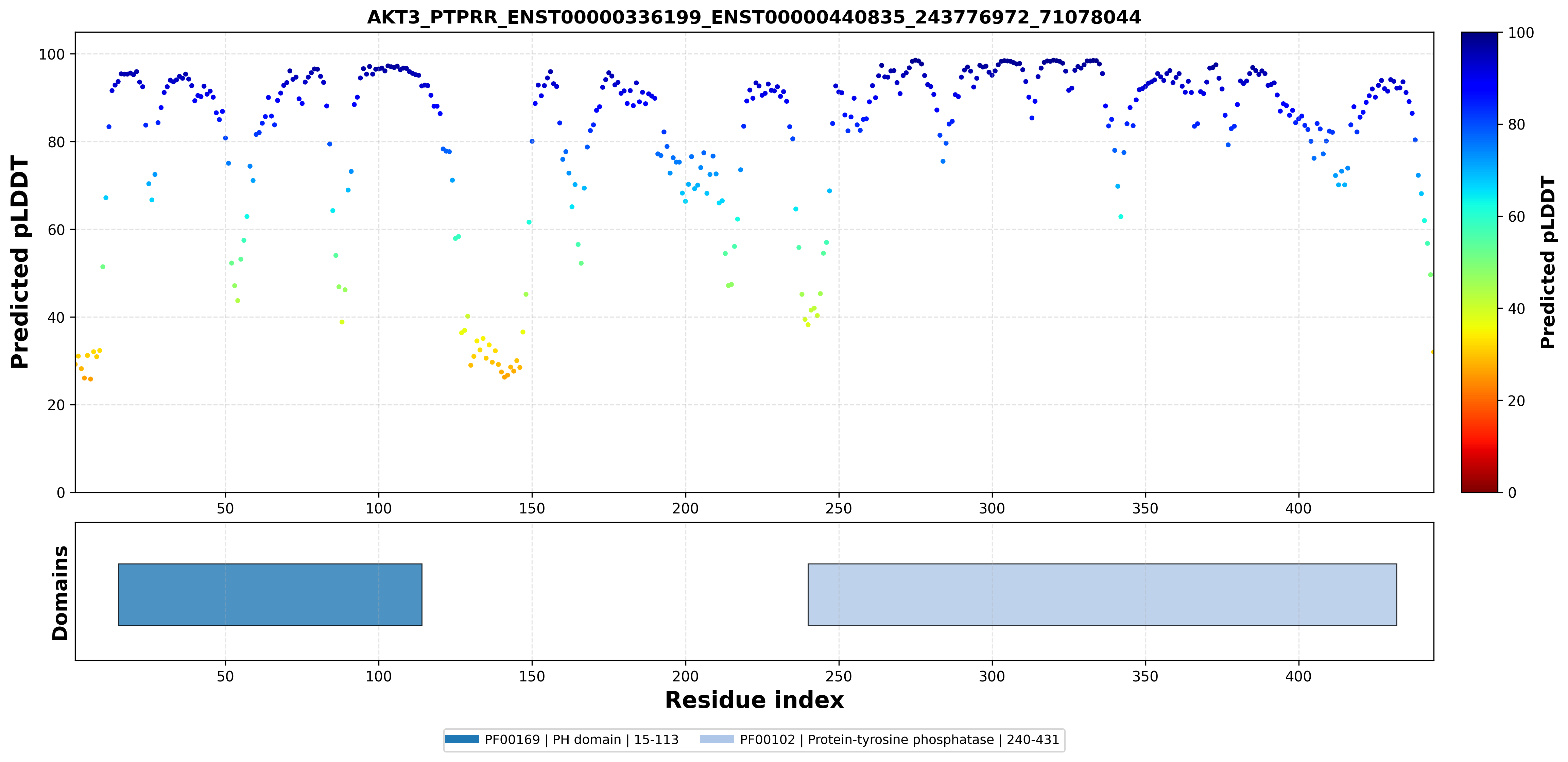 |  |  |
| AKT3_PTPRR_ENST00000336199_ENST00000440835_243776972_71078044 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4832
Å |
| | | |  |
| ALB_ADH1C_ENST00000509063_ENST00000515683_74272478_100264212 superimposed PDB: 1U3W of partner (ADH1C). RMSD:0.5788
Å |
 |  |  |  |  |
| ALCAM_PIEZO2_ENST00000306107_ENST00000503781_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:2.0101
Å |
 | 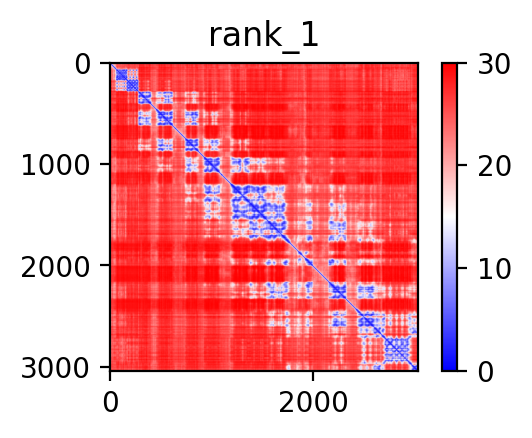 | 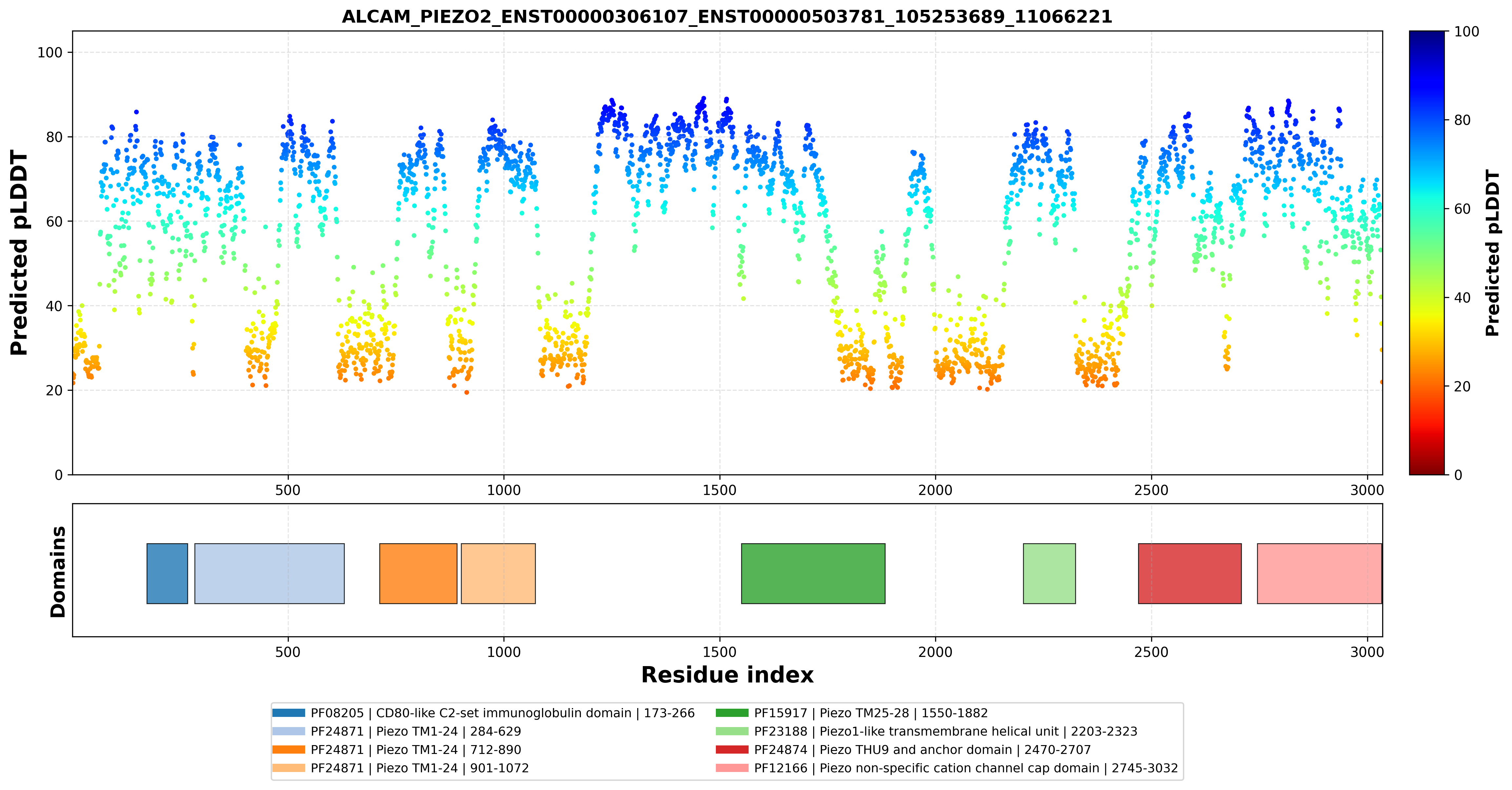 | 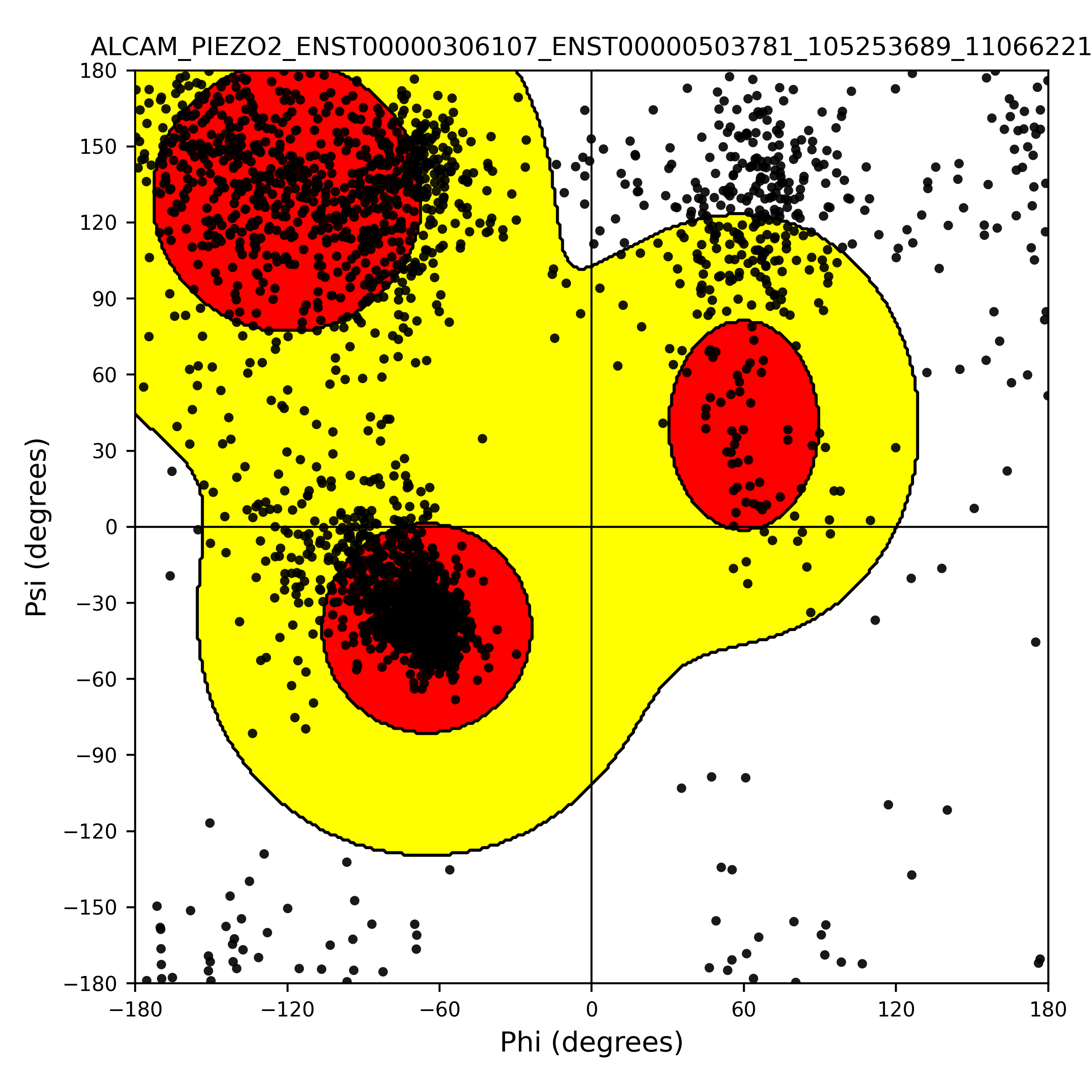 | 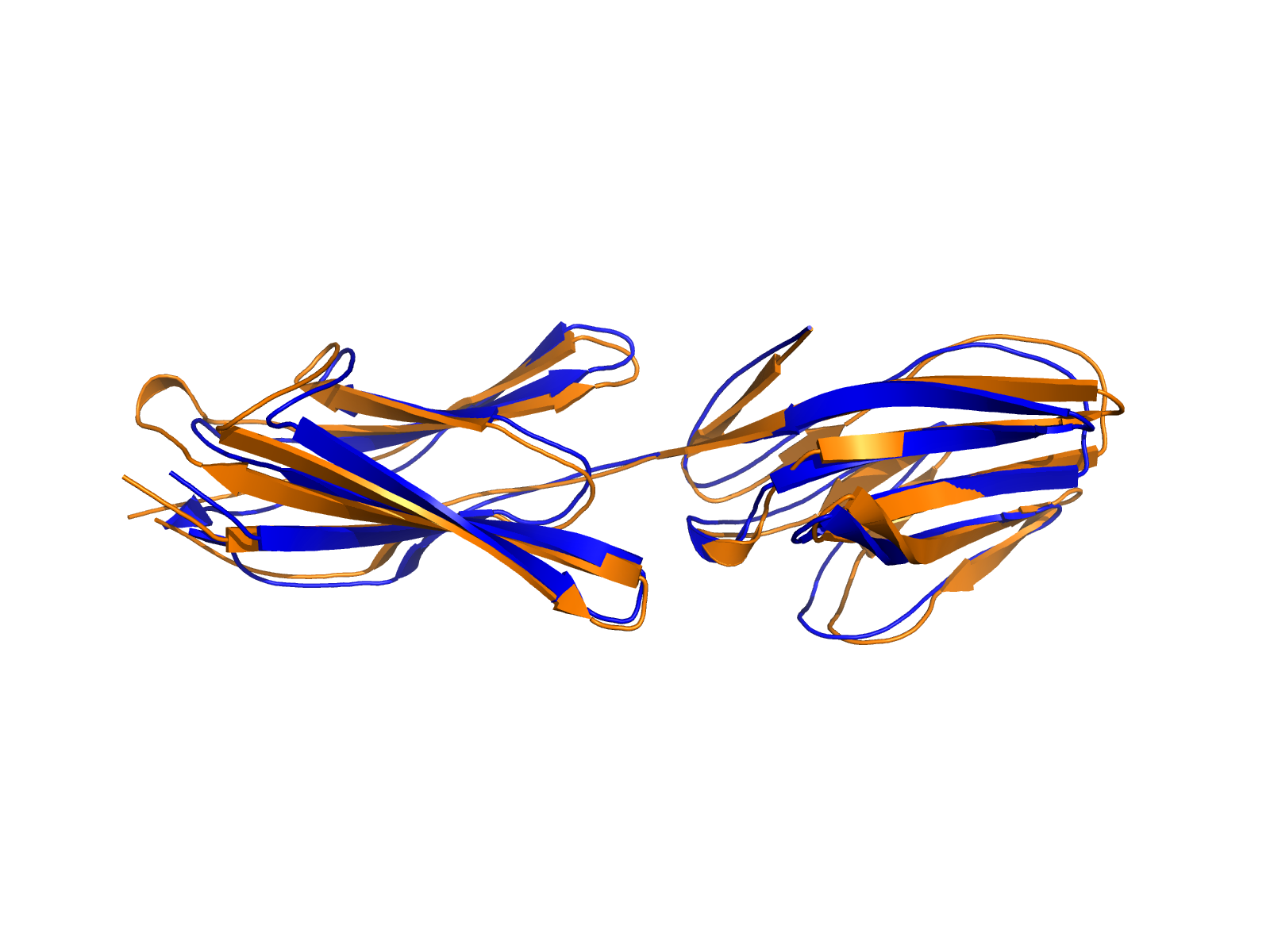 |
| ALCAM_PIEZO2_ENST00000306107_ENST00000503781_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.9212
Å |
| | | | 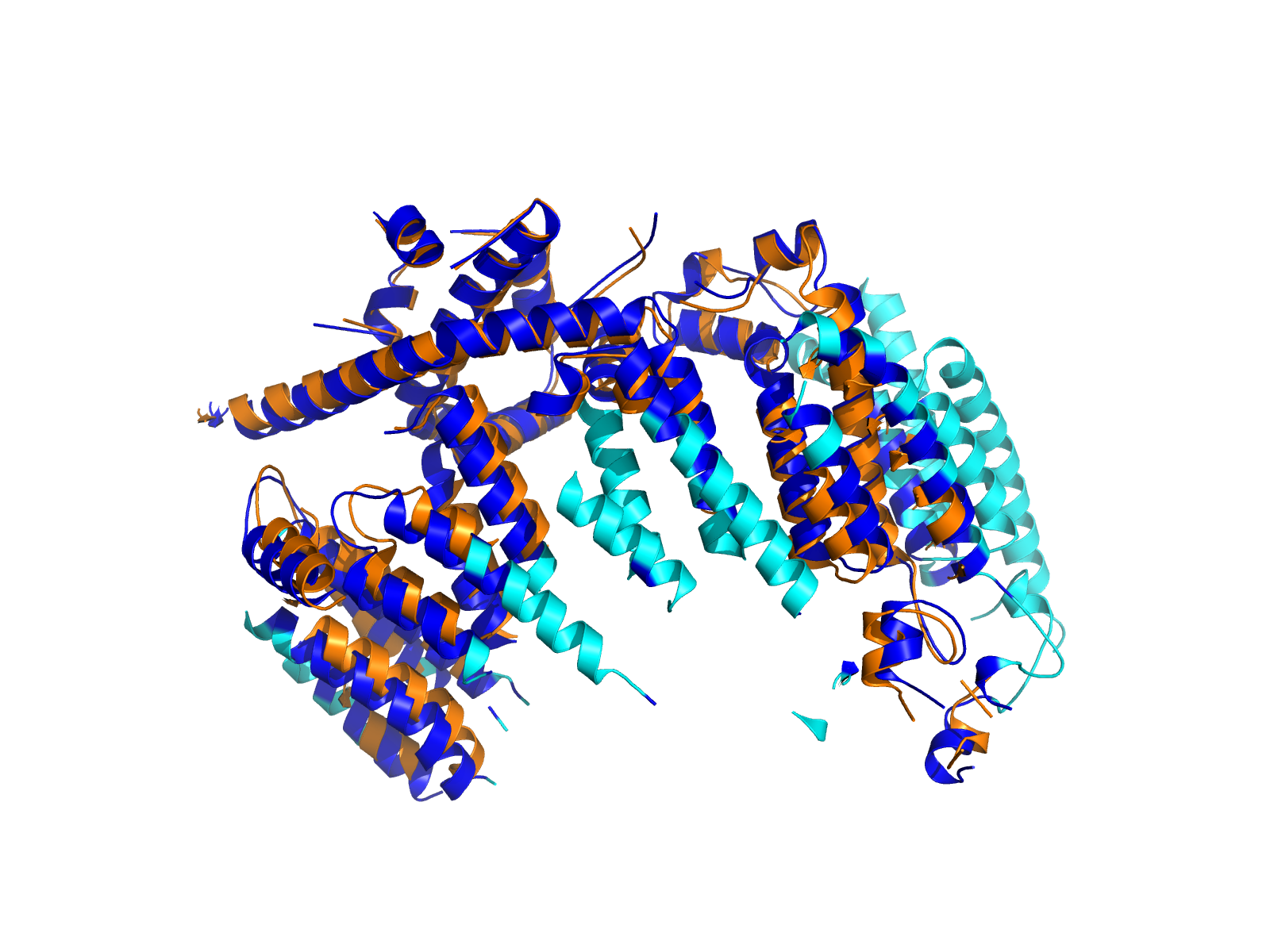 |
| ALCAM_PIEZO2_ENST00000306107_ENST00000580640_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:2.0029
Å |
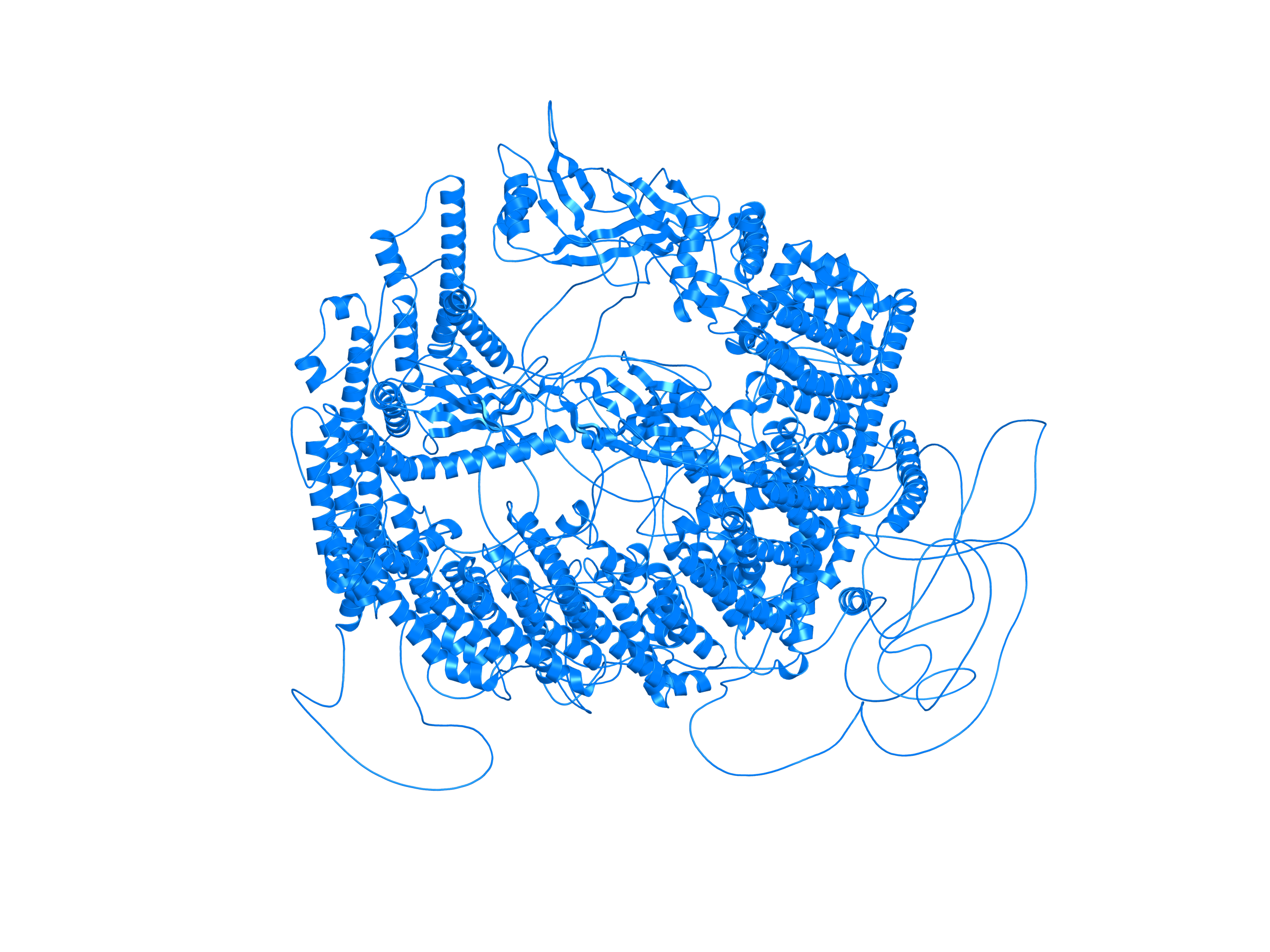 | 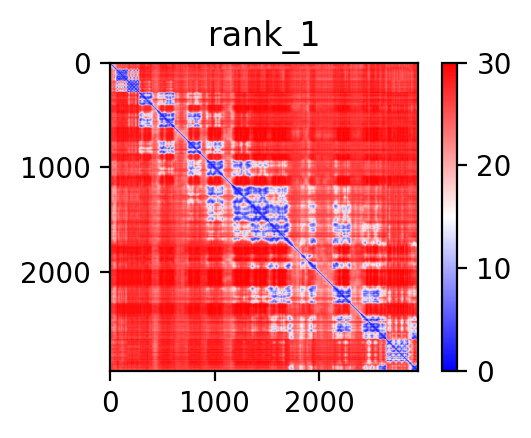 | 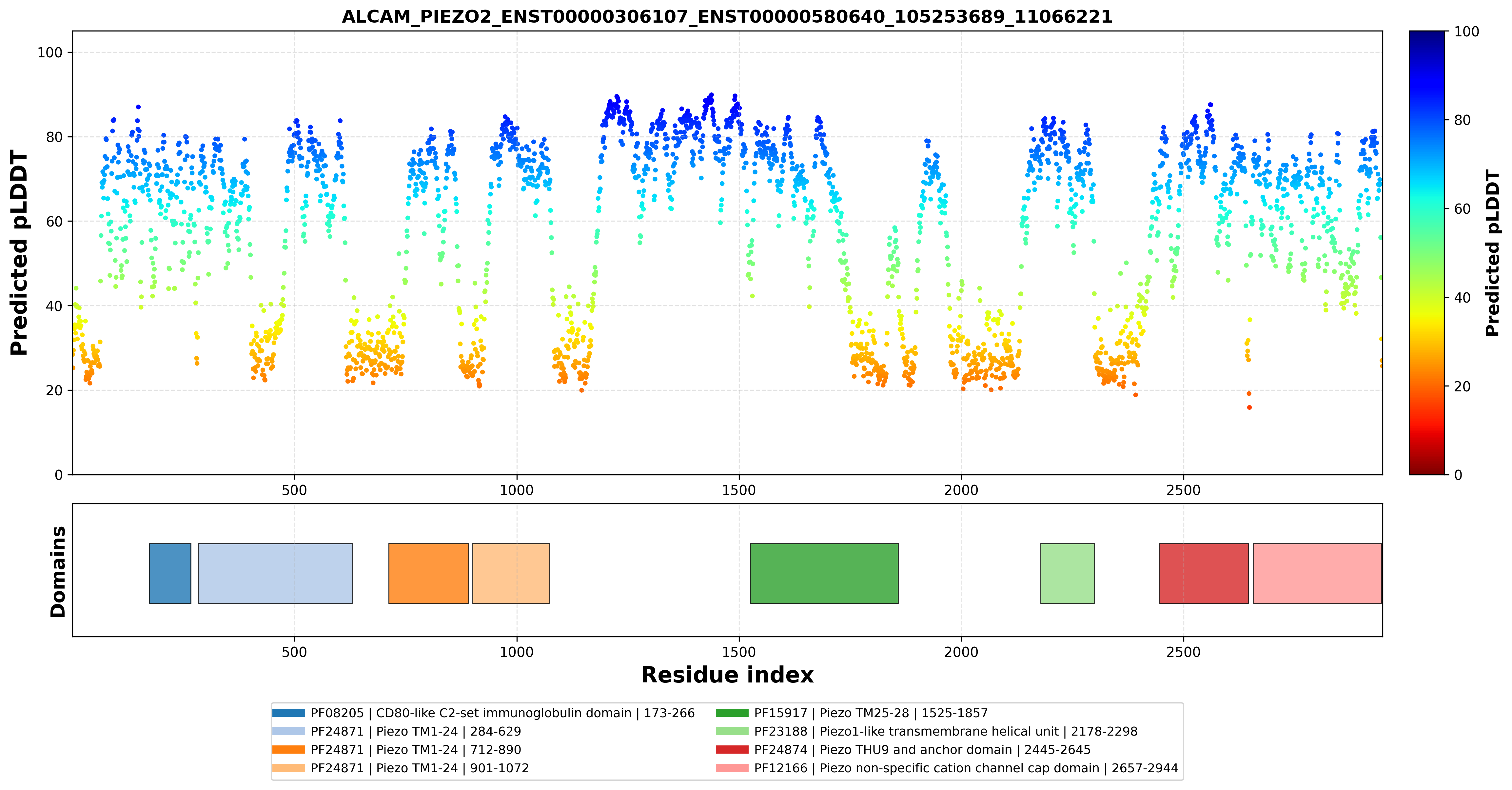 | 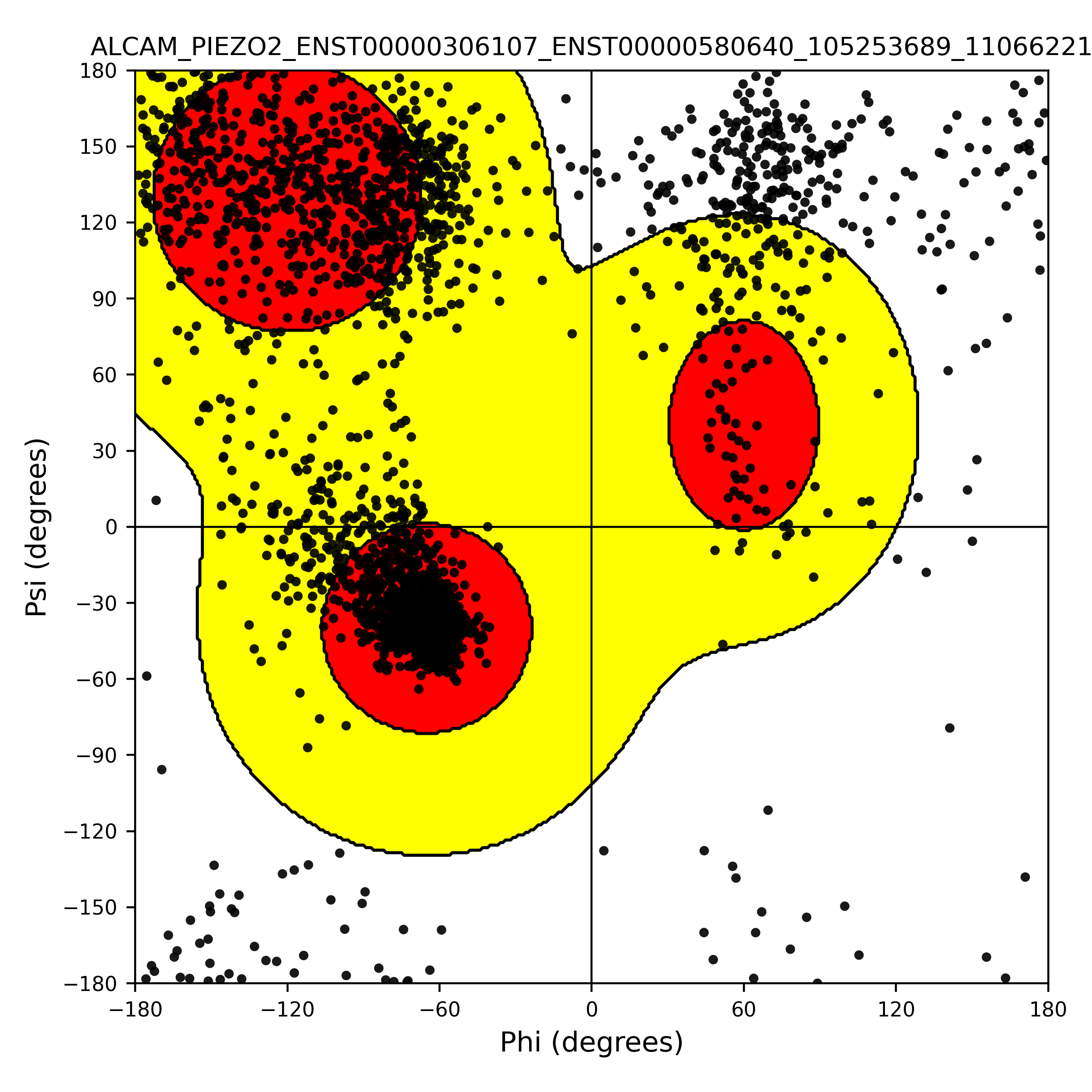 | 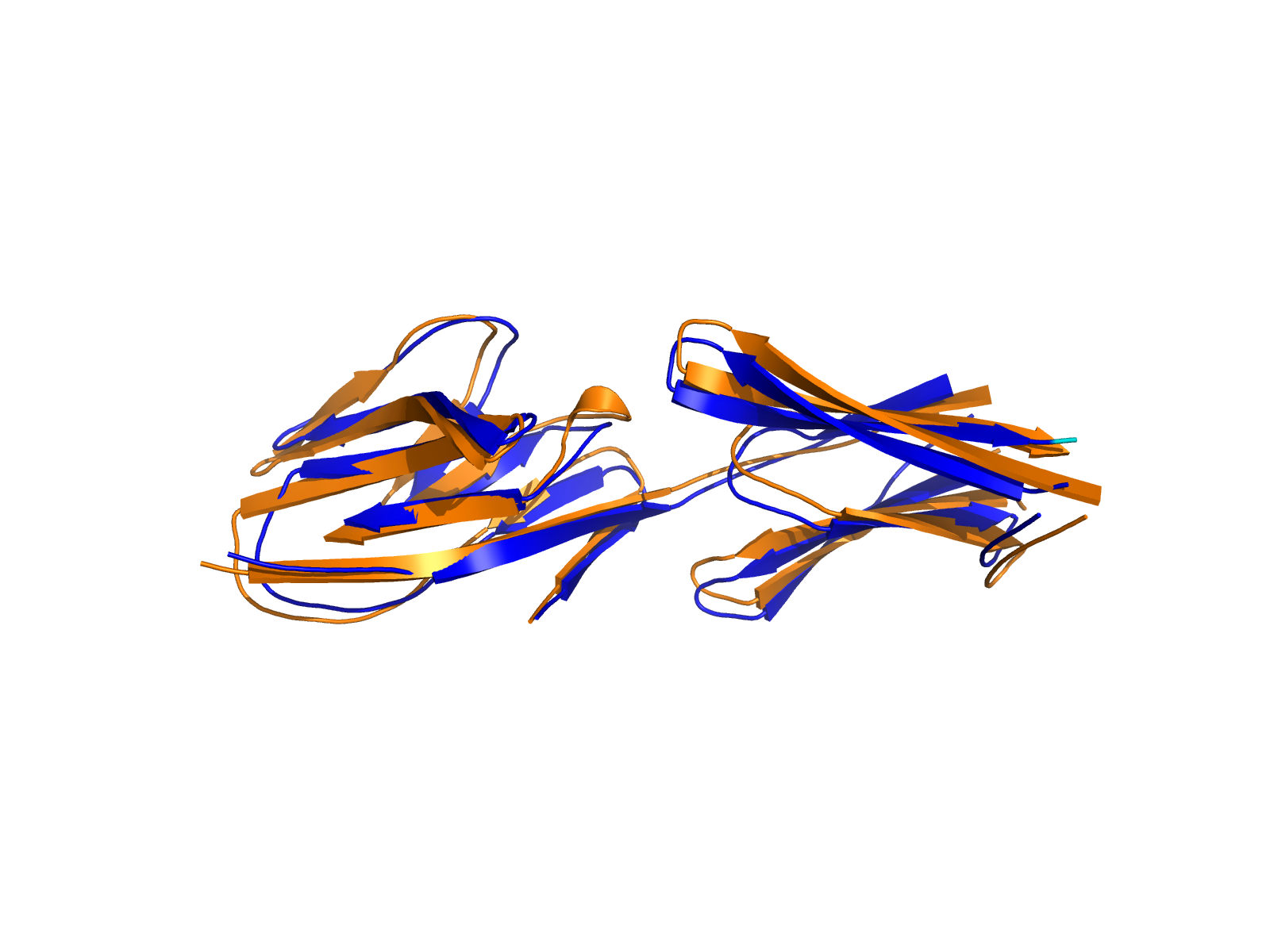 |
| ALCAM_PIEZO2_ENST00000306107_ENST00000580640_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.4802
Å |
| | | | 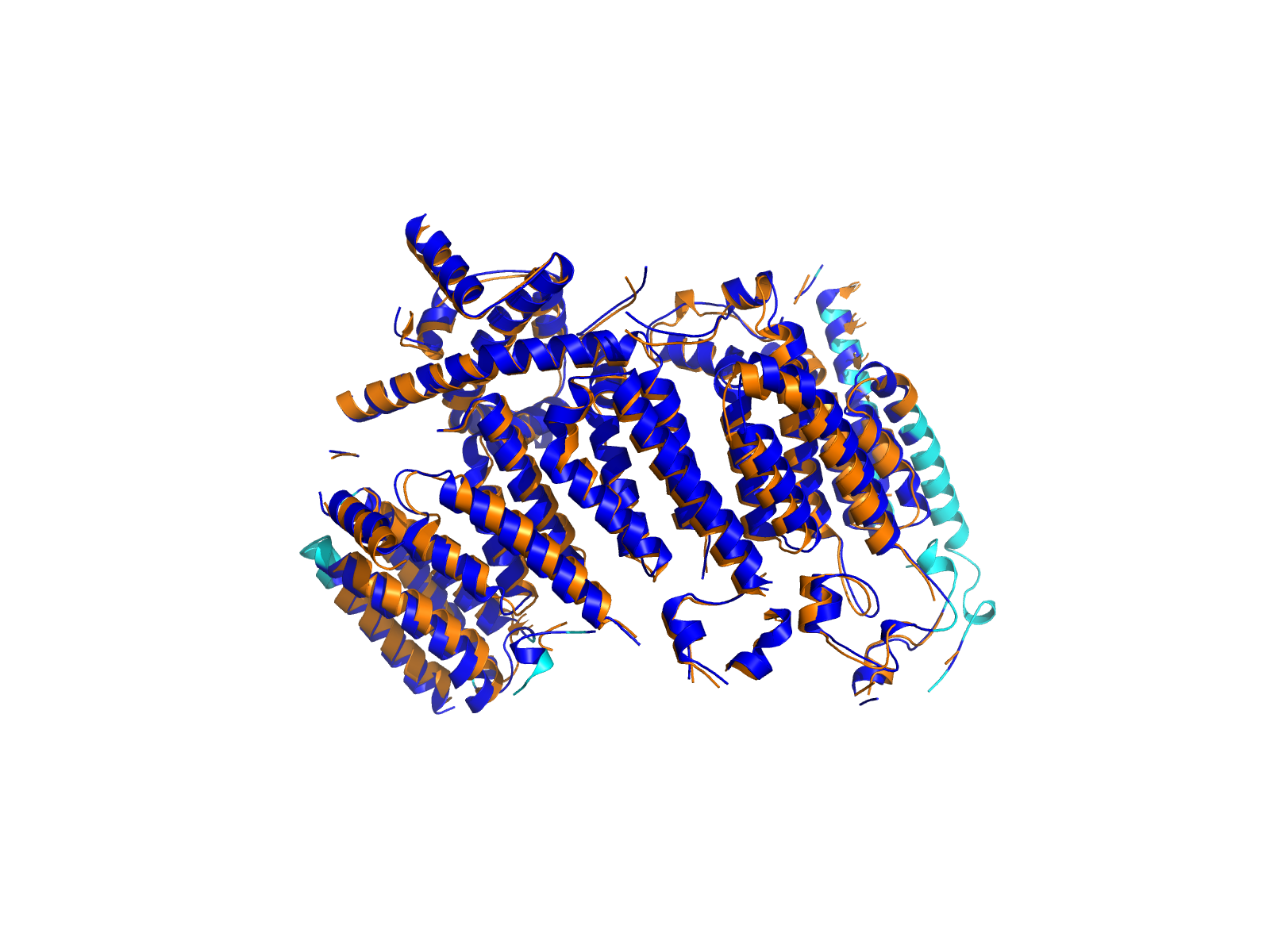 |
| ALCAM_PIEZO2_ENST00000389927_ENST00000302079_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:2.0153
Å |
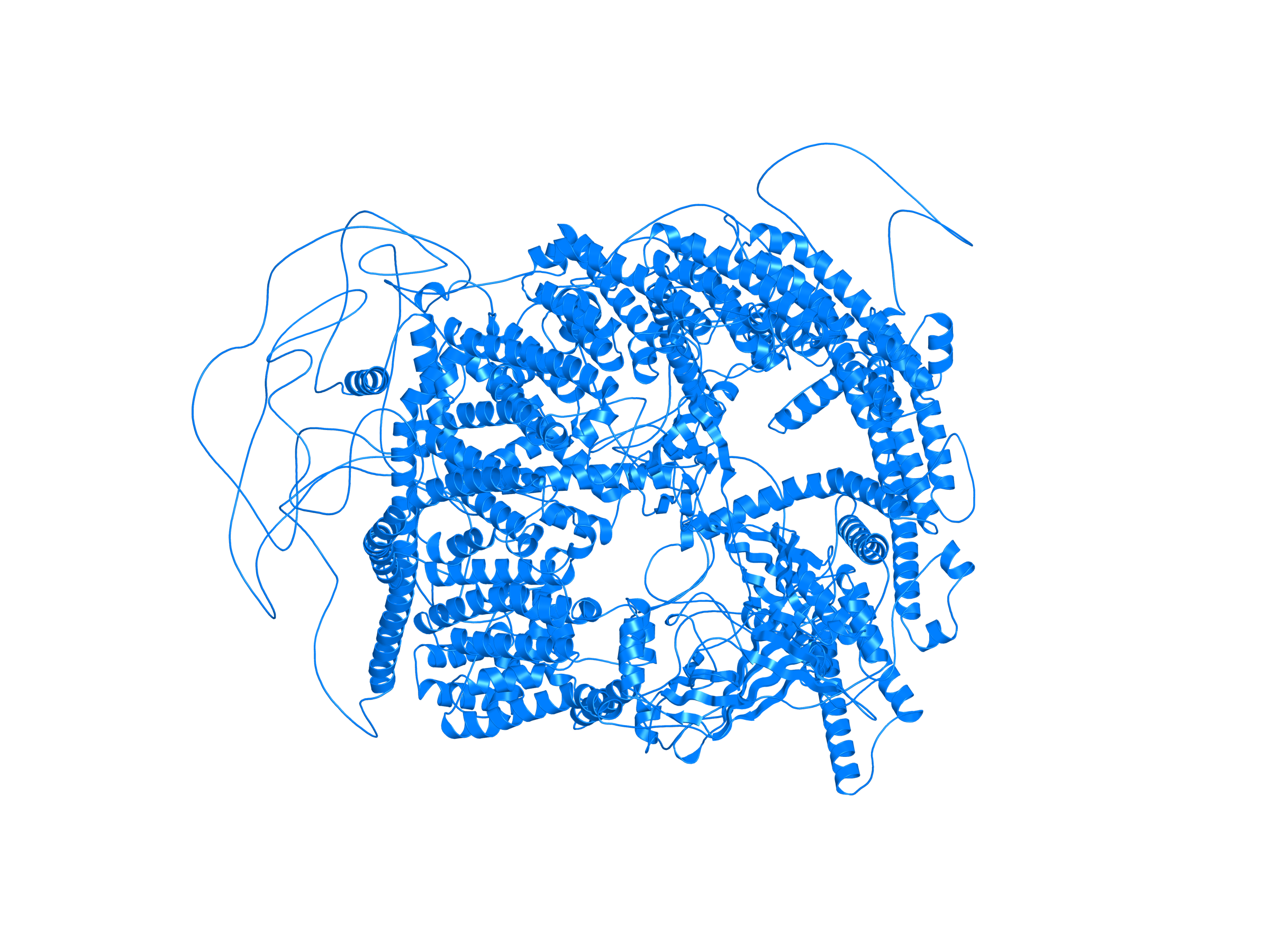 | 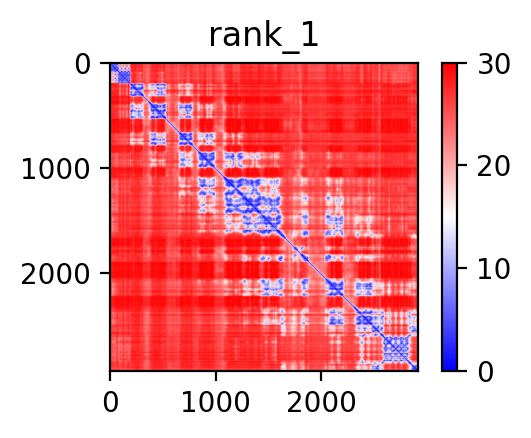 | 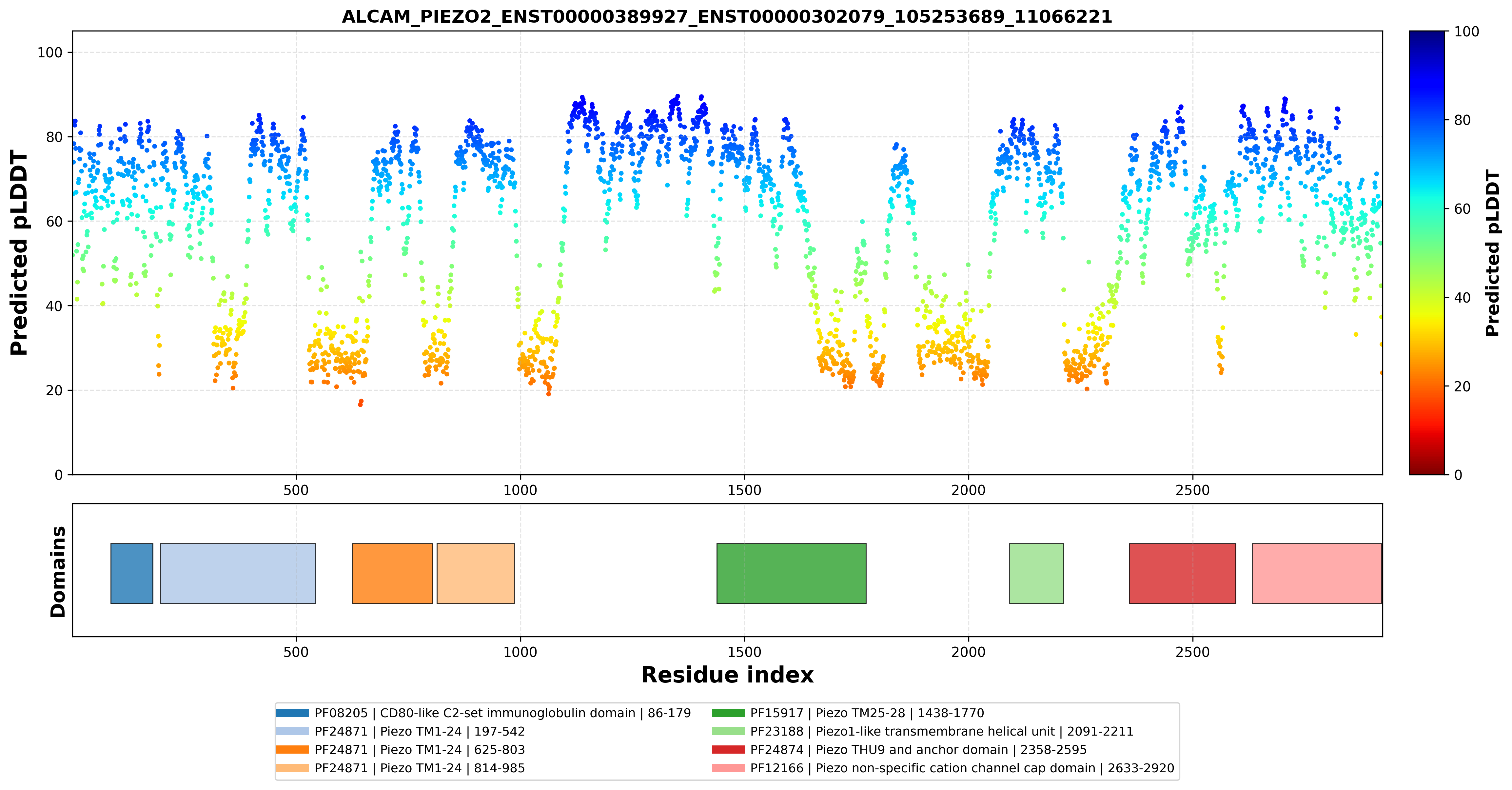 | 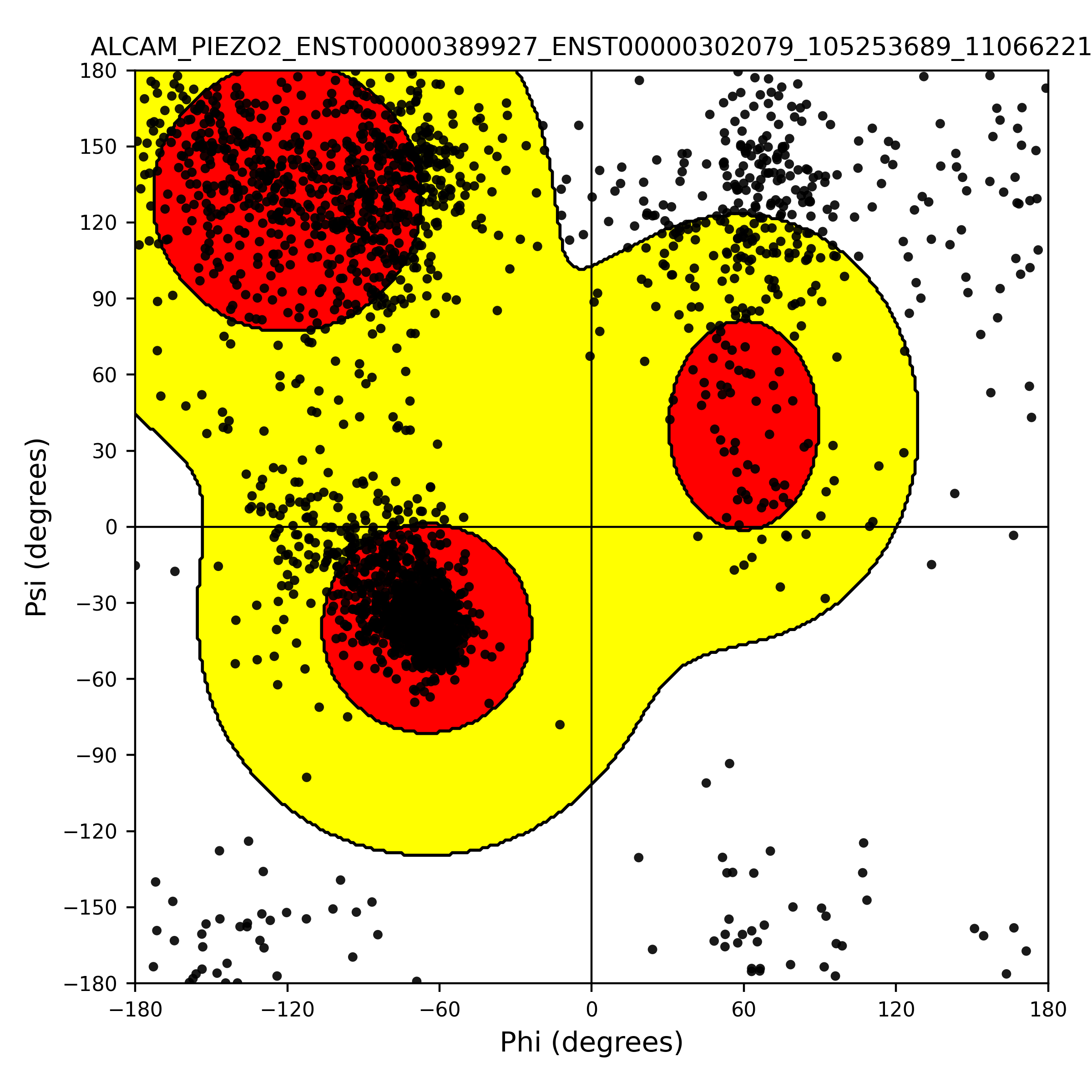 |  |
| ALCAM_PIEZO2_ENST00000389927_ENST00000302079_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.9715
Å |
| | | | 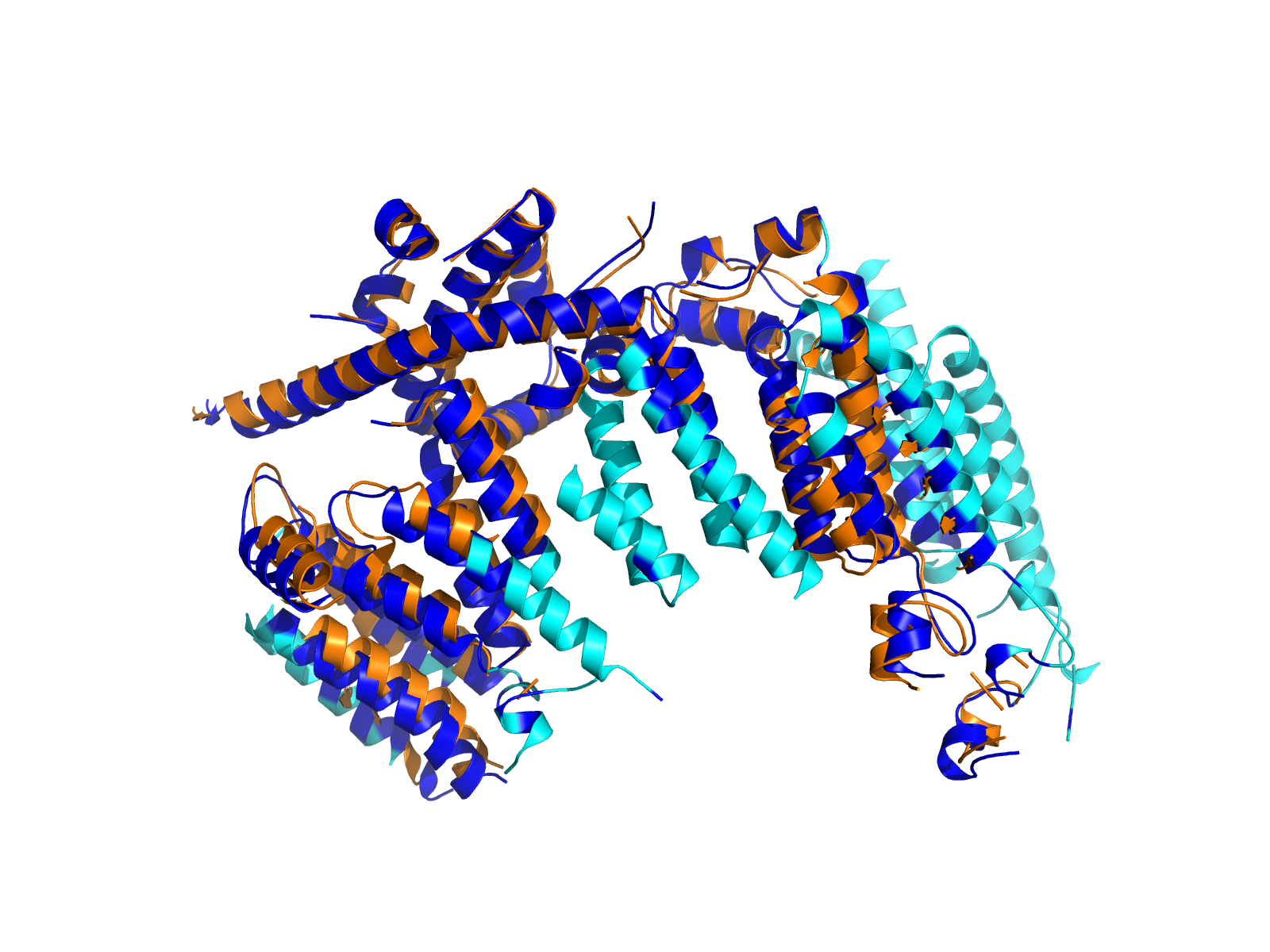 |
| ALCAM_PIEZO2_ENST00000389927_ENST00000503781_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.0306
Å |
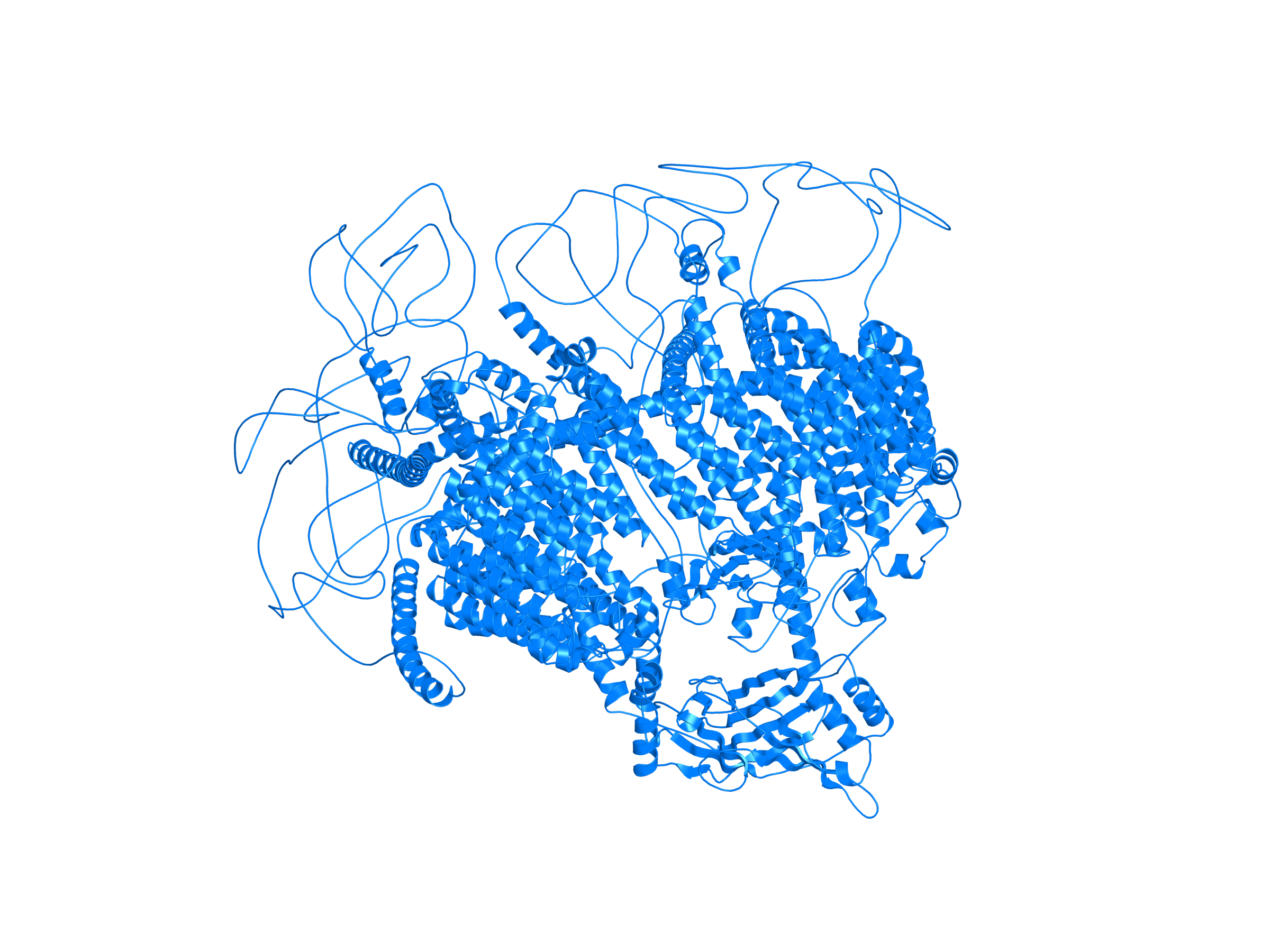 | 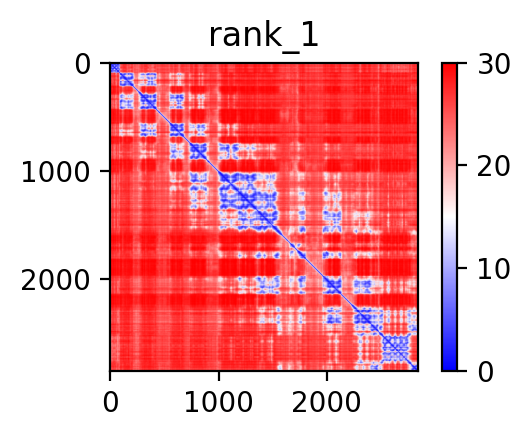 | 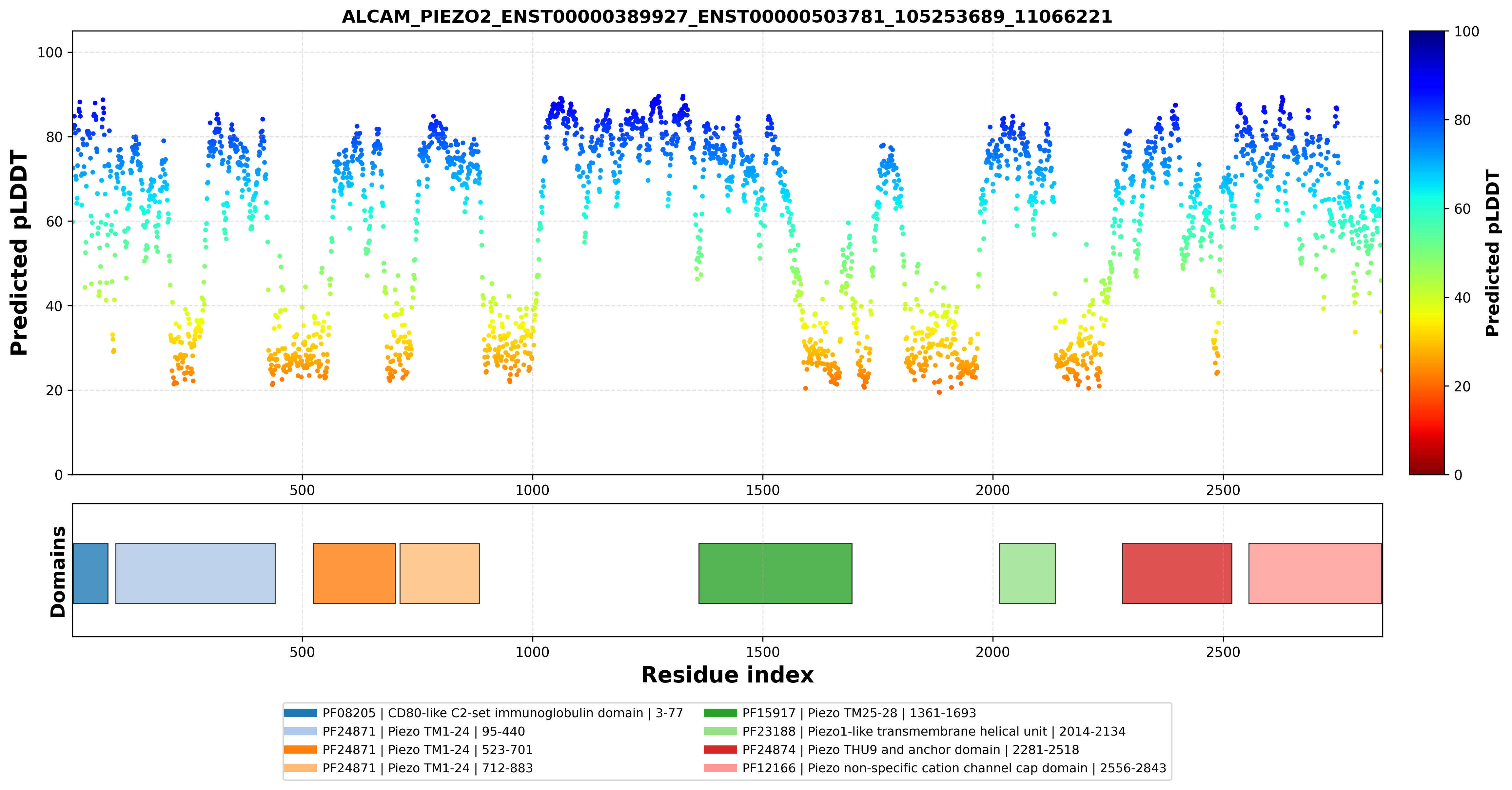 | 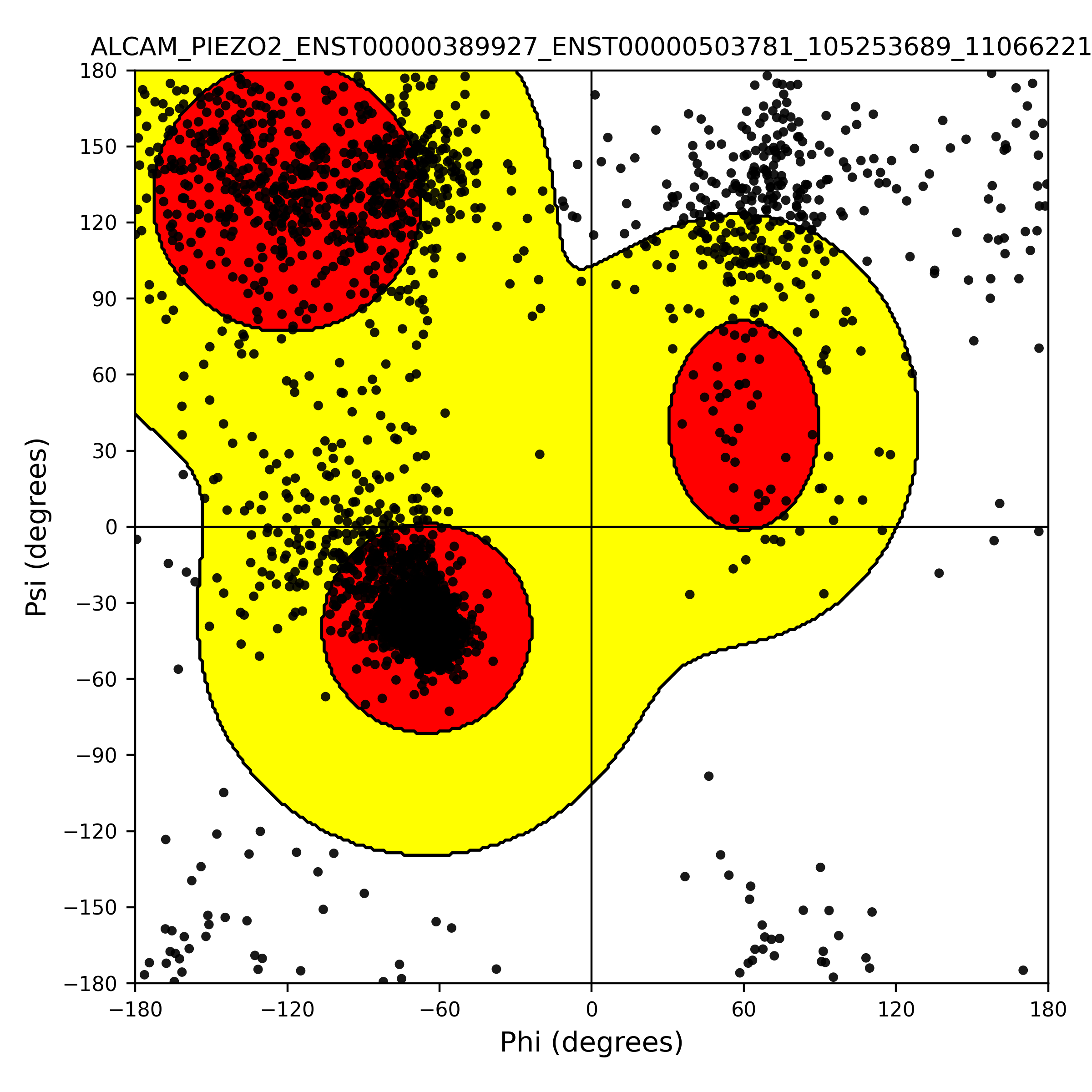 | 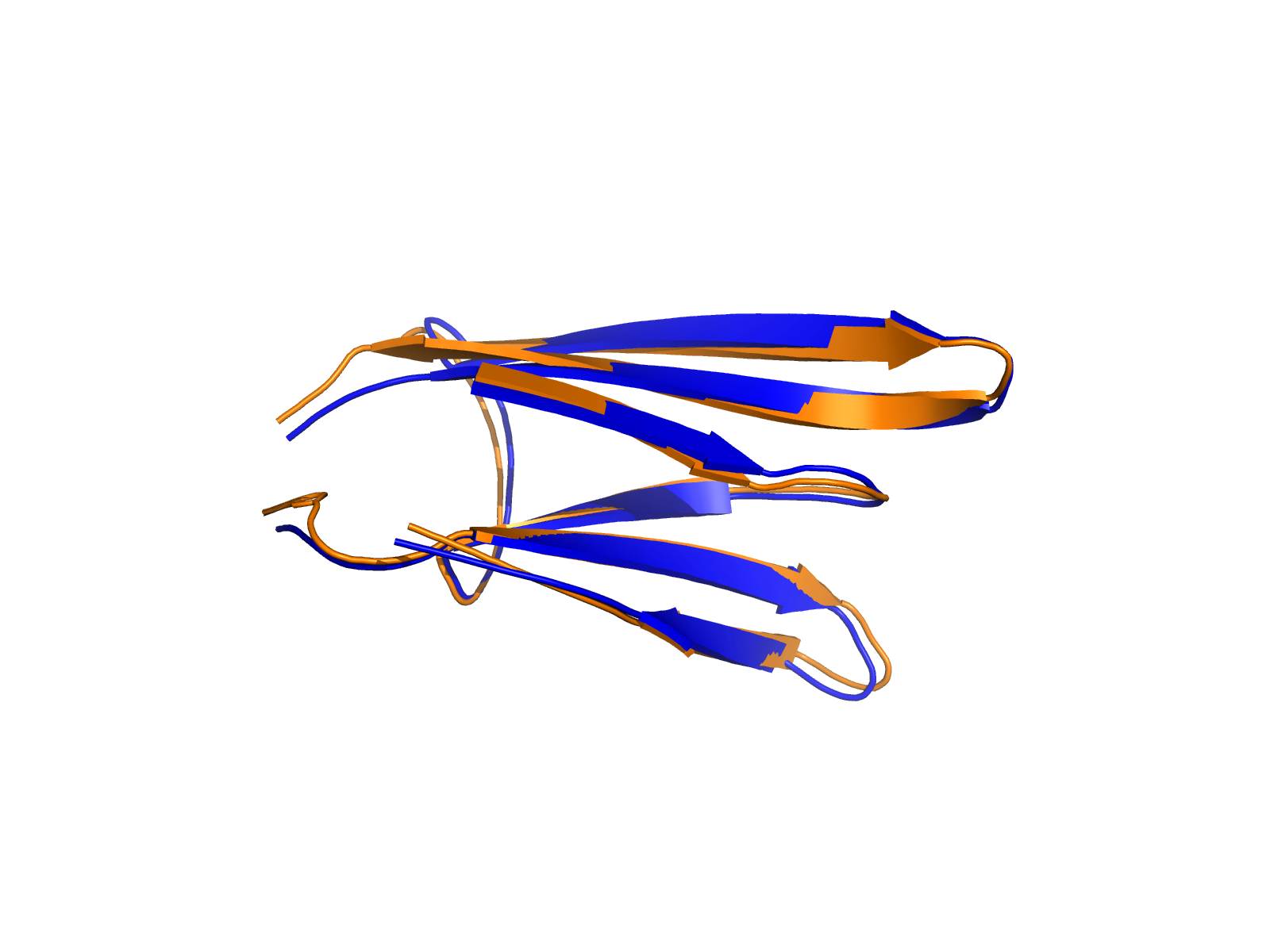 |
| ALCAM_PIEZO2_ENST00000389927_ENST00000503781_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:3.0031
Å |
| | | | 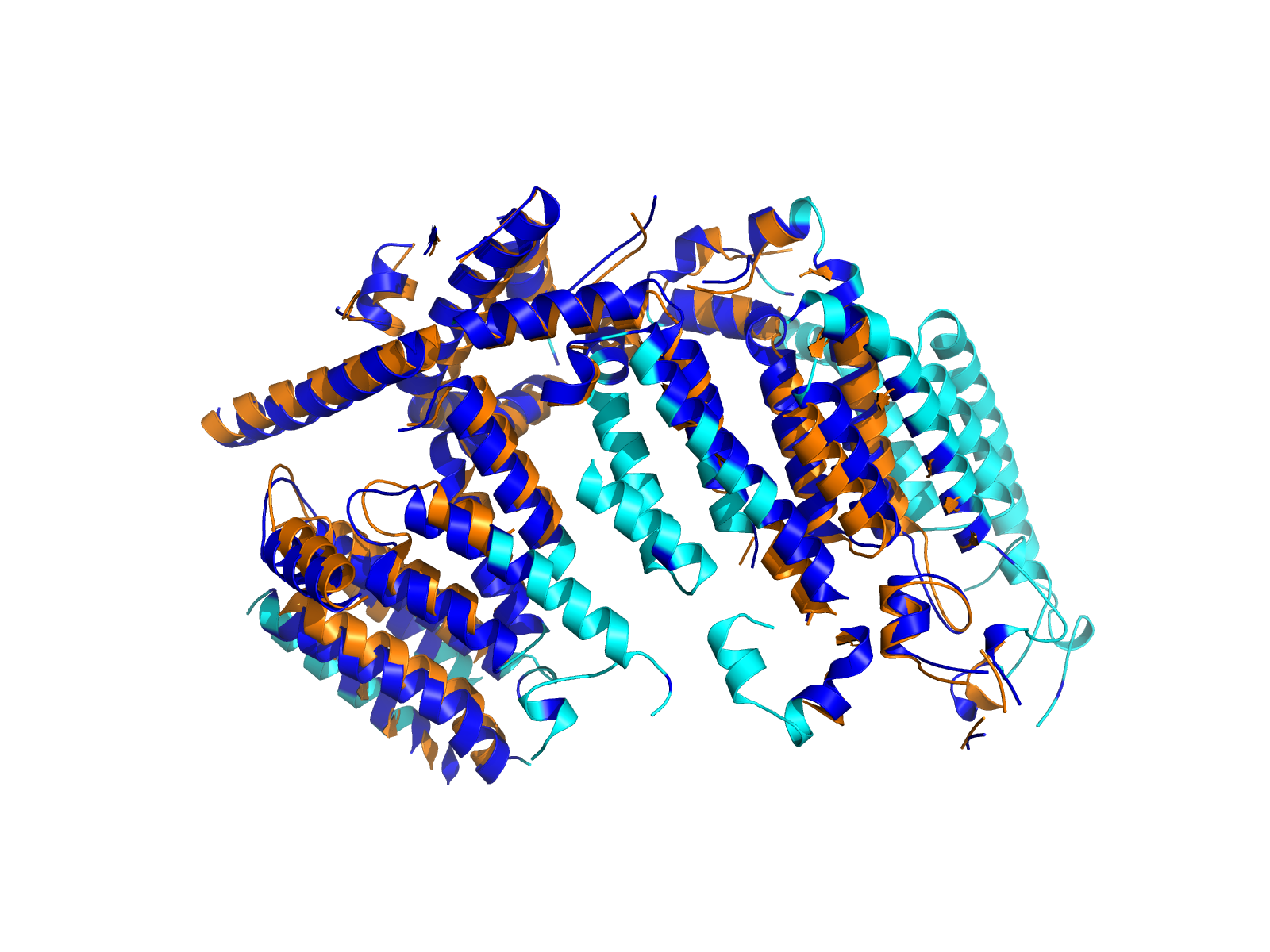 |
| ALCAM_PIEZO2_ENST00000389927_ENST00000580640_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.1896
Å |
 | 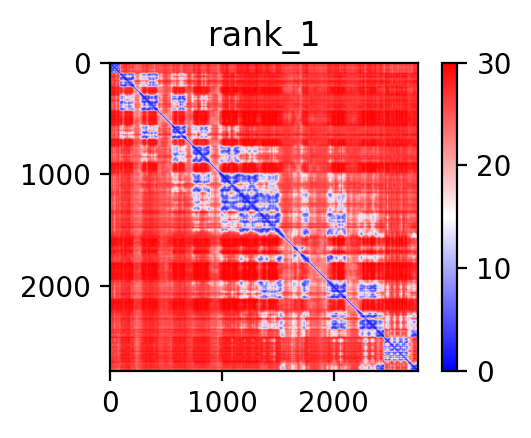 | 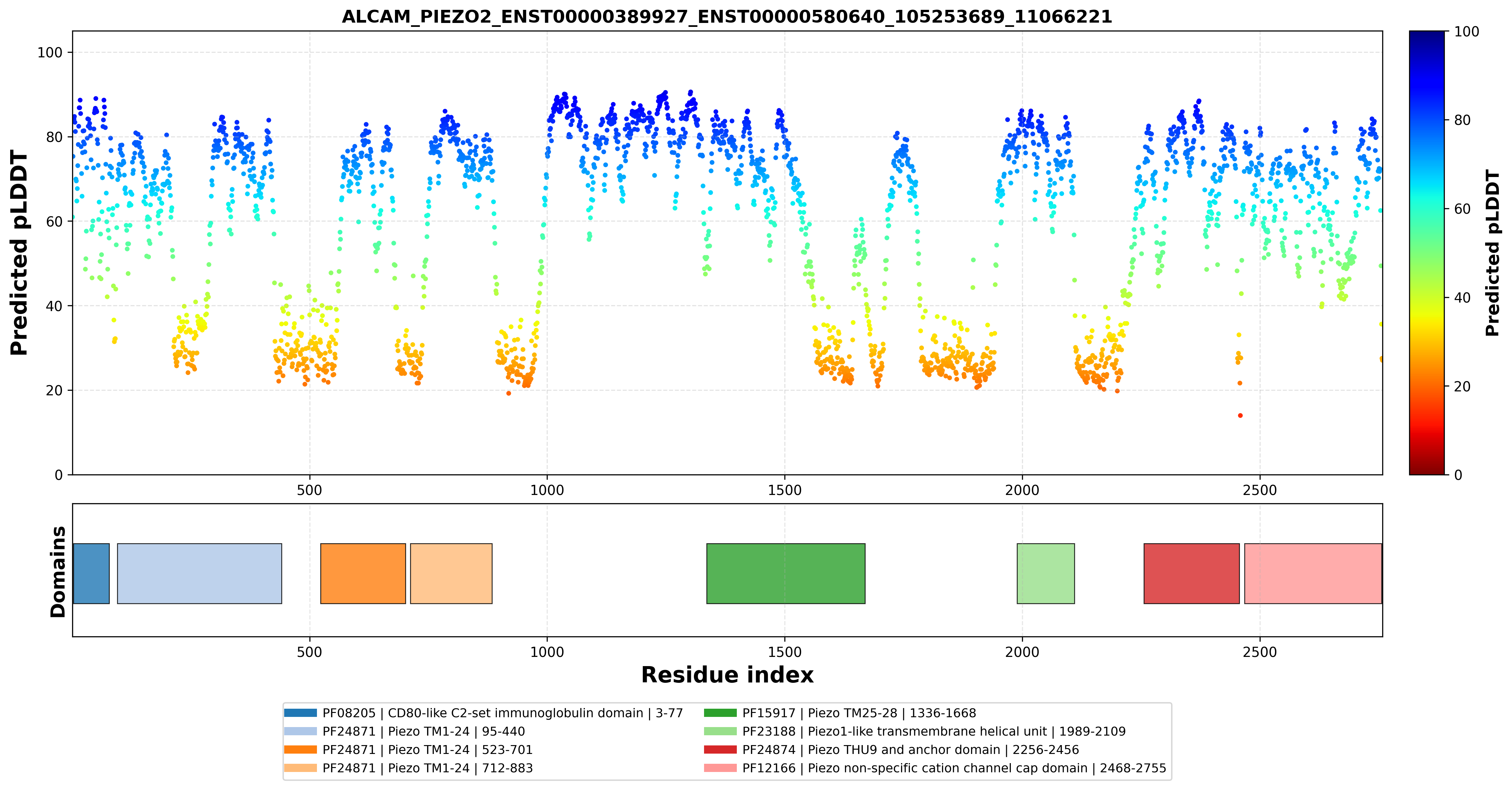 | 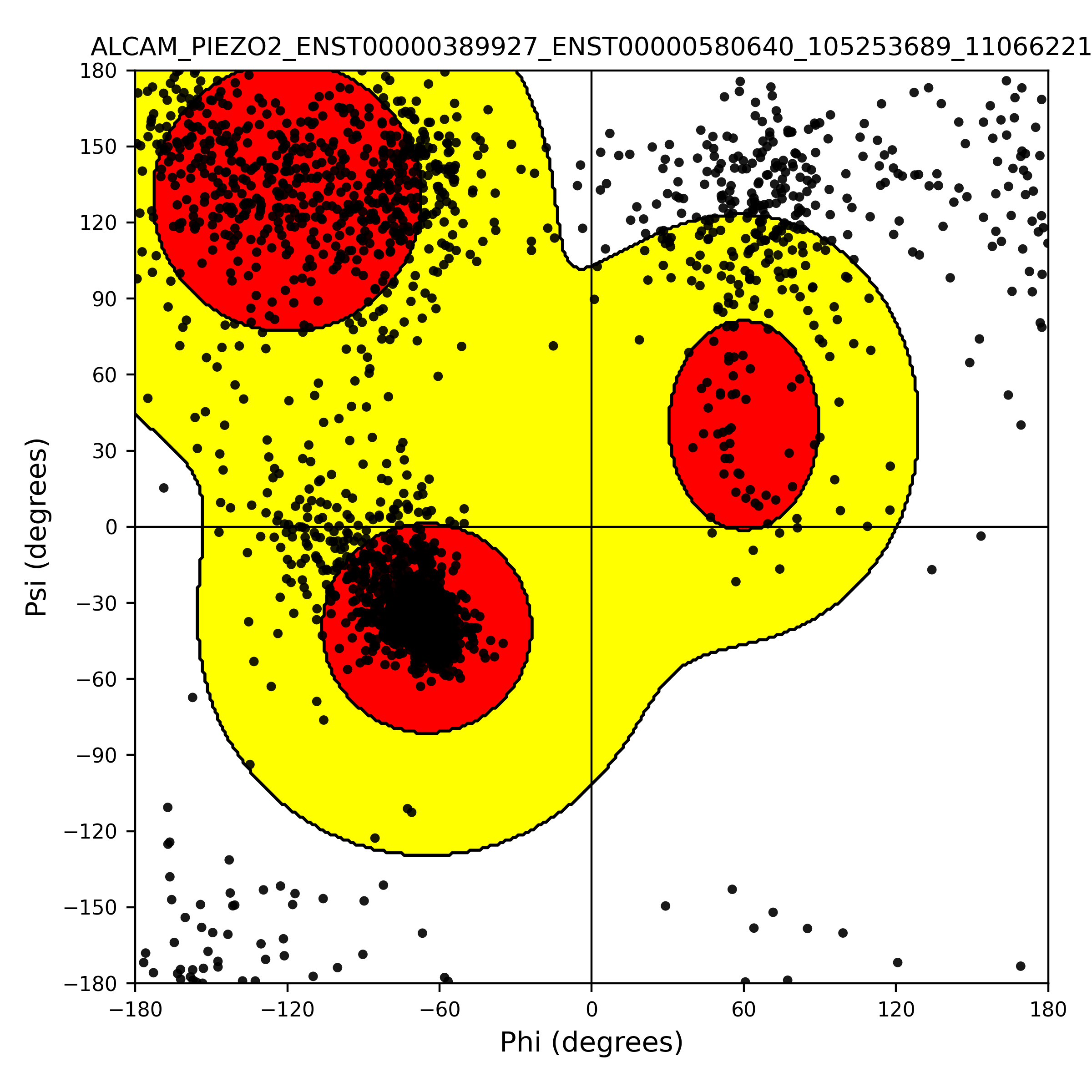 | 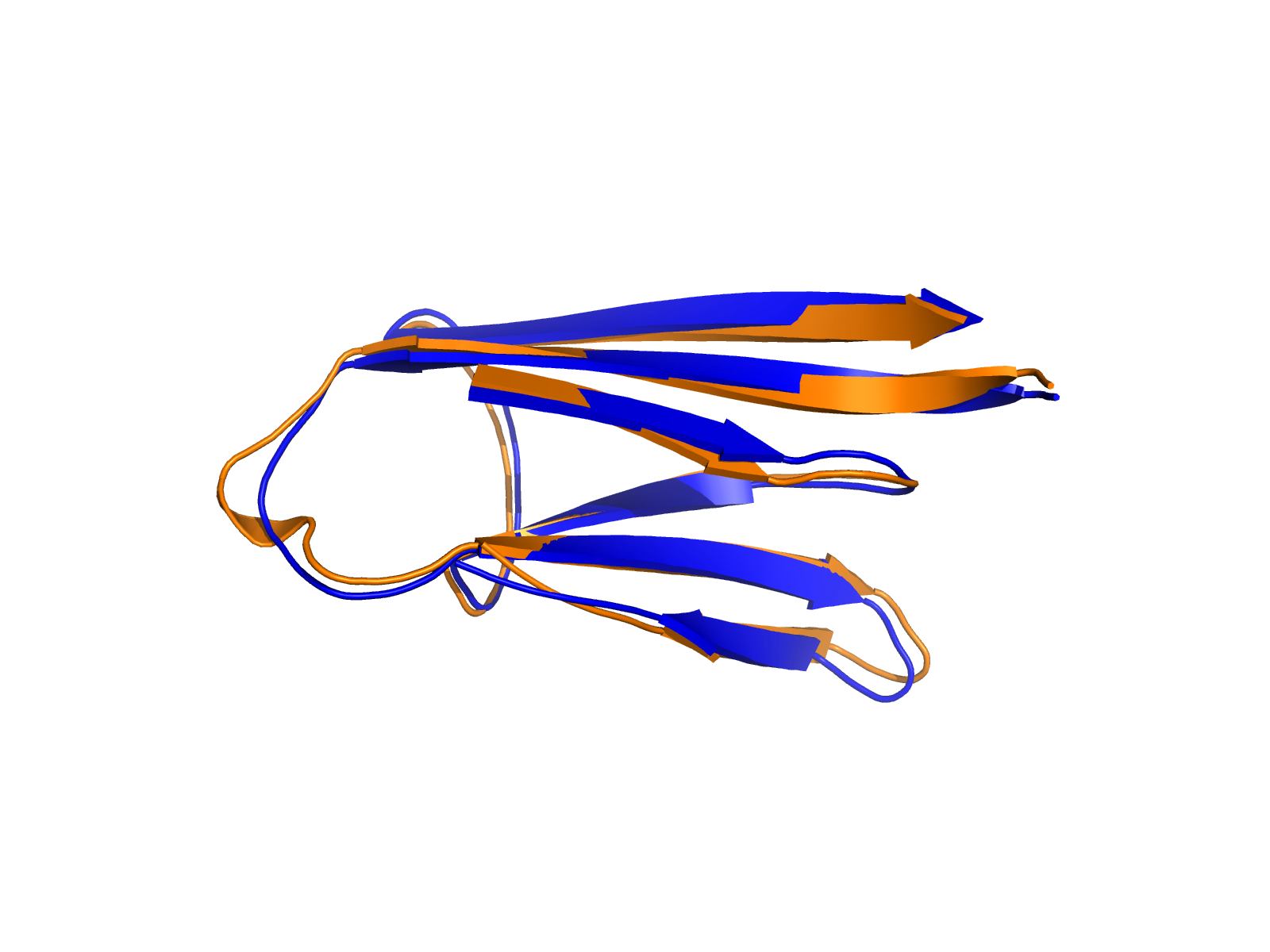 |
| ALCAM_PIEZO2_ENST00000389927_ENST00000580640_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.4024
Å |
| | | | 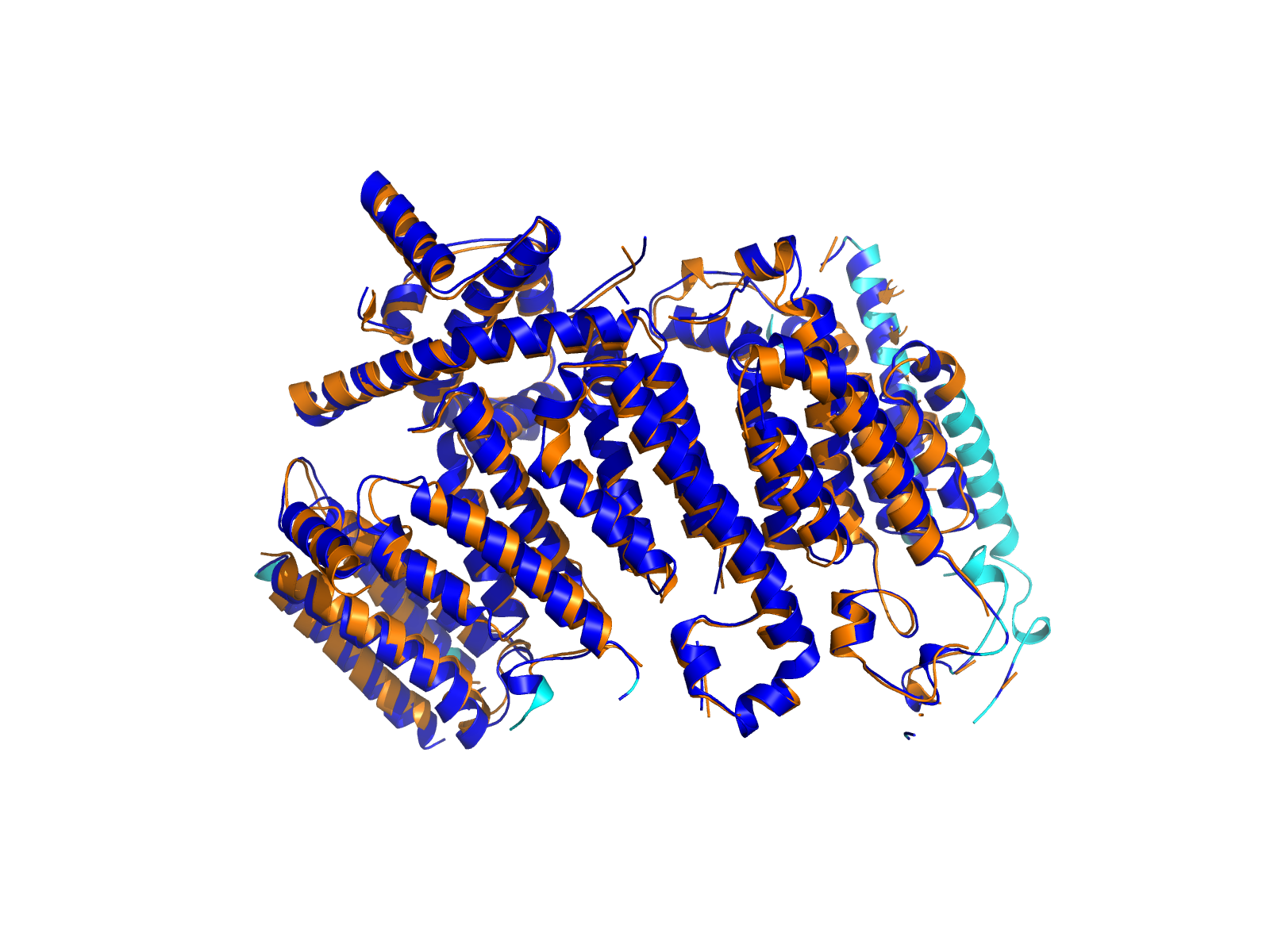 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000302079_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:2.0783
Å |
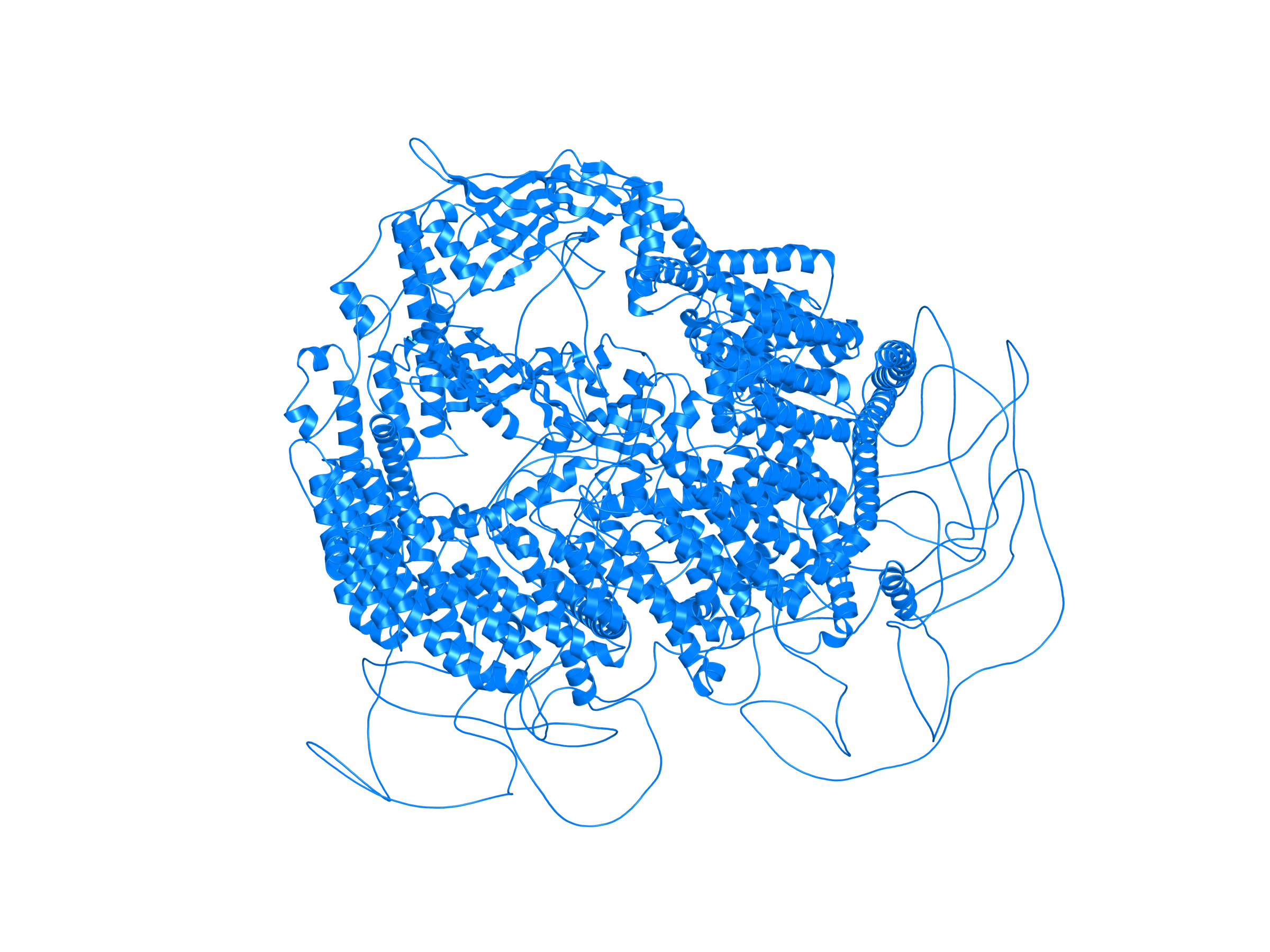 | 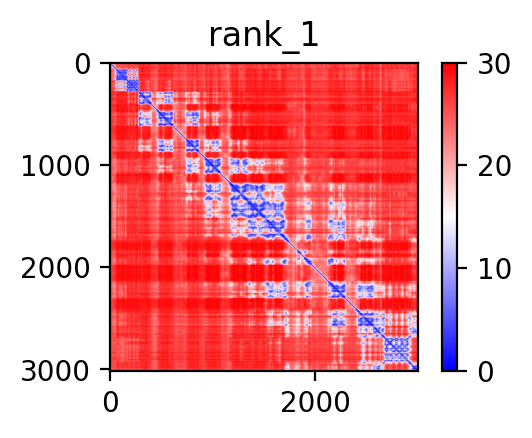 | 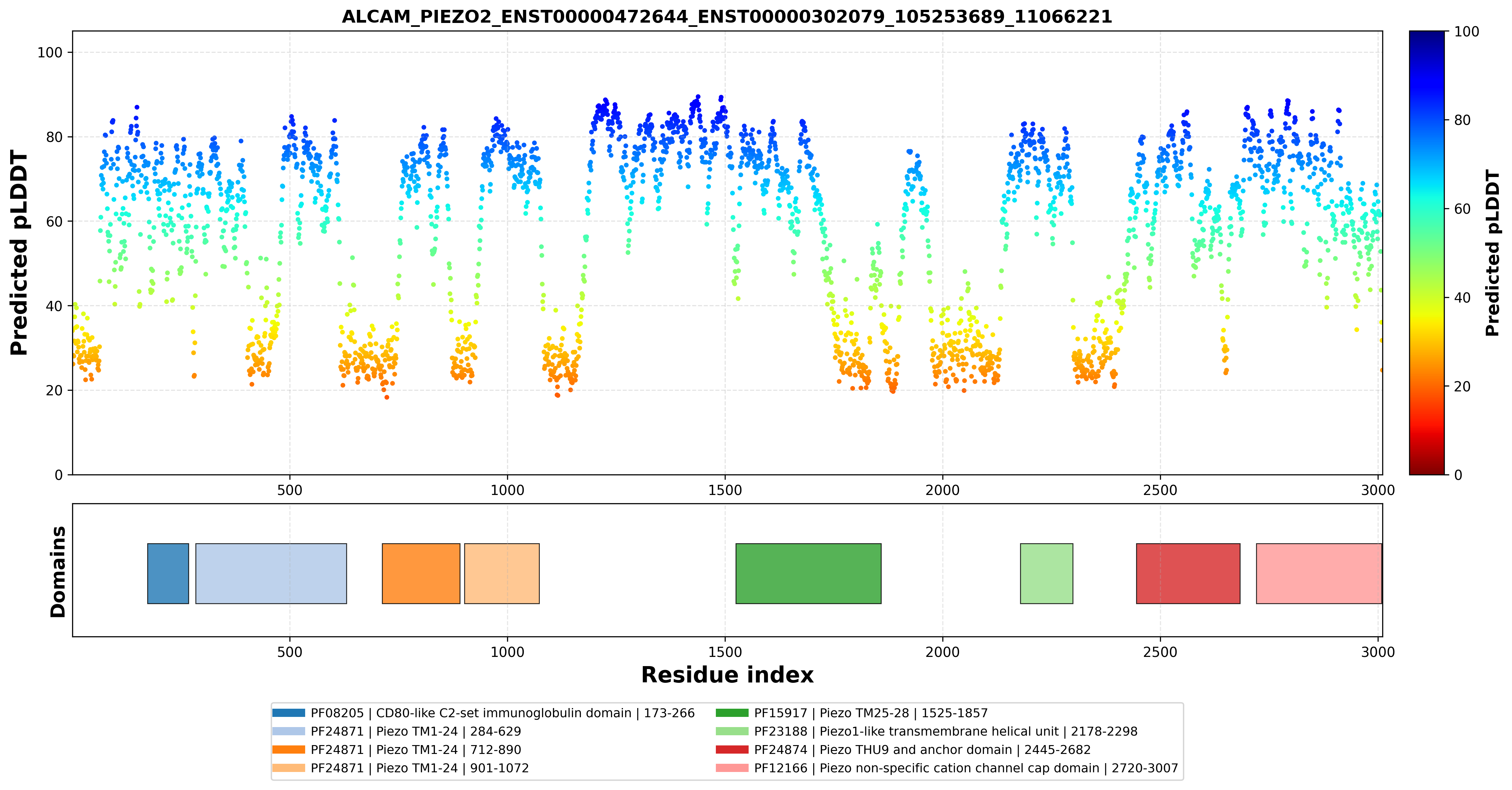 | 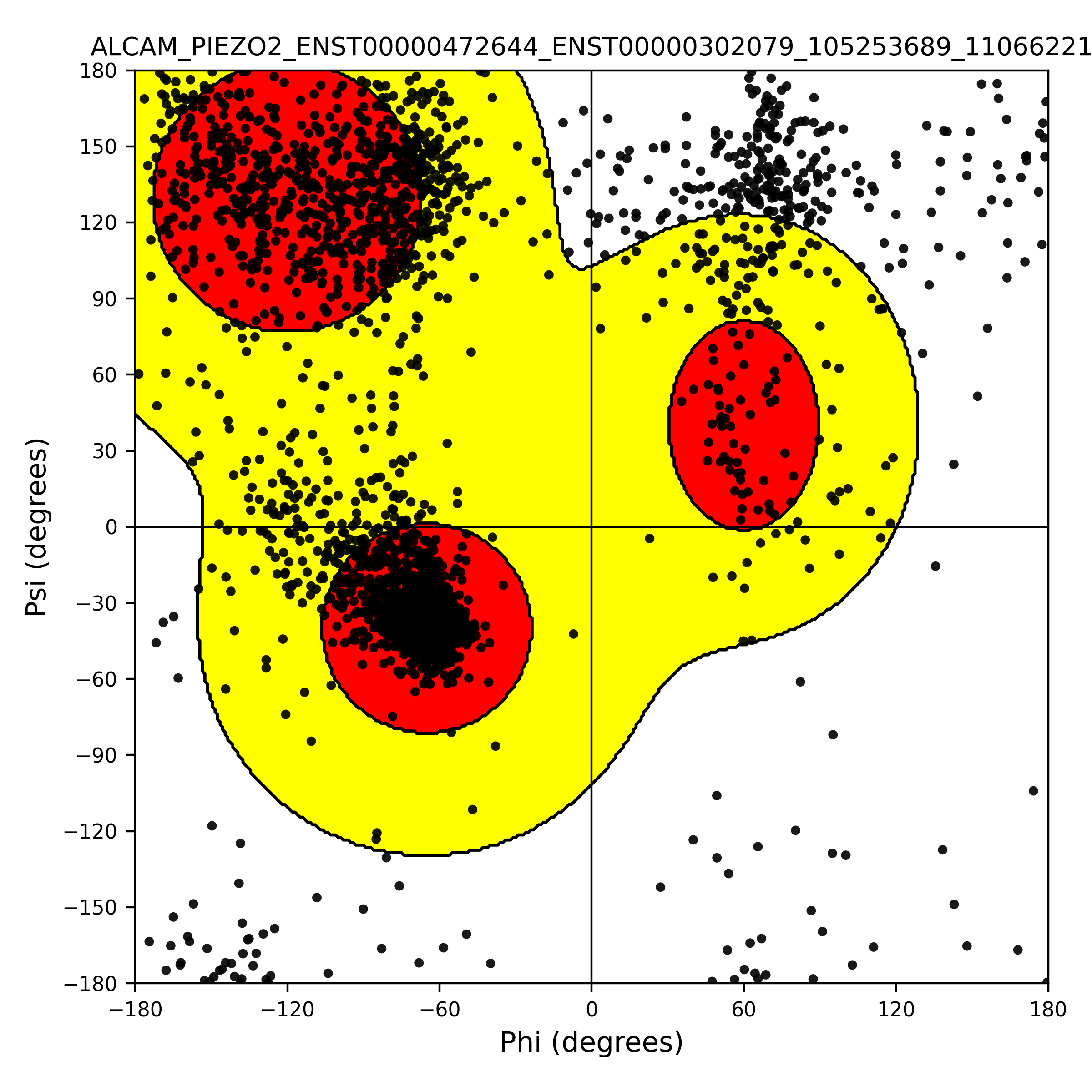 | 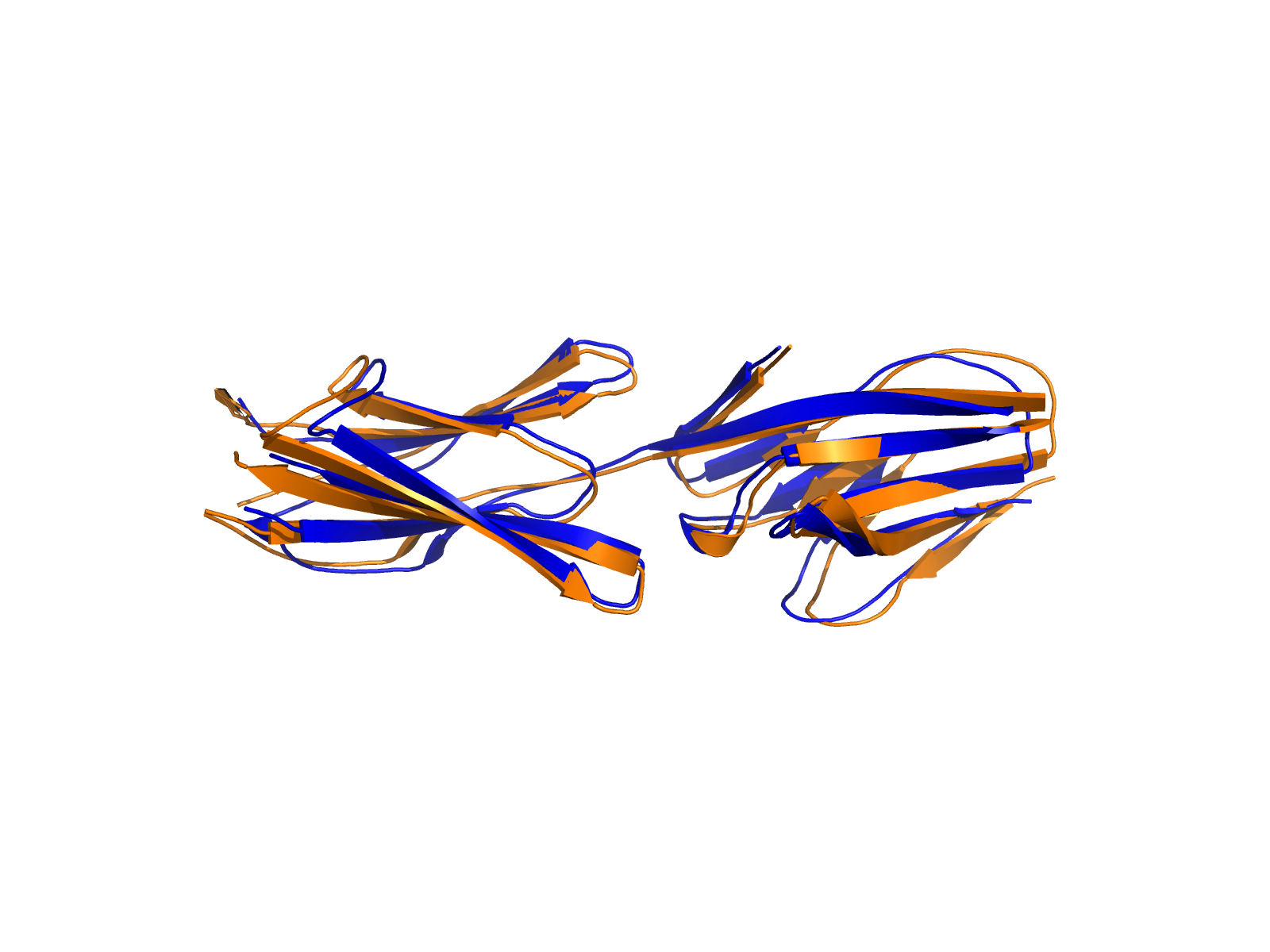 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000302079_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.9171
Å |
| | | | 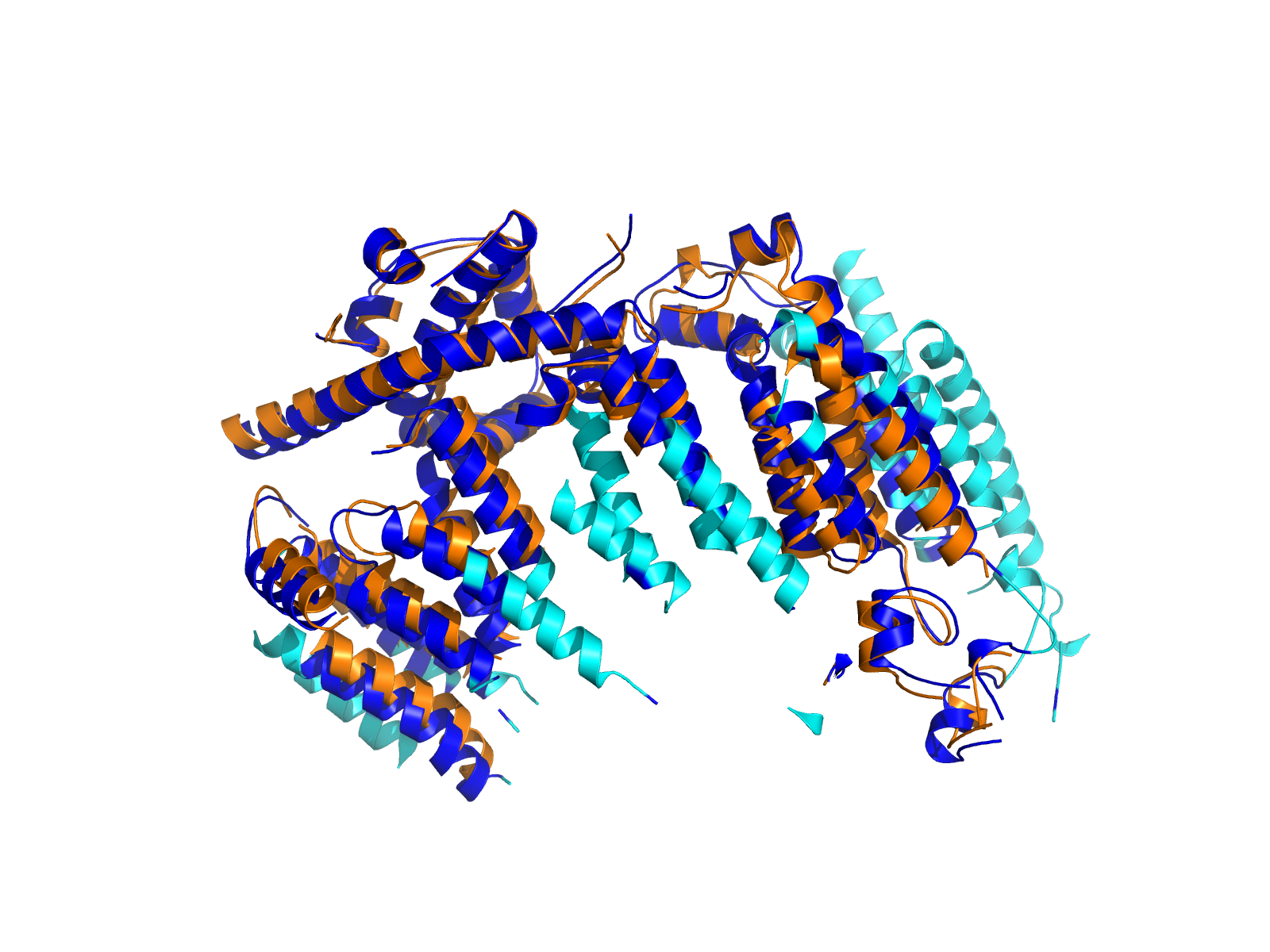 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000503781_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.414
Å |
 | 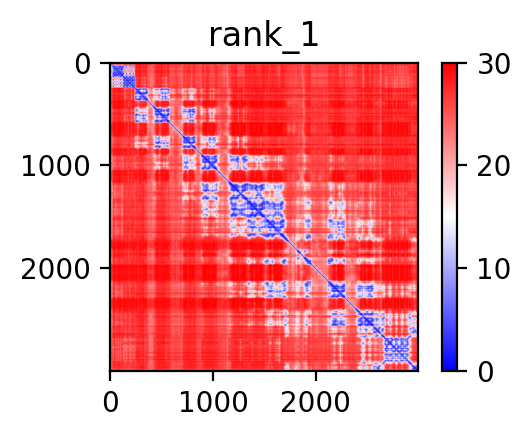 | 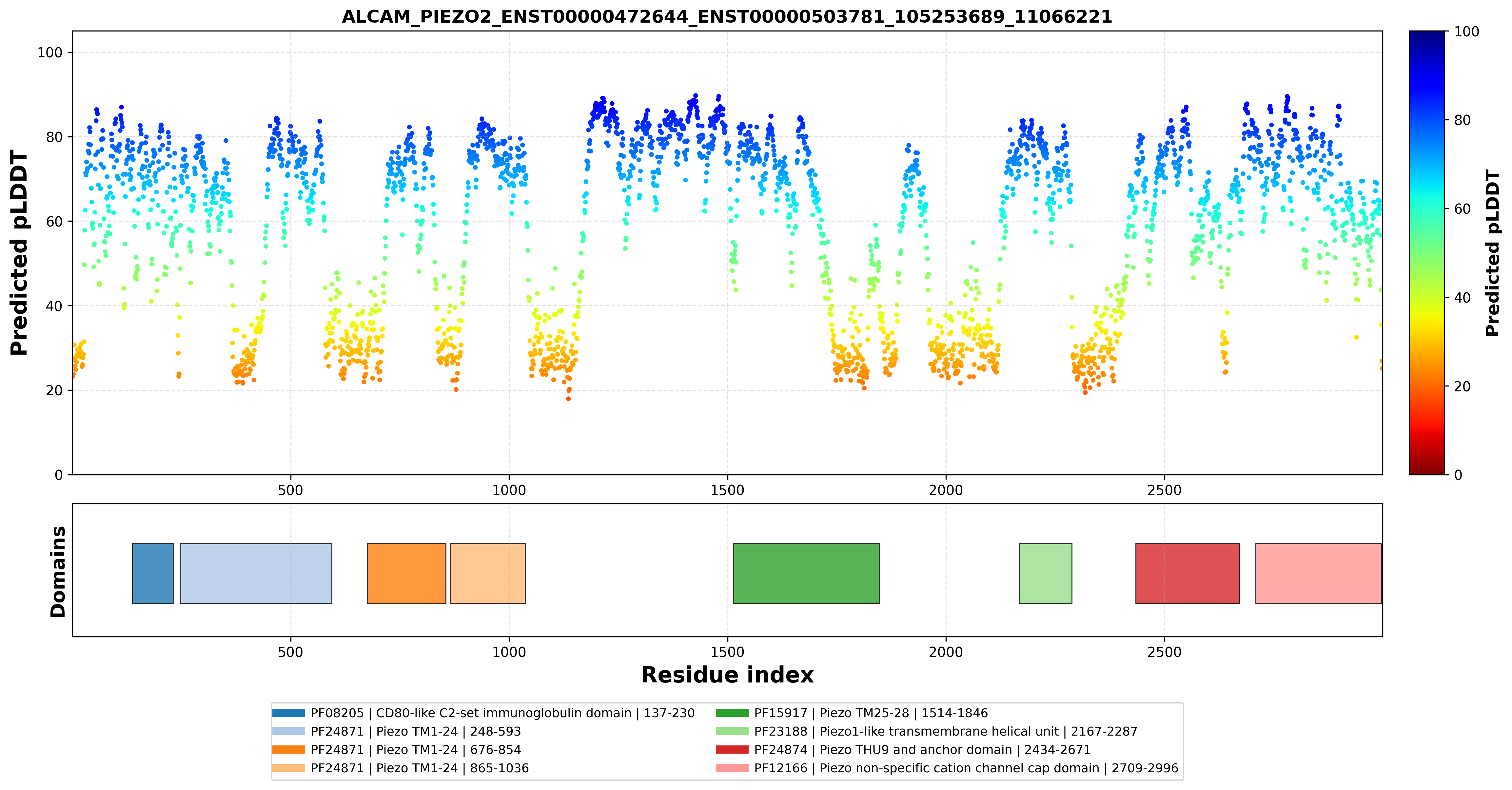 | 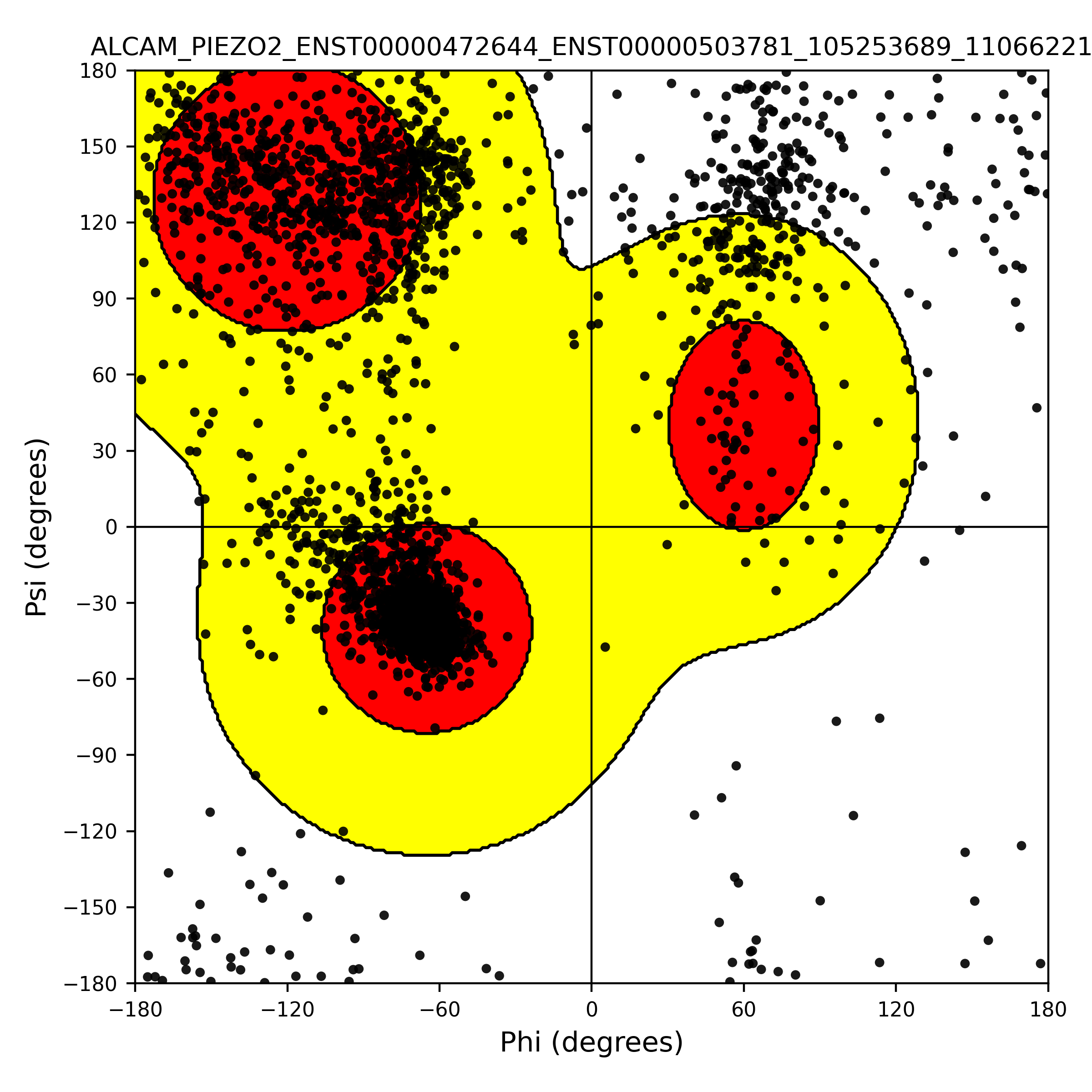 | 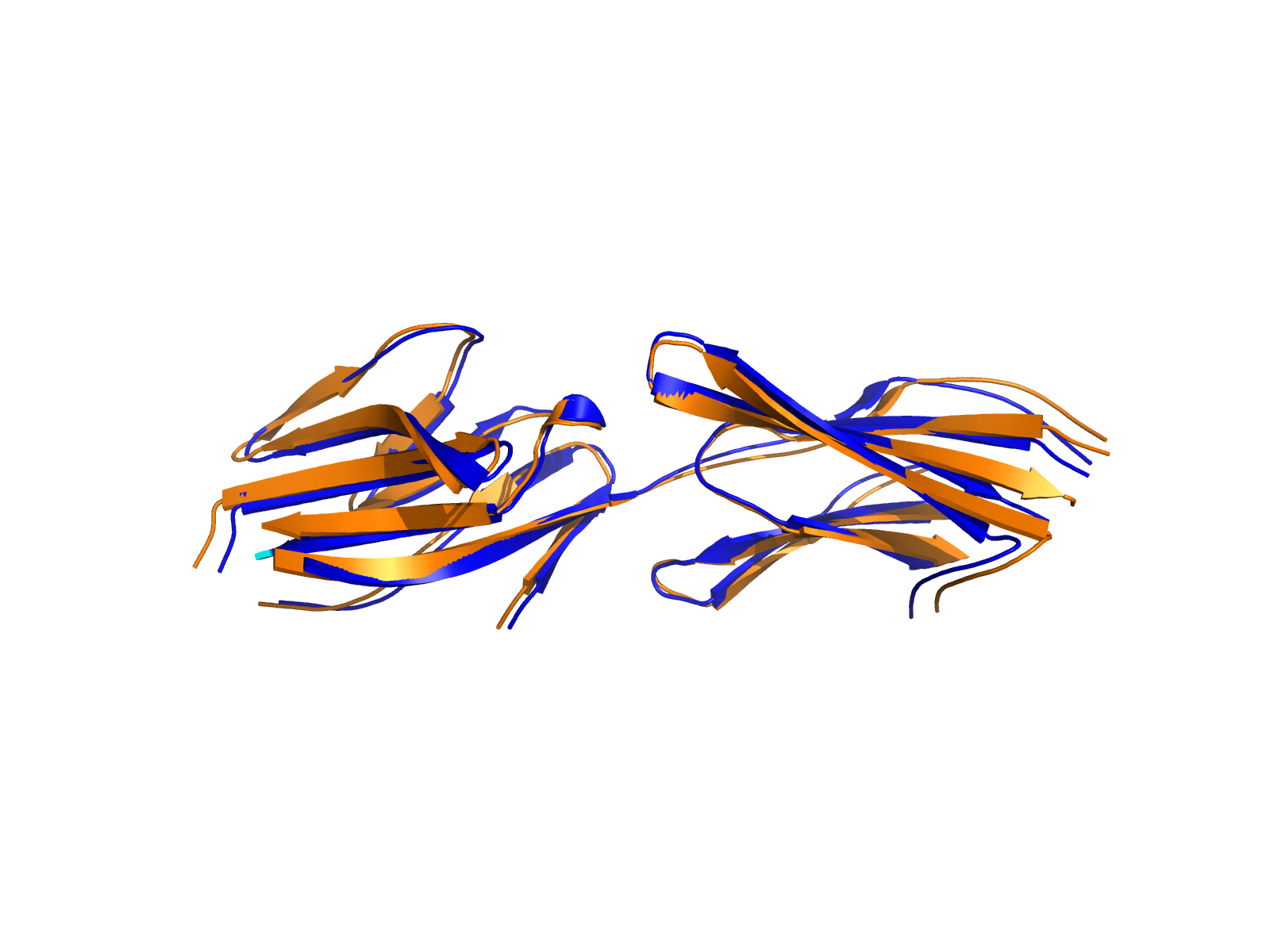 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000503781_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.7377
Å |
| | | | 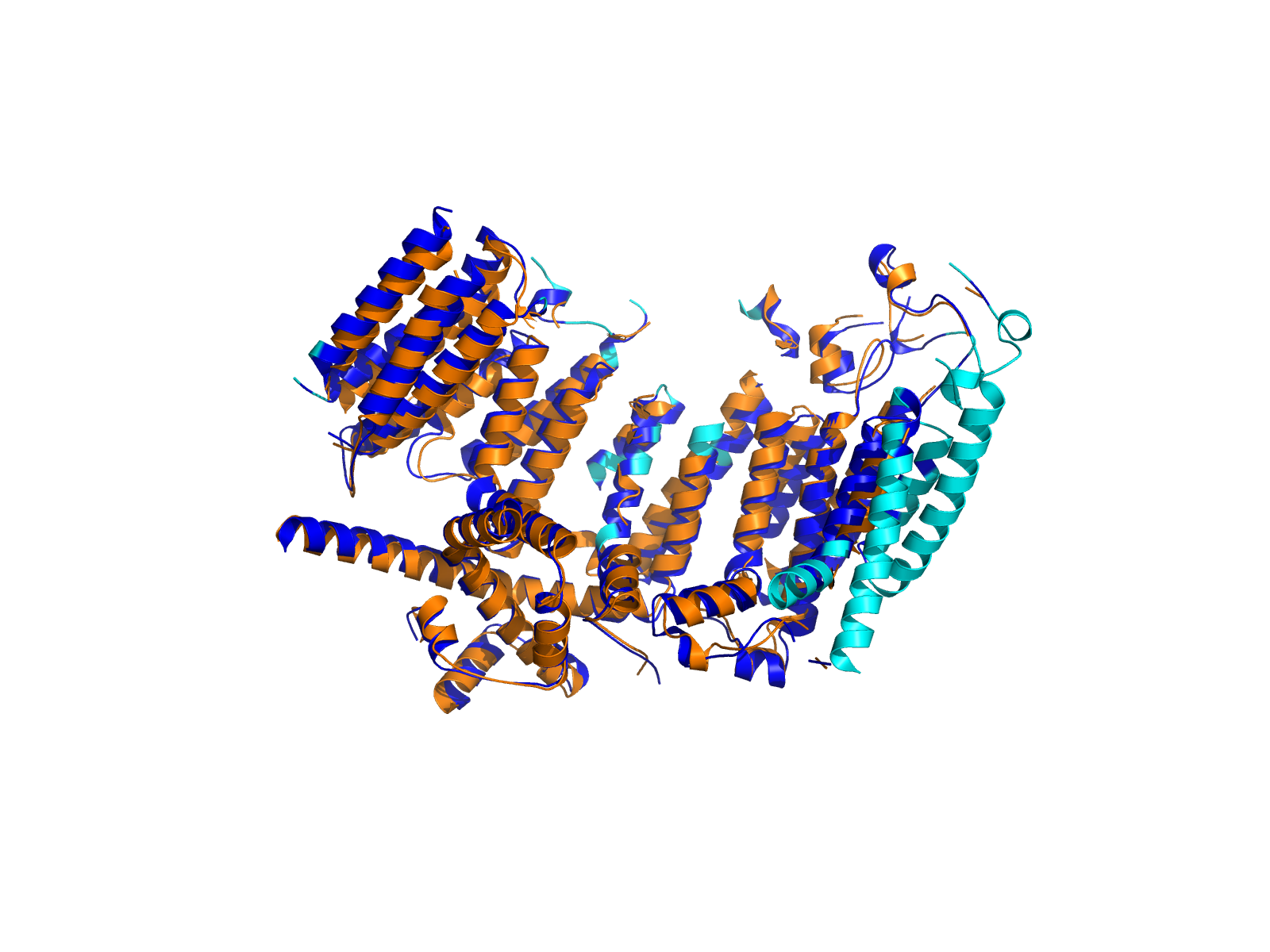 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000580640_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.1845
Å |
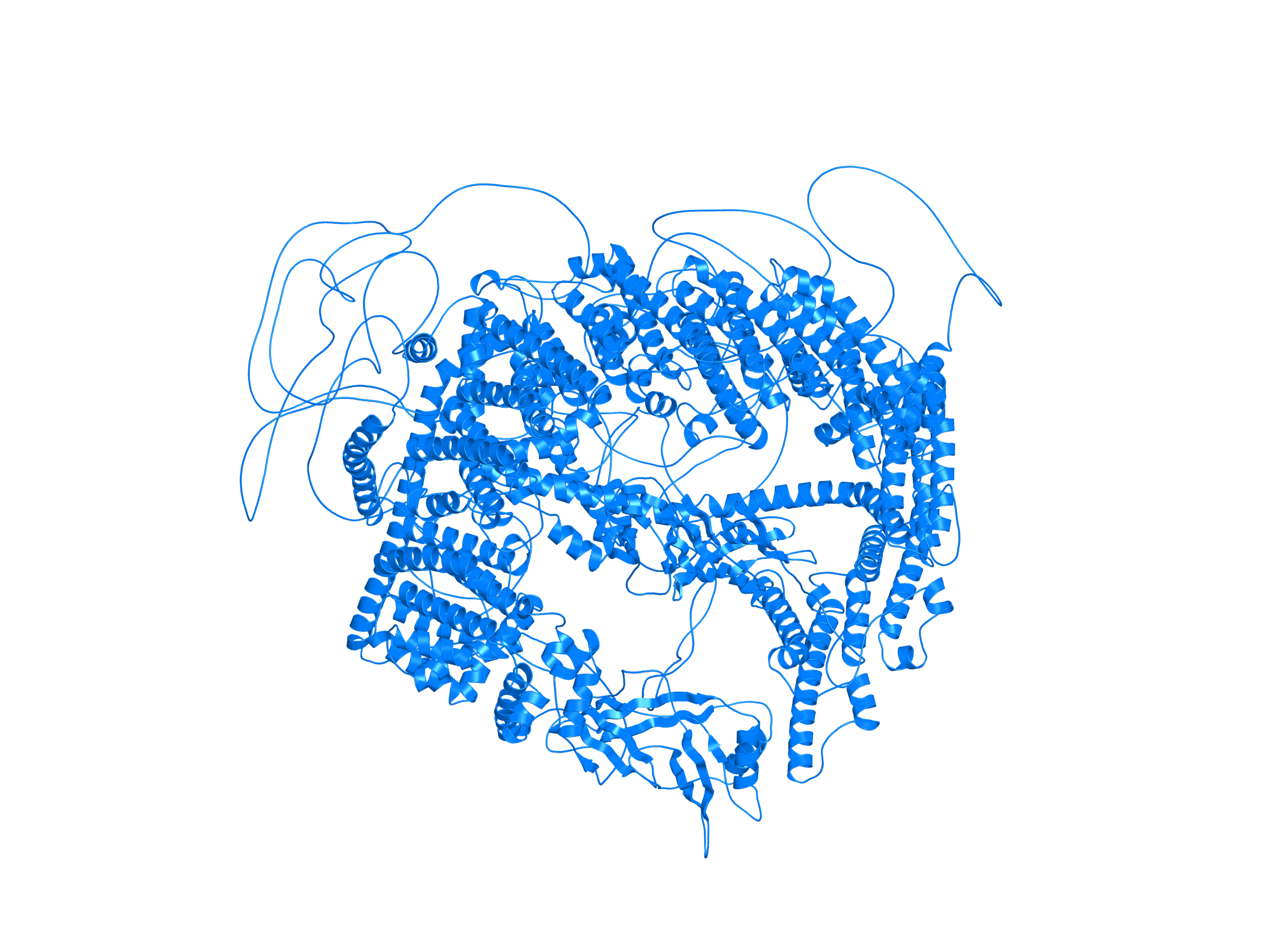 | 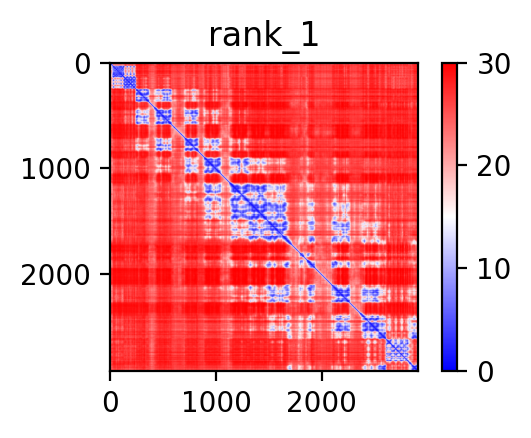 | 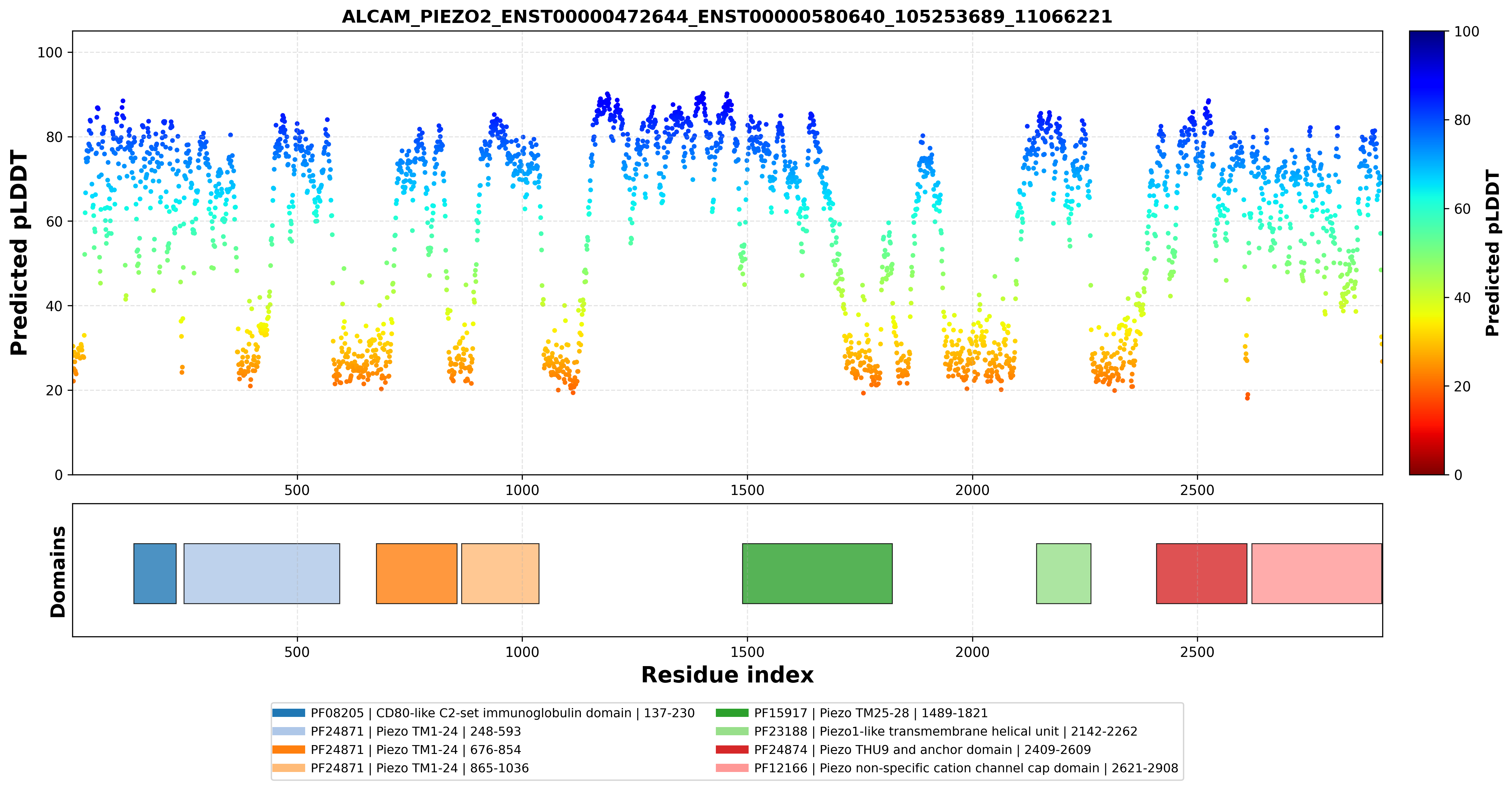 | 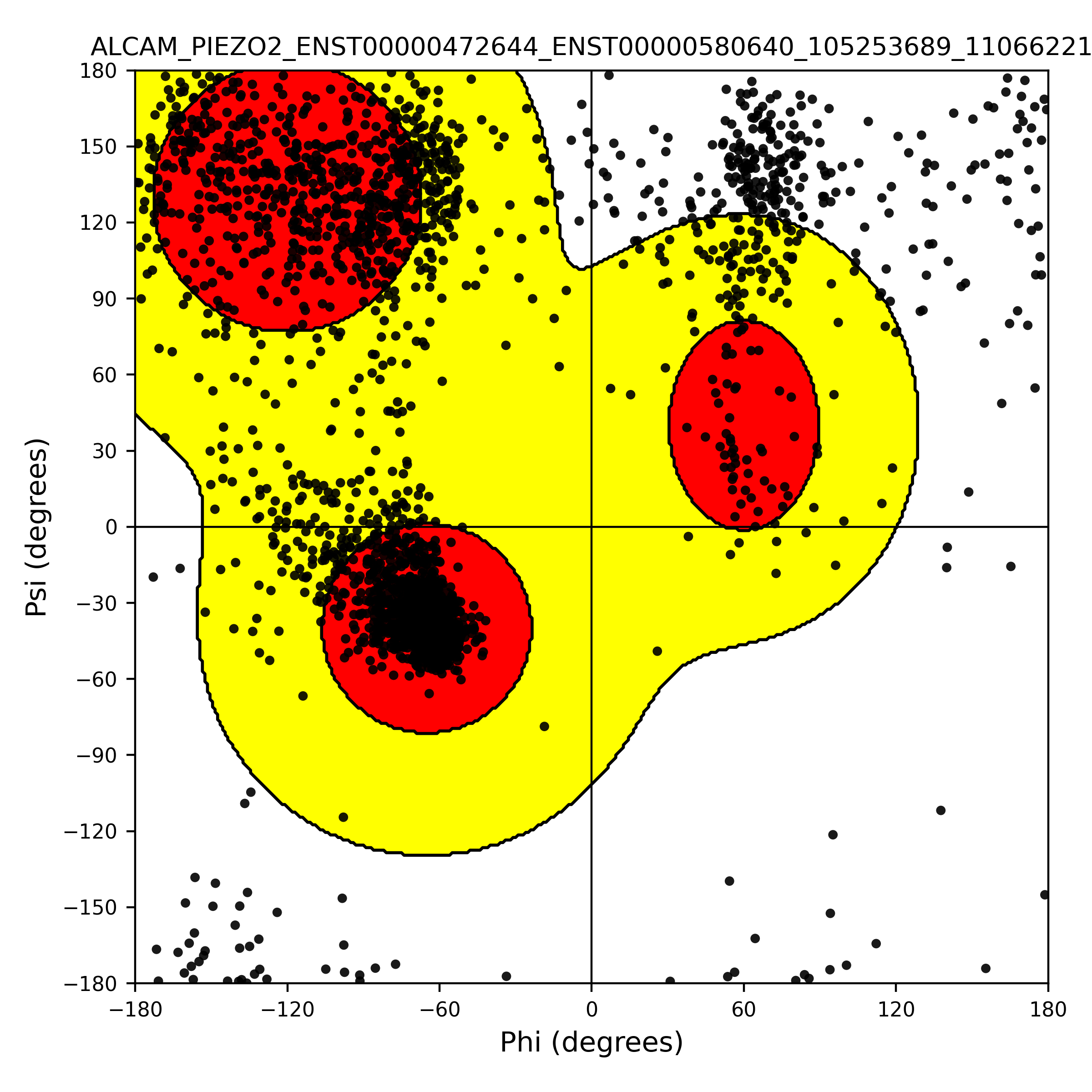 | 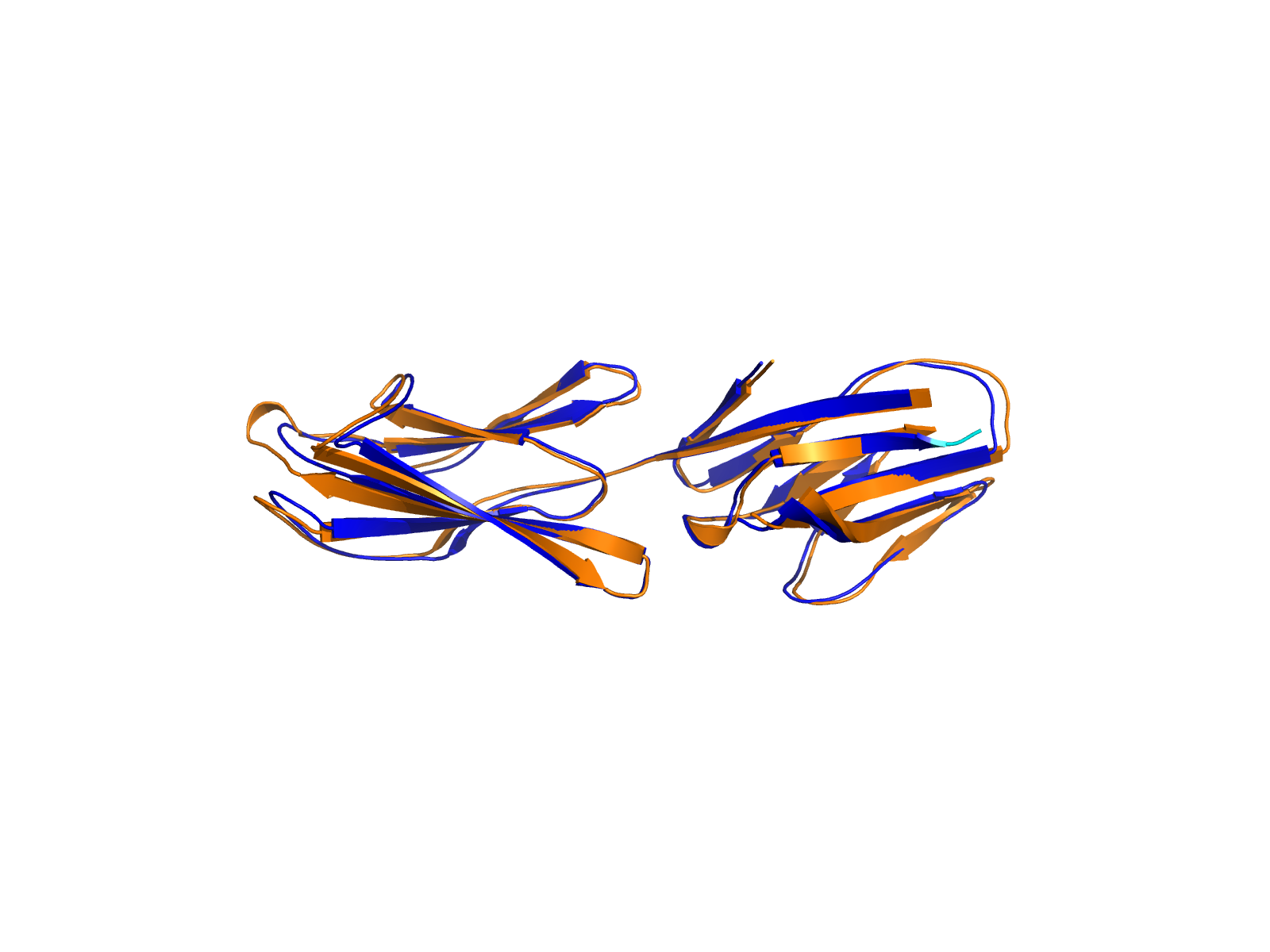 |
| ALCAM_PIEZO2_ENST00000472644_ENST00000580640_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.3903
Å |
| | | | 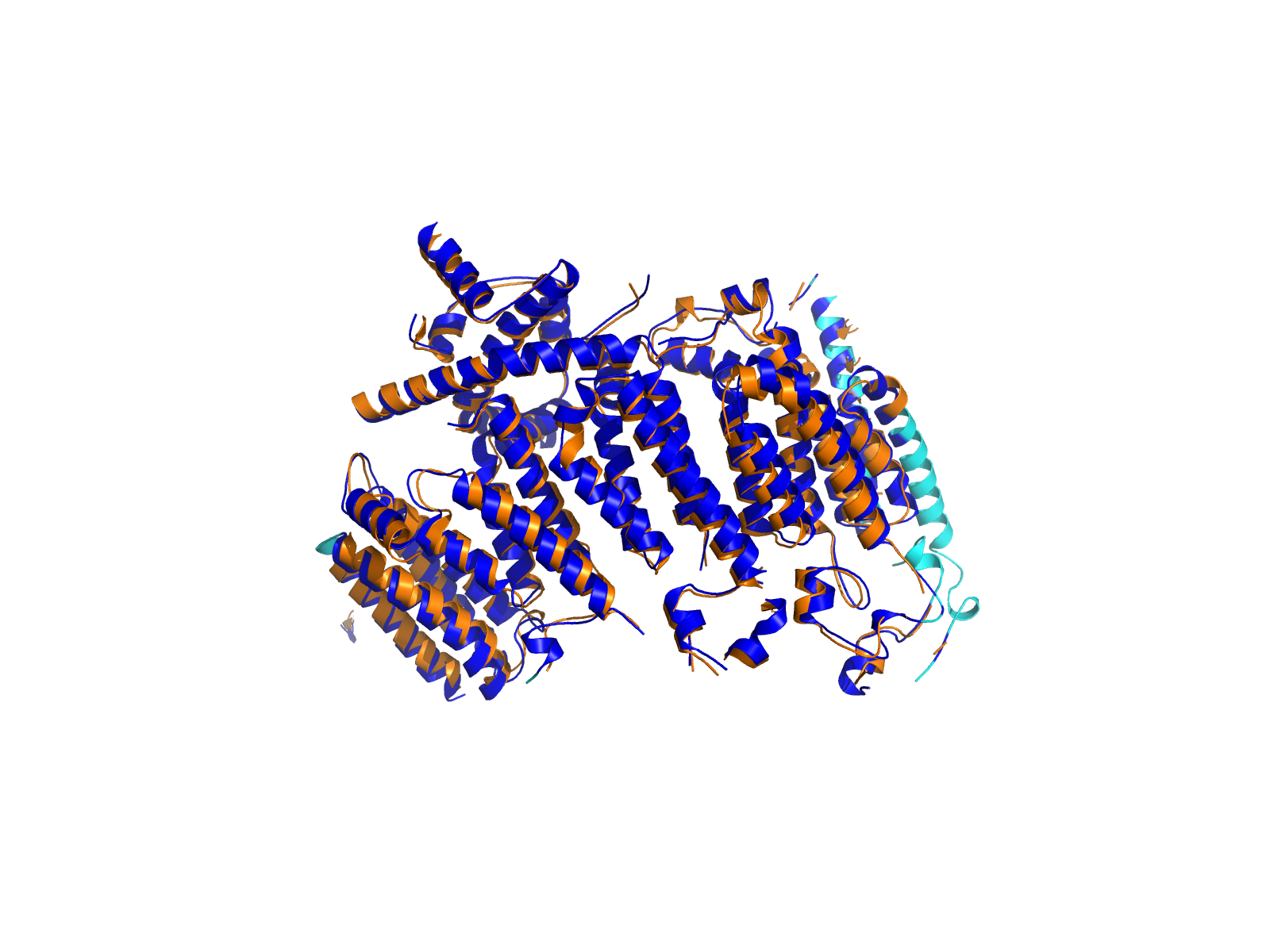 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000302079_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.4329
Å |
 | 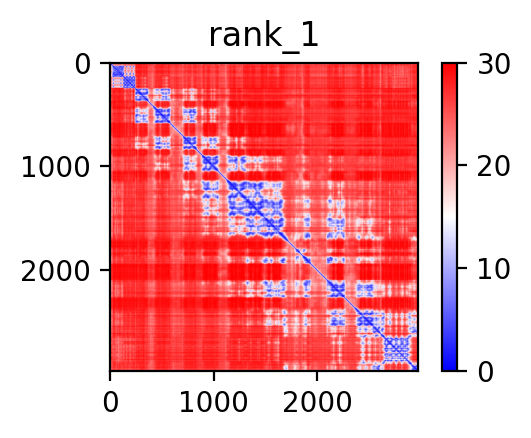 | 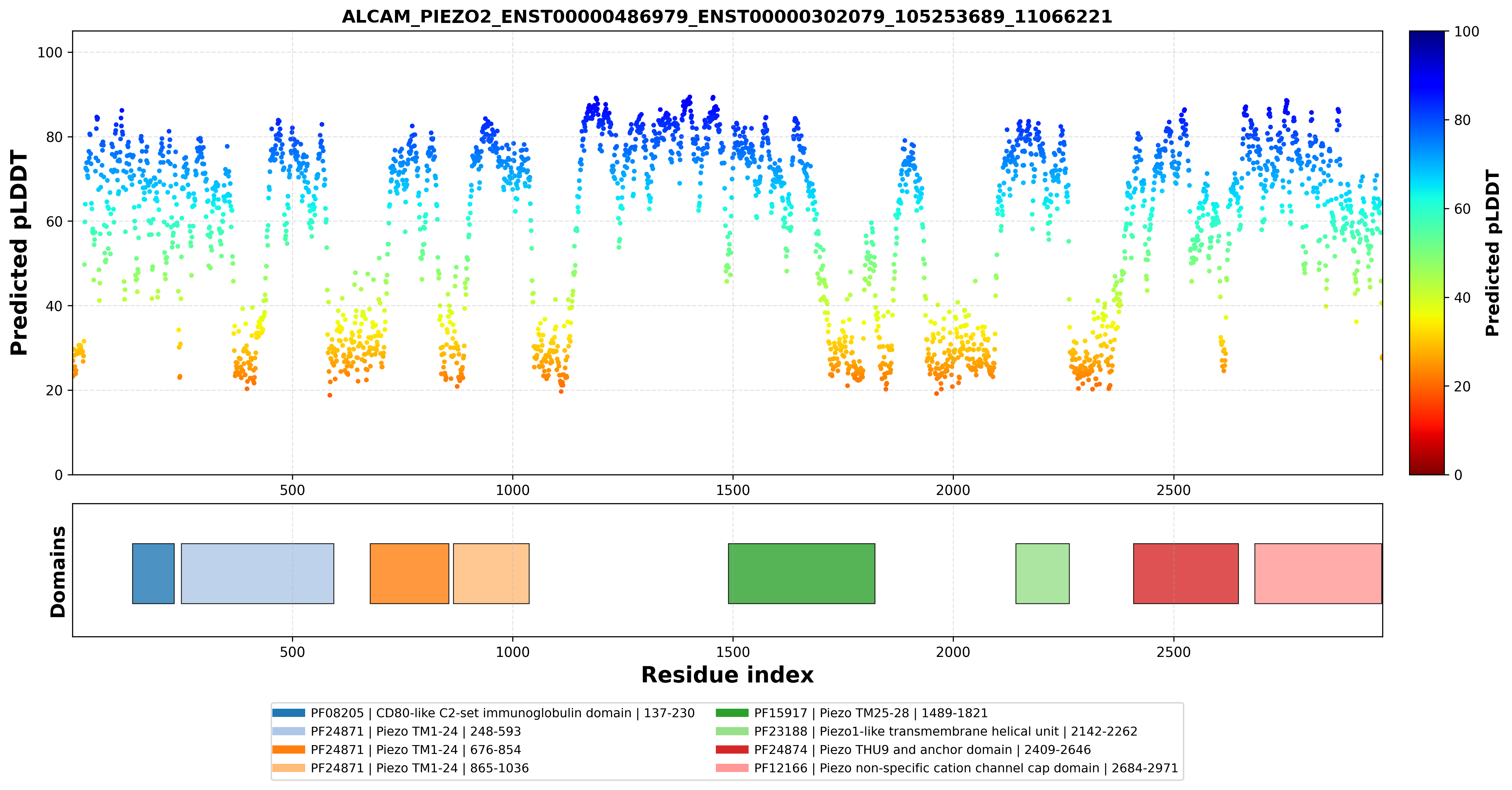 | 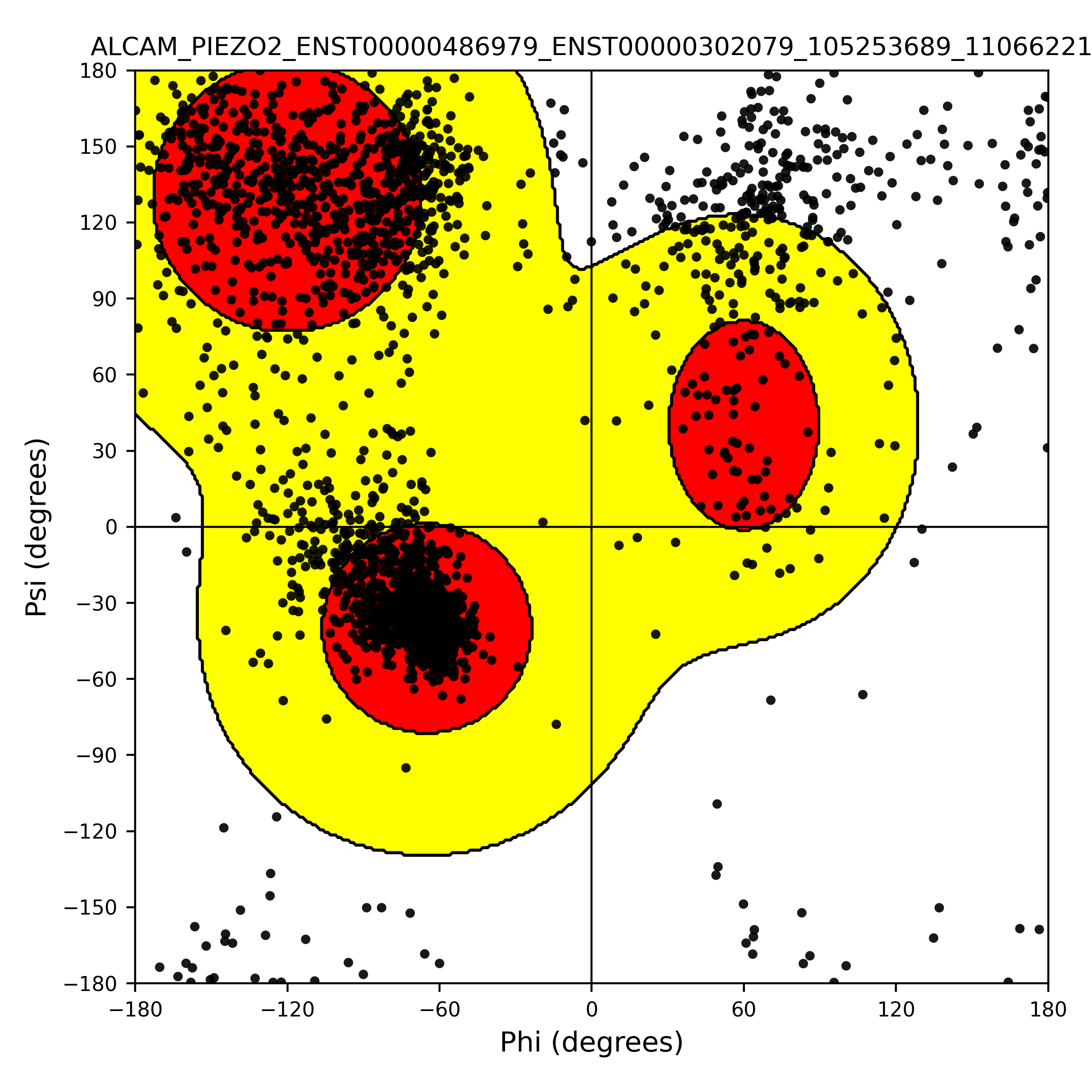 | 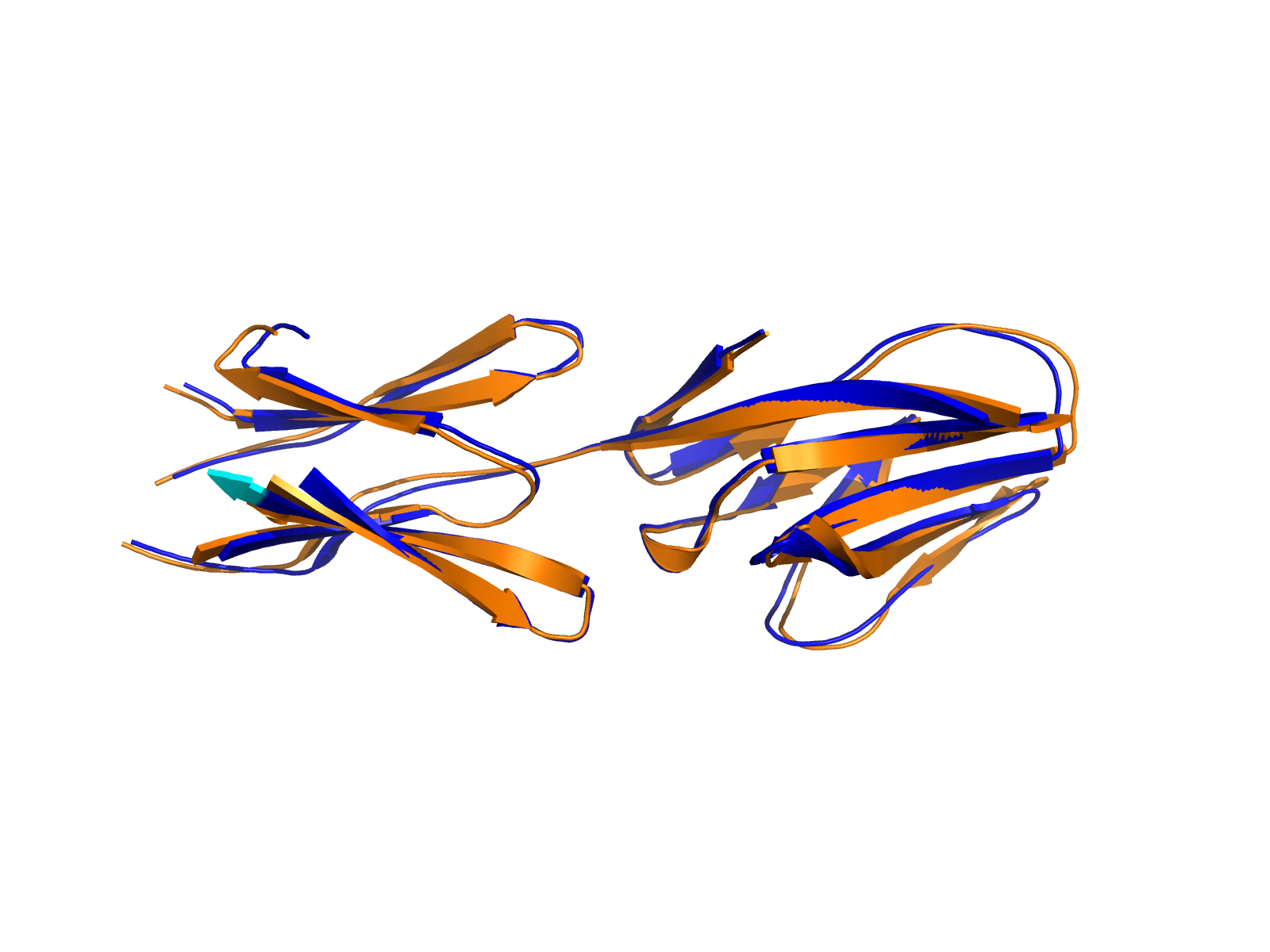 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000302079_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.669
Å |
| | | | 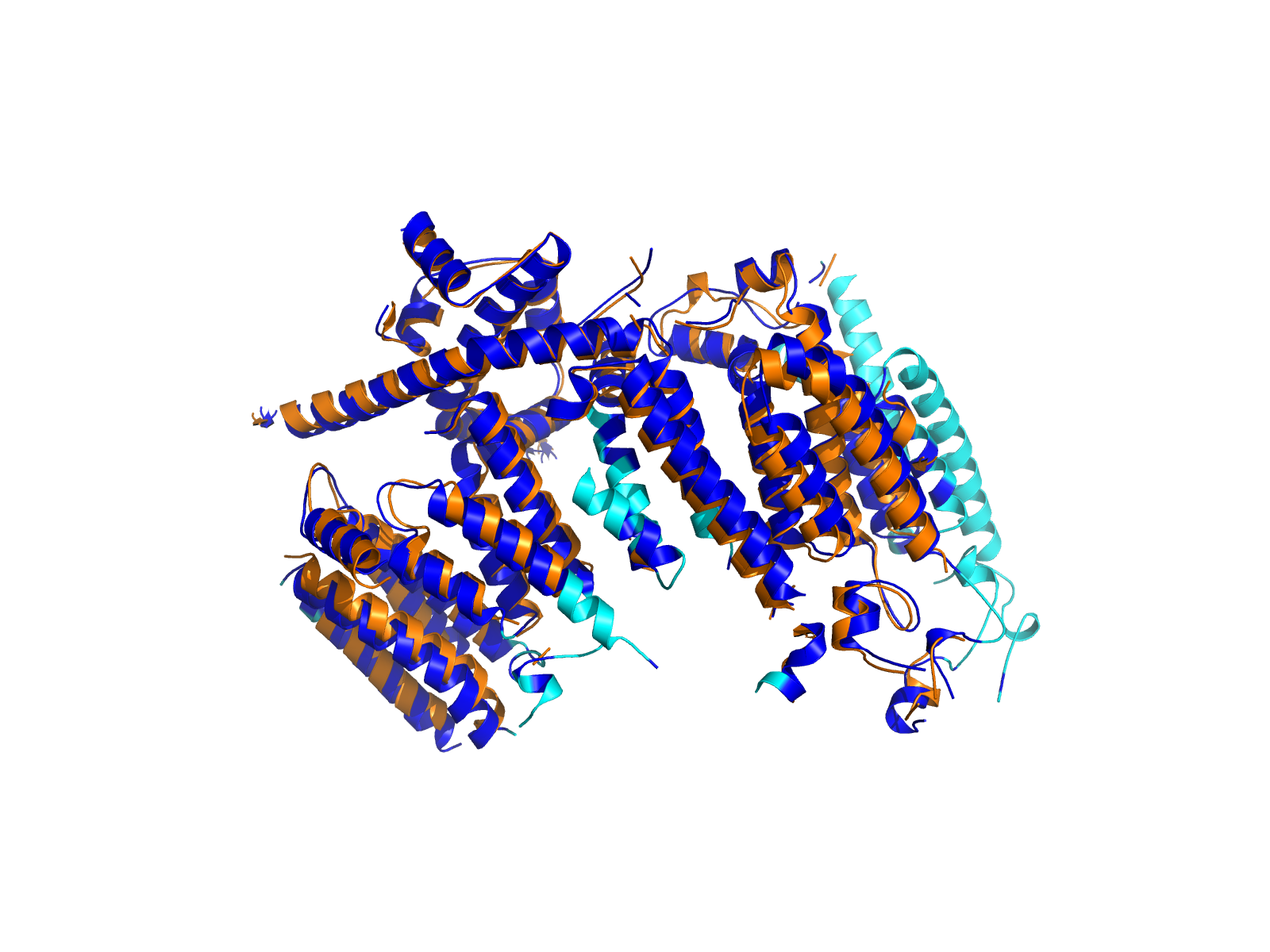 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000503781_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:2.3851
Å |
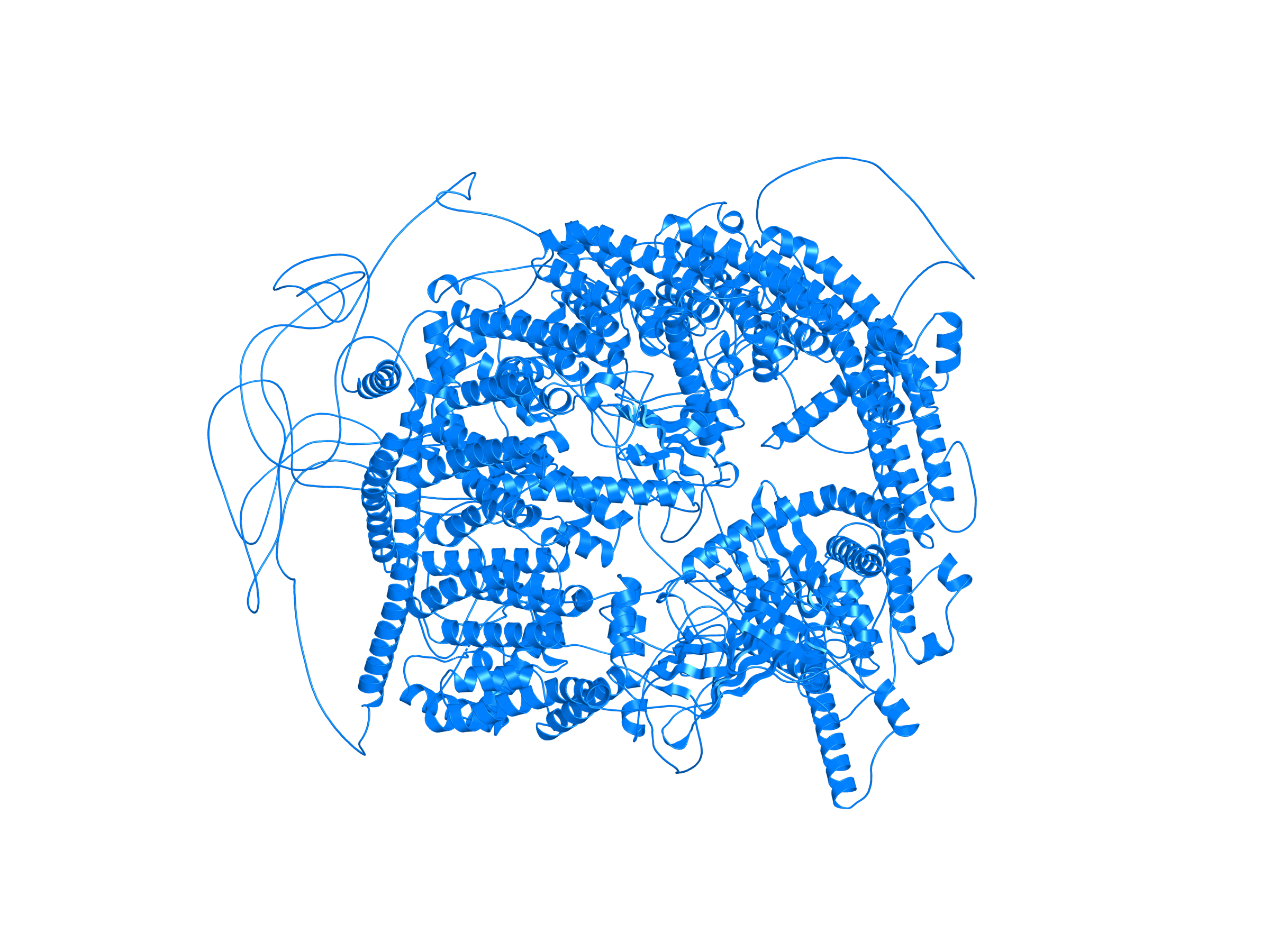 | 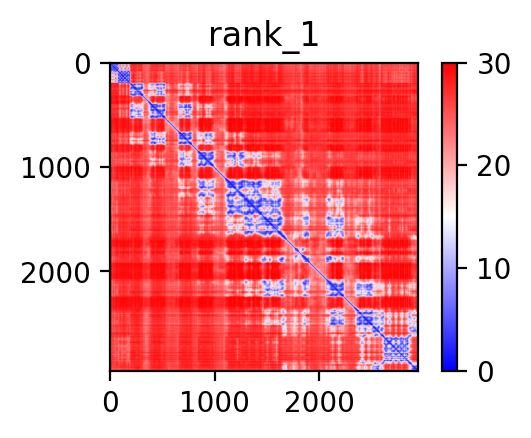 | 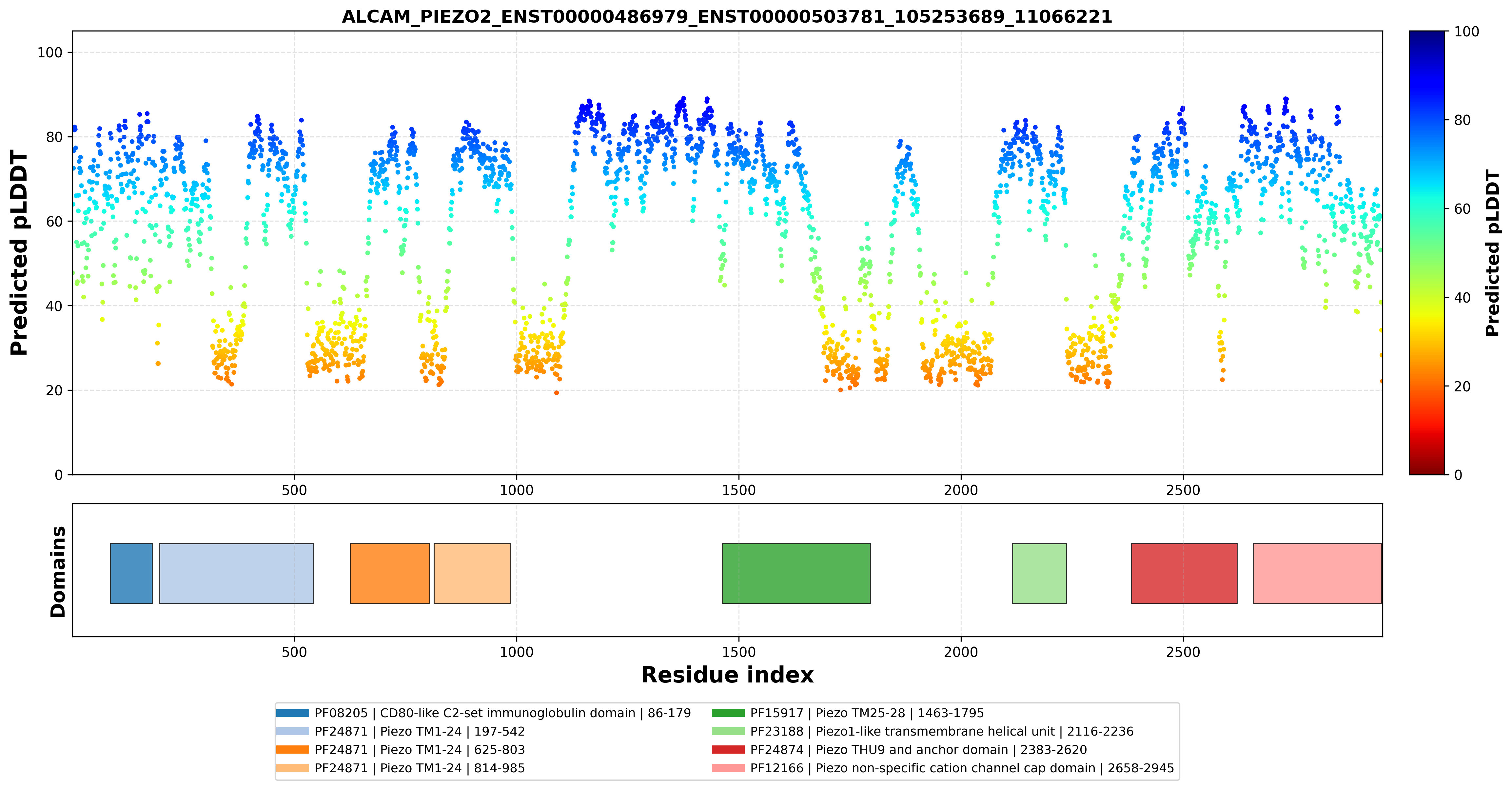 | 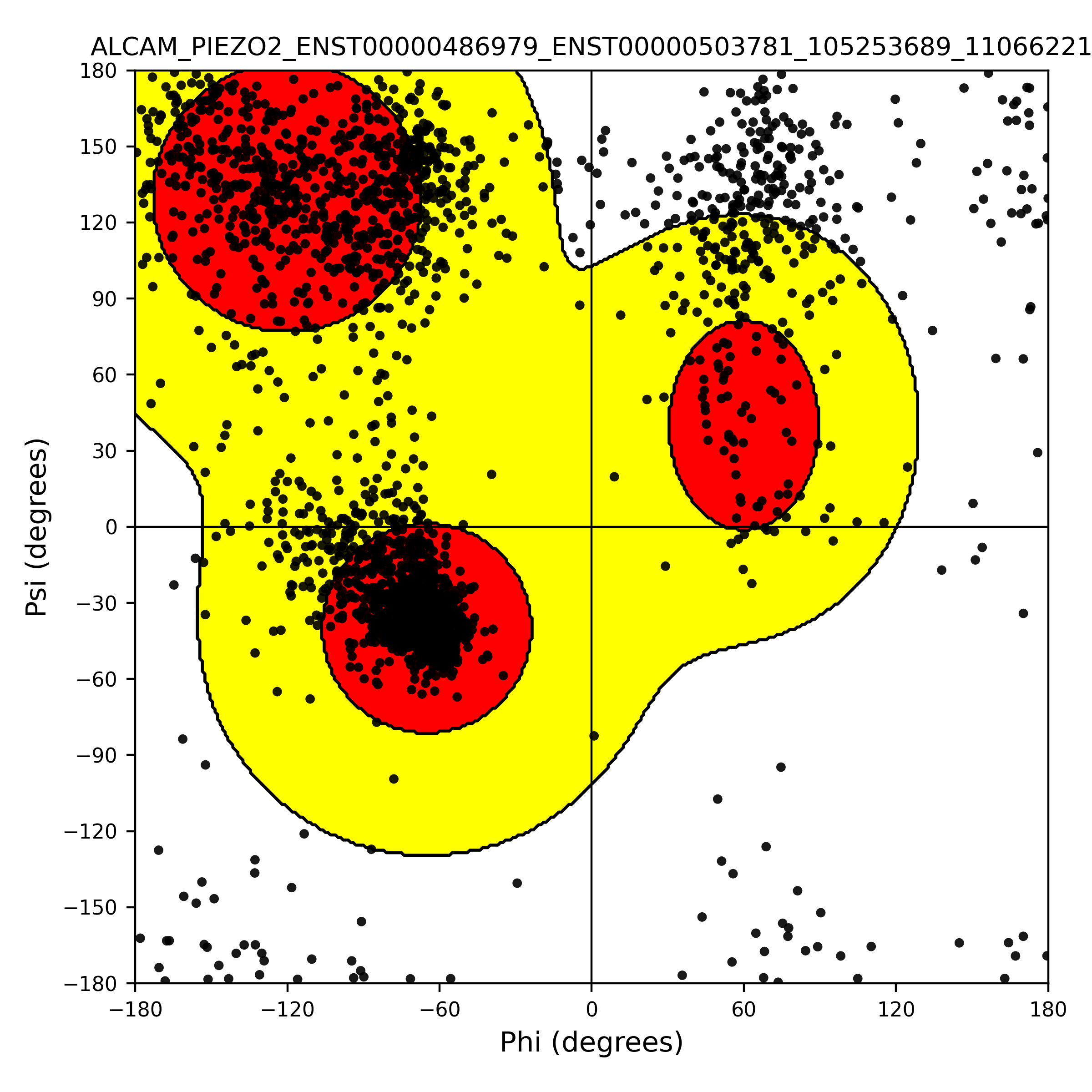 | 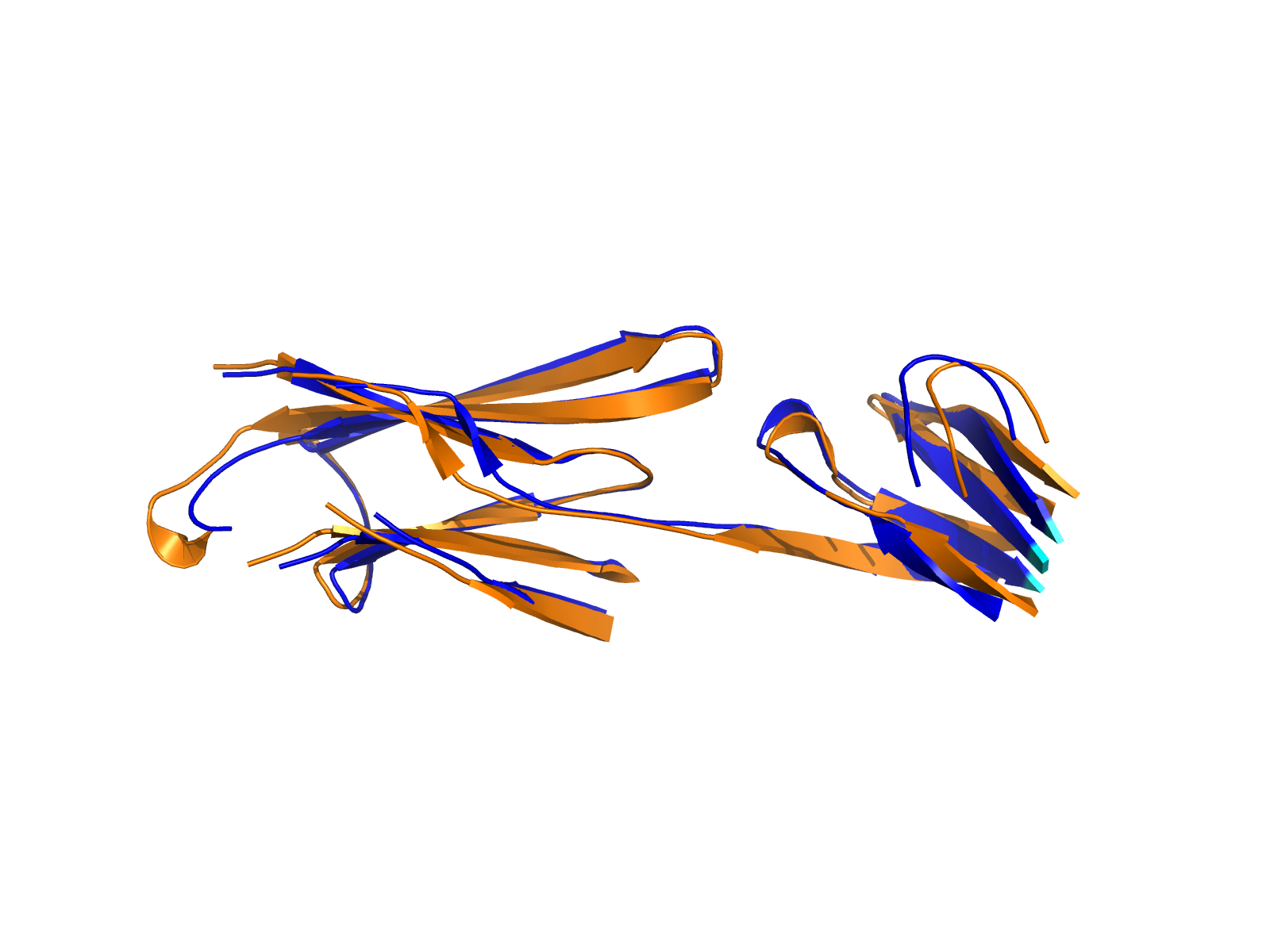 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000503781_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.8455
Å |
| | | | 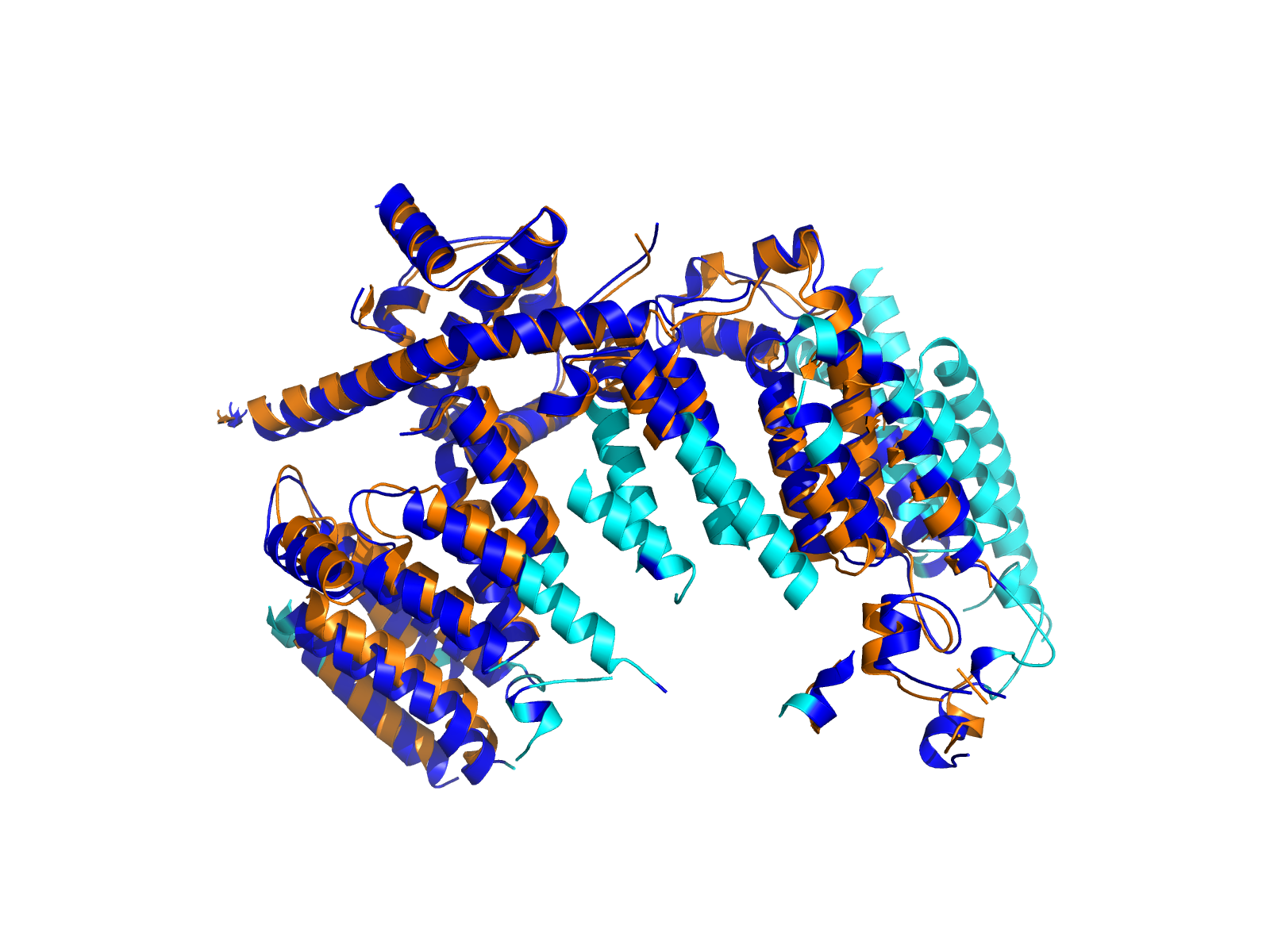 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000580640_105253689_11066221 superimposed PDB: 5A2F of partner (ALCAM). RMSD:1.6451
Å |
 | 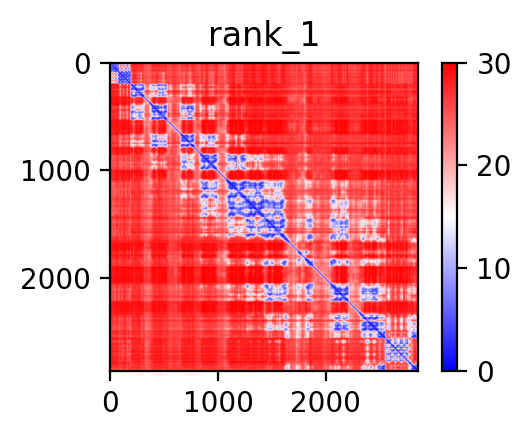 | 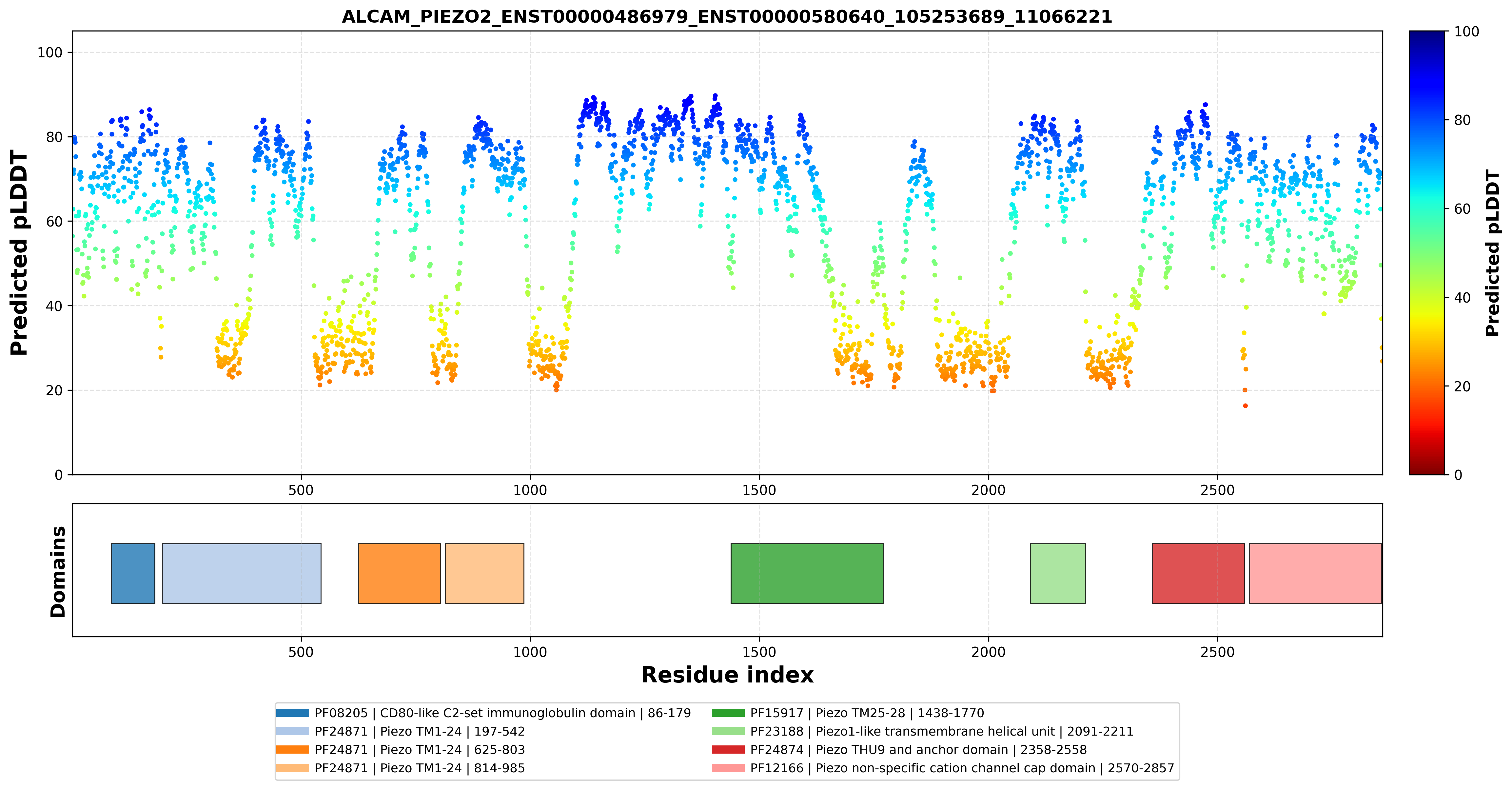 | 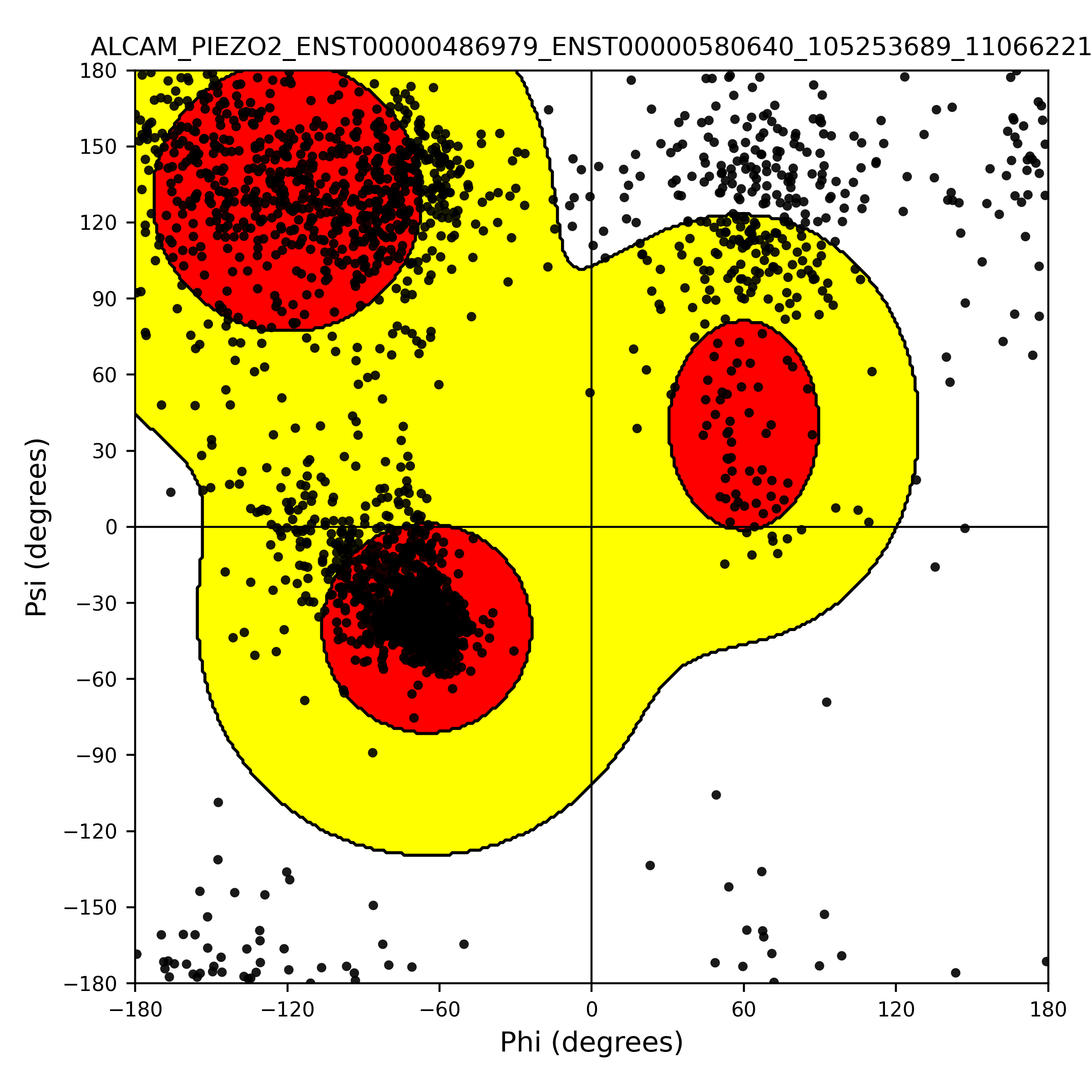 | 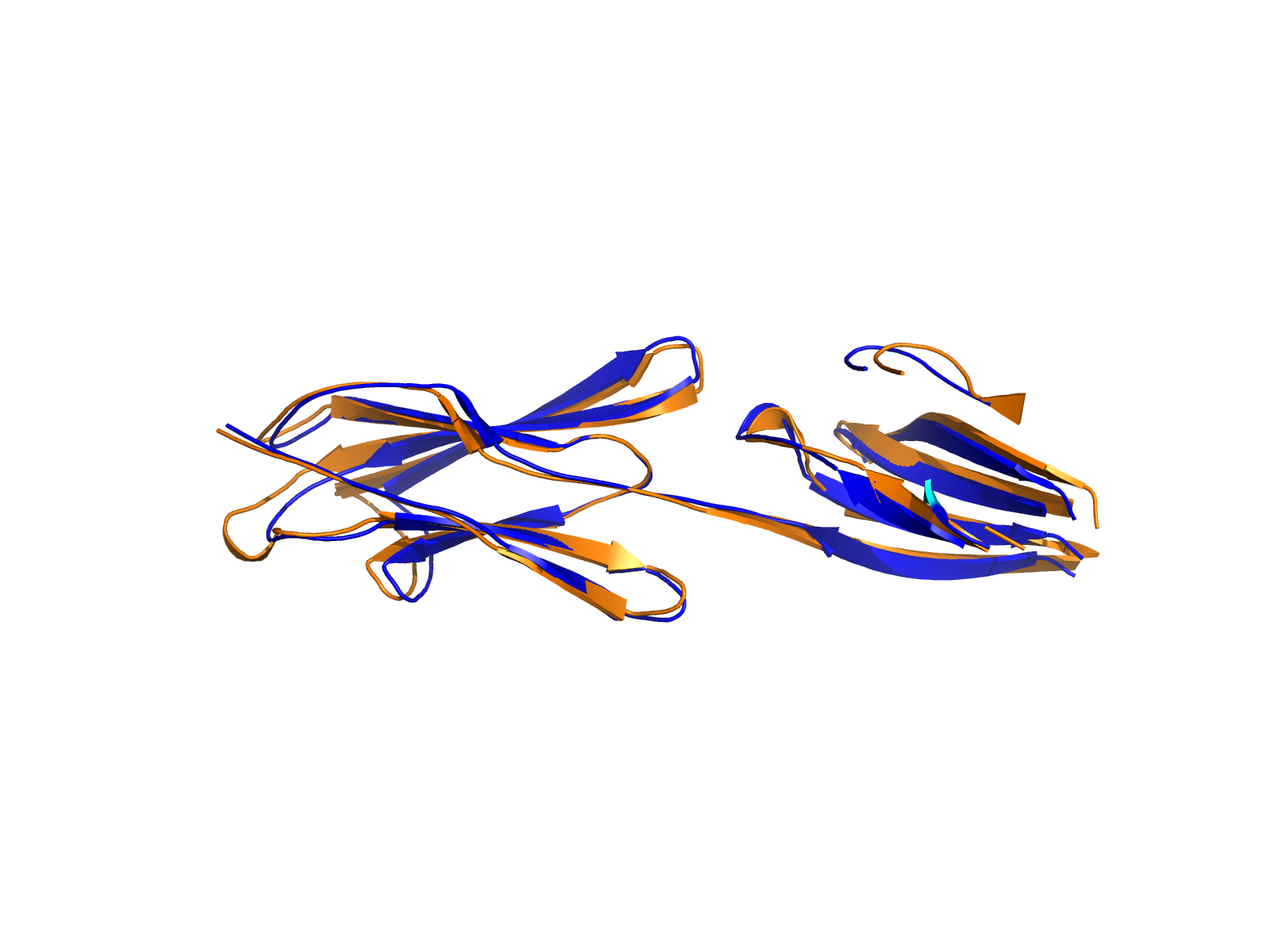 |
| ALCAM_PIEZO2_ENST00000486979_ENST00000580640_105253689_11066221 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.41
Å |
| | | | 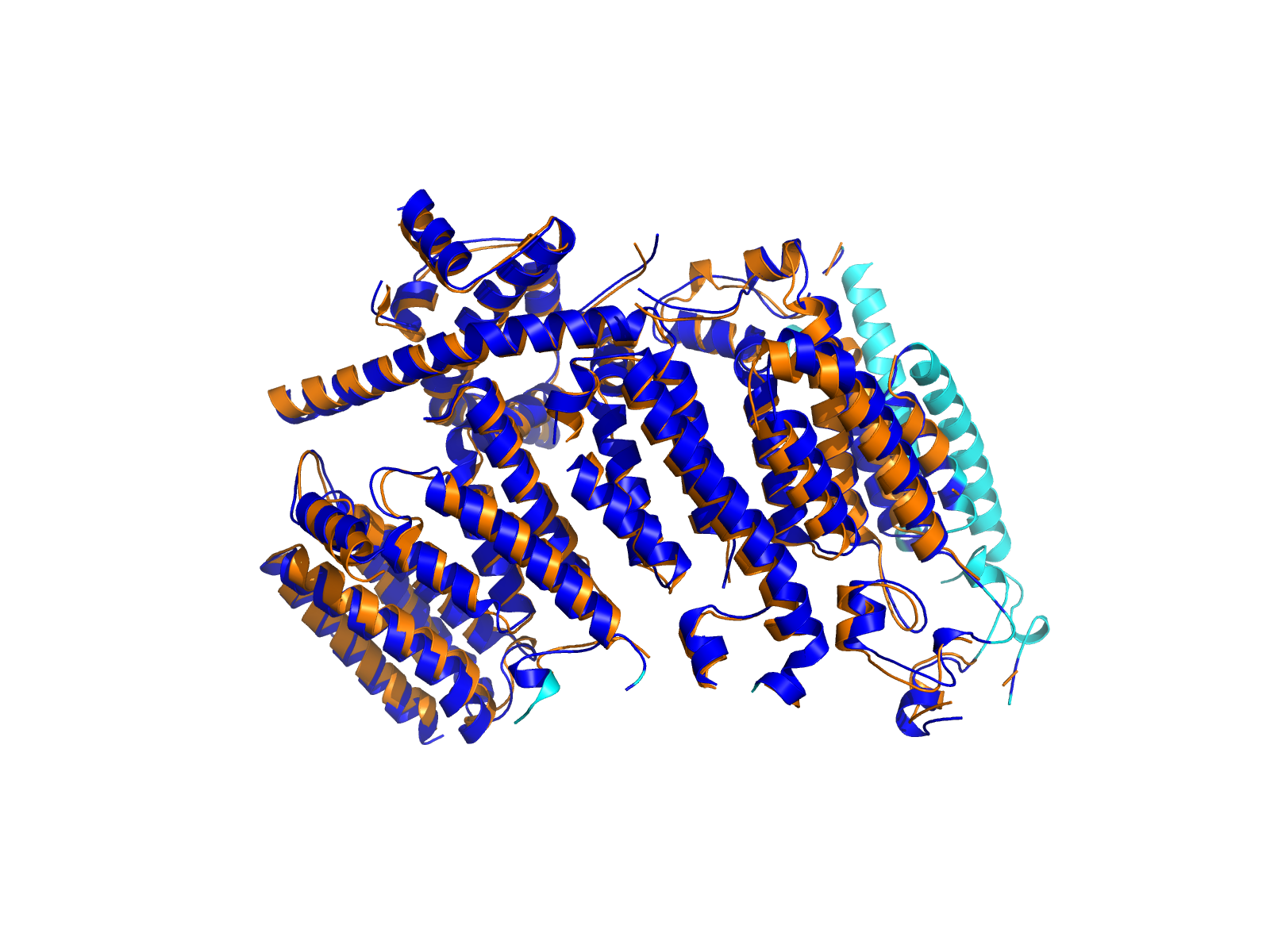 |
| ALDH1A2_ADAM10_ENST00000347587_ENST00000260408_58302846_59009926 superimposed PDB: 8ESV of partner (ADAM10). RMSD:3.2219
Å |
 |  |  |  |  |
| ALDH1A2_ADAM10_ENST00000537372_ENST00000260408_58302846_59009926 superimposed PDB: 8ESV of partner (ADAM10). RMSD:3.2126
Å |
 |  | 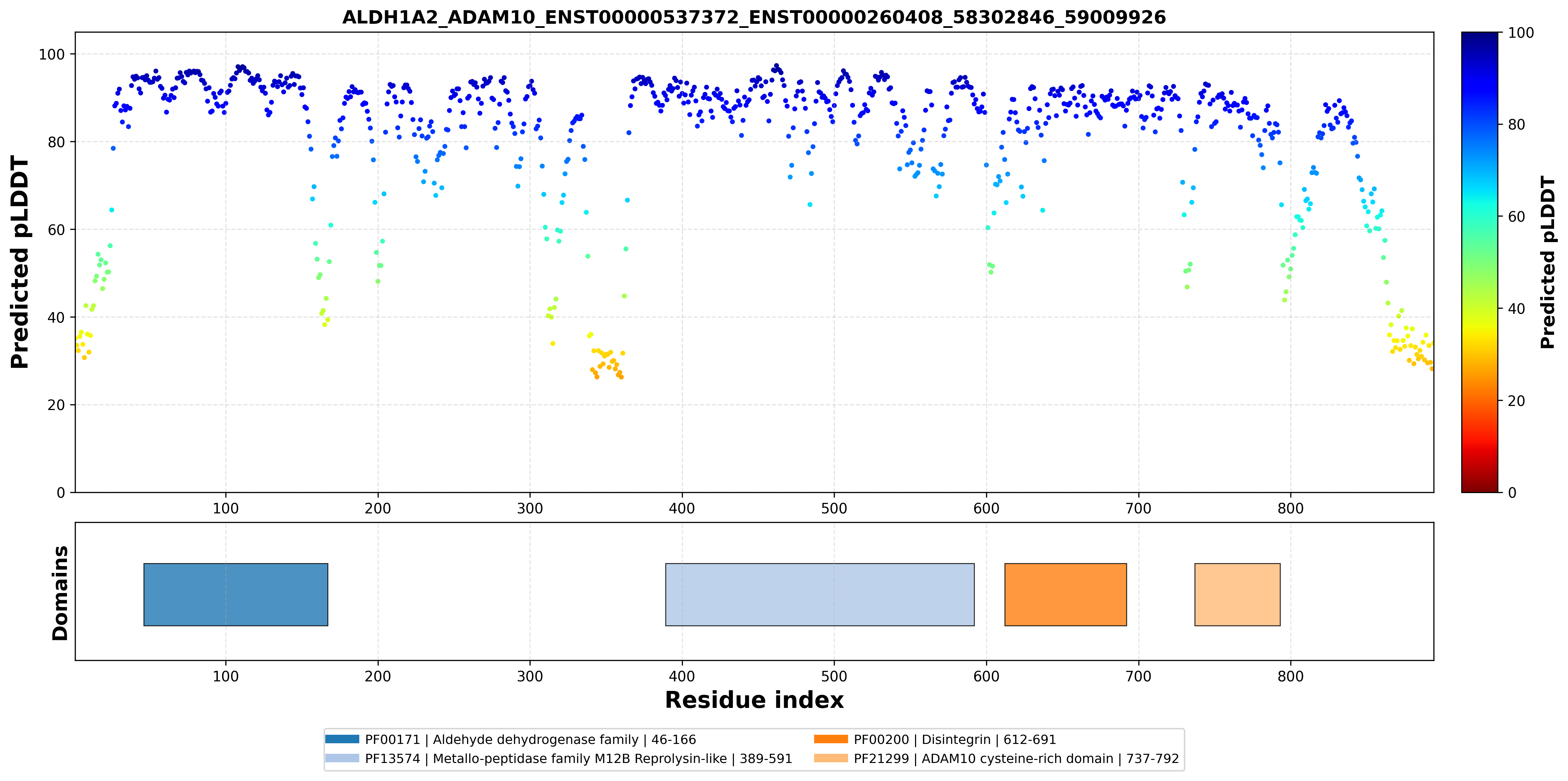 |  |  |
| ALDH1A2_ADAM10_ENST00000559517_ENST00000260408_58302846_59009926 superimposed PDB: 8ESV of partner (ADAM10). RMSD:3.3333
Å |
 |  |  |  |  |
| ALDH3A2_EIF5A_ENST00000339618_ENST00000336452_19575269_7212933 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:2.2622
Å |
 |  | 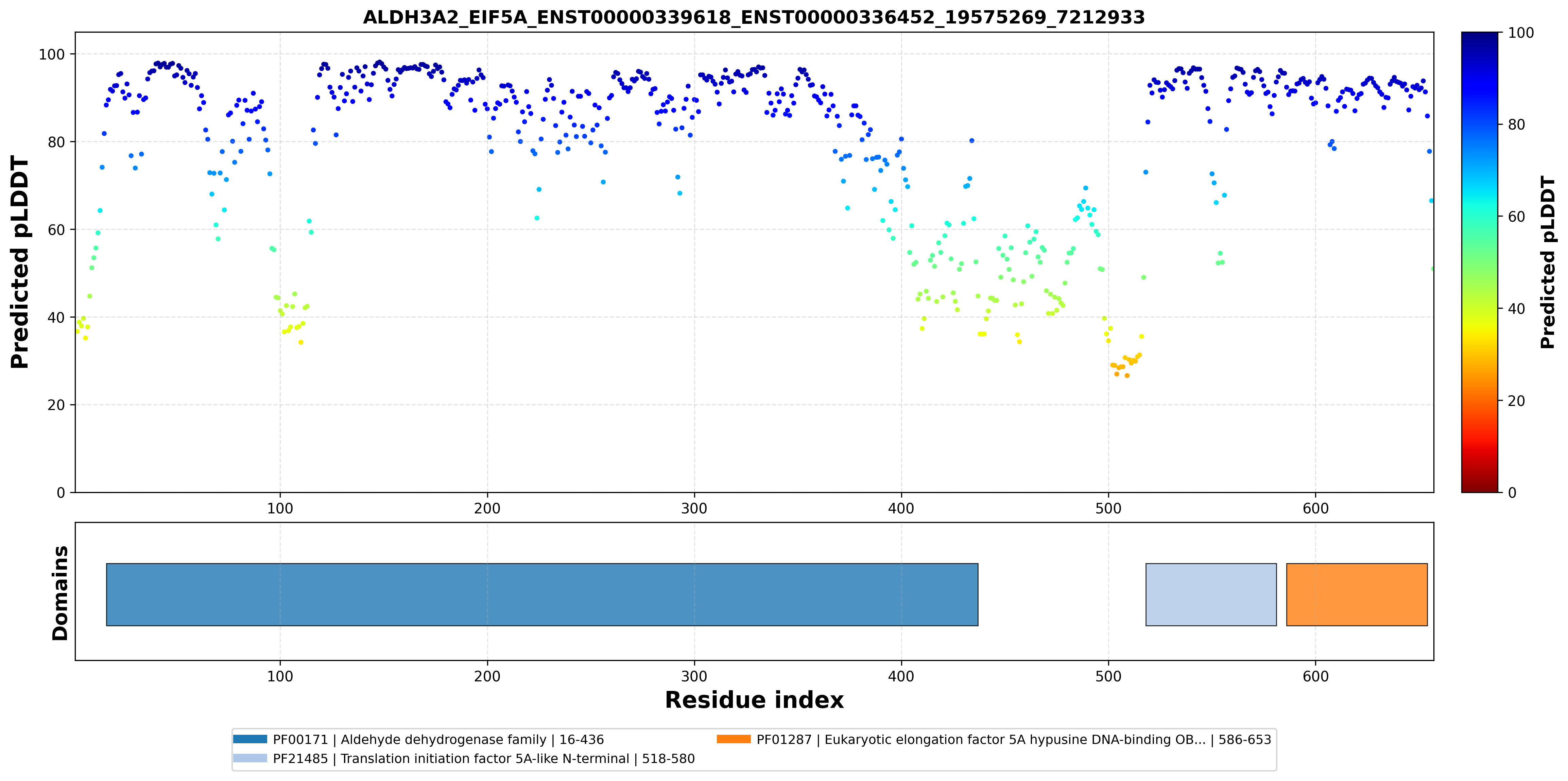 |  |  |
| ALDH3A2_EIF5A_ENST00000339618_ENST00000336452_19575269_7212933 superimposed PDB: 8A0E of partner (EIF5A). RMSD:1.0431
Å |
| | | |  |
| ALDH3A2_EIF5A_ENST00000579855_ENST00000336452_19575269_7212933 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.457
Å |
 |  | 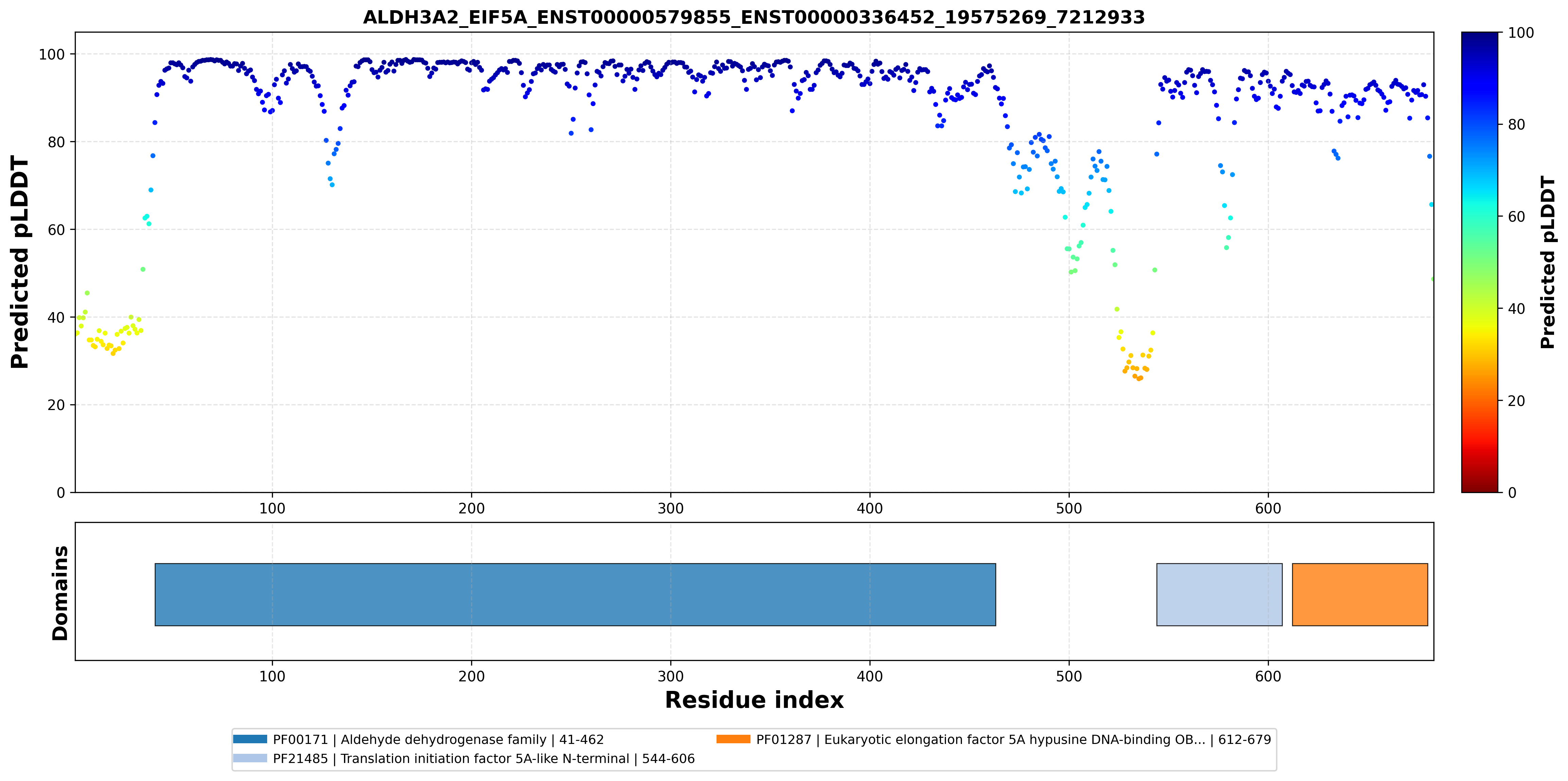 |  |  |
| ALDH3A2_EIF5A_ENST00000579855_ENST00000336452_19575269_7212933 superimposed PDB: 8A0E of partner (EIF5A). RMSD:1.1257
Å |
| | | |  |
| ALDH3A2_EIF5A_ENST00000581518_ENST00000336452_19575269_7212933 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.4941
Å |
 |  |  |  |  |
| ALDH3A2_EIF5A_ENST00000581518_ENST00000336452_19575269_7212933 superimposed PDB: 8A0E of partner (EIF5A). RMSD:1.0618
Å |
| | | |  |
| ALDH3A2_PITPNM2_ENST00000176643_ENST00000392428_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5172
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000176643_ENST00000542749_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.564
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000339618_ENST00000392428_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5257
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000339618_ENST00000542749_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5367
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000395575_ENST00000392428_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5088
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000395575_ENST00000542749_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5417
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000571163_ENST00000392428_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.782
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000571163_ENST00000542749_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.8355
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000579855_ENST00000392428_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5425
Å |
 |  |  |  |  |
| ALDH3A2_PITPNM2_ENST00000579855_ENST00000542749_19568360_123477216 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5693
Å |
 |  |  |  |  |
| ALDH3B1_PC_ENST00000342456_ENST00000393960_67786724_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7686
Å |
 |  |  |  |  |
| ALDH3B1_PC_ENST00000539229_ENST00000393960_67786724_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7613
Å |
 |  |  |  |  |
| ALDH3B2_ALDH3A1_ENST00000349015_ENST00000225740_67433786_19645525 superimposed PDB: 3SZA of partner (ALDH3A1). RMSD:0.4843
Å |
 |  |  |  |  |
| ALDH3B2_ALDH3A1_ENST00000349015_ENST00000494157_67433786_19645525 superimposed PDB: 3SZA of partner (ALDH3A1). RMSD:0.6683
Å |
 |  |  |  |  |
| ALDH4A1_CAPZB_ENST00000290597_ENST00000401084_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.2109
Å |
 |  |  |  |  |
| ALDH4A1_CAPZB_ENST00000375341_ENST00000264203_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.3482
Å |
 | 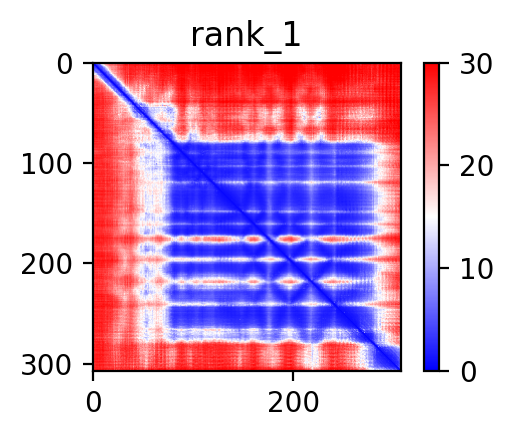 | 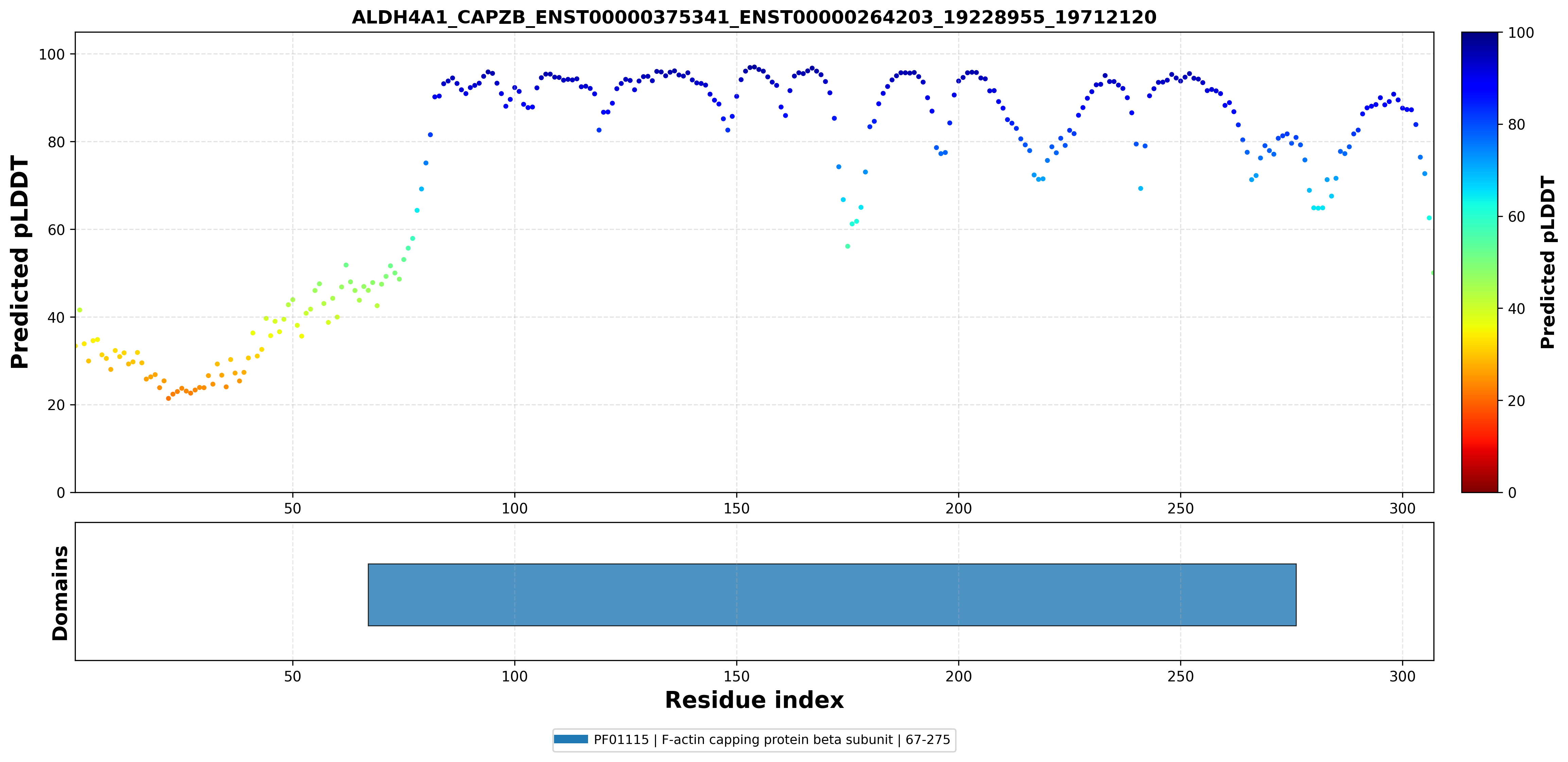 | 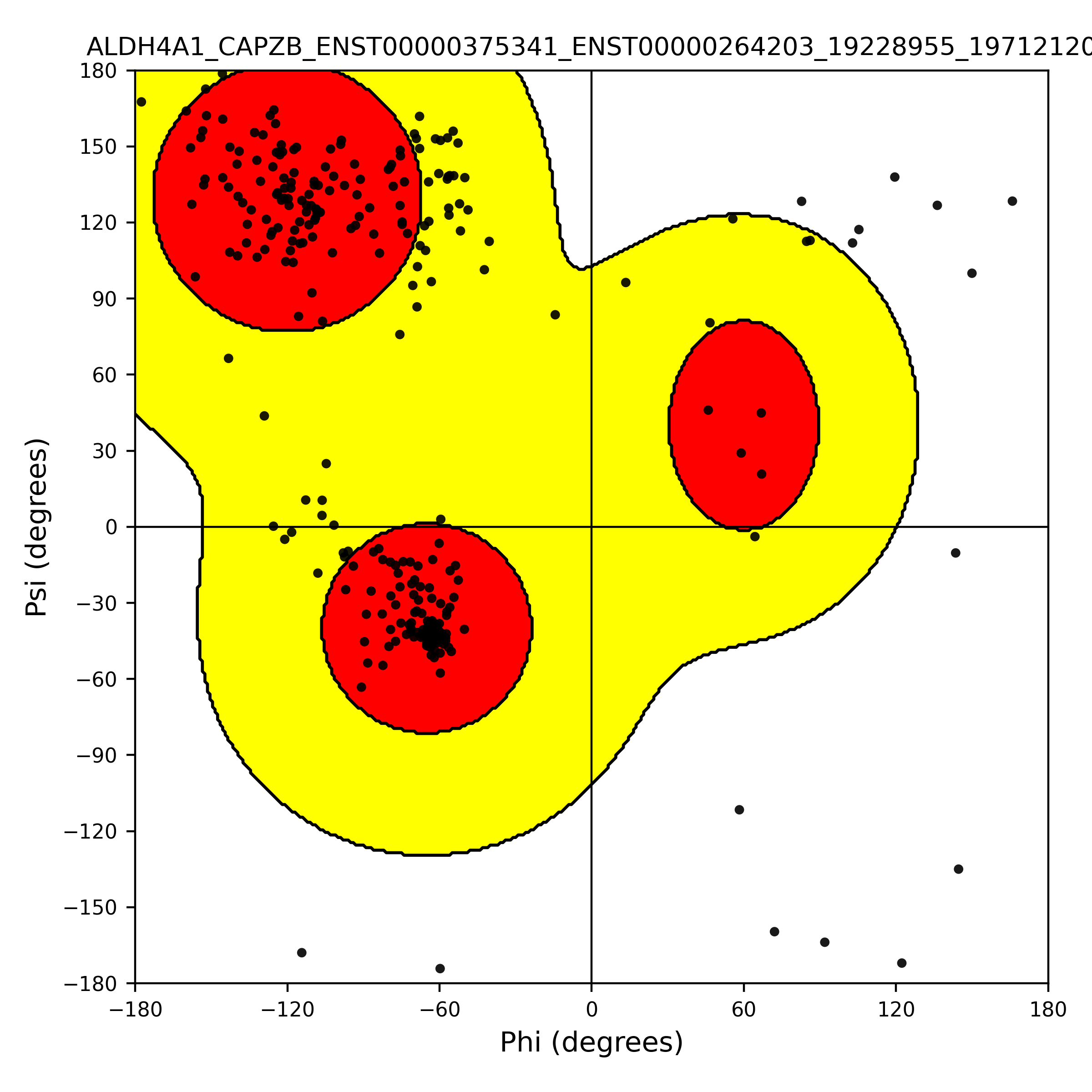 |  |
| ALDH4A1_CAPZB_ENST00000375341_ENST00000375142_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:0.9155
Å |
 | 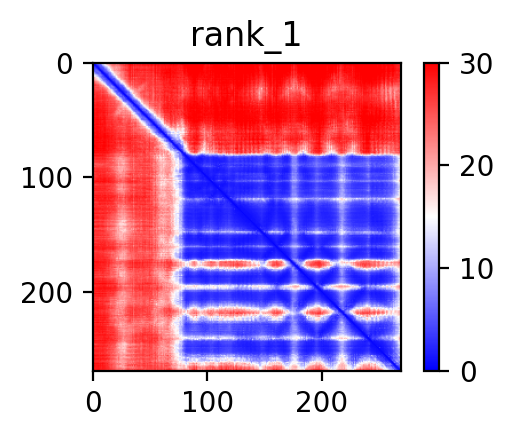 | 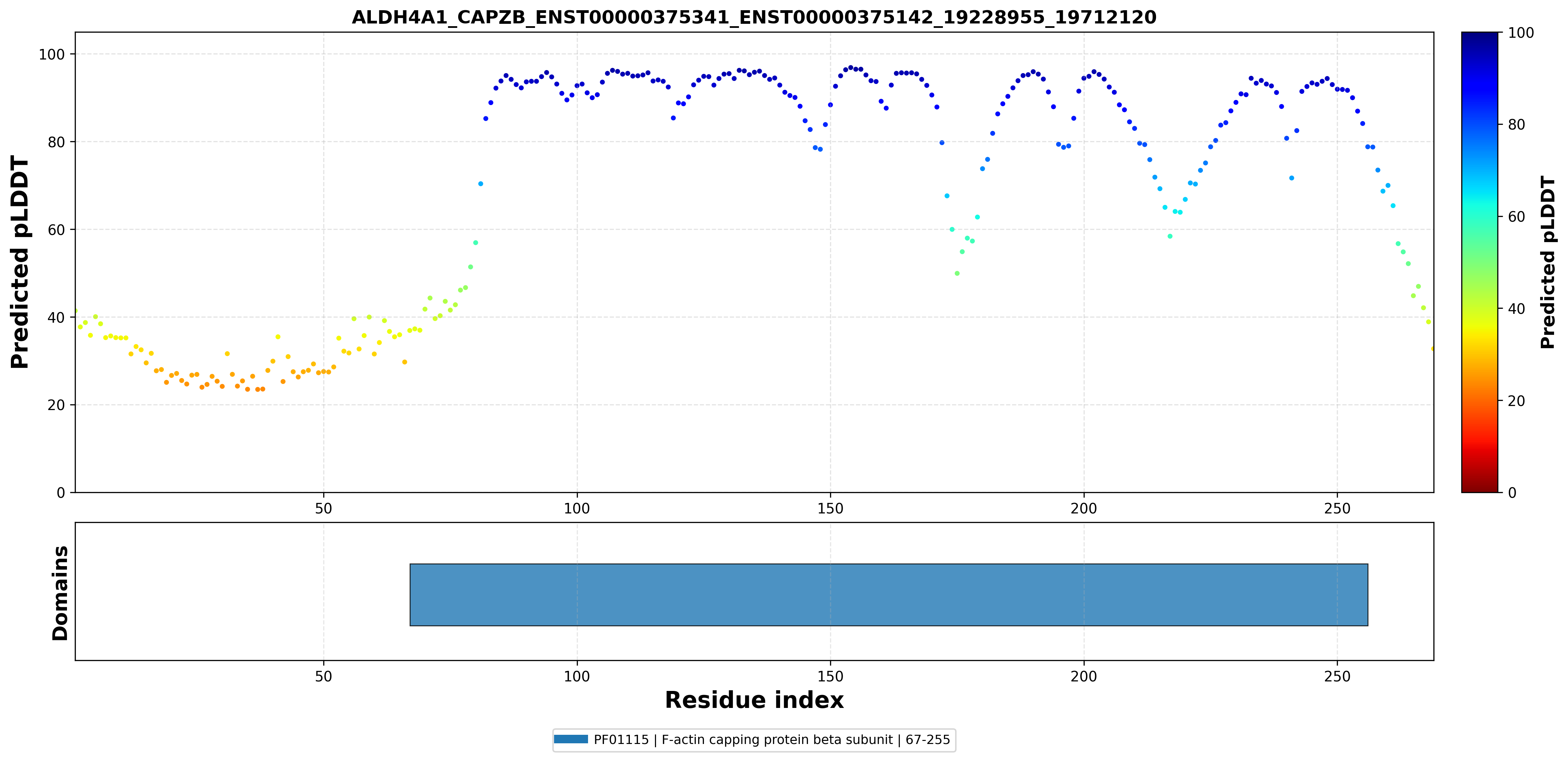 |  |  |
| ALDH4A1_CAPZB_ENST00000375341_ENST00000433834_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.3049
Å |
 | 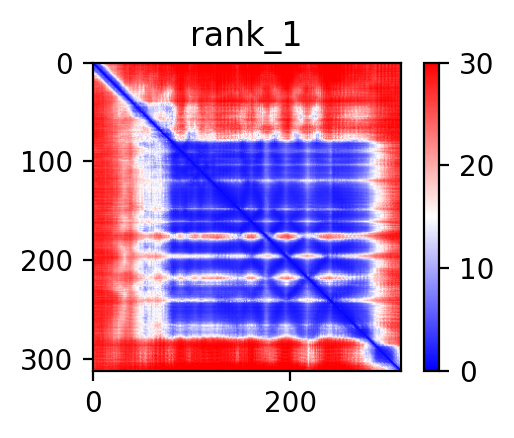 | 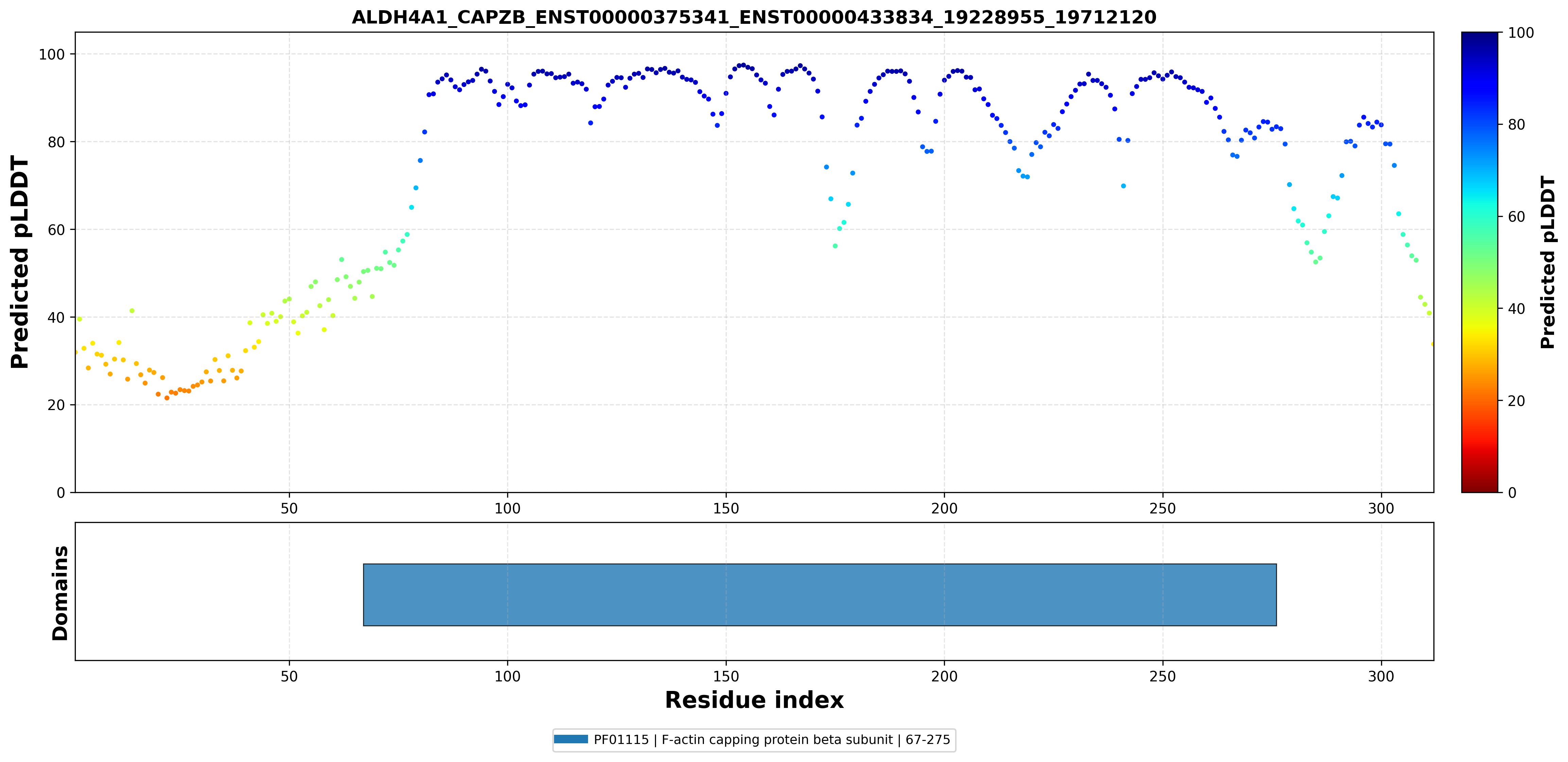 |  |  |
| ALDH4A1_CAPZB_ENST00000538839_ENST00000264203_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.263
Å |
 |  |  |  |  |
| ALDH4A1_CAPZB_ENST00000538839_ENST00000375142_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:0.8538
Å |
 |  |  |  |  |
| ALDH4A1_CAPZB_ENST00000538839_ENST00000433834_19228955_19712120 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.1211
Å |
 |  |  |  |  |
| ALDH5A1_DCDC2_ENST00000357578_ENST00000378450_24495578_24178860 superimposed PDB: 2DNF of partner (DCDC2). RMSD:2.7663
Å |
 |  |  |  |  |
| ALDH5A1_DCDC2_ENST00000491546_ENST00000378450_24495578_24178860 superimposed PDB: 2DNF of partner (DCDC2). RMSD:2.7679
Å |
 |  |  |  |  |
| ALDH5A1_MAP3K5_ENST00000348925_ENST00000355845_24505213_136880014 superimposed PDB: 2W8N of partner (ALDH5A1). RMSD:0.4633
Å |
 |  |  |  |  |
| ALDH5A1_MAP3K5_ENST00000357578_ENST00000355845_24505213_136880014 superimposed PDB: 2W8N of partner (ALDH5A1). RMSD:0.4547
Å |
 |  |  |  |  |
| ALDH5A1_MAP3K5_ENST00000491546_ENST00000355845_24505213_136880014 superimposed PDB: 8QGY of partner (MAP3K5). RMSD:3.2402
Å |
 |  |  |  |  |
| ALDH5A1_MAP3K5_ENST00000546278_ENST00000355845_24505213_136880014 superimposed PDB: 2W8N of partner (ALDH5A1). RMSD:0.5627
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000338110_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.8408
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000338110_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5191
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395240_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.788
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395240_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.6255
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395240_ENST00000600573_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:3.0158
Å |
| | | |  |
| ALDOA_PNKP_ENST00000395248_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.7696
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395248_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.7895
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395248_ENST00000596014_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:2.876
Å |
| | | |  |
| ALDOA_PNKP_ENST00000395248_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5542
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000395248_ENST00000600573_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:3.0198
Å |
| | | |  |
| ALDOA_PNKP_ENST00000412304_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.8219
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000412304_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.9237
Å |
 |  | 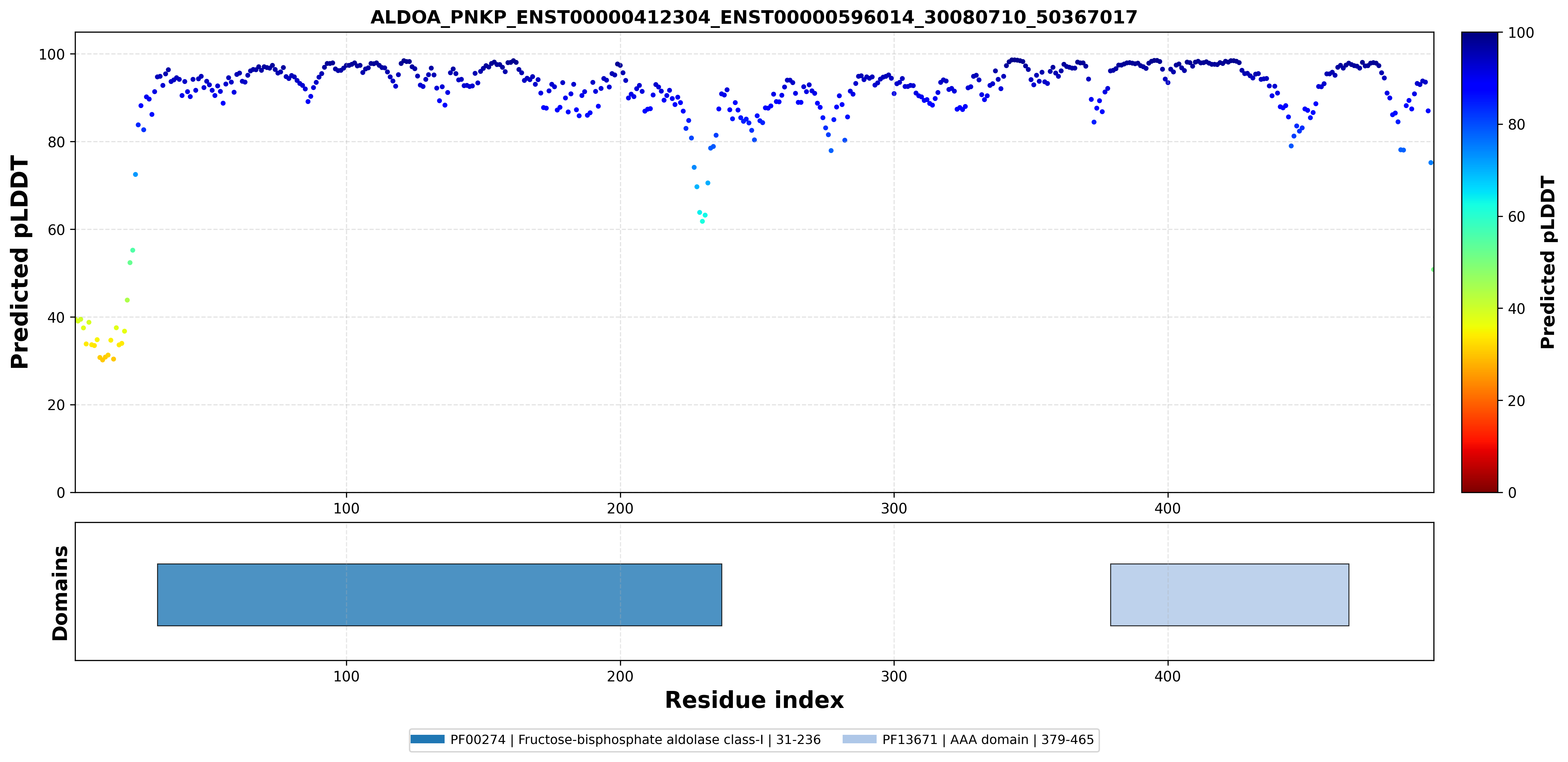 |  |  |
| ALDOA_PNKP_ENST00000412304_ENST00000596014_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:2.8687
Å |
| | | |  |
| ALDOA_PNKP_ENST00000412304_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5186
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000412304_ENST00000600573_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:3.0372
Å |
| | | |  |
| ALDOA_PNKP_ENST00000563060_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.6611
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000563060_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.921
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000563060_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5325
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000564546_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:1.3535
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000564546_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.6522
Å |
 |  | 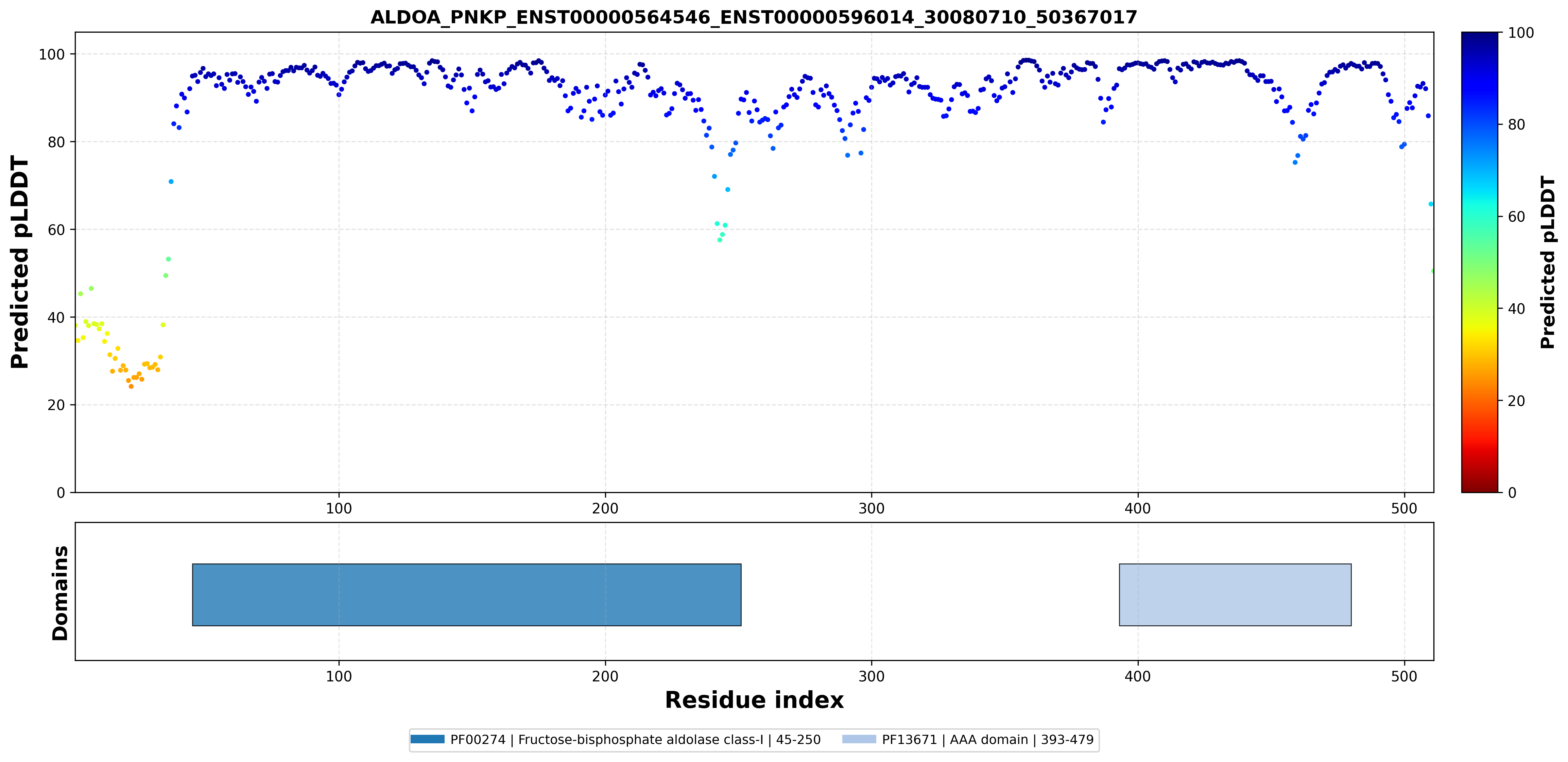 |  |  |
| ALDOA_PNKP_ENST00000564546_ENST00000596014_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:2.996
Å |
| | | |  |
| ALDOA_PNKP_ENST00000564546_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5257
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000564546_ENST00000600573_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:3.0031
Å |
| | | |  |
| ALDOA_PNKP_ENST00000564595_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.6501
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000564595_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.782
Å |
 |  | 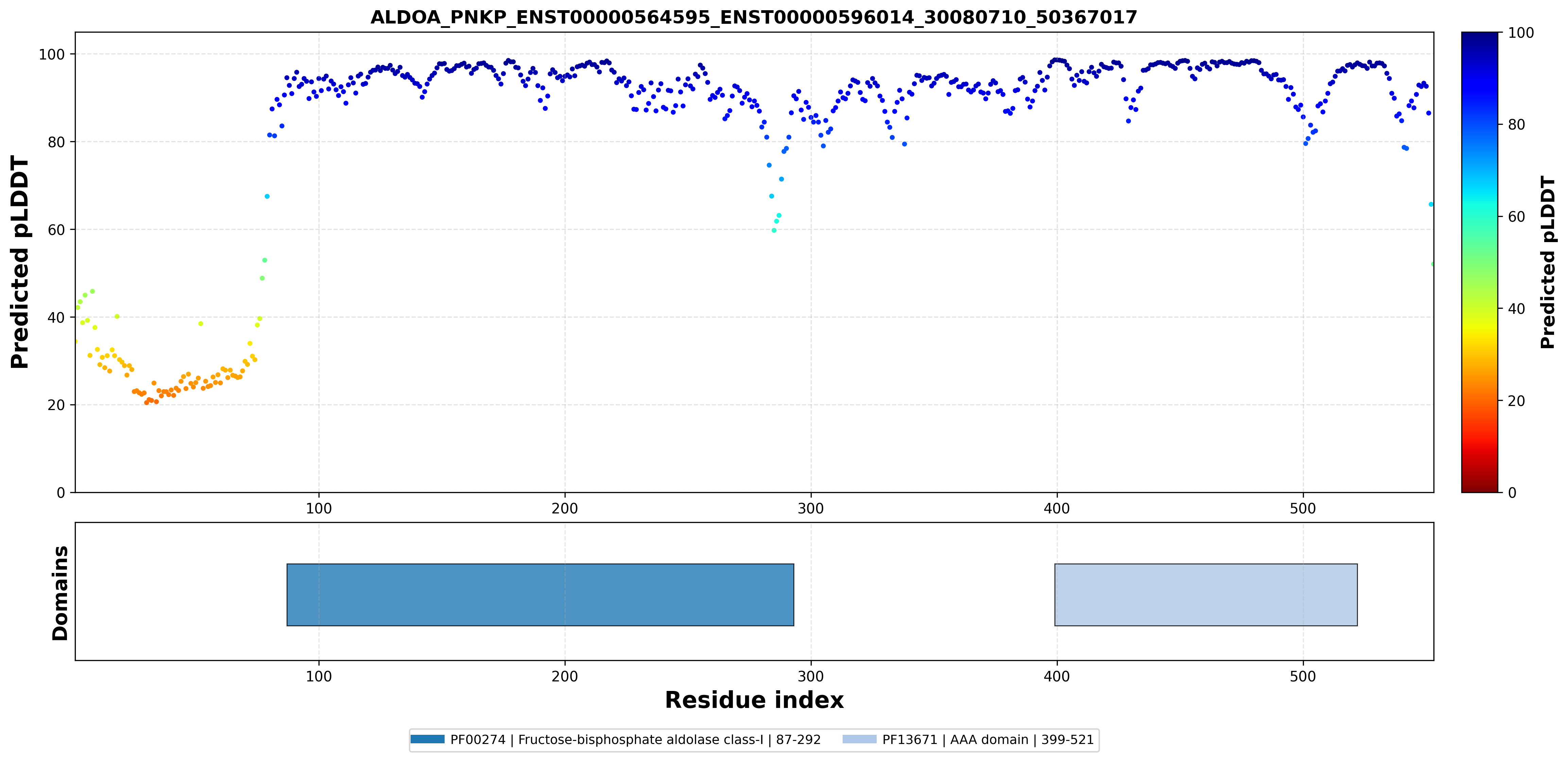 |  |  |
| ALDOA_PNKP_ENST00000564595_ENST00000596014_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:3.004
Å |
| | | |  |
| ALDOA_PNKP_ENST00000564595_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.4701
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000564595_ENST00000600573_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:2.8717
Å |
| | | |  |
| ALDOA_PNKP_ENST00000566897_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.7193
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000569545_ENST00000596014_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.8859
Å |
 |  | 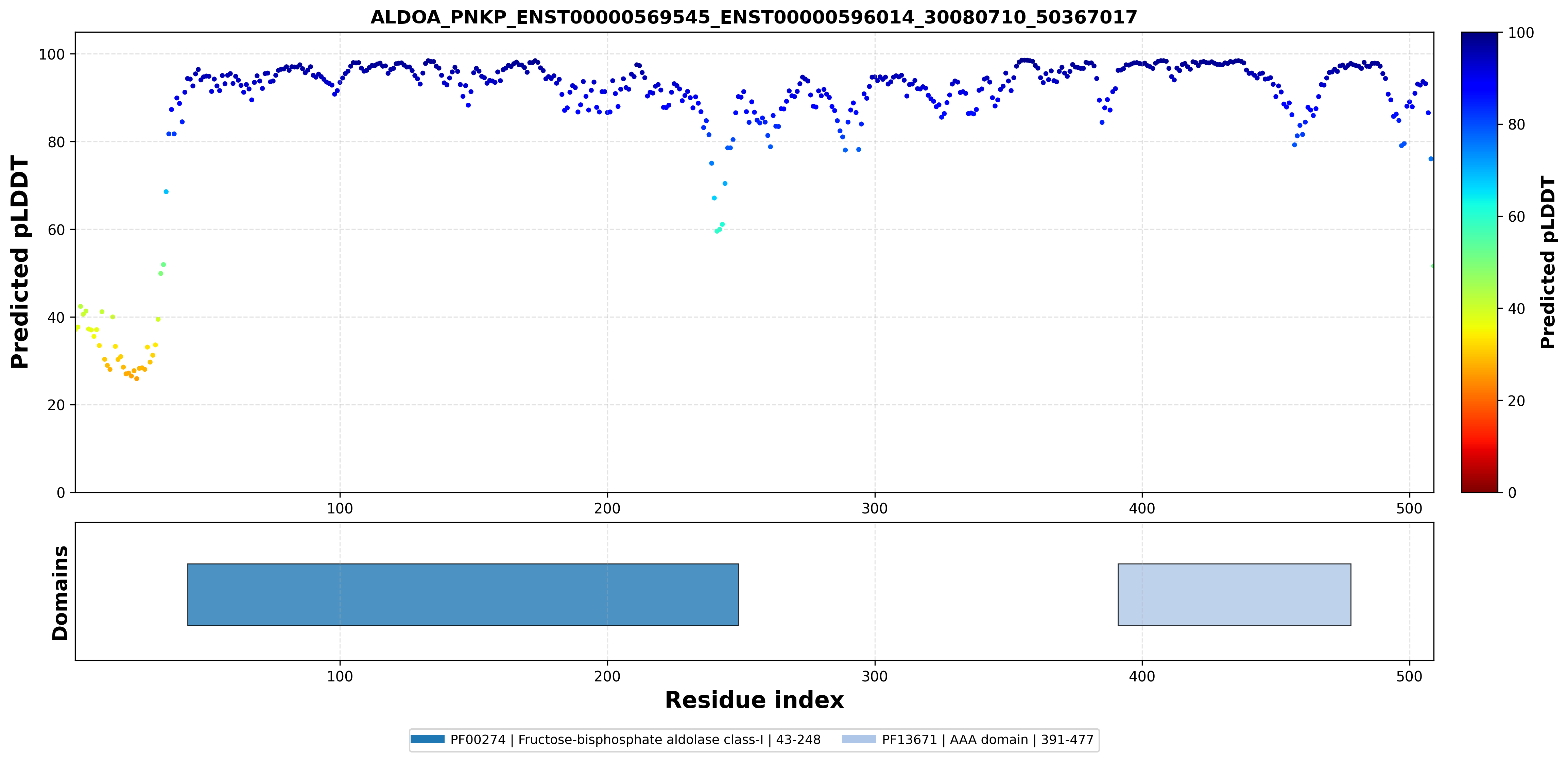 |  |  |
| ALDOA_PNKP_ENST00000569545_ENST00000596014_30080710_50367017 superimposed PDB: 2BRF of partner (PNKP). RMSD:2.8705
Å |
| | | |  |
| ALDOA_PNKP_ENST00000569545_ENST00000600573_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.5298
Å |
 |  |  |  |  |
| ALDOA_PNKP_ENST00000569798_ENST00000322344_30080710_50367017 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.6934
Å |
 |  |  |  |  |
| ALDOA_SIAE_ENST00000566897_ENST00000263593_30081732_124543777 superimposed PDB: 6XML of partner (ALDOA). RMSD:2.641
Å |
 |  |  |  |  |
| ALG14_ABCD3_ENST00000370205_ENST00000454898_95530421_94964157 superimposed PDB: 9W65 of partner (ABCD3). RMSD:0.9278
Å |
 |  |  |  |  |
| ALG5_PIGU_ENST00000443765_ENST00000452740_37559763_33176411 superimposed PDB: 7WLD of partner (PIGU). RMSD:2.3343
Å |
 |  |  |  |  |
| ALG6_DUT_ENST00000263440_ENST00000559935_63872797_48626613 superimposed PDB: 24OK of partner (DUT). RMSD:0.723
Å |
 |  |  |  |  |
| ALG6_DUT_ENST00000371108_ENST00000558813_63872797_48626613 superimposed PDB: 24OK of partner (DUT). RMSD:0.8065
Å |
 |  |  |  |  |
| ALG6_DUT_ENST00000371108_ENST00000559416_63872797_48626613 superimposed PDB: 24OK of partner (DUT). RMSD:0.8531
Å |
 |  |  |  |  |
| ALG9_DLG2_ENST00000531154_ENST00000376104_111680366_84245774 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4143
Å |
 |  |  |  |  |
| ALX4_STK33_ENST00000329255_ENST00000396672_44289043_8414257 superimposed PDB: 2M0C of partner (ALX4). RMSD:0.5856
Å |
 |  |  |  |  |
| AMBP_RBP4_ENST00000265132_ENST00000371467_116823703_95353792 superimposed PDB: 3QKG of partner (AMBP). RMSD:0.367
Å |
 |  |  |  |  |
| AMBP_RBP4_ENST00000265132_ENST00000371467_116823703_95353792 superimposed PDB: 6QBA of partner (RBP4). RMSD:0.8029
Å |
| | | |  |
| AMD1_MBOAT2_ENST00000368876_ENST00000305997_111210186_9004364 superimposed PDB: 1JL0 of partner (AMD1). RMSD:1.8091
Å |
 |  | 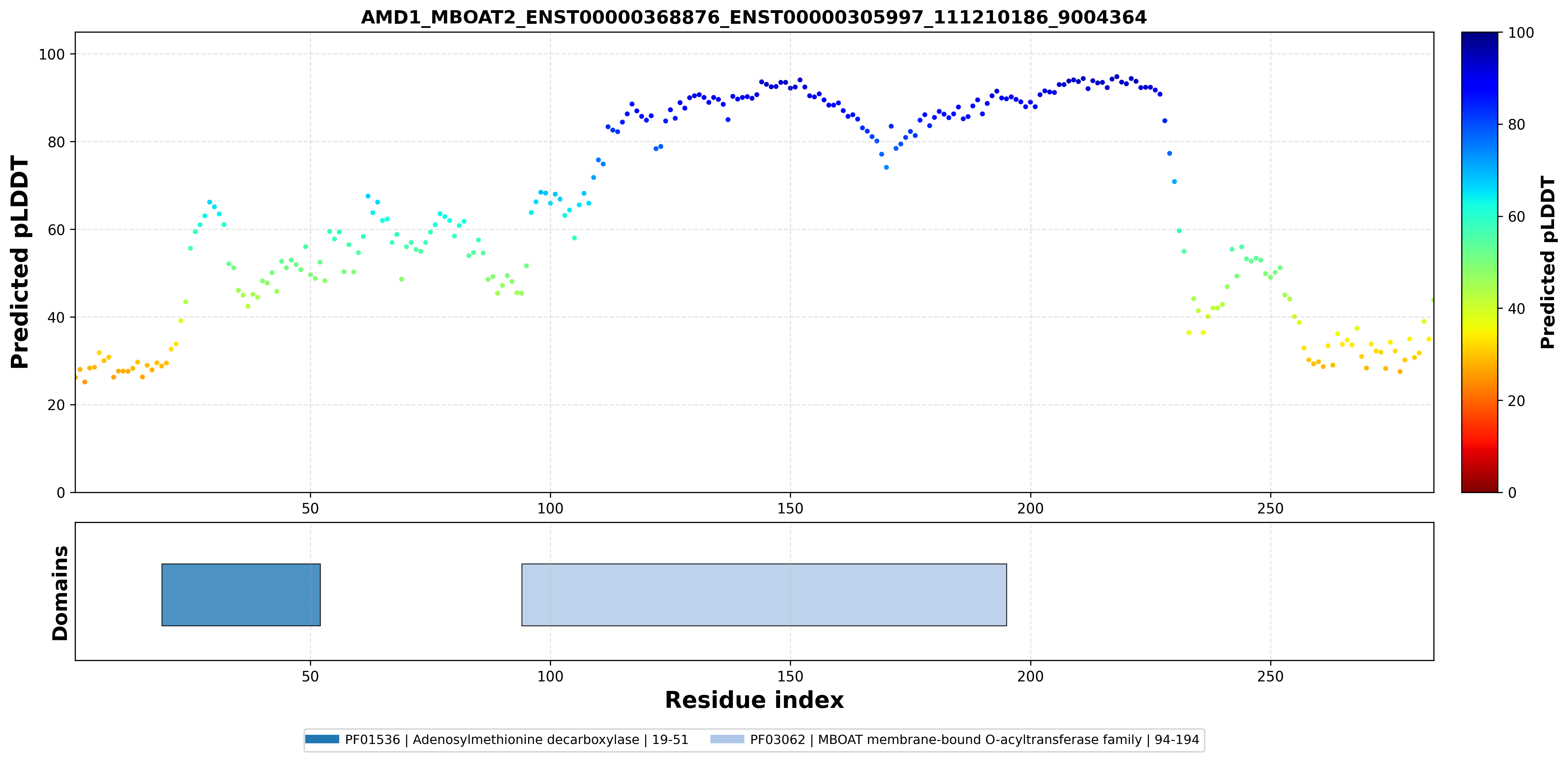 |  |  |
| AMD1_MBOAT2_ENST00000368877_ENST00000305997_111210186_9004364 superimposed PDB: 1JL0 of partner (AMD1). RMSD:0.5559
Å |
 |  | 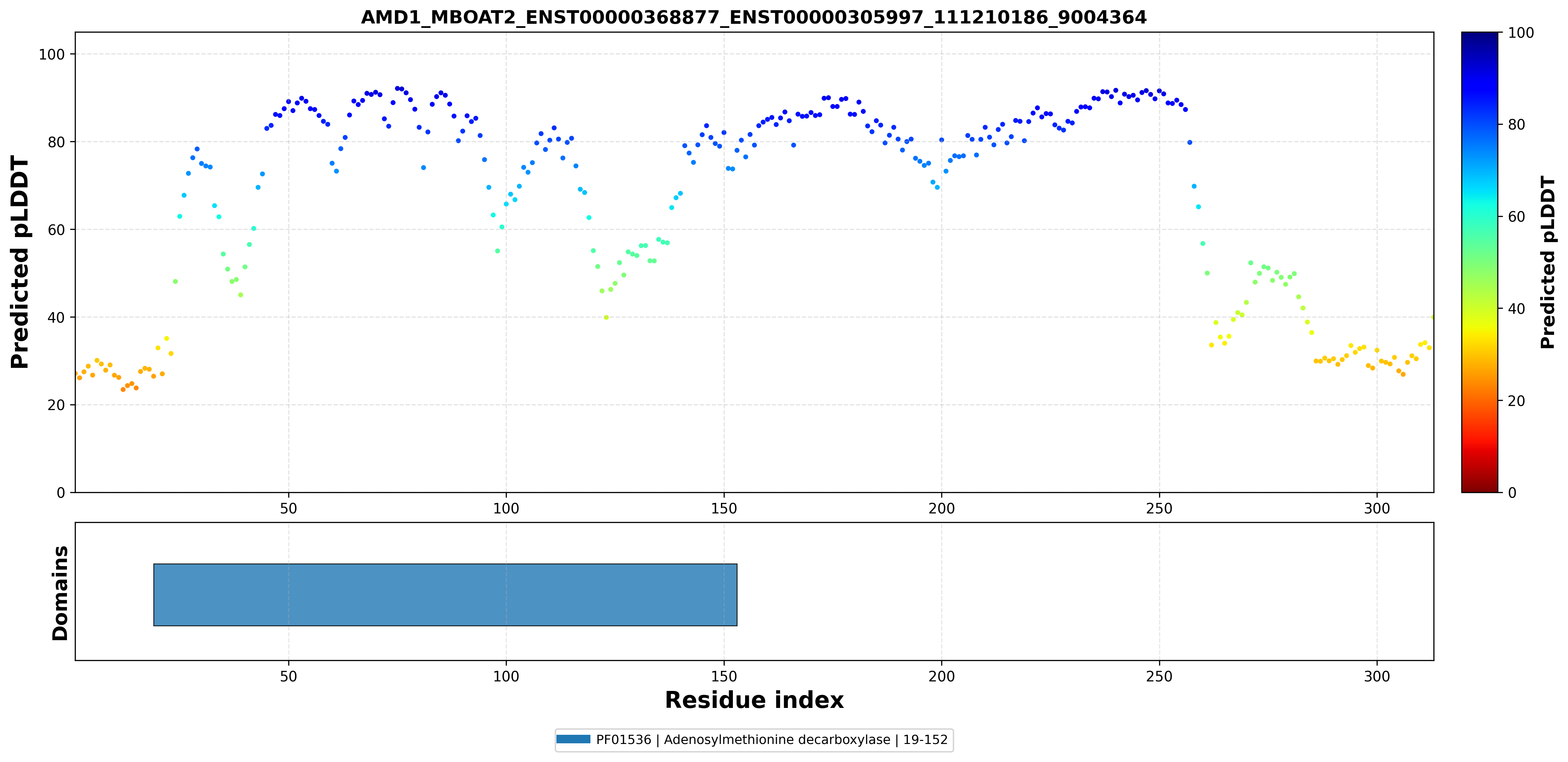 |  |  |
| AMFR_ITGAM_ENST00000290649_ENST00000544665_56419830_31332561 superimposed PDB: 7USL of partner (ITGAM). RMSD:2.8491
Å |
 |  |  |  |  |
| ANAPC16_MICU1_ENST00000299381_ENST00000361114_73983814_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.8149
Å |
 |  |  |  |  |
| ANAPC16_MICU1_ENST00000299381_ENST00000398761_73983814_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.593
Å |
 |  |  |  |  |
| ANAPC4_RBPJ_ENST00000315368_ENST00000342295_25398521_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8363
Å |
 |  |  |  |  |
| ANAPC4_RBPJ_ENST00000315368_ENST00000348160_25398521_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8458
Å |
 |  |  |  |  |
| ANAPC5_LTA4H_ENST00000441917_ENST00000552789_121756079_96402926 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:1.2892
Å |
 |  |  |  |  |
| ANAPC5_SRRM2_ENST00000261819_ENST00000301740_121766118_2808985 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:2.2427
Å |
 |  |  |  |  |
| ANAPC5_SRRM2_ENST00000344395_ENST00000301740_121766118_2808985 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:1.0091
Å |
 |  |  |  |  |
| ANAPC5_SRRM2_ENST00000535482_ENST00000301740_121766118_2808985 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:2.3127
Å |
 |  |  |  |  |
| ANAPC5_VDAC3_ENST00000261819_ENST00000392935_121785604_42260828 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:2.7772
Å |
 |  |  |  |  |
| ANK1_ADAM7_ENST00000289734_ENST00000520720_41591488_24384267 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.3559
Å |
 |  |  |  |  |
| ANK1_ADAM7_ENST00000347528_ENST00000520720_41591488_24384267 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6873
Å |
 |  |  |  |  |
| ANK1_CAPZA1_ENST00000289734_ENST00000263168_41615553_113189831 superimposed PDB: 8F8Q of partner (CAPZA1). RMSD:0.8453
Å |
 |  |  |  |  |
| ANK1_FUT10_ENST00000265709_ENST00000524021_41553880_33230322 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7893
Å |
 |  |  |  |  |
| ANK1_FUT10_ENST00000289734_ENST00000335589_41553880_33247316 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8321
Å |
 |  |  |  |  |
| ANK1_FUT10_ENST00000347528_ENST00000524021_41553880_33230322 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8772
Å |
 |  |  |  |  |
| ANK1_ZMAT4_ENST00000265709_ENST00000297737_41566295_40554920 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6538
Å |
 |  |  |  |  |
| ANK1_ZMAT4_ENST00000289734_ENST00000315769_41566295_40554920 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6717
Å |
 |  |  |  |  |
| ANK1_ZMAT4_ENST00000347528_ENST00000297737_41566295_40554920 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7123
Å |
 |  |  |  |  |
| ANK1_ZMAT4_ENST00000347528_ENST00000315769_41566295_40554920 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7791
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000280772_ENST00000222792_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.8078
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000280772_ENST00000495789_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:1.7676
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000280772_ENST00000539406_62021616_29433294 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.3903
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000373827_ENST00000222792_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.782
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000503366_ENST00000222792_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.7666
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000503366_ENST00000435288_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.8274
Å |
 |  |  |  |  |
| ANK3_CHN2_ENST00000503366_ENST00000495789_62021616_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.448
Å |
 |  |  |  |  |
| ANKFY1_SPINT2_ENST00000570535_ENST00000301244_4077203_38774266 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2916
Å |
 |  |  |  |  |
| ANKFY1_SPINT2_ENST00000574367_ENST00000301244_4077203_38774266 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.3003
Å |
 |  |  |  |  |
| ANKHD1_RICTOR_ENST00000297183_ENST00000357387_139781858_38978752 superimposed PDB: 9T94 of partner (RICTOR). RMSD:1.4831
Å |
 |  |  |  |  |
| ANKHD1_RICTOR_ENST00000360839_ENST00000296782_139781858_38978752 superimposed PDB: 9T94 of partner (RICTOR). RMSD:1.4521
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000337516_ENST00000377093_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9348
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000357997_ENST00000263934_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9569
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000357997_ENST00000377083_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9138
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000357997_ENST00000377086_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9952
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000357997_ENST00000377093_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.8974
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000539605_ENST00000263934_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9376
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000539605_ENST00000377083_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9038
Å |
 |  |  |  |  |
| ANKLE2_KIF1B_ENST00000539605_ENST00000377086_133324417_10318550 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9061
Å |
 |  |  |  |  |
| ANKLE2_NHP2L1_ENST00000357997_ENST00000215956_133324417_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.4063
Å |
 |  |  |  |  |
| ANKLE2_NHP2L1_ENST00000539605_ENST00000215956_133324417_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.3814
Å |
 |  |  |  |  |
| ANKRD12_MTHFD2L_ENST00000262126_ENST00000325278_9221997_75091018 superimposed PDB: 7QEI of partner (MTHFD2L). RMSD:1.4341
Å |
 |  |  |  |  |
| ANKRD12_MTHFD2L_ENST00000383440_ENST00000325278_9221997_75091018 superimposed PDB: 7QEI of partner (MTHFD2L). RMSD:1.319
Å |
 |  |  |  |  |
| ANKRD12_VAPA_ENST00000262126_ENST00000400000_9195696_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.6807
Å |
 |  |  |  |  |
| ANKRD12_VAPA_ENST00000383440_ENST00000340541_9195696_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.6914
Å |
 |  |  |  |  |
| ANKRD17_GC_ENST00000330838_ENST00000273951_74000833_72631360 superimposed PDB: 1KXP of partner (GC). RMSD:1.6543
Å |
 |  |  |  |  |
| ANKRD17_GC_ENST00000330838_ENST00000504199_74000833_72631360 superimposed PDB: 1KXP of partner (GC). RMSD:1.1471
Å |
 |  |  |  |  |
| ANKRD17_GC_ENST00000358602_ENST00000504199_74000833_72631360 superimposed PDB: 1KXP of partner (GC). RMSD:1.138
Å |
 |  |  |  |  |
| ANKRD17_GC_ENST00000509867_ENST00000273951_74000833_72631360 superimposed PDB: 1KXP of partner (GC). RMSD:1.1776
Å |
 |  |  |  |  |
| ANKRD17_GC_ENST00000509867_ENST00000504199_74000833_72631360 superimposed PDB: 1KXP of partner (GC). RMSD:1.1572
Å |
 |  |  |  |  |
| ANKRD17_PAK1_ENST00000358602_ENST00000278568_74123992_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6406
Å |
 |  |  |  |  |
| ANKRD17_PAK1_ENST00000358602_ENST00000528203_74123992_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.638
Å |
 |  |  |  |  |
| ANKRD17_PAK1_ENST00000358602_ENST00000530617_74123992_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.591
Å |
 |  |  |  |  |
| ANKRD17_WDFY3_ENST00000330838_ENST00000295888_73962833_85630500 superimposed PDB: 6W9N of partner (WDFY3). RMSD:2.0349
Å |
 |  |  |  |  |
| ANKRD17_WDFY3_ENST00000358602_ENST00000295888_73962833_85630500 superimposed PDB: 6W9N of partner (WDFY3). RMSD:1.9579
Å |
 |  |  |  |  |
| ANKRD17_WDFY3_ENST00000509867_ENST00000295888_73962833_85630500 superimposed PDB: 6W9N of partner (WDFY3). RMSD:1.9858
Å |
 |  |  |  |  |
| ANKRD27_PEPD_ENST00000306065_ENST00000244137_33118988_33902655 superimposed PDB: 4B93 of partner (ANKRD27). RMSD:0.4256
Å |
 |  |  |  |  |
| ANKRD28_BRIP1_ENST00000399451_ENST00000577598_15900883_59853923 superimposed PDB: 1T29 of partner (BRIP1). RMSD:1.6534
Å |
 |  |  |  |  |
| ANKRD28_PHF21A_ENST00000383777_ENST00000323180_15836729_45975176 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.6122
Å |
 |  |  |  |  |
| ANKRD28_PHF21A_ENST00000383777_ENST00000418153_15836729_45975176 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.622
Å |
 |  |  |  |  |
| ANKRD28_PHF21A_ENST00000399451_ENST00000323180_15836729_45975176 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.5911
Å |
 |  |  |  |  |
| ANKRD28_PHF21A_ENST00000399451_ENST00000418153_15836729_45975176 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.6497
Å |
 |  |  |  |  |
| ANKRD33B_NIPBL_ENST00000296657_ENST00000448238_10564945_37058992 superimposed PDB: 6WGE of partner (NIPBL). RMSD:2.4244
Å |
 |  |  |  |  |
| ANKRD40_TNPO1_ENST00000285243_ENST00000454282_48777928_72182896 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.1431
Å |
 |  |  |  |  |
| ANKS1A_DCDC2_ENST00000535627_ENST00000378454_34857376_24353851 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.7852
Å |
 |  |  |  |  |
| ANKS1A_SLC7A8_ENST00000360359_ENST00000316902_35021942_23635749 superimposed PDB: 2LMR of partner (ANKS1A). RMSD:2.8985
Å |
 |  |  |  |  |
| ANKS1A_SLC7A8_ENST00000360359_ENST00000469263_35021942_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.5367
Å |
 |  |  |  |  |
| ANKS3_GLYR1_ENST00000585773_ENST00000321919_4774750_4882913 superimposed PDB: 2UYY of partner (GLYR1). RMSD:0.3312
Å |
 |  |  |  |  |
| ANKS3_GLYR1_ENST00000585773_ENST00000381983_4774750_4882913 superimposed PDB: 2UYY of partner (GLYR1). RMSD:0.3181
Å |
 |  |  |  |  |
| ANKS3_GLYR1_ENST00000585773_ENST00000591451_4774750_4882913 superimposed PDB: 2UYY of partner (GLYR1). RMSD:0.3254
Å |
 |  |  |  |  |
| ANKS3_GLYR1_ENST00000592711_ENST00000436648_4774750_4882913 superimposed PDB: 2UYY of partner (GLYR1). RMSD:0.3212
Å |
 |  |  |  |  |
| ANLN_POU6F2_ENST00000265748_ENST00000518318_36483471_39125460 superimposed PDB: 4XH3 of partner (ANLN). RMSD:0.4409
Å |
 |  |  |  |  |
| ANLN_POU6F2_ENST00000396068_ENST00000403058_36483471_39125460 superimposed PDB: 4XH3 of partner (ANLN). RMSD:0.4091
Å |
 |  |  |  |  |
| ANLN_POU6F2_ENST00000396068_ENST00000518318_36483471_39125460 superimposed PDB: 4XH3 of partner (ANLN). RMSD:0.4877
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000355303_ENST00000469263_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.5575
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000398543_ENST00000316902_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.5011
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000398543_ENST00000469263_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.1368
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000530676_ENST00000316902_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.4174
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000530676_ENST00000469263_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.1833
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000531349_ENST00000316902_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.7712
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000531349_ENST00000469263_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:0.8301
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000538023_ENST00000316902_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.6414
Å |
 |  |  |  |  |
| ANO1_SLC7A8_ENST00000538023_ENST00000469263_70017145_23635749 superimposed PDB: 8A6L of partner (SLC7A8). RMSD:1.5472
Å |
 |  |  |  |  |
| ANP32A_DNAJC17_ENST00000560303_ENST00000220496_69113036_41072195 superimposed PDB: 2D9O of partner (DNAJC17). RMSD:1.0028
Å |
 |  |  |  |  |
| ANP32B_WNK2_ENST00000339399_ENST00000297954_100745891_96079801 superimposed PDB: 8R1L of partner (ANP32B). RMSD:2.5025
Å |
 |  | 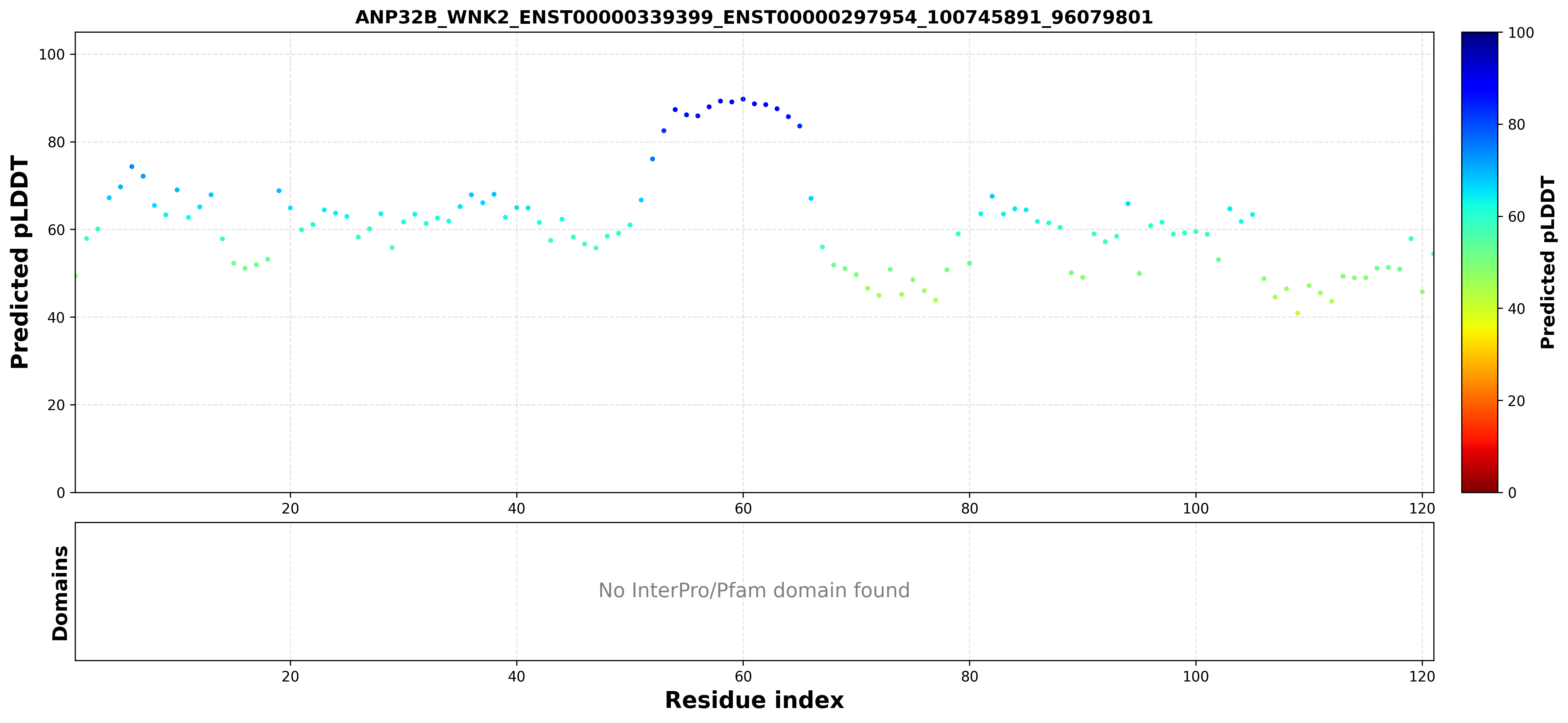 |  |  |
| ANTXR1_BRAF_ENST00000409349_ENST00000288602_69379396_140487384 superimposed PDB: 3N2N of partner (ANTXR1). RMSD:0.8072
Å |
 |  |  |  |  |
| ANTXR1_LRRTM4_ENST00000303714_ENST00000409884_69318051_76976042 superimposed PDB: 3N2N of partner (ANTXR1). RMSD:0.465
Å |
 |  |  |  |  |
| ANTXR2_TNFSF10_ENST00000346652_ENST00000420541_80905972_172232788 superimposed PDB: 1DG6 of partner (TNFSF10). RMSD:0.296
Å |
 |  |  |  |  |
| ANTXR2_TNFSF10_ENST00000346652_ENST00000420541_80929674_172232788 superimposed PDB: 1DG6 of partner (TNFSF10). RMSD:0.3099
Å |
 |  |  |  |  |
| ANTXR2_TNFSF10_ENST00000403729_ENST00000420541_80905972_172232788 superimposed PDB: 1DG6 of partner (TNFSF10). RMSD:0.3064
Å |
 |  |  |  |  |
| ANTXR2_TNFSF10_ENST00000403729_ENST00000420541_80929674_172232788 superimposed PDB: 1DG6 of partner (TNFSF10). RMSD:0.3266
Å |
 |  |  |  |  |
| ANXA1_RPL14_ENST00000257497_ENST00000396203_75774339_40503098 superimposed PDB: 9NP0 of partner (ANXA1). RMSD:2.8296
Å |
 |  |  |  |  |
| ANXA1_RPL14_ENST00000376911_ENST00000338970_75774339_40503098 superimposed PDB: 9NP0 of partner (ANXA1). RMSD:2.3294
Å |
 |  |  |  |  |
| ANXA1_RPL14_ENST00000376911_ENST00000396203_75774339_40503098 superimposed PDB: 9NP0 of partner (ANXA1). RMSD:3.2342
Å |
 |  |  |  |  |
| ANXA2_KANSL2_ENST00000332680_ENST00000420613_60653139_49048843 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3602
Å |
 |  |  |  |  |
| ANXA2_KANSL2_ENST00000396024_ENST00000420613_60653139_49048843 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.352
Å |
 |  |  |  |  |
| ANXA2_KANSL2_ENST00000421017_ENST00000420613_60653139_49048843 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3596
Å |
 |  |  |  |  |
| ANXA2_KANSL2_ENST00000451270_ENST00000420613_60653139_49048843 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3399
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000332680_ENST00000429094_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:2.5845
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000332680_ENST00000452445_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:2.6306
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000396024_ENST00000429094_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:2.5043
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000421017_ENST00000429094_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:2.5336
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000421017_ENST00000452445_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:3.5921
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000451270_ENST00000429094_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:2.6034
Å |
 |  |  |  |  |
| ANXA2_NELL2_ENST00000451270_ENST00000452445_60674540_45004753 superimposed PDB: 10FT of partner (NELL2). RMSD:3.1963
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000332680_ENST00000389146_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3419
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000332680_ENST00000552285_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3377
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000396024_ENST00000389146_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3564
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000421017_ENST00000389146_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3404
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000421017_ENST00000552285_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3545
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000451270_ENST00000389146_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3507
Å |
 |  |  |  |  |
| ANXA2_OS9_ENST00000451270_ENST00000552285_60653139_58109542 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3726
Å |
 |  |  |  |  |
| ANXA2_RNF114_ENST00000332680_ENST00000244061_60643391_48565784 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.5363
Å |
 |  |  |  |  |
| ANXA2_RNF114_ENST00000421017_ENST00000244061_60643391_48565784 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.5697
Å |
 |  |  |  |  |
| ANXA2_RNF114_ENST00000451270_ENST00000244061_60643391_48565784 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.5094
Å |
 |  |  |  |  |
| ANXA2_RORA_ENST00000332680_ENST00000309157_60674540_60824050 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5543
Å |
 |  |  |  |  |
| ANXA2_RORA_ENST00000396024_ENST00000309157_60674540_60824050 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5481
Å |
 |  |  |  |  |
| ANXA2_RORA_ENST00000396024_ENST00000335670_60674540_60824050 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3486
Å |
 |  |  |  |  |
| ANXA2_RORA_ENST00000421017_ENST00000309157_60674540_60824050 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5563
Å |
 |  |  |  |  |
| ANXA2_RORA_ENST00000451270_ENST00000309157_60674540_60824050 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5612
Å |
 |  |  |  |  |
| ANXA2_RPL5_ENST00000396024_ENST00000370321_60656627_93301746 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3383
Å |
 |  |  |  |  |
| ANXA2_SLC51A_ENST00000332680_ENST00000296327_60653139_195959289 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3605
Å |
 |  |  |  |  |
| ANXA2_SLC51A_ENST00000332680_ENST00000296327_60653139_195959289 superimposed PDB: 9UO2 of partner (SLC51A). RMSD:2.5217
Å |
| | | |  |
| ANXA2_SLC51A_ENST00000396024_ENST00000296327_60653139_195959289 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.5652
Å |
 |  |  |  |  |
| ANXA2_SLC51A_ENST00000421017_ENST00000296327_60653139_195959289 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3217
Å |
 |  |  |  |  |
| ANXA2_SLC51A_ENST00000421017_ENST00000296327_60653139_195959289 superimposed PDB: 9UO2 of partner (SLC51A). RMSD:1.3552
Å |
| | | |  |
| ANXA2_SLC51A_ENST00000451270_ENST00000296327_60653139_195959289 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3305
Å |
 |  |  |  |  |
| ANXA2_SLC51A_ENST00000451270_ENST00000296327_60653139_195959289 superimposed PDB: 9UO2 of partner (SLC51A). RMSD:1.5452
Å |
| | | |  |
| ANXA2_SMG1_ENST00000332680_ENST00000389467_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.3425
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000332680_ENST00000389467_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.9757
Å |
| | | |  |
| ANXA2_SMG1_ENST00000332680_ENST00000446231_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.7723
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000332680_ENST00000446231_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.9373
Å |
| | | |  |
| ANXA2_SMG1_ENST00000396024_ENST00000389467_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.5691
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000396024_ENST00000446231_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:2.3831
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000396024_ENST00000446231_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:3.116
Å |
| | | |  |
| ANXA2_SMG1_ENST00000421017_ENST00000389467_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.6285
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000421017_ENST00000389467_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.8393
Å |
| | | |  |
| ANXA2_SMG1_ENST00000421017_ENST00000446231_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.0834
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000421017_ENST00000446231_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.7894
Å |
| | | |  |
| ANXA2_SMG1_ENST00000451270_ENST00000389467_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.3163
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000451270_ENST00000389467_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.68
Å |
| | | |  |
| ANXA2_SMG1_ENST00000451270_ENST00000446231_60646352_18883946 superimposed PDB: 1W7B of partner (ANXA2). RMSD:1.2206
Å |
 |  |  |  |  |
| ANXA2_SMG1_ENST00000451270_ENST00000446231_60646352_18883946 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.7295
Å |
| | | |  |
| ANXA2_YWHAE_ENST00000332680_ENST00000264335_60674540_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3279
Å |
 |  |  |  |  |
| ANXA2_YWHAE_ENST00000421017_ENST00000264335_60674540_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3277
Å |
 |  |  |  |  |
| ANXA2_YWHAE_ENST00000451270_ENST00000264335_60674540_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3313
Å |
 |  |  |  |  |
| ANXA4_NUMB_ENST00000394295_ENST00000554546_70008706_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5495
Å |
 |  |  |  |  |
| ANXA4_NUMB_ENST00000409920_ENST00000356296_70008706_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5004
Å |
 |  |  |  |  |
| ANXA4_NUMB_ENST00000409920_ENST00000544991_70008706_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5166
Å |
 |  |  |  |  |
| ANXA4_NUMB_ENST00000409920_ENST00000555238_70008706_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5086
Å |
 |  |  |  |  |
| ANXA4_NUMB_ENST00000409920_ENST00000560335_70008706_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5318
Å |
 |  |  |  |  |
| ANXA4_PKN1_ENST00000394295_ENST00000242783_70008706_14578376 superimposed PDB: 4OTH of partner (PKN1). RMSD:0.9119
Å |
 |  |  |  |  |
| ANXA4_SAE1_ENST00000394295_ENST00000413379_70008706_47653458 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.8181
Å |
 |  |  |  |  |
| ANXA4_SEC23A_ENST00000409920_ENST00000307712_70033564_39514528 superimposed PDB: 2NUT of partner (SEC23A). RMSD:0.9816
Å |
 |  |  |  |  |
| ANXA4_SMU1_ENST00000394295_ENST00000536631_70047953_33053288 superimposed PDB: 9GA6 of partner (ANXA4). RMSD:0.7199
Å |
 |  |  |  |  |
| ANXA4_SMU1_ENST00000409920_ENST00000536631_70047953_33053288 superimposed PDB: 9GA6 of partner (ANXA4). RMSD:1.0888
Å |
 |  |  |  |  |
| ANXA4_SMU1_ENST00000536030_ENST00000536631_70047953_33053288 superimposed PDB: 9GA6 of partner (ANXA4). RMSD:0.7023
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000346832_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9069
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000346832_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7226
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000355394_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.966
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000355394_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3474
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000359188_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9573
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000359188_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3602
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376134_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9854
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376137_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9466
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376137_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7626
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376138_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.034
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376138_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.1217
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376139_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9879
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376140_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0808
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376140_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.9817
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376142_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9357
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376142_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3346
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376160_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0171
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376160_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.6455
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376166_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9773
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000376166_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5273
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000490841_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9694
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000354546_ENST00000490841_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3531
Å |
| | | |  |
| ANXA6_ABI1_ENST00000354546_ENST00000536334_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9373
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000346832_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.8624
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000346832_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.354
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000355394_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0077
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000355394_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6236
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000359188_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0152
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000359188_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3071
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376134_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.985
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376134_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.9098
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376137_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9483
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376137_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.418
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376138_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0359
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376138_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3331
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376139_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9837
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376139_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6038
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376140_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9608
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376140_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6922
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376142_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:3.0108
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376142_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:2.1023
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376160_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.8909
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376160_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:2.0707
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376166_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9112
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376166_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.4816
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376170_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9506
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000376170_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0845
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000490841_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9012
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000490841_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:2.0201
Å |
| | | |  |
| ANXA6_ABI1_ENST00000356496_ENST00000536334_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.8894
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000356496_ENST00000536334_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6889
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000346832_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5371
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000346832_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.6763
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000355394_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5531
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000355394_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0394
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000359188_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5448
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376134_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5268
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376137_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5581
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376137_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.9221
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376138_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5097
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376139_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5515
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376139_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0191
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376140_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5165
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376142_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5609
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376142_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.8519
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376160_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5004
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376160_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.6605
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376166_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5419
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376166_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.5887
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376170_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:2.9625
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000376170_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.2316
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000490841_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5425
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000490841_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.2144
Å |
| | | |  |
| ANXA6_ABI1_ENST00000377751_ENST00000536334_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5185
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000377751_ENST00000536334_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.8997
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000346832_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.6251
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000346832_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.8653
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000355394_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.7847
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000359188_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.7094
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376134_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.9013
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376137_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.6781
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376138_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.7394
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376139_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.6566
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376139_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6179
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376140_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.669
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376142_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.7549
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376160_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.8424
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376160_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0622
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376166_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.6885
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376166_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.4548
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376170_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.5442
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000376170_150483130_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.6986
Å |
| | | |  |
| ANXA6_ABI1_ENST00000521512_ENST00000490841_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.678
Å |
 |  |  |  |  |
| ANXA6_ABI1_ENST00000521512_ENST00000536334_150483130_27112234 superimposed PDB: 1M9I of partner (ANXA6). RMSD:0.6429
Å |
 |  |  |  |  |
| AOAH_ELMO1_ENST00000258749_ENST00000341056_36698770_36934622 superimposed PDB: 7DPA of partner (ELMO1). RMSD:1.6265
Å |
 |  |  |  |  |
| AOAH_ELMO1_ENST00000431169_ENST00000341056_36698770_36934622 superimposed PDB: 7DPA of partner (ELMO1). RMSD:1.6066
Å |
 |  |  |  |  |
| AP1G1_CYB5B_ENST00000433195_ENST00000307892_71779046_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:3.0915
Å |
 |  |  |  |  |
| AP1G1_FTO_ENST00000564155_ENST00000394647_71772844_53922743 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:0.9205
Å |
 |  |  |  |  |
| AP1G1_FTO_ENST00000564155_ENST00000394647_71772844_53922743 superimposed PDB: 4IE5 of partner (FTO). RMSD:1.1048
Å |
| | | |  |
| AP1G1_FTO_ENST00000569748_ENST00000394647_71772844_53922743 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:1.1165
Å |
 |  |  |  |  |
| AP1G1_FTO_ENST00000569748_ENST00000394647_71772844_53922743 superimposed PDB: 4IE5 of partner (FTO). RMSD:3.0282
Å |
| | | |  |
| AP2A2_TALDO1_ENST00000332231_ENST00000319006_984753_755878 superimposed PDB: 1F05 of partner (TALDO1). RMSD:0.3597
Å |
 |  | 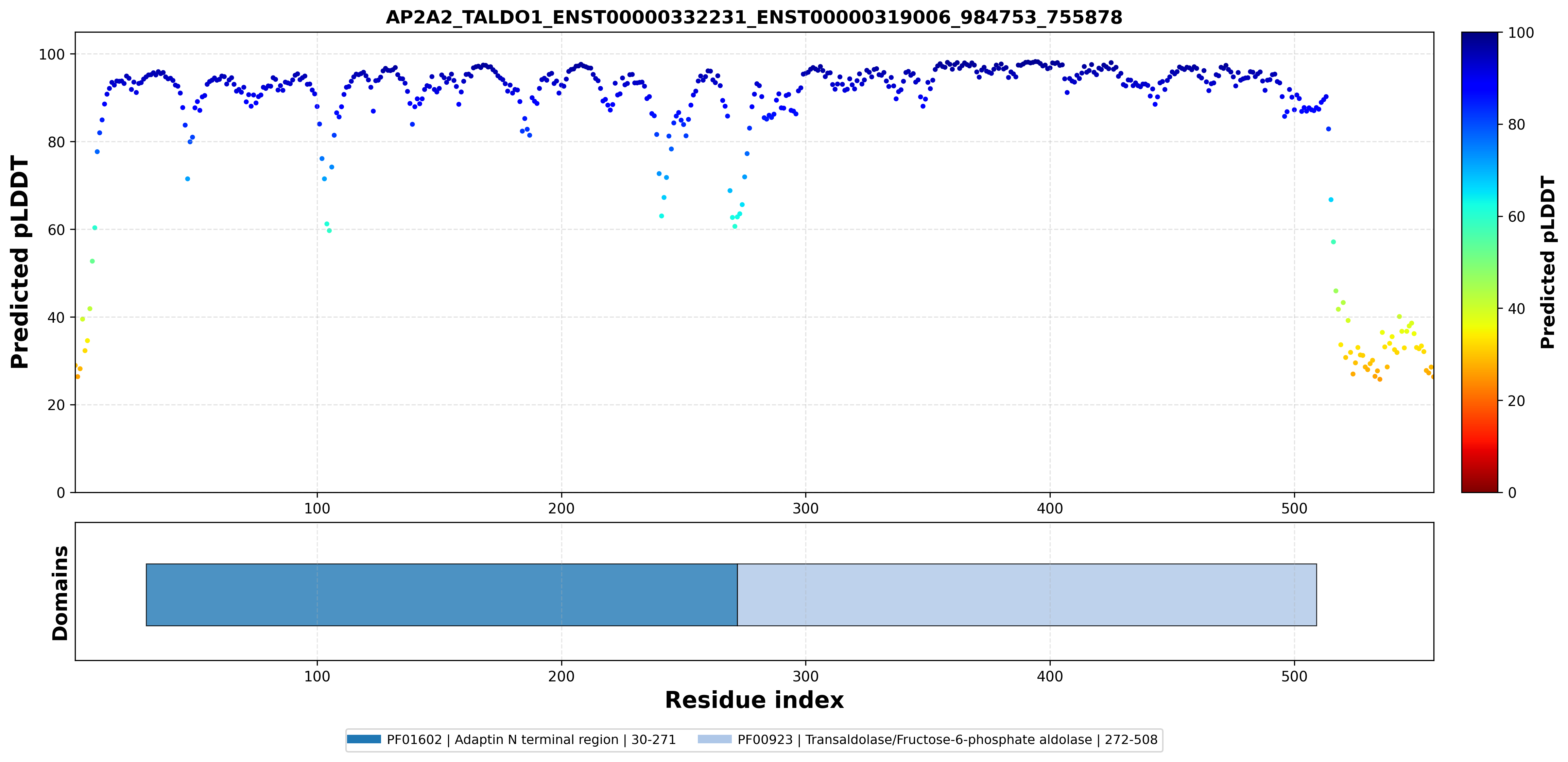 |  |  |
| AP2A2_TALDO1_ENST00000534328_ENST00000528097_984753_755878 superimposed PDB: 1F05 of partner (TALDO1). RMSD:0.3701
Å |
 |  | 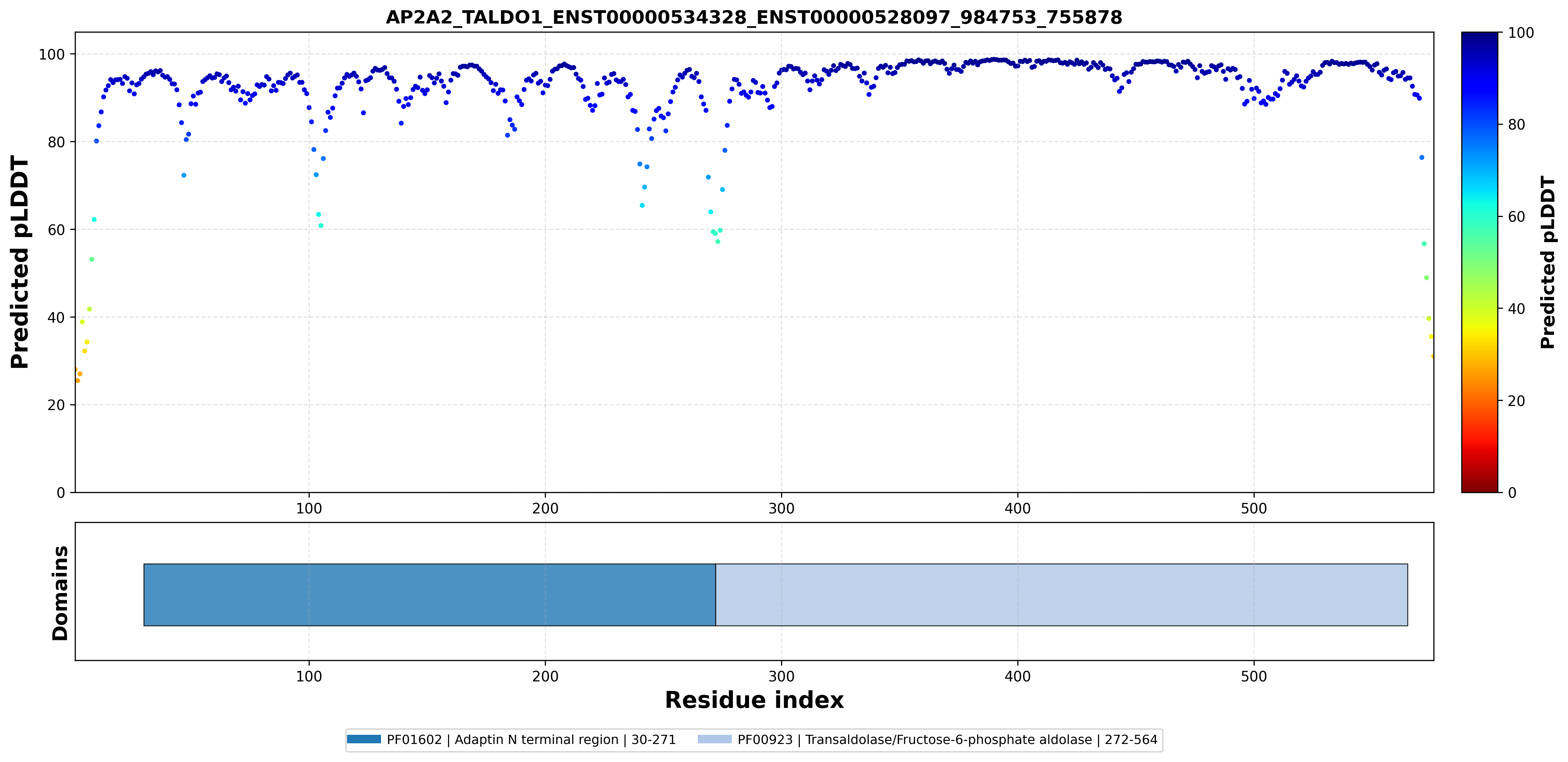 |  |  |
| AP2B1_CCT6B_ENST00000262325_ENST00000314144_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.5192
Å |
 |  |  |  |  |
| AP2B1_CCT6B_ENST00000262325_ENST00000436961_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.4975
Å |
 |  |  |  |  |
| AP2B1_CCT6B_ENST00000538556_ENST00000314144_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.5279
Å |
 |  |  |  |  |
| AP2B1_CCT6B_ENST00000538556_ENST00000436961_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.4292
Å |
 |  |  |  |  |
| AP2B1_CCT6B_ENST00000592545_ENST00000314144_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.5869
Å |
 |  |  |  |  |
| AP2B1_CCT6B_ENST00000592545_ENST00000436961_33968994_33281618 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.5083
Å |
 |  |  |  |  |
| AP3B1_BHMT_ENST00000255194_ENST00000524080_77563343_78411589 superimposed PDB: 4M3P of partner (BHMT). RMSD:0.4787
Å |
 |  |  |  |  |
| AP3B1_BHMT_ENST00000519295_ENST00000274353_77563343_78411589 superimposed PDB: 9C5A of partner (AP3B1). RMSD:0.3187
Å |
 |  |  |  |  |
| AP3B1_BHMT_ENST00000519295_ENST00000274353_77563343_78411589 superimposed PDB: 4M3P of partner (BHMT). RMSD:2.3032
Å |
| | | |  |
| AP3B1_BHMT_ENST00000519295_ENST00000524080_77563343_78411589 superimposed PDB: 4M3P of partner (BHMT). RMSD:0.4865
Å |
 |  |  |  |  |
| AP3B1_BRAF_ENST00000519295_ENST00000288602_77385216_140487384 superimposed PDB: 9C5A of partner (AP3B1). RMSD:1.2203
Å |
 |  |  |  |  |
| AP3B1_DCTN4_ENST00000255194_ENST00000447998_77423853_150136049 superimposed PDB: 9C5A of partner (AP3B1). RMSD:1.36
Å |
 | 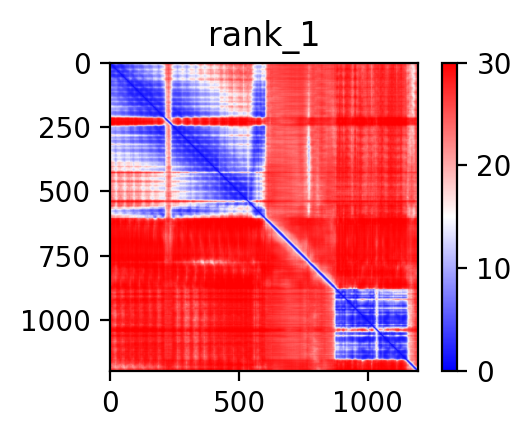 | 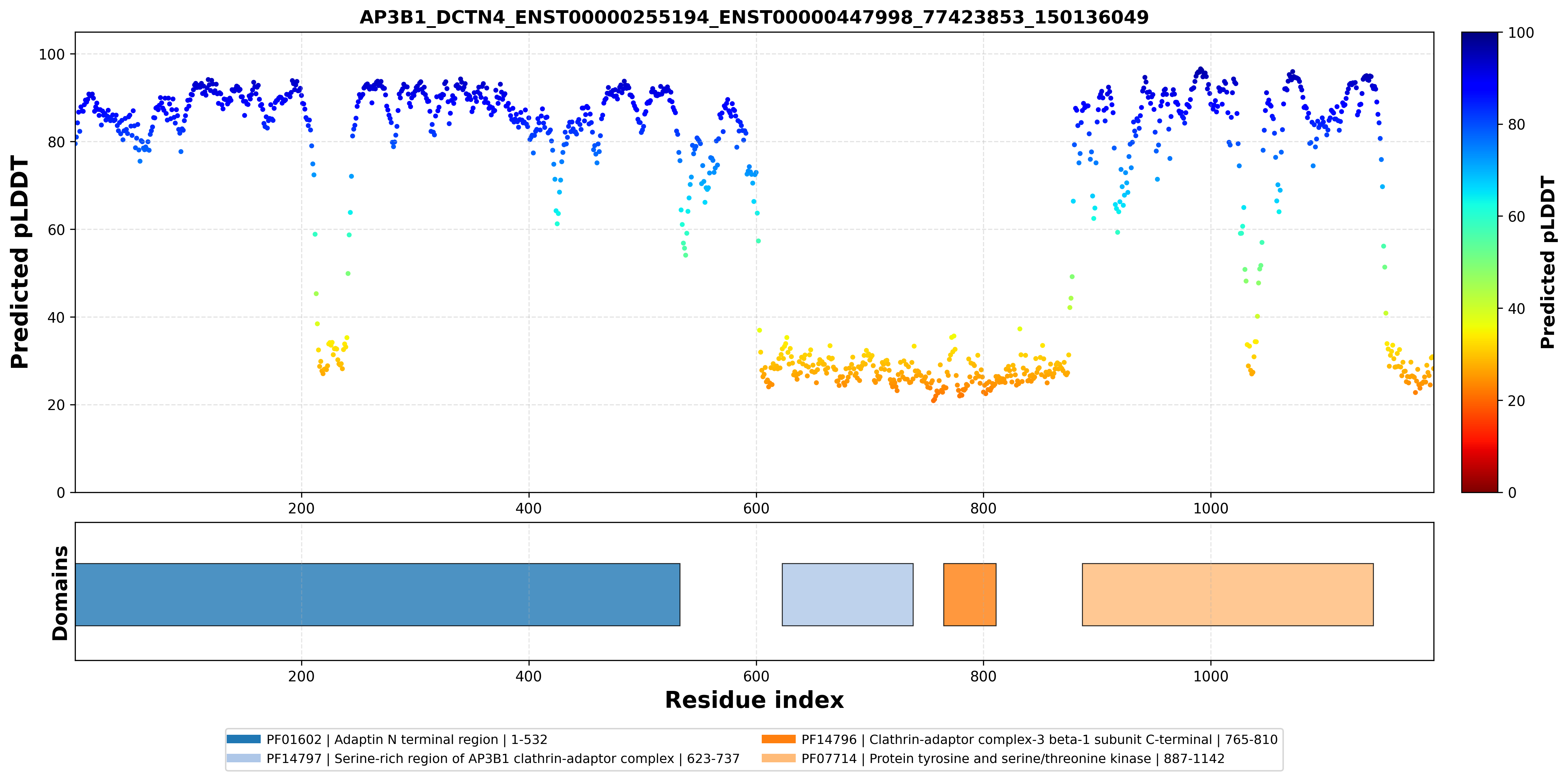 |  |  |
| AP3B1_DCTN4_ENST00000519295_ENST00000447998_77423853_150136049 superimposed PDB: 9C5A of partner (AP3B1). RMSD:1.5209
Å |
 | 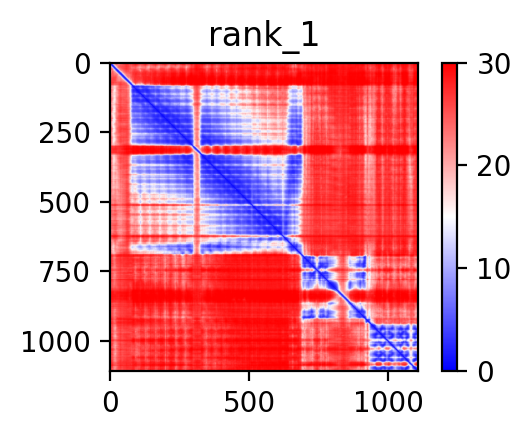 | 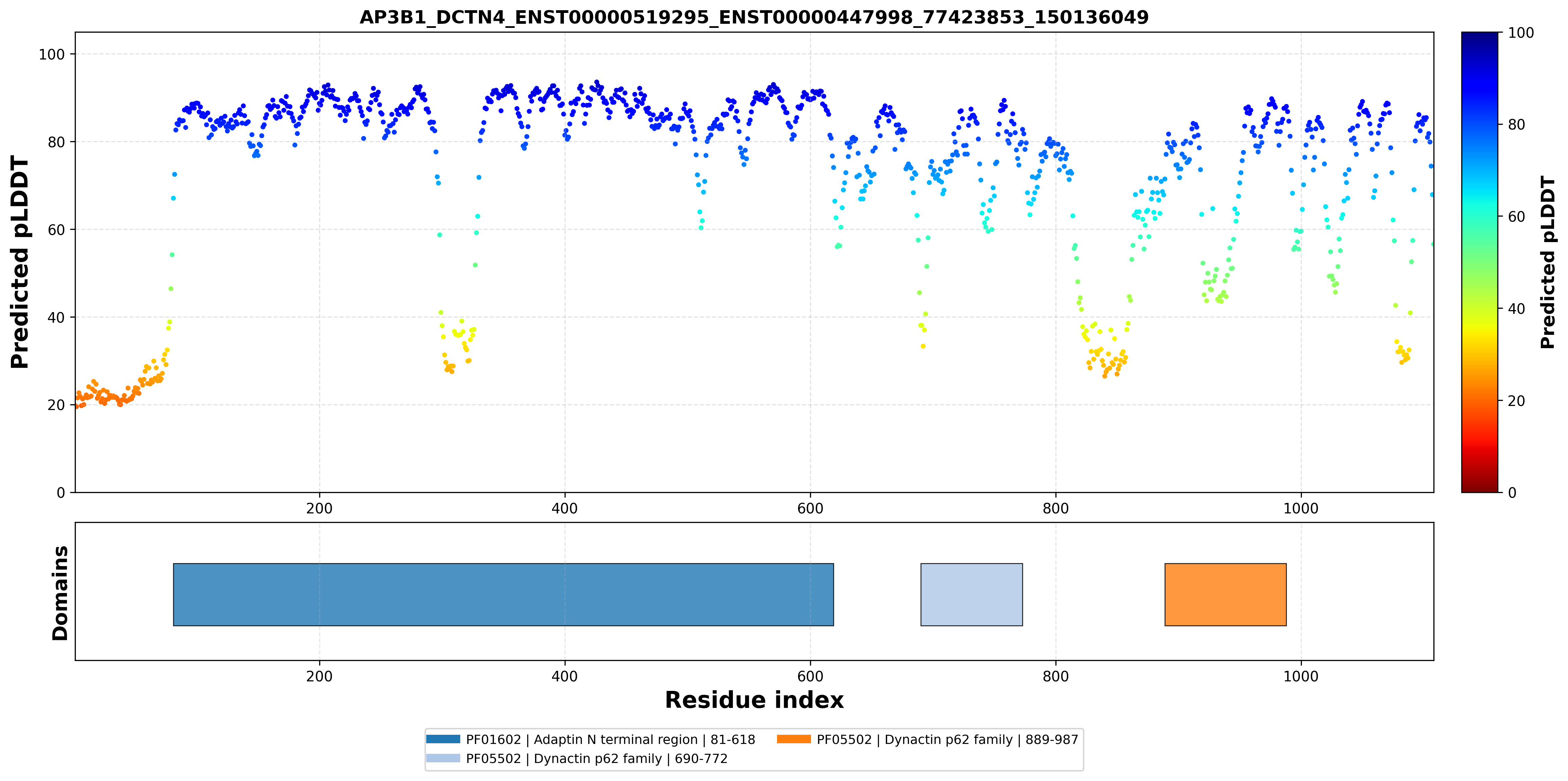 |  |  |
| AP3B1_DCTN4_ENST00000519295_ENST00000447998_77423853_150136049 superimposed PDB: 9B85 of partner (DCTN4). RMSD:3.1374
Å |
| | | |  |
| AP3B1_IPO11_ENST00000255194_ENST00000325324_77590275_61762957 superimposed PDB: 9C5A of partner (AP3B1). RMSD:1.5363
Å |
 |  |  |  |  |
| AP3B1_IPO11_ENST00000255194_ENST00000409296_77590275_61762957 superimposed PDB: 9C5A of partner (AP3B1). RMSD:2.7324
Å |
 |  |  |  |  |
| AP3B1_MRPS36_ENST00000519295_ENST00000256441_77385216_68522168 superimposed PDB: 9C5A of partner (AP3B1). RMSD:1.3165
Å |
 |  |  |  |  |
| AP3D1_AQP3_ENST00000356926_ENST00000297991_2137009_33443890 superimposed PDB: 9C59 of partner (AP3D1). RMSD:2.6339
Å |
 |  |  |  |  |
| AP3D1_AQP3_ENST00000356926_ENST00000297991_2137009_33443890 superimposed PDB: 9QSZ of partner (AQP3). RMSD:0.4537
Å |
| | | |  |
| AP4M1_AGAP3_ENST00000359593_ENST00000463381_99704137_150820880 superimposed PDB: 9U9I of partner (AP4M1). RMSD:1.0088
Å |
 |  |  |  |  |
| AP4M1_AGAP3_ENST00000421755_ENST00000463381_99704137_150820880 superimposed PDB: 9U9I of partner (AP4M1). RMSD:0.9399
Å |
 |  |  |  |  |
| AP4M1_AGAP3_ENST00000422582_ENST00000463381_99704137_150820880 superimposed PDB: 9U9I of partner (AP4M1). RMSD:0.9238
Å |
 |  |  |  |  |
| AP5S1_RNF24_ENST00000379567_ENST00000358395_3802940_3928926 superimposed PDB: 2EP4 of partner (RNF24). RMSD:1.0915
Å |
 |  |  |  |  |
| AP5S1_RNF24_ENST00000379573_ENST00000358395_3802940_3928926 superimposed PDB: 2EP4 of partner (RNF24). RMSD:1.0397
Å |
 |  |  |  |  |
| APAF1_TMPO_ENST00000333991_ENST00000556029_99056584_98931252 superimposed PDB: 3JBT of partner (APAF1). RMSD:1.0949
Å |
 |  | 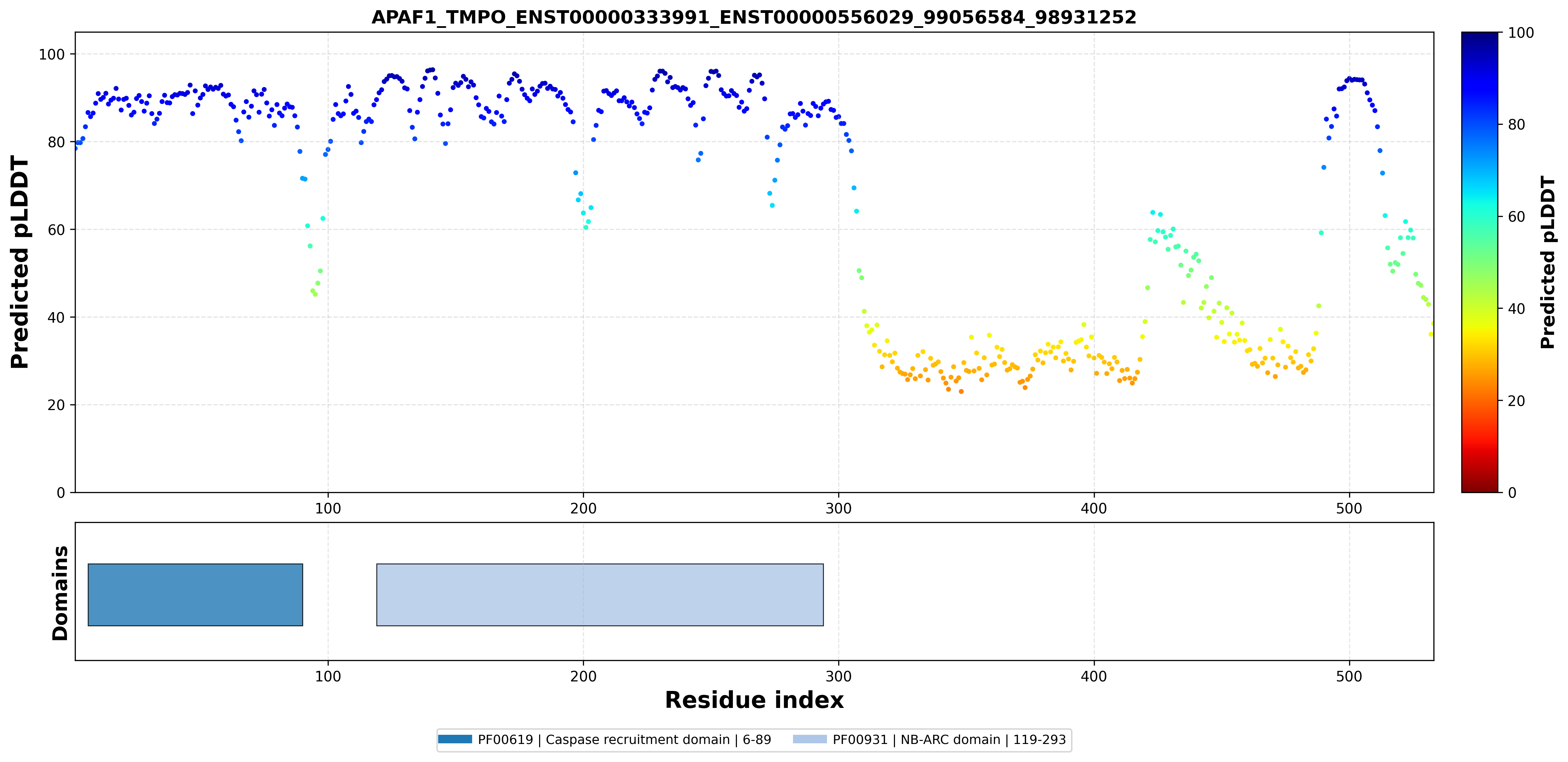 |  |  |
| APAF1_TMPO_ENST00000339433_ENST00000556029_99056584_98931252 superimposed PDB: 3JBT of partner (APAF1). RMSD:1.0963
Å |
 |  | 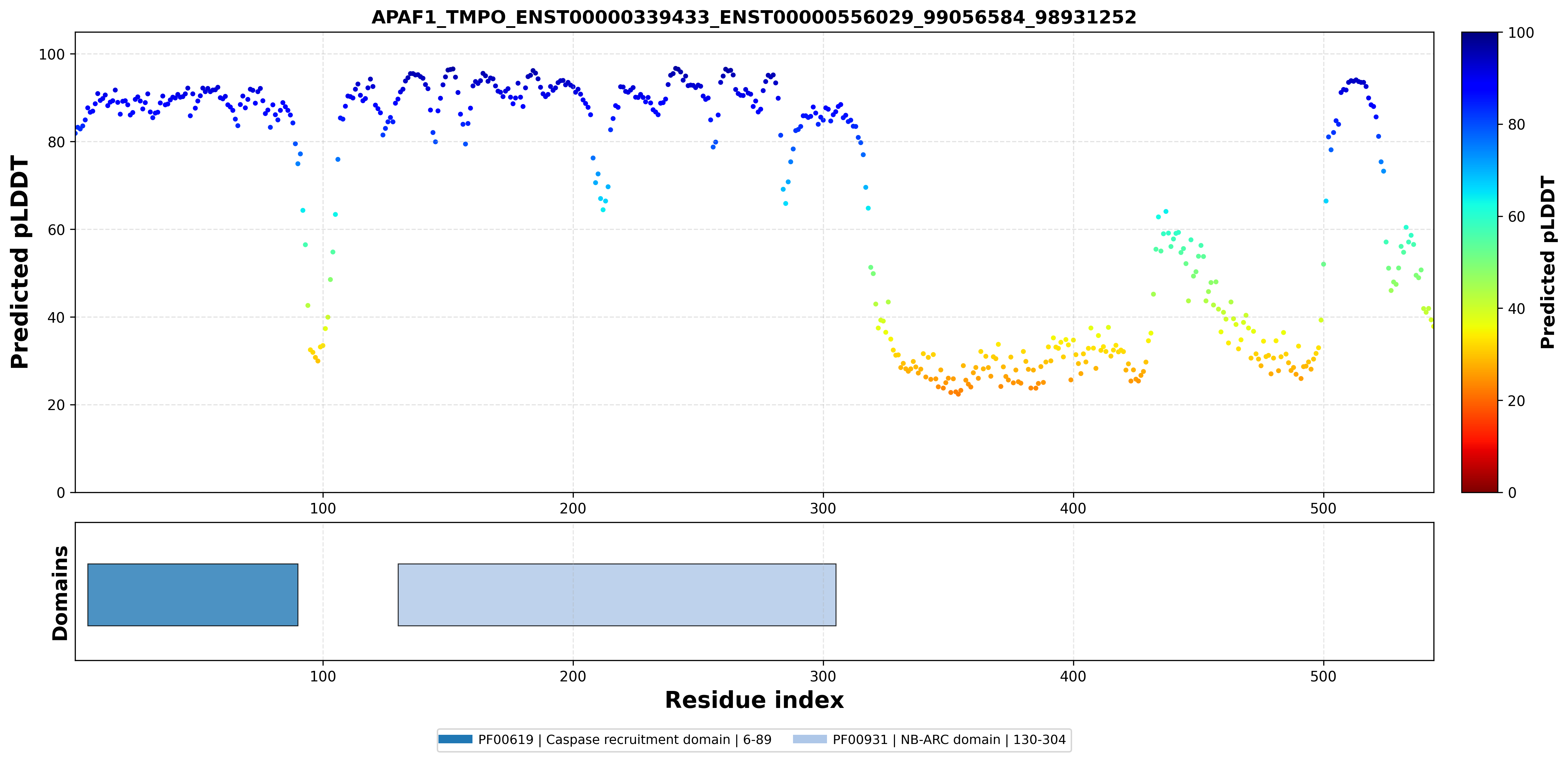 |  |  |
| APAF1_TMPO_ENST00000359972_ENST00000343315_99056584_98931252 superimposed PDB: 3JBT of partner (APAF1). RMSD:1.1013
Å |
 |  |  |  |  |
| APAF1_TMPO_ENST00000551964_ENST00000343315_99056584_98931252 superimposed PDB: 3JBT of partner (APAF1). RMSD:1.081
Å |
 |  | 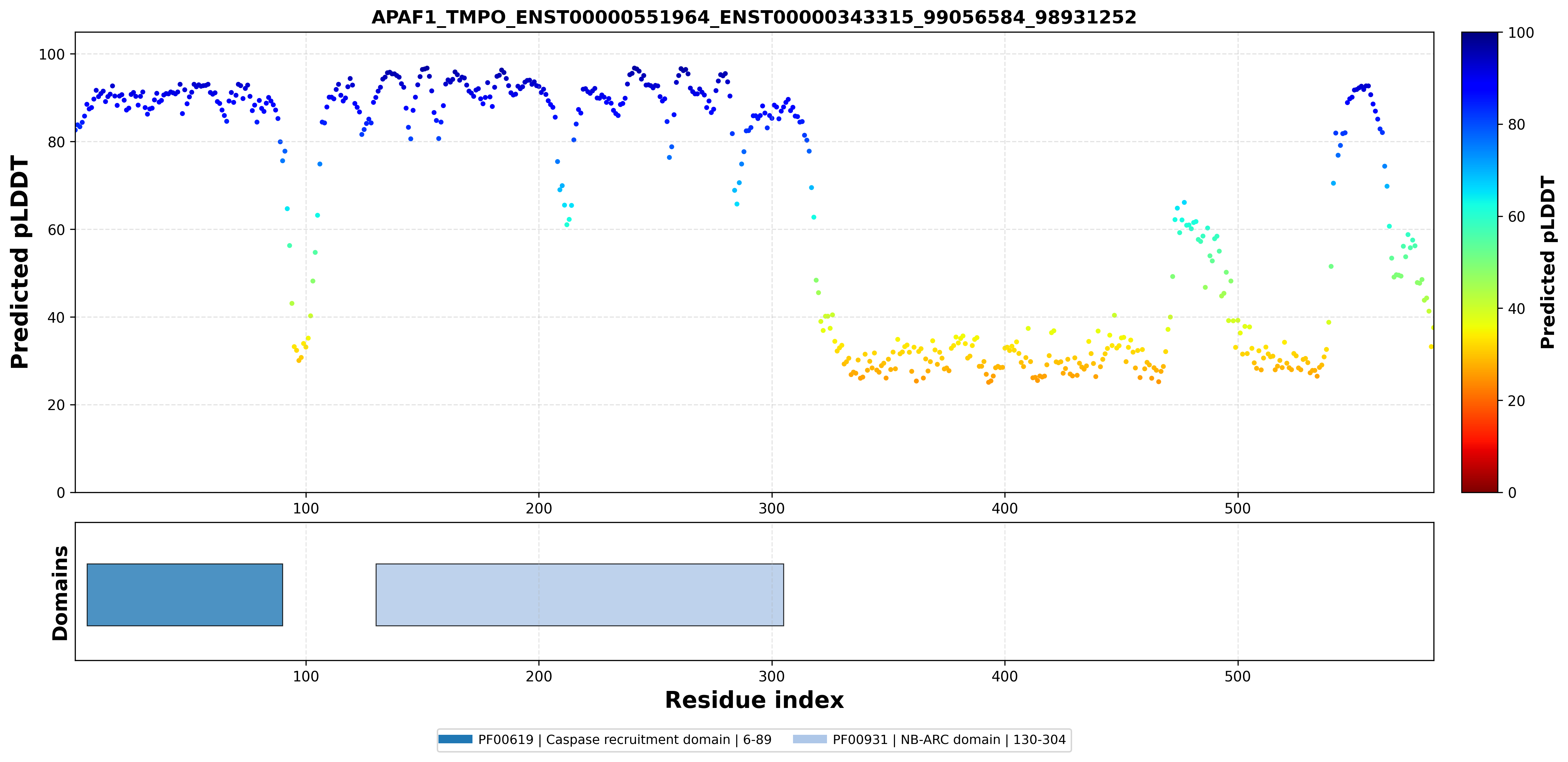 |  |  |
| APBB1IP_DNAJC1_ENST00000376236_ENST00000376946_26830621_22218070 superimposed PDB: 3ZDL of partner (APBB1IP). RMSD:0.3024
Å |
 |  |  |  |  |
| APBB1IP_DNAJC1_ENST00000376236_ENST00000376946_26830621_22218070 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.2628
Å |
| | | |  |
| API5_FOLH1_ENST00000378852_ENST00000343844_43357544_49168497 superimposed PDB: 6L4O of partner (API5). RMSD:0.6933
Å |
 | 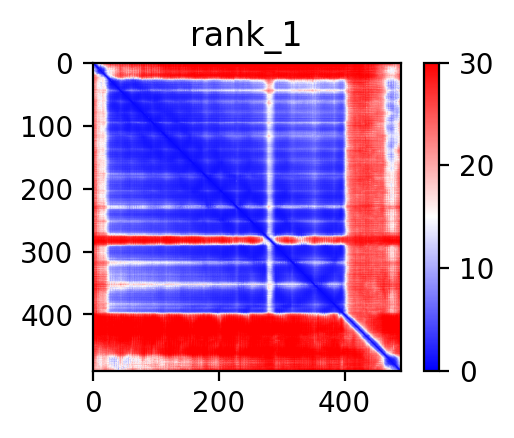 | 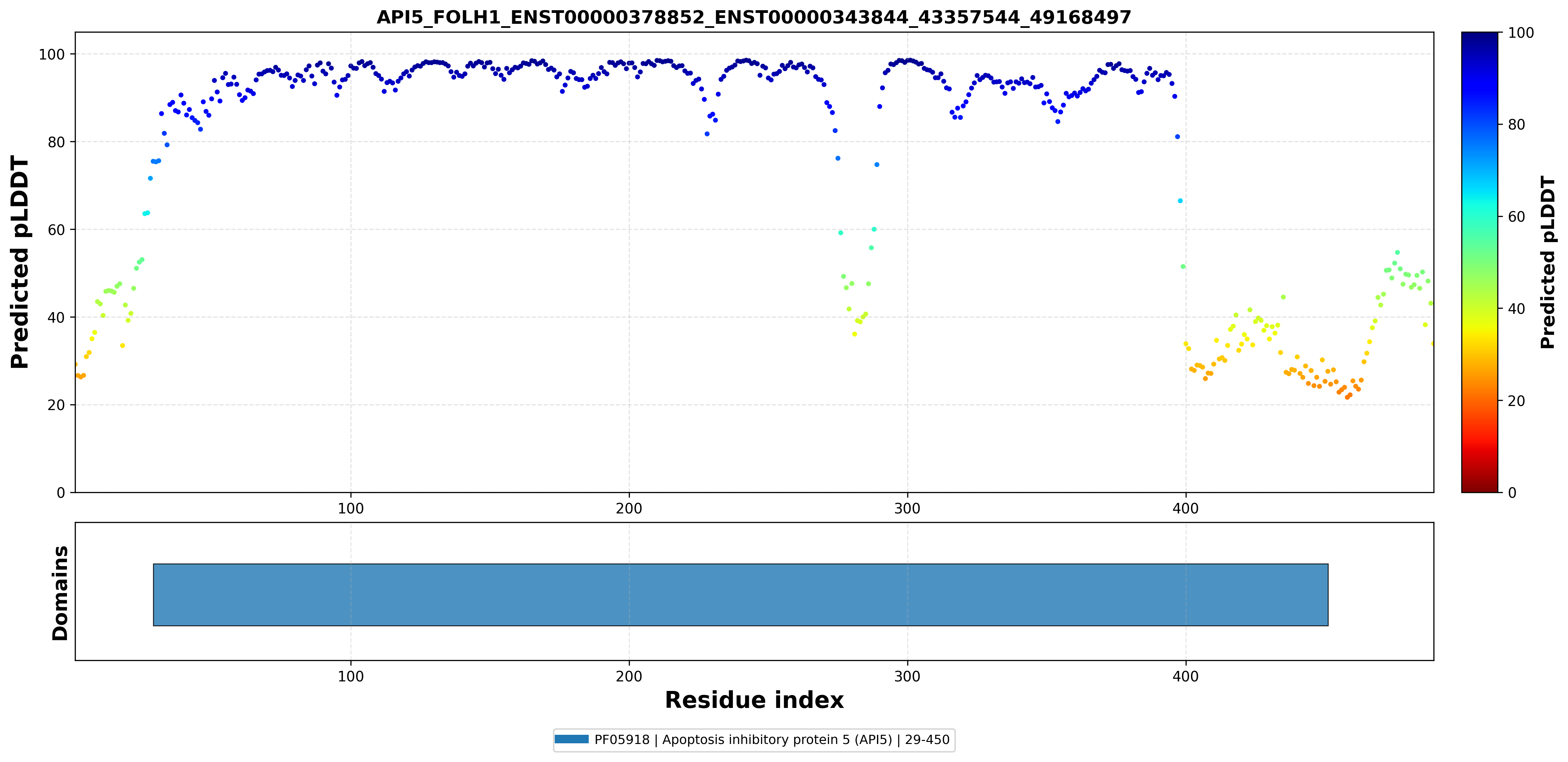 | 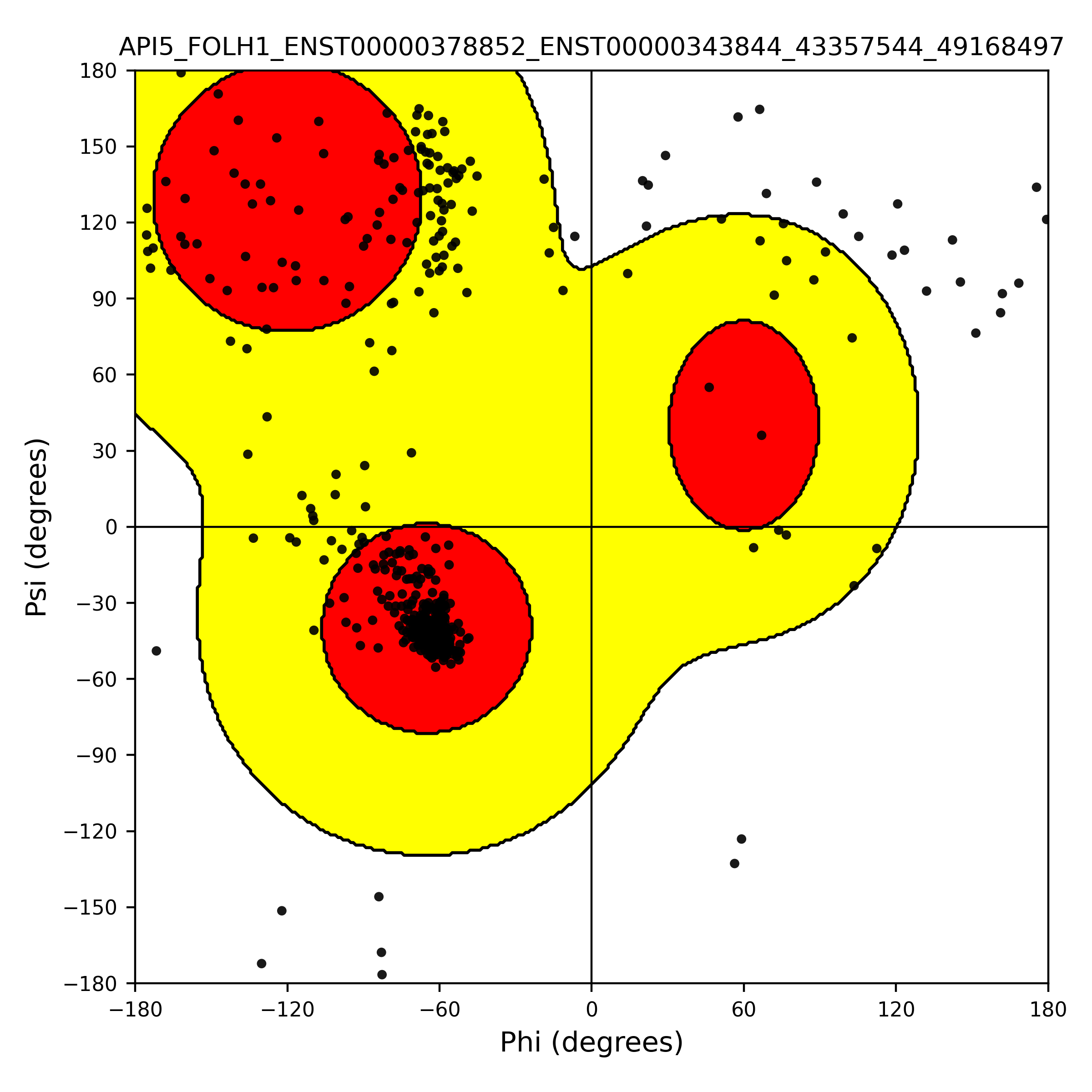 | 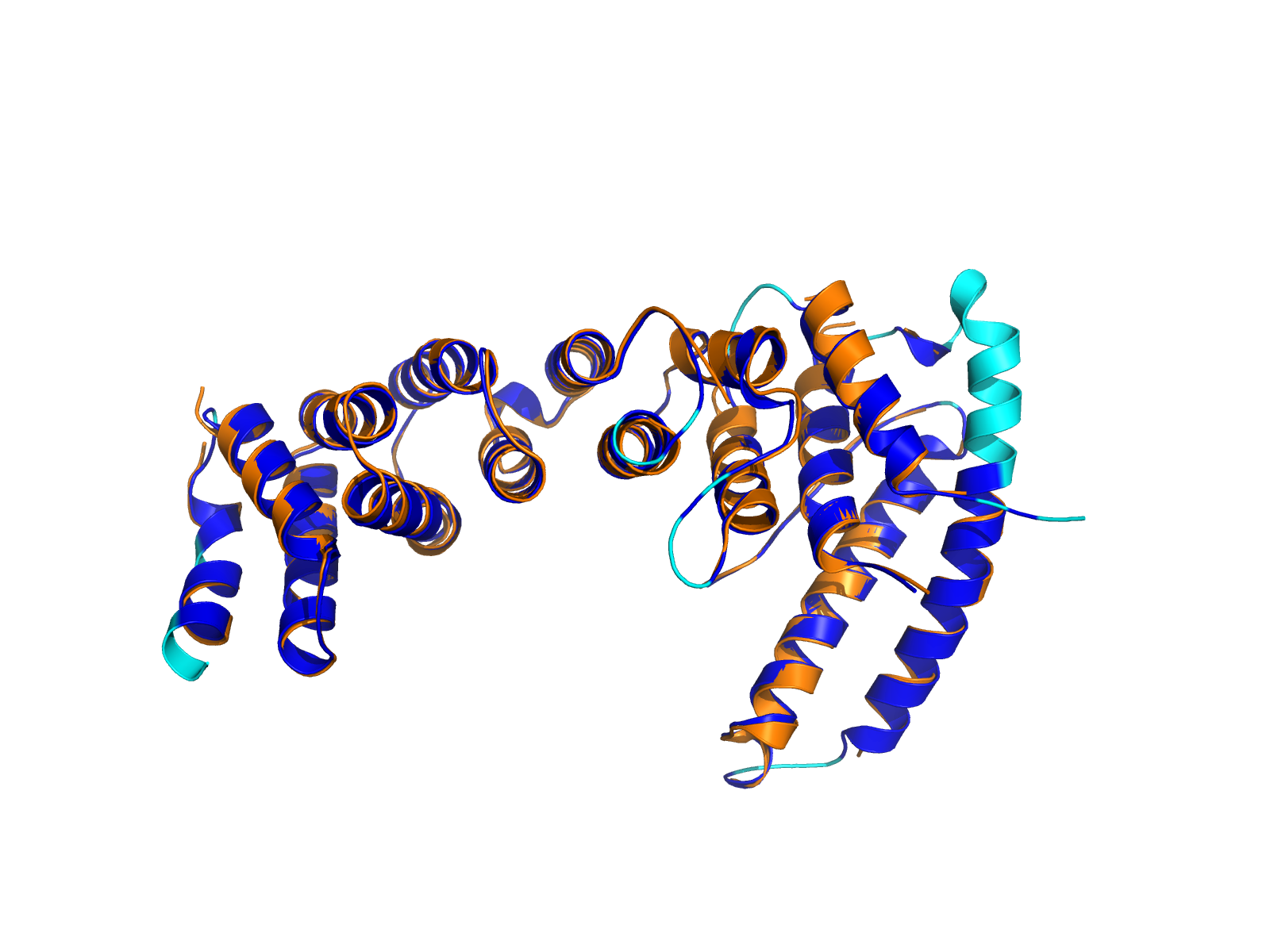 |
| API5_FOLH1_ENST00000420461_ENST00000343844_43357544_49168497 superimposed PDB: 6L4O of partner (API5). RMSD:0.8191
Å |
 | 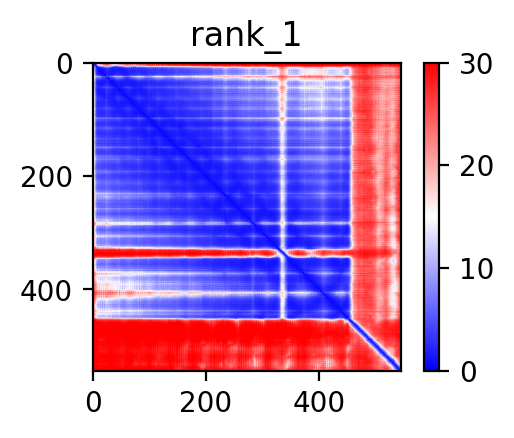 | 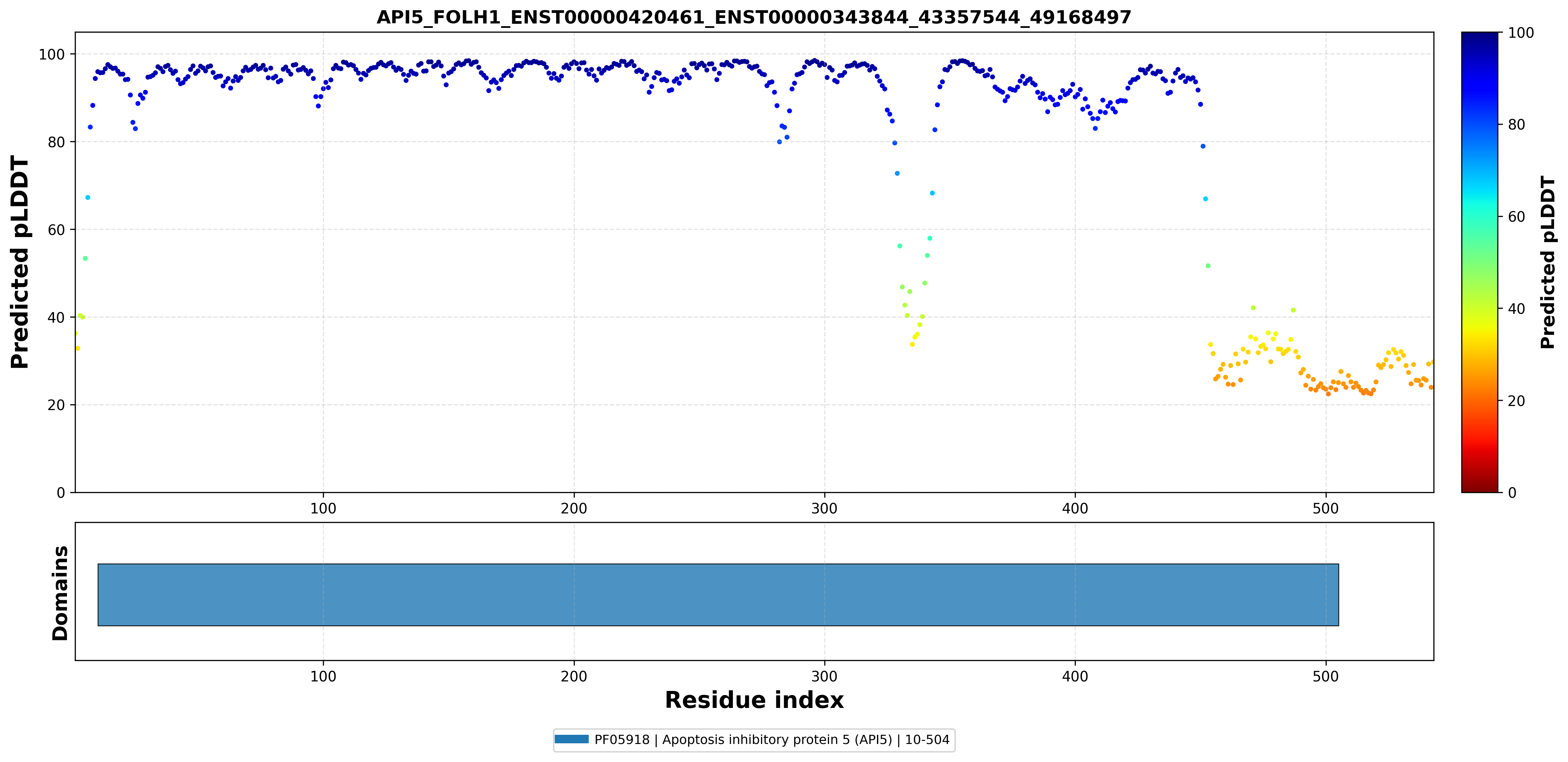 | 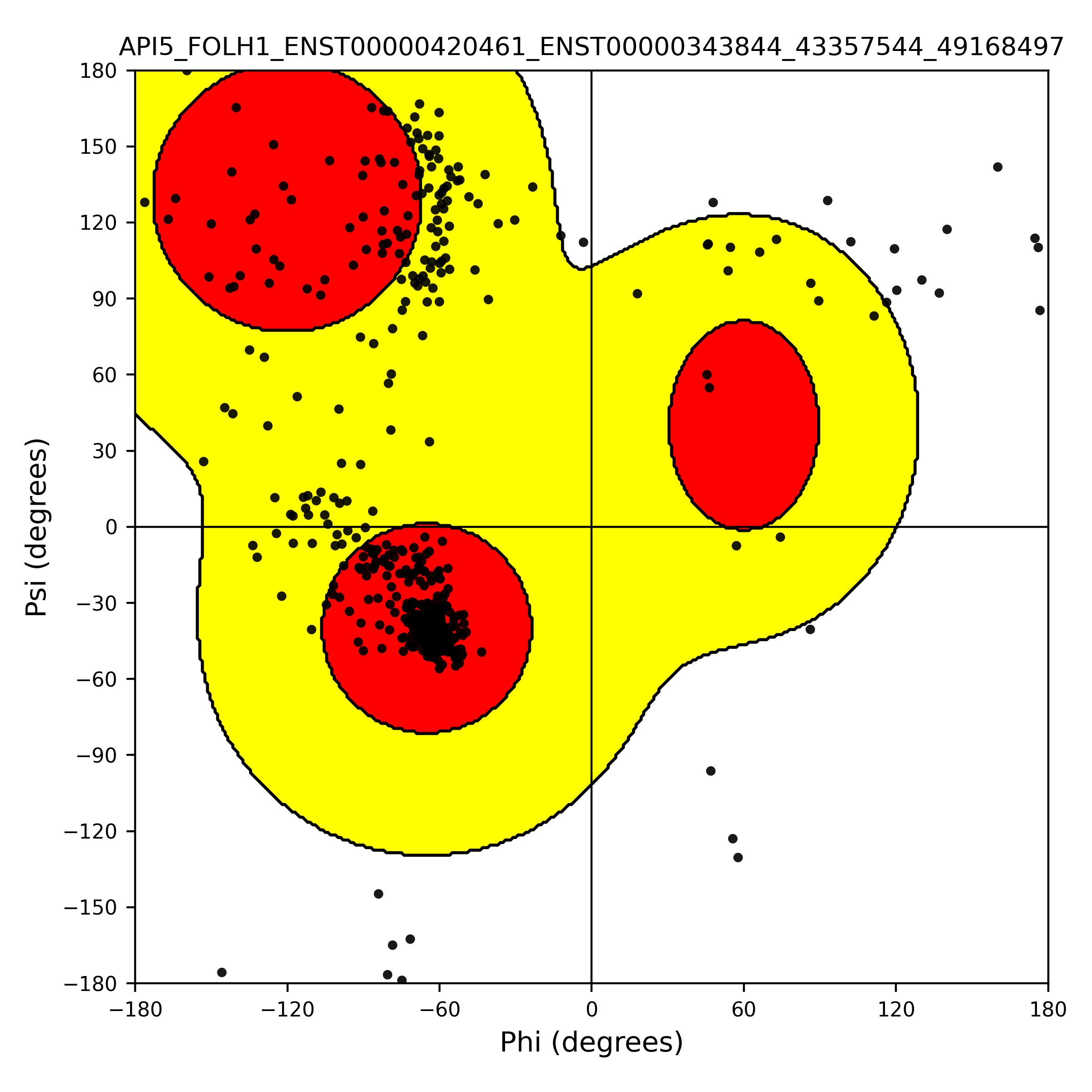 | 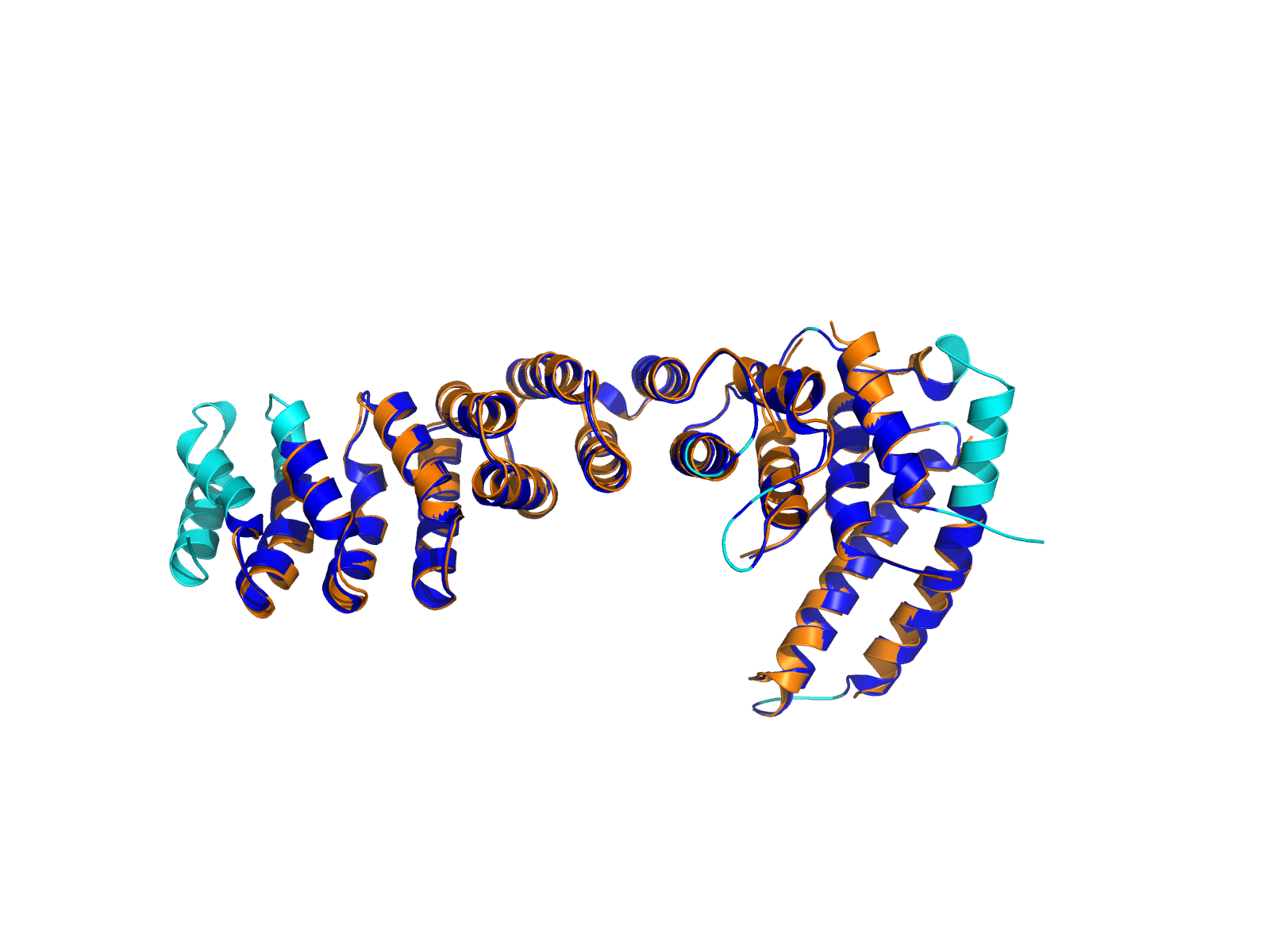 |
| API5_FOLH1_ENST00000531273_ENST00000343844_43357544_49168497 superimposed PDB: 6L4O of partner (API5). RMSD:0.8482
Å |
 | 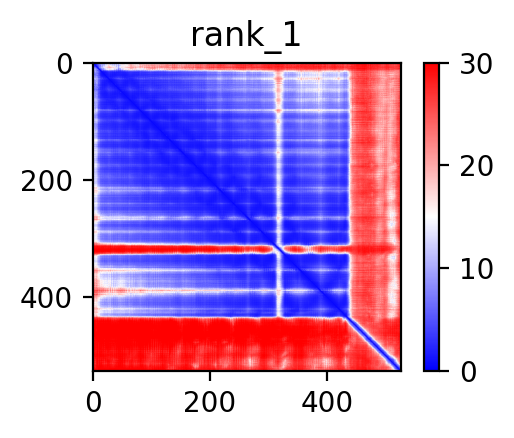 | 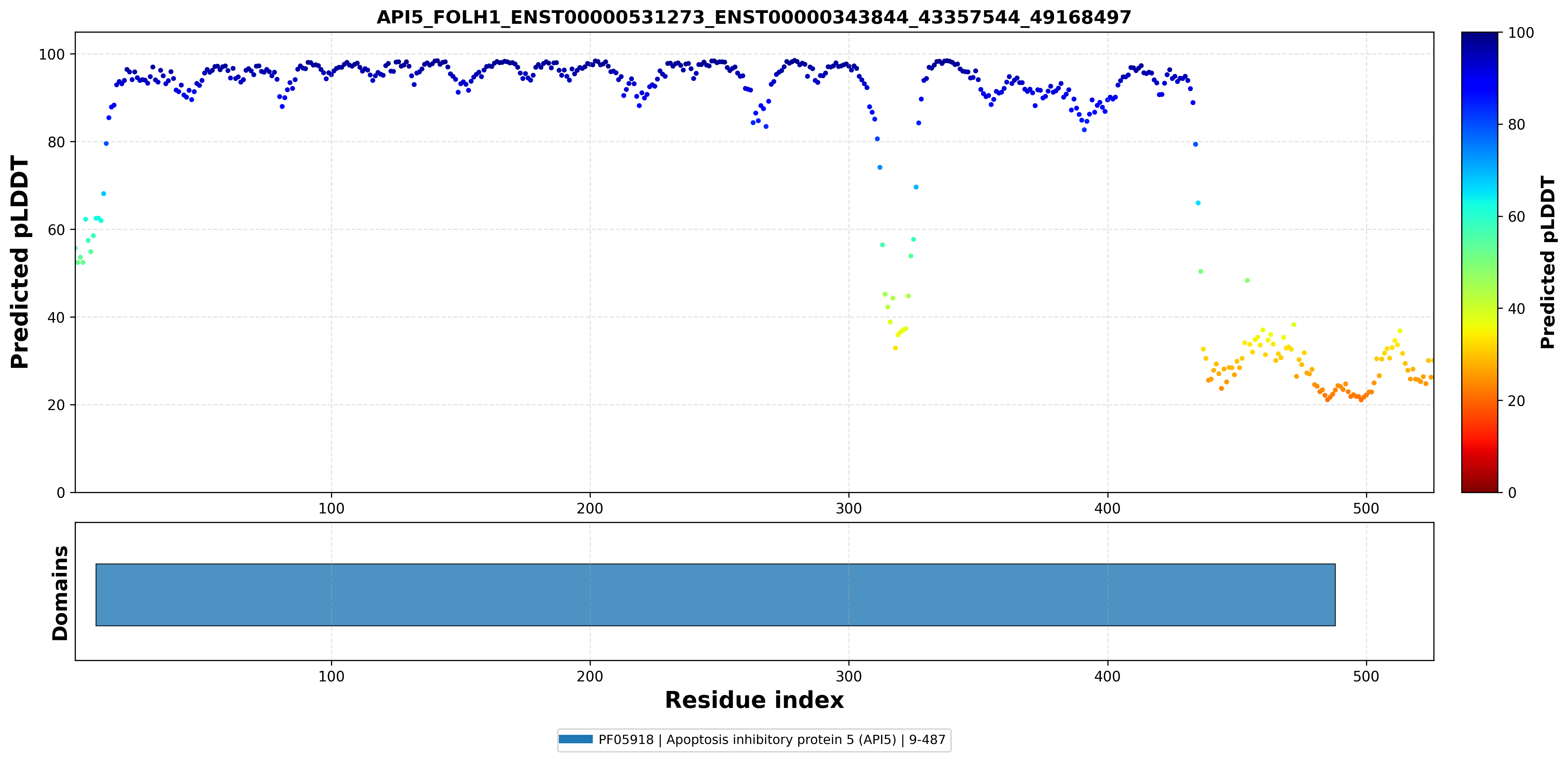 | 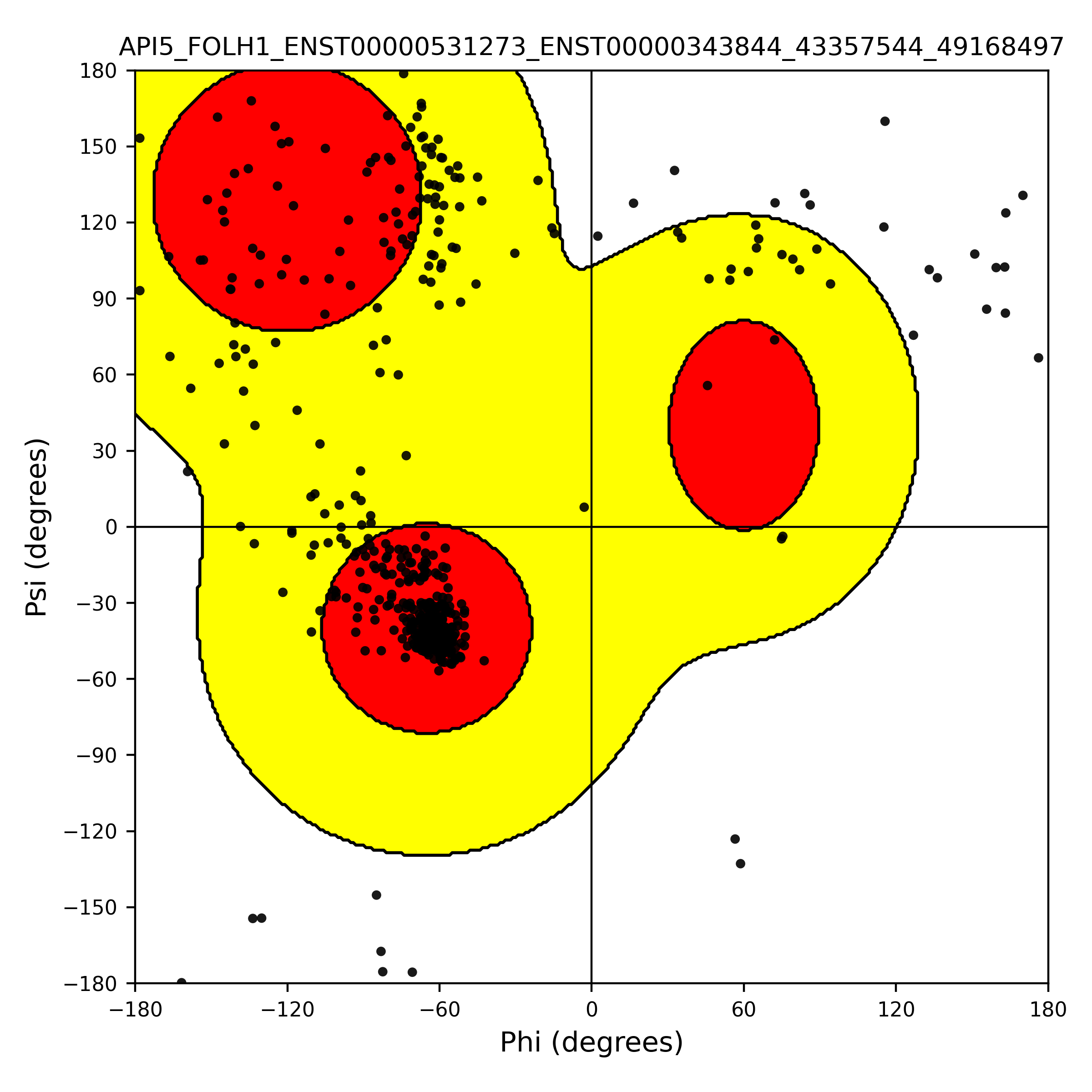 | 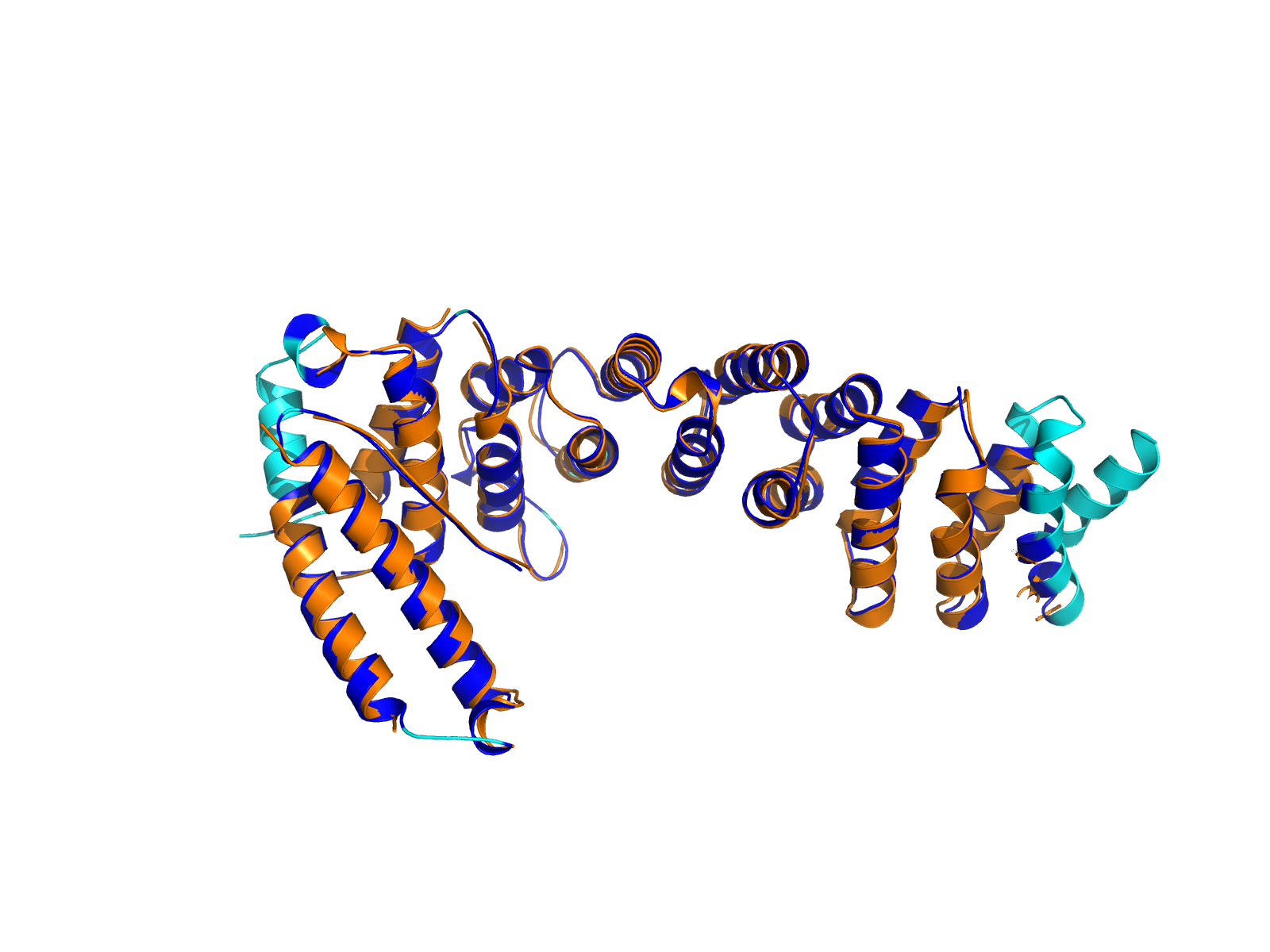 |
| API5_GANC_ENST00000455725_ENST00000318010_43343686_42598743 superimposed PDB: 6L4O of partner (API5). RMSD:0.9301
Å |
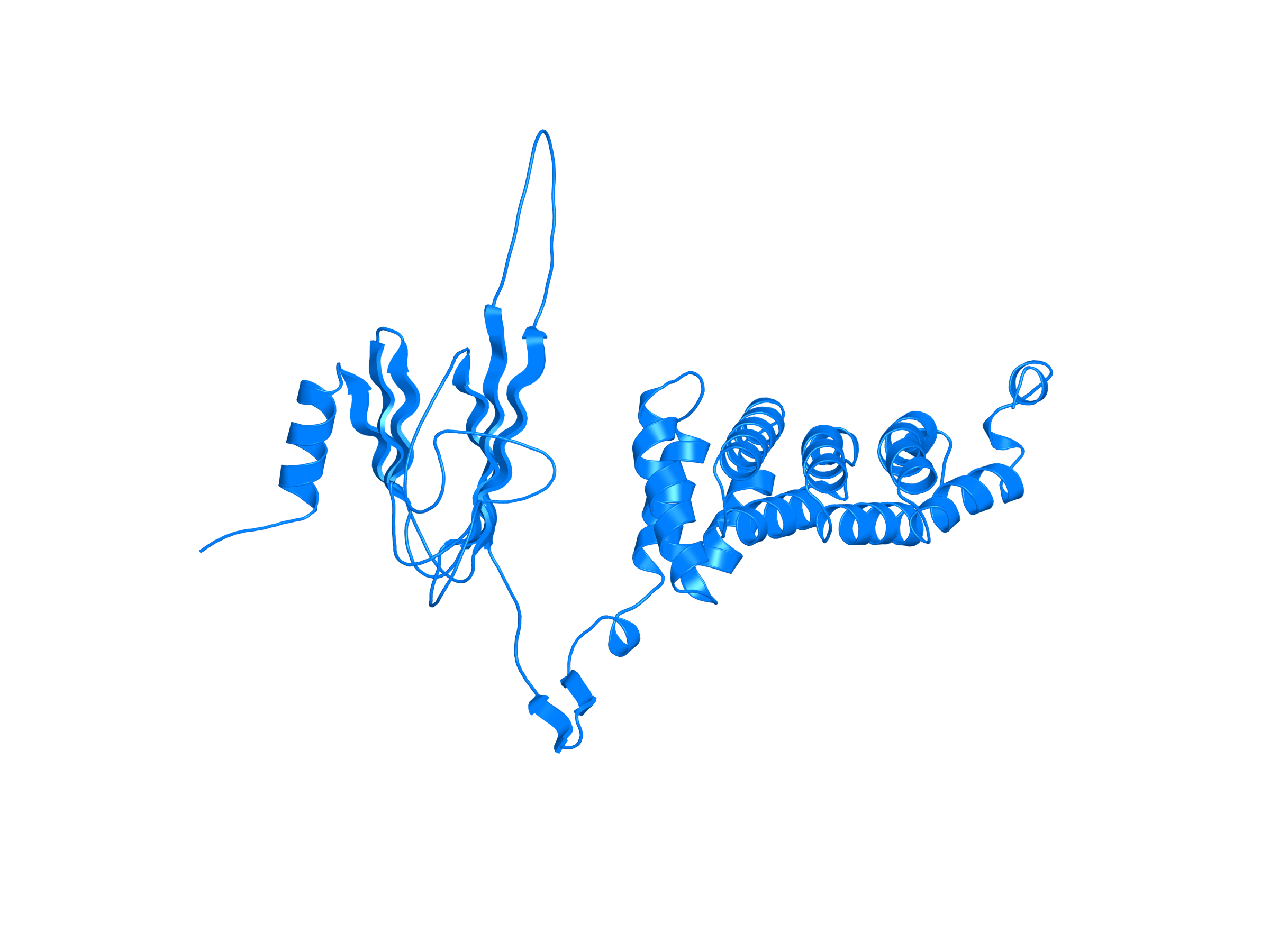 | 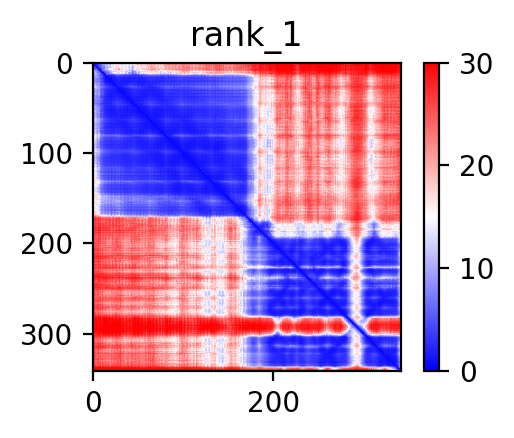 | 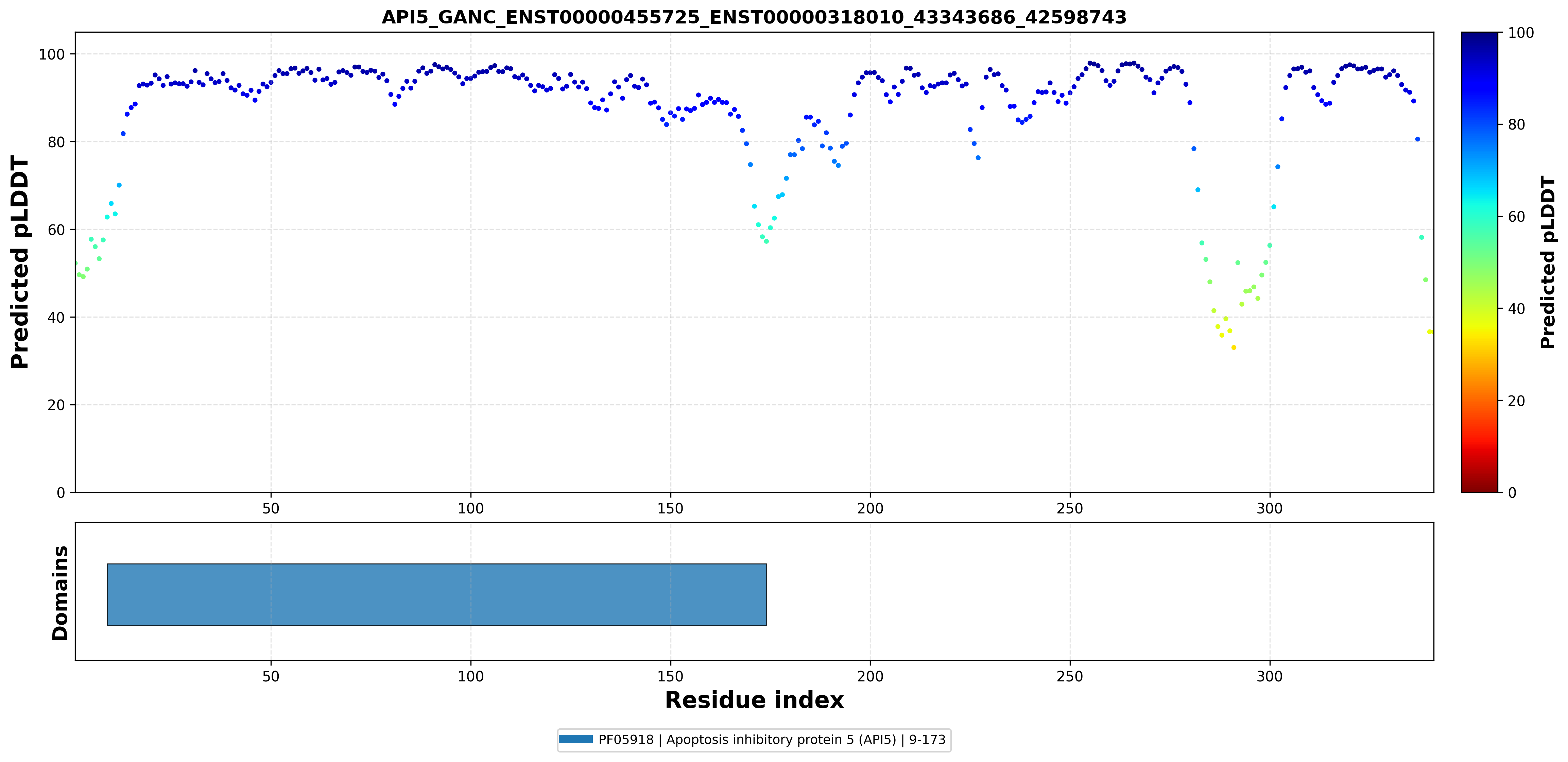 |  | 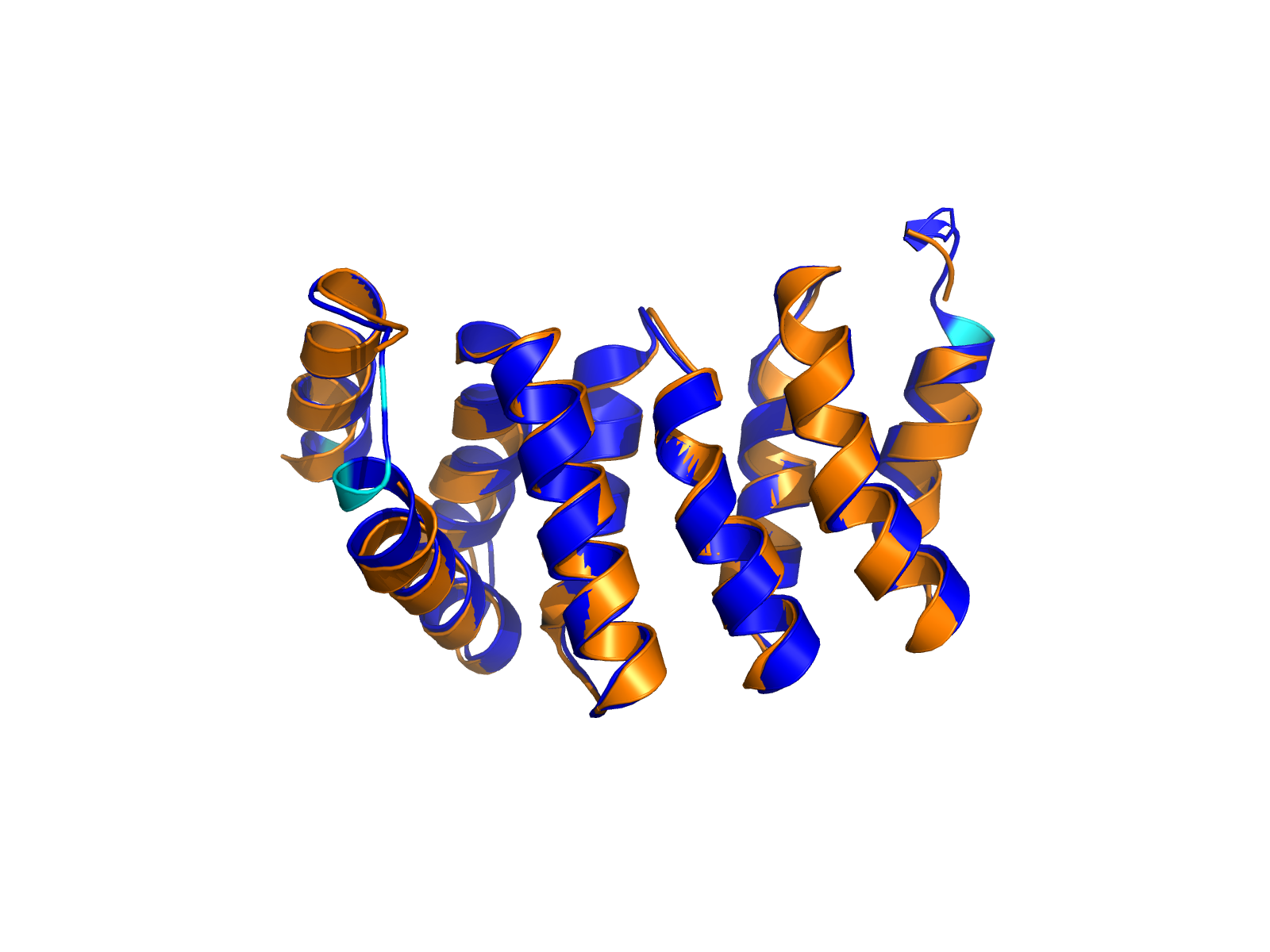 |
| API5_GANC_ENST00000531273_ENST00000318010_43343686_42598743 superimposed PDB: 6L4O of partner (API5). RMSD:0.8929
Å |
 |  | 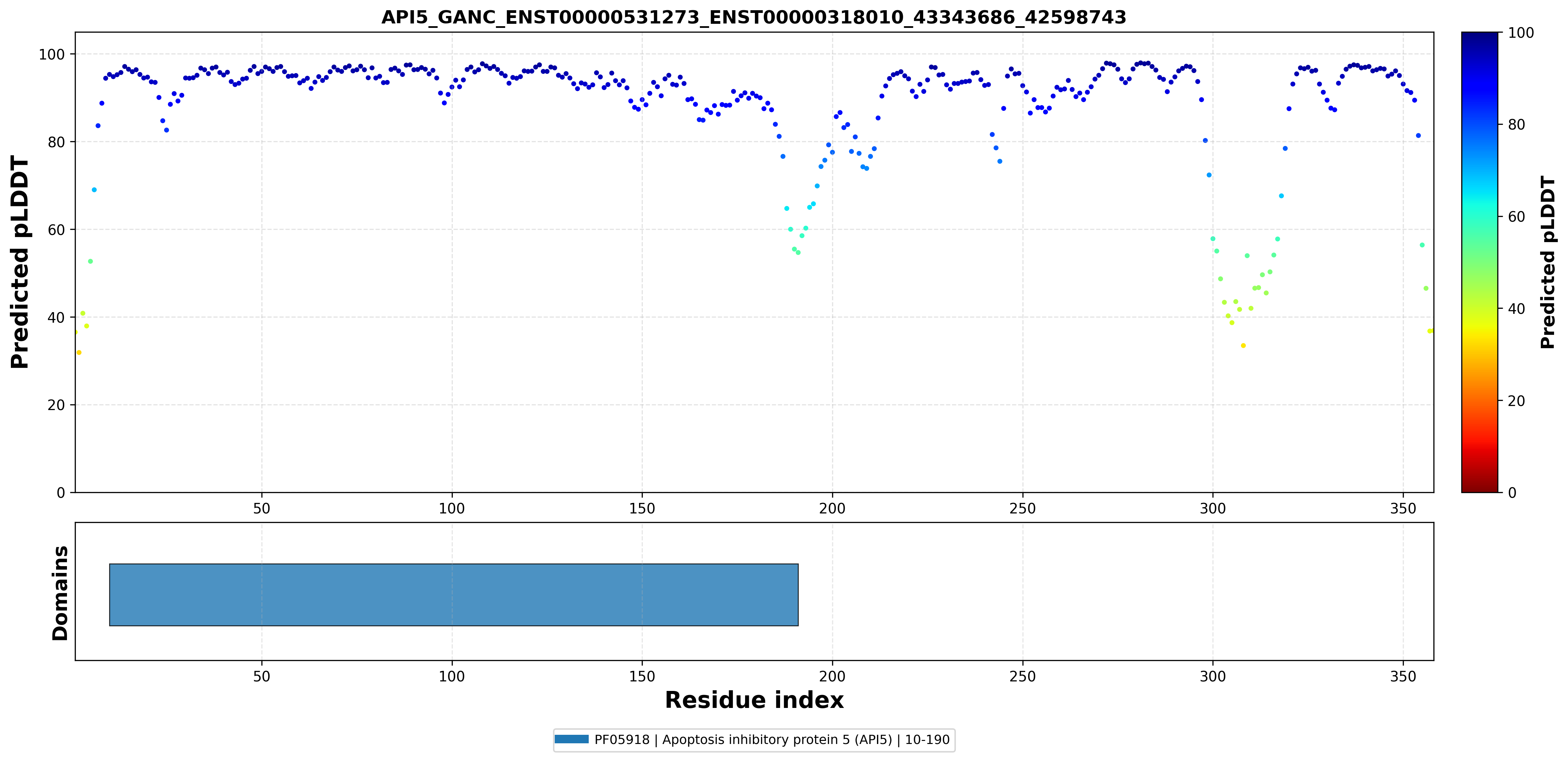 |  | 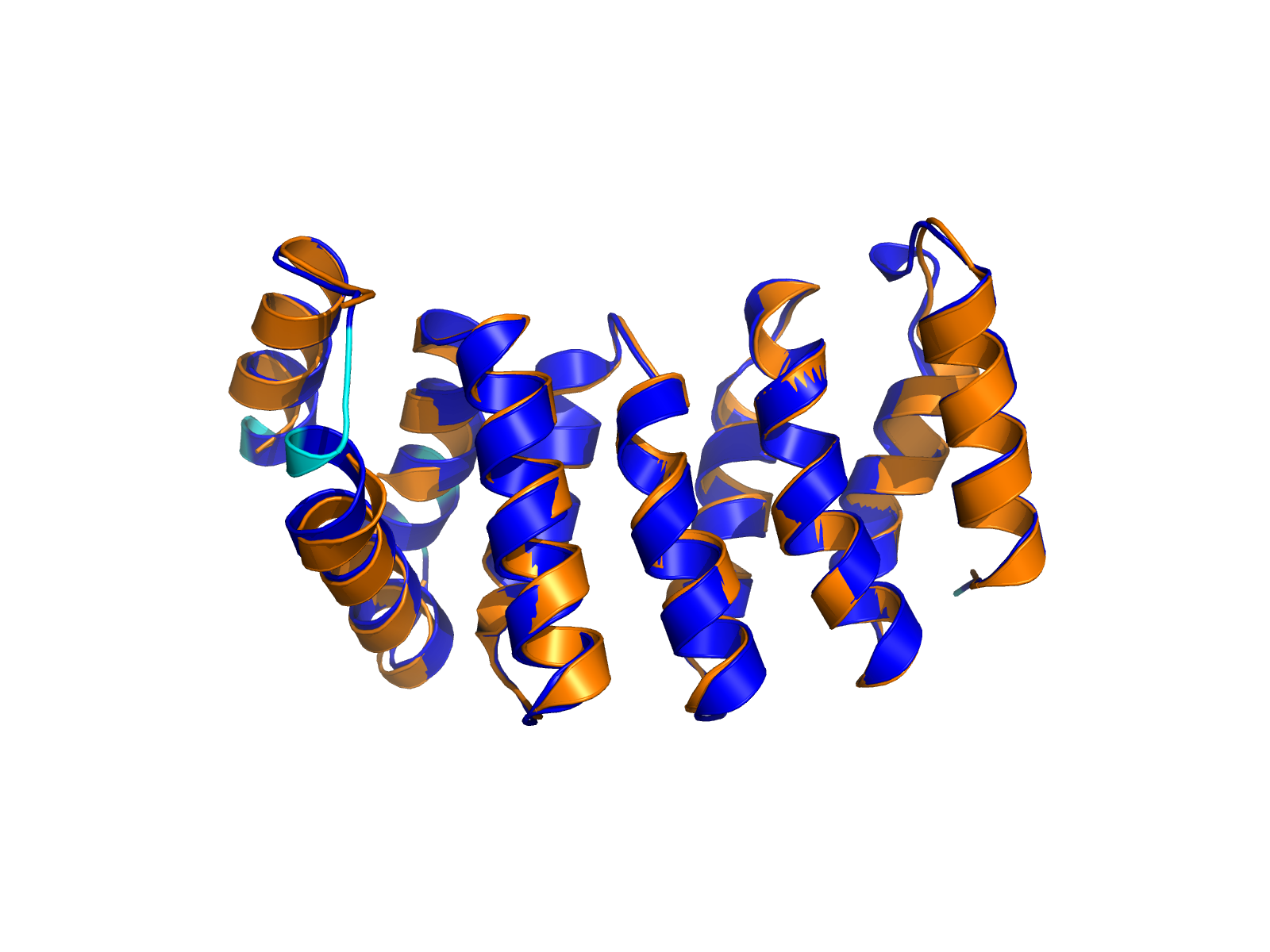 |
| API5_LCMT1_ENST00000378852_ENST00000399069_43357544_25172422 superimposed PDB: 6L4O of partner (API5). RMSD:0.7665
Å |
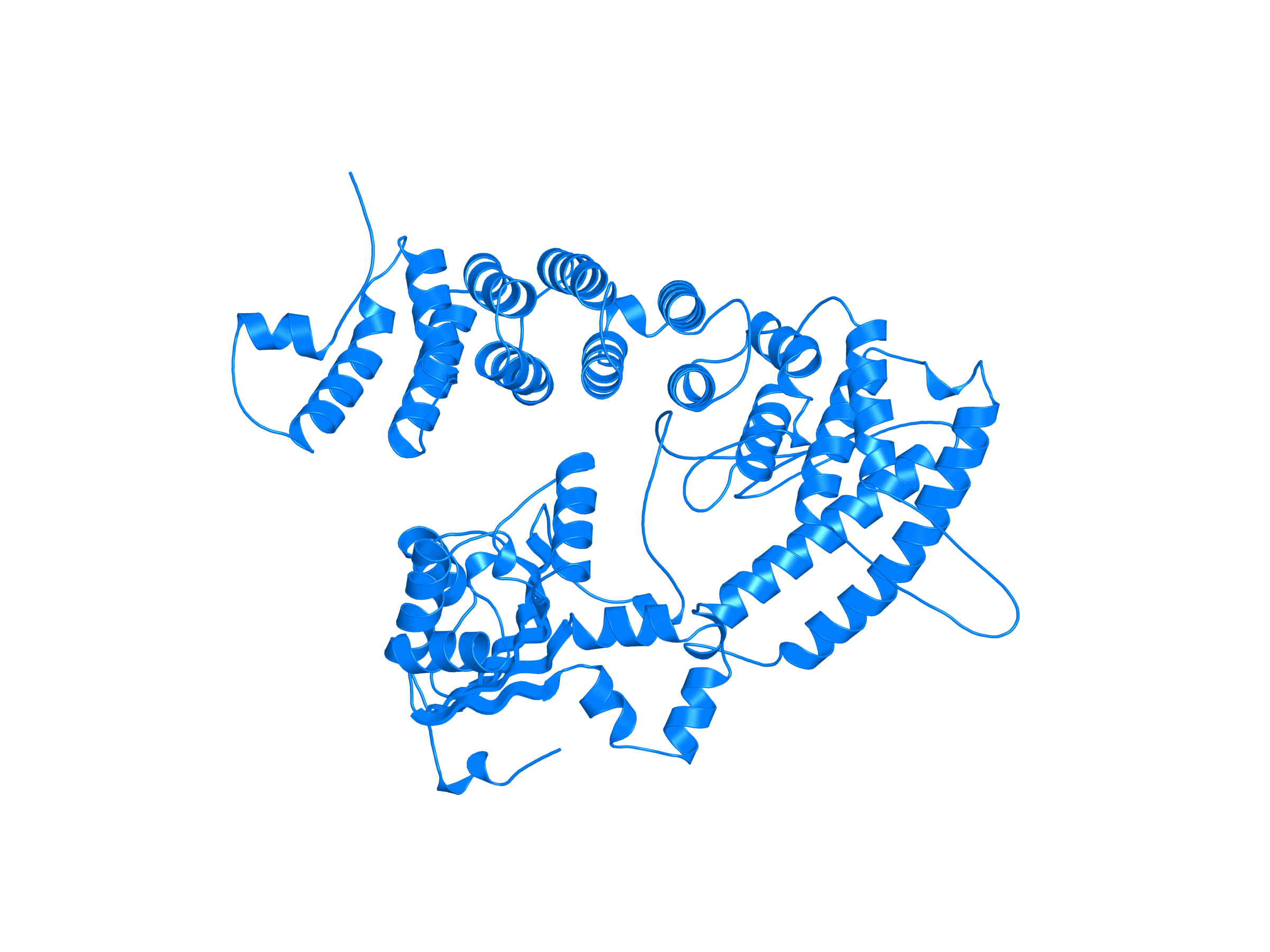 | 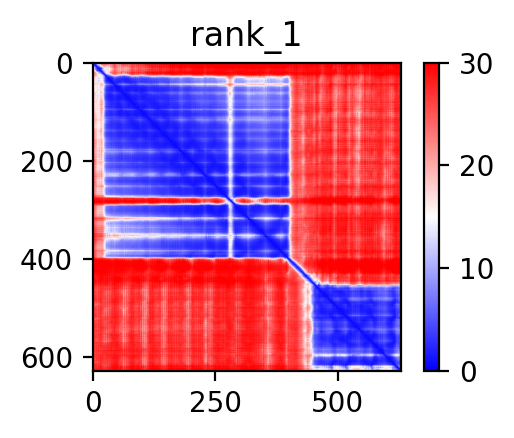 | 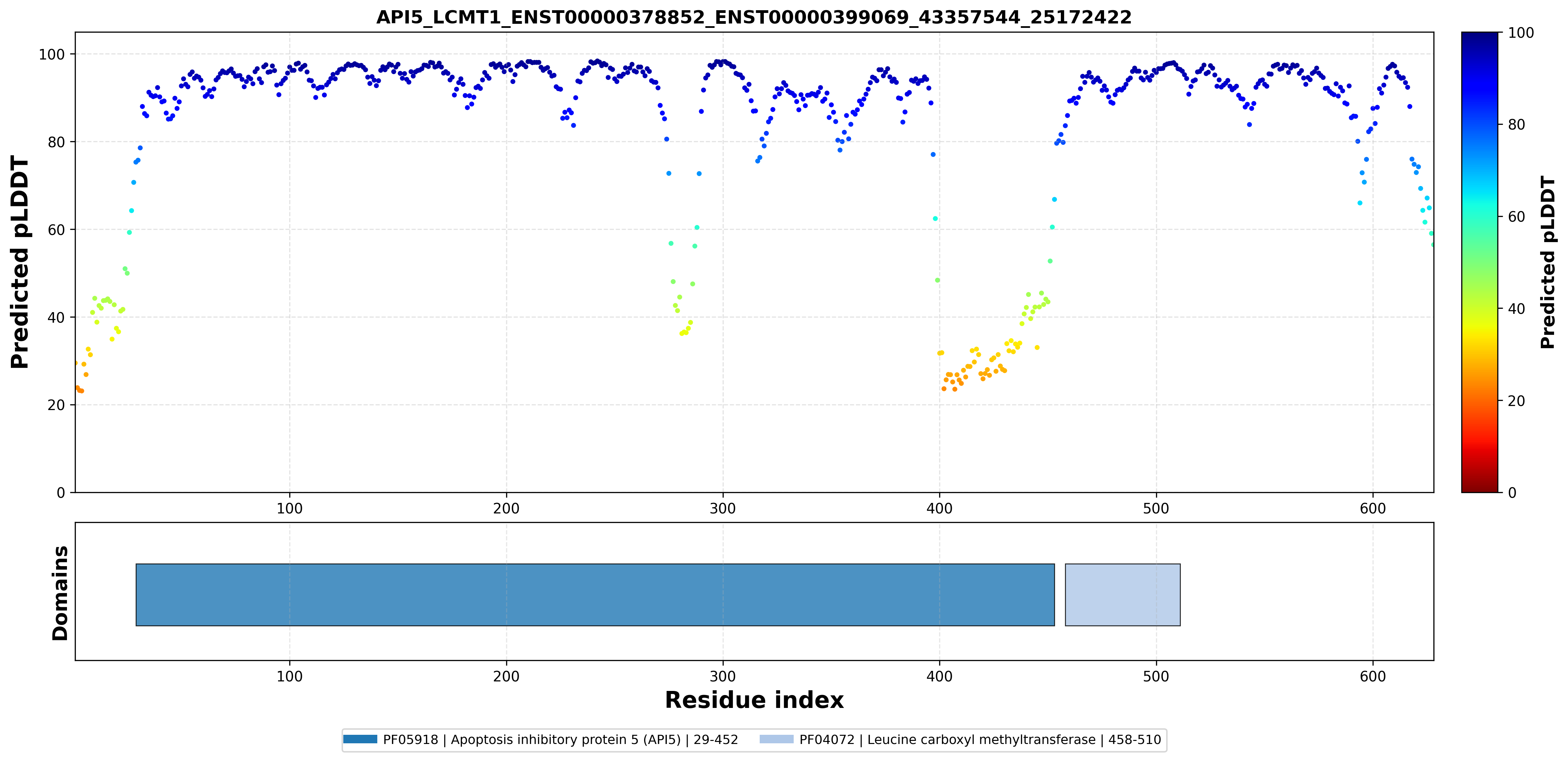 |  | 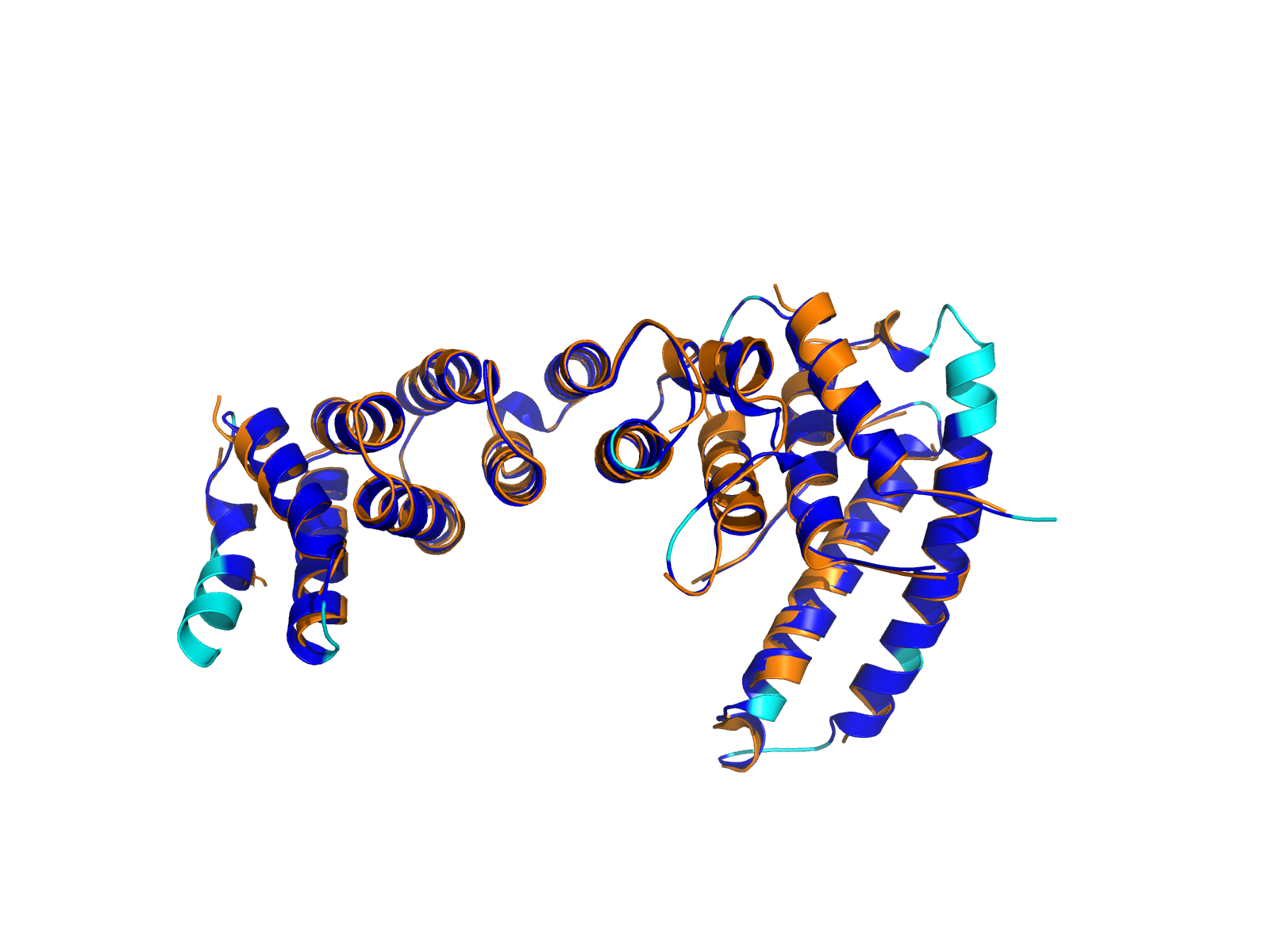 |
| API5_LCMT1_ENST00000378852_ENST00000399069_43357544_25172422 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.4862
Å |
| | | |  |
| API5_LCMT1_ENST00000420461_ENST00000399069_43357544_25172422 superimposed PDB: 6L4O of partner (API5). RMSD:1.0828
Å |
 | 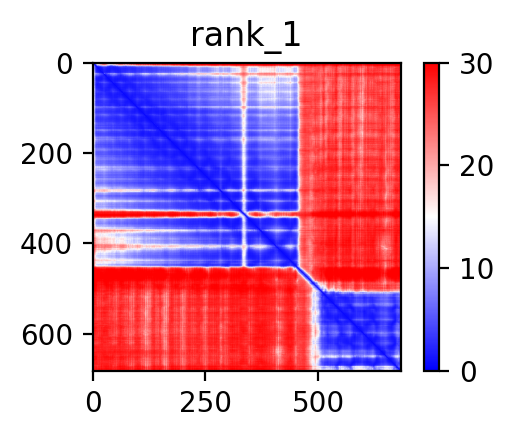 | 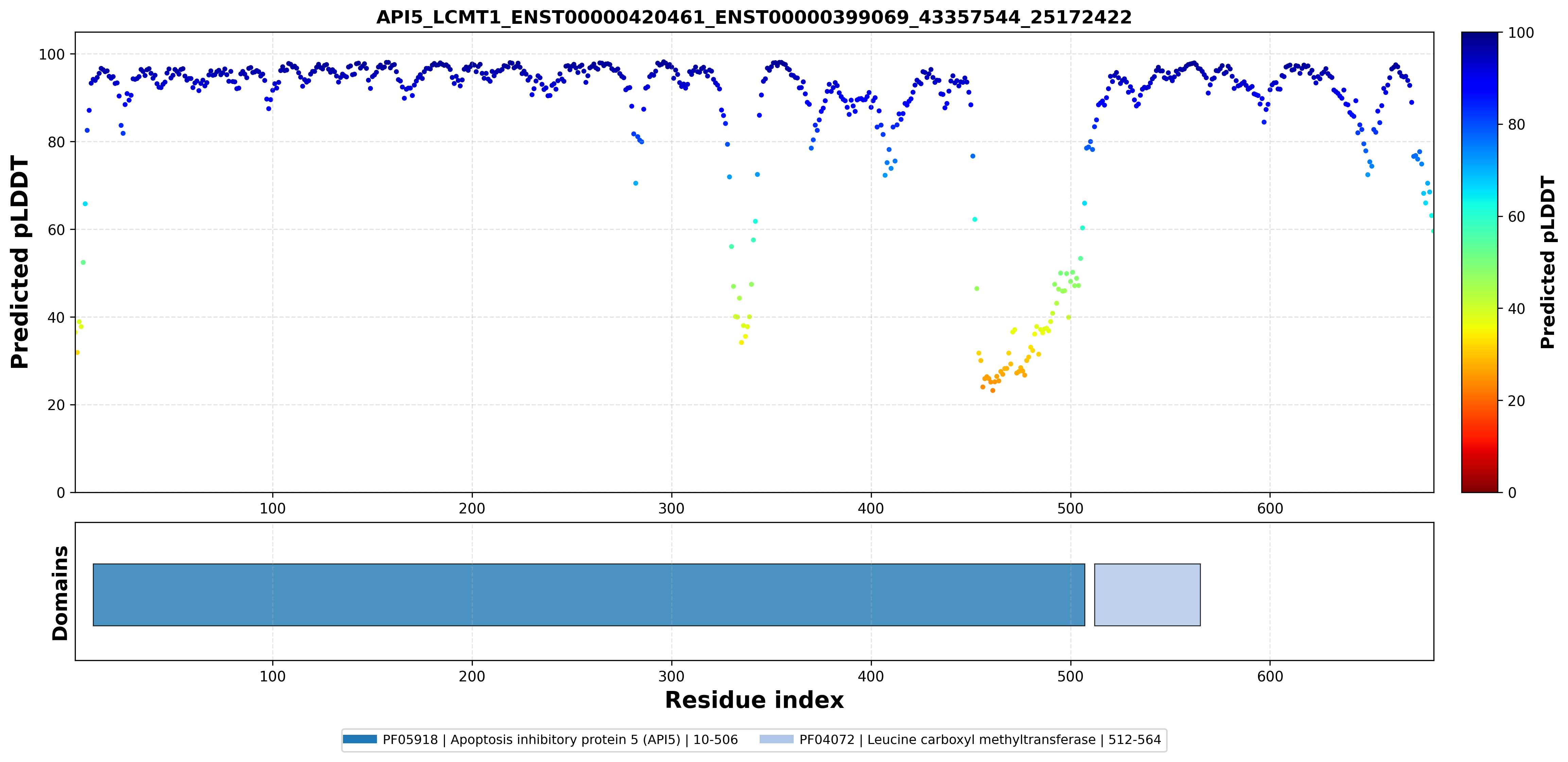 |  | 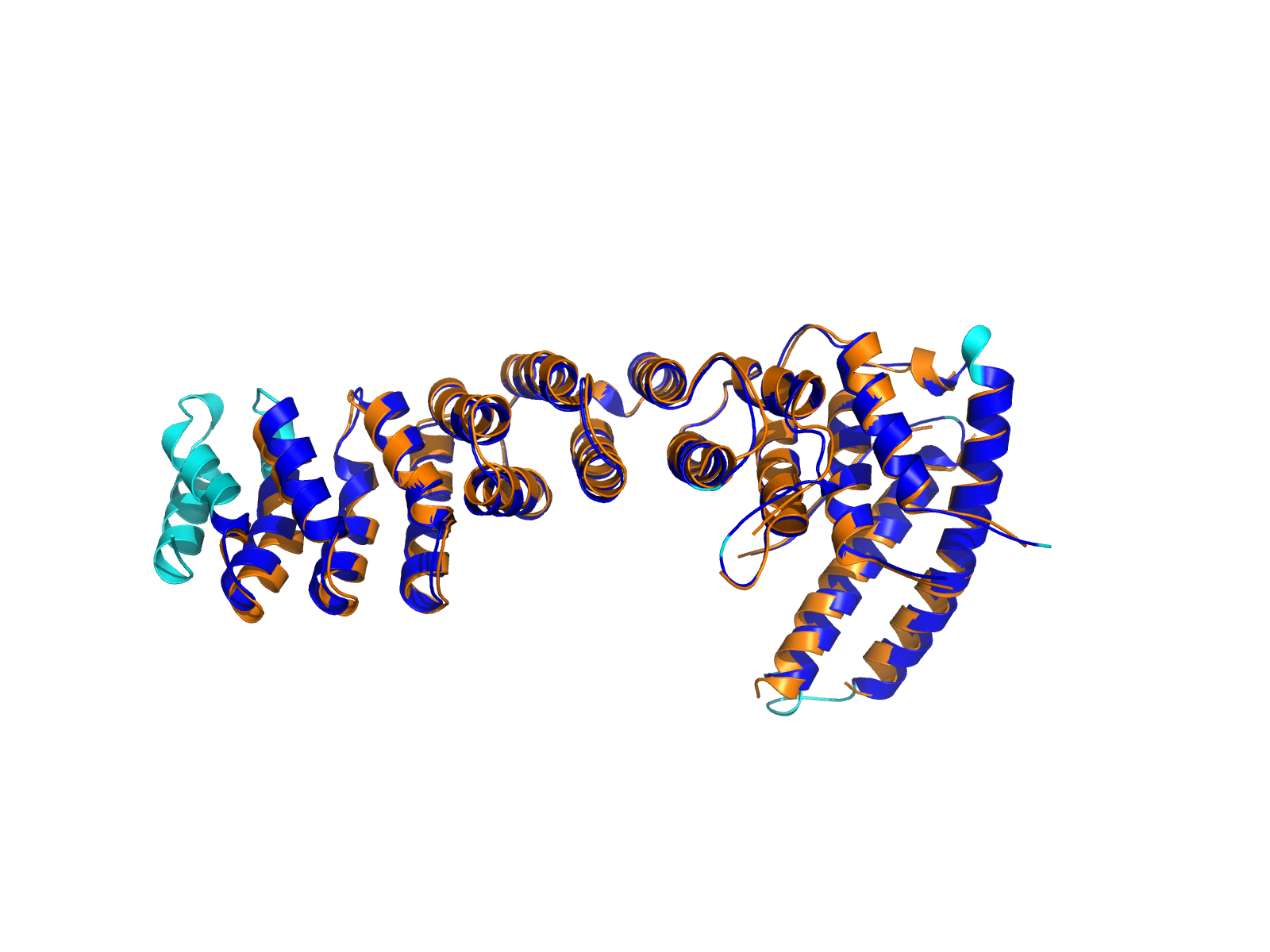 |
| API5_LCMT1_ENST00000420461_ENST00000399069_43357544_25172422 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.5374
Å |
| | | |  |
| API5_LCMT1_ENST00000531273_ENST00000399069_43357544_25172422 superimposed PDB: 6L4O of partner (API5). RMSD:1.102
Å |
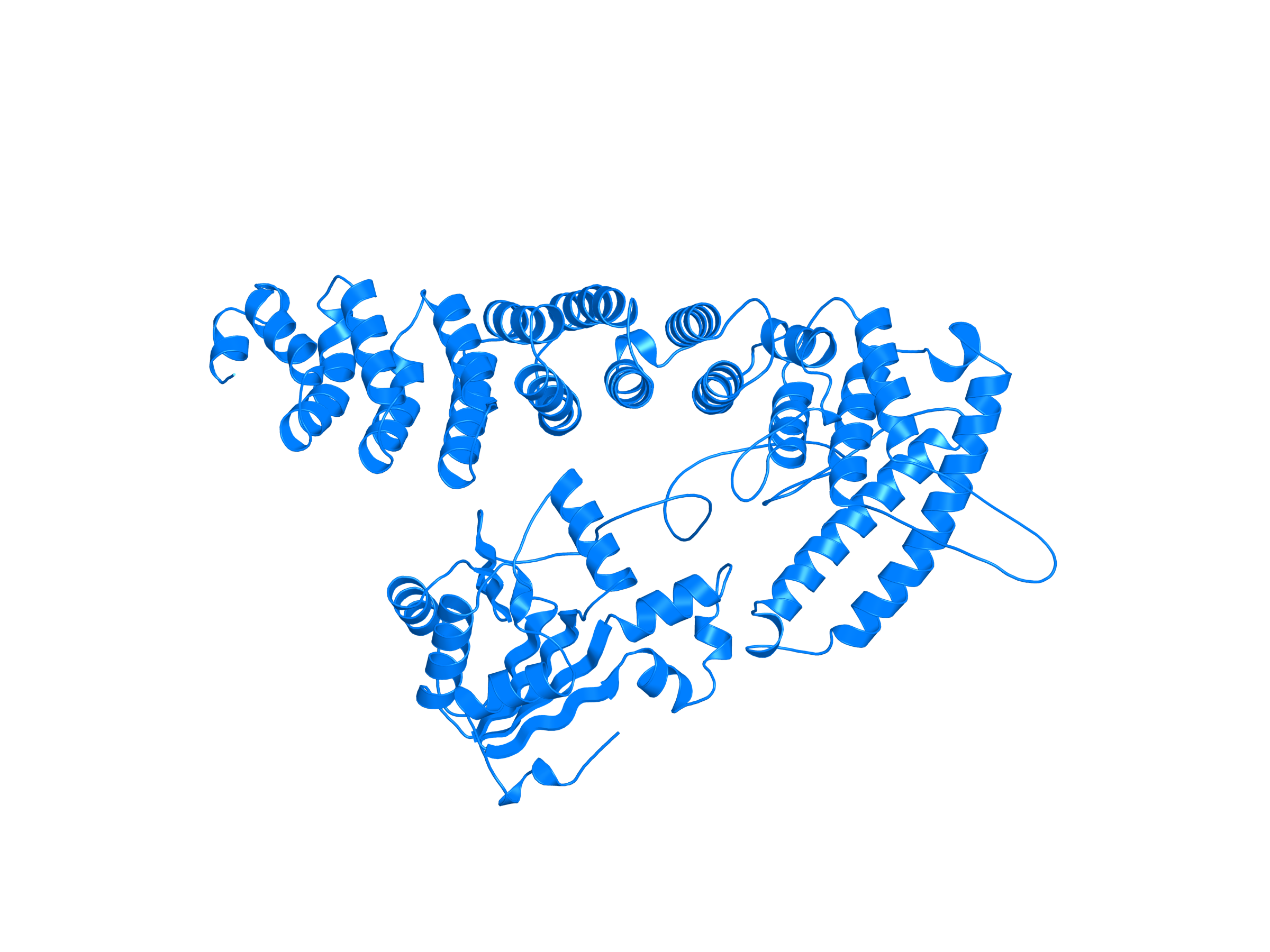 | 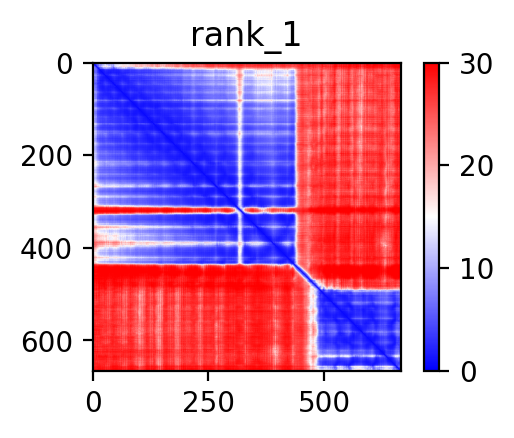 | 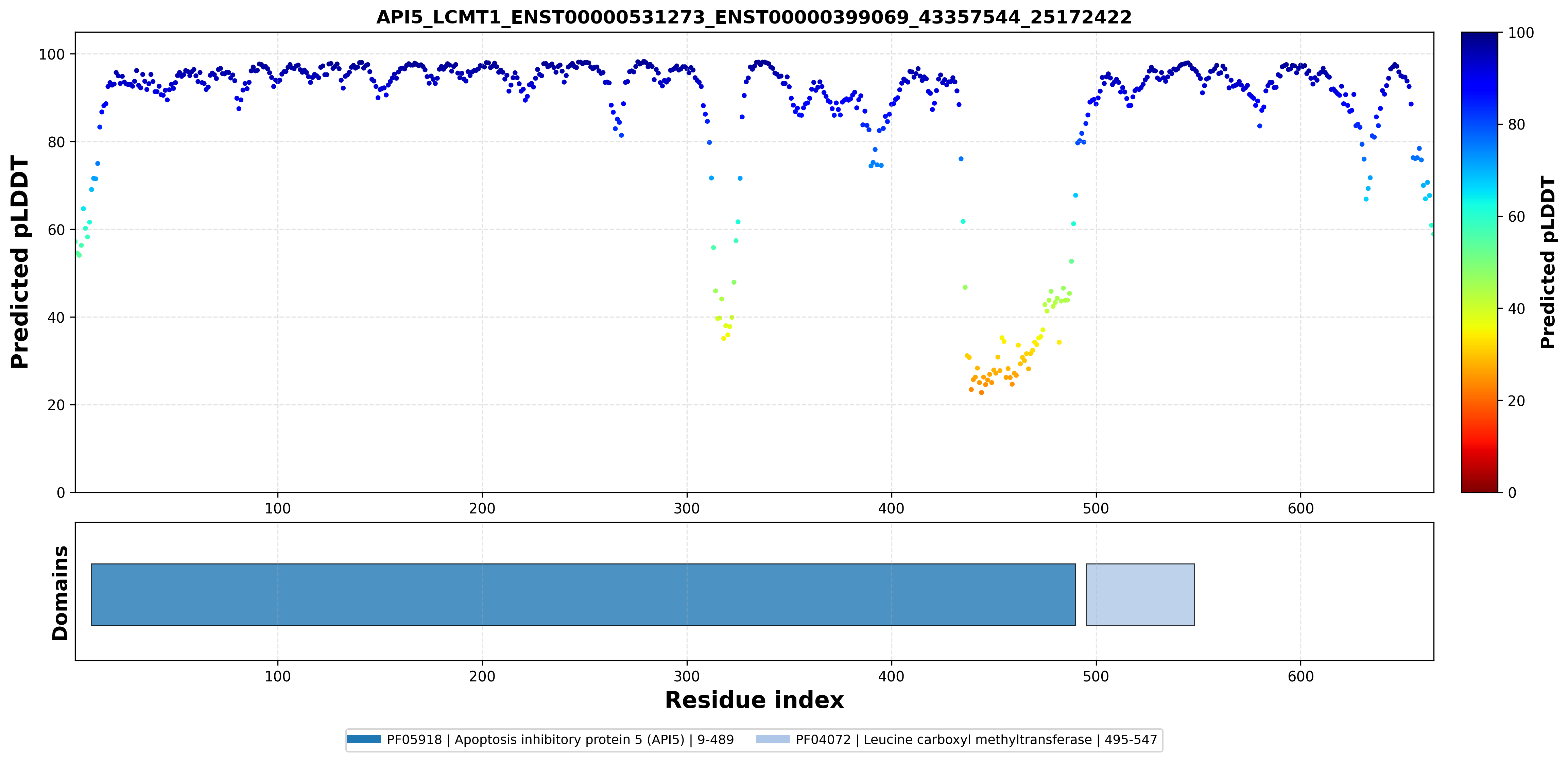 |  | 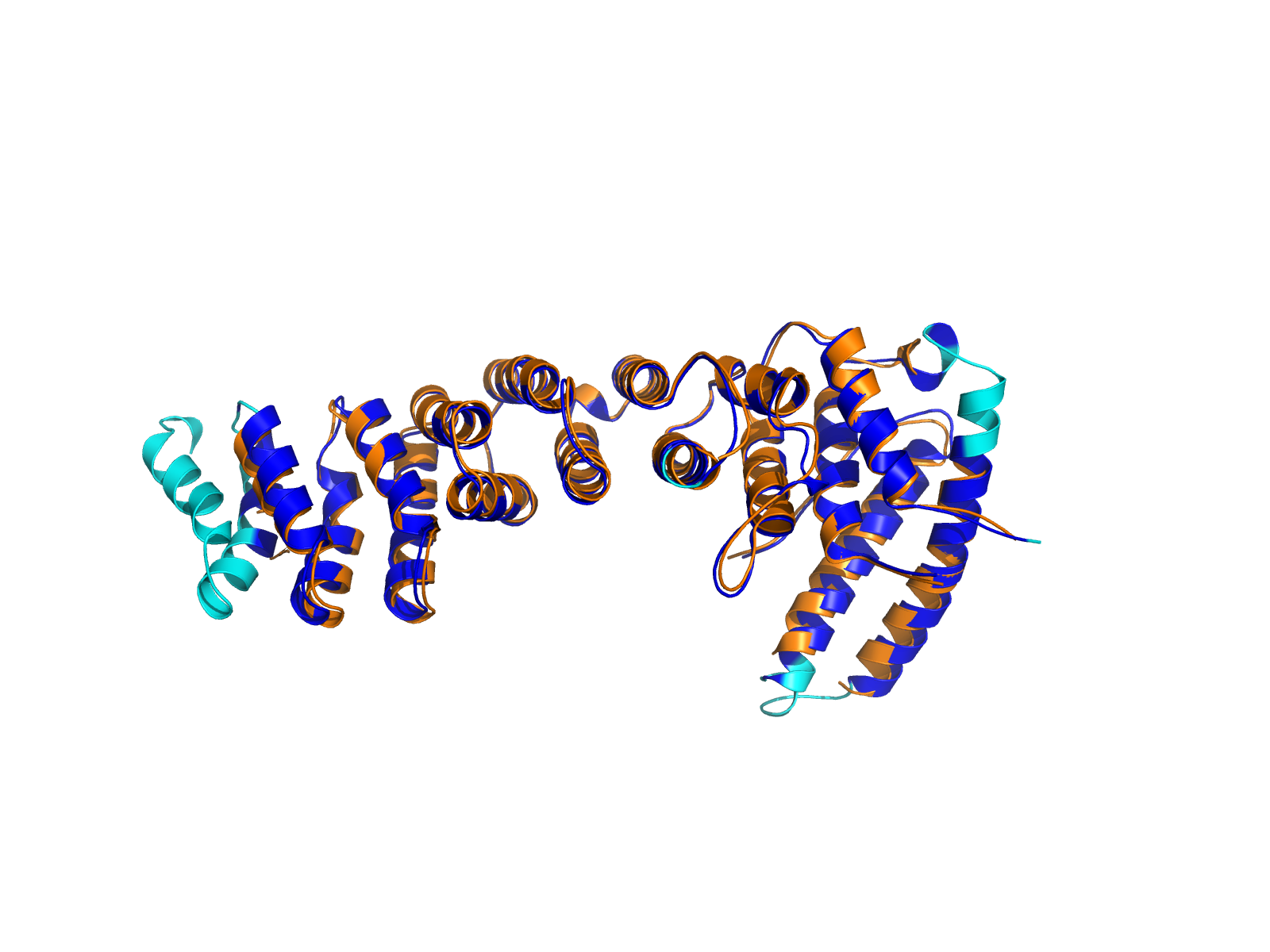 |
| API5_LCMT1_ENST00000531273_ENST00000399069_43357544_25172422 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.5004
Å |
| | | |  |
| APIP_SLC1A2_ENST00000395787_ENST00000395750_34909839_35287305 superimposed PDB: 4M6R of partner (APIP). RMSD:0.7326
Å |
 |  |  |  |  |
| APIP_SLC1A2_ENST00000395787_ENST00000395750_34909839_35287305 superimposed PDB: 9JVV of partner (SLC1A2). RMSD:2.5522
Å |
| | | |  |
| APLP2_SPCS2_ENST00000263574_ENST00000263672_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.8948
Å |
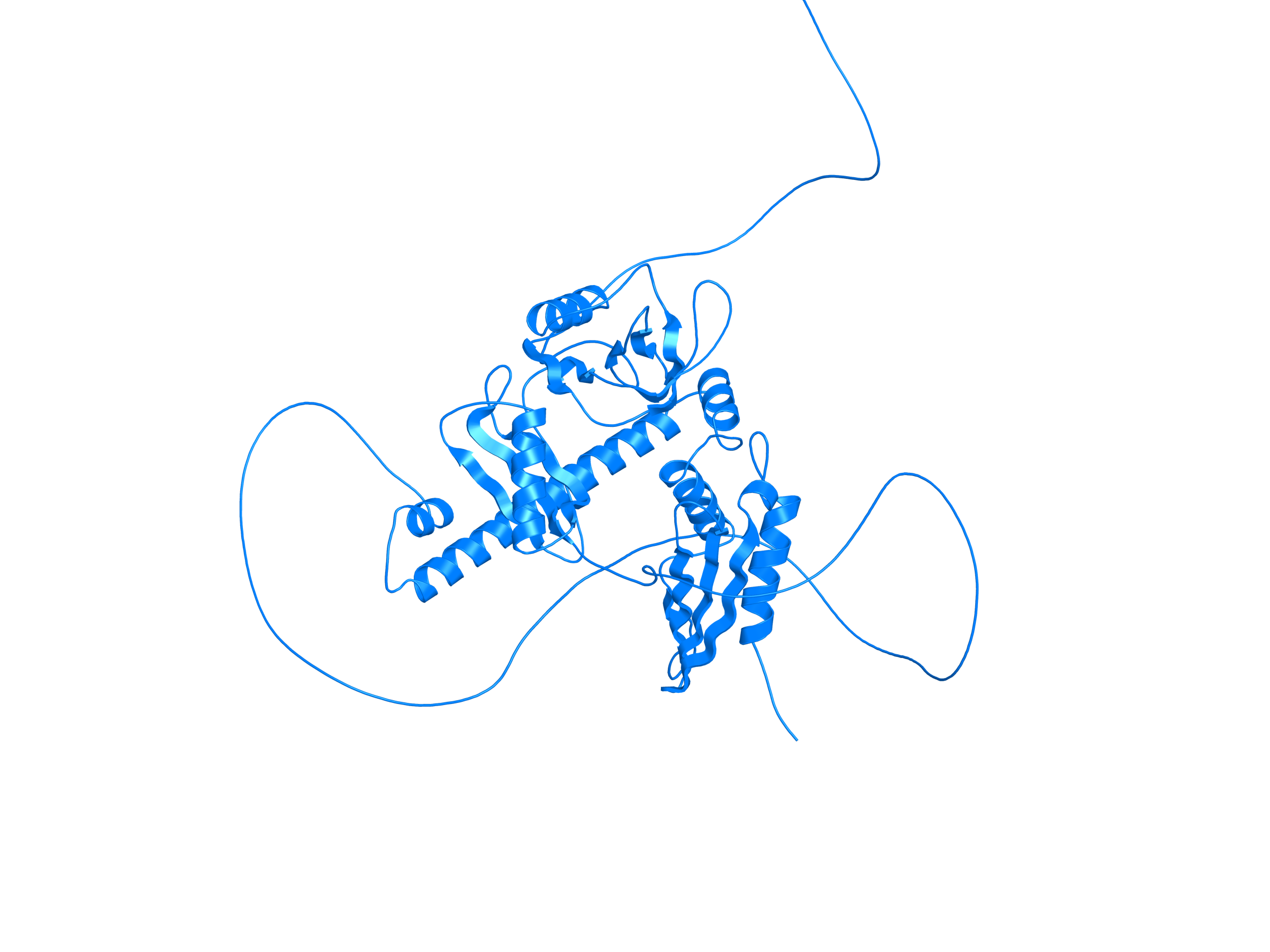 | 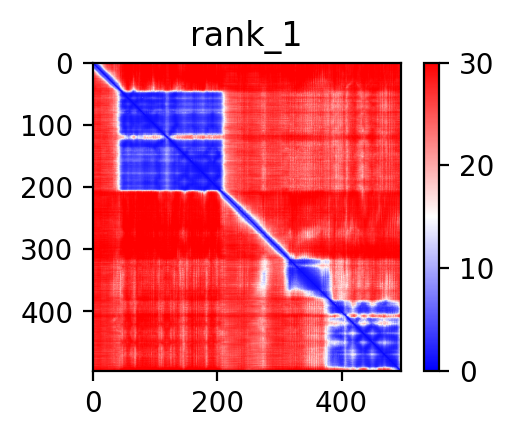 | 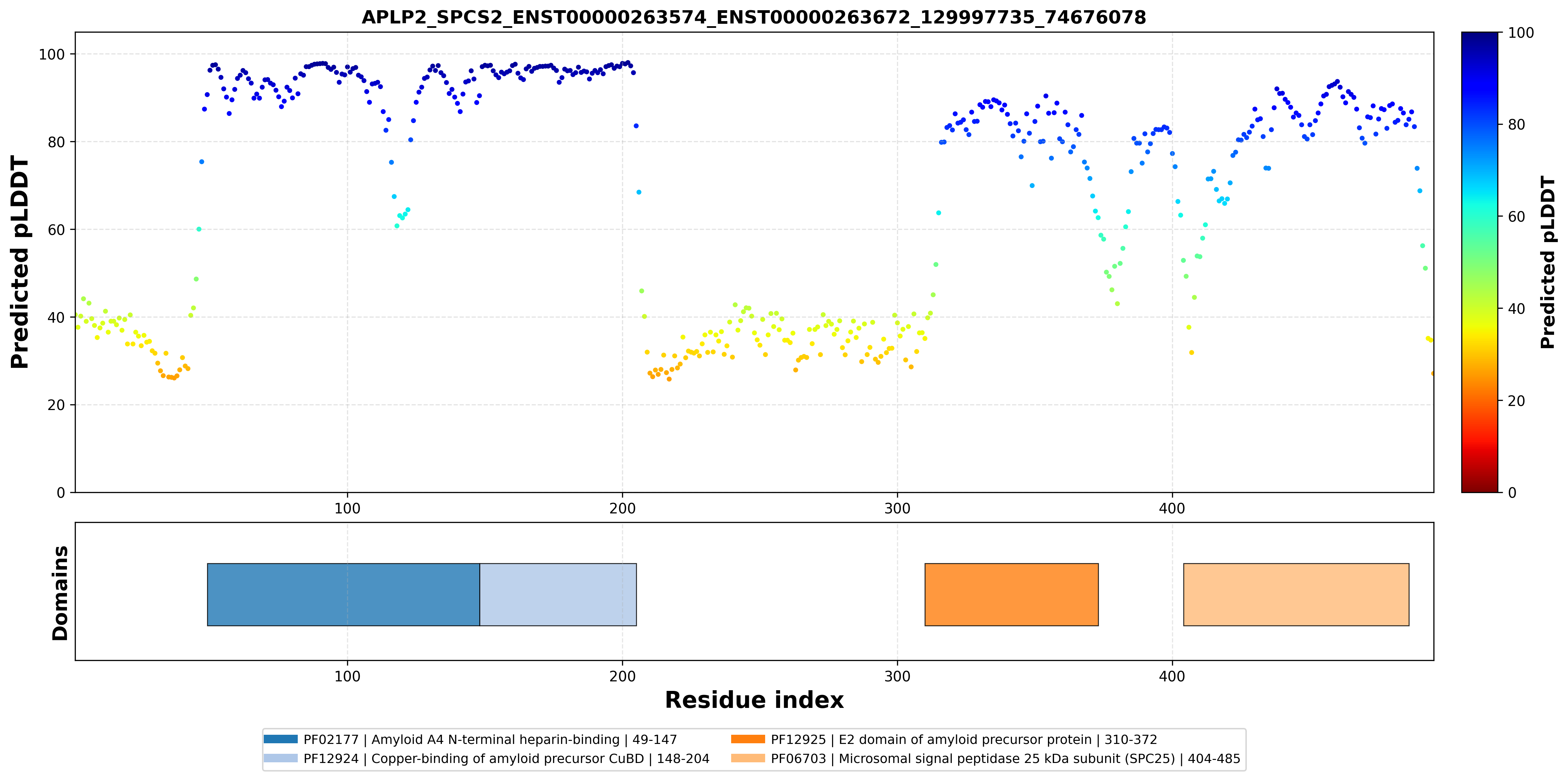 |  | 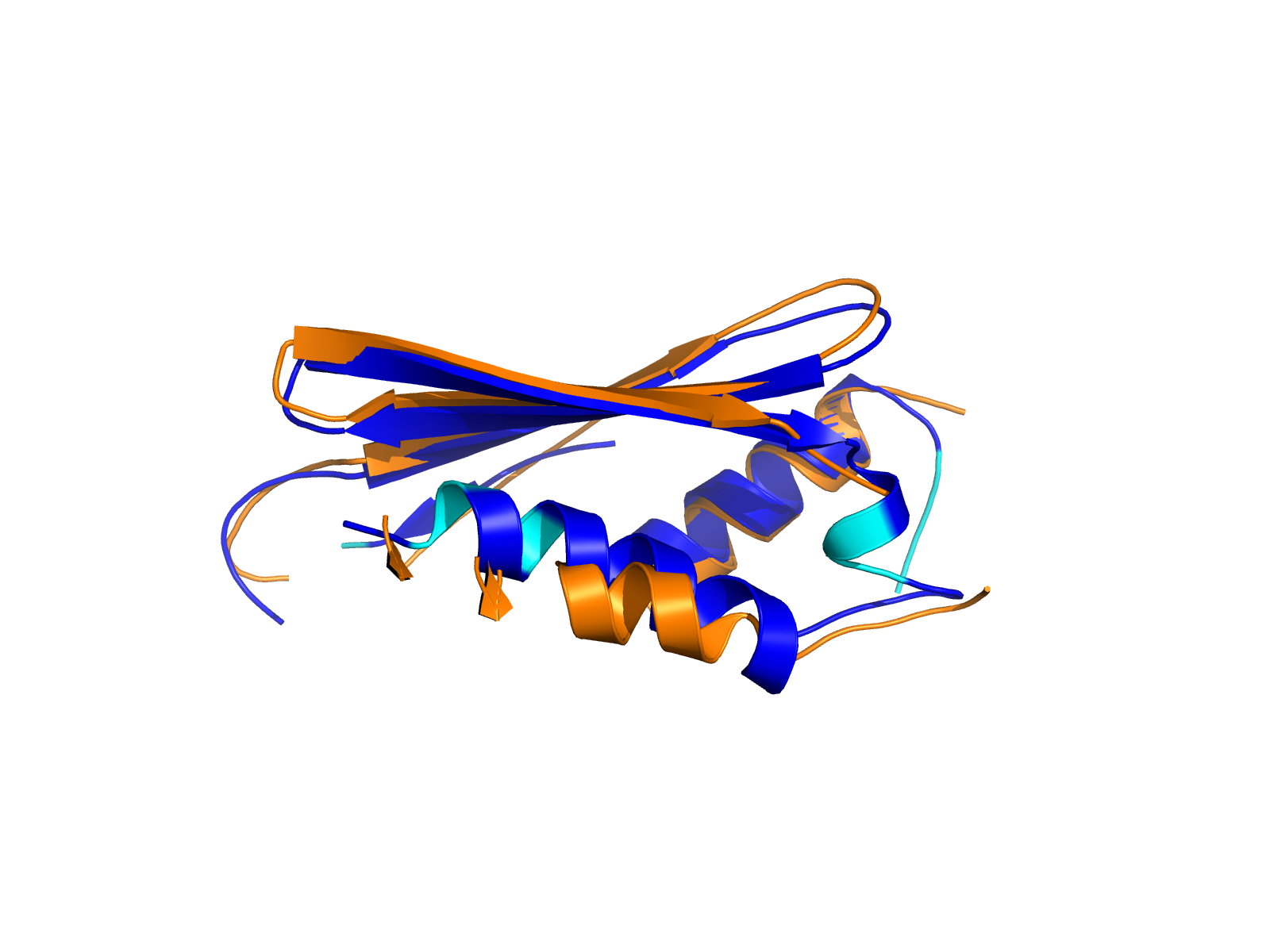 |
| APLP2_SPCS2_ENST00000263574_ENST00000530257_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.9513
Å |
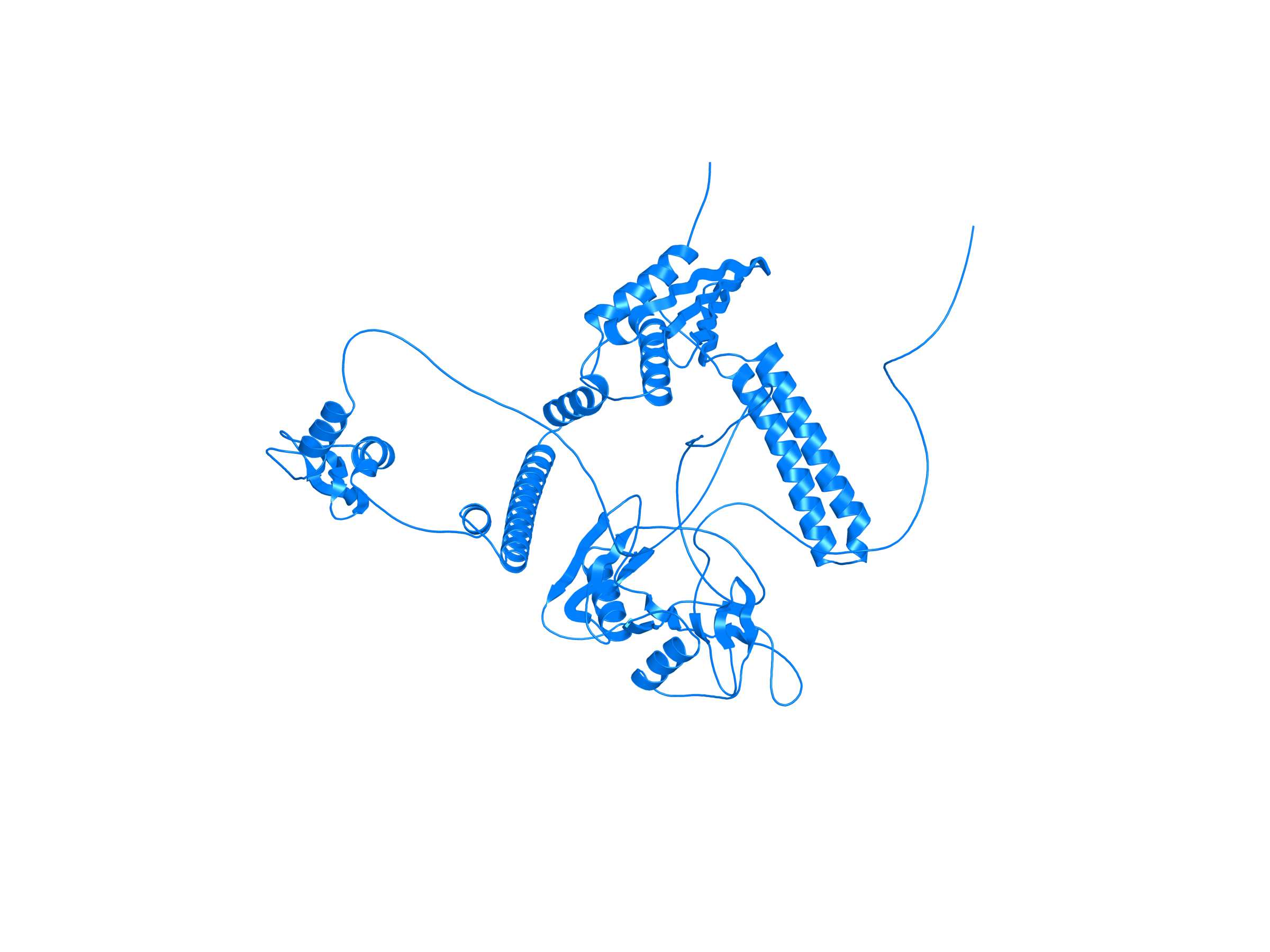 | 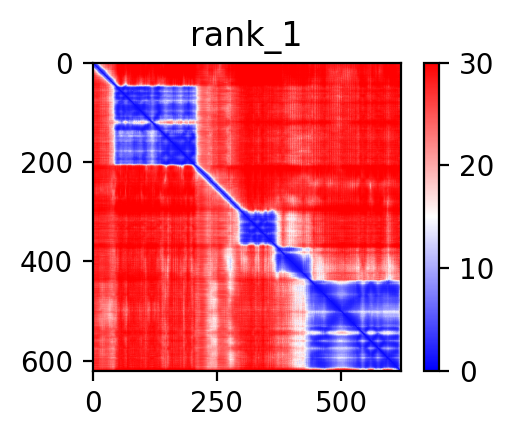 | 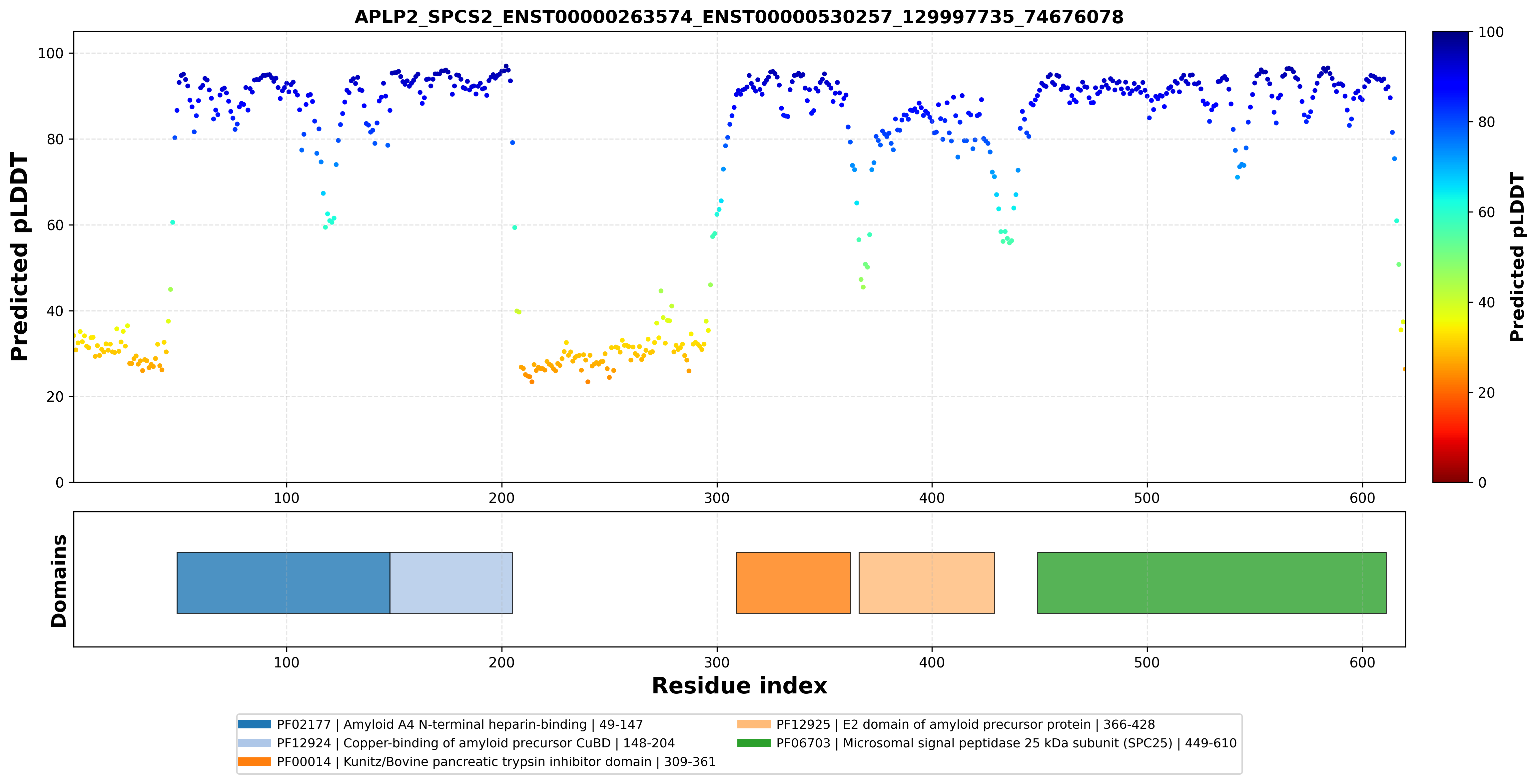 |  | 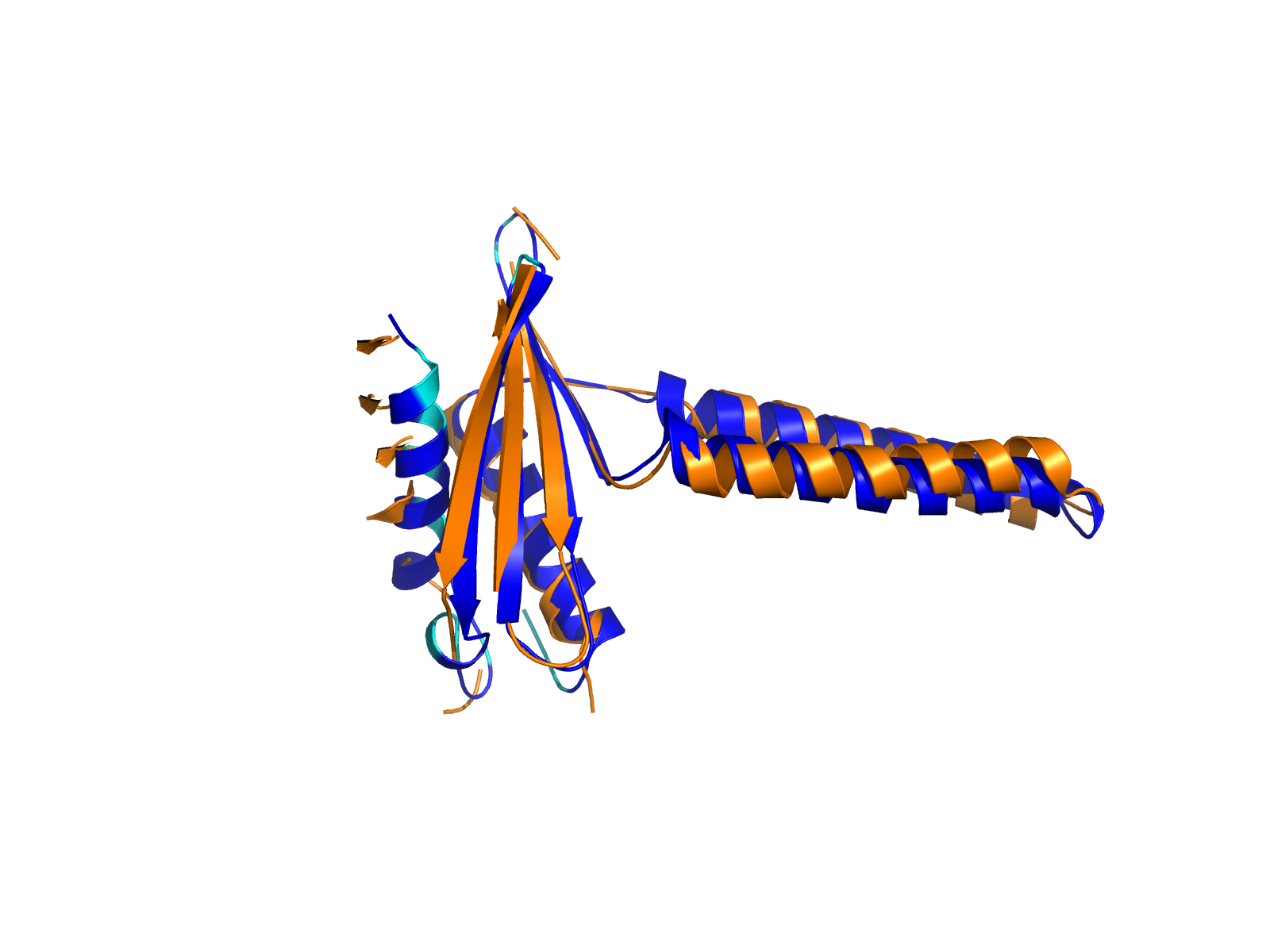 |
| APLP2_SPCS2_ENST00000278756_ENST00000530257_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.8312
Å |
 | 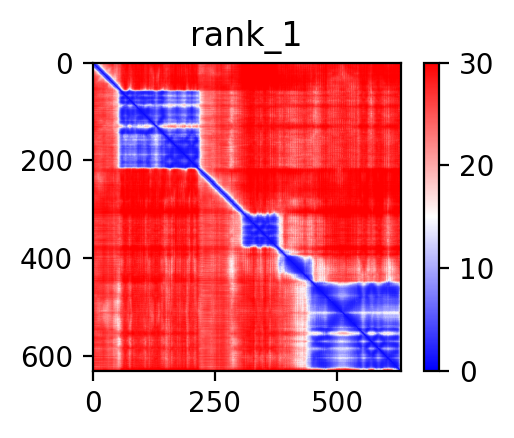 | 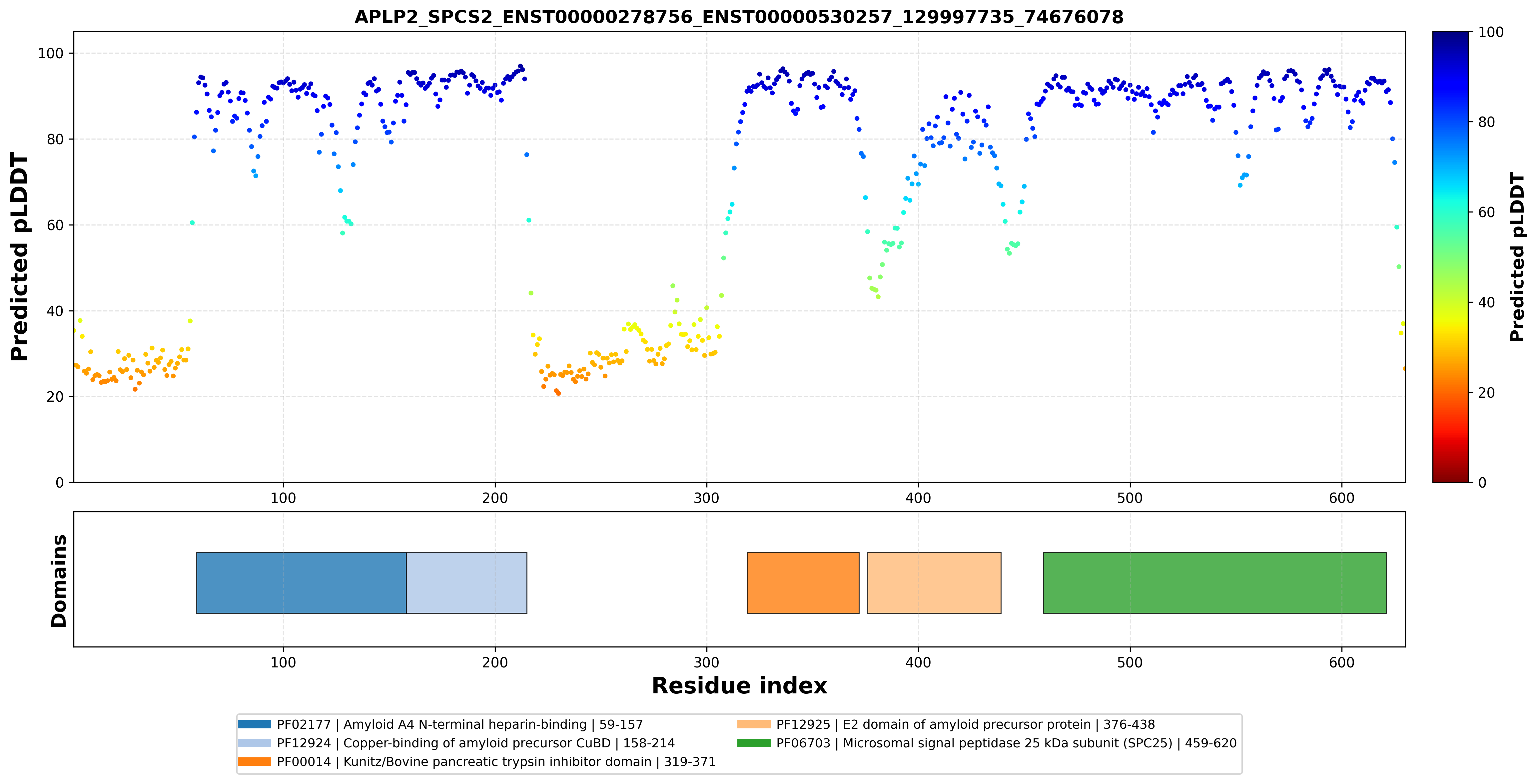 |  | 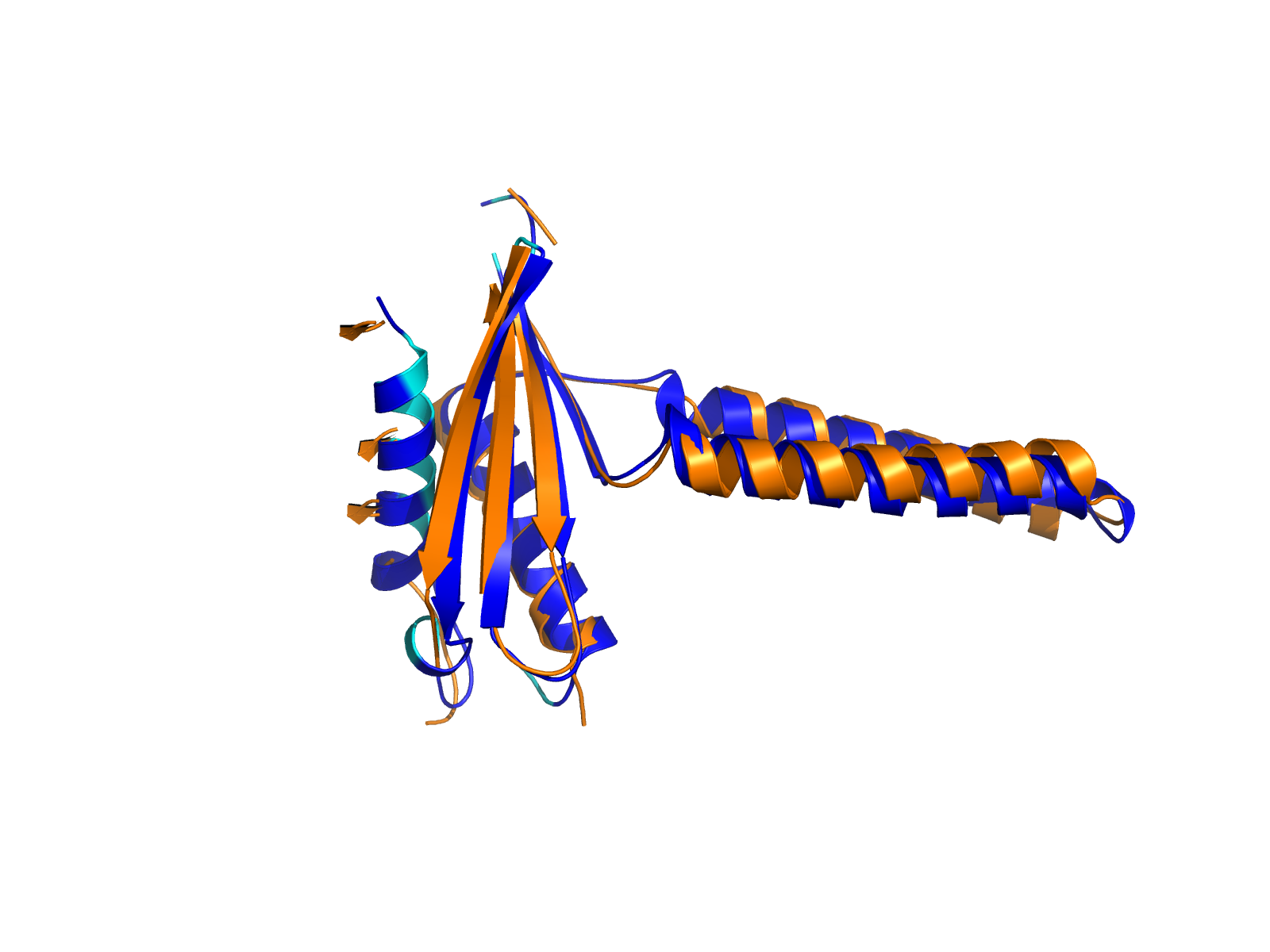 |
| APLP2_SPCS2_ENST00000338167_ENST00000263672_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.8735
Å |
 | 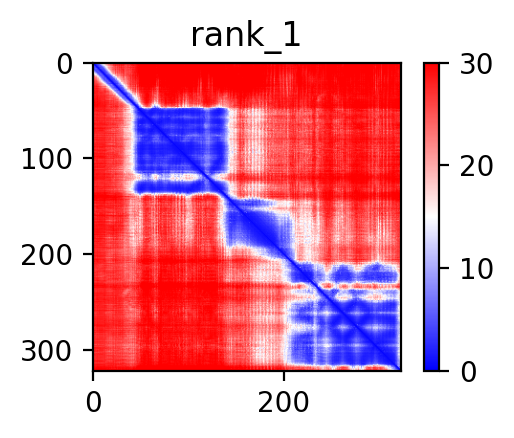 | 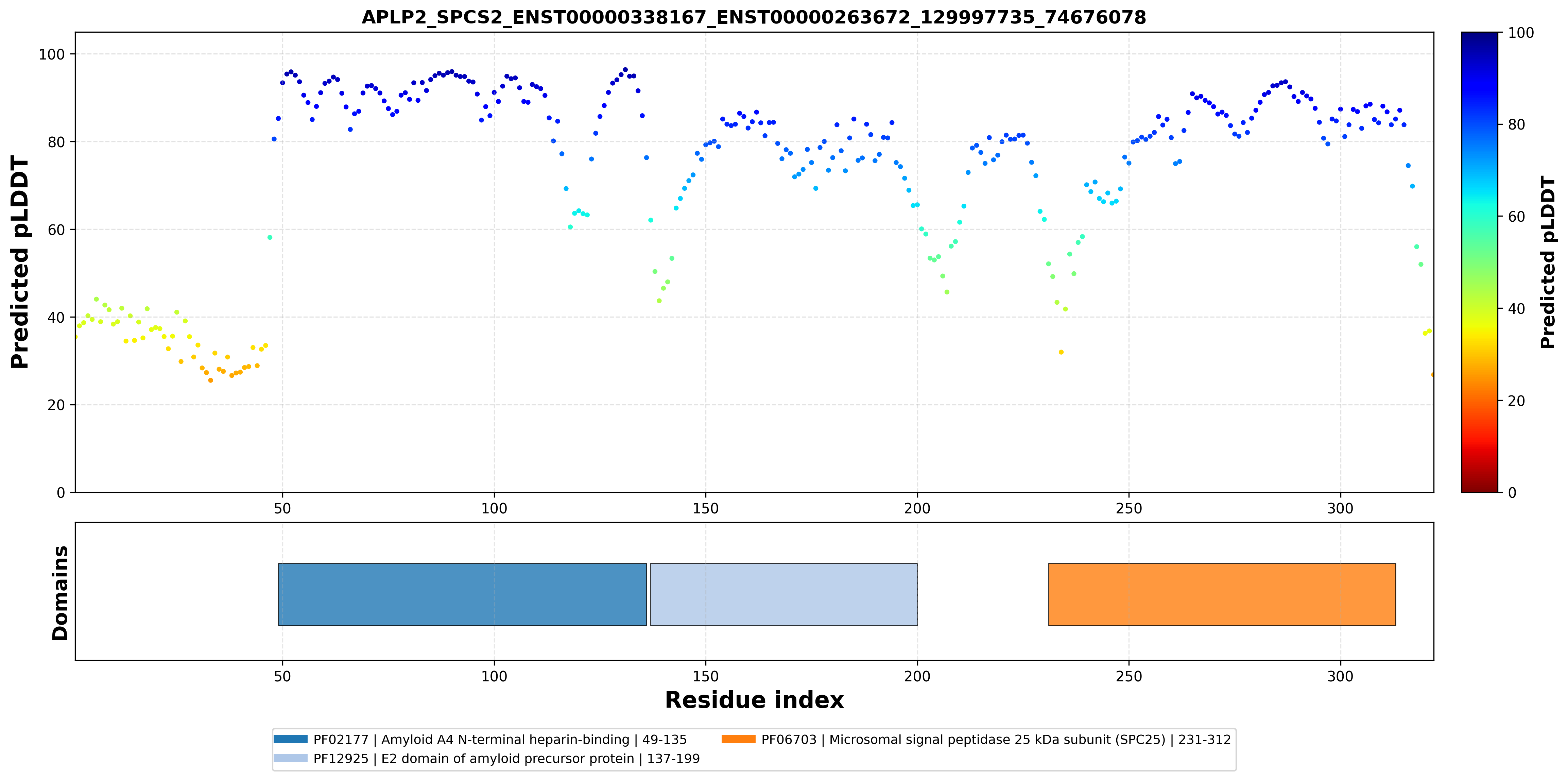 |  | 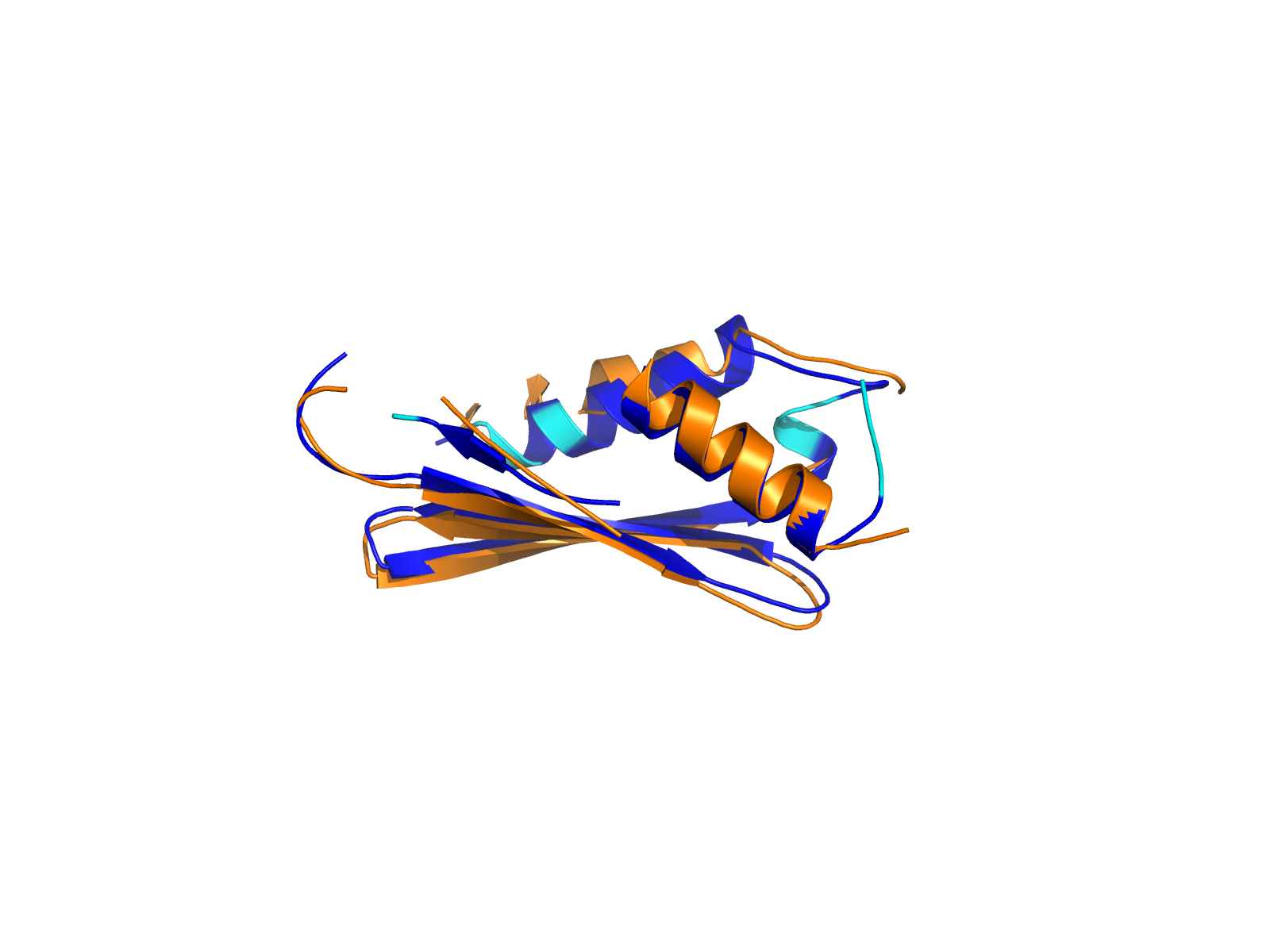 |
| APLP2_SPCS2_ENST00000345598_ENST00000263672_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.9421
Å |
 |  | 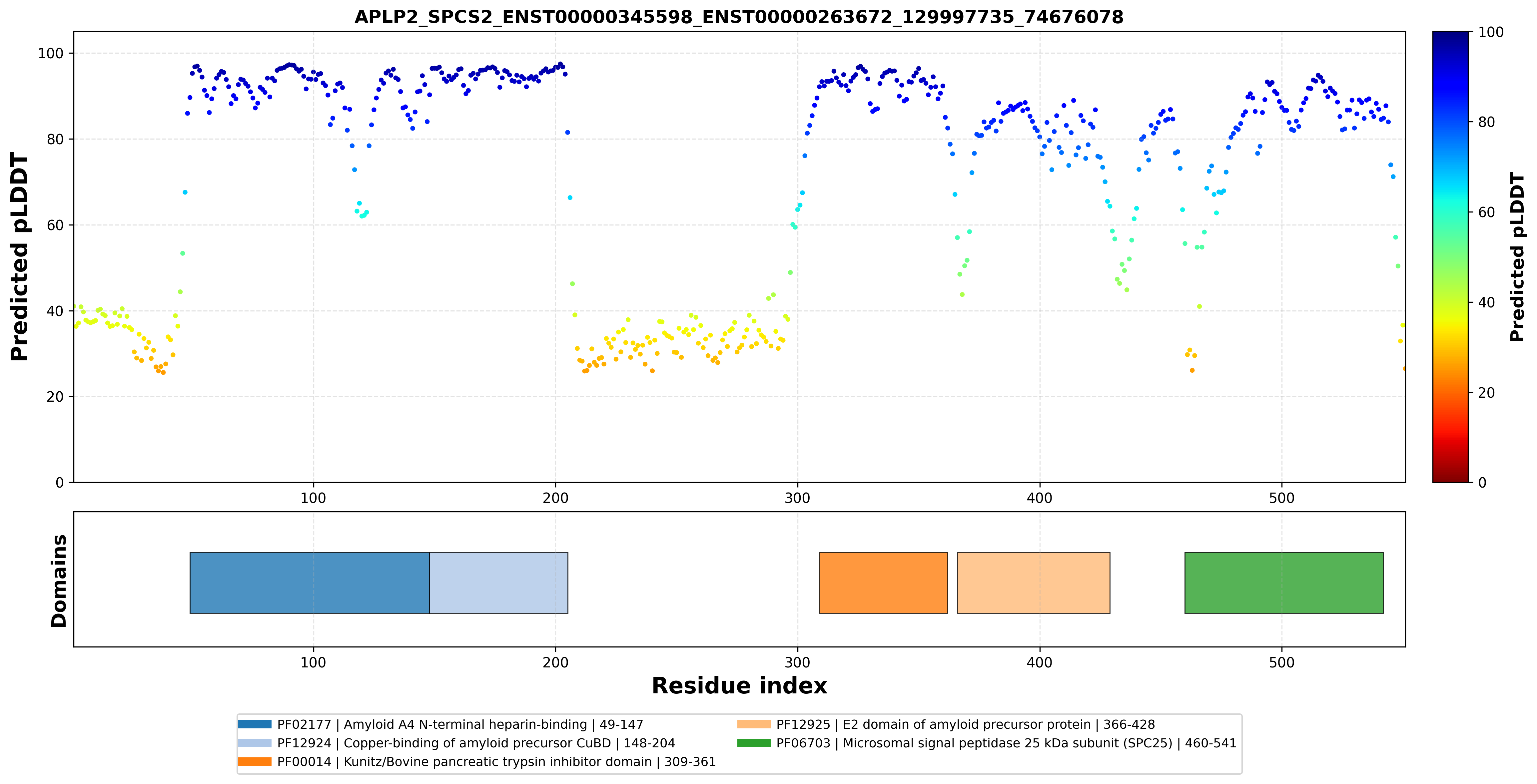 |  | 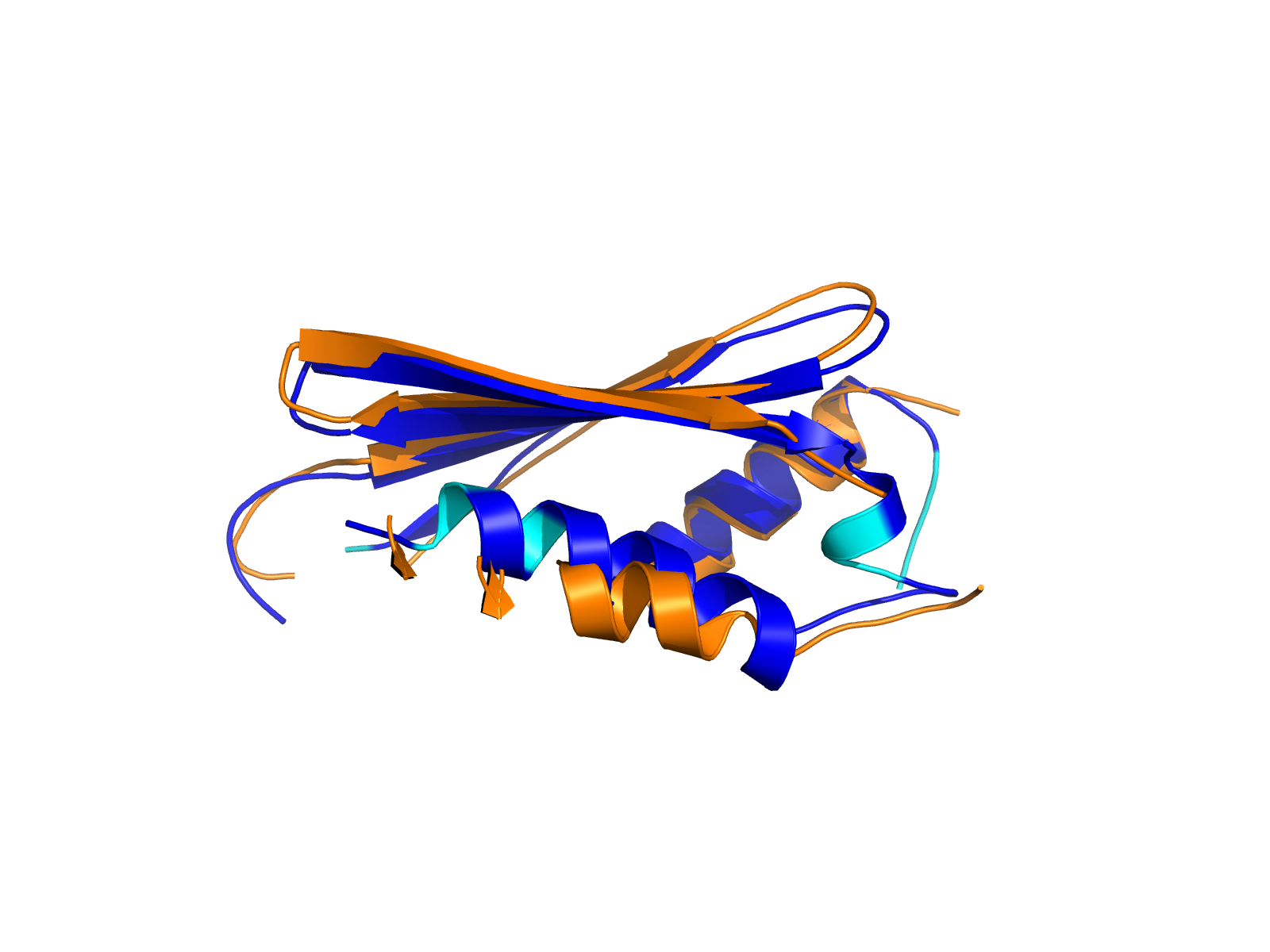 |
| APLP2_SPCS2_ENST00000345598_ENST00000530257_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.9682
Å |
 | 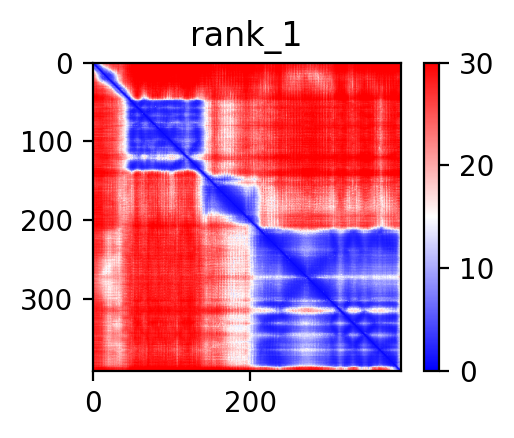 | 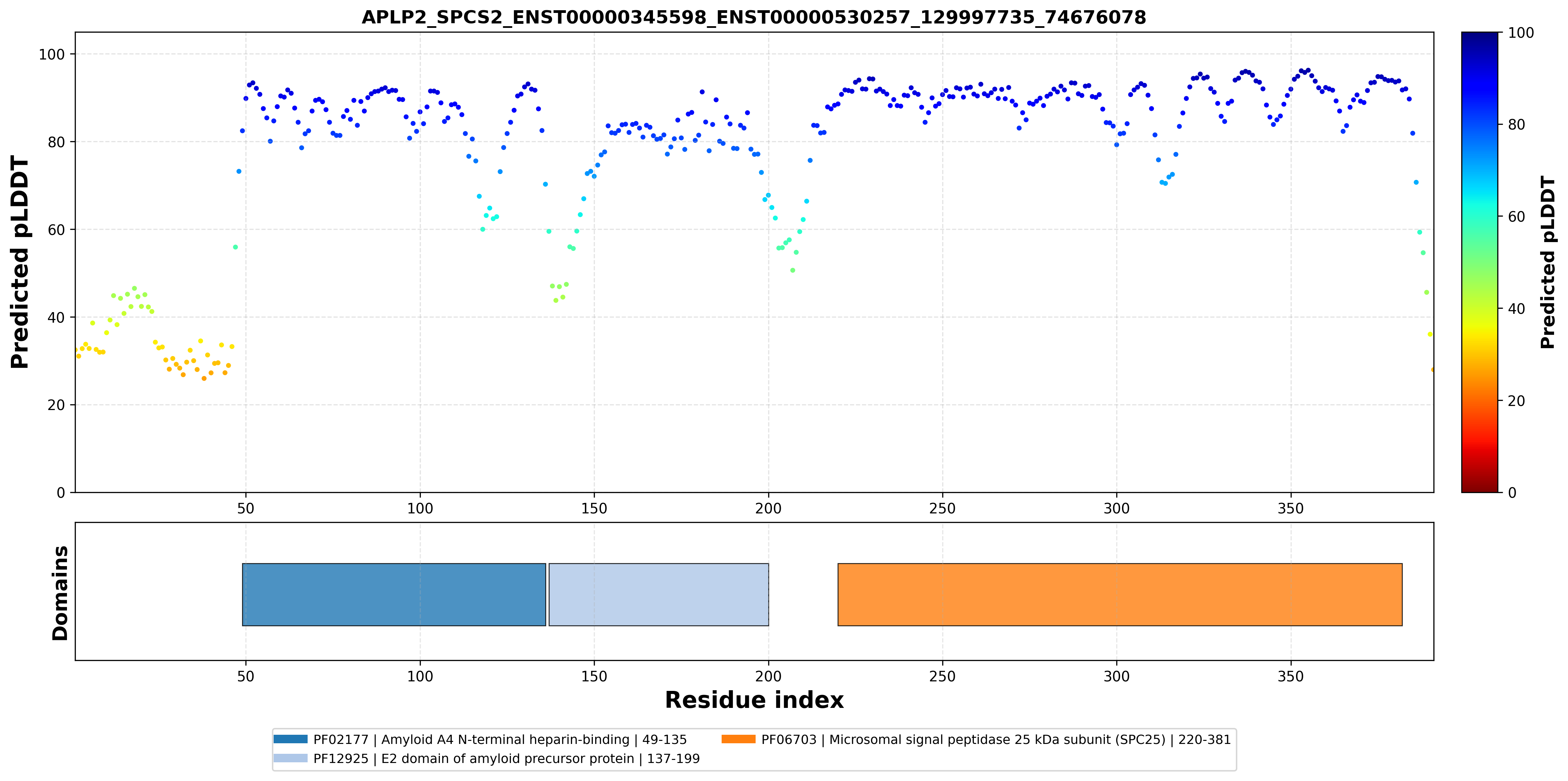 |  | 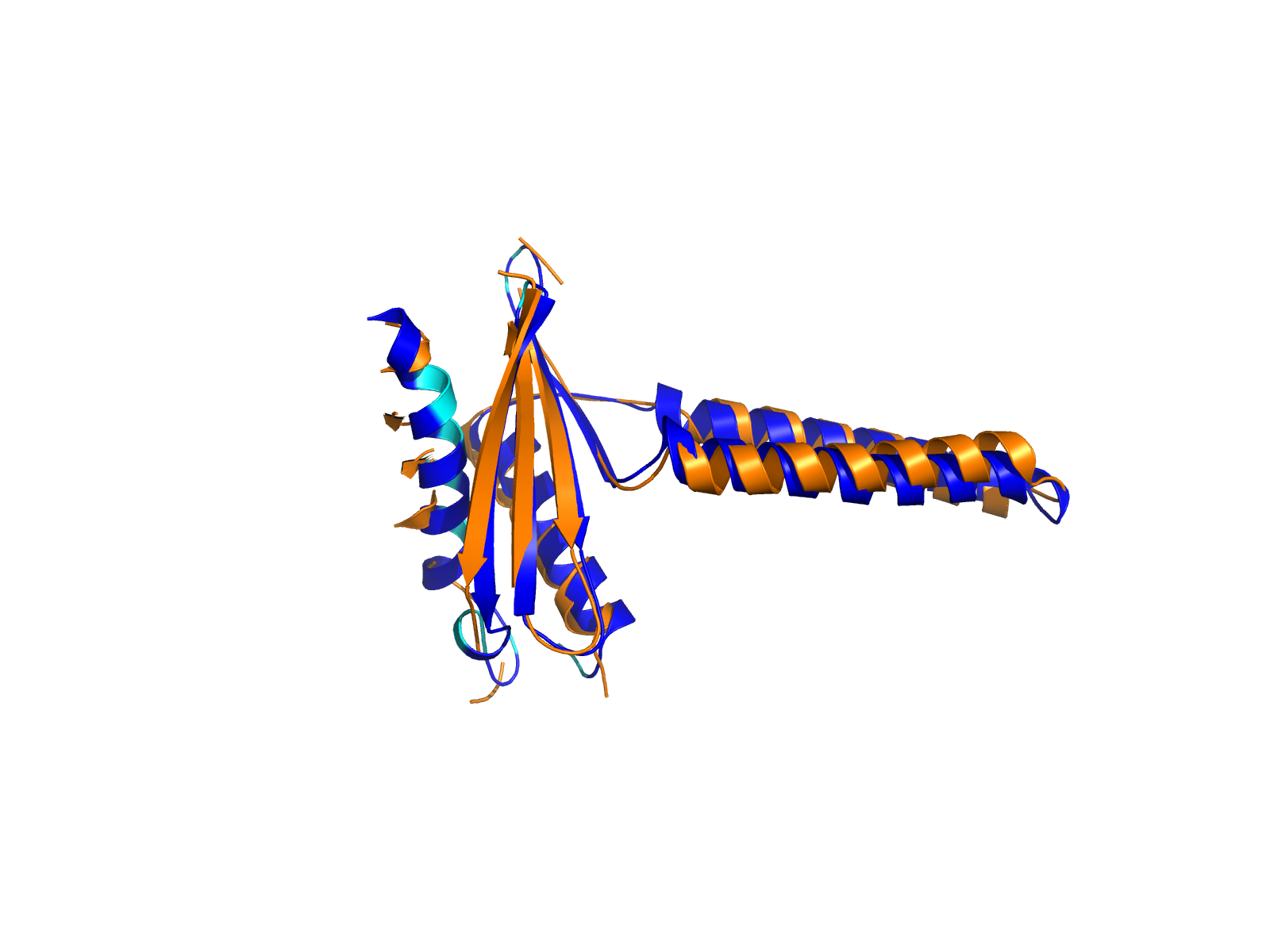 |
| APLP2_SPCS2_ENST00000528499_ENST00000263672_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.8874
Å |
 | 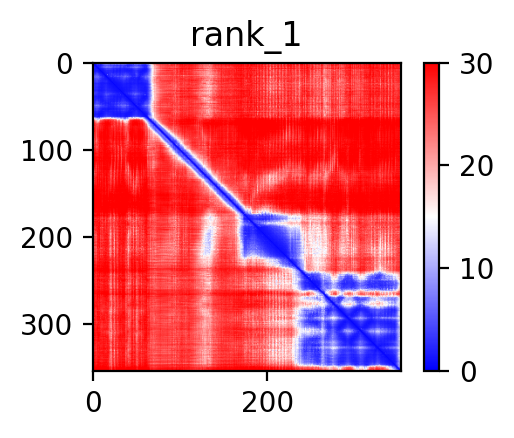 | 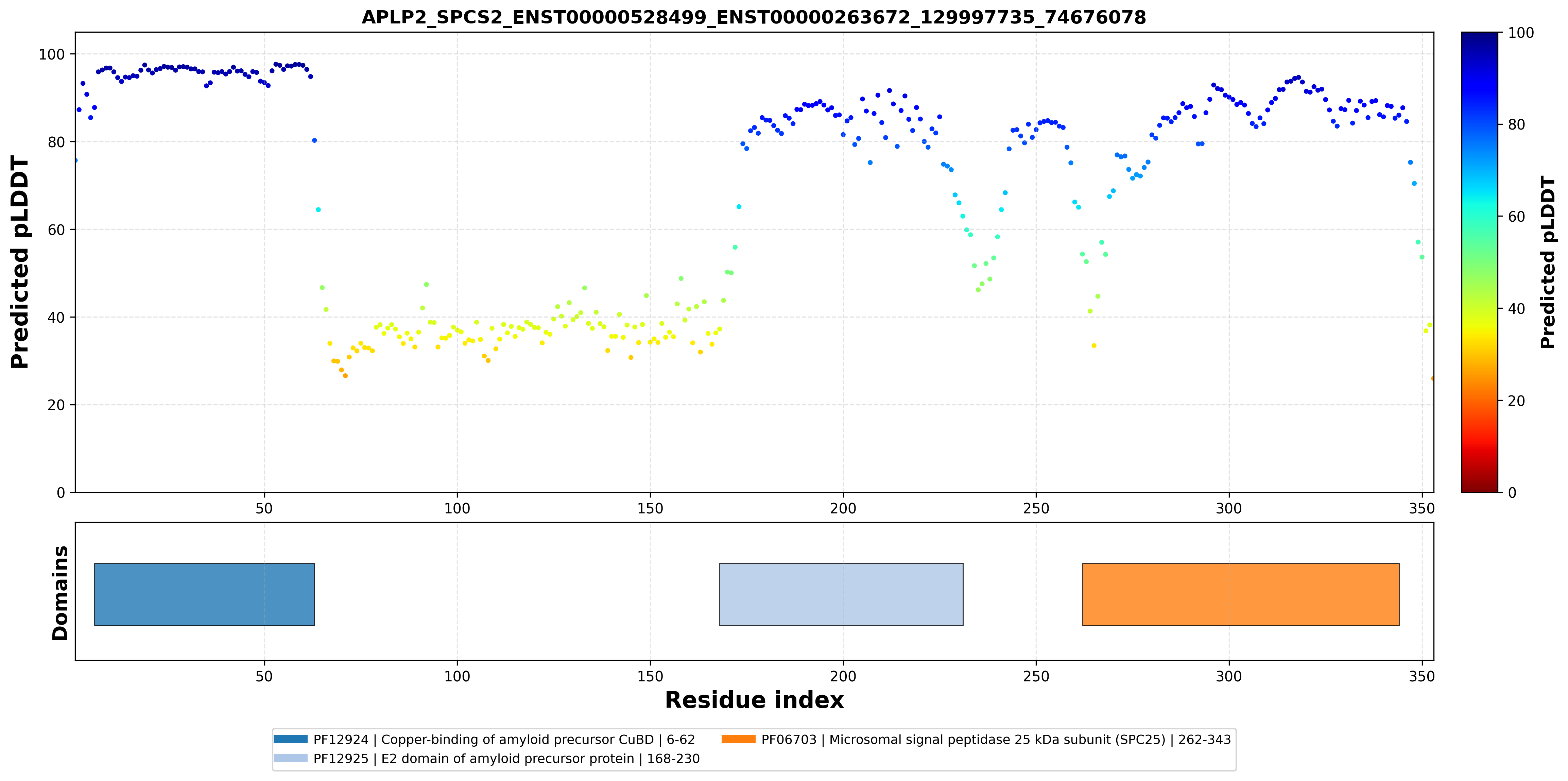 |  | 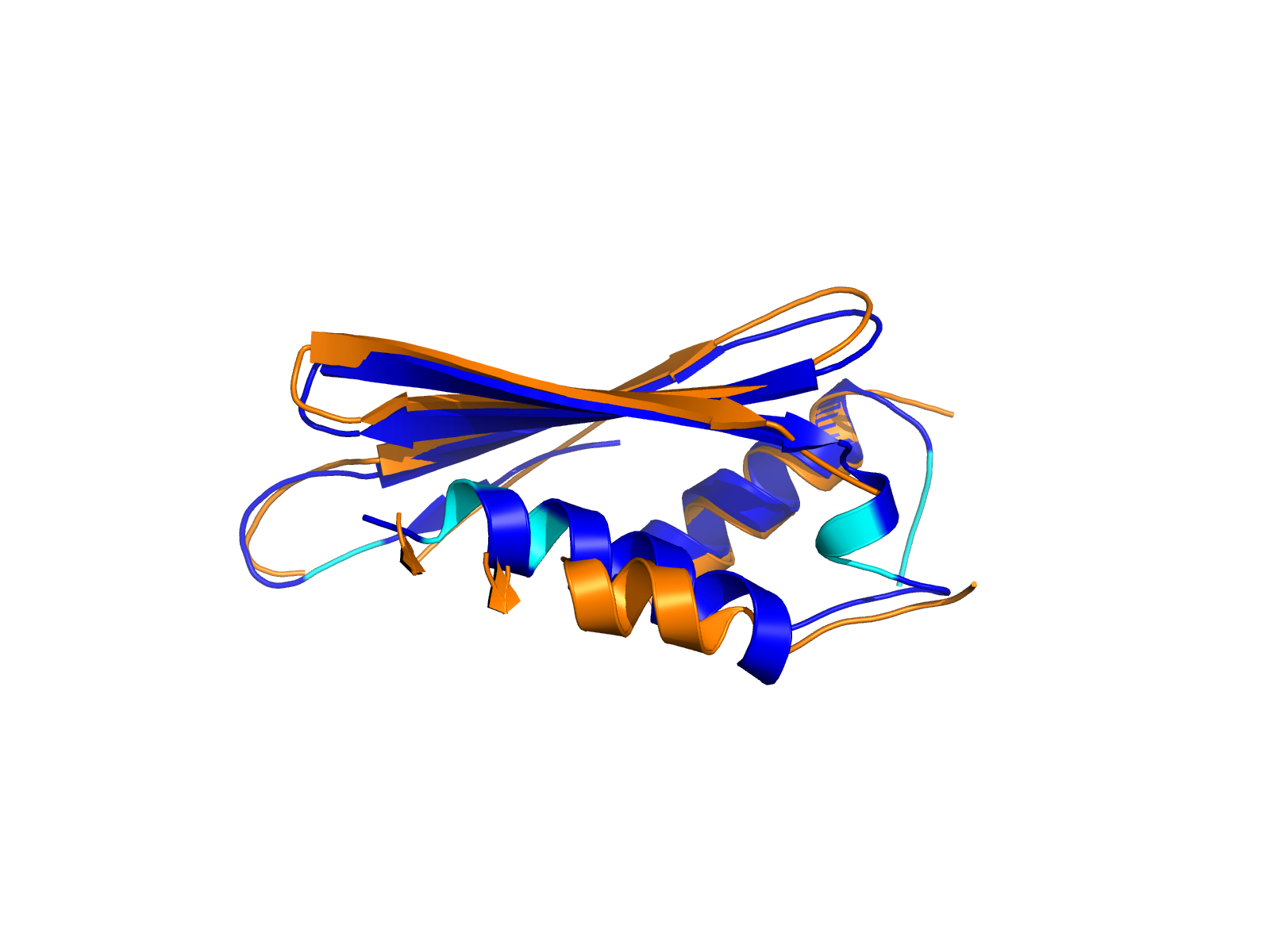 |
| APLP2_SPCS2_ENST00000528499_ENST00000530257_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.7713
Å |
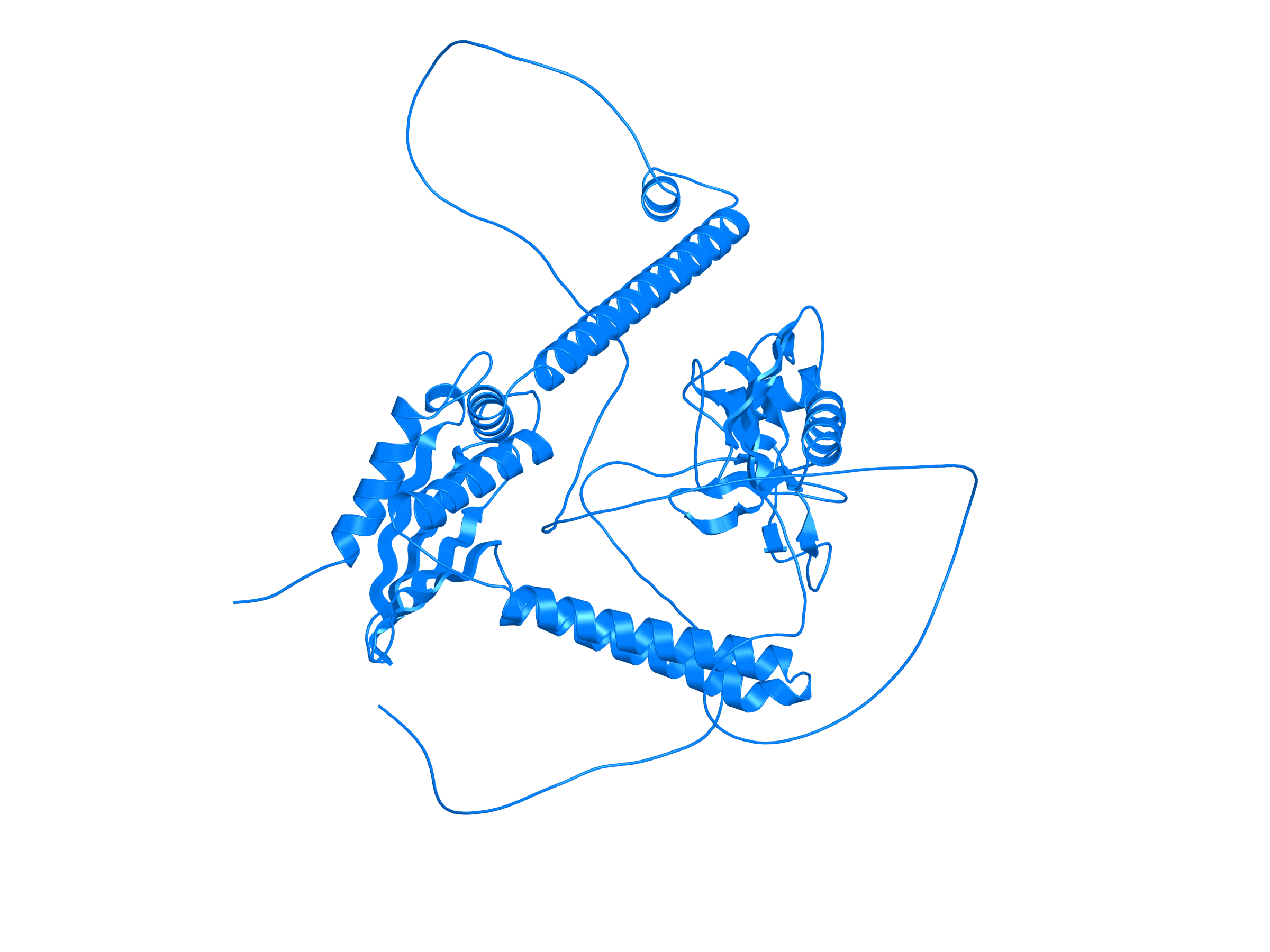 | 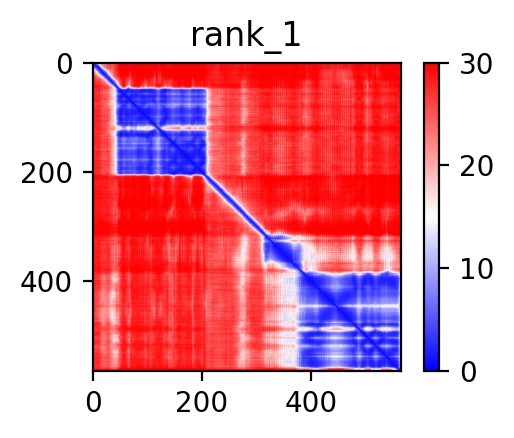 | 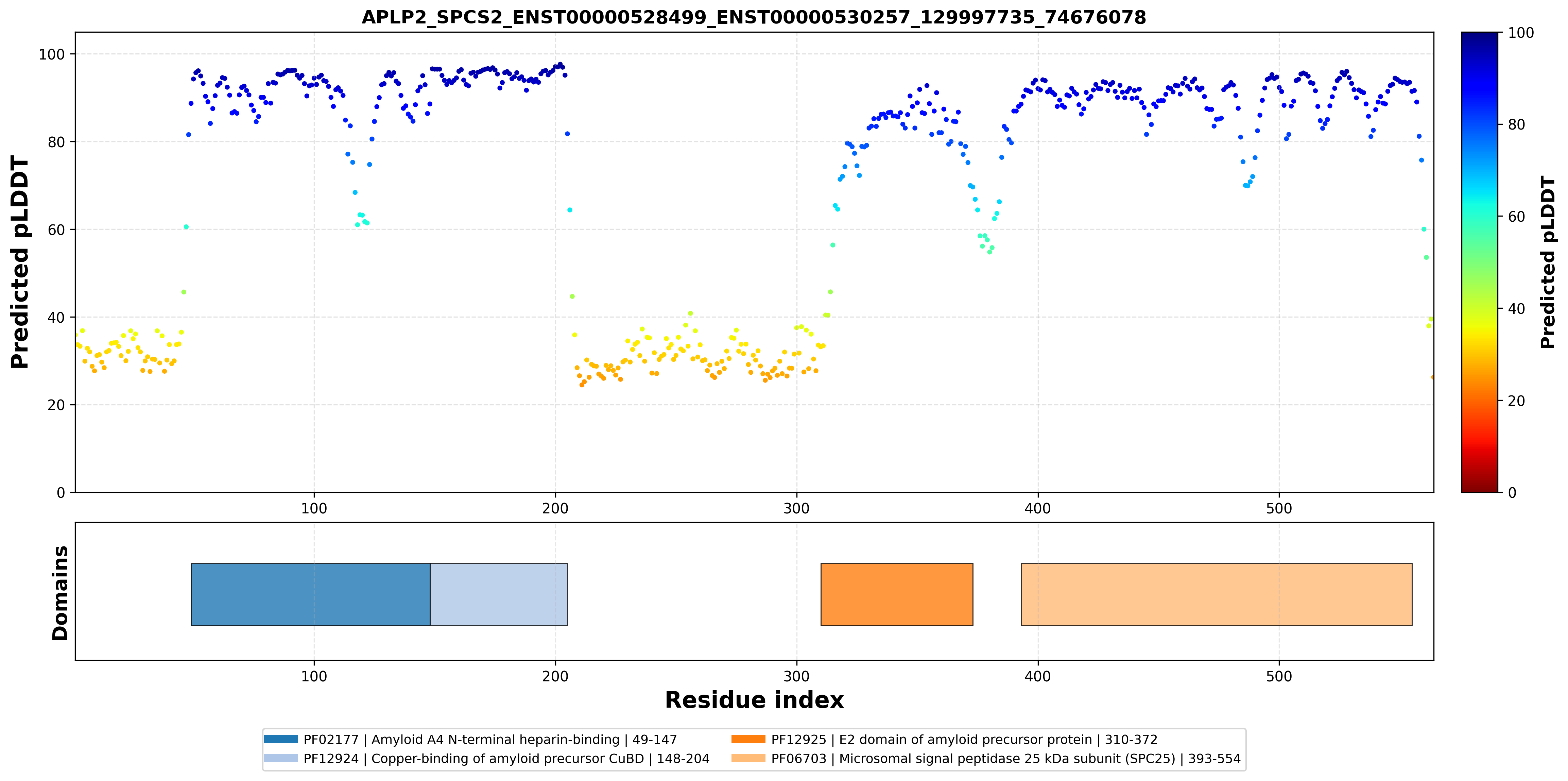 |  |  |
| APLP2_SPCS2_ENST00000539648_ENST00000530257_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.8935
Å |
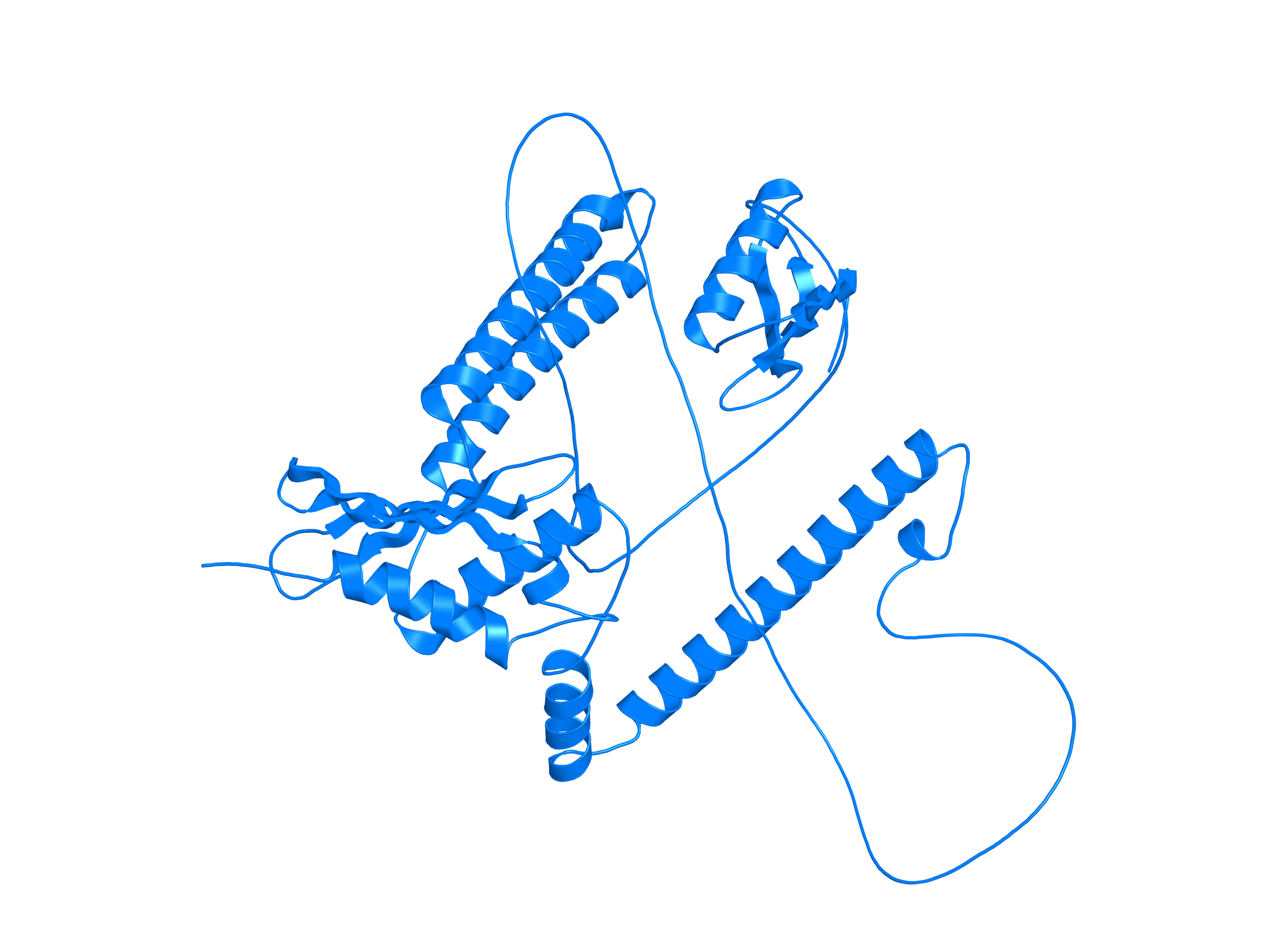 | 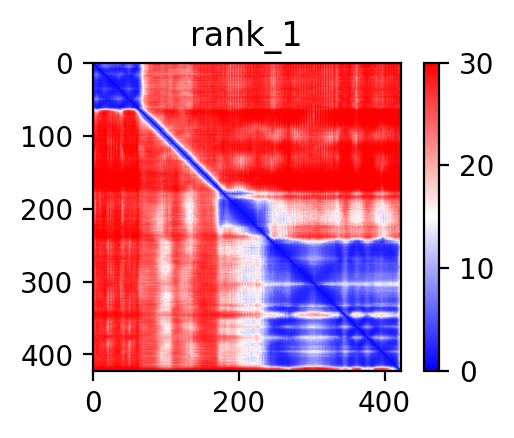 | 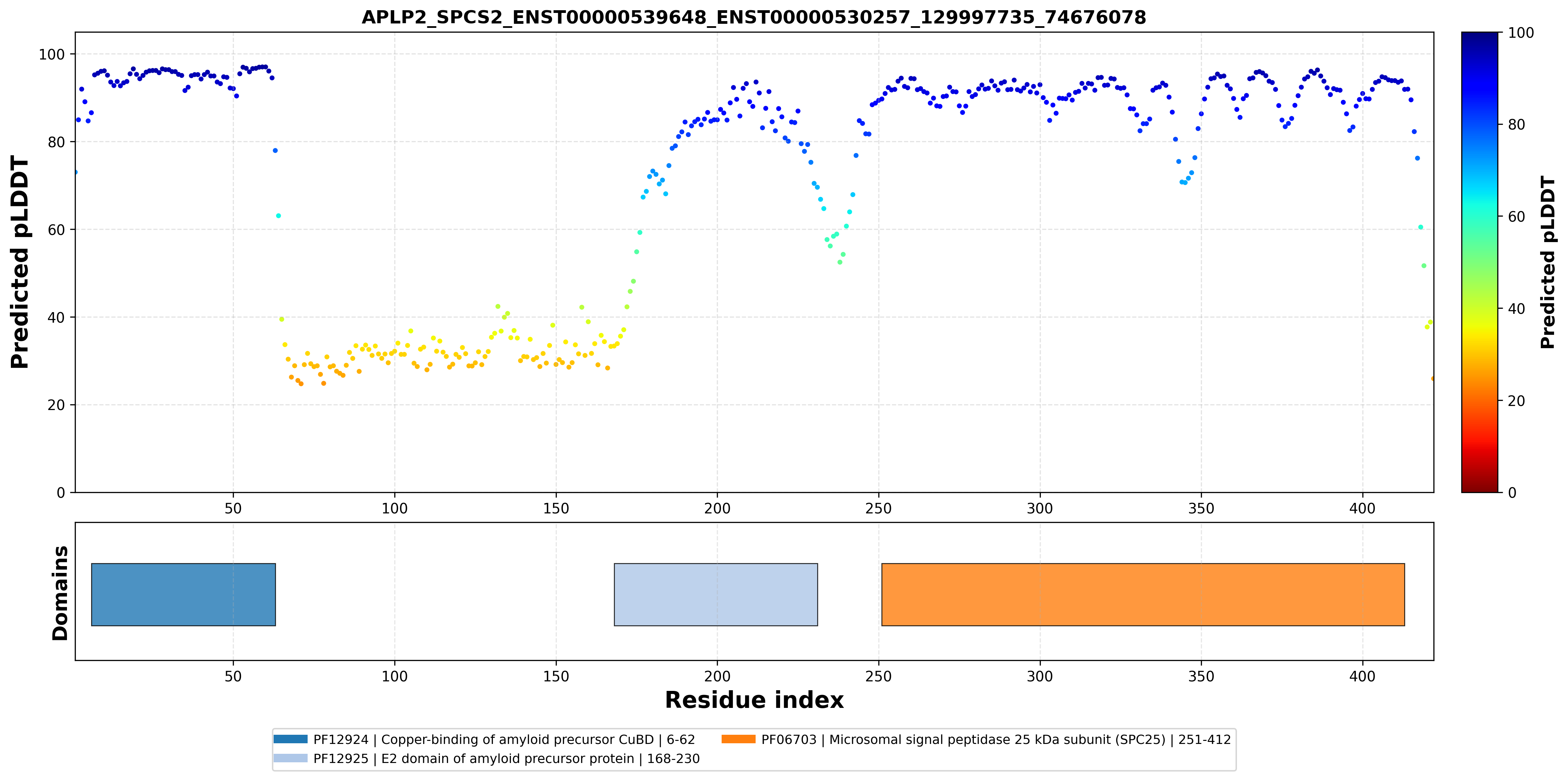 |  | 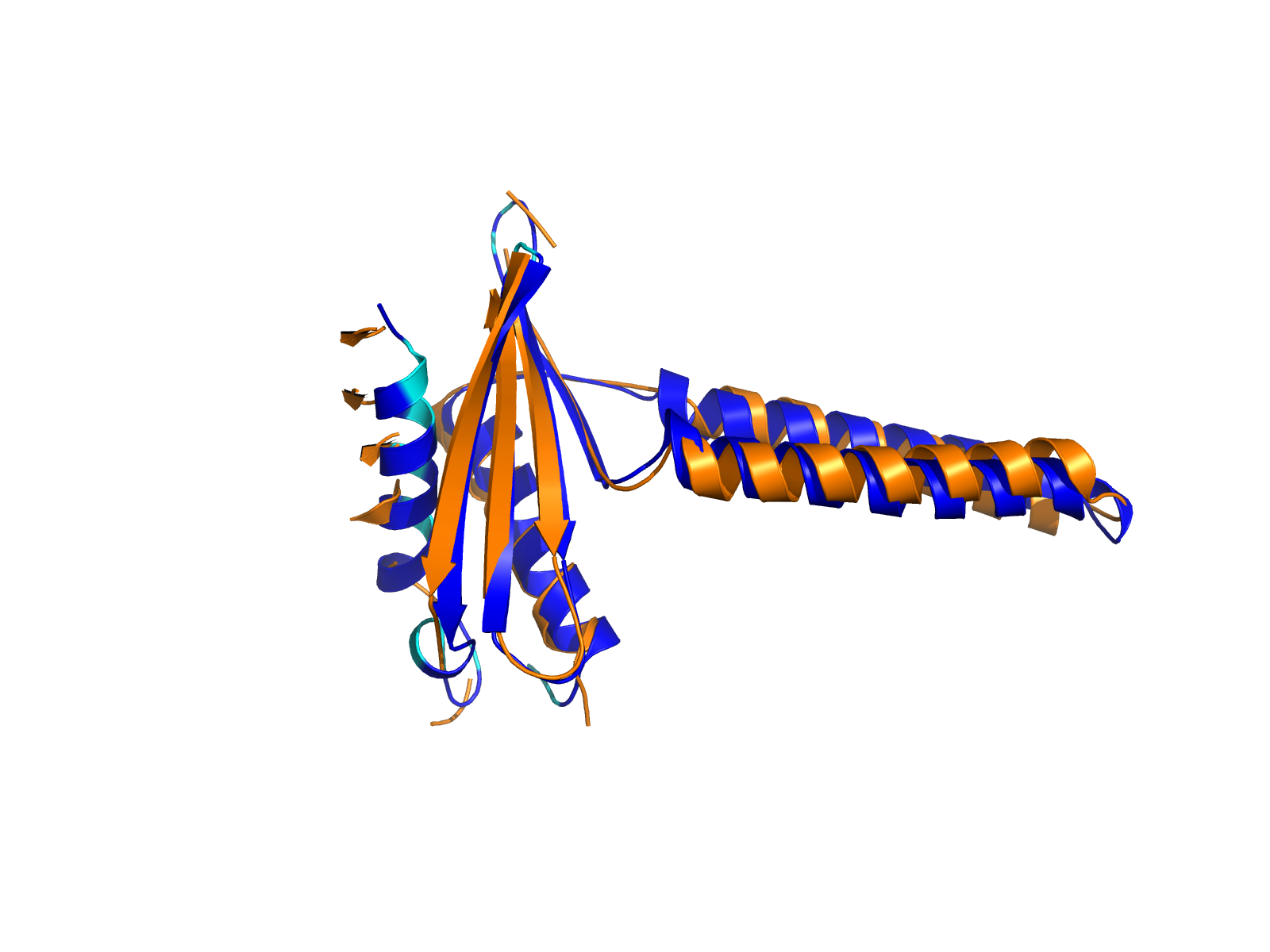 |
| APLP2_SPCS2_ENST00000543137_ENST00000263672_129997735_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:1.9335
Å |
 | 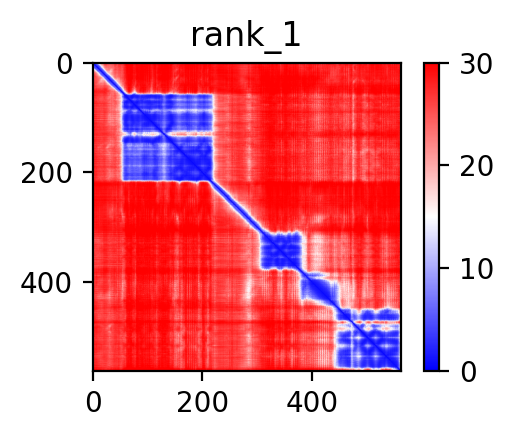 | 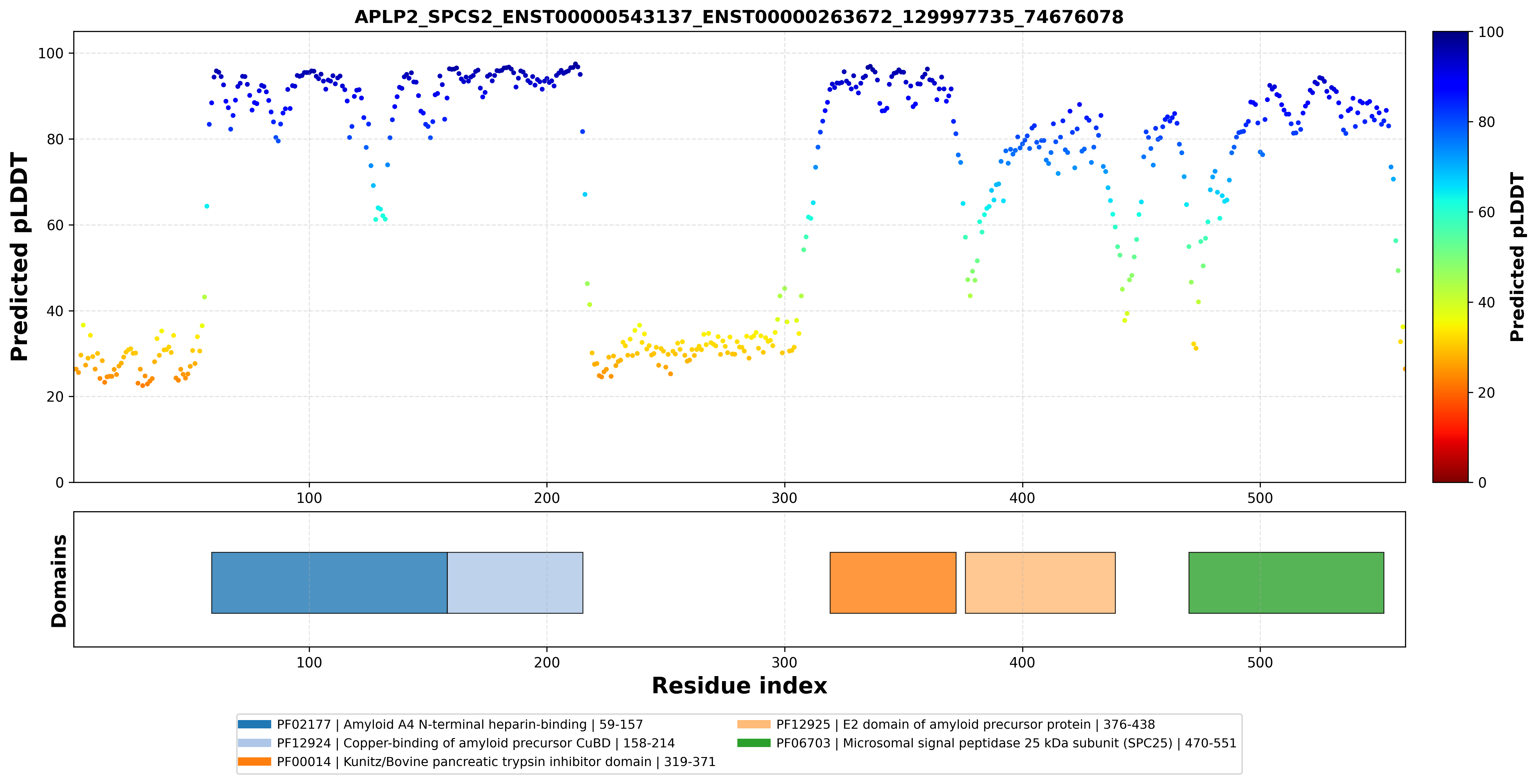 |  | 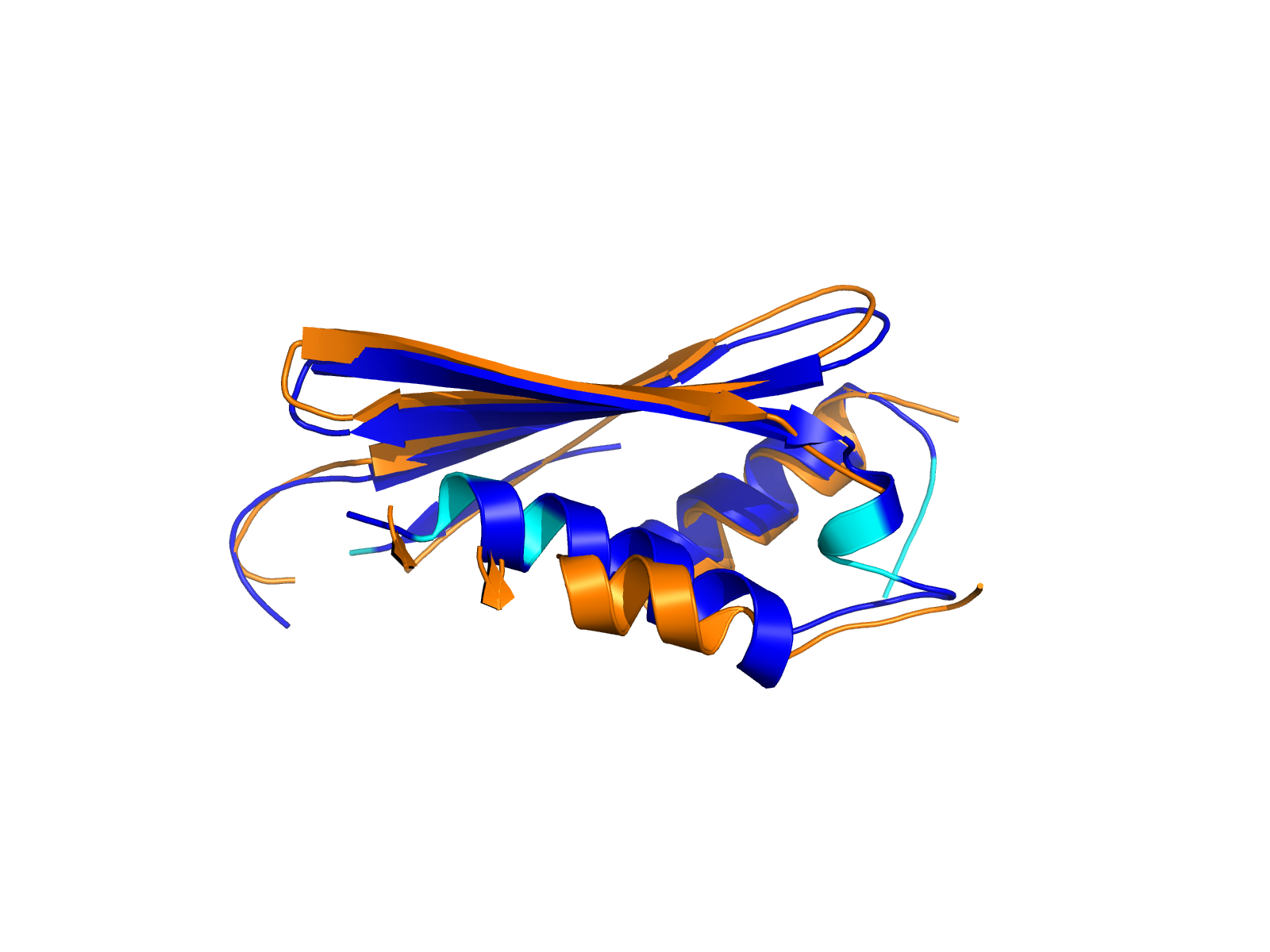 |
| APOL2_ULK2_ENST00000358502_ENST00000395544_36627385_19729499 superimposed PDB: 6QAV of partner (ULK2). RMSD:1.5439
Å |
 | 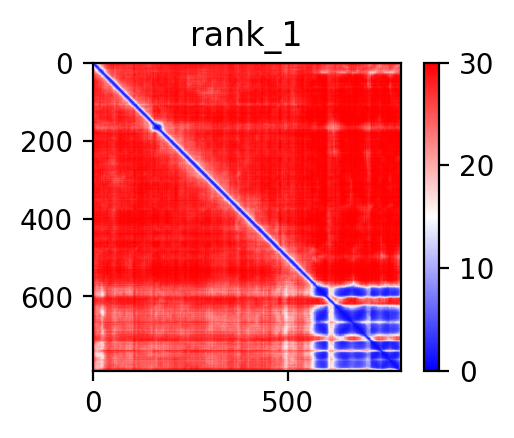 | 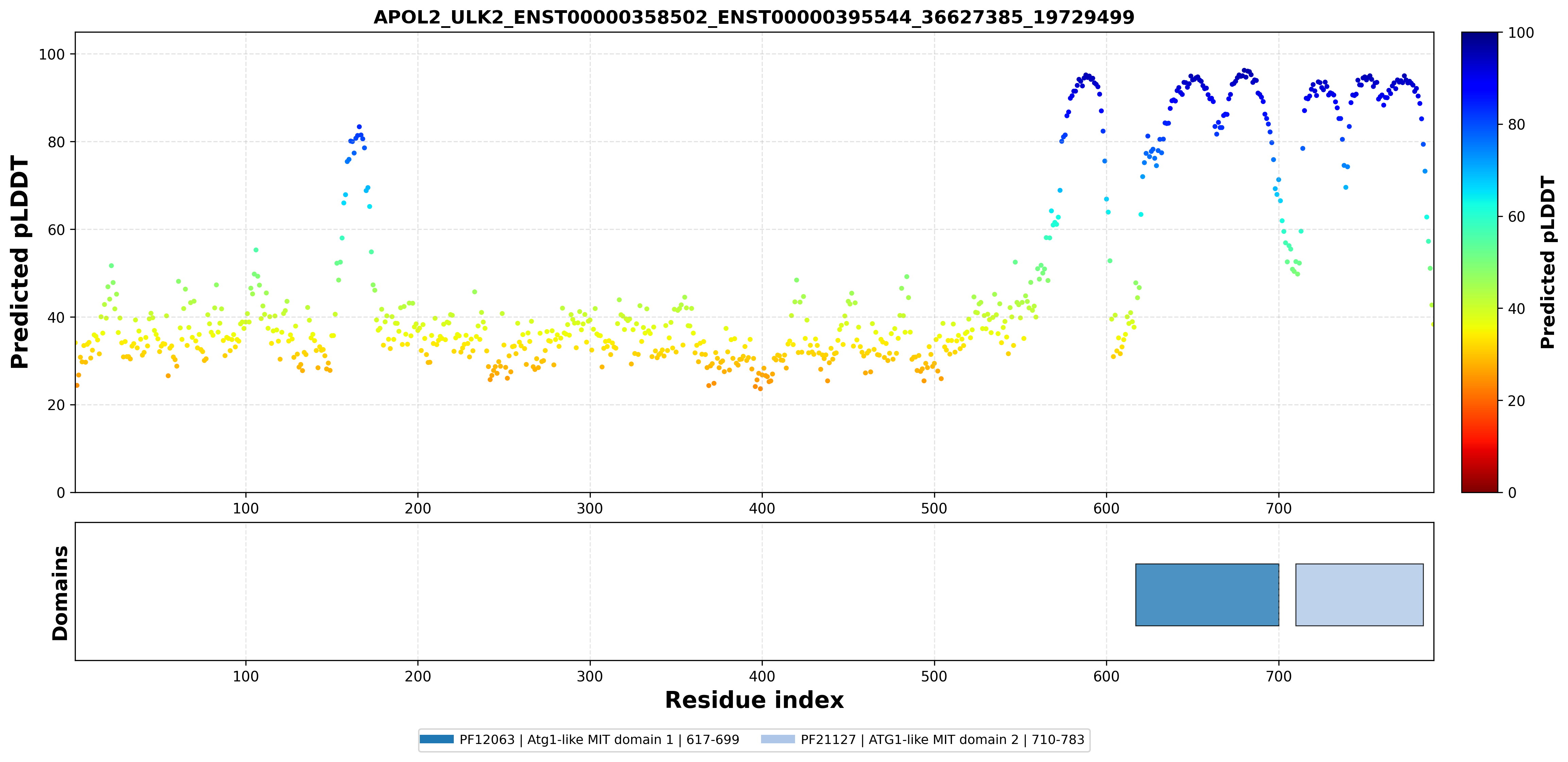 |  |  |
| APPBP2_RAB5C_ENST00000083182_ENST00000393860_58571826_40280818 superimposed PDB: 4KYI of partner (RAB5C). RMSD:0.4939
Å |
 |  | 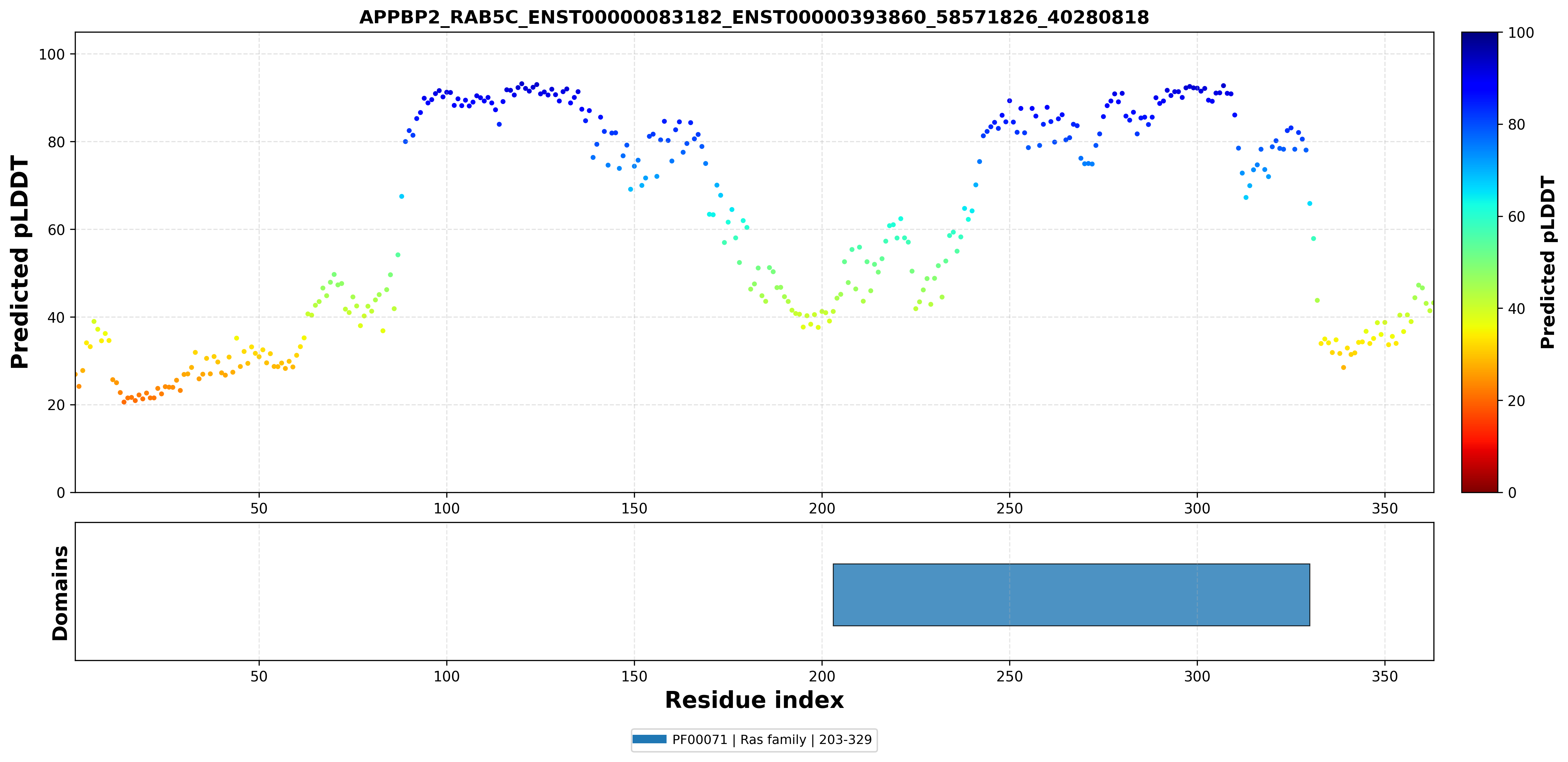 |  |  |
| APP_ABI1_ENST00000346798_ENST00000376142_27542881_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.1832
Å |
 |  |  |  |  |
| APP_ABI1_ENST00000346798_ENST00000376166_27542881_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3333
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000346798_ENST00000296800_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:2.6355
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000346798_ENST00000354209_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:2.5287
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000348990_ENST00000397128_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:0.8824
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000354192_ENST00000296800_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:1.4322
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000354192_ENST00000354209_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:2.6364
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000354192_ENST00000397128_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:0.7406
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000439274_ENST00000397128_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:0.58
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000440126_ENST00000296800_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:1.8045
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000440126_ENST00000354209_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:1.8279
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000440126_ENST00000397128_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:0.6863
Å |
 |  |  |  |  |
| APP_PRKAA1_ENST00000448388_ENST00000354209_27423315_40775605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:2.6741
Å |
 |  |  |  |  |
| APP_SLC3A2_ENST00000346798_ENST00000377890_27394155_62649364 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7031
Å |
 |  |  |  |  |
| APP_SLC3A2_ENST00000354192_ENST00000377890_27394155_62649364 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7253
Å |
 |  |  |  |  |
| APP_SLC3A2_ENST00000440126_ENST00000377890_27394155_62649364 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7339
Å |
 |  |  |  |  |
| APP_SLC3A2_ENST00000448388_ENST00000377890_27394155_62649364 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7177
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000346798_ENST00000340541_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4777
Å |
 |  | 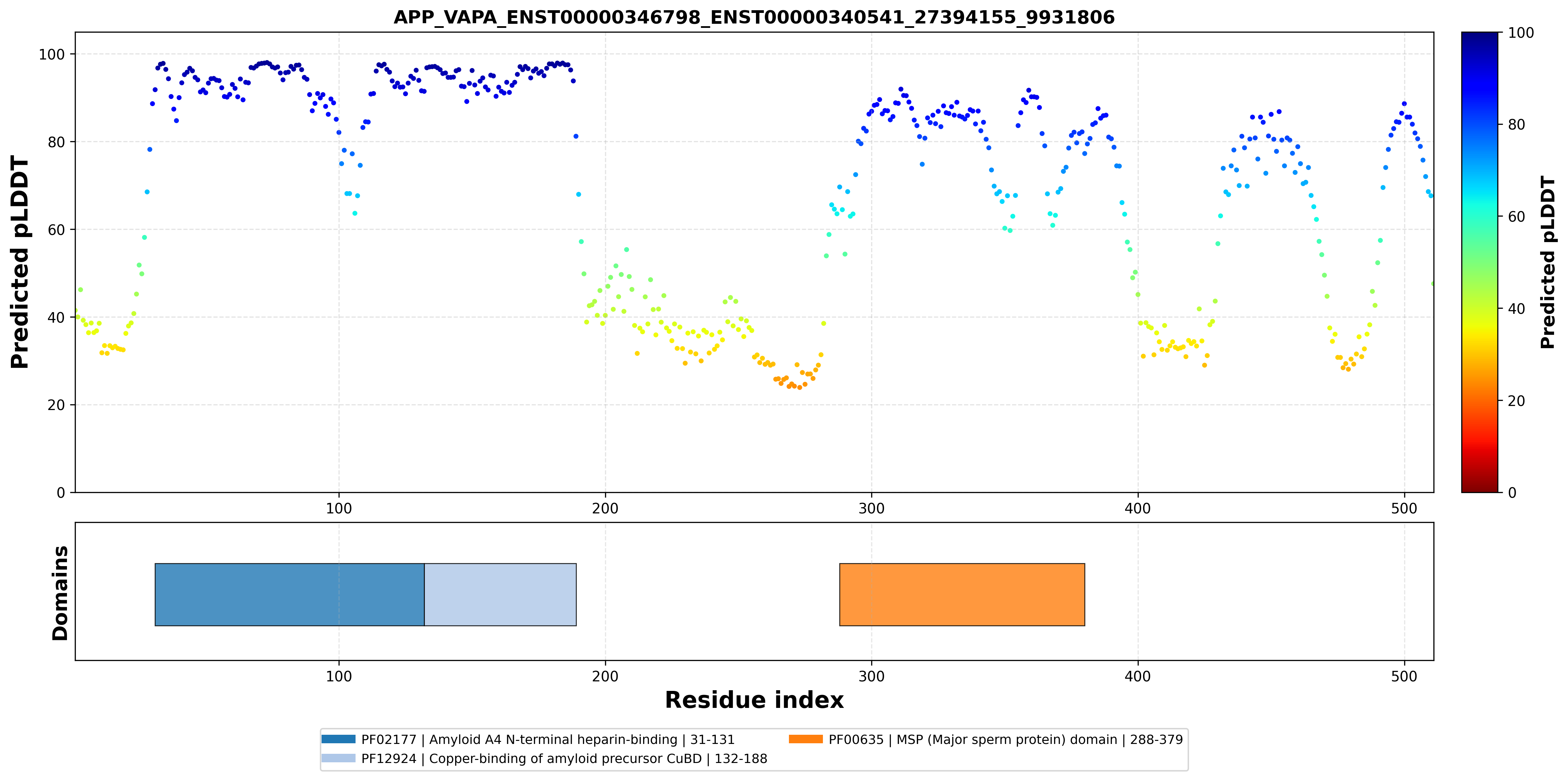 |  |  |
| APP_VAPA_ENST00000348990_ENST00000400000_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5971
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000354192_ENST00000340541_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5922
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000354192_ENST00000400000_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4798
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000439274_ENST00000400000_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5321
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000440126_ENST00000340541_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5623
Å |
 |  | 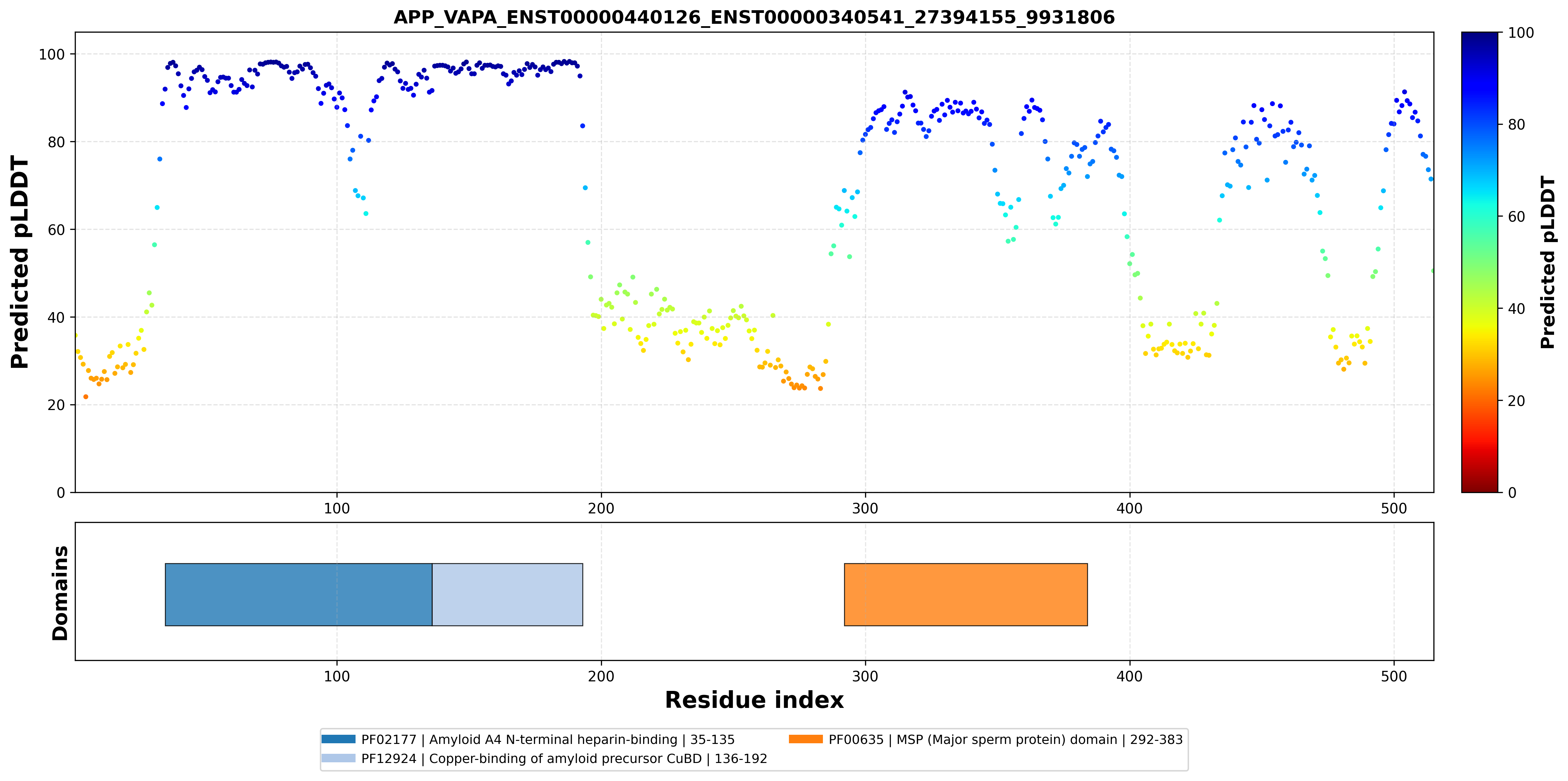 |  |  |
| APP_VAPA_ENST00000440126_ENST00000400000_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5257
Å |
 |  |  |  |  |
| APP_VAPA_ENST00000448388_ENST00000340541_27394155_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5437
Å |
 |  |  |  |  |
| APTX_NOL6_ENST00000309615_ENST00000379471_32984628_33464974 superimposed PDB: 4NDH of partner (APTX). RMSD:2.1079
Å |
 |  |  |  |  |
| APTX_NOL6_ENST00000379817_ENST00000379471_32984628_33464974 superimposed PDB: 4NDH of partner (APTX). RMSD:1.1302
Å |
 |  |  |  |  |
| APTX_NOL6_ENST00000476858_ENST00000379471_32984628_33464974 superimposed PDB: 4NDH of partner (APTX). RMSD:3.1087
Å |
 |  |  |  |  |
| ARAP1_FADD_ENST00000359373_ENST00000301838_72412693_70052238 superimposed PDB: 9U6E of partner (FADD). RMSD:3.0852
Å |
 |  |  |  |  |
| ARAP1_FADD_ENST00000393605_ENST00000301838_72412693_70052238 superimposed PDB: 4X1V of partner (ARAP1). RMSD:2.7688
Å |
 |  | 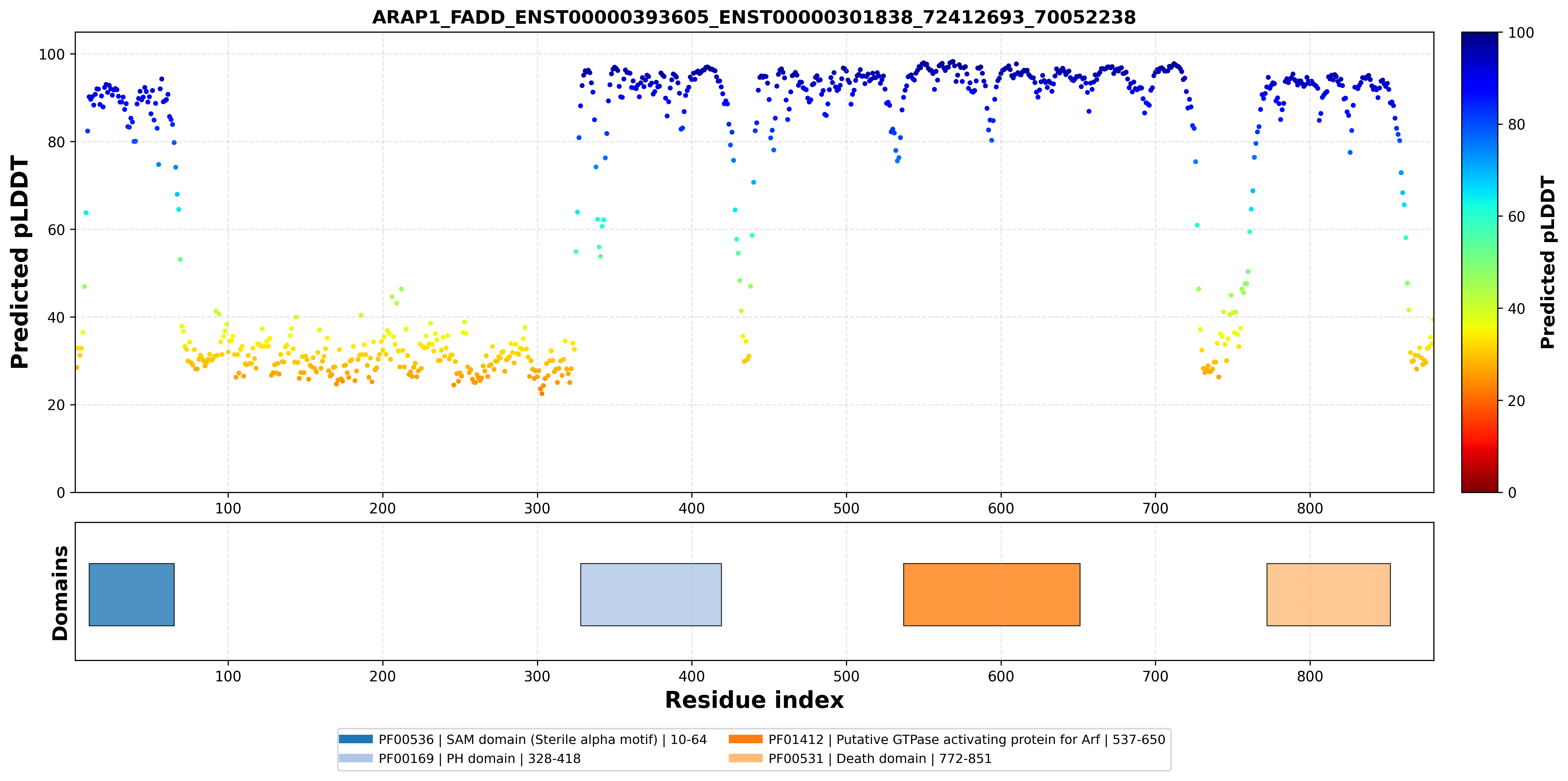 |  |  |
| ARAP1_FADD_ENST00000393605_ENST00000301838_72412693_70052238 superimposed PDB: 9U6E of partner (FADD). RMSD:3.0678
Å |
| | | |  |
| ARAP1_FADD_ENST00000455638_ENST00000301838_72412693_70052238 superimposed PDB: 9U6E of partner (FADD). RMSD:3.0716
Å |
 |  |  |  |  |
| ARAP1_IL12RB2_ENST00000359373_ENST00000541374_72404369_67816552 superimposed PDB: 4X1V of partner (ARAP1). RMSD:2.2564
Å |
 |  |  |  |  |
| ARFGAP2_FBRSL1_ENST00000426335_ENST00000261673_47187818_133144066 superimposed PDB: 2P57 of partner (ARFGAP2). RMSD:0.4191
Å |
 |  |  |  |  |
| ARFGAP2_FBRSL1_ENST00000524782_ENST00000261673_47187818_133144066 superimposed PDB: 2P57 of partner (ARFGAP2). RMSD:0.329
Å |
 |  |  |  |  |
| ARFGAP2_FBRSL1_ENST00000524782_ENST00000434748_47187818_133144066 superimposed PDB: 2P57 of partner (ARFGAP2). RMSD:0.4292
Å |
 |  |  |  |  |
| ARFGEF1_CPA6_ENST00000262215_ENST00000297770_68150969_68397024 superimposed PDB: 5EE5 of partner (ARFGEF1). RMSD:0.6062
Å |
 |  |  |  |  |
| ARFGEF1_CPA6_ENST00000262215_ENST00000518549_68150969_68397024 superimposed PDB: 5EE5 of partner (ARFGEF1). RMSD:0.5877
Å |
 |  |  |  |  |
| ARFGEF1_PPP1R42_ENST00000262215_ENST00000324682_68163533_67926827 superimposed PDB: 5EE5 of partner (ARFGEF1). RMSD:0.5692
Å |
 |  |  |  |  |
| ARFGEF1_PPP1R42_ENST00000520381_ENST00000522909_68163533_67926827 superimposed PDB: 5EE5 of partner (ARFGEF1). RMSD:0.5125
Å |
 |  |  |  |  |
| ARFGEF2_BCAS1_ENST00000371917_ENST00000371435_47626941_52645511 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.7825
Å |
 |  |  |  |  |
| ARFGEF2_BCAS1_ENST00000371917_ENST00000395961_47626941_52645511 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.7588
Å |
 |  |  |  |  |
| ARFGEF2_CNIH2_ENST00000371917_ENST00000311445_47558524_66049729 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:2.8891
Å |
 |  |  |  |  |
| ARFGEF2_CNIH2_ENST00000371917_ENST00000311445_47558524_66049729 superimposed PDB: 8SS7 of partner (CNIH2). RMSD:0.9999
Å |
| | | |  |
| ARFGEF2_STAU1_ENST00000371917_ENST00000371802_47558524_47736665 superimposed PDB: 6HTU of partner (STAU1). RMSD:1.2794
Å |
 |  |  |  |  |
| ARFGEF2_TTLL9_ENST00000371917_ENST00000375921_47634087_30510765 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.8115
Å |
 |  |  |  |  |
| ARFGEF2_TTLL9_ENST00000371917_ENST00000375922_47634087_30510765 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.8092
Å |
 |  |  |  |  |
| ARFGEF2_TTLL9_ENST00000371917_ENST00000375938_47634087_30510765 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.792
Å |
 |  |  |  |  |
| ARFGEF2_TTLL9_ENST00000371917_ENST00000535842_47634087_30510765 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.8049
Å |
 |  |  |  |  |
| ARHGAP12_ZEB1_ENST00000344936_ENST00000320985_32097576_31749965 superimposed PDB: 2E19 of partner (ZEB1). RMSD:0.6688
Å |
 |  | 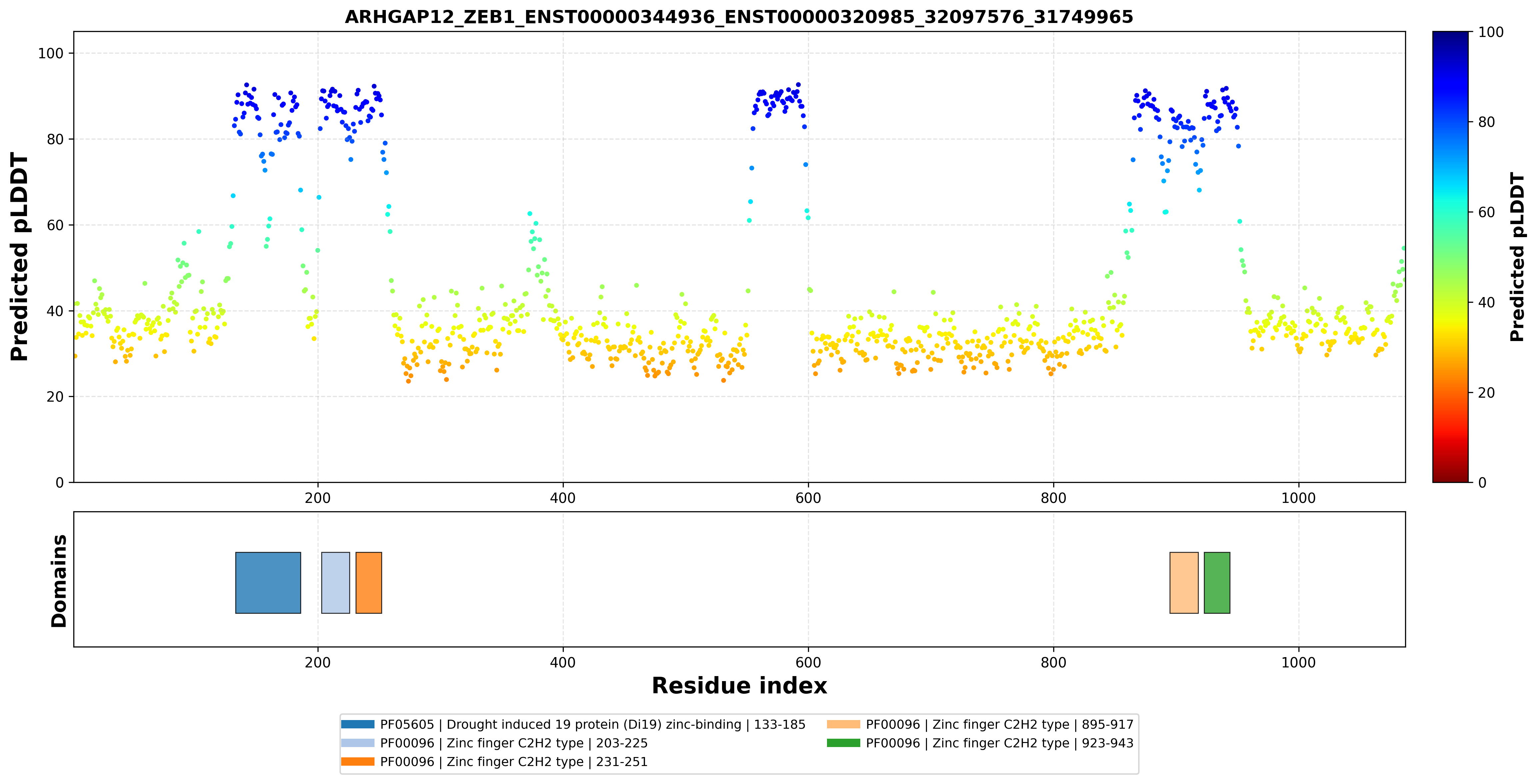 |  |  |
| ARHGAP12_ZEB1_ENST00000375250_ENST00000361642_32097576_31749965 superimposed PDB: 2E19 of partner (ZEB1). RMSD:0.6609
Å |
 |  |  |  |  |
| ARHGAP23_ASIC2_ENST00000431231_ENST00000359872_36636124_31351032 superimposed PDB: 6L6P of partner (ASIC2). RMSD:1.7155
Å |
 |  | 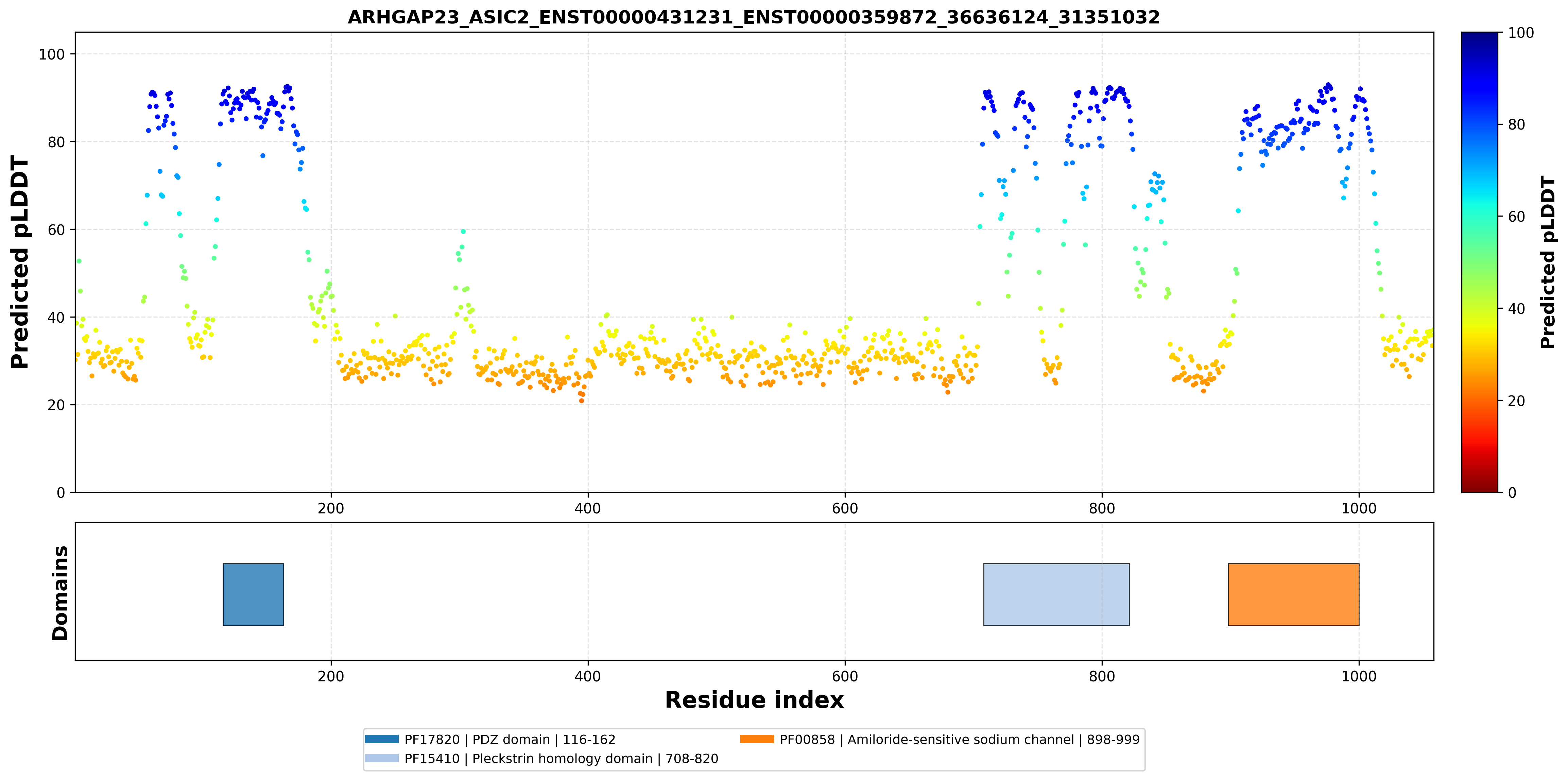 |  |  |
| ARHGAP23_ASIC2_ENST00000437668_ENST00000359872_36636124_31351032 superimposed PDB: 6L6P of partner (ASIC2). RMSD:2.3075
Å |
 |  | 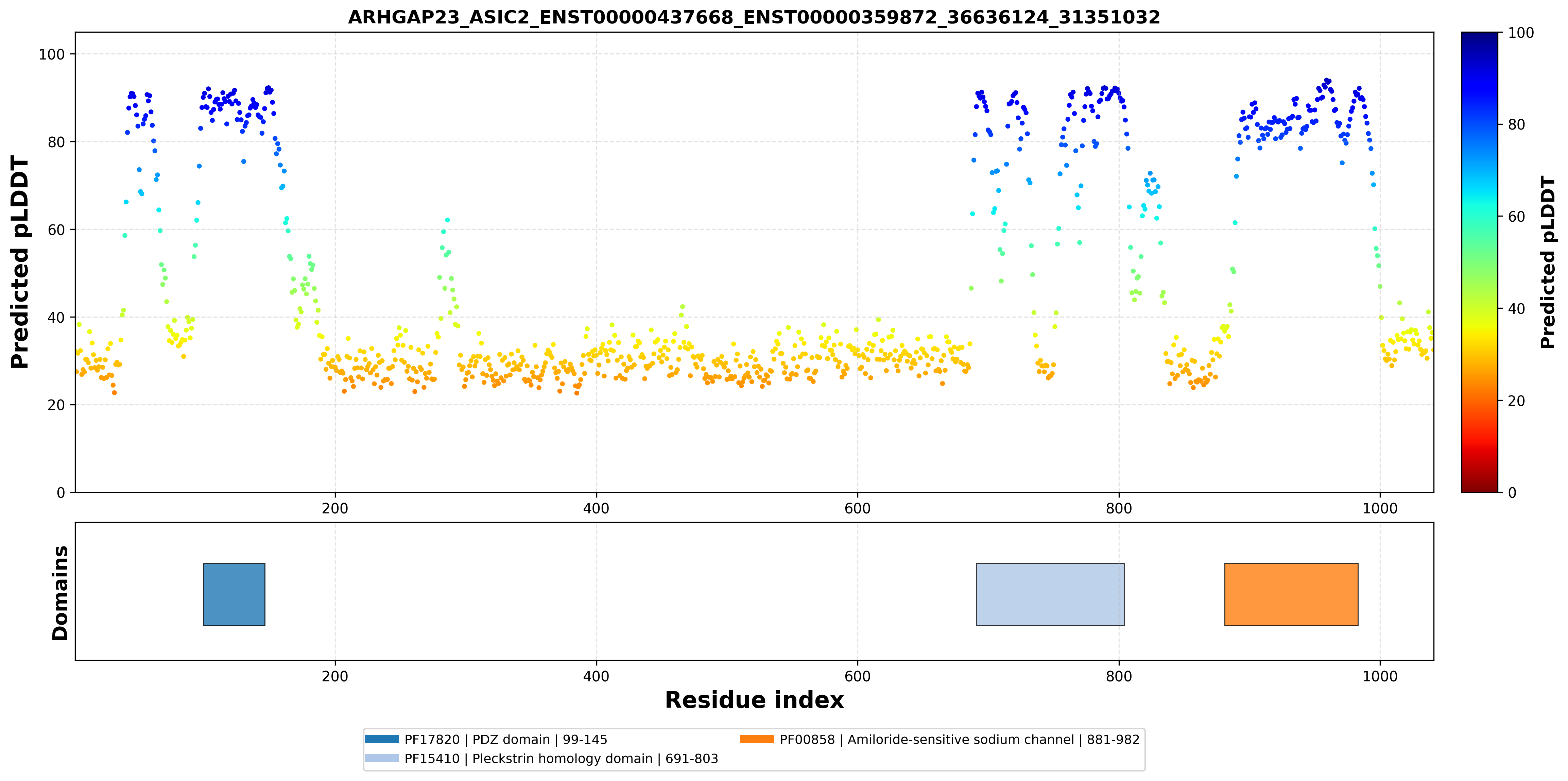 |  |  |
| ARHGAP23_ASIC2_ENST00000443378_ENST00000359872_36636124_31351032 superimposed PDB: 6L6P of partner (ASIC2). RMSD:1.9581
Å |
 |  | 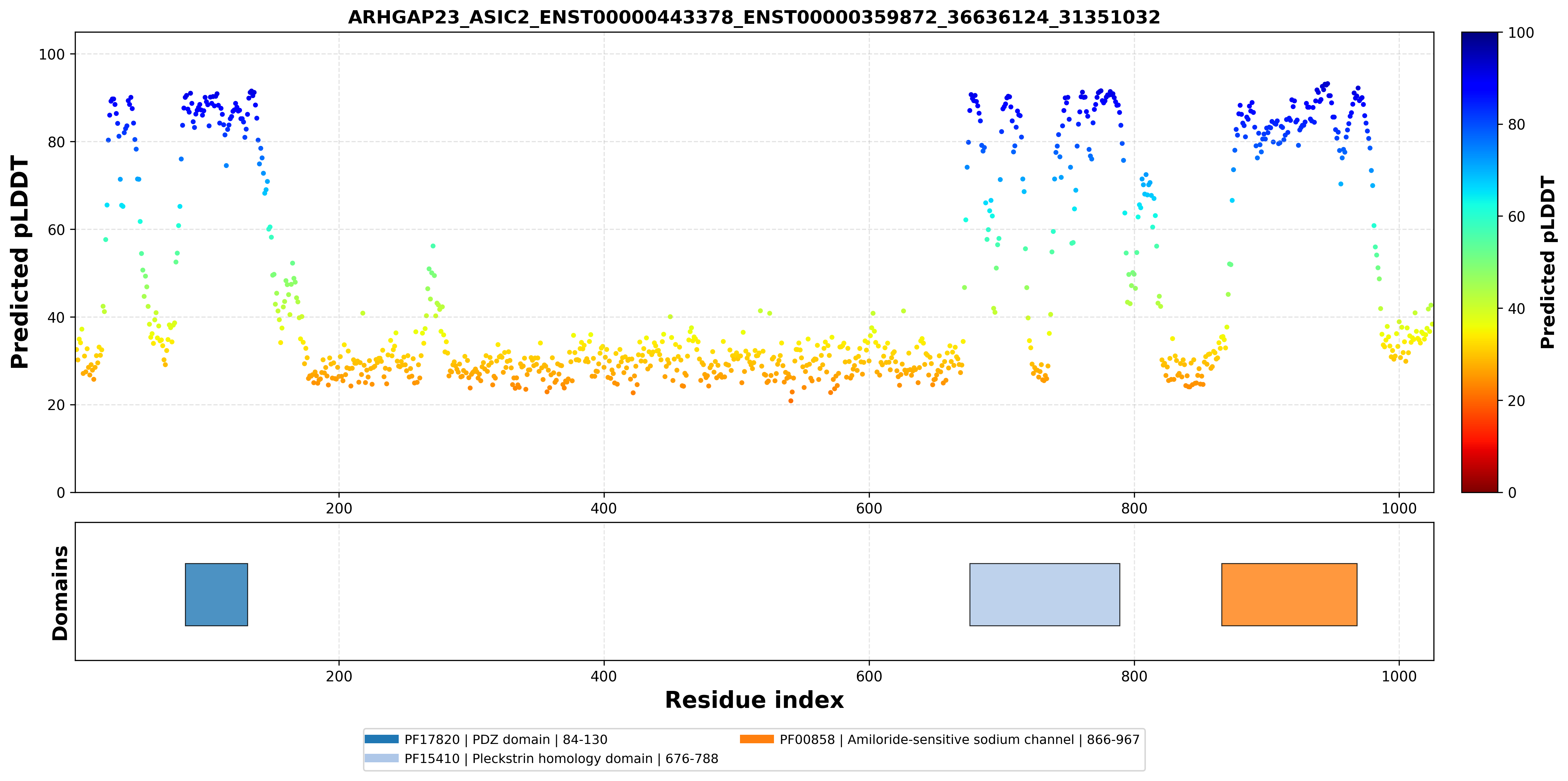 |  |  |
| ARHGAP23_PRTFDC1_ENST00000431231_ENST00000376378_36584792_25160992 superimposed PDB: 2JBH of partner (PRTFDC1). RMSD:0.9375
Å |
 |  | 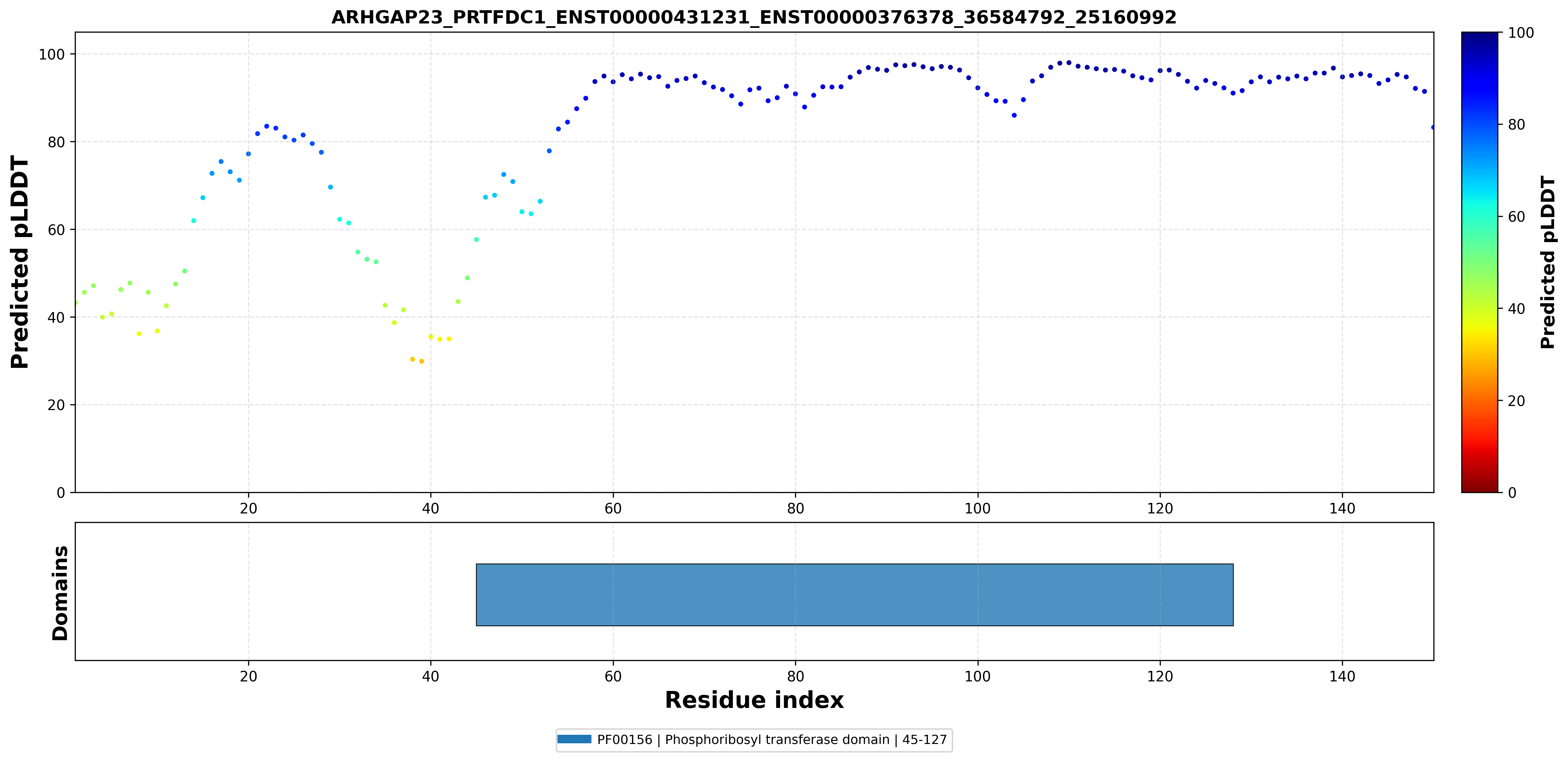 |  |  |
| ARHGAP23_PRTFDC1_ENST00000437668_ENST00000320152_36584792_25160992 superimposed PDB: 2JBH of partner (PRTFDC1). RMSD:0.6239
Å |
 |  | 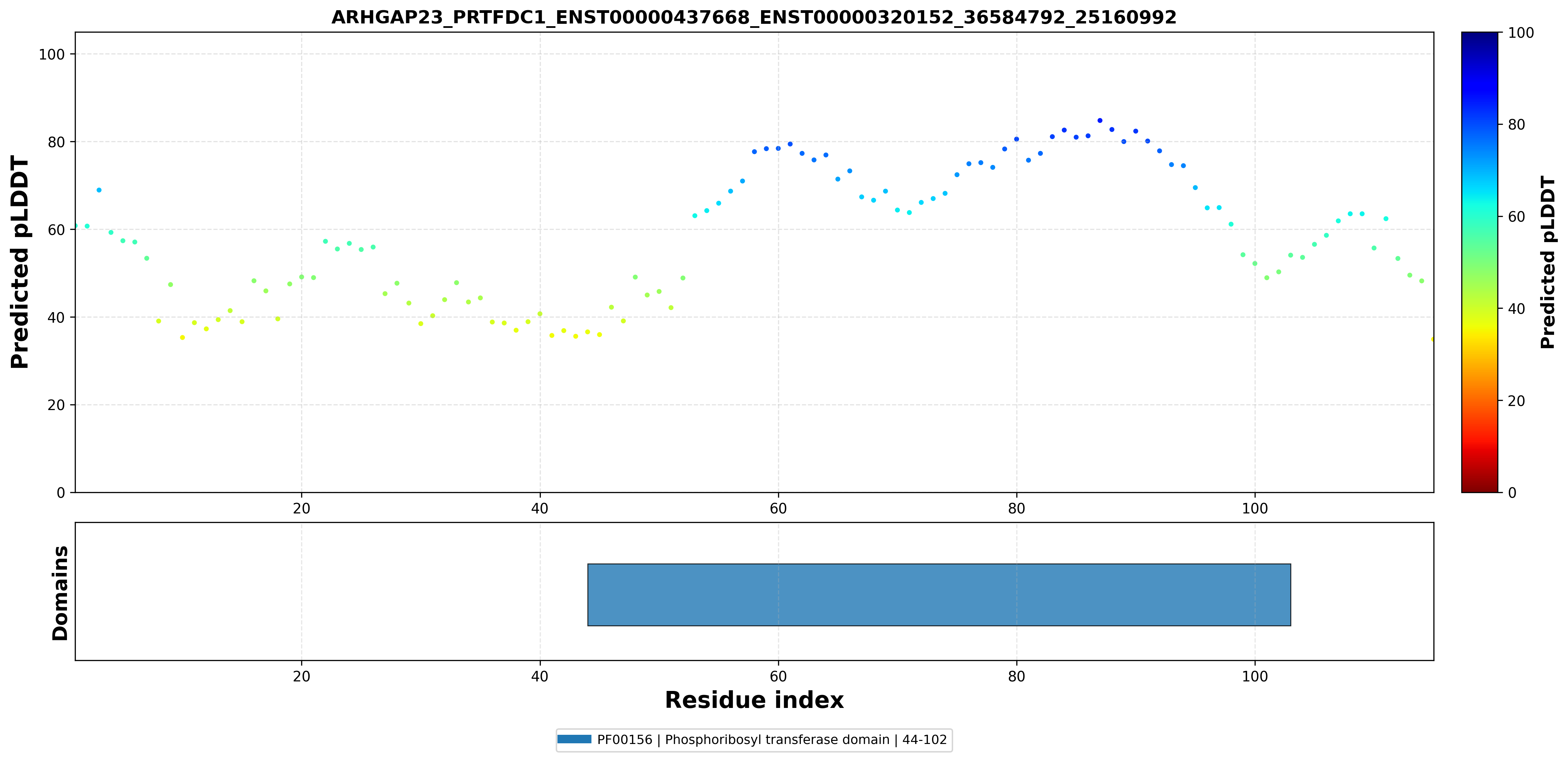 |  |  |
| ARHGAP23_PRTFDC1_ENST00000437668_ENST00000376378_36584792_25160992 superimposed PDB: 2JBH of partner (PRTFDC1). RMSD:0.9424
Å |
 |  | 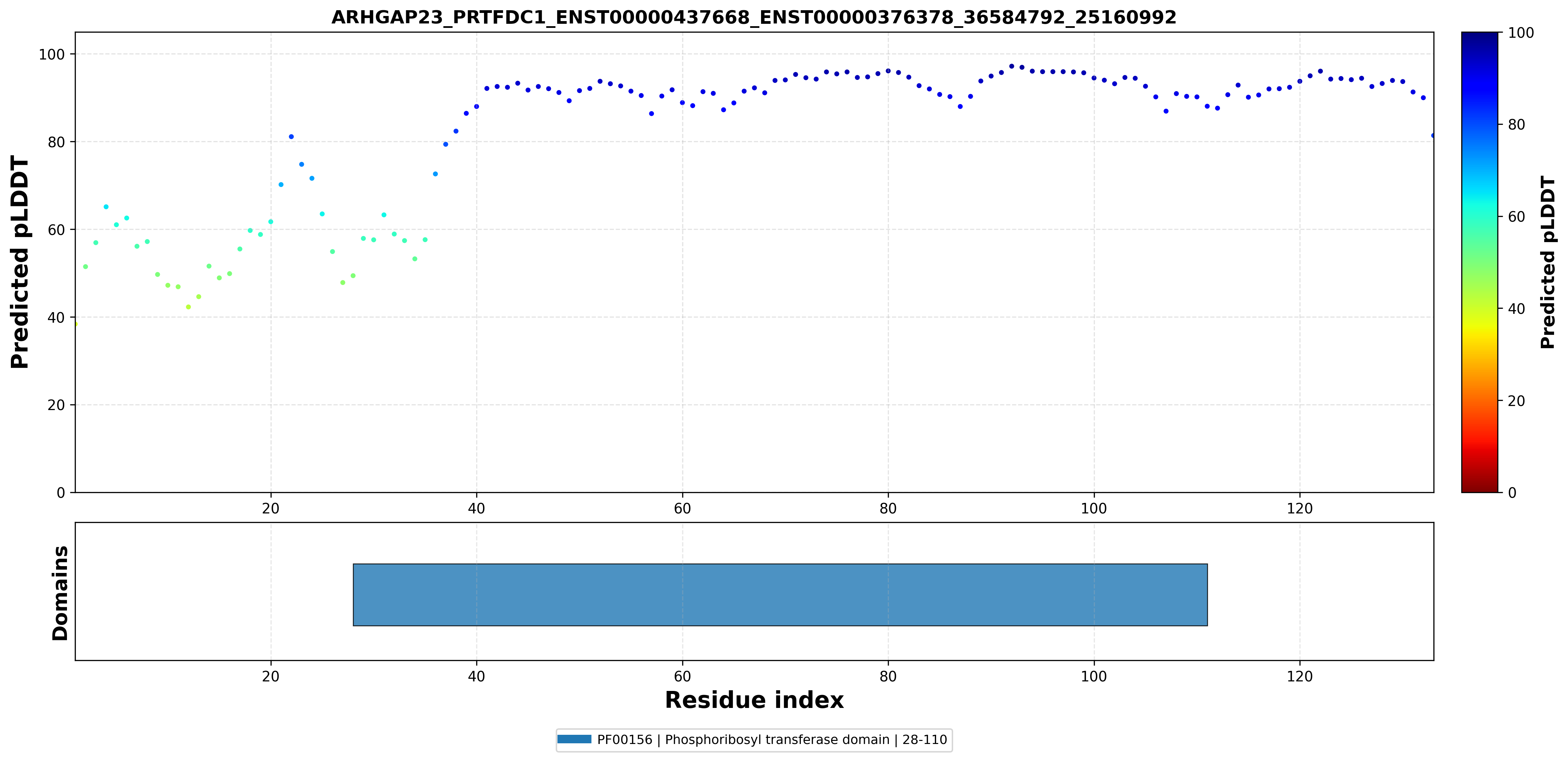 |  |  |
| ARHGAP32_CAPRIN1_ENST00000310343_ENST00000389645_128993340_34093272 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3084
Å |
 |  |  |  |  |
| ARHGAP32_CAPRIN1_ENST00000310343_ENST00000532820_128993340_34093272 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.2888
Å |
 |  |  |  |  |
| ARHGAP32_CAPRIN1_ENST00000524655_ENST00000389645_128993340_34093272 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3087
Å |
 |  |  |  |  |
| ARHGAP32_CAPRIN1_ENST00000524655_ENST00000532820_128993340_34093272 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.2964
Å |
 |  |  |  |  |
| ARHGAP35_VRK3_ENST00000404338_ENST00000377011_47440665_50504111 superimposed PDB: 3C5H of partner (ARHGAP35). RMSD:0.3548
Å |
 |  |  |  |  |
| ARHGAP35_VRK3_ENST00000404338_ENST00000377011_47440665_50504111 superimposed PDB: 2JII of partner (VRK3). RMSD:0.597
Å |
| | | |  |
| ARHGAP35_VRK3_ENST00000404338_ENST00000594092_47440665_50504111 superimposed PDB: 3C5H of partner (ARHGAP35). RMSD:0.3577
Å |
 |  |  |  |  |
| ARHGAP35_VRK3_ENST00000404338_ENST00000594092_47440665_50504111 superimposed PDB: 2JII of partner (VRK3). RMSD:0.5261
Å |
| | | |  |
| ARHGAP5_NUBPL_ENST00000556611_ENST00000536705_32586493_32142560 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:2.9527
Å |
 |  |  |  |  |
| ARHGEF12_CNTN5_ENST00000397843_ENST00000524871_120280159_99786785 superimposed PDB: 5E52 of partner (CNTN5). RMSD:0.9669
Å |
 |  |  |  |  |
| ARHGEF12_CNTN5_ENST00000397843_ENST00000528682_120280159_99786785 superimposed PDB: 5E52 of partner (CNTN5). RMSD:0.5756
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000358660_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:2.6895
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000358660_58008800_156841414 superimposed PDB: 7N3T of partner (NTRK1). RMSD:1.0332
Å |
| | | |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000368196_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:0.7066
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000368196_58008800_156841414 superimposed PDB: 7N3T of partner (NTRK1). RMSD:0.9792
Å |
| | | |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000392302_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:0.7464
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000286494_ENST00000392302_58008800_156841414 superimposed PDB: 7N3T of partner (NTRK1). RMSD:0.8358
Å |
| | | |  |
| ARHGEF25_NTRK1_ENST00000333972_ENST00000358660_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:2.9587
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000333972_ENST00000358660_58008800_156841414 superimposed PDB: 7N3T of partner (NTRK1). RMSD:0.9061
Å |
| | | |  |
| ARHGEF25_NTRK1_ENST00000333972_ENST00000368196_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:0.6866
Å |
 |  |  |  |  |
| ARHGEF25_NTRK1_ENST00000333972_ENST00000368196_58008800_156841414 superimposed PDB: 7N3T of partner (NTRK1). RMSD:0.9673
Å |
| | | |  |
| ARHGEF25_NTRK1_ENST00000333972_ENST00000392302_58008800_156841414 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:1.1066
Å |
 |  |  |  |  |
| ARHGEF3_ACP6_ENST00000496106_ENST00000369238_56916319_147131890 superimposed PDB: 4JOB of partner (ACP6). RMSD:0.575
Å |
 |  |  |  |  |
| ARHGEF3_RHAG_ENST00000496106_ENST00000229810_56916319_49587075 superimposed PDB: 7UZQ of partner (RHAG). RMSD:0.4307
Å |
 |  |  |  |  |
| ARHGEF7_CRYL1_ENST00000317133_ENST00000382812_111806338_20987526 superimposed PDB: 3F3S of partner (CRYL1). RMSD:2.8059
Å |
 |  |  |  |  |
| ARHGEF7_CRYL1_ENST00000370623_ENST00000382812_111806338_20987526 superimposed PDB: 3F3S of partner (CRYL1). RMSD:2.2373
Å |
 |  |  |  |  |
| ARID1A_DDX3X_ENST00000457599_ENST00000399959_27024031_41196660 superimposed PDB: 9E2C of partner (DDX3X). RMSD:2.751
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000324856_ENST00000236342_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.717
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000324856_ENST00000360009_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.6586
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000324856_ENST00000374185_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.7666
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000324856_ENST00000525682_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.6625
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000324856_ENST00000526219_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.5504
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000374152_ENST00000236342_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.8271
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000374152_ENST00000360009_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.6936
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000374152_ENST00000374185_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.7507
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000374152_ENST00000525682_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.6564
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000374152_ENST00000526219_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.5408
Å |
 |  |  |  |  |
| ARID1A_DHDDS_ENST00000457599_ENST00000427245_27059283_26764658 superimposed PDB: 7PAX of partner (DHDDS). RMSD:0.6601
Å |
 |  |  |  |  |
| ARID1A_MAST2_ENST00000324856_ENST00000361297_27024031_46290104 superimposed PDB: 2KQF of partner (MAST2). RMSD:1.0527
Å |
 |  |  |  |  |
| ARID1A_MAST2_ENST00000457599_ENST00000361297_27024031_46290104 superimposed PDB: 2KQF of partner (MAST2). RMSD:1.0595
Å |
 |  |  |  |  |
| ARID1A_MAST2_ENST00000457599_ENST00000372009_27024031_46290104 superimposed PDB: 2KQF of partner (MAST2). RMSD:1.0072
Å |
 |  |  |  |  |
| ARID1A_NUDC_ENST00000457599_ENST00000321265_27059283_27267947 superimposed PDB: 3QOR of partner (NUDC). RMSD:0.473
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000324856_ENST00000374166_27059283_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.2531
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000324856_ENST00000374166_27102198_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.529
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000374152_ENST00000374166_27059283_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.2562
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000374152_ENST00000374166_27102198_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.2136
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000457599_ENST00000374166_27102198_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.3214
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000457599_ENST00000374168_27024031_26881641 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:0.5867
Å |
 |  |  |  |  |
| ARID1A_RPS6KA1_ENST00000540690_ENST00000374166_27102198_26897939 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:0.7364
Å |
 |  |  |  |  |
| ARID1A_SEC11A_ENST00000324856_ENST00000268220_27094490_85234875 superimposed PDB: 7P2P of partner (SEC11A). RMSD:1.6804
Å |
 |  |  |  |  |
| ARID1A_SEC11A_ENST00000324856_ENST00000560266_27094490_85234875 superimposed PDB: 7P2P of partner (SEC11A). RMSD:1.5527
Å |
 |  |  |  |  |
| ARID1A_SEC11A_ENST00000374152_ENST00000268220_27094490_85234875 superimposed PDB: 7P2P of partner (SEC11A). RMSD:1.6123
Å |
 |  |  |  |  |
| ARID1A_SEC11A_ENST00000374152_ENST00000560266_27094490_85234875 superimposed PDB: 7P2P of partner (SEC11A). RMSD:1.613
Å |
 |  |  |  |  |
| ARID1A_SEC11A_ENST00000457599_ENST00000558134_27094490_85234875 superimposed PDB: 7P2P of partner (SEC11A). RMSD:1.6889
Å |
 |  |  |  |  |
| ARID1A_YTHDF2_ENST00000324856_ENST00000373812_27059283_29064169 superimposed PDB: 4WQN of partner (YTHDF2). RMSD:0.2805
Å |
 |  |  |  |  |
| ARID1A_YTHDF2_ENST00000374152_ENST00000373812_27059283_29064169 superimposed PDB: 4WQN of partner (YTHDF2). RMSD:0.2739
Å |
 |  |  |  |  |
| ARID1B_RCN2_ENST00000275248_ENST00000320963_157150555_77224701 superimposed PDB: 2CXY of partner (ARID1B). RMSD:3.0045
Å |
 |  |  |  |  |
| ARID1B_RCN2_ENST00000346085_ENST00000394885_157150555_77224701 superimposed PDB: 2CXY of partner (ARID1B). RMSD:2.8965
Å |
 |  |  |  |  |
| ARID1B_RCN2_ENST00000350026_ENST00000320963_157150555_77224701 superimposed PDB: 2CXY of partner (ARID1B). RMSD:2.9183
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000334344_ENST00000358214_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:2.9782
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000334344_ENST00000452533_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.9143
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000334344_ENST00000549701_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:2.8498
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000334344_ENST00000553257_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:2.908
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000422737_ENST00000358214_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.4815
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000422737_ENST00000452533_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:2.8521
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000422737_ENST00000549701_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.5013
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000422737_ENST00000553257_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.4957
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000444670_ENST00000358214_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:0.9748
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000444670_ENST00000452533_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.5867
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000444670_ENST00000549701_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:0.9619
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000444670_ENST00000553257_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:0.9619
Å |
 |  |  |  |  |
| ARID2_DNM1L_ENST00000457135_ENST00000452533_46246679_32854348 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.0108
Å |
 |  |  |  |  |
| ARID2_PTPRB_ENST00000334344_ENST00000334414_46125097_70933802 superimposed PDB: 2I4G of partner (PTPRB). RMSD:0.3812
Å |
 |  | 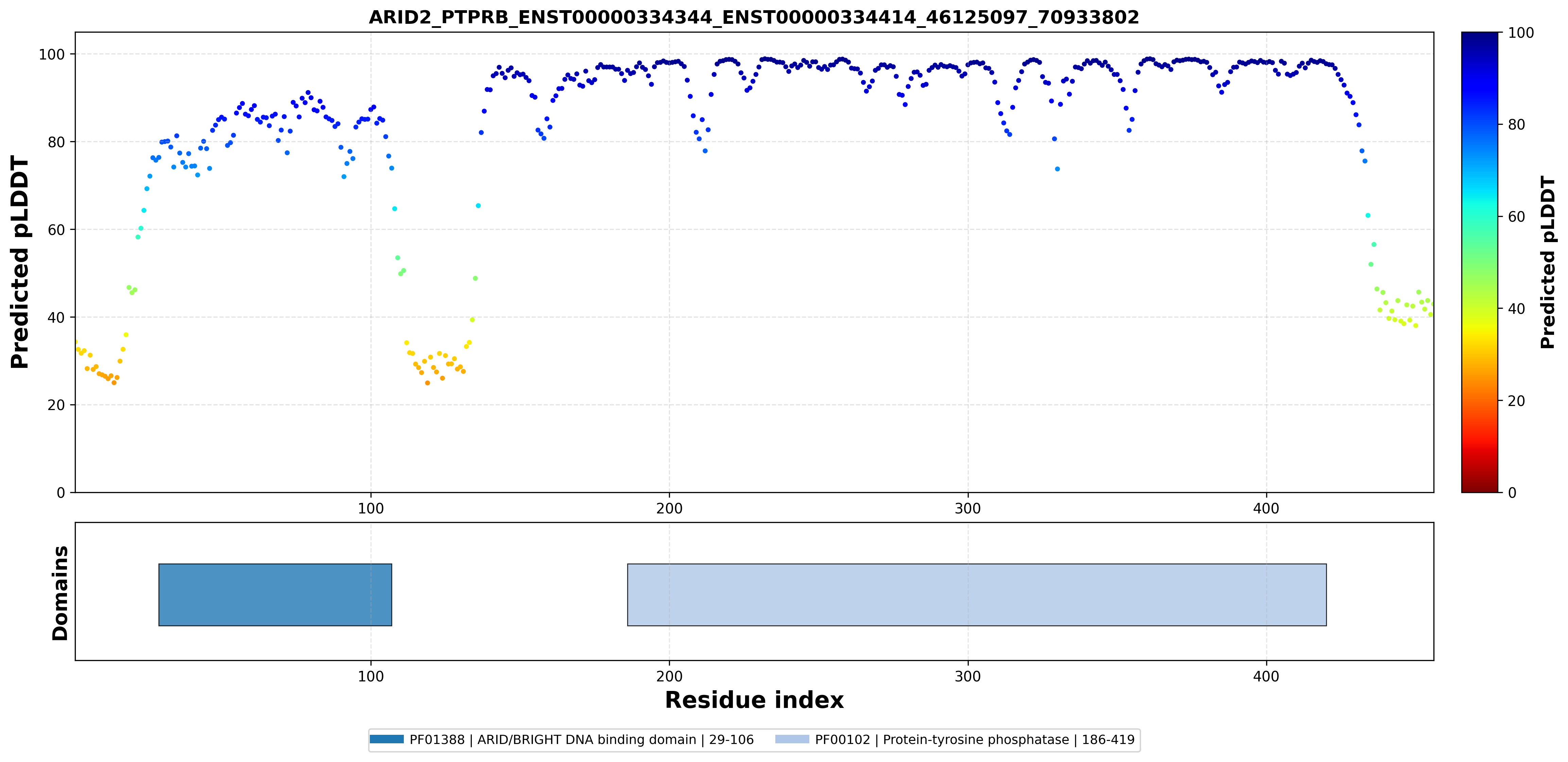 |  |  |
| ARID2_TMEM117_ENST00000334344_ENST00000536799_46125097_44693362 superimposed PDB: 7Y8R of partner (ARID2). RMSD:1.7831
Å |
 |  | 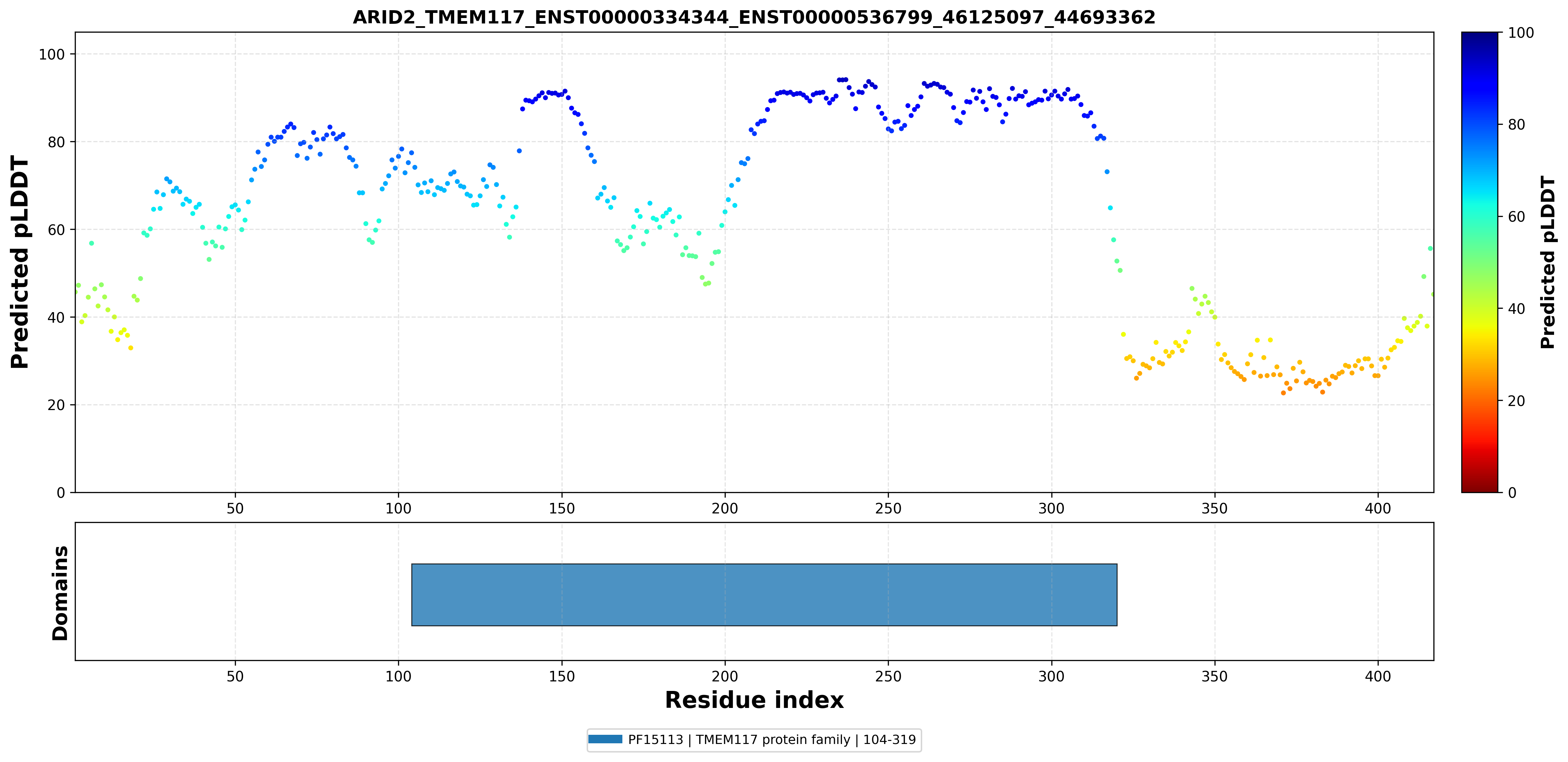 |  |  |
| ARID3B_RPS6KB1_ENST00000346246_ENST00000225577_74836829_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7344
Å |
 |  | 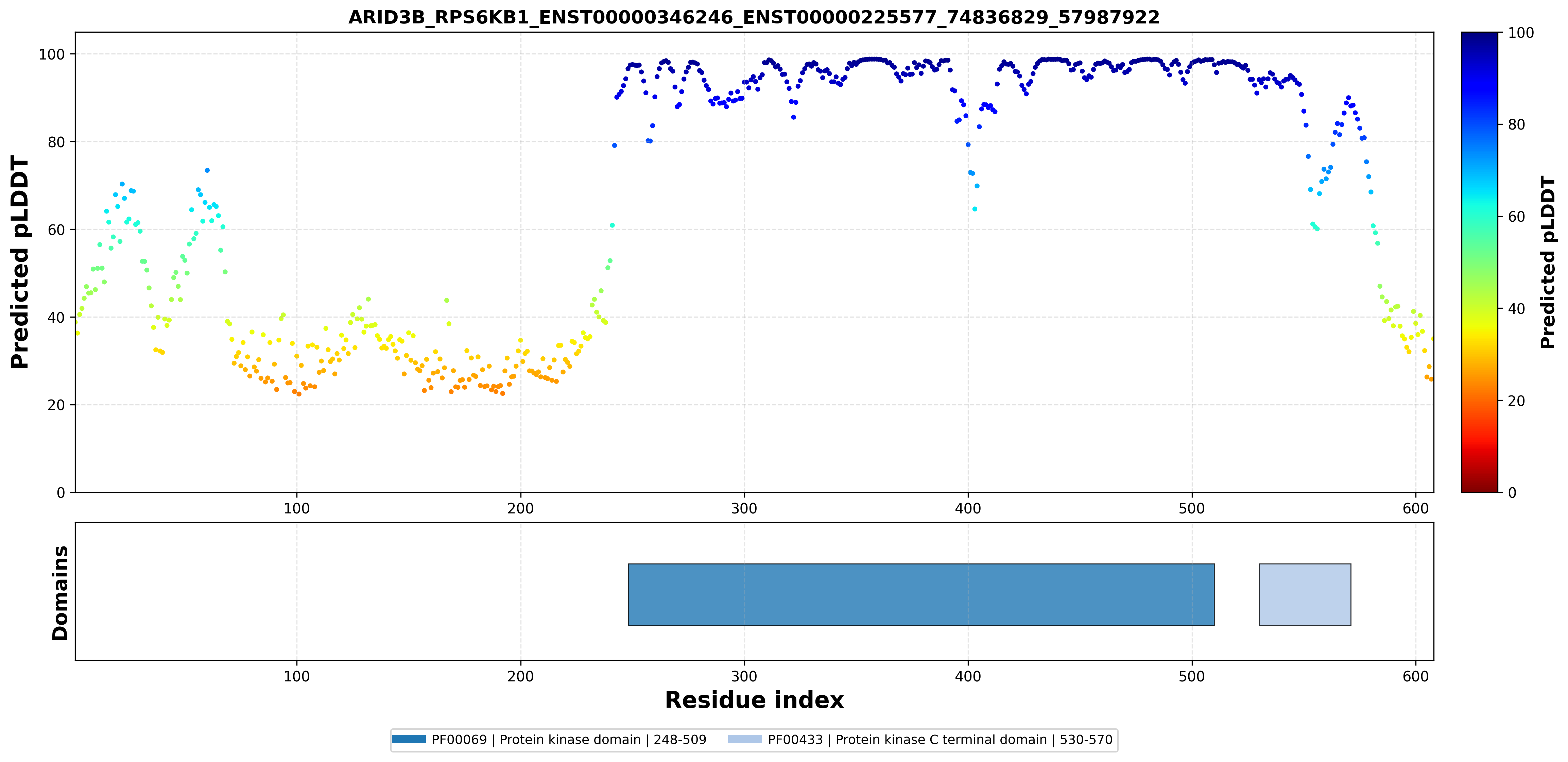 |  |  |
| ARID3B_RPS6KB1_ENST00000346246_ENST00000406116_74836829_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6445
Å |
 |  |  |  |  |
| ARIH2_CAMP_ENST00000356401_ENST00000576243_48965246_48265843 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:3.0495
Å |
 |  |  |  |  |
| ARIH2_CAMP_ENST00000356401_ENST00000576243_48965246_48265843 superimposed PDB: 4EYC of partner (CAMP). RMSD:1.1667
Å |
| | | |  |
| ARL13B_DLG1_ENST00000394222_ENST00000314062_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6184
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000394222_ENST00000346964_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6421
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000394222_ENST00000357674_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.647
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000394222_ENST00000392382_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6568
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000394222_ENST00000450955_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6085
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000471138_ENST00000357674_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6559
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000535334_ENST00000314062_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6475
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000535334_ENST00000346964_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6045
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000535334_ENST00000392382_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6447
Å |
 |  |  |  |  |
| ARL13B_DLG1_ENST00000535334_ENST00000450955_93722752_196812627 superimposed PDB: 3W9Y of partner (DLG1). RMSD:0.6267
Å |
 |  |  |  |  |
| ARL13B_EPS8_ENST00000394222_ENST00000281172_93714788_15823857 superimposed PDB: 2E8M of partner (EPS8). RMSD:0.7321
Å |
 |  |  |  |  |
| ARL15_GABRB2_ENST00000504924_ENST00000274547_53409031_160886850 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.707
Å |
 |  |  |  |  |
| ARL15_GABRB2_ENST00000504924_ENST00000517901_53409031_160886850 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.7182
Å |
 |  |  |  |  |
| ARL15_GABRB2_ENST00000507646_ENST00000274547_53409031_160886850 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.695
Å |
 |  |  |  |  |
| ARL15_GABRB2_ENST00000507646_ENST00000517901_53409031_160886850 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.7106
Å |
 |  |  |  |  |
| ARL15_HMGN3_ENST00000504924_ENST00000275036_53606261_79924739 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.8283
Å |
 |  |  |  |  |
| ARL15_MOCS2_ENST00000504924_ENST00000361377_53606261_52404473 superimposed PDB: 8F6D of partner (ARL15). RMSD:0.8828
Å |
 |  |  |  |  |
| ARL15_MOCS2_ENST00000504924_ENST00000361377_53606261_52404473 superimposed PDB: 5MPO of partner (MOCS2). RMSD:2.2885
Å |
| | | |  |
| ARL17A_IKZF3_ENST00000337845_ENST00000350532_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0887
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000337845_ENST00000351680_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0832
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000337845_ENST00000467757_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1852
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000346243_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1388
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000350532_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1623
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000351680_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1096
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000377944_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0594
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000394189_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0215
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000467757_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1913
Å |
 |  |  |  |  |
| ARL17A_IKZF3_ENST00000445552_ENST00000535189_44648124_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1947
Å |
 |  |  |  |  |
| ARL8B_CLASP2_ENST00000256496_ENST00000399362_5164273_33738425 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5782
Å |
 |  | 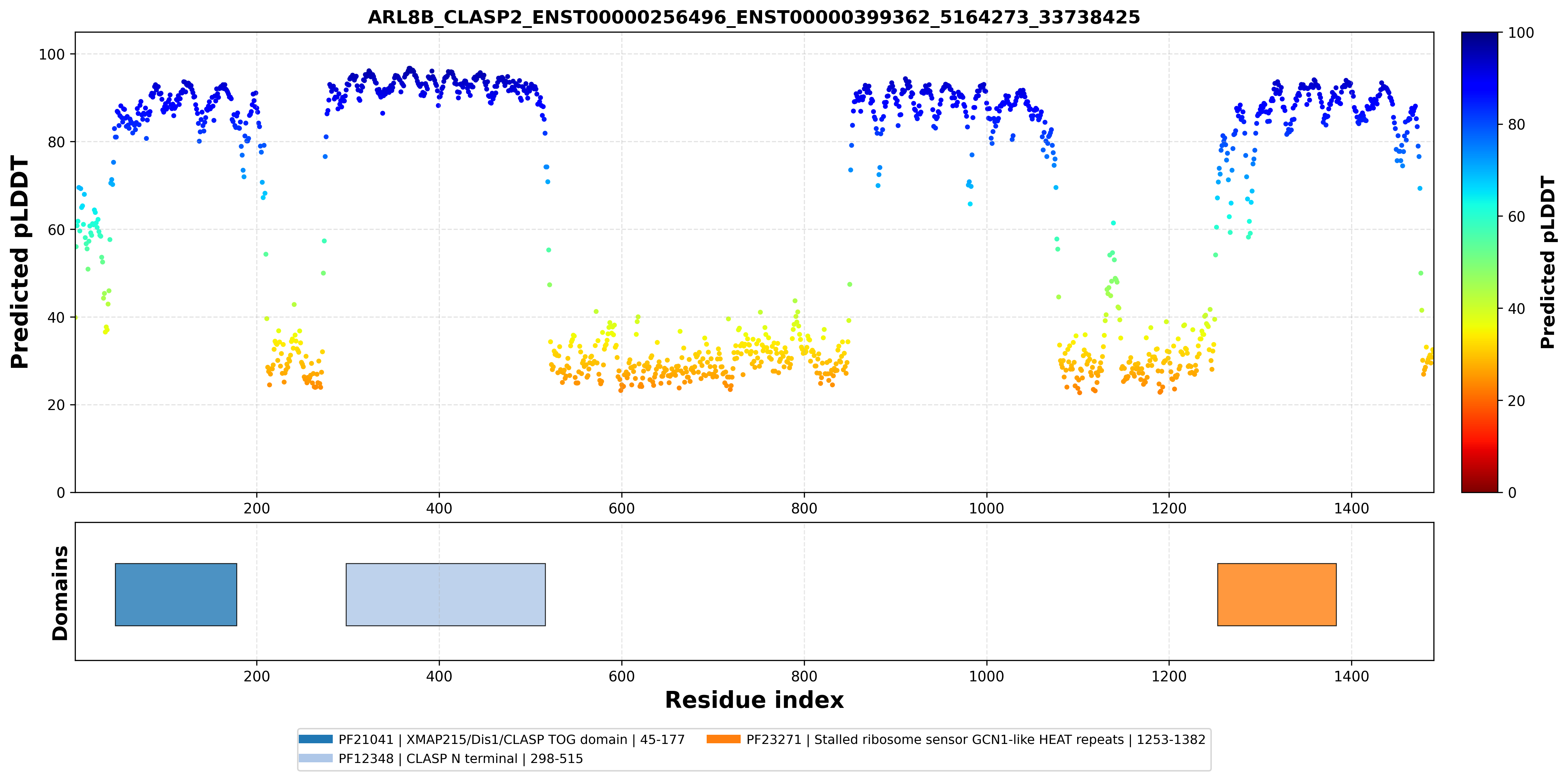 |  |  |
| ARL8B_CLASP2_ENST00000419534_ENST00000468888_5164273_33738425 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5825
Å |
 |  |  |  |  |
| ARL8B_USP4_ENST00000256496_ENST00000265560_5164273_49339975 superimposed PDB: 2Y6E of partner (USP4). RMSD:0.5459
Å |
 |  |  |  |  |
| ARMC1_UBE2W_ENST00000276569_ENST00000517608_66525478_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.671
Å |
 |  |  |  |  |
| ARMC1_UBE2W_ENST00000276569_ENST00000602969_66525478_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6495
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000393058_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2692
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000393058_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.1883
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000393058_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.3272
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000393058_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:2.0232
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000461822_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.0187
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000461822_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.0294
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000461822_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.192
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000461822_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.3341
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000469044_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2905
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000469044_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2376
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000469044_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.3289
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000469044_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2978
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000481646_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2811
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000481646_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.1143
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000481646_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.1446
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000481646_ENST00000415576_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:2.4717
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000485396_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.4565
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000485396_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.4856
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000485396_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.7668
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000485396_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:2.9209
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000491704_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2381
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000491704_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.2295
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000491704_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.3092
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000491704_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.5564
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000538260_ENST00000308268_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.9977
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000538260_ENST00000343848_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.5395
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000538260_ENST00000343848_137964025_23738085 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.982
Å |
 |  |  |  |  |
| ARMC8_PSMA8_ENST00000538260_ENST00000415576_137964025_23724522 superimposed PDB: 7NSC of partner (ARMC8). RMSD:1.3615
Å |
 |  |  |  |  |
| ARPC4-TTLL3_GRM7_ENST00000397256_ENST00000357716_9834808_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.4667
Å |
 |  |  |  |  |
| ARPC4-TTLL3_GRM7_ENST00000397256_ENST00000403881_9834808_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.4213
Å |
 |  |  |  |  |
| ARPC4-TTLL3_TBL1XR1_ENST00000397256_ENST00000457928_9855029_176765337 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.397
Å |
 |  |  |  |  |
| ARPC4_GRM7_ENST00000287613_ENST00000357716_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.6821
Å |
 |  | 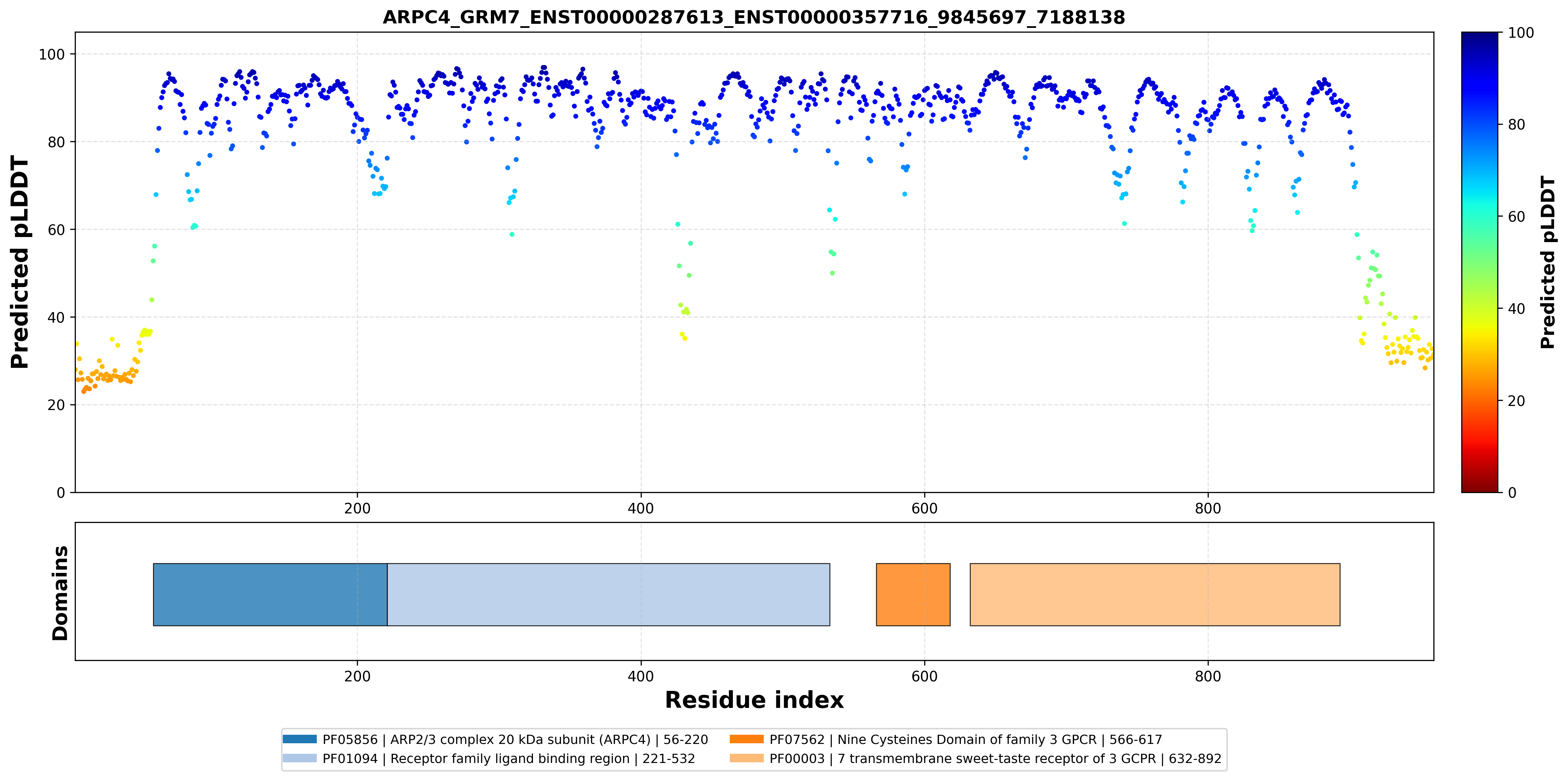 |  |  |
| ARPC4_GRM7_ENST00000287613_ENST00000357716_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7054
Å |
| | | |  |
| ARPC4_GRM7_ENST00000287613_ENST00000389336_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7254
Å |
 |  | 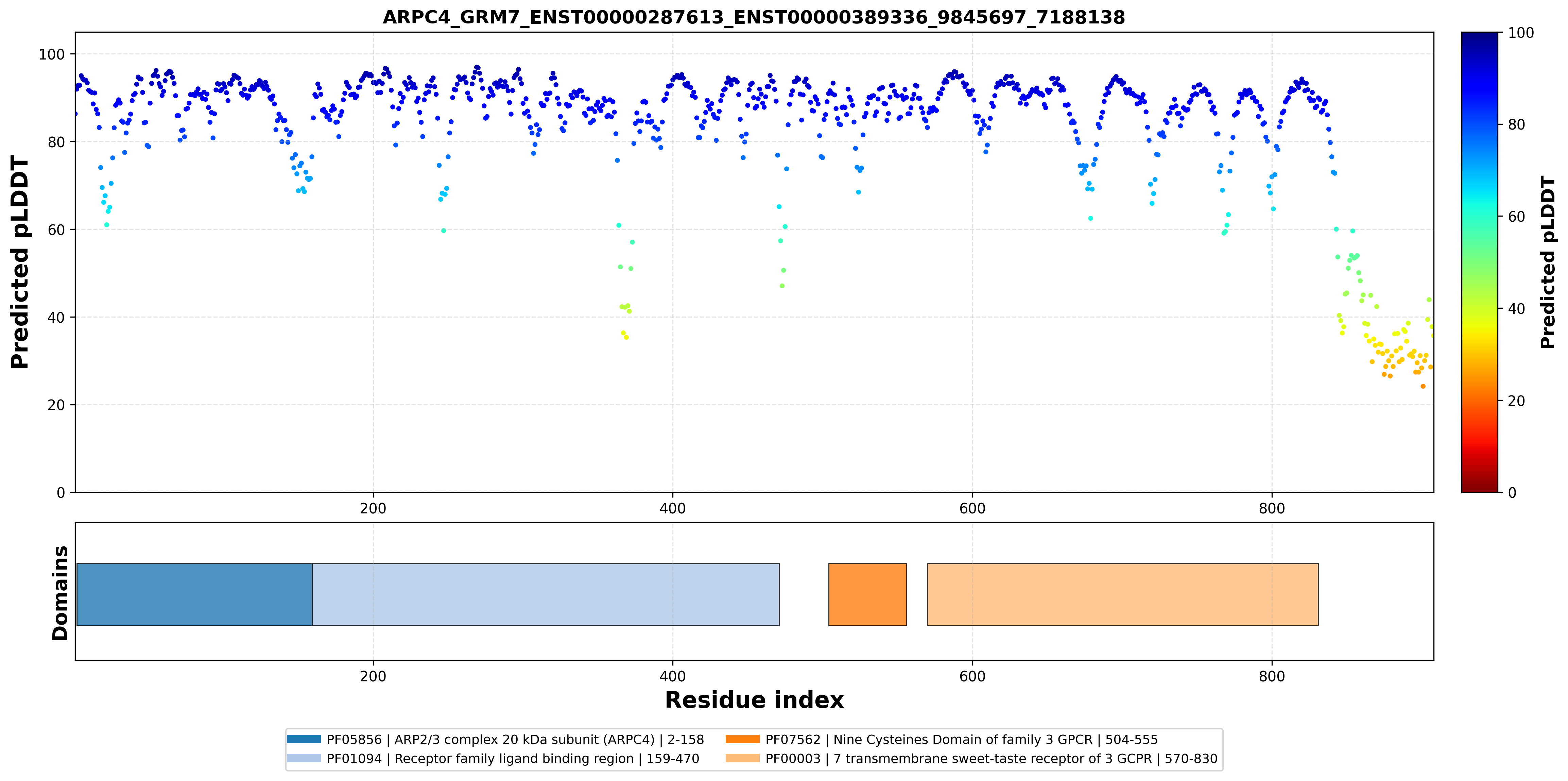 |  |  |
| ARPC4_GRM7_ENST00000287613_ENST00000389336_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7634
Å |
| | | |  |
| ARPC4_GRM7_ENST00000287613_ENST00000402647_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7536
Å |
 |  | 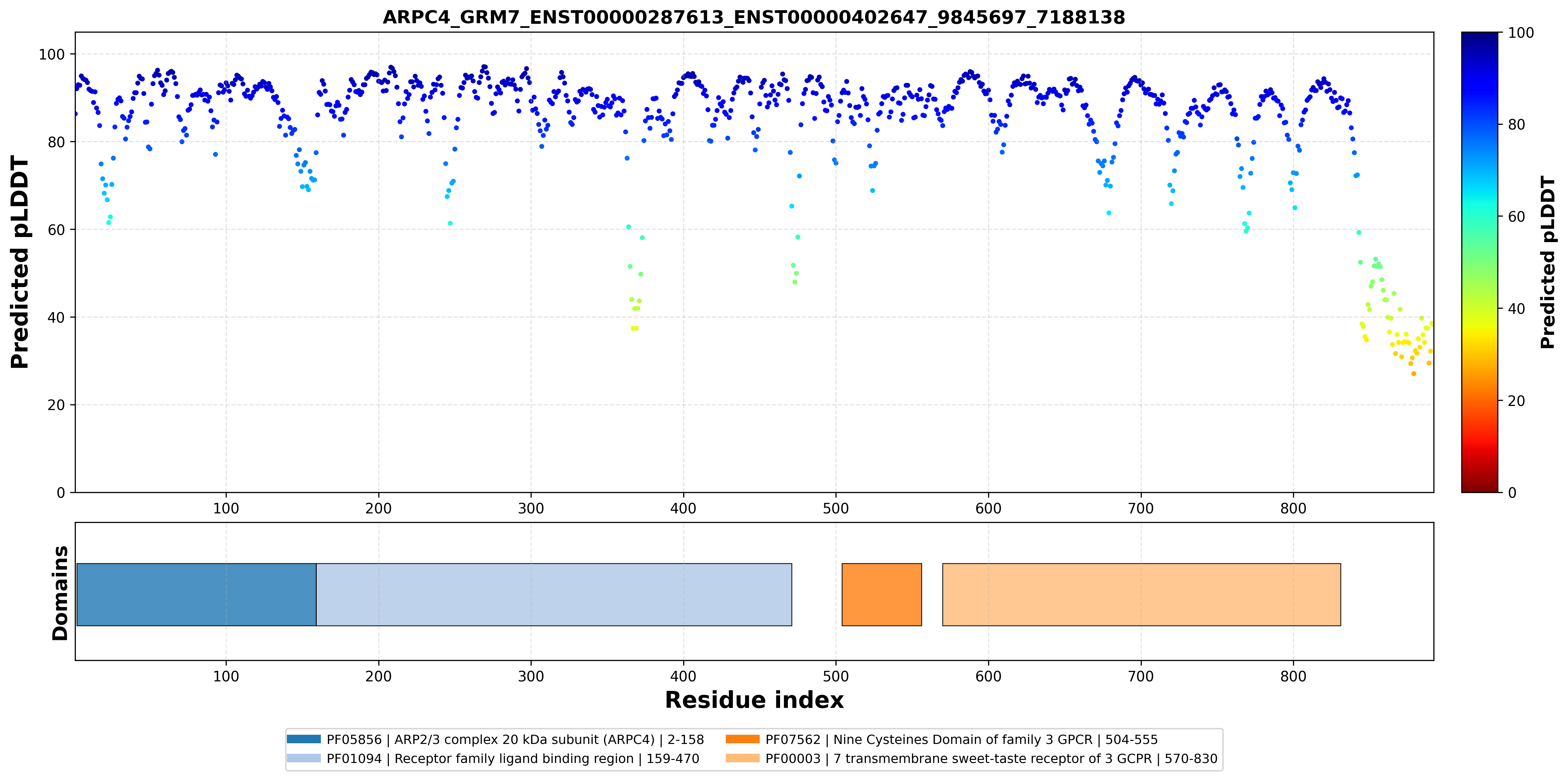 |  |  |
| ARPC4_GRM7_ENST00000287613_ENST00000402647_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7314
Å |
| | | |  |
| ARPC4_GRM7_ENST00000287613_ENST00000486284_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7102
Å |
 |  | 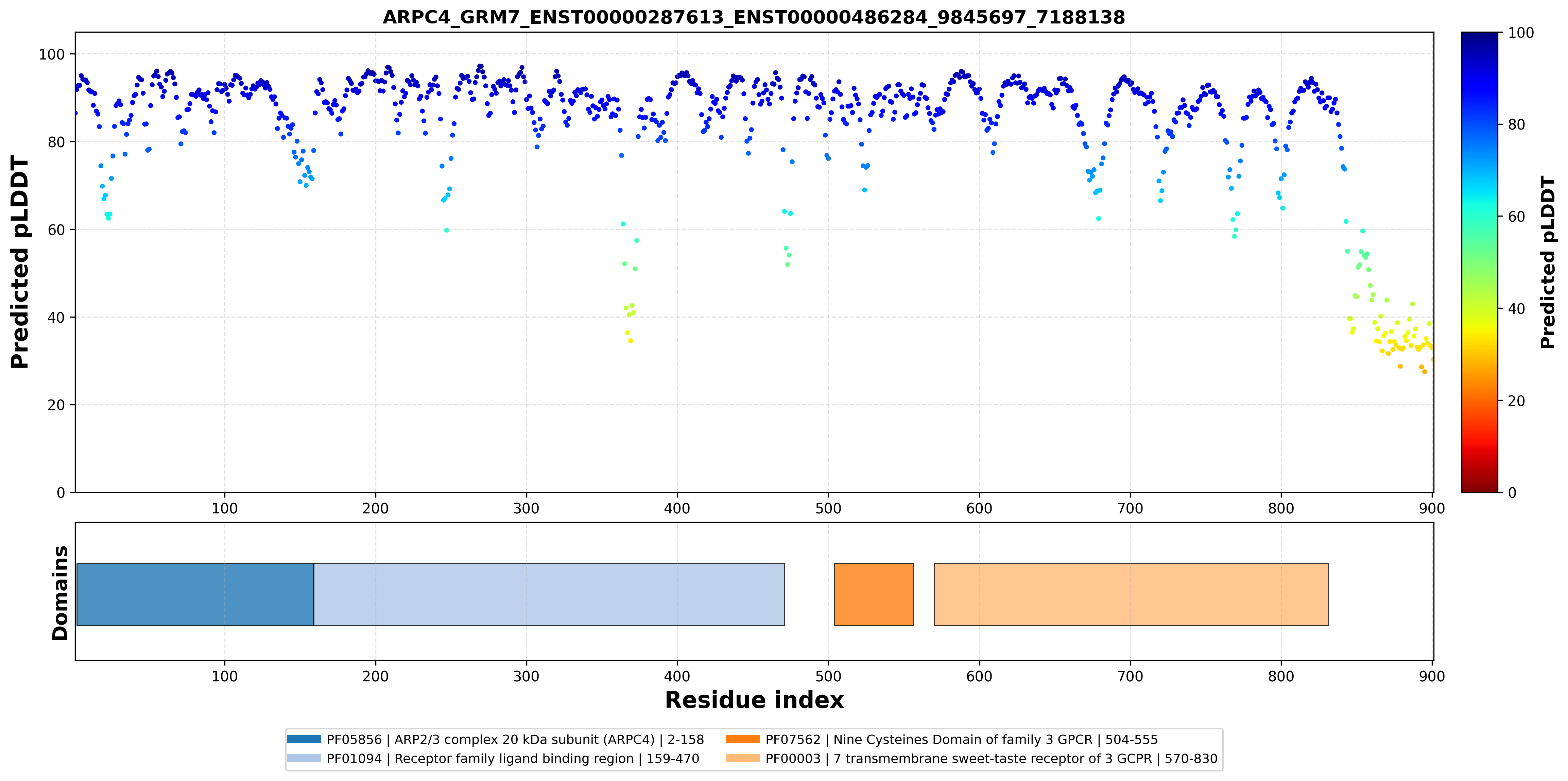 |  |  |
| ARPC4_GRM7_ENST00000287613_ENST00000486284_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7822
Å |
| | | |  |
| ARPC4_GRM7_ENST00000397261_ENST00000357716_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7484
Å |
 |  | 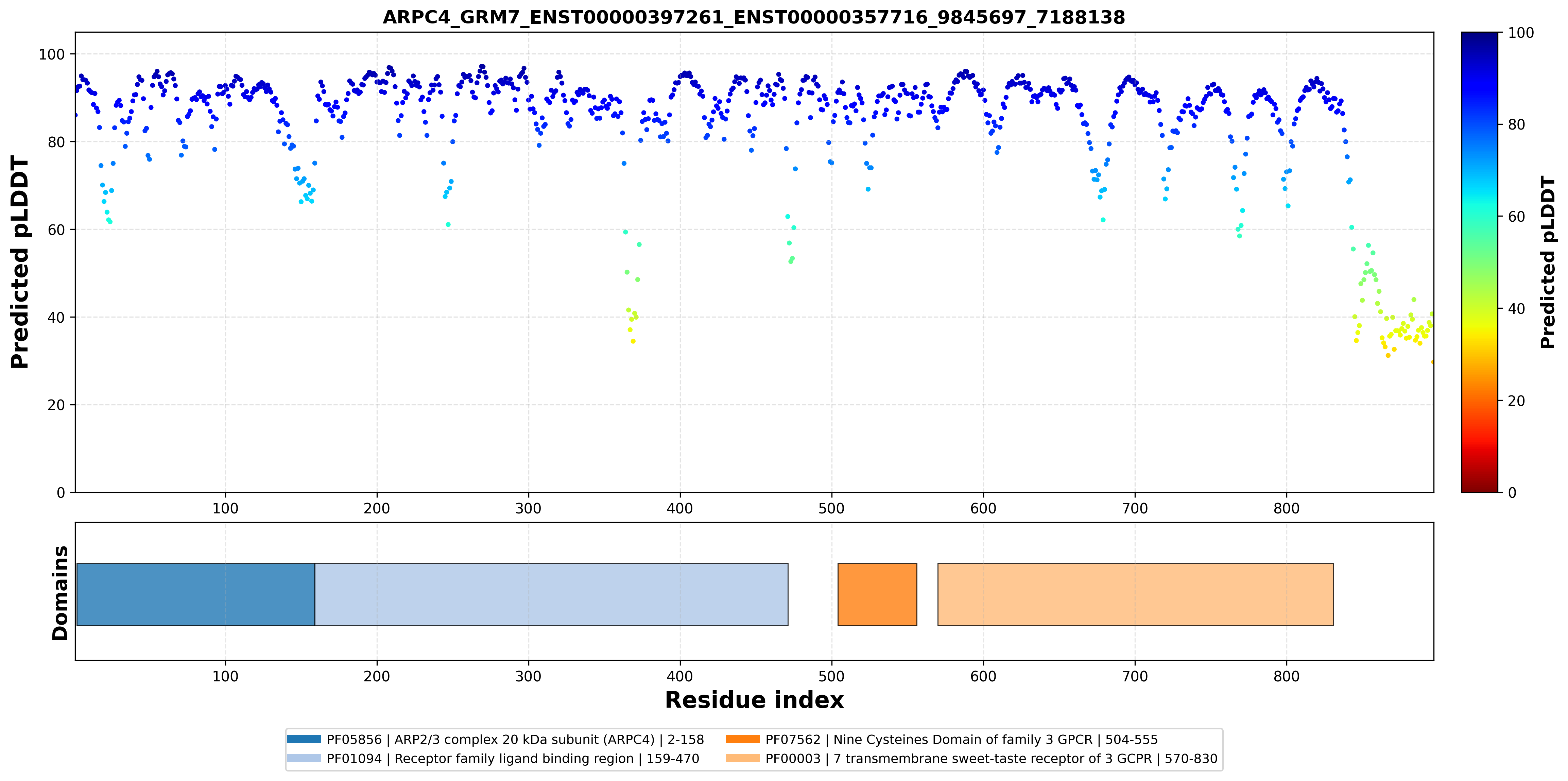 |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000357716_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7833
Å |
| | | |  |
| ARPC4_GRM7_ENST00000397261_ENST00000389336_9834808_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.4448
Å |
 |  |  |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000389336_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7312
Å |
 |  | 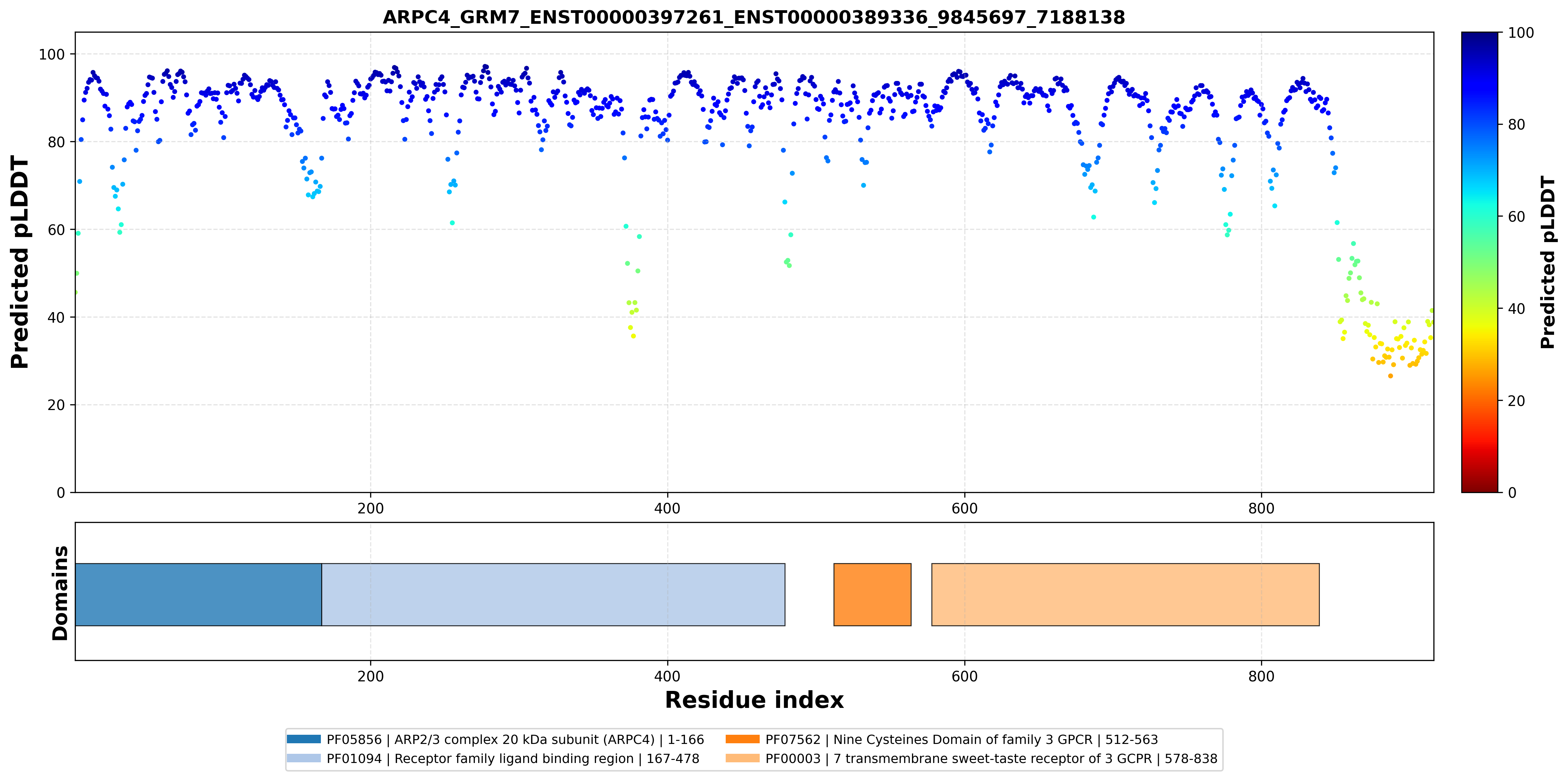 |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000389336_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7665
Å |
| | | |  |
| ARPC4_GRM7_ENST00000397261_ENST00000402647_9834808_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.567
Å |
 |  | 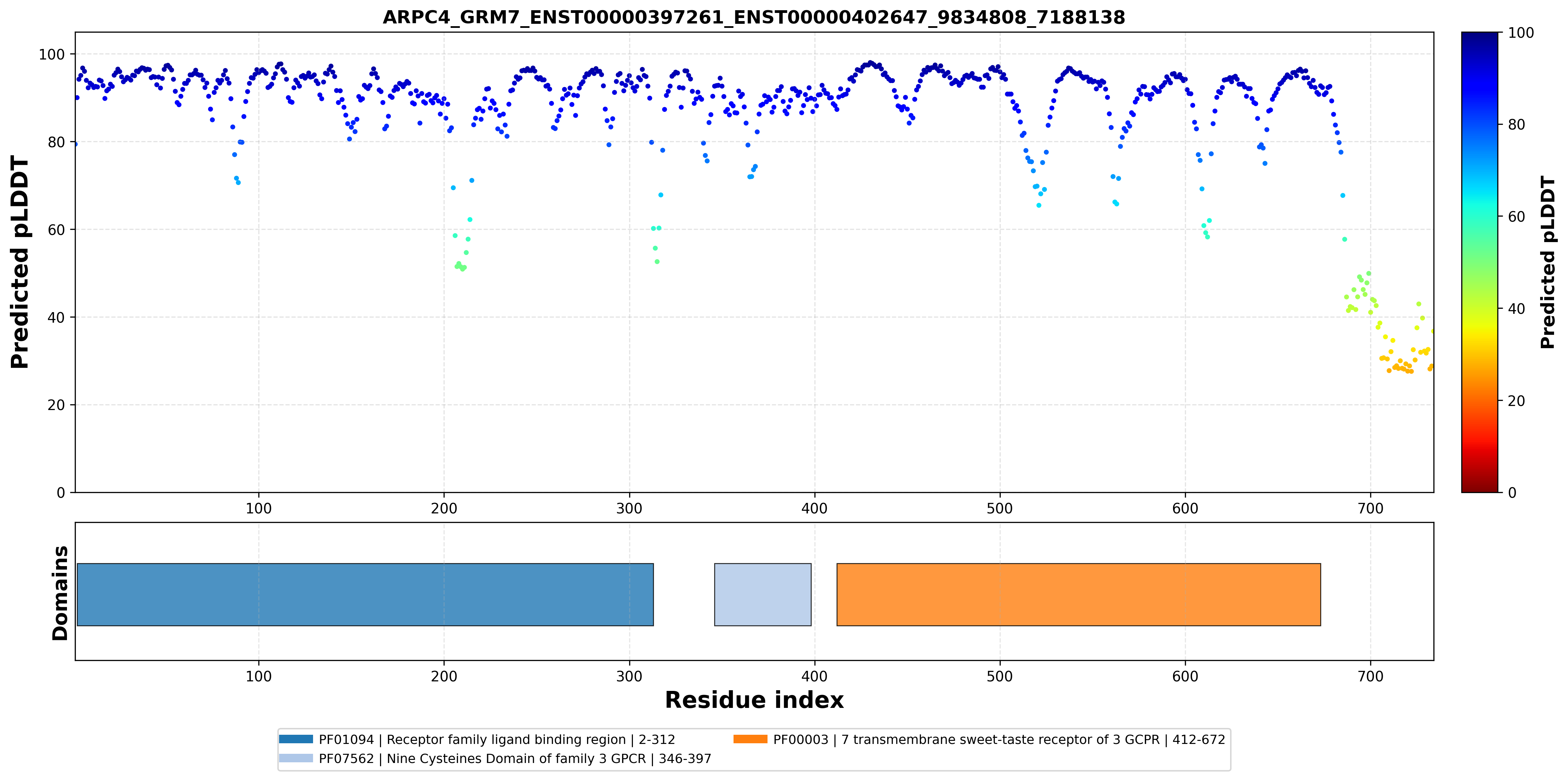 |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000402647_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7172
Å |
 |  | 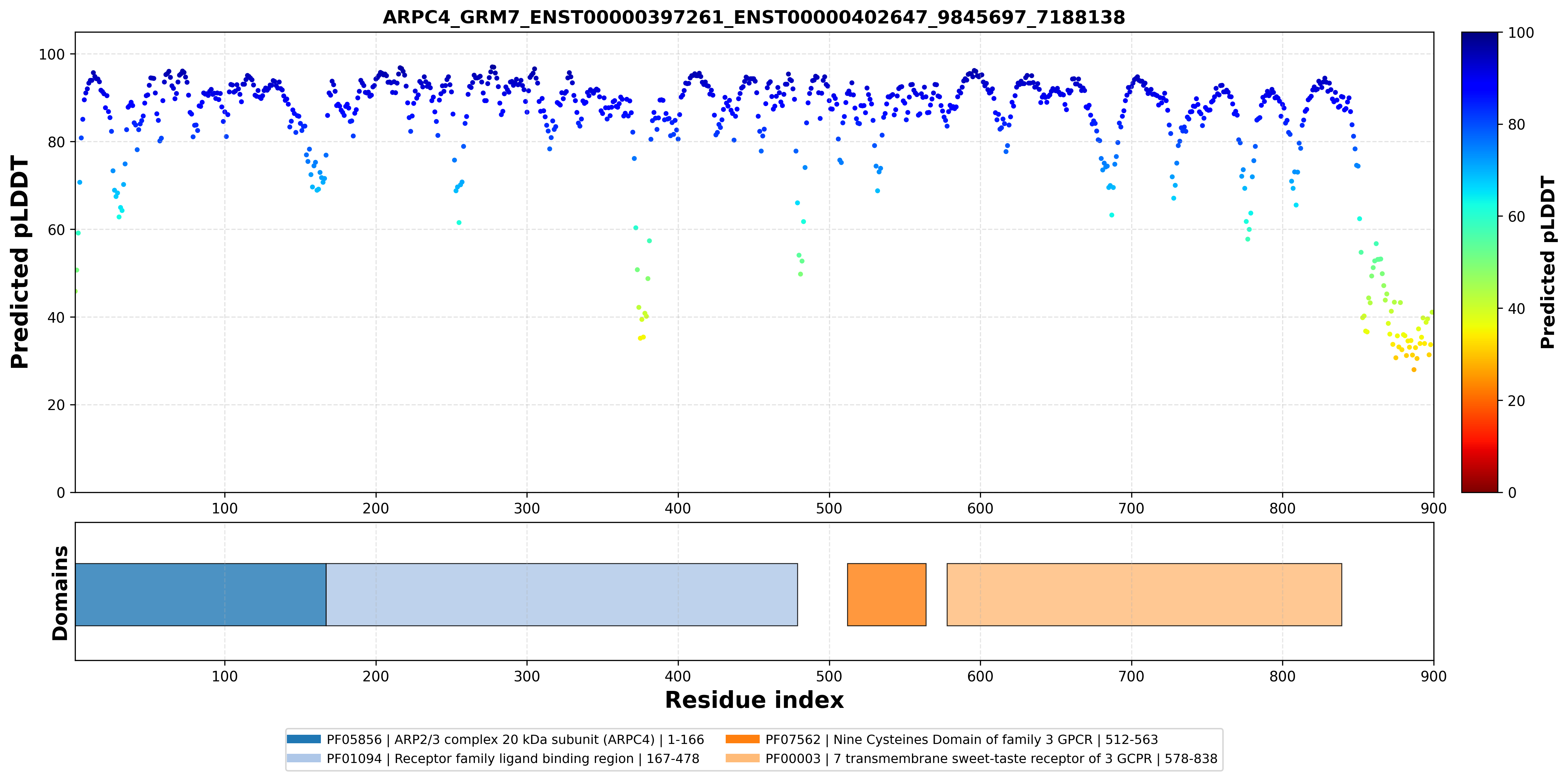 |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000402647_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7418
Å |
| | | |  |
| ARPC4_GRM7_ENST00000397261_ENST00000486284_9834808_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.4798
Å |
 |  |  |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000486284_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7153
Å |
 |  | 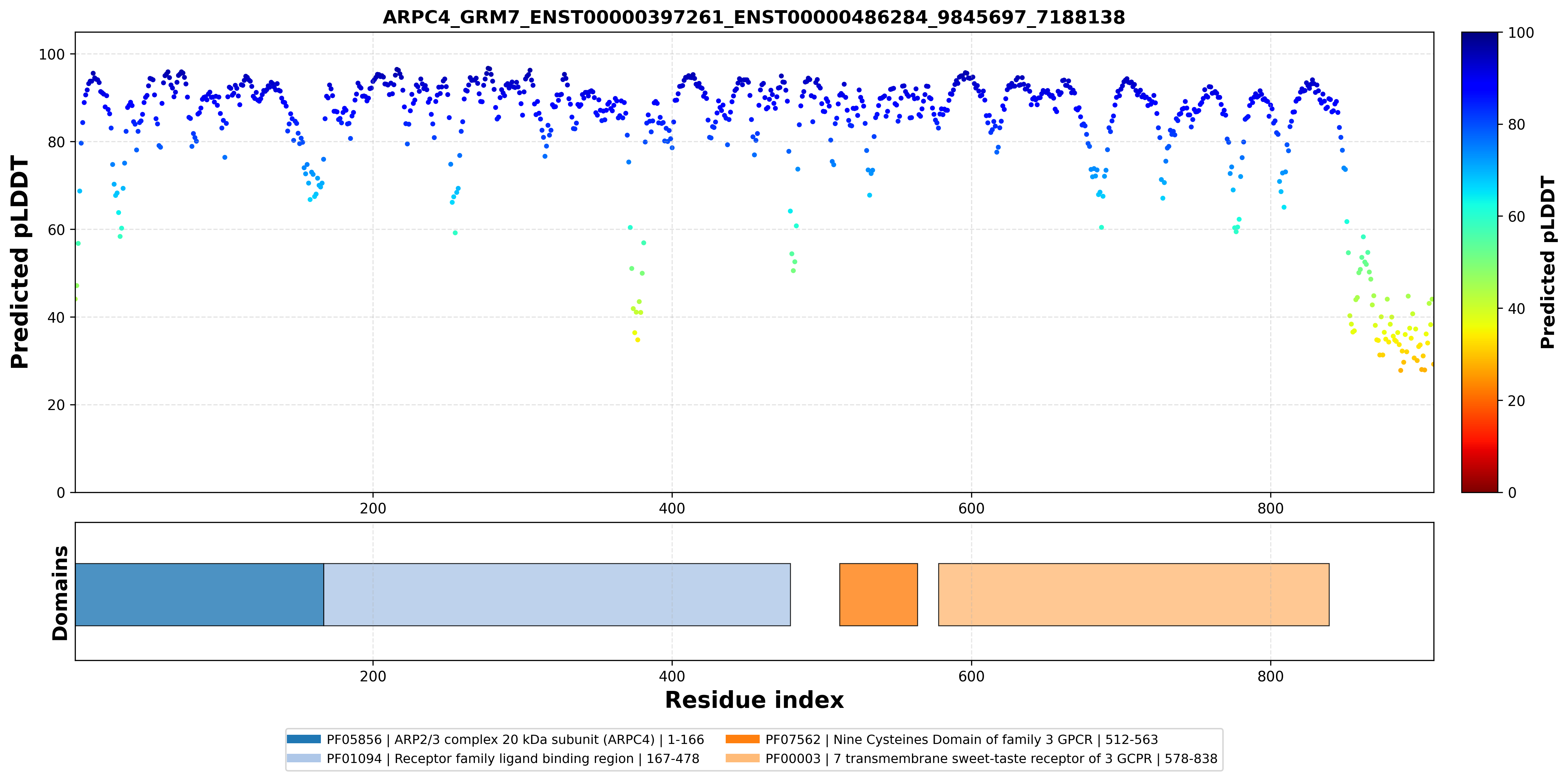 |  |  |
| ARPC4_GRM7_ENST00000397261_ENST00000486284_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7871
Å |
| | | |  |
| ARPC4_GRM7_ENST00000433034_ENST00000357716_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7021
Å |
 |  | 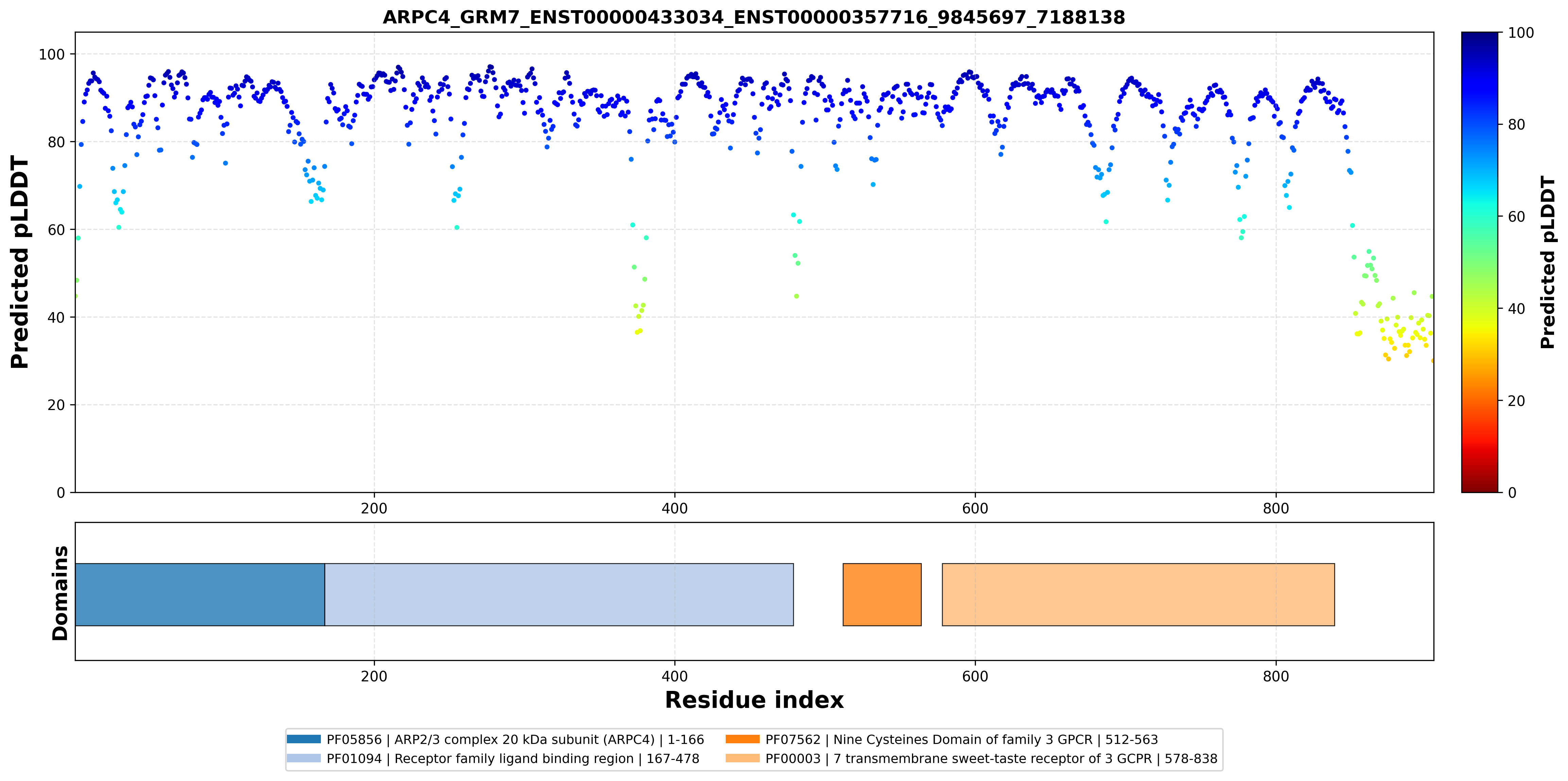 |  |  |
| ARPC4_GRM7_ENST00000433034_ENST00000357716_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7542
Å |
| | | |  |
| ARPC4_GRM7_ENST00000433034_ENST00000389336_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7399
Å |
 |  | 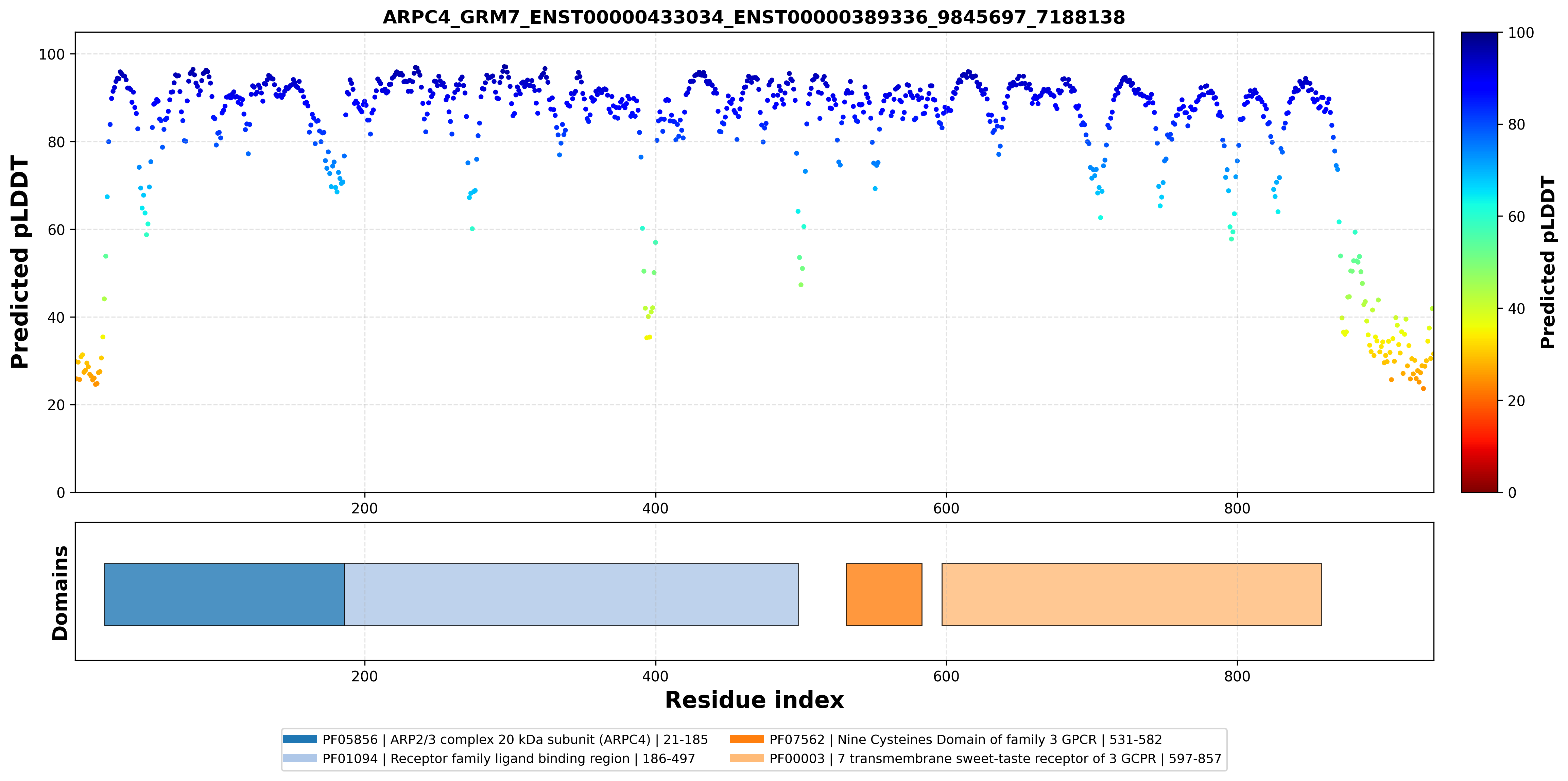 |  |  |
| ARPC4_GRM7_ENST00000433034_ENST00000389336_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7904
Å |
| | | |  |
| ARPC4_GRM7_ENST00000433034_ENST00000402647_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7575
Å |
 |  | 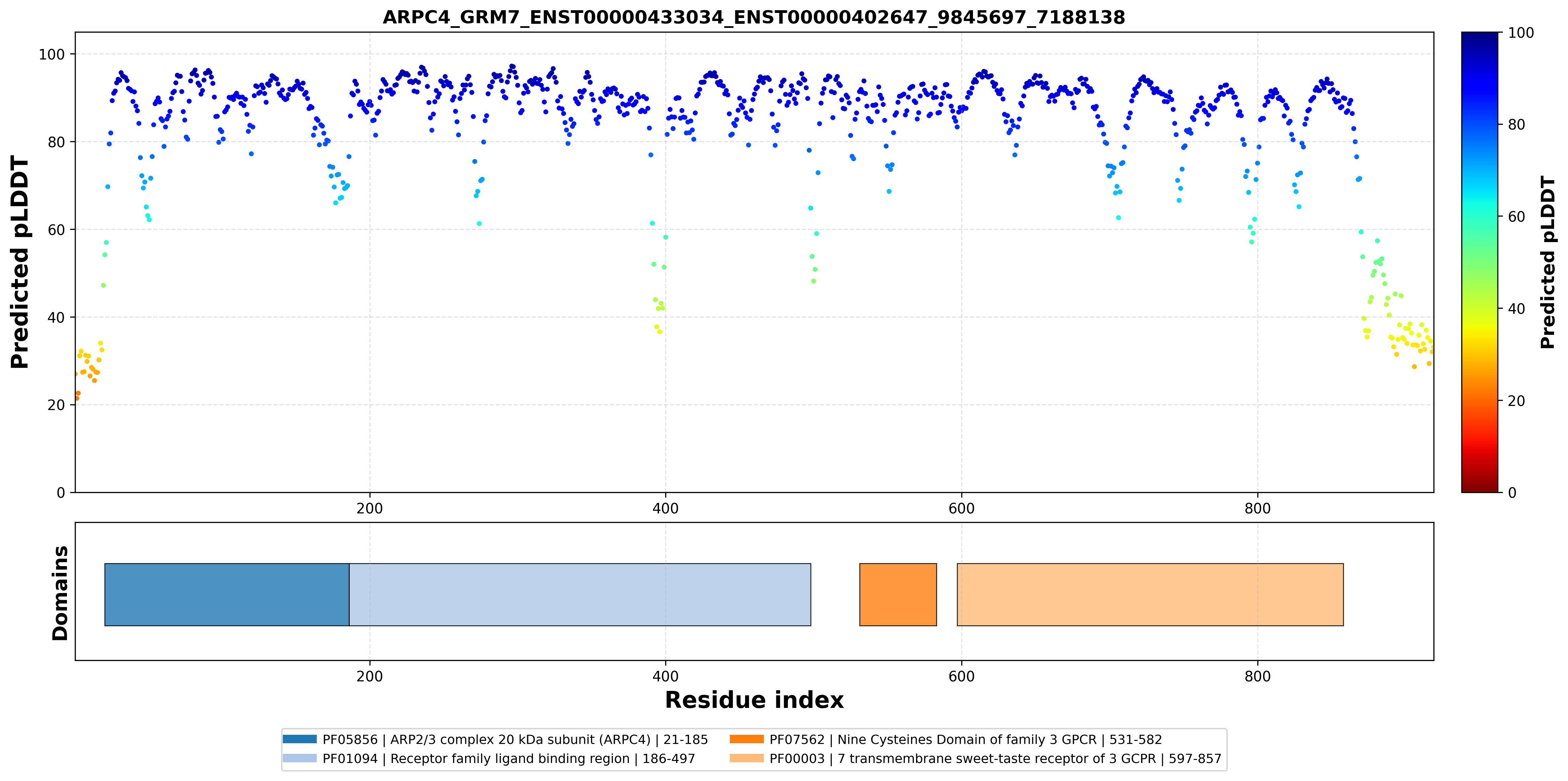 |  |  |
| ARPC4_GRM7_ENST00000433034_ENST00000402647_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7228
Å |
| | | |  |
| ARPC4_GRM7_ENST00000433034_ENST00000403881_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7292
Å |
 |  | 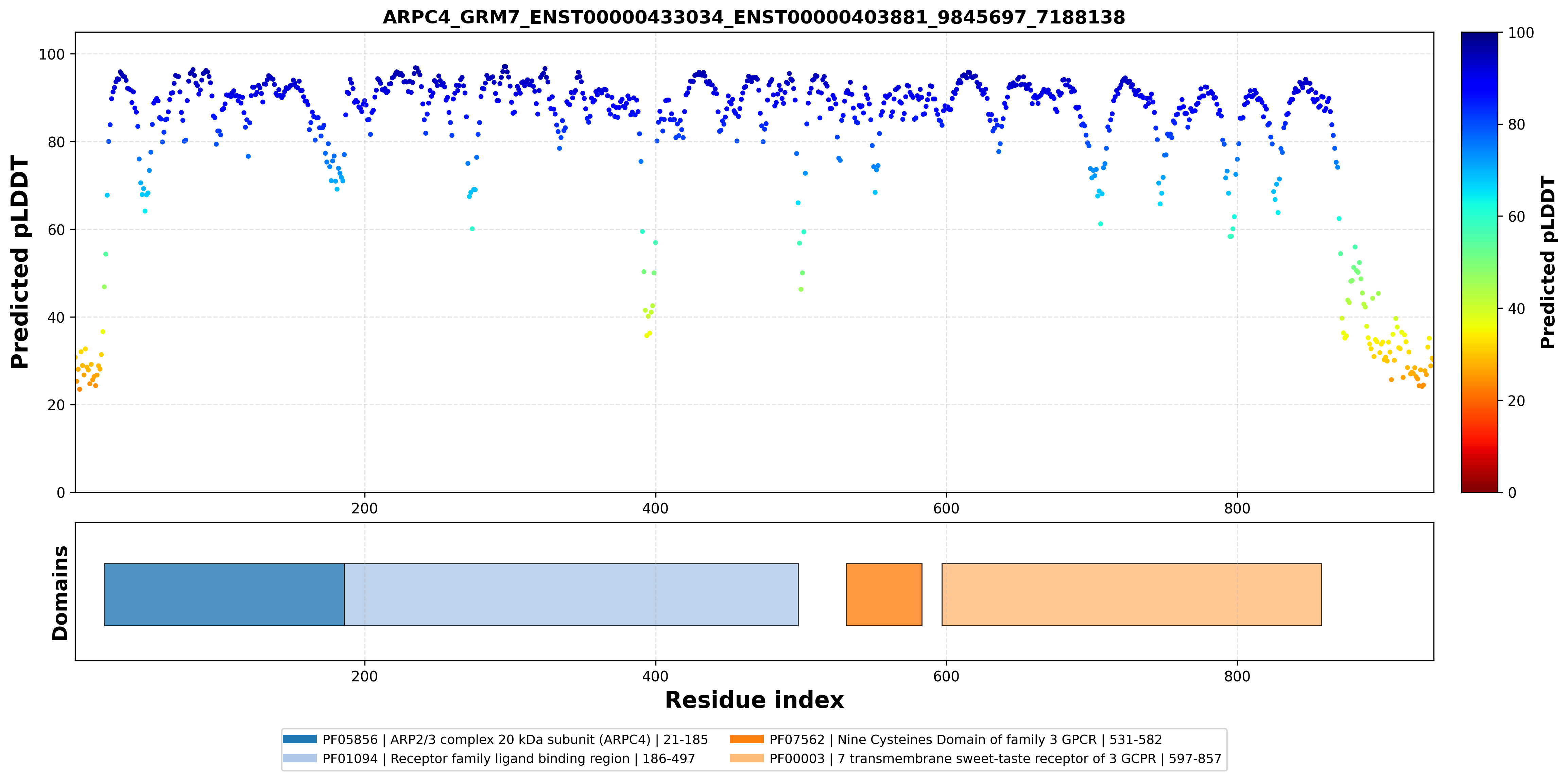 |  |  |
| ARPC4_GRM7_ENST00000433034_ENST00000403881_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7283
Å |
| | | |  |
| ARPC4_GRM7_ENST00000433034_ENST00000486284_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7634
Å |
 |  | 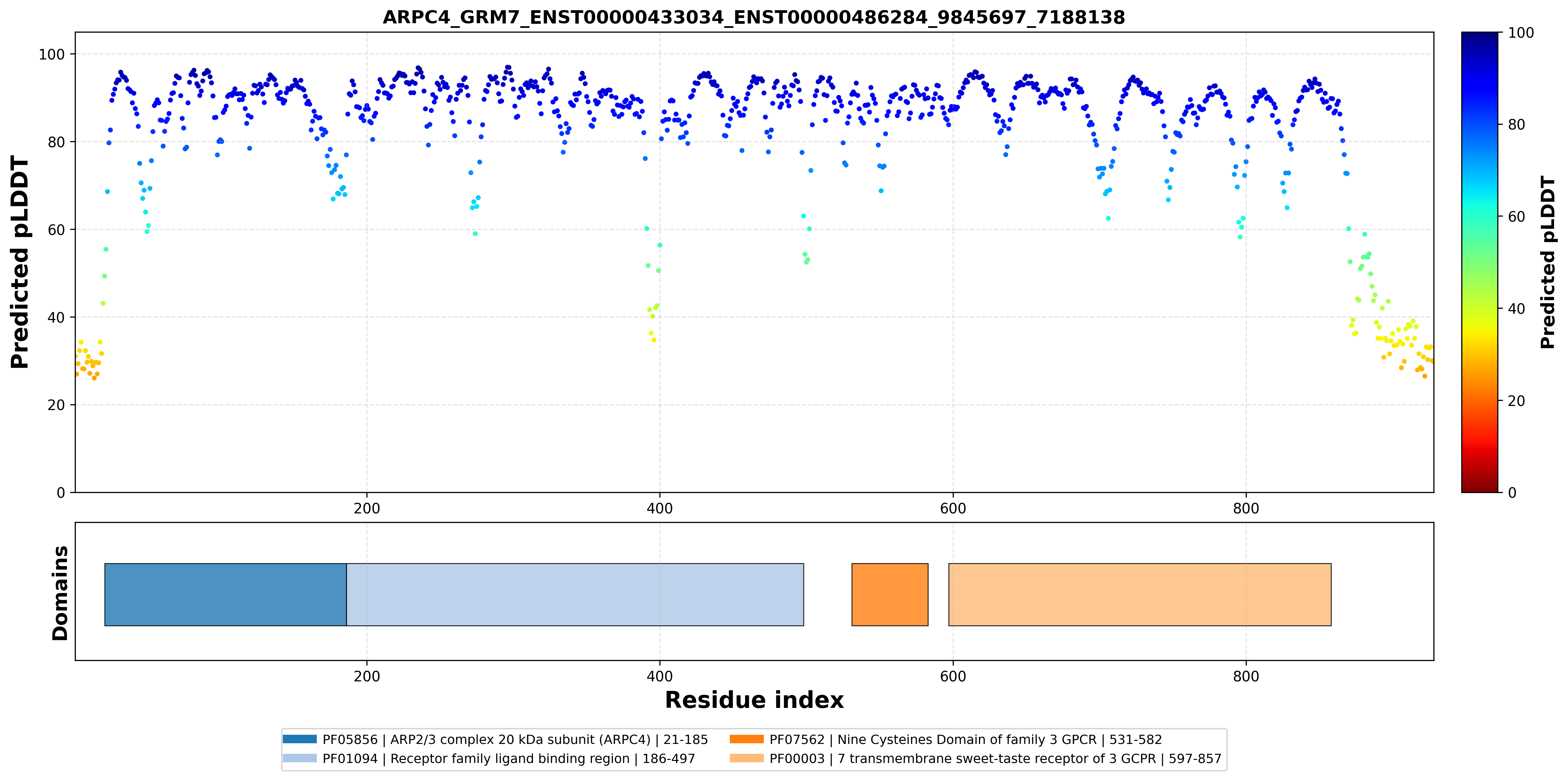 |  |  |
| ARPC4_GRM7_ENST00000433034_ENST00000486284_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7657
Å |
| | | |  |
| ARPC4_GRM7_ENST00000498623_ENST00000389336_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7114
Å |
 |  | 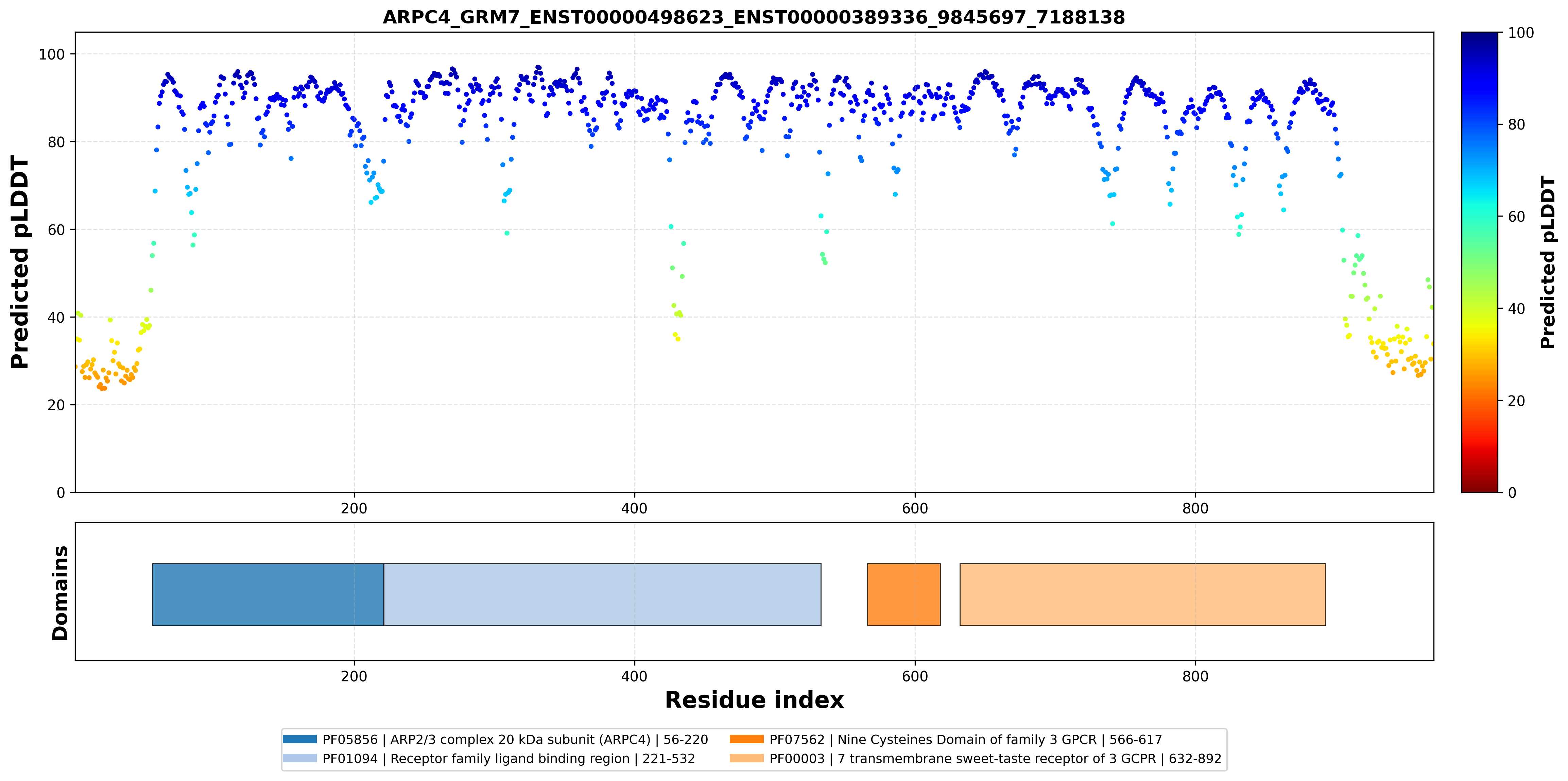 |  |  |
| ARPC4_GRM7_ENST00000498623_ENST00000389336_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.8114
Å |
| | | |  |
| ARPC4_GRM7_ENST00000498623_ENST00000402647_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7294
Å |
 |  | 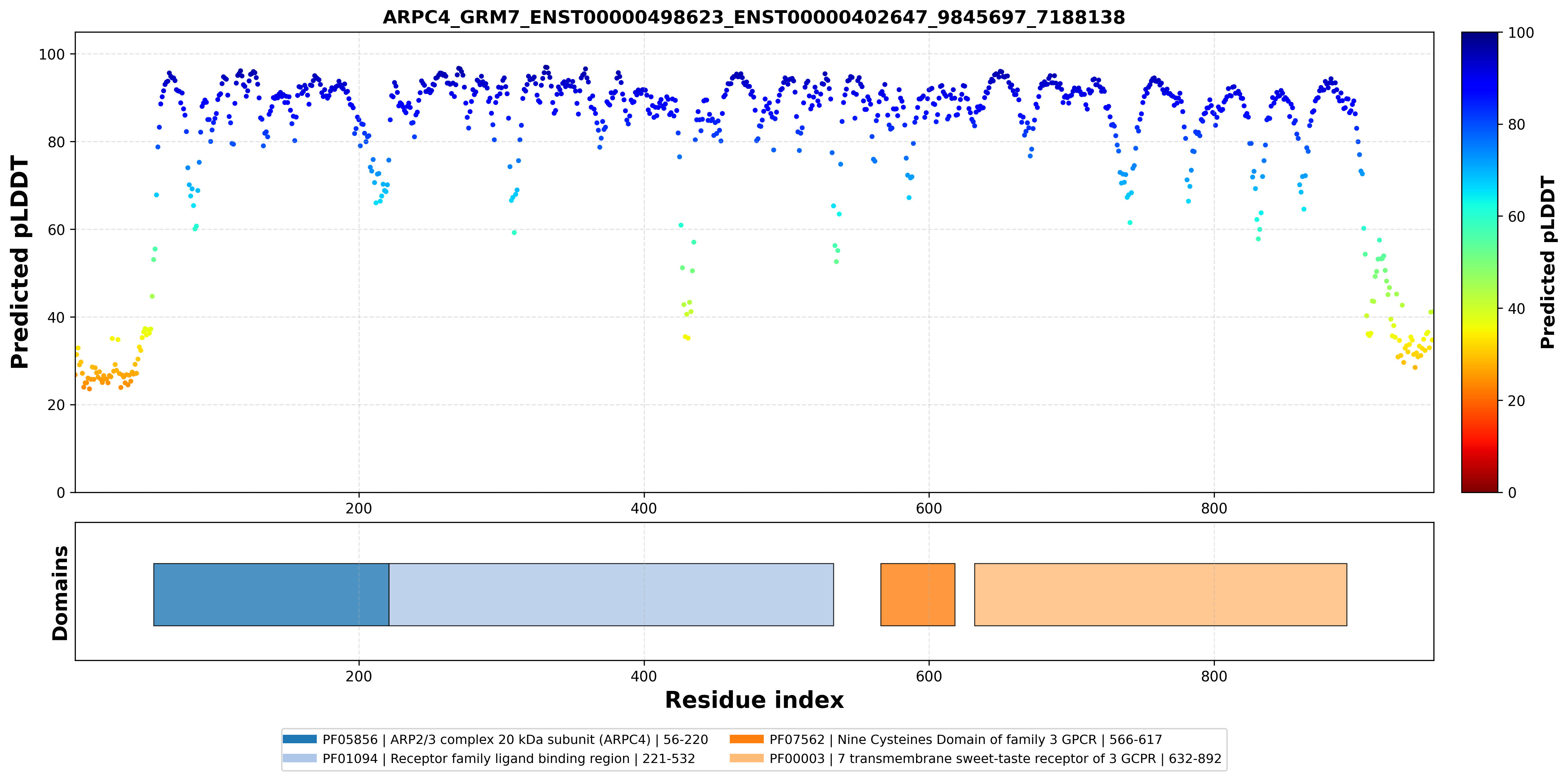 |  |  |
| ARPC4_GRM7_ENST00000498623_ENST00000402647_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.6817
Å |
| | | |  |
| ARPC4_GRM7_ENST00000498623_ENST00000403881_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7026
Å |
 |  | 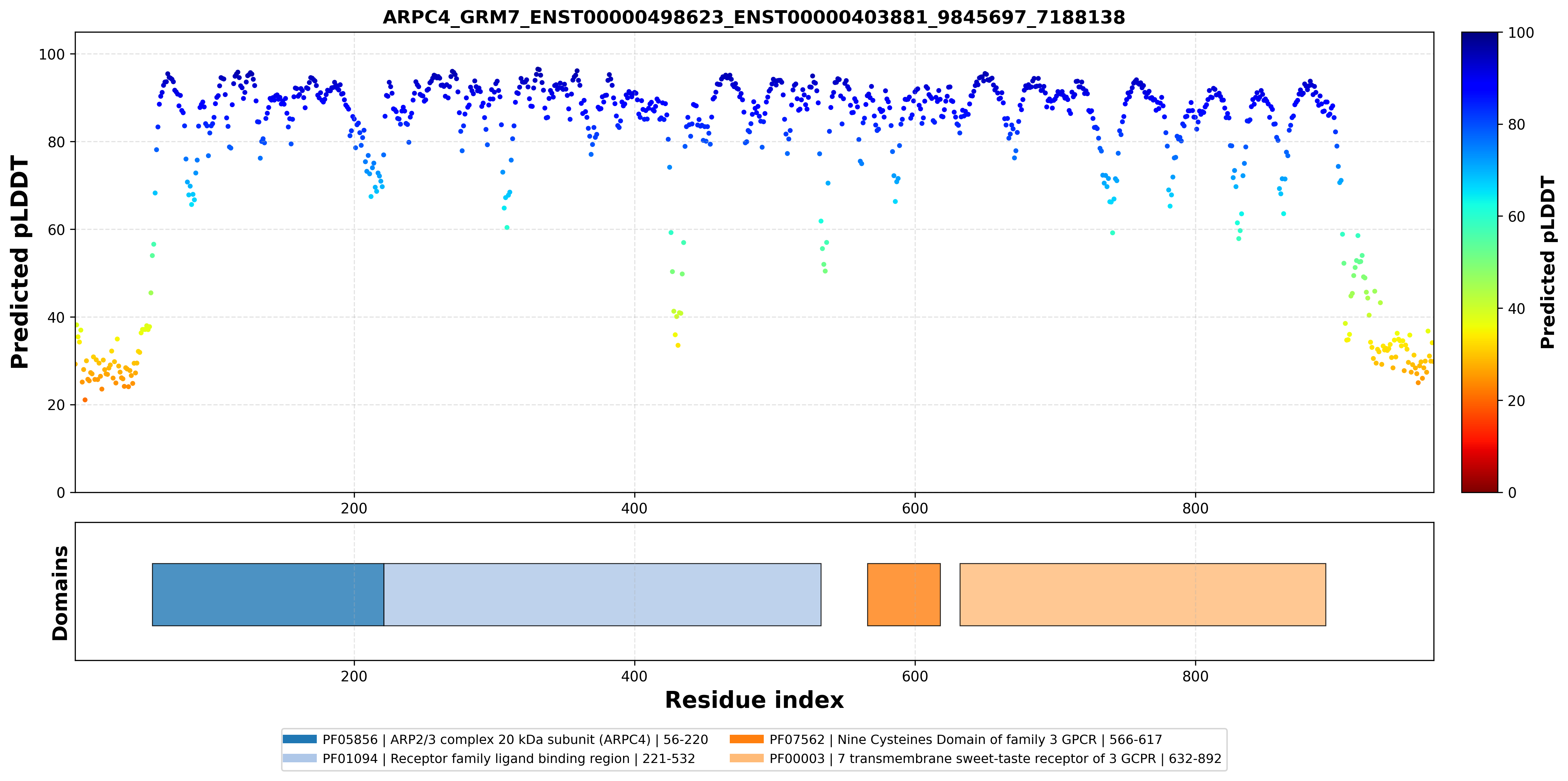 |  |  |
| ARPC4_GRM7_ENST00000498623_ENST00000403881_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.6867
Å |
| | | |  |
| ARPC4_GRM7_ENST00000498623_ENST00000486284_9845697_7188138 superimposed PDB: 9I2B of partner (ARPC4). RMSD:0.7594
Å |
 |  | 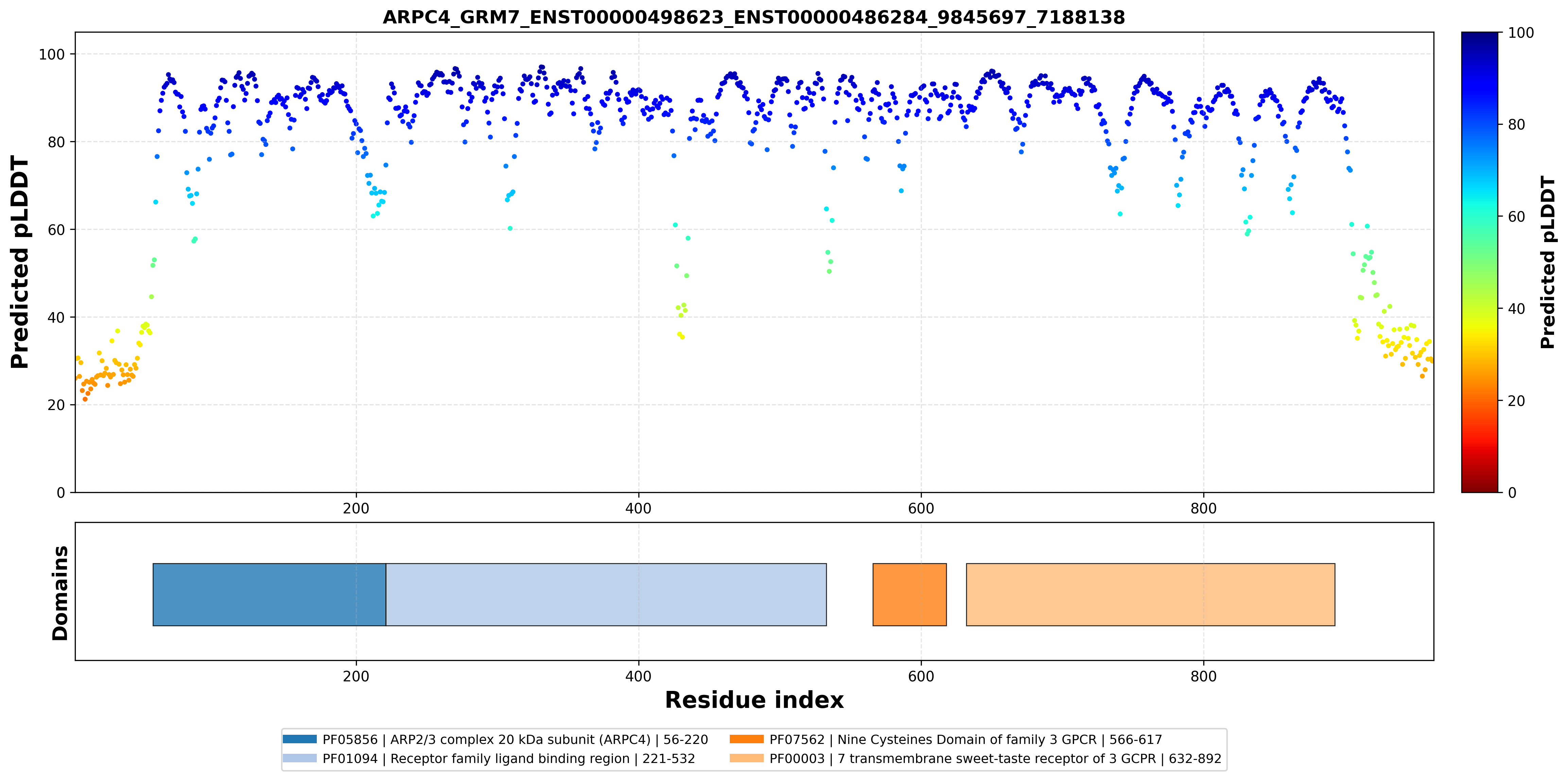 |  |  |
| ARPC4_GRM7_ENST00000498623_ENST00000486284_9845697_7188138 superimposed PDB: 9OMO of partner (GRM7). RMSD:2.7666
Å |
| | | |  |
| ARPP19_GNB5_ENST00000249822_ENST00000358784_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:0.9925
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000249822_ENST00000396335_52849296_52442122 superimposed PDB: 8TTB of partner (ARPP19). RMSD:1.0109
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000249822_ENST00000396335_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:1.0667
Å |
| | | |  |
| ARPP19_GNB5_ENST00000564163_ENST00000358784_52849296_52442122 superimposed PDB: 8TTB of partner (ARPP19). RMSD:2.9538
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000564163_ENST00000358784_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:0.9708
Å |
| | | |  |
| ARPP19_GNB5_ENST00000564163_ENST00000396335_52849296_52442122 superimposed PDB: 8TTB of partner (ARPP19). RMSD:1.8485
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000564163_ENST00000396335_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:1.0568
Å |
| | | |  |
| ARPP19_GNB5_ENST00000566423_ENST00000358784_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:0.9449
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000566423_ENST00000396335_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:1.0619
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000568196_ENST00000358784_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:0.9718
Å |
 |  |  |  |  |
| ARPP19_GNB5_ENST00000568196_ENST00000396335_52849296_52442122 superimposed PDB: 8SH9 of partner (GNB5). RMSD:1.0686
Å |
 |  |  |  |  |
| ARPP19_MYO5A_ENST00000249822_ENST00000356338_52861044_52606400 superimposed PDB: 8TTB of partner (ARPP19). RMSD:2.8227
Å |
 |  |  |  |  |
| ARPP19_MYO5A_ENST00000249822_ENST00000356338_52861044_52615641 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.5773
Å |
 |  |  |  |  |
| ARPP19_MYO5A_ENST00000566423_ENST00000356338_52861044_52615641 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.4534
Å |
 |  |  |  |  |
| ARRB1_ARRB2_ENST00000393505_ENST00000574954_74983938_4623687 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:1.1643
Å |
 |  |  |  |  |
| ARRB1_ARRB2_ENST00000393505_ENST00000574954_74983938_4623687 superimposed PDB: 9UYM of partner (ARRB2). RMSD:1.2023
Å |
| | | |  |
| ARRB1_ARRB2_ENST00000420843_ENST00000574954_74983938_4623687 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:1.1839
Å |
 |  |  |  |  |
| ARRB1_ARRB2_ENST00000420843_ENST00000574954_74983938_4623687 superimposed PDB: 9UYM of partner (ARRB2). RMSD:1.1288
Å |
| | | |  |
| ARRB1_GDPD5_ENST00000360025_ENST00000336898_74993005_75173934 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:0.7453
Å |
 |  |  |  |  |
| ARRB1_GDPD5_ENST00000393505_ENST00000336898_74993005_75173934 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:0.8777
Å |
 |  |  |  |  |
| ARRB1_PRCP_ENST00000393505_ENST00000393399_75062631_82549616 superimposed PDB: 3N2Z of partner (PRCP). RMSD:1.0547
Å |
 |  | 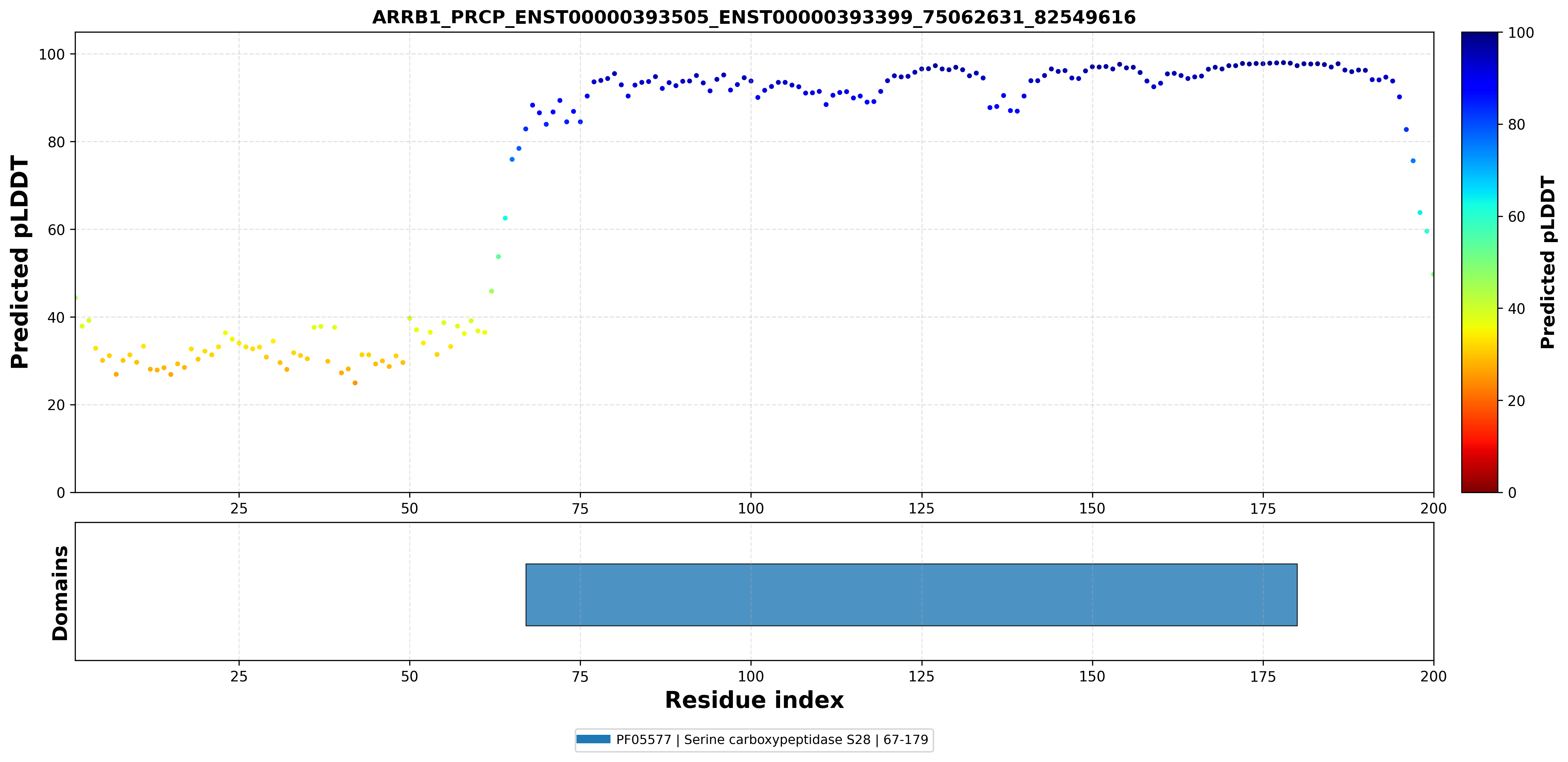 |  | 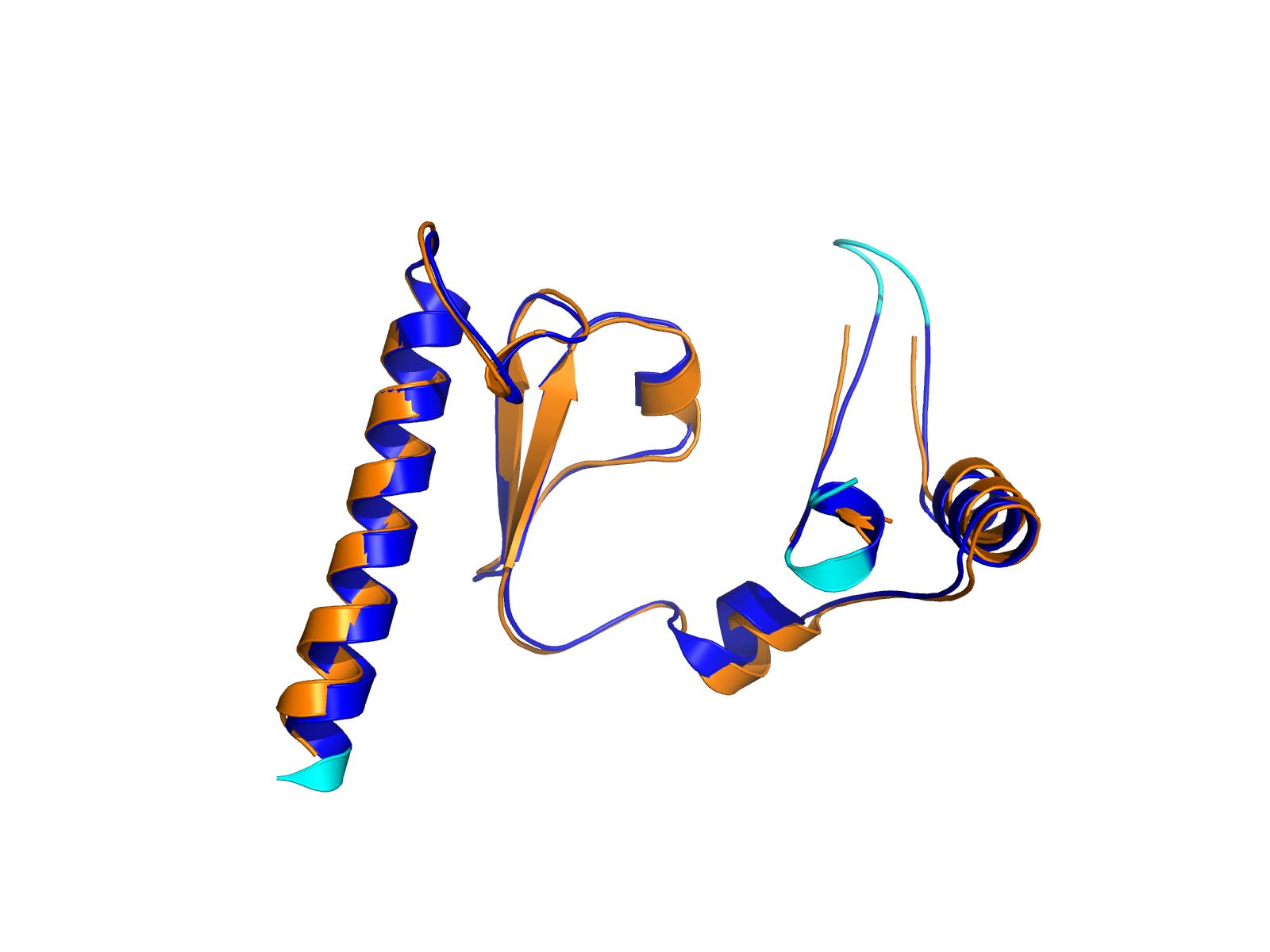 |
| ARRB1_PRCP_ENST00000393505_ENST00000393399_75062631_82550467 superimposed PDB: 3N2Z of partner (PRCP). RMSD:2.1457
Å |
 |  | 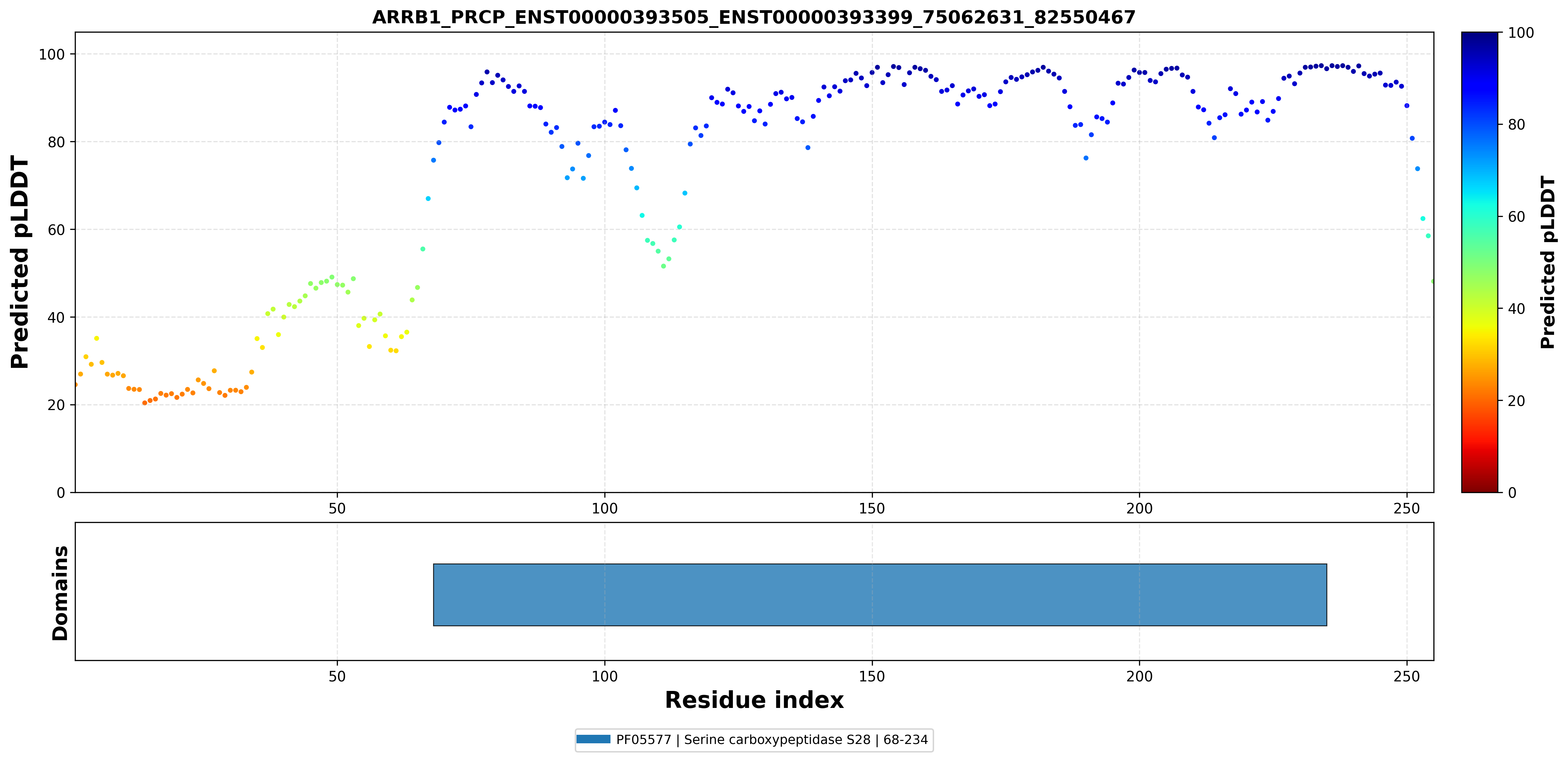 |  | 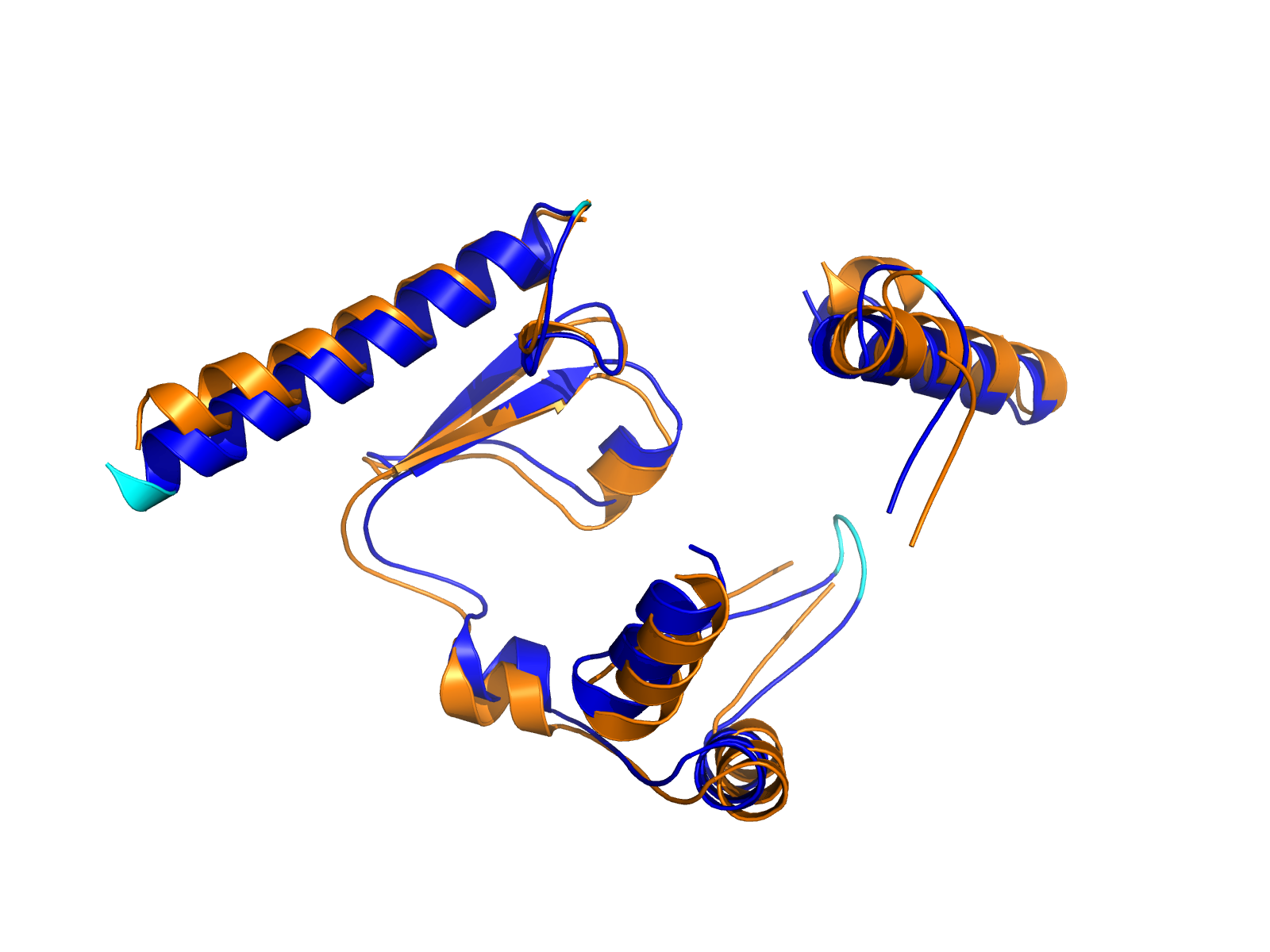 |
| ARRB1_PRCP_ENST00000420843_ENST00000393399_75062631_82549616 superimposed PDB: 3N2Z of partner (PRCP). RMSD:1.0182
Å |
 |  | 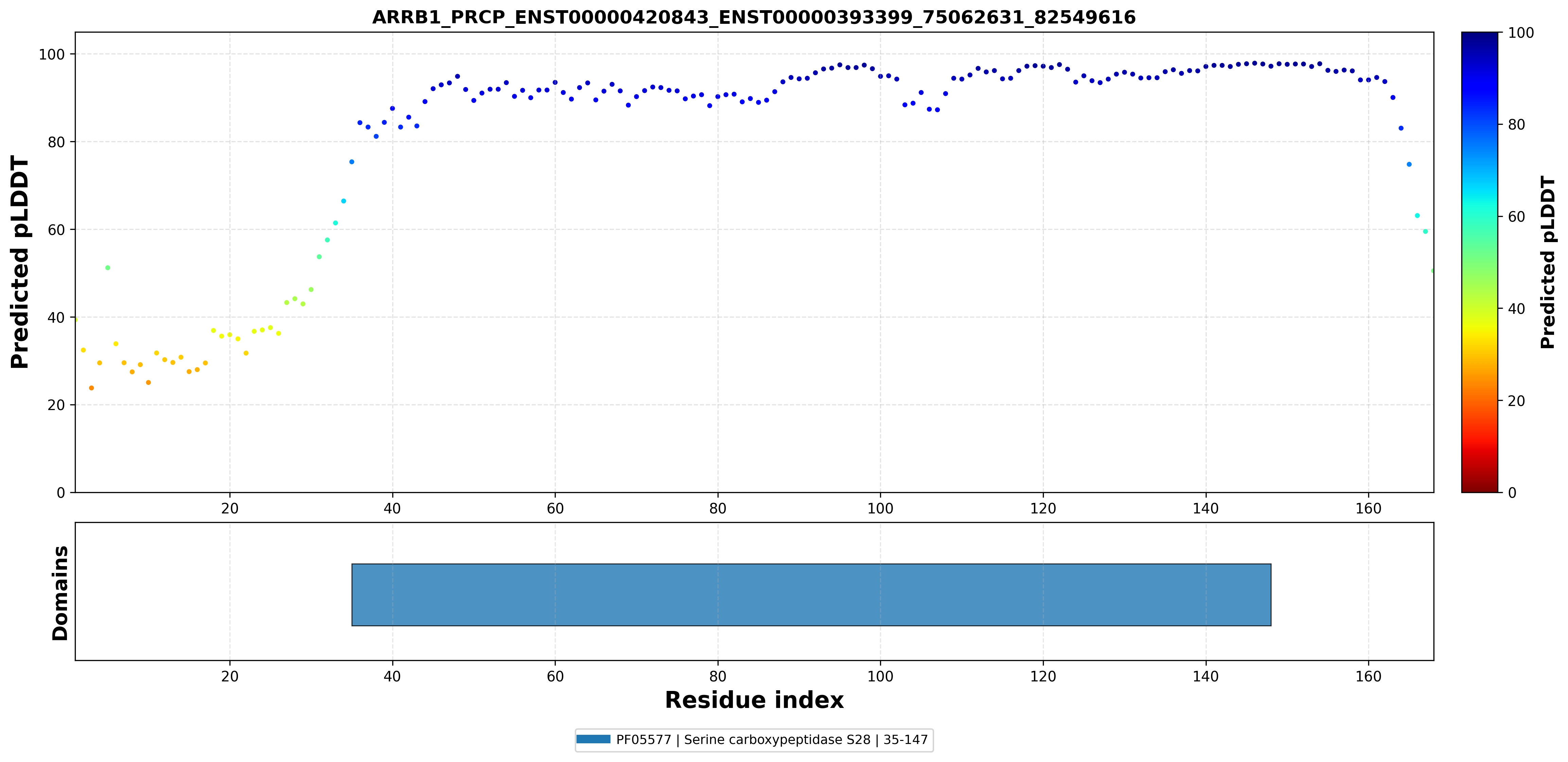 |  | 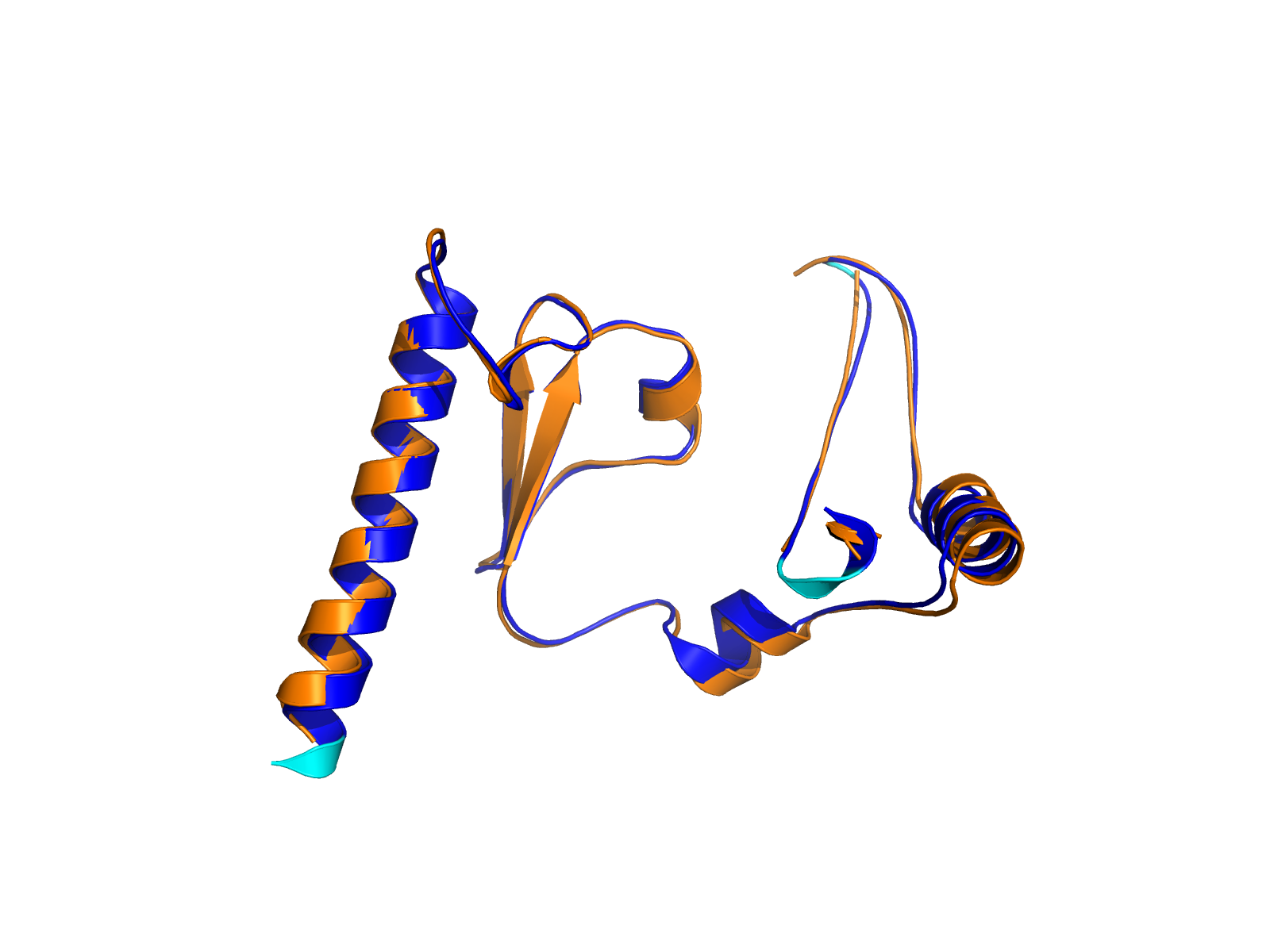 |
| ARRB1_PRCP_ENST00000420843_ENST00000393399_75062631_82550467 superimposed PDB: 3N2Z of partner (PRCP). RMSD:1.8485
Å |
 |  | 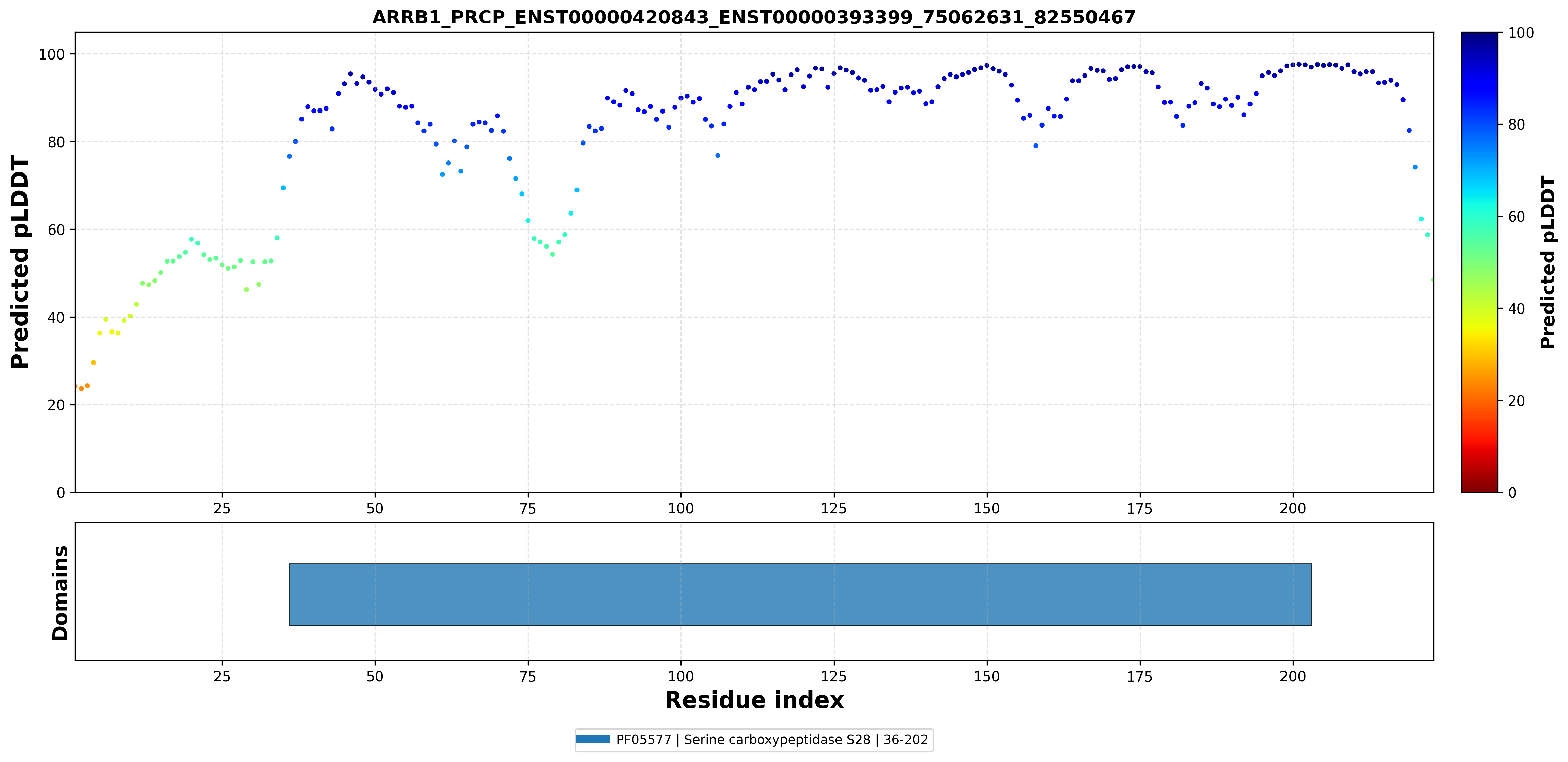 |  | 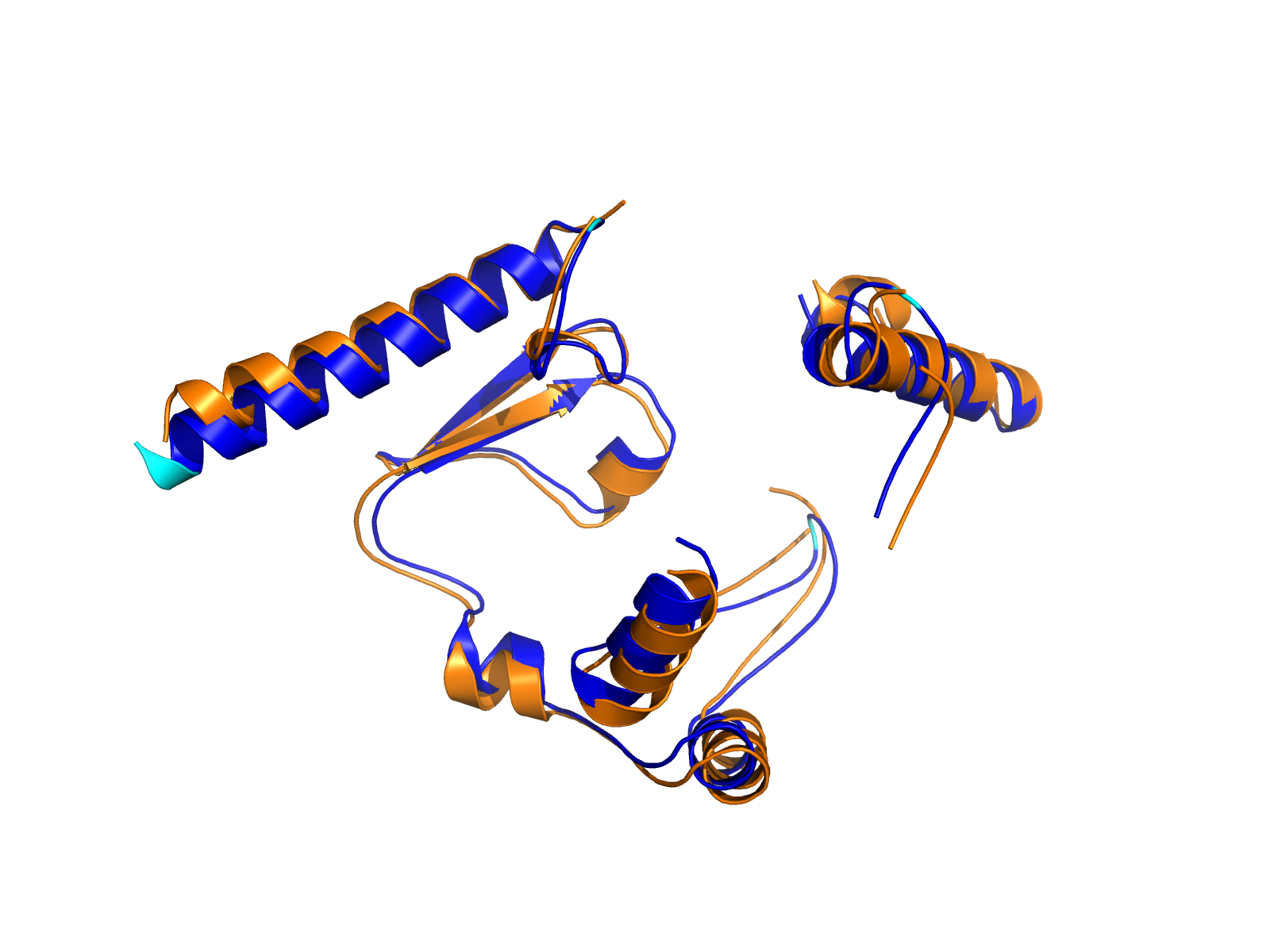 |
| ARRB1_TPCN2_ENST00000393505_ENST00000542467_74994330_68845949 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:0.7654
Å |
 |  |  |  |  |
| ARRB1_TPCN2_ENST00000393505_ENST00000542467_74994330_68845949 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.3951
Å |
| | | |  |
| ARRB1_TPCN2_ENST00000420843_ENST00000542467_74994330_68845949 superimposed PDB: 8AS4 of partner (ARRB1). RMSD:0.7931
Å |
 |  | 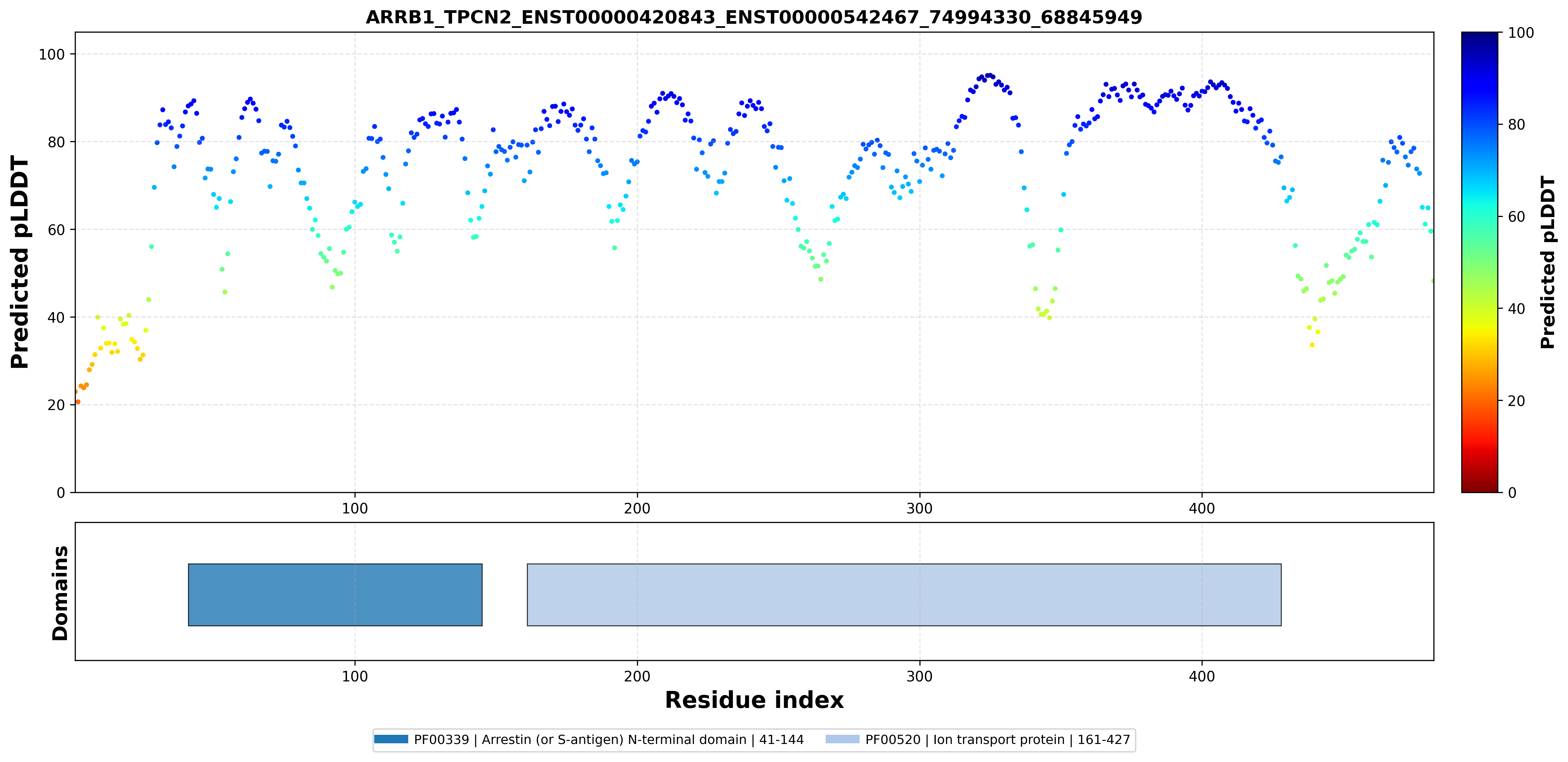 |  |  |
| ARRB1_TPCN2_ENST00000420843_ENST00000542467_74994330_68845949 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.2818
Å |
| | | |  |
| ARRB1_UVRAG_ENST00000393505_ENST00000528420_75062631_75599872 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.9911
Å |
 |  |  |  |  |
| ARRB1_UVRAG_ENST00000420843_ENST00000528420_75062631_75599872 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:3.1528
Å |
 |  |  |  |  |
| ARRDC2_DPYSL3_ENST00000379656_ENST00000343218_18112382_146781259 superimposed PDB: 4BKN of partner (DPYSL3). RMSD:0.5745
Å |
 |  | 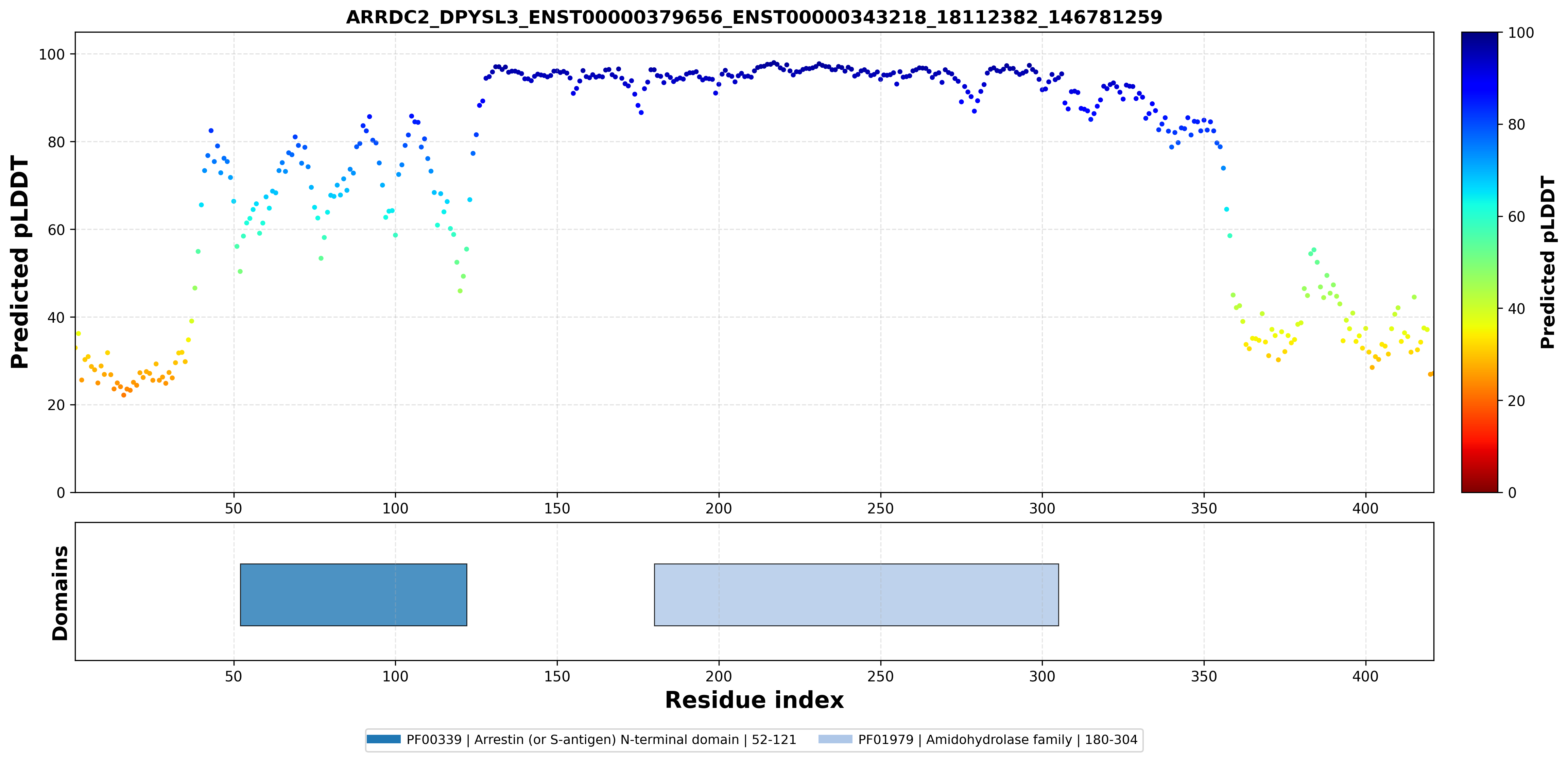 |  |  |
| ARSB_COMMD7_ENST00000264914_ENST00000446419_78251117_31294562 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.4924
Å |
 |  |  |  |  |
| ARSG_AP2B1_ENST00000448504_ENST00000592545_66366665_34044213 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.777
Å |
 |  |  |  |  |
| ARSG_AP2B1_ENST00000452479_ENST00000592545_66366665_34044213 superimposed PDB: 6YAF of partner (AP2B1). RMSD:2.512
Å |
 |  |  |  |  |
| ARSG_CDK12_ENST00000448504_ENST00000447079_66352945_37667781 superimposed PDB: 4NST of partner (CDK12). RMSD:0.424
Å |
 |  |  |  |  |
| ARSG_CDK12_ENST00000452479_ENST00000430627_66352945_37667781 superimposed PDB: 4NST of partner (CDK12). RMSD:0.4242
Å |
 |  |  |  |  |
| ARSG_CDK12_ENST00000452479_ENST00000447079_66352945_37667781 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3488
Å |
 |  |  |  |  |
| ASAP1_FAM19A5_ENST00000357668_ENST00000402357_131249167_49042408 superimposed PDB: 2DA0 of partner (ASAP1). RMSD:1.4377
Å |
 |  | 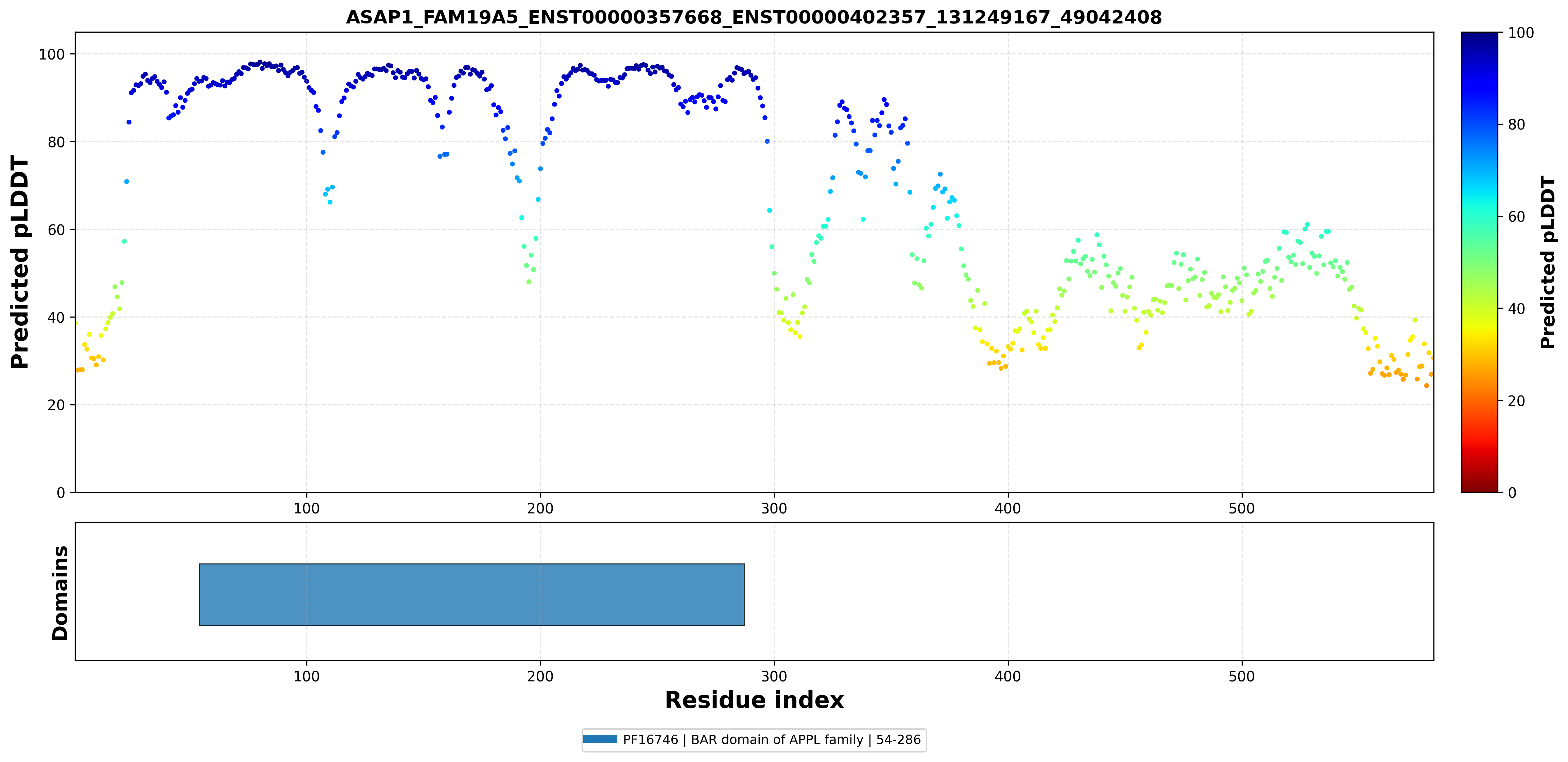 |  |  |
| ASAP2_CPSF3_ENST00000315273_ENST00000238112_9468040_9568893 superimposed PDB: 9NH5 of partner (CPSF3). RMSD:2.0184
Å |
 |  | 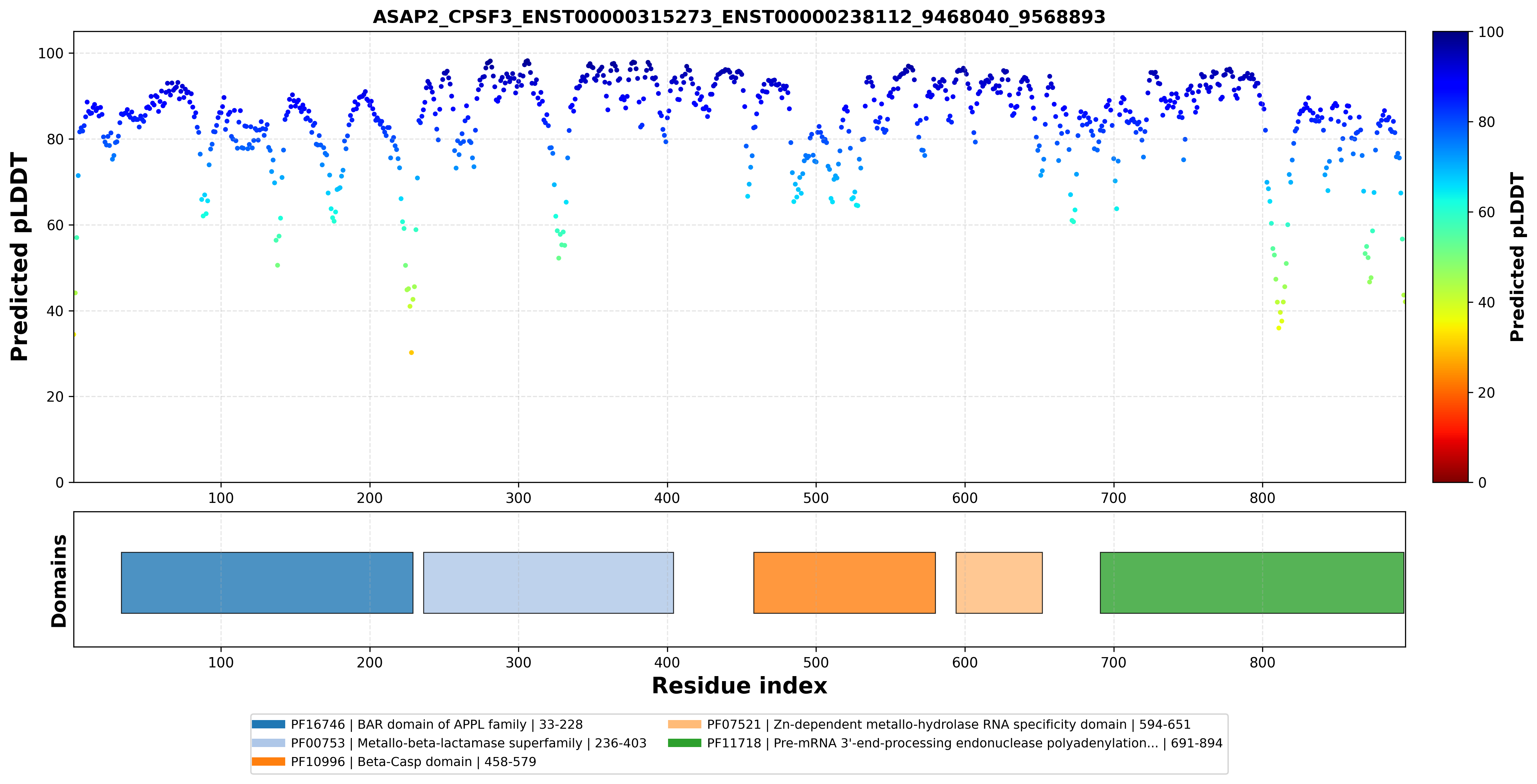 |  |  |
| ASCC1_MICU1_ENST00000342444_ENST00000361114_73892814_74135630 superimposed PDB: 8TLY of partner (ASCC1). RMSD:0.615
Å |
 |  |  |  |  |
| ASCC1_MICU1_ENST00000342444_ENST00000361114_73956568_74183129 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.3928
Å |
 |  | 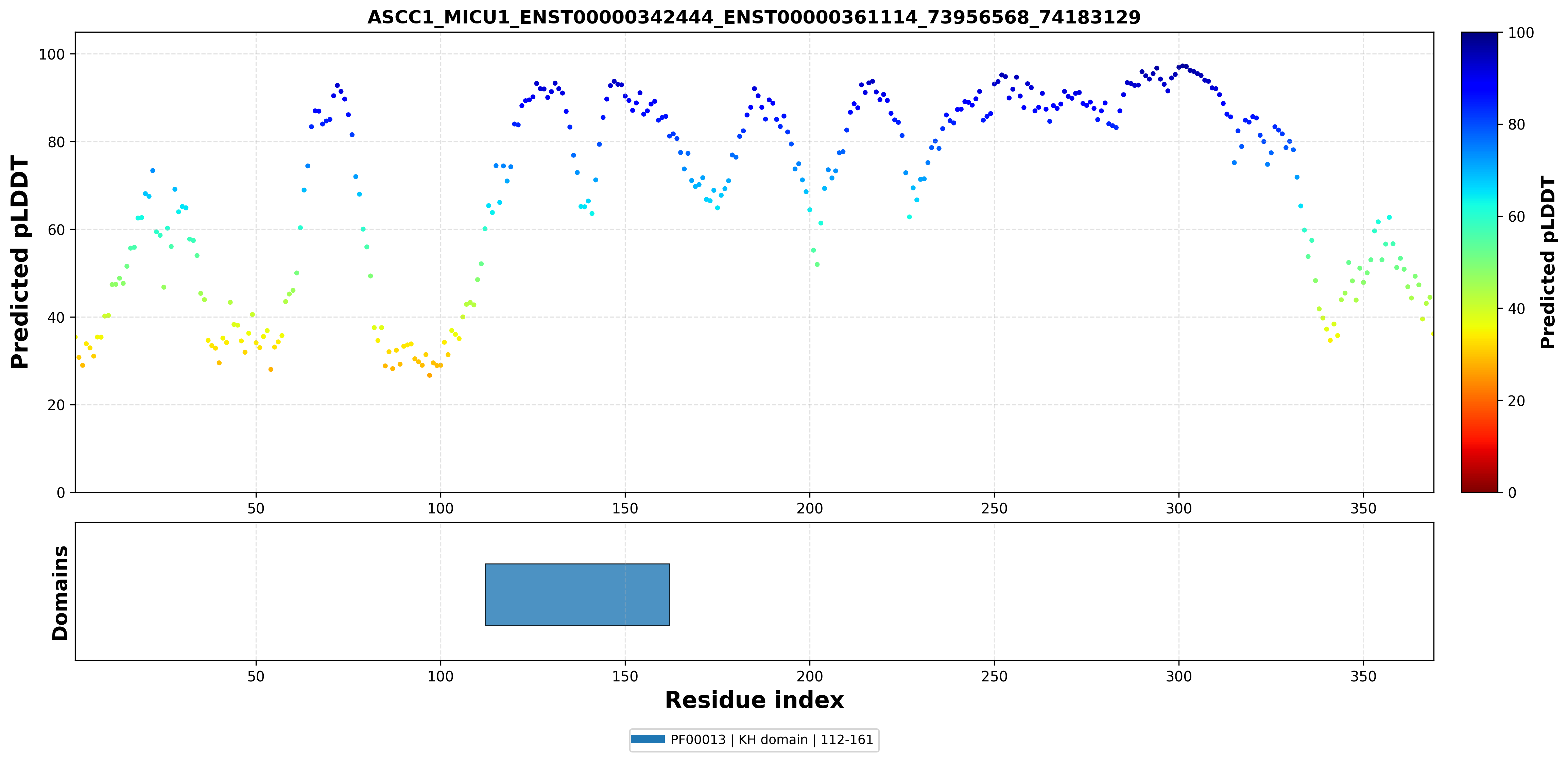 |  |  |
| ASCC1_MICU1_ENST00000342444_ENST00000361114_73972944_74183129 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.5458
Å |
 |  | 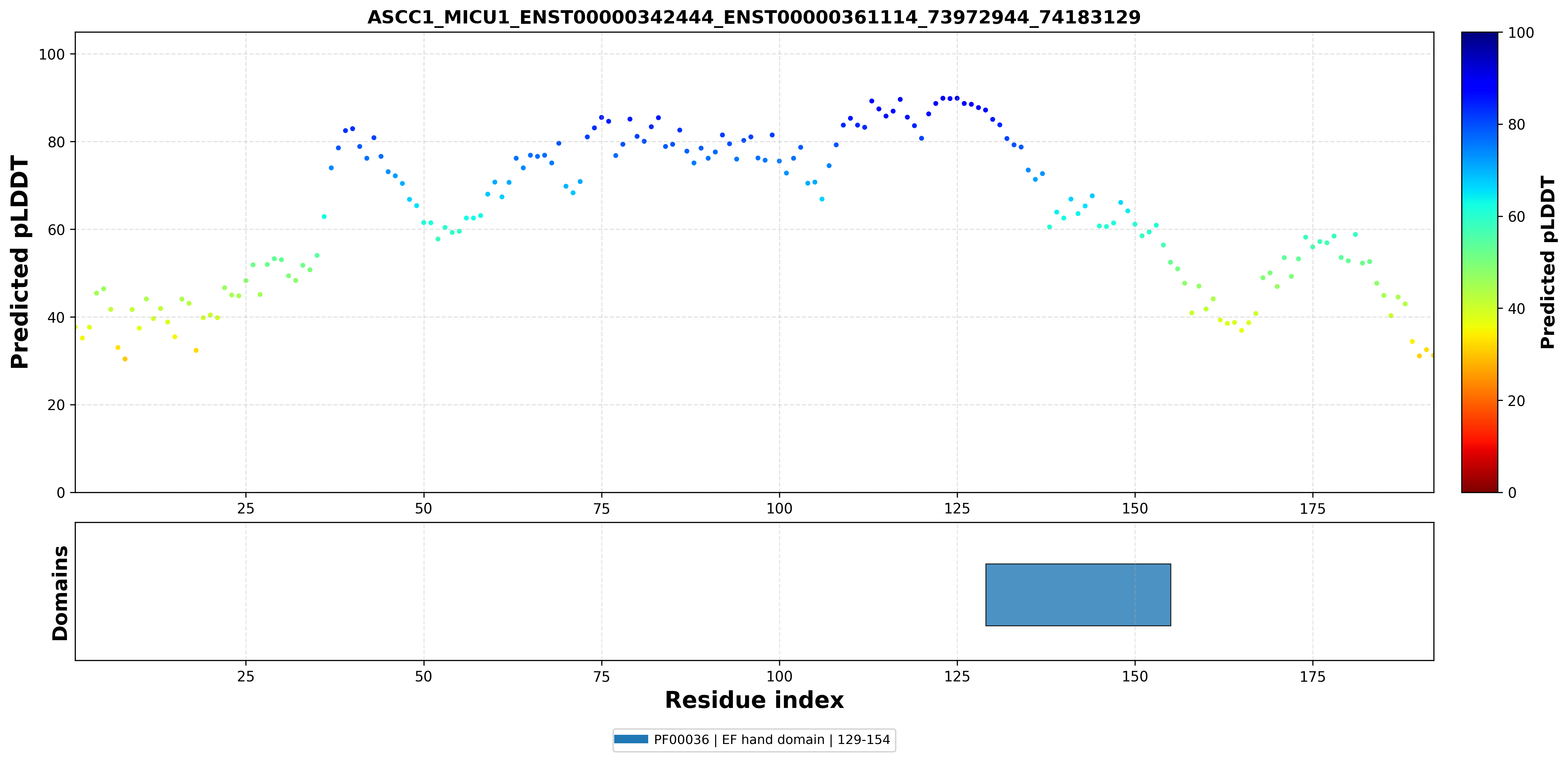 |  |  |
| ASCC1_MICU1_ENST00000342444_ENST00000401998_73956568_74167795 superimposed PDB: 8TLY of partner (ASCC1). RMSD:1.4188
Å |
 |  |  |  |  |
| ASCC1_MICU1_ENST00000394919_ENST00000361114_73887839_74135630 superimposed PDB: 8TLY of partner (ASCC1). RMSD:0.7764
Å |
 |  |  |  |  |
| ASCC1_MICU1_ENST00000394919_ENST00000361114_73956568_74135630 superimposed PDB: 6K7Y of partner (MICU1). RMSD:3.0653
Å |
 |  |  |  |  |
| ASCC1_MICU1_ENST00000545550_ENST00000361114_73892814_74135630 superimposed PDB: 8TLY of partner (ASCC1). RMSD:0.7395
Å |
 |  | 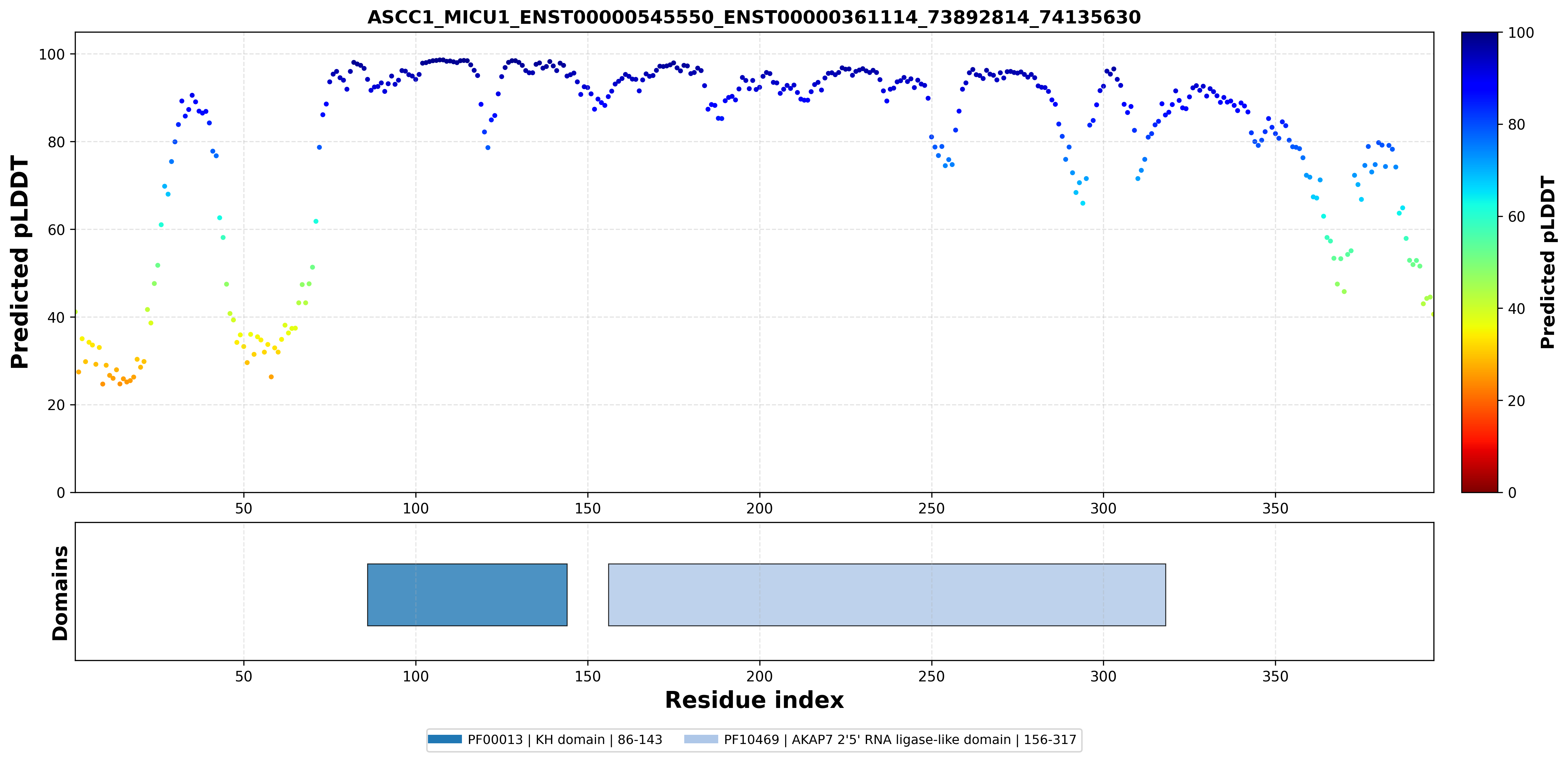 |  |  |
| ASCC1_MICU1_ENST00000545550_ENST00000361114_73956568_74183129 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.2478
Å |
 |  | 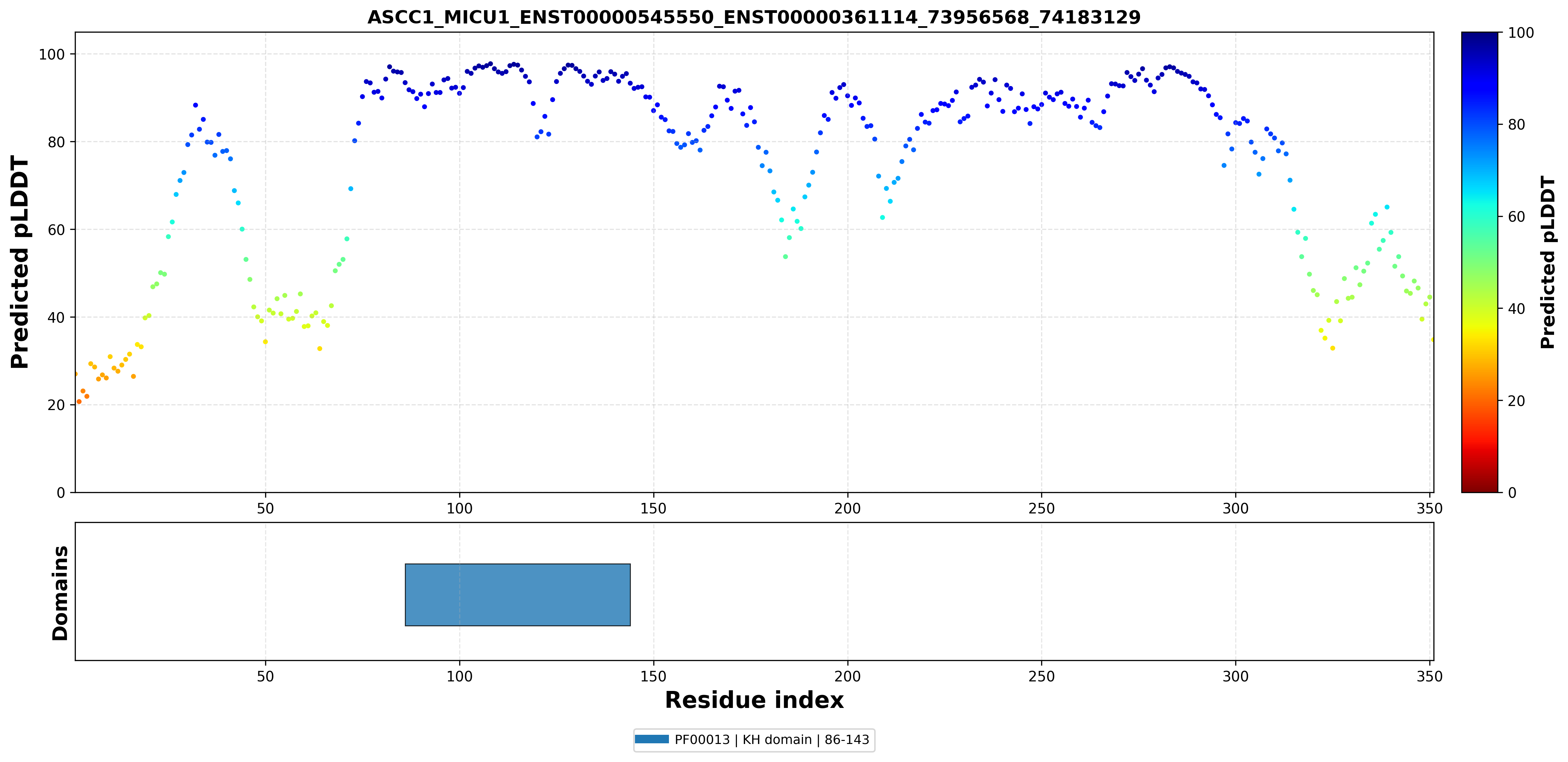 |  |  |
| ASH2L_CASS4_ENST00000250635_ENST00000360314_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8367
Å |
 |  | 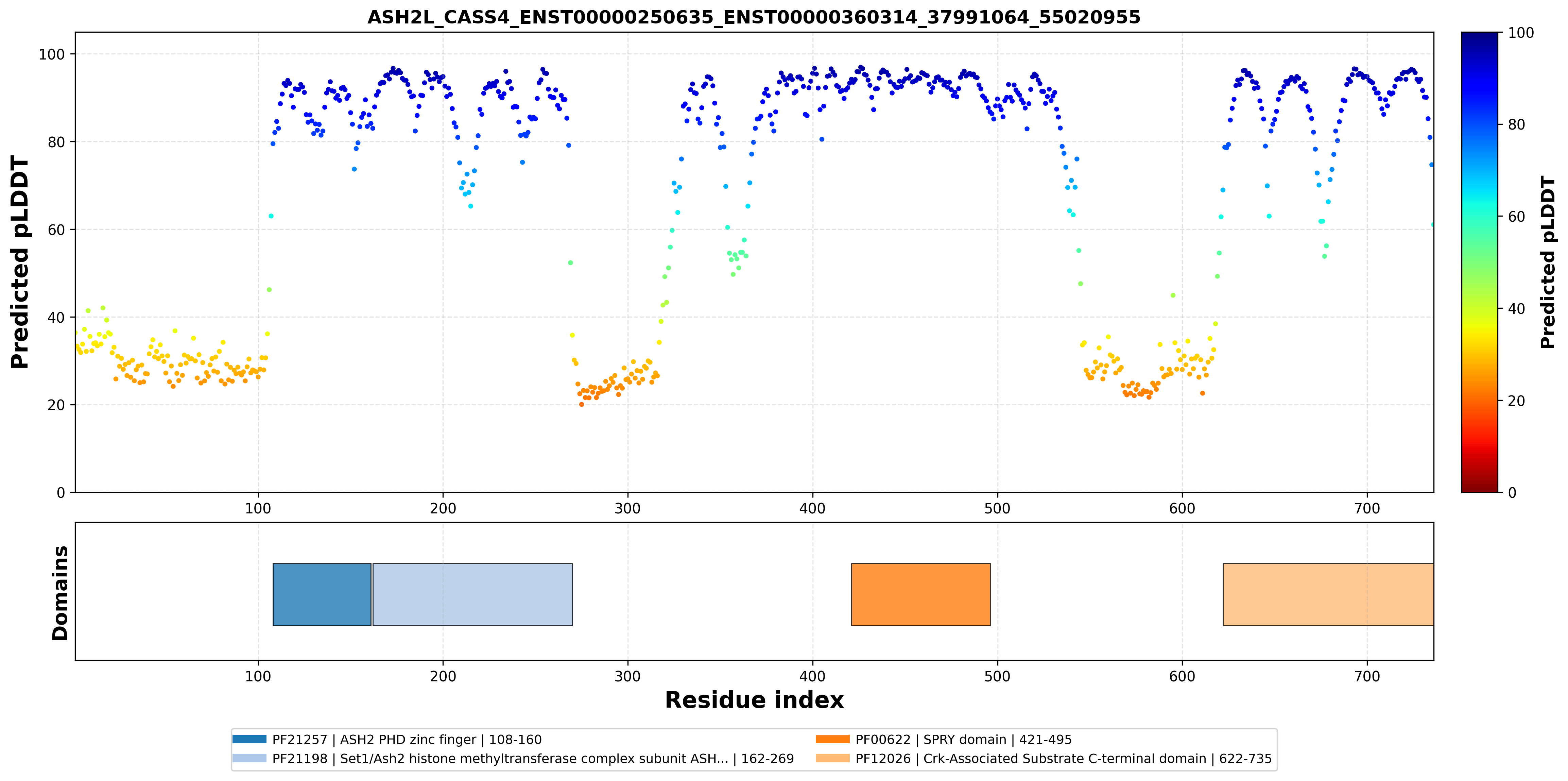 |  |  |
| ASH2L_CASS4_ENST00000343823_ENST00000371336_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.797
Å |
 |  | 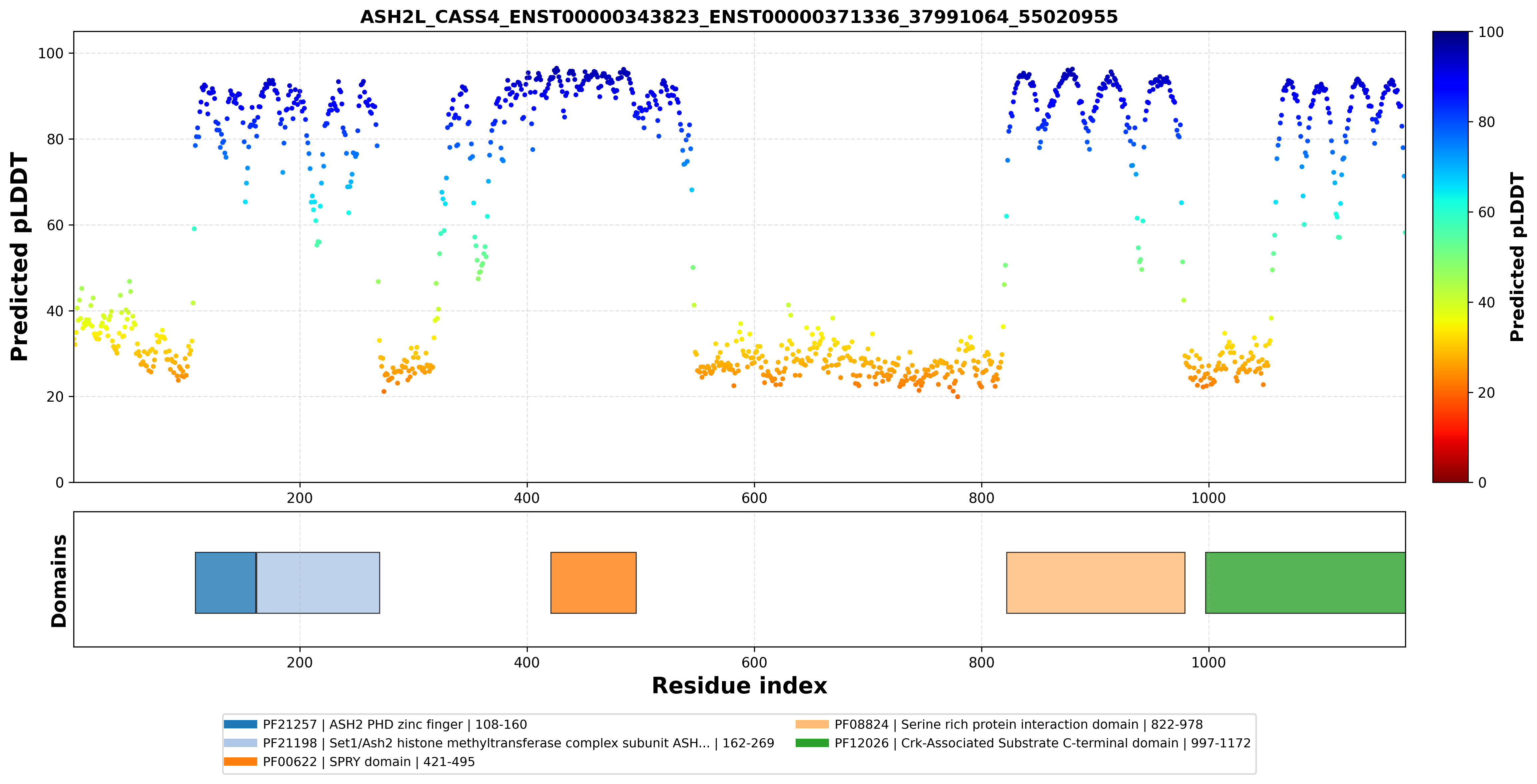 |  |  |
| ASH2L_CASS4_ENST00000428278_ENST00000360314_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8708
Å |
 |  | 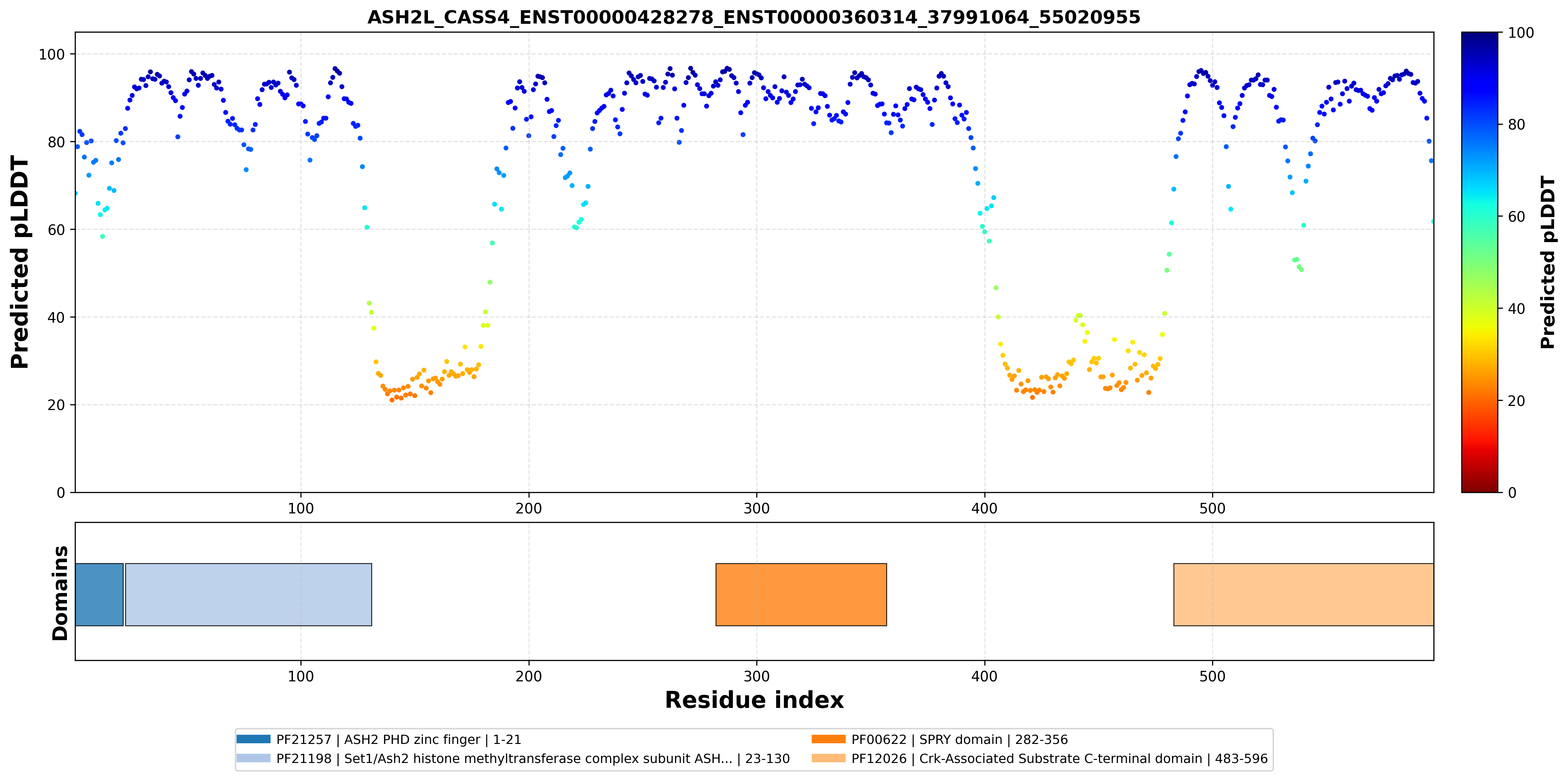 |  |  |
| ASH2L_CASS4_ENST00000428278_ENST00000371336_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8616
Å |
 |  | 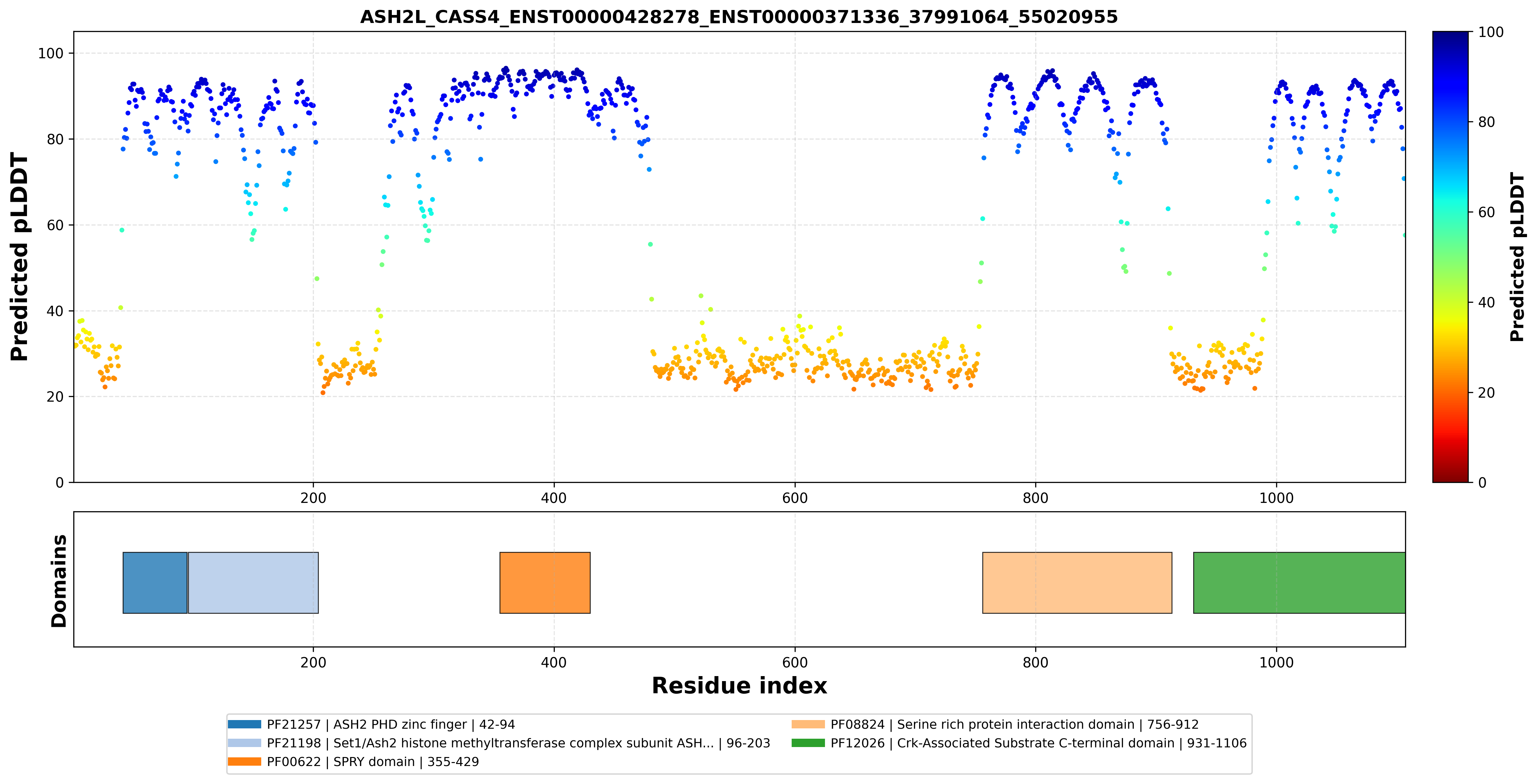 |  |  |
| ASH2L_CASS4_ENST00000521652_ENST00000360314_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8132
Å |
 |  | 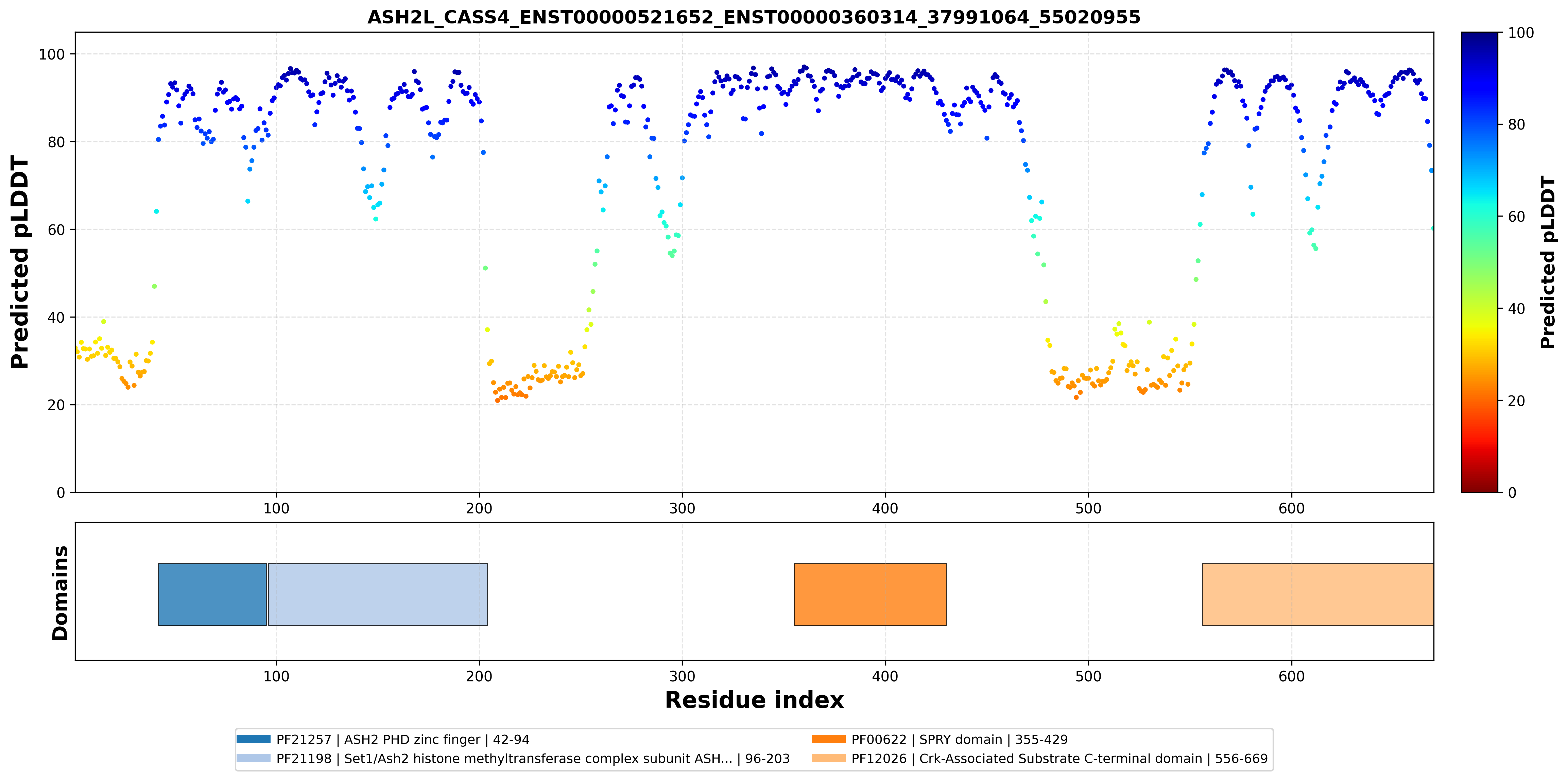 |  |  |
| ASH2L_CASS4_ENST00000545394_ENST00000371336_37991064_55020955 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8702
Å |
 |  | 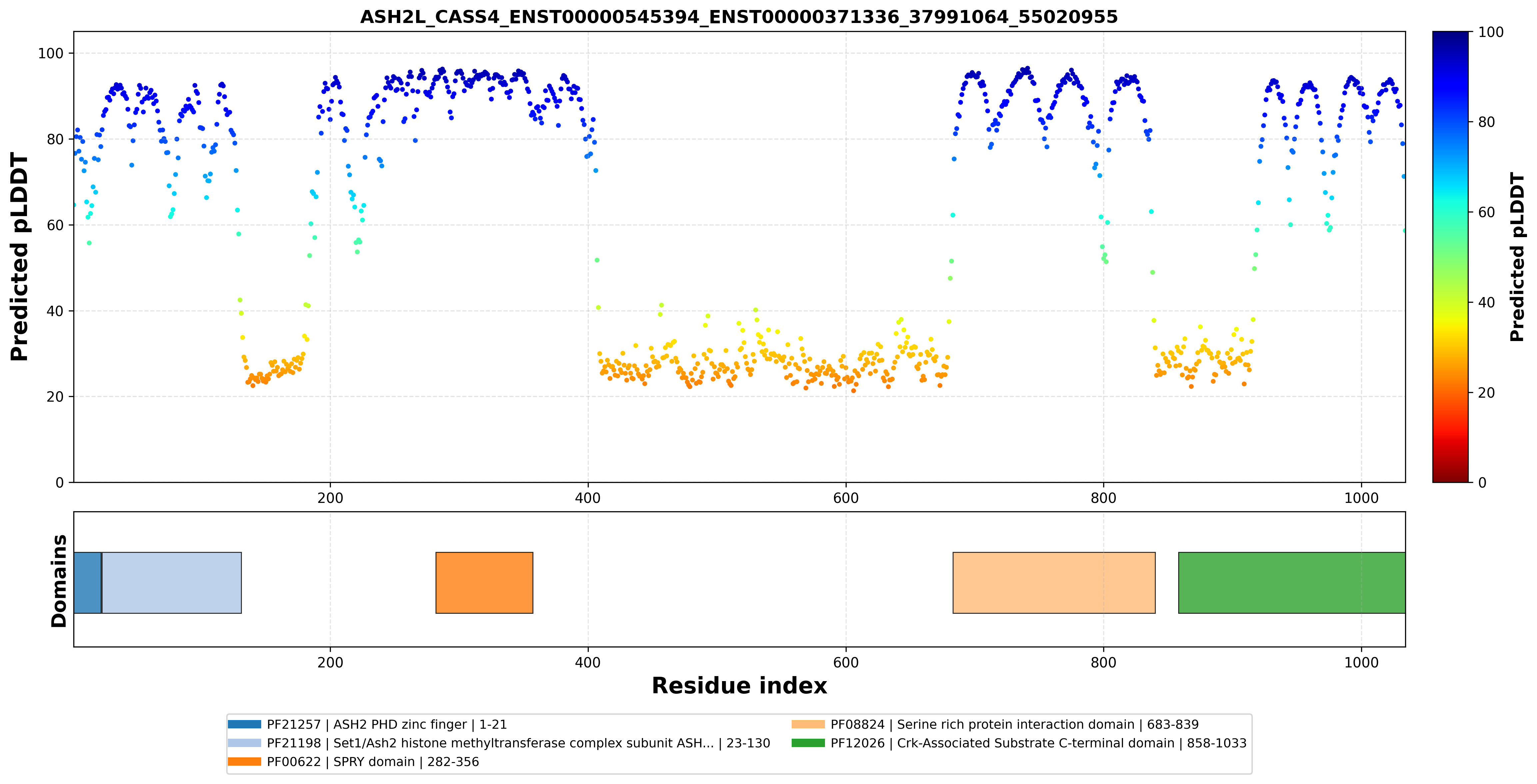 |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000250241_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8309
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000250241_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8533
Å |
| | | |  |
| ASH2L_ILF3_ENST00000343823_ENST00000407004_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8221
Å |
 |  | 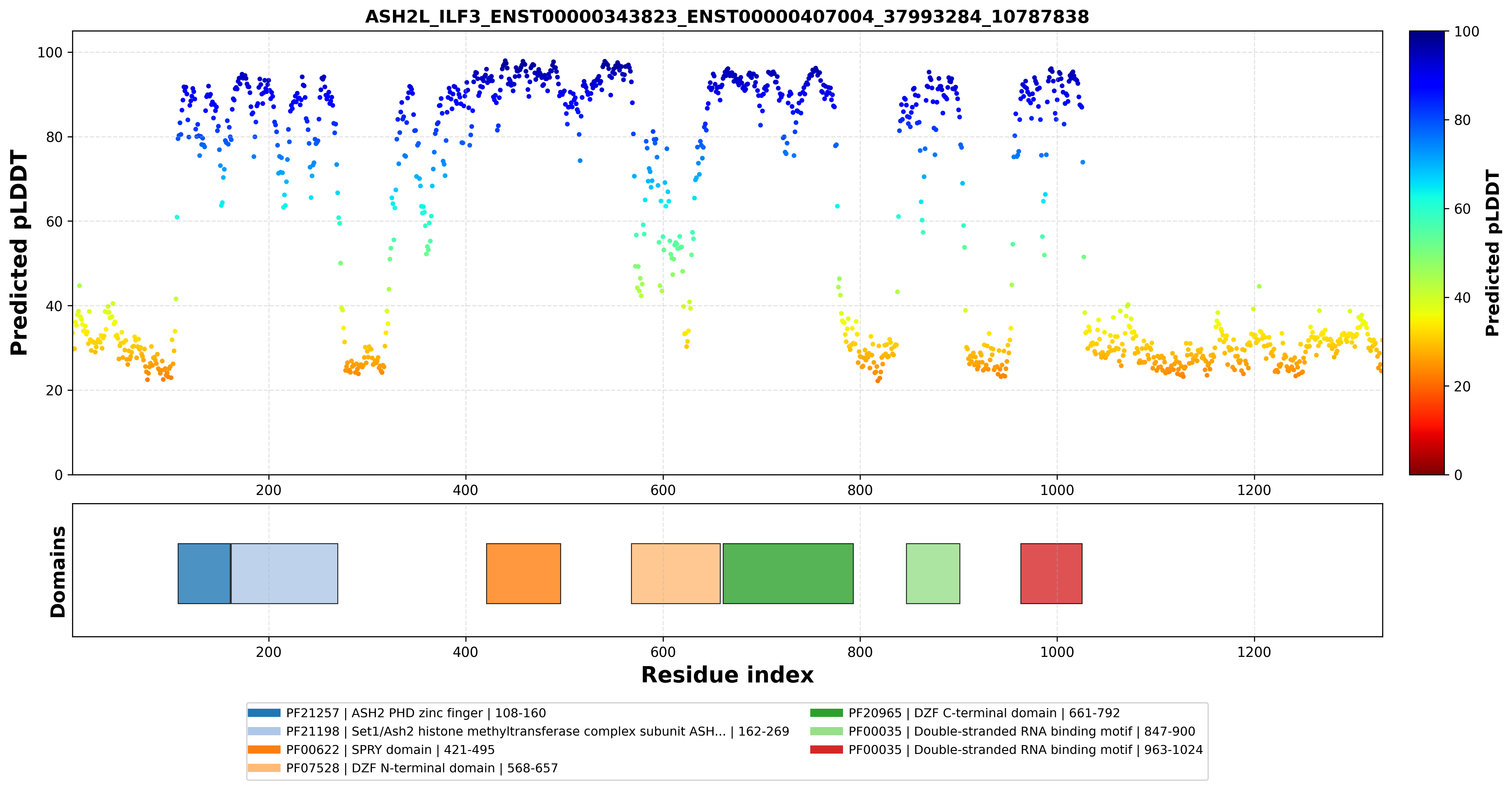 |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000407004_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8736
Å |
| | | |  |
| ASH2L_ILF3_ENST00000343823_ENST00000588657_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.9719
Å |
 |  | 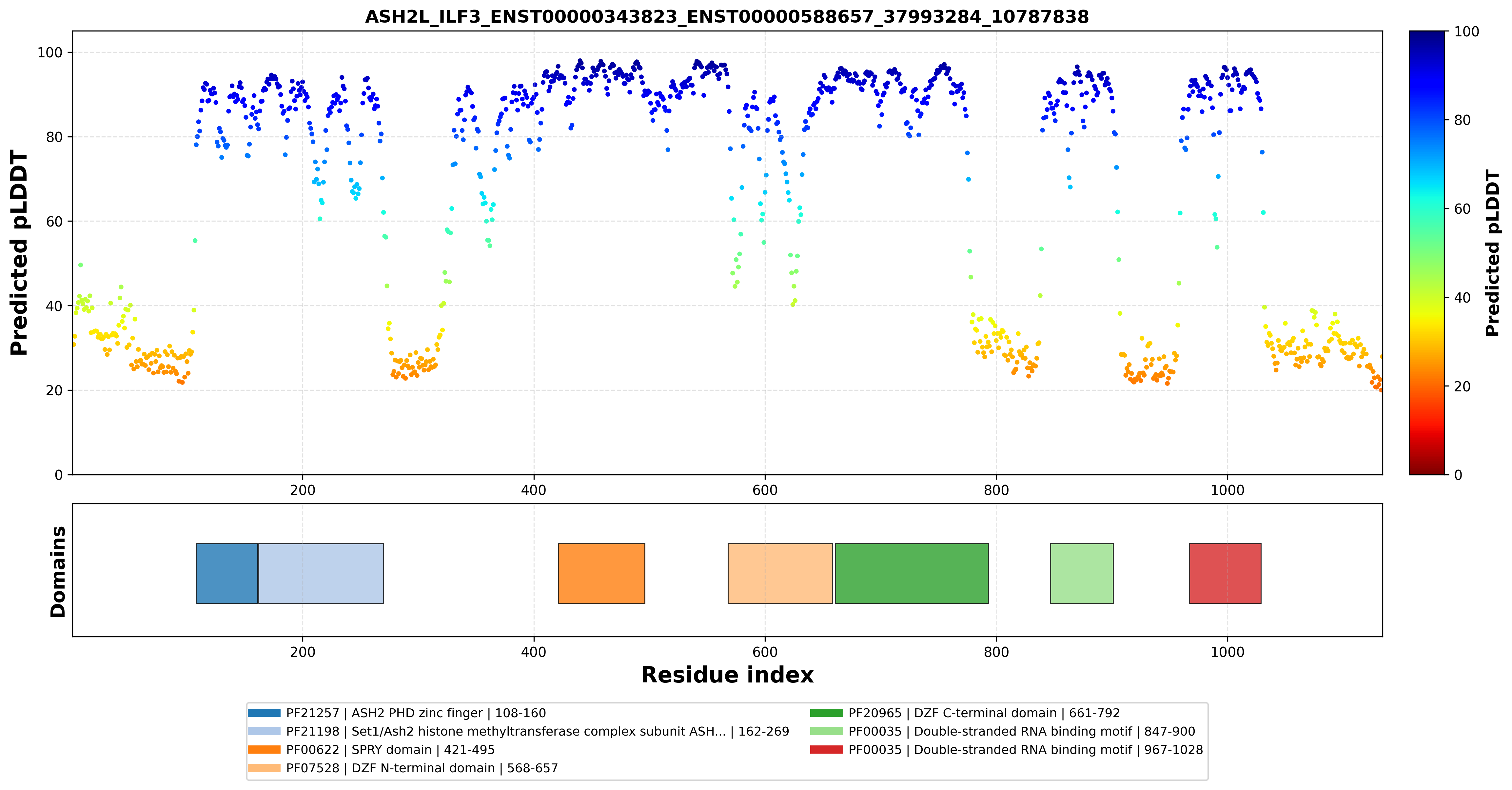 |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000588657_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8379
Å |
| | | |  |
| ASH2L_ILF3_ENST00000343823_ENST00000589998_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8539
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000589998_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8702
Å |
| | | |  |
| ASH2L_ILF3_ENST00000343823_ENST00000590261_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8124
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000590261_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8246
Å |
| | | |  |
| ASH2L_ILF3_ENST00000343823_ENST00000592763_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7952
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000343823_ENST00000592763_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.9083
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000250241_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8837
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000250241_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8979
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000318511_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7908
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000318511_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.835
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000407004_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8248
Å |
 |  | 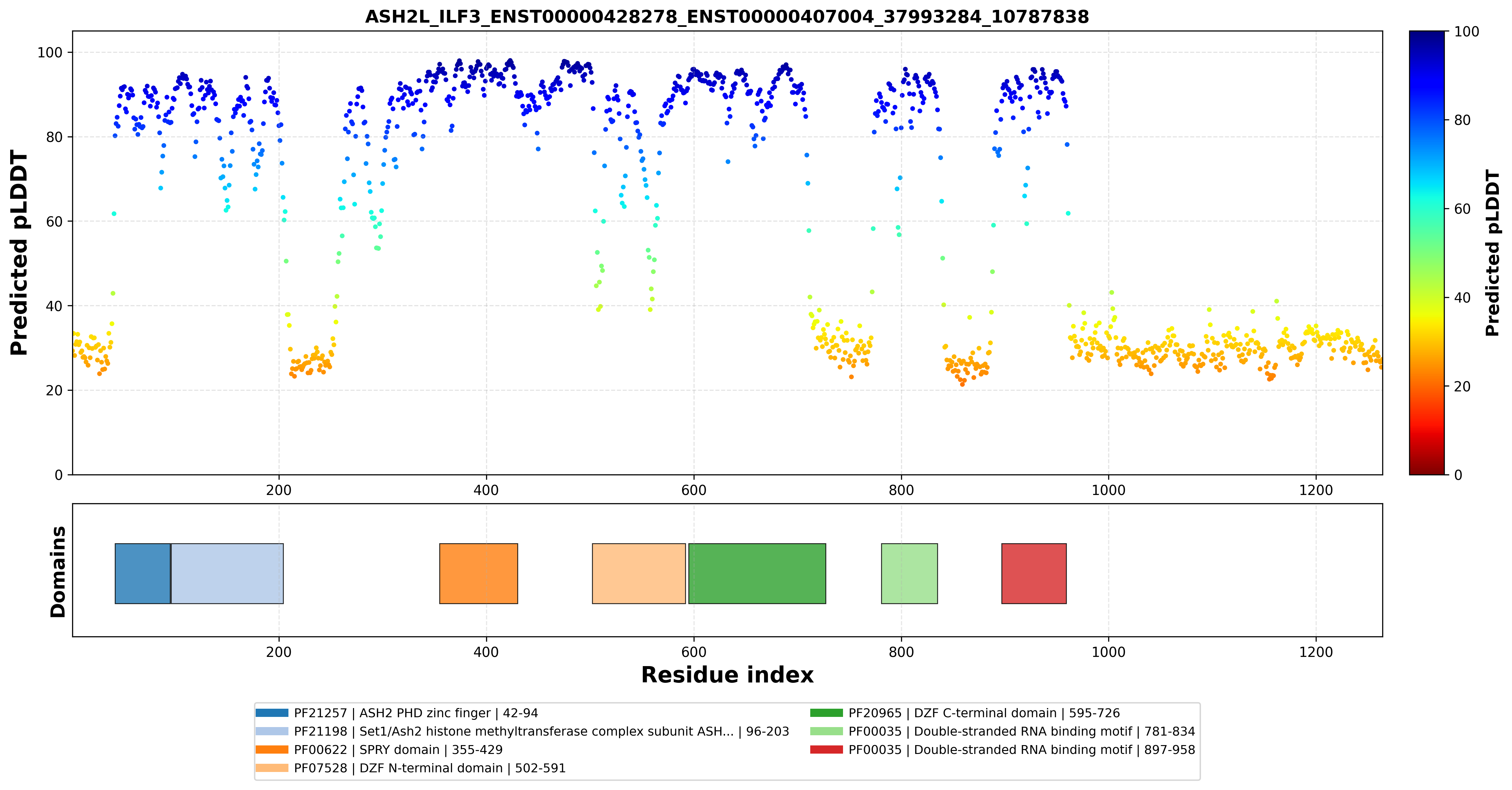 |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000407004_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.919
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000449870_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:1.0105
Å |
 |  | 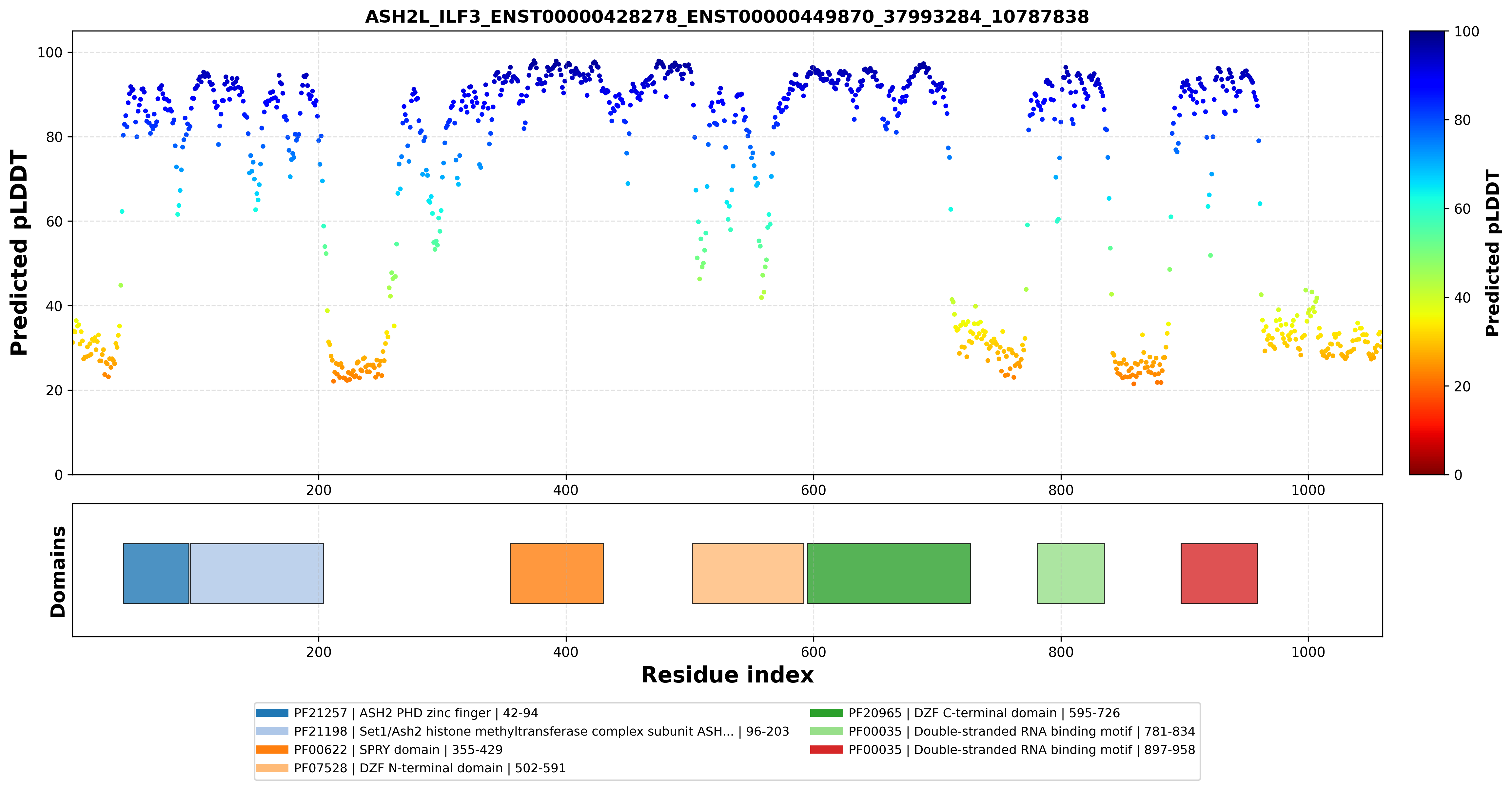 |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000449870_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8407
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000588657_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.9393
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000588657_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8788
Å |
| | | |  |
| ASH2L_ILF3_ENST00000428278_ENST00000589998_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8358
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000428278_ENST00000589998_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8359
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000250241_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8784
Å |
 |  | 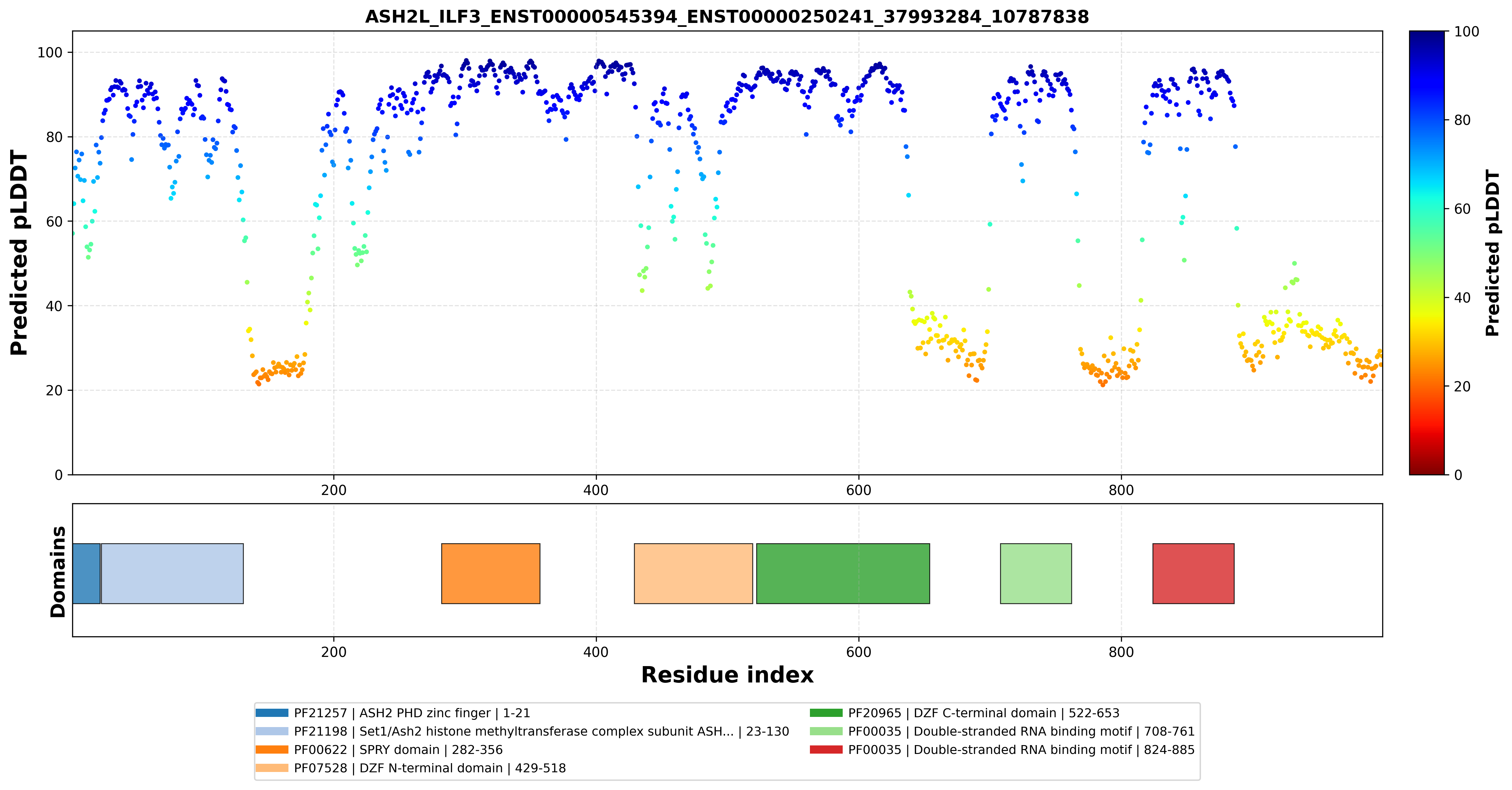 |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000250241_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8005
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000318511_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8631
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000318511_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8152
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000407004_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8975
Å |
 |  | 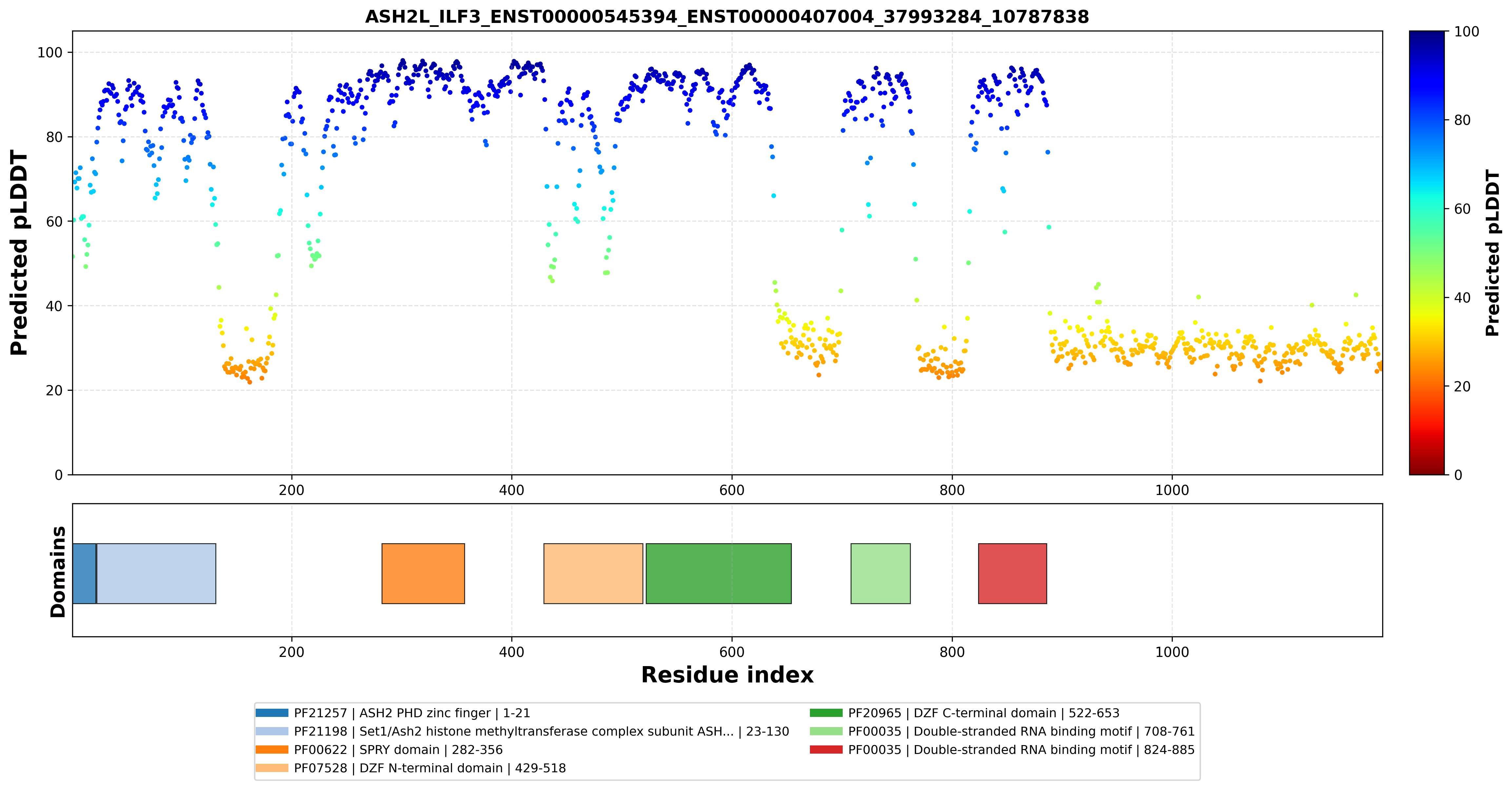 |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000407004_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8631
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000449870_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7835
Å |
 |  | 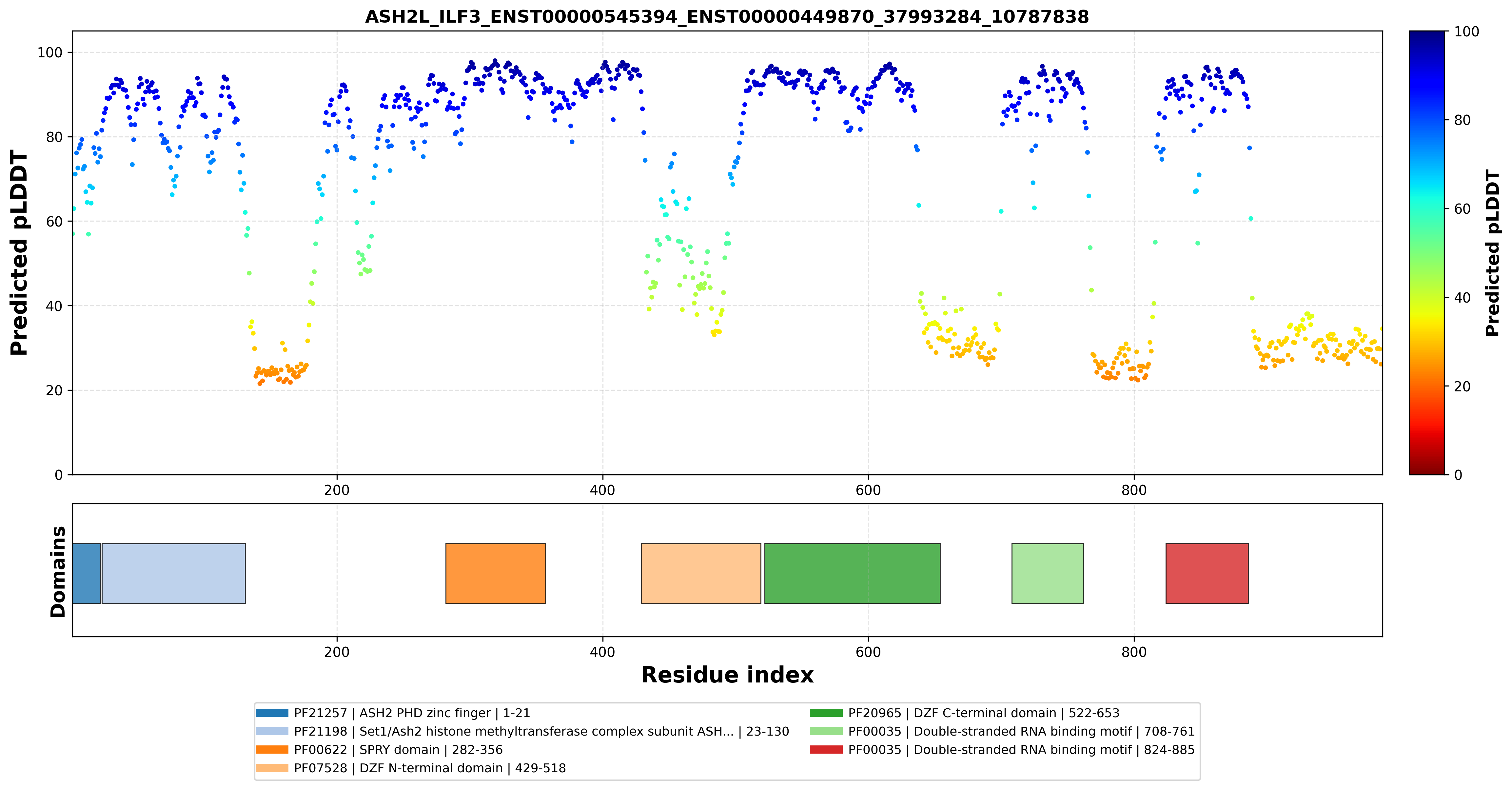 |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000449870_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8326
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000588657_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7851
Å |
 |  | 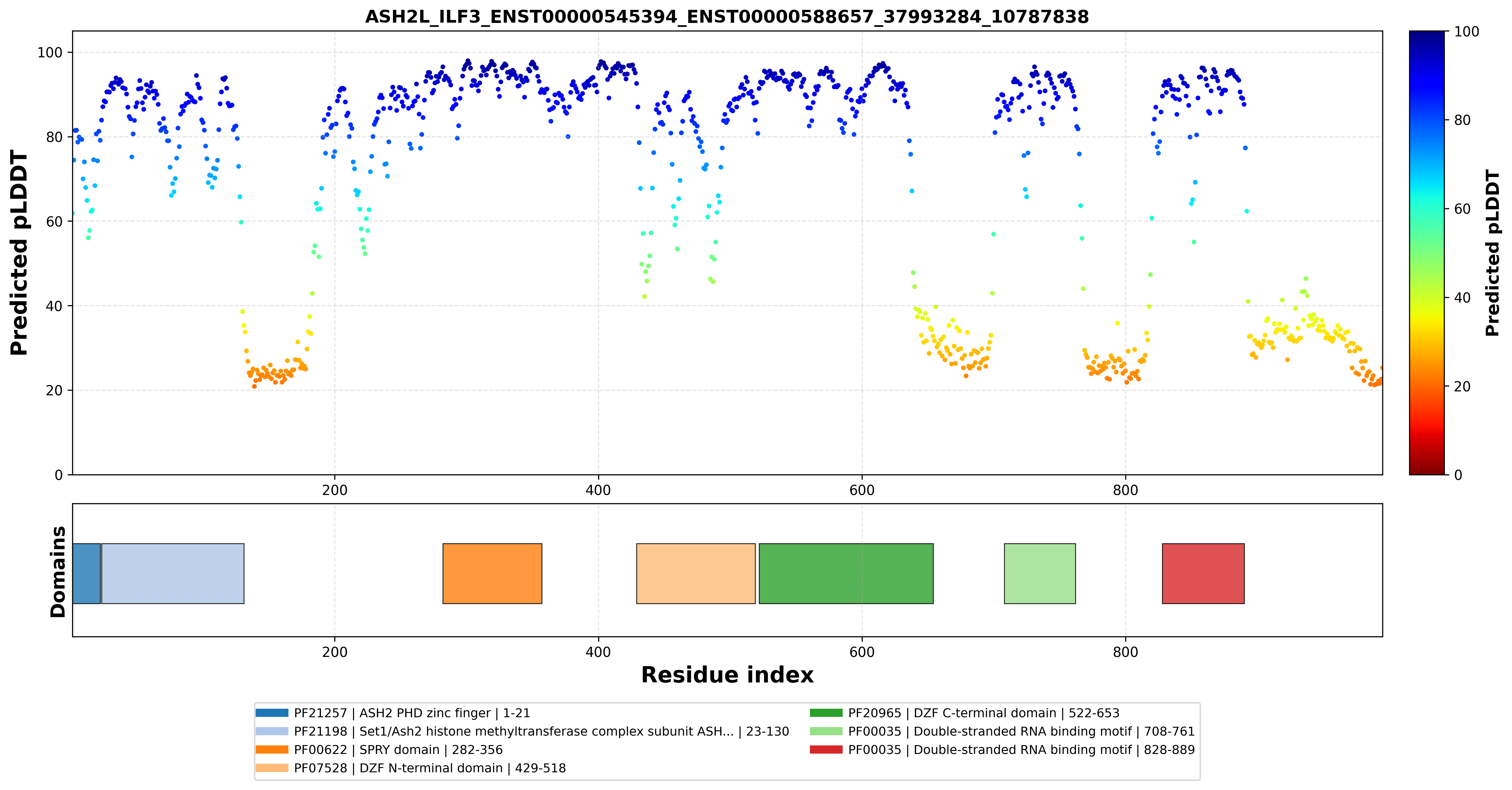 |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000588657_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8574
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000589998_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8023
Å |
 |  | 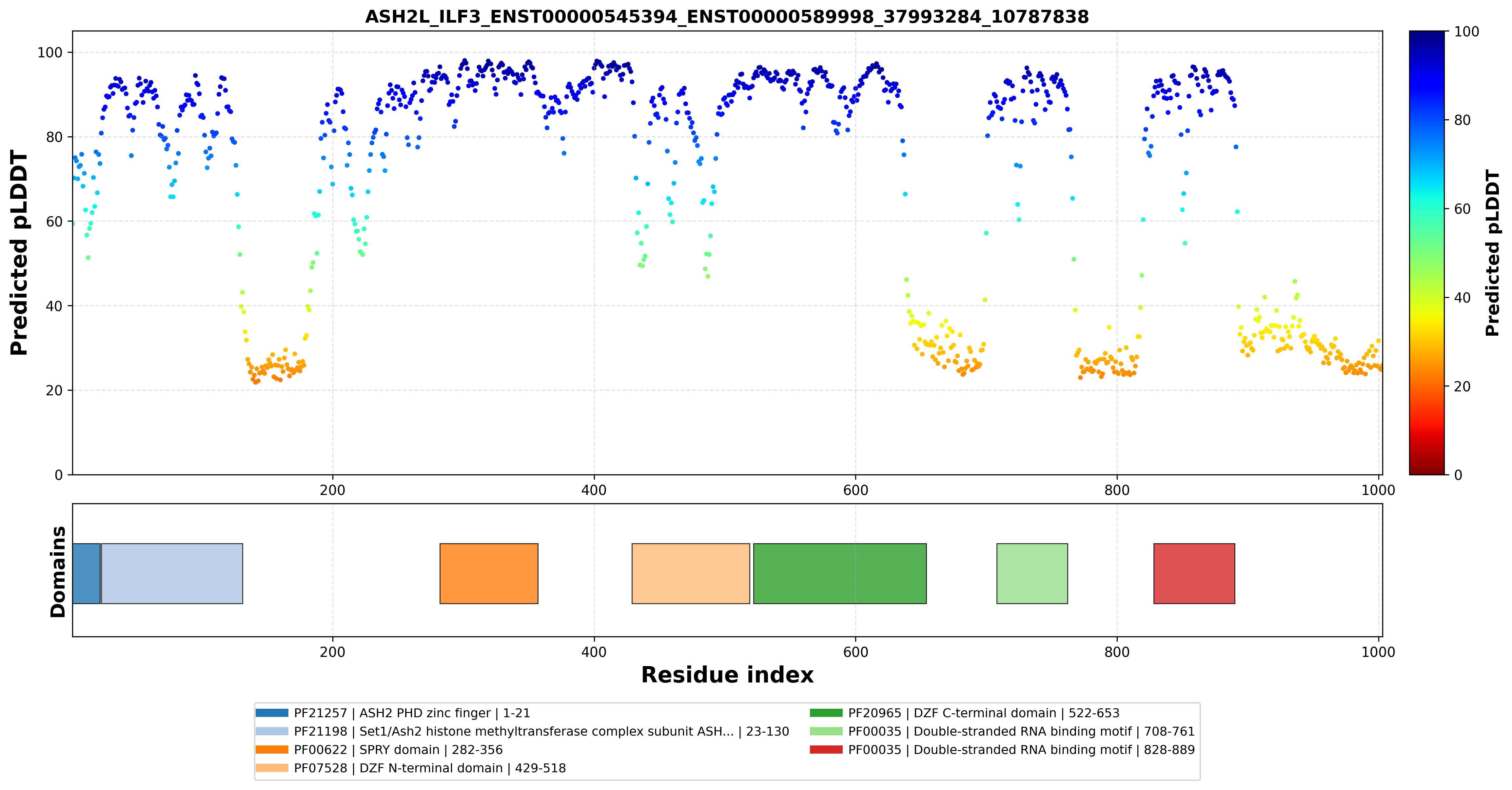 |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000589998_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8754
Å |
| | | |  |
| ASH2L_ILF3_ENST00000545394_ENST00000590261_37993284_10787838 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.856
Å |
 |  |  |  |  |
| ASH2L_ILF3_ENST00000545394_ENST00000590261_37993284_10787838 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8847
Å |
| | | |  |
| ASH2L_MLF1IP_ENST00000250635_ENST00000281453_37978667_185646216 superimposed PDB: 7R5S of partner (MLF1IP). RMSD:2.549
Å |
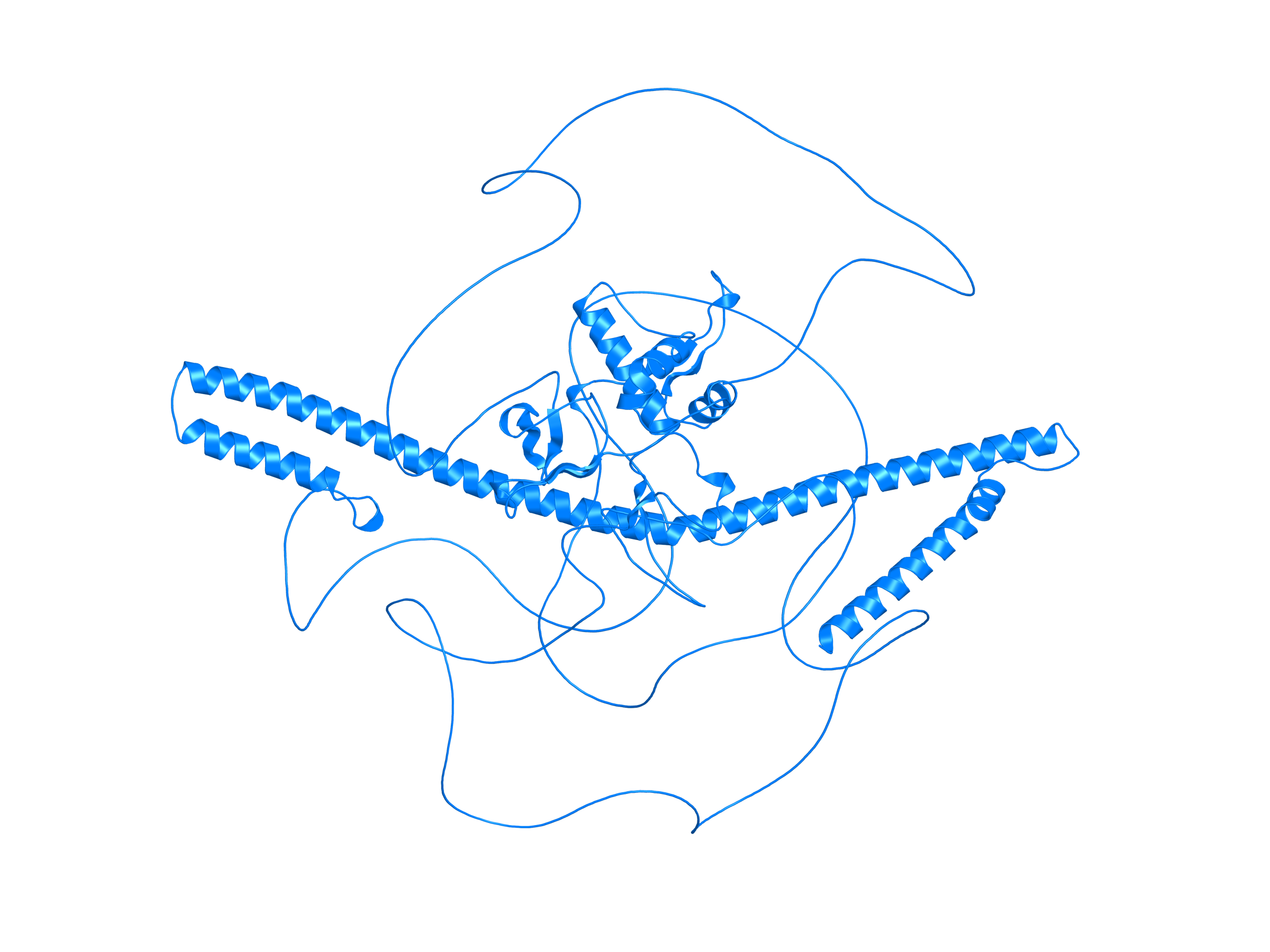 | 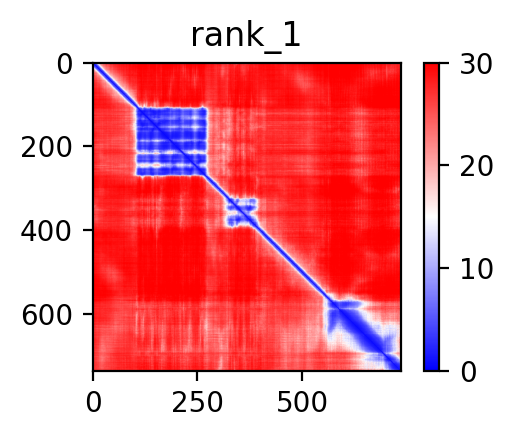 | 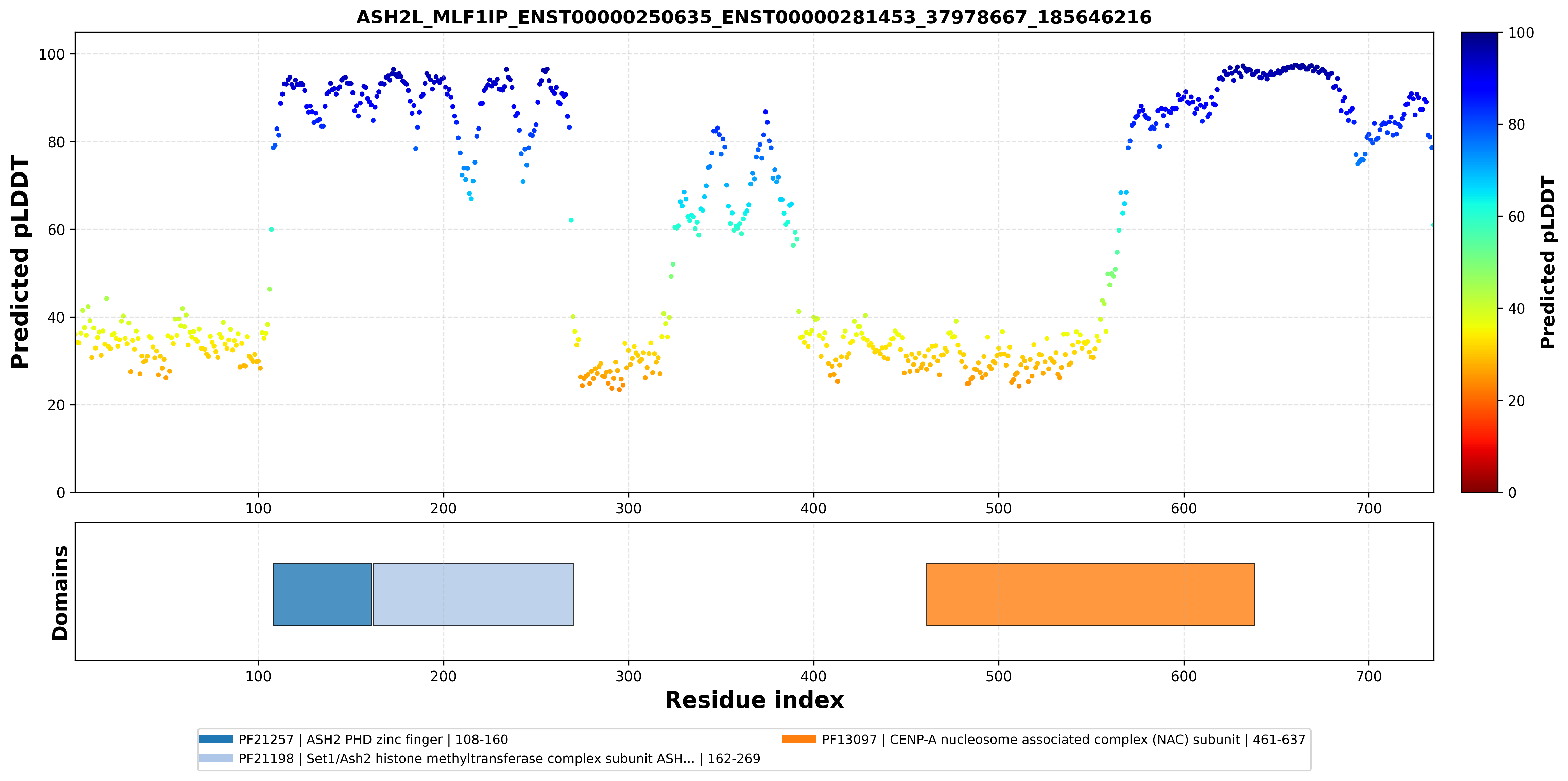 | 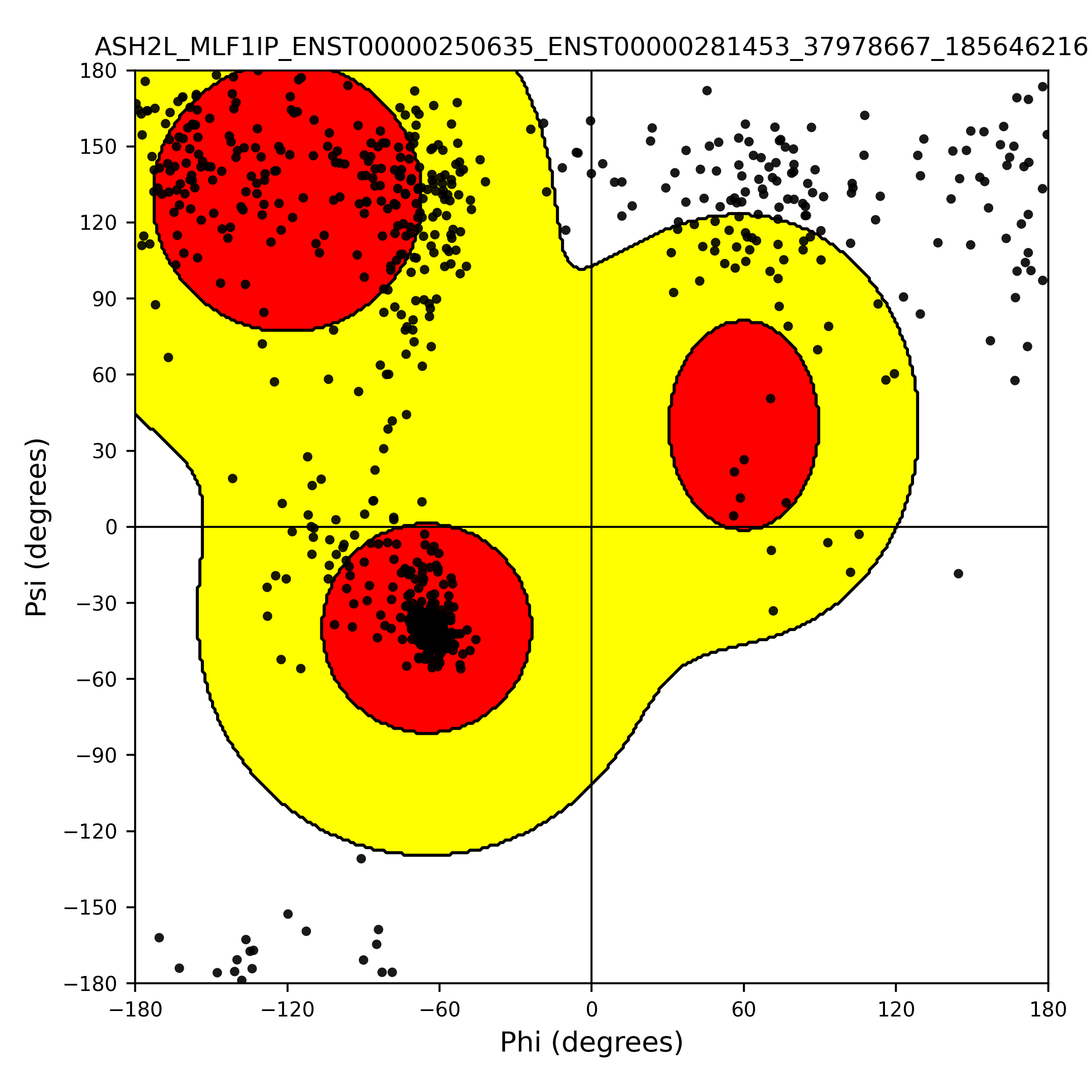 | 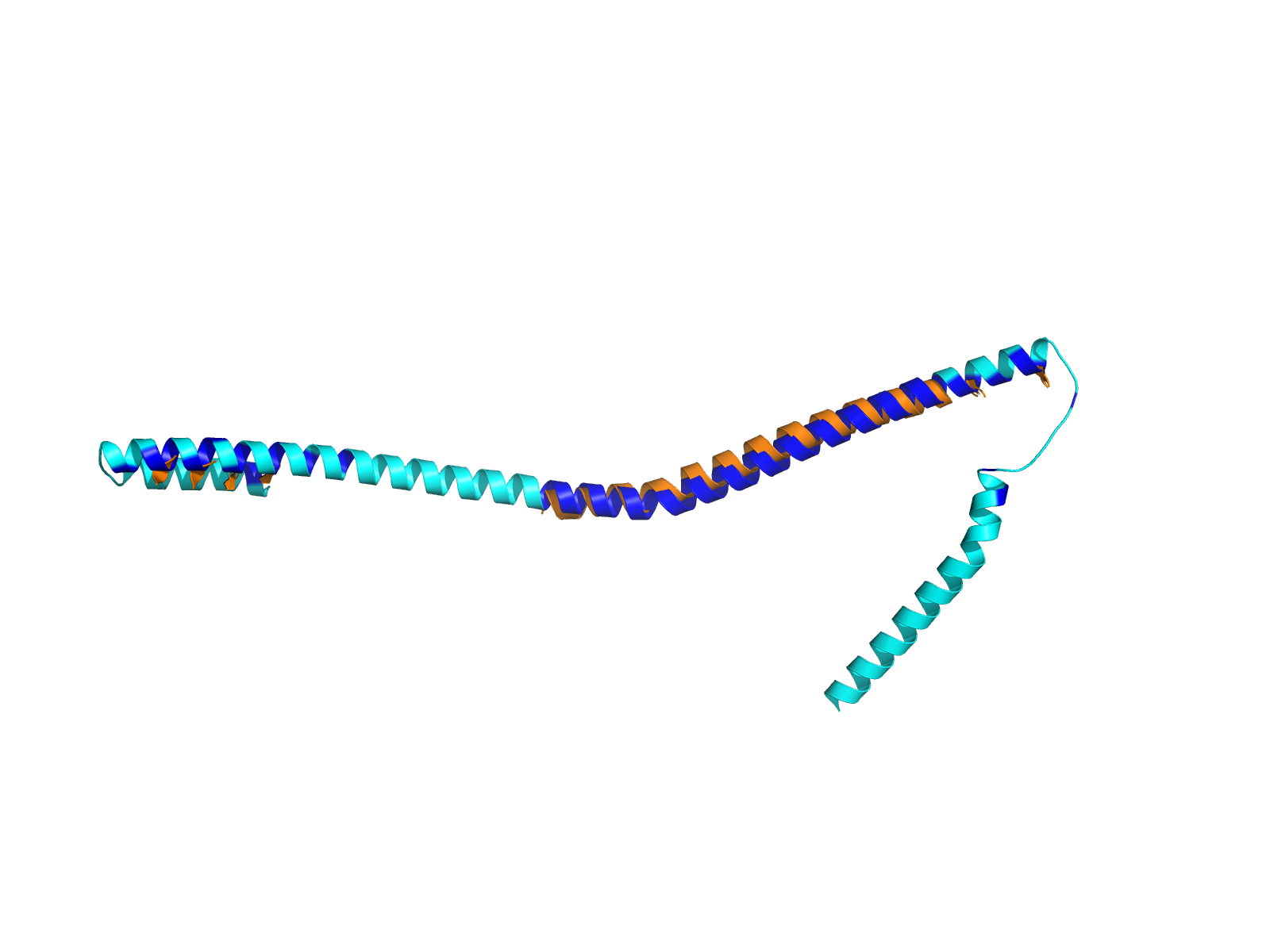 |
| ASH2L_MLF1IP_ENST00000428278_ENST00000281453_37978667_185646216 superimposed PDB: 7R5S of partner (MLF1IP). RMSD:2.4627
Å |
 | 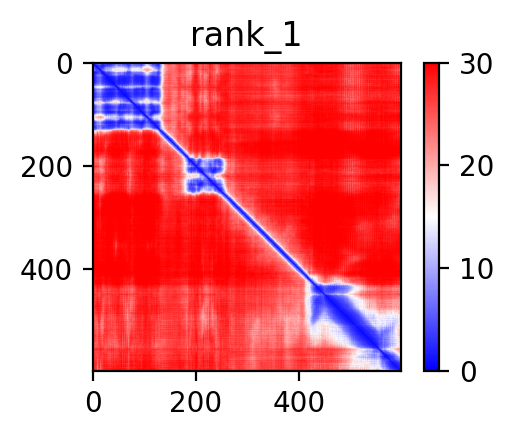 | 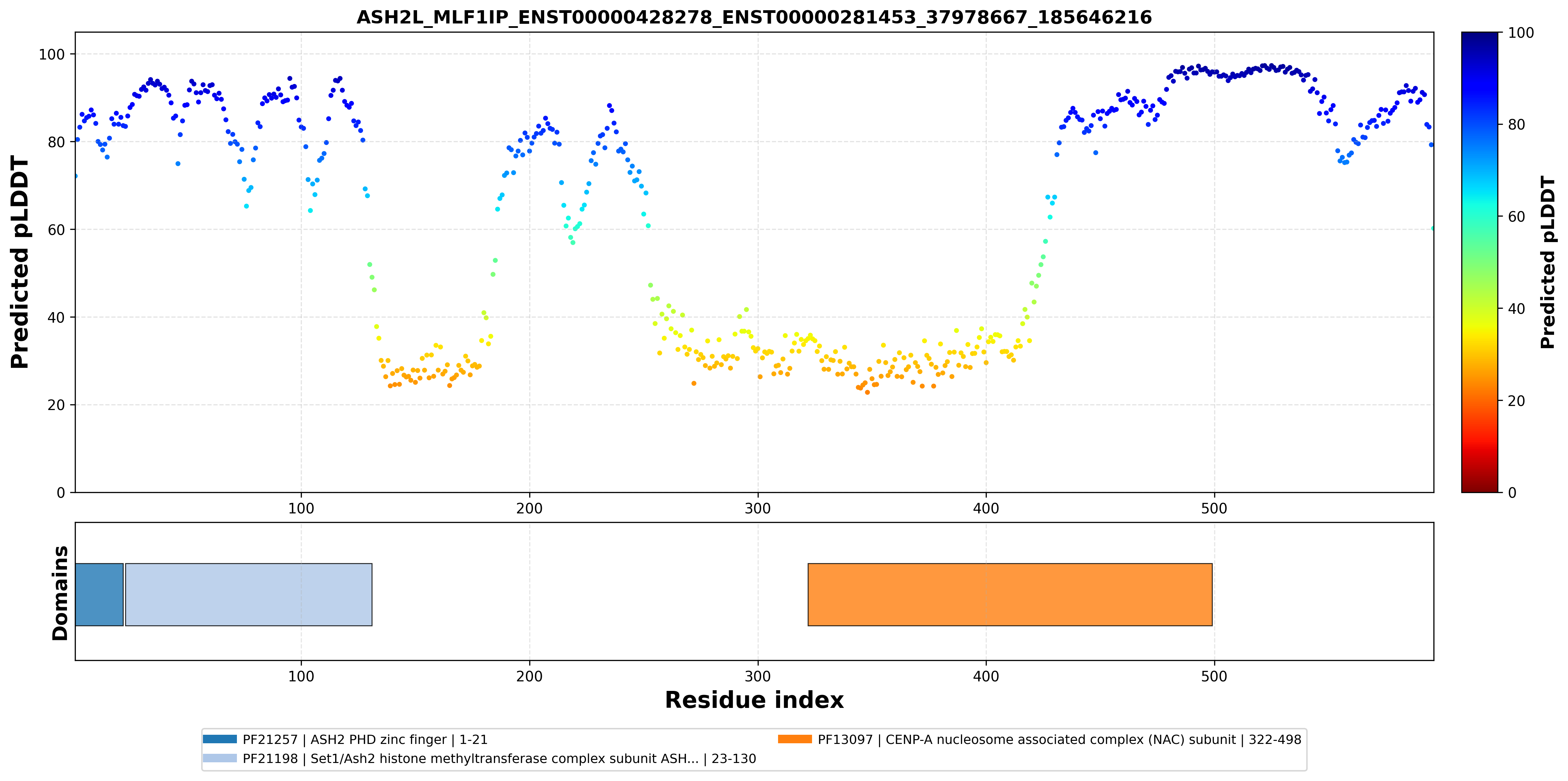 | 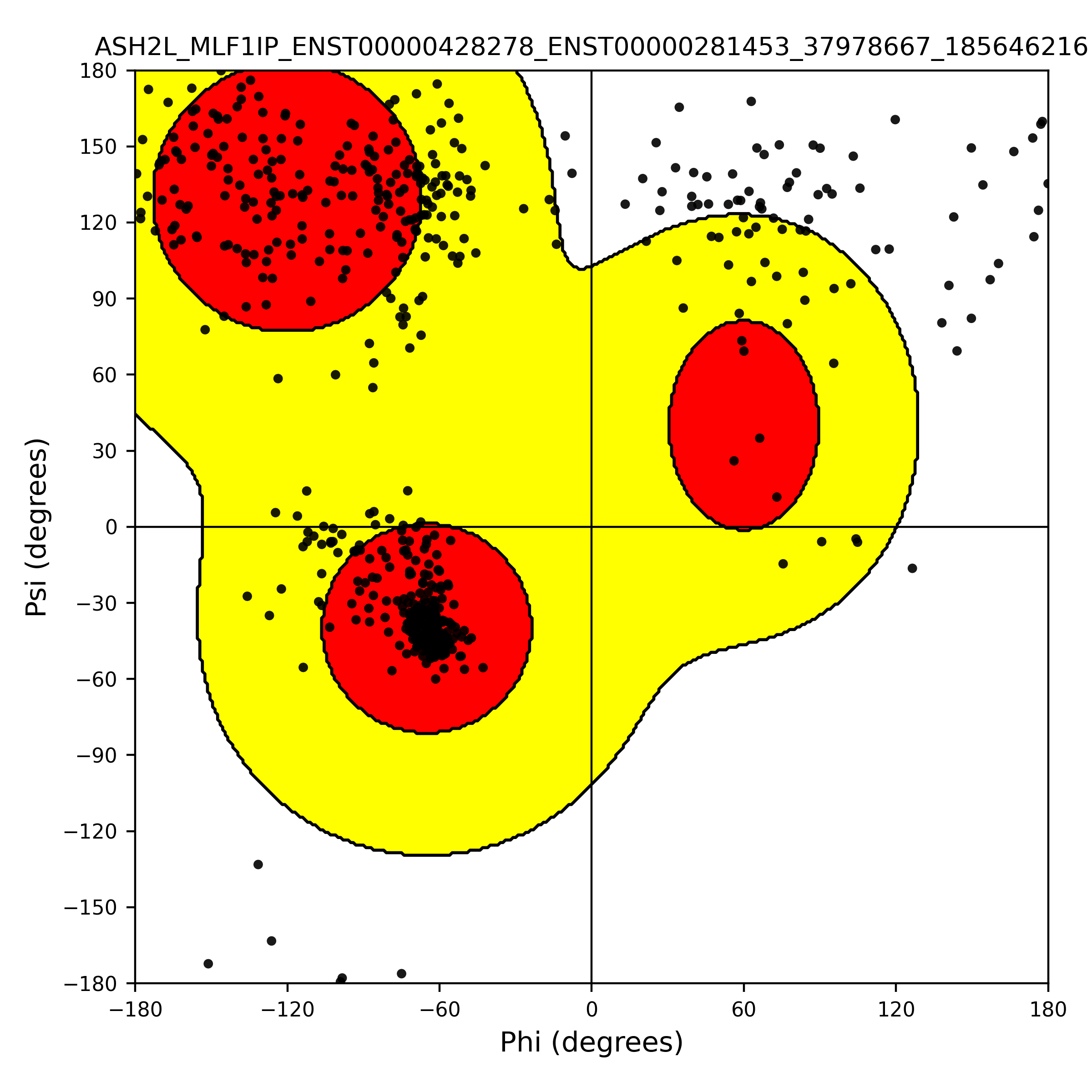 | 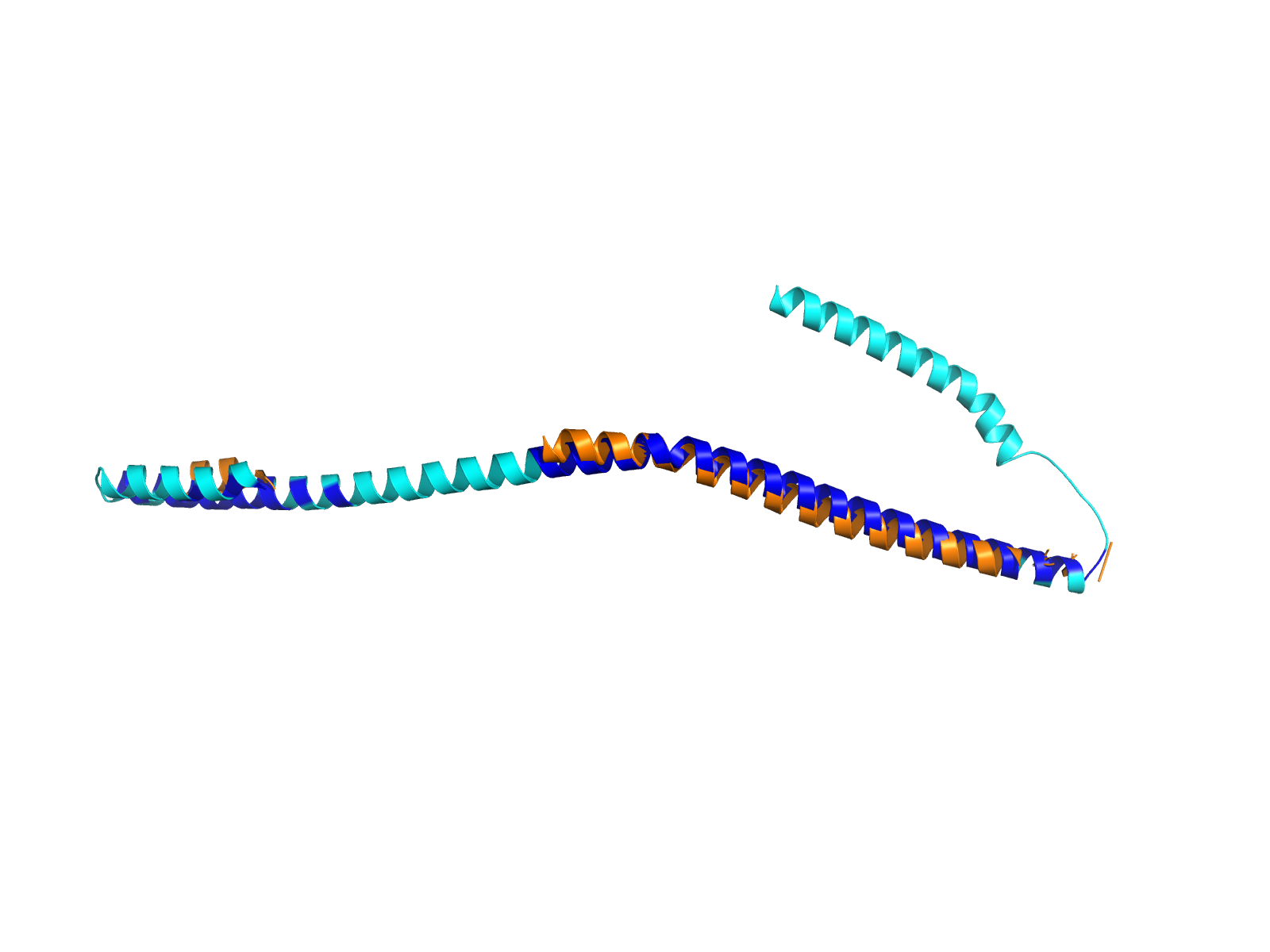 |
| ASH2L_MLF1IP_ENST00000521652_ENST00000281453_37978667_185646216 superimposed PDB: 7R5S of partner (MLF1IP). RMSD:2.375
Å |
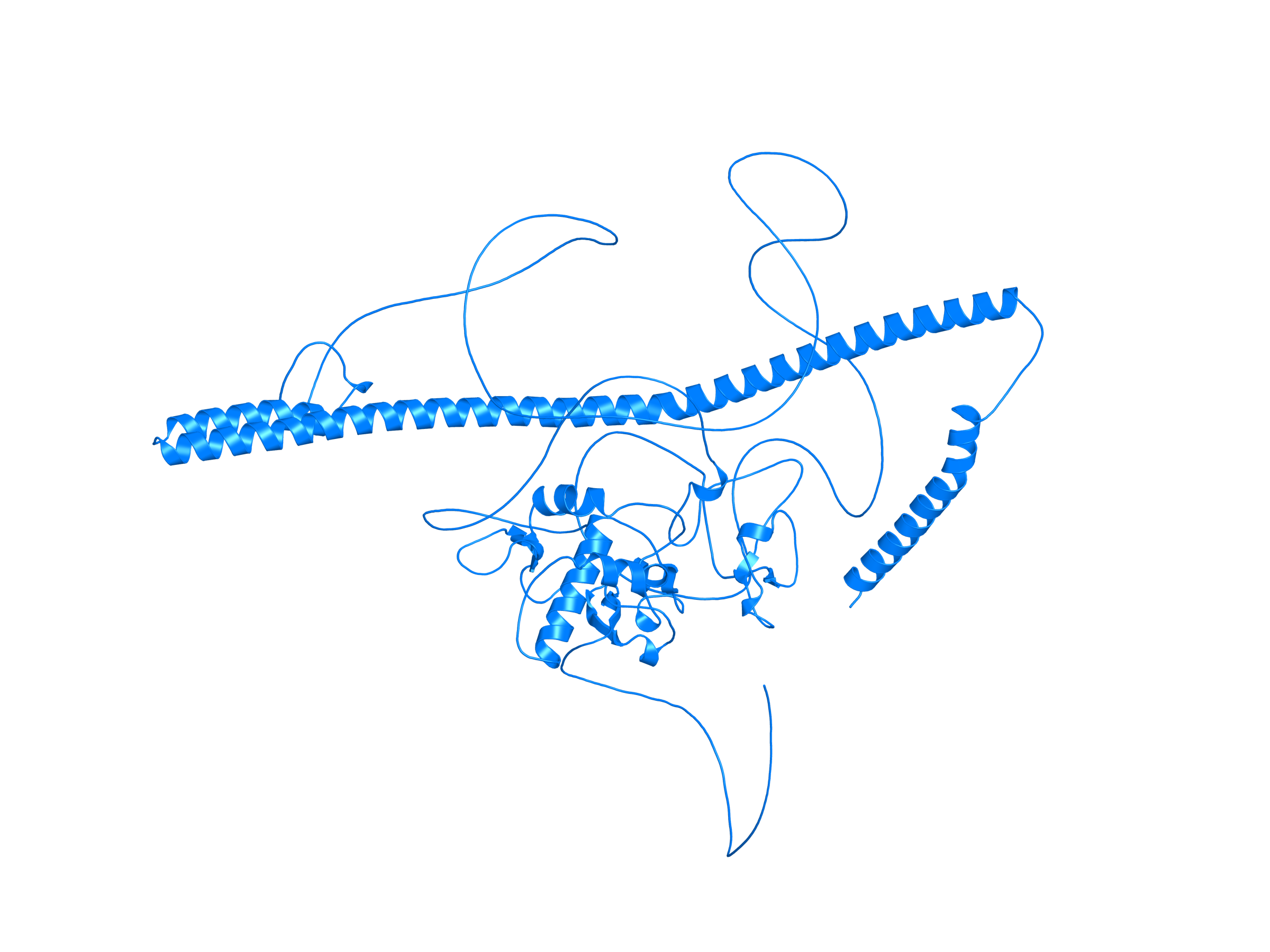 | 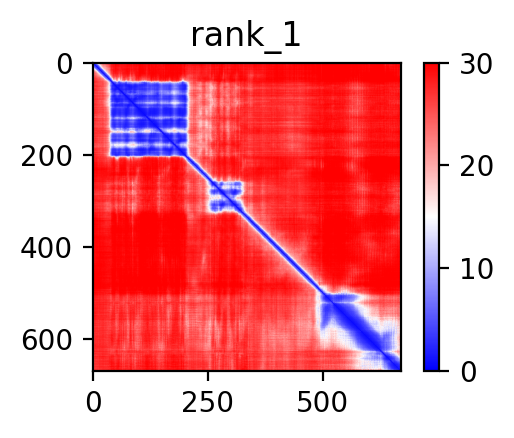 | 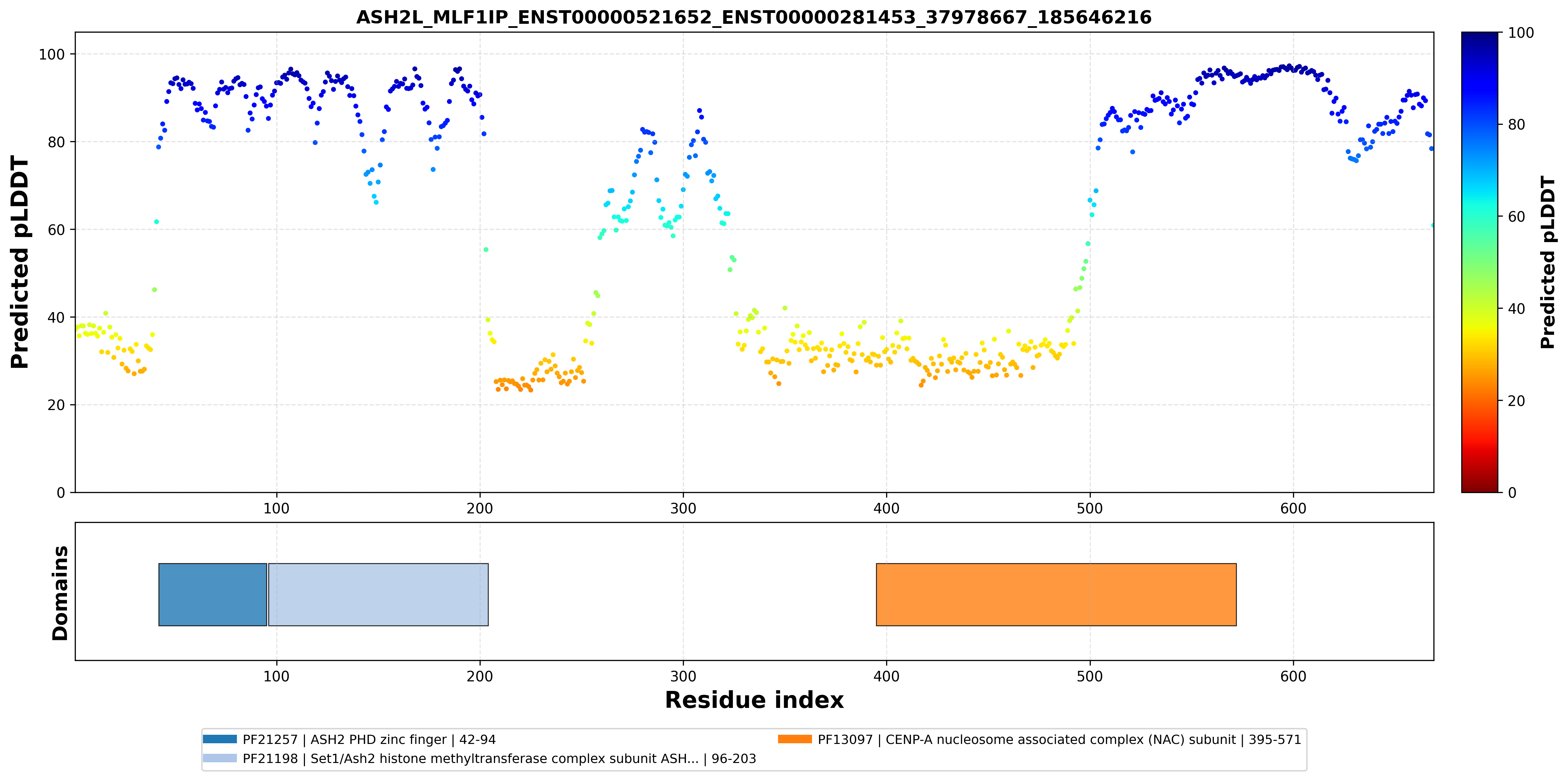 | 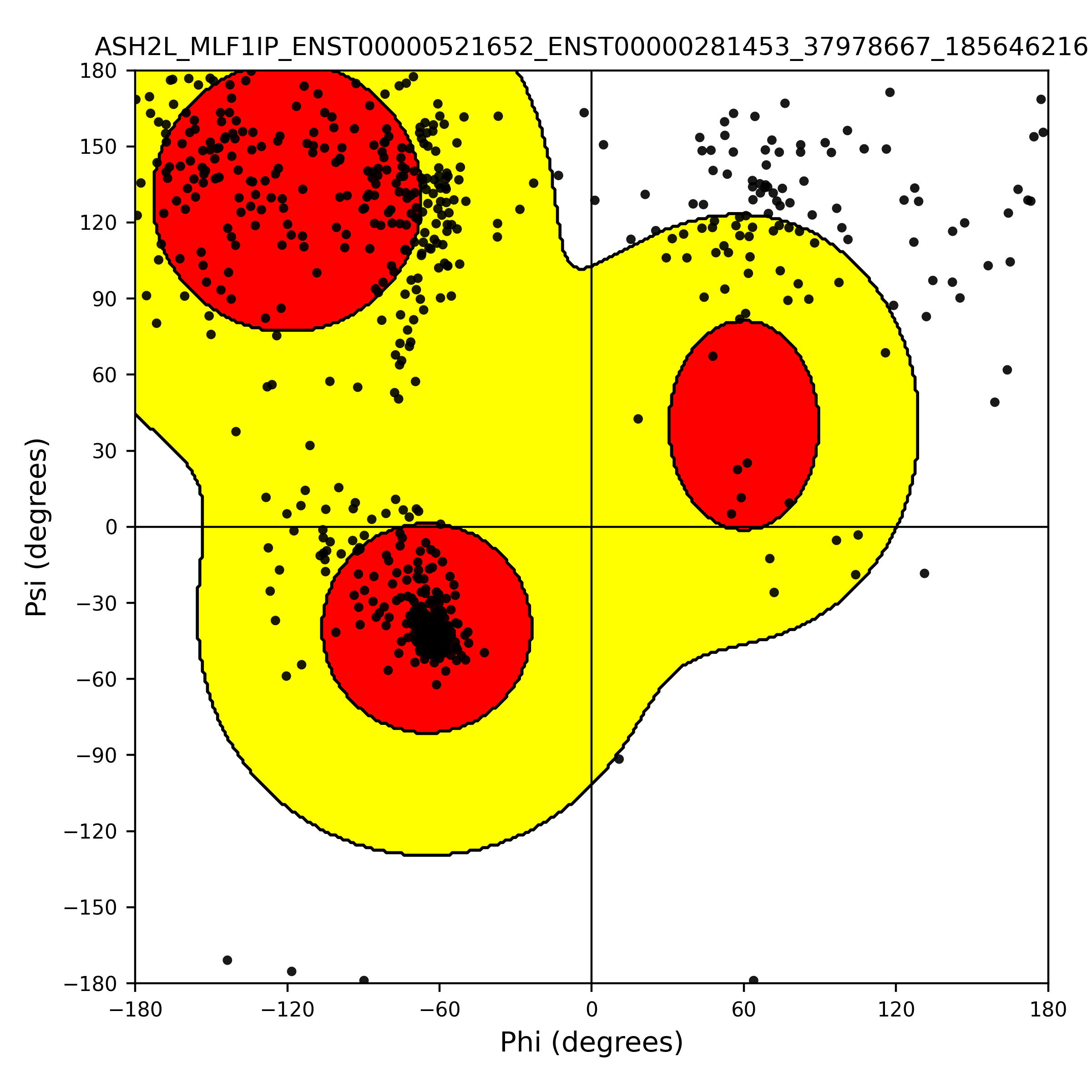 | 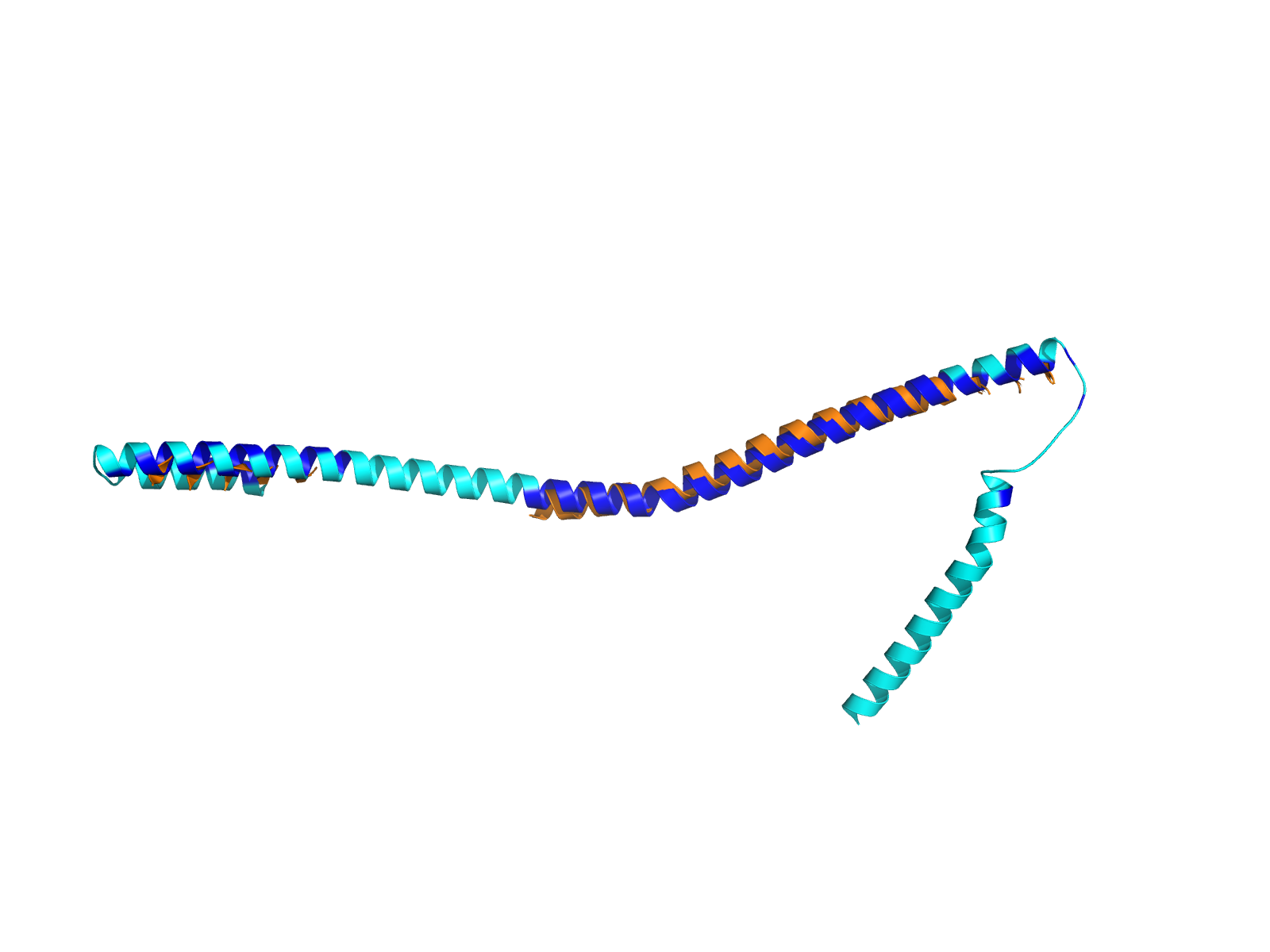 |
| ASL_GUSB_ENST00000304874_ENST00000421103_65541080_65432894 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.4608
Å |
 |  | 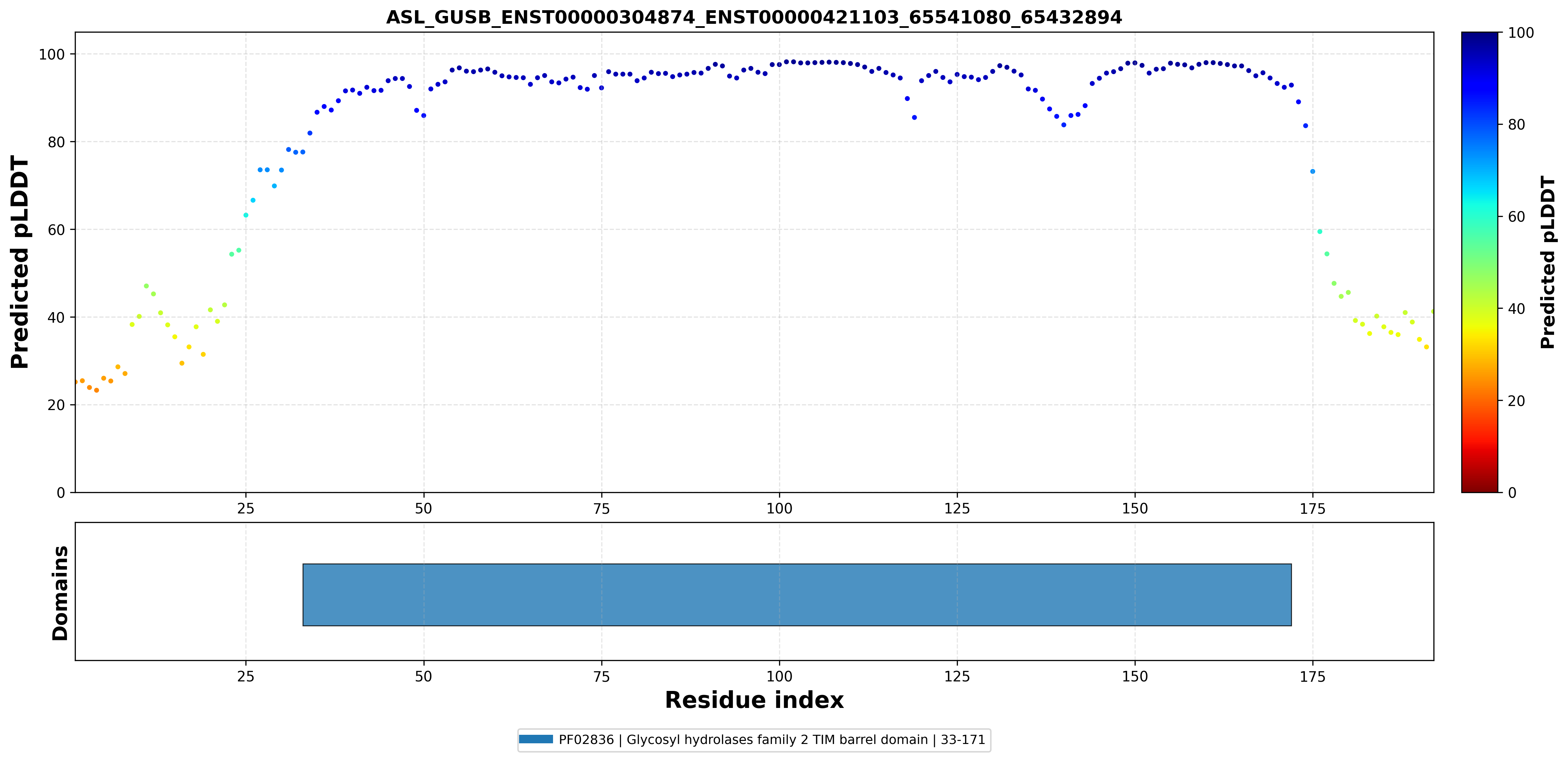 |  |  |
| ASL_GUSB_ENST00000380839_ENST00000421103_65541080_65432894 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.5061
Å |
 |  | 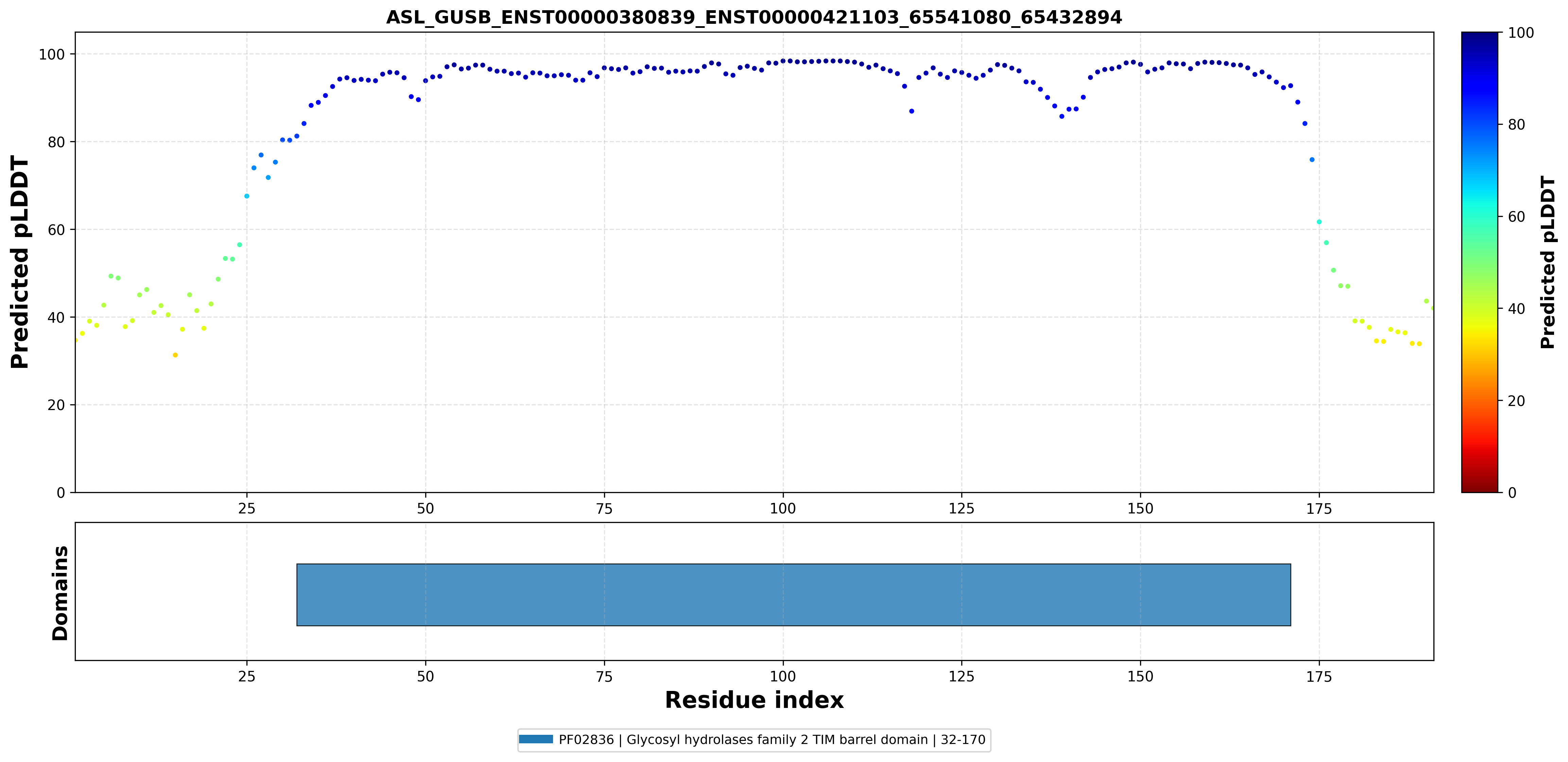 |  |  |
| ASL_IGLL1_ENST00000380839_ENST00000249053_65548161_23915772 superimposed PDB: 1K62 of partner (ASL). RMSD:0.4593
Å |
 |  | 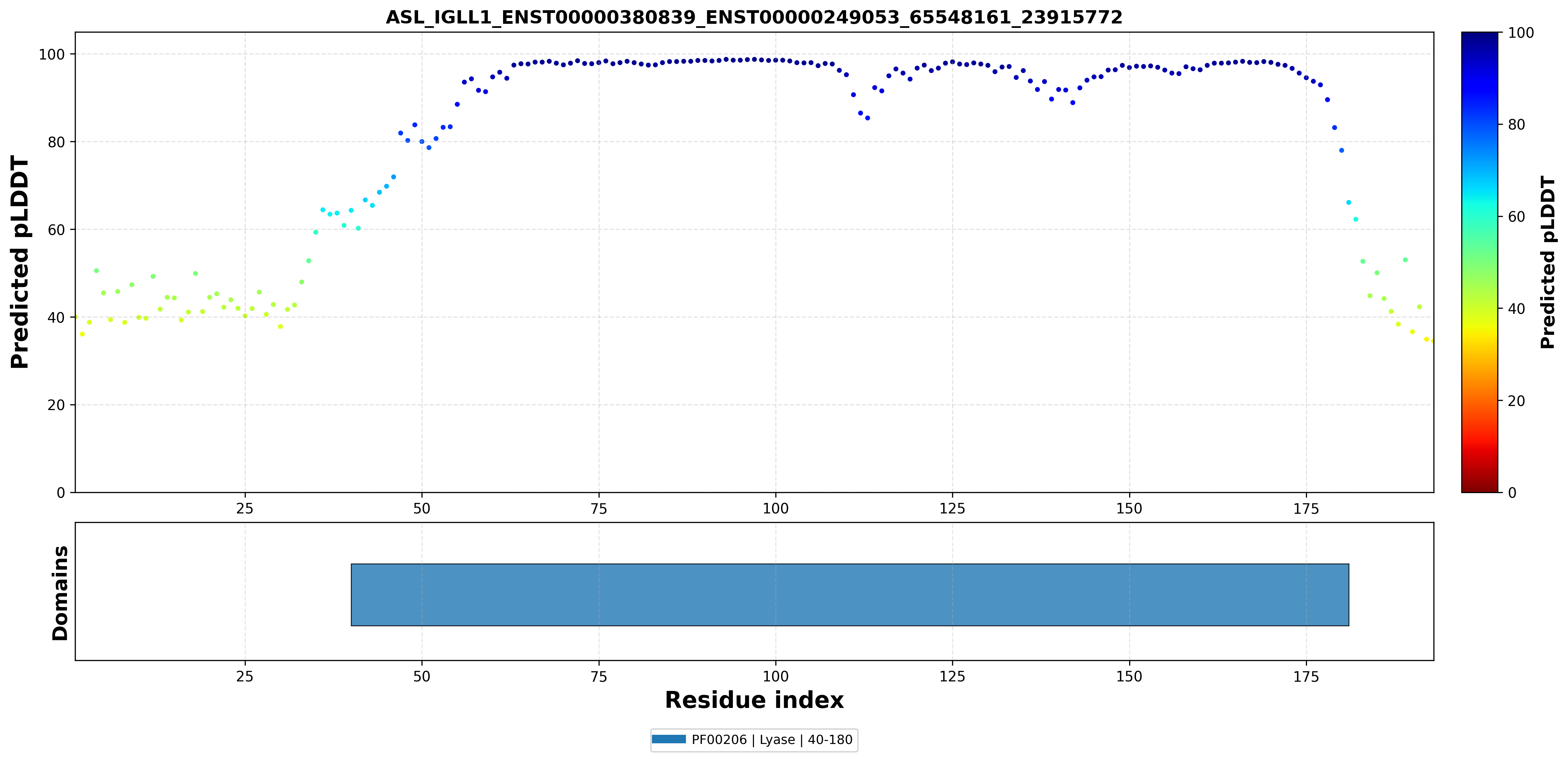 |  |  |
| ASL_IGLL1_ENST00000395332_ENST00000249053_65548161_23915772 superimposed PDB: 1K62 of partner (ASL). RMSD:0.4491
Å |
 |  |  |  |  |
| ASMTL_CLEC7A_ENST00000381333_ENST00000353231_1490550_10271189 superimposed PDB: 2P5X of partner (ASMTL). RMSD:0.3995
Å |
 |  | 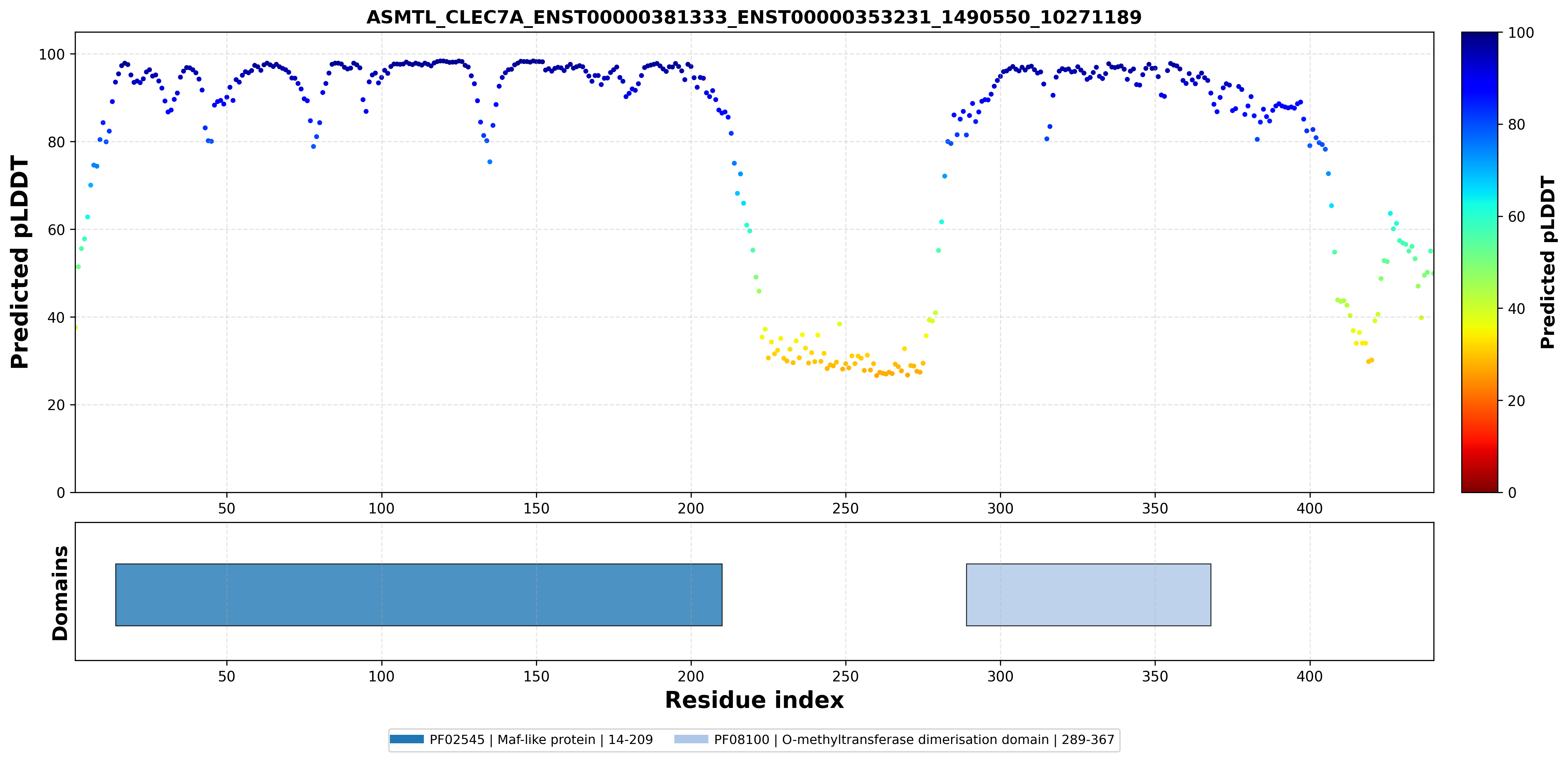 |  |  |
| ASMTL_CLEC7A_ENST00000416733_ENST00000533022_1490550_10271189 superimposed PDB: 2P5X of partner (ASMTL). RMSD:1.4358
Å |
 |  | 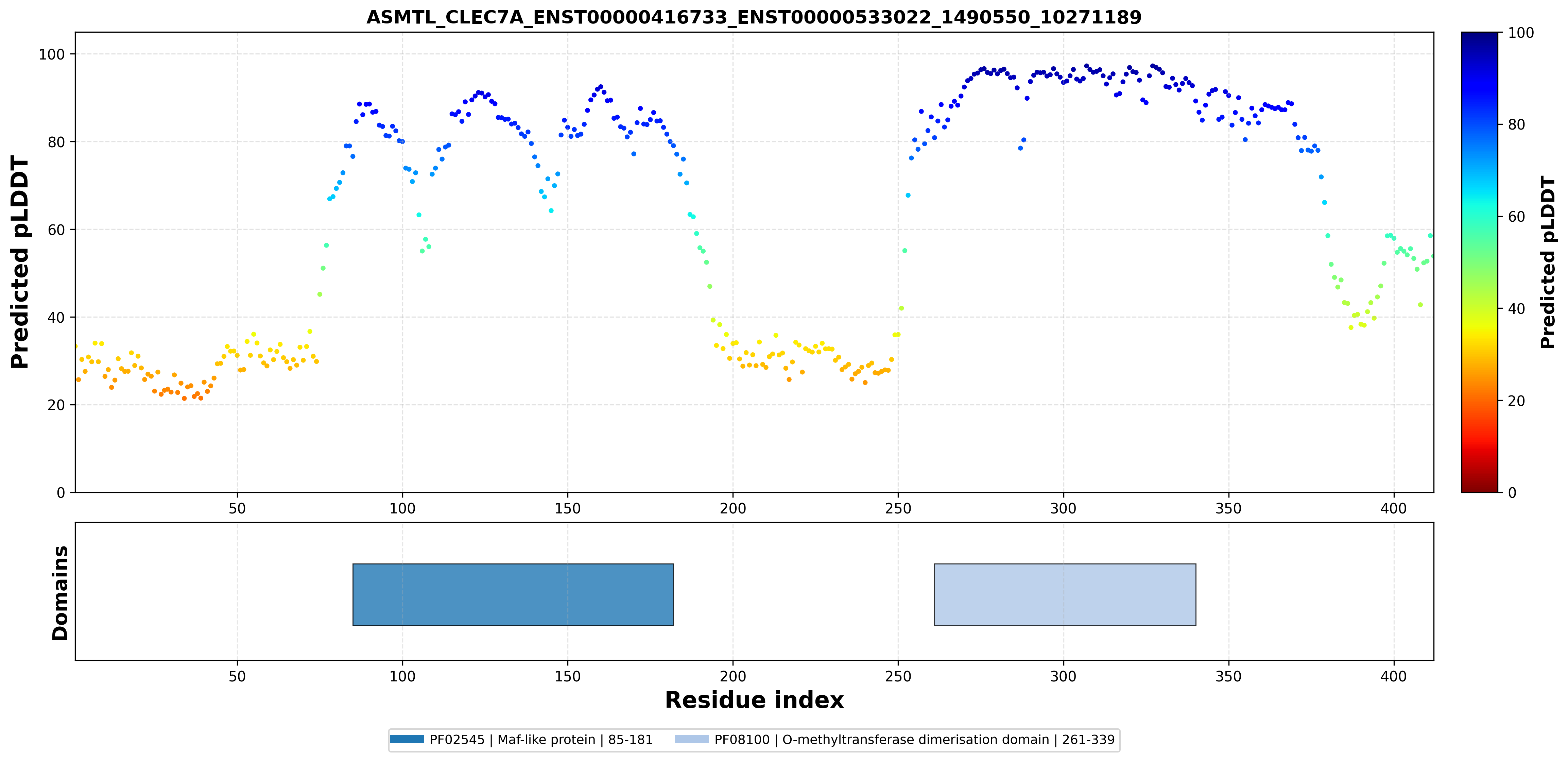 |  |  |
| ASMTL_CLEC7A_ENST00000534940_ENST00000533022_1490550_10271189 superimposed PDB: 2P5X of partner (ASMTL). RMSD:0.6609
Å |
 |  | 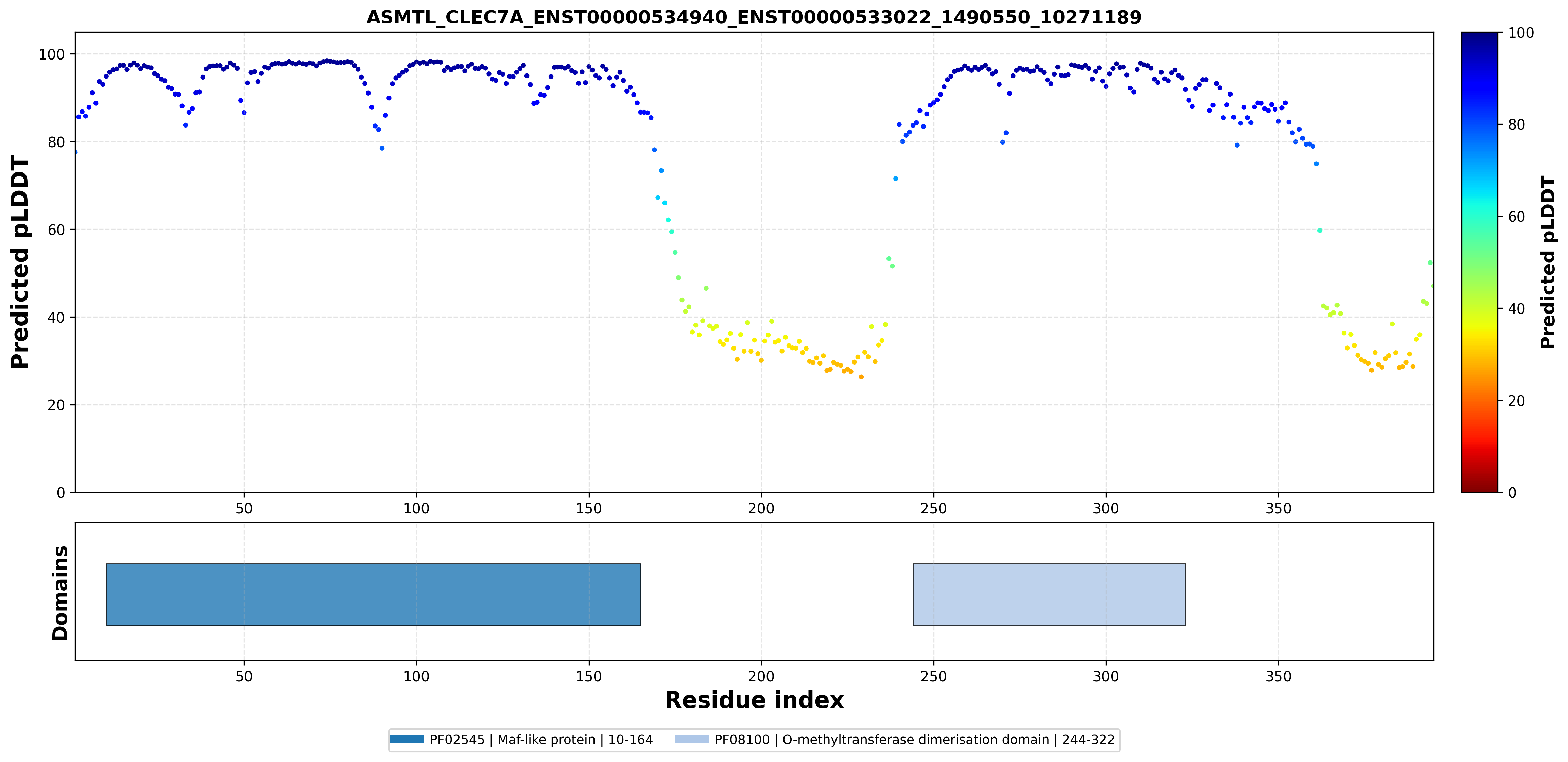 |  |  |
| ASMTL_UGT1A10_ENST00000381317_ENST00000344644_1521640_234675679 superimposed PDB: 2P5X of partner (ASMTL). RMSD:0.593
Å |
 |  |  |  |  |
| ASNSD1_SUPT6H_ENST00000607535_ENST00000347486_190526336_27020713 superimposed PDB: 9HVQ of partner (SUPT6H). RMSD:3.0758
Å |
 |  |  |  |  |
| ASNSD1_SUPT6H_ENST00000607690_ENST00000347486_190526336_27020713 superimposed PDB: 9HVQ of partner (SUPT6H). RMSD:3.1518
Å |
 |  |  |  |  |
| ASPSCR1_TFE3_ENST00000306729_ENST00000315869_79954722_48895639 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.7795
Å |
 |  |  |  |  |
| ASPSCR1_TFE3_ENST00000306739_ENST00000315869_79954722_48891766 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.6925
Å |
 |  | 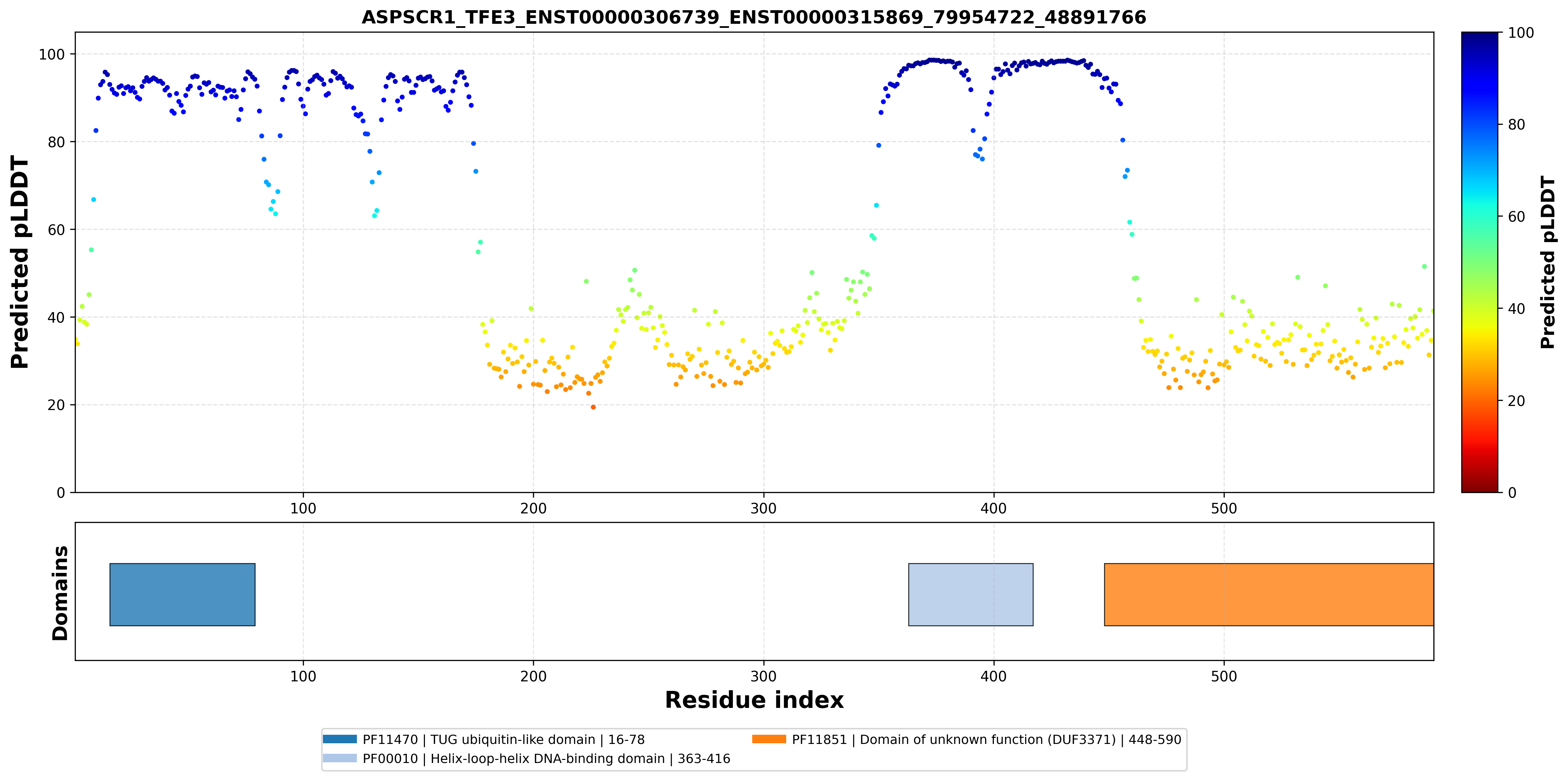 |  |  |
| ASPSCR1_TFE3_ENST00000306739_ENST00000315869_79954722_48895639 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.8327
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000313400_ENST00000318003_119488049_14028882 superimposed PDB: 5J67 of partner (ASTN2). RMSD:2.8585
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000313400_ENST00000318003_119488049_14028882 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.5777
Å |
| | | |  |
| ASTN2_CC2D1A_ENST00000313400_ENST00000589606_119488049_14028882 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.7214
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000361209_ENST00000318003_119488049_14028882 superimposed PDB: 5J67 of partner (ASTN2). RMSD:2.9638
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000361209_ENST00000318003_119488049_14028882 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.4066
Å |
| | | |  |
| ASTN2_CC2D1A_ENST00000361209_ENST00000589606_119488049_14028882 superimposed PDB: 5J67 of partner (ASTN2). RMSD:3.0694
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000361209_ENST00000589606_119488049_14028882 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.9239
Å |
| | | |  |
| ASTN2_CC2D1A_ENST00000373996_ENST00000589606_119488049_14028882 superimposed PDB: 5J67 of partner (ASTN2). RMSD:2.5113
Å |
 |  |  |  |  |
| ASTN2_CC2D1A_ENST00000373996_ENST00000589606_119488049_14028882 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.4501
Å |
| | | |  |
| ASXL2_DTNB_ENST00000435504_ENST00000288642_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:0.813
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000404103_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:1.5268
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000405222_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:0.8303
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000406818_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:1.5194
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000407038_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:1.4741
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000407186_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:1.5264
Å |
 |  |  |  |  |
| ASXL2_DTNB_ENST00000435504_ENST00000407661_26022253_25819109 superimposed PDB: 9ATN of partner (ASXL2). RMSD:0.8052
Å |
 |  |  |  |  |
| ASXL2_ITSN2_ENST00000435504_ENST00000355123_26022253_24538093 superimposed PDB: 3JZY of partner (ITSN2). RMSD:0.2879
Å |
 |  | 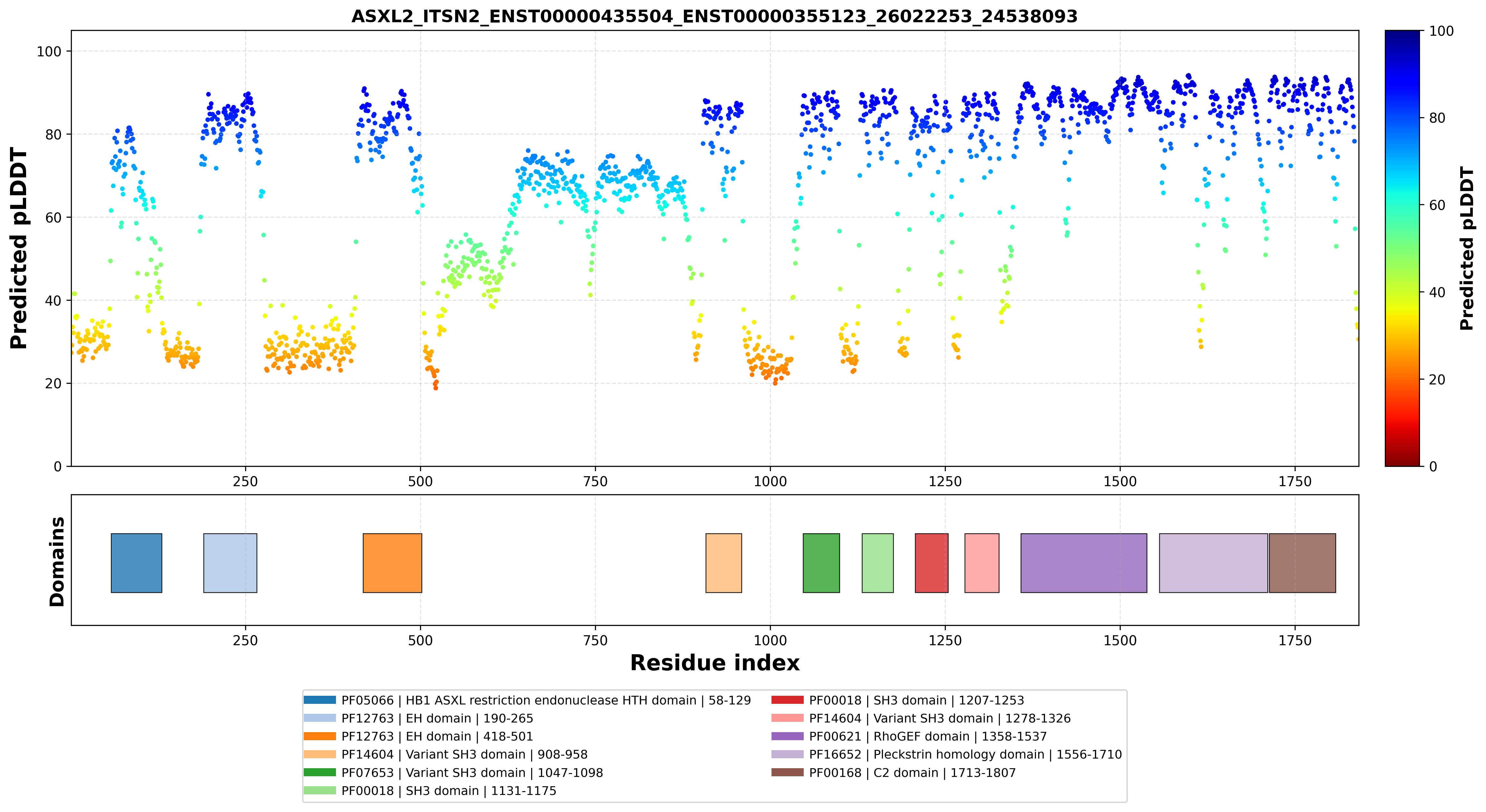 |  |  |
| ASXL2_ITSN2_ENST00000435504_ENST00000406921_26022253_24538093 superimposed PDB: 3JZY of partner (ITSN2). RMSD:0.2942
Å |
 |  | 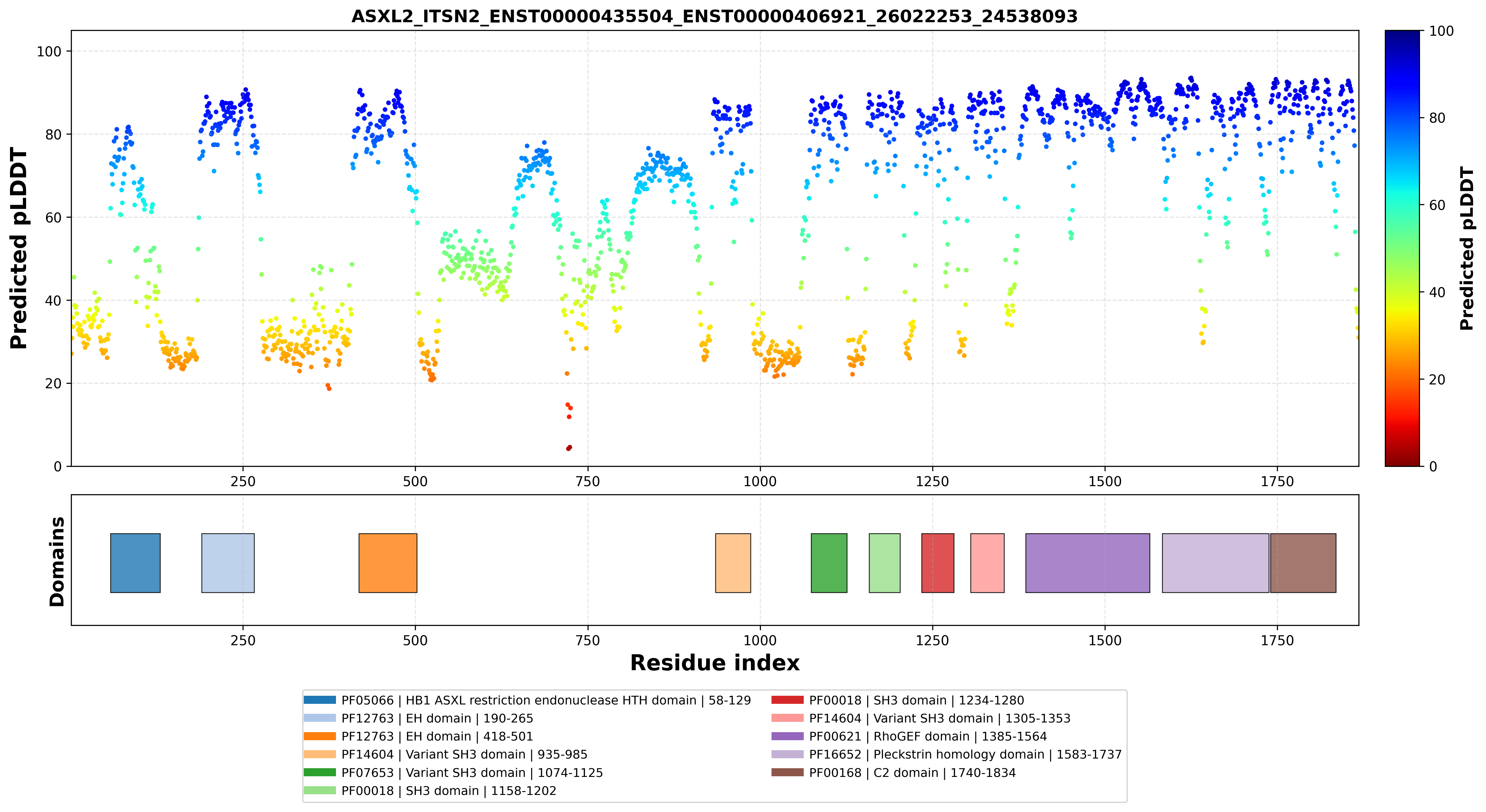 |  |  |
| ATAD1_JMJD1C_ENST00000328142_ENST00000399251_89530708_64968995 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5286
Å |
 |  |  |  |  |
| ATAD1_JMJD1C_ENST00000328142_ENST00000399251_89530708_64968995 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.5813
Å |
| | | |  |
| ATAD1_JMJD1C_ENST00000328142_ENST00000402544_89530708_64968995 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.4947
Å |
 |  |  |  |  |
| ATAD1_JMJD1C_ENST00000328142_ENST00000402544_89530708_64968995 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.5994
Å |
| | | |  |
| ATAD1_JMJD1C_ENST00000328142_ENST00000542921_89530708_64968995 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5703
Å |
 |  |  |  |  |
| ATAD1_KCNMA1_ENST00000328142_ENST00000404771_89574194_79011014 superimposed PDB: 7UPR of partner (ATAD1). RMSD:2.1534
Å |
 |  |  |  |  |
| ATAD1_LIPF_ENST00000400215_ENST00000394375_89550066_90427043 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.8927
Å |
 |  | 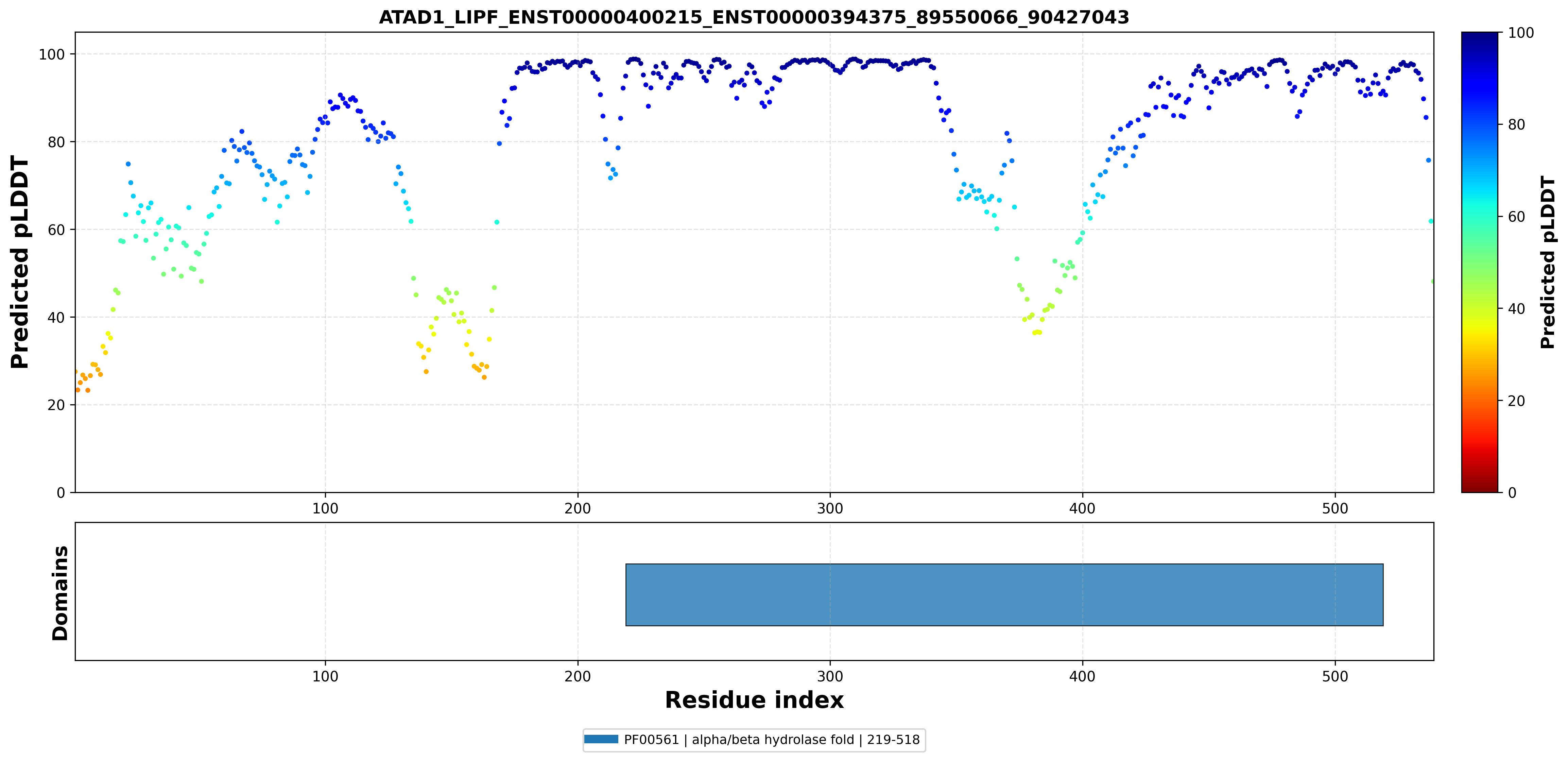 |  |  |
| ATAD1_LIPF_ENST00000400215_ENST00000394375_89550066_90427043 superimposed PDB: 1HLG of partner (LIPF). RMSD:0.5322
Å |
| | | |  |
| ATAD1_PFKFB4_ENST00000328142_ENST00000536104_89527429_48577204 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5611
Å |
 |  |  |  |  |
| ATAD1_PFKFB4_ENST00000328142_ENST00000541519_89527429_48577204 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5612
Å |
 |  |  |  |  |
| ATAD1_PFKFB4_ENST00000400215_ENST00000232375_89527429_48577204 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5479
Å |
 |  |  |  |  |
| ATAD1_PFKFB4_ENST00000400215_ENST00000536104_89527429_48577204 superimposed PDB: 7UPR of partner (ATAD1). RMSD:3.2123
Å |
 |  |  |  |  |
| ATAD1_PFKFB4_ENST00000400215_ENST00000541519_89527429_48577204 superimposed PDB: 7UPR of partner (ATAD1). RMSD:2.6505
Å |
 |  |  |  |  |
| ATAD1_RNLS_ENST00000308448_ENST00000437752_89574194_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5003
Å |
 |  | 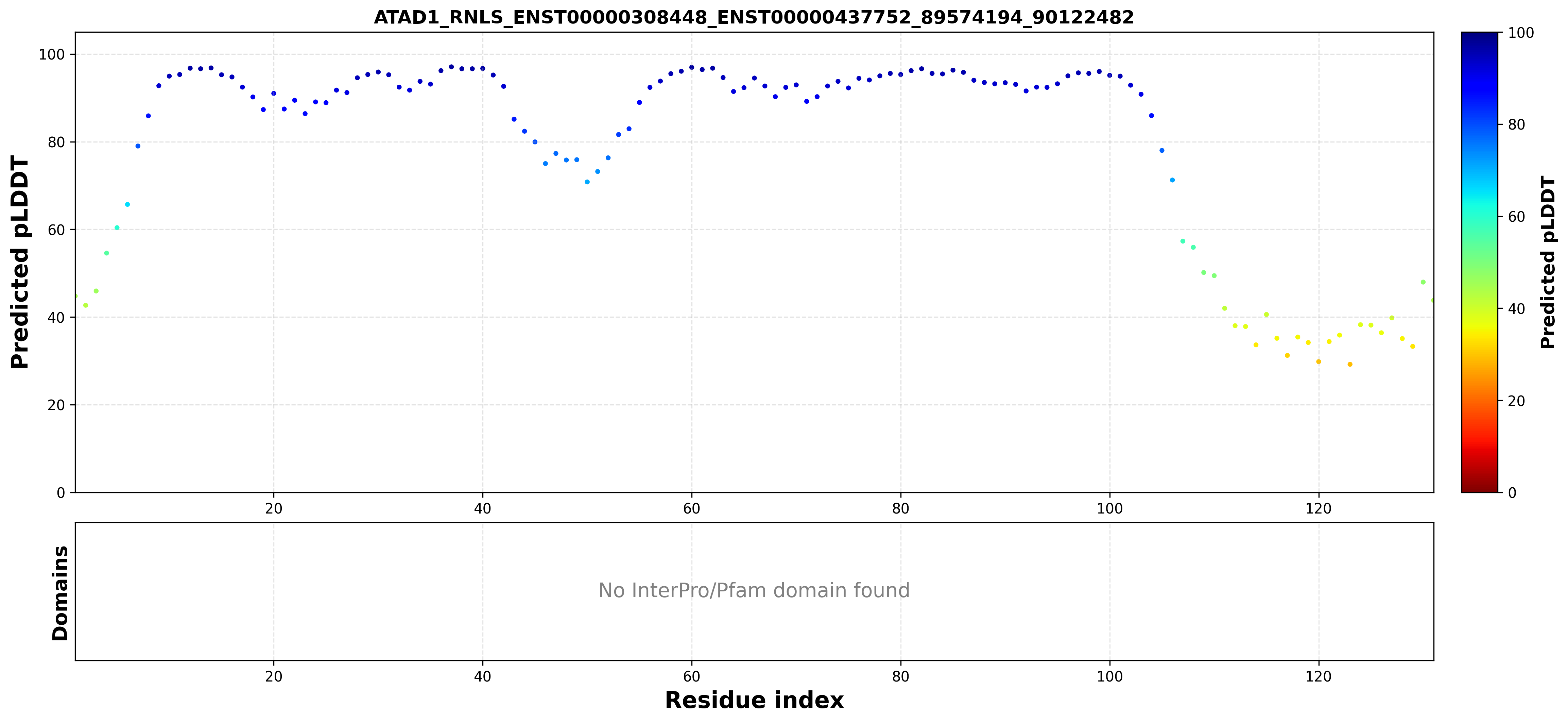 |  | 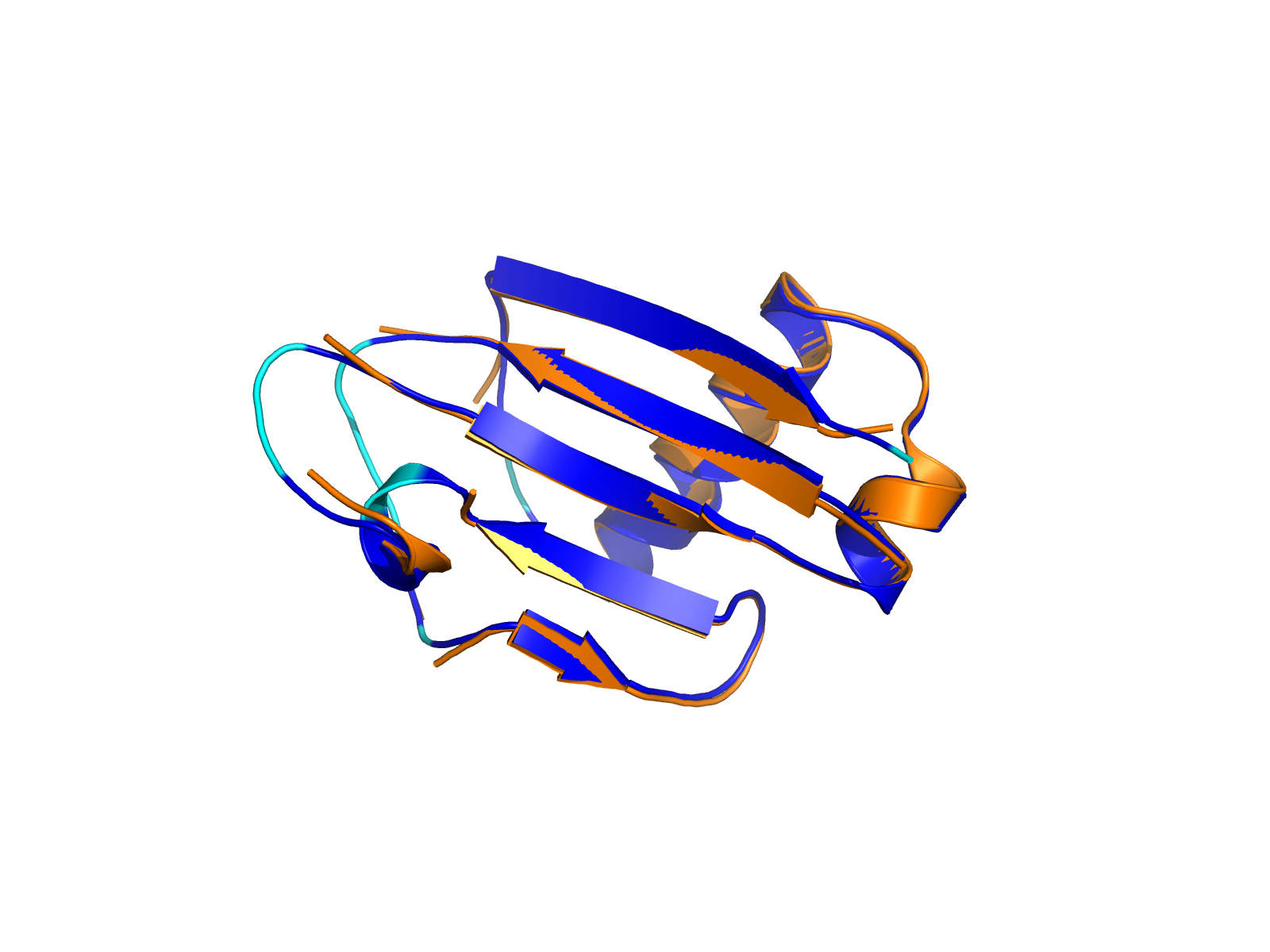 |
| ATAD1_RNLS_ENST00000541004_ENST00000371947_89574194_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.2897
Å |
 |  |  |  |  |
| ATAD2_FAM178B_ENST00000287394_ENST00000417561_124346117_97595057 superimposed PDB: 8H3H of partner (ATAD2). RMSD:2.5573
Å |
 |  |  |  |  |
| ATAD3B_HADHB_ENST00000308647_ENST00000405867_1407469_26486247 superimposed PDB: 5ZQZ of partner (HADHB). RMSD:1.1167
Å |
 |  |  |  |  |
| ATAD3B_HADHB_ENST00000308647_ENST00000537713_1407469_26486247 superimposed PDB: 5ZQZ of partner (HADHB). RMSD:1.2997
Å |
 |  |  |  |  |
| ATAD3B_HADHB_ENST00000308647_ENST00000545822_1407469_26486247 superimposed PDB: 5ZQZ of partner (HADHB). RMSD:1.1213
Å |
 |  |  |  |  |
| ATAD5_NF1_ENST00000321990_ENST00000358273_29159431_29483000 superimposed PDB: 7PGP of partner (NF1). RMSD:2.5873
Å |
 |  |  |  |  |
| ATAD5_NF1_ENST00000321990_ENST00000431387_29159431_29483000 superimposed PDB: 7PGP of partner (NF1). RMSD:2.7075
Å |
 |  |  |  |  |
| ATF1_HP1BP3_ENST00000539132_ENST00000312239_51208222_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.6394
Å |
 |  |  |  |  |
| ATF2_SOS2_ENST00000264110_ENST00000216373_175976295_50641270 superimposed PDB: 8UF2 of partner (SOS2). RMSD:2.0166
Å |
 |  | 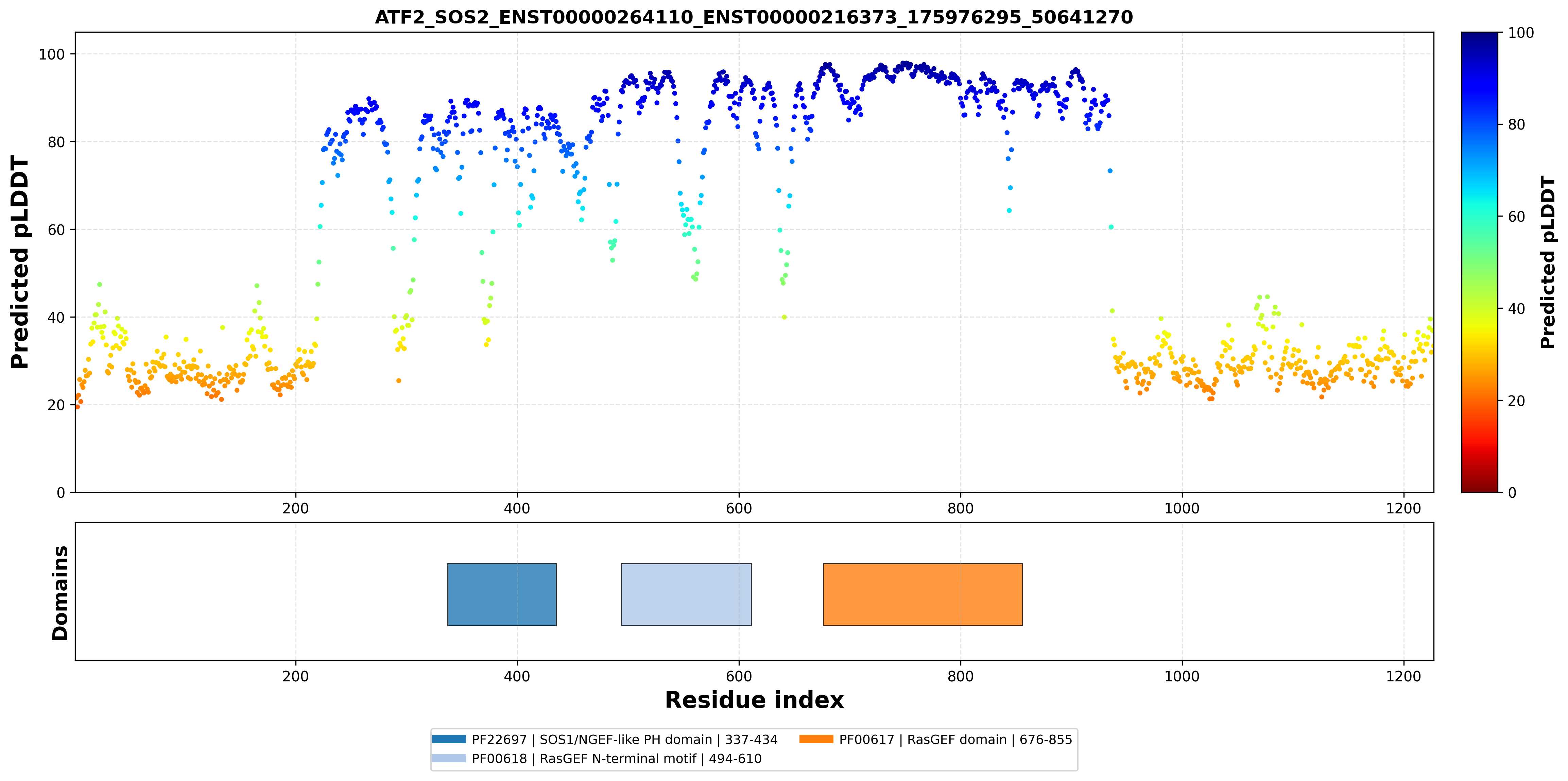 |  |  |
| ATF2_SOS2_ENST00000409635_ENST00000216373_175976295_50641270 superimposed PDB: 8UF2 of partner (SOS2). RMSD:2.0323
Å |
 |  | 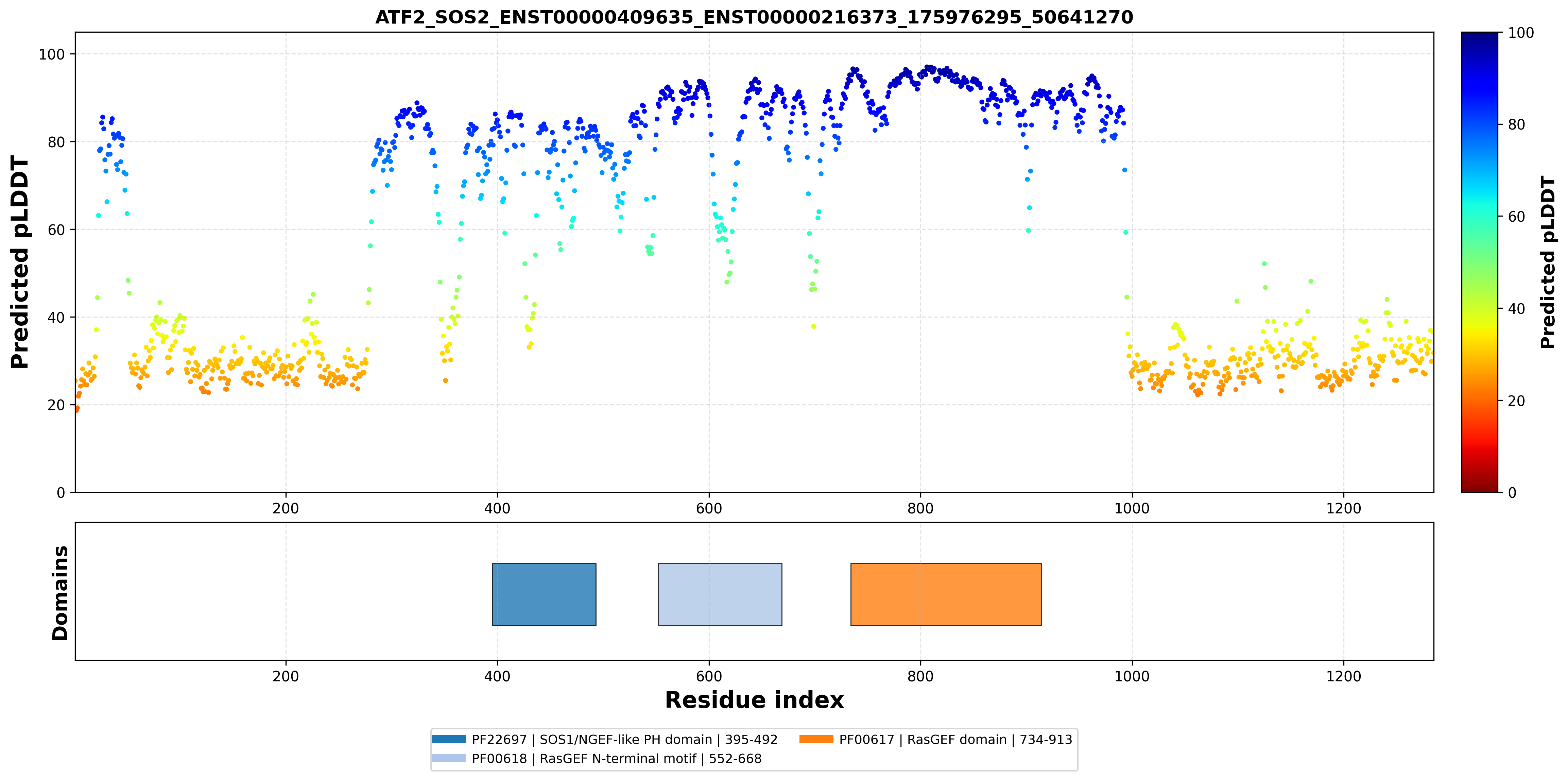 |  |  |
| ATF7IP_ABCB1_ENST00000544627_ENST00000543898_14538334_87225130 superimposed PDB: 8Y6H of partner (ABCB1). RMSD:1.0718
Å |
 |  |  |  |  |
| ATF7IP_JAK2_ENST00000536444_ENST00000381652_14634119_5081724 superimposed PDB: 2RPQ of partner (ATF7IP). RMSD:2.354
Å |
 |  |  |  |  |
| ATF7IP_TMPRSS2_ENST00000261168_ENST00000398585_14610229_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.6737
Å |
 | 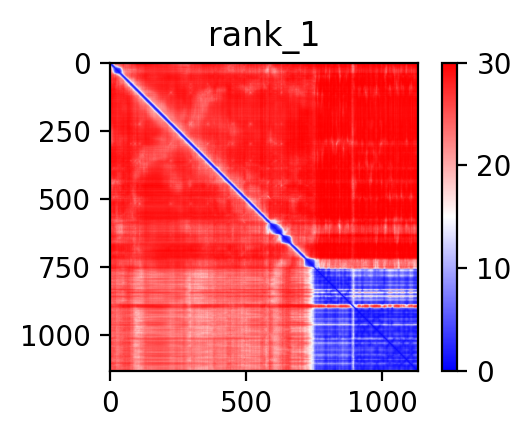 | 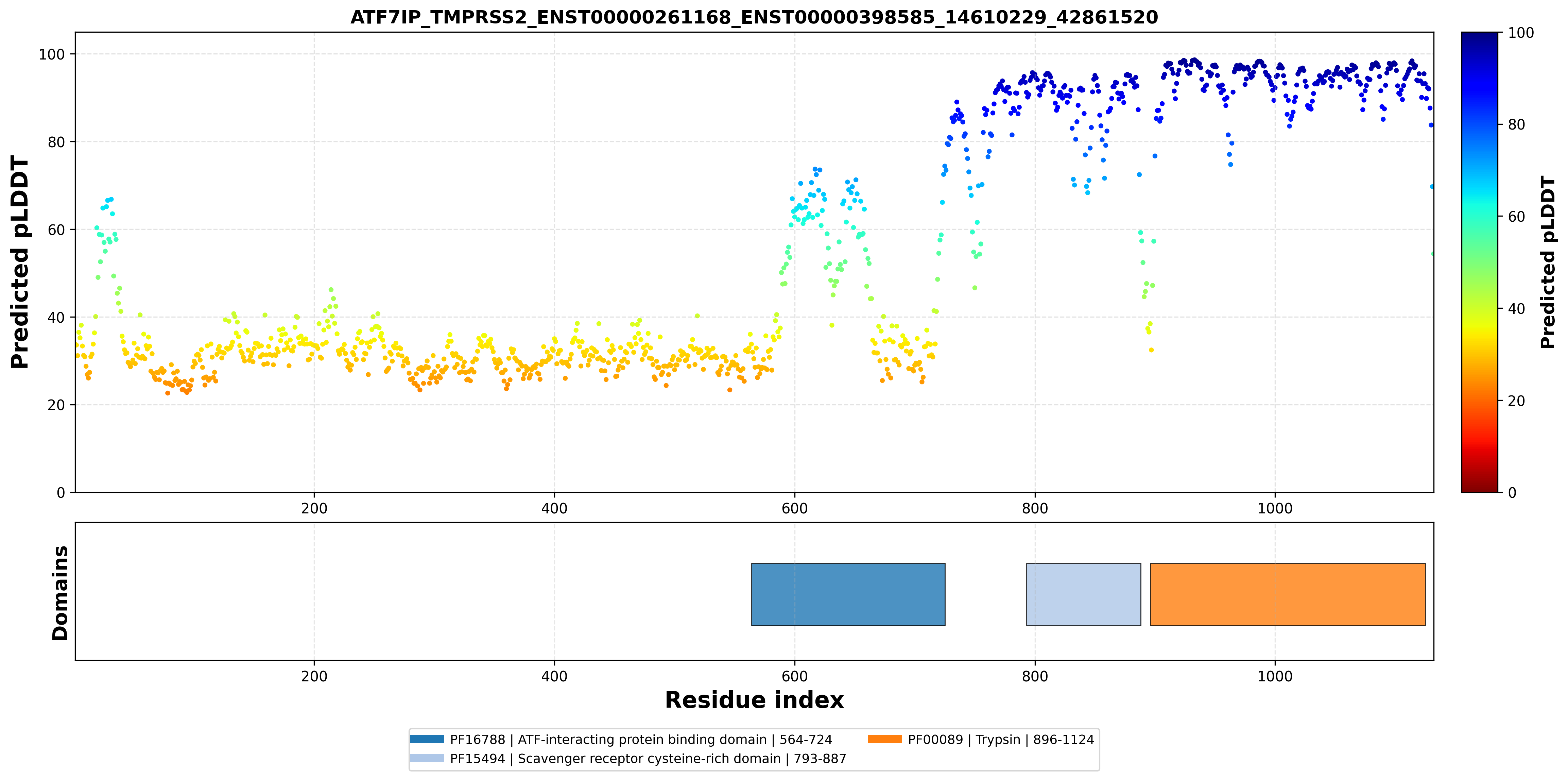 |  | 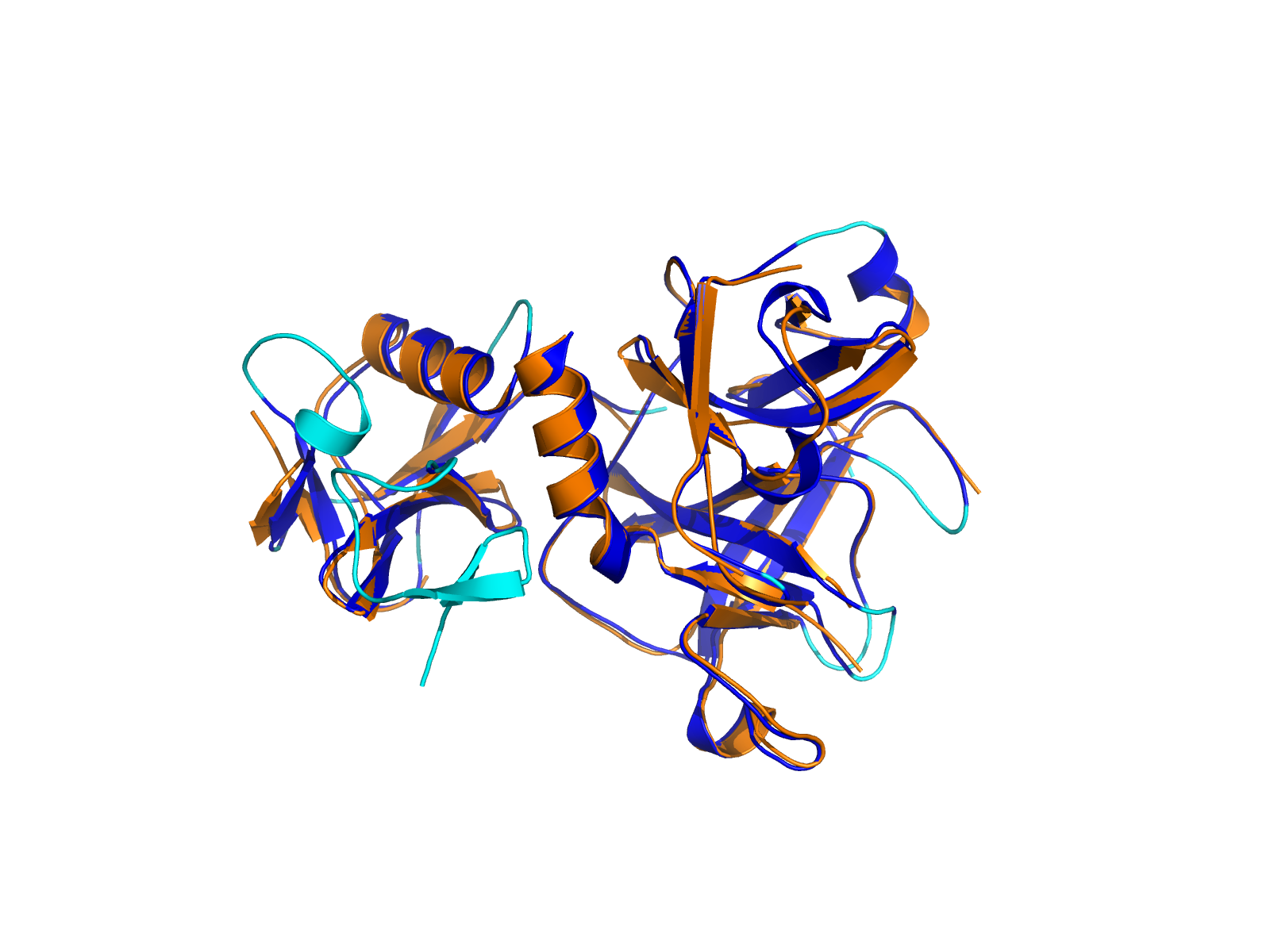 |
| ATF7IP_TMPRSS2_ENST00000543189_ENST00000398585_14610229_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.6878
Å |
 | 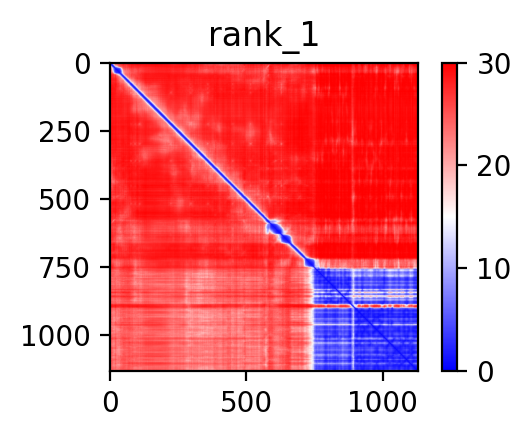 | 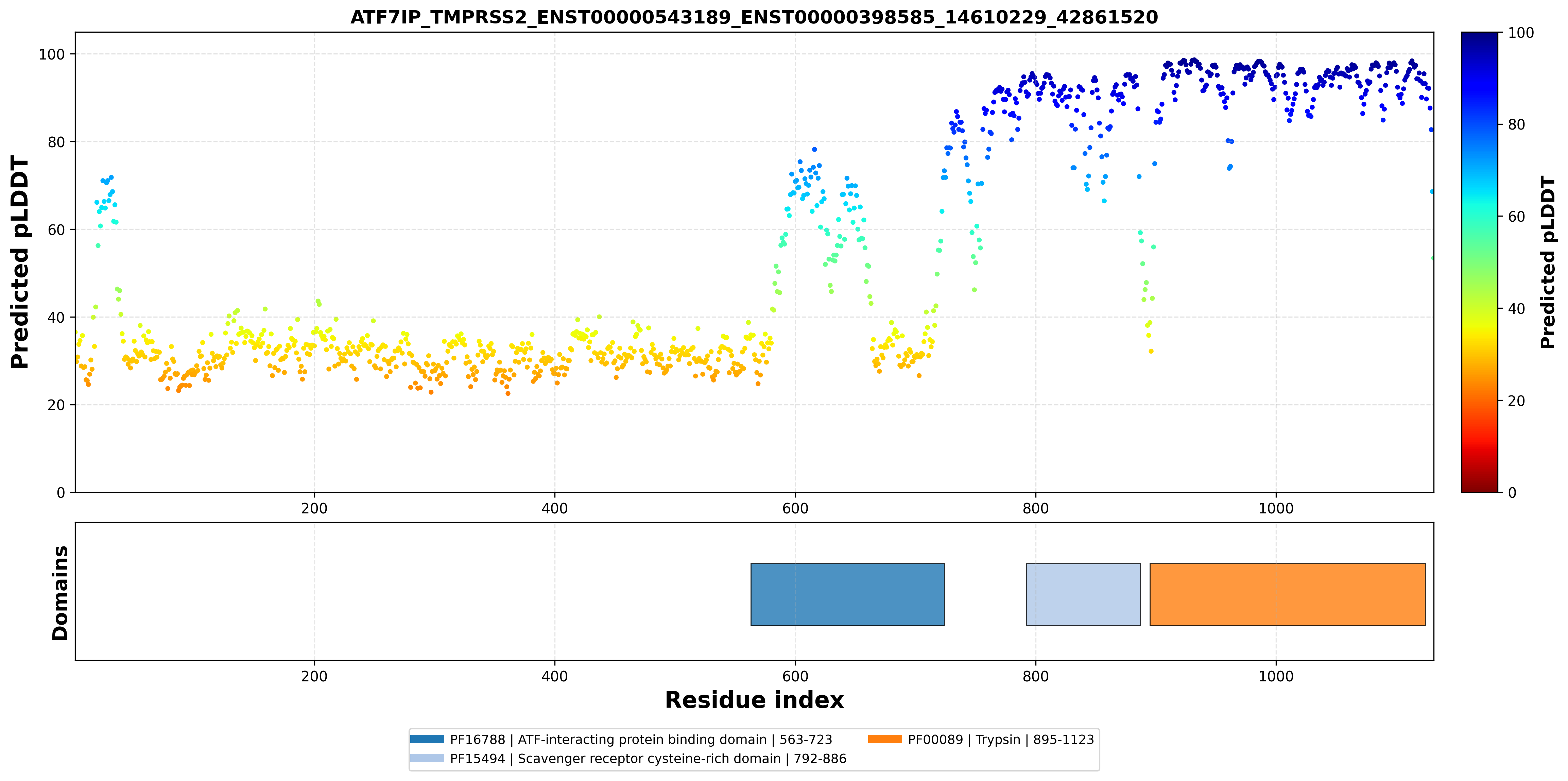 |  | 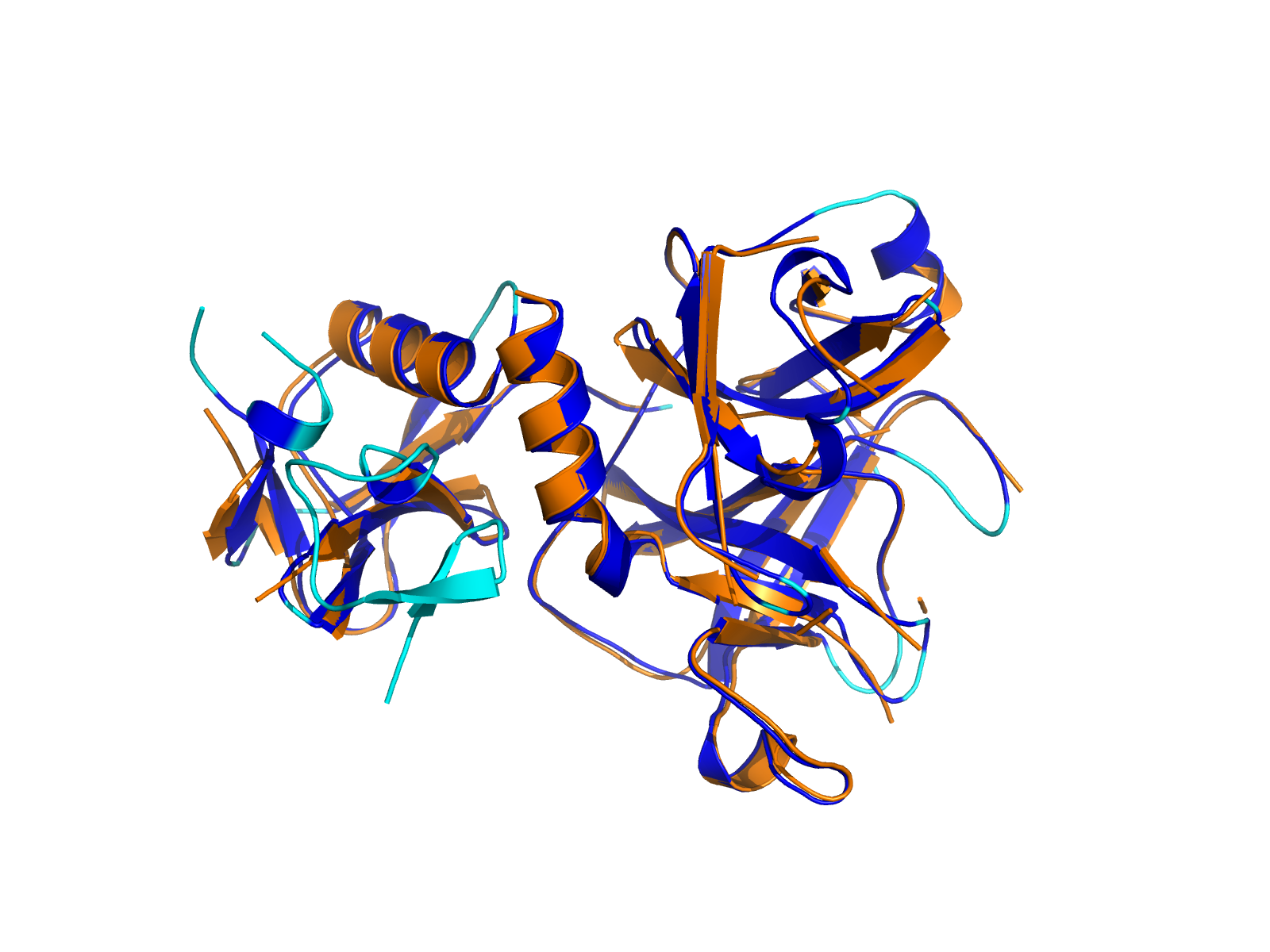 |
| ATF7IP_TMPRSS2_ENST00000544627_ENST00000398585_14610229_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.6855
Å |
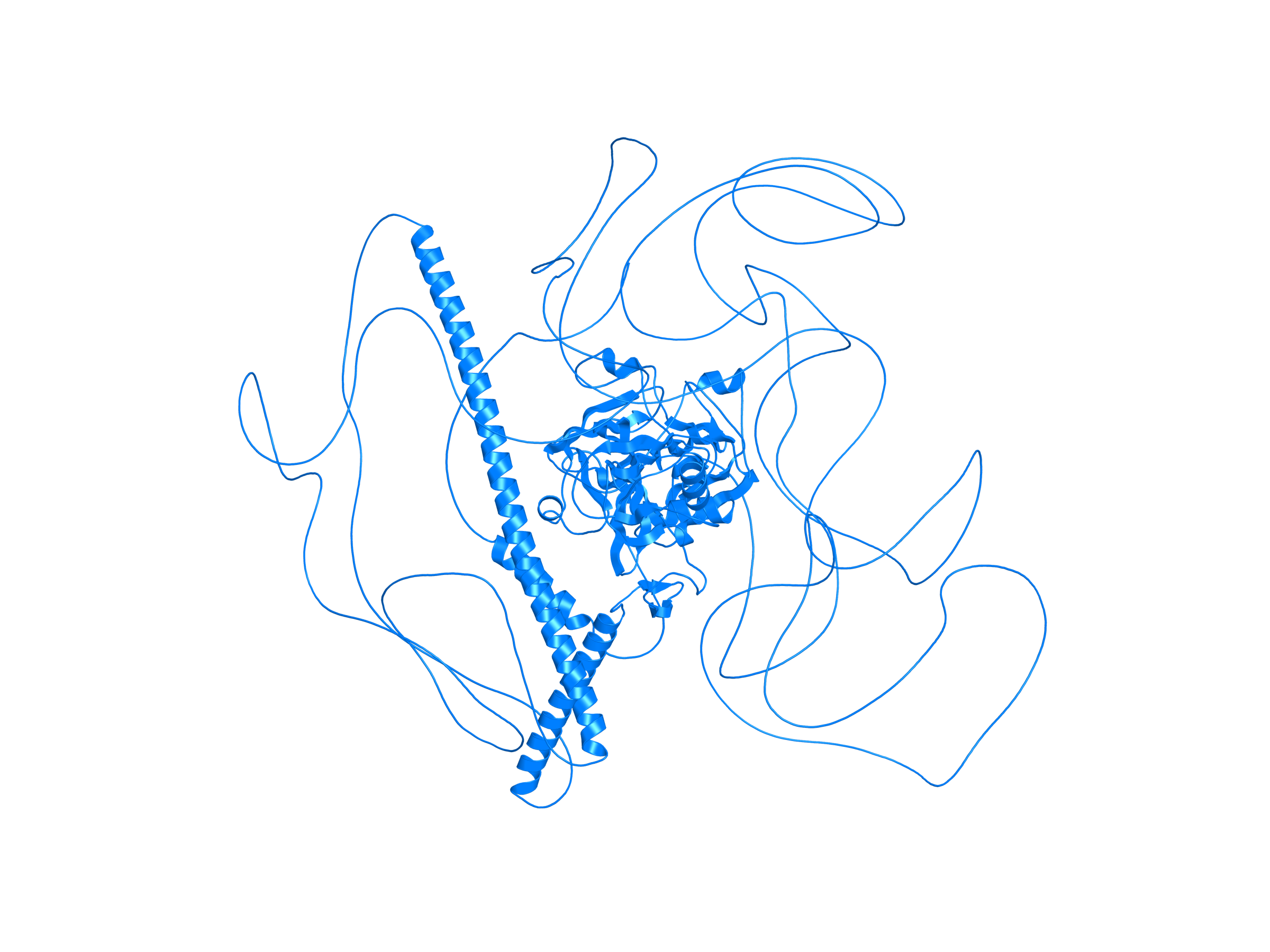 | 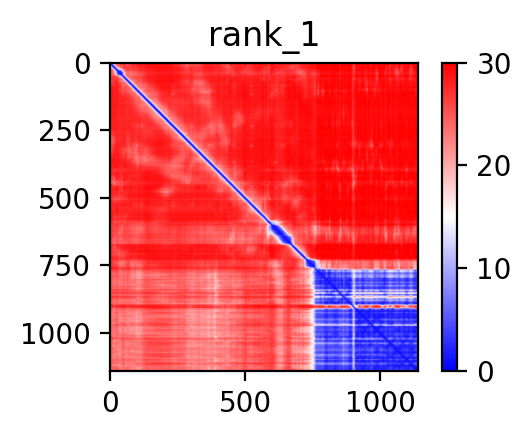 | 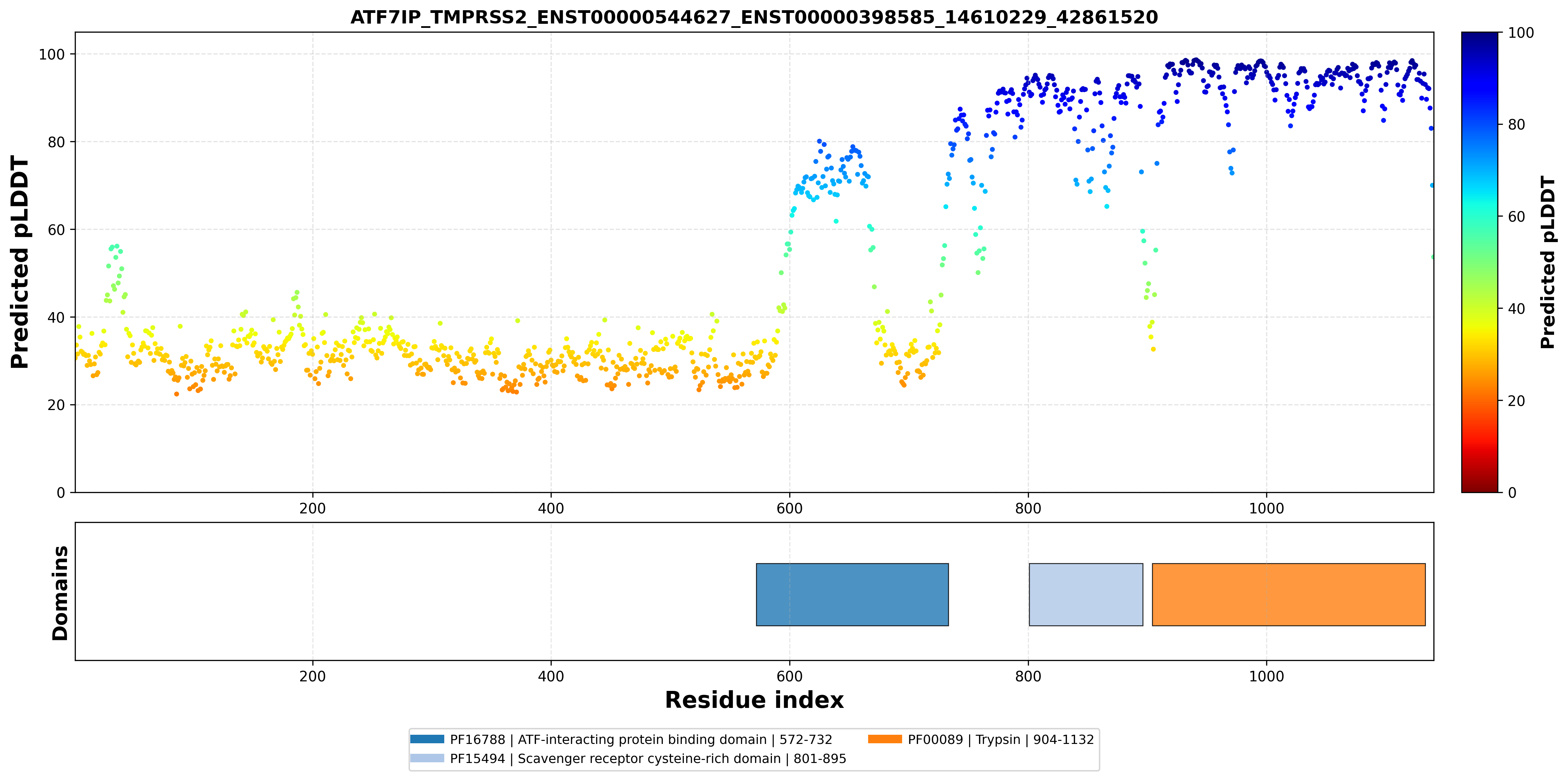 |  | 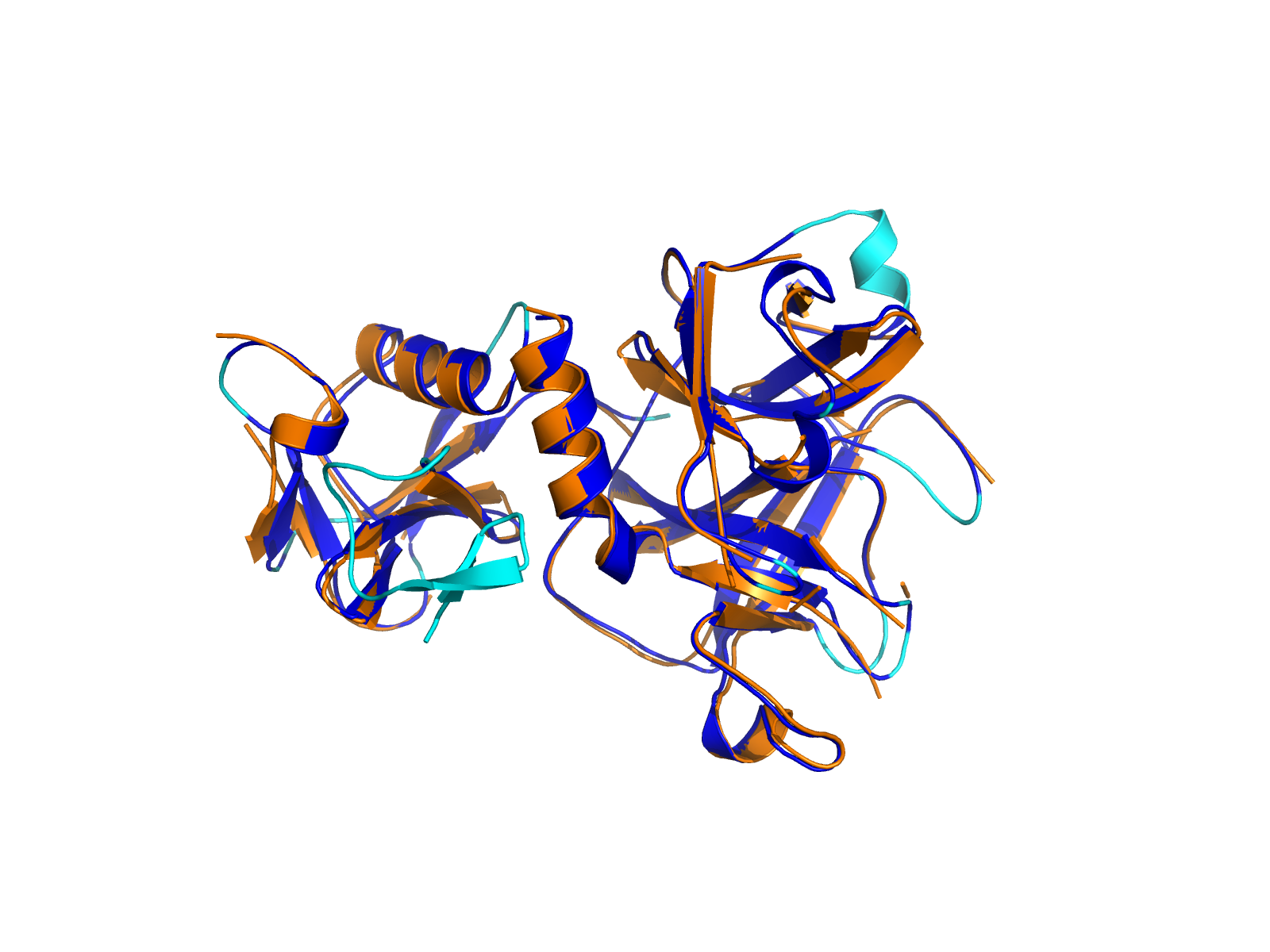 |
| ATG13_MTCH2_ENST00000312040_ENST00000302503_46667539_47656286 superimposed PDB: 12OZ of partner (MTCH2). RMSD:0.9764
Å |
 |  |  |  |  |
| ATG13_MTCH2_ENST00000526508_ENST00000302503_46667539_47656286 superimposed PDB: 12OZ of partner (MTCH2). RMSD:1.3553
Å |
 |  |  |  |  |
| ATG14_FUT8_ENST00000247178_ENST00000394586_55878319_66135960 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6427
Å |
 |  |  |  |  |
| ATG16L1_WAPAL_ENST00000347464_ENST00000372075_234191399_88206206 superimposed PDB: 5NUV of partner (ATG16L1). RMSD:0.3089
Å |
 |  |  |  |  |
| ATG16L1_WAPAL_ENST00000373525_ENST00000372075_234191399_88206206 superimposed PDB: 5NUV of partner (ATG16L1). RMSD:2.3557
Å |
 |  |  |  |  |
| ATG16L1_WAPAL_ENST00000373525_ENST00000372075_234191399_88206206 superimposed PDB: 4K6J of partner (WAPAL). RMSD:2.9965
Å |
| | | |  |
| ATG16L1_WAPAL_ENST00000392017_ENST00000372075_234191399_88206206 superimposed PDB: 5NUV of partner (ATG16L1). RMSD:0.3411
Å |
 |  |  |  |  |
| ATG16L1_WAPAL_ENST00000392018_ENST00000372075_234191399_88206206 superimposed PDB: 5NUV of partner (ATG16L1). RMSD:0.3665
Å |
 |  |  |  |  |
| ATG16L1_WAPAL_ENST00000392020_ENST00000372075_234191399_88206206 superimposed PDB: 5NUV of partner (ATG16L1). RMSD:0.3384
Å |
 |  |  |  |  |
| ATG16L2_TP53BP2_ENST00000321297_ENST00000343537_72528900_223980224 superimposed PDB: 1YCS of partner (TP53BP2). RMSD:0.5604
Å |
 |  |  |  |  |
| ATG2A_KLK10_ENST00000421419_ENST00000391805_64673034_51519412 superimposed PDB: 8KBX of partner (ATG2A). RMSD:2.742
Å |
 |  |  |  |  |
| ATG2A_KLK10_ENST00000421419_ENST00000391805_64673034_51519412 superimposed PDB: 5LPE of partner (KLK10). RMSD:0.9146
Å |
| | | |  |
| ATG5_CDC123_ENST00000360666_ENST00000281141_106763975_12259359 superimposed PDB: 8PHV of partner (CDC123). RMSD:1.0696
Å |
 |  |  |  |  |
| ATG5_EPHA7_ENST00000369076_ENST00000369303_106756238_93982140 superimposed PDB: 4TQ1 of partner (ATG5). RMSD:0.7255
Å |
 |  |  |  |  |
| ATG5_PLCG2_ENST00000369076_ENST00000359376_106763975_81902818 superimposed PDB: 8QJU of partner (PLCG2). RMSD:1.871
Å |
 |  |  |  |  |
| ATIC_ALK_ENST00000435675_ENST00000389048_216191701_29446394 superimposed PDB: 1PKX of partner (ATIC). RMSD:3.2611
Å |
 |  |  |  |  |
| ATIC_ALK_ENST00000540518_ENST00000389048_216191701_29446394 superimposed PDB: 1PKX of partner (ATIC). RMSD:3.1898
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000236959_ENST00000361162_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.9666
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000236959_ENST00000361162_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7421
Å |
| | | |  |
| ATIC_RBM39_ENST00000236959_ENST00000528062_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.9354
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000236959_ENST00000528062_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7617
Å |
| | | |  |
| ATIC_RBM39_ENST00000435675_ENST00000253363_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.8476
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000435675_ENST00000253363_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.741
Å |
| | | |  |
| ATIC_RBM39_ENST00000435675_ENST00000361162_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.885
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000435675_ENST00000361162_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7428
Å |
| | | |  |
| ATIC_RBM39_ENST00000435675_ENST00000528062_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.8614
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000435675_ENST00000528062_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7549
Å |
| | | |  |
| ATIC_RBM39_ENST00000540518_ENST00000253363_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.952
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000540518_ENST00000253363_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7161
Å |
| | | |  |
| ATIC_RBM39_ENST00000540518_ENST00000361162_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:1.0168
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000540518_ENST00000361162_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7413
Å |
| | | |  |
| ATIC_RBM39_ENST00000540518_ENST00000528062_216203630_34326939 superimposed PDB: 1PKX of partner (ATIC). RMSD:0.9624
Å |
 |  |  |  |  |
| ATIC_RBM39_ENST00000540518_ENST00000528062_216203630_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7577
Å |
| | | |  |
| ATP10D_TACC3_ENST00000273859_ENST00000313288_47556931_1746244 superimposed PDB: 5LXN of partner (TACC3). RMSD:1.5632
Å |
 |  |  |  |  |
| ATP1A1_ATP1A3_ENST00000295598_ENST00000545399_116939356_42480718 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:2.3286
Å |
 |  |  |  |  |
| ATP1A1_ATP1A3_ENST00000295598_ENST00000545399_116939356_42480718 superimposed PDB: 8D3V of partner (ATP1A3). RMSD:2.2282
Å |
| | | |  |
| ATP1A1_ATP1A3_ENST00000369496_ENST00000545399_116939356_42480718 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:2.1778
Å |
 |  |  |  |  |
| ATP1A1_ATP1A3_ENST00000369496_ENST00000545399_116939356_42480718 superimposed PDB: 8D3V of partner (ATP1A3). RMSD:2.255
Å |
| | | |  |
| ATP1A1_ATP1A3_ENST00000537345_ENST00000545399_116939356_42480718 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:2.2156
Å |
 |  |  |  |  |
| ATP1A1_ATP1A3_ENST00000537345_ENST00000545399_116939356_42480718 superimposed PDB: 8D3V of partner (ATP1A3). RMSD:2.2929
Å |
| | | |  |
| ATP1A2_CLU_ENST00000361216_ENST00000546343_160091041_27464041 superimposed PDB: 7ZET of partner (CLU). RMSD:2.6653
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000287845_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.744
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000338921_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.791
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000356819_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.733
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000405005_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.8242
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000519301_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7537
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000520407_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7368
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000521670_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7691
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367813_ENST00000523079_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7634
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367815_ENST00000519301_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.795
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000287845_169080736_32453345 superimposed PDB: 8ZYJ of partner (ATP1B1). RMSD:3.0658
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000287845_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7721
Å |
| | | |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000338921_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7755
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000356819_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7565
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000405005_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7808
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000519301_169080736_32453345 superimposed PDB: 8ZYJ of partner (ATP1B1). RMSD:3.0045
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000520407_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.762
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000521670_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.8039
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000367816_ENST00000523079_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7258
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000287845_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.74
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000338921_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7328
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000356819_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7372
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000405005_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7691
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000520407_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7631
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000521670_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.739
Å |
 |  |  |  |  |
| ATP1B1_NRG1_ENST00000499679_ENST00000523079_169080736_32453345 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7146
Å |
 |  |  |  |  |
| ATP2A2_ATP2A3_ENST00000308664_ENST00000309890_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.6196
Å |
 |  | 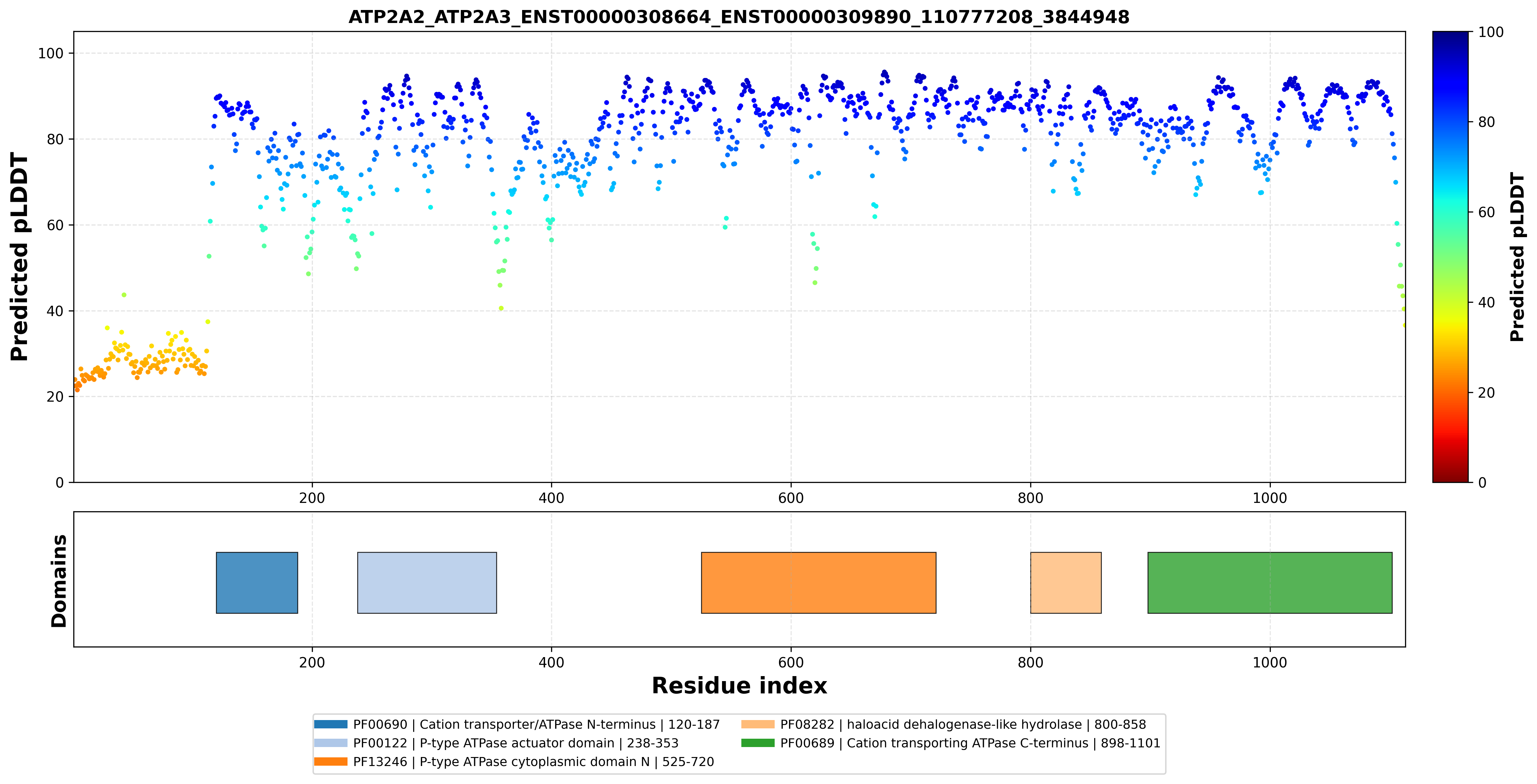 |  |  |
| ATP2A2_ATP2A3_ENST00000308664_ENST00000397041_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.54
Å |
 |  | 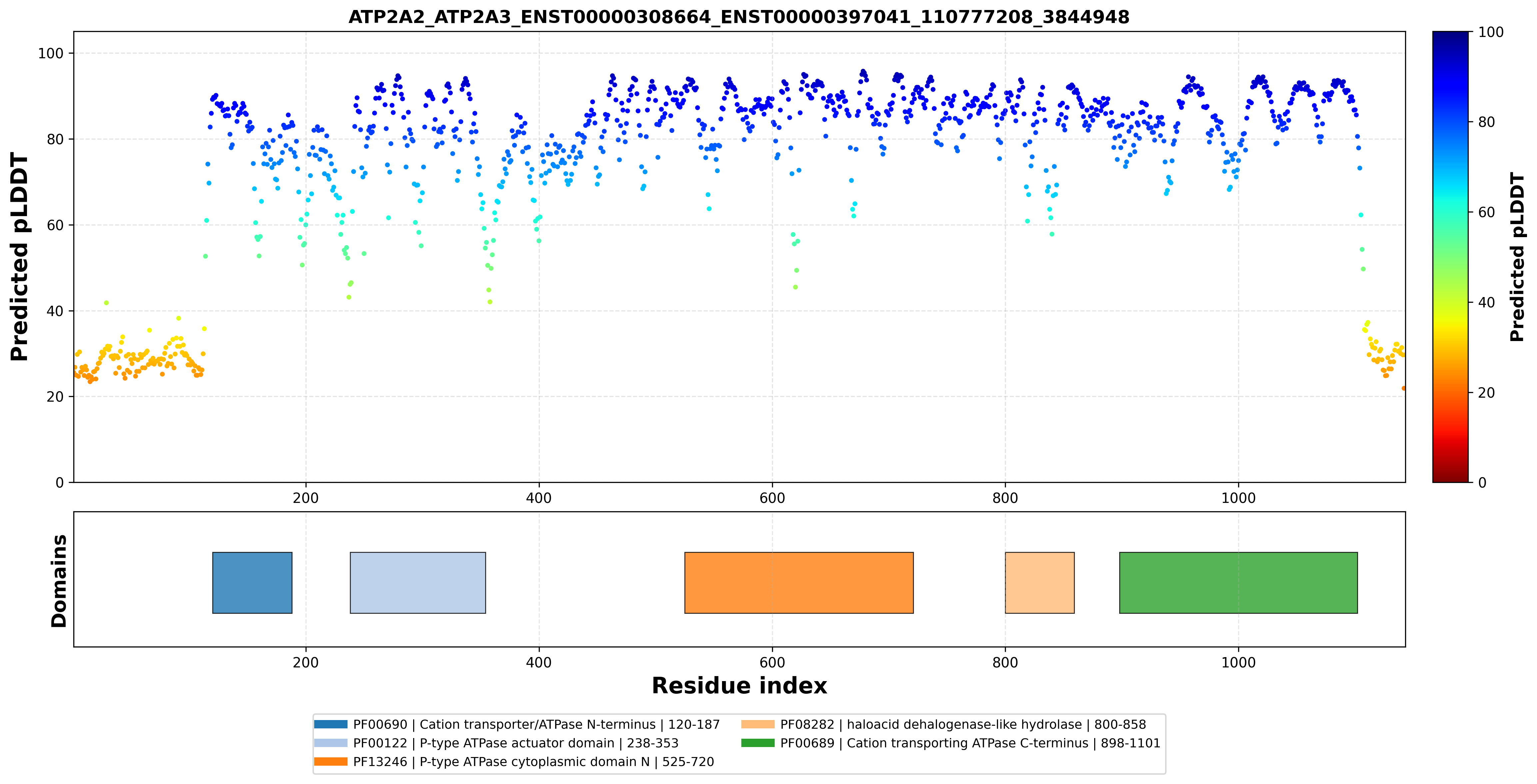 |  |  |
| ATP2A2_ATP2A3_ENST00000395494_ENST00000309890_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.5909
Å |
 |  |  |  |  |
| ATP2A2_ATP2A3_ENST00000395494_ENST00000397041_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.7222
Å |
 |  |  |  |  |
| ATP2A2_ATP2A3_ENST00000539276_ENST00000309890_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.6235
Å |
 |  |  |  |  |
| ATP2A2_ATP2A3_ENST00000539276_ENST00000397041_110777208_3844948 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.5005
Å |
 |  |  |  |  |
| ATP2A2_COL2A1_ENST00000308664_ENST00000380518_110771948_48378382 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.6764
Å |
 |  |  |  |  |
| ATP2A2_COL2A1_ENST00000395494_ENST00000380518_110771948_48378382 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.5494
Å |
 |  |  |  |  |
| ATP2A2_COL2A1_ENST00000539276_ENST00000380518_110771948_48378382 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.6851
Å |
 |  |  |  |  |
| ATP2A2_RRP1_ENST00000308664_ENST00000497547_110781239_45211230 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.5554
Å |
 |  |  |  |  |
| ATP2A2_RRP1_ENST00000395494_ENST00000497547_110781239_45211230 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.8824
Å |
 |  |  |  |  |
| ATP2A2_RRP1_ENST00000539276_ENST00000497547_110781239_45211230 superimposed PDB: 6LLY of partner (ATP2A2). RMSD:2.8013
Å |
 |  |  |  |  |
| ATP2B1_CEP290_ENST00000348959_ENST00000309041_90010578_88478629 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:3.1072
Å |
 |  |  |  |  |
| ATP2B1_CEP290_ENST00000348959_ENST00000547691_90010578_88478629 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:3.0808
Å |
 |  |  |  |  |
| ATP2B1_CEP290_ENST00000348959_ENST00000552810_90010578_88478629 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:3.1139
Å |
 |  |  |  |  |
| ATP2B1_CEP290_ENST00000393164_ENST00000552810_90010578_88478629 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:2.7306
Å |
 |  |  |  |  |
| ATP2B1_LIN7A_ENST00000261173_ENST00000552864_90003713_81283148 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:2.8077
Å |
 |  |  |  |  |
| ATP2B1_LIN7A_ENST00000348959_ENST00000552864_90003713_81283148 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:2.7462
Å |
 |  |  |  |  |
| ATP2B4_ASRGL1_ENST00000391954_ENST00000415229_203652526_62123796 superimposed PDB: 4O0C of partner (ASRGL1). RMSD:0.4201
Å |
 | 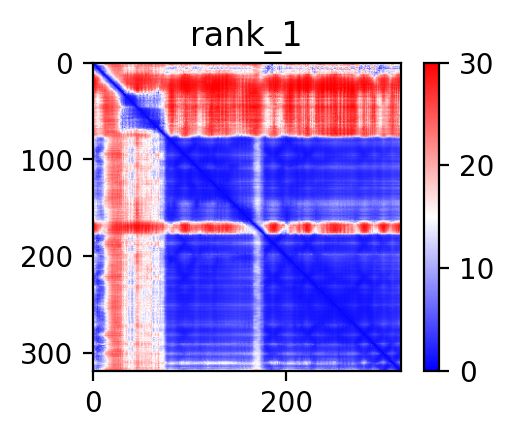 | 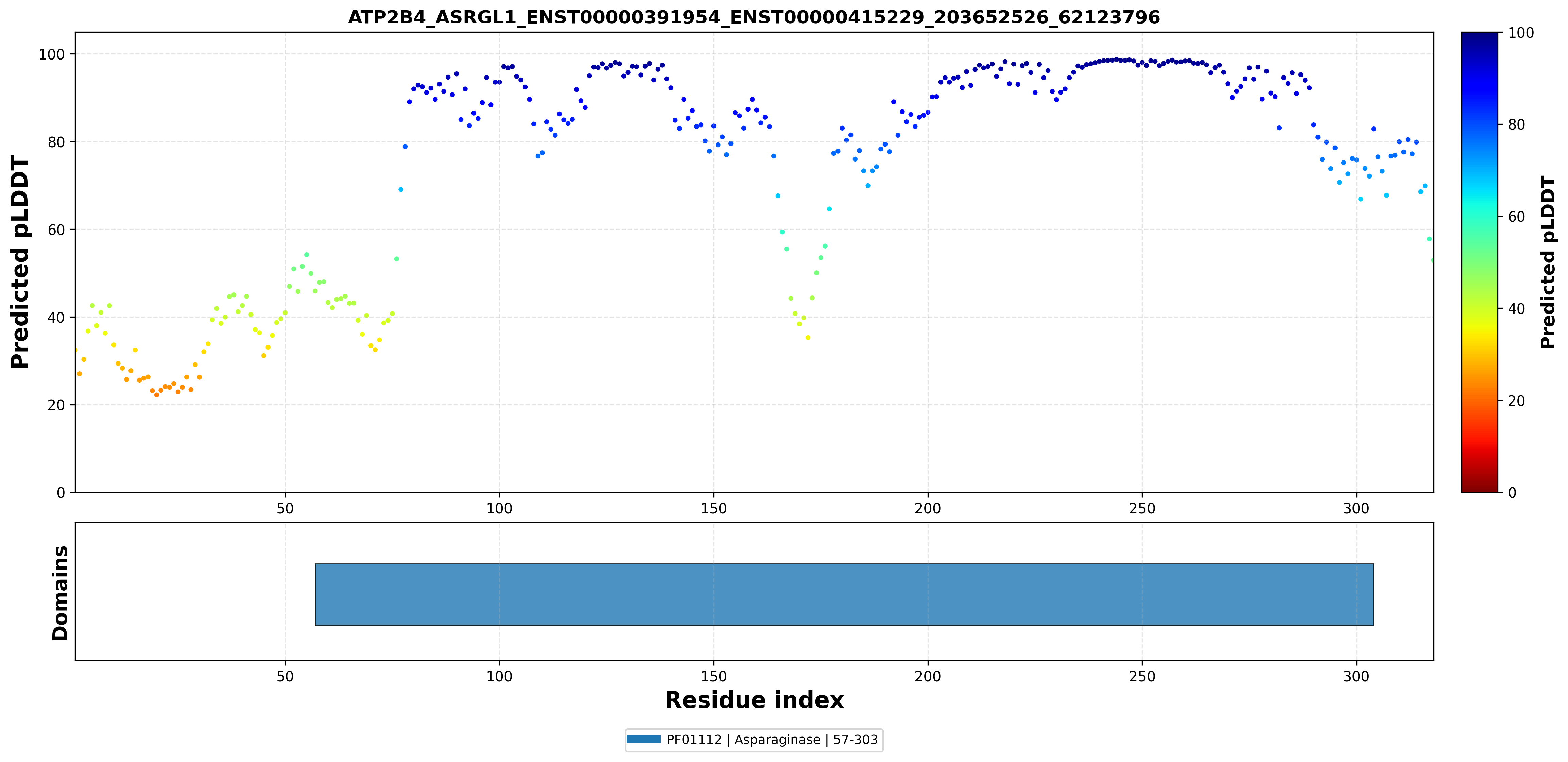 |  |  |
| ATP2C1_TMEM241_ENST00000504381_ENST00000383233_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.5887
Å |
 |  |  |  |  |
| ATP2C1_TMEM241_ENST00000504381_ENST00000450466_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.7906
Å |
 |  | 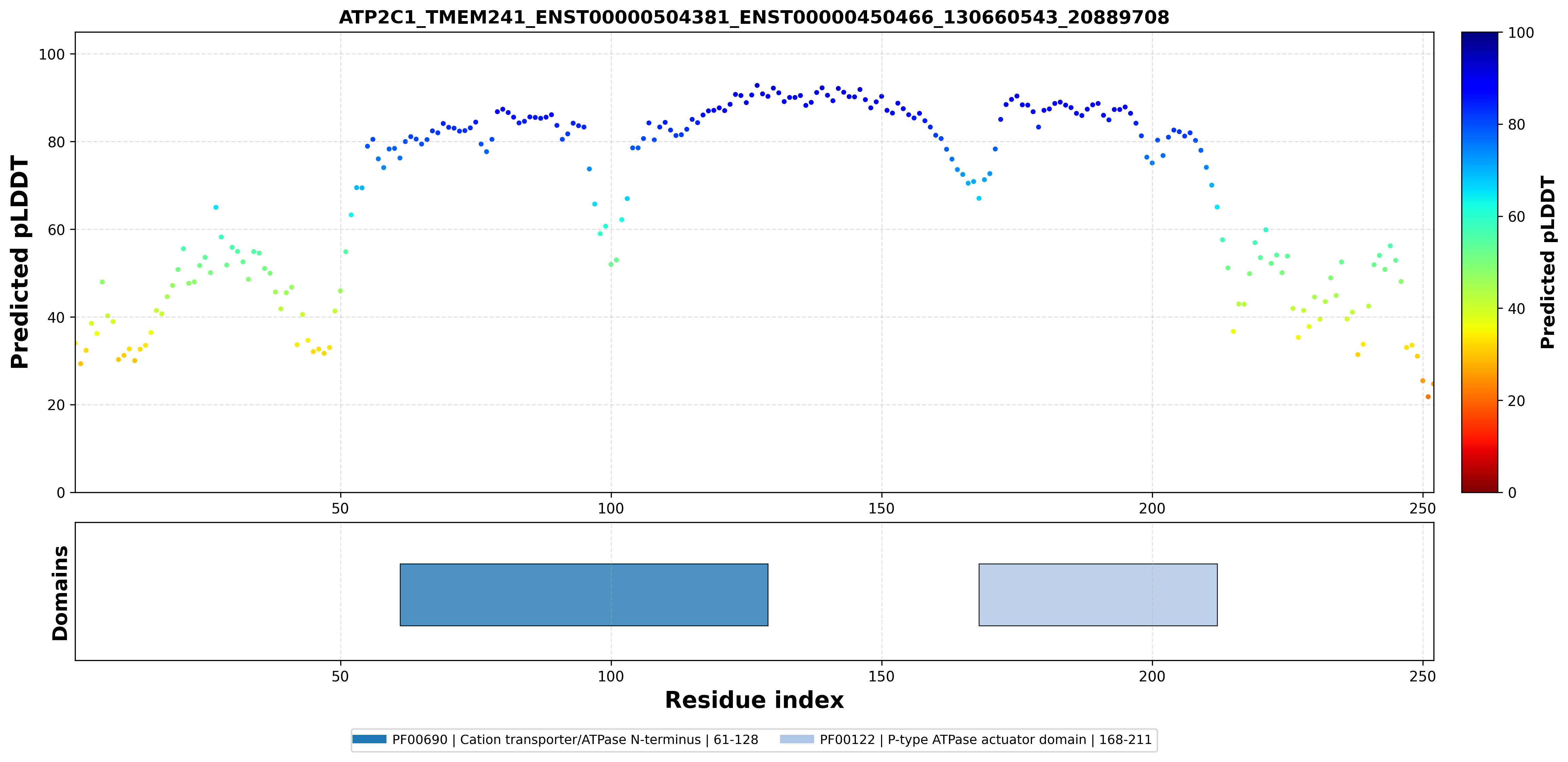 |  |  |
| ATP2C1_TMEM241_ENST00000504948_ENST00000383233_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.792
Å |
 |  | 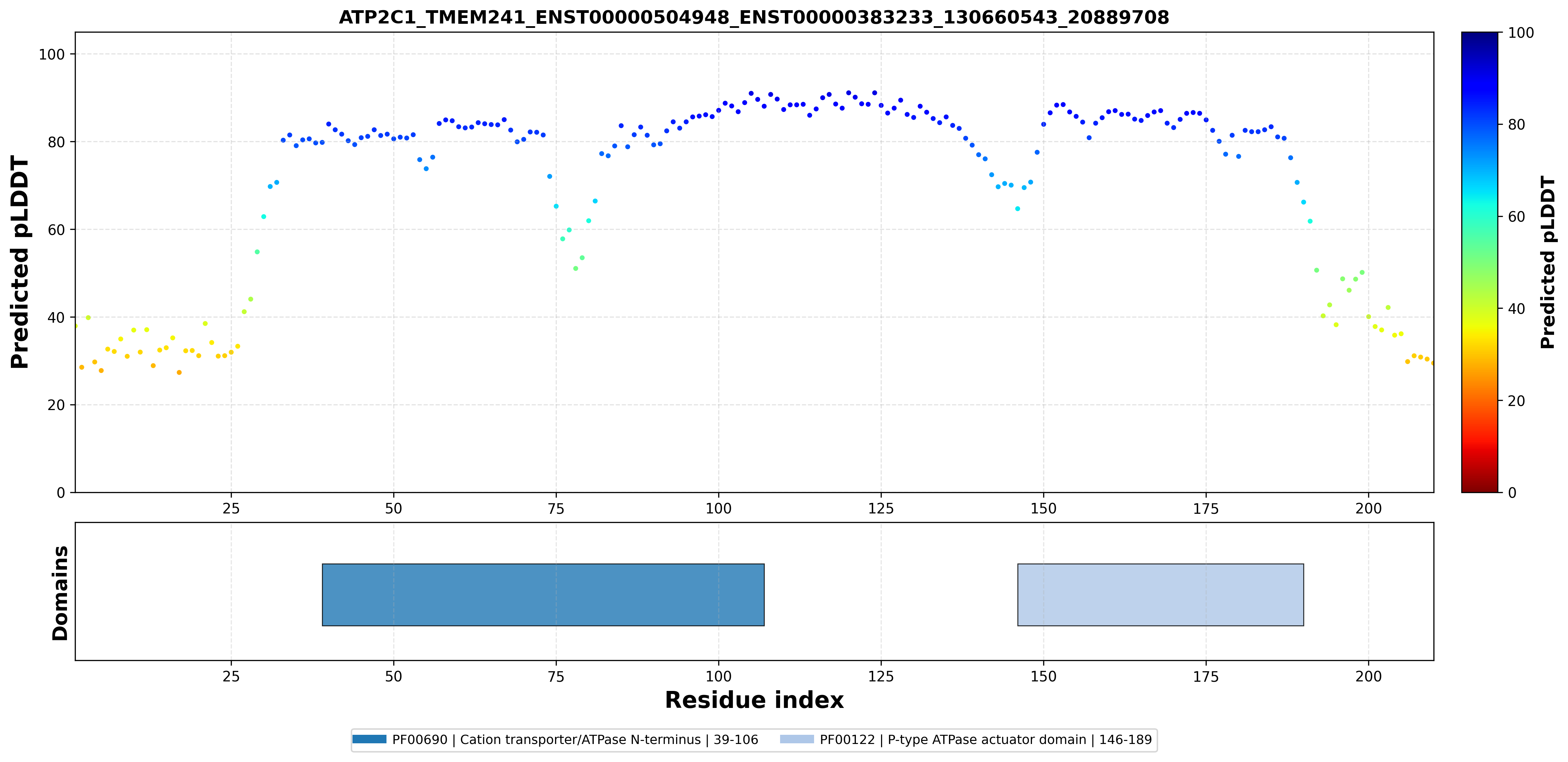 |  |  |
| ATP2C1_TMEM241_ENST00000505330_ENST00000383233_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.7441
Å |
 |  |  |  |  |
| ATP2C1_TMEM241_ENST00000507488_ENST00000450466_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.4319
Å |
 |  | 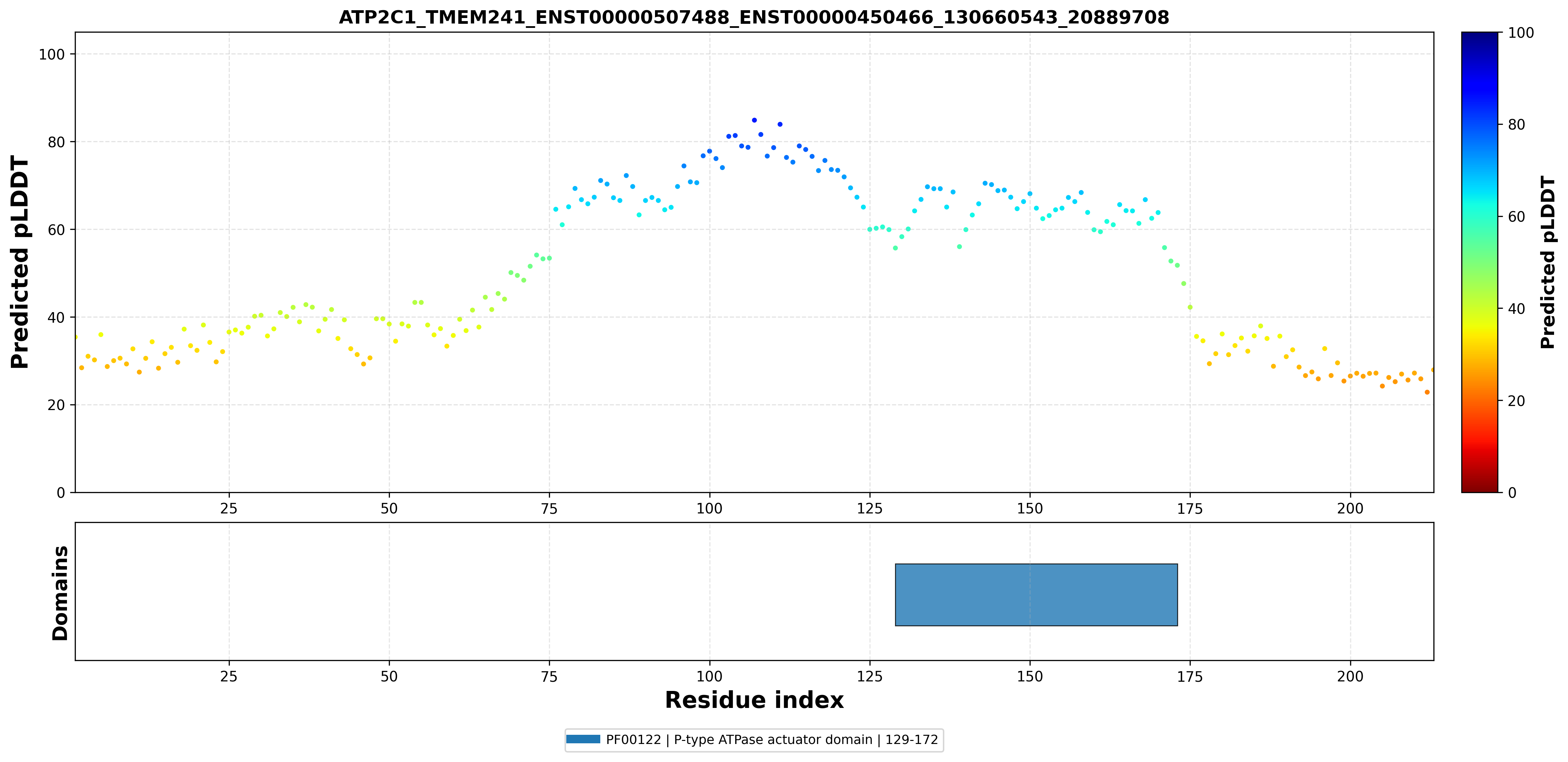 |  |  |
| ATP2C1_TMEM241_ENST00000508532_ENST00000450466_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.7959
Å |
 |  | 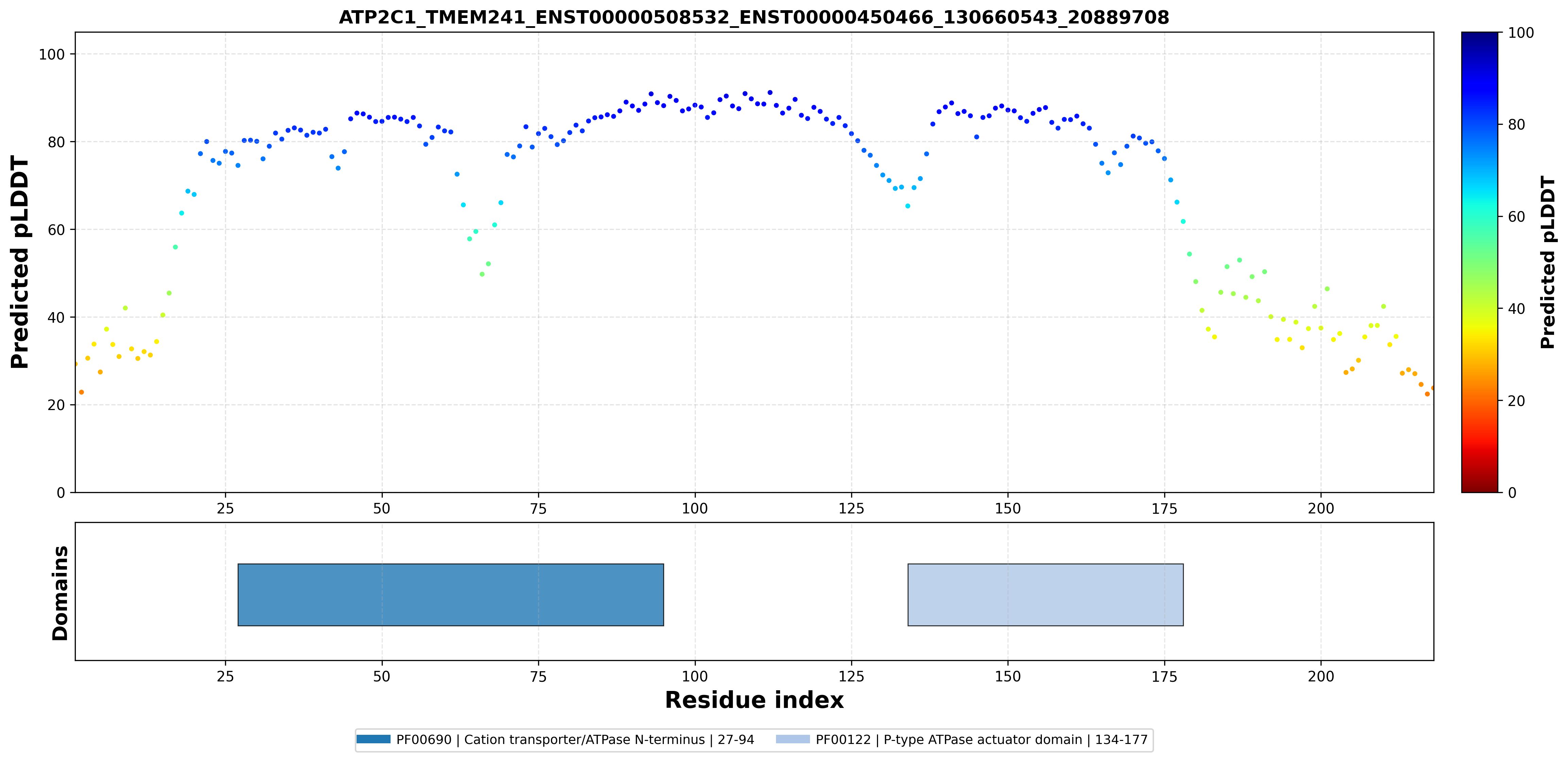 |  |  |
| ATP2C1_TMEM241_ENST00000510168_ENST00000383233_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.7581
Å |
 |  |  |  |  |
| ATP2C1_TMEM241_ENST00000513801_ENST00000450466_130660543_20889708 superimposed PDB: 7YAG of partner (ATP2C1). RMSD:2.715
Å |
 |  | 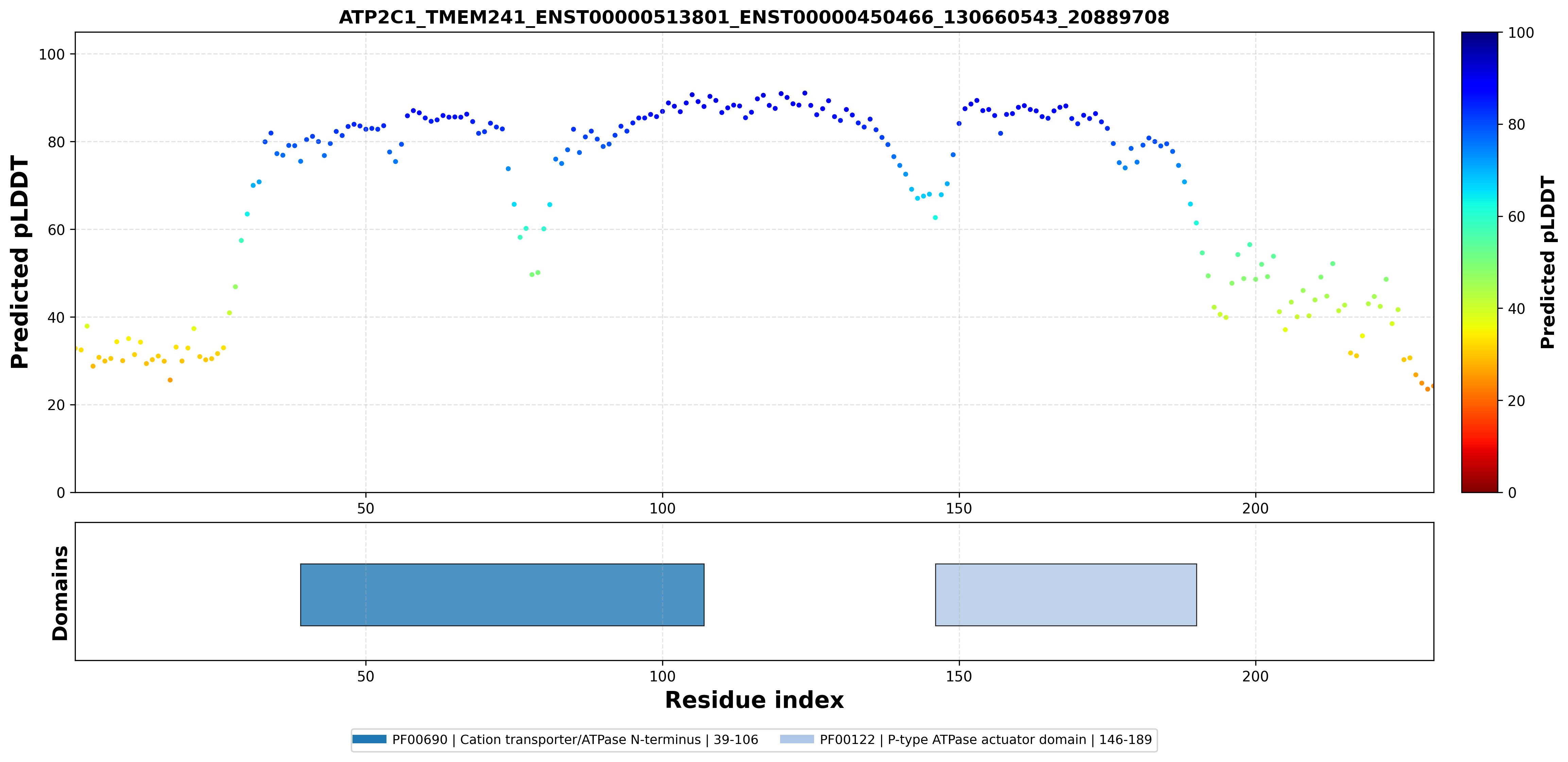 |  |  |
| ATP5B_CALCA_ENST00000552919_ENST00000486207_57039620_14992747 superimposed PDB: 7TYO of partner (CALCA). RMSD:2.6004
Å |
 |  |  |  |  |
| ATP5B_IVNS1ABP_ENST00000552919_ENST00000367498_57037186_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.4278
Å |
 |  |  |  |  |
| ATP5C1_ALDH7A1_ENST00000356708_ENST00000447989_7838118_125896816 superimposed PDB: 6O4C of partner (ALDH7A1). RMSD:0.4543
Å |
 |  |  |  |  |
| ATP5C1_ALDH7A1_ENST00000356708_ENST00000553117_7838118_125896816 superimposed PDB: 6O4C of partner (ALDH7A1). RMSD:1.2732
Å |
 |  |  |  |  |
| ATP5C1_MGEA5_ENST00000335698_ENST00000439817_7841157_103572884 superimposed PDB: 5M7U of partner (MGEA5). RMSD:0.3759
Å |
 |  |  |  |  |
| ATP5C1_MGEA5_ENST00000356708_ENST00000361464_7841157_103572884 superimposed PDB: 5M7U of partner (MGEA5). RMSD:0.5787
Å |
 |  |  |  |  |
| ATP5C1_MGEA5_ENST00000541227_ENST00000361464_7841157_103572884 superimposed PDB: 5M7U of partner (MGEA5). RMSD:0.6289
Å |
 |  |  |  |  |
| ATP5C1_MGEA5_ENST00000541227_ENST00000439817_7841157_103572884 superimposed PDB: 5M7U of partner (MGEA5). RMSD:0.3939
Å |
 |  |  |  |  |
| ATP5I_MARK3_ENST00000304312_ENST00000303622_666226_103933415 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.3518
Å |
 |  |  |  |  |
| ATP5I_MARK3_ENST00000304312_ENST00000335102_666226_103933415 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.3506
Å |
 |  |  |  |  |
| ATP5I_MARK3_ENST00000304312_ENST00000416682_666226_103933415 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.3673
Å |
 |  |  |  |  |
| ATP5I_MARK3_ENST00000304312_ENST00000429436_666226_103933415 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.3583
Å |
 |  |  |  |  |
| ATP5I_MARK3_ENST00000304312_ENST00000553942_666226_103933415 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.3308
Å |
 |  |  |  |  |
| ATP5SL_ETHE1_ENST00000221943_ENST00000292147_41945786_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3289
Å |
 |  |  |  |  |
| ATP5SL_ETHE1_ENST00000438807_ENST00000600651_41945786_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3336
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000264649_ENST00000284073_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.0438
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000264649_ENST00000322684_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.9751
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000264649_ENST00000442934_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.0872
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000393829_ENST00000284073_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.0686
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000393829_ENST00000322684_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.0186
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000393829_ENST00000442934_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.0808
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000537728_ENST00000284073_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.9982
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000537728_ENST00000322684_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.9533
Å |
 |  |  |  |  |
| ATP6V0A1_MSI2_ENST00000537728_ENST00000442934_40635149_55607036 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.9813
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000341165_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.2399
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000341165_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4911
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000422280_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.2089
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000422280_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4991
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000590996_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.1556
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000264649_ENST00000590996_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.5653
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000393829_ENST00000422280_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.1211
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000393829_ENST00000422280_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.5166
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000393829_ENST00000590996_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.1056
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000393829_ENST00000590996_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4392
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000537728_ENST00000422280_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.2797
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000537728_ENST00000422280_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4373
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000537728_ENST00000590996_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.3469
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000537728_ENST00000590996_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4536
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000544137_ENST00000422280_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.5704
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000544137_ENST00000422280_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4751
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000544137_ENST00000590996_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.3441
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000544137_ENST00000590996_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4665
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000546249_ENST00000341165_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.2783
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000546249_ENST00000341165_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4716
Å |
| | | |  |
| ATP6V0A1_NBR1_ENST00000585525_ENST00000341165_40659645_41338266 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.3293
Å |
 |  |  |  |  |
| ATP6V0A1_NBR1_ENST00000585525_ENST00000341165_40659645_41338266 superimposed PDB: 4OLE of partner (NBR1). RMSD:0.4984
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000264649_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8468
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000264649_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:2.0401
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000264649_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.765
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000264649_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.8808
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000343619_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8442
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000343619_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.2953
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000343619_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.7227
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000343619_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.6046
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000393829_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:1.3255
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000393829_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8547
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000393829_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.7962
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000537728_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.7243
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000537728_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.7614
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000537728_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.755
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000537728_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.9042
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000544137_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.7942
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000544137_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.6513
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000544137_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8915
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000544137_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.6009
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000546249_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.7898
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000546249_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.7855
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000546249_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8222
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000546249_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.9725
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000585525_ENST00000264657_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.7864
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000585525_ENST00000264657_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.7357
Å |
| | | |  |
| ATP6V0A1_STAT3_ENST00000585525_ENST00000585517_40666478_40498731 superimposed PDB: 6WLW of partner (ATP6V0A1). RMSD:0.8069
Å |
 |  |  |  |  |
| ATP6V0A1_STAT3_ENST00000585525_ENST00000585517_40666478_40498731 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.8391
Å |
| | | |  |
| ATP6V1E1_BID_ENST00000399796_ENST00000317361_18095577_18226779 superimposed PDB: 6WLZ of partner (ATP6V1E1). RMSD:2.0647
Å |
 |  |  |  |  |
| ATP6V1H_CHD7_ENST00000396774_ENST00000524602_54754137_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.8951
Å |
 |  |  |  |  |
| ATP6V1H_CHD7_ENST00000396774_ENST00000525508_54754137_61693558 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:2.8559
Å |
 |  |  |  |  |
| ATP6V1H_CHD7_ENST00000396774_ENST00000525508_54754137_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.7235
Å |
| | | |  |
| ATP6V1H_ST8SIA4_ENST00000520188_ENST00000451528_54723723_100231489 superimposed PDB: 6AHZ of partner (ST8SIA4). RMSD:3.1027
Å |
 |  |  |  |  |
| ATP6V1H_TCEA1_ENST00000355221_ENST00000396401_54742003_54912610 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:2.8882
Å |
 |  |  |  |  |
| ATP6V1H_TCEA1_ENST00000355221_ENST00000521604_54742003_54912610 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:2.657
Å |
 |  |  |  |  |
| ATP6V1H_TCEA1_ENST00000355221_ENST00000521604_54742003_54912610 superimposed PDB: 9MLC of partner (TCEA1). RMSD:1.0119
Å |
| | | |  |
| ATP8A1_CRMP1_ENST00000381668_ENST00000324989_42626552_5844888 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.6665
Å |
 |  |  |  |  |
| ATP8A1_CRMP1_ENST00000381668_ENST00000397890_42626552_5844888 superimposed PDB: 4B3Z of partner (CRMP1). RMSD:0.5081
Å |
 |  |  |  |  |
| ATP8A1_PDS5A_ENST00000264449_ENST00000303538_42551029_39865079 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.8547
Å |
 |  |  |  |  |
| ATP8A1_RASGEF1B_ENST00000264449_ENST00000264400_42545933_82369435 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.7202
Å |
 |  |  |  |  |
| ATP8A1_RASGEF1B_ENST00000264449_ENST00000335927_42545933_82369435 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.7906
Å |
 |  |  |  |  |
| ATP8A1_RASGEF1B_ENST00000381668_ENST00000264400_42545933_82369435 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:3.0535
Å |
 |  |  |  |  |
| ATP8A1_RASGEF1B_ENST00000381668_ENST00000335927_42545933_82369435 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.8436
Å |
 |  |  |  |  |
| ATP8B1_SLC50A1_ENST00000536015_ENST00000303343_55362402_155108774 superimposed PDB: 8OX7 of partner (ATP8B1). RMSD:2.3177
Å |
 |  |  |  |  |
| ATP8B1_SLC50A1_ENST00000536015_ENST00000368404_55362402_155108774 superimposed PDB: 8OX7 of partner (ATP8B1). RMSD:2.7967
Å |
 |  |  |  |  |
| ATP9A_MACROD2_ENST00000311637_ENST00000310348_50255881_15843389 superimposed PDB: 9VDK of partner (ATP9A). RMSD:3.0913
Å |
 |  |  |  |  |
| ATP9A_MACROD2_ENST00000338821_ENST00000217246_50255881_15843389 superimposed PDB: 9VDK of partner (ATP9A). RMSD:3.1705
Å |
 |  |  |  |  |
| ATP9A_MACROD2_ENST00000338821_ENST00000310348_50255881_15843389 superimposed PDB: 9VDK of partner (ATP9A). RMSD:2.5092
Å |
 |  |  |  |  |
| ATP9A_MACROD2_ENST00000402822_ENST00000217246_50255881_15843389 superimposed PDB: 9VDK of partner (ATP9A). RMSD:2.405
Å |
 |  |  |  |  |
| ATP9A_MACROD2_ENST00000402822_ENST00000310348_50255881_15843389 superimposed PDB: 9VDK of partner (ATP9A). RMSD:3.1477
Å |
 |  | 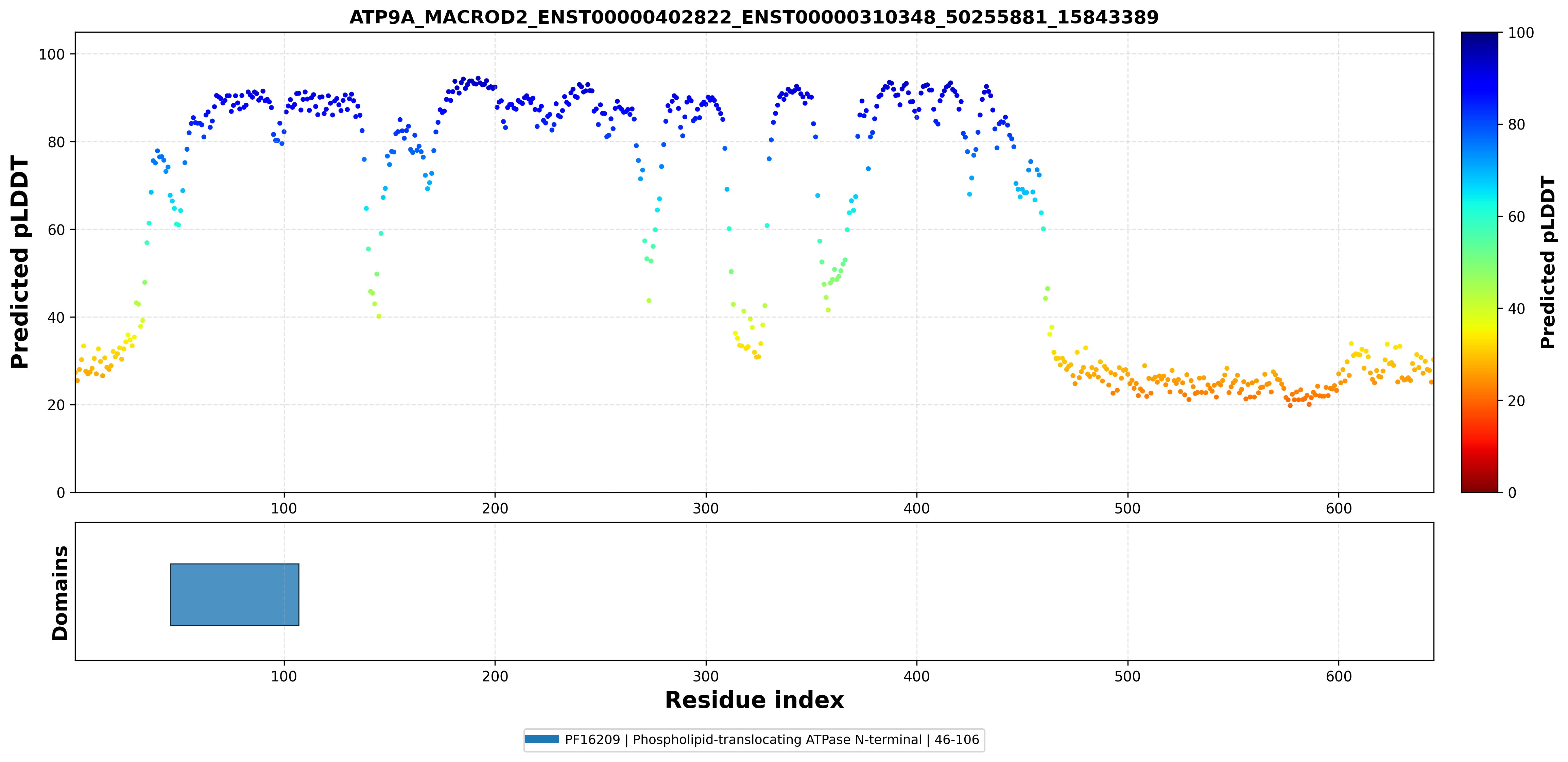 |  |  |
| ATP9A_PICALM_ENST00000338821_ENST00000532317_50312631_85742653 superimposed PDB: 9VDK of partner (ATP9A). RMSD:1.4343
Å |
 | 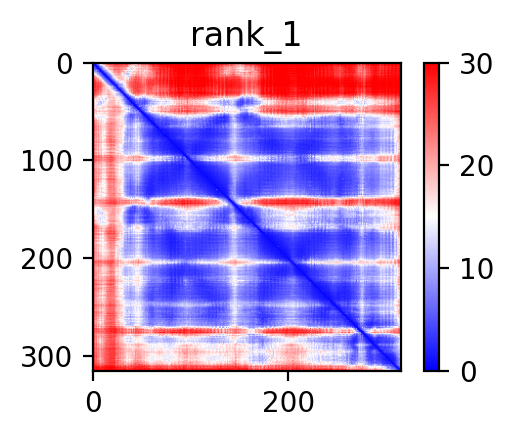 | 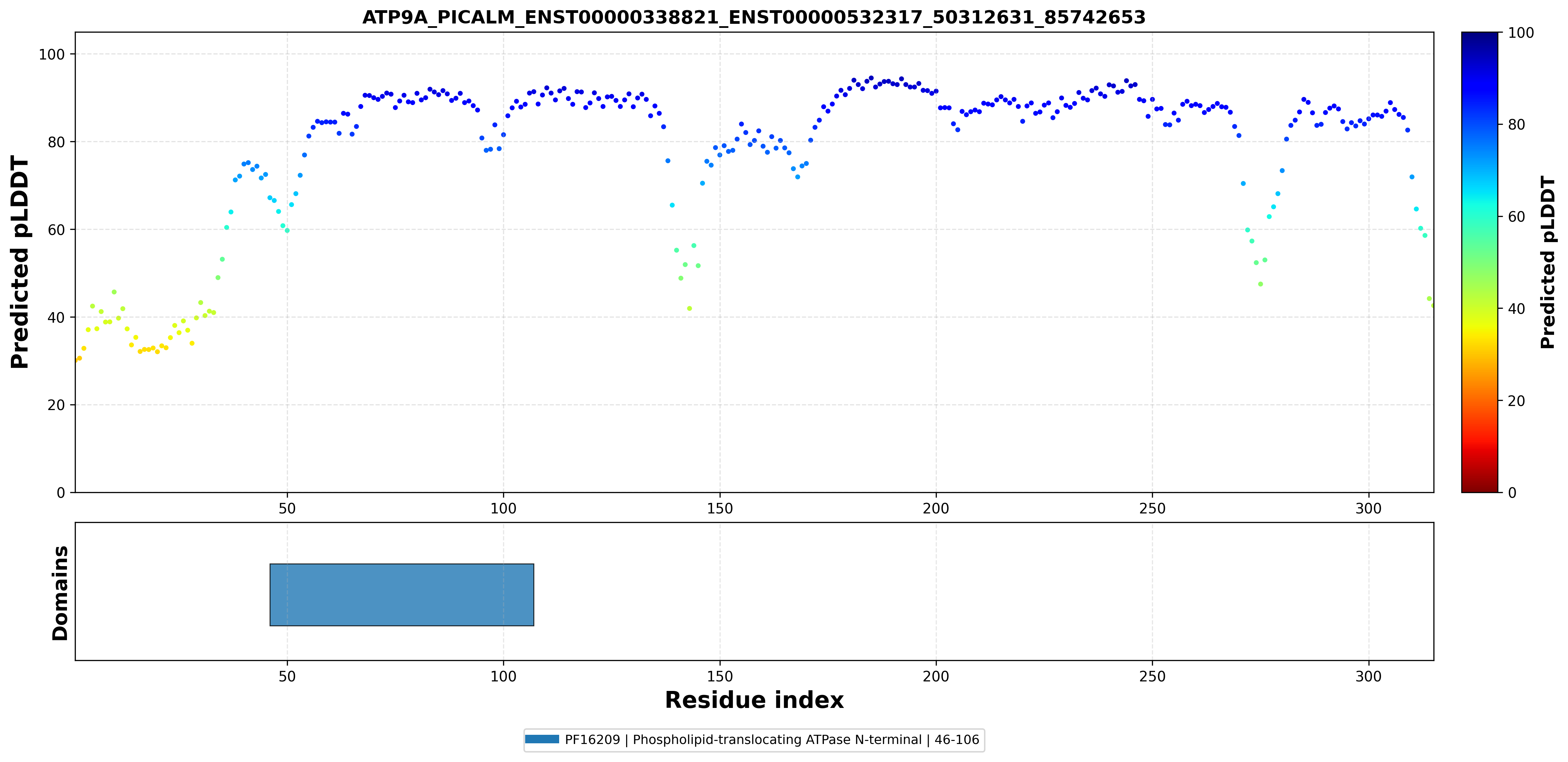 |  |  |
| ATP9A_WFDC8_ENST00000311637_ENST00000357199_50286535_44190858 superimposed PDB: 9VDK of partner (ATP9A). RMSD:3.0778
Å |
 | 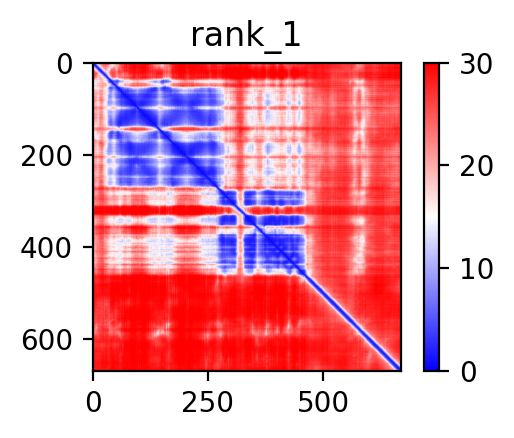 | 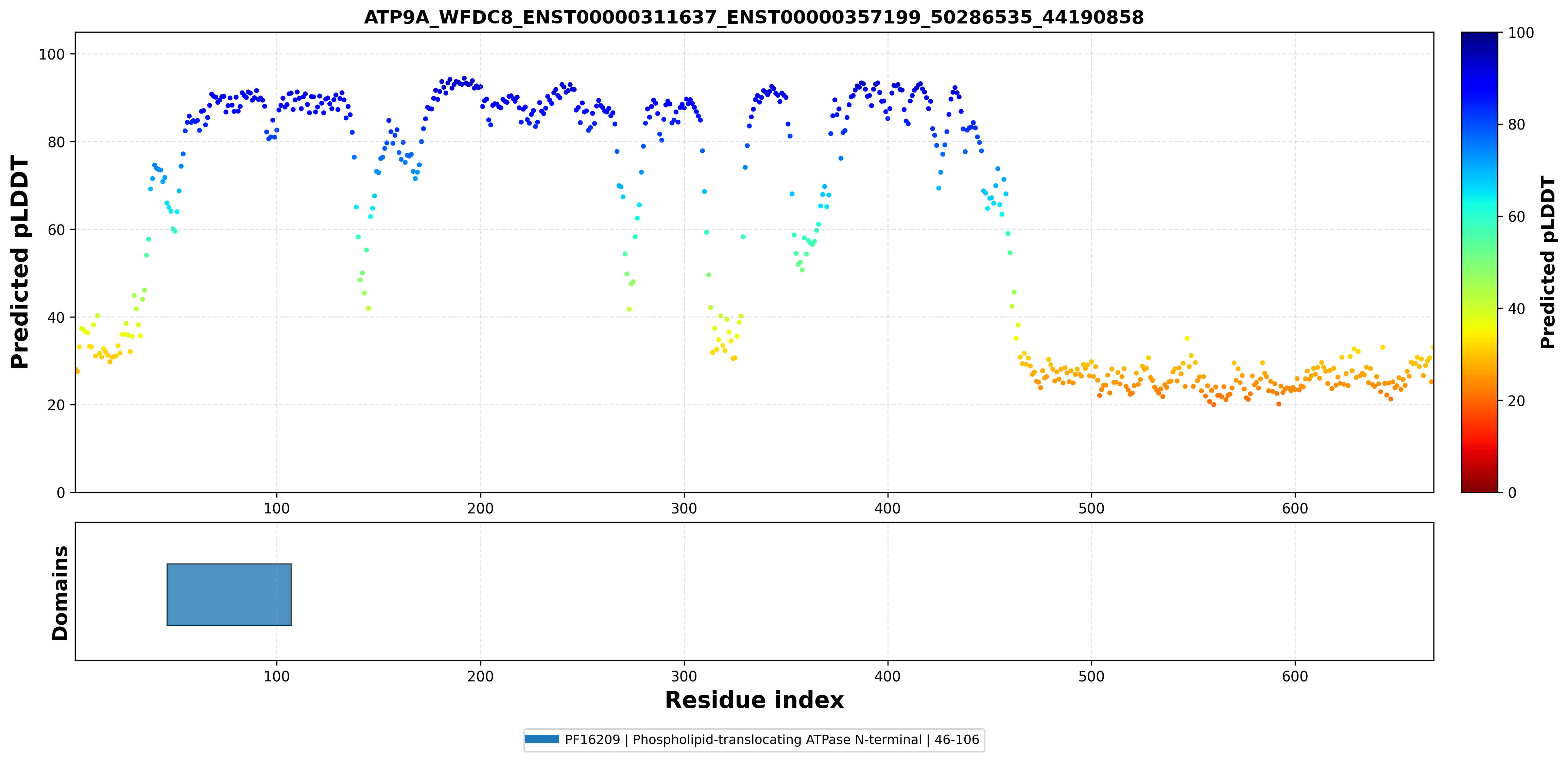 |  |  |
| ATP9A_WFDC8_ENST00000338821_ENST00000357199_50286535_44190858 superimposed PDB: 9VDK of partner (ATP9A). RMSD:1.4461
Å |
 |  | 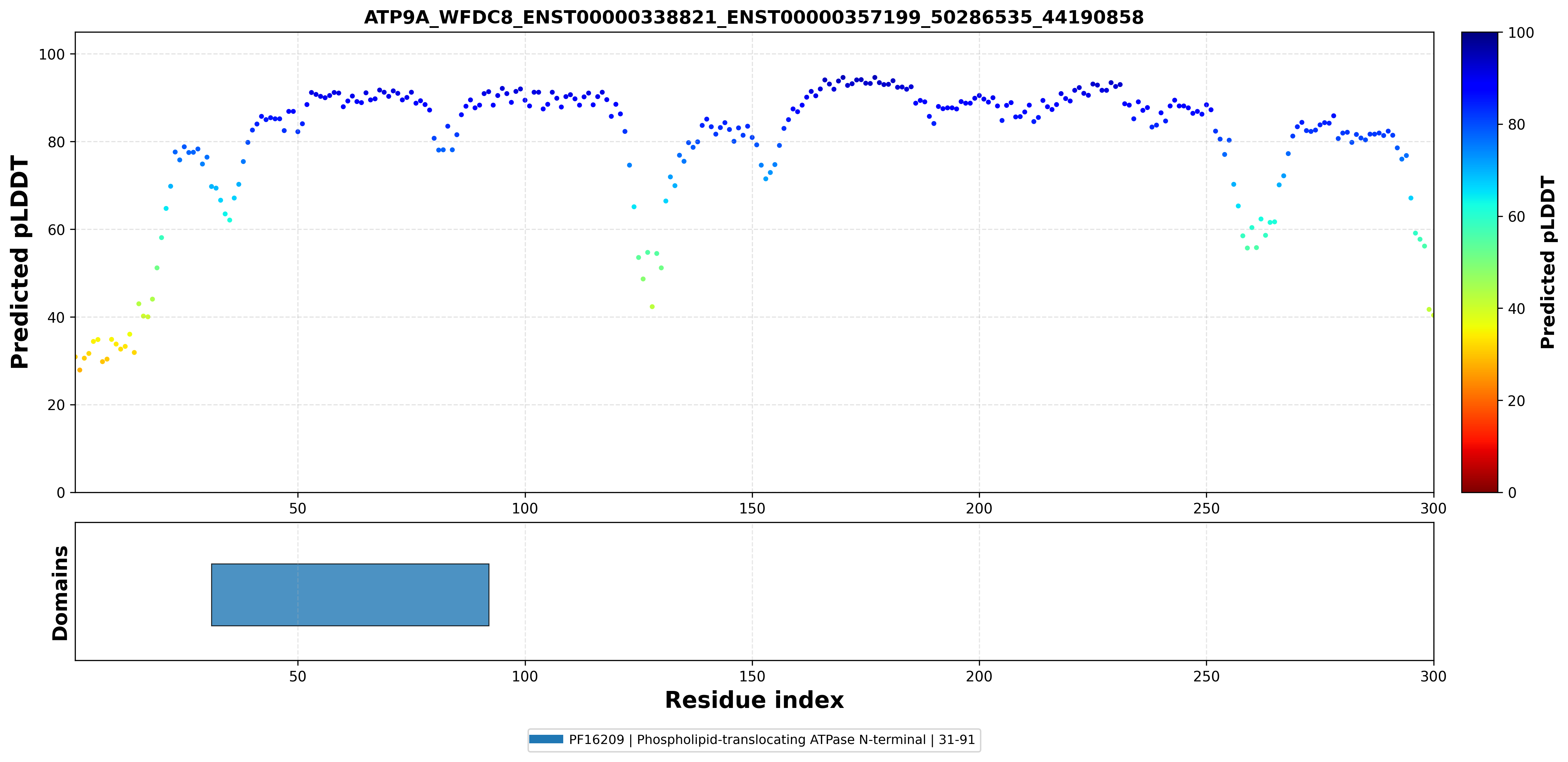 |  |  |
| ATP9A_WFDC8_ENST00000402822_ENST00000357199_50286535_44190858 superimposed PDB: 9VDK of partner (ATP9A). RMSD:1.7089
Å |
 | 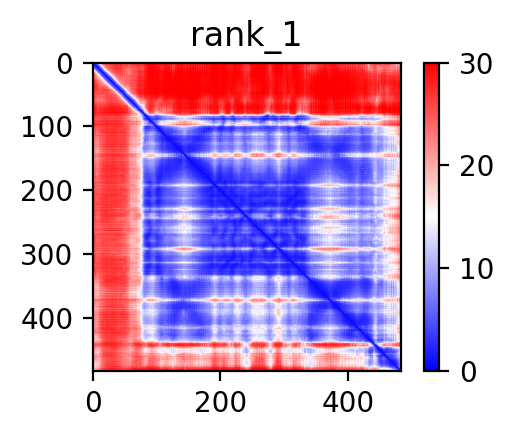 | 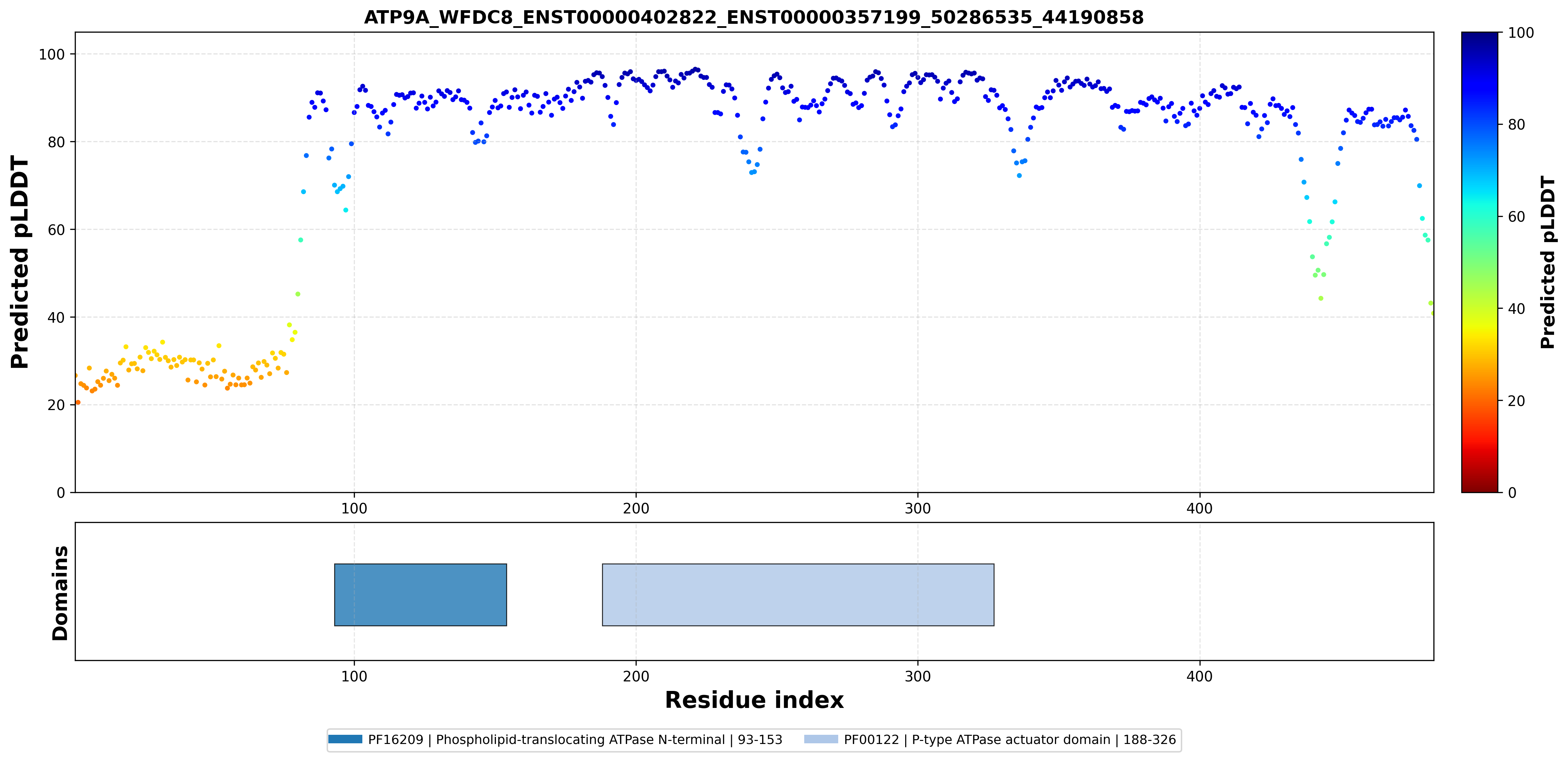 |  |  |
| ATRN_FOXP2_ENST00000446916_ENST00000393498_3584909_114269919 superimposed PDB: 2A07 of partner (FOXP2). RMSD:3.4008
Å |
 |  |  |  |  |
| ATRN_RNF24_ENST00000262919_ENST00000358395_3556595_3915720 superimposed PDB: 2EP4 of partner (RNF24). RMSD:0.9913
Å |
 |  |  |  |  |
| ATRN_TNKS2_ENST00000446916_ENST00000371627_3565527_93572739 superimposed PDB: 8W28 of partner (TNKS2). RMSD:2.7578
Å |
 |  |  |  |  |
| ATRX_ABCB7_ENST00000373344_ENST00000339447_77041467_74334666 superimposed PDB: 23PI of partner (ABCB7). RMSD:2.2832
Å |
 |  | 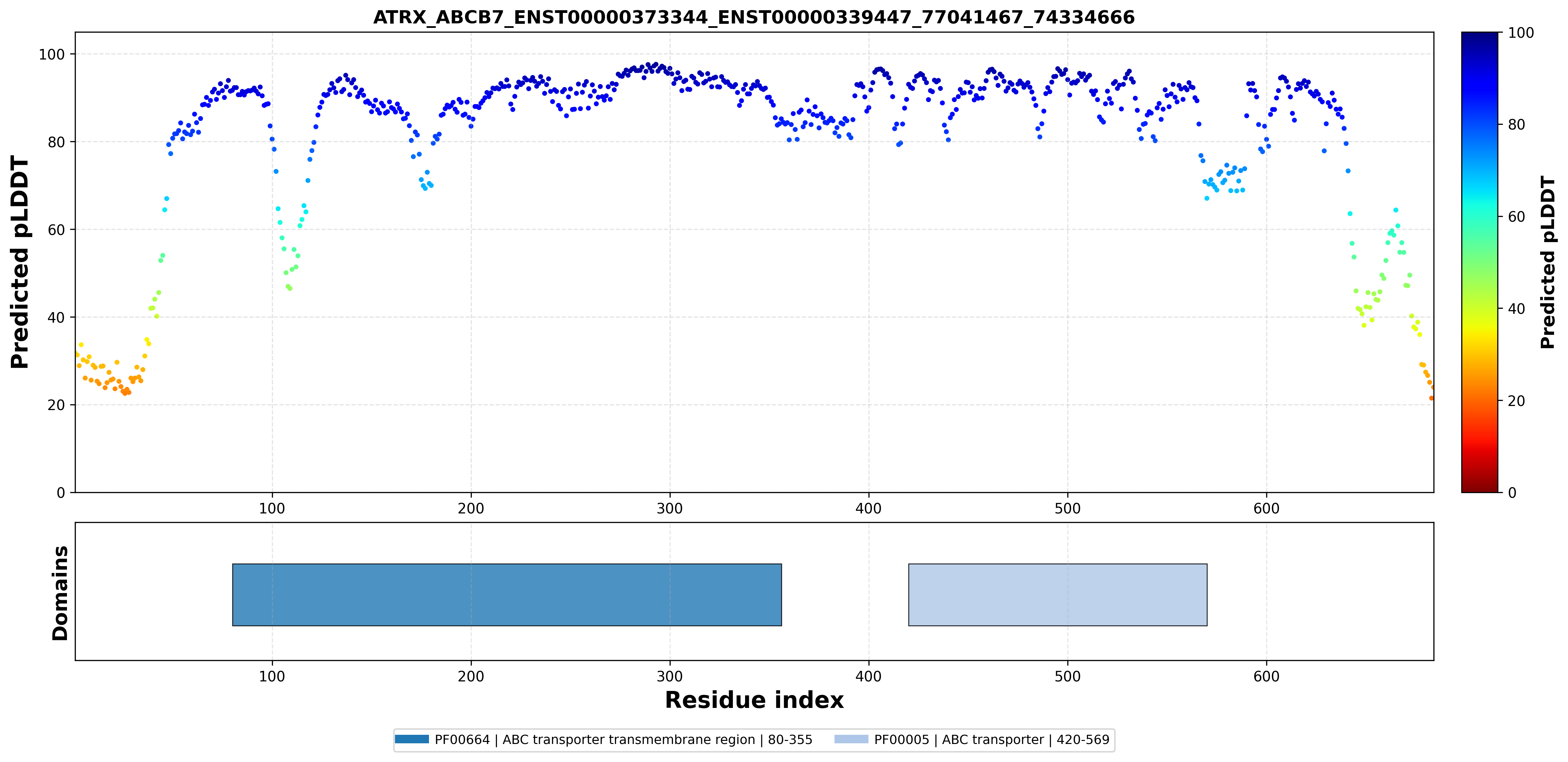 |  |  |
| ATRX_ABCB7_ENST00000373344_ENST00000373394_77041467_74334666 superimposed PDB: 23PI of partner (ABCB7). RMSD:2.2299
Å |
 |  | 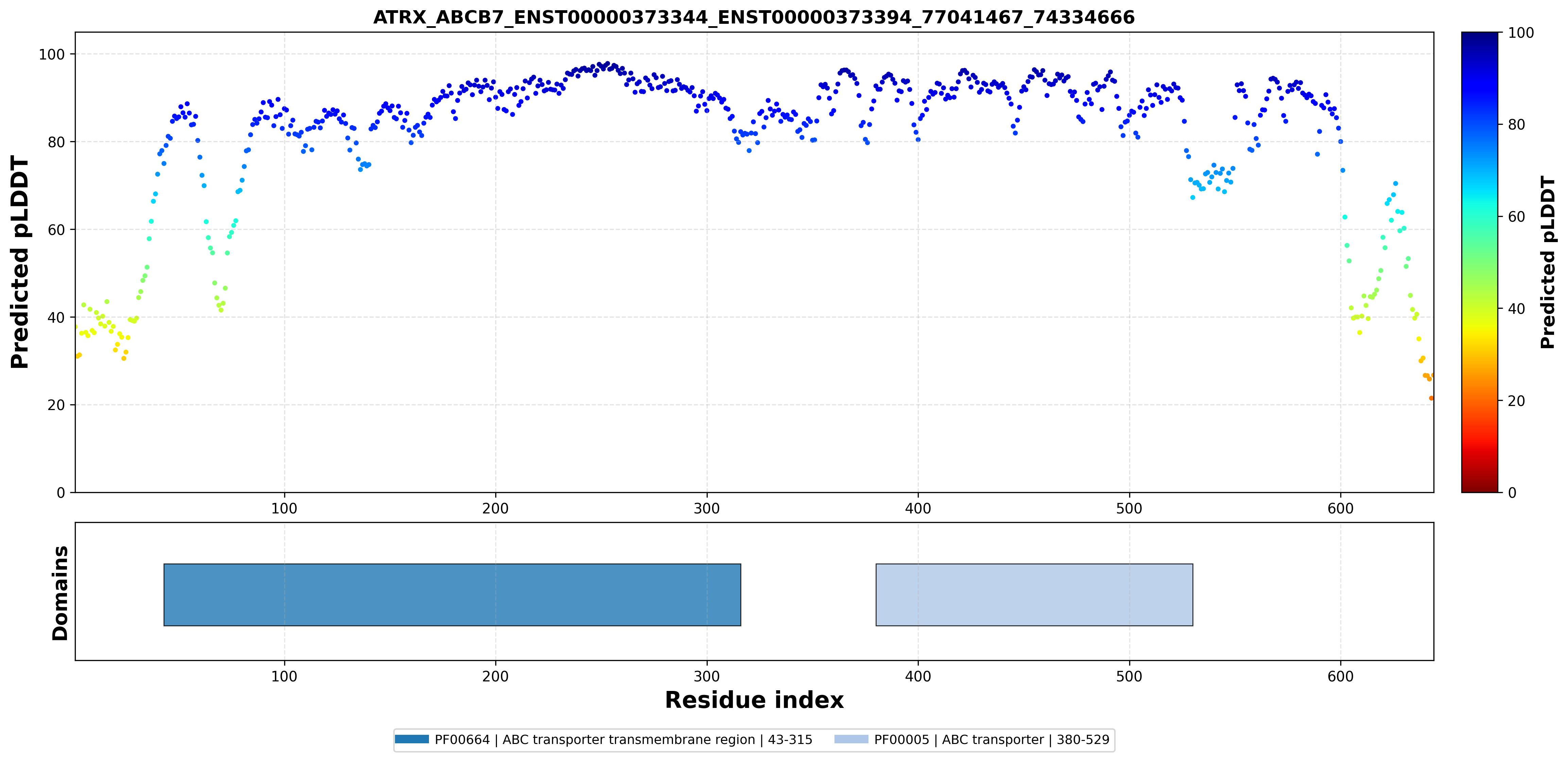 |  |  |
| ATRX_OGT_ENST00000373341_ENST00000373701_76972607_70775803 superimposed PDB: 7YEA of partner (OGT). RMSD:1.2776
Å |
 | 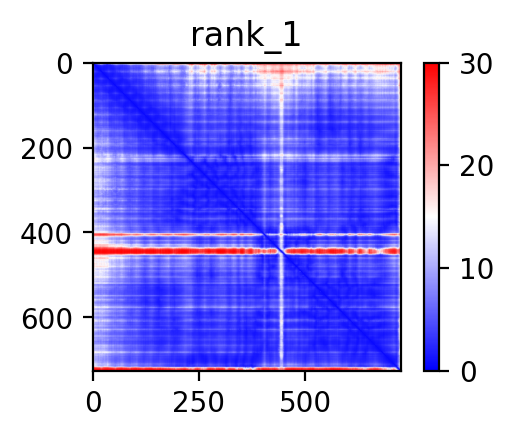 | 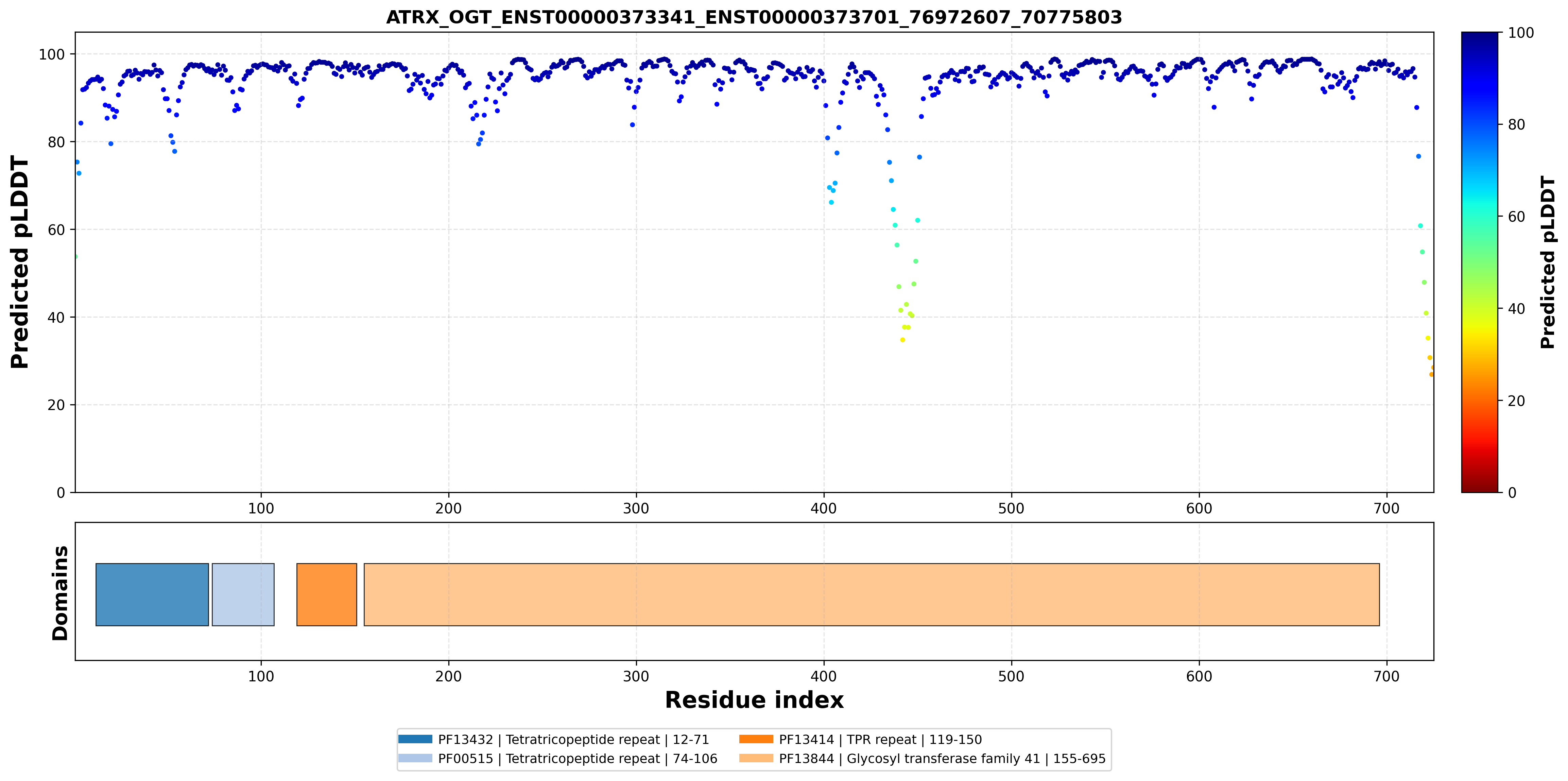 |  |  |
| ATRX_VSIG4_ENST00000373344_ENST00000412866_76875862_65253672 superimposed PDB: 2JM1 of partner (ATRX). RMSD:1.4463
Å |
 |  | 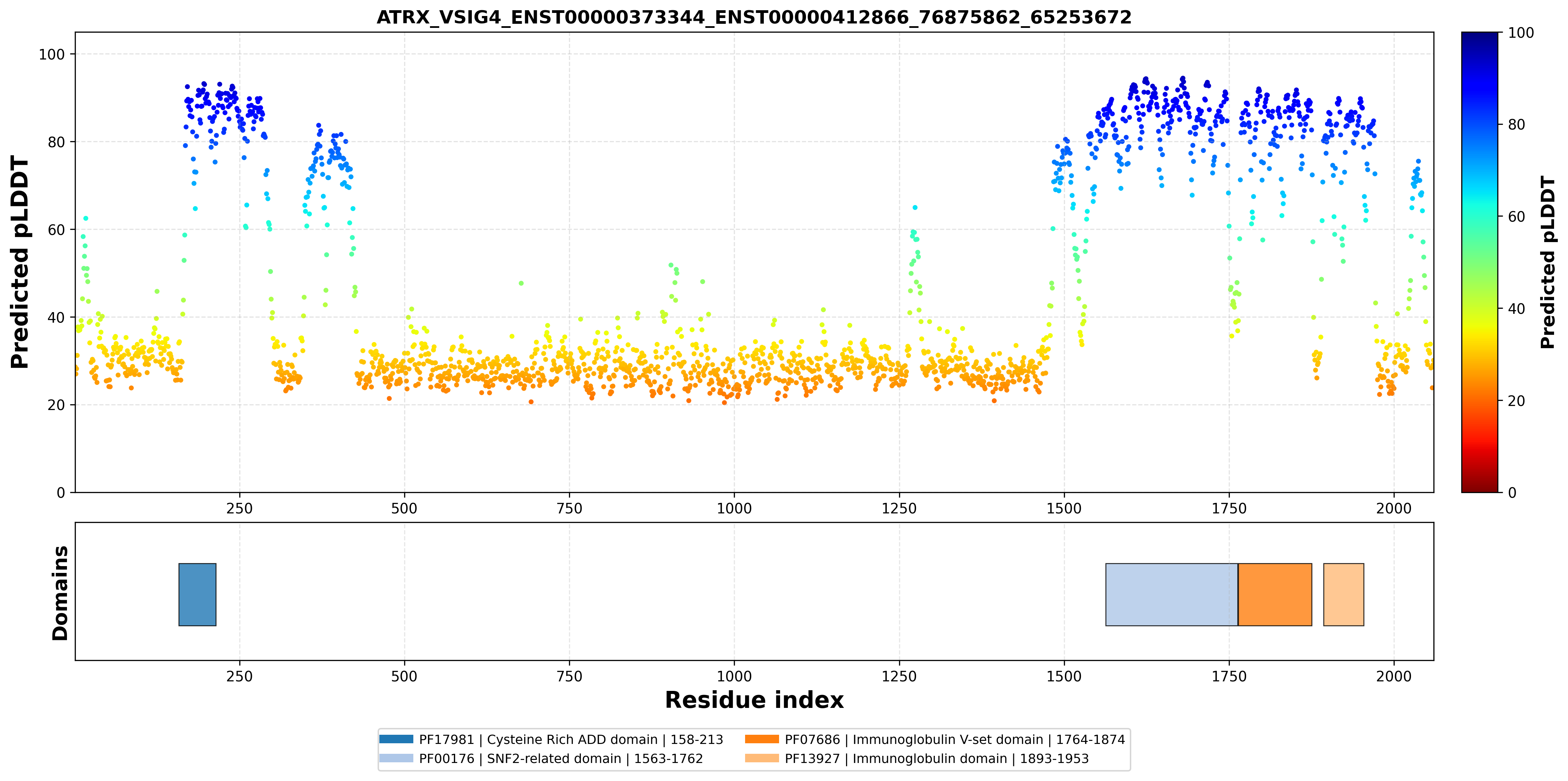 |  |  |
| ATRX_VSIG4_ENST00000373344_ENST00000412866_76875862_65253672 superimposed PDB: 5IMK of partner (VSIG4). RMSD:0.5791
Å |
| | | |  |
| ATRX_VSIG4_ENST00000373344_ENST00000455586_76875862_65253672 superimposed PDB: 2JM1 of partner (ATRX). RMSD:1.5927
Å |
 |  | 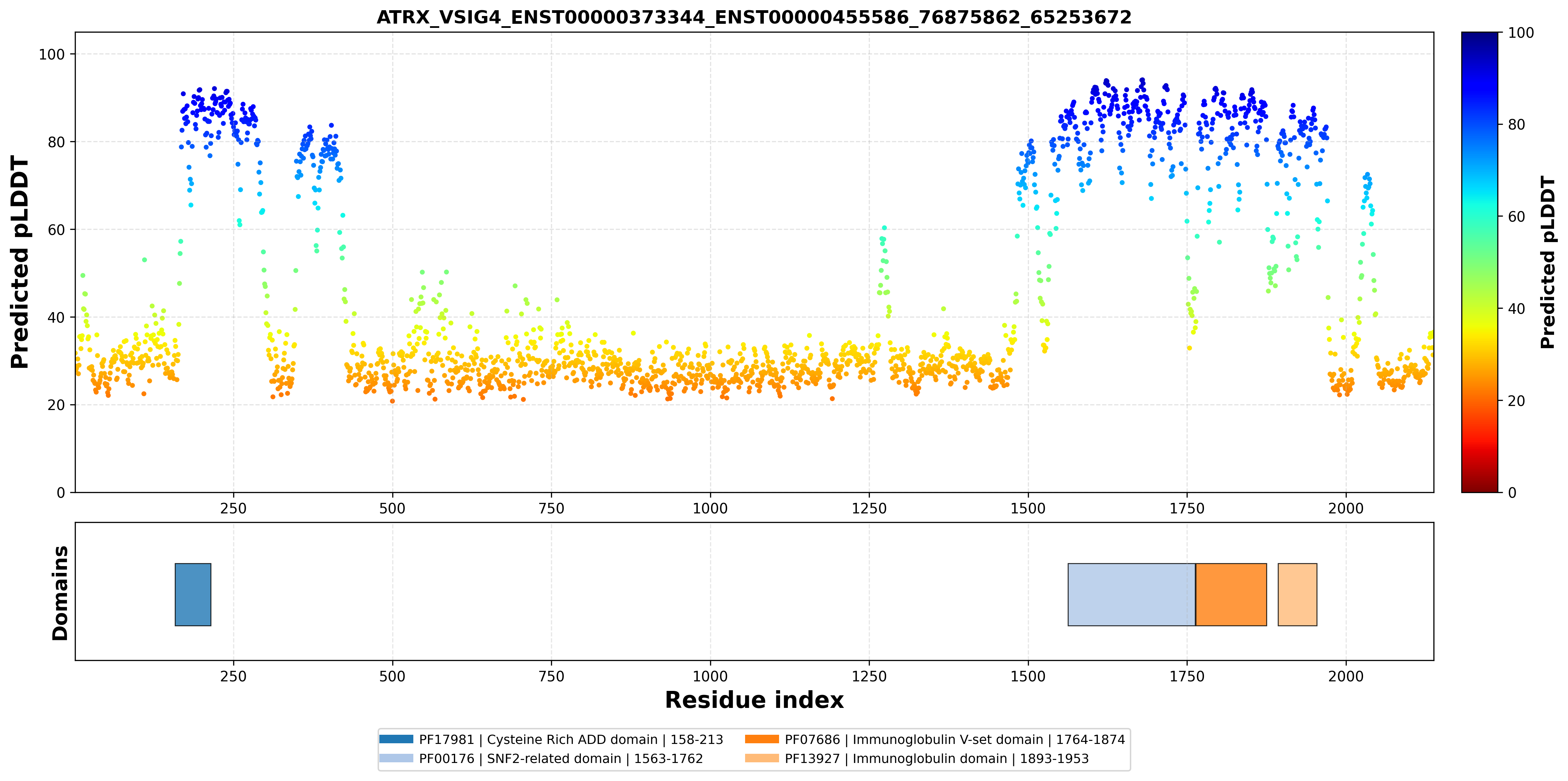 |  |  |
| ATRX_VSIG4_ENST00000373344_ENST00000455586_76875862_65253672 superimposed PDB: 5IMK of partner (VSIG4). RMSD:0.5417
Å |
| | | |  |
| ATRX_VSIG4_ENST00000395603_ENST00000374737_76875862_65253672 superimposed PDB: 2JM1 of partner (ATRX). RMSD:1.5698
Å |
 |  |  |  |  |
| ATRX_VSIG4_ENST00000395603_ENST00000374737_76875862_65253672 superimposed PDB: 5IMK of partner (VSIG4). RMSD:0.5609
Å |
| | | |  |
| ATRX_VSIG4_ENST00000395603_ENST00000412866_76875862_65253672 superimposed PDB: 2JM1 of partner (ATRX). RMSD:1.6818
Å |
 |  | 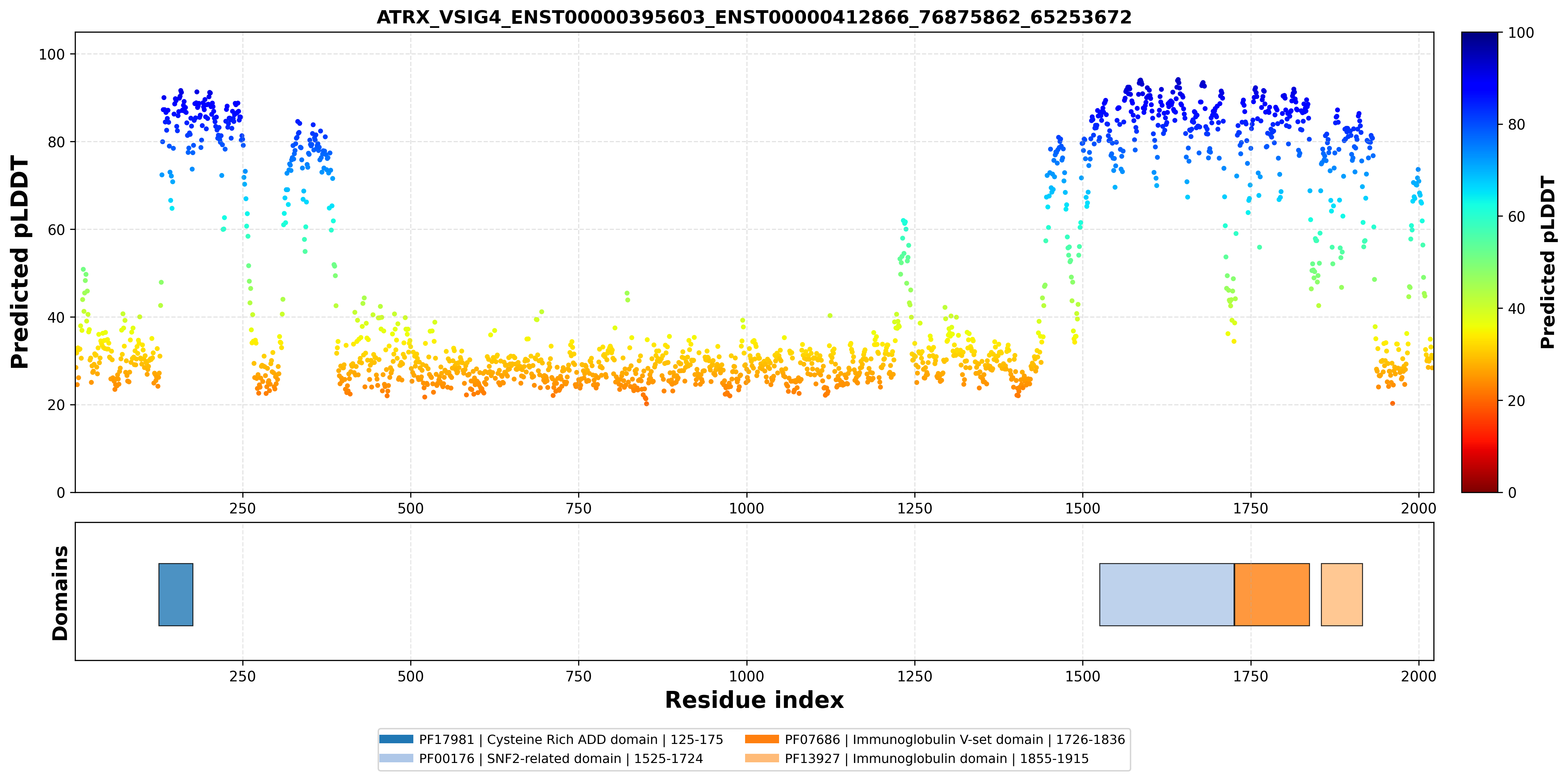 |  |  |
| ATRX_VSIG4_ENST00000395603_ENST00000412866_76875862_65253672 superimposed PDB: 5IMK of partner (VSIG4). RMSD:0.5016
Å |
| | | |  |
| ATRX_VSIG4_ENST00000395603_ENST00000455586_76875862_65253672 superimposed PDB: 2JM1 of partner (ATRX). RMSD:1.6837
Å |
 |  |  |  |  |
| ATRX_VSIG4_ENST00000395603_ENST00000455586_76875862_65253672 superimposed PDB: 5IMK of partner (VSIG4). RMSD:0.5121
Å |
| | | |  |
| ATXN2_CS_ENST00000377617_ENST00000351328_111893832_56669979 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.0173
Å |
 |  | 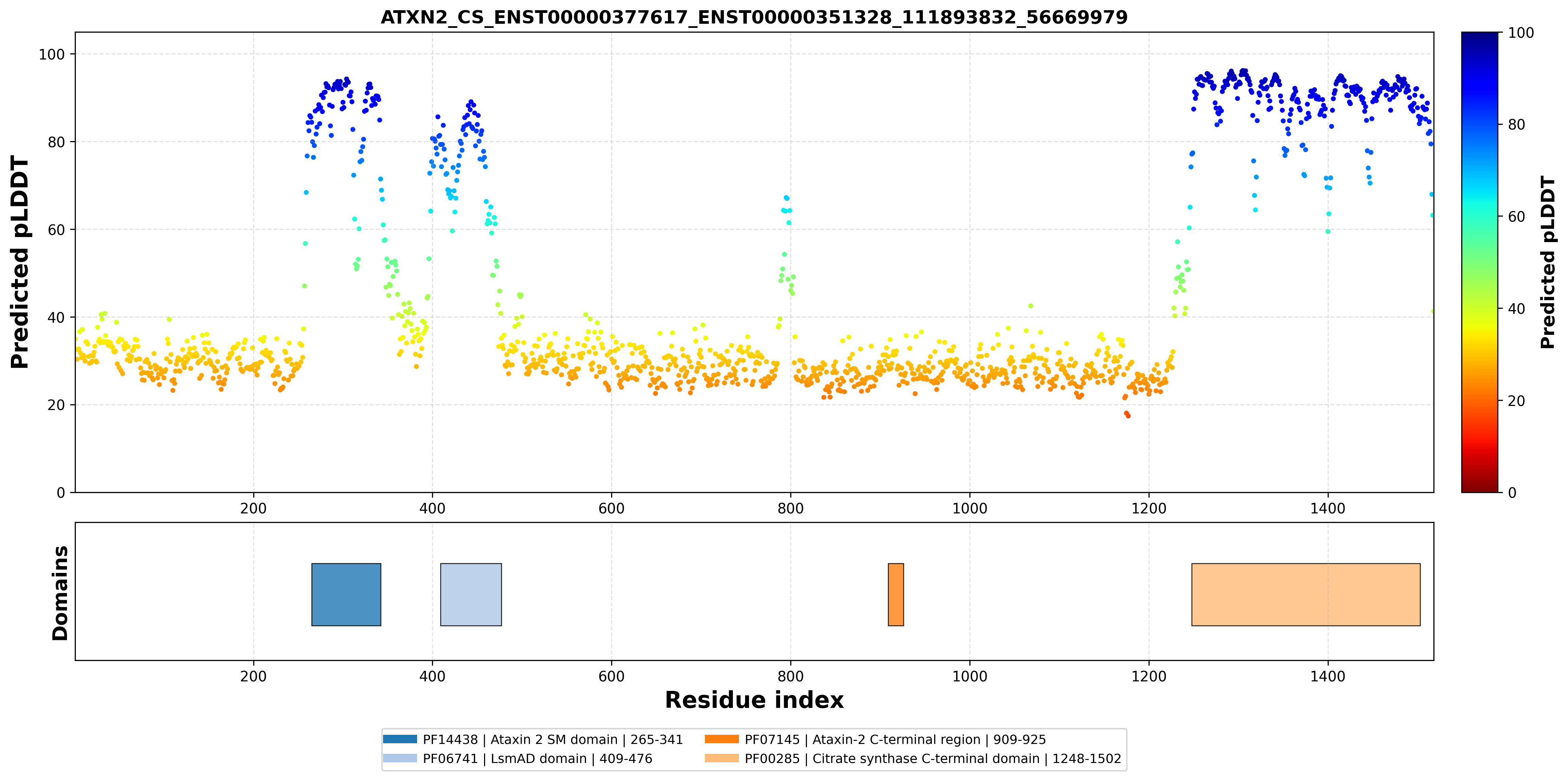 |  |  |
| ATXN2_CS_ENST00000377617_ENST00000351328_111893832_56669979 superimposed PDB: 5UZQ of partner (CS). RMSD:0.9684
Å |
| | | |  |
| ATXN2_CS_ENST00000389153_ENST00000351328_111893832_56669979 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.4336
Å |
 |  |  |  |  |
| ATXN2_CS_ENST00000389153_ENST00000351328_111893832_56669979 superimposed PDB: 5UZQ of partner (CS). RMSD:1.0526
Å |
| | | |  |
| ATXN2_CS_ENST00000535949_ENST00000351328_111893832_56669979 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.4922
Å |
 |  | 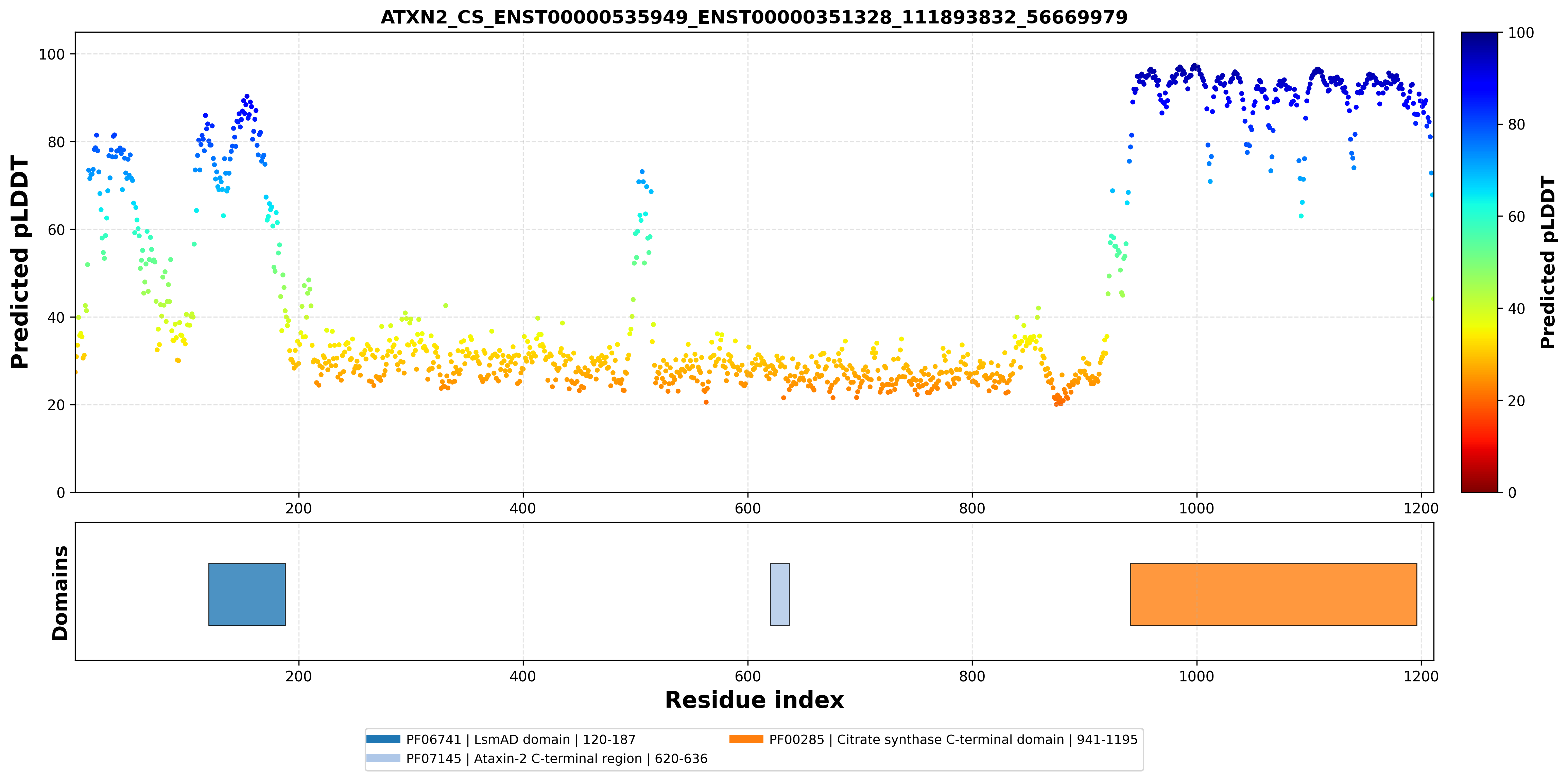 |  |  |
| ATXN2_CS_ENST00000535949_ENST00000351328_111893832_56669979 superimposed PDB: 5UZQ of partner (CS). RMSD:0.9943
Å |
| | | |  |
| ATXN2_CS_ENST00000608853_ENST00000351328_111893832_56669979 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.0192
Å |
 | 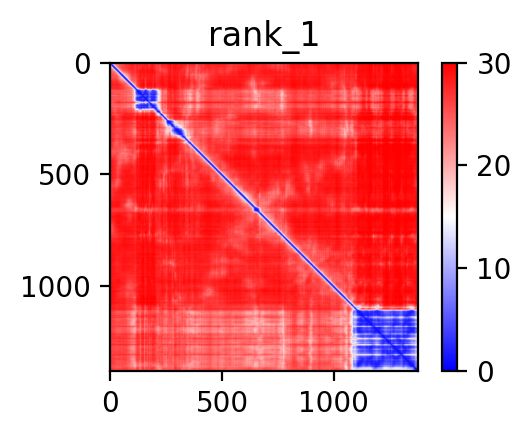 | 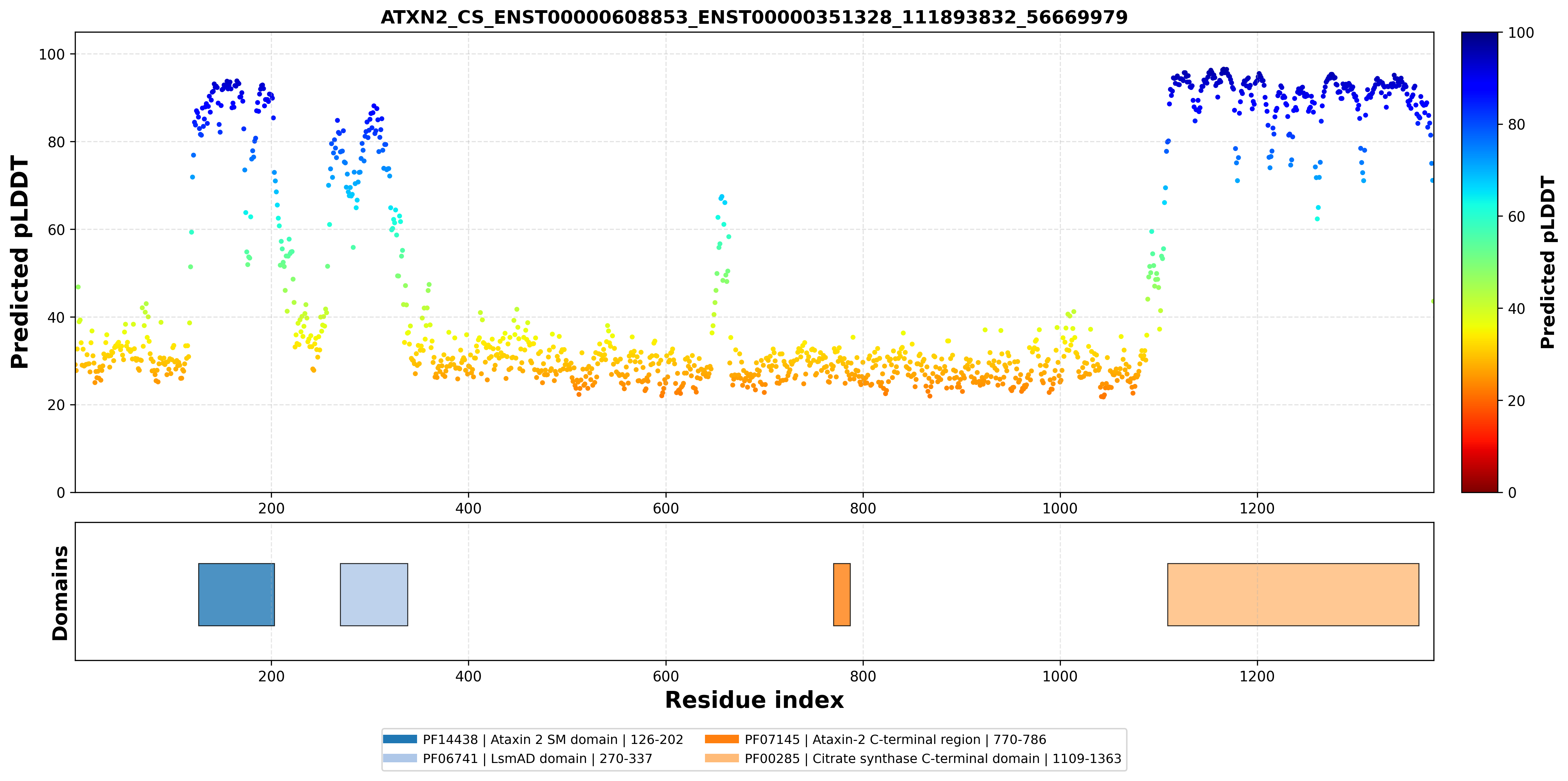 | 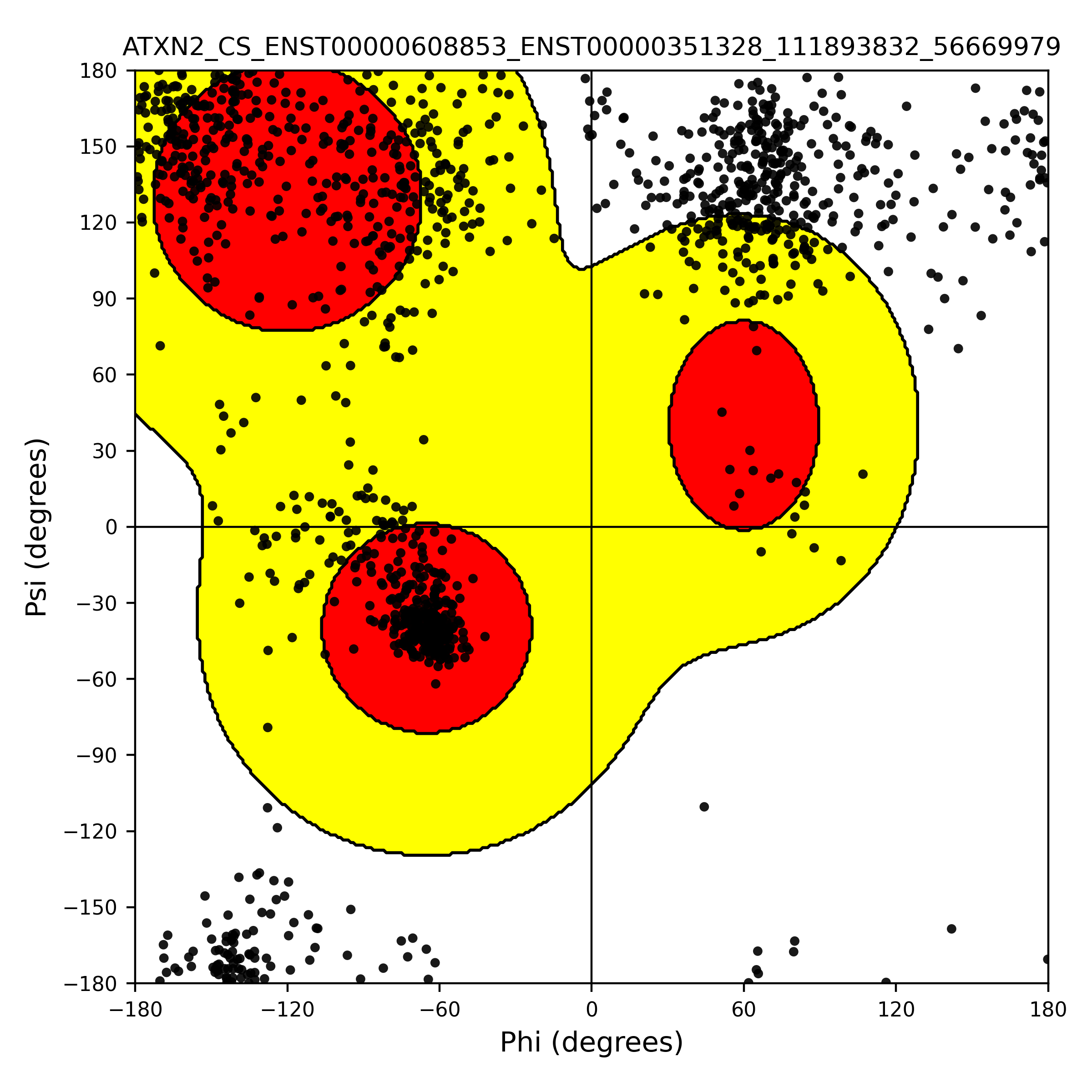 | 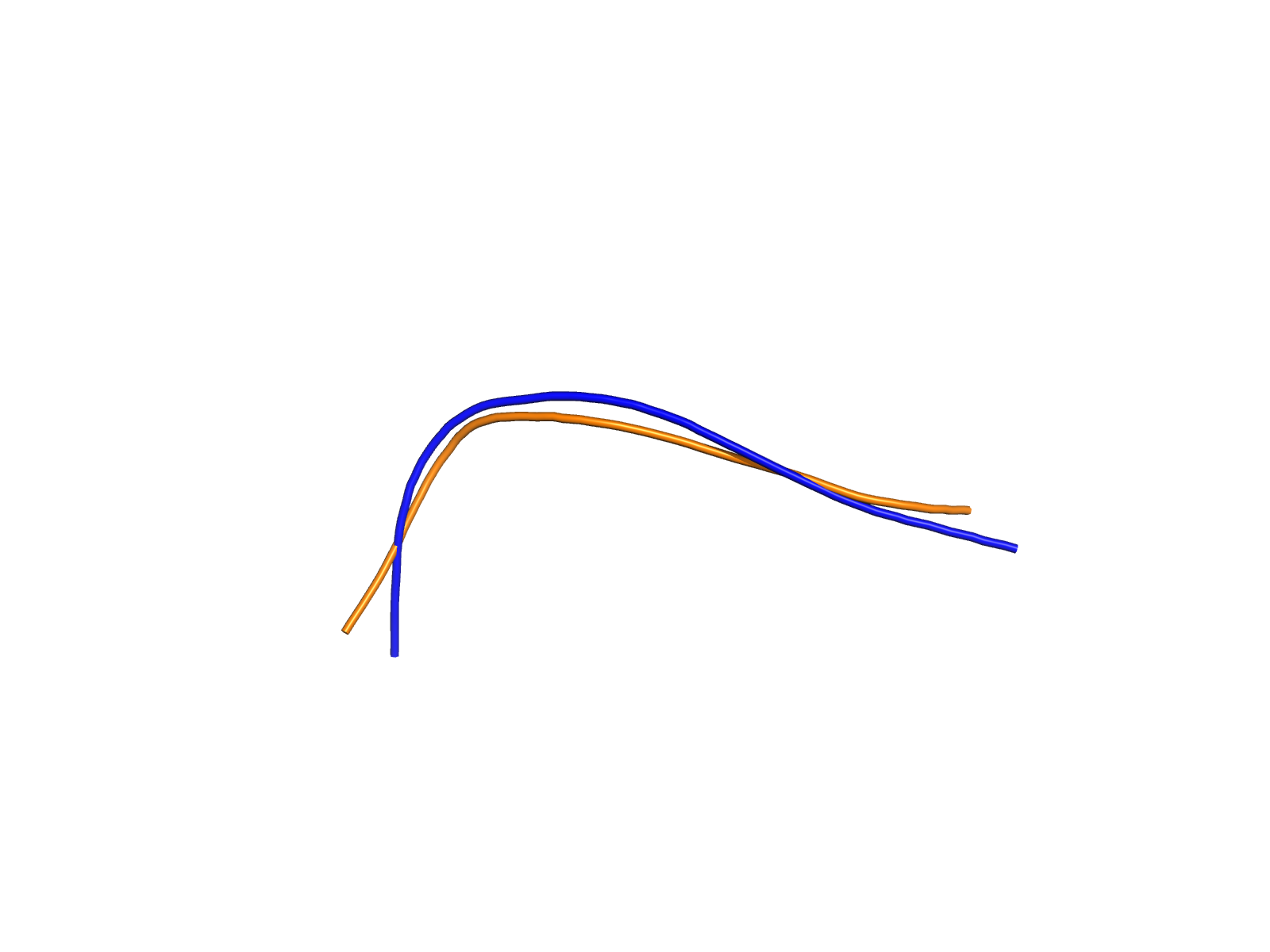 |
| ATXN2_CS_ENST00000608853_ENST00000351328_111893832_56669979 superimposed PDB: 5UZQ of partner (CS). RMSD:0.9294
Å |
| | | | 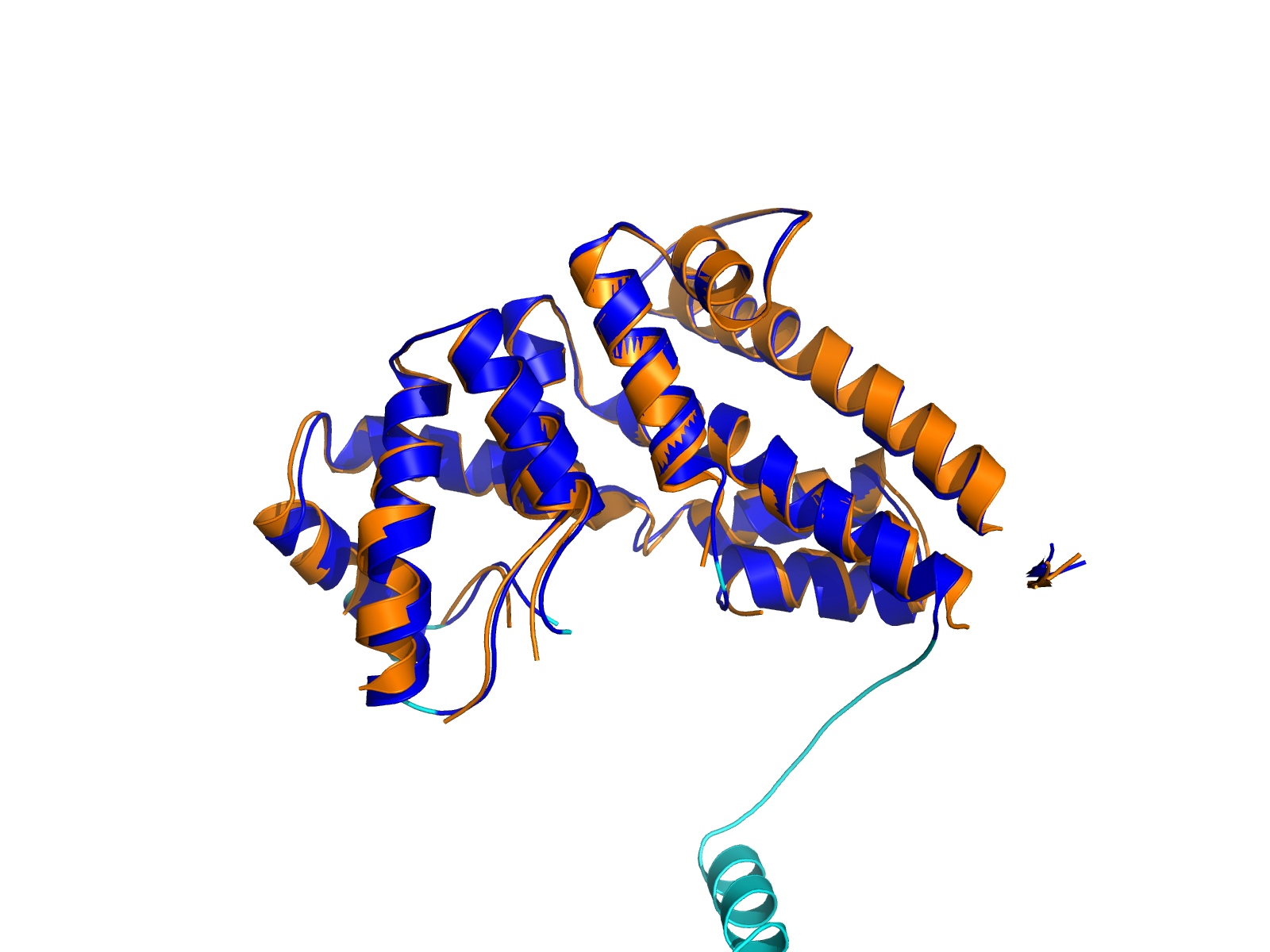 |
| ATXN2_STAT6_ENST00000377617_ENST00000538913_111902465_57493223 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.1164
Å |
 |  |  |  |  |
| ATXN2_STAT6_ENST00000377617_ENST00000538913_111902465_57493223 superimposed PDB: 4Y5U of partner (STAT6). RMSD:0.652
Å |
| | | |  |
| ATXN2_STAT6_ENST00000389153_ENST00000538913_111902465_57493223 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.7989
Å |
 |  |  |  |  |
| ATXN2_STAT6_ENST00000389153_ENST00000538913_111902465_57493223 superimposed PDB: 4Y5U of partner (STAT6). RMSD:0.7643
Å |
| | | |  |
| ATXN2_STAT6_ENST00000608853_ENST00000538913_111902465_57493223 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.0767
Å |
 |  | 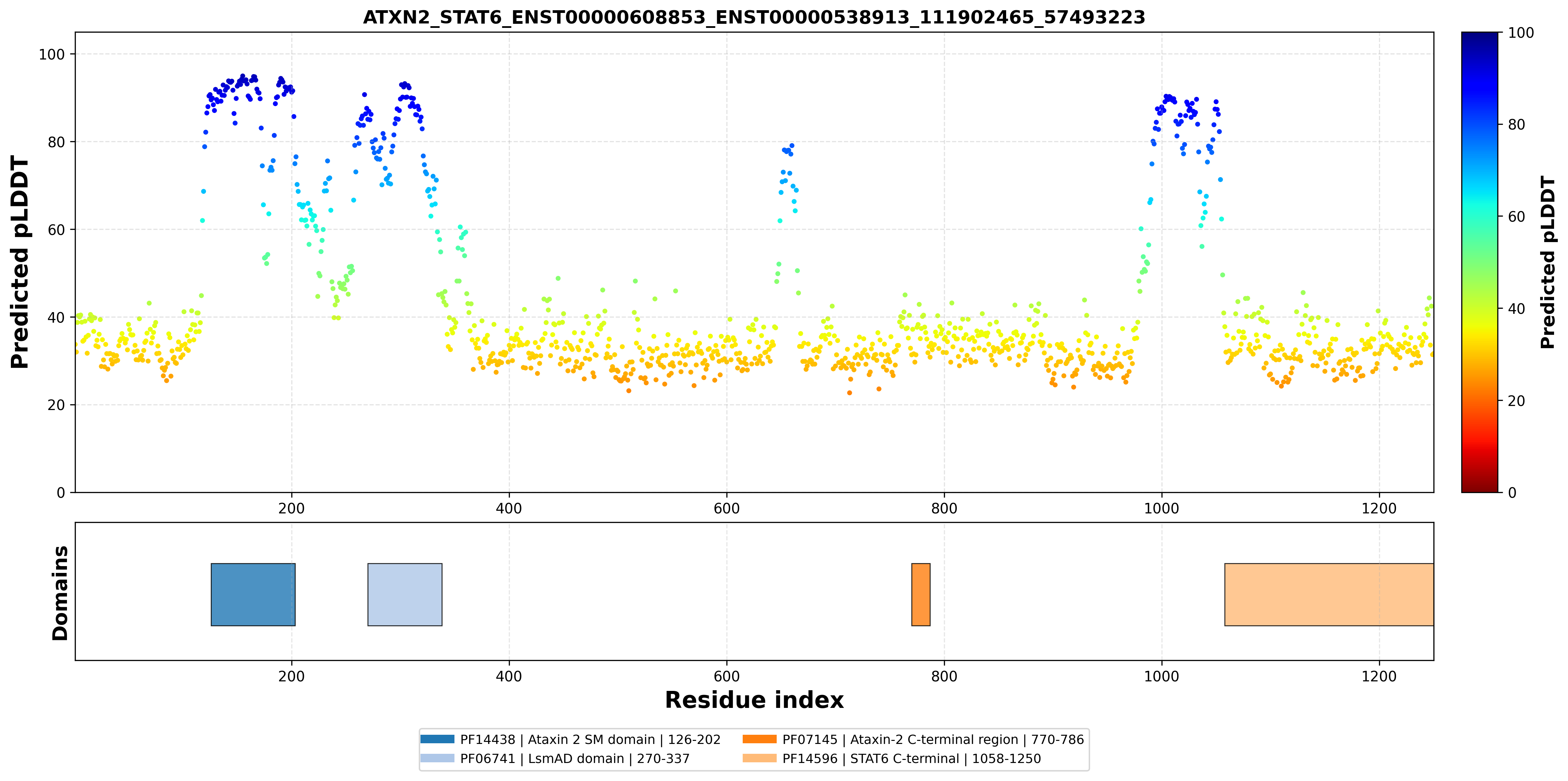 |  |  |
| ATXN2_STAT6_ENST00000608853_ENST00000538913_111902465_57493223 superimposed PDB: 4Y5U of partner (STAT6). RMSD:0.6828
Å |
| | | |  |
| ATXN2_TRIM37_ENST00000377617_ENST00000262294_111923074_57076820 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.038
Å |
 |  |  |  |  |
| ATXN2_TRIM37_ENST00000377617_ENST00000262294_111923074_57079075 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.5321
Å |
 |  |  |  |  |
| ATXN2_TRIM37_ENST00000389153_ENST00000262294_111923074_57079075 superimposed PDB: 3KTR of partner (ATXN2). RMSD:1.2925
Å |
 |  |  |  |  |
| ATXN2_TRIM37_ENST00000535949_ENST00000262294_111923074_57076820 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.2687
Å |
 |  |  |  |  |
| ATXN2_TRIM37_ENST00000535949_ENST00000262294_111923074_57079075 superimposed PDB: 3KTR of partner (ATXN2). RMSD:1.8463
Å |
 |  |  |  |  |
| ATXN2_UNC5C_ENST00000535949_ENST00000453304_111990083_96256782 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.0977
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000340660_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.619
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000340660_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.6417
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000340660_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.6685
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000393287_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:2.019
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000393287_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:2.0479
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000393287_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:2.0526
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000429774_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9591
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000429774_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9871
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000429774_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9367
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000502250_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.3738
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000502250_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.3942
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000502250_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.5306
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000503767_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.983
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000503767_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9823
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000503767_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9919
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000545170_ENST00000322875_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:1.9819
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000545170_ENST00000354848_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:2.0211
Å |
 |  |  |  |  |
| ATXN3_CD46_ENST00000545170_ENST00000441839_92537281_207943665 superimposed PDB: 2AGA of partner (ATXN3). RMSD:2.0489
Å |
 |  |  |  |  |
| ATXN7L1_SHFM1_ENST00000318724_ENST00000417009_105516257_96324203 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.4079
Å |
 |  |  |  |  |
| ATXN7L1_SHFM1_ENST00000419735_ENST00000248566_105516257_96324203 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.6365
Å |
 |  |  |  |  |
| ATXN7L1_SHFM1_ENST00000419735_ENST00000413065_105516257_96324203 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.8777
Å |
 |  |  |  |  |
| ATXN7L1_SHFM1_ENST00000419735_ENST00000444799_105516257_96324203 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.6516
Å |
 |  |  |  |  |
| AUH_NADSYN1_ENST00000375731_ENST00000319023_94058302_71166155 superimposed PDB: 1HZD of partner (AUH). RMSD:0.7202
Å |
 |  |  |  |  |
| AUH_NADSYN1_ENST00000375731_ENST00000319023_94058302_71166155 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.7793
Å |
| | | |  |
| AUH_NADSYN1_ENST00000422391_ENST00000319023_94058302_71166155 superimposed PDB: 1HZD of partner (AUH). RMSD:0.6115
Å |
 |  |  |  |  |
| AUH_NADSYN1_ENST00000422391_ENST00000319023_94058302_71166155 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.8383
Å |
| | | |  |
| AUH_TGFBR1_ENST00000303617_ENST00000374990_94118164_101891136 superimposed PDB: 1HZD of partner (AUH). RMSD:0.9799
Å |
 |  |  |  |  |
| AUH_TGFBR1_ENST00000375731_ENST00000374994_94118164_101891136 superimposed PDB: 1HZD of partner (AUH). RMSD:1.4711
Å |
 |  |  |  |  |
| AURKA_SOGA1_ENST00000312783_ENST00000237536_54956488_35445872 superimposed PDB: 2J4Z of partner (AURKA). RMSD:1.5985
Å |
 |  |  |  |  |
| AURKA_SOGA1_ENST00000312783_ENST00000279034_54956488_35445872 superimposed PDB: 2J4Z of partner (AURKA). RMSD:1.0344
Å |
 |  |  |  |  |
| AURKA_SOGA1_ENST00000371356_ENST00000279034_54956488_35445872 superimposed PDB: 2J4Z of partner (AURKA). RMSD:1.2442
Å |
 |  |  |  |  |
| AURKA_SOGA1_ENST00000395913_ENST00000237536_54956488_35445872 superimposed PDB: 2J4Z of partner (AURKA). RMSD:1.4122
Å |
 |  |  |  |  |
| AURKA_SOGA1_ENST00000395913_ENST00000279034_54956488_35445872 superimposed PDB: 2J4Z of partner (AURKA). RMSD:1.1057
Å |
 |  |  |  |  |
| AUTS2_ABCA4_ENST00000342771_ENST00000370225_69064948_94578622 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.8592
Å |
 |  | 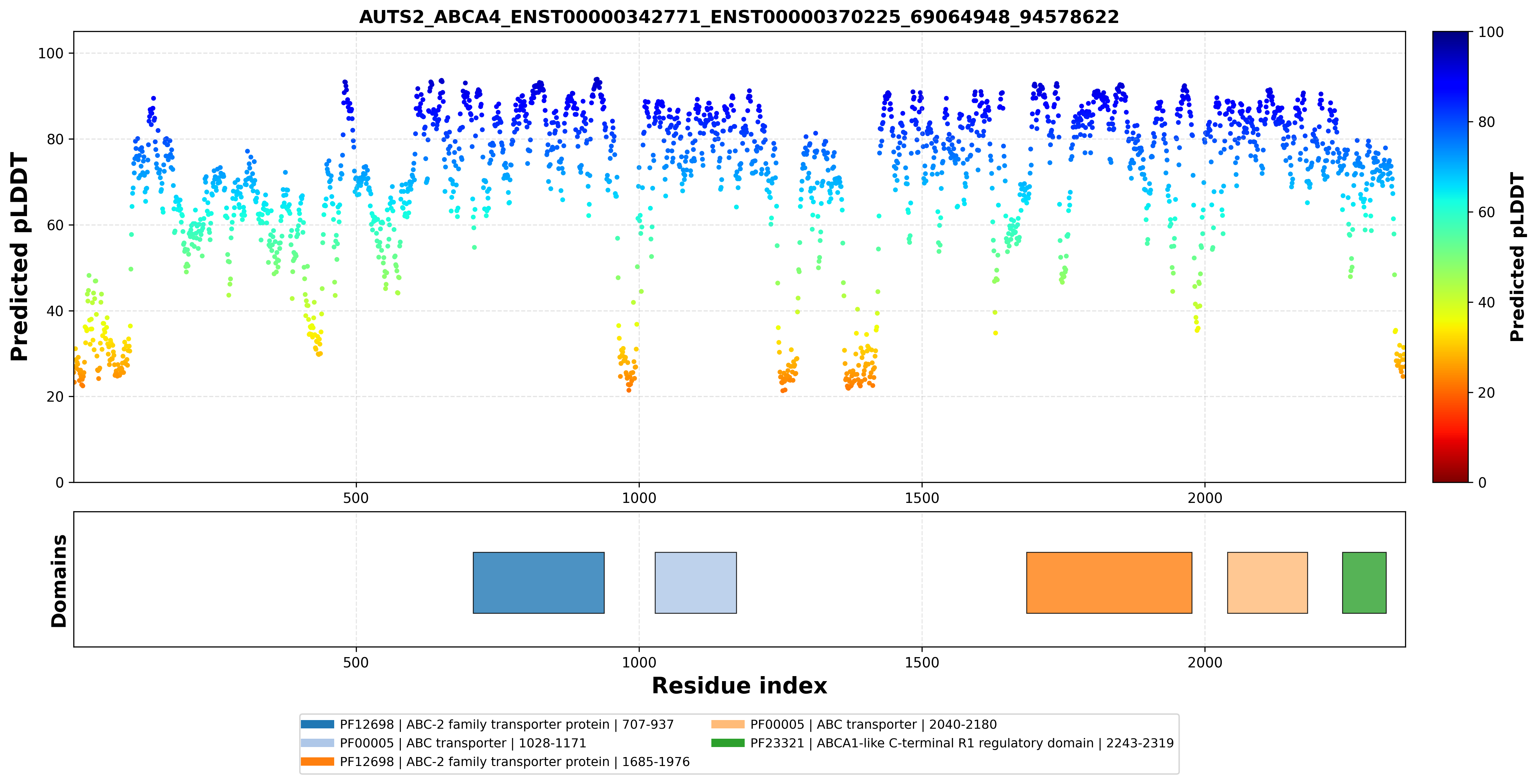 |  |  |
| AVEN_MEIS2_ENST00000306730_ENST00000219869_34330980_37242601 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.9078
Å |
 |  |  |  |  |
| AVEN_MEIS2_ENST00000306730_ENST00000382766_34330980_37242601 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.9807
Å |
 |  |  |  |  |
| AVEN_MEIS2_ENST00000306730_ENST00000397624_34330980_37242601 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.6992
Å |
 |  | 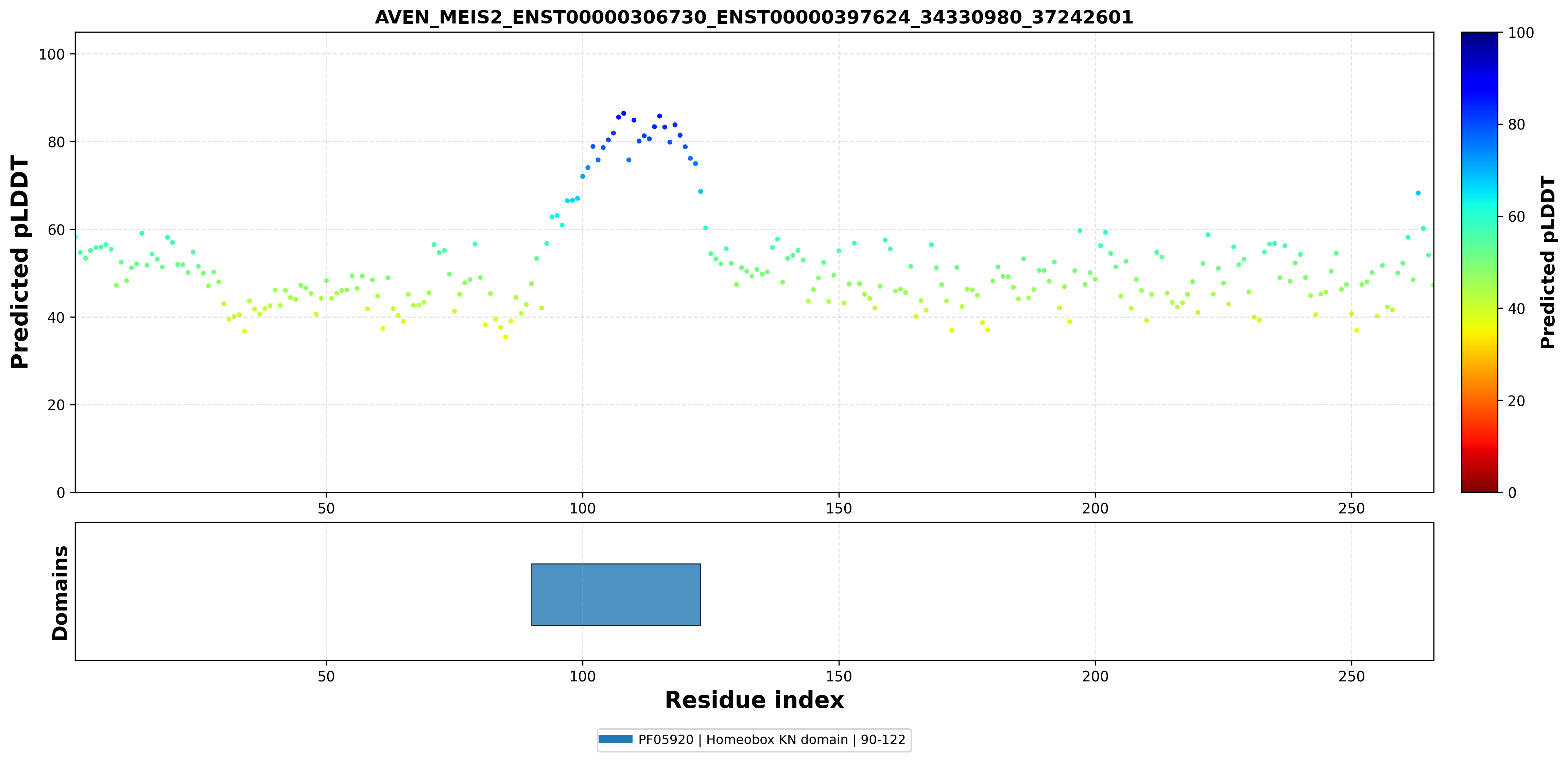 |  |  |
| AVEN_MEIS2_ENST00000306730_ENST00000561208_34330980_37242601 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.7527
Å |
 |  |  |  |  |
| AVL9_MICU1_ENST00000404479_ENST00000361114_32535414_74268027 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.607
Å |
 |  |  |  |  |
| AVL9_MICU1_ENST00000404479_ENST00000398761_32535414_74268027 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.6525
Å |
 |  |  |  |  |
| AXIN1_DNMT3A_ENST00000262320_ENST00000264709_354303_25523112 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5152
Å |
 |  |  |  |  |
| AXIN1_DNMT3A_ENST00000354866_ENST00000264709_354303_25523112 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.4481
Å |
 |  |  |  |  |
| AXIN1_DNMT3A_ENST00000354866_ENST00000264709_354303_25523112 superimposed PDB: 8QZM of partner (DNMT3A). RMSD:2.5644
Å |
| | | |  |
| AXIN1_DNMT3A_ENST00000354866_ENST00000321117_354303_25523112 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5432
Å |
 |  |  |  |  |
| AXIN1_DNMT3A_ENST00000354866_ENST00000321117_354303_25523112 superimposed PDB: 8QZM of partner (DNMT3A). RMSD:2.739
Å |
| | | |  |
| AXIN1_LMF1_ENST00000354866_ENST00000399843_354303_904706 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5187
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000262320_ENST00000293872_354303_243014 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5549
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000262320_ENST00000337351_354303_243014 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5844
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000262320_ENST00000337351_354303_249237 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.718
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000262320_ENST00000397783_354303_243014 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5784
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000262320_ENST00000397783_354303_249237 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6573
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000354866_ENST00000337351_354303_243014 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5593
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000354866_ENST00000337351_354303_249237 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6316
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000354866_ENST00000397783_354303_243014 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5611
Å |
 |  |  |  |  |
| AXIN1_LUC7L_ENST00000354866_ENST00000397783_354303_249237 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6212
Å |
 |  |  |  |  |
| AXIN1_MYO19_ENST00000262320_ENST00000268852_354303_34867294 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6285
Å |
 |  |  |  |  |
| AXIN1_MYO19_ENST00000354866_ENST00000268852_354303_34867294 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6005
Å |
 |  |  |  |  |
| AXIN1_MYO19_ENST00000354866_ENST00000431794_354303_34867294 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.6301
Å |
 |  |  |  |  |
| AXIN1_TMEM207_ENST00000354866_ENST00000354905_354303_190165616 superimposed PDB: 1DK8 of partner (AXIN1). RMSD:0.5895
Å |
 |  |  |  |  |
| AXL_ZNF565_ENST00000301178_ENST00000392173_41762516_36686058 superimposed PDB: 5U6B of partner (AXL). RMSD:1.5813
Å |
 |  |  |  |  |
| AXL_ZNF565_ENST00000359092_ENST00000392173_41762516_36686058 superimposed PDB: 5U6B of partner (AXL). RMSD:1.5994
Å |
 |  | 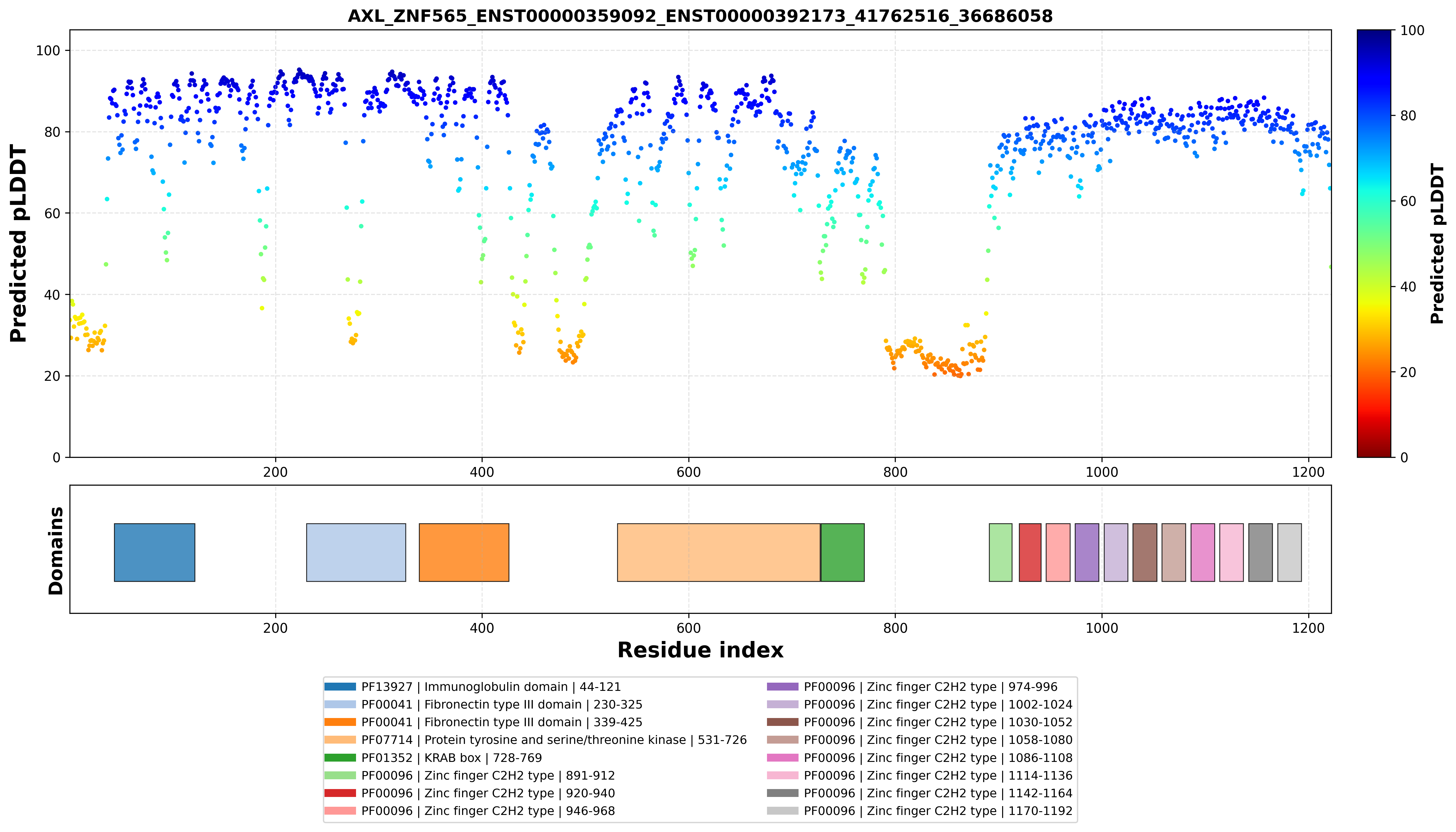 |  |  |
| AXL_ZNF565_ENST00000593513_ENST00000392173_41762516_36686058 superimposed PDB: 5U6B of partner (AXL). RMSD:1.6258
Å |
 |  |  |  |  |
| AZIN1_NDUFA13_ENST00000337198_ENST00000252576_103848483_19636990 superimposed PDB: 4ZGZ of partner (AZIN1). RMSD:1.0172
Å |
 |  |  |  |  |
| AZIN1_NUTM1_ENST00000347770_ENST00000438749_103855778_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.604
Å |
 |  |  |  |  |
| B2M_ANXA2_ENST00000558401_ENST00000451270_45003811_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.397
Å |
 |  |  |  |  |
| B2M_ANXA2_ENST00000559916_ENST00000451270_45003811_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3915
Å |
 |  |  |  |  |
| B2M_CDK2AP1_ENST00000544417_ENST00000261692_45003811_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.5892
Å |
 |  |  |  |  |
| B2M_CDK2AP1_ENST00000559916_ENST00000261692_45003811_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.5996
Å |
 |  |  |  |  |
| B2M_CTTN_ENST00000558401_ENST00000301843_45003811_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7393
Å |
 |  |  |  |  |
| B2M_CTTN_ENST00000559916_ENST00000301843_45003811_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7006
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000544417_ENST00000517671_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.7938
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000544417_ENST00000517671_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3688
Å |
| | | |  |
| B2M_NPM1_ENST00000558401_ENST00000296930_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.7827
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000558401_ENST00000296930_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3549
Å |
| | | |  |
| B2M_NPM1_ENST00000558401_ENST00000393820_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.779
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000558401_ENST00000393820_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3627
Å |
| | | |  |
| B2M_NPM1_ENST00000559916_ENST00000296930_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.7999
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000559916_ENST00000296930_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3538
Å |
| | | |  |
| B2M_NPM1_ENST00000559916_ENST00000393820_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.782
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000559916_ENST00000393820_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3576
Å |
| | | |  |
| B2M_NPM1_ENST00000559916_ENST00000517671_45003811_170817054 superimposed PDB: 6AT5 of partner (B2M). RMSD:2.809
Å |
 |  |  |  |  |
| B2M_NPM1_ENST00000559916_ENST00000517671_45003811_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3703
Å |
| | | |  |
| B2M_OAZ1_ENST00000544417_ENST00000588673_45003811_2271383 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.485
Å |
 |  |  |  |  |
| B2M_OAZ1_ENST00000559916_ENST00000588673_45003811_2271383 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.534
Å |
 |  |  |  |  |
| B2M_SEMA4D_ENST00000544417_ENST00000339861_45003811_91978865 superimposed PDB: 6AT5 of partner (B2M). RMSD:1.9078
Å |
 |  |  |  |  |
| B2M_SEMA4D_ENST00000558401_ENST00000420987_45003811_91978865 superimposed PDB: 6AT5 of partner (B2M). RMSD:1.7651
Å |
 |  |  |  |  |
| B2M_TFF1_ENST00000559916_ENST00000291527_45003811_43783516 superimposed PDB: 1HI7 of partner (TFF1). RMSD:0.9711
Å |
 |  |  |  |  |
| B4GALNT1_SLC28A3_ENST00000418555_ENST00000376238_58025697_86928369 superimposed PDB: 6KSW of partner (SLC28A3). RMSD:0.9574
Å |
 |  |  |  |  |
| B4GALNT1_SLC28A3_ENST00000418555_ENST00000376238_58025697_86955598 superimposed PDB: 6KSW of partner (SLC28A3). RMSD:0.8581
Å |
 |  |  |  |  |
| B4GALT1_LETM1_ENST00000379731_ENST00000302787_33135186_1827410 superimposed PDB: 6FWT of partner (B4GALT1). RMSD:0.684
Å |
 |  |  |  |  |
| B4GALT1_LETM1_ENST00000379731_ENST00000302787_33135186_1827410 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.5058
Å |
| | | |  |
| B4GALT1_RAF1_ENST00000535206_ENST00000442415_33166755_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0356
Å |
 |  |  |  |  |
| B4GALT1_UBE2R2_ENST00000379731_ENST00000263228_33135186_33886878 superimposed PDB: 6FWT of partner (B4GALT1). RMSD:0.7038
Å |
 |  |  |  |  |
| B4GALT1_UBE2R2_ENST00000379731_ENST00000263228_33135186_33886878 superimposed PDB: 8Q7R of partner (UBE2R2). RMSD:1.0567
Å |
| | | |  |
| B4GALT5_ERBB4_ENST00000371711_ENST00000342788_48330112_212812341 superimposed PDB: 3U9U of partner (ERBB4). RMSD:3.5748
Å |
 |  |  |  |  |
| BACE2_MACROD2_ENST00000330333_ENST00000310348_42629253_14474124 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.5191
Å |
 |  | 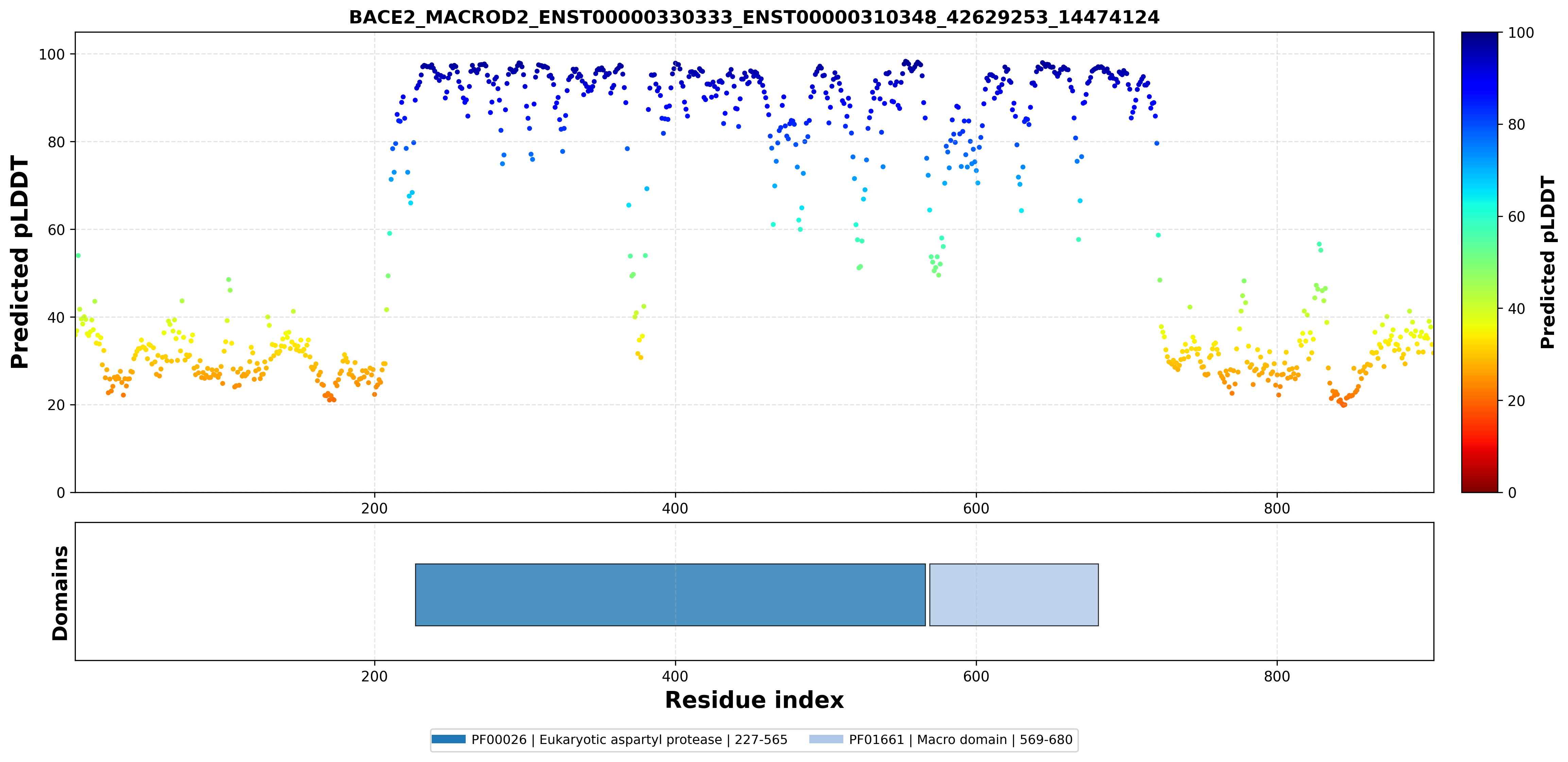 |  |  |
| BACE2_MACROD2_ENST00000330333_ENST00000310348_42629253_14474124 superimposed PDB: 4IQY of partner (MACROD2). RMSD:0.2818
Å |
| | | |  |
| BACE2_MACROD2_ENST00000347667_ENST00000217246_42629253_14474124 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.4965
Å |
 |  | 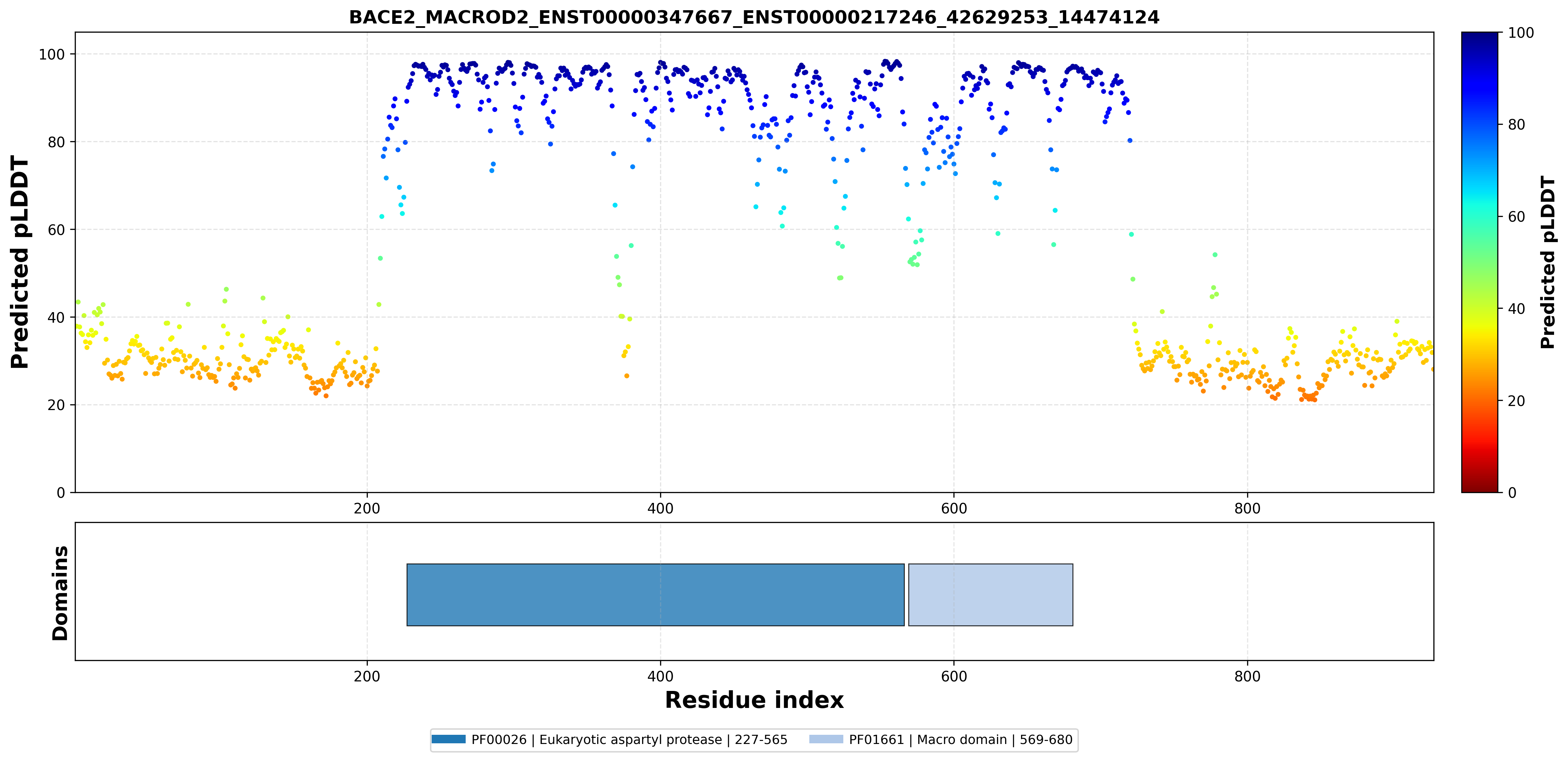 |  |  |
| BACE2_MACROD2_ENST00000347667_ENST00000217246_42629253_14474124 superimposed PDB: 4IQY of partner (MACROD2). RMSD:0.3185
Å |
| | | |  |
| BACE2_MACROD2_ENST00000347667_ENST00000310348_42629253_14474124 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.576
Å |
 |  | 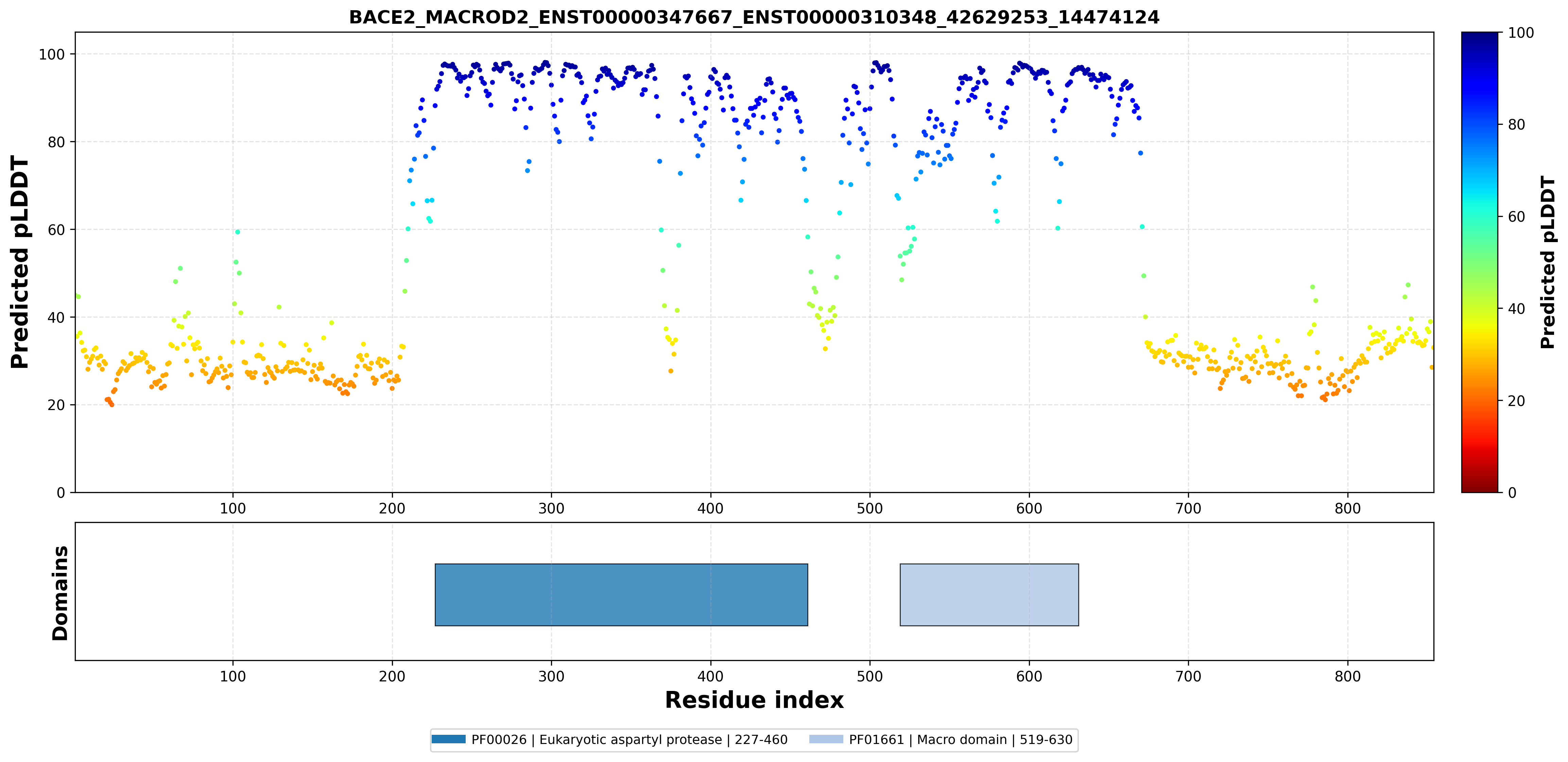 |  |  |
| BACE2_MACROD2_ENST00000347667_ENST00000310348_42629253_14474124 superimposed PDB: 4IQY of partner (MACROD2). RMSD:0.3468
Å |
| | | |  |
| BACH1_DSCR3_ENST00000399921_ENST00000309117_30702014_38612940 superimposed PDB: 8SYN of partner (DSCR3). RMSD:0.7232
Å |
 |  |  |  |  |
| BAG4_FGFR1_ENST00000287322_ENST00000397091_38050313_38283763 superimposed PDB: 1M7K of partner (BAG4). RMSD:0.7713
Å |
 |  |  |  |  |
| BAG4_FGFR1_ENST00000287322_ENST00000397091_38050313_38283763 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6467
Å |
| | | |  |
| BAG4_FGFR1_ENST00000287322_ENST00000397108_38050313_38283763 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6462
Å |
 |  |  |  |  |
| BAG4_FGFR1_ENST00000287322_ENST00000397113_38050313_38283763 superimposed PDB: 1M7K of partner (BAG4). RMSD:0.7913
Å |
 |  |  |  |  |
| BAG4_FGFR1_ENST00000287322_ENST00000397113_38050313_38283763 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6323
Å |
| | | |  |
| BAG4_FGFR1_ENST00000287322_ENST00000532791_38050313_38283763 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6953
Å |
 |  |  |  |  |
| BAI2_HS3ST4_ENST00000373658_ENST00000331351_32221599_26146932 superimposed PDB: 8OEK of partner (BAI2). RMSD:1.7467
Å |
 |  |  |  |  |
| BAIAP2L1_BCAS4_ENST00000005260_ENST00000371608_97984353_49493022 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.529
Å |
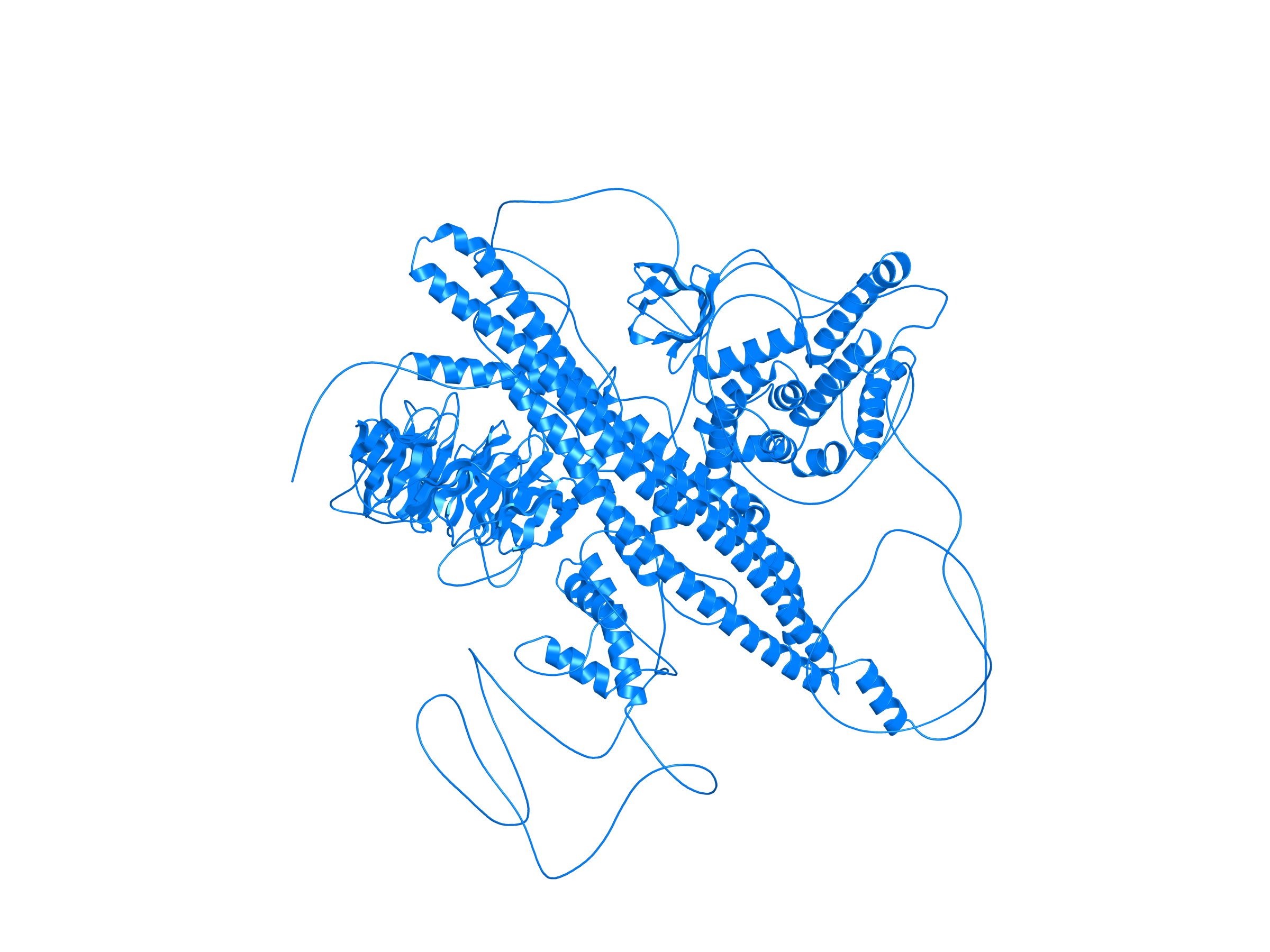 | 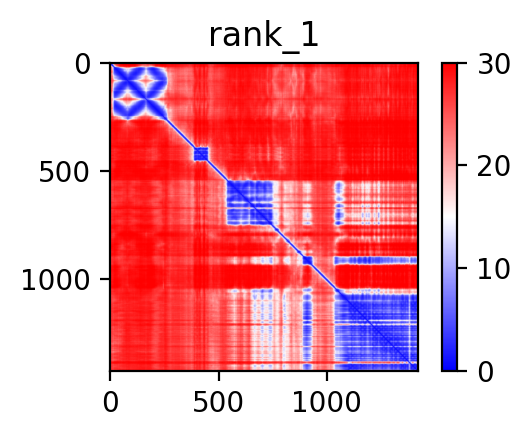 | 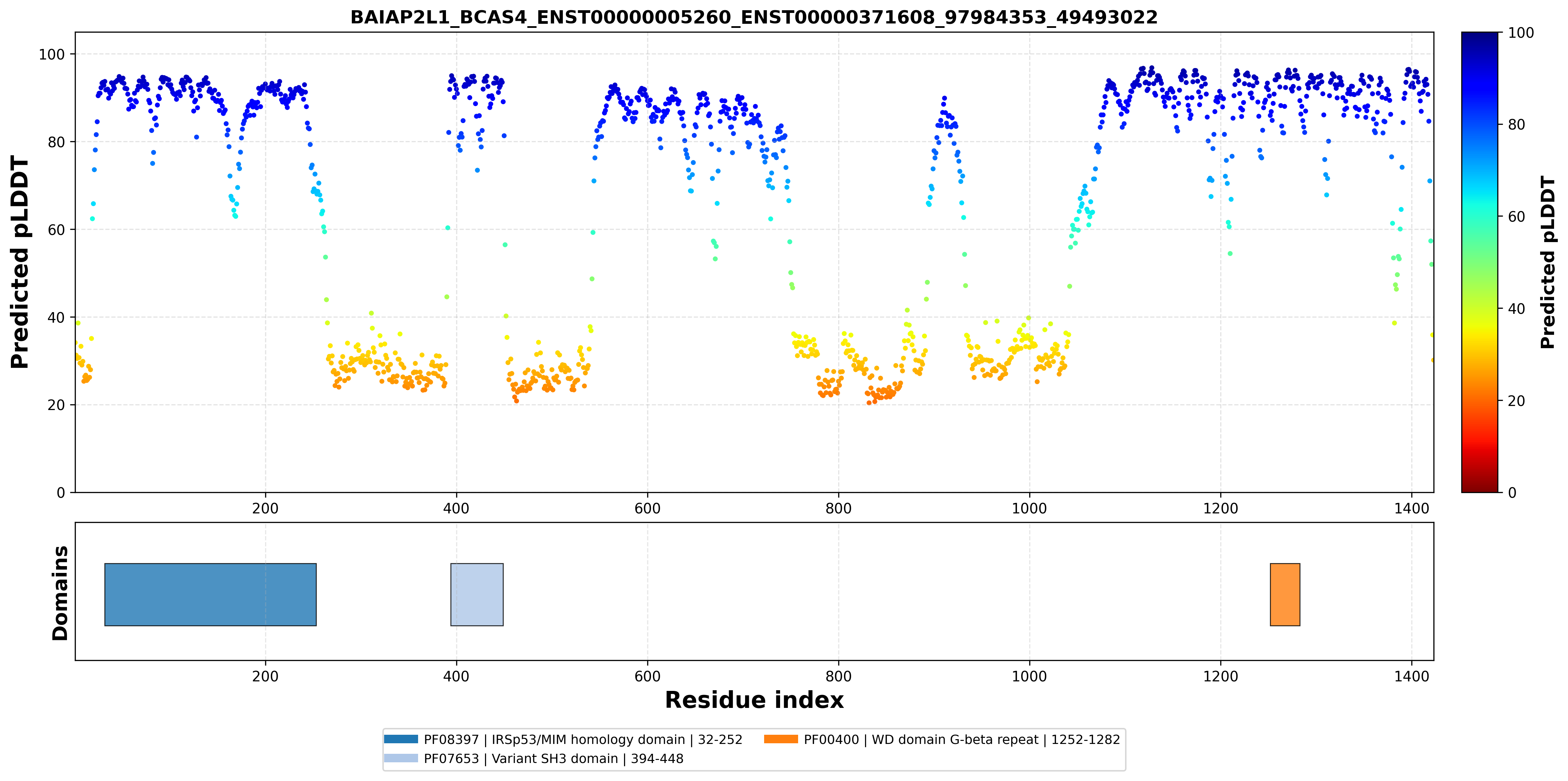 | 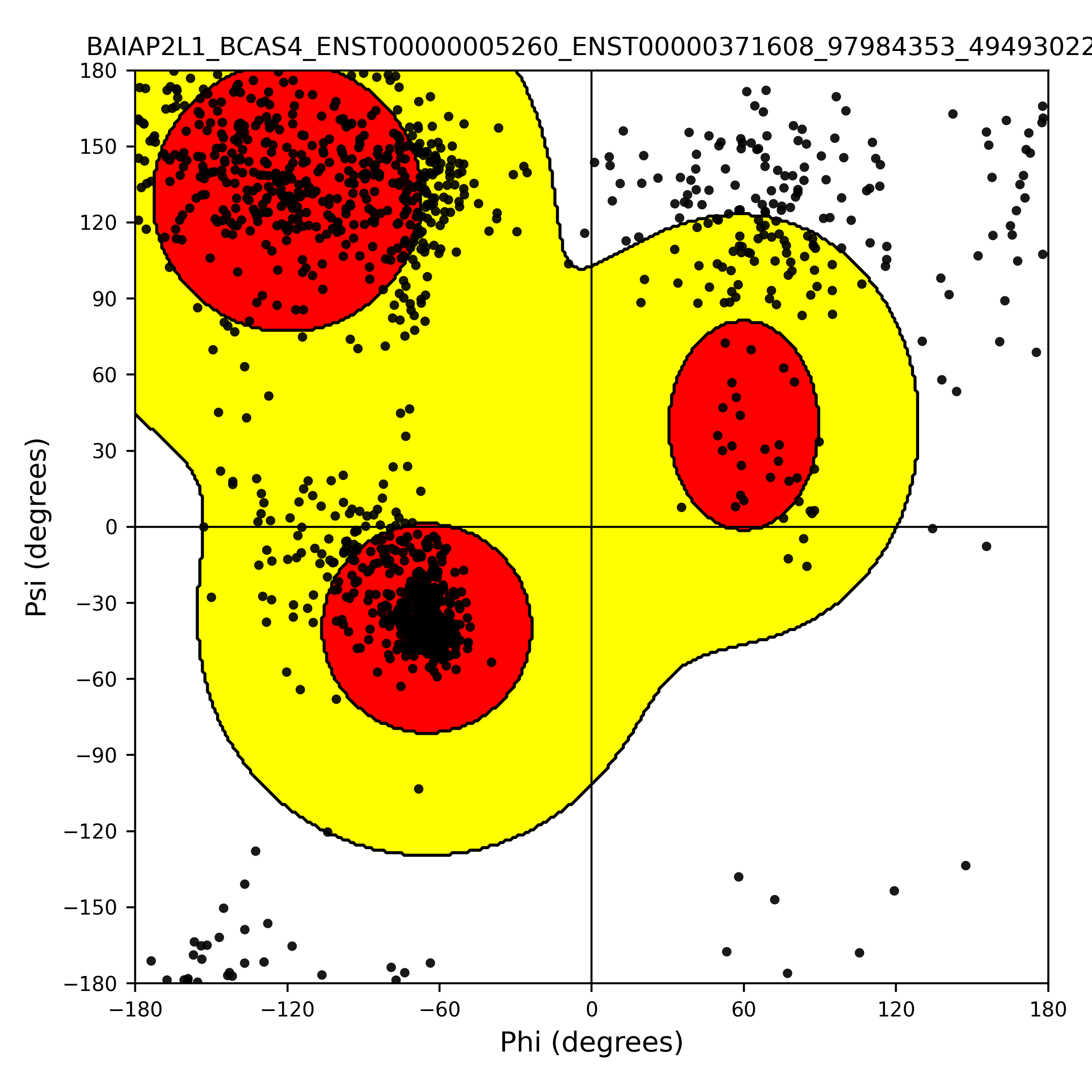 |  |
| BAIAP2L1_HSD17B14_ENST00000005260_ENST00000599157_98030113_49318398 superimposed PDB: 6H0M of partner (HSD17B14). RMSD:0.5095
Å |
 |  |  |  |  |
| BAIAP2L1_MET_ENST00000005260_ENST00000397752_97939756_116414934 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.5695
Å |
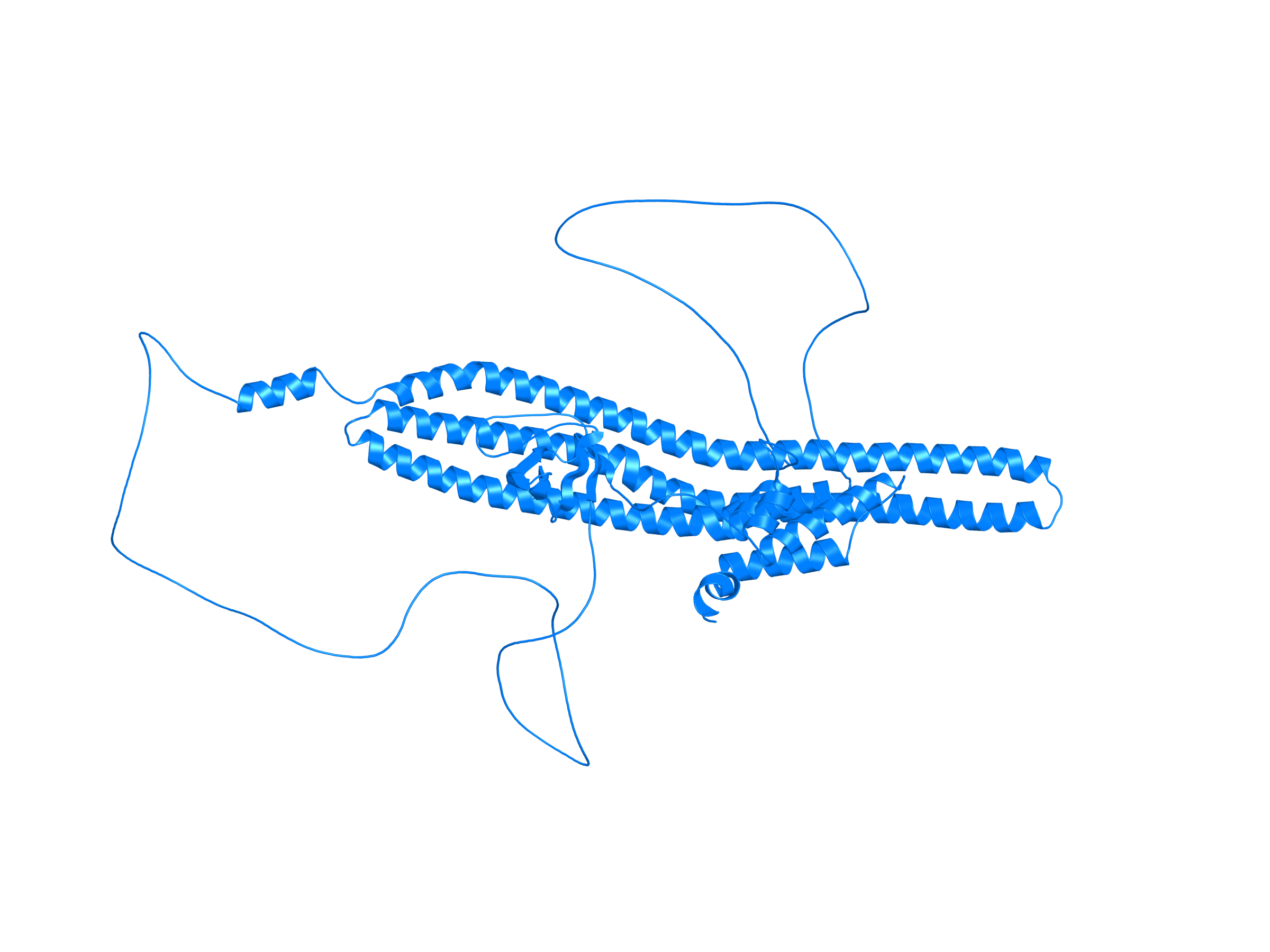 | 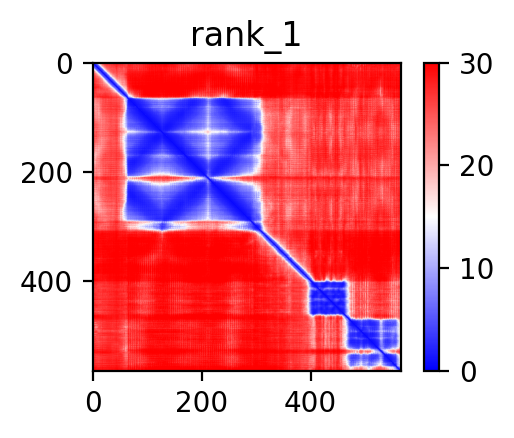 | 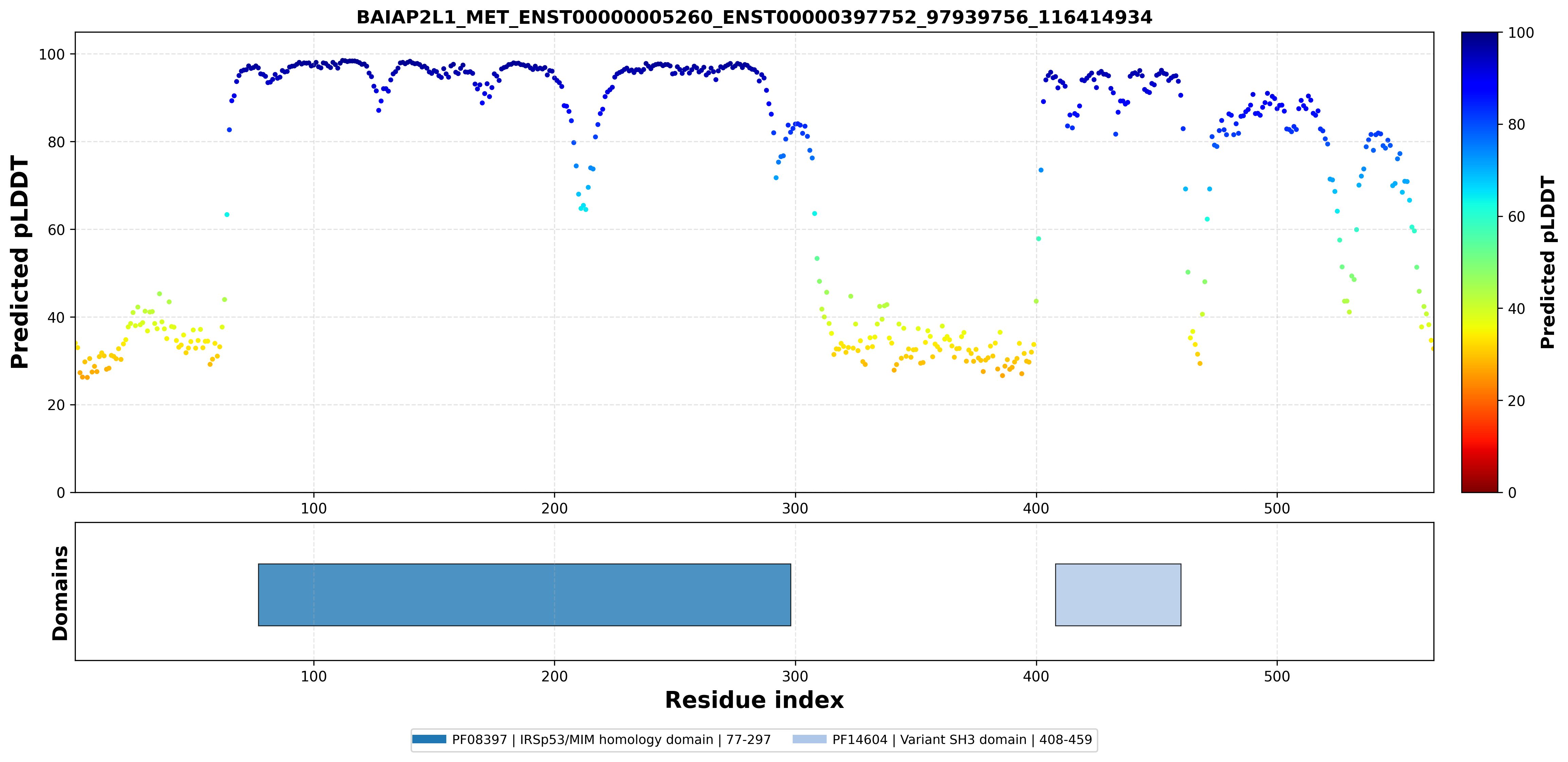 |  |  |
| BAIAP2_PSMD12_ENST00000321280_ENST00000357146_79009108_65338379 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:0.3542
Å |
 |  |  |  |  |
| BAIAP2_RPTOR_ENST00000321300_ENST00000306801_79089617_78796000 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:0.9548
Å |
 |  | 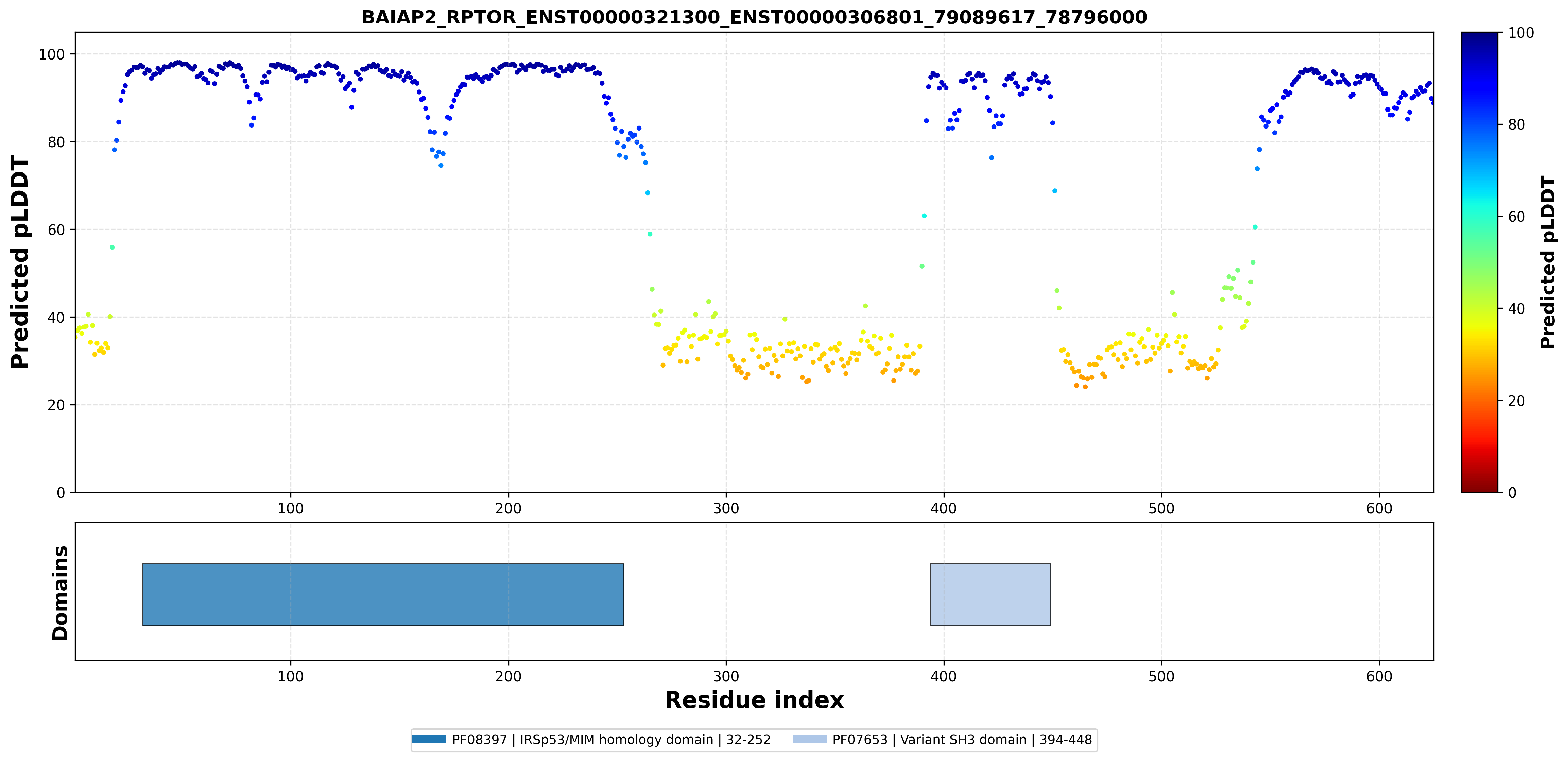 |  |  |
| BAIAP2_RPTOR_ENST00000321300_ENST00000544334_79089617_78796000 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.2106
Å |
 |  |  |  |  |
| BAIAP2_RPTOR_ENST00000321300_ENST00000544334_79089617_78796000 superimposed PDB: 8ERA of partner (RPTOR). RMSD:2.2092
Å |
| | | |  |
| BAIAP2_RPTOR_ENST00000321300_ENST00000570891_79089617_78796000 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.0124
Å |
 |  |  |  |  |
| BAIAP2_RPTOR_ENST00000321300_ENST00000570891_79089617_78796000 superimposed PDB: 8ERA of partner (RPTOR). RMSD:2.76
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000321280_ENST00000355528_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2906
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000321280_ENST00000397466_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.5058
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000321280_ENST00000397466_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2178
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000321280_ENST00000539345_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.9775
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000321280_ENST00000539345_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0994
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000392411_ENST00000397466_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.6425
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000392411_ENST00000397466_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.1939
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000428708_ENST00000355528_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.1934
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000428708_ENST00000355528_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.32
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000435091_ENST00000355528_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.0592
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000435091_ENST00000355528_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.4257
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000575245_ENST00000397466_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.4831
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000575245_ENST00000397466_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.288
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000575245_ENST00000539345_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.4892
Å |
 |  |  |  |  |
| BAIAP2_TBCD_ENST00000575245_ENST00000539345_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2335
Å |
| | | |  |
| BAIAP2_TBCD_ENST00000575712_ENST00000539345_79060380_80847543 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.9104
Å |
 |  | 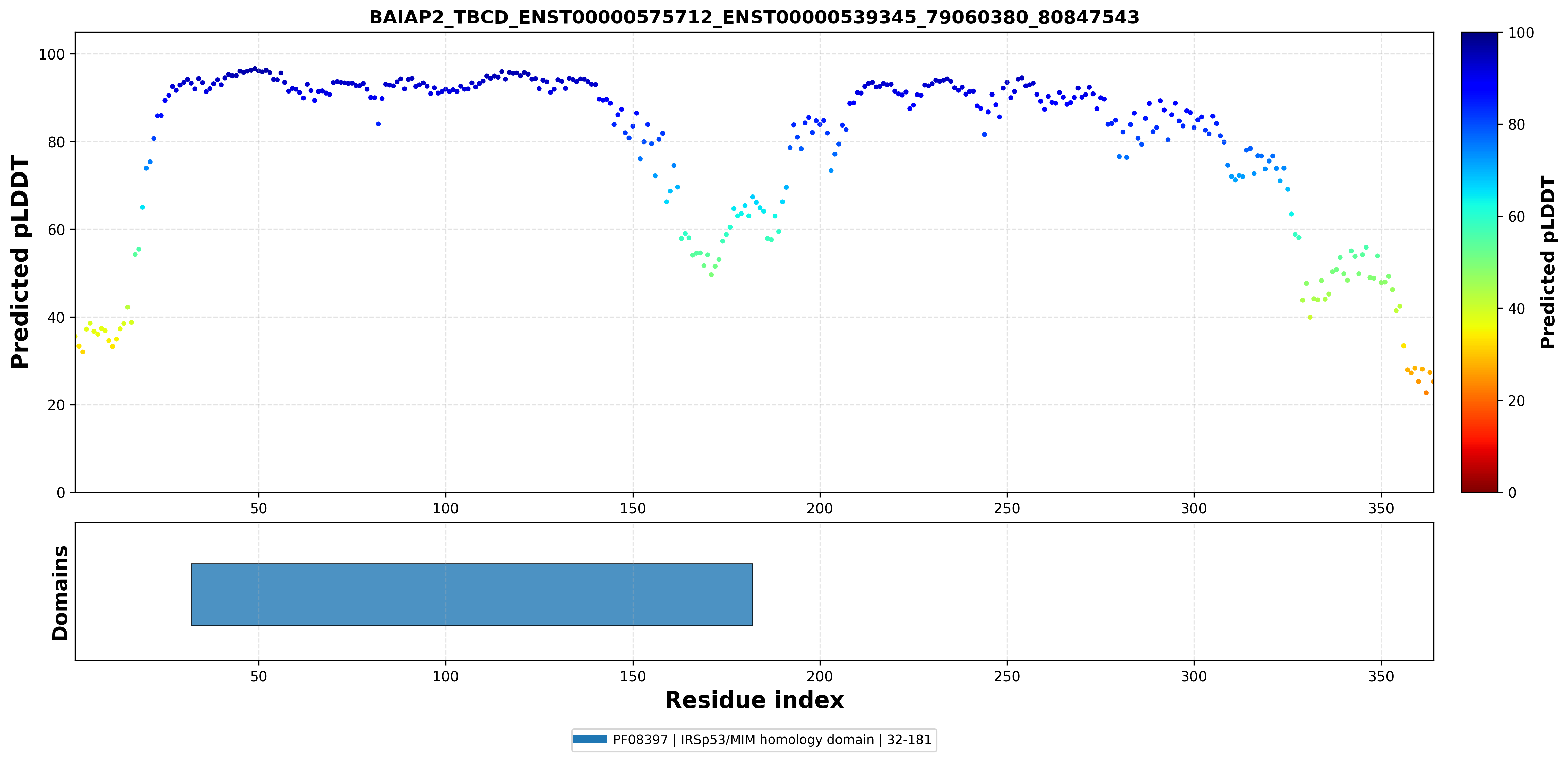 |  |  |
| BAIAP2_TBCD_ENST00000575712_ENST00000539345_79060380_80847543 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0088
Å |
| | | |  |
| BANP_JPH3_ENST00000355163_ENST00000284262_88052273_87677863 superimposed PDB: 7YUK of partner (BANP). RMSD:0.9844
Å |
 |  |  |  |  |
| BANP_JPH3_ENST00000393207_ENST00000284262_88052273_87677863 superimposed PDB: 7YUK of partner (BANP). RMSD:1.6618
Å |
 |  |  |  |  |
| BANP_JPH3_ENST00000393208_ENST00000284262_88052273_87677863 superimposed PDB: 7YUK of partner (BANP). RMSD:1.7456
Å |
 |  |  |  |  |
| BANP_JPH3_ENST00000479780_ENST00000284262_88052273_87677863 superimposed PDB: 7YUK of partner (BANP). RMSD:2.606
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000296302_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0133
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000296302_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2963
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000337303_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.2995
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000337303_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.4413
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000356770_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9643
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000356770_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1959
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000394830_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0867
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000394830_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1952
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000409057_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.1603
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000409057_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.249
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000409767_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.2102
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000296288_ENST00000409767_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3019
Å |
| | | |  |
| BAP1_PBRM1_ENST00000296288_ENST00000410007_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9934
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000296302_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9919
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000296302_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2733
Å |
| | | |  |
| BAP1_PBRM1_ENST00000460680_ENST00000337303_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9902
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000337303_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3284
Å |
| | | |  |
| BAP1_PBRM1_ENST00000460680_ENST00000394830_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0487
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000394830_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3056
Å |
| | | |  |
| BAP1_PBRM1_ENST00000460680_ENST00000409057_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0042
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000409057_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.236
Å |
| | | |  |
| BAP1_PBRM1_ENST00000460680_ENST00000409767_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9643
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000409767_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3654
Å |
| | | |  |
| BAP1_PBRM1_ENST00000460680_ENST00000410007_52438468_52663051 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0228
Å |
 |  |  |  |  |
| BAP1_PBRM1_ENST00000460680_ENST00000410007_52438468_52663051 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.201
Å |
| | | |  |
| BAP1_PLXNB1_ENST00000296288_ENST00000296440_52437153_48455480 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0255
Å |
 |  | 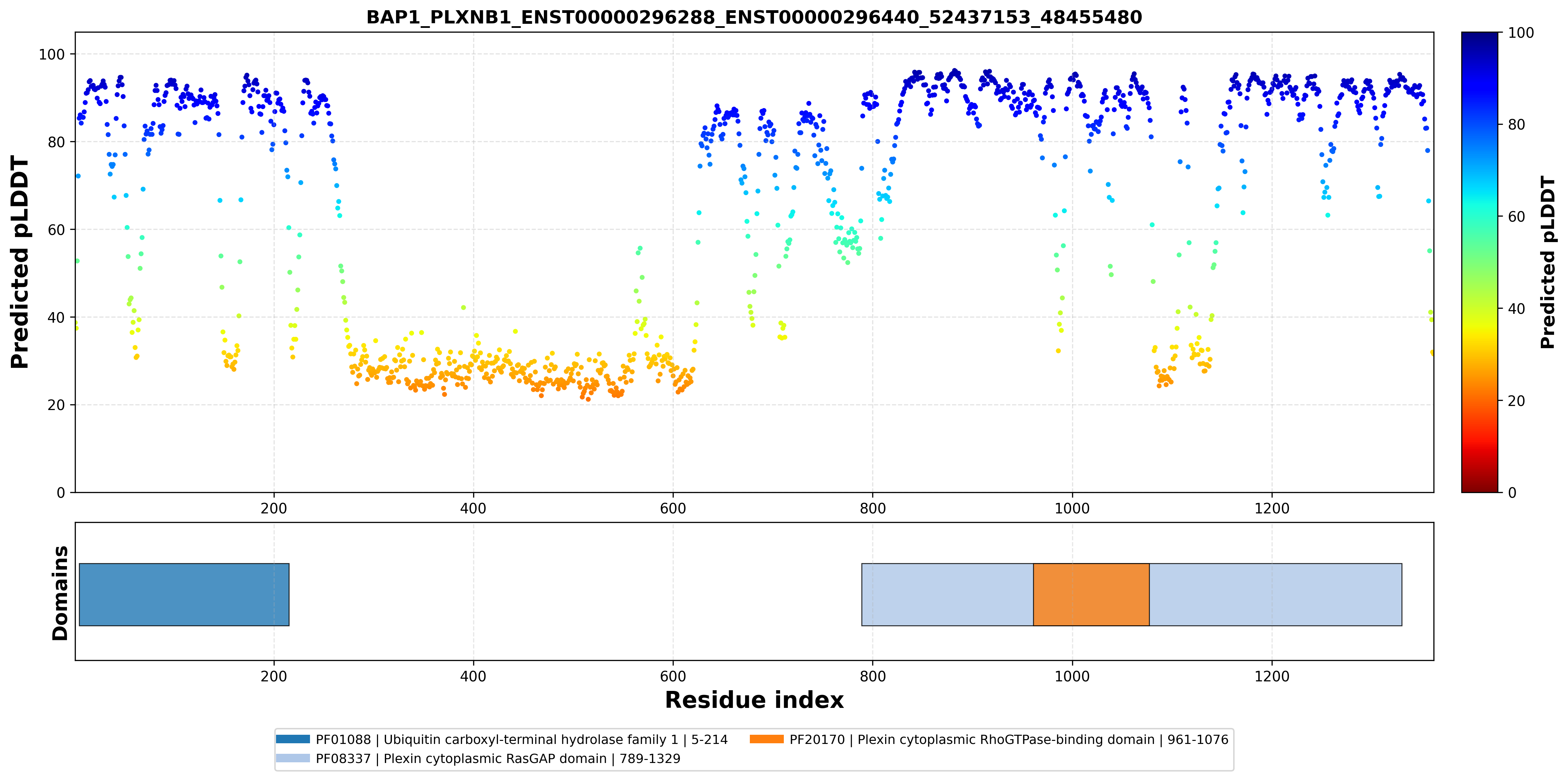 |  |  |
| BAP1_PLXNB1_ENST00000296288_ENST00000296440_52437153_48455480 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:0.8806
Å |
| | | |  |
| BAP1_PLXNB1_ENST00000296288_ENST00000358459_52437153_48455480 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.1579
Å |
 |  | 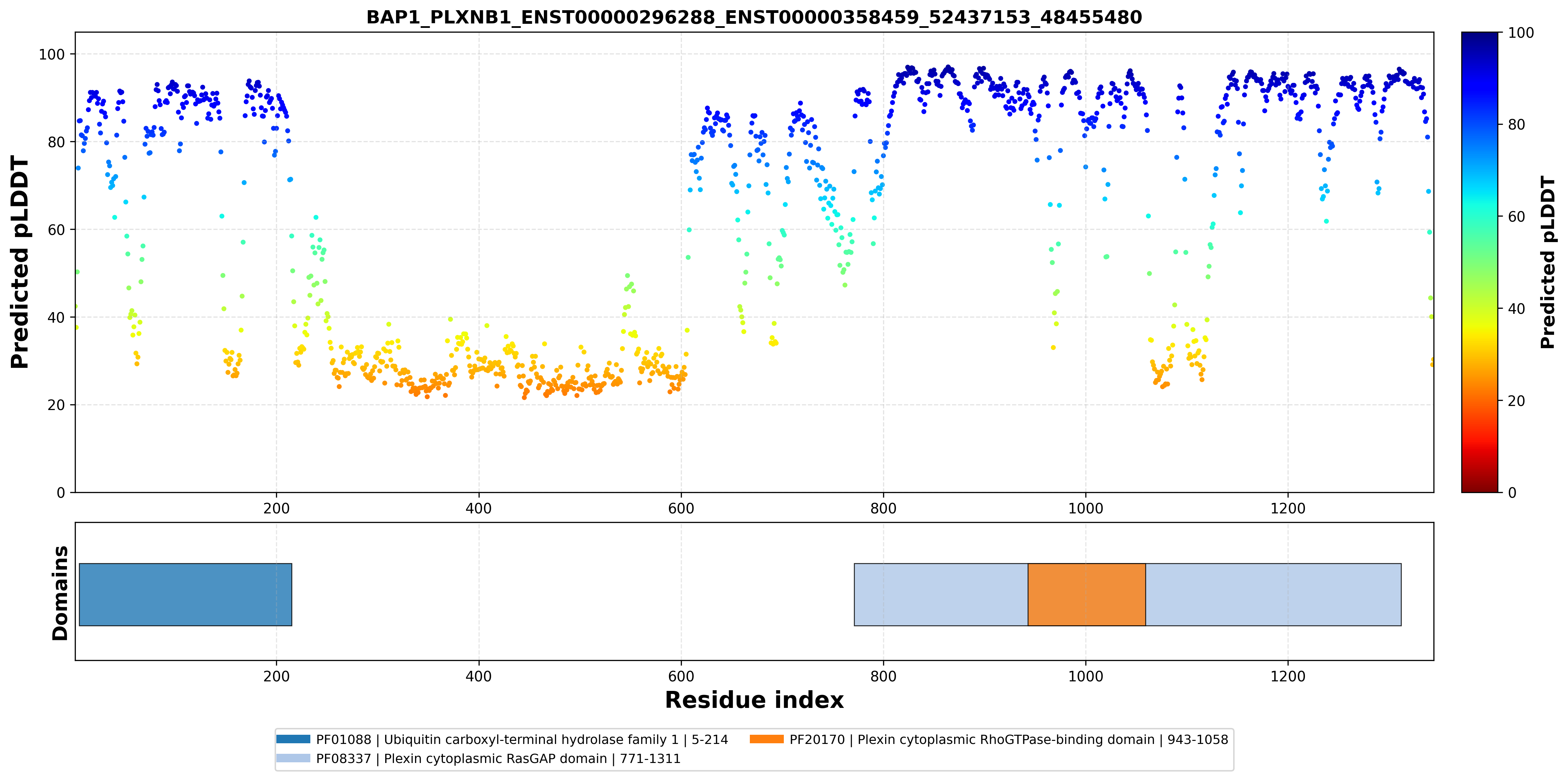 |  |  |
| BAP1_PLXNB1_ENST00000296288_ENST00000358459_52437153_48455480 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:0.7977
Å |
| | | |  |
| BAP1_PLXNB1_ENST00000460680_ENST00000358459_52437153_48455480 superimposed PDB: 8H1T of partner (BAP1). RMSD:0.9725
Å |
 |  | 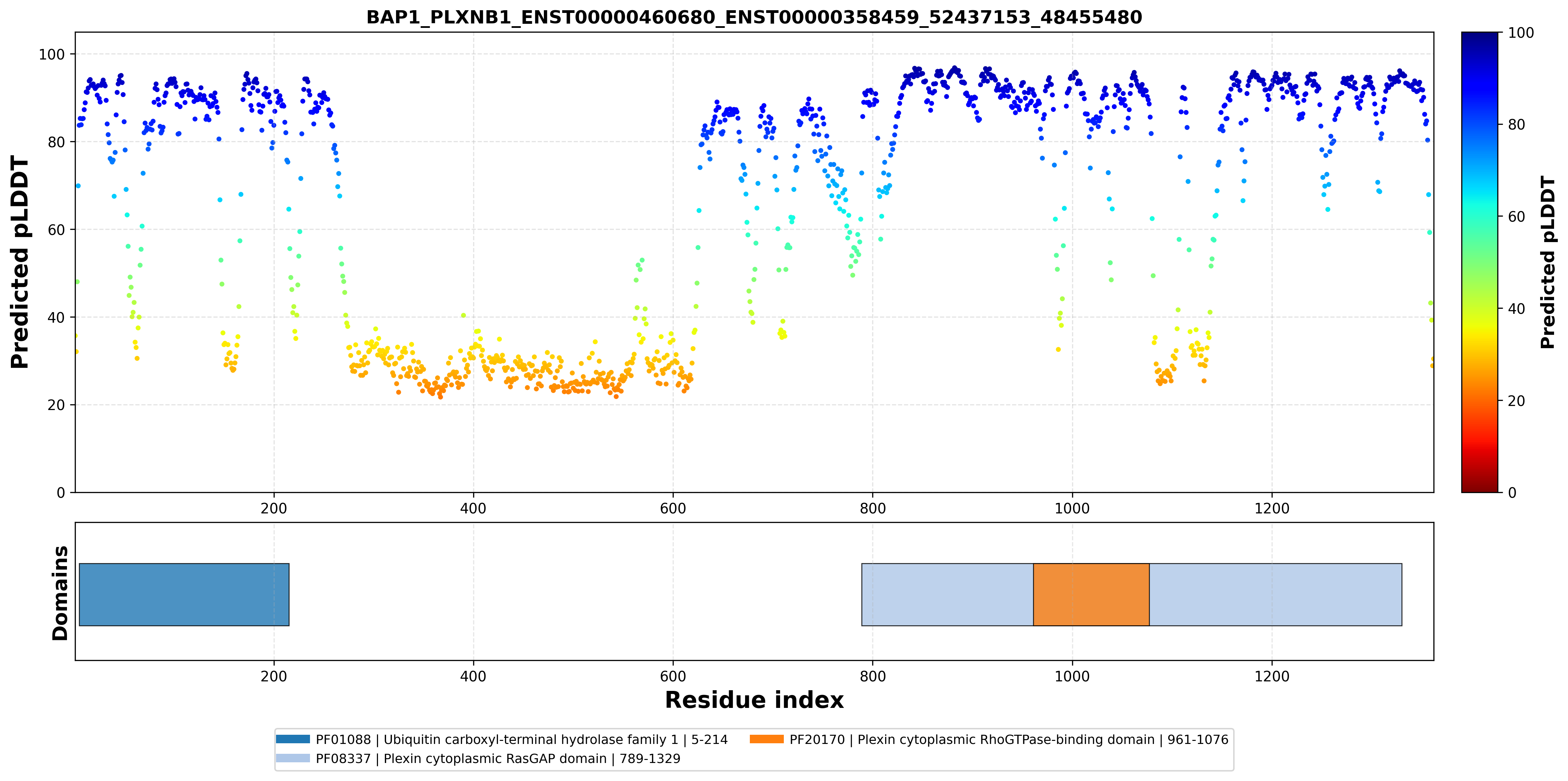 |  |  |
| BAP1_PLXNB1_ENST00000460680_ENST00000358459_52437153_48455480 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:0.8892
Å |
| | | |  |
| BAP1_TCEA3_ENST00000296288_ENST00000374601_52440268_23745632 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0597
Å |
 |  | 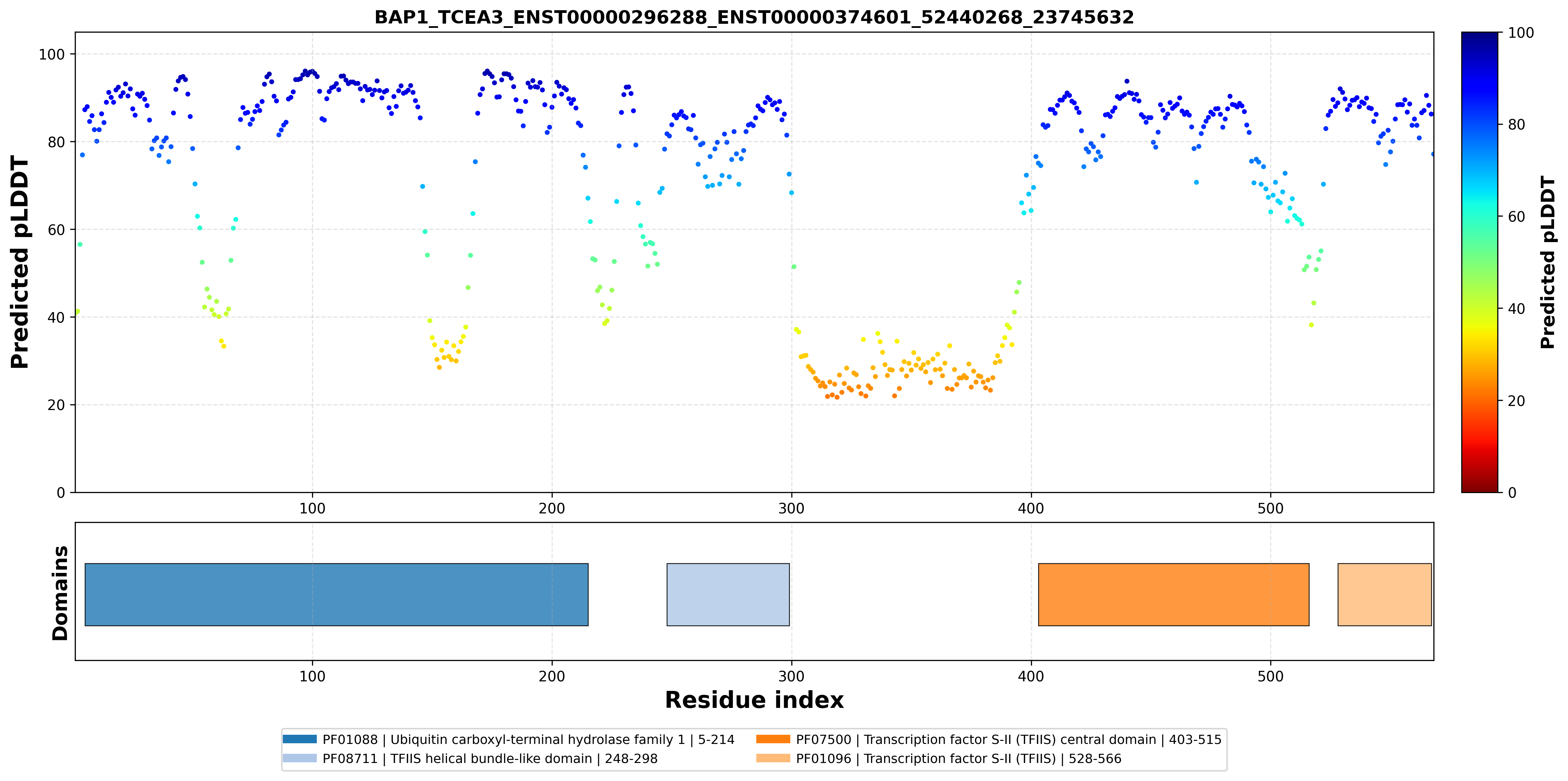 |  |  |
| BAP1_TCEA3_ENST00000460680_ENST00000374601_52440268_23745632 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.3466
Å |
 | 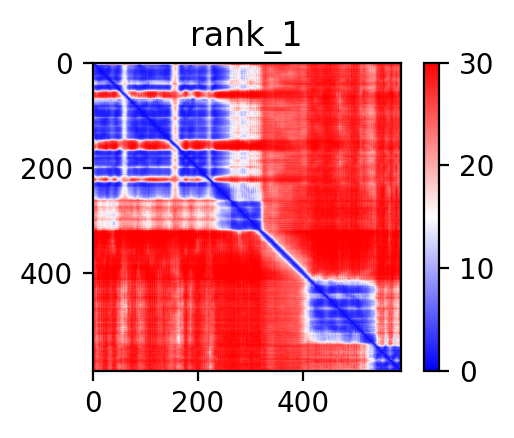 | 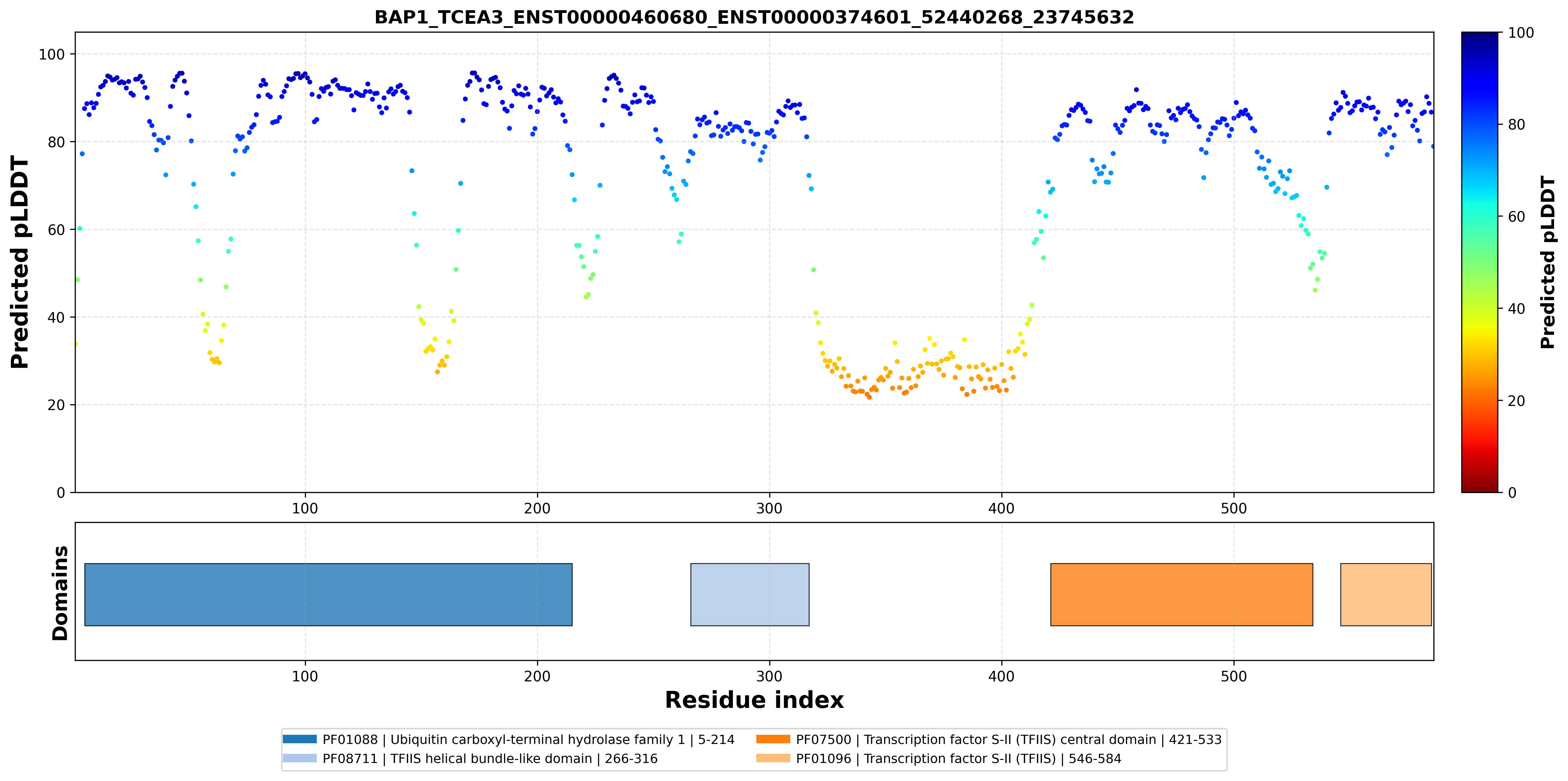 |  |  |
| BAP1_TCEA3_ENST00000460680_ENST00000450454_52440268_23745632 superimposed PDB: 8H1T of partner (BAP1). RMSD:1.0943
Å |
 | 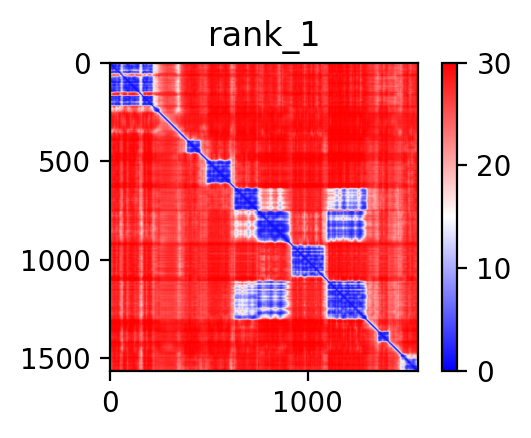 | 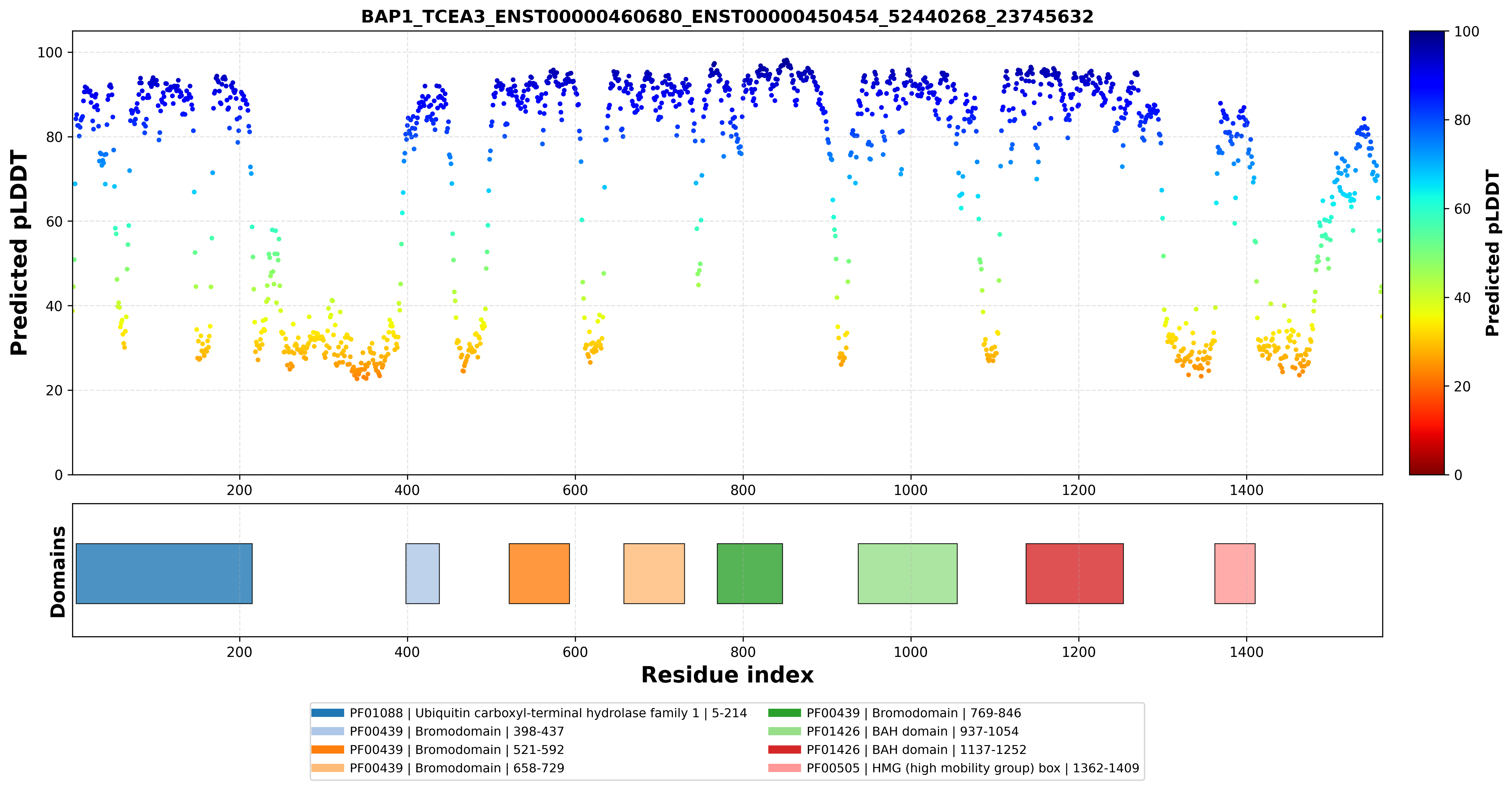 |  |  |
| BAX_VAV2_ENST00000345358_ENST00000371851_49464171_136629231 superimposed PDB: 5W60 of partner (BAX). RMSD:1.0307
Å |
 |  |  |  |  |
| BAX_VAV2_ENST00000354470_ENST00000371851_49464171_136629231 superimposed PDB: 5W60 of partner (BAX). RMSD:2.8991
Å |
 |  |  |  |  |
| BAX_VAV2_ENST00000354470_ENST00000371851_49464171_136629231 superimposed PDB: 4ROJ of partner (VAV2). RMSD:1.1934
Å |
| | | |  |
| BAX_VAV2_ENST00000415969_ENST00000371851_49464171_136629231 superimposed PDB: 5W60 of partner (BAX). RMSD:1.044
Å |
 |  |  |  |  |
| BAZ2A_PRIM1_ENST00000379441_ENST00000338193_57006798_57128029 superimposed PDB: 7MWI of partner (BAZ2A). RMSD:0.4889
Å |
 |  |  |  |  |
| BAZ2A_PRIM1_ENST00000551812_ENST00000338193_57003519_57128029 superimposed PDB: 7MWI of partner (BAZ2A). RMSD:0.4883
Å |
 |  |  |  |  |
| BAZ2A_PRIM1_ENST00000551812_ENST00000338193_57006798_57128029 superimposed PDB: 7MWI of partner (BAZ2A). RMSD:2.4769
Å |
 |  |  |  |  |
| BAZ2A_PRIM1_ENST00000551812_ENST00000338193_57008797_57128029 superimposed PDB: 4MHQ of partner (PRIM1). RMSD:2.245
Å |
 |  | 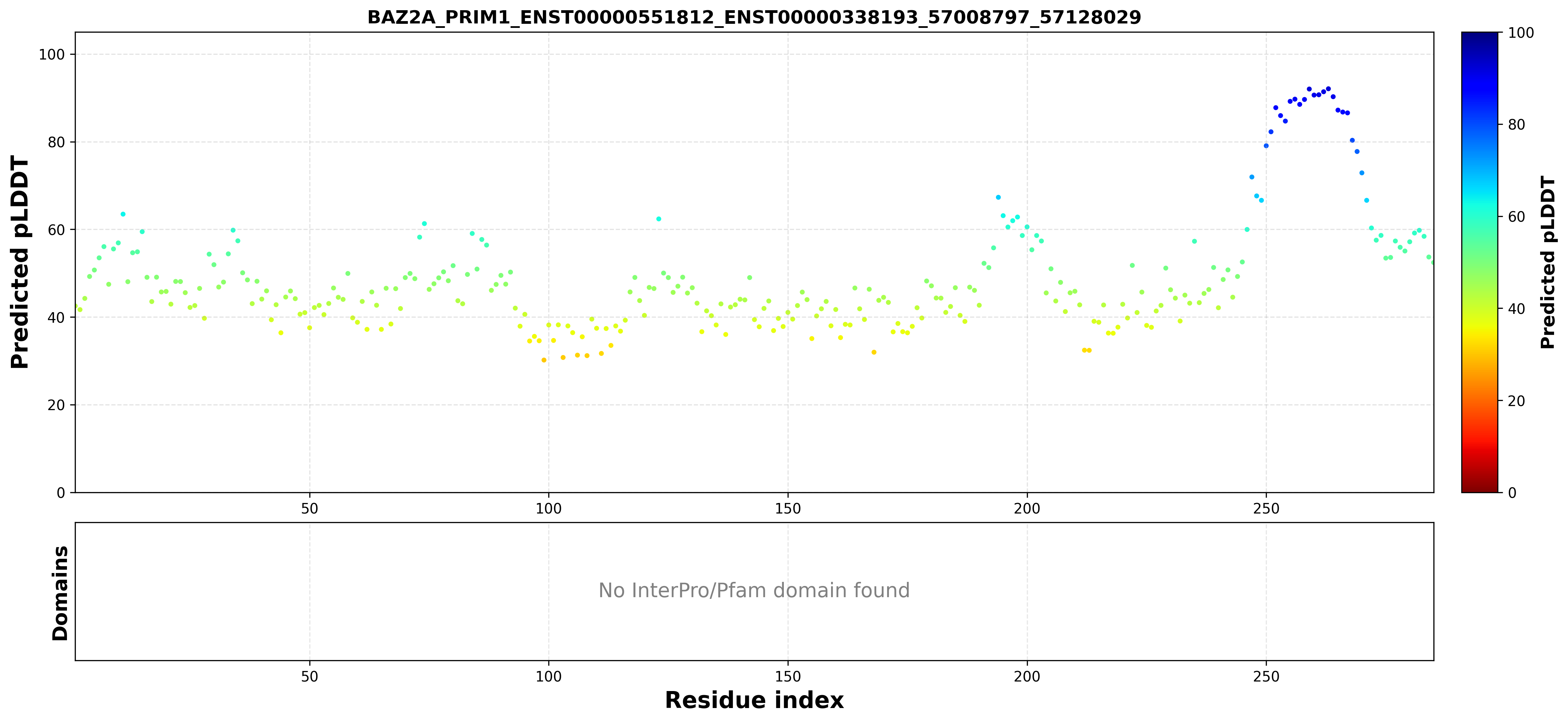 |  |  |
| BBC3_FCGRT_ENST00000439096_ENST00000426395_47729820_50029266 superimposed PDB: 6TQP of partner (BBC3). RMSD:1.6647
Å |
 |  |  |  |  |
| BBS4_CSNK1G1_ENST00000268057_ENST00000303052_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:1.1935
Å |
 | 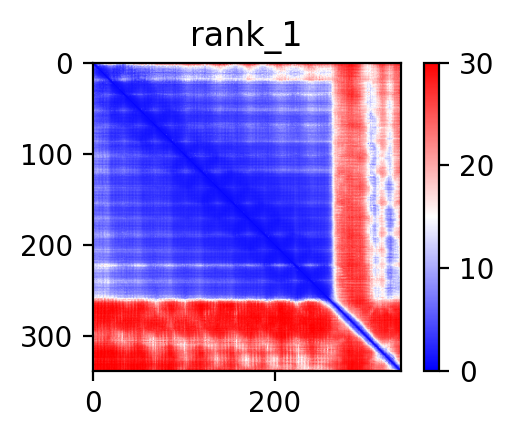 | 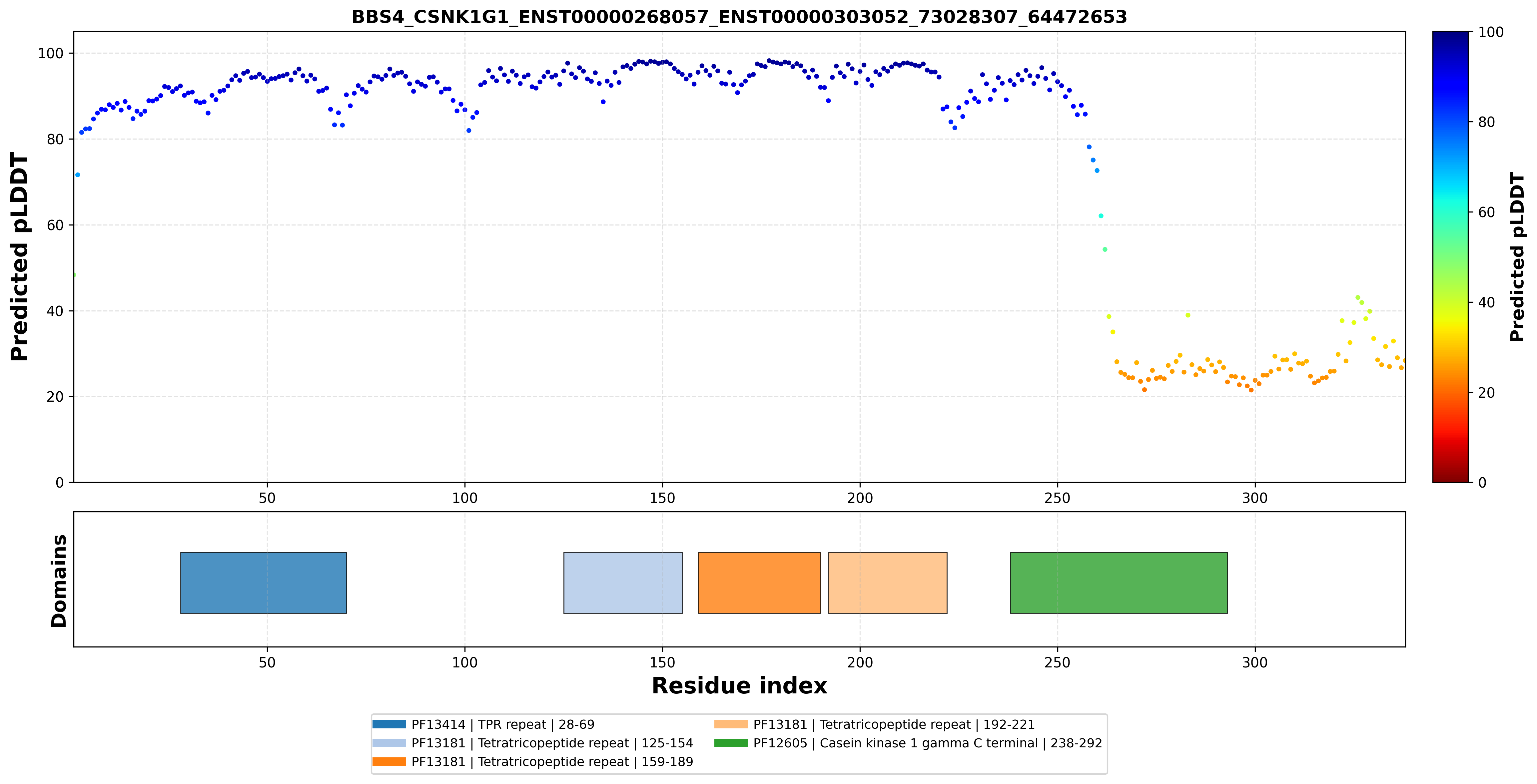 |  |  |
| BBS4_CSNK1G1_ENST00000268057_ENST00000607537_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:2.0043
Å |
 |  | 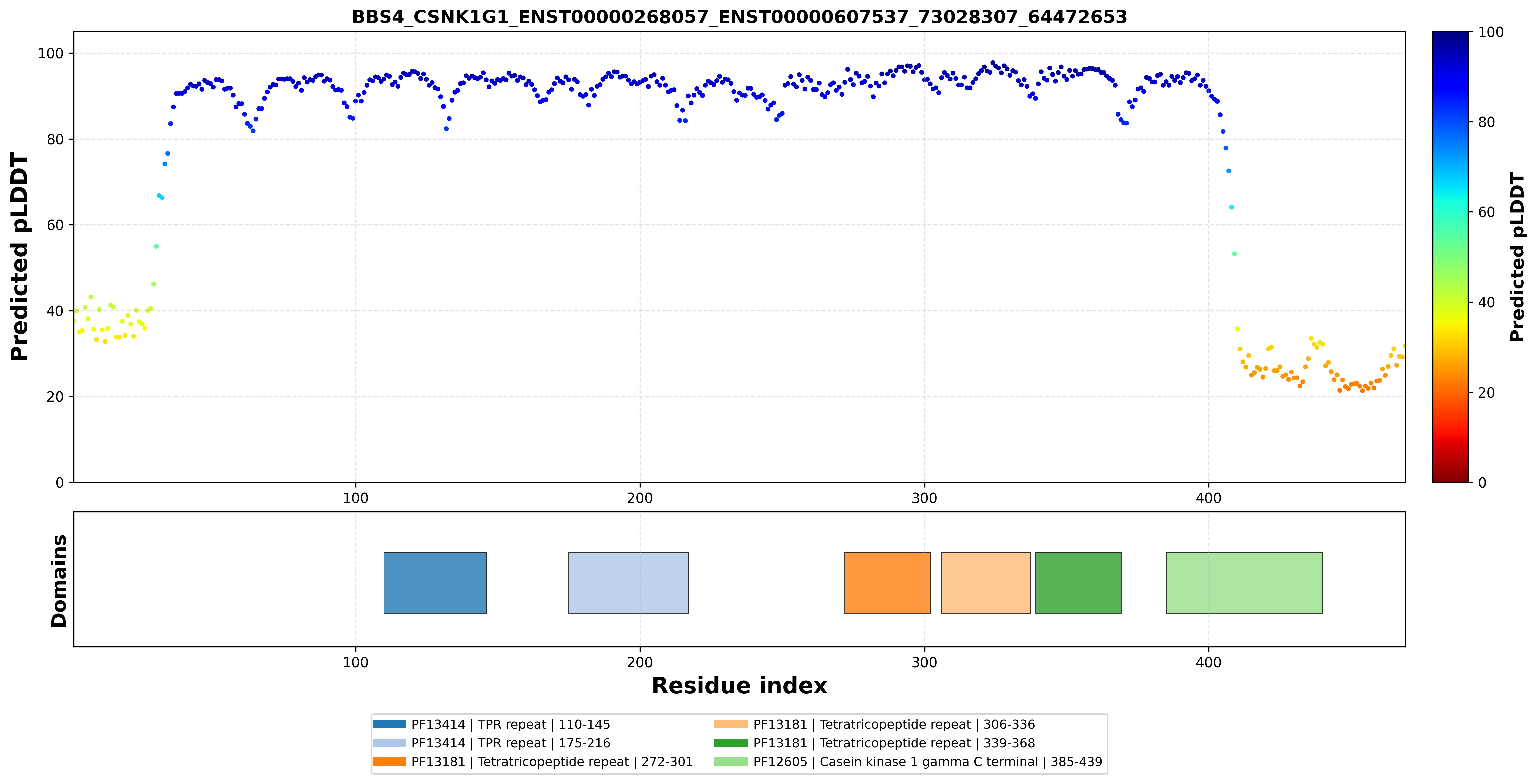 |  |  |
| BBS4_CSNK1G1_ENST00000395205_ENST00000303052_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:2.1538
Å |
 | 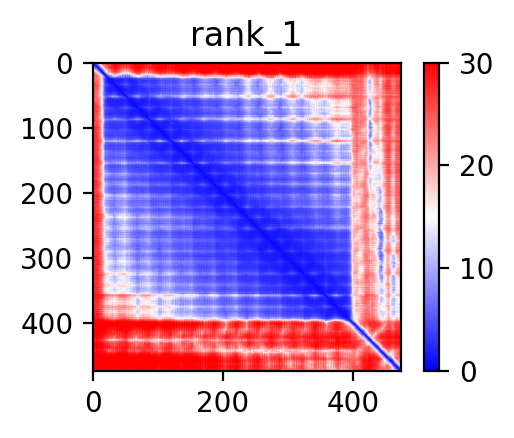 | 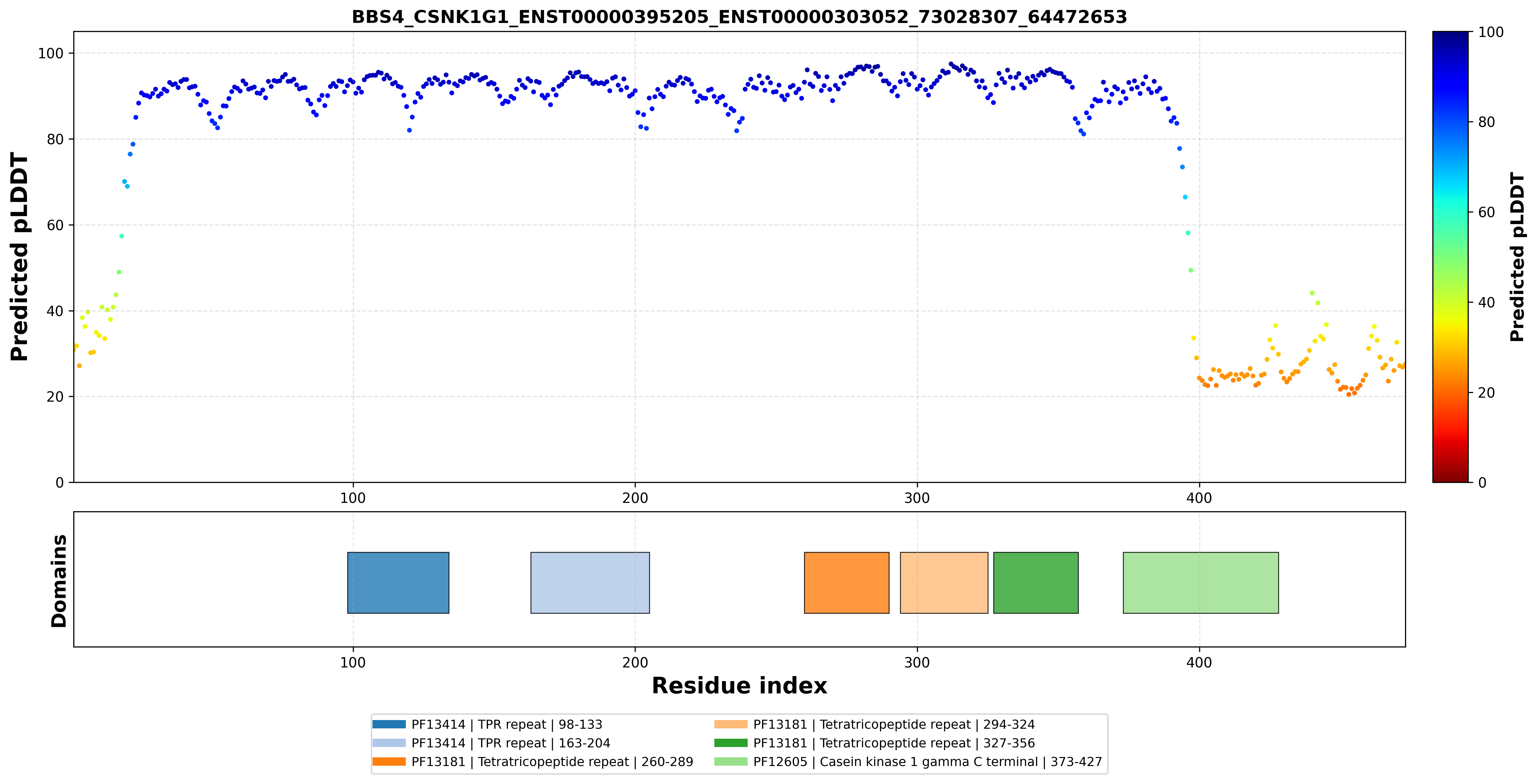 |  |  |
| BBS4_CSNK1G1_ENST00000395205_ENST00000607537_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:1.9537
Å |
 |  | 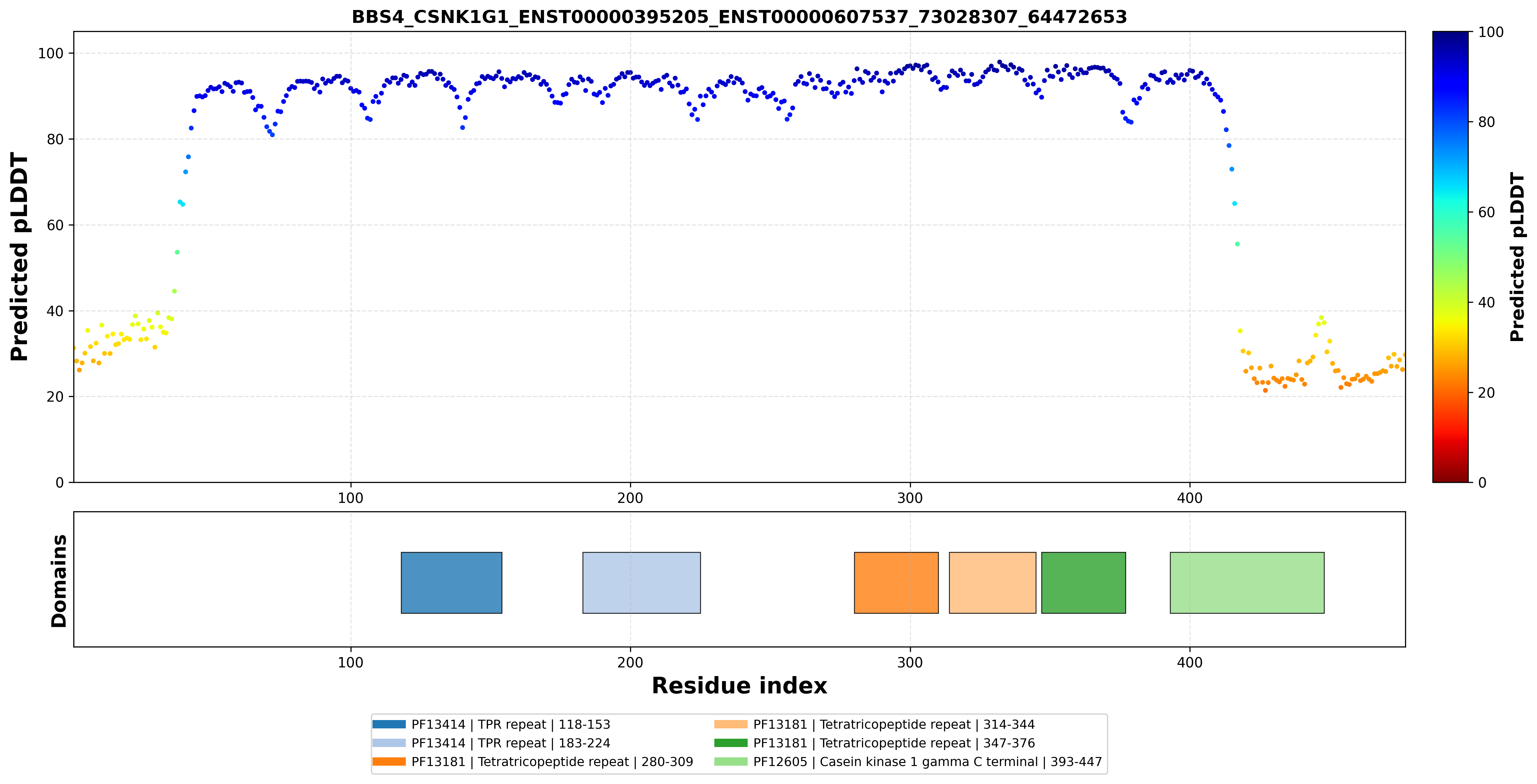 |  |  |
| BBS4_CSNK1G1_ENST00000539603_ENST00000303052_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:2.0365
Å |
 |  | 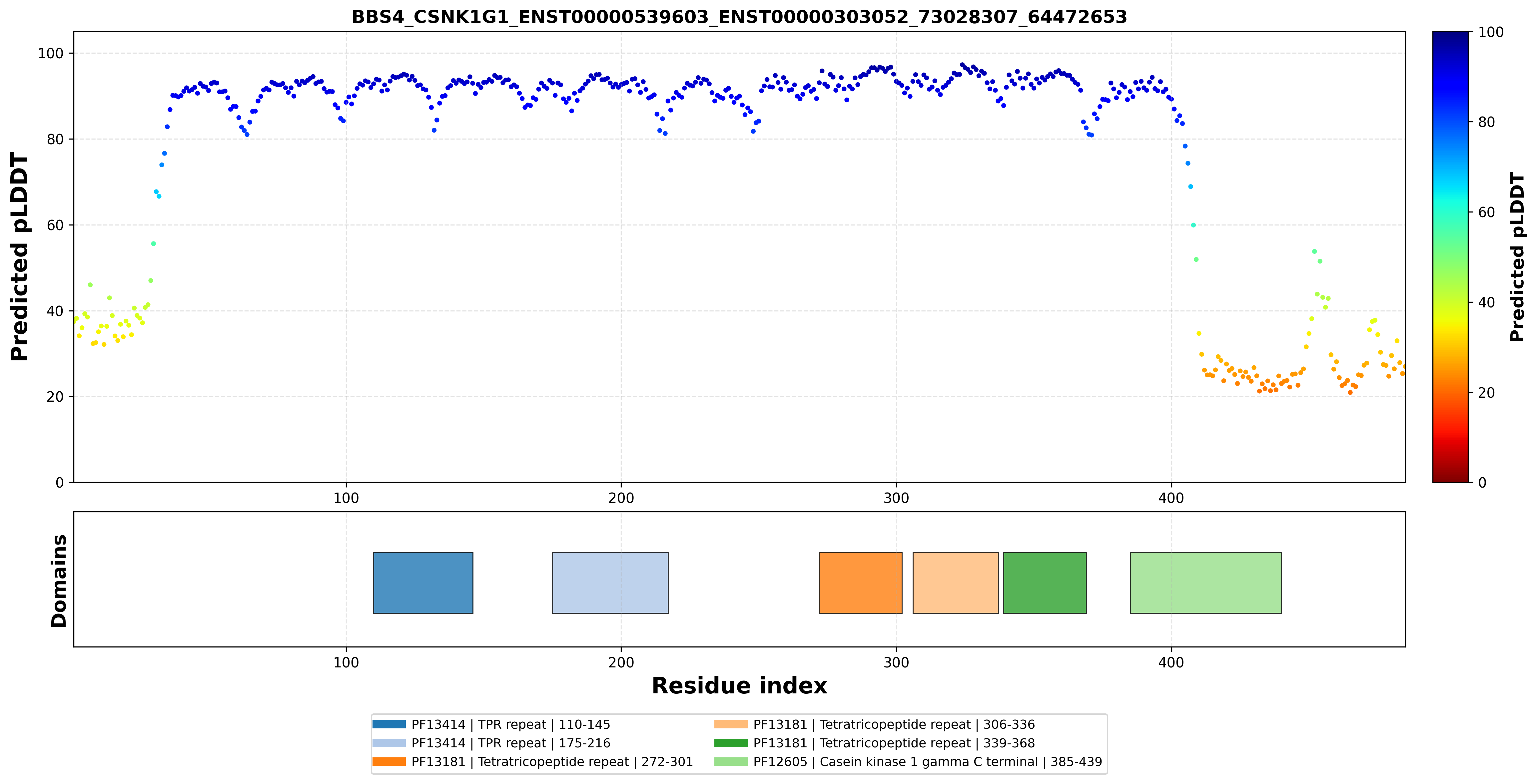 |  |  |
| BBS4_CSNK1G1_ENST00000539603_ENST00000607537_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:2.0163
Å |
 |  | 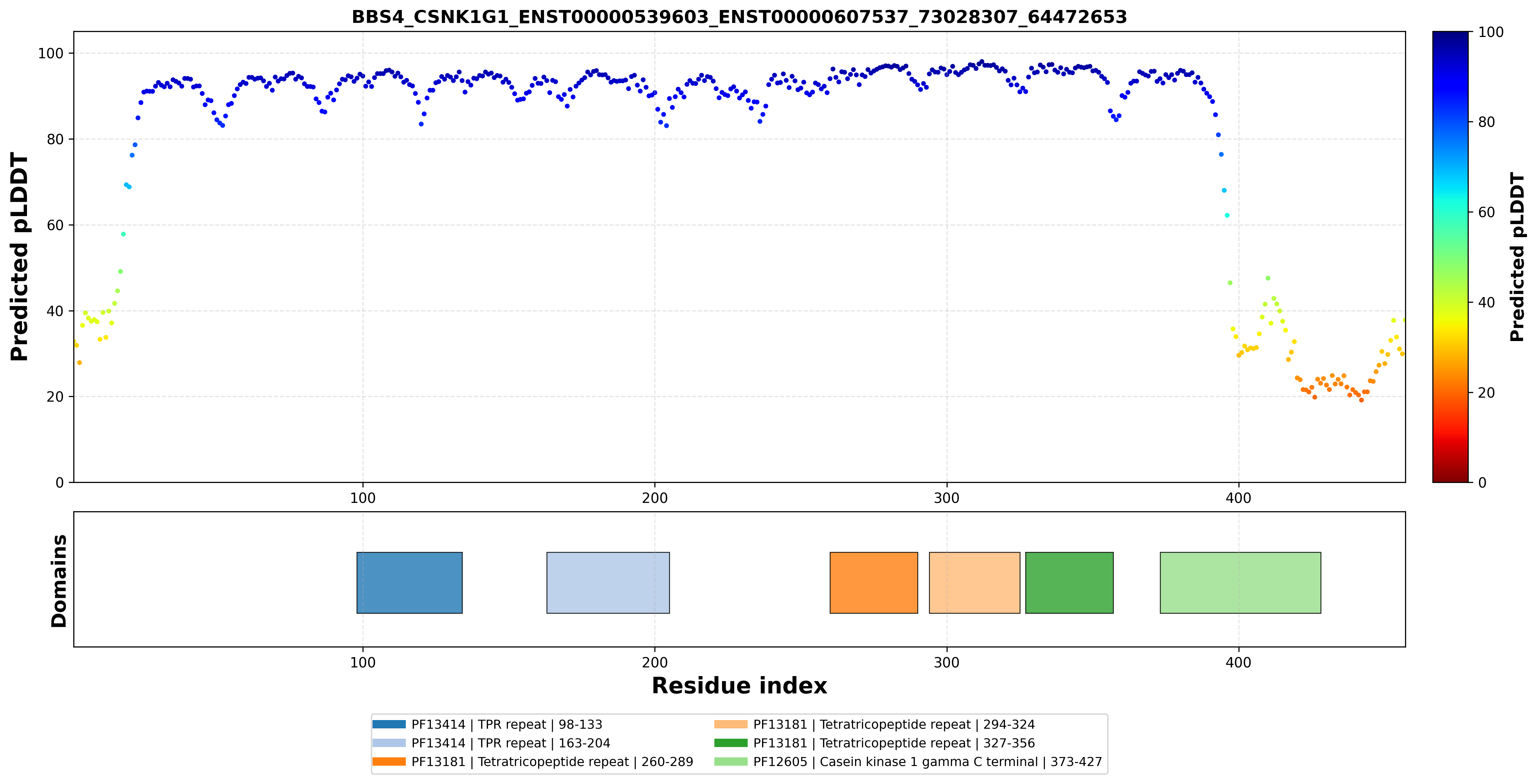 |  |  |
| BBS4_CSNK1G1_ENST00000542334_ENST00000607537_73028307_64472653 superimposed PDB: 6XT9 of partner (BBS4). RMSD:1.3321
Å |
 |  | 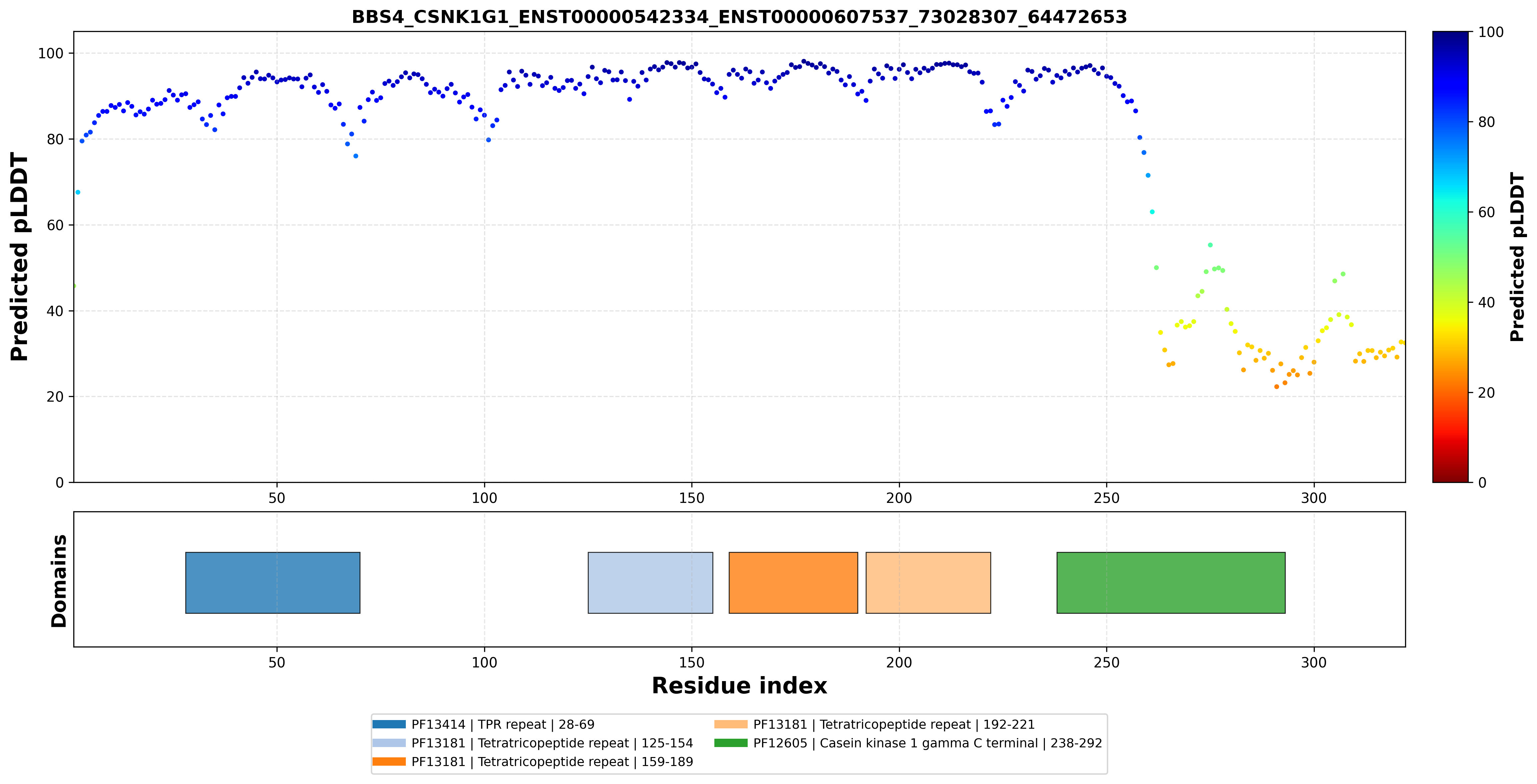 |  |  |
| BBS9_FKBP9_ENST00000242067_ENST00000538336_33217203_33035774 superimposed PDB: 6XT9 of partner (BBS9). RMSD:1.3651
Å |
 |  |  |  |  |
| BBS9_FKBP9_ENST00000242067_ENST00000538336_33217203_33035774 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5696
Å |
| | | |  |
| BCAR3_ABCA4_ENST00000370247_ENST00000370225_94054533_94495187 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.7838
Å |
 |  |  |  |  |
| BCAR3_EVI5_ENST00000370243_ENST00000540033_94037226_93202184 superimposed PDB: 3T6A of partner (BCAR3). RMSD:2.7955
Å |
 |  |  |  |  |
| BCAR3_EVI5_ENST00000370247_ENST00000540033_94037226_93202184 superimposed PDB: 3T6A of partner (BCAR3). RMSD:2.8703
Å |
 |  |  |  |  |
| BCAR3_SH2D3C_ENST00000370243_ENST00000373274_94057821_130511944 superimposed PDB: 3T6A of partner (BCAR3). RMSD:0.6421
Å |
 |  |  |  |  |
| BCAR3_SH2D3C_ENST00000370243_ENST00000373274_94057821_130511944 superimposed PDB: 3T6G of partner (SH2D3C). RMSD:0.5076
Å |
| | | |  |
| BCAR3_SH2D3C_ENST00000370247_ENST00000373274_94057821_130511944 superimposed PDB: 3T6A of partner (BCAR3). RMSD:0.656
Å |
 |  |  |  |  |
| BCAR3_SH2D3C_ENST00000370247_ENST00000373274_94057821_130511944 superimposed PDB: 3T6G of partner (SH2D3C). RMSD:0.507
Å |
| | | |  |
| BCAS1_RAF1_ENST00000371435_ENST00000442415_52601825_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9679
Å |
 |  |  |  |  |
| BCAS1_RAF1_ENST00000371440_ENST00000442415_52583444_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8705
Å |
 |  |  |  |  |
| BCAS1_RAF1_ENST00000371440_ENST00000442415_52601825_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9987
Å |
 |  |  |  |  |
| BCAS1_RAF1_ENST00000395961_ENST00000442415_52583444_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0122
Å |
 |  |  |  |  |
| BCAS1_RAF1_ENST00000434986_ENST00000442415_52601825_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0295
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000390652_ENST00000413795_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7781
Å |
 |  | 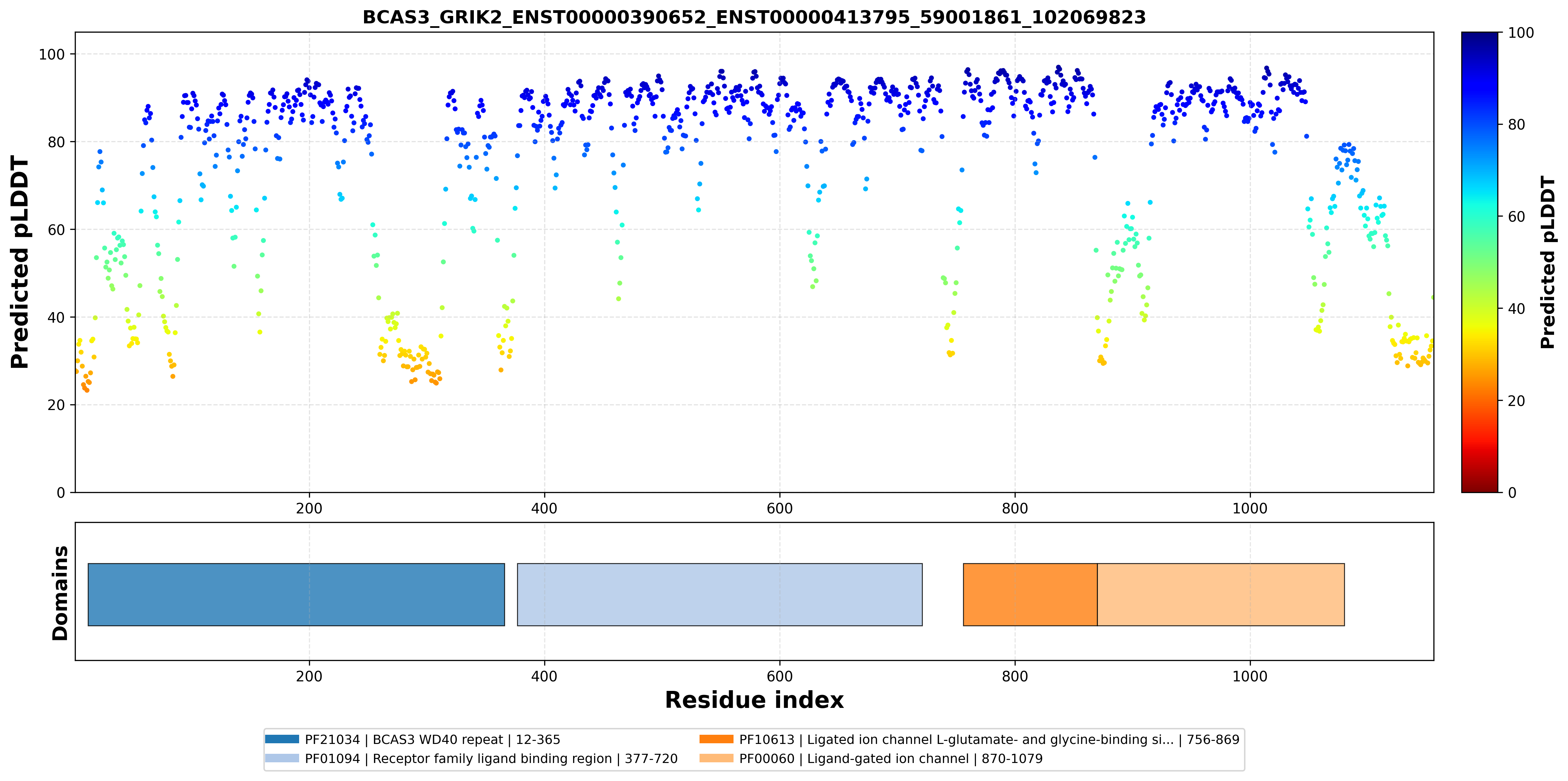 |  |  |
| BCAS3_GRIK2_ENST00000407086_ENST00000413795_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7625
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000585744_ENST00000358361_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9197
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000585744_ENST00000369137_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9179
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000585744_ENST00000369138_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8991
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000585744_ENST00000421544_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8617
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000588874_ENST00000358361_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8868
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000588874_ENST00000369137_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9043
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000588874_ENST00000369138_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8772
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000588874_ENST00000413795_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7129
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000588874_ENST00000421544_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8664
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000589222_ENST00000358361_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9459
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000589222_ENST00000369137_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9064
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000589222_ENST00000369138_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.888
Å |
 |  |  |  |  |
| BCAS3_GRIK2_ENST00000589222_ENST00000421544_59001861_102069823 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.9306
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000390652_ENST00000571680_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:1.768
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000407086_ENST00000559488_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:0.8118
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000408905_ENST00000559488_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:0.7646
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000585744_ENST00000571680_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:1.7591
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000588874_ENST00000559488_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:0.7801
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000588874_ENST00000571680_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:1.6754
Å |
 |  |  |  |  |
| BCAS3_ITGB3_ENST00000589222_ENST00000571680_59161925_45351784 superimposed PDB: 9E8A of partner (ITGB3). RMSD:1.5592
Å |
 |  |  |  |  |
| BCAS3_PRKAA2_ENST00000407086_ENST00000371244_58885437_57157066 superimposed PDB: 8BIK of partner (PRKAA2). RMSD:1.722
Å |
 |  | 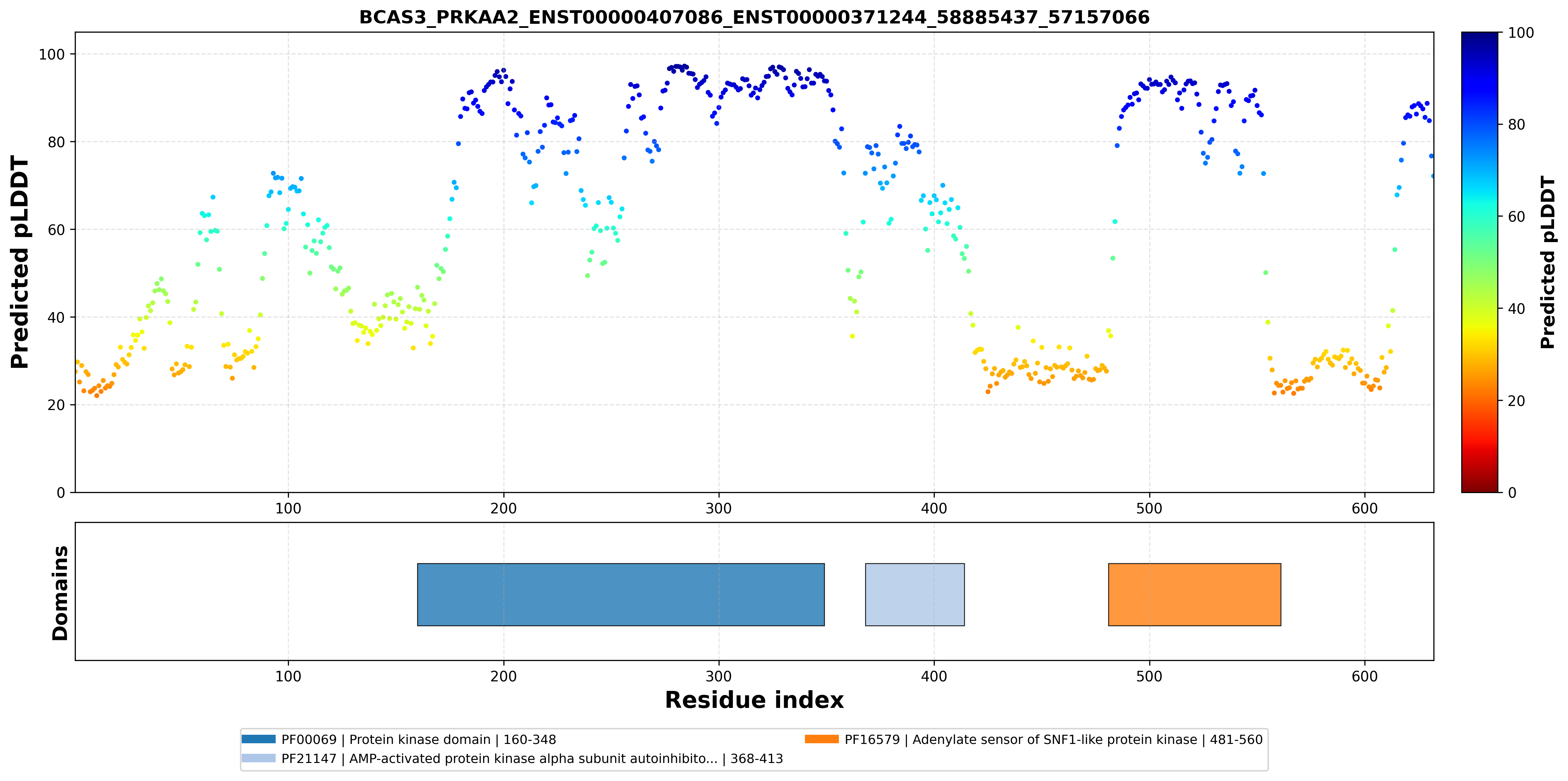 |  |  |
| BCAS3_RAD51C_ENST00000390652_ENST00000337432_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5602
Å |
 |  | 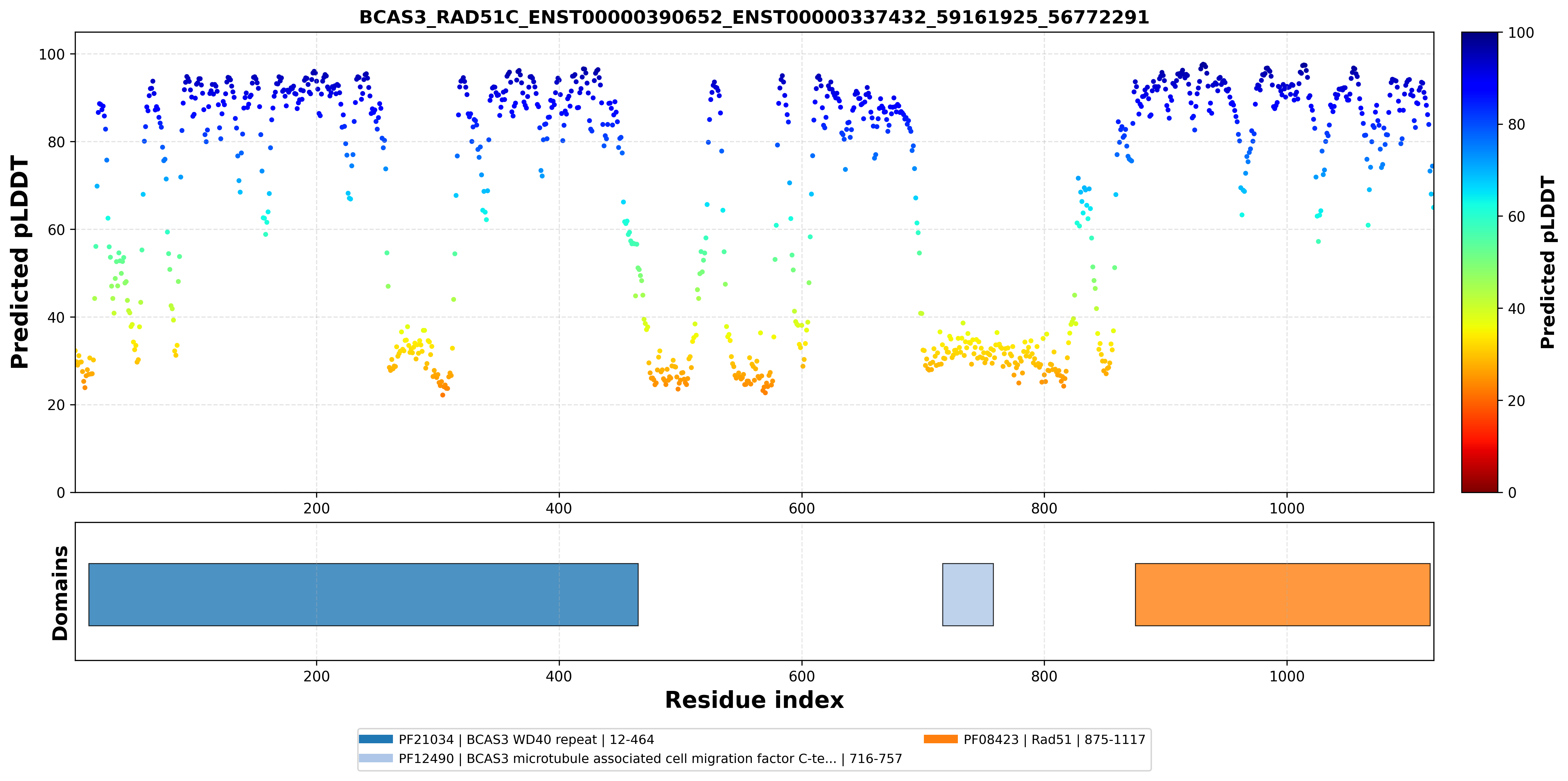 |  |  |
| BCAS3_RAD51C_ENST00000407086_ENST00000583539_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5281
Å |
 |  | 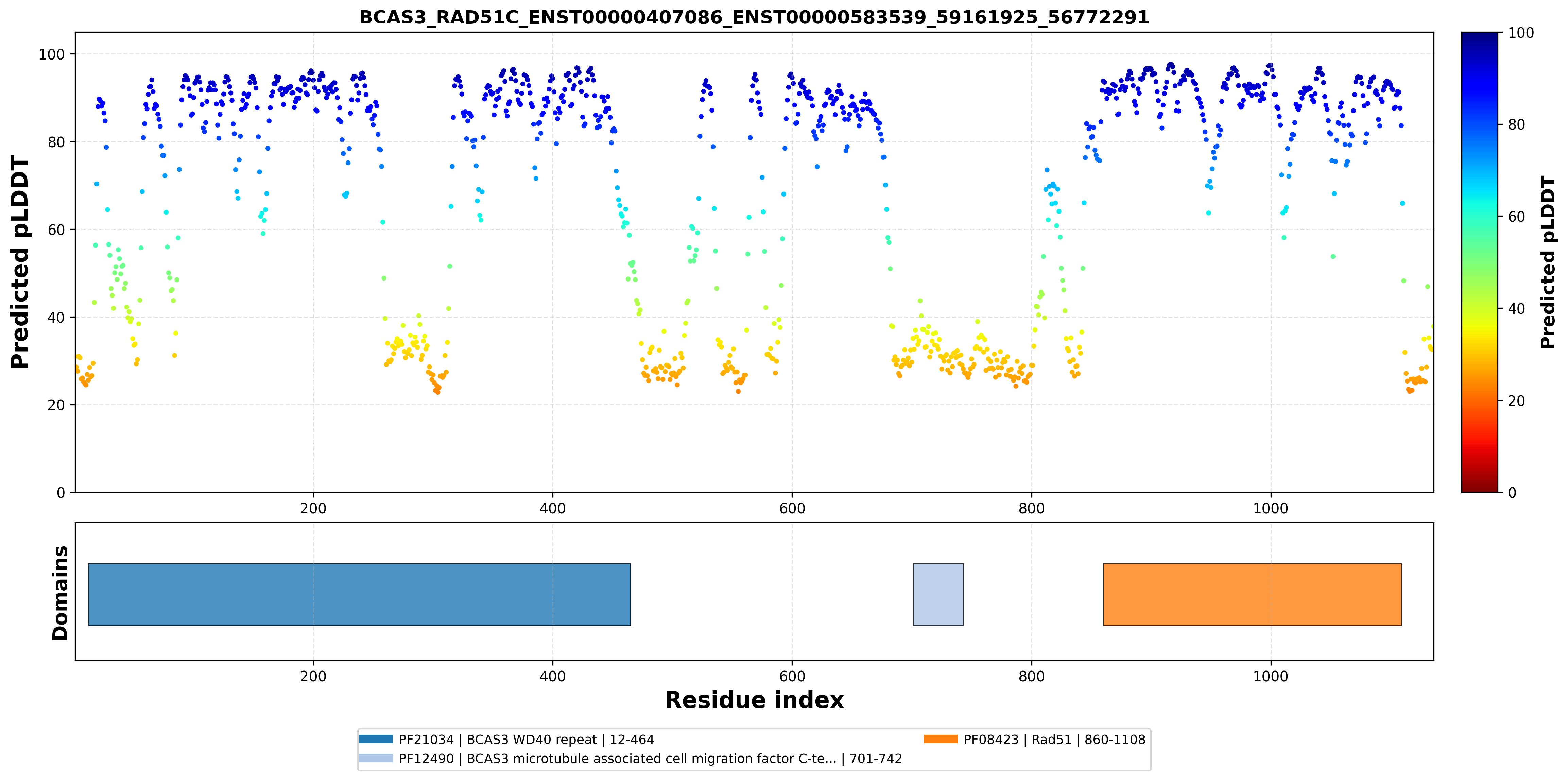 |  |  |
| BCAS3_RAD51C_ENST00000408905_ENST00000583539_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5253
Å |
 |  | 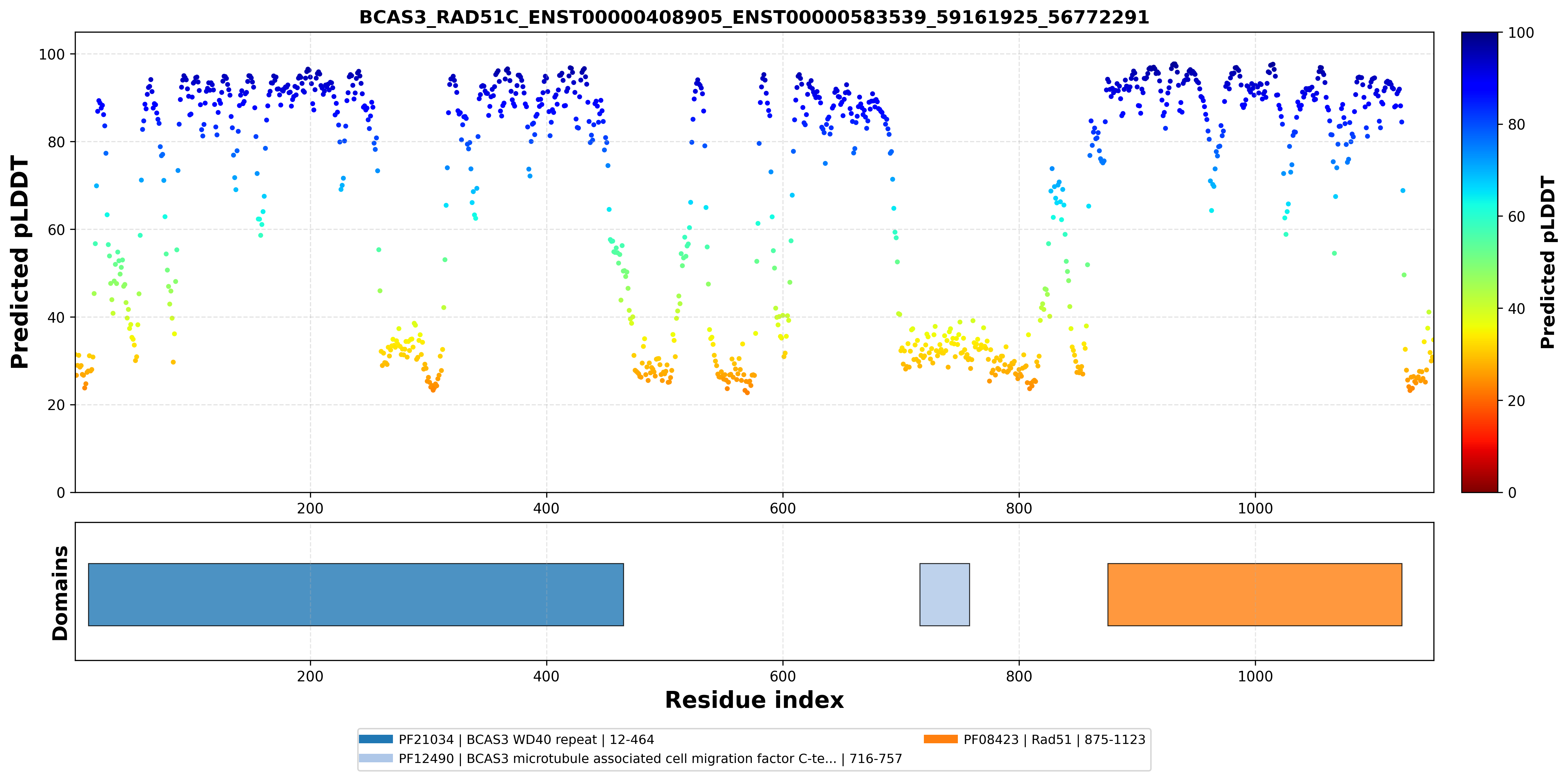 |  |  |
| BCAS3_RAD51C_ENST00000585744_ENST00000337432_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5554
Å |
 |  | 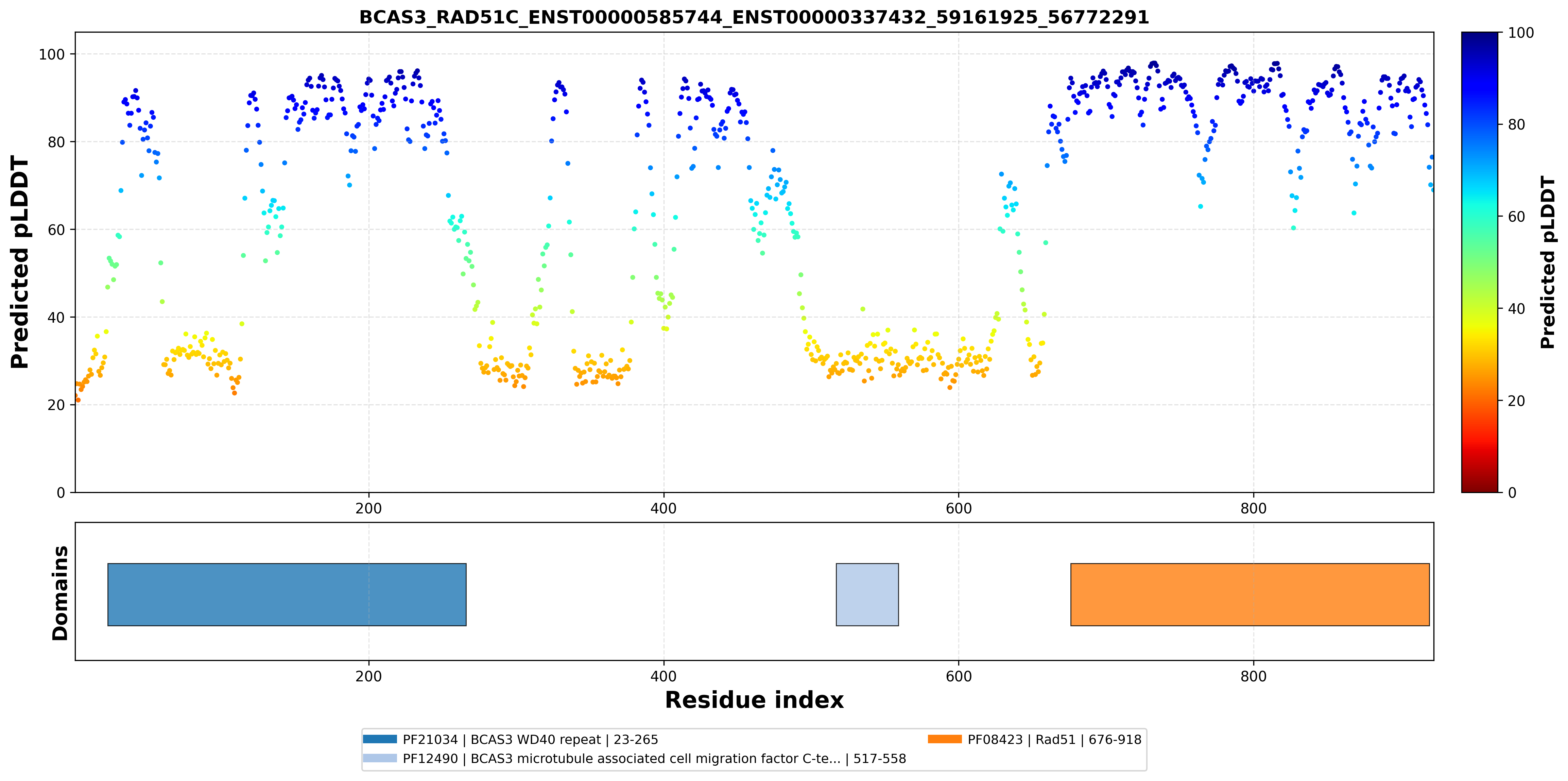 |  |  |
| BCAS3_RAD51C_ENST00000588874_ENST00000337432_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5682
Å |
 |  | 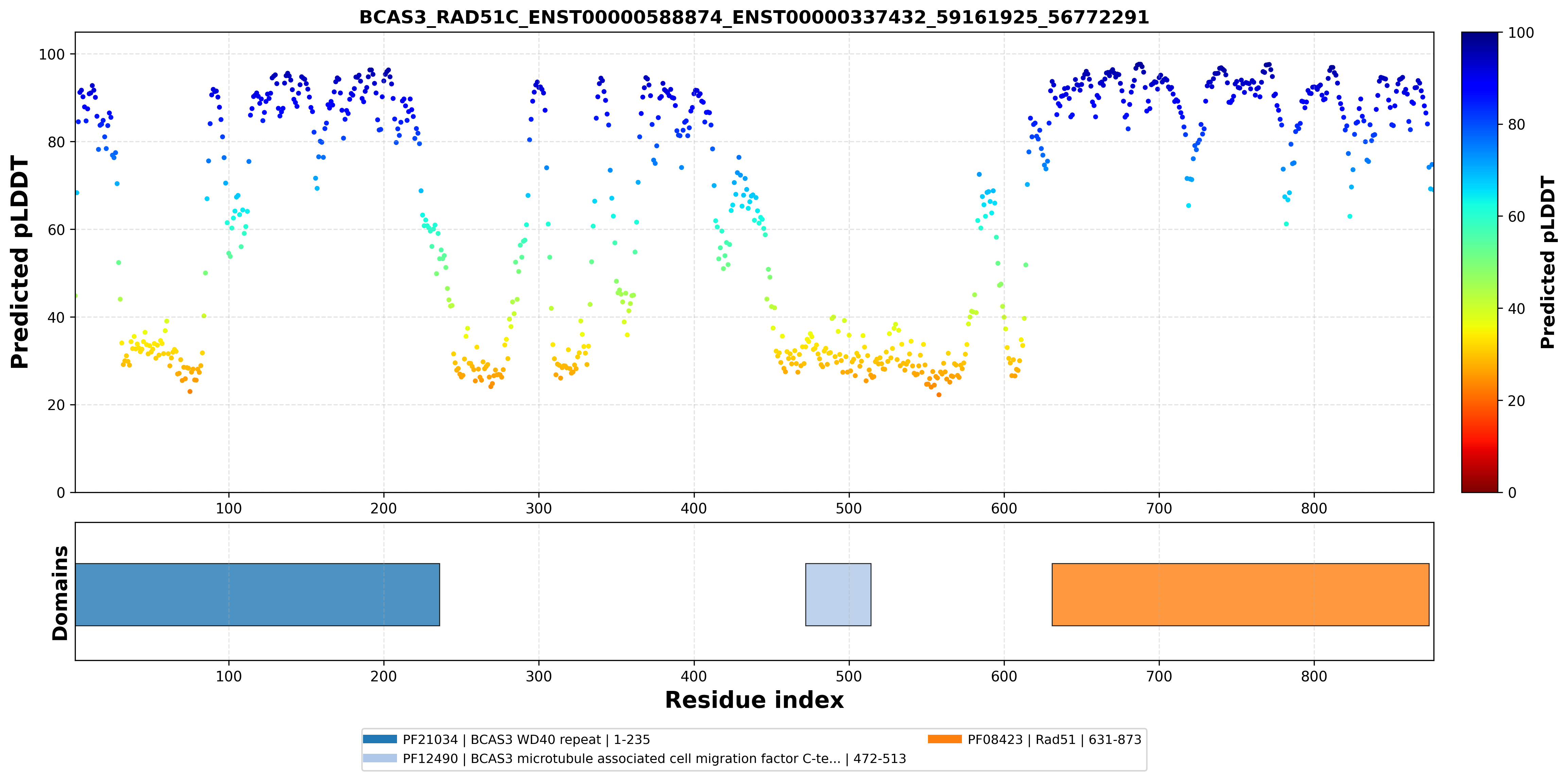 |  |  |
| BCAS3_RAD51C_ENST00000588874_ENST00000583539_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5098
Å |
 |  |  |  |  |
| BCAS3_RAD51C_ENST00000589222_ENST00000337432_59161925_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5347
Å |
 |  | 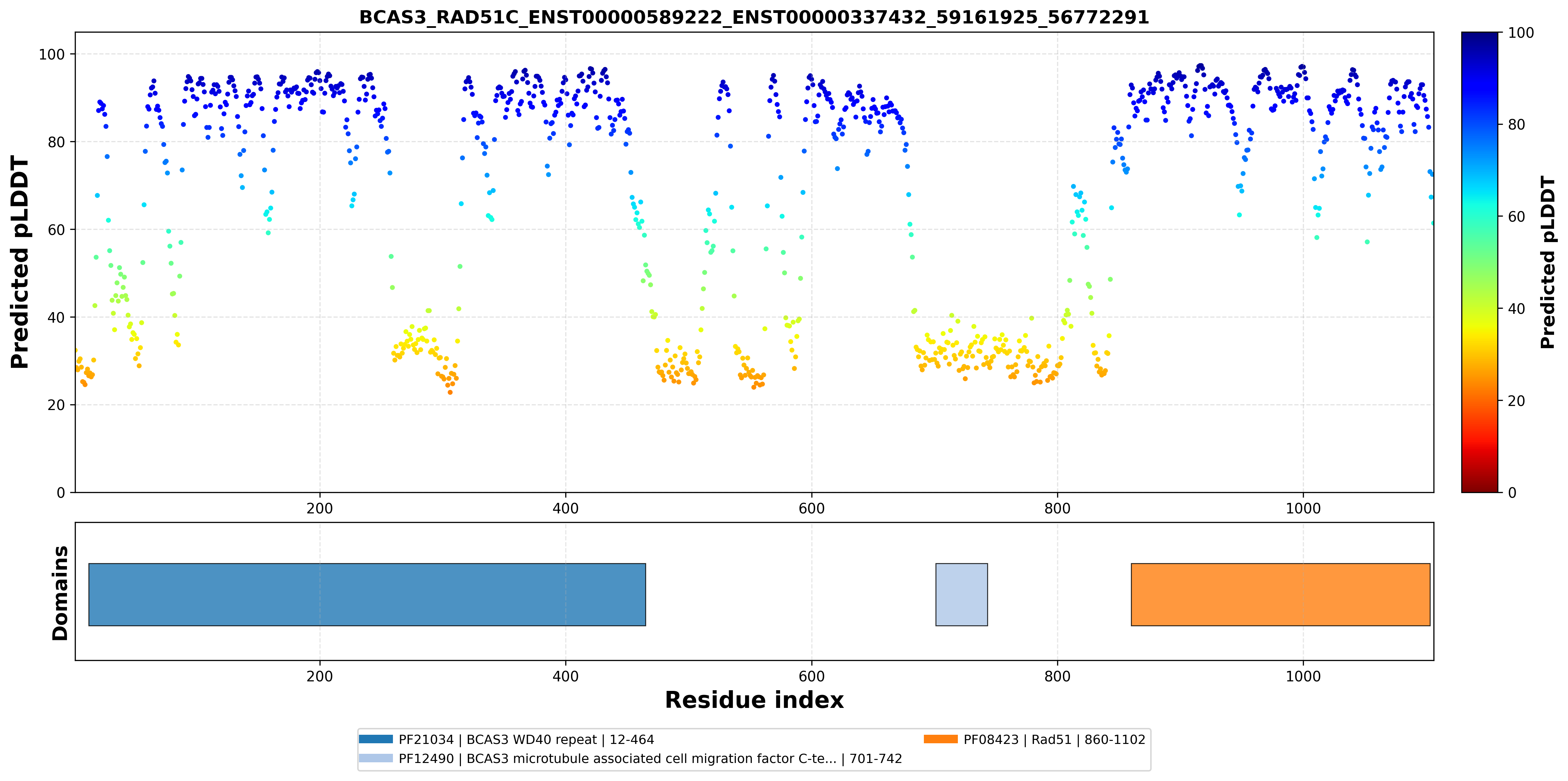 |  |  |
| BCAS3_SCN4A_ENST00000390652_ENST00000578147_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:2.078
Å |
 |  | 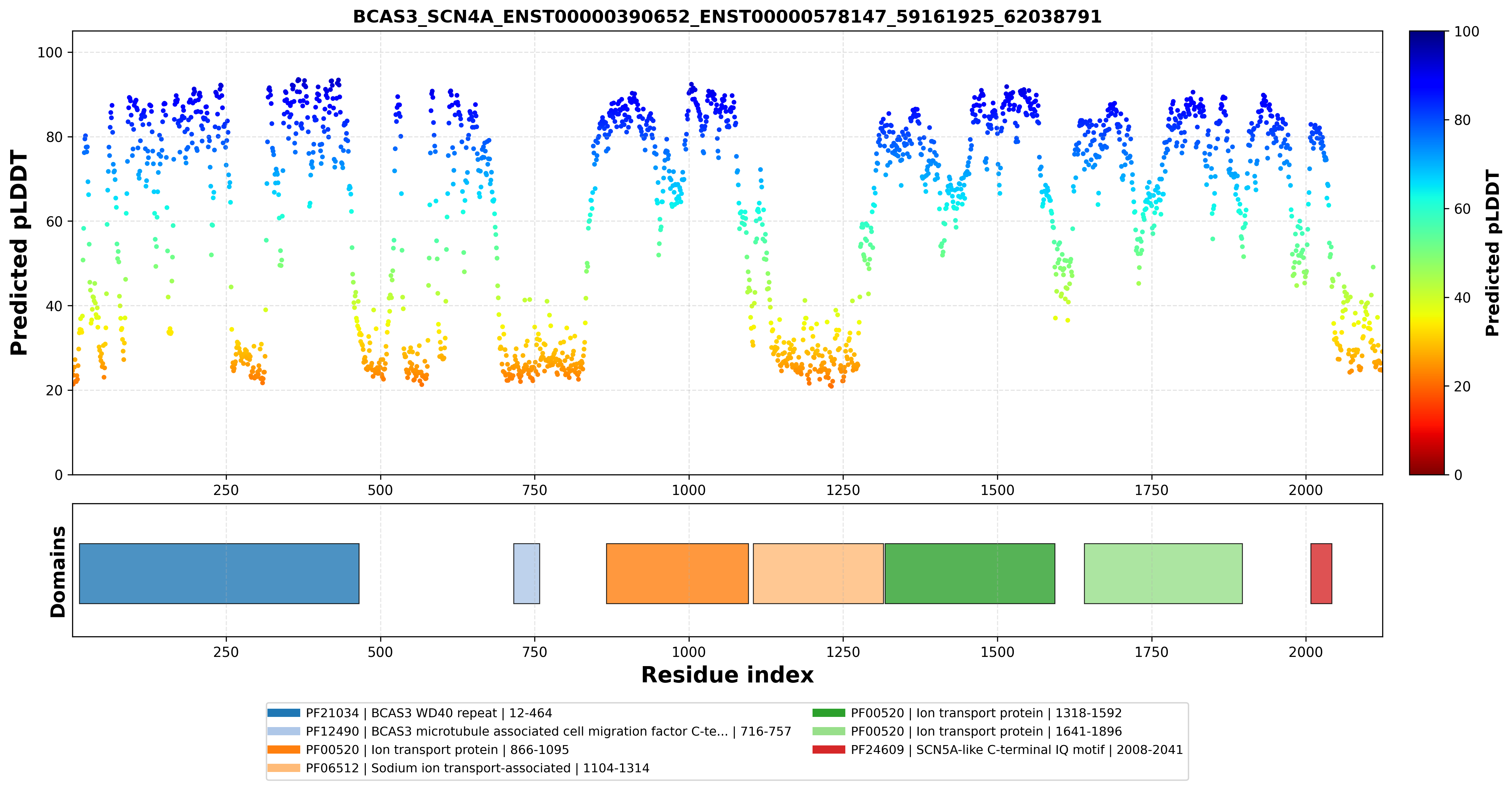 |  |  |
| BCAS3_SCN4A_ENST00000407086_ENST00000435607_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:1.9952
Å |
 | 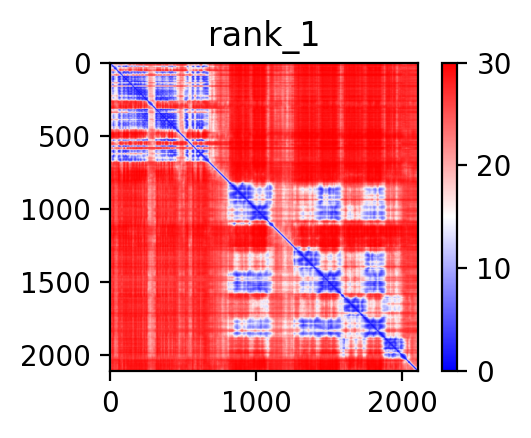 | 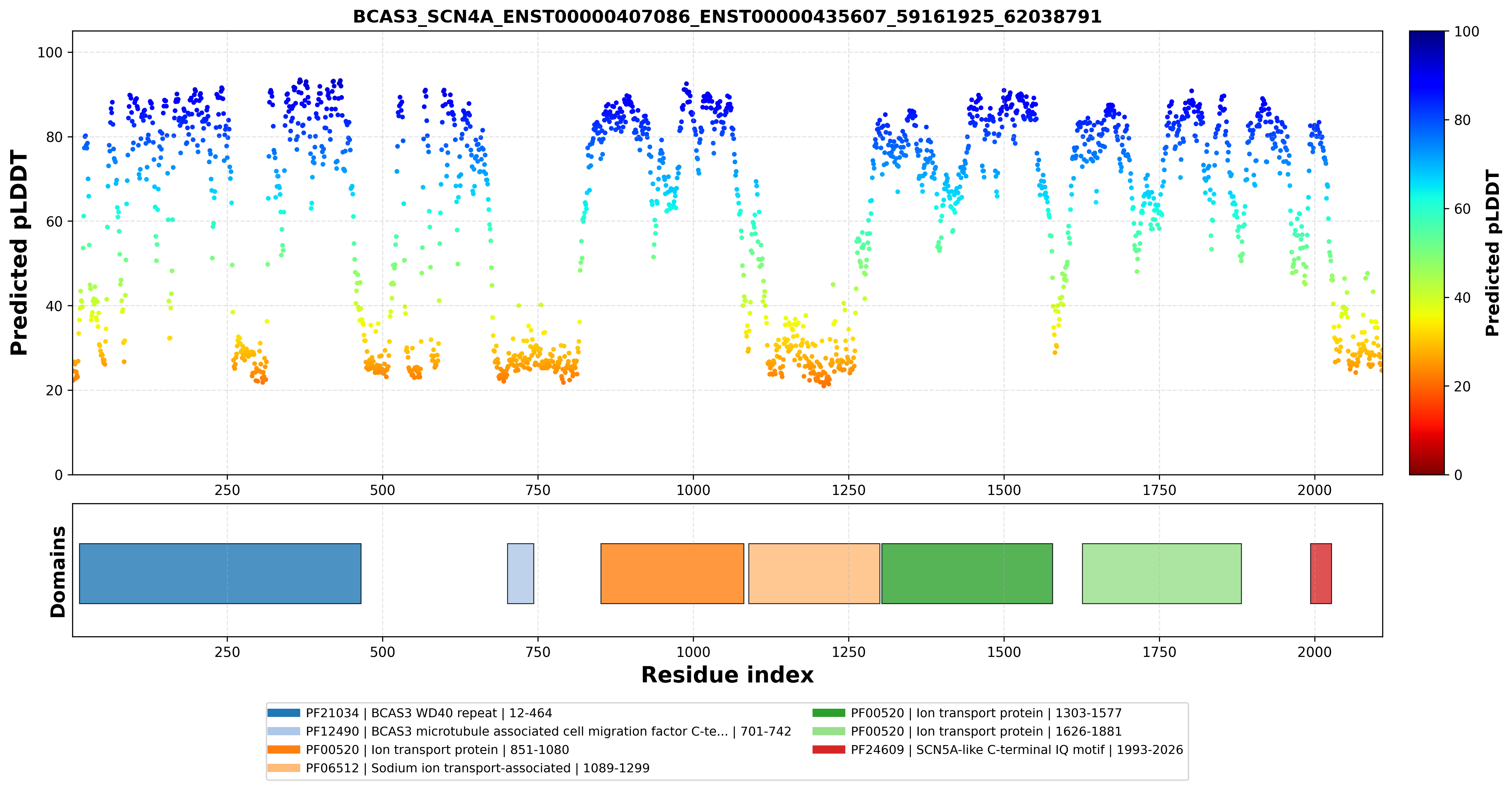 |  |  |
| BCAS3_SCN4A_ENST00000408905_ENST00000435607_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:2.0254
Å |
 | 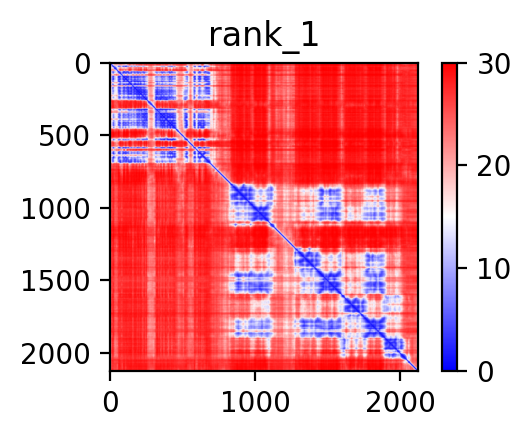 | 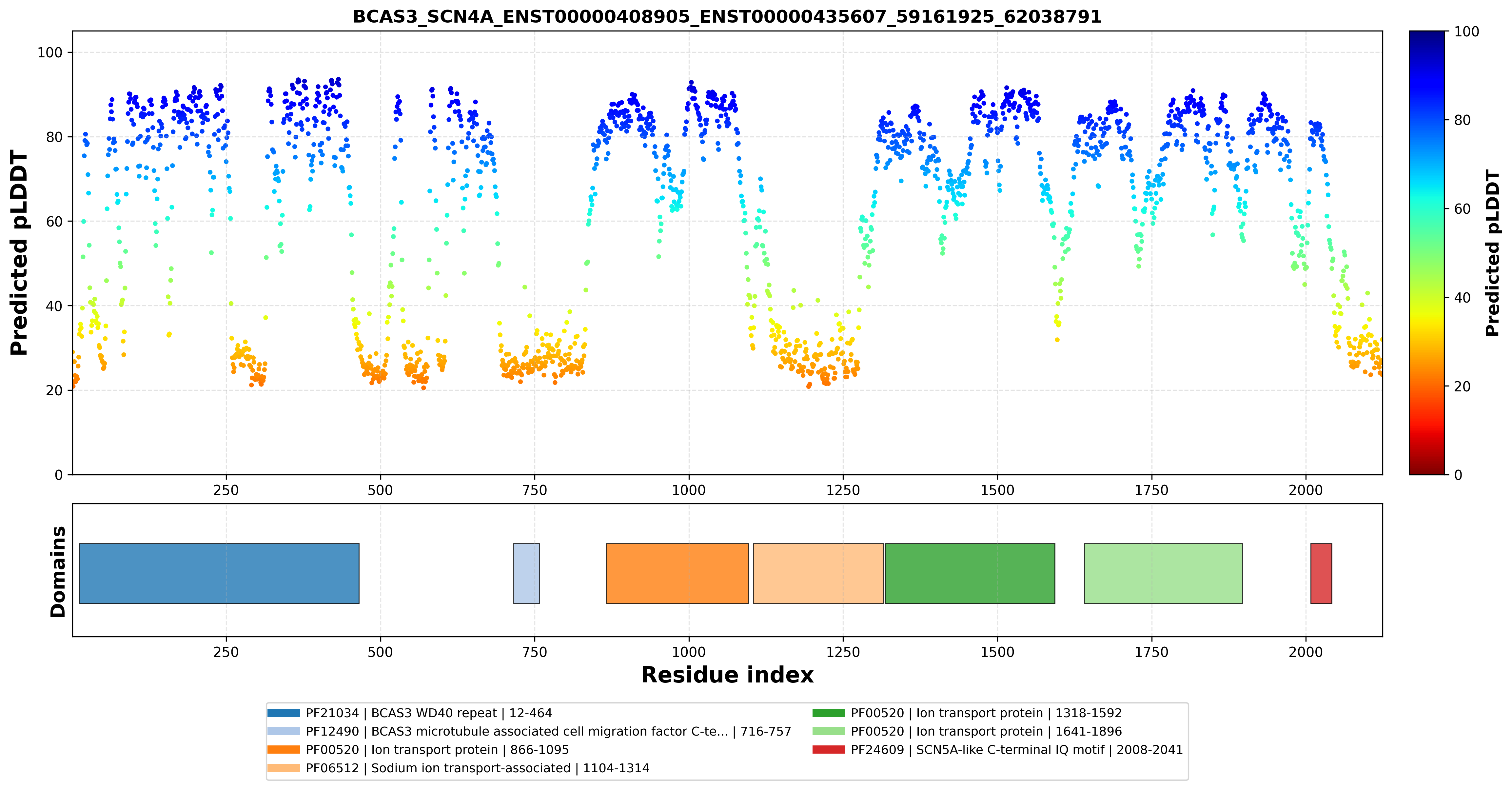 |  |  |
| BCAS3_SCN4A_ENST00000585744_ENST00000578147_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:2.075
Å |
 |  | 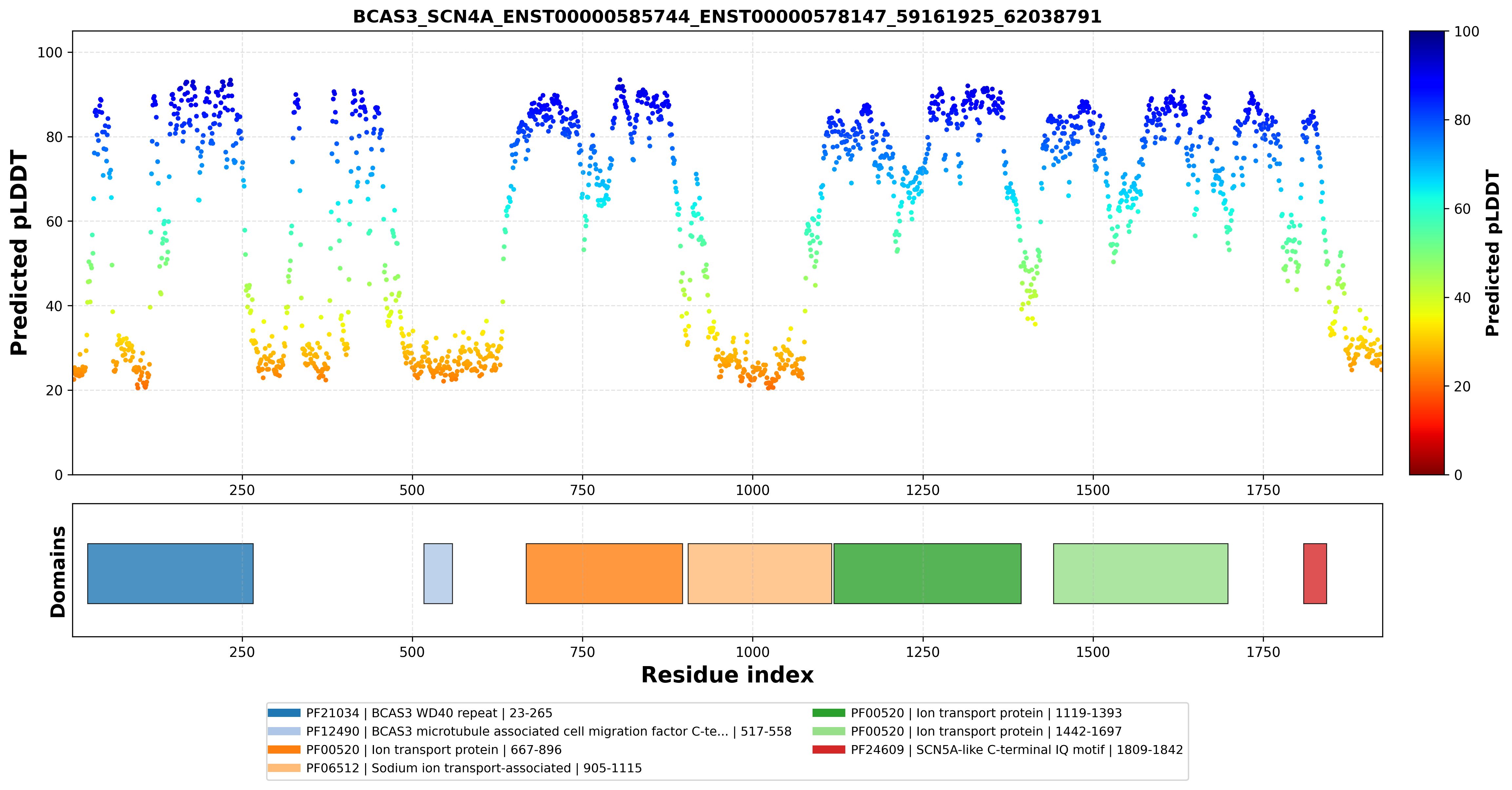 |  |  |
| BCAS3_SCN4A_ENST00000588874_ENST00000435607_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:1.9645
Å |
 |  | 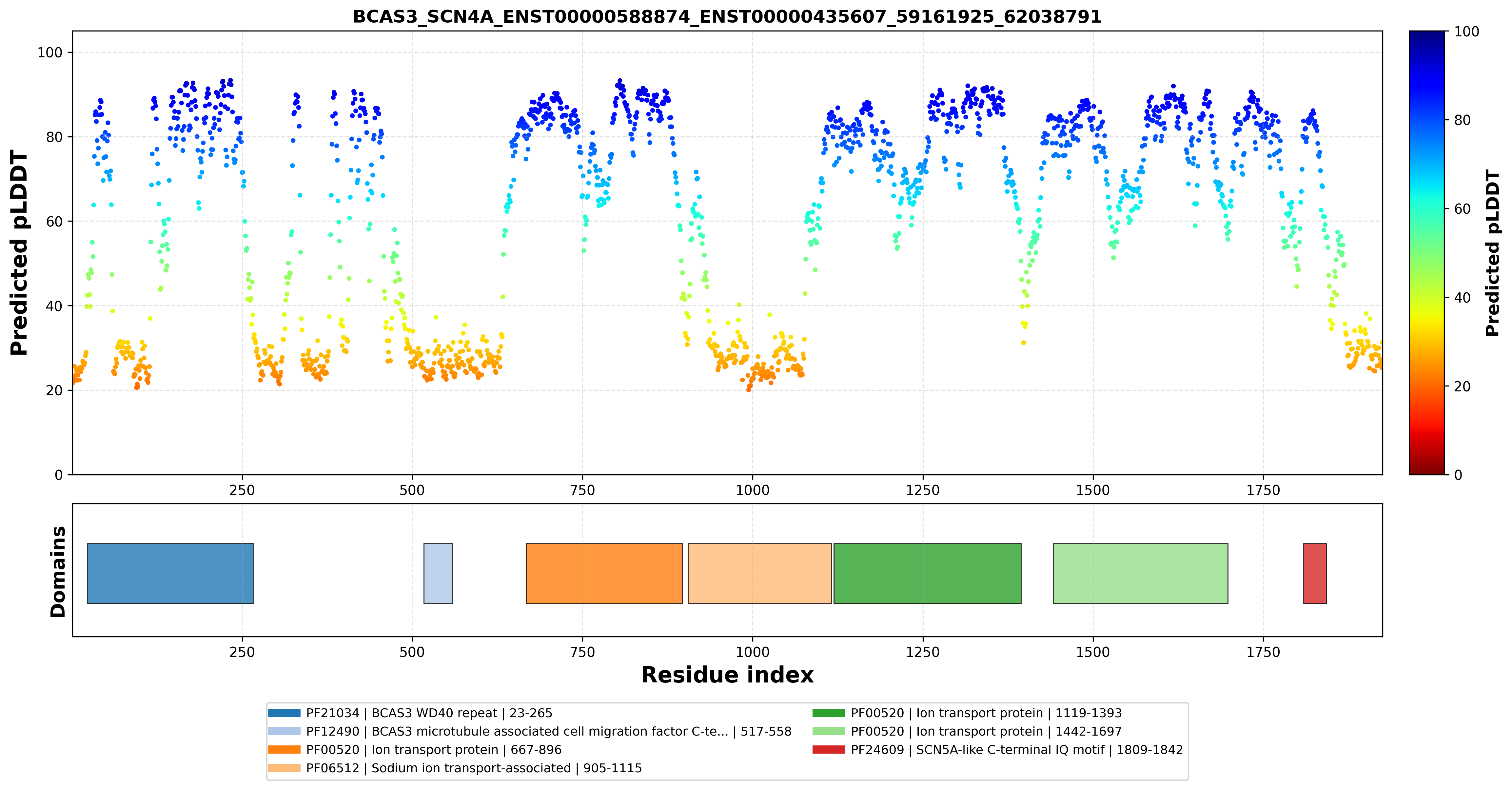 |  |  |
| BCAS3_SCN4A_ENST00000588874_ENST00000578147_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:2.0732
Å |
 |  | 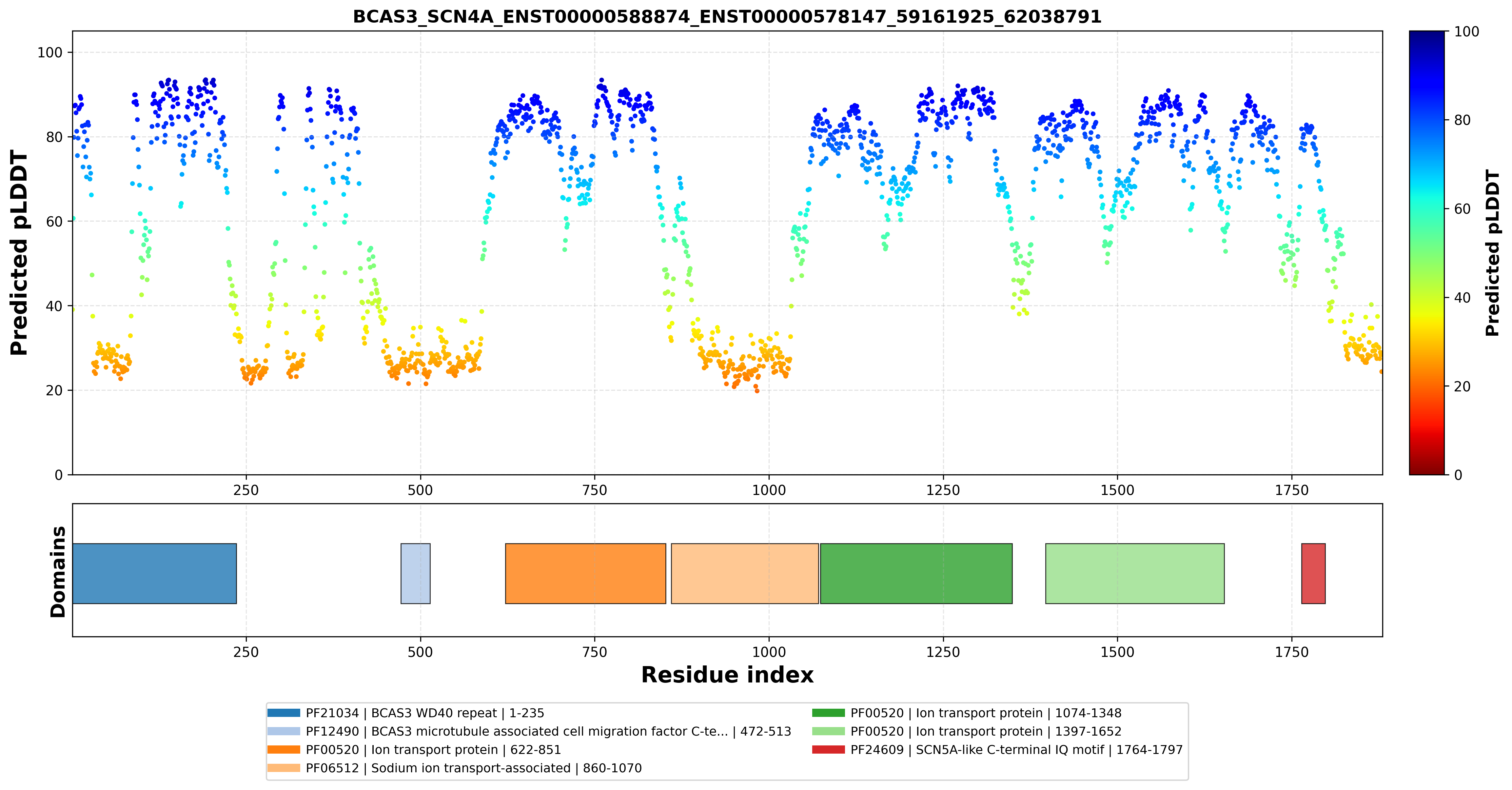 |  |  |
| BCAS3_SCN4A_ENST00000589222_ENST00000578147_59161925_62038791 superimposed PDB: 6AGF of partner (SCN4A). RMSD:2.0554
Å |
 |  | 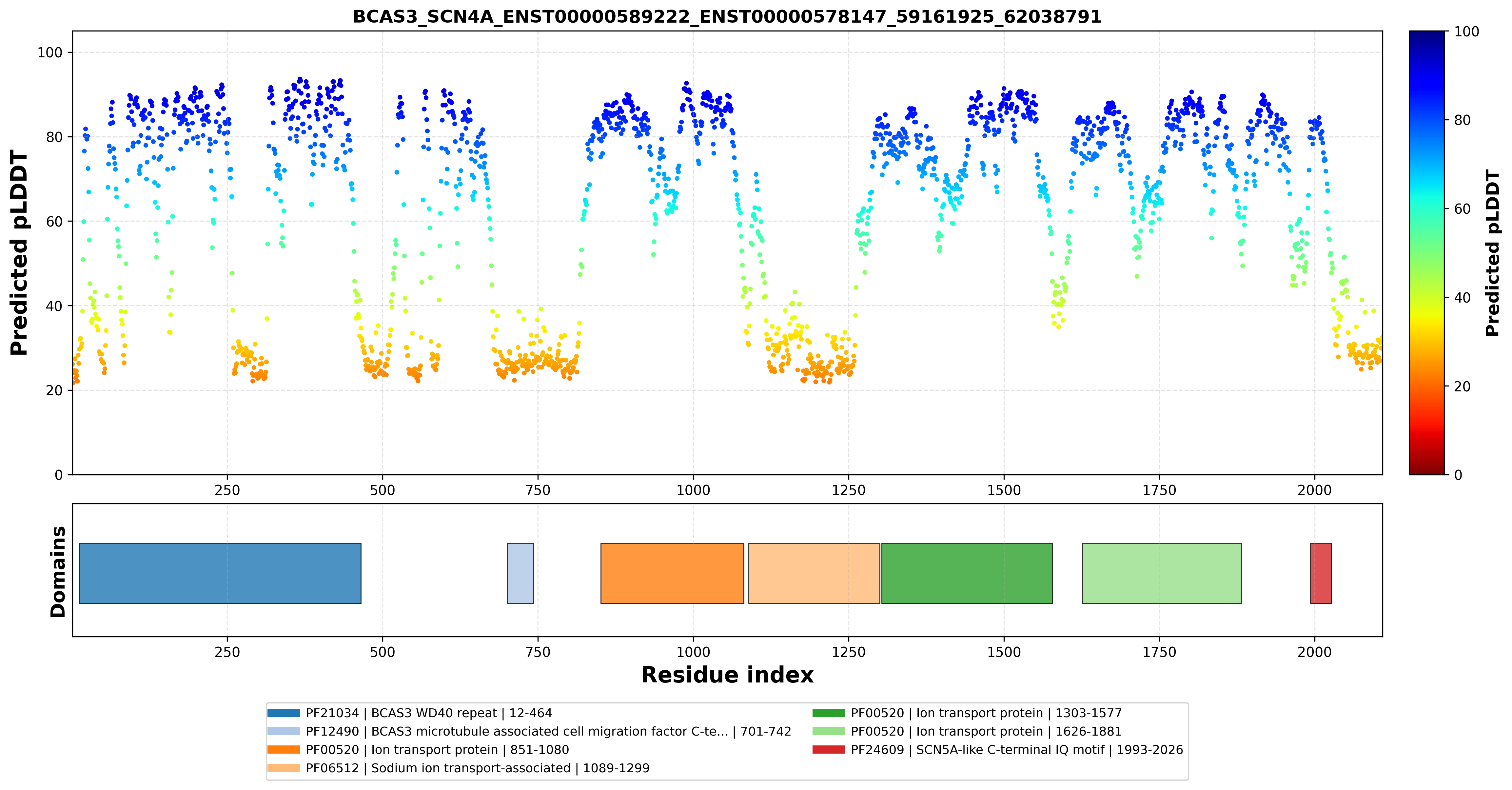 |  |  |
| BCAS4_PTPN1_ENST00000262591_ENST00000371621_49434819_49177899 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3139
Å |
 |  |  |  |  |
| BCAS4_PTPN1_ENST00000358791_ENST00000541713_49458437_49194956 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3661
Å |
 |  | 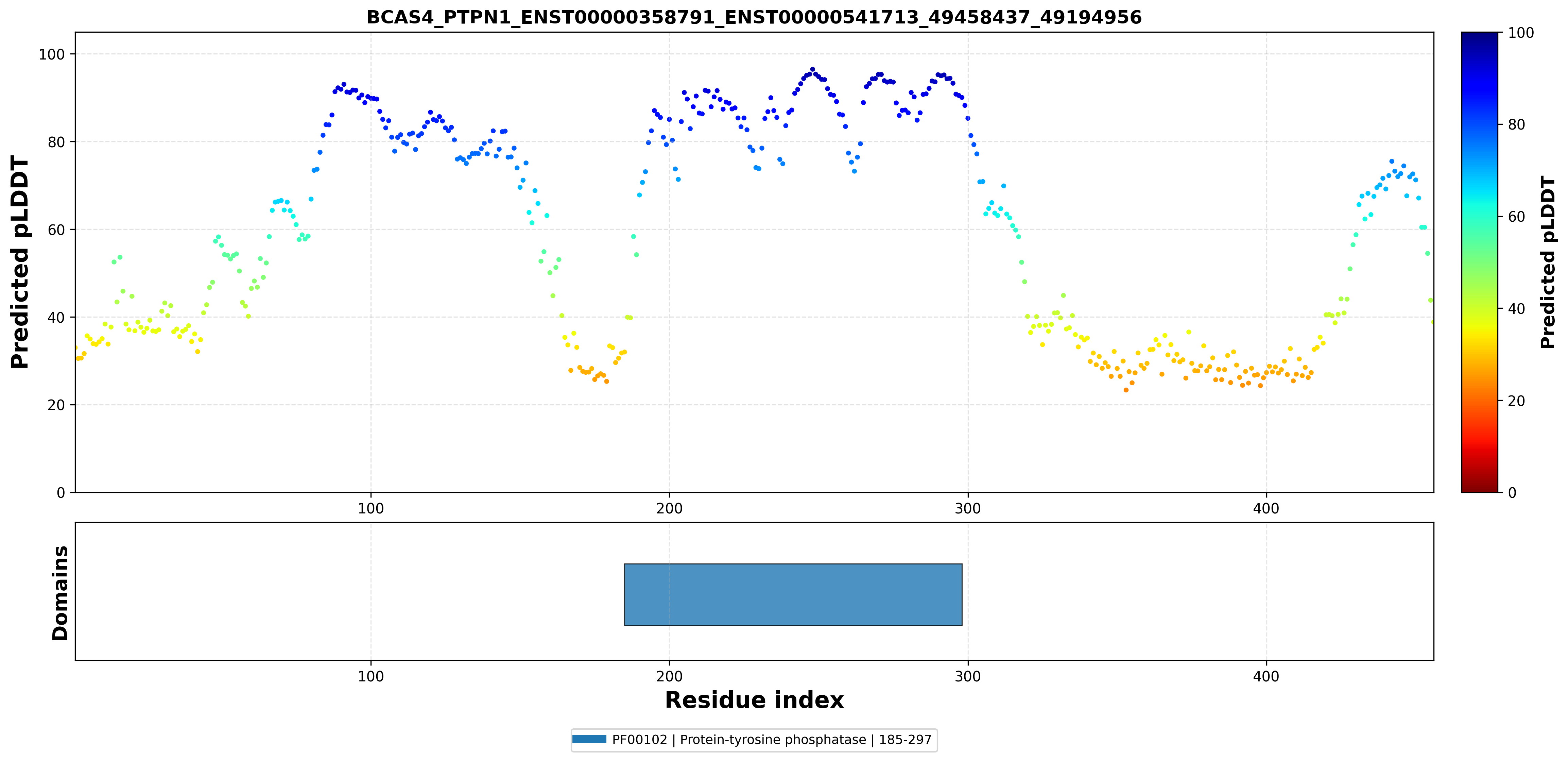 |  |  |
| BCAS4_PTPN1_ENST00000371608_ENST00000371621_49434819_49177899 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3255
Å |
 |  |  |  |  |
| BCAS4_PTPN1_ENST00000371608_ENST00000541713_49458437_49194956 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.443
Å |
 |  | 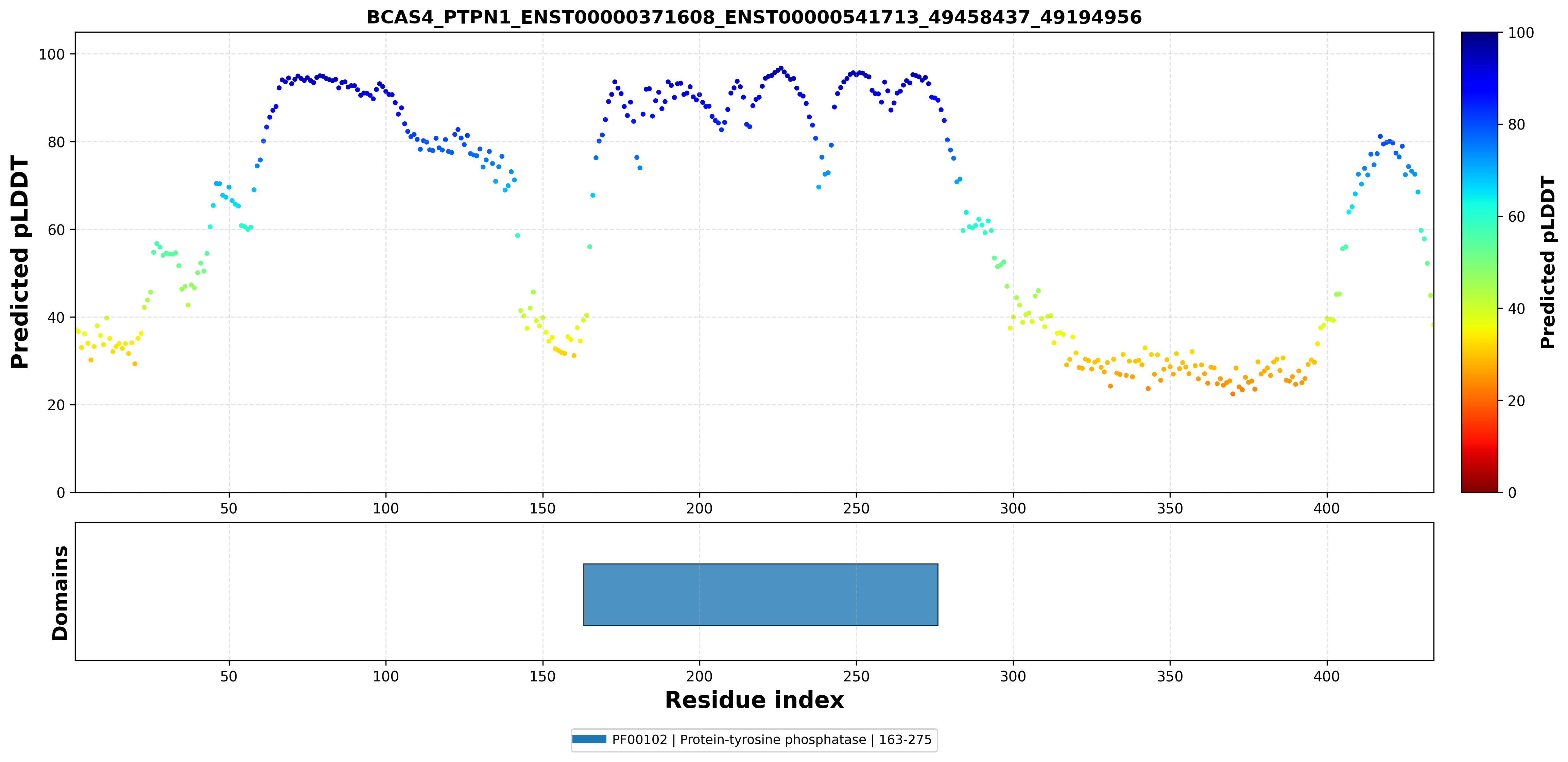 |  |  |
| BCAS4_PTPN1_ENST00000609336_ENST00000371621_49434819_49177899 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3172
Å |
 |  |  |  |  |
| BCAS4_PTPN1_ENST00000609336_ENST00000541713_49458437_49194956 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3851
Å |
 |  | 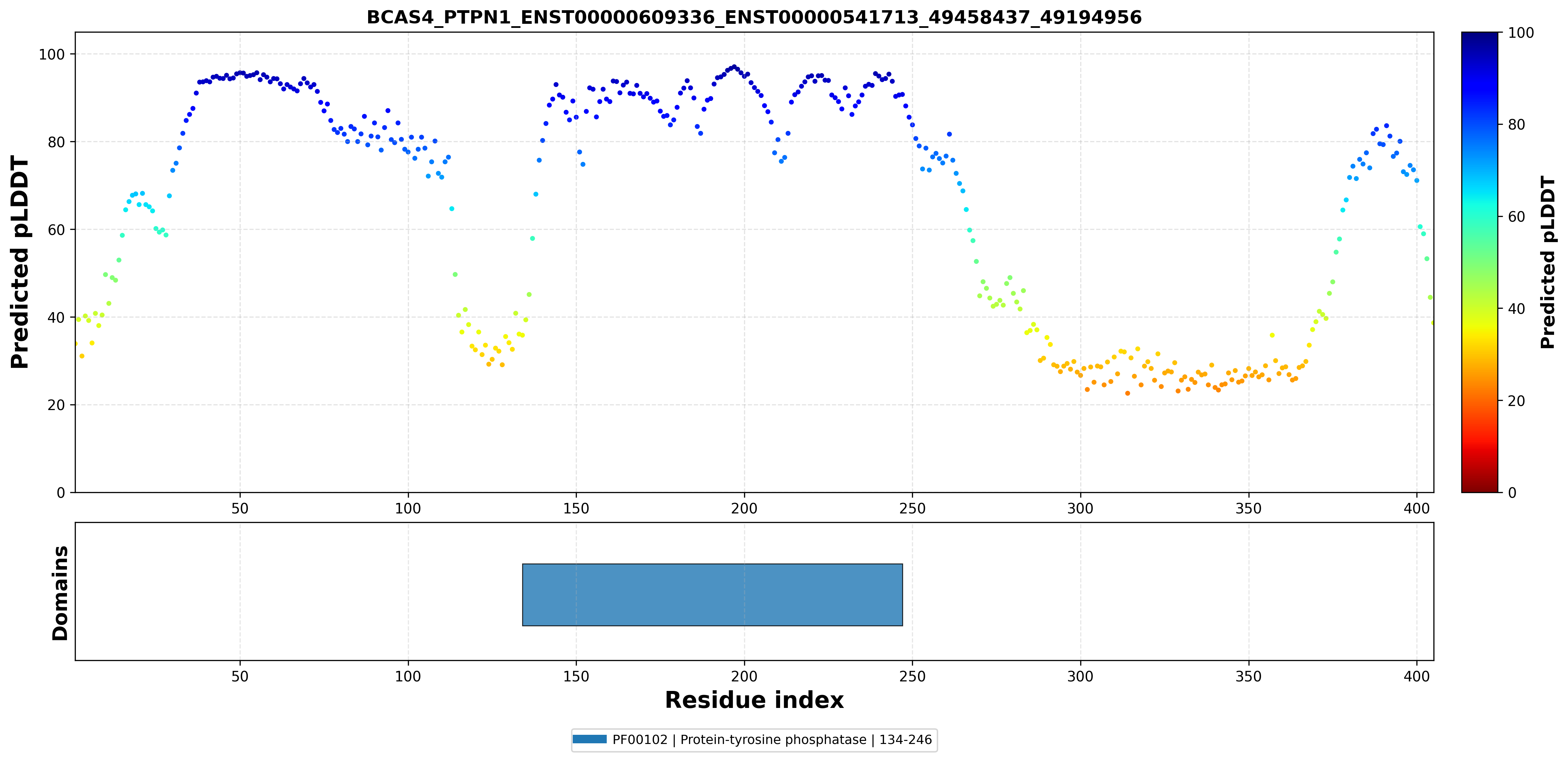 |  |  |
| BCAT1_KRAS_ENST00000261192_ENST00000311936_25101860_25380346 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.4388
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000261192_ENST00000311936_25101860_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.8533
Å |
| | | |  |
| BCAT1_KRAS_ENST00000342945_ENST00000311936_25047208_25380346 superimposed PDB: 7NWA of partner (BCAT1). RMSD:2.0606
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000342945_ENST00000311936_25047208_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.8108
Å |
| | | |  |
| BCAT1_KRAS_ENST00000342945_ENST00000311936_25101860_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.8528
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000538118_ENST00000311936_25047208_25380346 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.9929
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000538118_ENST00000311936_25047208_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.8753
Å |
| | | |  |
| BCAT1_KRAS_ENST00000539282_ENST00000311936_25047208_25380346 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.3472
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000539282_ENST00000311936_25047208_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.812
Å |
| | | |  |
| BCAT1_KRAS_ENST00000539780_ENST00000311936_25047208_25380346 superimposed PDB: 7NWA of partner (BCAT1). RMSD:1.94
Å |
 |  |  |  |  |
| BCAT1_KRAS_ENST00000539780_ENST00000311936_25047208_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.854
Å |
| | | |  |
| BCAT1_KRAS_ENST00000539780_ENST00000311936_25101860_25380346 superimposed PDB: 7VVB of partner (KRAS). RMSD:0.9101
Å |
 |  |  |  |  |
| BCAT2_AK1_ENST00000545387_ENST00000223836_49314240_130630791 superimposed PDB: 7DE3 of partner (AK1). RMSD:0.9846
Å |
 |  |  |  |  |
| BCAT2_TMEM143_ENST00000316273_ENST00000377431_49302931_48846066 superimposed PDB: 5MPR of partner (BCAT2). RMSD:2.4561
Å |
 |  |  |  |  |
| BCAT2_TMEM143_ENST00000545387_ENST00000377431_49302931_48846066 superimposed PDB: 5MPR of partner (BCAT2). RMSD:2.921
Å |
 |  | 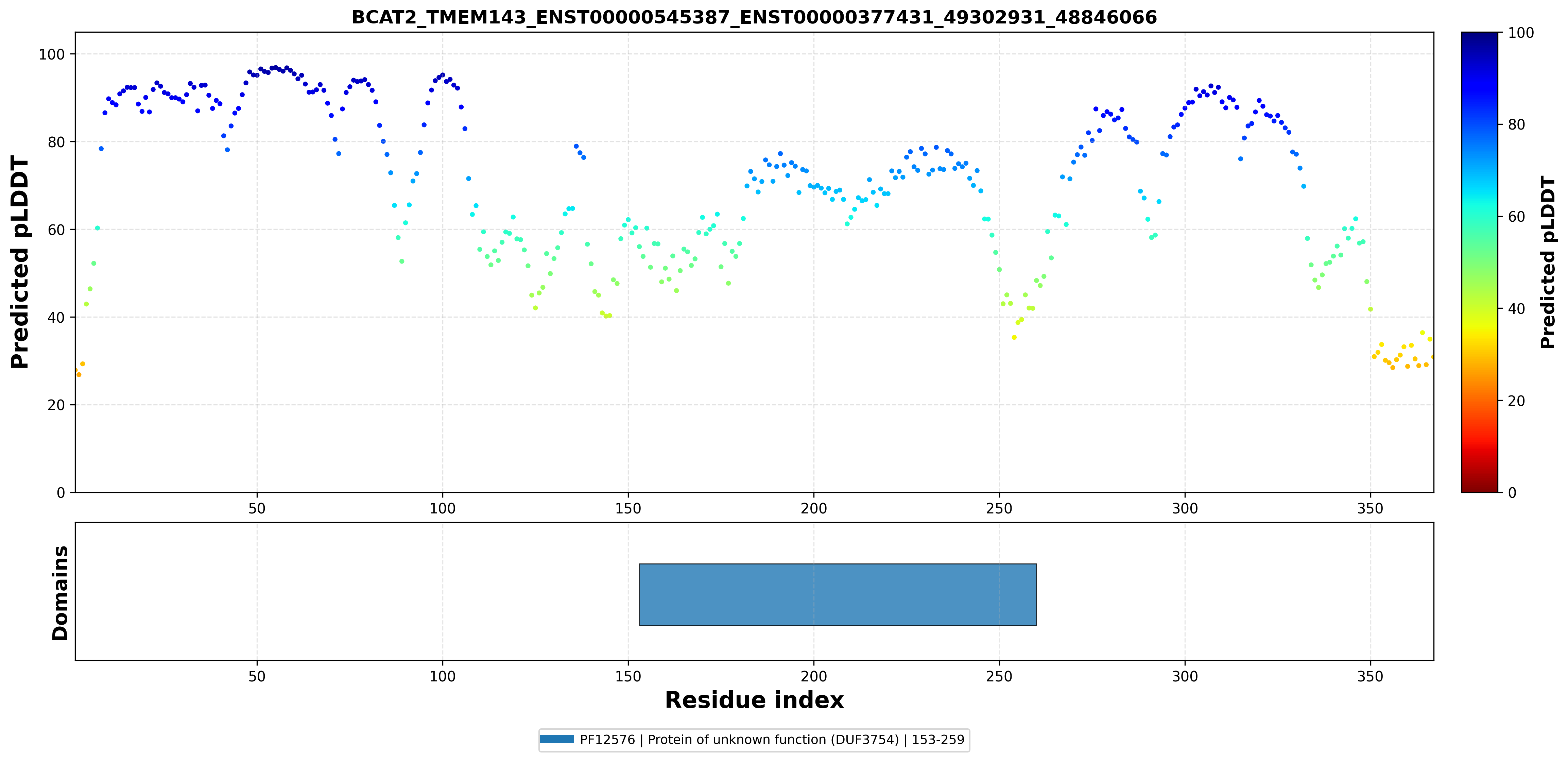 |  |  |
| BCKDHB_ME1_ENST00000320393_ENST00000369705_80912929_84117620 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.4311
Å |
 |  |  |  |  |
| BCKDHB_ME1_ENST00000320393_ENST00000369705_80912929_84117620 superimposed PDB: 7X11 of partner (ME1). RMSD:0.6395
Å |
| | | |  |
| BCL11B_TRDC_ENST00000345514_ENST00000390477_99723807_22931923 superimposed PDB: 8JBV of partner (TRDC). RMSD:0.5602
Å |
 |  |  |  |  |
| BCL11B_TRDC_ENST00000357195_ENST00000390477_99723807_22931923 superimposed PDB: 8JBV of partner (TRDC). RMSD:0.5708
Å |
 |  |  |  |  |
| BCL2L13_CUX2_ENST00000317582_ENST00000261726_18138598_111772244 superimposed PDB: 1WH8 of partner (CUX2). RMSD:0.5017
Å |
 |  |  |  |  |
| BCL2L14_ETV6_ENST00000266434_ENST00000396373_12232672_11992073 superimposed PDB: 9O0H of partner (ETV6). RMSD:2.7953
Å |
 |  |  |  |  |
| BCL2L14_ETV6_ENST00000308721_ENST00000396373_12232672_11992073 superimposed PDB: 9O0H of partner (ETV6). RMSD:2.9499
Å |
 |  |  |  |  |
| BCL2L14_ETV6_ENST00000586576_ENST00000396373_12232672_11992073 superimposed PDB: 9O0H of partner (ETV6). RMSD:2.6945
Å |
 |  |  |  |  |
| BCL2L1_RHAG_ENST00000376062_ENST00000229810_30309457_49583484 superimposed PDB: 8FY0 of partner (BCL2L1). RMSD:0.3461
Å |
 |  |  |  |  |
| BCL2L1_RHAG_ENST00000376062_ENST00000229810_30309457_49583484 superimposed PDB: 7UZQ of partner (RHAG). RMSD:0.625
Å |
| | | |  |
| BCL2L2-PABPN1_CHD8_ENST00000553781_ENST00000399982_23792275_21896413 superimposed PDB: 2CKA of partner (CHD8). RMSD:1.0055
Å |
 |  |  |  |  |
| BCL7A_KCNIP3_ENST00000261822_ENST00000295225_122473333_96040043 superimposed PDB: 2E6W of partner (KCNIP3). RMSD:1.0518
Å |
 |  |  |  |  |
| BCOR_CCNB3_ENST00000378463_ENST00000376038_39911365_50085200 superimposed PDB: 8HCU of partner (BCOR). RMSD:0.6385
Å |
 |  |  |  |  |
| BCOR_CCNB3_ENST00000378463_ENST00000376042_39911365_50085200 superimposed PDB: 8HCU of partner (BCOR). RMSD:0.6399
Å |
 |  |  |  |  |
| BCOR_L3MBTL2_ENST00000378444_ENST00000216237_39931601_41605699 superimposed PDB: 3F70 of partner (L3MBTL2). RMSD:0.6771
Å |
 |  |  |  |  |
| BCOR_RARA_ENST00000378444_ENST00000394089_39914620_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4255
Å |
 |  |  |  |  |
| BCOR_RARA_ENST00000397354_ENST00000394089_39914620_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4308
Å |
 |  |  |  |  |
| BCRP2_BCR_ENST00000461808_ENST00000305877_21476073_23653883 superimposed PDB: 5N7E of partner (BCR). RMSD:0.6751
Å |
 |  | 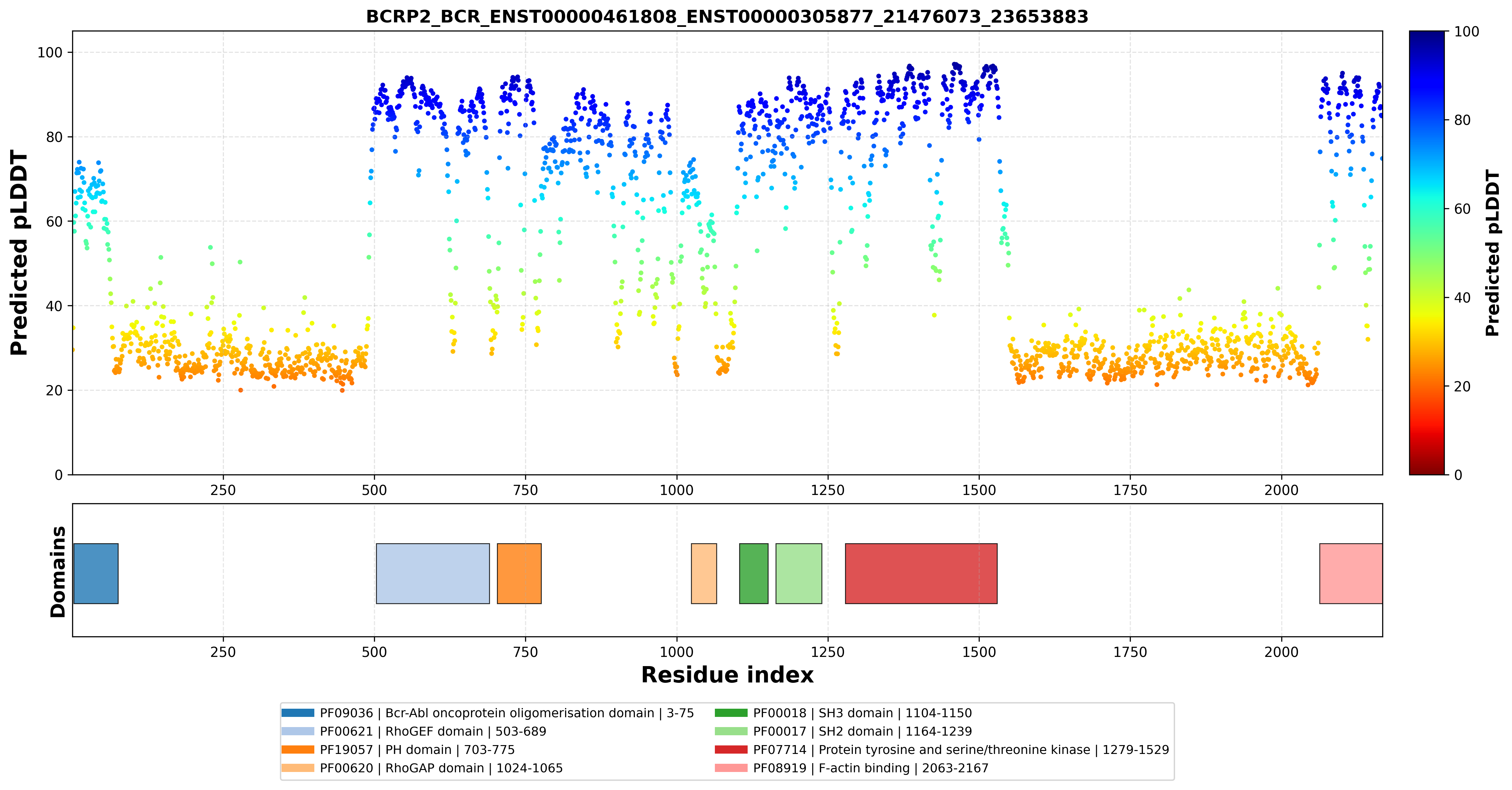 |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23524426_133729450 superimposed PDB: 1OPL of partner (ABL1). RMSD:2.5142
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23613779_133729450 superimposed PDB: 5N7E of partner (BCR). RMSD:0.9482
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23631808_133729450 superimposed PDB: 5N7E of partner (BCR). RMSD:0.5554
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23631808_133730187 superimposed PDB: 5N7E of partner (BCR). RMSD:0.5715
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23632600_133729450 superimposed PDB: 5N7E of partner (BCR). RMSD:0.6666
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23632600_133729450 superimposed PDB: 1OPL of partner (ABL1). RMSD:2.8769
Å |
| | | |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23632600_133730187 superimposed PDB: 5N7E of partner (BCR). RMSD:0.5312
Å |
 |  |  |  |  |
| BCR_ABL1_ENST00000359540_ENST00000318560_23654023_133729450 superimposed PDB: 5N7E of partner (BCR). RMSD:0.6464
Å |
 |  |  |  |  |
| BCR_ARVCF_ENST00000305877_ENST00000344269_23615961_19969614 superimposed PDB: 5N7E of partner (BCR). RMSD:0.475
Å |
 |  | 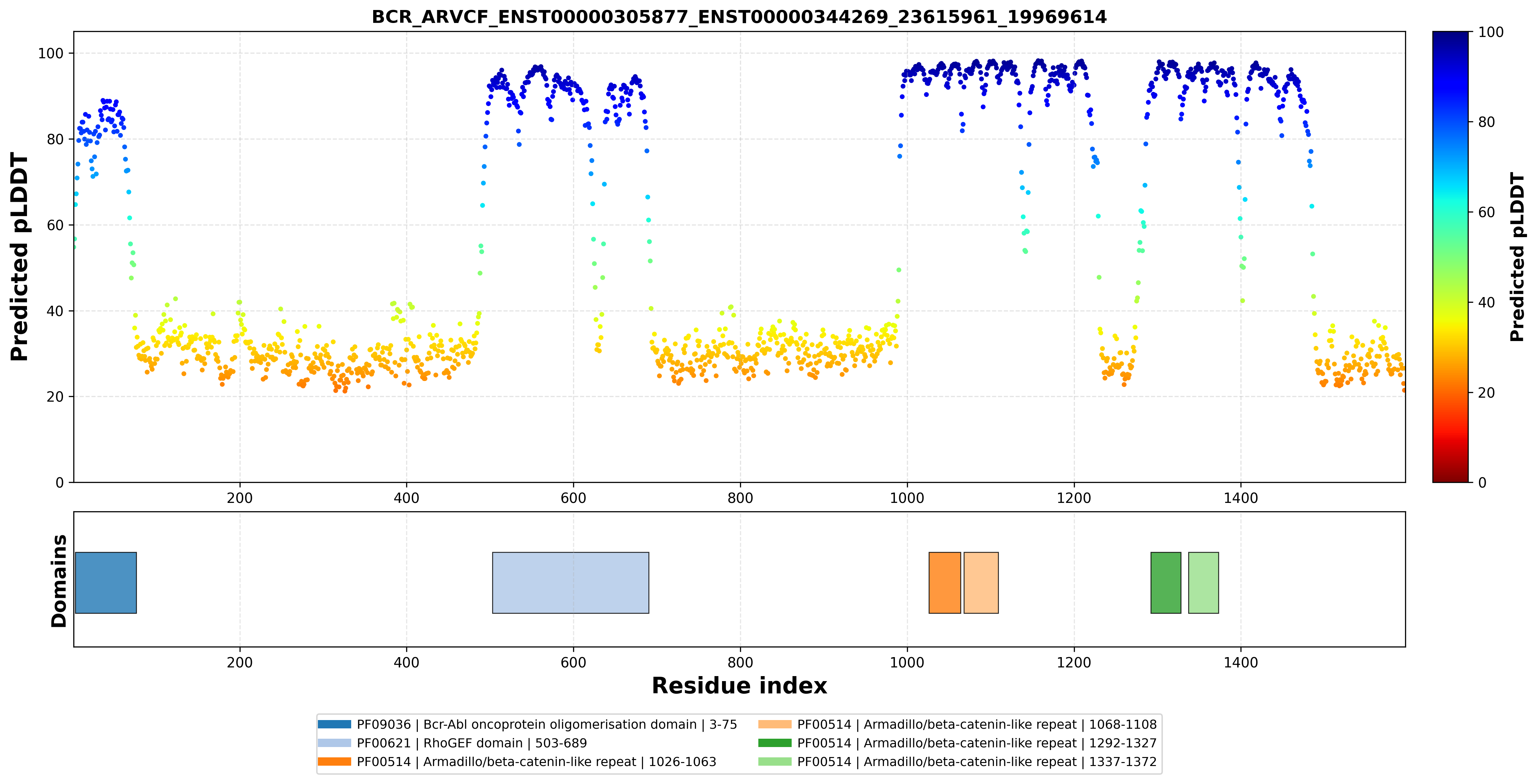 |  |  |
| BCR_ARVCF_ENST00000305877_ENST00000401994_23615961_19969614 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4474
Å |
 |  | 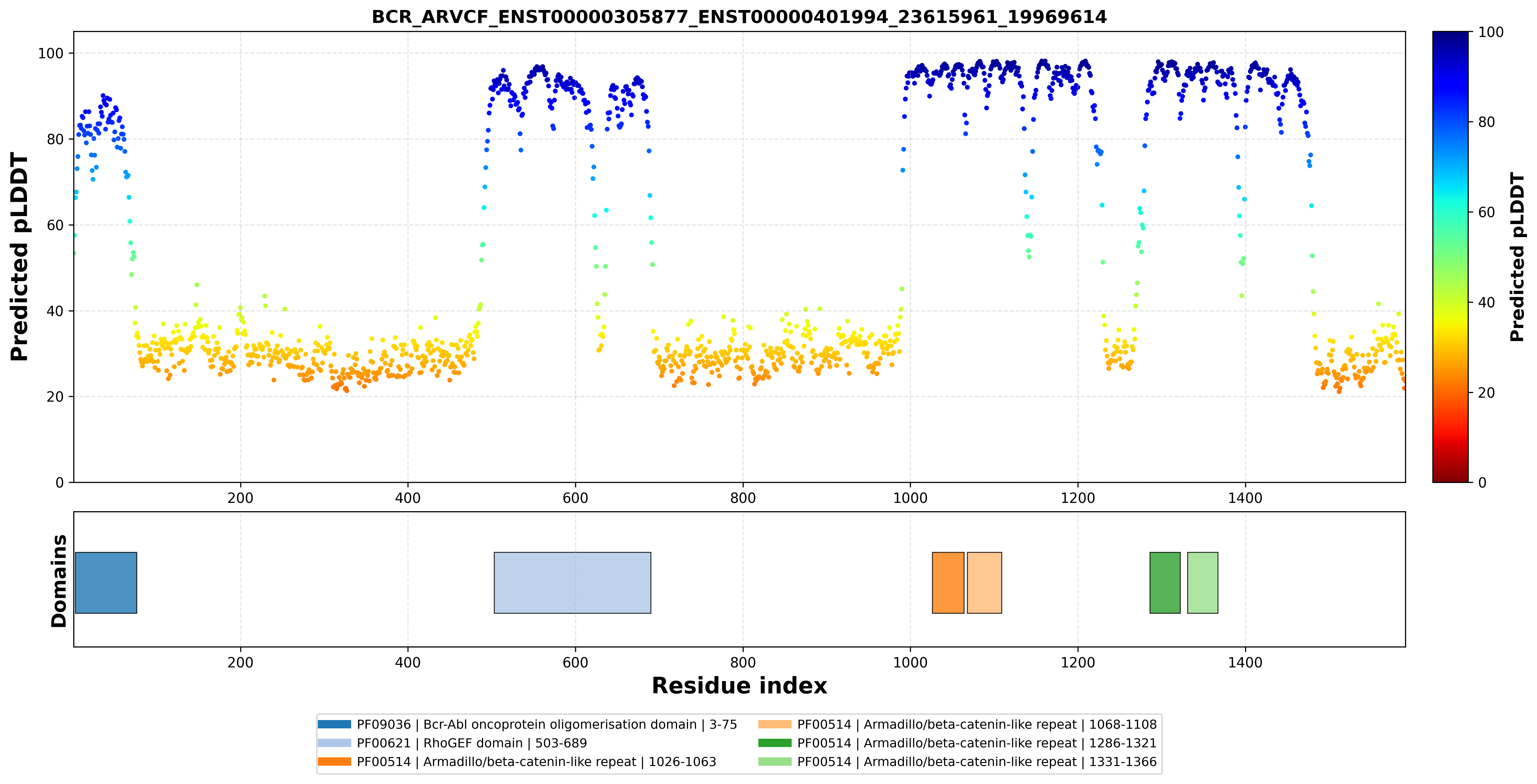 |  |  |
| BCR_ARVCF_ENST00000305877_ENST00000406259_23615961_19969614 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4671
Å |
 |  | 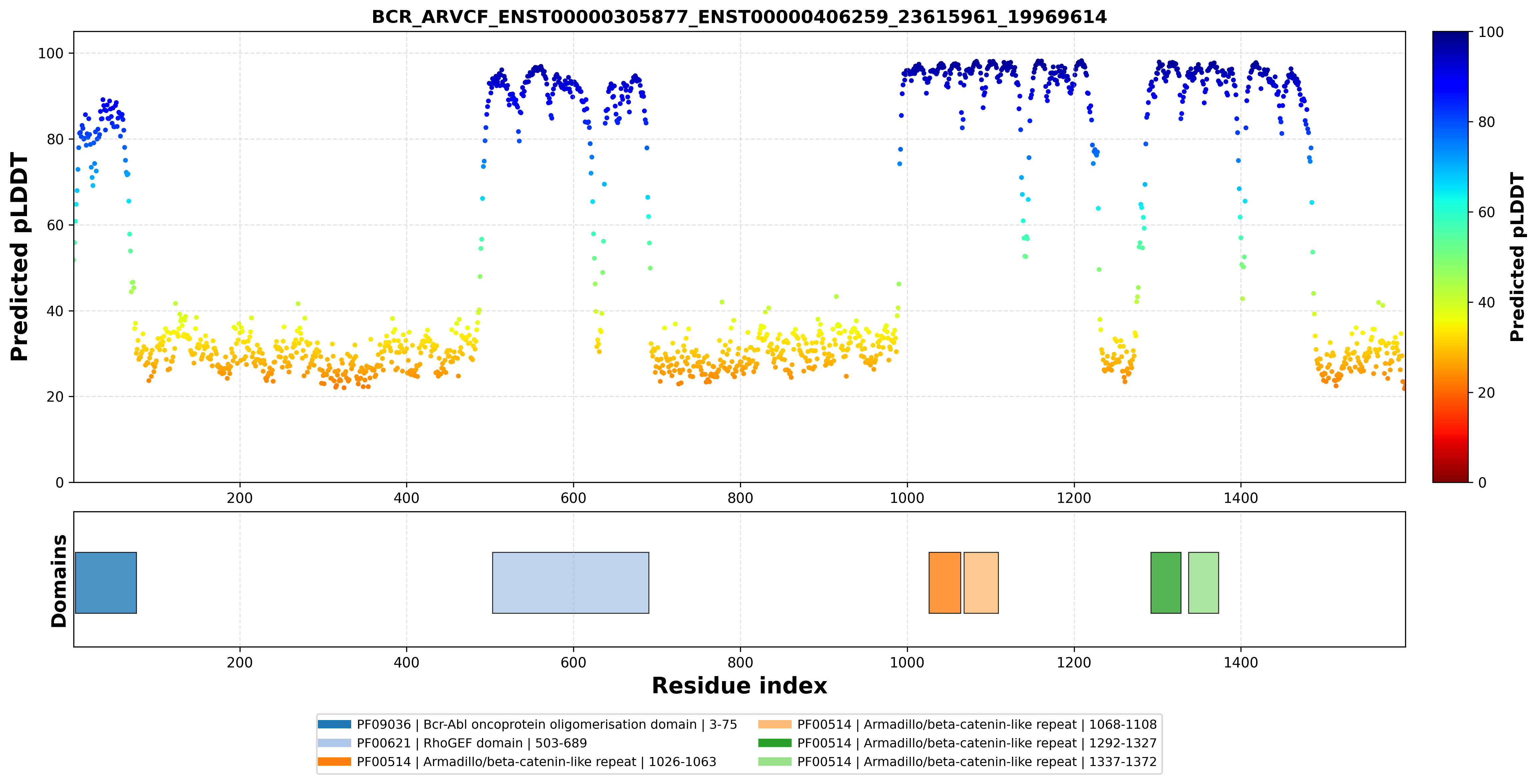 |  |  |
| BCR_DEFB118_ENST00000359540_ENST00000253381_23603727_29960659 superimposed PDB: 5N7E of partner (BCR). RMSD:0.7278
Å |
 |  |  |  |  |
| BCR_FGFR1_ENST00000305877_ENST00000397091_23603727_38275891 superimposed PDB: 5N7E of partner (BCR). RMSD:0.5375
Å |
 |  |  |  |  |
| BCR_FGFR1_ENST00000305877_ENST00000397091_23603727_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6918
Å |
| | | |  |
| BCR_FGFR1_ENST00000305877_ENST00000425967_23603727_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:1.1004
Å |
 |  |  |  |  |
| BCR_PDGFRA_ENST00000359540_ENST00000257290_23615320_55141007 superimposed PDB: 5N7E of partner (BCR). RMSD:0.698
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000305877_ENST00000259351_23615961_129831508 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4623
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000305877_ENST00000259351_23615961_129831508 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.8903
Å |
| | | |  |
| BCR_RALGPS1_ENST00000305877_ENST00000373434_23615961_129831508 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4703
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000305877_ENST00000373434_23615961_129831508 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:3.0726
Å |
| | | |  |
| BCR_RALGPS1_ENST00000305877_ENST00000373436_23615961_129831508 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4538
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000305877_ENST00000373436_23615961_129831508 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:3.1097
Å |
| | | |  |
| BCR_RALGPS1_ENST00000305877_ENST00000394022_23615961_129831508 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4932
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000305877_ENST00000394022_23615961_129831508 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.8724
Å |
| | | |  |
| BCR_RALGPS1_ENST00000359540_ENST00000424082_23615961_129831508 superimposed PDB: 5N7E of partner (BCR). RMSD:0.4665
Å |
 |  |  |  |  |
| BCR_RALGPS1_ENST00000359540_ENST00000424082_23615961_129831508 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.5831
Å |
| | | |  |
| BEND5_NTRK2_ENST00000371833_ENST00000376213_49224571_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7921
Å |
 |  |  |  |  |
| BEND5_NTRK2_ENST00000371833_ENST00000376214_49224571_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7908
Å |
 |  |  |  |  |
| BEST3_PTPRR_ENST00000330891_ENST00000283228_70065207_71158558 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4191
Å |
 |  | 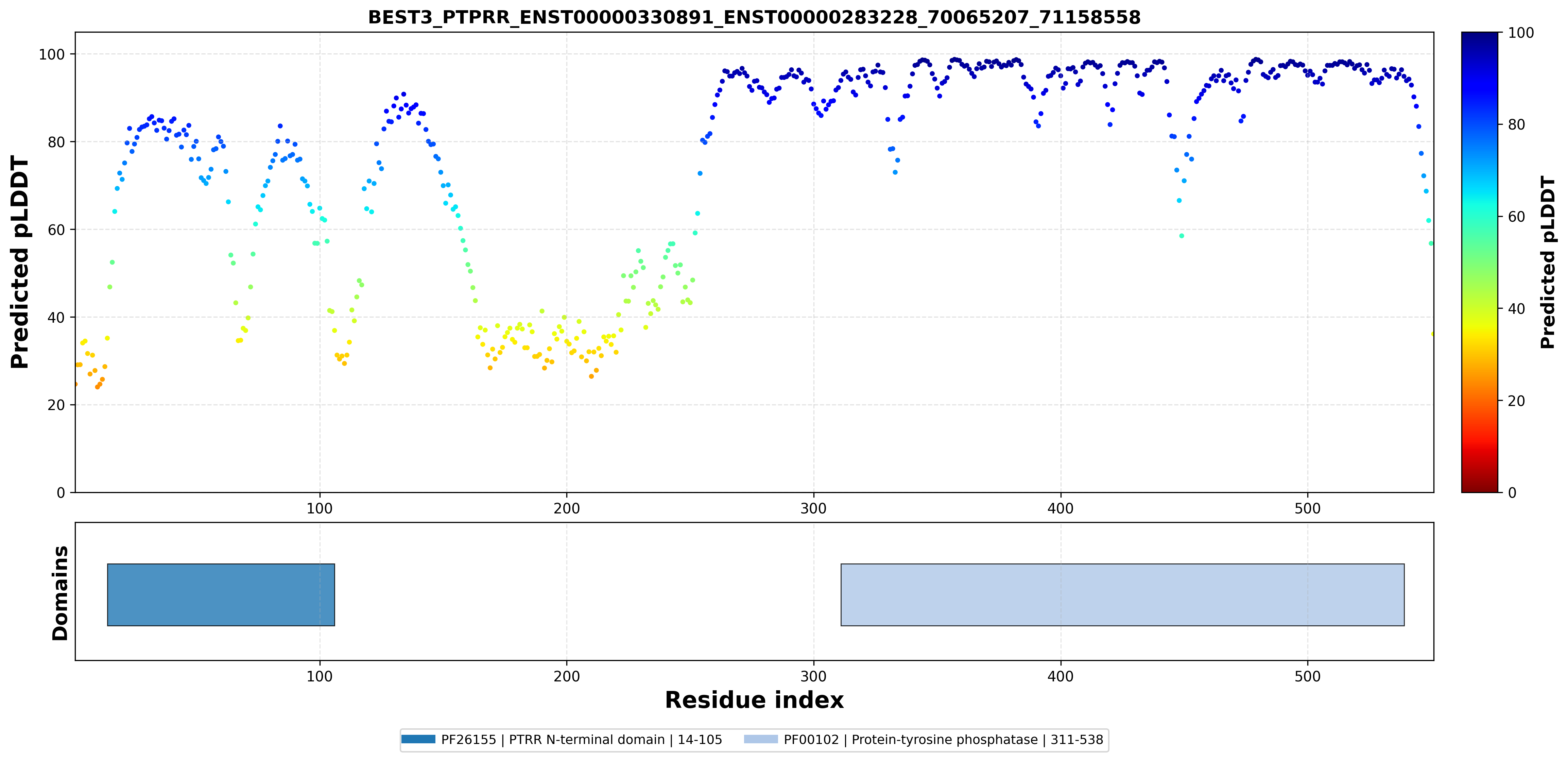 |  |  |
| BFAR_SPNS1_ENST00000261658_ENST00000311008_14749067_28994177 superimposed PDB: 9BOI of partner (SPNS1). RMSD:1.1364
Å |
 |  |  |  |  |
| BFAR_SPNS1_ENST00000426842_ENST00000311008_14749067_28994177 superimposed PDB: 9BOI of partner (SPNS1). RMSD:1.044
Å |
 |  |  |  |  |
| BFAR_SPNS1_ENST00000563971_ENST00000311008_14749067_28994177 superimposed PDB: 9BOI of partner (SPNS1). RMSD:1.1228
Å |
 |  |  |  |  |
| BHLHE40_ARL8B_ENST00000256495_ENST00000419534_5022093_5212187 superimposed PDB: 8JCA of partner (ARL8B). RMSD:0.6011
Å |
 |  |  |  |  |
| BICC1_FGFR2_ENST00000263103_ENST00000369061_60563002_123239535 superimposed PDB: 6GY4 of partner (BICC1). RMSD:0.4607
Å |
 |  |  |  |  |
| BICD2_DAB2IP_ENST00000356884_ENST00000259371_95526786_124538476 superimposed PDB: 6PSE of partner (BICD2). RMSD:0.9158
Å |
 |  |  |  |  |
| BICD2_DAB2IP_ENST00000375512_ENST00000259371_95526786_124536538 superimposed PDB: 6PSE of partner (BICD2). RMSD:0.7694
Å |
 |  |  |  |  |
| BICD2_DAB2IP_ENST00000375512_ENST00000309989_95526786_124536538 superimposed PDB: 6PSE of partner (BICD2). RMSD:0.6732
Å |
 |  | 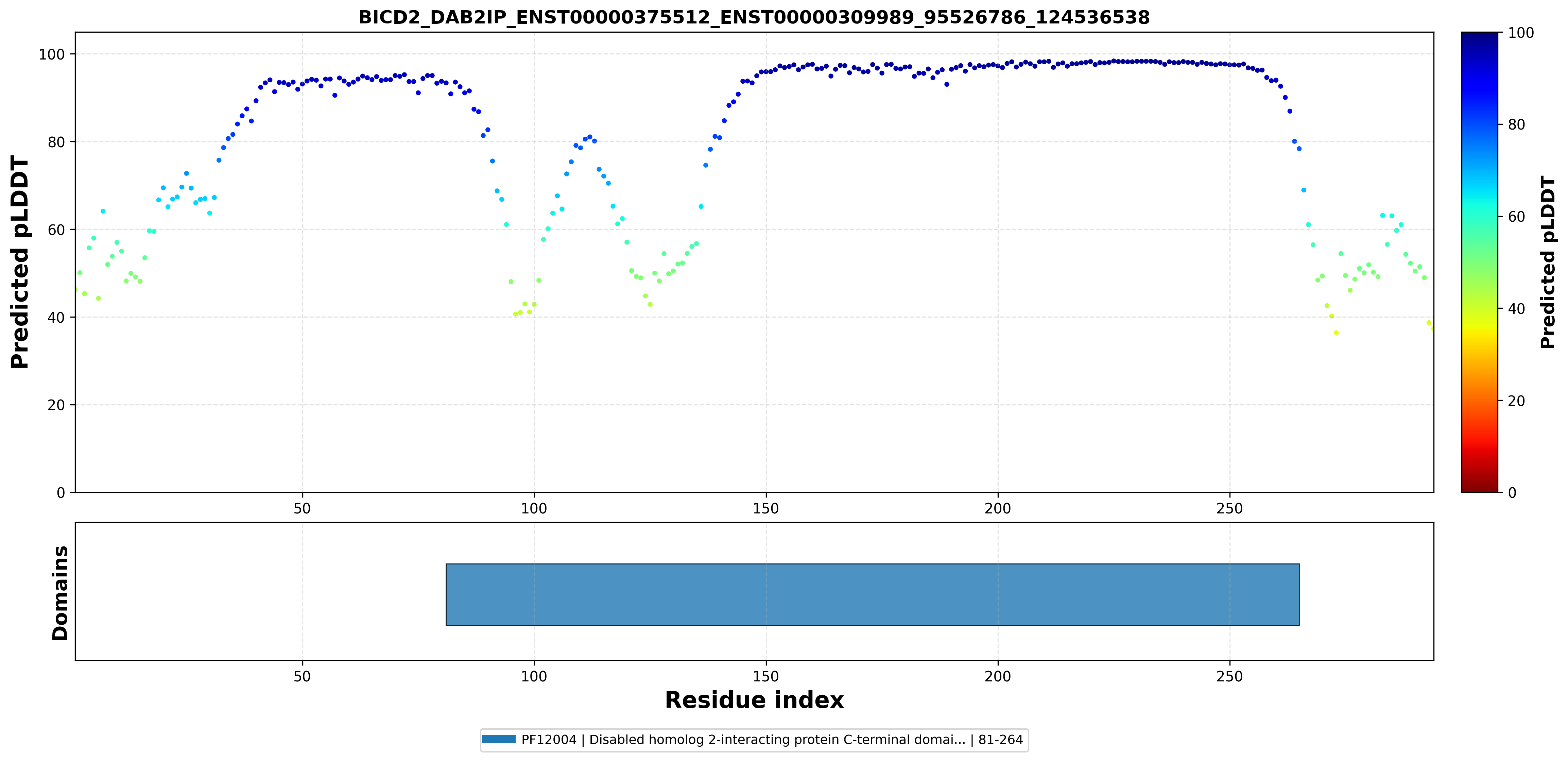 |  |  |
| BICD2_DAB2IP_ENST00000375512_ENST00000408936_95526786_124536538 superimposed PDB: 6PSE of partner (BICD2). RMSD:0.9603
Å |
 |  |  |  |  |
| BICD2_DAB2IP_ENST00000375512_ENST00000408936_95526786_124538476 superimposed PDB: 6PSE of partner (BICD2). RMSD:2.6469
Å |
 |  |  |  |  |
| BICD2_JAK2_ENST00000375512_ENST00000381652_95477534_5072491 superimposed PDB: 6PSE of partner (BICD2). RMSD:2.6117
Å |
 |  |  |  |  |
| BID_ATP6V1E1_ENST00000317361_ENST00000399796_18220782_18096086 superimposed PDB: 6WLZ of partner (ATP6V1E1). RMSD:1.3023
Å |
 |  |  |  |  |
| BID_ATP6V1E1_ENST00000551952_ENST00000399796_18220782_18096086 superimposed PDB: 6WLZ of partner (ATP6V1E1). RMSD:1.4797
Å |
 |  |  |  |  |
| BIRC3_MALT1_ENST00000263464_ENST00000345724_102201972_56363597 superimposed PDB: 2UVL of partner (BIRC3). RMSD:0.2988
Å |
 |  |  |  |  |
| BIRC3_MALT1_ENST00000263464_ENST00000345724_102201972_56363597 superimposed PDB: 7A41 of partner (MALT1). RMSD:0.7334
Å |
| | | |  |
| BIRC3_MALT1_ENST00000532808_ENST00000348428_102201972_56363597 superimposed PDB: 2UVL of partner (BIRC3). RMSD:0.3036
Å |
 |  |  |  |  |
| BIRC3_MALT1_ENST00000532808_ENST00000348428_102201972_56363597 superimposed PDB: 7A41 of partner (MALT1). RMSD:0.809
Å |
| | | |  |
| BLMH_ABCA9_ENST00000261714_ENST00000453985_28612405_66992155 superimposed PDB: 7V5L of partner (BLMH). RMSD:2.6181
Å |
 |  | 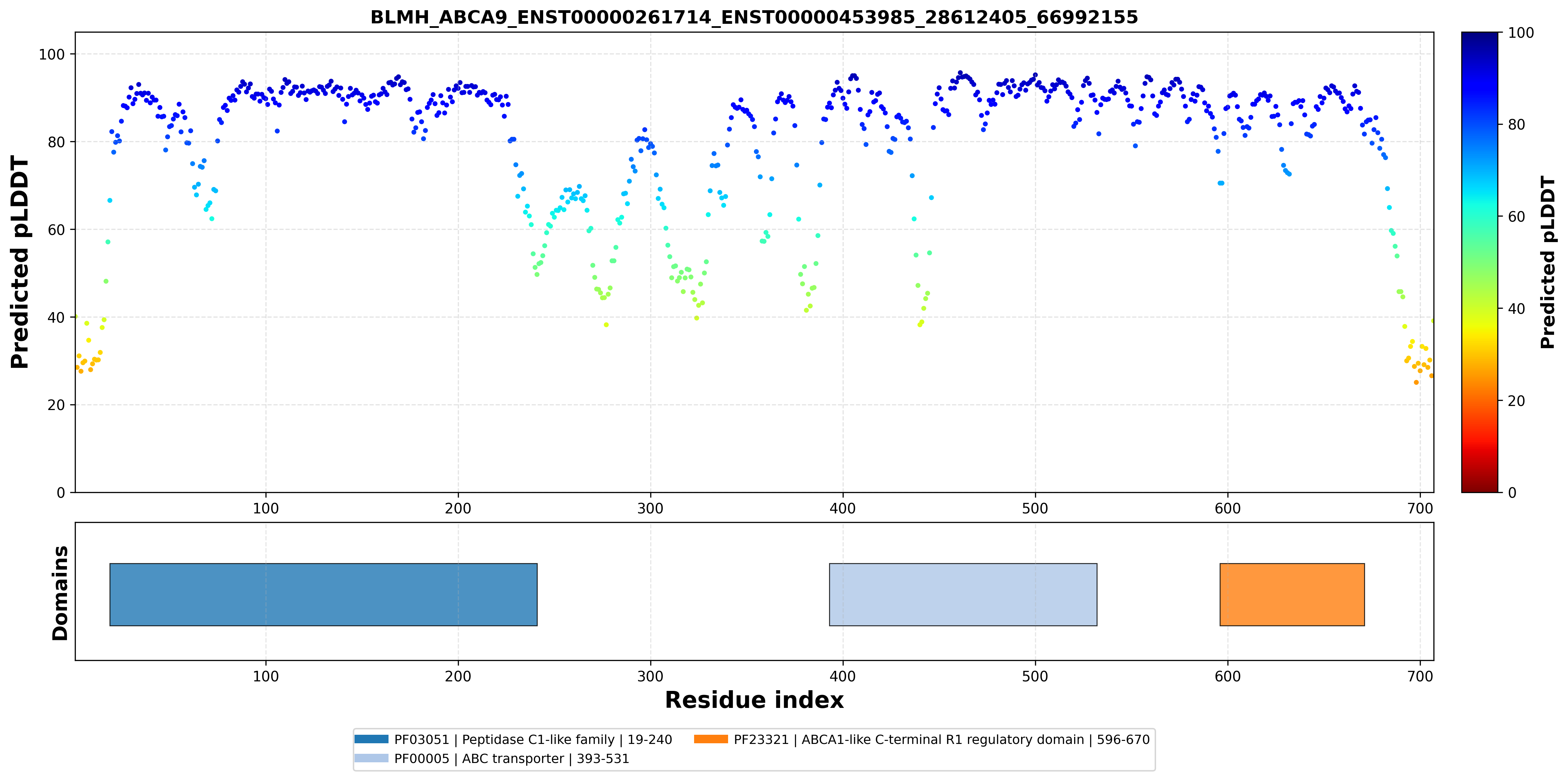 |  |  |
| BLM_IGF1R_ENST00000355112_ENST00000558762_91334074_99434553 superimposed PDB: 4CDG of partner (BLM). RMSD:3.1023
Å |
 | 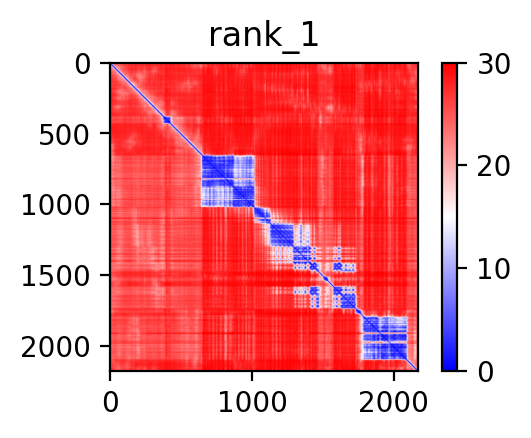 | 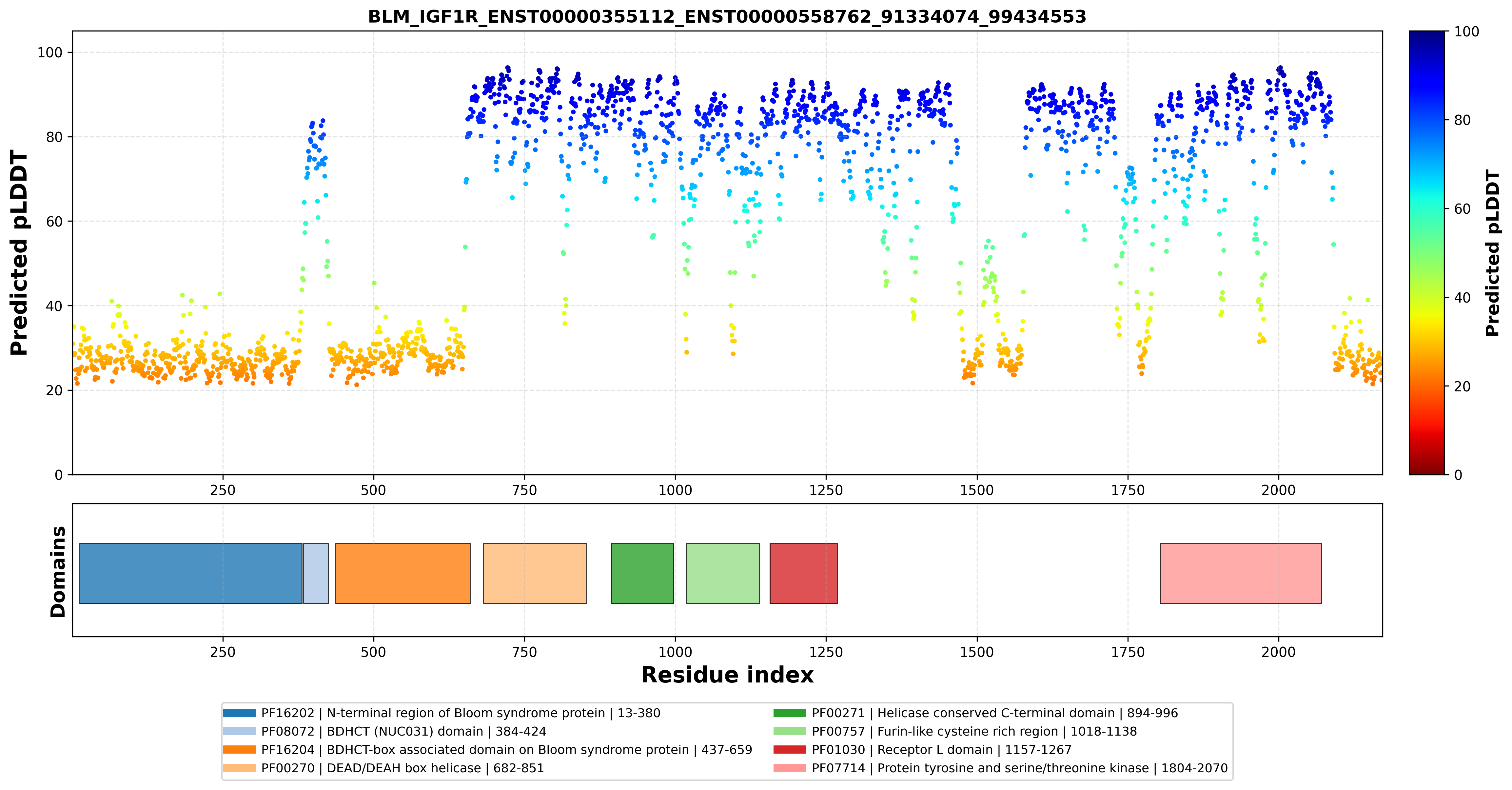 |  |  |
| BLM_IGF1R_ENST00000560509_ENST00000268035_91334074_99434553 superimposed PDB: 4CDG of partner (BLM). RMSD:3.1207
Å |
 | 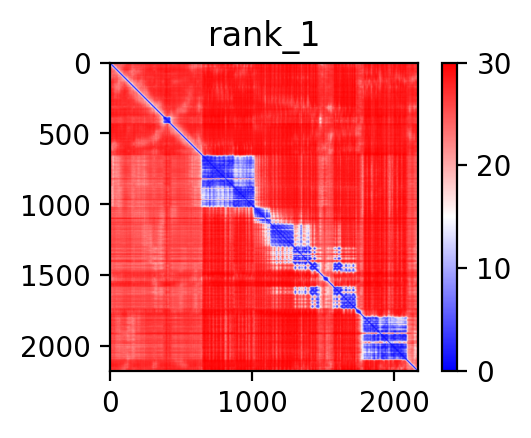 | 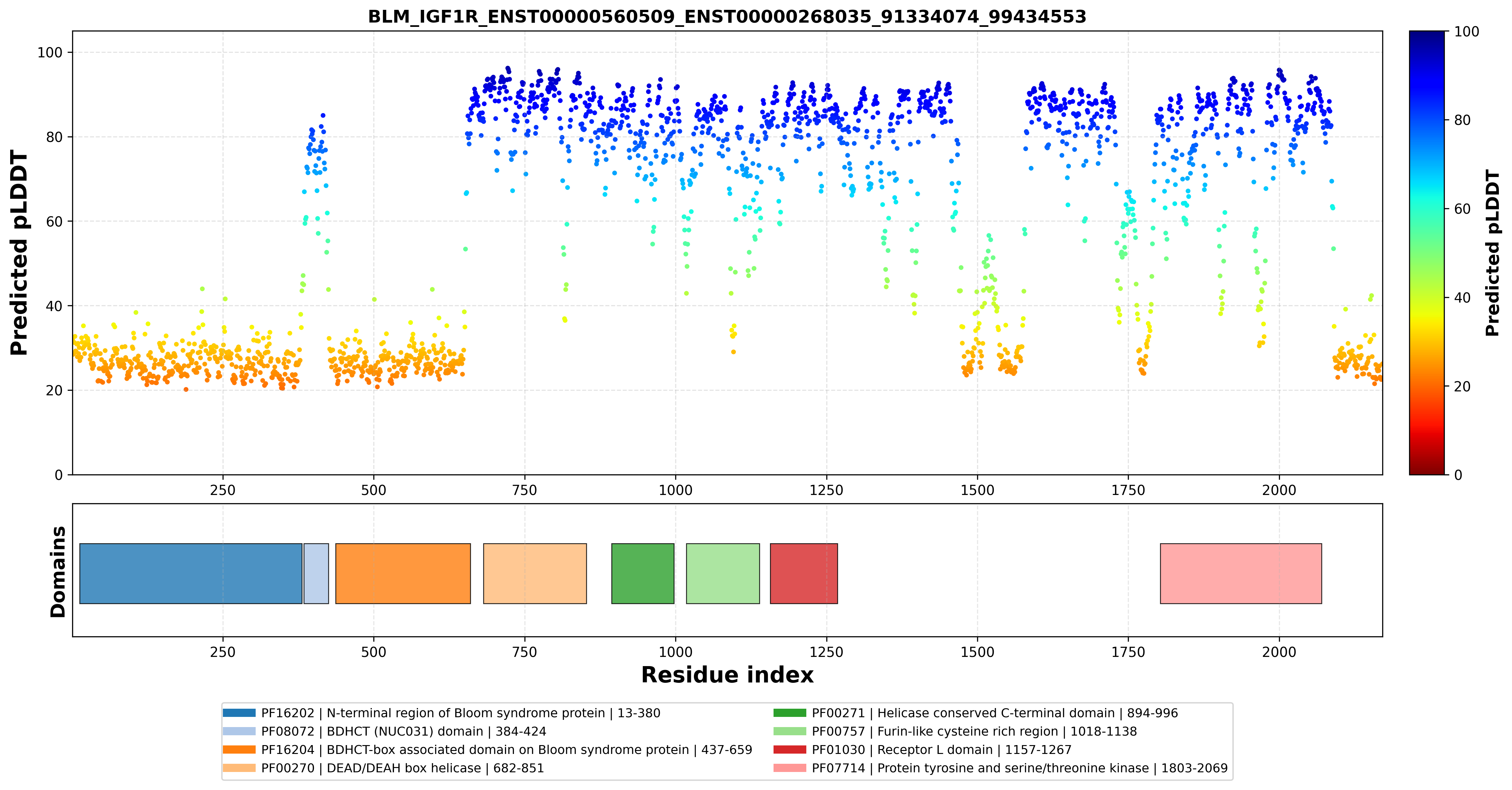 |  |  |
| BLNK_EPRS_ENST00000371176_ENST00000366923_97987165_220195860 superimposed PDB: 5VAD of partner (EPRS). RMSD:0.7007
Å |
 |  |  |  |  |
| BLOC1S1_CPM_ENST00000257899_ENST00000551568_56109980_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4611
Å |
 |  |  |  |  |
| BLOC1S5_TXNDC5_ENST00000543936_ENST00000379757_8041371_7904956 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7503
Å |
 |  |  |  |  |
| BMP2K_ANXA3_ENST00000502871_ENST00000264908_79747309_79494333 superimposed PDB: 4W9X of partner (BMP2K). RMSD:0.9048
Å |
 |  |  |  |  |
| BMP2K_ANXA3_ENST00000502871_ENST00000264908_79747309_79494333 superimposed PDB: 1AII of partner (ANXA3). RMSD:0.4476
Å |
| | | |  |
| BMP2K_SLC25A31_ENST00000502871_ENST00000281154_79786874_128694540 superimposed PDB: 4W9X of partner (BMP2K). RMSD:0.4782
Å |
 |  |  |  |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000340595_79772210_72352664 superimposed PDB: 4W9X of partner (BMP2K). RMSD:0.5085
Å |
 |  |  |  |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000340595_79772210_72352664 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.7194
Å |
| | | |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000351898_79772210_72352664 superimposed PDB: 4W9X of partner (BMP2K). RMSD:0.5
Å |
 |  |  |  |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000351898_79772210_72352664 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:2.0657
Å |
| | | |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000425175_79772210_72352664 superimposed PDB: 4W9X of partner (BMP2K). RMSD:0.5086
Å |
 |  |  |  |  |
| BMP2K_SLC4A4_ENST00000335016_ENST00000425175_79772210_72352664 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:2.032
Å |
| | | |  |
| BMP7_ZBP1_ENST00000395863_ENST00000395822_55777530_56190636 superimposed PDB: 4KA4 of partner (ZBP1). RMSD:0.2677
Å |
 |  |  |  |  |
| BMP7_ZBP1_ENST00000395864_ENST00000395822_55777530_56190636 superimposed PDB: 4KA4 of partner (ZBP1). RMSD:0.27
Å |
 |  |  |  |  |
| BMPR1A_ENTPD1_ENST00000372037_ENST00000543964_88659883_97604232 superimposed PDB: 2H62 of partner (BMPR1A). RMSD:0.6001
Å |
 |  |  |  |  |
| BMPR2_MTIF3_ENST00000374580_ENST00000431572_203397455_28011410 superimposed PDB: 6UNP of partner (BMPR2). RMSD:0.5359
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000346832_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.2543
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000355394_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.5406
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000359188_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.3741
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000376137_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.6997
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000376139_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.5123
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000376142_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.2536
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000376142_133784141_27054247 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.2557
Å |
| | | |  |
| BNIP3_ABI1_ENST00000368636_ENST00000376160_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.3437
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000536334_133784141_27054247 superimposed PDB: 2J5D of partner (BNIP3). RMSD:2.0444
Å |
 |  |  |  |  |
| BNIP3_ABI1_ENST00000368636_ENST00000536334_133784141_27054247 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3793
Å |
| | | |  |
| BPI_HNRNPD_ENST00000262865_ENST00000353341_36940339_83292737 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3191
Å |
 |  |  |  |  |
| BPTF_LRRC37A_ENST00000335221_ENST00000393465_65822453_44407815 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.6936
Å |
 | 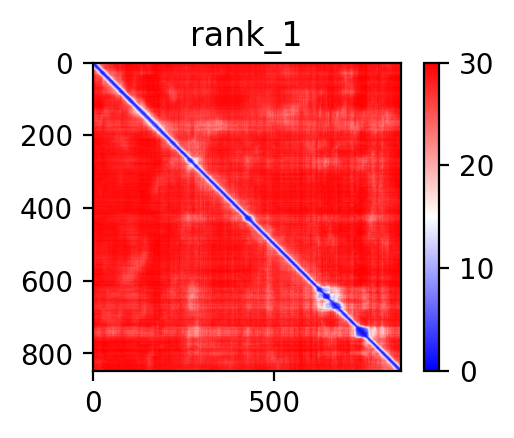 | 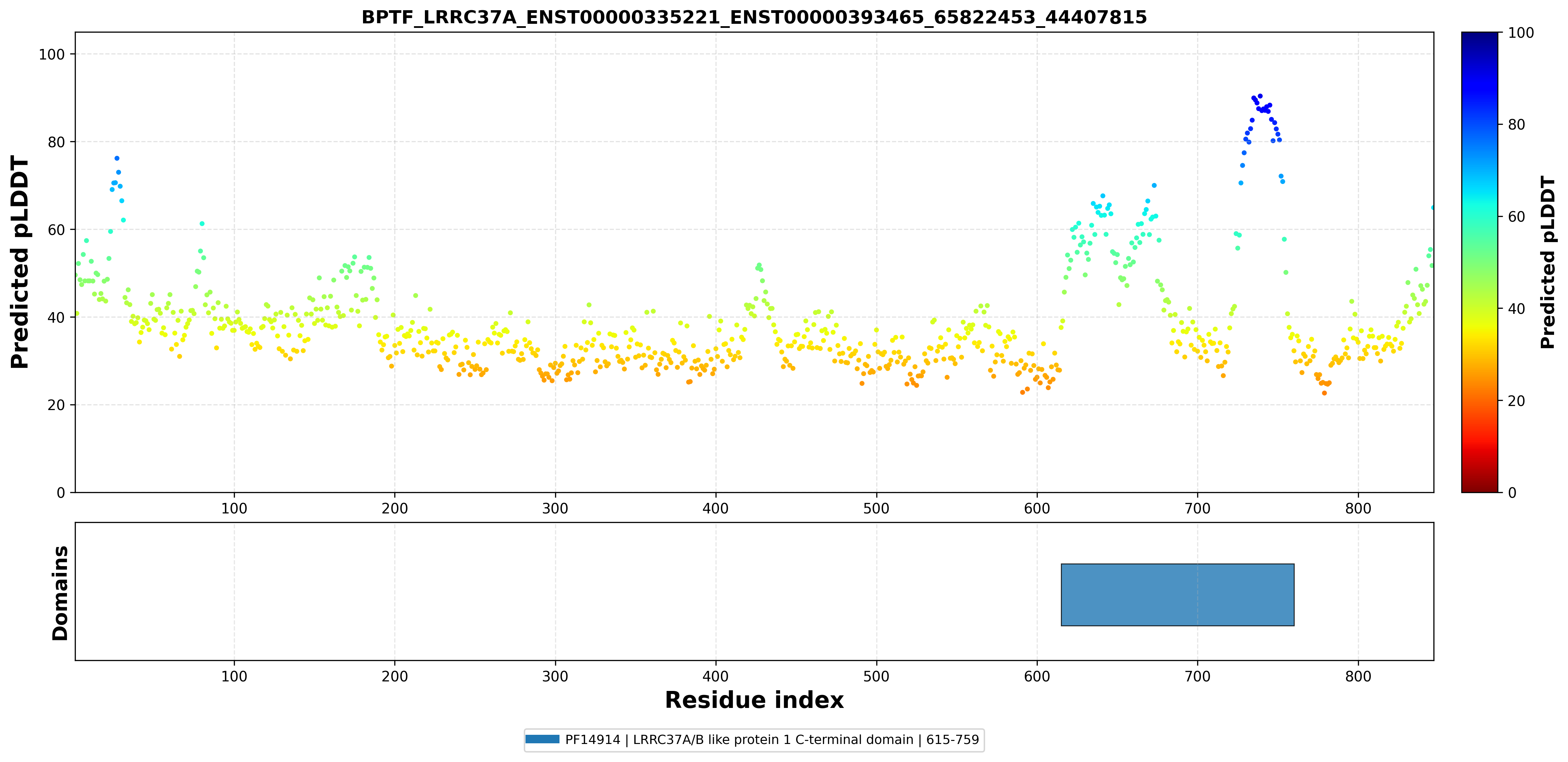 |  |  |
| BPTF_NOL11_ENST00000306378_ENST00000253247_65944422_65715789 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.2127
Å |
 |  |  |  |  |
| BPTF_NOL11_ENST00000321892_ENST00000253247_65944422_65715789 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.1027
Å |
 |  |  |  |  |
| BPTF_NOL11_ENST00000424123_ENST00000253247_65944422_65715789 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.2071
Å |
 |  |  |  |  |
| BPTF_NUP214_ENST00000306378_ENST00000411637_65962772_134072602 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.5636
Å |
 |  |  |  |  |
| BPTF_NUP214_ENST00000321892_ENST00000411637_65962772_134072602 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.6299
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000306378_ENST00000299954_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.3327
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000306378_ENST00000581322_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.3119
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000321892_ENST00000299954_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.3881
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000321892_ENST00000581322_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.2913
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000335221_ENST00000299954_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.2605
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000335221_ENST00000580974_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.3496
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000335221_ENST00000581322_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.2874
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000424123_ENST00000299954_65936772_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.3163
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000424123_ENST00000299954_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.24
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000424123_ENST00000581322_65936772_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.1539
Å |
 |  |  |  |  |
| BPTF_PITPNC1_ENST00000424123_ENST00000581322_65944422_65665623 superimposed PDB: 2RI7 of partner (BPTF). RMSD:3.331
Å |
 |  |  |  |  |
| BPTF_PLXDC1_ENST00000321892_ENST00000315392_65962772_37243955 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.6205
Å |
 |  |  |  |  |
| BPTF_PLXDC1_ENST00000424123_ENST00000315392_65962772_37243955 superimposed PDB: 2RI7 of partner (BPTF). RMSD:1.9844
Å |
 |  |  |  |  |
| BRCA1_BECN1_ENST00000591534_ENST00000590099_41209068_40968072 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3372
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000309486_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0964
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000346315_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0423
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000351666_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.9665
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000352993_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0237
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000354071_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.7578
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000357654_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0407
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000471181_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0478
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000491747_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.0692
Å |
 |  |  |  |  |
| BRCA1_FAM134C_ENST00000586385_ENST00000585894_41199659_40739882 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.7749
Å |
 |  |  |  |  |
| BRCA2_HSDL2_ENST00000544455_ENST00000398805_32921033_115179120 superimposed PDB: 8C3J of partner (BRCA2). RMSD:2.4169
Å |
 |  |  |  |  |
| BRCA2_HSDL2_ENST00000544455_ENST00000398805_32921033_115179120 superimposed PDB: 3KVO of partner (HSDL2). RMSD:0.8515
Å |
| | | |  |
| BRCA2_PDS5B_ENST00000544455_ENST00000315596_32921033_33306237 superimposed PDB: 8C3J of partner (BRCA2). RMSD:0.7365
Å |
 |  |  |  |  |
| BRCC3_TRAC_ENST00000330045_ENST00000478163_154345029_23016446 superimposed PDB: 7FJE of partner (TRAC). RMSD:2.3508
Å |
 |  |  |  |  |
| BRCC3_TRAC_ENST00000369459_ENST00000478163_154345029_23016446 superimposed PDB: 7FJE of partner (TRAC). RMSD:2.9249
Å |
 |  |  |  |  |
| BRD1_DENND6B_ENST00000342989_ENST00000413817_50181037_50757432 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.435
Å |
 |  |  |  |  |
| BRD9_NUTM1_ENST00000323510_ENST00000438749_870587_34640169 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3807
Å |
 |  |  |  |  |
| BRD9_NUTM1_ENST00000323510_ENST00000438749_870587_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7549
Å |
| | | |  |
| BRD9_NUTM1_ENST00000388890_ENST00000438749_870587_34640169 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3769
Å |
 |  |  |  |  |
| BRD9_NUTM1_ENST00000388890_ENST00000438749_870587_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7785
Å |
| | | |  |
| BRD9_NUTM1_ENST00000467963_ENST00000438749_870587_34640169 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3589
Å |
 |  |  |  |  |
| BRD9_NUTM1_ENST00000467963_ENST00000438749_870587_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7517
Å |
| | | |  |
| BRD9_NUTM1_ENST00000483173_ENST00000438749_870587_34640169 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.4347
Å |
 |  |  |  |  |
| BRD9_NUTM1_ENST00000483173_ENST00000438749_870587_34640169 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.8006
Å |
| | | |  |
| BRD9_STARD3_ENST00000323510_ENST00000336308_876215_37813260 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.4057
Å |
 |  | 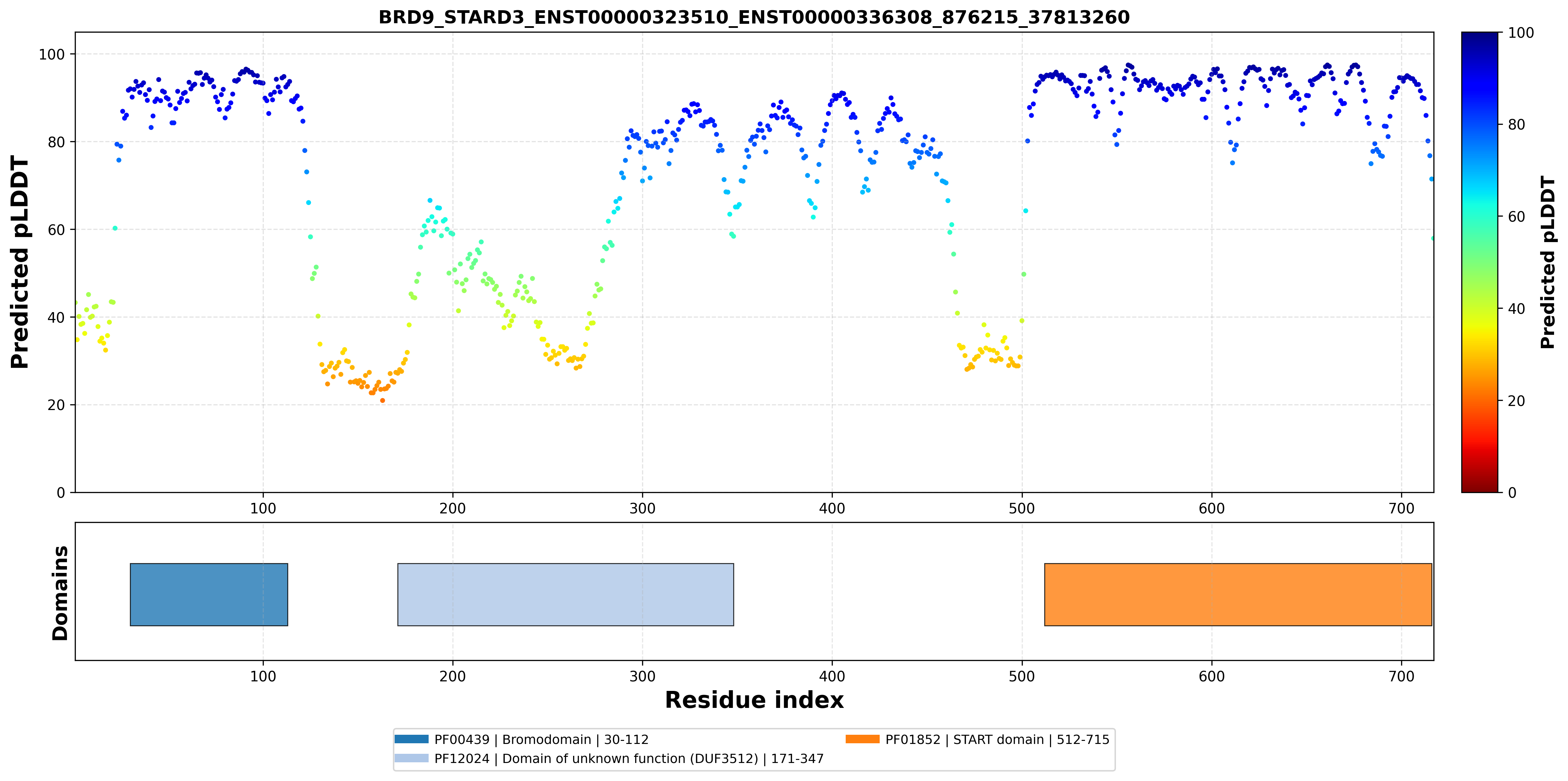 |  |  |
| BRD9_STARD3_ENST00000323510_ENST00000336308_876215_37813260 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.3905
Å |
| | | |  |
| BRD9_STARD3_ENST00000467963_ENST00000336308_876215_37813260 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3803
Å |
 |  | 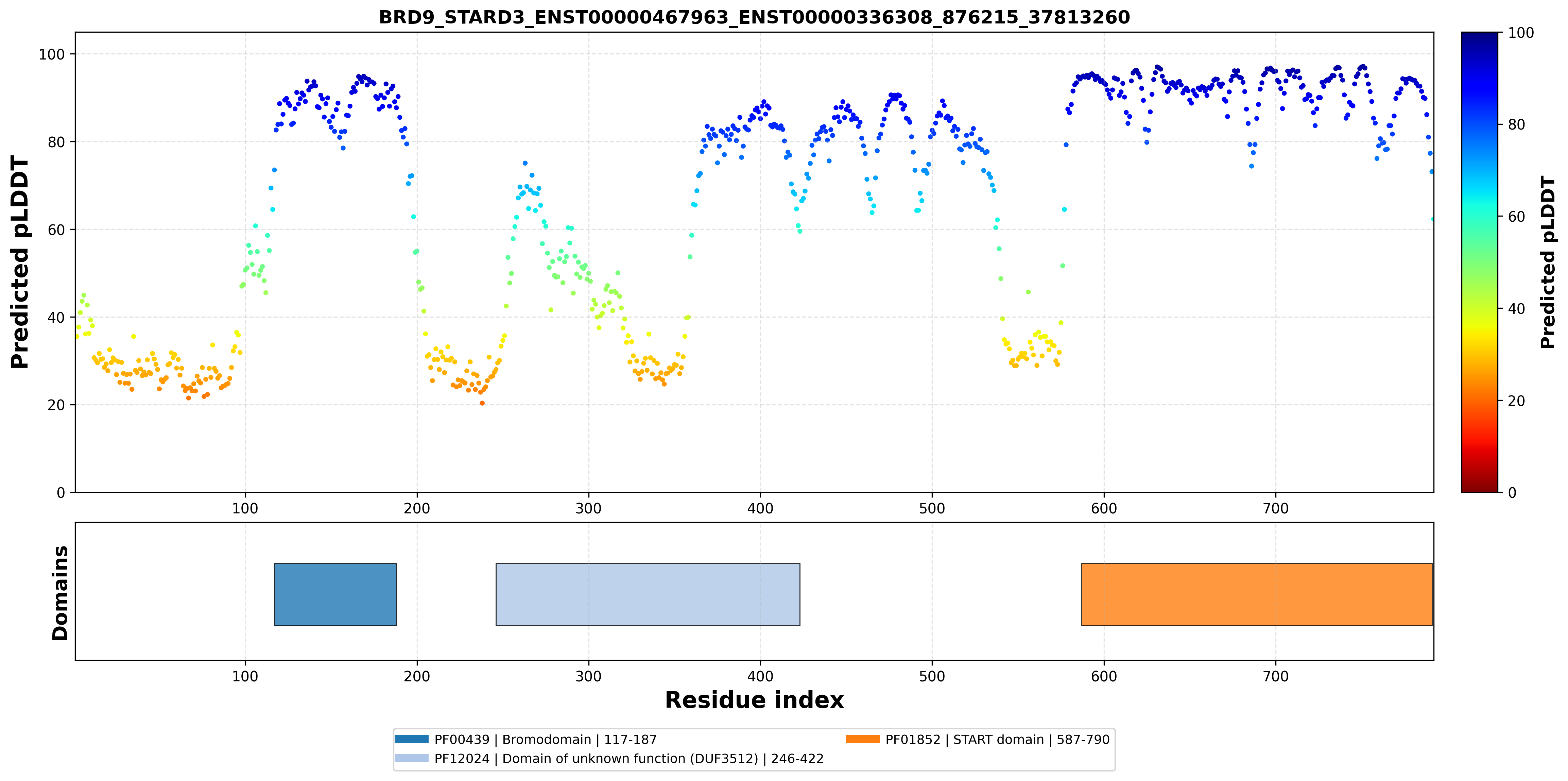 |  |  |
| BRD9_STARD3_ENST00000467963_ENST00000336308_876215_37813260 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.4091
Å |
| | | |  |
| BRD9_STARD3_ENST00000483173_ENST00000336308_876215_37813260 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3911
Å |
 |  | 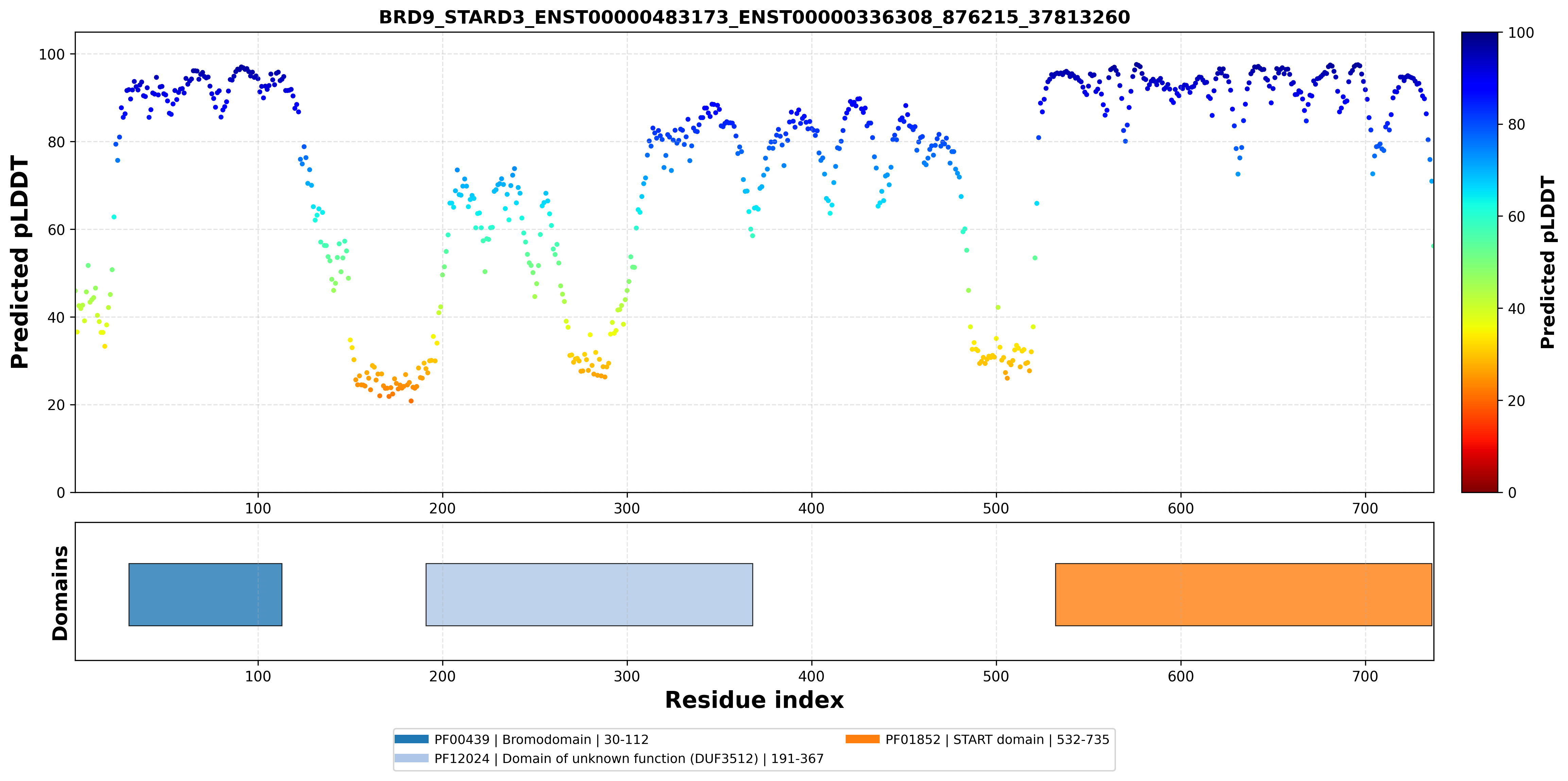 |  |  |
| BRD9_STARD3_ENST00000483173_ENST00000336308_876215_37813260 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.3797
Å |
| | | |  |
| BRD9_TERT_ENST00000435709_ENST00000310581_889701_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8647
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000435709_ENST00000334602_889701_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1123
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000435709_ENST00000508104_889701_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.4882
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000467963_ENST00000296820_892720_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.7644
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000467963_ENST00000310581_891269_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:2.3058
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000467963_ENST00000334602_891269_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1511
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000467963_ENST00000508104_891269_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.4096
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000483173_ENST00000296820_891269_1282739 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.2651
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000483173_ENST00000334602_889701_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1102
Å |
 |  |  |  |  |
| BRD9_TERT_ENST00000483173_ENST00000508104_889701_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.6741
Å |
 |  |  |  |  |
| BRD9_TPPP_ENST00000323510_ENST00000360578_886706_666238 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3424
Å |
 |  |  |  |  |
| BRD9_TPPP_ENST00000388890_ENST00000360578_886706_666238 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3858
Å |
 |  |  |  |  |
| BRD9_TPPP_ENST00000467963_ENST00000360578_886706_666238 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3398
Å |
 |  |  |  |  |
| BRD9_TPPP_ENST00000483173_ENST00000360578_886706_666238 superimposed PDB: 5TWX of partner (BRD9). RMSD:0.3632
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000288642_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.9647
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000404103_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.9268
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000405222_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.8203
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000406818_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:1.0409
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000407038_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.8373
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000407661_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.868
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000344773_ENST00000545439_28352247_25674504 superimposed PDB: 8PVY of partner (BRE). RMSD:0.927
Å |
 |  |  |  |  |
| BRE_DTNB_ENST00000379624_ENST00000496972_28352247_25678363 superimposed PDB: 8PVY of partner (BRE). RMSD:0.8457
Å |
 |  |  |  |  |
| BRE_PRKCE_ENST00000379624_ENST00000306156_28268666_46313346 superimposed PDB: 8PVY of partner (BRE). RMSD:1.0851
Å |
 |  | 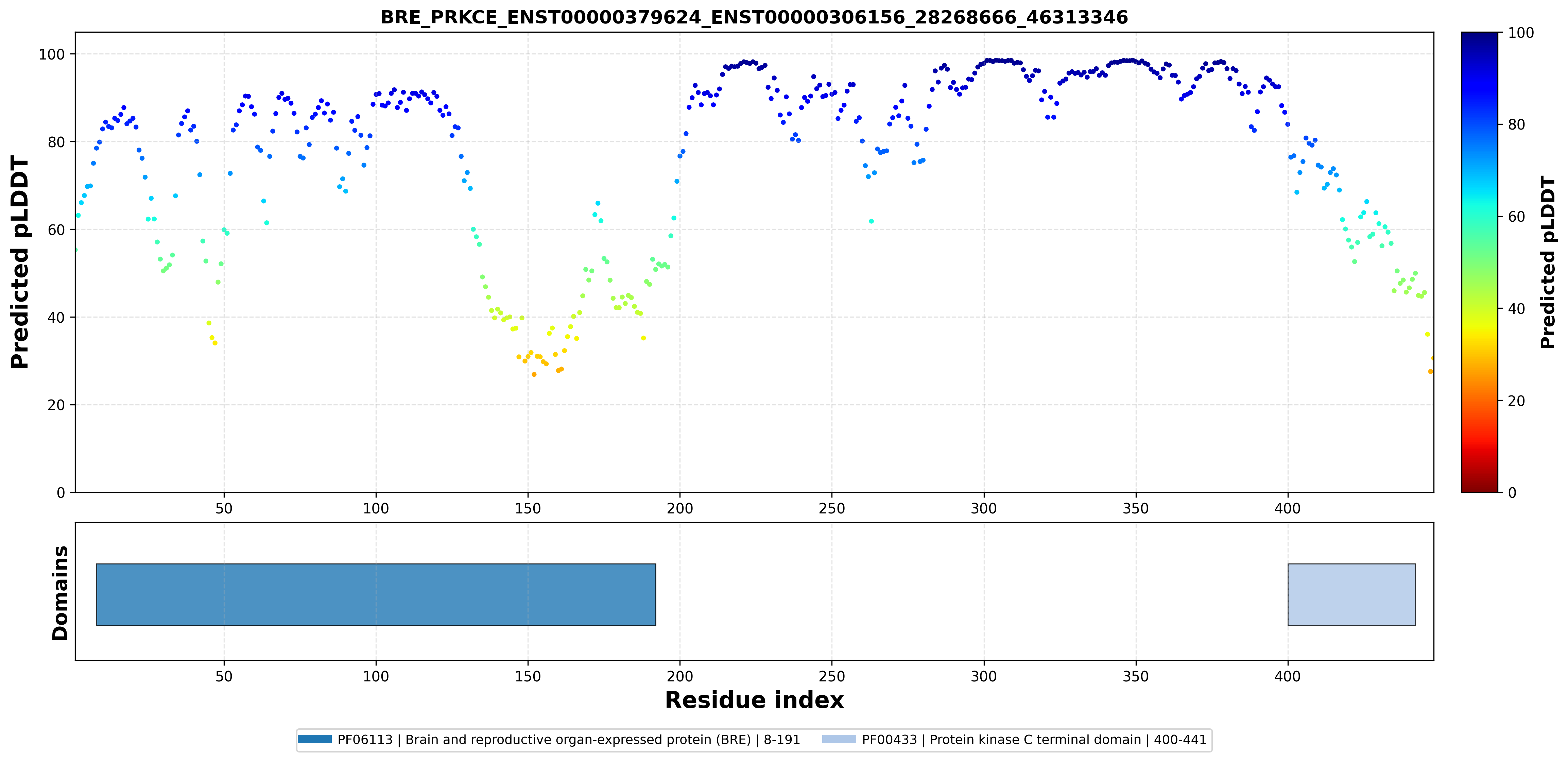 |  |  |
| BRIP1_SPAG9_ENST00000259008_ENST00000357122_59934418_49157065 superimposed PDB: 2W83 of partner (SPAG9). RMSD:0.993
Å |
 |  |  |  |  |
| BRIP1_SPAG9_ENST00000259008_ENST00000505279_59934418_49157065 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.0346
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229794_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:1.2358
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229794_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.3242
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229794_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.713
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229795_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.6865
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229795_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.0767
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000229795_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.6979
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000468133_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:1.0829
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000468133_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.2671
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000339717_ENST00000468133_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.711
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000229794_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.8268
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000229794_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.2552
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000229794_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.7265
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000229795_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.7833
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000468133_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.8597
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000468133_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.3453
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000357641_ENST00000468133_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.6954
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000534400_ENST00000229794_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:1.1071
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000534400_ENST00000468133_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.8564
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000229794_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.4903
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000229794_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.7816
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000229795_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.0939
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000229795_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.7587
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000468133_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:1.4263
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000534694_ENST00000468133_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:1.1006
Å |
| | | |  |
| BRPF3_MAPK14_ENST00000543502_ENST00000229795_36185787_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.7739
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000543502_ENST00000229795_36196833_36040649 superimposed PDB: 3PFS of partner (BRPF3). RMSD:0.9988
Å |
 |  |  |  |  |
| BRPF3_MAPK14_ENST00000543502_ENST00000229795_36196833_36040649 superimposed PDB: 3OEF of partner (MAPK14). RMSD:0.8109
Å |
| | | |  |
| BRPF3_ZFAND3_ENST00000339717_ENST00000287218_36185787_37897734 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:0.673
Å |
 |  |  |  |  |
| BRPF3_ZFAND3_ENST00000339717_ENST00000373391_36185787_37897734 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:0.7389
Å |
 |  |  |  |  |
| BRPF3_ZFAND3_ENST00000357641_ENST00000373391_36185787_37897734 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:0.7217
Å |
 |  |  |  |  |
| BRPF3_ZFAND3_ENST00000534400_ENST00000373391_36185787_37897734 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:0.6983
Å |
 |  |  |  |  |
| BRPF3_ZFAND3_ENST00000543502_ENST00000287218_36185787_37897734 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:0.7181
Å |
 |  |  |  |  |
| BRWD1_ABCG1_ENST00000342449_ENST00000398457_40665736_43645780 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.4299
Å |
 |  |  |  |  |
| BRWD1_ABCG1_ENST00000380800_ENST00000398457_40665736_43645780 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.4142
Å |
 |  |  |  |  |
| BRWD1_GNAI3_ENST00000342449_ENST00000369851_40670357_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:1.0781
Å |
 |  |  |  |  |
| BRWD1_GNAI3_ENST00000380800_ENST00000369851_40670357_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:1.062
Å |
 |  |  |  |  |
| BRWD1_HLCS_ENST00000333229_ENST00000399120_40584591_38269431 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.8791
Å |
 |  | 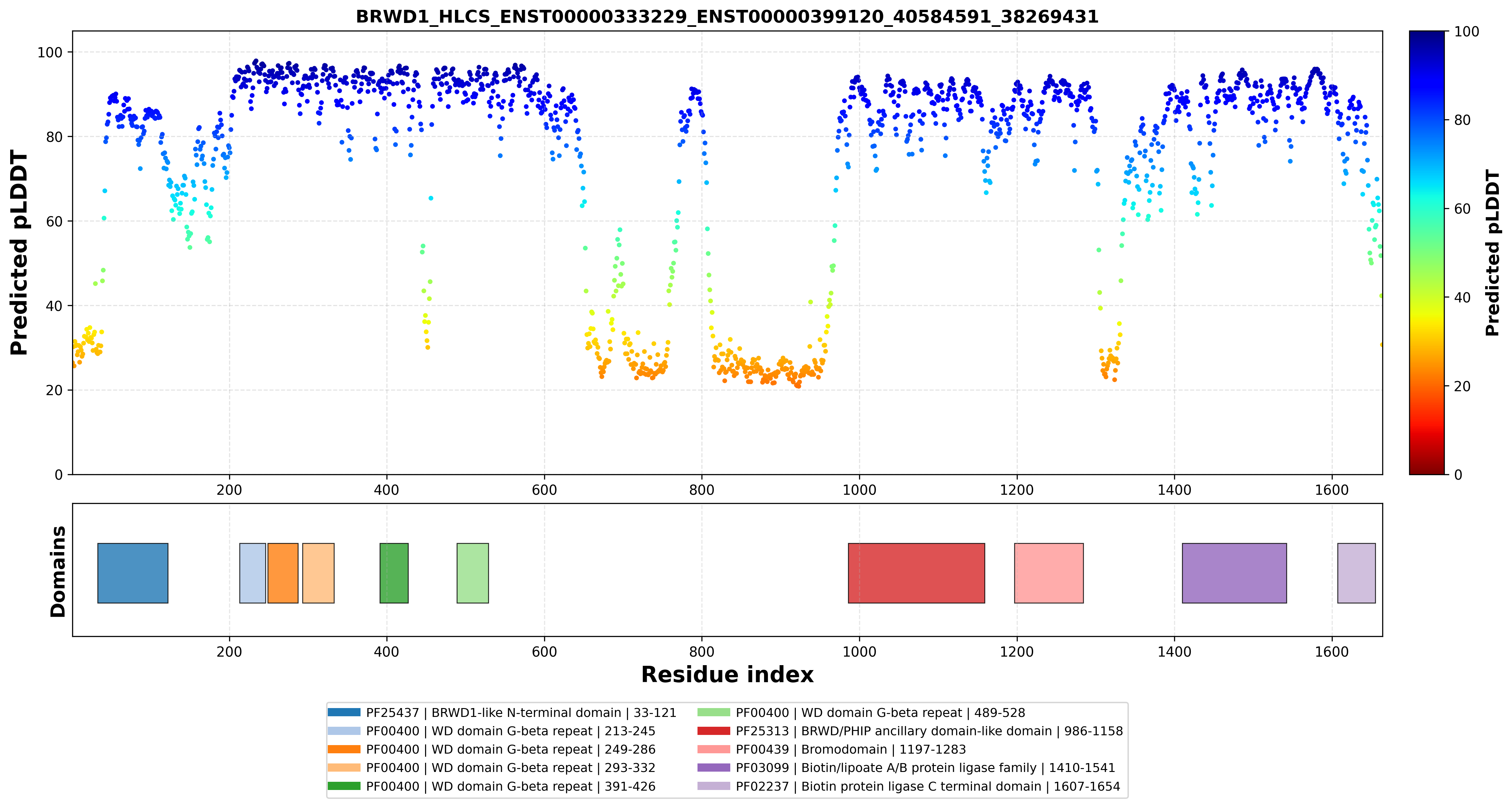 |  |  |
| BRWD1_HLCS_ENST00000342449_ENST00000399120_40584591_38269431 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.8678
Å |
 |  | 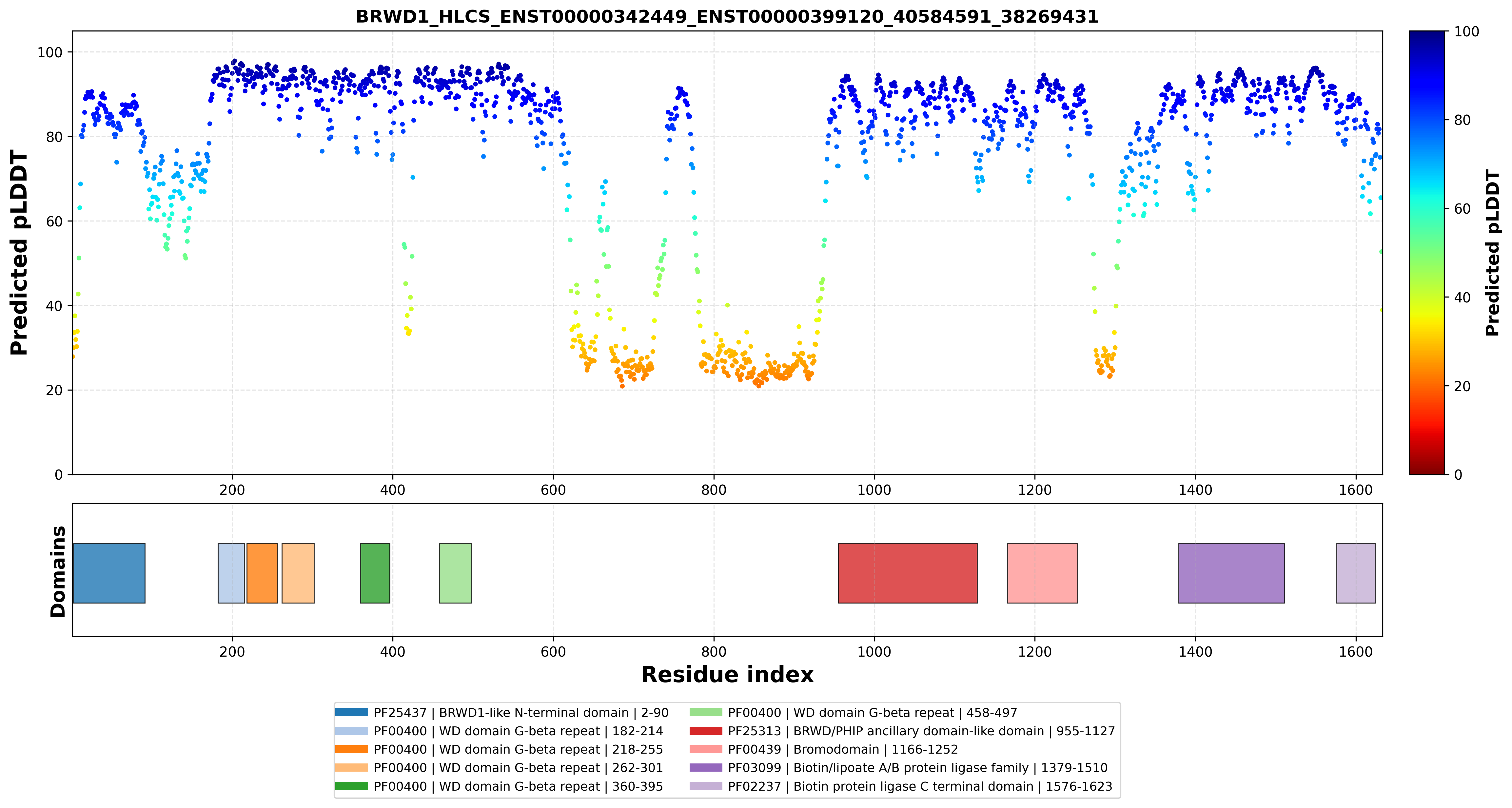 |  |  |
| BRWD1_SMC1A_ENST00000380800_ENST00000322213_40568423_53442118 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.5964
Å |
 |  |  |  |  |
| BRWD1_SMC1A_ENST00000380800_ENST00000322213_40568423_53442118 superimposed PDB: 6WGE of partner (SMC1A). RMSD:1.9474
Å |
| | | |  |
| BSG_ANXA2_ENST00000333511_ENST00000451270_572701_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3761
Å |
 |  |  |  |  |
| BSG_AP3D1_ENST00000353555_ENST00000355272_572701_2129456 superimposed PDB: 9C59 of partner (AP3D1). RMSD:1.3609
Å |
 | 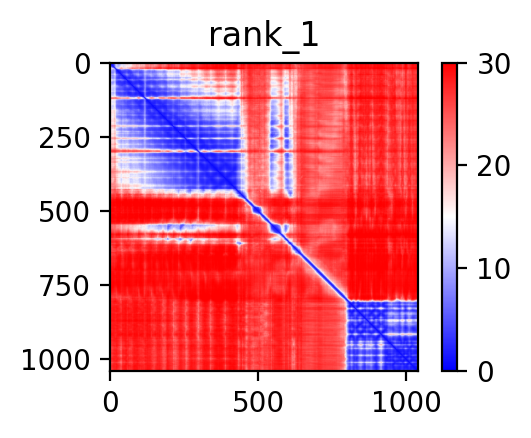 | 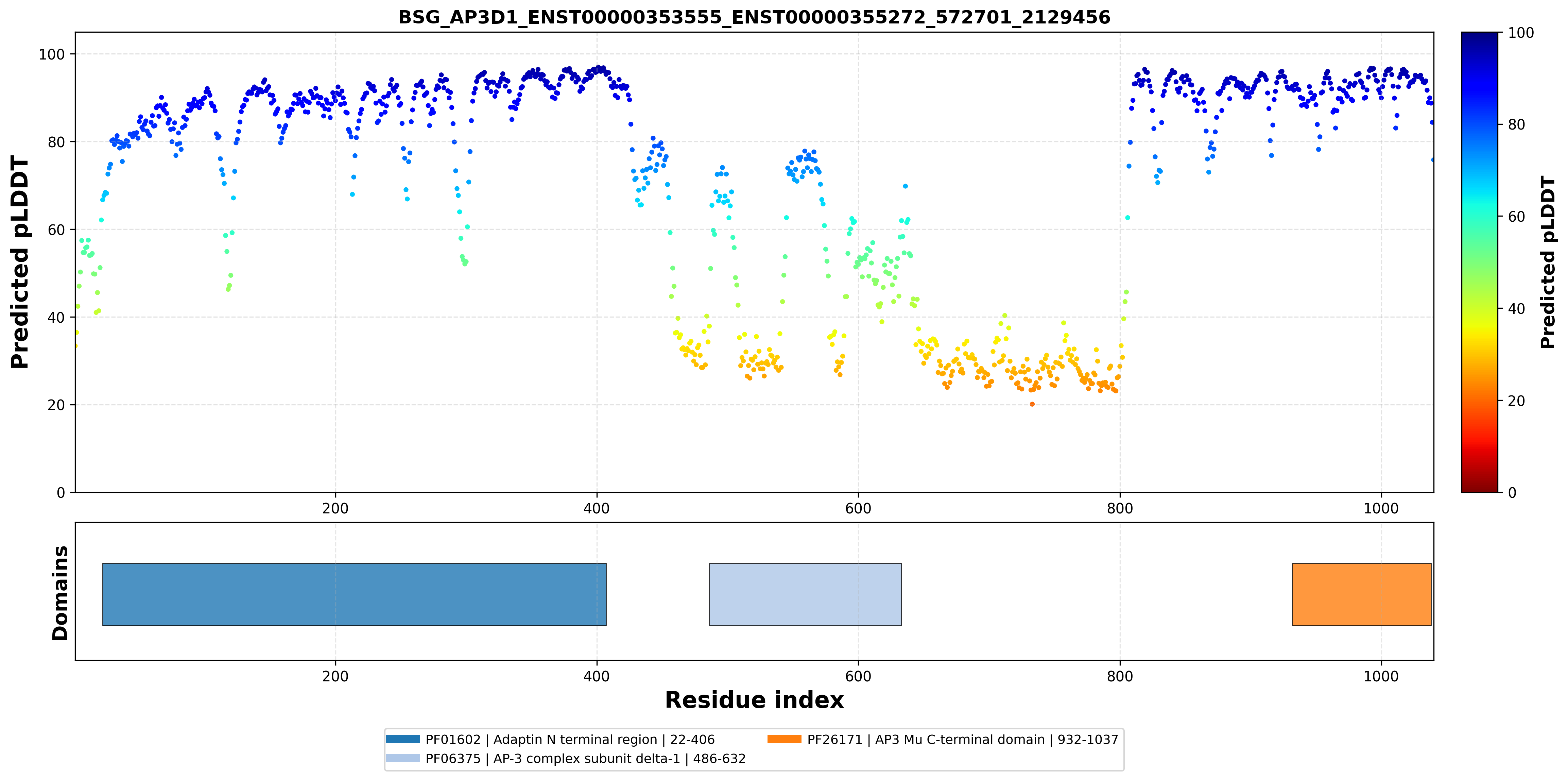 |  |  |
| BSG_PMEL_ENST00000333511_ENST00000550464_572701_56349647 superimposed PDB: 7CKO of partner (BSG). RMSD:3.1782
Å |
 |  |  |  |  |
| BSG_TCF3_ENST00000333511_ENST00000262965_572701_1627425 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6499
Å |
 |  | 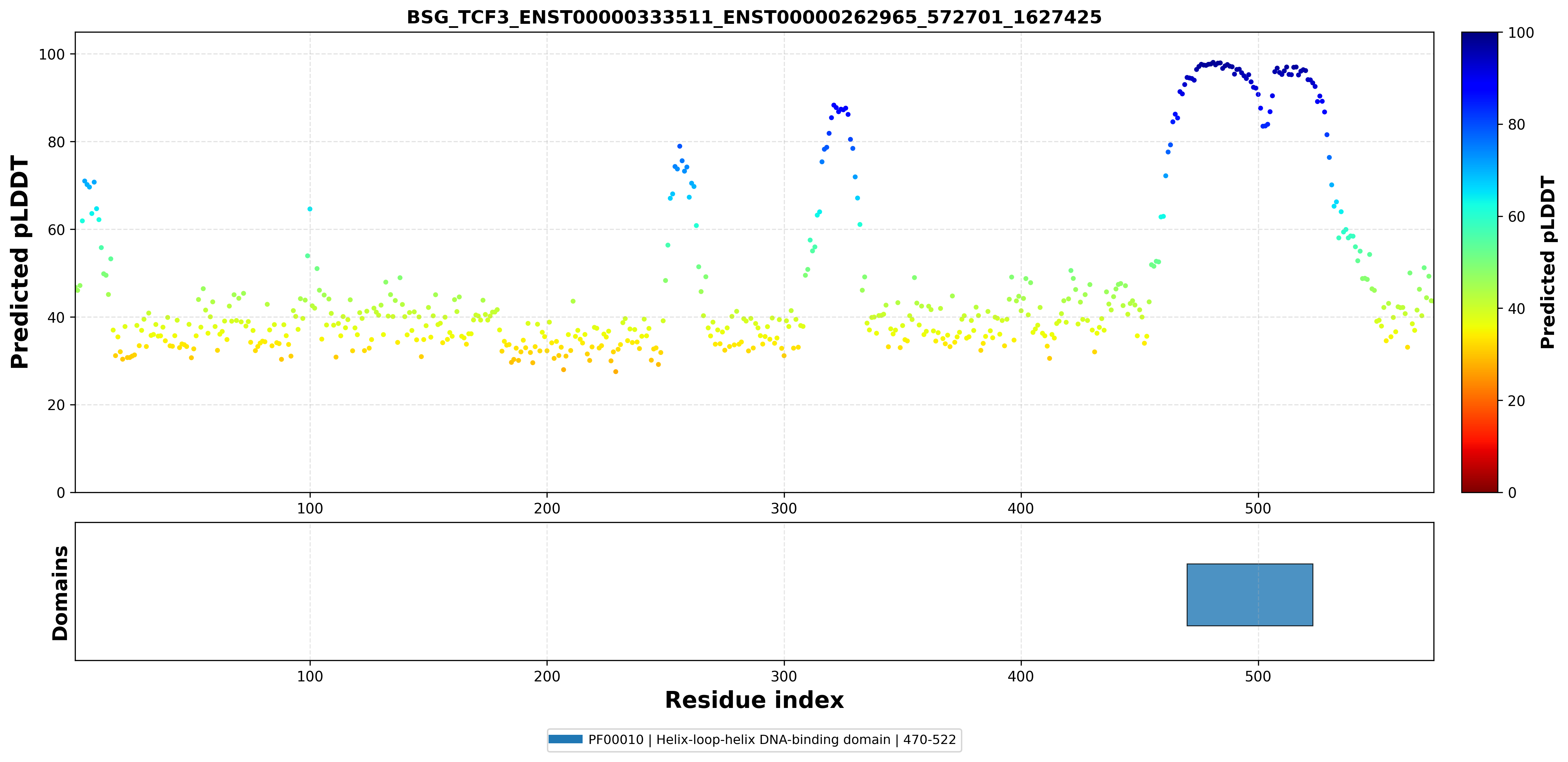 |  |  |
| BSG_TCF3_ENST00000333511_ENST00000262965_572701_1632404 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6683
Å |
 |  | 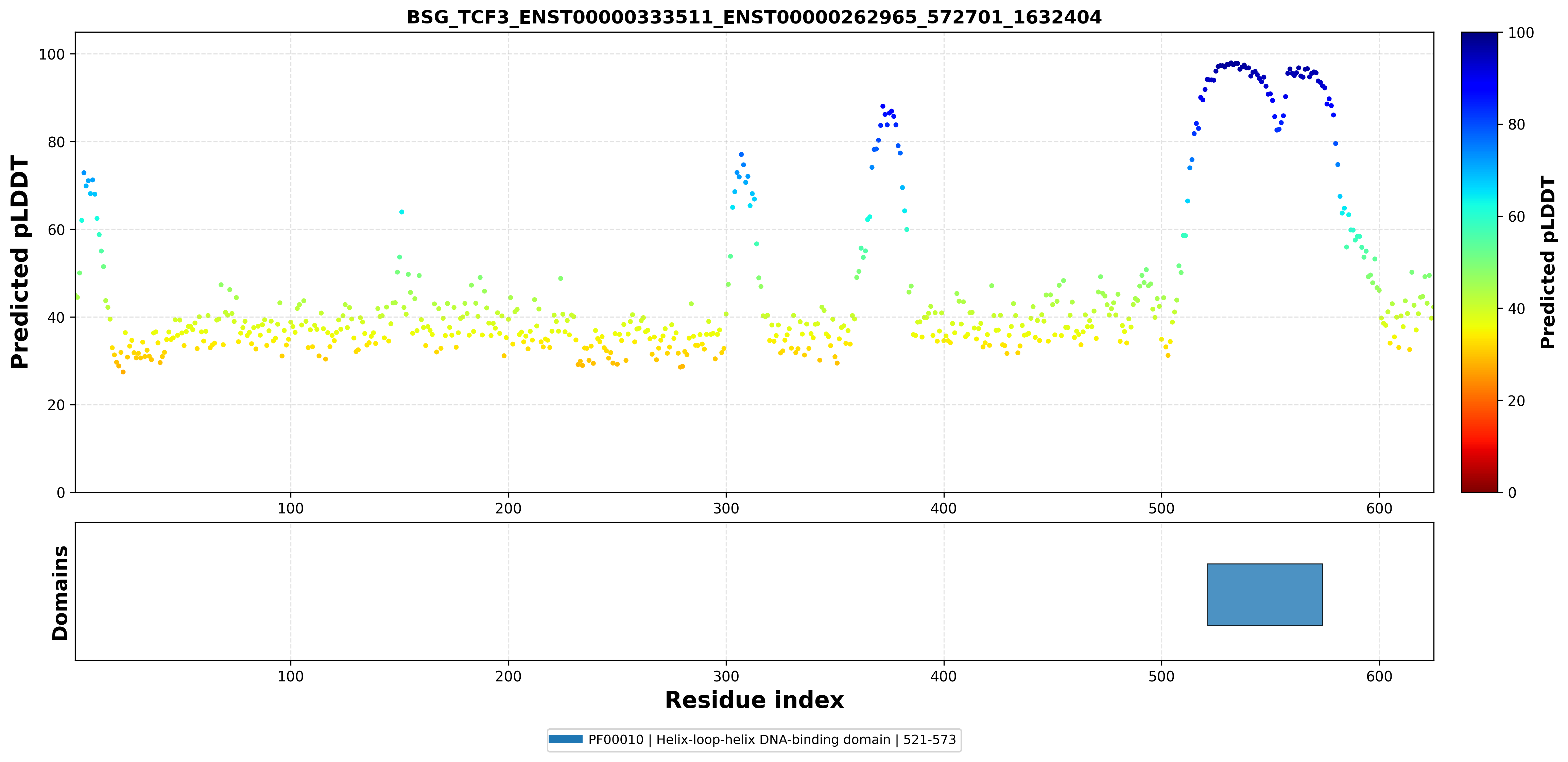 |  |  |
| BSG_TCF3_ENST00000333511_ENST00000395423_572701_1627425 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7562
Å |
 |  | 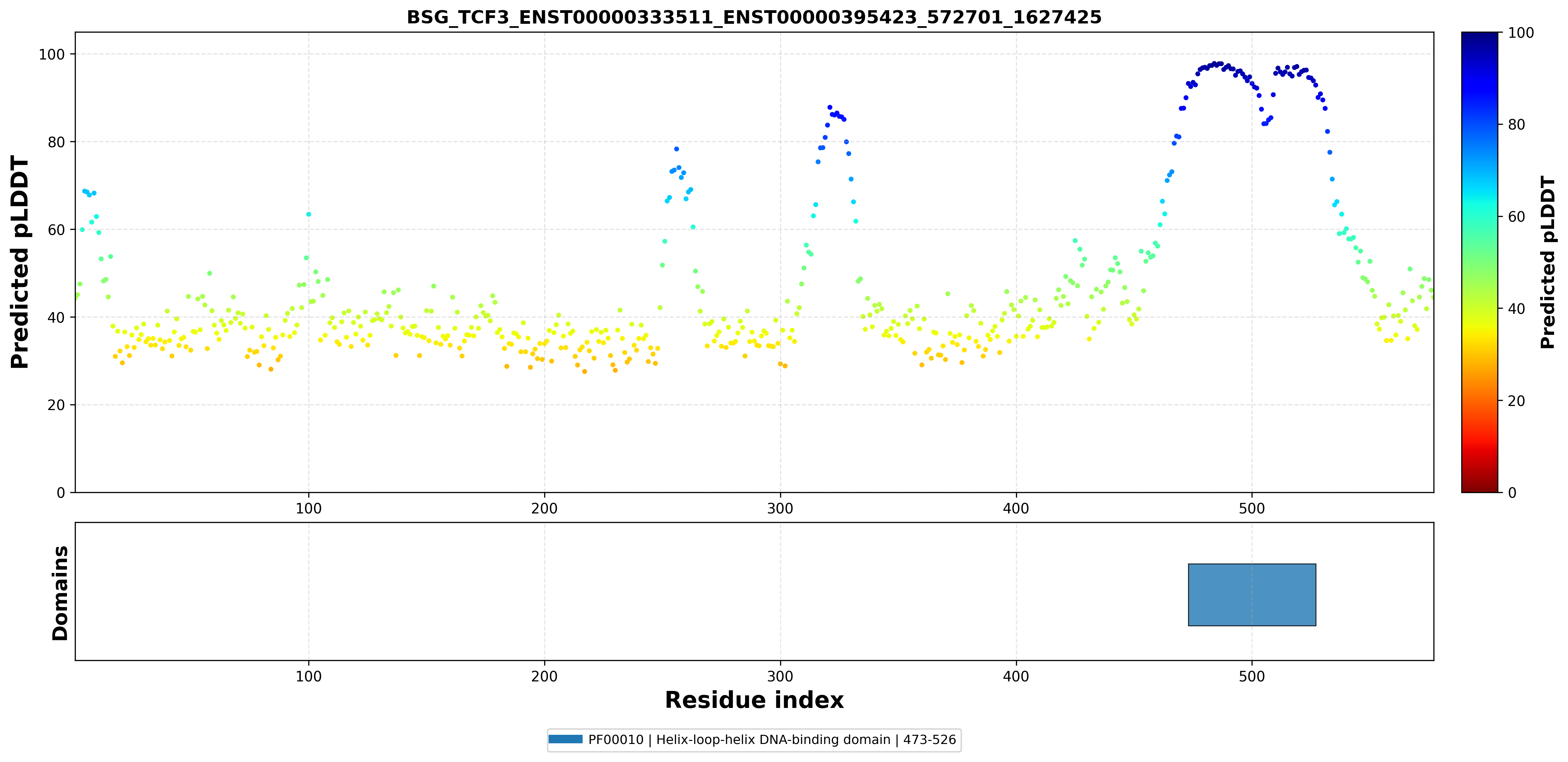 |  |  |
| BSG_TCF3_ENST00000333511_ENST00000588136_572701_1627425 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7055
Å |
 |  | 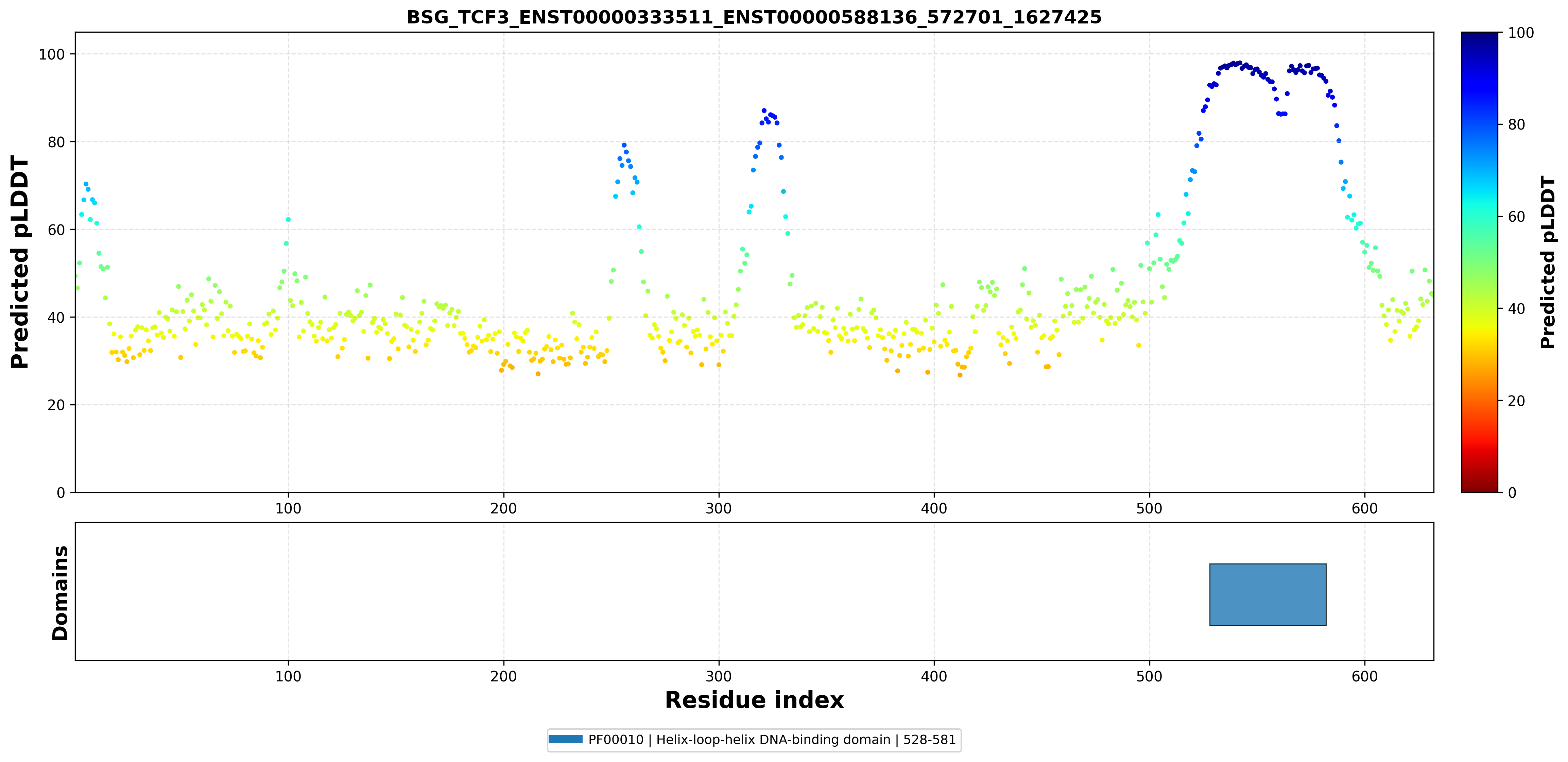 |  |  |
| BSG_TCF3_ENST00000353555_ENST00000344749_572701_1632404 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7021
Å |
 |  | 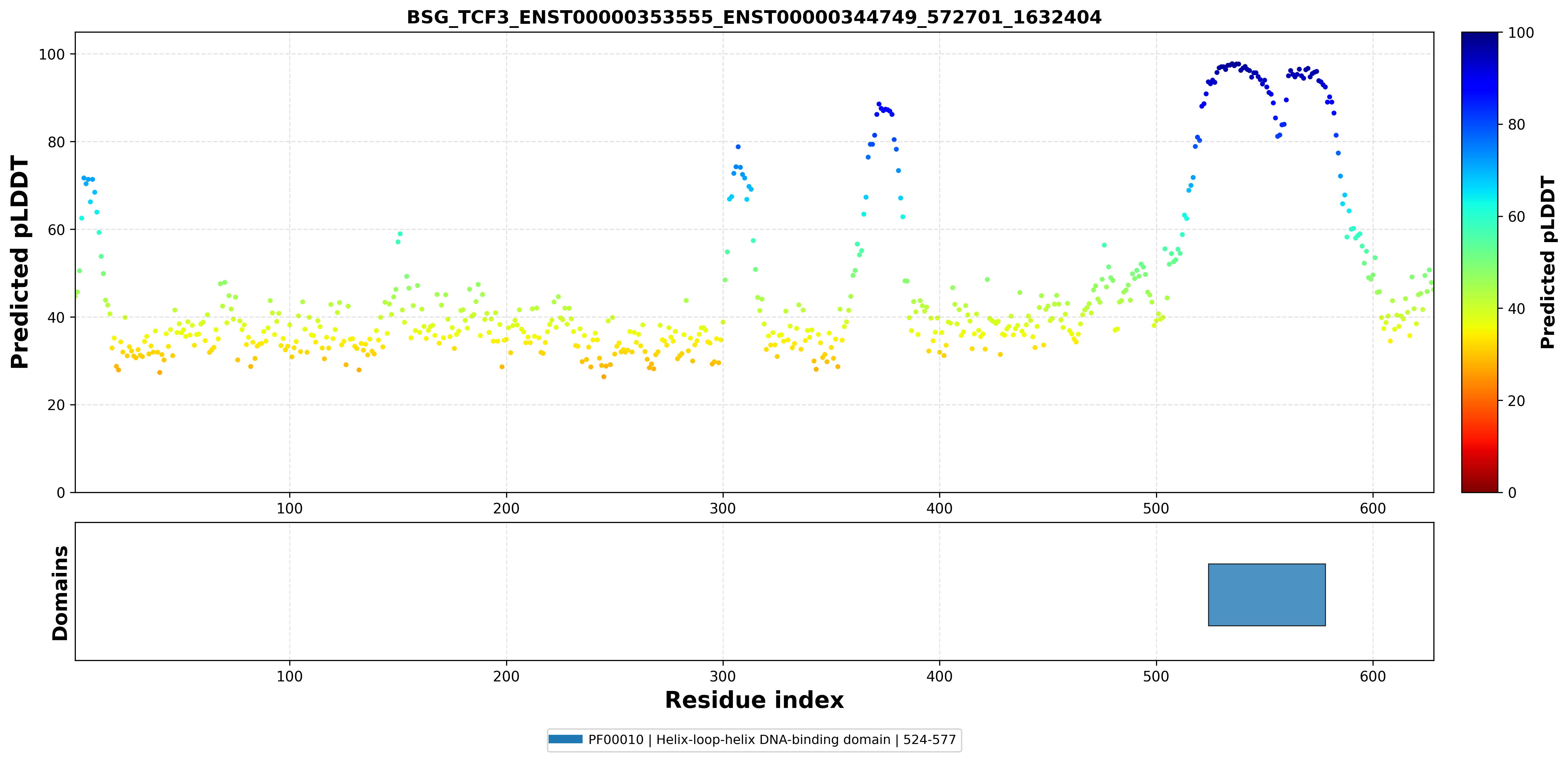 |  |  |
| BSN_ARL8B_ENST00000296452_ENST00000419534_49680585_5212187 superimposed PDB: 8JCA of partner (ARL8B). RMSD:0.4238
Å |
 |  |  |  |  |
| BTBD10_SET_ENST00000278174_ENST00000409104_13424714_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.26
Å |
 |  |  |  |  |
| BTBD10_SET_ENST00000528120_ENST00000409104_13424714_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.1995
Å |
 |  |  |  |  |
| BTBD10_SET_ENST00000530907_ENST00000409104_13424714_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.5225
Å |
 |  |  |  |  |
| BTBD1_BBOX1_ENST00000261721_ENST00000263182_83710479_27114714 superimposed PDB: 4C5W of partner (BBOX1). RMSD:0.6333
Å |
 |  |  |  |  |
| BTBD1_ETFA_ENST00000379403_ENST00000557943_83725140_76588078 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.4423
Å |
 |  |  |  |  |
| BTBD1_MRPL46_ENST00000379403_ENST00000312475_83725140_89009004 superimposed PDB: 7OF0 of partner (MRPL46). RMSD:1.7394
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000317501_83710479_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.8074
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000355254_83710479_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6892
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000355254_83710479_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6829
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000557856_83710479_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7302
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000557856_83710479_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7544
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000558676_83710479_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6904
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000261721_ENST00000558676_83710479_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7314
Å |
 |  |  |  |  |
| BTBD1_NTRK3_ENST00000379403_ENST00000394480_83710479_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6517
Å |
 |  |  |  |  |
| BTBD2_OAS2_ENST00000255608_ENST00000392583_1993018_113424842 superimposed PDB: 9H1Z of partner (OAS2). RMSD:0.9188
Å |
 |  |  |  |  |
| BTBD8_ASL_ENST00000342818_ENST00000304874_92568226_65553793 superimposed PDB: 1K62 of partner (ASL). RMSD:3.1136
Å |
 |  |  |  |  |
| BTBD8_ASL_ENST00000370382_ENST00000380839_92568226_65553793 superimposed PDB: 1K62 of partner (ASL). RMSD:2.1545
Å |
 |  |  |  |  |
| BTRC_TNNC2_ENST00000393441_ENST00000372555_103113985_44453473 superimposed PDB: 7KAA of partner (TNNC2). RMSD:1.744
Å |
 | 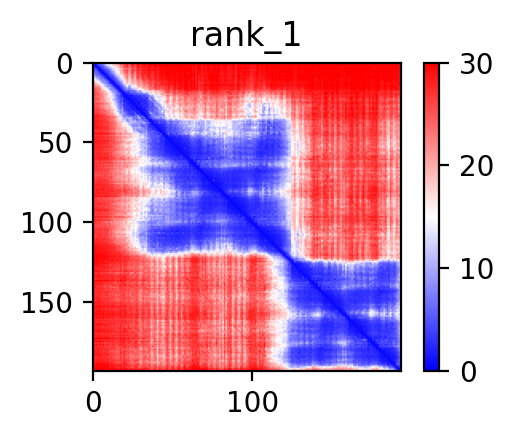 | 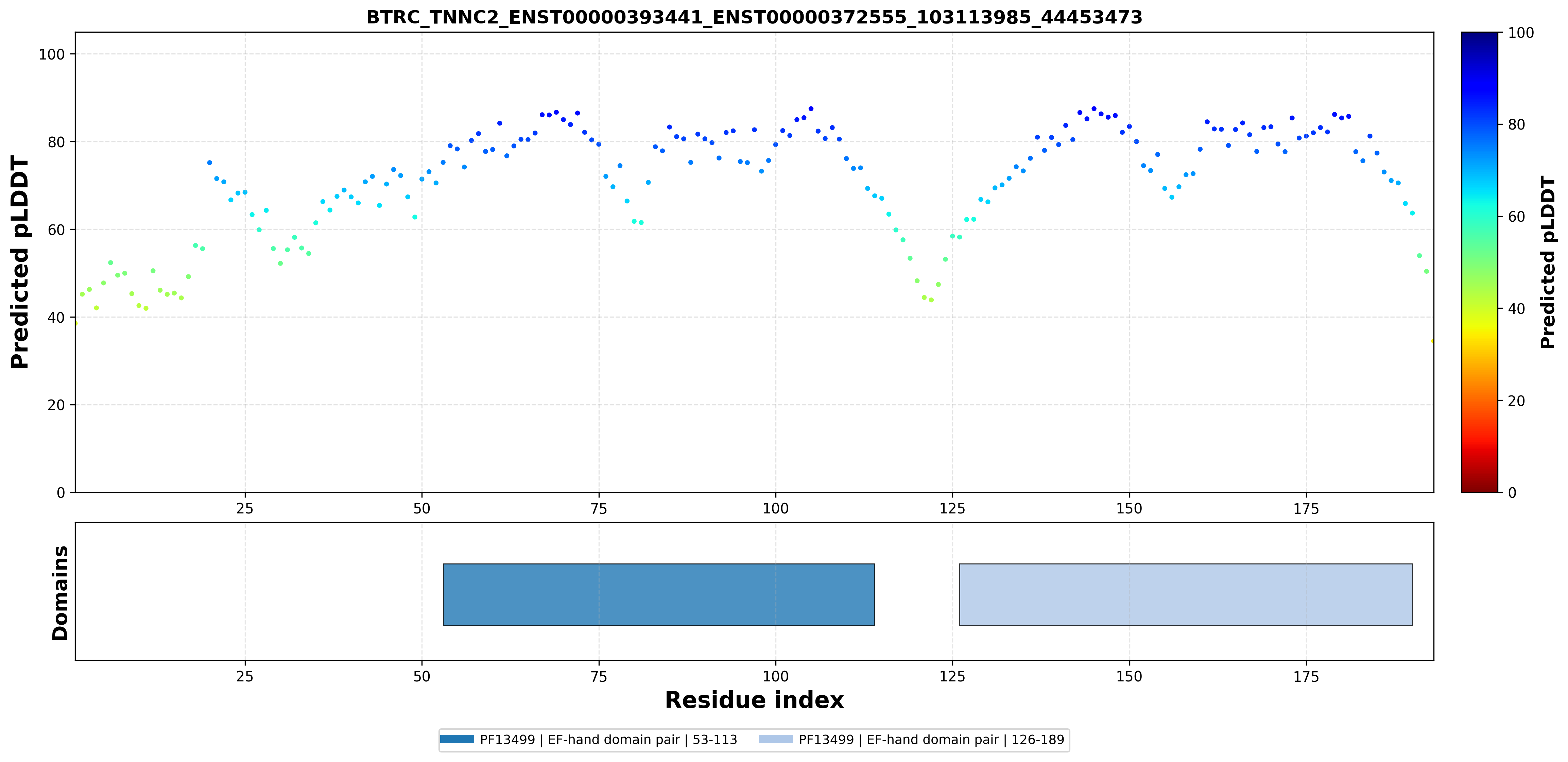 |  |  |
| BTRC_ZMIZ1_ENST00000393441_ENST00000478357_103113985_81036935 superimposed PDB: 6TTU of partner (BTRC). RMSD:2.1411
Å |
 |  |  |  |  |
| BTRC_ZMIZ1_ENST00000393441_ENST00000478357_103113985_81036935 superimposed PDB: 5AIZ of partner (ZMIZ1). RMSD:0.3947
Å |
| | | |  |
| C11orf30_SLC30A9_ENST00000334736_ENST00000264451_76183884_42088098 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.3956
Å |
 |  |  |  |  |
| C11orf30_SLC30A9_ENST00000343878_ENST00000264451_76183884_42088098 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.3524
Å |
 |  |  |  |  |
| C11orf30_SLC30A9_ENST00000525038_ENST00000264451_76183884_42088098 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.5795
Å |
 |  |  |  |  |
| C11orf30_SLC30A9_ENST00000525919_ENST00000264451_76183884_42088098 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.5686
Å |
 |  |  |  |  |
| C11orf30_UVRAG_ENST00000334736_ENST00000528420_76207513_75715048 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.4212
Å |
 |  |  |  |  |
| C11orf30_UVRAG_ENST00000334736_ENST00000528420_76207513_75715048 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.4564
Å |
| | | |  |
| C11orf30_UVRAG_ENST00000524767_ENST00000528420_76207513_75715048 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.5342
Å |
 |  |  |  |  |
| C11orf30_UVRAG_ENST00000524767_ENST00000528420_76207513_75715048 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.3449
Å |
| | | |  |
| C11orf30_UVRAG_ENST00000525919_ENST00000528420_76207513_75715048 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.4238
Å |
 |  |  |  |  |
| C11orf30_UVRAG_ENST00000525919_ENST00000528420_76207513_75715048 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.3232
Å |
| | | |  |
| C11orf30_UVRAG_ENST00000533248_ENST00000528420_76207513_75715048 superimposed PDB: 2FMM of partner (C11orf30). RMSD:0.586
Å |
 |  |  |  |  |
| C11orf30_UVRAG_ENST00000533248_ENST00000528420_76207513_75715048 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.1116
Å |
| | | |  |
| C11orf49_F2_ENST00000543718_ENST00000530231_47008861_46747408 superimposed PDB: 8RTN of partner (F2). RMSD:0.4647
Å |
 |  |  |  |  |
| C11orf54_EED_ENST00000528288_ENST00000351625_93487203_85988021 superimposed PDB: 1XCR of partner (C11orf54). RMSD:1.4024
Å |
 |  |  |  |  |
| C11orf54_EED_ENST00000528288_ENST00000351625_93487203_85988021 superimposed PDB: 8VMI of partner (EED). RMSD:1.3662
Å |
| | | |  |
| C11orf54_EED_ENST00000528288_ENST00000351625_93488552_85988021 superimposed PDB: 1XCR of partner (C11orf54). RMSD:0.7786
Å |
 |  |  |  |  |
| C11orf54_EED_ENST00000528288_ENST00000351625_93488552_85988021 superimposed PDB: 8VMI of partner (EED). RMSD:1.9614
Å |
| | | |  |
| C11orf54_EED_ENST00000528288_ENST00000528180_93487203_85988021 superimposed PDB: 1XCR of partner (C11orf54). RMSD:1.4681
Å |
 |  |  |  |  |
| C11orf54_EED_ENST00000528288_ENST00000528180_93487203_85988021 superimposed PDB: 8VMI of partner (EED). RMSD:1.0761
Å |
| | | |  |
| C11orf54_EED_ENST00000528288_ENST00000528180_93488552_85988021 superimposed PDB: 1XCR of partner (C11orf54). RMSD:1.1068
Å |
 |  |  |  |  |
| C11orf54_EED_ENST00000528288_ENST00000528180_93488552_85988021 superimposed PDB: 8VMI of partner (EED). RMSD:1.1893
Å |
| | | |  |
| C11orf58_PTGIS_ENST00000422258_ENST00000244043_16774441_48164556 superimposed PDB: 3B6H of partner (PTGIS). RMSD:0.5008
Å |
 |  |  |  |  |
| C12orf10_NFX1_ENST00000548632_ENST00000379540_53700104_33366626 superimposed PDB: 24AN of partner (C12orf10). RMSD:0.6101
Å |
 |  |  |  |  |
| C12orf49_ATP10A_ENST00000536380_ENST00000356865_117175594_25940293 superimposed PDB: 8UW8 of partner (C12orf49). RMSD:2.6225
Å |
 |  |  |  |  |
| C12orf49_MDM2_ENST00000261318_ENST00000356290_117175594_69229608 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.7326
Å |
 |  |  |  |  |
| C12orf49_MDM2_ENST00000536380_ENST00000462284_117175594_69229608 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.8597
Å |
 |  |  |  |  |
| C12orf56_USP15_ENST00000333722_ENST00000280377_64784093_62775270 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5202
Å |
 |  |  |  |  |
| C12orf56_USP15_ENST00000543942_ENST00000280377_64784093_62775270 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5236
Å |
 |  |  |  |  |
| C12orf76_GPX2_ENST00000549724_ENST00000389614_110486167_65406556 superimposed PDB: 2HE3 of partner (GPX2). RMSD:2.8903
Å |
 |  |  |  |  |
| C14orf80_PSME1_ENST00000392523_ENST00000206451_105960270_24606529 superimposed PDB: 7NAO of partner (PSME1). RMSD:0.755
Å |
 |  |  |  |  |
| C15orf41_RAC2_ENST00000338183_ENST00000249071_37002162_37628958 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.4623
Å |
 |  |  |  |  |
| C15orf41_RAC2_ENST00000437989_ENST00000249071_37002162_37628958 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.4487
Å |
 |  |  |  |  |
| C15orf41_RAC2_ENST00000562877_ENST00000249071_37002162_37628958 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.4403
Å |
 |  |  |  |  |
| C15orf41_RAC2_ENST00000567389_ENST00000249071_37002162_37628958 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.4323
Å |
 |  |  |  |  |
| C15orf41_RAC2_ENST00000569302_ENST00000249071_37002162_37628958 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.4336
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000300006_ENST00000345148_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.6264
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000300006_ENST00000346370_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.5633
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000300006_ENST00000349029_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.5598
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000300006_ENST00000351154_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.797
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000300006_ENST00000399408_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.7809
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000345148_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.6153
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000346370_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.5154
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000349029_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.6204
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000351154_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.7873
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000399408_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.8111
Å |
 |  |  |  |  |
| C16orf45_ABCC1_ENST00000566490_ENST00000399410_15528616_16170182 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.6796
Å |
 |  |  |  |  |
| C16orf70_ATP6V0D1_ENST00000219139_ENST00000290949_67144142_67487618 superimposed PDB: 6WLW of partner (ATP6V0D1). RMSD:0.9218
Å |
 |  |  |  |  |
| C16orf70_ATP6V0D1_ENST00000219139_ENST00000540149_67144142_67487618 superimposed PDB: 6WLW of partner (ATP6V0D1). RMSD:1.0134
Å |
 |  |  |  |  |
| C16orf70_ATP6V0D1_ENST00000569600_ENST00000540149_67144142_67487618 superimposed PDB: 6WLW of partner (ATP6V0D1). RMSD:1.0049
Å |
 |  |  |  |  |
| C16orf70_GNAO1_ENST00000219139_ENST00000262493_67159945_56362542 superimposed PDB: 9BSB of partner (GNAO1). RMSD:1.2455
Å |
 |  |  |  |  |
| C16orf70_GNAO1_ENST00000219139_ENST00000262494_67159945_56362542 superimposed PDB: 9BSB of partner (GNAO1). RMSD:1.3367
Å |
 |  |  |  |  |
| C16orf70_GNAO1_ENST00000569600_ENST00000262493_67159945_56362542 superimposed PDB: 9BSB of partner (GNAO1). RMSD:1.3799
Å |
 |  |  |  |  |
| C16orf70_GNAO1_ENST00000569600_ENST00000262494_67159945_56362542 superimposed PDB: 9BSB of partner (GNAO1). RMSD:1.6011
Å |
 |  |  |  |  |
| C17orf85_ATP2A3_ENST00000389005_ENST00000309890_3717615_3857004 superimposed PDB: 8BY6 of partner (C17orf85). RMSD:0.1664
Å |
 |  |  |  |  |
| C19orf10_MAP2K3_ENST00000262947_ENST00000342679_4659942_21201724 superimposed PDB: 6SVL of partner (C19orf10). RMSD:0.3557
Å |
 |  |  |  |  |
| C19orf25_MED1_ENST00000585675_ENST00000300651_1478772_37604157 superimposed PDB: 7EMF of partner (MED1). RMSD:0.6774
Å |
 |  |  |  |  |
| C19orf25_TCF3_ENST00000585675_ENST00000262965_1478772_1632404 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6877
Å |
 |  |  |  |  |
| C1orf52_PPP3CB_ENST00000471115_ENST00000342558_85724206_75231371 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.7019
Å |
 |  |  |  |  |
| C1orf52_PPP3CB_ENST00000471115_ENST00000394822_85724206_75231371 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:1.0402
Å |
 |  |  |  |  |
| C1orf52_PPP3CB_ENST00000471115_ENST00000394828_85724206_75231371 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.7593
Å |
 |  |  |  |  |
| C1orf52_PPP3CB_ENST00000471115_ENST00000394829_85724206_75231371 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.6384
Å |
 |  |  |  |  |
| C1orf52_PPP3CB_ENST00000471115_ENST00000545874_85724206_75231371 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.8667
Å |
 |  |  |  |  |
| C20orf194_ASPH_ENST00000453730_ENST00000379454_3285086_62559437 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.7697
Å |
 |  |  |  |  |
| C21orf59_BACE2_ENST00000290155_ENST00000330333_33975470_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.6773
Å |
 |  |  |  |  |
| C21orf59_BACE2_ENST00000290155_ENST00000347667_33975470_42598192 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:0.4662
Å |
 |  |  |  |  |
| C22orf39_MAPK1_ENST00000399562_ENST00000215832_19434900_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.5499
Å |
 |  |  |  |  |
| C2CD3_PC_ENST00000334126_ENST00000393960_73872443_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7581
Å |
 |  | 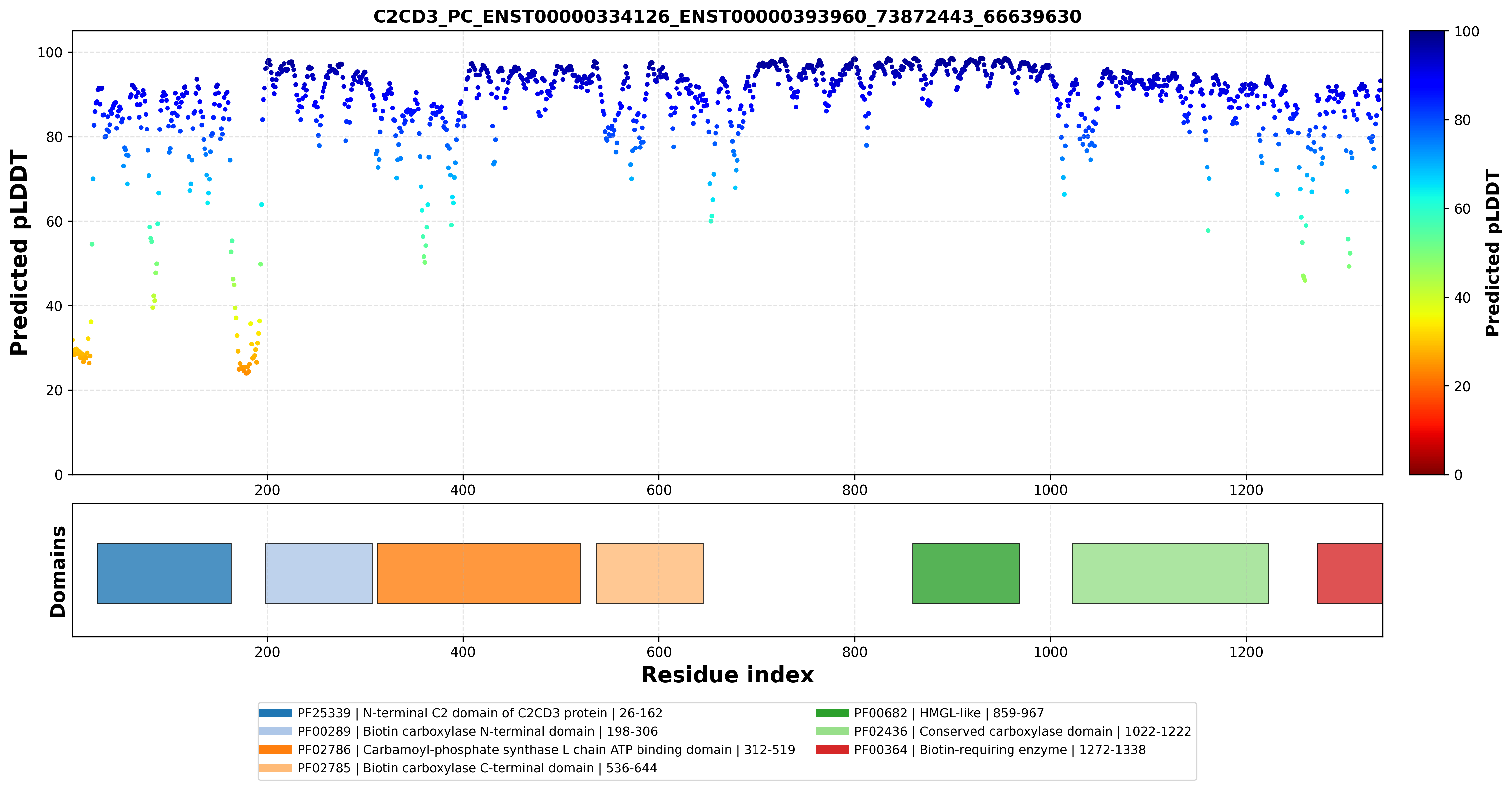 |  |  |
| C2CD5_BCAT1_ENST00000542676_ENST00000538118_22627684_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:0.5843
Å |
 |  |  |  |  |
| C2CD5_BCAT1_ENST00000544930_ENST00000538118_22627684_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:0.5917
Å |
 |  |  |  |  |
| C2orf70_CNOT10_ENST00000329615_ENST00000328834_26785554_32800949 superimposed PDB: 8BFI of partner (CNOT10). RMSD:0.8963
Å |
 |  |  |  |  |
| C2orf70_CNOT10_ENST00000329615_ENST00000454516_26785554_32800949 superimposed PDB: 8BFI of partner (CNOT10). RMSD:0.6231
Å |
 |  |  |  |  |
| C3_ZNF556_ENST00000245907_ENST00000586426_6690639_2873493 superimposed PDB: 9U62 of partner (C3). RMSD:2.2001
Å |
 |  |  |  |  |
| C4orf32_EIF4E_ENST00000309733_ENST00000280892_113066889_99823133 superimposed PDB: 5T46 of partner (EIF4E). RMSD:0.2927
Å |
 |  |  |  |  |
| C5AR1_HSD17B14_ENST00000355085_ENST00000599157_47813155_49318398 superimposed PDB: 8HK5 of partner (C5AR1). RMSD:1.5063
Å |
 |  |  |  |  |
| C5orf42_NPR3_ENST00000508244_ENST00000265074_37153841_32774813 superimposed PDB: 1YK0 of partner (NPR3). RMSD:2.1103
Å |
 |  |  |  |  |
| C5orf42_NPR3_ENST00000508244_ENST00000415685_37153841_32774813 superimposed PDB: 1YK0 of partner (NPR3). RMSD:2.2581
Å |
 |  |  |  |  |
| C6orf106_PRKCB_ENST00000374023_ENST00000303531_34574331_24043456 superimposed PDB: 6VHI of partner (C6orf106). RMSD:0.3288
Å |
 |  |  |  |  |
| C6orf106_PRKCB_ENST00000374023_ENST00000303531_34574331_24043456 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1543
Å |
| | | |  |
| C6orf106_PRKCB_ENST00000374026_ENST00000303531_34574331_24043456 superimposed PDB: 6VHI of partner (C6orf106). RMSD:0.7585
Å |
 |  |  |  |  |
| C6orf106_PRKCB_ENST00000374026_ENST00000303531_34574331_24043456 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.0185
Å |
| | | |  |
| C6orf106_PRKCB_ENST00000374026_ENST00000321728_34574331_24043456 superimposed PDB: 6VHI of partner (C6orf106). RMSD:0.3735
Å |
 |  |  |  |  |
| C6orf106_PRKCB_ENST00000374026_ENST00000321728_34574331_24043456 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1544
Å |
| | | |  |
| C6orf106_SPDEF_ENST00000374023_ENST00000374037_34614377_34508958 superimposed PDB: 6VHI of partner (C6orf106). RMSD:0.4365
Å |
 |  |  |  |  |
| C6orf106_SPDEF_ENST00000374023_ENST00000544425_34614377_34508958 superimposed PDB: 6VHI of partner (C6orf106). RMSD:0.4308
Å |
 |  |  |  |  |
| C6orf106_SPDEF_ENST00000374023_ENST00000544425_34614377_34508958 superimposed PDB: 1YO5 of partner (SPDEF). RMSD:0.3037
Å |
| | | |  |
| C6orf136_AKR1C1_ENST00000376473_ENST00000434459_30617736_5008105 superimposed PDB: 3C3U of partner (AKR1C1). RMSD:0.4544
Å |
 |  |  |  |  |
| C6orf136_AKR1C1_ENST00000528347_ENST00000434459_30617736_5008105 superimposed PDB: 3C3U of partner (AKR1C1). RMSD:0.4424
Å |
 |  |  |  |  |
| C7orf50_MAD1L1_ENST00000397100_ENST00000265854_1040105_1855864 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:3.0771
Å |
 |  |  |  |  |
| C7orf50_PDK2_ENST00000397100_ENST00000503176_1166892_48182734 superimposed PDB: 5M4P of partner (PDK2). RMSD:1.092
Å |
 |  |  |  |  |
| C7orf55_SLC25A13_ENST00000297534_ENST00000416240_139026268_95906650 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:1.004
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000297979_ENST00000346706_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.3904
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000375315_ENST00000346706_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.4154
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000375315_ENST00000535648_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.3973
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000425634_ENST00000346706_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.4036
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000433691_ENST00000346706_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.3853
Å |
 |  |  |  |  |
| C9orf3_TNC_ENST00000433691_ENST00000535648_97767898_117793964 superimposed PDB: 8FNB of partner (TNC). RMSD:0.3915
Å |
 |  |  |  |  |
| C9orf85_FXN_ENST00000334731_ENST00000396366_74526752_71679853 superimposed PDB: 5KZ5 of partner (FXN). RMSD:2.3077
Å |
 |  |  |  |  |
| C9orf85_FXN_ENST00000334731_ENST00000498653_74526752_71679853 superimposed PDB: 5KZ5 of partner (FXN). RMSD:2.552
Å |
 |  |  |  |  |
| C9orf85_FXN_ENST00000486911_ENST00000377270_74526752_71679853 superimposed PDB: 5KZ5 of partner (FXN). RMSD:3.0421
Å |
 |  |  |  |  |
| CA3_MYBL1_ENST00000285381_ENST00000517885_86356355_67479227 superimposed PDB: 3UYQ of partner (CA3). RMSD:1.7931
Å |
 |  |  |  |  |
| CAAP1_TNNI3K_ENST00000333916_ENST00000326637_26861063_74832939 superimposed PDB: 4YFI of partner (TNNI3K). RMSD:0.5067
Å |
 |  |  |  |  |
| CABIN1_GSTT2_ENST00000263119_ENST00000402588_24509715_24323138 superimposed PDB: 4MPG of partner (GSTT2). RMSD:0.6714
Å |
 |  |  |  |  |
| CABIN1_GSTT2_ENST00000398319_ENST00000215780_24509715_24323138 superimposed PDB: 4MPG of partner (GSTT2). RMSD:1.0601
Å |
 |  |  |  |  |
| CABIN1_GSTT2_ENST00000405822_ENST00000215780_24509715_24323138 superimposed PDB: 4MPG of partner (GSTT2). RMSD:0.8897
Å |
 |  |  |  |  |
| CABIN1_GSTT2_ENST00000405822_ENST00000402588_24509715_24323138 superimposed PDB: 4MPG of partner (GSTT2). RMSD:0.5759
Å |
 |  |  |  |  |
| CABLES1_RBBP8_ENST00000256925_ENST00000360790_20716571_20548768 superimposed PDB: 7BGF of partner (RBBP8). RMSD:1.9806
Å |
 |  |  |  |  |
| CABLES1_RBBP8_ENST00000256925_ENST00000399722_20716571_20548768 superimposed PDB: 7BGF of partner (RBBP8). RMSD:2.0278
Å |
 |  |  |  |  |
| CABLES1_RBBP8_ENST00000256925_ENST00000399722_20774504_20596790 superimposed PDB: 7BGF of partner (RBBP8). RMSD:2.2229
Å |
 |  |  |  |  |
| CACHD1_ROR1_ENST00000290039_ENST00000371080_65145439_64516357 superimposed PDB: 6TU9 of partner (ROR1). RMSD:1.1956
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000347598_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.061
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000399606_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1725
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000399634_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1367
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000399644_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.4182
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000399655_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.01
Å |
 |  |  |  |  |
| CACNA1C_DDX55_ENST00000480911_ENST00000538744_2711126_124104510 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1258
Å |
 |  |  |  |  |
| CACNA1C_DERA_ENST00000347598_ENST00000428559_2622150_16109869 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:3.2399
Å |
 |  |  |  |  |
| CACNA1C_EEA1_ENST00000399655_ENST00000322349_2229596_93213287 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.5703
Å |
 |  |  |  |  |
| CACNA1C_EEA1_ENST00000399655_ENST00000322349_2229596_93213287 superimposed PDB: 1JOC of partner (EEA1). RMSD:2.0901
Å |
| | | |  |
| CACNA1C_EEA1_ENST00000399655_ENST00000322349_2229596_93220061 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.8698
Å |
 |  |  |  |  |
| CACNA1C_EEA1_ENST00000399655_ENST00000322349_2229596_93220061 superimposed PDB: 1JOC of partner (EEA1). RMSD:2.1523
Å |
| | | |  |
| CACNA1D_GNL3_ENST00000288139_ENST00000394799_53804579_52724960 superimposed PDB: 7UHG of partner (CACNA1D). RMSD:2.1383
Å |
 |  |  |  |  |
| CACNA1D_GNL3_ENST00000350061_ENST00000394799_53804579_52724960 superimposed PDB: 7UHG of partner (CACNA1D). RMSD:2.0202
Å |
 |  |  |  |  |
| CACNA1D_GNL3_ENST00000422281_ENST00000394799_53804579_52724960 superimposed PDB: 7UHG of partner (CACNA1D). RMSD:2.0324
Å |
 |  |  |  |  |
| CACNA1D_GNL3_ENST00000540742_ENST00000394799_53804579_52724960 superimposed PDB: 7UHG of partner (CACNA1D). RMSD:1.9763
Å |
 |  |  |  |  |
| CACNA1D_PRKCD_ENST00000350061_ENST00000330452_53535747_53217467 superimposed PDB: 7UHG of partner (CACNA1D). RMSD:2.945
Å |
 |  |  |  |  |
| CACNA1G_CACNA1H_ENST00000360761_ENST00000358590_48650215_1250715 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5201
Å |
 |  |  |  |  |
| CACNA1G_CACNA1H_ENST00000360761_ENST00000565831_48650215_1250715 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.4692
Å |
 |  |  |  |  |
| CACNA1G_CACNA1H_ENST00000416767_ENST00000358590_48650215_1250715 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.4024
Å |
 |  |  |  |  |
| CACNA1G_CACNA1H_ENST00000416767_ENST00000565831_48650215_1250715 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.4178
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000352832_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7567
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000354983_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8585
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000354983_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:3.3827
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000358244_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8381
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000359106_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.0615
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000359106_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:3.3573
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000360761_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6126
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000429973_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.713
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000442258_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8244
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000502264_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.0309
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000502264_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.8293
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000503485_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7993
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000507336_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9613
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000507336_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.6849
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000507510_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8133
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000507510_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.8837
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000507609_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9203
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000507896_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.791
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000510115_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7291
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000510115_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:3.2582
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000510366_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9743
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000513689_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8125
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000513964_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8759
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000514079_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8928
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000514181_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9856
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000514717_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6133
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000515165_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.846
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000515411_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6735
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000515411_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.8899
Å |
| | | |  |
| CACNA1G_CREBBP_ENST00000515765_ENST00000382070_48701890_3781938 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9883
Å |
 |  |  |  |  |
| CACNA1G_CREBBP_ENST00000515765_ENST00000382070_48701890_3781938 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.4827
Å |
| | | |  |
| CACNA1G_MED24_ENST00000354983_ENST00000394126_48655925_38182584 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.3451
Å |
 |  |  |  |  |
| CACNA1G_MED24_ENST00000354983_ENST00000394126_48655925_38182584 superimposed PDB: 7EMF of partner (MED24). RMSD:2.7105
Å |
| | | |  |
| CACNA1G_MED24_ENST00000360761_ENST00000356271_48655925_38182584 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2488
Å |
 |  |  |  |  |
| CACNA1G_MED24_ENST00000360761_ENST00000356271_48655925_38182584 superimposed PDB: 7EMF of partner (MED24). RMSD:2.7279
Å |
| | | |  |
| CACNA1G_MED24_ENST00000416767_ENST00000356271_48655925_38182584 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2922
Å |
 |  |  |  |  |
| CACNA1G_MED24_ENST00000416767_ENST00000356271_48655925_38182584 superimposed PDB: 7EMF of partner (MED24). RMSD:2.5781
Å |
| | | |  |
| CACNA1G_MED24_ENST00000502264_ENST00000394126_48655925_38182584 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2235
Å |
 |  |  |  |  |
| CACNA1G_MED24_ENST00000502264_ENST00000394126_48655925_38182584 superimposed PDB: 7EMF of partner (MED24). RMSD:1.1764
Å |
| | | |  |
| CACNA1I_TAB1_ENST00000336649_ENST00000216160_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0883
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000336649_ENST00000331454_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0648
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000400164_ENST00000331454_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.1024
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000401624_ENST00000216160_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0029
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000401624_ENST00000331454_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0099
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000402142_ENST00000216160_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:1.6783
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000404898_ENST00000216160_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0177
Å |
 |  |  |  |  |
| CACNA1I_TAB1_ENST00000407673_ENST00000331454_40058440_39822707 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0413
Å |
 |  |  |  |  |
| CACNA2D3_FOXP1_ENST00000415676_ENST00000318789_54798378_71037228 superimposed PDB: 2KIU of partner (FOXP1). RMSD:2.1645
Å |
 |  |  |  |  |
| CACNA2D3_FOXP1_ENST00000415676_ENST00000475937_54798378_71037228 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3065
Å |
 |  |  |  |  |
| CACNA2D3_FOXP1_ENST00000415676_ENST00000484350_54798378_71037228 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3443
Å |
 |  |  |  |  |
| CACNA2D3_FOXP1_ENST00000490478_ENST00000475937_54798378_71037228 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.2927
Å |
 |  |  |  |  |
| CACNA2D3_FOXP1_ENST00000490478_ENST00000484350_54798378_71037228 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.2693
Å |
 |  |  |  |  |
| CACNA2D3_INTS4_ENST00000288197_ENST00000534064_54157621_77692622 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.8892
Å |
 |  |  |  |  |
| CACNB1_LASP1_ENST00000394303_ENST00000433206_37351136_37054664 superimposed PDB: 3I35 of partner (LASP1). RMSD:0.3766
Å |
 |  |  |  |  |
| CACNB1_MED24_ENST00000394310_ENST00000394126_37351136_38187873 superimposed PDB: 7EMF of partner (MED24). RMSD:3.1901
Å |
 |  |  |  |  |
| CACNB1_MED24_ENST00000394310_ENST00000394128_37351136_38187873 superimposed PDB: 7EMF of partner (MED24). RMSD:3.2531
Å |
 |  |  |  |  |
| CACNB1_PPP4C_ENST00000344140_ENST00000561610_37339965_30094714 superimposed PDB: 7VFS of partner (CACNB1). RMSD:0.8157
Å |
 |  |  |  |  |
| CACNB1_PPP4C_ENST00000394303_ENST00000561610_37339965_30094714 superimposed PDB: 7VFS of partner (CACNB1). RMSD:0.9
Å |
 |  |  |  |  |
| CACNG4_BPTF_ENST00000262138_ENST00000306378_64961247_65887959 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.7163
Å |
 |  |  |  |  |
| CACNG4_BPTF_ENST00000262138_ENST00000321892_64961247_65887959 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.0606
Å |
 |  |  |  |  |
| CADM1_PARD6G_ENST00000537058_ENST00000353265_115374988_77960815 superimposed PDB: 4H5S of partner (CADM1). RMSD:1.0393
Å |
 |  |  |  |  |
| CADPS_FHIT_ENST00000357948_ENST00000476844_62860263_59908140 superimposed PDB: 1FIT of partner (FHIT). RMSD:2.1033
Å |
 |  |  |  |  |
| CAD_KHK_ENST00000264705_ENST00000260598_27455562_27320370 superimposed PDB: 1IBX of partner (CAD). RMSD:0.6122
Å |
 |  |  |  |  |
| CAD_KHK_ENST00000264705_ENST00000260598_27455562_27320370 superimposed PDB: 2HQQ of partner (KHK). RMSD:0.4145
Å |
| | | |  |
| CAD_KHK_ENST00000403525_ENST00000260598_27455562_27320370 superimposed PDB: 1IBX of partner (CAD). RMSD:0.6157
Å |
 |  |  |  |  |
| CAD_KHK_ENST00000403525_ENST00000260598_27455562_27320370 superimposed PDB: 2HQQ of partner (KHK). RMSD:0.4113
Å |
| | | |  |
| CALCOCO2_WRAP53_ENST00000258947_ENST00000316024_46933549_7604058 superimposed PDB: 7EAA of partner (CALCOCO2). RMSD:0.3777
Å |
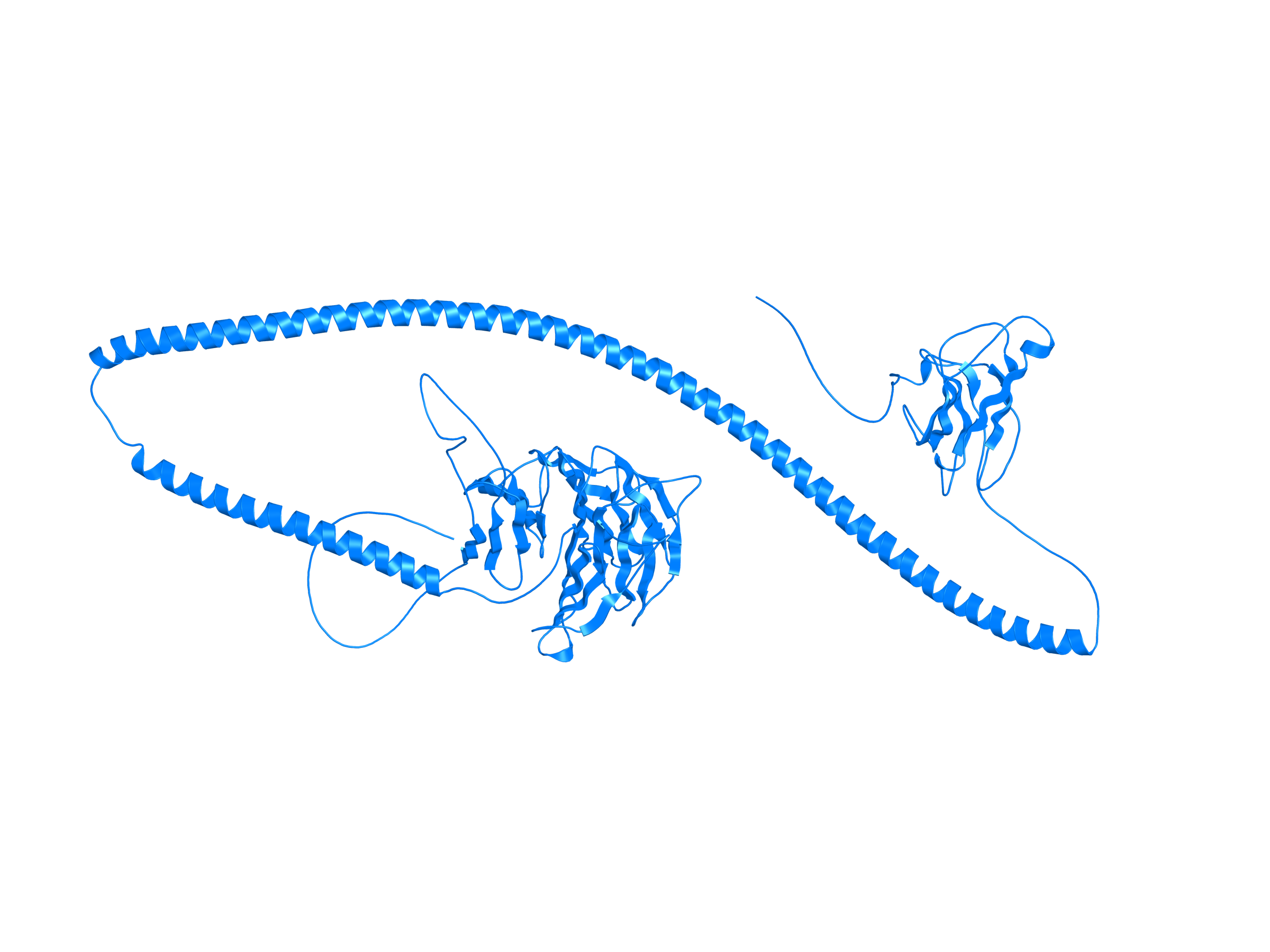 | 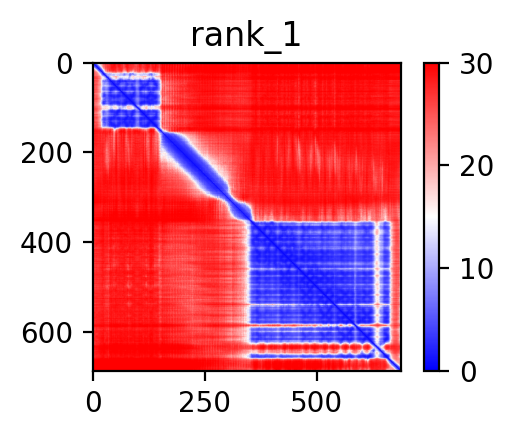 | 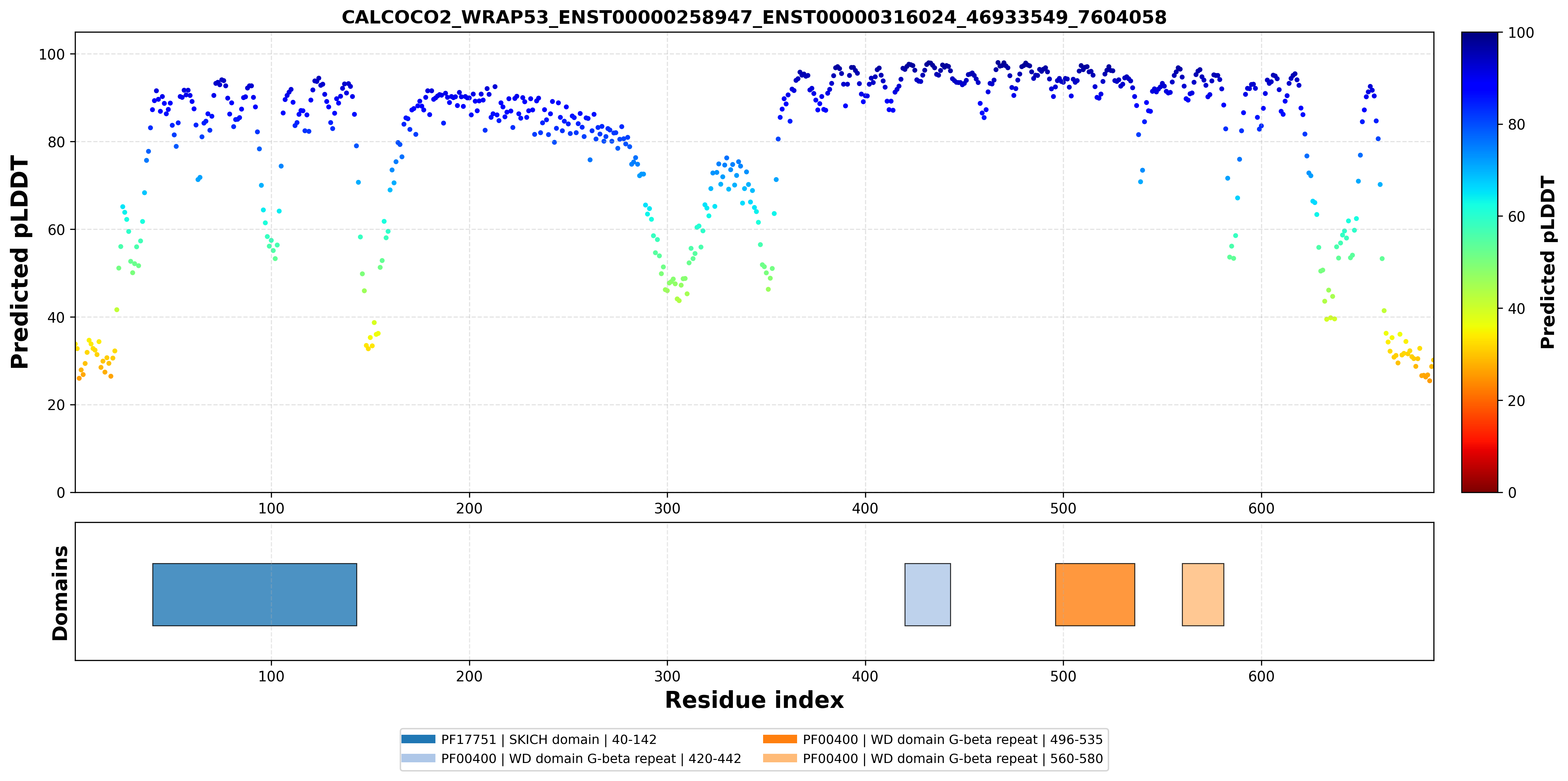 | 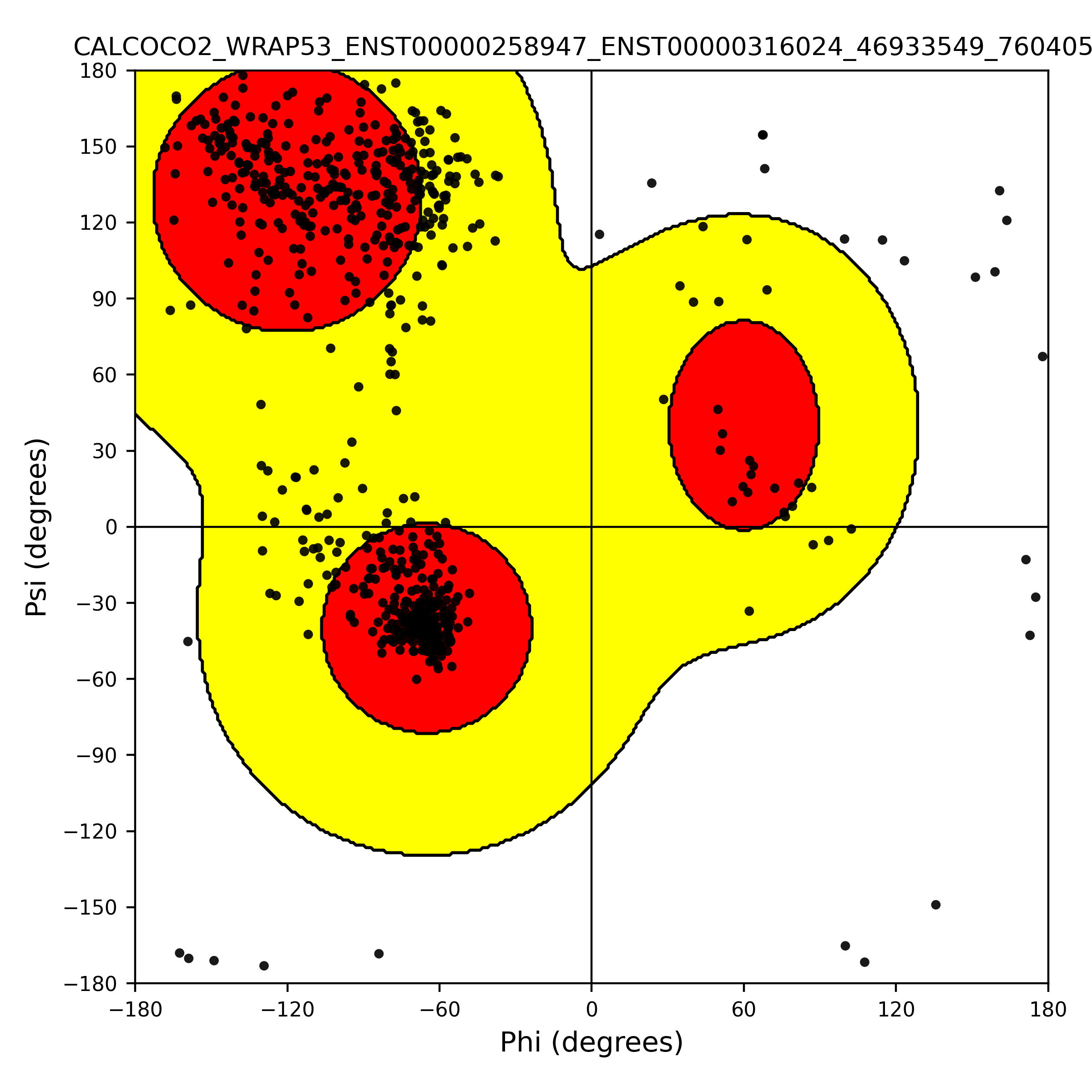 |  |
| CALCOCO2_WRAP53_ENST00000416445_ENST00000316024_46933549_7604058 superimposed PDB: 7EAA of partner (CALCOCO2). RMSD:0.4305
Å |
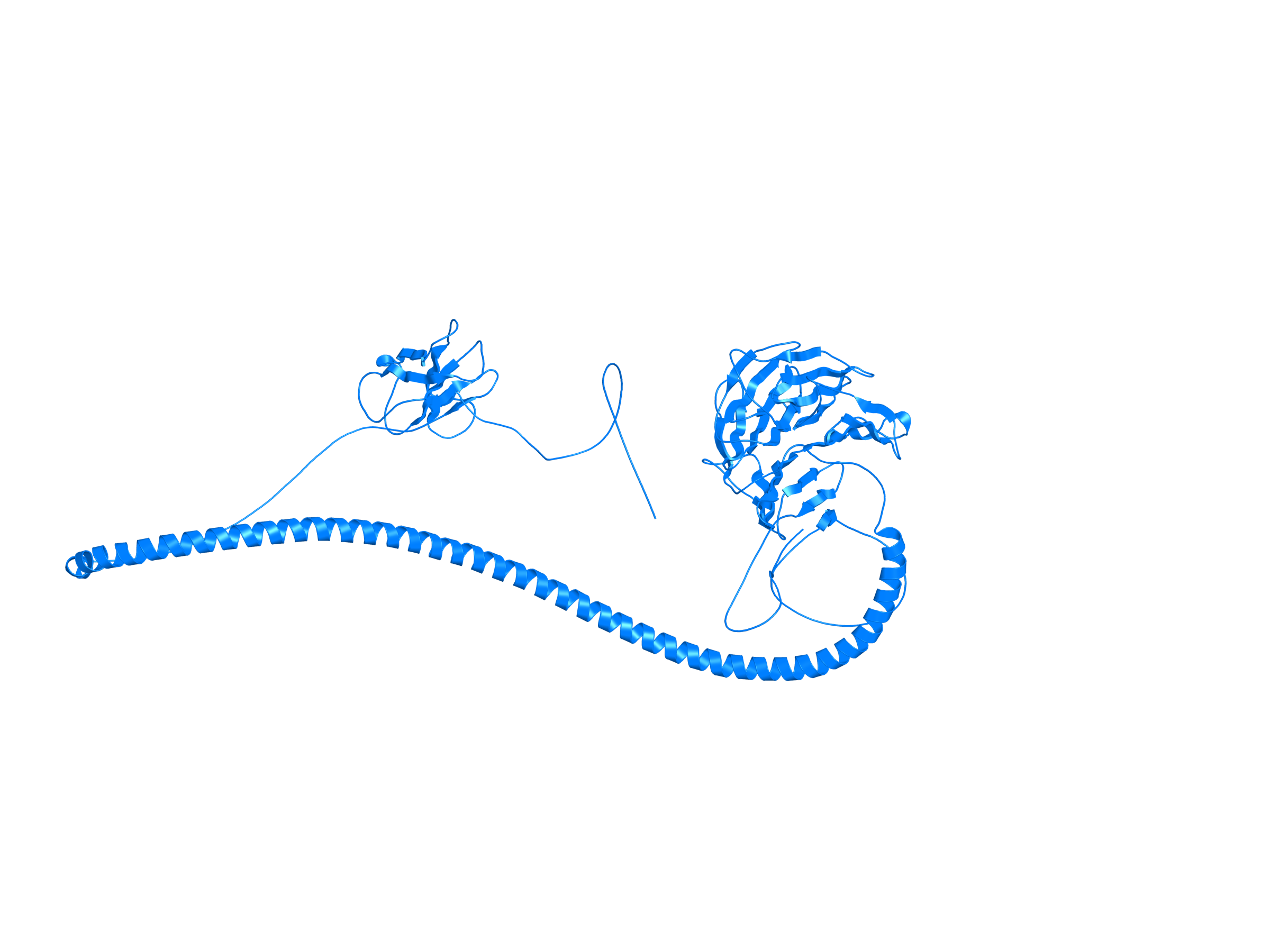 | 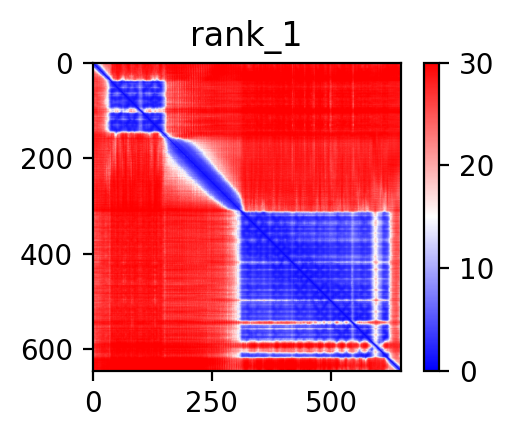 | 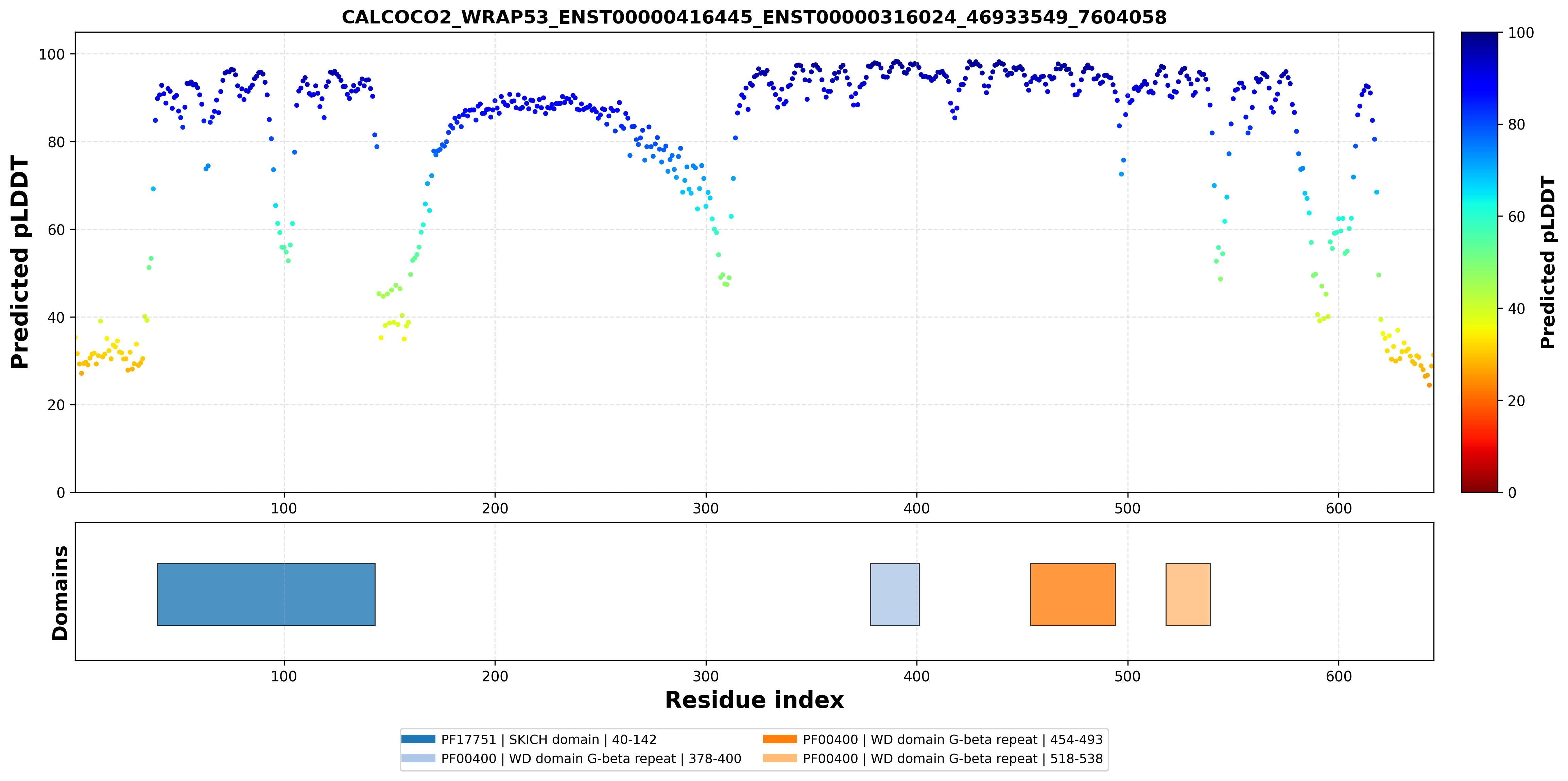 | 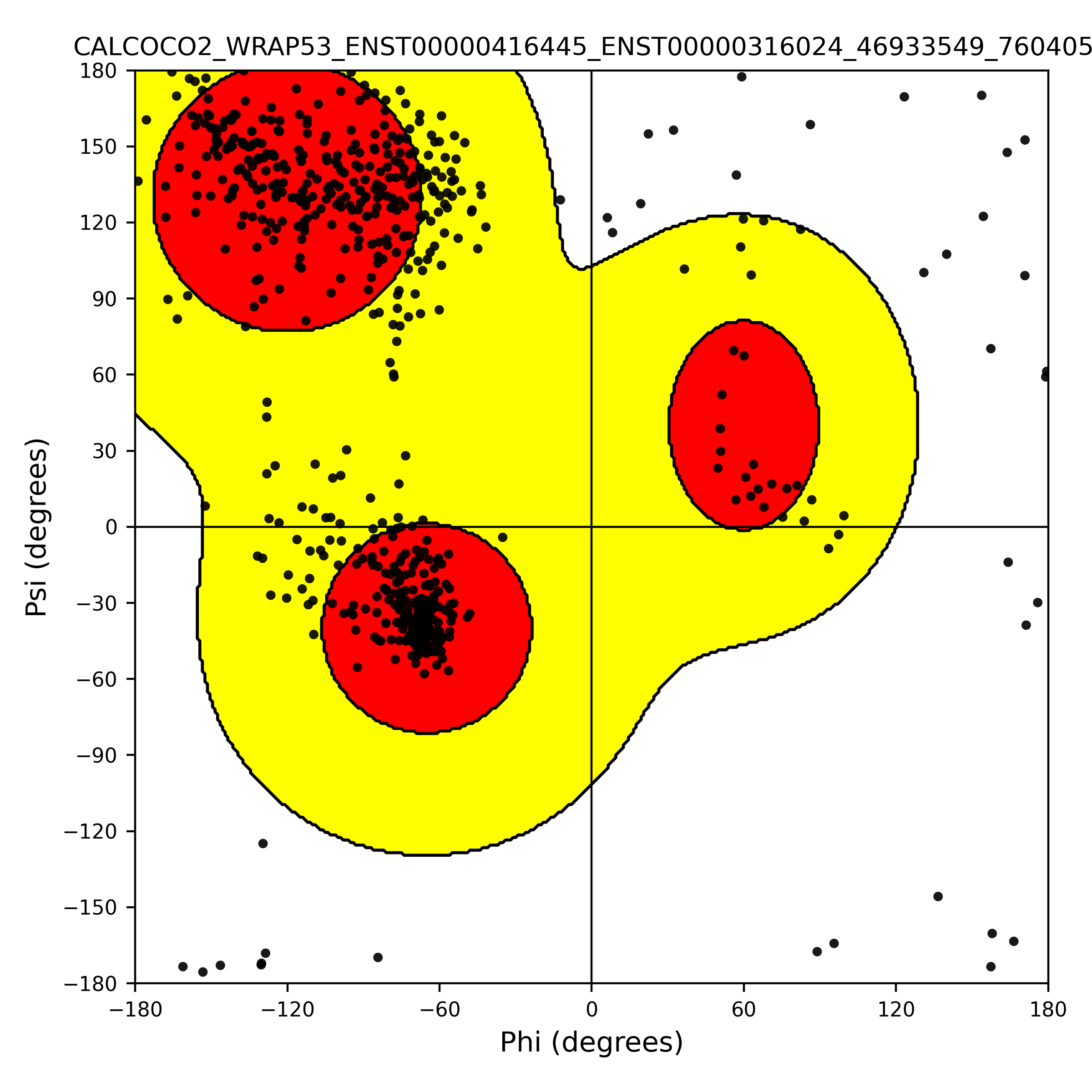 | 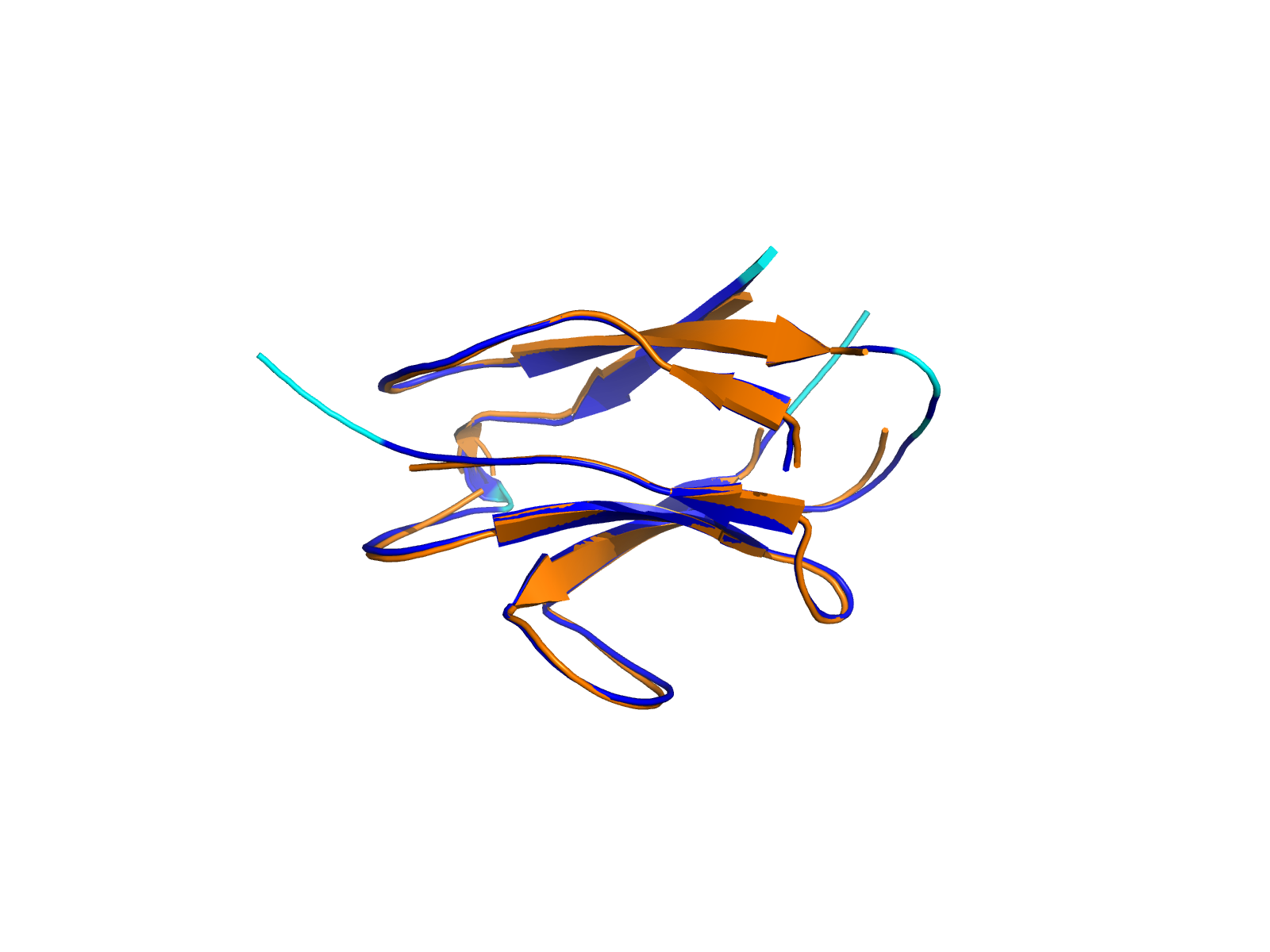 |
| CALCOCO2_WRAP53_ENST00000448105_ENST00000316024_46933549_7604058 superimposed PDB: 7EAA of partner (CALCOCO2). RMSD:0.3466
Å |
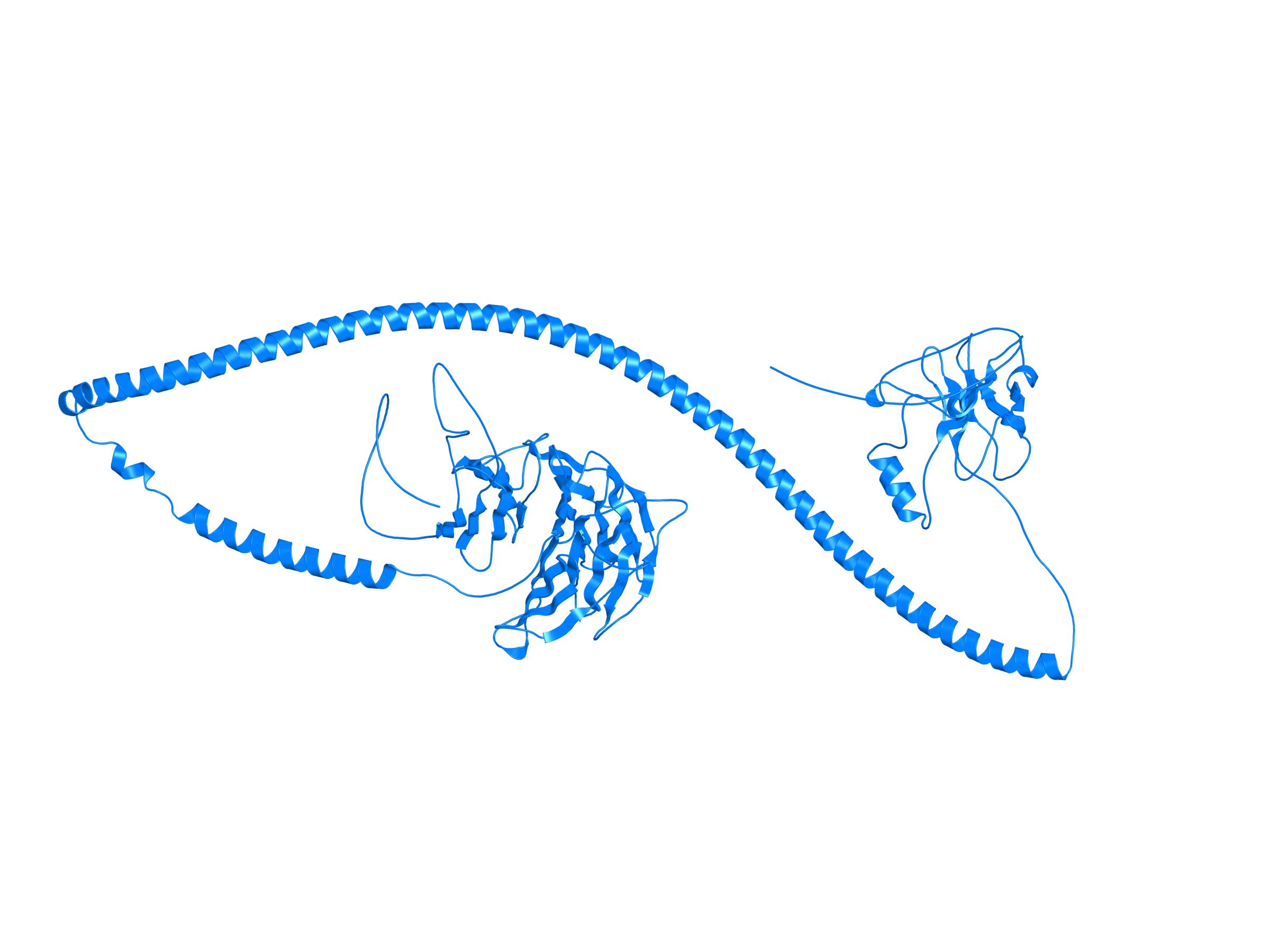 | 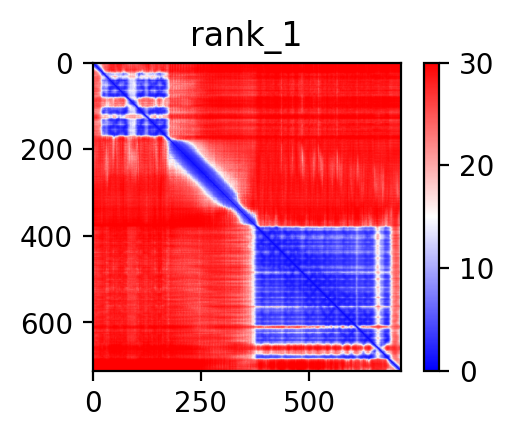 | 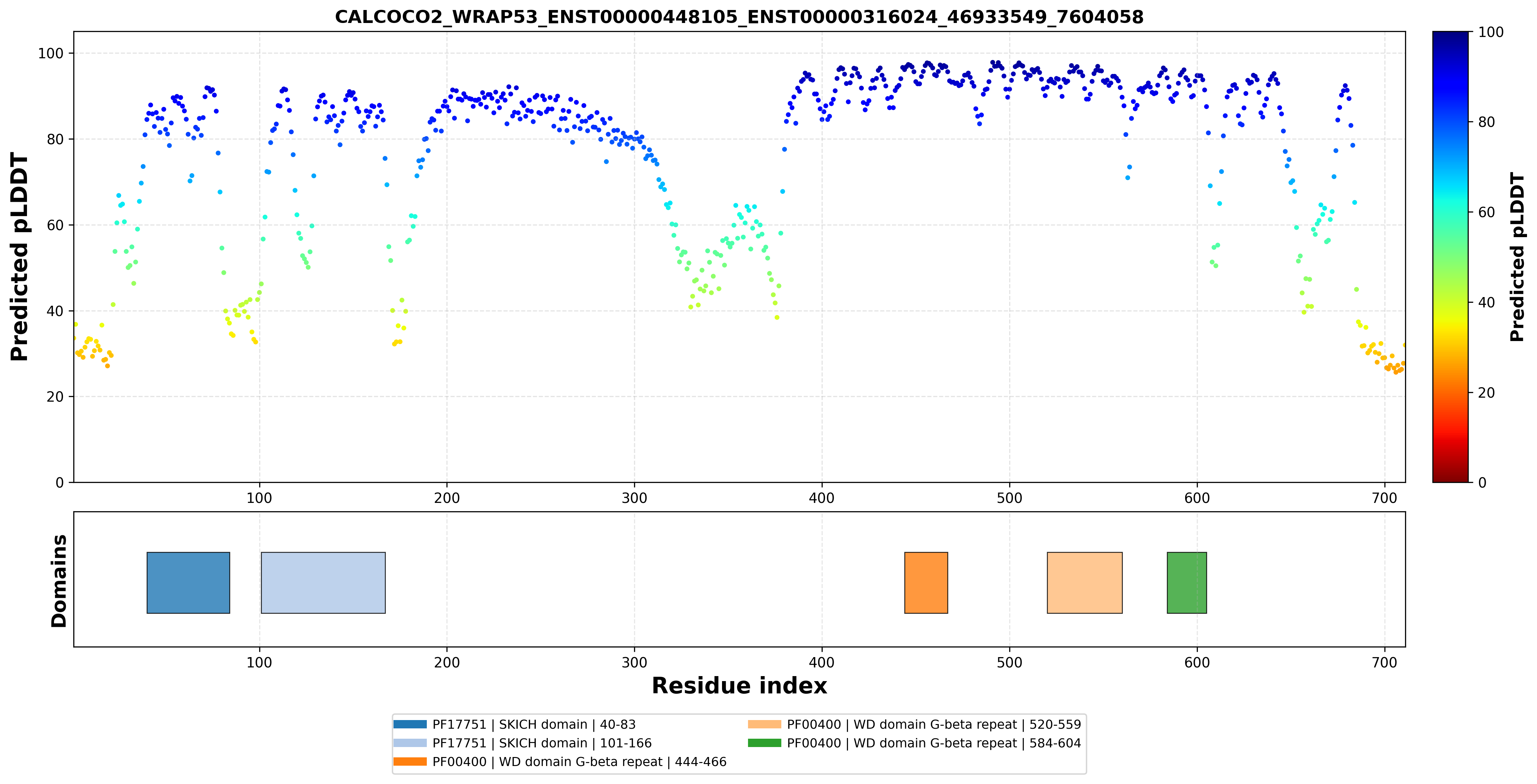 | 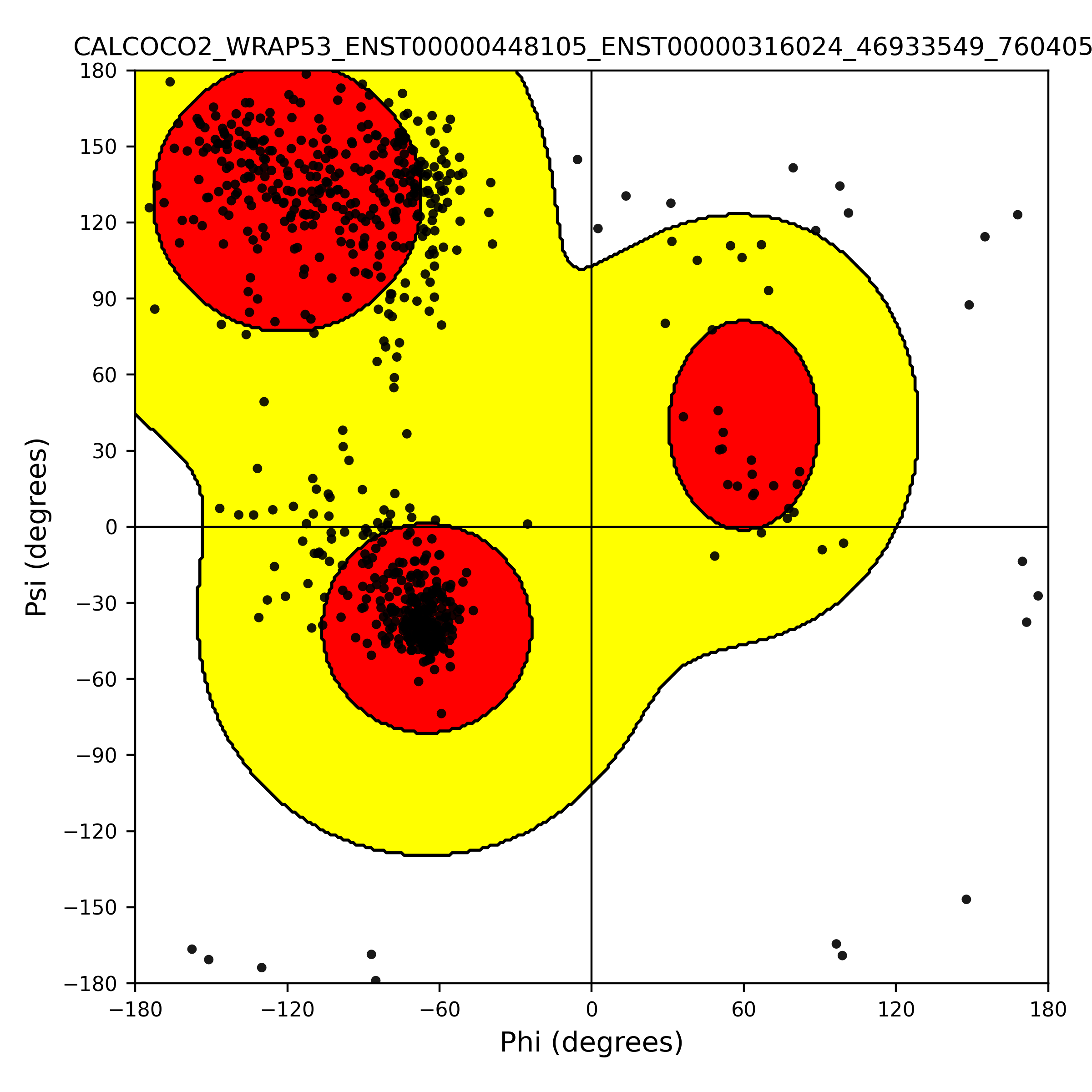 | 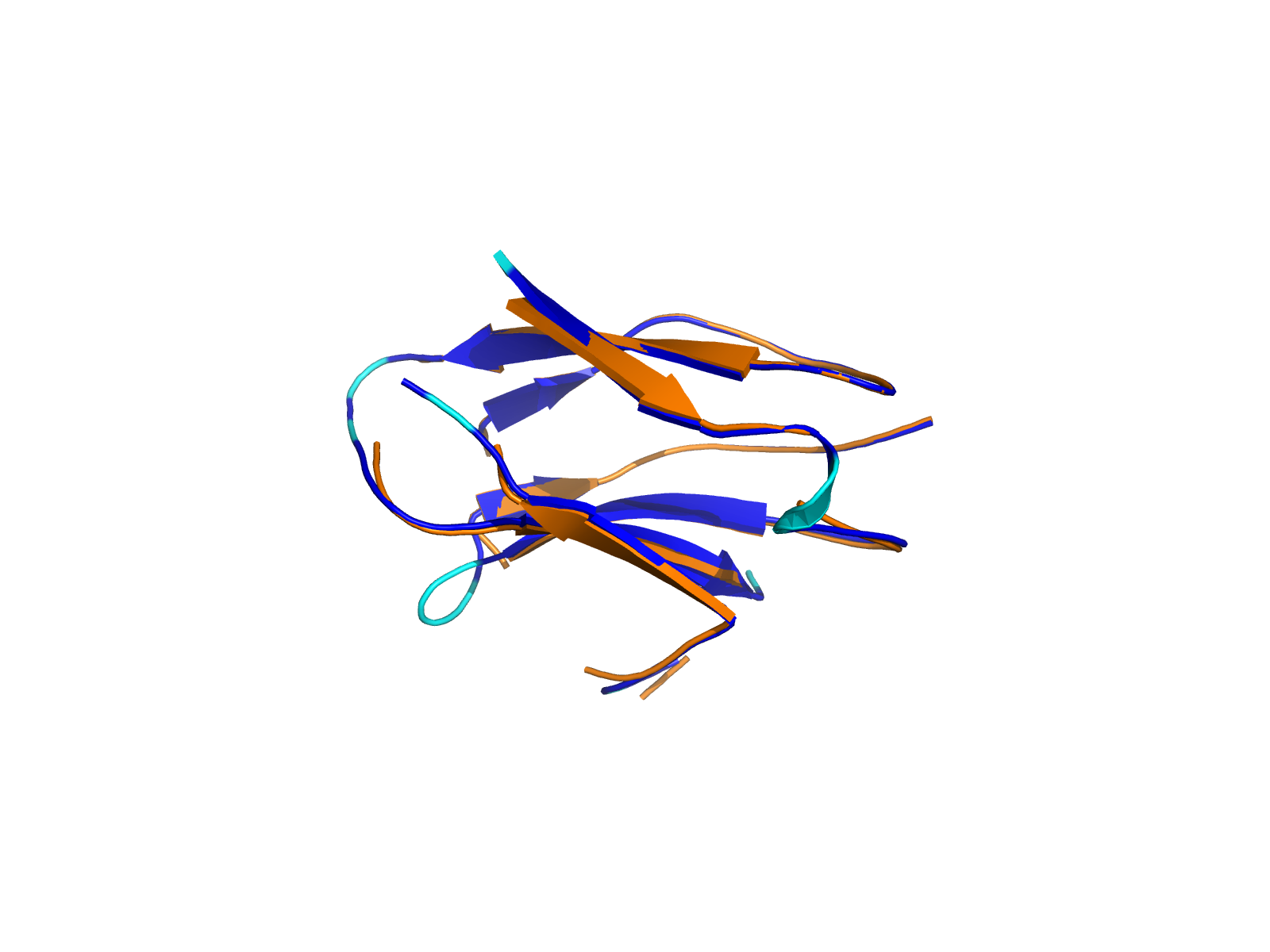 |
| CALCOCO2_WRAP53_ENST00000508679_ENST00000316024_46933549_7604058 superimposed PDB: 7EAA of partner (CALCOCO2). RMSD:0.4872
Å |
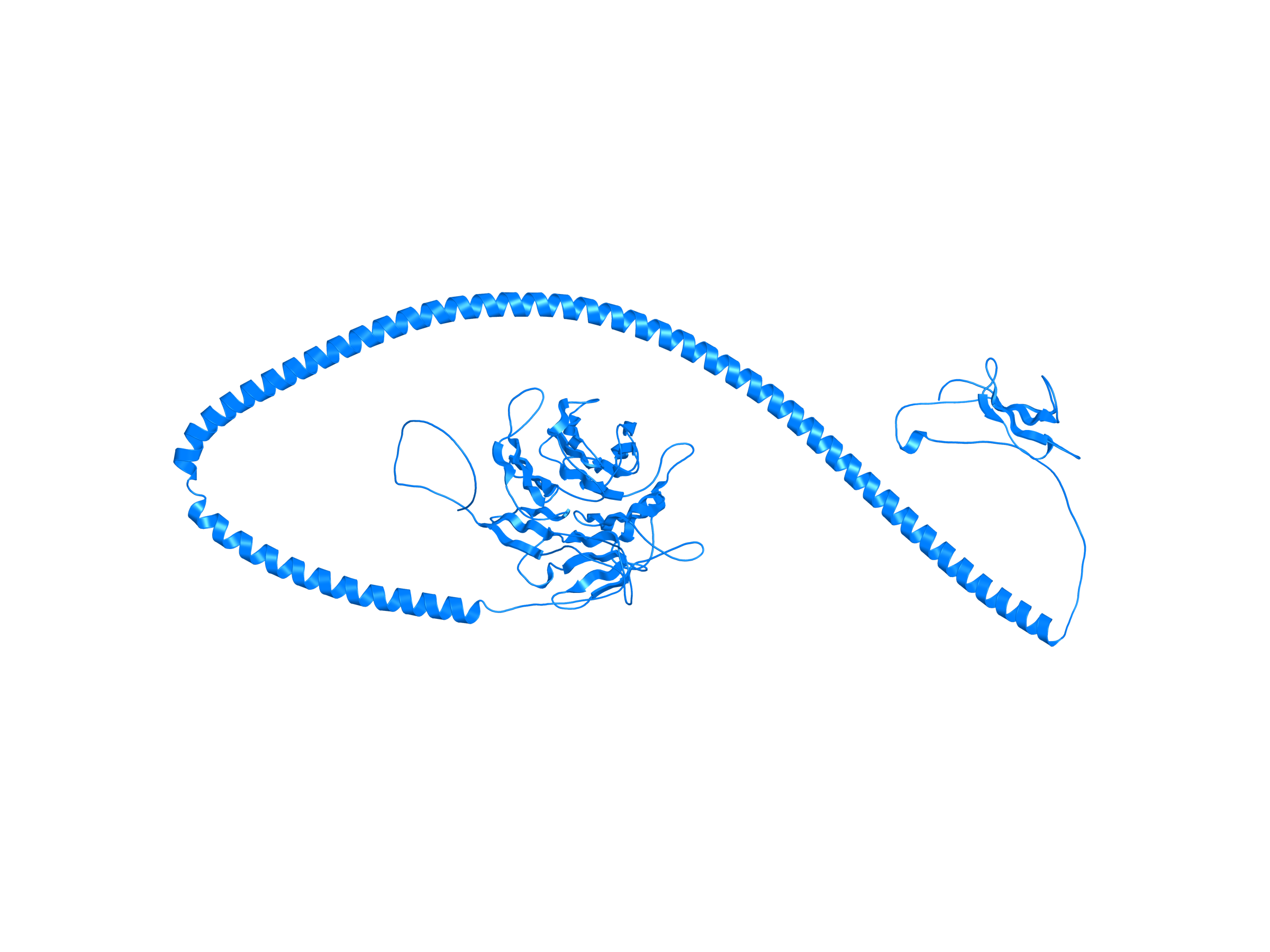 | 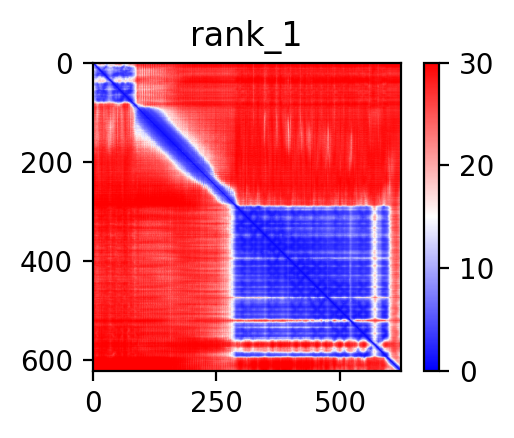 | 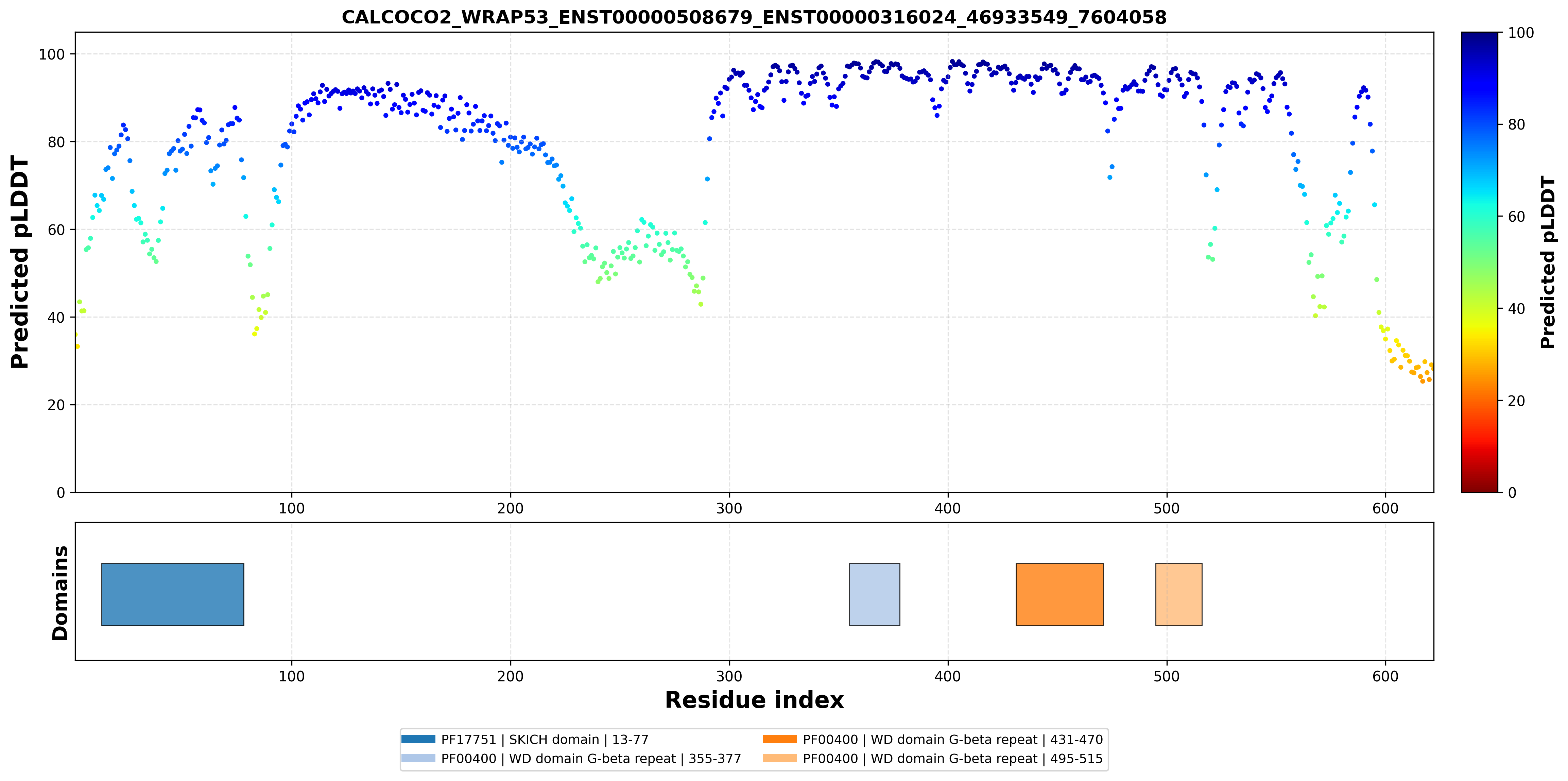 | 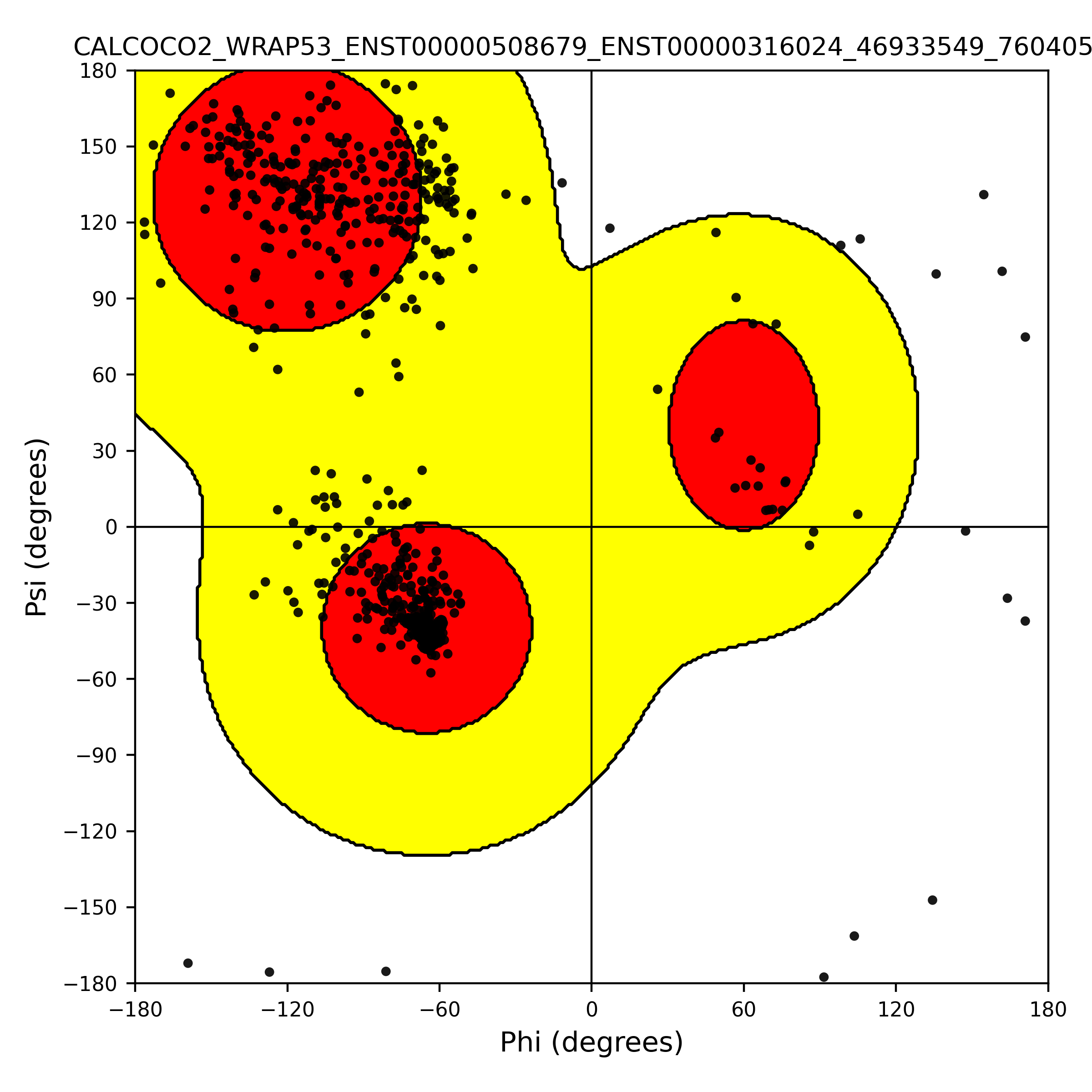 | 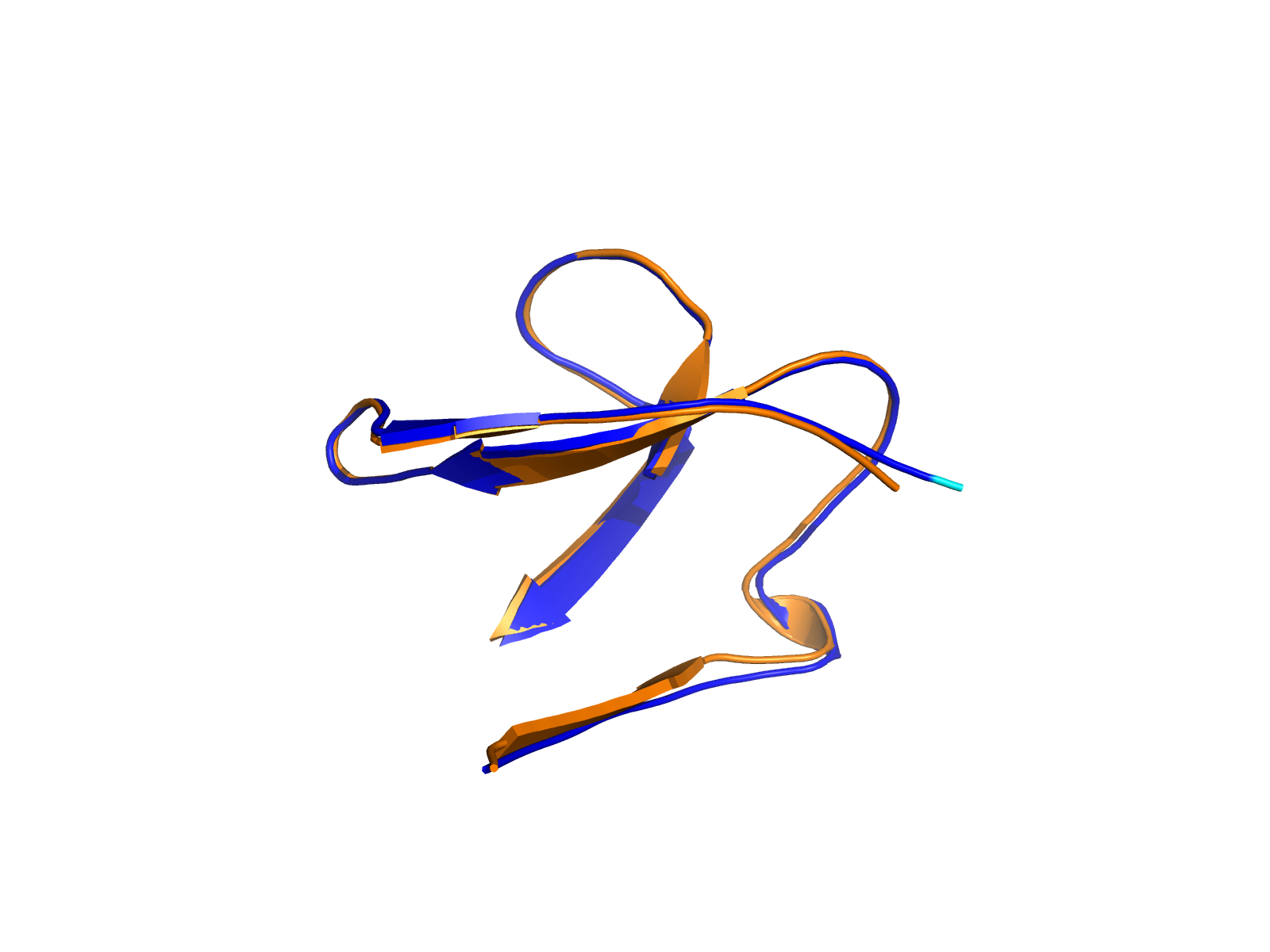 |
| CALCOCO2_WRAP53_ENST00000509507_ENST00000316024_46933549_7604058 superimposed PDB: 7EAA of partner (CALCOCO2). RMSD:0.3722
Å |
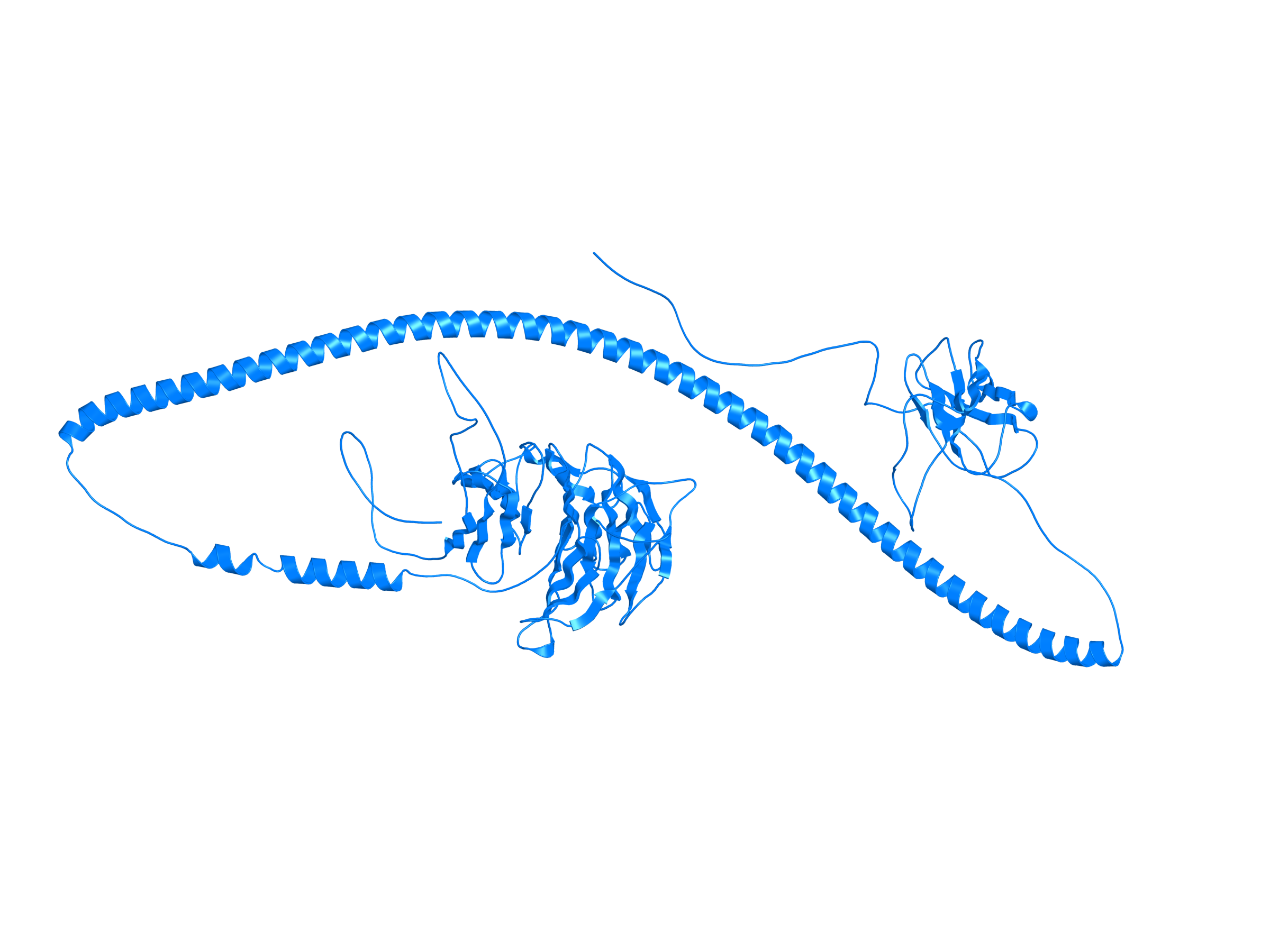 | 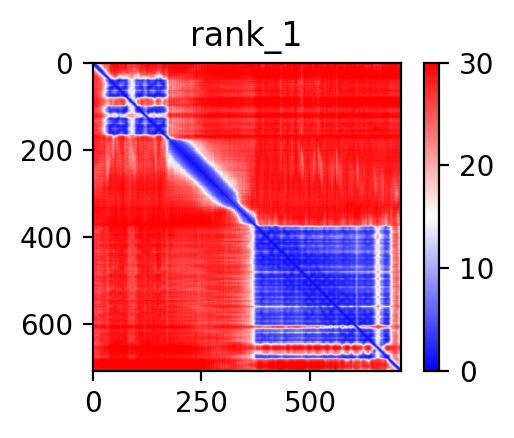 | 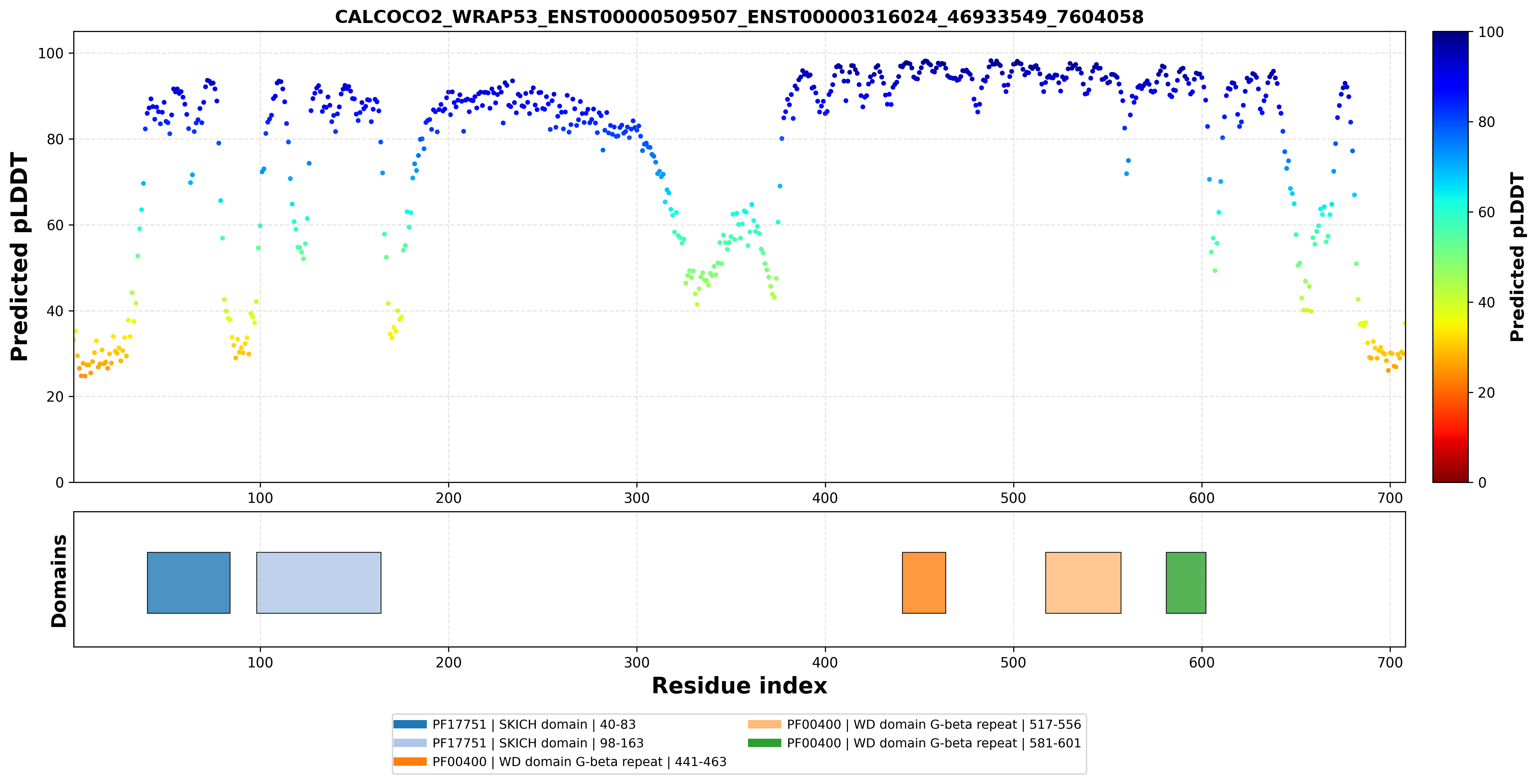 | 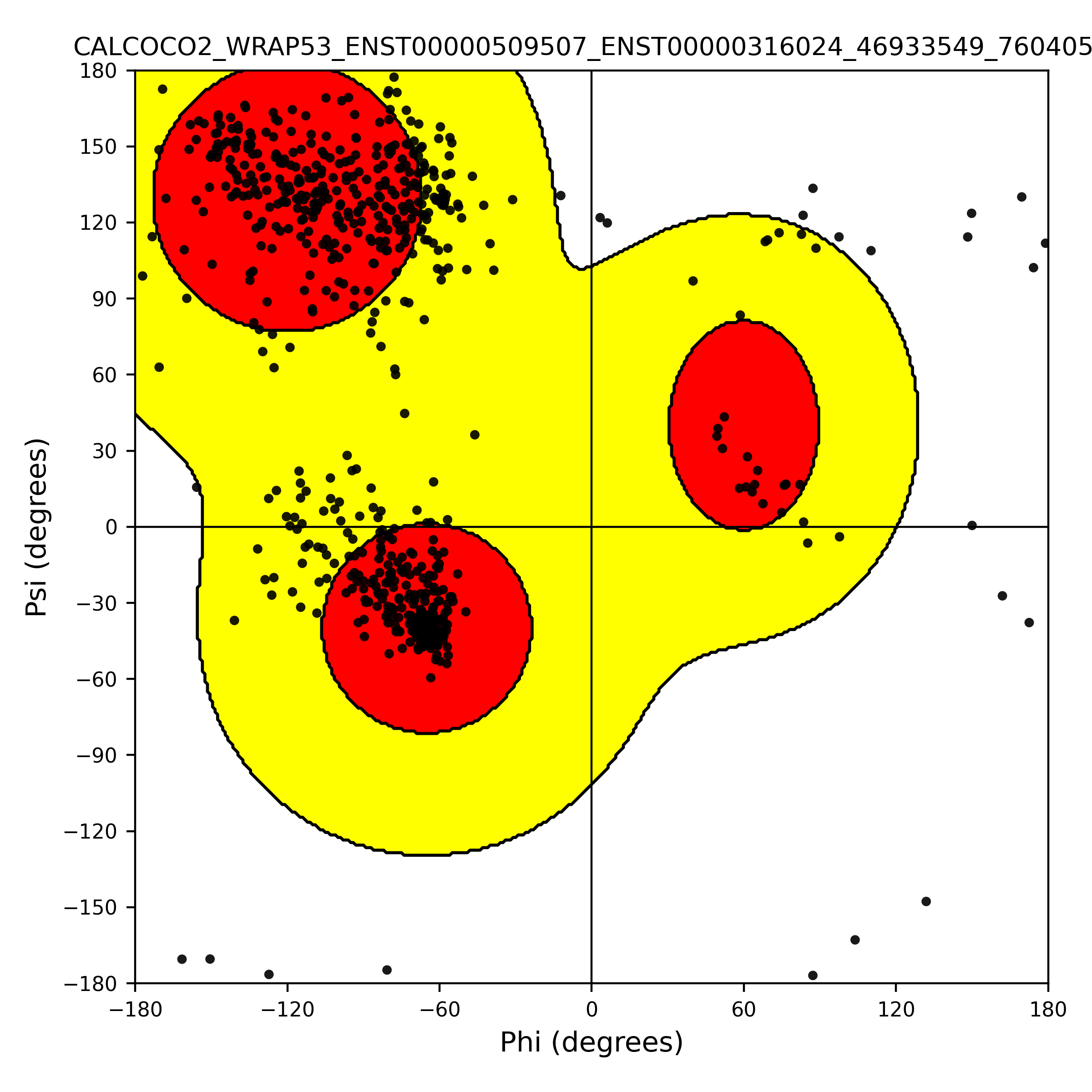 |  |
| CAMK1_CAMK1G_ENST00000256460_ENST00000361322_9799025_209781202 superimposed PDB: 4FG9 of partner (CAMK1). RMSD:0.4925
Å |
 |  |  |  |  |
| CAMK1_CAMK1G_ENST00000256460_ENST00000361322_9799025_209781202 superimposed PDB: 2JAM of partner (CAMK1G). RMSD:1.2691
Å |
| | | |  |
| CAMK2D_FKBP8_ENST00000454265_ENST00000597960_114680475_18644157 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:2.1048
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000296402_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6277
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000394526_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6413
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000418639_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6472
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000429180_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6355
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000454265_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6397
Å |
 |  |  |  |  |
| CAMK2D_STAC3_ENST00000511664_ENST00000332782_114386684_57638748 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6356
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000379773_ENST00000357947_114421618_98188505 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6844
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000379773_ENST00000357947_114421618_98192719 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6899
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000394522_ENST00000357947_114421618_98188505 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7786
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000394522_ENST00000357947_114421618_98192719 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.6963
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000505990_ENST00000357947_114421618_98188505 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7499
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000505990_ENST00000357947_114421618_98192719 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7243
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000514328_ENST00000357947_114421618_98188505 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7659
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000514328_ENST00000357947_114421618_98192719 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7068
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000515496_ENST00000357947_114421618_98188505 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7475
Å |
 |  |  |  |  |
| CAMK2D_TLL2_ENST00000515496_ENST00000357947_114421618_98192719 superimposed PDB: 2WEL of partner (CAMK2D). RMSD:0.7459
Å |
 |  |  |  |  |
| CAMK2G_AGAP5_ENST00000351293_ENST00000443782_75632746_75442552 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:3.2746
Å |
 |  |  |  |  |
| CAMK2G_KCNJ10_ENST00000322635_ENST00000368089_75612949_160012322 superimposed PDB: 9MAE of partner (KCNJ10). RMSD:2.9829
Å |
 |  |  |  |  |
| CAMKMT_NEBL_ENST00000402247_ENST00000417816_44617444_21076237 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.4311
Å |
 |  |  |  |  |
| CAMKMT_SLC3A1_ENST00000402247_ENST00000409229_44617444_44507854 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.643
Å |
 |  |  |  |  |
| CAMKMT_SLC3A1_ENST00000402247_ENST00000409387_44617444_44507854 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.6117
Å |
 |  |  |  |  |
| CAMKMT_SLC3A1_ENST00000402247_ENST00000409741_44617444_44507854 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.5635
Å |
 |  |  |  |  |
| CAMKMT_SLC3A1_ENST00000402247_ENST00000410056_44617444_44507854 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.6501
Å |
 |  |  |  |  |
| CAMKMT_SLC3A1_ENST00000407131_ENST00000260649_44617444_44507854 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.65
Å |
 |  |  |  |  |
| CAND1_ACSS3_ENST00000545606_ENST00000261206_67688936_81503338 superimposed PDB: 7Z8R of partner (CAND1). RMSD:1.0161
Å |
 |  |  |  |  |
| CANT1_PLEKHA7_ENST00000591773_ENST00000355661_76993073_16892729 superimposed PDB: 7KJO of partner (PLEKHA7). RMSD:0.4231
Å |
 |  |  |  |  |
| CANT1_PLEKHA7_ENST00000591773_ENST00000448080_76993073_16892729 superimposed PDB: 7KJO of partner (PLEKHA7). RMSD:0.4432
Å |
 |  |  |  |  |
| CANX_CCT4_ENST00000247461_ENST00000394440_179136060_62099723 superimposed PDB: 7NVL of partner (CCT4). RMSD:1.7852
Å |
 |  |  |  |  |
| CANX_IGJ_ENST00000415618_ENST00000254801_179134191_71527932 superimposed PDB: 6LX3 of partner (IGJ). RMSD:1.6591
Å |
 |  |  |  |  |
| CANX_IGJ_ENST00000452673_ENST00000543780_179134191_71527932 superimposed PDB: 6LX3 of partner (IGJ). RMSD:1.9156
Å |
 |  |  |  |  |
| CANX_IGJ_ENST00000504734_ENST00000543780_179134191_71527932 superimposed PDB: 6LX3 of partner (IGJ). RMSD:1.6022
Å |
 |  |  |  |  |
| CANX_TUBA1B_ENST00000247461_ENST00000336023_179136060_49522721 superimposed PDB: 6S8L of partner (TUBA1B). RMSD:0.957
Å |
 |  |  |  |  |
| CANX_TUBA1B_ENST00000415618_ENST00000336023_179136060_49522721 superimposed PDB: 6S8L of partner (TUBA1B). RMSD:0.9386
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000340450_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4378
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000340450_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4481
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372792_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4434
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372792_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4388
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372792_ENST00000509682_40527484_41285546 superimposed PDB: 7BYL of partner (KCNQ4). RMSD:2.7251
Å |
| | | |  |
| CAP1_KCNQ4_ENST00000372797_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.6659
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372797_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4715
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372797_ENST00000509682_40527484_41285546 superimposed PDB: 7BYL of partner (KCNQ4). RMSD:2.8115
Å |
| | | |  |
| CAP1_KCNQ4_ENST00000372798_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4441
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372798_ENST00000347132_40527484_41285546 superimposed PDB: 7BYL of partner (KCNQ4). RMSD:2.9645
Å |
| | | |  |
| CAP1_KCNQ4_ENST00000372798_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.3884
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372802_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.4403
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372802_ENST00000347132_40527484_41285546 superimposed PDB: 7BYL of partner (KCNQ4). RMSD:2.9319
Å |
| | | |  |
| CAP1_KCNQ4_ENST00000372802_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.446
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372805_ENST00000347132_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.392
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372805_ENST00000509682_40527484_41285546 superimposed PDB: 9Q7O of partner (CAP1). RMSD:0.3967
Å |
 |  |  |  |  |
| CAP1_KCNQ4_ENST00000372805_ENST00000509682_40527484_41285546 superimposed PDB: 7BYL of partner (KCNQ4). RMSD:2.7755
Å |
| | | |  |
| CAPN1_TNKS1BP1_ENST00000527323_ENST00000532437_64951063_57068515 superimposed PDB: 7X79 of partner (CAPN1). RMSD:1.1561
Å |
 |  |  |  |  |
| CAPN1_TNKS1BP1_ENST00000533129_ENST00000532437_64951063_57068515 superimposed PDB: 7X79 of partner (CAPN1). RMSD:1.1965
Å |
 |  |  |  |  |
| CAPN5_HSPA9_ENST00000456580_ENST00000297185_76804859_137892555 superimposed PDB: 9QIN of partner (HSPA9). RMSD:1.6157
Å |
 |  |  |  |  |
| CAPN5_HSPA9_ENST00000529629_ENST00000297185_76804859_137892555 superimposed PDB: 9QIN of partner (HSPA9). RMSD:1.5513
Å |
 |  |  |  |  |
| CAPN5_PELI3_ENST00000278559_ENST00000349459_76804859_66239839 superimposed PDB: 6P3Q of partner (CAPN5). RMSD:2.0835
Å |
 |  |  |  |  |
| CAPN5_PELI3_ENST00000456580_ENST00000349459_76804859_66239839 superimposed PDB: 6P3Q of partner (CAPN5). RMSD:1.6034
Å |
 |  |  |  |  |
| CAPN5_PELI3_ENST00000529629_ENST00000349459_76804859_66239839 superimposed PDB: 6P3Q of partner (CAPN5). RMSD:1.8581
Å |
 |  |  |  |  |
| CAPNS1_ARHGEF26_ENST00000588815_ENST00000356448_36641254_153842198 superimposed PDB: 1KFU of partner (CAPNS1). RMSD:1.3755
Å |
 |  |  |  |  |
| CAPRIN1_C11orf84_ENST00000389645_ENST00000294244_34113603_63585276 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3305
Å |
 |  |  |  |  |
| CAPRIN1_C11orf84_ENST00000529307_ENST00000294244_34113603_63585276 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3164
Å |
 |  |  |  |  |
| CAPRIN1_C11orf84_ENST00000530820_ENST00000294244_34113603_63585276 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.2984
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000389645_ENST00000241052_34093534_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4756
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000389645_ENST00000241052_34104588_34470738 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3863
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000389645_ENST00000241052_34104588_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4435
Å |
| | | |  |
| CAPRIN1_CAT_ENST00000529307_ENST00000241052_34093534_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.433
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000529307_ENST00000241052_34104588_34470738 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.337
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000529307_ENST00000241052_34104588_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4723
Å |
| | | |  |
| CAPRIN1_CAT_ENST00000530820_ENST00000241052_34093534_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4468
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000530820_ENST00000241052_34104588_34470738 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.374
Å |
 |  |  |  |  |
| CAPRIN1_CAT_ENST00000530820_ENST00000241052_34104588_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4899
Å |
| | | |  |
| CAPRIN1_CD151_ENST00000341394_ENST00000397421_34112225_838132 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3196
Å |
 |  |  |  |  |
| CAPRIN1_CD151_ENST00000529307_ENST00000397421_34112225_838132 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3351
Å |
 |  |  |  |  |
| CAPRIN1_CD151_ENST00000530820_ENST00000397421_34112225_838132 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3129
Å |
 |  |  |  |  |
| CAPRIN1_CD151_ENST00000532820_ENST00000397421_34112225_838132 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.309
Å |
 |  |  |  |  |
| CAPRIN1_CHMP1A_ENST00000341394_ENST00000253475_34119308_89713739 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3022
Å |
 |  |  |  |  |
| CAPRIN1_CHMP1A_ENST00000529307_ENST00000253475_34119308_89713739 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.301
Å |
 |  |  |  |  |
| CAPRIN1_CHMP1A_ENST00000532820_ENST00000253475_34119308_89713739 superimposed PDB: 4WBE of partner (CAPRIN1). RMSD:0.3082
Å |
 |  |  |  |  |
| CARD8_BCKDHA_ENST00000391898_ENST00000269980_48744218_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3283
Å |
 |  |  |  |  |
| CARD8_SEC24D_ENST00000359009_ENST00000379735_48737659_119659534 superimposed PDB: 3EFO of partner (SEC24D). RMSD:0.789
Å |
 |  |  |  |  |
| CARKD_ABCC4_ENST00000397191_ENST00000376887_111267994_95768255 superimposed PDB: 8XOK of partner (ABCC4). RMSD:1.2954
Å |
 |  |  |  |  |
| CARM1_HAUS8_ENST00000327064_ENST00000448593_10982598_17170902 superimposed PDB: 7SQK of partner (HAUS8). RMSD:2.7436
Å |
 |  |  |  |  |
| CARM1_HAUS8_ENST00000327064_ENST00000593360_10982598_17170902 superimposed PDB: 7SQK of partner (HAUS8). RMSD:3.0144
Å |
 |  |  |  |  |
| CARM1_HAUS8_ENST00000344150_ENST00000448593_10982598_17170902 superimposed PDB: 7SQK of partner (HAUS8). RMSD:3.0329
Å |
 |  |  |  |  |
| CARM1_HAUS8_ENST00000344150_ENST00000593360_10982598_17170902 superimposed PDB: 7SQK of partner (HAUS8). RMSD:2.9374
Å |
 |  |  |  |  |
| CARS_DCHS1_ENST00000278224_ENST00000299441_3059279_6655537 superimposed PDB: 8EGX of partner (DCHS1). RMSD:2.7768
Å |
 |  |  |  |  |
| CARS_DCHS1_ENST00000397111_ENST00000299441_3059279_6655537 superimposed PDB: 8EGX of partner (DCHS1). RMSD:2.9073
Å |
 |  |  |  |  |
| CASC3_ACLY_ENST00000264645_ENST00000353196_38324670_40024157 superimposed PDB: 6ICZ of partner (CASC3). RMSD:0.652
Å |
 |  |  |  |  |
| CASC3_NFE2L1_ENST00000264645_ENST00000357480_38325699_46133747 superimposed PDB: 6ICZ of partner (CASC3). RMSD:0.5296
Å |
 |  |  |  |  |
| CASC3_NFE2L1_ENST00000264645_ENST00000585291_38325699_46133747 superimposed PDB: 6ICZ of partner (CASC3). RMSD:0.4948
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000318588_ENST00000358400_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0229
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000318588_ENST00000359206_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0138
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000318588_ENST00000545634_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.021
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378158_ENST00000453593_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0171
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378163_ENST00000265723_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.9925
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378163_ENST00000358400_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.9984
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378163_ENST00000545634_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0186
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378166_ENST00000265723_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.037
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378166_ENST00000358400_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0418
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378166_ENST00000359206_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.9725
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378166_ENST00000453593_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.99
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000378166_ENST00000545634_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0129
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000421587_ENST00000265723_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.9907
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000421587_ENST00000358400_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000421587_ENST00000453593_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0004
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000421587_ENST00000545634_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:3.0441
Å |
 |  |  |  |  |
| CASK_ABCB4_ENST00000442742_ENST00000359206_41782182_87092224 superimposed PDB: 6S7P of partner (ABCB4). RMSD:2.9904
Å |
 |  |  |  |  |
| CASK_FHL2_ENST00000318588_ENST00000393352_41598636_105990190 superimposed PDB: 3TAC of partner (CASK). RMSD:1.2895
Å |
 |  |  |  |  |
| CASK_FHL2_ENST00000318588_ENST00000393352_41598636_105990190 superimposed PDB: 2MIU of partner (FHL2). RMSD:1.3966
Å |
| | | |  |
| CASP8_VMP1_ENST00000264274_ENST00000537567_202150040_57915655 superimposed PDB: 8YNM of partner (CASP8). RMSD:0.7533
Å |
 |  |  |  |  |
| CASP8_VMP1_ENST00000264275_ENST00000537567_202150040_57915655 superimposed PDB: 8YNM of partner (CASP8). RMSD:0.8246
Å |
 |  |  |  |  |
| CASP8_VMP1_ENST00000323492_ENST00000537567_202150040_57915655 superimposed PDB: 8YNM of partner (CASP8). RMSD:0.7322
Å |
 |  |  |  |  |
| CASP8_VMP1_ENST00000358485_ENST00000537567_202150040_57915655 superimposed PDB: 8YNM of partner (CASP8). RMSD:0.7469
Å |
 |  |  |  |  |
| CASP8_VMP1_ENST00000432109_ENST00000537567_202150040_57915655 superimposed PDB: 8YNM of partner (CASP8). RMSD:0.738
Å |
 |  |  |  |  |
| CASZ1_SLC9A1_ENST00000344008_ENST00000263980_10753930_27440777 superimposed PDB: 23XK of partner (SLC9A1). RMSD:1.0672
Å |
 |  |  |  |  |
| CATSPERG_RASSF1_ENST00000410018_ENST00000327761_38828144_50369585 superimposed PDB: 2KZU of partner (RASSF1). RMSD:2.4474
Å |
 |  |  |  |  |
| CBFB_CHPF_ENST00000290858_ENST00000535926_67070658_220405847 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.3489
Å |
 |  |  |  |  |
| CBFB_CHPF_ENST00000290858_ENST00000535926_67070658_220405847 superimposed PDB: 9Q8Z of partner (CHPF). RMSD:1.5437
Å |
| | | |  |
| CBFB_COG4_ENST00000290858_ENST00000323786_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:0.9648
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000290858_ENST00000393612_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.6995
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000290858_ENST00000393612_67100701_70553634 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.69
Å |
| | | |  |
| CBFB_COG4_ENST00000290858_ENST00000564653_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.7536
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000412916_ENST00000323786_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9607
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000412916_ENST00000564653_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.7591
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000561924_ENST00000393612_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.0437
Å |
 |  |  |  |  |
| CBFB_COG4_ENST00000561924_ENST00000393612_67100701_70553634 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.6358
Å |
| | | |  |
| CBFB_COG4_ENST00000561924_ENST00000564653_67100701_70553634 superimposed PDB: 8CX0 of partner (CBFB). RMSD:0.9844
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000396324_67100701_15813570 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.8022
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000396324_67100701_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0247
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000396324_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.3861
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000396324_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.2765
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000396324_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.7568
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000452625_67100701_15813570 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0635
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000452625_67100701_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9339
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000452625_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.8956
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000452625_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.8906
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000452625_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0458
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000576790_67100701_15813570 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0192
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000576790_67100701_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9606
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000576790_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9158
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000576790_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.861
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000290858_ENST00000576790_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0394
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000396324_67116211_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0349
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000396324_67116211_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.1128
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000396324_67116211_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.04
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000396324_67116211_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.002
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000452625_67116211_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.085
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000452625_67116211_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.051
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000452625_67116211_15818656 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0071
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000452625_67116211_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0341
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000452625_67116211_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0737
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000576790_67116211_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0679
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000576790_67116211_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0495
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000576790_67116211_15818656 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000576790_67116211_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.0484
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000412916_ENST00000576790_67116211_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.078
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000396324_67100701_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.076
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000396324_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9559
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000396324_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9218
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000396324_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.8236
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000452625_67100701_15813570 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.6888
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000452625_67100701_15814169 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.8619
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000452625_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.4457
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000452625_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.2224
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000452625_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.7538
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000576790_67100701_15813570 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.898
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000576790_67100701_15814908 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.5863
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000576790_67100701_15818849 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.2632
Å |
 |  |  |  |  |
| CBFB_MYH11_ENST00000561924_ENST00000576790_67100701_15820911 superimposed PDB: 8CX0 of partner (CBFB). RMSD:1.9461
Å |
 |  |  |  |  |
| CBFB_NAE1_ENST00000290858_ENST00000290810_67070658_66857503 superimposed PDB: 8CX0 of partner (CBFB). RMSD:3.0223
Å |
 |  |  |  |  |
| CBFB_NAE1_ENST00000290858_ENST00000290810_67070658_66857503 superimposed PDB: 1YOV of partner (NAE1). RMSD:0.6809
Å |
| | | |  |
| CBFB_NUTF2_ENST00000290858_ENST00000569436_67070658_67902242 superimposed PDB: 8CX0 of partner (CBFB). RMSD:3.0776
Å |
 |  |  |  |  |
| CBFB_NUTF2_ENST00000290858_ENST00000569436_67070658_67902242 superimposed PDB: 1GY5 of partner (NUTF2). RMSD:0.5326
Å |
| | | |  |
| CBLB_STAC_ENST00000394027_ENST00000273183_105586253_36484855 superimposed PDB: 6B25 of partner (STAC). RMSD:0.8869
Å |
 |  |  |  |  |
| CBLB_STAC_ENST00000394027_ENST00000457375_105586253_36484855 superimposed PDB: 6B25 of partner (STAC). RMSD:0.8896
Å |
 |  |  |  |  |
| CBLB_STAC_ENST00000545639_ENST00000273183_105586253_36484855 superimposed PDB: 6B25 of partner (STAC). RMSD:0.8862
Å |
 |  |  |  |  |
| CBLB_STAC_ENST00000545639_ENST00000457375_105572257_36484855 superimposed PDB: 6B25 of partner (STAC). RMSD:0.9083
Å |
 |  |  |  |  |
| CBL_MST1R_ENST00000264033_ENST00000344206_119142591_49928083 superimposed PDB: 5HKX of partner (CBL). RMSD:2.6319
Å |
 |  |  |  |  |
| CBR4_ALG8_ENST00000306193_ENST00000376156_169923221_77820627 superimposed PDB: 4CQM of partner (CBR4). RMSD:0.4456
Å |
 |  |  |  |  |
| CBR4_NPTN_ENST00000504480_ENST00000345330_169927905_73884478 superimposed PDB: 4CQM of partner (CBR4). RMSD:0.6555
Å |
 |  |  |  |  |
| CBR4_NPTN_ENST00000504480_ENST00000345330_169927905_73884478 superimposed PDB: 6A69 of partner (NPTN). RMSD:0.7028
Å |
| | | |  |
| CBX5_GTSF1_ENST00000550411_ENST00000305879_54645824_54858951 superimposed PDB: 8UXQ of partner (CBX5). RMSD:1.9117
Å |
 |  |  |  |  |
| CBX5_MARK2_ENST00000550411_ENST00000402010_54639898_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6667
Å |
 |  |  |  |  |
| CBX5_MARK2_ENST00000550411_ENST00000413835_54639898_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6559
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000262975_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6152
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000352431_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.63
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000360911_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6517
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000372023_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6118
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000396281_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6199
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000446994_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6412
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000458360_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6166
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000461685_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6535
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000471951_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6089
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000318003_ENST00000536340_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.8598
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000262975_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6822
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000311275_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6524
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000352431_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6471
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000360911_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6744
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000396281_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6959
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000446994_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.582
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000458360_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6433
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000461685_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6569
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000471951_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6626
Å |
 |  |  |  |  |
| CC2D1A_ZMYND8_ENST00000589606_ENST00000536340_14030015_45938948 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:1.0266
Å |
 |  |  |  |  |
| CC2D2A_BST1_ENST00000389652_ENST00000382346_15482451_15713429 superimposed PDB: 1ISI of partner (BST1). RMSD:0.5204
Å |
 |  |  |  |  |
| CC2D2A_BST1_ENST00000413206_ENST00000382346_15482451_15713429 superimposed PDB: 1ISI of partner (BST1). RMSD:0.7695
Å |
 |  |  |  |  |
| CC2D2A_BST1_ENST00000424120_ENST00000382346_15482451_15713429 superimposed PDB: 1ISI of partner (BST1). RMSD:0.7686
Å |
 |  |  |  |  |
| CCAR1_BLMH_ENST00000265872_ENST00000394819_70517134_28614965 superimposed PDB: 7V5L of partner (BLMH). RMSD:0.6896
Å |
 |  |  |  |  |
| CCAR1_BLMH_ENST00000535016_ENST00000394819_70517134_28614965 superimposed PDB: 7V5L of partner (BLMH). RMSD:0.7215
Å |
 |  |  |  |  |
| CCDC104_NDRG1_ENST00000339012_ENST00000354944_55750958_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:0.5946
Å |
 |  |  |  |  |
| CCDC104_NDRG1_ENST00000349456_ENST00000323851_55750958_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:1.0511
Å |
 |  |  |  |  |
| CCDC104_NDRG1_ENST00000406691_ENST00000323851_55750958_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:1.0647
Å |
 |  |  |  |  |
| CCDC104_NDRG1_ENST00000406691_ENST00000354944_55750958_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:0.6113
Å |
 |  |  |  |  |
| CCDC127_TERT_ENST00000296824_ENST00000334602_216843_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1319
Å |
 |  |  |  |  |
| CCDC127_TERT_ENST00000296824_ENST00000508104_216843_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.6661
Å |
 |  |  |  |  |
| CCDC12_SMC6_ENST00000292314_ENST00000448223_47018126_17906625 superimposed PDB: 9LWI of partner (SMC6). RMSD:2.3833
Å |
 |  |  |  |  |
| CCDC57_CSNK1D_ENST00000392346_ENST00000314028_80085567_80223672 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.6516
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000280772_61564177_61827767 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.6018
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000280772_61612310_62039397 superimposed PDB: 9O04 of partner (CCDC6). RMSD:1.2246
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000280772_61612310_62039397 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.3487
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61564177_61827767 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.3059
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61564177_61827767 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.3371
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61564177_61848116 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.6234
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61564177_61848116 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.3179
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61665879_61842495 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.2989
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61665879_61874089 superimposed PDB: 9O04 of partner (CCDC6). RMSD:0.4962
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000355288_61665879_61874089 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.352
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61564177_61827767 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.4724
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61564177_61827767 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.2923
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61564177_61848116 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.667
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61612310_61973268 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.9201
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61612310_61973268 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.5697
Å |
| | | |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61612310_62039397 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.6697
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61665879_61842495 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.4277
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000373827_61665879_61874089 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.4867
Å |
 |  |  |  |  |
| CCDC6_ANK3_ENST00000263102_ENST00000503366_61665879_61802517 superimposed PDB: 4O6X of partner (ANK3). RMSD:2.6589
Å |
 |  |  |  |  |
| CCDC6_RET_ENST00000263102_ENST00000340058_61554230_43612031 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.6222
Å |
 |  |  |  |  |
| CCDC6_RET_ENST00000263102_ENST00000355710_61665879_43612031 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.8075
Å |
 |  |  |  |  |
| CCDC6_UBE2D1_ENST00000263102_ENST00000373910_61665879_60121097 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.4314
Å |
 |  |  |  |  |
| CCDC6_UBE2D1_ENST00000263102_ENST00000373910_61665879_60121097 superimposed PDB: 4QPL of partner (UBE2D1). RMSD:0.4846
Å |
| | | |  |
| CCDC82_MTMR2_ENST00000423339_ENST00000346299_96104176_95583913 superimposed PDB: 1LW3 of partner (MTMR2). RMSD:0.363
Å |
 |  |  |  |  |
| CCDC85A_EYA2_ENST00000407595_ENST00000327619_56570090_45771697 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.2641
Å |
 |  |  |  |  |
| CCDC91_ASIC2_ENST00000306172_ENST00000359872_28637098_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.9172
Å |
 |  |  |  |  |
| CCDC91_ASIC2_ENST00000539107_ENST00000359872_28637098_31439085 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.2578
Å |
 |  |  |  |  |
| CCDC91_ASIC2_ENST00000539107_ENST00000359872_28637098_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.8473
Å |
| | | |  |
| CCDC91_ASIC2_ENST00000545336_ENST00000359872_28637098_31439085 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:1.8459
Å |
 |  |  |  |  |
| CCDC91_ASIC2_ENST00000545336_ENST00000359872_28637098_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.8503
Å |
| | | |  |
| CCDC91_CRTC3_ENST00000381256_ENST00000420329_28637098_91136867 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.6039
Å |
 |  |  |  |  |
| CCDC91_CRTC3_ENST00000545336_ENST00000420329_28637098_91136867 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.1341
Å |
 |  |  |  |  |
| CCDC91_NTSR1_ENST00000381259_ENST00000370501_28544344_61386036 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.0701
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000539107_ENST00000519419_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.5424
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000539107_ENST00000535192_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.0265
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000539107_ENST00000538769_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.4908
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000545336_ENST00000519419_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.0188
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000545336_ENST00000535192_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:1.8085
Å |
 |  |  |  |  |
| CCDC91_PTK2_ENST00000545336_ENST00000538769_28605587_141696793 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.1622
Å |
 |  |  |  |  |
| CCDC91_STAT4_ENST00000545336_ENST00000392320_28544344_191905874 superimposed PDB: 1OM9 of partner (CCDC91). RMSD:2.3936
Å |
 |  |  |  |  |
| CCM2_PDHA1_ENST00000258781_ENST00000540249_45039962_19375769 superimposed PDB: 2OZL of partner (PDHA1). RMSD:1.9332
Å |
 |  |  |  |  |
| CCM2_SEC31A_ENST00000258781_ENST00000513858_45039962_83748785 superimposed PDB: 4WJ7 of partner (CCM2). RMSD:2.9484
Å |
 |  |  |  |  |
| CCM2_TERT_ENST00000258781_ENST00000508104_45039962_1268748 superimposed PDB: 7QXA of partner (TERT). RMSD:1.0501
Å |
 |  |  |  |  |
| CCM2_TERT_ENST00000544363_ENST00000296820_45039962_1268748 superimposed PDB: 7QXA of partner (TERT). RMSD:2.8857
Å |
 |  |  |  |  |
| CCM2_TERT_ENST00000544363_ENST00000296820_45039962_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.067
Å |
 |  |  |  |  |
| CCND3_CCND1_ENST00000372987_ENST00000227507_41904972_69462761 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.4822
Å |
 |  |  |  |  |
| CCND3_CCND1_ENST00000372988_ENST00000536559_41904972_69462761 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.6077
Å |
 |  |  |  |  |
| CCND3_CCND1_ENST00000414200_ENST00000227507_41904972_69462761 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.5565
Å |
 |  |  |  |  |
| CCND3_CCND1_ENST00000510503_ENST00000536559_41904972_69462761 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.5951
Å |
 |  |  |  |  |
| CCND3_CCND1_ENST00000511642_ENST00000227507_41904972_69462761 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.6078
Å |
 |  |  |  |  |
| CCNI_SCARB2_ENST00000537948_ENST00000452464_77996624_77117017 superimposed PDB: 4Q4F of partner (SCARB2). RMSD:0.4534
Å |
 |  |  |  |  |
| CCNL2_SSU72_ENST00000408918_ENST00000291386_1328775_1500296 superimposed PDB: 9QKZ of partner (CCNL2). RMSD:0.7483
Å |
 |  |  |  |  |
| CCNL2_SSU72_ENST00000408918_ENST00000291386_1328775_1500296 superimposed PDB: 4H3K of partner (SSU72). RMSD:0.8692
Å |
| | | |  |
| CCNL2_SSU72_ENST00000408918_ENST00000359060_1330773_1500296 superimposed PDB: 9QKZ of partner (CCNL2). RMSD:0.5865
Å |
 |  |  |  |  |
| CCNT1_HSPD1_ENST00000261900_ENST00000345042_49099550_198353971 superimposed PDB: 9L8P of partner (HSPD1). RMSD:1.1695
Å |
 |  |  |  |  |
| CCNT2_SLC39A11_ENST00000295238_ENST00000255559_135700244_70845943 superimposed PDB: 2IVX of partner (CCNT2). RMSD:0.4722
Å |
 |  |  |  |  |
| CCNT2_SLC39A11_ENST00000295238_ENST00000542342_135696632_70845943 superimposed PDB: 2IVX of partner (CCNT2). RMSD:0.4228
Å |
 |  |  |  |  |
| CCNT2_SLC39A11_ENST00000295238_ENST00000542342_135700244_70845943 superimposed PDB: 2IVX of partner (CCNT2). RMSD:0.3998
Å |
 |  |  |  |  |
| CCNY_AKAP10_ENST00000339497_ENST00000395536_35626135_19871774 superimposed PDB: 3IM4 of partner (AKAP10). RMSD:0.4232
Å |
 |  |  |  |  |
| CCNY_AKAP10_ENST00000374704_ENST00000225737_35626135_19871774 superimposed PDB: 3IM4 of partner (AKAP10). RMSD:0.5782
Å |
 |  |  |  |  |
| CCT2_C12orf54_ENST00000299300_ENST00000548364_69993784_48879960 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.2638
Å |
 |  |  |  |  |
| CCT2_C12orf54_ENST00000543146_ENST00000548364_69993784_48879960 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3649
Å |
 |  |  |  |  |
| CCT2_DDX1_ENST00000299300_ENST00000233084_69980598_15770113 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.304
Å |
 |  |  |  |  |
| CCT2_DDX1_ENST00000543146_ENST00000233084_69980598_15770113 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.8242
Å |
 |  |  |  |  |
| CCT2_MDM2_ENST00000544368_ENST00000462284_69983467_69218142 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.7064
Å |
 |  |  |  |  |
| CCT2_MDM2_ENST00000544368_ENST00000462284_69983467_69218142 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.9371
Å |
| | | |  |
| CCT2_MYRFL_ENST00000299300_ENST00000299350_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.024
Å |
 |  |  |  |  |
| CCT2_MYRFL_ENST00000299300_ENST00000547771_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.0105
Å |
 |  |  |  |  |
| CCT2_MYRFL_ENST00000299300_ENST00000552032_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.4812
Å |
 |  |  |  |  |
| CCT2_MYRFL_ENST00000543146_ENST00000299350_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.1827
Å |
 |  |  |  |  |
| CCT2_MYRFL_ENST00000543146_ENST00000547771_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.2023
Å |
 |  |  |  |  |
| CCT2_MYRFL_ENST00000544368_ENST00000552032_69987393_70345892 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.1076
Å |
 |  |  |  |  |
| CCT2_NPM1_ENST00000299300_ENST00000296930_69981786_170834703 superimposed PDB: 7NVL of partner (CCT2). RMSD:0.699
Å |
 |  |  |  |  |
| CCT2_NPM1_ENST00000543146_ENST00000296930_69981786_170834703 superimposed PDB: 7NVL of partner (CCT2). RMSD:0.6146
Å |
 |  |  |  |  |
| CCT2_UNC5A_ENST00000299300_ENST00000261961_69991546_176295130 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.6747
Å |
 |  |  |  |  |
| CCT2_UNC5A_ENST00000299300_ENST00000261961_69991546_176295130 superimposed PDB: 4V2A of partner (UNC5A). RMSD:1.9945
Å |
| | | |  |
| CCT2_UNC5A_ENST00000299300_ENST00000329542_69991546_176295130 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.0398
Å |
 |  |  |  |  |
| CCT2_UNC5A_ENST00000543146_ENST00000261961_69991546_176295130 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.5873
Å |
 |  |  |  |  |
| CCT2_UNC5A_ENST00000543146_ENST00000261961_69991546_176295130 superimposed PDB: 4V2A of partner (UNC5A). RMSD:2.1388
Å |
| | | |  |
| CCT5_SOS2_ENST00000280326_ENST00000543680_10263426_50625364 superimposed PDB: 7NVL of partner (CCT5). RMSD:1.3508
Å |
 |  |  |  |  |
| CCT5_SOS2_ENST00000280326_ENST00000543680_10263426_50625364 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.6687
Å |
| | | |  |
| CCT5_SOS2_ENST00000503026_ENST00000543680_10263426_50625364 superimposed PDB: 7NVL of partner (CCT5). RMSD:1.4447
Å |
 |  |  |  |  |
| CCT5_SOS2_ENST00000503026_ENST00000543680_10263426_50625364 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.7177
Å |
| | | |  |
| CCT5_SOS2_ENST00000506600_ENST00000543680_10263426_50625364 superimposed PDB: 7NVL of partner (CCT5). RMSD:2.607
Å |
 |  |  |  |  |
| CCT5_SOS2_ENST00000506600_ENST00000543680_10263426_50625364 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.5799
Å |
| | | |  |
| CCT5_SOS2_ENST00000515390_ENST00000543680_10263426_50625364 superimposed PDB: 7NVL of partner (CCT5). RMSD:2.5428
Å |
 |  |  |  |  |
| CCT5_SOS2_ENST00000515390_ENST00000543680_10263426_50625364 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.7018
Å |
| | | |  |
| CCT5_SOS2_ENST00000515676_ENST00000543680_10263426_50625364 superimposed PDB: 7NVL of partner (CCT5). RMSD:1.5347
Å |
 |  |  |  |  |
| CCT5_SOS2_ENST00000515676_ENST00000543680_10263426_50625364 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.6381
Å |
| | | |  |
| CD151_DRD4_ENST00000322008_ENST00000176183_836442_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9778
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000322008_ENST00000176183_836843_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9304
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000397420_ENST00000176183_836843_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9356
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000397421_ENST00000176183_836442_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9045
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000397421_ENST00000176183_836843_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9905
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000528011_ENST00000176183_836442_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:0.9676
Å |
 |  |  |  |  |
| CD151_DRD4_ENST00000528011_ENST00000176183_836843_639432 superimposed PDB: 5WIU of partner (DRD4). RMSD:1.0229
Å |
 |  |  |  |  |
| CD22_CADPS_ENST00000419549_ENST00000283269_35823827_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9574
Å |
 |  |  |  |  |
| CD22_CADPS_ENST00000419549_ENST00000357948_35823827_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9438
Å |
 |  |  |  |  |
| CD22_CADPS_ENST00000419549_ENST00000490353_35823827_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9434
Å |
 |  |  |  |  |
| CD2AP_SLC25A13_ENST00000359314_ENST00000416240_47501491_95800836 superimposed PDB: 2J6F of partner (CD2AP). RMSD:0.2518
Å |
 |  |  |  |  |
| CD44_ANXA2_ENST00000263398_ENST00000451270_35211612_60656722 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7645
Å |
 |  |  |  |  |
| CD44_ANXA2_ENST00000263398_ENST00000451270_35211612_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4595
Å |
| | | |  |
| CD44_ANXA2_ENST00000428726_ENST00000451270_35211612_60656722 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7643
Å |
 |  |  |  |  |
| CD44_ANXA2_ENST00000428726_ENST00000451270_35211612_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4232
Å |
| | | |  |
| CD44_ANXA2_ENST00000434472_ENST00000451270_35211612_60656722 superimposed PDB: 2I83 of partner (CD44). RMSD:1.887
Å |
 |  |  |  |  |
| CD44_ANXA2_ENST00000434472_ENST00000451270_35211612_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4062
Å |
| | | |  |
| CD44_ANXA2_ENST00000449691_ENST00000451270_35211612_60656722 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8018
Å |
 |  |  |  |  |
| CD44_ANXA2_ENST00000449691_ENST00000451270_35211612_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.423
Å |
| | | |  |
| CD44_PAMR1_ENST00000263398_ENST00000378880_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6996
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000352818_ENST00000278360_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6922
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000360158_ENST00000278360_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6972
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000428726_ENST00000378880_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7223
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000433892_ENST00000278360_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7055
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000434472_ENST00000378880_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6527
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000449691_ENST00000278360_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7038
Å |
 |  |  |  |  |
| CD44_PAMR1_ENST00000449691_ENST00000378880_35201954_35496292 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6406
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0463
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0338
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35160917_34999670 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9627
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7719
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0459
Å |
| | | |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7212
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0445
Å |
| | | |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7568
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0074
Å |
| | | |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7887
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1348
Å |
| | | |  |
| CD44_PDHX_ENST00000263398_ENST00000448838_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8423
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000263398_ENST00000448838_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1556
Å |
| | | |  |
| CD44_PDHX_ENST00000278386_ENST00000227868_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0403
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000278386_ENST00000227868_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0612
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000278386_ENST00000227868_35160917_34999670 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9732
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000352818_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7619
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000352818_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0969
Å |
| | | |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6445
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.173
Å |
| | | |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7492
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1887
Å |
| | | |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8465
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000352818_ENST00000448838_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2793
Å |
| | | |  |
| CD44_PDHX_ENST00000360158_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7902
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.13
Å |
| | | |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1341
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.201
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6548
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1127
Å |
| | | |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7468
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1235
Å |
| | | |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7979
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000360158_ENST00000448838_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2684
Å |
| | | |  |
| CD44_PDHX_ENST00000415148_ENST00000227868_35222742_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.755
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000415148_ENST00000227868_35222742_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9992
Å |
| | | |  |
| CD44_PDHX_ENST00000415148_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7622
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000415148_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0901
Å |
| | | |  |
| CD44_PDHX_ENST00000415148_ENST00000448838_35222742_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.839
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000415148_ENST00000448838_35222742_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0791
Å |
| | | |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0124
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0296
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35160917_34999670 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.8851
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.725
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1302
Å |
| | | |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7446
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.08
Å |
| | | |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7558
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0484
Å |
| | | |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35222742_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7504
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35222742_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9944
Å |
| | | |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7495
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000428726_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.028
Å |
| | | |  |
| CD44_PDHX_ENST00000433354_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7286
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000433354_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0733
Å |
| | | |  |
| CD44_PDHX_ENST00000433892_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8285
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000433892_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0941
Å |
| | | |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7077
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1552
Å |
| | | |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7882
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0106
Å |
| | | |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000433892_ENST00000448838_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2957
Å |
| | | |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:2.3147
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0953
Å |
| | | |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7251
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0703
Å |
| | | |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8309
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0299
Å |
| | | |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7865
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000434472_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0929
Å |
| | | |  |
| CD44_PDHX_ENST00000434472_ENST00000448838_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1535
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000434472_ENST00000448838_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2254
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000437706_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7201
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000437706_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0662
Å |
| | | |  |
| CD44_PDHX_ENST00000437706_ENST00000448838_35222742_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8369
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000437706_ENST00000448838_35222742_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.164
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0425
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0234
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35160917_34999670 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9078
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7727
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0376
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7384
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0615
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7871
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0107
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35222742_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7487
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35222742_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:0.9886
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7727
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0568
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35201954_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.6106
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35201954_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2291
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35201954_34969052 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7564
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35201954_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0887
Å |
| | | |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35211612_34952950 superimposed PDB: 2I83 of partner (CD44). RMSD:1.76
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000449691_ENST00000448838_35211612_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2003
Å |
| | | |  |
| CD44_PDHX_ENST00000526025_ENST00000448838_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.173
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000526025_ENST00000448838_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.3281
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000526669_ENST00000227868_35243279_34988186 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7339
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000526669_ENST00000227868_35243279_34988186 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.0311
Å |
| | | |  |
| CD44_PDHX_ENST00000526669_ENST00000448838_35160917_34952950 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.1402
Å |
 |  |  |  |  |
| CD44_PDHX_ENST00000526669_ENST00000448838_35160917_34969052 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.2149
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000263398_ENST00000265393_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7934
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000263398_ENST00000265393_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:2.4945
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000352818_ENST00000543117_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7788
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000352818_ENST00000543117_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:2.7781
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000360158_ENST00000543117_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7834
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000360158_ENST00000543117_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:3.0322
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000428726_ENST00000265393_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7974
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000428726_ENST00000265393_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:3.0396
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000433892_ENST00000543117_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7886
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000433892_ENST00000543117_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:2.9772
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000434472_ENST00000265393_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7888
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000434472_ENST00000265393_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:2.8163
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000449691_ENST00000265393_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7558
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000449691_ENST00000265393_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:2.3334
Å |
| | | |  |
| CD44_TAX1BP1_ENST00000449691_ENST00000543117_35211612_27805452 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7848
Å |
 |  |  |  |  |
| CD44_TAX1BP1_ENST00000449691_ENST00000543117_35211612_27805452 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:3.0065
Å |
| | | |  |
| CD46_FAM124A_ENST00000322875_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.9494
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000354848_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.7366
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000357714_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:0.632
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000358170_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.3485
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000360212_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:2.0688
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000361067_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:2.0798
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000367041_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.686
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000367041_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.4212
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000367042_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:2.13
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000367047_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:0.5071
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000367047_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.4772
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000480003_ENST00000280057_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:2.3009
Å |
 |  |  |  |  |
| CD46_FAM124A_ENST00000480003_ENST00000322475_207959027_51805483 superimposed PDB: 8QK3 of partner (CD46). RMSD:1.5563
Å |
 |  |  |  |  |
| CD55_UBE2G2_ENST00000314754_ENST00000345496_207510754_46208010 superimposed PDB: 7LEW of partner (UBE2G2). RMSD:0.7937
Å |
 |  |  |  |  |
| CD55_UBE2G2_ENST00000367063_ENST00000345496_207510754_46208010 superimposed PDB: 3IYP of partner (CD55). RMSD:1.2892
Å |
 |  |  |  |  |
| CD55_UBE2G2_ENST00000367063_ENST00000345496_207510754_46208010 superimposed PDB: 7LEW of partner (UBE2G2). RMSD:0.8139
Å |
| | | |  |
| CD55_UBE2G2_ENST00000367064_ENST00000345496_207510754_46208010 superimposed PDB: 3IYP of partner (CD55). RMSD:0.8778
Å |
 |  |  |  |  |
| CD55_UBE2G2_ENST00000391920_ENST00000345496_207510754_46208010 superimposed PDB: 3IYP of partner (CD55). RMSD:1.4309
Å |
 |  |  |  |  |
| CD55_UBE2G2_ENST00000391920_ENST00000345496_207510754_46208010 superimposed PDB: 7LEW of partner (UBE2G2). RMSD:0.8144
Å |
| | | |  |
| CD58_RAD51B_ENST00000369487_ENST00000487861_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6248
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000369489_ENST00000390683_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.1494
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000369489_ENST00000471583_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0751
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000369489_ENST00000487270_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7551
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000369489_ENST00000488612_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5595
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000457047_ENST00000390683_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8348
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000457047_ENST00000471583_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1565
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000457047_ENST00000487270_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.262
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000457047_ENST00000487861_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.3263
Å |
 |  |  |  |  |
| CD58_RAD51B_ENST00000457047_ENST00000488612_117113524_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.371
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000257857_ENST00000267103_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:2.812
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000257857_ENST00000267103_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.4013
Å |
| | | |  |
| CD63_C12orf10_ENST00000420846_ENST00000267103_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.366
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000420846_ENST00000548632_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:2.0862
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000420846_ENST00000548632_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.8459
Å |
| | | |  |
| CD63_C12orf10_ENST00000548160_ENST00000267103_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:2.6764
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000548160_ENST00000267103_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.4152
Å |
| | | |  |
| CD63_C12orf10_ENST00000548160_ENST00000548632_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.6953
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000548898_ENST00000267103_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4163
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000548898_ENST00000548632_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.6211
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000552692_ENST00000267103_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.31
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000552692_ENST00000548632_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:2.3729
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000552692_ENST00000548632_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.6771
Å |
| | | |  |
| CD63_C12orf10_ENST00000552754_ENST00000548632_56120483_53693933 superimposed PDB: 9HUR of partner (CD63). RMSD:2.5202
Å |
 |  |  |  |  |
| CD63_C12orf10_ENST00000552754_ENST00000548632_56120483_53693933 superimposed PDB: 24AN of partner (C12orf10). RMSD:1.7743
Å |
| | | |  |
| CD63_MYL6_ENST00000420846_ENST00000293422_56120934_56552467 superimposed PDB: 9HUR of partner (CD63). RMSD:3.0945
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000257857_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4339
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000257857_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4279
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000257857_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3926
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000257857_ENST00000552285_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4584
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000420846_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.373
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000420846_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4046
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000420846_ENST00000389146_56119596_58109542 superimposed PDB: 9OG0 of partner (OS9). RMSD:2.7812
Å |
| | | |  |
| CD63_OS9_ENST00000420846_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4017
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000420846_ENST00000552285_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3646
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548160_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3714
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548160_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3999
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548160_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3678
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548160_ENST00000552285_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3983
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548898_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4082
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548898_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4078
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000548898_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3874
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552692_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4401
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552692_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4375
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552692_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4337
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552692_ENST00000552285_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.3818
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552754_ENST00000315970_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4382
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552754_ENST00000389146_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4474
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552754_ENST00000439210_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.4456
Å |
 |  |  |  |  |
| CD63_OS9_ENST00000552754_ENST00000552285_56119596_58109542 superimposed PDB: 9HUR of partner (CD63). RMSD:0.451
Å |
 |  |  |  |  |
| CD97_IGKC_ENST00000242786_ENST00000390237_14501891_89157196 superimposed PDB: 5EWI of partner (IGKC). RMSD:0.3549
Å |
 |  |  |  |  |
| CD97_IGKC_ENST00000357355_ENST00000390237_14501891_89157196 superimposed PDB: 5EWI of partner (IGKC). RMSD:0.3622
Å |
 |  |  |  |  |
| CD9_ADAMTS12_ENST00000009180_ENST00000352040_6334700_33684160 superimposed PDB: 6K4J of partner (CD9). RMSD:2.3498
Å |
 |  |  |  |  |
| CD9_ADAMTS12_ENST00000009180_ENST00000504830_6334700_33684160 superimposed PDB: 6K4J of partner (CD9). RMSD:2.3733
Å |
 |  |  |  |  |
| CD9_ADAMTS12_ENST00000382518_ENST00000352040_6334700_33684160 superimposed PDB: 6K4J of partner (CD9). RMSD:2.1772
Å |
 |  |  |  |  |
| CDC123_HK1_ENST00000281141_ENST00000298649_12240775_71136689 superimposed PDB: 1CZA of partner (HK1). RMSD:1.681
Å |
 |  |  |  |  |
| CDC123_HK1_ENST00000281141_ENST00000448642_12240775_71136689 superimposed PDB: 1CZA of partner (HK1). RMSD:1.7949
Å |
 |  |  |  |  |
| CDC123_MDM2_ENST00000378900_ENST00000462284_12240775_69214104 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.6868
Å |
 |  |  |  |  |
| CDC14B_SUSD1_ENST00000265659_ENST00000374264_99381500_114919893 superimposed PDB: 1OHE of partner (CDC14B). RMSD:2.8234
Å |
 |  |  |  |  |
| CDC14B_SUSD1_ENST00000375241_ENST00000374263_99381500_114919893 superimposed PDB: 1OHE of partner (CDC14B). RMSD:2.4793
Å |
 |  |  |  |  |
| CDC25A_PRKAR2A_ENST00000351231_ENST00000265563_48215773_48820525 superimposed PDB: 8ROZ of partner (CDC25A). RMSD:0.6166
Å |
 |  |  |  |  |
| CDC25A_SPINK8_ENST00000302506_ENST00000434006_48205796_48351436 superimposed PDB: 8ROZ of partner (CDC25A). RMSD:0.6607
Å |
 |  |  |  |  |
| CDC27_BRAF_ENST00000527547_ENST00000288602_45206758_140487384 superimposed PDB: 9GAW of partner (CDC27). RMSD:1.1204
Å |
 |  |  |  |  |
| CDC27_BRAF_ENST00000531206_ENST00000288602_45206758_140487384 superimposed PDB: 9GAW of partner (CDC27). RMSD:1.1023
Å |
 |  |  |  |  |
| CDC27_GPHN_ENST00000066544_ENST00000478722_45258927_67555699 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.7169
Å |
 |  |  |  |  |
| CDC27_SYT13_ENST00000531206_ENST00000020926_45266511_45277442 superimposed PDB: 1WFM of partner (SYT13). RMSD:0.8306
Å |
 |  |  |  |  |
| CDC37_KMT2C_ENST00000222005_ENST00000355193_10514053_151836876 superimposed PDB: 9KQN of partner (CDC37). RMSD:3.2489
Å |
 |  |  |  |  |
| CDC37_KMT2C_ENST00000222005_ENST00000355193_10514053_151836876 superimposed PDB: 6KIW of partner (KMT2C). RMSD:1.9538
Å |
| | | |  |
| CDC42BPB_C14orf182_ENST00000361246_ENST00000399206_103523335_50459591 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.8072
Å |
 |  |  |  |  |
| CDC42BPB_RGS6_ENST00000361246_ENST00000553525_103449892_73029124 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.0998
Å |
 |  |  |  |  |
| CDC42BPB_RGS6_ENST00000361246_ENST00000553530_103449892_73029124 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.0223
Å |
 |  |  |  |  |
| CDC42BPB_RGS6_ENST00000361246_ENST00000555571_103449892_73029124 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.0674
Å |
 |  |  |  |  |
| CDC42BPB_ZFYVE1_ENST00000361246_ENST00000318876_103452823_73465023 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.7252
Å |
 |  |  |  |  |
| CDC42BPB_ZFYVE1_ENST00000361246_ENST00000556143_103452823_73465023 superimposed PDB: 5OTE of partner (CDC42BPB). RMSD:1.6577
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000344548_ENST00000401084_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.4668
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000344548_ENST00000401084_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7833
Å |
| | | |  |
| CDC42_CAPZB_ENST00000400259_ENST00000264203_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.4708
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000400259_ENST00000264203_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.81
Å |
| | | |  |
| CDC42_CAPZB_ENST00000400259_ENST00000375142_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.5677
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000400259_ENST00000375142_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7782
Å |
| | | |  |
| CDC42_CAPZB_ENST00000400259_ENST00000433834_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.5137
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000400259_ENST00000433834_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.701
Å |
| | | |  |
| CDC42_CAPZB_ENST00000421089_ENST00000264203_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.565
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000421089_ENST00000264203_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8385
Å |
| | | |  |
| CDC42_CAPZB_ENST00000421089_ENST00000375142_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.6363
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000421089_ENST00000375142_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7203
Å |
| | | |  |
| CDC42_CAPZB_ENST00000421089_ENST00000433834_22413359_19746245 superimposed PDB: 2NGR of partner (CDC42). RMSD:0.7188
Å |
 |  |  |  |  |
| CDC42_CAPZB_ENST00000421089_ENST00000433834_22413359_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7052
Å |
| | | |  |
| CDC5L_HSP90AB1_ENST00000371477_ENST00000371554_44376369_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.6128
Å |
 |  |  |  |  |
| CDC5L_POLH_ENST00000371477_ENST00000535400_44376369_43568724 superimposed PDB: 6MXO of partner (POLH). RMSD:3.3159
Å |
 |  |  |  |  |
| CDC6_RAPGEFL1_ENST00000209728_ENST00000544503_38451708_38345117 superimposed PDB: 8S0E of partner (CDC6). RMSD:0.8629
Å |
 |  |  |  |  |
| CDC6_RAPGEFL1_ENST00000209728_ENST00000544503_38451708_38345117 superimposed PDB: 2DHZ of partner (RAPGEFL1). RMSD:0.9189
Å |
| | | |  |
| CDC6_SRCIN1_ENST00000209728_ENST00000264659_38453019_36735044 superimposed PDB: 8S0E of partner (CDC6). RMSD:0.9449
Å |
 |  |  |  |  |
| CDC6_SRCIN1_ENST00000209728_ENST00000578925_38453019_36735044 superimposed PDB: 8S0E of partner (CDC6). RMSD:0.69
Å |
 |  |  |  |  |
| CDCA8_GRIK3_ENST00000327331_ENST00000373093_38158705_37356697 superimposed PDB: 9SI3 of partner (CDCA8). RMSD:2.5813
Å |
 |  |  |  |  |
| CDH13_CDH13_ENST00000566620_ENST00000268613_82660742_83636058 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.6835
Å |
 |  |  |  |  |
| CDH13_CDH13_ENST00000566620_ENST00000268613_82660742_83636058 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.6835
Å |
| | | | |
| CDH13_DYNC1LI2_ENST00000268613_ENST00000258198_83520260_66757725 superimposed PDB: 2V37 of partner (CDH13). RMSD:0.8956
Å |
 |  |  |  |  |
| CDH13_DYNC1LI2_ENST00000428848_ENST00000258198_83520260_66757725 superimposed PDB: 2V37 of partner (CDH13). RMSD:0.8936
Å |
 |  |  |  |  |
| CDH13_HSBP1_ENST00000268613_ENST00000570259_83159106_83842284 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.1598
Å |
 |  |  |  |  |
| CDH13_HSBP1_ENST00000268613_ENST00000570259_83159106_83842284 superimposed PDB: 3CI9 of partner (HSBP1). RMSD:0.5726
Å |
| | | |  |
| CDH13_HSBP1_ENST00000566620_ENST00000570259_83159106_83842284 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.2249
Å |
 |  |  |  |  |
| CDH13_HSBP1_ENST00000566620_ENST00000570259_83159106_83842284 superimposed PDB: 3CI9 of partner (HSBP1). RMSD:0.5382
Å |
| | | |  |
| CDH13_HYDIN_ENST00000268613_ENST00000448089_82673070_71054220 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:2.2934
Å |
 |  |  |  |  |
| CDH13_HYDIN_ENST00000431540_ENST00000393567_82660742_71054220 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:2.6852
Å |
 |  |  |  |  |
| CDH13_HYDIN_ENST00000565636_ENST00000393567_82660742_71054220 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:2.6813
Å |
 |  |  |  |  |
| CDH13_HYDIN_ENST00000566620_ENST00000448089_82660742_71054220 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:1.9387
Å |
 |  |  |  |  |
| CDH13_WFDC1_ENST00000569454_ENST00000568638_83520260_84358024 superimposed PDB: 2V37 of partner (CDH13). RMSD:0.8863
Å |
 |  |  |  |  |
| CDH17_ERLIN2_ENST00000027335_ENST00000276461_95206862_37597882 superimposed PDB: 9O9U of partner (ERLIN2). RMSD:1.7304
Å |
 |  |  |  |  |
| CDH17_ERLIN2_ENST00000027335_ENST00000523887_95206862_37597882 superimposed PDB: 9O9U of partner (ERLIN2). RMSD:1.62
Å |
 |  |  |  |  |
| CDH18_TERT_ENST00000274170_ENST00000296820_19612542_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.9367
Å |
 |  |  |  |  |
| CDH1_CCDC132_ENST00000261769_ENST00000541136_68857529_92952922 superimposed PDB: 7STZ of partner (CDH1). RMSD:2.7881
Å |
 |  |  |  |  |
| CDH1_CCDC132_ENST00000261769_ENST00000544910_68857529_92952922 superimposed PDB: 7STZ of partner (CDH1). RMSD:3.063
Å |
 |  |  |  |  |
| CDH1_CDKL3_ENST00000422392_ENST00000521755_68856128_133644157 superimposed PDB: 7STZ of partner (CDH1). RMSD:2.4182
Å |
 |  |  |  |  |
| CDH1_CDKL3_ENST00000422392_ENST00000521755_68856128_133644157 superimposed PDB: 3ZDU of partner (CDKL3). RMSD:2.3643
Å |
| | | |  |
| CDH1_NPFFR2_ENST00000261769_ENST00000395999_68772314_73003756 superimposed PDB: 9M1O of partner (NPFFR2). RMSD:0.8472
Å |
 |  |  |  |  |
| CDH1_NPFFR2_ENST00000422392_ENST00000395999_68772314_73003756 superimposed PDB: 9M1O of partner (NPFFR2). RMSD:0.8478
Å |
 |  |  |  |  |
| CDH1_TRADD_ENST00000422392_ENST00000345057_68772314_67189557 superimposed PDB: 1F3V of partner (TRADD). RMSD:0.9155
Å |
 |  |  |  |  |
| CDH23_NSD1_ENST00000224721_ENST00000439151_73501678_176618884 superimposed PDB: 5VVM of partner (CDH23). RMSD:2.1463
Å |
 |  |  |  |  |
| CDH23_NSD1_ENST00000224721_ENST00000439151_73501678_176618884 superimposed PDB: 3OOI of partner (NSD1). RMSD:0.9078
Å |
| | | |  |
| CDH3_CHKA_ENST00000429102_ENST00000265689_68718727_67836404 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.3104
Å |
 |  |  |  |  |
| CDH3_CHKA_ENST00000429102_ENST00000265689_68718727_67836404 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3898
Å |
| | | |  |
| CDH4_EYA2_ENST00000360469_ENST00000327619_59829993_45700823 superimposed PDB: 4EGC of partner (EYA2). RMSD:3.0105
Å |
 |  |  |  |  |
| CDH4_EYA2_ENST00000360469_ENST00000327619_59829993_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.6533
Å |
 |  |  |  |  |
| CDH4_EYA2_ENST00000360469_ENST00000357410_59829993_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.3986
Å |
 |  |  |  |  |
| CDH4_NME1_ENST00000360469_ENST00000013034_60348238_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.2708
Å |
 |  |  |  |  |
| CDH4_NME1_ENST00000360469_ENST00000336097_60348238_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.6451
Å |
 |  |  |  |  |
| CDH4_NME1_ENST00000360469_ENST00000511355_60348238_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.9391
Å |
 |  |  |  |  |
| CDH4_NME1_ENST00000543233_ENST00000336097_60348238_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.7381
Å |
 |  |  |  |  |
| CDH4_NME1_ENST00000543233_ENST00000511355_60348238_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:3.2095
Å |
 |  |  |  |  |
| CDH8_RFX1_ENST00000577390_ENST00000254325_61935082_14083939 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.4025
Å |
 |  |  |  |  |
| CDK12_FAM20A_ENST00000447079_ENST00000592554_37628016_66551884 superimposed PDB: 5YH3 of partner (FAM20A). RMSD:0.5729
Å |
 |  |  |  |  |
| CDK12_LRP4_ENST00000447079_ENST00000378623_37619370_46912045 superimposed PDB: 8S9P of partner (LRP4). RMSD:1.5673
Å |
 |  |  |  |  |
| CDK12_TAF15_ENST00000430627_ENST00000311979_37682569_34169370 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5215
Å |
 |  |  |  |  |
| CDK12_TAF15_ENST00000430627_ENST00000592237_37682569_34169370 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5242
Å |
 |  |  |  |  |
| CDK12_TAF15_ENST00000447079_ENST00000311979_37682569_34169370 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5347
Å |
 |  |  |  |  |
| CDK12_TAF15_ENST00000447079_ENST00000592237_37682569_34169370 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5185
Å |
 |  |  |  |  |
| CDK13_C7orf10_ENST00000181839_ENST00000335693_40041630_40899914 superimposed PDB: 5EFQ of partner (CDK13). RMSD:1.2864
Å |
 |  |  |  |  |
| CDK13_POU6F2_ENST00000181839_ENST00000518318_40041630_39500145 superimposed PDB: 5EFQ of partner (CDK13). RMSD:0.8222
Å |
 |  |  |  |  |
| CDK13_POU6F2_ENST00000340829_ENST00000403058_40041630_39500145 superimposed PDB: 5EFQ of partner (CDK13). RMSD:0.8659
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000265741_ENST00000319801_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.8017
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000265741_ENST00000361078_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.6688
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000265741_ENST00000536417_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.7582
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000380050_ENST00000319801_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.8318
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000380050_ENST00000361078_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.6589
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000380050_ENST00000536417_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.7327
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000406263_ENST00000319801_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.8242
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000406263_ENST00000361078_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.6726
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000406263_ENST00000536417_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.6558
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000436577_ENST00000319801_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.7837
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000436577_ENST00000361078_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.6207
Å |
 |  |  |  |  |
| CDK14_PUM2_ENST00000436577_ENST00000536417_90547039_20483247 superimposed PDB: 3Q0Q of partner (PUM2). RMSD:0.7161
Å |
 |  |  |  |  |
| CDK14_SAV1_ENST00000406263_ENST00000324679_90675275_51111732 superimposed PDB: 6AO5 of partner (SAV1). RMSD:1.7067
Å |
 |  |  |  |  |
| CDK14_SAV1_ENST00000436577_ENST00000324679_90675275_51111732 superimposed PDB: 6AO5 of partner (SAV1). RMSD:2.1578
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000260967_ENST00000449475_202688450_71929604 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.5317
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000410091_ENST00000298223_202688450_71931913 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.6963
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000410091_ENST00000454954_202688450_71931913 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.6363
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000434439_ENST00000449475_202688450_71929604 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.5259
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000450471_ENST00000298223_202688450_71931913 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.787
Å |
 |  |  |  |  |
| CDK15_FOLR2_ENST00000450471_ENST00000454954_202688450_71931913 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.6284
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000357227_ENST00000284898_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.4225
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000357227_ENST00000317931_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.1887
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000357227_ENST00000535782_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.1232
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000457458_ENST00000284898_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.4018
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000457458_ENST00000317931_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.2192
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000457458_ENST00000535782_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.0745
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000518022_ENST00000284898_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.3697
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000518022_ENST00000317931_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.1262
Å |
 |  |  |  |  |
| CDK16_L3MBTL4_ENST00000518022_ENST00000535782_47086102_6093527 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.0946
Å |
 |  |  |  |  |
| CDK16_TIMP1_ENST00000457458_ENST00000218388_47078063_47444603 superimposed PDB: 9R2I of partner (CDK16). RMSD:1.2443
Å |
 |  |  |  |  |
| CDK17_LYZ_ENST00000542666_ENST00000261267_96717725_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.7138
Å |
 |  |  |  |  |
| CDK17_LYZ_ENST00000542666_ENST00000549690_96717725_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:1.1472
Å |
 |  |  |  |  |
| CDK19_CPM_ENST00000368911_ENST00000551568_111067328_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4951
Å |
 |  |  |  |  |
| CDK2_PAN2_ENST00000266970_ENST00000257931_56363360_56719238 superimposed PDB: 6Q4G of partner (CDK2). RMSD:1.4905
Å |
 |  |  |  |  |
| CDK2_PAN2_ENST00000266970_ENST00000440411_56363360_56719238 superimposed PDB: 6Q4G of partner (CDK2). RMSD:1.4549
Å |
 |  |  |  |  |
| CDK2_PAN2_ENST00000266970_ENST00000548043_56363360_56719238 superimposed PDB: 6Q4G of partner (CDK2). RMSD:1.4707
Å |
 |  |  |  |  |
| CDK5RAP3_RTEL1_ENST00000338399_ENST00000318100_46051814_62318990 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3395
Å |
 |  |  |  |  |
| CDK5RAP3_RTEL1_ENST00000338399_ENST00000370018_46051814_62318990 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3738
Å |
 |  |  |  |  |
| CDK5RAP3_RTEL1_ENST00000338399_ENST00000508582_46051814_62318990 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3724
Å |
 |  |  |  |  |
| CDK5RAP3_RTEL1_ENST00000536708_ENST00000318100_46051814_62318990 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3401
Å |
 |  |  |  |  |
| CDK5RAP3_RTEL1_ENST00000536708_ENST00000508582_46051814_62318990 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3592
Å |
 |  |  |  |  |
| CDK6_CPM_ENST00000265734_ENST00000546373_92354939_69279669 superimposed PDB: 1BLX of partner (CDK6). RMSD:2.0577
Å |
 |  |  |  |  |
| CDK6_CPM_ENST00000265734_ENST00000551568_92354939_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4944
Å |
 |  |  |  |  |
| CDK6_HEPACAM2_ENST00000424848_ENST00000394468_92404009_92821676 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.1739
Å |
 |  |  |  |  |
| CDK6_KMT2A_ENST00000424848_ENST00000354520_92404009_118360506 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.7758
Å |
 |  |  |  |  |
| CDK6_KMT2A_ENST00000424848_ENST00000354520_92404009_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.6036
Å |
| | | |  |
| CDK6_KMT2A_ENST00000424848_ENST00000389506_92404009_118360506 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.7437
Å |
 |  |  |  |  |
| CDK6_KMT2A_ENST00000424848_ENST00000389506_92404009_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.4532
Å |
| | | |  |
| CDK6_SHFM1_ENST00000265734_ENST00000417009_92404009_96324203 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.7949
Å |
 |  |  |  |  |
| CDK6_SHFM1_ENST00000265734_ENST00000417009_92404009_96324203 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.4872
Å |
| | | |  |
| CDK6_SHFM1_ENST00000265734_ENST00000444799_92404009_96324203 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.3061
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000372977_92354939_42023268 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.5731
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000372977_92462404_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.7215
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000372978_92354939_42023268 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.9525
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000372978_92354939_42023268 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.6682
Å |
| | | |  |
| CDK6_TAF8_ENST00000265734_ENST00000372982_92462404_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.6355
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000456846_92354939_42023268 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.8823
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000456846_92462404_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.0635
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000494547_92354939_42023268 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.6246
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000265734_ENST00000494547_92462404_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.8995
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000424848_ENST00000372977_92354939_42019094 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.8821
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000424848_ENST00000372977_92354939_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.0044
Å |
| | | |  |
| CDK6_TAF8_ENST00000424848_ENST00000372982_92354939_42019094 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.9839
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000424848_ENST00000372982_92354939_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.1513
Å |
| | | |  |
| CDK6_TAF8_ENST00000424848_ENST00000456846_92354939_42019094 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.9425
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000424848_ENST00000456846_92354939_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.2545
Å |
| | | |  |
| CDK6_TAF8_ENST00000424848_ENST00000494547_92354939_42019094 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.9169
Å |
 |  |  |  |  |
| CDK6_TAF8_ENST00000424848_ENST00000494547_92354939_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.8139
Å |
| | | |  |
| CDK7_SH3BGR_ENST00000256443_ENST00000380634_68531280_40871748 superimposed PDB: 8P79 of partner (CDK7). RMSD:0.4629
Å |
 |  |  |  |  |
| CDK8_ATP8A2_ENST00000536792_ENST00000381655_26928017_26402255 superimposed PDB: 8TQ2 of partner (CDK8). RMSD:2.5724
Å |
 |  |  |  |  |
| CDK8_FGF14_ENST00000536792_ENST00000468052_26928017_102527644 superimposed PDB: 8TQ2 of partner (CDK8). RMSD:1.3378
Å |
 |  |  |  |  |
| CDKAL1_ASH1L_ENST00000378610_ENST00000392403_20846409_155349907 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6378
Å |
 |  |  |  |  |
| CDKAL1_ASH1L_ENST00000378624_ENST00000392403_20846409_155349907 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6654
Å |
 |  |  |  |  |
| CDKAL1_CRHR2_ENST00000274695_ENST00000341843_21108694_30695628 superimposed PDB: 6PB1 of partner (CRHR2). RMSD:2.6582
Å |
 |  |  |  |  |
| CDKAL1_CRHR2_ENST00000378610_ENST00000471646_21108694_30695628 superimposed PDB: 6PB1 of partner (CRHR2). RMSD:2.6777
Å |
 |  |  |  |  |
| CDKAL1_GMDS_ENST00000274695_ENST00000380815_21065459_1961200 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.6356
Å |
 |  |  |  |  |
| CDKAL1_GMDS_ENST00000378624_ENST00000380815_21065459_1961200 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.632
Å |
 |  |  |  |  |
| CDKL1_DNM2_ENST00000395834_ENST00000359692_50862418_10939711 superimposed PDB: 4AGU of partner (CDKL1). RMSD:2.6395
Å |
 |  |  |  |  |
| CDKN2A_CAPZB_ENST00000579122_ENST00000264203_21974676_19671746 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:2.5088
Å |
 |  |  |  |  |
| CDKN2A_MTAP_ENST00000304494_ENST00000380172_21974676_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3244
Å |
 |  |  |  |  |
| CDKN2A_MTAP_ENST00000304494_ENST00000460874_21974676_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3252
Å |
 |  |  |  |  |
| CDKN2A_MTAP_ENST00000579122_ENST00000380172_21974676_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3387
Å |
 |  |  |  |  |
| CDKN2A_MTAP_ENST00000579122_ENST00000460874_21974676_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3418
Å |
 |  |  |  |  |
| CDKN2A_MYH10_ENST00000361570_ENST00000269243_21994137_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.2495
Å |
 |  |  |  |  |
| CDKN2A_MYH10_ENST00000361570_ENST00000379980_21994137_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.2726
Å |
 |  |  |  |  |
| CDKN2A_MYH10_ENST00000361570_ENST00000396239_21994137_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3984
Å |
 |  |  |  |  |
| CDKN2A_MYH10_ENST00000579755_ENST00000360416_21994137_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.2355
Å |
 |  |  |  |  |
| CDKN2A_PTPRD_ENST00000579755_ENST00000381196_21994137_10033790 superimposed PDB: 6X3A of partner (PTPRD). RMSD:3.0342
Å |
 |  |  |  |  |
| CDR2L_MEF2D_ENST00000337231_ENST00000348159_72995711_156445029 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.9359
Å |
 |  |  |  |  |
| CEACAM1_ABCC11_ENST00000161559_ENST00000356608_43025418_48230232 superimposed PDB: 9GH6 of partner (CEACAM1). RMSD:1.6196
Å |
 |  |  |  |  |
| CEACAM1_ABCC11_ENST00000161559_ENST00000394747_43025418_48230232 superimposed PDB: 9GH6 of partner (CEACAM1). RMSD:1.7189
Å |
 |  |  |  |  |
| CEACAM1_ABCC11_ENST00000352591_ENST00000356608_43025418_48230232 superimposed PDB: 9GH6 of partner (CEACAM1). RMSD:1.1314
Å |
 |  |  |  |  |
| CEACAM1_ABCC11_ENST00000352591_ENST00000394747_43025418_48230232 superimposed PDB: 9GH6 of partner (CEACAM1). RMSD:1.7486
Å |
 |  |  |  |  |
| CEACAM1_ABCC11_ENST00000403444_ENST00000353782_43025418_48230232 superimposed PDB: 9GH6 of partner (CEACAM1). RMSD:0.7859
Å |
 |  |  |  |  |
| CEACAM5_AP1G1_ENST00000398599_ENST00000569748_42224127_71767062 superimposed PDB: 1E07 of partner (CEACAM5). RMSD:3.4178
Å |
 |  |  |  |  |
| CEACAM5_AP1G1_ENST00000398599_ENST00000569748_42224127_71767062 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:2.7146
Å |
| | | |  |
| CEACAM5_AP1G1_ENST00000405816_ENST00000569748_42224127_71767062 superimposed PDB: 1E07 of partner (CEACAM5). RMSD:3.3096
Å |
 |  |  |  |  |
| CELF1_AMBRA1_ENST00000395292_ENST00000426438_47504246_46465148 superimposed PDB: 8WQR of partner (AMBRA1). RMSD:0.9254
Å |
 |  |  |  |  |
| CELF1_AMBRA1_ENST00000531165_ENST00000298834_47504246_46465148 superimposed PDB: 8WQR of partner (AMBRA1). RMSD:0.9655
Å |
 |  |  |  |  |
| CELF1_FNBP4_ENST00000310513_ENST00000263773_47505004_47741638 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.1618
Å |
 |  |  |  |  |
| CELF1_FNBP4_ENST00000395292_ENST00000263773_47504246_47739064 superimposed PDB: 2DHS of partner (CELF1). RMSD:1.9926
Å |
 |  |  |  |  |
| CELF1_FNBP4_ENST00000531165_ENST00000263773_47504246_47739064 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.0261
Å |
 |  |  |  |  |
| CELF1_MTCH2_ENST00000358597_ENST00000302503_47508301_47657123 superimposed PDB: 12OZ of partner (MTCH2). RMSD:1.3341
Å |
 |  |  |  |  |
| CELF1_RPL9_ENST00000358597_ENST00000449470_47498397_39456564 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.0243
Å |
 |  |  |  |  |
| CELF1_RPL9_ENST00000361904_ENST00000449470_47498397_39456564 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.2077
Å |
 |  |  |  |  |
| CELF1_RPL9_ENST00000395290_ENST00000449470_47498397_39456564 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.288
Å |
 |  |  |  |  |
| CELF1_RPL9_ENST00000532048_ENST00000449470_47498397_39456564 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.3745
Å |
 |  |  |  |  |
| CELF1_STK32A_ENST00000310513_ENST00000397936_47508301_146703460 superimposed PDB: 2DHS of partner (CELF1). RMSD:2.7969
Å |
 |  |  |  |  |
| CELF1_STK32A_ENST00000310513_ENST00000541094_47508301_146703460 superimposed PDB: 4FR4 of partner (STK32A). RMSD:0.4064
Å |
 |  |  |  |  |
| CELSR1_CD52_ENST00000395964_ENST00000374213_46859603_26646661 superimposed PDB: 8D40 of partner (CELSR1). RMSD:2.5192
Å |
 |  |  |  |  |
| CELSR1_CERK_ENST00000262738_ENST00000541677_46929523_47086097 superimposed PDB: 8D40 of partner (CELSR1). RMSD:1.9747
Å |
 |  |  |  |  |
| CELSR1_FLOT1_ENST00000262738_ENST00000456573_46804892_30698877 superimposed PDB: 8D40 of partner (CELSR1). RMSD:3.1063
Å |
 |  |  |  |  |
| CELSR1_STK24_ENST00000262738_ENST00000539966_46829289_99127612 superimposed PDB: 8D40 of partner (CELSR1). RMSD:2.5728
Å |
 |  |  |  |  |
| CELSR1_STK24_ENST00000262738_ENST00000539966_46829289_99127612 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5489
Å |
| | | |  |
| CENPM_NHP2L1_ENST00000215980_ENST00000215956_42339613_42076368 superimposed PDB: 28OP of partner (CENPM). RMSD:0.4209
Å |
 |  |  |  |  |
| CENPM_NHP2L1_ENST00000215980_ENST00000215956_42339613_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.3659
Å |
| | | |  |
| CENPM_NHP2L1_ENST00000215980_ENST00000215956_42342420_42071199 superimposed PDB: 28OP of partner (CENPM). RMSD:0.4456
Å |
 |  |  |  |  |
| CENPM_NHP2L1_ENST00000402338_ENST00000215956_42339613_42076368 superimposed PDB: 28OP of partner (CENPM). RMSD:0.3797
Å |
 |  |  |  |  |
| CENPM_NHP2L1_ENST00000402338_ENST00000215956_42339613_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.377
Å |
| | | |  |
| CENPT_DPEP3_ENST00000440851_ENST00000268793_67866130_68010678 superimposed PDB: 28OP of partner (CENPT). RMSD:2.9437
Å |
 |  |  |  |  |
| CENPT_DPEP3_ENST00000564817_ENST00000268793_67866130_68010678 superimposed PDB: 28OP of partner (CENPT). RMSD:2.9298
Å |
 |  |  |  |  |
| CEP135_POLR2B_ENST00000257287_ENST00000381227_56847545_57865782 superimposed PDB: 5FCN of partner (CEP135). RMSD:1.3216
Å |
 |  |  |  |  |
| CEP135_POLR2B_ENST00000257287_ENST00000431623_56847545_57865782 superimposed PDB: 5FCN of partner (CEP135). RMSD:2.4952
Å |
 |  |  |  |  |
| CEP135_POLR2B_ENST00000257287_ENST00000431623_56847545_57865782 superimposed PDB: 9EHZ of partner (POLR2B). RMSD:1.2717
Å |
| | | |  |
| CEP170_RAD51B_ENST00000366542_ENST00000390683_243349080_68758600 superimposed PDB: 4JON of partner (CEP170). RMSD:0.3519
Å |
 |  |  |  |  |
| CEP170_RAD51B_ENST00000366542_ENST00000471583_243349080_68758600 superimposed PDB: 4JON of partner (CEP170). RMSD:0.3591
Å |
 |  |  |  |  |
| CEP170_RAD51B_ENST00000366542_ENST00000487270_243349080_68758600 superimposed PDB: 4JON of partner (CEP170). RMSD:0.3512
Å |
 |  |  |  |  |
| CEP170_RAD51B_ENST00000366542_ENST00000487861_243349080_68758600 superimposed PDB: 4JON of partner (CEP170). RMSD:0.5289
Å |
 |  |  |  |  |
| CEP170_RAD51B_ENST00000366542_ENST00000488612_243349080_68758600 superimposed PDB: 4JON of partner (CEP170). RMSD:0.3454
Å |
 |  |  |  |  |
| CEP57_CD3E_ENST00000325486_ENST00000361763_95532552_118182867 superimposed PDB: 7FJE of partner (CD3E). RMSD:1.259
Å |
 |  |  |  |  |
| CEP57_CD3E_ENST00000325542_ENST00000361763_95532552_118182867 superimposed PDB: 7FJE of partner (CD3E). RMSD:1.1213
Å |
 |  |  |  |  |
| CEP72_PDCD6_ENST00000264935_ENST00000505221_620376_304291 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.7154
Å |
 |  |  |  |  |
| CEP72_PDCD6_ENST00000264935_ENST00000505221_634062_304291 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.8469
Å |
 |  |  |  |  |
| CEP95_MYC_ENST00000581056_ENST00000377970_62503234_128752641 superimposed PDB: 5I4Z of partner (MYC). RMSD:0.4441
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000326686_ENST00000241069_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.77
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000326686_ENST00000412389_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.8177
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000398354_ENST00000241069_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.9647
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000398354_ENST00000412389_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.9144
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000540579_ENST00000241069_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.8744
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000540579_ENST00000412389_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.8943
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000541479_ENST00000241069_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.922
Å |
 |  |  |  |  |
| CES4A_ACHE_ENST00000541479_ENST00000412389_67040720_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:0.9207
Å |
 |  |  |  |  |
| CFD_EIF3B_ENST00000327726_ENST00000397011_861956_2411411 superimposed PDB: 6QMT of partner (CFD). RMSD:0.5289
Å |
 |  |  |  |  |
| CFD_EIF3B_ENST00000592860_ENST00000397011_861956_2411411 superimposed PDB: 6QMT of partner (CFD). RMSD:0.6459
Å |
 |  |  |  |  |
| CHCHD1_SLC12A2_ENST00000372833_ENST00000343225_75542199_127448505 superimposed PDB: 9C0H of partner (SLC12A2). RMSD:1.6444
Å |
 |  |  |  |  |
| CHCHD3_CYP51A1_ENST00000448878_ENST00000003100_132570421_91761186 superimposed PDB: 3LD6 of partner (CYP51A1). RMSD:0.4658
Å |
 |  |  |  |  |
| CHCHD3_ITPKA_ENST00000262570_ENST00000260386_132659928_41794599 superimposed PDB: 9QGK of partner (ITPKA). RMSD:0.4464
Å |
 |  |  |  |  |
| CHCHD6_RB1_ENST00000508789_ENST00000267163_126423242_48916734 superimposed PDB: 4ELJ of partner (RB1). RMSD:3.2611
Å |
 |  |  |  |  |
| CHD1_SLCO6A1_ENST00000284049_ENST00000506729_98228228_101748847 superimposed PDB: 9EAR of partner (CHD1). RMSD:1.715
Å |
 |  |  |  |  |
| CHD3_RAD51C_ENST00000330494_ENST00000583539_7797253_56787219 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.3456
Å |
 |  |  |  |  |
| CHD3_RAD51C_ENST00000358181_ENST00000337432_7797253_56787219 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.5673
Å |
 |  |  |  |  |
| CHD3_RAD51C_ENST00000358181_ENST00000583539_7797253_56787219 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.3338
Å |
 |  |  |  |  |
| CHD3_RAD51C_ENST00000380358_ENST00000337432_7797253_56787219 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.2876
Å |
 |  |  |  |  |
| CHD6_CA3_ENST00000309279_ENST00000285381_40120337_86351940 superimposed PDB: 2EPB of partner (CHD6). RMSD:0.8872
Å |
 |  |  |  |  |
| CHD7_ASPH_ENST00000525508_ENST00000379454_61693989_62416068 superimposed PDB: 9FVU of partner (ASPH). RMSD:1.4744
Å |
 |  |  |  |  |
| CHD7_TCF7L2_ENST00000423902_ENST00000369397_61655656_114900942 superimposed PDB: 2GL7 of partner (TCF7L2). RMSD:2.5892
Å |
 |  |  |  |  |
| CHD7_TCF7L2_ENST00000524602_ENST00000534894_61655656_114900942 superimposed PDB: 2GL7 of partner (TCF7L2). RMSD:2.6616
Å |
 |  |  |  |  |
| CHEK2_OCIAD2_ENST00000328354_ENST00000508632_29120964_48899874 superimposed PDB: 3I6W of partner (CHEK2). RMSD:0.4407
Å |
 |  |  |  |  |
| CHEK2_OCIAD2_ENST00000402731_ENST00000508632_29120964_48899874 superimposed PDB: 3I6W of partner (CHEK2). RMSD:0.4403
Å |
 |  |  |  |  |
| CHEK2_OCIAD2_ENST00000404276_ENST00000508632_29120964_48899874 superimposed PDB: 3I6W of partner (CHEK2). RMSD:0.3887
Å |
 |  |  |  |  |
| CHEK2_THOC5_ENST00000544772_ENST00000397871_29085122_29932727 superimposed PDB: 7APK of partner (THOC5). RMSD:1.1066
Å |
 |  |  |  |  |
| CHERP_RHAG_ENST00000198939_ENST00000371175_16652680_49587075 superimposed PDB: 7UZQ of partner (RHAG). RMSD:0.3456
Å |
 |  |  |  |  |
| CHI3L1_UBA1_ENST00000255409_ENST00000335972_203151858_47069326 superimposed PDB: 8R4X of partner (CHI3L1). RMSD:0.4096
Å |
 |  |  |  |  |
| CHI3L1_UBA1_ENST00000255409_ENST00000335972_203151858_47069326 superimposed PDB: 9MC5 of partner (UBA1). RMSD:3.4124
Å |
| | | |  |
| CHI3L1_UBA1_ENST00000255409_ENST00000377351_203151858_47069326 superimposed PDB: 8R4X of partner (CHI3L1). RMSD:0.4589
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000263921_ENST00000306932_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5611
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000263921_ENST00000337488_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.547
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000263921_ENST00000358575_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7105
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000263921_ENST00000507922_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5477
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000512964_ENST00000306932_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5822
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000512964_ENST00000337488_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5456
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000512964_ENST00000358575_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7202
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000512964_ENST00000507166_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5488
Å |
 |  |  |  |  |
| CHIC2_FIP1L1_ENST00000512964_ENST00000507922_54915121_54249939 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5197
Å |
 |  |  |  |  |
| CHIC2_SPINK2_ENST00000263921_ENST00000506738_54915121_57677960 superimposed PDB: 6KBR of partner (SPINK2). RMSD:0.3746
Å |
 |  |  |  |  |
| CHIC2_SPINK2_ENST00000512964_ENST00000506738_54915121_57677960 superimposed PDB: 6KBR of partner (SPINK2). RMSD:0.3738
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000323541_ENST00000558762_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.9559
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000336845_ENST00000268035_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.8805
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000336845_ENST00000558762_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.7765
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000436108_ENST00000268035_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.6347
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000436108_ENST00000558762_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.7291
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000449825_ENST00000268035_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.7486
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000449825_ENST00000558762_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.9843
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000449825_ENST00000558762_900935_99250790 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:2.8022
Å |
| | | |  |
| CHID1_IGF1R_ENST00000454838_ENST00000268035_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.6203
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000454838_ENST00000558762_900935_99250790 superimposed PDB: 3BXW of partner (CHID1). RMSD:2.9585
Å |
 |  |  |  |  |
| CHID1_IGF1R_ENST00000454838_ENST00000558762_900935_99250790 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:2.7836
Å |
| | | |  |
| CHKA_CASC3_ENST00000265689_ENST00000264645_67864485_38318005 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.939
Å |
 |  |  |  |  |
| CHKA_CASC3_ENST00000356135_ENST00000264645_67864485_38318005 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3054
Å |
 |  |  |  |  |
| CHKA_CASC3_ENST00000356135_ENST00000264645_67864485_38318005 superimposed PDB: 6ICZ of partner (CASC3). RMSD:0.4865
Å |
| | | |  |
| CHKA_GDPD5_ENST00000356135_ENST00000336898_67842183_75173934 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3971
Å |
 |  |  |  |  |
| CHKA_KIAA1549L_ENST00000265689_ENST00000321505_67833252_33596247 superimposed PDB: 4DA5 of partner (CHKA). RMSD:1.202
Å |
 |  |  |  |  |
| CHKA_KIAA1549L_ENST00000265689_ENST00000389726_67833252_33596247 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.8061
Å |
 |  |  |  |  |
| CHKA_KIAA1549L_ENST00000356135_ENST00000321505_67833252_33596247 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.852
Å |
 |  |  |  |  |
| CHKA_KIAA1549L_ENST00000356135_ENST00000389726_67833252_33596247 superimposed PDB: 4DA5 of partner (CHKA). RMSD:1.0197
Å |
 |  |  |  |  |
| CHKA_PC_ENST00000265689_ENST00000393958_67864485_66639630 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.4135
Å |
 |  |  |  |  |
| CHKA_PC_ENST00000265689_ENST00000393960_67864485_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7508
Å |
 |  |  |  |  |
| CHKA_PC_ENST00000356135_ENST00000393958_67864485_66639630 superimposed PDB: 4DA5 of partner (CHKA). RMSD:2.7
Å |
 |  |  |  |  |
| CHKA_PC_ENST00000356135_ENST00000393960_67864485_66639630 superimposed PDB: 4DA5 of partner (CHKA). RMSD:3.5534
Å |
 |  |  |  |  |
| CHKA_PC_ENST00000356135_ENST00000393960_67864485_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7356
Å |
| | | |  |
| CHKA_PPFIA1_ENST00000356135_ENST00000253925_67829419_70228193 superimposed PDB: 4DA5 of partner (CHKA). RMSD:1.0381
Å |
 |  |  |  |  |
| CHKA_PPM1L_ENST00000265689_ENST00000497343_67864485_160679523 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.2935
Å |
 |  |  |  |  |
| CHKA_SLC5A12_ENST00000265689_ENST00000280467_67864485_26734253 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3191
Å |
 |  |  |  |  |
| CHKA_SLC5A12_ENST00000356135_ENST00000280467_67864485_26734253 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3283
Å |
 |  |  |  |  |
| CHKA_SLC5A12_ENST00000356135_ENST00000396005_67864485_26734253 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.3404
Å |
 |  |  |  |  |
| CHKA_XRRA1_ENST00000265689_ENST00000340360_67888294_74641417 superimposed PDB: 4DA5 of partner (CHKA). RMSD:0.337
Å |
 |  |  |  |  |
| CHMP2B_CUBN_ENST00000263780_ENST00000377833_87299127_17089602 superimposed PDB: 3KQ4 of partner (CUBN). RMSD:2.5571
Å |
 |  |  |  |  |
| CHMP2B_CUBN_ENST00000494980_ENST00000377833_87299127_17089602 superimposed PDB: 3KQ4 of partner (CUBN). RMSD:2.4696
Å |
 |  |  |  |  |
| CHMP4B_ZNF341_ENST00000217402_ENST00000342427_32440009_32328707 superimposed PDB: 3UM3 of partner (CHMP4B). RMSD:0.5547
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000295497_ENST00000495789_175664219_29433294 superimposed PDB: 3CXL of partner (CHN1). RMSD:0.4577
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000295497_ENST00000495789_175664219_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:0.8591
Å |
| | | |  |
| CHN1_CHN2_ENST00000409900_ENST00000222792_175664090_29433294 superimposed PDB: 3CXL of partner (CHN1). RMSD:2.9135
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000409900_ENST00000222792_175664090_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:2.9388
Å |
| | | |  |
| CHN1_CHN2_ENST00000488080_ENST00000222792_175664219_29433294 superimposed PDB: 3CXL of partner (CHN1). RMSD:0.7523
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000488080_ENST00000222792_175664219_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:1.176
Å |
| | | |  |
| CHN1_CHN2_ENST00000488080_ENST00000435288_175664219_29433294 superimposed PDB: 3CXL of partner (CHN1). RMSD:0.8035
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000488080_ENST00000435288_175664219_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:1.1933
Å |
| | | |  |
| CHN1_CHN2_ENST00000488080_ENST00000495789_175664219_29433294 superimposed PDB: 3CXL of partner (CHN1). RMSD:0.4371
Å |
 |  |  |  |  |
| CHN1_CHN2_ENST00000488080_ENST00000495789_175664219_29433294 superimposed PDB: 1XA6 of partner (CHN2). RMSD:0.6776
Å |
| | | |  |
| CHP1_ANXA2_ENST00000334660_ENST00000451270_41523647_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4105
Å |
 |  |  |  |  |
| CHP1_ANXA2_ENST00000560397_ENST00000451270_41523647_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4135
Å |
 |  |  |  |  |
| CHP1_FAM189A1_ENST00000560397_ENST00000261275_41562816_29674035 superimposed PDB: 2E30 of partner (CHP1). RMSD:2.0208
Å |
 |  |  |  |  |
| CHP1_RAD51_ENST00000334660_ENST00000267868_41562816_41011002 superimposed PDB: 2E30 of partner (CHP1). RMSD:2.2135
Å |
 |  |  |  |  |
| CHP1_RAD51_ENST00000334660_ENST00000267868_41562816_41011002 superimposed PDB: 9TRM of partner (RAD51). RMSD:0.4426
Å |
| | | |  |
| CHP1_RAD51_ENST00000560397_ENST00000267868_41562816_41011002 superimposed PDB: 2E30 of partner (CHP1). RMSD:2.1649
Å |
 |  |  |  |  |
| CHP1_RAD51_ENST00000560397_ENST00000267868_41562816_41011002 superimposed PDB: 9TRM of partner (RAD51). RMSD:0.4411
Å |
| | | |  |
| CHP1_RAD51_ENST00000560397_ENST00000423169_41562816_41011002 superimposed PDB: 2E30 of partner (CHP1). RMSD:2.1006
Å |
 |  |  |  |  |
| CHP1_RAD51_ENST00000560397_ENST00000423169_41562816_41011002 superimposed PDB: 9TRM of partner (RAD51). RMSD:0.5105
Å |
| | | |  |
| CHRAC1_SNTG1_ENST00000220913_ENST00000276467_141521745_51351102 superimposed PDB: 7PC7 of partner (SNTG1). RMSD:0.8229
Å |
 |  |  |  |  |
| CHRAC1_SNTG1_ENST00000220913_ENST00000517473_141521745_51351102 superimposed PDB: 7PC7 of partner (SNTG1). RMSD:0.9066
Å |
 |  |  |  |  |
| CHRAC1_SNTG1_ENST00000220913_ENST00000522124_141521745_51351102 superimposed PDB: 7PC7 of partner (SNTG1). RMSD:0.8378
Å |
 |  |  |  |  |
| CHRDL1_GLUD1_ENST00000434224_ENST00000537649_110002888_88827914 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.435
Å |
 |  |  |  |  |
| CHRD_ANXA2_ENST00000204604_ENST00000451270_184101430_60641396 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4856
Å |
 |  |  |  |  |
| CHRD_ANXA2_ENST00000545352_ENST00000451270_184101430_60641396 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.5217
Å |
 |  |  |  |  |
| CHRFAM7A_CHRNA7_ENST00000401522_ENST00000306901_30654260_32446107 superimposed PDB: 9LH5 of partner (CHRNA7). RMSD:2.2278
Å |
 |  |  |  |  |
| CHRFAM7A_CHRNA7_ENST00000401522_ENST00000454250_30654260_32446107 superimposed PDB: 9LH5 of partner (CHRNA7). RMSD:2.2173
Å |
 |  |  |  |  |
| CHRNB1_TXNDC17_ENST00000306071_ENST00000570330_7352107_6545072 superimposed PDB: 9DMS of partner (CHRNB1). RMSD:0.7381
Å |
 |  |  |  |  |
| CHRNB1_TXNDC17_ENST00000536404_ENST00000250101_7352107_6545072 superimposed PDB: 9DMS of partner (CHRNB1). RMSD:0.735
Å |
 |  |  |  |  |
| CHRNB1_TXNDC17_ENST00000536404_ENST00000570330_7352107_6545072 superimposed PDB: 9DMS of partner (CHRNB1). RMSD:1.0614
Å |
 |  |  |  |  |
| CHRNB1_TXNDC17_ENST00000536404_ENST00000570330_7352107_6545072 superimposed PDB: 1WOU of partner (TXNDC17). RMSD:1.8023
Å |
| | | |  |
| CHRNB1_TXNDC17_ENST00000576360_ENST00000250101_7352107_6545072 superimposed PDB: 9DMS of partner (CHRNB1). RMSD:0.9774
Å |
 |  |  |  |  |
| CHST11_PTPRR_ENST00000303694_ENST00000283228_104995769_71158558 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4318
Å |
 |  |  |  |  |
| CHST9_AQP4_ENST00000580774_ENST00000383168_24604079_24442560 superimposed PDB: 8V8S of partner (AQP4). RMSD:0.3445
Å |
 |  |  |  |  |
| CHST9_GNAL_ENST00000284224_ENST00000269162_24722652_11867166 superimposed PDB: 8EL8 of partner (GNAL). RMSD:0.9108
Å |
 |  |  |  |  |
| CHST9_GNAL_ENST00000284224_ENST00000535121_24722652_11867166 superimposed PDB: 8EL8 of partner (GNAL). RMSD:0.9137
Å |
 |  |  |  |  |
| CHSY3_NINJ2_ENST00000305031_ENST00000397265_129244053_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.689
Å |
 |  |  |  |  |
| CIC_NUTM1_ENST00000160740_ENST00000438749_42797988_34645936 superimposed PDB: 7M5W of partner (CIC). RMSD:0.5194
Å |
 |  |  |  |  |
| CIC_NUTM1_ENST00000160740_ENST00000438749_42797988_34645936 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.5837
Å |
| | | |  |
| CIC_NUTM1_ENST00000575354_ENST00000438749_42797988_34645936 superimposed PDB: 7M5W of partner (CIC). RMSD:1.0543
Å |
 |  |  |  |  |
| CIC_NUTM1_ENST00000575354_ENST00000438749_42797988_34645936 superimposed PDB: 7XEZ of partner (NUTM1). RMSD:2.7395
Å |
| | | |  |
| CIDEB_PTEN_ENST00000258807_ENST00000371953_24775579_89711874 superimposed PDB: 1D4B of partner (CIDEB). RMSD:2.7567
Å |
 |  |  |  |  |
| CIDEB_PTEN_ENST00000258807_ENST00000371953_24775579_89711874 superimposed PDB: 7JVX of partner (PTEN). RMSD:0.4095
Å |
| | | |  |
| CIT_LYZ_ENST00000261833_ENST00000548839_120260623_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4558
Å |
 |  |  |  |  |
| CKAP5_MTCH2_ENST00000415402_ENST00000302503_46817143_47657123 superimposed PDB: 4QMI of partner (CKAP5). RMSD:1.9015
Å |
 |  |  |  |  |
| CKAP5_MTCH2_ENST00000415402_ENST00000302503_46817143_47657123 superimposed PDB: 12OZ of partner (MTCH2). RMSD:0.6522
Å |
| | | |  |
| CKS2_PCSK5_ENST00000314355_ENST00000376752_91930212_78789901 superimposed PDB: 6GU2 of partner (CKS2). RMSD:0.3886
Å |
 |  |  |  |  |
| CKS2_PCSK5_ENST00000314355_ENST00000376767_91930212_78789901 superimposed PDB: 6GU2 of partner (CKS2). RMSD:0.316
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000313350_ENST00000307363_33673783_33114205 superimposed PDB: 3WOY of partner (CLASP2). RMSD:2.865
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000313350_ENST00000307363_33673783_33114205 superimposed PDB: 3THD of partner (GLB1). RMSD:0.5707
Å |
| | | |  |
| CLASP2_GLB1_ENST00000359576_ENST00000307363_33673783_33114205 superimposed PDB: 3WOY of partner (CLASP2). RMSD:2.5034
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000359576_ENST00000307363_33673783_33114205 superimposed PDB: 3THD of partner (GLB1). RMSD:0.5843
Å |
| | | |  |
| CLASP2_GLB1_ENST00000399362_ENST00000307363_33673783_33114205 superimposed PDB: 3WOY of partner (CLASP2). RMSD:2.8111
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000399362_ENST00000307363_33673783_33114205 superimposed PDB: 3THD of partner (GLB1). RMSD:0.564
Å |
| | | |  |
| CLASP2_GLB1_ENST00000461133_ENST00000307363_33673783_33114205 superimposed PDB: 3WOY of partner (CLASP2). RMSD:2.7443
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000461133_ENST00000307363_33673783_33114205 superimposed PDB: 3THD of partner (GLB1). RMSD:0.5771
Å |
| | | |  |
| CLASP2_GLB1_ENST00000487200_ENST00000307363_33673783_33114205 superimposed PDB: 3WOY of partner (CLASP2). RMSD:2.75
Å |
 |  |  |  |  |
| CLASP2_GLB1_ENST00000487200_ENST00000307363_33673783_33114205 superimposed PDB: 3THD of partner (GLB1). RMSD:0.565
Å |
| | | |  |
| CLASP2_UBP1_ENST00000313350_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5774
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000313350_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6183
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000333778_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5945
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000333778_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6142
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000399362_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6191
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000399362_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6067
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000461133_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6259
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000461133_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.619
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000468888_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5546
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000468888_ENST00000283629_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5714
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000468888_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5438
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000480013_ENST00000283628_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5964
Å |
 |  |  |  |  |
| CLASP2_UBP1_ENST00000480013_ENST00000447368_33648082_33467233 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6155
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000221455_ENST00000344956_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6656
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000221455_ENST00000403059_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.643
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000221455_ENST00000406449_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6464
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000391953_ENST00000344956_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6349
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000391953_ENST00000403059_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6503
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000391953_ENST00000406449_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6485
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000391953_ENST00000425690_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6535
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000544944_ENST00000344956_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6611
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000544944_ENST00000403059_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6414
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000544944_ENST00000406449_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6795
Å |
 |  |  |  |  |
| CLASRP_PVR_ENST00000544944_ENST00000425690_45573362_45157168 superimposed PDB: 3J8F of partner (PVR). RMSD:0.6399
Å |
 |  |  |  |  |
| CLASRP_TOMM40_ENST00000391953_ENST00000405636_45571738_45406286 superimposed PDB: 7VD2 of partner (TOMM40). RMSD:0.969
Å |
 |  |  |  |  |
| CLCN6_RAF1_ENST00000312413_ENST00000442415_11867247_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9975
Å |
 |  |  |  |  |
| CLDN12_SPCS3_ENST00000535571_ENST00000503362_90045268_177243320 superimposed PDB: 7P2P of partner (SPCS3). RMSD:3.4948
Å |
 |  |  |  |  |
| CLEC16A_TNFRSF17_ENST00000409790_ENST00000053243_11097162_12061426 superimposed PDB: 4ZFO of partner (TNFRSF17). RMSD:2.8296
Å |
 |  |  |  |  |
| CLEC3A_SPTLC2_ENST00000575655_ENST00000216484_78056638_77987924 superimposed PDB: 7K0K of partner (SPTLC2). RMSD:0.5199
Å |
 |  |  |  |  |
| CLIC1_NUDT3_ENST00000395892_ENST00000607016_31701342_34263462 superimposed PDB: 2FVV of partner (NUDT3). RMSD:3.0106
Å |
 |  |  |  |  |
| CLIC5_SUPT3H_ENST00000185206_ENST00000371459_45916992_45073743 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:0.7823
Å |
 |  |  |  |  |
| CLIC5_SUPT3H_ENST00000339561_ENST00000306867_45916992_45073743 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:0.8674
Å |
 |  |  |  |  |
| CLIC5_SUPT3H_ENST00000339561_ENST00000371459_45916992_45073743 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:0.7928
Å |
 |  |  |  |  |
| CLINT1_UCHL3_ENST00000523908_ENST00000377595_157285937_76134888 superimposed PDB: 1XD3 of partner (UCHL3). RMSD:0.488
Å |
 |  |  |  |  |
| CLIP2_ALK_ENST00000223398_ENST00000389048_73795193_29446394 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.8333
Å |
 |  |  |  |  |
| CLIP2_ALK_ENST00000361545_ENST00000389048_73795193_29446394 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.7806
Å |
 |  |  |  |  |
| CLIP2_ALK_ENST00000395060_ENST00000389048_73795193_29446394 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.8526
Å |
 |  |  |  |  |
| CLIP2_EIF4H_ENST00000361545_ENST00000265753_73731997_73609498 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.7991
Å |
 |  |  |  |  |
| CLIP2_NCF1_ENST00000223398_ENST00000289473_73778645_74193427 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.8113
Å |
 |  |  |  |  |
| CLIP2_NCF1_ENST00000223398_ENST00000289473_73787366_74193427 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.7881
Å |
 |  |  |  |  |
| CLIP2_NCF1_ENST00000223398_ENST00000289473_73787366_74193427 superimposed PDB: 8WEJ of partner (NCF1). RMSD:2.5744
Å |
| | | |  |
| CLIP2_NCF1_ENST00000395060_ENST00000289473_73787366_74193427 superimposed PDB: 2CP2 of partner (CLIP2). RMSD:0.8517
Å |
 |  |  |  |  |
| CLIP2_NCF1_ENST00000395060_ENST00000289473_73787366_74193427 superimposed PDB: 8WEJ of partner (NCF1). RMSD:2.4554
Å |
| | | |  |
| CLIP4_BRE_ENST00000401605_ENST00000342045_29344387_28521204 superimposed PDB: 8PVY of partner (BRE). RMSD:2.8149
Å |
 |  |  |  |  |
| CLIP4_BRE_ENST00000401605_ENST00000344773_29344387_28521204 superimposed PDB: 2Z0W of partner (CLIP4). RMSD:0.4961
Å |
 |  |  |  |  |
| CLIP4_BRE_ENST00000401605_ENST00000379624_29344387_28521204 superimposed PDB: 8PVY of partner (BRE). RMSD:2.1384
Å |
 |  |  |  |  |
| CLIP4_EPHB4_ENST00000401605_ENST00000358173_29375694_100417918 superimposed PDB: 2Z0W of partner (CLIP4). RMSD:0.5041
Å |
 |  |  |  |  |
| CLIP4_EPHB4_ENST00000401605_ENST00000358173_29375694_100417918 superimposed PDB: 2VWX of partner (EPHB4). RMSD:0.4131
Å |
| | | |  |
| CLIP4_EPHB4_ENST00000401617_ENST00000358173_29375694_100417918 superimposed PDB: 2Z0W of partner (CLIP4). RMSD:0.5743
Å |
 |  |  |  |  |
| CLIP4_EPHB4_ENST00000401617_ENST00000358173_29375694_100417918 superimposed PDB: 2VWX of partner (EPHB4). RMSD:0.4359
Å |
| | | |  |
| CLIP4_EPHB4_ENST00000401617_ENST00000360620_29375694_100417918 superimposed PDB: 2Z0W of partner (CLIP4). RMSD:0.4676
Å |
 |  |  |  |  |
| CLIP4_EPHB4_ENST00000401617_ENST00000360620_29375694_100417918 superimposed PDB: 2VWX of partner (EPHB4). RMSD:0.3588
Å |
| | | |  |
| CLIP4_EPHB4_ENST00000404424_ENST00000360620_29375694_100417918 superimposed PDB: 2Z0W of partner (CLIP4). RMSD:0.4916
Å |
 |  |  |  |  |
| CLIP4_EPHB4_ENST00000404424_ENST00000360620_29375694_100417918 superimposed PDB: 2VWX of partner (EPHB4). RMSD:0.3685
Å |
| | | |  |
| CLOCK_PHF21A_ENST00000309964_ENST00000323180_56319220_46001517 superimposed PDB: 6QPJ of partner (CLOCK). RMSD:0.5221
Å |
 |  |  |  |  |
| CLOCK_PHF21A_ENST00000309964_ENST00000323180_56319220_46001517 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.6354
Å |
| | | |  |
| CLOCK_PHF21A_ENST00000309964_ENST00000418153_56319220_46001517 superimposed PDB: 6QPJ of partner (CLOCK). RMSD:0.4813
Å |
 |  |  |  |  |
| CLOCK_PHF21A_ENST00000309964_ENST00000418153_56319220_46001517 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.7335
Å |
| | | |  |
| CLPB_PTPN1_ENST00000294053_ENST00000541713_72040750_49191053 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.5645
Å |
 |  |  |  |  |
| CLPB_PTPN1_ENST00000340729_ENST00000541713_72040750_49191053 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.477
Å |
 |  |  |  |  |
| CLPB_PTPN1_ENST00000437826_ENST00000541713_72040750_49191053 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.5037
Å |
 |  |  |  |  |
| CLPB_PTPN1_ENST00000538039_ENST00000541713_72040750_49191053 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.5505
Å |
 |  |  |  |  |
| CLPB_PTPN1_ENST00000543042_ENST00000541713_72040750_49191053 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.4811
Å |
 |  |  |  |  |
| CLSTN1_CTNNBIP1_ENST00000361311_ENST00000377263_9809518_9910834 superimposed PDB: 1M1E of partner (CTNNBIP1). RMSD:2.5394
Å |
 |  |  |  |  |
| CLSTN1_CTNNBIP1_ENST00000377288_ENST00000377263_9809518_9910834 superimposed PDB: 1M1E of partner (CTNNBIP1). RMSD:2.6592
Å |
 |  |  |  |  |
| CLSTN1_MRPL51_ENST00000361311_ENST00000229238_9833329_6602138 superimposed PDB: 7OF0 of partner (MRPL51). RMSD:1.6631
Å |
 |  |  |  |  |
| CLTC_ETV4_ENST00000393043_ENST00000393664_57744338_41613847 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.4353
Å |
 |  |  |  |  |
| CLTC_ETV4_ENST00000393043_ENST00000591713_57744338_41613847 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.5157
Å |
 |  |  |  |  |
| CLTC_ROS1_ENST00000269122_ENST00000368507_57768072_117642557 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.7075
Å |
 |  |  |  |  |
| CLTC_ROS1_ENST00000579456_ENST00000368507_57768072_117642557 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.5307
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000269122_ENST00000443572_57697534_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7807
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000269122_ENST00000443572_57728677_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8113
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000269122_ENST00000443572_57746301_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8252
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000225577_57697534_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7852
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000225577_57721844_58007477 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.5622
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000225577_57728677_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8059
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000225577_57746301_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8441
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000406116_57697534_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6706
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000406116_57721844_58007477 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.5527
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000406116_57728677_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.681
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000406116_57746301_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6415
Å |
 |  |  |  |  |
| CLTC_RPS6KB1_ENST00000393043_ENST00000443572_57697534_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:1.0342
Å |
 |  |  |  |  |
| CLTC_TFE3_ENST00000269122_ENST00000315869_57754549_48891766 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.507
Å |
 |  |  |  |  |
| CLU_MYH9_ENST00000405140_ENST00000216181_27463870_36723533 superimposed PDB: 7ZET of partner (CLU). RMSD:2.8564
Å |
 |  |  |  |  |
| CLU_RBP4_ENST00000316403_ENST00000371467_27455976_95353792 superimposed PDB: 7ZET of partner (CLU). RMSD:2.6368
Å |
 |  |  |  |  |
| CLU_RPS4X_ENST00000523500_ENST00000316084_27461807_71493239 superimposed PDB: 7ZET of partner (CLU). RMSD:3.0208
Å |
 |  |  |  |  |
| CLU_RPS4X_ENST00000560366_ENST00000316084_27461807_71493239 superimposed PDB: 7ZET of partner (CLU). RMSD:2.8617
Å |
 |  |  |  |  |
| CMC1_ANXA2_ENST00000466830_ENST00000451270_28304871_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3834
Å |
 |  |  |  |  |
| CMIP_CDYL2_ENST00000537098_ENST00000562812_81479146_80719026 superimposed PDB: 5JJZ of partner (CDYL2). RMSD:0.4201
Å |
 |  |  |  |  |
| CMIP_CDYL2_ENST00000537098_ENST00000566173_81479146_80719026 superimposed PDB: 5JJZ of partner (CDYL2). RMSD:0.3584
Å |
 |  |  |  |  |
| CMTM4_AKR1C4_ENST00000330687_ENST00000263126_66730242_5242143 superimposed PDB: 2FVL of partner (AKR1C4). RMSD:0.3569
Å |
 |  |  |  |  |
| CNDP1_MBP_ENST00000358821_ENST00000359645_72201926_74702016 superimposed PDB: 3DLJ of partner (CNDP1). RMSD:1.5347
Å |
 |  |  |  |  |
| CNGA1_TXK_ENST00000358519_ENST00000264316_47944057_48112620 superimposed PDB: 2DM0 of partner (TXK). RMSD:1.0748
Å |
 |  |  |  |  |
| CNGA1_TXK_ENST00000358519_ENST00000264316_47945197_48112620 superimposed PDB: 2DM0 of partner (TXK). RMSD:0.9899
Å |
 |  |  |  |  |
| CNKSR1_MAN1C1_ENST00000361530_ENST00000263979_26511103_26098147 superimposed PDB: 1WWV of partner (CNKSR1). RMSD:0.9142
Å |
 |  |  |  |  |
| CNKSR1_MAN1C1_ENST00000374253_ENST00000263979_26511103_26098147 superimposed PDB: 1WWV of partner (CNKSR1). RMSD:0.8383
Å |
 |  |  |  |  |
| CNKSR1_MAN1C1_ENST00000531191_ENST00000263979_26511103_26098147 superimposed PDB: 1WWV of partner (CNKSR1). RMSD:0.9257
Å |
 |  |  |  |  |
| CNN1_CNN2_ENST00000535659_ENST00000263097_11658722_1036414 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8164
Å |
 |  |  |  |  |
| CNN1_CNN2_ENST00000535659_ENST00000263097_11658722_1036414 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6605
Å |
| | | |  |
| CNN1_CNN2_ENST00000544952_ENST00000263097_11658722_1036414 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8286
Å |
 |  |  |  |  |
| CNN1_CNN2_ENST00000544952_ENST00000263097_11658722_1036414 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6545
Å |
| | | |  |
| CNN1_CNN2_ENST00000592923_ENST00000263097_11658722_1036414 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8374
Å |
 |  |  |  |  |
| CNN1_CNN2_ENST00000592923_ENST00000263097_11658722_1036414 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6591
Å |
| | | |  |
| CNN2_MED16_ENST00000263097_ENST00000269814_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6504
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000263097_ENST00000269814_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.7045
Å |
| | | |  |
| CNN2_MED16_ENST00000263097_ENST00000312090_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6731
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000263097_ENST00000312090_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.7571
Å |
| | | |  |
| CNN2_MED16_ENST00000263097_ENST00000325464_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6564
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000263097_ENST00000325464_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:3.268
Å |
| | | |  |
| CNN2_MED16_ENST00000263097_ENST00000589119_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6738
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000263097_ENST00000589119_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.6766
Å |
| | | |  |
| CNN2_MED16_ENST00000348419_ENST00000269814_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6487
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000348419_ENST00000269814_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.5987
Å |
| | | |  |
| CNN2_MED16_ENST00000348419_ENST00000312090_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6484
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000348419_ENST00000312090_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.6083
Å |
| | | |  |
| CNN2_MED16_ENST00000348419_ENST00000325464_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.6551
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000348419_ENST00000325464_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:3.1388
Å |
| | | |  |
| CNN2_MED16_ENST00000348419_ENST00000589119_1032695_877180 superimposed PDB: 1WYN of partner (CNN2). RMSD:0.639
Å |
 |  |  |  |  |
| CNN2_MED16_ENST00000348419_ENST00000589119_1032695_877180 superimposed PDB: 8TRH of partner (MED16). RMSD:1.565
Å |
| | | |  |
| CNNM2_RBP4_ENST00000369878_ENST00000371467_104679858_95353792 superimposed PDB: 6N7E of partner (CNNM2). RMSD:0.8377
Å |
 |  |  |  |  |
| CNNM2_RBP4_ENST00000369878_ENST00000371467_104679858_95353792 superimposed PDB: 6QBA of partner (RBP4). RMSD:1.2542
Å |
| | | |  |
| CNOT10_CACNA2D4_ENST00000328834_ENST00000585708_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.2867
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000328834_ENST00000585732_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.2639
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000328834_ENST00000587995_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.1672
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000454516_ENST00000382722_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.481
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000454516_ENST00000585708_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.2783
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000454516_ENST00000585732_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.2868
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000454516_ENST00000587995_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.1478
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000538368_ENST00000382722_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.2533
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000538368_ENST00000585708_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.4605
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000538368_ENST00000585732_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.6388
Å |
 |  |  |  |  |
| CNOT10_CACNA2D4_ENST00000538368_ENST00000587995_32778982_1955855 superimposed PDB: 8BFI of partner (CNOT10). RMSD:1.6675
Å |
 |  |  |  |  |
| CNOT1_GOT2_ENST00000317147_ENST00000434819_58608512_58757806 superimposed PDB: 9YB6 of partner (GOT2). RMSD:0.6388
Å |
 |  |  |  |  |
| CNOT1_GOT2_ENST00000569240_ENST00000245206_58608512_58757806 superimposed PDB: 9YB6 of partner (GOT2). RMSD:0.6112
Å |
 |  |  |  |  |
| CNOT2_IVNS1ABP_ENST00000418359_ENST00000367498_70704797_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.4477
Å |
 |  |  |  |  |
| CNOT2_MBD4_ENST00000229195_ENST00000249910_70713144_129152979 superimposed PDB: 4OFA of partner (MBD4). RMSD:0.4286
Å |
 |  |  |  |  |
| CNOT2_MBD4_ENST00000229195_ENST00000393278_70713144_129152979 superimposed PDB: 4OFA of partner (MBD4). RMSD:0.31
Å |
 |  |  |  |  |
| CNOT2_MBD4_ENST00000418359_ENST00000429544_70713144_129152979 superimposed PDB: 4OFA of partner (MBD4). RMSD:0.3764
Å |
 |  |  |  |  |
| CNOT2_PTPRR_ENST00000418359_ENST00000283228_70704797_71158558 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4392
Å |
 |  |  |  |  |
| CNOT2_SLC45A4_ENST00000229195_ENST00000433583_70713144_142231864 superimposed PDB: 9GIU of partner (SLC45A4). RMSD:2.5159
Å |
 |  |  |  |  |
| CNOT2_SLC45A4_ENST00000229195_ENST00000517878_70713144_142231864 superimposed PDB: 9GIU of partner (SLC45A4). RMSD:2.5117
Å |
 |  |  |  |  |
| CNOT2_SLC45A4_ENST00000418359_ENST00000519067_70713144_142231864 superimposed PDB: 9GIU of partner (SLC45A4). RMSD:2.491
Å |
 |  |  |  |  |
| CNOT2_TMEM2_ENST00000229195_ENST00000377066_70704797_74319719 superimposed PDB: 8C6I of partner (TMEM2). RMSD:2.4895
Å |
 |  |  |  |  |
| CNOT2_YEATS4_ENST00000229195_ENST00000548020_70736087_69756567 superimposed PDB: 4C0D of partner (CNOT2). RMSD:3.353
Å |
 |  |  |  |  |
| CNOT6_CLTC_ENST00000261951_ENST00000269122_179991743_57746137 superimposed PDB: 7AX1 of partner (CNOT6). RMSD:0.9645
Å |
 |  |  |  |  |
| CNOT6_CLTC_ENST00000393356_ENST00000269122_179991743_57746137 superimposed PDB: 7AX1 of partner (CNOT6). RMSD:2.2864
Å |
 |  |  |  |  |
| CNOT6_CLTC_ENST00000393356_ENST00000393043_179991743_57746137 superimposed PDB: 7AX1 of partner (CNOT6). RMSD:2.7448
Å |
 |  |  |  |  |
| CNRIP1_PPP3R1_ENST00000409559_ENST00000409752_68544288_68444263 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.6005
Å |
 |  |  |  |  |
| CNTLN_HSP90AB1_ENST00000262360_ENST00000371554_17416187_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.8853
Å |
 |  |  |  |  |
| CNTLN_HSP90AB1_ENST00000380647_ENST00000371554_17416187_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.7583
Å |
 |  |  |  |  |
| COG8_SF3B3_ENST00000306875_ENST00000302516_69368423_70582272 superimposed PDB: 7Q4O of partner (SF3B3). RMSD:2.0603
Å |
 |  |  |  |  |
| COG8_SF3B3_ENST00000562081_ENST00000302516_69368423_70582272 superimposed PDB: 7Q4O of partner (SF3B3). RMSD:2.1475
Å |
 |  |  |  |  |
| COL1A1_COL2A1_ENST00000225964_ENST00000380518_48272592_48380671 superimposed PDB: 5NIR of partner (COL2A1). RMSD:0.8149
Å |
 |  |  |  |  |
| COL1A1_COL3A1_ENST00000225964_ENST00000317840_48269148_189864010 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.573
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000323926_48265456_216300791 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1818
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000323926_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:1.5618
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000336916_48265456_216300791 superimposed PDB: 1FNF of partner (FN1). RMSD:2.4346
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000336916_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2107
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000345488_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:1.5781
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000346544_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:1.6107
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000357867_48265456_216300791 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0154
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000357867_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:3.6097
Å |
 |  |  |  |  |
| COL1A1_FN1_ENST00000225964_ENST00000359671_48266263_216242985 superimposed PDB: 1FNF of partner (FN1). RMSD:1.4858
Å |
 |  |  |  |  |
| COL1A1_PDGFB_ENST00000225964_ENST00000381551_48266102_39631879 superimposed PDB: 3MJG of partner (PDGFB). RMSD:0.8795
Å |
 |  |  |  |  |
| COL1A1_PDGFB_ENST00000225964_ENST00000381551_48269835_39631879 superimposed PDB: 3MJG of partner (PDGFB). RMSD:0.7381
Å |
 |  |  |  |  |
| COL1A1_PDGFB_ENST00000225964_ENST00000381551_48272592_39631879 superimposed PDB: 3MJG of partner (PDGFB). RMSD:0.7226
Å |
 |  |  |  |  |
| COL1A2_FSTL1_ENST00000297268_ENST00000295633_94054975_120134874 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.3617
Å |
 |  |  |  |  |
| COL1A2_IGFBP3_ENST00000297268_ENST00000275521_94045815_45956266 superimposed PDB: 7WRQ of partner (IGFBP3). RMSD:1.8721
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000370571_ENST00000369827_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.445
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000370571_ENST00000442650_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.8386
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000370571_ENST00000460717_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.481
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000436319_ENST00000369827_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.4589
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000436319_ENST00000442650_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.6302
Å |
 |  |  |  |  |
| COL24A1_GSTM2_ENST00000436319_ENST00000460717_86282470_110211046 superimposed PDB: 2C4J of partner (GSTM2). RMSD:0.4956
Å |
 |  |  |  |  |
| COL3A1_COL1A1_ENST00000304636_ENST00000225964_189863444_48268851 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.6697
Å |
 |  |  |  |  |
| COL3A1_COL1A1_ENST00000317840_ENST00000225964_189863444_48268851 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.8353
Å |
 |  |  |  |  |
| COL4A1_ZNF675_ENST00000375820_ENST00000600313_110959290_23845960 superimposed PDB: 5NAY of partner (COL4A1). RMSD:2.4007
Å |
 |  |  |  |  |
| COL4A3BP_MED9_ENST00000261415_ENST00000268711_74801806_17394592 superimposed PDB: 7EMF of partner (MED9). RMSD:2.6803
Å |
 |  |  |  |  |
| COL4A5_XRCC4_ENST00000361603_ENST00000282268_107683436_82648943 superimposed PDB: 9CQ3 of partner (XRCC4). RMSD:2.4612
Å |
 |  |  |  |  |
| COL5A2_YWHAQ_ENST00000374866_ENST00000238081_189936765_9731644 superimposed PDB: 6BCR of partner (YWHAQ). RMSD:0.3574
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000300527_ENST00000380244_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.3796
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000310645_ENST00000254108_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.9023
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000310645_ENST00000380244_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:2.8621
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000357838_ENST00000254108_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.9309
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000397763_ENST00000254108_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.4164
Å |
 |  |  |  |  |
| COL6A2_FUS_ENST00000409416_ENST00000380244_47546455_31199645 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.7811
Å |
 |  |  |  |  |
| COMMD10_NUP107_ENST00000274458_ENST00000229179_115428397_69135592 superimposed PDB: 8P0W of partner (COMMD10). RMSD:0.485
Å |
 |  |  |  |  |
| COMMD10_NUP107_ENST00000274458_ENST00000378905_115428397_69135592 superimposed PDB: 8P0W of partner (COMMD10). RMSD:1.1362
Å |
 |  |  |  |  |
| COMMD10_NUP107_ENST00000515539_ENST00000378905_115428397_69135592 superimposed PDB: 8P0W of partner (COMMD10). RMSD:1.2529
Å |
 |  |  |  |  |
| COMMD1_FARS2_ENST00000538736_ENST00000324331_62228117_5771523 superimposed PDB: 8P0W of partner (COMMD1). RMSD:1.1452
Å |
 |  |  |  |  |
| COMMD1_TRIB2_ENST00000538736_ENST00000155926_62132993_12863385 superimposed PDB: 8P0W of partner (COMMD1). RMSD:3.3009
Å |
 |  |  |  |  |
| COMMD1_TRIB2_ENST00000538736_ENST00000155926_62132993_12863385 superimposed PDB: 7UPM of partner (TRIB2). RMSD:0.3634
Å |
| | | |  |
| COMMD7_MMP24_ENST00000446419_ENST00000246186_31315699_33851593 superimposed PDB: 8P0W of partner (COMMD7). RMSD:1.138
Å |
 |  |  |  |  |
| COMMD9_CD59_ENST00000452374_ENST00000534312_36300026_33720060 superimposed PDB: 8P0W of partner (COMMD9). RMSD:1.401
Å |
 |  |  |  |  |
| COMMD9_CD59_ENST00000532705_ENST00000534312_36300026_33720060 superimposed PDB: 8P0W of partner (COMMD9). RMSD:1.3562
Å |
 |  |  |  |  |
| COPS4_NFXL1_ENST00000264389_ENST00000381538_83966858_47888016 superimposed PDB: 9QO4 of partner (COPS4). RMSD:2.0499
Å |
 |  |  |  |  |
| COPS4_NFXL1_ENST00000503682_ENST00000381538_83966858_47888016 superimposed PDB: 9QO4 of partner (COPS4). RMSD:1.8993
Å |
 |  |  |  |  |
| COPS4_NFXL1_ENST00000509093_ENST00000507489_83966858_47888016 superimposed PDB: 9QO4 of partner (COPS4). RMSD:1.8728
Å |
 |  |  |  |  |
| COQ10A_USP5_ENST00000308197_ENST00000389231_56663345_6964564 superimposed PDB: 3IHP of partner (USP5). RMSD:1.2619
Å |
 |  |  |  |  |
| COQ10A_USP5_ENST00000433805_ENST00000229268_56663345_6964564 superimposed PDB: 3IHP of partner (USP5). RMSD:1.3057
Å |
 |  |  |  |  |
| COQ10A_USP5_ENST00000433805_ENST00000389231_56663345_6964564 superimposed PDB: 3IHP of partner (USP5). RMSD:1.3238
Å |
 |  |  |  |  |
| COQ10A_USP5_ENST00000546544_ENST00000229268_56663345_6964564 superimposed PDB: 3IHP of partner (USP5). RMSD:1.2801
Å |
 |  |  |  |  |
| COQ10A_USP5_ENST00000546544_ENST00000389231_56663345_6964564 superimposed PDB: 3IHP of partner (USP5). RMSD:1.3173
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000422070_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:2.219
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000422070_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.3284
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000535565_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:1.8598
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000535565_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.309
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000547372_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:1.7857
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000547372_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.3008
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000550418_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:0.9654
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000553186_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:1.7584
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000261401_ENST00000553186_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.317
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000422070_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:2.1346
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000422070_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.3171
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000535565_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:1.7653
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000535565_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.3387
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000547372_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:2.1189
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000547372_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.335
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000550418_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:2.3025
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000553186_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:1.8608
Å |
 |  |  |  |  |
| CORO1C_RBFOX1_ENST00000420959_ENST00000553186_109094899_7568148 superimposed PDB: 4ZKA of partner (RBFOX1). RMSD:0.3148
Å |
| | | |  |
| CORO1C_RBFOX1_ENST00000549772_ENST00000550418_109094899_7568148 superimposed PDB: 7STY of partner (CORO1C). RMSD:2.226
Å |
 |  |  |  |  |
| CORO6_SLC20A2_ENST00000388767_ENST00000342228_27945807_42275485 superimposed PDB: 7KYX of partner (CORO6). RMSD:0.5422
Å |
 |  |  |  |  |
| CORO6_SLC20A2_ENST00000445145_ENST00000520262_27945807_42275485 superimposed PDB: 7KYX of partner (CORO6). RMSD:0.5151
Å |
 |  |  |  |  |
| CORO6_SLC20A2_ENST00000580212_ENST00000520262_27945807_42275485 superimposed PDB: 7KYX of partner (CORO6). RMSD:0.5572
Å |
 |  |  |  |  |
| CORO6_SLC20A2_ENST00000584969_ENST00000342228_27945807_42275485 superimposed PDB: 7KYX of partner (CORO6). RMSD:0.5177
Å |
 |  |  |  |  |
| COX6A1_GAPDH_ENST00000229379_ENST00000396856_120876324_6646266 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.4434
Å |
 |  |  |  |  |
| COX6B1_LIG1_ENST00000246554_ENST00000536218_36145573_48626575 superimposed PDB: 9I6F of partner (COX6B1). RMSD:0.9607
Å |
 |  |  |  |  |
| COX6B1_LIG1_ENST00000246554_ENST00000536218_36145573_48626575 superimposed PDB: 4U7L of partner (LIG1). RMSD:3.0086
Å |
| | | |  |
| COX6B1_LIG1_ENST00000392201_ENST00000536218_36145573_48626575 superimposed PDB: 9I6F of partner (COX6B1). RMSD:1.1842
Å |
 |  |  |  |  |
| COX6B1_LIG1_ENST00000392201_ENST00000536218_36145573_48626575 superimposed PDB: 4U7L of partner (LIG1). RMSD:2.9923
Å |
| | | |  |
| COX6B1_LIG1_ENST00000592141_ENST00000536218_36145573_48626575 superimposed PDB: 9I6F of partner (COX6B1). RMSD:0.8915
Å |
 |  |  |  |  |
| COX6B1_LIG1_ENST00000592141_ENST00000536218_36145573_48626575 superimposed PDB: 4U7L of partner (LIG1). RMSD:3.0189
Å |
| | | |  |
| CPAMD8_SAP18_ENST00000443236_ENST00000607003_17006986_21720943 superimposed PDB: 2HDE of partner (SAP18). RMSD:1.0801
Å |
 |  |  |  |  |
| CPD_HDAC5_ENST00000225719_ENST00000393622_28712254_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3226
Å |
 |  |  |  |  |
| CPD_HDAC5_ENST00000225719_ENST00000586802_28712254_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3033
Å |
 |  |  |  |  |
| CPD_HDAC5_ENST00000543464_ENST00000393622_28712254_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.318
Å |
 |  |  |  |  |
| CPD_HDAC5_ENST00000543464_ENST00000586802_28712254_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2645
Å |
 |  |  |  |  |
| CPD_PDE4D_ENST00000225719_ENST00000360047_28770989_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3584
Å |
 |  |  |  |  |
| CPD_PDE4D_ENST00000225719_ENST00000502575_28770989_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3824
Å |
 |  |  |  |  |
| CPD_PDE4D_ENST00000543464_ENST00000360047_28770989_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3361
Å |
 |  |  |  |  |
| CPD_SKAP1_ENST00000543464_ENST00000584924_28712254_46474147 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.5247
Å |
 |  |  |  |  |
| CPEB2_ATP8A1_ENST00000507071_ENST00000264449_15009210_42509171 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:0.9644
Å |
 |  |  |  |  |
| CPEB2_ATP8A1_ENST00000538197_ENST00000264449_15009210_42509171 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:1.0429
Å |
 |  |  |  |  |
| CPM_AVIL_ENST00000338356_ENST00000537081_69326457_58194995 superimposed PDB: 1UND of partner (AVIL). RMSD:0.719
Å |
 |  |  |  |  |
| CPM_AVIL_ENST00000551568_ENST00000537081_69326457_58194995 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7143
Å |
 |  |  |  |  |
| CPM_CCT2_ENST00000338356_ENST00000543146_69279571_69986755 superimposed PDB: 1UWY of partner (CPM). RMSD:0.906
Å |
 |  |  |  |  |
| CPM_CCT2_ENST00000338356_ENST00000543146_69279571_69986755 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.9502
Å |
| | | |  |
| CPM_CCT2_ENST00000338356_ENST00000544368_69279571_69986755 superimposed PDB: 1UWY of partner (CPM). RMSD:0.8006
Å |
 |  |  |  |  |
| CPM_CCT2_ENST00000338356_ENST00000544368_69279571_69986755 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.5609
Å |
| | | |  |
| CPM_RAB21_ENST00000546373_ENST00000261263_69326457_72163579 superimposed PDB: 1Z08 of partner (RAB21). RMSD:2.7362
Å |
 |  |  |  |  |
| CPM_RAB21_ENST00000551568_ENST00000261263_69326457_72163579 superimposed PDB: 1Z08 of partner (RAB21). RMSD:0.5591
Å |
 |  |  |  |  |
| CPM_YEATS4_ENST00000338356_ENST00000548020_69326457_69783926 superimposed PDB: 1UWY of partner (CPM). RMSD:0.643
Å |
 |  |  |  |  |
| CPM_YEATS4_ENST00000546373_ENST00000548020_69326457_69783926 superimposed PDB: 1UWY of partner (CPM). RMSD:0.9261
Å |
 |  |  |  |  |
| CPM_YEATS4_ENST00000551568_ENST00000548020_69326457_69783926 superimposed PDB: 1UWY of partner (CPM). RMSD:0.7643
Å |
 |  |  |  |  |
| CPNE8_PRMT8_ENST00000331366_ENST00000382622_39266805_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4492
Å |
 |  |  |  |  |
| CPNE8_PRMT8_ENST00000360449_ENST00000382622_39266805_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4448
Å |
 |  |  |  |  |
| CPNE8_PRMT8_ENST00000360449_ENST00000452611_39266805_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4606
Å |
 |  |  |  |  |
| CPNE8_TBK1_ENST00000331366_ENST00000331710_39117573_64878082 superimposed PDB: 6NT9 of partner (TBK1). RMSD:0.9744
Å |
 |  |  |  |  |
| CPNE8_TBK1_ENST00000360449_ENST00000331710_39117573_64875621 superimposed PDB: 6NT9 of partner (TBK1). RMSD:1.0432
Å |
 |  |  |  |  |
| CPNE8_TBK1_ENST00000360449_ENST00000331710_39117573_64878082 superimposed PDB: 6NT9 of partner (TBK1). RMSD:3.0222
Å |
 |  |  |  |  |
| CPQ_PRKDC_ENST00000220763_ENST00000314191_97797558_48696370 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:1.2329
Å |
 |  |  |  |  |
| CPSF1_AHNAK_ENST00000349769_ENST00000257247_145621562_62201363 superimposed PDB: 9T3X of partner (CPSF1). RMSD:1.4286
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000266679_ENST00000543146_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.5155
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000266679_ENST00000543146_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.9074
Å |
| | | |  |
| CPSF6_CCT2_ENST00000266679_ENST00000544368_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.5426
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000266679_ENST00000544368_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.1348
Å |
| | | |  |
| CPSF6_CCT2_ENST00000435070_ENST00000543146_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.5308
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000435070_ENST00000543146_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.0259
Å |
| | | |  |
| CPSF6_CCT2_ENST00000435070_ENST00000544368_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.547
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000435070_ENST00000544368_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.1744
Å |
| | | |  |
| CPSF6_CCT2_ENST00000456847_ENST00000543146_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.5485
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000456847_ENST00000543146_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3371
Å |
| | | |  |
| CPSF6_CCT2_ENST00000456847_ENST00000544368_69653977_69983264 superimposed PDB: 3Q2S of partner (CPSF6). RMSD:0.542
Å |
 |  |  |  |  |
| CPSF6_CCT2_ENST00000456847_ENST00000544368_69653977_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.8889
Å |
| | | |  |
| CPSF6_ETHE1_ENST00000435070_ENST00000600651_69633486_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3617
Å |
 |  |  |  |  |
| CPSF6_ETHE1_ENST00000456847_ENST00000292147_69633486_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3308
Å |
 |  |  |  |  |
| CPSF6_EZH2_ENST00000551516_ENST00000350995_69656342_148512638 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.7647
Å |
 |  |  |  |  |
| CPSF6_EZH2_ENST00000551516_ENST00000460911_69656342_148512638 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.6278
Å |
 |  |  |  |  |
| CPT1A_ADAM2_ENST00000540367_ENST00000379853_68540732_39607263 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.8205
Å |
 |  |  |  |  |
| CPT1A_FOLR1_ENST00000540367_ENST00000393681_68540732_71906314 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.1018
Å |
 |  |  |  |  |
| CPT1A_FOLR1_ENST00000540367_ENST00000393681_68540732_71906314 superimposed PDB: 5IZQ of partner (FOLR1). RMSD:0.5321
Å |
| | | |  |
| CPT1A_LPCAT2_ENST00000265641_ENST00000262134_68529002_55583188 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.8217
Å |
 |  |  |  |  |
| CPT1A_LPXN_ENST00000539743_ENST00000528489_68566685_58338186 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.9531
Å |
 |  |  |  |  |
| CPT1A_LPXN_ENST00000539743_ENST00000528489_68566685_58338186 superimposed PDB: 1X3H of partner (LPXN). RMSD:1.4496
Å |
| | | |  |
| CPT1A_MRGPRD_ENST00000539743_ENST00000309106_68540732_68748455 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.9508
Å |
 |  |  |  |  |
| CPT1A_PCTP_ENST00000539743_ENST00000573500_68548107_53844695 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.6945
Å |
 |  |  |  |  |
| CPT1A_PCTP_ENST00000539743_ENST00000573500_68548107_53844695 superimposed PDB: 7U9D of partner (PCTP). RMSD:0.9813
Å |
| | | |  |
| CPT1A_RNFT1_ENST00000265641_ENST00000305783_68527036_58030472 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.2757
Å |
 |  |  |  |  |
| CPT1A_RNFT1_ENST00000539743_ENST00000305783_68527036_58031507 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.9209
Å |
 |  |  |  |  |
| CPT1A_SUV420H1_ENST00000376618_ENST00000402789_68566685_67934645 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.4553
Å |
 |  |  |  |  |
| CPT1A_SUV420H1_ENST00000376618_ENST00000405515_68566685_67934645 superimposed PDB: 8T9F of partner (SUV420H1). RMSD:2.9662
Å |
 |  |  |  |  |
| CPT1A_TPCN2_ENST00000539743_ENST00000294309_68548107_68822188 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:1.7786
Å |
 |  |  |  |  |
| CPT1A_TPCN2_ENST00000539743_ENST00000294309_68548107_68822188 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.764
Å |
| | | |  |
| CPT1A_TPCN2_ENST00000539743_ENST00000294309_68548107_68825045 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.179
Å |
 |  |  |  |  |
| CPT1A_TPCN2_ENST00000539743_ENST00000294309_68548107_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:3.0454
Å |
| | | |  |
| CPT1A_TPCN2_ENST00000540367_ENST00000542467_68548107_68822188 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.3388
Å |
 |  |  |  |  |
| CPT1A_TPCN2_ENST00000540367_ENST00000542467_68548107_68822188 superimposed PDB: 8OUO of partner (TPCN2). RMSD:1.876
Å |
| | | |  |
| CPT1A_TPCN2_ENST00000540367_ENST00000542467_68548107_68825045 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.3523
Å |
 |  |  |  |  |
| CPT1A_TPCN2_ENST00000540367_ENST00000542467_68548107_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.2541
Å |
| | | |  |
| CPT1A_TRIM24_ENST00000539743_ENST00000343526_68574934_138235807 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.6143
Å |
 |  |  |  |  |
| CPT1A_TRIM24_ENST00000539743_ENST00000343526_68574934_138235807 superimposed PDB: 4YBM of partner (TRIM24). RMSD:0.4685
Å |
| | | |  |
| CPT1A_TRIM24_ENST00000540367_ENST00000415680_68574934_138235807 superimposed PDB: 2LE3 of partner (CPT1A). RMSD:2.5785
Å |
 |  |  |  |  |
| CPT1A_TRIM24_ENST00000540367_ENST00000415680_68574934_138235807 superimposed PDB: 4YBM of partner (TRIM24). RMSD:0.4903
Å |
| | | |  |
| CPT1B_SEC14L3_ENST00000312108_ENST00000403066_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:2.9669
Å |
 |  |  |  |  |
| CPT1B_SEC14L3_ENST00000312108_ENST00000540910_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:0.8688
Å |
 |  |  |  |  |
| CPT1B_SEC14L3_ENST00000405237_ENST00000403066_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:1.1587
Å |
 |  |  |  |  |
| CPT1B_SEC14L3_ENST00000405237_ENST00000540910_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:0.8647
Å |
 |  |  |  |  |
| CPT1B_SEC14L3_ENST00000440709_ENST00000403066_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:3.0061
Å |
 |  |  |  |  |
| CPT1B_SEC14L3_ENST00000440709_ENST00000540910_51016203_30864683 superimposed PDB: 4UYB of partner (SEC14L3). RMSD:0.9241
Å |
 |  |  |  |  |
| CP_SOX5_ENST00000264613_ENST00000546136_148939433_23999127 superimposed PDB: 4ENZ of partner (CP). RMSD:0.6983
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000332896_ENST00000261267_94072848_69743887 superimposed PDB: 2OF5 of partner (CRADD). RMSD:3.16
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000332896_ENST00000261267_94072848_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.6035
Å |
| | | |  |
| CRADD_LYZ_ENST00000332896_ENST00000261267_94072848_69745999 superimposed PDB: 1C7P of partner (LYZ). RMSD:1.1678
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000541813_ENST00000261267_94072848_69743887 superimposed PDB: 2OF5 of partner (CRADD). RMSD:3.0628
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000541813_ENST00000261267_94072848_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.703
Å |
| | | |  |
| CRADD_LYZ_ENST00000541813_ENST00000261267_94072848_69745999 superimposed PDB: 1C7P of partner (LYZ). RMSD:1.4942
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000542893_ENST00000549690_94072848_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4592
Å |
 |  |  |  |  |
| CRADD_LYZ_ENST00000552983_ENST00000549690_94072848_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4359
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000395326_ENST00000265727_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:1.3821
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000395326_ENST00000315984_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:1.4624
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000395326_ENST00000398201_65579957_87704940 superimposed PDB: 7AE1 of partner (CRCP). RMSD:2.5768
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000395326_ENST00000398201_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:0.5025
Å |
| | | |  |
| CRCP_ADAM22_ENST00000395326_ENST00000398209_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:1.5634
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000395326_ENST00000439864_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:1.5439
Å |
 |  |  |  |  |
| CRCP_ADAM22_ENST00000398684_ENST00000398204_65579957_87704940 superimposed PDB: 3G5C of partner (ADAM22). RMSD:1.5508
Å |
 |  |  |  |  |
| CREB3L2_SHANK2_ENST00000330387_ENST00000338508_137686349_70349036 superimposed PDB: 8B10 of partner (SHANK2). RMSD:0.6599
Å |
 |  |  |  |  |
| CREB3L2_SHANK2_ENST00000330387_ENST00000409161_137686349_70349036 superimposed PDB: 8B10 of partner (SHANK2). RMSD:0.5883
Å |
 |  |  |  |  |
| CREB3L2_SHANK2_ENST00000330387_ENST00000409530_137686349_70349036 superimposed PDB: 8B10 of partner (SHANK2). RMSD:0.6342
Å |
 |  |  |  |  |
| CREBBP_ADCY9_ENST00000262367_ENST00000294016_3929832_4043511 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.4186
Å |
 |  |  |  |  |
| CREBBP_ADCY9_ENST00000382070_ENST00000294016_3900297_4016967 superimposed PDB: 9U3P of partner (ADCY9). RMSD:0.9245
Å |
 |  |  |  |  |
| CREBBP_ADCY9_ENST00000382070_ENST00000294016_3929832_4043511 superimposed PDB: 9U3P of partner (ADCY9). RMSD:0.8663
Å |
 |  |  |  |  |
| CREBBP_C16orf59_ENST00000382070_ENST00000569496_3788559_2514039 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.1747
Å |
 |  |  |  |  |
| CREBBP_CASKIN1_ENST00000262367_ENST00000343516_3794894_2240359 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.2023
Å |
 |  |  |  |  |
| CREBBP_CASKIN1_ENST00000382070_ENST00000343516_3794894_2240359 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.1944
Å |
 |  |  |  |  |
| CREBBP_CASKIN1_ENST00000382070_ENST00000343516_3794894_2240359 superimposed PDB: 3SEN of partner (CASKIN1). RMSD:0.5229
Å |
| | | |  |
| CREBBP_KMT2A_ENST00000262367_ENST00000354520_3900297_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9257
Å |
 |  |  |  |  |
| CREBBP_KMT2A_ENST00000262367_ENST00000389506_3900297_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.4753
Å |
 |  |  |  |  |
| CREBBP_KMT2A_ENST00000382070_ENST00000354520_3900297_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8845
Å |
 |  |  |  |  |
| CREBBP_KMT2A_ENST00000382070_ENST00000389506_3900297_118359328 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.4903
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000262367_ENST00000340578_3900297_5941846 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1242
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000262367_ENST00000340578_3900297_5951607 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1433
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000262367_ENST00000439268_3900297_5951607 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1042
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000382070_ENST00000340578_3900297_5941846 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1309
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000382070_ENST00000340578_3900297_5951607 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1443
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000382070_ENST00000439268_3900297_5941846 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1044
Å |
 |  |  |  |  |
| CREBBP_RANBP3_ENST00000382070_ENST00000439268_3900297_5951607 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.1146
Å |
 |  |  |  |  |
| CREBBP_SH2D3C_ENST00000262367_ENST00000373277_3799627_130523929 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.7525
Å |
 |  |  |  |  |
| CREBBP_SH2D3C_ENST00000382070_ENST00000373277_3799627_130523929 superimposed PDB: 3T6G of partner (SH2D3C). RMSD:0.5156
Å |
 |  |  |  |  |
| CREBBP_SRL_ENST00000382070_ENST00000399609_3794894_4254635 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.7292
Å |
 |  |  |  |  |
| CREBBP_TCEB2_ENST00000382070_ENST00000409906_3929832_2827128 superimposed PDB: 4AJY of partner (TCEB2). RMSD:0.3515
Å |
 |  |  |  |  |
| CREBBP_TP53TG3_ENST00000382070_ENST00000398682_3900297_32685885 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.2736
Å |
 |  |  |  |  |
| CREBBP_ZSCAN32_ENST00000262367_ENST00000304926_3832684_3434941 superimposed PDB: 8HAN of partner (CREBBP). RMSD:2.7697
Å |
 |  |  |  |  |
| CRISPLD2_CDH13_ENST00000262424_ENST00000268613_84888435_83520081 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.8396
Å |
 |  |  |  |  |
| CRISPLD2_JAK1_ENST00000567845_ENST00000342505_84922969_65339206 superimposed PDB: 5L04 of partner (JAK1). RMSD:0.9475
Å |
 |  |  |  |  |
| CRKL_AP3D1_ENST00000354336_ENST00000345016_21288532_2138713 superimposed PDB: 2LQN of partner (CRKL). RMSD:2.8391
Å |
 |  |  |  |  |
| CRKL_AP3D1_ENST00000354336_ENST00000345016_21288532_2138713 superimposed PDB: 9C59 of partner (AP3D1). RMSD:2.8418
Å |
| | | |  |
| CRKL_AP3D1_ENST00000354336_ENST00000350812_21288532_2138713 superimposed PDB: 2LQN of partner (CRKL). RMSD:3.2692
Å |
 |  |  |  |  |
| CRKL_AP3D1_ENST00000354336_ENST00000350812_21288532_2138713 superimposed PDB: 9C59 of partner (AP3D1). RMSD:2.8146
Å |
| | | |  |
| CRKL_AP3D1_ENST00000354336_ENST00000356926_21288532_2138713 superimposed PDB: 9C59 of partner (AP3D1). RMSD:2.6733
Å |
 |  |  |  |  |
| CRKL_HPS4_ENST00000354336_ENST00000398145_21288532_26873102 superimposed PDB: 8ZWC of partner (HPS4). RMSD:2.7725
Å |
 |  |  |  |  |
| CRKL_HPS4_ENST00000354336_ENST00000402105_21288532_26873102 superimposed PDB: 8ZWC of partner (HPS4). RMSD:2.6554
Å |
 |  |  |  |  |
| CRK_SLC43A2_ENST00000300574_ENST00000301335_1359170_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.2762
Å |
 |  |  |  |  |
| CRK_SLC43A2_ENST00000398970_ENST00000382147_1359170_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.5426
Å |
 |  |  |  |  |
| CRK_SLC43A2_ENST00000398970_ENST00000412517_1359170_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.3898
Å |
 |  |  |  |  |
| CRK_SLC43A2_ENST00000398970_ENST00000571650_1359170_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.2949
Å |
 |  |  |  |  |
| CRLS1_TRAPPC6A_ENST00000378868_ENST00000006275_6012726_45668452 superimposed PDB: 2C0J of partner (TRAPPC6A). RMSD:0.5607
Å |
 |  |  |  |  |
| CRLS1_TRAPPC6A_ENST00000378868_ENST00000592647_6012726_45668228 superimposed PDB: 2C0J of partner (TRAPPC6A). RMSD:2.8583
Å |
 |  |  |  |  |
| CRTAP_TGFBR2_ENST00000320954_ENST00000359013_33166071_30729875 superimposed PDB: 8K0M of partner (CRTAP). RMSD:1.1422
Å |
 |  |  |  |  |
| CRTC1_HNRNPM_ENST00000321949_ENST00000325495_18860685_8548041 superimposed PDB: 2DO0 of partner (HNRNPM). RMSD:0.7371
Å |
 |  |  |  |  |
| CRTC1_HNRNPM_ENST00000338797_ENST00000325495_18860685_8548041 superimposed PDB: 2DO0 of partner (HNRNPM). RMSD:0.7204
Å |
 |  |  |  |  |
| CRTC1_HNRNPM_ENST00000594658_ENST00000325495_18860685_8548041 superimposed PDB: 7D8P of partner (CRTC1). RMSD:2.299
Å |
 |  |  |  |  |
| CRTC1_HNRNPM_ENST00000594658_ENST00000325495_18860685_8548041 superimposed PDB: 2DO0 of partner (HNRNPM). RMSD:0.7248
Å |
| | | |  |
| CRTC1_HNRNPM_ENST00000601916_ENST00000325495_18860685_8548041 superimposed PDB: 2DO0 of partner (HNRNPM). RMSD:0.7137
Å |
 |  |  |  |  |
| CRTC3_IQGAP1_ENST00000268184_ENST00000268182_91150710_90983733 superimposed PDB: 3FAY of partner (IQGAP1). RMSD:1.0074
Å |
 |  |  |  |  |
| CRYL1_SPACA7_ENST00000382812_ENST00000375699_21063508_113088798 superimposed PDB: 3F3S of partner (CRYL1). RMSD:0.4804
Å |
 |  |  |  |  |
| CRYL1_TPTE2_ENST00000298248_ENST00000400230_21086581_20039704 superimposed PDB: 3F3S of partner (CRYL1). RMSD:0.3856
Å |
 |  |  |  |  |
| CRYL1_TPTE2_ENST00000298248_ENST00000400230_21086581_20048215 superimposed PDB: 3F3S of partner (CRYL1). RMSD:0.4309
Å |
 |  |  |  |  |
| CSAD_ATXN2_ENST00000267085_ENST00000389153_53564206_111926584 superimposed PDB: 2JIS of partner (CSAD). RMSD:1.1788
Å |
 |  |  |  |  |
| CSAD_ATXN2_ENST00000267085_ENST00000535949_53564206_111926584 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.6328
Å |
 |  |  |  |  |
| CSAD_ATXN2_ENST00000267085_ENST00000542287_53564206_111926584 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.5191
Å |
 |  |  |  |  |
| CSAD_ATXN2_ENST00000267085_ENST00000608853_53564206_111926584 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.3924
Å |
 |  |  |  |  |
| CSAD_ATXN2_ENST00000379846_ENST00000389153_53564206_111926584 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.7508
Å |
 |  |  |  |  |
| CSAD_GADL1_ENST00000444623_ENST00000282538_53555056_30875426 superimposed PDB: 2JIS of partner (CSAD). RMSD:1.794
Å |
 |  |  |  |  |
| CSE1L_SMG1_ENST00000262982_ENST00000565224_47683817_18896484 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.9386
Å |
 |  |  |  |  |
| CSE1L_SMG1_ENST00000396192_ENST00000389467_47683817_18896484 superimposed PDB: 6L54 of partner (SMG1). RMSD:2.8827
Å |
 |  |  |  |  |
| CSNK1D_CCDC57_ENST00000314028_ENST00000389641_80209254_80059742 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.8071
Å |
 |  |  |  |  |
| CSNK1D_CCDC57_ENST00000398519_ENST00000389641_80209254_80059742 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7793
Å |
 |  |  |  |  |
| CSNK1D_CCDC57_ENST00000398519_ENST00000392347_80209254_80059742 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.1949
Å |
 |  |  |  |  |
| CSNK1D_POLR2E_ENST00000392334_ENST00000215587_80223561_1089550 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.223
Å |
 |  |  |  |  |
| CSNK1D_POLR2E_ENST00000392334_ENST00000215587_80223561_1090140 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.1248
Å |
 |  |  |  |  |
| CSNK1D_POLR2E_ENST00000392334_ENST00000215587_80223561_1090987 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.069
Å |
 |  |  |  |  |
| CSNK1D_POLR2E_ENST00000392334_ENST00000586746_80223561_1089550 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.0442
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000314028_ENST00000480567_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7876
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000314028_ENST00000496742_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7816
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000314028_ENST00000529008_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.78
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000398519_ENST00000295702_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.2147
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000398519_ENST00000480567_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7607
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000398519_ENST00000496742_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7801
Å |
 |  |  |  |  |
| CSNK1D_SSR2_ENST00000398519_ENST00000529008_80209254_155989958 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7785
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000314028_ENST00000311979_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.8011
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000314028_ENST00000592237_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.8539
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000392334_ENST00000311979_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7865
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000392334_ENST00000592237_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.8363
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000398519_ENST00000311979_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.7806
Å |
 |  |  |  |  |
| CSNK1D_TAF15_ENST00000398519_ENST00000592237_80210309_34151081 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.8081
Å |
 |  |  |  |  |
| CSNK1D_VCP_ENST00000314028_ENST00000358901_80213304_35059798 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.5009
Å |
 |  |  |  |  |
| CSNK1D_VCP_ENST00000314028_ENST00000358901_80213304_35059798 superimposed PDB: 10QQ of partner (VCP). RMSD:1.3497
Å |
| | | |  |
| CSNK1E_DDX17_ENST00000359867_ENST00000381633_38710086_38882445 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.7163
Å |
 |  |  |  |  |
| CSNK1E_DDX17_ENST00000359867_ENST00000396821_38710086_38882445 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.8898
Å |
 |  |  |  |  |
| CSNK1E_DMC1_ENST00000400206_ENST00000428462_38694790_38958374 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.7895
Å |
 |  |  |  |  |
| CSNK1E_PLA2G6_ENST00000403904_ENST00000335539_38689255_38512218 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.8838
Å |
 |  |  |  |  |
| CSNK1E_SPRR3_ENST00000400206_ENST00000331860_38694790_152974224 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.7853
Å |
 |  |  |  |  |
| CSNK1E_SPRR3_ENST00000400206_ENST00000495845_38694790_152974224 superimposed PDB: 4HNI of partner (CSNK1E). RMSD:0.8149
Å |
 |  |  |  |  |
| CSNK1G1_INTS2_ENST00000303052_ENST00000251334_64592517_59947349 superimposed PDB: 8RC4 of partner (INTS2). RMSD:0.6899
Å |
 |  |  |  |  |
| CSNK1G1_PPIB_ENST00000607537_ENST00000300026_64592517_64452396 superimposed PDB: 8K0M of partner (PPIB). RMSD:0.7503
Å |
 |  |  |  |  |
| CSPG4_DNM1_ENST00000308508_ENST00000341179_75974633_131012393 superimposed PDB: 7ML7 of partner (CSPG4). RMSD:0.8949
Å |
 |  |  |  |  |
| CSPG4_DNM1_ENST00000308508_ENST00000393594_75974633_131012393 superimposed PDB: 7ML7 of partner (CSPG4). RMSD:1.0278
Å |
 |  |  |  |  |
| CSTF3_HSP90AA1_ENST00000524827_ENST00000334701_33163212_102548158 superimposed PDB: 6URO of partner (CSTF3). RMSD:0.7571
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000351328_ENST00000267064_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:1.1154
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000351328_ENST00000267064_56679699_56565721 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:3.2825
Å |
| | | |  |
| CS_SMARCC2_ENST00000351328_ENST00000347471_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:2.0559
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000351328_ENST00000347471_56679699_56565721 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:2.6211
Å |
| | | |  |
| CS_SMARCC2_ENST00000351328_ENST00000550164_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:3.1528
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000351328_ENST00000550164_56679699_56565721 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:3.3481
Å |
| | | |  |
| CS_SMARCC2_ENST00000542324_ENST00000267064_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:3.0054
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000542324_ENST00000267064_56679699_56565721 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:3.1191
Å |
| | | |  |
| CS_SMARCC2_ENST00000542324_ENST00000347471_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:3.1308
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000542324_ENST00000550164_56679699_56565721 superimposed PDB: 5UZQ of partner (CS). RMSD:1.1377
Å |
 |  |  |  |  |
| CS_SMARCC2_ENST00000542324_ENST00000550164_56679699_56565721 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:2.6141
Å |
| | | |  |
| CTBP1_POLN_ENST00000382952_ENST00000511885_1231970_2097660 superimposed PDB: 4XVK of partner (POLN). RMSD:1.2289
Å |
 |  |  |  |  |
| CTBP2_ZNF726_ENST00000411419_ENST00000525354_126727565_24102174 superimposed PDB: 9WRI of partner (CTBP2). RMSD:2.9234
Å |
 |  |  |  |  |
| CTBS_ELAVL4_ENST00000370630_ENST00000371821_85039921_50659436 superimposed PDB: 1FXL of partner (ELAVL4). RMSD:3.114
Å |
 |  |  |  |  |
| CTBS_ELAVL4_ENST00000370630_ENST00000371827_85039921_50659436 superimposed PDB: 1FXL of partner (ELAVL4). RMSD:0.4725
Å |
 |  |  |  |  |
| CTDP1_NFATC1_ENST00000299543_ENST00000587635_77478016_77227449 superimposed PDB: 1ONV of partner (CTDP1). RMSD:1.3463
Å |
 |  |  |  |  |
| CTDP1_NFATC1_ENST00000299543_ENST00000591814_77478016_77227449 superimposed PDB: 1ONV of partner (CTDP1). RMSD:1.3837
Å |
 |  |  |  |  |
| CTDSP1_HSPB11_ENST00000273062_ENST00000371377_219264880_54389620 superimposed PDB: 1TVG of partner (HSPB11). RMSD:1.1406
Å |
 |  |  |  |  |
| CTDSPL2_UBR5_ENST00000260327_ENST00000220959_44751398_103358623 superimposed PDB: 8E0Q of partner (UBR5). RMSD:2.8277
Å |
 |  |  |  |  |
| CTDSPL2_UBR5_ENST00000396780_ENST00000520539_44751398_103358623 superimposed PDB: 8E0Q of partner (UBR5). RMSD:3.1583
Å |
 |  |  |  |  |
| CTIF_GRM4_ENST00000256413_ENST00000374181_46146116_34059876 superimposed PDB: 8JD4 of partner (GRM4). RMSD:2.3328
Å |
 |  |  |  |  |
| CTIF_GRM4_ENST00000256413_ENST00000374181_46197115_34059876 superimposed PDB: 8JD4 of partner (GRM4). RMSD:2.3292
Å |
 |  |  |  |  |
| CTIF_GRM4_ENST00000256413_ENST00000544773_46146116_34059876 superimposed PDB: 8JD4 of partner (GRM4). RMSD:2.3629
Å |
 |  |  |  |  |
| CTIF_GRM4_ENST00000256413_ENST00000544773_46197115_34059876 superimposed PDB: 8JD4 of partner (GRM4). RMSD:2.3256
Å |
 |  |  |  |  |
| CTNNA1_AP3B1_ENST00000302763_ENST00000519295_138223331_77477486 superimposed PDB: 6UPV of partner (CTNNA1). RMSD:2.8997
Å |
 |  |  |  |  |
| CTNNA1_AP3B1_ENST00000302763_ENST00000519295_138223331_77477486 superimposed PDB: 9C5A of partner (AP3B1). RMSD:2.8276
Å |
| | | |  |
| CTNNA1_AP3B1_ENST00000355078_ENST00000255194_138223331_77477486 superimposed PDB: 9C5A of partner (AP3B1). RMSD:2.725
Å |
 |  |  |  |  |
| CTNNA1_AP3B1_ENST00000355078_ENST00000519295_138223331_77477486 superimposed PDB: 9C5A of partner (AP3B1). RMSD:3.0329
Å |
 |  |  |  |  |
| CTNNA1_AP3B1_ENST00000540387_ENST00000519295_138223331_77477486 superimposed PDB: 9C5A of partner (AP3B1). RMSD:0.7222
Å |
 |  |  |  |  |
| CTNNAL1_TLE1_ENST00000325551_ENST00000376499_111775581_84268951 superimposed PDB: 1GXR of partner (TLE1). RMSD:0.3453
Å |
 |  |  |  |  |
| CTNNB1_FGFR2_ENST00000396183_ENST00000369061_41268843_123325218 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4576
Å |
 |  |  |  |  |
| CTNNB1_FGFR2_ENST00000396185_ENST00000369061_41268843_123325218 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4703
Å |
 |  |  |  |  |
| CTNNBL1_ETFA_ENST00000373469_ENST00000559602_36431450_76508938 superimposed PDB: 4CB9 of partner (CTNNBL1). RMSD:0.4291
Å |
 |  |  |  |  |
| CTNNBL1_ETFA_ENST00000373473_ENST00000559602_36431450_76508938 superimposed PDB: 4CB9 of partner (CTNNBL1). RMSD:0.4921
Å |
 |  |  |  |  |
| CTNNBL1_ETFA_ENST00000405275_ENST00000559602_36431450_76508938 superimposed PDB: 4CB9 of partner (CTNNBL1). RMSD:0.4803
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000358694_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5783
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000358694_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.609
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000399039_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5321
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000399039_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.6034
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000415361_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5726
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000415361_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5807
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000415361_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5766
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000415361_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5531
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000426142_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5367
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000426142_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5807
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000428599_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.55
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000428599_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5986
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000524630_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5518
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000524630_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5795
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000525902_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5244
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000525902_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5749
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000526938_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5132
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000526938_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5562
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000527467_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5542
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000527467_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5648
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000528232_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5913
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000528232_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5836
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000528621_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5836
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000528621_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5801
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000529873_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5976
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000529873_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5696
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000529919_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5769
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000529919_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.6057
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000529919_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5862
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000529919_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5935
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000530094_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5673
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000530094_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.611
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000531014_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5609
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000531014_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5742
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532245_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5249
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532245_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.582
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532245_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6171
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532245_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.6058
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532463_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5856
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532463_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5957
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532463_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.604
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532463_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5915
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532844_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5632
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532844_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5974
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000532844_ENST00000378004_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5795
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000532844_ENST00000378004_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.589
Å |
| | | |  |
| CTNND1_ARHGAP26_ENST00000534579_ENST00000274498_57577695_142393644 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5967
Å |
 |  |  |  |  |
| CTNND1_ARHGAP26_ENST00000534579_ENST00000274498_57577695_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5944
Å |
| | | |  |
| CTNND1_RSF1_ENST00000415361_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5833
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000426142_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6228
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000524630_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5675
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000527467_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6098
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000529873_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6282
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000529919_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6002
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000530094_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5791
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000531014_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5791
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000532245_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.529
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000532463_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6493
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000532844_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5507
Å |
 |  |  |  |  |
| CTNND1_RSF1_ENST00000534579_ENST00000360355_57576012_77413540 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5825
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000415361_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3888
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000415361_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.9084
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000426142_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3691
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000426142_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7484
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000428599_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3834
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000428599_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.8821
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000524630_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3629
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000524630_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7522
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000525902_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3667
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000525902_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:1.0224
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000526938_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3524
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000526938_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:1.0342
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000527467_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3834
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000527467_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7194
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000528232_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3378
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000528232_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.9327
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000529873_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3805
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000529873_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7475
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000529919_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3512
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000529919_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:1.5
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000530094_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3557
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000530094_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7172
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000532245_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3964
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000532245_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7246
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000532463_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3734
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000532463_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.9151
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000532463_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3741
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000532463_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7392
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000532844_ENST00000278407_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.3496
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000532844_ENST00000278407_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:1.532
Å |
| | | |  |
| CTNND1_SERPING1_ENST00000534579_ENST00000340687_57572252_57367351 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.349
Å |
 |  |  |  |  |
| CTNND1_SERPING1_ENST00000534579_ENST00000340687_57572252_57367351 superimposed PDB: 7AKV of partner (SERPING1). RMSD:0.7345
Å |
| | | |  |
| CTNND1_WDR5_ENST00000360682_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5543
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000360682_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4073
Å |
| | | |  |
| CTNND1_WDR5_ENST00000361391_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5626
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000361391_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4031
Å |
| | | |  |
| CTNND1_WDR5_ENST00000415361_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5301
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000415361_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4111
Å |
| | | |  |
| CTNND1_WDR5_ENST00000426142_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5858
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000426142_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4316
Å |
| | | |  |
| CTNND1_WDR5_ENST00000524630_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5556
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000524630_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4041
Å |
| | | |  |
| CTNND1_WDR5_ENST00000527467_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5738
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000527467_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3998
Å |
| | | |  |
| CTNND1_WDR5_ENST00000529526_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.562
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000529526_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4073
Å |
| | | |  |
| CTNND1_WDR5_ENST00000529873_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5567
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000529873_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3979
Å |
| | | |  |
| CTNND1_WDR5_ENST00000529919_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5562
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000529919_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4082
Å |
| | | |  |
| CTNND1_WDR5_ENST00000530094_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6233
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000530094_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4049
Å |
| | | |  |
| CTNND1_WDR5_ENST00000531014_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6033
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000531014_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3913
Å |
| | | |  |
| CTNND1_WDR5_ENST00000532245_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5067
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000532245_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3926
Å |
| | | |  |
| CTNND1_WDR5_ENST00000532463_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5509
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000532463_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.4091
Å |
| | | |  |
| CTNND1_WDR5_ENST00000532787_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5168
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000532787_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.385
Å |
| | | |  |
| CTNND1_WDR5_ENST00000532844_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6064
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000532844_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3964
Å |
| | | |  |
| CTNND1_WDR5_ENST00000533667_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5874
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000533667_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3928
Å |
| | | |  |
| CTNND1_WDR5_ENST00000534579_ENST00000425041_57582972_137005824 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5878
Å |
 |  |  |  |  |
| CTNND1_WDR5_ENST00000534579_ENST00000425041_57582972_137005824 superimposed PDB: 7BED of partner (WDR5). RMSD:0.3976
Å |
| | | |  |
| CTNND2_POLR1A_ENST00000304623_ENST00000409681_11732247_86257519 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:0.8927
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372651_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8354
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372651_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:1.0152
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372652_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8378
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372652_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9042
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372654_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8017
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000372654_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9601
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372616_ENST00000425457_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8083
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000425457_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9801
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372616_ENST00000427410_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.6469
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000427410_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.8326
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372616_ENST00000447388_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.7974
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000456393_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.7952
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372616_ENST00000456393_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9698
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372651_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8197
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372651_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9063
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372652_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8365
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372652_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.8806
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372654_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8033
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000372654_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9763
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372621_ENST00000425457_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8195
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000425457_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:1.116
Å |
| | | |  |
| CTPS1_NFYC_ENST00000372621_ENST00000447388_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.814
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000456393_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.8382
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000372621_ENST00000456393_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:1.045
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372651_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.7312
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372651_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.7999
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372652_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.6622
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372652_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.909
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372654_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.8168
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000372654_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.8603
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000425457_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.7093
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000425457_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.776
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000427410_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:0.7801
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000427410_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.9443
Å |
| | | |  |
| CTPS1_NFYC_ENST00000541520_ENST00000447388_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.4412
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000456393_41474386_41213205 superimposed PDB: 7MGZ of partner (CTPS1). RMSD:1.5783
Å |
 |  |  |  |  |
| CTPS1_NFYC_ENST00000541520_ENST00000456393_41474386_41213205 superimposed PDB: 8QU4 of partner (NFYC). RMSD:0.857
Å |
| | | |  |
| CTPS2_AKAP8_ENST00000359276_ENST00000269701_16711263_15480990 superimposed PDB: 7MII of partner (CTPS2). RMSD:3.06
Å |
 |  |  |  |  |
| CTPS2_AKAP8_ENST00000443824_ENST00000269701_16711263_15480990 superimposed PDB: 7MII of partner (CTPS2). RMSD:0.6721
Å |
 |  |  |  |  |
| CTR9_SNTG1_ENST00000361367_ENST00000276467_10794820_51569468 superimposed PDB: 9HVQ of partner (CTR9). RMSD:2.5869
Å |
 |  |  |  |  |
| CTR9_SNTG1_ENST00000361367_ENST00000522124_10794820_51569468 superimposed PDB: 9HVQ of partner (CTR9). RMSD:2.4855
Å |
 |  |  |  |  |
| CTSC_RAB38_ENST00000227266_ENST00000243662_88033697_87883123 superimposed PDB: 3PDF of partner (CTSC). RMSD:2.274
Å |
 |  |  |  |  |
| CTSC_RAB38_ENST00000227266_ENST00000243662_88033697_87883123 superimposed PDB: 6S5H of partner (RAB38). RMSD:0.7878
Å |
| | | |  |
| CTSD_REN_ENST00000236671_ENST00000272190_1782538_204130543 superimposed PDB: 4OD9 of partner (CTSD). RMSD:0.8415
Å |
 |  |  |  |  |
| CTSD_REN_ENST00000236671_ENST00000272190_1782538_204130543 superimposed PDB: 4AMT of partner (REN). RMSD:0.7238
Å |
| | | |  |
| CTSE_PGA3_ENST00000358184_ENST00000325558_206318467_60973981 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6756
Å |
 |  |  |  |  |
| CTSE_PGC_ENST00000358184_ENST00000373025_206318467_41712252 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6742
Å |
 |  |  |  |  |
| CTSE_PGC_ENST00000358184_ENST00000373025_206318467_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8234
Å |
| | | |  |
| CTSE_PGC_ENST00000361052_ENST00000425343_206318467_41712252 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.9419
Å |
 |  |  |  |  |
| CTSE_PGC_ENST00000361052_ENST00000425343_206318467_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.4683
Å |
| | | |  |
| CTSE_WBP2_ENST00000358184_ENST00000433525_206325437_73842868 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.5722
Å |
 |  |  |  |  |
| CTSE_WBP2_ENST00000360218_ENST00000433525_206325437_73842868 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.4994
Å |
 |  |  |  |  |
| CTSF_RANBP3_ENST00000310325_ENST00000340578_66335744_5921332 superimposed PDB: 2CRF of partner (RANBP3). RMSD:1.0763
Å |
 |  |  |  |  |
| CTSL_PSAP_ENST00000343150_ENST00000394934_90343724_73579657 superimposed PDB: 8GX2 of partner (CTSL). RMSD:0.3079
Å |
 |  |  |  |  |
| CTSZ_ZHX3_ENST00000217131_ENST00000558993_57571693_39813841 superimposed PDB: 1DEU of partner (CTSZ). RMSD:0.5182
Å |
 |  |  |  |  |
| CTTN_RXFP2_ENST00000301843_ENST00000298386_70279824_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.2317
Å |
 |  |  |  |  |
| CTTN_RXFP2_ENST00000301843_ENST00000380314_70279824_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.2934
Å |
 |  |  |  |  |
| CTTN_RXFP2_ENST00000346329_ENST00000298386_70279824_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.2486
Å |
 |  |  |  |  |
| CTTN_RXFP2_ENST00000376561_ENST00000380314_70279824_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.4198
Å |
 |  |  |  |  |
| CTTN_RXFP2_ENST00000538675_ENST00000298386_70279824_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.2333
Å |
 |  |  |  |  |
| CUEDC1_BRMS1_ENST00000360238_ENST00000359957_55945510_66106256 superimposed PDB: 2XUS of partner (BRMS1). RMSD:2.1494
Å |
 |  |  |  |  |
| CUEDC1_BRMS1_ENST00000577830_ENST00000359957_55945510_66106256 superimposed PDB: 2XUS of partner (BRMS1). RMSD:2.065
Å |
 |  |  |  |  |
| CUEDC1_BRMS1_ENST00000577840_ENST00000359957_55945510_66106256 superimposed PDB: 2XUS of partner (BRMS1). RMSD:2.4136
Å |
 |  |  |  |  |
| CUEDC1_HSF5_ENST00000577830_ENST00000323777_55962589_56536306 superimposed PDB: 2DHY of partner (CUEDC1). RMSD:1.0815
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000346874_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9996
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000350537_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.015
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000374788_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0082
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000374789_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9855
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000374790_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9838
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000374794_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0076
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000374746_ENST00000545693_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0203
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000346874_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9943
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000350537_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.901
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000374788_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0059
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000374789_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9871
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000374790_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.929
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000374794_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9587
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000545260_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9288
Å |
 |  |  |  |  |
| CUL2_PARD3_ENST00000537177_ENST00000545693_35333493_34806087 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9854
Å |
 |  |  |  |  |
| CUL2_ROBO1_ENST00000537177_ENST00000464233_35314059_79174689 superimposed PDB: 5OPE of partner (ROBO1). RMSD:2.9441
Å |
 |  |  |  |  |
| CUL4A_DDX17_ENST00000326335_ENST00000396821_113889459_38897285 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.3433
Å |
 |  |  |  |  |
| CUL4A_DDX17_ENST00000375440_ENST00000396821_113889459_38897285 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.4484
Å |
 |  |  |  |  |
| CUL4A_DDX17_ENST00000451881_ENST00000396821_113889459_38897285 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.4403
Å |
 |  |  |  |  |
| CUL4B_DAPK2_ENST00000404115_ENST00000457488_119691778_64275953 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.3856
Å |
 |  |  |  |  |
| CUL4B_SMG9_ENST00000336592_ENST00000270066_119680990_44244370 superimposed PDB: 7PW8 of partner (SMG9). RMSD:1.0322
Å |
 |  |  |  |  |
| CUL4B_SMG9_ENST00000336592_ENST00000601170_119680990_44244370 superimposed PDB: 7PW8 of partner (SMG9). RMSD:0.9755
Å |
 |  |  |  |  |
| CUL4B_SMG9_ENST00000371322_ENST00000270066_119680990_44244370 superimposed PDB: 4A0C of partner (CUL4B). RMSD:1.2685
Å |
 |  |  |  |  |
| CUL4B_SMG9_ENST00000371322_ENST00000601170_119680990_44244370 superimposed PDB: 7PW8 of partner (SMG9). RMSD:0.9642
Å |
 |  |  |  |  |
| CUL4B_XPO6_ENST00000404115_ENST00000565698_119672514_28109960 superimposed PDB: 4A0C of partner (CUL4B). RMSD:0.7956
Å |
 |  |  |  |  |
| CUTA_GRM4_ENST00000494751_ENST00000374177_33384873_33990647 superimposed PDB: 2ZFH of partner (CUTA). RMSD:0.9504
Å |
 |  |  |  |  |
| CUX1_THSD7A_ENST00000292538_ENST00000423059_101713697_11676588 superimposed PDB: 8OXR of partner (THSD7A). RMSD:2.5481
Å |
 |  |  |  |  |
| CUX1_THSD7A_ENST00000360264_ENST00000423059_101713697_11676588 superimposed PDB: 8OXR of partner (THSD7A). RMSD:2.6501
Å |
 |  |  |  |  |
| CUX1_THSD7A_ENST00000547394_ENST00000423059_101713697_11676588 superimposed PDB: 8OXR of partner (THSD7A). RMSD:2.2566
Å |
 |  |  |  |  |
| CUX1_THSD7A_ENST00000549414_ENST00000423059_101713697_11676588 superimposed PDB: 8OXR of partner (THSD7A). RMSD:2.5242
Å |
 |  |  |  |  |
| CWC25_LASP1_ENST00000225428_ENST00000318008_36971113_37074857 superimposed PDB: 6ZYM of partner (CWC25). RMSD:0.9819
Å |
 |  |  |  |  |
| CWC25_LASP1_ENST00000225428_ENST00000435347_36971113_37074857 superimposed PDB: 6ZYM of partner (CWC25). RMSD:0.8946
Å |
 |  |  |  |  |
| CWC25_SLC35B1_ENST00000225428_ENST00000240333_36981418_47783258 superimposed PDB: 6ZYM of partner (CWC25). RMSD:0.9081
Å |
 |  |  |  |  |
| CWC25_SLC35B1_ENST00000225428_ENST00000415270_36981418_47783258 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:2.3274
Å |
 |  |  |  |  |
| CWC27_GRIA4_ENST00000381070_ENST00000282499_64181373_105732749 superimposed PDB: 7DVQ of partner (CWC27). RMSD:0.3698
Å |
 |  |  |  |  |
| CWC27_GRIA4_ENST00000381070_ENST00000393127_64181373_105732749 superimposed PDB: 7DVQ of partner (CWC27). RMSD:0.36
Å |
 |  |  |  |  |
| CWC27_GRIA4_ENST00000381070_ENST00000428631_64181373_105732749 superimposed PDB: 7DVQ of partner (CWC27). RMSD:0.3568
Å |
 |  |  |  |  |
| CXADR_APP_ENST00000284878_ENST00000359726_18885490_27425664 superimposed PDB: 8KF4 of partner (APP). RMSD:3.0176
Å |
 |  |  |  |  |
| CXADR_APP_ENST00000284878_ENST00000448388_18885490_27425664 superimposed PDB: 8KF4 of partner (APP). RMSD:2.7359
Å |
 |  |  |  |  |
| CXADR_APP_ENST00000400166_ENST00000354192_18885490_27425664 superimposed PDB: 8KF4 of partner (APP). RMSD:3.0045
Å |
 |  |  |  |  |
| CXADR_APP_ENST00000400166_ENST00000359726_18885490_27425664 superimposed PDB: 8KF4 of partner (APP). RMSD:2.972
Å |
 |  |  |  |  |
| CXADR_APP_ENST00000400166_ENST00000448388_18885490_27425664 superimposed PDB: 8KF4 of partner (APP). RMSD:2.8192
Å |
 |  |  |  |  |
| CXorf23_SH3KBP1_ENST00000379682_ENST00000397821_19953926_19764559 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.6813
Å |
 |  |  |  |  |
| CYB5B_VPS4A_ENST00000307892_ENST00000254950_69458760_69356462 superimposed PDB: 3NER of partner (CYB5B). RMSD:0.5462
Å |
 |  |  |  |  |
| CYFIP1_ACACA_ENST00000313077_ENST00000360679_22935964_35634007 superimposed PDB: 8XL1 of partner (ACACA). RMSD:3.0866
Å |
 |  |  |  |  |
| CYFIP1_ACACA_ENST00000560848_ENST00000360679_22935964_35634007 superimposed PDB: 8XL1 of partner (ACACA). RMSD:3.0972
Å |
 |  |  |  |  |
| CYFIP2_PLCG2_ENST00000377576_ENST00000359376_156816435_81902818 superimposed PDB: 8QJU of partner (PLCG2). RMSD:3.2278
Å |
 |  |  |  |  |
| CYFIP2_PLCG2_ENST00000435847_ENST00000359376_156816435_81902818 superimposed PDB: 8QJU of partner (PLCG2). RMSD:1.5641
Å |
 |  |  |  |  |
| CYFIP2_PLCG2_ENST00000521420_ENST00000359376_156816435_81902818 superimposed PDB: 8QJU of partner (PLCG2). RMSD:3.6034
Å |
 |  |  |  |  |
| CYFIP2_PLCG2_ENST00000522463_ENST00000359376_156816435_81902818 superimposed PDB: 8QJU of partner (PLCG2). RMSD:2.7581
Å |
 |  |  |  |  |
| CYP17A1_ANXA2_ENST00000369887_ENST00000451270_104591264_60643450 superimposed PDB: 6WR1 of partner (CYP17A1). RMSD:1.3151
Å |
 |  |  |  |  |
| CYP2C18_HELLS_ENST00000285979_ENST00000348459_96466717_96331144 superimposed PDB: 9Z05 of partner (HELLS). RMSD:2.5193
Å |
 |  |  |  |  |
| CYP2C18_HELLS_ENST00000285979_ENST00000371332_96466717_96331144 superimposed PDB: 9Z05 of partner (HELLS). RMSD:1.3429
Å |
 |  |  |  |  |
| CYP2E1_AMACR_ENST00000252945_ENST00000335606_135342144_34006004 superimposed PDB: 3E6I of partner (CYP2E1). RMSD:0.597
Å |
 |  |  |  |  |
| CYP2E1_FTCD_ENST00000463117_ENST00000291670_135341076_47558837 superimposed PDB: 3E6I of partner (CYP2E1). RMSD:1.6832
Å |
 |  |  |  |  |
| CYP2E1_NEBL_ENST00000252945_ENST00000377159_135341076_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3721
Å |
 |  |  |  |  |
| CYP2E1_NEBL_ENST00000252945_ENST00000417816_135341076_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3808
Å |
 |  |  |  |  |
| CYP2E1_NEBL_ENST00000463117_ENST00000377122_135341076_21101869 superimposed PDB: 3E6I of partner (CYP2E1). RMSD:2.1647
Å |
 |  |  |  |  |
| CYP2E1_NEBL_ENST00000463117_ENST00000377122_135341076_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:2.8337
Å |
| | | |  |
| CYP2E1_NEBL_ENST00000463117_ENST00000377159_135341076_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3799
Å |
 |  |  |  |  |
| CYP2E1_NEBL_ENST00000463117_ENST00000417816_135341076_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3624
Å |
 |  |  |  |  |
| CYP2E1_REG3A_ENST00000252945_ENST00000393878_135341076_79384824 superimposed PDB: 1UV0 of partner (REG3A). RMSD:1.1656
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000271153_ENST00000423423_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:0.7086
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000371919_ENST00000308366_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:2.9347
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000371919_ENST00000423423_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:0.6813
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000371923_ENST00000423423_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:0.6703
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000452782_ENST00000308366_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:2.2487
Å |
 |  |  |  |  |
| CYP4B1_PLA2G1B_ENST00000452782_ENST00000423423_47282853_120763823 superimposed PDB: 3ELO of partner (PLA2G1B). RMSD:0.7194
Å |
 |  |  |  |  |
| CYP4F11_CIB3_ENST00000248041_ENST00000379859_16045020_16275724 superimposed PDB: 6WU7 of partner (CIB3). RMSD:1.1955
Å |
 |  |  |  |  |
| CYP51A1_KRIT1_ENST00000003100_ENST00000340022_91755566_91864960 superimposed PDB: 3LD6 of partner (CYP51A1). RMSD:1.7223
Å |
 |  |  |  |  |
| CYP51A1_KRIT1_ENST00000003100_ENST00000340022_91755566_91864960 superimposed PDB: 5D68 of partner (KRIT1). RMSD:0.8643
Å |
| | | |  |
| CYP7B1_EPS15_ENST00000310193_ENST00000371733_65517238_51946986 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.2294
Å |
 |  |  |  |  |
| CYTH1_CUX1_ENST00000589297_ENST00000292538_76696412_101916636 superimposed PDB: 1BC9 of partner (CYTH1). RMSD:2.673
Å |
 |  |  |  |  |
| CYTH1_CUX1_ENST00000589297_ENST00000437600_76696412_101916636 superimposed PDB: 1BC9 of partner (CYTH1). RMSD:2.5927
Å |
 |  |  |  |  |
| CYTH1_CUX1_ENST00000591455_ENST00000292538_76696412_101916636 superimposed PDB: 1BC9 of partner (CYTH1). RMSD:2.6409
Å |
 |  |  |  |  |
| CYTH3_MAD1L1_ENST00000350796_ENST00000399654_6210165_1938026 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:0.8214
Å |
 |  |  |  |  |
| CYTH3_MAD1L1_ENST00000350796_ENST00000399654_6210832_1938026 superimposed PDB: 6U3E of partner (CYTH3). RMSD:3.5064
Å |
 |  |  |  |  |
| CYTH3_MAD1L1_ENST00000350796_ENST00000399654_6210832_1938026 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.1827
Å |
| | | |  |
| CYTH3_MAD1L1_ENST00000396741_ENST00000399654_6210165_1938026 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:0.8032
Å |
 |  |  |  |  |
| CYTH3_MAD1L1_ENST00000396741_ENST00000399654_6210832_1938026 superimposed PDB: 6U3E of partner (CYTH3). RMSD:3.2426
Å |
 |  |  |  |  |
| CYTH3_MAD1L1_ENST00000396741_ENST00000399654_6210832_1938026 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:0.9161
Å |
| | | |  |
| DAB2_ARSB_ENST00000509337_ENST00000396151_39392466_78265015 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.4035
Å |
 |  |  |  |  |
| DAB2_ARSB_ENST00000509337_ENST00000565165_39392466_78265015 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.4002
Å |
 |  |  |  |  |
| DACH1_KLF12_ENST00000305425_ENST00000377666_72440053_74269808 superimposed PDB: 1L8R of partner (DACH1). RMSD:0.569
Å |
 |  |  |  |  |
| DAD1_RAB2B_ENST00000538631_ENST00000397762_23057852_21936911 superimposed PDB: 2A5J of partner (RAB2B). RMSD:1.5208
Å |
 |  |  |  |  |
| DAND5_NFIC_ENST00000317060_ENST00000341919_13080798_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5512
Å |
 |  |  |  |  |
| DAND5_NFIC_ENST00000585548_ENST00000346156_13080798_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5279
Å |
 |  |  |  |  |
| DAND5_NFIC_ENST00000585548_ENST00000395111_13080798_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5392
Å |
 |  |  |  |  |
| DAND5_NFIC_ENST00000585548_ENST00000586919_13080798_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5564
Å |
 |  |  |  |  |
| DAND5_NFIC_ENST00000585548_ENST00000590282_13080798_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6325
Å |
 |  |  |  |  |
| DAPK1_ABCA1_ENST00000472284_ENST00000374736_90114054_107565597 superimposed PDB: 7TBW of partner (ABCA1). RMSD:1.2108
Å |
 |  |  |  |  |
| DAPP1_SLC4A4_ENST00000296414_ENST00000351898_100774505_72399943 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:2.2437
Å |
 |  |  |  |  |
| DAPP1_SLC4A4_ENST00000296414_ENST00000425175_100774505_72399943 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:2.1539
Å |
 |  |  |  |  |
| DAP_CCT5_ENST00000230895_ENST00000503026_10748286_10258222 superimposed PDB: 7NVL of partner (CCT5). RMSD:1.82
Å |
 |  |  |  |  |
| DAP_SNX9_ENST00000432074_ENST00000392185_10748286_158327159 superimposed PDB: 2RAJ of partner (SNX9). RMSD:0.6554
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000341516_ENST00000390683_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6313
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000341516_ENST00000471583_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.567
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000341516_ENST00000487270_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6163
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000341516_ENST00000488612_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6193
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000389997_ENST00000487861_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6607
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000557386_ENST00000390683_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6423
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000557386_ENST00000471583_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.5763
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000557386_ENST00000487270_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6378
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000557386_ENST00000487861_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6398
Å |
 |  |  |  |  |
| DCAF5_RAD51B_ENST00000557386_ENST00000488612_69558390_68934888 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6198
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000341516_ENST00000428130_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000341516_ENST00000553384_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.5011
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000389997_ENST00000381346_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.4409
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000557386_ENST00000381346_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.4399
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000557386_ENST00000428130_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.6525
Å |
 |  |  |  |  |
| DCAF5_RDH11_ENST00000557386_ENST00000553384_69583082_68159769 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.5091
Å |
 |  |  |  |  |
| DCAF6_LETM1_ENST00000367843_ENST00000302787_167906246_1850936 superimposed PDB: 3I7O of partner (DCAF6). RMSD:0.4006
Å |
 |  |  |  |  |
| DCAF6_LETM1_ENST00000432587_ENST00000302787_167906246_1850936 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.469
Å |
 |  |  |  |  |
| DCBLD1_CCT2_ENST00000368503_ENST00000543146_117825142_69985838 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.6233
Å |
 |  |  |  |  |
| DCBLD1_CCT2_ENST00000368503_ENST00000544368_117825142_69985838 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.5596
Å |
 |  |  |  |  |
| DCDC2_GPLD1_ENST00000378450_ENST00000230036_24205229_24480187 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.7944
Å |
 |  |  |  |  |
| DCK_GRSF1_ENST00000504952_ENST00000254799_71863899_71702031 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:0.32
Å |
 |  |  |  |  |
| DCN_CPM_ENST00000552962_ENST00000551568_91572118_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4582
Å |
 |  |  |  |  |
| DCP2_TBCA_ENST00000389063_ENST00000380377_112312683_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:1.4599
Å |
 |  |  |  |  |
| DCP2_TBCA_ENST00000515408_ENST00000306388_112312683_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.0351
Å |
 |  |  |  |  |
| DCP2_TBCA_ENST00000515408_ENST00000520361_112312683_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:1.7144
Å |
 |  |  |  |  |
| DCUN1D4_USP46_ENST00000381437_ENST00000451218_52752804_53476783 superimposed PDB: 5L8H of partner (USP46). RMSD:1.3265
Å |
 |  |  |  |  |
| DCUN1D4_USP46_ENST00000381441_ENST00000451218_52752804_53476783 superimposed PDB: 5L8H of partner (USP46). RMSD:1.4295
Å |
 |  |  |  |  |
| DCUN1D4_USP46_ENST00000451288_ENST00000451218_52752804_53476783 superimposed PDB: 5L8H of partner (USP46). RMSD:1.2105
Å |
 |  |  |  |  |
| DDAH1_NEGR1_ENST00000284031_ENST00000357731_85930425_71873253 superimposed PDB: 7ULX of partner (DDAH1). RMSD:0.626
Å |
 |  |  |  |  |
| DDAH1_NEGR1_ENST00000539042_ENST00000357731_85930425_71873253 superimposed PDB: 7ULX of partner (DDAH1). RMSD:0.5805
Å |
 |  |  |  |  |
| DDR1_ABCF1_ENST00000361741_ENST00000376545_30862448_30557464 superimposed PDB: 5ZXD of partner (ABCF1). RMSD:1.3105
Å |
 |  |  |  |  |
| DDR1_KPNB1_ENST00000324771_ENST00000290158_30857207_45741524 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.8262
Å |
 |  |  |  |  |
| DDR1_KPNB1_ENST00000376567_ENST00000290158_30857207_45741524 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.939
Å |
 |  |  |  |  |
| DDR1_KPNB1_ENST00000418800_ENST00000290158_30857207_45741524 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.8466
Å |
 |  |  |  |  |
| DDR1_KPNB1_ENST00000508312_ENST00000290158_30857207_45741524 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.8834
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000324771_ENST00000278568_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1951
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000324771_ENST00000278568_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6384
Å |
| | | |  |
| DDR1_PAK1_ENST00000324771_ENST00000528203_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2043
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000324771_ENST00000528203_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6373
Å |
| | | |  |
| DDR1_PAK1_ENST00000324771_ENST00000530617_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2096
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000324771_ENST00000530617_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.622
Å |
| | | |  |
| DDR1_PAK1_ENST00000361741_ENST00000278568_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2859
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000361741_ENST00000278568_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6373
Å |
| | | |  |
| DDR1_PAK1_ENST00000361741_ENST00000528203_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1775
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000361741_ENST00000528203_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6098
Å |
| | | |  |
| DDR1_PAK1_ENST00000361741_ENST00000530617_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2224
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000361741_ENST00000530617_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6265
Å |
| | | |  |
| DDR1_PAK1_ENST00000376567_ENST00000278568_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1594
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000376567_ENST00000278568_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6485
Å |
| | | |  |
| DDR1_PAK1_ENST00000376567_ENST00000528203_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1652
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000376567_ENST00000528203_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6555
Å |
| | | |  |
| DDR1_PAK1_ENST00000376567_ENST00000530617_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2624
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000376567_ENST00000530617_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6046
Å |
| | | |  |
| DDR1_PAK1_ENST00000418800_ENST00000278568_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1459
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000418800_ENST00000278568_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6204
Å |
| | | |  |
| DDR1_PAK1_ENST00000418800_ENST00000528203_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1672
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000418800_ENST00000528203_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6726
Å |
| | | |  |
| DDR1_PAK1_ENST00000418800_ENST00000530617_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2246
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000418800_ENST00000530617_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6015
Å |
| | | |  |
| DDR1_PAK1_ENST00000508312_ENST00000278568_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1749
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000508312_ENST00000278568_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6284
Å |
| | | |  |
| DDR1_PAK1_ENST00000508312_ENST00000528203_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.1644
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000508312_ENST00000528203_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6607
Å |
| | | |  |
| DDR1_PAK1_ENST00000508312_ENST00000530617_30861200_77070062 superimposed PDB: 6BRJ of partner (DDR1). RMSD:1.2319
Å |
 |  |  |  |  |
| DDR1_PAK1_ENST00000508312_ENST00000530617_30861200_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6113
Å |
| | | |  |
| DDT_HMOX1_ENST00000403754_ENST00000216117_24315956_35789460 superimposed PDB: 7MW7 of partner (DDT). RMSD:0.4191
Å |
 |  |  |  |  |
| DDT_HMOX1_ENST00000430101_ENST00000216117_24315956_35789460 superimposed PDB: 7MW7 of partner (DDT). RMSD:0.4404
Å |
 |  |  |  |  |
| DDT_PAK1_ENST00000350608_ENST00000278568_24315956_77066887 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6101
Å |
 |  |  |  |  |
| DDT_PAK1_ENST00000350608_ENST00000356341_24315956_77066887 superimposed PDB: 7MW7 of partner (DDT). RMSD:0.4031
Å |
 |  |  |  |  |
| DDT_PAK1_ENST00000350608_ENST00000528203_24315956_77066887 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6321
Å |
 |  |  |  |  |
| DDT_PAK1_ENST00000350608_ENST00000530617_24315956_77066887 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.5858
Å |
 |  |  |  |  |
| DDT_SEC13_ENST00000398344_ENST00000350697_24315956_10343058 superimposed PDB: 7MW7 of partner (DDT). RMSD:2.4996
Å |
 |  |  |  |  |
| DDT_SEC13_ENST00000403754_ENST00000350697_24315956_10343058 superimposed PDB: 7MW7 of partner (DDT). RMSD:2.2883
Å |
 |  |  |  |  |
| DDX10_AIPL1_ENST00000526794_ENST00000381129_108594189_6331826 superimposed PDB: 2PL3 of partner (DDX10). RMSD:0.5195
Å |
 |  |  |  |  |
| DDX10_AIPL1_ENST00000526794_ENST00000381129_108594189_6331826 superimposed PDB: 5U9J of partner (AIPL1). RMSD:1.0168
Å |
| | | |  |
| DDX17_CDH10_ENST00000396821_ENST00000264463_38888060_24498628 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.4597
Å |
 |  |  |  |  |
| DDX17_CPT1B_ENST00000396821_ENST00000395650_38894089_51010551 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.6327
Å |
 |  |  |  |  |
| DDX17_CPT1B_ENST00000396821_ENST00000405237_38894089_51010551 superimposed PDB: 6UV3 of partner (DDX17). RMSD:1.1396
Å |
 |  |  |  |  |
| DDX1_HAUS1_ENST00000233084_ENST00000585518_15744633_43703264 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.674
Å |
 |  |  |  |  |
| DDX1_HAUS1_ENST00000233084_ENST00000585518_15746388_43703264 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.6442
Å |
 |  |  |  |  |
| DDX1_HNRNPA1_ENST00000233084_ENST00000547276_15770234_54677610 superimposed PDB: 8TBX of partner (DDX1). RMSD:3.3296
Å |
 |  |  |  |  |
| DDX1_HNRNPL_ENST00000381341_ENST00000600873_15746388_39331199 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.7401
Å |
 |  |  |  |  |
| DDX1_HNRNPL_ENST00000381341_ENST00000600873_15746388_39331199 superimposed PDB: 3TO8 of partner (HNRNPL). RMSD:0.3831
Å |
| | | |  |
| DDX1_HSP90AB1_ENST00000381341_ENST00000371646_15735677_44217113 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.7169
Å |
 |  |  |  |  |
| DDX1_NBAS_ENST00000381341_ENST00000281513_15736887_15330527 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.5782
Å |
 |  |  |  |  |
| DDX1_NBAS_ENST00000381341_ENST00000281513_15747437_15427307 superimposed PDB: 8TBX of partner (DDX1). RMSD:2.8343
Å |
 |  |  |  |  |
| DDX1_NUP107_ENST00000233084_ENST00000229179_15742755_69090598 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.6688
Å |
 |  |  |  |  |
| DDX1_NUP107_ENST00000233084_ENST00000229179_15746388_69084410 superimposed PDB: 8TBX of partner (DDX1). RMSD:0.7022
Å |
 |  |  |  |  |
| DDX42_BRIP1_ENST00000359353_ENST00000577598_61884014_59886118 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.0671
Å |
 |  |  |  |  |
| DDX42_BRIP1_ENST00000578681_ENST00000577598_61884014_59886118 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.3342
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000359353_ENST00000225577_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7929
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000359353_ENST00000406116_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6477
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000359353_ENST00000443572_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7934
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000389924_ENST00000443572_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8131
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000578681_ENST00000225577_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7896
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000578681_ENST00000406116_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6609
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000583590_ENST00000225577_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7612
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000583590_ENST00000406116_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6557
Å |
 |  |  |  |  |
| DDX42_RPS6KB1_ENST00000583590_ENST00000443572_61882535_57987922 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8107
Å |
 |  |  |  |  |
| DDX52_IKZF3_ENST00000349699_ENST00000439016_35985940_37922746 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4351
Å |
 |  |  |  |  |
| DDX52_IKZF3_ENST00000349699_ENST00000583368_35985940_37922746 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.3718
Å |
 |  |  |  |  |
| DDX52_IKZF3_ENST00000349699_ENST00000583368_35986833_37922746 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.3954
Å |
 |  |  |  |  |
| DDX52_IKZF3_ENST00000394367_ENST00000583368_35985940_37922746 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.376
Å |
 |  |  |  |  |
| DDX52_IKZF3_ENST00000394367_ENST00000583368_35986833_37922746 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4083
Å |
 |  |  |  |  |
| DDX52_PSMD3_ENST00000349699_ENST00000541736_35980917_38145991 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4613
Å |
 |  |  |  |  |
| DDX52_PSMD3_ENST00000394367_ENST00000264639_35980917_38145991 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4405
Å |
 |  |  |  |  |
| DDX52_PSMD3_ENST00000394367_ENST00000541736_35980917_38145991 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4556
Å |
 |  |  |  |  |
| DDX52_STAT5B_ENST00000394367_ENST00000293328_35988604_40354826 superimposed PDB: 3DKP of partner (DDX52). RMSD:0.4295
Å |
 |  |  |  |  |
| DDX5_PFKP_ENST00000225792_ENST00000381075_62495739_3177927 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.6771
Å |
 |  |  |  |  |
| DDX5_PFKP_ENST00000450599_ENST00000381075_62495739_3177927 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.57
Å |
 |  |  |  |  |
| DDX5_SKAP1_ENST00000450599_ENST00000584924_62496666_46474147 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.7024
Å |
 |  |  |  |  |
| DDX5_SKAP1_ENST00000450599_ENST00000584924_62496666_46474147 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.4542
Å |
| | | |  |
| DDX5_SKAP1_ENST00000578804_ENST00000584924_62496666_46474147 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.5243
Å |
 |  |  |  |  |
| DDX5_SKAP1_ENST00000578804_ENST00000584924_62496666_46474147 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.5213
Å |
| | | |  |
| DEAF1_PIDD_ENST00000382409_ENST00000411829_674535_804463 superimposed PDB: 2OF5 of partner (PIDD). RMSD:0.5497
Å |
 |  |  |  |  |
| DECR1_SAMSN1_ENST00000220764_ENST00000400566_91031400_15870913 superimposed PDB: 1W6U of partner (DECR1). RMSD:0.3485
Å |
 |  |  |  |  |
| DECR1_SAMSN1_ENST00000522161_ENST00000400566_91031400_15870913 superimposed PDB: 1W6U of partner (DECR1). RMSD:0.3068
Å |
 |  |  |  |  |
| DEK_NR1D2_ENST00000244776_ENST00000312521_18236682_24018713 superimposed PDB: 9L1X of partner (DEK). RMSD:0.2301
Å |
 |  |  |  |  |
| DEPDC1B_ELOVL7_ENST00000265036_ENST00000425382_59934576_60053472 superimposed PDB: 6Y7F of partner (ELOVL7). RMSD:1.4377
Å |
 |  |  |  |  |
| DEPDC1B_ELOVL7_ENST00000265036_ENST00000425382_59940571_60067920 superimposed PDB: 6Y7F of partner (ELOVL7). RMSD:0.4797
Å |
 |  |  |  |  |
| DEPDC5_BID_ENST00000400246_ENST00000317361_32154619_18232940 superimposed PDB: 9V0J of partner (DEPDC5). RMSD:1.2792
Å |
 |  |  |  |  |
| DERA_CA3_ENST00000532964_ENST00000285381_16064348_86351940 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.4789
Å |
 |  |  |  |  |
| DET1_PPIP5K2_ENST00000444300_ENST00000358359_89060012_102490373 superimposed PDB: 9LTJ of partner (DET1). RMSD:1.2068
Å |
 |  |  |  |  |
| DET1_PPIP5K2_ENST00000564406_ENST00000321521_89060012_102490373 superimposed PDB: 9LTJ of partner (DET1). RMSD:1.2313
Å |
 |  |  |  |  |
| DET1_PPIP5K2_ENST00000564406_ENST00000358359_89060012_102490373 superimposed PDB: 9LTJ of partner (DET1). RMSD:1.2801
Å |
 |  |  |  |  |
| DGCR2_RAC2_ENST00000263196_ENST00000249071_19109640_37637698 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.3812
Å |
 |  |  |  |  |
| DGKA_DSG1_ENST00000394147_ENST00000257192_56334217_28908151 superimposed PDB: 1TUZ of partner (DGKA). RMSD:1.1844
Å |
 |  |  |  |  |
| DGKA_DSG1_ENST00000551156_ENST00000257192_56334217_28908151 superimposed PDB: 1TUZ of partner (DGKA). RMSD:1.1786
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000318201_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.9806
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000318201_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.3481
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000318201_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1449
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000343674_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.867
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000343674_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.2999
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000395574_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.7683
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000395574_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1762
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000395574_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.8762
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000421244_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.8065
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000421244_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.2503
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000421244_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1135
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000454345_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.164
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000454345_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.3006
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000454345_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.6727
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000456247_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1252
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000456247_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.911
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000456247_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1457
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000527911_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1144
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000527911_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.6627
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000527911_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.8328
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000528615_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.1687
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000528615_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.2967
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000528615_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.8373
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000532868_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.5635
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000532868_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.2642
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000532868_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.2326
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000543978_ENST00000312040_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.4775
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000543978_ENST00000434074_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.4701
Å |
 |  |  |  |  |
| DGKZ_ATG13_ENST00000543978_ENST00000529655_46401118_46670686 superimposed PDB: 8DO8 of partner (ATG13). RMSD:1.6514
Å |
 |  |  |  |  |
| DHCR24_FKBP5_ENST00000371269_ENST00000536438_55340765_35554894 superimposed PDB: 5OMP of partner (FKBP5). RMSD:0.7654
Å |
 |  |  |  |  |
| DHCR24_FKBP5_ENST00000535035_ENST00000536438_55340765_35554894 superimposed PDB: 5OMP of partner (FKBP5). RMSD:0.7914
Å |
 |  |  |  |  |
| DHCR24_SLC2A1_ENST00000535035_ENST00000426263_55340765_43408992 superimposed PDB: 6THA of partner (SLC2A1). RMSD:0.5636
Å |
 |  |  |  |  |
| DHRS12_ATP7B_ENST00000218981_ENST00000400366_52373669_52516690 superimposed PDB: 7XUK of partner (ATP7B). RMSD:2.5721
Å |
 |  |  |  |  |
| DHRS12_ATP7B_ENST00000444610_ENST00000400366_52371961_52518427 superimposed PDB: 7XUK of partner (ATP7B). RMSD:2.7806
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000251241_ENST00000323322_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:1.2013
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000251241_ENST00000342364_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:0.8759
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000425628_ENST00000323322_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:0.9194
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000425628_ENST00000342364_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:0.8571
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000425628_ENST00000351388_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:2.8967
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000451169_ENST00000323322_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:0.9405
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000451169_ENST00000342364_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:0.7914
Å |
 |  |  |  |  |
| DHX40_GH1_ENST00000451169_ENST00000458650_57665414_61995866 superimposed PDB: 1HUW of partner (GH1). RMSD:3.1603
Å |
 |  |  |  |  |
| DHX58_FAM134C_ENST00000251642_ENST00000585894_40263313_40739882 superimposed PDB: 9LOV of partner (DHX58). RMSD:0.5466
Å |
 |  |  |  |  |
| DHX8_MSI2_ENST00000540306_ENST00000284073_41567831_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.339
Å |
 |  |  |  |  |
| DHX8_MSI2_ENST00000540306_ENST00000322684_41567831_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.4372
Å |
 |  |  |  |  |
| DHX8_MSI2_ENST00000540306_ENST00000442934_41567831_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.5583
Å |
 |  |  |  |  |
| DHX9_EP300_ENST00000367549_ENST00000263253_182853948_41536143 superimposed PDB: 8SZP of partner (DHX9). RMSD:2.1183
Å |
 |  |  |  |  |
| DIAPH2_F8_ENST00000373061_ENST00000360256_96013257_154066027 superimposed PDB: 7KWO of partner (F8). RMSD:0.5474
Å |
 |  |  |  |  |
| DIAPH2_NTRK2_ENST00000355827_ENST00000376213_96220206_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8161
Å |
 |  |  |  |  |
| DIAPH2_NTRK2_ENST00000373054_ENST00000376213_96220206_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8282
Å |
 |  |  |  |  |
| DIAPH2_NTRK2_ENST00000373054_ENST00000376214_96220206_87475954 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8254
Å |
 |  |  |  |  |
| DIAPH2_NTRK2_ENST00000373061_ENST00000376214_96220206_87475954 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8248
Å |
 |  |  |  |  |
| DIAPH3_TDRD3_ENST00000377908_ENST00000377894_60667761_61141658 superimposed PDB: 9CAH of partner (TDRD3). RMSD:2.7645
Å |
 |  |  |  |  |
| DIP2B_CPM_ENST00000301180_ENST00000551568_50899023_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4697
Å |
 |  |  |  |  |
| DIP2B_TAF8_ENST00000301180_ENST00000372977_51128913_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.903
Å |
 |  |  |  |  |
| DIP2B_TAF8_ENST00000301180_ENST00000372982_51128913_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.936
Å |
 |  |  |  |  |
| DIP2B_TAF8_ENST00000301180_ENST00000456846_51128913_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.1197
Å |
 |  |  |  |  |
| DIP2B_TAF8_ENST00000301180_ENST00000494547_51128913_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:1.0769
Å |
 |  |  |  |  |
| DISP2_CREBBP_ENST00000267889_ENST00000382070_40657926_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6861
Å |
 |  |  |  |  |
| DLC1_CLASP2_ENST00000512044_ENST00000399362_13133770_33592887 superimposed PDB: 3WOY of partner (CLASP2). RMSD:3.1212
Å |
 |  |  |  |  |
| DLC1_PIWIL2_ENST00000512044_ENST00000454009_13133770_22210471 superimposed PDB: 7YFX of partner (PIWIL2). RMSD:1.2448
Å |
 |  |  |  |  |
| DLC1_PIWIL2_ENST00000512044_ENST00000521356_13133770_22210471 superimposed PDB: 7YFX of partner (PIWIL2). RMSD:0.5256
Å |
 |  |  |  |  |
| DLG1_MYO9B_ENST00000357674_ENST00000397274_196921295_17301905 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.3679
Å |
 |  |  |  |  |
| DLG1_MYO9B_ENST00000357674_ENST00000594824_196921295_17301905 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.3451
Å |
 |  |  |  |  |
| DLG1_NADSYN1_ENST00000357674_ENST00000539574_196921295_71189440 superimposed PDB: 3W9Y of partner (DLG1). RMSD:3.2124
Å |
 |  |  |  |  |
| DLG1_NADSYN1_ENST00000357674_ENST00000539574_196921295_71189440 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.7382
Å |
| | | |  |
| DLG2_GBE1_ENST00000280241_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4111
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000280241_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6637
Å |
| | | |  |
| DLG2_GBE1_ENST00000330014_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4143
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000330014_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6768
Å |
| | | |  |
| DLG2_GBE1_ENST00000398309_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.441
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000398309_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6492
Å |
| | | |  |
| DLG2_GBE1_ENST00000418306_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.3943
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000418306_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6475
Å |
| | | |  |
| DLG2_GBE1_ENST00000531015_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4496
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000531015_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6885
Å |
| | | |  |
| DLG2_GBE1_ENST00000543673_ENST00000489715_83497732_81720104 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4361
Å |
 |  |  |  |  |
| DLG2_GBE1_ENST00000543673_ENST00000489715_83497732_81720104 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6639
Å |
| | | |  |
| DLG5_MYH11_ENST00000372391_ENST00000396324_79628886_15865569 superimposed PDB: 1UIT of partner (DLG5). RMSD:2.7583
Å |
 |  |  |  |  |
| DLG5_RET_ENST00000372388_ENST00000340058_79588639_43612031 superimposed PDB: 1UIT of partner (DLG5). RMSD:2.9482
Å |
 |  |  |  |  |
| DLG5_RET_ENST00000372388_ENST00000355710_79588639_43612031 superimposed PDB: 1UIT of partner (DLG5). RMSD:2.889
Å |
 |  |  |  |  |
| DLG5_RET_ENST00000372391_ENST00000340058_79588639_43612031 superimposed PDB: 1UIT of partner (DLG5). RMSD:2.6573
Å |
 |  |  |  |  |
| DLGAP1_RAB31_ENST00000400150_ENST00000578921_3814058_9792150 superimposed PDB: 5YPO of partner (DLGAP1). RMSD:2.3627
Å |
 |  |  |  |  |
| DLGAP1_RAB31_ENST00000400150_ENST00000578921_3814058_9792150 superimposed PDB: 2FG5 of partner (RAB31). RMSD:0.5463
Å |
| | | |  |
| DLGAP1_RAB31_ENST00000400155_ENST00000578921_3814058_9792150 superimposed PDB: 5YPO of partner (DLGAP1). RMSD:2.3902
Å |
 |  |  |  |  |
| DLGAP1_RAB31_ENST00000400155_ENST00000578921_3814058_9792150 superimposed PDB: 2FG5 of partner (RAB31). RMSD:0.5128
Å |
| | | |  |
| DLGAP1_RAB31_ENST00000539435_ENST00000578921_3814058_9792150 superimposed PDB: 5YPO of partner (DLGAP1). RMSD:2.3903
Å |
 |  |  |  |  |
| DLGAP1_RAB31_ENST00000539435_ENST00000578921_3814058_9792150 superimposed PDB: 2FG5 of partner (RAB31). RMSD:0.6049
Å |
| | | |  |
| DLGAP1_RAB31_ENST00000581527_ENST00000578921_3814058_9792150 superimposed PDB: 5YPO of partner (DLGAP1). RMSD:2.4758
Å |
 |  |  |  |  |
| DLGAP1_RAB31_ENST00000581527_ENST00000578921_3814058_9792150 superimposed PDB: 2FG5 of partner (RAB31). RMSD:0.6567
Å |
| | | |  |
| DLGAP4_RGMA_ENST00000340491_ENST00000543599_35091002_93595737 superimposed PDB: 4UHY of partner (RGMA). RMSD:0.4752
Å |
 |  |  |  |  |
| DMD_HNRNPD_ENST00000357033_ENST00000353341_32305645_83280792 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3185
Å |
 |  |  |  |  |
| DMD_HNRNPD_ENST00000357033_ENST00000543098_32305645_83280792 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3527
Å |
 |  |  |  |  |
| DMD_HNRNPD_ENST00000378677_ENST00000353341_32305645_83280792 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3641
Å |
 |  |  |  |  |
| DMD_HNRNPD_ENST00000378677_ENST00000543098_32305645_83280792 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3654
Å |
 |  |  |  |  |
| DMD_LIX1L_ENST00000359836_ENST00000369308_31279071_145487303 superimposed PDB: 1EG3 of partner (DMD). RMSD:1.4229
Å |
 |  |  |  |  |
| DMGDH_NMNAT2_ENST00000255189_ENST00000287713_78301095_183230438 superimposed PDB: 5L46 of partner (DMGDH). RMSD:0.5977
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000339686_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.3832
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000414866_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.3889
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000419602_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.4298
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000424570_ENST00000252891_36001085_41192900 superimposed PDB: 4F20 of partner (DMKN). RMSD:1.4591
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000424570_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.4144
Å |
| | | |  |
| DMKN_NUMBL_ENST00000436012_ENST00000252891_36001085_41192900 superimposed PDB: 4F20 of partner (DMKN). RMSD:2.2018
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000436012_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.4257
Å |
| | | |  |
| DMKN_NUMBL_ENST00000447113_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.3675
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000467637_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.3902
Å |
 |  |  |  |  |
| DMKN_NUMBL_ENST00000480502_ENST00000252891_36001085_41192900 superimposed PDB: 3F0W of partner (NUMBL). RMSD:0.3693
Å |
 |  |  |  |  |
| DMXL2_PTPRR_ENST00000543779_ENST00000283228_51914655_71158558 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4297
Å |
 |  |  |  |  |
| DMXL2_SLC9A1_ENST00000543779_ENST00000263980_51827859_27429803 superimposed PDB: 23XK of partner (SLC9A1). RMSD:0.8003
Å |
 |  |  |  |  |
| DNAJA3_CREBBP_ENST00000262375_ENST00000382070_4500498_3901010 superimposed PDB: 2CTT of partner (DNAJA3). RMSD:2.2947
Å |
 |  |  |  |  |
| DNAJA3_CREBBP_ENST00000262375_ENST00000382070_4500498_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.7564
Å |
| | | |  |
| DNAJA3_CREBBP_ENST00000355296_ENST00000262367_4500498_3901010 superimposed PDB: 2CTT of partner (DNAJA3). RMSD:2.0097
Å |
 |  |  |  |  |
| DNAJA3_CREBBP_ENST00000355296_ENST00000262367_4500498_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6511
Å |
| | | |  |
| DNAJA3_CREBBP_ENST00000431375_ENST00000382070_4500498_3901010 superimposed PDB: 2CTT of partner (DNAJA3). RMSD:1.8232
Å |
 |  |  |  |  |
| DNAJA3_CREBBP_ENST00000431375_ENST00000382070_4500498_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.7368
Å |
| | | |  |
| DNAJB1_EPS15L1_ENST00000254322_ENST00000248070_14628950_16472795 superimposed PDB: 3AGZ of partner (DNAJB1). RMSD:0.8088
Å |
 |  |  |  |  |
| DNAJB1_MED26_ENST00000396969_ENST00000263390_14627277_16689220 superimposed PDB: 3AGZ of partner (DNAJB1). RMSD:0.4018
Å |
 |  |  |  |  |
| DNAJB1_MED26_ENST00000396969_ENST00000263390_14627277_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:3.007
Å |
| | | |  |
| DNAJB6_PICALM_ENST00000262177_ENST00000532317_157160177_85742653 superimposed PDB: 6U3R of partner (DNAJB6). RMSD:2.9896
Å |
 |  |  |  |  |
| DNAJB6_PICALM_ENST00000429029_ENST00000393346_157160177_85742653 superimposed PDB: 6U3R of partner (DNAJB6). RMSD:2.7274
Å |
 |  |  |  |  |
| DNAJB6_PICALM_ENST00000429029_ENST00000526033_157160177_85742653 superimposed PDB: 6U3R of partner (DNAJB6). RMSD:3.2917
Å |
 |  |  |  |  |
| DNAJC17_INO80_ENST00000220496_ENST00000401393_41065924_41297885 superimposed PDB: 2D9O of partner (DNAJC17). RMSD:0.9844
Å |
 |  |  |  |  |
| DNAJC19_ADK_ENST00000382564_ENST00000286621_180705810_76349039 superimposed PDB: 4O1L of partner (ADK). RMSD:0.7209
Å |
 |  |  |  |  |
| DNAJC19_ADK_ENST00000491873_ENST00000286621_180705810_76349039 superimposed PDB: 4O1L of partner (ADK). RMSD:0.574
Å |
 |  |  |  |  |
| DNAJC1_PIP4K2A_ENST00000376980_ENST00000545335_22292141_22880710 superimposed PDB: 9L5Q of partner (PIP4K2A). RMSD:0.5911
Å |
 |  |  |  |  |
| DNAJC25_MARS_ENST00000313525_ENST00000262027_114394023_57905480 superimposed PDB: 5GL7 of partner (MARS). RMSD:0.6665
Å |
 |  |  |  |  |
| DNAJC25_MARS_ENST00000556107_ENST00000315473_114394023_57905480 superimposed PDB: 5GL7 of partner (MARS). RMSD:0.683
Å |
 |  |  |  |  |
| DNAJC2_ALDH1A1_ENST00000249270_ENST00000376939_102985005_75545935 superimposed PDB: 7JWS of partner (ALDH1A1). RMSD:0.6143
Å |
 |  |  |  |  |
| DNAJC2_ALDH1A1_ENST00000249270_ENST00000376939_102985005_75555168 superimposed PDB: 7JWS of partner (ALDH1A1). RMSD:0.5654
Å |
 |  |  |  |  |
| DNAJC2_ALDH1A1_ENST00000379263_ENST00000297785_102985005_75545935 superimposed PDB: 7JWS of partner (ALDH1A1). RMSD:0.4035
Å |
 |  |  |  |  |
| DNAJC2_ALDH1A1_ENST00000379263_ENST00000297785_102985005_75555168 superimposed PDB: 7JWS of partner (ALDH1A1). RMSD:0.3879
Å |
 |  |  |  |  |
| DNAJC3_BAZ1B_ENST00000602402_ENST00000404251_96361591_72884813 superimposed PDB: 1F62 of partner (BAZ1B). RMSD:1.2947
Å |
 |  |  |  |  |
| DNAJC3_FOXN3_ENST00000602402_ENST00000261302_96377506_89817152 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.7463
Å |
 |  |  |  |  |
| DNAJC3_FOXN3_ENST00000602402_ENST00000555353_96377506_89817152 superimposed PDB: 6NCE of partner (FOXN3). RMSD:2.9331
Å |
 |  |  |  |  |
| DNAJC3_GPC6_ENST00000376795_ENST00000377047_96416207_94197515 superimposed PDB: 2Y4T of partner (DNAJC3). RMSD:2.1612
Å |
 |  |  |  |  |
| DNAJC3_GPC6_ENST00000602402_ENST00000377047_96416207_94197515 superimposed PDB: 2Y4T of partner (DNAJC3). RMSD:2.4809
Å |
 |  |  |  |  |
| DNAJC3_STK24_ENST00000602402_ENST00000539966_96377506_99118815 superimposed PDB: 3A7I of partner (STK24). RMSD:2.9512
Å |
 |  |  |  |  |
| DNAL1_KPNA1_ENST00000554339_ENST00000344337_74111745_122152635 superimposed PDB: 6WX9 of partner (KPNA1). RMSD:0.6045
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000266481_ENST00000534526_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.1658
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000358214_ENST00000534526_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.2002
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000452533_ENST00000531134_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:2.8748
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000452533_ENST00000546442_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:2.986
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000549701_ENST00000427716_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.3391
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000549701_ENST00000531134_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.5359
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000549701_ENST00000534526_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.2586
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000549701_ENST00000546442_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.3098
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000553257_ENST00000427716_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.0179
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000553257_ENST00000534526_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.0157
Å |
 |  |  |  |  |
| DNM1L_FGD4_ENST00000553257_ENST00000546442_32886741_32772631 superimposed PDB: 8T1H of partner (DNM1L). RMSD:3.3405
Å |
 |  |  |  |  |
| DNM1_TRIO_ENST00000341179_ENST00000344204_130965910_14286979 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.4417
Å |
 |  |  |  |  |
| DNM1_TRIO_ENST00000475805_ENST00000509967_130965910_14286979 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6405
Å |
 |  |  |  |  |
| DNM1_TRIO_ENST00000475805_ENST00000537187_130965910_14286979 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.3587
Å |
 |  |  |  |  |
| DNM2_PDE4A_ENST00000585892_ENST00000380702_10829079_10556893 superimposed PDB: 2QYK of partner (PDE4A). RMSD:0.421
Å |
 |  |  |  |  |
| DNM2_PDE4A_ENST00000585892_ENST00000440014_10829079_10556893 superimposed PDB: 2QYK of partner (PDE4A). RMSD:0.4264
Å |
 |  |  |  |  |
| DNM3_CPM_ENST00000358155_ENST00000551568_171958288_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4897
Å |
 |  |  |  |  |
| DNM3_NDP_ENST00000355305_ENST00000378062_172348322_43809272 superimposed PDB: 5A3F of partner (DNM3). RMSD:3.112
Å |
 |  |  |  |  |
| DNM3_NDP_ENST00000355305_ENST00000378062_172348322_43809272 superimposed PDB: 5BQ8 of partner (NDP). RMSD:3.001
Å |
| | | |  |
| DNM3_NDP_ENST00000367731_ENST00000378062_172348322_43809272 superimposed PDB: 5A3F of partner (DNM3). RMSD:3.0145
Å |
 |  |  |  |  |
| DNM3_NDP_ENST00000367731_ENST00000378062_172348322_43809272 superimposed PDB: 5BQ8 of partner (NDP). RMSD:3.039
Å |
| | | |  |
| DNM3_NUP107_ENST00000358155_ENST00000229179_171810957_69082741 superimposed PDB: 5A3F of partner (DNM3). RMSD:2.7762
Å |
 |  |  |  |  |
| DNM3_TPH2_ENST00000355305_ENST00000333850_172222822_72388218 superimposed PDB: 5A3F of partner (DNM3). RMSD:2.9071
Å |
 |  |  |  |  |
| DNM3_TPH2_ENST00000355305_ENST00000333850_172222822_72388218 superimposed PDB: 7WIY of partner (TPH2). RMSD:1.3538
Å |
| | | |  |
| DNM3_TPH2_ENST00000367731_ENST00000333850_172222822_72388218 superimposed PDB: 5A3F of partner (DNM3). RMSD:2.953
Å |
 |  |  |  |  |
| DNM3_TPH2_ENST00000367731_ENST00000333850_172222822_72388218 superimposed PDB: 7WIY of partner (TPH2). RMSD:1.3741
Å |
| | | |  |
| DNMBP_CRTAC1_ENST00000342239_ENST00000298819_101714970_99696123 superimposed PDB: 1UG1 of partner (DNMBP). RMSD:1.9257
Å |
 |  |  |  |  |
| DNMT3B_DUSP15_ENST00000201963_ENST00000278979_31376818_30457400 superimposed PDB: 1YZ4 of partner (DUSP15). RMSD:0.3243
Å |
 |  |  |  |  |
| DNMT3B_DUSP15_ENST00000344505_ENST00000278979_31376818_30457400 superimposed PDB: 1YZ4 of partner (DUSP15). RMSD:0.3242
Å |
 |  |  |  |  |
| DNMT3B_DUSP15_ENST00000348286_ENST00000278979_31376818_30457400 superimposed PDB: 1YZ4 of partner (DUSP15). RMSD:0.3195
Å |
 |  |  |  |  |
| DNMT3B_DUSP15_ENST00000375623_ENST00000278979_31376818_30457400 superimposed PDB: 1YZ4 of partner (DUSP15). RMSD:0.3075
Å |
 |  |  |  |  |
| DOCK5_DLC1_ENST00000276440_ENST00000358919_25042466_12973166 superimposed PDB: 3KUQ of partner (DLC1). RMSD:0.4582
Å |
 |  |  |  |  |
| DOCK8_OSBP_ENST00000382329_ENST00000263847_390566_59369311 superimposed PDB: 7V62 of partner (OSBP). RMSD:0.5918
Å |
 |  |  |  |  |
| DOCK8_OSBP_ENST00000382331_ENST00000263847_390566_59369311 superimposed PDB: 7V62 of partner (OSBP). RMSD:0.5915
Å |
 |  |  |  |  |
| DOCK8_OSBP_ENST00000432829_ENST00000263847_390566_59369311 superimposed PDB: 7V62 of partner (OSBP). RMSD:0.576
Å |
 |  |  |  |  |
| DOCK9_STK24_ENST00000339416_ENST00000397517_99607688_99134575 superimposed PDB: 3A7I of partner (STK24). RMSD:0.3596
Å |
 |  |  |  |  |
| DOCK9_STK24_ENST00000442173_ENST00000397517_99607688_99134575 superimposed PDB: 3A7I of partner (STK24). RMSD:0.3641
Å |
 |  |  |  |  |
| DOCK9_STK24_ENST00000448493_ENST00000397517_99607688_99134575 superimposed PDB: 3A7I of partner (STK24). RMSD:0.3662
Å |
 |  |  |  |  |
| DOT1L_BTBD2_ENST00000398665_ENST00000255608_2223485_1997462 superimposed PDB: 3UWP of partner (DOT1L). RMSD:0.616
Å |
 |  |  |  |  |
| DOT1L_OAZ1_ENST00000398665_ENST00000588673_2164264_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.6131
Å |
 |  |  |  |  |
| DOT1L_OAZ1_ENST00000398665_ENST00000602676_2164264_2271780 superimposed PDB: 3UWP of partner (DOT1L). RMSD:2.1354
Å |
 |  |  |  |  |
| DOT1L_OAZ1_ENST00000398665_ENST00000602676_2164264_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.5689
Å |
| | | |  |
| DPM1_GRID1_ENST00000371582_ENST00000327946_49571722_87675996 superimposed PDB: 8BN2 of partner (GRID1). RMSD:0.6014
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000530165_ENST00000449942_66272245_64011312 superimposed PDB: 7OUP of partner (DPP3). RMSD:2.6687
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000530165_ENST00000449942_66272245_64011312 superimposed PDB: 4NNR of partner (FKBP2). RMSD:1.0489
Å |
| | | |  |
| DPP3_FKBP2_ENST00000531863_ENST00000309366_66272245_64011312 superimposed PDB: 7OUP of partner (DPP3). RMSD:2.4772
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000531863_ENST00000449942_66272245_64011312 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.606
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000531863_ENST00000449942_66272245_64011312 superimposed PDB: 4NNR of partner (FKBP2). RMSD:0.9609
Å |
| | | |  |
| DPP3_FKBP2_ENST00000532677_ENST00000449942_66272245_64011312 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.6275
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000532677_ENST00000449942_66272245_64011312 superimposed PDB: 4NNR of partner (FKBP2). RMSD:1.3992
Å |
| | | |  |
| DPP3_FKBP2_ENST00000541961_ENST00000449942_66272245_64011312 superimposed PDB: 7OUP of partner (DPP3). RMSD:2.6046
Å |
 |  |  |  |  |
| DPP3_FKBP2_ENST00000541961_ENST00000449942_66272245_64011312 superimposed PDB: 4NNR of partner (FKBP2). RMSD:1.0247
Å |
| | | |  |
| DPP3_KDM2A_ENST00000453114_ENST00000398645_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.3642
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000453114_ENST00000398645_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5467
Å |
| | | |  |
| DPP3_KDM2A_ENST00000530165_ENST00000398645_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.2316
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000530165_ENST00000398645_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5477
Å |
| | | |  |
| DPP3_KDM2A_ENST00000530165_ENST00000529006_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.7962
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000530165_ENST00000529006_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5141
Å |
| | | |  |
| DPP3_KDM2A_ENST00000531863_ENST00000398645_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.5762
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000531863_ENST00000529006_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.9835
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000531863_ENST00000529006_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5192
Å |
| | | |  |
| DPP3_KDM2A_ENST00000532677_ENST00000398645_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.5931
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000532677_ENST00000398645_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.7076
Å |
| | | |  |
| DPP3_KDM2A_ENST00000532677_ENST00000529006_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.1424
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000532677_ENST00000529006_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5019
Å |
| | | |  |
| DPP3_KDM2A_ENST00000541961_ENST00000529006_66264948_66995507 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.7664
Å |
 |  |  |  |  |
| DPP3_KDM2A_ENST00000541961_ENST00000529006_66264948_66995507 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.5067
Å |
| | | |  |
| DPP3_PACS1_ENST00000453114_ENST00000320580_66264948_65998018 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.6845
Å |
 |  |  |  |  |
| DPP3_PACS1_ENST00000530165_ENST00000320580_66264948_65998018 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.8163
Å |
 |  |  |  |  |
| DPP3_PACS1_ENST00000531863_ENST00000320580_66264948_65998018 superimposed PDB: 7OUP of partner (DPP3). RMSD:2.2513
Å |
 |  |  |  |  |
| DPP3_PACS1_ENST00000532677_ENST00000320580_66264948_65998018 superimposed PDB: 7OUP of partner (DPP3). RMSD:0.6824
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000453114_ENST00000371847_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.0843
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000530165_ENST00000371843_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.6576
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000530165_ENST00000371847_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.2776
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000531863_ENST00000371843_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.0311
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000532677_ENST00000371843_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.2151
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000532677_ENST00000371847_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.2349
Å |
 |  |  |  |  |
| DPP3_SPATA6_ENST00000541961_ENST00000371843_66261104_48918803 superimposed PDB: 7OUP of partner (DPP3). RMSD:1.1848
Å |
 |  |  |  |  |
| DPP6_EMP2_ENST00000332007_ENST00000359543_154685161_10626949 superimposed PDB: 7UKG of partner (DPP6). RMSD:0.364
Å |
 |  |  |  |  |
| DPP7_CARM1_ENST00000371579_ENST00000344150_140006141_11030270 superimposed PDB: 4EBB of partner (DPP7). RMSD:0.5521
Å |
 |  |  |  |  |
| DPP7_CARM1_ENST00000371579_ENST00000344150_140006141_11030270 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.9389
Å |
| | | |  |
| DPP8_EXT2_ENST00000341861_ENST00000358681_65777436_44253902 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.8001
Å |
 |  |  |  |  |
| DPP8_TRPM1_ENST00000341861_ENST00000256552_65766546_31327877 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.8131
Å |
 |  |  |  |  |
| DPYD_STAB2_ENST00000306031_ENST00000388887_98348819_104054108 superimposed PDB: 5N86 of partner (STAB2). RMSD:0.5018
Å |
 |  |  |  |  |
| DPYSL2_DPYSL3_ENST00000311151_ENST00000343218_26501607_146778815 superimposed PDB: 8DNM of partner (DPYSL2). RMSD:0.3853
Å |
 |  |  |  |  |
| DPYSL2_DPYSL3_ENST00000311151_ENST00000343218_26501607_146778815 superimposed PDB: 4BKN of partner (DPYSL3). RMSD:0.4128
Å |
| | | |  |
| DPYSL2_DPYSL3_ENST00000521913_ENST00000343218_26501607_146778815 superimposed PDB: 8DNM of partner (DPYSL2). RMSD:0.3978
Å |
 |  |  |  |  |
| DPYSL2_DPYSL3_ENST00000521913_ENST00000343218_26501607_146778815 superimposed PDB: 4BKN of partner (DPYSL3). RMSD:0.4089
Å |
| | | |  |
| DPYSL2_DPYSL3_ENST00000523027_ENST00000343218_26501607_146778815 superimposed PDB: 8DNM of partner (DPYSL2). RMSD:0.3919
Å |
 |  |  |  |  |
| DPYSL2_DPYSL3_ENST00000523027_ENST00000343218_26501607_146778815 superimposed PDB: 4BKN of partner (DPYSL3). RMSD:0.4131
Å |
| | | |  |
| DROSHA_TERT_ENST00000344624_ENST00000296820_31421378_1282739 superimposed PDB: 9ASM of partner (DROSHA). RMSD:1.6267
Å |
 |  |  |  |  |
| DROSHA_TERT_ENST00000442743_ENST00000296820_31421378_1282739 superimposed PDB: 9ASM of partner (DROSHA). RMSD:1.5806
Å |
 |  |  |  |  |
| DSCR3_NIPBL_ENST00000309117_ENST00000448238_38639538_37019412 superimposed PDB: 6WGE of partner (NIPBL). RMSD:1.9553
Å |
 |  |  |  |  |
| DSCR3_NIPBL_ENST00000399001_ENST00000282516_38639538_37019412 superimposed PDB: 6WGE of partner (NIPBL). RMSD:2.0058
Å |
 |  |  |  |  |
| DSCR3_NIPBL_ENST00000539844_ENST00000282516_38639538_37019412 superimposed PDB: 6WGE of partner (NIPBL). RMSD:2.0158
Å |
 |  |  |  |  |
| DSCR3_NIPBL_ENST00000539844_ENST00000448238_38639538_37019412 superimposed PDB: 6WGE of partner (NIPBL). RMSD:2.0437
Å |
 |  |  |  |  |
| DSG3_DSC3_ENST00000257189_ENST00000434452_29027888_28588491 superimposed PDB: 5EQX of partner (DSG3). RMSD:2.4771
Å |
 |  |  |  |  |
| DSP_RCAN2_ENST00000379802_ENST00000330430_7572301_46216633 superimposed PDB: 5DZZ of partner (DSP). RMSD:2.9424
Å |
 |  |  |  |  |
| DTD1_POU2F3_ENST00000377452_ENST00000260264_18608877_120186069 superimposed PDB: 2OKV of partner (DTD1). RMSD:0.3419
Å |
 |  |  |  |  |
| DTD1_POU2F3_ENST00000377452_ENST00000543440_18608877_120186069 superimposed PDB: 2OKV of partner (DTD1). RMSD:0.2785
Å |
 |  |  |  |  |
| DTNB_ASXL2_ENST00000496972_ENST00000336112_25818954_25991737 superimposed PDB: 9ATN of partner (ASXL2). RMSD:0.7312
Å |
 |  |  |  |  |
| DTNB_HADHA_ENST00000405222_ENST00000380649_25754341_26432758 superimposed PDB: 5ZQZ of partner (HADHA). RMSD:1.5085
Å |
 |  |  |  |  |
| DTNB_HADHA_ENST00000407661_ENST00000380649_25754341_26432758 superimposed PDB: 5ZQZ of partner (HADHA). RMSD:1.381
Å |
 |  |  |  |  |
| DUS2_CSNK1D_ENST00000358896_ENST00000392334_68072052_80223672 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.4959
Å |
 |  |  |  |  |
| DUSP16_FAT1_ENST00000228862_ENST00000441802_12672795_187584767 superimposed PDB: 2VSW of partner (DUSP16). RMSD:0.6216
Å |
 |  |  |  |  |
| DUSP22_STMND1_ENST00000419235_ENST00000536551_311962_17115192 superimposed PDB: 4WOH of partner (DUSP22). RMSD:0.5038
Å |
 |  |  |  |  |
| DUSP7_PBRM1_ENST00000495880_ENST00000394830_52087955_52588895 superimposed PDB: 4Y2E of partner (DUSP7). RMSD:0.6273
Å |
 |  |  |  |  |
| DVL1_OPTN_ENST00000378888_ENST00000263036_1284275_13154452 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.5045
Å |
 |  |  |  |  |
| DVL1_OPTN_ENST00000378891_ENST00000378764_1284275_13154452 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.5146
Å |
 |  |  |  |  |
| DVL2_TFE3_ENST00000005340_ENST00000315869_7133126_48896935 superimposed PDB: 8WMA of partner (DVL2). RMSD:0.9664
Å |
 |  |  |  |  |
| DVL2_TFE3_ENST00000575458_ENST00000315869_7133126_48896935 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.5911
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000324972_ENST00000242351_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:2.4677
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000324972_ENST00000464606_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:2.3209
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000324972_ENST00000471652_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:3.0471
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000447467_ENST00000464606_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:2.4778
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000447467_ENST00000471652_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:2.3358
Å |
 |  |  |  |  |
| DYNC1I1_ZC3HAV1_ENST00000457059_ENST00000242351_95457428_138774505 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:2.3994
Å |
 |  |  |  |  |
| DYNC2H1_NARS2_ENST00000334267_ENST00000281038_102988592_78239982 superimposed PDB: 8RGH of partner (DYNC2H1). RMSD:2.6101
Å |
 |  |  |  |  |
| DYNLT3_U2AF2_ENST00000378581_ENST00000308924_37700280_56179872 superimposed PDB: 6TR0 of partner (U2AF2). RMSD:0.7765
Å |
 |  |  |  |  |
| DYNLT3_U2AF2_ENST00000378581_ENST00000590551_37700280_56179872 superimposed PDB: 6TR0 of partner (U2AF2). RMSD:0.7559
Å |
 |  |  |  |  |
| DYNLT3_U2AF2_ENST00000432389_ENST00000308924_37700280_56179872 superimposed PDB: 6TR0 of partner (U2AF2). RMSD:0.8257
Å |
 |  |  |  |  |
| DYNLT3_U2AF2_ENST00000432389_ENST00000590551_37700280_56179872 superimposed PDB: 6TR0 of partner (U2AF2). RMSD:0.8224
Å |
 |  |  |  |  |
| E2F5_CA3_ENST00000256117_ENST00000285381_86124439_86351940 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.031
Å |
 |  |  |  |  |
| E2F5_CA3_ENST00000256117_ENST00000285381_86124439_86351940 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.4804
Å |
| | | |  |
| E2F5_CA3_ENST00000416274_ENST00000285381_86124439_86351940 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.2502
Å |
 |  |  |  |  |
| E2F5_CA3_ENST00000416274_ENST00000285381_86124439_86351940 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.4921
Å |
| | | |  |
| E2F5_CA3_ENST00000517476_ENST00000285381_86124439_86351940 superimposed PDB: 5TUV of partner (E2F5). RMSD:1.9734
Å |
 |  |  |  |  |
| E2F5_CA3_ENST00000517476_ENST00000285381_86124439_86351940 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.5007
Å |
| | | |  |
| E2F5_CA3_ENST00000521429_ENST00000285381_86124439_86351940 superimposed PDB: 5TUV of partner (E2F5). RMSD:1.7512
Å |
 |  |  |  |  |
| E2F5_CA3_ENST00000521429_ENST00000285381_86124439_86351940 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.5056
Å |
| | | |  |
| E2F5_NDRG1_ENST00000256117_ENST00000323851_86089889_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:1.1474
Å |
 |  |  |  |  |
| E2F5_NDRG1_ENST00000418930_ENST00000354944_86089889_134276895 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:0.5823
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000256117_ENST00000313382_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.1055
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000369349_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.0247
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000369351_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.2938
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000369354_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.1344
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000369356_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.2993
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000369359_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.1509
Å |
 |  |  |  |  |
| E2F5_PDE4DIP_ENST00000418930_ENST00000530740_86089889_144917932 superimposed PDB: 5TUV of partner (E2F5). RMSD:3.0945
Å |
 |  |  |  |  |
| ECE1_AKR7A2_ENST00000357071_ENST00000235835_21599191_19635136 superimposed PDB: 2BP1 of partner (AKR7A2). RMSD:0.5113
Å |
 |  |  |  |  |
| ECE1_AKR7A2_ENST00000374893_ENST00000235835_21599191_19635136 superimposed PDB: 2BP1 of partner (AKR7A2). RMSD:0.5266
Å |
 |  |  |  |  |
| ECE1_AKR7A2_ENST00000436918_ENST00000235835_21599191_19635136 superimposed PDB: 2BP1 of partner (AKR7A2). RMSD:0.491
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000264205_ENST00000264203_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8624
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000264205_ENST00000375142_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.6835
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000264205_ENST00000375142_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.9018
Å |
| | | |  |
| ECE1_CAPZB_ENST00000264205_ENST00000401084_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.7931
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000264205_ENST00000401084_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7703
Å |
| | | |  |
| ECE1_CAPZB_ENST00000264205_ENST00000433834_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.8651
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000264205_ENST00000433834_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8196
Å |
| | | |  |
| ECE1_CAPZB_ENST00000357071_ENST00000264203_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8979
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000357071_ENST00000375142_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.5804
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000357071_ENST00000375142_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7903
Å |
| | | |  |
| ECE1_CAPZB_ENST00000357071_ENST00000433834_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.7165
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000357071_ENST00000433834_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8549
Å |
| | | |  |
| ECE1_CAPZB_ENST00000374893_ENST00000264203_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:3.6007
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000374893_ENST00000264203_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8555
Å |
| | | |  |
| ECE1_CAPZB_ENST00000374893_ENST00000375142_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.587
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000374893_ENST00000375142_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8776
Å |
| | | |  |
| ECE1_CAPZB_ENST00000374893_ENST00000401084_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.805
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000374893_ENST00000401084_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7606
Å |
| | | |  |
| ECE1_CAPZB_ENST00000374893_ENST00000433834_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.8627
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000374893_ENST00000433834_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.9127
Å |
| | | |  |
| ECE1_CAPZB_ENST00000415912_ENST00000264203_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:3.5439
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000415912_ENST00000264203_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8692
Å |
| | | |  |
| ECE1_CAPZB_ENST00000415912_ENST00000375142_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.7443
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000415912_ENST00000375142_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8111
Å |
| | | |  |
| ECE1_CAPZB_ENST00000415912_ENST00000401084_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.3739
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000415912_ENST00000433834_21582439_19746245 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.8457
Å |
 |  |  |  |  |
| ECE1_CAPZB_ENST00000415912_ENST00000433834_21582439_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.8082
Å |
| | | |  |
| ECE1_HP1BP3_ENST00000357071_ENST00000312239_21571481_21097566 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.5026
Å |
 |  |  |  |  |
| ECE1_HP1BP3_ENST00000374893_ENST00000312239_21571481_21097566 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.5877
Å |
 |  |  |  |  |
| ECE1_HP1BP3_ENST00000436918_ENST00000312239_21571481_21097566 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.5839
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000264205_ENST00000453840_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.3982
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000357071_ENST00000344989_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.516
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000357071_ENST00000453840_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.5228
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000374893_ENST00000344989_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.3862
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000374893_ENST00000453840_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.4409
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000415912_ENST00000344989_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:3.3603
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000415912_ENST00000453840_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.3066
Å |
 |  |  |  |  |
| ECE1_SRSF10_ENST00000436918_ENST00000344989_21573713_24305307 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.4069
Å |
 |  |  |  |  |
| ECE1_WNT4_ENST00000264205_ENST00000542383_21599191_22448069 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.4047
Å |
 |  |  |  |  |
| ECE1_WNT4_ENST00000357071_ENST00000542383_21599191_22448069 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.5622
Å |
 |  |  |  |  |
| ECE1_WNT4_ENST00000374893_ENST00000542383_21599191_22448069 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.4548
Å |
 |  |  |  |  |
| ECE1_WNT4_ENST00000415912_ENST00000290167_21599191_22448069 superimposed PDB: 3DWB of partner (ECE1). RMSD:2.6123
Å |
 |  |  |  |  |
| ECE1_WNT4_ENST00000415912_ENST00000542383_21599191_22448069 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.647
Å |
 |  |  |  |  |
| ECI1_CTBP1_ENST00000301729_ENST00000290921_2296859_1208261 superimposed PDB: 1SG4 of partner (ECI1). RMSD:2.5746
Å |
 |  |  |  |  |
| ECI1_CTBP1_ENST00000301729_ENST00000382952_2296859_1208261 superimposed PDB: 1SG4 of partner (ECI1). RMSD:0.4148
Å |
 |  |  |  |  |
| ECI1_SUCLG1_ENST00000562238_ENST00000393868_2293046_84676876 superimposed PDB: 1SG4 of partner (ECI1). RMSD:0.4154
Å |
 |  |  |  |  |
| ECI1_SUCLG1_ENST00000562238_ENST00000393868_2293046_84676876 superimposed PDB: 6WCV of partner (SUCLG1). RMSD:0.6519
Å |
| | | |  |
| ECI1_SUCLG1_ENST00000570258_ENST00000393868_2293046_84676876 superimposed PDB: 1SG4 of partner (ECI1). RMSD:0.5493
Å |
 |  |  |  |  |
| ECI1_SUCLG1_ENST00000570258_ENST00000393868_2293046_84676876 superimposed PDB: 6WCV of partner (SUCLG1). RMSD:0.6037
Å |
| | | |  |
| ECT2_TPT1_ENST00000392692_ENST00000379056_172473164_45912911 superimposed PDB: 5O9M of partner (TPT1). RMSD:3.3846
Å |
 |  |  |  |  |
| EDNRB_COL4A1_ENST00000334286_ENST00000375820_78492225_110895081 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:0.9333
Å |
 |  |  |  |  |
| EDNRB_COL4A1_ENST00000377211_ENST00000375820_78492225_110895081 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:0.9088
Å |
 |  |  |  |  |
| EDNRB_COL4A1_ENST00000377211_ENST00000543140_78492225_110895081 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:0.6529
Å |
 |  |  |  |  |
| EDNRB_COL4A1_ENST00000377211_ENST00000543140_78492225_110895081 superimposed PDB: 5NAY of partner (COL4A1). RMSD:0.4535
Å |
| | | |  |
| EDNRB_COL4A1_ENST00000446573_ENST00000543140_78492225_110895081 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:0.7858
Å |
 |  |  |  |  |
| EDNRB_COL4A1_ENST00000446573_ENST00000543140_78492225_110895081 superimposed PDB: 5NAY of partner (COL4A1). RMSD:0.473
Å |
| | | |  |
| EDNRB_TBC1D4_ENST00000334286_ENST00000377636_78473993_75936743 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:1.297
Å |
 |  |  |  |  |
| EDNRB_TBC1D4_ENST00000334286_ENST00000377636_78473993_75936743 superimposed PDB: 3QYB of partner (TBC1D4). RMSD:0.7154
Å |
| | | |  |
| EDNRB_TBC1D4_ENST00000377211_ENST00000377636_78473993_75936743 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:1.2276
Å |
 |  |  |  |  |
| EDNRB_TBC1D4_ENST00000377211_ENST00000377636_78473993_75936743 superimposed PDB: 3QYB of partner (TBC1D4). RMSD:0.7656
Å |
| | | |  |
| EDNRB_TBC1D4_ENST00000377211_ENST00000431480_78473993_75936743 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:1.3152
Å |
 |  |  |  |  |
| EDNRB_TBC1D4_ENST00000377211_ENST00000431480_78473993_75936743 superimposed PDB: 3QYB of partner (TBC1D4). RMSD:0.7489
Å |
| | | |  |
| EDNRB_TBC1D4_ENST00000446573_ENST00000431480_78473993_75936743 superimposed PDB: 8IY5 of partner (EDNRB). RMSD:1.2723
Å |
 |  |  |  |  |
| EDNRB_TBC1D4_ENST00000446573_ENST00000431480_78473993_75936743 superimposed PDB: 3QYB of partner (TBC1D4). RMSD:0.7108
Å |
| | | |  |
| EEA1_ALDH2_ENST00000322349_ENST00000261733_93219941_112223070 superimposed PDB: 5L13 of partner (ALDH2). RMSD:0.386
Å |
 |  |  |  |  |
| EEA1_PAH_ENST00000322349_ENST00000307000_93258635_103249110 superimposed PDB: 6HPO of partner (PAH). RMSD:0.6259
Å |
 |  |  |  |  |
| EED_POLD3_ENST00000263360_ENST00000527458_85989033_74329581 superimposed PDB: 8VMI of partner (EED). RMSD:0.5155
Å |
 |  |  |  |  |
| EED_POLD3_ENST00000351625_ENST00000527458_85989033_74329581 superimposed PDB: 8VMI of partner (EED). RMSD:0.4782
Å |
 |  |  |  |  |
| EED_POLD3_ENST00000527888_ENST00000527458_85989033_74329581 superimposed PDB: 8VMI of partner (EED). RMSD:1.8922
Å |
 |  |  |  |  |
| EED_POLD3_ENST00000528180_ENST00000527458_85989033_74329581 superimposed PDB: 8VMI of partner (EED). RMSD:0.7344
Å |
 |  |  |  |  |
| EEF1A1_CCDC88A_ENST00000316292_ENST00000336838_74228076_55602019 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.8059
Å |
 |  |  |  |  |
| EEF1A1_CCDC88A_ENST00000316292_ENST00000413716_74228076_55602019 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.8151
Å |
 |  |  |  |  |
| EEF1A1_CCDC88A_ENST00000316292_ENST00000436346_74228076_55602019 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:3.145
Å |
 |  |  |  |  |
| EEF1A1_COX7A2_ENST00000316292_ENST00000230459_74229059_75950981 superimposed PDB: 9I6F of partner (COX7A2). RMSD:2.483
Å |
 |  |  |  |  |
| EEF1A1_HSP90AB1_ENST00000316292_ENST00000371554_74228076_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:2.0582
Å |
 |  |  |  |  |
| EEF1A1_HSP90AB1_ENST00000316292_ENST00000371646_74229059_44217411 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.5698
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000282486_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3247
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000324196_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3415
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000324210_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.2709
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000355460_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.4758
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000357472_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.1825
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000485910_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3182
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000493459_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3259
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000498502_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.32
Å |
 |  |  |  |  |
| EEF1A1_MBNL1_ENST00000316292_ENST00000545754_74228076_152132729 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3192
Å |
 |  |  |  |  |
| EEF1A1_PABPC1_ENST00000316292_ENST00000519004_74228076_101721959 superimposed PDB: 4F02 of partner (PABPC1). RMSD:2.386
Å |
 |  |  |  |  |
| EEF1A1_XPO1_ENST00000316292_ENST00000404992_74228076_61711240 superimposed PDB: 9OGD of partner (XPO1). RMSD:2.862
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000278893_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5802
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000278893_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.8391
Å |
| | | |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000360796_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.618
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000360796_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.8313
Å |
| | | |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000405837_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5407
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000433053_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5908
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000329251_ENST00000433053_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.8756
Å |
| | | |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000278893_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6344
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000278893_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.7884
Å |
| | | |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000360796_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6398
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000360796_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.8942
Å |
| | | |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000433053_62338436_62462183 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6466
Å |
 |  |  |  |  |
| EEF1G_BSCL2_ENST00000378019_ENST00000433053_62338436_62462183 superimposed PDB: 6DS5 of partner (BSCL2). RMSD:0.9359
Å |
| | | |  |
| EEF1G_EEF1A1_ENST00000329251_ENST00000316292_62340055_74227987 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6896
Å |
 |  |  |  |  |
| EEF1G_EEF1A1_ENST00000378019_ENST00000316292_62340055_74227987 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.727
Å |
 |  |  |  |  |
| EEF1G_ENG_ENST00000329251_ENST00000344849_62334870_130605524 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.55
Å |
 |  |  |  |  |
| EEF1G_ENG_ENST00000378019_ENST00000344849_62334870_130605524 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5545
Å |
 |  |  |  |  |
| EEF1G_ENG_ENST00000378019_ENST00000373203_62334870_130605524 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.515
Å |
 |  |  |  |  |
| EEF1G_KRT19_ENST00000329251_ENST00000361566_62338436_39681525 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.548
Å |
 |  |  |  |  |
| EEF1G_KRT19_ENST00000378019_ENST00000361566_62338436_39681525 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6377
Å |
 |  |  |  |  |
| EEF1G_ROS1_ENST00000329251_ENST00000368507_62334277_117641193 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4725
Å |
 |  |  |  |  |
| EEF1G_ROS1_ENST00000329251_ENST00000368507_62334277_117641193 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.5348
Å |
| | | |  |
| EEF1G_ROS1_ENST00000329251_ENST00000368508_62334277_117641193 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.7187
Å |
 |  |  |  |  |
| EEF1G_ROS1_ENST00000378019_ENST00000368507_62334277_117641193 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5171
Å |
 |  |  |  |  |
| EEF1G_ROS1_ENST00000378019_ENST00000368507_62334277_117641193 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.5318
Å |
| | | |  |
| EEF1G_RPL5_ENST00000378019_ENST00000370321_62327753_93299101 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5413
Å |
 |  |  |  |  |
| EEF1G_RPS12_ENST00000329251_ENST00000230050_62334277_133137599 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5862
Å |
 |  |  |  |  |
| EEF1G_RPS12_ENST00000378019_ENST00000230050_62334277_133137599 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.47
Å |
 |  |  |  |  |
| EEF1G_UBXN1_ENST00000329251_ENST00000301935_62340055_62444477 superimposed PDB: 5JPO of partner (EEF1G). RMSD:1.0
Å |
 |  |  |  |  |
| EFCAB2_FKBP3_ENST00000366522_ENST00000216330_245222760_45600003 superimposed PDB: 2MPH of partner (FKBP3). RMSD:2.4733
Å |
 |  |  |  |  |
| EFCAB2_FKBP3_ENST00000366523_ENST00000216330_245222760_45600003 superimposed PDB: 2MPH of partner (FKBP3). RMSD:2.9978
Å |
 |  |  |  |  |
| EFCAB5_ACACA_ENST00000378738_ENST00000360679_28296385_35564714 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.8459
Å |
 |  |  |  |  |
| EFCAB5_ACACA_ENST00000536908_ENST00000360679_28296385_35564714 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.9916
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000368408_ENST00000266497_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.555
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000368408_ENST00000538779_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.5583
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000418360_ENST00000266497_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.5401
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000418360_ENST00000538779_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.5494
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000556931_ENST00000266497_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.5363
Å |
 |  |  |  |  |
| EFNA3_PIK3C2G_ENST00000556931_ENST00000538779_155057880_18499574 superimposed PDB: 2WWE of partner (PIK3C2G). RMSD:0.5232
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000265709_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0064
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000289734_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9295
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000352337_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9084
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000379758_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.1657
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000396942_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9017
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000254624_ENST00000396945_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9744
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000265709_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7887
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000289734_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0991
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000347528_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0213
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000352337_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8946
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000379758_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.1183
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000396942_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8846
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000334503_ENST00000396945_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0309
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000265709_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7178
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000289734_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0129
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000347528_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.869
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000352337_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9708
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000379758_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9946
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000396942_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9604
Å |
 |  |  |  |  |
| EFR3A_ANK1_ENST00000519656_ENST00000396945_132958880_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.994
Å |
 |  |  |  |  |
| EGFR_ACADM_ENST00000455089_ENST00000370834_55087058_76198328 superimposed PDB: 8SGP of partner (ACADM). RMSD:0.4326
Å |
 |  |  |  |  |
| EGFR_ACADM_ENST00000455089_ENST00000541113_55087058_76198328 superimposed PDB: 8SGP of partner (ACADM). RMSD:0.4228
Å |
 |  |  |  |  |
| EGFR_ATXN7L1_ENST00000275493_ENST00000419735_55269475_105251050 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.8131
Å |
 |  |  |  |  |
| EGFR_ATXN7L1_ENST00000275493_ENST00000477775_55269475_105251050 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.4938
Å |
 |  |  |  |  |
| EGFR_ATXN7L1_ENST00000454757_ENST00000419735_55269475_105251050 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5323
Å |
 |  |  |  |  |
| EGFR_ATXN7L1_ENST00000454757_ENST00000477775_55269475_105251050 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6006
Å |
 |  |  |  |  |
| EGFR_ATXN7L1_ENST00000455089_ENST00000477775_55269475_105251050 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.8131
Å |
 |  |  |  |  |
| EGFR_CHCHD2_ENST00000342916_ENST00000395422_55229324_56169554 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.0123
Å |
 |  |  |  |  |
| EGFR_CHCHD2_ENST00000344576_ENST00000395422_55229324_56169554 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.929
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000275493_ENST00000304636_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6481
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000275493_ENST00000304636_55249171_189864195 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.5581
Å |
| | | |  |
| EGFR_COL3A1_ENST00000275493_ENST00000317840_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.4999
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000275493_ENST00000317840_55249171_189864195 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.6573
Å |
| | | |  |
| EGFR_COL3A1_ENST00000454757_ENST00000304636_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5821
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000454757_ENST00000304636_55249171_189864195 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.529
Å |
| | | |  |
| EGFR_COL3A1_ENST00000454757_ENST00000317840_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5158
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000454757_ENST00000317840_55249171_189864195 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.7274
Å |
| | | |  |
| EGFR_COL3A1_ENST00000455089_ENST00000304636_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.523
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000455089_ENST00000317840_55249171_189864195 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5388
Å |
 |  |  |  |  |
| EGFR_COL3A1_ENST00000455089_ENST00000317840_55249171_189864195 superimposed PDB: 6FZW of partner (COL3A1). RMSD:0.6749
Å |
| | | |  |
| EGFR_ERBB3_ENST00000275493_ENST00000450146_55260534_56492542 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.4984
Å |
 |  |  |  |  |
| EGFR_ERBB3_ENST00000275493_ENST00000450146_55260534_56492542 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.7284
Å |
| | | |  |
| EGFR_ERBB3_ENST00000454757_ENST00000450146_55260534_56492542 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6023
Å |
 |  |  |  |  |
| EGFR_ERBB3_ENST00000454757_ENST00000450146_55260534_56492542 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.8438
Å |
| | | |  |
| EGFR_ERBB3_ENST00000455089_ENST00000267101_55260534_56492542 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5585
Å |
 |  |  |  |  |
| EGFR_ERBB3_ENST00000455089_ENST00000267101_55260534_56492542 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.7758
Å |
| | | |  |
| EGFR_ERBB3_ENST00000455089_ENST00000450146_55260534_56492542 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5823
Å |
 |  |  |  |  |
| EGFR_ERBB3_ENST00000455089_ENST00000450146_55260534_56492542 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.7935
Å |
| | | |  |
| EGFR_ERP44_ENST00000342916_ENST00000262455_55087058_102784508 superimposed PDB: 5XWM of partner (ERP44). RMSD:2.9058
Å |
 |  |  |  |  |
| EGFR_GNS_ENST00000275493_ENST00000543646_55240817_65110599 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6034
Å |
 |  |  |  |  |
| EGFR_GNS_ENST00000454757_ENST00000543646_55240817_65110599 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.9798
Å |
 |  |  |  |  |
| EGFR_GYG1_ENST00000455089_ENST00000296048_55087058_148711928 superimposed PDB: 7Q0B of partner (GYG1). RMSD:1.1248
Å |
 |  |  |  |  |
| EGFR_GYG1_ENST00000455089_ENST00000483267_55087058_148711928 superimposed PDB: 7Q0B of partner (GYG1). RMSD:0.8741
Å |
 |  |  |  |  |
| EGFR_PSPH_ENST00000275493_ENST00000395471_55268106_56079562 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5605
Å |
 |  |  |  |  |
| EGFR_PSPH_ENST00000454757_ENST00000395471_55268106_56079562 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.7348
Å |
 |  |  |  |  |
| EGFR_PSPH_ENST00000455089_ENST00000275605_55268106_56079562 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5907
Å |
 |  |  |  |  |
| EGFR_PSPH_ENST00000455089_ENST00000395471_55268106_56079562 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.7557
Å |
 |  |  |  |  |
| EGFR_SEPT14_ENST00000275493_ENST00000388975_55268106_55886916 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6295
Å |
 |  |  |  |  |
| EGFR_SEPT14_ENST00000275493_ENST00000388975_55268106_55886916 superimposed PDB: 8SJJ of partner (SEPT14). RMSD:1.7257
Å |
| | | |  |
| EGFR_SEPT14_ENST00000342916_ENST00000388975_55087058_55874951 superimposed PDB: 8SJJ of partner (SEPT14). RMSD:1.5484
Å |
 |  |  |  |  |
| EGFR_SEPT14_ENST00000454757_ENST00000388975_55268106_55886916 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.563
Å |
 |  |  |  |  |
| EGFR_SEPT14_ENST00000454757_ENST00000388975_55268106_55886916 superimposed PDB: 8SJJ of partner (SEPT14). RMSD:1.8962
Å |
| | | |  |
| EGFR_SET_ENST00000455089_ENST00000409104_55087058_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:0.804
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000275493_ENST00000433959_55268106_55588823 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5791
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000342916_ENST00000433959_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.2926
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000342916_ENST00000545390_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.85
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000344576_ENST00000433959_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.7111
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000454757_ENST00000433959_55268106_55588823 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6352
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000454757_ENST00000545390_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.4772
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000455089_ENST00000285279_55268106_55588823 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.6052
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000455089_ENST00000433959_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5107
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000455089_ENST00000433959_55268106_55588823 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5177
Å |
 |  |  |  |  |
| EGFR_VOPP1_ENST00000455089_ENST00000545390_55229324_55540738 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.942
Å |
 |  |  |  |  |
| EGFR_ZNRF3_ENST00000275493_ENST00000332811_55242513_29438482 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.5548
Å |
 |  |  |  |  |
| EGFR_ZNRF3_ENST00000454757_ENST00000332811_55242513_29438482 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.554
Å |
 |  |  |  |  |
| EGFR_ZNRF3_ENST00000455089_ENST00000332811_55242513_29438482 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.635
Å |
 |  |  |  |  |
| EGLN1_PTPRF_ENST00000366641_ENST00000438120_231556743_44083115 superimposed PDB: 6KR4 of partner (PTPRF). RMSD:0.5519
Å |
 |  |  |  |  |
| EGLN2_PLD3_ENST00000303961_ENST00000409587_41307320_40877579 superimposed PDB: 5V1B of partner (EGLN2). RMSD:1.288
Å |
 |  |  |  |  |
| EGLN2_PLD3_ENST00000303961_ENST00000409587_41307320_40877579 superimposed PDB: 8V5T of partner (PLD3). RMSD:0.4116
Å |
| | | |  |
| EHBP1L1_POLA2_ENST00000309295_ENST00000541089_65343877_65061623 superimposed PDB: 4Y97 of partner (POLA2). RMSD:0.5217
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405015_ENST00000424009_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.408
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405015_ENST00000454930_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.4052
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405015_ENST00000509773_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.387
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405015_ENST00000510819_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.3962
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405289_ENST00000424009_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.3979
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405289_ENST00000454930_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.4106
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405289_ENST00000509773_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.3844
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000405289_ENST00000510819_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.4052
Å |
 |  |  |  |  |
| EHBP1_KAT7_ENST00000431489_ENST00000259021_62974587_47869247 superimposed PDB: 7D0P of partner (KAT7). RMSD:0.4292
Å |
 |  |  |  |  |
| EHBP1_MDH1_ENST00000263991_ENST00000409908_63170985_63831829 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.8635
Å |
 |  |  |  |  |
| EHBP1_MDH1_ENST00000405015_ENST00000409908_63170985_63831829 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.8745
Å |
 |  |  |  |  |
| EHBP1_MDH1_ENST00000405289_ENST00000233114_63101667_63821621 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.4171
Å |
 |  |  |  |  |
| EHBP1_MDH1_ENST00000405289_ENST00000409908_63170985_63831829 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.9051
Å |
 |  |  |  |  |
| EHBP1_MDH1_ENST00000431489_ENST00000233114_63101667_63821621 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.446
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000263991_ENST00000371850_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3562
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000263991_ENST00000371851_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3597
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000405015_ENST00000371850_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3608
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000405015_ENST00000371851_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3349
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000405289_ENST00000371850_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3114
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000405289_ENST00000371851_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.325
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000405289_ENST00000406606_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3633
Å |
 |  |  |  |  |
| EHBP1_VAV2_ENST00000431489_ENST00000406606_63101667_136726554 superimposed PDB: 4ROJ of partner (VAV2). RMSD:0.3201
Å |
 |  |  |  |  |
| EHMT1_ATP13A1_ENST00000462484_ENST00000357324_140611634_19770796 superimposed PDB: 9JBZ of partner (ATP13A1). RMSD:2.4783
Å |
 |  |  |  |  |
| EIF1B_EIF1_ENST00000232905_ENST00000469257_40351463_39846029 superimposed PDB: 9NPX of partner (EIF1). RMSD:0.7863
Å |
 |  |  |  |  |
| EIF1_MED28_ENST00000469257_ENST00000237380_39846193_17621523 superimposed PDB: 9NPX of partner (EIF1). RMSD:0.6778
Å |
 |  |  |  |  |
| EIF1_MED28_ENST00000469257_ENST00000237380_39846193_17621523 superimposed PDB: 7EMF of partner (MED28). RMSD:1.0509
Å |
| | | |  |
| EIF2AK3_HNRNPLL_ENST00000303236_ENST00000358367_88913241_38818790 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:0.5399
Å |
 |  |  |  |  |
| EIF2AK3_HNRNPLL_ENST00000303236_ENST00000409328_88913241_38818790 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:0.331
Å |
 |  |  |  |  |
| EIF2AK3_HNRNPLL_ENST00000303236_ENST00000409636_88913241_38818790 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:0.2908
Å |
 |  |  |  |  |
| EIF2AK3_HNRNPLL_ENST00000303236_ENST00000410076_88913241_38818790 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:0.4074
Å |
 |  |  |  |  |
| EIF2AK3_HNRNPLL_ENST00000303236_ENST00000608859_88913241_38818790 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:0.561
Å |
 |  |  |  |  |
| EIF2AK3_PRKD3_ENST00000303236_ENST00000234179_88913241_37520414 superimposed PDB: 4X7K of partner (EIF2AK3). RMSD:1.5855
Å |
 |  |  |  |  |
| EIF2AK3_PRKD3_ENST00000303236_ENST00000234179_88913241_37520414 superimposed PDB: 2D9Z of partner (PRKD3). RMSD:1.481
Å |
| | | |  |
| EIF2AK4_BUB1B_ENST00000263791_ENST00000412359_40309443_40504699 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:1.1852
Å |
 |  |  |  |  |
| EIF2AK4_BUB1B_ENST00000382727_ENST00000287598_40309443_40504699 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:3.3053
Å |
 |  |  |  |  |
| EIF2AK4_BUB1B_ENST00000382727_ENST00000412359_40309443_40504699 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:1.1171
Å |
 |  |  |  |  |
| EIF2AK4_FEM1B_ENST00000263791_ENST00000306917_40314806_68581944 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:1.4819
Å |
 |  |  |  |  |
| EIF2AK4_PKM_ENST00000263791_ENST00000319622_40301931_72502819 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:3.0225
Å |
 |  |  |  |  |
| EIF2AK4_PKM_ENST00000263791_ENST00000319622_40301931_72502819 superimposed PDB: 3GR4 of partner (PKM). RMSD:1.4674
Å |
| | | |  |
| EIF2AK4_PKM_ENST00000263791_ENST00000565184_40301931_72502819 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:3.3054
Å |
 |  |  |  |  |
| EIF2AK4_PKM_ENST00000263791_ENST00000565184_40301931_72502819 superimposed PDB: 3GR4 of partner (PKM). RMSD:1.2482
Å |
| | | |  |
| EIF2AK4_PKM_ENST00000382727_ENST00000565184_40301931_72502819 superimposed PDB: 8T7T of partner (EIF2AK4). RMSD:3.0327
Å |
 |  |  |  |  |
| EIF2AK4_PKM_ENST00000382727_ENST00000565184_40301931_72502819 superimposed PDB: 3GR4 of partner (PKM). RMSD:1.1866
Å |
| | | |  |
| EIF2B1_RNF41_ENST00000424014_ENST00000394013_124110971_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.4016
Å |
 |  |  |  |  |
| EIF2B1_RNF41_ENST00000424014_ENST00000552244_124110971_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.4191
Å |
 |  |  |  |  |
| EIF2B1_RNF41_ENST00000539951_ENST00000345093_124110971_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.8223
Å |
 |  |  |  |  |
| EIF2B1_RNF41_ENST00000539951_ENST00000394013_124110971_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.457
Å |
 |  |  |  |  |
| EIF2S1_GPHN_ENST00000256383_ENST00000478722_67841264_67291191 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3773
Å |
 |  |  |  |  |
| EIF2S1_GPHN_ENST00000466499_ENST00000315266_67841264_67291191 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3292
Å |
 |  |  |  |  |
| EIF2S2_NDRG3_ENST00000374980_ENST00000349004_32699901_35294795 superimposed PDB: 6L4B of partner (NDRG3). RMSD:1.0954
Å |
 |  |  |  |  |
| EIF2S2_NDRG3_ENST00000374980_ENST00000359675_32699901_35294795 superimposed PDB: 6L4B of partner (NDRG3). RMSD:0.7931
Å |
 |  |  |  |  |
| EIF3B_MAD1L1_ENST00000360876_ENST00000399654_2416710_1976533 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:0.9923
Å |
 |  |  |  |  |
| EIF3B_MAD1L1_ENST00000360876_ENST00000399654_2416710_2020176 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.2477
Å |
 |  |  |  |  |
| EIF3B_MAD1L1_ENST00000360876_ENST00000399654_2416710_2041756 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.1909
Å |
 |  |  |  |  |
| EIF3B_MAD1L1_ENST00000397011_ENST00000399654_2416710_1855864 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.131
Å |
 |  |  |  |  |
| EIF3H_BLVRB_ENST00000276682_ENST00000263368_117738254_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.7274
Å |
 |  |  |  |  |
| EIF3H_BLVRB_ENST00000276682_ENST00000595483_117738254_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.4816
Å |
 |  |  |  |  |
| EIF3H_BLVRB_ENST00000521861_ENST00000263368_117738254_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.6946
Å |
 |  |  |  |  |
| EIF3J_SORD_ENST00000261868_ENST00000558580_44829625_45332605 superimposed PDB: 6YBW of partner (EIF3J). RMSD:2.1217
Å |
 |  |  |  |  |
| EIF3J_SORD_ENST00000261868_ENST00000558580_44829625_45332605 superimposed PDB: 1PL8 of partner (SORD). RMSD:0.4875
Å |
| | | |  |
| EIF3J_TRIM69_ENST00000424492_ENST00000559390_44829625_45047097 superimposed PDB: 4NQJ of partner (TRIM69). RMSD:2.5133
Å |
 |  |  |  |  |
| EIF3K_CYP39A1_ENST00000248342_ENST00000275016_39123318_46607405 superimposed PDB: 1RZ4 of partner (EIF3K). RMSD:0.6047
Å |
 |  |  |  |  |
| EIF3K_CYP39A1_ENST00000538434_ENST00000275016_39123318_46607405 superimposed PDB: 1RZ4 of partner (EIF3K). RMSD:0.6647
Å |
 |  |  |  |  |
| EIF3K_CYP39A1_ENST00000545173_ENST00000275016_39123318_46607405 superimposed PDB: 1RZ4 of partner (EIF3K). RMSD:0.6482
Å |
 |  |  |  |  |
| EIF3L_CECR1_ENST00000381683_ENST00000449907_38274178_17672700 superimposed PDB: 3LGD of partner (CECR1). RMSD:0.6103
Å |
 |  |  |  |  |
| EIF3L_CECR1_ENST00000406934_ENST00000330232_38274178_17672700 superimposed PDB: 3LGD of partner (CECR1). RMSD:0.5964
Å |
 |  |  |  |  |
| EIF3L_CECR1_ENST00000406934_ENST00000449907_38274178_17672700 superimposed PDB: 3LGD of partner (CECR1). RMSD:0.6118
Å |
 |  |  |  |  |
| EIF3L_CECR1_ENST00000412331_ENST00000449907_38274178_17672700 superimposed PDB: 3LGD of partner (CECR1). RMSD:0.6595
Å |
 |  |  |  |  |
| EIF4A1_DDX5_ENST00000293831_ENST00000450599_7476182_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.7026
Å |
 |  |  |  |  |
| EIF4A1_DDX5_ENST00000293831_ENST00000578804_7476182_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.5463
Å |
 |  |  |  |  |
| EIF4A1_FTL_ENST00000577269_ENST00000331825_7478576_49469026 superimposed PDB: 5LG8 of partner (FTL). RMSD:0.5116
Å |
 |  |  |  |  |
| EIF4A1_GAPDH_ENST00000577269_ENST00000229239_7476182_6645659 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.6971
Å |
 |  |  |  |  |
| EIF4A2_ABHD12B_ENST00000323963_ENST00000337334_186505373_51368546 superimposed PDB: 3BOR of partner (EIF4A2). RMSD:0.416
Å |
 |  |  |  |  |
| EIF4A2_ABHD12B_ENST00000323963_ENST00000353130_186505373_51368546 superimposed PDB: 3BOR of partner (EIF4A2). RMSD:0.2959
Å |
 |  |  |  |  |
| EIF4A2_ABHD12B_ENST00000356531_ENST00000353130_186505373_51368546 superimposed PDB: 3BOR of partner (EIF4A2). RMSD:0.7114
Å |
 |  |  |  |  |
| EIF4A2_ABHD12B_ENST00000440191_ENST00000353130_186505373_51368546 superimposed PDB: 3BOR of partner (EIF4A2). RMSD:0.2812
Å |
 |  |  |  |  |
| EIF4B_ADAP1_ENST00000420463_ENST00000265846_53421972_975141 superimposed PDB: 3FM8 of partner (ADAP1). RMSD:0.643
Å |
 |  |  |  |  |
| EIF4B_CS_ENST00000262056_ENST00000351328_53413810_56676775 superimposed PDB: 5UZQ of partner (CS). RMSD:0.5783
Å |
 |  |  |  |  |
| EIF4G2_EEF1G_ENST00000339995_ENST00000378019_10820538_62335000 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.2943
Å |
 |  |  |  |  |
| EIF4G2_EEF1G_ENST00000339995_ENST00000378019_10820538_62335000 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5345
Å |
| | | |  |
| EIF4G2_EEF1G_ENST00000396525_ENST00000378019_10820538_62335000 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.2502
Å |
 |  |  |  |  |
| EIF4G2_EEF1G_ENST00000396525_ENST00000378019_10820538_62335000 superimposed PDB: 5JPO of partner (EEF1G). RMSD:1.0006
Å |
| | | |  |
| EIF4G2_EEF1G_ENST00000525681_ENST00000378019_10820538_62335000 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.1903
Å |
 |  |  |  |  |
| EIF4G2_EEF1G_ENST00000525681_ENST00000378019_10820538_62335000 superimposed PDB: 5JPO of partner (EEF1G). RMSD:1.1577
Å |
| | | |  |
| EIF4G2_PIP4K2B_ENST00000339995_ENST00000269554_10824576_36934053 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:1.3117
Å |
 |  |  |  |  |
| EIF4G2_PIP4K2B_ENST00000396525_ENST00000269554_10824576_36934053 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:0.8445
Å |
 |  |  |  |  |
| EIF4G2_RPL9_ENST00000339995_ENST00000449470_10820538_39458158 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.0723
Å |
 |  |  |  |  |
| EIF4G2_RPL9_ENST00000396525_ENST00000449470_10820538_39458158 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.1789
Å |
 |  |  |  |  |
| EIF4G2_RPL9_ENST00000525681_ENST00000449470_10820538_39458158 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:1.1658
Å |
 |  |  |  |  |
| EIF4G3_LIN28A_ENST00000264211_ENST00000254231_21267983_26737876 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.1726
Å |
 |  |  |  |  |
| EIF4G3_LIN28A_ENST00000356916_ENST00000254231_21267983_26737876 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.2141
Å |
 |  |  |  |  |
| EIF4G3_LIN28A_ENST00000374937_ENST00000254231_21267983_26737876 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.1153
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000290101_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4457
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000290101_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4159
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000374761_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.5156
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000374761_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4451
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000374765_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.3862
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000264211_ENST00000374765_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.2981
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000290101_21324093_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.375
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000290101_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.2743
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000290101_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4218
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000374765_21324093_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4464
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000374765_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.3408
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000356916_ENST00000374765_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4491
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000374935_ENST00000374761_21329205_21940582 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.3761
Å |
 |  |  |  |  |
| EIF4G3_RAP1GAP_ENST00000374935_ENST00000374761_21329205_21945565 superimposed PDB: 1SRQ of partner (RAP1GAP). RMSD:1.4167
Å |
 |  |  |  |  |
| ELAC2_COX10_ENST00000338034_ENST00000261643_12919084_14063193 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.4849
Å |
 |  |  |  |  |
| ELAC2_COX10_ENST00000338034_ENST00000536205_12919084_14063193 superimposed PDB: 8CBL of partner (ELAC2). RMSD:0.8712
Å |
 |  |  |  |  |
| ELAC2_COX10_ENST00000395962_ENST00000536205_12919084_14063193 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.5109
Å |
 |  |  |  |  |
| ELAC2_RYR3_ENST00000338034_ENST00000389232_12899019_34034566 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.4194
Å |
 |  |  |  |  |
| ELAC2_RYR3_ENST00000395962_ENST00000389232_12899019_34034566 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.7133
Å |
 |  |  |  |  |
| ELAC2_RYR3_ENST00000395962_ENST00000415757_12899019_34034566 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.4994
Å |
 |  |  |  |  |
| ELAC2_RYR3_ENST00000426905_ENST00000389232_12899019_34034566 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.2833
Å |
 |  |  |  |  |
| ELAC2_RYR3_ENST00000426905_ENST00000415757_12899019_34034566 superimposed PDB: 8CBL of partner (ELAC2). RMSD:1.6704
Å |
 |  |  |  |  |
| ELAVL1_ATXN10_ENST00000351593_ENST00000252934_8038608_46238870 superimposed PDB: 4ED5 of partner (ELAVL1). RMSD:2.9131
Å |
 |  |  |  |  |
| ELAVL1_TYK2_ENST00000351593_ENST00000524462_8056527_10465285 superimposed PDB: 4ED5 of partner (ELAVL1). RMSD:0.411
Å |
 |  |  |  |  |
| ELAVL1_TYK2_ENST00000351593_ENST00000524462_8056527_10465285 superimposed PDB: 4OLI of partner (TYK2). RMSD:0.5634
Å |
| | | |  |
| ELAVL4_FAF1_ENST00000357083_ENST00000371778_50642864_51267349 superimposed PDB: 1FXL of partner (ELAVL4). RMSD:2.2109
Å |
 |  |  |  |  |
| ELAVL4_FAF1_ENST00000357083_ENST00000371778_50642864_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.9017
Å |
| | | |  |
| ELAVL4_FAF1_ENST00000371821_ENST00000371778_50642864_51267349 superimposed PDB: 1FXL of partner (ELAVL4). RMSD:2.068
Å |
 |  |  |  |  |
| ELAVL4_FAF1_ENST00000371821_ENST00000371778_50642864_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8703
Å |
| | | |  |
| ELAVL4_FAF1_ENST00000371824_ENST00000371778_50642864_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8491
Å |
 |  |  |  |  |
| ELAVL4_FAF1_ENST00000371827_ENST00000371778_50642864_51267349 superimposed PDB: 1FXL of partner (ELAVL4). RMSD:3.0598
Å |
 |  |  |  |  |
| ELAVL4_FAF1_ENST00000371827_ENST00000371778_50642864_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.9137
Å |
| | | |  |
| ELAVL4_FAF1_ENST00000448907_ENST00000371778_50642864_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.9081
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000239882_ENST00000409078_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.3713
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000442101_ENST00000263710_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.4164
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000442101_ENST00000455322_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.4147
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000442101_ENST00000541377_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.3349
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000442101_ENST00000541859_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.3406
Å |
 |  |  |  |  |
| ELF1_CLASP1_ENST00000442101_ENST00000545861_41556118_122165288 superimposed PDB: 6MQ7 of partner (CLASP1). RMSD:2.4039
Å |
 |  |  |  |  |
| ELF1_EZR_ENST00000239882_ENST00000337147_41556118_159210403 superimposed PDB: 4RM8 of partner (EZR). RMSD:0.7856
Å |
 |  |  |  |  |
| ELF1_EZR_ENST00000442101_ENST00000367075_41556118_159210403 superimposed PDB: 4RM8 of partner (EZR). RMSD:0.5771
Å |
 |  |  |  |  |
| ELF1_FGFR1OP2_ENST00000239882_ENST00000229395_41556118_27116274 superimposed PDB: 8BZM of partner (ELF1). RMSD:2.5262
Å |
 |  |  |  |  |
| ELL2_ANXA2_ENST00000237853_ENST00000451270_95278705_60674640 superimposed PDB: 7OKX of partner (ELL2). RMSD:1.7658
Å |
 |  |  |  |  |
| ELL2_ANXA2_ENST00000237853_ENST00000451270_95278705_60674640 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4238
Å |
| | | |  |
| ELMO1_AOAH_ENST00000396040_ENST00000535891_36901263_36713614 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.6038
Å |
 |  |  |  |  |
| ELMO1_AOAH_ENST00000396045_ENST00000258749_36901263_36713614 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.5021
Å |
 |  |  |  |  |
| ELMO1_AOAH_ENST00000442504_ENST00000258749_36901263_36713614 superimposed PDB: 7DPA of partner (ELMO1). RMSD:2.0014
Å |
 |  |  |  |  |
| ELMO1_SCIN_ENST00000341056_ENST00000519209_37136223_12684208 superimposed PDB: 3FG6 of partner (SCIN). RMSD:2.5631
Å |
 |  |  |  |  |
| ELMO2_STAP1_ENST00000290246_ENST00000396225_45008891_68441102 superimposed PDB: 6IDX of partner (ELMO2). RMSD:1.301
Å |
 |  |  |  |  |
| ELMO2_STAP1_ENST00000290246_ENST00000396225_45008891_68441102 superimposed PDB: 1X1F of partner (STAP1). RMSD:1.0545
Å |
| | | |  |
| ELMO2_STAP1_ENST00000352077_ENST00000396225_45008891_68441102 superimposed PDB: 6IDX of partner (ELMO2). RMSD:1.1609
Å |
 |  |  |  |  |
| ELMO2_STAP1_ENST00000352077_ENST00000396225_45008891_68441102 superimposed PDB: 1X1F of partner (STAP1). RMSD:1.0151
Å |
| | | |  |
| ELMO2_STAP1_ENST00000439931_ENST00000396225_45008891_68441102 superimposed PDB: 6IDX of partner (ELMO2). RMSD:1.1002
Å |
 |  |  |  |  |
| ELMO2_STAP1_ENST00000439931_ENST00000396225_45008891_68441102 superimposed PDB: 1X1F of partner (STAP1). RMSD:0.8466
Å |
| | | |  |
| ELMSAN1_ANO1_ENST00000394071_ENST00000398543_74194160_69957812 superimposed PDB: 9R4I of partner (ELMSAN1). RMSD:2.0959
Å |
 |  |  |  |  |
| ELN_COL1A2_ENST00000252034_ENST00000297268_73478025_94059558 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.5656
Å |
 |  |  |  |  |
| ELN_COL1A2_ENST00000320492_ENST00000297268_73478025_94059558 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.7835
Å |
 |  |  |  |  |
| ELN_COL1A2_ENST00000357036_ENST00000297268_73478025_94059558 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.2856
Å |
 |  |  |  |  |
| ELN_COL1A2_ENST00000380584_ENST00000297268_73478025_94059558 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.5279
Å |
 |  |  |  |  |
| ELOVL6_ACTN1_ENST00000302274_ENST00000394419_111119402_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3513
Å |
 |  |  |  |  |
| ELOVL6_ACTN1_ENST00000302274_ENST00000438964_111119402_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3621
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000350494_ENST00000396172_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.8199
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000351393_ENST00000396172_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.7451
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000351393_ENST00000417556_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.8388
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000358232_ENST00000396172_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.8545
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000358232_ENST00000417556_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.9495
Å |
 |  |  |  |  |
| ELP2_DDX39B_ENST00000442325_ENST00000396172_33721164_31500688 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.7628
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000350494_ENST00000257209_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.1224
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000350494_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7051
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000350494_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.6243
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000350494_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8912
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000351393_ENST00000257209_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.1963
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000351393_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.37
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000351393_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2543
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000351393_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3306
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000358232_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.1833
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000358232_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.184
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000358232_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2439
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000423854_ENST00000257209_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3003
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000423854_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.5249
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000423854_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.1334
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000423854_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.1484
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000442325_ENST00000257209_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3458
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000442325_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2959
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000442325_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2146
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000442325_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2561
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000542824_ENST00000257209_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.84
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000542824_ENST00000359247_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7382
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000542824_ENST00000445677_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8112
Å |
 |  |  |  |  |
| ELP2_FHOD3_ENST00000542824_ENST00000590592_33739793_34081894 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8545
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000350494_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.5973
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000350494_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.5399
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000351393_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.9764
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000351393_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.0146
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000358232_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.8814
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000358232_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.899
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000423854_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3239
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000423854_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.6849
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000442325_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.8524
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000442325_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:0.8632
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000542824_ENST00000436190_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.0878
Å |
 |  |  |  |  |
| ELP2_MAPRE2_ENST00000542824_ENST00000589699_33734962_32681909 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.1363
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000350494_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0182
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000350494_ENST00000588737_33736617_33573263 superimposed PDB: 4JXT of partner (RPRD1A). RMSD:3.2699
Å |
| | | |  |
| ELP2_RPRD1A_ENST00000351393_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.277
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000358232_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.1369
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000423854_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3454
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000442325_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.2137
Å |
 |  |  |  |  |
| ELP2_RPRD1A_ENST00000542824_ENST00000588737_33736617_33573263 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.741
Å |
 |  |  |  |  |
| ELP3_MYO5C_ENST00000256398_ENST00000261839_28016150_52500840 superimposed PDB: 8PTX of partner (ELP3). RMSD:1.1335
Å |
 |  |  |  |  |
| ELP3_MYO5C_ENST00000524103_ENST00000261839_28016150_52500840 superimposed PDB: 8PTX of partner (ELP3). RMSD:1.052
Å |
 |  |  |  |  |
| ELP3_MYO5C_ENST00000537665_ENST00000261839_28016150_52500840 superimposed PDB: 8PTX of partner (ELP3). RMSD:1.1286
Å |
 |  |  |  |  |
| ELP3_MYO5C_ENST00000542181_ENST00000261839_28016150_52500840 superimposed PDB: 8PTX of partner (ELP3). RMSD:1.1349
Å |
 |  |  |  |  |
| ELP4_CSTF3_ENST00000350638_ENST00000524827_31671769_33129964 superimposed PDB: 6URO of partner (CSTF3). RMSD:1.1442
Å |
 |  |  |  |  |
| ELP4_CSTF3_ENST00000379163_ENST00000323959_31671769_33129964 superimposed PDB: 6URO of partner (CSTF3). RMSD:0.8895
Å |
 |  |  |  |  |
| ELP4_CSTF3_ENST00000379163_ENST00000524827_31671769_33129964 superimposed PDB: 6URO of partner (CSTF3). RMSD:1.1526
Å |
 |  |  |  |  |
| ELP4_CSTF3_ENST00000395934_ENST00000323959_31671769_33129964 superimposed PDB: 6URO of partner (CSTF3). RMSD:0.9576
Å |
 |  |  |  |  |
| EMC3_RHOA_ENST00000245046_ENST00000454011_10012265_49400059 superimposed PDB: 8J0O of partner (EMC3). RMSD:2.7046
Å |
 |  |  |  |  |
| EMC3_RHOA_ENST00000245046_ENST00000454011_10012265_49400059 superimposed PDB: 5C4M of partner (RHOA). RMSD:2.7114
Å |
| | | |  |
| EMG1_SLC4A8_ENST00000261406_ENST00000394856_7084540_51864175 superimposed PDB: 5JHO of partner (SLC4A8). RMSD:2.6159
Å |
 |  |  |  |  |
| EML1_GPI_ENST00000262233_ENST00000356487_100259880_34884632 superimposed PDB: 9FCW of partner (GPI). RMSD:0.6426
Å |
 |  |  |  |  |
| EML1_NTRK2_ENST00000262233_ENST00000376213_100259880_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7601
Å |
 |  |  |  |  |
| EML1_NTRK2_ENST00000262233_ENST00000376213_100317372_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7359
Å |
 |  |  |  |  |
| EML1_NTRK2_ENST00000262233_ENST00000376214_100317372_87475954 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.744
Å |
 |  |  |  |  |
| EML1_NTRK2_ENST00000327921_ENST00000376213_100317372_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7361
Å |
 |  |  |  |  |
| EML1_NTRK2_ENST00000334192_ENST00000376214_100317372_87475954 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.77
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000318522_ENST00000389048_42522656_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.438
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000318522_ENST00000389048_42522656_29446394__from_TCGA_14509 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4572
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000318522_ENST00000389048_42552694_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3211
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42491871_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3737
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42491871_29449940 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4192
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42491871_29450538 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4063
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42492091_29450538 superimposed PDB: 4CGC of partner (EML4). RMSD:0.36
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42492091_29450538 superimposed PDB: 7NX3 of partner (ALK). RMSD:2.2066
Å |
| | | |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42522656_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4425
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000401738_ENST00000389048_42552694_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4564
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42472827_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.6199
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42491871_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4363
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42491871_29449940 superimposed PDB: 4CGC of partner (EML4). RMSD:0.418
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42491871_29450538 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4017
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42522656_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4023
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000402711_ENST00000389048_42552694_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3441
Å |
 |  |  |  |  |
| EML4_ALK_ENST00000453191_ENST00000389048_42552694_29446394 superimposed PDB: 4CGC of partner (EML4). RMSD:0.6573
Å |
 |  |  |  |  |
| EML4_BRAF_ENST00000401738_ENST00000288602_42491871_140482957 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3961
Å |
 |  |  |  |  |
| EML4_BRAF_ENST00000402711_ENST00000288602_42491871_140482957 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4712
Å |
 |  |  |  |  |
| EML4_CASK_ENST00000318522_ENST00000318588_42396776_41420897 superimposed PDB: 4CGC of partner (EML4). RMSD:0.2052
Å |
 |  |  |  |  |
| EML4_CASK_ENST00000318522_ENST00000361962_42396776_41420897 superimposed PDB: 4CGC of partner (EML4). RMSD:0.1495
Å |
 |  |  |  |  |
| EML4_CASK_ENST00000318522_ENST00000378158_42396776_41420897 superimposed PDB: 4CGC of partner (EML4). RMSD:0.2605
Å |
 |  |  |  |  |
| EML4_CASK_ENST00000318522_ENST00000378163_42396776_41420897 superimposed PDB: 4CGC of partner (EML4). RMSD:0.249
Å |
 |  |  |  |  |
| EML4_CASK_ENST00000402711_ENST00000421587_42396776_41420897 superimposed PDB: 4CGC of partner (EML4). RMSD:0.1646
Å |
 |  |  |  |  |
| EML4_EPHA3_ENST00000318522_ENST00000336596_42528532_89498374 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3778
Å |
 |  |  |  |  |
| EML4_EPHA3_ENST00000318522_ENST00000336596_42528532_89498374 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.8611
Å |
| | | |  |
| EML4_EPHA3_ENST00000401738_ENST00000336596_42528532_89498374 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3845
Å |
 |  |  |  |  |
| EML4_EPHA3_ENST00000402711_ENST00000336596_42528532_89498374 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3992
Å |
 |  |  |  |  |
| EML4_MTA3_ENST00000318522_ENST00000405094_42472827_42836597 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3116
Å |
 |  |  |  |  |
| EML4_MTA3_ENST00000318522_ENST00000406652_42472827_42836597 superimposed PDB: 4CGC of partner (EML4). RMSD:0.4975
Å |
 |  |  |  |  |
| EML4_MTA3_ENST00000318522_ENST00000406652_42491871_42980513 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3031
Å |
 |  |  |  |  |
| EML4_MTA3_ENST00000318522_ENST00000406911_42472827_42836597 superimposed PDB: 4CGC of partner (EML4). RMSD:0.328
Å |
 |  |  |  |  |
| EML4_MTA3_ENST00000402711_ENST00000405592_42472827_42836597 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3434
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000318522_ENST00000317501_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3718
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000318522_ENST00000317501_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6677
Å |
| | | |  |
| EML4_NTRK3_ENST00000318522_ENST00000355254_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3774
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000318522_ENST00000355254_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7173
Å |
| | | |  |
| EML4_NTRK3_ENST00000318522_ENST00000557856_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3568
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000318522_ENST00000557856_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7057
Å |
| | | |  |
| EML4_NTRK3_ENST00000318522_ENST00000558676_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3623
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000318522_ENST00000558676_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6944
Å |
| | | |  |
| EML4_NTRK3_ENST00000401738_ENST00000394480_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3228
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000317501_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3679
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000317501_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6635
Å |
| | | |  |
| EML4_NTRK3_ENST00000402711_ENST00000355254_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3516
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000355254_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7034
Å |
| | | |  |
| EML4_NTRK3_ENST00000402711_ENST00000394480_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3198
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000557856_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3714
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000557856_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7088
Å |
| | | |  |
| EML4_NTRK3_ENST00000402711_ENST00000558676_42491871_88576276 superimposed PDB: 4CGC of partner (EML4). RMSD:0.3482
Å |
 |  |  |  |  |
| EML4_NTRK3_ENST00000402711_ENST00000558676_42491871_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.649
Å |
| | | |  |
| EML4_RTN4_ENST00000318522_ENST00000405240_42396776_55214834 superimposed PDB: 4CGC of partner (EML4). RMSD:0.2573
Å |
 |  |  |  |  |
| EML6_SPTBN1_ENST00000356458_ENST00000333896_55044022_54870119 superimposed PDB: 3EDV of partner (SPTBN1). RMSD:2.1983
Å |
 |  |  |  |  |
| EMP2_TERF2_ENST00000536829_ENST00000603068_10637426_69419389 superimposed PDB: 9Q9M of partner (TERF2). RMSD:2.5434
Å |
 |  |  |  |  |
| ENDOD1_RAB30_ENST00000278505_ENST00000260056_94823391_82698812 superimposed PDB: 2EW1 of partner (RAB30). RMSD:0.8147
Å |
 |  |  |  |  |
| ENDOD1_RAB30_ENST00000278505_ENST00000260056_94823391_82705164 superimposed PDB: 2EW1 of partner (RAB30). RMSD:1.1327
Å |
 |  |  |  |  |
| ENDOD1_RAB30_ENST00000278505_ENST00000534141_94823391_82698812 superimposed PDB: 2EW1 of partner (RAB30). RMSD:0.6726
Å |
 |  |  |  |  |
| ENDOD1_RAB30_ENST00000278505_ENST00000534141_94823391_82705164 superimposed PDB: 2EW1 of partner (RAB30). RMSD:0.7819
Å |
 |  |  |  |  |
| ENDOV_IKZF3_ENST00000517295_ENST00000394189_78403631_37922746 superimposed PDB: 6OZE of partner (ENDOV). RMSD:0.3503
Å |
 |  |  |  |  |
| ENDOV_IKZF3_ENST00000517795_ENST00000394189_78403631_37922746 superimposed PDB: 6OZE of partner (ENDOV). RMSD:0.5773
Å |
 |  |  |  |  |
| ENDOV_IKZF3_ENST00000518137_ENST00000394189_78403631_37922746 superimposed PDB: 6OZE of partner (ENDOV). RMSD:0.3143
Å |
 |  |  |  |  |
| ENDOV_IKZF3_ENST00000518901_ENST00000394189_78403631_37922746 superimposed PDB: 6OZE of partner (ENDOV). RMSD:0.3949
Å |
 |  |  |  |  |
| ENDOV_IKZF3_ENST00000520367_ENST00000394189_78403631_37922746 superimposed PDB: 6OZE of partner (ENDOV). RMSD:0.463
Å |
 |  |  |  |  |
| ENG_NOL9_ENST00000344849_ENST00000377705_130579427_6604982 superimposed PDB: 5I04 of partner (ENG). RMSD:0.9785
Å |
 |  |  |  |  |
| ENG_NOL9_ENST00000344849_ENST00000377705_130579427_6604982 superimposed PDB: 26LK of partner (NOL9). RMSD:0.921
Å |
| | | |  |
| ENO1_AXL_ENST00000234590_ENST00000359092_8927175_41726540 superimposed PDB: 5U6B of partner (AXL). RMSD:1.0007
Å |
 |  |  |  |  |
| ENO2_ACRBP_ENST00000229277_ENST00000229243_7027326_6756178 superimposed PDB: 4ZCW of partner (ENO2). RMSD:0.8684
Å |
 |  |  |  |  |
| ENO2_ACRBP_ENST00000538763_ENST00000414226_7027326_6756178 superimposed PDB: 4ZCW of partner (ENO2). RMSD:1.4181
Å |
 |  |  |  |  |
| ENO2_ACRBP_ENST00000541477_ENST00000414226_7027326_6756178 superimposed PDB: 4ZCW of partner (ENO2). RMSD:1.0582
Å |
 |  |  |  |  |
| ENO2_ACRBP_ENST00000544774_ENST00000229243_7027326_6756178 superimposed PDB: 4ZCW of partner (ENO2). RMSD:1.0406
Å |
 |  |  |  |  |
| ENOSF1_PPT1_ENST00000340116_ENST00000433473_706469_40558179 superimposed PDB: 4A35 of partner (ENOSF1). RMSD:1.5662
Å |
 |  |  |  |  |
| ENOSF1_PPT1_ENST00000340116_ENST00000433473_706469_40558179 superimposed PDB: 3GRO of partner (PPT1). RMSD:0.4322
Å |
| | | |  |
| ENOSF1_PPT1_ENST00000580982_ENST00000433473_706469_40558179 superimposed PDB: 3GRO of partner (PPT1). RMSD:0.465
Å |
 |  |  |  |  |
| ENPEP_SEC31A_ENST00000265162_ENST00000395310_111441522_83740406 superimposed PDB: 4KX7 of partner (ENPEP). RMSD:0.5588
Å |
 |  |  |  |  |
| ENPEP_SEC31A_ENST00000265162_ENST00000508502_111441522_83740406 superimposed PDB: 4KX7 of partner (ENPEP). RMSD:0.4318
Å |
 |  |  |  |  |
| ENPP2_FAM192A_ENST00000259486_ENST00000567439_120592355_57188419 superimposed PDB: 8C3P of partner (ENPP2). RMSD:0.5677
Å |
 |  |  |  |  |
| ENPP2_FAM192A_ENST00000427067_ENST00000567439_120592355_57188419 superimposed PDB: 8C3P of partner (ENPP2). RMSD:0.5887
Å |
 |  |  |  |  |
| ENPP2_FAM192A_ENST00000427067_ENST00000567439_120592355_57188419 superimposed PDB: 7W59 of partner (FAM192A). RMSD:2.7203
Å |
| | | |  |
| ENPP2_FAM192A_ENST00000522826_ENST00000309137_120592355_57188419 superimposed PDB: 8C3P of partner (ENPP2). RMSD:0.7799
Å |
 |  |  |  |  |
| ENPP2_FAM192A_ENST00000522826_ENST00000567439_120592355_57188419 superimposed PDB: 8C3P of partner (ENPP2). RMSD:0.5883
Å |
 |  |  |  |  |
| ENPP2_FAM192A_ENST00000522826_ENST00000567439_120592355_57188419 superimposed PDB: 7W59 of partner (FAM192A). RMSD:2.717
Å |
| | | |  |
| ENSA_FBP1_ENST00000361532_ENST00000415431_150598117_97382773 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.4373
Å |
 |  |  |  |  |
| ENSA_FBP1_ENST00000361631_ENST00000415431_150598117_97382773 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.4091
Å |
 |  |  |  |  |
| ENSA_FBP1_ENST00000369009_ENST00000415431_150598117_97382773 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.4145
Å |
 |  |  |  |  |
| ENSA_FBP1_ENST00000369014_ENST00000415431_150598117_97382773 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.4129
Å |
 |  |  |  |  |
| ENSA_FBP1_ENST00000369016_ENST00000415431_150598117_97382773 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.4314
Å |
 |  |  |  |  |
| ENTPD4_UBE2V2_ENST00000358689_ENST00000517630_23291829_48973241 superimposed PDB: 6WG5 of partner (ENTPD4). RMSD:2.5196
Å |
 |  |  |  |  |
| ENTPD4_UBE2V2_ENST00000417069_ENST00000517630_23291829_48973241 superimposed PDB: 6WG5 of partner (ENTPD4). RMSD:2.4634
Å |
 |  |  |  |  |
| ENTPD5_ALDH6A1_ENST00000557325_ENST00000350259_74436712_74541720 superimposed PDB: 9IZX of partner (ALDH6A1). RMSD:0.8685
Å |
 |  |  |  |  |
| ENTPD5_MICU1_ENST00000557325_ENST00000361114_74436712_74311099 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.9162
Å |
 |  |  |  |  |
| ENTPD5_MICU1_ENST00000557325_ENST00000398761_74436712_74311099 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.9049
Å |
 |  |  |  |  |
| ENTPD5_TSHR_ENST00000334696_ENST00000342443_74453516_81558874 superimposed PDB: 7UTZ of partner (TSHR). RMSD:2.5766
Å |
 |  |  |  |  |
| ENTPD6_COL1A2_ENST00000433259_ENST00000297268_25194042_94038081 superimposed PDB: 8YV3 of partner (COL1A2). RMSD:2.7283
Å |
 |  |  |  |  |
| ENY2_NSF_ENST00000521662_ENST00000225282_110352792_44751779 superimposed PDB: 4DHX of partner (ENY2). RMSD:2.6452
Å |
 |  |  |  |  |
| ENY2_NSF_ENST00000521662_ENST00000575068_110352792_44751779 superimposed PDB: 4DHX of partner (ENY2). RMSD:2.6619
Å |
 |  |  |  |  |
| ENY2_NSF_ENST00000521688_ENST00000225282_110352792_44751779 superimposed PDB: 4DHX of partner (ENY2). RMSD:2.8234
Å |
 |  |  |  |  |
| ENY2_NSF_ENST00000521688_ENST00000575068_110352792_44751779 superimposed PDB: 4DHX of partner (ENY2). RMSD:2.7102
Å |
 |  |  |  |  |
| EP300_BCOR_ENST00000263253_ENST00000342274_41572532_39930412 superimposed PDB: 8HAG of partner (EP300). RMSD:0.8148
Å |
 |  |  |  |  |
| EP300_BCOR_ENST00000263253_ENST00000342274_41572532_39930412 superimposed PDB: 8HCU of partner (BCOR). RMSD:0.6823
Å |
| | | |  |
| EP300_CARD8_ENST00000263253_ENST00000521613_41489102_48718641 superimposed PDB: 7JKQ of partner (CARD8). RMSD:2.0996
Å |
 |  |  |  |  |
| EP300_ETV6_ENST00000263253_ENST00000396373_41572532_11905383 superimposed PDB: 8HAG of partner (EP300). RMSD:0.8181
Å |
 |  |  |  |  |
| EP300_ETV6_ENST00000263253_ENST00000396373_41572532_11905383 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3532
Å |
| | | |  |
| EP300_HAUS8_ENST00000263253_ENST00000253669_41513825_17166812 superimposed PDB: 7SQK of partner (HAUS8). RMSD:2.7933
Å |
 |  |  |  |  |
| EP300_TMPRSS6_ENST00000263253_ENST00000346753_41568667_37480444 superimposed PDB: 8HAG of partner (EP300). RMSD:1.0406
Å |
 |  |  |  |  |
| EP300_TMPRSS6_ENST00000263253_ENST00000346753_41568667_37480444 superimposed PDB: 9NRC of partner (TMPRSS6). RMSD:3.0984
Å |
| | | |  |
| EP300_TMPRSS6_ENST00000263253_ENST00000406725_41568667_37480444 superimposed PDB: 8HAG of partner (EP300). RMSD:1.0415
Å |
 |  |  |  |  |
| EP300_TMPRSS6_ENST00000263253_ENST00000406725_41568667_37480444 superimposed PDB: 9NRC of partner (TMPRSS6). RMSD:3.1065
Å |
| | | |  |
| EP400_NAP1L1_ENST00000330386_ENST00000393263_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.7544
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000330386_ENST00000547993_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8787
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000330386_ENST00000549596_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8285
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000332482_ENST00000393263_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.6936
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000332482_ENST00000547993_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.7132
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000332482_ENST00000549596_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.0428
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000333577_ENST00000393263_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.9503
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000333577_ENST00000547993_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.9771
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000333577_ENST00000549596_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.6874
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389561_ENST00000393263_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8618
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389561_ENST00000547993_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8273
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389561_ENST00000549596_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.7652
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389562_ENST00000393263_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8714
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389562_ENST00000547993_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8667
Å |
 |  |  |  |  |
| EP400_NAP1L1_ENST00000389562_ENST00000549596_132512833_76447130 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.7683
Å |
 |  |  |  |  |
| EPB41L2_EPB41L3_ENST00000524581_ENST00000400111_131188598_5395706 superimposed PDB: 6IBE of partner (EPB41L3). RMSD:2.8479
Å |
 |  |  |  |  |
| EPB41L2_EPB41L3_ENST00000524581_ENST00000544123_131188598_5395706 superimposed PDB: 6IBE of partner (EPB41L3). RMSD:2.9315
Å |
 |  |  |  |  |
| EPB41L2_EPB41L3_ENST00000530757_ENST00000400111_131188598_5395706 superimposed PDB: 6IBE of partner (EPB41L3). RMSD:2.7318
Å |
 |  |  |  |  |
| EPB41L2_EPB41L3_ENST00000530757_ENST00000544123_131188598_5395706 superimposed PDB: 6IBE of partner (EPB41L3). RMSD:2.7412
Å |
 |  |  |  |  |
| EPB41_HGSNAT_ENST00000349460_ENST00000379644_29323831_43013717 superimposed PDB: 8JL3 of partner (HGSNAT). RMSD:0.8165
Å |
 |  |  |  |  |
| EPB41_HGSNAT_ENST00000356093_ENST00000379644_29323831_43013717 superimposed PDB: 8JL3 of partner (HGSNAT). RMSD:0.8172
Å |
 |  |  |  |  |
| EPB41_HGSNAT_ENST00000373797_ENST00000379644_29323831_43013717 superimposed PDB: 8JL3 of partner (HGSNAT). RMSD:0.8347
Å |
 |  |  |  |  |
| EPB41_HGSNAT_ENST00000373798_ENST00000379644_29323831_43013717 superimposed PDB: 8JL3 of partner (HGSNAT). RMSD:0.759
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000343067_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6696
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000343067_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6676
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000347529_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6816
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000347529_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.8276
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000349460_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6938
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000349460_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.7682
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000356093_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.7235
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000356093_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.852
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000373798_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.7373
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000373798_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6533
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000398863_ENST00000354582_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6791
Å |
 |  |  |  |  |
| EPB41_ITPR1_ENST00000398863_ENST00000423119_29435949_4774771 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.7301
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000343067_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6414
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000347529_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6211
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000349460_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.5993
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000356093_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6187
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000373798_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6041
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000373800_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6199
Å |
 |  |  |  |  |
| EPB41_YTHDF2_ENST00000398863_ENST00000541996_29391670_29095440 superimposed PDB: 1GG3 of partner (EPB41). RMSD:0.6139
Å |
 |  |  |  |  |
| EPC1_PTGR2_ENST00000319778_ENST00000555661_32635690_74340725 superimposed PDB: 2ZB4 of partner (PTGR2). RMSD:0.5355
Å |
 |  |  |  |  |
| EPHA2_FBXO42_ENST00000358432_ENST00000375592_16474872_16583254 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.5494
Å |
 |  |  |  |  |
| EPHA2_FBXO42_ENST00000461614_ENST00000375592_16474872_16583254 superimposed PDB: 2X10 of partner (EPHA2). RMSD:1.733
Å |
 |  |  |  |  |
| EPHA2_FBXO42_ENST00000461614_ENST00000375592_16474872_16583254 superimposed PDB: 9O04 of partner (FBXO42). RMSD:0.9313
Å |
| | | |  |
| EPHA2_LSM14B_ENST00000358432_ENST00000253001_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:1.7532
Å |
 |  |  |  |  |
| EPHA2_LSM14B_ENST00000358432_ENST00000279068_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.0871
Å |
 |  |  |  |  |
| EPHA2_LSM14B_ENST00000358432_ENST00000370915_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:1.6352
Å |
 |  |  |  |  |
| EPHA2_LSM14B_ENST00000461614_ENST00000253001_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:1.7609
Å |
 |  |  |  |  |
| EPHA2_LSM14B_ENST00000461614_ENST00000279068_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.0307
Å |
 |  |  |  |  |
| EPHA2_LSM14B_ENST00000461614_ENST00000370915_16474872_60699672 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.6305
Å |
 |  |  |  |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000426633_16464347_33273164 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.4323
Å |
 |  |  |  |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000426633_16464347_33273164 superimposed PDB: 9RCV of partner (TAPBP). RMSD:1.2784
Å |
| | | |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000456592_16464347_33273164 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.4591
Å |
 |  |  |  |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000456592_16464347_33273164 superimposed PDB: 9RCV of partner (TAPBP). RMSD:1.4067
Å |
| | | |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000475304_16464347_33273164 superimposed PDB: 2X10 of partner (EPHA2). RMSD:2.5786
Å |
 |  |  |  |  |
| EPHA2_TAPBP_ENST00000358432_ENST00000475304_16464347_33273164 superimposed PDB: 9RCV of partner (TAPBP). RMSD:1.3233
Å |
| | | |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000368207_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7772
Å |
 |  |  |  |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000368210_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.8487
Å |
 |  |  |  |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000368213_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7724
Å |
 |  |  |  |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000368215_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.2956
Å |
 |  |  |  |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000368227_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.8795
Å |
 |  |  |  |  |
| EPHA7_PTPRK_ENST00000369303_ENST00000532331_94066434_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.6301
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374627_ENST00000358660_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9843
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374627_ENST00000358660_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.738
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000374627_ENST00000368196_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9522
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374627_ENST00000368196_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.6976
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000374630_ENST00000358660_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9468
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374630_ENST00000358660_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.7932
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000374630_ENST00000368196_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9904
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374630_ENST00000368196_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.7415
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000374630_ENST00000392302_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9458
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000374632_ENST00000358660_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9567
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000400191_ENST00000392302_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9652
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000400191_ENST00000392302_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.7827
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000544305_ENST00000358660_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.9113
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000544305_ENST00000358660_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.7351
Å |
| | | |  |
| EPHB2_NTRK1_ENST00000544305_ENST00000368196_23111569_156843424 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.973
Å |
 |  |  |  |  |
| EPHB2_NTRK1_ENST00000544305_ENST00000368196_23111569_156843424 superimposed PDB: 7N3T of partner (NTRK1). RMSD:2.8437
Å |
| | | |  |
| EPHB2_ZBTB40_ENST00000544305_ENST00000404138_23111569_22843792 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.957
Å |
 |  |  |  |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000374627_184289170_23110884 superimposed PDB: 5L6O of partner (EPHB3). RMSD:0.3959
Å |
 |  |  |  |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000374627_184289170_23110884 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.4111
Å |
| | | |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000374632_184289170_23110884 superimposed PDB: 5L6O of partner (EPHB3). RMSD:0.3895
Å |
 |  |  |  |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000374632_184289170_23110884 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.3977
Å |
| | | |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000400191_184289170_23110884 superimposed PDB: 5L6O of partner (EPHB3). RMSD:0.4059
Å |
 |  |  |  |  |
| EPHB3_EPHB2_ENST00000330394_ENST00000400191_184289170_23110884 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.3955
Å |
| | | |  |
| EPS15L1_MED26_ENST00000248070_ENST00000263390_16503114_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:2.4655
Å |
 |  |  |  |  |
| EPS15L1_MED26_ENST00000248070_ENST00000263390_16582723_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:2.2826
Å |
 |  |  |  |  |
| EPS15L1_MED26_ENST00000535753_ENST00000263390_16503114_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:2.8971
Å |
 |  |  |  |  |
| EPS15L1_MED26_ENST00000535753_ENST00000263390_16582723_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:1.9814
Å |
 |  |  |  |  |
| EPS15L1_ZNF473_ENST00000455140_ENST00000270617_16545175_50547926 superimposed PDB: 2EMC of partner (ZNF473). RMSD:0.5871
Å |
 |  |  |  |  |
| EPS15_FAF1_ENST00000371730_ENST00000371778_51984870_51323669 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8761
Å |
 |  |  |  |  |
| EPS15_FAF1_ENST00000371733_ENST00000371778_51984870_51323669 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8819
Å |
 |  |  |  |  |
| EPS15_TTC39A_ENST00000371730_ENST00000413473_51912631_51787497 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.199
Å |
 |  |  |  |  |
| EPS15_TTC39A_ENST00000371733_ENST00000413473_51912631_51787497 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.1931
Å |
 |  |  |  |  |
| EPS15_TTC39A_ENST00000371733_ENST00000447632_51912631_51787497 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.1972
Å |
 |  |  |  |  |
| ERBB2IP_ASXL1_ENST00000380943_ENST00000375687_65350779_31015930 superimposed PDB: 8SVF of partner (ASXL1). RMSD:0.7649
Å |
 |  |  |  |  |
| ERBB2IP_ASXL1_ENST00000506030_ENST00000375687_65350779_31015930 superimposed PDB: 8SVF of partner (ASXL1). RMSD:0.8677
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000269571_ENST00000430627_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9616
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000269571_ENST00000430627_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3538
Å |
| | | |  |
| ERBB2_CDK12_ENST00000269571_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6423
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000269571_ENST00000447079_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9611
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000269571_ENST00000447079_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3742
Å |
| | | |  |
| ERBB2_CDK12_ENST00000269571_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6333
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000406381_ENST00000430627_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9638
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000406381_ENST00000430627_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3801
Å |
| | | |  |
| ERBB2_CDK12_ENST00000406381_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6383
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000406381_ENST00000447079_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9586
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000406381_ENST00000447079_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3687
Å |
| | | |  |
| ERBB2_CDK12_ENST00000406381_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.68
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000445658_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.628
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000540147_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.6761
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000540147_ENST00000447079_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.8953
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000540147_ENST00000447079_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3666
Å |
| | | |  |
| ERBB2_CDK12_ENST00000540147_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.671
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000541774_ENST00000430627_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.8536
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000541774_ENST00000430627_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3649
Å |
| | | |  |
| ERBB2_CDK12_ENST00000541774_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7077
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000578199_ENST00000430627_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9409
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000578199_ENST00000430627_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3711
Å |
| | | |  |
| ERBB2_CDK12_ENST00000578199_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6338
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584450_ENST00000430627_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9514
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584450_ENST00000430627_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.352
Å |
| | | |  |
| ERBB2_CDK12_ENST00000584450_ENST00000430627_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.648
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584450_ENST00000447079_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9202
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584450_ENST00000447079_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3794
Å |
| | | |  |
| ERBB2_CDK12_ENST00000584450_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6492
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584601_ENST00000447079_37866734_37657502 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9504
Å |
 |  |  |  |  |
| ERBB2_CDK12_ENST00000584601_ENST00000447079_37866734_37657502 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3569
Å |
| | | |  |
| ERBB2_CDK12_ENST00000584601_ENST00000447079_37868701_37680926 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6468
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000269571_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7441
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000269571_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7877
Å |
| | | |  |
| ERBB2_CTTN_ENST00000406381_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6764
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000406381_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7914
Å |
| | | |  |
| ERBB2_CTTN_ENST00000445658_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.4816
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000445658_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7347
Å |
| | | |  |
| ERBB2_CTTN_ENST00000540147_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6932
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000540147_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.8007
Å |
| | | |  |
| ERBB2_CTTN_ENST00000584450_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.748
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000584450_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7423
Å |
| | | |  |
| ERBB2_CTTN_ENST00000584601_ENST00000301843_37872192_70269045 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6502
Å |
 |  |  |  |  |
| ERBB2_CTTN_ENST00000584601_ENST00000301843_37872192_70269045 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.8166
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000346243_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.8889
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000346243_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:2.9483
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5119
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2756
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.511
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1889
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000377944_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.9124
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000377944_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1955
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000377945_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5659
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000377952_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5179
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000377958_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5177
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000394189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5128
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000394189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1975
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.9172
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000439167_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5702
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5733
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2597
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000535189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.6429
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000269571_ENST00000535189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2663
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000346243_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.627
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000346243_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2403
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5169
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1363
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5051
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1102
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000377944_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.8548
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000377944_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1159
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000377945_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5629
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000377952_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.56
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000377958_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5345
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000394189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5241
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000394189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0822
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.8864
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000439167_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5308
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.553
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1774
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000535189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.4526
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000406381_ENST00000535189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1961
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000346243_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.8816
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000346243_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0781
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5609
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2963
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5147
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2435
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000377944_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.514
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000377944_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1087
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000377945_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.509
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000377952_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.58
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000377958_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.564
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000394189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.521
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000394189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1538
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000439167_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5641
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5604
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2356
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000540147_ENST00000535189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1882
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.4941
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1184
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5177
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0886
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.5702
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6139
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000541774_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1688
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5332
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1645
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5662
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1258
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.9467
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000578199_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1335
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000346243_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.9794
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000346243_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2549
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5059
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.297
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5278
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2052
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000377944_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.5976
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000377944_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1243
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000377945_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5111
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000377952_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5968
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000377958_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5604
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000394189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5858
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000394189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0693
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.0808
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000439167_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5424
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5869
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2259
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000535189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.7799
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584450_ENST00000535189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1942
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000346243_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:1.8622
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000346243_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.3196
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000350532_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5123
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000350532_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2727
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000351680_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5718
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000351680_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1993
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000377944_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.0149
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000377944_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2288
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000377945_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5506
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000377952_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5352
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000377958_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5191
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000394189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5344
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000394189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1215
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000439016_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.7954
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000439167_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5711
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000467757_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5442
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000467757_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2165
Å |
| | | |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000535189_37866134_37988404 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:3.2292
Å |
 |  |  |  |  |
| ERBB2_IKZF3_ENST00000584601_ENST00000535189_37866134_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2326
Å |
| | | |  |
| ERBB2_NARS2_ENST00000269571_ENST00000281038_37866134_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5875
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000269571_ENST00000281038_37866734_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6122
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000406381_ENST00000281038_37866134_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5647
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000406381_ENST00000281038_37866734_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5887
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000541774_ENST00000281038_37866134_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5721
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000541774_ENST00000281038_37866734_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5914
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000578199_ENST00000281038_37866134_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6227
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000578199_ENST00000281038_37866734_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5891
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000584450_ENST00000281038_37866134_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.5844
Å |
 |  |  |  |  |
| ERBB2_NARS2_ENST00000584450_ENST00000281038_37866734_78147860 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6173
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000269571_ENST00000225426_37873733_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6384
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000269571_ENST00000225426_37873733_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.5733
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000269571_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6459
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000269571_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6601
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000406381_ENST00000225426_37873733_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6299
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000406381_ENST00000225426_37873733_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6351
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000406381_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6165
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000406381_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6297
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000540147_ENST00000225426_37873733_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6477
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000540147_ENST00000225426_37873733_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6964
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000540147_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7158
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000540147_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.8075
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000541774_ENST00000225426_37873733_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6149
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000541774_ENST00000225426_37873733_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.5876
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000541774_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6549
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000541774_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6579
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000584450_ENST00000225426_37873733_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6403
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000584450_ENST00000225426_37873733_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.5808
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000584450_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6589
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000584450_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6421
Å |
| | | |  |
| ERBB2_PSMB3_ENST00000584601_ENST00000225426_37876087_36916683 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6667
Å |
 |  |  |  |  |
| ERBB2_PSMB3_ENST00000584601_ENST00000225426_37876087_36916683 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.6454
Å |
| | | |  |
| ERBB2_SLC29A3_ENST00000269571_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7251
Å |
 |  |  |  |  |
| ERBB2_SLC29A3_ENST00000406381_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6893
Å |
 |  |  |  |  |
| ERBB2_SLC29A3_ENST00000540147_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:1.0437
Å |
 |  |  |  |  |
| ERBB2_SLC29A3_ENST00000541774_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7054
Å |
 |  |  |  |  |
| ERBB2_SLC29A3_ENST00000584450_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7364
Å |
 |  |  |  |  |
| ERBB2_SLC29A3_ENST00000584601_ENST00000373189_37883256_73121710 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6464
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000269571_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6503
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000269571_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6503
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000406381_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6765
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000406381_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6667
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000445658_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.4084
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000445658_ENST00000519548_37868701_125507783 superimposed PDB: 8EFG of partner (TATDN1). RMSD:2.8933
Å |
| | | |  |
| ERBB2_TATDN1_ENST00000540147_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:2.586
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000540147_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6934
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000541774_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6345
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000578199_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.7165
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000584450_ENST00000276692_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.665
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000584450_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6795
Å |
 |  |  |  |  |
| ERBB2_TATDN1_ENST00000584601_ENST00000519548_37868701_125507783 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.6401
Å |
 |  |  |  |  |
| ERBB3_EGFR_ENST00000415288_ENST00000455089_56492359_55266409 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:0.7343
Å |
 |  |  |  |  |
| ERBB3_EGFR_ENST00000415288_ENST00000455089_56492359_55266409 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.9853
Å |
| | | |  |
| ERBB3_EGFR_ENST00000450146_ENST00000455089_56492359_55266409 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.5626
Å |
 |  |  |  |  |
| ERBB3_EGFR_ENST00000450146_ENST00000455089_56492359_55266409 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.3893
Å |
| | | |  |
| ERBB3_EGFR_ENST00000553131_ENST00000455089_56492359_55266409 superimposed PDB: 7MN5 of partner (ERBB3). RMSD:2.4619
Å |
 |  |  |  |  |
| ERBB3_EGFR_ENST00000553131_ENST00000455089_56492359_55266409 superimposed PDB: 7SYD of partner (EGFR). RMSD:2.3162
Å |
| | | |  |
| ERC1_CACNA1C_ENST00000360905_ENST00000335762_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0799
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000327702_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2254
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000335762_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.17
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000344100_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0577
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000347598_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1812
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399591_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.9997
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399595_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1581
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399597_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1548
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399601_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1489
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399603_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0634
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399606_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1416
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399617_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1765
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399621_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0993
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399629_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0815
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399634_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1224
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399637_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.9576
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399638_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1471
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399641_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0753
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399644_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0774
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399649_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0669
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000399655_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0192
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000402845_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1378
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000406454_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1469
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000397203_ENST00000480911_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1152
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000327702_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1072
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000344100_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0525
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000347598_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1321
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399591_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0929
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399595_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1481
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399597_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1258
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399601_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0013
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399603_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1552
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399606_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.121
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399617_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1484
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399621_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1727
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399629_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2147
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399634_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0873
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399637_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1117
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399638_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.179
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399641_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1086
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399644_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0602
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399649_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0805
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000399655_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1372
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000402845_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0276
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000406454_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.132
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000543086_ENST00000480911_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1523
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000327702_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.089
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000335762_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0149
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000344100_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0524
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000347598_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1876
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399591_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0788
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399595_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.154
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399597_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1514
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399601_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0861
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399603_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1856
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399606_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1225
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399617_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0281
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399621_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0424
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399629_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1451
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399634_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1037
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399637_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.124
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399638_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.151
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399641_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1043
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399644_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0413
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399649_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.138
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000399655_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2158
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000402845_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1034
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000406454_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0029
Å |
 |  |  |  |  |
| ERC1_CACNA1C_ENST00000546231_ENST00000480911_1517413_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2415
Å |
 |  |  |  |  |
| ERC1_TACC3_ENST00000546231_ENST00000313288_1192746_1741428 superimposed PDB: 5LXN of partner (TACC3). RMSD:1.5138
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000360905_ENST00000535572_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7028
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000397203_ENST00000535572_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6507
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000543086_ENST00000315939_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6594
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000543086_ENST00000447667_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5705
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000543086_ENST00000530271_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7976
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000543086_ENST00000537687_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5657
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000546231_ENST00000315939_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7745
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000546231_ENST00000447667_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6447
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000546231_ENST00000530271_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8405
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000546231_ENST00000535572_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6217
Å |
 |  |  |  |  |
| ERC1_WNK1_ENST00000546231_ENST00000537687_1225199_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6807
Å |
 |  |  |  |  |
| ERCC2_NOVA2_ENST00000221481_ENST00000263257_45871887_46444203 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.7931
Å |
 |  |  |  |  |
| ERCC2_NOVA2_ENST00000221481_ENST00000263257_45871887_46444203 superimposed PDB: 1EC6 of partner (NOVA2). RMSD:0.5036
Å |
| | | |  |
| ERCC2_NOVA2_ENST00000391940_ENST00000263257_45871887_46444203 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.6565
Å |
 |  |  |  |  |
| ERCC2_NOVA2_ENST00000391940_ENST00000263257_45871887_46444203 superimposed PDB: 1EC6 of partner (NOVA2). RMSD:0.4626
Å |
| | | |  |
| ERCC2_NOVA2_ENST00000391944_ENST00000263257_45871887_46444203 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.7602
Å |
 |  |  |  |  |
| ERCC2_NOVA2_ENST00000391944_ENST00000263257_45871887_46444203 superimposed PDB: 1EC6 of partner (NOVA2). RMSD:0.4894
Å |
| | | |  |
| ERCC2_NOVA2_ENST00000485403_ENST00000263257_45871887_46444203 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.6556
Å |
 |  |  |  |  |
| ERCC2_NOVA2_ENST00000485403_ENST00000263257_45871887_46444203 superimposed PDB: 1EC6 of partner (NOVA2). RMSD:0.501
Å |
| | | |  |
| ERCC2_RTN2_ENST00000391940_ENST00000245923_45864781_45998397 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.2035
Å |
 |  |  |  |  |
| ERCC2_RTN2_ENST00000391944_ENST00000245923_45864781_45998397 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1688
Å |
 |  |  |  |  |
| ERCC2_RTN2_ENST00000485403_ENST00000245923_45864781_45998397 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.4914
Å |
 |  |  |  |  |
| ERCC6L2_ATP8A1_ENST00000288985_ENST00000264449_98718295_42526864 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.4969
Å |
 |  |  |  |  |
| ERCC6L2_ATP8A1_ENST00000288985_ENST00000264449_98718295_42526864 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.6613
Å |
| | | |  |
| ERCC6L2_ATP8A1_ENST00000288985_ENST00000381668_98718295_42526864 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.4223
Å |
 |  |  |  |  |
| ERCC6L2_ATP8A1_ENST00000437817_ENST00000264449_98718295_42526864 superimposed PDB: 6K7L of partner (ATP8A1). RMSD:2.0246
Å |
 |  |  |  |  |
| ERCC6L2_CDC14B_ENST00000407474_ENST00000375236_98766983_99304174 superimposed PDB: 1OHE of partner (CDC14B). RMSD:0.3406
Å |
 |  |  |  |  |
| ERCC6L2_CDC14B_ENST00000407474_ENST00000375240_98766983_99304174 superimposed PDB: 1OHE of partner (CDC14B). RMSD:0.365
Å |
 |  |  |  |  |
| ERCC6L2_CDC14B_ENST00000407474_ENST00000375241_98766983_99304174 superimposed PDB: 1OHE of partner (CDC14B). RMSD:0.3768
Å |
 |  |  |  |  |
| ERCC6L2_CDC14B_ENST00000407474_ENST00000463569_98766983_99304174 superimposed PDB: 1OHE of partner (CDC14B). RMSD:0.3693
Å |
 |  |  |  |  |
| ERCC6L2_TRPM6_ENST00000288985_ENST00000359047_98660253_77473664 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.7667
Å |
 |  |  |  |  |
| ERCC6L2_TRPM6_ENST00000288985_ENST00000360774_98660253_77473664 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.4189
Å |
 |  |  |  |  |
| ERCC6L2_TRPM6_ENST00000288985_ENST00000376864_98660253_77473664 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.4623
Å |
 |  |  |  |  |
| ERCC6L2_TRPM6_ENST00000288985_ENST00000376872_98660253_77473664 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.6586
Å |
 |  |  |  |  |
| ERCC6L2_TRPM6_ENST00000288985_ENST00000449912_98660253_77473664 superimposed PDB: 6HQ9 of partner (ERCC6L2). RMSD:0.662
Å |
 |  |  |  |  |
| ERCC6_PREX1_ENST00000355832_ENST00000396220_50736462_47324959 superimposed PDB: 8TUA of partner (PREX1). RMSD:1.7017
Å |
 |  |  |  |  |
| ERG_TAF8_ENST00000398911_ENST00000372977_39947585_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.6107
Å |
 |  |  |  |  |
| ERG_TAF8_ENST00000398911_ENST00000372982_39947585_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.5421
Å |
 |  |  |  |  |
| ERG_TAF8_ENST00000398911_ENST00000456846_39947585_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.6742
Å |
 |  |  |  |  |
| ERG_TAF8_ENST00000398911_ENST00000494547_39947585_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.9139
Å |
 |  |  |  |  |
| ERG_TAF8_ENST00000398919_ENST00000372978_39947585_42019094 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.609
Å |
 |  |  |  |  |
| ERG_TMPRSS2_ENST00000398910_ENST00000398585_39947585_42852529 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7536
Å |
 |  |  |  |  |
| ERG_TMPRSS2_ENST00000398910_ENST00000398585_39947585_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7389
Å |
 |  |  |  |  |
| ERG_TMPRSS2_ENST00000398911_ENST00000398585_39947585_42866505 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7082
Å |
 |  |  |  |  |
| ERG_ZNRF3_ENST00000398911_ENST00000332811_39947585_29383063 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.145
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000262109_ENST00000344419_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7133
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000262109_ENST00000392255_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.8053
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000262109_ENST00000392256_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.4206
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000262109_ENST00000425615_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7723
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000262109_ENST00000500320_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7239
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000522706_ENST00000344419_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7746
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000522706_ENST00000392255_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.8043
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000522706_ENST00000392256_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.3726
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000522706_ENST00000425615_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7434
Å |
 |  |  |  |  |
| ERICH1_IYD_ENST00000522706_ENST00000500320_618597_150710487 superimposed PDB: 5YAK of partner (IYD). RMSD:0.7495
Å |
 |  |  |  |  |
| ERLEC1_ACYP2_ENST00000185150_ENST00000607452_54040210_54278094 superimposed PDB: 8KET of partner (ERLEC1). RMSD:1.8044
Å |
 |  |  |  |  |
| ERLEC1_ACYP2_ENST00000405123_ENST00000607452_54040210_54278094 superimposed PDB: 8KET of partner (ERLEC1). RMSD:2.878
Å |
 |  |  |  |  |
| ERLIN2_FGFR1_ENST00000519638_ENST00000425967_37607370_38315052 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.7118
Å |
 |  |  |  |  |
| ERN1_SMURF2_ENST00000433197_ENST00000262435_62175480_62602758 superimposed PDB: 9FSH of partner (SMURF2). RMSD:2.1179
Å |
 |  |  |  |  |
| ERN2_EARS2_ENST00000256797_ENST00000563459_23713710_23556024 superimposed PDB: 9I3U of partner (ERN2). RMSD:0.6666
Å |
 |  |  |  |  |
| ERN2_EARS2_ENST00000457008_ENST00000563459_23713710_23556024 superimposed PDB: 9I3U of partner (ERN2). RMSD:0.7291
Å |
 |  |  |  |  |
| ERP44_CCNB1IP1_ENST00000262455_ENST00000398169_102778603_20781960 superimposed PDB: 5XWM of partner (ERP44). RMSD:1.5152
Å |
 |  |  |  |  |
| ERP44_CCNB1IP1_ENST00000262455_ENST00000398169_102778603_20781960 superimposed PDB: 9GES of partner (CCNB1IP1). RMSD:1.4519
Å |
| | | |  |
| ERP44_UBQLN1_ENST00000262455_ENST00000257468_102814698_86284242 superimposed PDB: 5XWM of partner (ERP44). RMSD:0.5429
Å |
 |  |  |  |  |
| ESCO2_EPHX2_ENST00000305188_ENST00000517536_27646495_27394300 superimposed PDB: 3I28 of partner (EPHX2). RMSD:0.8173
Å |
 |  |  |  |  |
| ESRP1_MYSM1_ENST00000358397_ENST00000472487_95680478_59150923 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.61
Å |
 |  |  |  |  |
| ESRP1_MYSM1_ENST00000358397_ENST00000472487_95680478_59150923 superimposed PDB: 2DCE of partner (MYSM1). RMSD:1.0853
Å |
| | | |  |
| ESRP1_MYSM1_ENST00000433389_ENST00000472487_95680478_59150923 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.5808
Å |
 |  |  |  |  |
| ESRP1_MYSM1_ENST00000433389_ENST00000472487_95680478_59150923 superimposed PDB: 2DCE of partner (MYSM1). RMSD:1.2269
Å |
| | | |  |
| ESRP1_MYSM1_ENST00000454170_ENST00000472487_95680478_59150923 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.573
Å |
 |  |  |  |  |
| ESRP1_MYSM1_ENST00000454170_ENST00000472487_95680478_59150923 superimposed PDB: 2DCE of partner (MYSM1). RMSD:1.1577
Å |
| | | |  |
| ETFA_ADPGK_ENST00000433983_ENST00000311669_76603690_73052868 superimposed PDB: 2A1U of partner (ETFA). RMSD:3.2411
Å |
 |  |  |  |  |
| ETFA_ADPGK_ENST00000559602_ENST00000311669_76603690_73052868 superimposed PDB: 2A1U of partner (ETFA). RMSD:3.2388
Å |
 |  |  |  |  |
| ETFA_EDC3_ENST00000433983_ENST00000426797_76576097_74948409 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.7492
Å |
 |  |  |  |  |
| ETFA_EDC3_ENST00000433983_ENST00000426797_76576097_74948409 superimposed PDB: 3D3J of partner (EDC3). RMSD:0.4393
Å |
| | | |  |
| ETFA_EDC3_ENST00000557943_ENST00000426797_76576097_74948409 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.461
Å |
 |  |  |  |  |
| ETFA_EDC3_ENST00000557943_ENST00000426797_76576097_74948409 superimposed PDB: 3D3J of partner (EDC3). RMSD:0.4675
Å |
| | | |  |
| ETFA_EDC3_ENST00000559602_ENST00000426797_76576097_74948409 superimposed PDB: 2A1U of partner (ETFA). RMSD:2.0808
Å |
 |  |  |  |  |
| ETFA_EDC3_ENST00000559602_ENST00000426797_76576097_74948409 superimposed PDB: 3D3J of partner (EDC3). RMSD:0.4223
Å |
| | | |  |
| ETFA_METTL9_ENST00000433983_ENST00000358154_76603690_21623965 superimposed PDB: 7YF2 of partner (METTL9). RMSD:0.5907
Å |
 |  |  |  |  |
| ETFA_METTL9_ENST00000433983_ENST00000396014_76603690_21623965 superimposed PDB: 7YF2 of partner (METTL9). RMSD:0.6564
Å |
 |  |  |  |  |
| ETFA_METTL9_ENST00000557943_ENST00000396014_76603690_21623965 superimposed PDB: 7YF2 of partner (METTL9). RMSD:0.638
Å |
 |  |  |  |  |
| ETFA_METTL9_ENST00000559602_ENST00000358154_76603690_21623965 superimposed PDB: 7YF2 of partner (METTL9). RMSD:0.6567
Å |
 |  |  |  |  |
| ETFA_SCAPER_ENST00000433983_ENST00000563290_76566752_76995343 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.7638
Å |
 |  |  |  |  |
| ETFA_SCAPER_ENST00000557943_ENST00000563290_76566752_76995343 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.496
Å |
 |  |  |  |  |
| ETFA_SCAPER_ENST00000559602_ENST00000563290_76566752_76995343 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.8794
Å |
 |  |  |  |  |
| ETFA_SCAPER_ENST00000560726_ENST00000563290_76566752_76995343 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.7339
Å |
 |  |  |  |  |
| ETHE1_BMP5_ENST00000292147_ENST00000446683_44030666_55639041 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4758
Å |
 |  |  |  |  |
| ETHE1_BMP5_ENST00000600651_ENST00000370830_44030666_55639041 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.5445
Å |
 |  |  |  |  |
| ETHE1_CADM4_ENST00000600651_ENST00000222374_44015588_44131942 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4307
Å |
 |  |  |  |  |
| ETHE1_CEACAM1_ENST00000292147_ENST00000161559_44030352_43013380 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3597
Å |
 |  |  |  |  |
| ETHE1_PLAUR_ENST00000292147_ENST00000340093_44030666_44159725 superimposed PDB: 4CHL of partner (ETHE1). RMSD:3.3057
Å |
 |  |  |  |  |
| ETHE1_PLAUR_ENST00000292147_ENST00000601723_44030666_44159725 superimposed PDB: 4CHL of partner (ETHE1). RMSD:2.7793
Å |
 |  |  |  |  |
| ETHE1_PLAUR_ENST00000292147_ENST00000601723_44030666_44159725 superimposed PDB: 1YWH of partner (PLAUR). RMSD:1.9363
Å |
| | | |  |
| ETHE1_PLAUR_ENST00000600651_ENST00000339082_44030666_44156523 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3736
Å |
 |  |  |  |  |
| ETHE1_PLAUR_ENST00000600651_ENST00000339082_44030666_44156523 superimposed PDB: 1YWH of partner (PLAUR). RMSD:1.197
Å |
| | | |  |
| ETHE1_ZNF235_ENST00000600651_ENST00000589799_44030352_44740882 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4941
Å |
 |  |  |  |  |
| ETNK1_MYO9B_ENST00000266517_ENST00000397274_22778520_17298743 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.3617
Å |
 |  |  |  |  |
| ETNK1_MYO9B_ENST00000266517_ENST00000594824_22778520_17298743 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.371
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000399357_ENST00000356253_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:0.9798
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000399357_ENST00000423588_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:1.0588
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000405192_ENST00000356253_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:1.0679
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000405192_ENST00000356860_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:3.2498
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000405192_ENST00000423588_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:1.1178
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000405358_ENST00000356253_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:0.9964
Å |
 |  |  |  |  |
| ETV1_CACNA2D1_ENST00000405358_ENST00000423588_14017051_81695840 superimposed PDB: 7VFS of partner (CACNA2D1). RMSD:1.0869
Å |
 |  |  |  |  |
| ETV4_CCL16_ENST00000393664_ENST00000293275_41610041_34305299 superimposed PDB: 7SCT of partner (CCL16). RMSD:0.3092
Å |
 |  |  |  |  |
| ETV4_CCL16_ENST00000545089_ENST00000293275_41610041_34305299 superimposed PDB: 7SCT of partner (CCL16). RMSD:0.3119
Å |
 |  |  |  |  |
| ETV4_CCL16_ENST00000591713_ENST00000293275_41610041_34305299 superimposed PDB: 7SCT of partner (CCL16). RMSD:0.2972
Å |
 |  |  |  |  |
| ETV4_TCAP_ENST00000591713_ENST00000309889_41610041_37821968 superimposed PDB: 2F8V of partner (TCAP). RMSD:2.3953
Å |
 |  |  |  |  |
| ETV6_ABL1_ENST00000396373_ENST00000318560_12022903_133729450__from_ChimerKB4_152 superimposed PDB: 1OPL of partner (ABL1). RMSD:0.8747
Å |
 |  |  |  |  |
| ETV6_JAK2_ENST00000396373_ENST00000381652_12022903_5069924 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3532
Å |
 |  |  |  |  |
| ETV6_JAK2_ENST00000396373_ENST00000381652_12022903_5081724 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.322
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000317501_12006495_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6473
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000355254_12006495_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7198
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000355254_12006495_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6842
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000355254_12022903_88483984 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3149
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000355254_12022903_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6898
Å |
| | | |  |
| ETV6_NTRK3_ENST00000396373_ENST00000394480_11803094_88423659 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3405
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000394480_12006495_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.9079
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000394480_12022903_88483984 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.2988
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000557856_12006495_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7421
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000557856_12006495_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7528
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000557856_12022903_88483984 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3526
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000557856_12022903_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6718
Å |
| | | |  |
| ETV6_NTRK3_ENST00000396373_ENST00000558676_12006495_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6412
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000558676_12006495_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6697
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000558676_12022903_88483984 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3354
Å |
 |  |  |  |  |
| ETV6_NTRK3_ENST00000396373_ENST00000558676_12022903_88483984 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6909
Å |
| | | |  |
| ETV6_RUNX1_ENST00000396373_ENST00000325074_12022903_36259393 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3883
Å |
 |  |  |  |  |
| ETV6_RUNX1_ENST00000396373_ENST00000437180_12022903_36259393 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3989
Å |
 |  |  |  |  |
| ETV6_RUNX1_ENST00000396373_ENST00000437180_12022903_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.377
Å |
| | | |  |
| ETV6_SYK_ENST00000396373_ENST00000375747_12022903_93627329 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3718
Å |
 |  |  |  |  |
| ETV6_SYK_ENST00000396373_ENST00000375751_12022903_93627329 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3509
Å |
 |  |  |  |  |
| ETV6_SYK_ENST00000396373_ENST00000375754_12022903_93627329 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3366
Å |
 |  |  |  |  |
| EVA1C_CBR3_ENST00000382699_ENST00000290354_33825816_37518373 superimposed PDB: 2HRB of partner (CBR3). RMSD:0.501
Å |
 |  |  |  |  |
| EVI5_GLRX2_ENST00000370331_ENST00000367440_93159358_193070334 superimposed PDB: 2HT9 of partner (GLRX2). RMSD:0.6114
Å |
 |  |  |  |  |
| EVL_MYH7_ENST00000392920_ENST00000355349_100551192_23902436 superimposed PDB: 8EFI of partner (MYH7). RMSD:2.2682
Å |
 |  |  |  |  |
| EVL_MYH7_ENST00000544450_ENST00000355349_100551192_23902436 superimposed PDB: 8EFI of partner (MYH7). RMSD:2.2985
Å |
 |  |  |  |  |
| EWSR1_CREB1_ENST00000332035_ENST00000432329_29683123_208439995 superimposed PDB: 5ZK1 of partner (CREB1). RMSD:1.3446
Å |
 |  |  |  |  |
| EWSR1_CREB1_ENST00000332050_ENST00000430624_29683123_208439995 superimposed PDB: 5ZK1 of partner (CREB1). RMSD:0.2102
Å |
 |  |  |  |  |
| EWSR1_CREB1_ENST00000332050_ENST00000432329_29683123_208439995 superimposed PDB: 5ZK1 of partner (CREB1). RMSD:1.2988
Å |
 |  |  |  |  |
| EWSR1_CREB1_ENST00000414183_ENST00000432329_29683123_208439995 superimposed PDB: 5ZK1 of partner (CREB1). RMSD:1.4034
Å |
 |  |  |  |  |
| EWSR1_ERG_ENST00000332035_ENST00000398905_29683123_39763637 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4206
Å |
 |  |  |  |  |
| EWSR1_ERG_ENST00000332050_ENST00000398905_29683123_39763637 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4189
Å |
 |  |  |  |  |
| EWSR1_ERG_ENST00000414183_ENST00000398905_29683123_39763637 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4021
Å |
 |  |  |  |  |
| EWSR1_ETV1_ENST00000332035_ENST00000399357_29683123_13946224 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4862
Å |
 |  |  |  |  |
| EWSR1_ETV1_ENST00000332050_ENST00000399357_29683123_13946224 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4466
Å |
 |  |  |  |  |
| EWSR1_ETV1_ENST00000414183_ENST00000399357_29683123_13946224 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.5142
Å |
 |  |  |  |  |
| EWSR1_ETV4_ENST00000332035_ENST00000393664_29683123_41607549 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.3049
Å |
 |  |  |  |  |
| EWSR1_ETV4_ENST00000332050_ENST00000393664_29683123_41607549 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.3251
Å |
 |  |  |  |  |
| EWSR1_ETV4_ENST00000414183_ENST00000393664_29683123_41607549 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.2803
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29683123_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.305
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29683123_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2896
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29683123_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3032
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29683123_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2964
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29687588_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3061
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29688158_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3126
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29688158_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3086
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29688158_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2894
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000344954_29688158_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2841
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332035_ENST00000534087_29683123_128680353 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2828
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29683123_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3065
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29683123_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2793
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29683123_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3025
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29683123_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2909
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29688158_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3068
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29688158_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.307
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29688158_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3003
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000344954_29688158_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2927
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000332050_ENST00000534087_29683123_128680353 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2831
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000397938_ENST00000344954_29687588_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2913
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000397938_ENST00000344954_29688158_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2954
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000397938_ENST00000344954_29688158_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3094
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000397938_ENST00000344954_29688158_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3009
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000397938_ENST00000344954_29688158_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3045
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000406548_ENST00000344954_29687588_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3111
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000406548_ENST00000344954_29688158_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3035
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000406548_ENST00000344954_29688158_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3091
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000406548_ENST00000344954_29688158_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3081
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000406548_ENST00000344954_29688158_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2979
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29683123_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3068
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29683123_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3091
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29683123_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3096
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29683123_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2959
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29687588_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3026
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29688158_128651852 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3017
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29688158_128675260 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3107
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29688158_128677074 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3057
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000344954_29688158_128679051 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.3068
Å |
 |  |  |  |  |
| EWSR1_FLI1_ENST00000414183_ENST00000534087_29683123_128680353 superimposed PDB: 9MX9 of partner (FLI1). RMSD:0.2819
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000332035_ENST00000286445_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5364
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000332035_ENST00000359742_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5519
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000332050_ENST00000286445_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4975
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000332050_ENST00000359742_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5276
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000333395_ENST00000398016_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5415
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000397938_ENST00000398016_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5151
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000414183_ENST00000286445_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5144
Å |
 |  |  |  |  |
| EWSR1_GRIP1_ENST00000414183_ENST00000359742_29683123_66911756 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4789
Å |
 |  |  |  |  |
| EWSR1_NFATC1_ENST00000332035_ENST00000591814_29684775_77193578 superimposed PDB: 1A66 of partner (NFATC1). RMSD:2.3525
Å |
 |  |  |  |  |
| EWSR1_NFATC1_ENST00000333395_ENST00000253506_29684775_77193578 superimposed PDB: 1A66 of partner (NFATC1). RMSD:2.3316
Å |
 |  |  |  |  |
| EWSR1_NFATC1_ENST00000397938_ENST00000591814_29684775_77193578 superimposed PDB: 1A66 of partner (NFATC1). RMSD:2.2974
Å |
 |  |  |  |  |
| EWSR1_NFATC1_ENST00000406548_ENST00000253506_29684775_77193578 superimposed PDB: 1A66 of partner (NFATC1). RMSD:2.3595
Å |
 |  |  |  |  |
| EWSR1_NFATC1_ENST00000414183_ENST00000591814_29684775_77193578 superimposed PDB: 1A66 of partner (NFATC1). RMSD:2.3512
Å |
 |  |  |  |  |
| EWSR1_NR4A3_ENST00000332050_ENST00000395097_29688595_102584136 superimposed PDB: 8XTT of partner (NR4A3). RMSD:2.7289
Å |
 |  |  |  |  |
| EWSR1_NR4A3_ENST00000397938_ENST00000338488_29688595_102584136 superimposed PDB: 8XTT of partner (NR4A3). RMSD:1.0471
Å |
 |  |  |  |  |
| EWSR1_NR4A3_ENST00000397938_ENST00000395097_29688595_102584136 superimposed PDB: 2CPE of partner (EWSR1). RMSD:2.2492
Å |
 |  |  |  |  |
| EWSR1_NR4A3_ENST00000406548_ENST00000395097_29688595_102584136 superimposed PDB: 2CPE of partner (EWSR1). RMSD:1.213
Å |
 |  |  |  |  |
| EWSR1_NR4A3_ENST00000414183_ENST00000395097_29688595_102584136 superimposed PDB: 2CPE of partner (EWSR1). RMSD:1.6007
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000332035_ENST00000367897_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3569
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000332035_ENST00000401534_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.2991
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000332035_ENST00000540236_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.2857
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000332035_ENST00000559240_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3072
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000332035_ENST00000560641_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.2865
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000397938_ENST00000367897_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.428
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000397938_ENST00000401534_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3184
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000397938_ENST00000540236_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3154
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000397938_ENST00000559240_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3186
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000397938_ENST00000560641_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.2904
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000414183_ENST00000367897_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3596
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000414183_ENST00000401534_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3022
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000414183_ENST00000559240_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3028
Å |
 |  |  |  |  |
| EWSR1_PBX1_ENST00000414183_ENST00000560641_29684775_164776778 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.2878
Å |
 |  |  |  |  |
| EWSR1_SMARCA5_ENST00000333395_ENST00000283131_29683123_144446603 superimposed PDB: 8V4Y of partner (SMARCA5). RMSD:1.5163
Å |
 |  |  |  |  |
| EWSR1_SMARCA5_ENST00000397938_ENST00000283131_29683123_144446603 superimposed PDB: 8V4Y of partner (SMARCA5). RMSD:1.6125
Å |
 |  |  |  |  |
| EWSR1_YY1_ENST00000333395_ENST00000262238_29683123_100728640 superimposed PDB: 1UBD of partner (YY1). RMSD:1.5914
Å |
 |  |  |  |  |
| EWSR1_YY1_ENST00000397938_ENST00000262238_29683123_100728640 superimposed PDB: 1UBD of partner (YY1). RMSD:1.7791
Å |
 |  |  |  |  |
| EXOC2_GMDS_ENST00000448181_ENST00000380815_572519_1742820 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.0572
Å |
 |  |  |  |  |
| EXOC4_CHIC2_ENST00000253861_ENST00000512964_133314894_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.5998
Å |
 |  |  |  |  |
| EXOC4_CHIC2_ENST00000539845_ENST00000263921_133314894_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.2573
Å |
 |  |  |  |  |
| EXOC4_CHIC2_ENST00000539845_ENST00000512964_133314894_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.5246
Å |
 |  |  |  |  |
| EXOC4_CHIC2_ENST00000545148_ENST00000263921_133314894_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.495
Å |
 |  |  |  |  |
| EXOC4_SLC25A13_ENST00000539845_ENST00000416240_133059756_95776008 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:2.7953
Å |
 |  |  |  |  |
| EXOC5_SUCLA2_ENST00000340918_ENST00000543413_57702428_48517580 superimposed PDB: 6G4Q of partner (SUCLA2). RMSD:2.9309
Å |
 |  |  |  |  |
| EXOC6B_TRPC1_ENST00000272427_ENST00000273482_73052926_142467099 superimposed PDB: 9KHI of partner (TRPC1). RMSD:1.469
Å |
 |  |  |  |  |
| EXOSC10_MTOR_ENST00000376936_ENST00000361445_11155814_11273623 superimposed PDB: 9T94 of partner (MTOR). RMSD:2.4556
Å |
 |  |  |  |  |
| EXT1_RSF1_ENST00000378204_ENST00000360355_118825110_77451981 superimposed PDB: 7SCK of partner (EXT1). RMSD:1.4365
Å |
 |  |  |  |  |
| EXT1_ZDHHC21_ENST00000378204_ENST00000380916_119122323_14619680 superimposed PDB: 7SCK of partner (EXT1). RMSD:2.1406
Å |
 |  |  |  |  |
| EXT2_ALKBH3_ENST00000343631_ENST00000302708_44151688_43940587 superimposed PDB: 7SCK of partner (EXT2). RMSD:0.6845
Å |
 |  |  |  |  |
| EXT2_ALKBH3_ENST00000343631_ENST00000302708_44151688_43940587 superimposed PDB: 2IUW of partner (ALKBH3). RMSD:1.571
Å |
| | | |  |
| EXT2_ALKBH3_ENST00000358681_ENST00000302708_44151688_43940587 superimposed PDB: 7SCK of partner (EXT2). RMSD:0.6843
Å |
 |  |  |  |  |
| EXT2_ALKBH3_ENST00000358681_ENST00000302708_44151688_43940587 superimposed PDB: 2IUW of partner (ALKBH3). RMSD:1.3014
Å |
| | | |  |
| EXT2_ALKBH3_ENST00000395673_ENST00000302708_44151688_43940587 superimposed PDB: 7SCK of partner (EXT2). RMSD:0.6751
Å |
 |  |  |  |  |
| EXT2_ALKBH3_ENST00000395673_ENST00000302708_44151688_43940587 superimposed PDB: 2IUW of partner (ALKBH3). RMSD:1.2934
Å |
| | | |  |
| EXT2_PRMT10_ENST00000343631_ENST00000322396_44151688_148601622 superimposed PDB: 7SCK of partner (EXT2). RMSD:2.6873
Å |
 |  |  |  |  |
| EXT2_PRMT10_ENST00000343631_ENST00000322396_44151688_148601622 superimposed PDB: 7RBQ of partner (PRMT10). RMSD:1.1902
Å |
| | | |  |
| EXT2_PRMT10_ENST00000358681_ENST00000322396_44151688_148601622 superimposed PDB: 7SCK of partner (EXT2). RMSD:2.7111
Å |
 |  |  |  |  |
| EXT2_PRMT10_ENST00000358681_ENST00000322396_44151688_148601622 superimposed PDB: 7RBQ of partner (PRMT10). RMSD:1.143
Å |
| | | |  |
| EXT2_PRMT10_ENST00000395673_ENST00000322396_44151688_148601622 superimposed PDB: 7SCK of partner (EXT2). RMSD:2.6879
Å |
 |  |  |  |  |
| EXT2_PRMT10_ENST00000395673_ENST00000322396_44151688_148601622 superimposed PDB: 7RBQ of partner (PRMT10). RMSD:1.1402
Å |
| | | |  |
| EXT2_TTC17_ENST00000358681_ENST00000299240_44151688_43436139 superimposed PDB: 7SCK of partner (EXT2). RMSD:2.8877
Å |
 |  |  |  |  |
| EXT2_TTC17_ENST00000395673_ENST00000039989_44151688_43436139 superimposed PDB: 7SCK of partner (EXT2). RMSD:0.9496
Å |
 |  |  |  |  |
| EXT2_TTC17_ENST00000395673_ENST00000299240_44151688_43436139 superimposed PDB: 7SCK of partner (EXT2). RMSD:3.1492
Å |
 |  |  |  |  |
| EXT2_TTC17_ENST00000533608_ENST00000039989_44151688_43436139 superimposed PDB: 7SCK of partner (EXT2). RMSD:0.8884
Å |
 |  |  |  |  |
| EYA2_MYLK2_ENST00000317304_ENST00000375985_45725807_30418621 superimposed PDB: 2LV6 of partner (MYLK2). RMSD:1.1634
Å |
 |  |  |  |  |
| EYA2_MYLK2_ENST00000357410_ENST00000375985_45725807_30418621 superimposed PDB: 2LV6 of partner (MYLK2). RMSD:1.1289
Å |
 |  |  |  |  |
| EYA2_SYS1_ENST00000327619_ENST00000372727_45725807_43994258 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.8088
Å |
 |  |  |  |  |
| EYA3_POP4_ENST00000373871_ENST00000585603_28315045_30104777 superimposed PDB: 9N0Y of partner (EYA3). RMSD:2.8494
Å |
 |  |  |  |  |
| EZH1_BRCA1_ENST00000435174_ENST00000351666_40872290_41228628 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3807
Å |
 |  |  |  |  |
| EZH1_IGFBP5_ENST00000435174_ENST00000233813_40879652_217543802 superimposed PDB: 7TD5 of partner (EZH1). RMSD:2.7547
Å |
 |  |  |  |  |
| EZH1_IGFBP5_ENST00000592743_ENST00000233813_40879652_217543802 superimposed PDB: 7UFG of partner (IGFBP5). RMSD:1.0142
Å |
 |  |  |  |  |
| EZH1_PDSS2_ENST00000585893_ENST00000369037_40879652_107595431 superimposed PDB: 7TD5 of partner (EZH1). RMSD:1.3711
Å |
 |  |  |  |  |
| EZH1_TOP2A_ENST00000590078_ENST00000423485_40854894_38561135 superimposed PDB: 6ZY5 of partner (TOP2A). RMSD:1.726
Å |
 |  |  |  |  |
| EZH2_AUTS2_ENST00000478654_ENST00000406775_148543588_70227855 superimposed PDB: 5HYN of partner (EZH2). RMSD:3.3309
Å |
 |  |  |  |  |
| EZH2_PSD3_ENST00000350995_ENST00000286485_148524255_18662408 superimposed PDB: 5HYN of partner (EZH2). RMSD:3.2062
Å |
 |  |  |  |  |
| EZH2_PSD3_ENST00000350995_ENST00000440756_148524255_18662408 superimposed PDB: 5HYN of partner (EZH2). RMSD:3.49
Å |
 |  |  |  |  |
| EZH2_PSD3_ENST00000460911_ENST00000286485_148524255_18662408 superimposed PDB: 5HYN of partner (EZH2). RMSD:2.6504
Å |
 |  |  |  |  |
| EZH2_PSD3_ENST00000478654_ENST00000327040_148523560_18662408 superimposed PDB: 5HYN of partner (EZH2). RMSD:3.2166
Å |
 |  |  |  |  |
| EZR_CALM2_ENST00000392177_ENST00000272298_159197439_47397903 superimposed PDB: 4RM8 of partner (EZR). RMSD:1.0251
Å |
 |  |  |  |  |
| EZR_RB1CC1_ENST00000367075_ENST00000025008_159206340_53537347 superimposed PDB: 4RM8 of partner (EZR). RMSD:1.6275
Å |
 |  |  |  |  |
| F3_SQSTM1_ENST00000370207_ENST00000376929_95007092_179260586 superimposed PDB: 8QOD of partner (F3). RMSD:2.5308
Å |
 |  |  |  |  |
| FA2H_KARS_ENST00000219368_ENST00000302445_74773920_75665753 superimposed PDB: 6CHD of partner (KARS). RMSD:0.846
Å |
 |  |  |  |  |
| FAF1_EPS15_ENST00000396153_ENST00000371730_51425438_51946986 superimposed PDB: 1EH2 of partner (EPS15). RMSD:2.1861
Å |
 |  |  |  |  |
| FAF1_EPS15_ENST00000396153_ENST00000371733_51171457_51946986 superimposed PDB: 9YW2 of partner (FAF1). RMSD:2.0409
Å |
 |  |  |  |  |
| FAF1_EPS15_ENST00000396153_ENST00000371733_51171457_51946986 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.2008
Å |
| | | |  |
| FAF1_EPS15_ENST00000396153_ENST00000371733_51323600_51946986 superimposed PDB: 9YW2 of partner (FAF1). RMSD:2.2261
Å |
 |  |  |  |  |
| FAF1_EPS15_ENST00000396153_ENST00000371733_51323600_51946986 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.1294
Å |
| | | |  |
| FAF1_EPS15_ENST00000396153_ENST00000371733_51425438_51946986 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.14
Å |
 |  |  |  |  |
| FAM104A_ACLY_ENST00000403627_ENST00000537919_71223303_40058066 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.7826
Å |
 |  |  |  |  |
| FAM104A_ACLY_ENST00000403627_ENST00000590151_71223303_40058066 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.8087
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000181796_ENST00000392403_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6983
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000378458_ENST00000368346_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6356
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000378458_ENST00000392403_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6593
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000378462_ENST00000368346_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6792
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000378462_ENST00000392403_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6124
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000478076_ENST00000368346_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6451
Å |
 |  |  |  |  |
| FAM107B_ASH1L_ENST00000478076_ENST00000392403_14572330_155385714 superimposed PDB: 6INE of partner (ASH1L). RMSD:0.6412
Å |
 |  |  |  |  |
| FAM117A_HDAC5_ENST00000240364_ENST00000393622_47809912_42162043 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2596
Å |
 |  |  |  |  |
| FAM118A_CYB5R3_ENST00000441876_ENST00000361740_45719308_43032852 superimposed PDB: 1UMK of partner (CYB5R3). RMSD:0.464
Å |
 |  |  |  |  |
| FAM120C_GYG2_ENST00000328235_ENST00000398806_54208932_2793850 superimposed PDB: 8Z0A of partner (GYG2). RMSD:1.4047
Å |
 |  |  |  |  |
| FAM126A_HIBADH_ENST00000409923_ENST00000265395_23023562_27672064 superimposed PDB: 2I9P of partner (HIBADH). RMSD:1.0655
Å |
 |  |  |  |  |
| FAM133B_CCND3_ENST00000427372_ENST00000511642_92207632_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:1.6405
Å |
 |  |  |  |  |
| FAM133B_CCND3_ENST00000438306_ENST00000511642_92207632_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:3.1543
Å |
 |  |  |  |  |
| FAM133B_CCND3_ENST00000445716_ENST00000511642_92207632_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:1.5872
Å |
 |  |  |  |  |
| FAM133B_CDK6_ENST00000427372_ENST00000265734_92195327_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3947
Å |
 |  |  |  |  |
| FAM133B_CDK6_ENST00000427372_ENST00000424848_92195327_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3618
Å |
 |  |  |  |  |
| FAM133B_CDK6_ENST00000438306_ENST00000424848_92195327_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3623
Å |
 |  |  |  |  |
| FAM133B_CDK6_ENST00000445716_ENST00000424848_92195327_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3805
Å |
 |  |  |  |  |
| FAM133B_CDK6_ENST00000445716_ENST00000424848_92219581_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3015
Å |
 |  |  |  |  |
| FAM133B_MDM2_ENST00000445716_ENST00000356290_92219581_69229608 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.9631
Å |
 |  |  |  |  |
| FAM172A_FHIT_ENST00000395965_ENST00000492590_93294481_59738047 superimposed PDB: 1FIT of partner (FHIT). RMSD:2.039
Å |
 |  |  |  |  |
| FAM177A1_PSMA6_ENST00000280987_ENST00000556506_35515834_35786454 superimposed PDB: 5LE5 of partner (PSMA6). RMSD:0.3697
Å |
 |  |  |  |  |
| FAM177A1_PSMA6_ENST00000382406_ENST00000556506_35515834_35786454 superimposed PDB: 5LE5 of partner (PSMA6). RMSD:0.4224
Å |
 |  |  |  |  |
| FAM177A1_PSMA6_ENST00000396472_ENST00000556506_35515834_35786454 superimposed PDB: 5LE5 of partner (PSMA6). RMSD:2.5331
Å |
 |  |  |  |  |
| FAM188A_COX7A2_ENST00000277632_ENST00000230459_15889862_75950981 superimposed PDB: 9I6F of partner (COX7A2). RMSD:1.1686
Å |
 |  |  |  |  |
| FAM189A1_TJP1_ENST00000261275_ENST00000356107_29862708_30065560 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7945
Å |
 |  |  |  |  |
| FAM189A1_TJP1_ENST00000261275_ENST00000400011_29862708_30065560 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6952
Å |
 |  |  |  |  |
| FAM189A1_TJP1_ENST00000261275_ENST00000495972_29862708_30065560 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7105
Å |
 |  |  |  |  |
| FAM189A1_TJP1_ENST00000261275_ENST00000545208_29862708_30065560 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7393
Å |
 |  |  |  |  |
| FAM35A_BMPR1A_ENST00000298786_ENST00000372037_88912636_88649818 superimposed PDB: 2H62 of partner (BMPR1A). RMSD:0.4537
Å |
 |  |  |  |  |
| FAM49A_DDX1_ENST00000381323_ENST00000233084_16769317_15757367 superimposed PDB: 8TBX of partner (DDX1). RMSD:2.675
Å |
 |  |  |  |  |
| FAM69C_CYB5A_ENST00000343998_ENST00000397914_72113840_71930712 superimposed PDB: 2I96 of partner (CYB5A). RMSD:2.2854
Å |
 |  |  |  |  |
| FAM73A_PIGU_ENST00000370791_ENST00000452740_78249036_33225789 superimposed PDB: 9JCW of partner (FAM73A). RMSD:2.921
Å |
 |  |  |  |  |
| FAM73A_PIGU_ENST00000370791_ENST00000452740_78249036_33225789 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9046
Å |
| | | |  |
| FAM98C_BLVRB_ENST00000252530_ENST00000595483_38894334_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.5794
Å |
 |  |  |  |  |
| FAM98C_BLVRB_ENST00000588262_ENST00000263368_38894334_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.787
Å |
 |  |  |  |  |
| FAM98C_SPINT2_ENST00000252530_ENST00000301244_38894334_38774266 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2722
Å |
 |  |  |  |  |
| FANCD2_WDR93_ENST00000287647_ENST00000560294_10107663_90260141 superimposed PDB: 8A9J of partner (FANCD2). RMSD:2.3901
Å |
 |  |  |  |  |
| FANCD2_WDR93_ENST00000383807_ENST00000268130_10107663_90260141 superimposed PDB: 8A9J of partner (FANCD2). RMSD:2.2422
Å |
 |  |  |  |  |
| FANCI_HADHB_ENST00000300027_ENST00000405867_89817535_26492820 superimposed PDB: 5ZQZ of partner (HADHB). RMSD:1.1201
Å |
 |  |  |  |  |
| FANCI_HADHB_ENST00000310775_ENST00000317799_89817535_26492820 superimposed PDB: 8A9J of partner (FANCI). RMSD:1.8168
Å |
 |  |  |  |  |
| FANCI_HADHB_ENST00000310775_ENST00000317799_89817535_26492820 superimposed PDB: 5ZQZ of partner (HADHB). RMSD:1.2716
Å |
| | | |  |
| FANCM_TC2N_ENST00000542564_ENST00000340892_45620731_92253971 superimposed PDB: 9EL5 of partner (FANCM). RMSD:1.9747
Å |
 |  |  |  |  |
| FANCM_TC2N_ENST00000556036_ENST00000340892_45620731_92253971 superimposed PDB: 9EL5 of partner (FANCM). RMSD:2.559
Å |
 |  |  |  |  |
| FAR1_RRAS2_ENST00000354817_ENST00000414023_13716501_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5282
Å |
 |  |  |  |  |
| FARP1_NME1_ENST00000595437_ENST00000013034_98865667_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:2.8025
Å |
 |  |  |  |  |
| FARP1_NME1_ENST00000595437_ENST00000336097_98865667_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.7595
Å |
 |  |  |  |  |
| FARP1_NME1_ENST00000595437_ENST00000393196_98865667_49237340 superimposed PDB: 4H6Y of partner (FARP1). RMSD:2.8773
Å |
 |  |  |  |  |
| FARP1_NME1_ENST00000595437_ENST00000511355_98865667_49237340 superimposed PDB: 8OOV of partner (NME1). RMSD:0.7415
Å |
 |  |  |  |  |
| FARP1_SLC15A1_ENST00000376586_ENST00000376503_99064288_99340831 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.6012
Å |
 |  |  |  |  |
| FARP1_STK24_ENST00000376586_ENST00000397517_98865667_99134575 superimposed PDB: 3A7I of partner (STK24). RMSD:0.3345
Å |
 |  |  |  |  |
| FARP1_STK24_ENST00000376586_ENST00000397517_98865667_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5516
Å |
 |  |  |  |  |
| FARP1_STK24_ENST00000595437_ENST00000539966_98865667_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5466
Å |
 |  |  |  |  |
| FARS2_DTNBP1_ENST00000274680_ENST00000344537_5613553_15593312 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.5562
Å |
 |  |  |  |  |
| FARS2_HPGDS_ENST00000274680_ENST00000295256_5431405_95239116 superimposed PDB: 3CMQ of partner (FARS2). RMSD:2.8232
Å |
 |  |  |  |  |
| FARS2_HPGDS_ENST00000274680_ENST00000295256_5431405_95239116 superimposed PDB: 7JR8 of partner (HPGDS). RMSD:0.4706
Å |
| | | |  |
| FARS2_LYRM4_ENST00000274680_ENST00000330636_5613553_5216971 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.5283
Å |
 |  |  |  |  |
| FARS2_LYRM4_ENST00000274680_ENST00000330636_5613553_5216971 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.9645
Å |
| | | |  |
| FASTK_COPS2_ENST00000297532_ENST00000388901_150777771_49437275 superimposed PDB: 9QO4 of partner (COPS2). RMSD:2.4998
Å |
 |  |  |  |  |
| FASTK_COPS2_ENST00000353841_ENST00000299259_150777771_49437275 superimposed PDB: 9QO4 of partner (COPS2). RMSD:2.4547
Å |
 |  |  |  |  |
| FAU_SRRM1_ENST00000525297_ENST00000323848_64888452_24975349 superimposed PDB: 7DVQ of partner (SRRM1). RMSD:1.1573
Å |
 |  |  |  |  |
| FAU_SRRM1_ENST00000525297_ENST00000374389_64888452_24975349 superimposed PDB: 7DVQ of partner (SRRM1). RMSD:1.3302
Å |
 |  |  |  |  |
| FAU_SRRM1_ENST00000525297_ENST00000447431_64888452_24975349 superimposed PDB: 7DVQ of partner (SRRM1). RMSD:1.261
Å |
 |  |  |  |  |
| FAU_SRRM1_ENST00000531743_ENST00000374389_64888452_24975349 superimposed PDB: 7DVQ of partner (SRRM1). RMSD:1.2396
Å |
 |  |  |  |  |
| FAU_SRRM1_ENST00000531743_ENST00000447431_64888452_24975349 superimposed PDB: 7DVQ of partner (SRRM1). RMSD:1.4089
Å |
 |  |  |  |  |
| FAXC_ASCC3_ENST00000389677_ENST00000369162_99796982_100988263 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:1.3043
Å |
 |  |  |  |  |
| FBLN1_PRKAR1B_ENST00000327858_ENST00000537384_45972988_619014 superimposed PDB: 4DIN of partner (PRKAR1B). RMSD:1.5543
Å |
 |  |  |  |  |
| FBLN1_PRKAR1B_ENST00000348697_ENST00000537384_45972988_619014 superimposed PDB: 4DIN of partner (PRKAR1B). RMSD:1.4551
Å |
 |  |  |  |  |
| FBN1_EIF3H_ENST00000316623_ENST00000276682_48888479_117671219 superimposed PDB: 5MS9 of partner (FBN1). RMSD:2.8746
Å |
 |  |  |  |  |
| FBP2_DAPK1_ENST00000375337_ENST00000472284_97346858_90317943 superimposed PDB: 5Q0C of partner (FBP2). RMSD:2.9743
Å |
 |  |  |  |  |
| FBXL12_CARM1_ENST00000588922_ENST00000344150_9929220_11015626 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.5109
Å |
 |  |  |  |  |
| FBXL17_XRCC4_ENST00000496714_ENST00000338635_107521817_82499370 superimposed PDB: 8UBT of partner (FBXL17). RMSD:0.831
Å |
 |  |  |  |  |
| FBXL17_XRCC4_ENST00000496714_ENST00000396027_107521817_82499370 superimposed PDB: 8UBT of partner (FBXL17). RMSD:0.8277
Å |
 |  |  |  |  |
| FBXL17_XRCC4_ENST00000542267_ENST00000338635_107521817_82499370 superimposed PDB: 8UBT of partner (FBXL17). RMSD:0.9174
Å |
 |  |  |  |  |
| FBXL17_XRCC4_ENST00000542267_ENST00000396027_107521817_82499370 superimposed PDB: 8UBT of partner (FBXL17). RMSD:0.9064
Å |
 |  |  |  |  |
| FBXL20_ACACA_ENST00000583610_ENST00000360679_37499432_35620797 superimposed PDB: 8XL1 of partner (ACACA). RMSD:3.0481
Å |
 |  |  |  |  |
| FBXL20_CDK12_ENST00000264658_ENST00000430627_37499432_37665957 superimposed PDB: 4NST of partner (CDK12). RMSD:0.647
Å |
 |  |  |  |  |
| FBXL20_CDK12_ENST00000394294_ENST00000447079_37499432_37665957 superimposed PDB: 4NST of partner (CDK12). RMSD:0.7252
Å |
 |  |  |  |  |
| FBXL20_CDK12_ENST00000577399_ENST00000447079_37499432_37665957 superimposed PDB: 4NST of partner (CDK12). RMSD:0.6137
Å |
 |  |  |  |  |
| FBXL20_PIP4K2B_ENST00000394294_ENST00000269554_37557613_36927525 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:1.4442
Å |
 |  |  |  |  |
| FBXL3_ZNF76_ENST00000355619_ENST00000440666_77589543_35259054 superimposed PDB: 4I6J of partner (FBXL3). RMSD:1.7983
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000341285_ENST00000447510_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5593
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000341285_ENST00000505450_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5372
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000341285_ENST00000539194_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.571
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000412094_ENST00000447510_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5806
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000412094_ENST00000505450_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5519
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000412094_ENST00000539194_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5311
Å |
 |  |  |  |  |
| FBXL5_PROM1_ENST00000412094_ENST00000540805_15613888_16020163 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.525
Å |
 |  |  |  |  |
| FBXL5_RAB28_ENST00000341285_ENST00000288723_15656826_13481150 superimposed PDB: 2HXS of partner (RAB28). RMSD:0.5697
Å |
 |  |  |  |  |
| FBXL5_RAB28_ENST00000341285_ENST00000330852_15656826_13481150 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5386
Å |
 |  |  |  |  |
| FBXL5_RAB28_ENST00000341285_ENST00000338176_15656826_13481150 superimposed PDB: 2HXS of partner (RAB28). RMSD:0.5684
Å |
 |  |  |  |  |
| FBXL5_RAB28_ENST00000412094_ENST00000330852_15656826_13481150 superimposed PDB: 2HXS of partner (RAB28). RMSD:0.5489
Å |
 |  |  |  |  |
| FBXL5_RTN4_ENST00000341285_ENST00000405240_15613888_55214834 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5419
Å |
 |  |  |  |  |
| FBXL5_RTN4_ENST00000412094_ENST00000405240_15613888_55214834 superimposed PDB: 6VCD of partner (FBXL5). RMSD:0.5656
Å |
 |  |  |  |  |
| FBXL7_TRIO_ENST00000329673_ENST00000344204_15616181_14270933 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.3139
Å |
 |  |  |  |  |
| FBXL7_TRIO_ENST00000329673_ENST00000509967_15616181_14270933 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6297
Å |
 |  |  |  |  |
| FBXL7_TRIO_ENST00000329673_ENST00000537187_15616181_14270933 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6662
Å |
 |  |  |  |  |
| FBXL7_TRIO_ENST00000504595_ENST00000509967_15616181_14270933 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.413
Å |
 |  |  |  |  |
| FBXL7_TRIO_ENST00000504595_ENST00000537187_15616181_14270933 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:2.0675
Å |
 |  |  |  |  |
| FBXL8_LCAT_ENST00000519917_ENST00000264005_67195840_67974381 superimposed PDB: 5BV7 of partner (LCAT). RMSD:0.6636
Å |
 |  |  |  |  |
| FBXO18_ITGA8_ENST00000362091_ENST00000378076_5960441_15648421 superimposed PDB: 9XZL of partner (FBXO18). RMSD:3.1054
Å |
 |  |  |  |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000320619_87393900_75127469 superimposed PDB: 5VZT of partner (FBXO31). RMSD:1.0308
Å |
 |  |  |  |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000320619_87393900_75127469 superimposed PDB: 5YWR of partner (ZNRF1). RMSD:1.2643
Å |
| | | |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000566250_87393900_75127469 superimposed PDB: 5VZT of partner (FBXO31). RMSD:2.7192
Å |
 |  |  |  |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000566250_87393900_75127469 superimposed PDB: 5YWR of partner (ZNRF1). RMSD:0.9341
Å |
| | | |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000567962_87393900_75127469 superimposed PDB: 5VZT of partner (FBXO31). RMSD:0.8323
Å |
 |  |  |  |  |
| FBXO31_ZNRF1_ENST00000311635_ENST00000567962_87393900_75127469 superimposed PDB: 5YWR of partner (ZNRF1). RMSD:2.8762
Å |
| | | |  |
| FBXO4_NIPBL_ENST00000509134_ENST00000448238_41934410_37063891 superimposed PDB: 9JKB of partner (FBXO4). RMSD:1.7864
Å |
 |  |  |  |  |
| FBXO9_CD74_ENST00000370939_ENST00000377795_52960462_149782188 superimposed PDB: 8VRW of partner (CD74). RMSD:2.7171
Å |
 |  |  |  |  |
| FCGRT_SNUPN_ENST00000221466_ENST00000308588_50017743_75891022 superimposed PDB: 6FGB of partner (FCGRT). RMSD:0.476
Å |
 |  |  |  |  |
| FCGRT_SNUPN_ENST00000426395_ENST00000308588_50017743_75891022 superimposed PDB: 6FGB of partner (FCGRT). RMSD:0.5109
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000252771_ENST00000370225_17877619_94505683 superimposed PDB: 7OHI of partner (FCHO1). RMSD:2.8292
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000252771_ENST00000370225_17877619_94505683 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.9194
Å |
| | | |  |
| FCHO1_ABCA4_ENST00000389133_ENST00000370225_17877619_94505683 superimposed PDB: 7OHI of partner (FCHO1). RMSD:2.829
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000389133_ENST00000370225_17877619_94505683 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.865
Å |
| | | |  |
| FCHO1_ABCA4_ENST00000539407_ENST00000370225_17877619_94505683 superimposed PDB: 7OHI of partner (FCHO1). RMSD:2.818
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000539407_ENST00000370225_17877619_94505683 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.8594
Å |
| | | |  |
| FCHO1_ABCA4_ENST00000596536_ENST00000370225_17877619_94505683 superimposed PDB: 7OHI of partner (FCHO1). RMSD:2.8213
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000596536_ENST00000370225_17877619_94505683 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.8935
Å |
| | | |  |
| FCHO1_ABCA4_ENST00000596951_ENST00000370225_17877619_94505683 superimposed PDB: 7OHI of partner (FCHO1). RMSD:2.8291
Å |
 |  |  |  |  |
| FCHO1_ABCA4_ENST00000596951_ENST00000370225_17877619_94505683 superimposed PDB: 7M1Q of partner (ABCA4). RMSD:2.8519
Å |
| | | |  |
| FCHSD2_ATP6V1H_ENST00000409314_ENST00000520188_72851075_54682303 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.1799
Å |
 |  |  |  |  |
| FCHSD2_TPCN2_ENST00000311172_ENST00000542467_72613587_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.0996
Å |
 |  |  |  |  |
| FCHSD2_TPCN2_ENST00000409314_ENST00000294309_72613587_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.6711
Å |
 |  |  |  |  |
| FCHSD2_TPCN2_ENST00000409314_ENST00000542467_72613587_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.1135
Å |
 |  |  |  |  |
| FCHSD2_TPCN2_ENST00000409418_ENST00000294309_72613587_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.7818
Å |
 |  |  |  |  |
| FCHSD2_TPCN2_ENST00000458644_ENST00000542467_72613587_68825045 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.0764
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8356
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5703
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.8744
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.47
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.7689
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5474
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8141
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5161
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8243
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5896
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.3619
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.613
Å |
| | | |  |
| FDFT1_CASK_ENST00000220584_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.9341
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000220584_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5157
Å |
| | | |  |
| FDFT1_CASK_ENST00000525777_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:3.0949
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525777_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5349
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8651
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.1462
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8176
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.8966
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.3896
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.8293
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.0512
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.8516
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.3145
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.8163
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.2029
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5041
Å |
| | | |  |
| FDFT1_CASK_ENST00000525900_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.116
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000525900_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.1593
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.1759
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5978
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.7144
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5506
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.2951
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.6132
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.4439
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.57
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.993
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5176
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.7209
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4963
Å |
| | | |  |
| FDFT1_CASK_ENST00000528643_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:3.0372
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528643_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5203
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.0857
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5277
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.4001
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5593
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.5752
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4965
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.7227
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4887
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.5107
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5032
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8868
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.0291
Å |
| | | |  |
| FDFT1_CASK_ENST00000528812_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.6622
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000528812_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5045
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.8656
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5367
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.7449
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5309
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:2.7434
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4734
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.2854
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5046
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.9585
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5875
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000421587_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.9861
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000421587_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4978
Å |
| | | |  |
| FDFT1_CASK_ENST00000530664_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.8793
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000530664_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.7384
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000318588_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.0632
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000318588_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.6218
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000361962_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.7623
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000361962_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4978
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000378158_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.7917
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000378158_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5433
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000378163_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.9441
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000378163_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.5217
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000378166_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.1964
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000378166_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.7299
Å |
| | | |  |
| FDFT1_CASK_ENST00000538689_ENST00000442742_11679387_41530783 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.0354
Å |
 |  |  |  |  |
| FDFT1_CASK_ENST00000538689_ENST00000442742_11679387_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:0.4916
Å |
| | | |  |
| FDFT1_DEFB135_ENST00000220584_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.5021
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000443614_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.5122
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000525777_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.468
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000525900_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.4154
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000528643_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4869
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000528812_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.5043
Å |
 |  |  |  |  |
| FDFT1_DEFB135_ENST00000530664_ENST00000382208_11683724_11841929 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4533
Å |
 |  |  |  |  |
| FDFT1_TNKS_ENST00000220584_ENST00000310430_11660440_9562172 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.6675
Å |
 |  |  |  |  |
| FDFT1_TNKS_ENST00000220584_ENST00000518281_11660440_9562172 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.7049
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000220584_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4302
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000220584_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3218
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000443614_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:1.337
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000443614_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.343
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000525900_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4462
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000525900_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3331
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000528643_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4341
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000528643_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3125
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000528812_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.409
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000528812_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3123
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000530664_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4341
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000530664_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3147
Å |
| | | |  |
| FDFT1_YWHAZ_ENST00000538689_ENST00000395958_11683724_101937267 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.4305
Å |
 |  |  |  |  |
| FDFT1_YWHAZ_ENST00000538689_ENST00000395958_11683724_101937267 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3333
Å |
| | | |  |
| FDPS_KHSRP_ENST00000356657_ENST00000398148_155282186_6422447 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.8256
Å |
 |  |  |  |  |
| FDPS_KHSRP_ENST00000356657_ENST00000398148_155282186_6422447 superimposed PDB: 2JVZ of partner (KHSRP). RMSD:2.9758
Å |
| | | |  |
| FDPS_KHSRP_ENST00000368356_ENST00000398148_155282186_6422447 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.7417
Å |
 |  |  |  |  |
| FDPS_KHSRP_ENST00000368356_ENST00000398148_155282186_6422447 superimposed PDB: 2JVZ of partner (KHSRP). RMSD:3.1254
Å |
| | | |  |
| FDPS_KHSRP_ENST00000447866_ENST00000398148_155282186_6422447 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.7798
Å |
 |  |  |  |  |
| FDPS_RPS6KB1_ENST00000368356_ENST00000225577_155282186_58018196 superimposed PDB: 2VF6 of partner (FDPS). RMSD:1.1277
Å |
 |  |  |  |  |
| FDPS_RPS6KB1_ENST00000447866_ENST00000225577_155282186_58018196 superimposed PDB: 2VF6 of partner (FDPS). RMSD:0.8732
Å |
 |  |  |  |  |
| FGF12_SYN3_ENST00000264730_ENST00000332840_192053149_32992722 superimposed PDB: 4JQ0 of partner (FGF12). RMSD:0.6172
Å |
 |  |  |  |  |
| FGF12_SYN3_ENST00000264730_ENST00000332840_192053149_32992722 superimposed PDB: 2P0A of partner (SYN3). RMSD:1.0571
Å |
| | | |  |
| FGF12_SYN3_ENST00000454309_ENST00000332840_192053149_32992722 superimposed PDB: 4JQ0 of partner (FGF12). RMSD:0.6061
Å |
 |  |  |  |  |
| FGF12_SYN3_ENST00000454309_ENST00000332840_192053149_32992722 superimposed PDB: 2P0A of partner (SYN3). RMSD:0.9829
Å |
| | | |  |
| FGFR1OP2_FGFR1_ENST00000229395_ENST00000397091_27110676_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6987
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000376887_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:1.017
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000376887_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.5207
Å |
| | | |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000431522_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:0.7689
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000431522_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.1654
Å |
| | | |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000536256_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:1.3946
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000349556_ENST00000536256_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.3866
Å |
| | | |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000376887_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:1.4029
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000376887_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.4585
Å |
| | | |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000431522_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:0.5846
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000431522_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.2717
Å |
| | | |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000536256_167417299_95847191 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:1.447
Å |
 |  |  |  |  |
| FGFR1OP_ABCC4_ENST00000366847_ENST00000536256_167417299_95847191 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.4072
Å |
| | | |  |
| FGFR1OP_FGFR1_ENST00000349556_ENST00000397091_167417889_38275891 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:0.6478
Å |
 |  |  |  |  |
| FGFR1OP_FGFR1_ENST00000349556_ENST00000397091_167417889_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.7094
Å |
| | | |  |
| FGFR1OP_FGFR1_ENST00000366847_ENST00000397091_167417889_38275891 superimposed PDB: 2D68 of partner (FGFR1OP). RMSD:0.725
Å |
 |  |  |  |  |
| FGFR1OP_FGFR1_ENST00000366847_ENST00000397091_167417889_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6706
Å |
| | | |  |
| FGFR1_CSMD1_ENST00000341462_ENST00000602723_38314873_3889621 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.4306
Å |
 |  |  |  |  |
| FGFR1_CSMD1_ENST00000356207_ENST00000602723_38314873_3889621 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.3565
Å |
 |  |  |  |  |
| FGFR1_CSMD1_ENST00000447712_ENST00000602723_38314873_3889621 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.5573
Å |
 |  |  |  |  |
| FGFR2_AP1M1_ENST00000346997_ENST00000291439_123256045_16314269 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:2.7596
Å |
 |  |  |  |  |
| FGFR2_AP1M1_ENST00000369056_ENST00000291439_123256045_16314269 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:2.6939
Å |
 |  |  |  |  |
| FGFR2_AP1M1_ENST00000369061_ENST00000291439_123256045_16314269 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4277
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000346997_ENST00000263103_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4635
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000346997_ENST00000373886_123243211_60461833 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4813
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000346997_ENST00000373886_123243211_60461833 superimposed PDB: 6GY4 of partner (BICC1). RMSD:0.5456
Å |
| | | |  |
| FGFR2_BICC1_ENST00000346997_ENST00000373886_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4808
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369056_ENST00000263103_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4423
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369056_ENST00000373886_123243211_60461833 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.5079
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369056_ENST00000373886_123243211_60461833 superimposed PDB: 6GY4 of partner (BICC1). RMSD:0.7246
Å |
| | | |  |
| FGFR2_BICC1_ENST00000369056_ENST00000373886_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4899
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369061_ENST00000263103_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4697
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369061_ENST00000373886_123243211_60461833 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4255
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369061_ENST00000373886_123243211_60566343 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.5016
Å |
 |  |  |  |  |
| FGFR2_BICC1_ENST00000369061_ENST00000373886_123243211_60566343 superimposed PDB: 6GY4 of partner (BICC1). RMSD:0.5825
Å |
| | | |  |
| FGFR2_CCAR2_ENST00000346997_ENST00000308511_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.442
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000346997_ENST00000389279_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.523
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000346997_ENST00000389279_123243211_22464119 superimposed PDB: 8EZ6 of partner (CCAR2). RMSD:0.2655
Å |
| | | |  |
| FGFR2_CCAR2_ENST00000351936_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4492
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000356226_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4505
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000358487_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4502
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000360144_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4607
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369056_ENST00000308511_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4168
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369056_ENST00000389279_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4593
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369056_ENST00000389279_123243211_22464119 superimposed PDB: 8EZ6 of partner (CCAR2). RMSD:0.2883
Å |
| | | |  |
| FGFR2_CCAR2_ENST00000369059_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4672
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369060_ENST00000521301_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4652
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369061_ENST00000308511_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4895
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369061_ENST00000389279_123243211_22464119 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4861
Å |
 |  |  |  |  |
| FGFR2_CCAR2_ENST00000369061_ENST00000389279_123243211_22464119 superimposed PDB: 8EZ6 of partner (CCAR2). RMSD:0.2804
Å |
| | | |  |
| FGFR2_CCDC6_ENST00000346997_ENST00000263102_123243211_61612460 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4824
Å |
 |  |  |  |  |
| FGFR2_CCDC6_ENST00000346997_ENST00000263102_123243211_61612460 superimposed PDB: 9O04 of partner (CCDC6). RMSD:1.9826
Å |
| | | |  |
| FGFR2_CCDC6_ENST00000369056_ENST00000263102_123243211_61612460 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4671
Å |
 |  |  |  |  |
| FGFR2_CCDC6_ENST00000369056_ENST00000263102_123243211_61612460 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.2981
Å |
| | | |  |
| FGFR2_CCDC6_ENST00000369061_ENST00000263102_123243211_61612460 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4566
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000346997_ENST00000380550_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4383
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000346997_ENST00000398395_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4898
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000369056_ENST00000380550_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4608
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000369056_ENST00000398395_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4655
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000369061_ENST00000380550_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4783
Å |
 |  |  |  |  |
| FGFR2_OFD1_ENST00000369061_ENST00000398395_123243211_13754596 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.494
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000346997_ENST00000263036_123243211_13158266 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4719
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000346997_ENST00000263036_123243211_13158266 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.8509
Å |
| | | |  |
| FGFR2_OPTN_ENST00000346997_ENST00000378764_123243211_13158266 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4644
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000346997_ENST00000378764_123243211_13158266 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.1686
Å |
| | | |  |
| FGFR2_OPTN_ENST00000369056_ENST00000263036_123243211_13158266 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4547
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000369056_ENST00000263036_123243211_13158266 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.7537
Å |
| | | |  |
| FGFR2_OPTN_ENST00000369056_ENST00000378764_123243211_13158266 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4608
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000369056_ENST00000378764_123243211_13158266 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.597
Å |
| | | |  |
| FGFR2_OPTN_ENST00000369061_ENST00000378764_123243211_13158266 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4318
Å |
 |  |  |  |  |
| FGFR2_OPTN_ENST00000369061_ENST00000378764_123243211_13158266 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.9374
Å |
| | | |  |
| FGFR2_SMN1_ENST00000346997_ENST00000351205_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4716
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000346997_ENST00000351205_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.7382
Å |
| | | |  |
| FGFR2_SMN1_ENST00000346997_ENST00000503079_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.461
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000346997_ENST00000503079_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.6874
Å |
| | | |  |
| FGFR2_SMN1_ENST00000346997_ENST00000506163_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4681
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000346997_ENST00000514951_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4519
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000346997_ENST00000514951_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.6847
Å |
| | | |  |
| FGFR2_SMN1_ENST00000369056_ENST00000351205_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4712
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369056_ENST00000351205_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.6812
Å |
| | | |  |
| FGFR2_SMN1_ENST00000369056_ENST00000503079_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.5144
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369056_ENST00000503079_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.7494
Å |
| | | |  |
| FGFR2_SMN1_ENST00000369056_ENST00000506163_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4704
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369056_ENST00000514951_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4705
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369056_ENST00000514951_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.7032
Å |
| | | |  |
| FGFR2_SMN1_ENST00000369061_ENST00000351205_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4444
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369061_ENST00000503079_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4525
Å |
 |  |  |  |  |
| FGFR2_SMN1_ENST00000369061_ENST00000503079_123243211_70234665 superimposed PDB: 1G5V of partner (SMN1). RMSD:0.6988
Å |
| | | |  |
| FGFR2_SMN1_ENST00000369061_ENST00000506163_123243211_70234665 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4465
Å |
 |  |  |  |  |
| FGFR3_AES_ENST00000340107_ENST00000327141_1808661_3061255 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.6926
Å |
 |  |  |  |  |
| FGFR3_AES_ENST00000440486_ENST00000327141_1808661_3061255 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.1581
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000260795_ENST00000298834_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.3854
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000340107_ENST00000298834_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:3.1967
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000340107_ENST00000426438_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.1976
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000412135_ENST00000298834_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:1.899
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000412135_ENST00000426438_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.8729
Å |
 |  |  |  |  |
| FGFR3_AMBRA1_ENST00000440486_ENST00000426438_1808661_46439602 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.403
Å |
 |  |  |  |  |
| FGFR3_BAIAP2L1_ENST00000260795_ENST00000005260_1808661_97991744 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.7666
Å |
 |  |  |  |  |
| FGFR3_BAIAP2L1_ENST00000260795_ENST00000005260_1808661_97991744 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.504
Å |
| | | |  |
| FGFR3_BAIAP2L1_ENST00000340107_ENST00000005260_1808661_97991744 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.6914
Å |
 |  |  |  |  |
| FGFR3_BAIAP2L1_ENST00000340107_ENST00000005260_1808661_97991744 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.5512
Å |
| | | |  |
| FGFR3_BAIAP2L1_ENST00000412135_ENST00000005260_1808661_97991744 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.7603
Å |
 |  |  |  |  |
| FGFR3_BAIAP2L1_ENST00000412135_ENST00000005260_1808661_97991744 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.5168
Å |
| | | |  |
| FGFR3_ELAVL3_ENST00000260795_ENST00000359227_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:3.0777
Å |
 |  |  |  |  |
| FGFR3_ELAVL3_ENST00000340107_ENST00000359227_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:1.4137
Å |
 |  |  |  |  |
| FGFR3_ELAVL3_ENST00000340107_ENST00000438662_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.9172
Å |
 |  |  |  |  |
| FGFR3_ELAVL3_ENST00000412135_ENST00000359227_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.3037
Å |
 |  |  |  |  |
| FGFR3_ELAVL3_ENST00000412135_ENST00000438662_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.4161
Å |
 |  |  |  |  |
| FGFR3_ELAVL3_ENST00000440486_ENST00000438662_1808661_11577642 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.4555
Å |
 |  |  |  |  |
| FGFR3_FBXO28_ENST00000260795_ENST00000366862_1808661_224340843 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.4216
Å |
 |  |  |  |  |
| FGFR3_FBXO28_ENST00000340107_ENST00000366862_1808661_224340843 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.8408
Å |
 |  |  |  |  |
| FGFR3_FBXO28_ENST00000412135_ENST00000366862_1808661_224340843 superimposed PDB: 1RY7 of partner (FGFR3). RMSD:2.3996
Å |
 |  |  |  |  |
| FGGY_CDH17_ENST00000303721_ENST00000027335_59978111_95174390 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.7901
Å |
 |  |  |  |  |
| FGGY_CDH17_ENST00000371212_ENST00000441892_59978111_95174390 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.1074
Å |
 |  |  |  |  |
| FGGY_CDH17_ENST00000371212_ENST00000450165_59978111_95174390 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.9573
Å |
 |  |  |  |  |
| FGGY_CDH17_ENST00000371218_ENST00000441892_59978111_95174390 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.9175
Å |
 |  |  |  |  |
| FGGY_CDH17_ENST00000371218_ENST00000450165_59978111_95174390 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.8794
Å |
 |  |  |  |  |
| FGG_P4HB_ENST00000405164_ENST00000331483_155533542_79804505 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.0338
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000350494_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.024
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000350494_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8397
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000351393_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7523
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000351393_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9877
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000351393_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8966
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000423854_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9251
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000423854_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9798
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000442325_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7787
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000442325_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8525
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000542824_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8709
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000542824_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3238
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000257209_ENST00000542824_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0072
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000350494_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7949
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000351393_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.799
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000358232_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0294
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000358232_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0055
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000423854_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9717
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000442325_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.875
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000359247_ENST00000542824_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0522
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000350494_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0124
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000350494_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7905
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000351393_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.6961
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000351393_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0357
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000351393_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9637
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000358232_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0906
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000358232_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0404
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000423854_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7827
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000423854_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0355
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000442325_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8304
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000442325_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.964
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000542824_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8735
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000542824_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3325
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000445677_ENST00000542824_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0529
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000350494_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0077
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000350494_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8614
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000351393_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.6897
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000351393_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0396
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000351393_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.7644
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000358232_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.3099
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000358232_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0605
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000423854_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8425
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000423854_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9921
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000442325_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9167
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000442325_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9769
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000542824_33877963_33713200 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9389
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000542824_33952707_33722788 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.3283
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000590592_ENST00000542824_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9788
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000350494_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.8983
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000351393_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0343
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000358232_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.1746
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000423854_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.0505
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000442325_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:2.1734
Å |
 |  |  |  |  |
| FHOD3_ELP2_ENST00000591635_ENST00000542824_34310767_33718232 superimposed PDB: 8PTX of partner (ELP2). RMSD:1.9367
Å |
 |  |  |  |  |
| FILIP1_TMEM30A_ENST00000237172_ENST00000230461_76124412_75977464 superimposed PDB: 8OX6 of partner (TMEM30A). RMSD:0.6635
Å |
 |  |  |  |  |
| FIP1L1_SLC38A8_ENST00000306932_ENST00000299709_54294350_84046657 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:1.8902
Å |
 |  |  |  |  |
| FIP1L1_SLC38A8_ENST00000337488_ENST00000299709_54294350_84046657 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5165
Å |
 |  |  |  |  |
| FIP1L1_SLC38A8_ENST00000358575_ENST00000299709_54294350_84046657 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.6821
Å |
 |  |  |  |  |
| FIP1L1_SLC38A8_ENST00000358575_ENST00000299709_54306775_84046657 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.5004
Å |
 |  |  |  |  |
| FIP1L1_SORCS1_ENST00000337488_ENST00000263054_54266006_108489872 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7758
Å |
 |  |  |  |  |
| FIP1L1_SORCS1_ENST00000358575_ENST00000263054_54266006_108489872 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7021
Å |
 |  |  |  |  |
| FKBP14_DAP_ENST00000222803_ENST00000432074_30062280_10748383 superimposed PDB: 4MSP of partner (FKBP14). RMSD:0.7438
Å |
 |  |  |  |  |
| FKBP14_EIF4A1_ENST00000222803_ENST00000577269_30062280_7478436 superimposed PDB: 4MSP of partner (FKBP14). RMSD:0.6059
Å |
 |  |  |  |  |
| FKBP14_EIF4A1_ENST00000222803_ENST00000582746_30062280_7478436 superimposed PDB: 4MSP of partner (FKBP14). RMSD:0.5704
Å |
 |  |  |  |  |
| FKBP1A_ACSL1_ENST00000381719_ENST00000515030_1356134_185689604 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:1.8994
Å |
 |  |  |  |  |
| FKBP1A_ACSL1_ENST00000381724_ENST00000454703_1356134_185689604 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:1.6153
Å |
 |  |  |  |  |
| FKBP1A_ACSL1_ENST00000381724_ENST00000515030_1356134_185689604 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:2.7036
Å |
 |  |  |  |  |
| FKBP1A_BORA_ENST00000400137_ENST00000377815_1373477_73312099 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:1.7611
Å |
 |  |  |  |  |
| FKBP1A_NR2C1_ENST00000381715_ENST00000333003_1356134_95456514 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:0.9924
Å |
 |  |  |  |  |
| FKBP1A_NR2C1_ENST00000381719_ENST00000333003_1356134_95456514 superimposed PDB: 8X6P of partner (FKBP1A). RMSD:1.25
Å |
 |  |  |  |  |
| FKBP8_HAUS8_ENST00000222308_ENST00000253669_18652488_17184145 superimposed PDB: 7SQK of partner (HAUS8). RMSD:2.7624
Å |
 |  |  |  |  |
| FKBP8_HAUS8_ENST00000610101_ENST00000448593_18652488_17184145 superimposed PDB: 7SQK of partner (HAUS8). RMSD:3.0926
Å |
 |  |  |  |  |
| FKBP8_SLC1A6_ENST00000453489_ENST00000430939_18644079_15061202 superimposed PDB: 5MGX of partner (FKBP8). RMSD:0.5247
Å |
 |  |  |  |  |
| FKBP8_SLC1A6_ENST00000596558_ENST00000600144_18644079_15061202 superimposed PDB: 5MGX of partner (FKBP8). RMSD:0.2953
Å |
 |  |  |  |  |
| FKBP8_SLC1A6_ENST00000608443_ENST00000221742_18644079_15061202 superimposed PDB: 5MGX of partner (FKBP8). RMSD:0.4745
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000242209_ENST00000350941_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.6651
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000242209_ENST00000354265_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.7239
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000242209_ENST00000355070_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.6693
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000242209_ENST00000396127_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.6908
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000242209_ENST00000425508_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.7048
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000242067_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5664
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000242067_33016111_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:0.8628
Å |
| | | |  |
| FKBP9_BBS9_ENST00000538336_ENST00000350941_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.648
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000354265_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.6142
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000355070_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5744
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000396127_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5872
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538336_ENST00000425508_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5786
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000242067_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.525
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000242067_33016111_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:0.8716
Å |
| | | |  |
| FKBP9_BBS9_ENST00000538443_ENST00000350941_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:1.0069
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000354265_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.9608
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000355070_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.933
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000355070_33016111_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:2.9809
Å |
| | | |  |
| FKBP9_BBS9_ENST00000538443_ENST00000396127_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.8678
Å |
 |  |  |  |  |
| FKBP9_BBS9_ENST00000538443_ENST00000396127_33016111_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:2.9457
Å |
| | | |  |
| FKBP9_BBS9_ENST00000538443_ENST00000425508_33016111_33217089 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.9452
Å |
 |  |  |  |  |
| FKBP9_RNPEP_ENST00000490776_ENST00000295640_33035961_201965274 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.6947
Å |
 |  |  |  |  |
| FKBP9_RNPEP_ENST00000538336_ENST00000295640_33035961_201965274 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.5569
Å |
 |  |  |  |  |
| FKBP9_RNPEP_ENST00000538443_ENST00000295640_33035961_201965274 superimposed PDB: 4C02 of partner (FKBP9). RMSD:0.7207
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000281428_ENST00000397938_128642880_29688476 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7074
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000281428_ENST00000397938_128651918_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7398
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000344954_ENST00000397938_128642880_29688476 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7088
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000344954_ENST00000397938_128651918_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7142
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000525560_ENST00000397938_128651918_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7436
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000527786_ENST00000397938_128642880_29688476 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7125
Å |
 |  |  |  |  |
| FLI1_EWSR1_ENST00000527786_ENST00000397938_128651918_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7038
Å |
 |  |  |  |  |
| FLNA_TIMM23_ENST00000369850_ENST00000260867_153582518_51612988 superimposed PDB: 4M9P of partner (FLNA). RMSD:1.2484
Å |
 |  |  |  |  |
| FLNA_TIMM23_ENST00000369856_ENST00000260867_153582518_51612988 superimposed PDB: 4M9P of partner (FLNA). RMSD:1.3917
Å |
 |  |  |  |  |
| FLNA_TIMM23_ENST00000422373_ENST00000260867_153582518_51612988 superimposed PDB: 4M9P of partner (FLNA). RMSD:1.0416
Å |
 |  |  |  |  |
| FLNB_ANXA2_ENST00000490882_ENST00000396024_57994583_60656722 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7169
Å |
 |  |  |  |  |
| FLNB_ANXA2_ENST00000490882_ENST00000451270_57994583_60656722 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.4238
Å |
 |  |  |  |  |
| FLNB_ANXA2_ENST00000490882_ENST00000451270_57994583_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3914
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000323926_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6794
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000323926_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:3.022
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000336916_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7154
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000336916_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7236
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000345488_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6862
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000345488_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8386
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000346544_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6414
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000346544_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8284
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000357009_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6948
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000357009_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9494
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000357867_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6983
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000357867_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9364
Å |
| | | |  |
| FLNB_FN1_ENST00000490882_ENST00000359671_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6815
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000490882_ENST00000359671_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9653
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000323926_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.2844
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000323926_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9197
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000336916_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.3676
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000336916_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9943
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000345488_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8864
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000345488_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7431
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000346544_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.778
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000346544_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8832
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000357009_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.9822
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000357009_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0322
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000357867_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8786
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000357867_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7307
Å |
| | | |  |
| FLNB_FN1_ENST00000493452_ENST00000359671_58090943_216244040 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.1263
Å |
 |  |  |  |  |
| FLNB_FN1_ENST00000493452_ENST00000359671_58090943_216244040 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1339
Å |
| | | |  |
| FLNB_RAD18_ENST00000295956_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.9945
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000295956_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:3.058
Å |
| | | |  |
| FLNB_RAD18_ENST00000348383_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.2397
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000348383_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:2.7205
Å |
| | | |  |
| FLNB_RAD18_ENST00000358537_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.199
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000358537_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:2.7032
Å |
| | | |  |
| FLNB_RAD18_ENST00000419752_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.1632
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000419752_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:2.5578
Å |
| | | |  |
| FLNB_RAD18_ENST00000429972_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.1646
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000429972_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:3.0386
Å |
| | | |  |
| FLNB_RAD18_ENST00000493452_ENST00000264926_58155520_8990254 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.0184
Å |
 |  |  |  |  |
| FLNB_RAD18_ENST00000493452_ENST00000264926_58155520_8990254 superimposed PDB: 2Y43 of partner (RAD18). RMSD:1.6381
Å |
| | | |  |
| FLNB_SLMAP_ENST00000295956_ENST00000295951_58124256_57843459 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.656
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295951_58084635_57857362 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7867
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295951_58084635_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.1205
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295951_58088067_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.1893
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295951_58107230_57843459 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.3521
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295951_58124256_57843459 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.639
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000419752_ENST00000295952_58090943_57898107 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.0859
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_57994583_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.5311
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58067503_57893610 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.5216
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58084635_57857362 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7328
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58084635_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6582
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58088067_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7063
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58107230_57843459 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.8802
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295951_58124256_57843459 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.5448
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000429972_ENST00000295952_58118658_57902632 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.8889
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000490882_ENST00000295951_58088067_57875767 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.1237
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000490882_ENST00000295952_58090943_57898107 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6921
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000490882_ENST00000295952_58118658_57902632 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7834
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000490882_ENST00000416870_58090943_57898107 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6719
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000493452_ENST00000295952_58090943_57898107 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8215
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000493452_ENST00000295952_58118658_57902632 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.9687
Å |
 |  |  |  |  |
| FLNB_SLMAP_ENST00000493452_ENST00000416870_58090943_57898107 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.9913
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000295956_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.8704
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000295956_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.5229
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000348383_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.1014
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000348383_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.752
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000358537_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.0426
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000358537_ENST00000568667_58154385_75131391 superimposed PDB: 6FDY of partner (ULK3). RMSD:2.8913
Å |
| | | |  |
| FLNB_ULK3_ENST00000358537_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.2269
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000419752_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7588
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000419752_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.1397
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000429972_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.6904
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000429972_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.0763
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000490882_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.88
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000490882_ENST00000568667_58154385_75131391 superimposed PDB: 6FDY of partner (ULK3). RMSD:2.9573
Å |
| | | |  |
| FLNB_ULK3_ENST00000490882_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.0725
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000493452_ENST00000568667_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.4924
Å |
 |  |  |  |  |
| FLNB_ULK3_ENST00000493452_ENST00000569437_58154385_75131391 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.956
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000348383_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.102
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000348383_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8748
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000348383_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.6954
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000348383_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.0397
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000429972_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:0.8856
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000429972_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8576
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000429972_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:0.8686
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000429972_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.7245
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000490882_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.533
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000490882_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7734
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000493452_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:0.971
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000493452_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.6839
Å |
| | | |  |
| FLNC_FLNB_ENST00000325888_ENST00000493452_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.1398
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000325888_ENST00000493452_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.6402
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000348383_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.3186
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000348383_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.88
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000348383_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.0341
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000348383_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7747
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000429972_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:0.9718
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000429972_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.9737
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000429972_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.0783
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000429972_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8419
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000493452_128491682_58133932 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.1821
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000493452_128491682_58133932 superimposed PDB: 4B7L of partner (FLNB). RMSD:1.1217
Å |
| | | |  |
| FLNC_FLNB_ENST00000346177_ENST00000493452_128491682_58134375 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.787
Å |
 |  |  |  |  |
| FLNC_FLNB_ENST00000346177_ENST00000493452_128491682_58134375 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.9897
Å |
| | | |  |
| FLOT2_SUPT6H_ENST00000394906_ENST00000347486_27224543_27013356 superimposed PDB: 9HVQ of partner (SUPT6H). RMSD:1.9057
Å |
 |  |  |  |  |
| FLOT2_SUPT6H_ENST00000394908_ENST00000347486_27224543_27013356 superimposed PDB: 9HVQ of partner (SUPT6H). RMSD:1.8147
Å |
 |  |  |  |  |
| FLT3_GALNT2_ENST00000241453_ENST00000366672_28597486_230313963 superimposed PDB: 7QDP of partner (FLT3). RMSD:2.1223
Å |
 |  |  |  |  |
| FLT3_GALNT2_ENST00000241453_ENST00000366672_28597486_230313963 superimposed PDB: 5AJO of partner (GALNT2). RMSD:0.8303
Å |
| | | |  |
| FMNL3_TUBA1A_ENST00000335154_ENST00000295766_50100837_49580616 superimposed PDB: 9WD9 of partner (TUBA1A). RMSD:0.762
Å |
 |  |  |  |  |
| FMNL3_TUBA1B_ENST00000550488_ENST00000336023_50100837_49523505 superimposed PDB: 6S8L of partner (TUBA1B). RMSD:0.8783
Å |
 |  |  |  |  |
| FN1_ACLY_ENST00000421182_ENST00000590151_216279559_40035177 superimposed PDB: 7RIG of partner (ACLY). RMSD:0.9169
Å |
 |  |  |  |  |
| FN1_AKR1C1_ENST00000357867_ENST00000434459_216279559_5008105 superimposed PDB: 3C3U of partner (AKR1C1). RMSD:0.4151
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000323926_ENST00000295956_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.6836
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000323926_ENST00000348383_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.9385
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000323926_ENST00000357272_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.0628
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000323926_ENST00000493452_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.6189
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000359671_ENST00000348383_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7954
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000359671_ENST00000348383_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.4175
Å |
| | | |  |
| FN1_FLNB_ENST00000359671_ENST00000419752_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7928
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000359671_ENST00000493452_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8022
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000359671_ENST00000493452_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7753
Å |
| | | |  |
| FN1_FLNB_ENST00000432072_ENST00000295956_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2263
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000432072_ENST00000295956_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.769
Å |
| | | |  |
| FN1_FLNB_ENST00000432072_ENST00000429972_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.0887
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000295956_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.8484
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000348383_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2738
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000348383_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.052
Å |
| | | |  |
| FN1_FLNB_ENST00000443816_ENST00000357272_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7459
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000357272_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.4177
Å |
| | | |  |
| FN1_FLNB_ENST00000443816_ENST00000429972_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8834
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000493452_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:3.176
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000443816_ENST00000493452_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:2.7877
Å |
| | | |  |
| FN1_FLNB_ENST00000446046_ENST00000429972_216238044_58118534 superimposed PDB: 4B7L of partner (FLNB). RMSD:3.095
Å |
 |  |  |  |  |
| FN1_FLNB_ENST00000446046_ENST00000490882_216238044_58118534 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1571
Å |
 |  |  |  |  |
| FN1_GTPBP4_ENST00000354785_ENST00000360803_216238044_1043147 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2433
Å |
 |  |  |  |  |
| FN1_GTPBP4_ENST00000357867_ENST00000360803_216238044_1043147 superimposed PDB: 1FNF of partner (FN1). RMSD:3.293
Å |
 |  |  |  |  |
| FN1_GTPBP4_ENST00000421182_ENST00000360803_216238044_1043147 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6605
Å |
 |  |  |  |  |
| FN1_LDHA_ENST00000357867_ENST00000422447_216299418_18424386 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.8352
Å |
 |  |  |  |  |
| FN1_LDHA_ENST00000421182_ENST00000227157_216299418_18424386 superimposed PDB: 5W8J of partner (LDHA). RMSD:1.1634
Å |
 |  |  |  |  |
| FN1_LDHA_ENST00000421182_ENST00000430553_216299418_18424386 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.8339
Å |
 |  |  |  |  |
| FN1_LDHA_ENST00000421182_ENST00000540430_216299418_18424386 superimposed PDB: 5W8J of partner (LDHA). RMSD:1.0142
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000323926_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6776
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000336916_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0204
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000346544_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7493
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000346544_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7353
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000354785_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0074
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000356005_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0297
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000357867_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0654
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000357867_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9462
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000359671_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9796
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000359671_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8596
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000421182_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8269
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000432072_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8583
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000443816_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8134
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000443816_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8889
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000446046_ENST00000010404_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9387
Å |
 |  |  |  |  |
| FN1_MGST1_ENST00000446046_ENST00000396210_216236631_16510538 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0234
Å |
 |  |  |  |  |
| FN1_PPT1_ENST00000336916_ENST00000433473_216238044_40555184 superimposed PDB: 3GRO of partner (PPT1). RMSD:0.9863
Å |
 |  |  |  |  |
| FN1_PPT1_ENST00000354785_ENST00000433473_216238044_40555184 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0941
Å |
 |  |  |  |  |
| FN1_PPT1_ENST00000354785_ENST00000433473_216238044_40555184 superimposed PDB: 3GRO of partner (PPT1). RMSD:1.3643
Å |
| | | |  |
| FN1_PPT1_ENST00000356005_ENST00000433473_216238044_40555184 superimposed PDB: 3GRO of partner (PPT1). RMSD:1.0917
Å |
 |  |  |  |  |
| FN1_PPT1_ENST00000357867_ENST00000433473_216238044_40555184 superimposed PDB: 1FNF of partner (FN1). RMSD:2.843
Å |
 |  |  |  |  |
| FN1_PPT1_ENST00000357867_ENST00000433473_216238044_40555184 superimposed PDB: 3GRO of partner (PPT1). RMSD:1.011
Å |
| | | |  |
| FN1_PPT1_ENST00000421182_ENST00000433473_216238044_40555184 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6769
Å |
 |  |  |  |  |
| FN1_RHOA_ENST00000357867_ENST00000418115_216279559_49405981 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.4723
Å |
 |  |  |  |  |
| FN1_RPLP1_ENST00000357867_ENST00000560274_216261859_69747766 superimposed PDB: 1FNF of partner (FN1). RMSD:2.4109
Å |
 |  |  |  |  |
| FN1_RPS6_ENST00000323926_ENST00000380394_216245533_19376649 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8982
Å |
 |  |  |  |  |
| FN1_RPS6_ENST00000336916_ENST00000380394_216245533_19376649 superimposed PDB: 1FNF of partner (FN1). RMSD:2.94
Å |
 |  |  |  |  |
| FN1_RPS6_ENST00000354785_ENST00000380394_216245533_19376649 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7676
Å |
 |  |  |  |  |
| FN1_RTN4_ENST00000421182_ENST00000394609_216256354_55214834 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1756
Å |
 |  |  |  |  |
| FN1_RTN4_ENST00000421182_ENST00000405240_216256354_55214834 superimposed PDB: 1FNF of partner (FN1). RMSD:1.1703
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000323926_ENST00000373238_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:0.5317
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000336916_ENST00000373238_216239936_71920825 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7348
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000336916_ENST00000373238_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:0.4569
Å |
| | | |  |
| FN1_SAR1A_ENST00000336916_ENST00000373242_216239936_71920825 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2432
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000336916_ENST00000373242_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:2.6359
Å |
| | | |  |
| FN1_SAR1A_ENST00000354785_ENST00000373242_216239936_71920825 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7829
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000354785_ENST00000373242_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:2.4968
Å |
| | | |  |
| FN1_SAR1A_ENST00000357867_ENST00000373242_216239936_71920825 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7578
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000357867_ENST00000373242_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:2.5765
Å |
| | | |  |
| FN1_SAR1A_ENST00000421182_ENST00000373238_216239936_71920825 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8291
Å |
 |  |  |  |  |
| FN1_SAR1A_ENST00000421182_ENST00000373238_216239936_71920825 superimposed PDB: 8DZM of partner (SAR1A). RMSD:0.4884
Å |
| | | |  |
| FN1_SEC31A_ENST00000345488_ENST00000505984_216248742_83750211 superimposed PDB: 1FNF of partner (FN1). RMSD:2.5217
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000323926_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9267
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000323926_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.9602
Å |
| | | |  |
| FN1_TUBB3_ENST00000336916_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.7243
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000345488_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7875
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000345488_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.8383
Å |
| | | |  |
| FN1_TUBB3_ENST00000346544_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:1.2704
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000354785_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.4875
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000354785_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:1.2023
Å |
| | | |  |
| FN1_TUBB3_ENST00000356005_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.798
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000357867_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8994
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000357867_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:1.3164
Å |
| | | |  |
| FN1_TUBB3_ENST00000359671_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:3.473
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000359671_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.8387
Å |
| | | |  |
| FN1_TUBB3_ENST00000432072_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:3.2298
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000432072_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.8327
Å |
| | | |  |
| FN1_TUBB3_ENST00000443816_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9734
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000443816_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.9113
Å |
| | | |  |
| FN1_TUBB3_ENST00000446046_ENST00000556922_216229601_89998978 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8098
Å |
 |  |  |  |  |
| FN1_TUBB3_ENST00000446046_ENST00000556922_216229601_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.859
Å |
| | | |  |
| FN1_UBA2_ENST00000357867_ENST00000246548_216279559_34921480 superimposed PDB: 9QN5 of partner (UBA2). RMSD:1.9172
Å |
 |  |  |  |  |
| FN1_XRCC6_ENST00000323926_ENST00000402580_216238044_42057334 superimposed PDB: 1FNF of partner (FN1). RMSD:2.5843
Å |
 |  |  |  |  |
| FN1_XRCC6_ENST00000336916_ENST00000402580_216238044_42057334 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8791
Å |
 |  |  |  |  |
| FN1_XRCC6_ENST00000421182_ENST00000360079_216238044_42057334 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8999
Å |
 |  |  |  |  |
| FN1_XRCC6_ENST00000421182_ENST00000402580_216238044_42057334 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9334
Å |
 |  |  |  |  |
| FN1_XRCC6_ENST00000432072_ENST00000402580_216238044_42057334 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8965
Å |
 |  |  |  |  |
| FNBP1_RAC2_ENST00000355681_ENST00000405484_132805230_37622843 superimposed PDB: 2EFL of partner (FNBP1). RMSD:2.9976
Å |
 |  |  |  |  |
| FNBP1_RAC2_ENST00000420781_ENST00000405484_132805230_37622843 superimposed PDB: 1DS6 of partner (RAC2). RMSD:0.7746
Å |
 |  |  |  |  |
| FNDC3A_RB1_ENST00000541916_ENST00000267163_49688867_49037866 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.4101
Å |
 |  |  |  |  |
| FNDC3A_RPS29_ENST00000398316_ENST00000245458_49720071_50052767 superimposed PDB: 1WK0 of partner (FNDC3A). RMSD:2.2992
Å |
 |  |  |  |  |
| FNDC3A_RPS29_ENST00000492622_ENST00000245458_49720071_50052767 superimposed PDB: 1WK0 of partner (FNDC3A). RMSD:2.317
Å |
 |  |  |  |  |
| FNDC3A_RPS29_ENST00000541916_ENST00000396020_49720071_50052767 superimposed PDB: 1WK0 of partner (FNDC3A). RMSD:2.3598
Å |
 |  |  |  |  |
| FNIP1_PDE4B_ENST00000307954_ENST00000371049_131006155_66821209 superimposed PDB: 4WZI of partner (PDE4B). RMSD:0.4387
Å |
 |  |  |  |  |
| FNIP1_PDE4B_ENST00000307954_ENST00000423207_131006155_66821209 superimposed PDB: 4WZI of partner (PDE4B). RMSD:0.4258
Å |
 |  |  |  |  |
| FNIP1_PDE4B_ENST00000307968_ENST00000371049_131006155_66821209 superimposed PDB: 4WZI of partner (PDE4B). RMSD:0.4298
Å |
 |  |  |  |  |
| FNIP1_PDE4B_ENST00000510461_ENST00000371049_131006155_66821209 superimposed PDB: 4WZI of partner (PDE4B). RMSD:0.4041
Å |
 |  |  |  |  |
| FOLH1_TRIM51_ENST00000256999_ENST00000244891_49204700_55657417 superimposed PDB: 9HLW of partner (FOLH1). RMSD:1.3992
Å |
 |  |  |  |  |
| FOSL1_SYT7_ENST00000448083_ENST00000540677_65667711_61295657 superimposed PDB: 2D8K of partner (SYT7). RMSD:0.783
Å |
 |  |  |  |  |
| FOSL1_SYT7_ENST00000448083_ENST00000542836_65667711_61295657 superimposed PDB: 2D8K of partner (SYT7). RMSD:0.7655
Å |
 |  |  |  |  |
| FOXJ3_CCDC23_ENST00000372573_ENST00000372521_42693553_43273171 superimposed PDB: 6J4P of partner (CCDC23). RMSD:0.3741
Å |
 |  |  |  |  |
| FOXJ3_HNRNPH1_ENST00000361346_ENST00000356731_42776720_179048398 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.1433
Å |
 |  |  |  |  |
| FOXJ3_HNRNPH1_ENST00000372572_ENST00000442819_42776720_179048398 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:3.0415
Å |
 |  |  |  |  |
| FOXJ3_HNRNPH1_ENST00000372573_ENST00000356731_42776720_179048398 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.8942
Å |
 |  |  |  |  |
| FOXK2_ABCA5_ENST00000335255_ENST00000392677_80542064_67273983 superimposed PDB: 2C6Y of partner (FOXK2). RMSD:0.3888
Å |
 |  |  |  |  |
| FOXK2_ABCA5_ENST00000335255_ENST00000588877_80542064_67273983 superimposed PDB: 2C6Y of partner (FOXK2). RMSD:0.3508
Å |
 |  |  |  |  |
| FOXM1_DCP1B_ENST00000342628_ENST00000397173_2975558_2062454 superimposed PDB: 3G73 of partner (FOXM1). RMSD:0.2742
Å |
 |  |  |  |  |
| FOXM1_SLC2A14_ENST00000342628_ENST00000543909_2977728_7970630 superimposed PDB: 3G73 of partner (FOXM1). RMSD:0.2434
Å |
 |  |  |  |  |
| FOXN2_SPTBN1_ENST00000340553_ENST00000333896_48573890_54849436 superimposed PDB: 3EDV of partner (SPTBN1). RMSD:2.3497
Å |
 |  |  |  |  |
| FOXN3_CDKL1_ENST00000557258_ENST00000395834_89878277_50796899 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.4125
Å |
 |  |  |  |  |
| FOXN3_CDKL1_ENST00000557258_ENST00000395834_89878277_50796899 superimposed PDB: 4AGU of partner (CDKL1). RMSD:3.181
Å |
| | | |  |
| FOXN3_KCNQ1_ENST00000345097_ENST00000155840_89747293_2790073 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.3602
Å |
 |  |  |  |  |
| FOXN3_KCNQ1_ENST00000345097_ENST00000335475_89747293_2790073 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.4037
Å |
 |  |  |  |  |
| FOXN3_SLC25A21_ENST00000261302_ENST00000331299_89656727_37344209 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.3267
Å |
 |  |  |  |  |
| FOXN3_SLC25A21_ENST00000261302_ENST00000331299_89747293_37344209 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.3958
Å |
 |  |  |  |  |
| FOXN3_SLC25A21_ENST00000261302_ENST00000555449_89656727_37344209 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.498
Å |
 |  |  |  |  |
| FOXN3_SLC25A21_ENST00000557258_ENST00000555449_89747293_37344209 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.3729
Å |
 |  |  |  |  |
| FOXO1_PDGFRB_ENST00000379561_ENST00000261799_41239719_149499686 superimposed PDB: 4LG0 of partner (FOXO1). RMSD:0.368
Å |
 |  |  |  |  |
| FOXO1_UBQLN1_ENST00000379561_ENST00000376395_41239719_86280060 superimposed PDB: 4LG0 of partner (FOXO1). RMSD:0.453
Å |
 |  |  |  |  |
| FOXO3_GMDS_ENST00000343882_ENST00000380815_108883032_1961200 superimposed PDB: 2K86 of partner (FOXO3). RMSD:2.595
Å |
 |  |  |  |  |
| FOXO3_GMDS_ENST00000343882_ENST00000380815_108883032_1961200 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.6376
Å |
| | | |  |
| FOXO3_GMDS_ENST00000343882_ENST00000530927_108883032_1961200 superimposed PDB: 2K86 of partner (FOXO3). RMSD:2.4744
Å |
 |  |  |  |  |
| FOXO3_GMDS_ENST00000406360_ENST00000380815_108883032_1961200 superimposed PDB: 2K86 of partner (FOXO3). RMSD:2.559
Å |
 |  |  |  |  |
| FOXO3_GMDS_ENST00000406360_ENST00000380815_108883032_1961200 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.6203
Å |
| | | |  |
| FOXO3_PPP1R9A_ENST00000343882_ENST00000340694_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.905
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000343882_ENST00000424654_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.9578
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000343882_ENST00000433881_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.9173
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000343882_ENST00000456331_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.923
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000406360_ENST00000340694_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.9004
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000406360_ENST00000424654_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.938
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000406360_ENST00000433881_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.8124
Å |
 |  |  |  |  |
| FOXO3_PPP1R9A_ENST00000406360_ENST00000456331_108883032_94876784 superimposed PDB: 2K86 of partner (FOXO3). RMSD:1.9534
Å |
 |  |  |  |  |
| FOXP1_ARMC8_ENST00000475937_ENST00000469044_71247352_137928658 superimposed PDB: 7NSC of partner (ARMC8). RMSD:2.4294
Å |
 |  |  |  |  |
| FOXP1_PDCD6IP_ENST00000484350_ENST00000457054_71247352_33853563 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:2.6829
Å |
 |  |  |  |  |
| FOXP1_PDZRN3_ENST00000491238_ENST00000263666_71026793_73453546 superimposed PDB: 1WH1 of partner (PDZRN3). RMSD:0.8543
Å |
 |  |  |  |  |
| FOXP1_PDZRN3_ENST00000498215_ENST00000263666_71026793_73453546 superimposed PDB: 2KIU of partner (FOXP1). RMSD:3.2729
Å |
 |  |  |  |  |
| FOXP1_PDZRN3_ENST00000498215_ENST00000263666_71026793_73453546 superimposed PDB: 1WH1 of partner (PDZRN3). RMSD:0.8605
Å |
| | | |  |
| FOXP1_RYBP_ENST00000491238_ENST00000477973_71090478_72428578 superimposed PDB: 9DBY of partner (RYBP). RMSD:2.5363
Å |
 |  |  |  |  |
| FOXP1_RYBP_ENST00000498215_ENST00000477973_71090478_72428578 superimposed PDB: 9DBY of partner (RYBP). RMSD:2.7777
Å |
 |  |  |  |  |
| FOXP1_SMC4_ENST00000475937_ENST00000360111_71247352_160129707 superimposed PDB: 9F5W of partner (SMC4). RMSD:2.1678
Å |
 |  |  |  |  |
| FOXP1_SMC4_ENST00000475937_ENST00000469762_71247352_160129707 superimposed PDB: 9F5W of partner (SMC4). RMSD:2.2035
Å |
 |  |  |  |  |
| FOXP1_UGGT1_ENST00000484350_ENST00000259253_71037144_128941248 superimposed PDB: 2KIU of partner (FOXP1). RMSD:2.0128
Å |
 |  |  |  |  |
| FOXP4_CCND3_ENST00000373063_ENST00000511642_41533702_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.6236
Å |
 |  |  |  |  |
| FOXP4_CCND3_ENST00000373063_ENST00000511642_41545819_41905132 superimposed PDB: 6XAT of partner (FOXP4). RMSD:2.8079
Å |
 |  |  |  |  |
| FOXP4_CCND3_ENST00000373063_ENST00000511642_41545819_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.6291
Å |
| | | |  |
| FOXP4_CCND3_ENST00000373063_ENST00000511642_41552629_41905132 superimposed PDB: 3G33 of partner (CCND3). RMSD:0.8254
Å |
 |  |  |  |  |
| FOXP4_PGC_ENST00000373060_ENST00000425343_41545819_41710227 superimposed PDB: 1HTR of partner (PGC). RMSD:0.6864
Å |
 |  |  |  |  |
| FOXP4_PGC_ENST00000373063_ENST00000373025_41545819_41710227 superimposed PDB: 1HTR of partner (PGC). RMSD:2.2635
Å |
 |  |  |  |  |
| FPGS_VPS13C_ENST00000373225_ENST00000261517_130566979_62148608 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.0105
Å |
 |  |  |  |  |
| FPGS_VPS13C_ENST00000373247_ENST00000261517_130566979_62148608 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:2.8893
Å |
 |  |  |  |  |
| FREM1_MPDZ_ENST00000380880_ENST00000381022_14841444_13162794 superimposed PDB: 2O2T of partner (MPDZ). RMSD:0.6387
Å |
 |  |  |  |  |
| FREM1_MPDZ_ENST00000380880_ENST00000541718_14841444_13162794 superimposed PDB: 2O2T of partner (MPDZ). RMSD:0.6285
Å |
 |  |  |  |  |
| FRMD4B_OXCT1_ENST00000398540_ENST00000509987_69267472_41801172 superimposed PDB: 3DLX of partner (OXCT1). RMSD:0.4187
Å |
 |  |  |  |  |
| FRS2_NUP107_ENST00000299293_ENST00000378905_69966061_69109406 superimposed PDB: 1XR0 of partner (FRS2). RMSD:0.9934
Å |
 |  |  |  |  |
| FRS2_NUP107_ENST00000299293_ENST00000539906_69966061_69109406 superimposed PDB: 1XR0 of partner (FRS2). RMSD:1.3207
Å |
 |  |  |  |  |
| FRS2_PIP4K2C_ENST00000299293_ENST00000540759_69962876_57994106 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.9601
Å |
 |  |  |  |  |
| FRYL_CNGA1_ENST00000503238_ENST00000514170_48611003_47945429 superimposed PDB: 9ZPV of partner (CNGA1). RMSD:2.494
Å |
 |  |  |  |  |
| FRY_RXFP2_ENST00000380250_ENST00000298386_32606002_32332394 superimposed PDB: 2M96 of partner (RXFP2). RMSD:1.363
Å |
 |  |  |  |  |
| FTH1_FTL_ENST00000526640_ENST00000331825_61732840_49469537 superimposed PDB: 7A6A of partner (FTH1). RMSD:0.3618
Å |
 |  |  |  |  |
| FTH1_FTL_ENST00000526640_ENST00000331825_61732840_49469537 superimposed PDB: 5LG8 of partner (FTL). RMSD:0.3707
Å |
| | | |  |
| FTH1_FTL_ENST00000529191_ENST00000331825_61734783_49469026 superimposed PDB: 7A6A of partner (FTH1). RMSD:0.4684
Å |
 |  |  |  |  |
| FTH1_FTL_ENST00000529191_ENST00000331825_61734783_49469026 superimposed PDB: 5LG8 of partner (FTL). RMSD:0.3787
Å |
| | | |  |
| FTH1_FTL_ENST00000529631_ENST00000331825_61734783_49469026 superimposed PDB: 7A6A of partner (FTH1). RMSD:0.4772
Å |
 |  |  |  |  |
| FTH1_FTL_ENST00000529631_ENST00000331825_61734783_49469026 superimposed PDB: 5LG8 of partner (FTL). RMSD:0.4822
Å |
| | | |  |
| FTH1_FTL_ENST00000532601_ENST00000331825_61732840_49469537 superimposed PDB: 7A6A of partner (FTH1). RMSD:0.4769
Å |
 |  |  |  |  |
| FTH1_FTL_ENST00000532601_ENST00000331825_61732840_49469537 superimposed PDB: 5LG8 of partner (FTL). RMSD:0.4551
Å |
| | | |  |
| FTO_HYDIN_ENST00000394647_ENST00000393567_53922863_70883850 superimposed PDB: 4IE5 of partner (FTO). RMSD:0.5558
Å |
 |  |  |  |  |
| FTO_HYDIN_ENST00000394647_ENST00000393567_53922863_70883850 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:2.2903
Å |
| | | |  |
| FTO_HYDIN_ENST00000431610_ENST00000393567_53922863_70883850 superimposed PDB: 4IE5 of partner (FTO). RMSD:1.189
Å |
 |  |  |  |  |
| FTO_HYDIN_ENST00000431610_ENST00000393567_53922863_70883850 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:2.1696
Å |
| | | |  |
| FTO_HYDIN_ENST00000460382_ENST00000393567_53922863_70883850 superimposed PDB: 4IE5 of partner (FTO). RMSD:0.653
Å |
 |  |  |  |  |
| FTO_HYDIN_ENST00000460382_ENST00000393567_53922863_70883850 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:1.9921
Å |
| | | |  |
| FUBP1_CHMP1A_ENST00000370768_ENST00000535997_78414839_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.8958
Å |
 |  |  |  |  |
| FUBP1_CHMP1A_ENST00000436586_ENST00000535997_78414839_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9147
Å |
 |  |  |  |  |
| FUBP1_IVNS1ABP_ENST00000370767_ENST00000367498_78414839_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.432
Å |
 |  |  |  |  |
| FUCA2_SYNCRIP_ENST00000002165_ENST00000369622_143818525_86333830 superimposed PDB: 6KOR of partner (SYNCRIP). RMSD:2.7872
Å |
 |  |  |  |  |
| FUS_ALDH9A1_ENST00000254108_ENST00000538148_31196500_165634367 superimposed PDB: 6QAP of partner (ALDH9A1). RMSD:2.6648
Å |
 |  |  |  |  |
| FUS_ALDH9A1_ENST00000380244_ENST00000538148_31196500_165634367 superimposed PDB: 6QAP of partner (ALDH9A1). RMSD:2.3296
Å |
 |  |  |  |  |
| FUS_ALDH9A1_ENST00000568685_ENST00000538148_31196500_165634367 superimposed PDB: 6QAP of partner (ALDH9A1). RMSD:2.5911
Å |
 |  |  |  |  |
| FUS_ATF1_ENST00000380244_ENST00000262053_31195717_51207792 superimposed PDB: 5YVG of partner (FUS). RMSD:0.5592
Å |
 |  |  |  |  |
| FUS_ATF1_ENST00000568685_ENST00000262053_31195717_51207792 superimposed PDB: 5YVG of partner (FUS). RMSD:0.5862
Å |
 |  |  |  |  |
| FUS_ATP6V0C_ENST00000380244_ENST00000330398_31191548_2569218 superimposed PDB: 5YVG of partner (FUS). RMSD:2.0615
Å |
 |  |  |  |  |
| FUS_ATP6V0C_ENST00000380244_ENST00000330398_31191548_2569218 superimposed PDB: 6WLW of partner (ATP6V0C). RMSD:0.4925
Å |
| | | |  |
| FUS_ATP6V0C_ENST00000568685_ENST00000330398_31191548_2569218 superimposed PDB: 5YVG of partner (FUS). RMSD:2.0609
Å |
 |  |  |  |  |
| FUS_ATP6V0C_ENST00000568685_ENST00000330398_31191548_2569218 superimposed PDB: 6WLW of partner (ATP6V0C). RMSD:0.4719
Å |
| | | |  |
| FUS_ERG_ENST00000254108_ENST00000398911_31198157_39755845 superimposed PDB: 4IRH of partner (ERG). RMSD:0.38
Å |
 |  |  |  |  |
| FUS_ERG_ENST00000380244_ENST00000398911_31198157_39755845 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4101
Å |
 |  |  |  |  |
| FUS_ERG_ENST00000568685_ENST00000398911_31198157_39755845 superimposed PDB: 4IRH of partner (ERG). RMSD:0.3843
Å |
 |  |  |  |  |
| FUS_GABRA3_ENST00000254108_ENST00000535043_31196500_151514174 superimposed PDB: 9CTP of partner (GABRA3). RMSD:0.9161
Å |
 |  |  |  |  |
| FUS_GABRA3_ENST00000380244_ENST00000535043_31196500_151514174 superimposed PDB: 9CTP of partner (GABRA3). RMSD:0.9328
Å |
 |  |  |  |  |
| FUS_GABRA3_ENST00000568685_ENST00000370314_31196500_151514174 superimposed PDB: 9CTP of partner (GABRA3). RMSD:0.8811
Å |
 |  |  |  |  |
| FUS_GABRA3_ENST00000568685_ENST00000535043_31196500_151514174 superimposed PDB: 9CTP of partner (GABRA3). RMSD:0.9024
Å |
 |  |  |  |  |
| FUS_IL9R_ENST00000254108_ENST00000424344_31193985_59337090 superimposed PDB: 7OX5 of partner (IL9R). RMSD:0.5931
Å |
 |  |  |  |  |
| FUS_IL9R_ENST00000380244_ENST00000244174_31193985_59335576 superimposed PDB: 7OX5 of partner (IL9R). RMSD:0.849
Å |
 |  |  |  |  |
| FUS_IL9R_ENST00000380244_ENST00000424344_31193985_59337090 superimposed PDB: 7OX5 of partner (IL9R). RMSD:0.6275
Å |
 |  |  |  |  |
| FUS_IL9R_ENST00000568685_ENST00000244174_31193985_59335576 superimposed PDB: 7OX5 of partner (IL9R). RMSD:0.7715
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000358307_ENST00000356296_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6266
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000358307_ENST00000356296_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0438
Å |
| | | |  |
| FUT8_NUMB_ENST00000358307_ENST00000544991_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6296
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000358307_ENST00000544991_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.1068
Å |
| | | |  |
| FUT8_NUMB_ENST00000358307_ENST00000555238_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6313
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000358307_ENST00000555238_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0485
Å |
| | | |  |
| FUT8_NUMB_ENST00000358307_ENST00000560335_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6654
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000358307_ENST00000560335_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0504
Å |
| | | |  |
| FUT8_NUMB_ENST00000360689_ENST00000356296_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6152
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000360689_ENST00000356296_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0025
Å |
| | | |  |
| FUT8_NUMB_ENST00000360689_ENST00000544991_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6334
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000360689_ENST00000544991_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0503
Å |
| | | |  |
| FUT8_NUMB_ENST00000360689_ENST00000555238_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.5999
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000360689_ENST00000555238_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.9866
Å |
| | | |  |
| FUT8_NUMB_ENST00000360689_ENST00000560335_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6547
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000360689_ENST00000560335_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0941
Å |
| | | |  |
| FUT8_NUMB_ENST00000394586_ENST00000554546_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6311
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000394586_ENST00000554546_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0181
Å |
| | | |  |
| FUT8_NUMB_ENST00000417683_ENST00000356296_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:1.7189
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000417683_ENST00000356296_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.6
Å |
| | | |  |
| FUT8_NUMB_ENST00000417683_ENST00000544991_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:2.695
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000417683_ENST00000544991_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.7282
Å |
| | | |  |
| FUT8_NUMB_ENST00000417683_ENST00000555238_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:2.2669
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000417683_ENST00000555238_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.6466
Å |
| | | |  |
| FUT8_NUMB_ENST00000417683_ENST00000560335_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:2.1944
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000417683_ENST00000560335_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5551
Å |
| | | |  |
| FUT8_NUMB_ENST00000557164_ENST00000356296_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6067
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000557164_ENST00000356296_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0818
Å |
| | | |  |
| FUT8_NUMB_ENST00000557164_ENST00000544991_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6292
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000557164_ENST00000544991_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.1374
Å |
| | | |  |
| FUT8_NUMB_ENST00000557164_ENST00000555238_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6449
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000557164_ENST00000555238_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.0882
Å |
| | | |  |
| FUT8_NUMB_ENST00000557164_ENST00000560335_66200099_73763993 superimposed PDB: 6X5H of partner (FUT8). RMSD:0.6131
Å |
 |  |  |  |  |
| FUT8_NUMB_ENST00000557164_ENST00000560335_66200099_73763993 superimposed PDB: 5NJJ of partner (NUMB). RMSD:1.2779
Å |
| | | |  |
| FXN_SMC5_ENST00000377270_ENST00000361138_71679951_72879219 superimposed PDB: 5KZ5 of partner (FXN). RMSD:2.9993
Å |
 |  |  |  |  |
| FXN_SMC5_ENST00000377270_ENST00000361138_71679951_72879219 superimposed PDB: 9LWI of partner (SMC5). RMSD:2.4725
Å |
| | | |  |
| FXR2_ETV4_ENST00000250113_ENST00000393664_7496301_41613847 superimposed PDB: 3H8Z of partner (FXR2). RMSD:0.7447
Å |
 |  |  |  |  |
| FXR2_ETV4_ENST00000250113_ENST00000393664_7496301_41613847 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.3153
Å |
| | | |  |
| FXR2_ETV4_ENST00000250113_ENST00000591713_7496301_41613847 superimposed PDB: 3H8Z of partner (FXR2). RMSD:0.7381
Å |
 |  |  |  |  |
| FXR2_ETV4_ENST00000250113_ENST00000591713_7496301_41613847 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.3331
Å |
| | | |  |
| FZD4_LAMTOR1_ENST00000531380_ENST00000535107_86665842_71810302 superimposed PDB: 6B9X of partner (LAMTOR1). RMSD:1.7977
Å |
 |  |  |  |  |
| FZD4_LAMTOR1_ENST00000531380_ENST00000538404_86665842_71810302 superimposed PDB: 6B9X of partner (LAMTOR1). RMSD:3.1769
Å |
 |  |  |  |  |
| FZR1_CNN1_ENST00000313639_ENST00000252456_3523056_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8249
Å |
 |  |  |  |  |
| FZR1_CNN1_ENST00000395095_ENST00000252456_3523056_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8508
Å |
 |  |  |  |  |
| FZR1_SH3YL1_ENST00000313639_ENST00000356150_3523056_230044 superimposed PDB: 2D8H of partner (SH3YL1). RMSD:0.5604
Å |
 |  |  |  |  |
| FZR1_SH3YL1_ENST00000313639_ENST00000405430_3523056_230044 superimposed PDB: 2D8H of partner (SH3YL1). RMSD:0.5225
Å |
 |  |  |  |  |
| FZR1_SH3YL1_ENST00000441788_ENST00000356150_3523056_230044 superimposed PDB: 2D8H of partner (SH3YL1). RMSD:0.541
Å |
 |  |  |  |  |
| FZR1_SH3YL1_ENST00000441788_ENST00000405430_3523056_230044 superimposed PDB: 2D8H of partner (SH3YL1). RMSD:0.4948
Å |
 |  |  |  |  |
| GAB2_ALG8_ENST00000361507_ENST00000376156_78128691_77817992 superimposed PDB: 2VWF of partner (GAB2). RMSD:2.6362
Å |
 |  |  |  |  |
| GAB2_PRCP_ENST00000361507_ENST00000393399_78128691_82571159 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.9088
Å |
 |  |  |  |  |
| GABBR1_FARS2_ENST00000355973_ENST00000274680_29581019_5404774 superimposed PDB: 7C7S of partner (GABBR1). RMSD:2.0477
Å |
 |  |  |  |  |
| GABBR1_FARS2_ENST00000377012_ENST00000324331_29581019_5404774 superimposed PDB: 7C7S of partner (GABBR1). RMSD:2.0498
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000299267_ENST00000356107_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6862
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000299267_ENST00000400011_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6772
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000299267_ENST00000495972_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.709
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000299267_ENST00000545208_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7393
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000311550_ENST00000356107_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.73
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000311550_ENST00000400011_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7325
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000311550_ENST00000495972_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7305
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000311550_ENST00000545208_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7557
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000541819_ENST00000356107_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7259
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000541819_ENST00000400011_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7391
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000541819_ENST00000495972_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7022
Å |
 |  |  |  |  |
| GABRB3_TJP1_ENST00000541819_ENST00000545208_27017548_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7084
Å |
 |  |  |  |  |
| GAK_MAGI1_ENST00000314167_ENST00000402939_905460_65607763 superimposed PDB: 4Y8D of partner (GAK). RMSD:3.069
Å |
 |  |  |  |  |
| GAK_MAGI1_ENST00000314167_ENST00000402939_905460_65607763 superimposed PDB: 2KPK of partner (MAGI1). RMSD:1.0727
Å |
| | | |  |
| GAK_MAGI1_ENST00000314167_ENST00000483466_905460_65607763 superimposed PDB: 4Y8D of partner (GAK). RMSD:2.877
Å |
 |  |  |  |  |
| GAK_MAGI1_ENST00000314167_ENST00000483466_905460_65607763 superimposed PDB: 2KPK of partner (MAGI1). RMSD:1.0519
Å |
| | | |  |
| GAK_MAGI1_ENST00000314167_ENST00000497477_905460_65607763 superimposed PDB: 4Y8D of partner (GAK). RMSD:2.8697
Å |
 |  |  |  |  |
| GAK_MAGI1_ENST00000314167_ENST00000497477_905460_65607763 superimposed PDB: 2KPK of partner (MAGI1). RMSD:1.0751
Å |
| | | |  |
| GAK_MEX3D_ENST00000511163_ENST00000402693_875694_1556922 superimposed PDB: 4Y8D of partner (GAK). RMSD:0.4211
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000327171_ENST00000265175_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5662
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000327171_ENST00000399100_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5759
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000396509_ENST00000265175_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5769
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000396509_ENST00000399100_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5821
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000544523_ENST00000265175_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5513
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000544523_ENST00000399100_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5704
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000560031_ENST00000265175_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5367
Å |
 |  |  |  |  |
| GALK2_SEC24B_ENST00000560031_ENST00000399100_49493447_110412482 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5602
Å |
 |  |  |  |  |
| GALNS_ECI1_ENST00000268695_ENST00000562238_88923165_2293440 superimposed PDB: 1SG4 of partner (ECI1). RMSD:0.5909
Å |
 |  |  |  |  |
| GALNS_ECI1_ENST00000268695_ENST00000570258_88923165_2293440 superimposed PDB: 1SG4 of partner (ECI1). RMSD:1.4044
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000337827_ENST00000390683_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6592
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000337827_ENST00000488612_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6951
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000448469_ENST00000487270_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7927
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000553669_ENST00000390683_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.1565
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000553669_ENST00000471583_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6202
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000553669_ENST00000487270_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.2583
Å |
 |  |  |  |  |
| GALNT16_RAD51B_ENST00000553669_ENST00000488612_69727184_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7451
Å |
 |  |  |  |  |
| GALNT18_TH_ENST00000227756_ENST00000381178_11394061_2191101 superimposed PDB: 6ZVP of partner (TH). RMSD:0.8551
Å |
 |  |  |  |  |
| GALNT2_PRKCQ_ENST00000366672_ENST00000397176_230203153_6506366 superimposed PDB: 5F9E of partner (PRKCQ). RMSD:0.3286
Å |
 |  |  |  |  |
| GALNT2_PRKCQ_ENST00000366672_ENST00000539722_230203153_6506366 superimposed PDB: 5F9E of partner (PRKCQ). RMSD:0.8766
Å |
 |  |  |  |  |
| GALNT7_CHIC2_ENST00000265000_ENST00000512964_174169591_54915472 superimposed PDB: 6IWR of partner (GALNT7). RMSD:2.7606
Å |
 |  |  |  |  |
| GALNT7_CHIC2_ENST00000265000_ENST00000512964_174169591_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.6046
Å |
| | | |  |
| GALNT7_CHIC2_ENST00000512285_ENST00000263921_174169591_54915472 superimposed PDB: 6IWR of partner (GALNT7). RMSD:2.0338
Å |
 |  |  |  |  |
| GALNT7_CHIC2_ENST00000512285_ENST00000263921_174169591_54915472 superimposed PDB: 8SUV of partner (CHIC2). RMSD:1.2646
Å |
| | | |  |
| GALNT8_PRMT8_ENST00000252318_ENST00000382622_4874712_3662816 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.5467
Å |
 |  |  |  |  |
| GALT_WDR72_ENST00000378842_ENST00000557913_34648453_53889471 superimposed PDB: 6GQD of partner (GALT). RMSD:1.305
Å |
 |  |  |  |  |
| GALT_WDR72_ENST00000378842_ENST00000557913_34649561_53889471 superimposed PDB: 6GQD of partner (GALT). RMSD:0.5773
Å |
 |  |  |  |  |
| GALT_WDR72_ENST00000450095_ENST00000557913_34648453_53889471 superimposed PDB: 6GQD of partner (GALT). RMSD:1.5562
Å |
 |  |  |  |  |
| GALT_WDR72_ENST00000450095_ENST00000557913_34649561_53889471 superimposed PDB: 6GQD of partner (GALT). RMSD:0.4548
Å |
 |  |  |  |  |
| GALT_WDR72_ENST00000556278_ENST00000557913_34648453_53889471 superimposed PDB: 6GQD of partner (GALT). RMSD:2.35
Å |
 |  |  |  |  |
| GANC_AP2S1_ENST00000566442_ENST00000599990_42602661_47342835 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.7975
Å |
 |  |  |  |  |
| GAPDH_EEF1G_ENST00000229239_ENST00000378019_6646176_62340214 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5275
Å |
 |  |  |  |  |
| GAPDH_EEF1G_ENST00000396856_ENST00000378019_6646176_62340214 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5235
Å |
 |  |  |  |  |
| GAPDH_EEF1G_ENST00000396858_ENST00000378019_6646176_62340214 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5022
Å |
 |  |  |  |  |
| GAPDH_EEF1G_ENST00000396859_ENST00000378019_6646176_62340214 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4653
Å |
 |  |  |  |  |
| GAPDH_EEF1G_ENST00000396861_ENST00000378019_6646176_62340214 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.5234
Å |
 |  |  |  |  |
| GAPDH_PMEL_ENST00000229239_ENST00000360714_6644027_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.6687
Å |
 |  |  |  |  |
| GAPDH_PMEL_ENST00000396859_ENST00000360714_6644027_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.6966
Å |
 |  |  |  |  |
| GAPDH_PMEL_ENST00000396859_ENST00000536427_6644027_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.6963
Å |
 |  |  |  |  |
| GAPDH_PMEL_ENST00000396861_ENST00000360714_6644027_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.6592
Å |
 |  |  |  |  |
| GAPDH_PMEL_ENST00000396861_ENST00000536427_6644027_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.7755
Å |
 |  |  |  |  |
| GAPDH_TNC_ENST00000396856_ENST00000350763_6646176_117783546 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.4393
Å |
 |  |  |  |  |
| GAPDH_TNC_ENST00000396858_ENST00000350763_6646176_117783546 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.4238
Å |
 |  |  |  |  |
| GAPDH_TNC_ENST00000396859_ENST00000350763_6646176_117783546 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.53
Å |
 |  |  |  |  |
| GART_PCP4_ENST00000381831_ENST00000328619_34883558_41300908 superimposed PDB: 2QK4 of partner (GART). RMSD:0.668
Å |
 |  |  |  |  |
| GAS6_LTBP3_ENST00000327773_ENST00000322147_114541041_65320453 superimposed PDB: 1H30 of partner (GAS6). RMSD:2.3421
Å |
 |  |  |  |  |
| GAS6_LTBP3_ENST00000355761_ENST00000301873_114541041_65320453 superimposed PDB: 1H30 of partner (GAS6). RMSD:2.2129
Å |
 |  |  |  |  |
| GAS6_LTBP3_ENST00000357389_ENST00000301873_114541041_65320453 superimposed PDB: 1H30 of partner (GAS6). RMSD:2.3548
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000323816_ENST00000347519_9923093_24681035 superimposed PDB: 5MK1 of partner (CHMP4A). RMSD:0.4892
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000396115_ENST00000347519_9923093_24681035 superimposed PDB: 5MK1 of partner (CHMP4A). RMSD:0.4447
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000432992_ENST00000347519_9923093_24681035 superimposed PDB: 5MK1 of partner (CHMP4A). RMSD:0.4428
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000437099_ENST00000347519_9923093_24681035 superimposed PDB: 2LX7 of partner (GAS7). RMSD:1.5761
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000585266_ENST00000347519_9923093_24681035 superimposed PDB: 2LX7 of partner (GAS7). RMSD:1.5716
Å |
 |  |  |  |  |
| GAS7_CHMP4A_ENST00000585266_ENST00000347519_9923093_24681035 superimposed PDB: 5MK1 of partner (CHMP4A). RMSD:0.4506
Å |
| | | |  |
| GATA4_TRIB1_ENST00000532059_ENST00000311922_11566437_126448247 superimposed PDB: 5CEM of partner (TRIB1). RMSD:0.9377
Å |
 |  |  |  |  |
| GATC_EED_ENST00000551765_ENST00000327320_120884364_85961337 superimposed PDB: 8VMI of partner (EED). RMSD:0.5114
Å |
 |  |  |  |  |
| GATC_EED_ENST00000551765_ENST00000351625_120884364_85961337 superimposed PDB: 8VMI of partner (EED). RMSD:0.4438
Å |
 |  |  |  |  |
| GATC_EED_ENST00000551765_ENST00000528180_120884364_85961337 superimposed PDB: 8VMI of partner (EED). RMSD:0.4259
Å |
 |  |  |  |  |
| GBE1_FAM19A1_ENST00000429644_ENST00000496687_81643058_68466429 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.5459
Å |
 |  |  |  |  |
| GBE1_FAM19A1_ENST00000489715_ENST00000496687_81643058_68466429 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.5488
Å |
 |  |  |  |  |
| GBE1_KIF20B_ENST00000429644_ENST00000260753_81719988_91518462 superimposed PDB: 4BZY of partner (GBE1). RMSD:1.4728
Å |
 |  |  |  |  |
| GBE1_KIF20B_ENST00000429644_ENST00000416354_81719988_91518462 superimposed PDB: 4BZY of partner (GBE1). RMSD:1.3565
Å |
 |  |  |  |  |
| GBE1_KIF20B_ENST00000489715_ENST00000260753_81719988_91518462 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.9908
Å |
 |  |  |  |  |
| GBE1_KIF20B_ENST00000489715_ENST00000416354_81719988_91518462 superimposed PDB: 4BZY of partner (GBE1). RMSD:1.0865
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000248924_ENST00000337437_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:1.0406
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000248924_ENST00000381756_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.5861
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000248924_ENST00000405147_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.622
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000248924_ENST00000414350_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.6465
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000323205_ENST00000337437_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.9605
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000323205_ENST00000381756_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.5156
Å |
 |  |  |  |  |
| GCAT_GGA1_ENST00000323205_ENST00000405147_38204170_38010202 superimposed PDB: 1OXZ of partner (GGA1). RMSD:0.5699
Å |
 |  |  |  |  |
| GEMIN2_CTAGE5_ENST00000250379_ENST00000341749_39601272_39746137 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:1.0652
Å |
 |  |  |  |  |
| GEMIN2_CTAGE5_ENST00000308317_ENST00000341749_39601272_39746137 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:0.7165
Å |
 |  |  |  |  |
| GEMIN2_CTAGE5_ENST00000396249_ENST00000341502_39601272_39746137 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:0.7574
Å |
 |  |  |  |  |
| GEMIN2_CTAGE5_ENST00000396249_ENST00000341749_39601272_39746137 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:0.7329
Å |
 |  |  |  |  |
| GFPT2_PPFIA2_ENST00000253778_ENST00000549325_179757699_81747118 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.6053
Å |
 |  |  |  |  |
| GFPT2_PPFIA2_ENST00000253778_ENST00000550584_179757699_81747118 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.5067
Å |
 |  |  |  |  |
| GFRA3_TTC8_ENST00000274721_ENST00000536576_137588975_89341369 superimposed PDB: 6Q2S of partner (GFRA3). RMSD:0.6403
Å |
 |  |  |  |  |
| GFRA3_TTC8_ENST00000378362_ENST00000536576_137588975_89341369 superimposed PDB: 6Q2S of partner (GFRA3). RMSD:0.6278
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000405147_ENST00000262965_38004910_1619852 superimposed PDB: 1OXZ of partner (GGA1). RMSD:3.0426
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000405147_ENST00000262965_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.681
Å |
| | | |  |
| GGA1_TCF3_ENST00000405147_ENST00000395423_38004910_1619852 superimposed PDB: 1OXZ of partner (GGA1). RMSD:2.6598
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000405147_ENST00000395423_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6926
Å |
| | | |  |
| GGA1_TCF3_ENST00000405147_ENST00000453954_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7202
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000405147_ENST00000588136_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7036
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000414350_ENST00000262965_38004910_1619852 superimposed PDB: 1OXZ of partner (GGA1). RMSD:2.5072
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000414350_ENST00000262965_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6897
Å |
| | | |  |
| GGA1_TCF3_ENST00000414350_ENST00000395423_38004910_1619852 superimposed PDB: 1OXZ of partner (GGA1). RMSD:2.6621
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000414350_ENST00000395423_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.594
Å |
| | | |  |
| GGA1_TCF3_ENST00000414350_ENST00000453954_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7012
Å |
 |  |  |  |  |
| GGA1_TCF3_ENST00000414350_ENST00000588136_38004910_1619852 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6763
Å |
 |  |  |  |  |
| GGA1_TRIM22_ENST00000325180_ENST00000379965_38013004_5719544 superimposed PDB: 1OXZ of partner (GGA1). RMSD:2.7231
Å |
 |  |  |  |  |
| GGA1_TRIM22_ENST00000405147_ENST00000379965_38013004_5719544 superimposed PDB: 1OXZ of partner (GGA1). RMSD:2.6745
Å |
 |  |  |  |  |
| GGA2_PRKCB_ENST00000309859_ENST00000303531_23502997_23999828 superimposed PDB: 1MHQ of partner (GGA2). RMSD:0.5624
Å |
 |  |  |  |  |
| GGA2_PRKCB_ENST00000309859_ENST00000303531_23502997_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1098
Å |
| | | |  |
| GGA2_PRKCB_ENST00000567468_ENST00000321728_23502997_23999828 superimposed PDB: 1MHQ of partner (GGA2). RMSD:0.5709
Å |
 |  |  |  |  |
| GGA2_PRKCB_ENST00000567468_ENST00000321728_23502997_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.2386
Å |
| | | |  |
| GGA3_MUC20_ENST00000245541_ENST00000320736_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.3511
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000245541_ENST00000436408_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.3698
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000245541_ENST00000447234_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:2.4775
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000351904_ENST00000320736_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:2.8811
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000351904_ENST00000436408_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:2.4898
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000582486_ENST00000320736_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.4007
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000582486_ENST00000436408_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.3779
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000582486_ENST00000447234_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.4191
Å |
 |  |  |  |  |
| GGA3_MUC20_ENST00000582717_ENST00000447234_73237480_195451550 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.438
Å |
 |  |  |  |  |
| GGH_ZFAND1_ENST00000260118_ENST00000220669_63930051_82630459 superimposed PDB: 1L9X of partner (GGH). RMSD:0.3597
Å |
 |  |  |  |  |
| GGH_ZFAND1_ENST00000260118_ENST00000220669_63930051_82630459 superimposed PDB: 7Y39 of partner (ZFAND1). RMSD:0.7949
Å |
| | | |  |
| GGNBP2_ASIC2_ENST00000304718_ENST00000359872_34942628_31439085 superimposed PDB: 8BFJ of partner (GGNBP2). RMSD:0.4815
Å |
 |  |  |  |  |
| GGNBP2_ASIC2_ENST00000304718_ENST00000359872_34942628_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.7398
Å |
| | | |  |
| GGNBP2_ASIC2_ENST00000304718_ENST00000359872_34943675_31439085 superimposed PDB: 8BFJ of partner (GGNBP2). RMSD:0.5218
Å |
 |  |  |  |  |
| GGNBP2_ASIC2_ENST00000304718_ENST00000359872_34943675_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.8317
Å |
| | | |  |
| GGNBP2_NEBL_ENST00000304718_ENST00000377159_34901666_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.404
Å |
 |  |  |  |  |
| GGNBP2_NEBL_ENST00000304718_ENST00000417816_34901666_21101869 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3984
Å |
 |  |  |  |  |
| GGPS1_ZNF143_ENST00000488594_ENST00000396597_235498649_9533994 superimposed PDB: 9CSL of partner (GGPS1). RMSD:1.2948
Å |
 |  |  |  |  |
| GGPS1_ZNF143_ENST00000488594_ENST00000396602_235498649_9533994 superimposed PDB: 9CSL of partner (GGPS1). RMSD:0.7946
Å |
 |  |  |  |  |
| GIPR_PRR12_ENST00000263281_ENST00000418929_46181484_50117789 superimposed PDB: 7RBT of partner (GIPR). RMSD:1.2706
Å |
 |  |  |  |  |
| GIPR_RBM42_ENST00000590918_ENST00000262633_46173992_36128059 superimposed PDB: 7RBT of partner (GIPR). RMSD:0.5144
Å |
 |  |  |  |  |
| GK5_MED6_ENST00000392993_ENST00000430055_141906545_71064494 superimposed PDB: 7EMF of partner (MED6). RMSD:1.9327
Å |
 |  |  |  |  |
| GK5_MED6_ENST00000392993_ENST00000440435_141906545_71064494 superimposed PDB: 7EMF of partner (MED6). RMSD:1.5321
Å |
 |  |  |  |  |
| GK5_MED6_ENST00000544571_ENST00000554963_141906545_71064494 superimposed PDB: 7EMF of partner (MED6). RMSD:2.3169
Å |
 |  |  |  |  |
| GKAP1_UBQLN1_ENST00000376365_ENST00000376395_86414099_86301070 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.6444
Å |
 |  |  |  |  |
| GKAP1_UBQLN1_ENST00000376371_ENST00000257468_86414099_86301070 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.7135
Å |
 |  |  |  |  |
| GLB1_CMTM7_ENST00000307363_ENST00000349718_33055547_32483331 superimposed PDB: 3THD of partner (GLB1). RMSD:0.7597
Å |
 |  |  |  |  |
| GLB1_CMTM7_ENST00000307377_ENST00000334983_33055547_32483331 superimposed PDB: 3THD of partner (GLB1). RMSD:0.7629
Å |
 |  |  |  |  |
| GLB1_CMTM7_ENST00000307377_ENST00000349718_33055547_32483331 superimposed PDB: 3THD of partner (GLB1). RMSD:0.8034
Å |
 |  |  |  |  |
| GLB1_CMTM7_ENST00000445488_ENST00000334983_33055547_32483331 superimposed PDB: 3THD of partner (GLB1). RMSD:0.7468
Å |
 |  |  |  |  |
| GLB1_CMTM7_ENST00000445488_ENST00000349718_33055547_32483331 superimposed PDB: 3THD of partner (GLB1). RMSD:0.7829
Å |
 |  |  |  |  |
| GLB1_INSC_ENST00000307363_ENST00000424273_33109721_15260464 superimposed PDB: 3THD of partner (GLB1). RMSD:0.4985
Å |
 |  |  |  |  |
| GLB1_INSC_ENST00000307363_ENST00000525218_33109721_15260464 superimposed PDB: 3THD of partner (GLB1). RMSD:0.5631
Å |
 |  |  |  |  |
| GLB1_INSC_ENST00000445488_ENST00000424273_33109721_15260464 superimposed PDB: 3THD of partner (GLB1). RMSD:0.4671
Å |
 |  |  |  |  |
| GLB1_INSC_ENST00000445488_ENST00000525218_33109721_15260464 superimposed PDB: 3THD of partner (GLB1). RMSD:0.6335
Å |
 |  |  |  |  |
| GLB1_PSD2_ENST00000307377_ENST00000274710_33094982_139215307 superimposed PDB: 3THD of partner (GLB1). RMSD:0.471
Å |
 |  |  |  |  |
| GLB1_PSD2_ENST00000445488_ENST00000274710_33094982_139215307 superimposed PDB: 3THD of partner (GLB1). RMSD:0.4685
Å |
 |  |  |  |  |
| GLB1_SUSD5_ENST00000307363_ENST00000309558_33109721_33216566 superimposed PDB: 3THD of partner (GLB1). RMSD:0.8421
Å |
 |  |  |  |  |
| GLB1_SUSD5_ENST00000445488_ENST00000309558_33109721_33216566 superimposed PDB: 3THD of partner (GLB1). RMSD:0.8553
Å |
 |  |  |  |  |
| GLG1_BCAR1_ENST00000422840_ENST00000162330_74640554_75276988 superimposed PDB: 3T6G of partner (BCAR1). RMSD:0.4154
Å |
 |  |  |  |  |
| GLG1_ME2_ENST00000205061_ENST00000321341_74501653_48450467 superimposed PDB: 1QR6 of partner (ME2). RMSD:3.3985
Å |
 |  |  |  |  |
| GLG1_RFWD3_ENST00000205061_ENST00000571750_74491771_74666571 superimposed PDB: 6CVZ of partner (RFWD3). RMSD:0.749
Å |
 |  |  |  |  |
| GLG1_RFWD3_ENST00000447066_ENST00000571750_74491771_74666571 superimposed PDB: 6CVZ of partner (RFWD3). RMSD:0.7599
Å |
 |  |  |  |  |
| GLIPR1_RHD_ENST00000266659_ENST00000454452_75892500_25611063 superimposed PDB: 3Q2U of partner (GLIPR1). RMSD:0.3632
Å |
 |  |  |  |  |
| GLIS3_CTNNA2_ENST00000324333_ENST00000402739_4117767_80874709 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:1.6828
Å |
 |  |  |  |  |
| GLIS3_CTNNA2_ENST00000381971_ENST00000540488_4117767_80874709 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:3.5098
Å |
 |  |  |  |  |
| GLIS3_GOLM1_ENST00000381971_ENST00000388711_4286037_88661487 superimposed PDB: 8YBC of partner (GOLM1). RMSD:1.8813
Å |
 |  |  |  |  |
| GLOD4_EIF5A_ENST00000301328_ENST00000336452_673108_7212933 superimposed PDB: 9CSJ of partner (GLOD4). RMSD:0.463
Å |
 |  |  |  |  |
| GLOD4_EIF5A_ENST00000301328_ENST00000336452_673108_7212933 superimposed PDB: 8A0E of partner (EIF5A). RMSD:0.9885
Å |
| | | |  |
| GLOD4_EIF5A_ENST00000536578_ENST00000336452_673108_7212933 superimposed PDB: 9CSJ of partner (GLOD4). RMSD:0.5635
Å |
 |  |  |  |  |
| GLOD4_EIF5A_ENST00000536578_ENST00000336452_673108_7212933 superimposed PDB: 8A0E of partner (EIF5A). RMSD:1.0228
Å |
| | | |  |
| GLRX3_PPM1G_ENST00000331244_ENST00000350803_131943583_27610025 superimposed PDB: 2WZ9 of partner (GLRX3). RMSD:1.0729
Å |
 |  |  |  |  |
| GMDS_CCND3_ENST00000380815_ENST00000511642_2245554_41905132 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.3023
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000379715_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.3696
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000379715_2116004_8097700 superimposed PDB: 4BL7 of partner (EEF1E1). RMSD:0.567
Å |
| | | |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000429723_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.9597
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000429723_2116004_8097700 superimposed PDB: 4BL7 of partner (EEF1E1). RMSD:0.5968
Å |
| | | |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000507463_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.2053
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000380815_ENST00000507463_2116004_8097700 superimposed PDB: 4BL7 of partner (EEF1E1). RMSD:0.3505
Å |
| | | |  |
| GMDS_EEF1E1_ENST00000530927_ENST00000379715_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.7532
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000530927_ENST00000379715_2116004_8097700 superimposed PDB: 4BL7 of partner (EEF1E1). RMSD:0.6783
Å |
| | | |  |
| GMDS_EEF1E1_ENST00000530927_ENST00000429723_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.4503
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000530927_ENST00000507463_2116004_8097700 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.6083
Å |
 |  |  |  |  |
| GMDS_EEF1E1_ENST00000530927_ENST00000507463_2116004_8097700 superimposed PDB: 4BL7 of partner (EEF1E1). RMSD:0.3504
Å |
| | | |  |
| GMDS_EXOC2_ENST00000380815_ENST00000448181_1726649_556564 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.0667
Å |
 |  |  |  |  |
| GMDS_EXOC2_ENST00000530927_ENST00000448181_1726649_556564 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.316
Å |
 |  |  |  |  |
| GMDS_FKBP5_ENST00000380815_ENST00000536438_1960100_35565181 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.4114
Å |
 |  |  |  |  |
| GMDS_FKBP5_ENST00000380815_ENST00000536438_1960100_35565181 superimposed PDB: 5OMP of partner (FKBP5). RMSD:2.4679
Å |
| | | |  |
| GMDS_FKBP5_ENST00000530927_ENST00000536438_1960100_35565181 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.4502
Å |
 |  |  |  |  |
| GMDS_FKBP5_ENST00000530927_ENST00000536438_1960100_35565181 superimposed PDB: 5OMP of partner (FKBP5). RMSD:2.5866
Å |
| | | |  |
| GMDS_METTL24_ENST00000380815_ENST00000338882_1930336_110644075 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.425
Å |
 |  |  |  |  |
| GMDS_METTL24_ENST00000530927_ENST00000338882_1930336_110644075 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.5026
Å |
 |  |  |  |  |
| GMDS_MRPS18B_ENST00000380815_ENST00000259873_1726649_30590608 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.6261
Å |
 |  |  |  |  |
| GMDS_MRPS18B_ENST00000380815_ENST00000506373_1726649_30592659 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.5905
Å |
 |  |  |  |  |
| GMDS_MRPS18B_ENST00000530927_ENST00000506373_1726649_30592659 superimposed PDB: 6GPK of partner (GMDS). RMSD:0.5626
Å |
 |  |  |  |  |
| GMDS_PDE8B_ENST00000380815_ENST00000264917_2245554_76607818 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.7727
Å |
 |  |  |  |  |
| GMDS_PDE8B_ENST00000380815_ENST00000346042_2245554_76607818 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.7291
Å |
 |  |  |  |  |
| GMDS_RIC8B_ENST00000380815_ENST00000392837_2245554_107177774 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.8544
Å |
 |  |  |  |  |
| GMPR_MAN1A1_ENST00000259727_ENST00000368466_16254966_119628157 superimposed PDB: 2BLE of partner (GMPR). RMSD:0.5584
Å |
 |  |  |  |  |
| GNA11_SLC30A6_ENST00000078429_ENST00000379343_3094785_32400387 superimposed PDB: 9P87 of partner (GNA11). RMSD:0.5472
Å |
 |  |  |  |  |
| GNA12_ADSS_ENST00000407904_ENST00000366535_2834561_244601070 superimposed PDB: 2V40 of partner (ADSS). RMSD:0.6529
Å |
 |  |  |  |  |
| GNA12_ADSS_ENST00000544127_ENST00000366535_2834561_244601070 superimposed PDB: 2V40 of partner (ADSS). RMSD:0.7486
Å |
 |  |  |  |  |
| GNA12_AMACR_ENST00000544127_ENST00000335606_2883486_33998932 superimposed PDB: 7YDJ of partner (GNA12). RMSD:1.9213
Å |
 |  |  |  |  |
| GNA13_ASPSCR1_ENST00000439174_ENST00000306729_63049619_79966912 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:3.0402
Å |
 |  |  |  |  |
| GNA13_ASPSCR1_ENST00000439174_ENST00000306739_63049619_79966912 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:1.1404
Å |
 |  |  |  |  |
| GNA13_ASPSCR1_ENST00000439174_ENST00000580534_63049619_79966912 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:0.5049
Å |
 |  |  |  |  |
| GNA13_BMI1_ENST00000541118_ENST00000376663_63049619_22617062 superimposed PDB: 9DBY of partner (BMI1). RMSD:2.096
Å |
 |  |  |  |  |
| GNAI2_SLC39A11_ENST00000313601_ENST00000255559_50273885_70732858 superimposed PDB: 7YK7 of partner (GNAI2). RMSD:2.6872
Å |
 |  |  |  |  |
| GNAQ_C9orf64_ENST00000286548_ENST00000314700_80409378_86559904 superimposed PDB: 7UGK of partner (C9orf64). RMSD:1.3391
Å |
 |  |  |  |  |
| GNAQ_C9orf64_ENST00000397476_ENST00000314700_80409378_86559904 superimposed PDB: 7UGK of partner (C9orf64). RMSD:0.8453
Å |
 |  |  |  |  |
| GNAQ_HNRNPH1_ENST00000286548_ENST00000442819_80412435_179045324 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.0419
Å |
 |  |  |  |  |
| GNAQ_HNRNPH1_ENST00000286548_ENST00000510411_80412435_179045324 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:0.8828
Å |
 |  |  |  |  |
| GNAQ_MAD1L1_ENST00000397476_ENST00000399654_80409378_1855864 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:2.8211
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000323926_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8643
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000345488_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.4192
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000346544_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6161
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000354785_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6568
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000356005_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.898
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000357867_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.2305
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000359671_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7817
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000432072_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9413
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000443816_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.9794
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371100_ENST00000446046_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7108
Å |
 |  |  |  |  |
| GNAS_FN1_ENST00000371102_ENST00000421182_57486241_216274837 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7762
Å |
 |  |  |  |  |
| GNB3_GNB1_ENST00000435982_ENST00000378609_6952401_1736020 superimposed PDB: 9M8L of partner (GNB3). RMSD:0.7623
Å |
 |  |  |  |  |
| GNB3_GNB1_ENST00000435982_ENST00000378609_6952401_1736020 superimposed PDB: 6WZG of partner (GNB1). RMSD:0.3726
Å |
| | | |  |
| GNE_ERP27_ENST00000396594_ENST00000540097_36276890_15073982 superimposed PDB: 4F9Z of partner (ERP27). RMSD:0.6299
Å |
 |  |  |  |  |
| GNE_LOH12CR1_ENST00000396594_ENST00000314565_36218179_12588561 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5192
Å |
 |  |  |  |  |
| GNE_LOH12CR1_ENST00000539208_ENST00000314565_36218179_12588561 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.9702
Å |
 |  |  |  |  |
| GNE_LOH12CR1_ENST00000539815_ENST00000314565_36218179_12588561 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5182
Å |
 |  |  |  |  |
| GNE_LOH12CR1_ENST00000543356_ENST00000314565_36218179_12588561 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5759
Å |
 |  |  |  |  |
| GNE_RNF38_ENST00000543356_ENST00000259605_36276890_36390613 superimposed PDB: 9Q88 of partner (RNF38). RMSD:0.391
Å |
 |  |  |  |  |
| GNE_ROCK1_ENST00000377902_ENST00000399799_36236828_18650574 superimposed PDB: 3V8S of partner (ROCK1). RMSD:0.834
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000396594_ENST00000394224_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5277
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000396594_ENST00000527525_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5144
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000539208_ENST00000394224_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:1.0088
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000539208_ENST00000527525_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:1.0531
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000543356_ENST00000394224_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5703
Å |
 |  |  |  |  |
| GNE_SIPA1_ENST00000543356_ENST00000527525_36227244_65412425 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5596
Å |
 |  |  |  |  |
| GNG5_NMI_ENST00000370641_ENST00000243346_84971693_152127389 superimposed PDB: 21NH of partner (NMI). RMSD:0.8818
Å |
 |  |  |  |  |
| GNPDA1_RNGTT_ENST00000311337_ENST00000369485_141384496_89616159 superimposed PDB: 8P4B of partner (RNGTT). RMSD:0.6043
Å |
 |  |  |  |  |
| GNPDA1_RNGTT_ENST00000513454_ENST00000265607_141384496_89616159 superimposed PDB: 8P4B of partner (RNGTT). RMSD:1.2916
Å |
 |  |  |  |  |
| GNPDA1_RNGTT_ENST00000513454_ENST00000538899_141384496_89616159 superimposed PDB: 8P4B of partner (RNGTT). RMSD:0.9788
Å |
 |  |  |  |  |
| GNPTAB_CNOT2_ENST00000299314_ENST00000418359_102173929_70704674 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.6844
Å |
 |  |  |  |  |
| GNS_RAB3IP_ENST00000542058_ENST00000247833_65138588_70206743 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:3.1474
Å |
 |  |  |  |  |
| GOLGA4_CTDSPL_ENST00000356847_ENST00000273179_37315092_38006061 superimposed PDB: 2HHL of partner (CTDSPL). RMSD:0.4176
Å |
 |  |  |  |  |
| GOLGA4_HSPA8_ENST00000444882_ENST00000532636_37292975_122930976 superimposed PDB: 1UPT of partner (GOLGA4). RMSD:1.8925
Å |
 |  |  |  |  |
| GOLGA4_HSPA8_ENST00000444882_ENST00000532636_37292975_122930976 superimposed PDB: 4H5R of partner (HSPA8). RMSD:1.1608
Å |
| | | |  |
| GOLGA4_MLH1_ENST00000356847_ENST00000231790_37343823_37058996 superimposed PDB: 4P7A of partner (MLH1). RMSD:0.5926
Å |
 |  |  |  |  |
| GOLGA4_MLH1_ENST00000356847_ENST00000458205_37343823_37058996 superimposed PDB: 4P7A of partner (MLH1). RMSD:0.7539
Å |
 |  |  |  |  |
| GOLGA4_MLH1_ENST00000361924_ENST00000231790_37343823_37058996 superimposed PDB: 4P7A of partner (MLH1). RMSD:0.6304
Å |
 |  |  |  |  |
| GOLGA4_MLH1_ENST00000361924_ENST00000458205_37343823_37058996 superimposed PDB: 4P7A of partner (MLH1). RMSD:0.7395
Å |
 |  |  |  |  |
| GOLGA4_RAF1_ENST00000356847_ENST00000442415_37323763_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9953
Å |
 |  |  |  |  |
| GOLGA4_RAF1_ENST00000356847_ENST00000442415_37327552_12641914 superimposed PDB: 1UPT of partner (GOLGA4). RMSD:0.2328
Å |
 |  |  |  |  |
| GOLGA4_RAF1_ENST00000356847_ENST00000442415_37327552_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9994
Å |
| | | |  |
| GOLGA4_RAF1_ENST00000361924_ENST00000442415_37323763_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0525
Å |
 |  |  |  |  |
| GOLGA4_RAF1_ENST00000361924_ENST00000442415_37327552_12641914 superimposed PDB: 1UPT of partner (GOLGA4). RMSD:0.2753
Å |
 |  |  |  |  |
| GOLGA4_RAF1_ENST00000361924_ENST00000442415_37327552_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0125
Å |
| | | |  |
| GOLGA4_RRM1_ENST00000361924_ENST00000423050_37292975_4150303 superimposed PDB: 3HNC of partner (RRM1). RMSD:1.0508
Å |
 |  |  |  |  |
| GOLGA5_CYP46A1_ENST00000355976_ENST00000261835_93276722_100165802 superimposed PDB: 7N6F of partner (CYP46A1). RMSD:0.5108
Å |
 |  |  |  |  |
| GOLGA5_RIN3_ENST00000355976_ENST00000216487_93275864_93022095 superimposed PDB: 3U23 of partner (RIN3). RMSD:2.7086
Å |
 |  |  |  |  |
| GOLGA8A_DDB2_ENST00000359187_ENST00000378603_34680033_47259387 superimposed PDB: 9J8W of partner (DDB2). RMSD:0.8781
Å |
 |  |  |  |  |
| GPATCH1_FCGRT_ENST00000170564_ENST00000426395_33610023_50027763 superimposed PDB: 6FGB of partner (FCGRT). RMSD:0.3903
Å |
 |  |  |  |  |
| GPC6_GCHFR_ENST00000377047_ENST00000561160_94958377_41058024 superimposed PDB: 7ALC of partner (GCHFR). RMSD:0.5032
Å |
 |  |  |  |  |
| GPD1L_CMTM7_ENST00000282541_ENST00000349718_32188226_32483331 superimposed PDB: 2PLA of partner (GPD1L). RMSD:0.4502
Å |
 |  |  |  |  |
| GPD1L_CNOT10_ENST00000282541_ENST00000328834_32188226_32750161 superimposed PDB: 2PLA of partner (GPD1L). RMSD:0.4537
Å |
 |  |  |  |  |
| GPD1L_CNOT10_ENST00000282541_ENST00000328834_32188226_32750161 superimposed PDB: 8BFI of partner (CNOT10). RMSD:2.1653
Å |
| | | |  |
| GPD1L_CNOT10_ENST00000282541_ENST00000331889_32188226_32750161 superimposed PDB: 2PLA of partner (GPD1L). RMSD:0.4371
Å |
 |  |  |  |  |
| GPHN_DCAF5_ENST00000305960_ENST00000341516_67147903_69558604 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.7691
Å |
 |  |  |  |  |
| GPHN_DCAF5_ENST00000315266_ENST00000554215_67147903_69558604 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.5846
Å |
 |  |  |  |  |
| GPHN_DCAF5_ENST00000543237_ENST00000554215_67147903_69558604 superimposed PDB: 8TL6 of partner (DCAF5). RMSD:0.5535
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000315266_ENST00000390683_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.514
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000315266_ENST00000471583_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5121
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000315266_ENST00000487270_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5124
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000315266_ENST00000488612_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5083
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000478722_ENST00000487861_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5172
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000543237_ENST00000390683_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5272
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000543237_ENST00000471583_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5283
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000543237_ENST00000487270_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5144
Å |
 |  |  |  |  |
| GPHN_RAD51B_ENST00000543237_ENST00000488612_67243239_68301796 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5082
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000305960_ENST00000356921_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3754
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000305960_ENST00000381269_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3422
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000315266_ENST00000356921_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3427
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000478722_ENST00000356921_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3236
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000478722_ENST00000381269_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3355
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000543237_ENST00000356921_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.343
Å |
 |  |  |  |  |
| GPHN_SLC8A3_ENST00000543237_ENST00000381269_67589094_70527656 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3399
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000356487_ENST00000323786_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.1298
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000356487_ENST00000393612_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.3083
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000356487_ENST00000393612_34859607_70553634 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.7117
Å |
| | | |  |
| GPI_COG4_ENST00000356487_ENST00000564653_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:0.998
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000415930_ENST00000393612_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.3723
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000415930_ENST00000393612_34859607_70553634 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.7552
Å |
| | | |  |
| GPI_COG4_ENST00000415930_ENST00000564653_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.1276
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000586425_ENST00000323786_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:0.9379
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000586425_ENST00000393612_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.2372
Å |
 |  |  |  |  |
| GPI_COG4_ENST00000586425_ENST00000393612_34859607_70553634 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.7225
Å |
| | | |  |
| GPI_COG4_ENST00000586425_ENST00000564653_34859607_70553634 superimposed PDB: 9FCW of partner (GPI). RMSD:1.0529
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000356487_ENST00000370616_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.5431
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000356487_ENST00000370621_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.5311
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000356487_ENST00000503581_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:1.2684
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000415930_ENST00000370616_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.9216
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000415930_ENST00000370621_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.7595
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000586425_ENST00000370616_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.6076
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000586425_ENST00000370621_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.6238
Å |
 |  |  |  |  |
| GPI_EYS_ENST00000586425_ENST00000503581_34887335_65767620 superimposed PDB: 9FCW of partner (GPI). RMSD:0.6349
Å |
 |  |  |  |  |
| GPI_UBAP1L_ENST00000356487_ENST00000502113_34859607_65386914 superimposed PDB: 9FCW of partner (GPI). RMSD:0.9394
Å |
 |  |  |  |  |
| GPI_UBAP1L_ENST00000415930_ENST00000502113_34859607_65386914 superimposed PDB: 9FCW of partner (GPI). RMSD:1.0508
Å |
 |  |  |  |  |
| GPI_UBAP1L_ENST00000415930_ENST00000559089_34859607_65386914 superimposed PDB: 9FCW of partner (GPI). RMSD:0.9477
Å |
 |  |  |  |  |
| GPI_UBAP1L_ENST00000586425_ENST00000502113_34859607_65386914 superimposed PDB: 9FCW of partner (GPI). RMSD:0.9304
Å |
 |  |  |  |  |
| GPN3_USP36_ENST00000228827_ENST00000312010_110893390_76810634 superimposed PDB: 8BS3 of partner (USP36). RMSD:2.9051
Å |
 |  |  |  |  |
| GPN3_USP36_ENST00000537466_ENST00000312010_110893390_76810634 superimposed PDB: 8BS3 of partner (USP36). RMSD:3.1217
Å |
 |  |  |  |  |
| GPN3_USP36_ENST00000537466_ENST00000542802_110893390_76810634 superimposed PDB: 8BS3 of partner (USP36). RMSD:1.3478
Å |
 |  |  |  |  |
| GPN3_USP36_ENST00000543199_ENST00000312010_110893390_76810634 superimposed PDB: 8BS3 of partner (USP36). RMSD:1.009
Å |
 |  |  |  |  |
| GPN3_USP36_ENST00000543199_ENST00000542802_110893390_76810634 superimposed PDB: 8BS3 of partner (USP36). RMSD:0.8689
Å |
 |  |  |  |  |
| GPR110_TNFRSF21_ENST00000371243_ENST00000296861_46989693_47254331 superimposed PDB: 3U3P of partner (TNFRSF21). RMSD:1.0175
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000315215_ENST00000414019_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7345
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000315215_ENST00000537535_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.888
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000315215_ENST00000541648_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.9887
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000412232_ENST00000221130_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:1.1452
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000412232_ENST00000414019_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7063
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000412232_ENST00000537535_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.9105
Å |
 |  |  |  |  |
| GPR124_GSR_ENST00000412232_ENST00000541648_37691646_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.9897
Å |
 |  |  |  |  |
| GPR158_MYO16_ENST00000376351_ENST00000357550_25465251_109644723 superimposed PDB: 7EWP of partner (GPR158). RMSD:2.6534
Å |
 |  |  |  |  |
| GPR89A_SPG7_ENST00000534502_ENST00000341316_145803307_89576897 superimposed PDB: 2QZ4 of partner (SPG7). RMSD:0.8173
Å |
 |  |  |  |  |
| GPT2_GPT_ENST00000340124_ENST00000394955_46950619_145731377 superimposed PDB: 3IHJ of partner (GPT2). RMSD:1.0262
Å |
 |  |  |  |  |
| GPT2_GPT_ENST00000440783_ENST00000394955_46950619_145731377 superimposed PDB: 3IHJ of partner (GPT2). RMSD:0.7766
Å |
 |  |  |  |  |
| GPX3_GPX6_ENST00000388825_ENST00000474923_150405054_28474206 superimposed PDB: 2R37 of partner (GPX3). RMSD:0.5103
Å |
 |  |  |  |  |
| GPX3_GPX6_ENST00000388825_ENST00000474923_150405054_28474206 superimposed PDB: 2P31 of partner (GPX6). RMSD:0.7212
Å |
| | | |  |
| GPX4_TNK2_ENST00000589115_ENST00000381916_1104126_195615477 superimposed PDB: 4HZS of partner (TNK2). RMSD:0.6834
Å |
 |  |  |  |  |
| GRAMD1A_CCDC88A_ENST00000317991_ENST00000436346_35491390_55616022 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.7942
Å |
 |  |  |  |  |
| GRAMD1A_CCDC88A_ENST00000411896_ENST00000336838_35491390_55616022 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.1035
Å |
 |  |  |  |  |
| GRAMD1A_CCDC88A_ENST00000411896_ENST00000436346_35491390_55616022 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.6638
Å |
 |  |  |  |  |
| GRAMD1A_CCDC88A_ENST00000424536_ENST00000413716_35491390_55616022 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.0162
Å |
 |  |  |  |  |
| GRAMD1A_CCDC88A_ENST00000424536_ENST00000436346_35491390_55616022 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:2.589
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000344138_ENST00000342989_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4535
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000344138_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4386
Å |
| | | |  |
| GRAP2_BRD1_ENST00000344138_ENST00000404034_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4169
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000344138_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4581
Å |
| | | |  |
| GRAP2_BRD1_ENST00000344138_ENST00000457780_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4567
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000344138_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4639
Å |
| | | |  |
| GRAP2_BRD1_ENST00000344138_ENST00000542442_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.465
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000344138_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4451
Å |
| | | |  |
| GRAP2_BRD1_ENST00000399090_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4138
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000399090_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4148
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000399090_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4626
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000399090_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4305
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000407075_ENST00000342989_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4928
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000407075_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4564
Å |
| | | |  |
| GRAP2_BRD1_ENST00000407075_ENST00000404034_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.5316
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000407075_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4445
Å |
| | | |  |
| GRAP2_BRD1_ENST00000407075_ENST00000457780_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4153
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000407075_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4511
Å |
| | | |  |
| GRAP2_BRD1_ENST00000407075_ENST00000542442_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4413
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000407075_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4313
Å |
| | | |  |
| GRAP2_BRD1_ENST00000540310_ENST00000342989_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.5552
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000540310_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4117
Å |
| | | |  |
| GRAP2_BRD1_ENST00000540310_ENST00000404034_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.5515
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000540310_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4501
Å |
| | | |  |
| GRAP2_BRD1_ENST00000540310_ENST00000457780_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.578
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000540310_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4504
Å |
| | | |  |
| GRAP2_BRD1_ENST00000540310_ENST00000542442_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.5544
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000540310_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.429
Å |
| | | |  |
| GRAP2_BRD1_ENST00000543252_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4189
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000543252_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4588
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000543252_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4606
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000543252_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.456
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000544756_ENST00000342989_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.3269
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000544756_ENST00000342989_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4307
Å |
| | | |  |
| GRAP2_BRD1_ENST00000544756_ENST00000404034_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.311
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000544756_ENST00000404034_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4521
Å |
| | | |  |
| GRAP2_BRD1_ENST00000544756_ENST00000457780_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.2897
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000544756_ENST00000457780_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4621
Å |
| | | |  |
| GRAP2_BRD1_ENST00000544756_ENST00000542442_40365537_50192767 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.3662
Å |
 |  |  |  |  |
| GRAP2_BRD1_ENST00000544756_ENST00000542442_40365537_50192767 superimposed PDB: 5PQI of partner (BRD1). RMSD:0.4356
Å |
| | | |  |
| GRB10_DDC_ENST00000398810_ENST00000431062_50737418_50537869 superimposed PDB: 9HRH of partner (DDC). RMSD:0.4182
Å |
 |  |  |  |  |
| GRB10_DDC_ENST00000398812_ENST00000431062_50737418_50537869 superimposed PDB: 9HRH of partner (DDC). RMSD:0.4403
Å |
 |  |  |  |  |
| GRB10_DDC_ENST00000402578_ENST00000431062_50737418_50537869 superimposed PDB: 9HRH of partner (DDC). RMSD:0.4463
Å |
 |  |  |  |  |
| GRB10_DDC_ENST00000439599_ENST00000431062_50737418_50537869 superimposed PDB: 9HRH of partner (DDC). RMSD:0.4258
Å |
 |  |  |  |  |
| GRB10_LANCL2_ENST00000357271_ENST00000254770_50799968_55459485 superimposed PDB: 6WQ1 of partner (LANCL2). RMSD:0.4667
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398810_ENST00000354947_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7718
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398810_ENST00000540759_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.251
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398810_ENST00000550465_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8124
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398812_ENST00000354947_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7857
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398812_ENST00000540759_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.1634
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000398812_ENST00000550465_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8247
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000402578_ENST00000354947_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7689
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000402578_ENST00000540759_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.9279
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000402578_ENST00000550465_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8329
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000439599_ENST00000354947_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7597
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000439599_ENST00000540759_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.2519
Å |
 |  |  |  |  |
| GRB10_PIP4K2C_ENST00000439599_ENST00000550465_50737418_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8329
Å |
 |  |  |  |  |
| GRB10_SCIN_ENST00000357271_ENST00000297029_50737418_12662425 superimposed PDB: 3FG6 of partner (SCIN). RMSD:0.5887
Å |
 |  |  |  |  |
| GRB10_SCIN_ENST00000398812_ENST00000297029_50737418_12662425 superimposed PDB: 3FG6 of partner (SCIN). RMSD:0.6391
Å |
 |  |  |  |  |
| GRB10_SCIN_ENST00000402578_ENST00000297029_50737418_12662425 superimposed PDB: 3FG6 of partner (SCIN). RMSD:0.6626
Å |
 |  |  |  |  |
| GRB10_SCIN_ENST00000439599_ENST00000297029_50737418_12662425 superimposed PDB: 3FG6 of partner (SCIN). RMSD:0.6194
Å |
 |  |  |  |  |
| GRB10_SCMH1_ENST00000335866_ENST00000397174_50682466_41494398 superimposed PDB: 3HK0 of partner (GRB10). RMSD:1.2659
Å |
 |  |  |  |  |
| GRB10_SCMH1_ENST00000401949_ENST00000397174_50682466_41494398 superimposed PDB: 3HK0 of partner (GRB10). RMSD:1.214
Å |
 |  |  |  |  |
| GRB10_SCMH1_ENST00000403097_ENST00000397174_50682466_41494398 superimposed PDB: 3HK0 of partner (GRB10). RMSD:1.2341
Å |
 |  |  |  |  |
| GRB2_CASKIN2_ENST00000316804_ENST00000321617_73389631_73504366 superimposed PDB: 8DGO of partner (GRB2). RMSD:3.0681
Å |
 |  |  |  |  |
| GRB2_CASKIN2_ENST00000392564_ENST00000321617_73389631_73502010 superimposed PDB: 8DGO of partner (GRB2). RMSD:0.3834
Å |
 |  |  |  |  |
| GRB7_ACTN3_ENST00000309156_ENST00000513398_37902455_66318709 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.3458
Å |
 |  |  |  |  |
| GRB7_ACTN3_ENST00000309156_ENST00000513398_37902455_66318709 superimposed PDB: 1WKU of partner (ACTN3). RMSD:0.5371
Å |
| | | |  |
| GRB7_ACTN3_ENST00000394209_ENST00000513398_37902455_66318709 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.3101
Å |
 |  |  |  |  |
| GRB7_ACTN3_ENST00000394209_ENST00000513398_37902455_66318709 superimposed PDB: 1WKU of partner (ACTN3). RMSD:0.6108
Å |
| | | |  |
| GRB7_ACTN3_ENST00000445327_ENST00000513398_37902455_66318709 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.3501
Å |
 |  |  |  |  |
| GRB7_ACTN3_ENST00000445327_ENST00000513398_37902455_66318709 superimposed PDB: 1WKU of partner (ACTN3). RMSD:0.5463
Å |
| | | |  |
| GRB7_BRIP1_ENST00000309156_ENST00000577598_37902041_59934592 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.1084
Å |
 |  |  |  |  |
| GRB7_MED13_ENST00000394209_ENST00000397786_37902455_60024378 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.6912
Å |
 |  |  |  |  |
| GRB7_MED13_ENST00000394211_ENST00000397786_37902455_60024378 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.5078
Å |
 |  |  |  |  |
| GRB7_PPP1R1B_ENST00000309156_ENST00000580825_37902455_37792068 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.5453
Å |
 |  |  |  |  |
| GRB7_PPP1R1B_ENST00000394209_ENST00000580825_37902455_37792068 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.4923
Å |
 |  |  |  |  |
| GRB7_PPP1R1B_ENST00000394211_ENST00000580825_37902455_37792068 superimposed PDB: 5EEQ of partner (GRB7). RMSD:0.4411
Å |
 |  |  |  |  |
| GRB7_SAMHD1_ENST00000394204_ENST00000262878_37899723_35547922 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.9893
Å |
 |  |  |  |  |
| GRB7_SAMHD1_ENST00000394209_ENST00000262878_37899723_35547922 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.9008
Å |
 |  |  |  |  |
| GRB7_SAMHD1_ENST00000394209_ENST00000373694_37899723_35547922 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:1.9845
Å |
 |  |  |  |  |
| GRB7_SAMHD1_ENST00000445327_ENST00000373694_37899723_35547922 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:1.9088
Å |
 |  |  |  |  |
| GRHL2_MAP2K2_ENST00000395927_ENST00000262948_102565010_4117627 superimposed PDB: 1S9I of partner (MAP2K2). RMSD:0.597
Å |
 |  |  |  |  |
| GRIA4_NAALAD2_ENST00000393125_ENST00000321955_105732934_89906991 superimposed PDB: 3FED of partner (NAALAD2). RMSD:0.7238
Å |
 |  |  |  |  |
| GRIA4_NAALAD2_ENST00000428631_ENST00000321955_105732934_89906991 superimposed PDB: 3FED of partner (NAALAD2). RMSD:0.7498
Å |
 |  |  |  |  |
| GRID1_AFAP1L2_ENST00000327946_ENST00000369271_88123697_116100490 superimposed PDB: 2COF of partner (AFAP1L2). RMSD:0.9358
Å |
 |  |  |  |  |
| GRID1_AFAP1L2_ENST00000327946_ENST00000545353_88123697_116100490 superimposed PDB: 2COF of partner (AFAP1L2). RMSD:0.9257
Å |
 |  |  |  |  |
| GRIK2_PRKD3_ENST00000318991_ENST00000234179_102134228_37520414 superimposed PDB: 2D9Z of partner (PRKD3). RMSD:1.245
Å |
 |  |  |  |  |
| GRIK2_PRKD3_ENST00000369134_ENST00000234179_102134228_37520414 superimposed PDB: 2D9Z of partner (PRKD3). RMSD:1.365
Å |
 |  |  |  |  |
| GRIK2_PRKD3_ENST00000413795_ENST00000234179_102134228_37520414 superimposed PDB: 2D9Z of partner (PRKD3). RMSD:1.4147
Å |
 |  |  |  |  |
| GRK5_SUMF1_ENST00000369108_ENST00000534863_121191039_4110429 superimposed PDB: 4TND of partner (GRK5). RMSD:0.9055
Å |
 |  |  |  |  |
| GSE1_CDH13_ENST00000253458_ENST00000268613_85647004_83520081 superimposed PDB: 2V37 of partner (CDH13). RMSD:2.6769
Å |
 |  |  |  |  |
| GSK3A_ZNF564_ENST00000398249_ENST00000339282_42744106_12639510 superimposed PDB: 7SXF of partner (GSK3A). RMSD:3.2571
Å |
 |  |  |  |  |
| GSK3B_ME3_ENST00000264235_ENST00000359636_119812193_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:1.1816
Å |
 |  |  |  |  |
| GSK3B_ME3_ENST00000316626_ENST00000393324_119812193_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:0.6807
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373808_ENST00000263867_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0047
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373808_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0791
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373808_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0579
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373818_ENST00000263867_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0462
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373818_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:2.9678
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373818_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:2.9504
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373823_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.029
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000373823_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0156
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000412819_ENST00000263867_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0896
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000436847_ENST00000263867_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:2.958
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000436847_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0414
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000436847_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:2.9923
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000449733_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:2.9758
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000449733_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.009
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000545652_ENST00000409670_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0632
Å |
 |  |  |  |  |
| GSN_CAPG_ENST00000545652_ENST00000409921_124073123_85626408 superimposed PDB: 3FFN of partner (GSN). RMSD:3.0328
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000221130_ENST00000400186_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7652
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000221130_ENST00000400186_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.4206
Å |
| | | |  |
| GSR_CSMD1_ENST00000221130_ENST00000542608_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7793
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000221130_ENST00000542608_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.6625
Å |
| | | |  |
| GSR_CSMD1_ENST00000221130_ENST00000602557_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7854
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000221130_ENST00000602557_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.7076
Å |
| | | |  |
| GSR_CSMD1_ENST00000414019_ENST00000400186_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8328
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000414019_ENST00000400186_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.4348
Å |
| | | |  |
| GSR_CSMD1_ENST00000414019_ENST00000602557_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8068
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000414019_ENST00000602557_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.9905
Å |
| | | |  |
| GSR_CSMD1_ENST00000414019_ENST00000602723_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7706
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000414019_ENST00000602723_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.5551
Å |
| | | |  |
| GSR_CSMD1_ENST00000537535_ENST00000400186_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:1.0207
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000537535_ENST00000400186_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.508
Å |
| | | |  |
| GSR_CSMD1_ENST00000537535_ENST00000602557_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:2.0324
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000537535_ENST00000602557_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.7358
Å |
| | | |  |
| GSR_CSMD1_ENST00000541648_ENST00000400186_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8382
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000541648_ENST00000400186_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.5462
Å |
| | | |  |
| GSR_CSMD1_ENST00000541648_ENST00000602557_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:1.2547
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000541648_ENST00000602557_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.629
Å |
| | | |  |
| GSR_CSMD1_ENST00000546342_ENST00000400186_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.9218
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000546342_ENST00000400186_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.4811
Å |
| | | |  |
| GSR_CSMD1_ENST00000546342_ENST00000602557_30541604_2887035 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8044
Å |
 |  |  |  |  |
| GSR_CSMD1_ENST00000546342_ENST00000602557_30541604_2887035 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.5667
Å |
| | | |  |
| GSR_OTOA_ENST00000221130_ENST00000388956_30550485_21771790 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7097
Å |
 |  |  |  |  |
| GSR_OTOA_ENST00000414019_ENST00000388956_30550485_21771790 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.6492
Å |
 |  |  |  |  |
| GSR_RBPMS_ENST00000537535_ENST00000287771_30585046_30416403 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.6597
Å |
 |  |  |  |  |
| GSS_TTI1_ENST00000216951_ENST00000373447_33529515_36627730 superimposed PDB: 8FBZ of partner (GSS). RMSD:1.0305
Å |
 |  |  |  |  |
| GSTP1_CPT1A_ENST00000398603_ENST00000376618_67352712_68530229 superimposed PDB: 2A2R of partner (GSTP1). RMSD:2.5795
Å |
 |  |  |  |  |
| GSTP1_CPT1A_ENST00000398603_ENST00000539743_67352712_68530229 superimposed PDB: 2A2R of partner (GSTP1). RMSD:2.5473
Å |
 |  |  |  |  |
| GSTP1_CPT1A_ENST00000398606_ENST00000376618_67352712_68530229 superimposed PDB: 2A2R of partner (GSTP1). RMSD:3.2873
Å |
 |  |  |  |  |
| GTF2F1_ACP5_ENST00000394456_ENST00000433365_6383321_11686067 superimposed PDB: 7NVU of partner (GTF2F1). RMSD:1.0458
Å |
 |  |  |  |  |
| GTF2F1_ACP5_ENST00000429701_ENST00000433365_6383321_11686067 superimposed PDB: 7NVU of partner (GTF2F1). RMSD:2.6137
Å |
 |  |  |  |  |
| GTF2F2_NBEA_ENST00000340473_ENST00000400445_45781640_35923244 superimposed PDB: 7NVU of partner (GTF2F2). RMSD:2.7832
Å |
 |  |  |  |  |
| GTF2F2_NBEA_ENST00000340473_ENST00000400445_45781640_35923244 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.854
Å |
| | | |  |
| GTF2F2_NBEA_ENST00000340473_ENST00000540320_45781640_35923244 superimposed PDB: 7NVU of partner (GTF2F2). RMSD:0.9551
Å |
 |  |  |  |  |
| GTF2IRD1_ALK_ENST00000424337_ENST00000389048_73935627_29446394 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.2514
Å |
 |  |  |  |  |
| GTF2IRD1_ALK_ENST00000455841_ENST00000389048_73935627_29446394 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.1246
Å |
 |  |  |  |  |
| GTF2IRD1_ZAN_ENST00000265755_ENST00000546213_73953090_100389587 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.2059
Å |
 |  |  |  |  |
| GTF2IRD1_ZAN_ENST00000424337_ENST00000546213_73953090_100389587 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.6883
Å |
 |  |  |  |  |
| GTF2IRD1_ZAN_ENST00000455841_ENST00000546213_73953090_100389587 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.6965
Å |
 |  |  |  |  |
| GTF2I_BCAP29_ENST00000324896_ENST00000005259_74125440_107253776 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.9611
Å |
 |  |  |  |  |
| GTF2I_BCAP29_ENST00000324896_ENST00000465919_74125440_107253776 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.9563
Å |
 |  |  |  |  |
| GTF2I_BCAP29_ENST00000324896_ENST00000465919_74125440_107253776 superimposed PDB: 4W7Z of partner (BCAP29). RMSD:1.8575
Å |
| | | |  |
| GTF2I_BCAP29_ENST00000443166_ENST00000465919_74125440_107253776 superimposed PDB: 2EJE of partner (GTF2I). RMSD:1.21
Å |
 |  |  |  |  |
| GTF2I_BCAP29_ENST00000443166_ENST00000465919_74125440_107253776 superimposed PDB: 4W7Z of partner (BCAP29). RMSD:1.9204
Å |
| | | |  |
| GTF2I_CCT2_ENST00000346152_ENST00000299300_74162453_69993642 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.8115
Å |
 |  |  |  |  |
| GTF2I_CCT2_ENST00000346152_ENST00000299300_74162453_69993642 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.7791
Å |
| | | |  |
| GTF2I_CCT2_ENST00000353920_ENST00000299300_74162453_69993642 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.7938
Å |
 |  |  |  |  |
| GTF2I_CCT2_ENST00000353920_ENST00000299300_74162453_69993642 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.9662
Å |
| | | |  |
| GTF2I_CCT2_ENST00000416070_ENST00000299300_74162453_69993642 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.8127
Å |
 |  |  |  |  |
| GTF2I_EIF4H_ENST00000324896_ENST00000353999_74131270_73604002 superimposed PDB: 2EJE of partner (GTF2I). RMSD:1.0129
Å |
 |  |  |  |  |
| GTF2I_EIF4H_ENST00000346152_ENST00000265753_74131270_73604002 superimposed PDB: 2EJE of partner (GTF2I). RMSD:1.0389
Å |
 |  |  |  |  |
| GTF2I_EIF4H_ENST00000353920_ENST00000265753_74131270_73604002 superimposed PDB: 2EJE of partner (GTF2I). RMSD:1.0339
Å |
 |  |  |  |  |
| GTF2I_EIF4H_ENST00000353920_ENST00000353999_74131270_73604002 superimposed PDB: 2EJE of partner (GTF2I). RMSD:1.0085
Å |
 |  |  |  |  |
| GTF2I_GTF2IRD2_ENST00000353920_ENST00000405086_74103561_74248066 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.9792
Å |
 |  |  |  |  |
| GTSE1_PPARA_ENST00000454366_ENST00000262735_46712309_46611069 superimposed PDB: 1K7L of partner (PPARA). RMSD:0.6265
Å |
 |  |  |  |  |
| GUCD1_MB_ENST00000435822_ENST00000397328_24950916_36003490 superimposed PDB: 3RGK of partner (MB). RMSD:3.0444
Å |
 |  |  |  |  |
| GUSB_IGLL1_ENST00000345660_ENST00000330377_65429309_23915772 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.5387
Å |
 |  |  |  |  |
| GUSB_IGLL1_ENST00000345660_ENST00000330377_65429309_23915772 superimposed PDB: 2H32 of partner (IGLL1). RMSD:0.6005
Å |
| | | |  |
| GUSB_IGLL1_ENST00000421103_ENST00000330377_65429309_23915772 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.4157
Å |
 |  |  |  |  |
| GUSB_IGLL1_ENST00000421103_ENST00000330377_65429309_23915772 superimposed PDB: 2H32 of partner (IGLL1). RMSD:0.6178
Å |
| | | |  |
| GUSB_IGLL5_ENST00000304895_ENST00000526893_65429309_23237554 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.5515
Å |
 |  |  |  |  |
| GUSB_IGLL5_ENST00000304895_ENST00000526893_65429309_23237554 superimposed PDB: 7T17 of partner (IGLL5). RMSD:0.9542
Å |
| | | |  |
| GUSB_IGLL5_ENST00000304895_ENST00000532223_65429309_23237554 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.4114
Å |
 |  |  |  |  |
| GUSB_IGLL5_ENST00000304895_ENST00000532223_65429309_23237554 superimposed PDB: 7T17 of partner (IGLL5). RMSD:0.9217
Å |
| | | |  |
| GUSB_IGLL5_ENST00000345660_ENST00000532223_65429309_23237554 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.521
Å |
 |  |  |  |  |
| GUSB_IGLL5_ENST00000345660_ENST00000532223_65429309_23237554 superimposed PDB: 7T17 of partner (IGLL5). RMSD:0.9304
Å |
| | | |  |
| GUSB_IGLL5_ENST00000421103_ENST00000532223_65429309_23237554 superimposed PDB: 3HN3 of partner (GUSB). RMSD:0.5427
Å |
 |  |  |  |  |
| GUSB_IGLL5_ENST00000421103_ENST00000532223_65429309_23237554 superimposed PDB: 7T17 of partner (IGLL5). RMSD:0.9346
Å |
| | | |  |
| GUSB_NAIP_ENST00000304895_ENST00000503719_65429309_70281713 superimposed PDB: 8FVU of partner (NAIP). RMSD:2.8025
Å |
 |  |  |  |  |
| GUSB_NAIP_ENST00000304895_ENST00000517649_65429309_70281713 superimposed PDB: 8FVU of partner (NAIP). RMSD:2.7715
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000256678_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:2.0953
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000317560_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.9774
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000395568_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.9293
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000395580_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:2.1229
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000432191_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.9015
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000280876_ENST00000549190_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:2.3339
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000398675_ENST00000256678_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.8249
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000398675_ENST00000317560_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.9507
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000398675_ENST00000395568_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.9354
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000398675_ENST00000395580_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.3158
Å |
 |  |  |  |  |
| GXYLT1_PPHLN1_ENST00000398675_ENST00000432191_42491243_42835116 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:1.4265
Å |
 |  |  |  |  |
| GXYLT2_VAV1_ENST00000389617_ENST00000539284_72971486_6821632 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.287
Å |
 |  |  |  |  |
| GXYLT2_VAV1_ENST00000389617_ENST00000596764_72971486_6821632 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.3665
Å |
 |  |  |  |  |
| GXYLT2_VAV1_ENST00000389617_ENST00000602142_72971486_6821632 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.2921
Å |
 |  |  |  |  |
| GYS1_EIF4EBP1_ENST00000263276_ENST00000338825_49477469_37914598 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.3686
Å |
 |  |  |  |  |
| GYS1_EIF4EBP1_ENST00000541188_ENST00000338825_49477469_37914598 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.5921
Å |
 |  |  |  |  |
| GYS1_EIF4EBP1_ENST00000544287_ENST00000338825_49477469_37914598 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.5495
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000263276_ENST00000245925_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.7228
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000263276_ENST00000536630_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.7576
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000323798_ENST00000245925_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6013
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000323798_ENST00000536630_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6283
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000323798_ENST00000589876_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6464
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000541188_ENST00000245925_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6253
Å |
 |  |  |  |  |
| GYS1_EML2_ENST00000541188_ENST00000536630_49488717_46116929 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6076
Å |
 |  |  |  |  |
| GYS1_HOMER3_ENST00000323798_ENST00000221222_49494558_19045219 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.7181
Å |
 |  |  |  |  |
| GYS1_HOMER3_ENST00000323798_ENST00000392351_49494558_19045219 superimposed PDB: 7ZBN of partner (GYS1). RMSD:0.6802
Å |
 |  |  |  |  |
| GYS1_KDELR1_ENST00000323798_ENST00000597017_49489106_48892968 superimposed PDB: 7ZBN of partner (GYS1). RMSD:2.5796
Å |
 |  |  |  |  |
| GYS1_KDELR1_ENST00000541188_ENST00000597017_49489106_48892968 superimposed PDB: 7ZBN of partner (GYS1). RMSD:2.7026
Å |
 |  |  |  |  |
| GYS1_PLD3_ENST00000540532_ENST00000409587_49488717_40880387 superimposed PDB: 8V5T of partner (PLD3). RMSD:0.4238
Å |
 |  |  |  |  |
| GYS1_POLG2_ENST00000263276_ENST00000539111_49473802_62476506 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.4943
Å |
 |  |  |  |  |
| GYS1_POLG2_ENST00000541188_ENST00000539111_49473802_62476506 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.3837
Å |
 |  |  |  |  |
| GYS1_POLG2_ENST00000544287_ENST00000539111_49473802_62476506 superimposed PDB: 7ZBN of partner (GYS1). RMSD:1.3458
Å |
 |  |  |  |  |
| HAGH_PCNT_ENST00000566709_ENST00000359568_1859754_47864606 superimposed PDB: 1QH5 of partner (HAGH). RMSD:0.3161
Å |
 |  |  |  |  |
| HAGH_ZNF598_ENST00000566709_ENST00000563630_1869897_2048586 superimposed PDB: 1QH5 of partner (HAGH). RMSD:2.868
Å |
 |  |  |  |  |
| HAMP_GPI_ENST00000598398_ENST00000356487_35773570_34884152 superimposed PDB: 9FCW of partner (GPI). RMSD:0.6181
Å |
 |  |  |  |  |
| HAT1_EXOC6B_ENST00000264108_ENST00000272427_172844276_72411316 superimposed PDB: 6VO5 of partner (HAT1). RMSD:0.4803
Å |
 |  |  |  |  |
| HBS1L_POLN_ENST00000367826_ENST00000511885_135360710_2087471 superimposed PDB: 4XVK of partner (POLN). RMSD:1.3386
Å |
 |  |  |  |  |
| HBS1L_POLN_ENST00000367837_ENST00000511885_135360710_2087471 superimposed PDB: 4XVK of partner (POLN). RMSD:1.2697
Å |
 |  |  |  |  |
| HBS1L_POLN_ENST00000525067_ENST00000511885_135360710_2087471 superimposed PDB: 4XVK of partner (POLN). RMSD:1.2293
Å |
 |  |  |  |  |
| HCN2_ALS2CR11_ENST00000251287_ENST00000439140_590577_202412333 superimposed PDB: 9R1V of partner (HCN2). RMSD:1.2088
Å |
 |  |  |  |  |
| HCN2_ALS2CR11_ENST00000251287_ENST00000439802_590577_202412333 superimposed PDB: 9R1V of partner (HCN2). RMSD:1.1198
Å |
 |  |  |  |  |
| HDAC1_KPNA6_ENST00000373548_ENST00000373625_32790154_32620188 superimposed PDB: 9R4I of partner (HDAC1). RMSD:0.7861
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000225983_ENST00000006750_42163939_62007248 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:1.1364
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000225983_ENST00000006750_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:0.9704
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000225983_ENST00000349817_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:1.431
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000336057_ENST00000392795_42163939_62007248 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:1.9121
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000336057_ENST00000392795_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:0.813
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000393622_ENST00000006750_42163939_62007248 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:1.2248
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000393622_ENST00000006750_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:0.8988
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000393622_ENST00000349817_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:1.2309
Å |
 |  |  |  |  |
| HDAC5_CD79B_ENST00000393622_ENST00000392795_42163939_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:0.962
Å |
 |  |  |  |  |
| HDDC2_FAM47E_ENST00000368377_ENST00000339906_125613986_77184856 superimposed PDB: 4L1J of partner (HDDC2). RMSD:1.0894
Å |
 |  |  |  |  |
| HDDC2_FAM47E_ENST00000368377_ENST00000424749_125613986_77184856 superimposed PDB: 4L1J of partner (HDDC2). RMSD:1.1966
Å |
 |  |  |  |  |
| HDDC2_FAM47E_ENST00000398153_ENST00000339906_125613986_77184856 superimposed PDB: 4L1J of partner (HDDC2). RMSD:0.3975
Å |
 |  |  |  |  |
| HDDC2_FAM47E_ENST00000398153_ENST00000424749_125613986_77184856 superimposed PDB: 4L1J of partner (HDDC2). RMSD:0.3378
Å |
 |  |  |  |  |
| HDDC2_FAM47E_ENST00000398153_ENST00000510197_125613986_77184856 superimposed PDB: 4L1J of partner (HDDC2). RMSD:1.0216
Å |
 |  |  |  |  |
| HDDC2_SRPK1_ENST00000398153_ENST00000423325_125619859_35810381 superimposed PDB: 4L1J of partner (HDDC2). RMSD:1.94
Å |
 |  |  |  |  |
| HDDC2_SRPK1_ENST00000398153_ENST00000423325_125619859_35810381 superimposed PDB: 5MXX of partner (SRPK1). RMSD:1.013
Å |
| | | |  |
| HDDC2_SRPK1_ENST00000608284_ENST00000373825_125619859_35810381 superimposed PDB: 4L1J of partner (HDDC2). RMSD:3.2502
Å |
 |  |  |  |  |
| HDDC2_SRPK1_ENST00000608284_ENST00000373825_125619859_35810381 superimposed PDB: 5MXX of partner (SRPK1). RMSD:1.1883
Å |
| | | |  |
| HDDC2_SRPK1_ENST00000608295_ENST00000423325_125621683_35810381 superimposed PDB: 5MXX of partner (SRPK1). RMSD:0.8336
Å |
 |  |  |  |  |
| HDHD1_REPS2_ENST00000381077_ENST00000303843_7066093_17065469 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.5531
Å |
 |  |  |  |  |
| HDHD1_REPS2_ENST00000412827_ENST00000357277_7066093_17065469 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.5622
Å |
 |  |  |  |  |
| HDLBP_DSP_ENST00000310931_ENST00000379802_242173234_7576526 superimposed PDB: 5DZZ of partner (DSP). RMSD:2.7927
Å |
 |  |  |  |  |
| HDLBP_DSP_ENST00000391976_ENST00000418664_242173234_7576526 superimposed PDB: 5DZZ of partner (DSP). RMSD:3.0675
Å |
 |  |  |  |  |
| HDLBP_TMPRSS2_ENST00000391975_ENST00000398585_242173234_42845423 superimposed PDB: 2CTK of partner (HDLBP). RMSD:0.8463
Å |
 |  |  |  |  |
| HECTD1_CNOT1_ENST00000399332_ENST00000569240_31574588_58594266 superimposed PDB: 2LC3 of partner (HECTD1). RMSD:0.8753
Å |
 |  |  |  |  |
| HECTD1_MED26_ENST00000553700_ENST00000263390_31675002_16689220 superimposed PDB: 7EMF of partner (MED26). RMSD:2.268
Å |
 |  |  |  |  |
| HELLS_ZKSCAN5_ENST00000394044_ENST00000451158_96336466_99110075 superimposed PDB: 2EM5 of partner (ZKSCAN5). RMSD:0.5178
Å |
 |  |  |  |  |
| HELLS_ZKSCAN5_ENST00000394045_ENST00000451158_96336562_99110075 superimposed PDB: 2EM5 of partner (ZKSCAN5). RMSD:0.4927
Å |
 |  |  |  |  |
| HERC1_DAPK2_ENST00000443617_ENST00000261891_63988322_64263760 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.5288
Å |
 |  |  |  |  |
| HERC1_DAPK2_ENST00000443617_ENST00000457488_63988322_64263760 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.549
Å |
 |  |  |  |  |
| HERC1_KIAA0101_ENST00000443617_ENST00000559519_64045156_64658274 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.6072
Å |
 |  |  |  |  |
| HERPUD1_RPS7_ENST00000300302_ENST00000403564_56970729_3627699 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.9183
Å |
 |  |  |  |  |
| HERPUD1_RPS7_ENST00000379792_ENST00000403564_56970729_3627699 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.7255
Å |
 |  |  |  |  |
| HERPUD1_RPS7_ENST00000439977_ENST00000403564_56970729_3627699 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.9604
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000300302_ENST00000405975_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.8965
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000300302_ENST00000415080_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.8708
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000300302_ENST00000415080_56970729_43657441 superimposed PDB: 8Y2O of partner (THADA). RMSD:1.8434
Å |
| | | |  |
| HERPUD1_THADA_ENST00000379792_ENST00000405975_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.7878
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000379792_ENST00000405975_56970729_43657441 superimposed PDB: 8Y2O of partner (THADA). RMSD:0.8707
Å |
| | | |  |
| HERPUD1_THADA_ENST00000379792_ENST00000415080_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.9217
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000379792_ENST00000415080_56970729_43657441 superimposed PDB: 8Y2O of partner (THADA). RMSD:1.8635
Å |
| | | |  |
| HERPUD1_THADA_ENST00000439977_ENST00000405975_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.8901
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000439977_ENST00000405975_56970729_43657441 superimposed PDB: 8Y2O of partner (THADA). RMSD:3.0816
Å |
| | | |  |
| HERPUD1_THADA_ENST00000439977_ENST00000415080_56970729_43657441 superimposed PDB: 1WGD of partner (HERPUD1). RMSD:0.9161
Å |
 |  |  |  |  |
| HERPUD1_THADA_ENST00000439977_ENST00000415080_56970729_43657441 superimposed PDB: 8Y2O of partner (THADA). RMSD:1.8679
Å |
| | | |  |
| HEXB_CBX6_ENST00000261416_ENST00000216083_73992931_39267950 superimposed PDB: 3LMY of partner (HEXB). RMSD:0.4624
Å |
 |  |  |  |  |
| HEXB_CBX6_ENST00000261416_ENST00000216083_73992931_39267950 superimposed PDB: 3GV6 of partner (CBX6). RMSD:0.6247
Å |
| | | |  |
| HEXB_UBA6_ENST00000261416_ENST00000420827_73989529_68531010 superimposed PDB: 3LMY of partner (HEXB). RMSD:0.4992
Å |
 |  |  |  |  |
| HEXB_UBA6_ENST00000261416_ENST00000420827_73989529_68531010 superimposed PDB: 7PVN of partner (UBA6). RMSD:1.3413
Å |
| | | |  |
| HGFAC_PRSS57_ENST00000511533_ENST00000329267_3448021_692002 superimposed PDB: 1YC0 of partner (HGFAC). RMSD:0.6971
Å |
 |  |  |  |  |
| HGFAC_PRSS57_ENST00000511533_ENST00000329267_3448021_692002 superimposed PDB: 4Q7Z of partner (PRSS57). RMSD:0.5367
Å |
| | | |  |
| HGF_RPS3A_ENST00000444829_ENST00000274065_81381435_152022126 superimposed PDB: 7MO9 of partner (HGF). RMSD:2.0052
Å |
 |  |  |  |  |
| HGF_RPS3A_ENST00000453411_ENST00000274065_81381435_152022126 superimposed PDB: 7MO9 of partner (HGF). RMSD:1.8238
Å |
 |  |  |  |  |
| HGF_RPS3A_ENST00000457544_ENST00000274065_81381435_152022126 superimposed PDB: 7MO9 of partner (HGF). RMSD:1.4572
Å |
 |  |  |  |  |
| HGS_CASC1_ENST00000329138_ENST00000395987_79657772_25314131 superimposed PDB: 3ZYQ of partner (HGS). RMSD:0.4704
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000308852_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.0196
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000308852_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.1224
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000367010_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.7234
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000367010_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.1002
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000391905_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.7238
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000391905_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.0862
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000413764_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.7713
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000413764_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.1245
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000537898_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.9517
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000537898_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.0645
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000541565_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.6864
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000541565_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:0.8464
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000545154_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.818
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000545154_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:0.8052
Å |
| | | |  |
| HHAT_ATP6V1H_ENST00000545781_ENST00000520188_210637999_54656250 superimposed PDB: 7MHY of partner (HHAT). RMSD:0.9437
Å |
 |  |  |  |  |
| HHAT_ATP6V1H_ENST00000545781_ENST00000520188_210637999_54656250 superimposed PDB: 6WM2 of partner (ATP6V1H). RMSD:1.3881
Å |
| | | |  |
| HHAT_KIF5B_ENST00000261458_ENST00000302418_210591669_32329385 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.5591
Å |
 |  |  |  |  |
| HHAT_KIF5B_ENST00000308852_ENST00000302418_210591669_32329385 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.553
Å |
 |  |  |  |  |
| HHAT_KIF5B_ENST00000391905_ENST00000302418_210591669_32329385 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.9367
Å |
 |  |  |  |  |
| HHAT_KIF5B_ENST00000537898_ENST00000302418_210591669_32329385 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.8682
Å |
 |  |  |  |  |
| HHAT_KIF5B_ENST00000545781_ENST00000302418_210591669_32329385 superimposed PDB: 7MHY of partner (HHAT). RMSD:1.8528
Å |
 |  |  |  |  |
| HIBCH_CTNNA2_ENST00000392332_ENST00000402739_191175479_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.5116
Å |
 |  |  |  |  |
| HIBCH_CTNNA2_ENST00000392332_ENST00000496558_191175479_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4943
Å |
 |  |  |  |  |
| HIBCH_CTNNA2_ENST00000392332_ENST00000540488_191175479_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4711
Å |
 |  |  |  |  |
| HIF1A_PRKCH_ENST00000337138_ENST00000555082_62207906_61995792 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:0.4179
Å |
 |  |  |  |  |
| HIF1A_PRKCH_ENST00000394997_ENST00000555082_62162557_61995792 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:0.5141
Å |
 |  |  |  |  |
| HIF1A_PRKCH_ENST00000394997_ENST00000555082_62207906_61995792 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:0.4402
Å |
 |  |  |  |  |
| HIF1A_PRKCH_ENST00000557538_ENST00000555082_62207906_61995792 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:0.3919
Å |
 |  |  |  |  |
| HIF1A_SF3B1_ENST00000323441_ENST00000335508_62203827_198283312 superimposed PDB: 7Q4O of partner (SF3B1). RMSD:1.4925
Å |
 |  |  |  |  |
| HIF1A_SF3B1_ENST00000337138_ENST00000335508_62203827_198283312 superimposed PDB: 7Q4O of partner (SF3B1). RMSD:2.0007
Å |
 |  |  |  |  |
| HIF1A_SF3B1_ENST00000539097_ENST00000335508_62203827_198283312 superimposed PDB: 7Q4O of partner (SF3B1). RMSD:2.1693
Å |
 |  |  |  |  |
| HIP1_PDGFRB_ENST00000434438_ENST00000261799_75168642_149506177 superimposed PDB: 3I00 of partner (HIP1). RMSD:2.3365
Å |
 |  |  |  |  |
| HIPK3_ADPGK_ENST00000303296_ENST00000311669_33309057_73067438 superimposed PDB: 7O7I of partner (HIPK3). RMSD:0.7694
Å |
 |  |  |  |  |
| HIPK3_ADPGK_ENST00000379016_ENST00000311669_33309057_73067438 superimposed PDB: 7O7I of partner (HIPK3). RMSD:0.6822
Å |
 |  |  |  |  |
| HIPK3_CAT_ENST00000303296_ENST00000241052_33373811_34470738 superimposed PDB: 7O7I of partner (HIPK3). RMSD:0.5797
Å |
 |  |  |  |  |
| HIPK3_CAT_ENST00000303296_ENST00000241052_33373811_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4358
Å |
| | | |  |
| HIPK3_CAT_ENST00000379016_ENST00000241052_33373811_34470738 superimposed PDB: 7O7I of partner (HIPK3). RMSD:0.5529
Å |
 |  |  |  |  |
| HIPK3_CAT_ENST00000379016_ENST00000241052_33373811_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4937
Å |
| | | |  |
| HIPK3_CAT_ENST00000456517_ENST00000241052_33373811_34470738 superimposed PDB: 7O7I of partner (HIPK3). RMSD:0.5381
Å |
 |  |  |  |  |
| HIPK3_CAT_ENST00000456517_ENST00000241052_33373811_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4651
Å |
| | | |  |
| HIRA_CABIN1_ENST00000541063_ENST00000405822_19371142_24560367 superimposed PDB: 1N6J of partner (CABIN1). RMSD:2.044
Å |
 |  |  |  |  |
| HIRA_SULT4A1_ENST00000263208_ENST00000330884_19385514_44237812 superimposed PDB: 1ZD1 of partner (SULT4A1). RMSD:0.8056
Å |
 |  |  |  |  |
| HIVEP3_UBR5_ENST00000247584_ENST00000520539_42041214_103293747 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.1488
Å |
 |  |  |  |  |
| HIVEP3_UBR5_ENST00000372584_ENST00000220959_42041214_103293747 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.0897
Å |
 |  |  |  |  |
| HK1_UTP23_ENST00000298649_ENST00000520733_71146174_117861126 superimposed PDB: 1CZA of partner (HK1). RMSD:2.898
Å |
 |  |  |  |  |
| HK1_UTP23_ENST00000359426_ENST00000520733_71146174_117861126 superimposed PDB: 1CZA of partner (HK1). RMSD:2.8616
Å |
 |  |  |  |  |
| HK1_UTP23_ENST00000404387_ENST00000520733_71146174_117861126 superimposed PDB: 1CZA of partner (HK1). RMSD:2.89
Å |
 |  |  |  |  |
| HK1_UTP23_ENST00000448642_ENST00000520733_71146174_117861126 superimposed PDB: 1CZA of partner (HK1). RMSD:2.8963
Å |
 |  |  |  |  |
| HK1_VPS26A_ENST00000359426_ENST00000263559_71078766_70915567 superimposed PDB: 2FAU of partner (VPS26A). RMSD:1.2349
Å |
 |  |  |  |  |
| HK1_VPS26A_ENST00000359426_ENST00000546041_71078766_70915567 superimposed PDB: 2FAU of partner (VPS26A). RMSD:1.2187
Å |
 |  |  |  |  |
| HKR1_CHMP2A_ENST00000392153_ENST00000601220_37826159_59063552 superimposed PDB: 7ZCG of partner (CHMP2A). RMSD:2.7917
Å |
 |  |  |  |  |
| HKR1_CHMP2A_ENST00000591259_ENST00000601220_37826159_59063552 superimposed PDB: 7ZCG of partner (CHMP2A). RMSD:2.802
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000309434_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9959
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000389124_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9862
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000389125_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9975
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000399907_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:2.0173
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000399909_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.966
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000399913_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9933
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000399914_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:2.0022
Å |
 |  |  |  |  |
| HLCS_GRIK1_ENST00000336648_ENST00000535441_38269159_30971257 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:2.0212
Å |
 |  |  |  |  |
| HMBOX1_FGF20_ENST00000444075_ENST00000180166_28837673_16853267 superimposed PDB: 3F1R of partner (FGF20). RMSD:0.4336
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000278715_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.8792
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000278715_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9399
Å |
| | | |  |
| HMBS_EHBP1_ENST00000278715_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.8899
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000278715_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.836
Å |
| | | |  |
| HMBS_EHBP1_ENST00000278715_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.9291
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000278715_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9478
Å |
| | | |  |
| HMBS_EHBP1_ENST00000392841_ENST00000405015_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.1373
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000392841_ENST00000405015_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.903
Å |
| | | |  |
| HMBS_EHBP1_ENST00000442944_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.8852
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000442944_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9308
Å |
| | | |  |
| HMBS_EHBP1_ENST00000442944_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.992
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000442944_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:2.051
Å |
| | | |  |
| HMBS_EHBP1_ENST00000442944_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.908
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000442944_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9369
Å |
| | | |  |
| HMBS_EHBP1_ENST00000537841_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.9363
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000537841_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.859
Å |
| | | |  |
| HMBS_EHBP1_ENST00000537841_ENST00000405015_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.9464
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000537841_ENST00000405015_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.7465
Å |
| | | |  |
| HMBS_EHBP1_ENST00000537841_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.9522
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000537841_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9191
Å |
| | | |  |
| HMBS_EHBP1_ENST00000537841_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.9124
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000537841_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9397
Å |
| | | |  |
| HMBS_EHBP1_ENST00000542729_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.5387
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000542729_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.8767
Å |
| | | |  |
| HMBS_EHBP1_ENST00000542729_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.5362
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000542729_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9095
Å |
| | | |  |
| HMBS_EHBP1_ENST00000542729_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.5315
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000542729_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.93
Å |
| | | |  |
| HMBS_EHBP1_ENST00000543090_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.1834
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000543090_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.7292
Å |
| | | |  |
| HMBS_EHBP1_ENST00000543090_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.2151
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000543090_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9363
Å |
| | | |  |
| HMBS_EHBP1_ENST00000543090_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.2168
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000543090_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9127
Å |
| | | |  |
| HMBS_EHBP1_ENST00000544387_ENST00000263991_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.5509
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000544387_ENST00000263991_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9749
Å |
| | | |  |
| HMBS_EHBP1_ENST00000544387_ENST00000405015_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:0.8874
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000544387_ENST00000405015_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.959
Å |
| | | |  |
| HMBS_EHBP1_ENST00000544387_ENST00000405289_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.6022
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000544387_ENST00000405289_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9546
Å |
| | | |  |
| HMBS_EHBP1_ENST00000544387_ENST00000431489_118963521_63053221 superimposed PDB: 7AAK of partner (HMBS). RMSD:1.5185
Å |
 |  |  |  |  |
| HMBS_EHBP1_ENST00000544387_ENST00000431489_118963521_63053221 superimposed PDB: 6ZSI of partner (EHBP1). RMSD:1.9603
Å |
| | | |  |
| HMGA1_ARIH2_ENST00000311487_ENST00000356401_34211295_49019092 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:0.7629
Å |
 |  |  |  |  |
| HMGA1_ARIH2_ENST00000311487_ENST00000449376_34211295_49019092 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:0.6948
Å |
 |  |  |  |  |
| HMGA1_ARIH2_ENST00000374116_ENST00000356401_34211295_49019092 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:0.7967
Å |
 |  |  |  |  |
| HMGA1_ARIH2_ENST00000447654_ENST00000449376_34211295_49019092 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:0.7041
Å |
 |  |  |  |  |
| HMGA2_ALDH2_ENST00000393577_ENST00000416293_66232349_112247346 superimposed PDB: 5L13 of partner (ALDH2). RMSD:2.9549
Å |
 |  |  |  |  |
| HMGA2_CCNB1IP1_ENST00000541363_ENST00000398169_66221867_20781960 superimposed PDB: 9GES of partner (CCNB1IP1). RMSD:1.1
Å |
 |  |  |  |  |
| HMGA2_CHMP1A_ENST00000541363_ENST00000535997_66221867_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.8828
Å |
 |  |  |  |  |
| HMGA2_MSRB3_ENST00000393577_ENST00000308259_66232349_65856934 superimposed PDB: 6Q9V of partner (MSRB3). RMSD:2.7535
Å |
 |  |  |  |  |
| HMGA2_PCBP2_ENST00000541363_ENST00000437231_66232349_53856276 superimposed PDB: 2JZX of partner (PCBP2). RMSD:0.8341
Å |
 |  |  |  |  |
| HMGA2_PCBP2_ENST00000541363_ENST00000455667_66232349_53856276 superimposed PDB: 2JZX of partner (PCBP2). RMSD:0.8219
Å |
 |  |  |  |  |
| HMGA2_PCBP2_ENST00000541363_ENST00000552296_66232349_53856276 superimposed PDB: 2JZX of partner (PCBP2). RMSD:0.8472
Å |
 |  |  |  |  |
| HMGA2_PPFIA2_ENST00000403681_ENST00000549325_66232349_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.6131
Å |
 |  |  |  |  |
| HMGA2_PPFIA2_ENST00000403681_ENST00000550584_66232349_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.5998
Å |
 |  |  |  |  |
| HMGA2_PPFIA2_ENST00000541363_ENST00000549396_66232349_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.6028
Å |
 |  |  |  |  |
| HMGA2_RAD51B_ENST00000393577_ENST00000487861_66232349_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.583
Å |
 |  |  |  |  |
| HMGA2_RAD51B_ENST00000541363_ENST00000390683_66232349_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1749
Å |
 |  |  |  |  |
| HMGA2_RAD51B_ENST00000541363_ENST00000471583_66232349_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.2098
Å |
 |  |  |  |  |
| HMGA2_RAD51B_ENST00000541363_ENST00000487270_66232349_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.6535
Å |
 |  |  |  |  |
| HMGA2_RAD51B_ENST00000541363_ENST00000488612_66232349_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.5496
Å |
 |  |  |  |  |
| HMGA2_TBK1_ENST00000541363_ENST00000331710_66232349_64868009 superimposed PDB: 6NT9 of partner (TBK1). RMSD:0.8099
Å |
 |  |  |  |  |
| HMGB1_CCNA1_ENST00000405805_ENST00000440264_31036674_37011765 superimposed PDB: 9CG9 of partner (HMGB1). RMSD:0.797
Å |
 |  |  |  |  |
| HMGCR_RIMS2_ENST00000287936_ENST00000406091_74646774_104709313 superimposed PDB: 1V27 of partner (RIMS2). RMSD:0.8563
Å |
 |  |  |  |  |
| HMGCR_RIMS2_ENST00000343975_ENST00000406091_74646774_104709313 superimposed PDB: 1V27 of partner (RIMS2). RMSD:0.8444
Å |
 |  |  |  |  |
| HMGCS2_PSMA2_ENST00000369406_ENST00000223321_120298049_42964396 superimposed PDB: 2WYA of partner (HMGCS2). RMSD:0.6035
Å |
 |  |  |  |  |
| HMGCS2_PSMA2_ENST00000369406_ENST00000223321_120298049_42964396 superimposed PDB: 5LE5 of partner (PSMA2). RMSD:0.9122
Å |
| | | |  |
| HMGCS2_PSMA2_ENST00000544913_ENST00000223321_120298049_42964396 superimposed PDB: 2WYA of partner (HMGCS2). RMSD:0.9211
Å |
 |  |  |  |  |
| HMGCS2_PSMA2_ENST00000544913_ENST00000223321_120298049_42964396 superimposed PDB: 5LE5 of partner (PSMA2). RMSD:0.8363
Å |
| | | |  |
| HMGCS2_PSMA2_ENST00000544913_ENST00000442788_120298049_42964396 superimposed PDB: 2WYA of partner (HMGCS2). RMSD:0.5687
Å |
 |  |  |  |  |
| HMGCS2_PSMA2_ENST00000544913_ENST00000442788_120298049_42964396 superimposed PDB: 5LE5 of partner (PSMA2). RMSD:1.3737
Å |
| | | |  |
| HMGN2_SEPT5_ENST00000361427_ENST00000406395_26799118_19707124 superimposed PDB: 6WCU of partner (SEPT5). RMSD:0.5035
Å |
 |  |  |  |  |
| HN1_GGA3_ENST00000409753_ENST00000245541_73142760_73242877 superimposed PDB: 1JUQ of partner (GGA3). RMSD:1.4292
Å |
 |  |  |  |  |
| HN1_GGA3_ENST00000470924_ENST00000245541_73142760_73242877 superimposed PDB: 1JUQ of partner (GGA3). RMSD:1.3307
Å |
 |  |  |  |  |
| HN1_GGA3_ENST00000470924_ENST00000351904_73142760_73242877 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.4498
Å |
 |  |  |  |  |
| HN1_GGA3_ENST00000482348_ENST00000245541_73142760_73242877 superimposed PDB: 1JUQ of partner (GGA3). RMSD:1.1613
Å |
 |  |  |  |  |
| HN1_GGA3_ENST00000482348_ENST00000351904_73142760_73242877 superimposed PDB: 1JUQ of partner (GGA3). RMSD:0.4417
Å |
 |  |  |  |  |
| HNF1B_ANAPC16_ENST00000560016_ENST00000299381_36091585_73990123 superimposed PDB: 2H8R of partner (HNF1B). RMSD:0.8525
Å |
 |  |  |  |  |
| HNF1B_ANAPC16_ENST00000560016_ENST00000299381_36091585_73990123 superimposed PDB: 9GAW of partner (ANAPC16). RMSD:1.2285
Å |
| | | |  |
| HNF1B_ANAPC16_ENST00000561193_ENST00000299381_36091585_73990123 superimposed PDB: 2H8R of partner (HNF1B). RMSD:0.936
Å |
 |  |  |  |  |
| HNF1B_ANAPC16_ENST00000561193_ENST00000299381_36091585_73990123 superimposed PDB: 9GAW of partner (ANAPC16). RMSD:1.2137
Å |
| | | |  |
| HNF1B_NOTCH1_ENST00000561193_ENST00000277541_36099430_139396940 superimposed PDB: 2H8R of partner (HNF1B). RMSD:0.4858
Å |
 |  |  |  |  |
| HNF1B_NOTCH1_ENST00000561193_ENST00000277541_36099430_139396940 superimposed PDB: 6PY8 of partner (NOTCH1). RMSD:0.5716
Å |
| | | |  |
| HNRNPA1_NME2_ENST00000340913_ENST00000555572_54674606_49245602 superimposed PDB: 7KPF of partner (NME2). RMSD:0.5065
Å |
 |  |  |  |  |
| HNRNPA1_ODC1_ENST00000340913_ENST00000405333_54674606_10582300 superimposed PDB: 2OO0 of partner (ODC1). RMSD:0.6718
Å |
 |  |  |  |  |
| HNRNPA1_ODC1_ENST00000546500_ENST00000405333_54674606_10582300 superimposed PDB: 2OO0 of partner (ODC1). RMSD:0.6681
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000330752_ENST00000359282_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5009
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000359282_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5272
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000359462_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5676
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000437231_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5745
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000447282_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4759
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000455667_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5423
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000546463_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5241
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000549863_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5464
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000552296_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5492
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000552819_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5371
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000340913_ENST00000603815_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5197
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000359462_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5227
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000437231_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5749
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000447282_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5012
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000455667_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4592
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000546463_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5139
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000549863_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5374
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000552296_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4966
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000552819_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.546
Å |
 |  |  |  |  |
| HNRNPA1_PCBP2_ENST00000546500_ENST00000603815_54674606_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5029
Å |
 |  |  |  |  |
| HNRNPA1_RPLP0_ENST00000340913_ENST00000551150_54674606_120635265 superimposed PDB: 9GKF of partner (HNRNPA1). RMSD:2.6926
Å |
 |  |  |  |  |
| HNRNPA1_RPLP0_ENST00000340913_ENST00000551150_54675286_120635265 superimposed PDB: 9GKF of partner (HNRNPA1). RMSD:2.7557
Å |
 |  |  |  |  |
| HNRNPA2B1_CALM1_ENST00000354667_ENST00000447653_26240191_90866408 superimposed PDB: 9MXD of partner (CALM1). RMSD:3.2683
Å |
 |  |  |  |  |
| HNRNPA2B1_CTNNA1_ENST00000354667_ENST00000302763_26240191_138160218 superimposed PDB: 6UPV of partner (CTNNA1). RMSD:2.0616
Å |
 |  |  |  |  |
| HNRNPA2B1_CTNNA1_ENST00000356674_ENST00000355078_26240191_138160218 superimposed PDB: 6UPV of partner (CTNNA1). RMSD:1.1064
Å |
 |  |  |  |  |
| HNRNPA2B1_HSD17B10_ENST00000354667_ENST00000168216_26240191_53460833 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.3967
Å |
 |  |  |  |  |
| HNRNPA2B1_HSD17B10_ENST00000354667_ENST00000375298_26240191_53460833 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.3588
Å |
 |  |  |  |  |
| HNRNPA2B1_PMEL_ENST00000354667_ENST00000550464_26236176_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.7908
Å |
 |  |  |  |  |
| HNRNPA2B1_PMEL_ENST00000354667_ENST00000552882_26236176_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.696
Å |
 |  |  |  |  |
| HNRNPA2B1_PMEL_ENST00000356674_ENST00000550464_26236176_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.7524
Å |
 |  |  |  |  |
| HNRNPA2B1_PMEL_ENST00000356674_ENST00000552882_26236176_56352391 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.7642
Å |
 |  |  |  |  |
| HNRNPAB_SAMM50_ENST00000504898_ENST00000350028_177634226_44371934 superimposed PDB: 3S7R of partner (HNRNPAB). RMSD:0.289
Å |
 |  |  |  |  |
| HNRNPAB_SAMM50_ENST00000506339_ENST00000350028_177634226_44371934 superimposed PDB: 3S7R of partner (HNRNPAB). RMSD:0.3157
Å |
 |  |  |  |  |
| HNRNPC_CD38_ENST00000430246_ENST00000226279_21698477_15818133 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6881
Å |
 |  |  |  |  |
| HNRNPC_CD38_ENST00000430246_ENST00000226279_21698477_15818133 superimposed PDB: 3F6Y of partner (CD38). RMSD:1.4431
Å |
| | | |  |
| HNRNPC_CD38_ENST00000556897_ENST00000226279_21698477_15818133 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.707
Å |
 |  |  |  |  |
| HNRNPC_CD38_ENST00000556897_ENST00000226279_21698477_15818133 superimposed PDB: 3F6Y of partner (CD38). RMSD:1.3338
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000298684_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6785
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000298684_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.7737
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000298687_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6749
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000298687_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.6047
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000397855_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6851
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000397855_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.7794
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000554143_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.682
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000320084_ENST00000554143_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:3.4382
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000298684_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6861
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000298684_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.8772
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000298687_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.7022
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000298687_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.6045
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000397855_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.7005
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000397855_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.7627
Å |
| | | |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000554143_21698477_21490038 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.7
Å |
 |  |  |  |  |
| HNRNPC_NDRG2_ENST00000430246_ENST00000554143_21698477_21490038 superimposed PDB: 2XMR of partner (NDRG2). RMSD:1.3049
Å |
| | | |  |
| HNRNPC_RPL22_ENST00000449098_ENST00000234875_21681118_6257816 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6987
Å |
 |  |  |  |  |
| HNRNPC_RPL22_ENST00000556142_ENST00000234875_21681118_6257816 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6888
Å |
 |  |  |  |  |
| HNRNPC_WRN_ENST00000430246_ENST00000298139_21698477_31030510 superimposed PDB: 2MXY of partner (HNRNPC). RMSD:0.6949
Å |
 |  |  |  |  |
| HNRNPH1_ERG_ENST00000442819_ENST00000398897_179047892_39755845 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.8738
Å |
 |  |  |  |  |
| HNRNPH1_ERG_ENST00000442819_ENST00000398897_179047892_39755845 superimposed PDB: 4IRH of partner (ERG). RMSD:0.3592
Å |
| | | |  |
| HNRNPH1_INSR_ENST00000356731_ENST00000341500_179044989_7184648 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.8204
Å |
 |  |  |  |  |
| HNRNPH1_INSR_ENST00000442819_ENST00000302850_179044989_7184648 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.9635
Å |
 |  |  |  |  |
| HNRNPH1_RPL9_ENST00000442819_ENST00000449470_179047892_39456564 superimposed PDB: 6DHS of partner (HNRNPH1). RMSD:2.8739
Å |
 |  |  |  |  |
| HNRNPK_UBQLN1_ENST00000351839_ENST00000257468_86589431_86301070 superimposed PDB: 1KHM of partner (HNRNPK). RMSD:1.2874
Å |
 |  |  |  |  |
| HNRNPK_UBQLN1_ENST00000351839_ENST00000257468_86589431_86301070 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5941
Å |
| | | |  |
| HNRNPK_UBQLN1_ENST00000351839_ENST00000257468_86591909_86301070 superimposed PDB: 1KHM of partner (HNRNPK). RMSD:2.9822
Å |
 |  |  |  |  |
| HNRNPK_UBQLN1_ENST00000351839_ENST00000257468_86591909_86301070 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.6868
Å |
| | | |  |
| HNRNPK_ZBTB11_ENST00000360384_ENST00000312938_86586187_101370527 superimposed PDB: 1KHM of partner (HNRNPK). RMSD:1.0339
Å |
 |  |  |  |  |
| HNRNPLL_TUBB2B_ENST00000378915_ENST00000259818_38829579_3226903 superimposed PDB: 9OX7 of partner (TUBB2B). RMSD:0.7751
Å |
 |  |  |  |  |
| HNRNPLL_TUBB2B_ENST00000409636_ENST00000259818_38829579_3226903 superimposed PDB: 9OX7 of partner (TUBB2B). RMSD:0.7137
Å |
 |  |  |  |  |
| HNRNPR_RPS10_ENST00000426846_ENST00000344700_23660010_34386201 superimposed PDB: 9EJY of partner (HNRNPR). RMSD:3.1496
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000263367_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3714
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000352456_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.358
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000392006_ENST00000269980_41787180_41916541 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5051
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000392006_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3529
Å |
| | | |  |
| HNRNPUL1_BCKDHA_ENST00000593587_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3638
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000595018_ENST00000269980_41787180_41916541 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:2.8036
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000595018_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3436
Å |
| | | |  |
| HNRNPUL1_BCKDHA_ENST00000602130_ENST00000269980_41787180_41916541 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5185
Å |
 |  |  |  |  |
| HNRNPUL1_BCKDHA_ENST00000602130_ENST00000269980_41787180_41916541 superimposed PDB: 2BFD of partner (BCKDHA). RMSD:0.3715
Å |
| | | |  |
| HNRNPUL1_BRSK1_ENST00000593587_ENST00000590333_41787180_55795888 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5113
Å |
 |  |  |  |  |
| HNRNPUL1_BRSK1_ENST00000602130_ENST00000590333_41787180_55795888 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.563
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000263367_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8103
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000378215_ENST00000252456_41800591_11651890 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5306
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000378215_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8082
Å |
| | | |  |
| HNRNPUL1_CNN1_ENST00000392006_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8447
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000593587_ENST00000252456_41800591_11651890 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5151
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000593587_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.815
Å |
| | | |  |
| HNRNPUL1_CNN1_ENST00000595018_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.8322
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000602130_ENST00000252456_41800591_11651890 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.8495
Å |
 |  |  |  |  |
| HNRNPUL1_CNN1_ENST00000602130_ENST00000252456_41800591_11651890 superimposed PDB: 1WYP of partner (CNN1). RMSD:0.7848
Å |
| | | |  |
| HNRNPUL1_SLC8A2_ENST00000593587_ENST00000236877_41787180_47960851 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5604
Å |
 |  |  |  |  |
| HNRNPUL1_SLC8A2_ENST00000602130_ENST00000236877_41787180_47960851 superimposed PDB: 1ZRJ of partner (HNRNPUL1). RMSD:0.5657
Å |
 |  |  |  |  |
| HOMER1_MAST2_ENST00000334082_ENST00000361297_78808592_46348035 superimposed PDB: 2KQF of partner (MAST2). RMSD:1.0713
Å |
 |  |  |  |  |
| HOMER1_MAST2_ENST00000535690_ENST00000372009_78808592_46348035 superimposed PDB: 2KQF of partner (MAST2). RMSD:0.9726
Å |
 |  |  |  |  |
| HOMEZ_CDKL1_ENST00000357460_ENST00000216378_23755121_50808940 superimposed PDB: 4AGU of partner (CDKL1). RMSD:0.3802
Å |
 |  |  |  |  |
| HOOK2_NFIX_ENST00000264827_ENST00000397661_12885482_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.3663
Å |
 |  |  |  |  |
| HOOK2_NFIX_ENST00000264827_ENST00000587760_12885482_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4621
Å |
 |  |  |  |  |
| HOOK2_NFIX_ENST00000397668_ENST00000587760_12885482_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4983
Å |
 |  |  |  |  |
| HOOK2_NFIX_ENST00000397668_ENST00000592199_12885482_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.472
Å |
 |  |  |  |  |
| HOOK3_ADAM32_ENST00000307602_ENST00000379907_42761401_39091417 superimposed PDB: 6B9H of partner (HOOK3). RMSD:2.3888
Å |
 |  |  |  |  |
| HOOK3_ADAM32_ENST00000307602_ENST00000519315_42761401_39091417 superimposed PDB: 6B9H of partner (HOOK3). RMSD:2.3639
Å |
 |  |  |  |  |
| HOOK3_GTF2E2_ENST00000307602_ENST00000355904_42798588_30492640 superimposed PDB: 6B9H of partner (HOOK3). RMSD:0.5065
Å |
 |  |  |  |  |
| HOOK3_IKBKB_ENST00000307602_ENST00000416505_42798588_42162704 superimposed PDB: 6B9H of partner (HOOK3). RMSD:0.3076
Å |
 |  |  |  |  |
| HOOK3_IKBKB_ENST00000307602_ENST00000416505_42798588_42162704 superimposed PDB: 8OMV of partner (IKBKB). RMSD:1.8611
Å |
| | | |  |
| HOOK3_IKBKB_ENST00000307602_ENST00000520810_42798588_42162704 superimposed PDB: 6B9H of partner (HOOK3). RMSD:0.2886
Å |
 |  |  |  |  |
| HOOK3_IKBKB_ENST00000307602_ENST00000520835_42798588_42162704 superimposed PDB: 6B9H of partner (HOOK3). RMSD:0.329
Å |
 |  |  |  |  |
| HOOK3_RET_ENST00000307602_ENST00000340058_42823357_43612031 superimposed PDB: 6B9H of partner (HOOK3). RMSD:0.3612
Å |
 |  |  |  |  |
| HOOK3_TGS1_ENST00000307602_ENST00000260129_42761401_56695306 superimposed PDB: 3GDH of partner (TGS1). RMSD:1.6696
Å |
 |  |  |  |  |
| HOXB3_FAP_ENST00000465120_ENST00000443424_46651198_163044873 superimposed PDB: 9DVQ of partner (FAP). RMSD:0.8978
Å |
 |  |  |  |  |
| HP1BP3_PINK1_ENST00000375000_ENST00000321556_21103089_20970982 superimposed PDB: 9EII of partner (PINK1). RMSD:0.6824
Å |
 |  |  |  |  |
| HPGDS_MAP7_ENST00000295256_ENST00000454590_95223296_136677932 superimposed PDB: 7JR8 of partner (HPGDS). RMSD:0.651
Å |
 |  |  |  |  |
| HPGDS_MAP7_ENST00000295256_ENST00000454590_95223296_136677932 superimposed PDB: 7SGS of partner (MAP7). RMSD:2.2408
Å |
| | | |  |
| HPRT1_CTPS2_ENST00000298556_ENST00000359276_133609394_16657366 superimposed PDB: 5HIA of partner (HPRT1). RMSD:1.5733
Å |
 |  |  |  |  |
| HPS4_PI4KA_ENST00000398145_ENST00000572273_26859882_21107468 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.3188
Å |
 |  |  |  |  |
| HP_RBP4_ENST00000355906_ENST00000371467_72090530_95353792 superimposed PDB: 6QBA of partner (RBP4). RMSD:0.7286
Å |
 |  |  |  |  |
| HP_RBP4_ENST00000357763_ENST00000371467_72090530_95353792 superimposed PDB: 6QBA of partner (RBP4). RMSD:0.6794
Å |
 |  |  |  |  |
| HS2ST1_SH3GLB1_ENST00000370550_ENST00000370558_87380843_87185189 superimposed PDB: 9G2U of partner (SH3GLB1). RMSD:1.4358
Å |
 |  |  |  |  |
| HS6ST2_NPFFR2_ENST00000370836_ENST00000395999_132090835_73003756 superimposed PDB: 9M1O of partner (NPFFR2). RMSD:0.2729
Å |
 |  |  |  |  |
| HS6ST3_EFNA5_ENST00000376705_ENST00000509503_96743823_106763210 superimposed PDB: 2X11 of partner (EFNA5). RMSD:0.5912
Å |
 |  |  |  |  |
| HSD17B11_UGT2A3_ENST00000358290_ENST00000420231_88312012_69796960 superimposed PDB: 1YB1 of partner (HSD17B11). RMSD:2.5372
Å |
 |  |  |  |  |
| HSD17B12_WT1_ENST00000278353_ENST00000332351_43702537_32450165 superimposed PDB: 6BLW of partner (WT1). RMSD:1.694
Å |
 |  |  |  |  |
| HSD17B12_WT1_ENST00000278353_ENST00000448076_43702537_32450165 superimposed PDB: 6BLW of partner (WT1). RMSD:1.997
Å |
 |  |  |  |  |
| HSD17B12_WT1_ENST00000278353_ENST00000530998_43702537_32450165 superimposed PDB: 6BLW of partner (WT1). RMSD:2.0394
Å |
 |  |  |  |  |
| HSD17B3_CDC14B_ENST00000375262_ENST00000463569_99060697_99327765 superimposed PDB: 1OHE of partner (CDC14B). RMSD:0.4466
Å |
 |  |  |  |  |
| HSF1_CPSF3L_ENST00000400780_ENST00000411962_145537302_1250998 superimposed PDB: 5D5V of partner (HSF1). RMSD:0.8081
Å |
 |  |  |  |  |
| HSF1_CPSF3L_ENST00000400780_ENST00000411962_145537302_1250998 superimposed PDB: 8RC4 of partner (CPSF3L). RMSD:2.6318
Å |
| | | |  |
| HSF1_CPSF3L_ENST00000528838_ENST00000411962_145537302_1250998 superimposed PDB: 5D5V of partner (HSF1). RMSD:0.4142
Å |
 |  |  |  |  |
| HSF1_CPSF3L_ENST00000528838_ENST00000411962_145537302_1250998 superimposed PDB: 8RC4 of partner (CPSF3L). RMSD:2.8095
Å |
| | | |  |
| HSP90AA1_DDX5_ENST00000334701_ENST00000450599_102551017_62499216 superimposed PDB: 7KRJ of partner (HSP90AA1). RMSD:2.7085
Å |
 |  |  |  |  |
| HSP90AA1_RPL4_ENST00000216281_ENST00000568588_102549370_66792714 superimposed PDB: 7KRJ of partner (HSP90AA1). RMSD:3.6293
Å |
 |  |  |  |  |
| HSP90AA1_SLC25A3_ENST00000334701_ENST00000228318_102549370_98991633 superimposed PDB: 7KRJ of partner (HSP90AA1). RMSD:1.7134
Å |
 |  |  |  |  |
| HSP90AB1_MKL2_ENST00000371646_ENST00000318282_44220004_14354765 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:3.4572
Å |
 |  |  |  |  |
| HSP90B1_MDM2_ENST00000299767_ENST00000356290_104341208_69229608 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.9282
Å |
 |  |  |  |  |
| HSPA4_ERCC8_ENST00000304858_ENST00000265038_132432978_60200700 superimposed PDB: 9BZ0 of partner (ERCC8). RMSD:0.772
Å |
 |  |  |  |  |
| HSPA5_DCN_ENST00000324460_ENST00000552962_128000419_91540029 superimposed PDB: 6ASY of partner (HSPA5). RMSD:0.5416
Å |
 |  |  |  |  |
| HSPA8_VSTM5_ENST00000534624_ENST00000409977_122931300_93554489 superimposed PDB: 4H5R of partner (HSPA8). RMSD:0.6294
Å |
 |  |  |  |  |
| HSPB11_BROX_ENST00000194214_ENST00000340934_54405657_222895760 superimposed PDB: 3ULY of partner (BROX). RMSD:0.672
Å |
 |  |  |  |  |
| HSPB11_BROX_ENST00000194214_ENST00000340934_54405657_222897433 superimposed PDB: 3ULY of partner (BROX). RMSD:0.6502
Å |
 |  |  |  |  |
| HSPB11_NDC1_ENST00000194214_ENST00000371429_54389576_54238162 superimposed PDB: 1TVG of partner (HSPB11). RMSD:0.6913
Å |
 |  |  |  |  |
| HSPB11_ZCCHC11_ENST00000371376_ENST00000371544_54405657_52962855 superimposed PDB: 8OST of partner (ZCCHC11). RMSD:1.0625
Å |
 |  |  |  |  |
| HSPD1_EIF2S3_ENST00000345042_ENST00000253039_198354920_24094838 superimposed PDB: 9L8P of partner (HSPD1). RMSD:2.7241
Å |
 |  |  |  |  |
| HSPD1_RPL38_ENST00000345042_ENST00000534490_198361863_72205325 superimposed PDB: 9L8P of partner (HSPD1). RMSD:0.7707
Å |
 |  |  |  |  |
| HSPD1_RPL38_ENST00000388968_ENST00000534490_198361863_72205325 superimposed PDB: 9L8P of partner (HSPD1). RMSD:2.7531
Å |
 |  |  |  |  |
| HSPG2_MATN2_ENST00000374695_ENST00000521689_22165863_98991113 superimposed PDB: 3SH4 of partner (HSPG2). RMSD:1.2505
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000320027_ENST00000380753_31728769_5043873 superimposed PDB: 6GFA of partner (HSPH1). RMSD:0.5552
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000320027_ENST00000380753_31728769_5043873 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.3734
Å |
| | | |  |
| HSPH1_AKR1C2_ENST00000380405_ENST00000407674_31728769_5043873 superimposed PDB: 6GFA of partner (HSPH1). RMSD:1.7523
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000380405_ENST00000407674_31728769_5043873 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.5165
Å |
| | | |  |
| HSPH1_AKR1C2_ENST00000380405_ENST00000421196_31728769_5043873 superimposed PDB: 6GFA of partner (HSPH1). RMSD:2.8994
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000380405_ENST00000421196_31728769_5043873 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.5247
Å |
| | | |  |
| HSPH1_AKR1C2_ENST00000445273_ENST00000407674_31728769_5043873 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.6172
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000445273_ENST00000421196_31728769_5043873 superimposed PDB: 6GFA of partner (HSPH1). RMSD:2.9333
Å |
 |  |  |  |  |
| HSPH1_AKR1C2_ENST00000445273_ENST00000421196_31728769_5043873 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.5012
Å |
| | | |  |
| HTT_GRK4_ENST00000355072_ENST00000398052_3132150_3015414 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.9128
Å |
 |  |  |  |  |
| HTT_GRK4_ENST00000355072_ENST00000504933_3132150_3015414 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.9535
Å |
 |  |  |  |  |
| HUWE1_BICD1_ENST00000218328_ENST00000281474_53651555_32520603 superimposed PDB: 7JQ9 of partner (HUWE1). RMSD:0.9154
Å |
 |  |  |  |  |
| HUWE1_PHF8_ENST00000342160_ENST00000322659_53635812_54049276 superimposed PDB: 3KV4 of partner (PHF8). RMSD:0.5745
Å |
 |  |  |  |  |
| HUWE1_PHF8_ENST00000342160_ENST00000357988_53635812_54049276 superimposed PDB: 3KV4 of partner (PHF8). RMSD:0.5766
Å |
 |  |  |  |  |
| HYDIN_PSMD11_ENST00000393567_ENST00000457654_71052031_30791066 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:1.0584
Å |
 |  |  |  |  |
| HYDIN_PSMD11_ENST00000448089_ENST00000457654_71052031_30791066 superimposed PDB: 2YS4 of partner (HYDIN). RMSD:1.0793
Å |
 |  |  |  |  |
| ICAM1_HNRNPM_ENST00000264832_ENST00000325495_10385704_8550486 superimposed PDB: 7BG7 of partner (ICAM1). RMSD:0.4698
Å |
 |  |  |  |  |
| ICAM1_HNRNPM_ENST00000264832_ENST00000325495_10385704_8550486 superimposed PDB: 2DO0 of partner (HNRNPM). RMSD:0.7378
Å |
| | | |  |
| ICOSLG_KCNJ6_ENST00000344330_ENST00000288309_45649936_39087434 superimposed PDB: 6X4T of partner (ICOSLG). RMSD:1.2127
Å |
 |  |  |  |  |
| ICOSLG_KCNJ6_ENST00000400377_ENST00000288309_45649936_39087434 superimposed PDB: 6X4T of partner (ICOSLG). RMSD:0.6373
Å |
 |  |  |  |  |
| ICOSLG_KCNJ6_ENST00000407780_ENST00000609713_45649936_39087434 superimposed PDB: 6X4T of partner (ICOSLG). RMSD:1.0853
Å |
 |  |  |  |  |
| IDH2_KHNYN_ENST00000330062_ENST00000556842_90628232_24905273 superimposed PDB: 5I96 of partner (IDH2). RMSD:1.803
Å |
 |  |  |  |  |
| IDH2_KHNYN_ENST00000540499_ENST00000556842_90628232_24905273 superimposed PDB: 5I96 of partner (IDH2). RMSD:1.752
Å |
 |  |  |  |  |
| IDH2_KHNYN_ENST00000559482_ENST00000556842_90628232_24905273 superimposed PDB: 5I96 of partner (IDH2). RMSD:2.0282
Å |
 |  |  |  |  |
| IFI6_ATP1B3_ENST00000362020_ENST00000286371_27994736_141644372 superimposed PDB: 9KCI of partner (ATP1B3). RMSD:2.2264
Å |
 |  |  |  |  |
| IFNAR2_IFNGR2_ENST00000382264_ENST00000381995_34617379_34793786 superimposed PDB: 5EH1 of partner (IFNGR2). RMSD:0.6492
Å |
 |  |  |  |  |
| IFNAR2_IFNGR2_ENST00000404220_ENST00000381995_34617379_34793786 superimposed PDB: 5EH1 of partner (IFNGR2). RMSD:0.6511
Å |
 |  |  |  |  |
| IFNAR2_IFNGR2_ENST00000413881_ENST00000381995_34617379_34793786 superimposed PDB: 5EH1 of partner (IFNGR2). RMSD:0.6146
Å |
 |  |  |  |  |
| IFNGR2_NUDCD3_ENST00000381995_ENST00000355451_34805178_44444182 superimposed PDB: 5EH1 of partner (IFNGR2). RMSD:0.4714
Å |
 |  |  |  |  |
| IFNGR2_NUDCD3_ENST00000381995_ENST00000355451_34805178_44444182 superimposed PDB: 1WGV of partner (NUDCD3). RMSD:0.9015
Å |
| | | |  |
| IFNGR2_NUDCD3_ENST00000405436_ENST00000355451_34805178_44444182 superimposed PDB: 5EH1 of partner (IFNGR2). RMSD:0.4236
Å |
 |  |  |  |  |
| IFNGR2_NUDCD3_ENST00000405436_ENST00000355451_34805178_44444182 superimposed PDB: 1WGV of partner (NUDCD3). RMSD:0.8688
Å |
| | | |  |
| IFT20_SUZ12_ENST00000395418_ENST00000322652_26656198_30267304 superimposed PDB: 8VMI of partner (SUZ12). RMSD:0.5343
Å |
 |  |  |  |  |
| IFT20_SUZ12_ENST00000579419_ENST00000580398_26656198_30267304 superimposed PDB: 8VMI of partner (SUZ12). RMSD:0.5389
Å |
 |  |  |  |  |
| IFT74_WNK2_ENST00000433700_ENST00000297954_26962085_96079801 superimposed PDB: 6ELM of partner (WNK2). RMSD:2.4163
Å |
 |  |  |  |  |
| IGF1R_AGBL1_ENST00000558762_ENST00000441037_99251336_87572055 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:2.0988
Å |
 |  |  |  |  |
| IGF1R_ARID1B_ENST00000268035_ENST00000275248_99251336_157469757 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:1.1803
Å |
 |  |  |  |  |
| IGF1R_ARID1B_ENST00000268035_ENST00000275248_99251336_157469757 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.5958
Å |
| | | |  |
| IGF1R_ARID1B_ENST00000268035_ENST00000346085_99251336_157469757 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.5793
Å |
 |  |  |  |  |
| IGF1R_EFTUD1_ENST00000268035_ENST00000359445_99251336_82456325 superimposed PDB: 5ANB of partner (EFTUD1). RMSD:2.4006
Å |
 |  |  |  |  |
| IGF1R_MAP7_ENST00000268035_ENST00000454590_99251336_136742937 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:1.189
Å |
 |  |  |  |  |
| IGF1R_MAP7_ENST00000268035_ENST00000454590_99251336_136742937 superimposed PDB: 7SGS of partner (MAP7). RMSD:2.0413
Å |
| | | |  |
| IGF1R_MAP7_ENST00000558762_ENST00000354570_99251336_136742937 superimposed PDB: 6JK8 of partner (IGF1R). RMSD:1.1635
Å |
 |  |  |  |  |
| IGF1R_MAP7_ENST00000558762_ENST00000354570_99251336_136742937 superimposed PDB: 7SGS of partner (MAP7). RMSD:2.0283
Å |
| | | |  |
| IGF2BP2_AMFR_ENST00000382199_ENST00000290649_185542570_56448256 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:2.6216
Å |
 |  |  |  |  |
| IGF2R_PPAP2A_ENST00000356956_ENST00000264775_160448346_54737736 superimposed PDB: 6P8I of partner (IGF2R). RMSD:1.587
Å |
 |  |  |  |  |
| IGF2R_PPAP2A_ENST00000356956_ENST00000307259_160448346_54737736 superimposed PDB: 6P8I of partner (IGF2R). RMSD:0.8026
Å |
 |  |  |  |  |
| IGF2R_PPAP2A_ENST00000356956_ENST00000307259_160448346_54737736 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.6204
Å |
| | | |  |
| IGFBP4_CD63_ENST00000269593_ENST00000548160_38610314_56120045 superimposed PDB: 2DSP of partner (IGFBP4). RMSD:0.5702
Å |
 |  |  |  |  |
| IGFBP4_CD63_ENST00000269593_ENST00000548160_38610314_56120045 superimposed PDB: 9HUR of partner (CD63). RMSD:0.6132
Å |
| | | |  |
| IGFBP4_CD63_ENST00000269593_ENST00000552067_38610314_56120045 superimposed PDB: 2DSP of partner (IGFBP4). RMSD:0.4258
Å |
 |  |  |  |  |
| IGFBP4_CD63_ENST00000269593_ENST00000552067_38610314_56120045 superimposed PDB: 9HUR of partner (CD63). RMSD:0.7076
Å |
| | | |  |
| IGFBP4_CD63_ENST00000542955_ENST00000548160_38610314_56120045 superimposed PDB: 9HUR of partner (CD63). RMSD:0.7898
Å |
 |  |  |  |  |
| IGFBP4_CD63_ENST00000542955_ENST00000552067_38610314_56120045 superimposed PDB: 9HUR of partner (CD63). RMSD:0.6659
Å |
 |  |  |  |  |
| IGHG3_COL1A1_ENST00000390551_ENST00000225964_106236629_48267741 superimposed PDB: 6G1E of partner (IGHG3). RMSD:0.6893
Å |
 |  |  |  |  |
| IGHMBP2_GPR137_ENST00000255078_ENST00000377702_68679071_64055811 superimposed PDB: 4B3F of partner (IGHMBP2). RMSD:2.2433
Å |
 |  |  |  |  |
| IGHMBP2_GPR137_ENST00000255078_ENST00000438980_68679071_64055811 superimposed PDB: 4B3F of partner (IGHMBP2). RMSD:1.5949
Å |
 |  |  |  |  |
| IGHMBP2_GPR137_ENST00000255078_ENST00000539851_68679071_64055811 superimposed PDB: 4B3F of partner (IGHMBP2). RMSD:1.679
Å |
 |  |  |  |  |
| IGSF3_KDM2A_ENST00000369483_ENST00000529006_117208905_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4355
Å |
 |  |  |  |  |
| IGSF3_KDM2A_ENST00000369486_ENST00000398645_117208905_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4686
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000519735_ENST00000347528_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8109
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000519735_ENST00000347528_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8364
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000265709_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.107
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000265709_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6896
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000265709_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7267
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000289734_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.1247
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000289734_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6299
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000289734_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7204
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000352337_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.0927
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000352337_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7633
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000352337_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6658
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000379758_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.0927
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000379758_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7522
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000379758_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7059
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396942_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.1274
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396942_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.56
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396942_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8168
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396945_42129723_41566493 superimposed PDB: 7UZU of partner (ANK1). RMSD:2.1322
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396945_42129723_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.894
Å |
 |  |  |  |  |
| IKBKB_ANK1_ENST00000520810_ENST00000396945_42129723_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8767
Å |
 |  |  |  |  |
| IKBKB_FDFT1_ENST00000520810_ENST00000220584_42129723_11683532 superimposed PDB: 3VJ8 of partner (FDFT1). RMSD:0.3667
Å |
 |  |  |  |  |
| IKZF2_MICU2_ENST00000342002_ENST00000382374_213914436_22069457 superimposed PDB: 8DEY of partner (IKZF2). RMSD:1.4726
Å |
 |  |  |  |  |
| IKZF2_MICU2_ENST00000374319_ENST00000382374_213914436_22069457 superimposed PDB: 8DEY of partner (IKZF2). RMSD:1.4755
Å |
 |  |  |  |  |
| IKZF2_MICU2_ENST00000374319_ENST00000382374_213914436_22069457 superimposed PDB: 6XJV of partner (MICU2). RMSD:2.8943
Å |
| | | |  |
| IKZF2_MICU2_ENST00000413091_ENST00000382374_213914436_22069457 superimposed PDB: 8DEY of partner (IKZF2). RMSD:1.298
Å |
 |  |  |  |  |
| IKZF2_MICU2_ENST00000421754_ENST00000382374_213914436_22069457 superimposed PDB: 8DEY of partner (IKZF2). RMSD:1.5153
Å |
 |  |  |  |  |
| IKZF2_MICU2_ENST00000451136_ENST00000382374_213914436_22069457 superimposed PDB: 8DEY of partner (IKZF2). RMSD:1.3748
Å |
 |  |  |  |  |
| IKZF3_MED24_ENST00000346872_ENST00000394127_37985639_38176186 superimposed PDB: 7EMF of partner (MED24). RMSD:1.7034
Å |
 |  |  |  |  |
| IKZF3_MED24_ENST00000394189_ENST00000394126_37985639_38176186 superimposed PDB: 7EMF of partner (MED24). RMSD:1.2612
Å |
 |  |  |  |  |
| IKZF3_P4HB_ENST00000346872_ENST00000439918_37985639_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:0.9173
Å |
 |  |  |  |  |
| IKZF3_P4HB_ENST00000346872_ENST00000576390_37985639_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.8521
Å |
 |  |  |  |  |
| IKZF3_P4HB_ENST00000394189_ENST00000331483_37985639_79813462 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.8752
Å |
 |  |  |  |  |
| IKZF3_P4HB_ENST00000394189_ENST00000331483_37985639_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.1803
Å |
 |  |  |  |  |
| IKZF3_SMARCE1_ENST00000346872_ENST00000400122_37985639_38788619 superimposed PDB: 6LTH of partner (SMARCE1). RMSD:2.8214
Å |
 |  |  |  |  |
| IKZF3_SMARCE1_ENST00000346872_ENST00000544009_37985639_38788619 superimposed PDB: 6LTH of partner (SMARCE1). RMSD:2.7922
Å |
 |  |  |  |  |
| IKZF3_SRCIN1_ENST00000346872_ENST00000578925_37985639_36735044 superimposed PDB: 9UUM of partner (IKZF3). RMSD:2.295
Å |
 |  |  |  |  |
| IKZF3_SRCIN1_ENST00000394189_ENST00000264659_37985639_36735044 superimposed PDB: 9UUM of partner (IKZF3). RMSD:2.3786
Å |
 |  |  |  |  |
| IL12RB2_PDE4B_ENST00000262345_ENST00000423207_67796493_66837995 superimposed PDB: 8YI7 of partner (IL12RB2). RMSD:0.6641
Å |
 |  |  |  |  |
| IL12RB2_SDC3_ENST00000262345_ENST00000339394_67816772_31350012 superimposed PDB: 8YI7 of partner (IL12RB2). RMSD:0.6894
Å |
 |  |  |  |  |
| IL17RE_SLC3A2_ENST00000383814_ENST00000377890_9950967_62650379 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.803
Å |
 |  |  |  |  |
| IL17RE_SLC3A2_ENST00000421412_ENST00000377890_9950967_62650379 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.8621
Å |
 |  |  |  |  |
| IL17RE_SLC3A2_ENST00000454190_ENST00000377890_9950967_62650379 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.8387
Å |
 |  |  |  |  |
| IL1RAPL1_CXorf57_ENST00000302196_ENST00000372544_29686621_105880989 superimposed PDB: 5WY8 of partner (IL1RAPL1). RMSD:0.9481
Å |
 |  |  |  |  |
| IL1RAPL1_CXorf57_ENST00000302196_ENST00000372548_29686621_105880989 superimposed PDB: 5WY8 of partner (IL1RAPL1). RMSD:0.9708
Å |
 |  |  |  |  |
| IL1RAPL1_CXorf57_ENST00000378993_ENST00000372548_29686621_105880989 superimposed PDB: 5WY8 of partner (IL1RAPL1). RMSD:0.9741
Å |
 |  |  |  |  |
| IL20RB_NR4A1_ENST00000329582_ENST00000545748_136677043_52448110 superimposed PDB: 2QW4 of partner (NR4A1). RMSD:0.4703
Å |
 |  |  |  |  |
| IL2RA_RPL10A_ENST00000256876_ENST00000322203_6061390_35437955 superimposed PDB: 9KMC of partner (IL2RA). RMSD:3.0444
Å |
 |  |  |  |  |
| IL2RA_RPL10A_ENST00000379954_ENST00000322203_6061390_35437955 superimposed PDB: 9KMC of partner (IL2RA). RMSD:0.723
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000170630_ENST00000261588_27357939_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:0.6275
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000170630_ENST00000261588_27370315_27659924 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.002
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000170630_ENST00000261588_27370315_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.128
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000380922_ENST00000261588_27370315_27659924 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.1284
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000380922_ENST00000261588_27370315_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.113
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000449195_ENST00000261588_27357939_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:0.7804
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000543915_ENST00000261588_27357939_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:0.9867
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000543915_ENST00000261588_27370315_27659924 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.1554
Å |
 |  |  |  |  |
| IL4R_KIAA0556_ENST00000543915_ENST00000261588_27370315_27689049 superimposed PDB: 1IAR of partner (IL4R). RMSD:1.262
Å |
 |  |  |  |  |
| IL6ST_ANKRD55_ENST00000336909_ENST00000504958_55248077_55398413 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.7352
Å |
 |  |  |  |  |
| IL6ST_ANKRD55_ENST00000381294_ENST00000504958_55248077_55398413 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.6766
Å |
 |  |  |  |  |
| IL6ST_ANKRD55_ENST00000381298_ENST00000341048_55248077_55398413 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.0474
Å |
 |  |  |  |  |
| IL6ST_ANKRD55_ENST00000381298_ENST00000504958_55248077_55398413 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.6651
Å |
 |  |  |  |  |
| IL6ST_ANKRD55_ENST00000502326_ENST00000341048_55259179_55455720 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.7571
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000339582_55250637_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.2806
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000339582_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.0149
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000405249_55250637_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.1934
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000405249_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.0214
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000444921_55250637_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.8888
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000336909_ENST00000444921_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.7862
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381294_ENST00000444921_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.851
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381298_ENST00000339582_55250637_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.4975
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381298_ENST00000339582_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.8728
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381298_ENST00000405249_55250637_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.5605
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381298_ENST00000405249_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.7992
Å |
 |  |  |  |  |
| IL6ST_GRM8_ENST00000381298_ENST00000444921_55251852_126410119 superimposed PDB: 8D82 of partner (IL6ST). RMSD:1.893
Å |
 |  |  |  |  |
| IL6ST_LAMC2_ENST00000336909_ENST00000264144_55247291_183177015 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.3425
Å |
 |  |  |  |  |
| IL6ST_LAMC2_ENST00000336909_ENST00000493293_55247291_183177015 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.8805
Å |
 |  |  |  |  |
| IL6ST_LAMC2_ENST00000381294_ENST00000264144_55247291_183177015 superimposed PDB: 8D82 of partner (IL6ST). RMSD:2.9479
Å |
 |  |  |  |  |
| IL6ST_LAMC2_ENST00000381294_ENST00000493293_55247291_183177015 superimposed PDB: 8D82 of partner (IL6ST). RMSD:3.1272
Å |
 |  |  |  |  |
| IL6ST_LAMC2_ENST00000381298_ENST00000264144_55247291_183177015 superimposed PDB: 8D82 of partner (IL6ST). RMSD:3.038
Å |
 |  |  |  |  |
| IL6ST_YTHDC2_ENST00000381287_ENST00000161863_55272042_112926737 superimposed PDB: 6K6U of partner (YTHDC2). RMSD:0.358
Å |
 |  |  |  |  |
| ILF3_POC5_ENST00000318511_ENST00000446329_10794646_74970403 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8677
Å |
 |  |  |  |  |
| ILF3_POC5_ENST00000449870_ENST00000446329_10794646_74970403 superimposed PDB: 2L33 of partner (ILF3). RMSD:0.8601
Å |
 |  |  |  |  |
| IMMP2L_GTF2I_ENST00000452895_ENST00000353920_111127293_74143123 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.8602
Å |
 |  |  |  |  |
| IMPDH1_IMPDH2_ENST00000348127_ENST00000326739_128045820_49066239 superimposed PDB: 1JCN of partner (IMPDH1). RMSD:0.5308
Å |
 |  |  |  |  |
| IMPDH1_IMPDH2_ENST00000354269_ENST00000326739_128045820_49066239 superimposed PDB: 1JCN of partner (IMPDH1). RMSD:0.5331
Å |
 |  |  |  |  |
| INADL_APITD1_ENST00000316485_ENST00000309048_62293255_10493898 superimposed PDB: 6IRD of partner (INADL). RMSD:3.0802
Å |
 |  |  |  |  |
| INADL_APITD1_ENST00000316485_ENST00000309048_62293255_10493898 superimposed PDB: 28OP of partner (APITD1). RMSD:0.8763
Å |
| | | |  |
| INADL_APITD1_ENST00000316485_ENST00000602787_62293255_10493898 superimposed PDB: 6IRD of partner (INADL). RMSD:3.1507
Å |
 |  |  |  |  |
| INADL_APITD1_ENST00000316485_ENST00000602787_62293255_10493898 superimposed PDB: 28OP of partner (APITD1). RMSD:0.7862
Å |
| | | |  |
| INADL_APITD1_ENST00000371158_ENST00000602296_62293255_10493898 superimposed PDB: 6IRD of partner (INADL). RMSD:3.001
Å |
 |  |  |  |  |
| INADL_APITD1_ENST00000371158_ENST00000602296_62293255_10493898 superimposed PDB: 28OP of partner (APITD1). RMSD:0.8208
Å |
| | | |  |
| INADL_EIF3E_ENST00000316485_ENST00000220849_62456036_109241424 superimposed PDB: 6IRD of partner (INADL). RMSD:3.3042
Å |
 |  |  |  |  |
| INADL_EIF3E_ENST00000543708_ENST00000519030_62456036_109241424 superimposed PDB: 6IRD of partner (INADL). RMSD:1.8132
Å |
 |  |  |  |  |
| ING3_CHMP1A_ENST00000315870_ENST00000535997_120595678_89713739 superimposed PDB: 8COK of partner (ING3). RMSD:0.78
Å |
 |  |  |  |  |
| ING3_CHMP1A_ENST00000315870_ENST00000535997_120595678_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.8723
Å |
| | | |  |
| ING3_CHMP1A_ENST00000431467_ENST00000535997_120595678_89713739 superimposed PDB: 8COK of partner (ING3). RMSD:0.7445
Å |
 |  |  |  |  |
| ING3_CHMP1A_ENST00000431467_ENST00000535997_120595678_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.8798
Å |
| | | |  |
| ING4_A2ML1_ENST00000396807_ENST00000299698_6772230_9027020 superimposed PDB: 4AFL of partner (ING4). RMSD:1.2849
Å |
 |  |  |  |  |
| ING4_A2ML1_ENST00000423703_ENST00000299698_6772230_9027020 superimposed PDB: 4AFL of partner (ING4). RMSD:1.2322
Å |
 |  |  |  |  |
| INPP5A_ACTN1_ENST00000368593_ENST00000193403_134464009_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4048
Å |
 |  |  |  |  |
| INPP5A_ACTN1_ENST00000368594_ENST00000394419_134464009_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4121
Å |
 |  |  |  |  |
| INPP5A_ACTN1_ENST00000368594_ENST00000438964_134464009_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4129
Å |
 |  |  |  |  |
| INPP5A_ADK_ENST00000368594_ENST00000286621_134464009_76153898 superimposed PDB: 4O1L of partner (ADK). RMSD:0.8421
Å |
 |  |  |  |  |
| INPP5A_ADK_ENST00000368594_ENST00000372734_134464009_76153898 superimposed PDB: 4O1L of partner (ADK). RMSD:0.4827
Å |
 |  |  |  |  |
| INPP5A_DLG2_ENST00000368594_ENST00000376104_134464009_84245774 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4162
Å |
 |  |  |  |  |
| INPP5B_TRIT1_ENST00000373026_ENST00000316891_38351309_40313332 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.9603
Å |
 |  |  |  |  |
| INPP5B_TRIT1_ENST00000373027_ENST00000316891_38351309_40313332 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.9833
Å |
 |  |  |  |  |
| INPP5B_TRIT1_ENST00000373027_ENST00000441669_38351309_40313332 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.463
Å |
 |  |  |  |  |
| INSR_EIF6_ENST00000302850_ENST00000374436_7267355_33868632 superimposed PDB: 8U4C of partner (INSR). RMSD:0.6304
Å |
 |  |  |  |  |
| INTS10_MSR1_ENST00000397977_ENST00000262101_19684070_16021760 superimposed PDB: 8RC4 of partner (INTS10). RMSD:2.5806
Å |
 |  |  |  |  |
| INTS10_MSR1_ENST00000397977_ENST00000262101_19684070_16021760 superimposed PDB: 7DPX of partner (MSR1). RMSD:1.8604
Å |
| | | |  |
| INTS10_MSR1_ENST00000397977_ENST00000445506_19684070_16021760 superimposed PDB: 8RC4 of partner (INTS10). RMSD:2.5587
Å |
 |  |  |  |  |
| INTS10_MSR1_ENST00000397977_ENST00000445506_19684070_16021760 superimposed PDB: 7DPX of partner (MSR1). RMSD:0.4591
Å |
| | | |  |
| INTS2_RPS6KB1_ENST00000444766_ENST00000225577_59996760_58011530 superimposed PDB: 8RC4 of partner (INTS2). RMSD:2.7865
Å |
 |  |  |  |  |
| INTS2_RPS6KB1_ENST00000444766_ENST00000225577_59996760_58011530 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:3.6195
Å |
| | | |  |
| INTS2_RPS6KB1_ENST00000444766_ENST00000406116_59996760_58011530 superimposed PDB: 8RC4 of partner (INTS2). RMSD:2.6472
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000529807_ENST00000299626_77649696_77820627 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.8899
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000534064_ENST00000299626_77602364_77817992 superimposed PDB: 8RC4 of partner (INTS4). RMSD:1.0629
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000534064_ENST00000376156_77602364_77817992 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.5762
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000534064_ENST00000376156_77649696_77820627 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.6279
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000535943_ENST00000299626_77602364_77817992 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.4093
Å |
 |  |  |  |  |
| INTS4_ALG8_ENST00000535943_ENST00000376156_77602364_77817992 superimposed PDB: 8RC4 of partner (INTS4). RMSD:0.7725
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000534064_ENST00000275603_77602726_56123316 superimposed PDB: 8RC4 of partner (INTS4). RMSD:1.4408
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000534064_ENST00000275603_77602726_56123316 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.635
Å |
| | | |  |
| INTS4_CCT6A_ENST00000534064_ENST00000335503_77602726_56123316 superimposed PDB: 8RC4 of partner (INTS4). RMSD:1.6616
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000534064_ENST00000335503_77602726_56123316 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.837
Å |
| | | |  |
| INTS4_CCT6A_ENST00000534064_ENST00000335503_77614585_56123316 superimposed PDB: 8RC4 of partner (INTS4). RMSD:1.4429
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000534064_ENST00000335503_77614585_56123316 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.9885
Å |
| | | |  |
| INTS4_CCT6A_ENST00000535943_ENST00000275603_77602726_56122061 superimposed PDB: 8RC4 of partner (INTS4). RMSD:2.8074
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000535943_ENST00000275603_77602726_56122061 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.7502
Å |
| | | |  |
| INTS4_CCT6A_ENST00000535943_ENST00000335503_77602726_56123316 superimposed PDB: 8RC4 of partner (INTS4). RMSD:1.7518
Å |
 |  |  |  |  |
| INTS4_CCT6A_ENST00000535943_ENST00000335503_77602726_56123316 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.9508
Å |
| | | |  |
| INTS4_CCT6A_ENST00000535943_ENST00000335503_77614585_56123316 superimposed PDB: 7NVL of partner (CCT6A). RMSD:0.8599
Å |
 |  |  |  |  |
| IP6K2_CNDP2_ENST00000328631_ENST00000579847_48732522_72186183 superimposed PDB: 4RUH of partner (CNDP2). RMSD:1.0338
Å |
 |  |  |  |  |
| IP6K2_CNDP2_ENST00000450045_ENST00000579847_48732522_72186183 superimposed PDB: 4RUH of partner (CNDP2). RMSD:1.1782
Å |
 |  |  |  |  |
| IPMK_PRKG1_ENST00000373935_ENST00000373985_60027181_53814243 superimposed PDB: 7LV3 of partner (PRKG1). RMSD:2.7073
Å |
 |  |  |  |  |
| IPO8_ASPSCR1_ENST00000256079_ENST00000306739_30848497_79966912 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:2.193
Å |
 |  |  |  |  |
| IPO8_ASPSCR1_ENST00000256079_ENST00000580534_30848497_79966912 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:0.7521
Å |
 |  |  |  |  |
| IPPK_ZNF484_ENST00000287996_ENST00000395506_95432189_95618600 superimposed PDB: 2EMF of partner (ZNF484). RMSD:0.4077
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000320394_ENST00000345148_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.368
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000320394_ENST00000346370_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3339
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000320394_ENST00000349029_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3717
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000320394_ENST00000351154_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9965
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000320394_ENST00000399408_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3115
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000433597_ENST00000345148_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3444
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000433597_ENST00000346370_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3243
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000433597_ENST00000349029_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3679
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000433597_ENST00000351154_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9671
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000433597_ENST00000399408_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3086
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000541926_ENST00000399410_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0782
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000345148_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3366
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000346370_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3366
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000349029_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.357
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000351154_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9609
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000399408_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2858
Å |
 |  |  |  |  |
| IQCK_ABCC1_ENST00000564186_ENST00000399410_19746772_16126965 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0618
Å |
 |  |  |  |  |
| IQCK_PRKCB_ENST00000541926_ENST00000303531_19838459_24043456 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.2432
Å |
 |  |  |  |  |
| IRAK2_SRGAP3_ENST00000256458_ENST00000360413_10206732_9166601 superimposed PDB: 3MOP of partner (IRAK2). RMSD:2.7272
Å |
 |  |  |  |  |
| IREB2_CTSH_ENST00000560440_ENST00000220166_78732223_79231513 superimposed PDB: 6CZS of partner (CTSH). RMSD:0.3458
Å |
 |  |  |  |  |
| IST1_RBL2_ENST00000329908_ENST00000262133_71956583_53493362 superimposed PDB: 8V2S of partner (IST1). RMSD:0.384
Å |
 |  |  |  |  |
| IST1_RBL2_ENST00000541571_ENST00000262133_71956583_53493362 superimposed PDB: 8V2S of partner (IST1). RMSD:0.5945
Å |
 |  |  |  |  |
| IST1_RBL2_ENST00000606369_ENST00000262133_71956583_53493362 superimposed PDB: 8V2S of partner (IST1). RMSD:0.6058
Å |
 |  |  |  |  |
| ITCH_ASIP_ENST00000262650_ENST00000374954_33057925_32856796 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.0686
Å |
 |  |  |  |  |
| ITCH_ASIP_ENST00000262650_ENST00000374954_33057925_32856796 superimposed PDB: 1Y7J of partner (ASIP). RMSD:2.5373
Å |
| | | |  |
| ITCH_ASIP_ENST00000374864_ENST00000374954_33057925_32856796 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.0512
Å |
 |  |  |  |  |
| ITCH_ASIP_ENST00000374864_ENST00000374954_33057925_32856796 superimposed PDB: 1Y7J of partner (ASIP). RMSD:2.2976
Å |
| | | |  |
| ITCH_ASIP_ENST00000535650_ENST00000374954_33057925_32856796 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.0301
Å |
 |  |  |  |  |
| ITCH_ASIP_ENST00000535650_ENST00000374954_33057925_32856796 superimposed PDB: 1Y7J of partner (ASIP). RMSD:3.0715
Å |
| | | |  |
| ITCH_DEFB118_ENST00000262650_ENST00000253381_33059320_29960659 superimposed PDB: 3TUG of partner (ITCH). RMSD:2.8028
Å |
 |  |  |  |  |
| ITCH_DEFB118_ENST00000535650_ENST00000253381_33059320_29960659 superimposed PDB: 3TUG of partner (ITCH). RMSD:2.7328
Å |
 |  |  |  |  |
| ITCH_MAK16_ENST00000262650_ENST00000360128_33077731_33345895 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.388
Å |
 |  |  |  |  |
| ITCH_MAK16_ENST00000535650_ENST00000360128_33077731_33345895 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.3581
Å |
 |  |  |  |  |
| ITCH_MYL9_ENST00000262650_ENST00000279022_33080402_35176434 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.3011
Å |
 |  |  |  |  |
| ITCH_MYL9_ENST00000374864_ENST00000279022_33080402_35176434 superimposed PDB: 3TUG of partner (ITCH). RMSD:2.8511
Å |
 |  |  |  |  |
| ITCH_MYL9_ENST00000535650_ENST00000279022_33080402_35176434 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.2678
Å |
 |  |  |  |  |
| ITCH_THAP4_ENST00000262650_ENST00000402136_32981687_242545888 superimposed PDB: 3TUG of partner (ITCH). RMSD:2.2075
Å |
 |  |  |  |  |
| ITCH_THAP4_ENST00000262650_ENST00000402136_32981687_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3556
Å |
| | | |  |
| ITCH_THAP4_ENST00000374864_ENST00000407315_32981687_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3329
Å |
 |  |  |  |  |
| ITFG1_PHKB_ENST00000320640_ENST00000299167_47409786_47674945 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.1468
Å |
 |  |  |  |  |
| ITFG1_PHKB_ENST00000320640_ENST00000455779_47409786_47674945 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.0893
Å |
 |  |  |  |  |
| ITGA2_MYO18B_ENST00000296585_ENST00000335473_52353931_26388328 superimposed PDB: 1V7P of partner (ITGA2). RMSD:0.3848
Å |
 |  |  |  |  |
| ITGA3_PPP5C_ENST00000007722_ENST00000012443_48141971_46886667 superimposed PDB: 8GAE of partner (PPP5C). RMSD:1.5265
Å |
 |  |  |  |  |
| ITGA9_SEC13_ENST00000264741_ENST00000337354_37792060_10347376 superimposed PDB: 9LWF of partner (SEC13). RMSD:0.7827
Å |
 |  |  |  |  |
| ITGA9_SEC13_ENST00000264741_ENST00000383801_37792060_10347376 superimposed PDB: 9LWF of partner (SEC13). RMSD:0.8388
Å |
 |  |  |  |  |
| ITGAV_ANXA2_ENST00000261023_ENST00000451270_187501836_60639888 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.4996
Å |
 |  |  |  |  |
| ITGAV_ANXA2_ENST00000374907_ENST00000451270_187501836_60639888 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.6432
Å |
 |  |  |  |  |
| ITGAV_ANXA2_ENST00000433736_ENST00000451270_187501836_60639888 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.4584
Å |
 |  |  |  |  |
| ITGAV_C19orf43_ENST00000261023_ENST00000242784_187519435_12841882 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.547
Å |
 |  |  |  |  |
| ITGAV_C19orf43_ENST00000374907_ENST00000242784_187519435_12841882 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.4448
Å |
 |  |  |  |  |
| ITGAV_C19orf43_ENST00000433736_ENST00000242784_187519435_12841882 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.7182
Å |
 |  |  |  |  |
| ITGAV_CNTN5_ENST00000261023_ENST00000524871_187466878_99690274 superimposed PDB: 5E52 of partner (CNTN5). RMSD:0.8558
Å |
 |  |  |  |  |
| ITGAV_CNTN5_ENST00000261023_ENST00000528682_187466878_99690274 superimposed PDB: 5E52 of partner (CNTN5). RMSD:0.5174
Å |
 |  |  |  |  |
| ITGAV_CNTN5_ENST00000433736_ENST00000524871_187466878_99690274 superimposed PDB: 5E52 of partner (CNTN5). RMSD:1.073
Å |
 |  |  |  |  |
| ITGAV_CNTN5_ENST00000433736_ENST00000528682_187466878_99690274 superimposed PDB: 5E52 of partner (CNTN5). RMSD:0.6433
Å |
 |  |  |  |  |
| ITGAV_SMAD2_ENST00000261023_ENST00000402690_187490314_45377698 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.5975
Å |
 |  |  |  |  |
| ITGAV_SMAD2_ENST00000261023_ENST00000402690_187490314_45377698 superimposed PDB: 1KHX of partner (SMAD2). RMSD:0.508
Å |
| | | |  |
| ITGAV_SMAD2_ENST00000374907_ENST00000262160_187490314_45377698 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.6177
Å |
 |  |  |  |  |
| ITGAV_SMAD2_ENST00000374907_ENST00000262160_187490314_45377698 superimposed PDB: 1KHX of partner (SMAD2). RMSD:0.4579
Å |
| | | |  |
| ITGAV_SMAD2_ENST00000433736_ENST00000402690_187490314_45377698 superimposed PDB: 8XEL of partner (ITGAV). RMSD:0.5258
Å |
 |  |  |  |  |
| ITGAV_SMAD2_ENST00000433736_ENST00000402690_187490314_45377698 superimposed PDB: 1KHX of partner (SMAD2). RMSD:0.391
Å |
| | | |  |
| ITGAX_PHKG2_ENST00000268296_ENST00000328273_31388586_30764714 superimposed PDB: 5ES4 of partner (ITGAX). RMSD:2.4234
Å |
 |  |  |  |  |
| ITGAX_PHKG2_ENST00000268296_ENST00000328273_31388586_30764714 superimposed PDB: 2Y7J of partner (PHKG2). RMSD:0.421
Å |
| | | |  |
| ITGAX_PHKG2_ENST00000268296_ENST00000424889_31388586_30764714 superimposed PDB: 5ES4 of partner (ITGAX). RMSD:2.7181
Å |
 |  |  |  |  |
| ITGAX_PHKG2_ENST00000268296_ENST00000424889_31388586_30764714 superimposed PDB: 2Y7J of partner (PHKG2). RMSD:0.411
Å |
| | | |  |
| ITGAX_PHKG2_ENST00000562522_ENST00000563588_31388586_30764714 superimposed PDB: 5ES4 of partner (ITGAX). RMSD:2.4253
Å |
 |  |  |  |  |
| ITGAX_PHKG2_ENST00000562522_ENST00000563588_31388586_30764714 superimposed PDB: 2Y7J of partner (PHKG2). RMSD:0.4399
Å |
| | | |  |
| ITGB1_VIM_ENST00000302278_ENST00000544301_33212512_17279228 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.895
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000200181_ENST00000167462_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.7355
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000339591_ENST00000167462_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.7435
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000339591_ENST00000375227_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.747
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000339591_ENST00000392550_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.6453
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000339591_ENST00000578363_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.7335
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000579662_ENST00000375227_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.7317
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000579662_ENST00000392550_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.594
Å |
 |  |  |  |  |
| ITGB4_LLGL2_ENST00000579662_ENST00000578363_73723586_73552126 superimposed PDB: 6N8R of partner (LLGL2). RMSD:0.7569
Å |
 |  |  |  |  |
| ITGB4_PTN_ENST00000339591_ENST00000393083_73753899_136938384 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.7948
Å |
 |  |  |  |  |
| ITGB4_RBM39_ENST00000339591_ENST00000361162_73720862_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.668
Å |
 |  |  |  |  |
| ITGB4_RBM39_ENST00000339591_ENST00000528062_73720862_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6458
Å |
 |  |  |  |  |
| ITGB4_RBM39_ENST00000579662_ENST00000361162_73720862_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.671
Å |
 |  |  |  |  |
| ITGB4_RBM39_ENST00000579662_ENST00000528062_73720862_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6651
Å |
 |  |  |  |  |
| ITGB4_SLC16A5_ENST00000200181_ENST00000580123_73747192_73094132 superimposed PDB: 3F7R of partner (ITGB4). RMSD:0.6749
Å |
 |  |  |  |  |
| ITGB4_SLC16A5_ENST00000339591_ENST00000580123_73747192_73094132 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.8227
Å |
 |  |  |  |  |
| ITGB8_ABCB5_ENST00000222573_ENST00000258738_20421508_20792982 superimposed PDB: 6UJA of partner (ITGB8). RMSD:0.8108
Å |
 |  |  |  |  |
| ITGB8_ABCB5_ENST00000537992_ENST00000258738_20421508_20792982 superimposed PDB: 6UJA of partner (ITGB8). RMSD:0.7577
Å |
 |  |  |  |  |
| ITGB8_ATM_ENST00000222573_ENST00000278616_20403345_108137897 superimposed PDB: 6UJA of partner (ITGB8). RMSD:1.6137
Å |
 |  |  |  |  |
| ITGB8_ATM_ENST00000222573_ENST00000452508_20403345_108137897 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.1694
Å |
 |  |  |  |  |
| ITIH4_FGA_ENST00000266041_ENST00000403106_52864568_155510714 superimposed PDB: 3GHG of partner (FGA). RMSD:3.3335
Å |
 |  |  |  |  |
| ITIH4_FGA_ENST00000346281_ENST00000302053_52864568_155510714 superimposed PDB: 3GHG of partner (FGA). RMSD:2.8492
Å |
 |  |  |  |  |
| ITK_SYK_ENST00000422843_ENST00000375754_156644917_93636485 superimposed PDB: 4FL3 of partner (SYK). RMSD:0.7167
Å |
 |  |  |  |  |
| ITM2B_HSP90AB1_ENST00000378565_ENST00000371646_48830519_44217411 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.5668
Å |
 |  |  |  |  |
| ITM2B_RB1_ENST00000378549_ENST00000267163_48828072_49027128 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.4126
Å |
 |  |  |  |  |
| ITM2B_RB1_ENST00000378565_ENST00000267163_48828072_49027128 superimposed PDB: 4ELJ of partner (RB1). RMSD:2.8526
Å |
 |  |  |  |  |
| ITPA_SLC22A24_ENST00000399838_ENST00000417740_3194704_62847469 superimposed PDB: 2CAR of partner (ITPA). RMSD:1.1386
Å |
 |  |  |  |  |
| ITPA_SLC22A24_ENST00000455664_ENST00000417740_3194704_62847469 superimposed PDB: 2CAR of partner (ITPA). RMSD:0.8798
Å |
 |  |  |  |  |
| ITPK1_BTBD7_ENST00000555495_ENST00000554565_93418290_93717998 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.8933
Å |
 |  |  |  |  |
| ITPK1_BTBD7_ENST00000556603_ENST00000334746_93542939_93730339 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.9321
Å |
 |  |  |  |  |
| ITPK1_MIPOL1_ENST00000556603_ENST00000327441_93460224_37969112 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.8226
Å |
 |  |  |  |  |
| ITPR1_SETMAR_ENST00000354582_ENST00000425863_4695570_4354581 superimposed PDB: 3BO5 of partner (SETMAR). RMSD:0.5917
Å |
 |  |  |  |  |
| ITPR1_SETMAR_ENST00000423119_ENST00000358065_4695570_4354581 superimposed PDB: 3BO5 of partner (SETMAR). RMSD:0.9351
Å |
 |  |  |  |  |
| ITPR3_SNX14_ENST00000374316_ENST00000314673_33623664_86235955 superimposed PDB: 4BGJ of partner (SNX14). RMSD:2.6214
Å |
 |  |  |  |  |
| ITSN2_OTOF_ENST00000355123_ENST00000272371_24550920_26739467 superimposed PDB: 3JZY of partner (ITSN2). RMSD:1.3394
Å |
 |  |  |  |  |
| ITSN2_OTOF_ENST00000361999_ENST00000403946_24550920_26739467 superimposed PDB: 3JZY of partner (ITSN2). RMSD:1.2752
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000249760_ENST00000264205_40705286_21586885 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.6164
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000249760_ENST00000264205_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.0055
Å |
| | | |  |
| IVD_ECE1_ENST00000249760_ENST00000357071_40705286_21586885 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.6597
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000249760_ENST00000357071_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:0.9947
Å |
| | | |  |
| IVD_ECE1_ENST00000479013_ENST00000264205_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.005
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000479013_ENST00000357071_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:0.9794
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000487418_ENST00000264205_40705286_21586885 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.6472
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000487418_ENST00000264205_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:0.9515
Å |
| | | |  |
| IVD_ECE1_ENST00000487418_ENST00000357071_40705286_21586885 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.8114
Å |
 |  |  |  |  |
| IVD_ECE1_ENST00000487418_ENST00000357071_40705286_21586885 superimposed PDB: 3DWB of partner (ECE1). RMSD:0.9842
Å |
| | | |  |
| IVD_IGHG3_ENST00000249760_ENST00000390551_40705286_106236674 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4846
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000249760_ENST00000390551_40705286_106236674 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.0305
Å |
| | | |  |
| IVD_IGHG3_ENST00000249760_ENST00000390551_40705286_106236862 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4742
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000249760_ENST00000390551_40705286_106236862 superimposed PDB: 6G1E of partner (IGHG3). RMSD:1.9986
Å |
| | | |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236486 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4914
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236486 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.0929
Å |
| | | |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236674 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4675
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236674 superimposed PDB: 6G1E of partner (IGHG3). RMSD:1.9123
Å |
| | | |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236862 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.5136
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000479013_ENST00000390551_40705286_106236862 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.0855
Å |
| | | |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236486 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4689
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236486 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.0898
Å |
| | | |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236674 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4407
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236674 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.1265
Å |
| | | |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236862 superimposed PDB: 9JQ3 of partner (IVD). RMSD:0.4877
Å |
 |  |  |  |  |
| IVD_IGHG3_ENST00000487418_ENST00000390551_40705286_106236862 superimposed PDB: 6G1E of partner (IGHG3). RMSD:2.0793
Å |
| | | |  |
| IWS1_OPTN_ENST00000295321_ENST00000378764_128283750_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.4749
Å |
 |  |  |  |  |
| JAG1_INPP5A_ENST00000254958_ENST00000368593_10653348_134421418 superimposed PDB: 4CC0 of partner (JAG1). RMSD:0.8359
Å |
 |  |  |  |  |
| JAG1_INPP5A_ENST00000254958_ENST00000368594_10653348_134421418 superimposed PDB: 4CC0 of partner (JAG1). RMSD:2.5995
Å |
 |  |  |  |  |
| JAK2_DOCK8_ENST00000381652_ENST00000453981_5055788_286460 superimposed PDB: 4Z32 of partner (JAK2). RMSD:1.4161
Å |
 |  |  |  |  |
| JAK2_ETV6_ENST00000381652_ENST00000396373_5080683_12037378 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6647
Å |
 |  |  |  |  |
| JAK2_ETV6_ENST00000539801_ENST00000396373_5080683_12037378 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.9154
Å |
 |  |  |  |  |
| JAK2_GLDC_ENST00000381652_ENST00000321612_5029906_6565429 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.4783
Å |
 |  |  |  |  |
| JAK2_GLDC_ENST00000381652_ENST00000321612_5029906_6565429 superimposed PDB: 6I35 of partner (GLDC). RMSD:0.6701
Å |
| | | |  |
| JAK2_PCM1_ENST00000381652_ENST00000325083_5069208_17842955 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6907
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000539801_ENST00000519253_5066789_17882869 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.656
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000539801_ENST00000519253_5069208_17842955 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6984
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000539801_ENST00000519253_5077580_17882869 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6003
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000539801_ENST00000524226_5069208_17842955 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6802
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000544510_ENST00000519253_5066789_17882869 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.8951
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000544510_ENST00000519253_5069208_17842955 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.8779
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000544510_ENST00000519253_5077580_17882869 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.8185
Å |
 |  |  |  |  |
| JAK2_PCM1_ENST00000544510_ENST00000524226_5069208_17842955 superimposed PDB: 4Z32 of partner (JAK2). RMSD:1.8174
Å |
 |  |  |  |  |
| JAK2_UHRF2_ENST00000381652_ENST00000276893_5090911_6475390 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6236
Å |
 |  |  |  |  |
| JARID2_ATM_ENST00000341776_ENST00000452508_15246815_108213948 superimposed PDB: 8VMI of partner (JARID2). RMSD:3.0569
Å |
 |  |  |  |  |
| JARID2_ATM_ENST00000341776_ENST00000452508_15246815_108213948 superimposed PDB: 8OXQ of partner (ATM). RMSD:0.6324
Å |
| | | |  |
| JAZF1_SNX13_ENST00000283928_ENST00000409389_28220081_17931258 superimposed PDB: 7WF6 of partner (SNX13). RMSD:0.8461
Å |
 |  |  |  |  |
| JAZF1_SNX13_ENST00000283928_ENST00000409604_28220081_17931258 superimposed PDB: 7WF6 of partner (SNX13). RMSD:0.7921
Å |
 |  |  |  |  |
| JMJD1C_NEMF_ENST00000399262_ENST00000382135_64936056_50256061 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.7606
Å |
 |  |  |  |  |
| JMJD1C_TSN_ENST00000399262_ENST00000389682_65140077_122514815 superimposed PDB: 1J1J of partner (TSN). RMSD:0.4355
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000397625_ENST00000326165_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.5849
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000397625_ENST00000326165_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.339
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000464910_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.5887
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000464910_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3455
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000469092_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.6347
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000469092_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3491
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000583937_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.6237
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000445478_ENST00000583937_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3066
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000326165_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.6038
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000326165_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3226
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000464910_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.6748
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000464910_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3341
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000469092_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.6342
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000469092_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.349
Å |
| | | |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000583937_74719853_72700955 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.5942
Å |
 |  |  |  |  |
| JMJD6_CD300LF_ENST00000585429_ENST00000583937_74719853_72700955 superimposed PDB: 2NMS of partner (CD300LF). RMSD:0.3344
Å |
| | | |  |
| JUP_DPP9_ENST00000393930_ENST00000598800_39923630_4690969 superimposed PDB: 7SVL of partner (DPP9). RMSD:0.6377
Å |
 |  |  |  |  |
| JUP_PTN_ENST00000393930_ENST00000393083_39910855_136938384 superimposed PDB: 3IFQ of partner (JUP). RMSD:0.6484
Å |
 |  |  |  |  |
| KANSL1_AARS_ENST00000575318_ENST00000261772_44143902_70295060 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:2.5834
Å |
 |  |  |  |  |
| KANSL1_GLRA3_ENST00000262419_ENST00000340217_44109412_175688181 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.76
Å |
 |  |  |  |  |
| KANSL1_LAYN_ENST00000574590_ENST00000375615_44127898_111414647 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:2.481
Å |
 |  |  |  |  |
| KANSL1_LAYN_ENST00000575318_ENST00000375614_44127898_111414647 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:2.6666
Å |
 |  |  |  |  |
| KARS_PLGRKT_ENST00000319410_ENST00000223864_75674081_5361888 superimposed PDB: 6CHD of partner (KARS). RMSD:0.8525
Å |
 |  |  |  |  |
| KARS_WDR59_ENST00000302445_ENST00000262144_75681475_74999720 superimposed PDB: 6CHD of partner (KARS). RMSD:2.6635
Å |
 |  |  |  |  |
| KAT2B_KANSL1_ENST00000263754_ENST00000572904_20136900_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.6049
Å |
 |  |  |  |  |
| KAT2B_KANSL1_ENST00000263754_ENST00000575318_20136900_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.3663
Å |
 |  |  |  |  |
| KAT5_RASIP1_ENST00000341318_ENST00000222145_65484278_49225258 superimposed PDB: 2OU2 of partner (KAT5). RMSD:0.3927
Å |
 |  |  |  |  |
| KAT5_RASIP1_ENST00000352980_ENST00000222145_65484278_49225258 superimposed PDB: 2OU2 of partner (KAT5). RMSD:0.3958
Å |
 |  |  |  |  |
| KAT5_RASIP1_ENST00000530446_ENST00000222145_65484278_49225258 superimposed PDB: 2OU2 of partner (KAT5). RMSD:0.4061
Å |
 |  |  |  |  |
| KAT5_RASIP1_ENST00000530446_ENST00000222145_65484278_49225258 superimposed PDB: 5KHO of partner (RASIP1). RMSD:3.0172
Å |
| | | |  |
| KAT5_RASIP1_ENST00000534650_ENST00000222145_65484278_49225258 superimposed PDB: 2OU2 of partner (KAT5). RMSD:0.4002
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000265709_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9971
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000289734_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8781
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000352337_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8414
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000379758_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8517
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000396942_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7899
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000265713_ENST00000396945_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.1098
Å |
 |  |  |  |  |
| KAT6A_ANK1_ENST00000396930_ENST00000347528_41905895_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8314
Å |
 |  |  |  |  |
| KAT6A_ASXL2_ENST00000396930_ENST00000435504_41800310_26068432 superimposed PDB: 9DZN of partner (KAT6A). RMSD:0.8107
Å |
 |  |  |  |  |
| KAT6A_ASXL2_ENST00000396930_ENST00000435504_41800310_26068432 superimposed PDB: 9ATN of partner (ASXL2). RMSD:0.9477
Å |
| | | |  |
| KAT6A_CREBBP_ENST00000265713_ENST00000382070_41794773_3901010 superimposed PDB: 9DZN of partner (KAT6A). RMSD:0.9893
Å |
 |  |  |  |  |
| KAT6A_CREBBP_ENST00000265713_ENST00000382070_41794773_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.9548
Å |
| | | |  |
| KAT6A_CREBBP_ENST00000396930_ENST00000262367_41794773_3901010 superimposed PDB: 9DZN of partner (KAT6A). RMSD:0.8149
Å |
 |  |  |  |  |
| KAT6A_CREBBP_ENST00000396930_ENST00000262367_41794773_3901010 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.8736
Å |
| | | |  |
| KAT6A_CREBBP_ENST00000406337_ENST00000382070_41786996_3860780 superimposed PDB: 9DZN of partner (KAT6A). RMSD:2.9602
Å |
 |  |  |  |  |
| KAT6A_CREBBP_ENST00000406337_ENST00000382070_41786996_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6469
Å |
| | | |  |
| KAT6A_CSMD1_ENST00000406337_ENST00000400186_41905895_4495080 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.337
Å |
 |  |  |  |  |
| KAT6A_CSMD1_ENST00000406337_ENST00000539096_41905895_4495080 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.344
Å |
 |  |  |  |  |
| KAT6A_CSMD1_ENST00000406337_ENST00000542608_41905895_4495080 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.5935
Å |
 |  |  |  |  |
| KAT6A_CSMD1_ENST00000406337_ENST00000602557_41905895_4495080 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.4103
Å |
 |  |  |  |  |
| KAT6A_IKBKB_ENST00000396930_ENST00000520810_41905895_42146151 superimposed PDB: 8OMV of partner (IKBKB). RMSD:1.9156
Å |
 |  |  |  |  |
| KAT6A_IKBKB_ENST00000406337_ENST00000416505_41905895_42162704 superimposed PDB: 8OMV of partner (IKBKB). RMSD:1.8224
Å |
 |  |  |  |  |
| KAT6A_PLEKHA5_ENST00000406337_ENST00000309364_41905895_19285326 superimposed PDB: 9DZN of partner (KAT6A). RMSD:0.5271
Å |
 |  |  |  |  |
| KAT6A_PLEKHA5_ENST00000406337_ENST00000317589_41905895_19285326 superimposed PDB: 2DKP of partner (PLEKHA5). RMSD:1.3856
Å |
 |  |  |  |  |
| KAT6A_PLEKHA5_ENST00000406337_ENST00000355397_41905895_19285326 superimposed PDB: 2DKP of partner (PLEKHA5). RMSD:1.3749
Å |
 |  |  |  |  |
| KAT6A_PLEKHA5_ENST00000406337_ENST00000359180_41905895_19285326 superimposed PDB: 2DKP of partner (PLEKHA5). RMSD:1.5087
Å |
 |  |  |  |  |
| KAT6A_PLEKHA5_ENST00000406337_ENST00000429027_41905895_19285326 superimposed PDB: 2DKP of partner (PLEKHA5). RMSD:1.3999
Å |
 |  |  |  |  |
| KAT6A_SPPL2A_ENST00000396930_ENST00000261854_41832221_51041943 superimposed PDB: 9K92 of partner (SPPL2A). RMSD:0.4638
Å |
 |  |  |  |  |
| KAT6B_ADK_ENST00000372725_ENST00000286621_76603236_76349039 superimposed PDB: 4O1L of partner (ADK). RMSD:0.5634
Å |
 |  |  |  |  |
| KAT6B_CCDC172_ENST00000372714_ENST00000333254_76741686_118100245 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3535
Å |
 |  |  |  |  |
| KAT6B_CCDC172_ENST00000372724_ENST00000333254_76741686_118100245 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.2951
Å |
 |  |  |  |  |
| KAT6B_DDX50_ENST00000372724_ENST00000373585_76603236_70666466 superimposed PDB: 2E29 of partner (DDX50). RMSD:0.7801
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000287239_ENST00000342558_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3093
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000287239_ENST00000394822_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3228
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000287239_ENST00000394828_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3154
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000287239_ENST00000394829_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3198
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000287239_ENST00000545874_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3413
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000342558_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3152
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000394822_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3257
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000394828_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.2892
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000394829_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.2967
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000544628_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.2995
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372711_ENST00000545874_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3067
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372724_ENST00000544628_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3202
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372725_ENST00000342558_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3458
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372725_ENST00000394822_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.32
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372725_ENST00000394828_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3101
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372725_ENST00000394829_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.3303
Å |
 |  |  |  |  |
| KAT6B_PPP3CB_ENST00000372725_ENST00000545874_76748870_75206331 superimposed PDB: 6OIE of partner (KAT6B). RMSD:0.2983
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000259021_ENST00000331134_47895373_79589304 superimposed PDB: 7D0P of partner (KAT7). RMSD:1.6645
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000259021_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6541
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000424009_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.645
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000424009_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6496
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000435742_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6742
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000435742_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6283
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000454930_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6419
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000454930_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6501
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000503935_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6938
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000503935_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6164
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000509773_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6487
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000509773_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6364
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000510819_ENST00000331134_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6376
Å |
 |  |  |  |  |
| KAT7_NPLOC4_ENST00000510819_ENST00000374747_47895373_79589304 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:0.6345
Å |
 |  |  |  |  |
| KATNA1_PPP2R1A_ENST00000335647_ENST00000444322_149922729_52719781 superimposed PDB: 2IE4 of partner (PPP2R1A). RMSD:2.8871
Å |
 |  |  |  |  |
| KATNA1_PPP2R1A_ENST00000335647_ENST00000444322_149924403_52719781 superimposed PDB: 2IE4 of partner (PPP2R1A). RMSD:3.2305
Å |
 |  |  |  |  |
| KATNAL1_CUL4A_ENST00000380617_ENST00000326335_30857752_113907395 superimposed PDB: 7OPC of partner (CUL4A). RMSD:2.6134
Å |
 |  |  |  |  |
| KATNAL1_CUL4A_ENST00000380617_ENST00000451881_30857752_113907395 superimposed PDB: 7OPC of partner (CUL4A). RMSD:2.6447
Å |
 |  |  |  |  |
| KATNBL1_TP53BP1_ENST00000256544_ENST00000382039_34437598_43714324 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5208
Å |
 |  |  |  |  |
| KATNBL1_TP53BP1_ENST00000256544_ENST00000382044_34437598_43714324 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5192
Å |
 |  |  |  |  |
| KCMF1_DNAH6_ENST00000409785_ENST00000237449_85198590_85023429 superimposed PDB: 9QWS of partner (KCMF1). RMSD:2.8777
Å |
 |  |  |  |  |
| KCMF1_PRKDC_ENST00000409785_ENST00000314191_85255179_48772320 superimposed PDB: 9QWS of partner (KCMF1). RMSD:0.3687
Å |
 |  |  |  |  |
| KCMF1_PRKDC_ENST00000409785_ENST00000314191_85255179_48772320 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:2.2491
Å |
| | | |  |
| KCMF1_RTN4_ENST00000409785_ENST00000405240_85198590_55214834 superimposed PDB: 9QWS of partner (KCMF1). RMSD:2.8235
Å |
 |  |  |  |  |
| KCNC3_PRKDC_ENST00000376959_ENST00000314191_50823849_48730122 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:1.8713
Å |
 |  |  |  |  |
| KCNC3_PRKDC_ENST00000477616_ENST00000338368_50823849_48730122 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:1.7914
Å |
 |  |  |  |  |
| KCNMA1_DLG5_ENST00000286627_ENST00000372391_79397022_79584234 superimposed PDB: 1UIT of partner (DLG5). RMSD:1.325
Å |
 |  |  |  |  |
| KCNMA1_DLG5_ENST00000286628_ENST00000372388_79397022_79584234 superimposed PDB: 1UIT of partner (DLG5). RMSD:1.3119
Å |
 |  |  |  |  |
| KCNMA1_DLG5_ENST00000372440_ENST00000372391_79397022_79584234 superimposed PDB: 1UIT of partner (DLG5). RMSD:1.2667
Å |
 |  |  |  |  |
| KCNMA1_DLG5_ENST00000404771_ENST00000372388_79397022_79584234 superimposed PDB: 1UIT of partner (DLG5). RMSD:1.3099
Å |
 |  |  |  |  |
| KCNMA1_MSMB_ENST00000286627_ENST00000358559_78869930_51555730 superimposed PDB: 2IZ3 of partner (MSMB). RMSD:2.3259
Å |
 |  |  |  |  |
| KCNMA1_MSMB_ENST00000372440_ENST00000358559_78869930_51555730 superimposed PDB: 2IZ3 of partner (MSMB). RMSD:2.4023
Å |
 |  |  |  |  |
| KCNQ1_GALNTL6_ENST00000155840_ENST00000508122_2799267_173930328 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:1.9396
Å |
 |  |  |  |  |
| KCNQ1_GALNTL6_ENST00000335475_ENST00000508122_2799267_173930328 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:1.6595
Å |
 |  |  |  |  |
| KCNQ1_LSP1_ENST00000155840_ENST00000381775_2466714_1901316 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:0.9158
Å |
 |  |  |  |  |
| KCNQ1_NCOR2_ENST00000155840_ENST00000404621_2799267_124911346 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:2.8121
Å |
 |  |  |  |  |
| KCNQ1_NCOR2_ENST00000155840_ENST00000404621_2799267_124911346 superimposed PDB: 4A69 of partner (NCOR2). RMSD:1.5225
Å |
| | | |  |
| KCNQ1_NCOR2_ENST00000155840_ENST00000405201_2799267_124911346 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:1.5714
Å |
 |  |  |  |  |
| KCNQ1_NCOR2_ENST00000335475_ENST00000404621_2799267_124911346 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:2.8009
Å |
 |  |  |  |  |
| KCNQ1_NCOR2_ENST00000335475_ENST00000404621_2799267_124911346 superimposed PDB: 4A69 of partner (NCOR2). RMSD:1.8249
Å |
| | | |  |
| KCNQ1_NCOR2_ENST00000335475_ENST00000405201_2799267_124911346 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:2.825
Å |
 |  |  |  |  |
| KCNQ1_NCOR2_ENST00000335475_ENST00000405201_2799267_124911346 superimposed PDB: 4A69 of partner (NCOR2). RMSD:2.5788
Å |
| | | |  |
| KCNQ1_TSPAN32_ENST00000335475_ENST00000182290_2549248_2324073 superimposed PDB: 7XNN of partner (KCNQ1). RMSD:2.8014
Å |
 |  |  |  |  |
| KCNQ5_ALK_ENST00000355194_ENST00000389048_73332315_29498362 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.877
Å |
 |  |  |  |  |
| KCNQ5_ALK_ENST00000355194_ENST00000389048_73332315_29498362 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4221
Å |
| | | |  |
| KCNQ5_ALK_ENST00000370398_ENST00000389048_73332315_29498362 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4213
Å |
 |  |  |  |  |
| KCNQ5_AMPH_ENST00000342056_ENST00000356264_73815090_38433814 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.838
Å |
 |  |  |  |  |
| KCNQ5_AMPH_ENST00000355194_ENST00000356264_73815090_38433814 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.8758
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000342056_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.5921
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000342056_ENST00000532507_73843364_65367239 superimposed PDB: 6AQB of partner (MAP3K11). RMSD:2.7727
Å |
| | | |  |
| KCNQ5_MAP3K11_ENST00000355194_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.6321
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000355635_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.6558
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000355635_ENST00000532507_73843364_65367239 superimposed PDB: 6AQB of partner (MAP3K11). RMSD:2.3621
Å |
| | | |  |
| KCNQ5_MAP3K11_ENST00000370398_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.5745
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000370398_ENST00000532507_73843364_65367239 superimposed PDB: 6AQB of partner (MAP3K11). RMSD:1.9778
Å |
| | | |  |
| KCNQ5_MAP3K11_ENST00000402622_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.6059
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000402622_ENST00000532507_73843364_65367239 superimposed PDB: 6AQB of partner (MAP3K11). RMSD:2.6018
Å |
| | | |  |
| KCNQ5_MAP3K11_ENST00000403813_ENST00000532507_73843364_65367239 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.6245
Å |
 |  |  |  |  |
| KCNQ5_MAP3K11_ENST00000403813_ENST00000532507_73843364_65367239 superimposed PDB: 6AQB of partner (MAP3K11). RMSD:2.7892
Å |
| | | |  |
| KCNQ5_RNF217_ENST00000342056_ENST00000560949_73713721_125397802 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.2311
Å |
 |  |  |  |  |
| KCNQ5_RNF217_ENST00000355194_ENST00000560949_73713721_125397802 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:1.5488
Å |
 |  |  |  |  |
| KCTD5_TSC2_ENST00000301738_ENST00000382538_2747998_2136193 superimposed PDB: 9CE3 of partner (TSC2). RMSD:0.767
Å |
 |  |  |  |  |
| KDELR2_B2M_ENST00000463747_ENST00000559916_6485583_45007620 superimposed PDB: 6AT5 of partner (B2M). RMSD:0.3954
Å |
 |  |  |  |  |
| KDM1B_PITPNC1_ENST00000297792_ENST00000581322_18171710_65574301 superimposed PDB: 7XE2 of partner (KDM1B). RMSD:0.8192
Å |
 |  |  |  |  |
| KDM1B_PITPNC1_ENST00000388870_ENST00000580974_18171710_65574301 superimposed PDB: 7XE2 of partner (KDM1B). RMSD:0.9068
Å |
 |  |  |  |  |
| KDM1B_PITPNC1_ENST00000397244_ENST00000581322_18171710_65574301 superimposed PDB: 7XE2 of partner (KDM1B). RMSD:0.8268
Å |
 |  |  |  |  |
| KDM2A_SYNDIG1_ENST00000529006_ENST00000376862_66999431_24565491 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.3778
Å |
 |  |  |  |  |
| KDM2A_SYT12_ENST00000398645_ENST00000525457_66999431_66812063 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.357
Å |
 |  |  |  |  |
| KDM2B_CELF2_ENST00000536437_ENST00000416382_121951078_11207448 superimposed PDB: 9URH of partner (CELF2). RMSD:3.0051
Å |
 |  |  |  |  |
| KDM2B_CELF2_ENST00000536437_ENST00000542579_121951078_11207448 superimposed PDB: 9URH of partner (CELF2). RMSD:2.4964
Å |
 |  |  |  |  |
| KDM3A_IVNS1ABP_ENST00000312912_ENST00000367498_86709225_185276794 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.4137
Å |
 |  |  |  |  |
| KDM3A_SUCLG2_ENST00000312912_ENST00000493112_86669356_67660020 superimposed PDB: 6WCV of partner (SUCLG2). RMSD:1.8291
Å |
 |  |  |  |  |
| KDM3A_SUCLG2_ENST00000409556_ENST00000307227_86669356_67660020 superimposed PDB: 6WCV of partner (SUCLG2). RMSD:1.7821
Å |
 |  |  |  |  |
| KDM3A_SUCLG2_ENST00000409556_ENST00000492795_86669356_67660020 superimposed PDB: 6WCV of partner (SUCLG2). RMSD:1.9397
Å |
 |  |  |  |  |
| KDM4A_FAF1_ENST00000372396_ENST00000371778_44163684_50957473 superimposed PDB: 6G5X of partner (KDM4A). RMSD:0.4715
Å |
 |  |  |  |  |
| KDM4A_FAF1_ENST00000372396_ENST00000371778_44163684_50957473 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.9699
Å |
| | | |  |
| KDM4A_FAF1_ENST00000372396_ENST00000396153_44163684_50957473 superimposed PDB: 6G5X of partner (KDM4A). RMSD:0.4367
Å |
 |  |  |  |  |
| KDM4A_MPL_ENST00000372396_ENST00000372470_44134970_43803769 superimposed PDB: 6G5X of partner (KDM4A). RMSD:2.773
Å |
 |  |  |  |  |
| KDM4A_MPL_ENST00000372396_ENST00000413998_44134970_43803769 superimposed PDB: 6G5X of partner (KDM4A). RMSD:0.4369
Å |
 |  |  |  |  |
| KDM4A_MPL_ENST00000372396_ENST00000413998_44134970_43803769 superimposed PDB: 8G04 of partner (MPL). RMSD:2.6951
Å |
| | | |  |
| KDM4A_MPL_ENST00000372396_ENST00000413998_44169783_43805634 superimposed PDB: 6G5X of partner (KDM4A). RMSD:0.4737
Å |
 |  |  |  |  |
| KDM4A_MPL_ENST00000372396_ENST00000413998_44169783_43805634 superimposed PDB: 8G04 of partner (MPL). RMSD:2.2521
Å |
| | | |  |
| KDM4B_AKAP8L_ENST00000159111_ENST00000595465_5144913_15491423 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4798
Å |
 |  |  |  |  |
| KDM4B_AKAP8L_ENST00000536461_ENST00000595465_5144913_15491423 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4764
Å |
 |  |  |  |  |
| KDM4B_ATCAY_ENST00000159111_ENST00000301260_5047680_3902484 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.5488
Å |
 |  |  |  |  |
| KDM4B_ATCAY_ENST00000159111_ENST00000450849_5047680_3902484 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.5161
Å |
 |  |  |  |  |
| KDM4B_ATCAY_ENST00000381759_ENST00000450849_5047680_3902484 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.5802
Å |
 |  |  |  |  |
| KDM4B_ATCAY_ENST00000536461_ENST00000450849_5047680_3902484 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.5744
Å |
 |  |  |  |  |
| KDM4B_CHAF1A_ENST00000381759_ENST00000301280_5082515_4418016 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4033
Å |
 |  |  |  |  |
| KDM4B_FST_ENST00000159111_ENST00000396947_5119863_52778709 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4854
Å |
 |  |  |  |  |
| KDM4B_FST_ENST00000159111_ENST00000396947_5119863_52778709 superimposed PDB: 2P6A of partner (FST). RMSD:2.1719
Å |
| | | |  |
| KDM4B_FST_ENST00000536461_ENST00000256759_5119863_52778709 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4881
Å |
 |  |  |  |  |
| KDM4B_FST_ENST00000536461_ENST00000256759_5119863_52778709 superimposed PDB: 2P6A of partner (FST). RMSD:1.9653
Å |
| | | |  |
| KDM4B_FST_ENST00000536461_ENST00000396947_5119863_52778709 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4835
Å |
 |  |  |  |  |
| KDM4B_FST_ENST00000536461_ENST00000396947_5119863_52778709 superimposed PDB: 2P6A of partner (FST). RMSD:2.1721
Å |
| | | |  |
| KDM4B_KLF11_ENST00000381759_ENST00000305883_5041262_10186276 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:2.279
Å |
 |  |  |  |  |
| KDM4B_MPND_ENST00000159111_ENST00000359935_5082515_4345741 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4305
Å |
 |  |  |  |  |
| KDM4B_MPND_ENST00000159111_ENST00000599840_5082515_4345741 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4393
Å |
 |  |  |  |  |
| KDM4B_MPND_ENST00000381759_ENST00000262966_5082515_4345741 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4188
Å |
 |  |  |  |  |
| KDM4B_OAZ1_ENST00000159111_ENST00000588673_5144913_2271780 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4866
Å |
 |  |  |  |  |
| KDM4B_OAZ1_ENST00000159111_ENST00000588673_5144913_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.5983
Å |
| | | |  |
| KDM4B_OAZ1_ENST00000159111_ENST00000602676_5144913_2271780 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4772
Å |
 |  |  |  |  |
| KDM4B_OAZ1_ENST00000159111_ENST00000602676_5144913_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.5246
Å |
| | | |  |
| KDM4B_OAZ1_ENST00000536461_ENST00000588673_5144913_2271780 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4686
Å |
 |  |  |  |  |
| KDM4B_OAZ1_ENST00000536461_ENST00000588673_5144913_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.5987
Å |
| | | |  |
| KDM4B_OAZ1_ENST00000536461_ENST00000602676_5144913_2271780 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4893
Å |
 |  |  |  |  |
| KDM4B_OAZ1_ENST00000536461_ENST00000602676_5144913_2271780 superimposed PDB: 5BWA of partner (OAZ1). RMSD:0.5356
Å |
| | | |  |
| KDM4B_RNF126_ENST00000536461_ENST00000292363_5144913_652884 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.5049
Å |
 |  |  |  |  |
| KDM4B_SBNO2_ENST00000159111_ENST00000438103_5082515_1127764 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.3888
Å |
 |  |  |  |  |
| KDM4B_SBNO2_ENST00000159111_ENST00000587024_5082515_1127764 superimposed PDB: 7JM5 of partner (KDM4B). RMSD:0.4118
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000442236_ENST00000314367_6849700_121573 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.6886
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000535193_ENST00000314367_6849700_121573 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.7171
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000535193_ENST00000356521_6814745_122090 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5267
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000535193_ENST00000377400_6814745_122090 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:2.3517
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000536108_ENST00000314367_6849700_121573 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:2.8364
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000543771_ENST00000314367_6849700_121573 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.6047
Å |
 |  |  |  |  |
| KDM4C_CBWD1_ENST00000543771_ENST00000377400_6814745_122090 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:2.3529
Å |
 |  |  |  |  |
| KDM4C_DMRT3_ENST00000535193_ENST00000190165_6814745_990040 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5533
Å |
 |  |  |  |  |
| KDM4C_EQTN_ENST00000381306_ENST00000484994_6893232_27296738 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5082
Å |
 |  |  |  |  |
| KDM4C_EQTN_ENST00000536108_ENST00000484994_6893232_27296738 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.4472
Å |
 |  |  |  |  |
| KDM4C_EQTN_ENST00000543771_ENST00000484994_6893232_27296738 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.4491
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000381306_ENST00000353265_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5214
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000428870_ENST00000353265_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.4868
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000428870_ENST00000470488_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.7078
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000442236_ENST00000470488_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5489
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000535193_ENST00000353265_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.3829
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000535193_ENST00000470488_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5333
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000536108_ENST00000353265_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5254
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000536108_ENST00000470488_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.4795
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000543771_ENST00000353265_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.4953
Å |
 |  |  |  |  |
| KDM4C_PARD6G_ENST00000543771_ENST00000470488_7015929_77960815 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:0.5083
Å |
 |  |  |  |  |
| KDM5A_ANO2_ENST00000399788_ENST00000546188_427271_5708795 superimposed PDB: 5V9P of partner (KDM5A). RMSD:0.6895
Å |
 |  |  |  |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_404738_675344 superimposed PDB: 5V9P of partner (KDM5A). RMSD:0.7317
Å |
 |  |  |  |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_404738_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.7889
Å |
| | | |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_430160_675344 superimposed PDB: 5V9P of partner (KDM5A). RMSD:0.6928
Å |
 |  |  |  |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_430160_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.6921
Å |
| | | |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_459786_675344 superimposed PDB: 5V9P of partner (KDM5A). RMSD:2.647
Å |
 |  |  |  |  |
| KDM5A_NINJ2_ENST00000399788_ENST00000397265_459786_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.538
Å |
| | | |  |
| KDM5A_RAE1_ENST00000399788_ENST00000371242_459786_55940411 superimposed PDB: 3MMY of partner (RAE1). RMSD:0.3683
Å |
 |  |  |  |  |
| KDM5A_RAE1_ENST00000399788_ENST00000395840_459786_55940411 superimposed PDB: 3MMY of partner (RAE1). RMSD:0.3668
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375379_ENST00000353546_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7685
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375379_ENST00000519604_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7163
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375379_ENST00000547204_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.804
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375383_ENST00000353546_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.9241
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375383_ENST00000519604_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.731
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375383_ENST00000547204_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7315
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375401_ENST00000353546_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7867
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375401_ENST00000519604_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7725
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000375401_ENST00000547204_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7967
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000404049_ENST00000353546_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.787
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000404049_ENST00000519604_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7922
Å |
 |  |  |  |  |
| KDM5C_ARFGAP1_ENST00000404049_ENST00000547204_53222618_61916217 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7981
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000375379_ENST00000375304_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.684
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000375383_ENST00000168216_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.6895
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000375383_ENST00000375298_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.4396
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000375401_ENST00000168216_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.6315
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000375401_ENST00000375298_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.3843
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000404049_ENST00000168216_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.5959
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000404049_ENST00000375298_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.3693
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000404049_ENST00000375304_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.67
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000452825_ENST00000168216_53246324_53459359 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:1.1706
Å |
 |  |  |  |  |
| KDM5C_HSD17B10_ENST00000452825_ENST00000168216_53246324_53459359 superimposed PDB: 2O23 of partner (HSD17B10). RMSD:0.6072
Å |
| | | |  |
| KDM5C_KDM5D_ENST00000375383_ENST00000541639_53225867_21870899 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.768
Å |
 |  |  |  |  |
| KDM5C_KDM5D_ENST00000375383_ENST00000541639_53225867_21870899 superimposed PDB: 2YQE of partner (KDM5D). RMSD:1.2716
Å |
| | | |  |
| KDM5C_KDM5D_ENST00000375401_ENST00000541639_53225867_21870899 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.7916
Å |
 |  |  |  |  |
| KDM5C_KDM5D_ENST00000375401_ENST00000541639_53225867_21870899 superimposed PDB: 2YQE of partner (KDM5D). RMSD:1.2139
Å |
| | | |  |
| KDM5C_KDM5D_ENST00000404049_ENST00000541639_53225867_21870899 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.8015
Å |
 |  |  |  |  |
| KDM5C_KDM5D_ENST00000404049_ENST00000541639_53225867_21870899 superimposed PDB: 2YQE of partner (KDM5D). RMSD:1.1881
Å |
| | | |  |
| KDM5C_KDM5D_ENST00000452825_ENST00000541639_53225867_21870899 superimposed PDB: 5FWJ of partner (KDM5C). RMSD:0.9044
Å |
 |  |  |  |  |
| KDM5C_KDM5D_ENST00000452825_ENST00000541639_53225867_21870899 superimposed PDB: 2YQE of partner (KDM5D). RMSD:3.1474
Å |
| | | |  |
| KDM5C_SMC1A_ENST00000404049_ENST00000322213_53250020_53436434 superimposed PDB: 6WGE of partner (SMC1A). RMSD:1.9314
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000343523_44733233_31676261 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3492
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000343523_44833960_31497220 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3922
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000359836_44733233_31676261 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.382
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000359836_44833960_31497220 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3636
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000378677_44733233_31676261 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3473
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000378677_44833960_31497220 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3781
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000541735_44733233_31676261 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3858
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000377967_ENST00000541735_44833960_31497220 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3857
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000382899_ENST00000378707_44733233_31676261 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3618
Å |
 |  |  |  |  |
| KDM6A_DMD_ENST00000382899_ENST00000378707_44833960_31497220 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3732
Å |
 |  |  |  |  |
| KDM6A_FANCD2_ENST00000377967_ENST00000383806_44733233_10105475 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.7416
Å |
 |  |  |  |  |
| KDM6A_FANCD2_ENST00000377967_ENST00000383807_44733233_10105475 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.726
Å |
 |  |  |  |  |
| KDM6A_FANCD2_ENST00000377967_ENST00000419585_44733233_10105475 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.5969
Å |
 |  |  |  |  |
| KDM6A_WNK1_ENST00000377967_ENST00000315939_44833960_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5245
Å |
 |  |  |  |  |
| KDM6A_WNK1_ENST00000377967_ENST00000447667_44833960_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5182
Å |
 |  |  |  |  |
| KDM6A_WNK1_ENST00000377967_ENST00000530271_44833960_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6192
Å |
 |  |  |  |  |
| KDM6A_WNK1_ENST00000377967_ENST00000537687_44833960_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5181
Å |
 |  |  |  |  |
| KDM6A_WNK1_ENST00000382899_ENST00000535572_44833960_922807 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6002
Å |
 |  |  |  |  |
| KDSR_SERPINB2_ENST00000406396_ENST00000457692_61018120_61564324 superimposed PDB: 2ARR of partner (SERPINB2). RMSD:1.7222
Å |
 |  |  |  |  |
| KEAP1_RAD23A_ENST00000393623_ENST00000316856_10610070_13063502 superimposed PDB: 6WCQ of partner (KEAP1). RMSD:0.6113
Å |
 |  |  |  |  |
| KHDRBS3_ADI1_ENST00000355849_ENST00000382093_136594316_3504764 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.5611
Å |
 |  |  |  |  |
| KHDRBS3_ADI1_ENST00000355849_ENST00000382093_136594316_3504764 superimposed PDB: 4QGN of partner (ADI1). RMSD:0.4277
Å |
| | | |  |
| KHDRBS3_DECR1_ENST00000520981_ENST00000220764_136533598_91029351 superimposed PDB: 1W6U of partner (DECR1). RMSD:0.3332
Å |
 |  |  |  |  |
| KHSRP_CD70_ENST00000398148_ENST00000245903_6418493_6590147 superimposed PDB: 2JVZ of partner (KHSRP). RMSD:1.2025
Å |
 |  |  |  |  |
| KIAA0232_HNRNPD_ENST00000307659_ENST00000352301_6843931_83280792 superimposed PDB: 5IM0 of partner (HNRNPD). RMSD:0.3261
Å |
 |  |  |  |  |
| KIAA0319L_PHC2_ENST00000373266_ENST00000373422_35907846_33790620 superimposed PDB: 6NZ0 of partner (KIAA0319L). RMSD:0.4399
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000250377_ENST00000556611_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.3717
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000250377_ENST00000556611_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1156
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000321130_ENST00000539826_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:2.7541
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000321130_ENST00000539826_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1898
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000534898_ENST00000556611_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:2.8993
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000534898_ENST00000556611_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1707
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000557565_ENST00000539826_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.9975
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000557565_ENST00000539826_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.146
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000557565_ENST00000556611_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.1145
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000557565_ENST00000556611_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1983
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000604948_ENST00000539826_35649983_32586348 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.2701
Å |
 |  |  |  |  |
| KIAA0391_ARHGAP5_ENST00000604948_ENST00000539826_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1749
Å |
| | | |  |
| KIAA0391_ARHGAP5_ENST00000605870_ENST00000539826_35649983_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1731
Å |
 |  |  |  |  |
| KIAA0556_IL21R_ENST00000261588_ENST00000564089_27713016_27448808 superimposed PDB: 7KQ7 of partner (IL21R). RMSD:0.8084
Å |
 |  |  |  |  |
| KIAA0947_TERT_ENST00000296564_ENST00000334602_5448010_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1204
Å |
 |  |  |  |  |
| KIAA0947_TERT_ENST00000296564_ENST00000508104_5448010_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.6958
Å |
 |  |  |  |  |
| KIAA1217_PDLIM1_ENST00000376452_ENST00000329399_24508838_97031541 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5258
Å |
 |  |  |  |  |
| KIAA1217_PDLIM1_ENST00000376454_ENST00000329399_24508838_97031541 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5478
Å |
 |  |  |  |  |
| KIAA1217_PDLIM1_ENST00000458595_ENST00000329399_24508838_97031541 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.7124
Å |
 |  |  |  |  |
| KIAA1328_SUPT3H_ENST00000280020_ENST00000371460_34415339_44797594 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:1.8401
Å |
 |  |  |  |  |
| KIAA1429_PNLIPRP1_ENST00000437199_ENST00000442761_95556054_118350641 superimposed PDB: 2PPL of partner (PNLIPRP1). RMSD:0.6279
Å |
 |  |  |  |  |
| KIAA1429_PNLIPRP1_ENST00000437199_ENST00000528052_95556054_118350641 superimposed PDB: 2PPL of partner (PNLIPRP1). RMSD:0.6125
Å |
 |  |  |  |  |
| KIAA1671_SEC14L2_ENST00000358431_ENST00000312932_25445331_30795631 superimposed PDB: 1OLM of partner (SEC14L2). RMSD:1.2913
Å |
 |  |  |  |  |
| KIAA1671_ZNRF3_ENST00000406486_ENST00000332811_25445331_29383063 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:1.5111
Å |
 |  |  |  |  |
| KIDINS220_PINX1_ENST00000418530_ENST00000426190_8890241_10692285 superimposed PDB: 9JXQ of partner (KIDINS220). RMSD:2.2818
Å |
 |  |  |  |  |
| KIF11_GRB14_ENST00000260731_ENST00000543549_94397302_165358845 superimposed PDB: 3HQD of partner (KIF11). RMSD:0.5216
Å |
 |  |  |  |  |
| KIF11_STAT4_ENST00000260731_ENST00000392320_94373376_191941051 superimposed PDB: 3HQD of partner (KIF11). RMSD:1.3045
Å |
 |  |  |  |  |
| KIF13A_F13A1_ENST00000259711_ENST00000264870_17987284_6197559 superimposed PDB: 8CMU of partner (F13A1). RMSD:1.9787
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000259711_ENST00000368226_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.2799
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000368207_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.8047
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000368210_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9258
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000368213_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.2255
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000368215_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9936
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000368227_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.874
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378814_ENST00000532331_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.8958
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000368207_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7161
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000368210_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.1964
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000368213_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.8205
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000368215_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.8035
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000368227_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9115
Å |
 |  |  |  |  |
| KIF13A_PTPRK_ENST00000378816_ENST00000532331_17825998_128718833 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.498
Å |
 |  |  |  |  |
| KIF13A_TPMT_ENST00000259711_ENST00000309983_17987284_18134120 superimposed PDB: 2BZG of partner (TPMT). RMSD:0.6242
Å |
 |  |  |  |  |
| KIF13A_UBE2K_ENST00000259711_ENST00000261427_17987284_39776453 superimposed PDB: 3K9O of partner (UBE2K). RMSD:0.6115
Å |
 |  |  |  |  |
| KIF13B_C20orf194_ENST00000521515_ENST00000252032_29013242_3262412 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.6493
Å |
 |  |  |  |  |
| KIF13B_C20orf194_ENST00000524189_ENST00000252032_29013242_3262412 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.6794
Å |
 |  |  |  |  |
| KIF13B_CSGALNACT1_ENST00000524189_ENST00000332246_28965655_19266205 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.713
Å |
 |  |  |  |  |
| KIF13B_CSGALNACT1_ENST00000524189_ENST00000454498_28965655_19266205 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.7157
Å |
 |  |  |  |  |
| KIF13B_EYA2_ENST00000524189_ENST00000327619_28950261_45771697 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.782
Å |
 |  |  |  |  |
| KIF13B_FUT10_ENST00000521515_ENST00000327671_29102862_33230322 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:2.7928
Å |
 |  |  |  |  |
| KIF13B_INTS9_ENST00000524189_ENST00000416984_28988049_28717080 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.7961
Å |
 |  |  |  |  |
| KIF13B_INTS9_ENST00000524189_ENST00000416984_28988049_28717080 superimposed PDB: 8RC4 of partner (INTS9). RMSD:0.6901
Å |
| | | |  |
| KIF13B_INTS9_ENST00000524189_ENST00000521022_28988049_28717080 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.7093
Å |
 |  |  |  |  |
| KIF13B_SLC25A21_ENST00000404075_ENST00000555449_28950261_37344209 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.686
Å |
 |  |  |  |  |
| KIF13B_SLC25A21_ENST00000524189_ENST00000331299_28956649_37344209 superimposed PDB: 3GBJ of partner (KIF13B). RMSD:0.7381
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000326047_ENST00000355994_44872510_74702016 superimposed PDB: 7RYP of partner (KIF15). RMSD:1.9652
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000326047_ENST00000355994_44872510_74702016 superimposed PDB: 1YMM of partner (MBP). RMSD:2.4992
Å |
| | | |  |
| KIF15_MBP_ENST00000326047_ENST00000359645_44872510_74702016 superimposed PDB: 7RYP of partner (KIF15). RMSD:1.9657
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000326047_ENST00000397866_44872510_74702016 superimposed PDB: 7RYP of partner (KIF15). RMSD:1.9403
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000326047_ENST00000397866_44872510_74702016 superimposed PDB: 1YMM of partner (MBP). RMSD:2.8213
Å |
| | | |  |
| KIF15_MBP_ENST00000326047_ENST00000527041_44872510_74702016 superimposed PDB: 7RYP of partner (KIF15). RMSD:1.9257
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000326047_ENST00000527041_44872510_74702016 superimposed PDB: 1YMM of partner (MBP). RMSD:2.6909
Å |
| | | |  |
| KIF15_MBP_ENST00000425755_ENST00000397866_44872510_74702016 superimposed PDB: 1YMM of partner (MBP). RMSD:2.1949
Å |
 |  |  |  |  |
| KIF15_MBP_ENST00000425755_ENST00000527041_44872510_74702016 superimposed PDB: 1YMM of partner (MBP). RMSD:2.4312
Å |
 |  |  |  |  |
| KIF1B_HAGH_ENST00000377081_ENST00000455446_10428596_1873038 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9015
Å |
 |  |  |  |  |
| KIF1B_HAGH_ENST00000377086_ENST00000455446_10428596_1873038 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9046
Å |
 |  |  |  |  |
| KIF1B_HMGN2_ENST00000377081_ENST00000361427_10408791_26801603 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9286
Å |
 |  |  |  |  |
| KIF1B_HMGN2_ENST00000377086_ENST00000361427_10408791_26801603 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.984
Å |
 |  |  |  |  |
| KIF1B_NF1_ENST00000263934_ENST00000356175_10403345_29683477 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9183
Å |
 |  |  |  |  |
| KIF1B_NF1_ENST00000263934_ENST00000358273_10403345_29683477 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9832
Å |
 |  |  |  |  |
| KIF1B_NF1_ENST00000377081_ENST00000358273_10403345_29683477 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9739
Å |
 |  |  |  |  |
| KIF1B_NF1_ENST00000377086_ENST00000358273_10403345_29683477 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9955
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000263934_ENST00000359567_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9349
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000263934_ENST00000359567_10412794_162372592 superimposed PDB: 5KAZ of partner (SH2D1B). RMSD:1.6997
Å |
| | | |  |
| KIF1B_SH2D1B_ENST00000263934_ENST00000367929_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9655
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000377081_ENST00000359567_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9906
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000377081_ENST00000359567_10412794_162372592 superimposed PDB: 5KAZ of partner (SH2D1B). RMSD:2.0599
Å |
| | | |  |
| KIF1B_SH2D1B_ENST00000377081_ENST00000367929_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9922
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000377086_ENST00000359567_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9853
Å |
 |  |  |  |  |
| KIF1B_SH2D1B_ENST00000377086_ENST00000359567_10412794_162372592 superimposed PDB: 5KAZ of partner (SH2D1B). RMSD:1.7108
Å |
| | | |  |
| KIF1B_SH2D1B_ENST00000377086_ENST00000367929_10412794_162372592 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9108
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377081_ENST00000343090_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.8988
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377081_ENST00000343090_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.5372
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377081_ENST00000377157_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9823
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377081_ENST00000377157_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.391
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377083_ENST00000343090_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9577
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377083_ENST00000343090_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.5144
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377083_ENST00000377157_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.958
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377083_ENST00000377157_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.3703
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377086_ENST00000343090_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.895
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377086_ENST00000343090_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.5842
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377086_ENST00000377157_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9863
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377086_ENST00000377157_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.3762
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377093_ENST00000343090_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9721
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377093_ENST00000343090_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.5288
Å |
| | | |  |
| KIF1B_UBE4B_ENST00000377093_ENST00000377157_10357304_10238701 superimposed PDB: 2EH0 of partner (KIF1B). RMSD:0.9141
Å |
 |  |  |  |  |
| KIF1B_UBE4B_ENST00000377093_ENST00000377157_10357304_10238701 superimposed PDB: 3L1X of partner (UBE4B). RMSD:0.3886
Å |
| | | |  |
| KIF1C_HLCS_ENST00000320785_ENST00000336648_4910837_38269431 superimposed PDB: 2G1L of partner (KIF1C). RMSD:0.4258
Å |
 |  |  |  |  |
| KIF20B_GBE1_ENST00000260753_ENST00000489715_91514430_81699072 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6885
Å |
 |  |  |  |  |
| KIF20B_GBE1_ENST00000394289_ENST00000489715_91514430_81699072 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.7703
Å |
 |  |  |  |  |
| KIF20B_GBE1_ENST00000416354_ENST00000489715_91514430_81699072 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.7374
Å |
 |  |  |  |  |
| KIF21A_SENP1_ENST00000395670_ENST00000339976_39836728_48491907 superimposed PDB: 2XPH of partner (SENP1). RMSD:0.4841
Å |
 |  |  |  |  |
| KIF24_GNE_ENST00000379174_ENST00000396594_34306249_36249394 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5252
Å |
 |  |  |  |  |
| KIF24_GNE_ENST00000402558_ENST00000539815_34306249_36249394 superimposed PDB: 4ZHT of partner (GNE). RMSD:0.5294
Å |
 |  |  |  |  |
| KIF26B_ALDOA_ENST00000407071_ENST00000395248_245319985_30079966 superimposed PDB: 6XML of partner (ALDOA). RMSD:0.4688
Å |
 |  |  |  |  |
| KIF3C_ADCY3_ENST00000264712_ENST00000260600_26203241_25095588 superimposed PDB: 3B6V of partner (KIF3C). RMSD:0.654
Å |
 |  |  |  |  |
| KIF3C_SNTG2_ENST00000264712_ENST00000407292_26203241_1079203 superimposed PDB: 3B6V of partner (KIF3C). RMSD:0.4134
Å |
 |  |  |  |  |
| KIF3C_SRM_ENST00000405914_ENST00000376957_26203241_11119402 superimposed PDB: 3B6V of partner (KIF3C). RMSD:0.4209
Å |
 |  |  |  |  |
| KIF5A_STK24_ENST00000455537_ENST00000397517_57944183_99116090 superimposed PDB: 4UXY of partner (KIF5A). RMSD:1.2106
Å |
 |  |  |  |  |
| KIFC3_CNGB1_ENST00000541240_ENST00000251102_57828910_57965782 superimposed PDB: 9UPG of partner (CNGB1). RMSD:1.493
Å |
 |  |  |  |  |
| KITLG_CCDC6_ENST00000347404_ENST00000263102_88974040_61612460 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.1728
Å |
 |  |  |  |  |
| KLC1_CALM2_ENST00000347839_ENST00000272298_104145855_47397903 superimposed PDB: 7AI4 of partner (KLC1). RMSD:1.5013
Å |
 |  |  |  |  |
| KLC1_CALM2_ENST00000555836_ENST00000272298_104145855_47397903 superimposed PDB: 7AI4 of partner (KLC1). RMSD:1.4962
Å |
 |  |  |  |  |
| KLHDC2_SNTB1_ENST00000298307_ENST00000517992_50249312_121561198 superimposed PDB: 8EBN of partner (KLHDC2). RMSD:0.3798
Å |
 |  |  |  |  |
| KLHL22_XPNPEP3_ENST00000440659_ENST00000357137_20819144_41277773 superimposed PDB: 8W4J of partner (KLHL22). RMSD:3.1397
Å |
 |  |  |  |  |
| KLHL22_XPNPEP3_ENST00000440659_ENST00000544094_20819144_41277773 superimposed PDB: 5X49 of partner (XPNPEP3). RMSD:0.527
Å |
 |  |  |  |  |
| KLHL26_GATAD2A_ENST00000300976_ENST00000360315_18747947_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9935
Å |
 |  |  |  |  |
| KLHL26_GATAD2A_ENST00000595182_ENST00000252577_18747947_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9663
Å |
 |  |  |  |  |
| KLHL2_OPTN_ENST00000226725_ENST00000378764_166220808_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.2271
Å |
 |  |  |  |  |
| KLHL2_OPTN_ENST00000421009_ENST00000378764_166220808_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.4725
Å |
 |  |  |  |  |
| KLHL2_OPTN_ENST00000506761_ENST00000378764_166220808_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.3919
Å |
 |  |  |  |  |
| KLHL2_OPTN_ENST00000514860_ENST00000378764_166220808_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.2587
Å |
 |  |  |  |  |
| KLHL2_OPTN_ENST00000538127_ENST00000378764_166220808_13165994 superimposed PDB: 5B83 of partner (OPTN). RMSD:1.7958
Å |
 |  |  |  |  |
| KLHL2_STK24_ENST00000226725_ENST00000539966_166160051_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5653
Å |
 |  |  |  |  |
| KLHL2_STK24_ENST00000514860_ENST00000397517_166160051_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.4565
Å |
 |  |  |  |  |
| KLHL2_STK24_ENST00000514860_ENST00000539966_166160051_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5693
Å |
 |  |  |  |  |
| KLHL2_STK24_ENST00000538127_ENST00000397517_166160051_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.419
Å |
 |  |  |  |  |
| KLHL2_STK24_ENST00000538127_ENST00000539966_166160051_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5593
Å |
 |  |  |  |  |
| KLHL7_TPCN2_ENST00000322275_ENST00000294309_23145765_68830351 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.7993
Å |
 |  |  |  |  |
| KLHL7_TPCN2_ENST00000339077_ENST00000542467_23145765_68830351 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.1024
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000325321_ENST00000399357_51376775_13950932 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4426
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000325321_ENST00000399357_51378136_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.3781
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000325321_ENST00000405358_51378136_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4089
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000325321_ENST00000430479_51376775_13950932 superimposed PDB: 4NFE of partner (KLK2). RMSD:0.6745
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000358049_ENST00000399357_51376775_13950932 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4283
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000358049_ENST00000399357_51378136_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.3697
Å |
 |  |  |  |  |
| KLK2_ETV1_ENST00000358049_ENST00000405358_51378136_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.392
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000346997_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.434
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000346997_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4385
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000356226_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.416
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000356226_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4216
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000357555_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4179
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000357555_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4437
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000358487_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4365
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000358487_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4528
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000360144_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4268
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000360144_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4261
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369056_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4358
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369056_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.3981
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369059_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4625
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369059_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4329
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369060_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4698
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369060_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4515
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000325321_ENST00000369061_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.7243
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000346997_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4332
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000351936_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4333
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000356226_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4339
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000357555_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4483
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000358487_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.442
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000360144_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4088
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000369056_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4011
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000369059_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4433
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000369060_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4595
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000358049_ENST00000457416_51376775_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4089
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000391810_ENST00000351936_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4114
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000391810_ENST00000360144_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.4417
Å |
 |  |  |  |  |
| KLK2_FGFR2_ENST00000391810_ENST00000457416_51380014_123310973 superimposed PDB: 6V6Q of partner (FGFR2). RMSD:0.453
Å |
 |  |  |  |  |
| KLK2_PVRL2_ENST00000325321_ENST00000252483_51376775_45368527 superimposed PDB: 3R0N of partner (PVRL2). RMSD:0.3946
Å |
 |  |  |  |  |
| KLK2_PVRL2_ENST00000358049_ENST00000252483_51376775_45368527 superimposed PDB: 3R0N of partner (PVRL2). RMSD:0.4185
Å |
 |  |  |  |  |
| KLK2_PVRL2_ENST00000358049_ENST00000252485_51376775_45368527 superimposed PDB: 3R0N of partner (PVRL2). RMSD:0.4092
Å |
 |  |  |  |  |
| KLK3_TMPRSS11A_ENST00000360617_ENST00000396188_51361851_68777221 superimposed PDB: 6O1G of partner (KLK3). RMSD:0.6258
Å |
 |  |  |  |  |
| KLK3_TMPRSS11A_ENST00000360617_ENST00000396188_51361851_68777221 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.9418
Å |
| | | |  |
| KLK3_TMPRSS11A_ENST00000595952_ENST00000396188_51361851_68777221 superimposed PDB: 6O1G of partner (KLK3). RMSD:0.6312
Å |
 |  |  |  |  |
| KLK3_TMPRSS11A_ENST00000595952_ENST00000396188_51361851_68777221 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.936
Å |
| | | |  |
| KLK3_TMPRSS11A_ENST00000597483_ENST00000396188_51361851_68777221 superimposed PDB: 6O1G of partner (KLK3). RMSD:0.625
Å |
 |  |  |  |  |
| KLK3_TMPRSS11A_ENST00000597483_ENST00000396188_51361851_68777221 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.8588
Å |
| | | |  |
| KMT2A_ABI1_ENST00000389506_ENST00000376170_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.8635
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000355394_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.613
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000359188_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6307
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000376138_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:2.4847
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000376139_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.9335
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000376142_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.4274
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000376160_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6675
Å |
 |  |  |  |  |
| KMT2A_ABI1_ENST00000534358_ENST00000376166_118353210_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5544
Å |
 |  |  |  |  |
| KMT2A_ACTN4_ENST00000534358_ENST00000424234_118353210_39191239 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.6222
Å |
 |  |  |  |  |
| KMT2A_ELL_ENST00000389506_ENST00000262809_118353210_18576728 superimposed PDB: 2DOA of partner (ELL). RMSD:0.6667
Å |
 |  |  |  |  |
| KMT2A_ELL_ENST00000389506_ENST00000262809_118355029_18576728 superimposed PDB: 2DOA of partner (ELL). RMSD:0.7643
Å |
 |  |  |  |  |
| KMT2A_ELL_ENST00000389506_ENST00000262809_118355029_18583692 superimposed PDB: 2DOA of partner (ELL). RMSD:0.7015
Å |
 |  |  |  |  |
| KMT2A_ELL_ENST00000534358_ENST00000596124_118355690_18569139 superimposed PDB: 2DOA of partner (ELL). RMSD:1.0216
Å |
 |  |  |  |  |
| KMT2A_EP300_ENST00000389506_ENST00000263253_118355029_41547836 superimposed PDB: 8HAG of partner (EP300). RMSD:0.818
Å |
 |  |  |  |  |
| KMT2A_EP300_ENST00000389506_ENST00000263253_118355690_41547836 superimposed PDB: 8HAG of partner (EP300). RMSD:0.8112
Å |
 |  |  |  |  |
| KMT2A_EP300_ENST00000389506_ENST00000263253_118359475_41547836 superimposed PDB: 8HAG of partner (EP300). RMSD:0.7868
Å |
 |  |  |  |  |
| KMT2A_GPHN_ENST00000534358_ENST00000478722_118355029_67490349 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.6573
Å |
 |  |  |  |  |
| KMT2A_GPHN_ENST00000534358_ENST00000478722_118355690_67490349 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.6898
Å |
 |  |  |  |  |
| KMT2A_LASP1_ENST00000534358_ENST00000433206_118355690_37070577 superimposed PDB: 3I35 of partner (LASP1). RMSD:0.369
Å |
 |  |  |  |  |
| KMT2A_MLLT1_ENST00000389506_ENST00000252674_118353210_6230724 superimposed PDB: 8PJI of partner (MLLT1). RMSD:2.3757
Å |
 |  |  |  |  |
| KMT2A_MLLT1_ENST00000389506_ENST00000252674_118355029_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5881
Å |
 |  |  |  |  |
| KMT2A_MLLT1_ENST00000389506_ENST00000252674_118355690_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5705
Å |
 |  |  |  |  |
| KMT2A_TET1_ENST00000389506_ENST00000373644_118353210_70441155 superimposed PDB: 6ASD of partner (TET1). RMSD:0.7241
Å |
 |  |  |  |  |
| KMT2C_GTF2IRD1_ENST00000262189_ENST00000455841_151902190_74004179 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.3639
Å |
 |  |  |  |  |
| KMT2C_GTF2IRD1_ENST00000355193_ENST00000265755_151902190_74004179 superimposed PDB: 2DZR of partner (GTF2IRD1). RMSD:1.3424
Å |
 |  |  |  |  |
| KNSTRN_HP1BP3_ENST00000249776_ENST00000312239_40679407_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.6468
Å |
 |  |  |  |  |
| KPNB1_IVNS1ABP_ENST00000290158_ENST00000367498_45741635_185274775 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.749
Å |
 |  |  |  |  |
| KPNB1_IVNS1ABP_ENST00000290158_ENST00000367498_45741635_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.3766
Å |
| | | |  |
| KPNB1_IVNS1ABP_ENST00000540627_ENST00000367498_45741635_185274775 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.7957
Å |
 |  |  |  |  |
| KPNB1_IVNS1ABP_ENST00000540627_ENST00000367498_45741635_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.3848
Å |
| | | |  |
| KPNB1_SBDS_ENST00000290158_ENST00000246868_45740544_66458404 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.7018
Å |
 |  |  |  |  |
| KPNB1_SBDS_ENST00000290158_ENST00000246868_45740544_66458404 superimposed PDB: 5AN9 of partner (SBDS). RMSD:2.8829
Å |
| | | |  |
| KPNB1_SBDS_ENST00000537679_ENST00000246868_45740544_66458404 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.7594
Å |
 |  |  |  |  |
| KPNB1_SBDS_ENST00000537679_ENST00000246868_45740544_66458404 superimposed PDB: 5AN9 of partner (SBDS). RMSD:2.7924
Å |
| | | |  |
| KPNB1_SBDS_ENST00000540627_ENST00000246868_45740544_66458404 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.7053
Å |
 |  |  |  |  |
| KPNB1_SBDS_ENST00000540627_ENST00000246868_45740544_66458404 superimposed PDB: 5AN9 of partner (SBDS). RMSD:2.9219
Å |
| | | |  |
| KPNB1_UBAP2L_ENST00000290158_ENST00000271877_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5421
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000290158_ENST00000361546_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5541
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000290158_ENST00000428931_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5297
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000535458_ENST00000271877_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5232
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000535458_ENST00000361546_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5446
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000535458_ENST00000428931_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.55
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000537679_ENST00000271877_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5168
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000537679_ENST00000361546_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5514
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000537679_ENST00000428931_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.6141
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000540627_ENST00000271877_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5689
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000540627_ENST00000361546_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5646
Å |
 |  |  |  |  |
| KPNB1_UBAP2L_ENST00000540627_ENST00000428931_45736026_154231452 superimposed PDB: 1QGR of partner (KPNB1). RMSD:0.5465
Å |
 |  |  |  |  |
| KRAS_ETNK1_ENST00000311936_ENST00000335148_25398207_22796696 superimposed PDB: 7VVB of partner (KRAS). RMSD:2.9753
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000312962_ENST00000314646_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0249
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000312962_ENST00000355667_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9315
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000312962_ENST00000359692_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9259
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000312962_ENST00000389253_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.8955
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000361821_ENST00000314646_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9179
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000361821_ENST00000355667_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9193
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000361821_ENST00000359692_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9202
Å |
 |  |  |  |  |
| KRI1_DNM2_ENST00000361821_ENST00000389253_10672342_10916591 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.8992
Å |
 |  |  |  |  |
| KRT13_TIMM22_ENST00000246635_ENST00000327158_39658938_902751 superimposed PDB: 7CGP of partner (TIMM22). RMSD:0.5586
Å |
 |  |  |  |  |
| KRT6A_SPINK5_ENST00000330722_ENST00000256084_52884641_147465967 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.7064
Å |
 |  |  |  |  |
| KRT6A_SPINK5_ENST00000330722_ENST00000359874_52884641_147465967 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.5138
Å |
 |  |  |  |  |
| KRT7_VIM_ENST00000331817_ENST00000224237_52639416_17277844 superimposed PDB: 4XIF of partner (KRT7). RMSD:2.2043
Å |
 |  |  |  |  |
| KRT8_CSAD_ENST00000293308_ENST00000379843_53293558_53555173 superimposed PDB: 2JIS of partner (CSAD). RMSD:2.2242
Å |
 |  |  |  |  |
| KRT8_CSAD_ENST00000552150_ENST00000267085_53293558_53555173 superimposed PDB: 2JIS of partner (CSAD). RMSD:2.3995
Å |
 |  |  |  |  |
| KRT8_CSAD_ENST00000552150_ENST00000379843_53293558_53555173 superimposed PDB: 2JIS of partner (CSAD). RMSD:2.4398
Å |
 |  |  |  |  |
| KRTCAP3_BAZ1A_ENST00000407293_ENST00000360310_27666399_35272194 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.358
Å |
 |  |  |  |  |
| KRTCAP3_BAZ1A_ENST00000407293_ENST00000382422_27666399_35272194 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.3252
Å |
 |  |  |  |  |
| KRTCAP3_BAZ1A_ENST00000543753_ENST00000360310_27666399_35272194 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.5733
Å |
 |  |  |  |  |
| KRTCAP3_BAZ1A_ENST00000543753_ENST00000382422_27666399_35272194 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.3406
Å |
 |  |  |  |  |
| KSR1_INTS4_ENST00000319524_ENST00000534064_25783900_77652297 superimposed PDB: 8RC4 of partner (INTS4). RMSD:3.0455
Å |
 |  |  |  |  |
| KSR1_MSI2_ENST00000509603_ENST00000284073_25783900_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4653
Å |
 |  |  |  |  |
| KSR1_MSI2_ENST00000509603_ENST00000322684_25783900_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4634
Å |
 |  |  |  |  |
| KSR1_MSI2_ENST00000509603_ENST00000442934_25783900_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5145
Å |
 |  |  |  |  |
| KSR1_NOS2_ENST00000398988_ENST00000313735_25935036_26086101 superimposed PDB: 7JUW of partner (KSR1). RMSD:3.3675
Å |
 |  |  |  |  |
| L3MBTL2_EFCAB6_ENST00000216237_ENST00000262726_41610030_44074043 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4798
Å |
 |  |  |  |  |
| L3MBTL2_TEF_ENST00000216237_ENST00000266304_41605937_41783354 superimposed PDB: 4U5T of partner (TEF). RMSD:0.372
Å |
 |  |  |  |  |
| LAD1_PLD3_ENST00000367313_ENST00000409419_201355462_40883692 superimposed PDB: 8V5T of partner (PLD3). RMSD:1.3768
Å |
 |  |  |  |  |
| LAD1_PLD3_ENST00000367313_ENST00000409587_201355462_40883692 superimposed PDB: 8V5T of partner (PLD3). RMSD:1.1069
Å |
 |  |  |  |  |
| LAMA2_NUP107_ENST00000421865_ENST00000378905_129641800_69135592 superimposed PDB: 4YEQ of partner (LAMA2). RMSD:0.4956
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000269217_ENST00000344150_21456371_11024552 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7213
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000269217_ENST00000344150_21456371_11030270 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6312
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000269217_ENST00000344150_21462009_11027371 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6087
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000313654_ENST00000344150_21456371_11024552 superimposed PDB: 2Y1W of partner (CARM1). RMSD:1.9377
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000313654_ENST00000344150_21456371_11030270 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6442
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000313654_ENST00000344150_21462009_11027371 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6653
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000399516_ENST00000327064_21456371_11024552 superimposed PDB: 2Y1W of partner (CARM1). RMSD:2.2142
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000399516_ENST00000327064_21456371_11030270 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7014
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000399516_ENST00000327064_21462009_11027371 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6889
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000587184_ENST00000327064_21456371_11024552 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7162
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000587184_ENST00000327064_21456371_11030270 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.714
Å |
 |  |  |  |  |
| LAMA3_CARM1_ENST00000587184_ENST00000327064_21462009_11027371 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.5573
Å |
 |  |  |  |  |
| LANCL2_TFDP2_ENST00000254770_ENST00000489671_55469013_141682805 superimposed PDB: 6WQ1 of partner (LANCL2). RMSD:0.7701
Å |
 |  |  |  |  |
| LAP3_DDX1_ENST00000226299_ENST00000233084_17583437_15746273 superimposed PDB: 8TBX of partner (DDX1). RMSD:2.8574
Å |
 |  |  |  |  |
| LAP3_DDX1_ENST00000606142_ENST00000233084_17583437_15746273 superimposed PDB: 8TBX of partner (DDX1). RMSD:2.9129
Å |
 |  |  |  |  |
| LARGE_CBX7_ENST00000337431_ENST00000475962_34157357_39545837 superimposed PDB: 9E1T of partner (LARGE). RMSD:0.8175
Å |
 |  |  |  |  |
| LARP4B_ADARB2_ENST00000316157_ENST00000381312_888871_1263059 superimposed PDB: 3PTH of partner (LARP4B). RMSD:2.2214
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000360521_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.8197
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379775_909682_6255585 superimposed PDB: 3PTH of partner (LARP4B). RMSD:2.5001
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379775_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.7787
Å |
| | | |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379782_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.8099
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379785_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.7738
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379789_909682_6255585 superimposed PDB: 3PTH of partner (LARP4B). RMSD:2.4991
Å |
 |  |  |  |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000379789_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.318
Å |
| | | |  |
| LARP4B_PFKFB3_ENST00000316157_ENST00000540253_909682_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.835
Å |
 |  |  |  |  |
| LARP4_HPD_ENST00000293618_ENST00000543163_50824353_122285120 superimposed PDB: 5EC3 of partner (HPD). RMSD:0.7421
Å |
 |  |  |  |  |
| LARP4_HPD_ENST00000429001_ENST00000543163_50824353_122285120 superimposed PDB: 5EC3 of partner (HPD). RMSD:0.7679
Å |
 |  |  |  |  |
| LARP4_HPD_ENST00000518444_ENST00000543163_50824353_122285120 superimposed PDB: 5EC3 of partner (HPD). RMSD:0.7437
Å |
 |  |  |  |  |
| LARP4_HPD_ENST00000518561_ENST00000543163_50824353_122285120 superimposed PDB: 5EC3 of partner (HPD). RMSD:0.7523
Å |
 |  |  |  |  |
| LARS2_TBL1XR1_ENST00000265537_ENST00000457928_45461221_176769514 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.3542
Å |
 |  |  |  |  |
| LARS2_TBL1XR1_ENST00000414984_ENST00000457928_45461221_176769514 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.3647
Å |
 |  |  |  |  |
| LASP1_KMT2A_ENST00000318008_ENST00000389506_37071399_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9208
Å |
 |  |  |  |  |
| LASP1_KMT2A_ENST00000433206_ENST00000389506_37071399_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9311
Å |
 |  |  |  |  |
| LASP1_KMT2A_ENST00000433206_ENST00000534358_37071399_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7445
Å |
 |  |  |  |  |
| LASP1_KMT2A_ENST00000435347_ENST00000534358_37071399_118355576 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8922
Å |
 |  |  |  |  |
| LASP1_PSMB3_ENST00000433206_ENST00000225426_37054772_36918663 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.4355
Å |
 |  |  |  |  |
| LASP1_PSMB3_ENST00000435347_ENST00000225426_37054772_36918663 superimposed PDB: 5LE5 of partner (PSMB3). RMSD:0.813
Å |
 |  |  |  |  |
| LATS2_CRYL1_ENST00000382592_ENST00000382812_21619823_21063635 superimposed PDB: 4ZRI of partner (LATS2). RMSD:0.3604
Å |
 |  |  |  |  |
| LATS2_CRYL1_ENST00000382592_ENST00000382812_21619823_21063635 superimposed PDB: 3F3S of partner (CRYL1). RMSD:0.5919
Å |
| | | |  |
| LBH_FLT4_ENST00000406087_ENST00000393347_30457373_180058778 superimposed PDB: 4BSJ of partner (FLT4). RMSD:1.3699
Å |
 |  |  |  |  |
| LBH_FLT4_ENST00000406087_ENST00000502649_30457373_180058778 superimposed PDB: 4BSJ of partner (FLT4). RMSD:1.3869
Å |
 |  |  |  |  |
| LCLAT1_ALK_ENST00000319406_ENST00000389048_30791042_29754982 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.5249
Å |
 |  |  |  |  |
| LCLAT1_ALK_ENST00000359433_ENST00000389048_30791042_29754982 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4016
Å |
 |  |  |  |  |
| LCLAT1_EPHA3_ENST00000319406_ENST00000336596_30756180_89390065 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.3992
Å |
 |  |  |  |  |
| LCLAT1_EPHA3_ENST00000319406_ENST00000452448_30756180_89390065 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.5201
Å |
 |  |  |  |  |
| LCLAT1_EPHA3_ENST00000359433_ENST00000336596_30756180_89390065 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.4317
Å |
 |  |  |  |  |
| LCLAT1_EPHA3_ENST00000379509_ENST00000452448_30756180_89390065 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.5066
Å |
 |  |  |  |  |
| LCLAT1_EPHA3_ENST00000540623_ENST00000452448_30756180_89390065 superimposed PDB: 2QOL of partner (EPHA3). RMSD:0.4127
Å |
 |  |  |  |  |
| LCN2_SUV420H1_ENST00000277480_ENST00000402185_130914563_67934645 superimposed PDB: 3CBC of partner (LCN2). RMSD:0.2574
Å |
 |  |  |  |  |
| LCN2_SUV420H1_ENST00000372998_ENST00000402185_130914563_67934645 superimposed PDB: 3CBC of partner (LCN2). RMSD:0.2606
Å |
 |  |  |  |  |
| LCN2_SUV420H1_ENST00000373013_ENST00000402185_130914563_67934645 superimposed PDB: 3CBC of partner (LCN2). RMSD:0.2618
Å |
 |  |  |  |  |
| LCN2_SUV420H1_ENST00000373017_ENST00000402185_130914563_67934645 superimposed PDB: 3CBC of partner (LCN2). RMSD:0.2573
Å |
 |  |  |  |  |
| LCOR_PDLIM1_ENST00000371097_ENST00000329399_98711953_97007123 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:1.6412
Å |
 |  |  |  |  |
| LCOR_PDLIM1_ENST00000371103_ENST00000329399_98711953_97007123 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:1.8072
Å |
 |  |  |  |  |
| LDHB_ATP1A1_ENST00000396076_ENST00000537345_21807476_116930752 superimposed PDB: 7E20 of partner (ATP1A1). RMSD:1.6617
Å |
 |  |  |  |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000496558_21790004_80620335 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.4842
Å |
 |  |  |  |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000496558_21790004_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4674
Å |
| | | |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000540488_21790004_80620335 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.4811
Å |
 |  |  |  |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000540488_21790004_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4825
Å |
| | | |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000541047_21790004_80620335 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.4722
Å |
 |  |  |  |  |
| LDHB_CTNNA2_ENST00000396076_ENST00000541047_21790004_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.8126
Å |
| | | |  |
| LDHB_LDHA_ENST00000396076_ENST00000227157_21794885_18425240 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.6148
Å |
 |  |  |  |  |
| LDHB_LDHA_ENST00000396076_ENST00000227157_21794885_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.6429
Å |
| | | |  |
| LDHB_LDHA_ENST00000396076_ENST00000430553_21794885_18425240 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.5091
Å |
 |  |  |  |  |
| LDHB_LDHA_ENST00000396076_ENST00000430553_21794885_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.5979
Å |
| | | |  |
| LDHB_LDHA_ENST00000396076_ENST00000540430_21794885_18425240 superimposed PDB: 8S88 of partner (LDHB). RMSD:0.6354
Å |
 |  |  |  |  |
| LDHB_LDHA_ENST00000396076_ENST00000540430_21794885_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.7411
Å |
| | | |  |
| LDHB_TOP2B_ENST00000396076_ENST00000264331_21807476_25656779 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.0944
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000278386_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9456
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000352818_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.822
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000360158_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9096
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000415148_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8388
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000428726_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7636
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000433354_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8015
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000433892_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7752
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000434472_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:0.8562
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000434472_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7283
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000437706_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7648
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000449691_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7659
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000315571_ENST00000526669_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9298
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000263398_35965694_35236398 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8218
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000263398_36120011_35208378 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7654
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000278386_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9081
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000278386_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9008
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000352818_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9354
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000352818_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9056
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000360158_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8431
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000360158_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8253
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000415148_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8827
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000415148_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8489
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000428726_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8446
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000428726_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8289
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000433354_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9184
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000433354_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9577
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000433892_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7514
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000433892_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7523
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000437706_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.835
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000437706_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8037
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000449691_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9213
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000449691_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7662
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000526669_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7386
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000524419_ENST00000526669_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8198
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000528989_ENST00000263398_35965694_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8123
Å |
 |  |  |  |  |
| LDLRAD3_CD44_ENST00000528989_ENST00000263398_36120011_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.9008
Å |
 |  |  |  |  |
| LDLRAD3_EPHX2_ENST00000315571_ENST00000517536_36120011_27398070 superimposed PDB: 3I28 of partner (EPHX2). RMSD:2.4472
Å |
 |  |  |  |  |
| LDLRAD3_EPHX2_ENST00000524419_ENST00000517536_36120011_27398070 superimposed PDB: 3I28 of partner (EPHX2). RMSD:1.3321
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000455727_ENST00000474890_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:2.4785
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000455727_ENST00000592798_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.6644
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000535915_ENST00000263382_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.8074
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000535915_ENST00000592798_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.7118
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000545707_ENST00000263382_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.8332
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000545707_ENST00000592798_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.7192
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000557933_ENST00000263382_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.8593
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000558013_ENST00000263382_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.9488
Å |
 |  |  |  |  |
| LDLR_ASF1B_ENST00000558518_ENST00000592798_11218190_14237049 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.7705
Å |
 |  |  |  |  |
| LDLR_BRK1_ENST00000535915_ENST00000256463_11216276_10167309 superimposed PDB: 3P8C of partner (BRK1). RMSD:0.4158
Å |
 |  |  |  |  |
| LDLR_BRK1_ENST00000557933_ENST00000530758_11213462_10167309 superimposed PDB: 3P8C of partner (BRK1). RMSD:0.4003
Å |
 |  |  |  |  |
| LDLR_BRK1_ENST00000557933_ENST00000530758_11216276_10167309 superimposed PDB: 3P8C of partner (BRK1). RMSD:0.4627
Å |
 |  |  |  |  |
| LDLR_BRK1_ENST00000558518_ENST00000256463_11213462_10167309 superimposed PDB: 3P8C of partner (BRK1). RMSD:0.457
Å |
 |  |  |  |  |
| LDLR_BRK1_ENST00000558518_ENST00000256463_11216276_10167309 superimposed PDB: 3P8C of partner (BRK1). RMSD:0.4289
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000455727_ENST00000253099_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.7305
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000455727_ENST00000393733_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.0312
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000535915_ENST00000253099_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.6022
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000535915_ENST00000307422_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:2.6881
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000535915_ENST00000393733_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.0165
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000535915_ENST00000588502_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:2.615
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000545707_ENST00000253099_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.7164
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000545707_ENST00000307422_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.9187
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000545707_ENST00000393733_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.9864
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000545707_ENST00000588502_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.9902
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000557933_ENST00000307422_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.9557
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000558013_ENST00000307422_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:2.4606
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000558518_ENST00000253099_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.6139
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000558518_ENST00000393733_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.9452
Å |
 |  |  |  |  |
| LDLR_MRPL4_ENST00000558518_ENST00000588502_11218190_10368897 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.7772
Å |
 |  |  |  |  |
| LEMD3_LYZ_ENST00000308330_ENST00000549690_65564898_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.6451
Å |
 |  |  |  |  |
| LEPRE1_ERI3_ENST00000236040_ENST00000537474_43227993_44687312 superimposed PDB: 8K0M of partner (LEPRE1). RMSD:2.1069
Å |
 |  |  |  |  |
| LEPRE1_ERI3_ENST00000236040_ENST00000537474_43227993_44687312 superimposed PDB: 7LPZ of partner (ERI3). RMSD:2.7505
Å |
| | | |  |
| LEPRE1_ERI3_ENST00000296388_ENST00000537474_43227993_44687312 superimposed PDB: 8K0M of partner (LEPRE1). RMSD:1.9768
Å |
 |  |  |  |  |
| LEPRE1_ERI3_ENST00000296388_ENST00000537474_43227993_44687312 superimposed PDB: 7LPZ of partner (ERI3). RMSD:2.7443
Å |
| | | |  |
| LEPROTL1_SET_ENST00000321250_ENST00000409104_29953044_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.4077
Å |
 |  |  |  |  |
| LEPROTL1_SET_ENST00000523116_ENST00000409104_29953044_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.2366
Å |
 |  |  |  |  |
| LETM1_RGS12_ENST00000302787_ENST00000344733_1824714_3344663 superimposed PDB: 2EBZ of partner (RGS12). RMSD:1.3255
Å |
 |  |  |  |  |
| LETM1_RGS12_ENST00000302787_ENST00000382788_1824714_3344663 superimposed PDB: 2EBZ of partner (RGS12). RMSD:1.2301
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000297720_ENST00000221481_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.2004
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000297720_ENST00000391940_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1944
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000297720_ENST00000391944_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1242
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000297720_ENST00000485403_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1668
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000379957_ENST00000221481_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.0799
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000379957_ENST00000391940_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.0264
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000379957_ENST00000391944_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1138
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000379957_ENST00000391945_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.2157
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000379957_ENST00000485403_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1537
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000523983_ENST00000221481_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.159
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000523983_ENST00000391940_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.0295
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000523983_ENST00000391944_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1428
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000523983_ENST00000391945_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.8943
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000523983_ENST00000485403_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.2046
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000524874_ENST00000221481_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1186
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000524874_ENST00000391940_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1521
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000524874_ENST00000391944_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.0825
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000524874_ENST00000391945_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.93
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000524874_ENST00000485403_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1882
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000527710_ENST00000391944_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:1.1381
Å |
 |  |  |  |  |
| LETM2_ERCC2_ENST00000527710_ENST00000391945_38262024_45872405 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.9505
Å |
 |  |  |  |  |
| LGALS9B_LGALS9_ENST00000324290_ENST00000310394_20363664_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:0.4139
Å |
 |  |  |  |  |
| LGALS9B_LGALS9_ENST00000423676_ENST00000302228_20363664_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:2.839
Å |
 |  |  |  |  |
| LGALS9B_LGALS9_ENST00000423676_ENST00000313648_20363664_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:2.7691
Å |
 |  |  |  |  |
| LGALS9B_LGALS9_ENST00000423676_ENST00000395473_20363664_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:2.8334
Å |
 |  |  |  |  |
| LIG3_ZFAT_ENST00000378526_ENST00000520727_33321450_135490964 superimposed PDB: 3L2P of partner (LIG3). RMSD:0.6886
Å |
 |  |  |  |  |
| LIMA1_ITGA5_ENST00000341247_ENST00000293379_50625447_54805748 superimposed PDB: 7NWL of partner (ITGA5). RMSD:1.156
Å |
 |  |  |  |  |
| LIMA1_USP22_ENST00000552783_ENST00000537526_50615803_20931987 superimposed PDB: 2D8Y of partner (LIMA1). RMSD:2.5843
Å |
 |  |  |  |  |
| LIMA1_USP22_ENST00000552823_ENST00000537526_50615803_20931987 superimposed PDB: 2D8Y of partner (LIMA1). RMSD:2.5872
Å |
 |  |  |  |  |
| LIMK1_GNAT3_ENST00000336180_ENST00000398291_73530288_80123963 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.4336
Å |
 |  |  |  |  |
| LIMK1_GNAT3_ENST00000418310_ENST00000398291_73530288_80123963 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.5028
Å |
 |  |  |  |  |
| LIMK1_GNAT3_ENST00000538333_ENST00000398291_73530288_80123963 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.4601
Å |
 |  |  |  |  |
| LIMK1_TYW1_ENST00000336180_ENST00000359626_73526328_66489886 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.6159
Å |
 |  |  |  |  |
| LIMK1_TYW1_ENST00000538333_ENST00000359626_73526328_66489886 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.553
Å |
 |  |  |  |  |
| LIMK2_CDC45_ENST00000331728_ENST00000437685_31664186_19504049 superimposed PDB: 7QHG of partner (LIMK2). RMSD:1.6783
Å |
 |  |  |  |  |
| LIMK2_CDC45_ENST00000333611_ENST00000437685_31664186_19504049 superimposed PDB: 7QHG of partner (LIMK2). RMSD:1.5369
Å |
 |  |  |  |  |
| LIMK2_CDC45_ENST00000406516_ENST00000437685_31664186_19504049 superimposed PDB: 7QHG of partner (LIMK2). RMSD:1.4391
Å |
 |  |  |  |  |
| LIMK2_CDC45_ENST00000444929_ENST00000437685_31664186_19504049 superimposed PDB: 7QHG of partner (LIMK2). RMSD:1.6909
Å |
 |  |  |  |  |
| LIMK2_PPP2CA_ENST00000331728_ENST00000481195_31654412_133541822 superimposed PDB: 4I5L of partner (PPP2CA). RMSD:0.3422
Å |
 |  |  |  |  |
| LIMK2_PPP2CA_ENST00000333611_ENST00000481195_31654412_133541822 superimposed PDB: 4I5L of partner (PPP2CA). RMSD:0.3665
Å |
 |  |  |  |  |
| LIMK2_PPP2CA_ENST00000340552_ENST00000481195_31654412_133541822 superimposed PDB: 4I5L of partner (PPP2CA). RMSD:0.3371
Å |
 |  |  |  |  |
| LIMK2_RUFY1_ENST00000444929_ENST00000319449_31621805_179007947 superimposed PDB: 7QHG of partner (LIMK2). RMSD:1.258
Å |
 |  |  |  |  |
| LIMK2_RUFY1_ENST00000444929_ENST00000377001_31621805_179007947 superimposed PDB: 2YW8 of partner (RUFY1). RMSD:0.3394
Å |
 |  |  |  |  |
| LIMK2_RUFY1_ENST00000444929_ENST00000437570_31621805_179007947 superimposed PDB: 2YW8 of partner (RUFY1). RMSD:0.3437
Å |
 |  |  |  |  |
| LIPF_TMED6_ENST00000238983_ENST00000288025_90431722_69383554 superimposed PDB: 1HLG of partner (LIPF). RMSD:0.59
Å |
 |  |  |  |  |
| LIPF_TMED6_ENST00000355843_ENST00000288025_90431722_69383554 superimposed PDB: 1HLG of partner (LIPF). RMSD:0.6006
Å |
 |  |  |  |  |
| LIPF_TMED6_ENST00000608620_ENST00000288025_90431722_69383554 superimposed PDB: 1HLG of partner (LIPF). RMSD:0.6182
Å |
 |  |  |  |  |
| LLPH_ADK_ENST00000266604_ENST00000286621_66522675_76349039 superimposed PDB: 4O1L of partner (ADK). RMSD:0.6463
Å |
 |  |  |  |  |
| LMBR1L_SSU72_ENST00000395141_ENST00000291386_49495032_1480382 superimposed PDB: 4H3K of partner (SSU72). RMSD:0.7842
Å |
 |  |  |  |  |
| LMBR1L_SSU72_ENST00000547382_ENST00000291386_49495032_1480382 superimposed PDB: 4H3K of partner (SSU72). RMSD:0.7402
Å |
 |  |  |  |  |
| LMNA_COL1A1_ENST00000368300_ENST00000225964_156108548_48273728 superimposed PDB: 6JLB of partner (LMNA). RMSD:3.2594
Å |
 |  |  |  |  |
| LMNA_COL1A1_ENST00000448611_ENST00000225964_156108548_48273728 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8611
Å |
 |  |  |  |  |
| LMNA_COL1A1_ENST00000473598_ENST00000225964_156108548_48273728 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.1961
Å |
 |  |  |  |  |
| LMNA_KRT7_ENST00000361308_ENST00000331817_156105912_52641960 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.4585
Å |
 |  |  |  |  |
| LMNA_KRT7_ENST00000368297_ENST00000331817_156105912_52641960 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8675
Å |
 |  |  |  |  |
| LMNA_KRT7_ENST00000368301_ENST00000331817_156105912_52641960 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.6672
Å |
 |  |  |  |  |
| LMNA_KRT7_ENST00000392353_ENST00000331817_156105912_52641960 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8676
Å |
 |  |  |  |  |
| LMNA_KRT7_ENST00000473598_ENST00000331817_156105912_52641960 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.802
Å |
 |  |  |  |  |
| LMNA_KRT8_ENST00000368297_ENST00000293308_156105912_53292303 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8921
Å |
 |  |  |  |  |
| LMNA_KRT8_ENST00000368301_ENST00000293308_156105912_53292303 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.3936
Å |
 |  |  |  |  |
| LMNA_KRT8_ENST00000448611_ENST00000293308_156105912_53292303 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8155
Å |
 |  |  |  |  |
| LMNA_KRT8_ENST00000473598_ENST00000293308_156105912_53292303 superimposed PDB: 6JLB of partner (LMNA). RMSD:3.0351
Å |
 |  |  |  |  |
| LMNA_LMNB2_ENST00000368297_ENST00000582871_156105912_2434103 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.9417
Å |
 |  |  |  |  |
| LMNA_LMNB2_ENST00000368297_ENST00000582871_156105912_2434103 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1193
Å |
| | | |  |
| LMNA_LMNB2_ENST00000368301_ENST00000582871_156105912_2434103 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.318
Å |
 |  |  |  |  |
| LMNA_LMNB2_ENST00000368301_ENST00000582871_156105912_2434103 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1194
Å |
| | | |  |
| LMNA_LMNB2_ENST00000448611_ENST00000582871_156105912_2434103 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.9091
Å |
 |  |  |  |  |
| LMNA_LMNB2_ENST00000448611_ENST00000582871_156105912_2434103 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1241
Å |
| | | |  |
| LMNA_LMNB2_ENST00000473598_ENST00000582871_156105912_2434103 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.9352
Å |
 |  |  |  |  |
| LMNA_LMNB2_ENST00000473598_ENST00000582871_156105912_2434103 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1083
Å |
| | | |  |
| LMNA_RAF1_ENST00000368300_ENST00000251849_156107534_12641914 superimposed PDB: 6JLB of partner (LMNA). RMSD:1.2675
Å |
 |  |  |  |  |
| LMNA_RAF1_ENST00000368300_ENST00000251849_156107534_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:2.0628
Å |
| | | |  |
| LMNA_RAF1_ENST00000368300_ENST00000442415_156107534_12641914 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.997
Å |
 |  |  |  |  |
| LMNA_RAF1_ENST00000368300_ENST00000442415_156107534_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0603
Å |
| | | |  |
| LMNA_RAF1_ENST00000448611_ENST00000442415_156107534_12641914 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.0509
Å |
 |  |  |  |  |
| LMNA_RAF1_ENST00000448611_ENST00000442415_156107534_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9687
Å |
| | | |  |
| LMNA_RAF1_ENST00000473598_ENST00000442415_156107534_12641914 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8396
Å |
 |  |  |  |  |
| LMNA_RAF1_ENST00000473598_ENST00000442415_156107534_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9871
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000361308_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.0819
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000361308_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.7267
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368297_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.0792
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368297_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.843
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368299_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1108
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368299_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.8618
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368300_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.0091
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368300_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.7511
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368301_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1254
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000368301_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.7787
Å |
| | | |  |
| LMNB2_LMNA_ENST00000325327_ENST00000448611_2434292_156106004 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1359
Å |
 |  |  |  |  |
| LMNB2_LMNA_ENST00000325327_ENST00000448611_2434292_156106004 superimposed PDB: 6JLB of partner (LMNA). RMSD:2.0201
Å |
| | | |  |
| LMTK2_SRPK2_ENST00000297293_ENST00000357311_97800986_104844232 superimposed PDB: 2X7G of partner (SRPK2). RMSD:0.3786
Å |
 |  |  |  |  |
| LMTK3_DBP_ENST00000270238_ENST00000599385_48994364_49134309 superimposed PDB: 6SEQ of partner (LMTK3). RMSD:0.4516
Å |
 |  |  |  |  |
| LMTK3_DBP_ENST00000600059_ENST00000599385_48994364_49134309 superimposed PDB: 6SEQ of partner (LMTK3). RMSD:0.5019
Å |
 |  |  |  |  |
| LNPEP_PPIP5K2_ENST00000395770_ENST00000358359_96322374_102537222 superimposed PDB: 5MJ6 of partner (LNPEP). RMSD:0.5472
Å |
 |  |  |  |  |
| LNX1_USP46_ENST00000263925_ENST00000451218_54373483_53494330 superimposed PDB: 5L8H of partner (USP46). RMSD:0.6008
Å |
 |  |  |  |  |
| LONP1_MAP2K7_ENST00000585374_ENST00000397979_5719714_7974639 superimposed PDB: 6YG1 of partner (MAP2K7). RMSD:1.2116
Å |
 |  |  |  |  |
| LONP1_MAP2K7_ENST00000585374_ENST00000397983_5719714_7974639 superimposed PDB: 6YG1 of partner (MAP2K7). RMSD:1.2162
Å |
 |  |  |  |  |
| LONP1_MAP2K7_ENST00000585374_ENST00000545011_5719714_7974639 superimposed PDB: 6YG1 of partner (MAP2K7). RMSD:1.4732
Å |
 |  |  |  |  |
| LONP1_RAD51_ENST00000540670_ENST00000267868_5700799_41023252 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4612
Å |
 |  |  |  |  |
| LONP1_RAD51_ENST00000590729_ENST00000267868_5700799_41023252 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4222
Å |
 |  |  |  |  |
| LONP1_RAD51_ENST00000593119_ENST00000267868_5700799_41023252 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4335
Å |
 |  |  |  |  |
| LONP1_SAFB2_ENST00000360614_ENST00000252542_5705782_5600271 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4097
Å |
 |  |  |  |  |
| LONP1_SAFB2_ENST00000540670_ENST00000252542_5705782_5600271 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4694
Å |
 |  |  |  |  |
| LONP1_SAFB2_ENST00000585374_ENST00000252542_5705782_5604947 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.3133
Å |
 |  |  |  |  |
| LONP1_SAFB2_ENST00000590729_ENST00000252542_5705782_5600271 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.4127
Å |
 |  |  |  |  |
| LONP1_SAFB2_ENST00000593119_ENST00000252542_5705782_5600271 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.3558
Å |
 |  |  |  |  |
| LONP2_HIRA_ENST00000285737_ENST00000263208_48337216_19398301 superimposed PDB: 5YJE of partner (HIRA). RMSD:1.2143
Å |
 |  |  |  |  |
| LONP2_HIRA_ENST00000535754_ENST00000263208_48337216_19398301 superimposed PDB: 5YJE of partner (HIRA). RMSD:1.0349
Å |
 |  |  |  |  |
| LONP2_HIRA_ENST00000535754_ENST00000340170_48337216_19398301 superimposed PDB: 5YJE of partner (HIRA). RMSD:1.0945
Å |
 |  |  |  |  |
| LPCAT1_AHRR_ENST00000283415_ENST00000316418_1501575_353844 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.3719
Å |
 |  |  |  |  |
| LPCAT1_SKP2_ENST00000283415_ENST00000274255_1501575_36152872 superimposed PDB: 7Z8V of partner (SKP2). RMSD:0.8412
Å |
 |  |  |  |  |
| LPCAT1_SKP2_ENST00000283415_ENST00000508514_1501575_36152872 superimposed PDB: 7Z8V of partner (SKP2). RMSD:0.8077
Å |
 |  |  |  |  |
| LPHN1_LGALS4_ENST00000361434_ENST00000307751_14288342_39299588 superimposed PDB: 5DUW of partner (LGALS4). RMSD:0.3774
Å |
 |  |  |  |  |
| LPHN2_AK5_ENST00000370723_ENST00000344720_82302742_77759477 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.8643
Å |
 |  |  |  |  |
| LPL_ASAH1_ENST00000311322_ENST00000417108_19813594_17915132 superimposed PDB: 6OAU of partner (LPL). RMSD:0.3305
Å |
 |  |  |  |  |
| LRCH1_NADSYN1_ENST00000389798_ENST00000319023_47127838_71166155 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.6621
Å |
 |  |  |  |  |
| LRCH1_SPG20_ENST00000311191_ENST00000355182_47127838_36878769 superimposed PDB: 2DL1 of partner (SPG20). RMSD:3.0516
Å |
 |  |  |  |  |
| LRCH3_RAF1_ENST00000334859_ENST00000442415_197574892_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0105
Å |
 |  |  |  |  |
| LRCH3_RAF1_ENST00000414675_ENST00000442415_197574892_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.7452
Å |
 |  |  |  |  |
| LRCH3_RAF1_ENST00000438796_ENST00000442415_197574892_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.7199
Å |
 |  |  |  |  |
| LRCH3_RAF1_ENST00000441090_ENST00000442415_197574892_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8199
Å |
 |  |  |  |  |
| LRCH3_RAF1_ENST00000536618_ENST00000442415_197574892_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.1722
Å |
 |  |  |  |  |
| LRIG1_PPM1L_ENST00000273261_ENST00000498165_66550613_160679523 superimposed PDB: 4U7L of partner (LRIG1). RMSD:2.4858
Å |
 |  |  |  |  |
| LRIG1_PPM1L_ENST00000383703_ENST00000498165_66550613_160679523 superimposed PDB: 4U7L of partner (LRIG1). RMSD:1.5029
Å |
 |  |  |  |  |
| LRP10_MSL1_ENST00000546834_ENST00000577454_23346262_38282435 superimposed PDB: 4B86 of partner (MSL1). RMSD:2.7493
Å |
 |  |  |  |  |
| LRP10_MSL1_ENST00000546834_ENST00000578648_23346262_38282435 superimposed PDB: 4B86 of partner (MSL1). RMSD:2.2684
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000323926_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1874
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000345488_57589786_216259442 superimposed PDB: 2FYJ of partner (LRP1). RMSD:2.8735
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000346544_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.8312
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000354785_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.4633
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000357009_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.0297
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000357867_57563090_216230353 superimposed PDB: 2FYJ of partner (LRP1). RMSD:2.6564
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000357867_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1903
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000359671_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7656
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000432072_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.008
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000443816_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6585
Å |
 |  |  |  |  |
| LRP1_FN1_ENST00000243077_ENST00000446046_57589786_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:3.1115
Å |
 |  |  |  |  |
| LRP1_MCRS1_ENST00000243077_ENST00000546244_57604662_49953604 superimposed PDB: 2FYJ of partner (LRP1). RMSD:2.6158
Å |
 |  |  |  |  |
| LRP1_OS9_ENST00000243077_ENST00000315970_57552421_58114188 superimposed PDB: 9OG0 of partner (OS9). RMSD:0.6156
Å |
 |  |  |  |  |
| LRP3_LSM14A_ENST00000253193_ENST00000433627_33685764_34685382 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.9682
Å |
 |  |  |  |  |
| LRP3_LSM14A_ENST00000253193_ENST00000544216_33685764_34685382 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.9734
Å |
 |  |  |  |  |
| LRP6_NINJ2_ENST00000261349_ENST00000397265_12332743_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.7021
Å |
 |  |  |  |  |
| LRP6_PTPRO_ENST00000261349_ENST00000348962_12332743_15733630 superimposed PDB: 2GJT of partner (PTPRO). RMSD:0.5679
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000263334_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6998
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000263334_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.728
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000263335_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7486
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000263335_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7292
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000348715_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7535
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000397647_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7026
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000397647_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6246
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000429538_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7017
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000306052_ENST00000429538_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6918
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000263334_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6849
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000263334_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6612
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000263335_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7358
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000263335_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7468
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000348715_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7036
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000397647_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7133
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000397647_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.71
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000429538_53722914_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7164
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000347547_ENST00000429538_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6578
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000354412_ENST00000263334_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.5987
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000354412_ENST00000263335_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.5982
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000354412_ENST00000348715_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7426
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000354412_ENST00000397647_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7157
Å |
 |  |  |  |  |
| LRP8_PAX8_ENST00000354412_ENST00000429538_53723990_114004496 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.5641
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000306052_ENST00000337432_53720788_56772291 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7062
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000306052_ENST00000337432_53720788_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.7035
Å |
| | | |  |
| LRP8_RAD51C_ENST00000347547_ENST00000337432_53720788_56772291 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7396
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000347547_ENST00000337432_53720788_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.9883
Å |
| | | |  |
| LRP8_RAD51C_ENST00000347547_ENST00000583539_53720788_56772291 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.5588
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000347547_ENST00000583539_53720788_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.4716
Å |
| | | |  |
| LRP8_RAD51C_ENST00000354412_ENST00000337432_53720788_56772291 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.7871
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000354412_ENST00000337432_53720788_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.5042
Å |
| | | |  |
| LRP8_RAD51C_ENST00000371454_ENST00000583539_53720788_56772291 superimposed PDB: 5B4X of partner (LRP8). RMSD:0.6934
Å |
 |  |  |  |  |
| LRP8_RAD51C_ENST00000371454_ENST00000583539_53720788_56772291 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:0.6698
Å |
| | | |  |
| LRRC1_HSP90AB1_ENST00000370888_ENST00000371554_53660213_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.5833
Å |
 |  |  |  |  |
| LRRFIP1_CARD10_ENST00000244815_ENST00000403299_238668848_37912305 superimposed PDB: 4H22 of partner (LRRFIP1). RMSD:1.145
Å |
 |  |  |  |  |
| LRRFIP1_CARD10_ENST00000289175_ENST00000403299_238668848_37912305 superimposed PDB: 4H22 of partner (LRRFIP1). RMSD:1.3773
Å |
 |  |  |  |  |
| LRRFIP1_CARD10_ENST00000392000_ENST00000403299_238668848_37912305 superimposed PDB: 4H22 of partner (LRRFIP1). RMSD:1.0611
Å |
 |  |  |  |  |
| LRRK2_CCT2_ENST00000343742_ENST00000543146_40681341_69985838 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.8161
Å |
 |  |  |  |  |
| LRRK2_CCT2_ENST00000343742_ENST00000544368_40681341_69985838 superimposed PDB: 7NVL of partner (CCT2). RMSD:2.3929
Å |
 |  |  |  |  |
| LSM12_ATXN7L3_ENST00000293406_ENST00000389384_42141168_42272508 superimposed PDB: 2KKT of partner (ATXN7L3). RMSD:1.9359
Å |
 |  |  |  |  |
| LSM12_PAIP1_ENST00000293406_ENST00000436644_42141168_43543218 superimposed PDB: 6YXJ of partner (PAIP1). RMSD:0.5811
Å |
 |  |  |  |  |
| LSM12_PAIP1_ENST00000585388_ENST00000306846_42141168_43543218 superimposed PDB: 6YXJ of partner (PAIP1). RMSD:0.5875
Å |
 |  |  |  |  |
| LSM14A_SCGB2B2_ENST00000433627_ENST00000601241_34699956_35084504 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.5176
Å |
 |  |  |  |  |
| LSM14A_SLC7A9_ENST00000433627_ENST00000590341_34712643_33333223 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.3995
Å |
 |  |  |  |  |
| LSM14A_SLC7A9_ENST00000433627_ENST00000590341_34712643_33333223 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:1.4877
Å |
| | | |  |
| LSM14A_SLC7A9_ENST00000540746_ENST00000023064_34712643_33333223 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.3898
Å |
 |  |  |  |  |
| LSM14A_SLC7A9_ENST00000540746_ENST00000023064_34712643_33333223 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:1.5022
Å |
| | | |  |
| LSM14A_SLC7A9_ENST00000544216_ENST00000023064_34712643_33333223 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.4279
Å |
 |  |  |  |  |
| LSM14A_SLC7A9_ENST00000544216_ENST00000023064_34712643_33333223 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:1.5545
Å |
| | | |  |
| LSM14A_SLC7A9_ENST00000544216_ENST00000590341_34712643_33333223 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.4078
Å |
 |  |  |  |  |
| LSM14A_SLC7A9_ENST00000544216_ENST00000590341_34712643_33333223 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:1.7817
Å |
| | | |  |
| LSM14A_TDRD12_ENST00000433627_ENST00000444215_34706566_33263658 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.4284
Å |
 |  |  |  |  |
| LSM14A_TDRD12_ENST00000540746_ENST00000421545_34706566_33263658 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.4709
Å |
 |  |  |  |  |
| LSM14A_TDRD12_ENST00000544216_ENST00000421545_34706566_33263658 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.3907
Å |
 |  |  |  |  |
| LSM14A_TDRD12_ENST00000544216_ENST00000444215_34706566_33263658 superimposed PDB: 6F9W of partner (LSM14A). RMSD:0.4082
Å |
 |  |  |  |  |
| LSM1_WHSC1L1_ENST00000311351_ENST00000316985_38033792_38196125 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.422
Å |
 |  |  |  |  |
| LSM1_WHSC1L1_ENST00000311351_ENST00000433384_38033792_38196125 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.4236
Å |
 |  |  |  |  |
| LSM1_WHSC1L1_ENST00000311351_ENST00000527502_38033792_38196125 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.3712
Å |
 |  |  |  |  |
| LSM4_ELL_ENST00000252816_ENST00000262809_18423413_18583692 superimposed PDB: 2DOA of partner (ELL). RMSD:0.793
Å |
 |  |  |  |  |
| LSP1_STRN_ENST00000405957_ENST00000263918_1908096_37152351 superimposed PDB: 4NO2 of partner (LSP1). RMSD:2.9367
Å |
 |  |  |  |  |
| LSS_CHORDC1_ENST00000397728_ENST00000320585_47626585_89951352 superimposed PDB: 1W6K of partner (LSS). RMSD:0.5504
Å |
 |  |  |  |  |
| LSS_CHORDC1_ENST00000397728_ENST00000320585_47626585_89951352 superimposed PDB: 2YRT of partner (CHORDC1). RMSD:3.1939
Å |
| | | |  |
| LSS_CHORDC1_ENST00000522411_ENST00000320585_47626585_89951352 superimposed PDB: 1W6K of partner (LSS). RMSD:0.624
Å |
 |  |  |  |  |
| LSS_CHORDC1_ENST00000522411_ENST00000320585_47626585_89951352 superimposed PDB: 2YRT of partner (CHORDC1). RMSD:0.7172
Å |
| | | |  |
| LTA4H_CDK17_ENST00000228740_ENST00000542666_96400091_96694138 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.5512
Å |
 |  |  |  |  |
| LTA4H_CDK17_ENST00000228740_ENST00000543119_96400091_96694138 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.5436
Å |
 |  |  |  |  |
| LTA4H_CDK17_ENST00000552789_ENST00000542666_96400091_96694138 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.6373
Å |
 |  |  |  |  |
| LTA4H_CDK17_ENST00000552789_ENST00000543119_96400091_96694138 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.6081
Å |
 |  |  |  |  |
| LTA4H_SLC25A24_ENST00000228740_ENST00000370041_96402871_108686332 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.4772
Å |
 |  |  |  |  |
| LTA4H_SLC25A24_ENST00000552789_ENST00000370041_96402871_108686332 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.5427
Å |
 |  |  |  |  |
| LTBP2_NEK9_ENST00000556690_ENST00000238616_74999128_75558181 superimposed PDB: 3ZKE of partner (NEK9). RMSD:1.2914
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000204005_ENST00000361162_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7237
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000204005_ENST00000528062_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6974
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000308370_ENST00000361162_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7507
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000308370_ENST00000528062_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7774
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000396819_ENST00000361162_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6917
Å |
 |  |  |  |  |
| LTBP4_RBM39_ENST00000396819_ENST00000528062_41114509_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6959
Å |
 |  |  |  |  |
| LTBR_PRSS3_ENST00000228918_ENST00000342836_6495610_33796640 superimposed PDB: 4MXW of partner (LTBR). RMSD:2.4223
Å |
 |  |  |  |  |
| LTBR_PRSS3_ENST00000228918_ENST00000342836_6495610_33796640 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3101
Å |
| | | |  |
| LTBR_PRSS3_ENST00000539925_ENST00000342836_6495610_33796640 superimposed PDB: 4MXW of partner (LTBR). RMSD:2.6808
Å |
 |  |  |  |  |
| LTBR_PRSS3_ENST00000539925_ENST00000342836_6495610_33796640 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3148
Å |
| | | |  |
| LTBR_PRSS3_ENST00000541102_ENST00000342836_6495610_33796640 superimposed PDB: 4MXW of partner (LTBR). RMSD:2.4026
Å |
 |  |  |  |  |
| LTBR_PRSS3_ENST00000541102_ENST00000342836_6495610_33796640 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.2911
Å |
| | | |  |
| LTK_ITGB4_ENST00000453182_ENST00000200181_41799292_73746760 superimposed PDB: 7NX1 of partner (LTK). RMSD:0.4259
Å |
 |  |  |  |  |
| LTK_ITGB4_ENST00000453182_ENST00000200181_41799292_73746760 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.0024
Å |
| | | |  |
| LTK_ITGB4_ENST00000453182_ENST00000339591_41799292_73746760 superimposed PDB: 7NX1 of partner (LTK). RMSD:0.489
Å |
 |  |  |  |  |
| LTK_ITGB4_ENST00000453182_ENST00000339591_41799292_73746760 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.2103
Å |
| | | |  |
| LTK_ITGB4_ENST00000453182_ENST00000450894_41799292_73746760 superimposed PDB: 7NX1 of partner (LTK). RMSD:0.5257
Å |
 |  |  |  |  |
| LTK_ITGB4_ENST00000453182_ENST00000450894_41799292_73746760 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.1988
Å |
| | | |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000358244_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7069
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000359106_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8054
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000429973_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9532
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000505165_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2224
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000507336_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7438
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000507609_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8022
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000507896_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6243
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000510366_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9307
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000512389_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.696
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000513689_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5731
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000513964_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9893
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000514079_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6106
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000240304_ENST00000514717_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5598
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000393227_ENST00000515411_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7741
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000352832_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7459
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000354983_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6613
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000416767_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7131
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000442258_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8203
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000502264_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6594
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000503485_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7264
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000507510_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7778
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000510115_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7127
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000514181_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5371
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000515165_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.1958
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000515411_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.835
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000505658_ENST00000515765_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5879
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000352832_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7165
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000354983_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9036
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000358244_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7582
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000359106_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6699
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000360761_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7487
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000416767_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5892
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000429973_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.867
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000442258_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7211
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000502264_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9341
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000503485_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7252
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000505165_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.1439
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000507336_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7264
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000507510_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8348
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000507609_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7217
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000507896_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7904
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000510115_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6406
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000510366_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2116
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000512389_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7411
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000513689_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.742
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000513964_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9926
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000514079_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6346
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000514181_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8267
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000514717_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.4901
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000515165_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2472
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000515411_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6986
Å |
 |  |  |  |  |
| LUC7L3_CACNA1G_ENST00000544170_ENST00000515765_48819092_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.6595
Å |
 |  |  |  |  |
| LUC7L_CPM_ENST00000293872_ENST00000551568_270647_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.5459
Å |
 |  |  |  |  |
| LUC7L_TXNL4A_ENST00000337351_ENST00000269601_249060_77737701 superimposed PDB: 1QGV of partner (TXNL4A). RMSD:1.2226
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000317501_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.2192
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000317501_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7196
Å |
| | | |  |
| LYN_NTRK3_ENST00000519728_ENST00000355254_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.0437
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000355254_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7119
Å |
| | | |  |
| LYN_NTRK3_ENST00000519728_ENST00000394480_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:2.3316
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000557856_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.0296
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000557856_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6678
Å |
| | | |  |
| LYN_NTRK3_ENST00000519728_ENST00000558676_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:0.9296
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000519728_ENST00000558676_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7232
Å |
| | | |  |
| LYN_NTRK3_ENST00000520220_ENST00000317501_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.1729
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000520220_ENST00000317501_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7109
Å |
| | | |  |
| LYN_NTRK3_ENST00000520220_ENST00000355254_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.0144
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000520220_ENST00000355254_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6875
Å |
| | | |  |
| LYN_NTRK3_ENST00000520220_ENST00000394480_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.4644
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000520220_ENST00000557856_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:1.0779
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000520220_ENST00000557856_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7137
Å |
| | | |  |
| LYN_NTRK3_ENST00000520220_ENST00000558676_56866543_88576276 superimposed PDB: 3A4O of partner (LYN). RMSD:0.9228
Å |
 |  |  |  |  |
| LYN_NTRK3_ENST00000520220_ENST00000558676_56866543_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7088
Å |
| | | |  |
| LYN_TGS1_ENST00000519728_ENST00000260129_56879456_56723439 superimposed PDB: 3A4O of partner (LYN). RMSD:1.2668
Å |
 |  |  |  |  |
| LYN_TGS1_ENST00000520220_ENST00000260129_56879456_56723439 superimposed PDB: 3A4O of partner (LYN). RMSD:3.3225
Å |
 |  |  |  |  |
| LYN_TGS1_ENST00000520220_ENST00000260129_56879456_56723439 superimposed PDB: 3GDH of partner (TGS1). RMSD:0.5058
Å |
| | | |  |
| LYPLA1_TPD52_ENST00000316963_ENST00000379096_55013467_80954903 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:2.7511
Å |
 |  |  |  |  |
| LYPLA1_TPD52_ENST00000343231_ENST00000379096_55013467_80954903 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:2.5876
Å |
 |  |  |  |  |
| LYPLA1_TPD52_ENST00000343231_ENST00000518937_55013467_80954903 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:2.6042
Å |
 |  |  |  |  |
| LYPLA1_TPD52_ENST00000522007_ENST00000379096_55013467_80954903 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:2.5402
Å |
 |  |  |  |  |
| LYPLA1_TPD52_ENST00000522007_ENST00000518937_55013467_80954903 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:2.6862
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000380716_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.4483
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000380716_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:0.9862
Å |
| | | |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000380733_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.3726
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000380733_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.2103
Å |
| | | |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000397519_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.4537
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000330636_ENST00000397519_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.0917
Å |
| | | |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000380716_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.364
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000380716_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.1753
Å |
| | | |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000380733_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.3404
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000380733_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.0774
Å |
| | | |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000397519_5216850_15506635 superimposed PDB: 6UXE of partner (LYRM4). RMSD:0.3799
Å |
 |  |  |  |  |
| LYRM4_PSIP1_ENST00000464010_ENST00000397519_5216850_15506635 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.251
Å |
| | | |  |
| LYSMD2_MYO5A_ENST00000267838_ENST00000356338_52029546_52613706 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.379
Å |
 |  |  |  |  |
| LYZ_CCT2_ENST00000261267_ENST00000543146_69746078_69983264 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.3995
Å |
 |  |  |  |  |
| LYZ_CCT2_ENST00000261267_ENST00000543146_69746078_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.8499
Å |
| | | |  |
| LYZ_CCT2_ENST00000261267_ENST00000544368_69746078_69983264 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.3953
Å |
 |  |  |  |  |
| LYZ_CCT2_ENST00000261267_ENST00000544368_69746078_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.6361
Å |
| | | |  |
| LYZ_LARS_ENST00000261267_ENST00000545646_69746078_145519824 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.3197
Å |
 |  |  |  |  |
| LYZ_LARS_ENST00000261267_ENST00000545646_69746078_145519824 superimposed PDB: 6KID of partner (LARS). RMSD:1.1618
Å |
| | | |  |
| MACF1_BRAF_ENST00000317713_ENST00000288602_39896580_140487384 superimposed PDB: 4Z6G of partner (MACF1). RMSD:1.7034
Å |
 |  |  |  |  |
| MACF1_BRAF_ENST00000567887_ENST00000288602_39896580_140487384 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.8275
Å |
 |  |  |  |  |
| MACF1_DHX58_ENST00000289893_ENST00000251642_39835858_40261404 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.9372
Å |
 |  |  |  |  |
| MACF1_DHX58_ENST00000361689_ENST00000251642_39835858_40261404 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.8384
Å |
 |  |  |  |  |
| MACF1_DHX58_ENST00000372915_ENST00000251642_39835858_40261404 superimposed PDB: 4Z6G of partner (MACF1). RMSD:3.0032
Å |
 |  |  |  |  |
| MACF1_DHX58_ENST00000372915_ENST00000251642_39835858_40261404 superimposed PDB: 9LOV of partner (DHX58). RMSD:3.214
Å |
| | | |  |
| MACF1_DHX58_ENST00000567887_ENST00000251642_39835858_40261404 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.7106
Å |
 |  |  |  |  |
| MACF1_DHX58_ENST00000567887_ENST00000251642_39835858_40261404 superimposed PDB: 9LOV of partner (DHX58). RMSD:1.9958
Å |
| | | |  |
| MACF1_FOXJ3_ENST00000317713_ENST00000372573_39910507_42664901 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.4716
Å |
 |  |  |  |  |
| MACF1_FOXJ3_ENST00000539005_ENST00000372573_39910507_42664901 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.8872
Å |
 |  |  |  |  |
| MACF1_FOXJ3_ENST00000545844_ENST00000372573_39910507_42664901 superimposed PDB: 4Z6G of partner (MACF1). RMSD:3.1603
Å |
 |  |  |  |  |
| MACF1_INPP5B_ENST00000372915_ENST00000373026_39550110_38357126 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.2695
Å |
 |  |  |  |  |
| MACF1_INPP5B_ENST00000545844_ENST00000373026_39550110_38357126 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.261
Å |
 |  |  |  |  |
| MACF1_INPP5B_ENST00000567887_ENST00000373026_39550110_38357126 superimposed PDB: 4CML of partner (INPP5B). RMSD:0.2793
Å |
 |  |  |  |  |
| MACF1_LYPLA1_ENST00000289893_ENST00000343231_39854330_54965316 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:1.4633
Å |
 |  |  |  |  |
| MACF1_LYPLA1_ENST00000539005_ENST00000343231_39854330_54965316 superimposed PDB: 4Z6G of partner (MACF1). RMSD:3.0452
Å |
 |  |  |  |  |
| MACF1_LYPLA1_ENST00000539005_ENST00000343231_39854330_54965316 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:0.5839
Å |
| | | |  |
| MACF1_LYPLA1_ENST00000545844_ENST00000343231_39854330_54965316 superimposed PDB: 4Z6G of partner (MACF1). RMSD:2.8487
Å |
 |  |  |  |  |
| MACF1_LYPLA1_ENST00000545844_ENST00000343231_39854330_54965316 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:0.4399
Å |
| | | |  |
| MACF1_SLC35B1_ENST00000361689_ENST00000240333_39715775_47778872 superimposed PDB: 4Z6G of partner (MACF1). RMSD:0.7685
Å |
 |  |  |  |  |
| MACF1_SLC35B1_ENST00000372915_ENST00000240333_39715775_47778872 superimposed PDB: 4Z6G of partner (MACF1). RMSD:0.7053
Å |
 |  |  |  |  |
| MACF1_SLC35B1_ENST00000536367_ENST00000240333_39715775_47778872 superimposed PDB: 4Z6G of partner (MACF1). RMSD:0.6347
Å |
 |  |  |  |  |
| MACF1_SLC35B1_ENST00000536367_ENST00000240333_39715775_47778872 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:3.0152
Å |
| | | |  |
| MACF1_SLC35B1_ENST00000567887_ENST00000240333_39715775_47778872 superimposed PDB: 4Z6G of partner (MACF1). RMSD:0.9028
Å |
 |  |  |  |  |
| MACF1_SLC35B1_ENST00000567887_ENST00000240333_39715775_47778872 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:2.9318
Å |
| | | |  |
| MACROD2_DCLK2_ENST00000217246_ENST00000296550_13983050_151023629 superimposed PDB: 4IQY of partner (MACROD2). RMSD:1.0867
Å |
 |  |  |  |  |
| MACROD2_DCLK2_ENST00000217246_ENST00000302176_13983050_151023629 superimposed PDB: 4IQY of partner (MACROD2). RMSD:3.1389
Å |
 |  |  |  |  |
| MACROD2_DCLK2_ENST00000217246_ENST00000506325_13983050_151023629 superimposed PDB: 4IQY of partner (MACROD2). RMSD:3.1408
Å |
 |  |  |  |  |
| MACROD2_DCLK2_ENST00000310348_ENST00000302176_13983050_151023629 superimposed PDB: 4IQY of partner (MACROD2). RMSD:2.7641
Å |
 |  |  |  |  |
| MACROD2_SPTLC3_ENST00000217246_ENST00000378194_14066374_13090758 superimposed PDB: 4IQY of partner (MACROD2). RMSD:1.7861
Å |
 |  |  |  |  |
| MACROD2_SPTLC3_ENST00000217246_ENST00000399002_14066374_13090758 superimposed PDB: 4IQY of partner (MACROD2). RMSD:1.1593
Å |
 |  |  |  |  |
| MAEA_ATP6V0C_ENST00000505177_ENST00000568562_1283770_2569218 superimposed PDB: 6WLW of partner (ATP6V0C). RMSD:1.2827
Å |
 |  |  |  |  |
| MAGI1_MITF_ENST00000330909_ENST00000448226_66023670_69998201 superimposed PDB: 2KPK of partner (MAGI1). RMSD:2.4744
Å |
 |  |  |  |  |
| MAGI1_MITF_ENST00000330909_ENST00000448226_66023670_69998201 superimposed PDB: 7D8S of partner (MITF). RMSD:0.92
Å |
| | | |  |
| MAGI1_MITF_ENST00000330909_ENST00000472437_66023670_69998201 superimposed PDB: 7D8S of partner (MITF). RMSD:0.9726
Å |
 |  |  |  |  |
| MAGI1_MITF_ENST00000402939_ENST00000352241_66023670_69998201 superimposed PDB: 2KPK of partner (MAGI1). RMSD:2.6247
Å |
 |  |  |  |  |
| MAGI1_MITF_ENST00000402939_ENST00000352241_66023670_69998201 superimposed PDB: 7D8S of partner (MITF). RMSD:0.9522
Å |
| | | |  |
| MAK16_ANGPT2_ENST00000360128_ENST00000415216_33347857_6390008 superimposed PDB: 4ZFG of partner (ANGPT2). RMSD:0.298
Å |
 |  |  |  |  |
| MAML2_YAP1_ENST00000524717_ENST00000526343_96074546_102094352 superimposed PDB: 4RE1 of partner (YAP1). RMSD:3.1368
Å |
 |  |  |  |  |
| MAN1A2_CHMP1A_ENST00000356554_ENST00000535997_117963271_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:1.007
Å |
 |  |  |  |  |
| MAN1A2_LPXN_ENST00000356554_ENST00000528954_118045592_58322413 superimposed PDB: 1X3H of partner (LPXN). RMSD:1.3609
Å |
 |  |  |  |  |
| MAN2A1_TRIM9_ENST00000261483_ENST00000338969_109026253_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.375
Å |
 |  |  |  |  |
| MAN2A1_TRIM9_ENST00000261483_ENST00000360392_109026253_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.3769
Å |
 |  |  |  |  |
| MANBAL_UBR5_ENST00000373606_ENST00000220959_35929816_103341627 superimposed PDB: 8E0Q of partner (UBR5). RMSD:2.7969
Å |
 |  |  |  |  |
| MANBAL_UBR5_ENST00000397156_ENST00000520539_35929816_103341627 superimposed PDB: 8E0Q of partner (UBR5). RMSD:2.7277
Å |
 |  |  |  |  |
| MAP1LC3B_MCHR1_ENST00000565788_ENST00000381433_87426073_41076952 superimposed PDB: 8WSS of partner (MCHR1). RMSD:1.9418
Å |
 |  |  |  |  |
| MAP2K2_BEST2_ENST00000262948_ENST00000042931_4110506_12868464 superimposed PDB: 1S9I of partner (MAP2K2). RMSD:0.79
Å |
 |  |  |  |  |
| MAP2K4_CD79B_ENST00000353533_ENST00000006750_11924318_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:2.0938
Å |
 |  |  |  |  |
| MAP2K4_CD79B_ENST00000353533_ENST00000392795_11924318_62008745 superimposed PDB: 3ALN of partner (MAP2K4). RMSD:1.6512
Å |
 |  |  |  |  |
| MAP2K4_CD79B_ENST00000415385_ENST00000392795_11924318_62008745 superimposed PDB: 7XQ8 of partner (CD79B). RMSD:2.4901
Å |
 |  |  |  |  |
| MAP2K4_PGGT1B_ENST00000415385_ENST00000419445_11924318_114557705 superimposed PDB: 3ALN of partner (MAP2K4). RMSD:2.1507
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000178640_ENST00000567476_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.6758
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000340972_ENST00000286744_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:1.9236
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000354498_ENST00000286744_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.5488
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000354498_ENST00000567476_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:1.8917
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000395476_ENST00000286744_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.8002
Å |
 |  |  |  |  |
| MAP2K5_ADAMTSL3_ENST00000395476_ENST00000567476_68040939_84373140 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.6215
Å |
 |  |  |  |  |
| MAP2K5_IQCH_ENST00000178640_ENST00000335894_68020283_67757464 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.5708
Å |
 |  |  |  |  |
| MAP2K5_IQCH_ENST00000178640_ENST00000358767_68020283_67757464 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:1.0919
Å |
 |  |  |  |  |
| MAP2K5_IQCH_ENST00000178640_ENST00000546225_68020283_67757464 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.5426
Å |
 |  |  |  |  |
| MAP2K5_IQCH_ENST00000354498_ENST00000335894_68020283_67757464 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:2.9036
Å |
 |  |  |  |  |
| MAP2K5_IQCH_ENST00000354498_ENST00000546225_68020283_67757464 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:1.2615
Å |
 |  |  |  |  |
| MAP2K5_MYRFL_ENST00000178640_ENST00000547771_67893087_70272807 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.5201
Å |
 |  |  |  |  |
| MAP2K5_MYRFL_ENST00000354498_ENST00000547771_67893087_70272807 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.9805
Å |
 |  |  |  |  |
| MAP2K5_MYRFL_ENST00000395476_ENST00000552032_67893087_70272807 superimposed PDB: 4IC7 of partner (MAP2K5). RMSD:0.5148
Å |
 |  |  |  |  |
| MAP3K10_SUPT5H_ENST00000253055_ENST00000359191_40712064_39948314 superimposed PDB: 2RF0 of partner (MAP3K10). RMSD:0.3754
Å |
 |  |  |  |  |
| MAP3K10_SUPT5H_ENST00000253055_ENST00000359191_40712064_39948314 superimposed PDB: 9HVQ of partner (SUPT5H). RMSD:3.1651
Å |
| | | |  |
| MAP3K10_SUPT5H_ENST00000253055_ENST00000432763_40712064_39948314 superimposed PDB: 2RF0 of partner (MAP3K10). RMSD:0.3519
Å |
 |  |  |  |  |
| MAP3K10_SUPT5H_ENST00000253055_ENST00000432763_40712064_39948314 superimposed PDB: 9HVQ of partner (SUPT5H). RMSD:3.0735
Å |
| | | |  |
| MAP3K3_BRIP1_ENST00000361357_ENST00000259008_61744420_59763526 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.4817
Å |
 |  |  |  |  |
| MAP3K3_BRIP1_ENST00000579585_ENST00000577598_61744420_59763526 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.3513
Å |
 |  |  |  |  |
| MAP3K3_BRIP1_ENST00000584573_ENST00000259008_61744420_59763526 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.5041
Å |
 |  |  |  |  |
| MAP3K3_MRC2_ENST00000584573_ENST00000303375_61700123_60741908 superimposed PDB: 5EW6 of partner (MRC2). RMSD:1.0764
Å |
 |  |  |  |  |
| MAP3K3_SMURF2_ENST00000361357_ENST00000262435_61762950_62553840 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.4773
Å |
 |  |  |  |  |
| MAP3K3_SMURF2_ENST00000361357_ENST00000262435_61762950_62553840 superimposed PDB: 9FSH of partner (SMURF2). RMSD:1.9661
Å |
| | | |  |
| MAP3K3_SMURF2_ENST00000361733_ENST00000262435_61762950_62553840 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.5785
Å |
 |  |  |  |  |
| MAP3K3_SMURF2_ENST00000361733_ENST00000262435_61762950_62553840 superimposed PDB: 9FSH of partner (SMURF2). RMSD:2.5482
Å |
| | | |  |
| MAP3K3_SMURF2_ENST00000577395_ENST00000262435_61762938_62553840 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.9134
Å |
 |  |  |  |  |
| MAP3K3_SMURF2_ENST00000577395_ENST00000262435_61762938_62553840 superimposed PDB: 9FSH of partner (SMURF2). RMSD:2.4901
Å |
| | | |  |
| MAP3K3_SMURF2_ENST00000579585_ENST00000262435_61762950_62553840 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.4393
Å |
 |  |  |  |  |
| MAP3K3_SMURF2_ENST00000579585_ENST00000262435_61762950_62553840 superimposed PDB: 9FSH of partner (SMURF2). RMSD:1.9298
Å |
| | | |  |
| MAP4K3_CRCP_ENST00000341681_ENST00000395326_39664032_65595730 superimposed PDB: 7AE1 of partner (CRCP). RMSD:1.337
Å |
 |  |  |  |  |
| MAP4K3_EML4_ENST00000263881_ENST00000318522_39605206_42507989 superimposed PDB: 5J5T of partner (MAP4K3). RMSD:0.5551
Å |
 |  |  |  |  |
| MAP4K3_EML4_ENST00000263881_ENST00000402711_39605206_42507989 superimposed PDB: 5J5T of partner (MAP4K3). RMSD:1.0061
Å |
 |  |  |  |  |
| MAP4K3_SRGAP2_ENST00000341681_ENST00000414007_39664032_206557367 superimposed PDB: 5I6R of partner (SRGAP2). RMSD:2.8387
Å |
 |  |  |  |  |
| MAP4K4_TXNL4A_ENST00000324219_ENST00000269601_102407238_77737701 superimposed PDB: 1QGV of partner (TXNL4A). RMSD:0.7706
Å |
 |  |  |  |  |
| MAP4K4_TXNL4A_ENST00000347699_ENST00000269601_102407238_77737701 superimposed PDB: 1QGV of partner (TXNL4A). RMSD:0.7385
Å |
 |  |  |  |  |
| MAP4K4_TXNL4A_ENST00000350198_ENST00000269601_102407238_77737701 superimposed PDB: 1QGV of partner (TXNL4A). RMSD:0.7206
Å |
 |  |  |  |  |
| MAP4K4_TXNL4A_ENST00000456652_ENST00000269601_102407238_77737701 superimposed PDB: 1QGV of partner (TXNL4A). RMSD:0.7459
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000398822_ENST00000247291_22127161_133986983 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.7144
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000398822_ENST00000247291_22127161_133986983 superimposed PDB: 2JJZ of partner (AIF1L). RMSD:2.6139
Å |
| | | |  |
| MAPK1_AIF1L_ENST00000398822_ENST00000372302_22127161_133986983 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.739
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000398822_ENST00000372302_22127161_133986983 superimposed PDB: 2JJZ of partner (AIF1L). RMSD:0.8076
Å |
| | | |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000247291_22127161_133986983 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:1.1114
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000247291_22127161_133986983 superimposed PDB: 2JJZ of partner (AIF1L). RMSD:3.046
Å |
| | | |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000372302_22127161_133986983 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:1.0997
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000372302_22127161_133986983 superimposed PDB: 2JJZ of partner (AIF1L). RMSD:0.8878
Å |
| | | |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000372309_22127161_133986983 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.7026
Å |
 |  |  |  |  |
| MAPK1_AIF1L_ENST00000544786_ENST00000372309_22127161_133986983 superimposed PDB: 2JJZ of partner (AIF1L). RMSD:3.172
Å |
| | | |  |
| MAPK8IP3_TELO2_ENST00000356010_ENST00000262319_1813007_1551663 superimposed PDB: 7F4U of partner (TELO2). RMSD:2.6698
Å |
 |  |  |  |  |
| MAPRE1_KMT2A_ENST00000375571_ENST00000354520_31427662_118354897 superimposed PDB: 2R8U of partner (MAPRE1). RMSD:0.4977
Å |
 |  |  |  |  |
| MAPRE1_KMT2A_ENST00000375571_ENST00000354520_31427662_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:2.0578
Å |
| | | |  |
| MAPRE1_KMT2A_ENST00000375571_ENST00000389506_31427662_118354897 superimposed PDB: 2R8U of partner (MAPRE1). RMSD:0.4239
Å |
 |  |  |  |  |
| MAPRE1_KMT2A_ENST00000375571_ENST00000389506_31427662_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.8484
Å |
| | | |  |
| MAPRE1_USP28_ENST00000375571_ENST00000260188_31427662_113705057 superimposed PDB: 2R8U of partner (MAPRE1). RMSD:0.2692
Å |
 |  |  |  |  |
| MAPRE1_USP28_ENST00000375571_ENST00000260188_31427662_113705057 superimposed PDB: 6H4I of partner (USP28). RMSD:1.4963
Å |
| | | |  |
| MARK2_BUB1B_ENST00000377809_ENST00000412359_63607032_40468677 superimposed PDB: 5EAK of partner (MARK2). RMSD:2.7464
Å |
 |  |  |  |  |
| MARK2_PLA2G16_ENST00000502399_ENST00000415826_63607032_63342518 superimposed PDB: 5EAK of partner (MARK2). RMSD:2.8222
Å |
 |  |  |  |  |
| MARK2_STIP1_ENST00000377809_ENST00000305218_63607032_63960549 superimposed PDB: 7KW7 of partner (STIP1). RMSD:1.4687
Å |
 |  |  |  |  |
| MARK2_STIP1_ENST00000377809_ENST00000543847_63607032_63960549 superimposed PDB: 7KW7 of partner (STIP1). RMSD:1.3791
Å |
 |  |  |  |  |
| MARK2_STIP1_ENST00000402010_ENST00000358794_63607032_63960549 superimposed PDB: 7KW7 of partner (STIP1). RMSD:1.786
Å |
 |  |  |  |  |
| MARK3_EXOSC10_ENST00000416682_ENST00000304457_103928798_11137708 superimposed PDB: 3FE3 of partner (MARK3). RMSD:1.3149
Å |
 |  |  |  |  |
| MARK3_EXOSC10_ENST00000416682_ENST00000376936_103928798_11137708 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.5956
Å |
 |  |  |  |  |
| MARK3_EXOSC10_ENST00000429436_ENST00000304457_103928798_11137708 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.6969
Å |
 |  |  |  |  |
| MARK3_EXOSC10_ENST00000440884_ENST00000376936_103928798_11137708 superimposed PDB: 3FE3 of partner (MARK3). RMSD:1.3771
Å |
 |  |  |  |  |
| MARK3_NDRG2_ENST00000416682_ENST00000403829_103871604_21491480 superimposed PDB: 3FE3 of partner (MARK3). RMSD:0.7291
Å |
 |  |  |  |  |
| MARK3_NDRG2_ENST00000416682_ENST00000403829_103871604_21491480 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.4146
Å |
| | | |  |
| MARS_AVIL_ENST00000262027_ENST00000257861_57894305_58208009 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7565
Å |
 |  |  |  |  |
| MARS_AVIL_ENST00000315473_ENST00000257861_57894305_58208009 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7814
Å |
 |  |  |  |  |
| MARS_AVIL_ENST00000315473_ENST00000537081_57894305_58208009 superimposed PDB: 1UND of partner (AVIL). RMSD:0.7785
Å |
 |  |  |  |  |
| MARS_NOP2_ENST00000262027_ENST00000399466_57898082_6673112 superimposed PDB: 5GL7 of partner (MARS). RMSD:3.2687
Å |
 |  |  |  |  |
| MARS_NOP2_ENST00000262027_ENST00000537442_57898082_6673112 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.1532
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000315970_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.2308
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000315970_57909774_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:0.5942
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000389146_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.0443
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000389146_57909774_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:0.573
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000439210_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.1826
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000262027_ENST00000439210_57909774_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:0.5586
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000315473_ENST00000315970_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.2894
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000315473_ENST00000389146_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.2151
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000315473_ENST00000439210_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.2508
Å |
 |  |  |  |  |
| MARS_OS9_ENST00000315473_ENST00000552285_57894305_58109542 superimposed PDB: 5GL7 of partner (MARS). RMSD:1.0726
Å |
 |  |  |  |  |
| MARS_TMEM120B_ENST00000315473_ENST00000449592_57898082_122181534 superimposed PDB: 5GL7 of partner (MARS). RMSD:3.0956
Å |
 |  |  |  |  |
| MARS_TMEM120B_ENST00000315473_ENST00000449592_57898082_122181534 superimposed PDB: 7F73 of partner (TMEM120B). RMSD:1.2295
Å |
| | | |  |
| MAST2_HP1BP3_ENST00000361297_ENST00000312239_46295253_21076375 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.6875
Å |
 |  |  |  |  |
| MAVS_STK24_ENST00000416600_ENST00000539966_3845435_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5857
Å |
 |  |  |  |  |
| MAVS_STK24_ENST00000428216_ENST00000397517_3845435_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.5418
Å |
 |  |  |  |  |
| MAVS_STK24_ENST00000428216_ENST00000539966_3845435_99171727 superimposed PDB: 2MS7 of partner (MAVS). RMSD:2.0633
Å |
 |  |  |  |  |
| MAVS_STK24_ENST00000428216_ENST00000539966_3845435_99171727 superimposed PDB: 3A7I of partner (STK24). RMSD:0.6045
Å |
| | | |  |
| MAX_ACTN1_ENST00000284165_ENST00000193403_65560425_69392389 superimposed PDB: 1HLO of partner (MAX). RMSD:2.9377
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000284165_ENST00000193403_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3648
Å |
| | | |  |
| MAX_ACTN1_ENST00000341653_ENST00000394419_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.366
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000341653_ENST00000438964_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3733
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000358402_ENST00000193403_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3584
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000358402_ENST00000394419_65560425_69392389 superimposed PDB: 1HLO of partner (MAX). RMSD:3.0906
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000358402_ENST00000394419_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3687
Å |
| | | |  |
| MAX_ACTN1_ENST00000358402_ENST00000438964_65560425_69392389 superimposed PDB: 1HLO of partner (MAX). RMSD:2.9784
Å |
 |  |  |  |  |
| MAX_ACTN1_ENST00000358402_ENST00000438964_65560425_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3673
Å |
| | | |  |
| MAX_VTI1B_ENST00000284165_ENST00000554659_65560425_68126639 superimposed PDB: 1HLO of partner (MAX). RMSD:1.6623
Å |
 |  |  |  |  |
| MAX_VTI1B_ENST00000284165_ENST00000554659_65560425_68126639 superimposed PDB: 2V8S of partner (VTI1B). RMSD:0.5075
Å |
| | | |  |
| MAX_VTI1B_ENST00000358402_ENST00000554659_65560425_68126639 superimposed PDB: 2V8S of partner (VTI1B). RMSD:0.5198
Å |
 |  |  |  |  |
| MB21D1_BTRC_ENST00000370315_ENST00000393441_74161247_103281395 superimposed PDB: 6TTU of partner (BTRC). RMSD:0.8806
Å |
 |  |  |  |  |
| MB21D1_BTRC_ENST00000370318_ENST00000393441_74161247_103281395 superimposed PDB: 6TTU of partner (BTRC). RMSD:0.8514
Å |
 |  |  |  |  |
| MBD2_C18orf42_ENST00000583046_ENST00000580650_51750387_5145754 superimposed PDB: 7AO8 of partner (MBD2). RMSD:0.9495
Å |
 |  |  |  |  |
| MBD2_DOCK2_ENST00000256429_ENST00000540750_51715243_169502950 superimposed PDB: 7AO8 of partner (MBD2). RMSD:0.3787
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000282486_ENST00000251849_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9246
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000282486_ENST00000251849_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8675
Å |
| | | |  |
| MBNL1_RAF1_ENST00000282486_ENST00000442415_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9662
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000282486_ENST00000442415_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8796
Å |
| | | |  |
| MBNL1_RAF1_ENST00000282486_ENST00000442415_152164546_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9732
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000282486_ENST00000442415_152164546_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8243
Å |
| | | |  |
| MBNL1_RAF1_ENST00000282488_ENST00000442415_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9807
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000282488_ENST00000442415_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0173
Å |
| | | |  |
| MBNL1_RAF1_ENST00000324210_ENST00000251849_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3897
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000324210_ENST00000251849_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8474
Å |
| | | |  |
| MBNL1_RAF1_ENST00000355460_ENST00000251849_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9238
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000355460_ENST00000251849_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9101
Å |
| | | |  |
| MBNL1_RAF1_ENST00000493459_ENST00000251849_152164546_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:0.9154
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000493459_ENST00000251849_152164546_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9732
Å |
| | | |  |
| MBNL1_RAF1_ENST00000493459_ENST00000442415_152163328_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3743
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000493459_ENST00000442415_152163328_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.8577
Å |
| | | |  |
| MBNL1_RAF1_ENST00000493459_ENST00000442415_152164546_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3387
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000493459_ENST00000442415_152164546_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9264
Å |
| | | |  |
| MBNL1_RAF1_ENST00000498502_ENST00000251849_152164546_12650422 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.3849
Å |
 |  |  |  |  |
| MBNL1_RAF1_ENST00000498502_ENST00000251849_152164546_12650422 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9121
Å |
| | | |  |
| MBNL1_UBA3_ENST00000282488_ENST00000349511_152018156_69120768 superimposed PDB: 5U6H of partner (MBNL1). RMSD:1.1916
Å |
 |  |  |  |  |
| MBNL1_UBA3_ENST00000282488_ENST00000349511_152018156_69120768 superimposed PDB: 3GZN of partner (UBA3). RMSD:1.3553
Å |
| | | |  |
| MBNL1_UBA3_ENST00000282488_ENST00000415609_152018156_69120768 superimposed PDB: 5U6H of partner (MBNL1). RMSD:2.6405
Å |
 |  |  |  |  |
| MBOAT1_DCDC2_ENST00000324607_ENST00000378454_20126747_24302272 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.8056
Å |
 |  |  |  |  |
| MBOAT1_DCDC2_ENST00000536798_ENST00000378454_20126747_24302272 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.7614
Å |
 |  |  |  |  |
| MBOAT1_F13A1_ENST00000324607_ENST00000264870_20113106_6225093 superimposed PDB: 8CMU of partner (F13A1). RMSD:1.0581
Å |
 |  |  |  |  |
| MBOAT1_FYN_ENST00000324607_ENST00000368678_20212366_111983150 superimposed PDB: 2DQ7 of partner (FYN). RMSD:1.0422
Å |
 |  |  |  |  |
| MBOAT7_FXYD5_ENST00000245615_ENST00000392219_54682481_35651611 superimposed PDB: 8ERC of partner (MBOAT7). RMSD:0.6726
Å |
 |  |  |  |  |
| MBOAT7_FXYD5_ENST00000338624_ENST00000392219_54682481_35651611 superimposed PDB: 8ERC of partner (MBOAT7). RMSD:0.9215
Å |
 |  |  |  |  |
| MBOAT7_TARM1_ENST00000245615_ENST00000432826_54682481_54573414 superimposed PDB: 8ERC of partner (MBOAT7). RMSD:0.7516
Å |
 |  |  |  |  |
| MBOAT7_TARM1_ENST00000338624_ENST00000432826_54682481_54573414 superimposed PDB: 8ERC of partner (MBOAT7). RMSD:0.9119
Å |
 |  |  |  |  |
| MBTD1_SRCIN1_ENST00000415868_ENST00000578925_49270142_36735044 superimposed PDB: 3FEO of partner (MBTD1). RMSD:0.7291
Å |
 |  |  |  |  |
| MBTD1_SYBU_ENST00000415868_ENST00000424158_49284248_110631268 superimposed PDB: 3FEO of partner (MBTD1). RMSD:2.7227
Å |
 |  |  |  |  |
| MBTD1_SYBU_ENST00000415868_ENST00000533895_49284248_110631268 superimposed PDB: 3FEO of partner (MBTD1). RMSD:0.7465
Å |
 |  |  |  |  |
| MCCC2_NNT_ENST00000340941_ENST00000344920_70900295_43675612 superimposed PDB: 1DJL of partner (NNT). RMSD:0.3542
Å |
 |  |  |  |  |
| MCC_PPAP2A_ENST00000302475_ENST00000307259_112630025_54763977 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.5173
Å |
 |  |  |  |  |
| MCFD2_SRBD1_ENST00000409105_ENST00000535761_47134948_45647033 superimposed PDB: 2VRG of partner (MCFD2). RMSD:2.717
Å |
 |  |  |  |  |
| MCFD2_SRBD1_ENST00000409207_ENST00000535761_47134948_45647033 superimposed PDB: 2VRG of partner (MCFD2). RMSD:2.7373
Å |
 |  |  |  |  |
| MCFD2_SRBD1_ENST00000444761_ENST00000535761_47134948_45647033 superimposed PDB: 2VRG of partner (MCFD2). RMSD:2.4233
Å |
 |  |  |  |  |
| MCM5_LYN_ENST00000216122_ENST00000520220_35799535_56910904 superimposed PDB: 3A4O of partner (LYN). RMSD:0.7018
Å |
 |  |  |  |  |
| MCPH1_CSMD1_ENST00000344683_ENST00000400186_6312773_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.6392
Å |
 |  |  |  |  |
| MCPH1_CSMD1_ENST00000344683_ENST00000539096_6312773_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.4056
Å |
 |  |  |  |  |
| MCPH1_CSMD1_ENST00000344683_ENST00000542608_6312773_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.7823
Å |
 |  |  |  |  |
| MCPH1_CSMD1_ENST00000344683_ENST00000602557_6312773_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.8429
Å |
 |  |  |  |  |
| MCTP1_TNC_ENST00000312216_ENST00000350763_94259666_117783546 superimposed PDB: 8FNB of partner (TNC). RMSD:2.9504
Å |
 |  |  |  |  |
| MCU_NFIX_ENST00000357157_ENST00000397661_74452059_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.3935
Å |
 |  |  |  |  |
| MCU_NFIX_ENST00000373053_ENST00000587760_74452059_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5523
Å |
 |  |  |  |  |
| MCU_NFIX_ENST00000373053_ENST00000592199_74452059_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.367
Å |
 |  |  |  |  |
| MDGA1_PTK7_ENST00000297153_ENST00000349241_37623475_43126554 superimposed PDB: 6VG3 of partner (PTK7). RMSD:0.7292
Å |
 |  |  |  |  |
| MDGA2_MTA1_ENST00000399232_ENST00000405646_47351246_105905008 superimposed PDB: 7AO8 of partner (MTA1). RMSD:3.477
Å |
 |  |  |  |  |
| MDGA2_MTA1_ENST00000399232_ENST00000406191_47351246_105905008 superimposed PDB: 7AO8 of partner (MTA1). RMSD:3.5682
Å |
 |  |  |  |  |
| MDGA2_MTA1_ENST00000439988_ENST00000331320_47351246_105905008 superimposed PDB: 7AO8 of partner (MTA1). RMSD:3.5519
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000303145_ENST00000345148_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2303
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000303145_ENST00000346370_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2308
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000303145_ENST00000349029_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2388
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000303145_ENST00000351154_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.9774
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000303145_ENST00000399408_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2061
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000345148_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2639
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000346370_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2534
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000349029_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.239
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000351154_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:1.949
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000399408_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.1729
Å |
 |  |  |  |  |
| MDM1_ABCC1_ENST00000411698_ENST00000399410_68707222_16108347 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.0056
Å |
 |  |  |  |  |
| MDM1_INSR_ENST00000411698_ENST00000302850_68696399_7152938 superimposed PDB: 8U4C of partner (INSR). RMSD:3.0443
Å |
 |  |  |  |  |
| MDM1_PTPRR_ENST00000411698_ENST00000283228_68707222_71158558 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4736
Å |
 |  |  |  |  |
| MDM1_RAP1B_ENST00000303145_ENST00000393436_68707222_69044179 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.5996
Å |
 |  |  |  |  |
| MDM1_RAP1B_ENST00000411698_ENST00000393436_68707222_69044179 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.6214
Å |
 |  |  |  |  |
| MDM2_ANXA2_ENST00000258148_ENST00000451270_69203072_60653253 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3951
Å |
 |  |  |  |  |
| MDM2_ANXA2_ENST00000348801_ENST00000451270_69203072_60653253 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3743
Å |
 |  |  |  |  |
| MDM2_ANXA2_ENST00000462284_ENST00000451270_69203072_60653253 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4429
Å |
 |  |  |  |  |
| MDM2_ANXA2_ENST00000544561_ENST00000451270_69203072_60653253 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3813
Å |
 |  |  |  |  |
| MDM2_ANXA2_ENST00000545204_ENST00000451270_69203072_60653253 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4236
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000265734_69202271_92404145 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.387
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000265734_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.4212
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000424848_69202271_92404145 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3938
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000424848_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3498
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000424848_69207408_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.324
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000424848_69210725_92252400 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.9398
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258148_ENST00000424848_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.4017
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258149_ENST00000265734_69210725_92252400 superimposed PDB: 1BLX of partner (CDK6). RMSD:2.823
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258149_ENST00000265734_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3853
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000258149_ENST00000424848_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.396
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000348801_ENST00000424848_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3379
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000350057_ENST00000265734_69210725_92252400 superimposed PDB: 1BLX of partner (CDK6). RMSD:1.0926
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000350057_ENST00000265734_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3956
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000350057_ENST00000424848_69210725_92252400 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.797
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000350057_ENST00000424848_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.437
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000356290_ENST00000265734_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3989
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000356290_ENST00000265734_69207408_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3632
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000462284_ENST00000424848_69202271_92404145 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3829
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000462284_ENST00000424848_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3978
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000462284_ENST00000424848_69207408_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3721
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000462284_ENST00000424848_69210725_92252400 superimposed PDB: 1BLX of partner (CDK6). RMSD:2.5488
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000462284_ENST00000424848_69222711_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3903
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000544561_ENST00000265734_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3593
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000544561_ENST00000265734_69207408_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3593
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000544561_ENST00000424848_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3294
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000544561_ENST00000424848_69207408_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3588
Å |
 |  |  |  |  |
| MDM2_CDK6_ENST00000545204_ENST00000424848_69203072_92300849 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3673
Å |
 |  |  |  |  |
| MDM2_FN1_ENST00000356290_ENST00000357009_69203072_216299547 superimposed PDB: 1FNF of partner (FN1). RMSD:2.5244
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000258148_ENST00000312442_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6388
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000356290_ENST00000378695_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6322
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000393410_ENST00000378695_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6467
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000462284_ENST00000312442_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6633
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000544561_ENST00000312442_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6355
Å |
 |  |  |  |  |
| MDM2_GLIPR1L1_ENST00000544561_ENST00000378695_69207408_75741401 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.6054
Å |
 |  |  |  |  |
| MDM2_IL22_ENST00000258148_ENST00000538666_69222711_68642656 superimposed PDB: 3DLQ of partner (IL22). RMSD:2.6184
Å |
 |  |  |  |  |
| MDM2_IL22_ENST00000350057_ENST00000538666_69222711_68642656 superimposed PDB: 3DLQ of partner (IL22). RMSD:2.3949
Å |
 |  |  |  |  |
| MDM2_IL26_ENST00000258148_ENST00000229134_69230529_68595863 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.8859
Å |
 |  |  |  |  |
| MDM2_IL26_ENST00000350057_ENST00000229134_69230529_68595863 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.701
Å |
 |  |  |  |  |
| MDM2_IL26_ENST00000360430_ENST00000229134_69230529_68595863 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.9443
Å |
 |  |  |  |  |
| MDM2_IL26_ENST00000540827_ENST00000229134_69230529_68595863 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.8634
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000258148_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5467
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000258149_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5891
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000299252_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5577
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000350057_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5563
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000356290_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5653
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000360430_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5184
Å |
 |  |  |  |  |
| MDM2_PPM1H_ENST00000540827_ENST00000228705_69230529_63195940 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.5587
Å |
 |  |  |  |  |
| MDM2_RAB3IP_ENST00000258148_ENST00000378815_69222711_70178499 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:0.5235
Å |
 |  |  |  |  |
| MDM2_RAB3IP_ENST00000258149_ENST00000378815_69222711_70178499 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:0.4207
Å |
 |  |  |  |  |
| MDM2_RAB3IP_ENST00000350057_ENST00000378815_69222711_70178499 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:0.4176
Å |
 |  |  |  |  |
| MDM2_RAB3IP_ENST00000462284_ENST00000378815_69222711_70178499 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:0.4432
Å |
 |  |  |  |  |
| MDM2_RAP1B_ENST00000258148_ENST00000393436_69207408_69047891 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.546
Å |
 |  |  |  |  |
| MDM2_RAP1B_ENST00000462284_ENST00000393436_69207408_69047891 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.5643
Å |
 |  |  |  |  |
| MDM2_RAP1B_ENST00000544561_ENST00000393436_69207408_69047891 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.5205
Å |
 |  |  |  |  |
| MDN1_CYB5R4_ENST00000369393_ENST00000369679_90482291_84603240 superimposed PDB: 6MV2 of partner (CYB5R4). RMSD:1.0448
Å |
 |  |  |  |  |
| ME1_UBE3D_ENST00000369705_ENST00000369747_84108085_83667169 superimposed PDB: 7X11 of partner (ME1). RMSD:0.6632
Å |
 |  |  |  |  |
| ME2_DCC_ENST00000321341_ENST00000412726_48466756_50831947 superimposed PDB: 1QR6 of partner (ME2). RMSD:1.0593
Å |
 |  |  |  |  |
| ME2_DCC_ENST00000321341_ENST00000412726_48466756_50831947 superimposed PDB: 5X83 of partner (DCC). RMSD:1.3107
Å |
| | | |  |
| ME2_DCC_ENST00000321341_ENST00000581580_48466756_50831947 superimposed PDB: 1QR6 of partner (ME2). RMSD:1.0159
Å |
 |  |  |  |  |
| ME2_DCC_ENST00000321341_ENST00000581580_48466756_50831947 superimposed PDB: 5X83 of partner (DCC). RMSD:0.6557
Å |
| | | |  |
| ME2_NARS_ENST00000382927_ENST00000256854_48443878_55283207 superimposed PDB: 1QR6 of partner (ME2). RMSD:0.9738
Å |
 |  |  |  |  |
| ME2_NARS_ENST00000382927_ENST00000256854_48443878_55283207 superimposed PDB: 8TC8 of partner (NARS). RMSD:0.5137
Å |
| | | |  |
| ME2_RIT2_ENST00000321341_ENST00000589109_48466756_40613832 superimposed PDB: 1QR6 of partner (ME2). RMSD:0.8136
Å |
 |  |  |  |  |
| ME3_SYTL2_ENST00000393324_ENST00000389960_86382803_85411636 superimposed PDB: 8E76 of partner (ME3). RMSD:1.4406
Å |
 |  |  |  |  |
| ME3_TYR_ENST00000393324_ENST00000263321_86382803_88924369 superimposed PDB: 8E76 of partner (ME3). RMSD:1.5188
Å |
 |  |  |  |  |
| MECOM_LMAN2L_ENST00000494292_ENST00000264963_169381123_97400263 superimposed PDB: 6BW3 of partner (MECOM). RMSD:0.8887
Å |
 |  |  |  |  |
| MED10_KIF21A_ENST00000255764_ENST00000361418_6377278_39752175 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.43
Å |
 |  |  |  |  |
| MED10_KIF21A_ENST00000255764_ENST00000395670_6377278_39752175 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4458
Å |
 |  |  |  |  |
| MED10_KIF21A_ENST00000255764_ENST00000541463_6377278_39752175 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4323
Å |
 |  |  |  |  |
| MED10_KIF21A_ENST00000255764_ENST00000544797_6377278_39752175 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4266
Å |
 |  |  |  |  |
| MED13L_LYZ_ENST00000281928_ENST00000549690_116675272_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4053
Å |
 |  |  |  |  |
| MED15_AHRR_ENST00000263205_ENST00000505113_20909435_376724 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.5088
Å |
 |  |  |  |  |
| MED15_AHRR_ENST00000292733_ENST00000316418_20909435_376724 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.4945
Å |
 |  |  |  |  |
| MED15_AHRR_ENST00000406969_ENST00000316418_20909435_376724 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.4545
Å |
 |  |  |  |  |
| MED15_AHRR_ENST00000541476_ENST00000316418_20909435_376724 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.472
Å |
 |  |  |  |  |
| MED15_AHRR_ENST00000541476_ENST00000505113_20909435_376724 superimposed PDB: 5Y7Y of partner (AHRR). RMSD:0.5514
Å |
 |  |  |  |  |
| MED15_BRD1_ENST00000406969_ENST00000404034_20905774_50171461 superimposed PDB: 5PQI of partner (BRD1). RMSD:2.0206
Å |
 |  |  |  |  |
| MED15_BRD1_ENST00000425759_ENST00000404034_20905774_50171461 superimposed PDB: 5PQI of partner (BRD1). RMSD:2.2315
Å |
 |  |  |  |  |
| MED15_BRD1_ENST00000541476_ENST00000404034_20905774_50171461 superimposed PDB: 5PQI of partner (BRD1). RMSD:2.0199
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000263205_ENST00000512215_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3522
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000292733_ENST00000323055_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3559
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000292733_ENST00000394853_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3399
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000406969_ENST00000323055_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3534
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000406969_ENST00000394853_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3291
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000541476_ENST00000323055_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3464
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000541476_ENST00000394853_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3218
Å |
 |  |  |  |  |
| MED15_PPP3CA_ENST00000541476_ENST00000512215_20909435_102117273 superimposed PDB: 1AUI of partner (PPP3CA). RMSD:0.3684
Å |
 |  |  |  |  |
| MED16_CAPN8_ENST00000589119_ENST00000366872_889637_223718212 superimposed PDB: 8TRH of partner (MED16). RMSD:1.1535
Å |
 |  |  |  |  |
| MED16_POLR2E_ENST00000589119_ENST00000215587_879936_1089550 superimposed PDB: 8TRH of partner (MED16). RMSD:1.148
Å |
 |  |  |  |  |
| MED1_ABCC3_ENST00000300651_ENST00000285238_37604050_48733192 superimposed PDB: 8HVH of partner (ABCC3). RMSD:2.4276
Å |
 |  |  |  |  |
| MED1_ABCC3_ENST00000300651_ENST00000285238_37604050_48734062 superimposed PDB: 8HVH of partner (ABCC3). RMSD:2.466
Å |
 |  |  |  |  |
| MED1_ARHGAP23_ENST00000300651_ENST00000431231_37604050_36614345 superimposed PDB: 7EMF of partner (MED1). RMSD:3.4678
Å |
 |  |  |  |  |
| MED1_GDPD1_ENST00000300651_ENST00000284116_37579579_57335111 superimposed PDB: 7EMF of partner (MED1). RMSD:1.5714
Å |
 |  |  |  |  |
| MED1_GDPD1_ENST00000394287_ENST00000581140_37579579_57335111 superimposed PDB: 7EMF of partner (MED1). RMSD:1.6616
Å |
 |  |  |  |  |
| MED1_GDPD1_ENST00000394287_ENST00000581276_37579579_57335111 superimposed PDB: 7EMF of partner (MED1). RMSD:1.5735
Å |
 |  |  |  |  |
| MED1_GSDMB_ENST00000300651_ENST00000360317_37575969_38063240 superimposed PDB: 7EMF of partner (MED1). RMSD:0.7566
Å |
 |  |  |  |  |
| MED1_GSDMB_ENST00000300651_ENST00000360317_37575969_38063240 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.1226
Å |
| | | |  |
| MED1_GSDMB_ENST00000394287_ENST00000394175_37575969_38062524 superimposed PDB: 7EMF of partner (MED1). RMSD:0.7184
Å |
 |  |  |  |  |
| MED1_GSDMB_ENST00000394287_ENST00000394175_37575969_38062524 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.0513
Å |
| | | |  |
| MED1_PIP4K2B_ENST00000300651_ENST00000269554_37607290_36943173 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:0.633
Å |
 |  |  |  |  |
| MED1_RHBDL3_ENST00000394287_ENST00000538145_37604050_30615810 superimposed PDB: 7EMF of partner (MED1). RMSD:2.9436
Å |
 |  |  |  |  |
| MED1_STAG1_ENST00000300651_ENST00000383202_37587367_136221621 superimposed PDB: 7EMF of partner (MED1). RMSD:1.9349
Å |
 |  |  |  |  |
| MED1_STAG1_ENST00000394287_ENST00000236698_37587367_136221621 superimposed PDB: 7EMF of partner (MED1). RMSD:1.9019
Å |
 |  |  |  |  |
| MED20_TLL2_ENST00000409060_ENST00000357947_41884522_98240216 superimposed PDB: 7EMF of partner (MED20). RMSD:1.8072
Å |
 |  |  |  |  |
| MED20_TLL2_ENST00000409312_ENST00000357947_41884522_98240216 superimposed PDB: 7EMF of partner (MED20). RMSD:1.8277
Å |
 |  |  |  |  |
| MED21_LTA4H_ENST00000282892_ENST00000552789_27175554_96394884 superimposed PDB: 3FUN of partner (LTA4H). RMSD:0.4733
Å |
 |  |  |  |  |
| MED21_PIP5K1C_ENST00000282892_ENST00000335312_27175554_3661999 superimposed PDB: 7EMF of partner (MED21). RMSD:0.3032
Å |
 |  |  |  |  |
| MED21_PIP5K1C_ENST00000546323_ENST00000537021_27175554_3661999 superimposed PDB: 7EMF of partner (MED21). RMSD:0.3296
Å |
 |  |  |  |  |
| MED21_PIP5K1C_ENST00000546323_ENST00000539785_27175554_3661999 superimposed PDB: 7EMF of partner (MED21). RMSD:0.327
Å |
 |  |  |  |  |
| MED21_PIP5K1C_ENST00000546323_ENST00000589578_27175554_3661999 superimposed PDB: 7EMF of partner (MED21). RMSD:0.3118
Å |
 |  |  |  |  |
| MED23_ANO2_ENST00000354577_ENST00000546188_131908848_5841796 superimposed PDB: 6H02 of partner (MED23). RMSD:0.9424
Å |
 |  |  |  |  |
| MED23_ANO2_ENST00000368060_ENST00000546188_131908848_5841796 superimposed PDB: 6H02 of partner (MED23). RMSD:1.023
Å |
 |  |  |  |  |
| MED23_KLHL32_ENST00000354577_ENST00000369261_131939546_97489367 superimposed PDB: 6H02 of partner (MED23). RMSD:0.8878
Å |
 |  |  |  |  |
| MED24_IKZF3_ENST00000501516_ENST00000346872_38176525_37949186 superimposed PDB: 7EMF of partner (MED24). RMSD:2.7267
Å |
 |  |  |  |  |
| MED24_IKZF3_ENST00000501516_ENST00000346872_38176525_37949186 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.235
Å |
| | | |  |
| MED24_KRT40_ENST00000394126_ENST00000377755_38209550_39135276 superimposed PDB: 7EMF of partner (MED24). RMSD:0.5385
Å |
 |  |  |  |  |
| MED24_KRT40_ENST00000394126_ENST00000398486_38209550_39135276 superimposed PDB: 7EMF of partner (MED24). RMSD:2.9518
Å |
 |  |  |  |  |
| MED24_KRT40_ENST00000394128_ENST00000398486_38209550_39134548 superimposed PDB: 7EMF of partner (MED24). RMSD:0.3589
Å |
 |  |  |  |  |
| MED24_KRT40_ENST00000501516_ENST00000398486_38209550_39135276 superimposed PDB: 7EMF of partner (MED24). RMSD:2.3619
Å |
 |  |  |  |  |
| MED24_PPP1R1B_ENST00000394127_ENST00000254079_38182408_37791859 superimposed PDB: 7EMF of partner (MED24). RMSD:2.8162
Å |
 |  |  |  |  |
| MED24_PPP1R1B_ENST00000394127_ENST00000580825_38182408_37791859 superimposed PDB: 7EMF of partner (MED24). RMSD:2.8062
Å |
 |  |  |  |  |
| MED24_SLC4A1_ENST00000501516_ENST00000262418_38179383_42328700 superimposed PDB: 7EMF of partner (MED24). RMSD:2.8967
Å |
 |  |  |  |  |
| MED24_SSH2_ENST00000394127_ENST00000540801_38209550_28030080 superimposed PDB: 2NT2 of partner (SSH2). RMSD:0.369
Å |
 |  |  |  |  |
| MED24_TMED10_ENST00000501516_ENST00000303575_38209550_75602589 superimposed PDB: 7EMF of partner (MED24). RMSD:1.0344
Å |
 |  |  |  |  |
| MED25_CCDC155_ENST00000538643_ENST00000447857_50335672_49910142 superimposed PDB: 7EMF of partner (MED25). RMSD:0.4593
Å |
 |  |  |  |  |
| MED25_EEF2_ENST00000538643_ENST00000309311_50339202_3976745 superimposed PDB: 7EMF of partner (MED25). RMSD:0.503
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000312865_ENST00000338033_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:2.4269
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000312865_ENST00000395107_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:0.4601
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000312865_ENST00000395108_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:0.4895
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000538643_ENST00000338033_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:0.4359
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000538643_ENST00000395107_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:1.4508
Å |
 |  |  |  |  |
| MED25_MAPK15_ENST00000538643_ENST00000395108_50335672_144799863 superimposed PDB: 7EMF of partner (MED25). RMSD:1.7048
Å |
 |  |  |  |  |
| MED29_ADAM18_ENST00000315588_ENST00000379866_39884277_39550118 superimposed PDB: 7EMF of partner (MED29). RMSD:1.0146
Å |
 |  |  |  |  |
| MED29_ADAM18_ENST00000594368_ENST00000379866_39884277_39550118 superimposed PDB: 7EMF of partner (MED29). RMSD:0.9786
Å |
 |  |  |  |  |
| MED29_MYO1D_ENST00000315588_ENST00000394649_39884277_31076024 superimposed PDB: 7EMF of partner (MED29). RMSD:1.2724
Å |
 |  |  |  |  |
| MED29_MYO1D_ENST00000594368_ENST00000318217_39884277_31076024 superimposed PDB: 7EMF of partner (MED29). RMSD:0.9101
Å |
 |  |  |  |  |
| MED29_MYO1D_ENST00000594368_ENST00000394649_39884277_31076024 superimposed PDB: 7EMF of partner (MED29). RMSD:0.8831
Å |
 |  |  |  |  |
| MED29_MYO1D_ENST00000599213_ENST00000318217_39884277_31076024 superimposed PDB: 7EMF of partner (MED29). RMSD:1.0847
Å |
 |  |  |  |  |
| MED29_TXN_ENST00000315588_ENST00000374517_39884277_113007123 superimposed PDB: 7EMF of partner (MED29). RMSD:0.6633
Å |
 |  |  |  |  |
| MED29_TXN_ENST00000594368_ENST00000374517_39884277_113007123 superimposed PDB: 7EMF of partner (MED29). RMSD:0.6911
Å |
 |  |  |  |  |
| MED31_CHMP1A_ENST00000575197_ENST00000253475_6553675_89713739 superimposed PDB: 7EMF of partner (MED31). RMSD:0.9606
Å |
 |  |  |  |  |
| MED31_FBXW10_ENST00000225728_ENST00000301938_6553675_18651253 superimposed PDB: 7EMF of partner (MED31). RMSD:1.4155
Å |
 |  |  |  |  |
| MED31_FBXW10_ENST00000225728_ENST00000308799_6553675_18651253 superimposed PDB: 7EMF of partner (MED31). RMSD:2.048
Å |
 |  |  |  |  |
| MED31_FBXW10_ENST00000225728_ENST00000395665_6553675_18651253 superimposed PDB: 7EMF of partner (MED31). RMSD:1.4331
Å |
 |  |  |  |  |
| MED31_FBXW10_ENST00000575197_ENST00000395667_6553675_18651253 superimposed PDB: 7EMF of partner (MED31). RMSD:2.2752
Å |
 |  |  |  |  |
| MED4_HTR2A_ENST00000258648_ENST00000542664_48653979_47409774 superimposed PDB: 7EMF of partner (MED4). RMSD:2.5276
Å |
 |  |  |  |  |
| MED4_HTR2A_ENST00000258648_ENST00000542664_48653979_47409774 superimposed PDB: 9AS8 of partner (HTR2A). RMSD:1.7283
Å |
| | | |  |
| MED4_HTR2A_ENST00000378586_ENST00000542664_48653979_47409774 superimposed PDB: 7EMF of partner (MED4). RMSD:3.1027
Å |
 |  |  |  |  |
| MED4_HTR2A_ENST00000378586_ENST00000542664_48653979_47409774 superimposed PDB: 9AS8 of partner (HTR2A). RMSD:1.8073
Å |
| | | |  |
| MED6_MAP3K9_ENST00000256379_ENST00000554752_71063327_71227899 superimposed PDB: 4UY9 of partner (MAP3K9). RMSD:0.8307
Å |
 |  |  |  |  |
| MED6_MAP3K9_ENST00000554963_ENST00000555993_71063327_71227899 superimposed PDB: 4UY9 of partner (MAP3K9). RMSD:0.7689
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000340875_ENST00000336761_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.4649
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000340875_ENST00000336761_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.3376
Å |
| | | |  |
| MEF2D_DAZAP1_ENST00000348159_ENST00000233078_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.5356
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000348159_ENST00000233078_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.2964
Å |
| | | |  |
| MEF2D_DAZAP1_ENST00000348159_ENST00000336761_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.4707
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000348159_ENST00000336761_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.3325
Å |
| | | |  |
| MEF2D_DAZAP1_ENST00000353795_ENST00000233078_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.4482
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000353795_ENST00000233078_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.3832
Å |
| | | |  |
| MEF2D_DAZAP1_ENST00000353795_ENST00000336761_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.5332
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000353795_ENST00000336761_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.2073
Å |
| | | |  |
| MEF2D_DAZAP1_ENST00000464356_ENST00000233078_156449081_1425876 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.4702
Å |
 |  |  |  |  |
| MEF2D_DAZAP1_ENST00000464356_ENST00000233078_156449081_1425876 superimposed PDB: 2DH8 of partner (DAZAP1). RMSD:1.4095
Å |
| | | |  |
| MEF2D_HNRNPUL1_ENST00000340875_ENST00000392006_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7653
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000340875_ENST00000593587_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7415
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000340875_ENST00000595018_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7211
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000348159_ENST00000392006_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.5775
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000348159_ENST00000593587_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7461
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000348159_ENST00000595018_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7683
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000353795_ENST00000392006_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.6536
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000353795_ENST00000593587_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.6288
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000353795_ENST00000595018_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.6112
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000368240_ENST00000392006_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.5767
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000368240_ENST00000593587_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.5637
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000368240_ENST00000595018_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.8163
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000464356_ENST00000352456_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.519
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000464356_ENST00000392006_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.513
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000464356_ENST00000593587_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.6884
Å |
 |  |  |  |  |
| MEF2D_HNRNPUL1_ENST00000464356_ENST00000595018_156444899_41808569 superimposed PDB: 7X1N of partner (MEF2D). RMSD:0.7205
Å |
 |  |  |  |  |
| MEGF8_ITPKC_ENST00000251268_ENST00000263370_42875634_41231244 superimposed PDB: 2A98 of partner (ITPKC). RMSD:0.8949
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000398506_ENST00000306867_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.6073
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000398506_ENST00000371459_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5888
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000407092_ENST00000371460_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5801
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000407092_ENST00000371460_66739426_44900500 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:3.2386
Å |
| | | |  |
| MEIS1_SUPT3H_ENST00000495021_ENST00000306867_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.6448
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000495021_ENST00000371459_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.6179
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000495021_ENST00000371460_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5638
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000495021_ENST00000371460_66739426_44900500 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:3.0134
Å |
| | | |  |
| MEIS1_SUPT3H_ENST00000560281_ENST00000306867_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5617
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000560281_ENST00000371459_66739426_44900500 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.6081
Å |
 |  |  |  |  |
| MEIS1_SUPT3H_ENST00000560281_ENST00000371459_66739426_44900500 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:3.3094
Å |
| | | |  |
| MEIS2_BBS2_ENST00000219869_ENST00000568104_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4635
Å |
 |  |  |  |  |
| MEIS2_BBS2_ENST00000338564_ENST00000245157_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:2.4543
Å |
 |  |  |  |  |
| MEIS2_BBS2_ENST00000338564_ENST00000561951_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:2.4853
Å |
 |  |  |  |  |
| MEIS2_BBS2_ENST00000338564_ENST00000568104_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3349
Å |
 |  |  |  |  |
| MEIS2_BBS2_ENST00000397624_ENST00000568104_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4693
Å |
 |  |  |  |  |
| MEIS2_BBS2_ENST00000444725_ENST00000568104_37242524_56545190 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4641
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000219869_ENST00000338183_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4261
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000219869_ENST00000437989_37242524_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3018
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000338564_ENST00000338183_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3691
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000338564_ENST00000437989_37242524_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.2906
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000340545_ENST00000437989_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4332
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000340545_ENST00000562877_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4282
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000397620_ENST00000569302_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4714
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000397624_ENST00000338183_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3482
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000397624_ENST00000437989_37242524_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3075
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000397624_ENST00000567389_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4109
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000557796_ENST00000338183_37242524_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3147
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000559085_ENST00000566621_37242524_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3122
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000559085_ENST00000567389_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3859
Å |
 |  |  |  |  |
| MEIS2_C15orf41_ENST00000561208_ENST00000562877_37329014_37100524 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3597
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000356338_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.6239
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000356338_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.5235
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000358212_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:1.3196
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000358212_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.511
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000399233_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:1.0634
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000399233_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.5015
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000553916_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:1.672
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000340545_ENST00000553916_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.4937
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000382766_ENST00000399231_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.715
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000382766_ENST00000399231_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.5403
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000559561_ENST00000399231_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:1.0419
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000559561_ENST00000399231_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.477
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000356338_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.6078
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000356338_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.4866
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000358212_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.5735
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000358212_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.4846
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000399233_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.5549
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000399233_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.5019
Å |
| | | |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000553916_37329014_52664560 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.6428
Å |
 |  |  |  |  |
| MEIS2_MYO5A_ENST00000561208_ENST00000553916_37329014_52664560 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.4824
Å |
| | | |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000491071_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7788
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000491071_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7907
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000517960_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7755
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000517960_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7856
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000520567_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7964
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000520567_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7825
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000521978_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7907
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000521978_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7779
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000522291_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.797
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000397620_ENST00000522291_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.775
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000264839_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7756
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000264839_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7866
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000348717_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7853
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000348717_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7721
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000517960_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7974
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000517960_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7712
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000518273_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7778
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000518273_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.767
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000520567_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7912
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000520567_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.8664
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000521978_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7708
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000521978_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.782
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000522291_37329014_72678685 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7836
Å |
 |  |  |  |  |
| MEIS2_RIMS1_ENST00000557796_ENST00000522291_37329014_72806651 superimposed PDB: 2CSS of partner (RIMS1). RMSD:0.7797
Å |
 |  |  |  |  |
| MEIS2_ZNF143_ENST00000340545_ENST00000396597_37329014_9516192 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3935
Å |
 |  |  |  |  |
| MEIS2_ZNF143_ENST00000340545_ENST00000396602_37329014_9516192 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.4157
Å |
 |  |  |  |  |
| MEIS2_ZNF143_ENST00000561208_ENST00000396597_37329014_9516192 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.7051
Å |
 |  |  |  |  |
| MEIS2_ZNF143_ENST00000561208_ENST00000396602_37329014_9516192 superimposed PDB: 3K2A of partner (MEIS2). RMSD:0.3915
Å |
 |  |  |  |  |
| MEMO1_KCNB1_ENST00000426310_ENST00000371741_32235255_47991529 superimposed PDB: 9O10 of partner (KCNB1). RMSD:1.8345
Å |
 |  |  |  |  |
| MEMO1_TRIB2_ENST00000426310_ENST00000155926_32235255_12863385 superimposed PDB: 7UPM of partner (TRIB2). RMSD:0.3529
Å |
 |  |  |  |  |
| MEN1_PTPRJ_ENST00000315422_ENST00000418331_64577136_48149331 superimposed PDB: 8GPN of partner (MEN1). RMSD:1.9936
Å |
 |  |  |  |  |
| MEN1_PTPRJ_ENST00000315422_ENST00000418331_64577136_48149331 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:1.5639
Å |
| | | |  |
| MEN1_PTPRJ_ENST00000315422_ENST00000440289_64577136_48149331 superimposed PDB: 8GPN of partner (MEN1). RMSD:2.466
Å |
 |  |  |  |  |
| MEN1_PTPRJ_ENST00000315422_ENST00000440289_64577136_48149331 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:1.5994
Å |
| | | |  |
| MEN1_PTPRJ_ENST00000377321_ENST00000440289_64577136_48149331 superimposed PDB: 8GPN of partner (MEN1). RMSD:2.2283
Å |
 |  |  |  |  |
| MEN1_PTPRJ_ENST00000377321_ENST00000440289_64577136_48149331 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:1.8014
Å |
| | | |  |
| METAP1_SET_ENST00000296411_ENST00000372692_99970027_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:3.4022
Å |
 |  |  |  |  |
| METAP1_SET_ENST00000296411_ENST00000409104_99970027_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.4258
Å |
 |  |  |  |  |
| METAP1_SET_ENST00000544031_ENST00000409104_99970027_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.3731
Å |
 |  |  |  |  |
| METTL21B_LYZ_ENST00000300209_ENST00000261267_58166911_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.9554
Å |
 |  |  |  |  |
| METTL21B_LYZ_ENST00000300209_ENST00000549690_58166911_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5917
Å |
 |  |  |  |  |
| METTL21B_LYZ_ENST00000333012_ENST00000261267_58166911_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5869
Å |
 |  |  |  |  |
| METTL21B_LYZ_ENST00000548256_ENST00000549690_58166911_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4837
Å |
 |  |  |  |  |
| METTL25_ATP2B1_ENST00000248306_ENST00000261173_82793173_90005149 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:2.0286
Å |
 |  |  |  |  |
| METTL25_ATP2B1_ENST00000248306_ENST00000359142_82793173_90005149 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:1.9571
Å |
 |  |  |  |  |
| METTL25_ATP2B1_ENST00000248306_ENST00000428670_82793173_90005149 superimposed PDB: 6A69 of partner (ATP2B1). RMSD:1.8871
Å |
 |  |  |  |  |
| MET_C8orf34_ENST00000318493_ENST00000518698_116412043_69358563 superimposed PDB: 7MO9 of partner (MET). RMSD:0.9373
Å |
 |  |  |  |  |
| MET_C8orf34_ENST00000397752_ENST00000518698_116412043_69358563 superimposed PDB: 7MO9 of partner (MET). RMSD:0.9181
Å |
 |  |  |  |  |
| MFN1_ZNF792_ENST00000263969_ENST00000404801_179096602_35451898 superimposed PDB: 5GOE of partner (MFN1). RMSD:2.4195
Å |
 |  |  |  |  |
| MFSD10_ZDHHC6_ENST00000514800_ENST00000369404_2934832_114193039 superimposed PDB: 6S4M of partner (MFSD10). RMSD:2.2785
Å |
 |  |  |  |  |
| MFSD2A_ATF6_ENST00000372809_ENST00000367942_40431686_161789422 superimposed PDB: 7OIX of partner (MFSD2A). RMSD:1.0999
Å |
 |  |  |  |  |
| MFSD2A_ATF6_ENST00000420632_ENST00000367942_40431686_161789422 superimposed PDB: 7OIX of partner (MFSD2A). RMSD:0.6664
Å |
 |  |  |  |  |
| MGAT4A_MGAT4B_ENST00000264968_ENST00000292591_99261890_179226636 superimposed PDB: 7XTL of partner (MGAT4A). RMSD:0.5719
Å |
 |  |  |  |  |
| MGAT4A_MGAT4B_ENST00000414521_ENST00000292591_99261890_179226636 superimposed PDB: 7XTL of partner (MGAT4A). RMSD:0.5521
Å |
 |  |  |  |  |
| MGA_PLA2G4D_ENST00000219905_ENST00000290472_42042813_42373331 superimposed PDB: 5IZ5 of partner (PLA2G4D). RMSD:3.1495
Å |
 |  |  |  |  |
| MGA_PLA2G4D_ENST00000389936_ENST00000290472_42042813_42373331 superimposed PDB: 5IZ5 of partner (PLA2G4D). RMSD:2.882
Å |
 |  |  |  |  |
| MGLL_MICU1_ENST00000434178_ENST00000361114_127429418_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.5581
Å |
 |  |  |  |  |
| MGLL_MICU1_ENST00000434178_ENST00000398761_127429418_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.6011
Å |
 |  |  |  |  |
| MGMT_NPTN_ENST00000306010_ENST00000351217_131334641_73879959 superimposed PDB: 6A69 of partner (NPTN). RMSD:0.8009
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000262370_ENST00000539790_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:2.0303
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000262370_ENST00000540499_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:1.9258
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000415496_ENST00000539790_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:2.0878
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000415496_ENST00000540499_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:1.9477
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000588994_ENST00000539790_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:2.1118
Å |
 |  |  |  |  |
| MGRN1_IDH2_ENST00000588994_ENST00000540499_4715152_90630807 superimposed PDB: 5I96 of partner (IDH2). RMSD:2.0011
Å |
 |  |  |  |  |
| MIA_TTC28_ENST00000597784_ENST00000397906_41282984_28397541 superimposed PDB: 1I1J of partner (MIA). RMSD:0.3797
Å |
 |  |  |  |  |
| MIB1_HLTF_ENST00000261537_ENST00000494055_19353689_148802676 superimposed PDB: 4S0N of partner (HLTF). RMSD:0.4755
Å |
 |  |  |  |  |
| MIB1_MYO5B_ENST00000261537_ENST00000324581_19438607_47406825 superimposed PDB: 4XI6 of partner (MIB1). RMSD:3.0514
Å |
 |  |  |  |  |
| MIB1_MYO5B_ENST00000261537_ENST00000324581_19438607_47406825 superimposed PDB: 4J5M of partner (MYO5B). RMSD:0.4599
Å |
| | | |  |
| MICAL2_RRAS2_ENST00000537344_ENST00000414023_12261132_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5247
Å |
 |  |  |  |  |
| MICAL3_BID_ENST00000414725_ENST00000317361_18368643_18226779 superimposed PDB: 6ICI of partner (MICAL3). RMSD:1.1147
Å |
 |  |  |  |  |
| MICALL1_RBM39_ENST00000215957_ENST00000361162_38333799_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7045
Å |
 |  |  |  |  |
| MICALL1_RBM39_ENST00000215957_ENST00000528062_38333799_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7141
Å |
 |  |  |  |  |
| MICALL2_CA3_ENST00000297508_ENST00000285381_1481827_86354301 superimposed PDB: 3UYQ of partner (CA3). RMSD:0.5959
Å |
 |  |  |  |  |
| MICU1_ARHGAP22_ENST00000361114_ENST00000417247_74167686_49654662 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.1775
Å |
 |  |  |  |  |
| MICU1_ARHGAP22_ENST00000398761_ENST00000417247_74167686_49654662 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.1575
Å |
 |  |  |  |  |
| MICU1_ARHGAP22_ENST00000398763_ENST00000435790_74167686_49654662 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.2079
Å |
 |  |  |  |  |
| MICU1_ARHGAP22_ENST00000418483_ENST00000249601_74167686_49654662 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.1804
Å |
 |  |  |  |  |
| MICU1_ARHGAP22_ENST00000418483_ENST00000435790_74167686_49654662 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.1379
Å |
 |  |  |  |  |
| MICU1_DNAJB12_ENST00000361114_ENST00000338820_74234857_74096454 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.5084
Å |
 |  |  |  |  |
| MICU1_DNAJB12_ENST00000398761_ENST00000338820_74234857_74096454 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.4992
Å |
 |  |  |  |  |
| MICU1_DNAJB12_ENST00000401998_ENST00000338820_74234857_74096454 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.501
Å |
 |  |  |  |  |
| MICU1_DNAJB12_ENST00000401998_ENST00000394903_74234857_74096454 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.9783
Å |
 |  |  |  |  |
| MICU1_DNAJB12_ENST00000401998_ENST00000394903_74234857_74096454 superimposed PDB: 2CTP of partner (DNAJB12). RMSD:2.6927
Å |
| | | |  |
| MICU1_PLA2G12B_ENST00000398763_ENST00000373032_74182991_74701092 superimposed PDB: 6K7Y of partner (MICU1). RMSD:2.0871
Å |
 |  |  |  |  |
| MICU1_TSPAN15_ENST00000398763_ENST00000373290_74234857_71243446 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.5277
Å |
 |  |  |  |  |
| MICU1_TSPAN15_ENST00000398763_ENST00000373290_74234857_71243446 superimposed PDB: 8ESV of partner (TSPAN15). RMSD:1.6005
Å |
| | | |  |
| MICU3_TGFBR3_ENST00000318063_ENST00000370399_16885169_92200516 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.4129
Å |
 |  |  |  |  |
| MICU3_TGFBR3_ENST00000318063_ENST00000525962_16885169_92200516 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.2336
Å |
 |  |  |  |  |
| MID1_SPAG17_ENST00000380779_ENST00000336338_10450519_118598537 superimposed PDB: 7QRY of partner (MID1). RMSD:2.8633
Å |
 |  |  |  |  |
| MIDN_ABCA7_ENST00000300952_ENST00000433129_1251900_1061780 superimposed PDB: 8Y1P of partner (ABCA7). RMSD:2.3145
Å |
 |  |  |  |  |
| MIDN_ABCA7_ENST00000591446_ENST00000263094_1251900_1061780 superimposed PDB: 8Y1P of partner (ABCA7). RMSD:2.1667
Å |
 |  |  |  |  |
| MINK1_ALOX12_ENST00000347992_ENST00000251535_4736935_6903654 superimposed PDB: 8GHE of partner (ALOX12). RMSD:0.5408
Å |
 |  |  |  |  |
| MINK1_USO1_ENST00000355280_ENST00000514213_4736935_76720774 superimposed PDB: 2W3C of partner (USO1). RMSD:0.3866
Å |
 |  |  |  |  |
| MINK1_USO1_ENST00000453408_ENST00000514213_4736935_76720774 superimposed PDB: 2W3C of partner (USO1). RMSD:0.3885
Å |
 |  |  |  |  |
| MIOS_ADAP1_ENST00000405785_ENST00000265846_7613827_975141 superimposed PDB: 9LWF of partner (MIOS). RMSD:2.8377
Å |
 |  |  |  |  |
| MIOS_ADAP1_ENST00000405785_ENST00000265846_7613827_975141 superimposed PDB: 3FM8 of partner (ADAP1). RMSD:0.815
Å |
| | | |  |
| MKLN1_CDK14_ENST00000352689_ENST00000265741_131082135_90376995 superimposed PDB: 8TTQ of partner (MKLN1). RMSD:2.7768
Å |
 |  |  |  |  |
| MKLN1_CDK14_ENST00000421797_ENST00000265741_131082135_90376995 superimposed PDB: 8TTQ of partner (MKLN1). RMSD:2.8685
Å |
 |  |  |  |  |
| MKLN1_CDK14_ENST00000429546_ENST00000265741_131082135_90376995 superimposed PDB: 8TTQ of partner (MKLN1). RMSD:3.0226
Å |
 |  |  |  |  |
| MKNK2_RNF126_ENST00000591588_ENST00000292363_2041838_652884 superimposed PDB: 2AC3 of partner (MKNK2). RMSD:0.8808
Å |
 |  |  |  |  |
| MKNK2_RNF126_ENST00000591601_ENST00000292363_2041838_652884 superimposed PDB: 2AC3 of partner (MKNK2). RMSD:2.2882
Å |
 |  |  |  |  |
| MKNK2_RNF126_ENST00000591601_ENST00000292363_2041838_652884 superimposed PDB: 2N9O of partner (RNF126). RMSD:2.4259
Å |
| | | |  |
| MKRN2_SCN10A_ENST00000411987_ENST00000449082_12611751_38763903 superimposed PDB: 7WE4 of partner (SCN10A). RMSD:1.3977
Å |
 |  |  |  |  |
| MKRN2_SCN10A_ENST00000448482_ENST00000449082_12611751_38763903 superimposed PDB: 7WE4 of partner (SCN10A). RMSD:1.3351
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000346832_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5633
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000355394_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6153
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000359188_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5865
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376134_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5873
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376134_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.9303
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376138_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5724
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376139_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5781
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376139_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0216
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376140_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6067
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376140_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.2043
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376142_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5933
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376160_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5816
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376160_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.246
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376166_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5987
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376166_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3184
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000376170_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6225
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000490841_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000490841_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7705
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377059_ENST00000536334_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5762
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377059_ENST00000536334_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.9635
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377072_ENST00000376170_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6024
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377072_ENST00000376170_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.1616
Å |
| | | |  |
| MLLT10_ABI1_ENST00000377100_ENST00000376170_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5944
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000377100_ENST00000376170_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.8474
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000346832_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5915
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000346832_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:2.0321
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000355394_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6044
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000359188_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6023
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376134_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5634
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376138_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5481
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376139_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5971
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376139_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376140_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6053
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376140_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.0101
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376142_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5847
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376142_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.4856
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376160_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5839
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376166_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.602
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000376166_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7886
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000490841_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6001
Å |
 |  |  |  |  |
| MLLT10_ABI1_ENST00000446906_ENST00000490841_21827841_27112234 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5267
Å |
| | | |  |
| MLLT10_ABI1_ENST00000446906_ENST00000536334_21827841_27112234 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5941
Å |
 |  |  |  |  |
| MLLT10_CCNT1_ENST00000377072_ENST00000261900_21827841_49099679 superimposed PDB: 6GZH of partner (CCNT1). RMSD:2.4879
Å |
 |  |  |  |  |
| MLLT10_CCNT1_ENST00000377100_ENST00000261900_21827841_49099679 superimposed PDB: 6GZH of partner (CCNT1). RMSD:2.6387
Å |
 |  |  |  |  |
| MLLT10_DNAJC1_ENST00000307729_ENST00000376980_22002879_22193541 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4165
Å |
 |  |  |  |  |
| MLLT10_DNAJC1_ENST00000307729_ENST00000376980_22002879_22193541 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.3282
Å |
| | | |  |
| MLLT10_DNAJC1_ENST00000377072_ENST00000376980_22002879_22193541 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4158
Å |
 |  |  |  |  |
| MLLT10_DNAJC1_ENST00000377072_ENST00000376980_22002879_22193541 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.2937
Å |
| | | |  |
| MLLT10_PICALM_ENST00000377059_ENST00000356360_21827841_85670103 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.471
Å |
 |  |  |  |  |
| MLLT10_PICALM_ENST00000377059_ENST00000356360_21906136_85670103 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4441
Å |
 |  |  |  |  |
| MLLT10_PICALM_ENST00000377059_ENST00000526033_21827841_85685855 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6211
Å |
 |  |  |  |  |
| MLLT10_PICALM_ENST00000446906_ENST00000356360_21827841_85670103 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4559
Å |
 |  |  |  |  |
| MLLT10_PICALM_ENST00000446906_ENST00000356360_21906136_85670103 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4187
Å |
 |  |  |  |  |
| MLLT10_PICALM_ENST00000446906_ENST00000526033_21827841_85685855 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6449
Å |
 |  |  |  |  |
| MLLT10_PPP2R1B_ENST00000377059_ENST00000426998_21940697_111626174 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4379
Å |
 |  |  |  |  |
| MLLT10_PPP2R1B_ENST00000377059_ENST00000426998_21940697_111626174 superimposed PDB: 9MF5 of partner (PPP2R1B). RMSD:0.9213
Å |
| | | |  |
| MLLT10_PPP2R1B_ENST00000446906_ENST00000426998_21940697_111626174 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4439
Å |
 |  |  |  |  |
| MLLT10_PPP2R1B_ENST00000446906_ENST00000426998_21940697_111626174 superimposed PDB: 9MF5 of partner (PPP2R1B). RMSD:1.0217
Å |
| | | |  |
| MLLT10_SNTG1_ENST00000307729_ENST00000522124_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4318
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000377059_ENST00000276467_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4423
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000377059_ENST00000522124_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4472
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000377072_ENST00000276467_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.412
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000377072_ENST00000522124_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4436
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000446906_ENST00000276467_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4223
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000446906_ENST00000518864_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4242
Å |
 |  |  |  |  |
| MLLT10_SNTG1_ENST00000446906_ENST00000522124_22024164_51415337 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4427
Å |
 |  |  |  |  |
| MLLT10_USP15_ENST00000377059_ENST00000280377_21940697_62777620 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4789
Å |
 |  |  |  |  |
| MLLT10_USP15_ENST00000377059_ENST00000280377_21940697_62777620 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5244
Å |
| | | |  |
| MLLT10_USP15_ENST00000446906_ENST00000280377_21940697_62777620 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.442
Å |
 |  |  |  |  |
| MLLT10_USP15_ENST00000446906_ENST00000280377_21940697_62777620 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5481
Å |
| | | |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000354520_6222131_118354897 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5695
Å |
 |  |  |  |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000354520_6222131_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9898
Å |
| | | |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000354520_6262238_118354897 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.6576
Å |
 |  |  |  |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000354520_6262238_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9863
Å |
| | | |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000389506_6222131_118354897 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.7154
Å |
 |  |  |  |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000389506_6222131_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.9121
Å |
| | | |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000389506_6262238_118354897 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.8894
Å |
 |  |  |  |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000389506_6262238_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:2.1172
Å |
| | | |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000534358_6262238_118354897 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5987
Å |
 |  |  |  |  |
| MLLT1_KMT2A_ENST00000252674_ENST00000534358_6262238_118354897 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.6859
Å |
| | | |  |
| MLLT1_MAD1L1_ENST00000252674_ENST00000399654_6230580_2041756 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5026
Å |
 |  |  |  |  |
| MLLT1_MAD1L1_ENST00000252674_ENST00000399654_6230580_2041756 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:0.9932
Å |
| | | |  |
| MLLT3_IZUMO3_ENST00000380338_ENST00000543880_20620652_24545059 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.5111
Å |
 |  |  |  |  |
| MLLT3_IZUMO3_ENST00000380338_ENST00000604921_20620652_24545059 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.9706
Å |
 |  |  |  |  |
| MLLT3_IZUMO3_ENST00000429426_ENST00000543880_20620652_24545059 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:2.1141
Å |
 |  |  |  |  |
| MLLT3_IZUMO3_ENST00000429426_ENST00000604921_20620652_24545059 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:1.0425
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000354520_20413718_118360506 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6352
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000354520_20413718_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.5191
Å |
| | | |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000389506_20413718_118360506 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6015
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000389506_20413718_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.4605
Å |
| | | |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000534358_20413718_118360506 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.5311
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000380338_ENST00000534358_20413718_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.6787
Å |
| | | |  |
| MLLT3_KMT2A_ENST00000429426_ENST00000354520_20413718_118360506 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6764
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000429426_ENST00000354520_20413718_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7611
Å |
| | | |  |
| MLLT3_KMT2A_ENST00000429426_ENST00000389506_20413718_118360506 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.6418
Å |
 |  |  |  |  |
| MLLT3_KMT2A_ENST00000429426_ENST00000389506_20413718_118360506 superimposed PDB: 3LQH of partner (KMT2A). RMSD:1.7306
Å |
| | | |  |
| MLLT3_SLC28A3_ENST00000429426_ENST00000376238_20456701_86928369 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.4926
Å |
 |  |  |  |  |
| MLLT3_SLC28A3_ENST00000429426_ENST00000376238_20456701_86928369 superimposed PDB: 6KSW of partner (SLC28A3). RMSD:0.9541
Å |
| | | |  |
| MLLT3_SOD2_ENST00000380338_ENST00000538183_20620652_160109274 superimposed PDB: 8SKS of partner (SOD2). RMSD:0.3806
Å |
 |  |  |  |  |
| MLLT3_SOD2_ENST00000380338_ENST00000546087_20620652_160109274 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:3.3556
Å |
 |  |  |  |  |
| MLLT3_SOD2_ENST00000429426_ENST00000538183_20620652_160109274 superimposed PDB: 8SKS of partner (SOD2). RMSD:0.3857
Å |
 |  |  |  |  |
| MLYCD_MGRN1_ENST00000262430_ENST00000399577_83945972_4718265 superimposed PDB: 4F0X of partner (MLYCD). RMSD:1.3918
Å |
 |  |  |  |  |
| MLYCD_MGRN1_ENST00000262430_ENST00000415496_83945972_4718265 superimposed PDB: 4F0X of partner (MLYCD). RMSD:1.3858
Å |
 |  |  |  |  |
| MLYCD_MGRN1_ENST00000262430_ENST00000586183_83945972_4718265 superimposed PDB: 4F0X of partner (MLYCD). RMSD:1.4041
Å |
 |  |  |  |  |
| MLYCD_MGRN1_ENST00000262430_ENST00000588994_83945972_4718265 superimposed PDB: 4F0X of partner (MLYCD). RMSD:1.4716
Å |
 |  |  |  |  |
| MMACHC_CSNK1D_ENST00000401061_ENST00000314028_45966085_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.4888
Å |
 |  |  |  |  |
| MMACHC_CSNK1D_ENST00000401061_ENST00000392334_45966085_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.503
Å |
 |  |  |  |  |
| MME_PGK1_ENST00000492661_ENST00000442431_154860119_77378691 superimposed PDB: 6SUK of partner (MME). RMSD:2.0527
Å |
 |  |  |  |  |
| MME_PGK1_ENST00000492661_ENST00000442431_154860119_77378691 superimposed PDB: 9FDF of partner (PGK1). RMSD:2.6455
Å |
| | | |  |
| MMP2_DYNC1LI2_ENST00000219070_ENST00000379482_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.0336
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000219070_ENST00000443351_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.2283
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000437642_ENST00000379482_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.0493
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000437642_ENST00000443351_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.057
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000543485_ENST00000379482_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.0991
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000543485_ENST00000443351_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:1.9928
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000570308_ENST00000379482_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:1.9803
Å |
 |  |  |  |  |
| MMP2_DYNC1LI2_ENST00000570308_ENST00000443351_55536800_66770147 superimposed PDB: 1CK7 of partner (MMP2). RMSD:2.0156
Å |
 |  |  |  |  |
| MMP2_MMP25_ENST00000219070_ENST00000336577_55536800_3108827 superimposed PDB: 1CK7 of partner (MMP2). RMSD:1.2769
Å |
 |  |  |  |  |
| MMP2_MMP25_ENST00000437642_ENST00000336577_55536800_3108827 superimposed PDB: 1CK7 of partner (MMP2). RMSD:1.2441
Å |
 |  |  |  |  |
| MMP2_MMP25_ENST00000543485_ENST00000336577_55536800_3108827 superimposed PDB: 1CK7 of partner (MMP2). RMSD:1.8678
Å |
 |  |  |  |  |
| MMS22L_REV1_ENST00000275053_ENST00000258428_97599646_100065966 superimposed PDB: 3GQC of partner (REV1). RMSD:0.8886
Å |
 |  |  |  |  |
| MNS1_NEDD4_ENST00000260453_ENST00000338963_56735627_56134361 superimposed PDB: 2XBF of partner (NEDD4). RMSD:1.0274
Å |
 |  |  |  |  |
| MNS1_NEDD4_ENST00000260453_ENST00000338963_56735627_56139232 superimposed PDB: 2XBF of partner (NEDD4). RMSD:0.8412
Å |
 |  |  |  |  |
| MOB3B_TEK_ENST00000262244_ENST00000380036_27455130_27172613 superimposed PDB: 4K0V of partner (TEK). RMSD:2.8757
Å |
 |  |  |  |  |
| MOB3B_TEK_ENST00000262244_ENST00000406359_27455130_27172613 superimposed PDB: 4K0V of partner (TEK). RMSD:2.397
Å |
 |  |  |  |  |
| MORC3_PTK2_ENST00000400485_ENST00000519419_37717329_141685598 superimposed PDB: 6O1E of partner (MORC3). RMSD:0.6665
Å |
 |  |  |  |  |
| MORC3_PTK2_ENST00000400485_ENST00000535192_37717329_141685598 superimposed PDB: 6O1E of partner (MORC3). RMSD:0.5707
Å |
 |  |  |  |  |
| MORC3_PTK2_ENST00000400485_ENST00000538769_37717329_141685598 superimposed PDB: 6O1E of partner (MORC3). RMSD:0.7458
Å |
 |  |  |  |  |
| MORN1_CMPK1_ENST00000378529_ENST00000371873_2316416_47834140 superimposed PDB: 1TEV of partner (CMPK1). RMSD:1.0782
Å |
 |  |  |  |  |
| MOSPD2_PIR_ENST00000380492_ENST00000380421_14891880_15415653 superimposed PDB: 6H1H of partner (PIR). RMSD:2.2495
Å |
 |  |  |  |  |
| MOSPD2_PIR_ENST00000380492_ENST00000380421_14891880_15425672 superimposed PDB: 6H1H of partner (PIR). RMSD:0.8208
Å |
 |  |  |  |  |
| MPHOSPH9_PTPRR_ENST00000541076_ENST00000440835_123705918_71095103 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4256
Å |
 |  |  |  |  |
| MPP5_GPHN_ENST00000261681_ENST00000478722_67770316_67576856 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.7651
Å |
 |  |  |  |  |
| MPP5_GPHN_ENST00000261681_ENST00000478722_67784196_67555699 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.72
Å |
 |  |  |  |  |
| MPP5_GPHN_ENST00000555925_ENST00000478722_67770316_67576856 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.7572
Å |
 |  |  |  |  |
| MPP5_GPHN_ENST00000555925_ENST00000478722_67784196_67555699 superimposed PDB: 4WSI of partner (MPP5). RMSD:2.7782
Å |
 |  |  |  |  |
| MPP5_GPHN_ENST00000555925_ENST00000478722_67784196_67555699 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.7289
Å |
| | | |  |
| MPP7_ZEB1_ENST00000337532_ENST00000361642_28491081_31791275 superimposed PDB: 2E19 of partner (ZEB1). RMSD:0.6684
Å |
 |  |  |  |  |
| MPPE1_PIEZO2_ENST00000317235_ENST00000302079_11889385_10871413 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.7857
Å |
 |  |  |  |  |
| MPPE1_PIEZO2_ENST00000317235_ENST00000503781_11889385_10871413 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.624
Å |
 |  |  |  |  |
| MPPE1_PIEZO2_ENST00000344987_ENST00000302079_11889385_10871413 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.6499
Å |
 |  |  |  |  |
| MPPE1_PIEZO2_ENST00000588072_ENST00000503781_11889385_10871413 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.7901
Å |
 |  |  |  |  |
| MPPE1_PIEZO2_ENST00000588072_ENST00000580640_11889385_10871413 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.2925
Å |
 |  |  |  |  |
| MPRIP_BAZ2A_ENST00000395811_ENST00000179765_17083402_56999111 superimposed PDB: 7MWI of partner (BAZ2A). RMSD:2.7827
Å |
 |  |  |  |  |
| MPRIP_BAZ2A_ENST00000444976_ENST00000179765_17083402_56999111 superimposed PDB: 7MWI of partner (BAZ2A). RMSD:2.796
Å |
 |  |  |  |  |
| MPRIP_MED9_ENST00000341712_ENST00000268711_16946285_17394592 superimposed PDB: 7EMF of partner (MED9). RMSD:2.725
Å |
 |  |  |  |  |
| MPRIP_MED9_ENST00000395806_ENST00000268711_16946285_17394592 superimposed PDB: 7EMF of partner (MED9). RMSD:2.718
Å |
 |  |  |  |  |
| MPRIP_MED9_ENST00000444976_ENST00000268711_16946285_17394592 superimposed PDB: 7EMF of partner (MED9). RMSD:2.74
Å |
 |  |  |  |  |
| MPRIP_PABPC1_ENST00000395811_ENST00000519004_16981390_101730116 superimposed PDB: 4F02 of partner (PABPC1). RMSD:0.5672
Å |
 |  |  |  |  |
| MPRIP_RAF1_ENST00000395811_ENST00000442415_17083402_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9215
Å |
 |  |  |  |  |
| MPRIP_RAF1_ENST00000444976_ENST00000442415_17083402_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.167
Å |
 |  |  |  |  |
| MRC1_PICALM_ENST00000239761_ENST00000356360_18145281_85670103 superimposed PDB: 5XTS of partner (MRC1). RMSD:0.7206
Å |
 |  |  |  |  |
| MRC2_MAP3K3_ENST00000303375_ENST00000584573_60705281_61710040 superimposed PDB: 4Y5O of partner (MAP3K3). RMSD:0.4741
Å |
 |  |  |  |  |
| MRE11A_YAP1_ENST00000393241_ENST00000282441_94163076_102033186 superimposed PDB: 9Q9K of partner (MRE11A). RMSD:0.5213
Å |
 |  |  |  |  |
| MRE11A_YAP1_ENST00000393241_ENST00000531439_94163076_102033186 superimposed PDB: 9Q9K of partner (MRE11A). RMSD:0.5405
Å |
 |  |  |  |  |
| MRE11A_YAP1_ENST00000393241_ENST00000537274_94163076_102033186 superimposed PDB: 9Q9K of partner (MRE11A). RMSD:0.5464
Å |
 |  |  |  |  |
| MRI1_MYO1F_ENST00000040663_ENST00000338257_13879862_8587713 superimposed PDB: 4LDR of partner (MRI1). RMSD:1.5942
Å |
 |  |  |  |  |
| MROH2B_MRPS30_ENST00000399564_ENST00000507110_41017951_44813207 superimposed PDB: 7OF0 of partner (MRPS30). RMSD:0.8
Å |
 |  |  |  |  |
| MRPL10_SKAP1_ENST00000290208_ENST00000584924_45904002_46266862 superimposed PDB: 7OF0 of partner (MRPL10). RMSD:1.5808
Å |
 |  |  |  |  |
| MRPL10_SKAP1_ENST00000290208_ENST00000584924_45904002_46266862 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.5164
Å |
| | | |  |
| MRPL10_SKAP1_ENST00000351111_ENST00000584924_45904002_46266862 superimposed PDB: 7OF0 of partner (MRPL10). RMSD:1.9496
Å |
 |  |  |  |  |
| MRPL10_SKAP1_ENST00000351111_ENST00000584924_45904002_46266862 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.5589
Å |
| | | |  |
| MRPL11_ST8SIA1_ENST00000310999_ENST00000539510_66204574_22402032 superimposed PDB: 7OF0 of partner (MRPL11). RMSD:1.3773
Å |
 |  |  |  |  |
| MRPL11_ST8SIA1_ENST00000430466_ENST00000539510_66204574_22402032 superimposed PDB: 7OF0 of partner (MRPL11). RMSD:1.1468
Å |
 |  |  |  |  |
| MRPL21_CLNS1A_ENST00000362034_ENST00000263309_68665394_77333718 superimposed PDB: 7OF0 of partner (MRPL21). RMSD:1.624
Å |
 |  |  |  |  |
| MRPL21_FAM168A_ENST00000362034_ENST00000064778_68665394_73122581 superimposed PDB: 7OF0 of partner (MRPL21). RMSD:3.4833
Å |
 |  |  |  |  |
| MRPL21_SHANK2_ENST00000450904_ENST00000409161_68660357_70319544 superimposed PDB: 8B10 of partner (SHANK2). RMSD:0.7673
Å |
 |  |  |  |  |
| MRPL21_SSH3_ENST00000362034_ENST00000308298_68663982_67074308 superimposed PDB: 7OF0 of partner (MRPL21). RMSD:3.1447
Å |
 |  |  |  |  |
| MRPL21_SSH3_ENST00000362034_ENST00000376757_68663982_67074308 superimposed PDB: 7OF0 of partner (MRPL21). RMSD:2.1657
Å |
 |  |  |  |  |
| MRPL35_CTNNA2_ENST00000254644_ENST00000402739_86434450_80772106 superimposed PDB: 7OF0 of partner (MRPL35). RMSD:2.5709
Å |
 |  |  |  |  |
| MRPL35_CTNNA2_ENST00000254644_ENST00000402739_86434450_80772106 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.5337
Å |
| | | |  |
| MRPL35_CTNNA2_ENST00000254644_ENST00000496558_86434450_80772106 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4881
Å |
 |  |  |  |  |
| MRPL35_CTNNA2_ENST00000254644_ENST00000540488_86434450_80772106 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.512
Å |
 |  |  |  |  |
| MRPL35_CTNNA2_ENST00000254644_ENST00000541047_86434450_80772106 superimposed PDB: 7OF0 of partner (MRPL35). RMSD:2.9918
Å |
 |  |  |  |  |
| MRPL37_MASP2_ENST00000605337_ENST00000400897_54666262_11090939 superimposed PDB: 1ZJK of partner (MASP2). RMSD:0.7224
Å |
 |  |  |  |  |
| MRPL39_ADAMTS5_ENST00000352957_ENST00000284987_26979714_28305363 superimposed PDB: 2RJQ of partner (ADAMTS5). RMSD:2.2638
Å |
 |  |  |  |  |
| MRPL39_SLC35G6_ENST00000352957_ENST00000412468_26972110_7385306 superimposed PDB: 7OF0 of partner (MRPL39). RMSD:0.8174
Å |
 |  |  |  |  |
| MRPL42_POLR3B_ENST00000361630_ENST00000228347_93881436_106903197 superimposed PDB: 7OF0 of partner (MRPL42). RMSD:3.6536
Å |
 |  |  |  |  |
| MRPL42_POLR3B_ENST00000361630_ENST00000228347_93881436_106903197 superimposed PDB: 7AE1 of partner (POLR3B). RMSD:1.2086
Å |
| | | |  |
| MRPL42_POLR3B_ENST00000552217_ENST00000228347_93881436_106903197 superimposed PDB: 7AE1 of partner (POLR3B). RMSD:1.7062
Å |
 |  |  |  |  |
| MRPL48_PICK1_ENST00000314282_ENST00000404072_73556021_38455240 superimposed PDB: 7OF0 of partner (MRPL48). RMSD:1.8303
Å |
 |  |  |  |  |
| MRPL48_PICK1_ENST00000314282_ENST00000404072_73556021_38455240 superimposed PDB: 6AR4 of partner (PICK1). RMSD:0.2776
Å |
| | | |  |
| MRPL48_PICK1_ENST00000398483_ENST00000404072_73556021_38455240 superimposed PDB: 6AR4 of partner (PICK1). RMSD:0.2835
Å |
 |  |  |  |  |
| MRPL48_PICK1_ENST00000411840_ENST00000404072_73556021_38455240 superimposed PDB: 6AR4 of partner (PICK1). RMSD:0.3017
Å |
 |  |  |  |  |
| MRPL48_PICK1_ENST00000535529_ENST00000404072_73556021_38455240 superimposed PDB: 6AR4 of partner (PICK1). RMSD:0.2763
Å |
 |  |  |  |  |
| MRPL48_SUGP2_ENST00000542303_ENST00000452918_73516124_19121151 superimposed PDB: 1X4P of partner (SUGP2). RMSD:2.7116
Å |
 |  |  |  |  |
| MRPL49_ARL2_ENST00000526171_ENST00000246747_64889896_64787890 superimposed PDB: 9M1J of partner (ARL2). RMSD:1.0158
Å |
 |  |  |  |  |
| MRPS18C_ENOPH1_ENST00000507019_ENST00000273920_84378111_83369072 superimposed PDB: 1YNS of partner (ENOPH1). RMSD:1.7661
Å |
 |  |  |  |  |
| MRPS18C_ENOPH1_ENST00000507349_ENST00000273920_84378111_83369072 superimposed PDB: 1YNS of partner (ENOPH1). RMSD:1.6986
Å |
 |  |  |  |  |
| MRS2_CTSC_ENST00000535061_ENST00000227266_24405469_88045722 superimposed PDB: 8IP5 of partner (MRS2). RMSD:2.9444
Å |
 |  |  |  |  |
| MRS2_CTSC_ENST00000535061_ENST00000227266_24405469_88045722 superimposed PDB: 3PDF of partner (CTSC). RMSD:0.32
Å |
| | | |  |
| MSH2_M1AP_ENST00000233146_ENST00000409585_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.8501
Å |
 |  |  |  |  |
| MSH2_M1AP_ENST00000233146_ENST00000536235_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.821
Å |
 |  |  |  |  |
| MSH2_M1AP_ENST00000406134_ENST00000290536_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.352
Å |
 |  |  |  |  |
| MSH2_M1AP_ENST00000543555_ENST00000290536_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.791
Å |
 |  |  |  |  |
| MSH2_M1AP_ENST00000543555_ENST00000409585_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.3585
Å |
 |  |  |  |  |
| MSH2_M1AP_ENST00000543555_ENST00000536235_47672796_74787418 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.3778
Å |
 |  |  |  |  |
| MSH2_SLC3A1_ENST00000233146_ENST00000409387_47637511_44539724 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:0.9956
Å |
 |  |  |  |  |
| MSH2_SLC3A1_ENST00000406134_ENST00000260649_47637511_44539724 superimposed PDB: 8RB1 of partner (MSH2). RMSD:2.4186
Å |
 |  |  |  |  |
| MSH2_SLC3A1_ENST00000543555_ENST00000260649_47637511_44539724 superimposed PDB: 8RB1 of partner (MSH2). RMSD:1.7249
Å |
 |  |  |  |  |
| MSH2_SLC3A1_ENST00000543555_ENST00000409387_47637511_44539724 superimposed PDB: 6YUZ of partner (SLC3A1). RMSD:2.7004
Å |
 |  |  |  |  |
| MSH2_TTC7A_ENST00000233146_ENST00000319190_47641557_47233060 superimposed PDB: 8RB1 of partner (MSH2). RMSD:3.0286
Å |
 |  |  |  |  |
| MSH3_ARSB_ENST00000265081_ENST00000396151_79974912_78135249 superimposed PDB: 8RB2 of partner (MSH3). RMSD:1.3242
Å |
 |  |  |  |  |
| MSH3_ARSB_ENST00000265081_ENST00000565165_79974912_78135249 superimposed PDB: 8RB2 of partner (MSH3). RMSD:1.1949
Å |
 |  |  |  |  |
| MSH3_SERINC5_ENST00000265081_ENST00000509193_80088663_79498872 superimposed PDB: 8RB2 of partner (MSH3). RMSD:0.6412
Å |
 |  |  |  |  |
| MSH3_SERINC5_ENST00000265081_ENST00000512721_80088663_79498872 superimposed PDB: 8RB2 of partner (MSH3). RMSD:0.7063
Å |
 |  |  |  |  |
| MSH3_SERINC5_ENST00000265081_ENST00000512972_80088663_79498872 superimposed PDB: 8RB2 of partner (MSH3). RMSD:0.6889
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000284073_ENST00000390652_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3488
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000284073_ENST00000407086_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3394
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000284073_ENST00000408905_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3479
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000284073_ENST00000588462_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3319
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000284073_ENST00000589222_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3401
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000416426_ENST00000390652_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3521
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000416426_ENST00000407086_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3388
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000416426_ENST00000408905_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3607
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000416426_ENST00000588462_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3345
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000442934_ENST00000390652_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5689
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000442934_ENST00000407086_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5091
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000442934_ENST00000408905_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5496
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000442934_ENST00000588462_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5175
Å |
 |  |  |  |  |
| MSI2_BCAS3_ENST00000442934_ENST00000589222_55729522_58885364 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3412
Å |
 |  |  |  |  |
| MSI2_CISD3_ENST00000284073_ENST00000439660_55478832_36887012 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3338
Å |
 |  |  |  |  |
| MSI2_CISD3_ENST00000284073_ENST00000439660_55478832_36887012 superimposed PDB: 6AVJ of partner (CISD3). RMSD:0.3308
Å |
| | | |  |
| MSI2_CISD3_ENST00000322684_ENST00000439660_55478832_36887012 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3233
Å |
 |  |  |  |  |
| MSI2_CISD3_ENST00000322684_ENST00000439660_55478832_36887012 superimposed PDB: 6AVJ of partner (CISD3). RMSD:0.2912
Å |
| | | |  |
| MSI2_CISD3_ENST00000416426_ENST00000439660_55478832_36887012 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3566
Å |
 |  |  |  |  |
| MSI2_CISD3_ENST00000442934_ENST00000439660_55478832_36887012 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3297
Å |
 |  |  |  |  |
| MSI2_CISD3_ENST00000442934_ENST00000439660_55478832_36887012 superimposed PDB: 6AVJ of partner (CISD3). RMSD:0.3245
Å |
| | | |  |
| MSI2_CISD3_ENST00000579180_ENST00000439660_55478832_36887012 superimposed PDB: 6AVJ of partner (CISD3). RMSD:0.4074
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000284073_ENST00000262109_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3958
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000284073_ENST00000522706_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3637
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000322684_ENST00000262109_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3819
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000322684_ENST00000522706_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3743
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000416426_ENST00000262109_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3885
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000442934_ENST00000262109_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.9351
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000442934_ENST00000522706_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3733
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000579180_ENST00000262109_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.8259
Å |
 |  |  |  |  |
| MSI2_ERICH1_ENST00000579180_ENST00000522706_55607085_624047 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.9852
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000284073_ENST00000578379_55704664_62081324 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3289
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000284073_ENST00000578379_55704664_62081324 superimposed PDB: 1ZXQ of partner (ICAM2). RMSD:0.393
Å |
| | | |  |
| MSI2_ICAM2_ENST00000322684_ENST00000578379_55704664_62081324 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3462
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000322684_ENST00000578379_55704664_62081324 superimposed PDB: 1ZXQ of partner (ICAM2). RMSD:0.4044
Å |
| | | |  |
| MSI2_ICAM2_ENST00000416426_ENST00000578379_55704664_62081324 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3607
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000416426_ENST00000578379_55704664_62081324 superimposed PDB: 1ZXQ of partner (ICAM2). RMSD:0.3861
Å |
| | | |  |
| MSI2_ICAM2_ENST00000442934_ENST00000578379_55704664_62081324 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4802
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000442934_ENST00000578379_55704664_62081324 superimposed PDB: 1ZXQ of partner (ICAM2). RMSD:0.437
Å |
| | | |  |
| MSI2_ICAM2_ENST00000579180_ENST00000578379_55704664_62081324 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4659
Å |
 |  |  |  |  |
| MSI2_ICAM2_ENST00000579180_ENST00000578379_55704664_62081324 superimposed PDB: 1ZXQ of partner (ICAM2). RMSD:0.5389
Å |
| | | |  |
| MSI2_PCTP_ENST00000284073_ENST00000573500_55339553_53844695 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3234
Å |
 |  |  |  |  |
| MSI2_PCTP_ENST00000284073_ENST00000573500_55339553_53844695 superimposed PDB: 7U9D of partner (PCTP). RMSD:1.1958
Å |
| | | |  |
| MSI2_PCTP_ENST00000322684_ENST00000573500_55339553_53844695 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3326
Å |
 |  |  |  |  |
| MSI2_PCTP_ENST00000322684_ENST00000573500_55339553_53844695 superimposed PDB: 7U9D of partner (PCTP). RMSD:1.2649
Å |
| | | |  |
| MSI2_SLC39A11_ENST00000284073_ENST00000255559_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3153
Å |
 |  |  |  |  |
| MSI2_SLC39A11_ENST00000284073_ENST00000542342_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3416
Å |
 |  |  |  |  |
| MSI2_SLC39A11_ENST00000322684_ENST00000255559_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.2986
Å |
 |  |  |  |  |
| MSI2_SLC39A11_ENST00000322684_ENST00000542342_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.335
Å |
 |  |  |  |  |
| MSI2_SLC39A11_ENST00000416426_ENST00000255559_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3195
Å |
 |  |  |  |  |
| MSI2_SLC39A11_ENST00000416426_ENST00000542342_55339553_71027853 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3093
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000284073_ENST00000307142_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3446
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000284073_ENST00000429713_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3451
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000284073_ENST00000434046_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3363
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000284073_ENST00000448416_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3698
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000322684_ENST00000307142_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3445
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000322684_ENST00000429713_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3239
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000322684_ENST00000434046_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.34
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000322684_ENST00000448416_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3184
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000416426_ENST00000429713_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3151
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000416426_ENST00000434046_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3553
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000416426_ENST00000448416_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3386
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000442934_ENST00000307142_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.342
Å |
 |  |  |  |  |
| MSI2_SYNPO2_ENST00000579180_ENST00000429713_55478832_119944584 superimposed PDB: 6NTY of partner (MSI2). RMSD:3.0296
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000284073_ENST00000583097_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3099
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000284073_ENST00000584379_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3088
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000322684_ENST00000583097_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3209
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000322684_ENST00000584379_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3102
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000416426_ENST00000583097_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.2999
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000416426_ENST00000584379_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.298
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000442934_ENST00000583097_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.6191
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000442934_ENST00000584379_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.5626
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000579180_ENST00000583097_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.6779
Å |
 |  |  |  |  |
| MSI2_TEX2_ENST00000579180_ENST00000584379_55478832_62272455 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.1599
Å |
 |  |  |  |  |
| MSI2_TRIM25_ENST00000284073_ENST00000316881_55339553_54985924 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3307
Å |
 |  |  |  |  |
| MSI2_TRIM25_ENST00000284073_ENST00000316881_55339553_54985924 superimposed PDB: 4CFG of partner (TRIM25). RMSD:1.8596
Å |
| | | |  |
| MSI2_TRIM25_ENST00000322684_ENST00000316881_55339553_54985924 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3414
Å |
 |  |  |  |  |
| MSI2_TRIM25_ENST00000322684_ENST00000316881_55339553_54985924 superimposed PDB: 4CFG of partner (TRIM25). RMSD:1.9562
Å |
| | | |  |
| MSI2_TRIM25_ENST00000416426_ENST00000316881_55339553_54985924 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.3319
Å |
 |  |  |  |  |
| MSL1_KRT24_ENST00000577454_ENST00000264651_38279633_38858185 superimposed PDB: 4B86 of partner (MSL1). RMSD:0.5368
Å |
 |  |  |  |  |
| MSRB3_CNOT2_ENST00000355192_ENST00000418359_65672645_70729217 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.0698
Å |
 |  |  |  |  |
| MSRB3_HMGA2_ENST00000308259_ENST00000541363_65762806_66345162 superimposed PDB: 6Q9V of partner (MSRB3). RMSD:0.566
Å |
 |  |  |  |  |
| MSRB3_HMGA2_ENST00000540804_ENST00000541363_65762806_66345162 superimposed PDB: 6Q9V of partner (MSRB3). RMSD:0.5027
Å |
 |  |  |  |  |
| MTA1_LONP2_ENST00000331320_ENST00000535754_105916661_48381417 superimposed PDB: 7AO8 of partner (MTA1). RMSD:2.6469
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000405592_ENST00000608853_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.647
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406652_ENST00000389153_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.6558
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406652_ENST00000535949_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.7632
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406652_ENST00000608853_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.7632
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406911_ENST00000389153_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.3701
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406911_ENST00000535949_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.6974
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000406911_ENST00000608853_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.6481
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000407270_ENST00000389153_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.7714
Å |
 |  |  |  |  |
| MTA3_ATXN2_ENST00000407270_ENST00000608853_42806340_111908546 superimposed PDB: 3KTR of partner (ATXN2). RMSD:2.3024
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405094_ENST00000339490_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.6984
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405094_ENST00000373545_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7218
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405094_ENST00000541944_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7711
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405592_ENST00000339490_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.6616
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405592_ENST00000373545_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7194
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000405592_ENST00000541944_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7396
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406652_ENST00000339490_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7145
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406652_ENST00000373545_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7535
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406652_ENST00000541944_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7353
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406911_ENST00000339490_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7147
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406911_ENST00000373545_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.6979
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000406911_ENST00000541944_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7089
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000407270_ENST00000339490_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7232
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000407270_ENST00000373545_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7717
Å |
 |  |  |  |  |
| MTA3_PHKA1_ENST00000407270_ENST00000541944_42806340_71822123 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7133
Å |
 |  |  |  |  |
| MTAP_BNC2_ENST00000380172_ENST00000380672_21854869_16437522 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4082
Å |
 |  |  |  |  |
| MTAP_BNC2_ENST00000460874_ENST00000380667_21854869_16437522 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4211
Å |
 |  |  |  |  |
| MTAP_BNC2_ENST00000580900_ENST00000380666_21854869_16437522 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4184
Å |
 |  |  |  |  |
| MTAP_BNC2_ENST00000580900_ENST00000380667_21854869_16437522 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4127
Å |
 |  |  |  |  |
| MTAP_BNC2_ENST00000580900_ENST00000380672_21854869_16437522 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.6694
Å |
 |  |  |  |  |
| MTAP_CDH15_ENST00000380172_ENST00000289746_21838009_89245823 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.6865
Å |
 |  |  |  |  |
| MTAP_DNAI1_ENST00000380172_ENST00000242317_21854869_34483445 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4516
Å |
 |  |  |  |  |
| MTAP_DNAI1_ENST00000460874_ENST00000545019_21854869_34483445 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3966
Å |
 |  |  |  |  |
| MTAP_DNAI1_ENST00000580900_ENST00000242317_21854869_34483445 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3912
Å |
 |  |  |  |  |
| MTAP_DNAI1_ENST00000580900_ENST00000545019_21854869_34483445 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3841
Å |
 |  |  |  |  |
| MTAP_EEF1A2_ENST00000580900_ENST00000217182_21802780_62127388 superimposed PDB: 8B6Z of partner (EEF1A2). RMSD:2.9696
Å |
 |  |  |  |  |
| MTAP_EXOC6B_ENST00000380172_ENST00000272427_21854869_72606999 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4182
Å |
 |  |  |  |  |
| MTAP_PCDH7_ENST00000380172_ENST00000543491_21854869_30921774 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3814
Å |
 |  |  |  |  |
| MTAP_PCDH7_ENST00000580900_ENST00000543491_21854869_30921774 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.4411
Å |
 |  |  |  |  |
| MTBP_ABCB7_ENST00000305949_ENST00000339447_121463562_74288971 superimposed PDB: 23PI of partner (ABCB7). RMSD:0.9969
Å |
 |  |  |  |  |
| MTCH2_FHIT_ENST00000302503_ENST00000492590_47660250_59738047 superimposed PDB: 12OZ of partner (MTCH2). RMSD:2.6145
Å |
 |  |  |  |  |
| MTDH_TRHR_ENST00000519934_ENST00000311762_98657115_110131276 superimposed PDB: 7XW9 of partner (TRHR). RMSD:2.5594
Å |
 |  |  |  |  |
| MTF1_SF3A3_ENST00000373036_ENST00000448721_38322922_38435407 superimposed PDB: 7Q4O of partner (SF3A3). RMSD:0.5951
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000370298_ENST00000370267_93584958_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:0.6972
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000370298_ENST00000370267_93584958_93826049 superimposed PDB: 1JFI of partner (DR1). RMSD:0.2977
Å |
| | | |  |
| MTF2_DR1_ENST00000370298_ENST00000370272_93586229_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:0.7398
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000370303_ENST00000370267_93584958_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:1.0969
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000370303_ENST00000370267_93584958_93826049 superimposed PDB: 1JFI of partner (DR1). RMSD:0.9644
Å |
| | | |  |
| MTF2_DR1_ENST00000370303_ENST00000370272_93586229_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:1.1431
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000540243_ENST00000370267_93584958_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:0.818
Å |
 |  |  |  |  |
| MTF2_DR1_ENST00000540243_ENST00000370267_93584958_93826049 superimposed PDB: 1JFI of partner (DR1). RMSD:0.965
Å |
| | | |  |
| MTF2_DR1_ENST00000540243_ENST00000370272_93586229_93826049 superimposed PDB: 5XFR of partner (MTF2). RMSD:1.0313
Å |
 |  |  |  |  |
| MTHFD1L_RNF216_ENST00000367321_ENST00000389902_151293194_5760803 superimposed PDB: 7M4M of partner (RNF216). RMSD:1.8595
Å |
 |  |  |  |  |
| MTHFD1L_RNF216_ENST00000367321_ENST00000425013_151293194_5760803 superimposed PDB: 7M4M of partner (RNF216). RMSD:0.7996
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000318588_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.6038
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000318588_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.8835
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000361962_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.586
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000361962_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.3091
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378158_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.658
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378158_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.3955
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378163_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5825
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378163_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.1702
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378166_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.6053
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000378166_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.0476
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000421587_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5838
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000421587_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.106
Å |
| | | |  |
| MTHFD1_CASK_ENST00000216605_ENST00000442742_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.6077
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000216605_ENST00000442742_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.9165
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000318588_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5683
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000318588_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.3525
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000361962_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5848
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000361962_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.8459
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378158_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.6015
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378158_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.4307
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378163_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5793
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378163_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.2223
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378166_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5734
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000378166_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:2.2349
Å |
| | | |  |
| MTHFD1_CASK_ENST00000545908_ENST00000442742_64916340_41530783 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.6087
Å |
 |  |  |  |  |
| MTHFD1_CASK_ENST00000545908_ENST00000442742_64916340_41530783 superimposed PDB: 3TAC of partner (CASK). RMSD:1.7296
Å |
| | | |  |
| MTHFD1_SYNE2_ENST00000216605_ENST00000344113_64915035_64669518 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5191
Å |
 |  |  |  |  |
| MTHFD1_SYNE2_ENST00000216605_ENST00000358025_64915035_64669518 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5551
Å |
 |  |  |  |  |
| MTHFD1_SYNE2_ENST00000545908_ENST00000344113_64915035_64669518 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5599
Å |
 |  |  |  |  |
| MTHFD1_SYNE2_ENST00000545908_ENST00000358025_64915035_64669518 superimposed PDB: 1DIA of partner (MTHFD1). RMSD:0.5452
Å |
 |  |  |  |  |
| MTIF2_PPP3R1_ENST00000394600_ENST00000409752_55489451_68415822 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.6581
Å |
 |  |  |  |  |
| MTMR1_HS1BP3_ENST00000370390_ENST00000304031_149924337_20840940 superimposed PDB: 5C16 of partner (MTMR1). RMSD:0.482
Å |
 |  |  |  |  |
| MTMR1_HS1BP3_ENST00000370390_ENST00000402541_149924337_20840940 superimposed PDB: 5C16 of partner (MTMR1). RMSD:0.4799
Å |
 |  |  |  |  |
| MTMR1_HS1BP3_ENST00000445323_ENST00000402541_149924337_20840940 superimposed PDB: 5C16 of partner (MTMR1). RMSD:0.4777
Å |
 |  |  |  |  |
| MTMR1_HS1BP3_ENST00000541925_ENST00000402541_149924337_20840940 superimposed PDB: 5C16 of partner (MTMR1). RMSD:0.4826
Å |
 |  |  |  |  |
| MTMR1_HS1BP3_ENST00000544228_ENST00000304031_149924337_20840940 superimposed PDB: 5C16 of partner (MTMR1). RMSD:0.4677
Å |
 |  |  |  |  |
| MTMR2_CLNS1A_ENST00000346299_ENST00000528364_95657038_77340944 superimposed PDB: 9E3B of partner (CLNS1A). RMSD:2.7917
Å |
 |  |  |  |  |
| MTMR2_CLNS1A_ENST00000346299_ENST00000532069_95657038_77340944 superimposed PDB: 1LW3 of partner (MTMR2). RMSD:2.7015
Å |
 |  |  |  |  |
| MTMR2_CLNS1A_ENST00000346299_ENST00000532069_95657038_77340944 superimposed PDB: 9E3B of partner (CLNS1A). RMSD:2.6507
Å |
| | | |  |
| MTMR2_MAML2_ENST00000346299_ENST00000524717_95578116_95724887 superimposed PDB: 1LW3 of partner (MTMR2). RMSD:0.5316
Å |
 |  |  |  |  |
| MTMR2_MAML2_ENST00000393223_ENST00000524717_95598764_95724887 superimposed PDB: 1LW3 of partner (MTMR2). RMSD:0.9509
Å |
 |  |  |  |  |
| MTMR2_MAML2_ENST00000409459_ENST00000524717_95578116_95724887 superimposed PDB: 1LW3 of partner (MTMR2). RMSD:0.8105
Å |
 |  |  |  |  |
| MTOR_CAMTA1_ENST00000361445_ENST00000439411_11313895_6880240 superimposed PDB: 2CXK of partner (CAMTA1). RMSD:0.3447
Å |
 |  |  |  |  |
| MTRR_NMD3_ENST00000264668_ENST00000460469_7897360_160965045 superimposed PDB: 2QTL of partner (MTRR). RMSD:0.7203
Å |
 |  |  |  |  |
| MTRR_NMD3_ENST00000264668_ENST00000472947_7897360_160965045 superimposed PDB: 2QTL of partner (MTRR). RMSD:0.5933
Å |
 |  |  |  |  |
| MTRR_NMD3_ENST00000440940_ENST00000460469_7897360_160965045 superimposed PDB: 2QTL of partner (MTRR). RMSD:0.5979
Å |
 |  |  |  |  |
| MTRR_NMD3_ENST00000440940_ENST00000472947_7897360_160965045 superimposed PDB: 2QTL of partner (MTRR). RMSD:0.7005
Å |
 |  |  |  |  |
| MTUS1_ASAH1_ENST00000519263_ENST00000381733_17601112_17920739 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.4583
Å |
 |  |  |  |  |
| MTUS1_FGL1_ENST00000381861_ENST00000522444_17570722_17726513 superimposed PDB: 9Q35 of partner (FGL1). RMSD:0.54
Å |
 |  |  |  |  |
| MTUS1_FGL1_ENST00000519263_ENST00000522444_17570722_17726513 superimposed PDB: 9Q35 of partner (FGL1). RMSD:0.5734
Å |
 |  |  |  |  |
| MTUS1_FGL1_ENST00000544260_ENST00000522444_17570722_17726513 superimposed PDB: 9Q35 of partner (FGL1). RMSD:0.5066
Å |
 |  |  |  |  |
| MTUS2_NBEA_ENST00000380808_ENST00000400445_30014186_35770000 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.8947
Å |
 |  |  |  |  |
| MTUS2_NBEA_ENST00000431530_ENST00000400445_30014186_35770000 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.8893
Å |
 |  |  |  |  |
| MUC16_RNASEH2B_ENST00000397910_ENST00000422660_9080450_51501542 superimposed PDB: 8YJZ of partner (RNASEH2B). RMSD:1.3556
Å |
 |  |  |  |  |
| MVK_CPM_ENST00000228510_ENST00000338356_110023930_69250459 superimposed PDB: 2R3V of partner (MVK). RMSD:0.74
Å |
 |  |  |  |  |
| MVK_CPM_ENST00000392727_ENST00000338356_110023930_69250459 superimposed PDB: 2R3V of partner (MVK). RMSD:2.2612
Å |
 |  |  |  |  |
| MX1_ABCG1_ENST00000288383_ENST00000398457_42812952_43691179 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.2124
Å |
 |  |  |  |  |
| MX1_ABCG1_ENST00000398598_ENST00000398457_42812952_43691179 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.2296
Å |
 |  |  |  |  |
| MXD1_ANTXR1_ENST00000264444_ENST00000409349_70148897_69267175 superimposed PDB: 3N2N of partner (ANTXR1). RMSD:0.6017
Å |
 |  |  |  |  |
| MXD1_ANTXR1_ENST00000264444_ENST00000409829_70148897_69267175 superimposed PDB: 3N2N of partner (ANTXR1). RMSD:0.7788
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000316528_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4359
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000316528_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4769
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000316528_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.431
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000316528_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4356
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000316528_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4525
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000341911_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4686
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000341911_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5122
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000341911_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4248
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000341911_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4968
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000367814_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4684
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000442647_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4712
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000442647_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4475
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000442647_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4609
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000442647_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4796
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000442647_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4691
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000525369_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4937
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000525369_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4282
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000525369_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4532
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000525369_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4084
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000527615_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4259
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000528774_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5451
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000528774_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4768
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000528774_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4216
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000528774_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.45
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000528774_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4822
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000533624_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5929
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000533624_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4581
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000533624_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4742
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000533624_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4313
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000533624_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4593
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534044_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4216
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534044_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5345
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534044_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4875
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534044_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4431
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534044_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4768
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534121_ENST00000380934_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4679
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534121_ENST00000380959_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5113
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534121_ENST00000397575_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4342
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534121_ENST00000397579_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5976
Å |
 |  |  |  |  |
| MYB_NFIB_ENST00000534121_ENST00000397581_135521553_14307519 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4697
Å |
 |  |  |  |  |
| MYCBP2_CPB2_ENST00000407578_ENST00000181383_77862295_46638876 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.376
Å |
 |  |  |  |  |
| MYCBP2_CPB2_ENST00000407578_ENST00000439329_77862295_46638876 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.5569
Å |
 |  |  |  |  |
| MYCBP2_CPB2_ENST00000544440_ENST00000439329_77862295_46638876 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.5161
Å |
 |  |  |  |  |
| MYCN_GPN1_ENST00000281043_ENST00000424214_16082976_27872981 superimposed PDB: 5G1X of partner (MYCN). RMSD:1.5826
Å |
 |  |  |  |  |
| MYH10_CDKN2A_ENST00000360416_ENST00000361570_8526219_21971207 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3825
Å |
 |  |  |  |  |
| MYH10_CDKN2A_ENST00000360416_ENST00000579755_8526219_21971207 superimposed PDB: 4PD3 of partner (MYH10). RMSD:0.9526
Å |
 |  |  |  |  |
| MYH11_MYLK_ENST00000452625_ENST00000359169_15809020_123383105 superimposed PDB: 6C6M of partner (MYLK). RMSD:0.8216
Å |
 |  |  |  |  |
| MYH11_MYLK_ENST00000576790_ENST00000359169_15809020_123383105 superimposed PDB: 6C6M of partner (MYLK). RMSD:0.8729
Å |
 |  |  |  |  |
| MYH11_MYLK_ENST00000576790_ENST00000360772_15809020_123383105 superimposed PDB: 6C6M of partner (MYLK). RMSD:0.7358
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000262269_ENST00000216181_50783398_36689527 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.2854
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000262269_ENST00000216181_50783398_36689527 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.2883
Å |
| | | |  |
| MYH14_MYH9_ENST00000376970_ENST00000216181_50783398_36689527 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.2884
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000376970_ENST00000216181_50783398_36689527 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.2969
Å |
| | | |  |
| MYH14_MYH9_ENST00000425460_ENST00000216181_50783398_36689527 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3094
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000425460_ENST00000216181_50783398_36689527 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.2005
Å |
| | | |  |
| MYH14_MYH9_ENST00000440075_ENST00000216181_50783398_36689527 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.2815
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000440075_ENST00000216181_50783398_36689527 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.3362
Å |
| | | |  |
| MYH14_MYH9_ENST00000601313_ENST00000216181_50783398_36689527 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.2751
Å |
 |  |  |  |  |
| MYH14_MYH9_ENST00000601313_ENST00000216181_50783398_36689527 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.2868
Å |
| | | |  |
| MYH14_ZNF473_ENST00000376970_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3183
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000376970_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:1.6551
Å |
| | | |  |
| MYH14_ZNF473_ENST00000425460_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.2354
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000425460_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:2.4767
Å |
| | | |  |
| MYH14_ZNF473_ENST00000440075_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3805
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000440075_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:1.875
Å |
| | | |  |
| MYH14_ZNF473_ENST00000596571_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3166
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000596571_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:2.1295
Å |
| | | |  |
| MYH14_ZNF473_ENST00000598205_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3208
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000598205_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:1.9277
Å |
| | | |  |
| MYH14_ZNF473_ENST00000601313_ENST00000391821_50796944_50542417 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.3402
Å |
 |  |  |  |  |
| MYH14_ZNF473_ENST00000601313_ENST00000391821_50796944_50542417 superimposed PDB: 2EMC of partner (ZNF473). RMSD:0.8682
Å |
| | | |  |
| MYH3_CYP3A5_ENST00000226209_ENST00000343703_10532913_99264688 superimposed PDB: 7LAD of partner (CYP3A5). RMSD:1.2827
Å |
 |  |  |  |  |
| MYH9_FOXRED2_ENST00000216181_ENST00000216187_36710189_36897454 superimposed PDB: 9SYU of partner (MYH9). RMSD:0.8157
Å |
 |  |  |  |  |
| MYH9_FOXRED2_ENST00000216181_ENST00000397224_36710189_36897454 superimposed PDB: 9SYU of partner (MYH9). RMSD:0.607
Å |
 |  |  |  |  |
| MYH9_TXN2_ENST00000216181_ENST00000416967_36744948_36863964 superimposed PDB: 9SYU of partner (MYH9). RMSD:1.3224
Å |
 |  |  |  |  |
| MYH9_TXN2_ENST00000216181_ENST00000416967_36744948_36863964 superimposed PDB: 1W4V of partner (TXN2). RMSD:2.8024
Å |
| | | |  |
| MYL6_ANXA2_ENST00000548400_ENST00000451270_56553406_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3896
Å |
 |  |  |  |  |
| MYL6_GTF2I_ENST00000293422_ENST00000353920_56552495_74162351 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.7904
Å |
 |  |  |  |  |
| MYL6_GTF2I_ENST00000549566_ENST00000353920_56552495_74162351 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.8293
Å |
 |  |  |  |  |
| MYL6_GTF2I_ENST00000550697_ENST00000353920_56552495_74162351 superimposed PDB: 2EJE of partner (GTF2I). RMSD:0.8087
Å |
 |  |  |  |  |
| MYL6_NAP1L1_ENST00000548400_ENST00000393263_56553406_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.6125
Å |
 |  |  |  |  |
| MYL6_NAP1L1_ENST00000548400_ENST00000547993_56553406_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.0581
Å |
 |  |  |  |  |
| MYL6_NAP1L1_ENST00000548400_ENST00000549596_56553406_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.4288
Å |
 |  |  |  |  |
| MYL6_PHGDH_ENST00000548400_ENST00000369407_56553406_120277917 superimposed PDB: 6RJ3 of partner (PHGDH). RMSD:0.3381
Å |
 |  |  |  |  |
| MYL9_ANXA2_ENST00000279022_ENST00000451270_35173471_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3893
Å |
 |  |  |  |  |
| MYL9_ANXA2_ENST00000346786_ENST00000451270_35173471_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3724
Å |
 |  |  |  |  |
| MYLK_NXPH1_ENST00000359169_ENST00000405863_123367817_8790637 superimposed PDB: 6C6M of partner (MYLK). RMSD:0.5838
Å |
 |  |  |  |  |
| MYLK_NXPH1_ENST00000360304_ENST00000405863_123367817_8790637 superimposed PDB: 6C6M of partner (MYLK). RMSD:0.426
Å |
 |  |  |  |  |
| MYLK_USP48_ENST00000360772_ENST00000400301_123512523_22016592 superimposed PDB: 6C6M of partner (MYLK). RMSD:1.5001
Å |
 |  |  |  |  |
| MYLK_USP48_ENST00000475616_ENST00000308271_123512523_22016592 superimposed PDB: 6C6M of partner (MYLK). RMSD:2.8532
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000304164_ENST00000376887_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.2659
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000339514_ENST00000376887_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.4335
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000339514_ENST00000412704_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.5488
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000392316_ENST00000376887_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.3317
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000392316_ENST00000412704_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.3446
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000392318_ENST00000412704_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.3136
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000439065_ENST00000376887_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.001
Å |
 |  |  |  |  |
| MYO1B_ABCC4_ENST00000439065_ENST00000412704_192261223_95887088 superimposed PDB: 8XOK of partner (ABCC4). RMSD:2.31
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000359786_ENST00000558011_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0315
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000359786_ENST00000560940_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0898
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000361007_ENST00000336418_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0703
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000361007_ENST00000558011_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0559
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000361007_ENST00000560940_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0541
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000438665_ENST00000336418_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.15
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000438665_ENST00000558011_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9918
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000438665_ENST00000560940_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0498
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000545534_ENST00000336418_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.1382
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000545534_ENST00000558011_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0672
Å |
 |  |  |  |  |
| MYO1C_AP3S2_ENST00000545534_ENST00000560940_1370535_90432372 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0184
Å |
 |  |  |  |  |
| MYO1C_SMG6_ENST00000359786_ENST00000263073_1377903_1989195 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0137
Å |
 |  |  |  |  |
| MYO1C_SMG6_ENST00000359786_ENST00000544865_1377903_1989195 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0401
Å |
 |  |  |  |  |
| MYO1C_SMG6_ENST00000361007_ENST00000263073_1377903_1989195 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0007
Å |
 |  |  |  |  |
| MYO1C_SMG6_ENST00000438665_ENST00000263073_1377903_1989195 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9854
Å |
 |  |  |  |  |
| MYO1C_SMG6_ENST00000545534_ENST00000263073_1377903_1989195 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9766
Å |
 |  |  |  |  |
| MYO1C_YWHAE_ENST00000359786_ENST00000571732_1385771_1248793 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.0753
Å |
 |  |  |  |  |
| MYO1C_YWHAE_ENST00000359786_ENST00000573026_1385771_1248793 superimposed PDB: 4BYF of partner (MYO1C). RMSD:1.3555
Å |
 |  |  |  |  |
| MYO1C_YWHAE_ENST00000361007_ENST00000571732_1385771_1248793 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9032
Å |
 |  |  |  |  |
| MYO1C_YWHAE_ENST00000361007_ENST00000571732_1385771_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:3.3421
Å |
| | | |  |
| MYO1C_YWHAE_ENST00000438665_ENST00000573026_1385771_1248793 superimposed PDB: 4BYF of partner (MYO1C). RMSD:0.9266
Å |
 |  |  |  |  |
| MYO1C_YWHAE_ENST00000438665_ENST00000573026_1385771_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:3.3496
Å |
| | | |  |
| MYO1D_ACACA_ENST00000318217_ENST00000360679_31203795_35506898 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.8664
Å |
 |  |  |  |  |
| MYO1D_ASIC2_ENST00000318217_ENST00000359872_31203795_31355410 superimposed PDB: 6L6P of partner (ASIC2). RMSD:2.2428
Å |
 |  |  |  |  |
| MYO1D_PIGS_ENST00000318217_ENST00000308360_31203795_26897981 superimposed PDB: 7WLD of partner (PIGS). RMSD:1.9413
Å |
 |  |  |  |  |
| MYO1E_ANXA2_ENST00000288235_ENST00000451270_59453271_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4863
Å |
 |  |  |  |  |
| MYO3A_SCD5_ENST00000543632_ENST00000282709_26243937_83626566 superimposed PDB: 6JLE of partner (MYO3A). RMSD:0.2371
Å |
 |  |  |  |  |
| MYO5A_DCBLD2_ENST00000356338_ENST00000326857_52599484_98520493 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.8021
Å |
 |  |  |  |  |
| MYO5A_DCBLD2_ENST00000399231_ENST00000326857_52599484_98520493 superimposed PDB: 4J5L of partner (MYO5A). RMSD:0.6836
Å |
 |  |  |  |  |
| MYO5A_NEDD4_ENST00000356338_ENST00000435532_52632392_56216897 superimposed PDB: 2XBF of partner (NEDD4). RMSD:2.5097
Å |
 |  |  |  |  |
| MYO5A_NEDD4_ENST00000358212_ENST00000435532_52632392_56216897 superimposed PDB: 2XBF of partner (NEDD4). RMSD:2.4892
Å |
 |  |  |  |  |
| MYO5A_NEDD4_ENST00000399233_ENST00000435532_52632392_56216897 superimposed PDB: 2XBF of partner (NEDD4). RMSD:2.3241
Å |
 |  |  |  |  |
| MYO5A_NEDD4_ENST00000553916_ENST00000435532_52632392_56216897 superimposed PDB: 2XBF of partner (NEDD4). RMSD:2.5855
Å |
 |  |  |  |  |
| MYO5A_OIP5_ENST00000356338_ENST00000220514_52689397_41611978 superimposed PDB: 7SFY of partner (OIP5). RMSD:1.0528
Å |
 |  |  |  |  |
| MYO5A_OIP5_ENST00000399233_ENST00000220514_52689397_41611978 superimposed PDB: 7SFY of partner (OIP5). RMSD:0.8173
Å |
 |  |  |  |  |
| MYO5C_TRPM7_ENST00000443683_ENST00000560955_52561949_50854005 superimposed PDB: 4ZG4 of partner (MYO5C). RMSD:1.3517
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369977_ENST00000243583_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.6942
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369977_ENST00000450541_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.7817
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369981_ENST00000243583_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.6697
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369981_ENST00000324464_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:1.3134
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369981_ENST00000450541_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.921
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369985_ENST00000243583_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.2937
Å |
 |  |  |  |  |
| MYO6_ADCK4_ENST00000369985_ENST00000450541_76618344_41216041 superimposed PDB: 8W41 of partner (MYO6). RMSD:2.9083
Å |
 |  |  |  |  |
| MYO9A_PKM_ENST00000356056_ENST00000565184_72338064_72501232 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.8241
Å |
 |  |  |  |  |
| MYO9A_PKM_ENST00000444904_ENST00000319622_72338064_72501232 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.7948
Å |
 |  |  |  |  |
| MYO9B_ATP13A1_ENST00000595618_ENST00000357324_17213367_19758337 superimposed PDB: 9JBZ of partner (ATP13A1). RMSD:2.4283
Å |
 |  |  |  |  |
| MYSM1_INADL_ENST00000472487_ENST00000371158_59165656_62253425 superimposed PDB: 6IRD of partner (INADL). RMSD:0.7367
Å |
 |  |  |  |  |
| MZT1_TERF1_ENST00000377818_ENST00000276602_73293089_73939174 superimposed PDB: 6L81 of partner (MZT1). RMSD:0.977
Å |
 |  |  |  |  |
| MZT1_TERF1_ENST00000377818_ENST00000276602_73293089_73939174 superimposed PDB: 8OX1 of partner (TERF1). RMSD:0.5065
Å |
| | | |  |
| NAA20_ATP8B4_ENST00000334982_ENST00000559829_20013297_50273491 superimposed PDB: 7STX of partner (NAA20). RMSD:0.6999
Å |
 |  |  |  |  |
| NAA20_ATP8B4_ENST00000398602_ENST00000559829_20013297_50273491 superimposed PDB: 7STX of partner (NAA20). RMSD:0.556
Å |
 |  |  |  |  |
| NAA25_PRKAR1B_ENST00000261745_ENST00000537384_112471036_720363 superimposed PDB: 8G0L of partner (NAA25). RMSD:1.7124
Å |
 |  |  |  |  |
| NAA25_PRKAR1B_ENST00000261745_ENST00000537384_112471036_720363 superimposed PDB: 4DIN of partner (PRKAR1B). RMSD:2.5491
Å |
| | | |  |
| NAA25_SLC25A21_ENST00000261745_ENST00000331299_112525486_37154130 superimposed PDB: 8G0L of partner (NAA25). RMSD:0.7704
Å |
 |  |  |  |  |
| NAA25_SLC25A21_ENST00000261745_ENST00000555449_112525486_37154130 superimposed PDB: 8G0L of partner (NAA25). RMSD:0.9942
Å |
 |  |  |  |  |
| NACC1_NACC2_ENST00000292431_ENST00000277554_13248190_138905142 superimposed PDB: 7BV9 of partner (NACC1). RMSD:1.1301
Å |
 |  |  |  |  |
| NADK2_BAZ2B_ENST00000282512_ENST00000343439_36225643_160206868 superimposed PDB: 5PG1 of partner (BAZ2B). RMSD:0.2743
Å |
 |  |  |  |  |
| NADSYN1_SPAG9_ENST00000319023_ENST00000262013_71193071_49048217 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.8058
Å |
 |  |  |  |  |
| NADSYN1_SPAG9_ENST00000319023_ENST00000505279_71193071_49048217 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.5067
Å |
 |  |  |  |  |
| NADSYN1_SPAG9_ENST00000539574_ENST00000505279_71193071_49048217 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:2.2212
Å |
 |  |  |  |  |
| NADSYN1_TRIM9_ENST00000319023_ENST00000338969_71189515_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.3749
Å |
 |  |  |  |  |
| NADSYN1_TRIM9_ENST00000319023_ENST00000360392_71189515_51492078 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:0.607
Å |
 |  |  |  |  |
| NADSYN1_TRIM9_ENST00000319023_ENST00000360392_71189515_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.3377
Å |
| | | |  |
| NADSYN1_TRIM9_ENST00000539574_ENST00000338969_71189515_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.3825
Å |
 |  |  |  |  |
| NADSYN1_TRIM9_ENST00000539574_ENST00000360392_71189515_51492078 superimposed PDB: 7B2S of partner (TRIM9). RMSD:0.3673
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000396398_ENST00000335626_42456927_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.396
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000396398_ENST00000335626_42458830_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3583
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000396398_ENST00000359486_42458830_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.4182
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000396398_ENST00000404876_42456927_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3684
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000335626_42456927_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3922
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000335626_42458830_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3506
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000359486_42456927_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3832
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000359486_42458830_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3575
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000404876_42456927_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3891
Å |
 |  |  |  |  |
| NAGA_TCF20_ENST00000403363_ENST00000404876_42458830_42575708 superimposed PDB: 4DO4 of partner (NAGA). RMSD:0.3701
Å |
 |  |  |  |  |
| NAP1L1_KRR1_ENST00000547773_ENST00000229214_76467982_75902226 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.678
Å |
 |  |  |  |  |
| NAP1L1_METAP2_ENST00000393263_ENST00000546753_76467982_95897840 superimposed PDB: 1B6A of partner (METAP2). RMSD:0.8306
Å |
 |  |  |  |  |
| NAPG_PEPD_ENST00000322897_ENST00000397032_10526155_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.38
Å |
 |  |  |  |  |
| NAPG_RCHY1_ENST00000322897_ENST00000380840_10526155_76419389 superimposed PDB: 7YNX of partner (RCHY1). RMSD:0.6656
Å |
 |  |  |  |  |
| NAPG_RCHY1_ENST00000322897_ENST00000451788_10526155_76419389 superimposed PDB: 7YNX of partner (RCHY1). RMSD:0.6682
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000309794_ENST00000331483_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.0899
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000309794_ENST00000576390_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.7623
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000345415_ENST00000331483_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.3516
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000345415_ENST00000439918_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.708
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000345415_ENST00000576390_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.4914
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000390006_ENST00000576390_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.5574
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000412079_ENST00000331483_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.9633
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000412079_ENST00000439918_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.9875
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000412079_ENST00000576390_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.8457
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000457415_ENST00000331483_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.9634
Å |
 |  |  |  |  |
| NARF_P4HB_ENST00000457415_ENST00000576390_80439087_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.6112
Å |
 |  |  |  |  |
| NARF_TBK1_ENST00000345415_ENST00000331710_80417948_64889262 superimposed PDB: 6NT9 of partner (TBK1). RMSD:2.1564
Å |
 |  |  |  |  |
| NARS2_ME3_ENST00000281038_ENST00000359636_78176921_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:1.1526
Å |
 |  |  |  |  |
| NARS2_ME3_ENST00000528850_ENST00000359636_78176921_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:1.221
Å |
 |  |  |  |  |
| NARS2_ME3_ENST00000528850_ENST00000393324_78176921_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:0.6808
Å |
 |  |  |  |  |
| NARS2_TOP1_ENST00000528850_ENST00000361337_78239887_39721111 superimposed PDB: 1K4T of partner (TOP1). RMSD:0.6093
Å |
 |  |  |  |  |
| NASP_IGF2BP2_ENST00000350030_ENST00000382199_46049877_185416135 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:0.4324
Å |
 |  |  |  |  |
| NASP_IGF2BP2_ENST00000537798_ENST00000421047_46049877_185416135 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:0.45
Å |
 |  |  |  |  |
| NASP_IGF2BP2_ENST00000537798_ENST00000457616_46049877_185416135 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:0.4772
Å |
 |  |  |  |  |
| NASP_PLRG1_ENST00000350030_ENST00000393905_46082065_155462086 superimposed PDB: 7V6P of partner (NASP). RMSD:0.4805
Å |
 |  |  |  |  |
| NASP_PLRG1_ENST00000351223_ENST00000393905_46082065_155462086 superimposed PDB: 7V6P of partner (NASP). RMSD:0.4309
Å |
 |  |  |  |  |
| NASP_PLRG1_ENST00000402363_ENST00000393905_46082065_155462086 superimposed PDB: 7V6P of partner (NASP). RMSD:0.4849
Å |
 |  |  |  |  |
| NASP_PLRG1_ENST00000537798_ENST00000393905_46082065_155462086 superimposed PDB: 7V6P of partner (NASP). RMSD:0.4223
Å |
 |  |  |  |  |
| NBAS_DDX1_ENST00000281513_ENST00000233084_15467873_15735268 superimposed PDB: 8TBX of partner (DDX1). RMSD:3.0767
Å |
 |  |  |  |  |
| NBAS_DDX1_ENST00000441750_ENST00000233084_15467873_15735268 superimposed PDB: 8TBX of partner (DDX1). RMSD:2.9237
Å |
 |  |  |  |  |
| NBAS_MDM2_ENST00000281513_ENST00000462284_15674666_69202991 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.8182
Å |
 |  |  |  |  |
| NBAS_SRPK1_ENST00000281513_ENST00000373825_15514731_35837678 superimposed PDB: 5MXX of partner (SRPK1). RMSD:0.7114
Å |
 |  |  |  |  |
| NBAS_SRPK1_ENST00000281513_ENST00000423325_15514731_35837678 superimposed PDB: 5MXX of partner (SRPK1). RMSD:0.5378
Å |
 |  |  |  |  |
| NBAS_SRPK1_ENST00000441750_ENST00000423325_15514731_35837678 superimposed PDB: 5MXX of partner (SRPK1). RMSD:0.6067
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000310336_ENST00000541179_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:3.0169
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000379742_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.3781
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000379743_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:3.0156
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000379747_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.9911
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000379749_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.8917
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000541179_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.9956
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000379939_ENST00000541481_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.8642
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000379742_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.794
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000379743_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.6144
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000379747_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.9278
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000379749_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.9764
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000541179_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:3.0183
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000400445_ENST00000541481_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.9904
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000540320_ENST00000379742_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.5484
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000540320_ENST00000379743_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.4877
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000540320_ENST00000379747_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.2381
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000540320_ENST00000379749_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:2.5293
Å |
 |  |  |  |  |
| NBEA_POSTN_ENST00000540320_ENST00000541481_35883729_38171419 superimposed PDB: 5YJH of partner (POSTN). RMSD:3.0108
Å |
 |  |  |  |  |
| NBPF3_EPHB2_ENST00000318249_ENST00000544305_21771712_23189529 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.39
Å |
 |  |  |  |  |
| NBPF3_EPHB2_ENST00000454000_ENST00000374627_21771712_23189529 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.3696
Å |
 |  |  |  |  |
| NBPF3_EPHB2_ENST00000454000_ENST00000374632_21771712_23189529 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.3807
Å |
 |  |  |  |  |
| NBPF3_EPHB2_ENST00000454000_ENST00000400191_21771712_23189529 superimposed PDB: 3ZFM of partner (EPHB2). RMSD:0.3802
Å |
 |  |  |  |  |
| NCAM2_CHMP1A_ENST00000284894_ENST00000253475_22849792_89713739 superimposed PDB: 2JLL of partner (NCAM2). RMSD:1.4323
Å |
 |  |  |  |  |
| NCAM2_CRYL1_ENST00000284894_ENST00000382812_22370936_20978880 superimposed PDB: 3F3S of partner (CRYL1). RMSD:1.8617
Å |
 |  |  |  |  |
| NCAM2_CRYL1_ENST00000400546_ENST00000382812_22370936_20978880 superimposed PDB: 3F3S of partner (CRYL1). RMSD:2.9407
Å |
 |  |  |  |  |
| NCAM2_MIS18A_ENST00000284894_ENST00000290130_22370936_33647207 superimposed PDB: 7SFZ of partner (MIS18A). RMSD:0.6997
Å |
 |  |  |  |  |
| NCAN_UPF1_ENST00000252575_ENST00000599848_19351494_18968128 superimposed PDB: 2WJY of partner (UPF1). RMSD:0.6237
Å |
 |  |  |  |  |
| NCAN_UPF1_ENST00000538881_ENST00000599848_19351494_18968128 superimposed PDB: 2WJY of partner (UPF1). RMSD:0.5861
Å |
 |  |  |  |  |
| NCAPH2_GEMIN2_ENST00000420993_ENST00000250379_50954977_39601161 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:1.7324
Å |
 |  |  |  |  |
| NCAPH2_GEMIN2_ENST00000420993_ENST00000396249_50954977_39601161 superimposed PDB: 5XJL of partner (GEMIN2). RMSD:1.1307
Å |
 |  |  |  |  |
| NCK1_HEBP1_ENST00000481752_ENST00000014930_136665137_13128413 superimposed PDB: 2CI9 of partner (NCK1). RMSD:0.5355
Å |
 |  |  |  |  |
| NCKAP1_CPSF3_ENST00000361354_ENST00000460593_183902719_9593041 superimposed PDB: 9NH5 of partner (CPSF3). RMSD:1.2516
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000346874_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9879
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000350537_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9969
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000374788_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0004
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000374789_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.5846
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000374789_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.983
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000374790_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0089
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000374794_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0052
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000545260_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.0278
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000545260_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9877
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000360982_ENST00000545693_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0635
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000346874_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.2102
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000346874_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9721
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000350537_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.8126
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000350537_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0497
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374788_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.6821
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374788_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9774
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374789_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.9855
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374789_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0555
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374790_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:2.7716
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374790_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0742
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374794_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:3.1829
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000374794_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.991
Å |
| | | |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000545693_183888533_34985347 superimposed PDB: 3P8C of partner (NCKAP1). RMSD:3.1745
Å |
 |  |  |  |  |
| NCKAP1_PARD3_ENST00000361354_ENST00000545693_183888533_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9463
Å |
| | | |  |
| NCOR1_ACER3_ENST00000395851_ENST00000532485_15995176_76637600 superimposed PDB: 2EQR of partner (NCOR1). RMSD:0.8297
Å |
 |  |  |  |  |
| NCOR1_CCDC144A_ENST00000268712_ENST00000443444_15964714_16664738 superimposed PDB: 2EQR of partner (NCOR1). RMSD:0.8072
Å |
 |  |  |  |  |
| NCOR1_CYP2C9_ENST00000395848_ENST00000260682_16021201_96701614 superimposed PDB: 2EQR of partner (NCOR1). RMSD:0.818
Å |
 |  |  |  |  |
| NCOR1_CYP2C9_ENST00000395848_ENST00000260682_16021201_96701614 superimposed PDB: 5X23 of partner (CYP2C9). RMSD:0.9825
Å |
| | | |  |
| NCOR1_ZNF287_ENST00000268712_ENST00000395825_16089867_16456740 superimposed PDB: 2EQR of partner (NCOR1). RMSD:0.8001
Å |
 |  |  |  |  |
| NDRG1_ERG_ENST00000323851_ENST00000288319_134292474_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4305
Å |
 |  |  |  |  |
| NDRG1_ERG_ENST00000323851_ENST00000398905_134292474_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4329
Å |
 |  |  |  |  |
| NDRG1_ERG_ENST00000354944_ENST00000398907_134292474_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4244
Å |
 |  |  |  |  |
| NDRG1_VIM_ENST00000537882_ENST00000224237_134256597_17277844 superimposed PDB: 6ZMM of partner (NDRG1). RMSD:0.6353
Å |
 |  |  |  |  |
| NDRG2_SPARC_ENST00000360463_ENST00000231061_21486921_151049345 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.502
Å |
 |  |  |  |  |
| NDRG2_SPARC_ENST00000360463_ENST00000231061_21486921_151049345 superimposed PDB: 2V53 of partner (SPARC). RMSD:0.9305
Å |
| | | |  |
| NDRG2_SPARC_ENST00000397858_ENST00000231061_21486921_151049345 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.4771
Å |
 |  |  |  |  |
| NDRG2_SPARC_ENST00000397858_ENST00000231061_21486921_151049345 superimposed PDB: 2V53 of partner (SPARC). RMSD:0.8933
Å |
| | | |  |
| NDRG2_SPARC_ENST00000554143_ENST00000231061_21486921_151049345 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.4695
Å |
 |  |  |  |  |
| NDRG2_SPARC_ENST00000554143_ENST00000231061_21486921_151049345 superimposed PDB: 2V53 of partner (SPARC). RMSD:0.8088
Å |
| | | |  |
| NDRG2_SPARC_ENST00000556147_ENST00000231061_21486921_151049345 superimposed PDB: 2XMR of partner (NDRG2). RMSD:0.4817
Å |
 |  |  |  |  |
| NDRG2_SPARC_ENST00000556147_ENST00000231061_21486921_151049345 superimposed PDB: 2V53 of partner (SPARC). RMSD:0.9805
Å |
| | | |  |
| NDRG3_EIF3D_ENST00000349004_ENST00000216190_35312815_36907833 superimposed PDB: 6L4B of partner (NDRG3). RMSD:0.8403
Å |
 |  |  |  |  |
| NDRG3_EIF3D_ENST00000359675_ENST00000216190_35312815_36907833 superimposed PDB: 6L4B of partner (NDRG3). RMSD:0.7227
Å |
 |  |  |  |  |
| NDRG3_RBL1_ENST00000349004_ENST00000373664_35309218_35675593 superimposed PDB: 6L4B of partner (NDRG3). RMSD:3.4538
Å |
 |  |  |  |  |
| NDRG3_RBL1_ENST00000349004_ENST00000373664_35309218_35675593 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.4789
Å |
| | | |  |
| NDRG3_RBL1_ENST00000359675_ENST00000344359_35309218_35675593 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.6193
Å |
 |  |  |  |  |
| NDRG3_RBL1_ENST00000359675_ENST00000373664_35309218_35675593 superimposed PDB: 6L4B of partner (NDRG3). RMSD:3.1358
Å |
 |  |  |  |  |
| NDRG3_RBL1_ENST00000359675_ENST00000373664_35309218_35675593 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.4856
Å |
| | | |  |
| NDRG3_RBL1_ENST00000373803_ENST00000344359_35309218_35675593 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.6028
Å |
 |  |  |  |  |
| NDRG3_RBL1_ENST00000540765_ENST00000344359_35309218_35675593 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.4782
Å |
 |  |  |  |  |
| NDUFA11_POLRMT_ENST00000308961_ENST00000588649_5896463_632938 superimposed PDB: 9MN7 of partner (POLRMT). RMSD:1.3399
Å |
 |  |  |  |  |
| NDUFA12_MRPL11_ENST00000547157_ENST00000430466_95396581_66205730 superimposed PDB: 7OF0 of partner (MRPL11). RMSD:1.2378
Å |
 |  |  |  |  |
| NDUFAF2_MAST4_ENST00000296597_ENST00000403625_60241209_66084497 superimposed PDB: 2W7R of partner (MAST4). RMSD:0.629
Å |
 |  |  |  |  |
| NDUFAF2_MAST4_ENST00000296597_ENST00000406374_60241209_66084497 superimposed PDB: 2W7R of partner (MAST4). RMSD:0.6637
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000286687_ENST00000441892_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.0706
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000286687_ENST00000441892_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.2599
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396111_ENST00000027335_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.7903
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396111_ENST00000027335_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.3202
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396113_ENST00000027335_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.7934
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396113_ENST00000441892_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:1.9529
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396113_ENST00000441892_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.0998
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396124_ENST00000441892_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.2444
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000396124_ENST00000441892_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.3398
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000542894_ENST00000027335_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.3791
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000542894_ENST00000027335_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.6446
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000542894_ENST00000441892_96060786_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.0173
Å |
 |  |  |  |  |
| NDUFAF6_CDH17_ENST00000542894_ENST00000441892_96064458_95201513 superimposed PDB: 7CYM of partner (CDH17). RMSD:3.444
Å |
 |  |  |  |  |
| NDUFS1_RBM39_ENST00000233190_ENST00000361162_207018341_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7202
Å |
 |  |  |  |  |
| NDUFS1_RBM39_ENST00000233190_ENST00000528062_207018341_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.714
Å |
 |  |  |  |  |
| NDUFS1_RBM39_ENST00000455934_ENST00000361162_207018341_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6711
Å |
 |  |  |  |  |
| NDUFS1_RBM39_ENST00000455934_ENST00000528062_207018341_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6846
Å |
 |  |  |  |  |
| NEBL_DNAJC1_ENST00000377119_ENST00000376980_21177025_22055238 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.3612
Å |
 |  |  |  |  |
| NEBL_DNAJC1_ENST00000377122_ENST00000376946_21134186_22218070 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.289
Å |
 |  |  |  |  |
| NEBL_DNAJC1_ENST00000377122_ENST00000376946_21139323_22218070 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.5388
Å |
 |  |  |  |  |
| NEBL_DNAJC1_ENST00000377159_ENST00000376980_21250600_22095028 superimposed PDB: 2CQR of partner (DNAJC1). RMSD:1.3797
Å |
 |  |  |  |  |
| NEDD4L_MBD2_ENST00000400345_ENST00000256429_55711940_51715381 superimposed PDB: 9GIK of partner (NEDD4L). RMSD:2.669
Å |
 |  |  |  |  |
| NEDD4L_MORC3_ENST00000357895_ENST00000400485_55833093_37728917 superimposed PDB: 6O1E of partner (MORC3). RMSD:2.6084
Å |
 |  |  |  |  |
| NEDD4L_MORC3_ENST00000400345_ENST00000400485_55833093_37728917 superimposed PDB: 6O1E of partner (MORC3). RMSD:1.4935
Å |
 |  |  |  |  |
| NEDD4L_MORC3_ENST00000586263_ENST00000400485_55833093_37728917 superimposed PDB: 6O1E of partner (MORC3). RMSD:1.7503
Å |
 |  |  |  |  |
| NEDD4L_TBC1D17_ENST00000256830_ENST00000535102_55919286_50381754 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.7907
Å |
 |  |  |  |  |
| NEDD4L_TBC1D17_ENST00000356462_ENST00000535102_55919286_50381754 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.8523
Å |
 |  |  |  |  |
| NEDD4L_TBC1D17_ENST00000357895_ENST00000535102_55919286_50381754 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.7832
Å |
 |  |  |  |  |
| NEDD8_NRL_ENST00000524927_ENST00000397002_24701455_24550777 superimposed PDB: 4FBJ of partner (NEDD8). RMSD:2.8848
Å |
 |  |  |  |  |
| NEGR1_PTGER3_ENST00000306821_ENST00000370931_72058499_71478167 superimposed PDB: 6DLD of partner (NEGR1). RMSD:1.1323
Å |
 |  |  |  |  |
| NEGR1_PTGER3_ENST00000306821_ENST00000370932_72058499_71478167 superimposed PDB: 6DLD of partner (NEGR1). RMSD:2.2923
Å |
 |  |  |  |  |
| NEGR1_PTGER3_ENST00000357731_ENST00000370924_72058499_71478167 superimposed PDB: 6DLD of partner (NEGR1). RMSD:2.2694
Å |
 |  |  |  |  |
| NEGR1_TCF20_ENST00000306821_ENST00000335626_72400761_42575708 superimposed PDB: 6DLD of partner (NEGR1). RMSD:0.6228
Å |
 |  |  |  |  |
| NEGR1_TCF20_ENST00000306821_ENST00000359486_72400761_42575708 superimposed PDB: 6DLD of partner (NEGR1). RMSD:3.4654
Å |
 |  |  |  |  |
| NEIL2_TTC7B_ENST00000284503_ENST00000357056_11637459_91146879 superimposed PDB: 9B9G of partner (TTC7B). RMSD:1.6187
Å |
 |  |  |  |  |
| NEIL2_TTC7B_ENST00000403422_ENST00000328459_11637459_91146879 superimposed PDB: 9B9G of partner (TTC7B). RMSD:1.6137
Å |
 |  |  |  |  |
| NEIL2_TTC7B_ENST00000436750_ENST00000328459_11637459_91146879 superimposed PDB: 9B9G of partner (TTC7B). RMSD:1.5675
Å |
 |  |  |  |  |
| NEIL2_TTC7B_ENST00000455213_ENST00000357056_11637459_91146879 superimposed PDB: 9B9G of partner (TTC7B). RMSD:1.6469
Å |
 |  |  |  |  |
| NEK11_WDPCP_ENST00000356918_ENST00000409199_130828765_63540446 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.8243
Å |
 |  |  |  |  |
| NEK11_WDPCP_ENST00000508196_ENST00000409199_130828765_63540446 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:2.2899
Å |
 |  |  |  |  |
| NEK9_EPC1_ENST00000238616_ENST00000319778_75562074_32562209 superimposed PDB: 3ZKE of partner (NEK9). RMSD:2.0451
Å |
 |  |  |  |  |
| NEK9_SOS2_ENST00000238616_ENST00000543680_75553720_50628327 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.8658
Å |
 |  |  |  |  |
| NELFA_POLN_ENST00000382882_ENST00000511885_2010476_2210214 superimposed PDB: 4XVK of partner (POLN). RMSD:0.836
Å |
 |  |  |  |  |
| NELFA_POLN_ENST00000411638_ENST00000511885_2010476_2210214 superimposed PDB: 4XVK of partner (POLN). RMSD:0.8545
Å |
 |  |  |  |  |
| NEMF_CDKL1_ENST00000298310_ENST00000216378_50295008_50808940 superimposed PDB: 4AGU of partner (CDKL1). RMSD:0.5289
Å |
 |  |  |  |  |
| NEMF_CDKL1_ENST00000545773_ENST00000216378_50295008_50808940 superimposed PDB: 4AGU of partner (CDKL1). RMSD:0.5049
Å |
 |  |  |  |  |
| NEMF_CDKL1_ENST00000545773_ENST00000395834_50295008_50808940 superimposed PDB: 4AGU of partner (CDKL1). RMSD:0.7415
Å |
 |  |  |  |  |
| NEMF_CDKL1_ENST00000546046_ENST00000395834_50295008_50808940 superimposed PDB: 4AGU of partner (CDKL1). RMSD:0.7771
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000261908_ENST00000341861_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:1.1567
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000339362_ENST00000300141_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:1.9782
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000339362_ENST00000321118_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.8734
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000339362_ENST00000358939_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.6594
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000558964_ENST00000300141_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:2.0273
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000558964_ENST00000321118_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.8326
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000558964_ENST00000358939_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.6153
Å |
 |  |  |  |  |
| NEO1_DPP8_ENST00000560262_ENST00000341861_73345146_65766626 superimposed PDB: 6EOP of partner (DPP8). RMSD:1.127
Å |
 |  |  |  |  |
| NEO1_YWHAE_ENST00000261908_ENST00000264335_73470768_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.2825
Å |
 |  |  |  |  |
| NEO1_YWHAE_ENST00000560262_ENST00000264335_73470768_1268352 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3233
Å |
 |  |  |  |  |
| NEU3_POLA2_ENST00000531509_ENST00000265465_74705765_65043362 superimposed PDB: 4Y97 of partner (POLA2). RMSD:0.4593
Å |
 |  |  |  |  |
| NEU3_POLA2_ENST00000531619_ENST00000265465_74705765_65043362 superimposed PDB: 4Y97 of partner (POLA2). RMSD:0.4646
Å |
 |  |  |  |  |
| NEU3_POLA2_ENST00000544263_ENST00000265465_74705765_65043362 superimposed PDB: 4Y97 of partner (POLA2). RMSD:0.4429
Å |
 |  |  |  |  |
| NEXN_AK5_ENST00000330010_ENST00000344720_78399164_77949001 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.7949
Å |
 |  |  |  |  |
| NEXN_AK5_ENST00000334785_ENST00000344720_78399164_77949001 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.7816
Å |
 |  |  |  |  |
| NEXN_AK5_ENST00000457030_ENST00000344720_78399164_77949001 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.8031
Å |
 |  |  |  |  |
| NF1_ABCB5_ENST00000358273_ENST00000404938_29676269_20671681 superimposed PDB: 7PGP of partner (NF1). RMSD:2.4778
Å |
 |  |  |  |  |
| NF1_ABCB5_ENST00000417592_ENST00000404938_29676269_20671681 superimposed PDB: 7PGP of partner (NF1). RMSD:2.0997
Å |
 |  |  |  |  |
| NF1_ACACA_ENST00000356175_ENST00000360679_29422387_35518964 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.8846
Å |
 |  |  |  |  |
| NF1_ASIC2_ENST00000356175_ENST00000359872_29560231_31439085 superimposed PDB: 6L6P of partner (ASIC2). RMSD:0.7729
Å |
 |  |  |  |  |
| NF1_ATAD5_ENST00000358273_ENST00000321990_29497015_29192721 superimposed PDB: 8UII of partner (ATAD5). RMSD:2.2084
Å |
 |  |  |  |  |
| NF1_GFPT1_ENST00000356175_ENST00000361060_29664600_69556930 superimposed PDB: 7PGP of partner (NF1). RMSD:1.1123
Å |
 |  |  |  |  |
| NF1_GFPT1_ENST00000356175_ENST00000361060_29664600_69556930 superimposed PDB: 6R4H of partner (GFPT1). RMSD:3.1542
Å |
| | | |  |
| NF1_GFPT1_ENST00000358273_ENST00000361060_29664600_69556930 superimposed PDB: 7PGP of partner (NF1). RMSD:1.1346
Å |
 |  |  |  |  |
| NF1_MAP2K4_ENST00000356175_ENST00000415385_29509683_12028610 superimposed PDB: 7PGP of partner (NF1). RMSD:3.3196
Å |
 |  |  |  |  |
| NF1_MAP2K4_ENST00000356175_ENST00000415385_29509683_12028610 superimposed PDB: 3ALN of partner (MAP2K4). RMSD:0.7588
Å |
| | | |  |
| NF1_POLDIP2_ENST00000358273_ENST00000540200_29592357_26682902 superimposed PDB: 6Z9C of partner (POLDIP2). RMSD:0.9373
Å |
 |  |  |  |  |
| NF1_SAFB2_ENST00000356175_ENST00000252542_29592357_5600271 superimposed PDB: 9RMV of partner (SAFB2). RMSD:2.8112
Å |
 |  |  |  |  |
| NF1_TRMT61B_ENST00000358273_ENST00000306108_29497015_29084174 superimposed PDB: 2B25 of partner (TRMT61B). RMSD:0.8245
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000334961_ENST00000262726_30051665_44083461 superimposed PDB: 7LWH of partner (NF2). RMSD:0.7252
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000334961_ENST00000262726_30051665_44083461 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4714
Å |
| | | |  |
| NF2_EFCAB6_ENST00000338641_ENST00000262726_30051665_44083461 superimposed PDB: 7LWH of partner (NF2). RMSD:0.593
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000338641_ENST00000262726_30051665_44083461 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4228
Å |
| | | |  |
| NF2_EFCAB6_ENST00000361166_ENST00000262726_30051665_44083461 superimposed PDB: 7LWH of partner (NF2). RMSD:0.5987
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000361166_ENST00000262726_30051665_44083461 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4218
Å |
| | | |  |
| NF2_EFCAB6_ENST00000361452_ENST00000262726_30051665_44083461 superimposed PDB: 7LWH of partner (NF2). RMSD:2.3439
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000361452_ENST00000262726_30051665_44083461 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4057
Å |
| | | |  |
| NF2_EFCAB6_ENST00000361676_ENST00000262726_30051665_44083461 superimposed PDB: 7LWH of partner (NF2). RMSD:0.9509
Å |
 |  |  |  |  |
| NF2_EFCAB6_ENST00000361676_ENST00000262726_30051665_44083461 superimposed PDB: 1WLZ of partner (EFCAB6). RMSD:0.4567
Å |
| | | |  |
| NF2_GRAP2_ENST00000338641_ENST00000344138_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:1.2772
Å |
 |  |  |  |  |
| NF2_GRAP2_ENST00000338641_ENST00000543252_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.3923
Å |
 |  |  |  |  |
| NF2_GRAP2_ENST00000361166_ENST00000344138_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:1.1433
Å |
 |  |  |  |  |
| NF2_GRAP2_ENST00000361676_ENST00000344138_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:1.166
Å |
 |  |  |  |  |
| NF2_GRAP2_ENST00000397789_ENST00000543252_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:0.4343
Å |
 |  |  |  |  |
| NF2_GRAP2_ENST00000413209_ENST00000344138_30035201_40351822 superimposed PDB: 5GJH of partner (GRAP2). RMSD:1.4825
Å |
 |  |  |  |  |
| NF2_HORMAD2_ENST00000353887_ENST00000403975_30054253_30572051 superimposed PDB: 7LWH of partner (NF2). RMSD:0.599
Å |
 |  |  |  |  |
| NF2_HORMAD2_ENST00000397789_ENST00000403975_30054253_30572051 superimposed PDB: 7LWH of partner (NF2). RMSD:0.5561
Å |
 |  |  |  |  |
| NF2_HORMAD2_ENST00000403435_ENST00000403975_30054253_30572051 superimposed PDB: 7LWH of partner (NF2). RMSD:0.5726
Å |
 |  |  |  |  |
| NF2_HORMAD2_ENST00000403999_ENST00000403975_30054253_30572051 superimposed PDB: 7LWH of partner (NF2). RMSD:1.4056
Å |
 |  |  |  |  |
| NF2_PIAS1_ENST00000347330_ENST00000545237_30000101_68378643 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7655
Å |
 |  |  |  |  |
| NF2_PIAS1_ENST00000361166_ENST00000545237_30000101_68378643 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7646
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000347330_ENST00000452095_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:3.1326
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000361166_ENST00000267811_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:0.587
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000361166_ENST00000452095_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:0.5213
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000361676_ENST00000267811_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:1.6893
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000361676_ENST00000452095_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:1.5107
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000413209_ENST00000267811_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:0.4664
Å |
 |  |  |  |  |
| NF2_TCF12_ENST00000413209_ENST00000452095_30038274_57523349 superimposed PDB: 7LWH of partner (NF2). RMSD:0.5005
Å |
 |  |  |  |  |
| NFAT5_CYB5B_ENST00000567239_ENST00000515314_69602451_69496332 superimposed PDB: 1IMH of partner (NFAT5). RMSD:2.5975
Å |
 |  |  |  |  |
| NFAT5_NQO1_ENST00000432919_ENST00000320623_69602451_69752437 superimposed PDB: 5FUQ of partner (NQO1). RMSD:0.4268
Å |
 |  |  |  |  |
| NFAT5_NQO1_ENST00000432919_ENST00000379046_69602451_69752437 superimposed PDB: 5FUQ of partner (NQO1). RMSD:0.4168
Å |
 |  |  |  |  |
| NFAT5_NQO1_ENST00000432919_ENST00000379047_69602451_69752437 superimposed PDB: 5FUQ of partner (NQO1). RMSD:0.4337
Å |
 |  |  |  |  |
| NFAT5_NQO1_ENST00000432919_ENST00000439109_69602451_69752437 superimposed PDB: 5FUQ of partner (NQO1). RMSD:0.5845
Å |
 |  |  |  |  |
| NFAT5_NQO1_ENST00000567239_ENST00000561500_69602451_69752437 superimposed PDB: 5FUQ of partner (NQO1). RMSD:0.5315
Å |
 |  |  |  |  |
| NFAT5_VPS4A_ENST00000354436_ENST00000254950_69600277_69350127 superimposed PDB: 2JQ9 of partner (VPS4A). RMSD:0.8862
Å |
 |  |  |  |  |
| NFAT5_VPS4A_ENST00000567239_ENST00000254950_69602451_69350127 superimposed PDB: 2JQ9 of partner (VPS4A). RMSD:1.9282
Å |
 |  |  |  |  |
| NFATC2IP_HS3ST4_ENST00000568148_ENST00000331351_28970421_26146932 superimposed PDB: 2L76 of partner (NFATC2IP). RMSD:0.7933
Å |
 |  |  |  |  |
| NFATC2_ATP9A_ENST00000371564_ENST00000338821_50071084_50292747 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:0.6976
Å |
 |  |  |  |  |
| NFATC2_ATP9A_ENST00000371564_ENST00000338821_50071084_50292747 superimposed PDB: 9VDK of partner (ATP9A). RMSD:2.5883
Å |
| | | |  |
| NFATC2_ATP9A_ENST00000609943_ENST00000338821_50071084_50292747 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:0.6968
Å |
 |  |  |  |  |
| NFATC2_ATP9A_ENST00000609943_ENST00000338821_50071084_50292747 superimposed PDB: 9VDK of partner (ATP9A). RMSD:2.1556
Å |
| | | |  |
| NFATC2_LBP_ENST00000396009_ENST00000217407_50133322_36993229 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:0.5537
Å |
 |  |  |  |  |
| NFATC2_PTPN1_ENST00000414705_ENST00000371621_50051724_49177899 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:0.6689
Å |
 |  |  |  |  |
| NFATC3_CDH1_ENST00000575270_ENST00000422392_68225678_68835572 superimposed PDB: 7STZ of partner (CDH1). RMSD:2.8733
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000357480_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7455
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000357480_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7385
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000361665_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7322
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000361665_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7249
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000362042_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7001
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000536222_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6762
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000536222_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6853
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000582155_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7415
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000582155_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.616
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000583378_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6483
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000583378_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.6883
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000585291_ENST00000327064_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7703
Å |
 |  |  |  |  |
| NFE2L1_CARM1_ENST00000585291_ENST00000344150_46134864_11022859 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.7194
Å |
 |  |  |  |  |
| NFE2L2_VMP1_ENST00000397062_ENST00000262291_178129259_57851114 superimposed PDB: 7X5E of partner (NFE2L2). RMSD:3.3241
Å |
 |  |  |  |  |
| NFE2L3_NPY_ENST00000056233_ENST00000407573_26192688_24324859 superimposed PDB: 7RTA of partner (NPY). RMSD:0.4369
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000357977_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4223
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000357977_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.857
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000371184_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4458
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000371184_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.7235
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000371185_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4722
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000371185_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.7954
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000371187_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4754
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000371187_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.6191
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000371189_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5157
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000371189_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.638
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000403491_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4842
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000403491_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.7738
Å |
| | | |  |
| NFIA_CDK2AP1_ENST00000407417_ENST00000261692_61872399_123751829 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4602
Å |
 |  |  |  |  |
| NFIA_CDK2AP1_ENST00000407417_ENST00000261692_61872399_123751829 superimposed PDB: 2KW6 of partner (CDK2AP1). RMSD:0.6223
Å |
| | | |  |
| NFIA_CYP2J2_ENST00000371185_ENST00000371204_61554352_60359501 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5399
Å |
 |  |  |  |  |
| NFIA_CYP2J2_ENST00000371187_ENST00000371204_61554352_60359501 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4454
Å |
 |  |  |  |  |
| NFIA_CYP2J2_ENST00000371189_ENST00000371204_61554352_60359501 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5735
Å |
 |  |  |  |  |
| NFIA_CYP2J2_ENST00000403491_ENST00000371204_61554352_60359501 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4759
Å |
 |  |  |  |  |
| NFIA_CYP2J2_ENST00000407417_ENST00000371204_61554352_60359501 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4975
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371185_ENST00000331772_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4575
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371185_ENST00000331772_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.6028
Å |
| | | |  |
| NFIA_RNLS_ENST00000371185_ENST00000371947_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5161
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371185_ENST00000371947_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.1244
Å |
| | | |  |
| NFIA_RNLS_ENST00000371187_ENST00000371947_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5153
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371187_ENST00000371947_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.1494
Å |
| | | |  |
| NFIA_RNLS_ENST00000371189_ENST00000331772_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5149
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371189_ENST00000331772_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5901
Å |
| | | |  |
| NFIA_RNLS_ENST00000371189_ENST00000371947_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4875
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371189_ENST00000371947_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.0235
Å |
| | | |  |
| NFIA_RNLS_ENST00000371189_ENST00000437752_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4522
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371189_ENST00000437752_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5917
Å |
| | | |  |
| NFIA_RNLS_ENST00000371191_ENST00000331772_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4393
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371191_ENST00000331772_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.6391
Å |
| | | |  |
| NFIA_RNLS_ENST00000371191_ENST00000437752_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4791
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000371191_ENST00000437752_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5582
Å |
| | | |  |
| NFIA_RNLS_ENST00000403491_ENST00000331772_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.502
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000403491_ENST00000331772_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.6067
Å |
| | | |  |
| NFIA_RNLS_ENST00000403491_ENST00000371947_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4179
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000403491_ENST00000371947_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.1724
Å |
| | | |  |
| NFIA_RNLS_ENST00000403491_ENST00000437752_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4725
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000403491_ENST00000437752_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.592
Å |
| | | |  |
| NFIA_RNLS_ENST00000407417_ENST00000331772_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4435
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000407417_ENST00000331772_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5884
Å |
| | | |  |
| NFIA_RNLS_ENST00000407417_ENST00000371947_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5068
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000407417_ENST00000371947_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:1.045
Å |
| | | |  |
| NFIA_RNLS_ENST00000407417_ENST00000437752_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4636
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000407417_ENST00000437752_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.623
Å |
| | | |  |
| NFIA_RNLS_ENST00000485903_ENST00000437752_61554352_90122482 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4304
Å |
 |  |  |  |  |
| NFIA_RNLS_ENST00000485903_ENST00000437752_61554352_90122482 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.6032
Å |
| | | |  |
| NFIA_SCP2_ENST00000371185_ENST00000371514_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.3799
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000371187_ENST00000371514_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.3265
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000371189_ENST00000371514_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4357
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000371189_ENST00000528311_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:1.0534
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000371191_ENST00000528311_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:1.053
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000403491_ENST00000371514_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.3694
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000403491_ENST00000528311_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.3487
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000407417_ENST00000371514_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.3413
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000407417_ENST00000528311_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5264
Å |
 |  |  |  |  |
| NFIA_SCP2_ENST00000485903_ENST00000528311_61554352_53440440 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4356
Å |
 |  |  |  |  |
| NFIB_ADAMTSL1_ENST00000380953_ENST00000380545_14116206_18887828 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4618
Å |
 |  |  |  |  |
| NFIB_UBE2H_ENST00000380934_ENST00000473814_14306987_129479175 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5841
Å |
 |  |  |  |  |
| NFIB_UBE2H_ENST00000380934_ENST00000473814_14306987_129479175 superimposed PDB: 8PJN of partner (UBE2H). RMSD:1.6768
Å |
| | | |  |
| NFIB_UBE2H_ENST00000380959_ENST00000355621_14306987_129479175 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.6124
Å |
 |  |  |  |  |
| NFIB_UBE2H_ENST00000380959_ENST00000355621_14306987_129479175 superimposed PDB: 8PJN of partner (UBE2H). RMSD:1.5997
Å |
| | | |  |
| NFIB_UBE2H_ENST00000380959_ENST00000473814_14306987_129479175 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.4926
Å |
 |  |  |  |  |
| NFIB_UBE2H_ENST00000380959_ENST00000473814_14306987_129479175 superimposed PDB: 8PJN of partner (UBE2H). RMSD:2.6139
Å |
| | | |  |
| NFIB_ZDHHC21_ENST00000380934_ENST00000380916_14306987_14662324 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.5271
Å |
 |  |  |  |  |
| NFIB_ZDHHC21_ENST00000380953_ENST00000380916_14306987_14662324 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.6452
Å |
 |  |  |  |  |
| NFIB_ZDHHC21_ENST00000380959_ENST00000380916_14306987_14662324 superimposed PDB: 9W7S of partner (NFIB). RMSD:0.6127
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000341919_ENST00000541430_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5426
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000341919_ENST00000541430_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9089
Å |
| | | |  |
| NFIC_CELF5_ENST00000341919_ENST00000541430_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5587
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000341919_ENST00000541430_3435205_3284899 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.2399
Å |
| | | |  |
| NFIC_CELF5_ENST00000346156_ENST00000292672_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.4946
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000346156_ENST00000292672_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.0032
Å |
| | | |  |
| NFIC_CELF5_ENST00000346156_ENST00000292672_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5289
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000346156_ENST00000541430_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5399
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000346156_ENST00000541430_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9402
Å |
| | | |  |
| NFIC_CELF5_ENST00000346156_ENST00000541430_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6772
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000346156_ENST00000541430_3435205_3284899 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.2069
Å |
| | | |  |
| NFIC_CELF5_ENST00000395111_ENST00000292672_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6093
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000395111_ENST00000292672_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9716
Å |
| | | |  |
| NFIC_CELF5_ENST00000395111_ENST00000292672_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5641
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000395111_ENST00000541430_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6885
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000395111_ENST00000541430_3435205_3284899 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.1983
Å |
| | | |  |
| NFIC_CELF5_ENST00000586919_ENST00000292672_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5369
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000589123_ENST00000541430_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5143
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000589123_ENST00000541430_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9705
Å |
| | | |  |
| NFIC_CELF5_ENST00000589123_ENST00000541430_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6285
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000589123_ENST00000541430_3435205_3284899 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.248
Å |
| | | |  |
| NFIC_CELF5_ENST00000590282_ENST00000292672_3382241_3250982 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.4997
Å |
 |  |  |  |  |
| NFIC_CELF5_ENST00000590282_ENST00000292672_3382241_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9434
Å |
| | | |  |
| NFIC_CELF5_ENST00000590282_ENST00000292672_3435205_3284899 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5415
Å |
 |  |  |  |  |
| NFIC_LSM7_ENST00000346156_ENST00000252622_3435205_2324195 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5411
Å |
 |  |  |  |  |
| NFIC_LSM7_ENST00000395111_ENST00000252622_3435205_2324195 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5155
Å |
 |  |  |  |  |
| NFIC_LSM7_ENST00000586919_ENST00000252622_3435205_2324195 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5566
Å |
 |  |  |  |  |
| NFIC_LSM7_ENST00000590282_ENST00000252622_3435205_2324195 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5397
Å |
 |  |  |  |  |
| NFIC_UNC13A_ENST00000341919_ENST00000550896_3425175_17722664 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7213
Å |
 |  |  |  |  |
| NFIC_UNC13A_ENST00000395111_ENST00000550896_3425175_17722664 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7187
Å |
 |  |  |  |  |
| NFIC_UNC13A_ENST00000589123_ENST00000550896_3425175_17722664 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5987
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000397661_ENST00000314646_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9718
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000397661_ENST00000355667_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9933
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000397661_ENST00000359692_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9659
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000397661_ENST00000389253_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9966
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000397661_ENST00000408974_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9797
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000314646_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0039
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000355667_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9788
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000359692_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9463
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000389253_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9597
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000408974_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0708
Å |
 |  |  |  |  |
| NFIX_DNM2_ENST00000592199_ENST00000585892_13106678_10897239 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9964
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000358552_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4514
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000358552_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9803
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000360105_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5038
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000360105_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:1.0288
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000360105_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4597
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000360105_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9231
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000397661_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4485
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000397661_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.8616
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000585575_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4651
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000585575_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9212
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000585575_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4759
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000585575_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9447
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000587260_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4242
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000587260_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9302
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000587260_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.486
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000587260_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9922
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000587760_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4643
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000587760_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:1.0509
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000587760_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4377
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000587760_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9134
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000588228_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5264
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000588228_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.9919
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000588228_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4911
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000588228_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:0.8124
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000592199_ENST00000252577_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4747
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000592199_ENST00000252577_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:1.0159
Å |
| | | |  |
| NFIX_GATAD2A_ENST00000592199_ENST00000360315_13184840_19603114 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.3954
Å |
 |  |  |  |  |
| NFIX_GATAD2A_ENST00000592199_ENST00000360315_13184840_19603114 superimposed PDB: 2L2L of partner (GATAD2A). RMSD:1.0316
Å |
| | | |  |
| NFIX_GCDH_ENST00000358552_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.3284
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000358552_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4885
Å |
| | | |  |
| NFIX_GCDH_ENST00000360105_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5396
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000360105_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4896
Å |
| | | |  |
| NFIX_GCDH_ENST00000360105_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5573
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000360105_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.773
Å |
| | | |  |
| NFIX_GCDH_ENST00000360105_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5908
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000360105_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4636
Å |
| | | |  |
| NFIX_GCDH_ENST00000360105_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5258
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000360105_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5091
Å |
| | | |  |
| NFIX_GCDH_ENST00000397661_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5139
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000397661_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.6012
Å |
| | | |  |
| NFIX_GCDH_ENST00000397661_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4602
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000397661_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4797
Å |
| | | |  |
| NFIX_GCDH_ENST00000397661_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4376
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000397661_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5415
Å |
| | | |  |
| NFIX_GCDH_ENST00000585575_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4332
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000585575_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.485
Å |
| | | |  |
| NFIX_GCDH_ENST00000585575_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5304
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000585575_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.681
Å |
| | | |  |
| NFIX_GCDH_ENST00000585575_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.8746
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000585575_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4612
Å |
| | | |  |
| NFIX_GCDH_ENST00000585575_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4738
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000585575_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5275
Å |
| | | |  |
| NFIX_GCDH_ENST00000587260_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4613
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587260_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4838
Å |
| | | |  |
| NFIX_GCDH_ENST00000587260_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5962
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587260_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5494
Å |
| | | |  |
| NFIX_GCDH_ENST00000587260_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.526
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587260_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4855
Å |
| | | |  |
| NFIX_GCDH_ENST00000587260_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5552
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587260_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5104
Å |
| | | |  |
| NFIX_GCDH_ENST00000587760_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4629
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587760_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4968
Å |
| | | |  |
| NFIX_GCDH_ENST00000587760_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5165
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587760_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.6789
Å |
| | | |  |
| NFIX_GCDH_ENST00000587760_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4974
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587760_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4501
Å |
| | | |  |
| NFIX_GCDH_ENST00000587760_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5318
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000587760_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4917
Å |
| | | |  |
| NFIX_GCDH_ENST00000588228_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4886
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000588228_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.475
Å |
| | | |  |
| NFIX_GCDH_ENST00000588228_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4655
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000588228_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.6101
Å |
| | | |  |
| NFIX_GCDH_ENST00000588228_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4867
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000588228_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4472
Å |
| | | |  |
| NFIX_GCDH_ENST00000588228_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4657
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000588228_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5562
Å |
| | | |  |
| NFIX_GCDH_ENST00000592199_ENST00000222214_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4598
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000592199_ENST00000222214_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5062
Å |
| | | |  |
| NFIX_GCDH_ENST00000592199_ENST00000422947_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4993
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000592199_ENST00000422947_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.6141
Å |
| | | |  |
| NFIX_GCDH_ENST00000592199_ENST00000591470_13136366_13002929 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4985
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000592199_ENST00000591470_13136366_13002929 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.4638
Å |
| | | |  |
| NFIX_GCDH_ENST00000592199_ENST00000591470_13136366_13006805 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5379
Å |
 |  |  |  |  |
| NFIX_GCDH_ENST00000592199_ENST00000591470_13136366_13006805 superimposed PDB: 2R0N of partner (GCDH). RMSD:0.5289
Å |
| | | |  |
| NFIX_LRP4_ENST00000358552_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4533
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000358552_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.3643
Å |
| | | |  |
| NFIX_LRP4_ENST00000360105_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4771
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000360105_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.3541
Å |
| | | |  |
| NFIX_LRP4_ENST00000585575_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:2.9267
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000585575_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.5663
Å |
| | | |  |
| NFIX_LRP4_ENST00000587260_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4357
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000587260_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.7191
Å |
| | | |  |
| NFIX_LRP4_ENST00000587760_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.6491
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000587760_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.4515
Å |
| | | |  |
| NFIX_LRP4_ENST00000588228_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4443
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000588228_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.6708
Å |
| | | |  |
| NFIX_LRP4_ENST00000592199_ENST00000378623_13136366_46924480 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.6098
Å |
 |  |  |  |  |
| NFIX_LRP4_ENST00000592199_ENST00000378623_13136366_46924480 superimposed PDB: 8S9P of partner (LRP4). RMSD:2.4078
Å |
| | | |  |
| NFIX_MAST1_ENST00000358552_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.7918
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000360105_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:1.1846
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000585575_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.847
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000587260_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.9876
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000587760_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:1.2582
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000588228_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.853
Å |
 |  |  |  |  |
| NFIX_MAST1_ENST00000592199_ENST00000251472_13136366_12975622 superimposed PDB: 9WA7 of partner (NFIX). RMSD:1.2897
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000358552_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5104
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000358552_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.4517
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4858
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.6118
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5182
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.2134
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4956
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.8896
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4948
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.4804
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4753
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000360105_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.8218
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.467
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.6418
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4544
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.8219
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4332
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.7981
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5172
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000397661_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.8882
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.535
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.6269
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4798
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.8317
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4653
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.4248
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4464
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.5351
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000585575_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.451
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4908
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.6037
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4987
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.3495
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4463
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.5849
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4531
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.4215
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4384
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587260_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.3918
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4257
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4392
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4725
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4496
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4679
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000587760_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.5686
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4269
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:3.0174
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5255
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.0175
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4454
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.2429
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4402
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.9302
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4931
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000588228_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.822
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000259351_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5665
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000259351_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.0385
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000373434_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4978
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000373434_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.5713
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000373436_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4622
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000373436_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.7318
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000394022_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5038
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000394022_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:2.6571
Å |
| | | |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000424082_13136366_129928347 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5243
Å |
 |  |  |  |  |
| NFIX_RALGPS1_ENST00000592199_ENST00000424082_13136366_129928347 superimposed PDB: 3QXL of partner (RALGPS1). RMSD:1.9978
Å |
| | | |  |
| NFIX_RFX1_ENST00000592199_ENST00000254325_13106678_14088898 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.3676
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000360105_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5634
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000585575_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5198
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000587260_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5132
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000587760_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5187
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000588228_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.532
Å |
 |  |  |  |  |
| NFIX_WDR26_ENST00000592199_ENST00000295024_13136366_224581715 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5373
Å |
 |  |  |  |  |
| NFKBIB_LGALS7B_ENST00000313582_ENST00000314980_39390851_39281328 superimposed PDB: 3ZXF of partner (LGALS7B). RMSD:0.5074
Å |
 |  |  |  |  |
| NFX1_ACO1_ENST00000379540_ENST00000379923_33351788_32440462 superimposed PDB: 2B3Y of partner (ACO1). RMSD:0.6175
Å |
 |  |  |  |  |
| NHLRC3_PAK1_ENST00000379599_ENST00000356341_39613848_77091039 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6438
Å |
 |  |  |  |  |
| NHLRC3_PAK1_ENST00000379600_ENST00000278568_39613848_77091039 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6225
Å |
 |  |  |  |  |
| NHLRC3_PAK1_ENST00000379600_ENST00000530617_39613848_77091039 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.5803
Å |
 |  |  |  |  |
| NID1_HDAC5_ENST00000264187_ENST00000393622_236148678_42156645 superimposed PDB: 5UWI of partner (HDAC5). RMSD:1.72
Å |
 |  |  |  |  |
| NID1_HDAC5_ENST00000366595_ENST00000393622_236148678_42156645 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.6623
Å |
 |  |  |  |  |
| NIN_ALKBH1_ENST00000382041_ENST00000216489_51226574_78146313 superimposed PDB: 6IE3 of partner (ALKBH1). RMSD:1.2398
Å |
 |  |  |  |  |
| NIN_ALKBH1_ENST00000530997_ENST00000216489_51226574_78146313 superimposed PDB: 6IE3 of partner (ALKBH1). RMSD:1.2991
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000282516_ENST00000261178_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4374
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000282516_ENST00000266503_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4298
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000282516_ENST00000311001_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4205
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000282516_ENST00000395901_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4428
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000282516_ENST00000546179_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.3873
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000448238_ENST00000261178_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4296
Å |
 |  |  |  |  |
| NIPBL_ARNTL2_ENST00000448238_ENST00000544915_36972143_27521194 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4245
Å |
 |  |  |  |  |
| NIPBL_FGF10_ENST00000448238_ENST00000264664_36962376_44310632 superimposed PDB: 1NUN of partner (FGF10). RMSD:0.4452
Å |
 |  |  |  |  |
| NIPBL_MYO10_ENST00000282516_ENST00000507288_37010327_16877816 superimposed PDB: 5I0I of partner (MYO10). RMSD:1.1
Å |
 |  |  |  |  |
| NIPBL_MYO10_ENST00000448238_ENST00000513610_37010327_16877816 superimposed PDB: 6WGE of partner (NIPBL). RMSD:1.5635
Å |
 |  |  |  |  |
| NIPBL_MYO10_ENST00000448238_ENST00000513610_37010327_16877816 superimposed PDB: 5I0I of partner (MYO10). RMSD:0.5267
Å |
| | | |  |
| NIPBL_NUP155_ENST00000282516_ENST00000381843_37027514_37310845 superimposed PDB: 7EYQ of partner (NUP155). RMSD:2.9064
Å |
 |  |  |  |  |
| NIPBL_WDR70_ENST00000448238_ENST00000265107_37010327_37697756 superimposed PDB: 6WGE of partner (NIPBL). RMSD:1.8641
Å |
 |  |  |  |  |
| NIPBL_WDR70_ENST00000448238_ENST00000265107_37010327_37697756 superimposed PDB: 6ZYM of partner (WDR70). RMSD:1.1945
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000296302_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:0.6938
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000296302_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.217
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000337303_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.8329
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000337303_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2873
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000394830_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.2984
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000394830_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.0993
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000409057_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.3906
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000409057_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2761
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000409767_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.1152
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000409767_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.5931
Å |
| | | |  |
| NISCH_PBRM1_ENST00000345716_ENST00000410007_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.39
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000345716_ENST00000410007_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.0875
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000296302_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:0.8426
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000296302_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.7438
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000337303_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.8061
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000337303_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.4938
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000394830_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.293
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000394830_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2803
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000409057_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.29
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000409057_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2505
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000409767_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:0.9999
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000409767_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:0.7267
Å |
| | | |  |
| NISCH_PBRM1_ENST00000479054_ENST00000410007_52524849_52643971 superimposed PDB: 8ESF of partner (NISCH). RMSD:1.8193
Å |
 |  |  |  |  |
| NISCH_PBRM1_ENST00000479054_ENST00000410007_52524849_52643971 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3032
Å |
| | | |  |
| NKD2_OXCT1_ENST00000274150_ENST00000510634_1009675_41762302 superimposed PDB: 3DLX of partner (OXCT1). RMSD:0.3987
Å |
 |  |  |  |  |
| NKD2_OXCT1_ENST00000296849_ENST00000509987_1034445_41762302 superimposed PDB: 3DLX of partner (OXCT1). RMSD:0.5936
Å |
 |  |  |  |  |
| NKTR_RNF41_ENST00000232978_ENST00000394013_42674315_56602082 superimposed PDB: 2HE9 of partner (NKTR). RMSD:0.3915
Å |
 |  |  |  |  |
| NKTR_RNF41_ENST00000232978_ENST00000394013_42674315_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.4633
Å |
| | | |  |
| NKTR_RNF41_ENST00000232978_ENST00000552244_42674315_56602082 superimposed PDB: 2HE9 of partner (NKTR). RMSD:0.3949
Å |
 |  |  |  |  |
| NKTR_RNF41_ENST00000232978_ENST00000552244_42674315_56602082 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.5139
Å |
| | | |  |
| NKTR_ULK4_ENST00000232978_ENST00000420927_42642556_41977432 superimposed PDB: 6TSZ of partner (ULK4). RMSD:0.4795
Å |
 |  |  |  |  |
| NKTR_ULK4_ENST00000442970_ENST00000301831_42642556_41977432 superimposed PDB: 6TSZ of partner (ULK4). RMSD:0.4624
Å |
 |  |  |  |  |
| NKTR_ULK4_ENST00000442970_ENST00000420927_42642556_41977432 superimposed PDB: 6TSZ of partner (ULK4). RMSD:0.4211
Å |
 |  |  |  |  |
| NLK_LGALS9_ENST00000407008_ENST00000302228_26370357_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:1.9727
Å |
 |  |  |  |  |
| NLK_LGALS9_ENST00000407008_ENST00000313648_26370357_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:1.2277
Å |
 |  |  |  |  |
| NLK_LGALS9_ENST00000407008_ENST00000395473_26370357_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:1.3829
Å |
 |  |  |  |  |
| NLK_LGALS9_ENST00000582037_ENST00000310394_26370357_25967597 superimposed PDB: 3WV6 of partner (LGALS9). RMSD:0.4363
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000393198_ENST00000357122_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.0498
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000393198_ENST00000505279_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.3092
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000503064_ENST00000357122_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:0.8999
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000503064_ENST00000505279_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.3871
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000512737_ENST00000357122_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.3558
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000512737_ENST00000505279_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.502
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000514264_ENST00000357122_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.1851
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000514264_ENST00000505279_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.2628
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000608447_ENST00000357122_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.1811
Å |
 |  |  |  |  |
| NME1-NME2_SPAG9_ENST00000608447_ENST00000505279_49245704_49098726 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.308
Å |
 |  |  |  |  |
| NMT2_PDE3A_ENST00000378150_ENST00000359062_15210501_20709593 superimposed PDB: 7LRC of partner (PDE3A). RMSD:0.4165
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000310101_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5221
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000348262_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.504
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000382002_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5174
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000397391_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5654
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000511486_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5288
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000264663_ENST00000513753_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5525
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000310101_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5281
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000342362_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5667
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000348262_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5069
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000382002_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5523
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000397391_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.528
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000511486_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.4933
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000344920_ENST00000513753_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5289
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000310101_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5319
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000342362_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5571
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000348262_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.556
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000382002_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.4989
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000397391_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5026
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000511486_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5468
Å |
 |  |  |  |  |
| NNT_PRLR_ENST00000512996_ENST00000513753_43628489_35072846 superimposed PDB: 1BP3 of partner (PRLR). RMSD:0.5605
Å |
 |  |  |  |  |
| NOL8_FXN_ENST00000545558_ENST00000377270_95076548_71661300 superimposed PDB: 5KZ5 of partner (FXN). RMSD:3.0376
Å |
 |  |  |  |  |
| NOL8_FXN_ENST00000545558_ENST00000396366_95076548_71661300 superimposed PDB: 5KZ5 of partner (FXN). RMSD:2.5294
Å |
 |  |  |  |  |
| NOMO2_TUBB_ENST00000543392_ENST00000330914_18553493_30691116 superimposed PDB: 7TTT of partner (TUBB). RMSD:1.0294
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000263012_ENST00000399410_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3002
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000399336_ENST00000345148_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.4288
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000399336_ENST00000346370_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3717
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000399336_ENST00000349029_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.458
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000399336_ENST00000351154_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.2388
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000399336_ENST00000399408_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.3638
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000538468_ENST00000345148_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.4586
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000538468_ENST00000346370_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.451
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000538468_ENST00000349029_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.4698
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000538468_ENST00000351154_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.1657
Å |
 |  |  |  |  |
| NOMO3_ABCC1_ENST00000538468_ENST00000399408_16364685_16138306 superimposed PDB: 8VUX of partner (ABCC1). RMSD:2.4473
Å |
 |  |  |  |  |
| NOP56_GRSF1_ENST00000329276_ENST00000439371_2634039_71698990 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:0.4876
Å |
 |  |  |  |  |
| NOTCH1_HNF1B_ENST00000277541_ENST00000427275_139397633_36093736 superimposed PDB: 2H8R of partner (HNF1B). RMSD:2.9338
Å |
 |  |  |  |  |
| NOTCH3_ERF_ENST00000263388_ENST00000222329_15303187_42754717 superimposed PDB: 5CZX of partner (NOTCH3). RMSD:0.641
Å |
 |  |  |  |  |
| NOTCH3_UBTF_ENST00000263388_ENST00000343638_15270443_42288699 superimposed PDB: 5CZX of partner (NOTCH3). RMSD:0.784
Å |
 |  |  |  |  |
| NOTCH3_UBTF_ENST00000263388_ENST00000343638_15270443_42288699 superimposed PDB: 1K99 of partner (UBTF). RMSD:2.5243
Å |
| | | |  |
| NPAS2_GNLY_ENST00000335681_ENST00000524600_101565942_85922442 superimposed PDB: 1L9L of partner (GNLY). RMSD:0.6037
Å |
 |  |  |  |  |
| NPAS2_GNLY_ENST00000542504_ENST00000524600_101565942_85922442 superimposed PDB: 1L9L of partner (GNLY). RMSD:0.5721
Å |
 |  |  |  |  |
| NPC1_FGD4_ENST00000269228_ENST00000531134_21124923_32751430 superimposed PDB: 6W5S of partner (NPC1). RMSD:2.6067
Å |
 |  |  |  |  |
| NPEPPS_ARL17B_ENST00000322157_ENST00000434041_45677105_44377031 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.8679
Å |
 |  |  |  |  |
| NPEPPS_ARL17B_ENST00000530173_ENST00000434041_45677105_44377031 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.8289
Å |
 |  |  |  |  |
| NPEPPS_ARL17B_ENST00000530173_ENST00000570618_45677105_44377031 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.0574
Å |
 |  |  |  |  |
| NPEPPS_ARL17B_ENST00000544660_ENST00000434041_45677105_44377031 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.9855
Å |
 |  |  |  |  |
| NPEPPS_CREB3L1_ENST00000322157_ENST00000288400_45623359_46341814 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.1883
Å |
 |  |  |  |  |
| NPEPPS_CREB3L1_ENST00000530173_ENST00000288400_45623359_46341814 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.1823
Å |
 |  |  |  |  |
| NPEPPS_CREB3L1_ENST00000544660_ENST00000288400_45623359_46341814 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.0746
Å |
 |  |  |  |  |
| NPEPPS_FAM117A_ENST00000322157_ENST00000240364_45623359_47810082 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.7836
Å |
 |  |  |  |  |
| NPEPPS_FAM117A_ENST00000544660_ENST00000240364_45623359_47810082 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.7793
Å |
 |  |  |  |  |
| NPEPPS_GNGT2_ENST00000322157_ENST00000503070_45646860_47280394 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.9954
Å |
 |  |  |  |  |
| NPEPPS_GNGT2_ENST00000544660_ENST00000503070_45646860_47280394 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.8918
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000322157_ENST00000393622_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.2459
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000322157_ENST00000393622_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3018
Å |
| | | |  |
| NPEPPS_HDAC5_ENST00000322157_ENST00000586802_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.2477
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000322157_ENST00000586802_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.304
Å |
| | | |  |
| NPEPPS_HDAC5_ENST00000530173_ENST00000225983_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.7977
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000530173_ENST00000225983_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:2.0735
Å |
| | | |  |
| NPEPPS_HDAC5_ENST00000530173_ENST00000393622_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.2688
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000530173_ENST00000393622_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:1.5776
Å |
| | | |  |
| NPEPPS_HDAC5_ENST00000530173_ENST00000586802_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3105
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000544660_ENST00000393622_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.3249
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000544660_ENST00000393622_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2836
Å |
| | | |  |
| NPEPPS_HDAC5_ENST00000544660_ENST00000586802_45623359_42171202 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:1.3664
Å |
 |  |  |  |  |
| NPEPPS_HDAC5_ENST00000544660_ENST00000586802_45623359_42171202 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2988
Å |
| | | |  |
| NPEPPS_KPNB1_ENST00000322157_ENST00000290158_45608921_45740454 superimposed PDB: 1QGR of partner (KPNB1). RMSD:2.1948
Å |
 |  |  |  |  |
| NPEPPS_KPNB1_ENST00000322157_ENST00000535458_45608921_45740454 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.6237
Å |
 |  |  |  |  |
| NPEPPS_KPNB1_ENST00000530173_ENST00000290158_45608921_45740454 superimposed PDB: 1QGR of partner (KPNB1). RMSD:2.2003
Å |
 |  |  |  |  |
| NPEPPS_KPNB1_ENST00000544660_ENST00000290158_45608921_45740454 superimposed PDB: 1QGR of partner (KPNB1). RMSD:2.1757
Å |
 |  |  |  |  |
| NPEPPS_KPNB1_ENST00000544660_ENST00000535458_45608921_45740454 superimposed PDB: 1QGR of partner (KPNB1). RMSD:1.5583
Å |
 |  |  |  |  |
| NPEPPS_RPH3AL_ENST00000322157_ENST00000323434_45656877_97076 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.8691
Å |
 |  |  |  |  |
| NPEPPS_RPH3AL_ENST00000530173_ENST00000323434_45656877_97076 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.9563
Å |
 |  |  |  |  |
| NPEPPS_RPH3AL_ENST00000544660_ENST00000323434_45656877_97076 superimposed PDB: 9O5K of partner (NPEPPS). RMSD:0.9694
Å |
 |  |  |  |  |
| NPLOC4_P4HB_ENST00000374747_ENST00000331483_79577235_79801968 superimposed PDB: 9YRC of partner (NPLOC4). RMSD:2.2902
Å |
 |  |  |  |  |
| NPM1_ALK_ENST00000296930_ENST00000389048_170818803_29446394 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3775
Å |
 |  |  |  |  |
| NPM1_ALK_ENST00000351986_ENST00000389048_170818803_29446394 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3716
Å |
 |  |  |  |  |
| NPM1_ALK_ENST00000393820_ENST00000389048_170818803_29446394 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3843
Å |
 |  |  |  |  |
| NPM1_RARA_ENST00000296930_ENST00000394089_170818803_38504567 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.358
Å |
 |  |  |  |  |
| NPM1_RARA_ENST00000296930_ENST00000394089_170818803_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4261
Å |
| | | |  |
| NPM1_RARA_ENST00000351986_ENST00000394089_170818803_38504567 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.383
Å |
 |  |  |  |  |
| NPM1_RARA_ENST00000351986_ENST00000394089_170818803_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4698
Å |
| | | |  |
| NPM1_RARA_ENST00000517671_ENST00000394089_170818803_38504567 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3505
Å |
 |  |  |  |  |
| NPM1_RARA_ENST00000517671_ENST00000394089_170818803_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4668
Å |
| | | |  |
| NPM1_RPS11_ENST00000296930_ENST00000270625_170834778_50000776 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3765
Å |
 |  |  |  |  |
| NPM1_RPS11_ENST00000296930_ENST00000596873_170834778_50000776 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3963
Å |
 |  |  |  |  |
| NPM1_RPS11_ENST00000351986_ENST00000270625_170834778_50000776 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3601
Å |
 |  |  |  |  |
| NPM1_RPS11_ENST00000351986_ENST00000596873_170834778_50000776 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3709
Å |
 |  |  |  |  |
| NPM1_RPS11_ENST00000517671_ENST00000596873_170834778_50000776 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3729
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000296930_ENST00000264818_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3342
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000296930_ENST00000264818_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:1.2055
Å |
| | | |  |
| NPM1_TYK2_ENST00000296930_ENST00000524462_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3581
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000296930_ENST00000524462_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:2.7795
Å |
| | | |  |
| NPM1_TYK2_ENST00000351986_ENST00000264818_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3544
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000351986_ENST00000264818_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:1.6486
Å |
| | | |  |
| NPM1_TYK2_ENST00000351986_ENST00000524462_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3582
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000351986_ENST00000524462_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:2.6509
Å |
| | | |  |
| NPM1_TYK2_ENST00000393820_ENST00000264818_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.389
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000393820_ENST00000264818_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:1.4053
Å |
| | | |  |
| NPM1_TYK2_ENST00000393820_ENST00000524462_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3533
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000393820_ENST00000524462_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:2.6796
Å |
| | | |  |
| NPM1_TYK2_ENST00000517671_ENST00000524462_170832407_10468814 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3865
Å |
 |  |  |  |  |
| NPM1_TYK2_ENST00000517671_ENST00000524462_170832407_10468814 superimposed PDB: 4OLI of partner (TYK2). RMSD:2.7013
Å |
| | | |  |
| NPM1_VIM_ENST00000296930_ENST00000224237_170832407_17277167 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3577
Å |
 |  |  |  |  |
| NPM1_VIM_ENST00000351986_ENST00000224237_170832407_17277167 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3368
Å |
 |  |  |  |  |
| NPM1_VIM_ENST00000393820_ENST00000224237_170832407_17277167 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.363
Å |
 |  |  |  |  |
| NPM1_VIM_ENST00000517671_ENST00000224237_170832407_17277167 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3631
Å |
 |  |  |  |  |
| NPM1_VIM_ENST00000517671_ENST00000544301_170832407_17277167 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3341
Å |
 |  |  |  |  |
| NPR2_GCKR_ENST00000342694_ENST00000424318_35799728_27730547 superimposed PDB: 4BB9 of partner (GCKR). RMSD:1.7526
Å |
 |  |  |  |  |
| NPR3_CCDC80_ENST00000415167_ENST00000439685_32712651_112337951 superimposed PDB: 1YK0 of partner (NPR3). RMSD:2.247
Å |
 |  |  |  |  |
| NPTN_PIGS_ENST00000545878_ENST00000308360_73879864_26883990 superimposed PDB: 7WLD of partner (PIGS). RMSD:3.6134
Å |
 |  |  |  |  |
| NR1D2_UBE2E2_ENST00000312521_ENST00000396703_24004096_23574044 superimposed PDB: 9LTO of partner (UBE2E2). RMSD:0.8954
Å |
 |  |  |  |  |
| NRD1_KIF5A_ENST00000352171_ENST00000455537_52305897_57957221 superimposed PDB: 4UXY of partner (KIF5A). RMSD:1.3432
Å |
 |  |  |  |  |
| NRDE2_CALM1_ENST00000354366_ENST00000447653_90752697_90866408 superimposed PDB: 9MXD of partner (CALM1). RMSD:3.138
Å |
 |  |  |  |  |
| NRF1_IDH2_ENST00000353868_ENST00000330062_129297414_90634876 superimposed PDB: 5I96 of partner (IDH2). RMSD:1.3352
Å |
 |  |  |  |  |
| NRG1_LRRC28_ENST00000405005_ENST00000558879_32474403_99926234 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7207
Å |
 |  |  |  |  |
| NRG1_LRRC28_ENST00000523079_ENST00000422500_32474403_99926234 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7995
Å |
 |  |  |  |  |
| NRG1_SCARA5_ENST00000520407_ENST00000380385_31498245_27737283 superimposed PDB: 7C00 of partner (SCARA5). RMSD:0.3523
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000338921_ENST00000220876_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7992
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000405005_ENST00000220876_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7621
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000519301_ENST00000518111_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7666
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000520407_ENST00000220876_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7953
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000520407_ENST00000518111_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7813
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000521670_ENST00000518111_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7755
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000523079_ENST00000220876_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.7573
Å |
 |  |  |  |  |
| NRG1_STMN2_ENST00000523079_ENST00000518111_32463201_80549036 superimposed PDB: 7SJL of partner (NRG1). RMSD:0.8407
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374821_ENST00000376170_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8539
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374821_ENST00000376170_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6984
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000355394_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.9962
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000355394_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5702
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000359188_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:3.0315
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000359188_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.4913
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000376138_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8987
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000376138_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7356
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000376139_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8931
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000376139_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5547
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000376142_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8772
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000376160_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8287
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000376160_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.7071
Å |
| | | |  |
| NRP1_ABI1_ENST00000374867_ENST00000376166_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:3.0956
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000374867_ENST00000376166_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3863
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000355394_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:3.0723
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000359188_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8456
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000359188_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.16
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000376138_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.9538
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376138_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.6093
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000376139_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.7228
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376139_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.5048
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000376142_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.8785
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376142_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.2437
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000376160_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:3.1116
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376166_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:3.0209
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376166_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:0.8892
Å |
| | | |  |
| NRP1_ABI1_ENST00000395995_ENST00000376170_33542955_27066170 superimposed PDB: 2QQM of partner (NRP1). RMSD:2.836
Å |
 |  |  |  |  |
| NRP1_ABI1_ENST00000395995_ENST00000376170_33542955_27066170 superimposed PDB: 7LXE of partner (ABI1). RMSD:1.3106
Å |
| | | |  |
| NRP1_ATE1_ENST00000432372_ENST00000535655_33619635_123549804 superimposed PDB: 2QQM of partner (NRP1). RMSD:1.1159
Å |
 |  |  |  |  |
| NRP1_CUL2_ENST00000374821_ENST00000374751_33619635_35299370 superimposed PDB: 2QQM of partner (NRP1). RMSD:0.8886
Å |
 |  |  |  |  |
| NRP1_CUL2_ENST00000395995_ENST00000374751_33619635_35299370 superimposed PDB: 2QQM of partner (NRP1). RMSD:0.9262
Å |
 |  |  |  |  |
| NRP1_RSU1_ENST00000374822_ENST00000377921_33619635_16635495 superimposed PDB: 2QQM of partner (NRP1). RMSD:1.2597
Å |
 |  |  |  |  |
| NRP1_RUFY2_ENST00000374867_ENST00000602465_33619635_70123870 superimposed PDB: 2QQM of partner (NRP1). RMSD:0.9038
Å |
 |  |  |  |  |
| NRP1_RUFY2_ENST00000395995_ENST00000602465_33619635_70123870 superimposed PDB: 2QQM of partner (NRP1). RMSD:1.0242
Å |
 |  |  |  |  |
| NRXN3_ACAA2_ENST00000335750_ENST00000285093_79454484_47329223 superimposed PDB: 4C2J of partner (ACAA2). RMSD:0.3638
Å |
 |  |  |  |  |
| NSD1_NCKIPSD_ENST00000354179_ENST00000294129_176563031_48717662 superimposed PDB: 9I2B of partner (NCKIPSD). RMSD:0.6346
Å |
 |  |  |  |  |
| NSD1_NCKIPSD_ENST00000354179_ENST00000416649_176563031_48717662 superimposed PDB: 9I2B of partner (NCKIPSD). RMSD:0.5592
Å |
 |  |  |  |  |
| NSD1_NCKIPSD_ENST00000439151_ENST00000294129_176563031_48717662 superimposed PDB: 9I2B of partner (NCKIPSD). RMSD:0.6988
Å |
 |  |  |  |  |
| NSD1_NCKIPSD_ENST00000439151_ENST00000416649_176563031_48717662 superimposed PDB: 9I2B of partner (NCKIPSD). RMSD:0.6163
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000354179_ENST00000396009_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.6199
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000354179_ENST00000609943_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.3018
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000361032_ENST00000396009_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.327
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000361032_ENST00000609943_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.3135
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000439151_ENST00000396009_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.3821
Å |
 |  |  |  |  |
| NSD1_NFATC2_ENST00000439151_ENST00000609943_176675325_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.3447
Å |
 |  |  |  |  |
| NSMCE1_GTF3C1_ENST00000361439_ENST00000356183_27268755_27523222 superimposed PDB: 8CLI of partner (GTF3C1). RMSD:1.7097
Å |
 |  |  |  |  |
| NSMCE2_ADORA2B_ENST00000522563_ENST00000304222_126194498_15877992 superimposed PDB: 8HDO of partner (ADORA2B). RMSD:2.1904
Å |
 |  |  |  |  |
| NSRP1_CDK12_ENST00000247026_ENST00000430627_28443881_37646809 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5103
Å |
 |  |  |  |  |
| NSRP1_CDK12_ENST00000584423_ENST00000447079_28443881_37646809 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5214
Å |
 |  |  |  |  |
| NSUN4_NCCRP1_ENST00000536062_ENST00000339852_46812747_39688692 superimposed PDB: 7OF0 of partner (NSUN4). RMSD:1.7516
Å |
 |  |  |  |  |
| NSUN4_NCCRP1_ENST00000537428_ENST00000339852_46812747_39688692 superimposed PDB: 7OF0 of partner (NSUN4). RMSD:1.6297
Å |
 |  |  |  |  |
| NT5E_ASCC3_ENST00000257770_ENST00000369162_86160196_101054964 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:1.1632
Å |
 |  |  |  |  |
| NT5E_MDM2_ENST00000257770_ENST00000462284_86160196_69207333 superimposed PDB: 8BGU of partner (MDM2). RMSD:0.8102
Å |
 |  |  |  |  |
| NT5E_MDM2_ENST00000369646_ENST00000356290_86160196_69207333 superimposed PDB: 8BGU of partner (MDM2). RMSD:2.8086
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374784_ENST00000402739_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.005
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374784_ENST00000402739_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4752
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374784_ENST00000496558_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0012
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374784_ENST00000496558_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4896
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374784_ENST00000540488_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9301
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374784_ENST00000540488_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4376
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374784_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0002
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374784_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:2.8302
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374786_ENST00000402739_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0145
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374786_ENST00000402739_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4804
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374786_ENST00000496558_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8922
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374786_ENST00000496558_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4721
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374786_ENST00000540488_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0193
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374786_ENST00000540488_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4725
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374786_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0326
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374786_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:2.507
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374791_ENST00000402739_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9387
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374791_ENST00000402739_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4705
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374791_ENST00000466387_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8746
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374791_ENST00000496558_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8101
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374791_ENST00000496558_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4793
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374791_ENST00000540488_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9062
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374791_ENST00000540488_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4785
Å |
| | | |  |
| NTM_CTNNA2_ENST00000374791_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0432
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000374791_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:2.7207
Å |
| | | |  |
| NTM_CTNNA2_ENST00000425719_ENST00000402739_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9212
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000425719_ENST00000402739_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.5068
Å |
| | | |  |
| NTM_CTNNA2_ENST00000425719_ENST00000496558_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8978
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000425719_ENST00000496558_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4755
Å |
| | | |  |
| NTM_CTNNA2_ENST00000425719_ENST00000540488_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8908
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000425719_ENST00000540488_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4365
Å |
| | | |  |
| NTM_CTNNA2_ENST00000425719_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9887
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000425719_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.915
Å |
| | | |  |
| NTM_CTNNA2_ENST00000427481_ENST00000496558_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8855
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000427481_ENST00000496558_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4751
Å |
| | | |  |
| NTM_CTNNA2_ENST00000427481_ENST00000540488_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.9407
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000427481_ENST00000540488_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4589
Å |
| | | |  |
| NTM_CTNNA2_ENST00000427481_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:0.8728
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000427481_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.8699
Å |
| | | |  |
| NTM_CTNNA2_ENST00000539799_ENST00000541047_132082041_80085138 superimposed PDB: 6DLF of partner (NTM). RMSD:1.0276
Å |
 |  |  |  |  |
| NTM_CTNNA2_ENST00000539799_ENST00000541047_132082041_80085138 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:1.0736
Å |
| | | |  |
| NTN1_DHRS7C_ENST00000173229_ENST00000571134_8926708_9684911 superimposed PDB: 7NE1 of partner (NTN1). RMSD:0.539
Å |
 |  |  |  |  |
| NTN1_DHRS7C_ENST00000538852_ENST00000330255_8926708_9684911 superimposed PDB: 7NE1 of partner (NTN1). RMSD:0.616
Å |
 |  |  |  |  |
| NTN1_STX8_ENST00000173229_ENST00000574431_8926708_9281970 superimposed PDB: 7NE1 of partner (NTN1). RMSD:0.5724
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000343702_ENST00000543146_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.6956
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000343702_ENST00000544368_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3639
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000344911_ENST00000543146_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.36
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000344911_ENST00000544368_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3062
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000553059_ENST00000543146_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.6146
Å |
 |  |  |  |  |
| NTN4_CCT2_ENST00000553059_ENST00000544368_96106989_69990935 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3709
Å |
 |  |  |  |  |
| NTN4_RAP1B_ENST00000343702_ENST00000393436_96180716_69050085 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.4946
Å |
 |  |  |  |  |
| NTN4_RAP1B_ENST00000344911_ENST00000393436_96180716_69050085 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.4758
Å |
 |  |  |  |  |
| NTN4_RAP1B_ENST00000553059_ENST00000393436_96180716_69050085 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.4785
Å |
 |  |  |  |  |
| NTRK3_PEAK1_ENST00000558676_ENST00000560626_88726648_77407661 superimposed PDB: 6KZD of partner (NTRK3). RMSD:3.1183
Å |
 |  |  |  |  |
| NTRK3_PEAK1_ENST00000558676_ENST00000560626_88726648_77407661 superimposed PDB: 6BHC of partner (PEAK1). RMSD:0.5509
Å |
| | | |  |
| NUBPL_APP_ENST00000281081_ENST00000354192_32142780_27462388 superimposed PDB: 8KF4 of partner (APP). RMSD:2.9084
Å |
 |  |  |  |  |
| NUBPL_APP_ENST00000281081_ENST00000358918_32142780_27462388 superimposed PDB: 8KF4 of partner (APP). RMSD:2.5674
Å |
 |  |  |  |  |
| NUBPL_APP_ENST00000281081_ENST00000359726_32142780_27462388 superimposed PDB: 8KF4 of partner (APP). RMSD:3.1909
Å |
 |  |  |  |  |
| NUBPL_APP_ENST00000536705_ENST00000358918_32142780_27462388 superimposed PDB: 8KF4 of partner (APP). RMSD:2.8142
Å |
 |  |  |  |  |
| NUDCD3_CAMK2B_ENST00000355451_ENST00000350811_44444038_44323824 superimposed PDB: 3BHH of partner (CAMK2B). RMSD:0.3139
Å |
 |  |  |  |  |
| NUDCD3_CAMK2B_ENST00000355451_ENST00000395749_44431895_44323824 superimposed PDB: 3BHH of partner (CAMK2B). RMSD:0.2991
Å |
 |  |  |  |  |
| NUDCD3_CAMK2B_ENST00000355451_ENST00000395749_44444038_44323824 superimposed PDB: 3BHH of partner (CAMK2B). RMSD:0.3169
Å |
 |  |  |  |  |
| NUDCD3_CAMK2B_ENST00000355451_ENST00000457475_44431895_44323824 superimposed PDB: 3BHH of partner (CAMK2B). RMSD:0.3165
Å |
 |  |  |  |  |
| NUDCD3_CAMK2B_ENST00000355451_ENST00000457475_44444038_44323824 superimposed PDB: 3BHH of partner (CAMK2B). RMSD:0.3099
Å |
 |  |  |  |  |
| NUDCD3_PDE1C_ENST00000355451_ENST00000396193_44524566_31920473 superimposed PDB: 1WGV of partner (NUDCD3). RMSD:1.2887
Å |
 |  |  |  |  |
| NUDCD3_SON_ENST00000355451_ENST00000290239_44444038_34931535 superimposed PDB: 1WGV of partner (NUDCD3). RMSD:1.1938
Å |
 |  |  |  |  |
| NUDCD3_SON_ENST00000355451_ENST00000381692_44444038_34931535 superimposed PDB: 1WGV of partner (NUDCD3). RMSD:1.1973
Å |
 |  |  |  |  |
| NUDC_MICU1_ENST00000321265_ENST00000361114_27250657_74183129 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.2638
Å |
 |  |  |  |  |
| NUDT7_IFT57_ENST00000268533_ENST00000264538_77759481_107886711 superimposed PDB: 5T3P of partner (NUDT7). RMSD:2.6835
Å |
 |  |  |  |  |
| NUDT7_IFT57_ENST00000437314_ENST00000264538_77759481_107886711 superimposed PDB: 5T3P of partner (NUDT7). RMSD:2.3525
Å |
 |  |  |  |  |
| NUMA1_RARA_ENST00000351960_ENST00000394089_71717080_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4046
Å |
 |  |  |  |  |
| NUMA1_RARA_ENST00000393695_ENST00000394089_71717080_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.6136
Å |
 |  |  |  |  |
| NUMB_TTLL5_ENST00000544991_ENST00000557636_73759441_76286349 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5002
Å |
 |  |  |  |  |
| NUMB_TTLL5_ENST00000555394_ENST00000557636_73759441_76286349 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5737
Å |
 |  |  |  |  |
| NUMB_TTLL5_ENST00000555394_ENST00000557636_73759441_76286349 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6683
Å |
| | | |  |
| NUMB_TTLL5_ENST00000557597_ENST00000557636_73759441_76286349 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5332
Å |
 |  |  |  |  |
| NUMB_TTLL5_ENST00000559312_ENST00000557636_73759441_76286349 superimposed PDB: 5NJJ of partner (NUMB). RMSD:0.5674
Å |
 |  |  |  |  |
| NUP107_LGR5_ENST00000229179_ENST00000536515_69080853_71965293 superimposed PDB: 4UFR of partner (LGR5). RMSD:0.3591
Å |
 |  |  |  |  |
| NUP155_ZFYVE26_ENST00000513532_ENST00000347230_37370922_68244965 superimposed PDB: 8YAD of partner (ZFYVE26). RMSD:2.6645
Å |
 |  |  |  |  |
| NUP210_MAST1_ENST00000254508_ENST00000591495_13418955_12962747 superimposed PDB: 2M9X of partner (MAST1). RMSD:2.97
Å |
 |  |  |  |  |
| NUP210_SLC6A6_ENST00000254508_ENST00000360861_13393378_14518712 superimposed PDB: 9L1C of partner (SLC6A6). RMSD:1.1828
Å |
 |  |  |  |  |
| NUP85_NR5A2_ENST00000245544_ENST00000236914_73201889_200080329 superimposed PDB: 3TX7 of partner (NR5A2). RMSD:0.5829
Å |
 |  |  |  |  |
| NUP88_NLRP1_ENST00000573584_ENST00000269280_5319832_5440260 superimposed PDB: 6X6C of partner (NLRP1). RMSD:1.2192
Å |
 |  |  |  |  |
| NUP88_NLRP1_ENST00000573584_ENST00000345221_5319832_5440260 superimposed PDB: 6X6C of partner (NLRP1). RMSD:1.1003
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000308159_ENST00000307892_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:2.6089
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000308159_ENST00000561792_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.7429
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000542526_ENST00000307892_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:2.2099
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000542526_ENST00000512062_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.7327
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000542526_ENST00000561792_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.8151
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000564887_ENST00000307892_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:2.2097
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000564887_ENST00000561792_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.6848
Å |
 |  |  |  |  |
| NUP93_CYB5B_ENST00000569842_ENST00000512062_56839544_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.597
Å |
 |  |  |  |  |
| NUP98_ADD3_ENST00000324932_ENST00000360162_3765738_111893083 superimposed PDB: 7F90 of partner (NUP98). RMSD:0.4568
Å |
 |  |  |  |  |
| NUP98_ADD3_ENST00000359171_ENST00000360162_3765738_111893083 superimposed PDB: 7F90 of partner (NUP98). RMSD:0.3788
Å |
 |  |  |  |  |
| NUP98_CCDC28A_ENST00000324932_ENST00000332797_3765738_139100958 superimposed PDB: 7F90 of partner (NUP98). RMSD:0.4166
Å |
 |  |  |  |  |
| NUP98_CCDC28A_ENST00000359171_ENST00000332797_3765738_139100958 superimposed PDB: 7F90 of partner (NUP98). RMSD:0.407
Å |
 |  |  |  |  |
| NUP98_HOXC13_ENST00000355260_ENST00000243056_3744386_54338783 superimposed PDB: 7F90 of partner (NUP98). RMSD:0.4312
Å |
 |  |  |  |  |
| NXF1_KLK10_ENST00000532297_ENST00000391805_62567848_51520546 superimposed PDB: 6E5U of partner (NXF1). RMSD:0.8149
Å |
 |  |  |  |  |
| NYAP2_KCNU1_ENST00000409269_ENST00000399881_226273817_36763225 superimposed PDB: 4HPF of partner (KCNU1). RMSD:1.3037
Å |
 |  |  |  |  |
| OAF_SLC26A11_ENST00000328965_ENST00000411502_120097705_78215569 superimposed PDB: 9IAS of partner (SLC26A11). RMSD:1.7503
Å |
 |  |  |  |  |
| OAF_SLC26A11_ENST00000531220_ENST00000411502_120097705_78215569 superimposed PDB: 9IAS of partner (SLC26A11). RMSD:2.1261
Å |
 |  |  |  |  |
| OAS3_MIER3_ENST00000228928_ENST00000381213_113376512_56246479 superimposed PDB: 4S3N of partner (OAS3). RMSD:2.9607
Å |
 |  |  |  |  |
| OAS3_MIER3_ENST00000551007_ENST00000381213_113376512_56246479 superimposed PDB: 4S3N of partner (OAS3). RMSD:2.5309
Å |
 |  |  |  |  |
| OAZ1_GAPDH_ENST00000602676_ENST00000229239_2269743_6645659 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.6986
Å |
 |  |  |  |  |
| OAZ1_YBX2_ENST00000602676_ENST00000007699_2269743_7195378 superimposed PDB: 7F3K of partner (YBX2). RMSD:0.8004
Å |
 |  |  |  |  |
| OBSCN_CASZ1_ENST00000284548_ENST00000344008_228412435_10725628 superimposed PDB: 2CR6 of partner (OBSCN). RMSD:1.8485
Å |
 |  |  |  |  |
| OBSCN_CASZ1_ENST00000422127_ENST00000377022_228412435_10725628 superimposed PDB: 2CR6 of partner (OBSCN). RMSD:2.0253
Å |
 |  |  |  |  |
| OBSCN_CASZ1_ENST00000570156_ENST00000344008_228412435_10725628 superimposed PDB: 2CR6 of partner (OBSCN). RMSD:1.8128
Å |
 |  |  |  |  |
| OBSCN_CASZ1_ENST00000570156_ENST00000377022_228412435_10725628 superimposed PDB: 2CR6 of partner (OBSCN). RMSD:1.8625
Å |
 |  |  |  |  |
| OBSCN_IGSF21_ENST00000570156_ENST00000251296_228402799_18554391 superimposed PDB: 2CR6 of partner (OBSCN). RMSD:1.5885
Å |
 |  |  |  |  |
| OCLN_ARHGAP26_ENST00000355237_ENST00000274498_68809936_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5385
Å |
 |  |  |  |  |
| OCLN_ARHGAP26_ENST00000396442_ENST00000378004_68809936_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5346
Å |
 |  |  |  |  |
| OCLN_ARHGAP26_ENST00000538151_ENST00000274498_68809936_142393644 superimposed PDB: 1UGV of partner (ARHGAP26). RMSD:0.5351
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000222673_ENST00000325590_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.3937
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000222673_ENST00000325590_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7015
Å |
| | | |  |
| OGDH_AMPH_ENST00000222673_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4319
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000222673_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.6032
Å |
| | | |  |
| OGDH_AMPH_ENST00000222673_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7148
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000439616_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:2.7468
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000439616_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.5261
Å |
| | | |  |
| OGDH_AMPH_ENST00000439616_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.6541
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000444676_ENST00000325590_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4527
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000444676_ENST00000325590_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.6714
Å |
| | | |  |
| OGDH_AMPH_ENST00000444676_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4688
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000444676_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7058
Å |
| | | |  |
| OGDH_AMPH_ENST00000444676_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7429
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000447398_ENST00000325590_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:2.9587
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000447398_ENST00000325590_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.5795
Å |
| | | |  |
| OGDH_AMPH_ENST00000447398_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4503
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000447398_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7719
Å |
| | | |  |
| OGDH_AMPH_ENST00000447398_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7022
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000449767_ENST00000325590_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4338
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000449767_ENST00000325590_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7334
Å |
| | | |  |
| OGDH_AMPH_ENST00000449767_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4486
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000449767_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.8165
Å |
| | | |  |
| OGDH_AMPH_ENST00000449767_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7563
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000543843_ENST00000325590_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.3906
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000543843_ENST00000325590_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7119
Å |
| | | |  |
| OGDH_AMPH_ENST00000543843_ENST00000356264_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.4453
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000543843_ENST00000356264_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.6625
Å |
| | | |  |
| OGDH_AMPH_ENST00000543843_ENST00000428293_44721447_38574611 superimposed PDB: 8I0K of partner (OGDH). RMSD:2.7528
Å |
 |  |  |  |  |
| OGDH_AMPH_ENST00000543843_ENST00000428293_44721447_38574611 superimposed PDB: 4ATM of partner (AMPH). RMSD:0.7524
Å |
| | | |  |
| OGDH_TRIM24_ENST00000222673_ENST00000415680_44687358_138189034 superimposed PDB: 4YBM of partner (TRIM24). RMSD:0.5487
Å |
 |  |  |  |  |
| OGDH_TRIM24_ENST00000443864_ENST00000415680_44687358_138189034 superimposed PDB: 4YBM of partner (TRIM24). RMSD:0.4942
Å |
 |  |  |  |  |
| OGDH_TRIM24_ENST00000444676_ENST00000343526_44687358_138189034 superimposed PDB: 4YBM of partner (TRIM24). RMSD:0.5125
Å |
 |  |  |  |  |
| OGT_DMXL1_ENST00000373701_ENST00000311085_70784603_118582689 superimposed PDB: 7YEA of partner (OGT). RMSD:2.8733
Å |
 |  |  |  |  |
| OGT_MCCC1_ENST00000373701_ENST00000492597_70764485_182740342 superimposed PDB: 7YEA of partner (OGT). RMSD:2.6434
Å |
 |  |  |  |  |
| OGT_MCCC1_ENST00000373719_ENST00000492597_70764485_182740342 superimposed PDB: 7YEA of partner (OGT). RMSD:1.7652
Å |
 |  |  |  |  |
| OGT_POLA1_ENST00000373701_ENST00000379059_70757922_24828014 superimposed PDB: 8QJ7 of partner (POLA1). RMSD:3.0909
Å |
 |  |  |  |  |
| OGT_POLA1_ENST00000373719_ENST00000379059_70757922_24828014 superimposed PDB: 8QJ7 of partner (POLA1). RMSD:3.1459
Å |
 |  |  |  |  |
| OPA3_TNPO1_ENST00000263275_ENST00000337273_46087880_72144211 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.3979
Å |
 |  |  |  |  |
| OPA3_TNPO1_ENST00000323060_ENST00000454282_46087880_72144211 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.8855
Å |
 |  |  |  |  |
| ORMDL3_PPP1R1B_ENST00000304046_ENST00000254079_38080282_37785422 superimposed PDB: 7YIY of partner (ORMDL3). RMSD:2.2401
Å |
 |  |  |  |  |
| ORMDL3_PPP1R1B_ENST00000394169_ENST00000254079_38080282_37785422 superimposed PDB: 7YIY of partner (ORMDL3). RMSD:2.005
Å |
 |  |  |  |  |
| ORMDL3_PPP1R1B_ENST00000394169_ENST00000580825_38080282_37785422 superimposed PDB: 7YIY of partner (ORMDL3). RMSD:2.5064
Å |
 |  |  |  |  |
| OS9_KIF5A_ENST00000439210_ENST00000286452_58090156_57960908 superimposed PDB: 4UXY of partner (KIF5A). RMSD:1.1812
Å |
 |  |  |  |  |
| OS9_KIF5A_ENST00000552285_ENST00000286452_58088709_57960908 superimposed PDB: 4UXY of partner (KIF5A). RMSD:1.0054
Å |
 |  |  |  |  |
| OS9_KIF5A_ENST00000552285_ENST00000286452_58090156_57960908 superimposed PDB: 9OG0 of partner (OS9). RMSD:3.0764
Å |
 |  |  |  |  |
| OS9_KIF5A_ENST00000552285_ENST00000286452_58090156_57960908 superimposed PDB: 4UXY of partner (KIF5A). RMSD:1.4034
Å |
| | | |  |
| OS9_KIF5A_ENST00000552285_ENST00000455537_58090156_57960908 superimposed PDB: 9OG0 of partner (OS9). RMSD:2.9885
Å |
 |  |  |  |  |
| OS9_SERPINE2_ENST00000439210_ENST00000258405_58089626_224849667 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:2.1326
Å |
 |  |  |  |  |
| OS9_SERPINE2_ENST00000439210_ENST00000409840_58089626_224849667 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:2.3028
Å |
 |  |  |  |  |
| OS9_SERPINE2_ENST00000552285_ENST00000258405_58089626_224849667 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:3.4978
Å |
 |  |  |  |  |
| OS9_SERPINE2_ENST00000552285_ENST00000409840_58089626_224849667 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:2.6643
Å |
 |  |  |  |  |
| OS9_YEATS4_ENST00000439210_ENST00000548020_58090156_69764485 superimposed PDB: 9OG0 of partner (OS9). RMSD:1.1905
Å |
 |  |  |  |  |
| OS9_YEATS4_ENST00000552285_ENST00000548020_58090156_69764485 superimposed PDB: 9OG0 of partner (OS9). RMSD:2.72
Å |
 |  |  |  |  |
| OSBPL10_FOXP1_ENST00000396556_ENST00000475937_31917924_71161788 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3513
Å |
 |  |  |  |  |
| OSBPL10_FOXP1_ENST00000396556_ENST00000484350_31917924_71161788 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3371
Å |
 |  |  |  |  |
| OSBPL10_FOXP1_ENST00000438237_ENST00000318789_31917924_71161788 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.2975
Å |
 |  |  |  |  |
| OSBPL1A_RIOK3_ENST00000399443_ENST00000339486_21805005_21053392 superimposed PDB: 5ZM6 of partner (OSBPL1A). RMSD:2.8623
Å |
 |  |  |  |  |
| OSBPL1A_RIOK3_ENST00000399443_ENST00000581585_21805005_21053392 superimposed PDB: 8ZDB of partner (RIOK3). RMSD:1.0356
Å |
 |  |  |  |  |
| OSBP_GIF_ENST00000263847_ENST00000541311_59361076_59597018 superimposed PDB: 2PMV of partner (GIF). RMSD:2.4102
Å |
 |  |  |  |  |
| OSGIN2_DECR1_ENST00000451899_ENST00000220764_90933399_91054955 superimposed PDB: 1W6U of partner (DECR1). RMSD:1.342
Å |
 |  |  |  |  |
| OTUB1_IRF7_ENST00000422031_ENST00000397574_63764120_612800 superimposed PDB: 4DDG of partner (OTUB1). RMSD:0.7937
Å |
 |  |  |  |  |
| OTUB1_IRF7_ENST00000535715_ENST00000397574_63764120_612800 superimposed PDB: 4DDG of partner (OTUB1). RMSD:0.8013
Å |
 |  |  |  |  |
| OTUB1_IRF7_ENST00000538426_ENST00000397574_63764120_612800 superimposed PDB: 4DDG of partner (OTUB1). RMSD:0.7897
Å |
 |  |  |  |  |
| OTUB1_IRF7_ENST00000543004_ENST00000397574_63764120_612800 superimposed PDB: 4DDG of partner (OTUB1). RMSD:0.7473
Å |
 |  |  |  |  |
| OTUB1_RPS6KA4_ENST00000422031_ENST00000528057_63756224_64132772 superimposed PDB: 4DDG of partner (OTUB1). RMSD:2.8435
Å |
 |  |  |  |  |
| OTUB1_RPS6KA4_ENST00000428192_ENST00000528057_63756224_64132772 superimposed PDB: 4DDG of partner (OTUB1). RMSD:2.6769
Å |
 |  |  |  |  |
| OTUB1_RPS6KA4_ENST00000543004_ENST00000528057_63756224_64132772 superimposed PDB: 4DDG of partner (OTUB1). RMSD:2.7605
Å |
 |  |  |  |  |
| OTUB1_RPS6KA4_ENST00000543988_ENST00000528057_63756224_64132772 superimposed PDB: 4DDG of partner (OTUB1). RMSD:3.0915
Å |
 |  |  |  |  |
| OTUD5_PCSK1N_ENST00000376488_ENST00000218230_48791736_48690751 superimposed PDB: 3TMP of partner (OTUD5). RMSD:0.4432
Å |
 |  |  |  |  |
| OXSR1_ATXN7_ENST00000446845_ENST00000295900_38232330_63938054 superimposed PDB: 2VWI of partner (OXSR1). RMSD:0.8734
Å |
 |  |  |  |  |
| OXSR1_ATXN7_ENST00000446845_ENST00000295900_38232330_63938054 superimposed PDB: 9RDK of partner (ATXN7). RMSD:2.7776
Å |
| | | |  |
| OXSR1_ATXN7_ENST00000446845_ENST00000487717_38232330_63938054 superimposed PDB: 2VWI of partner (OXSR1). RMSD:0.8895
Å |
 |  |  |  |  |
| OXSR1_ATXN7_ENST00000446845_ENST00000487717_38232330_63938054 superimposed PDB: 9RDK of partner (ATXN7). RMSD:2.9317
Å |
| | | |  |
| P4HA1_ANK3_ENST00000307116_ENST00000373827_74831786_62039397 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.5973
Å |
 |  |  |  |  |
| P4HA1_ANK3_ENST00000373008_ENST00000280772_74831786_62039397 superimposed PDB: 4O6X of partner (ANK3). RMSD:0.3334
Å |
 |  |  |  |  |
| P4HB_ACOX1_ENST00000331483_ENST00000537812_79813017_73947045 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.3952
Å |
 |  |  |  |  |
| P4HB_AMBP_ENST00000439918_ENST00000265132_79813017_116825038 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.809
Å |
 |  |  |  |  |
| P4HB_RPLP0_ENST00000439918_ENST00000392514_79817054_120635265 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.8539
Å |
 |  |  |  |  |
| P4HB_RPLP0_ENST00000439918_ENST00000551150_79817054_120635265 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.7121
Å |
 |  |  |  |  |
| P4HB_SLC29A2_ENST00000439918_ENST00000544554_79817054_66131895 superimposed PDB: 8EOJ of partner (P4HB). RMSD:0.9215
Å |
 |  |  |  |  |
| P4HB_STRA13_ENST00000331483_ENST00000580435_79813017_79977785 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.7509
Å |
 |  |  |  |  |
| PA2G4_USP30_ENST00000303305_ENST00000257548_56498609_109505328 superimposed PDB: 5OHN of partner (USP30). RMSD:0.8233
Å |
 |  |  |  |  |
| PA2G4_USP30_ENST00000552766_ENST00000257548_56498609_109505328 superimposed PDB: 5OHN of partner (USP30). RMSD:0.7319
Å |
 |  |  |  |  |
| PABPC1_GRSF1_ENST00000318607_ENST00000254799_101730000_71691148 superimposed PDB: 4F02 of partner (PABPC1). RMSD:1.3669
Å |
 |  |  |  |  |
| PABPC1_GRSF1_ENST00000318607_ENST00000254799_101730000_71691148 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:2.3173
Å |
| | | |  |
| PABPC1_GRSF1_ENST00000318607_ENST00000439371_101730000_71691148 superimposed PDB: 4F02 of partner (PABPC1). RMSD:0.4718
Å |
 |  |  |  |  |
| PABPC1_GRSF1_ENST00000318607_ENST00000439371_101730000_71691148 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:1.4254
Å |
| | | |  |
| PABPC1_GRSF1_ENST00000519004_ENST00000439371_101730000_71691148 superimposed PDB: 4F02 of partner (PABPC1). RMSD:0.6491
Å |
 |  |  |  |  |
| PABPC1_GRSF1_ENST00000519004_ENST00000439371_101730000_71691148 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:1.4473
Å |
| | | |  |
| PABPC1_GRSF1_ENST00000522387_ENST00000439371_101730000_71691148 superimposed PDB: 4F02 of partner (PABPC1). RMSD:3.1456
Å |
 |  |  |  |  |
| PABPC1_GRSF1_ENST00000522387_ENST00000439371_101730000_71691148 superimposed PDB: 4QU6 of partner (GRSF1). RMSD:0.786
Å |
| | | |  |
| PABPC1_RPS23_ENST00000522387_ENST00000512493_101730410_81573671 superimposed PDB: 4F02 of partner (PABPC1). RMSD:0.6061
Å |
 |  |  |  |  |
| PABPN1_CHD8_ENST00000216727_ENST00000399982_23792275_21896413 superimposed PDB: 2CKA of partner (CHD8). RMSD:0.8206
Å |
 |  |  |  |  |
| PABPN1_CHD8_ENST00000556821_ENST00000399982_23792275_21896413 superimposed PDB: 2CKA of partner (CHD8). RMSD:0.7524
Å |
 |  |  |  |  |
| PACS1_FOLH1_ENST00000320580_ENST00000343844_65961044_49179595 superimposed PDB: 9HLW of partner (FOLH1). RMSD:1.3452
Å |
 |  |  |  |  |
| PACS1_FOLH1_ENST00000320580_ENST00000356696_65961044_49179595 superimposed PDB: 9HLW of partner (FOLH1). RMSD:1.0157
Å |
 |  |  |  |  |
| PACSIN2_CABIN1_ENST00000337959_ENST00000398319_43308026_24456386 superimposed PDB: 1N6J of partner (CABIN1). RMSD:1.0979
Å |
 |  |  |  |  |
| PACSIN2_CABIN1_ENST00000337959_ENST00000405822_43308026_24456386 superimposed PDB: 1N6J of partner (CABIN1). RMSD:0.6746
Å |
 |  |  |  |  |
| PACSIN2_LGALS1_ENST00000402229_ENST00000215909_43272142_38072992 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:0.7837
Å |
 |  |  |  |  |
| PACSIN2_NUPL2_ENST00000337959_ENST00000258742_43308026_23224688 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:0.7824
Å |
 |  |  |  |  |
| PACSIN2_NUPL2_ENST00000337959_ENST00000410002_43308026_23224688 superimposed PDB: 6B4J of partner (NUPL2). RMSD:0.5596
Å |
 |  |  |  |  |
| PADI2_EXD3_ENST00000375486_ENST00000340951_17422403_140218308 superimposed PDB: 4N2K of partner (PADI2). RMSD:1.3709
Å |
 |  |  |  |  |
| PADI2_EXD3_ENST00000375486_ENST00000340951_17422403_140218595 superimposed PDB: 4N2K of partner (PADI2). RMSD:1.5768
Å |
 |  |  |  |  |
| PADI2_EXD3_ENST00000444885_ENST00000342129_17422403_140218308 superimposed PDB: 4N2K of partner (PADI2). RMSD:1.1698
Å |
 |  |  |  |  |
| PADI2_EXD3_ENST00000444885_ENST00000342129_17422403_140218595 superimposed PDB: 4N2K of partner (PADI2). RMSD:0.9538
Å |
 |  |  |  |  |
| PAFAH1B2_GPR137_ENST00000527958_ENST00000411458_117023244_64053981 superimposed PDB: 1VYH of partner (PAFAH1B2). RMSD:2.9038
Å |
 |  |  |  |  |
| PAFAH1B2_GPR137_ENST00000530272_ENST00000411458_117023244_64053981 superimposed PDB: 1VYH of partner (PAFAH1B2). RMSD:1.9138
Å |
 |  |  |  |  |
| PAGR1_CDH1_ENST00000320330_ENST00000422392_29828613_68835572 superimposed PDB: 7STZ of partner (CDH1). RMSD:3.0852
Å |
 |  |  |  |  |
| PAGR1_CDH1_ENST00000609618_ENST00000261769_29828613_68835572 superimposed PDB: 7STZ of partner (CDH1). RMSD:3.6233
Å |
 |  |  |  |  |
| PAH_NINJ2_ENST00000553106_ENST00000397265_103306568_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:3.0826
Å |
 |  |  |  |  |
| PAK2_PAK1_ENST00000327134_ENST00000278568_196537524_77060332 superimposed PDB: 9M41 of partner (PAK2). RMSD:1.0588
Å |
 |  |  |  |  |
| PAK2_PAK1_ENST00000327134_ENST00000278568_196537524_77060332 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.5979
Å |
| | | |  |
| PAK2_PAK1_ENST00000327134_ENST00000528203_196537524_77060332 superimposed PDB: 9M41 of partner (PAK2). RMSD:1.1175
Å |
 |  |  |  |  |
| PAK2_PAK1_ENST00000327134_ENST00000528203_196537524_77060332 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.5997
Å |
| | | |  |
| PAK2_PAK1_ENST00000327134_ENST00000530617_196537524_77060332 superimposed PDB: 9M41 of partner (PAK2). RMSD:0.9032
Å |
 |  |  |  |  |
| PAK2_PAK1_ENST00000327134_ENST00000530617_196537524_77060332 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.5569
Å |
| | | |  |
| PAMR1_SLC1A2_ENST00000378878_ENST00000278379_35461174_35339063 superimposed PDB: 9JVV of partner (SLC1A2). RMSD:3.1764
Å |
 |  |  |  |  |
| PAMR1_SLC1A2_ENST00000378880_ENST00000278379_35461174_35339063 superimposed PDB: 9JVV of partner (SLC1A2). RMSD:3.2241
Å |
 |  |  |  |  |
| PAN3_FLT3_ENST00000380958_ENST00000380982_28794515_28644749 superimposed PDB: 7QDP of partner (FLT3). RMSD:2.028
Å |
 |  |  |  |  |
| PAN3_FLT3_ENST00000380958_ENST00000537084_28794515_28644749 superimposed PDB: 7QDP of partner (FLT3). RMSD:1.8222
Å |
 |  |  |  |  |
| PAN3_FLT3_ENST00000399613_ENST00000241453_28794515_28644749 superimposed PDB: 7QDP of partner (FLT3). RMSD:2.1455
Å |
 |  |  |  |  |
| PAN3_FLT3_ENST00000399613_ENST00000380982_28794515_28644749 superimposed PDB: 7QDP of partner (FLT3). RMSD:1.6184
Å |
 |  |  |  |  |
| PAN3_FLT3_ENST00000399613_ENST00000537084_28794515_28644749 superimposed PDB: 7QDP of partner (FLT3). RMSD:1.5013
Å |
 |  |  |  |  |
| PAN3_MICU2_ENST00000399613_ENST00000382374_28794515_22096789 superimposed PDB: 6XJV of partner (MICU2). RMSD:1.3475
Å |
 |  |  |  |  |
| PAN3_NTRK2_ENST00000380958_ENST00000376213_28713224_87549076 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7115
Å |
 |  |  |  |  |
| PAPD7_RAF1_ENST00000230859_ENST00000442415_6751310_12641307 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.061
Å |
 |  |  |  |  |
| PAPOLG_ABCA12_ENST00000238714_ENST00000272895_60997646_215821502 superimposed PDB: 4LT6 of partner (PAPOLG). RMSD:0.7645
Å |
 |  |  |  |  |
| PAPOLG_ABCA12_ENST00000238714_ENST00000389661_60997646_215821502 superimposed PDB: 4LT6 of partner (PAPOLG). RMSD:0.8054
Å |
 |  |  |  |  |
| PAPPA2_RPS19_ENST00000367662_ENST00000598742_176640251_42373100 superimposed PDB: 8SL1 of partner (PAPPA2). RMSD:3.0069
Å |
 |  |  |  |  |
| PAPSS2_BID_ENST00000456849_ENST00000317361_89469070_18222254 superimposed PDB: 7FH3 of partner (PAPSS2). RMSD:2.912
Å |
 |  |  |  |  |
| PAPSS2_MINPP1_ENST00000361175_ENST00000371994_89419765_89311838 superimposed PDB: 7FH3 of partner (PAPSS2). RMSD:0.5767
Å |
 |  |  |  |  |
| PAPSS2_PTEN_ENST00000456849_ENST00000371953_89419765_89711874 superimposed PDB: 7JVX of partner (PTEN). RMSD:0.4318
Å |
 |  |  |  |  |
| PARD3_COLQ_ENST00000545260_ENST00000435459_34759012_15520889 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9724
Å |
 |  |  |  |  |
| PARD3_IL2RA_ENST00000545260_ENST00000256876_34805906_6067988 superimposed PDB: 2KOM of partner (PARD3). RMSD:2.1996
Å |
 |  |  |  |  |
| PARD3_IL2RA_ENST00000545260_ENST00000256876_34805906_6067988 superimposed PDB: 9KMC of partner (IL2RA). RMSD:2.8463
Å |
| | | |  |
| PARD3_IL2RA_ENST00000545260_ENST00000379954_34805906_6067988 superimposed PDB: 2KOM of partner (PARD3). RMSD:2.6871
Å |
 |  |  |  |  |
| PARD3_IL2RA_ENST00000545260_ENST00000379954_34805906_6067988 superimposed PDB: 9KMC of partner (IL2RA). RMSD:0.6136
Å |
| | | |  |
| PARD3_IL2RA_ENST00000545693_ENST00000379959_34805906_6067988 superimposed PDB: 2KOM of partner (PARD3). RMSD:2.5381
Å |
 |  |  |  |  |
| PARD3_IL2RA_ENST00000545693_ENST00000379959_34805906_6067988 superimposed PDB: 9KMC of partner (IL2RA). RMSD:0.6848
Å |
| | | |  |
| PARD3_NRXN1_ENST00000346874_ENST00000342183_34985245_50318632 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:1.825
Å |
 |  |  |  |  |
| PARD3_NRXN1_ENST00000350537_ENST00000402717_34985245_50318632 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.6779
Å |
 |  |  |  |  |
| PARD3_NRXN1_ENST00000545260_ENST00000401710_34985245_50318632 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.7319
Å |
 |  |  |  |  |
| PARD3_NRXN1_ENST00000545260_ENST00000406316_34985245_50318632 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.8232
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000346874_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0233
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000346874_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.4206
Å |
| | | |  |
| PARD3_NSUN6_ENST00000350537_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9993
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000350537_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.4046
Å |
| | | |  |
| PARD3_NSUN6_ENST00000374788_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.037
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000374788_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.2286
Å |
| | | |  |
| PARD3_NSUN6_ENST00000374789_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0646
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000374789_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.3681
Å |
| | | |  |
| PARD3_NSUN6_ENST00000374790_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9818
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000374790_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.4868
Å |
| | | |  |
| PARD3_NSUN6_ENST00000374794_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0292
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000374794_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.3491
Å |
| | | |  |
| PARD3_NSUN6_ENST00000545693_ENST00000377304_34558584_18905222 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.0931
Å |
 |  |  |  |  |
| PARD3_NSUN6_ENST00000545693_ENST00000377304_34558584_18905222 superimposed PDB: 5WWQ of partner (NSUN6). RMSD:1.4001
Å |
| | | |  |
| PARD3_PARD6G_ENST00000545260_ENST00000470488_34985245_77960815 superimposed PDB: 2KOM of partner (PARD3). RMSD:1.8882
Å |
 |  |  |  |  |
| PARD3_WAPAL_ENST00000545260_ENST00000372075_35103803_88206206 superimposed PDB: 4K6J of partner (WAPAL). RMSD:0.6485
Å |
 |  |  |  |  |
| PARD6B_PTPN1_ENST00000396039_ENST00000371621_49348389_49177899 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.301
Å |
 |  |  |  |  |
| PARK7_GNB1_ENST00000493678_ENST00000378609_8022935_1749314 superimposed PDB: 6WZG of partner (GNB1). RMSD:0.3742
Å |
 |  |  |  |  |
| PARN_ANKS3_ENST00000420015_ENST00000304283_14645877_4755254 superimposed PDB: 2A1R of partner (PARN). RMSD:0.6981
Å |
 |  |  |  |  |
| PARN_ANKS3_ENST00000420015_ENST00000304283_14645877_4755254 superimposed PDB: 4NL9 of partner (ANKS3). RMSD:0.4369
Å |
| | | |  |
| PARN_ANKS3_ENST00000420015_ENST00000446014_14645877_4755254 superimposed PDB: 2A1R of partner (PARN). RMSD:0.4986
Å |
 |  |  |  |  |
| PARN_ANKS3_ENST00000437198_ENST00000304283_14645877_4755254 superimposed PDB: 2A1R of partner (PARN). RMSD:0.4951
Å |
 |  |  |  |  |
| PARN_ANKS3_ENST00000437198_ENST00000304283_14645877_4755254 superimposed PDB: 4NL9 of partner (ANKS3). RMSD:0.3887
Å |
| | | |  |
| PARN_ANKS3_ENST00000539279_ENST00000304283_14645877_4755254 superimposed PDB: 2A1R of partner (PARN). RMSD:1.1389
Å |
 |  |  |  |  |
| PARN_ANKS3_ENST00000539279_ENST00000304283_14645877_4755254 superimposed PDB: 4NL9 of partner (ANKS3). RMSD:0.4102
Å |
| | | |  |
| PARN_ANKS3_ENST00000539279_ENST00000446014_14645877_4755254 superimposed PDB: 2A1R of partner (PARN). RMSD:0.771
Å |
 |  |  |  |  |
| PARN_CACHD1_ENST00000437198_ENST00000290039_14687157_65016276 superimposed PDB: 2A1R of partner (PARN). RMSD:1.1281
Å |
 |  |  |  |  |
| PARN_CACHD1_ENST00000437198_ENST00000371073_14687157_65016276 superimposed PDB: 2A1R of partner (PARN). RMSD:0.5833
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000420015_ENST00000198767_14711446_15178562 superimposed PDB: 2A1R of partner (PARN). RMSD:0.7776
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000420015_ENST00000198767_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:1.0723
Å |
| | | |  |
| PARN_RRN3_ENST00000420015_ENST00000429751_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:0.9372
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000420015_ENST00000563559_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:0.8924
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000420015_ENST00000564131_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:1.1141
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000437198_ENST00000429751_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:0.9261
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000437198_ENST00000563559_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:0.9198
Å |
 |  |  |  |  |
| PARN_RRN3_ENST00000437198_ENST00000564131_14711446_15178562 superimposed PDB: 7OBA of partner (RRN3). RMSD:1.0934
Å |
 |  |  |  |  |
| PARN_SMG1_ENST00000420015_ENST00000389467_14645877_18849788 superimposed PDB: 2A1R of partner (PARN). RMSD:0.6735
Å |
 |  |  |  |  |
| PARN_SMG1_ENST00000420015_ENST00000446231_14645877_18849788 superimposed PDB: 2A1R of partner (PARN). RMSD:0.8585
Å |
 |  |  |  |  |
| PARN_SMG1_ENST00000437198_ENST00000446231_14645877_18849788 superimposed PDB: 2A1R of partner (PARN). RMSD:0.6508
Å |
 |  |  |  |  |
| PARN_SMG1_ENST00000539279_ENST00000389467_14645877_18849788 superimposed PDB: 2A1R of partner (PARN). RMSD:0.8045
Å |
 |  |  |  |  |
| PARN_SMG1_ENST00000539279_ENST00000446231_14645877_18849788 superimposed PDB: 2A1R of partner (PARN). RMSD:0.6556
Å |
 |  |  |  |  |
| PARP11_B3GALNT2_ENST00000228820_ENST00000313984_3938075_235658138 superimposed PDB: 2DK6 of partner (PARP11). RMSD:2.059
Å |
 |  |  |  |  |
| PARP11_NINJ2_ENST00000228820_ENST00000305108_3982377_675344 superimposed PDB: 2DK6 of partner (PARP11). RMSD:1.8944
Å |
 |  |  |  |  |
| PARP11_NINJ2_ENST00000228820_ENST00000397265_3982377_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:3.1924
Å |
 |  |  |  |  |
| PARP2_ABCD4_ENST00000250416_ENST00000298816_20822406_74755468 superimposed PDB: 6X0L of partner (PARP2). RMSD:0.798
Å |
 |  |  |  |  |
| PARP2_ABCD4_ENST00000250416_ENST00000298816_20822406_74755468 superimposed PDB: 6JBJ of partner (ABCD4). RMSD:0.8819
Å |
| | | |  |
| PARP2_ABCD4_ENST00000250416_ENST00000356924_20822406_74755468 superimposed PDB: 6X0L of partner (PARP2). RMSD:0.8158
Å |
 |  |  |  |  |
| PARP2_ABCD4_ENST00000250416_ENST00000356924_20822406_74755468 superimposed PDB: 6JBJ of partner (ABCD4). RMSD:0.8937
Å |
| | | |  |
| PARP2_ABCD4_ENST00000429687_ENST00000298816_20822406_74755468 superimposed PDB: 6X0L of partner (PARP2). RMSD:0.8199
Å |
 |  |  |  |  |
| PARP2_ABCD4_ENST00000429687_ENST00000298816_20822406_74755468 superimposed PDB: 6JBJ of partner (ABCD4). RMSD:0.8993
Å |
| | | |  |
| PARP2_ABCD4_ENST00000527915_ENST00000356924_20822406_74755468 superimposed PDB: 6X0L of partner (PARP2). RMSD:0.7893
Å |
 |  |  |  |  |
| PARP2_ABCD4_ENST00000527915_ENST00000356924_20822406_74755468 superimposed PDB: 6JBJ of partner (ABCD4). RMSD:0.858
Å |
| | | |  |
| PARP9_PHYH_ENST00000360356_ENST00000263038_122255014_13320354 superimposed PDB: 9QYE of partner (PARP9). RMSD:0.2809
Å |
 |  |  |  |  |
| PARVA_RORA_ENST00000334956_ENST00000309157_12525976_60806956 superimposed PDB: 9UIU of partner (PARVA). RMSD:2.8681
Å |
 |  |  |  |  |
| PARVA_RORA_ENST00000334956_ENST00000309157_12525976_60806956 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5395
Å |
| | | |  |
| PARVA_RORA_ENST00000538608_ENST00000309157_12525976_60806956 superimposed PDB: 9UIU of partner (PARVA). RMSD:2.9469
Å |
 |  |  |  |  |
| PARVA_RORA_ENST00000538608_ENST00000309157_12525976_60806956 superimposed PDB: 4S15 of partner (RORA). RMSD:0.4852
Å |
| | | |  |
| PARVA_RORA_ENST00000539723_ENST00000309157_12525976_60806956 superimposed PDB: 9UIU of partner (PARVA). RMSD:2.8451
Å |
 |  |  |  |  |
| PARVA_RORA_ENST00000539723_ENST00000309157_12525976_60806956 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5518
Å |
| | | |  |
| PARVA_RORA_ENST00000550549_ENST00000309157_12525976_60806956 superimposed PDB: 9UIU of partner (PARVA). RMSD:2.8815
Å |
 |  |  |  |  |
| PARVA_RORA_ENST00000550549_ENST00000309157_12525976_60806956 superimposed PDB: 4S15 of partner (RORA). RMSD:0.5119
Å |
| | | |  |
| PATL1_NAP1L1_ENST00000300146_ENST00000393263_59415226_76448870 superimposed PDB: 2XEQ of partner (PATL1). RMSD:0.7888
Å |
 |  |  |  |  |
| PATL1_NAP1L1_ENST00000300146_ENST00000547993_59415226_76448870 superimposed PDB: 2XEQ of partner (PATL1). RMSD:0.794
Å |
 |  |  |  |  |
| PATL1_NAP1L1_ENST00000300146_ENST00000549596_59415226_76448870 superimposed PDB: 2XEQ of partner (PATL1). RMSD:0.8411
Å |
 |  |  |  |  |
| PAWR_PTPRR_ENST00000328827_ENST00000440835_80083508_71092129 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4103
Å |
 |  |  |  |  |
| PAX3_FOXO1_ENST00000344493_ENST00000379561_223084858_41134997 superimposed PDB: 3CMY of partner (PAX3). RMSD:0.3235
Å |
 |  |  |  |  |
| PAX3_FOXO1_ENST00000344493_ENST00000379561_223084858_41134997 superimposed PDB: 4LG0 of partner (FOXO1). RMSD:2.5216
Å |
| | | |  |
| PAX5_ETV6_ENST00000377847_ENST00000396373_37006469_11992073 superimposed PDB: 1K78 of partner (PAX5). RMSD:0.4685
Å |
 |  |  |  |  |
| PAX5_ETV6_ENST00000377847_ENST00000396373_37006469_11992073 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3225
Å |
| | | |  |
| PAX5_ETV6_ENST00000523241_ENST00000396373_37006469_11992073 superimposed PDB: 1K78 of partner (PAX5). RMSD:2.974
Å |
 |  |  |  |  |
| PAX5_ETV6_ENST00000523241_ENST00000396373_37006469_11992073 superimposed PDB: 9O0H of partner (ETV6). RMSD:0.3153
Å |
| | | |  |
| PAX5_KANK1_ENST00000377847_ENST00000382303_37002644_730050 superimposed PDB: 5YBU of partner (KANK1). RMSD:0.6045
Å |
 |  |  |  |  |
| PAX5_KANK1_ENST00000523241_ENST00000382303_37002644_730050 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.2238
Å |
 |  |  |  |  |
| PAX5_KANK1_ENST00000523241_ENST00000382303_37002644_730050 superimposed PDB: 5YBU of partner (KANK1). RMSD:0.5951
Å |
| | | |  |
| PAX6_MUC2_ENST00000419022_ENST00000441003_31823418_1079657 superimposed PDB: 6PAX of partner (PAX6). RMSD:2.8488
Å |
 |  |  |  |  |
| PAX7_FOXO1_ENST00000420770_ENST00000379561_19029790_41134997 superimposed PDB: 4LG0 of partner (FOXO1). RMSD:2.2386
Å |
 |  |  |  |  |
| PAXBP1_TP53I3_ENST00000290178_ENST00000407482_34131390_24300631 superimposed PDB: 2J8Z of partner (TP53I3). RMSD:2.7932
Å |
 |  |  |  |  |
| PAXBP1_TP53I3_ENST00000331923_ENST00000407482_34131390_24300631 superimposed PDB: 2J8Z of partner (TP53I3). RMSD:2.9631
Å |
 |  |  |  |  |
| PBRM1_CACNA2D3_ENST00000394830_ENST00000415676_52637536_54420741 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3013
Å |
 |  |  |  |  |
| PBRM1_KYNU_ENST00000337303_ENST00000264170_52692214_143742652 superimposed PDB: 3E9K of partner (KYNU). RMSD:2.5722
Å |
 |  |  |  |  |
| PBRM1_KYNU_ENST00000356770_ENST00000375773_52692214_143742652 superimposed PDB: 3E9K of partner (KYNU). RMSD:2.7071
Å |
 |  |  |  |  |
| PBRM1_TMEM110-MUSTN1_ENST00000296302_ENST00000504329_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3225
Å |
 |  |  |  |  |
| PBRM1_TMEM110-MUSTN1_ENST00000409114_ENST00000504329_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2432
Å |
 |  |  |  |  |
| PBRM1_TMEM110-MUSTN1_ENST00000410007_ENST00000504329_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1959
Å |
 |  |  |  |  |
| PBRM1_TMEM110_ENST00000296302_ENST00000355083_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.042
Å |
 |  |  |  |  |
| PBRM1_TMEM110_ENST00000337303_ENST00000355083_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.5456
Å |
 |  |  |  |  |
| PBRM1_TMEM110_ENST00000409057_ENST00000355083_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:0.7243
Å |
 |  |  |  |  |
| PBRM1_TMEM110_ENST00000409114_ENST00000355083_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1611
Å |
 |  |  |  |  |
| PBRM1_TMEM110_ENST00000410007_ENST00000355083_52584436_52889460 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:0.6769
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000359282_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3881
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000359462_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3593
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000437231_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3965
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000447282_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.329
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000546463_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3657
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000549863_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3994
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000552296_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3433
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000552819_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3351
Å |
 |  |  |  |  |
| PCBP2_ITGB7_ENST00000603815_ENST00000338737_53865591_53585420 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4509
Å |
 |  |  |  |  |
| PCBP2_PFDN5_ENST00000359282_ENST00000351500_53856351_53691633 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2651
Å |
 |  |  |  |  |
| PCBP2_PFDN5_ENST00000359282_ENST00000351500_53856351_53691633 superimposed PDB: 7WU7 of partner (PFDN5). RMSD:2.9529
Å |
| | | |  |
| PCBP2_PFDN5_ENST00000603815_ENST00000351500_53856351_53691633 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3239
Å |
 |  |  |  |  |
| PCBP2_RPLP0_ENST00000359282_ENST00000551150_53853187_120635265 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.6553
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000366159_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4572
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000366159_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:0.8781
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000366159_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3628
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000366159_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:3.0884
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000437813_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3707
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000437813_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.0892
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000437813_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3108
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000437813_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.0862
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000540022_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4572
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000540022_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.1967
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000540022_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4422
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000359282_ENST00000540022_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.1551
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000366159_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.339
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000366159_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:0.9148
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000437813_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4132
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000437813_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.0762
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000540022_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4324
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000447282_ENST00000540022_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.2235
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000366159_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4448
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000366159_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.0889
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000437813_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2758
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000437813_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.1053
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000540022_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4402
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000546463_ENST00000540022_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.3027
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000366159_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4383
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000366159_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:0.9814
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000366159_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4383
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000366159_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:0.9557
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000437813_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3825
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000437813_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.0625
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000437813_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3324
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000437813_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.026
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000540022_53856351_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4287
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000540022_53856351_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.1673
Å |
| | | |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000540022_53859757_6443410 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.427
Å |
 |  |  |  |  |
| PCBP2_TNFRSF1A_ENST00000603815_ENST00000540022_53859757_6443410 superimposed PDB: 8ZUI of partner (TNFRSF1A). RMSD:1.3112
Å |
| | | |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000359462_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3606
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000437231_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3158
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000447282_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2561
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000455667_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.271
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000546463_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2902
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000549863_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3702
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000552296_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3798
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000552819_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.363
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400304_ENST00000603815_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.1946
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400310_ENST00000359282_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3776
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000359462_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3417
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000437231_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3906
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000447282_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2884
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000455667_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4314
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000546463_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3526
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000549863_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.413
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000552296_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3882
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000552819_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4488
Å |
 |  |  |  |  |
| PCBP3_PCBP2_ENST00000400314_ENST00000603815_47320537_53849668 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4607
Å |
 |  |  |  |  |
| PCBP4_TLR9_ENST00000322099_ENST00000494383_51994881_52258328 superimposed PDB: 8AR3 of partner (TLR9). RMSD:2.6513
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376279_ENST00000400319_100861717_60616954 superimposed PDB: 7YBU of partner (PCCA). RMSD:3.0043
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376279_ENST00000400319_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6079
Å |
| | | |  |
| PCCA_DIAPH3_ENST00000376279_ENST00000400320_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6778
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376279_ENST00000400330_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6155
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376285_ENST00000400319_100861717_60616954 superimposed PDB: 7YBU of partner (PCCA). RMSD:2.7104
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376285_ENST00000400319_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6002
Å |
| | | |  |
| PCCA_DIAPH3_ENST00000376285_ENST00000400320_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6202
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376285_ENST00000400324_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:1.9522
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376285_ENST00000400330_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6258
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376286_ENST00000400319_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.756
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376286_ENST00000400320_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.5024
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376286_ENST00000400324_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:1.9549
Å |
 |  |  |  |  |
| PCCA_DIAPH3_ENST00000376286_ENST00000400330_100861717_60616954 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.5751
Å |
 |  |  |  |  |
| PCCA_DNAJC3_ENST00000376279_ENST00000602402_100888132_96443126 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.3878
Å |
 |  |  |  |  |
| PCCA_DNAJC3_ENST00000376285_ENST00000602402_100888132_96443126 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.7708
Å |
 |  |  |  |  |
| PCCA_DNAJC3_ENST00000376286_ENST00000602402_100888132_96443126 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.8474
Å |
 |  |  |  |  |
| PCCA_FARP1_ENST00000376279_ENST00000376586_100809594_98996015 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.6504
Å |
 |  |  |  |  |
| PCCA_FARP1_ENST00000376285_ENST00000376586_100809594_98996015 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.6749
Å |
 |  |  |  |  |
| PCCA_FARP1_ENST00000376285_ENST00000595437_100809594_98996015 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.5945
Å |
 |  |  |  |  |
| PCCA_FARP1_ENST00000376286_ENST00000376586_100809594_98996015 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.6923
Å |
 |  |  |  |  |
| PCCA_FARP1_ENST00000376286_ENST00000595437_100809594_98996015 superimposed PDB: 4H6Y of partner (FARP1). RMSD:0.6093
Å |
 |  |  |  |  |
| PCCA_GRM3_ENST00000376285_ENST00000361669_101167821_86415576 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.7588
Å |
 |  |  |  |  |
| PCCA_GRM3_ENST00000376285_ENST00000361669_101167821_86415576 superimposed PDB: 9II2 of partner (GRM3). RMSD:2.893
Å |
| | | |  |
| PCCA_GRM3_ENST00000376286_ENST00000361669_101167821_86415576 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.6892
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000343600_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.0681
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000343600_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2711
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000345429_100809594_98043575 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.3681
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000376673_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.0897
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000376673_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4827
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000376673_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2407
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376279_ENST00000445661_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.0398
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000445661_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4748
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376279_ENST00000445661_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2831
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376285_ENST00000343600_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2867
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000343600_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.3259
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000345429_100809594_98043575 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4074
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000376673_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2524
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000376673_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4684
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000376673_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2984
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376285_ENST00000397601_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4073
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000445661_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.3517
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000445661_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4646
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376285_ENST00000445661_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2477
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376286_ENST00000343600_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.041
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000343600_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:3.0763
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000343600_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2294
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376286_ENST00000345429_100809594_98043575 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.3818
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000376673_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.0781
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000376673_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4701
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000376673_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2422
Å |
| | | |  |
| PCCA_MBNL2_ENST00000376286_ENST00000397601_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4078
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000445661_100764315_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.0144
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000445661_100861717_97986529 superimposed PDB: 7YBU of partner (PCCA). RMSD:0.4459
Å |
 |  |  |  |  |
| PCCA_MBNL2_ENST00000376286_ENST00000445661_100861717_97986529 superimposed PDB: 2E5S of partner (MBNL2). RMSD:1.2433
Å |
| | | |  |
| PCCA_SNX13_ENST00000376279_ENST00000409389_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.2573
Å |
 |  |  |  |  |
| PCCA_SNX13_ENST00000376279_ENST00000428135_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:3.234
Å |
 |  |  |  |  |
| PCCA_SNX13_ENST00000376285_ENST00000409389_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.237
Å |
 |  |  |  |  |
| PCCA_SNX13_ENST00000376285_ENST00000428135_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.6573
Å |
 |  |  |  |  |
| PCCA_SNX13_ENST00000376286_ENST00000409389_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.1929
Å |
 |  |  |  |  |
| PCCA_SNX13_ENST00000376286_ENST00000428135_100925600_17874488 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.6935
Å |
 |  |  |  |  |
| PCCA_UBAC2_ENST00000376285_ENST00000376440_100764315_99992573 superimposed PDB: 7YBU of partner (PCCA). RMSD:2.5872
Å |
 |  |  |  |  |
| PCDHGA6_JMJD1C_ENST00000517434_ENST00000399262_140756074_65024524 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.7168
Å |
 |  |  |  |  |
| PCDHGB3_JMJD1C_ENST00000576222_ENST00000399262_140752376_65024524 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.7927
Å |
 |  |  |  |  |
| PCGF3_FANCI_ENST00000362003_ENST00000310775_738476_89856134 superimposed PDB: 8A9J of partner (FANCI). RMSD:2.356
Å |
 |  |  |  |  |
| PCGF3_FANCI_ENST00000521023_ENST00000310775_738476_89856134 superimposed PDB: 8A9J of partner (FANCI). RMSD:2.6921
Å |
 |  |  |  |  |
| PCGF5_RPP30_ENST00000336126_ENST00000413330_93021181_92655636 superimposed PDB: 4S3O of partner (PCGF5). RMSD:0.3913
Å |
 |  |  |  |  |
| PCGF5_RPP30_ENST00000336126_ENST00000413330_93021181_92655636 superimposed PDB: 9UH7 of partner (RPP30). RMSD:3.1226
Å |
| | | |  |
| PCGF5_RPP30_ENST00000543648_ENST00000371703_93021181_92655636 superimposed PDB: 4S3O of partner (PCGF5). RMSD:0.4255
Å |
 |  |  |  |  |
| PCGF5_RPP30_ENST00000543648_ENST00000371703_93021181_92655636 superimposed PDB: 9UH7 of partner (RPP30). RMSD:2.6646
Å |
| | | |  |
| PCK1_PCK2_ENST00000319441_ENST00000216780_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.6837
Å |
 |  |  |  |  |
| PCK1_PCK2_ENST00000319441_ENST00000396973_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.7457
Å |
 |  |  |  |  |
| PCK1_PCK2_ENST00000319441_ENST00000545054_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.6338
Å |
 |  |  |  |  |
| PCK1_PCK2_ENST00000535860_ENST00000216780_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.7409
Å |
 |  |  |  |  |
| PCK1_PCK2_ENST00000535860_ENST00000396973_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.8094
Å |
 |  |  |  |  |
| PCK1_PCK2_ENST00000535860_ENST00000545054_56138271_24568766 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.9139
Å |
 |  |  |  |  |
| PCK2_PCK1_ENST00000216780_ENST00000319441_24568445_56138620 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.8176
Å |
 |  |  |  |  |
| PCK2_PCK1_ENST00000396973_ENST00000319441_24568445_56138620 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.8607
Å |
 |  |  |  |  |
| PCK2_PCK1_ENST00000558096_ENST00000319441_24568445_56138620 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.7864
Å |
 |  |  |  |  |
| PCK2_PCK1_ENST00000561286_ENST00000319441_24568445_56138620 superimposed PDB: 1KHB of partner (PCK1). RMSD:0.8684
Å |
 |  |  |  |  |
| PCM1_JAK2_ENST00000325083_ENST00000381652_17843596_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:3.0773
Å |
 |  |  |  |  |
| PCM1_JAK2_ENST00000325083_ENST00000381652_17872349_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:1.2924
Å |
 |  |  |  |  |
| PCM1_JAK2_ENST00000327578_ENST00000381652_17843596_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:1.0704
Å |
 |  |  |  |  |
| PCM1_JAK2_ENST00000327578_ENST00000381652_17872349_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.6208
Å |
 |  |  |  |  |
| PCM1_JAK2_ENST00000519253_ENST00000381652_17872349_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:1.262
Å |
 |  |  |  |  |
| PCMTD1_FBXO3_ENST00000522514_ENST00000526785_52758220_33763630 superimposed PDB: 9OMA of partner (PCMTD1). RMSD:0.8571
Å |
 |  |  |  |  |
| PCMTD1_MRPL15_ENST00000544451_ENST00000260102_52811489_55049070 superimposed PDB: 9OMA of partner (PCMTD1). RMSD:0.9849
Å |
 |  |  |  |  |
| PCMTD1_SLCO5A1_ENST00000360540_ENST00000260126_52758220_70674110 superimposed PDB: 9OMA of partner (PCMTD1). RMSD:0.928
Å |
 |  |  |  |  |
| PCNX_RAD51B_ENST00000238570_ENST00000390683_71374720_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2431
Å |
 |  |  |  |  |
| PCNX_RAD51B_ENST00000238570_ENST00000471583_71374720_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1974
Å |
 |  |  |  |  |
| PCNX_RAD51B_ENST00000238570_ENST00000487270_71374720_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.3439
Å |
 |  |  |  |  |
| PCNX_RAD51B_ENST00000238570_ENST00000488612_71374720_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2384
Å |
 |  |  |  |  |
| PCNX_RAD51B_ENST00000304743_ENST00000487861_71374720_68758600 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.097
Å |
 |  |  |  |  |
| PCSK5_KIF21A_ENST00000376767_ENST00000361961_78722267_39735926 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4657
Å |
 |  |  |  |  |
| PCSK5_KIF21A_ENST00000545128_ENST00000361418_78722267_39735926 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4438
Å |
 |  |  |  |  |
| PCSK5_KIF21A_ENST00000545128_ENST00000395670_78722267_39735926 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4293
Å |
 |  |  |  |  |
| PCSK5_KIF21A_ENST00000545128_ENST00000544797_78722267_39735926 superimposed PDB: 7KLJ of partner (KIF21A). RMSD:0.4397
Å |
 |  |  |  |  |
| PCSK5_RAB3IP_ENST00000545128_ENST00000378815_78506289_70178499 superimposed PDB: 4UJ5 of partner (RAB3IP). RMSD:0.5162
Å |
 |  |  |  |  |
| PCTP_BRIP1_ENST00000268896_ENST00000259008_53828605_59861785 superimposed PDB: 7U9D of partner (PCTP). RMSD:3.1093
Å |
 |  |  |  |  |
| PCTP_BRIP1_ENST00000576183_ENST00000259008_53828605_59861785 superimposed PDB: 7U9D of partner (PCTP). RMSD:2.9933
Å |
 |  |  |  |  |
| PCTP_MEI4_ENST00000268896_ENST00000602452_53851256_78400374 superimposed PDB: 7U9D of partner (PCTP). RMSD:0.8601
Å |
 |  |  |  |  |
| PCTP_MEI4_ENST00000576183_ENST00000602452_53851256_78400374 superimposed PDB: 7U9D of partner (PCTP). RMSD:0.891
Å |
 |  |  |  |  |
| PC_ACTN4_ENST00000393955_ENST00000424234_66631244_39191239 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.6375
Å |
 |  |  |  |  |
| PC_ACTN4_ENST00000393960_ENST00000424234_66631244_39191239 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.6595
Å |
 |  |  |  |  |
| PC_CAT_ENST00000393955_ENST00000241052_66631244_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4138
Å |
 |  |  |  |  |
| PDCD1LG2_IGHV7-81_ENST00000397747_ENST00000390639_5563211_107283096 superimposed PDB: 6UMT of partner (PDCD1LG2). RMSD:0.4222
Å |
 |  |  |  |  |
| PDCD6IP_GADL1_ENST00000457054_ENST00000282538_33870461_30769907 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5106
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000307296_ENST00000280700_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5462
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000307296_ENST00000396649_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.4781
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000307296_ENST00000417874_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5304
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000307296_ENST00000428257_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5855
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000457054_ENST00000280700_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.563
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000457054_ENST00000396649_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5136
Å |
 |  |  |  |  |
| PDCD6IP_NGLY1_ENST00000457054_ENST00000417874_33870461_25792754 superimposed PDB: 2XS1 of partner (PDCD6IP). RMSD:0.5842
Å |
 |  |  |  |  |
| PDCD6_FRS2_ENST00000264933_ENST00000549921_272887_69965055 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.387
Å |
 |  |  |  |  |
| PDCD6_FRS2_ENST00000505221_ENST00000549921_272887_69965055 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.4442
Å |
 |  |  |  |  |
| PDCD6_SLC12A7_ENST00000505221_ENST00000264930_272887_1094363 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:2.8131
Å |
 |  |  |  |  |
| PDCD6_SLC12A7_ENST00000509581_ENST00000264930_272887_1094363 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:2.8937
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000264933_ENST00000334602_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.553
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000264933_ENST00000334602_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1601
Å |
| | | |  |
| PDCD6_TERT_ENST00000264933_ENST00000334602_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.596
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000264933_ENST00000334602_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1443
Å |
| | | |  |
| PDCD6_TERT_ENST00000264933_ENST00000508104_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.5174
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000264933_ENST00000508104_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.712
Å |
| | | |  |
| PDCD6_TERT_ENST00000264933_ENST00000508104_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.6
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000264933_ENST00000508104_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8634
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000310581_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.3465
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000310581_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:2.2059
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000310581_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.4376
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000310581_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8199
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000334602_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.7265
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000334602_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.0768
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000334602_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.6769
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000334602_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.1535
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000508104_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.6305
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000508104_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8092
Å |
| | | |  |
| PDCD6_TERT_ENST00000505221_ENST00000508104_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.4665
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000505221_ENST00000508104_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.9651
Å |
| | | |  |
| PDCD6_TERT_ENST00000507528_ENST00000310581_304336_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.2856
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000507528_ENST00000310581_304336_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8328
Å |
| | | |  |
| PDCD6_TERT_ENST00000509581_ENST00000310581_272887_1282739 superimposed PDB: 2ZN8 of partner (PDCD6). RMSD:0.4247
Å |
 |  |  |  |  |
| PDCD6_TERT_ENST00000509581_ENST00000310581_272887_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.8206
Å |
| | | |  |
| PDCD7_TAF15_ENST00000204549_ENST00000588240_65421369_34144719 superimposed PDB: 9RDK of partner (TAF15). RMSD:2.3419
Å |
 |  |  |  |  |
| PDE3B_EEF1G_ENST00000282096_ENST00000378019_14808231_62335000 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.6147
Å |
 |  |  |  |  |
| PDE3B_EPS8_ENST00000282096_ENST00000281172_14666599_15784598 superimposed PDB: 2E8M of partner (EPS8). RMSD:0.8706
Å |
 |  |  |  |  |
| PDE3B_PLCXD3_ENST00000282096_ENST00000328457_14889304_41313872 superimposed PDB: 8SYC of partner (PDE3B). RMSD:0.4589
Å |
 |  |  |  |  |
| PDE3B_PLCXD3_ENST00000455098_ENST00000328457_14889304_41313872 superimposed PDB: 8SYC of partner (PDE3B). RMSD:0.5079
Å |
 |  |  |  |  |
| PDE3B_RRAS2_ENST00000282096_ENST00000414023_14666599_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5402
Å |
 |  |  |  |  |
| PDE4B_ITGB3BP_ENST00000423207_ENST00000283568_66458825_63974241 superimposed PDB: 28OP of partner (ITGB3BP). RMSD:2.7419
Å |
 |  |  |  |  |
| PDE4D_CDHR2_ENST00000358923_ENST00000261944_58334685_175995678 superimposed PDB: 7N86 of partner (CDHR2). RMSD:1.6047
Å |
 |  |  |  |  |
| PDE4D_ELOVL7_ENST00000546160_ENST00000505959_59481383_60050660 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:2.8556
Å |
 |  |  |  |  |
| PDE4D_ERCC8_ENST00000546160_ENST00000265038_59481383_60200700 superimposed PDB: 9BZ0 of partner (ERCC8). RMSD:0.5174
Å |
 |  |  |  |  |
| PDE4D_FYB_ENST00000502484_ENST00000515010_59481383_39124380 superimposed PDB: 2GTJ of partner (FYB). RMSD:1.8748
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000340635_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.4715
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000360047_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.4699
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000405755_ENST00000355849_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:3.1759
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000405755_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.5978
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000502575_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.5082
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000503258_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.4738
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000507116_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.477
Å |
 |  |  |  |  |
| PDE4D_KHDRBS3_ENST00000546160_ENST00000520981_58476420_136533479 superimposed PDB: 5EMO of partner (KHDRBS3). RMSD:0.4679
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000360047_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:0.6074
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000405755_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:0.5464
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000502575_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:2.7549
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000503258_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:0.577
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000507116_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:0.5839
Å |
 |  |  |  |  |
| PDE4D_NOA1_ENST00000546160_ENST00000264230_58476420_57840188 superimposed PDB: 8CSP of partner (NOA1). RMSD:0.6079
Å |
 |  |  |  |  |
| PDE4D_PLK2_ENST00000360047_ENST00000274289_58334685_57754919 superimposed PDB: 4I5P of partner (PLK2). RMSD:0.5697
Å |
 |  |  |  |  |
| PDE4D_PLK2_ENST00000405755_ENST00000274289_58334685_57754919 superimposed PDB: 4I5P of partner (PLK2). RMSD:0.575
Å |
 |  |  |  |  |
| PDE4D_PLK2_ENST00000503258_ENST00000274289_58334685_57754919 superimposed PDB: 4I5P of partner (PLK2). RMSD:0.5723
Å |
 |  |  |  |  |
| PDE4D_PLK2_ENST00000507116_ENST00000274289_58334685_57754919 superimposed PDB: 4I5P of partner (PLK2). RMSD:0.5674
Å |
 |  |  |  |  |
| PDE4D_PLK2_ENST00000546160_ENST00000274289_58334685_57754919 superimposed PDB: 4I5P of partner (PLK2). RMSD:0.5631
Å |
 |  |  |  |  |
| PDE7A_NRG1_ENST00000379419_ENST00000338921_66691954_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.5746
Å |
 |  |  |  |  |
| PDE7A_NRG1_ENST00000379419_ENST00000523079_66691954_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.4926
Å |
 |  |  |  |  |
| PDE7A_NRG1_ENST00000396642_ENST00000523079_66691954_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.7095
Å |
 |  |  |  |  |
| PDE7A_NRG1_ENST00000401827_ENST00000338921_66691954_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.5631
Å |
 |  |  |  |  |
| PDE7A_NRG1_ENST00000401827_ENST00000523079_66691954_32585466 superimposed PDB: 1ZKL of partner (PDE7A). RMSD:1.9167
Å |
 |  |  |  |  |
| PDE7A_PREX2_ENST00000396642_ENST00000288368_66647028_68950393 superimposed PDB: 6BNM of partner (PREX2). RMSD:0.4274
Å |
 |  |  |  |  |
| PDE8A_CIB1_ENST00000394553_ENST00000328649_85525579_90774739 superimposed PDB: 6OCX of partner (CIB1). RMSD:0.9164
Å |
 |  |  |  |  |
| PDE8A_CIB1_ENST00000394553_ENST00000328649_85525579_90776935 superimposed PDB: 6OCX of partner (CIB1). RMSD:0.6929
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000310298_ENST00000361162_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7852
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000310298_ENST00000528062_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.773
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000339708_ENST00000361162_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7511
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000339708_ENST00000528062_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7887
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000394553_ENST00000253363_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.755
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000557957_ENST00000253363_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7815
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000557957_ENST00000361162_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7686
Å |
 |  |  |  |  |
| PDE8A_RBM39_ENST00000557957_ENST00000528062_85669605_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7255
Å |
 |  |  |  |  |
| PDE8A_SND1_ENST00000394553_ENST00000354725_85620018_127326666 superimposed PDB: 3BDL of partner (SND1). RMSD:2.8772
Å |
 |  |  |  |  |
| PDE9A_ABCG1_ENST00000291539_ENST00000398457_44073993_43645780 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.3639
Å |
 |  |  |  |  |
| PDGFA_NT5C3A_ENST00000402802_ENST00000381626_550445_33063720 superimposed PDB: 2VKQ of partner (NT5C3A). RMSD:0.5511
Å |
 |  |  |  |  |
| PDGFD_PRCP_ENST00000393158_ENST00000393399_104034531_82571159 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.9556
Å |
 |  |  |  |  |
| PDGFRA_USP8_ENST00000257290_ENST00000433963_55156721_50751196 superimposed PDB: 7LBF of partner (PDGFRA). RMSD:3.2984
Å |
 |  |  |  |  |
| PDGFRA_USP8_ENST00000257290_ENST00000433963_55156721_50751196 superimposed PDB: 2GFO of partner (USP8). RMSD:0.5887
Å |
| | | |  |
| PDHX_CAT_ENST00000227868_ENST00000241052_34953031_34485651 superimposed PDB: 6H60 of partner (PDHX). RMSD:2.6926
Å |
 |  |  |  |  |
| PDHX_CAT_ENST00000227868_ENST00000241052_34953031_34485651 superimposed PDB: 9T0K of partner (CAT). RMSD:2.8421
Å |
| | | |  |
| PDHX_CAT_ENST00000227868_ENST00000241052_34999729_34477557 superimposed PDB: 6H60 of partner (PDHX). RMSD:2.6779
Å |
 |  |  |  |  |
| PDHX_CAT_ENST00000227868_ENST00000241052_34999729_34477557 superimposed PDB: 9T0K of partner (CAT). RMSD:1.0265
Å |
| | | |  |
| PDHX_CAT_ENST00000430469_ENST00000241052_34953031_34485651 superimposed PDB: 6H60 of partner (PDHX). RMSD:2.7105
Å |
 |  |  |  |  |
| PDHX_CAT_ENST00000430469_ENST00000241052_34953031_34485651 superimposed PDB: 9T0K of partner (CAT). RMSD:0.8977
Å |
| | | |  |
| PDHX_CD44_ENST00000227868_ENST00000263398_34938362_35208378 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7553
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000278386_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8588
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000352818_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7502
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000360158_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7415
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000415148_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8788
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000428726_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7338
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000433354_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7381
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000433892_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7596
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000434472_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.1596
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000437706_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8753
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000449691_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7532
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000526025_35006275_35198121 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.5012
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000227868_ENST00000526669_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7399
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000263398_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7127
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000278386_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7644
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000352818_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7496
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000360158_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.8983
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000415148_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7439
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000428726_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7285
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000433354_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7693
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000433892_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7064
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000434472_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.1642
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000437706_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7403
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000449691_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7153
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000526025_35006275_35198121 superimposed PDB: 6H60 of partner (PDHX). RMSD:1.5593
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000430469_ENST00000526669_34938362_35198121 superimposed PDB: 2I83 of partner (CD44). RMSD:1.7312
Å |
 |  |  |  |  |
| PDHX_CD44_ENST00000448838_ENST00000263398_34953031_35236398 superimposed PDB: 6H60 of partner (PDHX). RMSD:2.5678
Å |
 |  |  |  |  |
| PDIA3_NAA50_ENST00000300289_ENST00000477813_44038904_113442939 superimposed PDB: 6WFN of partner (NAA50). RMSD:0.3907
Å |
 |  |  |  |  |
| PDIA3_SF3B1_ENST00000538521_ENST00000335508_44059108_198257912 superimposed PDB: 7QNG of partner (PDIA3). RMSD:2.1687
Å |
 |  |  |  |  |
| PDIA3_SF3B1_ENST00000538521_ENST00000335508_44059108_198257912 superimposed PDB: 7Q4O of partner (SF3B1). RMSD:0.4439
Å |
| | | |  |
| PDIA6_DDX1_ENST00000272227_ENST00000233084_10925059_15757367 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.3477
Å |
 |  |  |  |  |
| PDIA6_DDX1_ENST00000404371_ENST00000233084_10925059_15757367 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.3523
Å |
 |  |  |  |  |
| PDIA6_DDX1_ENST00000404824_ENST00000233084_10925059_15757367 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.3313
Å |
 |  |  |  |  |
| PDIA6_ODC1_ENST00000272227_ENST00000405333_10925059_10582300 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.4027
Å |
 |  |  |  |  |
| PDIA6_ODC1_ENST00000404371_ENST00000405333_10925059_10582300 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.384
Å |
 |  |  |  |  |
| PDIA6_ODC1_ENST00000404824_ENST00000405333_10925059_10582300 superimposed PDB: 8CPQ of partner (PDIA6). RMSD:0.3544
Å |
 |  |  |  |  |
| PDK2_CDK12_ENST00000007708_ENST00000447079_48182806_37627131 superimposed PDB: 5M4P of partner (PDK2). RMSD:0.8398
Å |
 |  |  |  |  |
| PDK2_CDK12_ENST00000007708_ENST00000447079_48182806_37627131 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5511
Å |
| | | |  |
| PDK2_CDK12_ENST00000503176_ENST00000430627_48182806_37627131 superimposed PDB: 5M4P of partner (PDK2). RMSD:0.8637
Å |
 |  |  |  |  |
| PDK2_CDK12_ENST00000503176_ENST00000430627_48182806_37627131 superimposed PDB: 4NST of partner (CDK12). RMSD:0.538
Å |
| | | |  |
| PDK2_CDK12_ENST00000503176_ENST00000447079_48182806_37627131 superimposed PDB: 5M4P of partner (PDK2). RMSD:0.6544
Å |
 |  |  |  |  |
| PDK2_CDK12_ENST00000503176_ENST00000447079_48182806_37627131 superimposed PDB: 4NST of partner (CDK12). RMSD:0.4961
Å |
| | | |  |
| PDK3_NAV3_ENST00000379162_ENST00000397909_24523415_78579380 superimposed PDB: 1Y8O of partner (PDK3). RMSD:0.6073
Å |
 |  |  |  |  |
| PDK3_NAV3_ENST00000379162_ENST00000536525_24523415_78579380 superimposed PDB: 1Y8O of partner (PDK3). RMSD:0.9922
Å |
 |  |  |  |  |
| PDK3_NAV3_ENST00000441463_ENST00000397909_24523415_78579380 superimposed PDB: 1Y8O of partner (PDK3). RMSD:0.5849
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000306402_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.6018
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000306402_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.7685
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000306402_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.2488
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000347291_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5444
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000347291_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.4497
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000353505_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5707
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000353505_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.7633
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000353505_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.1032
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371227_97050576_97170534 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5783
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371227_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.0184
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371239_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5901
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371239_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.1098
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371239_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.2229
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371241_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5627
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371241_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.148
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371241_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.8062
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371245_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5757
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371245_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.7106
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371246_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5745
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371246_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.9175
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371246_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.3142
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371247_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5628
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371247_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.2177
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371247_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.2631
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371249_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5743
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000371249_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.455
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000393949_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5533
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000393949_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.105
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000393949_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.1156
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000607232_97006971_97144042 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.5606
Å |
 |  |  |  |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000607232_97006971_97144042 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.9333
Å |
| | | |  |
| PDLIM1_SORBS1_ENST00000329399_ENST00000607232_97050576_97170534 superimposed PDB: 2MOX of partner (SORBS1). RMSD:3.3274
Å |
 |  |  |  |  |
| PDLIM5_GRID2_ENST00000538141_ENST00000282020_95445026_94436366 superimposed PDB: 9F6S of partner (PDLIM5). RMSD:0.4608
Å |
 |  |  |  |  |
| PDLIM5_SHISA5_ENST00000317968_ENST00000296444_95539342_48538726 superimposed PDB: 9F6S of partner (PDLIM5). RMSD:0.435
Å |
 |  |  |  |  |
| PDLIM5_SHISA5_ENST00000514743_ENST00000296444_95539342_48538726 superimposed PDB: 9F6S of partner (PDLIM5). RMSD:2.5449
Å |
 |  |  |  |  |
| PDLIM5_SHISA5_ENST00000542407_ENST00000296444_95539342_48538726 superimposed PDB: 9F6S of partner (PDLIM5). RMSD:0.4343
Å |
 |  |  |  |  |
| PDLIM5_TIMM23_ENST00000538141_ENST00000260867_95376535_51613311 superimposed PDB: 9F6S of partner (PDLIM5). RMSD:2.8802
Å |
 |  |  |  |  |
| PDLIM7_MED24_ENST00000356618_ENST00000356271_176919405_38187873 superimposed PDB: 2Q3G of partner (PDLIM7). RMSD:0.3198
Å |
 |  |  |  |  |
| PDLIM7_MED24_ENST00000356618_ENST00000356271_176919405_38187873 superimposed PDB: 7EMF of partner (MED24). RMSD:3.3262
Å |
| | | |  |
| PDSS2_DCLK1_ENST00000369037_ENST00000255448_107595232_36413313 superimposed PDB: 6KYQ of partner (DCLK1). RMSD:0.8135
Å |
 |  |  |  |  |
| PDSS2_DCLK1_ENST00000453874_ENST00000360631_107595232_36413313 superimposed PDB: 6KYQ of partner (DCLK1). RMSD:0.7005
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000327574_ENST00000322229_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.463
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000327574_ENST00000357345_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4157
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000327574_ENST00000382499_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4372
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000327574_ENST00000433931_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4522
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000398081_ENST00000322229_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4558
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000398081_ENST00000357345_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4385
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000398081_ENST00000382499_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4499
Å |
 |  |  |  |  |
| PDXK_SYNJ1_ENST00000398081_ENST00000433931_45154004_34074357 superimposed PDB: 7A0V of partner (SYNJ1). RMSD:0.4413
Å |
 |  |  |  |  |
| PDZRN3_FOXP1_ENST00000263666_ENST00000475937_73651504_71102924 superimposed PDB: 1WH1 of partner (PDZRN3). RMSD:0.9776
Å |
 |  |  |  |  |
| PDZRN3_FOXP1_ENST00000263666_ENST00000475937_73651504_71102924 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3641
Å |
| | | |  |
| PDZRN3_FOXP1_ENST00000308537_ENST00000318789_73651504_71102924 superimposed PDB: 1WH1 of partner (PDZRN3). RMSD:1.1513
Å |
 |  |  |  |  |
| PDZRN3_FOXP1_ENST00000308537_ENST00000318789_73651504_71102924 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3701
Å |
| | | |  |
| PEAK1_PSTPIP1_ENST00000312493_ENST00000267939_77471131_77317624 superimposed PDB: 7AAL of partner (PSTPIP1). RMSD:1.7414
Å |
 |  |  |  |  |
| PEAK1_PSTPIP1_ENST00000312493_ENST00000379595_77471131_77317624 superimposed PDB: 7AAL of partner (PSTPIP1). RMSD:1.636
Å |
 |  |  |  |  |
| PEAK1_PSTPIP1_ENST00000312493_ENST00000559295_77471131_77317624 superimposed PDB: 7AAL of partner (PSTPIP1). RMSD:1.6337
Å |
 |  |  |  |  |
| PELI2_GPHN_ENST00000267460_ENST00000478722_56645182_67490349 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.717
Å |
 |  |  |  |  |
| PELI2_GPHN_ENST00000267460_ENST00000543237_56645182_67490349 superimposed PDB: 3EGB of partner (PELI2). RMSD:2.5889
Å |
 |  |  |  |  |
| PELP1_CHRNE_ENST00000269230_ENST00000293780_4579651_4806058 superimposed PDB: 9DMS of partner (CHRNE). RMSD:1.5038
Å |
 |  |  |  |  |
| PELP1_CHRNE_ENST00000572293_ENST00000293780_4579651_4806058 superimposed PDB: 9DMS of partner (CHRNE). RMSD:1.409
Å |
 |  |  |  |  |
| PELP1_YBX2_ENST00000572293_ENST00000007699_4607157_7196857 superimposed PDB: 7F3K of partner (YBX2). RMSD:0.4245
Å |
 |  |  |  |  |
| PEPD_FAM20C_ENST00000244137_ENST00000313766_33902577_298611 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.7889
Å |
 |  |  |  |  |
| PEPD_FAM20C_ENST00000397032_ENST00000313766_33902577_298611 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.5775
Å |
 |  |  |  |  |
| PEPD_FAM20C_ENST00000436370_ENST00000313766_33902577_298611 superimposed PDB: 6QSC of partner (PEPD). RMSD:1.2152
Å |
 |  |  |  |  |
| PEPD_GRAMD1A_ENST00000244137_ENST00000317991_33953900_35500022 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.372
Å |
 |  |  |  |  |
| PEPD_GRAMD1A_ENST00000244137_ENST00000599564_33953900_35500022 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.9785
Å |
 |  |  |  |  |
| PEPD_GRAMD1A_ENST00000436370_ENST00000317991_33953900_35500022 superimposed PDB: 6QSC of partner (PEPD). RMSD:1.0949
Å |
 |  |  |  |  |
| PEPD_GRAMD1A_ENST00000436370_ENST00000599564_33953900_35500022 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.4163
Å |
 |  |  |  |  |
| PEPD_NDUFB7_ENST00000397032_ENST00000215565_33892626_14677745 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.422
Å |
 |  |  |  |  |
| PEPD_NDUFB7_ENST00000436370_ENST00000215565_33892626_14677745 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.7762
Å |
 |  |  |  |  |
| PEPD_SKAP1_ENST00000244137_ENST00000584924_33953900_46214699 superimposed PDB: 6QSC of partner (PEPD). RMSD:1.1421
Å |
 |  |  |  |  |
| PEPD_SKAP1_ENST00000436370_ENST00000584924_33953900_46214699 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.4019
Å |
 |  |  |  |  |
| PEX1_CDK6_ENST00000248633_ENST00000424848_92157620_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3222
Å |
 |  |  |  |  |
| PEX1_CDK6_ENST00000438045_ENST00000424848_92157620_92355107 superimposed PDB: 1BLX of partner (CDK6). RMSD:0.3156
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000248633_ENST00000310336_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:1.0457
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000248633_ENST00000400445_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:1.0473
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000248633_ENST00000540320_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.9453
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000428214_ENST00000310336_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.9897
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000428214_ENST00000400445_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:1.1201
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000428214_ENST00000540320_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.9583
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000438045_ENST00000310336_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.9948
Å |
 |  |  |  |  |
| PEX1_NBEA_ENST00000438045_ENST00000400445_92129017_35615069 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.9441
Å |
 |  |  |  |  |
| PEX5_LPL_ENST00000266563_ENST00000311322_7343120_19810820 superimposed PDB: 6OAU of partner (LPL). RMSD:0.9632
Å |
 |  |  |  |  |
| PEX5_LPL_ENST00000266564_ENST00000311322_7343120_19810820 superimposed PDB: 6OAU of partner (LPL). RMSD:1.0339
Å |
 |  |  |  |  |
| PEX5_LPL_ENST00000420616_ENST00000311322_7343120_19810820 superimposed PDB: 6OAU of partner (LPL). RMSD:1.0157
Å |
 |  |  |  |  |
| PEX5_LPL_ENST00000434354_ENST00000311322_7343165_19810820 superimposed PDB: 6OAU of partner (LPL). RMSD:0.9396
Å |
 |  |  |  |  |
| PFDN1_DNMT3L_ENST00000261813_ENST00000418993_139680000_45666445 superimposed PDB: 7WU7 of partner (PFDN1). RMSD:3.4795
Å |
 |  |  |  |  |
| PFDN1_DNMT3L_ENST00000524074_ENST00000270172_139680000_45666445 superimposed PDB: 7WU7 of partner (PFDN1). RMSD:3.4607
Å |
 |  |  |  |  |
| PFDN1_DNMT3L_ENST00000524074_ENST00000418993_139680000_45666445 superimposed PDB: 7WU7 of partner (PFDN1). RMSD:3.5457
Å |
 |  |  |  |  |
| PFDN5_CAPN2_ENST00000551018_ENST00000295006_53689423_223949887 superimposed PDB: 7WU7 of partner (PFDN5). RMSD:0.438
Å |
 |  |  |  |  |
| PFDN5_CAPN2_ENST00000551018_ENST00000295006_53689423_223949887 superimposed PDB: 1KFU of partner (CAPN2). RMSD:1.3372
Å |
| | | |  |
| PFKM_ZDHHC13_ENST00000340802_ENST00000399351_48534654_19186598 superimposed PDB: 4OMT of partner (PFKM). RMSD:0.7194
Å |
 |  |  |  |  |
| PFKM_ZDHHC13_ENST00000359794_ENST00000399351_48534654_19186598 superimposed PDB: 4OMT of partner (PFKM). RMSD:0.6693
Å |
 |  |  |  |  |
| PFKM_ZDHHC13_ENST00000395233_ENST00000399351_48534654_19186598 superimposed PDB: 4OMT of partner (PFKM). RMSD:1.5621
Å |
 |  |  |  |  |
| PFKM_ZDHHC13_ENST00000547587_ENST00000399351_48534654_19186598 superimposed PDB: 4OMT of partner (PFKM). RMSD:0.6496
Å |
 |  |  |  |  |
| PFKP_ACLY_ENST00000381075_ENST00000590151_3151672_40025840 superimposed PDB: 4XYJ of partner (PFKP). RMSD:1.2612
Å |
 |  |  |  |  |
| PFKP_ACLY_ENST00000381125_ENST00000352035_3151672_40025840 superimposed PDB: 4XYJ of partner (PFKP). RMSD:2.2792
Å |
 |  |  |  |  |
| PFKP_ACLY_ENST00000381125_ENST00000590151_3151672_40025840 superimposed PDB: 4XYJ of partner (PFKP). RMSD:1.0501
Å |
 |  |  |  |  |
| PFKP_PSG1_ENST00000381125_ENST00000244296_3109899_43372507 superimposed PDB: 4XYJ of partner (PFKP). RMSD:2.834
Å |
 |  |  |  |  |
| PFKP_PSG1_ENST00000381125_ENST00000595124_3109899_43372507 superimposed PDB: 4XYJ of partner (PFKP). RMSD:2.8862
Å |
 |  |  |  |  |
| PGA3_CKB_ENST00000538258_ENST00000348956_60978907_103988287 superimposed PDB: 3B6R of partner (CKB). RMSD:0.7072
Å |
 |  |  |  |  |
| PGA3_CKB_ENST00000543125_ENST00000348956_60978907_103988287 superimposed PDB: 3B6R of partner (CKB). RMSD:0.5567
Å |
 |  |  |  |  |
| PGA3_CTSE_ENST00000325558_ENST00000358184_60971741_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6326
Å |
 |  |  |  |  |
| PGA3_CTSE_ENST00000325558_ENST00000360218_60971741_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6324
Å |
 |  |  |  |  |
| PGA3_CTSE_ENST00000325558_ENST00000432969_60971741_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.8042
Å |
 |  |  |  |  |
| PGA3_PGC_ENST00000325558_ENST00000373025_60974099_41711127 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7788
Å |
 |  |  |  |  |
| PGA3_PGC_ENST00000325558_ENST00000425343_60974099_41711127 superimposed PDB: 1HTR of partner (PGC). RMSD:0.4943
Å |
 |  |  |  |  |
| PGA4_CAPN2_ENST00000378149_ENST00000295006_60990577_223946971 superimposed PDB: 1KFU of partner (CAPN2). RMSD:1.9546
Å |
 |  |  |  |  |
| PGA4_CAPN2_ENST00000378149_ENST00000433674_60990577_223946971 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.9178
Å |
 |  |  |  |  |
| PGA4_CAPN2_ENST00000422676_ENST00000295006_60990577_223946971 superimposed PDB: 1KFU of partner (CAPN2). RMSD:2.0493
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000378149_ENST00000358184_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6392
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000378149_ENST00000358184_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6601
Å |
| | | |  |
| PGA4_CTSE_ENST00000378149_ENST00000360218_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6273
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000378149_ENST00000360218_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6129
Å |
| | | |  |
| PGA4_CTSE_ENST00000378149_ENST00000361052_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6335
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000378149_ENST00000361052_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.5785
Å |
| | | |  |
| PGA4_CTSE_ENST00000378149_ENST00000432969_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.5884
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000378149_ENST00000432969_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.795
Å |
| | | |  |
| PGA4_CTSE_ENST00000422676_ENST00000358184_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6052
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000422676_ENST00000358184_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6196
Å |
| | | |  |
| PGA4_CTSE_ENST00000422676_ENST00000360218_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6794
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000422676_ENST00000360218_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.6677
Å |
| | | |  |
| PGA4_CTSE_ENST00000422676_ENST00000432969_60990577_206319100 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.5807
Å |
 |  |  |  |  |
| PGA4_CTSE_ENST00000422676_ENST00000432969_60990577_206319100 superimposed PDB: 1TZS of partner (CTSE). RMSD:0.8077
Å |
| | | |  |
| PGA4_PGC_ENST00000378149_ENST00000373025_60990577_41712252 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.653
Å |
 |  |  |  |  |
| PGA4_PGC_ENST00000378149_ENST00000373025_60990577_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.6915
Å |
| | | |  |
| PGA4_PGC_ENST00000378149_ENST00000373025_60994791_41708348 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6869
Å |
 |  |  |  |  |
| PGA4_PGC_ENST00000378149_ENST00000373025_60994791_41708348 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7978
Å |
| | | |  |
| PGA4_PGC_ENST00000422676_ENST00000373025_60990577_41712252 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.6898
Å |
 |  |  |  |  |
| PGA4_PGC_ENST00000422676_ENST00000373025_60990577_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8164
Å |
| | | |  |
| PGA4_PGC_ENST00000422676_ENST00000373025_60994791_41708348 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.7268
Å |
 |  |  |  |  |
| PGA4_PGC_ENST00000422676_ENST00000373025_60994791_41708348 superimposed PDB: 1HTR of partner (PGC). RMSD:0.6106
Å |
| | | |  |
| PGA4_PGC_ENST00000422676_ENST00000425343_60990577_41712252 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.8808
Å |
 |  |  |  |  |
| PGA4_PGC_ENST00000422676_ENST00000425343_60990577_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.496
Å |
| | | |  |
| PGA5_PGC_ENST00000312403_ENST00000373025_61009403_41712252 superimposed PDB: 1HTR of partner (PGC). RMSD:0.5743
Å |
 |  |  |  |  |
| PGA5_PGC_ENST00000312403_ENST00000425343_61011754_41711127 superimposed PDB: 1HTR of partner (PGC). RMSD:0.5199
Å |
 |  |  |  |  |
| PGAP3_BPTF_ENST00000300658_ENST00000424123_37842174_65978367 superimposed PDB: 2RI7 of partner (BPTF). RMSD:2.7885
Å |
 |  |  |  |  |
| PGAP3_PTPN12_ENST00000579146_ENST00000415482_37844086_77227158 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.7448
Å |
 |  |  |  |  |
| PGAP3_PTPN12_ENST00000579146_ENST00000435495_37844086_77227158 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.7449
Å |
 |  |  |  |  |
| PGAP3_TOP2A_ENST00000300658_ENST00000423485_37844086_38556915 superimposed PDB: 6ZY5 of partner (TOP2A). RMSD:2.6139
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000373025_ENST00000325558_41704448_60980024 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7652
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000373025_ENST00000325558_41705467_60980024 superimposed PDB: 1HTR of partner (PGC). RMSD:0.509
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000373025_ENST00000325558_41710027_60977313 superimposed PDB: 1HTR of partner (PGC). RMSD:0.5856
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000425343_ENST00000325558_41710027_60977313 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7152
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000425343_ENST00000325558_41711008_60975762 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8329
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000425343_ENST00000325558_41712134_60974968 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8739
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000425343_ENST00000325558_41712395_60973981 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8278
Å |
 |  |  |  |  |
| PGC_PGA3_ENST00000425343_ENST00000543125_41710027_60980024 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7101
Å |
 |  |  |  |  |
| PGC_PGA4_ENST00000425343_ENST00000378149_41712134_60993797 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8751
Å |
 |  |  |  |  |
| PGC_PGA4_ENST00000425343_ENST00000378149_41712134_60993797 superimposed PDB: 1QRP of partner (PGA4). RMSD:0.5969
Å |
| | | |  |
| PGC_PGA5_ENST00000425343_ENST00000312403_41710027_61015890 superimposed PDB: 1HTR of partner (PGC). RMSD:0.7319
Å |
 |  |  |  |  |
| PGC_PGA5_ENST00000425343_ENST00000312403_41712395_61011636 superimposed PDB: 1HTR of partner (PGC). RMSD:0.8343
Å |
 |  |  |  |  |
| PGC_USE1_ENST00000373025_ENST00000263897_41710027_17330021 superimposed PDB: 1HTR of partner (PGC). RMSD:0.705
Å |
 |  |  |  |  |
| PGD_PEX14_ENST00000270776_ENST00000356607_10460629_10596269 superimposed PDB: 2W84 of partner (PEX14). RMSD:0.7021
Å |
 |  |  |  |  |
| PGM1_FOXJ3_ENST00000371084_ENST00000372573_64059405_42660735 superimposed PDB: 5JN5 of partner (PGM1). RMSD:0.4635
Å |
 |  |  |  |  |
| PGM1_KIAA0368_ENST00000371083_ENST00000259335_64120137_114152003 superimposed PDB: 5JN5 of partner (PGM1). RMSD:0.831
Å |
 |  |  |  |  |
| PGM1_KIAA0368_ENST00000371084_ENST00000259335_64120137_114152003 superimposed PDB: 5JN5 of partner (PGM1). RMSD:0.7736
Å |
 |  |  |  |  |
| PGM1_KIAA0368_ENST00000540265_ENST00000259335_64120137_114152003 superimposed PDB: 5JN5 of partner (PGM1). RMSD:0.6126
Å |
 |  |  |  |  |
| PGM2L1_UVRAG_ENST00000298198_ENST00000528420_74109095_75694430 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.9201
Å |
 |  |  |  |  |
| PGPEP1_GTF2F1_ENST00000269919_ENST00000429701_18466821_6389648 superimposed PDB: 7NVU of partner (GTF2F1). RMSD:1.749
Å |
 |  |  |  |  |
| PGS1_BPTF_ENST00000262764_ENST00000306378_76400170_65916130 superimposed PDB: 2RI7 of partner (BPTF). RMSD:1.0752
Å |
 |  |  |  |  |
| PGS1_BPTF_ENST00000262764_ENST00000321892_76400170_65916130 superimposed PDB: 2RI7 of partner (BPTF). RMSD:1.1421
Å |
 |  |  |  |  |
| PGS1_BPTF_ENST00000329897_ENST00000306378_76400170_65916130 superimposed PDB: 2RI7 of partner (BPTF). RMSD:0.9637
Å |
 |  |  |  |  |
| PGS1_BPTF_ENST00000329897_ENST00000321892_76400170_65916130 superimposed PDB: 2RI7 of partner (BPTF). RMSD:1.0766
Å |
 |  |  |  |  |
| PGS1_BPTF_ENST00000329897_ENST00000335221_76400170_65916130 superimposed PDB: 2RI7 of partner (BPTF). RMSD:1.0468
Å |
 |  |  |  |  |
| PHACTR1_BCL11A_ENST00000332995_ENST00000359629_12750022_60679801 superimposed PDB: 6U9Q of partner (BCL11A). RMSD:2.2913
Å |
 |  |  |  |  |
| PHC3_GNA12_ENST00000467570_ENST00000275364_169896560_2834777 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.0734
Å |
 |  |  |  |  |
| PHC3_GNA12_ENST00000494943_ENST00000275364_169896560_2834777 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.1773
Å |
 |  |  |  |  |
| PHC3_GNA12_ENST00000494943_ENST00000544127_169896560_2834777 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.231
Å |
 |  |  |  |  |
| PHC3_GNA12_ENST00000495893_ENST00000544127_169896560_2834777 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.1694
Å |
 |  |  |  |  |
| PHF12_CDK12_ENST00000332830_ENST00000447079_27277082_37627131 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5067
Å |
 |  |  |  |  |
| PHF12_CDK12_ENST00000577226_ENST00000430627_27277082_37627131 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5081
Å |
 |  |  |  |  |
| PHF1_IVNS1ABP_ENST00000374516_ENST00000367498_33380199_185274775 superimposed PDB: 5XFP of partner (PHF1). RMSD:2.4696
Å |
 |  |  |  |  |
| PHF1_IVNS1ABP_ENST00000374516_ENST00000367498_33380199_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.4672
Å |
| | | |  |
| PHF1_RPS10-NUDT3_ENST00000374516_ENST00000605528_33382606_34309749 superimposed PDB: 5XFP of partner (PHF1). RMSD:0.7334
Å |
 |  |  |  |  |
| PHF20L1_CHMP1A_ENST00000395376_ENST00000535997_133811418_89713739 superimposed PDB: 2EQM of partner (PHF20L1). RMSD:1.3557
Å |
 |  |  |  |  |
| PHF20L1_CHMP1A_ENST00000395376_ENST00000535997_133811418_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9469
Å |
| | | |  |
| PHF20L1_CHMP1A_ENST00000395386_ENST00000397901_133811418_89713739 superimposed PDB: 2EQM of partner (PHF20L1). RMSD:1.4833
Å |
 |  |  |  |  |
| PHF20L1_CHMP1A_ENST00000395386_ENST00000535997_133811418_89713739 superimposed PDB: 2EQM of partner (PHF20L1). RMSD:1.3671
Å |
 |  |  |  |  |
| PHF20L1_CHMP1A_ENST00000395386_ENST00000535997_133811418_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9333
Å |
| | | |  |
| PHF20_EPB41L1_ENST00000374012_ENST00000373950_34430666_34800193 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.4392
Å |
 |  |  |  |  |
| PHF20_EPB41L1_ENST00000374012_ENST00000441639_34430666_34800193 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.4476
Å |
 |  |  |  |  |
| PHF20_EPB41L1_ENST00000439301_ENST00000202028_34430666_34800193 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.472
Å |
 |  |  |  |  |
| PHF20_MROH8_ENST00000374012_ENST00000400441_34515801_35800460 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.2554
Å |
 |  |  |  |  |
| PHF20_MROH8_ENST00000374012_ENST00000441008_34515801_35800460 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.4581
Å |
 |  |  |  |  |
| PHF20_RPN2_ENST00000374012_ENST00000237530_34528969_35812582 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.3556
Å |
 |  |  |  |  |
| PHF20_RPN2_ENST00000374012_ENST00000373622_34528969_35812582 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.341
Å |
 |  |  |  |  |
| PHF20_STX8_ENST00000374012_ENST00000574431_34487570_9395238 superimposed PDB: 2LDM of partner (PHF20). RMSD:1.3592
Å |
 |  |  |  |  |
| PHF21A_ACSL6_ENST00000257821_ENST00000379264_46098304_131309093 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.3137
Å |
 |  |  |  |  |
| PHF21A_ACSL6_ENST00000323180_ENST00000379264_46098304_131309093 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.3016
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000257821_ENST00000312055_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.6339
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000257821_ENST00000354558_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.5863
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000257821_ENST00000415402_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.571
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000418153_ENST00000312055_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.5605
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000418153_ENST00000354558_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.6076
Å |
 |  |  |  |  |
| PHF21A_CKAP5_ENST00000418153_ENST00000415402_45986865_46804918 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.5449
Å |
 |  |  |  |  |
| PHF21A_ELF1_ENST00000323180_ENST00000442101_46100684_41533152 superimposed PDB: 8BZM of partner (ELF1). RMSD:0.6325
Å |
 |  |  |  |  |
| PHF21A_NUTF2_ENST00000257821_ENST00000568396_46098304_67902242 superimposed PDB: 1GY5 of partner (NUTF2). RMSD:0.4766
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000259238_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7231
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000346226_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.5645
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000348750_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.5662
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000351659_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.5674
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000352848_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.7055
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000357970_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.5834
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000393040_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.575
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000393041_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.5794
Å |
 |  |  |  |  |
| PHKA1_BIN1_ENST00000373542_ENST00000409400_71872393_127819773 superimposed PDB: 8XYA of partner (PHKA1). RMSD:0.6548
Å |
 |  |  |  |  |
| PHKB_ABCC11_ENST00000299167_ENST00000356608_47549512_48212597 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.481
Å |
 |  |  |  |  |
| PHKB_ABCC11_ENST00000299167_ENST00000394747_47549512_48212597 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.8795
Å |
 |  |  |  |  |
| PHKB_ABCC11_ENST00000566044_ENST00000356608_47549512_48212597 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.8157
Å |
 |  |  |  |  |
| PHKB_ABCC11_ENST00000566044_ENST00000394747_47549512_48212597 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.8418
Å |
 |  |  |  |  |
| PHKB_GPR89A_ENST00000299167_ENST00000454423_47549512_145771730 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.6258
Å |
 |  |  |  |  |
| PHKB_GPR89A_ENST00000299167_ENST00000454423_47549512_145787864 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.711
Å |
 |  |  |  |  |
| PHKB_GPR89A_ENST00000566044_ENST00000454423_47549512_145771730 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.6934
Å |
 |  |  |  |  |
| PHKB_GPR89A_ENST00000566044_ENST00000454423_47549512_145787864 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.7291
Å |
 |  |  |  |  |
| PHKB_NETO2_ENST00000299167_ENST00000303155_47630442_47165936 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.952
Å |
 |  |  |  |  |
| PHKB_NETO2_ENST00000323584_ENST00000562435_47630442_47165936 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.8943
Å |
 |  |  |  |  |
| PHKB_NETO2_ENST00000455779_ENST00000562435_47630442_47165936 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.9122
Å |
 |  |  |  |  |
| PHKB_NETO2_ENST00000566044_ENST00000303155_47630442_47165936 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.9866
Å |
 |  |  |  |  |
| PHKB_VRK2_ENST00000299167_ENST00000417641_47531399_58313473 superimposed PDB: 2V62 of partner (VRK2). RMSD:0.5185
Å |
 |  |  |  |  |
| PHKB_VRK2_ENST00000323584_ENST00000435505_47531399_58313473 superimposed PDB: 2V62 of partner (VRK2). RMSD:0.5302
Å |
 |  |  |  |  |
| PHKB_VRK2_ENST00000455779_ENST00000435505_47531399_58313473 superimposed PDB: 2V62 of partner (VRK2). RMSD:0.5161
Å |
 |  |  |  |  |
| PHKB_VRK2_ENST00000566044_ENST00000417641_47531399_58313473 superimposed PDB: 2V62 of partner (VRK2). RMSD:0.5195
Å |
 |  |  |  |  |
| PHKB_VRK2_ENST00000566044_ENST00000435505_47531399_58313473 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.8337
Å |
 |  |  |  |  |
| PHKG2_ELAVL1_ENST00000328273_ENST00000596459_30764878_8032674 superimposed PDB: 2Y7J of partner (PHKG2). RMSD:0.8277
Å |
 |  |  |  |  |
| PHKG2_ELAVL1_ENST00000563588_ENST00000596459_30764878_8032674 superimposed PDB: 2Y7J of partner (PHKG2). RMSD:0.8956
Å |
 |  |  |  |  |
| PHYH_ZNF148_ENST00000263038_ENST00000544464_13322975_124951498 superimposed PDB: 2A1X of partner (PHYH). RMSD:0.299
Å |
 |  |  |  |  |
| PHYH_ZNF148_ENST00000396920_ENST00000544464_13322975_124951498 superimposed PDB: 2A1X of partner (PHYH). RMSD:0.3199
Å |
 |  |  |  |  |
| PI4K2A_AS3MT_ENST00000370649_ENST00000369880_99426877_104650300 superimposed PDB: 5I0N of partner (PI4K2A). RMSD:0.5488
Å |
 |  |  |  |  |
| PI4K2B_INSR_ENST00000264864_ENST00000341500_25236053_7267907 superimposed PDB: 4WTV of partner (PI4K2B). RMSD:0.685
Å |
 |  |  |  |  |
| PI4KA_BCAT1_ENST00000255882_ENST00000538118_21212857_25054819 superimposed PDB: 7NWA of partner (BCAT1). RMSD:0.4613
Å |
 |  |  |  |  |
| PI4KA_FAM19A5_ENST00000572273_ENST00000358295_21147480_49103528 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.0841
Å |
 |  |  |  |  |
| PI4KA_FAM19A5_ENST00000572273_ENST00000402357_21147480_49103528 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.1292
Å |
 |  |  |  |  |
| PI4KA_TTC39C_ENST00000572273_ENST00000317571_21107190_21694517 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.5901
Å |
 |  |  |  |  |
| PI4KA_ZNF274_ENST00000572273_ENST00000326804_21101870_58718086 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.8288
Å |
 |  |  |  |  |
| PIAS1_DTNBP1_ENST00000249636_ENST00000355917_68379088_15533626 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7478
Å |
 |  |  |  |  |
| PIAS1_DTNBP1_ENST00000249636_ENST00000462989_68379088_15533626 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7348
Å |
 |  |  |  |  |
| PIAS1_DTNBP1_ENST00000545237_ENST00000355917_68379088_15533626 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7445
Å |
 |  |  |  |  |
| PIAS1_DTNBP1_ENST00000545237_ENST00000462989_68379088_15533626 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7056
Å |
 |  |  |  |  |
| PIAS1_HMCN2_ENST00000545237_ENST00000428715_68379088_133297963 superimposed PDB: 1V66 of partner (PIAS1). RMSD:0.7863
Å |
 |  |  |  |  |
| PIAS2_ST8SIA5_ENST00000324794_ENST00000315087_44407921_44272218 superimposed PDB: 4FO9 of partner (PIAS2). RMSD:0.7322
Å |
 |  |  |  |  |
| PIAS2_ST8SIA5_ENST00000324794_ENST00000315087_44407921_44284627 superimposed PDB: 4FO9 of partner (PIAS2). RMSD:0.7152
Å |
 |  |  |  |  |
| PIAS2_ST8SIA5_ENST00000545673_ENST00000315087_44407921_44272218 superimposed PDB: 4FO9 of partner (PIAS2). RMSD:0.4155
Å |
 |  |  |  |  |
| PIAS2_ST8SIA5_ENST00000545673_ENST00000315087_44407921_44284627 superimposed PDB: 4FO9 of partner (PIAS2). RMSD:0.4227
Å |
 |  |  |  |  |
| PIAS2_ST8SIA5_ENST00000585916_ENST00000315087_44407921_44272218 superimposed PDB: 4FO9 of partner (PIAS2). RMSD:1.5131
Å |
 |  |  |  |  |
| PIAS3_BZRAP1_ENST00000369298_ENST00000343736_145584836_56384329 superimposed PDB: 4MVT of partner (PIAS3). RMSD:1.6057
Å |
 |  |  |  |  |
| PIAS3_BZRAP1_ENST00000369298_ENST00000355701_145584836_56384329 superimposed PDB: 4MVT of partner (PIAS3). RMSD:1.5636
Å |
 |  |  |  |  |
| PIAS3_BZRAP1_ENST00000393045_ENST00000268893_145584836_56384329 superimposed PDB: 4MVT of partner (PIAS3). RMSD:0.7317
Å |
 |  |  |  |  |
| PIAS3_BZRAP1_ENST00000393045_ENST00000343736_145584836_56384329 superimposed PDB: 4MVT of partner (PIAS3). RMSD:1.648
Å |
 |  |  |  |  |
| PIAS3_BZRAP1_ENST00000393045_ENST00000355701_145584836_56384329 superimposed PDB: 4MVT of partner (PIAS3). RMSD:1.6649
Å |
 |  |  |  |  |
| PICALM_CTSC_ENST00000526033_ENST00000227266_85779692_88045722 superimposed PDB: 3PDF of partner (CTSC). RMSD:0.3315
Å |
 |  |  |  |  |
| PICALM_ME3_ENST00000393346_ENST00000393324_85779692_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:0.7064
Å |
 |  |  |  |  |
| PICALM_ME3_ENST00000526033_ENST00000393324_85779692_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:0.6917
Å |
 |  |  |  |  |
| PICALM_ME3_ENST00000532317_ENST00000359636_85779692_86270862 superimposed PDB: 8E76 of partner (ME3). RMSD:1.1852
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000307729_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5121
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000307729_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5138
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000377059_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5244
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000377059_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5784
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000377072_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5093
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000356360_ENST00000377072_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5184
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000307729_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4937
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000307729_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5197
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000377059_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5146
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000377059_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5956
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000377072_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4892
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000393346_ENST00000377072_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5001
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000307729_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5009
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000307729_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5373
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000377059_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4998
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000377059_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5371
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000377072_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4886
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000526033_ENST00000377072_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5305
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000307729_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4741
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000307729_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5046
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000377059_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5161
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000377059_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.6206
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000377072_85685750_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.4907
Å |
 |  |  |  |  |
| PICALM_MLLT10_ENST00000532317_ENST00000377072_85692171_21875222 superimposed PDB: 5DAG of partner (MLLT10). RMSD:0.5153
Å |
 |  |  |  |  |
| PICALM_NFATC2_ENST00000532317_ENST00000396009_85779692_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.424
Å |
 |  |  |  |  |
| PICALM_NFATC2_ENST00000532317_ENST00000609943_85779692_50092197 superimposed PDB: 8OW4 of partner (NFATC2). RMSD:1.4523
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000405557_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.8273
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000407936_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.3341
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000442738_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.6408
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000460648_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.4516
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000470701_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.4934
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000356976_ENST00000488684_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.5392
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000404072_ENST00000405557_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.8628
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000404072_ENST00000442738_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.6106
Å |
 |  |  |  |  |
| PICK1_POLR2F_ENST00000404072_ENST00000470701_38453857_38352779 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.516
Å |
 |  |  |  |  |
| PIEZO1_MNS1_ENST00000301015_ENST00000260453_88851308_56756445 superimposed PDB: 8ZU3 of partner (PIEZO1). RMSD:1.9797
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000370812_ENST00000370399_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6306
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000370812_ENST00000370399_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.3075
Å |
| | | |  |
| PIGK_TGFBR3_ENST00000370812_ENST00000525962_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6829
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000370812_ENST00000525962_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.1984
Å |
| | | |  |
| PIGK_TGFBR3_ENST00000370813_ENST00000370399_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6575
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000370813_ENST00000370399_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.2079
Å |
| | | |  |
| PIGK_TGFBR3_ENST00000370813_ENST00000525962_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6217
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000370813_ENST00000525962_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.2232
Å |
| | | |  |
| PIGK_TGFBR3_ENST00000445065_ENST00000370399_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6611
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000445065_ENST00000370399_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.3536
Å |
| | | |  |
| PIGK_TGFBR3_ENST00000445065_ENST00000525962_77587959_92187701 superimposed PDB: 7W72 of partner (PIGK). RMSD:0.6414
Å |
 |  |  |  |  |
| PIGK_TGFBR3_ENST00000445065_ENST00000525962_77587959_92187701 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:2.1357
Å |
| | | |  |
| PIGQ_ERCC1_ENST00000409527_ENST00000423698_626254_45920155 superimposed PDB: 9QEC of partner (ERCC1). RMSD:2.5604
Å |
 |  |  |  |  |
| PIGU_ACSS2_ENST00000374820_ENST00000336325_33225679_33500898 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.7316
Å |
 |  |  |  |  |
| PIGU_AHCY_ENST00000374820_ENST00000217426_33203845_32873440 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.7781
Å |
 |  |  |  |  |
| PIGU_AHCY_ENST00000374820_ENST00000217426_33203845_32873440 superimposed PDB: 1LI4 of partner (AHCY). RMSD:0.9969
Å |
| | | |  |
| PIGU_AHCY_ENST00000374820_ENST00000538132_33203845_32873440 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9213
Å |
 |  |  |  |  |
| PIGU_PITPNC1_ENST00000374820_ENST00000580974_33231967_65528917 superimposed PDB: 7WLD of partner (PIGU). RMSD:3.4209
Å |
 |  |  |  |  |
| PIGU_PITPNC1_ENST00000452740_ENST00000299954_33231967_65528917 superimposed PDB: 7WLD of partner (PIGU). RMSD:1.3516
Å |
 |  |  |  |  |
| PIGU_PITPNC1_ENST00000452740_ENST00000335257_33231967_65528917 superimposed PDB: 7WLD of partner (PIGU). RMSD:1.3681
Å |
 |  |  |  |  |
| PIGU_PITPNC1_ENST00000452740_ENST00000581322_33231967_65528917 superimposed PDB: 7WLD of partner (PIGU). RMSD:1.3972
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000356100_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.8779
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000356100_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3663
Å |
| | | |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373187_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.8893
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373187_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3669
Å |
| | | |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373190_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9802
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373190_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3633
Å |
| | | |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373193_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9448
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373193_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3426
Å |
| | | |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373198_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.9093
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373198_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3717
Å |
| | | |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373201_33162907_40911165 superimposed PDB: 7WLD of partner (PIGU). RMSD:0.8995
Å |
 |  |  |  |  |
| PIGU_PTPRT_ENST00000374820_ENST00000373201_33162907_40911165 superimposed PDB: 2OOQ of partner (PTPRT). RMSD:0.3424
Å |
| | | |  |
| PIK3C2G_CTDSP2_ENST00000433979_ENST00000398073_18435693_58218102 superimposed PDB: 2Q5E of partner (CTDSP2). RMSD:0.4217
Å |
 |  |  |  |  |
| PIK3R3_MKNK1_ENST00000372006_ENST00000341183_46546313_47049001 superimposed PDB: 2HW6 of partner (MKNK1). RMSD:0.6517
Å |
 |  |  |  |  |
| PIK3R3_MKNK1_ENST00000372006_ENST00000371945_46546313_47049001 superimposed PDB: 2HW6 of partner (MKNK1). RMSD:0.665
Å |
 |  |  |  |  |
| PIK3R3_MKNK1_ENST00000372006_ENST00000428112_46546313_47049001 superimposed PDB: 2HW6 of partner (MKNK1). RMSD:0.5172
Å |
 |  |  |  |  |
| PIK3R3_MKNK1_ENST00000372006_ENST00000465783_46546313_47049001 superimposed PDB: 2HW6 of partner (MKNK1). RMSD:1.1283
Å |
 |  |  |  |  |
| PINX1_HGSNAT_ENST00000314787_ENST00000379644_10683661_43037287 superimposed PDB: 8JL3 of partner (HGSNAT). RMSD:0.7159
Å |
 |  |  |  |  |
| PINX1_SOX17_ENST00000426190_ENST00000297316_10683661_55371617 superimposed PDB: 4A3N of partner (SOX17). RMSD:1.5439
Å |
 |  |  |  |  |
| PIP4K2B_FBXL20_ENST00000269554_ENST00000583610_36955518_37499494 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:1.1666
Å |
 |  |  |  |  |
| PIP4K2B_MED24_ENST00000269554_ENST00000356271_36933939_38188343 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:1.1857
Å |
 |  |  |  |  |
| PIP4K2B_MED24_ENST00000269554_ENST00000356271_36933939_38188343 superimposed PDB: 7EMF of partner (MED24). RMSD:3.4271
Å |
| | | |  |
| PIP4K2B_MED24_ENST00000269554_ENST00000394126_36933939_38188343 superimposed PDB: 1BO1 of partner (PIP4K2B). RMSD:1.2295
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000335312_ENST00000341919_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6074
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000335312_ENST00000346156_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6546
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000335312_ENST00000395111_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6521
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000335312_ENST00000586919_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.596
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000335312_ENST00000590282_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6803
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000539785_ENST00000346156_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6286
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000539785_ENST00000395111_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5793
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000539785_ENST00000586919_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6181
Å |
 |  |  |  |  |
| PIP5K1C_NFIC_ENST00000539785_ENST00000590282_3638881_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6503
Å |
 |  |  |  |  |
| PIR_ITGB4_ENST00000380420_ENST00000200181_15444028_73737062 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.1112
Å |
 |  |  |  |  |
| PIR_ITGB4_ENST00000380420_ENST00000339591_15444028_73737062 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.2658
Å |
 |  |  |  |  |
| PIR_ITGB4_ENST00000380420_ENST00000450894_15444028_73737062 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.1962
Å |
 |  |  |  |  |
| PIR_TMEM27_ENST00000380420_ENST00000380342_15509284_15682518 superimposed PDB: 6H1H of partner (PIR). RMSD:0.515
Å |
 |  |  |  |  |
| PIR_ZNF138_ENST00000380421_ENST00000440155_15415570_64291828 superimposed PDB: 6H1H of partner (PIR). RMSD:0.5341
Å |
 |  |  |  |  |
| PISD_EIF4ENIF1_ENST00000336566_ENST00000330125_32044086_31867903 superimposed PDB: 5ANR of partner (EIF4ENIF1). RMSD:2.3811
Å |
 |  |  |  |  |
| PISD_EIF4ENIF1_ENST00000439502_ENST00000344710_32044086_31867903 superimposed PDB: 5ANR of partner (EIF4ENIF1). RMSD:2.5265
Å |
 |  |  |  |  |
| PITPNB_TRIO_ENST00000320996_ENST00000344204_28290542_14387546 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:0.9995
Å |
 |  |  |  |  |
| PITPNB_TRIO_ENST00000335272_ENST00000509967_28290542_14387546 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.2539
Å |
 |  |  |  |  |
| PITPNB_TRIO_ENST00000335272_ENST00000537187_28290542_14387546 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.4533
Å |
 |  |  |  |  |
| PITPNB_TRIO_ENST00000455418_ENST00000509967_28290542_14387546 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.4467
Å |
 |  |  |  |  |
| PITPNB_TRIO_ENST00000455418_ENST00000537187_28290542_14387546 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.3528
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000224949_ENST00000369327_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0842
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000224949_ENST00000369329_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.1042
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000224949_ENST00000369332_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0685
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000380989_ENST00000369325_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0455
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000380989_ENST00000369327_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0641
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000380989_ENST00000369329_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0929
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000380989_ENST00000369332_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.1001
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000451104_ENST00000369325_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.0823
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000451104_ENST00000369327_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.2404
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000451104_ENST00000369329_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.3031
Å |
 |  |  |  |  |
| PITRM1_MAP3K7_ENST00000451104_ENST00000369332_3187787_91260268 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.2745
Å |
 |  |  |  |  |
| PITRM1_PAFAH1B3_ENST00000224949_ENST00000262890_3201105_42801517 superimposed PDB: 4L3T of partner (PITRM1). RMSD:1.2527
Å |
 |  |  |  |  |
| PITRM1_PAFAH1B3_ENST00000380989_ENST00000262890_3201105_42801517 superimposed PDB: 4L3T of partner (PITRM1). RMSD:0.6218
Å |
 |  |  |  |  |
| PKD1_RAVER1_ENST00000262304_ENST00000293677_2168676_10439787 superimposed PDB: 3VF0 of partner (RAVER1). RMSD:0.6718
Å |
 |  |  |  |  |
| PKLR_PKM_ENST00000342741_ENST00000565184_155264025_72499221 superimposed PDB: 7QDN of partner (PKLR). RMSD:0.4022
Å |
 |  |  |  |  |
| PKLR_PKM_ENST00000342741_ENST00000565184_155264025_72499221 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.5678
Å |
| | | |  |
| PKLR_PKM_ENST00000342741_ENST00000568883_155264025_72499221 superimposed PDB: 7QDN of partner (PKLR). RMSD:0.4054
Å |
 |  |  |  |  |
| PKLR_PKM_ENST00000342741_ENST00000568883_155264025_72499221 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.6135
Å |
| | | |  |
| PKLR_PKM_ENST00000392414_ENST00000565184_155264025_72499221 superimposed PDB: 7QDN of partner (PKLR). RMSD:0.4033
Å |
 |  |  |  |  |
| PKLR_PKM_ENST00000392414_ENST00000565184_155264025_72499221 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.5859
Å |
| | | |  |
| PKLR_PKM_ENST00000392414_ENST00000568883_155264025_72499221 superimposed PDB: 7QDN of partner (PKLR). RMSD:0.3899
Å |
 |  |  |  |  |
| PKLR_PKM_ENST00000392414_ENST00000568883_155264025_72499221 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.607
Å |
| | | |  |
| PKM_PKLR_ENST00000449901_ENST00000342741_72500961_155264176 superimposed PDB: 3GR4 of partner (PKM). RMSD:1.5298
Å |
 |  |  |  |  |
| PKM_PKLR_ENST00000449901_ENST00000342741_72500961_155264176 superimposed PDB: 7QDN of partner (PKLR). RMSD:0.6325
Å |
| | | |  |
| PKM_RPLP1_ENST00000449901_ENST00000357790_72499068_69747508 superimposed PDB: 3GR4 of partner (PKM). RMSD:1.3605
Å |
 |  |  |  |  |
| PKM_TRPV3_ENST00000449901_ENST00000301365_72502013_3439007 superimposed PDB: 3GR4 of partner (PKM). RMSD:2.7782
Å |
 |  |  |  |  |
| PKM_TRPV3_ENST00000449901_ENST00000301365_72502013_3439007 superimposed PDB: 8V6K of partner (TRPV3). RMSD:2.1277
Å |
| | | |  |
| PKM_TRPV3_ENST00000449901_ENST00000572519_72502013_3436231 superimposed PDB: 3GR4 of partner (PKM). RMSD:2.732
Å |
 |  |  |  |  |
| PKM_TRPV3_ENST00000449901_ENST00000572519_72502013_3436231 superimposed PDB: 8V6K of partner (TRPV3). RMSD:2.1156
Å |
| | | |  |
| PKM_TRPV3_ENST00000449901_ENST00000572519_72502013_3439007 superimposed PDB: 8V6K of partner (TRPV3). RMSD:2.1194
Å |
 |  |  |  |  |
| PKM_TRPV3_ENST00000449901_ENST00000576742_72502013_3436231 superimposed PDB: 3GR4 of partner (PKM). RMSD:2.6903
Å |
 |  |  |  |  |
| PKM_TRPV3_ENST00000449901_ENST00000576742_72502013_3436231 superimposed PDB: 8V6K of partner (TRPV3). RMSD:2.1218
Å |
| | | |  |
| PKM_TRPV3_ENST00000449901_ENST00000576742_72502013_3439007 superimposed PDB: 8V6K of partner (TRPV3). RMSD:2.0775
Å |
 |  |  |  |  |
| PKN1_KCNIP4_ENST00000242783_ENST00000382150_14544354_20760513 superimposed PDB: 4OTH of partner (PKN1). RMSD:2.8206
Å |
 |  |  |  |  |
| PKN1_POLA2_ENST00000242783_ENST00000541089_14544354_65062016 superimposed PDB: 4Y97 of partner (POLA2). RMSD:0.5656
Å |
 |  |  |  |  |
| PLA2G6_EEF1D_ENST00000335539_ENST00000419152_38539111_144662376 superimposed PDB: 2N51 of partner (EEF1D). RMSD:1.0874
Å |
 |  |  |  |  |
| PLA2G6_EEF1D_ENST00000402064_ENST00000419152_38539111_144662376 superimposed PDB: 2N51 of partner (EEF1D). RMSD:1.083
Å |
 |  |  |  |  |
| PLAA_PTPLAD2_ENST00000397292_ENST00000495827_26946894_21016009 superimposed PDB: 3EBB of partner (PLAA). RMSD:2.9714
Å |
 |  |  |  |  |
| PLAA_PTPLAD2_ENST00000520884_ENST00000513293_26946894_21029397 superimposed PDB: 3EBB of partner (PLAA). RMSD:2.8901
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000220809_ENST00000391806_42036414_51499470 superimposed PDB: 1BDA of partner (PLAT). RMSD:0.4846
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000220809_ENST00000391806_42036414_51499470 superimposed PDB: 5MS4 of partner (KLK8). RMSD:0.7252
Å |
| | | |  |
| PLAT_KLK8_ENST00000352041_ENST00000600767_42036414_51499470 superimposed PDB: 1BDA of partner (PLAT). RMSD:0.4817
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000352041_ENST00000600767_42036414_51499470 superimposed PDB: 5MS4 of partner (KLK8). RMSD:0.7227
Å |
| | | |  |
| PLAT_KLK8_ENST00000429710_ENST00000600767_42036414_51499470 superimposed PDB: 1BDA of partner (PLAT). RMSD:0.4853
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000429710_ENST00000600767_42036414_51499470 superimposed PDB: 5MS4 of partner (KLK8). RMSD:0.7028
Å |
| | | |  |
| PLAT_KLK8_ENST00000519510_ENST00000600767_42036414_51499470 superimposed PDB: 1BDA of partner (PLAT). RMSD:0.4756
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000519510_ENST00000600767_42036414_51499470 superimposed PDB: 5MS4 of partner (KLK8). RMSD:0.708
Å |
| | | |  |
| PLAT_KLK8_ENST00000524009_ENST00000600767_42036414_51499470 superimposed PDB: 1BDA of partner (PLAT). RMSD:0.4718
Å |
 |  |  |  |  |
| PLAT_KLK8_ENST00000524009_ENST00000600767_42036414_51499470 superimposed PDB: 5MS4 of partner (KLK8). RMSD:0.7248
Å |
| | | |  |
| PLAT_PKM_ENST00000519510_ENST00000565184_42048889_72492097 superimposed PDB: 1BDA of partner (PLAT). RMSD:2.6891
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000339082_ENST00000452463_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.6423
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000339082_ENST00000456390_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.6218
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000339082_ENST00000458726_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.6255
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000340093_ENST00000452463_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.652
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000340093_ENST00000456390_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.6076
Å |
 |  |  |  |  |
| PLAUR_CREB3L2_ENST00000340093_ENST00000458726_44169467_137600758 superimposed PDB: 1YWH of partner (PLAUR). RMSD:0.6457
Å |
 |  |  |  |  |
| PLAUR_LYPD5_ENST00000221264_ENST00000377950_44156376_44303986 superimposed PDB: 1YWH of partner (PLAUR). RMSD:2.0257
Å |
 |  |  |  |  |
| PLAUR_LYPD5_ENST00000340093_ENST00000377950_44156376_44303986 superimposed PDB: 1YWH of partner (PLAUR). RMSD:2.137
Å |
 |  |  |  |  |
| PLAUR_MARK4_ENST00000339082_ENST00000300843_44174217_45762246 superimposed PDB: 5ES1 of partner (MARK4). RMSD:0.5325
Å |
 |  |  |  |  |
| PLAUR_MARK4_ENST00000601723_ENST00000262891_44174217_45762246 superimposed PDB: 5ES1 of partner (MARK4). RMSD:0.5324
Å |
 |  |  |  |  |
| PLAUR_XRCC1_ENST00000221264_ENST00000543982_44156376_44050258 superimposed PDB: 1YWH of partner (PLAUR). RMSD:1.6528
Å |
 |  |  |  |  |
| PLAUR_XRCC1_ENST00000339082_ENST00000543982_44156376_44050258 superimposed PDB: 1YWH of partner (PLAUR). RMSD:2.107
Å |
 |  |  |  |  |
| PLAUR_XRCC1_ENST00000340093_ENST00000543982_44156376_44050258 superimposed PDB: 1YWH of partner (PLAUR). RMSD:1.9561
Å |
 |  |  |  |  |
| PLCB1_MCM8_ENST00000338037_ENST00000378883_8703068_5937771 superimposed PDB: 8S94 of partner (MCM8). RMSD:1.1255
Å |
 |  |  |  |  |
| PLCB1_MCM8_ENST00000378641_ENST00000265187_8703068_5937771 superimposed PDB: 8S94 of partner (MCM8). RMSD:1.0983
Å |
 |  |  |  |  |
| PLCB1_MCM8_ENST00000378641_ENST00000378886_8703068_5937771 superimposed PDB: 8S94 of partner (MCM8). RMSD:1.1067
Å |
 |  |  |  |  |
| PLCB1_MCM8_ENST00000378641_ENST00000378896_8703068_5937771 superimposed PDB: 8S94 of partner (MCM8). RMSD:1.1496
Å |
 |  |  |  |  |
| PLCB1_RBL1_ENST00000338037_ENST00000373664_8131018_35651229 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.4069
Å |
 |  |  |  |  |
| PLCB1_RBL1_ENST00000378641_ENST00000344359_8131018_35651229 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.3919
Å |
 |  |  |  |  |
| PLCB2_EPN1_ENST00000260402_ENST00000085079_40584049_56206513 superimposed PDB: 2ZKM of partner (PLCB2). RMSD:0.5494
Å |
 |  |  |  |  |
| PLCB2_EPN1_ENST00000557821_ENST00000085079_40584049_56206513 superimposed PDB: 2ZKM of partner (PLCB2). RMSD:0.5603
Å |
 |  |  |  |  |
| PLCB3_FCGRT_ENST00000279230_ENST00000426395_64024236_50027763 superimposed PDB: 8EMX of partner (PLCB3). RMSD:1.0741
Å |
 |  |  |  |  |
| PLCB3_FCGRT_ENST00000279230_ENST00000426395_64024236_50027763 superimposed PDB: 6FGB of partner (FCGRT). RMSD:2.621
Å |
| | | |  |
| PLCB3_FCGRT_ENST00000325234_ENST00000426395_64024236_50027763 superimposed PDB: 8EMX of partner (PLCB3). RMSD:2.4219
Å |
 |  |  |  |  |
| PLCB3_FCGRT_ENST00000325234_ENST00000426395_64024236_50027763 superimposed PDB: 6FGB of partner (FCGRT). RMSD:2.723
Å |
| | | |  |
| PLCB3_FCGRT_ENST00000540288_ENST00000426395_64024236_50027763 superimposed PDB: 8EMX of partner (PLCB3). RMSD:1.1114
Å |
 |  |  |  |  |
| PLCB3_FCGRT_ENST00000540288_ENST00000426395_64024236_50027763 superimposed PDB: 6FGB of partner (FCGRT). RMSD:2.9107
Å |
| | | |  |
| PLCG1_EYA2_ENST00000244007_ENST00000327619_39798909_45797786 superimposed PDB: 4FBN of partner (PLCG1). RMSD:3.1115
Å |
 |  |  |  |  |
| PLCG1_EYA2_ENST00000373271_ENST00000357410_39798909_45797786 superimposed PDB: 4FBN of partner (PLCG1). RMSD:2.8321
Å |
 |  |  |  |  |
| PLCG1_EYA2_ENST00000373271_ENST00000357410_39798909_45797786 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.6522
Å |
| | | |  |
| PLCG1_EYA2_ENST00000373272_ENST00000327619_39798909_45797786 superimposed PDB: 4FBN of partner (PLCG1). RMSD:3.1334
Å |
 |  |  |  |  |
| PLCG1_EYA2_ENST00000373272_ENST00000357410_39798909_45797786 superimposed PDB: 4FBN of partner (PLCG1). RMSD:2.9795
Å |
 |  |  |  |  |
| PLCG1_EYA2_ENST00000373272_ENST00000357410_39798909_45797786 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.5881
Å |
| | | |  |
| PLCZ1_PTHLH_ENST00000435379_ENST00000539239_18847843_28111501 superimposed PDB: 3FFD of partner (PTHLH). RMSD:2.4139
Å |
 |  |  |  |  |
| PLCZ1_PTHLH_ENST00000447925_ENST00000539239_18847843_28111501 superimposed PDB: 3FFD of partner (PTHLH). RMSD:2.4327
Å |
 |  |  |  |  |
| PLCZ1_PTHLH_ENST00000538330_ENST00000539239_18847843_28111501 superimposed PDB: 3FFD of partner (PTHLH). RMSD:2.4151
Å |
 |  |  |  |  |
| PLCZ1_PTHLH_ENST00000541695_ENST00000539239_18847843_28111501 superimposed PDB: 3FFD of partner (PTHLH). RMSD:2.4202
Å |
 |  |  |  |  |
| PLEC_JPH1_ENST00000436759_ENST00000342232_145012318_75171738 superimposed PDB: 5J1I of partner (PLEC). RMSD:1.8071
Å |
 |  |  |  |  |
| PLEC_KANSL1_ENST00000356346_ENST00000572904_145047570_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:2.1672
Å |
 |  |  |  |  |
| PLEC_KANSL1_ENST00000356346_ENST00000575318_145047570_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.1621
Å |
 |  |  |  |  |
| PLEC_NDUFAF6_ENST00000436759_ENST00000396113_145007364_96059221 superimposed PDB: 5J1I of partner (PLEC). RMSD:1.7158
Å |
 |  |  |  |  |
| PLEKHA1_CYP2C18_ENST00000368990_ENST00000285979_124159904_96484102 superimposed PDB: 1EAZ of partner (PLEKHA1). RMSD:0.8405
Å |
 |  |  |  |  |
| PLEKHH1_GPHN_ENST00000329153_ENST00000478722_68028752_67525365 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.7114
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587394_ENST00000262965_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6285
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587394_ENST00000395423_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.5913
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587394_ENST00000453954_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.8025
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587394_ENST00000588136_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7456
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587962_ENST00000262965_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.5607
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587962_ENST00000395423_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6729
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587962_ENST00000453954_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.6877
Å |
 |  |  |  |  |
| PLEKHJ1_TCF3_ENST00000587962_ENST00000588136_2235921_1622414 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.5545
Å |
 |  |  |  |  |
| PLEKHM2_ECE1_ENST00000375799_ENST00000264205_16045120_21573856 superimposed PDB: 8JCA of partner (PLEKHM2). RMSD:0.4354
Å |
 |  |  |  |  |
| PLEKHM2_ECE1_ENST00000375799_ENST00000264205_16045120_21573856 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.3872
Å |
| | | |  |
| PLEKHM2_ECE1_ENST00000375799_ENST00000357071_16045120_21573856 superimposed PDB: 8JCA of partner (PLEKHM2). RMSD:0.438
Å |
 |  |  |  |  |
| PLEKHM2_ECE1_ENST00000375799_ENST00000357071_16045120_21573856 superimposed PDB: 3DWB of partner (ECE1). RMSD:1.0095
Å |
| | | |  |
| PLEKHM2_IGF2BP2_ENST00000375793_ENST00000382199_16046415_185410550 superimposed PDB: 8JCA of partner (PLEKHM2). RMSD:0.4937
Å |
 |  |  |  |  |
| PLEKHM2_IGF2BP2_ENST00000375793_ENST00000382199_16046415_185410550 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:0.4447
Å |
| | | |  |
| PLEKHM2_IGF2BP2_ENST00000375799_ENST00000346192_16046415_185410550 superimposed PDB: 8JCA of partner (PLEKHM2). RMSD:0.4517
Å |
 |  |  |  |  |
| PLEKHM2_IGF2BP2_ENST00000375799_ENST00000346192_16046415_185410550 superimposed PDB: 6ROL of partner (IGF2BP2). RMSD:0.4773
Å |
| | | |  |
| PLG_TMPRSS2_ENST00000308192_ENST00000332149_161173292_42839813 superimposed PDB: 4DUR of partner (PLG). RMSD:2.6004
Å |
 |  |  |  |  |
| PLG_TMPRSS2_ENST00000308192_ENST00000332149_161173292_42839813 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.122
Å |
| | | |  |
| PLG_TMPRSS2_ENST00000308192_ENST00000398585_161173292_42839813 superimposed PDB: 4DUR of partner (PLG). RMSD:3.2251
Å |
 |  |  |  |  |
| PLG_TMPRSS2_ENST00000308192_ENST00000398585_161173292_42839813 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.1672
Å |
| | | |  |
| PLLP_CNGB1_ENST00000219207_ENST00000251102_57318317_57946898 superimposed PDB: 9UPG of partner (CNGB1). RMSD:1.7183
Å |
 |  |  |  |  |
| PLOD2_ABCG1_ENST00000360060_ENST00000398457_145824318_43645780 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.3878
Å |
 |  |  |  |  |
| PLSCR1_MACROD2_ENST00000342435_ENST00000310348_146234792_16021845 superimposed PDB: 1Y2A of partner (PLSCR1). RMSD:2.1409
Å |
 |  |  |  |  |
| PLSCR1_MACROD2_ENST00000342435_ENST00000310348_146234792_16021845 superimposed PDB: 4IQY of partner (MACROD2). RMSD:2.6428
Å |
| | | |  |
| PLSCR1_MACROD2_ENST00000487389_ENST00000310348_146234792_16021845 superimposed PDB: 1Y2A of partner (PLSCR1). RMSD:1.9871
Å |
 |  |  |  |  |
| PLSCR1_MACROD2_ENST00000487389_ENST00000310348_146234792_16021845 superimposed PDB: 4IQY of partner (MACROD2). RMSD:2.6373
Å |
| | | |  |
| PLXDC2_METTL3_ENST00000377252_ENST00000298717_20466338_21967946 superimposed PDB: 5TEY of partner (METTL3). RMSD:0.9636
Å |
 |  |  |  |  |
| PLXNB1_PLXNB3_ENST00000296440_ENST00000361971_48450978_153043402 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:1.8604
Å |
 |  |  |  |  |
| PLXNB1_PLXNB3_ENST00000456774_ENST00000361971_48450978_153043402 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:1.4622
Å |
 |  |  |  |  |
| PLXNB1_SLC26A6_ENST00000358459_ENST00000420764_48460985_48667144 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:2.663
Å |
 |  |  |  |  |
| PLXNB2_MAST4_ENST00000359337_ENST00000403625_50722030_66195778 superimposed PDB: 2W7R of partner (MAST4). RMSD:0.6101
Å |
 |  |  |  |  |
| PLXNB2_MAST4_ENST00000359337_ENST00000406374_50722030_66195778 superimposed PDB: 2W7R of partner (MAST4). RMSD:0.8055
Å |
 |  |  |  |  |
| PLXNC1_APPL2_ENST00000547057_ENST00000258530_94659001_105623001 superimposed PDB: 6VXK of partner (PLXNC1). RMSD:1.7787
Å |
 |  |  |  |  |
| PLXNC1_TXNRD1_ENST00000547057_ENST00000540716_94676177_104742130 superimposed PDB: 6VXK of partner (PLXNC1). RMSD:1.7226
Å |
 |  |  |  |  |
| PM20D2_HIPK2_ENST00000275072_ENST00000342645_89856328_139313785 superimposed PDB: 7YH4 of partner (PM20D2). RMSD:0.5871
Å |
 |  |  |  |  |
| PM20D2_HIPK2_ENST00000275072_ENST00000342645_89856328_139313785 superimposed PDB: 6P5S of partner (HIPK2). RMSD:2.9026
Å |
| | | |  |
| PM20D2_HIPK2_ENST00000275072_ENST00000428878_89856328_139313785 superimposed PDB: 7YH4 of partner (PM20D2). RMSD:0.5123
Å |
 |  |  |  |  |
| PM20D2_HIPK2_ENST00000275072_ENST00000428878_89856328_139313785 superimposed PDB: 6P5S of partner (HIPK2). RMSD:2.7128
Å |
| | | |  |
| PMEL_ANAPC5_ENST00000449260_ENST00000541887_56359719_121747666 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:0.6091
Å |
 |  |  |  |  |
| PMEL_ANXA2_ENST00000536427_ENST00000451270_56359719_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3866
Å |
 |  |  |  |  |
| PMEL_ANXA5_ENST00000536427_ENST00000501272_56359719_122591167 superimposed PDB: 1AVH of partner (ANXA5). RMSD:0.4587
Å |
 |  |  |  |  |
| PMEL_GANAB_ENST00000552882_ENST00000356638_56359719_62407203 superimposed PDB: 8D43 of partner (GANAB). RMSD:0.5158
Å |
 |  |  |  |  |
| PMEL_HSPA8_ENST00000536427_ENST00000534624_56359719_122929969 superimposed PDB: 4H5R of partner (HSPA8). RMSD:1.0299
Å |
 |  |  |  |  |
| PMEL_NPM1_ENST00000536427_ENST00000296930_56359719_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3436
Å |
 |  |  |  |  |
| PMEL_NPM1_ENST00000536427_ENST00000393820_56359719_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.3916
Å |
 |  |  |  |  |
| PMEL_NPM1_ENST00000539511_ENST00000517671_56359719_170817054 superimposed PDB: 8AS5 of partner (NPM1). RMSD:0.4036
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000359462_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5713
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000437231_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.6195
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000447282_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4487
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000455667_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4706
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000546463_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5793
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000549863_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.509
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000552296_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2938
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000552819_56359719_53854798 superimposed PDB: 9LIP of partner (PMEL). RMSD:3.191
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000449260_ENST00000552819_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5107
Å |
| | | |  |
| PMEL_PCBP2_ENST00000449260_ENST00000603815_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4591
Å |
 |  |  |  |  |
| PMEL_PCBP2_ENST00000550464_ENST00000359282_56359719_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5652
Å |
 |  |  |  |  |
| PMEL_RBM39_ENST00000536427_ENST00000361162_56359719_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6705
Å |
 |  |  |  |  |
| PMEL_RBM39_ENST00000536427_ENST00000528062_56359719_34301018 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.6691
Å |
 |  |  |  |  |
| PMEL_SLC3A2_ENST00000536427_ENST00000377890_56359719_62650379 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.9748
Å |
 |  |  |  |  |
| PMEL_WARS_ENST00000449260_ENST00000358655_56355100_100809724 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.7019
Å |
 |  |  |  |  |
| PMEL_WARS_ENST00000449260_ENST00000392882_56355100_100809724 superimposed PDB: 9LIP of partner (PMEL). RMSD:0.5406
Å |
 |  |  |  |  |
| PMEL_WARS_ENST00000548493_ENST00000358655_56355100_100809724 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.7447
Å |
 |  |  |  |  |
| PMEL_WARS_ENST00000548747_ENST00000358655_56355100_100809724 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.7111
Å |
 |  |  |  |  |
| PMEL_WARS_ENST00000550447_ENST00000358655_56355100_100809724 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.7619
Å |
 |  |  |  |  |
| PMEL_XRCC6_ENST00000536427_ENST00000402580_56359719_42024121 superimposed PDB: 9LIP of partner (PMEL). RMSD:3.3228
Å |
 |  |  |  |  |
| PMEL_XRCC6_ENST00000536427_ENST00000402580_56359719_42024121 superimposed PDB: 8AG4 of partner (XRCC6). RMSD:2.3874
Å |
| | | |  |
| PMEL_XRCC6_ENST00000539511_ENST00000360079_56359719_42024121 superimposed PDB: 8AG4 of partner (XRCC6). RMSD:2.509
Å |
 |  |  |  |  |
| PML_RARA_ENST00000268059_ENST00000394089_74325755_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4517
Å |
 |  |  |  |  |
| PML_RARA_ENST00000354026_ENST00000394089_74325755_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4412
Å |
 |  |  |  |  |
| PML_RARA_ENST00000395132_ENST00000394089_74315749_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4497
Å |
 |  |  |  |  |
| PML_RARA_ENST00000395135_ENST00000394089_74315749_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4279
Å |
 |  |  |  |  |
| PML_RARA_ENST00000395135_ENST00000394089_74325755_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4552
Å |
 |  |  |  |  |
| PML_RARA_ENST00000563500_ENST00000394089_74315749_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4452
Å |
 |  |  |  |  |
| PMM2_UBFD1_ENST00000268261_ENST00000395878_8906963_23573526 superimposed PDB: 7O58 of partner (PMM2). RMSD:1.0867
Å |
 |  |  |  |  |
| PMM2_UBFD1_ENST00000537352_ENST00000395878_8906963_23573526 superimposed PDB: 7O58 of partner (PMM2). RMSD:0.5367
Å |
 |  |  |  |  |
| PMM2_UBFD1_ENST00000539622_ENST00000395878_8906963_23573526 superimposed PDB: 7O58 of partner (PMM2). RMSD:0.3677
Å |
 |  |  |  |  |
| PMM2_UBFD1_ENST00000566983_ENST00000395878_8906963_23573526 superimposed PDB: 7O58 of partner (PMM2). RMSD:0.5666
Å |
 |  |  |  |  |
| PMM2_UBFD1_ENST00000569958_ENST00000395878_8906963_23573526 superimposed PDB: 7O58 of partner (PMM2). RMSD:1.7319
Å |
 |  |  |  |  |
| PNISR_CPS1_ENST00000438806_ENST00000233072_99858616_211532909 superimposed PDB: 6UEL of partner (CPS1). RMSD:1.0819
Å |
 |  |  |  |  |
| PNKP_C19orf57_ENST00000596014_ENST00000454313_50369655_13996868 superimposed PDB: 2BRF of partner (PNKP). RMSD:1.1005
Å |
 |  |  |  |  |
| PNKP_C19orf57_ENST00000596014_ENST00000454313_50369655_13996868 superimposed PDB: 8A51 of partner (C19orf57). RMSD:0.6083
Å |
| | | |  |
| PNKP_C19orf57_ENST00000596014_ENST00000591586_50369655_13996868 superimposed PDB: 2BRF of partner (PNKP). RMSD:1.2955
Å |
 |  |  |  |  |
| PNPLA2_EPS8L2_ENST00000336615_ENST00000533256_822606_720061 superimposed PDB: 1WWU of partner (EPS8L2). RMSD:0.6584
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000296302_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2219
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000337303_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3116
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000394830_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2181
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000409057_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1977
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000409767_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1671
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000296484_ENST00000410007_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1457
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000337303_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1807
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000356770_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.2498
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000394830_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.1884
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000409057_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.204
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000409767_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.0848
Å |
 |  |  |  |  |
| POC1A_PBRM1_ENST00000394970_ENST00000410007_52172184_52661386 superimposed PDB: 7Y8R of partner (PBRM1). RMSD:1.3237
Å |
 |  |  |  |  |
| POC1A_TWF2_ENST00000296484_ENST00000499914_52156394_52265011 superimposed PDB: 2W0I of partner (TWF2). RMSD:0.4537
Å |
 |  |  |  |  |
| POC1A_TWF2_ENST00000394970_ENST00000305533_52156394_52265011 superimposed PDB: 2W0I of partner (TWF2). RMSD:0.5375
Å |
 |  |  |  |  |
| POC1A_TWF2_ENST00000394970_ENST00000499914_52156394_52265011 superimposed PDB: 2W0I of partner (TWF2). RMSD:0.4284
Å |
 |  |  |  |  |
| POC5_COL4A3BP_ENST00000446329_ENST00000405807_74981031_74722303 superimposed PDB: 2E3N of partner (COL4A3BP). RMSD:0.4954
Å |
 |  |  |  |  |
| POFUT1_HCK_ENST00000375749_ENST00000520553_30795868_30671696 superimposed PDB: 1AD5 of partner (HCK). RMSD:1.4584
Å |
 |  |  |  |  |
| POFUT1_HCK_ENST00000375749_ENST00000538448_30795868_30671696 superimposed PDB: 1AD5 of partner (HCK). RMSD:1.2177
Å |
 |  |  |  |  |
| POFUT1_HCK_ENST00000375749_ENST00000538448_30818864_30689119 superimposed PDB: 5UX6 of partner (POFUT1). RMSD:0.8923
Å |
 |  |  |  |  |
| POFUT1_HCK_ENST00000539210_ENST00000538448_30818864_30689119 superimposed PDB: 5UX6 of partner (POFUT1). RMSD:1.0085
Å |
 |  |  |  |  |
| POFUT1_ITCH_ENST00000375749_ENST00000535650_30804524_33030012 superimposed PDB: 5UX6 of partner (POFUT1). RMSD:0.4966
Å |
 |  |  |  |  |
| POFUT1_ITCH_ENST00000375749_ENST00000535650_30804524_33030012 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.1405
Å |
| | | |  |
| POLA1_PGK1_ENST00000379059_ENST00000442431_24717666_77378691 superimposed PDB: 9FDF of partner (PGK1). RMSD:0.5735
Å |
 |  |  |  |  |
| POLA1_PGK1_ENST00000379068_ENST00000442431_24717666_77378691 superimposed PDB: 9FDF of partner (PGK1). RMSD:0.6792
Å |
 |  |  |  |  |
| POLA1_TSPAN7_ENST00000379059_ENST00000422612_24767109_38525374 superimposed PDB: 8QJ7 of partner (POLA1). RMSD:0.7209
Å |
 |  |  |  |  |
| POLA1_TSPAN7_ENST00000379068_ENST00000422612_24767109_38525374 superimposed PDB: 8QJ7 of partner (POLA1). RMSD:0.6944
Å |
 |  |  |  |  |
| POLA2_OOSP1_ENST00000541089_ENST00000398992_65049992_59710319 superimposed PDB: 4Y97 of partner (POLA2). RMSD:1.8389
Å |
 |  |  |  |  |
| POLA2_PPFIA1_ENST00000541089_ENST00000253925_65047097_70200406 superimposed PDB: 4Y97 of partner (POLA2). RMSD:3.0636
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000265421_ENST00000250635_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:1.2178
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000265421_ENST00000250635_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7525
Å |
| | | |  |
| POLB_ASH2L_ENST00000265421_ENST00000545394_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:1.3222
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000265421_ENST00000545394_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.9064
Å |
| | | |  |
| POLB_ASH2L_ENST00000521492_ENST00000250635_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:0.7032
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000521492_ENST00000250635_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.8092
Å |
| | | |  |
| POLB_ASH2L_ENST00000521492_ENST00000545394_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:0.8352
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000521492_ENST00000545394_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.889
Å |
| | | |  |
| POLB_ASH2L_ENST00000538005_ENST00000250635_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:0.3354
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000538005_ENST00000250635_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.7804
Å |
| | | |  |
| POLB_ASH2L_ENST00000538005_ENST00000545394_42227506_37976787 superimposed PDB: 8VFG of partner (POLB). RMSD:0.381
Å |
 |  |  |  |  |
| POLB_ASH2L_ENST00000538005_ENST00000545394_42227506_37976787 superimposed PDB: 9YM8 of partner (ASH2L). RMSD:0.9192
Å |
| | | |  |
| POLB_UVRAG_ENST00000265421_ENST00000528420_42202537_75719850 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:0.5407
Å |
 |  |  |  |  |
| POLD3_PPME1_ENST00000263681_ENST00000398427_74324055_73914772 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.8493
Å |
 |  |  |  |  |
| POLD3_PPME1_ENST00000263681_ENST00000398427_74324055_73914772 superimposed PDB: 7SOY of partner (PPME1). RMSD:0.9397
Å |
| | | |  |
| POLD3_PPME1_ENST00000527458_ENST00000328257_74324055_73914772 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.9139
Å |
 |  |  |  |  |
| POLD3_PPME1_ENST00000527458_ENST00000328257_74324055_73914772 superimposed PDB: 7SOY of partner (PPME1). RMSD:0.9534
Å |
| | | |  |
| POLD3_PPME1_ENST00000527458_ENST00000398427_74324055_73914772 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.9231
Å |
 |  |  |  |  |
| POLD3_PPME1_ENST00000527458_ENST00000398427_74324055_73914772 superimposed PDB: 7SOY of partner (PPME1). RMSD:0.9578
Å |
| | | |  |
| POLD3_PPME1_ENST00000532497_ENST00000328257_74324055_73914772 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.8693
Å |
 |  |  |  |  |
| POLD3_PPME1_ENST00000532497_ENST00000328257_74324055_73914772 superimposed PDB: 7SOY of partner (PPME1). RMSD:0.9409
Å |
| | | |  |
| POLD3_PPME1_ENST00000532497_ENST00000398427_74324055_73914772 superimposed PDB: 7SOY of partner (PPME1). RMSD:0.9476
Å |
 |  |  |  |  |
| POLD3_RNF169_ENST00000527458_ENST00000299563_74347320_74500670 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.7754
Å |
 |  |  |  |  |
| POLD3_RNF169_ENST00000532497_ENST00000299563_74347320_74500670 superimposed PDB: 9EKB of partner (POLD3). RMSD:0.8147
Å |
 |  |  |  |  |
| POLE_ANKS1B_ENST00000320574_ENST00000329257_133263839_99225914 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2695
Å |
 |  |  |  |  |
| POLE_ANKS1B_ENST00000320574_ENST00000547010_133263839_99225914 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2677
Å |
 |  |  |  |  |
| POLE_ANKS1B_ENST00000535270_ENST00000547010_133263839_99225914 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2558
Å |
 |  |  |  |  |
| POLE_ANKS1B_ENST00000535270_ENST00000547776_133263839_99225914 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.235
Å |
 |  |  |  |  |
| POLG_CGNL1_ENST00000442287_ENST00000281282_89866634_57808977 superimposed PDB: 8UDL of partner (POLG). RMSD:2.3041
Å |
 |  |  |  |  |
| POLH_C12orf71_ENST00000372226_ENST00000429849_43573056_27234400 superimposed PDB: 6MXO of partner (POLH). RMSD:0.7819
Å |
 |  |  |  |  |
| POLH_C12orf71_ENST00000535400_ENST00000429849_43573056_27234400 superimposed PDB: 6MXO of partner (POLH). RMSD:0.5741
Å |
 |  |  |  |  |
| POLK_AP3B1_ENST00000241436_ENST00000519295_74848416_77473260 superimposed PDB: 9C5A of partner (AP3B1). RMSD:0.6648
Å |
 |  |  |  |  |
| POLK_TBCA_ENST00000352007_ENST00000380377_74848416_76989177 superimposed PDB: 7NV0 of partner (POLK). RMSD:1.08
Å |
 |  |  |  |  |
| POLK_TBCA_ENST00000352007_ENST00000380377_74848416_76989177 superimposed PDB: 1H7C of partner (TBCA). RMSD:0.8611
Å |
| | | |  |
| POLM_OGDH_ENST00000242248_ENST00000439616_44113223_44739739 superimposed PDB: 9CQ3 of partner (POLM). RMSD:3.1992
Å |
 |  |  |  |  |
| POLM_OGDH_ENST00000242248_ENST00000439616_44113223_44739739 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.9683
Å |
| | | |  |
| POLM_OGDH_ENST00000395831_ENST00000439616_44113223_44739739 superimposed PDB: 9CQ3 of partner (POLM). RMSD:1.6954
Å |
 |  |  |  |  |
| POLR1A_AFF3_ENST00000263857_ENST00000356421_86276006_100210751 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.8389
Å |
 |  |  |  |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000402739_86265822_80831198 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.4129
Å |
 |  |  |  |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000402739_86265822_80831198 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:1.6596
Å |
| | | |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000496558_86265822_80831198 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.3959
Å |
 |  |  |  |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000496558_86265822_80831198 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:1.6886
Å |
| | | |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000540488_86265822_80831198 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.3261
Å |
 |  |  |  |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000540488_86265822_80831198 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:1.5083
Å |
| | | |  |
| POLR1A_CTNNA2_ENST00000263857_ENST00000541047_86265822_80831198 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.3629
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000304004_ENST00000297153_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:2.0255
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000372344_ENST00000297153_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.9471
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000372344_ENST00000434837_43487576_37631882 superimposed PDB: 7OB9 of partner (POLR1C). RMSD:3.2366
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000372344_ENST00000434837_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.9391
Å |
| | | |  |
| POLR1C_MDGA1_ENST00000372344_ENST00000505425_43487576_37631882 superimposed PDB: 7OB9 of partner (POLR1C). RMSD:2.785
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000372344_ENST00000505425_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:2.0107
Å |
| | | |  |
| POLR1C_MDGA1_ENST00000372389_ENST00000434837_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:2.1152
Å |
 |  |  |  |  |
| POLR1C_MDGA1_ENST00000372389_ENST00000505425_43487576_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.9143
Å |
 |  |  |  |  |
| POLR1C_MRPS18A_ENST00000304004_ENST00000372116_43488786_43639643 superimposed PDB: 7OB9 of partner (POLR1C). RMSD:1.6093
Å |
 |  |  |  |  |
| POLR1C_MRPS18A_ENST00000372344_ENST00000372116_43488786_43639643 superimposed PDB: 7OB9 of partner (POLR1C). RMSD:1.6841
Å |
 |  |  |  |  |
| POLR2E_SLC44A4_ENST00000215587_ENST00000375562_1095257_31831525 superimposed PDB: 9EHZ of partner (POLR2E). RMSD:0.2461
Å |
 |  |  |  |  |
| POLR2F_EIF3L_ENST00000405557_ENST00000412331_38363177_38251571 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.9825
Å |
 |  |  |  |  |
| POLR2F_EIF3L_ENST00000407936_ENST00000381683_38363177_38251571 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.9426
Å |
 |  |  |  |  |
| POLR2F_EIF3L_ENST00000470701_ENST00000381683_38363177_38251571 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.9518
Å |
 |  |  |  |  |
| POLR2G_CADPS2_ENST00000301788_ENST00000334010_62529376_122091529 superimposed PDB: 9EHZ of partner (POLR2G). RMSD:0.7031
Å |
 |  |  |  |  |
| POLR2G_CADPS2_ENST00000301788_ENST00000412584_62529376_122091529 superimposed PDB: 9EHZ of partner (POLR2G). RMSD:0.9474
Å |
 |  |  |  |  |
| POLR2G_CADPS2_ENST00000301788_ENST00000449022_62529376_122091529 superimposed PDB: 9EHZ of partner (POLR2G). RMSD:0.8988
Å |
 |  |  |  |  |
| POLR3H_CTNND2_ENST00000337566_ENST00000304623_41936702_11732384 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.8813
Å |
 |  |  |  |  |
| POLR3H_CTNND2_ENST00000355209_ENST00000304623_41936702_11732384 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.7869
Å |
 |  |  |  |  |
| POLR3H_CTNND2_ENST00000355209_ENST00000359640_41936702_11732384 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.7962
Å |
 |  |  |  |  |
| POLR3H_CTNND2_ENST00000396504_ENST00000359640_41936702_11732384 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.8098
Å |
 |  |  |  |  |
| POLR3H_ENTHD1_ENST00000337566_ENST00000325157_41936702_40258012 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.8278
Å |
 |  |  |  |  |
| POLR3H_ENTHD1_ENST00000355209_ENST00000325157_41936702_40258012 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.695
Å |
 |  |  |  |  |
| POLR3H_ST13_ENST00000337566_ENST00000216218_41926690_41244373 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.7936
Å |
 |  |  |  |  |
| POLR3H_ST13_ENST00000355209_ENST00000216218_41926690_41244373 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:0.8661
Å |
 |  |  |  |  |
| POLR3K_EMC10_ENST00000293860_ENST00000376918_103475_50981185 superimposed PDB: 6WW7 of partner (EMC10). RMSD:0.6136
Å |
 |  |  |  |  |
| POLR3K_EMC10_ENST00000293860_ENST00000598585_103475_50981185 superimposed PDB: 6WW7 of partner (EMC10). RMSD:0.5905
Å |
 |  |  |  |  |
| POLR3K_L3MBTL4_ENST00000293860_ENST00000284898_101557_6215834 superimposed PDB: 7AE1 of partner (POLR3K). RMSD:2.364
Å |
 |  |  |  |  |
| POLR3K_L3MBTL4_ENST00000293860_ENST00000317931_101557_6215834 superimposed PDB: 7AE1 of partner (POLR3K). RMSD:2.4401
Å |
 |  |  |  |  |
| POLRMT_PALM_ENST00000588649_ENST00000338448_618487_726137 superimposed PDB: 9MN7 of partner (POLRMT). RMSD:1.3532
Å |
 |  |  |  |  |
| POM121C_HIP1_ENST00000257665_ENST00000434438_75066792_75228565 superimposed PDB: 3I00 of partner (HIP1). RMSD:1.7333
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000265709_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6135
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000289734_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.3537
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000352337_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7208
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000379758_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6624
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000396942_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6437
Å |
 |  |  |  |  |
| POMK_ANK1_ENST00000331373_ENST00000396945_42958973_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.5936
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000275569_ENST00000313375_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.5082
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000275569_ENST00000354613_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.4858
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000275569_ENST00000395189_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.5084
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000275569_ENST00000429400_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.5157
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000275569_ENST00000434326_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.4942
Å |
 |  |  |  |  |
| POMZP3_MLXIPL_ENST00000310842_ENST00000414749_76254838_73030507 superimposed PDB: 6YGJ of partner (MLXIPL). RMSD:0.5053
Å |
 |  |  |  |  |
| PON2_NUDC_ENST00000433091_ENST00000321265_95045553_27267947 superimposed PDB: 3QOR of partner (NUDC). RMSD:0.4837
Å |
 |  |  |  |  |
| POR_PTPN12_ENST00000394893_ENST00000248594_75601779_77200394 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.5241
Å |
 |  |  |  |  |
| POSTN_YY1_ENST00000379743_ENST00000262238_38136727_100728640 superimposed PDB: 5YJH of partner (POSTN). RMSD:1.8591
Å |
 |  |  |  |  |
| POSTN_YY1_ENST00000379749_ENST00000262238_38136727_100728640 superimposed PDB: 5YJH of partner (POSTN). RMSD:1.9352
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367862_ENST00000323947_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:3.2942
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367862_ENST00000358144_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.1162
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367862_ENST00000377656_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.6261
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367866_ENST00000323947_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.9918
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367866_ENST00000358144_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:1.4464
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000367866_ENST00000377656_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.6517
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000420254_ENST00000297668_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.4735
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000429375_ENST00000297668_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.0948
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000429375_ENST00000323947_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.2382
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000429375_ENST00000358144_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.1215
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000429375_ENST00000377656_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.4613
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000541643_ENST00000297668_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.3916
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000541643_ENST00000323947_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:3.0064
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000541643_ENST00000358144_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:1.8074
Å |
 |  |  |  |  |
| POU2F1_CNTNAP3_ENST00000541643_ENST00000377656_167382351_39118256 superimposed PDB: 1CQT of partner (POU2F1). RMSD:2.687
Å |
 |  |  |  |  |
| PPA1_MICU1_ENST00000373232_ENST00000401998_71993019_74268027 superimposed PDB: 8J7Q of partner (PPA1). RMSD:0.8486
Å |
 |  |  |  |  |
| PPAP2A_ANKRD55_ENST00000264775_ENST00000341048_54737678_55422933 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.5208
Å |
 |  |  |  |  |
| PPAP2A_ANKRD55_ENST00000264775_ENST00000504958_54737678_55422933 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.9334
Å |
 |  |  |  |  |
| PPAP2A_ANKRD55_ENST00000307259_ENST00000504958_54737678_55422933 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.941
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000264775_ENST00000296733_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:1.0483
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000264775_ENST00000322374_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.895
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000264775_ENST00000331730_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.9941
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000264775_ENST00000334206_54830399_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.9744
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000264775_ENST00000381375_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.8419
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000307259_ENST00000296733_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:1.0388
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000307259_ENST00000322374_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.8857
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000307259_ENST00000331730_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.8073
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000307259_ENST00000334206_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:1.1308
Å |
 |  |  |  |  |
| PPAP2A_CDC20B_ENST00000307259_ENST00000381375_54737678_54442684 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.8879
Å |
 |  |  |  |  |
| PPAP2A_DIAPH1_ENST00000264775_ENST00000389057_54830399_140966764 superimposed PDB: 8FG1 of partner (DIAPH1). RMSD:0.817
Å |
 |  |  |  |  |
| PPAP2A_DIAPH1_ENST00000264775_ENST00000398557_54830399_140966764 superimposed PDB: 8FG1 of partner (DIAPH1). RMSD:0.828
Å |
 |  |  |  |  |
| PPAP2A_DIAPH1_ENST00000264775_ENST00000398566_54830399_140966764 superimposed PDB: 8FG1 of partner (DIAPH1). RMSD:0.8119
Å |
 |  |  |  |  |
| PPAP2A_DIAPH1_ENST00000264775_ENST00000520569_54830399_140966764 superimposed PDB: 8FG1 of partner (DIAPH1). RMSD:0.862
Å |
 |  |  |  |  |
| PPAP2A_HCN1_ENST00000307259_ENST00000303230_54830399_45353348 superimposed PDB: 8T4M of partner (HCN1). RMSD:0.8633
Å |
 |  |  |  |  |
| PPAP2A_MAPK1_ENST00000264775_ENST00000398822_54830399_22143097 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.8528
Å |
 |  |  |  |  |
| PPAP2A_MAPK1_ENST00000307259_ENST00000215832_54830399_22143097 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:1.522
Å |
 |  |  |  |  |
| PPAP2A_SMN1_ENST00000264775_ENST00000380707_54830399_70247767 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.3258
Å |
 |  |  |  |  |
| PPAP2A_SMN1_ENST00000307259_ENST00000351205_54830399_70247767 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.6366
Å |
 |  |  |  |  |
| PPAP2A_SMN2_ENST00000307259_ENST00000380741_54830399_69372845 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:1.7222
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000287820_ENST00000378610_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:2.6438
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000287820_ENST00000378624_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:2.3422
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000397010_ENST00000378610_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:2.8544
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000397010_ENST00000378624_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:2.2484
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000397026_ENST00000378610_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:2.4818
Å |
 |  |  |  |  |
| PPARG_CDKAL1_ENST00000397026_ENST00000378624_12458653_20649523 superimposed PDB: 3DZY of partner (PPARG). RMSD:1.3736
Å |
 |  |  |  |  |
| PPFIA1_BBOX1_ENST00000253925_ENST00000263182_70202360_27136998 superimposed PDB: 4C5W of partner (BBOX1). RMSD:0.6993
Å |
 |  |  |  |  |
| PPFIA1_DYNC2H1_ENST00000253925_ENST00000334267_70118542_102984265 superimposed PDB: 8RGH of partner (DYNC2H1). RMSD:3.0146
Å |
 |  |  |  |  |
| PPFIA1_DYNC2H1_ENST00000253925_ENST00000398093_70118542_102984265 superimposed PDB: 8RGH of partner (DYNC2H1). RMSD:2.7844
Å |
 |  |  |  |  |
| PPFIA1_DYNC2H1_ENST00000389547_ENST00000375735_70118542_102984265 superimposed PDB: 8RGH of partner (DYNC2H1). RMSD:2.9058
Å |
 |  |  |  |  |
| PPFIA1_MARK2_ENST00000253925_ENST00000402010_70118542_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6455
Å |
 |  |  |  |  |
| PPFIA1_MARK2_ENST00000253925_ENST00000413835_70118542_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6326
Å |
 |  |  |  |  |
| PPFIA1_MARK2_ENST00000389547_ENST00000377809_70118542_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.664
Å |
 |  |  |  |  |
| PPFIBP1_HP1BP3_ENST00000228425_ENST00000312239_27825416_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.6092
Å |
 |  |  |  |  |
| PPFIBP1_HP1BP3_ENST00000318304_ENST00000312239_27825416_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.6991
Å |
 |  |  |  |  |
| PPFIBP1_HP1BP3_ENST00000542629_ENST00000312239_27825416_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.7503
Å |
 |  |  |  |  |
| PPFIBP1_NHP2L1_ENST00000318304_ENST00000215956_27803074_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.4063
Å |
 |  |  |  |  |
| PPFIBP1_NHP2L1_ENST00000537927_ENST00000215956_27803074_42076368 superimposed PDB: 2OZB of partner (NHP2L1). RMSD:0.3873
Å |
 |  |  |  |  |
| PPIA_OGDH_ENST00000468812_ENST00000439616_44836392_44733423 superimposed PDB: 8I0K of partner (OGDH). RMSD:1.638
Å |
 |  |  |  |  |
| PPIC_TRPM7_ENST00000306442_ENST00000313478_122364999_50905026 superimposed PDB: 2ESL of partner (PPIC). RMSD:0.3901
Å |
 |  |  |  |  |
| PPIP5K2_PRODH_ENST00000321521_ENST00000334029_102509676_18907311 superimposed PDB: 3T54 of partner (PPIP5K2). RMSD:0.4795
Å |
 |  |  |  |  |
| PPIP5K2_PRODH_ENST00000321521_ENST00000420436_102509676_18907311 superimposed PDB: 3T54 of partner (PPIP5K2). RMSD:0.4991
Å |
 |  |  |  |  |
| PPM1B_ABCG8_ENST00000282412_ENST00000272286_44445676_44071645 superimposed PDB: 2P8E of partner (PPM1B). RMSD:0.3178
Å |
 |  |  |  |  |
| PPM1B_ABCG8_ENST00000282412_ENST00000272286_44445676_44071645 superimposed PDB: 7R89 of partner (ABCG8). RMSD:0.9244
Å |
| | | |  |
| PPM1D_NUP85_ENST00000305921_ENST00000245544_58725443_73221197 superimposed PDB: 8T2J of partner (PPM1D). RMSD:0.566
Å |
 |  |  |  |  |
| PPM1D_NUP85_ENST00000305921_ENST00000541827_58725443_73221197 superimposed PDB: 8T2J of partner (PPM1D). RMSD:0.4023
Å |
 |  |  |  |  |
| PPM1D_TRAPPC9_ENST00000305921_ENST00000438773_58711338_140744445 superimposed PDB: 8T2J of partner (PPM1D). RMSD:0.6981
Å |
 |  |  |  |  |
| PPM1G_HSD17B14_ENST00000344034_ENST00000599157_27632169_49318398 superimposed PDB: 6H0M of partner (HSD17B14). RMSD:0.5056
Å |
 |  |  |  |  |
| PPM1G_KATNA1_ENST00000344034_ENST00000335643_27632169_149919486 superimposed PDB: 5ZQL of partner (KATNA1). RMSD:1.7845
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000327702_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.8388
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000327702_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.096
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000344100_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.1548
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000344100_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0264
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000347598_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.6254
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000347598_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0551
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399591_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.9385
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399591_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0723
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399595_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.2839
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399595_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0653
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399597_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.987
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399597_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0041
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399601_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.4585
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399601_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.9664
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399603_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.5991
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399603_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0701
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399606_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.2581
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399606_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0287
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399617_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.6831
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399617_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0714
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399621_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.3645
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399621_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0766
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399629_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.11
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399629_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1487
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399634_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.6789
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399634_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0871
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399637_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.0822
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399637_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0963
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399638_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.0465
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399638_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0748
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399641_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.9121
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399641_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0532
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399644_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1152
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399649_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.9887
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399649_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.002
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399655_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.9306
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000399655_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1052
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000402845_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.0773
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000402845_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0131
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000406454_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.4116
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000406454_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0148
Å |
| | | |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000480911_63195595_2558141 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.3047
Å |
 |  |  |  |  |
| PPM1H_CACNA1C_ENST00000228705_ENST00000480911_63195595_2558141 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0881
Å |
| | | |  |
| PPM1H_KIF13B_ENST00000228705_ENST00000524189_63328271_29023289 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.8823
Å |
 |  |  |  |  |
| PPM1H_PRMT8_ENST00000228705_ENST00000382622_63328271_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4644
Å |
 |  |  |  |  |
| PPM1H_PRMT8_ENST00000228705_ENST00000452611_63328271_3649771 superimposed PDB: 7KPR of partner (PPM1H). RMSD:3.0669
Å |
 |  |  |  |  |
| PPM1H_SLC6A15_ENST00000228705_ENST00000266682_63131281_85264449 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.7759
Å |
 |  |  |  |  |
| PPM1H_SLC6A15_ENST00000228705_ENST00000309283_63131281_85264449 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.8761
Å |
 |  |  |  |  |
| PPM1H_SLC6A15_ENST00000228705_ENST00000552192_63131281_85264449 superimposed PDB: 7KPR of partner (PPM1H). RMSD:0.7428
Å |
 |  |  |  |  |
| PPM1H_WIF1_ENST00000228705_ENST00000286574_63087715_65471634 superimposed PDB: 7KPR of partner (PPM1H). RMSD:1.2762
Å |
 |  |  |  |  |
| PPME1_AP000769 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.9992
Å |
 |  |  |  |  |
| PPME1_NARS2_ENST00000398427_ENST00000281038_73915490_78239982 superimposed PDB: 7SOY of partner (PPME1). RMSD:2.0029
Å |
 |  |  |  |  |
| PPME1_TENM4_ENST00000398427_ENST00000278550_73915490_78383374 superimposed PDB: 7SOY of partner (PPME1). RMSD:1.6698
Å |
 |  |  |  |  |
| PPME1_TENM4_ENST00000398427_ENST00000278550_73915490_78383374 superimposed PDB: 7BAN of partner (TENM4). RMSD:1.0443
Å |
| | | |  |
| PPP1CB_BRE_ENST00000296122_ENST00000342045_28975042_28521204 superimposed PDB: 8PVY of partner (BRE). RMSD:3.2131
Å |
 |  |  |  |  |
| PPP1CB_BRE_ENST00000296122_ENST00000379624_28975042_28521204 superimposed PDB: 8PVY of partner (BRE). RMSD:2.9984
Å |
 |  |  |  |  |
| PPP1CB_BRE_ENST00000358506_ENST00000379624_28975042_28521204 superimposed PDB: 8PVY of partner (BRE). RMSD:2.9575
Å |
 |  |  |  |  |
| PPP1CB_EIF2B4_ENST00000296122_ENST00000493344_28975042_27587466 superimposed PDB: 7VLK of partner (EIF2B4). RMSD:2.7391
Å |
 |  |  |  |  |
| PPP1CB_EIF2B4_ENST00000395366_ENST00000493344_28975042_27587466 superimposed PDB: 7VLK of partner (EIF2B4). RMSD:2.57
Å |
 |  |  |  |  |
| PPP1CB_SALL4_ENST00000296122_ENST00000217086_29006844_50408891 superimposed PDB: 8U17 of partner (SALL4). RMSD:2.569
Å |
 |  |  |  |  |
| PPP1CB_SALL4_ENST00000395366_ENST00000217086_29006844_50408891 superimposed PDB: 8U17 of partner (SALL4). RMSD:2.5725
Å |
 |  |  |  |  |
| PPP1CC_KCNC2_ENST00000335007_ENST00000550433_111180457_75434986 superimposed PDB: 1JK7 of partner (PPP1CC). RMSD:0.4346
Å |
 |  |  |  |  |
| PPP1R10_MDC1_ENST00000376511_ENST00000376405_30572364_30675231 superimposed PDB: 6ZV2 of partner (PPP1R10). RMSD:1.0757
Å |
 |  |  |  |  |
| PPP1R10_MDC1_ENST00000376511_ENST00000376405_30572364_30675231 superimposed PDB: 2AZM of partner (MDC1). RMSD:0.5366
Å |
| | | |  |
| PPP1R12A_PAWR_ENST00000261207_ENST00000328827_80201005_80014987 superimposed PDB: 2KJY of partner (PPP1R12A). RMSD:2.5248
Å |
 |  |  |  |  |
| PPP1R12A_PAWR_ENST00000550107_ENST00000328827_80187642_80014987 superimposed PDB: 2KJY of partner (PPP1R12A). RMSD:3.0447
Å |
 |  |  |  |  |
| PPP1R12A_PSEN1_ENST00000261207_ENST00000324501_80328474_73678476 superimposed PDB: 8KCS of partner (PSEN1). RMSD:3.2314
Å |
 |  |  |  |  |
| PPP1R12A_PSEN1_ENST00000261207_ENST00000324501_80328474_73683833 superimposed PDB: 8KCS of partner (PSEN1). RMSD:3.1443
Å |
 |  |  |  |  |
| PPP1R12A_PSEN1_ENST00000261207_ENST00000357710_80328474_73678476 superimposed PDB: 2KJY of partner (PPP1R12A). RMSD:2.9598
Å |
 |  |  |  |  |
| PPP1R12A_PSEN1_ENST00000437004_ENST00000357710_80328474_73678476 superimposed PDB: 2KJY of partner (PPP1R12A). RMSD:2.9744
Å |
 |  |  |  |  |
| PPP1R12A_PSEN1_ENST00000437004_ENST00000357710_80328474_73678476 superimposed PDB: 8KCS of partner (PSEN1). RMSD:2.8638
Å |
| | | |  |
| PPP1R13L_MBOAT7_ENST00000418234_ENST00000245615_45885784_54678125 superimposed PDB: 2VGE of partner (PPP1R13L). RMSD:0.6867
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000254079_ENST00000537919_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.7047
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000254079_ENST00000590151_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.6508
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000394265_ENST00000537919_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.4457
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000394265_ENST00000590151_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.8139
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000394267_ENST00000537919_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.8222
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000394267_ENST00000590151_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.6343
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000579000_ENST00000537919_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.5211
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000579000_ENST00000590151_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.8519
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000580825_ENST00000537919_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9026
Å |
 |  |  |  |  |
| PPP1R1B_ACLY_ENST00000580825_ENST00000590151_37790339_40055038 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.6767
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000346243_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0819
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000350532_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:2.1908
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000351680_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.129
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000377944_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1206
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000394189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0983
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000467757_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0639
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000254079_ENST00000535189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0574
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000346243_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1232
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000350532_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0267
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000351680_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2106
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000377944_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0041
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000394189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2061
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000467757_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1357
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394265_ENST00000535189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1976
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000346243_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1459
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000350532_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0875
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000351680_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1247
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000377944_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0483
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000394189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0589
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000467757_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1778
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000394267_ENST00000535189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.177
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000346243_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0861
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000350532_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:2.9748
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000351680_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2082
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000377944_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0328
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000394189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1464
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000467757_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1654
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000579000_ENST00000535189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.2079
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000346243_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0445
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000350532_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0203
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000351680_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1367
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000377944_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0589
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000394189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1722
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000467757_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1136
Å |
 |  |  |  |  |
| PPP1R1B_IKZF3_ENST00000580825_ENST00000535189_37791979_37988404 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1367
Å |
 |  |  |  |  |
| PPP1R21_WARS2_ENST00000281394_ENST00000235521_48725874_119619230 superimposed PDB: 7ND2 of partner (PPP1R21). RMSD:1.2748
Å |
 |  |  |  |  |
| PPP1R21_WARS2_ENST00000281394_ENST00000235521_48725874_119619230 superimposed PDB: 5EKD of partner (WARS2). RMSD:0.4305
Å |
| | | |  |
| PPP1R21_WARS2_ENST00000294952_ENST00000369426_48725874_119619230 superimposed PDB: 7ND2 of partner (PPP1R21). RMSD:1.5919
Å |
 |  |  |  |  |
| PPP1R21_WARS2_ENST00000294952_ENST00000369426_48725874_119619230 superimposed PDB: 5EKD of partner (WARS2). RMSD:1.3457
Å |
| | | |  |
| PPP1R21_WARS2_ENST00000449090_ENST00000235521_48725874_119619230 superimposed PDB: 7ND2 of partner (PPP1R21). RMSD:1.2476
Å |
 |  |  |  |  |
| PPP1R21_WARS2_ENST00000449090_ENST00000235521_48725874_119619230 superimposed PDB: 5EKD of partner (WARS2). RMSD:0.4627
Å |
| | | |  |
| PPP2CB_GTF2E2_ENST00000518564_ENST00000355904_30669835_30472232 superimposed PDB: 7NVU of partner (GTF2E2). RMSD:2.6025
Å |
 |  |  |  |  |
| PPP2R1A_CENPP_ENST00000477989_ENST00000375587_52693427_95373595 superimposed PDB: 28OP of partner (CENPP). RMSD:1.3041
Å |
 |  |  |  |  |
| PPP2R1A_ETHE1_ENST00000322088_ENST00000600651_52693427_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3608
Å |
 |  |  |  |  |
| PPP2R1A_ETHE1_ENST00000477989_ENST00000292147_52693427_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4855
Å |
 |  |  |  |  |
| PPP2R1A_KLK5_ENST00000322088_ENST00000336334_52705287_51453372 superimposed PDB: 2IE4 of partner (PPP2R1A). RMSD:1.6296
Å |
 |  |  |  |  |
| PPP2R1A_KLK5_ENST00000322088_ENST00000336334_52705287_51453372 superimposed PDB: 6QFE of partner (KLK5). RMSD:0.4969
Å |
| | | |  |
| PPP2R2A_DHTKD1_ENST00000315985_ENST00000263035_26151256_12123470 superimposed PDB: 6U3J of partner (DHTKD1). RMSD:0.5344
Å |
 |  |  |  |  |
| PPP2R4_PAX5_ENST00000348141_ENST00000358127_131911225_37034103 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.1282
Å |
 |  |  |  |  |
| PPP2R4_PAX5_ENST00000393370_ENST00000358127_131911225_37034103 superimposed PDB: 2HV6 of partner (PPP2R4). RMSD:3.1273
Å |
 |  |  |  |  |
| PPP2R4_PAX5_ENST00000393370_ENST00000358127_131911225_37034103 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.0119
Å |
| | | |  |
| PPP2R5C_ABCG1_ENST00000328724_ENST00000398457_102252520_43691179 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.2672
Å |
 |  |  |  |  |
| PPP2R5C_SCN1B_ENST00000350249_ENST00000415950_102276373_35523431 superimposed PDB: 7W9K of partner (SCN1B). RMSD:1.7236
Å |
 |  |  |  |  |
| PPP2R5C_SCN1B_ENST00000445439_ENST00000262631_102276373_35523431 superimposed PDB: 7W9K of partner (SCN1B). RMSD:0.5379
Å |
 |  |  |  |  |
| PPP2R5D_ASCC3_ENST00000394110_ENST00000369162_42957426_101215221 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:1.3261
Å |
 |  |  |  |  |
| PPP2R5D_ASCC3_ENST00000394110_ENST00000522650_42957426_101215221 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:2.6046
Å |
 |  |  |  |  |
| PPP2R5D_ASCC3_ENST00000472118_ENST00000369162_42957426_101215221 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:1.2788
Å |
 |  |  |  |  |
| PPP2R5D_ASCC3_ENST00000485511_ENST00000522650_42957426_101215221 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:2.6514
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000305762_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3635
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000305762_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4454
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000322635_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3574
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000322635_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4437
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000322680_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3413
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000322680_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4167
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000372765_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3737
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000372765_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4255
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000394762_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3366
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000394762_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3785
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000423381_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.344
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000360663_ENST00000423381_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3664
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000305762_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3701
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000305762_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3833
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000322635_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3619
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000322635_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4383
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000322680_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3524
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000322680_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3795
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000351293_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.354
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000351293_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.422
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000372765_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3232
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000372765_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3619
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000394762_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3285
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000394762_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3918
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000423381_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3273
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394828_ENST00000423381_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.5005
Å |
| | | |  |
| PPP3CB_CAMK2G_ENST00000394829_ENST00000351293_75204482_75620647 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.3229
Å |
 |  |  |  |  |
| PPP3CB_CAMK2G_ENST00000394829_ENST00000351293_75204482_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4247
Å |
| | | |  |
| PPP3CB_TTC18_ENST00000545874_ENST00000401621_75214169_75035356 superimposed PDB: 4OR9 of partner (PPP3CB). RMSD:0.2761
Å |
 |  |  |  |  |
| PPP3CC_PIWIL2_ENST00000518852_ENST00000454009_22333137_22138632 superimposed PDB: 7YFX of partner (PIWIL2). RMSD:2.2405
Å |
 |  |  |  |  |
| PPP3CC_PIWIL2_ENST00000518852_ENST00000521356_22333137_22138632 superimposed PDB: 7YFX of partner (PIWIL2). RMSD:1.1312
Å |
 |  |  |  |  |
| PPP3CC_TNFRSF10A_ENST00000240139_ENST00000221132_22333137_23069725 superimposed PDB: 5CIR of partner (TNFRSF10A). RMSD:1.2321
Å |
 |  |  |  |  |
| PPP3R1_CBWD2_ENST00000234310_ENST00000416503_68413599_114251333 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.4974
Å |
 |  |  |  |  |
| PPP3R1_CBWD2_ENST00000409752_ENST00000416503_68413599_114251333 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.5195
Å |
 |  |  |  |  |
| PPP3R1_CNRIP1_ENST00000409377_ENST00000263655_68413599_68544439 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.4551
Å |
 |  |  |  |  |
| PPP3R1_WDPCP_ENST00000409377_ENST00000409199_68444223_63631792 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.8907
Å |
 |  |  |  |  |
| PPP4C_HSPD1_ENST00000279387_ENST00000345042_30092631_198353971 superimposed PDB: 9L8P of partner (HSPD1). RMSD:1.1976
Å |
 |  |  |  |  |
| PPP4C_MVP_ENST00000561610_ENST00000357402_30087796_29855813 superimposed PDB: 11EE of partner (MVP). RMSD:0.6062
Å |
 |  |  |  |  |
| PPP4R1_DPP4_ENST00000400555_ENST00000360534_9561977_162851882 superimposed PDB: 2QT9 of partner (DPP4). RMSD:0.8122
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000012443_ENST00000599990_46857246_47342835 superimposed PDB: 8GAE of partner (PPP5C). RMSD:1.7341
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000012443_ENST00000599990_46857246_47342835 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.6606
Å |
| | | |  |
| PPP5C_AP2S1_ENST00000012443_ENST00000599990_46857246_47349399 superimposed PDB: 8GAE of partner (PPP5C). RMSD:1.8126
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000012443_ENST00000599990_46857246_47349399 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.4889
Å |
| | | |  |
| PPP5C_AP2S1_ENST00000012443_ENST00000601498_46857246_47349399 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.5053
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000391919_ENST00000599990_46857246_47342835 superimposed PDB: 8GAE of partner (PPP5C). RMSD:1.7376
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000391919_ENST00000599990_46857246_47342835 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.6296
Å |
| | | |  |
| PPP5C_AP2S1_ENST00000391919_ENST00000599990_46857246_47349399 superimposed PDB: 8GAE of partner (PPP5C). RMSD:1.7726
Å |
 |  |  |  |  |
| PPP5C_AP2S1_ENST00000391919_ENST00000599990_46857246_47349399 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.491
Å |
| | | |  |
| PPP5C_AP2S1_ENST00000391919_ENST00000601498_46857246_47349399 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.5185
Å |
 |  |  |  |  |
| PPP6R2_CBX1_ENST00000216061_ENST00000225603_50845304_46152462 superimposed PDB: 5T1G of partner (CBX1). RMSD:0.2393
Å |
 |  |  |  |  |
| PPP6R2_CBX1_ENST00000359139_ENST00000225603_50845304_46152462 superimposed PDB: 5T1G of partner (CBX1). RMSD:0.2942
Å |
 |  |  |  |  |
| PPP6R2_CBX1_ENST00000395741_ENST00000393408_50845304_46152462 superimposed PDB: 5T1G of partner (CBX1). RMSD:0.3518
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000265636_ENST00000402010_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6517
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000265636_ENST00000413835_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.658
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000393799_ENST00000402010_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6452
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000393799_ENST00000413835_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6285
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000393800_ENST00000377809_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6719
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000524845_ENST00000377809_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6637
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000529710_ENST00000377809_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6638
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000534534_ENST00000402010_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6663
Å |
 |  |  |  |  |
| PPP6R3_MARK2_ENST00000534534_ENST00000413835_68343511_63662626 superimposed PDB: 5EAK of partner (MARK2). RMSD:0.6344
Å |
 |  |  |  |  |
| PPP6R3_YAP1_ENST00000393799_ENST00000282441_68326147_102098199 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.827
Å |
 |  |  |  |  |
| PPT1_EP400_ENST00000433473_ENST00000389561_40555081_132537690 superimposed PDB: 3GRO of partner (PPT1). RMSD:0.5683
Å |
 |  |  |  |  |
| PRCC_TFE3_ENST00000353233_ENST00000315869_156738031_48895967 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.8618
Å |
 |  |  |  |  |
| PRCP_BCO2_ENST00000535099_ENST00000438022_82549428_112088483 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.7637
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000280241_82564218_83810090 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.533
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000280241_82564218_83810090 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.3936
Å |
| | | |  |
| PRCP_DLG2_ENST00000313010_ENST00000280241_82611276_83497835 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.6774
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82564218_83810090 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.7384
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82564218_83810090 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4472
Å |
| | | |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82611276_83497835 superimposed PDB: 3N2Z of partner (PRCP). RMSD:2.5906
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82611276_83497835 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.7505
Å |
| | | |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82611276_83962334 superimposed PDB: 3N2Z of partner (PRCP). RMSD:1.5313
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000313010_ENST00000376104_82611276_83962334 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.3953
Å |
| | | |  |
| PRCP_DLG2_ENST00000393399_ENST00000280241_82564218_83810090 superimposed PDB: 3N2Z of partner (PRCP). RMSD:1.1037
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000393399_ENST00000280241_82564218_83810090 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.4118
Å |
| | | |  |
| PRCP_DLG2_ENST00000393399_ENST00000376104_82564218_83810090 superimposed PDB: 3N2Z of partner (PRCP). RMSD:0.8654
Å |
 |  |  |  |  |
| PRCP_DLG2_ENST00000393399_ENST00000376104_82564218_83810090 superimposed PDB: 2HE2 of partner (DLG2). RMSD:0.3921
Å |
| | | |  |
| PRCP_INTS4_ENST00000393399_ENST00000534064_82571018_77672184 superimposed PDB: 8RC4 of partner (INTS4). RMSD:3.0484
Å |
 |  |  |  |  |
| PRDM11_FOLH1_ENST00000263765_ENST00000533034_45204674_49168497 superimposed PDB: 3RAY of partner (PRDM11). RMSD:1.2822
Å |
 |  |  |  |  |
| PRDM11_FOLH1_ENST00000424263_ENST00000533034_45204674_49168497 superimposed PDB: 3RAY of partner (PRDM11). RMSD:1.2515
Å |
 |  |  |  |  |
| PRDM2_BMP8B_ENST00000311066_ENST00000372827_14075982_40240710 superimposed PDB: 2JV0 of partner (PRDM2). RMSD:1.822
Å |
 |  |  |  |  |
| PRDM2_BMP8B_ENST00000376048_ENST00000397360_14075982_40240710 superimposed PDB: 2JV0 of partner (PRDM2). RMSD:1.867
Å |
 |  |  |  |  |
| PRDM2_PUM1_ENST00000376048_ENST00000257075_14075982_31426828 superimposed PDB: 2JV0 of partner (PRDM2). RMSD:1.8353
Å |
 |  |  |  |  |
| PRDM2_PUM1_ENST00000376048_ENST00000257075_14075982_31426828 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6211
Å |
| | | |  |
| PRDM2_PUM1_ENST00000376048_ENST00000426105_14075982_31426828 superimposed PDB: 2JV0 of partner (PRDM2). RMSD:1.8418
Å |
 |  |  |  |  |
| PRDM2_PUM1_ENST00000376048_ENST00000426105_14075982_31426828 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6591
Å |
| | | |  |
| PREX2_SDHB_ENST00000288368_ENST00000375499_68864770_17371383 superimposed PDB: 6BNM of partner (PREX2). RMSD:3.0216
Å |
 |  |  |  |  |
| PRIM2_BAG2_ENST00000607273_ENST00000545080_57190843_57048575 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:0.8212
Å |
 |  |  |  |  |
| PRIM2_COL21A1_ENST00000607273_ENST00000244728_57246966_55929420 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:0.8293
Å |
 |  |  |  |  |
| PRIM2_COL21A1_ENST00000607273_ENST00000370819_57246966_55929420 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:1.7464
Å |
 |  |  |  |  |
| PRIM2_EYS_ENST00000607273_ENST00000370621_57372355_64431693 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:1.9653
Å |
 |  |  |  |  |
| PRIM2_LMBRD1_ENST00000607273_ENST00000370577_57246966_70500364 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.5398
Å |
 |  |  |  |  |
| PRIM2_NKAIN2_ENST00000607273_ENST00000368417_57190843_124676412 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:0.8414
Å |
 |  |  |  |  |
| PRIM2_NKAIN2_ENST00000607273_ENST00000545433_57190843_124676412 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:0.9082
Å |
 |  |  |  |  |
| PRIM2_NKAIN2_ENST00000607273_ENST00000546092_57190843_124676412 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:0.8758
Å |
 |  |  |  |  |
| PRIM2_TRPC4AP_ENST00000607273_ENST00000252015_57190843_33657215 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.9244
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000296800_ENST00000322350_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:0.9816
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000296800_ENST00000336740_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:0.9882
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000354209_ENST00000322350_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:1.001
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000354209_ENST00000336740_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:1.0244
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000397128_ENST00000322350_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:0.9613
Å |
 |  |  |  |  |
| PRKAA1_EGFLAM_ENST00000397128_ENST00000336740_40775511_38409105 superimposed PDB: 8D1B of partner (EGFLAM). RMSD:0.998
Å |
 |  |  |  |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000264203_57140195_19684057 superimposed PDB: 8BIK of partner (PRKAA2). RMSD:2.0611
Å |
 |  |  |  |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000264203_57140195_19684057 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.2259
Å |
| | | |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000375142_57140195_19684057 superimposed PDB: 8BIK of partner (PRKAA2). RMSD:2.9817
Å |
 |  |  |  |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000375142_57140195_19684057 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:0.7972
Å |
| | | |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000433834_57140195_19684057 superimposed PDB: 8BIK of partner (PRKAA2). RMSD:1.7866
Å |
 |  |  |  |  |
| PRKAA2_CAPZB_ENST00000371244_ENST00000433834_57140195_19684057 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.2547
Å |
| | | |  |
| PRKAG1_TUBA1B_ENST00000548065_ENST00000336023_49412514_49523505 superimposed PDB: 6S8L of partner (TUBA1B). RMSD:0.8347
Å |
 |  |  |  |  |
| PRKAR1A_CHMP1A_ENST00000358598_ENST00000535997_66511717_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9359
Å |
 |  |  |  |  |
| PRKAR1A_CHMP1A_ENST00000536854_ENST00000535997_66511717_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.8947
Å |
 |  |  |  |  |
| PRKAR1A_CHMP1A_ENST00000586397_ENST00000535997_66511717_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9261
Å |
 |  |  |  |  |
| PRKAR1A_CHMP1A_ENST00000589228_ENST00000535997_66511717_89713739 superimposed PDB: 2JQ9 of partner (CHMP1A). RMSD:0.9333
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000358598_ENST00000340058_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.6803
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000392711_ENST00000355710_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.676
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000536854_ENST00000340058_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.7087
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000536854_ENST00000355710_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.7385
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000586397_ENST00000340058_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.8582
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000586397_ENST00000355710_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.6961
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000588188_ENST00000355710_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.7717
Å |
 |  |  |  |  |
| PRKAR1A_RET_ENST00000589228_ENST00000340058_66522053_43612031 superimposed PDB: 5KJZ of partner (PRKAR1A). RMSD:0.7866
Å |
 |  |  |  |  |
| PRKAR1B_GNA12_ENST00000403562_ENST00000275364_645829_2773135 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.0815
Å |
 |  |  |  |  |
| PRKAR1B_GNA12_ENST00000406797_ENST00000275364_645829_2773135 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.0599
Å |
 |  |  |  |  |
| PRKAR1B_MAD1L1_ENST00000406797_ENST00000399654_645829_2020176 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.3375
Å |
 |  |  |  |  |
| PRKAR1B_MAD1L1_ENST00000544935_ENST00000399654_645829_2020176 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.266
Å |
 |  |  |  |  |
| PRKAR2A_CSNK2A1_ENST00000265563_ENST00000349736_48884767_469422 superimposed PDB: 6TLS of partner (CSNK2A1). RMSD:0.6965
Å |
 |  |  |  |  |
| PRKAR2A_CSNK2A1_ENST00000454963_ENST00000400227_48884767_469422 superimposed PDB: 6TLS of partner (CSNK2A1). RMSD:0.687
Å |
 |  |  |  |  |
| PRKAR2A_USP4_ENST00000265563_ENST00000265560_48827976_49362196 superimposed PDB: 2Y6E of partner (USP4). RMSD:0.3823
Å |
 |  |  |  |  |
| PRKAR2A_USP4_ENST00000454963_ENST00000351842_48827976_49362196 superimposed PDB: 2Y6E of partner (USP4). RMSD:0.3962
Å |
 |  |  |  |  |
| PRKCB_RPS2_ENST00000303531_ENST00000343262_24135302_2013257 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:2.6897
Å |
 |  |  |  |  |
| PRKCB_RPS2_ENST00000321728_ENST00000343262_24135302_2013257 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:3.3778
Å |
 |  |  |  |  |
| PRKCB_RPS2_ENST00000321728_ENST00000526522_24135302_2013257 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:2.1613
Å |
 |  |  |  |  |
| PRKCB_RPS2_ENST00000321728_ENST00000529806_24135302_2013257 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:2.1995
Å |
 |  |  |  |  |
| PRKCB_RPS2_ENST00000321728_ENST00000530225_24135302_2013257 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:2.1644
Å |
 |  |  |  |  |
| PRKCE_SNX17_ENST00000306156_ENST00000233575_45879587_27595489 superimposed PDB: 4TKN of partner (SNX17). RMSD:0.7978
Å |
 |  |  |  |  |
| PRKCH_HIF1A_ENST00000332981_ENST00000394997_61858006_62200855 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:2.3667
Å |
 |  |  |  |  |
| PRKCH_SPTB_ENST00000555082_ENST00000389722_61924397_65289863 superimposed PDB: 3KBT of partner (SPTB). RMSD:2.1334
Å |
 |  |  |  |  |
| PRKD1_ARHGAP5_ENST00000331968_ENST00000539826_30194741_32615468 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.2705
Å |
 |  |  |  |  |
| PRKD1_ARHGAP5_ENST00000415220_ENST00000539826_30194741_32615468 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.2326
Å |
 |  |  |  |  |
| PRKD2_CKM_ENST00000433867_ENST00000221476_47207425_45815178 superimposed PDB: 1I0E of partner (CKM). RMSD:0.8067
Å |
 |  |  |  |  |
| PRKD2_GLUD1_ENST00000291281_ENST00000277865_47192793_88819030 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0576
Å |
 |  |  |  |  |
| PRKD2_GLUD1_ENST00000291281_ENST00000537649_47192793_88819030 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0655
Å |
 |  |  |  |  |
| PRKD2_GLUD1_ENST00000433867_ENST00000537649_47192793_88819030 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0616
Å |
 |  |  |  |  |
| PRKD2_HPSE2_ENST00000600194_ENST00000370549_47181652_100249953 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0288
Å |
 |  |  |  |  |
| PRKD2_HPSE2_ENST00000600194_ENST00000370552_47181652_100249953 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0762
Å |
 |  |  |  |  |
| PRKD2_HPSE2_ENST00000600194_ENST00000404542_47181652_100249953 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.066
Å |
 |  |  |  |  |
| PRKD2_HPSE2_ENST00000601806_ENST00000370552_47181652_100249953 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0163
Å |
 |  |  |  |  |
| PRKD2_HPSE2_ENST00000601806_ENST00000404542_47181652_100249953 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.011
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000291281_ENST00000376970_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.9192
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000291281_ENST00000425460_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:3.1493
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000291281_ENST00000440075_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.7402
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000433867_ENST00000376970_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:3.0226
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000433867_ENST00000425460_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:3.0404
Å |
 |  |  |  |  |
| PRKD2_MYH14_ENST00000433867_ENST00000440075_47207425_50747498 superimposed PDB: 5JLH of partner (MYH14). RMSD:2.9002
Å |
 |  |  |  |  |
| PRKD2_ZNF28_ENST00000433867_ENST00000594602_47184906_53311386 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0762
Å |
 |  |  |  |  |
| PRKD2_ZNF468_ENST00000291281_ENST00000595646_47184906_53352466 superimposed PDB: 2COA of partner (PRKD2). RMSD:1.0368
Å |
 |  |  |  |  |
| PRKD2_ZNF468_ENST00000433867_ENST00000595646_47184906_53352466 superimposed PDB: 2COA of partner (PRKD2). RMSD:0.9944
Å |
 |  |  |  |  |
| PRKD3_HNRNPLL_ENST00000379066_ENST00000409636_37520275_38797067 superimposed PDB: 7EVS of partner (HNRNPLL). RMSD:1.0881
Å |
 |  |  |  |  |
| PRKD3_HNRNPLL_ENST00000379066_ENST00000449105_37520275_38797067 superimposed PDB: 2D9Z of partner (PRKD3). RMSD:1.2106
Å |
 |  |  |  |  |
| PRKDC_CCDC138_ENST00000314191_ENST00000412964_48701466_109421344 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.1123
Å |
 |  |  |  |  |
| PRKDC_CCDC138_ENST00000338368_ENST00000295124_48701466_109421344 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.1299
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000314191_ENST00000399231_48730010_52667657 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.0279
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000314191_ENST00000399231_48730010_52667657 superimposed PDB: 4J5L of partner (MYO5A). RMSD:1.6586
Å |
| | | |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000356338_48730010_52667657 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.163
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000356338_48730010_52667657 superimposed PDB: 4J5L of partner (MYO5A). RMSD:2.0215
Å |
| | | |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000358212_48730010_52667657 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.0978
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000358212_48730010_52667657 superimposed PDB: 4J5L of partner (MYO5A). RMSD:1.8807
Å |
| | | |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000399233_48730010_52667657 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.1259
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000399233_48730010_52667657 superimposed PDB: 4J5L of partner (MYO5A). RMSD:1.6211
Å |
| | | |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000553916_48730010_52667657 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:3.1668
Å |
 |  |  |  |  |
| PRKDC_MYO5A_ENST00000338368_ENST00000553916_48730010_52667657 superimposed PDB: 4J5L of partner (MYO5A). RMSD:2.2495
Å |
| | | |  |
| PRKDC_PRIM2_ENST00000314191_ENST00000607273_48824969_57244698 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:2.9207
Å |
 |  |  |  |  |
| PRKDC_PRIM2_ENST00000314191_ENST00000607273_48824969_57244698 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.4402
Å |
| | | |  |
| PRKDC_TOMM70A_ENST00000314191_ENST00000284320_48868433_100092489 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:2.7562
Å |
 |  |  |  |  |
| PRKDC_TOMM70A_ENST00000314191_ENST00000284320_48868433_100092489 superimposed PDB: 7DHG of partner (TOMM70A). RMSD:1.1722
Å |
| | | |  |
| PRMT1_PTOV1_ENST00000454376_ENST00000221557_50183845_50361805 superimposed PDB: 6NT2 of partner (PRMT1). RMSD:2.8132
Å |
 |  |  |  |  |
| PRMT1_PTOV1_ENST00000454376_ENST00000601638_50183845_50361805 superimposed PDB: 6NT2 of partner (PRMT1). RMSD:3.1505
Å |
 |  |  |  |  |
| PRMT1_PTOV1_ENST00000532489_ENST00000601638_50183845_50361805 superimposed PDB: 6NT2 of partner (PRMT1). RMSD:3.1755
Å |
 |  |  |  |  |
| PRMT2_MRPS6_ENST00000397638_ENST00000399312_48069651_35497640 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8527
Å |
 |  |  |  |  |
| PRMT2_SLC41A2_ENST00000397638_ENST00000258538_48069651_105199115 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8474
Å |
 |  |  |  |  |
| PRMT2_STX18_ENST00000355680_ENST00000306200_48068531_4473433 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8653
Å |
 |  |  |  |  |
| PRMT2_STX18_ENST00000397638_ENST00000505286_48068531_4473433 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8368
Å |
 |  |  |  |  |
| PRMT2_WRB_ENST00000355680_ENST00000398753_48069651_40762623 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8544
Å |
 |  |  |  |  |
| PRMT2_WRB_ENST00000355680_ENST00000398753_48069651_40762623 superimposed PDB: 8CR1 of partner (WRB). RMSD:1.0662
Å |
| | | |  |
| PRMT2_WRB_ENST00000355680_ENST00000541890_48069651_40762623 superimposed PDB: 1X2P of partner (PRMT2). RMSD:0.8287
Å |
 |  |  |  |  |
| PRMT2_WRB_ENST00000355680_ENST00000541890_48069651_40762623 superimposed PDB: 8CR1 of partner (WRB). RMSD:1.1333
Å |
| | | |  |
| PRMT3_NAV2_ENST00000331079_ENST00000311043_20429578_20057504 superimposed PDB: 8SHR of partner (PRMT3). RMSD:2.8413
Å |
 |  |  |  |  |
| PRMT3_PI4KA_ENST00000331079_ENST00000572273_20409700_21115674 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.3166
Å |
 |  |  |  |  |
| PRMT3_RBM4B_ENST00000331079_ENST00000310046_20409320_66436762 superimposed PDB: 2DGT of partner (RBM4B). RMSD:2.4954
Å |
 |  |  |  |  |
| PRMT3_RBM4B_ENST00000437750_ENST00000310046_20409320_66436762 superimposed PDB: 2DGT of partner (RBM4B). RMSD:2.3948
Å |
 |  |  |  |  |
| PROSC_SET_ENST00000328195_ENST00000409104_37623873_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.7563
Å |
 |  |  |  |  |
| PROSC_WHSC1L1_ENST00000328195_ENST00000433384_37623873_38173560 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.4314
Å |
 |  |  |  |  |
| PROSC_WHSC1L1_ENST00000328195_ENST00000527502_37623873_38173560 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.4438
Å |
 |  |  |  |  |
| PRPF18_CACNB2_ENST00000378572_ENST00000282343_13647744_18439811 superimposed PDB: 2DK4 of partner (PRPF18). RMSD:1.0777
Å |
 |  |  |  |  |
| PRPF18_CACNB2_ENST00000378572_ENST00000352115_13647744_18439811 superimposed PDB: 2DK4 of partner (PRPF18). RMSD:1.1089
Å |
 |  |  |  |  |
| PRPF18_CACNB2_ENST00000378572_ENST00000377328_13647744_18439811 superimposed PDB: 2DK4 of partner (PRPF18). RMSD:1.1137
Å |
 |  |  |  |  |
| PRPF38A_ABCD3_ENST00000257181_ENST00000454898_52871511_94924162 superimposed PDB: 9W65 of partner (ABCD3). RMSD:1.0645
Å |
 |  |  |  |  |
| PRPF4B_NAP1L1_ENST00000337659_ENST00000393263_4032989_76454059 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.9357
Å |
 |  |  |  |  |
| PRPF4B_NAP1L1_ENST00000337659_ENST00000547773_4032989_76454059 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.9433
Å |
 |  |  |  |  |
| PRPF4B_NAP1L1_ENST00000538861_ENST00000393263_4032989_76454059 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.936
Å |
 |  |  |  |  |
| PRPF4B_NAP1L1_ENST00000538861_ENST00000547773_4032989_76454059 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.9047
Å |
 |  |  |  |  |
| PRR14L_CC2D1A_ENST00000434485_ENST00000589606_32134372_14034145 superimposed PDB: 9VHM of partner (CC2D1A). RMSD:1.8362
Å |
 |  |  |  |  |
| PRSS1_KLK5_ENST00000311737_ENST00000391809_142460418_51447042 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.996
Å |
 |  |  |  |  |
| PRSS1_KLK5_ENST00000311737_ENST00000391809_142460418_51447042 superimposed PDB: 6QFE of partner (KLK5). RMSD:0.612
Å |
| | | |  |
| PRSS1_KLK6_ENST00000311737_ENST00000594641_142460418_51462572 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:1.0199
Å |
 |  |  |  |  |
| PRSS1_KLK6_ENST00000311737_ENST00000594641_142460418_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5543
Å |
| | | |  |
| PRSS1_KLK6_ENST00000486171_ENST00000594641_142460418_51462572 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.9608
Å |
 |  |  |  |  |
| PRSS1_KLK6_ENST00000486171_ENST00000594641_142460418_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5525
Å |
| | | |  |
| PRSS3_KLK6_ENST00000342836_ENST00000594641_33798620_51462572 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3948
Å |
 |  |  |  |  |
| PRSS3_KLK6_ENST00000342836_ENST00000594641_33798620_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5014
Å |
| | | |  |
| PRSS3_KLK6_ENST00000361005_ENST00000594641_33798620_51462572 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3527
Å |
 |  |  |  |  |
| PRSS3_KLK6_ENST00000361005_ENST00000594641_33798620_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5517
Å |
| | | |  |
| PRSS3_KLK6_ENST00000379405_ENST00000594641_33798620_51462572 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3554
Å |
 |  |  |  |  |
| PRSS3_KLK6_ENST00000379405_ENST00000594641_33798620_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5101
Å |
| | | |  |
| PRSS3_KLK6_ENST00000429677_ENST00000594641_33798620_51462572 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3506
Å |
 |  |  |  |  |
| PRSS3_KLK6_ENST00000429677_ENST00000594641_33798620_51462572 superimposed PDB: 6SKB of partner (KLK6). RMSD:0.5122
Å |
| | | |  |
| PRSS3_PRSS1_ENST00000342836_ENST00000311737_33798080_142460281 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3245
Å |
 |  |  |  |  |
| PRSS3_PRSS1_ENST00000342836_ENST00000311737_33798080_142460281 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.9781
Å |
| | | |  |
| PRSS3_PRSS1_ENST00000361005_ENST00000311737_33798080_142460281 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3158
Å |
 |  |  |  |  |
| PRSS3_PRSS1_ENST00000361005_ENST00000311737_33798080_142460281 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.9813
Å |
| | | |  |
| PRSS3_PRSS1_ENST00000379405_ENST00000311737_33798080_142460281 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3305
Å |
 |  |  |  |  |
| PRSS3_PRSS1_ENST00000379405_ENST00000311737_33798080_142460281 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.99
Å |
| | | |  |
| PRSS3_PRSS1_ENST00000379405_ENST00000486171_33798080_142460281 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.3244
Å |
 |  |  |  |  |
| PRSS3_PRSS1_ENST00000379405_ENST00000486171_33798080_142460281 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.9835
Å |
| | | |  |
| PRSS3_PRSS1_ENST00000429677_ENST00000311737_33798080_142460281 superimposed PDB: 5TP0 of partner (PRSS3). RMSD:0.328
Å |
 |  |  |  |  |
| PRSS3_PRSS1_ENST00000429677_ENST00000311737_33798080_142460281 superimposed PDB: 8ZIY of partner (PRSS1). RMSD:0.9485
Å |
| | | |  |
| PRTG_B2M_ENST00000389286_ENST00000559916_56032579_45007620 superimposed PDB: 6AT5 of partner (B2M). RMSD:0.4204
Å |
 |  |  |  |  |
| PRTG_PYGO1_ENST00000389286_ENST00000563719_56032579_55841193 superimposed PDB: 2VP7 of partner (PYGO1). RMSD:0.5454
Å |
 |  |  |  |  |
| PSAP_ABCA1_ENST00000394934_ENST00000374736_73576057_107567001 superimposed PDB: 7TBW of partner (ABCA1). RMSD:1.2307
Å |
 |  |  |  |  |
| PSAP_C3_ENST00000394934_ENST00000245907_73576057_6720693 superimposed PDB: 9U62 of partner (C3). RMSD:2.1806
Å |
 |  |  |  |  |
| PSAT1_WAC_ENST00000347159_ENST00000375646_80923499_28905101 superimposed PDB: 8A5V of partner (PSAT1). RMSD:0.4964
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000286485_ENST00000320203_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5047
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000286485_ENST00000339877_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5289
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000286485_ENST00000397323_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4991
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000286485_ENST00000517860_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5246
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000286485_ENST00000538486_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4954
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000327040_ENST00000320203_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5555
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000327040_ENST00000339877_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.49
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000327040_ENST00000397323_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4834
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000327040_ENST00000517860_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4817
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000440756_ENST00000320203_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5138
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000440756_ENST00000339877_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.509
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000440756_ENST00000397323_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5229
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000440756_ENST00000517860_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5271
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000440756_ENST00000538486_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5252
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000523619_ENST00000320203_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4972
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000523619_ENST00000339877_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5187
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000523619_ENST00000397323_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5328
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000523619_ENST00000517860_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5088
Å |
 |  |  |  |  |
| PSD3_RBPMS_ENST00000523619_ENST00000538486_18656804_30332294 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5181
Å |
 |  |  |  |  |
| PSMA1_ODC1_ENST00000396394_ENST00000405333_14541842_10582300 superimposed PDB: 2OO0 of partner (ODC1). RMSD:1.0472
Å |
 |  |  |  |  |
| PSMA1_ODC1_ENST00000555531_ENST00000234111_14541842_10582300 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:1.1105
Å |
 |  |  |  |  |
| PSMA1_ODC1_ENST00000555531_ENST00000405333_14541842_10582300 superimposed PDB: 2OO0 of partner (ODC1). RMSD:0.7704
Å |
 |  |  |  |  |
| PSMB2_C1orf94_ENST00000373237_ENST00000488417_36096874_34673757 superimposed PDB: 5LE5 of partner (PSMB2). RMSD:1.0646
Å |
 |  |  |  |  |
| PSMB2_POLG2_ENST00000373237_ENST00000539111_36096874_62474105 superimposed PDB: 5LE5 of partner (PSMB2). RMSD:0.5717
Å |
 |  |  |  |  |
| PSMB5_HOMEZ_ENST00000425762_ENST00000561013_23502576_23746396 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.7336
Å |
 |  |  |  |  |
| PSMB5_HOMEZ_ENST00000425762_ENST00000561013_23502576_23746396 superimposed PDB: 2ECC of partner (HOMEZ). RMSD:0.849
Å |
| | | |  |
| PSMB5_HOMEZ_ENST00000493471_ENST00000561013_23502576_23746396 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.7519
Å |
 |  |  |  |  |
| PSMB5_HOMEZ_ENST00000493471_ENST00000561013_23502576_23746396 superimposed PDB: 2ECC of partner (HOMEZ). RMSD:0.8765
Å |
| | | |  |
| PSMB5_MRPL2_ENST00000361611_ENST00000230413_23502576_43022224 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.6446
Å |
 |  |  |  |  |
| PSMB5_MRPL2_ENST00000425762_ENST00000230413_23502576_43022224 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.7728
Å |
 |  |  |  |  |
| PSMB5_MRPL2_ENST00000493471_ENST00000230413_23502576_43022224 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.7942
Å |
 |  |  |  |  |
| PSMC1_HSD17B14_ENST00000261303_ENST00000599157_90722944_49318398 superimposed PDB: 6H0M of partner (HSD17B14). RMSD:0.5103
Å |
 |  |  |  |  |
| PSMC4_RXRB_ENST00000157812_ENST00000374680_40480735_33167193 superimposed PDB: 7A78 of partner (RXRB). RMSD:0.3692
Å |
 |  |  |  |  |
| PSMC4_RXRB_ENST00000157812_ENST00000374685_40480735_33167193 superimposed PDB: 7A78 of partner (RXRB). RMSD:3.0143
Å |
 |  |  |  |  |
| PSMC4_RXRB_ENST00000455878_ENST00000374680_40480735_33167193 superimposed PDB: 7A78 of partner (RXRB). RMSD:0.3445
Å |
 |  |  |  |  |
| PSMC4_RXRB_ENST00000455878_ENST00000374685_40480735_33167193 superimposed PDB: 7A78 of partner (RXRB). RMSD:0.3281
Å |
 |  |  |  |  |
| PSMD12_SEC24B_ENST00000356126_ENST00000265175_65362527_110427483 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.574
Å |
 |  |  |  |  |
| PSMD12_SEC24B_ENST00000356126_ENST00000399100_65362527_110427483 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5564
Å |
 |  |  |  |  |
| PSMD12_SEC24B_ENST00000357146_ENST00000265175_65362527_110427483 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5572
Å |
 |  |  |  |  |
| PSMD12_SEC24B_ENST00000357146_ENST00000399100_65362527_110427483 superimposed PDB: 3EH1 of partner (SEC24B). RMSD:0.5714
Å |
 |  |  |  |  |
| PSMD13_SQRDL_ENST00000352303_ENST00000260324_249057_45962125 superimposed PDB: 6OIB of partner (SQRDL). RMSD:0.5474
Å |
 |  |  |  |  |
| PSMD13_SQRDL_ENST00000431206_ENST00000260324_249057_45962125 superimposed PDB: 6OIB of partner (SQRDL). RMSD:0.5717
Å |
 |  |  |  |  |
| PSMD13_SQRDL_ENST00000532097_ENST00000260324_249057_45962125 superimposed PDB: 6OIB of partner (SQRDL). RMSD:0.5912
Å |
 |  |  |  |  |
| PSMD3_CASC3_ENST00000541736_ENST00000264645_38146450_38318005 superimposed PDB: 6ICZ of partner (CASC3). RMSD:1.5231
Å |
 |  |  |  |  |
| PSMD8_MAP3K10_ENST00000215071_ENST00000253055_38867094_40710391 superimposed PDB: 2RF0 of partner (MAP3K10). RMSD:2.5044
Å |
 |  |  |  |  |
| PSME2_ADCY4_ENST00000216802_ENST00000554068_24614266_24789094 superimposed PDB: 7NAO of partner (PSME2). RMSD:2.1058
Å |
 |  |  |  |  |
| PSME2_ADCY4_ENST00000560410_ENST00000554068_24614266_24789094 superimposed PDB: 7NAO of partner (PSME2). RMSD:3.7838
Å |
 |  |  |  |  |
| PSME4_ACYP2_ENST00000404125_ENST00000607452_54197679_54531824 superimposed PDB: 6KWY of partner (PSME4). RMSD:0.8519
Å |
 |  |  |  |  |
| PSME4_SLC22A16_ENST00000404125_ENST00000456137_54101475_110778220 superimposed PDB: 6KWY of partner (PSME4). RMSD:1.3639
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000309660_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6388
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000309660_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.9389
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000327283_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6638
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000327283_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.9685
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000353319_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6603
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000353319_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:1.0541
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000591115_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6254
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000317615_ENST00000591115_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.8766
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000309660_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6838
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000309660_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:1.0609
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000353319_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6923
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000353319_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.9823
Å |
| | | |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000591115_12724618_12825943 superimposed PDB: 8QYL of partner (PSMG2). RMSD:0.6455
Å |
 |  |  |  |  |
| PSMG2_PTPN2_ENST00000585331_ENST00000591115_12724618_12825943 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.8658
Å |
| | | |  |
| PSMG2_SETMAR_ENST00000317615_ENST00000430981_12706720_4354581 superimposed PDB: 3BO5 of partner (SETMAR). RMSD:0.5433
Å |
 |  |  |  |  |
| PSMG4_GMDS_ENST00000451246_ENST00000380815_3259430_1742820 superimposed PDB: 5WTQ of partner (PSMG4). RMSD:2.7756
Å |
 |  |  |  |  |
| PSMG4_GMDS_ENST00000451246_ENST00000380815_3259430_1742820 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.1987
Å |
| | | |  |
| PSPC1_CRYL1_ENST00000338910_ENST00000298248_20304378_20987526 superimposed PDB: 3SDE of partner (PSPC1). RMSD:1.8265
Å |
 |  |  |  |  |
| PSPC1_CRYL1_ENST00000338910_ENST00000382812_20304378_20987526 superimposed PDB: 3SDE of partner (PSPC1). RMSD:1.6395
Å |
 |  |  |  |  |
| PSPC1_METTL21C_ENST00000338910_ENST00000267273_20356525_103339407 superimposed PDB: 3SDE of partner (PSPC1). RMSD:1.7827
Å |
 |  |  |  |  |
| PTAR1_PIP5K1B_ENST00000340434_ENST00000265382_72347054_71503896 superimposed PDB: 6O60 of partner (PTAR1). RMSD:0.8162
Å |
 |  |  |  |  |
| PTAR1_PIP5K1B_ENST00000340434_ENST00000541509_72347054_71503896 superimposed PDB: 6O60 of partner (PTAR1). RMSD:2.7592
Å |
 |  |  |  |  |
| PTAR1_PIP5K1B_ENST00000377200_ENST00000265382_72347054_71503896 superimposed PDB: 6O60 of partner (PTAR1). RMSD:2.8985
Å |
 |  |  |  |  |
| PTBP1_UBE3C_ENST00000349038_ENST00000348165_804438_157009560 superimposed PDB: 6K2C of partner (UBE3C). RMSD:0.9092
Å |
 |  |  |  |  |
| PTBP2_MYSM1_ENST00000370197_ENST00000472487_97250810_59127183 superimposed PDB: 2MJU of partner (PTBP2). RMSD:3.2225
Å |
 |  |  |  |  |
| PTBP2_MYSM1_ENST00000370197_ENST00000472487_97250810_59127183 superimposed PDB: 2DCE of partner (MYSM1). RMSD:2.7404
Å |
| | | |  |
| PTBP2_MYSM1_ENST00000394184_ENST00000472487_97250810_59127183 superimposed PDB: 2MJU of partner (PTBP2). RMSD:3.1058
Å |
 |  |  |  |  |
| PTBP2_MYSM1_ENST00000394184_ENST00000472487_97250810_59127183 superimposed PDB: 2DCE of partner (MYSM1). RMSD:2.6466
Å |
| | | |  |
| PTBP2_MYSM1_ENST00000541987_ENST00000472487_97250810_59127183 superimposed PDB: 2DCE of partner (MYSM1). RMSD:2.818
Å |
 |  |  |  |  |
| PTBP2_NUP54_ENST00000609116_ENST00000264883_97243502_77045909 superimposed PDB: 2MJU of partner (PTBP2). RMSD:2.1812
Å |
 |  |  |  |  |
| PTBP3_GARS_ENST00000374255_ENST00000389266_115095749_30638411 superimposed PDB: 2ZT5 of partner (GARS). RMSD:1.2167
Å |
 |  |  |  |  |
| PTCH1_FANCC_ENST00000331920_ENST00000375305_98238315_97879672 superimposed PDB: 6E1H of partner (PTCH1). RMSD:1.1278
Å |
 |  |  |  |  |
| PTCH1_FANCC_ENST00000375274_ENST00000375305_98238315_97879672 superimposed PDB: 6E1H of partner (PTCH1). RMSD:1.2754
Å |
 |  |  |  |  |
| PTCH1_FANCC_ENST00000437951_ENST00000375305_98238315_97879672 superimposed PDB: 6E1H of partner (PTCH1). RMSD:1.1133
Å |
 |  |  |  |  |
| PTCH1_FLNA_ENST00000421141_ENST00000422373_98232094_153578575 superimposed PDB: 6E1H of partner (PTCH1). RMSD:1.0641
Å |
 |  |  |  |  |
| PTCH1_IPPK_ENST00000437951_ENST00000287996_98268688_95381847 superimposed PDB: 6E1H of partner (PTCH1). RMSD:2.3294
Å |
 |  |  |  |  |
| PTCHD4_CD2AP_ENST00000543600_ENST00000359314_47976369_47471015 superimposed PDB: 2J6F of partner (CD2AP). RMSD:0.2846
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000455950_ENST00000522684_97321850_141840625 superimposed PDB: 9KQJ of partner (PTDSS1). RMSD:1.1506
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000455950_ENST00000522684_97321850_141840625 superimposed PDB: 4NY0 of partner (PTK2). RMSD:2.9809
Å |
| | | |  |
| PTDSS1_PTK2_ENST00000455950_ENST00000535192_97321850_141840625 superimposed PDB: 9KQJ of partner (PTDSS1). RMSD:1.6926
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000455950_ENST00000535192_97321850_141840625 superimposed PDB: 4NY0 of partner (PTK2). RMSD:2.7674
Å |
| | | |  |
| PTDSS1_PTK2_ENST00000517309_ENST00000535192_97321850_141840625 superimposed PDB: 9KQJ of partner (PTDSS1). RMSD:1.0634
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000517309_ENST00000535192_97321850_141840625 superimposed PDB: 4NY0 of partner (PTK2). RMSD:2.9117
Å |
| | | |  |
| PTDSS1_PTK2_ENST00000522072_ENST00000522684_97321850_141840625 superimposed PDB: 9KQJ of partner (PTDSS1). RMSD:1.566
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000522072_ENST00000522684_97321850_141840625 superimposed PDB: 4NY0 of partner (PTK2). RMSD:3.7402
Å |
| | | |  |
| PTDSS1_PTK2_ENST00000522072_ENST00000535192_97321850_141840625 superimposed PDB: 9KQJ of partner (PTDSS1). RMSD:1.7976
Å |
 |  |  |  |  |
| PTDSS1_PTK2_ENST00000522072_ENST00000535192_97321850_141840625 superimposed PDB: 4NY0 of partner (PTK2). RMSD:2.5657
Å |
| | | |  |
| PTEN_C1orf226_ENST00000371953_ENST00000458626_89653866_162352971 superimposed PDB: 7JVX of partner (PTEN). RMSD:1.8655
Å |
 |  |  |  |  |
| PTEN_KCNMB4_ENST00000371953_ENST00000258111_89720875_70793988 superimposed PDB: 7JVX of partner (PTEN). RMSD:0.5936
Å |
 |  |  |  |  |
| PTEN_PAPSS2_ENST00000371953_ENST00000427144_89693008_89475488 superimposed PDB: 7JVX of partner (PTEN). RMSD:3.1506
Å |
 |  |  |  |  |
| PTEN_PAPSS2_ENST00000371953_ENST00000427144_89693008_89475488 superimposed PDB: 7FH3 of partner (PAPSS2). RMSD:0.5588
Å |
| | | |  |
| PTEN_PAPSS2_ENST00000371953_ENST00000456849_89693008_89475488 superimposed PDB: 7JVX of partner (PTEN). RMSD:3.0279
Å |
 |  |  |  |  |
| PTEN_PAPSS2_ENST00000371953_ENST00000456849_89693008_89475488 superimposed PDB: 7FH3 of partner (PAPSS2). RMSD:0.5324
Å |
| | | |  |
| PTEN_PRDX3_ENST00000371953_ENST00000298510_89653866_120933384 superimposed PDB: 5UCX of partner (PRDX3). RMSD:0.5945
Å |
 |  |  |  |  |
| PTGDS_ACTG1_ENST00000224167_ENST00000573283_139872144_79478652 superimposed PDB: 7NVM of partner (ACTG1). RMSD:1.7542
Å |
 |  |  |  |  |
| PTGDS_MFSD10_ENST00000371625_ENST00000514800_139872144_2935671 superimposed PDB: 6S4M of partner (MFSD10). RMSD:1.9416
Å |
 |  |  |  |  |
| PTGES2_CCT2_ENST00000338961_ENST00000543146_130885980_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.9016
Å |
 |  |  |  |  |
| PTGES2_CCT2_ENST00000338961_ENST00000544368_130885980_69983264 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.9549
Å |
 |  |  |  |  |
| PTGR1_LMAN2L_ENST00000238248_ENST00000377079_114337013_97373570 superimposed PDB: 9D6Z of partner (PTGR1). RMSD:0.7862
Å |
 |  |  |  |  |
| PTGR2_NDUFAF1_ENST00000555661_ENST00000260361_74327360_41680720 superimposed PDB: 2ZB4 of partner (PTGR2). RMSD:2.9213
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000517887_ENST00000222572_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8066
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000517887_ENST00000433091_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8102
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000521059_ENST00000222572_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8407
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000521059_ENST00000433091_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8337
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000535192_ENST00000222572_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8326
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000535192_ENST00000433091_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.8109
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000538769_ENST00000222572_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.3802
Å |
 |  |  |  |  |
| PTK2_PON2_ENST00000538769_ENST00000433091_141710989_95041789 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.3762
Å |
 |  |  |  |  |
| PTK2_PPP2R5E_ENST00000520892_ENST00000555899_141900641_63920603 superimposed PDB: 8UWB of partner (PPP2R5E). RMSD:0.9012
Å |
 |  |  |  |  |
| PTPN11_EPYC_ENST00000351677_ENST00000261172_112892484_91372039 superimposed PDB: 4GWF of partner (PTPN11). RMSD:2.6158
Å |
 |  |  |  |  |
| PTPN11_PRKAR1B_ENST00000392597_ENST00000537384_112920009_716957 superimposed PDB: 4GWF of partner (PTPN11). RMSD:3.3994
Å |
 |  |  |  |  |
| PTPN11_PRKAR1B_ENST00000392597_ENST00000537384_112920009_716957 superimposed PDB: 4DIN of partner (PRKAR1B). RMSD:2.988
Å |
| | | |  |
| PTPN12_AC027763 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.6534
Å |
 |  |  |  |  |
| PTPN12_AC027763 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.8246
Å |
| | | |  |
| PTPN12_AC027763 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3371
Å |
| | | |  |
| PTPN12_AC027763 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3914
Å |
| | | |  |
| PTPN12_DYNC1I1_ENST00000248594_ENST00000437599_77166962_95705368 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.9779
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000275575_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.7005
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000275575_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.4188
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000275575_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4695
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000307305_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.8308
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000307305_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.5849
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000307305_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.5077
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000415251_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.7685
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000415251_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.2553
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000415251_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4984
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000416283_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.6235
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000416283_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.1663
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000424760_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.9292
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000424760_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.5249
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000450574_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.2615
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000450574_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.6753
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000248594_ENST00000450574_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4803
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000275575_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3392
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000275575_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.358
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000275575_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.426
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000307305_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3597
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000307305_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3898
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000307305_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4632
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000307305_77247882_77584174 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.6131
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000415251_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3657
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000415251_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3698
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000415251_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4548
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000416283_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3699
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000416283_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4244
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000424760_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3368
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000424760_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.426
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000450574_77212967_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3755
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000450574_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4097
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000415482_ENST00000450574_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4494
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000275575_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.5668
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000275575_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:2.7784
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000307305_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:3.2094
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000307305_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.0563
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000307305_77247882_77584174 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4253
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000415251_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.4073
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000415251_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.9864
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000416283_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.5881
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000450574_77214898_77522924 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.9188
Å |
 |  |  |  |  |
| PTPN12_PHTF2_ENST00000435495_ENST00000450574_77230123_77549595 superimposed PDB: 5J8R of partner (PTPN12). RMSD:1.0441
Å |
 |  |  |  |  |
| PTPN12_RSBN1L_ENST00000248594_ENST00000334955_77256992_77365726 superimposed PDB: 5J8R of partner (PTPN12). RMSD:2.2224
Å |
 |  |  |  |  |
| PTPN12_RSBN1L_ENST00000415482_ENST00000334955_77256992_77365726 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.5951
Å |
 |  |  |  |  |
| PTPN12_RSBN1L_ENST00000435495_ENST00000334955_77256992_77365726 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4762
Å |
 |  |  |  |  |
| PTPN12_UBR1_ENST00000415482_ENST00000290650_77230123_43294902 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.4878
Å |
 |  |  |  |  |
| PTPN12_UBR1_ENST00000435495_ENST00000290650_77230123_43294902 superimposed PDB: 5J8R of partner (PTPN12). RMSD:0.3787
Å |
 |  |  |  |  |
| PTPN1_PREX1_ENST00000371621_ENST00000396220_49191191_47361684 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:1.0824
Å |
 |  |  |  |  |
| PTPN1_PREX1_ENST00000371621_ENST00000396220_49191191_47361684 superimposed PDB: 8TUA of partner (PREX1). RMSD:2.9035
Å |
| | | |  |
| PTPN1_PREX1_ENST00000541713_ENST00000371941_49191191_47361684 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:1.2431
Å |
 |  |  |  |  |
| PTPN1_PREX1_ENST00000541713_ENST00000371941_49191191_47361684 superimposed PDB: 8TUA of partner (PREX1). RMSD:2.9338
Å |
| | | |  |
| PTPN1_PREX1_ENST00000541713_ENST00000396220_49191191_47361684 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:1.0119
Å |
 |  |  |  |  |
| PTPN1_PREX1_ENST00000541713_ENST00000396220_49191191_47361684 superimposed PDB: 8TUA of partner (PREX1). RMSD:2.1507
Å |
| | | |  |
| PTPN1_ROMO1_ENST00000371621_ENST00000374077_49191191_34287554 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3765
Å |
 |  |  |  |  |
| PTPN1_ROMO1_ENST00000371621_ENST00000374078_49191191_34287554 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:1.1658
Å |
 |  |  |  |  |
| PTPN1_ROMO1_ENST00000371621_ENST00000397416_49191191_34287554 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.3684
Å |
 |  |  |  |  |
| PTPN1_ROMO1_ENST00000541713_ENST00000374077_49191191_34287554 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.5741
Å |
 |  |  |  |  |
| PTPN1_ROMO1_ENST00000541713_ENST00000397416_49191191_34287554 superimposed PDB: 1A5Y of partner (PTPN1). RMSD:0.4493
Å |
 |  |  |  |  |
| PTPN2_L3MBTL4_ENST00000591497_ENST00000317931_12814201_5969561 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.442
Å |
 |  |  |  |  |
| PTPN2_PIEZO2_ENST00000327283_ENST00000503781_12859162_10715814 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.2637
Å |
 |  |  |  |  |
| PTPN2_PIEZO2_ENST00000327283_ENST00000580640_12859162_10715814 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.7502
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000318974_ENST00000251761_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:2.4438
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000318974_ENST00000396725_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:3.0322
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000399448_ENST00000251761_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:2.5048
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000447931_ENST00000251761_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:2.8422
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000447931_ENST00000396725_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:2.3321
Å |
 |  |  |  |  |
| PTPN6_LEPREL2_ENST00000456013_ENST00000396725_7066948_6948163 superimposed PDB: 3PS5 of partner (PTPN6). RMSD:2.3968
Å |
 |  |  |  |  |
| PTPN6_PEX5_ENST00000399448_ENST00000266563_7055902_7354346 superimposed PDB: 1FCH of partner (PEX5). RMSD:0.4232
Å |
 |  |  |  |  |
| PTPN6_PEX5_ENST00000447931_ENST00000455147_7055902_7354346 superimposed PDB: 1FCH of partner (PEX5). RMSD:0.4159
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000216877_ENST00000262384_2998559_48596355 superimposed PDB: 6UZT of partner (PTPRA). RMSD:2.049
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000216877_ENST00000262384_2998559_48596355 superimposed PDB: 6Q3V of partner (N4BP1). RMSD:0.4493
Å |
| | | |  |
| PTPRA_N4BP1_ENST00000318266_ENST00000262384_2998559_48596355 superimposed PDB: 6UZT of partner (PTPRA). RMSD:1.6639
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000318266_ENST00000262384_2998559_48596355 superimposed PDB: 6Q3V of partner (N4BP1). RMSD:0.4268
Å |
| | | |  |
| PTPRA_N4BP1_ENST00000356147_ENST00000262384_2998559_48596355 superimposed PDB: 6UZT of partner (PTPRA). RMSD:1.8887
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000356147_ENST00000262384_2998559_48596355 superimposed PDB: 6Q3V of partner (N4BP1). RMSD:0.4753
Å |
| | | |  |
| PTPRA_N4BP1_ENST00000358719_ENST00000262384_2998559_48596355 superimposed PDB: 6UZT of partner (PTPRA). RMSD:1.8584
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000358719_ENST00000262384_2998559_48596355 superimposed PDB: 6Q3V of partner (N4BP1). RMSD:0.4302
Å |
| | | |  |
| PTPRA_N4BP1_ENST00000399903_ENST00000262384_2998559_48596355 superimposed PDB: 6UZT of partner (PTPRA). RMSD:1.5117
Å |
 |  |  |  |  |
| PTPRA_N4BP1_ENST00000399903_ENST00000262384_2998559_48596355 superimposed PDB: 6Q3V of partner (N4BP1). RMSD:0.4523
Å |
| | | |  |
| PTPRF_DHRS4_ENST00000359947_ENST00000558263_44064584_24429110 superimposed PDB: 3O4R of partner (DHRS4). RMSD:0.4613
Å |
 |  |  |  |  |
| PTPRF_DHRS4_ENST00000422171_ENST00000558263_44064584_24429110 superimposed PDB: 3O4R of partner (DHRS4). RMSD:0.5196
Å |
 |  |  |  |  |
| PTPRG_CADPS_ENST00000295874_ENST00000283269_61989171_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9161
Å |
 |  |  |  |  |
| PTPRG_CADPS_ENST00000295874_ENST00000357948_61989171_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9318
Å |
 |  |  |  |  |
| PTPRG_CADPS_ENST00000295874_ENST00000490353_61989171_62751659 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9001
Å |
 |  |  |  |  |
| PTPRJ_LPXN_ENST00000418331_ENST00000528954_48002560_58331674 superimposed PDB: 1X3H of partner (LPXN). RMSD:1.4126
Å |
 |  |  |  |  |
| PTPRJ_LPXN_ENST00000440289_ENST00000528954_48002560_58331674 superimposed PDB: 1X3H of partner (LPXN). RMSD:1.4569
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000368215_ENST00000320393_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.335
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000368215_ENST00000356489_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.4055
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000368226_ENST00000320393_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.3682
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000368226_ENST00000356489_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.3521
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000532331_ENST00000320393_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.335
Å |
 |  |  |  |  |
| PTPRK_BCKDHB_ENST00000532331_ENST00000356489_128718710_80837263 superimposed PDB: 2BFD of partner (BCKDHB). RMSD:0.4031
Å |
 |  |  |  |  |
| PTPRK_C11orf48_ENST00000368215_ENST00000525675_128841403_62432445 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.292
Å |
 |  |  |  |  |
| PTPRK_C11orf48_ENST00000368226_ENST00000524958_128841403_62432445 superimposed PDB: 8A1F of partner (PTPRK). RMSD:0.6673
Å |
 |  |  |  |  |
| PTPRK_C11orf48_ENST00000532331_ENST00000525675_128841403_62432445 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.7054
Å |
 |  |  |  |  |
| PTPRK_FGF7_ENST00000368207_ENST00000267843_128505576_49775347 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.3224
Å |
 |  |  |  |  |
| PTPRK_FGF7_ENST00000368213_ENST00000267843_128505576_49775347 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.2249
Å |
 |  |  |  |  |
| PTPRK_FGF7_ENST00000368227_ENST00000267843_128505576_49775347 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.4643
Å |
 |  |  |  |  |
| PTPRK_KCNK13_ENST00000368207_ENST00000282146_128505576_90650454 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.3792
Å |
 |  |  |  |  |
| PTPRK_KCNK13_ENST00000368207_ENST00000282146_128505576_90650454 superimposed PDB: 9M9M of partner (KCNK13). RMSD:1.266
Å |
| | | |  |
| PTPRK_KCNK13_ENST00000368213_ENST00000282146_128505576_90650454 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.4575
Å |
 |  |  |  |  |
| PTPRK_KCNK13_ENST00000368213_ENST00000282146_128505576_90650454 superimposed PDB: 9M9M of partner (KCNK13). RMSD:1.4647
Å |
| | | |  |
| PTPRK_KCNK13_ENST00000368226_ENST00000282146_128505576_90650454 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.5379
Å |
 |  |  |  |  |
| PTPRK_KCNK13_ENST00000368227_ENST00000282146_128505576_90650454 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.5098
Å |
 |  |  |  |  |
| PTPRK_KCNK13_ENST00000368227_ENST00000282146_128505576_90650454 superimposed PDB: 9M9M of partner (KCNK13). RMSD:1.4922
Å |
| | | |  |
| PTPRK_PRKCA_ENST00000368207_ENST00000413366_128718710_64492318 superimposed PDB: 4RA4 of partner (PRKCA). RMSD:0.5804
Å |
 |  |  |  |  |
| PTPRK_PRKCA_ENST00000368213_ENST00000413366_128718710_64492318 superimposed PDB: 4RA4 of partner (PRKCA). RMSD:0.6123
Å |
 |  |  |  |  |
| PTPRK_PRKCA_ENST00000368227_ENST00000413366_128718710_64492318 superimposed PDB: 4RA4 of partner (PRKCA). RMSD:0.6533
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368207_ENST00000548724_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.2796
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368210_ENST00000548724_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.4388
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368213_ENST00000548724_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.2518
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368215_ENST00000396700_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.4248
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368226_ENST00000396700_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.4623
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368226_ENST00000548724_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.5683
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000368227_ENST00000548724_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.3705
Å |
 |  |  |  |  |
| PTPRK_STXBP6_ENST00000532331_ENST00000396700_128505576_25326363 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.3699
Å |
 |  |  |  |  |
| PTPRM_ELP4_ENST00000332175_ENST00000395934_8143777_31804940 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.1727
Å |
 |  |  |  |  |
| PTPRM_ELP4_ENST00000400053_ENST00000395934_8143777_31804940 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.6066
Å |
 |  |  |  |  |
| PTPRM_ELP4_ENST00000444013_ENST00000395934_8143777_31804940 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.6922
Å |
 |  |  |  |  |
| PTPRM_KCTD1_ENST00000400053_ENST00000417602_7926681_24039889 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.5656
Å |
 |  |  |  |  |
| PTPRM_KCTD1_ENST00000400053_ENST00000417602_7926681_24039889 superimposed PDB: 9FQ1 of partner (KCTD1). RMSD:1.2657
Å |
| | | |  |
| PTPRM_KCTD1_ENST00000400060_ENST00000417602_7926681_24039889 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.5597
Å |
 |  |  |  |  |
| PTPRM_KCTD1_ENST00000400060_ENST00000417602_7926681_24039889 superimposed PDB: 9FQ1 of partner (KCTD1). RMSD:1.4585
Å |
| | | |  |
| PTPRM_KCTD1_ENST00000580170_ENST00000417602_7926681_24039889 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.5727
Å |
 |  |  |  |  |
| PTPRM_KCTD1_ENST00000580170_ENST00000417602_7926681_24039889 superimposed PDB: 9FQ1 of partner (KCTD1). RMSD:1.2247
Å |
| | | |  |
| PTPRM_L3MBTL4_ENST00000400053_ENST00000317931_7955412_5969561 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.721
Å |
 |  |  |  |  |
| PTPRM_L3MBTL4_ENST00000400060_ENST00000317931_7955412_5969561 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.7264
Å |
 |  |  |  |  |
| PTPRM_L3MBTL4_ENST00000444013_ENST00000317931_7955412_5969561 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.8712
Å |
 |  |  |  |  |
| PTPRM_L3MBTL4_ENST00000580170_ENST00000317931_7955412_5969561 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.6456
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000309660_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.1341
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000309660_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4845
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000327283_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.4074
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000327283_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.476
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000353319_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.7019
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000353319_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4736
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000591115_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.8651
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000332175_ENST00000591115_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.512
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000309660_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.8062
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000309660_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4794
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000327283_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.4753
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000327283_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4756
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000353319_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.2621
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000353319_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.5015
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000591115_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.1126
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400053_ENST00000591115_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4964
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000309660_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.2017
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000309660_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4452
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000327283_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.6992
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000327283_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4771
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000353319_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.6942
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000353319_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.468
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000591115_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.4511
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000400060_ENST00000591115_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4897
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000309660_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.5964
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000309660_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4984
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000327283_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.2174
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000327283_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4942
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000353319_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.6178
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000353319_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4599
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000591115_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.5034
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000444013_ENST00000591115_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4524
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000309660_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.1204
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000309660_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4977
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000327283_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:2.4435
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000353319_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.0185
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000353319_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4667
Å |
| | | |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000591115_8253412_12859253 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:1.4933
Å |
 |  |  |  |  |
| PTPRM_PTPN2_ENST00000580170_ENST00000591115_8253412_12859253 superimposed PDB: 7F5N of partner (PTPN2). RMSD:0.4931
Å |
| | | |  |
| PTPRM_RAB12_ENST00000332175_ENST00000329286_7955412_8624935 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.719
Å |
 |  |  |  |  |
| PTPRM_RAB12_ENST00000332175_ENST00000329286_7955412_8624935 superimposed PDB: 8VH5 of partner (RAB12). RMSD:1.0521
Å |
| | | |  |
| PTPRM_RAB12_ENST00000400053_ENST00000329286_7955412_8624935 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.8195
Å |
 |  |  |  |  |
| PTPRM_RAB12_ENST00000400053_ENST00000329286_7955412_8624935 superimposed PDB: 8VH5 of partner (RAB12). RMSD:0.9625
Å |
| | | |  |
| PTPRM_RAB12_ENST00000444013_ENST00000329286_7955412_8624935 superimposed PDB: 2V5Y of partner (PTPRM). RMSD:0.6637
Å |
 |  |  |  |  |
| PTPRM_RAB12_ENST00000444013_ENST00000329286_7955412_8624935 superimposed PDB: 8VH5 of partner (RAB12). RMSD:1.045
Å |
| | | |  |
| PTPRR_CPM_ENST00000283228_ENST00000551568_71077906_69265736 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.3839
Å |
 |  |  |  |  |
| PTPRR_CPM_ENST00000283228_ENST00000551568_71077906_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.5157
Å |
| | | |  |
| PTPRR_CPM_ENST00000342084_ENST00000551568_71077906_69265736 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.5849
Å |
 |  |  |  |  |
| PTPRR_CPM_ENST00000342084_ENST00000551568_71077906_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.5167
Å |
| | | |  |
| PTPRR_CPM_ENST00000378778_ENST00000551568_71077906_69265736 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.8225
Å |
 |  |  |  |  |
| PTPRR_CPM_ENST00000378778_ENST00000551568_71077906_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4715
Å |
| | | |  |
| PTPRR_CPM_ENST00000440835_ENST00000551568_71077906_69265736 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0511
Å |
 |  |  |  |  |
| PTPRR_CPM_ENST00000440835_ENST00000551568_71077906_69265736 superimposed PDB: 1UWY of partner (CPM). RMSD:0.5298
Å |
| | | |  |
| PTPRR_KCNC2_ENST00000549308_ENST00000550433_71092044_75445097 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.2102
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000283228_ENST00000228327_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.9838
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000283228_ENST00000266692_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.1273
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000283228_ENST00000397909_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0535
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000342084_ENST00000228327_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.123
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000342084_ENST00000266692_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.954
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000342084_ENST00000397909_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.9903
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000342084_ENST00000536525_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.1254
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000378778_ENST00000228327_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0421
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000378778_ENST00000266692_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.127
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000378778_ENST00000397909_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0809
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000378778_ENST00000536525_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.1911
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000440835_ENST00000228327_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:1.9254
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000440835_ENST00000266692_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.076
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000440835_ENST00000397909_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0801
Å |
 |  |  |  |  |
| PTPRR_NAV3_ENST00000440835_ENST00000536525_71077906_78360008 superimposed PDB: 2A8B of partner (PTPRR). RMSD:2.0515
Å |
 |  |  |  |  |
| PTPRR_SNRPF_ENST00000283228_ENST00000552085_71314112_96254945 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.2546
Å |
 |  |  |  |  |
| PTPRR_SNRPF_ENST00000283228_ENST00000553192_71314112_96254945 superimposed PDB: 5XJL of partner (SNRPF). RMSD:0.4483
Å |
 |  |  |  |  |
| PTPRS_ANGPTL4_ENST00000588012_ENST00000301455_5286060_8430837 superimposed PDB: 6EUB of partner (ANGPTL4). RMSD:0.4805
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000402788_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8324
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000404301_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8139
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000406236_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8267
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000407322_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8424
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000553530_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8249
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000555571_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8343
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000587303_ENST00000556437_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8402
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000588012_ENST00000553525_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7625
Å |
 |  |  |  |  |
| PTPRS_RGS6_ENST00000592099_ENST00000553525_5286060_72818802 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7507
Å |
 |  |  |  |  |
| PTPRU_UBIAD1_ENST00000373779_ENST00000376810_29563229_11345700 superimposed PDB: 6SUB of partner (PTPRU). RMSD:2.826
Å |
 |  |  |  |  |
| PTPRZ1_GLUD1_ENST00000449182_ENST00000277865_121513611_88836413 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.0396
Å |
 |  |  |  |  |
| PTPRZ1_RCHY1_ENST00000449182_ENST00000324439_121671613_76407876 superimposed PDB: 5AWX of partner (PTPRZ1). RMSD:0.5088
Å |
 |  |  |  |  |
| PUM1_BAI2_ENST00000373742_ENST00000398556_31532050_32222416 superimposed PDB: 8OEK of partner (BAI2). RMSD:0.9118
Å |
 |  |  |  |  |
| PUM1_GFPT1_ENST00000373741_ENST00000361060_31452908_69601245 superimposed PDB: 6R4H of partner (GFPT1). RMSD:1.4419
Å |
 |  |  |  |  |
| PUM1_GFPT1_ENST00000373742_ENST00000357308_31452908_69601245 superimposed PDB: 6R4H of partner (GFPT1). RMSD:1.6697
Å |
 |  |  |  |  |
| PUM1_GFPT1_ENST00000373742_ENST00000361060_31452908_69601245 superimposed PDB: 6R4H of partner (GFPT1). RMSD:1.4974
Å |
 |  |  |  |  |
| PUM1_HNRNPR_ENST00000373741_ENST00000374616_31532050_23648156 superimposed PDB: 9EJY of partner (HNRNPR). RMSD:1.3033
Å |
 |  |  |  |  |
| PUM1_HNRNPR_ENST00000373742_ENST00000374616_31532050_23648156 superimposed PDB: 9EJY of partner (HNRNPR). RMSD:0.5007
Å |
 |  |  |  |  |
| PUM1_KANSL1_ENST00000373741_ENST00000572904_31532050_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:2.0203
Å |
 |  |  |  |  |
| PUM1_KANSL1_ENST00000373741_ENST00000575318_31532050_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.6491
Å |
 |  |  |  |  |
| PUM1_KANSL1_ENST00000373742_ENST00000572904_31532050_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.819
Å |
 |  |  |  |  |
| PUM1_KANSL1_ENST00000373742_ENST00000575318_31532050_44145033 superimposed PDB: 4CY1 of partner (KANSL1). RMSD:1.5747
Å |
 |  |  |  |  |
| PUM1_NKAIN1_ENST00000373741_ENST00000373736_31447497_31661034 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.4413
Å |
 |  |  |  |  |
| PUM1_NKAIN1_ENST00000373742_ENST00000373736_31422979_31661034 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.4664
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368207_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7712
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368210_31478699_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7805
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368210_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.8394
Å |
| | | |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368213_31478699_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7982
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368213_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.3707
Å |
| | | |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368215_31478699_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7824
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368215_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7916
Å |
| | | |  |
| PUM1_PTPRK_ENST00000257075_ENST00000368227_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.6129
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000532331_31478699_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7923
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000257075_ENST00000532331_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.6025
Å |
| | | |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368207_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9178
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368210_31479840_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7665
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368210_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.2848
Å |
| | | |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368213_31479840_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7948
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368213_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.7593
Å |
| | | |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368215_31479840_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7769
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368215_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9524
Å |
| | | |  |
| PUM1_PTPRK_ENST00000373741_ENST00000368227_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.9831
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000532331_31479840_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.8116
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373741_ENST00000532331_31479840_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:2.3266
Å |
| | | |  |
| PUM1_PTPRK_ENST00000373747_ENST00000368226_31478699_128643455 superimposed PDB: 1IB2 of partner (PUM1). RMSD:2.7948
Å |
 |  |  |  |  |
| PUM1_PTPRK_ENST00000373747_ENST00000368226_31478699_128643455 superimposed PDB: 8A1F of partner (PTPRK). RMSD:1.5783
Å |
| | | |  |
| PVRL3_CASK_ENST00000319792_ENST00000421587_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.1487
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000485303_ENST00000318588_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.2702
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000485303_ENST00000361962_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.1297
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000485303_ENST00000378158_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.228
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000485303_ENST00000378163_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:0.9332
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000485303_ENST00000421587_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.048
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000493615_ENST00000318588_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.1992
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000493615_ENST00000361962_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.1872
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000493615_ENST00000378158_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:0.9229
Å |
 |  |  |  |  |
| PVRL3_CASK_ENST00000493615_ENST00000378163_110845182_41469278 superimposed PDB: 4FOM of partner (PVRL3). RMSD:1.1589
Å |
 |  |  |  |  |
| PVR_HPN_ENST00000403059_ENST00000262626_45162033_35556153 superimposed PDB: 3J8F of partner (PVR). RMSD:1.4236
Å |
 |  |  |  |  |
| PVR_HPN_ENST00000403059_ENST00000262626_45162033_35556153 superimposed PDB: 1Z8G of partner (HPN). RMSD:0.4851
Å |
| | | |  |
| PVR_HPN_ENST00000403059_ENST00000392226_45162033_35556153 superimposed PDB: 3J8F of partner (PVR). RMSD:0.7209
Å |
 |  |  |  |  |
| PVR_SIRT2_ENST00000344956_ENST00000249396_45147475_39372131 superimposed PDB: 9DPD of partner (SIRT2). RMSD:2.6548
Å |
 |  |  |  |  |
| PVR_SIRT2_ENST00000406449_ENST00000392081_45147475_39372131 superimposed PDB: 9DPD of partner (SIRT2). RMSD:1.3661
Å |
 |  |  |  |  |
| PVR_SIRT2_ENST00000425690_ENST00000392081_45147475_39372131 superimposed PDB: 9DPD of partner (SIRT2). RMSD:1.4754
Å |
 |  |  |  |  |
| PVR_ZNF233_ENST00000344956_ENST00000334152_45150842_44768465 superimposed PDB: 3J8F of partner (PVR). RMSD:0.7449
Å |
 |  |  |  |  |
| PVR_ZNF233_ENST00000344956_ENST00000334152_45150842_44768465 superimposed PDB: 2ELY of partner (ZNF233). RMSD:0.5708
Å |
| | | |  |
| PXDN_NRXN1_ENST00000252804_ENST00000401710_1667376_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.4786
Å |
 |  |  |  |  |
| PXDN_NRXN1_ENST00000252804_ENST00000401710_1669985_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.5419
Å |
 |  |  |  |  |
| PXDN_NRXN1_ENST00000252804_ENST00000401710_1677414_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.5031
Å |
 |  |  |  |  |
| PXDN_NRXN1_ENST00000252804_ENST00000406316_1667376_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.4906
Å |
 |  |  |  |  |
| PXDN_NRXN1_ENST00000252804_ENST00000406316_1669985_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.5007
Å |
 |  |  |  |  |
| PXDN_NRXN1_ENST00000252804_ENST00000406316_1677414_50464108 superimposed PDB: 3B3Q of partner (NRXN1). RMSD:0.5086
Å |
 |  |  |  |  |
| PXK_FLNB_ENST00000356151_ENST00000348383_58318817_58128376 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.8902
Å |
 |  |  |  |  |
| PXK_FLNB_ENST00000356151_ENST00000429972_58318817_58145280 superimposed PDB: 4B7L of partner (FLNB). RMSD:0.8954
Å |
 |  |  |  |  |
| PXMP2_RPA1_ENST00000428960_ENST00000254719_133277955_1782286 superimposed PDB: 8RK2 of partner (RPA1). RMSD:0.8432
Å |
 |  |  |  |  |
| PYGB_CCNL2_ENST00000216962_ENST00000400809_25264887_1323445 superimposed PDB: 5IKO of partner (PYGB). RMSD:0.754
Å |
 |  |  |  |  |
| PYGB_CNBD2_ENST00000216962_ENST00000349339_25273249_34575316 superimposed PDB: 5IKO of partner (PYGB). RMSD:0.6846
Å |
 |  |  |  |  |
| PYGB_CNBD2_ENST00000216962_ENST00000538900_25273249_34575316 superimposed PDB: 5IKO of partner (PYGB). RMSD:0.7261
Å |
 |  |  |  |  |
| QKI_NTRK2_ENST00000275262_ENST00000376213_163984751_87482157 superimposed PDB: 4JVH of partner (QKI). RMSD:0.8292
Å |
 |  |  |  |  |
| QKI_NTRK2_ENST00000275262_ENST00000376213_163984751_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8447
Å |
| | | |  |
| QKI_NTRK2_ENST00000361195_ENST00000376213_163984751_87482157 superimposed PDB: 4JVH of partner (QKI). RMSD:0.9046
Å |
 |  |  |  |  |
| QKI_NTRK2_ENST00000361195_ENST00000376213_163984751_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7676
Å |
| | | |  |
| QPCTL_ETHE1_ENST00000012049_ENST00000600651_46198976_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:1.1707
Å |
 |  |  |  |  |
| QPCTL_MRPL4_ENST00000012049_ENST00000253099_46196814_10363072 superimposed PDB: 3PB6 of partner (QPCTL). RMSD:2.4985
Å |
 |  |  |  |  |
| QPCTL_MRPL4_ENST00000012049_ENST00000253099_46196814_10363072 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:0.6986
Å |
| | | |  |
| QPCTL_MRPL4_ENST00000012049_ENST00000393733_46196814_10363072 superimposed PDB: 3PB6 of partner (QPCTL). RMSD:2.6132
Å |
 |  |  |  |  |
| QPCTL_MRPL4_ENST00000012049_ENST00000393733_46196814_10363072 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.3305
Å |
| | | |  |
| QPCTL_MRPL4_ENST00000366382_ENST00000307422_46196814_10363072 superimposed PDB: 7OF0 of partner (MRPL4). RMSD:1.4182
Å |
 |  |  |  |  |
| QPCTL_NDUFB4_ENST00000366382_ENST00000184266_46196814_120319957 superimposed PDB: 3PB6 of partner (QPCTL). RMSD:2.9165
Å |
 |  |  |  |  |
| QRICH1_PRKAR2A_ENST00000357496_ENST00000454963_49081822_48845117 superimposed PDB: 9HJU of partner (QRICH1). RMSD:0.5608
Å |
 |  |  |  |  |
| QRICH1_TRAIP_ENST00000395443_ENST00000469027_49114141_49869501 superimposed PDB: 4ZTD of partner (TRAIP). RMSD:2.0665
Å |
 |  |  |  |  |
| QRICH1_USP4_ENST00000357496_ENST00000351842_49094294_49315884 superimposed PDB: 2Y6E of partner (USP4). RMSD:2.1097
Å |
 |  |  |  |  |
| R3HDM4_JAK3_ENST00000361574_ENST00000534444_913086_17953981 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.4746
Å |
 |  |  |  |  |
| R3HDM4_JAK3_ENST00000587975_ENST00000458235_913086_17953981 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.5393
Å |
 |  |  |  |  |
| RAB10_SDC1_ENST00000264710_ENST00000254351_26350820_20405185 superimposed PDB: 5SZJ of partner (RAB10). RMSD:0.7852
Å |
 |  |  |  |  |
| RAB10_SDC1_ENST00000264710_ENST00000381150_26350820_20405185 superimposed PDB: 5SZJ of partner (RAB10). RMSD:0.3941
Å |
 |  |  |  |  |
| RAB11B_HAO2_ENST00000328024_ENST00000361035_8455340_119923700 superimposed PDB: 2F9L of partner (RAB11B). RMSD:0.9422
Å |
 |  |  |  |  |
| RAB11FIP3_CREB5_ENST00000262305_ENST00000357727_521389_28843815 superimposed PDB: 2HV8 of partner (RAB11FIP3). RMSD:2.415
Å |
 |  |  |  |  |
| RAB11FIP3_TUBB3_ENST00000457159_ENST00000556922_521389_89998978 superimposed PDB: 6S8L of partner (TUBB3). RMSD:0.8403
Å |
 |  |  |  |  |
| RAB18_SVIL_ENST00000356940_ENST00000375398_27798859_29762918 superimposed PDB: 1X3S of partner (RAB18). RMSD:2.7041
Å |
 |  |  |  |  |
| RAB18_SVIL_ENST00000356940_ENST00000375398_27798859_29762918 superimposed PDB: 2K6M of partner (SVIL). RMSD:1.5415
Å |
| | | |  |
| RAB1A_ACTR2_ENST00000409784_ENST00000260641_65357026_65466985 superimposed PDB: 9I2B of partner (ACTR2). RMSD:0.8657
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000275575_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.9341
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000307305_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.6689
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000415251_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.6627
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000416283_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.7763
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000424760_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.8167
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000260638_ENST00000450574_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.6669
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000275575_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.2151
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000307305_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.7015
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000415251_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.1817
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000416283_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.7731
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000424760_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.2273
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409751_ENST00000450574_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.1921
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000275575_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.1108
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000275575_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.0597
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000307305_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.0356
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000307305_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.8072
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000415251_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.8363
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000415251_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.7491
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000416283_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:1.2748
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000416283_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.9974
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000424760_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.7315
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000424760_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.6817
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000450574_65318116_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.7207
Å |
 |  |  |  |  |
| RAB1A_PHTF2_ENST00000409784_ENST00000450574_65325104_77522924 superimposed PDB: 9MHF of partner (RAB1A). RMSD:0.7646
Å |
 |  |  |  |  |
| RAB1B_ARFGEF2_ENST00000527397_ENST00000371917_66043406_47567859 superimposed PDB: 5SZH of partner (RAB1B). RMSD:0.5572
Å |
 |  |  |  |  |
| RAB1B_ARFGEF2_ENST00000527397_ENST00000371917_66043406_47567859 superimposed PDB: 3L8N of partner (ARFGEF2). RMSD:0.7838
Å |
| | | |  |
| RAB21_DNM3_ENST00000261263_ENST00000367731_72149068_172050971 superimposed PDB: 1Z08 of partner (RAB21). RMSD:1.7409
Å |
 |  |  |  |  |
| RAB21_DNM3_ENST00000261263_ENST00000367733_72149068_172050971 superimposed PDB: 1Z08 of partner (RAB21). RMSD:1.4945
Å |
 |  |  |  |  |
| RAB21_DNM3_ENST00000261263_ENST00000520906_72149068_172050971 superimposed PDB: 1Z08 of partner (RAB21). RMSD:1.0995
Å |
 |  |  |  |  |
| RAB21_MDM1_ENST00000261263_ENST00000303145_72164479_68696652 superimposed PDB: 1Z08 of partner (RAB21). RMSD:0.7253
Å |
 |  |  |  |  |
| RAB21_MDM1_ENST00000261263_ENST00000540418_72164479_68696652 superimposed PDB: 1Z08 of partner (RAB21). RMSD:0.7711
Å |
 |  |  |  |  |
| RAB27A_ASTN2_ENST00000336787_ENST00000313400_55516086_119626012 superimposed PDB: 9LA9 of partner (RAB27A). RMSD:0.7185
Å |
 |  |  |  |  |
| RAB27A_ASTN2_ENST00000336787_ENST00000313400_55516086_119626012 superimposed PDB: 5J67 of partner (ASTN2). RMSD:2.1958
Å |
| | | |  |
| RAB28_ASTN2_ENST00000288723_ENST00000313400_13475941_119739064 superimposed PDB: 5J67 of partner (ASTN2). RMSD:1.1588
Å |
 |  |  |  |  |
| RAB28_ASTN2_ENST00000288723_ENST00000361209_13475941_119739064 superimposed PDB: 5J67 of partner (ASTN2). RMSD:1.4268
Å |
 |  |  |  |  |
| RAB31_SS18_ENST00000578921_ENST00000542420_9708441_23667541 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4649
Å |
 |  |  |  |  |
| RAB3B_PKN2_ENST00000371655_ENST00000316005_52442561_89206670 superimposed PDB: 8A4C of partner (RAB3B). RMSD:0.455
Å |
 |  |  |  |  |
| RAB3B_PKN2_ENST00000371655_ENST00000370521_52442561_89206670 superimposed PDB: 8A4C of partner (RAB3B). RMSD:1.6538
Å |
 |  |  |  |  |
| RAB3GAP1_MAP4K3_ENST00000264158_ENST00000263881_135911446_39499683 superimposed PDB: 8VYB of partner (RAB3GAP1). RMSD:1.2019
Å |
 |  |  |  |  |
| RAB3GAP1_MAP4K3_ENST00000264158_ENST00000437545_135911446_39499683 superimposed PDB: 8VYB of partner (RAB3GAP1). RMSD:0.9856
Å |
 |  |  |  |  |
| RAB3GAP1_MAP4K3_ENST00000539493_ENST00000437545_135911446_39499683 superimposed PDB: 8VYB of partner (RAB3GAP1). RMSD:1.132
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000338921_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.6905
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000356819_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.6319
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000405005_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.421
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000520407_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.6067
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000520502_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.2904
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000521670_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.6732
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000301773_ENST00000523079_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.689
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000287842_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.3967
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000338921_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.3313
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000356819_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.3754
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000405005_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.3022
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000520407_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.2128
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000520502_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.158
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000521670_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.0901
Å |
 |  |  |  |  |
| RAB3IL1_NRG1_ENST00000394836_ENST00000523079_61666785_32585466 superimposed PDB: 4LI0 of partner (RAB3IL1). RMSD:1.3881
Å |
 |  |  |  |  |
| RAB3IP_CHD1L_ENST00000362025_ENST00000431239_70150443_146736080 superimposed PDB: 7ENN of partner (CHD1L). RMSD:2.0678
Å |
 |  |  |  |  |
| RAB3IP_CHD1L_ENST00000378815_ENST00000431239_70150443_146736080 superimposed PDB: 7ENN of partner (CHD1L). RMSD:1.9138
Å |
 |  |  |  |  |
| RAB3IP_CNOT2_ENST00000247833_ENST00000418359_70178595_70713077 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.1582
Å |
 |  |  |  |  |
| RAB3IP_CNOT2_ENST00000550536_ENST00000418359_70178595_70713077 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.0982
Å |
 |  |  |  |  |
| RAB3IP_RPAP3_ENST00000325555_ENST00000005386_70189124_48061634 superimposed PDB: 6FO1 of partner (RPAP3). RMSD:1.3168
Å |
 |  |  |  |  |
| RAB3IP_RPAP3_ENST00000362025_ENST00000005386_70189124_48061634 superimposed PDB: 6FO1 of partner (RPAP3). RMSD:1.3405
Å |
 |  |  |  |  |
| RAB3IP_RPAP3_ENST00000553099_ENST00000005386_70189124_48061634 superimposed PDB: 6FO1 of partner (RPAP3). RMSD:1.3869
Å |
 |  |  |  |  |
| RAB40B_YBX2_ENST00000538809_ENST00000007699_80656330_7193854 superimposed PDB: 7F3K of partner (YBX2). RMSD:3.3241
Å |
 |  |  |  |  |
| RAB7A_TRMT1_ENST00000265062_ENST00000357720_128526514_13221120 superimposed PDB: 1T91 of partner (RAB7A). RMSD:0.3984
Å |
 |  |  |  |  |
| RAB7A_TRMT1_ENST00000265062_ENST00000592062_128526514_13221120 superimposed PDB: 1T91 of partner (RAB7A). RMSD:0.4072
Å |
 |  |  |  |  |
| RAB7A_TRMT1_ENST00000482525_ENST00000357720_128526514_13221120 superimposed PDB: 1T91 of partner (RAB7A). RMSD:0.7708
Å |
 |  |  |  |  |
| RAB7A_TRMT1_ENST00000482525_ENST00000592062_128526514_13221120 superimposed PDB: 1T91 of partner (RAB7A). RMSD:0.6771
Å |
 |  |  |  |  |
| RAB8A_ADAM18_ENST00000300935_ENST00000379866_16232620_39550118 superimposed PDB: 5SZI of partner (RAB8A). RMSD:0.8036
Å |
 |  |  |  |  |
| RAB8A_ADAM18_ENST00000586682_ENST00000379866_16232620_39550118 superimposed PDB: 5SZI of partner (RAB8A). RMSD:0.733
Å |
 |  |  |  |  |
| RABAC1_BLVRB_ENST00000222008_ENST00000263368_42461169_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.821
Å |
 |  |  |  |  |
| RABAC1_ERF_ENST00000222008_ENST00000222329_42462437_42754717 superimposed PDB: 7JSA of partner (ERF). RMSD:0.4423
Å |
 |  |  |  |  |
| RABAC1_ERF_ENST00000601891_ENST00000222329_42462437_42754717 superimposed PDB: 7JSA of partner (ERF). RMSD:0.4241
Å |
 |  |  |  |  |
| RABEP1_ALG14_ENST00000262477_ENST00000370205_5264970_95492816 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.5773
Å |
 |  |  |  |  |
| RABEP1_ALG14_ENST00000262477_ENST00000370205_5266311_95492816 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.5959
Å |
 |  |  |  |  |
| RABEP1_ALG14_ENST00000408982_ENST00000370205_5266311_95492816 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.5432
Å |
 |  |  |  |  |
| RABEP1_ALG14_ENST00000546142_ENST00000370205_5264970_95492816 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.4964
Å |
 |  |  |  |  |
| RABEP1_ALG14_ENST00000546142_ENST00000370205_5266311_95492816 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.4633
Å |
 |  |  |  |  |
| RABEP1_ASPA_ENST00000262477_ENST00000456349_5185815_3397643 superimposed PDB: 4MXU of partner (ASPA). RMSD:0.4584
Å |
 |  |  |  |  |
| RABEP1_ASPA_ENST00000341923_ENST00000263080_5185815_3397643 superimposed PDB: 4MXU of partner (ASPA). RMSD:0.5959
Å |
 |  |  |  |  |
| RABEP1_ASPA_ENST00000408982_ENST00000263080_5185815_3397643 superimposed PDB: 4MXU of partner (ASPA). RMSD:0.4668
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000341923_ENST00000379102_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.8935
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000341923_ENST00000460380_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.8361
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000341923_ENST00000508862_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.0907
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000408982_ENST00000379102_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.801
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000408982_ENST00000379103_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.4896
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000408982_ENST00000460380_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.0793
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000408982_ENST00000508862_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.8889
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000537505_ENST00000379102_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.8661
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000537505_ENST00000460380_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.9087
Å |
 |  |  |  |  |
| RABEP1_LYRM9_ENST00000537505_ENST00000508862_5281527_26207392 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.9448
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000262477_ENST00000355280_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.4547
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000341923_ENST00000347992_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.3964
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000341923_ENST00000453408_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.7503
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000408982_ENST00000347992_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.0427
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000408982_ENST00000453408_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.2914
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000537505_ENST00000347992_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.5975
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000537505_ENST00000453408_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:1.7237
Å |
 |  |  |  |  |
| RABEP1_MINK1_ENST00000546142_ENST00000355280_5281527_4781611 superimposed PDB: 1X79 of partner (RABEP1). RMSD:2.264
Å |
 |  |  |  |  |
| RABEP1_RORB_ENST00000408982_ENST00000396204_5250220_77245197 superimposed PDB: 1X79 of partner (RABEP1). RMSD:3.1313
Å |
 |  |  |  |  |
| RABEP1_RORB_ENST00000537505_ENST00000396204_5250220_77245197 superimposed PDB: 1X79 of partner (RABEP1). RMSD:3.4246
Å |
 |  |  |  |  |
| RABEPK_PIK3R1_ENST00000259460_ENST00000521657_127970000_67569217 superimposed PDB: 8W9A of partner (PIK3R1). RMSD:2.3168
Å |
 |  |  |  |  |
| RABGAP1_CDS2_ENST00000373643_ENST00000379062_125839041_5170380 superimposed PDB: 4NC6 of partner (RABGAP1). RMSD:0.4094
Å |
 |  |  |  |  |
| RABGAP1_CDS2_ENST00000373647_ENST00000379062_125839041_5170380 superimposed PDB: 4NC6 of partner (RABGAP1). RMSD:0.6504
Å |
 |  |  |  |  |
| RAC1_AIMP2_ENST00000356142_ENST00000223029_6431672_6054776 superimposed PDB: 1I4D of partner (RAC1). RMSD:3.2553
Å |
 |  |  |  |  |
| RAC1_AIMP2_ENST00000356142_ENST00000223029_6431672_6054776 superimposed PDB: 5A1N of partner (AIMP2). RMSD:0.7032
Å |
| | | |  |
| RAC1_CKAP5_ENST00000348035_ENST00000312055_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.349
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000348035_ENST00000354558_6431672_46792532 superimposed PDB: 1I4D of partner (RAC1). RMSD:2.8118
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000348035_ENST00000354558_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.3626
Å |
| | | |  |
| RAC1_CKAP5_ENST00000348035_ENST00000415402_6431672_46792532 superimposed PDB: 1I4D of partner (RAC1). RMSD:2.9403
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000348035_ENST00000415402_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.3164
Å |
| | | |  |
| RAC1_CKAP5_ENST00000348035_ENST00000529230_6431672_46792532 superimposed PDB: 1I4D of partner (RAC1). RMSD:3.4497
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000356142_ENST00000312055_6431672_46792532 superimposed PDB: 1I4D of partner (RAC1). RMSD:2.6085
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000356142_ENST00000312055_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.3384
Å |
| | | |  |
| RAC1_CKAP5_ENST00000356142_ENST00000354558_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.3419
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000356142_ENST00000415402_6431672_46792532 superimposed PDB: 1I4D of partner (RAC1). RMSD:2.997
Å |
 |  |  |  |  |
| RAC1_CKAP5_ENST00000356142_ENST00000415402_6431672_46792532 superimposed PDB: 4QMI of partner (CKAP5). RMSD:0.3006
Å |
| | | |  |
| RAC1_EIF2AK1_ENST00000348035_ENST00000536084_6431672_6068663 superimposed PDB: 1I4D of partner (RAC1). RMSD:0.6994
Å |
 |  |  |  |  |
| RAC1_EIF2AK1_ENST00000356142_ENST00000199389_6431672_6068663 superimposed PDB: 1I4D of partner (RAC1). RMSD:0.7716
Å |
 |  |  |  |  |
| RAC1_EIF2AK1_ENST00000356142_ENST00000536084_6431672_6068663 superimposed PDB: 1I4D of partner (RAC1). RMSD:0.6346
Å |
 |  |  |  |  |
| RAC1_WDR70_ENST00000348035_ENST00000504564_6431672_37443340 superimposed PDB: 1I4D of partner (RAC1). RMSD:1.0204
Å |
 |  |  |  |  |
| RAC1_WDR70_ENST00000348035_ENST00000504564_6431672_37443340 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.9882
Å |
| | | |  |
| RAC1_WDR70_ENST00000356142_ENST00000265107_6431672_37443340 superimposed PDB: 1I4D of partner (RAC1). RMSD:0.6558
Å |
 |  |  |  |  |
| RAC1_WDR70_ENST00000356142_ENST00000265107_6431672_37443340 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.8286
Å |
| | | |  |
| RAC1_WDR70_ENST00000356142_ENST00000504564_6431672_37443340 superimposed PDB: 1I4D of partner (RAC1). RMSD:1.0282
Å |
 |  |  |  |  |
| RAC1_WDR70_ENST00000356142_ENST00000504564_6431672_37443340 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.9887
Å |
| | | |  |
| RAC3_ABCA8_ENST00000306897_ENST00000430352_79989672_66865920 superimposed PDB: 2C2H of partner (RAC3). RMSD:1.4991
Å |
 |  |  |  |  |
| RAD17_SEC24A_ENST00000354868_ENST00000398844_68670538_134050713 superimposed PDB: 2NUT of partner (SEC24A). RMSD:0.5847
Å |
 |  |  |  |  |
| RAD17_SEC24A_ENST00000380774_ENST00000398844_68670538_134050713 superimposed PDB: 2NUT of partner (SEC24A). RMSD:0.6705
Å |
 |  |  |  |  |
| RAD17_SEC24A_ENST00000509734_ENST00000398844_68670538_134050713 superimposed PDB: 2NUT of partner (SEC24A). RMSD:0.5679
Å |
 |  |  |  |  |
| RAD18_FANCD2_ENST00000264926_ENST00000287647_9000603_10114936 superimposed PDB: 2Y43 of partner (RAD18). RMSD:0.3746
Å |
 |  |  |  |  |
| RAD18_FANCD2_ENST00000264926_ENST00000383806_9000603_10114936 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.6226
Å |
 |  |  |  |  |
| RAD18_FANCD2_ENST00000264926_ENST00000383807_9000603_10114936 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.6038
Å |
 |  |  |  |  |
| RAD18_FANCD2_ENST00000264926_ENST00000419585_9000603_10114936 superimposed PDB: 2Y43 of partner (RAD18). RMSD:2.8738
Å |
 |  |  |  |  |
| RAD18_FANCD2_ENST00000264926_ENST00000419585_9000603_10114936 superimposed PDB: 8A9J of partner (FANCD2). RMSD:0.477
Å |
| | | |  |
| RAD21_TPM2_ENST00000297338_ENST00000378292_117862856_35685548 superimposed PDB: 7ZJS of partner (RAD21). RMSD:2.6913
Å |
 |  |  |  |  |
| RAD50_CADPS_ENST00000265335_ENST00000283269_131911620_62578423 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.9112
Å |
 |  |  |  |  |
| RAD50_CADPS_ENST00000265335_ENST00000357948_131911620_62578423 superimposed PDB: 9Q9K of partner (RAD50). RMSD:3.0994
Å |
 |  |  |  |  |
| RAD50_CADPS_ENST00000265335_ENST00000357948_131911620_62578423 superimposed PDB: 1WI1 of partner (CADPS). RMSD:0.8569
Å |
| | | |  |
| RAD50_LIPF_ENST00000378823_ENST00000608620_131915194_90429593 superimposed PDB: 9Q9K of partner (RAD50). RMSD:0.8144
Å |
 |  |  |  |  |
| RAD50_LIPF_ENST00000378823_ENST00000608620_131915194_90429593 superimposed PDB: 1HLG of partner (LIPF). RMSD:0.9862
Å |
| | | |  |
| RAD51AP1_SLCO1C1_ENST00000321524_ENST00000381552_4653070_20890040 superimposed PDB: 9DXP of partner (SLCO1C1). RMSD:1.4069
Å |
 |  |  |  |  |
| RAD51AP1_SLCO1C1_ENST00000321524_ENST00000540354_4653070_20890040 superimposed PDB: 9DXP of partner (SLCO1C1). RMSD:1.4619
Å |
 |  |  |  |  |
| RAD51AP1_SLCO1C1_ENST00000544927_ENST00000381552_4653070_20890040 superimposed PDB: 9DXP of partner (SLCO1C1). RMSD:1.5134
Å |
 |  |  |  |  |
| RAD51AP1_SLCO1C1_ENST00000544927_ENST00000540354_4653070_20890040 superimposed PDB: 9DXP of partner (SLCO1C1). RMSD:1.3013
Å |
 |  |  |  |  |
| RAD51B_AP5M1_ENST00000390683_ENST00000431972_68353921_57746912 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4765
Å |
 |  |  |  |  |
| RAD51B_AP5M1_ENST00000471583_ENST00000431972_68353921_57746912 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5531
Å |
 |  |  |  |  |
| RAD51B_AP5M1_ENST00000487861_ENST00000431972_68353921_57746912 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4134
Å |
 |  |  |  |  |
| RAD51B_AP5M1_ENST00000488612_ENST00000431972_68353921_57746912 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5745
Å |
 |  |  |  |  |
| RAD51B_CEP170_ENST00000390683_ENST00000366542_68353921_243349374 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1145
Å |
 |  |  |  |  |
| RAD51B_CEP170_ENST00000471583_ENST00000366542_68353921_243349374 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0147
Å |
 |  |  |  |  |
| RAD51B_CEP170_ENST00000487270_ENST00000366542_68353921_243349374 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1472
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000390683_ENST00000478722_68353921_67626131 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.4717
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000390683_ENST00000478722_68353921_67626131 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.599
Å |
| | | |  |
| RAD51B_GPHN_ENST00000390683_ENST00000478722_68878244_67588972 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0183
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000390683_ENST00000478722_68878244_67588972 superimposed PDB: 1JLJ of partner (GPHN). RMSD:1.8325
Å |
| | | |  |
| RAD51B_GPHN_ENST00000471583_ENST00000478722_68353921_67626131 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.6222
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000471583_ENST00000478722_68353921_67626131 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.5173
Å |
| | | |  |
| RAD51B_GPHN_ENST00000471583_ENST00000478722_68878244_67588972 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0323
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000471583_ENST00000478722_68878244_67588972 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.1215
Å |
| | | |  |
| RAD51B_GPHN_ENST00000487861_ENST00000315266_68878244_67588972 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0413
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000487861_ENST00000478722_68353921_67626131 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.9037
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000487861_ENST00000478722_68878244_67588972 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1612
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000487861_ENST00000478722_68878244_67588972 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.1773
Å |
| | | |  |
| RAD51B_GPHN_ENST00000488612_ENST00000478722_68353921_67626131 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.8565
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000488612_ENST00000478722_68878244_67588972 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.16
Å |
 |  |  |  |  |
| RAD51B_GPHN_ENST00000488612_ENST00000478722_68878244_67588972 superimposed PDB: 1JLJ of partner (GPHN). RMSD:2.4408
Å |
| | | |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000354636_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.119
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000354636_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6969
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000393577_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5204
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000393577_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1416
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000393578_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4998
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000393578_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.9975
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000403681_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6989
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000403681_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.931
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000425208_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7729
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000425208_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.9636
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000536545_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4031
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000536545_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1537
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000541363_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.0122
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000390683_ENST00000541363_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:2.0302
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000354636_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8517
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000354636_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.8747
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000393577_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4622
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000393577_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.783
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000393578_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0935
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000393578_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2493
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000403681_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8005
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000403681_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5365
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000425208_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8665
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000425208_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0532
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000536545_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4494
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000536545_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7782
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000541363_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6745
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000471583_ENST00000541363_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8651
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487270_ENST00000403681_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6012
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487270_ENST00000403681_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.9825
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000354636_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.9233
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000354636_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.9135
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000393577_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.3742
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000393577_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.8641
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000393578_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2123
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000393578_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1988
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000403681_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4591
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000425208_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6782
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000425208_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4731
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000536545_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2618
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000536545_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8436
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000541363_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1291
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000487861_ENST00000541363_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6429
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000354636_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.9467
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000354636_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.8564
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000393577_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5721
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000393577_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6942
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000393578_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4793
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000393578_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2468
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000425208_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8341
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000425208_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.0424
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000536545_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6087
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000536545_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2869
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000541363_68353921_66221780 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.806
Å |
 |  |  |  |  |
| RAD51B_HMGA2_ENST00000488612_ENST00000541363_68353921_66232298 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7478
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000390683_ENST00000303622_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1572
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000390683_ENST00000335102_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.853
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000390683_ENST00000416682_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.8504
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000390683_ENST00000429436_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.3141
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000471583_ENST00000303622_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.828
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000471583_ENST00000335102_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2982
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000471583_ENST00000416682_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.856
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000471583_ENST00000429436_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.2569
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000471583_ENST00000440884_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.5774
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000487861_ENST00000303622_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4468
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000487861_ENST00000335102_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.7782
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000487861_ENST00000416682_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.602
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000487861_ENST00000429436_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6989
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000488612_ENST00000303622_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.1595
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000488612_ENST00000335102_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6183
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000488612_ENST00000416682_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.6291
Å |
 |  |  |  |  |
| RAD51B_MARK3_ENST00000488612_ENST00000429436_68353921_103946723 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:1.4372
Å |
 |  |  |  |  |
| RAD51B_UVRAG_ENST00000390683_ENST00000531818_68934967_75851754 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.7008
Å |
 |  |  |  |  |
| RAD51B_UVRAG_ENST00000471583_ENST00000531818_68934967_75851754 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.5764
Å |
 |  |  |  |  |
| RAD51B_UVRAG_ENST00000487270_ENST00000531818_68934967_75851754 superimposed PDB: 9Q2A of partner (RAD51B). RMSD:0.637
Å |
 |  |  |  |  |
| RAD51C_ATXN7_ENST00000583539_ENST00000295900_56798173_63965590 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.4704
Å |
 |  |  |  |  |
| RAD51C_ATXN7_ENST00000583539_ENST00000487717_56798173_63965590 superimposed PDB: 8OUZ of partner (RAD51C). RMSD:1.6356
Å |
 |  |  |  |  |
| RAD51D_MAP2K4_ENST00000394589_ENST00000415385_33428219_11984672 superimposed PDB: 3ALN of partner (MAP2K4). RMSD:1.1316
Å |
 |  |  |  |  |
| RAD51D_TBC1D2_ENST00000345365_ENST00000342112_33445519_100965690 superimposed PDB: 8OUZ of partner (RAD51D). RMSD:0.7298
Å |
 |  |  |  |  |
| RAD51D_TBC1D2_ENST00000345365_ENST00000375064_33445519_100965690 superimposed PDB: 8OUZ of partner (RAD51D). RMSD:0.7373
Å |
 |  |  |  |  |
| RAD51D_TBC1D2_ENST00000360276_ENST00000375063_33445519_100965690 superimposed PDB: 8OUZ of partner (RAD51D). RMSD:0.7707
Å |
 |  |  |  |  |
| RAD51_ARPP19_ENST00000382643_ENST00000249822_40993399_52849419 superimposed PDB: 9TRM of partner (RAD51). RMSD:2.7082
Å |
 |  |  |  |  |
| RAD51_ARPP19_ENST00000423169_ENST00000249822_40993399_52849419 superimposed PDB: 9TRM of partner (RAD51). RMSD:2.9327
Å |
 |  |  |  |  |
| RAD54L_MAST2_ENST00000371975_ENST00000361297_46715791_46498267 superimposed PDB: 2KQF of partner (MAST2). RMSD:0.8309
Å |
 |  |  |  |  |
| RAD54L_MAST2_ENST00000371975_ENST00000372009_46715791_46498267 superimposed PDB: 2KQF of partner (MAST2). RMSD:0.8286
Å |
 |  |  |  |  |
| RAD54L_MAST2_ENST00000442598_ENST00000361297_46715791_46498267 superimposed PDB: 2KQF of partner (MAST2). RMSD:0.8008
Å |
 |  |  |  |  |
| RAD9A_CLPB_ENST00000307980_ENST00000340729_67159549_72141407 superimposed PDB: 7XBK of partner (CLPB). RMSD:1.3632
Å |
 |  |  |  |  |
| RAD9A_CLPB_ENST00000307980_ENST00000538039_67159549_72141407 superimposed PDB: 7XBK of partner (CLPB). RMSD:1.313
Å |
 |  |  |  |  |
| RAF1_GOLGA4_ENST00000442415_ENST00000361924_12645634_37356910 superimposed PDB: 1UPT of partner (GOLGA4). RMSD:0.7043
Å |
 |  |  |  |  |
| RAF1_MFN1_ENST00000534997_ENST00000471841_12641650_179103356 superimposed PDB: 5GOE of partner (MFN1). RMSD:2.5979
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000265109_ENST00000343111_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2621
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000265109_ENST00000347470_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2441
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000265109_ENST00000393360_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2393
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000265109_ENST00000425491_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.1982
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000265109_ENST00000455781_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2738
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000343111_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2733
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000347470_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2749
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000393360_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2724
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000425491_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.1948
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000452135_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2917
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000397449_ENST00000455781_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2814
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000343111_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2569
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000347470_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2837
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000393360_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2298
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000425491_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.1936
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000452135_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2848
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000506376_ENST00000455781_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2865
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000512629_ENST00000452135_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.3307
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000515799_ENST00000343111_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2714
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000515799_ENST00000347470_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.1937
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000515799_ENST00000393360_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2436
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000515799_ENST00000425491_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.1605
Å |
 |  |  |  |  |
| RAI14_MAPK9_ENST00000515799_ENST00000455781_34757703_179696409 superimposed PDB: 8ELC of partner (MAPK9). RMSD:1.2706
Å |
 |  |  |  |  |
| RALGAPA2_RPS16_ENST00000202677_ENST00000251453_20505049_39924401 superimposed PDB: 9QWP of partner (RALGAPA2). RMSD:1.7416
Å |
 |  |  |  |  |
| RALGAPA2_RPS16_ENST00000202677_ENST00000339471_20505049_39924401 superimposed PDB: 9QWP of partner (RALGAPA2). RMSD:1.704
Å |
 |  |  |  |  |
| RALGAPA2_RPS16_ENST00000202677_ENST00000601655_20505049_39924401 superimposed PDB: 9QWP of partner (RALGAPA2). RMSD:1.8958
Å |
 |  |  |  |  |
| RALGAPB_ITCH_ENST00000397038_ENST00000374864_37199490_33000320 superimposed PDB: 9QWP of partner (RALGAPB). RMSD:1.9943
Å |
 |  |  |  |  |
| RALGAPB_ITCH_ENST00000397038_ENST00000374864_37199490_33000320 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.5378
Å |
| | | |  |
| RALGAPB_ITCH_ENST00000397040_ENST00000374864_37199490_33000320 superimposed PDB: 9QWP of partner (RALGAPB). RMSD:1.7614
Å |
 |  |  |  |  |
| RALGAPB_ITCH_ENST00000397040_ENST00000374864_37199490_33000320 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.6194
Å |
| | | |  |
| RALGAPB_ITCH_ENST00000397042_ENST00000374864_37199490_33000320 superimposed PDB: 9QWP of partner (RALGAPB). RMSD:1.7418
Å |
 |  |  |  |  |
| RALGAPB_ITCH_ENST00000397042_ENST00000374864_37199490_33000320 superimposed PDB: 3TUG of partner (ITCH). RMSD:1.5417
Å |
| | | |  |
| RALGAPB_RPRD1B_ENST00000397042_ENST00000373433_37128276_36718127 superimposed PDB: 9QWP of partner (RALGAPB). RMSD:0.8159
Å |
 |  |  |  |  |
| RALGAPB_RPRD1B_ENST00000397042_ENST00000373433_37128276_36718127 superimposed PDB: 4NAD of partner (RPRD1B). RMSD:2.7796
Å |
| | | |  |
| RALGAPB_RPRD1B_ENST00000397042_ENST00000373433_37145013_36694482 superimposed PDB: 9QWP of partner (RALGAPB). RMSD:0.817
Å |
 |  |  |  |  |
| RALGAPB_RPRD1B_ENST00000397042_ENST00000373433_37145013_36694482 superimposed PDB: 4NAD of partner (RPRD1B). RMSD:2.6867
Å |
| | | |  |
| RANBP10_KARS_ENST00000317506_ENST00000302445_67839330_75675621 superimposed PDB: 6CHD of partner (KARS). RMSD:1.07
Å |
 |  |  |  |  |
| RANBP10_KARS_ENST00000448631_ENST00000302445_67839330_75675621 superimposed PDB: 6CHD of partner (KARS). RMSD:1.0133
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000317506_ENST00000316341_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.5473
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000317506_ENST00000537830_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.664
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000411657_ENST00000316341_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.6242
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000411657_ENST00000537830_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.5936
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000448631_ENST00000316341_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.5837
Å |
 |  |  |  |  |
| RANBP10_SLC12A4_ENST00000448631_ENST00000537830_67805936_67988676 superimposed PDB: 6KKR of partner (SLC12A4). RMSD:1.5981
Å |
 |  |  |  |  |
| RANBP10_SLC7A6_ENST00000317506_ENST00000566454_67839330_68328607 superimposed PDB: 9LDR of partner (SLC7A6). RMSD:2.4465
Å |
 |  |  |  |  |
| RANBP10_SLC7A6_ENST00000448631_ENST00000566454_67839330_68328607 superimposed PDB: 9LDR of partner (SLC7A6). RMSD:2.2622
Å |
 |  |  |  |  |
| RANBP3_MLLT1_ENST00000034275_ENST00000252674_5924837_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5355
Å |
 |  |  |  |  |
| RANBP3_MLLT1_ENST00000340578_ENST00000252674_5924837_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5201
Å |
 |  |  |  |  |
| RANBP3_MLLT1_ENST00000541471_ENST00000252674_5924837_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5377
Å |
 |  |  |  |  |
| RANBP3_MLLT1_ENST00000591092_ENST00000252674_5924837_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.532
Å |
 |  |  |  |  |
| RANBP9_BLOC1S5_ENST00000011619_ENST00000543936_13697016_8016061 superimposed PDB: 7NSC of partner (RANBP9). RMSD:0.7784
Å |
 |  |  |  |  |
| RANBP9_TXNDC5_ENST00000011619_ENST00000379757_13697016_7904956 superimposed PDB: 7NSC of partner (RANBP9). RMSD:3.557
Å |
 |  |  |  |  |
| RANBP9_TXNDC5_ENST00000011619_ENST00000379757_13697016_7904956 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7561
Å |
| | | |  |
| RANGAP1_DSP_ENST00000407260_ENST00000379802_41653951_7563968 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:2.9744
Å |
 |  |  |  |  |
| RANGAP1_DSP_ENST00000407260_ENST00000379802_41653951_7563968 superimposed PDB: 5DZZ of partner (DSP). RMSD:2.8657
Å |
| | | |  |
| RANGAP1_DSP_ENST00000407260_ENST00000418664_41653951_7563968 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:2.8427
Å |
 |  |  |  |  |
| RANGAP1_DSP_ENST00000407260_ENST00000418664_41653951_7563968 superimposed PDB: 5DZZ of partner (DSP). RMSD:2.842
Å |
| | | |  |
| RANGAP1_DSP_ENST00000455915_ENST00000418664_41653951_7563968 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:2.8096
Å |
 |  |  |  |  |
| RANGAP1_DSP_ENST00000455915_ENST00000418664_41653951_7563968 superimposed PDB: 5DZZ of partner (DSP). RMSD:3.0712
Å |
| | | |  |
| RANGAP1_PMM1_ENST00000407260_ENST00000216259_41664100_41974885 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:1.0372
Å |
 |  |  |  |  |
| RANGAP1_PMM1_ENST00000407260_ENST00000216259_41664100_41974885 superimposed PDB: 2FUE of partner (PMM1). RMSD:2.809
Å |
| | | |  |
| RANGAP1_PMM1_ENST00000455915_ENST00000216259_41664100_41974885 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:2.8342
Å |
 |  |  |  |  |
| RANGAP1_RPL3_ENST00000455915_ENST00000216146_41660667_39714597 superimposed PDB: 9B62 of partner (RANGAP1). RMSD:2.8416
Å |
 |  |  |  |  |
| RAP1A_RAP1B_ENST00000356415_ENST00000393436_112240119_69047891 superimposed PDB: 4KVG of partner (RAP1A). RMSD:0.2333
Å |
 |  |  |  |  |
| RAP1A_RAP1B_ENST00000356415_ENST00000393436_112240119_69047891 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.2721
Å |
| | | |  |
| RAP1B_RAP1A_ENST00000250559_ENST00000436150_69045831_112245957 superimposed PDB: 4HDO of partner (RAP1B). RMSD:0.3034
Å |
 |  |  |  |  |
| RAP1B_RAP1A_ENST00000250559_ENST00000436150_69045831_112245957 superimposed PDB: 4KVG of partner (RAP1A). RMSD:0.2511
Å |
| | | |  |
| RAP1GAP_NSDHL_ENST00000290101_ENST00000370274_21976253_152027313 superimposed PDB: 6JKG of partner (NSDHL). RMSD:0.5311
Å |
 |  |  |  |  |
| RAPGEF1_FARS2_ENST00000372189_ENST00000274680_134514021_5613401 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.6321
Å |
 |  |  |  |  |
| RAPGEF1_FARS2_ENST00000372190_ENST00000274680_134514021_5613401 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.6417
Å |
 |  |  |  |  |
| RAPGEF1_FARS2_ENST00000372190_ENST00000324331_134514021_5613401 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.6557
Å |
 |  |  |  |  |
| RAPGEF1_FARS2_ENST00000372195_ENST00000274680_134514021_5613401 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.5948
Å |
 |  |  |  |  |
| RAPGEF1_FARS2_ENST00000372195_ENST00000324331_134514021_5613401 superimposed PDB: 3CMQ of partner (FARS2). RMSD:0.6217
Å |
 |  |  |  |  |
| RAPGEF3_MYRFL_ENST00000405493_ENST00000547771_48142236_70349142 superimposed PDB: 6H7E of partner (RAPGEF3). RMSD:1.2692
Å |
 |  |  |  |  |
| RAPGEF5_ISPD_ENST00000401957_ENST00000407010_22186514_16415866 superimposed PDB: 1WGY of partner (RAPGEF5). RMSD:1.0815
Å |
 |  |  |  |  |
| RAPGEF5_ISPD_ENST00000401957_ENST00000407010_22186514_16415866 superimposed PDB: 4CVH of partner (ISPD). RMSD:2.4058
Å |
| | | |  |
| RAPGEF6_BCL2L1_ENST00000509018_ENST00000307677_130928075_30253889 superimposed PDB: 2D93 of partner (RAPGEF6). RMSD:2.2884
Å |
 |  |  |  |  |
| RARA_SKAP1_ENST00000394081_ENST00000336915_38499119_46214699 superimposed PDB: 1U5D of partner (SKAP1). RMSD:2.1892
Å |
 |  |  |  |  |
| RARA_SLC9A3R1_ENST00000394081_ENST00000262613_38508759_72758150 superimposed PDB: 2KRG of partner (SLC9A3R1). RMSD:2.5837
Å |
 |  |  |  |  |
| RARA_SLC9A3R1_ENST00000394089_ENST00000262613_38508759_72758150 superimposed PDB: 2KRG of partner (SLC9A3R1). RMSD:2.8159
Å |
 |  |  |  |  |
| RARB_FAM19A4_ENST00000330688_ENST00000295569_25542814_68802169 superimposed PDB: 5UAN of partner (RARB). RMSD:0.3426
Å |
 |  |  |  |  |
| RARB_FAM19A4_ENST00000437042_ENST00000295569_25542814_68802169 superimposed PDB: 5UAN of partner (RARB). RMSD:0.3601
Å |
 |  |  |  |  |
| RARB_FAM19A4_ENST00000458646_ENST00000295569_25542814_68802169 superimposed PDB: 5UAN of partner (RARB). RMSD:0.3418
Å |
 |  |  |  |  |
| RARB_FGF12_ENST00000330688_ENST00000264730_25502832_191888445 superimposed PDB: 4JQ0 of partner (FGF12). RMSD:1.1477
Å |
 |  |  |  |  |
| RARB_FGF12_ENST00000404969_ENST00000264730_25502832_191888445 superimposed PDB: 4JQ0 of partner (FGF12). RMSD:1.1906
Å |
 |  |  |  |  |
| RASA2_ADIPOR2_ENST00000286364_ENST00000357103_141299293_1887019 superimposed PDB: 5LX9 of partner (ADIPOR2). RMSD:0.4771
Å |
 |  |  |  |  |
| RASA2_ADIPOR2_ENST00000286364_ENST00000357103_141300019_1887019 superimposed PDB: 5LX9 of partner (ADIPOR2). RMSD:0.4511
Å |
 |  |  |  |  |
| RASA2_HSP90AB1_ENST00000452898_ENST00000371554_141248644_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.5274
Å |
 |  |  |  |  |
| RASSF3_TBK1_ENST00000542104_ENST00000331710_65004523_64889262 superimposed PDB: 6NT9 of partner (TBK1). RMSD:1.7107
Å |
 |  |  |  |  |
| RB1CC1_PTPN3_ENST00000539297_ENST00000446349_53580580_112153841 superimposed PDB: 8SRM of partner (RB1CC1). RMSD:2.0791
Å |
 |  |  |  |  |
| RB1CC1_SNX16_ENST00000025008_ENST00000396330_53568567_82736175 superimposed PDB: 8SRM of partner (RB1CC1). RMSD:2.0534
Å |
 |  |  |  |  |
| RB1_DIAPH3_ENST00000267163_ENST00000400330_48881542_60707123 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.8
Å |
 |  |  |  |  |
| RB1_HTR2C_ENST00000267163_ENST00000276198_48881542_114141151 superimposed PDB: 8DPF of partner (HTR2C). RMSD:2.1964
Å |
 |  |  |  |  |
| RB1_KCNRG_ENST00000267163_ENST00000312942_48939107_50594349 superimposed PDB: 4ELJ of partner (RB1). RMSD:1.4347
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000373493_ENST00000380084_33134733_16867424 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.5599
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000373493_ENST00000380084_33134733_16867424 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.8147
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000373493_ENST00000380084_33134733_16870998 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.3447
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000373493_ENST00000380084_33134733_16870998 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.4359
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000414241_ENST00000380084_33134733_16867424 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.5052
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000414241_ENST00000380084_33134733_16867424 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.6621
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000414241_ENST00000380084_33134733_16870998 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.3439
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000414241_ENST00000380084_33134733_16870998 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.4374
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000458695_ENST00000380084_33134733_16867424 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.5374
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000458695_ENST00000380084_33134733_16867424 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.6205
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000458695_ENST00000380084_33134733_16870998 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.3396
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000458695_ENST00000380084_33134733_16870998 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.4407
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000544435_ENST00000380084_33134733_16867424 superimposed PDB: 4R7A of partner (RBBP4). RMSD:2.7793
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000544435_ENST00000380084_33134733_16867424 superimposed PDB: 3CFS of partner (RBBP7). RMSD:3.0062
Å |
| | | |  |
| RBBP4_RBBP7_ENST00000544435_ENST00000380084_33134733_16870998 superimposed PDB: 4R7A of partner (RBBP4). RMSD:0.375
Å |
 |  |  |  |  |
| RBBP4_RBBP7_ENST00000544435_ENST00000380084_33134733_16870998 superimposed PDB: 3CFS of partner (RBBP7). RMSD:0.4674
Å |
| | | |  |
| RBFOX2_MED15_ENST00000438146_ENST00000425759_36424287_20905722 superimposed PDB: 2CQ3 of partner (RBFOX2). RMSD:2.6082
Å |
 |  |  |  |  |
| RBKS_ALK_ENST00000444339_ENST00000389048_28065933_29754982 superimposed PDB: 9CVB of partner (RBKS). RMSD:0.7108
Å |
 |  |  |  |  |
| RBKS_ALK_ENST00000444339_ENST00000389048_28065933_29754982 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4827
Å |
| | | |  |
| RBL1_BCAS1_ENST00000373664_ENST00000395961_35651052_52561535 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.3797
Å |
 |  |  |  |  |
| RBL1_BCAS1_ENST00000373664_ENST00000434986_35651052_52561535 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.3373
Å |
 |  |  |  |  |
| RBL1_NDRG3_ENST00000344359_ENST00000373803_35651052_35335410 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.4349
Å |
 |  |  |  |  |
| RBL1_NDRG3_ENST00000344359_ENST00000373803_35651052_35335410 superimposed PDB: 6L4B of partner (NDRG3). RMSD:0.4165
Å |
| | | |  |
| RBL1_PPP4R1L_ENST00000344359_ENST00000334187_35675455_56861502 superimposed PDB: 7SMD of partner (RBL1). RMSD:0.3961
Å |
 |  |  |  |  |
| RBL1_TMPRSS15_ENST00000344359_ENST00000284885_35668555_19770646 superimposed PDB: 8ZIY of partner (TMPRSS15). RMSD:2.9178
Å |
 |  |  |  |  |
| RBM10_ACTN4_ENST00000329236_ENST00000252699_47035985_39207725 superimposed PDB: 2M2B of partner (RBM10). RMSD:1.8479
Å |
 |  |  |  |  |
| RBM10_ACTN4_ENST00000345781_ENST00000252699_47035985_39207725 superimposed PDB: 2M2B of partner (RBM10). RMSD:2.0021
Å |
 |  |  |  |  |
| RBM10_TFE3_ENST00000329236_ENST00000315869_47041725_48895639 superimposed PDB: 2M2B of partner (RBM10). RMSD:2.8132
Å |
 |  |  |  |  |
| RBM10_TFE3_ENST00000329236_ENST00000315869_47041725_48895639 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.2275
Å |
| | | |  |
| RBM10_TFE3_ENST00000345781_ENST00000315869_47041725_48895639 superimposed PDB: 2M2B of partner (RBM10). RMSD:2.8212
Å |
 |  |  |  |  |
| RBM10_TFE3_ENST00000345781_ENST00000315869_47041725_48895639 superimposed PDB: 7F09 of partner (TFE3). RMSD:1.5972
Å |
| | | |  |
| RBM14_C11orf80_ENST00000310137_ENST00000360962_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.9323
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000393979_ENST00000346672_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.9478
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000393979_ENST00000360962_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.8282
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000409372_ENST00000346672_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.9009
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000409738_ENST00000346672_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.9802
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000409738_ENST00000360962_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.9192
Å |
 |  |  |  |  |
| RBM14_C11orf80_ENST00000443702_ENST00000360962_66384528_66526513 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.8065
Å |
 |  |  |  |  |
| RBM14_ZC3H3_ENST00000310137_ENST00000262577_66384528_144590069 superimposed PDB: 2DNP of partner (RBM14). RMSD:0.8708
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000379775_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.8082
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000379782_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.817
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000379785_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.7672
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000379789_6154324_6255585 superimposed PDB: 6HIP of partner (RBM17). RMSD:0.4905
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000379789_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.361
Å |
| | | |  |
| RBM17_PFKFB3_ENST00000379888_ENST00000540253_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.79
Å |
 |  |  |  |  |
| RBM17_PFKFB3_ENST00000446108_ENST00000360521_6154324_6255585 superimposed PDB: 6HVI of partner (PFKFB3). RMSD:0.8292
Å |
 |  |  |  |  |
| RBM17_PRKACB_ENST00000446108_ENST00000370689_6148201_84644859 superimposed PDB: 6HIP of partner (RBM17). RMSD:0.5038
Å |
 |  |  |  |  |
| RBM23_PSMB5_ENST00000359890_ENST00000493471_23375409_23502883 superimposed PDB: 8BZL of partner (PSMB5). RMSD:0.6187
Å |
 |  |  |  |  |
| RBM28_AOAH_ENST00000223073_ENST00000258749_127957711_36634036 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.7129
Å |
 |  |  |  |  |
| RBM28_AOAH_ENST00000223073_ENST00000538464_127957711_36634036 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.6187
Å |
 |  |  |  |  |
| RBM28_AOAH_ENST00000415472_ENST00000258749_127957711_36634036 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.5954
Å |
 |  |  |  |  |
| RBM28_AOAH_ENST00000415472_ENST00000538464_127957711_36634036 superimposed PDB: 5W7C of partner (AOAH). RMSD:0.6112
Å |
 |  |  |  |  |
| RBM38_FRMD4B_ENST00000356208_ENST00000542259_55968389_69267530 superimposed PDB: 2CQD of partner (RBM38). RMSD:0.8899
Å |
 |  |  |  |  |
| RBM38_FRMD4B_ENST00000371219_ENST00000542259_55968389_69267530 superimposed PDB: 2CQD of partner (RBM38). RMSD:1.3842
Å |
 |  |  |  |  |
| RBM39_VMP1_ENST00000253363_ENST00000262291_34309661_57842331 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.5013
Å |
 |  |  |  |  |
| RBM39_VMP1_ENST00000253363_ENST00000537567_34309661_57842331 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.4352
Å |
 |  |  |  |  |
| RBM39_VMP1_ENST00000407261_ENST00000537567_34309661_57842331 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.4464
Å |
 |  |  |  |  |
| RBM39_VMP1_ENST00000528062_ENST00000537567_34309661_57842331 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.4352
Å |
 |  |  |  |  |
| RBM39_WFDC13_ENST00000361162_ENST00000305479_34300940_44333082 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.4952
Å |
 |  |  |  |  |
| RBM39_WFDC13_ENST00000407261_ENST00000305479_34300940_44333082 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:2.5034
Å |
 |  |  |  |  |
| RBM45_DGUOK_ENST00000286070_ENST00000348222_178977573_74173845 superimposed PDB: 7CSZ of partner (RBM45). RMSD:0.318
Å |
 |  |  |  |  |
| RBM45_DGUOK_ENST00000286070_ENST00000348222_178977573_74173845 superimposed PDB: 2OCP of partner (DGUOK). RMSD:0.6591
Å |
| | | |  |
| RBM6_ARIH2_ENST00000266022_ENST00000449376_50099541_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:2.212
Å |
 |  |  |  |  |
| RBM6_ARIH2_ENST00000442092_ENST00000449376_50099541_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:1.7713
Å |
 |  |  |  |  |
| RBM6_ARIH2_ENST00000443081_ENST00000449376_50099541_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:2.2271
Å |
 |  |  |  |  |
| RBM6_ARIH2_ENST00000539992_ENST00000449376_50099541_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:1.8269
Å |
 |  |  |  |  |
| RBMS2_NACA_ENST00000262031_ENST00000550952_56980710_57106974 superimposed PDB: 1X4E of partner (RBMS2). RMSD:0.8547
Å |
 |  |  |  |  |
| RBMS2_NACA_ENST00000542360_ENST00000550952_56980710_57106974 superimposed PDB: 1X4E of partner (RBMS2). RMSD:0.7525
Å |
 |  |  |  |  |
| RBMS2_NACA_ENST00000550726_ENST00000550952_56980710_57106974 superimposed PDB: 1X4E of partner (RBMS2). RMSD:0.6726
Å |
 |  |  |  |  |
| RBMS3_DPH3_ENST00000383766_ENST00000488423_29985745_16305736 superimposed PDB: 2JR7 of partner (DPH3). RMSD:1.4438
Å |
 |  |  |  |  |
| RBMS3_DPH3_ENST00000383767_ENST00000488423_29985745_16305736 superimposed PDB: 2JR7 of partner (DPH3). RMSD:1.4311
Å |
 |  |  |  |  |
| RBP4_GPC3_ENST00000371467_ENST00000370818_95360149_132670321 superimposed PDB: 6QBA of partner (RBP4). RMSD:0.9165
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000397323_ENST00000394480_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5594
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000317501_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4659
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000317501_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6862
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000355254_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4418
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000355254_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7435
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000557856_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4628
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000557856_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7436
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000558676_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.3963
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000517860_ENST00000558676_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6696
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000317501_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4518
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000317501_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6639
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000355254_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4826
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000355254_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6655
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000394480_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5057
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000557856_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4451
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000557856_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7105
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000558676_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4284
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000519647_ENST00000558676_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6727
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000317501_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4488
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000317501_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6806
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000355254_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4691
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000355254_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6928
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000394480_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4931
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000557856_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4302
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000557856_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6916
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000558676_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4238
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520161_ENST00000558676_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6616
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000317501_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4586
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000317501_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7521
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000355254_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4745
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000355254_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.703
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000394480_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4526
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000557856_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4653
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000557856_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7432
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000558676_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4459
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000520191_ENST00000558676_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6625
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000317501_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4403
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000317501_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6918
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000355254_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4952
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000355254_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6923
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000394480_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:1.6271
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000557856_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4785
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000557856_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6983
Å |
| | | |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000558676_30361953_88576276 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.4416
Å |
 |  |  |  |  |
| RBPMS_NTRK3_ENST00000538486_ENST00000558676_30361953_88576276 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.7089
Å |
| | | |  |
| RBPMS_RILPL1_ENST00000538486_ENST00000376874_30242674_123970352 superimposed PDB: 5CYJ of partner (RBPMS). RMSD:0.5903
Å |
 |  |  |  |  |
| RCAN1_CD180_ENST00000481448_ENST00000256447_35893796_66481845 superimposed PDB: 3B2D of partner (CD180). RMSD:0.5769
Å |
 |  |  |  |  |
| RCAN1_RUNX1_ENST00000313806_ENST00000325074_35987058_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3531
Å |
 |  |  |  |  |
| RCAN1_RUNX1_ENST00000313806_ENST00000486278_35987058_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3413
Å |
 |  |  |  |  |
| RCCD1_BLM_ENST00000555155_ENST00000355112_91500955_91328150 superimposed PDB: 4CDG of partner (BLM). RMSD:1.7927
Å |
 |  |  |  |  |
| RCOR1_KIT_ENST00000570597_ENST00000288135_103148315_55561677 superimposed PDB: 8DFP of partner (KIT). RMSD:2.721
Å |
 |  |  |  |  |
| RCOR3_TTI1_ENST00000367006_ENST00000373447_211433506_36624864 superimposed PDB: 4CZZ of partner (RCOR3). RMSD:2.9387
Å |
 |  |  |  |  |
| RECK_KDM4C_ENST00000377966_ENST00000381309_36065621_6980924 superimposed PDB: 8TZP of partner (RECK). RMSD:2.1072
Å |
 |  |  |  |  |
| RECK_KDM4C_ENST00000377966_ENST00000381309_36065621_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.6778
Å |
| | | |  |
| RECK_KDM4C_ENST00000377966_ENST00000442236_36065621_6980924 superimposed PDB: 8TZP of partner (RECK). RMSD:2.1853
Å |
 |  |  |  |  |
| RECK_KDM4C_ENST00000377966_ENST00000442236_36065621_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.7597
Å |
| | | |  |
| RECK_KDM4C_ENST00000377966_ENST00000543771_36065621_6980924 superimposed PDB: 8TZP of partner (RECK). RMSD:2.2456
Å |
 |  |  |  |  |
| RECK_KDM4C_ENST00000377966_ENST00000543771_36065621_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:2.8367
Å |
| | | |  |
| RECK_NUDCD3_ENST00000377966_ENST00000355451_36065621_44524883 superimposed PDB: 8TZP of partner (RECK). RMSD:2.2449
Å |
 |  |  |  |  |
| REG3A_SERPINA1_ENST00000409839_ENST00000448921_79385776_94847478 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.6168
Å |
 |  |  |  |  |
| REL_MVP_ENST00000394479_ENST00000357402_61144152_29847024 superimposed PDB: 11EE of partner (MVP). RMSD:0.6744
Å |
 |  |  |  |  |
| REPS2_GLRA2_ENST00000303843_ENST00000218075_17121902_14708831 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6392
Å |
 |  |  |  |  |
| REPS2_GLRA2_ENST00000303843_ENST00000218075_17121902_14708831 superimposed PDB: 9Y7P of partner (GLRA2). RMSD:0.8394
Å |
| | | |  |
| REPS2_GLRA2_ENST00000357277_ENST00000218075_17121902_14708831 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6462
Å |
 |  |  |  |  |
| REPS2_GLRA2_ENST00000357277_ENST00000218075_17121902_14708831 superimposed PDB: 9Y7P of partner (GLRA2). RMSD:0.9979
Å |
| | | |  |
| REPS2_GLRA2_ENST00000380064_ENST00000218075_17121902_14708831 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.682
Å |
 |  |  |  |  |
| REPS2_SMARCA1_ENST00000303843_ENST00000371122_17047746_128615162 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.9242
Å |
 |  |  |  |  |
| REPS2_SMARCA1_ENST00000357277_ENST00000371122_17047746_128615162 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.9163
Å |
 |  |  |  |  |
| REPS2_SMARCA1_ENST00000380064_ENST00000371122_17047746_128615162 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.4878
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000303843_ENST00000380122_17121902_16836696 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.7104
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000303843_ENST00000398155_17121902_16847698 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6408
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000303843_ENST00000398155_17152030_16852405 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.675
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000357277_ENST00000380122_17121902_16847698 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6715
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000357277_ENST00000398155_17121902_16847698 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.647
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000357277_ENST00000398155_17152030_16852405 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6258
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000380064_ENST00000380122_17121902_16836696 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6481
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000380064_ENST00000398155_17121902_16847698 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6496
Å |
 |  |  |  |  |
| REPS2_TXLNG_ENST00000380064_ENST00000398155_17152030_16852405 superimposed PDB: 1IQ3 of partner (REPS2). RMSD:1.6335
Å |
 |  |  |  |  |
| RERE_CYP4A11_ENST00000337907_ENST00000310638_8525984_47403809 superimposed PDB: 2YQK of partner (RERE). RMSD:0.9846
Å |
 |  |  |  |  |
| RERE_SLC2A7_ENST00000400907_ENST00000400906_8716031_9085133 superimposed PDB: 9J2N of partner (SLC2A7). RMSD:0.6813
Å |
 |  |  |  |  |
| RERE_TPM3_ENST00000337907_ENST00000368533_8684368_154148724 superimposed PDB: 6OTN of partner (TPM3). RMSD:0.5429
Å |
 |  |  |  |  |
| RERE_TPM3_ENST00000400907_ENST00000368533_8674619_154148724 superimposed PDB: 6OTN of partner (TPM3). RMSD:0.5412
Å |
 |  |  |  |  |
| RERE_TPM3_ENST00000400907_ENST00000368533_8684368_154148724 superimposed PDB: 6OTN of partner (TPM3). RMSD:0.3672
Å |
 |  |  |  |  |
| RET_CCDC6_ENST00000340058_ENST00000263102_43610184_61612460 superimposed PDB: 6Q2O of partner (RET). RMSD:2.5146
Å |
 |  |  |  |  |
| RET_CCDC6_ENST00000340058_ENST00000263102_43610184_61612460 superimposed PDB: 9O04 of partner (CCDC6). RMSD:2.9903
Å |
| | | |  |
| RET_GOLGA5_ENST00000340058_ENST00000163416_43610184_93286052 superimposed PDB: 6Q2O of partner (RET). RMSD:2.4583
Å |
 |  |  |  |  |
| RET_GOLGA5_ENST00000355710_ENST00000355976_43610184_93286052 superimposed PDB: 6Q2O of partner (RET). RMSD:2.5732
Å |
 |  |  |  |  |
| RET_NCOA4_ENST00000340058_ENST00000438493_43610184_51582795 superimposed PDB: 6Q2O of partner (RET). RMSD:2.5082
Å |
 |  |  |  |  |
| RET_NCOA4_ENST00000340058_ENST00000438493_43610184_51582795 superimposed PDB: 9L93 of partner (NCOA4). RMSD:1.3309
Å |
| | | |  |
| RET_NCOA4_ENST00000340058_ENST00000438493_43610184_51584615 superimposed PDB: 6Q2O of partner (RET). RMSD:2.2341
Å |
 |  |  |  |  |
| RET_NCOA4_ENST00000340058_ENST00000438493_43610184_51584615 superimposed PDB: 9L93 of partner (NCOA4). RMSD:1.9954
Å |
| | | |  |
| RET_NCOA4_ENST00000355710_ENST00000452682_43610184_51582795 superimposed PDB: 6Q2O of partner (RET). RMSD:2.4162
Å |
 |  |  |  |  |
| RET_NCOA4_ENST00000355710_ENST00000452682_43610184_51582795 superimposed PDB: 9L93 of partner (NCOA4). RMSD:1.7387
Å |
| | | |  |
| RET_NCOA4_ENST00000355710_ENST00000452682_43610184_51584615 superimposed PDB: 6Q2O of partner (RET). RMSD:2.3923
Å |
 |  |  |  |  |
| RET_NCOA4_ENST00000355710_ENST00000452682_43610184_51584615 superimposed PDB: 9L93 of partner (NCOA4). RMSD:1.7846
Å |
| | | |  |
| REV3L_ARHGEF25_ENST00000368802_ENST00000286494_111803952_58008471 superimposed PDB: 2RGN of partner (ARHGEF25). RMSD:0.724
Å |
 |  |  |  |  |
| REV3L_C4B_ENST00000368802_ENST00000425700_111726672_32002290 superimposed PDB: 9U60 of partner (C4B). RMSD:0.8936
Å |
 |  |  |  |  |
| REV3L_FN3KRP_ENST00000368802_ENST00000535965_111628563_80684355 superimposed PDB: 3ABD of partner (REV3L). RMSD:2.0587
Å |
 |  |  |  |  |
| RFT1_UQCRC2_ENST00000296292_ENST00000561553_53137968_21982845 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.4143
Å |
 |  |  |  |  |
| RFT1_UQCRC2_ENST00000394738_ENST00000268379_53137968_21982845 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:3.4738
Å |
 |  |  |  |  |
| RFT1_UQCRC2_ENST00000394738_ENST00000561553_53137968_21982845 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.3248
Å |
 |  |  |  |  |
| RFTN1_GPD1L_ENST00000334133_ENST00000282541_16535231_32201059 superimposed PDB: 2PLA of partner (GPD1L). RMSD:0.5088
Å |
 |  |  |  |  |
| RFXANK_TECR_ENST00000303088_ENST00000215567_19309041_14673336 superimposed PDB: 3V30 of partner (RFXANK). RMSD:0.321
Å |
 |  |  |  |  |
| RFXANK_TECR_ENST00000303088_ENST00000215567_19309041_14673336 superimposed PDB: 2DZJ of partner (TECR). RMSD:0.7903
Å |
| | | |  |
| RFXANK_TECR_ENST00000407360_ENST00000215567_19309041_14673336 superimposed PDB: 3V30 of partner (RFXANK). RMSD:0.3265
Å |
 |  |  |  |  |
| RFXANK_TECR_ENST00000407360_ENST00000215567_19309041_14673336 superimposed PDB: 2DZJ of partner (TECR). RMSD:0.7881
Å |
| | | |  |
| RFXANK_TECR_ENST00000456252_ENST00000215567_19309041_14673336 superimposed PDB: 3V30 of partner (RFXANK). RMSD:0.33
Å |
 |  |  |  |  |
| RFXANK_TECR_ENST00000456252_ENST00000215567_19309041_14673336 superimposed PDB: 2DZJ of partner (TECR). RMSD:0.7886
Å |
| | | |  |
| RGPD5_NBEA_ENST00000393283_ENST00000400445_110565981_36158034 superimposed PDB: 1MI1 of partner (NBEA). RMSD:0.7189
Å |
 |  |  |  |  |
| RGS12_PDZRN3_ENST00000336727_ENST00000263666_3319778_73657835 superimposed PDB: 1WH1 of partner (PDZRN3). RMSD:0.8772
Å |
 |  |  |  |  |
| RGS12_USP2_ENST00000306648_ENST00000260187_3344780_119230944 superimposed PDB: 6DGF of partner (USP2). RMSD:0.4912
Å |
 |  |  |  |  |
| RGS12_USP2_ENST00000543385_ENST00000260187_3344780_119230944 superimposed PDB: 6DGF of partner (USP2). RMSD:0.5285
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000269051_ENST00000295854_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.7935
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000269051_ENST00000472206_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.6183
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000536287_ENST00000295854_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.6694
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000536287_ENST00000472206_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.7626
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000538145_ENST00000295854_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.9291
Å |
 |  |  |  |  |
| RHBDL3_CTLA4_ENST00000538145_ENST00000472206_30625223_204735308 superimposed PDB: 2X44 of partner (CTLA4). RMSD:0.8507
Å |
 |  |  |  |  |
| RHCG_MAN2C1_ENST00000544600_ENST00000563622_90022552_75649243 superimposed PDB: 3HD6 of partner (RHCG). RMSD:0.4548
Å |
 |  |  |  |  |
| RHCG_MAN2C1_ENST00000544600_ENST00000565683_90022552_75649243 superimposed PDB: 3HD6 of partner (RHCG). RMSD:0.4797
Å |
 |  |  |  |  |
| RHOA_EMC3_ENST00000422781_ENST00000245046_49405860_10011485 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.6926
Å |
 |  |  |  |  |
| RHOA_QRICH1_ENST00000418115_ENST00000357496_49412866_49084679 superimposed PDB: 9HJU of partner (QRICH1). RMSD:0.5983
Å |
 |  |  |  |  |
| RHOA_RHOC_ENST00000418115_ENST00000369642_49399928_113244335 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3967
Å |
 |  |  |  |  |
| RHOA_RHOC_ENST00000418115_ENST00000369642_49399928_113244335 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4287
Å |
| | | |  |
| RHOC_RHOA_ENST00000285735_ENST00000418115_113245620_49400059 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4122
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000285735_ENST00000418115_113245620_49400059 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3775
Å |
| | | |  |
| RHOC_RHOA_ENST00000285735_ENST00000454011_113245620_49400059 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4229
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000285735_ENST00000454011_113245620_49400059 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3801
Å |
| | | |  |
| RHOC_RHOA_ENST00000369632_ENST00000418115_113245620_49400059 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.5616
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000369632_ENST00000418115_113245620_49400059 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.5711
Å |
| | | |  |
| RHOC_RHOA_ENST00000369632_ENST00000454011_113245620_49400059 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4142
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000369632_ENST00000454011_113245620_49400059 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3688
Å |
| | | |  |
| RHOC_RHOA_ENST00000369637_ENST00000418115_113245184_49397815 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4346
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000369637_ENST00000418115_113245184_49397815 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3825
Å |
| | | |  |
| RHOC_RHOA_ENST00000369642_ENST00000418115_113245184_49397815 superimposed PDB: 1Z2C of partner (RHOC). RMSD:0.4155
Å |
 |  |  |  |  |
| RHOC_RHOA_ENST00000369642_ENST00000418115_113245184_49397815 superimposed PDB: 5C4M of partner (RHOA). RMSD:0.3756
Å |
| | | |  |
| RHOD_PFDN4_ENST00000532559_ENST00000371419_66824505_52830889 superimposed PDB: 7WU7 of partner (PFDN4). RMSD:1.4319
Å |
 |  |  |  |  |
| RHOD_PFDN4_ENST00000533360_ENST00000371419_66824505_52830889 superimposed PDB: 7WU7 of partner (PFDN4). RMSD:1.4187
Å |
 |  |  |  |  |
| RHOD_PFDN4_ENST00000533360_ENST00000371419_66834318_52830889 superimposed PDB: 2J1L of partner (RHOD). RMSD:0.8745
Å |
 |  |  |  |  |
| RHOD_PFDN4_ENST00000533360_ENST00000371419_66834318_52830889 superimposed PDB: 7WU7 of partner (PFDN4). RMSD:1.4417
Å |
| | | |  |
| RHOQ_CALM2_ENST00000238738_ENST00000272298_46770951_47397903 superimposed PDB: 2ATX of partner (RHOQ). RMSD:2.8006
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000244137_33481419_33980963 superimposed PDB: 2VSV of partner (RHPN2). RMSD:0.4523
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000397032_33481419_33980963 superimposed PDB: 2VSV of partner (RHPN2). RMSD:0.3626
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000397032_33481419_33980963 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.5722
Å |
| | | |  |
| RHPN2_PEPD_ENST00000254260_ENST00000397032_33481419_33984243 superimposed PDB: 2VSV of partner (RHPN2). RMSD:0.3495
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000397032_33481419_33984243 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.5701
Å |
| | | |  |
| RHPN2_PEPD_ENST00000254260_ENST00000397032_33535154_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.3748
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000436370_33481419_33980963 superimposed PDB: 2VSV of partner (RHPN2). RMSD:0.3587
Å |
 |  |  |  |  |
| RHPN2_PEPD_ENST00000254260_ENST00000436370_33481419_33980963 superimposed PDB: 6QSC of partner (PEPD). RMSD:2.7219
Å |
| | | |  |
| RHPN2_PEPD_ENST00000254260_ENST00000436370_33481419_33984243 superimposed PDB: 2VSV of partner (RHPN2). RMSD:0.3691
Å |
 |  |  |  |  |
| RHPN2_SLC7A9_ENST00000254260_ENST00000023064_33512476_33324229 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:2.4592
Å |
 |  |  |  |  |
| RHPN2_SLC7A9_ENST00000254260_ENST00000023064_33512476_33333223 superimposed PDB: 6YUP of partner (SLC7A9). RMSD:2.1375
Å |
 |  |  |  |  |
| RICTOR_DTNBP1_ENST00000357387_ENST00000355917_39074212_15533626 superimposed PDB: 9T94 of partner (RICTOR). RMSD:3.5775
Å |
 |  |  |  |  |
| RICTOR_DTNBP1_ENST00000357387_ENST00000462989_39074212_15533626 superimposed PDB: 9T94 of partner (RICTOR). RMSD:3.5816
Å |
 |  |  |  |  |
| RICTOR_FGF10_ENST00000296782_ENST00000264664_39074212_44310632 superimposed PDB: 1NUN of partner (FGF10). RMSD:0.4551
Å |
 |  |  |  |  |
| RIF1_XPO1_ENST00000433166_ENST00000404992_152285436_61709674 superimposed PDB: 9OGD of partner (XPO1). RMSD:3.1303
Å |
 |  |  |  |  |
| RIMKLB_CLEC4D_ENST00000357529_ENST00000299665_8866637_8667831 superimposed PDB: 3WHD of partner (CLEC4D). RMSD:0.3798
Å |
 |  |  |  |  |
| RLF_MFSD2A_ENST00000372771_ENST00000372811_40627308_40424372 superimposed PDB: 7OIX of partner (MFSD2A). RMSD:2.4759
Å |
 |  |  |  |  |
| RMDN1_ESRP1_ENST00000406452_ENST00000358397_87519223_95674728 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.9441
Å |
 |  |  |  |  |
| RMDN1_ESRP1_ENST00000406452_ENST00000433389_87519223_95674728 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.9668
Å |
 |  |  |  |  |
| RMDN1_ESRP1_ENST00000406452_ENST00000454170_87519223_95674728 superimposed PDB: 7WRN of partner (ESRP1). RMSD:0.9733
Å |
 |  |  |  |  |
| RMDN1_ESRP1_ENST00000519966_ENST00000423620_87519223_95674728 superimposed PDB: 7WRN of partner (ESRP1). RMSD:1.063
Å |
 |  |  |  |  |
| RMI2_CLEC16A_ENST00000312499_ENST00000409552_11439623_11214471 superimposed PDB: 3MXN of partner (RMI2). RMSD:1.8238
Å |
 |  |  |  |  |
| RNF115_ARNTL2_ENST00000369291_ENST00000311001_145663367_27533179 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.3979
Å |
 |  |  |  |  |
| RNF115_ARNTL2_ENST00000369291_ENST00000395901_145663367_27533179 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4176
Å |
 |  |  |  |  |
| RNF115_ARNTL2_ENST00000369291_ENST00000544915_145663367_27533179 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4339
Å |
 |  |  |  |  |
| RNF121_PPP3R1_ENST00000361756_ENST00000409752_71640170_68444263 superimposed PDB: 4F0Z of partner (PPP3R1). RMSD:0.5892
Å |
 |  |  |  |  |
| RNF121_SPCS2_ENST00000361756_ENST00000530257_71640170_74676078 superimposed PDB: 7P2P of partner (SPCS2). RMSD:2.0858
Å |
 |  |  |  |  |
| RNF123_CROCC_ENST00000327697_ENST00000375541_49728942_17264135 superimposed PDB: 2MA6 of partner (RNF123). RMSD:1.408
Å |
 |  |  |  |  |
| RNF125_RPRD1A_ENST00000217740_ENST00000357384_29622236_33573263 superimposed PDB: 5DKA of partner (RNF125). RMSD:0.5324
Å |
 |  |  |  |  |
| RNF139_ASPH_ENST00000303545_ENST00000379454_125487531_62566219 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.7878
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000274542_ENST00000360047_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3425
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000274542_ENST00000360047_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.334
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000424310_ENST00000360047_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3278
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000424310_ENST00000360047_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3435
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000518802_ENST00000360047_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3554
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000518802_ENST00000360047_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3274
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000520638_ENST00000360047_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3425
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000520638_ENST00000360047_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3176
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000520638_ENST00000502575_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3376
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000520638_ENST00000502575_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3155
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000521606_ENST00000360047_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3475
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000521606_ENST00000360047_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3266
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000521606_ENST00000502575_158595880_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3443
Å |
 |  |  |  |  |
| RNF145_PDE4D_ENST00000521606_ENST00000502575_158596686_58511794 superimposed PDB: 5WH6 of partner (PDE4D). RMSD:0.3253
Å |
 |  |  |  |  |
| RNF165_ADAM10_ENST00000587853_ENST00000260408_43914298_58957396 superimposed PDB: 8ESV of partner (ADAM10). RMSD:2.9318
Å |
 |  |  |  |  |
| RNF165_ADAM10_ENST00000590330_ENST00000260408_43914298_58957396 superimposed PDB: 8ESV of partner (ADAM10). RMSD:2.805
Å |
 |  |  |  |  |
| RNF169_CBX1_ENST00000299563_ENST00000225603_74528759_46153540 superimposed PDB: 5T1G of partner (CBX1). RMSD:0.2117
Å |
 |  |  |  |  |
| RNF169_POLD3_ENST00000299563_ENST00000527458_74500744_74322543 superimposed PDB: 9EKB of partner (POLD3). RMSD:3.2575
Å |
 |  |  |  |  |
| RNF213_ALK_ENST00000456466_ENST00000389048_78302277_29446394 superimposed PDB: 8S24 of partner (RNF213). RMSD:2.8303
Å |
 |  |  |  |  |
| RNF213_ALK_ENST00000582970_ENST00000389048_78302277_29446394 superimposed PDB: 8S24 of partner (RNF213). RMSD:2.8307
Å |
 |  |  |  |  |
| RNF213_CEP104_ENST00000336301_ENST00000378230_78337114_3732934 superimposed PDB: 8S24 of partner (RNF213). RMSD:3.0214
Å |
 |  |  |  |  |
| RNF213_CEP104_ENST00000582970_ENST00000378230_78337114_3732934 superimposed PDB: 8S24 of partner (RNF213). RMSD:2.981
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000336301_ENST00000314028_78354787_80211120 superimposed PDB: 8S24 of partner (RNF213). RMSD:2.8566
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000336301_ENST00000314028_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.1568
Å |
| | | |  |
| RNF213_CSNK1D_ENST00000336301_ENST00000392334_78354787_80211120 superimposed PDB: 8S24 of partner (RNF213). RMSD:2.8109
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000336301_ENST00000392334_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.3771
Å |
| | | |  |
| RNF213_CSNK1D_ENST00000336301_ENST00000398519_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.6751
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000508628_ENST00000314028_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.1104
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000508628_ENST00000392334_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.4028
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000508628_ENST00000398519_78354787_80211120 superimposed PDB: 8S24 of partner (RNF213). RMSD:3.0373
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000582970_ENST00000314028_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.1792
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000582970_ENST00000392334_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.0336
Å |
 |  |  |  |  |
| RNF213_CSNK1D_ENST00000582970_ENST00000398519_78354787_80211120 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:1.3271
Å |
 |  |  |  |  |
| RNF213_HSD17B14_ENST00000456466_ENST00000599157_78286967_49318398 superimposed PDB: 8S24 of partner (RNF213). RMSD:1.7092
Å |
 |  |  |  |  |
| RNF213_HSD17B14_ENST00000456466_ENST00000599157_78286967_49318398 superimposed PDB: 6H0M of partner (HSD17B14). RMSD:0.5015
Å |
| | | |  |
| RNF213_HSD17B14_ENST00000508628_ENST00000599157_78286967_49318398 superimposed PDB: 8S24 of partner (RNF213). RMSD:1.7611
Å |
 |  |  |  |  |
| RNF213_HSD17B14_ENST00000508628_ENST00000599157_78286967_49318398 superimposed PDB: 6H0M of partner (HSD17B14). RMSD:0.5162
Å |
| | | |  |
| RNF213_IL22RA1_ENST00000456466_ENST00000270800_78237577_24465204 superimposed PDB: 3DLQ of partner (IL22RA1). RMSD:0.7392
Å |
 |  |  |  |  |
| RNF213_SLC43A2_ENST00000336301_ENST00000571650_78363996_1486630 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.0363
Å |
 |  |  |  |  |
| RNF215_SYN3_ENST00000382363_ENST00000332840_30782604_32924995 superimposed PDB: 2P0A of partner (SYN3). RMSD:2.1989
Å |
 |  |  |  |  |
| RNF215_SYN3_ENST00000382363_ENST00000332840_30783017_32924995 superimposed PDB: 2P0A of partner (SYN3). RMSD:0.6667
Å |
 |  |  |  |  |
| RNF216_JAZF1_ENST00000389902_ENST00000283928_5680784_28031600 superimposed PDB: 7M4M of partner (RNF216). RMSD:2.5779
Å |
 |  |  |  |  |
| RNF220_QSOX1_ENST00000355387_ENST00000367600_44878394_180135625 superimposed PDB: 3LLK of partner (QSOX1). RMSD:0.3666
Å |
 |  |  |  |  |
| RNF220_QSOX1_ENST00000361799_ENST00000367602_44878394_180135625 superimposed PDB: 3LLK of partner (QSOX1). RMSD:0.3588
Å |
 |  |  |  |  |
| RNF24_ISM1_ENST00000432261_ENST00000262487_3925823_13260280 superimposed PDB: 9C6T of partner (ISM1). RMSD:0.6398
Å |
 |  |  |  |  |
| RNF2_PTPRR_ENST00000367509_ENST00000440835_185069094_71056385 superimposed PDB: 9DBY of partner (RNF2). RMSD:1.386
Å |
 |  |  |  |  |
| RNF2_PTPRR_ENST00000367509_ENST00000440835_185069094_71056385 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.7798
Å |
| | | |  |
| RNF2_PTPRR_ENST00000367510_ENST00000440835_185069094_71056385 superimposed PDB: 9DBY of partner (RNF2). RMSD:0.6392
Å |
 |  |  |  |  |
| RNF2_PTPRR_ENST00000367510_ENST00000440835_185069094_71056385 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.9141
Å |
| | | |  |
| RNF2_SEC31A_ENST00000367509_ENST00000348405_185056772_83770130 superimposed PDB: 9DBY of partner (RNF2). RMSD:2.598
Å |
 |  |  |  |  |
| RNF2_SEC31A_ENST00000367510_ENST00000500777_185056772_83770130 superimposed PDB: 9DBY of partner (RNF2). RMSD:2.5785
Å |
 |  |  |  |  |
| RNF2_SEC31A_ENST00000367510_ENST00000505984_185056772_83770130 superimposed PDB: 9DBY of partner (RNF2). RMSD:2.5944
Å |
 |  |  |  |  |
| RNF34_NEBL_ENST00000392464_ENST00000377122_121855714_21158770 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.3616
Å |
 |  |  |  |  |
| RNF34_NEBL_ENST00000392465_ENST00000377122_121855714_21158770 superimposed PDB: 4F14 of partner (NEBL). RMSD:0.386
Å |
 |  |  |  |  |
| RNF41_CSPG5_ENST00000552656_ENST00000264723_56601429_47614364 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.3394
Å |
 |  |  |  |  |
| RNF41_CSPG5_ENST00000552656_ENST00000383738_56601429_47614364 superimposed PDB: 2FZP of partner (RNF41). RMSD:0.5629
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000331772_ENST00000308448_90074222_89552512 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:2.9452
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000331772_ENST00000308448_90074222_89552512 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5833
Å |
| | | |  |
| RNLS_ATAD1_ENST00000331772_ENST00000308448_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:2.5235
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000331772_ENST00000308448_90332659_89536184 superimposed PDB: 7UPR of partner (ATAD1). RMSD:2.234
Å |
| | | |  |
| RNLS_ATAD1_ENST00000371947_ENST00000328142_90074222_89552512 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.6497
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000371947_ENST00000328142_90074222_89552512 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.6371
Å |
| | | |  |
| RNLS_ATAD1_ENST00000371947_ENST00000328142_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.7183
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000371947_ENST00000328142_90332659_89536184 superimposed PDB: 7UPR of partner (ATAD1). RMSD:2.5504
Å |
| | | |  |
| RNLS_ATAD1_ENST00000371947_ENST00000541004_90074222_89552512 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5997
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000371947_ENST00000541004_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:2.6069
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000308448_90074222_89552512 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.5253
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000308448_90074222_89552512 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.5996
Å |
| | | |  |
| RNLS_ATAD1_ENST00000437752_ENST00000308448_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:0.7757
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000328142_90074222_89552512 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:3.0968
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000328142_90074222_89552512 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.6983
Å |
| | | |  |
| RNLS_ATAD1_ENST00000437752_ENST00000328142_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:2.9429
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000328142_90332659_89536184 superimposed PDB: 7UPR of partner (ATAD1). RMSD:1.701
Å |
| | | |  |
| RNLS_ATAD1_ENST00000437752_ENST00000541004_90332659_89536184 superimposed PDB: 3QJ4 of partner (RNLS). RMSD:2.9552
Å |
 |  |  |  |  |
| RNLS_ATAD1_ENST00000437752_ENST00000541004_90332659_89536184 superimposed PDB: 7UPR of partner (ATAD1). RMSD:0.9453
Å |
| | | |  |
| ROBO1_THAP4_ENST00000436010_ENST00000407315_78763546_242545888 superimposed PDB: 5OPE of partner (ROBO1). RMSD:2.5594
Å |
 |  |  |  |  |
| ROBO1_THAP4_ENST00000436010_ENST00000407315_78763546_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3707
Å |
| | | |  |
| ROBO1_THAP4_ENST00000467549_ENST00000402136_78742497_242545888 superimposed PDB: 5OPE of partner (ROBO1). RMSD:2.6276
Å |
 |  |  |  |  |
| ROBO1_THAP4_ENST00000467549_ENST00000402136_78742497_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3684
Å |
| | | |  |
| ROBO1_THAP4_ENST00000495273_ENST00000402136_78763546_242545888 superimposed PDB: 5OPE of partner (ROBO1). RMSD:2.5879
Å |
 |  |  |  |  |
| ROBO1_THAP4_ENST00000495273_ENST00000402136_78763546_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3878
Å |
| | | |  |
| ROBO1_THAP4_ENST00000495273_ENST00000407315_78742497_242545888 superimposed PDB: 5OPE of partner (ROBO1). RMSD:2.612
Å |
 |  |  |  |  |
| ROBO1_THAP4_ENST00000495273_ENST00000407315_78742497_242545888 superimposed PDB: 3IA8 of partner (THAP4). RMSD:0.3663
Å |
| | | |  |
| ROBO2_ERLIN2_ENST00000461745_ENST00000276461_77147491_37602088 superimposed PDB: 6IAA of partner (ROBO2). RMSD:0.4226
Å |
 |  |  |  |  |
| ROBO2_ERLIN2_ENST00000487694_ENST00000276461_77147491_37602088 superimposed PDB: 6IAA of partner (ROBO2). RMSD:0.42
Å |
 |  |  |  |  |
| ROBO2_ERLIN2_ENST00000487694_ENST00000397228_77147491_37602088 superimposed PDB: 6IAA of partner (ROBO2). RMSD:0.4952
Å |
 |  |  |  |  |
| ROBO2_TRIM33_ENST00000487694_ENST00000369543_75986753_115007010 superimposed PDB: 7ZDD of partner (TRIM33). RMSD:0.3283
Å |
 |  |  |  |  |
| ROCK1_ABHD3_ENST00000399799_ENST00000580981_18690778_19283708 superimposed PDB: 3V8S of partner (ROCK1). RMSD:2.8017
Å |
 |  |  |  |  |
| ROCK1_ANKRD29_ENST00000399799_ENST00000322980_18595391_21181273 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1101
Å |
 |  |  |  |  |
| ROCK1_CHD2_ENST00000399799_ENST00000394196_18600111_93510554 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1205
Å |
 |  |  |  |  |
| ROCK1_CHD2_ENST00000399799_ENST00000557381_18600111_93510554 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.0088
Å |
 |  |  |  |  |
| ROCK1_DCC_ENST00000399799_ENST00000412726_18586311_50912412 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1141
Å |
 |  |  |  |  |
| ROCK1_DCC_ENST00000399799_ENST00000412726_18586311_50912412 superimposed PDB: 5X83 of partner (DCC). RMSD:0.8727
Å |
| | | |  |
| ROCK1_DCC_ENST00000399799_ENST00000442544_18586311_50912412 superimposed PDB: 3V8S of partner (ROCK1). RMSD:0.9141
Å |
 |  |  |  |  |
| ROCK1_DCC_ENST00000399799_ENST00000581580_18586311_50912412 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1142
Å |
 |  |  |  |  |
| ROCK1_DCC_ENST00000399799_ENST00000581580_18586311_50912412 superimposed PDB: 5X83 of partner (DCC). RMSD:0.8589
Å |
| | | |  |
| ROCK1_EPS15_ENST00000399799_ENST00000371733_18690778_51938620 superimposed PDB: 1EH2 of partner (EPS15). RMSD:1.1285
Å |
 |  |  |  |  |
| ROCK1_GUCA2B_ENST00000399799_ENST00000372581_18603580_42620350 superimposed PDB: 3V8S of partner (ROCK1). RMSD:0.9943
Å |
 |  |  |  |  |
| ROCK1_LAMP5_ENST00000399799_ENST00000246070_18619432_9510288 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1279
Å |
 |  |  |  |  |
| ROCK1_LRIG3_ENST00000399799_ENST00000320743_18625252_59308117 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.7942
Å |
 |  |  |  |  |
| ROCK1_LRIG3_ENST00000399799_ENST00000379141_18625252_59308117 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.0506
Å |
 |  |  |  |  |
| ROCK1_OSBPL1A_ENST00000399799_ENST00000319481_18603580_21883682 superimposed PDB: 3V8S of partner (ROCK1). RMSD:1.1111
Å |
 |  |  |  |  |
| ROCK1_RNF38_ENST00000399799_ENST00000353739_18690778_36376124 superimposed PDB: 9Q88 of partner (RNF38). RMSD:0.3934
Å |
 |  |  |  |  |
| ROCK2_ASAP2_ENST00000315872_ENST00000315273_11338616_9419445 superimposed PDB: 6P5M of partner (ROCK2). RMSD:0.6736
Å |
 |  |  |  |  |
| ROCK2_BTNL2_ENST00000315872_ENST00000454136_11351806_32369582 superimposed PDB: 6P5M of partner (ROCK2). RMSD:0.6555
Å |
 |  |  |  |  |
| ROCK2_DTNB_ENST00000315872_ENST00000496972_11484121_25656864 superimposed PDB: 6P5M of partner (ROCK2). RMSD:0.7579
Å |
 |  |  |  |  |
| ROCK2_E2F6_ENST00000315872_ENST00000307236_11426664_11597359 superimposed PDB: 6P5M of partner (ROCK2). RMSD:2.9252
Å |
 |  |  |  |  |
| ROCK2_E2F6_ENST00000315872_ENST00000381525_11484121_11597359 superimposed PDB: 6P5M of partner (ROCK2). RMSD:3.1462
Å |
 |  |  |  |  |
| ROCK2_MEIS1_ENST00000315872_ENST00000272369_11484121_66775074 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5848
Å |
 |  |  |  |  |
| ROCK2_MEIS1_ENST00000315872_ENST00000407092_11484121_66775074 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.8206
Å |
 |  |  |  |  |
| ROR1_ITGB3BP_ENST00000371079_ENST00000371092_64516388_63974241 superimposed PDB: 28OP of partner (ITGB3BP). RMSD:2.8732
Å |
 |  |  |  |  |
| ROR1_ITGB3BP_ENST00000371080_ENST00000283568_64516388_63974241 superimposed PDB: 28OP of partner (ITGB3BP). RMSD:2.7615
Å |
 |  |  |  |  |
| ROR1_PGM1_ENST00000371080_ENST00000540265_64240179_64114187 superimposed PDB: 5JN5 of partner (PGM1). RMSD:1.0256
Å |
 |  |  |  |  |
| RPA2_FCN3_ENST00000313433_ENST00000354982_28233438_27697463 superimposed PDB: 2PI2 of partner (RPA2). RMSD:2.3446
Å |
 |  |  |  |  |
| RPA2_FCN3_ENST00000313433_ENST00000354982_28233438_27697463 superimposed PDB: 2J5Z of partner (FCN3). RMSD:0.3466
Å |
| | | |  |
| RPA2_FCN3_ENST00000373909_ENST00000354982_28233438_27697463 superimposed PDB: 2PI2 of partner (RPA2). RMSD:3.1918
Å |
 |  |  |  |  |
| RPA2_FCN3_ENST00000373909_ENST00000354982_28233438_27697463 superimposed PDB: 2J5Z of partner (FCN3). RMSD:0.351
Å |
| | | |  |
| RPA2_FCN3_ENST00000373912_ENST00000354982_28233438_27697463 superimposed PDB: 2PI2 of partner (RPA2). RMSD:1.1608
Å |
 |  |  |  |  |
| RPA2_FCN3_ENST00000373912_ENST00000354982_28233438_27697463 superimposed PDB: 2J5Z of partner (FCN3). RMSD:0.3192
Å |
| | | |  |
| RPAIN_FHIT_ENST00000405578_ENST00000492590_5326149_59999878 superimposed PDB: 1FIT of partner (FHIT). RMSD:0.3112
Å |
 |  |  |  |  |
| RPAIN_FHIT_ENST00000536255_ENST00000492590_5326149_59999878 superimposed PDB: 1FIT of partner (FHIT). RMSD:0.4185
Å |
 |  |  |  |  |
| RPAP3_AVIL_ENST00000005386_ENST00000257861_48073275_58197452 superimposed PDB: 1UND of partner (AVIL). RMSD:0.8066
Å |
 |  |  |  |  |
| RPL10_CD36_ENST00000369817_ENST00000309881_153628282_80300292 superimposed PDB: 5LGD of partner (CD36). RMSD:0.6041
Å |
 |  |  |  |  |
| RPL10_CD36_ENST00000406022_ENST00000309881_153628282_80300292 superimposed PDB: 5LGD of partner (CD36). RMSD:0.5664
Å |
 |  |  |  |  |
| RPL10_CTSD_ENST00000424325_ENST00000236671_153628282_1776258 superimposed PDB: 4OD9 of partner (CTSD). RMSD:0.5782
Å |
 |  |  |  |  |
| RPL10_PKM_ENST00000369817_ENST00000565184_153626883_72492996 superimposed PDB: 3GR4 of partner (PKM). RMSD:0.5894
Å |
 |  |  |  |  |
| RPL12_IGKC_ENST00000536368_ENST00000390237_130211559_89157196 superimposed PDB: 5EWI of partner (IGKC). RMSD:0.5475
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000361436_ENST00000422447_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.7222
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000361436_ENST00000430553_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:1.3783
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000361436_ENST00000540430_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:2.0581
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000536368_ENST00000422447_130211559_18422383 superimposed PDB: 5W8J of partner (LDHA). RMSD:0.7274
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000536368_ENST00000422447_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:1.3608
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000536368_ENST00000430553_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:1.2908
Å |
 |  |  |  |  |
| RPL12_LDHA_ENST00000536368_ENST00000540430_130211559_18425240 superimposed PDB: 5W8J of partner (LDHA). RMSD:2.1052
Å |
 |  |  |  |  |
| RPL13A_TXNRD1_ENST00000391857_ENST00000397736_49990901_104725311 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.5674
Å |
 |  |  |  |  |
| RPL13A_TXNRD1_ENST00000391857_ENST00000429002_49990901_104725311 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.5744
Å |
 |  |  |  |  |
| RPL13_ETHE1_ENST00000311528_ENST00000600651_89627776_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.6201
Å |
 |  |  |  |  |
| RPL13_ETHE1_ENST00000567815_ENST00000292147_89627776_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4467
Å |
 |  |  |  |  |
| RPL17-C18orf32_NAP1L1_ENST00000584895_ENST00000393263_47017774_76453658 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.8344
Å |
 |  |  |  |  |
| RPL17_NAP1L1_ENST00000580210_ENST00000393263_47017774_76453658 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.8254
Å |
 |  |  |  |  |
| RPL22_DDX5_ENST00000234875_ENST00000450599_6252989_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.694
Å |
 |  |  |  |  |
| RPL22_DDX5_ENST00000234875_ENST00000578804_6252989_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.5668
Å |
 |  |  |  |  |
| RPL22_DDX5_ENST00000484532_ENST00000450599_6252989_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.7103
Å |
 |  |  |  |  |
| RPL22_DDX5_ENST00000484532_ENST00000578804_6252989_62500960 superimposed PDB: 4A4D of partner (DDX5). RMSD:0.5461
Å |
 |  |  |  |  |
| RPL23A_ACLY_ENST00000394938_ENST00000590151_27047908_40028435 superimposed PDB: 7RIG of partner (ACLY). RMSD:0.8157
Å |
 |  |  |  |  |
| RPL23A_ACLY_ENST00000422514_ENST00000590151_27047908_40028435 superimposed PDB: 7RIG of partner (ACLY). RMSD:0.7955
Å |
 |  |  |  |  |
| RPL27A_EEF1G_ENST00000314138_ENST00000378019_8706439_62339373 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4316
Å |
 |  |  |  |  |
| RPL27A_EEF1G_ENST00000524496_ENST00000378019_8706439_62339373 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4584
Å |
 |  |  |  |  |
| RPL27A_EEF1G_ENST00000526562_ENST00000378019_8706439_62339373 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4133
Å |
 |  |  |  |  |
| RPL27A_EEF1G_ENST00000530022_ENST00000378019_8706439_62339373 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4282
Å |
 |  |  |  |  |
| RPL27A_EEF1G_ENST00000532359_ENST00000378019_8706439_62339373 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.4183
Å |
 |  |  |  |  |
| RPL27_NBR1_ENST00000589913_ENST00000422280_41150848_41346980 superimposed PDB: 4OLE of partner (NBR1). RMSD:3.4773
Å |
 |  |  |  |  |
| RPL27_NBR1_ENST00000589913_ENST00000590996_41150848_41346980 superimposed PDB: 4OLE of partner (NBR1). RMSD:3.1795
Å |
 |  |  |  |  |
| RPL28_ASPH_ENST00000344063_ENST00000379454_55898061_62496588 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.6976
Å |
 |  |  |  |  |
| RPL28_ASPH_ENST00000344063_ENST00000379454_55899416_62489417 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.5644
Å |
 |  |  |  |  |
| RPL28_ASPH_ENST00000428193_ENST00000379454_55898061_62496588 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.921
Å |
 |  |  |  |  |
| RPL28_ASPH_ENST00000558815_ENST00000379454_55899416_62489417 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.6708
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000344063_ENST00000369138_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7215
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000344063_ENST00000421544_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7687
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000558815_ENST00000369138_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7962
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000558815_ENST00000413795_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8189
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000558815_ENST00000421544_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.7822
Å |
 |  |  |  |  |
| RPL28_GRIK2_ENST00000560055_ENST00000413795_55899416_102247522 superimposed PDB: 3QXM of partner (GRIK2). RMSD:0.8022
Å |
 |  |  |  |  |
| RPL30_OCIAD1_ENST00000287038_ENST00000509122_99054872_48859229 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.4682
Å |
 |  |  |  |  |
| RPL30_OCIAD1_ENST00000396070_ENST00000509122_99054872_48859229 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.4158
Å |
 |  |  |  |  |
| RPL30_PPHLN1_ENST00000396070_ENST00000549190_99057170_42768664 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.6981
Å |
 |  |  |  |  |
| RPL30_PPHLN1_ENST00000396070_ENST00000549190_99057170_42768664 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:0.6655
Å |
| | | |  |
| RPL30_PPHLN1_ENST00000521291_ENST00000358314_99057170_42768664 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.8072
Å |
 |  |  |  |  |
| RPL30_PPHLN1_ENST00000521291_ENST00000358314_99057170_42768664 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:0.6694
Å |
| | | |  |
| RPL30_PPHLN1_ENST00000521291_ENST00000395580_99057170_42768664 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.6934
Å |
 |  |  |  |  |
| RPL30_PPHLN1_ENST00000521291_ENST00000395580_99057170_42768664 superimposed PDB: 6SWG of partner (PPHLN1). RMSD:0.68
Å |
| | | |  |
| RPL30_TPT1_ENST00000287038_ENST00000379056_99054872_45911523 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.723
Å |
 |  |  |  |  |
| RPL30_TPT1_ENST00000396070_ENST00000379056_99054872_45911523 superimposed PDB: 3VI6 of partner (RPL30). RMSD:0.4976
Å |
 |  |  |  |  |
| RPL30_TPT1_ENST00000521291_ENST00000379056_99054872_45911523 superimposed PDB: 3VI6 of partner (RPL30). RMSD:1.1821
Å |
 |  |  |  |  |
| RPL31_BAZ1B_ENST00000264258_ENST00000404251_101622533_72884813 superimposed PDB: 1F62 of partner (BAZ1B). RMSD:1.4222
Å |
 |  |  |  |  |
| RPL3_AKR1C2_ENST00000216146_ENST00000421196_39713465_5037676 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.8244
Å |
 |  |  |  |  |
| RPL3_AKR1C2_ENST00000401609_ENST00000421196_39713465_5037676 superimposed PDB: 4JTR of partner (AKR1C2). RMSD:0.8009
Å |
 |  |  |  |  |
| RPL3_PLXNB1_ENST00000216146_ENST00000358459_39713465_48454578 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:0.647
Å |
 |  |  |  |  |
| RPL3_PLXNB1_ENST00000401609_ENST00000358459_39713465_48454578 superimposed PDB: 3HM6 of partner (PLXNB1). RMSD:0.6415
Å |
 |  |  |  |  |
| RPL4_NME4_ENST00000307961_ENST00000382940_66795395_449378 superimposed PDB: 1EHW of partner (NME4). RMSD:0.9042
Å |
 |  |  |  |  |
| RPL4_TSTA3_ENST00000307961_ENST00000425753_66795395_144695465 superimposed PDB: 4E5Y of partner (TSTA3). RMSD:2.4084
Å |
 |  |  |  |  |
| RPL5_HSP90AB1_ENST00000370321_ENST00000371554_93297674_44216366 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.5813
Å |
 |  |  |  |  |
| RPL6_NAE1_ENST00000202773_ENST00000290810_112844097_66850575 superimposed PDB: 1YOV of partner (NAE1). RMSD:2.2499
Å |
 |  |  |  |  |
| RPL7A_APP_ENST00000323345_ENST00000354192_136215897_27284274 superimposed PDB: 8KF4 of partner (APP). RMSD:2.7883
Å |
 |  |  |  |  |
| RPL7A_APP_ENST00000323345_ENST00000359726_136215897_27284274 superimposed PDB: 8KF4 of partner (APP). RMSD:2.972
Å |
 |  |  |  |  |
| RPL7A_UNC45A_ENST00000323345_ENST00000418476_136217174_91493383 superimposed PDB: 2DBA of partner (UNC45A). RMSD:2.9761
Å |
 |  |  |  |  |
| RPL8_FAF1_ENST00000527914_ENST00000371778_146017376_51061888 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8989
Å |
 |  |  |  |  |
| RPL8_FAF1_ENST00000528957_ENST00000371778_146017376_51061888 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.9217
Å |
 |  |  |  |  |
| RPL9_RAF1_ENST00000449470_ENST00000442415_39459813_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.027
Å |
 |  |  |  |  |
| RPLP1_HSP90AB1_ENST00000260379_ENST00000371646_69746060_44217113 superimposed PDB: 9W5I of partner (HSP90AB1). RMSD:1.7926
Å |
 |  |  |  |  |
| RPLP1_TJP1_ENST00000260379_ENST00000356107_69745359_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7164
Å |
 |  |  |  |  |
| RPLP1_TJP1_ENST00000260379_ENST00000400011_69745359_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6873
Å |
 |  |  |  |  |
| RPLP1_TJP1_ENST00000260379_ENST00000495972_69745359_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7296
Å |
 |  |  |  |  |
| RPLP1_TJP1_ENST00000260379_ENST00000545208_69745359_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7251
Å |
 |  |  |  |  |
| RPLP1_TJP1_ENST00000560274_ENST00000495972_69745359_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7272
Å |
 |  |  |  |  |
| RPN2_RERE_ENST00000373622_ENST00000337907_35842268_8617582 superimposed PDB: 2YQK of partner (RERE). RMSD:0.9467
Å |
 |  |  |  |  |
| RPN2_STAU1_ENST00000237530_ENST00000347458_35842268_47741124 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.4861
Å |
 |  |  |  |  |
| RPN2_STAU1_ENST00000237530_ENST00000360426_35842268_47741124 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.4803
Å |
 |  |  |  |  |
| RPN2_STAU1_ENST00000373622_ENST00000347458_35842268_47741124 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.4398
Å |
 |  |  |  |  |
| RPN2_STAU1_ENST00000373622_ENST00000360426_35842268_47741124 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.4945
Å |
 |  |  |  |  |
| RPRD1A_CEP192_ENST00000337059_ENST00000506447_33606862_13124630 superimposed PDB: 4JXT of partner (RPRD1A). RMSD:0.3868
Å |
 |  |  |  |  |
| RPRD1A_CEP192_ENST00000590898_ENST00000325971_33606862_13124630 superimposed PDB: 4JXT of partner (RPRD1A). RMSD:0.5992
Å |
 |  |  |  |  |
| RPRD1A_CHMP2B_ENST00000357384_ENST00000471660_33647216_87294863 superimposed PDB: 2JQK of partner (CHMP2B). RMSD:0.6158
Å |
 |  |  |  |  |
| RPRD1A_CHMP2B_ENST00000399022_ENST00000263780_33647216_87294863 superimposed PDB: 2JQK of partner (CHMP2B). RMSD:0.6183
Å |
 |  |  |  |  |
| RPRD1A_RALGAPA2_ENST00000588737_ENST00000202677_33610770_20661445 superimposed PDB: 9QWP of partner (RALGAPA2). RMSD:1.6976
Å |
 |  |  |  |  |
| RPRD1B_CTNNBL1_ENST00000373433_ENST00000405275_36694658_36393598 superimposed PDB: 4NAD of partner (RPRD1B). RMSD:1.2053
Å |
 |  |  |  |  |
| RPRD1B_CTNNBL1_ENST00000373433_ENST00000405275_36694658_36393598 superimposed PDB: 4CB9 of partner (CTNNBL1). RMSD:0.9709
Å |
| | | |  |
| RPS11_HP1BP3_ENST00000594493_ENST00000312239_50001303_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.7
Å |
 |  |  |  |  |
| RPS15A_GAPDH_ENST00000565420_ENST00000229239_18800302_6645849 superimposed PDB: 6YND of partner (GAPDH). RMSD:0.6453
Å |
 |  |  |  |  |
| RPS16_SIRT2_ENST00000339471_ENST00000249396_39926246_39374396 superimposed PDB: 9DPD of partner (SIRT2). RMSD:1.7209
Å |
 |  |  |  |  |
| RPS16_SIRT2_ENST00000599539_ENST00000392081_39926246_39374396 superimposed PDB: 9DPD of partner (SIRT2). RMSD:1.8734
Å |
 |  |  |  |  |
| RPS19_CEACAM5_ENST00000598742_ENST00000221992_42365281_42224841 superimposed PDB: 1E07 of partner (CEACAM5). RMSD:1.9524
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000305762_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.6026
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000305762_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.8082
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000322635_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.3799
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000322635_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.8139
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000322680_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:3.08
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000322680_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:1.1255
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000372765_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.7044
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000372765_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.9725
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000394762_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.4999
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000394762_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.899
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000423381_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.4621
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000435275_ENST00000423381_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.8024
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000440692_ENST00000351293_79795478_75602299 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:2.3128
Å |
 |  |  |  |  |
| RPS24_CAMK2G_ENST00000440692_ENST00000351293_79795478_75607105 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.9013
Å |
 |  |  |  |  |
| RPS27_EEF1G_ENST00000368567_ENST00000378019_153963699_62339154 superimposed PDB: 5JPO of partner (EEF1G). RMSD:0.3742
Å |
 |  |  |  |  |
| RPS29_TRIP12_ENST00000396020_ENST00000389045_50052667_230650571 superimposed PDB: 9KEN of partner (TRIP12). RMSD:1.5535
Å |
 |  |  |  |  |
| RPS3_CAV1_ENST00000530164_ENST00000341049_75110621_116166578 superimposed PDB: 7SC0 of partner (CAV1). RMSD:2.7251
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000374162_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.164
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000374162_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:3.0505
Å |
| | | |  |
| RPS6KA1_LIN28A_ENST00000374166_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.4376
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000374166_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.9803
Å |
| | | |  |
| RPS6KA1_LIN28A_ENST00000374168_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.1716
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000374168_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.9328
Å |
| | | |  |
| RPS6KA1_LIN28A_ENST00000526792_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.17
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000526792_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.9127
Å |
| | | |  |
| RPS6KA1_LIN28A_ENST00000530003_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.1739
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000530003_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.9584
Å |
| | | |  |
| RPS6KA1_LIN28A_ENST00000531382_ENST00000254231_26885428_26751793 superimposed PDB: 3RNY of partner (RPS6KA1). RMSD:1.1756
Å |
 |  |  |  |  |
| RPS6KA1_LIN28A_ENST00000531382_ENST00000254231_26885428_26751793 superimposed PDB: 8OPT of partner (LIN28A). RMSD:2.9792
Å |
| | | |  |
| RPS6KA3_NUP50_ENST00000379548_ENST00000347635_20187519_45567480 superimposed PDB: 7MO0 of partner (NUP50). RMSD:0.579
Å |
 |  |  |  |  |
| RPS6KA3_NUP50_ENST00000540702_ENST00000347635_20187519_45567480 superimposed PDB: 7MO0 of partner (NUP50). RMSD:0.6043
Å |
 |  |  |  |  |
| RPS6KA3_SH3KBP1_ENST00000379565_ENST00000379716_20252875_19663593 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.5058
Å |
 |  |  |  |  |
| RPS6KA3_SH3KBP1_ENST00000540702_ENST00000379716_20252875_19663593 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.5825
Å |
 |  |  |  |  |
| RPS6KA5_ZBP1_ENST00000261991_ENST00000395822_91444649_56190636 superimposed PDB: 1VZO of partner (RPS6KA5). RMSD:2.0095
Å |
 |  |  |  |  |
| RPS6KA5_ZBP1_ENST00000261991_ENST00000395822_91444649_56190636 superimposed PDB: 4KA4 of partner (ZBP1). RMSD:0.2382
Å |
| | | |  |
| RPS6KA5_ZBP1_ENST00000418736_ENST00000371173_91444649_56191524 superimposed PDB: 1VZO of partner (RPS6KA5). RMSD:2.8942
Å |
 |  |  |  |  |
| RPS6KA5_ZBP1_ENST00000418736_ENST00000371173_91444649_56191524 superimposed PDB: 4KA4 of partner (ZBP1). RMSD:0.2506
Å |
| | | |  |
| RPS6KA6_HDX_ENST00000543399_ENST00000506585_83441068_83588850 superimposed PDB: 2DA4 of partner (HDX). RMSD:1.6537
Å |
 |  |  |  |  |
| RPS6KB1_CLTC_ENST00000393021_ENST00000579456_57992064_57767996 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.4807
Å |
 |  |  |  |  |
| RPS6KB1_CLTC_ENST00000406116_ENST00000579456_57992064_57767996 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.48
Å |
 |  |  |  |  |
| RPS6KB1_DIAPH3_ENST00000225577_ENST00000400324_58007535_60240980 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:1.1072
Å |
 |  |  |  |  |
| RPS6KB1_DIAPH3_ENST00000406116_ENST00000400324_58007535_60240980 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:2.4764
Å |
 |  |  |  |  |
| RPS6KB1_LASP1_ENST00000443572_ENST00000435347_57970686_37070577 superimposed PDB: 3I35 of partner (LASP1). RMSD:0.3606
Å |
 |  |  |  |  |
| RPS6KB1_SNF8_ENST00000406116_ENST00000502492_57970686_47021337 superimposed PDB: 2ZME of partner (SNF8). RMSD:0.6079
Å |
 |  |  |  |  |
| RPS6KB1_SNF8_ENST00000443572_ENST00000290330_57970686_47021337 superimposed PDB: 2ZME of partner (SNF8). RMSD:0.6383
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000225577_ENST00000539763_58022879_57917128 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7877
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_57992064_57842331 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.5368
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_57992064_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.5154
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_58011885_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8711
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_58012661_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.953
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_58013902_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7685
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_58018304_57889030 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7745
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000393021_ENST00000537567_58022879_57915655 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7588
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_57992064_57842331 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.4545
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_57992064_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.4758
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_58011885_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7982
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_58012661_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.9623
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_58013902_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7679
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_58018304_57889030 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7896
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000537567_58022879_57915655 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.7834
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000406116_ENST00000539763_58022879_57917128 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6926
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000262291_58011885_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:1.172
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000537567_58011885_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:1.3051
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000537567_58012661_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.8751
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000537567_58013902_57886156 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6731
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000537567_58018304_57889030 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6462
Å |
 |  |  |  |  |
| RPS6KB1_VMP1_ENST00000443572_ENST00000537567_58022879_57915655 superimposed PDB: 4L42 of partner (RPS6KB1). RMSD:0.6474
Å |
 |  |  |  |  |
| RPS8_NAP1L1_ENST00000372209_ENST00000393263_45242386_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.5681
Å |
 |  |  |  |  |
| RPS8_NAP1L1_ENST00000372209_ENST00000547993_45242386_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:1.8216
Å |
 |  |  |  |  |
| RPS8_NAP1L1_ENST00000372209_ENST00000549596_45242386_76446890 superimposed PDB: 11BC of partner (NAP1L1). RMSD:2.1263
Å |
 |  |  |  |  |
| RPSA_ANXA2_ENST00000301821_ENST00000451270_39449277_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.3756
Å |
 |  |  |  |  |
| RPSA_DDX1_ENST00000301821_ENST00000233084_39450215_15757367 superimposed PDB: 8TBX of partner (DDX1). RMSD:3.2217
Å |
 |  |  |  |  |
| RPTOR_EYA2_ENST00000306801_ENST00000327619_78867665_45630066 superimposed PDB: 8ERA of partner (RPTOR). RMSD:1.4716
Å |
 |  |  |  |  |
| RPTOR_EYA2_ENST00000306801_ENST00000327619_78867665_45630066 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.8823
Å |
| | | |  |
| RPTOR_EYA2_ENST00000544334_ENST00000327619_78867665_45630066 superimposed PDB: 8ERA of partner (RPTOR). RMSD:1.2606
Å |
 |  |  |  |  |
| RPTOR_EYA2_ENST00000544334_ENST00000327619_78867665_45630066 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.6913
Å |
| | | |  |
| RPTOR_EYA2_ENST00000544334_ENST00000357410_78867665_45630066 superimposed PDB: 8ERA of partner (RPTOR). RMSD:1.4404
Å |
 |  |  |  |  |
| RPTOR_EYA2_ENST00000544334_ENST00000357410_78867665_45630066 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.3978
Å |
| | | |  |
| RPTOR_JMJD6_ENST00000306801_ENST00000445478_78519591_74721937 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.3894
Å |
 |  |  |  |  |
| RPTOR_JMJD6_ENST00000570891_ENST00000397625_78519591_74721937 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.4173
Å |
 |  |  |  |  |
| RPTOR_JMJD6_ENST00000570891_ENST00000585429_78519591_74721937 superimposed PDB: 6GDY of partner (JMJD6). RMSD:0.3724
Å |
 |  |  |  |  |
| RPTOR_RNF213_ENST00000306801_ENST00000508628_78617610_78341547 superimposed PDB: 8S24 of partner (RNF213). RMSD:1.8395
Å |
 |  |  |  |  |
| RRAS2_FAR1_ENST00000256196_ENST00000354817_14380308_13733474 superimposed PDB: 9B4S of partner (RRAS2). RMSD:2.4787
Å |
 |  |  |  |  |
| RRAS2_FHIT_ENST00000545643_ENST00000476844_14380308_59738047 superimposed PDB: 9B4S of partner (RRAS2). RMSD:1.8726
Å |
 |  |  |  |  |
| RRAS2_FHIT_ENST00000545643_ENST00000492590_14380308_59738047 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.8457
Å |
 |  |  |  |  |
| RRAS2_MBLAC2_ENST00000526063_ENST00000316610_14316016_89757369 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.6622
Å |
 |  |  |  |  |
| RRAS2_MBLAC2_ENST00000537760_ENST00000316610_14316016_89757369 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.7082
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000256196_ENST00000419365_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.6196
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000256196_ENST00000419365_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.7234
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000256196_ENST00000555531_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.6255
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000256196_ENST00000555531_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.3875
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000526063_ENST00000419365_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.8279
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000526063_ENST00000419365_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:1.0396
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000526063_ENST00000555531_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.9042
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000526063_ENST00000555531_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.3749
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000529237_ENST00000418988_14316305_14529312 superimposed PDB: 9B4S of partner (RRAS2). RMSD:1.0634
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000532814_ENST00000418988_14316305_14529312 superimposed PDB: 9B4S of partner (RRAS2). RMSD:1.0659
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000534746_ENST00000418988_14316305_14529312 superimposed PDB: 9B4S of partner (RRAS2). RMSD:1.8703
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000537760_ENST00000419365_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.7267
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000537760_ENST00000419365_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:1.8247
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000537760_ENST00000555531_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.7964
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000537760_ENST00000555531_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.3778
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000545643_ENST00000419365_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.6504
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000545643_ENST00000419365_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.8644
Å |
| | | |  |
| RRAS2_PSMA1_ENST00000545643_ENST00000555531_14316016_14540587 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5738
Å |
 |  |  |  |  |
| RRAS2_PSMA1_ENST00000545643_ENST00000555531_14316016_14540587 superimposed PDB: 5LE5 of partner (PSMA1). RMSD:0.3919
Å |
| | | |  |
| RREB1_LYRM4_ENST00000379938_ENST00000330636_7189555_5216971 superimposed PDB: 6UXE of partner (LYRM4). RMSD:1.3916
Å |
 |  |  |  |  |
| RRM2B_ZNF704_ENST00000395912_ENST00000327835_103231041_81555364 superimposed PDB: 3HF1 of partner (RRM2B). RMSD:0.9593
Å |
 |  |  |  |  |
| RRN3_BANP_ENST00000327307_ENST00000355163_15157052_88014641 superimposed PDB: 7OBA of partner (RRN3). RMSD:1.0499
Å |
 |  |  |  |  |
| RSBN1L_HGF_ENST00000334955_ENST00000453411_77326372_81374436 superimposed PDB: 7MO9 of partner (HGF). RMSD:1.0439
Å |
 |  |  |  |  |
| RSBN1L_HGF_ENST00000334955_ENST00000457544_77326372_81374436 superimposed PDB: 7MO9 of partner (HGF). RMSD:2.8078
Å |
 |  |  |  |  |
| RSF1_PAK1_ENST00000308488_ENST00000278568_77475642_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6242
Å |
 |  |  |  |  |
| RSF1_PAK1_ENST00000308488_ENST00000528203_77475642_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6363
Å |
 |  |  |  |  |
| RSF1_PAK1_ENST00000308488_ENST00000530617_77475642_77070062 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6098
Å |
 |  |  |  |  |
| RSF1_PSMA4_ENST00000308488_ENST00000044462_77451775_78837210 superimposed PDB: 5LE5 of partner (PSMA4). RMSD:0.5631
Å |
 |  |  |  |  |
| RSF1_PSMA4_ENST00000360355_ENST00000044462_77451775_78837210 superimposed PDB: 5LE5 of partner (PSMA4). RMSD:0.565
Å |
 |  |  |  |  |
| RSF1_TENM4_ENST00000360355_ENST00000278550_77436589_78567223 superimposed PDB: 7BAN of partner (TENM4). RMSD:1.464
Å |
 |  |  |  |  |
| RSU1_CUBN_ENST00000377921_ENST00000377833_16794537_17130344 superimposed PDB: 7LT8 of partner (RSU1). RMSD:0.47
Å |
 |  |  |  |  |
| RSU1_CUBN_ENST00000377921_ENST00000377833_16794537_17130344 superimposed PDB: 3KQ4 of partner (CUBN). RMSD:2.5116
Å |
| | | |  |
| RSU1_FANCI_ENST00000377921_ENST00000300027_16858971_89816607 superimposed PDB: 7LT8 of partner (RSU1). RMSD:0.3503
Å |
 |  |  |  |  |
| RSU1_FANCI_ENST00000377921_ENST00000310775_16858971_89816607 superimposed PDB: 8A9J of partner (FANCI). RMSD:1.6475
Å |
 |  |  |  |  |
| RSU1_PARG_ENST00000377921_ENST00000402038_16794537_51051678 superimposed PDB: 7LT8 of partner (RSU1). RMSD:2.1941
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000341307_ENST00000400186_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.9574
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000341307_ENST00000539096_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.3562
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000341307_ENST00000542608_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.7827
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000341307_ENST00000602557_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.9166
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000354497_ENST00000400186_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.5963
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000354497_ENST00000539096_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.5768
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000354497_ENST00000542608_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.1525
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000354497_ENST00000602557_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.566
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000356000_ENST00000602723_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.2404
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000537981_ENST00000602723_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.2799
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000540798_ENST00000539096_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.5209
Å |
 |  |  |  |  |
| RTN3_CSMD1_ENST00000540798_ENST00000542608_63449250_3855632 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.2533
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000341307_ENST00000404295_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:2.2729
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000341307_ENST00000404295_63449250_4519466 superimposed PDB: 3DXF of partner (NMRAL1). RMSD:0.5267
Å |
| | | |  |
| RTN3_NMRAL1_ENST00000354497_ENST00000283429_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:3.385
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000354497_ENST00000404295_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:2.2954
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000354497_ENST00000404295_63449250_4519466 superimposed PDB: 3DXF of partner (NMRAL1). RMSD:0.5399
Å |
| | | |  |
| RTN3_NMRAL1_ENST00000354497_ENST00000574733_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:3.2972
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000377819_ENST00000574733_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:3.2943
Å |
 |  |  |  |  |
| RTN3_NMRAL1_ENST00000537981_ENST00000574733_63449250_4519466 superimposed PDB: 7BRU of partner (RTN3). RMSD:3.1828
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000335099_ENST00000361796_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6209
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000335099_ENST00000399039_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6024
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000335099_ENST00000529919_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5703
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000395120_ENST00000524630_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5982
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000533205_ENST00000361796_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6257
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000533205_ENST00000399039_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.6043
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000533205_ENST00000524630_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5332
Å |
 |  |  |  |  |
| RTN4RL2_CTNND1_ENST00000533205_ENST00000529919_57235563_57561481 superimposed PDB: 3L6X of partner (CTNND1). RMSD:0.5056
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000317610_ENST00000193403_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3641
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000317610_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4216
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000317610_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4069
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000337526_ENST00000193403_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4025
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000337526_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.5255
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000337526_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.5242
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000354474_ENST00000193403_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.5071
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000354474_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4806
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000354474_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.5092
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000357732_ENST00000193403_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3934
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000357732_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.4043
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000357732_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3828
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000394609_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3662
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000394609_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3827
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000402434_ENST00000193403_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.5139
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000402434_ENST00000394419_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3667
Å |
 |  |  |  |  |
| RTN4_ACTN1_ENST00000402434_ENST00000438964_55209650_69392389 superimposed PDB: 2EYI of partner (ACTN1). RMSD:0.3867
Å |
 |  |  |  |  |
| RTN4_CCDC88A_ENST00000317610_ENST00000263630_55276880_55646052 superimposed PDB: 2G31 of partner (RTN4). RMSD:2.6151
Å |
 |  |  |  |  |
| RTN4_CCDC88A_ENST00000317610_ENST00000263630_55276880_55646052 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:1.7324
Å |
| | | |  |
| RTN4_CCDC88A_ENST00000317610_ENST00000413716_55276880_55646052 superimposed PDB: 2G31 of partner (RTN4). RMSD:2.7765
Å |
 |  |  |  |  |
| RTN4_CCDC88A_ENST00000317610_ENST00000436346_55276880_55646052 superimposed PDB: 2G31 of partner (RTN4). RMSD:2.8049
Å |
 |  |  |  |  |
| RTN4_CCDC88A_ENST00000357732_ENST00000336838_55276880_55646052 superimposed PDB: 2G31 of partner (RTN4). RMSD:2.5509
Å |
 |  |  |  |  |
| RTN4_MEMO1_ENST00000394609_ENST00000379383_55237222_32095021 superimposed PDB: 7M8H of partner (MEMO1). RMSD:0.4986
Å |
 |  |  |  |  |
| RTN4_TMEM66_ENST00000317610_ENST00000256255_55209650_29927575 superimposed PDB: 6O2V of partner (TMEM66). RMSD:1.1207
Å |
 |  |  |  |  |
| RTN4_TMEM66_ENST00000337526_ENST00000256255_55209650_29927575 superimposed PDB: 6O2V of partner (TMEM66). RMSD:1.4259
Å |
 |  |  |  |  |
| RTN4_TMEM66_ENST00000354474_ENST00000256255_55209650_29927575 superimposed PDB: 6O2V of partner (TMEM66). RMSD:1.112
Å |
 |  |  |  |  |
| RTN4_TMEM66_ENST00000357732_ENST00000256255_55209650_29927575 superimposed PDB: 6O2V of partner (TMEM66). RMSD:1.1501
Å |
 |  |  |  |  |
| RTN4_TMEM66_ENST00000402434_ENST00000256255_55209650_29927575 superimposed PDB: 6O2V of partner (TMEM66). RMSD:1.1241
Å |
 |  |  |  |  |
| RUFY3_PTK2_ENST00000381006_ENST00000535192_71660611_141889736 superimposed PDB: 4NY0 of partner (PTK2). RMSD:1.2368
Å |
 |  |  |  |  |
| RUFY3_PTK2_ENST00000502653_ENST00000522684_71660611_141889736 superimposed PDB: 4NY0 of partner (PTK2). RMSD:0.9899
Å |
 |  |  |  |  |
| RUFY3_PTK2_ENST00000502653_ENST00000535192_71660611_141889736 superimposed PDB: 4NY0 of partner (PTK2). RMSD:1.1257
Å |
 |  |  |  |  |
| RUFY3_TMPRSS11A_ENST00000381006_ENST00000396188_71640950_68784950 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.5426
Å |
 |  |  |  |  |
| RUFY3_TMPRSS11A_ENST00000417478_ENST00000396188_71640950_68784950 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.4729
Å |
 |  |  |  |  |
| RUFY3_TMPRSS11A_ENST00000502653_ENST00000396188_71640950_68784950 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.4388
Å |
 |  |  |  |  |
| RUFY3_TMPRSS11A_ENST00000536664_ENST00000396188_71640950_68784950 superimposed PDB: 9P1C of partner (TMPRSS11A). RMSD:0.47
Å |
 |  |  |  |  |
| RUNX1_PROS1_ENST00000300305_ENST00000394236_36206706_93646251 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4064
Å |
 |  |  |  |  |
| RUNX1_PROS1_ENST00000300305_ENST00000394236_36206706_93646251 superimposed PDB: 1Z6C of partner (PROS1). RMSD:2.8689
Å |
| | | |  |
| RUNX1_PROS1_ENST00000325074_ENST00000394236_36206706_93646251 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3916
Å |
 |  |  |  |  |
| RUNX1_PROS1_ENST00000325074_ENST00000394236_36206706_93646251 superimposed PDB: 1Z6C of partner (PROS1). RMSD:2.8536
Å |
| | | |  |
| RUNX1_PROS1_ENST00000358356_ENST00000394236_36206706_93646251 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3916
Å |
 |  |  |  |  |
| RUNX1_PROS1_ENST00000358356_ENST00000394236_36206706_93646251 superimposed PDB: 1Z6C of partner (PROS1). RMSD:2.8532
Å |
| | | |  |
| RUNX1_PTPRR_ENST00000300305_ENST00000283228_36252853_71286757 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.5565
Å |
 |  |  |  |  |
| RUNX1_PTPRR_ENST00000300305_ENST00000283228_36252853_71286757 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.437
Å |
| | | |  |
| RUNX1_PTPRR_ENST00000325074_ENST00000283228_36252853_71286757 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.6351
Å |
 |  |  |  |  |
| RUNX1_PTPRR_ENST00000325074_ENST00000283228_36252853_71286757 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4512
Å |
| | | |  |
| RUNX1_PTPRR_ENST00000399240_ENST00000283228_36252853_71286757 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.6064
Å |
 |  |  |  |  |
| RUNX1_PTPRR_ENST00000399240_ENST00000283228_36252853_71286757 superimposed PDB: 2A8B of partner (PTPRR). RMSD:0.4553
Å |
| | | |  |
| RUNX1_RUNX1T1_ENST00000300305_ENST00000396218_36231770_93029591 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3844
Å |
 |  |  |  |  |
| RUNX1_RUNX1T1_ENST00000300305_ENST00000396218_36231770_93029591 superimposed PDB: 2PP4 of partner (RUNX1T1). RMSD:3.0022
Å |
| | | |  |
| RUNX1_RUNX1T1_ENST00000325074_ENST00000396218_36231770_93029591 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4088
Å |
 |  |  |  |  |
| RUNX1_RUNX1T1_ENST00000325074_ENST00000396218_36231770_93029591 superimposed PDB: 2PP4 of partner (RUNX1T1). RMSD:2.9832
Å |
| | | |  |
| RUNX1_RUNX1T1_ENST00000344691_ENST00000396218_36231770_93029591 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4139
Å |
 |  |  |  |  |
| RUNX1_RUNX1T1_ENST00000344691_ENST00000396218_36231770_93029591 superimposed PDB: 2PP4 of partner (RUNX1T1). RMSD:2.9657
Å |
| | | |  |
| RUNX1_RUNX1T1_ENST00000344691_ENST00000523629_36231770_93029591 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4204
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000300305_ENST00000323084_36206706_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3696
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000300305_ENST00000323084_36231770_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3505
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000325074_ENST00000323084_36206706_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3565
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000325074_ENST00000323084_36231770_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3657
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000358356_ENST00000323084_36206706_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3489
Å |
 |  |  |  |  |
| RUNX1_TSPEAR_ENST00000399240_ENST00000323084_36231770_45987889 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.393
Å |
 |  |  |  |  |
| RUNX1_USP42_ENST00000300305_ENST00000306177_36171597_6154953 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4519
Å |
 |  |  |  |  |
| RUNX1_USP42_ENST00000325074_ENST00000306177_36171597_6154953 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4413
Å |
 |  |  |  |  |
| RUNX1_USP42_ENST00000399240_ENST00000306177_36171597_6154953 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3983
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000359524_ENST00000344691_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5549
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000359524_ENST00000344691_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3603
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371432_ENST00000325074_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.6002
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371432_ENST00000325074_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3743
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371432_ENST00000486278_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5312
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371432_ENST00000486278_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3521
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000325074_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5887
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000325074_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3747
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000344691_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5595
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000344691_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3784
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000486278_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5652
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371436_ENST00000486278_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3697
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371438_ENST00000325074_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.6068
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371438_ENST00000325074_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3874
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000371438_ENST00000486278_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5684
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000371438_ENST00000486278_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3665
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000465038_ENST00000344691_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5612
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000465038_ENST00000344691_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3691
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000541979_ENST00000325074_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5847
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000541979_ENST00000325074_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.371
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000541979_ENST00000486278_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5389
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000541979_ENST00000486278_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3712
Å |
| | | |  |
| RUNX2_RUNX1_ENST00000576263_ENST00000344691_45390694_36253010 superimposed PDB: 6VGD of partner (RUNX2). RMSD:0.5774
Å |
 |  |  |  |  |
| RUNX2_RUNX1_ENST00000576263_ENST00000344691_45390694_36253010 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3578
Å |
| | | |  |
| RYBP_FHIT_ENST00000477973_ENST00000492590_72495646_59738047 superimposed PDB: 9DBY of partner (RYBP). RMSD:0.4716
Å |
 |  |  |  |  |
| RYBP_FOXP1_ENST00000477973_ENST00000475937_72495646_71161788 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3016
Å |
 |  |  |  |  |
| RYBP_FOXP1_ENST00000477973_ENST00000484350_72495646_71161788 superimposed PDB: 2KIU of partner (FOXP1). RMSD:1.3258
Å |
 |  |  |  |  |
| RYR3_LARP4_ENST00000389232_ENST00000293618_34034645_50821544 superimposed PDB: 6I9B of partner (LARP4). RMSD:3.1266
Å |
 |  |  |  |  |
| RYR3_LARP4_ENST00000415757_ENST00000429001_34034645_50821544 superimposed PDB: 6I9B of partner (LARP4). RMSD:3.168
Å |
 |  |  |  |  |
| S100A11_HBA2_ENST00000271638_ENST00000251595_152004981_222845 superimposed PDB: 2LUC of partner (S100A11). RMSD:2.6873
Å |
 |  |  |  |  |
| S100A11_HBA2_ENST00000271638_ENST00000251595_152004981_222845 superimposed PDB: 1BAB of partner (HBA2). RMSD:0.343
Å |
| | | |  |
| SAE1_BAX_ENST00000392776_ENST00000345358_47646862_49464066 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.5912
Å |
 |  |  |  |  |
| SAE1_BAX_ENST00000413379_ENST00000345358_47646862_49464066 superimposed PDB: 9QN5 of partner (SAE1). RMSD:3.127
Å |
 |  |  |  |  |
| SAE1_BAX_ENST00000598840_ENST00000345358_47646862_49464066 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.6606
Å |
 |  |  |  |  |
| SAE1_FGF9_ENST00000392776_ENST00000382353_47646862_22275328 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.8459
Å |
 |  |  |  |  |
| SAE1_FGF9_ENST00000392776_ENST00000382353_47646862_22275328 superimposed PDB: 1IHK of partner (FGF9). RMSD:1.4108
Å |
| | | |  |
| SAE1_FGF9_ENST00000413379_ENST00000382353_47646862_22275328 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.6984
Å |
 |  |  |  |  |
| SAE1_FGF9_ENST00000598840_ENST00000382353_47646862_22275328 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.6104
Å |
 |  |  |  |  |
| SAE1_FGF9_ENST00000598840_ENST00000382353_47646862_22275328 superimposed PDB: 1IHK of partner (FGF9). RMSD:1.5705
Å |
| | | |  |
| SAE1_GRIN2D_ENST00000392776_ENST00000263269_47634285_48945025 superimposed PDB: 9QN5 of partner (SAE1). RMSD:3.1455
Å |
 |  |  |  |  |
| SAE1_GRIN2D_ENST00000392776_ENST00000263269_47634285_48945025 superimposed PDB: 7YFF of partner (GRIN2D). RMSD:3.0308
Å |
| | | |  |
| SAE1_GRIN2D_ENST00000598840_ENST00000263269_47634285_48945025 superimposed PDB: 9QN5 of partner (SAE1). RMSD:3.1286
Å |
 |  |  |  |  |
| SAE1_GRIN2D_ENST00000598840_ENST00000263269_47634285_48945025 superimposed PDB: 7YFF of partner (GRIN2D). RMSD:3.095
Å |
| | | |  |
| SAE1_RPA2_ENST00000270225_ENST00000373909_47658470_28233793 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.428
Å |
 |  |  |  |  |
| SAE1_RPA2_ENST00000270225_ENST00000373909_47658470_28233793 superimposed PDB: 2PI2 of partner (RPA2). RMSD:0.3244
Å |
| | | |  |
| SAE1_RPA2_ENST00000392776_ENST00000373909_47658470_28233793 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.4264
Å |
 |  |  |  |  |
| SAE1_RPA2_ENST00000392776_ENST00000373909_47658470_28233793 superimposed PDB: 2PI2 of partner (RPA2). RMSD:0.3062
Å |
| | | |  |
| SAE1_RPA2_ENST00000413379_ENST00000373909_47658470_28233793 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.4373
Å |
 |  |  |  |  |
| SAE1_RPA2_ENST00000413379_ENST00000373909_47658470_28233793 superimposed PDB: 2PI2 of partner (RPA2). RMSD:0.3371
Å |
| | | |  |
| SAE1_RPA2_ENST00000540850_ENST00000373909_47658470_28233793 superimposed PDB: 2PI2 of partner (RPA2). RMSD:0.3218
Å |
 |  |  |  |  |
| SAE1_SLC9A1_ENST00000413379_ENST00000263980_47646862_27429803 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.5224
Å |
 |  |  |  |  |
| SAE1_ZBTB45_ENST00000270225_ENST00000594051_47646862_59029040 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.6579
Å |
 |  |  |  |  |
| SAE1_ZBTB45_ENST00000392776_ENST00000594051_47646862_59029040 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.635
Å |
 |  |  |  |  |
| SAE1_ZBTB45_ENST00000413379_ENST00000594051_47646862_59029040 superimposed PDB: 9QN5 of partner (SAE1). RMSD:0.7561
Å |
 |  |  |  |  |
| SAFB2_LONP1_ENST00000252542_ENST00000585374_5598803_5708414 superimposed PDB: 9RMV of partner (SAFB2). RMSD:1.7201
Å |
 |  |  |  |  |
| SAFB2_LONP1_ENST00000252542_ENST00000585374_5598803_5708414 superimposed PDB: 7OXO of partner (LONP1). RMSD:2.9285
Å |
| | | |  |
| SAMD11_PROZ_ENST00000342066_ENST00000375547_861393_113824726 superimposed PDB: 3H5C of partner (PROZ). RMSD:0.5062
Å |
 |  |  |  |  |
| SAMD4B_PAK4_ENST00000598913_ENST00000321944_39870724_39665951 superimposed PDB: 5UPL of partner (PAK4). RMSD:0.4308
Å |
 |  |  |  |  |
| SAMD8_ADK_ENST00000372690_ENST00000286621_76871480_76349039 superimposed PDB: 4O1L of partner (ADK). RMSD:0.5072
Å |
 |  |  |  |  |
| SAMHD1_MRPL52_ENST00000262878_ENST00000397496_35559162_23303380 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.656
Å |
 |  |  |  |  |
| SAMHD1_YIF1B_ENST00000262878_ENST00000392124_35547766_38796147 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.4859
Å |
 |  |  |  |  |
| SAMHD1_YIF1B_ENST00000373694_ENST00000392124_35547766_38796147 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.7633
Å |
 |  |  |  |  |
| SAMM50_PIP4K2C_ENST00000350028_ENST00000354947_44360433_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7361
Å |
 |  |  |  |  |
| SAMM50_PIP4K2C_ENST00000350028_ENST00000540759_44360433_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.1135
Å |
 |  |  |  |  |
| SAMM50_PIP4K2C_ENST00000350028_ENST00000550465_44360433_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7654
Å |
 |  |  |  |  |
| SAR1A_CDK12_ENST00000458634_ENST00000447079_71917519_37646809 superimposed PDB: 4NST of partner (CDK12). RMSD:0.5545
Å |
 |  |  |  |  |
| SAR1A_NODAL_ENST00000431664_ENST00000287139_71920759_72195739 superimposed PDB: 8DZM of partner (SAR1A). RMSD:3.0842
Å |
 |  |  |  |  |
| SAR1A_NODAL_ENST00000431664_ENST00000287139_71920759_72195739 superimposed PDB: 4N1D of partner (NODAL). RMSD:0.6504
Å |
| | | |  |
| SAR1A_TAMM41_ENST00000373241_ENST00000273037_71913593_11832055 superimposed PDB: 8DZM of partner (SAR1A). RMSD:0.4904
Å |
 |  |  |  |  |
| SARNP_KCNN4_ENST00000552080_ENST00000262888_56211449_44280788 superimposed PDB: 6CNM of partner (KCNN4). RMSD:2.2352
Å |
 |  |  |  |  |
| SARS_LPCAT4_ENST00000369923_ENST00000314891_109778053_34657902 superimposed PDB: 8P7B of partner (SARS). RMSD:1.9553
Å |
 |  |  |  |  |
| SATB1_TOP2B_ENST00000417717_ENST00000435706_18462248_25686946 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.9563
Å |
 |  |  |  |  |
| SBF2_PRMT3_ENST00000256190_ENST00000437750_10315561_20473675 superimposed PDB: 8SHR of partner (PRMT3). RMSD:0.556
Å |
 |  |  |  |  |
| SBF2_RNF141_ENST00000256190_ENST00000265981_10215448_10546920 superimposed PDB: 2ECN of partner (RNF141). RMSD:3.2836
Å |
 |  |  |  |  |
| SBF2_RNF141_ENST00000256190_ENST00000528665_10215448_10546920 superimposed PDB: 2ECN of partner (RNF141). RMSD:2.5097
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000286835_ENST00000325074_33057361_36259393 superimposed PDB: 6XKB of partner (SCAF4). RMSD:0.2547
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000286835_ENST00000325074_33057361_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3766
Å |
| | | |  |
| SCAF4_RUNX1_ENST00000286835_ENST00000437180_33057361_36259393 superimposed PDB: 6XKB of partner (SCAF4). RMSD:0.2598
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000286835_ENST00000437180_33057361_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4122
Å |
| | | |  |
| SCAF4_RUNX1_ENST00000399804_ENST00000437180_33057361_36259393 superimposed PDB: 6XKB of partner (SCAF4). RMSD:0.2404
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000399804_ENST00000437180_33057361_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.4013
Å |
| | | |  |
| SCAF4_RUNX1_ENST00000434667_ENST00000325074_33057361_36259393 superimposed PDB: 6XKB of partner (SCAF4). RMSD:0.2486
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000434667_ENST00000325074_33057361_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3547
Å |
| | | |  |
| SCAF4_RUNX1_ENST00000434667_ENST00000437180_33057361_36259393 superimposed PDB: 6XKB of partner (SCAF4). RMSD:0.4451
Å |
 |  |  |  |  |
| SCAF4_RUNX1_ENST00000434667_ENST00000437180_33057361_36259393 superimposed PDB: 1E50 of partner (RUNX1). RMSD:0.3839
Å |
| | | |  |
| SCAF8_DIMT1_ENST00000367178_ENST00000199320_155109156_61686809 superimposed PDB: 2DIW of partner (SCAF8). RMSD:2.8292
Å |
 |  |  |  |  |
| SCAF8_DIMT1_ENST00000367186_ENST00000199320_155099179_61686809 superimposed PDB: 2DIW of partner (SCAF8). RMSD:0.9585
Å |
 |  |  |  |  |
| SCAF8_DIMT1_ENST00000367186_ENST00000199320_155109156_61686809 superimposed PDB: 2DIW of partner (SCAF8). RMSD:0.8065
Å |
 |  |  |  |  |
| SCAMP1_ARSB_ENST00000538629_ENST00000396151_77717784_78135249 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.8253
Å |
 |  |  |  |  |
| SCAPER_KMT2C_ENST00000563290_ENST00000262189_77150149_151843820 superimposed PDB: 6KIW of partner (KMT2C). RMSD:1.6219
Å |
 |  |  |  |  |
| SCAPER_KMT2C_ENST00000563290_ENST00000355193_77150149_151843820 superimposed PDB: 6KIW of partner (KMT2C). RMSD:1.7385
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000305762_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3747
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000322635_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.365
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000322680_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3485
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000372765_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3646
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000394762_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3578
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000265565_ENST00000423381_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3467
Å |
 |  |  |  |  |
| SCAP_CAMK2G_ENST00000441517_ENST00000351293_47466974_75620647 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.3597
Å |
 |  |  |  |  |
| SCARB1_SUB1_ENST00000339570_ENST00000515355_125348140_32599066 superimposed PDB: 6YCS of partner (SUB1). RMSD:0.6948
Å |
 |  |  |  |  |
| SCARB1_SUB1_ENST00000415380_ENST00000265073_125348140_32599066 superimposed PDB: 6YCS of partner (SUB1). RMSD:0.7906
Å |
 |  |  |  |  |
| SCARB1_SUB1_ENST00000546215_ENST00000265073_125348140_32599066 superimposed PDB: 6YCS of partner (SUB1). RMSD:0.8701
Å |
 |  |  |  |  |
| SCD_SEC61A2_ENST00000370355_ENST00000298428_102116521_12191593 superimposed PDB: 4ZYO of partner (SCD). RMSD:0.4501
Å |
 |  |  |  |  |
| SCD_SEC61A2_ENST00000370355_ENST00000379033_102116521_12191593 superimposed PDB: 4ZYO of partner (SCD). RMSD:0.4059
Å |
 |  |  |  |  |
| SCFD2_FIP1L1_ENST00000388940_ENST00000507166_54139992_54265896 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7207
Å |
 |  |  |  |  |
| SCFD2_FIP1L1_ENST00000401642_ENST00000306932_54139992_54265896 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7283
Å |
 |  |  |  |  |
| SCFD2_FIP1L1_ENST00000401642_ENST00000337488_54139992_54265896 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7209
Å |
 |  |  |  |  |
| SCFD2_FIP1L1_ENST00000401642_ENST00000507922_54139992_54265896 superimposed PDB: 7ZYH of partner (FIP1L1). RMSD:0.7126
Å |
 |  |  |  |  |
| SCFD2_KIT_ENST00000388940_ENST00000288135_54011499_55561677 superimposed PDB: 8DFP of partner (KIT). RMSD:2.9016
Å |
 |  |  |  |  |
| SCFD2_POLR2B_ENST00000401642_ENST00000431623_54139992_57860569 superimposed PDB: 9EHZ of partner (POLR2B). RMSD:0.997
Å |
 |  |  |  |  |
| SCMH1_EIF2B3_ENST00000326197_ENST00000360403_41578954_45316675 superimposed PDB: 2P0K of partner (SCMH1). RMSD:1.1293
Å |
 |  |  |  |  |
| SCMH1_EIF2B3_ENST00000402904_ENST00000360403_41578954_45316675 superimposed PDB: 2P0K of partner (SCMH1). RMSD:1.1534
Å |
 |  |  |  |  |
| SCMH1_FMNL1_ENST00000361191_ENST00000328118_41578954_43313502 superimposed PDB: 4YDH of partner (FMNL1). RMSD:0.7757
Å |
 |  |  |  |  |
| SCMH1_FMNL1_ENST00000361705_ENST00000331495_41578954_43313502 superimposed PDB: 4YDH of partner (FMNL1). RMSD:1.1319
Å |
 |  |  |  |  |
| SCMH1_PPT1_ENST00000326197_ENST00000433473_41536266_40539855 superimposed PDB: 2P0K of partner (SCMH1). RMSD:1.1183
Å |
 |  |  |  |  |
| SCMH1_PPT1_ENST00000402904_ENST00000433473_41536266_40539855 superimposed PDB: 2P0K of partner (SCMH1). RMSD:1.1702
Å |
 |  |  |  |  |
| SCML2_SH3KBP1_ENST00000251900_ENST00000379716_18338451_19564168 superimposed PDB: 2BIV of partner (SCML2). RMSD:0.4278
Å |
 |  |  |  |  |
| SCN8A_ANO2_ENST00000550891_ENST00000327087_52056877_5756967 superimposed PDB: 25II of partner (SCN8A). RMSD:2.2338
Å |
 |  |  |  |  |
| SCN8A_ATF1_ENST00000545061_ENST00000262053_52184286_51189691 superimposed PDB: 25II of partner (SCN8A). RMSD:2.204
Å |
 |  |  |  |  |
| SCN8A_DBF4B_ENST00000354534_ENST00000315005_52082633_42800247 superimposed PDB: 25II of partner (SCN8A). RMSD:0.977
Å |
 |  |  |  |  |
| SCN8A_DBF4B_ENST00000354534_ENST00000398338_52082633_42800247 superimposed PDB: 25II of partner (SCN8A). RMSD:0.9496
Å |
 |  |  |  |  |
| SCN8A_DBF4B_ENST00000545061_ENST00000393547_52082633_42800247 superimposed PDB: 25II of partner (SCN8A). RMSD:0.9539
Å |
 |  |  |  |  |
| SCN8A_DBF4B_ENST00000550891_ENST00000315005_52082880_42800247 superimposed PDB: 25II of partner (SCN8A). RMSD:0.9412
Å |
 |  |  |  |  |
| SCN8A_DBF4B_ENST00000550891_ENST00000398338_52082880_42800247 superimposed PDB: 25II of partner (SCN8A). RMSD:0.938
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000549325_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.0247
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000549325_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.7971
Å |
| | | |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000549396_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.2365
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000549396_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.7465
Å |
| | | |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000550584_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.4879
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000354534_ENST00000550584_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.6459
Å |
| | | |  |
| SCN8A_PPFIA2_ENST00000545061_ENST00000549396_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.2712
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000545061_ENST00000549396_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.6267
Å |
| | | |  |
| SCN8A_PPFIA2_ENST00000550891_ENST00000549325_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.3502
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000550891_ENST00000549325_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.7733
Å |
| | | |  |
| SCN8A_PPFIA2_ENST00000550891_ENST00000550584_52145377_81851645 superimposed PDB: 25II of partner (SCN8A). RMSD:2.6036
Å |
 |  |  |  |  |
| SCN8A_PPFIA2_ENST00000550891_ENST00000550584_52145377_81851645 superimposed PDB: 3TAC of partner (PPFIA2). RMSD:0.7459
Å |
| | | |  |
| SCNN1A_DCP1B_ENST00000228916_ENST00000280665_6457892_2055452 superimposed PDB: 6WTH of partner (SCNN1A). RMSD:1.2448
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000371509_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7916
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000371514_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7945
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000407246_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.8561
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000430330_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7319
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000435345_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.6928
Å |
 |  |  |  |  |
| SCP2_TMPRSS2_ENST00000528311_ENST00000398585_53504718_42861520 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.7292
Å |
 |  |  |  |  |
| SCRN2_CBX1_ENST00000584123_ENST00000225603_45918035_46152462 superimposed PDB: 5T1G of partner (CBX1). RMSD:0.2515
Å |
 |  |  |  |  |
| SCUBE2_LDHC_ENST00000309263_ENST00000541669_9090916_18451283 superimposed PDB: 8ZKJ of partner (LDHC). RMSD:1.8598
Å |
 |  |  |  |  |
| SCUBE2_LDHC_ENST00000450649_ENST00000280704_9090916_18451283 superimposed PDB: 8ZKJ of partner (LDHC). RMSD:0.7428
Å |
 |  |  |  |  |
| SCUBE2_LDHC_ENST00000457346_ENST00000280704_9090916_18451283 superimposed PDB: 8ZKJ of partner (LDHC). RMSD:0.7459
Å |
 |  |  |  |  |
| SCUBE2_LDHC_ENST00000520467_ENST00000541669_9090916_18451283 superimposed PDB: 8ZKJ of partner (LDHC). RMSD:1.9011
Å |
 |  |  |  |  |
| SCYL1_PACS1_ENST00000270176_ENST00000320580_65300276_65977832 superimposed PDB: 9Z30 of partner (PACS1). RMSD:1.8002
Å |
 |  |  |  |  |
| SDC4_NRG1_ENST00000537976_ENST00000338921_43959005_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.7161
Å |
 |  |  |  |  |
| SDC4_NRG1_ENST00000537976_ENST00000523079_43959005_32585466 superimposed PDB: 1EJP of partner (SDC4). RMSD:1.9997
Å |
 |  |  |  |  |
| SDC4_NRG1_ENST00000537976_ENST00000523079_43959005_32585466 superimposed PDB: 7SJL of partner (NRG1). RMSD:2.6414
Å |
| | | |  |
| SDHAF2_ACTN3_ENST00000301761_ENST00000513398_61197654_66318709 superimposed PDB: 1WKU of partner (ACTN3). RMSD:0.3385
Å |
 |  |  |  |  |
| SDHAF2_RIN1_ENST00000301761_ENST00000424433_61205585_66101129 superimposed PDB: 6VAX of partner (SDHAF2). RMSD:0.4964
Å |
 |  |  |  |  |
| SDHAF2_RIN1_ENST00000301761_ENST00000530056_61205585_66101129 superimposed PDB: 6VAX of partner (SDHAF2). RMSD:0.5251
Å |
 |  |  |  |  |
| SDHA_GIF_ENST00000510361_ENST00000541311_228448_59599269 superimposed PDB: 2PMV of partner (GIF). RMSD:2.5007
Å |
 |  |  |  |  |
| SDK1_BAIAP2L1_ENST00000389531_ENST00000005260_3341516_97949610 superimposed PDB: 2KXC of partner (BAIAP2L1). RMSD:0.6215
Å |
 |  |  |  |  |
| SEC14L1_GALK1_ENST00000392476_ENST00000588479_75139741_73760167 superimposed PDB: 7RCM of partner (GALK1). RMSD:0.8923
Å |
 |  |  |  |  |
| SEC14L2_UQCR10_ENST00000403484_ENST00000330029_30812076_30165666 superimposed PDB: 1OLM of partner (SEC14L2). RMSD:0.4132
Å |
 |  |  |  |  |
| SEC14L2_UQCR10_ENST00000405717_ENST00000330029_30812076_30165666 superimposed PDB: 1OLM of partner (SEC14L2). RMSD:0.4386
Å |
 |  |  |  |  |
| SEC23A_PSMC1_ENST00000548032_ENST00000261303_39565101_90738616 superimposed PDB: 2NUT of partner (SEC23A). RMSD:2.5086
Å |
 |  |  |  |  |
| SEC23B_CNGB3_ENST00000336714_ENST00000320005_18516386_87751964 superimposed PDB: 8ETP of partner (CNGB3). RMSD:1.9466
Å |
 |  |  |  |  |
| SEC31A_AGMO_ENST00000326950_ENST00000342526_83801951_15405244 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.9897
Å |
 |  |  |  |  |
| SEC31A_AGMO_ENST00000500777_ENST00000342526_83801951_15405244 superimposed PDB: 7SUL of partner (SEC31A). RMSD:1.0814
Å |
 |  |  |  |  |
| SEC31A_AGMO_ENST00000513858_ENST00000342526_83801951_15405244 superimposed PDB: 7SUL of partner (SEC31A). RMSD:1.0622
Å |
 |  |  |  |  |
| SEC31A_ALK_ENST00000326950_ENST00000389048_83763292_29446394 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5172
Å |
 |  |  |  |  |
| SEC31A_ALK_ENST00000355196_ENST00000389048_83769956_29446394 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5346
Å |
 |  |  |  |  |
| SEC31A_ALK_ENST00000395310_ENST00000389048_83763292_29446394 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.4946
Å |
 |  |  |  |  |
| SEC31A_ALK_ENST00000432794_ENST00000389048_83763292_29446394 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5375
Å |
 |  |  |  |  |
| SEC31A_ALK_ENST00000505472_ENST00000389048_83763292_29446394 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5043
Å |
 |  |  |  |  |
| SEC31A_ANAPC10_ENST00000348405_ENST00000451299_83739814_145985844 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5123
Å |
 |  |  |  |  |
| SEC31A_ANAPC10_ENST00000395310_ENST00000451299_83739814_145985844 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5179
Å |
 |  |  |  |  |
| SEC31A_ANAPC10_ENST00000513858_ENST00000451299_83739814_145985844 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.4932
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000348405_ENST00000349655_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5762
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000348405_ENST00000602300_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.6226
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000443462_ENST00000349655_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:1.0246
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000443462_ENST00000602300_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.8699
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000505472_ENST00000349655_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5793
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000505472_ENST00000602300_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5897
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000509142_ENST00000349655_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.6228
Å |
 |  |  |  |  |
| SEC31A_HNRNPDL_ENST00000509142_ENST00000602300_83799882_83348717 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.648
Å |
 |  |  |  |  |
| SEC31A_INTS12_ENST00000326950_ENST00000451321_83784470_106604474 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5534
Å |
 |  |  |  |  |
| SEC31A_INTS12_ENST00000500777_ENST00000451321_83784470_106604474 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5017
Å |
 |  |  |  |  |
| SEC31A_INTS12_ENST00000505984_ENST00000451321_83784470_106604474 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5577
Å |
 |  |  |  |  |
| SEC31A_INTS12_ENST00000509142_ENST00000451321_83784470_106604474 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.7063
Å |
 |  |  |  |  |
| SEC31A_INTS12_ENST00000513858_ENST00000451321_83784470_106604474 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5363
Å |
 |  |  |  |  |
| SEC31A_SCD5_ENST00000326950_ENST00000282709_83795763_83626566 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.4976
Å |
 |  |  |  |  |
| SEC31A_SCD5_ENST00000500777_ENST00000282709_83795763_83626566 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5153
Å |
 |  |  |  |  |
| SEC31A_SCD5_ENST00000509142_ENST00000282709_83795763_83626566 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.7213
Å |
 |  |  |  |  |
| SEC31A_SCD5_ENST00000513858_ENST00000282709_83795763_83626566 superimposed PDB: 7SUL of partner (SEC31A). RMSD:0.5025
Å |
 |  |  |  |  |
| SEC61B_RTEL1_ENST00000223641_ENST00000318100_101984648_62316875 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.3914
Å |
 |  |  |  |  |
| SEC61B_RTEL1_ENST00000223641_ENST00000508582_101984648_62316875 superimposed PDB: 8P8H of partner (RTEL1). RMSD:0.372
Å |
 |  |  |  |  |
| SEC61G_C7orf57_ENST00000395535_ENST00000348904_54823471_48099822 superimposed PDB: 8DNZ of partner (SEC61G). RMSD:0.6693
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000352861_ENST00000275493_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:0.7414
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000352861_ENST00000342916_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.6619
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000352861_ENST00000344576_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.3471
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000352861_ENST00000420316_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.4965
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000352861_ENST00000442591_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.7956
Å |
 |  |  |  |  |
| SEC61G_EGFR_ENST00000415949_ENST00000455089_54825187_55224225 superimposed PDB: 7SYD of partner (EGFR). RMSD:1.4945
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000359462_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2381
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000437231_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3272
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000447282_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2616
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000455667_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2758
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000546463_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3598
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000549863_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3778
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000552296_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.1683
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000552819_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2254
Å |
 |  |  |  |  |
| SEC63_PCBP2_ENST00000369002_ENST00000603815_108214685_53853055 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.2409
Å |
 |  |  |  |  |
| SECISBP2_TOP2B_ENST00000339901_ENST00000264331_91934712_25656779 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.2258
Å |
 |  |  |  |  |
| SEL1L3_ATG12_ENST00000264868_ENST00000509910_25766947_115168361 superimposed PDB: 4NAW of partner (ATG12). RMSD:0.5095
Å |
 |  |  |  |  |
| SEL1L3_ATG12_ENST00000399878_ENST00000509910_25766947_115168361 superimposed PDB: 4NAW of partner (ATG12). RMSD:0.535
Å |
 |  |  |  |  |
| SEMA3A_MAGI2_ENST00000436949_ENST00000354212_83739785_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.9058
Å |
 |  |  |  |  |
| SEMA3A_MAGI2_ENST00000436949_ENST00000522391_83739785_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8855
Å |
 |  |  |  |  |
| SEMA3A_MAGI2_ENST00000436949_ENST00000535697_83739785_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8756
Å |
 |  |  |  |  |
| SEMA3A_MAGI2_ENST00000436949_ENST00000536571_83739785_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8998
Å |
 |  |  |  |  |
| SEMA3A_MDFIC_ENST00000265362_ENST00000257724_83823790_114655741 superimposed PDB: 8ZU3 of partner (MDFIC). RMSD:0.4873
Å |
 |  |  |  |  |
| SEMA3F_RNF123_ENST00000002829_ENST00000432042_50197167_49742082 superimposed PDB: 2MA6 of partner (RNF123). RMSD:0.8326
Å |
 |  |  |  |  |
| SEMA4B_ARID1B_ENST00000379122_ENST00000275248_90744967_157495141 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.5635
Å |
 |  |  |  |  |
| SEMA4B_ARID1B_ENST00000379122_ENST00000346085_90744967_157495141 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.5666
Å |
 |  |  |  |  |
| SEMA4B_ARID1B_ENST00000411539_ENST00000275248_90744967_157495141 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.4942
Å |
 |  |  |  |  |
| SEMA4B_ARID1B_ENST00000411539_ENST00000346085_90744967_157495141 superimposed PDB: 2CXY of partner (ARID1B). RMSD:0.5057
Å |
 |  |  |  |  |
| SEMA4B_GLUD1_ENST00000379122_ENST00000537649_90744967_88827914 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.0612
Å |
 |  |  |  |  |
| SEMA4B_GLUD1_ENST00000411539_ENST00000537649_90744967_88827914 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.0595
Å |
 |  |  |  |  |
| SENP2_ANKRD27_ENST00000296257_ENST00000587352_185304302_33133051 superimposed PDB: 4B93 of partner (ANKRD27). RMSD:0.4636
Å |
 |  |  |  |  |
| SENP6_ACACB_ENST00000370010_ENST00000377854_76333676_109680241 superimposed PDB: 3FF6 of partner (ACACB). RMSD:0.5798
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000370010_ENST00000410055_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.7665
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000370010_ENST00000544863_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.6696
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000370014_ENST00000410055_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.5212
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000370014_ENST00000544863_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.7029
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000447266_ENST00000410055_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.6863
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000447266_ENST00000544863_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.7354
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000541192_ENST00000410055_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.2839
Å |
 |  |  |  |  |
| SENP6_PDK1_ENST00000541192_ENST00000544863_76380436_173451005 superimposed PDB: 2Q8G of partner (PDK1). RMSD:1.4144
Å |
 |  |  |  |  |
| SEPT14_ASNS_ENST00000388975_ENST00000437628_55929635_97481780 superimposed PDB: 6GQ3 of partner (ASNS). RMSD:0.4331
Å |
 |  |  |  |  |
| SEPT7_GLI3_ENST00000350320_ENST00000395925_35872510_42116456 superimposed PDB: 7M6J of partner (SEPT7). RMSD:1.2337
Å |
 |  |  |  |  |
| SEPT7_GLI3_ENST00000399034_ENST00000395925_35872510_42116456 superimposed PDB: 7M6J of partner (SEPT7). RMSD:1.7526
Å |
 |  |  |  |  |
| SEPT7_GLI3_ENST00000435235_ENST00000395925_35872510_42116456 superimposed PDB: 7M6J of partner (SEPT7). RMSD:1.1203
Å |
 |  |  |  |  |
| SEPT7_GLI3_ENST00000469679_ENST00000395925_35872510_42116456 superimposed PDB: 7M6J of partner (SEPT7). RMSD:1.5242
Å |
 |  |  |  |  |
| SEPT7_GLI3_ENST00000494488_ENST00000395925_35872510_42116456 superimposed PDB: 7M6J of partner (SEPT7). RMSD:1.5198
Å |
 |  |  |  |  |
| SEPT9_MPO_ENST00000427177_ENST00000225275_75303279_56353063 superimposed PDB: 6BMT of partner (MPO). RMSD:0.3366
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000329047_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7615
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000423034_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7644
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000427177_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.6964
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000427180_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.8392
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000427674_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7637
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000431235_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7694
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000449803_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7809
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000541152_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.4749
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000585930_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7771
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000588690_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7234
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000591088_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.4887
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000591198_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.8022
Å |
 |  |  |  |  |
| SEPT9_SMG6_ENST00000592951_ENST00000263073_75478417_2091809 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.8102
Å |
 |  |  |  |  |
| SERINC3_NCOA5_ENST00000342374_ENST00000290231_43139929_44691528 superimposed PDB: 7RU6 of partner (SERINC3). RMSD:1.557
Å |
 |  |  |  |  |
| SERINC5_CDYL2_ENST00000507668_ENST00000562812_79551714_80719026 superimposed PDB: 5JJZ of partner (CDYL2). RMSD:0.3907
Å |
 |  |  |  |  |
| SERINC5_CDYL2_ENST00000507668_ENST00000566173_79551714_80719026 superimposed PDB: 5JJZ of partner (CDYL2). RMSD:0.4167
Å |
 |  |  |  |  |
| SERPINA1_FGG_ENST00000393087_ENST00000336098_94847207_155526218 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.4023
Å |
 |  |  |  |  |
| SERPINA1_FGG_ENST00000393088_ENST00000404648_94847207_155526218 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.4255
Å |
 |  |  |  |  |
| SERPINA1_FGG_ENST00000393088_ENST00000405164_94847207_155526218 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.4419
Å |
 |  |  |  |  |
| SERPINA1_FGG_ENST00000404814_ENST00000405164_94847207_155526218 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.3409
Å |
 |  |  |  |  |
| SERPINA1_FGG_ENST00000449399_ENST00000405164_94847207_155526218 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.3749
Å |
 |  |  |  |  |
| SERPINA1_RPS13_ENST00000437397_ENST00000228140_94847207_17099024 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.4746
Å |
 |  |  |  |  |
| SERPINA1_RPS13_ENST00000448921_ENST00000228140_94847207_17099024 superimposed PDB: 6HX4 of partner (SERPINA1). RMSD:1.4233
Å |
 |  |  |  |  |
| SERPINB5_CDH19_ENST00000489441_ENST00000262150_61151829_64178922 superimposed PDB: 8EGX of partner (CDH19). RMSD:2.8541
Å |
 |  |  |  |  |
| SERPINE1_COL1A2_ENST00000445463_ENST00000297268_100771945_94059558 superimposed PDB: 1C5G of partner (SERPINE1). RMSD:0.8933
Å |
 |  |  |  |  |
| SERPINE2_HLA-DRB1_ENST00000258405_ENST00000360004_224862831_32549615 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:2.7115
Å |
 |  |  |  |  |
| SERPINE2_HLA-DRB1_ENST00000258405_ENST00000360004_224862831_32549615 superimposed PDB: 8VRW of partner (HLA-DRB1). RMSD:0.7089
Å |
| | | |  |
| SERPINE2_HLA-DRB1_ENST00000409304_ENST00000360004_224862831_32549615 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:1.2058
Å |
 |  |  |  |  |
| SERPINE2_HLA-DRB1_ENST00000447280_ENST00000360004_224862831_32549615 superimposed PDB: 4DY0 of partner (SERPINE2). RMSD:2.7669
Å |
 |  |  |  |  |
| SERPINE2_HLA-DRB1_ENST00000447280_ENST00000360004_224862831_32549615 superimposed PDB: 8VRW of partner (HLA-DRB1). RMSD:0.7107
Å |
| | | |  |
| SERPING1_A1BG_ENST00000340687_ENST00000263100_57369642_58859006 superimposed PDB: 7AKV of partner (SERPING1). RMSD:2.4283
Å |
 |  |  |  |  |
| SERPING1_A1BG_ENST00000378323_ENST00000263100_57369642_58859006 superimposed PDB: 7AKV of partner (SERPING1). RMSD:1.8555
Å |
 |  |  |  |  |
| SERPING1_A1BG_ENST00000378324_ENST00000263100_57369642_58859006 superimposed PDB: 7AKV of partner (SERPING1). RMSD:2.7578
Å |
 |  |  |  |  |
| SETD2_KIF9_ENST00000409792_ENST00000265529_47205343_47316980 superimposed PDB: 3NWN of partner (KIF9). RMSD:0.448
Å |
 |  |  |  |  |
| SETD2_KIF9_ENST00000409792_ENST00000452770_47205343_47316980 superimposed PDB: 3NWN of partner (KIF9). RMSD:0.4305
Å |
 |  |  |  |  |
| SETD2_RNF216_ENST00000409792_ENST00000389902_47125209_5756397 superimposed PDB: 7M4M of partner (RNF216). RMSD:2.0933
Å |
 |  |  |  |  |
| SETD6_IFT172_ENST00000219315_ENST00000260570_58550832_27672963 superimposed PDB: 3QXY of partner (SETD6). RMSD:1.0077
Å |
 |  |  |  |  |
| SETD6_IFT172_ENST00000219315_ENST00000260570_58550832_27672963 superimposed PDB: 9H2D of partner (IFT172). RMSD:0.3934
Å |
| | | |  |
| SETD6_IFT172_ENST00000394266_ENST00000260570_58550832_27672963 superimposed PDB: 3QXY of partner (SETD6). RMSD:0.7662
Å |
 |  |  |  |  |
| SETD6_IFT172_ENST00000394266_ENST00000260570_58550832_27672963 superimposed PDB: 9H2D of partner (IFT172). RMSD:0.3804
Å |
| | | |  |
| SET_BRD1_ENST00000322030_ENST00000404034_131451934_50171461 superimposed PDB: 5PQI of partner (BRD1). RMSD:2.0275
Å |
 |  |  |  |  |
| SF1_ENO1_ENST00000377390_ENST00000234590_64543969_8930569 superimposed PDB: 2PSN of partner (ENO1). RMSD:0.4984
Å |
 |  |  |  |  |
| SF1_ENO1_ENST00000377394_ENST00000234590_64543969_8930569 superimposed PDB: 2PSN of partner (ENO1). RMSD:0.5381
Å |
 |  |  |  |  |
| SF1_HRASLS2_ENST00000227503_ENST00000255695_64534371_63326132 superimposed PDB: 4DPZ of partner (HRASLS2). RMSD:0.5383
Å |
 |  |  |  |  |
| SF1_HRASLS2_ENST00000377390_ENST00000255695_64534371_63326132 superimposed PDB: 4DPZ of partner (HRASLS2). RMSD:0.6406
Å |
 |  |  |  |  |
| SF1_ITPR1_ENST00000377387_ENST00000544951_64543969_4669446 superimposed PDB: 4QJR of partner (SF1). RMSD:3.0465
Å |
 |  |  |  |  |
| SF1_PLEKHA8_ENST00000377387_ENST00000396259_64543969_30100499 superimposed PDB: 5KDI of partner (PLEKHA8). RMSD:1.4319
Å |
 |  |  |  |  |
| SF1_PLEKHA8_ENST00000377390_ENST00000396257_64543969_30100499 superimposed PDB: 5KDI of partner (PLEKHA8). RMSD:1.369
Å |
 |  |  |  |  |
| SF1_SAGE1_ENST00000377387_ENST00000535938_64543969_134988182 superimposed PDB: 8HPP of partner (SAGE1). RMSD:0.4126
Å |
 |  |  |  |  |
| SF1_SAGE1_ENST00000377390_ENST00000535938_64543969_134988182 superimposed PDB: 8HPP of partner (SAGE1). RMSD:0.4107
Å |
 |  |  |  |  |
| SF3B3_ADAM12_ENST00000302516_ENST00000368676_70604052_127967557 superimposed PDB: 7Q4O of partner (SF3B3). RMSD:1.0565
Å |
 |  |  |  |  |
| SF3B3_ADAM12_ENST00000302516_ENST00000368679_70604052_127967557 superimposed PDB: 7Q4O of partner (SF3B3). RMSD:1.8246
Å |
 |  |  |  |  |
| SF3B3_DDX19B_ENST00000302516_ENST00000563392_70595687_70358487 superimposed PDB: 7Q4O of partner (SF3B3). RMSD:3.0815
Å |
 |  |  |  |  |
| SFMBT1_EML1_ENST00000394750_ENST00000262233_52988330_100357535 superimposed PDB: 4CI8 of partner (EML1). RMSD:0.6545
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000358080_ENST00000342056_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.9923
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000355194_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:3.0561
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000355635_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:2.3468
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000370398_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:3.1182
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000402622_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:3.0583
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000403813_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:3.0033
Å |
 |  |  |  |  |
| SFMBT1_KCNQ5_ENST00000394750_ENST00000414165_53003116_73751658 superimposed PDB: 9J38 of partner (KCNQ5). RMSD:3.0559
Å |
 |  |  |  |  |
| SFMBT1_WNT7A_ENST00000296295_ENST00000285018_53003116_13896300 superimposed PDB: 8TZO of partner (WNT7A). RMSD:1.5241
Å |
 |  |  |  |  |
| SFPQ_FAM134B_ENST00000357214_ENST00000306320_35654603_16572211 superimposed PDB: 7UK1 of partner (SFPQ). RMSD:2.0424
Å |
 |  |  |  |  |
| SFPQ_TFE3_ENST00000357214_ENST00000315869_35654603_48898095 superimposed PDB: 7UK1 of partner (SFPQ). RMSD:1.9176
Å |
 |  |  |  |  |
| SFPQ_ZFP36L1_ENST00000357214_ENST00000439696_35652601_69257209 superimposed PDB: 7UK1 of partner (SFPQ). RMSD:2.1022
Å |
 |  |  |  |  |
| SFTPB_MPC1_ENST00000342375_ENST00000341756_85893739_166778941 superimposed PDB: 2DWF of partner (SFTPB). RMSD:2.9311
Å |
 |  |  |  |  |
| SFXN4_SIRT3_ENST00000330036_ENST00000382743_120925048_224239 superimposed PDB: 8BBK of partner (SIRT3). RMSD:1.7873
Å |
 |  |  |  |  |
| SFXN4_SIRT3_ENST00000355697_ENST00000525319_120925048_224239 superimposed PDB: 8BBK of partner (SIRT3). RMSD:1.6797
Å |
 |  |  |  |  |
| SGCD_RARA_ENST00000435422_ENST00000394089_156022061_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4546
Å |
 |  |  |  |  |
| SGCD_RARA_ENST00000517913_ENST00000394089_156022061_38504567 superimposed PDB: 3A9E of partner (RARA). RMSD:0.4551
Å |
 |  |  |  |  |
| SGCE_SLC25A13_ENST00000265735_ENST00000416240_94285301_95822495 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.3752
Å |
 |  |  |  |  |
| SGCE_SLC25A13_ENST00000265735_ENST00000542654_94285301_95822495 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.3823
Å |
 |  |  |  |  |
| SGK3_CTNND2_ENST00000521198_ENST00000359640_67716682_10988354 superimposed PDB: 6EDX of partner (SGK3). RMSD:1.4064
Å |
 |  |  |  |  |
| SGK3_DNAJC5B_ENST00000522398_ENST00000276570_67710860_66992611 superimposed PDB: 6EDX of partner (SGK3). RMSD:1.1288
Å |
 |  |  |  |  |
| SGK3_KRT9_ENST00000522398_ENST00000246662_67743546_39726472 superimposed PDB: 6EDX of partner (SGK3). RMSD:0.358
Å |
 |  |  |  |  |
| SGMS1_GAB2_ENST00000361781_ENST00000361507_52086964_77961446 superimposed PDB: 2VWF of partner (GAB2). RMSD:2.297
Å |
 |  |  |  |  |
| SGPL1_COL13A1_ENST00000373202_ENST00000398964_72617447_71655305 superimposed PDB: 4Q6R of partner (SGPL1). RMSD:2.2908
Å |
 |  |  |  |  |
| SGPL1_COL13A1_ENST00000373202_ENST00000517713_72617447_71655305 superimposed PDB: 4Q6R of partner (SGPL1). RMSD:2.3825
Å |
 |  |  |  |  |
| SGPL1_COL13A1_ENST00000373202_ENST00000520133_72617447_71655305 superimposed PDB: 4Q6R of partner (SGPL1). RMSD:2.8328
Å |
 |  |  |  |  |
| SGPL1_COL13A1_ENST00000373202_ENST00000522165_72617447_71655305 superimposed PDB: 4Q6R of partner (SGPL1). RMSD:2.3902
Å |
 |  |  |  |  |
| SGSH_EIF3D_ENST00000326317_ENST00000216190_78187970_36912837 superimposed PDB: 4MHX of partner (SGSH). RMSD:0.4836
Å |
 |  |  |  |  |
| SGSM2_EIF2B4_ENST00000268989_ENST00000445933_2276807_27591330 superimposed PDB: 7VLK of partner (EIF2B4). RMSD:0.5899
Å |
 |  |  |  |  |
| SGSM2_EIF2B4_ENST00000426855_ENST00000445933_2276807_27591330 superimposed PDB: 7VLK of partner (EIF2B4). RMSD:0.5634
Å |
 |  |  |  |  |
| SGSM2_EIF2B4_ENST00000426855_ENST00000493344_2276807_27591330 superimposed PDB: 7VLK of partner (EIF2B4). RMSD:0.5845
Å |
 |  |  |  |  |
| SGSM2_PTK6_ENST00000268989_ENST00000542869_2241039_62165057 superimposed PDB: 6CZ4 of partner (PTK6). RMSD:0.7879
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000322610_ENST00000298223_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:1.0606
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000322610_ENST00000454954_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.9514
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000337120_ENST00000298223_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.9275
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000337120_ENST00000454954_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.999
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000395532_ENST00000298223_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:1.0131
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000395532_ENST00000454954_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.9569
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000538342_ENST00000298223_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.7985
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000538342_ENST00000454954_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.8472
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000545570_ENST00000298223_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:1.2544
Å |
 |  |  |  |  |
| SH2B1_FOLR2_ENST00000545570_ENST00000454954_28878753_71932219 superimposed PDB: 4KMY of partner (FOLR2). RMSD:0.9474
Å |
 |  |  |  |  |
| SH3BP1_CACNA1I_ENST00000357436_ENST00000400164_38039795_40057969 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.1345
Å |
 |  |  |  |  |
| SH3BP1_CACNA1I_ENST00000357436_ENST00000401624_38039795_40057969 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0579
Å |
 |  |  |  |  |
| SH3BP1_CACNA1I_ENST00000599616_ENST00000400164_38039795_40057969 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0196
Å |
 |  |  |  |  |
| SH3BP1_CACNA1I_ENST00000599616_ENST00000401624_38039795_40057969 superimposed PDB: 7WLI of partner (CACNA1I). RMSD:2.0365
Å |
 |  |  |  |  |
| SH3GL1_MLLT1_ENST00000598564_ENST00000252674_4400320_6270770 superimposed PDB: 8PJI of partner (MLLT1). RMSD:0.5418
Å |
 |  |  |  |  |
| SH3KBP1_RPS6KA3_ENST00000397821_ENST00000379565_19854242_20227522 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.6886
Å |
 |  |  |  |  |
| SH3KBP1_RPS6KA3_ENST00000397821_ENST00000540702_19854242_20227522 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:2.0147
Å |
 |  |  |  |  |
| SH3KBP1_RPS6KA3_ENST00000397821_ENST00000540702_19854242_20227522 superimposed PDB: 4D9T of partner (RPS6KA3). RMSD:0.7466
Å |
| | | |  |
| SH3KBP1_RPS6KA3_ENST00000397821_ENST00000544447_19854242_20227522 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.7406
Å |
 |  |  |  |  |
| SH3KBP1_RPS6KA3_ENST00000397821_ENST00000544447_19854242_20227522 superimposed PDB: 4D9T of partner (RPS6KA3). RMSD:0.7572
Å |
| | | |  |
| SH3KBP1_ZNF92_ENST00000379697_ENST00000328747_19701940_64852814 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.6619
Å |
 |  |  |  |  |
| SH3KBP1_ZNF92_ENST00000379698_ENST00000328747_19701940_64852814 superimposed PDB: 2O2O of partner (SH3KBP1). RMSD:1.6646
Å |
 |  |  |  |  |
| SH3PXD2A_PDLIM1_ENST00000355946_ENST00000329399_105561039_97031541 superimposed PDB: 2PKT of partner (PDLIM1). RMSD:0.7708
Å |
 |  |  |  |  |
| SH3PXD2A_RB1_ENST00000355946_ENST00000267163_105371337_49039133 superimposed PDB: 2EKH of partner (SH3PXD2A). RMSD:0.8722
Å |
 |  |  |  |  |
| SH3PXD2A_RB1_ENST00000355946_ENST00000267163_105371337_49039133 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.6748
Å |
| | | |  |
| SH3PXD2A_RB1_ENST00000369774_ENST00000267163_105371337_49039133 superimposed PDB: 2EKH of partner (SH3PXD2A). RMSD:0.8591
Å |
 |  |  |  |  |
| SH3PXD2A_RB1_ENST00000369774_ENST00000267163_105371337_49039133 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.4168
Å |
| | | |  |
| SH3PXD2A_RB1_ENST00000538130_ENST00000267163_105371337_49039133 superimposed PDB: 2EKH of partner (SH3PXD2A). RMSD:0.863
Å |
 |  |  |  |  |
| SH3PXD2A_RB1_ENST00000538130_ENST00000267163_105371337_49039133 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.6418
Å |
| | | |  |
| SH3PXD2A_RB1_ENST00000540321_ENST00000267163_105371337_49039133 superimposed PDB: 2EKH of partner (SH3PXD2A). RMSD:0.886
Å |
 |  |  |  |  |
| SH3PXD2A_RB1_ENST00000540321_ENST00000267163_105371337_49039133 superimposed PDB: 4ELJ of partner (RB1). RMSD:0.4571
Å |
| | | |  |
| SHANK1_MTHFD1L_ENST00000293441_ENST00000367321_51175274_151330954 superimposed PDB: 6YX0 of partner (SHANK1). RMSD:0.2512
Å |
 |  |  |  |  |
| SHANK1_MTHFD1L_ENST00000359082_ENST00000367321_51175274_151330954 superimposed PDB: 6YX0 of partner (SHANK1). RMSD:0.2874
Å |
 |  |  |  |  |
| SHANK2_CTTN_ENST00000338508_ENST00000301843_70505932_70271437 superimposed PDB: 8B10 of partner (SHANK2). RMSD:2.9091
Å |
 |  |  |  |  |
| SHANK2_CTTN_ENST00000338508_ENST00000301843_70505932_70271437 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7813
Å |
| | | |  |
| SHANK2_CTTN_ENST00000409161_ENST00000301843_70505932_70271437 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.717
Å |
 |  |  |  |  |
| SHANK2_CTTN_ENST00000423696_ENST00000301843_70505932_70271437 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7004
Å |
 |  |  |  |  |
| SHANK2_CTTN_ENST00000449833_ENST00000301843_70505932_70271437 superimposed PDB: 1X69 of partner (CTTN). RMSD:0.7258
Å |
 |  |  |  |  |
| SHANK2_ELP4_ENST00000409530_ENST00000350638_70505932_31804940 superimposed PDB: 8B10 of partner (SHANK2). RMSD:3.0063
Å |
 |  |  |  |  |
| SHANK2_HMGN3_ENST00000338508_ENST00000344726_70505932_79924739 superimposed PDB: 8B10 of partner (SHANK2). RMSD:2.9792
Å |
 |  |  |  |  |
| SHANK2_HMGN3_ENST00000409530_ENST00000275036_70505932_79924739 superimposed PDB: 8B10 of partner (SHANK2). RMSD:2.9979
Å |
 |  |  |  |  |
| SHANK2_NEU3_ENST00000409530_ENST00000294064_70505932_74716457 superimposed PDB: 8B10 of partner (SHANK2). RMSD:2.9728
Å |
 |  |  |  |  |
| SHANK2_PATL1_ENST00000338508_ENST00000300146_70858165_59434437 superimposed PDB: 8B10 of partner (SHANK2). RMSD:2.853
Å |
 |  |  |  |  |
| SHANK3_MAPK1_ENST00000262795_ENST00000215832_51115121_22153417 superimposed PDB: 7C7I of partner (SHANK3). RMSD:0.3674
Å |
 |  |  |  |  |
| SHANK3_MAPK1_ENST00000262795_ENST00000215832_51115121_22153417 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:3.1895
Å |
| | | |  |
| SHANK3_MAPK1_ENST00000414786_ENST00000398822_51115121_22153417 superimposed PDB: 7C7I of partner (SHANK3). RMSD:0.3962
Å |
 |  |  |  |  |
| SHANK3_MAPK1_ENST00000414786_ENST00000398822_51115121_22153417 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:1.249
Å |
| | | |  |
| SHANK3_MAPK1_ENST00000445220_ENST00000215832_51115121_22153417 superimposed PDB: 7C7I of partner (SHANK3). RMSD:0.3774
Å |
 |  |  |  |  |
| SHB_PAX5_ENST00000377700_ENST00000358127_38016007_37020798 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.0435
Å |
 |  |  |  |  |
| SHB_PAX5_ENST00000377707_ENST00000377852_38016007_37020798 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.2554
Å |
 |  |  |  |  |
| SHB_PAX5_ENST00000377707_ENST00000377853_38016007_37020798 superimposed PDB: 1K78 of partner (PAX5). RMSD:2.9855
Å |
 |  |  |  |  |
| SHB_PAX5_ENST00000377707_ENST00000520154_38016007_37020798 superimposed PDB: 1K78 of partner (PAX5). RMSD:3.3173
Å |
 |  |  |  |  |
| SHB_PAX5_ENST00000377707_ENST00000523241_38016007_37020798 superimposed PDB: 1K78 of partner (PAX5). RMSD:2.9729
Å |
 |  |  |  |  |
| SHB_SLC28A3_ENST00000377700_ENST00000376238_38067925_86928369 superimposed PDB: 6KSW of partner (SLC28A3). RMSD:0.9184
Å |
 |  |  |  |  |
| SHFM1_EZH2_ENST00000417009_ENST00000350995_96324109_148512638 superimposed PDB: 3T5X of partner (SHFM1). RMSD:2.6672
Å |
 |  |  |  |  |
| SHFM1_EZH2_ENST00000417009_ENST00000350995_96324109_148512638 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.891
Å |
| | | |  |
| SHFM1_EZH2_ENST00000417009_ENST00000460911_96324109_148512638 superimposed PDB: 3T5X of partner (SHFM1). RMSD:1.5967
Å |
 |  |  |  |  |
| SHFM1_EZH2_ENST00000417009_ENST00000460911_96324109_148512638 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.7156
Å |
| | | |  |
| SHMT1_DOK5_ENST00000352886_ENST00000262593_18250809_53171471 superimposed PDB: 1J0W of partner (DOK5). RMSD:0.4058
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000328923_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.6298
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000393827_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.892
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000414700_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.6221
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000449049_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.6767
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000553474_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.6186
Å |
 |  |  |  |  |
| SHMT2_SLC16A7_ENST00000557487_ENST00000547379_57627893_60164999 superimposed PDB: 6QVL of partner (SHMT2). RMSD:0.6401
Å |
 |  |  |  |  |
| SHROOM3_SCARB2_ENST00000296043_ENST00000452464_77692051_77117017 superimposed PDB: 4Q4F of partner (SCARB2). RMSD:0.541
Å |
 |  |  |  |  |
| SHROOM4_ARID3A_ENST00000289292_ENST00000263620_50556901_960091 superimposed PDB: 4LJX of partner (ARID3A). RMSD:0.4407
Å |
 |  |  |  |  |
| SHROOM4_ARID3A_ENST00000376020_ENST00000263620_50556901_960091 superimposed PDB: 2EDP of partner (SHROOM4). RMSD:1.241
Å |
 |  |  |  |  |
| SIDT2_CYP2C8_ENST00000431081_ENST00000371270_117064679_96827448 superimposed PDB: 7Y68 of partner (SIDT2). RMSD:1.6999
Å |
 |  |  |  |  |
| SIDT2_CYP2C8_ENST00000431081_ENST00000371270_117064679_96827448 superimposed PDB: 2VN0 of partner (CYP2C8). RMSD:1.1211
Å |
| | | |  |
| SIDT2_CYP2C8_ENST00000532062_ENST00000371270_117064679_96827448 superimposed PDB: 7Y68 of partner (SIDT2). RMSD:1.5669
Å |
 |  |  |  |  |
| SIDT2_CYP2C8_ENST00000532062_ENST00000371270_117064679_96827448 superimposed PDB: 2VN0 of partner (CYP2C8). RMSD:1.0877
Å |
| | | |  |
| SIGIRR_DEAF1_ENST00000382520_ENST00000338675_406842_644654 superimposed PDB: 2JW6 of partner (DEAF1). RMSD:2.6214
Å |
 |  |  |  |  |
| SIGIRR_DEAF1_ENST00000397632_ENST00000338675_406842_644654 superimposed PDB: 2JW6 of partner (DEAF1). RMSD:1.9786
Å |
 |  |  |  |  |
| SIK2_PIR_ENST00000304987_ENST00000380421_111583099_15477863 superimposed PDB: 6H1H of partner (PIR). RMSD:0.591
Å |
 |  |  |  |  |
| SIK3_CTNNBIP1_ENST00000375300_ENST00000377256_116968858_9910834 superimposed PDB: 1M1E of partner (CTNNBIP1). RMSD:2.3603
Å |
 |  |  |  |  |
| SIK3_PACS1_ENST00000292055_ENST00000320580_116968858_65983589 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.4643
Å |
 |  |  |  |  |
| SIK3_PACS1_ENST00000292055_ENST00000320580_116968858_65983589 superimposed PDB: 9Z30 of partner (PACS1). RMSD:2.8442
Å |
| | | |  |
| SIK3_PACS1_ENST00000542607_ENST00000320580_116968858_65983589 superimposed PDB: 8OKU of partner (SIK3). RMSD:1.1838
Å |
 |  |  |  |  |
| SIK3_PACS1_ENST00000542607_ENST00000320580_116968858_65983589 superimposed PDB: 9Z30 of partner (PACS1). RMSD:2.3768
Å |
| | | |  |
| SIK3_PPP1R1B_ENST00000292055_ENST00000254079_116968858_37785422 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.5604
Å |
 |  |  |  |  |
| SIK3_PPP1R1B_ENST00000292055_ENST00000580825_116968858_37785422 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.5367
Å |
 |  |  |  |  |
| SIK3_PPP1R1B_ENST00000375300_ENST00000254079_116968858_37785422 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.55
Å |
 |  |  |  |  |
| SIK3_PPP1R1B_ENST00000446921_ENST00000254079_116968858_37785422 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.5288
Å |
 |  |  |  |  |
| SIK3_PPP1R1B_ENST00000542607_ENST00000580825_116968858_37785422 superimposed PDB: 8OKU of partner (SIK3). RMSD:0.4871
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000309434_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8736
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000389124_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8371
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000389125_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9078
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000399907_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8729
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000399909_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8336
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000399913_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8893
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000399914_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8513
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000290399_ENST00000535441_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8454
Å |
 |  |  |  |  |
| SIM2_GRIK1_ENST00000430056_ENST00000327783_38072221_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8691
Å |
 |  |  |  |  |
| SIN3A_EWSR1_ENST00000394947_ENST00000397938_75714987_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7479
Å |
 |  |  |  |  |
| SIN3B_C19orf57_ENST00000248054_ENST00000454313_16952779_13996868 superimposed PDB: 8BPB of partner (SIN3B). RMSD:1.4813
Å |
 |  |  |  |  |
| SIN3B_C19orf57_ENST00000248054_ENST00000454313_16952779_13996868 superimposed PDB: 8A51 of partner (C19orf57). RMSD:0.589
Å |
| | | |  |
| SIN3B_C19orf57_ENST00000248054_ENST00000591586_16952779_13996868 superimposed PDB: 8BPB of partner (SIN3B). RMSD:1.4819
Å |
 |  |  |  |  |
| SIN3B_C19orf57_ENST00000248054_ENST00000591586_16952779_13996868 superimposed PDB: 8A51 of partner (C19orf57). RMSD:0.7236
Å |
| | | |  |
| SIN3B_PLEKHA4_ENST00000248054_ENST00000263265_16965072_49341386 superimposed PDB: 8BPB of partner (SIN3B). RMSD:1.3541
Å |
 |  |  |  |  |
| SIN3B_TBC1D17_ENST00000248054_ENST00000535102_16987389_50383535 superimposed PDB: 8BPB of partner (SIN3B). RMSD:2.6733
Å |
 |  |  |  |  |
| SIN3B_TBC1D17_ENST00000248054_ENST00000535102_16987389_50383535 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.7759
Å |
| | | |  |
| SIN3B_TBC1D17_ENST00000379803_ENST00000535102_16987389_50383535 superimposed PDB: 8BPB of partner (SIN3B). RMSD:2.4791
Å |
 |  |  |  |  |
| SIN3B_TBC1D17_ENST00000379803_ENST00000535102_16987389_50383535 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.7795
Å |
| | | |  |
| SIN3B_TBC1D17_ENST00000595541_ENST00000535102_16987389_50383535 superimposed PDB: 8BPB of partner (SIN3B). RMSD:2.6449
Å |
 |  |  |  |  |
| SIN3B_TBC1D17_ENST00000595541_ENST00000535102_16987389_50383535 superimposed PDB: 9SI7 of partner (TBC1D17). RMSD:0.774
Å |
| | | |  |
| SIRPA_CWF19L2_ENST00000356025_ENST00000433523_1915400_107263621 superimposed PDB: 2WNG of partner (SIRPA). RMSD:1.7737
Å |
 |  |  |  |  |
| SIRPA_CWF19L2_ENST00000356025_ENST00000433523_1915400_107263621 superimposed PDB: 6ID1 of partner (CWF19L2). RMSD:1.4662
Å |
| | | |  |
| SIRPA_CWF19L2_ENST00000358771_ENST00000282251_1915400_107263621 superimposed PDB: 2WNG of partner (SIRPA). RMSD:1.2027
Å |
 |  |  |  |  |
| SIRPA_CWF19L2_ENST00000358771_ENST00000282251_1915400_107263621 superimposed PDB: 6ID1 of partner (CWF19L2). RMSD:2.525
Å |
| | | |  |
| SIRT1_MYPN_ENST00000212015_ENST00000540630_69651312_69954119 superimposed PDB: 5BTR of partner (SIRT1). RMSD:3.5173
Å |
 |  |  |  |  |
| SIRT2_RYR1_ENST00000249396_ENST00000360985_39379726_39070621 superimposed PDB: 9DPD of partner (SIRT2). RMSD:2.2061
Å |
 |  |  |  |  |
| SIRT2_RYR1_ENST00000358931_ENST00000355481_39379726_39070621 superimposed PDB: 9DPD of partner (SIRT2). RMSD:2.1485
Å |
 |  |  |  |  |
| SIRT3_SAMM50_ENST00000524564_ENST00000350028_230451_44392217 superimposed PDB: 8BBK of partner (SIRT3). RMSD:1.1383
Å |
 |  |  |  |  |
| SIRT3_SAMM50_ENST00000525319_ENST00000350028_230451_44392217 superimposed PDB: 8BBK of partner (SIRT3). RMSD:1.2189
Å |
 |  |  |  |  |
| SIRT3_SAMM50_ENST00000532956_ENST00000350028_230451_44392217 superimposed PDB: 8BBK of partner (SIRT3). RMSD:1.037
Å |
 |  |  |  |  |
| SKA2_MAPK1_ENST00000578105_ENST00000215832_57232491_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.432
Å |
 |  |  |  |  |
| SKI_ATAD3A_ENST00000378536_ENST00000378755_2161174_1454300 superimposed PDB: 1SBX of partner (SKI). RMSD:0.4248
Å |
 |  |  |  |  |
| SKI_CAPZB_ENST00000378536_ENST00000264203_2161174_19746245 superimposed PDB: 1SBX of partner (SKI). RMSD:0.3875
Å |
 |  |  |  |  |
| SKI_CAPZB_ENST00000378536_ENST00000264203_2161174_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.6991
Å |
| | | |  |
| SKI_CAPZB_ENST00000378536_ENST00000375142_2161174_19746245 superimposed PDB: 1SBX of partner (SKI). RMSD:0.3995
Å |
 |  |  |  |  |
| SKI_CAPZB_ENST00000378536_ENST00000375142_2161174_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.5934
Å |
| | | |  |
| SKI_CAPZB_ENST00000378536_ENST00000433834_2161174_19746245 superimposed PDB: 1SBX of partner (SKI). RMSD:0.3978
Å |
 |  |  |  |  |
| SKI_CAPZB_ENST00000378536_ENST00000433834_2161174_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7075
Å |
| | | |  |
| SKI_FAF1_ENST00000378536_ENST00000371778_2161174_51267349 superimposed PDB: 1SBX of partner (SKI). RMSD:0.3959
Å |
 |  |  |  |  |
| SKI_FAF1_ENST00000378536_ENST00000371778_2161174_51267349 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8356
Å |
| | | |  |
| SKP1_RUNX1_ENST00000517625_ENST00000325074_133509616_36171759 superimposed PDB: 2E31 of partner (SKP1). RMSD:0.6495
Å |
 |  |  |  |  |
| SKP2_TTC23L_ENST00000274255_ENST00000505624_36177394_34845591 superimposed PDB: 7Z8V of partner (SKP2). RMSD:0.9415
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000318386_ENST00000302787_1696500_1827410 superimposed PDB: 4QOZ of partner (SLBP). RMSD:0.3064
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000318386_ENST00000302787_1696500_1827410 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.3945
Å |
| | | |  |
| SLBP_LETM1_ENST00000318386_ENST00000302787_1713600_1817529 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.1657
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000488267_ENST00000302787_1696500_1827410 superimposed PDB: 4QOZ of partner (SLBP). RMSD:0.3729
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000488267_ENST00000302787_1696500_1827410 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.5476
Å |
| | | |  |
| SLBP_LETM1_ENST00000488267_ENST00000302787_1713600_1817529 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.1922
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000489418_ENST00000302787_1696500_1827410 superimposed PDB: 4QOZ of partner (SLBP). RMSD:0.2756
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000489418_ENST00000302787_1696500_1827410 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.3944
Å |
| | | |  |
| SLBP_LETM1_ENST00000489418_ENST00000302787_1713600_1817529 superimposed PDB: 4QOZ of partner (SLBP). RMSD:0.3397
Å |
 |  |  |  |  |
| SLBP_LETM1_ENST00000489418_ENST00000302787_1713600_1817529 superimposed PDB: 9BA1 of partner (LETM1). RMSD:1.5084
Å |
| | | |  |
| SLC11A2_PFKM_ENST00000541174_ENST00000340802_51386592_48516549 superimposed PDB: 4OMT of partner (PFKM). RMSD:0.8974
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000262461_ENST00000379806_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.4003
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000262461_ENST00000422285_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3761
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000262461_ENST00000540249_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.388
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000262461_ENST00000545074_127420402_19367429 superimposed PDB: 9C0H of partner (SLC12A2). RMSD:3.1644
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000343225_ENST00000379806_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.4173
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000343225_ENST00000422285_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3628
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000343225_ENST00000540249_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3728
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000343225_ENST00000545074_127420402_19367429 superimposed PDB: 9C0H of partner (SLC12A2). RMSD:2.8375
Å |
 |  |  |  |  |
| SLC12A2_PDHA1_ENST00000343225_ENST00000545074_127420402_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.7187
Å |
| | | |  |
| SLC12A7_CLPTM1L_ENST00000264930_ENST00000320895_1073747_1331998 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.598
Å |
 |  |  |  |  |
| SLC12A7_CLPTM1L_ENST00000264930_ENST00000320927_1073747_1331998 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.4605
Å |
 |  |  |  |  |
| SLC12A7_CLPTM1L_ENST00000264930_ENST00000507807_1073747_1331998 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.4972
Å |
 |  |  |  |  |
| SLC12A7_SKIV2L2_ENST00000264930_ENST00000545714_1057585_54720547 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.9909
Å |
 |  |  |  |  |
| SLC12A7_STK25_ENST00000264930_ENST00000316586_1093647_242441123 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.3063
Å |
 |  |  |  |  |
| SLC12A7_STK25_ENST00000264930_ENST00000403346_1093647_242441123 superimposed PDB: 7Z4V of partner (STK25). RMSD:0.49
Å |
 |  |  |  |  |
| SLC12A7_TERT_ENST00000264930_ENST00000296820_1060458_1282739 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:2.1119
Å |
 |  |  |  |  |
| SLC12A7_TERT_ENST00000264930_ENST00000296820_1074681_1266650 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:1.4896
Å |
 |  |  |  |  |
| SLC12A7_TERT_ENST00000264930_ENST00000296820_1074681_1266650 superimposed PDB: 7QXA of partner (TERT). RMSD:0.8526
Å |
| | | |  |
| SLC16A1_SENP6_ENST00000369626_ENST00000370014_113471713_76331247 superimposed PDB: 7CKO of partner (SLC16A1). RMSD:1.0176
Å |
 |  |  |  |  |
| SLC16A1_SENP6_ENST00000369626_ENST00000447266_113471713_76331247 superimposed PDB: 7CKO of partner (SLC16A1). RMSD:1.0101
Å |
 |  |  |  |  |
| SLC16A1_SENP6_ENST00000538576_ENST00000370010_113471713_76331247 superimposed PDB: 7CKO of partner (SLC16A1). RMSD:0.9559
Å |
 |  |  |  |  |
| SLC19A1_SNX4_ENST00000311124_ENST00000536067_46957684_125195600 superimposed PDB: 7XTK of partner (SLC19A1). RMSD:2.4449
Å |
 |  |  |  |  |
| SLC1A3_FYB_ENST00000265113_ENST00000515010_36608706_39110491 superimposed PDB: 5LLM of partner (SLC1A3). RMSD:1.4602
Å |
 |  |  |  |  |
| SLC1A3_MAPKAP1_ENST00000265113_ENST00000350766_36608706_128420078 superimposed PDB: 7VVB of partner (MAPKAP1). RMSD:0.5272
Å |
 |  |  |  |  |
| SLC1A3_MAPKAP1_ENST00000265113_ENST00000373498_36608706_128420078 superimposed PDB: 7VVB of partner (MAPKAP1). RMSD:0.5401
Å |
 |  |  |  |  |
| SLC1A3_MAPKAP1_ENST00000381918_ENST00000373511_36608706_128420078 superimposed PDB: 7VVB of partner (MAPKAP1). RMSD:0.7537
Å |
 |  |  |  |  |
| SLC1A3_METTL15_ENST00000265113_ENST00000342303_36671335_28311752 superimposed PDB: 5LLM of partner (SLC1A3). RMSD:2.2963
Å |
 |  |  |  |  |
| SLC1A3_METTL15_ENST00000265113_ENST00000407364_36671335_28311752 superimposed PDB: 5LLM of partner (SLC1A3). RMSD:2.7403
Å |
 |  |  |  |  |
| SLC1A5_GTF2H2_ENST00000434726_ENST00000425596_47285639_70338111 superimposed PDB: 8OUD of partner (SLC1A5). RMSD:1.2574
Å |
 |  |  |  |  |
| SLC1A5_GTF2H2_ENST00000542575_ENST00000425596_47285639_70338111 superimposed PDB: 8OUD of partner (SLC1A5). RMSD:2.1713
Å |
 |  |  |  |  |
| SLC1A5_GTF2H2_ENST00000594991_ENST00000425596_47285639_70338111 superimposed PDB: 8OUD of partner (SLC1A5). RMSD:1.0583
Å |
 |  |  |  |  |
| SLC1A5_GTF2H2_ENST00000594991_ENST00000425596_47285639_70338111 superimposed PDB: 28JM of partner (GTF2H2). RMSD:3.0689
Å |
| | | |  |
| SLC1A5_UBTF_ENST00000542575_ENST00000302904_47278141_42288699 superimposed PDB: 8OUD of partner (SLC1A5). RMSD:3.3165
Å |
 |  |  |  |  |
| SLC22A1_PAFAH2_ENST00000324965_ENST00000374282_160564681_26288574 superimposed PDB: 8SC1 of partner (SLC22A1). RMSD:1.3274
Å |
 |  |  |  |  |
| SLC22A23_CAMTA1_ENST00000380302_ENST00000439411_3410421_6880240 superimposed PDB: 2CXK of partner (CAMTA1). RMSD:0.3277
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000380298_ENST00000398016_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3822
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000406686_ENST00000286445_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3728
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000406686_ENST00000359742_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4064
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000406686_ENST00000398016_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.365
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000436008_ENST00000286445_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4221
Å |
 |  |  |  |  |
| SLC22A23_GRIP1_ENST00000436008_ENST00000359742_3410421_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4142
Å |
 |  |  |  |  |
| SLC23A2_TEAD4_ENST00000338244_ENST00000359864_4848415_3147133 superimposed PDB: 6GEI of partner (TEAD4). RMSD:0.5474
Å |
 |  |  |  |  |
| SLC23A2_TEAD4_ENST00000424750_ENST00000359864_4848415_3147133 superimposed PDB: 6GEI of partner (TEAD4). RMSD:0.6116
Å |
 |  |  |  |  |
| SLC25A13_CD2AP_ENST00000416240_ENST00000359314_95813588_47512341 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.9426
Å |
 |  |  |  |  |
| SLC25A13_CD2AP_ENST00000416240_ENST00000359314_95813588_47512341 superimposed PDB: 2J6F of partner (CD2AP). RMSD:0.4306
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000354212_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.8847
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000354212_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8901
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000522391_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.846
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000522391_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.9648
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000535697_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.7554
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000535697_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8696
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000536571_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.8584
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000265631_ENST00000536571_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8992
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000354212_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.8372
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000354212_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.95
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000522391_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.9455
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000522391_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.9299
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000535697_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.6679
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000535697_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8855
Å |
| | | |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000536571_95814238_77998530 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.8846
Å |
 |  |  |  |  |
| SLC25A13_MAGI2_ENST00000416240_ENST00000536571_95814238_77998530 superimposed PDB: 1UEQ of partner (MAGI2). RMSD:0.8972
Å |
| | | |  |
| SLC25A13_SH2D3C_ENST00000542654_ENST00000373274_95813588_130504238 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.8779
Å |
 |  |  |  |  |
| SLC25A13_SH2D3C_ENST00000542654_ENST00000373277_95813588_130504238 superimposed PDB: 4P5W of partner (SLC25A13). RMSD:0.9107
Å |
 |  |  |  |  |
| SLC25A15_ATP1B1_ENST00000338625_ENST00000367815_41367417_169094121 superimposed PDB: 8ZYJ of partner (ATP1B1). RMSD:0.6431
Å |
 |  |  |  |  |
| SLC25A21_FOXA1_ENST00000331299_ENST00000250448_37344160_38061916 superimposed PDB: 8VG1 of partner (FOXA1). RMSD:0.84
Å |
 |  |  |  |  |
| SLC25A24_DHRS12_ENST00000370041_ENST00000444610_108724562_52373803 superimposed PDB: 4N5X of partner (SLC25A24). RMSD:1.6838
Å |
 |  |  |  |  |
| SLC25A26_ARIH2_ENST00000336733_ENST00000449376_66313803_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:1.907
Å |
 |  |  |  |  |
| SLC25A26_ARIH2_ENST00000354883_ENST00000449376_66313803_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:2.1108
Å |
 |  |  |  |  |
| SLC25A26_ARIH2_ENST00000413054_ENST00000449376_66313803_48999044 superimposed PDB: 7OD1 of partner (ARIH2). RMSD:1.9334
Å |
 |  |  |  |  |
| SLC25A26_IMMT_ENST00000336733_ENST00000449247_66313803_86374956 superimposed PDB: 9QWR of partner (IMMT). RMSD:3.0768
Å |
 |  |  |  |  |
| SLC25A26_REM1_ENST00000536651_ENST00000201979_66271553_30070089 superimposed PDB: 2NZJ of partner (REM1). RMSD:0.4101
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000188376_ENST00000329257_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2231
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000188376_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2692
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000188376_ENST00000547776_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2471
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000228318_ENST00000329257_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.257
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000228318_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.3102
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000228318_ENST00000547776_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2346
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000401722_ENST00000329257_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2711
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000401722_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.3301
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000547534_ENST00000547776_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.246
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000548847_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2591
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000551917_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.3027
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000551917_ENST00000547776_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2346
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000552981_ENST00000547010_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.3551
Å |
 |  |  |  |  |
| SLC25A3_ANKS1B_ENST00000552981_ENST00000547776_98987913_99640642 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2263
Å |
 |  |  |  |  |
| SLC25A3_EZH2_ENST00000188376_ENST00000460911_98987913_148511229 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.6841
Å |
 |  |  |  |  |
| SLC25A3_EZH2_ENST00000228318_ENST00000460911_98987913_148511229 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.6889
Å |
 |  |  |  |  |
| SLC25A3_EZH2_ENST00000401722_ENST00000460911_98987913_148511229 superimposed PDB: 5HYN of partner (EZH2). RMSD:0.6683
Å |
 |  |  |  |  |
| SLC25A40_ABCB1_ENST00000341119_ENST00000543898_87476263_87214996 superimposed PDB: 8Y6H of partner (ABCB1). RMSD:0.9911
Å |
 |  |  |  |  |
| SLC25A43_YWHAH_ENST00000336249_ENST00000248975_118533641_32352125 superimposed PDB: 2C63 of partner (YWHAH). RMSD:0.4099
Å |
 |  |  |  |  |
| SLC25A45_SLC3A2_ENST00000398802_ENST00000377890_65149385_62650379 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.9897
Å |
 |  |  |  |  |
| SLC26A11_OAF_ENST00000361193_ENST00000531220_78211393_120099576 superimposed PDB: 9IAS of partner (SLC26A11). RMSD:1.7104
Å |
 |  |  |  |  |
| SLC26A11_OAF_ENST00000546047_ENST00000531220_78211393_120099576 superimposed PDB: 9IAS of partner (SLC26A11). RMSD:1.7728
Å |
 |  |  |  |  |
| SLC26A11_OAF_ENST00000572725_ENST00000531220_78211393_120099576 superimposed PDB: 9IAS of partner (SLC26A11). RMSD:1.723
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000337000_ENST00000454963_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:2.0488
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000358747_ENST00000265563_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:1.6029
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000358747_ENST00000454963_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:0.9072
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000395550_ENST00000265563_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:0.9297
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000420764_ENST00000454963_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:0.9288
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000455886_ENST00000265563_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:1.6976
Å |
 |  |  |  |  |
| SLC26A6_PRKAR2A_ENST00000455886_ENST00000454963_48665378_48828060 superimposed PDB: 8OPQ of partner (SLC26A6). RMSD:1.7873
Å |
 |  |  |  |  |
| SLC27A1_KIAA0391_ENST00000252595_ENST00000557565_17599926_35735932 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.9114
Å |
 |  |  |  |  |
| SLC27A1_KIAA0391_ENST00000442725_ENST00000557565_17599926_35735932 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.9938
Å |
 |  |  |  |  |
| SLC27A1_KIAA0391_ENST00000598424_ENST00000557565_17599926_35735932 superimposed PDB: 7ONU of partner (KIAA0391). RMSD:1.213
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000252595_ENST00000426920_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.422
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000252595_ENST00000433821_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.8522
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000252595_ENST00000454404_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.6156
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000252595_ENST00000586305_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:0.8459
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000442725_ENST00000293062_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.9181
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000442725_ENST00000426920_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.6565
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000442725_ENST00000433821_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:3.0298
Å |
 |  |  |  |  |
| SLC27A1_RASGRP4_ENST00000442725_ENST00000454404_17581516_38910902 superimposed PDB: 6AXG of partner (RASGRP4). RMSD:2.694
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000359462_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5415
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000437231_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5594
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000447282_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5287
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000455667_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5011
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000546463_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.6145
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000549863_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4708
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000552296_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5198
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000552819_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5941
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000357440_ENST00000603815_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4158
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000359282_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5471
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000359462_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5002
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000437231_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5477
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000447282_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4434
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000455667_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5271
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000546463_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.3908
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000549863_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5046
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000552296_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5254
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000552819_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.4248
Å |
 |  |  |  |  |
| SLC29A2_PCBP2_ENST00000544554_ENST00000603815_66133406_53854798 superimposed PDB: 2JZX of partner (PCBP2). RMSD:1.5261
Å |
 |  |  |  |  |
| SLC2A13_ARHGDIB_ENST00000280871_ENST00000228945_40422102_15100883 superimposed PDB: 1DS6 of partner (ARHGDIB). RMSD:3.1563
Å |
 |  |  |  |  |
| SLC2A13_ARHGDIB_ENST00000280871_ENST00000541644_40422102_15100883 superimposed PDB: 1DS6 of partner (ARHGDIB). RMSD:1.4479
Å |
 |  |  |  |  |
| SLC2A13_ARHGDIB_ENST00000380858_ENST00000541644_40422102_15100883 superimposed PDB: 1DS6 of partner (ARHGDIB). RMSD:1.5646
Å |
 |  |  |  |  |
| SLC2A1_CAPZB_ENST00000415851_ENST00000401084_43424304_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7017
Å |
 |  |  |  |  |
| SLC2A1_CAPZB_ENST00000426263_ENST00000264203_43424304_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7798
Å |
 |  |  |  |  |
| SLC2A1_CAPZB_ENST00000426263_ENST00000375142_43424304_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7463
Å |
 |  |  |  |  |
| SLC2A1_CAPZB_ENST00000426263_ENST00000433834_43424304_19746245 superimposed PDB: 9Y9L of partner (CAPZB). RMSD:1.7091
Å |
 |  |  |  |  |
| SLC2A1_LEPRE1_ENST00000415851_ENST00000397054_43408896_43228146 superimposed PDB: 6THA of partner (SLC2A1). RMSD:1.777
Å |
 |  |  |  |  |
| SLC2A1_LEPRE1_ENST00000415851_ENST00000397054_43408896_43228146 superimposed PDB: 8K0M of partner (LEPRE1). RMSD:3.1683
Å |
| | | |  |
| SLC2A1_LEPRE1_ENST00000426263_ENST00000236040_43408896_43228146 superimposed PDB: 6THA of partner (SLC2A1). RMSD:1.2091
Å |
 |  |  |  |  |
| SLC2A1_LEPRE1_ENST00000426263_ENST00000236040_43408896_43228146 superimposed PDB: 8K0M of partner (LEPRE1). RMSD:3.0759
Å |
| | | |  |
| SLC2A1_LEPRE1_ENST00000426263_ENST00000296388_43408896_43228146 superimposed PDB: 6THA of partner (SLC2A1). RMSD:1.1552
Å |
 |  |  |  |  |
| SLC2A1_LEPRE1_ENST00000426263_ENST00000296388_43408896_43228146 superimposed PDB: 8K0M of partner (LEPRE1). RMSD:3.1702
Å |
| | | |  |
| SLC2A9_RAD51_ENST00000264784_ENST00000267868_10020598_40998374 superimposed PDB: 9TRM of partner (RAD51). RMSD:0.4882
Å |
 |  |  |  |  |
| SLC30A4_AMACR_ENST00000261867_ENST00000382072_45814161_34006004 superimposed PDB: 9JJ3 of partner (SLC30A4). RMSD:0.7622
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000379343_ENST00000342045_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.1427
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000379343_ENST00000361704_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.0203
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000379343_ENST00000379624_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.1121
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000538303_ENST00000342045_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.1889
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000538303_ENST00000361704_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.0544
Å |
 |  |  |  |  |
| SLC30A6_BRE_ENST00000538303_ENST00000379624_32400430_28460068 superimposed PDB: 8PVY of partner (BRE). RMSD:3.1364
Å |
 |  |  |  |  |
| SLC34A2_ROS1_ENST00000382051_ENST00000368507_25665952_117650609 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.4912
Å |
 |  |  |  |  |
| SLC34A2_ROS1_ENST00000503434_ENST00000368507_25665952_117650609 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.4945
Å |
 |  |  |  |  |
| SLC34A2_ROS1_ENST00000504570_ENST00000368507_25665952_117650609 superimposed PDB: 7Z5X of partner (ROS1). RMSD:0.5027
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000323926_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.6004
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000323926_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.1354
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000336916_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:2.0102
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000336916_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.6556
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000345488_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.9704
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000345488_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.1581
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000346544_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.8657
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000346544_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.1379
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000354785_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.7875
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000354785_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.3757
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000356005_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.5248
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000356005_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.2086
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000357009_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.7779
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000357009_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.7391
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000357867_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.4877
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000357867_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.2018
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000359671_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.4102
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000359671_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.1764
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000432072_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:2.0543
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000432072_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.114
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000443816_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.8009
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000443816_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.1218
Å |
| | | |  |
| SLC35B1_FN1_ENST00000240333_ENST00000446046_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.6421
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000240333_ENST00000446046_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.0852
Å |
| | | |  |
| SLC35B1_FN1_ENST00000415270_ENST00000421182_47783227_216259442 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.5091
Å |
 |  |  |  |  |
| SLC35B1_FN1_ENST00000415270_ENST00000421182_47783227_216259442 superimposed PDB: 1FNF of partner (FN1). RMSD:2.3267
Å |
| | | |  |
| SLC35B1_IGFBP4_ENST00000240333_ENST00000269593_47784326_38609236 superimposed PDB: 9I20 of partner (SLC35B1). RMSD:1.2275
Å |
 |  |  |  |  |
| SLC35E3_ANAPC5_ENST00000398004_ENST00000261819_69145970_121785684 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:1.4157
Å |
 |  |  |  |  |
| SLC35E3_ANAPC5_ENST00000398004_ENST00000541887_69145970_121785684 superimposed PDB: 9GAW of partner (ANAPC5). RMSD:1.4311
Å |
 |  |  |  |  |
| SLC35E3_COPZ1_ENST00000398004_ENST00000455864_69145970_54735989 superimposed PDB: 2HF6 of partner (COPZ1). RMSD:0.8187
Å |
 |  |  |  |  |
| SLC35E3_COPZ1_ENST00000398004_ENST00000549043_69145970_54735989 superimposed PDB: 2HF6 of partner (COPZ1). RMSD:0.8108
Å |
 |  |  |  |  |
| SLC35E3_COPZ1_ENST00000398004_ENST00000552362_69145970_54735989 superimposed PDB: 2HF6 of partner (COPZ1). RMSD:0.8194
Å |
 |  |  |  |  |
| SLC35E3_COPZ1_ENST00000398004_ENST00000553231_69145970_54735989 superimposed PDB: 2HF6 of partner (COPZ1). RMSD:0.7401
Å |
 |  |  |  |  |
| SLC35G1_IKZF3_ENST00000371408_ENST00000346872_95653968_37949186 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.0803
Å |
 |  |  |  |  |
| SLC37A1_ABCG1_ENST00000352133_ENST00000398457_43979199_43697004 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.7605
Å |
 |  |  |  |  |
| SLC37A1_ABCG1_ENST00000352133_ENST00000398457_43979199_43702383 superimposed PDB: 7FDV of partner (ABCG1). RMSD:1.9714
Å |
 |  |  |  |  |
| SLC38A10_BAIAP2_ENST00000288439_ENST00000392411_79244717_79060242 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.1587
Å |
 |  |  |  |  |
| SLC38A10_BAIAP2_ENST00000374759_ENST00000321280_79244717_79060242 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:1.8444
Å |
 |  |  |  |  |
| SLC38A10_BAIAP2_ENST00000374759_ENST00000428708_79244717_79060242 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.152
Å |
 |  |  |  |  |
| SLC38A10_BAIAP2_ENST00000374759_ENST00000435091_79244717_79060242 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.0642
Å |
 |  |  |  |  |
| SLC38A10_BAIAP2_ENST00000374759_ENST00000575245_79244717_79060242 superimposed PDB: 2YKT of partner (BAIAP2). RMSD:2.1832
Å |
 |  |  |  |  |
| SLC38A10_MIS18A_ENST00000288439_ENST00000290130_79234037_33647207 superimposed PDB: 7SFZ of partner (MIS18A). RMSD:0.7583
Å |
 |  |  |  |  |
| SLC38A10_UFD1L_ENST00000288439_ENST00000263202_79263490_19462623 superimposed PDB: 9YRC of partner (UFD1L). RMSD:1.8933
Å |
 |  |  |  |  |
| SLC38A1_HDAC7_ENST00000549049_ENST00000354334_46599862_48196057 superimposed PDB: 8Q9N of partner (HDAC7). RMSD:0.4759
Å |
 |  |  |  |  |
| SLC38A1_HDAC7_ENST00000552197_ENST00000080059_46599862_48196057 superimposed PDB: 8Q9N of partner (HDAC7). RMSD:0.4784
Å |
 |  |  |  |  |
| SLC39A11_ITGA2B_ENST00000255559_ENST00000262407_70845772_42455158 superimposed PDB: 9E8A of partner (ITGA2B). RMSD:2.9639
Å |
 |  |  |  |  |
| SLC39A11_ITGA2B_ENST00000542342_ENST00000262407_70845772_42455158 superimposed PDB: 9E8A of partner (ITGA2B). RMSD:2.8431
Å |
 |  |  |  |  |
| SLC39A11_ITGA2B_ENST00000542342_ENST00000353281_70845772_42455158 superimposed PDB: 9E8A of partner (ITGA2B). RMSD:1.9922
Å |
 |  |  |  |  |
| SLC39A11_ITGA2B_ENST00000579732_ENST00000353281_70845772_42455158 superimposed PDB: 9E8A of partner (ITGA2B). RMSD:2.2258
Å |
 |  |  |  |  |
| SLC39A3_DDX39A_ENST00000269740_ENST00000454233_2737045_14522410 superimposed PDB: 8IJU of partner (DDX39A). RMSD:0.6699
Å |
 |  |  |  |  |
| SLC39A3_DDX39A_ENST00000269740_ENST00000592927_2737045_14522410 superimposed PDB: 8IJU of partner (DDX39A). RMSD:2.8343
Å |
 |  |  |  |  |
| SLC39A3_DDX39A_ENST00000545664_ENST00000454233_2737045_14522410 superimposed PDB: 8IJU of partner (DDX39A). RMSD:0.7453
Å |
 |  |  |  |  |
| SLC39A3_DDX39A_ENST00000545664_ENST00000592927_2737045_14522410 superimposed PDB: 8IJU of partner (DDX39A). RMSD:2.8033
Å |
 |  |  |  |  |
| SLC39A3_ETHE1_ENST00000269740_ENST00000292147_2737045_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.5474
Å |
 |  |  |  |  |
| SLC39A3_ETHE1_ENST00000269740_ENST00000600651_2737045_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.8936
Å |
 |  |  |  |  |
| SLC39A3_ETHE1_ENST00000545664_ENST00000600651_2737045_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.7986
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000338663_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7853
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000338663_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.8205
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377889_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7825
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377889_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7549
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377890_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7755
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377890_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7479
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377891_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7595
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377891_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.8207
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377892_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7332
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000377892_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7962
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000535296_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.7558
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000535296_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.8677
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000536981_ENST00000344138_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.9081
Å |
 |  |  |  |  |
| SLC3A2_GRAP2_ENST00000536981_ENST00000540310_62653080_40365414 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:0.9456
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000338663_ENST00000356819_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.4678
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000338663_ENST00000520407_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.4029
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000377889_ENST00000338921_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.0996
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000377889_ENST00000356819_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:2.9999
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000377889_ENST00000405005_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.4404
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000377890_ENST00000338921_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.0961
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000377891_ENST00000523079_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:2.8045
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000535296_ENST00000338921_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.2522
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000535296_ENST00000520502_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:2.8851
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000535296_ENST00000521670_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:3.0341
Å |
 |  |  |  |  |
| SLC3A2_NRG1_ENST00000535296_ENST00000523079_62649538_32585466 superimposed PDB: 9KJU of partner (SLC3A2). RMSD:2.7513
Å |
 |  |  |  |  |
| SLC43A2_SMG6_ENST00000301335_ENST00000263073_1516488_2187029 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:0.6704
Å |
 |  |  |  |  |
| SLC43A2_SMG6_ENST00000301335_ENST00000263073_1516488_2187029 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.5438
Å |
| | | |  |
| SLC43A2_VAT1_ENST00000301335_ENST00000587173_1516488_41170816 superimposed PDB: 6K9Y of partner (VAT1). RMSD:0.4132
Å |
 |  |  |  |  |
| SLC45A3_AP1G2_ENST00000367145_ENST00000308724_205626978_24037279 superimposed PDB: 2E9G of partner (AP1G2). RMSD:0.8438
Å |
 |  |  |  |  |
| SLC4A4_GOLGA4_ENST00000425175_ENST00000361924_72413437_37396591 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.0361
Å |
 |  |  |  |  |
| SLC4A4_RASGRF1_ENST00000264485_ENST00000419573_72425971_79312446 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.0402
Å |
 |  |  |  |  |
| SLC4A4_RASGRF1_ENST00000340595_ENST00000419573_72425971_79312446 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.0898
Å |
 |  |  |  |  |
| SLC4A4_RASGRF1_ENST00000340595_ENST00000558480_72425971_79312446 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.5437
Å |
 |  |  |  |  |
| SLC4A4_RASGRF1_ENST00000351898_ENST00000419573_72425971_79312446 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.497
Å |
 |  |  |  |  |
| SLC4A4_RASGRF1_ENST00000425175_ENST00000558480_72425971_79312446 superimposed PDB: 6CAA of partner (SLC4A4). RMSD:1.0987
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000295736_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:2.0011
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000295736_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.1127
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000428386_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.7664
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000428386_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.0418
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000435667_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.3874
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000437179_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:2.2744
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000437179_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.016
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000440156_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:2.0462
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000440156_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.0564
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000445684_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.9343
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000445684_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:1.6261
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000446700_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.9156
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000446700_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.1604
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000454389_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.9157
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000454389_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.002
Å |
| | | |  |
| SLC4A7_SUMF1_ENST00000455077_ENST00000534863_27442254_4452662 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.7775
Å |
 |  |  |  |  |
| SLC4A7_SUMF1_ENST00000455077_ENST00000534863_27442254_4452662 superimposed PDB: 5SSX of partner (SUMF1). RMSD:1.9178
Å |
| | | |  |
| SLC4A7_TYR_ENST00000435667_ENST00000263321_27525557_88924369 superimposed PDB: 9OVR of partner (SLC4A7). RMSD:1.2292
Å |
 |  |  |  |  |
| SLC5A1_PIGR_ENST00000543737_ENST00000356495_32495338_207119811 superimposed PDB: 6UE7 of partner (PIGR). RMSD:2.0708
Å |
 |  |  |  |  |
| SLC5A1_YWHAH_ENST00000543737_ENST00000397492_32500878_32352125 superimposed PDB: 7SLA of partner (SLC5A1). RMSD:1.8622
Å |
 |  |  |  |  |
| SLC7A6_TANGO6_ENST00000566454_ENST00000261778_68309152_69007930 superimposed PDB: 9LDR of partner (SLC7A6). RMSD:2.3491
Å |
 |  |  |  |  |
| SLC9A3R1_FBXO18_ENST00000262613_ENST00000362091_72745426_5978418 superimposed PDB: 2KRG of partner (SLC9A3R1). RMSD:1.4482
Å |
 |  |  |  |  |
| SLC9A3R1_FBXO18_ENST00000262613_ENST00000362091_72745426_5978418 superimposed PDB: 9XZL of partner (FBXO18). RMSD:1.2631
Å |
| | | |  |
| SLC9A7_OGT_ENST00000328306_ENST00000373701_46541770_70775803 superimposed PDB: 7YEA of partner (OGT). RMSD:1.2876
Å |
 |  |  |  |  |
| SLCO3A1_BACE2_ENST00000424469_ENST00000328735_92397318_42622678 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:1.048
Å |
 |  |  |  |  |
| SLCO3A1_BACE2_ENST00000424469_ENST00000330333_92397318_42622678 superimposed PDB: 6UJ0 of partner (BACE2). RMSD:2.8033
Å |
 |  |  |  |  |
| SLIRP_CYP3A5_ENST00000557342_ENST00000343703_78182222_99250402 superimposed PDB: 7LAD of partner (CYP3A5). RMSD:0.9167
Å |
 |  |  |  |  |
| SLIT2_PACRGL_ENST00000504154_ENST00000538990_20270504_20728907 superimposed PDB: 2V70 of partner (SLIT2). RMSD:1.25
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000332966_ENST00000306388_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:1.6535
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000332966_ENST00000380377_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:1.1989
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000404867_ENST00000306388_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:1.4832
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000404867_ENST00000518338_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.2208
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000404867_ENST00000520361_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.2932
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000519560_ENST00000518338_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.2953
Å |
 |  |  |  |  |
| SLIT3_TBCA_ENST00000519560_ENST00000520361_168620482_77004172 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.2674
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000295951_ENST00000496292_57908750_57563114 superimposed PDB: 6AR0 of partner (SLMAP). RMSD:0.4986
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000295951_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:1.6356
Å |
| | | |  |
| SLMAP_ARF4_ENST00000428312_ENST00000496292_57908750_57563114 superimposed PDB: 6AR0 of partner (SLMAP). RMSD:0.4885
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000428312_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:0.593
Å |
| | | |  |
| SLMAP_ARF4_ENST00000442599_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:0.628
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000449503_ENST00000496292_57908750_57563114 superimposed PDB: 6AR0 of partner (SLMAP). RMSD:0.4735
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000449503_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:0.5264
Å |
| | | |  |
| SLMAP_ARF4_ENST00000494088_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:0.635
Å |
 |  |  |  |  |
| SLMAP_ARF4_ENST00000495364_ENST00000496292_57908750_57563114 superimposed PDB: 1Z6X of partner (ARF4). RMSD:0.761
Å |
 |  |  |  |  |
| SMAD3_AAGAB_ENST00000559092_ENST00000261880_67391362_67529158 superimposed PDB: 1MK2 of partner (SMAD3). RMSD:0.3205
Å |
 |  |  |  |  |
| SMAD4_SKAP1_ENST00000342988_ENST00000336915_48593557_46474147 superimposed PDB: 1DD1 of partner (SMAD4). RMSD:0.4509
Å |
 |  |  |  |  |
| SMAD6_FAM96A_ENST00000457357_ENST00000300030_67008836_64373350 superimposed PDB: 2M5H of partner (FAM96A). RMSD:1.2564
Å |
 |  |  |  |  |
| SMAGP_CACNA1E_ENST00000603864_ENST00000358338_51663028_181620473 superimposed PDB: 7YG5 of partner (CACNA1E). RMSD:2.1357
Å |
 |  |  |  |  |
| SMAP2_RFX5_ENST00000539317_ENST00000290524_40882768_151317664 superimposed PDB: 2IQJ of partner (SMAP2). RMSD:1.178
Å |
 |  |  |  |  |
| SMAP2_RFX5_ENST00000539317_ENST00000368870_40882768_151317664 superimposed PDB: 2IQJ of partner (SMAP2). RMSD:0.9613
Å |
 |  |  |  |  |
| SMAP2_RFX5_ENST00000539317_ENST00000368870_40882768_151317664 superimposed PDB: 8ZJR of partner (RFX5). RMSD:0.4919
Å |
| | | |  |
| SMARCA2_SMARCA4_ENST00000349721_ENST00000344626_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5672
Å |
 |  |  |  |  |
| SMARCA2_SMARCA4_ENST00000357248_ENST00000344626_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7163
Å |
 |  |  |  |  |
| SMARCA2_SMARCA4_ENST00000382186_ENST00000344626_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:1.8164
Å |
 |  |  |  |  |
| SMARCA2_SMARCA4_ENST00000382186_ENST00000589677_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.0265
Å |
 |  |  |  |  |
| SMARCA2_SMARCA4_ENST00000382194_ENST00000589677_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5821
Å |
 |  |  |  |  |
| SMARCA2_SMARCA4_ENST00000382203_ENST00000589677_2182242_11170428 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8362
Å |
 |  |  |  |  |
| SMARCA4_C19orf38_ENST00000344626_ENST00000397820_11101999_10979893 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0256
Å |
 |  |  |  |  |
| SMARCA4_C19orf38_ENST00000450717_ENST00000397820_11101999_10979893 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.1423
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000344626_ENST00000585892_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.1586
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000344626_ENST00000585892_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0679
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000314646_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.0887
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000314646_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9775
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000314646_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.917
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000314646_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.6082
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000355667_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.4159
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000355667_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0559
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000359692_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5857
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000359692_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9803
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000359692_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.4346
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000359692_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.712
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000389253_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.4897
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000389253_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0191
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000408974_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.3644
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000358026_ENST00000408974_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0013
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000314646_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.4216
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000314646_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9763
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000314646_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8822
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000314646_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.6387
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000355667_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7046
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000355667_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0104
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000359692_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5654
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000359692_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0499
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000359692_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:1.8704
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000359692_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:2.7919
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000389253_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6273
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000389253_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0587
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000408974_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5528
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000413806_ENST00000408974_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9401
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000314646_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.3837
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000314646_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0242
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000314646_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:1.7885
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000314646_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.7116
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000355667_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.2844
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000355667_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.009
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000359692_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5469
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000359692_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9607
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000359692_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.54
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000359692_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.8004
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000389253_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8225
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000389253_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0142
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000408974_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.1958
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000429416_ENST00000408974_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.91
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000450717_ENST00000585892_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.1596
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000450717_ENST00000585892_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0141
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000314646_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.838
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000314646_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9901
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000314646_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7376
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000314646_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.6344
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000355667_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6348
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000355667_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0096
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000359692_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0405
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000359692_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:0.9974
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000359692_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6808
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000359692_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.4872
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000389253_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5957
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000389253_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0084
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000408974_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.1945
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000408974_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.07
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000585892_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.293
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000541122_ENST00000585892_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0064
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000314646_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8052
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000314646_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0088
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000314646_11136184_10930655 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.4888
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000314646_11136184_10930655 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.6061
Å |
| | | |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000585892_11123788_10904395 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.437
Å |
 |  |  |  |  |
| SMARCA4_DNM2_ENST00000589677_ENST00000585892_11123788_10904395 superimposed PDB: 2YS1 of partner (DNM2). RMSD:1.0147
Å |
| | | |  |
| SMARCA4_SMARCA2_ENST00000344626_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6172
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000344626_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6274
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000358026_ENST00000349721_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.831
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000358026_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8439
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000358026_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0466
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000358026_ENST00000382203_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6063
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000413806_ENST00000349721_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7626
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000413806_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7135
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000413806_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.757
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000413806_ENST00000382203_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.9207
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000429416_ENST00000349721_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.9328
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000429416_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7293
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000429416_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7715
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000429416_ENST00000382203_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.363
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000444061_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0007
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000444061_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.6564
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000450717_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.8071
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000450717_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.9501
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000541122_ENST00000349721_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.798
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000541122_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7603
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000541122_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.9066
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000541122_ENST00000382203_11141569_2115821 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7629
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000589677_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7501
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000589677_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.5933
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000590574_ENST00000349721_11169039_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7648
Å |
 |  |  |  |  |
| SMARCA4_SMARCA2_ENST00000590574_ENST00000349721_11169565_2186095 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:1.7708
Å |
 |  |  |  |  |
| SMARCA4_SMIM7_ENST00000358026_ENST00000597711_11107220_16758072 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0487
Å |
 |  |  |  |  |
| SMARCA4_SMIM7_ENST00000413806_ENST00000597711_11107220_16758072 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:3.0189
Å |
 |  |  |  |  |
| SMARCA4_SMIM7_ENST00000429416_ENST00000597711_11107220_16758072 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.7963
Å |
 |  |  |  |  |
| SMARCA4_SMIM7_ENST00000541122_ENST00000597711_11107220_16758072 superimposed PDB: 6LTH of partner (SMARCA4). RMSD:2.9052
Å |
 |  |  |  |  |
| SMARCA5_ADAMTS20_ENST00000283131_ENST00000553158_144468656_43840515 superimposed PDB: 8V4Y of partner (SMARCA5). RMSD:0.9587
Å |
 |  |  |  |  |
| SMARCAD1_GRID2_ENST00000457823_ENST00000282020_95174158_94128554 superimposed PDB: 9JAO of partner (SMARCAD1). RMSD:1.3569
Å |
 |  |  |  |  |
| SMARCC1_CELSR3_ENST00000254480_ENST00000164024_47651555_48694781 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.8642
Å |
 |  |  |  |  |
| SMARCC1_CELSR3_ENST00000254480_ENST00000544264_47651555_48692827 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:1.1466
Å |
 |  |  |  |  |
| SMARCC1_CELSR3_ENST00000254480_ENST00000544264_47651555_48694781 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:1.5212
Å |
 |  |  |  |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000200181_47676679_73744921 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6247
Å |
 |  |  |  |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000200181_47676679_73744921 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.2674
Å |
| | | |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000339591_47676679_73744921 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.5658
Å |
 |  |  |  |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000339591_47676679_73744921 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.3437
Å |
| | | |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000450894_47676679_73744921 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6233
Å |
 |  |  |  |  |
| SMARCC1_ITGB4_ENST00000254480_ENST00000450894_47676679_73744921 superimposed PDB: 3F7R of partner (ITGB4). RMSD:1.3243
Å |
| | | |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000360240_47702783_47919013 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6259
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000360240_47702783_47963368 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6119
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000360240_47702783_47969840 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6662
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000383737_47702783_47969840 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6674
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000395734_47702783_47919013 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6567
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000395734_47702783_47963368 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.664
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000395734_47702783_47969840 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6627
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000426837_47702783_47919013 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.628
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000426837_47702783_47963368 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.651
Å |
 |  |  |  |  |
| SMARCC1_MAP4_ENST00000254480_ENST00000426837_47702783_47969840 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6588
Å |
 |  |  |  |  |
| SMARCC1_PACS2_ENST00000254480_ENST00000430725_47814306_105818714 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.7296
Å |
 |  |  |  |  |
| SMARCC1_SHISA5_ENST00000254480_ENST00000296444_47747898_48511242 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6383
Å |
 |  |  |  |  |
| SMARCC1_SHISA5_ENST00000254480_ENST00000444115_47747898_48511242 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6156
Å |
 |  |  |  |  |
| SMARCC1_SPINK8_ENST00000254480_ENST00000434006_47721926_48351436 superimposed PDB: 6YXP of partner (SMARCC1). RMSD:0.6759
Å |
 |  |  |  |  |
| SMARCE1_RARA_ENST00000377808_ENST00000394089_38792182_38511514 superimposed PDB: 3A9E of partner (RARA). RMSD:1.6623
Å |
 |  |  |  |  |
| SMARCE1_RARA_ENST00000544009_ENST00000394089_38792182_38511514 superimposed PDB: 3A9E of partner (RARA). RMSD:1.3462
Å |
 |  |  |  |  |
| SMC5_IMMP2L_ENST00000361138_ENST00000331762_72882891_110603621 superimposed PDB: 9LWI of partner (SMC5). RMSD:1.3941
Å |
 |  |  |  |  |
| SMC5_IMMP2L_ENST00000361138_ENST00000405709_72882891_110603621 superimposed PDB: 9LWI of partner (SMC5). RMSD:1.8861
Å |
 |  |  |  |  |
| SMC5_IMMP2L_ENST00000361138_ENST00000447215_72882891_110603621 superimposed PDB: 9LWI of partner (SMC5). RMSD:1.3928
Å |
 |  |  |  |  |
| SMCHD1_NDC80_ENST00000261598_ENST00000261597_2688745_2585111 superimposed PDB: 9N9G of partner (NDC80). RMSD:1.8971
Å |
 |  |  |  |  |
| SMEK1_CCDC88C_ENST00000337238_ENST00000389857_91951975_91739997 superimposed PDB: 6R8I of partner (SMEK1). RMSD:0.372
Å |
 |  |  |  |  |
| SMEK1_CCDC88C_ENST00000554943_ENST00000331194_91951975_91739997 superimposed PDB: 6R8I of partner (SMEK1). RMSD:0.3396
Å |
 |  |  |  |  |
| SMEK1_IFNGR2_ENST00000554684_ENST00000381995_91947919_34804483 superimposed PDB: 6R8I of partner (SMEK1). RMSD:0.3061
Å |
 |  |  |  |  |
| SMEK1_IFNGR2_ENST00000554943_ENST00000381995_91947919_34804483 superimposed PDB: 6R8I of partner (SMEK1). RMSD:0.2771
Å |
 |  |  |  |  |
| SMEK2_ALK_ENST00000272313_ENST00000431873_55804450_29940563 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4937
Å |
 |  |  |  |  |
| SMEK2_ALK_ENST00000345102_ENST00000431873_55804450_29940563 superimposed PDB: 7NX3 of partner (ALK). RMSD:0.4903
Å |
 |  |  |  |  |
| SMEK2_CCDC88A_ENST00000345102_ENST00000336838_55785910_55646052 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:3.0549
Å |
 |  |  |  |  |
| SMG1_LRRK1_ENST00000389467_ENST00000532029_18907373_101528838 superimposed PDB: 8FAC of partner (LRRK1). RMSD:3.4319
Å |
 |  |  |  |  |
| SMG1_LRRK1_ENST00000565224_ENST00000532029_18907373_101528838 superimposed PDB: 8FAC of partner (LRRK1). RMSD:3.4369
Å |
 |  |  |  |  |
| SMG1_SNF8_ENST00000389467_ENST00000290330_18937271_47018424 superimposed PDB: 2ZME of partner (SNF8). RMSD:0.5583
Å |
 |  |  |  |  |
| SMG1_SNF8_ENST00000446231_ENST00000502492_18937271_47018424 superimposed PDB: 2ZME of partner (SNF8). RMSD:0.5931
Å |
 |  |  |  |  |
| SMG1_SULT1A2_ENST00000389467_ENST00000335715_18907373_28606996 superimposed PDB: 1Z29 of partner (SULT1A2). RMSD:1.0404
Å |
 |  |  |  |  |
| SMG1_SULT1A2_ENST00000389467_ENST00000395630_18907373_28606996 superimposed PDB: 1Z29 of partner (SULT1A2). RMSD:0.4186
Å |
 |  |  |  |  |
| SMG1_SULT1A2_ENST00000565224_ENST00000335715_18907373_28606996 superimposed PDB: 1Z29 of partner (SULT1A2). RMSD:1.3941
Å |
 |  |  |  |  |
| SMG1_SULT1A2_ENST00000565224_ENST00000395630_18907373_28606996 superimposed PDB: 1Z29 of partner (SULT1A2). RMSD:0.4208
Å |
 |  |  |  |  |
| SMG6_SHPK_ENST00000263073_ENST00000225519_2139785_3518831 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.6969
Å |
 |  |  |  |  |
| SMG6_SHPK_ENST00000354901_ENST00000225519_2139785_3518831 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.7516
Å |
 |  |  |  |  |
| SMG6_SHPK_ENST00000536871_ENST00000225519_2139785_3518831 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.5886
Å |
 |  |  |  |  |
| SMG6_SLC16A14_ENST00000263073_ENST00000295190_2139785_230914620 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.6088
Å |
 |  |  |  |  |
| SMG6_SLC16A14_ENST00000354901_ENST00000295190_2139785_230914620 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.5373
Å |
 |  |  |  |  |
| SMG6_SLC16A14_ENST00000536871_ENST00000295190_2139785_230914620 superimposed PDB: 4UM2 of partner (SMG6). RMSD:2.2669
Å |
 |  |  |  |  |
| SMG6_SLC16A14_ENST00000544865_ENST00000295190_2139785_230914620 superimposed PDB: 4UM2 of partner (SMG6). RMSD:1.9648
Å |
 |  |  |  |  |
| SMG6_VPS53_ENST00000263073_ENST00000437048_2075951_565135 superimposed PDB: 4UM2 of partner (SMG6). RMSD:1.4424
Å |
 |  |  |  |  |
| SMG6_VPS53_ENST00000354901_ENST00000437048_2075951_565135 superimposed PDB: 4UM2 of partner (SMG6). RMSD:1.3451
Å |
 |  |  |  |  |
| SMG6_VPS53_ENST00000536871_ENST00000437048_2075951_565135 superimposed PDB: 4UM2 of partner (SMG6). RMSD:0.533
Å |
 |  |  |  |  |
| SMG6_WDR20_ENST00000263073_ENST00000335263_2206926_102661274 superimposed PDB: 4UM2 of partner (SMG6). RMSD:3.2229
Å |
 |  |  |  |  |
| SMPX_PDHA1_ENST00000379494_ENST00000379806_21761867_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3894
Å |
 |  |  |  |  |
| SMPX_PDHA1_ENST00000379494_ENST00000422285_21761867_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3368
Å |
 |  |  |  |  |
| SMPX_PDHA1_ENST00000379494_ENST00000540249_21761867_19367429 superimposed PDB: 2OZL of partner (PDHA1). RMSD:0.3678
Å |
 |  |  |  |  |
| SMS_DYRK2_ENST00000379404_ENST00000344096_21958991_68043576 superimposed PDB: 5LXC of partner (DYRK2). RMSD:0.6596
Å |
 |  |  |  |  |
| SMUG1_PPP2R5A_ENST00000514685_ENST00000537030_54576287_212506838 superimposed PDB: 9GGS of partner (SMUG1). RMSD:0.748
Å |
 |  |  |  |  |
| SMUG1_PPP2R5A_ENST00000514685_ENST00000537030_54576287_212506838 superimposed PDB: 8SZK of partner (PPP2R5A). RMSD:1.5283
Å |
| | | |  |
| SMURF1_GJC3_ENST00000361125_ENST00000312891_98741348_99527243 superimposed PDB: 6L3T of partner (GJC3). RMSD:1.1686
Å |
 |  |  |  |  |
| SMYD2_WNK2_ENST00000366957_ENST00000427277_214503621_96018580 superimposed PDB: 4WUY of partner (SMYD2). RMSD:0.6282
Å |
 |  |  |  |  |
| SMYD2_WNK2_ENST00000415093_ENST00000297954_214503621_96018580 superimposed PDB: 4WUY of partner (SMYD2). RMSD:0.5514
Å |
 |  |  |  |  |
| SMYD3_WLS_ENST00000541742_ENST00000354777_246518332_68659910 superimposed PDB: 7DRT of partner (WLS). RMSD:1.3427
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000388985_ENST00000314607_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.7891
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000388985_ENST00000373297_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.681
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000403792_ENST00000314607_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.7132
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000403792_ENST00000373297_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.7381
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000490107_ENST00000314607_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.7405
Å |
 |  |  |  |  |
| SMYD3_ZMYM4_ENST00000490107_ENST00000373297_246490502_35835629 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:1.3526
Å |
 |  |  |  |  |
| SMYD4_SMG6_ENST00000305513_ENST00000263073_1690103_1989195 superimposed PDB: 4UM2 of partner (SMG6). RMSD:2.7895
Å |
 |  |  |  |  |
| SNAP29_MAPK1_ENST00000215730_ENST00000544786_21224821_22162135 superimposed PDB: 7BV6 of partner (SNAP29). RMSD:1.8362
Å |
 |  |  |  |  |
| SNAP29_MAPK1_ENST00000215730_ENST00000544786_21224821_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.5682
Å |
| | | |  |
| SNIP1_PUM1_ENST00000296215_ENST00000257075_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6304
Å |
 |  |  |  |  |
| SNIP1_PUM1_ENST00000296215_ENST00000373741_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6499
Å |
 |  |  |  |  |
| SNIP1_PUM1_ENST00000296215_ENST00000373742_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6287
Å |
 |  |  |  |  |
| SNIP1_PUM1_ENST00000296215_ENST00000373747_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.5841
Å |
 |  |  |  |  |
| SNIP1_PUM1_ENST00000296215_ENST00000426105_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6511
Å |
 |  |  |  |  |
| SNIP1_PUM1_ENST00000296215_ENST00000440538_38018245_31501711 superimposed PDB: 1IB2 of partner (PUM1). RMSD:0.6474
Å |
 |  |  |  |  |
| SNRNP70_TIMM44_ENST00000221448_ENST00000270538_49589818_8006082 superimposed PDB: 2CW9 of partner (TIMM44). RMSD:0.799
Å |
 |  |  |  |  |
| SNRPB_ACTG1_ENST00000438552_ENST00000573283_2451333_79478652 superimposed PDB: 7NVM of partner (ACTG1). RMSD:1.6976
Å |
 |  |  |  |  |
| SNRPF_NT5DC3_ENST00000553192_ENST00000392876_96255071_104190809 superimposed PDB: 5XJL of partner (SNRPF). RMSD:1.2251
Å |
 |  |  |  |  |
| SNTB2_CYB5B_ENST00000336278_ENST00000307892_69294163_69481052 superimposed PDB: 2VRF of partner (SNTB2). RMSD:0.3401
Å |
 |  |  |  |  |
| SNTB2_CYB5B_ENST00000336278_ENST00000307892_69294163_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:1.3388
Å |
| | | |  |
| SNTB2_CYB5B_ENST00000336278_ENST00000561792_69294163_69481052 superimposed PDB: 2VRF of partner (SNTB2). RMSD:0.3856
Å |
 |  |  |  |  |
| SNTB2_CYB5B_ENST00000336278_ENST00000561792_69294163_69481052 superimposed PDB: 3NER of partner (CYB5B). RMSD:2.317
Å |
| | | |  |
| SNUPN_ZNF233_ENST00000564644_ENST00000334152_75909748_44768465 superimposed PDB: 2ELY of partner (ZNF233). RMSD:0.6784
Å |
 |  |  |  |  |
| SNX13_STAP2_ENST00000409389_ENST00000600324_17979906_4333813 superimposed PDB: 2EL8 of partner (STAP2). RMSD:1.3718
Å |
 |  |  |  |  |
| SNX13_STAP2_ENST00000409389_ENST00000600324_17979906_4334041 superimposed PDB: 2EL8 of partner (STAP2). RMSD:1.4017
Å |
 |  |  |  |  |
| SNX13_STAP2_ENST00000428135_ENST00000594605_17979906_4333813 superimposed PDB: 2EL8 of partner (STAP2). RMSD:1.3549
Å |
 |  |  |  |  |
| SNX13_STAP2_ENST00000428135_ENST00000594605_17979906_4334041 superimposed PDB: 2EL8 of partner (STAP2). RMSD:1.4349
Å |
 |  |  |  |  |
| SNX13_TSPAN13_ENST00000409389_ENST00000262067_17979906_16815835 superimposed PDB: 7WF6 of partner (SNX13). RMSD:0.3361
Å |
 |  |  |  |  |
| SNX14_PPP2R2A_ENST00000314673_ENST00000315985_86267693_26196405 superimposed PDB: 3DW8 of partner (PPP2R2A). RMSD:0.4303
Å |
 |  |  |  |  |
| SNX14_PPP2R2A_ENST00000346348_ENST00000315985_86267693_26196405 superimposed PDB: 3DW8 of partner (PPP2R2A). RMSD:0.4403
Å |
 |  |  |  |  |
| SNX14_PPP2R2A_ENST00000505648_ENST00000315985_86267693_26196405 superimposed PDB: 3DW8 of partner (PPP2R2A). RMSD:0.43
Å |
 |  |  |  |  |
| SNX27_CDKN3_ENST00000368843_ENST00000335183_151584988_54882616 superimposed PDB: 8TTV of partner (SNX27). RMSD:1.0856
Å |
 |  |  |  |  |
| SNX5_PCSK2_ENST00000377759_ENST00000377899_17933230_17338971 superimposed PDB: 8AFZ of partner (SNX5). RMSD:2.5272
Å |
 |  |  |  |  |
| SNX6_BAZ1A_ENST00000362031_ENST00000382422_35062250_35243696 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.2962
Å |
 |  |  |  |  |
| SNX6_BAZ1A_ENST00000396526_ENST00000382422_35062250_35243696 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.2999
Å |
 |  |  |  |  |
| SNX6_BAZ1A_ENST00000396534_ENST00000360310_35072553_35331528 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.42
Å |
 |  |  |  |  |
| SNX6_BAZ1A_ENST00000396534_ENST00000382422_35072553_35331528 superimposed PDB: 5UIY of partner (BAZ1A). RMSD:0.3471
Å |
 |  |  |  |  |
| SNX7_DPYD_ENST00000306121_ENST00000370192_99203945_98348930 superimposed PDB: 3IQ2 of partner (SNX7). RMSD:3.1195
Å |
 |  |  |  |  |
| SNX8_MAD1L1_ENST00000222990_ENST00000399654_2309193_2041756 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.2804
Å |
 |  |  |  |  |
| SNX8_MAD1L1_ENST00000222990_ENST00000399654_2317734_2054277 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.1575
Å |
 |  |  |  |  |
| SNX8_MAD1L1_ENST00000222990_ENST00000399654_2353962_2054277 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.1911
Å |
 |  |  |  |  |
| SOGA1_GPI_ENST00000237536_ENST00000356487_35421651_34884152 superimposed PDB: 9FCW of partner (GPI). RMSD:1.5726
Å |
 |  |  |  |  |
| SOGA1_SAMHD1_ENST00000237536_ENST00000262878_35421651_35563592 superimposed PDB: 8D94 of partner (SAMHD1). RMSD:0.5739
Å |
 |  |  |  |  |
| SOGA3_LOXL2_ENST00000556132_ENST00000389131_127796437_23198716 superimposed PDB: 5ZE3 of partner (LOXL2). RMSD:1.2686
Å |
 |  |  |  |  |
| SOGA3_NPC1L1_ENST00000556132_ENST00000289547_127796437_44561841 superimposed PDB: 7N4X of partner (NPC1L1). RMSD:1.0531
Å |
 |  |  |  |  |
| SORBS1_FAM135B_ENST00000277982_ENST00000395297_97106162_139255311 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.8018
Å |
 |  |  |  |  |
| SORBS1_FAM135B_ENST00000361941_ENST00000395297_97106162_139255311 superimposed PDB: 2MOX of partner (SORBS1). RMSD:2.6503
Å |
 |  |  |  |  |
| SORBS2_ASPH_ENST00000393528_ENST00000379454_186599576_62489417 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.7558
Å |
 |  |  |  |  |
| SORCS2_CMTR1_ENST00000329016_ENST00000373451_7668940_37414066 superimposed PDB: 8P4E of partner (CMTR1). RMSD:1.1729
Å |
 |  |  |  |  |
| SORD_IKZF3_ENST00000558580_ENST00000346872_45335619_37949186 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.161
Å |
 |  |  |  |  |
| SORL1_GLT8D1_ENST00000260197_ENST00000394783_121483541_52731950 superimposed PDB: 3WSX of partner (SORL1). RMSD:1.0401
Å |
 |  |  |  |  |
| SORL1_SYTL2_ENST00000260197_ENST00000389960_121466481_85428573 superimposed PDB: 3WSX of partner (SORL1). RMSD:1.2768
Å |
 |  |  |  |  |
| SORL1_SYTL2_ENST00000525532_ENST00000389960_121466481_85428573 superimposed PDB: 3WSX of partner (SORL1). RMSD:1.2424
Å |
 |  |  |  |  |
| SORL1_SYTL2_ENST00000527934_ENST00000389960_121466481_85428573 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:2.228
Å |
 |  |  |  |  |
| SORL1_SYTL2_ENST00000532694_ENST00000389960_121466481_85428573 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:2.2206
Å |
 |  |  |  |  |
| SORL1_SYTL2_ENST00000534286_ENST00000389960_121466481_85428573 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:2.2324
Å |
 |  |  |  |  |
| SOS1_CMTM6_ENST00000395038_ENST00000205636_39347476_32533378 superimposed PDB: 3KSY of partner (SOS1). RMSD:2.4354
Å |
 |  |  |  |  |
| SOS1_MAP4K3_ENST00000395038_ENST00000263881_39278284_39605264 superimposed PDB: 5J5T of partner (MAP4K3). RMSD:0.4009
Å |
 |  |  |  |  |
| SOS1_MAP4K3_ENST00000395038_ENST00000263881_39283842_39605264 superimposed PDB: 5J5T of partner (MAP4K3). RMSD:0.4322
Å |
 |  |  |  |  |
| SOS1_MAP4K3_ENST00000402219_ENST00000341681_39347476_39542529 superimposed PDB: 3KSY of partner (SOS1). RMSD:2.4465
Å |
 |  |  |  |  |
| SOS1_MAP4K3_ENST00000402219_ENST00000437545_39347476_39542529 superimposed PDB: 3KSY of partner (SOS1). RMSD:2.1827
Å |
 |  |  |  |  |
| SOS1_SLC12A1_ENST00000395038_ENST00000380993_39233552_48518672 superimposed PDB: 3KSY of partner (SOS1). RMSD:2.4087
Å |
 |  |  |  |  |
| SOS2_CHD8_ENST00000216373_ENST00000399982_50612194_21854335 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.2893
Å |
 |  |  |  |  |
| SOS2_CHD8_ENST00000216373_ENST00000399982_50612194_21854335 superimposed PDB: 2CKA of partner (CHD8). RMSD:2.4259
Å |
| | | |  |
| SOS2_CHD8_ENST00000543680_ENST00000399982_50612194_21854335 superimposed PDB: 8UF2 of partner (SOS2). RMSD:1.0267
Å |
 |  |  |  |  |
| SOS2_CHD8_ENST00000543680_ENST00000399982_50612194_21854335 superimposed PDB: 2CKA of partner (CHD8). RMSD:2.4173
Å |
| | | |  |
| SOS2_POLN_ENST00000216373_ENST00000511885_50697914_2176478 superimposed PDB: 4XVK of partner (POLN). RMSD:0.8878
Å |
 |  |  |  |  |
| SOS2_POLN_ENST00000216373_ENST00000511885_50697914_2178061 superimposed PDB: 4XVK of partner (POLN). RMSD:0.9003
Å |
 |  |  |  |  |
| SOS2_POLN_ENST00000543680_ENST00000511885_50697914_2176478 superimposed PDB: 4XVK of partner (POLN). RMSD:0.8966
Å |
 |  |  |  |  |
| SOS2_POLN_ENST00000543680_ENST00000511885_50697914_2178061 superimposed PDB: 4XVK of partner (POLN). RMSD:0.9548
Å |
 |  |  |  |  |
| SOX6_PTPRJ_ENST00000528252_ENST00000418331_16362557_48134298 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:2.8293
Å |
 |  |  |  |  |
| SOX6_PTPRJ_ENST00000528252_ENST00000440289_16362557_48134298 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:1.4619
Å |
 |  |  |  |  |
| SOX6_PTPRJ_ENST00000528429_ENST00000418331_16362557_48134298 superimposed PDB: 7U08 of partner (PTPRJ). RMSD:1.2143
Å |
 |  |  |  |  |
| SPAG1_STK3_ENST00000251809_ENST00000523601_101245765_99719539 superimposed PDB: 9HB4 of partner (SPAG1). RMSD:3.1829
Å |
 |  |  |  |  |
| SPAG1_STK3_ENST00000251809_ENST00000523601_101245765_99719539 superimposed PDB: 3A7I of partner (STK3). RMSD:3.2947
Å |
| | | |  |
| SPAG1_STK3_ENST00000388798_ENST00000523601_101245765_99719539 superimposed PDB: 9HB4 of partner (SPAG1). RMSD:3.1595
Å |
 |  |  |  |  |
| SPAG1_STK3_ENST00000388798_ENST00000523601_101245765_99719539 superimposed PDB: 3A7I of partner (STK3). RMSD:3.2313
Å |
| | | |  |
| SPAG9_BRIP1_ENST00000262013_ENST00000259008_49133772_59924581 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.4015
Å |
 |  |  |  |  |
| SPAG9_BRIP1_ENST00000262013_ENST00000577598_49133772_59924581 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.2831
Å |
 |  |  |  |  |
| SPAG9_BRIP1_ENST00000262013_ENST00000577598_49133772_59924581 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.4911
Å |
| | | |  |
| SPAG9_BRIP1_ENST00000505279_ENST00000259008_49133772_59924581 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.4467
Å |
 |  |  |  |  |
| SPAG9_MBTD1_ENST00000262013_ENST00000415868_49133772_49284366 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.7031
Å |
 |  |  |  |  |
| SPAG9_MBTD1_ENST00000262013_ENST00000415868_49133772_49284366 superimposed PDB: 3FEO of partner (MBTD1). RMSD:0.8794
Å |
| | | |  |
| SPAG9_MBTD1_ENST00000505279_ENST00000586178_49133772_49284366 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.3844
Å |
 |  |  |  |  |
| SPAG9_MBTD1_ENST00000505279_ENST00000586178_49133772_49284366 superimposed PDB: 3FEO of partner (MBTD1). RMSD:1.6236
Å |
| | | |  |
| SPAG9_NGFR_ENST00000262013_ENST00000504201_49067810_47587773 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.5061
Å |
 |  |  |  |  |
| SPAG9_NGFR_ENST00000262013_ENST00000504201_49067810_47587773 superimposed PDB: 2N83 of partner (NGFR). RMSD:1.6451
Å |
| | | |  |
| SPAG9_NGFR_ENST00000357122_ENST00000504201_49067810_47587773 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.1965
Å |
 |  |  |  |  |
| SPAG9_NGFR_ENST00000357122_ENST00000504201_49067810_47587773 superimposed PDB: 2N83 of partner (NGFR). RMSD:1.5993
Å |
| | | |  |
| SPAG9_NGFR_ENST00000505279_ENST00000504201_49067810_47587773 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.3398
Å |
 |  |  |  |  |
| SPAG9_NGFR_ENST00000505279_ENST00000504201_49067810_47587773 superimposed PDB: 2N83 of partner (NGFR). RMSD:1.6538
Å |
| | | |  |
| SPAG9_NGFR_ENST00000510283_ENST00000504201_49067810_47587773 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.1053
Å |
 |  |  |  |  |
| SPAG9_NGFR_ENST00000510283_ENST00000504201_49067810_47587773 superimposed PDB: 2N83 of partner (NGFR). RMSD:1.636
Å |
| | | |  |
| SPAG9_P4HB_ENST00000262013_ENST00000439918_49156944_79817263 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.4041
Å |
 |  |  |  |  |
| SPAG9_P4HB_ENST00000262013_ENST00000439918_49156944_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.3434
Å |
| | | |  |
| SPAG9_P4HB_ENST00000262013_ENST00000576390_49156944_79817263 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.8475
Å |
 |  |  |  |  |
| SPAG9_P4HB_ENST00000262013_ENST00000576390_49156944_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:2.8158
Å |
| | | |  |
| SPAG9_P4HB_ENST00000505279_ENST00000331483_49156944_79817263 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.8707
Å |
 |  |  |  |  |
| SPAG9_P4HB_ENST00000505279_ENST00000331483_49156944_79817263 superimposed PDB: 8EOJ of partner (P4HB). RMSD:3.3502
Å |
| | | |  |
| SPAG9_TRIM37_ENST00000262013_ENST00000262294_49059884_57168701 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.2931
Å |
 |  |  |  |  |
| SPAG9_TRIM37_ENST00000262013_ENST00000262294_49059884_57168701 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:2.9934
Å |
| | | |  |
| SPAG9_TRIM37_ENST00000262013_ENST00000393066_49059884_57168701 superimposed PDB: 2W83 of partner (SPAG9). RMSD:0.7339
Å |
 |  |  |  |  |
| SPAG9_TRIM37_ENST00000357122_ENST00000262294_49059884_57168701 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.1201
Å |
 |  |  |  |  |
| SPAG9_TRIM37_ENST00000505279_ENST00000262294_49059884_57168701 superimposed PDB: 2W83 of partner (SPAG9). RMSD:1.9855
Å |
 |  |  |  |  |
| SPAG9_TRIM37_ENST00000505279_ENST00000262294_49059884_57168701 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:2.6762
Å |
| | | |  |
| SPAG9_TRIM37_ENST00000510283_ENST00000262294_49059884_57168701 superimposed PDB: 2W83 of partner (SPAG9). RMSD:2.0152
Å |
 |  |  |  |  |
| SPAG9_TRIM37_ENST00000510283_ENST00000262294_49059884_57168701 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:2.818
Å |
| | | |  |
| SPATA6_MAD2L2_ENST00000396199_ENST00000376669_48917223_11737005 superimposed PDB: 6BCD of partner (MAD2L2). RMSD:0.7825
Å |
 |  |  |  |  |
| SPATA6_MAD2L2_ENST00000396199_ENST00000376692_48917223_11737005 superimposed PDB: 6BCD of partner (MAD2L2). RMSD:0.7828
Å |
 |  |  |  |  |
| SPATA7_NAA50_ENST00000356583_ENST00000240922_88897569_113442939 superimposed PDB: 6WFN of partner (NAA50). RMSD:2.2827
Å |
 |  |  |  |  |
| SPATA7_NAA50_ENST00000393545_ENST00000240922_88897569_113442939 superimposed PDB: 6WFN of partner (NAA50). RMSD:2.7323
Å |
 |  |  |  |  |
| SPATA7_NAA50_ENST00000393545_ENST00000477813_88897569_113442939 superimposed PDB: 6WFN of partner (NAA50). RMSD:0.4016
Å |
 |  |  |  |  |
| SPATA7_NAA50_ENST00000556553_ENST00000477813_88897569_113442939 superimposed PDB: 6WFN of partner (NAA50). RMSD:0.382
Å |
 |  |  |  |  |
| SPCS2_DCPS_ENST00000530257_ENST00000263579_74660444_126176464 superimposed PDB: 7P2P of partner (SPCS2). RMSD:3.0073
Å |
 |  |  |  |  |
| SPCS2_DCPS_ENST00000530257_ENST00000263579_74660444_126176464 superimposed PDB: 1ST0 of partner (DCPS). RMSD:0.8199
Å |
| | | |  |
| SPCS2_TCN1_ENST00000530257_ENST00000257264_74660444_59623531 superimposed PDB: 4KKI of partner (TCN1). RMSD:1.0514
Å |
 |  |  |  |  |
| SPECC1L_MED15_ENST00000314328_ENST00000425759_24808675_20905722 superimposed PDB: 7EMF of partner (MED15). RMSD:2.658
Å |
 |  |  |  |  |
| SPECC1_TATDN1_ENST00000395522_ENST00000276692_20059549_125528271 superimposed PDB: 8EFG of partner (TATDN1). RMSD:0.653
Å |
 |  |  |  |  |
| SPECC1_TATDN1_ENST00000395522_ENST00000519548_20059549_125528271 superimposed PDB: 8EFG of partner (TATDN1). RMSD:0.5164
Å |
 |  |  |  |  |
| SPECC1_TATDN1_ENST00000395525_ENST00000276692_20059549_125528271 superimposed PDB: 8EFG of partner (TATDN1). RMSD:0.7164
Å |
 |  |  |  |  |
| SPECC1_TATDN1_ENST00000395525_ENST00000519548_20059549_125528271 superimposed PDB: 8EFG of partner (TATDN1). RMSD:0.542
Å |
 |  |  |  |  |
| SPECC1_TATDN1_ENST00000395530_ENST00000519548_20059549_125528271 superimposed PDB: 8EFG of partner (TATDN1). RMSD:0.505
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000305762_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:1.9666
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000305762_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.5186
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000322635_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:2.3694
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000322635_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4749
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000322680_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:1.993
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000322680_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4967
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000372765_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:1.7694
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000372765_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4929
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000394762_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:2.2501
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000394762_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.5413
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000423381_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:2.0338
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000261866_ENST00000423381_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.4978
Å |
| | | |  |
| SPG11_CAMK2G_ENST00000427534_ENST00000351293_44865744_75613004 superimposed PDB: 8YAH of partner (SPG11). RMSD:2.1156
Å |
 |  |  |  |  |
| SPG11_CAMK2G_ENST00000427534_ENST00000351293_44865744_75613004 superimposed PDB: 2V7O of partner (CAMK2G). RMSD:0.6802
Å |
| | | |  |
| SPG7_EFCAB12_ENST00000268704_ENST00000326085_89599044_129140646 superimposed PDB: 2QZ4 of partner (SPG7). RMSD:0.731
Å |
 |  |  |  |  |
| SPG7_MOB1A_ENST00000341316_ENST00000396049_89579445_74394234 superimposed PDB: 5BRK of partner (MOB1A). RMSD:0.452
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000265709_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.5665
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000289734_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2421
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000352337_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.4271
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000379758_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2035
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000396942_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8766
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000297423_ENST00000396945_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0937
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000265709_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9343
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000289734_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0439
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000347528_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2486
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000352337_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7731
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000379758_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6535
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000396942_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7564
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000517693_ENST00000396945_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8773
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000265709_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.3549
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000289734_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9988
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000347528_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2186
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000352337_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6391
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000379758_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.268
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000396942_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7265
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000518074_ENST00000396945_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0782
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000265709_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.3542
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000289734_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8716
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000347528_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2235
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000352337_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.9101
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000379758_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.2302
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000396942_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.0129
Å |
 |  |  |  |  |
| SPIDR_ANK1_ENST00000541342_ENST00000396945_48614577_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.3998
Å |
 |  |  |  |  |
| SPIDR_PRKDC_ENST00000297423_ENST00000314191_48353104_48686938 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:0.7672
Å |
 |  |  |  |  |
| SPIDR_PRKDC_ENST00000518074_ENST00000314191_48353104_48686938 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:0.6522
Å |
 |  |  |  |  |
| SPIDR_PRKDC_ENST00000541342_ENST00000314191_48353104_48686938 superimposed PDB: 7Z87 of partner (PRKDC). RMSD:0.6861
Å |
 |  |  |  |  |
| SPIDR_UBE2V2_ENST00000517693_ENST00000523111_48626203_48955592 superimposed PDB: 4ONL of partner (UBE2V2). RMSD:0.317
Å |
 |  |  |  |  |
| SPIDR_UBE2V2_ENST00000518074_ENST00000523111_48320523_48955592 superimposed PDB: 4ONL of partner (UBE2V2). RMSD:0.3508
Å |
 |  |  |  |  |
| SPIDR_UBE2V2_ENST00000518074_ENST00000523111_48626203_48955592 superimposed PDB: 4ONL of partner (UBE2V2). RMSD:0.3474
Å |
 |  |  |  |  |
| SPIDR_UBE2V2_ENST00000541342_ENST00000523111_48320523_48955592 superimposed PDB: 4ONL of partner (UBE2V2). RMSD:0.3156
Å |
 |  |  |  |  |
| SPIDR_UBE2V2_ENST00000541342_ENST00000523111_48626203_48955592 superimposed PDB: 4ONL of partner (UBE2V2). RMSD:0.3132
Å |
 |  |  |  |  |
| SPINK5_DNAJC21_ENST00000256084_ENST00000342382_147505413_34945865 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.8147
Å |
 |  |  |  |  |
| SPINK5_DNAJC21_ENST00000256084_ENST00000382021_147505413_34945865 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.5447
Å |
 |  |  |  |  |
| SPINK5_DNAJC21_ENST00000256084_ENST00000512136_147505413_34945865 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.8815
Å |
 |  |  |  |  |
| SPINK5_DNAJC21_ENST00000359874_ENST00000382021_147505413_34945865 superimposed PDB: 1UVG of partner (SPINK5). RMSD:2.0082
Å |
 |  |  |  |  |
| SPINK5_DNAJC21_ENST00000359874_ENST00000512136_147505413_34945865 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.7912
Å |
 |  |  |  |  |
| SPINK5_NCOA3_ENST00000256084_ENST00000371997_147506642_46277748 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.7166
Å |
 |  |  |  |  |
| SPINK5_NCOA3_ENST00000256084_ENST00000372004_147506642_46277748 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.7427
Å |
 |  |  |  |  |
| SPINK5_NCOA3_ENST00000359874_ENST00000341724_147506642_46277748 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.6036
Å |
 |  |  |  |  |
| SPINK5_NCOA3_ENST00000359874_ENST00000371997_147506642_46277748 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.8777
Å |
 |  |  |  |  |
| SPINK5_NCOA3_ENST00000359874_ENST00000372004_147506642_46277748 superimposed PDB: 1UVG of partner (SPINK5). RMSD:1.8459
Å |
 |  |  |  |  |
| SPINT1_HIF1A_ENST00000431806_ENST00000557538_41137227_62213651 superimposed PDB: 5H7V of partner (SPINT1). RMSD:1.0007
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000301244_ENST00000286445_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2919
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000301244_ENST00000286445_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3865
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000301244_ENST00000359742_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2818
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000301244_ENST00000359742_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3946
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000286445_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.4052
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000286445_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3804
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000359742_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.4142
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000359742_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3844
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000398016_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2501
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000454580_ENST00000398016_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3969
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000286445_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.3272
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000286445_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4016
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000359742_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.4193
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000359742_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.4235
Å |
| | | |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000398016_38781215_66935730 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.3351
Å |
 |  |  |  |  |
| SPINT2_GRIP1_ENST00000587090_ENST00000398016_38781215_66935730 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.3926
Å |
| | | |  |
| SPINT2_MAP4K1_ENST00000301244_ENST00000591517_38781215_39087777 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.3886
Å |
 |  |  |  |  |
| SPINT2_MAP4K1_ENST00000454580_ENST00000591517_38781215_39087777 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2553
Å |
 |  |  |  |  |
| SPINT2_MAP4K1_ENST00000587090_ENST00000591517_38781215_39087777 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.3081
Å |
 |  |  |  |  |
| SPINT2_PAK1_ENST00000301244_ENST00000278568_38755638_77085410 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6614
Å |
 |  |  |  |  |
| SPINT2_PAK1_ENST00000301244_ENST00000528203_38755638_77085410 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.6703
Å |
 |  |  |  |  |
| SPINT2_PAK1_ENST00000301244_ENST00000530617_38755638_77085410 superimposed PDB: 3Q52 of partner (PAK1). RMSD:0.584
Å |
 |  |  |  |  |
| SPINT2_TYROBP_ENST00000301244_ENST00000544690_38755638_36398482 superimposed PDB: 4WOL of partner (TYROBP). RMSD:0.6011
Å |
 |  |  |  |  |
| SPIRE1_PTPN2_ENST00000309836_ENST00000591115_12493070_12794484 superimposed PDB: 3R7G of partner (SPIRE1). RMSD:0.4505
Å |
 |  |  |  |  |
| SPIRE1_PTPN2_ENST00000453447_ENST00000591115_12493070_12794484 superimposed PDB: 3R7G of partner (SPIRE1). RMSD:0.6738
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000311008_ENST00000303531_28986878_23999828 superimposed PDB: 9BOI of partner (SPNS1). RMSD:2.6279
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000311008_ENST00000303531_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.0627
Å |
| | | |  |
| SPNS1_PRKCB_ENST00000311008_ENST00000321728_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1505
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000323081_ENST00000303531_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.051
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000323081_ENST00000321728_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1102
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000334536_ENST00000321728_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.2616
Å |
 |  |  |  |  |
| SPNS1_PRKCB_ENST00000565975_ENST00000303531_28986878_23999828 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:1.1102
Å |
 |  |  |  |  |
| SPOP_NBPF1_ENST00000503676_ENST00000430580_47688641_16890681 superimposed PDB: 8DWU of partner (SPOP). RMSD:0.884
Å |
 |  |  |  |  |
| SPP1_CLU_ENST00000360804_ENST00000546343_88901586_27464041 superimposed PDB: 7ZET of partner (CLU). RMSD:2.7566
Å |
 |  |  |  |  |
| SPP1_CLU_ENST00000395080_ENST00000546343_88901586_27464041 superimposed PDB: 7ZET of partner (CLU). RMSD:2.7723
Å |
 |  |  |  |  |
| SPRED2_MEIS1_ENST00000356388_ENST00000272369_65659095_66664868 superimposed PDB: 2JP2 of partner (SPRED2). RMSD:2.7866
Å |
 |  |  |  |  |
| SPRED2_MEIS1_ENST00000356388_ENST00000272369_65659095_66664868 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.5937
Å |
| | | |  |
| SPRED2_MEIS1_ENST00000356388_ENST00000407092_65659095_66664868 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.6477
Å |
 |  |  |  |  |
| SPRED2_MEIS1_ENST00000356388_ENST00000488550_65659095_66664868 superimposed PDB: 4XRS of partner (MEIS1). RMSD:1.706
Å |
 |  |  |  |  |
| SPTBN1_ANXA2_ENST00000356805_ENST00000451270_54753703_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.4253
Å |
 |  |  |  |  |
| SPTBN1_RTN4_ENST00000356805_ENST00000394609_54753703_55214834 superimposed PDB: 2G31 of partner (RTN4). RMSD:3.2092
Å |
 |  |  |  |  |
| SPTBN2_PC_ENST00000533211_ENST00000393958_66488554_66639630 superimposed PDB: 6ANU of partner (SPTBN2). RMSD:1.3088
Å |
 |  |  |  |  |
| SPTBN2_PC_ENST00000533211_ENST00000393960_66488554_66639630 superimposed PDB: 8XL9 of partner (PC). RMSD:0.7795
Å |
 |  |  |  |  |
| SPTBN4_JAK3_ENST00000352632_ENST00000458235_41012293_17942607 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.3421
Å |
 |  |  |  |  |
| SPTBN4_JAK3_ENST00000352632_ENST00000458235_41012293_17943738 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.6068
Å |
 |  |  |  |  |
| SPTBN4_JAK3_ENST00000595535_ENST00000534444_41012293_17942607 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.3596
Å |
 |  |  |  |  |
| SPTBN4_JAK3_ENST00000595535_ENST00000534444_41012293_17943738 superimposed PDB: 3LXL of partner (JAK3). RMSD:0.4902
Å |
 |  |  |  |  |
| SPTBN4_SPTBN1_ENST00000352632_ENST00000356805_40996155_54843343 superimposed PDB: 3EDV of partner (SPTBN1). RMSD:3.4424
Å |
 |  |  |  |  |
| SPTBN4_SPTBN1_ENST00000595535_ENST00000333896_40996155_54843343 superimposed PDB: 3EDV of partner (SPTBN1). RMSD:3.4544
Å |
 |  |  |  |  |
| SPTLC1_NOL8_ENST00000337841_ENST00000442668_94842297_95084028 superimposed PDB: 7K0K of partner (SPTLC1). RMSD:1.9676
Å |
 |  |  |  |  |
| SPTLC2_DIAPH3_ENST00000216484_ENST00000400320_78043109_60348957 superimposed PDB: 7K0K of partner (SPTLC2). RMSD:2.0689
Å |
 |  |  |  |  |
| SPTLC2_DIAPH3_ENST00000216484_ENST00000400320_78043109_60348957 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6689
Å |
| | | |  |
| SPTLC2_DIAPH3_ENST00000216484_ENST00000400330_78043109_60348957 superimposed PDB: 7K0K of partner (SPTLC2). RMSD:2.9339
Å |
 |  |  |  |  |
| SPTLC2_DIAPH3_ENST00000216484_ENST00000400330_78043109_60348957 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6705
Å |
| | | |  |
| SPTLC2_RBKS_ENST00000216484_ENST00000302188_78063528_28070964 superimposed PDB: 7K0K of partner (SPTLC2). RMSD:2.6427
Å |
 |  |  |  |  |
| SPTLC2_RBKS_ENST00000216484_ENST00000444339_78063528_28070964 superimposed PDB: 9CVB of partner (RBKS). RMSD:0.4197
Å |
 |  |  |  |  |
| SPTLC2_STAM2_ENST00000216484_ENST00000263904_78043109_153006743 superimposed PDB: 7K0K of partner (SPTLC2). RMSD:1.4756
Å |
 |  |  |  |  |
| SPTLC3_PPAP2A_ENST00000399002_ENST00000264775_13090864_54737736 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.6788
Å |
 |  |  |  |  |
| SPTLC3_PPAP2A_ENST00000399002_ENST00000307259_13090864_54737736 superimposed PDB: 9L0U of partner (PPAP2A). RMSD:0.4665
Å |
 |  |  |  |  |
| SQSTM1_CDKN1C_ENST00000360718_ENST00000440480_179251323_2905364 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:0.8265
Å |
 |  |  |  |  |
| SQSTM1_CDKN1C_ENST00000376929_ENST00000430149_179251323_2905364 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:0.9191
Å |
 |  |  |  |  |
| SQSTM1_CDKN1C_ENST00000389805_ENST00000440480_179251323_2905364 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:0.4913
Å |
 |  |  |  |  |
| SQSTM1_NTRK2_ENST00000360718_ENST00000376213_179252226_87549076 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:1.2589
Å |
 |  |  |  |  |
| SQSTM1_NTRK2_ENST00000360718_ENST00000376213_179252226_87549076 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.6927
Å |
| | | |  |
| SQSTM1_NTRK2_ENST00000376929_ENST00000376213_179252226_87549076 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:0.9291
Å |
 |  |  |  |  |
| SQSTM1_NTRK2_ENST00000376929_ENST00000376213_179252226_87549076 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.6873
Å |
| | | |  |
| SQSTM1_NTRK2_ENST00000376929_ENST00000376214_179252226_87549076 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:1.3098
Å |
 |  |  |  |  |
| SQSTM1_NTRK2_ENST00000376929_ENST00000376214_179252226_87549076 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7975
Å |
| | | |  |
| SQSTM1_NTRK2_ENST00000389805_ENST00000376213_179252226_87549076 superimposed PDB: 6TGY of partner (SQSTM1). RMSD:0.4596
Å |
 |  |  |  |  |
| SQSTM1_NTRK2_ENST00000389805_ENST00000376213_179252226_87549076 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7207
Å |
| | | |  |
| SRCAP_IL11RA_ENST00000344771_ENST00000318041_30725032_34655214 superimposed PDB: 8QY4 of partner (IL11RA). RMSD:1.1691
Å |
 |  |  |  |  |
| SRCAP_IL11RA_ENST00000344771_ENST00000441545_30725032_34655214 superimposed PDB: 8QY4 of partner (IL11RA). RMSD:1.1389
Å |
 |  |  |  |  |
| SRD5A1_GRK4_ENST00000274192_ENST00000398052_6663079_3024140 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.8154
Å |
 |  |  |  |  |
| SRD5A1_GRK4_ENST00000274192_ENST00000504933_6663079_3024140 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.8649
Å |
 |  |  |  |  |
| SRD5A1_GRK4_ENST00000538824_ENST00000398052_6663079_3024140 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.7959
Å |
 |  |  |  |  |
| SRD5A1_GRK4_ENST00000538824_ENST00000504933_6663079_3024140 superimposed PDB: 4YHJ of partner (GRK4). RMSD:0.8963
Å |
 |  |  |  |  |
| SREBF1_MED9_ENST00000261646_ENST00000268711_17740040_17394592 superimposed PDB: 1AM9 of partner (SREBF1). RMSD:2.6926
Å |
 |  |  |  |  |
| SREBF1_MED9_ENST00000355815_ENST00000268711_17740040_17394592 superimposed PDB: 1AM9 of partner (SREBF1). RMSD:2.6105
Å |
 |  |  |  |  |
| SREBF1_MED9_ENST00000435530_ENST00000268711_17740040_17394592 superimposed PDB: 1AM9 of partner (SREBF1). RMSD:2.5472
Å |
 |  |  |  |  |
| SREBF2_POLR3H_ENST00000361204_ENST00000355209_42271728_41936799 superimposed PDB: 1UKL of partner (SREBF2). RMSD:0.8262
Å |
 |  |  |  |  |
| SREBF2_POLR3H_ENST00000361204_ENST00000355209_42271728_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:1.2942
Å |
| | | |  |
| SREBF2_POLR3H_ENST00000361204_ENST00000407461_42271728_41936799 superimposed PDB: 1UKL of partner (SREBF2). RMSD:0.7182
Å |
 |  |  |  |  |
| SREBF2_POLR3H_ENST00000361204_ENST00000407461_42271728_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:1.6024
Å |
| | | |  |
| SREBF2_XRCC6_ENST00000361204_ENST00000402580_42293165_42049532 superimposed PDB: 1UKL of partner (SREBF2). RMSD:0.7218
Å |
 |  |  |  |  |
| SREBF2_XRCC6_ENST00000361204_ENST00000402580_42293165_42049532 superimposed PDB: 8AG4 of partner (XRCC6). RMSD:2.1696
Å |
| | | |  |
| SRF_CRIP3_ENST00000265354_ENST00000274990_43144405_43276147 superimposed PDB: 1K6O of partner (SRF). RMSD:0.4232
Å |
 |  |  |  |  |
| SRF_CRIP3_ENST00000457278_ENST00000274990_43144405_43276147 superimposed PDB: 1K6O of partner (SRF). RMSD:0.6768
Å |
 |  |  |  |  |
| SRF_CRIP3_ENST00000457278_ENST00000372569_43144405_43276147 superimposed PDB: 1K6O of partner (SRF). RMSD:0.434
Å |
 |  |  |  |  |
| SRF_F5_ENST00000265354_ENST00000367797_43141851_169483697 superimposed PDB: 1K6O of partner (SRF). RMSD:0.4552
Å |
 |  |  |  |  |
| SRF_F5_ENST00000265354_ENST00000367797_43141851_169483697 superimposed PDB: 8TN9 of partner (F5). RMSD:1.1732
Å |
| | | |  |
| SRF_F5_ENST00000457278_ENST00000367797_43141851_169483697 superimposed PDB: 1K6O of partner (SRF). RMSD:0.7177
Å |
 |  |  |  |  |
| SRF_F5_ENST00000457278_ENST00000367797_43141851_169483697 superimposed PDB: 8TN9 of partner (F5). RMSD:1.0334
Å |
| | | |  |
| SRGAP1_ULBP3_ENST00000357825_ENST00000438272_64238663_150387298 superimposed PDB: 1KCG of partner (ULBP3). RMSD:0.5536
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000354947_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:0.6994
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000354947_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7702
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000422156_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:1.9875
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000540759_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:1.0497
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000540759_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.0444
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000550465_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:1.6639
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000265729_ENST00000550465_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8272
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000354947_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:0.6841
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000354947_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.7542
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000540759_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:0.9345
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000540759_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.0312
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000550465_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:1.3551
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000394641_ENST00000550465_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8367
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000354947_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:0.9744
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000354947_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.6958
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000540759_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:0.6372
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000540759_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:1.0144
Å |
| | | |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000550465_87840196_57987807 superimposed PDB: 4USL of partner (SRI). RMSD:2.3155
Å |
 |  |  |  |  |
| SRI_PIP4K2C_ENST00000490437_ENST00000550465_87840196_57987807 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:0.8009
Å |
| | | |  |
| SRM_USP33_ENST00000376957_ENST00000357428_11115837_78167156 superimposed PDB: 2O07 of partner (SRM). RMSD:0.3825
Å |
 |  |  |  |  |
| SRM_USP33_ENST00000376957_ENST00000357428_11115837_78167156 superimposed PDB: 2UZG of partner (USP33). RMSD:2.9231
Å |
| | | |  |
| SRP19_EIF4G2_ENST00000282999_ENST00000525681_112200225_10825750 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:0.9225
Å |
 |  |  |  |  |
| SRP19_EIF4G2_ENST00000282999_ENST00000526148_112200225_10825750 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:0.9336
Å |
 |  |  |  |  |
| SRP19_EIF4G2_ENST00000505459_ENST00000525681_112200225_10825750 superimposed PDB: 3L6A of partner (EIF4G2). RMSD:0.9718
Å |
 |  |  |  |  |
| SRP72_STAT5B_ENST00000510663_ENST00000293328_57357734_40369482 superimposed PDB: 8QVX of partner (SRP72). RMSD:1.2859
Å |
 |  |  |  |  |
| SRPK1_STK38_ENST00000373822_ENST00000229812_35855800_36489594 superimposed PDB: 5MXX of partner (SRPK1). RMSD:3.3774
Å |
 |  |  |  |  |
| SRPK1_STK38_ENST00000373822_ENST00000229812_35855800_36489594 superimposed PDB: 6BXI of partner (STK38). RMSD:0.6846
Å |
| | | |  |
| SRR_NXN_ENST00000576848_ENST00000336868_2226639_729318 superimposed PDB: 3L6B of partner (SRR). RMSD:0.6342
Å |
 |  |  |  |  |
| SRSF1_SUCLG1_ENST00000584773_ENST00000393868_56083703_84658783 superimposed PDB: 6WCV of partner (SUCLG1). RMSD:0.6259
Å |
 |  |  |  |  |
| SRSF3_DNAJC7_ENST00000373715_ENST00000426588_36566760_40135654 superimposed PDB: 9ASQ of partner (SRSF3). RMSD:0.5951
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000342295_38973285_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.7991
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000342295_38973285_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8886
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000342295_38973835_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.8101
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000342295_38973835_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8728
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000348160_38973285_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.7534
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000348160_38973285_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8929
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000348160_38973835_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.8013
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000313117_ENST00000348160_38973835_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8709
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000409276_ENST00000342295_38973285_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.6281
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000409276_ENST00000342295_38973285_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8572
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000409276_ENST00000342295_38973835_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.6172
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000409276_ENST00000342295_38973835_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.9032
Å |
| | | |  |
| SRSF7_RBPJ_ENST00000446327_ENST00000342295_38973835_26407796 superimposed PDB: 2HVZ of partner (SRSF7). RMSD:1.6089
Å |
 |  |  |  |  |
| SRSF7_RBPJ_ENST00000446327_ENST00000342295_38973835_26407796 superimposed PDB: 6PY8 of partner (RBPJ). RMSD:0.8606
Å |
| | | |  |
| SS18L1_TAF4_ENST00000331758_ENST00000252996_60718945_60551391 superimposed PDB: 7EGG of partner (TAF4). RMSD:3.1285
Å |
 |  |  |  |  |
| SS18_CHST9_ENST00000269137_ENST00000581714_23619252_24524330 superimposed PDB: 7VRB of partner (SS18). RMSD:0.3676
Å |
 |  |  |  |  |
| SS18_CHST9_ENST00000415083_ENST00000581714_23619252_24524330 superimposed PDB: 7VRB of partner (SS18). RMSD:0.3824
Å |
 |  |  |  |  |
| SS18_CHST9_ENST00000545952_ENST00000581714_23619252_24524330 superimposed PDB: 7VRB of partner (SS18). RMSD:3.3326
Å |
 |  |  |  |  |
| SS18_DOCK2_ENST00000269137_ENST00000256935_23612362_169267760 superimposed PDB: 7VRB of partner (SS18). RMSD:0.507
Å |
 |  |  |  |  |
| SS18_DOCK2_ENST00000545952_ENST00000256935_23612362_169267760 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4605
Å |
 |  |  |  |  |
| SS18_SSX1_ENST00000269137_ENST00000376919_23612362_48123216 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4387
Å |
 |  |  |  |  |
| SS18_SSX1_ENST00000415083_ENST00000376919_23612362_48123216 superimposed PDB: 7VRB of partner (SS18). RMSD:2.9238
Å |
 |  |  |  |  |
| SS18_SSX1_ENST00000545952_ENST00000376919_23612362_48123216 superimposed PDB: 7VRB of partner (SS18). RMSD:0.461
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000269137_ENST00000276049_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4068
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000269137_ENST00000375515_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:0.5016
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000415083_ENST00000276049_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4775
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000415083_ENST00000276049_23612362_52786930 superimposed PDB: 8HQY of partner (SSX2B). RMSD:3.0076
Å |
| | | |  |
| SS18_SSX2B_ENST00000415083_ENST00000375515_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:2.5894
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000415083_ENST00000375515_23612362_52786930 superimposed PDB: 8HQY of partner (SSX2B). RMSD:2.9851
Å |
| | | |  |
| SS18_SSX2B_ENST00000545952_ENST00000276049_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:2.7377
Å |
 |  |  |  |  |
| SS18_SSX2B_ENST00000545952_ENST00000276049_23612362_52786930 superimposed PDB: 8HQY of partner (SSX2B). RMSD:2.8882
Å |
| | | |  |
| SS18_SSX2B_ENST00000545952_ENST00000375515_23612362_52786930 superimposed PDB: 7VRB of partner (SS18). RMSD:0.4961
Å |
 |  |  |  |  |
| SS18_SSX2_ENST00000415083_ENST00000336777_23612362_52729628 superimposed PDB: 7VRB of partner (SS18). RMSD:2.5886
Å |
 |  |  |  |  |
| SS18_ZNF521_ENST00000542420_ENST00000584787_23658039_22672045 superimposed PDB: 7VRB of partner (SS18). RMSD:1.8541
Å |
 |  |  |  |  |
| SSBP2_LGALS2_ENST00000509053_ENST00000215886_80911291_37967938 superimposed PDB: 8HIB of partner (SSBP2). RMSD:0.9242
Å |
 |  |  |  |  |
| SSBP2_LGALS2_ENST00000509053_ENST00000215886_80911291_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:0.4021
Å |
| | | |  |
| SSBP2_NTRK1_ENST00000320672_ENST00000358660_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.9362
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000320672_ENST00000368196_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8366
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000505980_ENST00000358660_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8691
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000505980_ENST00000368196_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8965
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000509053_ENST00000368196_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8115
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000509053_ENST00000392302_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8195
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000514493_ENST00000358660_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.681
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000514493_ENST00000392302_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.848
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000515395_ENST00000358660_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.0214
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000515395_ENST00000368196_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:3.0691
Å |
 |  |  |  |  |
| SSBP2_NTRK1_ENST00000515395_ENST00000392302_80742686_156845311 superimposed PDB: 8HIB of partner (SSBP2). RMSD:2.8904
Å |
 |  |  |  |  |
| SSBP3_NFIA_ENST00000371319_ENST00000407417_54867533_61553820 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.4763
Å |
 |  |  |  |  |
| SSBP3_NFIA_ENST00000371320_ENST00000407417_54867533_61553820 superimposed PDB: 9XVQ of partner (NFIA). RMSD:0.5102
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000265709_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.993
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000289734_28256955_41615655 superimposed PDB: 2NT2 of partner (SSH2). RMSD:2.8256
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000289734_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6046
Å |
| | | |  |
| SSH2_ANK1_ENST00000269033_ENST00000352337_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6599
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000379758_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8264
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000396942_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.5508
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000269033_ENST00000396945_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7047
Å |
 |  |  |  |  |
| SSH2_ANK1_ENST00000540801_ENST00000347528_28256955_41615655 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6398
Å |
 |  |  |  |  |
| SSH2_ASAP1_ENST00000540801_ENST00000357668_28256955_131414216 superimposed PDB: 2DA0 of partner (ASAP1). RMSD:0.8986
Å |
 |  |  |  |  |
| SSH2_HP1BP3_ENST00000269033_ENST00000312239_27982578_21100103 superimposed PDB: 2NT2 of partner (SSH2). RMSD:0.3392
Å |
 |  |  |  |  |
| SSH2_HP1BP3_ENST00000540801_ENST00000312239_27982578_21100103 superimposed PDB: 2NT2 of partner (SSH2). RMSD:2.3144
Å |
 |  |  |  |  |
| SSH2_HP1BP3_ENST00000540801_ENST00000312239_27982578_21100103 superimposed PDB: 2RQP of partner (HP1BP3). RMSD:2.755
Å |
| | | |  |
| SSH2_SLC35B1_ENST00000540801_ENST00000240333_27962985_47778872 superimposed PDB: 2NT2 of partner (SSH2). RMSD:0.364
Å |
 |  |  |  |  |
| SSH2_SUCLG1_ENST00000269033_ENST00000393868_28029976_84660559 superimposed PDB: 2NT2 of partner (SSH2). RMSD:2.1571
Å |
 |  |  |  |  |
| SSH2_SUCLG1_ENST00000540801_ENST00000393868_28029976_84660559 superimposed PDB: 6WCV of partner (SUCLG1). RMSD:0.4953
Å |
 |  |  |  |  |
| SSH3_KDM2A_ENST00000308127_ENST00000529006_67077810_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4261
Å |
 |  |  |  |  |
| SSH3_KDM2A_ENST00000308298_ENST00000398645_67077810_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4386
Å |
 |  |  |  |  |
| SSH3_KDM2A_ENST00000308298_ENST00000529006_67077810_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4058
Å |
 |  |  |  |  |
| SSR1_FARS2_ENST00000474597_ENST00000274680_7303782_5545412 superimposed PDB: 3CMQ of partner (FARS2). RMSD:1.3615
Å |
 |  |  |  |  |
| SSR1_FARS2_ENST00000479365_ENST00000274680_7303782_5545412 superimposed PDB: 3CMQ of partner (FARS2). RMSD:1.5317
Å |
 |  |  |  |  |
| SSR1_HADH_ENST00000474597_ENST00000403312_7310149_108944629 superimposed PDB: 3RQS of partner (HADH). RMSD:0.7706
Å |
 |  |  |  |  |
| SSR1_HADH_ENST00000474597_ENST00000505878_7310149_108944629 superimposed PDB: 3RQS of partner (HADH). RMSD:0.8051
Å |
 |  |  |  |  |
| SSR3_CLU_ENST00000265044_ENST00000523500_156271443_27455767 superimposed PDB: 7ZET of partner (CLU). RMSD:0.9903
Å |
 |  |  |  |  |
| SSR3_CLU_ENST00000463503_ENST00000546343_156271443_27455767 superimposed PDB: 7ZET of partner (CLU). RMSD:1.0579
Å |
 |  |  |  |  |
| SSX2IP_YTHDF2_ENST00000342203_ENST00000373812_85135363_29064169 superimposed PDB: 4WQN of partner (YTHDF2). RMSD:0.2679
Å |
 |  |  |  |  |
| SSX2IP_YTHDF2_ENST00000437941_ENST00000373812_85135363_29064169 superimposed PDB: 4WQN of partner (YTHDF2). RMSD:0.2733
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000377332_ENST00000263857_86115946_86258758 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.7324
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000377332_ENST00000409681_86088303_86274386 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.7654
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000377332_ENST00000409681_86115946_86258758 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:2.453
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000393808_ENST00000263857_86088303_86274386 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.9714
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000393808_ENST00000409681_86088303_86274386 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.8236
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000525834_ENST00000263857_86088303_86274386 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.8315
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000525834_ENST00000263857_86115946_86258758 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.1198
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000525834_ENST00000409681_86088303_86274386 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.7773
Å |
 |  |  |  |  |
| ST3GAL5_POLR1A_ENST00000525834_ENST00000409681_86115946_86258758 superimposed PDB: 7OB9 of partner (POLR1A). RMSD:1.6623
Å |
 |  |  |  |  |
| ST6GALNAC3_AK5_ENST00000328299_ENST00000344720_76540569_77949001 superimposed PDB: 2BWJ of partner (AK5). RMSD:0.8029
Å |
 |  |  |  |  |
| ST8SIA1_AEBP2_ENST00000539510_ENST00000398864_22401939_19665331 superimposed PDB: 8FYH of partner (AEBP2). RMSD:2.7616
Å |
 |  |  |  |  |
| STAG1_ANKS1B_ENST00000236698_ENST00000547010_136183722_99548173 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2818
Å |
 |  |  |  |  |
| STAG1_ANKS1B_ENST00000383202_ENST00000329257_136183722_99548173 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.27
Å |
 |  |  |  |  |
| STAG1_ANKS1B_ENST00000383202_ENST00000547010_136183722_99548173 superimposed PDB: 2M38 of partner (ANKS1B). RMSD:1.2748
Å |
 |  |  |  |  |
| STAG2_C16orf45_ENST00000218089_ENST00000452191_123220620_15609161 superimposed PDB: 9HMV of partner (STAG2). RMSD:2.0156
Å |
 |  |  |  |  |
| STAG2_C16orf45_ENST00000218089_ENST00000566490_123220620_15609161 superimposed PDB: 9HMV of partner (STAG2). RMSD:1.9501
Å |
 |  |  |  |  |
| STAG2_PTGER3_ENST00000218089_ENST00000370931_123217399_71419472 superimposed PDB: 9HMV of partner (STAG2). RMSD:0.8379
Å |
 |  |  |  |  |
| STAG2_PTGER3_ENST00000354548_ENST00000370931_123217399_71419472 superimposed PDB: 9HMV of partner (STAG2). RMSD:2.1049
Å |
 |  |  |  |  |
| STAG2_PTGER3_ENST00000354548_ENST00000370931_123217399_71419472 superimposed PDB: 8GDC of partner (PTGER3). RMSD:3.0264
Å |
| | | |  |
| STAMBP_AQP4_ENST00000394070_ENST00000383168_74058186_24442560 superimposed PDB: 8V8S of partner (AQP4). RMSD:0.3327
Å |
 |  |  |  |  |
| STAMBP_AQP4_ENST00000409707_ENST00000383168_74058186_24442560 superimposed PDB: 8V8S of partner (AQP4). RMSD:0.3387
Å |
 |  |  |  |  |
| STAMBP_AQP4_ENST00000536064_ENST00000383168_74058186_24442560 superimposed PDB: 8V8S of partner (AQP4). RMSD:0.325
Å |
 |  |  |  |  |
| STAMBP_TPRKB_ENST00000394070_ENST00000272424_74072389_73959412 superimposed PDB: 7SZC of partner (TPRKB). RMSD:0.8179
Å |
 |  |  |  |  |
| STAMBP_TPRKB_ENST00000409707_ENST00000272424_74072389_73959412 superimposed PDB: 7SZC of partner (TPRKB). RMSD:0.7743
Å |
 |  |  |  |  |
| STAMBP_TPRKB_ENST00000536064_ENST00000272424_74072389_73959412 superimposed PDB: 7SZC of partner (TPRKB). RMSD:0.8472
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000336308_ENST00000352035_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:1.0227
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000336308_ENST00000537919_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.5439
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000336308_ENST00000537919_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9616
Å |
| | | |  |
| STARD3_ACLY_ENST00000336308_ENST00000590151_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.5495
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000336308_ENST00000590151_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9444
Å |
| | | |  |
| STARD3_ACLY_ENST00000394250_ENST00000537919_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.4905
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000394250_ENST00000537919_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9677
Å |
| | | |  |
| STARD3_ACLY_ENST00000394250_ENST00000590151_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.5666
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000394250_ENST00000590151_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9742
Å |
| | | |  |
| STARD3_ACLY_ENST00000544210_ENST00000537919_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.4989
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000544210_ENST00000537919_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9249
Å |
| | | |  |
| STARD3_ACLY_ENST00000544210_ENST00000590151_37818597_40054092 superimposed PDB: 5I9J of partner (STARD3). RMSD:0.5016
Å |
 |  |  |  |  |
| STARD3_ACLY_ENST00000544210_ENST00000590151_37818597_40054092 superimposed PDB: 7RIG of partner (ACLY). RMSD:2.9423
Å |
| | | |  |
| STARD3_NFIX_ENST00000336308_ENST00000587760_37810003_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4517
Å |
 |  |  |  |  |
| STARD3_NFIX_ENST00000336308_ENST00000592199_37810003_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4412
Å |
 |  |  |  |  |
| STARD3_NFIX_ENST00000544210_ENST00000397661_37810003_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4229
Å |
 |  |  |  |  |
| STARD3_UVRAG_ENST00000336308_ENST00000528420_37810003_75599872 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.6734
Å |
 |  |  |  |  |
| STAT3_FAM134C_ENST00000585517_ENST00000585894_40490748_40739882 superimposed PDB: 6TLC of partner (STAT3). RMSD:0.9578
Å |
 |  |  |  |  |
| STAT3_KAT2A_ENST00000588969_ENST00000225916_40500406_40272847 superimposed PDB: 1Z4R of partner (KAT2A). RMSD:0.3947
Å |
 |  |  |  |  |
| STAT3_RAB5C_ENST00000264657_ENST00000393860_40475021_40278866 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.3472
Å |
 |  |  |  |  |
| STAT3_RAB5C_ENST00000585517_ENST00000393860_40475021_40278866 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.3648
Å |
 |  |  |  |  |
| STAT5A_ARNTL2_ENST00000345506_ENST00000311001_40447811_27538413 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4122
Å |
 |  |  |  |  |
| STAT5A_ARNTL2_ENST00000345506_ENST00000395901_40447811_27538413 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4239
Å |
 |  |  |  |  |
| STAT5A_ARNTL2_ENST00000546010_ENST00000311001_40447811_27538413 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.3958
Å |
 |  |  |  |  |
| STAT5A_ARNTL2_ENST00000546010_ENST00000395901_40447811_27538413 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4443
Å |
 |  |  |  |  |
| STAT5A_ARNTL2_ENST00000590949_ENST00000546179_40447811_27538413 superimposed PDB: 2KDK of partner (ARNTL2). RMSD:1.4283
Å |
 |  |  |  |  |
| STAU1_CYP26B1_ENST00000347458_ENST00000001146_47768118_72362548 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.9158
Å |
 |  |  |  |  |
| STAU1_CYP26B1_ENST00000371802_ENST00000001146_47768118_72362548 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.9168
Å |
 |  |  |  |  |
| STAU2_PDE7A_ENST00000522695_ENST00000379419_74464246_66695078 superimposed PDB: 1ZKL of partner (PDE7A). RMSD:0.3727
Å |
 |  |  |  |  |
| STAU2_PDE7A_ENST00000522695_ENST00000396642_74464246_66695078 superimposed PDB: 1ZKL of partner (PDE7A). RMSD:0.3425
Å |
 |  |  |  |  |
| STAU2_UBE2W_ENST00000521210_ENST00000517608_74585341_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6415
Å |
 |  |  |  |  |
| STAU2_UBE2W_ENST00000521210_ENST00000602969_74585341_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6243
Å |
 |  |  |  |  |
| STIM1_FITM2_ENST00000527651_ENST00000396825_4103581_42935880 superimposed PDB: 2K60 of partner (STIM1). RMSD:2.0669
Å |
 |  |  |  |  |
| STIM1_HOMEZ_ENST00000527651_ENST00000561013_4045217_23746396 superimposed PDB: 2K60 of partner (STIM1). RMSD:2.2002
Å |
 |  |  |  |  |
| STIM1_HOMEZ_ENST00000527651_ENST00000561013_4045217_23746396 superimposed PDB: 2ECC of partner (HOMEZ). RMSD:0.8624
Å |
| | | |  |
| STIM1_WT1_ENST00000300737_ENST00000332351_4076867_32421590 superimposed PDB: 2K60 of partner (STIM1). RMSD:2.2315
Å |
 |  |  |  |  |
| STIM1_WT1_ENST00000300737_ENST00000332351_4076867_32421590 superimposed PDB: 6BLW of partner (WT1). RMSD:1.6642
Å |
| | | |  |
| STIM1_WT1_ENST00000300737_ENST00000530998_4076867_32421590 superimposed PDB: 2K60 of partner (STIM1). RMSD:2.4376
Å |
 |  |  |  |  |
| STIM1_WT1_ENST00000300737_ENST00000530998_4076867_32421590 superimposed PDB: 6BLW of partner (WT1). RMSD:2.1475
Å |
| | | |  |
| STIP1_PAK1_ENST00000305218_ENST00000528203_63953742_77043912 superimposed PDB: 3Q52 of partner (PAK1). RMSD:1.7006
Å |
 |  |  |  |  |
| STIP1_PAK1_ENST00000538945_ENST00000356341_63953742_77043912 superimposed PDB: 7KW7 of partner (STIP1). RMSD:0.6098
Å |
 |  |  |  |  |
| STIP1_UBE2G1_ENST00000538945_ENST00000396981_63953742_4210418 superimposed PDB: 6D68 of partner (UBE2G1). RMSD:0.44
Å |
 |  |  |  |  |
| STK11_HMHA1_ENST00000326873_ENST00000313093_1222005_1080253 superimposed PDB: 8VSU of partner (STK11). RMSD:0.7023
Å |
 |  |  |  |  |
| STK11_HMHA1_ENST00000326873_ENST00000590214_1222005_1080253 superimposed PDB: 8VSU of partner (STK11). RMSD:0.7014
Å |
 |  |  |  |  |
| STK11_TYK2_ENST00000326873_ENST00000264818_1207202_10476574 superimposed PDB: 4OLI of partner (TYK2). RMSD:0.4964
Å |
 |  |  |  |  |
| STK11_TYK2_ENST00000326873_ENST00000524462_1207202_10473333 superimposed PDB: 8VSU of partner (STK11). RMSD:3.1311
Å |
 |  |  |  |  |
| STK11_TYK2_ENST00000326873_ENST00000524462_1207202_10473333 superimposed PDB: 4OLI of partner (TYK2). RMSD:2.9662
Å |
| | | |  |
| STK11_TYK2_ENST00000326873_ENST00000524462_1207202_10476574 superimposed PDB: 4OLI of partner (TYK2). RMSD:3.0139
Å |
 |  |  |  |  |
| STK24_ANO2_ENST00000376547_ENST00000546188_99171496_5756967 superimposed PDB: 3A7I of partner (STK24). RMSD:0.7861
Å |
 |  |  |  |  |
| STK24_ANO2_ENST00000397517_ENST00000546188_99171496_5756967 superimposed PDB: 3A7I of partner (STK24). RMSD:0.9661
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000376547_ENST00000339416_99171496_99532926 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8528
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000376547_ENST00000448493_99171496_99532926 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8308
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000397517_ENST00000339416_99171496_99532926 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8221
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000397517_ENST00000339416_99228998_99462545 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:1.028
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000397517_ENST00000448493_99171496_99532926 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.8251
Å |
 |  |  |  |  |
| STK24_DOCK9_ENST00000539966_ENST00000376460_99228998_99462545 superimposed PDB: 2WM9 of partner (DOCK9). RMSD:0.9921
Å |
 |  |  |  |  |
| STK24_PCCA_ENST00000376547_ENST00000376285_99171496_100959445 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.3636
Å |
 |  |  |  |  |
| STK24_PCCA_ENST00000376547_ENST00000376286_99171496_100959445 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.7965
Å |
 |  |  |  |  |
| STK24_PCCA_ENST00000397517_ENST00000376285_99171496_100959445 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.2697
Å |
 |  |  |  |  |
| STK24_PCCA_ENST00000397517_ENST00000376286_99171496_100959445 superimposed PDB: 7YBU of partner (PCCA). RMSD:1.1292
Å |
 |  |  |  |  |
| STK24_TMTC4_ENST00000539966_ENST00000376234_99228998_101258681 superimposed PDB: 3A7I of partner (STK24). RMSD:2.8005
Å |
 |  |  |  |  |
| STK38L_CCDC91_ENST00000389032_ENST00000545336_27462130_28603093 superimposed PDB: 5XQZ of partner (STK38L). RMSD:1.5867
Å |
 |  |  |  |  |
| STK38L_FAR2_ENST00000539577_ENST00000536681_27455121_29446232 superimposed PDB: 5XQZ of partner (STK38L). RMSD:1.6128
Å |
 |  |  |  |  |
| STK38_GMDS_ENST00000229812_ENST00000380815_36467649_1742820 superimposed PDB: 6BXI of partner (STK38). RMSD:1.2209
Å |
 |  |  |  |  |
| STK39_FUS_ENST00000355999_ENST00000380244_168869143_31199645 superimposed PDB: 7O86 of partner (STK39). RMSD:0.4888
Å |
 |  |  |  |  |
| STK3_COX6C_ENST00000419617_ENST00000520271_99718694_100899846 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7777
Å |
 |  |  |  |  |
| STK3_MEP1A_ENST00000523601_ENST00000230588_99761503_46794090 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7518
Å |
 |  |  |  |  |
| STK3_MTDH_ENST00000419617_ENST00000519934_99718694_98673299 superimposed PDB: 3A7I of partner (STK3). RMSD:0.9173
Å |
 |  |  |  |  |
| STK3_MTDH_ENST00000419617_ENST00000519934_99718694_98673299 superimposed PDB: 4QMG of partner (MTDH). RMSD:2.4066
Å |
| | | |  |
| STK3_NIPAL2_ENST00000419617_ENST00000341166_99538969_99224729 superimposed PDB: 3A7I of partner (STK3). RMSD:0.716
Å |
 |  |  |  |  |
| STK3_NIPAL2_ENST00000419617_ENST00000341166_99538969_99266315 superimposed PDB: 3A7I of partner (STK3). RMSD:0.735
Å |
 |  |  |  |  |
| STK3_NIPAL2_ENST00000419617_ENST00000430223_99538969_99224729 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7352
Å |
 |  |  |  |  |
| STK3_NIPAL2_ENST00000419617_ENST00000430223_99538969_99266315 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7505
Å |
 |  |  |  |  |
| STK3_PTPRM_ENST00000419617_ENST00000332175_99591891_8406106 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7984
Å |
 |  |  |  |  |
| STK3_PTPRM_ENST00000419617_ENST00000400060_99591891_8406106 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7239
Å |
 |  |  |  |  |
| STK3_SULT1A3_ENST00000419617_ENST00000354723_99718694_30214010 superimposed PDB: 3A7I of partner (STK3). RMSD:0.7661
Å |
 |  |  |  |  |
| STK3_SULT1A4_ENST00000419617_ENST00000344620_99718694_29474665 superimposed PDB: 3A7I of partner (STK3). RMSD:0.8403
Å |
 |  |  |  |  |
| STK3_SULT1A4_ENST00000419617_ENST00000395400_99718694_29474665 superimposed PDB: 3A7I of partner (STK3). RMSD:0.8949
Å |
 |  |  |  |  |
| STRADA_GRB2_ENST00000582137_ENST00000316804_61790765_73328878 superimposed PDB: 8VSU of partner (STRADA). RMSD:0.9469
Å |
 |  |  |  |  |
| STRADA_LYZ_ENST00000336174_ENST00000548839_61805693_69743887 superimposed PDB: 8VSU of partner (STRADA). RMSD:0.972
Å |
 |  |  |  |  |
| STRADB_NINJ2_ENST00000194530_ENST00000397265_202342914_675344 superimposed PDB: 8SZB of partner (NINJ2). RMSD:0.7633
Å |
 |  |  |  |  |
| STRN3_METTL3_ENST00000355683_ENST00000298717_31404368_21972024 superimposed PDB: 5TEY of partner (METTL3). RMSD:0.4746
Å |
 |  |  |  |  |
| STRN3_METTL3_ENST00000357479_ENST00000298717_31404368_21972024 superimposed PDB: 5TEY of partner (METTL3). RMSD:0.4644
Å |
 |  |  |  |  |
| STRN4_ZC3H4_ENST00000391910_ENST00000253048_47241420_47597865 superimposed PDB: 2CQE of partner (ZC3H4). RMSD:1.6605
Å |
 |  |  |  |  |
| STRN_ALK_ENST00000379213_ENST00000389048_37143220_29446394 superimposed PDB: 7NX3 of partner (ALK). RMSD:2.4906
Å |
 |  |  |  |  |
| STRN_SULT1C2_ENST00000263918_ENST00000251481_37193372_108921029 superimposed PDB: 3BFX of partner (SULT1C2). RMSD:0.6803
Å |
 |  |  |  |  |
| STRN_SULT1C2_ENST00000263918_ENST00000326853_37193372_108921029 superimposed PDB: 3BFX of partner (SULT1C2). RMSD:0.6268
Å |
 |  |  |  |  |
| STRN_SULT1C2_ENST00000379213_ENST00000326853_37193372_108917355 superimposed PDB: 3BFX of partner (SULT1C2). RMSD:0.6869
Å |
 |  |  |  |  |
| STRN_SULT1C2_ENST00000379213_ENST00000326853_37193372_108921029 superimposed PDB: 3BFX of partner (SULT1C2). RMSD:0.6158
Å |
 |  |  |  |  |
| STX12_ERCC2_ENST00000373943_ENST00000391944_28120143_45860629 superimposed PDB: 2DNX of partner (STX12). RMSD:1.0746
Å |
 |  |  |  |  |
| STX12_ERCC2_ENST00000373943_ENST00000391944_28120143_45860629 superimposed PDB: 28JM of partner (ERCC2). RMSD:0.8537
Å |
| | | |  |
| STXBP4_GRN_ENST00000376352_ENST00000589265_53068318_42429708 superimposed PDB: 2JYE of partner (GRN). RMSD:1.7978
Å |
 |  |  |  |  |
| STXBP4_MSI2_ENST00000376352_ENST00000416426_53150437_55693330 superimposed PDB: 6NTY of partner (MSI2). RMSD:2.4713
Å |
 |  |  |  |  |
| STXBP6_ZNF410_ENST00000323944_ENST00000324593_25443870_74370662 superimposed PDB: 6WMI of partner (ZNF410). RMSD:2.1934
Å |
 |  |  |  |  |
| STXBP6_ZNF410_ENST00000358326_ENST00000324593_25443870_74370662 superimposed PDB: 6WMI of partner (ZNF410). RMSD:2.1441
Å |
 |  |  |  |  |
| STXBP6_ZNF410_ENST00000546511_ENST00000324593_25443870_74370662 superimposed PDB: 6WMI of partner (ZNF410). RMSD:1.975
Å |
 |  |  |  |  |
| STXBP6_ZNF410_ENST00000546511_ENST00000540593_25443870_74370662 superimposed PDB: 6WMI of partner (ZNF410). RMSD:2.3886
Å |
 |  |  |  |  |
| STXBP6_ZNF410_ENST00000550887_ENST00000540593_25443870_74370662 superimposed PDB: 6WMI of partner (ZNF410). RMSD:1.9554
Å |
 |  |  |  |  |
| SUDS3_EEA1_ENST00000397564_ENST00000322349_118841322_93251261 superimposed PDB: 1JOC of partner (EEA1). RMSD:2.6797
Å |
 |  |  |  |  |
| SUFU_ADK_ENST00000369899_ENST00000539909_104309863_76468078 superimposed PDB: 4KM9 of partner (SUFU). RMSD:0.6252
Å |
 |  |  |  |  |
| SUFU_ADK_ENST00000369899_ENST00000539909_104309863_76468078 superimposed PDB: 4O1L of partner (ADK). RMSD:0.4339
Å |
| | | |  |
| SUFU_CYP26A1_ENST00000369902_ENST00000224356_104377185_94835582 superimposed PDB: 4KM9 of partner (SUFU). RMSD:0.9461
Å |
 |  |  |  |  |
| SUFU_ZCCHC24_ENST00000369899_ENST00000372333_104309863_81154196 superimposed PDB: 4KM9 of partner (SUFU). RMSD:0.6474
Å |
 |  |  |  |  |
| SUGP1_PEPD_ENST00000247001_ENST00000397032_19427230_33904549 superimposed PDB: 8GXM of partner (SUGP1). RMSD:3.1286
Å |
 |  |  |  |  |
| SUGP1_PEPD_ENST00000247001_ENST00000397032_19427230_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.3973
Å |
| | | |  |
| SUGP1_PEPD_ENST00000334782_ENST00000397032_19427230_33904549 superimposed PDB: 8GXM of partner (SUGP1). RMSD:3.1672
Å |
 |  |  |  |  |
| SUGP1_PEPD_ENST00000334782_ENST00000397032_19427230_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.3826
Å |
| | | |  |
| SUGP2_CARM1_ENST00000600377_ENST00000327064_19135427_11015626 superimposed PDB: 1X4P of partner (SUGP2). RMSD:1.289
Å |
 |  |  |  |  |
| SUGP2_CARM1_ENST00000600377_ENST00000344150_19135427_11015626 superimposed PDB: 2Y1W of partner (CARM1). RMSD:0.5248
Å |
 |  |  |  |  |
| SUGP2_UPF1_ENST00000600377_ENST00000599848_19112421_18956788 superimposed PDB: 1X4P of partner (SUGP2). RMSD:1.3793
Å |
 |  |  |  |  |
| SUGP2_UPF1_ENST00000600377_ENST00000599848_19112421_18956788 superimposed PDB: 2WJY of partner (UPF1). RMSD:1.7335
Å |
| | | |  |
| SULT1B1_CSN2_ENST00000310613_ENST00000353151_70596218_70825797 superimposed PDB: 3CKL of partner (SULT1B1). RMSD:0.4797
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000336686_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.4856
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000336686_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.6807
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000354379_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.5075
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000354379_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.639
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000396428_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.4651
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000396428_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.6338
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000440230_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.5225
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000383843_ENST00000440230_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.6833
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000336686_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:3.1554
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000336686_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.1672
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000354379_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:1.6328
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000396428_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:1.297
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000396428_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:2.0259
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000458465_ENST00000440230_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:1.3827
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000336686_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.4282
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000336686_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.628
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000354379_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.4386
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000354379_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.6443
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000396428_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.3881
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000396428_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.5421
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000440230_4418013_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.4334
Å |
 |  |  |  |  |
| SUMF1_LRRFIP2_ENST00000534863_ENST00000440230_4452548_37170640 superimposed PDB: 5SSX of partner (SUMF1). RMSD:0.6624
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3153
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3902
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2802
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3216
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2305
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1882
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2525
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2847
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1821
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3066
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2231
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.242
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3508
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2963
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2267
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.8061
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3072
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3277
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1714
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000389574_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.345
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3689
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2562
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3471
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2616
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.276
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2964
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.336
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2839
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.315
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.295
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3576
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2486
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3552
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3068
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2813
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.8825
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3199
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2445
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2969
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000401592_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3444
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1347
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3172
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3246
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1155
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3376
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2241
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3913
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2497
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2758
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2371
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0549
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2967
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3148
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.264
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1994
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.4169
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.305
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2376
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3152
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000405266_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2797
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2809
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3289
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1953
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2388
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2901
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2652
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2966
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1235
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.224
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1983
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1768
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1905
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2262
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.253
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1806
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.8723
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2432
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2607
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2102
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000413514_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1831
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3311
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3092
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2551
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2348
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2734
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2401
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.377
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2413
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2031
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3233
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2954
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3296
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3252
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3073
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3178
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.8529
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2177
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2392
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2802
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000425407_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3584
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2644
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000335762_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3792
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1424
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:1.9577
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0951
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2363
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2191
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2268
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1715
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.182
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1778
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2532
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1827
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2157
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1102
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.4223
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2298
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.0883
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2593
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000452783_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1275
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000327702_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3282
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000344100_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.28
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000347598_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.113
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399591_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1818
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399595_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1696
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399597_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3188
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399601_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.1464
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399606_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3272
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399617_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2445
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399621_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3032
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399629_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2615
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399637_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.236
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399638_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2811
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399641_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2383
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399644_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2871
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399649_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3039
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000399655_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3249
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000402845_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.2189
Å |
 |  |  |  |  |
| SUN1_CACNA1C_ENST00000456758_ENST00000406454_896038_2690755 superimposed PDB: 8FHS of partner (CACNA1C). RMSD:2.3849
Å |
 |  |  |  |  |
| SUPT3H_CLIC5_ENST00000371459_ENST00000185206_45332937_45882146 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:2.8331
Å |
 |  |  |  |  |
| SUPT4H1_CEP112_ENST00000577396_ENST00000392769_56424548_63685336 superimposed PDB: 9HVQ of partner (SUPT4H1). RMSD:1.1799
Å |
 |  |  |  |  |
| SUPT4H1_CEP112_ENST00000580947_ENST00000392769_56424548_63685336 superimposed PDB: 9HVQ of partner (SUPT4H1). RMSD:0.6258
Å |
 |  |  |  |  |
| SUV420H1_MYO1D_ENST00000304363_ENST00000394649_67947598_30965853 superimposed PDB: 8T9F of partner (SUV420H1). RMSD:0.5617
Å |
 |  |  |  |  |
| SUV420H1_MYO1D_ENST00000304363_ENST00000394649_67953247_30965853 superimposed PDB: 8T9F of partner (SUV420H1). RMSD:2.6844
Å |
 |  |  |  |  |
| SUV420H1_MYO1D_ENST00000401547_ENST00000318217_67953247_30965853 superimposed PDB: 8T9F of partner (SUV420H1). RMSD:0.706
Å |
 |  |  |  |  |
| SUZ12_NF1_ENST00000322652_ENST00000358273_30303633_29576001 superimposed PDB: 7PGP of partner (NF1). RMSD:1.044
Å |
 |  |  |  |  |
| SUZ12_NF1_ENST00000580398_ENST00000356175_30303633_29576001 superimposed PDB: 7PGP of partner (NF1). RMSD:1.0595
Å |
 |  |  |  |  |
| SUZ12_NF1_ENST00000580398_ENST00000358273_30303633_29576001 superimposed PDB: 7PGP of partner (NF1). RMSD:1.018
Å |
 |  |  |  |  |
| SUZ12_RFWD3_ENST00000322652_ENST00000571750_30315516_74666571 superimposed PDB: 6CVZ of partner (RFWD3). RMSD:0.6919
Å |
 |  |  |  |  |
| SUZ12_RFWD3_ENST00000580398_ENST00000571750_30315516_74666571 superimposed PDB: 6CVZ of partner (RFWD3). RMSD:0.6656
Å |
 |  |  |  |  |
| SWAP70_ZNF143_ENST00000318950_ENST00000396597_9754257_9516192 superimposed PDB: 2DN6 of partner (SWAP70). RMSD:0.7928
Å |
 |  |  |  |  |
| SWAP70_ZNF143_ENST00000318950_ENST00000396602_9754257_9516192 superimposed PDB: 2DN6 of partner (SWAP70). RMSD:0.7919
Å |
 |  |  |  |  |
| SWAP70_ZNF143_ENST00000447399_ENST00000396597_9754257_9516192 superimposed PDB: 2DN6 of partner (SWAP70). RMSD:0.8237
Å |
 |  |  |  |  |
| SWAP70_ZNF143_ENST00000447399_ENST00000396602_9754257_9516192 superimposed PDB: 2DN6 of partner (SWAP70). RMSD:0.8084
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000311275_58467044_45927691 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6543
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000372023_58467044_45927616 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.699
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000396281_58467044_45927616 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7425
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000446994_58467044_45927616 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6647
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000458360_58467044_45927616 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7059
Å |
 |  |  |  |  |
| SYCP2_ZMYND8_ENST00000357552_ENST00000540497_58467044_45927616 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:1.0436
Å |
 |  |  |  |  |
| SYMPK_CRYL1_ENST00000245934_ENST00000382812_46352007_20987526 superimposed PDB: 9NH5 of partner (SYMPK). RMSD:2.1232
Å |
 |  |  |  |  |
| SYNE1_CACNA1C_ENST00000356820_ENST00000399655_152614722_2778098 superimposed PDB: 6XF2 of partner (SYNE1). RMSD:2.6273
Å |
 |  |  |  |  |
| SYNE2_ITPK1_ENST00000358025_ENST00000354313_64486811_93460342 superimposed PDB: 6XF1 of partner (SYNE2). RMSD:0.8506
Å |
 |  |  |  |  |
| SYNE2_ITPK1_ENST00000358025_ENST00000354313_64486811_93460342 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:1.0099
Å |
| | | |  |
| SYNE2_ITPK1_ENST00000358025_ENST00000556603_64486811_93460342 superimposed PDB: 6XF1 of partner (SYNE2). RMSD:1.1054
Å |
 |  |  |  |  |
| SYNE2_ITPK1_ENST00000358025_ENST00000556603_64486811_93460342 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:0.8634
Å |
| | | |  |
| SYNJ1_PDE9A_ENST00000433931_ENST00000539837_34099082_44163885 superimposed PDB: 4Y86 of partner (PDE9A). RMSD:0.3986
Å |
 |  |  |  |  |
| SYNPO2_SUPT3H_ENST00000307142_ENST00000306867_119810296_44988369 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:1.1676
Å |
 |  |  |  |  |
| SYNPO2_SUPT3H_ENST00000307142_ENST00000371459_119810296_44988369 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:1.2128
Å |
 |  |  |  |  |
| SYNPR_PTPRG_ENST00000295894_ENST00000474889_63466632_62278095 superimposed PDB: 2NLK of partner (PTPRG). RMSD:0.6746
Å |
 |  |  |  |  |
| SYNPR_PTPRG_ENST00000460711_ENST00000474889_63466632_62278095 superimposed PDB: 2NLK of partner (PTPRG). RMSD:0.6353
Å |
 |  |  |  |  |
| SYNPR_PTPRG_ENST00000478300_ENST00000474889_63466632_62278095 superimposed PDB: 2NLK of partner (PTPRG). RMSD:0.6621
Å |
 |  |  |  |  |
| SYNRG_ACACA_ENST00000339208_ENST00000360679_35956269_35583373 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7687
Å |
 |  |  |  |  |
| SYNRG_ACACA_ENST00000502449_ENST00000360679_35956269_35583373 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7477
Å |
 |  |  |  |  |
| SYNRG_ACACA_ENST00000585472_ENST00000360679_35956269_35583373 superimposed PDB: 8XL1 of partner (ACACA). RMSD:2.7591
Å |
 |  |  |  |  |
| SYNRG_CCR7_ENST00000346661_ENST00000246657_35921296_38715194 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3892
Å |
 |  |  |  |  |
| SYNRG_CCR7_ENST00000346661_ENST00000246657_35921296_38715194 superimposed PDB: 9XHH of partner (CCR7). RMSD:1.1117
Å |
| | | |  |
| SYNRG_CCR7_ENST00000394378_ENST00000246657_35921296_38715194 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4125
Å |
 |  |  |  |  |
| SYNRG_CCR7_ENST00000394378_ENST00000246657_35921296_38715194 superimposed PDB: 9XHH of partner (CCR7). RMSD:1.1705
Å |
| | | |  |
| SYNRG_CCR7_ENST00000502449_ENST00000246657_35921296_38715194 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3263
Å |
 |  |  |  |  |
| SYNRG_CCR7_ENST00000502449_ENST00000246657_35921296_38715194 superimposed PDB: 9XHH of partner (CCR7). RMSD:1.07
Å |
| | | |  |
| SYNRG_CCR7_ENST00000591288_ENST00000246657_35921296_38715194 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.367
Å |
 |  |  |  |  |
| SYNRG_CCR7_ENST00000591288_ENST00000246657_35921296_38715194 superimposed PDB: 9XHH of partner (CCR7). RMSD:1.1145
Å |
| | | |  |
| SYNRG_EVX1_ENST00000339208_ENST00000222761_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4391
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000339208_ENST00000496902_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3509
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000345615_ENST00000222761_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3308
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000345615_ENST00000496902_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4028
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000394378_ENST00000496902_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4072
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000502449_ENST00000222761_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4109
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000502449_ENST00000496902_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3648
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000585472_ENST00000222761_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3751
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000591288_ENST00000222761_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4194
Å |
 |  |  |  |  |
| SYNRG_EVX1_ENST00000591288_ENST00000496902_35913216_27284666 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4177
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000339208_ENST00000225893_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3585
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000339208_ENST00000427275_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3399
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000339208_ENST00000561193_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3902
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000345615_ENST00000427275_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3808
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000345615_ENST00000561193_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3473
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000346661_ENST00000225893_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3962
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000394378_ENST00000225893_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3904
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000502449_ENST00000225893_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4191
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000502449_ENST00000427275_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4121
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000502449_ENST00000561193_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.406
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000585472_ENST00000427275_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4138
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000585472_ENST00000561193_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3805
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000591288_ENST00000225893_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3963
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000591288_ENST00000427275_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3982
Å |
 |  |  |  |  |
| SYNRG_HNF1B_ENST00000591288_ENST00000561193_35921296_36070671 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4103
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3094
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4102
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.34
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3135
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3729
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000339208_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.2686
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000345615_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3592
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000345615_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4009
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000345615_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3734
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000345615_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4048
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000346661_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3941
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000346661_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3937
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.273
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3796
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4536
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4225
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3274
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000394378_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3774
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3558
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3286
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3223
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3226
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3814
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000502449_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3912
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.374
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3933
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3653
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.2984
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3543
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000585472_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4116
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000255389_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4875
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000255389_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4256
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000395782_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.346
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000395782_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.3569
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000395783_35896080_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4063
Å |
 |  |  |  |  |
| SYNRG_PEMT_ENST00000591288_ENST00000395783_35899293_17425709 superimposed PDB: 2MX7 of partner (SYNRG). RMSD:2.4085
Å |
 |  |  |  |  |
| SYS1_SMYD3_ENST00000243918_ENST00000541742_43994326_245927451 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:2.4628
Å |
 |  |  |  |  |
| SYS1_SMYD3_ENST00000414310_ENST00000490107_43994326_245927451 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:2.9826
Å |
 |  |  |  |  |
| SYTL2_PICALM_ENST00000316356_ENST00000528398_85456679_85670103 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:0.8023
Å |
 |  |  |  |  |
| SYTL2_PICALM_ENST00000524452_ENST00000532317_85468667_85685855 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:0.5286
Å |
 |  |  |  |  |
| SYTL2_PICALM_ENST00000527523_ENST00000393346_85456679_85670103 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:0.3361
Å |
 |  |  |  |  |
| SYTL2_PICALM_ENST00000528231_ENST00000532317_85468667_85685855 superimposed PDB: 3BC1 of partner (SYTL2). RMSD:0.6712
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378928_ENST00000343523_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3656
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378928_ENST00000359836_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3816
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378928_ENST00000378677_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3727
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378928_ENST00000378707_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4006
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378928_ENST00000541735_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3621
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378930_ENST00000343523_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3792
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378930_ENST00000359836_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3906
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378930_ENST00000378677_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3888
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378930_ENST00000541735_30870894_31366751 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4066
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378932_ENST00000378707_30877603_31165635 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3749
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378933_ENST00000343523_30877603_31241238 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3424
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378933_ENST00000359836_30877603_31241238 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3604
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378933_ENST00000378677_30877603_31241238 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3486
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378933_ENST00000378723_30877603_31241238 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3435
Å |
 |  |  |  |  |
| TAB3_DMD_ENST00000378933_ENST00000541735_30877603_31241238 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.3464
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000394395_ENST00000343523_35804870_31341775 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.64
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000394395_ENST00000343523_35804870_31341775 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4192
Å |
| | | |  |
| TADA2A_DMD_ENST00000394395_ENST00000359836_35804870_31341775 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.7593
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000394395_ENST00000359836_35804870_31341775 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4074
Å |
| | | |  |
| TADA2A_DMD_ENST00000394395_ENST00000378677_35804870_31341775 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6544
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000394395_ENST00000378677_35804870_31341775 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4256
Å |
| | | |  |
| TADA2A_DMD_ENST00000394395_ENST00000541735_35804870_31341775 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6346
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000394395_ENST00000541735_35804870_31341775 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4144
Å |
| | | |  |
| TADA2A_DMD_ENST00000586023_ENST00000378707_35804870_31341775 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6657
Å |
 |  |  |  |  |
| TADA2A_DMD_ENST00000586023_ENST00000378707_35804870_31341775 superimposed PDB: 1EG3 of partner (DMD). RMSD:0.4117
Å |
| | | |  |
| TADA2A_MAST1_ENST00000225396_ENST00000251472_35834734_12962747 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6601
Å |
 |  |  |  |  |
| TADA2A_MAST1_ENST00000225396_ENST00000251472_35834734_12962747 superimposed PDB: 2M9X of partner (MAST1). RMSD:2.0348
Å |
| | | |  |
| TADA2A_MAST1_ENST00000394395_ENST00000591495_35834734_12962747 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.7116
Å |
 |  |  |  |  |
| TADA2A_MAST1_ENST00000394395_ENST00000591495_35834734_12962747 superimposed PDB: 2M9X of partner (MAST1). RMSD:2.1342
Å |
| | | |  |
| TADA2A_MED24_ENST00000586023_ENST00000394126_35802753_38192407 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6984
Å |
 |  |  |  |  |
| TADA2A_MED24_ENST00000586023_ENST00000394126_35802753_38192407 superimposed PDB: 7EMF of partner (MED24). RMSD:1.7136
Å |
| | | |  |
| TADA2A_MYO1D_ENST00000586023_ENST00000318217_35802753_30821933 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6492
Å |
 |  |  |  |  |
| TADA2A_MYO1D_ENST00000586023_ENST00000394649_35804870_30821933 superimposed PDB: 1X41 of partner (TADA2A). RMSD:0.6438
Å |
 |  |  |  |  |
| TAF11_ACOX1_ENST00000361288_ENST00000293217_34848065_73947045 superimposed PDB: 7EGF of partner (TAF11). RMSD:0.9007
Å |
 |  |  |  |  |
| TAF13_LYPLA1_ENST00000338366_ENST00000343231_109617608_54967693 superimposed PDB: 7EGF of partner (TAF13). RMSD:1.879
Å |
 |  |  |  |  |
| TAF13_LYPLA1_ENST00000338366_ENST00000343231_109617608_54967693 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:0.4385
Å |
| | | |  |
| TAF15_AP2B1_ENST00000311979_ENST00000538556_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.2823
Å |
 |  |  |  |  |
| TAF15_AP2B1_ENST00000311979_ENST00000592545_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.2807
Å |
 |  |  |  |  |
| TAF15_AP2B1_ENST00000588240_ENST00000538556_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.3082
Å |
 |  |  |  |  |
| TAF15_AP2B1_ENST00000588240_ENST00000592545_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.2496
Å |
 |  |  |  |  |
| TAF15_AP2B1_ENST00000592237_ENST00000538556_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.2876
Å |
 |  |  |  |  |
| TAF15_AP2B1_ENST00000592237_ENST00000592545_34151202_33966613 superimposed PDB: 6YAF of partner (AP2B1). RMSD:1.3015
Å |
 |  |  |  |  |
| TAF15_MAN1A2_ENST00000311979_ENST00000356554_34169463_118035768 superimposed PDB: 9RDK of partner (TAF15). RMSD:3.2925
Å |
 |  |  |  |  |
| TAF15_MAN1A2_ENST00000592237_ENST00000356554_34169463_118035768 superimposed PDB: 9RDK of partner (TAF15). RMSD:3.2255
Å |
 |  |  |  |  |
| TAF15_MPP2_ENST00000311979_ENST00000377184_34136580_41975748 superimposed PDB: 2E7K of partner (MPP2). RMSD:1.0531
Å |
 |  |  |  |  |
| TAF15_MPP2_ENST00000588240_ENST00000269095_34136580_41975748 superimposed PDB: 9RDK of partner (TAF15). RMSD:2.4665
Å |
 |  |  |  |  |
| TAF15_MPP2_ENST00000588240_ENST00000269095_34136580_41975748 superimposed PDB: 2E7K of partner (MPP2). RMSD:0.9756
Å |
| | | |  |
| TAF1A_SLC12A7_ENST00000543857_ENST00000264930_222757469_1085588 superimposed PDB: 7D99 of partner (SLC12A7). RMSD:2.858
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000348990_8019286_27394358 superimposed PDB: 7EGF of partner (TAF3). RMSD:1.1978
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000354192_8019286_27394358 superimposed PDB: 7EGF of partner (TAF3). RMSD:1.1367
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000358918_8019286_27394358 superimposed PDB: 7EGF of partner (TAF3). RMSD:1.201
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000359726_8019286_27394358 superimposed PDB: 7EGF of partner (TAF3). RMSD:1.08
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000448388_8019286_27394358 superimposed PDB: 7EGF of partner (TAF3). RMSD:1.1254
Å |
 |  |  |  |  |
| TAF3_APP_ENST00000344293_ENST00000448388_8019286_27394358 superimposed PDB: 8KF4 of partner (APP). RMSD:3.2126
Å |
| | | |  |
| TAF4_BRIP1_ENST00000252996_ENST00000577598_60639506_59924581 superimposed PDB: 1T29 of partner (BRIP1). RMSD:2.1755
Å |
 |  |  |  |  |
| TAF4_FAF1_ENST00000252996_ENST00000371778_60587870_51050483 superimposed PDB: 9YW2 of partner (FAF1). RMSD:0.8761
Å |
 |  |  |  |  |
| TAF4_FAF1_ENST00000252996_ENST00000396153_60587870_51050483 superimposed PDB: 7EGG of partner (TAF4). RMSD:2.7133
Å |
 |  |  |  |  |
| TAF4_STX16_ENST00000252996_ENST00000361770_60572605_57242545 superimposed PDB: 7EGG of partner (TAF4). RMSD:2.8326
Å |
 |  |  |  |  |
| TAF4_TCFL5_ENST00000252996_ENST00000217162_60572605_61490878 superimposed PDB: 7EGG of partner (TAF4). RMSD:2.6829
Å |
 |  |  |  |  |
| TAF6L_TMEM109_ENST00000294168_ENST00000536171_62550297_60688357 superimposed PDB: 9RDK of partner (TAF6L). RMSD:3.3826
Å |
 |  |  |  |  |
| TAF8_BYSL_ENST00000494547_ENST00000230340_42023752_41895111 superimposed PDB: 7EGG of partner (TAF8). RMSD:0.7289
Å |
 |  |  |  |  |
| TAF8_BYSL_ENST00000494547_ENST00000230340_42023752_41895111 superimposed PDB: 7WTU of partner (BYSL). RMSD:1.0205
Å |
| | | |  |
| TAF8_CRISP1_ENST00000465926_ENST00000329411_42036345_49819842 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.8094
Å |
 |  |  |  |  |
| TAF8_CRISP1_ENST00000465926_ENST00000335847_42036345_49819842 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.9997
Å |
 |  |  |  |  |
| TAF8_CRISP1_ENST00000494547_ENST00000329411_42036345_49819842 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.7393
Å |
 |  |  |  |  |
| TAF8_CRISP1_ENST00000494547_ENST00000335847_42036345_49819842 superimposed PDB: 7EGG of partner (TAF8). RMSD:2.7644
Å |
 |  |  |  |  |
| TAF9_PLXNB2_ENST00000380818_ENST00000449103_68665483_50717440 superimposed PDB: 4E71 of partner (PLXNB2). RMSD:0.3575
Å |
 |  |  |  |  |
| TANC2_ARHGEF12_ENST00000424789_ENST00000356641_61151375_120317111 superimposed PDB: 1TXD of partner (ARHGEF12). RMSD:2.8282
Å |
 |  |  |  |  |
| TANC2_CA4_ENST00000389520_ENST00000300900_61151375_58232674 superimposed PDB: 3FW3 of partner (CA4). RMSD:0.4037
Å |
 |  |  |  |  |
| TANC2_ERN1_ENST00000389520_ENST00000433197_61176607_62144292 superimposed PDB: 6W39 of partner (ERN1). RMSD:1.0642
Å |
 |  |  |  |  |
| TANC2_PRKCA_ENST00000389520_ENST00000413366_61151375_64683228 superimposed PDB: 4RA4 of partner (PRKCA). RMSD:0.6139
Å |
 |  |  |  |  |
| TANGO6_DUS2_ENST00000261778_ENST00000358896_68901123_68087466 superimposed PDB: 4XP7 of partner (DUS2). RMSD:0.491
Å |
 |  |  |  |  |
| TAOK1_ACER3_ENST00000536202_ENST00000532485_27825539_76687332 superimposed PDB: 6YXH of partner (ACER3). RMSD:0.596
Å |
 |  |  |  |  |
| TAPT1_YWHAE_ENST00000405303_ENST00000573026_16227881_1248793 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3417
Å |
 |  |  |  |  |
| TASP1_SEL1L2_ENST00000539805_ENST00000284951_13604092_13830965 superimposed PDB: 2A8J of partner (TASP1). RMSD:1.4039
Å |
 |  |  |  |  |
| TASP1_SEL1L2_ENST00000539805_ENST00000378072_13604092_13830965 superimposed PDB: 2A8J of partner (TASP1). RMSD:0.3681
Å |
 |  |  |  |  |
| TATDN1_CCT2_ENST00000276692_ENST00000544368_125551265_69980049 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.3616
Å |
 |  |  |  |  |
| TATDN1_CCT2_ENST00000605953_ENST00000299300_125551265_69980049 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.5361
Å |
 |  |  |  |  |
| TAX1BP1_BRAF_ENST00000265393_ENST00000288602_27827222_140481493 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.3255
Å |
 |  |  |  |  |
| TAX1BP1_JAZF1_ENST00000265393_ENST00000283928_27797752_28031600 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.5644
Å |
 |  |  |  |  |
| TAX1BP1_RABGEF1_ENST00000433216_ENST00000284957_27809453_66260497 superimposed PDB: 4Q9U of partner (RABGEF1). RMSD:1.2241
Å |
 |  |  |  |  |
| TAX1BP1_RABGEF1_ENST00000543117_ENST00000284957_27809453_66260497 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.295
Å |
 |  |  |  |  |
| TAX1BP1_RABGEF1_ENST00000543117_ENST00000284957_27809453_66260497 superimposed PDB: 4Q9U of partner (RABGEF1). RMSD:1.0955
Å |
| | | |  |
| TAX1BP1_RPRD1A_ENST00000396319_ENST00000588737_27856657_33573263 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.2949
Å |
 |  |  |  |  |
| TAX1BP1_RPRD1A_ENST00000409980_ENST00000588737_27856657_33573263 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.3048
Å |
 |  |  |  |  |
| TAX1BP1_RPRD1A_ENST00000543117_ENST00000588737_27856657_33573263 superimposed PDB: 4NLH of partner (TAX1BP1). RMSD:0.2827
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000265709_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8853
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000289734_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.773
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000352337_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6892
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000379758_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.8093
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000396942_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7235
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000215790_ENST00000396945_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:1.644
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000265709_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7851
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000289734_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7082
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000347528_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6428
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000352337_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7816
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000379758_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.6494
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000396942_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7901
Å |
 |  |  |  |  |
| TBC1D10A_ANK1_ENST00000403477_ENST00000396945_30700519_41591587 superimposed PDB: 7UZU of partner (ANK1). RMSD:0.7067
Å |
 |  |  |  |  |
| TBC1D10A_POLR3H_ENST00000215790_ENST00000355209_30695432_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:1.042
Å |
 |  |  |  |  |
| TBC1D10A_POLR3H_ENST00000215790_ENST00000407461_30695432_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:2.1564
Å |
 |  |  |  |  |
| TBC1D10A_POLR3H_ENST00000403477_ENST00000355209_30695432_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:1.0469
Å |
 |  |  |  |  |
| TBC1D10A_POLR3H_ENST00000403477_ENST00000407461_30695432_41936799 superimposed PDB: 7AE1 of partner (POLR3H). RMSD:1.9978
Å |
 |  |  |  |  |
| TBC1D14_GRPEL1_ENST00000409757_ENST00000264954_6925838_7065950 superimposed PDB: 9QIN of partner (GRPEL1). RMSD:1.6387
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000409757_ENST00000307358_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:0.529
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000409757_ENST00000382512_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:2.8028
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000410031_ENST00000307358_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:0.5425
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000410031_ENST00000382512_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:2.8971
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000448507_ENST00000382512_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:2.7713
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000451522_ENST00000307358_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:0.5778
Å |
 |  |  |  |  |
| TBC1D14_HTRA3_ENST00000451522_ENST00000382512_6996029_8288287 superimposed PDB: 4RI0 of partner (HTRA3). RMSD:3.0039
Å |
 |  |  |  |  |
| TBC1D15_E2F5_ENST00000485960_ENST00000256117_72233591_86114381 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.3799
Å |
 |  |  |  |  |
| TBC1D15_E2F5_ENST00000485960_ENST00000416274_72233591_86114381 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.3302
Å |
 |  |  |  |  |
| TBC1D15_E2F5_ENST00000485960_ENST00000418930_72233591_86114381 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.4347
Å |
 |  |  |  |  |
| TBC1D15_E2F5_ENST00000550746_ENST00000256117_72233591_86114381 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.5136
Å |
 |  |  |  |  |
| TBC1D15_E2F5_ENST00000550746_ENST00000416274_72233591_86114381 superimposed PDB: 5TUV of partner (E2F5). RMSD:2.2944
Å |
 |  |  |  |  |
| TBC1D15_NAP1L1_ENST00000485960_ENST00000393263_72233591_76449941 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.8296
Å |
 |  |  |  |  |
| TBC1D15_NAP1L1_ENST00000550746_ENST00000393263_72233591_76449941 superimposed PDB: 11BC of partner (NAP1L1). RMSD:0.8111
Å |
 |  |  |  |  |
| TBC1D1_PTPRO_ENST00000261439_ENST00000348962_38119813_15704484 superimposed PDB: 3QYE of partner (TBC1D1). RMSD:0.6216
Å |
 |  |  |  |  |
| TBC1D1_PTPRO_ENST00000261439_ENST00000348962_38119813_15704484 superimposed PDB: 2GJT of partner (PTPRO). RMSD:0.5014
Å |
| | | |  |
| TBC1D1_PTPRO_ENST00000261439_ENST00000542557_38119813_15704484 superimposed PDB: 3QYE of partner (TBC1D1). RMSD:0.6991
Å |
 |  |  |  |  |
| TBC1D1_PTPRO_ENST00000261439_ENST00000542557_38119813_15704484 superimposed PDB: 2GJT of partner (PTPRO). RMSD:0.5075
Å |
| | | |  |
| TBC1D22A_CNGB3_ENST00000337137_ENST00000320005_47393605_87738885 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.671
Å |
 |  |  |  |  |
| TBC1D22A_CNGB3_ENST00000337137_ENST00000320005_47393605_87738885 superimposed PDB: 8ETP of partner (CNGB3). RMSD:1.9901
Å |
| | | |  |
| TBC1D22A_CNGB3_ENST00000355704_ENST00000320005_47393605_87738885 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7456
Å |
 |  |  |  |  |
| TBC1D22A_CNGB3_ENST00000355704_ENST00000320005_47393605_87738885 superimposed PDB: 8ETP of partner (CNGB3). RMSD:1.5445
Å |
| | | |  |
| TBC1D22A_CNGB3_ENST00000406733_ENST00000320005_47393605_87738885 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7272
Å |
 |  |  |  |  |
| TBC1D22A_CNGB3_ENST00000406733_ENST00000320005_47393605_87738885 superimposed PDB: 8ETP of partner (CNGB3). RMSD:1.6127
Å |
| | | |  |
| TBC1D22A_CNGB3_ENST00000407381_ENST00000320005_47393605_87738885 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7592
Å |
 |  |  |  |  |
| TBC1D22A_CNGB3_ENST00000407381_ENST00000320005_47393605_87738885 superimposed PDB: 8ETP of partner (CNGB3). RMSD:1.6075
Å |
| | | |  |
| TBC1D22A_FBLN1_ENST00000380995_ENST00000348697_47193517_45946371 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.0977
Å |
 |  |  |  |  |
| TBC1D22A_GCAT_ENST00000337137_ENST00000248924_47393605_38206033 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.5647
Å |
 |  |  |  |  |
| TBC1D22A_GCAT_ENST00000355704_ENST00000248924_47393605_38206033 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7382
Å |
 |  |  |  |  |
| TBC1D22A_GCAT_ENST00000406733_ENST00000248924_47393605_38206033 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.8448
Å |
 |  |  |  |  |
| TBC1D22A_GCAT_ENST00000407381_ENST00000248924_47393605_38206033 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.8169
Å |
 |  |  |  |  |
| TBC1D22A_GKN1_ENST00000337137_ENST00000377938_47274619_69204626 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.6182
Å |
 |  |  |  |  |
| TBC1D22A_GKN1_ENST00000355704_ENST00000377938_47274619_69204626 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.7652
Å |
 |  |  |  |  |
| TBC1D22A_GKN1_ENST00000380995_ENST00000377938_47274619_69204626 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.3326
Å |
 |  |  |  |  |
| TBC1D22A_GKN1_ENST00000406733_ENST00000377938_47274619_69204626 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.8097
Å |
 |  |  |  |  |
| TBC1D22A_NFIB_ENST00000337137_ENST00000380934_47193517_14155892 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.5522
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000337137_ENST00000424469_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.5553
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000355704_ENST00000318445_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:1.6567
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000355704_ENST00000424469_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:1.7479
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000380995_ENST00000318445_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7874
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000406733_ENST00000318445_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:1.1119
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000406733_ENST00000424469_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.5654
Å |
 |  |  |  |  |
| TBC1D22A_SLCO3A1_ENST00000407381_ENST00000424469_47290742_92459222 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:1.8759
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000337137_ENST00000490107_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.4333
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000337137_ENST00000490107_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.7298
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000337137_ENST00000541742_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.3409
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000355704_ENST00000490107_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.0925
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000355704_ENST00000490107_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8468
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000355704_ENST00000541742_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:1.9562
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000355704_ENST00000541742_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8883
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000380995_ENST00000541742_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.3969
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000380995_ENST00000541742_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8353
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000406733_ENST00000490107_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.4056
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000406733_ENST00000490107_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8369
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000406733_ENST00000541742_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.0503
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000406733_ENST00000541742_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8798
Å |
| | | |  |
| TBC1D22A_SMYD3_ENST00000407381_ENST00000490107_47274619_246093239 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:2.0634
Å |
 |  |  |  |  |
| TBC1D22A_SMYD3_ENST00000407381_ENST00000490107_47274619_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8461
Å |
| | | |  |
| TBC1D22A_SREBF2_ENST00000355704_ENST00000361204_47308084_42262834 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.701
Å |
 |  |  |  |  |
| TBC1D22A_SREBF2_ENST00000355704_ENST00000361204_47308084_42262834 superimposed PDB: 1UKL of partner (SREBF2). RMSD:1.0974
Å |
| | | |  |
| TBC1D22A_SREBF2_ENST00000380995_ENST00000361204_47308084_42262834 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.5525
Å |
 |  |  |  |  |
| TBC1D22A_SREBF2_ENST00000380995_ENST00000361204_47308084_42262834 superimposed PDB: 1UKL of partner (SREBF2). RMSD:0.9875
Å |
| | | |  |
| TBC1D22A_SREBF2_ENST00000406733_ENST00000361204_47308084_42262834 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7308
Å |
 |  |  |  |  |
| TBC1D22A_SREBF2_ENST00000406733_ENST00000361204_47308084_42262834 superimposed PDB: 1UKL of partner (SREBF2). RMSD:1.1205
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000337137_ENST00000340541_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7511
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000337137_ENST00000340541_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5872
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000355704_ENST00000340541_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.9425
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000355704_ENST00000340541_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5527
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000355704_ENST00000400000_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.8096
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000355704_ENST00000400000_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5276
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000380995_ENST00000400000_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7535
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000380995_ENST00000400000_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5885
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000406733_ENST00000340541_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.8236
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000406733_ENST00000340541_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4748
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000406733_ENST00000400000_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.7611
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000406733_ENST00000400000_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4968
Å |
| | | |  |
| TBC1D22A_VAPA_ENST00000407381_ENST00000340541_47308084_9931806 superimposed PDB: 2QFZ of partner (TBC1D22A). RMSD:0.8151
Å |
 |  |  |  |  |
| TBC1D22A_VAPA_ENST00000407381_ENST00000340541_47308084_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.5177
Å |
| | | |  |
| TBC1D2B_ETFA_ENST00000409931_ENST00000557943_78369634_76588078 superimposed PDB: 2A1U of partner (ETFA). RMSD:0.446
Å |
 |  |  |  |  |
| TBC1D5_AZI2_ENST00000429924_ENST00000479665_17413566_28368441 superimposed PDB: 5GTU of partner (TBC1D5). RMSD:0.3959
Å |
 |  |  |  |  |
| TBC1D5_AZI2_ENST00000429924_ENST00000479665_17413566_28368441 superimposed PDB: 5Z7L of partner (AZI2). RMSD:3.0263
Å |
| | | |  |
| TBCA_ARSB_ENST00000522370_ENST00000396151_77004066_78135249 superimposed PDB: 1FSU of partner (ARSB). RMSD:2.8335
Å |
 |  |  |  |  |
| TBCA_ARSB_ENST00000522370_ENST00000565165_77004066_78135249 superimposed PDB: 1H7C of partner (TBCA). RMSD:2.8396
Å |
 |  |  |  |  |
| TBCD_ASPSCR1_ENST00000355528_ENST00000306739_80730383_79967361 superimposed PDB: 9M1M of partner (TBCD). RMSD:0.6288
Å |
 |  |  |  |  |
| TBCD_ASPSCR1_ENST00000355528_ENST00000306739_80730383_79967361 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:0.785
Å |
| | | |  |
| TBCD_ASPSCR1_ENST00000355528_ENST00000580534_80730383_79967361 superimposed PDB: 9M1M of partner (TBCD). RMSD:0.6426
Å |
 |  |  |  |  |
| TBCD_ASPSCR1_ENST00000355528_ENST00000580534_80730383_79967361 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:0.4687
Å |
| | | |  |
| TBCD_ASPSCR1_ENST00000539345_ENST00000306729_80730383_79967361 superimposed PDB: 9M1M of partner (TBCD). RMSD:0.6571
Å |
 |  |  |  |  |
| TBCD_ASPSCR1_ENST00000539345_ENST00000306729_80730383_79967361 superimposed PDB: 5IFS of partner (ASPSCR1). RMSD:0.4997
Å |
| | | |  |
| TBCD_CPM_ENST00000355528_ENST00000551568_80772810_69279669 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.8309
Å |
 |  |  |  |  |
| TBCD_CPM_ENST00000355528_ENST00000551568_80772810_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4801
Å |
| | | |  |
| TBCD_CSNK1D_ENST00000355528_ENST00000314028_80710253_80223672 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.7998
Å |
 |  |  |  |  |
| TBCD_CSNK1D_ENST00000355528_ENST00000314028_80710253_80223672 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.6406
Å |
| | | |  |
| TBCD_CSNK1D_ENST00000539345_ENST00000398519_80710253_80223672 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.9753
Å |
 |  |  |  |  |
| TBCD_CSNK1D_ENST00000539345_ENST00000398519_80710253_80223672 superimposed PDB: 6PXN of partner (CSNK1D). RMSD:0.6193
Å |
| | | |  |
| TBCD_FN3KRP_ENST00000397466_ENST00000269373_80842078_80676781 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0258
Å |
 |  |  |  |  |
| TBCD_FOXK2_ENST00000397466_ENST00000335255_80828256_80521229 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.3711
Å |
 |  |  |  |  |
| TBCD_FOXK2_ENST00000397466_ENST00000335255_80828256_80521229 superimposed PDB: 2C6Y of partner (FOXK2). RMSD:0.4287
Å |
| | | |  |
| TBCD_HLCS_ENST00000355528_ENST00000399120_80888519_38139586 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1491
Å |
 |  |  |  |  |
| TBCD_METRNL_ENST00000355528_ENST00000570778_80869665_81050911 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.6053
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000341919_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1393
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000341919_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7681
Å |
| | | |  |
| TBCD_NFIC_ENST00000355528_ENST00000346156_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1646
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000346156_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.736
Å |
| | | |  |
| TBCD_NFIC_ENST00000355528_ENST00000395111_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1724
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000395111_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7907
Å |
| | | |  |
| TBCD_NFIC_ENST00000355528_ENST00000586919_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1299
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000586919_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.753
Å |
| | | |  |
| TBCD_NFIC_ENST00000355528_ENST00000590282_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.4043
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000355528_ENST00000590282_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7757
Å |
| | | |  |
| TBCD_NFIC_ENST00000539345_ENST00000346156_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.2347
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000539345_ENST00000346156_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7479
Å |
| | | |  |
| TBCD_NFIC_ENST00000539345_ENST00000395111_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.2974
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000539345_ENST00000395111_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7412
Å |
| | | |  |
| TBCD_NFIC_ENST00000539345_ENST00000586919_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.2736
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000539345_ENST00000586919_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.7043
Å |
| | | |  |
| TBCD_NFIC_ENST00000539345_ENST00000590282_80899359_3381709 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.3748
Å |
 |  |  |  |  |
| TBCD_NFIC_ENST00000539345_ENST00000590282_80899359_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.706
Å |
| | | |  |
| TBCD_NFIX_ENST00000355528_ENST00000587760_80899359_13135834 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.0987
Å |
 |  |  |  |  |
| TBCD_NFIX_ENST00000355528_ENST00000587760_80899359_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5609
Å |
| | | |  |
| TBCD_NFIX_ENST00000355528_ENST00000592199_80899359_13135834 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1516
Å |
 |  |  |  |  |
| TBCD_NFIX_ENST00000355528_ENST00000592199_80899359_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5885
Å |
| | | |  |
| TBCD_NFIX_ENST00000539345_ENST00000397661_80899359_13135834 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1431
Å |
 |  |  |  |  |
| TBCD_NFIX_ENST00000539345_ENST00000397661_80899359_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4886
Å |
| | | |  |
| TBCD_NFIX_ENST00000539345_ENST00000587760_80899359_13135834 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.1796
Å |
 |  |  |  |  |
| TBCD_NFIX_ENST00000539345_ENST00000587760_80899359_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4831
Å |
| | | |  |
| TBCD_NFIX_ENST00000539345_ENST00000592199_80899359_13135834 superimposed PDB: 9M1M of partner (TBCD). RMSD:2.2999
Å |
 |  |  |  |  |
| TBCD_NFIX_ENST00000539345_ENST00000592199_80899359_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4585
Å |
| | | |  |
| TBCD_SCARA5_ENST00000539345_ENST00000354914_80710253_27779762 superimposed PDB: 7C00 of partner (SCARA5). RMSD:0.2998
Å |
 |  |  |  |  |
| TBCD_SCARA5_ENST00000539345_ENST00000354914_80714091_27779762 superimposed PDB: 7C00 of partner (SCARA5). RMSD:0.3545
Å |
 |  |  |  |  |
| TBCD_SLC9A3R1_ENST00000397466_ENST00000262613_80847573_72758150 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0857
Å |
 |  |  |  |  |
| TBK1_ARHGAP5_ENST00000331710_ENST00000539826_64849737_32586348 superimposed PDB: 2EE5 of partner (ARHGAP5). RMSD:1.1556
Å |
 |  |  |  |  |
| TBL1XR1_RET_ENST00000430069_ENST00000340058_176765087_43612031 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.5149
Å |
 |  |  |  |  |
| TBL1XR1_RET_ENST00000430069_ENST00000355710_176765087_43612031 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:2.6185
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000346387_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7453
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000354437_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7332
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000357733_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7434
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000378285_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.731
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000378288_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7368
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000378295_176771560_3624112 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.5404
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000603362_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7252
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000604074_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7168
Å |
 |  |  |  |  |
| TBL1XR1_TP73_ENST00000430069_ENST00000604479_176771560_3624112 superimposed PDB: 2XWC of partner (TP73). RMSD:0.7359
Å |
 |  |  |  |  |
| TCEA2_ITGAE_ENST00000343484_ENST00000263087_62697891_3655168 superimposed PDB: 8ZJF of partner (ITGAE). RMSD:2.256
Å |
 |  |  |  |  |
| TCEA2_ITGAE_ENST00000395053_ENST00000263087_62697891_3655168 superimposed PDB: 8ZJF of partner (ITGAE). RMSD:2.4026
Å |
 |  |  |  |  |
| TCEANC2_MICU1_ENST00000234827_ENST00000361114_54534570_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.9426
Å |
 |  |  |  |  |
| TCEANC2_MICU1_ENST00000234827_ENST00000398761_54534570_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.8981
Å |
 |  |  |  |  |
| TCEANC2_MICU1_ENST00000371331_ENST00000361114_54534570_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.7935
Å |
 |  |  |  |  |
| TCEANC2_MICU1_ENST00000371331_ENST00000398761_54534570_74237014 superimposed PDB: 6K7Y of partner (MICU1). RMSD:1.871
Å |
 |  |  |  |  |
| TCEB1_LRSAM1_ENST00000518127_ENST00000373324_74868145_130263288 superimposed PDB: 8C13 of partner (TCEB1). RMSD:0.4372
Å |
 |  |  |  |  |
| TCF12_BPGM_ENST00000267811_ENST00000393132_57213296_134363604 superimposed PDB: 7THI of partner (BPGM). RMSD:2.958
Å |
 |  |  |  |  |
| TCF12_BPGM_ENST00000438423_ENST00000393132_57213296_134363604 superimposed PDB: 7THI of partner (BPGM). RMSD:2.8226
Å |
 |  |  |  |  |
| TCF12_RGMA_ENST00000267811_ENST00000543599_57384089_93595737 superimposed PDB: 4UHY of partner (RGMA). RMSD:0.4904
Å |
 |  |  |  |  |
| TCF12_RGMA_ENST00000438423_ENST00000543599_57384089_93595737 superimposed PDB: 4UHY of partner (RGMA). RMSD:0.4754
Å |
 |  |  |  |  |
| TCF12_RGMA_ENST00000452095_ENST00000543599_57384089_93595737 superimposed PDB: 4UHY of partner (RGMA). RMSD:0.4896
Å |
 |  |  |  |  |
| TCF20_CENPM_ENST00000335626_ENST00000215980_42605656_42342500 superimposed PDB: 28OP of partner (CENPM). RMSD:0.6875
Å |
 |  |  |  |  |
| TCF3_PBX1_ENST00000395423_ENST00000367897_1619109_164761728 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3043
Å |
 |  |  |  |  |
| TCF3_PBX1_ENST00000395423_ENST00000401534_1619109_164761728 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3041
Å |
 |  |  |  |  |
| TCF3_PBX1_ENST00000395423_ENST00000540236_1619109_164761728 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3073
Å |
 |  |  |  |  |
| TCF3_PBX1_ENST00000395423_ENST00000559240_1619109_164761728 superimposed PDB: 1B72 of partner (PBX1). RMSD:0.3131
Å |
 |  |  |  |  |
| TCF3_SYTL5_ENST00000262965_ENST00000357972_1615283_37985840 superimposed PDB: 2YPA of partner (TCF3). RMSD:0.7687
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000349937_ENST00000524602_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.9424
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000349937_ENST00000525508_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.7082
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000352065_ENST00000524602_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.9244
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000352065_ENST00000525508_114799885_61693558 superimposed PDB: 2GL7 of partner (TCF7L2). RMSD:2.3455
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000352065_ENST00000525508_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.7372
Å |
| | | |  |
| TCF7L2_CHD7_ENST00000355717_ENST00000524602_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.8609
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000355717_ENST00000525508_114799885_61693558 superimposed PDB: 2GL7 of partner (TCF7L2). RMSD:3.1763
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000355717_ENST00000525508_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.6879
Å |
| | | |  |
| TCF7L2_CHD7_ENST00000369397_ENST00000524602_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.8443
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000369397_ENST00000525508_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.7763
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000534894_ENST00000524602_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:1.0473
Å |
 |  |  |  |  |
| TCF7L2_CHD7_ENST00000534894_ENST00000525508_114799885_61693558 superimposed PDB: 2V0F of partner (CHD7). RMSD:0.7087
Å |
 |  |  |  |  |
| TCHP_UBR4_ENST00000312777_ENST00000375217_110350877_19505714 superimposed PDB: 9QWS of partner (UBR4). RMSD:3.3952
Å |
 |  |  |  |  |
| TCHP_UBR4_ENST00000405876_ENST00000375267_110350877_19505714 superimposed PDB: 9QWS of partner (UBR4). RMSD:3.2673
Å |
 |  |  |  |  |
| TCIRG1_BBS9_ENST00000265686_ENST00000354265_67812569_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:2.7841
Å |
 |  |  |  |  |
| TCIRG1_BBS9_ENST00000265686_ENST00000396127_67812569_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:2.8239
Å |
 |  |  |  |  |
| TCIRG1_BBS9_ENST00000265686_ENST00000425508_67812569_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:3.5007
Å |
 |  |  |  |  |
| TCIRG1_BBS9_ENST00000532635_ENST00000242067_67812569_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:0.8332
Å |
 |  |  |  |  |
| TCIRG1_BBS9_ENST00000532635_ENST00000355070_67812569_33217089 superimposed PDB: 6XT9 of partner (BBS9). RMSD:3.2481
Å |
 |  |  |  |  |
| TCN1_MS4A4A_ENST00000257264_ENST00000337908_59622124_60059697 superimposed PDB: 4KKI of partner (TCN1). RMSD:0.6746
Å |
 |  |  |  |  |
| TCN2_THOC5_ENST00000215838_ENST00000397871_31010488_29908125 superimposed PDB: 7QBF of partner (TCN2). RMSD:1.0912
Å |
 |  |  |  |  |
| TCN2_THOC5_ENST00000215838_ENST00000397871_31010488_29908125 superimposed PDB: 7APK of partner (THOC5). RMSD:3.0241
Å |
| | | |  |
| TCN2_THOC5_ENST00000405742_ENST00000397871_31010488_29908125 superimposed PDB: 7QBF of partner (TCN2). RMSD:1.0877
Å |
 |  |  |  |  |
| TCN2_THOC5_ENST00000405742_ENST00000397871_31010488_29908125 superimposed PDB: 7APK of partner (THOC5). RMSD:2.5763
Å |
| | | |  |
| TCN2_THOC5_ENST00000407817_ENST00000397871_31010488_29908125 superimposed PDB: 7QBF of partner (TCN2). RMSD:3.1685
Å |
 |  |  |  |  |
| TDG_KIF5B_ENST00000266775_ENST00000302418_104379506_32304587 superimposed PDB: 1WYW of partner (TDG). RMSD:0.5538
Å |
 |  |  |  |  |
| TDG_KIF5B_ENST00000542036_ENST00000302418_104379506_32304587 superimposed PDB: 1WYW of partner (TDG). RMSD:0.5372
Å |
 |  |  |  |  |
| TDG_KIF5B_ENST00000544861_ENST00000302418_104379506_32304587 superimposed PDB: 1WYW of partner (TDG). RMSD:0.5686
Å |
 |  |  |  |  |
| TDP2_DCDC2_ENST00000341060_ENST00000378454_24653210_24302272 superimposed PDB: 5INO of partner (TDP2). RMSD:0.5521
Å |
 |  |  |  |  |
| TDP2_DCDC2_ENST00000341060_ENST00000378454_24653210_24302272 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.7352
Å |
| | | |  |
| TDP2_DCDC2_ENST00000545995_ENST00000378454_24653210_24302272 superimposed PDB: 5INO of partner (TDP2). RMSD:0.5483
Å |
 |  |  |  |  |
| TDP2_DCDC2_ENST00000545995_ENST00000378454_24653210_24302272 superimposed PDB: 2DNF of partner (DCDC2). RMSD:0.7287
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400319_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.9098
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400319_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6157
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400320_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.7381
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400320_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.595
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400324_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:3.123
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400330_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.9643
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000196169_ENST00000400330_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6025
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000377881_ENST00000400320_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.7147
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000377881_ENST00000400320_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.5362
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000377881_ENST00000400324_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.7337
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000377881_ENST00000400324_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:2.0193
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000377894_ENST00000400324_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.744
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000377894_ENST00000400324_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:2.0077
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000535286_ENST00000400319_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.7348
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000535286_ENST00000400319_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.5898
Å |
| | | |  |
| TDRD3_DIAPH3_ENST00000535286_ENST00000400330_61018882_60385057 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.5756
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000535286_ENST00000400330_61084889_60499004 superimposed PDB: 9CAH of partner (TDRD3). RMSD:0.7389
Å |
 |  |  |  |  |
| TDRD3_DIAPH3_ENST00000535286_ENST00000400330_61084889_60499004 superimposed PDB: 5UWP of partner (DIAPH3). RMSD:0.6125
Å |
| | | |  |
| TEAD1_ABCC8_ENST00000361905_ENST00000302539_12923660_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6302
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000361905_ENST00000302539_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6224
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000361905_ENST00000389817_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.5721
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000361985_ENST00000302539_12923660_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6346
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000361985_ENST00000302539_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.5408
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000526600_ENST00000302539_12923660_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.5379
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000526600_ENST00000302539_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.5558
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000526600_ENST00000389817_12923660_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6509
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000526600_ENST00000389817_12923660_17483372 superimposed PDB: 7CMM of partner (TEAD1). RMSD:2.1244
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000526600_ENST00000389817_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.5199
Å |
| | | |  |
| TEAD1_ABCC8_ENST00000527636_ENST00000389817_12923660_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6383
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000527636_ENST00000389817_12923660_17483372 superimposed PDB: 7CMM of partner (TEAD1). RMSD:2.3553
Å |
 |  |  |  |  |
| TEAD1_ABCC8_ENST00000527636_ENST00000389817_12923660_17483372 superimposed PDB: 6C3O of partner (ABCC8). RMSD:2.6073
Å |
| | | |  |
| TEAD1_CTR9_ENST00000526600_ENST00000361367_12923660_10784977 superimposed PDB: 9HVQ of partner (CTR9). RMSD:1.6621
Å |
 |  |  |  |  |
| TEAD1_CTR9_ENST00000527636_ENST00000361367_12923660_10784977 superimposed PDB: 9HVQ of partner (CTR9). RMSD:1.8953
Å |
 |  |  |  |  |
| TEK_IFT74_ENST00000380036_ENST00000443698_27192621_27055606 superimposed PDB: 4K0V of partner (TEK). RMSD:1.1403
Å |
 |  |  |  |  |
| TERF2_COG4_ENST00000567296_ENST00000323786_69418482_70524295 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.4647
Å |
 |  |  |  |  |
| TERF2_COG4_ENST00000603068_ENST00000323786_69418482_70524295 superimposed PDB: 3HR0 of partner (COG4). RMSD:0.5661
Å |
 |  |  |  |  |
| TESC_ASAH1_ENST00000335209_ENST00000381733_117537029_17933096 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.323
Å |
 |  |  |  |  |
| TESK2_GNA12_ENST00000372084_ENST00000544127_45851583_2834777 superimposed PDB: 7YDJ of partner (GNA12). RMSD:2.0682
Å |
 |  |  |  |  |
| TET1_ASCC1_ENST00000373644_ENST00000317168_70360791_73921432 superimposed PDB: 6ASD of partner (TET1). RMSD:0.3425
Å |
 |  |  |  |  |
| TET1_ASCC1_ENST00000373644_ENST00000317168_70360791_73921432 superimposed PDB: 8TLY of partner (ASCC1). RMSD:1.8872
Å |
| | | |  |
| TET1_ASCC1_ENST00000373644_ENST00000342444_70360791_73921432 superimposed PDB: 6ASD of partner (TET1). RMSD:0.408
Å |
 |  |  |  |  |
| TET1_ASCC1_ENST00000373644_ENST00000342444_70360791_73921432 superimposed PDB: 8TLY of partner (ASCC1). RMSD:0.9537
Å |
| | | |  |
| TFAP2A_CDK5RAP1_ENST00000319516_ENST00000346416_10402724_31958435 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:0.9489
Å |
 |  |  |  |  |
| TFAP2A_CDK5RAP1_ENST00000379608_ENST00000346416_10402724_31958435 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:1.2565
Å |
 |  |  |  |  |
| TFAP2A_CDK5RAP1_ENST00000379613_ENST00000346416_10402724_31958435 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:1.3068
Å |
 |  |  |  |  |
| TFAP2A_CDK5RAP1_ENST00000482890_ENST00000346416_10402724_31958435 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:1.4166
Å |
 |  |  |  |  |
| TFAP2A_MAK_ENST00000319516_ENST00000474039_10404740_10764839 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:0.9651
Å |
 |  |  |  |  |
| TFAP2A_MAK_ENST00000379608_ENST00000474039_10404740_10764839 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:0.6585
Å |
 |  |  |  |  |
| TFAP2A_MAK_ENST00000379613_ENST00000474039_10404740_10764839 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:0.6329
Å |
 |  |  |  |  |
| TFAP2A_MAK_ENST00000482890_ENST00000474039_10404740_10764839 superimposed PDB: 8J0L of partner (TFAP2A). RMSD:0.6549
Å |
 |  |  |  |  |
| TFE3_PRCC_ENST00000315869_ENST00000271526_48896631_156756399 superimposed PDB: 7F09 of partner (TFE3). RMSD:2.4364
Å |
 |  |  |  |  |
| TFE3_PRCC_ENST00000315869_ENST00000353233_48896631_156752073 superimposed PDB: 7F09 of partner (TFE3). RMSD:2.4479
Å |
 |  |  |  |  |
| TFE3_PRCC_ENST00000315869_ENST00000353233_48896631_156756399 superimposed PDB: 7F09 of partner (TFE3). RMSD:2.3985
Å |
 |  |  |  |  |
| TFEB_SUPT3H_ENST00000403298_ENST00000371460_41657468_44797594 superimposed PDB: 7UX2 of partner (TFEB). RMSD:2.7726
Å |
 |  |  |  |  |
| TFG_ALK_ENST00000240851_ENST00000389048_100463775_29446394 superimposed PDB: 9E7C of partner (TFG). RMSD:0.5392
Å |
 |  |  |  |  |
| TFG_ALK_ENST00000418917_ENST00000389048_100463775_29446394 superimposed PDB: 9E7C of partner (TFG). RMSD:0.4561
Å |
 |  |  |  |  |
| TFG_ALK_ENST00000490574_ENST00000389048_100447702_29446394 superimposed PDB: 9E7C of partner (TFG). RMSD:0.5222
Å |
 |  |  |  |  |
| TFG_ALK_ENST00000490574_ENST00000389048_100463775_29446394 superimposed PDB: 9E7C of partner (TFG). RMSD:0.5628
Å |
 |  |  |  |  |
| TFRC_BLOC1S5_ENST00000360110_ENST00000397457_195803934_8041501 superimposed PDB: 7ZQS of partner (TFRC). RMSD:2.4437
Å |
 |  |  |  |  |
| TF_CYP2C8_ENST00000264998_ENST00000371270_133478173_96827448 superimposed PDB: 3V83 of partner (TF). RMSD:1.9461
Å |
 |  |  |  |  |
| TF_CYP2C8_ENST00000264998_ENST00000371270_133478173_96827448 superimposed PDB: 2VN0 of partner (CYP2C8). RMSD:0.998
Å |
| | | |  |
| TGFBI_VIM_ENST00000442011_ENST00000224237_135385269_17278292 superimposed PDB: 5NV6 of partner (TGFBI). RMSD:1.6928
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000295754_ENST00000359576_30715738_33686395 superimposed PDB: 5QIN of partner (TGFBR2). RMSD:0.4898
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000295754_ENST00000359576_30715738_33686395 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6148
Å |
| | | |  |
| TGFBR2_CLASP2_ENST00000295754_ENST00000399362_30715738_33686395 superimposed PDB: 5QIN of partner (TGFBR2). RMSD:0.4945
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000295754_ENST00000399362_30715738_33686395 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5851
Å |
| | | |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000359576_30715738_33686395 superimposed PDB: 5QIN of partner (TGFBR2). RMSD:0.4751
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000359576_30715738_33686395 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.6233
Å |
| | | |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000399362_30715738_33686395 superimposed PDB: 5QIN of partner (TGFBR2). RMSD:0.5283
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000399362_30715738_33686395 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.606
Å |
| | | |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000468888_30715738_33686395 superimposed PDB: 5QIN of partner (TGFBR2). RMSD:0.4899
Å |
 |  |  |  |  |
| TGFBR2_CLASP2_ENST00000359013_ENST00000468888_30715738_33686395 superimposed PDB: 3WOY of partner (CLASP2). RMSD:0.5855
Å |
| | | |  |
| TGFBR3_NRD1_ENST00000212355_ENST00000354831_92327027_52306186 superimposed PDB: 7LBG of partner (TGFBR3). RMSD:0.4805
Å |
 |  |  |  |  |
| THADA_EML4_ENST00000405975_ENST00000318522_43571260_42556025 superimposed PDB: 8Y2O of partner (THADA). RMSD:2.9903
Å |
 |  |  |  |  |
| THADA_EML4_ENST00000405975_ENST00000318522_43571260_42556025 superimposed PDB: 4CGC of partner (EML4). RMSD:1.1906
Å |
| | | |  |
| THADA_EML4_ENST00000405975_ENST00000402711_43571260_42556025 superimposed PDB: 8Y2O of partner (THADA). RMSD:2.3501
Å |
 |  |  |  |  |
| THADA_EML4_ENST00000405975_ENST00000402711_43571260_42556025 superimposed PDB: 4CGC of partner (EML4). RMSD:1.1861
Å |
| | | |  |
| THADA_EML4_ENST00000415080_ENST00000402711_43571260_42556025 superimposed PDB: 8Y2O of partner (THADA). RMSD:3.3225
Å |
 |  |  |  |  |
| THADA_EML4_ENST00000415080_ENST00000402711_43571260_42556025 superimposed PDB: 4CGC of partner (EML4). RMSD:1.2062
Å |
| | | |  |
| THADA_LYZ_ENST00000402360_ENST00000261267_43817962_69746932 superimposed PDB: 8Y2O of partner (THADA). RMSD:1.1488
Å |
 |  |  |  |  |
| THBS1_COL6A2_ENST00000260356_ENST00000310645_39883824_47535785 superimposed PDB: 1UX6 of partner (THBS1). RMSD:3.2219
Å |
 |  |  |  |  |
| THBS1_COL6A2_ENST00000260356_ENST00000310645_39883824_47535785 superimposed PDB: 9GTU of partner (COL6A2). RMSD:0.5908
Å |
| | | |  |
| THBS1_COL6A2_ENST00000260356_ENST00000357838_39883824_47535785 superimposed PDB: 1UX6 of partner (THBS1). RMSD:3.429
Å |
 |  |  |  |  |
| THBS1_COL6A2_ENST00000260356_ENST00000357838_39883824_47535785 superimposed PDB: 9GTU of partner (COL6A2). RMSD:1.4642
Å |
| | | |  |
| THBS1_COL6A2_ENST00000260356_ENST00000409416_39883824_47535785 superimposed PDB: 1UX6 of partner (THBS1). RMSD:3.0329
Å |
 |  |  |  |  |
| THBS1_COL6A2_ENST00000260356_ENST00000409416_39883824_47535785 superimposed PDB: 9GTU of partner (COL6A2). RMSD:2.2037
Å |
| | | |  |
| THEM6_FANCI_ENST00000336138_ENST00000310775_143809277_89844556 superimposed PDB: 8A9J of partner (FANCI). RMSD:0.4908
Å |
 |  |  |  |  |
| THOC2_SUCLG1_ENST00000355725_ENST00000393868_122840707_84650896 superimposed PDB: 7ZNL of partner (THOC2). RMSD:2.9373
Å |
 |  |  |  |  |
| THOC5_LYZ_ENST00000397872_ENST00000261267_29913017_69745999 superimposed PDB: 7APK of partner (THOC5). RMSD:1.6406
Å |
 |  |  |  |  |
| THRA_CDK12_ENST00000264637_ENST00000430627_38245586_37686883 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6642
Å |
 |  |  |  |  |
| THRB_LMCD1_ENST00000280696_ENST00000157600_24184991_8574422 superimposed PDB: 7WMH of partner (THRB). RMSD:1.6844
Å |
 |  |  |  |  |
| THRB_LMCD1_ENST00000280696_ENST00000535732_24184991_8574422 superimposed PDB: 7WMH of partner (THRB). RMSD:0.846
Å |
 |  |  |  |  |
| THRB_LMCD1_ENST00000356447_ENST00000157600_24184991_8574422 superimposed PDB: 7WMH of partner (THRB). RMSD:1.3081
Å |
 |  |  |  |  |
| THRB_LMCD1_ENST00000396671_ENST00000535732_24184991_8574422 superimposed PDB: 7WMH of partner (THRB). RMSD:1.4175
Å |
 |  |  |  |  |
| THSD4_ADAM10_ENST00000261862_ENST00000260408_71549054_58957396 superimposed PDB: 8ESV of partner (ADAM10). RMSD:2.9219
Å |
 |  |  |  |  |
| THSD4_ALDH1A2_ENST00000355327_ENST00000347587_71704162_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:0.5797
Å |
 |  |  |  |  |
| THSD4_ALDH1A2_ENST00000355327_ENST00000537372_71704162_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:0.6588
Å |
 |  |  |  |  |
| THSD4_TJP1_ENST00000261862_ENST00000346128_71549054_30020223 superimposed PDB: 3SHW of partner (TJP1). RMSD:2.8423
Å |
 |  |  |  |  |
| THSD4_WARS_ENST00000357769_ENST00000358655_71839820_100803539 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.7696
Å |
 |  |  |  |  |
| THSD7A_PRKAR1B_ENST00000423059_ENST00000537384_11457076_591107 superimposed PDB: 8OXR of partner (THSD7A). RMSD:1.519
Å |
 |  |  |  |  |
| TICRR_EWSR1_ENST00000268138_ENST00000397938_90152180_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7466
Å |
 |  |  |  |  |
| TICRR_EWSR1_ENST00000560985_ENST00000397938_90152180_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7325
Å |
 |  |  |  |  |
| TIMM23_PARG_ENST00000374064_ENST00000402038_51623108_51093341 superimposed PDB: 7KG8 of partner (PARG). RMSD:0.414
Å |
 |  |  |  |  |
| TIMP1_TIMP3_ENST00000456754_ENST00000266085_47442935_33245438 superimposed PDB: 3V96 of partner (TIMP1). RMSD:1.0189
Å |
 |  |  |  |  |
| TIMP1_TIMP3_ENST00000456754_ENST00000266085_47442935_33245438 superimposed PDB: 3CKI of partner (TIMP3). RMSD:0.5673
Å |
| | | |  |
| TIMP3_CD74_ENST00000266085_ENST00000009530_33245521_149785884 superimposed PDB: 8VRW of partner (CD74). RMSD:2.8918
Å |
 |  |  |  |  |
| TIMP3_CD74_ENST00000266085_ENST00000353334_33245521_149785884 superimposed PDB: 8VRW of partner (CD74). RMSD:2.476
Å |
 |  |  |  |  |
| TIMP3_CD74_ENST00000266085_ENST00000377795_33245521_149785884 superimposed PDB: 3CKI of partner (TIMP3). RMSD:1.0913
Å |
 |  |  |  |  |
| TIMP3_CD74_ENST00000266085_ENST00000524315_33245521_149785884 superimposed PDB: 8VRW of partner (CD74). RMSD:2.5048
Å |
 |  |  |  |  |
| TJAP1_MRPS18A_ENST00000372445_ENST00000372116_43471444_43643354 superimposed PDB: 7OF0 of partner (MRPS18A). RMSD:2.9387
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000262968_ENST00000317243_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:3.0185
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000262968_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.5685
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000382008_ENST00000317243_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:2.3776
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000382008_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.5331
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000539908_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.5329
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000541714_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.4883
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000587686_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.5832
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000589378_ENST00000317243_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:2.7439
Å |
 |  |  |  |  |
| TJP3_ZNF554_ENST00000589378_ENST00000591265_3740761_2832300 superimposed PDB: 3KFV of partner (TJP3). RMSD:0.5732
Å |
 |  |  |  |  |
| TK1_CDC14A_ENST00000301634_ENST00000542213_76171609_100920960 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3933
Å |
 |  |  |  |  |
| TK1_CDC14A_ENST00000405273_ENST00000542213_76171130_100920960 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3875
Å |
 |  |  |  |  |
| TK1_CDC14A_ENST00000405273_ENST00000542213_76171609_100920960 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3898
Å |
 |  |  |  |  |
| TK1_CDC14A_ENST00000588734_ENST00000542213_76171609_100920960 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3921
Å |
 |  |  |  |  |
| TK1_CDC14A_ENST00000590862_ENST00000542213_76171130_100920960 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3853
Å |
 |  |  |  |  |
| TK1_DNAH17_ENST00000405273_ENST00000585328_76171130_76423189 superimposed PDB: 2ORV of partner (TK1). RMSD:0.3957
Å |
 |  |  |  |  |
| TK1_DNAH17_ENST00000590862_ENST00000585328_76171130_76423189 superimposed PDB: 2ORV of partner (TK1). RMSD:0.4067
Å |
 |  |  |  |  |
| TLE3_YWHAH_ENST00000559191_ENST00000248975_70345565_32352125 superimposed PDB: 2C63 of partner (YWHAH). RMSD:0.4797
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000265284_ENST00000393622_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2931
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000265284_ENST00000586802_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2866
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000376520_ENST00000393622_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2827
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000376520_ENST00000586802_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2868
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000376552_ENST00000225983_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3836
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000376552_ENST00000393622_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.3008
Å |
 |  |  |  |  |
| TLE4_HDAC5_ENST00000376552_ENST00000586802_82320857_42165064 superimposed PDB: 5UWI of partner (HDAC5). RMSD:0.2879
Å |
 |  |  |  |  |
| TLK1_CAT_ENST00000360843_ENST00000241052_171974248_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:3.0152
Å |
 |  |  |  |  |
| TLK1_CAT_ENST00000431350_ENST00000241052_171974248_34470738 superimposed PDB: 9T0K of partner (CAT). RMSD:0.4566
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000326270_ENST00000392769_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:0.6889
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000343388_ENST00000392769_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:0.6532
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000346027_ENST00000392769_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:0.6884
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000542523_ENST00000392769_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:0.6606
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000582809_ENST00000392769_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:0.6928
Å |
 |  |  |  |  |
| TLK2_CEP112_ENST00000582809_ENST00000535342_60685509_63685336 superimposed PDB: 5O0Y of partner (TLK2). RMSD:1.3015
Å |
 |  |  |  |  |
| TLK2_IRAK3_ENST00000326270_ENST00000261233_60679541_66620502 superimposed PDB: 5O0Y of partner (TLK2). RMSD:1.3202
Å |
 |  |  |  |  |
| TLK2_IRAK3_ENST00000326270_ENST00000261233_60679541_66620502 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.4495
Å |
| | | |  |
| TLK2_IRAK3_ENST00000343388_ENST00000261233_60679541_66620502 superimposed PDB: 5O0Y of partner (TLK2). RMSD:1.2936
Å |
 |  |  |  |  |
| TLK2_IRAK3_ENST00000343388_ENST00000261233_60679541_66620502 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.461
Å |
| | | |  |
| TLK2_IRAK3_ENST00000346027_ENST00000261233_60679541_66620502 superimposed PDB: 5O0Y of partner (TLK2). RMSD:1.1919
Å |
 |  |  |  |  |
| TLK2_IRAK3_ENST00000346027_ENST00000261233_60679541_66620502 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.4424
Å |
| | | |  |
| TLK2_IRAK3_ENST00000542523_ENST00000261233_60679541_66620502 superimposed PDB: 5O0Y of partner (TLK2). RMSD:1.2625
Å |
 |  |  |  |  |
| TLK2_IRAK3_ENST00000542523_ENST00000261233_60679541_66620502 superimposed PDB: 6ZIW of partner (IRAK3). RMSD:0.453
Å |
| | | |  |
| TLK2_THRA_ENST00000326270_ENST00000264637_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6696
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000326270_ENST00000450525_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6432
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000326270_ENST00000546243_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.4611
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000343388_ENST00000264637_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6922
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000343388_ENST00000450525_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6636
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000343388_ENST00000546243_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.4358
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000346027_ENST00000264637_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6733
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000346027_ENST00000450525_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6556
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000346027_ENST00000546243_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.425
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000542523_ENST00000264637_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6374
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000542523_ENST00000450525_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6513
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000542523_ENST00000546243_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.42
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000582809_ENST00000264637_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.6834
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000582809_ENST00000450525_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.63
Å |
 |  |  |  |  |
| TLK2_THRA_ENST00000582809_ENST00000546243_60613698_38240087 superimposed PDB: 3ILZ of partner (THRA). RMSD:0.4051
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000412303_ENST00000284073_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4917
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000412303_ENST00000322684_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4786
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000412303_ENST00000442934_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4844
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000456397_ENST00000284073_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4658
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000456397_ENST00000322684_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4704
Å |
 |  |  |  |  |
| TM2D2_MSI2_ENST00000456397_ENST00000442934_38852836_55478739 superimposed PDB: 6NTY of partner (MSI2). RMSD:0.4713
Å |
 |  |  |  |  |
| TM9SF3_JMJD1C_ENST00000371142_ENST00000402544_98319415_64946143 superimposed PDB: 2YPD of partner (JMJD1C). RMSD:0.6609
Å |
 |  |  |  |  |
| TM9SF4_ZNF423_ENST00000217315_ENST00000561648_30723976_49823457 superimposed PDB: 2MDG of partner (ZNF423). RMSD:1.9691
Å |
 |  |  |  |  |
| TMED10_MRPL48_ENST00000303575_ENST00000535529_75643057_73555851 superimposed PDB: 7OF0 of partner (MRPL48). RMSD:0.8638
Å |
 |  |  |  |  |
| TMEM104_DLC1_ENST00000417024_ENST00000276297_72785009_13259128 superimposed PDB: 3KUQ of partner (DLC1). RMSD:0.4837
Å |
 |  |  |  |  |
| TMEM104_DLC1_ENST00000582773_ENST00000276297_72785009_13259128 superimposed PDB: 3KUQ of partner (DLC1). RMSD:0.433
Å |
 |  |  |  |  |
| TMEM104_PCYT2_ENST00000582773_ENST00000538936_72781742_79867478 superimposed PDB: 3ELB of partner (PCYT2). RMSD:0.5121
Å |
 |  |  |  |  |
| TMEM106C_SENP1_ENST00000256686_ENST00000448372_48358206_48482743 superimposed PDB: 2XPH of partner (SENP1). RMSD:0.4831
Å |
 |  |  |  |  |
| TMEM106C_SENP1_ENST00000256686_ENST00000551330_48358206_48482743 superimposed PDB: 2XPH of partner (SENP1). RMSD:0.5176
Å |
 |  |  |  |  |
| TMEM106C_SENP1_ENST00000429772_ENST00000004980_48358206_48482743 superimposed PDB: 2XPH of partner (SENP1). RMSD:0.5133
Å |
 |  |  |  |  |
| TMEM106C_SENP1_ENST00000550552_ENST00000549595_48358206_48482743 superimposed PDB: 2XPH of partner (SENP1). RMSD:0.4998
Å |
 |  |  |  |  |
| TMEM117_PRIM1_ENST00000266534_ENST00000338193_44238731_57144979 superimposed PDB: 4MHQ of partner (PRIM1). RMSD:0.5346
Å |
 |  |  |  |  |
| TMEM117_PSMB1_ENST00000266534_ENST00000262193_44338145_170858201 superimposed PDB: 8BZL of partner (PSMB1). RMSD:0.4149
Å |
 |  |  |  |  |
| TMEM123_ANXA2_ENST00000398136_ENST00000451270_102319542_60656722 superimposed PDB: 1W7B of partner (ANXA2). RMSD:0.406
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370061_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6986
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370065_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6979
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370066_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6558
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370068_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6966
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370070_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6416
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370071_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.66
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370072_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6546
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000370074_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.6047
Å |
 |  |  |  |  |
| TMEM127_NTNG1_ENST00000432959_ENST00000542803_96930875_107866903 superimposed PDB: 3ZYJ of partner (NTNG1). RMSD:0.7002
Å |
 |  |  |  |  |
| TMEM132B_CCT5_ENST00000535886_ENST00000503026_126137178_10260903 superimposed PDB: 7NVL of partner (CCT5). RMSD:2.341
Å |
 |  |  |  |  |
| TMEM165_PDGFRA_ENST00000381334_ENST00000257290_56262563_55133455 superimposed PDB: 7LBF of partner (PDGFRA). RMSD:2.4277
Å |
 |  |  |  |  |
| TMEM167B_LYPLA1_ENST00000338272_ENST00000343231_109635643_54967693 superimposed PDB: 5SYM of partner (LYPLA1). RMSD:0.4555
Å |
 |  |  |  |  |
| TMEM170A_BCAR1_ENST00000566980_ENST00000162330_75485635_75276988 superimposed PDB: 3T6G of partner (BCAR1). RMSD:0.4243
Å |
 |  |  |  |  |
| TMEM194A_SMARCC2_ENST00000300128_ENST00000347471_57456901_56568548 superimposed PDB: 6LTH of partner (SMARCC2). RMSD:3.0572
Å |
 |  |  |  |  |
| TMEM234_RUSC1_ENST00000344461_ENST00000368347_32681800_155295106 superimposed PDB: 4GIW of partner (RUSC1). RMSD:0.5064
Å |
 |  |  |  |  |
| TMEM234_RUSC1_ENST00000344461_ENST00000368352_32681800_155295106 superimposed PDB: 4GIW of partner (RUSC1). RMSD:1.3084
Å |
 |  |  |  |  |
| TMEM241_NPC1_ENST00000383233_ENST00000412552_20889643_21125113 superimposed PDB: 6W5S of partner (NPC1). RMSD:1.4081
Å |
 |  |  |  |  |
| TMEM241_NPC1_ENST00000383233_ENST00000412552_21001330_21125113 superimposed PDB: 6W5S of partner (NPC1). RMSD:1.6104
Å |
 |  |  |  |  |
| TMEM241_NPC1_ENST00000450466_ENST00000412552_20889643_21125113 superimposed PDB: 6W5S of partner (NPC1). RMSD:1.4483
Å |
 |  |  |  |  |
| TMEM242_TIMM9_ENST00000400788_ENST00000395159_157739813_58877656 superimposed PDB: 2BSK of partner (TIMM9). RMSD:0.2936
Å |
 |  |  |  |  |
| TMEM245_ZNF484_ENST00000374586_ENST00000395506_111881614_95618600 superimposed PDB: 2EMF of partner (ZNF484). RMSD:0.4725
Å |
 |  |  |  |  |
| TMEM248_BCAT1_ENST00000341567_ENST00000538118_66416122_25002883 superimposed PDB: 7NWA of partner (BCAT1). RMSD:0.5933
Å |
 |  |  |  |  |
| TMEM30A_ZNF259_ENST00000370050_ENST00000227322_75968495_116655164 superimposed PDB: 8OX6 of partner (TMEM30A). RMSD:0.9156
Å |
 |  |  |  |  |
| TMEM30A_ZNF259_ENST00000475111_ENST00000227322_75968495_116655164 superimposed PDB: 8OX6 of partner (TMEM30A). RMSD:0.6814
Å |
 |  |  |  |  |
| TMEM53_EIF2B3_ENST00000372237_ENST00000372183_45125845_45341367 superimposed PDB: 7VLK of partner (EIF2B3). RMSD:2.8361
Å |
 |  |  |  |  |
| TMEM53_EIF2B3_ENST00000372242_ENST00000372183_45125845_45341367 superimposed PDB: 7VLK of partner (EIF2B3). RMSD:2.8125
Å |
 |  |  |  |  |
| TMEM53_EIF2B3_ENST00000372243_ENST00000360403_45125845_45341367 superimposed PDB: 7VLK of partner (EIF2B3). RMSD:2.8511
Å |
 |  |  |  |  |
| TMEM59_BAZ2B_ENST00000371348_ENST00000343439_54507396_160189197 superimposed PDB: 5PG1 of partner (BAZ2B). RMSD:0.2355
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000307216_ENST00000356577_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:3.1519
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000389834_ENST00000290239_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:1.5699
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000389834_ENST00000356577_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:1.6874
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000389834_ENST00000381692_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:1.5475
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000448392_ENST00000290239_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:3.131
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000448392_ENST00000356577_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:1.4317
Å |
 |  |  |  |  |
| TMEM87A_SON_ENST00000448392_ENST00000381692_42553155_34931535 superimposed PDB: 8HSI of partner (TMEM87A). RMSD:2.1482
Å |
 |  |  |  |  |
| TMEM97_BLMH_ENST00000226230_ENST00000394819_26646391_28601215 superimposed PDB: 7V5L of partner (BLMH). RMSD:0.8208
Å |
 |  |  |  |  |
| TMEM97_BLMH_ENST00000582113_ENST00000394819_26646391_28601215 superimposed PDB: 7V5L of partner (BLMH). RMSD:0.7529
Å |
 |  |  |  |  |
| TMEM97_SKAP1_ENST00000582113_ENST00000336915_26646391_46474147 superimposed PDB: 1U5D of partner (SKAP1). RMSD:0.4572
Å |
 |  |  |  |  |
| TMEM9B_PSIP1_ENST00000534025_ENST00000380716_8983638_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.6227
Å |
 |  |  |  |  |
| TMEM9B_PSIP1_ENST00000534025_ENST00000380733_8983638_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.5876
Å |
 |  |  |  |  |
| TMEM9B_PSIP1_ENST00000534025_ENST00000397519_8983638_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.5527
Å |
 |  |  |  |  |
| TMLHE_NEDD9_ENST00000334398_ENST00000379446_154743646_11193925 superimposed PDB: 2L81 of partner (NEDD9). RMSD:0.8463
Å |
 |  |  |  |  |
| TMPRSS2_CALB1_ENST00000458356_ENST00000265431_42848503_91072928 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.9996
Å |
 |  |  |  |  |
| TMPRSS2_CALB1_ENST00000458356_ENST00000518457_42848503_91072928 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.4904
Å |
 |  |  |  |  |
| TMPRSS2_DIAPH1_ENST00000332149_ENST00000398566_42842574_140914000 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.5163
Å |
 |  |  |  |  |
| TMPRSS2_DIAPH1_ENST00000332149_ENST00000520569_42842574_140914000 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.155
Å |
 |  |  |  |  |
| TMPRSS2_DIAPH1_ENST00000398585_ENST00000398566_42842574_140914000 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.1483
Å |
 |  |  |  |  |
| TMPRSS2_DIAPH1_ENST00000398585_ENST00000520569_42842574_140914000 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:1.2765
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000332149_ENST00000288319_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4142
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000332149_ENST00000398905_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4265
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000332149_ENST00000398907_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.3734
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000288319_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4336
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000288319_42879876_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4281
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000398905_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4182
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000398905_42879876_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4314
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000398907_42870045_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4108
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000398585_ENST00000398907_42879876_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4008
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000288319_42860320_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4127
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000288319_42866282_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4225
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000288319_42870045_39795483 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4191
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000398905_42860320_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4495
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000398905_42866282_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4209
Å |
 |  |  |  |  |
| TMPRSS2_ERG_ENST00000458356_ENST00000398905_42870045_39795483 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4356
Å |
 |  |  |  |  |
| TMPRSS2_ETV1_ENST00000332149_ENST00000399357_42866282_13950932 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4631
Å |
 |  |  |  |  |
| TMPRSS2_ETV1_ENST00000332149_ENST00000430479_42866282_13950932 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4492
Å |
 |  |  |  |  |
| TMPRSS2_ETV1_ENST00000398585_ENST00000399357_42866282_13950932 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4561
Å |
 |  |  |  |  |
| TMPRSS2_ETV1_ENST00000458356_ENST00000399357_42870045_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4676
Å |
 |  |  |  |  |
| TMPRSS2_ETV1_ENST00000458356_ENST00000405358_42870045_13971374 superimposed PDB: 4AVP of partner (ETV1). RMSD:0.4825
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000332149_ENST00000393664_42866282_41607549 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:2.705
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000332149_ENST00000393664_42866282_41607549 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.2745
Å |
| | | |  |
| TMPRSS2_ETV4_ENST00000332149_ENST00000393664_42870045_41622735 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.2795
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000398585_ENST00000319349_42879876_41622735 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.5264
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000398585_ENST00000393664_42866282_41607549 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:2.7241
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000398585_ENST00000393664_42866282_41607549 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.3118
Å |
| | | |  |
| TMPRSS2_ETV4_ENST00000398585_ENST00000393664_42870045_41622735 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.2913
Å |
 |  |  |  |  |
| TMPRSS2_ETV4_ENST00000398585_ENST00000393664_42879876_41622735 superimposed PDB: 4CO8 of partner (ETV4). RMSD:0.2818
Å |
 |  |  |  |  |
| TMPRSS2_GRHL2_ENST00000458356_ENST00000395927_42860320_102564942 superimposed PDB: 5MR7 of partner (GRHL2). RMSD:0.4605
Å |
 |  |  |  |  |
| TMPRSS2_GRHL2_ENST00000458356_ENST00000395927_42861433_102564942 superimposed PDB: 5MR7 of partner (GRHL2). RMSD:0.4843
Å |
 |  |  |  |  |
| TMPRSS2_HSF2BP_ENST00000332149_ENST00000542962_42845251_44949842 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:2.8594
Å |
 |  |  |  |  |
| TMPRSS2_HSF2BP_ENST00000398585_ENST00000542962_42845251_44949842 superimposed PDB: 8JI0 of partner (TMPRSS2). RMSD:0.8637
Å |
 |  |  |  |  |
| TMPRSS2_MORC3_ENST00000398585_ENST00000400485_42870045_37705943 superimposed PDB: 6O1E of partner (MORC3). RMSD:0.5677
Å |
 |  |  |  |  |
| TMPRSS2_PDE9A_ENST00000332149_ENST00000539837_42866282_44163885 superimposed PDB: 4Y86 of partner (PDE9A). RMSD:0.3943
Å |
 |  |  |  |  |
| TMPRSS2_PDE9A_ENST00000398585_ENST00000539837_42866282_44163885 superimposed PDB: 4Y86 of partner (PDE9A). RMSD:0.4031
Å |
 |  |  |  |  |
| TMPRSS2_SARS_ENST00000332149_ENST00000369923_42860320_109766599 superimposed PDB: 8P7B of partner (SARS). RMSD:0.4486
Å |
 |  |  |  |  |
| TMPRSS2_SARS_ENST00000398585_ENST00000234677_42860320_109766599 superimposed PDB: 8P7B of partner (SARS). RMSD:0.4483
Å |
 |  |  |  |  |
| TMPRSS2_SARS_ENST00000398585_ENST00000369923_42860320_109766599 superimposed PDB: 8P7B of partner (SARS). RMSD:0.441
Å |
 |  |  |  |  |
| TMPRSS6_EME1_ENST00000381792_ENST00000338165_37485617_48455955 superimposed PDB: 9NRC of partner (TMPRSS6). RMSD:0.5373
Å |
 |  |  |  |  |
| TMPRSS6_EME1_ENST00000381792_ENST00000393271_37485617_48455955 superimposed PDB: 9NRC of partner (TMPRSS6). RMSD:2.7043
Å |
 |  |  |  |  |
| TMSB4X_S100A9_ENST00000380635_ENST00000368738_12995346_153330329 superimposed PDB: 4GGF of partner (S100A9). RMSD:0.6458
Å |
 |  |  |  |  |
| TMTC1_PGD_ENST00000539277_ENST00000541529_29904598_10459685 superimposed PDB: 2JKV of partner (PGD). RMSD:0.6363
Å |
 |  |  |  |  |
| TMTC1_PGD_ENST00000551659_ENST00000270776_29904598_10459685 superimposed PDB: 2JKV of partner (PGD). RMSD:0.7666
Å |
 |  |  |  |  |
| TMTC1_PGD_ENST00000552618_ENST00000270776_29904598_10459685 superimposed PDB: 2JKV of partner (PGD). RMSD:0.9623
Å |
 |  |  |  |  |
| TMTC1_PGD_ENST00000552618_ENST00000541529_29904598_10459685 superimposed PDB: 2JKV of partner (PGD). RMSD:0.6136
Å |
 |  |  |  |  |
| TMTC2_HERC1_ENST00000548305_ENST00000443617_83081448_63956793 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.3838
Å |
 |  |  |  |  |
| TMTC3_SHMT1_ENST00000266712_ENST00000352886_88570096_18250970 superimposed PDB: 6M5W of partner (SHMT1). RMSD:0.6927
Å |
 |  |  |  |  |
| TMX3_IQGAP2_ENST00000299608_ENST00000379730_66364462_75948574 superimposed PDB: 5CJP of partner (IQGAP2). RMSD:0.9306
Å |
 |  |  |  |  |
| TMX3_IQGAP2_ENST00000443099_ENST00000379730_66364462_75948574 superimposed PDB: 5CJP of partner (IQGAP2). RMSD:0.8772
Å |
 |  |  |  |  |
| TNFRSF10B_WDR11_ENST00000347739_ENST00000263461_22888271_122640337 superimposed PDB: 8Z9M of partner (WDR11). RMSD:2.985
Å |
 |  |  |  |  |
| TNFSF12_PI4KA_ENST00000293825_ENST00000572273_7454295_21068988 superimposed PDB: 9B9G of partner (PI4KA). RMSD:1.7404
Å |
 |  |  |  |  |
| TNFSF12_PI4KA_ENST00000557233_ENST00000572273_7454295_21068988 superimposed PDB: 9B9G of partner (PI4KA). RMSD:1.731
Å |
 |  |  |  |  |
| TNIP1_ZWILCH_ENST00000523200_ENST00000307897_150411847_66820194 superimposed PDB: 7EAL of partner (TNIP1). RMSD:1.0017
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000518281_ENST00000381733_9473187_17920739 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.3588
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000518281_ENST00000381733_9473187_17920739 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.4773
Å |
| | | |  |
| TNKS_ASAH1_ENST00000518281_ENST00000381733_9473187_17922040 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.3275
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000518281_ENST00000381733_9473187_17922040 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.3943
Å |
| | | |  |
| TNKS_ASAH1_ENST00000520408_ENST00000262097_9473187_17920739 superimposed PDB: 5JHQ of partner (TNKS). RMSD:1.7193
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000520408_ENST00000381733_9473187_17920739 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.3645
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000520408_ENST00000381733_9473187_17920739 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.4754
Å |
| | | |  |
| TNKS_ASAH1_ENST00000520408_ENST00000381733_9473187_17922040 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.3484
Å |
 |  |  |  |  |
| TNKS_ASAH1_ENST00000520408_ENST00000381733_9473187_17922040 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.3805
Å |
| | | |  |
| TNKS_KHDRBS3_ENST00000310430_ENST00000355849_9622300_136619197 superimposed PDB: 5JHQ of partner (TNKS). RMSD:3.2413
Å |
 |  |  |  |  |
| TNKS_KHDRBS3_ENST00000310430_ENST00000520981_9622300_136619197 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.9663
Å |
 |  |  |  |  |
| TNKS_KHDRBS3_ENST00000518281_ENST00000520981_9622300_136619197 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.8745
Å |
 |  |  |  |  |
| TNKS_MSRA_ENST00000310430_ENST00000317173_9473187_10065342 superimposed PDB: 5JHQ of partner (TNKS). RMSD:2.6906
Å |
 |  |  |  |  |
| TNKS_MSRA_ENST00000518281_ENST00000441698_9473187_10065342 superimposed PDB: 5JHQ of partner (TNKS). RMSD:3.1005
Å |
 |  |  |  |  |
| TNKS_MSRA_ENST00000518281_ENST00000518255_9473187_10065342 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.3111
Å |
 |  |  |  |  |
| TNKS_MSRA_ENST00000520408_ENST00000441698_9473187_10065342 superimposed PDB: 5JHQ of partner (TNKS). RMSD:2.7501
Å |
 |  |  |  |  |
| TNKS_MSRA_ENST00000520408_ENST00000518255_9473187_10065342 superimposed PDB: 5JHQ of partner (TNKS). RMSD:0.434
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000337273_ENST00000453061_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.0483
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000337273_ENST00000504346_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.0498
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000454282_ENST00000296306_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:0.8347
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000454282_ENST00000453061_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:0.8933
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000454282_ENST00000504346_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:0.9081
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000506351_ENST00000453061_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:0.9465
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000506351_ENST00000504346_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:0.9583
Å |
 |  |  |  |  |
| TNPO1_PIGG_ENST00000523768_ENST00000296306_72179059_509761 superimposed PDB: 8SGH of partner (TNPO1). RMSD:1.5848
Å |
 |  |  |  |  |
| TNPO2_RFX1_ENST00000441499_ENST00000254325_12821434_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.4315
Å |
 |  |  |  |  |
| TNPO2_RFX1_ENST00000450764_ENST00000254325_12821434_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.433
Å |
 |  |  |  |  |
| TNPO2_RFX1_ENST00000588216_ENST00000254325_12821434_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.4136
Å |
 |  |  |  |  |
| TNRC18_ZC3HAV1_ENST00000399537_ENST00000464606_5460690_138768778 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:1.0697
Å |
 |  |  |  |  |
| TNRC18_ZC3HAV1_ENST00000399537_ENST00000471652_5460690_138768778 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:1.8226
Å |
 |  |  |  |  |
| TNRC18_ZC3HAV1_ENST00000430969_ENST00000242351_5460690_138768778 superimposed PDB: 6UEJ of partner (ZC3HAV1). RMSD:1.1039
Å |
 |  |  |  |  |
| TNRC6A_LCMT1_ENST00000315183_ENST00000380966_24741621_25139795 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.3359
Å |
 |  |  |  |  |
| TNRC6A_LCMT1_ENST00000395799_ENST00000399069_24741621_25139795 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.4125
Å |
 |  |  |  |  |
| TNRC6A_PRKCB_ENST00000315183_ENST00000303531_24741621_24192110 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:0.6942
Å |
 |  |  |  |  |
| TNRC6A_PRKCB_ENST00000395799_ENST00000321728_24741621_24192110 superimposed PDB: 8SE3 of partner (PRKCB). RMSD:0.77
Å |
 |  |  |  |  |
| TNS3_PLCB1_ENST00000311160_ENST00000338037_47341783_8352028 superimposed PDB: 9QN7 of partner (TNS3). RMSD:0.6447
Å |
 |  |  |  |  |
| TNS3_PLCB1_ENST00000355730_ENST00000338037_47341783_8352028 superimposed PDB: 9QN7 of partner (TNS3). RMSD:1.9696
Å |
 |  |  |  |  |
| TNS3_PLCB1_ENST00000355730_ENST00000378637_47341783_8352028 superimposed PDB: 9QN7 of partner (TNS3). RMSD:1.9716
Å |
 |  |  |  |  |
| TNS3_PLCB1_ENST00000398879_ENST00000338037_47341783_8352028 superimposed PDB: 9QN7 of partner (TNS3). RMSD:0.6194
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000263646_ENST00000355528_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0747
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000263646_ENST00000397466_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.1599
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000317204_ENST00000397466_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2301
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000525159_ENST00000355528_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.0966
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000525159_ENST00000397466_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2438
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000527886_ENST00000355528_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.158
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000527886_ENST00000397466_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.2552
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000542915_ENST00000355528_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.1841
Å |
 |  |  |  |  |
| TOLLIP_TBCD_ENST00000542915_ENST00000397466_1307231_80863811 superimposed PDB: 9M1M of partner (TBCD). RMSD:1.185
Å |
 |  |  |  |  |
| TOM1L2_ALDH3A2_ENST00000581396_ENST00000395575_17875575_19554859 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5587
Å |
 |  |  |  |  |
| TOM1L2_ALDH3A2_ENST00000581396_ENST00000395575_17875575_19559678 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.561
Å |
 |  |  |  |  |
| TOM1L2_ALDH3A2_ENST00000581396_ENST00000581518_17875575_19554859 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5388
Å |
 |  |  |  |  |
| TOM1L2_ALDH3A2_ENST00000581396_ENST00000581518_17875575_19559678 superimposed PDB: 4QGK of partner (ALDH3A2). RMSD:0.5457
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000318094_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6268
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000379504_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6216
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000535933_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6187
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000540946_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6046
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000542206_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6649
Å |
 |  |  |  |  |
| TOM1L2_ULK2_ENST00000581396_ENST00000395544_17782940_19769141 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.6172
Å |
 |  |  |  |  |
| TOMM40_CEACAM19_ENST00000252487_ENST00000358777_45397323_45175867 superimposed PDB: 7VD2 of partner (TOMM40). RMSD:1.7031
Å |
 |  |  |  |  |
| TOMM40_CEACAM19_ENST00000405636_ENST00000403660_45397323_45175867 superimposed PDB: 7VD2 of partner (TOMM40). RMSD:1.9227
Å |
 |  |  |  |  |
| TOP2A_STAU1_ENST00000423485_ENST00000347458_38560403_47752468 superimposed PDB: 6ZY5 of partner (TOP2A). RMSD:2.8069
Å |
 |  |  |  |  |
| TOP2A_STAU1_ENST00000423485_ENST00000347458_38560403_47752468 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.6166
Å |
| | | |  |
| TOP2A_STAU1_ENST00000423485_ENST00000360426_38560403_47752468 superimposed PDB: 6ZY5 of partner (TOP2A). RMSD:2.775
Å |
 |  |  |  |  |
| TOP2A_STAU1_ENST00000423485_ENST00000360426_38560403_47752468 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.6693
Å |
| | | |  |
| TOP2A_STAU1_ENST00000423485_ENST00000371802_38560403_47752468 superimposed PDB: 6ZY5 of partner (TOP2A). RMSD:1.2889
Å |
 |  |  |  |  |
| TOP2A_STAU1_ENST00000423485_ENST00000371802_38560403_47752468 superimposed PDB: 6HTU of partner (STAU1). RMSD:0.5834
Å |
| | | |  |
| TOP2B_NGLY1_ENST00000264331_ENST00000280700_25654005_25775473 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.8588
Å |
 |  |  |  |  |
| TOP2B_NGLY1_ENST00000264331_ENST00000417874_25654005_25775473 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.7532
Å |
 |  |  |  |  |
| TOP2B_NGLY1_ENST00000264331_ENST00000428257_25654005_25775473 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.8002
Å |
 |  |  |  |  |
| TOP2B_NGLY1_ENST00000435706_ENST00000280700_25654005_25775473 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.8027
Å |
 |  |  |  |  |
| TOP2B_NGLY1_ENST00000435706_ENST00000417874_25654005_25775473 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.7671
Å |
 |  |  |  |  |
| TOP2B_TPM1_ENST00000264331_ENST00000288398_25656695_63354413 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.9518
Å |
 |  |  |  |  |
| TOP2B_TPM1_ENST00000264331_ENST00000358278_25656695_63354413 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.839
Å |
 |  |  |  |  |
| TOP2B_TPM1_ENST00000435706_ENST00000288398_25656695_63354413 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.9146
Å |
 |  |  |  |  |
| TOP2B_TPM1_ENST00000435706_ENST00000358278_25656695_63354413 superimposed PDB: 7YQ8 of partner (TOP2B). RMSD:1.8684
Å |
 |  |  |  |  |
| TOP3A_HEATR6_ENST00000321105_ENST00000184956_18205198_58151247 superimposed PDB: 4CGY of partner (TOP3A). RMSD:0.8102
Å |
 |  |  |  |  |
| TOP3A_HEATR6_ENST00000321105_ENST00000585976_18205198_58151247 superimposed PDB: 4CGY of partner (TOP3A). RMSD:0.7389
Å |
 |  |  |  |  |
| TOP3B_MAPK1_ENST00000357179_ENST00000544786_22328728_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.5759
Å |
 |  |  |  |  |
| TOP3B_MAPK1_ENST00000398793_ENST00000215832_22328728_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.7334
Å |
 |  |  |  |  |
| TOPBP1_NETO2_ENST00000260810_ENST00000562435_133368226_47117712 superimposed PDB: 8OK2 of partner (TOPBP1). RMSD:0.7552
Å |
 |  |  |  |  |
| TOX3_PHKB_ENST00000219746_ENST00000299167_52580548_47627410 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.4364
Å |
 |  |  |  |  |
| TOX3_PHKB_ENST00000219746_ENST00000455779_52580548_47627410 superimposed PDB: 8XYA of partner (PHKB). RMSD:2.2742
Å |
 |  |  |  |  |
| TP53BP1_AP1G1_ENST00000263801_ENST00000423132_43707791_71773244 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:0.4043
Å |
 |  |  |  |  |
| TP53BP1_AP1G1_ENST00000382039_ENST00000423132_43707791_71773244 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:0.3852
Å |
 |  |  |  |  |
| TP53BP1_AP1G1_ENST00000382044_ENST00000423132_43707791_71773244 superimposed PDB: 1IU1 of partner (AP1G1). RMSD:0.4394
Å |
 |  |  |  |  |
| TP53BP1_DAPK2_ENST00000263801_ENST00000457488_43771594_64263760 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.5719
Å |
 |  |  |  |  |
| TP53BP1_DAPK2_ENST00000382039_ENST00000261891_43771594_64263760 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.7147
Å |
 |  |  |  |  |
| TP53BP1_DAPK2_ENST00000382039_ENST00000457488_43771594_64263760 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.4804
Å |
 |  |  |  |  |
| TP53BP1_DAPK2_ENST00000382044_ENST00000261891_43771594_64263760 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.718
Å |
 |  |  |  |  |
| TP53_HSF2BP_ENST00000359597_ENST00000542962_7576852_45053302 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.4342
Å |
 |  |  |  |  |
| TP53_HSF2BP_ENST00000359597_ENST00000542962_7576852_45053302 superimposed PDB: 7LDG of partner (HSF2BP). RMSD:0.6252
Å |
| | | |  |
| TP53_HSF2BP_ENST00000445888_ENST00000291560_7576852_45064273 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.4424
Å |
 |  |  |  |  |
| TP53_HSF2BP_ENST00000455263_ENST00000542962_7576852_45053302 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.4225
Å |
 |  |  |  |  |
| TP53_HSF2BP_ENST00000455263_ENST00000542962_7576852_45053302 superimposed PDB: 7LDG of partner (HSF2BP). RMSD:0.6521
Å |
| | | |  |
| TP53_PXDNL_ENST00000359597_ENST00000356297_7577498_52567320 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.7311
Å |
 |  |  |  |  |
| TP53_PXDNL_ENST00000420246_ENST00000356297_7577498_52567320 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.7234
Å |
 |  |  |  |  |
| TP53_PXDNL_ENST00000455263_ENST00000356297_7577498_52567320 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.8698
Å |
 |  |  |  |  |
| TP53_RPLP0_ENST00000455263_ENST00000551150_7579311_120635265 superimposed PDB: 9R2Q of partner (TP53). RMSD:2.8078
Å |
 |  |  |  |  |
| TP53_SLC35G6_ENST00000359597_ENST00000412468_7578176_7385306 superimposed PDB: 9R2Q of partner (TP53). RMSD:1.0273
Å |
 |  |  |  |  |
| TP53_SLC35G6_ENST00000413465_ENST00000412468_7578176_7385306 superimposed PDB: 9R2Q of partner (TP53). RMSD:0.6795
Å |
 |  |  |  |  |
| TP63_FOXK2_ENST00000382063_ENST00000335255_189456563_80529599 superimposed PDB: 2C6Y of partner (FOXK2). RMSD:0.4723
Å |
 |  |  |  |  |
| TP63_FOXK2_ENST00000440651_ENST00000335255_189456563_80529599 superimposed PDB: 2C6Y of partner (FOXK2). RMSD:0.4548
Å |
 |  |  |  |  |
| TP63_PINX1_ENST00000264731_ENST00000519088_189526315_10623426 superimposed PDB: 2RMN of partner (TP63). RMSD:2.421
Å |
 |  |  |  |  |
| TP63_PINX1_ENST00000354600_ENST00000519088_189526315_10623426 superimposed PDB: 2RMN of partner (TP63). RMSD:2.8827
Å |
 |  |  |  |  |
| TP63_PINX1_ENST00000392460_ENST00000519088_189526315_10623426 superimposed PDB: 2RMN of partner (TP63). RMSD:2.8905
Å |
 |  |  |  |  |
| TP63_PINX1_ENST00000437221_ENST00000519088_189526315_10623426 superimposed PDB: 2RMN of partner (TP63). RMSD:2.9808
Å |
 |  |  |  |  |
| TP73_PACSIN2_ENST00000378295_ENST00000263246_3599744_43289619 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:1.2342
Å |
 |  |  |  |  |
| TP73_PACSIN2_ENST00000378295_ENST00000407585_3599744_43289619 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:1.2506
Å |
 |  |  |  |  |
| TP73_PACSIN2_ENST00000603362_ENST00000263246_3599744_43289619 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:1.1247
Å |
 |  |  |  |  |
| TP73_PACSIN2_ENST00000603362_ENST00000407585_3599744_43289619 superimposed PDB: 3HAJ of partner (PACSIN2). RMSD:1.3044
Å |
 |  |  |  |  |
| TPCN2_BEST3_ENST00000542467_ENST00000331471_68837963_70072673 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.9068
Å |
 |  |  |  |  |
| TPCN2_CCND1_ENST00000542467_ENST00000227507_68825162_69465885 superimposed PDB: 8OUO of partner (TPCN2). RMSD:1.2989
Å |
 |  |  |  |  |
| TPCN2_NADSYN1_ENST00000294309_ENST00000539574_68831435_71208528 superimposed PDB: 8OUO of partner (TPCN2). RMSD:1.166
Å |
 |  |  |  |  |
| TPCN2_NADSYN1_ENST00000294309_ENST00000539574_68831435_71208528 superimposed PDB: 6OFB of partner (NADSYN1). RMSD:2.675
Å |
| | | |  |
| TPCN2_NADSYN1_ENST00000294309_ENST00000539574_68846261_71208528 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.081
Å |
 |  |  |  |  |
| TPCN2_NADSYN1_ENST00000294309_ENST00000539574_68846488_71208528 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.5704
Å |
 |  |  |  |  |
| TPCN2_NADSYN1_ENST00000294309_ENST00000539574_68848967_71208528 superimposed PDB: 8OUO of partner (TPCN2). RMSD:2.0494
Å |
 |  |  |  |  |
| TPCN2_RAB11FIP1_ENST00000542467_ENST00000287263_68831435_37720631 superimposed PDB: 8OUO of partner (TPCN2). RMSD:1.6916
Å |
 |  |  |  |  |
| TPCN2_RAB11FIP1_ENST00000542467_ENST00000287263_68831435_37720631 superimposed PDB: 4D0G of partner (RAB11FIP1). RMSD:0.4451
Å |
| | | |  |
| TPD52L1_PARVA_ENST00000304877_ENST00000539723_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.6241
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000304877_ENST00000550549_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.7155
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000368388_ENST00000334956_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:1.021
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000368388_ENST00000539723_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.5564
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000368388_ENST00000550549_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.6185
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000368402_ENST00000539723_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.6193
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000368402_ENST00000550549_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.6256
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000527711_ENST00000334956_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.8431
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000528193_ENST00000539723_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.5565
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000528193_ENST00000550549_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.5956
Å |
 |  |  |  |  |
| TPD52L1_PARVA_ENST00000534000_ENST00000334956_125475116_12518004 superimposed PDB: 9UIU of partner (PARVA). RMSD:0.7454
Å |
 |  |  |  |  |
| TPI1_SMARCC2_ENST00000229270_ENST00000347471_6978937_56557549 superimposed PDB: 9FFC of partner (TPI1). RMSD:0.4906
Å |
 |  |  |  |  |
| TPI1_SMARCC2_ENST00000396705_ENST00000347471_6978937_56557549 superimposed PDB: 9FFC of partner (TPI1). RMSD:0.4768
Å |
 |  |  |  |  |
| TPI1_SMARCC2_ENST00000488464_ENST00000347471_6978937_56557549 superimposed PDB: 9FFC of partner (TPI1). RMSD:0.6888
Å |
 |  |  |  |  |
| TPI1_SMARCC2_ENST00000535434_ENST00000347471_6978937_56557549 superimposed PDB: 9FFC of partner (TPI1). RMSD:0.6846
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000267996_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:2.059
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000317516_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:1.2228
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000334895_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:2.3976
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000357980_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:2.473
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000358278_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:2.5094
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000404484_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:1.6824
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000559281_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:1.2537
Å |
 |  |  |  |  |
| TPM1_ALK_ENST00000559556_ENST00000389048_63354844_29446394 superimposed PDB: 9ZBL of partner (TPM1). RMSD:2.2833
Å |
 |  |  |  |  |
| TPM2_FLNC_ENST00000378292_ENST00000346177_35685060_128478320 superimposed PDB: 7OUU of partner (FLNC). RMSD:1.7488
Å |
 |  |  |  |  |
| TPM3_JAK2_ENST00000330188_ENST00000381652_154142875_5080228 superimposed PDB: 6OTN of partner (TPM3). RMSD:2.1088
Å |
 |  |  |  |  |
| TPM3_JAK2_ENST00000341485_ENST00000381652_154142875_5080228 superimposed PDB: 6OTN of partner (TPM3). RMSD:0.8371
Å |
 |  |  |  |  |
| TPM3_JAK2_ENST00000368533_ENST00000381652_154142875_5080228 superimposed PDB: 6OTN of partner (TPM3). RMSD:1.8191
Å |
 |  |  |  |  |
| TPSAB1_PRSS27_ENST00000461509_ENST00000302641_1291991_2762815 superimposed PDB: 6P0P of partner (TPSAB1). RMSD:0.4916
Å |
 |  |  |  |  |
| TPST1_AUTS2_ENST00000304842_ENST00000342771_65751696_70163554 superimposed PDB: 5WRI of partner (TPST1). RMSD:0.5213
Å |
 |  |  |  |  |
| TPST1_AUTS2_ENST00000304842_ENST00000406775_65751696_70163554 superimposed PDB: 5WRI of partner (TPST1). RMSD:0.4429
Å |
 |  |  |  |  |
| TPST1_TRIM47_ENST00000304842_ENST00000254816_65751696_73872573 superimposed PDB: 5WRI of partner (TPST1). RMSD:0.5241
Å |
 |  |  |  |  |
| TPST1_TRIM47_ENST00000304842_ENST00000587339_65751696_73872573 superimposed PDB: 5WRI of partner (TPST1). RMSD:0.5388
Å |
 |  |  |  |  |
| TPT1_NACA_ENST00000379055_ENST00000356769_45914128_57106692 superimposed PDB: 5O9M of partner (TPT1). RMSD:2.1764
Å |
 |  |  |  |  |
| TPT1_RPL14_ENST00000379055_ENST00000338970_45914128_40503431 superimposed PDB: 5O9M of partner (TPT1). RMSD:1.5532
Å |
 |  |  |  |  |
| TPT1_RPL14_ENST00000379060_ENST00000396203_45914128_40503431 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.7697
Å |
 |  |  |  |  |
| TPT1_RPL21_ENST00000379060_ENST00000272274_45912794_27829378 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.5386
Å |
 |  |  |  |  |
| TPT1_RPL21_ENST00000530705_ENST00000272274_45912794_27829378 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.459
Å |
 |  |  |  |  |
| TPT1_RPL24_ENST00000309246_ENST00000394077_45914128_101401336 superimposed PDB: 5O9M of partner (TPT1). RMSD:2.3103
Å |
 |  |  |  |  |
| TPT1_RPL24_ENST00000379060_ENST00000394077_45914128_101401336 superimposed PDB: 5O9M of partner (TPT1). RMSD:1.0791
Å |
 |  |  |  |  |
| TPT1_RPS18_ENST00000379060_ENST00000439602_45912794_33243573 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.5726
Å |
 |  |  |  |  |
| TPT1_RPS27A_ENST00000379055_ENST00000272317_45912794_55461254 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.6365
Å |
 |  |  |  |  |
| TPT1_RPS27A_ENST00000379056_ENST00000272317_45912794_55461254 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.7141
Å |
 |  |  |  |  |
| TPT1_RPS27A_ENST00000379056_ENST00000402285_45912794_55461254 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.7145
Å |
 |  |  |  |  |
| TPT1_RPS6_ENST00000309246_ENST00000380394_45913631_19378916 superimposed PDB: 5O9M of partner (TPT1). RMSD:1.4155
Å |
 |  |  |  |  |
| TPT1_RPS6_ENST00000379060_ENST00000380394_45913631_19378916 superimposed PDB: 5O9M of partner (TPT1). RMSD:0.7283
Å |
 |  |  |  |  |
| TRA2A_AQP1_ENST00000297071_ENST00000509504_23571407_30961680 superimposed PDB: 7UZE of partner (AQP1). RMSD:1.4936
Å |
 |  |  |  |  |
| TRA2B_BCAR1_ENST00000342294_ENST00000162330_185655612_75276988 superimposed PDB: 3T6G of partner (BCAR1). RMSD:0.4223
Å |
 |  |  |  |  |
| TRAF3IP1_ITSN2_ENST00000373327_ENST00000361999_239237983_24498718 superimposed PDB: 2EQO of partner (TRAF3IP1). RMSD:0.8579
Å |
 |  |  |  |  |
| TRAF3IP1_ITSN2_ENST00000391993_ENST00000355123_239237983_24498718 superimposed PDB: 2EQO of partner (TRAF3IP1). RMSD:0.8609
Å |
 |  |  |  |  |
| TRAF3IP1_ITSN2_ENST00000391993_ENST00000355123_239237983_24498718 superimposed PDB: 3JZY of partner (ITSN2). RMSD:0.3101
Å |
| | | |  |
| TRAF3_ITPK1_ENST00000347662_ENST00000354313_103342862_93424711 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:2.3551
Å |
 |  |  |  |  |
| TRAF3_ITPK1_ENST00000539721_ENST00000354313_103342862_93424711 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:2.4698
Å |
 |  |  |  |  |
| TRAF3_ITPK1_ENST00000560371_ENST00000354313_103342862_93424711 superimposed PDB: 2Q7D of partner (ITPK1). RMSD:2.1852
Å |
 |  |  |  |  |
| TRAK1_RAF1_ENST00000327628_ENST00000442415_42235390_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.01
Å |
 |  |  |  |  |
| TRAK1_RAF1_ENST00000341421_ENST00000442415_42235390_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:1.0235
Å |
 |  |  |  |  |
| TRAK1_RAF1_ENST00000449246_ENST00000442415_42235390_12641914 superimposed PDB: 9MMQ of partner (RAF1). RMSD:0.9188
Å |
 |  |  |  |  |
| TRAM2_PLA2G7_ENST00000182527_ENST00000537365_52400580_46684833 superimposed PDB: 3D59 of partner (PLA2G7). RMSD:0.3681
Å |
 |  |  |  |  |
| TRAP1_ADCY9_ENST00000538171_ENST00000294016_3721722_4029276 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.3085
Å |
 |  |  |  |  |
| TRAP1_ADCY9_ENST00000538171_ENST00000294016_3721722_4029276 superimposed PDB: 9U3P of partner (ADCY9). RMSD:0.8181
Å |
| | | |  |
| TRAP1_ADCY9_ENST00000575671_ENST00000294016_3721722_4029276 superimposed PDB: 7KLV of partner (TRAP1). RMSD:0.9862
Å |
 |  |  |  |  |
| TRAP1_ADCY9_ENST00000575671_ENST00000294016_3721722_4029276 superimposed PDB: 9U3P of partner (ADCY9). RMSD:0.8167
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000262367_3735996_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.4266
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000262367_3735996_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6884
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000382070_3729719_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:2.1516
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000382070_3729719_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6723
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000382070_3735996_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:2.0507
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000246957_ENST00000382070_3735996_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.7111
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000262367_3729719_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.9035
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000262367_3729719_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6973
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000262367_3735996_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.7209
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000262367_3735996_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.7039
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000382070_3729719_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.3564
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000382070_3729719_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6546
Å |
| | | |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000382070_3735996_3860780 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.1125
Å |
 |  |  |  |  |
| TRAP1_CREBBP_ENST00000538171_ENST00000382070_3735996_3860780 superimposed PDB: 8HAN of partner (CREBBP). RMSD:0.6854
Å |
| | | |  |
| TRAPPC10_BRWD1_ENST00000291574_ENST00000342449_45432441_40630598 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.5044
Å |
 |  |  |  |  |
| TRAPPC10_BRWD1_ENST00000291574_ENST00000380800_45432441_40630598 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.469
Å |
 |  |  |  |  |
| TRAPPC10_BRWD1_ENST00000380221_ENST00000333229_45432441_40630598 superimposed PDB: 3Q2E of partner (BRWD1). RMSD:0.4813
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000309434_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9002
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000389124_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9085
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000389125_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9296
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000399907_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8912
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000399909_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9022
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000399913_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8932
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000399914_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.9111
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000291574_ENST00000535441_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8839
Å |
 |  |  |  |  |
| TRAPPC10_GRIK1_ENST00000380221_ENST00000327783_45432441_31066382 superimposed PDB: 4MF3 of partner (GRIK1). RMSD:1.8975
Å |
 |  |  |  |  |
| TRAPPC11_KCNN4_ENST00000357207_ENST00000262888_184589270_44276287 superimposed PDB: 6CNM of partner (KCNN4). RMSD:2.1677
Å |
 |  |  |  |  |
| TRERF1_SUPT3H_ENST00000340840_ENST00000371459_42210985_44988369 superimposed PDB: 9RDK of partner (SUPT3H). RMSD:1.2713
Å |
 |  |  |  |  |
| TRIM24_FGFR1_ENST00000415680_ENST00000341462_138255748_38277253 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.7086
Å |
 |  |  |  |  |
| TRIM24_NTRK2_ENST00000343526_ENST00000376213_138258387_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.8518
Å |
 |  |  |  |  |
| TRIM24_NTRK2_ENST00000343526_ENST00000376214_138258387_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:1.271
Å |
 |  |  |  |  |
| TRIM24_NTRK2_ENST00000415680_ENST00000376213_138258387_87482157 superimposed PDB: 4ASZ of partner (NTRK2). RMSD:0.7525
Å |
 |  |  |  |  |
| TRIM25_MSI2_ENST00000316881_ENST00000284073_54972703_55674228 superimposed PDB: 4CFG of partner (TRIM25). RMSD:1.5452
Å |
 |  |  |  |  |
| TRIM25_MSI2_ENST00000316881_ENST00000284073_54972703_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.2833
Å |
| | | |  |
| TRIM25_MSI2_ENST00000316881_ENST00000322684_54972703_55674228 superimposed PDB: 4CFG of partner (TRIM25). RMSD:1.7063
Å |
 |  |  |  |  |
| TRIM25_MSI2_ENST00000316881_ENST00000322684_54972703_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.2834
Å |
| | | |  |
| TRIM25_MSI2_ENST00000316881_ENST00000442934_54972703_55674228 superimposed PDB: 4CFG of partner (TRIM25). RMSD:1.8223
Å |
 |  |  |  |  |
| TRIM25_MSI2_ENST00000316881_ENST00000442934_54972703_55674228 superimposed PDB: 6NTY of partner (MSI2). RMSD:1.2425
Å |
| | | |  |
| TRIM26_MPP5_ENST00000437089_ENST00000555925_30166205_67786946 superimposed PDB: 4WSI of partner (MPP5). RMSD:0.6336
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000400186_59060607_3351248 superimposed PDB: 6H3A of partner (TRIM28). RMSD:2.5031
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000400186_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.335
Å |
| | | |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000539096_59060607_3351248 superimposed PDB: 6H3A of partner (TRIM28). RMSD:2.58
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000539096_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.5272
Å |
| | | |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000542608_59060607_3351248 superimposed PDB: 6H3A of partner (TRIM28). RMSD:2.6977
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000542608_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.2175
Å |
| | | |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000602557_59060607_3351248 superimposed PDB: 6H3A of partner (TRIM28). RMSD:2.4662
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000253024_ENST00000602557_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.4499
Å |
| | | |  |
| TRIM28_CSMD1_ENST00000341753_ENST00000400186_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.2646
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000341753_ENST00000602557_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:2.8128
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000341753_ENST00000602723_59060607_3351248 superimposed PDB: 6H3A of partner (TRIM28). RMSD:2.0923
Å |
 |  |  |  |  |
| TRIM28_CSMD1_ENST00000341753_ENST00000602723_59060607_3351248 superimposed PDB: 2EHF of partner (CSMD1). RMSD:1.3935
Å |
| | | |  |
| TRIM29_RHCG_ENST00000341846_ENST00000268122_119998043_90021205 superimposed PDB: 2CSV of partner (TRIM29). RMSD:1.0708
Å |
 |  |  |  |  |
| TRIM29_RHCG_ENST00000341846_ENST00000268122_119998043_90021205 superimposed PDB: 3HD6 of partner (RHCG). RMSD:1.1354
Å |
| | | |  |
| TRIM29_RHCG_ENST00000529044_ENST00000268122_119998043_90021205 superimposed PDB: 3HD6 of partner (RHCG). RMSD:1.1311
Å |
 |  |  |  |  |
| TRIM29_RHCG_ENST00000529044_ENST00000544600_119998043_90021205 superimposed PDB: 3HD6 of partner (RHCG). RMSD:1.1779
Å |
 |  |  |  |  |
| TRIM29_RHCG_ENST00000541857_ENST00000268122_119998043_90021205 superimposed PDB: 3HD6 of partner (RHCG). RMSD:1.0321
Å |
 |  |  |  |  |
| TRIM29_RHCG_ENST00000541857_ENST00000544600_119998043_90021205 superimposed PDB: 2CSV of partner (TRIM29). RMSD:1.056
Å |
 |  |  |  |  |
| TRIM29_RHCG_ENST00000541857_ENST00000544600_119998043_90021205 superimposed PDB: 3HD6 of partner (RHCG). RMSD:1.1356
Å |
| | | |  |
| TRIM33_CSMD2_ENST00000358465_ENST00000373380_114948031_34128692 superimposed PDB: 7ZDD of partner (TRIM33). RMSD:1.0786
Å |
 |  |  |  |  |
| TRIM33_CSMD2_ENST00000358465_ENST00000373381_114948031_34128692 superimposed PDB: 7ZDD of partner (TRIM33). RMSD:2.8571
Å |
 |  |  |  |  |
| TRIM33_CSMD2_ENST00000369543_ENST00000373381_114948031_34128692 superimposed PDB: 7ZDD of partner (TRIM33). RMSD:0.6025
Å |
 |  |  |  |  |
| TRIM35_CCDC25_ENST00000521253_ENST00000356537_27168317_27610104 superimposed PDB: 7EOF of partner (CCDC25). RMSD:3.2263
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000305364_ENST00000414019_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.6075
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000305364_ENST00000537535_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7515
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000305364_ENST00000541648_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8505
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000521253_ENST00000221130_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8261
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000521253_ENST00000414019_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.6252
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000521253_ENST00000537535_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7711
Å |
 |  |  |  |  |
| TRIM35_GSR_ENST00000521253_ENST00000541648_27151596_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7572
Å |
 |  |  |  |  |
| TRIM37_DNAH17_ENST00000262294_ENST00000389840_57161362_76441762 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.454
Å |
 |  |  |  |  |
| TRIM37_DNAH17_ENST00000393065_ENST00000585328_57161362_76441762 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:2.8056
Å |
 |  |  |  |  |
| TRIM37_DNAH17_ENST00000393066_ENST00000585328_57161362_76441762 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.477
Å |
 |  |  |  |  |
| TRIM37_MSI2_ENST00000376149_ENST00000284073_57148183_55478739 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.4835
Å |
 |  |  |  |  |
| TRIM37_MYO19_ENST00000262294_ENST00000431794_57161362_34863351 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.5241
Å |
 |  |  |  |  |
| TRIM37_MYO19_ENST00000376149_ENST00000431794_57161362_34863763 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.9865
Å |
 |  |  |  |  |
| TRIM37_PCTP_ENST00000262294_ENST00000573500_57183801_53844695 superimposed PDB: 7U9D of partner (PCTP). RMSD:0.971
Å |
 |  |  |  |  |
| TRIM37_TUBD1_ENST00000393066_ENST00000346141_57181653_57937785 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:2.4901
Å |
 |  |  |  |  |
| TRIM37_TUBD1_ENST00000584889_ENST00000346141_57181653_57937785 superimposed PDB: 3LRQ of partner (TRIM37). RMSD:0.4094
Å |
 |  |  |  |  |
| TRIM41_ASB9_ENST00000315073_ENST00000380483_180651812_15277067 superimposed PDB: 2EGM of partner (TRIM41). RMSD:2.7148
Å |
 |  |  |  |  |
| TRIM41_ASB9_ENST00000315073_ENST00000380483_180651812_15277067 superimposed PDB: 6V9H of partner (ASB9). RMSD:0.6189
Å |
| | | |  |
| TRIM41_ASB9_ENST00000351937_ENST00000380485_180651812_15277067 superimposed PDB: 2EGM of partner (TRIM41). RMSD:3.0684
Å |
 |  |  |  |  |
| TRIM41_ASB9_ENST00000351937_ENST00000380485_180651812_15277067 superimposed PDB: 6V9H of partner (ASB9). RMSD:3.868
Å |
| | | |  |
| TRIOBP_POLR2F_ENST00000403663_ENST00000460648_38164183_38363105 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:1.1058
Å |
 |  |  |  |  |
| TRIOBP_POLR2F_ENST00000406386_ENST00000460648_38164183_38363105 superimposed PDB: 9EHZ of partner (POLR2F). RMSD:0.794
Å |
 |  |  |  |  |
| TRIO_ABCC8_ENST00000344204_ENST00000302539_14406781_17474830 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.2671
Å |
 |  |  |  |  |
| TRIO_ABCC8_ENST00000344204_ENST00000302539_14406781_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:1.6517
Å |
| | | |  |
| TRIO_ABCC8_ENST00000537187_ENST00000389817_14406781_17474830 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.0469
Å |
 |  |  |  |  |
| TRIO_ABCC8_ENST00000537187_ENST00000389817_14406781_17474830 superimposed PDB: 6C3O of partner (ABCC8). RMSD:1.5882
Å |
| | | |  |
| TRIO_CDH18_ENST00000344204_ENST00000274170_14420130_19612710 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.4081
Å |
 |  |  |  |  |
| TRIO_CDH18_ENST00000344204_ENST00000507958_14420130_19612710 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.2328
Å |
 |  |  |  |  |
| TRIO_CDH18_ENST00000344204_ENST00000511273_14420130_19612710 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.7408
Å |
 |  |  |  |  |
| TRIO_CDH18_ENST00000537187_ENST00000382275_14420130_19612710 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.7158
Å |
 |  |  |  |  |
| TRIO_DAP_ENST00000344204_ENST00000432074_14420130_10748383 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.4894
Å |
 |  |  |  |  |
| TRIO_DAP_ENST00000537187_ENST00000230895_14420130_10748383 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.382
Å |
 |  |  |  |  |
| TRIO_FBXL7_ENST00000537187_ENST00000504595_14420130_15616090 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.3201
Å |
 |  |  |  |  |
| TRIO_PPP2R5E_ENST00000344204_ENST00000422769_14280545_63848875 superimposed PDB: 8UWB of partner (PPP2R5E). RMSD:2.6574
Å |
 |  |  |  |  |
| TRIO_PPP2R5E_ENST00000344204_ENST00000555899_14280545_63848875 superimposed PDB: 8UWB of partner (PPP2R5E). RMSD:2.1197
Å |
 |  |  |  |  |
| TRIO_PPP2R5E_ENST00000509967_ENST00000422769_14280545_63848875 superimposed PDB: 8UWB of partner (PPP2R5E). RMSD:2.629
Å |
 |  |  |  |  |
| TRIO_PPP2R5E_ENST00000509967_ENST00000555899_14280545_63848875 superimposed PDB: 8UWB of partner (PPP2R5E). RMSD:2.041
Å |
 |  |  |  |  |
| TRIO_TBC1D8_ENST00000344204_ENST00000409318_14472767_101648847 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6077
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000344204_ENST00000334602_14420130_1282739 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.2646
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000344204_ENST00000334602_14420130_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.3341
Å |
| | | |  |
| TRIO_TERT_ENST00000344204_ENST00000508104_14406781_1268748 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.5844
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000344204_ENST00000508104_14420130_1282739 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.1044
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000344204_ENST00000508104_14420130_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:1.9601
Å |
| | | |  |
| TRIO_TERT_ENST00000537187_ENST00000296820_14406781_1282739 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6473
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000537187_ENST00000310581_14420130_1282739 superimposed PDB: 7SJ4 of partner (TRIO). RMSD:1.6531
Å |
 |  |  |  |  |
| TRIO_TERT_ENST00000537187_ENST00000310581_14420130_1282739 superimposed PDB: 7QXA of partner (TERT). RMSD:2.6494
Å |
| | | |  |
| TRIT1_ADH1B_ENST00000316891_ENST00000305046_40348989_100240043 superimposed PDB: 1U3U of partner (ADH1B). RMSD:0.531
Å |
 |  |  |  |  |
| TRIT1_ADH1C_ENST00000316891_ENST00000515683_40348989_100268301 superimposed PDB: 1U3W of partner (ADH1C). RMSD:0.5365
Å |
 |  |  |  |  |
| TRIT1_DNAJC8_ENST00000316891_ENST00000263697_40348989_28541507 superimposed PDB: 7VPX of partner (DNAJC8). RMSD:1.5323
Å |
 |  |  |  |  |
| TRIT1_IL22RA1_ENST00000316891_ENST00000270800_40348989_24454769 superimposed PDB: 3DLQ of partner (IL22RA1). RMSD:2.5093
Å |
 |  |  |  |  |
| TRMT10B_AR_ENST00000297994_ENST00000374690_37776402_66905851 superimposed PDB: 5CJ6 of partner (AR). RMSD:0.5497
Å |
 |  |  |  |  |
| TRMT10B_AR_ENST00000377754_ENST00000374690_37776402_66905851 superimposed PDB: 5CJ6 of partner (AR). RMSD:0.4419
Å |
 |  |  |  |  |
| TRMT10B_AR_ENST00000537911_ENST00000374690_37776402_66905851 superimposed PDB: 5CJ6 of partner (AR). RMSD:0.5004
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000323874_28880249_29618380 superimposed PDB: 2DHG of partner (TRNAU1AP). RMSD:2.0499
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000323874_28880249_29618380 superimposed PDB: 6SUB of partner (PTPRU). RMSD:0.5427
Å |
| | | |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000356870_28880249_29618380 superimposed PDB: 2DHG of partner (TRNAU1AP). RMSD:2.0941
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000356870_28880249_29618380 superimposed PDB: 6SUB of partner (PTPRU). RMSD:0.4824
Å |
| | | |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000373779_28880249_29618380 superimposed PDB: 2DHG of partner (TRNAU1AP). RMSD:2.1336
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000373779_28880249_29618380 superimposed PDB: 6SUB of partner (PTPRU). RMSD:0.4943
Å |
| | | |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000428026_28880249_29618380 superimposed PDB: 2DHG of partner (TRNAU1AP). RMSD:2.0005
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000428026_28880249_29618380 superimposed PDB: 6SUB of partner (PTPRU). RMSD:0.5613
Å |
| | | |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000460170_28880249_29618380 superimposed PDB: 2DHG of partner (TRNAU1AP). RMSD:2.0999
Å |
 |  |  |  |  |
| TRNAU1AP_PTPRU_ENST00000373830_ENST00000460170_28880249_29618380 superimposed PDB: 6SUB of partner (PTPRU). RMSD:0.4832
Å |
| | | |  |
| TROVE2_PGD_ENST00000400968_ENST00000270776_193051838_10464217 superimposed PDB: 2JKV of partner (PGD). RMSD:0.4536
Å |
 |  |  |  |  |
| TROVE2_PGD_ENST00000432079_ENST00000270776_193051838_10464217 superimposed PDB: 2JKV of partner (PGD). RMSD:0.4928
Å |
 |  |  |  |  |
| TRPC4AP_KCNB1_ENST00000252015_ENST00000371741_33657098_47991529 superimposed PDB: 9O10 of partner (KCNB1). RMSD:1.7047
Å |
 |  |  |  |  |
| TRPC4AP_RBM39_ENST00000451813_ENST00000361162_33657098_34304727 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.742
Å |
 |  |  |  |  |
| TRPC4AP_RBM39_ENST00000451813_ENST00000528062_33657098_34304727 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7442
Å |
 |  |  |  |  |
| TRPM4_RPL37A_ENST00000252826_ENST00000600880_49669472_217363992 superimposed PDB: 9MRT of partner (TRPM4). RMSD:2.8111
Å |
 |  |  |  |  |
| TRPM4_RPL37A_ENST00000427978_ENST00000600880_49669472_217363992 superimposed PDB: 9MRT of partner (TRPM4). RMSD:2.6735
Å |
 |  |  |  |  |
| TRPS1_C19orf66_ENST00000519076_ENST00000397881_116599227_10200332 superimposed PDB: 9KBO of partner (C19orf66). RMSD:2.0273
Å |
 |  |  |  |  |
| TRPS1_C19orf66_ENST00000519076_ENST00000591813_116599227_10200332 superimposed PDB: 9KBO of partner (C19orf66). RMSD:1.8751
Å |
 |  |  |  |  |
| TRPS1_C19orf66_ENST00000520276_ENST00000397881_116599227_10200332 superimposed PDB: 9KBO of partner (C19orf66). RMSD:2.2606
Å |
 |  |  |  |  |
| TRPS1_C19orf66_ENST00000520276_ENST00000591813_116599227_10200332 superimposed PDB: 9KBO of partner (C19orf66). RMSD:1.832
Å |
 |  |  |  |  |
| TRPS1_LASP1_ENST00000520276_ENST00000318008_116631358_37034338 superimposed PDB: 3I35 of partner (LASP1). RMSD:0.3635
Å |
 |  |  |  |  |
| TRPV3_UBE2G1_ENST00000301365_ENST00000572484_3438866_4192703 superimposed PDB: 8V6K of partner (TRPV3). RMSD:0.5611
Å |
 |  |  |  |  |
| TRPV3_UBE2G1_ENST00000301365_ENST00000572484_3438866_4192703 superimposed PDB: 6D68 of partner (UBE2G1). RMSD:1.3251
Å |
| | | |  |
| TRPV3_UBE2G1_ENST00000301365_ENST00000572484_3445815_4192703 superimposed PDB: 8V6K of partner (TRPV3). RMSD:0.7259
Å |
 |  |  |  |  |
| TRPV3_UBE2G1_ENST00000301365_ENST00000572484_3445815_4192703 superimposed PDB: 6D68 of partner (UBE2G1). RMSD:1.1925
Å |
| | | |  |
| TRPV3_UBE2G1_ENST00000576742_ENST00000572484_3438866_4192703 superimposed PDB: 8V6K of partner (TRPV3). RMSD:0.5316
Å |
 |  |  |  |  |
| TRPV3_UBE2G1_ENST00000576742_ENST00000572484_3438866_4192703 superimposed PDB: 6D68 of partner (UBE2G1). RMSD:1.4256
Å |
| | | |  |
| TRPV3_UBE2G1_ENST00000576742_ENST00000572484_3445815_4192703 superimposed PDB: 8V6K of partner (TRPV3). RMSD:0.7698
Å |
 |  |  |  |  |
| TRPV3_UBE2G1_ENST00000576742_ENST00000572484_3445815_4192703 superimposed PDB: 6D68 of partner (UBE2G1). RMSD:1.3959
Å |
| | | |  |
| TRPV6_FOXN3_ENST00000359396_ENST00000261302_142583133_89817152 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.5359
Å |
 |  |  |  |  |
| TRPV6_FOXN3_ENST00000359396_ENST00000555353_142583133_89817152 superimposed PDB: 6NCE of partner (FOXN3). RMSD:0.5777
Å |
 |  |  |  |  |
| TRRAP_ASNS_ENST00000355540_ENST00000394309_98557113_97493808 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.382
Å |
 |  |  |  |  |
| TRRAP_ASNS_ENST00000355540_ENST00000394309_98557113_97493808 superimposed PDB: 6GQ3 of partner (ASNS). RMSD:0.8171
Å |
| | | |  |
| TRRAP_ASNS_ENST00000359863_ENST00000394309_98557113_97493808 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.3342
Å |
 |  |  |  |  |
| TRRAP_ASNS_ENST00000359863_ENST00000394309_98557113_97493808 superimposed PDB: 6GQ3 of partner (ASNS). RMSD:0.8878
Å |
| | | |  |
| TRRAP_ASNS_ENST00000446306_ENST00000394309_98557113_97493808 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.3589
Å |
 |  |  |  |  |
| TRRAP_ASNS_ENST00000446306_ENST00000394309_98557113_97493808 superimposed PDB: 6GQ3 of partner (ASNS). RMSD:1.1642
Å |
| | | |  |
| TRRAP_SON_ENST00000355540_ENST00000290239_98495489_34931535 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.5723
Å |
 |  |  |  |  |
| TRRAP_SON_ENST00000355540_ENST00000381692_98495489_34931535 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.6006
Å |
 |  |  |  |  |
| TRRAP_SON_ENST00000359863_ENST00000356577_98495489_34931535 superimposed PDB: 9RDK of partner (TRRAP). RMSD:2.6486
Å |
 |  |  |  |  |
| TSC2_RBP1_ENST00000350773_ENST00000232219_2108874_139258671 superimposed PDB: 9CE3 of partner (TSC2). RMSD:1.5165
Å |
 |  |  |  |  |
| TSC2_RBP1_ENST00000353929_ENST00000232219_2108874_139258671 superimposed PDB: 9CE3 of partner (TSC2). RMSD:1.0619
Å |
 |  |  |  |  |
| TSC2_RBP1_ENST00000382538_ENST00000232219_2108874_139258671 superimposed PDB: 9CE3 of partner (TSC2). RMSD:1.0386
Å |
 |  |  |  |  |
| TSC2_RBP1_ENST00000401874_ENST00000232219_2108874_139258671 superimposed PDB: 9CE3 of partner (TSC2). RMSD:0.9623
Å |
 |  |  |  |  |
| TSEN2_PPARG_ENST00000314571_ENST00000309576_12545283_12434112 superimposed PDB: 8HMZ of partner (TSEN2). RMSD:2.0981
Å |
 |  |  |  |  |
| TSEN2_PPARG_ENST00000314571_ENST00000309576_12545283_12434112 superimposed PDB: 3DZY of partner (PPARG). RMSD:0.5891
Å |
| | | |  |
| TSEN2_PPARG_ENST00000314571_ENST00000539812_12545283_12434112 superimposed PDB: 8HMZ of partner (TSEN2). RMSD:2.6653
Å |
 |  |  |  |  |
| TSEN2_PPARG_ENST00000314571_ENST00000539812_12545283_12434112 superimposed PDB: 3DZY of partner (PPARG). RMSD:3.1949
Å |
| | | |  |
| TSEN2_PPARG_ENST00000454502_ENST00000309576_12545283_12434112 superimposed PDB: 8HMZ of partner (TSEN2). RMSD:2.6636
Å |
 |  |  |  |  |
| TSEN2_PPARG_ENST00000454502_ENST00000309576_12545283_12434112 superimposed PDB: 3DZY of partner (PPARG). RMSD:0.5915
Å |
| | | |  |
| TSFM_CNOT2_ENST00000454289_ENST00000418359_58177066_70732222 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6632
Å |
 |  |  |  |  |
| TSFM_CNOT2_ENST00000454289_ENST00000418359_58177066_70732222 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.2898
Å |
| | | |  |
| TSFM_CNOT2_ENST00000543727_ENST00000418359_58177066_70732222 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6764
Å |
 |  |  |  |  |
| TSFM_CNOT2_ENST00000543727_ENST00000418359_58177066_70732222 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.0214
Å |
| | | |  |
| TSFM_CNOT2_ENST00000550559_ENST00000418359_58177066_70732222 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6434
Å |
 |  |  |  |  |
| TSFM_CNOT2_ENST00000550559_ENST00000418359_58177066_70732222 superimposed PDB: 4C0D of partner (CNOT2). RMSD:2.0617
Å |
| | | |  |
| TSFM_CPM_ENST00000323833_ENST00000551568_58186856_69279669 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6603
Å |
 |  |  |  |  |
| TSFM_CPM_ENST00000323833_ENST00000551568_58186856_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4869
Å |
| | | |  |
| TSFM_CPM_ENST00000350762_ENST00000551568_58186856_69279669 superimposed PDB: 2CP9 of partner (TSFM). RMSD:1.2458
Å |
 |  |  |  |  |
| TSFM_CPM_ENST00000350762_ENST00000551568_58186856_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4829
Å |
| | | |  |
| TSFM_CPM_ENST00000454289_ENST00000551568_58186856_69279669 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6536
Å |
 |  |  |  |  |
| TSFM_CPM_ENST00000454289_ENST00000551568_58186856_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4859
Å |
| | | |  |
| TSFM_CPM_ENST00000543727_ENST00000551568_58186856_69279669 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.649
Å |
 |  |  |  |  |
| TSFM_CPM_ENST00000543727_ENST00000551568_58186856_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4717
Å |
| | | |  |
| TSFM_CPM_ENST00000550559_ENST00000551568_58186856_69279669 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6807
Å |
 |  |  |  |  |
| TSFM_CPM_ENST00000550559_ENST00000551568_58186856_69279669 superimposed PDB: 1UWY of partner (CPM). RMSD:0.4567
Å |
| | | |  |
| TSFM_HMGA2_ENST00000454289_ENST00000393577_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.7006
Å |
 |  |  |  |  |
| TSFM_HMGA2_ENST00000540550_ENST00000403681_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6815
Å |
 |  |  |  |  |
| TSFM_HMGA2_ENST00000543727_ENST00000393577_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6867
Å |
 |  |  |  |  |
| TSFM_HMGA2_ENST00000548851_ENST00000403681_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6768
Å |
 |  |  |  |  |
| TSFM_HMGA2_ENST00000550559_ENST00000393577_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.7003
Å |
 |  |  |  |  |
| TSFM_HMGA2_ENST00000550559_ENST00000403681_58180074_66345162 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.664
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000323833_ENST00000261267_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6247
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000323833_ENST00000261267_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.581
Å |
| | | |  |
| TSFM_LYZ_ENST00000323833_ENST00000549690_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6371
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000323833_ENST00000549690_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5568
Å |
| | | |  |
| TSFM_LYZ_ENST00000350762_ENST00000261267_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6156
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000350762_ENST00000261267_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.6864
Å |
| | | |  |
| TSFM_LYZ_ENST00000350762_ENST00000549690_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:2.569
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000350762_ENST00000549690_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5296
Å |
| | | |  |
| TSFM_LYZ_ENST00000454289_ENST00000549690_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.666
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000454289_ENST00000549690_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5627
Å |
| | | |  |
| TSFM_LYZ_ENST00000543727_ENST00000549690_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6149
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000543727_ENST00000549690_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5679
Å |
| | | |  |
| TSFM_LYZ_ENST00000548851_ENST00000261267_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.5753
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000548851_ENST00000261267_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.4592
Å |
| | | |  |
| TSFM_LYZ_ENST00000550559_ENST00000261267_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.6739
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000550559_ENST00000261267_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5608
Å |
| | | |  |
| TSFM_LYZ_ENST00000550559_ENST00000549690_58186856_69743887 superimposed PDB: 2CP9 of partner (TSFM). RMSD:0.639
Å |
 |  |  |  |  |
| TSFM_LYZ_ENST00000550559_ENST00000549690_58186856_69743887 superimposed PDB: 1C7P of partner (LYZ). RMSD:0.5184
Å |
| | | |  |
| TSHZ1_RNASEH2B_ENST00000580243_ENST00000422660_72923871_51501542 superimposed PDB: 8YJZ of partner (RNASEH2B). RMSD:1.1394
Å |
 |  |  |  |  |
| TSHZ3_IFNL1_ENST00000558569_ENST00000333625_31840085_39787444 superimposed PDB: 3OG6 of partner (IFNL1). RMSD:0.8218
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000298649_71244971_71124538 superimposed PDB: 8ESV of partner (TSPAN15). RMSD:1.0232
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000298649_71244971_71124538 superimposed PDB: 1CZA of partner (HK1). RMSD:2.3839
Å |
| | | |  |
| TSPAN15_HK1_ENST00000373290_ENST00000298649_71258152_71103582 superimposed PDB: 8ESV of partner (TSPAN15). RMSD:2.7754
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000298649_71258152_71103582 superimposed PDB: 1CZA of partner (HK1). RMSD:2.6502
Å |
| | | |  |
| TSPAN15_HK1_ENST00000373290_ENST00000360289_71244971_71124538 superimposed PDB: 1CZA of partner (HK1). RMSD:0.7698
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000448642_71244971_71124538 superimposed PDB: 8ESV of partner (TSPAN15). RMSD:0.9831
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000448642_71244971_71124538 superimposed PDB: 1CZA of partner (HK1). RMSD:2.3524
Å |
| | | |  |
| TSPAN15_HK1_ENST00000373290_ENST00000448642_71258152_71103582 superimposed PDB: 8ESV of partner (TSPAN15). RMSD:2.8548
Å |
 |  |  |  |  |
| TSPAN15_HK1_ENST00000373290_ENST00000448642_71258152_71103582 superimposed PDB: 1CZA of partner (HK1). RMSD:2.6679
Å |
| | | |  |
| TSPAN31_WIF1_ENST00000547472_ENST00000286574_58140914_65471634 superimposed PDB: 2YGQ of partner (WIF1). RMSD:2.3997
Å |
 |  |  |  |  |
| TSPAN31_WIF1_ENST00000547992_ENST00000286574_58140914_65471634 superimposed PDB: 2YGQ of partner (WIF1). RMSD:2.7204
Å |
 |  |  |  |  |
| TSPAN3_CHRNA3_ENST00000558745_ENST00000326828_77344726_78894606 superimposed PDB: 6PV7 of partner (CHRNA3). RMSD:2.0456
Å |
 |  |  |  |  |
| TSPAN3_ELF1_ENST00000346495_ENST00000442101_77363233_41533152 superimposed PDB: 8BZM of partner (ELF1). RMSD:0.6425
Å |
 |  |  |  |  |
| TSPAN3_ELF1_ENST00000424443_ENST00000442101_77363233_41533152 superimposed PDB: 8BZM of partner (ELF1). RMSD:0.6244
Å |
 |  |  |  |  |
| TSPAN5_ADH4_ENST00000305798_ENST00000265512_99579296_100063931 superimposed PDB: 3COS of partner (ADH4). RMSD:0.6082
Å |
 |  |  |  |  |
| TTBK2_TP53BP1_ENST00000267890_ENST00000382039_43120125_43733781 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5285
Å |
 |  |  |  |  |
| TTBK2_TP53BP1_ENST00000267890_ENST00000382044_43120125_43733781 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5077
Å |
 |  |  |  |  |
| TTBK2_TP53BP1_ENST00000567840_ENST00000263801_43120125_43733781 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5269
Å |
 |  |  |  |  |
| TTC13_JAK2_ENST00000366661_ENST00000381652_231075131_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.5875
Å |
 |  |  |  |  |
| TTC13_JAK2_ENST00000366662_ENST00000381652_231075131_5064882 superimposed PDB: 4Z32 of partner (JAK2). RMSD:0.9022
Å |
 |  |  |  |  |
| TTC21A_GBE1_ENST00000301819_ENST00000489715_39156233_81754764 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.6336
Å |
 |  |  |  |  |
| TTC21A_GBE1_ENST00000431162_ENST00000489715_39156233_81754764 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.618
Å |
 |  |  |  |  |
| TTC21A_GBE1_ENST00000440121_ENST00000489715_39156233_81754764 superimposed PDB: 4BZY of partner (GBE1). RMSD:0.5975
Å |
 |  |  |  |  |
| TTC28_PI4KA_ENST00000397906_ENST00000572273_28426213_21154054 superimposed PDB: 9B9G of partner (PI4KA). RMSD:3.2384
Å |
 |  |  |  |  |
| TTC37_CTNNA2_ENST00000358746_ENST00000496558_94872520_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.5177
Å |
 |  |  |  |  |
| TTC37_CTNNA2_ENST00000358746_ENST00000540488_94872520_80620335 superimposed PDB: 6DUW of partner (CTNNA2). RMSD:0.4888
Å |
 |  |  |  |  |
| TTC39B_PSIP1_ENST00000512701_ENST00000380716_15267911_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.418
Å |
 |  |  |  |  |
| TTC39B_PSIP1_ENST00000512701_ENST00000380733_15267911_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.4116
Å |
 |  |  |  |  |
| TTC39B_PSIP1_ENST00000512701_ENST00000397519_15267911_15490122 superimposed PDB: 8PEO of partner (PSIP1). RMSD:1.4153
Å |
 |  |  |  |  |
| TTC39C_NPC1_ENST00000317571_ENST00000269228_21663045_21153538 superimposed PDB: 6W5S of partner (NPC1). RMSD:1.9358
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000319190_ENST00000304421_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.4602
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000319190_ENST00000304421_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.3898
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000319190_ENST00000346173_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.5927
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000319190_ENST00000346173_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.8838
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000319190_ENST00000406846_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:3.2246
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000394850_ENST00000304421_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.6358
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000394850_ENST00000304421_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.5847
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000394850_ENST00000346173_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.6928
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000394850_ENST00000346173_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.8931
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000394850_ENST00000406846_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.9401
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000409245_ENST00000304421_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.5755
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000409245_ENST00000304421_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.5287
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000409245_ENST00000346173_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:2.7927
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000409245_ENST00000406846_47206046_49247299 superimposed PDB: 8I2H of partner (FSHR). RMSD:3.1926
Å |
 |  |  |  |  |
| TTC7A_FSHR_ENST00000409245_ENST00000406846_47206046_49295429 superimposed PDB: 8I2H of partner (FSHR). RMSD:3.0145
Å |
 |  |  |  |  |
| TTC8_PTPRB_ENST00000345383_ENST00000334414_89291165_70928431 superimposed PDB: 2I4G of partner (PTPRB). RMSD:0.4667
Å |
 |  |  |  |  |
| TTC8_PTPRB_ENST00000345383_ENST00000334414_89291165_70928735 superimposed PDB: 2I4G of partner (PTPRB). RMSD:0.6244
Å |
 |  |  |  |  |
| TTK_TMEM63B_ENST00000509894_ENST00000323267_80721265_44119582 superimposed PDB: 8EHX of partner (TMEM63B). RMSD:1.3146
Å |
 |  |  |  |  |
| TTLL3_TBL1XR1_ENST00000426895_ENST00000457928_9855029_176765337 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.4215
Å |
 |  |  |  |  |
| TTLL3_TBL1XR1_ENST00000547186_ENST00000457928_9855029_176765337 superimposed PDB: 4LG9 of partner (TBL1XR1). RMSD:0.4907
Å |
 |  |  |  |  |
| TTLL3_TGFB1_ENST00000547186_ENST00000221930_9859443_41854360 superimposed PDB: 8REW of partner (TGFB1). RMSD:0.6388
Å |
 |  |  |  |  |
| TTLL5_JDP2_ENST00000298832_ENST00000419727_76259443_75928128 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5317
Å |
 |  |  |  |  |
| TTLL5_JDP2_ENST00000554510_ENST00000419727_76259443_75928128 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6971
Å |
 |  |  |  |  |
| TTLL5_JDP2_ENST00000556893_ENST00000419727_76259443_75928128 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6127
Å |
 |  |  |  |  |
| TTLL5_JDP2_ENST00000557636_ENST00000419727_76259443_75928128 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.8292
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000402788_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5773
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000402788_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7959
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000404301_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5427
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000404301_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7828
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000406236_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5636
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000406236_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.774
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000407322_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.567
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000407322_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.77
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000553525_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5805
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000553525_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.759
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000553530_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5567
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000553530_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7109
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000555571_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5836
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000555571_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7445
Å |
| | | |  |
| TTLL5_RGS6_ENST00000298832_ENST00000556437_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5988
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000298832_ENST00000556437_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8083
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000402788_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.7091
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000402788_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8128
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000404301_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6738
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000404301_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8689
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000406236_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6116
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000406236_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8037
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000407322_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6967
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000407322_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8485
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000553525_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6889
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000553525_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7865
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000553530_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.712
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000553530_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7894
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000555571_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5855
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000555571_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.869
Å |
| | | |  |
| TTLL5_RGS6_ENST00000554510_ENST00000556437_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6651
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000554510_ENST00000556437_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8288
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000402788_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6361
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000402788_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8157
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000404301_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6495
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000404301_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8341
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000406236_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6572
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000406236_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7764
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000407322_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6695
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000407322_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7977
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000553525_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6707
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000553525_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7313
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000553530_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.7962
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000553530_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8401
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000555571_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6275
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000555571_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8327
Å |
| | | |  |
| TTLL5_RGS6_ENST00000556893_ENST00000556437_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.741
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000556893_ENST00000556437_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7935
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000402788_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5508
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000402788_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8079
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000404301_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5891
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000404301_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8139
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000406236_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5589
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000406236_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.8157
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000407322_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.53
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000407322_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7701
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000553530_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6185
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000553530_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.786
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000555571_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5838
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000555571_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7687
Å |
| | | |  |
| TTLL5_RGS6_ENST00000557636_ENST00000556437_76249873_72921235 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5483
Å |
 |  |  |  |  |
| TTLL5_RGS6_ENST00000557636_ENST00000556437_76249873_72921235 superimposed PDB: 2ES0 of partner (RGS6). RMSD:0.7773
Å |
| | | |  |
| TTLL5_TSHR_ENST00000298832_ENST00000298171_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.56
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000298832_ENST00000298171_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.4944
Å |
| | | |  |
| TTLL5_TSHR_ENST00000298832_ENST00000342443_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6153
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000298832_ENST00000342443_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:2.1012
Å |
| | | |  |
| TTLL5_TSHR_ENST00000298832_ENST00000541158_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5706
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000298832_ENST00000541158_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.5386
Å |
| | | |  |
| TTLL5_TSHR_ENST00000298832_ENST00000554435_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5965
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000298832_ENST00000554435_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.5696
Å |
| | | |  |
| TTLL5_TSHR_ENST00000554510_ENST00000298171_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6473
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000554510_ENST00000298171_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.4521
Å |
| | | |  |
| TTLL5_TSHR_ENST00000554510_ENST00000342443_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5597
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000554510_ENST00000342443_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:2.5184
Å |
| | | |  |
| TTLL5_TSHR_ENST00000554510_ENST00000541158_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.7224
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000554510_ENST00000541158_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.5033
Å |
| | | |  |
| TTLL5_TSHR_ENST00000554510_ENST00000554435_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6226
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000554510_ENST00000554435_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.4511
Å |
| | | |  |
| TTLL5_TSHR_ENST00000556893_ENST00000298171_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.678
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000556893_ENST00000298171_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.4646
Å |
| | | |  |
| TTLL5_TSHR_ENST00000556893_ENST00000342443_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6782
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000556893_ENST00000342443_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:2.0776
Å |
| | | |  |
| TTLL5_TSHR_ENST00000556893_ENST00000541158_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5635
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000556893_ENST00000541158_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.5287
Å |
| | | |  |
| TTLL5_TSHR_ENST00000556893_ENST00000554435_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.7229
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000556893_ENST00000554435_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.44
Å |
| | | |  |
| TTLL5_TSHR_ENST00000557636_ENST00000298171_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.568
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000557636_ENST00000298171_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.4865
Å |
| | | |  |
| TTLL5_TSHR_ENST00000557636_ENST00000342443_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.6339
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000557636_ENST00000342443_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:2.2656
Å |
| | | |  |
| TTLL5_TSHR_ENST00000557636_ENST00000541158_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.7144
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000557636_ENST00000554435_76286504_81528491 superimposed PDB: 9PHH of partner (TTLL5). RMSD:0.5482
Å |
 |  |  |  |  |
| TTLL5_TSHR_ENST00000557636_ENST00000554435_76286504_81528491 superimposed PDB: 7UTZ of partner (TSHR). RMSD:0.5646
Å |
| | | |  |
| TTLL7_SAMD13_ENST00000260505_ENST00000370671_84369761_84791319 superimposed PDB: 4YLR of partner (TTLL7). RMSD:0.4836
Å |
 |  |  |  |  |
| TTYH3_MAD1L1_ENST00000407643_ENST00000399654_2671912_2020176 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.034
Å |
 |  |  |  |  |
| TTYH3_MAD1L1_ENST00000407643_ENST00000399654_2686887_1976533 superimposed PDB: 9QNR of partner (TTYH3). RMSD:2.2548
Å |
 |  |  |  |  |
| TTYH3_MAD1L1_ENST00000407643_ENST00000399654_2686887_1976533 superimposed PDB: 7B1F of partner (MAD1L1). RMSD:1.0785
Å |
| | | |  |
| TUBA1C_KRT14_ENST00000549183_ENST00000167586_49658967_39741309 superimposed PDB: 3TNU of partner (KRT14). RMSD:1.027
Å |
 |  |  |  |  |
| TUBB2A_SLC22A23_ENST00000333628_ENST00000406686_3155858_3324236 superimposed PDB: 7NVN of partner (TUBB2A). RMSD:0.7478
Å |
 |  |  |  |  |
| TUBD1_CDK12_ENST00000325752_ENST00000430627_57943969_37667781 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3728
Å |
 |  |  |  |  |
| TUBD1_CDK12_ENST00000346141_ENST00000447079_57943969_37667781 superimposed PDB: 4NST of partner (CDK12). RMSD:0.3682
Å |
 |  |  |  |  |
| TUFT1_PKN2_ENST00000392712_ENST00000316005_151512902_89206670 superimposed PDB: 4CRS of partner (PKN2). RMSD:0.4281
Å |
 |  |  |  |  |
| TULP3_GGNBP2_ENST00000397132_ENST00000304718_3043727_34937773 superimposed PDB: 8BFJ of partner (GGNBP2). RMSD:2.3431
Å |
 |  |  |  |  |
| TUSC3_LAMA2_ENST00000506802_ENST00000421865_15480758_129581855 superimposed PDB: 4YEQ of partner (LAMA2). RMSD:0.6155
Å |
 |  |  |  |  |
| TUSC3_SORBS3_ENST00000506802_ENST00000240123_15480758_22421499 superimposed PDB: 4M91 of partner (TUSC3). RMSD:2.0447
Å |
 |  |  |  |  |
| TUSC3_SORBS3_ENST00000506802_ENST00000240123_15480758_22421499 superimposed PDB: 2YUP of partner (SORBS3). RMSD:1.1008
Å |
| | | |  |
| TXLNG_CTPS2_ENST00000380122_ENST00000359276_16804712_16657366 superimposed PDB: 7MII of partner (CTPS2). RMSD:0.4759
Å |
 |  |  |  |  |
| TXNDC5_BLOC1S5_ENST00000379757_ENST00000543936_7895338_8026658 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7553
Å |
 |  |  |  |  |
| TXNDC5_BLOC1S5_ENST00000473453_ENST00000543936_7899808_8016061 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.8937
Å |
 |  |  |  |  |
| TXNDC5_BLOC1S5_ENST00000539054_ENST00000543936_7895338_8026658 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:1.0245
Å |
 |  |  |  |  |
| TXNDC5_COX7A2_ENST00000379757_ENST00000460985_7889727_75947704 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7359
Å |
 |  |  |  |  |
| TXNDC5_COX7A2_ENST00000473453_ENST00000370081_7889727_75947704 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7541
Å |
 |  |  |  |  |
| TXNDC5_COX7A2_ENST00000473453_ENST00000509698_7889727_75947704 superimposed PDB: 8EKY of partner (TXNDC5). RMSD:0.7392
Å |
 |  |  |  |  |
| TXNL4B_RPL22_ENST00000423037_ENST00000234875_72122885_6257816 superimposed PDB: 1XBS of partner (TXNL4B). RMSD:0.4548
Å |
 |  |  |  |  |
| TXNL4B_RPL22_ENST00000426362_ENST00000234875_72122885_6257816 superimposed PDB: 1XBS of partner (TXNL4B). RMSD:0.4813
Å |
 |  |  |  |  |
| TXNL4B_SMG1_ENST00000423037_ENST00000389467_72122885_18891041 superimposed PDB: 1XBS of partner (TXNL4B). RMSD:0.4619
Å |
 |  |  |  |  |
| TXNL4B_SMG1_ENST00000423037_ENST00000446231_72122885_18891041 superimposed PDB: 6L54 of partner (SMG1). RMSD:3.4163
Å |
 |  |  |  |  |
| TXNL4B_SMG1_ENST00000423037_ENST00000565224_72122885_18891041 superimposed PDB: 6L54 of partner (SMG1). RMSD:3.3246
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000388854_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4439
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000397736_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4243
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000427956_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4335
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000429002_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4341
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000526390_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.433
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000526691_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4418
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000526950_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4603
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000529546_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4454
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000540716_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.5217
Å |
 |  |  |  |  |
| TXNRD1_EEF1A1_ENST00000542918_ENST00000491404_104725419_74229140 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4443
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000378070_ENST00000302278_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.9145
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000378070_ENST00000396033_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8554
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000378070_ENST00000423113_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8694
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000388854_ENST00000423113_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.889
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000429002_ENST00000423113_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8798
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000525566_ENST00000302278_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8534
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000525566_ENST00000396033_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8656
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000526691_ENST00000302278_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.9334
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000526691_ENST00000396033_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8833
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000542918_ENST00000302278_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.8515
Å |
 |  |  |  |  |
| TXNRD1_ITGB1_ENST00000542918_ENST00000396033_104682818_33224486 superimposed PDB: 7NWL of partner (ITGB1). RMSD:2.819
Å |
 |  |  |  |  |
| TXNRD2_HMOX1_ENST00000400519_ENST00000216117_19929223_35782677 superimposed PDB: 6EHA of partner (HMOX1). RMSD:0.5572
Å |
 |  |  |  |  |
| TXN_GNB1_ENST00000374517_ENST00000378609_113007057_1720708 superimposed PDB: 4OO4 of partner (TXN). RMSD:1.1514
Å |
 |  |  |  |  |
| TXN_GNB1_ENST00000374517_ENST00000378609_113007057_1720708 superimposed PDB: 6WZG of partner (GNB1). RMSD:0.4908
Å |
| | | |  |
| TYK2_CIB3_ENST00000525621_ENST00000379859_10488889_16275724 superimposed PDB: 6WU7 of partner (CIB3). RMSD:1.1833
Å |
 |  |  |  |  |
| TYK2_SHC2_ENST00000524462_ENST00000264554_10468439_430747 superimposed PDB: 4OLI of partner (TYK2). RMSD:0.5015
Å |
 |  |  |  |  |
| TYK2_SHC2_ENST00000525621_ENST00000264554_10468439_430747 superimposed PDB: 4OLI of partner (TYK2). RMSD:0.486
Å |
 |  |  |  |  |
| TYRO3_MAPKBP1_ENST00000263798_ENST00000456763_41859735_42117406 superimposed PDB: 1RHF of partner (TYRO3). RMSD:1.1103
Å |
 |  |  |  |  |
| TYRO3_MAPKBP1_ENST00000559066_ENST00000456763_41859735_42117406 superimposed PDB: 1RHF of partner (TYRO3). RMSD:1.0385
Å |
 |  |  |  |  |
| TYR_SET_ENST00000263321_ENST00000409104_88924586_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.2497
Å |
 |  |  |  |  |
| U2AF2_RERE_ENST00000450554_ENST00000377464_56172555_8426034 superimposed PDB: 2YQK of partner (RERE). RMSD:2.0728
Å |
 |  |  |  |  |
| U2AF2_RERE_ENST00000450554_ENST00000400908_56172555_8426034 superimposed PDB: 2YQK of partner (RERE). RMSD:2.2527
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000322954_ENST00000374152_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8047
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000322954_ENST00000374152_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8528
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000322954_ENST00000457599_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.9348
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000322954_ENST00000457599_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8373
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000324856_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.9493
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000324856_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8439
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000374152_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8478
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000374152_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.7762
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000457599_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.9194
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000379983_ENST00000457599_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.785
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000539319_ENST00000374152_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.7776
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000539319_ENST00000374152_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8928
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000539319_ENST00000457599_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8416
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000539319_ENST00000457599_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8001
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000560441_ENST00000374152_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8019
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000560441_ENST00000374152_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.7982
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000560441_ENST00000457599_70957000_27094280 superimposed PDB: 6LTH of partner (ARID1A). RMSD:1.0299
Å |
 |  |  |  |  |
| UACA_ARID1A_ENST00000560441_ENST00000457599_70957000_27097609 superimposed PDB: 6LTH of partner (ARID1A). RMSD:0.8074
Å |
 |  |  |  |  |
| UBA1_PFKFB1_ENST00000335972_ENST00000545676_47061009_54961442 superimposed PDB: 9MC5 of partner (UBA1). RMSD:1.6315
Å |
 |  |  |  |  |
| UBA1_PFKFB1_ENST00000377351_ENST00000545676_47061009_54961442 superimposed PDB: 9MC5 of partner (UBA1). RMSD:1.4633
Å |
 |  |  |  |  |
| UBA2_FUCA2_ENST00000439527_ENST00000002165_34929671_143818634 superimposed PDB: 9QN5 of partner (UBA2). RMSD:0.3983
Å |
 |  |  |  |  |
| UBA2_MIER2_ENST00000246548_ENST00000264819_34941269_334542 superimposed PDB: 9QN5 of partner (UBA2). RMSD:0.5462
Å |
 |  |  |  |  |
| UBA2_MIER2_ENST00000439527_ENST00000264819_34941269_334542 superimposed PDB: 9QN5 of partner (UBA2). RMSD:2.584
Å |
 |  |  |  |  |
| UBA3_FRMD4B_ENST00000361055_ENST00000398540_69120685_69221132 superimposed PDB: 3GZN of partner (UBA3). RMSD:1.5295
Å |
 |  |  |  |  |
| UBA3_RAB12_ENST00000349511_ENST00000329286_69110964_8624935 superimposed PDB: 3GZN of partner (UBA3). RMSD:1.9295
Å |
 |  |  |  |  |
| UBA3_RAB12_ENST00000349511_ENST00000329286_69110964_8624935 superimposed PDB: 8VH5 of partner (RAB12). RMSD:0.8956
Å |
| | | |  |
| UBA3_RAB12_ENST00000361055_ENST00000329286_69110964_8624935 superimposed PDB: 3GZN of partner (UBA3). RMSD:1.7296
Å |
 |  |  |  |  |
| UBA3_RAB12_ENST00000361055_ENST00000329286_69110964_8624935 superimposed PDB: 8VH5 of partner (RAB12). RMSD:0.9913
Å |
| | | |  |
| UBAP2_APTX_ENST00000360802_ENST00000309615_34017047_32988127 superimposed PDB: 4NDH of partner (APTX). RMSD:0.2702
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000360802_ENST00000379817_34017047_32987844 superimposed PDB: 4NDH of partner (APTX). RMSD:0.3209
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000360802_ENST00000379817_34017047_32988127 superimposed PDB: 4NDH of partner (APTX). RMSD:0.3309
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000360802_ENST00000379819_34017047_32987844 superimposed PDB: 4NDH of partner (APTX). RMSD:0.3726
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000360802_ENST00000379819_34017047_32988127 superimposed PDB: 4NDH of partner (APTX). RMSD:0.3383
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000360802_ENST00000397172_34017047_32987844 superimposed PDB: 4NDH of partner (APTX). RMSD:0.2739
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000379238_ENST00000309615_34017047_32987844 superimposed PDB: 4NDH of partner (APTX). RMSD:1.0413
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000379238_ENST00000436040_34017047_32988127 superimposed PDB: 4NDH of partner (APTX). RMSD:1.3203
Å |
 |  |  |  |  |
| UBAP2_APTX_ENST00000449054_ENST00000436040_34017047_32987844 superimposed PDB: 4NDH of partner (APTX). RMSD:0.2536
Å |
 |  |  |  |  |
| UBAP2_TEAD1_ENST00000449054_ENST00000334310_33996220_12901254 superimposed PDB: 7CMM of partner (TEAD1). RMSD:0.7705
Å |
 |  |  |  |  |
| UBAP2_TEAD1_ENST00000449054_ENST00000527636_33996220_12901254 superimposed PDB: 7CMM of partner (TEAD1). RMSD:0.5321
Å |
 |  |  |  |  |
| UBB_ACAT1_ENST00000578649_ENST00000299355_16286054_108004546 superimposed PDB: 2IB8 of partner (ACAT1). RMSD:0.3644
Å |
 |  |  |  |  |
| UBE2E1_COL24A1_ENST00000346855_ENST00000436319_23929190_86315089 superimposed PDB: 3BZH of partner (UBE2E1). RMSD:0.6432
Å |
 |  |  |  |  |
| UBE2E1_COL24A1_ENST00000424381_ENST00000436319_23929190_86315089 superimposed PDB: 3BZH of partner (UBE2E1). RMSD:0.5012
Å |
 |  |  |  |  |
| UBE2E1_COL24A1_ENST00000467766_ENST00000370571_23929190_86315089 superimposed PDB: 3BZH of partner (UBE2E1). RMSD:0.4795
Å |
 |  |  |  |  |
| UBE2E1_INTS10_ENST00000346855_ENST00000397977_23929190_19687916 superimposed PDB: 8RC4 of partner (INTS10). RMSD:2.8281
Å |
 |  |  |  |  |
| UBE2E1_INTS10_ENST00000424381_ENST00000397977_23929190_19687916 superimposed PDB: 8RC4 of partner (INTS10). RMSD:2.8069
Å |
 |  |  |  |  |
| UBE2E1_INTS10_ENST00000467766_ENST00000397977_23929190_19687916 superimposed PDB: 8RC4 of partner (INTS10). RMSD:2.8857
Å |
 |  |  |  |  |
| UBE2E1_WNT7A_ENST00000306627_ENST00000285018_23853001_13916670 superimposed PDB: 8TZO of partner (WNT7A). RMSD:1.0362
Å |
 |  |  |  |  |
| UBE2E1_WNT7A_ENST00000346855_ENST00000285018_23848912_13916670 superimposed PDB: 8TZO of partner (WNT7A). RMSD:1.0842
Å |
 |  |  |  |  |
| UBE2E1_WNT7A_ENST00000424381_ENST00000285018_23853001_13916670 superimposed PDB: 8TZO of partner (WNT7A). RMSD:0.9924
Å |
 |  |  |  |  |
| UBE2E1_WNT7A_ENST00000467766_ENST00000285018_23853001_13916670 superimposed PDB: 8TZO of partner (WNT7A). RMSD:0.9257
Å |
 |  |  |  |  |
| UBE2E3_SLC9A7_ENST00000392415_ENST00000328306_181848820_46466638 superimposed PDB: 9P1Q of partner (UBE2E3). RMSD:2.8057
Å |
 |  |  |  |  |
| UBE2E3_SLC9A7_ENST00000410062_ENST00000328306_181848820_46466638 superimposed PDB: 9P1Q of partner (UBE2E3). RMSD:0.653
Å |
 |  |  |  |  |
| UBE2E3_SLC9A7_ENST00000602632_ENST00000328306_181848820_46466638 superimposed PDB: 9P1Q of partner (UBE2E3). RMSD:0.5904
Å |
 |  |  |  |  |
| UBE2G2_GART_ENST00000345496_ENST00000381831_46197213_34897307 superimposed PDB: 7LEW of partner (UBE2G2). RMSD:1.1633
Å |
 |  |  |  |  |
| UBE2G2_GART_ENST00000345496_ENST00000381831_46197213_34897307 superimposed PDB: 2QK4 of partner (GART). RMSD:1.138
Å |
| | | |  |
| UBE2J2_PGR_ENST00000339385_ENST00000325455_1198725_100962607 superimposed PDB: 2F4W of partner (UBE2J2). RMSD:0.3651
Å |
 |  |  |  |  |
| UBE2J2_PGR_ENST00000339385_ENST00000325455_1198725_100962607 superimposed PDB: 1SQN of partner (PGR). RMSD:0.6369
Å |
| | | |  |
| UBE2J2_PGR_ENST00000339385_ENST00000534013_1198725_100962607 superimposed PDB: 1SQN of partner (PGR). RMSD:0.4932
Å |
 |  |  |  |  |
| UBE2J2_PGR_ENST00000349431_ENST00000534013_1198725_100962607 superimposed PDB: 2F4W of partner (UBE2J2). RMSD:0.7977
Å |
 |  |  |  |  |
| UBE2J2_PGR_ENST00000349431_ENST00000534013_1198725_100962607 superimposed PDB: 1SQN of partner (PGR). RMSD:0.492
Å |
| | | |  |
| UBE2J2_PGR_ENST00000400930_ENST00000325455_1198725_100962607 superimposed PDB: 1SQN of partner (PGR). RMSD:0.5773
Å |
 |  |  |  |  |
| UBE2J2_PGR_ENST00000400930_ENST00000534013_1198725_100962607 superimposed PDB: 2F4W of partner (UBE2J2). RMSD:1.3277
Å |
 |  |  |  |  |
| UBE2J2_PGR_ENST00000400930_ENST00000534013_1198725_100962607 superimposed PDB: 1SQN of partner (PGR). RMSD:0.5166
Å |
| | | |  |
| UBE2K_ENOPH1_ENST00000261427_ENST00000273920_39757359_83375874 superimposed PDB: 1YNS of partner (ENOPH1). RMSD:2.7832
Å |
 |  |  |  |  |
| UBE2K_ENOPH1_ENST00000261427_ENST00000509635_39757359_83375874 superimposed PDB: 3K9O of partner (UBE2K). RMSD:0.876
Å |
 |  |  |  |  |
| UBE2K_ENOPH1_ENST00000261427_ENST00000509635_39757359_83375874 superimposed PDB: 1YNS of partner (ENOPH1). RMSD:0.3869
Å |
| | | |  |
| UBE2K_ENOPH1_ENST00000503368_ENST00000509635_39757359_83375874 superimposed PDB: 1YNS of partner (ENOPH1). RMSD:0.3682
Å |
 |  |  |  |  |
| UBE2L3_BID_ENST00000342192_ENST00000317361_21965332_18222254 superimposed PDB: 7V8F of partner (UBE2L3). RMSD:1.3827
Å |
 |  |  |  |  |
| UBE2L3_BID_ENST00000458578_ENST00000317361_21965332_18222254 superimposed PDB: 7V8F of partner (UBE2L3). RMSD:1.0231
Å |
 |  |  |  |  |
| UBE2L3_BID_ENST00000545681_ENST00000317361_21965332_18222254 superimposed PDB: 7V8F of partner (UBE2L3). RMSD:1.0431
Å |
 |  |  |  |  |
| UBE2N_APPL2_ENST00000550657_ENST00000258530_93835630_105623001 superimposed PDB: 4ONL of partner (UBE2N). RMSD:2.8386
Å |
 |  |  |  |  |
| UBE2R2_ACO1_ENST00000263228_ENST00000309951_33817932_32440462 superimposed PDB: 8Q7R of partner (UBE2R2). RMSD:1.5106
Å |
 |  |  |  |  |
| UBE2R2_ACO1_ENST00000263228_ENST00000309951_33817932_32440462 superimposed PDB: 2B3Y of partner (ACO1). RMSD:0.796
Å |
| | | |  |
| UBE2R2_FAAH2_ENST00000263228_ENST00000374900_33817932_57318930 superimposed PDB: 8Q7R of partner (UBE2R2). RMSD:1.395
Å |
 |  |  |  |  |
| UBE2R2_NFX1_ENST00000263228_ENST00000379540_33817932_33366626 superimposed PDB: 8Q7R of partner (UBE2R2). RMSD:1.5226
Å |
 |  |  |  |  |
| UBE2R2_SH3GL2_ENST00000263228_ENST00000380607_33817932_17747063 superimposed PDB: 8Q7R of partner (UBE2R2). RMSD:1.4609
Å |
 |  |  |  |  |
| UBE2V2_PRKAA1_ENST00000523111_ENST00000354209_48921030_40769605 superimposed PDB: 4RER of partner (PRKAA1). RMSD:2.6269
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000419880_ENST00000379454_74717885_62531578 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6945
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000419880_ENST00000379454_74717885_62531578 superimposed PDB: 9FVU of partner (ASPH). RMSD:0.9268
Å |
| | | |  |
| UBE2W_ASPH_ENST00000453587_ENST00000379454_74717885_62531578 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6566
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000453587_ENST00000379454_74717885_62531578 superimposed PDB: 9FVU of partner (ASPH). RMSD:1.0532
Å |
| | | |  |
| UBE2W_ASPH_ENST00000517608_ENST00000379454_74717885_62531578 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6402
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000517608_ENST00000379454_74717885_62531578 superimposed PDB: 9FVU of partner (ASPH). RMSD:1.0608
Å |
| | | |  |
| UBE2W_ASPH_ENST00000602593_ENST00000379454_74717885_62531578 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6384
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000602593_ENST00000379454_74717885_62531578 superimposed PDB: 9FVU of partner (ASPH). RMSD:1.0429
Å |
| | | |  |
| UBE2W_ASPH_ENST00000602969_ENST00000379454_74717885_62531578 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6382
Å |
 |  |  |  |  |
| UBE2W_ASPH_ENST00000602969_ENST00000379454_74717885_62531578 superimposed PDB: 9FVU of partner (ASPH). RMSD:1.046
Å |
| | | |  |
| UBE2W_STAU2_ENST00000419880_ENST00000355780_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.7666
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000419880_ENST00000519961_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8501
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000419880_ENST00000524300_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8453
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000453587_ENST00000355780_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8223
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000453587_ENST00000519961_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8569
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000453587_ENST00000523558_74791042_74334937 superimposed PDB: 8A58 of partner (UBE2W). RMSD:2.2438
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000453587_ENST00000524300_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.854
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000453587_ENST00000524300_74791042_74334937 superimposed PDB: 8A58 of partner (UBE2W). RMSD:2.4257
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000517608_ENST00000355780_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.9035
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000517608_ENST00000519961_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.9045
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000517608_ENST00000524300_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.894
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602593_ENST00000355780_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8547
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602593_ENST00000519961_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8661
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602593_ENST00000524300_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8839
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602969_ENST00000355780_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.81
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602969_ENST00000519961_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8774
Å |
 |  |  |  |  |
| UBE2W_STAU2_ENST00000602969_ENST00000524300_74737381_74516098 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.8077
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000419880_ENST00000495972_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6764
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000453587_ENST00000356107_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7136
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000453587_ENST00000400011_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6883
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000453587_ENST00000495972_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.747
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000453587_ENST00000545208_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.904
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000517608_ENST00000356107_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.666
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000517608_ENST00000400011_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7392
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000517608_ENST00000495972_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6412
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000517608_ENST00000545208_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6967
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000602969_ENST00000356107_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.7211
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000602969_ENST00000400011_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6877
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000602969_ENST00000495972_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6384
Å |
 |  |  |  |  |
| UBE2W_TJP1_ENST00000602969_ENST00000545208_74791042_30092905 superimposed PDB: 3SHW of partner (TJP1). RMSD:0.6681
Å |
 |  |  |  |  |
| UBE2Z_FKBP5_ENST00000360943_ENST00000536438_47000299_35604935 superimposed PDB: 5A4P of partner (UBE2Z). RMSD:0.5096
Å |
 |  |  |  |  |
| UBE2Z_FKBP5_ENST00000360943_ENST00000536438_47000299_35604935 superimposed PDB: 5OMP of partner (FKBP5). RMSD:1.0812
Å |
| | | |  |
| UBE2Z_FKBP5_ENST00000360943_ENST00000539068_47000299_35604935 superimposed PDB: 5A4P of partner (UBE2Z). RMSD:0.4474
Å |
 |  |  |  |  |
| UBE4B_ASCC3_ENST00000343090_ENST00000369162_10093752_101127628 superimposed PDB: 8ALZ of partner (ASCC3). RMSD:2.2866
Å |
 |  |  |  |  |
| UBE4B_PARK7_ENST00000253251_ENST00000493678_10132272_8037711 superimposed PDB: 9YFR of partner (PARK7). RMSD:3.1052
Å |
 |  |  |  |  |
| UBE4B_PEX14_ENST00000343090_ENST00000356607_10093752_10596269 superimposed PDB: 2W84 of partner (PEX14). RMSD:0.6619
Å |
 |  |  |  |  |
| UBE4B_PLEKHG5_ENST00000253251_ENST00000377732_10093752_6537718 superimposed PDB: 3L1X of partner (UBE4B). RMSD:3.031
Å |
 |  |  |  |  |
| UBE4B_PLEKHG5_ENST00000343090_ENST00000377748_10093752_6537718 superimposed PDB: 3L1X of partner (UBE4B). RMSD:3.0151
Å |
 |  |  |  |  |
| UBL3_SUCLA2_ENST00000380680_ENST00000378654_30423648_48547527 superimposed PDB: 2GOW of partner (UBL3). RMSD:2.7698
Å |
 |  |  |  |  |
| UBL3_SUCLA2_ENST00000380680_ENST00000544100_30423648_48547527 superimposed PDB: 6G4Q of partner (SUCLA2). RMSD:1.3016
Å |
 |  |  |  |  |
| UBN1_C16orf96_ENST00000545171_ENST00000444310_4909160_4621561 superimposed PDB: 4ZBJ of partner (UBN1). RMSD:1.4032
Å |
 |  |  |  |  |
| UBN1_MGRN1_ENST00000262376_ENST00000399577_4925435_4731550 superimposed PDB: 4ZBJ of partner (UBN1). RMSD:1.7704
Å |
 |  |  |  |  |
| UBN1_MGRN1_ENST00000262376_ENST00000415496_4925435_4731550 superimposed PDB: 4ZBJ of partner (UBN1). RMSD:1.9363
Å |
 |  |  |  |  |
| UBN1_MGRN1_ENST00000262376_ENST00000586183_4925435_4731550 superimposed PDB: 4ZBJ of partner (UBN1). RMSD:2.0227
Å |
 |  |  |  |  |
| UBQLN1_NLRP5_ENST00000257468_ENST00000390649_86292641_56530707 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.4806
Å |
 |  |  |  |  |
| UBQLN1_NLRP5_ENST00000257468_ENST00000390649_86292641_56530707 superimposed PDB: 9L4L of partner (NLRP5). RMSD:2.81
Å |
| | | |  |
| UBQLN1_NLRP5_ENST00000257468_ENST00000390649_86292641_56531740 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5614
Å |
 |  |  |  |  |
| UBQLN1_NLRP5_ENST00000257468_ENST00000390649_86292641_56531740 superimposed PDB: 9L4L of partner (NLRP5). RMSD:2.8028
Å |
| | | |  |
| UBQLN1_TLE1_ENST00000257468_ENST00000376499_86322414_84235472 superimposed PDB: 1GXR of partner (TLE1). RMSD:0.3415
Å |
 |  |  |  |  |
| UBQLN1_TTLL4_ENST00000257468_ENST00000392102_86279944_219613558 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5033
Å |
 |  |  |  |  |
| UBQLN1_TTLL4_ENST00000257468_ENST00000442769_86279944_219613558 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5215
Å |
 |  |  |  |  |
| UBQLN1_TTLL4_ENST00000376395_ENST00000392102_86279944_219613558 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5188
Å |
 |  |  |  |  |
| UBQLN1_TTLL4_ENST00000376395_ENST00000442769_86279944_219613558 superimposed PDB: 2KLC of partner (UBQLN1). RMSD:1.5121
Å |
 |  |  |  |  |
| UBR1_TGM5_ENST00000290650_ENST00000349114_43276094_43528035 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.4089
Å |
 |  |  |  |  |
| UBR1_TGM5_ENST00000290650_ENST00000349114_43290365_43552777 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.459
Å |
 |  |  |  |  |
| UBR1_TTBK2_ENST00000290650_ENST00000267890_43258350_43132631 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.4374
Å |
 |  |  |  |  |
| UBR1_TTBK2_ENST00000290650_ENST00000567274_43258350_43132631 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.5443
Å |
 |  |  |  |  |
| UBR1_TTBK2_ENST00000290650_ENST00000567274_43258350_43132631 superimposed PDB: 6VRF of partner (TTBK2). RMSD:0.377
Å |
| | | |  |
| UBR1_TTBK2_ENST00000290650_ENST00000567840_43258350_43132631 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.4632
Å |
 |  |  |  |  |
| UBR1_TTBK2_ENST00000290650_ENST00000567840_43258350_43132631 superimposed PDB: 6VRF of partner (TTBK2). RMSD:0.5663
Å |
| | | |  |
| UBR1_ZSCAN29_ENST00000290650_ENST00000396972_43360095_43654139 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.4236
Å |
 |  |  |  |  |
| UBR1_ZSCAN29_ENST00000382177_ENST00000396972_43360095_43654139 superimposed PDB: 9MUX of partner (UBR1). RMSD:0.4219
Å |
 |  |  |  |  |
| UBR2_XPO5_ENST00000372899_ENST00000265351_42650849_43501744 superimposed PDB: 5TDA of partner (UBR2). RMSD:0.5839
Å |
 |  |  |  |  |
| UBR2_XPO5_ENST00000372901_ENST00000265351_42650849_43501744 superimposed PDB: 5TDA of partner (UBR2). RMSD:0.5339
Å |
 |  |  |  |  |
| UBR2_XPO5_ENST00000372901_ENST00000265351_42650849_43501744 superimposed PDB: 3A6P of partner (XPO5). RMSD:3.2045
Å |
| | | |  |
| UBR4_ASAH1_ENST00000375217_ENST00000381733_19518681_17919932 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.5888
Å |
 |  |  |  |  |
| UBR4_C1QC_ENST00000375226_ENST00000374637_19447682_22973719 superimposed PDB: 2WNV of partner (C1QC). RMSD:0.6323
Å |
 |  |  |  |  |
| UBR4_C1QC_ENST00000375254_ENST00000374637_19447682_22973719 superimposed PDB: 2WNV of partner (C1QC). RMSD:0.5352
Å |
 |  |  |  |  |
| UBR4_C1QC_ENST00000375267_ENST00000374637_19447682_22973719 superimposed PDB: 2WNV of partner (C1QC). RMSD:0.698
Å |
 |  |  |  |  |
| UBTF_SLC44A4_ENST00000302904_ENST00000229729_42286719_31831525 superimposed PDB: 1K99 of partner (UBTF). RMSD:1.464
Å |
 |  |  |  |  |
| UBTF_SLC44A4_ENST00000302904_ENST00000375562_42286719_31831525 superimposed PDB: 1K99 of partner (UBTF). RMSD:1.4369
Å |
 |  |  |  |  |
| UBTF_SLC44A4_ENST00000529383_ENST00000229729_42286719_31831525 superimposed PDB: 1K99 of partner (UBTF). RMSD:1.4115
Å |
 |  |  |  |  |
| UBXN6_GRM4_ENST00000394765_ENST00000374181_4452360_34008525 superimposed PDB: 8FCN of partner (UBXN6). RMSD:0.5678
Å |
 |  |  |  |  |
| UBXN6_GRM4_ENST00000394765_ENST00000374181_4452360_34008525 superimposed PDB: 8JD4 of partner (GRM4). RMSD:2.3305
Å |
| | | |  |
| UCKL1_TXN_ENST00000369892_ENST00000374515_62587612_113013742 superimposed PDB: 4OO4 of partner (TXN). RMSD:0.4015
Å |
 |  |  |  |  |
| UEVLD_PRMT3_ENST00000396197_ENST00000437750_18610159_20473675 superimposed PDB: 8SHR of partner (PRMT3). RMSD:0.4675
Å |
 |  |  |  |  |
| UGGT2_ATP6V0D1_ENST00000376747_ENST00000540149_96485180_67477081 superimposed PDB: 6WLW of partner (ATP6V0D1). RMSD:0.6966
Å |
 |  |  |  |  |
| UGGT2_COL4A1_ENST00000376747_ENST00000543140_96665560_110895081 superimposed PDB: 5NAY of partner (COL4A1). RMSD:0.4696
Å |
 |  |  |  |  |
| UGGT2_TNFSF11_ENST00000376714_ENST00000358545_96705408_43174887 superimposed PDB: 5BNQ of partner (TNFSF11). RMSD:0.3614
Å |
 |  |  |  |  |
| UGGT2_TNFSF11_ENST00000376747_ENST00000405262_96705408_43174887 superimposed PDB: 5BNQ of partner (TNFSF11). RMSD:0.4395
Å |
 |  |  |  |  |
| UGP2_MDH1_ENST00000337130_ENST00000233114_64085070_63821621 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.4192
Å |
 |  |  |  |  |
| UGP2_MDH1_ENST00000445915_ENST00000233114_64085070_63821621 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.4327
Å |
 |  |  |  |  |
| UGP2_MDH1_ENST00000467648_ENST00000233114_64085070_63821621 superimposed PDB: 7RM9 of partner (MDH1). RMSD:0.4229
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000337130_ENST00000427836_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:2.9128
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000337130_ENST00000457206_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:2.6415
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000394417_ENST00000389247_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:1.0871
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000394417_ENST00000457206_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:2.3525
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000445915_ENST00000389247_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:1.0649
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000445915_ENST00000427836_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:3.1104
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000467648_ENST00000427836_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:2.9421
Å |
 |  |  |  |  |
| UGP2_PLEKHM3_ENST00000467648_ENST00000457206_64085070_208795843 superimposed PDB: 3R3I of partner (UGP2). RMSD:1.02
Å |
 |  |  |  |  |
| UHRF2_KDM4C_ENST00000276893_ENST00000381309_6421142_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.853
Å |
 |  |  |  |  |
| UHRF2_KDM4C_ENST00000276893_ENST00000543771_6421142_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.5581
Å |
 |  |  |  |  |
| UHRF2_KDM4C_ENST00000381373_ENST00000442236_6421142_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.9168
Å |
 |  |  |  |  |
| UHRF2_KDM4C_ENST00000381373_ENST00000535193_6421142_6980924 superimposed PDB: 5KR7 of partner (KDM4C). RMSD:1.569
Å |
 |  |  |  |  |
| ULK2_ACADVL_ENST00000361658_ENST00000356839_19741817_7123440 superimposed PDB: 7S7G of partner (ACADVL). RMSD:0.339
Å |
 |  |  |  |  |
| ULK2_B9D1_ENST00000361658_ENST00000477478_19768115_19251193 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.9913
Å |
 |  |  |  |  |
| ULK2_B9D1_ENST00000395544_ENST00000575403_19768115_19251193 superimposed PDB: 6QAV of partner (ULK2). RMSD:0.7499
Å |
 |  |  |  |  |
| UNC13B_PTPRD_ENST00000378495_ENST00000540109_35386290_8636844 superimposed PDB: 6X3A of partner (PTPRD). RMSD:2.9608
Å |
 |  |  |  |  |
| UNC45A_BLM_ENST00000394275_ENST00000560509_91493845_91298040 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.9686
Å |
 |  |  |  |  |
| UNC45A_BLM_ENST00000394275_ENST00000560509_91493845_91298040 superimposed PDB: 4CDG of partner (BLM). RMSD:1.9256
Å |
| | | |  |
| UNC45A_BLM_ENST00000418476_ENST00000355112_91493845_91298040 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.931
Å |
 |  |  |  |  |
| UNC45A_BLM_ENST00000418476_ENST00000355112_91493845_91298040 superimposed PDB: 4CDG of partner (BLM). RMSD:2.175
Å |
| | | |  |
| UNC45A_BLM_ENST00000418476_ENST00000560509_91493845_91298040 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.9225
Å |
 |  |  |  |  |
| UNC45A_BLM_ENST00000418476_ENST00000560509_91493845_91298040 superimposed PDB: 4CDG of partner (BLM). RMSD:1.9041
Å |
| | | |  |
| UNC45A_IQGAP1_ENST00000394275_ENST00000560738_91483703_91029261 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.956
Å |
 |  |  |  |  |
| UNC45A_IQGAP1_ENST00000394275_ENST00000560738_91483703_91029261 superimposed PDB: 3FAY of partner (IQGAP1). RMSD:2.8518
Å |
| | | |  |
| UNC45A_IQGAP1_ENST00000418476_ENST00000560738_91483703_91029261 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.9546
Å |
 |  |  |  |  |
| UNC45A_IQGAP1_ENST00000418476_ENST00000560738_91483703_91029261 superimposed PDB: 3FAY of partner (IQGAP1). RMSD:3.1241
Å |
| | | |  |
| UNC45A_TXNRD1_ENST00000394275_ENST00000429002_91479690_104705067 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.9172
Å |
 |  |  |  |  |
| UNC45A_TXNRD1_ENST00000394275_ENST00000429002_91479690_104705067 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4945
Å |
| | | |  |
| UNC45A_TXNRD1_ENST00000418476_ENST00000429002_91479690_104705067 superimposed PDB: 2DBA of partner (UNC45A). RMSD:0.9474
Å |
 |  |  |  |  |
| UNC45A_TXNRD1_ENST00000418476_ENST00000429002_91479690_104705067 superimposed PDB: 2J3N of partner (TXNRD1). RMSD:0.4838
Å |
| | | |  |
| UNC79_BRF1_ENST00000553484_ENST00000546474_94069764_105752713 superimposed PDB: 7WJI of partner (UNC79). RMSD:2.6471
Å |
 |  |  |  |  |
| UNC79_BRF1_ENST00000555664_ENST00000546474_94069764_105752713 superimposed PDB: 7WJI of partner (UNC79). RMSD:2.5764
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000272845_ENST00000264657_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.5865
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000272845_ENST00000389272_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:3.0557
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000272845_ENST00000585517_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.6469
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000272845_ENST00000585517_210834615_40478217 superimposed PDB: 6TLC of partner (STAT3). RMSD:3.202
Å |
| | | |  |
| UNC80_STAT3_ENST00000439458_ENST00000389272_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.8351
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000439458_ENST00000585517_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.711
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000439458_ENST00000585517_210834615_40478217 superimposed PDB: 6TLC of partner (STAT3). RMSD:3.3133
Å |
| | | |  |
| UNC80_STAT3_ENST00000539183_ENST00000264657_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.6365
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000539183_ENST00000264657_210834615_40478217 superimposed PDB: 6TLC of partner (STAT3). RMSD:3.2699
Å |
| | | |  |
| UNC80_STAT3_ENST00000539183_ENST00000389272_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:3.0481
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000539183_ENST00000389272_210834615_40478217 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.0518
Å |
| | | |  |
| UNC80_STAT3_ENST00000539183_ENST00000585517_210834615_40478217 superimposed PDB: 7SX3 of partner (UNC80). RMSD:2.6973
Å |
 |  |  |  |  |
| UNC80_STAT3_ENST00000539183_ENST00000585517_210834615_40478217 superimposed PDB: 6TLC of partner (STAT3). RMSD:1.1339
Å |
| | | |  |
| UNK_DTYMK_ENST00000589666_ENST00000305784_73781065_242619734 superimposed PDB: 1NN5 of partner (DTYMK). RMSD:0.6568
Å |
 |  |  |  |  |
| UPF3B_TRPM4_ENST00000276201_ENST00000427978_118979160_49705220 superimposed PDB: 7NWU of partner (UPF3B). RMSD:0.4151
Å |
 |  |  |  |  |
| UPF3B_TRPM4_ENST00000276201_ENST00000427978_118979160_49705220 superimposed PDB: 9MRT of partner (TRPM4). RMSD:3.206
Å |
| | | |  |
| UQCC1_RBM39_ENST00000359226_ENST00000361162_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7729
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000359226_ENST00000528062_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7589
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374384_ENST00000253363_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7271
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374384_ENST00000361162_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7379
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374384_ENST00000528062_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7403
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374385_ENST00000253363_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7247
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374385_ENST00000361162_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7178
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000374385_ENST00000528062_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7372
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000397556_ENST00000253363_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7446
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000397556_ENST00000361162_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7297
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000397556_ENST00000528062_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7753
Å |
 |  |  |  |  |
| UQCC1_RBM39_ENST00000542501_ENST00000253363_33969720_34326939 superimposed PDB: 4OZ1 of partner (RBM39). RMSD:0.7448
Å |
 |  |  |  |  |
| UQCRC2_BAZ1B_ENST00000268379_ENST00000404251_21964777_72892899 superimposed PDB: 1F62 of partner (BAZ1B). RMSD:1.3069
Å |
 |  |  |  |  |
| UQCRC2_LCMT1_ENST00000561553_ENST00000399069_21969920_25162874 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.9569
Å |
 |  |  |  |  |
| UQCRC2_LCMT1_ENST00000561553_ENST00000399069_21969920_25162874 superimposed PDB: 3IEI of partner (LCMT1). RMSD:0.5291
Å |
| | | |  |
| UQCRC2_SLC18B1_ENST00000268379_ENST00000275227_21987564_133092268 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:0.9522
Å |
 |  |  |  |  |
| UQCRC2_SLC18B1_ENST00000268379_ENST00000275227_21987564_133092268 superimposed PDB: 9D7V of partner (SLC18B1). RMSD:2.8399
Å |
| | | |  |
| UQCRC2_SLC18B1_ENST00000561553_ENST00000275227_21987564_133092268 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.1229
Å |
 |  |  |  |  |
| UQCRC2_SLC18B1_ENST00000561553_ENST00000275227_21987564_133092268 superimposed PDB: 9D7V of partner (SLC18B1). RMSD:2.4345
Å |
| | | |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367449_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.1715
Å |
 |  |  |  |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367449_21987564_192993076 superimposed PDB: 4UEL of partner (UCHL5). RMSD:2.9394
Å |
| | | |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367451_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.1455
Å |
 |  |  |  |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367452_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.1896
Å |
 |  |  |  |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367452_21987564_192993076 superimposed PDB: 4UEL of partner (UCHL5). RMSD:3.2341
Å |
| | | |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000367454_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.0869
Å |
 |  |  |  |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000530098_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.2876
Å |
 |  |  |  |  |
| UQCRC2_UCHL5_ENST00000268379_ENST00000530098_21987564_192993076 superimposed PDB: 4UEL of partner (UCHL5). RMSD:3.1801
Å |
| | | |  |
| UQCRC2_UCHL5_ENST00000561553_ENST00000367455_21987564_192993076 superimposed PDB: 9HZL of partner (UQCRC2). RMSD:1.0333
Å |
 |  |  |  |  |
| URI1_PDCD5_ENST00000542441_ENST00000419343_30433571_33073100 superimposed PDB: 2K6B of partner (PDCD5). RMSD:1.5584
Å |
 |  |  |  |  |
| URI1_PDCD5_ENST00000542441_ENST00000592786_30433571_33073100 superimposed PDB: 2K6B of partner (PDCD5). RMSD:0.9299
Å |
 |  |  |  |  |
| URI1_PEPD_ENST00000360605_ENST00000397032_30462134_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.4035
Å |
 |  |  |  |  |
| URI1_PEPD_ENST00000542441_ENST00000397032_30462134_33904549 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.404
Å |
 |  |  |  |  |
| URI1_XRCC1_ENST00000542441_ENST00000543982_30433571_44058956 superimposed PDB: 3LQC of partner (XRCC1). RMSD:1.0722
Å |
 |  |  |  |  |
| URI1_XRCC1_ENST00000542441_ENST00000543982_30433571_44065172 superimposed PDB: 3LQC of partner (XRCC1). RMSD:0.5891
Å |
 |  |  |  |  |
| URM1_TP53BP1_ENST00000372850_ENST00000382039_131140385_43762264 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5473
Å |
 |  |  |  |  |
| URM1_TP53BP1_ENST00000372850_ENST00000382044_131140385_43762264 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5371
Å |
 |  |  |  |  |
| URM1_TP53BP1_ENST00000372853_ENST00000382039_131140385_43762264 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5564
Å |
 |  |  |  |  |
| URM1_TP53BP1_ENST00000372853_ENST00000382044_131140385_43762264 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.5838
Å |
 |  |  |  |  |
| URM1_TP53BP1_ENST00000452446_ENST00000263801_131140385_43762264 superimposed PDB: 5ECG of partner (TP53BP1). RMSD:0.558
Å |
 |  |  |  |  |
| USB1_CNOT1_ENST00000219281_ENST00000569240_58044016_58555221 superimposed PDB: 4H7W of partner (USB1). RMSD:2.6054
Å |
 |  |  |  |  |
| USB1_CNOT1_ENST00000561743_ENST00000569240_58044016_58555221 superimposed PDB: 4H7W of partner (USB1). RMSD:2.8705
Å |
 |  |  |  |  |
| USB1_MAPKAPK5_ENST00000219281_ENST00000550735_58051343_112308888 superimposed PDB: 4H7W of partner (USB1). RMSD:1.5734
Å |
 |  |  |  |  |
| USB1_MAPKAPK5_ENST00000219281_ENST00000551404_58051343_112308888 superimposed PDB: 4H7W of partner (USB1). RMSD:1.4747
Å |
 |  |  |  |  |
| USB1_MAPKAPK5_ENST00000539737_ENST00000550735_58051343_112308888 superimposed PDB: 4H7W of partner (USB1). RMSD:1.1809
Å |
 |  |  |  |  |
| USB1_MAPKAPK5_ENST00000561743_ENST00000551404_58051343_112308888 superimposed PDB: 4H7W of partner (USB1). RMSD:1.1571
Å |
 |  |  |  |  |
| USH1C_PLEKHA7_ENST00000527020_ENST00000531066_17538947_16800567 superimposed PDB: 5F3X of partner (USH1C). RMSD:0.6039
Å |
 |  |  |  |  |
| USH1C_PLEKHA7_ENST00000527720_ENST00000531066_17538947_16800567 superimposed PDB: 5F3X of partner (USH1C). RMSD:0.5859
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000219473_ENST00000379655_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.1244
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000219473_ENST00000445690_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.0995
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000219473_ENST00000562903_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.1454
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000570191_ENST00000379655_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.1734
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000570191_ENST00000445690_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.1514
Å |
 |  |  |  |  |
| USP10_KIFC3_ENST00000570191_ENST00000562903_84767109_57800897 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.1193
Å |
 |  |  |  |  |
| USP11_FUNDC1_ENST00000218348_ENST00000378045_47101098_44386611 superimposed PDB: 8OYP of partner (USP11). RMSD:0.4205
Å |
 |  |  |  |  |
| USP12_LNX2_ENST00000282344_ENST00000316334_27669737_28134122 superimposed PDB: 5L8W of partner (USP12). RMSD:1.2775
Å |
 |  |  |  |  |
| USP14_DDB2_ENST00000261601_ENST00000378603_166819_47259387 superimposed PDB: 9J8W of partner (DDB2). RMSD:1.0167
Å |
 |  |  |  |  |
| USP14_DDB2_ENST00000582707_ENST00000378603_166819_47259387 superimposed PDB: 9J8W of partner (DDB2). RMSD:0.9681
Å |
 |  |  |  |  |
| USP15_PKP4_ENST00000280377_ENST00000389757_62783768_159497138 superimposed PDB: 6GH9 of partner (USP15). RMSD:1.6666
Å |
 |  |  |  |  |
| USP15_PKP4_ENST00000280377_ENST00000389759_62783768_159497138 superimposed PDB: 6GH9 of partner (USP15). RMSD:1.701
Å |
 |  |  |  |  |
| USP15_PKP4_ENST00000353364_ENST00000389759_62783768_159497138 superimposed PDB: 6GH9 of partner (USP15). RMSD:1.5185
Å |
 |  |  |  |  |
| USP15_PKP4_ENST00000393654_ENST00000389757_62783768_159497138 superimposed PDB: 6GH9 of partner (USP15). RMSD:1.6404
Å |
 |  |  |  |  |
| USP15_PKP4_ENST00000393654_ENST00000389759_62783768_159497138 superimposed PDB: 6GH9 of partner (USP15). RMSD:2.7717
Å |
 |  |  |  |  |
| USP15_PPM1H_ENST00000280377_ENST00000228705_62696701_63114069 superimposed PDB: 7KPR of partner (PPM1H). RMSD:2.3604
Å |
 |  |  |  |  |
| USP18_DAPK2_ENST00000215794_ENST00000457488_18643035_64275953 superimposed PDB: 2A2A of partner (DAPK2). RMSD:0.4916
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000261497_ENST00000269243_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.1908
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000261497_ENST00000379980_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3375
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000261497_ENST00000396239_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3586
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000537526_ENST00000269243_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3998
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000537526_ENST00000360416_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3735
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000537526_ENST00000379980_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.3458
Å |
 |  |  |  |  |
| USP22_MYH10_ENST00000537526_ENST00000396239_20921254_8508300 superimposed PDB: 4PD3 of partner (MYH10). RMSD:2.5321
Å |
 |  |  |  |  |
| USP32_CDK12_ENST00000586881_ENST00000447079_58378959_37646809 superimposed PDB: 4NST of partner (CDK12). RMSD:0.4694
Å |
 |  |  |  |  |
| USP33_CCDC53_ENST00000357428_ENST00000545679_78177431_102406970 superimposed PDB: 2UZG of partner (USP33). RMSD:1.1092
Å |
 |  |  |  |  |
| USP36_DNAH17_ENST00000449938_ENST00000389840_76808941_76433950 superimposed PDB: 8BS3 of partner (USP36). RMSD:0.4461
Å |
 |  |  |  |  |
| USP36_DNAH17_ENST00000449938_ENST00000585328_76808941_76433950 superimposed PDB: 8BS3 of partner (USP36). RMSD:0.7576
Å |
 |  |  |  |  |
| USP36_DNAH17_ENST00000542802_ENST00000585328_76808941_76433950 superimposed PDB: 8BS3 of partner (USP36). RMSD:0.4332
Å |
 |  |  |  |  |
| USP3_HERC1_ENST00000380324_ENST00000443617_63797029_63955403 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.3459
Å |
 |  |  |  |  |
| USP3_HERC1_ENST00000536001_ENST00000443617_63797029_63955403 superimposed PDB: 4O2W of partner (HERC1). RMSD:0.3682
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000441222_ENST00000388940_53494116_54140168 superimposed PDB: 5L8H of partner (USP46). RMSD:0.4974
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000441222_ENST00000401642_53525281_53752033 superimposed PDB: 5L8H of partner (USP46). RMSD:0.5338
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000451218_ENST00000388940_53494116_54140168 superimposed PDB: 5L8H of partner (USP46). RMSD:0.6423
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000451218_ENST00000401642_53494116_54140168 superimposed PDB: 5L8H of partner (USP46). RMSD:0.5165
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000508499_ENST00000388940_53494116_54140168 superimposed PDB: 5L8H of partner (USP46). RMSD:0.4973
Å |
 |  |  |  |  |
| USP46_SCFD2_ENST00000508499_ENST00000401642_53494116_54140168 superimposed PDB: 5L8H of partner (USP46). RMSD:0.5994
Å |
 |  |  |  |  |
| USP47_RRAS2_ENST00000339865_ENST00000414023_11863771_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5351
Å |
 |  |  |  |  |
| USP47_RRAS2_ENST00000527733_ENST00000537760_11863771_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.585
Å |
 |  |  |  |  |
| USP49_DAAM2_ENST00000373010_ENST00000398904_41766612_39851737 superimposed PDB: 9YC2 of partner (USP49). RMSD:0.6474
Å |
 |  |  |  |  |
| USP54_PSMA6_ENST00000408019_ENST00000261479_75331178_35786454 superimposed PDB: 8C61 of partner (USP54). RMSD:1.7212
Å |
 |  |  |  |  |
| USP54_UBE2W_ENST00000408019_ENST00000517608_75301132_74742707 superimposed PDB: 8C61 of partner (USP54). RMSD:1.0943
Å |
 |  |  |  |  |
| USP54_UBE2W_ENST00000408019_ENST00000517608_75301132_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.5875
Å |
| | | |  |
| USP54_UBE2W_ENST00000408019_ENST00000602969_75301132_74742707 superimposed PDB: 8C61 of partner (USP54). RMSD:1.1404
Å |
 |  |  |  |  |
| USP54_UBE2W_ENST00000408019_ENST00000602969_75301132_74742707 superimposed PDB: 8A58 of partner (UBE2W). RMSD:0.6123
Å |
| | | |  |
| USP6NL_UPF2_ENST00000277575_ENST00000357604_11532830_11973781 superimposed PDB: 9LTP of partner (USP6NL). RMSD:1.1398
Å |
 |  |  |  |  |
| USP6NL_UPF2_ENST00000379237_ENST00000357604_11532830_11973781 superimposed PDB: 9LTP of partner (USP6NL). RMSD:1.2064
Å |
 |  |  |  |  |
| USP6NL_UPF2_ENST00000609104_ENST00000357604_11532830_11973781 superimposed PDB: 9LTP of partner (USP6NL). RMSD:1.7264
Å |
 |  |  |  |  |
| USP6_PTRH2_ENST00000250066_ENST00000409433_5052062_57775339 superimposed PDB: 1Q7S of partner (PTRH2). RMSD:0.3824
Å |
 |  |  |  |  |
| USP6_PTRH2_ENST00000304328_ENST00000409433_5052062_57775339 superimposed PDB: 1Q7S of partner (PTRH2). RMSD:0.3706
Å |
 |  |  |  |  |
| USP9X_BLVRB_ENST00000324545_ENST00000595483_41078484_40964452 superimposed PDB: 7YXY of partner (USP9X). RMSD:2.4492
Å |
 |  |  |  |  |
| USP9X_BLVRB_ENST00000324545_ENST00000595483_41078484_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.5518
Å |
| | | |  |
| USP9X_BLVRB_ENST00000378308_ENST00000263368_41078484_40964452 superimposed PDB: 7YXY of partner (USP9X). RMSD:2.3071
Å |
 |  |  |  |  |
| USP9X_BLVRB_ENST00000378308_ENST00000263368_41078484_40964452 superimposed PDB: 1HDO of partner (BLVRB). RMSD:0.5912
Å |
| | | |  |
| USP9X_BLVRB_ENST00000378308_ENST00000595483_41078484_40964452 superimposed PDB: 7YXY of partner (USP9X). RMSD:1.9882
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367526_ENST00000305960_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3872
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367526_ENST00000315266_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:1.4303
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367526_ENST00000315266_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.7926
Å |
| | | |  |
| UTRN_GPHN_ENST00000367526_ENST00000459628_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.3809
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367526_ENST00000478722_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.4043
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367526_ENST00000543237_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.5748
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000305960_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.8684
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000305960_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.8894
Å |
| | | |  |
| UTRN_GPHN_ENST00000367545_ENST00000315266_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7921
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000459628_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7599
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000459628_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.6345
Å |
| | | |  |
| UTRN_GPHN_ENST00000367545_ENST00000478722_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7553
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000478722_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.6507
Å |
| | | |  |
| UTRN_GPHN_ENST00000367545_ENST00000543237_144999714_67243181 superimposed PDB: 6M5G of partner (UTRN). RMSD:1.0945
Å |
 |  |  |  |  |
| UTRN_GPHN_ENST00000367545_ENST00000543237_144999714_67243181 superimposed PDB: 1JLJ of partner (GPHN). RMSD:0.684
Å |
| | | |  |
| UTRN_HMGA2_ENST00000367526_ENST00000403681_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7423
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000354636_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.693
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000393577_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.654
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000393578_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.6638
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000425208_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.6518
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000536545_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7848
Å |
 |  |  |  |  |
| UTRN_HMGA2_ENST00000367545_ENST00000541363_145021379_66232298 superimposed PDB: 6M5G of partner (UTRN). RMSD:0.7025
Å |
 |  |  |  |  |
| UTY_KDM6A_ENST00000540140_ENST00000382899_15470343_44920568 superimposed PDB: 4UF0 of partner (UTY). RMSD:0.5906
Å |
 |  |  |  |  |
| UTY_KDM6A_ENST00000540140_ENST00000382899_15470343_44920568 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6024
Å |
| | | |  |
| UTY_KDM6A_ENST00000545955_ENST00000377967_15470343_44920568 superimposed PDB: 4UF0 of partner (UTY). RMSD:0.5851
Å |
 |  |  |  |  |
| UTY_KDM6A_ENST00000545955_ENST00000377967_15470343_44920568 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6097
Å |
| | | |  |
| UTY_KDM6A_ENST00000545955_ENST00000382899_15470343_44920568 superimposed PDB: 4UF0 of partner (UTY). RMSD:0.6032
Å |
 |  |  |  |  |
| UTY_KDM6A_ENST00000545955_ENST00000382899_15470343_44920568 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.5912
Å |
| | | |  |
| UVRAG_ACER3_ENST00000532130_ENST00000532485_75728024_76726059 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.7177
Å |
 |  |  |  |  |
| UVRAG_ACER3_ENST00000539288_ENST00000532485_75728024_76726059 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.7705
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000356136_ENST00000452508_75728024_108159703 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.2434
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000528420_ENST00000452508_75728024_108159703 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.2465
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000531818_ENST00000452508_75728024_108159703 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.6299
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000531818_ENST00000452508_75728024_108159703 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.152
Å |
| | | |  |
| UVRAG_ATM_ENST00000532130_ENST00000452508_75728024_108159703 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.9986
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000532130_ENST00000452508_75728024_108159703 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.1835
Å |
| | | |  |
| UVRAG_ATM_ENST00000533454_ENST00000452508_75728024_108159703 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.1281
Å |
 |  |  |  |  |
| UVRAG_ATM_ENST00000533454_ENST00000452508_75728024_108159703 superimposed PDB: 8OXQ of partner (ATM). RMSD:2.2383
Å |
| | | |  |
| UVRAG_CMPK1_ENST00000528420_ENST00000371873_75672593_47834140 superimposed PDB: 1TEV of partner (CMPK1). RMSD:1.2323
Å |
 |  |  |  |  |
| UVRAG_INTS4_ENST00000356136_ENST00000534064_75623083_77618856 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.2084
Å |
 |  |  |  |  |
| UVRAG_KCTD14_ENST00000531818_ENST00000353172_75776832_77728316 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:0.4835
Å |
 |  |  |  |  |
| UVRAG_KCTD14_ENST00000532130_ENST00000353172_75776832_77728316 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.6263
Å |
 |  |  |  |  |
| UVRAG_KCTD14_ENST00000539288_ENST00000353172_75776832_77728316 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.4075
Å |
 |  |  |  |  |
| UVRAG_MAP6_ENST00000528420_ENST00000304771_75623083_75319367 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.2606
Å |
 |  |  |  |  |
| UVRAG_NUDT3_ENST00000356136_ENST00000607016_75599947_34309749 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.8273
Å |
 |  |  |  |  |
| UVRAG_NUDT3_ENST00000528420_ENST00000607016_75599947_34309749 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:0.6935
Å |
 |  |  |  |  |
| UVRAG_NUDT3_ENST00000528420_ENST00000607016_75599947_34309749 superimposed PDB: 2FVV of partner (NUDT3). RMSD:0.3938
Å |
| | | |  |
| UVRAG_PELI3_ENST00000531818_ENST00000320740_75728024_66238712 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.7477
Å |
 |  |  |  |  |
| UVRAG_PELI3_ENST00000531818_ENST00000349459_75728024_66238712 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:1.9595
Å |
 |  |  |  |  |
| UVRAG_PELI3_ENST00000532130_ENST00000320740_75728024_66238712 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.7316
Å |
 |  |  |  |  |
| UVRAG_PELI3_ENST00000532130_ENST00000349459_75728024_66238712 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.8309
Å |
 |  |  |  |  |
| UVRAG_PELI3_ENST00000539288_ENST00000349459_75728024_66238712 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.846
Å |
 |  |  |  |  |
| UVRAG_RPS3_ENST00000356136_ENST00000278572_75572825_75111737 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.1963
Å |
 |  |  |  |  |
| UVRAG_RPS3_ENST00000356136_ENST00000527446_75572825_75111737 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.527
Å |
 |  |  |  |  |
| UVRAG_RRAS2_ENST00000356136_ENST00000414023_75526569_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.61
Å |
 |  |  |  |  |
| UVRAG_SETMAR_ENST00000356136_ENST00000425863_75572825_4354581 superimposed PDB: 3BO5 of partner (SETMAR). RMSD:0.5761
Å |
 |  |  |  |  |
| UVRAG_ZMAT4_ENST00000356136_ENST00000315769_75599947_40625249 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:0.7161
Å |
 |  |  |  |  |
| UVRAG_ZMAT4_ENST00000528420_ENST00000315769_75728024_40389757 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:3.0934
Å |
 |  |  |  |  |
| UVRAG_ZMAT4_ENST00000532130_ENST00000315769_75728024_40389757 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.7861
Å |
 |  |  |  |  |
| UVRAG_ZMAT4_ENST00000539288_ENST00000315769_75728024_40389757 superimposed PDB: 9ZPD of partner (UVRAG). RMSD:2.6712
Å |
 |  |  |  |  |
| UVSSA_CTBP1_ENST00000389851_ENST00000290921_1349033_1222131 superimposed PDB: 9BZ0 of partner (UVSSA). RMSD:0.4432
Å |
 |  |  |  |  |
| UVSSA_CTBP1_ENST00000389851_ENST00000290921_1349033_1222131 superimposed PDB: 8ARI of partner (CTBP1). RMSD:1.1421
Å |
| | | |  |
| UVSSA_CTBP1_ENST00000507531_ENST00000290921_1349033_1222131 superimposed PDB: 9BZ0 of partner (UVSSA). RMSD:0.4341
Å |
 |  |  |  |  |
| UVSSA_CTBP1_ENST00000507531_ENST00000290921_1349033_1222131 superimposed PDB: 8ARI of partner (CTBP1). RMSD:1.1128
Å |
| | | |  |
| UVSSA_CTBP1_ENST00000511216_ENST00000290921_1349033_1222131 superimposed PDB: 9BZ0 of partner (UVSSA). RMSD:0.4484
Å |
 |  |  |  |  |
| UVSSA_CTBP1_ENST00000511216_ENST00000290921_1349033_1222131 superimposed PDB: 8ARI of partner (CTBP1). RMSD:1.1032
Å |
| | | |  |
| VAMP2_SET_ENST00000316509_ENST00000409104_8064790_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:0.8159
Å |
 |  |  |  |  |
| VAMP2_SET_ENST00000488857_ENST00000409104_8064790_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:0.8902
Å |
 |  |  |  |  |
| VAPA_PPP4R1_ENST00000340541_ENST00000400555_9914332_9595100 superimposed PDB: 6TQR of partner (VAPA). RMSD:3.4843
Å |
 |  |  |  |  |
| VAPA_PSPC1_ENST00000340541_ENST00000338910_9937063_20283739 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4169
Å |
 |  |  |  |  |
| VAPA_RALBP1_ENST00000400000_ENST00000383432_9937063_9530831 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.4182
Å |
 |  |  |  |  |
| VAPB_CDH12_ENST00000475243_ENST00000382254_57009761_21802529 superimposed PDB: 3IKK of partner (VAPB). RMSD:0.5528
Å |
 |  |  |  |  |
| VAPB_GNAI3_ENST00000395802_ENST00000369851_56964573_110116358 superimposed PDB: 3IKK of partner (VAPB). RMSD:3.0986
Å |
 |  |  |  |  |
| VAPB_GNAI3_ENST00000395802_ENST00000369851_56964573_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:1.094
Å |
| | | |  |
| VCAN_GABRA5_ENST00000265077_ENST00000355395_82849341_27188361 superimposed PDB: 6A96 of partner (GABRA5). RMSD:1.4788
Å |
 |  |  |  |  |
| VCAN_GABRA5_ENST00000342785_ENST00000355395_82849341_27188361 superimposed PDB: 6A96 of partner (GABRA5). RMSD:1.212
Å |
 |  |  |  |  |
| VCAN_GABRA5_ENST00000343200_ENST00000355395_82849341_27188361 superimposed PDB: 6A96 of partner (GABRA5). RMSD:1.4418
Å |
 |  |  |  |  |
| VCAN_GABRA5_ENST00000502527_ENST00000355395_82849341_27188361 superimposed PDB: 6A96 of partner (GABRA5). RMSD:2.0055
Å |
 |  |  |  |  |
| VCAN_XRCC4_ENST00000513984_ENST00000511817_82779407_82648943 superimposed PDB: 9CQ3 of partner (XRCC4). RMSD:0.1518
Å |
 |  |  |  |  |
| VCL_FGFR2_ENST00000372755_ENST00000369061_75758133_123239535 superimposed PDB: 6UPW of partner (VCL). RMSD:0.3993
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000398706_75758133_75553345 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.67
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000398706_75758133_75553904 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.9821
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000603114_75758133_75553345 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.5758
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000603114_75758133_75553904 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:2.0742
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000604524_75758133_75553345 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.6238
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000604524_75758133_75553904 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.9809
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000605216_75758133_75553345 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.8839
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000211998_ENST00000605216_75758133_75553904 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:2.0334
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000372755_ENST00000604729_75758133_75553345 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:1.6446
Å |
 |  |  |  |  |
| VCL_ZSWIM8_ENST00000372755_ENST00000604729_75758133_75553904 superimposed PDB: 9RWZ of partner (ZSWIM8). RMSD:2.0398
Å |
 |  |  |  |  |
| VCPIP1_CDH17_ENST00000310421_ENST00000441892_67563692_95178204 superimposed PDB: 9MPR of partner (VCPIP1). RMSD:0.5374
Å |
 |  |  |  |  |
| VCPIP1_CDH17_ENST00000310421_ENST00000450165_67563692_95178204 superimposed PDB: 9MPR of partner (VCPIP1). RMSD:0.3969
Å |
 |  |  |  |  |
| VDAC2_ZEB1_ENST00000332211_ENST00000320985_76970947_31749965 superimposed PDB: 2E19 of partner (ZEB1). RMSD:0.6787
Å |
 |  |  |  |  |
| VDAC2_ZEB1_ENST00000543351_ENST00000361642_76970947_31749965 superimposed PDB: 2E19 of partner (ZEB1). RMSD:0.6592
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000229022_ENST00000230671_48258829_149583469 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.6029
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000229022_ENST00000524041_48258829_149583469 superimposed PDB: 1IE9 of partner (VDR). RMSD:2.7431
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000229022_ENST00000524041_48258829_149583469 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.0607
Å |
| | | |  |
| VDR_SLC6A7_ENST00000395324_ENST00000524041_48258829_149583229 superimposed PDB: 1IE9 of partner (VDR). RMSD:3.0901
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000395324_ENST00000524041_48258829_149583229 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.6967
Å |
| | | |  |
| VDR_SLC6A7_ENST00000535672_ENST00000230671_48258829_149583229 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.7772
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000535672_ENST00000524041_48258829_149583229 superimposed PDB: 1IE9 of partner (VDR). RMSD:2.9635
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000535672_ENST00000524041_48258829_149583229 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.5613
Å |
| | | |  |
| VDR_SLC6A7_ENST00000549336_ENST00000230671_48258829_149583229 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.8386
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000550325_ENST00000524041_48258829_149583229 superimposed PDB: 1IE9 of partner (VDR). RMSD:3.0414
Å |
 |  |  |  |  |
| VDR_SLC6A7_ENST00000550325_ENST00000524041_48258829_149583229 superimposed PDB: 9WX7 of partner (SLC6A7). RMSD:1.5737
Å |
| | | |  |
| VEGFA_STK38_ENST00000324450_ENST00000229812_43745402_36467767 superimposed PDB: 6BXI of partner (STK38). RMSD:0.7985
Å |
 |  |  |  |  |
| VEGFA_STK38_ENST00000417285_ENST00000229812_43745402_36467767 superimposed PDB: 6BXI of partner (STK38). RMSD:0.5961
Å |
 |  |  |  |  |
| VEGFA_STK38_ENST00000520948_ENST00000229812_43745402_36467767 superimposed PDB: 6BXI of partner (STK38). RMSD:0.6974
Å |
 |  |  |  |  |
| VEGFA_STK38_ENST00000523873_ENST00000229812_43745402_36467767 superimposed PDB: 6BXI of partner (STK38). RMSD:0.6882
Å |
 |  |  |  |  |
| VEGFA_STK38_ENST00000523950_ENST00000229812_43745402_36467767 superimposed PDB: 6BXI of partner (STK38). RMSD:0.5872
Å |
 |  |  |  |  |
| VIM_KRT7_ENST00000224237_ENST00000331817_17277388_52641960 superimposed PDB: 4XIF of partner (KRT7). RMSD:2.3155
Å |
 |  |  |  |  |
| VKORC1L1_ACHE_ENST00000360768_ENST00000241069_65338552_100488959 superimposed PDB: 1F8U of partner (ACHE). RMSD:1.0529
Å |
 |  |  |  |  |
| VLDLR_SLC1A1_ENST00000382099_ENST00000262352_2622271_4544566 superimposed PDB: 8CUA of partner (SLC1A1). RMSD:2.3032
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000262291_ENST00000351666_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4082
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000262291_ENST00000352993_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4616
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000262291_ENST00000354071_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4124
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000536180_ENST00000351666_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3661
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000536180_ENST00000352993_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.5654
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000536180_ENST00000354071_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4402
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000536180_ENST00000357654_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.6441
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000537567_ENST00000351666_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3465
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000537567_ENST00000352993_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.5793
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000537567_ENST00000354071_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.437
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000537567_ENST00000357654_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.603
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000539763_ENST00000351666_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3908
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000539763_ENST00000352993_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4991
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000539763_ENST00000354071_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.4191
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000539763_ENST00000357654_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.5938
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000545362_ENST00000351666_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3987
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000545362_ENST00000352993_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:1.1004
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000545362_ENST00000354071_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.3731
Å |
 |  |  |  |  |
| VMP1_BRCA1_ENST00000545362_ENST00000357654_57851246_41234592 superimposed PDB: 8RS8 of partner (BRCA1). RMSD:0.6337
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000262291_ENST00000529006_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4377
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000536180_ENST00000398645_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4506
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000536180_ENST00000529006_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4289
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000537567_ENST00000398645_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4815
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000537567_ENST00000529006_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4389
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000539763_ENST00000398645_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4178
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000539763_ENST00000529006_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4329
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000545362_ENST00000398645_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4431
Å |
 |  |  |  |  |
| VMP1_KDM2A_ENST00000545362_ENST00000529006_57851246_66947549 superimposed PDB: 7UV9 of partner (KDM2A). RMSD:0.4219
Å |
 |  |  |  |  |
| VMP1_SDC2_ENST00000536180_ENST00000302190_57842499_97605707 superimposed PDB: 6ITH of partner (SDC2). RMSD:0.7694
Å |
 |  |  |  |  |
| VMP1_SDC2_ENST00000537567_ENST00000302190_57842499_97605707 superimposed PDB: 6ITH of partner (SDC2). RMSD:0.6032
Å |
 |  |  |  |  |
| VMP1_SDC2_ENST00000539763_ENST00000302190_57842499_97605707 superimposed PDB: 6ITH of partner (SDC2). RMSD:0.7582
Å |
 |  |  |  |  |
| VPS13B_CDH17_ENST00000395996_ENST00000441892_100050794_95189949 superimposed PDB: 7CYM of partner (CDH17). RMSD:2.7277
Å |
 |  |  |  |  |
| VPS13B_GMDS_ENST00000357162_ENST00000380815_100836206_1742820 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.5768
Å |
 |  |  |  |  |
| VPS13B_GMDS_ENST00000357162_ENST00000380815_100844880_1726746 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.0674
Å |
 |  |  |  |  |
| VPS13B_GMDS_ENST00000358544_ENST00000380815_100836206_1742820 superimposed PDB: 6GPK of partner (GMDS). RMSD:1.6408
Å |
 |  |  |  |  |
| VPS13B_GMDS_ENST00000358544_ENST00000380815_100844880_1726746 superimposed PDB: 6GPK of partner (GMDS). RMSD:2.719
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000249837_ENST00000347587_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.1155
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000249837_ENST00000347587_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.6548
Å |
| | | |  |
| VPS13C_ALDH1A2_ENST00000249837_ENST00000537372_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:2.7628
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000249837_ENST00000537372_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.4774
Å |
| | | |  |
| VPS13C_ALDH1A2_ENST00000261517_ENST00000347587_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.0328
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000261517_ENST00000347587_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.6763
Å |
| | | |  |
| VPS13C_ALDH1A2_ENST00000261517_ENST00000537372_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.179
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000261517_ENST00000537372_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.6591
Å |
| | | |  |
| VPS13C_ALDH1A2_ENST00000395898_ENST00000347587_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.4117
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000395898_ENST00000347587_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.6159
Å |
| | | |  |
| VPS13C_ALDH1A2_ENST00000395898_ENST00000537372_62199462_58306479 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.2279
Å |
 |  |  |  |  |
| VPS13C_ALDH1A2_ENST00000395898_ENST00000537372_62199462_58306479 superimposed PDB: 9R3Z of partner (ALDH1A2). RMSD:1.49
Å |
| | | |  |
| VPS13C_HERC1_ENST00000249837_ENST00000443617_62232845_63904755 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:3.0216
Å |
 |  |  |  |  |
| VPS13C_HERC1_ENST00000261517_ENST00000443617_62232845_63904755 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:1.9937
Å |
 |  |  |  |  |
| VPS13C_HERC1_ENST00000395896_ENST00000443617_62232845_63904755 superimposed PDB: 9YQQ of partner (VPS13C). RMSD:1.9044
Å |
 |  |  |  |  |
| VPS13D_VEGFC_ENST00000356315_ENST00000280193_12353761_177650900 superimposed PDB: 4BSK of partner (VEGFC). RMSD:0.7381
Å |
 |  |  |  |  |
| VPS18_NTRK3_ENST00000220509_ENST00000557856_41193212_88423659 superimposed PDB: 6KZD of partner (NTRK3). RMSD:0.6236
Å |
 |  |  |  |  |
| VPS35_PHKB_ENST00000299138_ENST00000455779_46723042_47730291 superimposed PDB: 7BLN of partner (VPS35). RMSD:3.1694
Å |
 |  |  |  |  |
| VPS35_PHKB_ENST00000299138_ENST00000455779_46723042_47730291 superimposed PDB: 8XYA of partner (PHKB). RMSD:0.9978
Å |
| | | |  |
| VPS4B_FBP1_ENST00000238497_ENST00000415431_61089465_97369234 superimposed PDB: 7WJV of partner (FBP1). RMSD:0.5059
Å |
 |  |  |  |  |
| VPS53_UBR5_ENST00000291074_ENST00000220959_526772_103277503 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.3255
Å |
 |  |  |  |  |
| VPS53_UBR5_ENST00000291074_ENST00000518205_526772_103277503 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.4734
Å |
 |  |  |  |  |
| VPS53_UBR5_ENST00000437048_ENST00000220959_526772_103277503 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.6328
Å |
 |  |  |  |  |
| VPS53_UBR5_ENST00000437048_ENST00000518205_526772_103277503 superimposed PDB: 8E0Q of partner (UBR5). RMSD:1.5515
Å |
 |  |  |  |  |
| VRK2_IVNS1ABP_ENST00000417641_ENST00000367498_58316858_185274775 superimposed PDB: 2V62 of partner (VRK2). RMSD:1.1075
Å |
 |  |  |  |  |
| VRK2_IVNS1ABP_ENST00000417641_ENST00000367498_58316858_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.5034
Å |
| | | |  |
| VRK2_IVNS1ABP_ENST00000440705_ENST00000367498_58316858_185274775 superimposed PDB: 2V62 of partner (VRK2). RMSD:0.9562
Å |
 |  |  |  |  |
| VRK2_IVNS1ABP_ENST00000440705_ENST00000367498_58316858_185274775 superimposed PDB: 6N3H of partner (IVNS1ABP). RMSD:0.4765
Å |
| | | |  |
| VRK2_JAG1_ENST00000417641_ENST00000254958_58276102_10639370 superimposed PDB: 4CC0 of partner (JAG1). RMSD:1.5521
Å |
 |  |  |  |  |
| VRK2_JAG1_ENST00000440705_ENST00000254958_58276102_10639370 superimposed PDB: 4CC0 of partner (JAG1). RMSD:2.2682
Å |
 |  |  |  |  |
| VRK3_PPP6R1_ENST00000316763_ENST00000587283_50504046_55753856 superimposed PDB: 2JII of partner (VRK3). RMSD:3.1671
Å |
 |  |  |  |  |
| VRK3_PPP6R1_ENST00000377011_ENST00000587283_50504046_55753856 superimposed PDB: 2JII of partner (VRK3). RMSD:2.2171
Å |
 |  |  |  |  |
| VRK3_TGFB1_ENST00000443401_ENST00000221930_50504046_41838186 superimposed PDB: 2JII of partner (VRK3). RMSD:0.4466
Å |
 |  |  |  |  |
| VRK3_TGFB1_ENST00000594092_ENST00000221930_50504046_41838186 superimposed PDB: 2JII of partner (VRK3). RMSD:0.4171
Å |
 |  |  |  |  |
| VTI1A_GLUD1_ENST00000432306_ENST00000537649_114298089_88827914 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.3701
Å |
 |  |  |  |  |
| VTI1A_HDAC1_ENST00000393077_ENST00000373548_114298089_32790079 superimposed PDB: 9R4I of partner (HDAC1). RMSD:0.4655
Å |
 |  |  |  |  |
| VTI1A_UBE2D1_ENST00000393077_ENST00000373910_114224416_60123368 superimposed PDB: 4QPL of partner (UBE2D1). RMSD:0.5642
Å |
 |  |  |  |  |
| VTI1A_UBE2D1_ENST00000393077_ENST00000373910_114224416_60124530 superimposed PDB: 4QPL of partner (UBE2D1). RMSD:0.5679
Å |
 |  |  |  |  |
| VWA2_PRKCH_ENST00000392982_ENST00000332981_116008524_61909828 superimposed PDB: 8FP1 of partner (PRKCH). RMSD:0.4436
Å |
 |  |  |  |  |
| VWA8_RB1_ENST00000281496_ENST00000267163_42439871_48916734 superimposed PDB: 4ELJ of partner (RB1). RMSD:3.1973
Å |
 |  |  |  |  |
| VWA8_RICTOR_ENST00000281496_ENST00000357387_42534988_38964994 superimposed PDB: 9T94 of partner (RICTOR). RMSD:1.7423
Å |
 |  |  |  |  |
| VWA8_RICTOR_ENST00000379310_ENST00000296782_42534988_38964994 superimposed PDB: 9T94 of partner (RICTOR). RMSD:1.666
Å |
 |  |  |  |  |
| WAC_SH3BGRL3_ENST00000347934_ENST00000270792_28872434_26607255 superimposed PDB: 1SJ6 of partner (SH3BGRL3). RMSD:1.5217
Å |
 |  |  |  |  |
| WAC_SH3BGRL3_ENST00000354911_ENST00000270792_28872434_26607255 superimposed PDB: 1SJ6 of partner (SH3BGRL3). RMSD:1.473
Å |
 |  |  |  |  |
| WARS2_TPST1_ENST00000235521_ENST00000304842_119618972_65817491 superimposed PDB: 5EKD of partner (WARS2). RMSD:0.6
Å |
 |  |  |  |  |
| WARS2_TPST1_ENST00000369426_ENST00000304842_119618972_65817491 superimposed PDB: 5EKD of partner (WARS2). RMSD:0.4439
Å |
 |  |  |  |  |
| WARS_PPP2R3C_ENST00000392882_ENST00000555644_100800124_35585943 superimposed PDB: 5UJJ of partner (WARS). RMSD:0.5609
Å |
 |  |  |  |  |
| WASF2_FGR_ENST00000430629_ENST00000399173_27755270_27939861 superimposed PDB: 2A40 of partner (WASF2). RMSD:0.3123
Å |
 |  |  |  |  |
| WASF2_FGR_ENST00000430629_ENST00000399173_27755270_27939861 superimposed PDB: 7UY0 of partner (FGR). RMSD:0.7282
Å |
| | | |  |
| WBP1L_PTEN_ENST00000369889_ENST00000371953_104557852_89692769 superimposed PDB: 7JVX of partner (PTEN). RMSD:0.4594
Å |
 |  |  |  |  |
| WBSCR22_LIMK1_ENST00000265758_ENST00000336180_73112024_73520204 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.3397
Å |
 |  |  |  |  |
| WBSCR22_LIMK1_ENST00000423497_ENST00000336180_73112024_73520204 superimposed PDB: 7WTU of partner (WBSCR22). RMSD:0.5993
Å |
 |  |  |  |  |
| WBSCR22_LIMK1_ENST00000423497_ENST00000336180_73112024_73520204 superimposed PDB: 5HVJ of partner (LIMK1). RMSD:0.3511
Å |
| | | |  |
| WDFY3_CCT3_ENST00000322366_ENST00000368259_85781564_156294880 superimposed PDB: 7NVL of partner (CCT3). RMSD:1.7515
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000383366_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.8624
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000429253_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.8849
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000507910_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9264
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000510688_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.919
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000510769_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.8924
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000272321_ENST00000511262_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9069
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000356918_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0458
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000383366_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9895
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000429253_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9531
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000507910_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0166
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000508196_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0152
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000510688_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9685
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000510769_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0067
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000398544_ENST00000511262_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0031
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000356918_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9579
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000383366_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0625
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000429253_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0805
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000507910_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.1143
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000508196_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0523
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000510688_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0366
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000510769_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0605
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409120_ENST00000511262_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:1.0779
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000383366_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.941
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000429253_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9252
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000507910_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9446
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000508196_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9366
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000510688_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9692
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000510769_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.909
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409199_ENST00000511262_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9964
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409562_ENST00000356918_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.9823
Å |
 |  |  |  |  |
| WDPCP_NEK11_ENST00000409562_ENST00000510769_63605520_130851588 superimposed PDB: 7Q3D of partner (WDPCP). RMSD:0.8594
Å |
 |  |  |  |  |
| WDR13_ST6GALNAC2_ENST00000218056_ENST00000225276_48456425_74574898 superimposed PDB: 6APL of partner (ST6GALNAC2). RMSD:0.4769
Å |
 |  |  |  |  |
| WDR1_SLC2A9_ENST00000382451_ENST00000506583_10078927_9836632 superimposed PDB: 9QFQ of partner (WDR1). RMSD:0.8598
Å |
 |  |  |  |  |
| WDR1_SLC2A9_ENST00000499869_ENST00000506583_10078927_9836632 superimposed PDB: 9QFQ of partner (WDR1). RMSD:0.856
Å |
 |  |  |  |  |
| WDR20_LGALS2_ENST00000322340_ENST00000215886_102606509_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:0.4251
Å |
 |  |  |  |  |
| WDR20_LGALS2_ENST00000322340_ENST00000215886_102661457_37967938 superimposed PDB: 5K19 of partner (WDR20). RMSD:2.6126
Å |
 |  |  |  |  |
| WDR20_LGALS2_ENST00000322340_ENST00000215886_102661457_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:0.4162
Å |
| | | |  |
| WDR20_LGALS2_ENST00000335263_ENST00000215886_102606509_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:2.2071
Å |
 |  |  |  |  |
| WDR20_LGALS2_ENST00000454394_ENST00000215886_102606509_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:0.3814
Å |
 |  |  |  |  |
| WDR20_LGALS2_ENST00000556511_ENST00000215886_102606509_37967938 superimposed PDB: 5DG2 of partner (LGALS2). RMSD:0.3897
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000281405_ENST00000405094_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.935
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000281405_ENST00000406652_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9133
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000281405_ENST00000406911_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9092
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000281405_ENST00000472767_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9764
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000345530_ENST00000405094_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9443
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000345530_ENST00000405592_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9562
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000345530_ENST00000406652_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9824
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000345530_ENST00000406911_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:2.0302
Å |
 |  |  |  |  |
| WDR35_MTA3_ENST00000345530_ENST00000472767_20132043_42922904 superimposed PDB: 8BBE of partner (WDR35). RMSD:1.9516
Å |
 |  |  |  |  |
| WDR43_ATP1A3_ENST00000407426_ENST00000545399_29150566_42490381 superimposed PDB: 8D3V of partner (ATP1A3). RMSD:2.4285
Å |
 |  |  |  |  |
| WDR44_PHF21A_ENST00000254029_ENST00000323180_117566857_45959863 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.6735
Å |
 |  |  |  |  |
| WDR44_PHF21A_ENST00000371822_ENST00000323180_117566857_45959863 superimposed PDB: 2PUY of partner (PHF21A). RMSD:0.7485
Å |
 |  |  |  |  |
| WDR48_HERC2_ENST00000544962_ENST00000261609_39093564_28397976 superimposed PDB: 7Q42 of partner (HERC2). RMSD:0.4907
Å |
 |  |  |  |  |
| WDR59_KARS_ENST00000262144_ENST00000302445_74982416_75670445 superimposed PDB: 6CHD of partner (KARS). RMSD:1.1379
Å |
 |  |  |  |  |
| WDR59_KIFC3_ENST00000262144_ENST00000379655_75018861_57795083 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.4231
Å |
 |  |  |  |  |
| WDR59_KIFC3_ENST00000262144_ENST00000445690_75018861_57795083 superimposed PDB: 5WDE of partner (KIFC3). RMSD:1.4185
Å |
 |  |  |  |  |
| WDR61_RAD21_ENST00000267973_ENST00000523986_78581960_117859930 superimposed PDB: 9HVQ of partner (WDR61). RMSD:0.6932
Å |
 |  |  |  |  |
| WDR61_RAD21_ENST00000558459_ENST00000523986_78581960_117859930 superimposed PDB: 9HVQ of partner (WDR61). RMSD:0.5794
Å |
 |  |  |  |  |
| WDR62_CLC_ENST00000401500_ENST00000221804_36549773_40225133 superimposed PDB: 6GKS of partner (CLC). RMSD:0.5112
Å |
 |  |  |  |  |
| WDR62_CLC_ENST00000401500_ENST00000221804_36550932_40225133 superimposed PDB: 6GKS of partner (CLC). RMSD:0.4466
Å |
 |  |  |  |  |
| WDR62_MXD1_ENST00000401500_ENST00000540449_36583713_70162482 superimposed PDB: 1NLW of partner (MXD1). RMSD:1.018
Å |
 |  |  |  |  |
| WDR62_TRAPPC6A_ENST00000401500_ENST00000585934_36580208_45668228 superimposed PDB: 2C0J of partner (TRAPPC6A). RMSD:0.551
Å |
 |  |  |  |  |
| WDR6_MT2A_ENST00000608424_ENST00000245185_49044964_56642903 superimposed PDB: 1MHU of partner (MT2A). RMSD:2.0018
Å |
 |  |  |  |  |
| WDR70_ADAMTS12_ENST00000265107_ENST00000352040_37605340_33751653 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.8726
Å |
 |  |  |  |  |
| WDR70_ADAMTS12_ENST00000265107_ENST00000504830_37605340_33751653 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.7171
Å |
 |  |  |  |  |
| WDR70_ADAMTS12_ENST00000504564_ENST00000504830_37605340_33751653 superimposed PDB: 6ZYM of partner (WDR70). RMSD:0.9864
Å |
 |  |  |  |  |
| WDR76_IDH3A_ENST00000381246_ENST00000558554_44120564_78461263 superimposed PDB: 7CE3 of partner (IDH3A). RMSD:1.0156
Å |
 |  |  |  |  |
| WEE1_CHRNA3_ENST00000299613_ENST00000326828_9608403_78894606 superimposed PDB: 8BJU of partner (WEE1). RMSD:0.4516
Å |
 |  |  |  |  |
| WEE1_CHRNA3_ENST00000299613_ENST00000326828_9608403_78894606 superimposed PDB: 6PV7 of partner (CHRNA3). RMSD:1.0886
Å |
| | | |  |
| WEE1_CHRNA3_ENST00000299613_ENST00000348639_9608403_78894606 superimposed PDB: 8BJU of partner (WEE1). RMSD:0.4698
Å |
 |  |  |  |  |
| WEE1_CHRNA3_ENST00000299613_ENST00000348639_9608403_78894606 superimposed PDB: 6PV7 of partner (CHRNA3). RMSD:1.9327
Å |
| | | |  |
| WEE1_CHRNA3_ENST00000450114_ENST00000326828_9608403_78894606 superimposed PDB: 8BJU of partner (WEE1). RMSD:0.4538
Å |
 |  |  |  |  |
| WEE1_CHRNA3_ENST00000450114_ENST00000326828_9608403_78894606 superimposed PDB: 6PV7 of partner (CHRNA3). RMSD:1.2742
Å |
| | | |  |
| WHSC1L1_ADAM32_ENST00000433384_ENST00000437682_38138984_39131830 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.6464
Å |
 |  |  |  |  |
| WHSC1L1_FGFR1_ENST00000317025_ENST00000341462_38162104_38277253 superimposed PDB: 7CRQ of partner (WHSC1L1). RMSD:1.6282
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000382888_ENST00000309481_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.9369
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000382888_ENST00000394175_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.7429
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000382888_ENST00000418519_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.8189
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000382888_ENST00000520542_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.9997
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000382892_ENST00000360317_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.983
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000508803_ENST00000309481_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.9363
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000508803_ENST00000394175_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.9855
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000508803_ENST00000418519_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.9712
Å |
 |  |  |  |  |
| WHSC1_GSDMB_ENST00000508803_ENST00000520542_1957915_38068750 superimposed PDB: 8EFP of partner (GSDMB). RMSD:2.8911
Å |
 |  |  |  |  |
| WHSC1_POLN_ENST00000382888_ENST00000511885_1977127_2200444 superimposed PDB: 4XVK of partner (POLN). RMSD:0.8668
Å |
 |  |  |  |  |
| WHSC1_POLN_ENST00000508803_ENST00000511885_1977127_2200444 superimposed PDB: 4XVK of partner (POLN). RMSD:0.8261
Å |
 |  |  |  |  |
| WHSC1_TACC3_ENST00000382892_ENST00000313288_1906105_1742552 superimposed PDB: 5LXN of partner (TACC3). RMSD:1.3279
Å |
 |  |  |  |  |
| WIPF2_ERBB2_ENST00000323571_ENST00000269571_38421398_37872553 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9378
Å |
 |  |  |  |  |
| WIPF2_ERBB2_ENST00000323571_ENST00000406381_38421398_37872553 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9349
Å |
 |  |  |  |  |
| WIPF2_ERBB2_ENST00000323571_ENST00000540042_38421398_37872553 superimposed PDB: 7MN5 of partner (ERBB2). RMSD:0.9736
Å |
 |  |  |  |  |
| WIPF2_IKZF3_ENST00000585043_ENST00000346872_38421398_37949186 superimposed PDB: 9UUM of partner (IKZF3). RMSD:3.1504
Å |
 |  |  |  |  |
| WLS_TBX3_ENST00000262348_ENST00000257566_68603462_115110107 superimposed PDB: 7DRT of partner (WLS). RMSD:1.2725
Å |
 |  |  |  |  |
| WLS_TBX3_ENST00000354777_ENST00000257566_68603462_115110107 superimposed PDB: 7DRT of partner (WLS). RMSD:1.1836
Å |
 |  |  |  |  |
| WNK1_ATP6V1G1_ENST00000315939_ENST00000374050_998389_117359849 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6792
Å |
 |  |  |  |  |
| WNK1_ATP6V1G1_ENST00000340908_ENST00000374050_998389_117359849 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7234
Å |
 |  |  |  |  |
| WNK1_ATP6V1G1_ENST00000530271_ENST00000374050_998389_117359849 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7282
Å |
 |  |  |  |  |
| WNK1_ATP6V1G1_ENST00000537687_ENST00000374050_998389_117359849 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7108
Å |
 |  |  |  |  |
| WNK1_B4GALNT3_ENST00000537687_ENST00000266383_939326_657396 superimposed PDB: 5WE8 of partner (WNK1). RMSD:1.0987
Å |
 |  |  |  |  |
| WNK1_CWC22_ENST00000530271_ENST00000295749_863490_180853371 superimposed PDB: 5WE8 of partner (WNK1). RMSD:2.6346
Å |
 |  |  |  |  |
| WNK1_CWC22_ENST00000530271_ENST00000410053_863490_180853371 superimposed PDB: 5WE8 of partner (WNK1). RMSD:2.8008
Å |
 |  |  |  |  |
| WNK1_CWC22_ENST00000535572_ENST00000295749_863490_180853371 superimposed PDB: 5WE8 of partner (WNK1). RMSD:2.9259
Å |
 |  |  |  |  |
| WNK1_DUSP16_ENST00000537687_ENST00000228862_863490_12640121 superimposed PDB: 5WE8 of partner (WNK1). RMSD:2.7706
Å |
 |  |  |  |  |
| WNK1_IQSEC3_ENST00000530271_ENST00000326261_922980_234798 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8884
Å |
 |  |  |  |  |
| WNK1_IQSEC3_ENST00000535572_ENST00000326261_922980_234798 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8823
Å |
 |  |  |  |  |
| WNK1_IQSEC3_ENST00000535572_ENST00000538872_863490_247432 superimposed PDB: 5WE8 of partner (WNK1). RMSD:2.7795
Å |
 |  |  |  |  |
| WNK1_IQSEC3_ENST00000535572_ENST00000538872_922980_234798 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.4355
Å |
 |  |  |  |  |
| WNK1_KDM5A_ENST00000535572_ENST00000399788_939326_432947 superimposed PDB: 5WE8 of partner (WNK1). RMSD:1.1017
Å |
 |  |  |  |  |
| WNK1_KDM5A_ENST00000537687_ENST00000399788_939326_432947 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7565
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000530271_ENST00000377967_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.7133
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000530271_ENST00000377967_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6247
Å |
| | | |  |
| WNK1_KDM6A_ENST00000530271_ENST00000382899_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.6912
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000530271_ENST00000382899_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6031
Å |
| | | |  |
| WNK1_KDM6A_ENST00000530271_ENST00000536777_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.3831
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000530271_ENST00000536777_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6142
Å |
| | | |  |
| WNK1_KDM6A_ENST00000530271_ENST00000543216_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.4727
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000530271_ENST00000543216_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.5975
Å |
| | | |  |
| WNK1_KDM6A_ENST00000535572_ENST00000382899_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.4286
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000535572_ENST00000382899_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6279
Å |
| | | |  |
| WNK1_KDM6A_ENST00000535572_ENST00000536777_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.5933
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000535572_ENST00000536777_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6431
Å |
| | | |  |
| WNK1_KDM6A_ENST00000535572_ENST00000543216_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.415
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000535572_ENST00000543216_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6119
Å |
| | | |  |
| WNK1_KDM6A_ENST00000537687_ENST00000377967_863490_44894175 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.643
Å |
 |  |  |  |  |
| WNK1_KDM6A_ENST00000537687_ENST00000377967_863490_44894175 superimposed PDB: 6G8F of partner (KDM6A). RMSD:0.6157
Å |
| | | |  |
| WNK1_PIP4K2C_ENST00000340908_ENST00000354947_966415_57995308 superimposed PDB: 5WE8 of partner (WNK1). RMSD:1.1217
Å |
 |  |  |  |  |
| WNK1_PIP4K2C_ENST00000340908_ENST00000354947_966415_57995308 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:3.1441
Å |
| | | |  |
| WNK1_PIP4K2C_ENST00000535572_ENST00000354947_966415_57995308 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8916
Å |
 |  |  |  |  |
| WNK1_PIP4K2C_ENST00000537687_ENST00000354947_966415_57995308 superimposed PDB: 5WE8 of partner (WNK1). RMSD:1.0273
Å |
 |  |  |  |  |
| WNK1_PIP4K2C_ENST00000537687_ENST00000354947_966415_57995308 superimposed PDB: 2GK9 of partner (PIP4K2C). RMSD:3.1891
Å |
| | | |  |
| WNK1_PRMT8_ENST00000340908_ENST00000382622_971436_3649771 superimposed PDB: 5WE8 of partner (WNK1). RMSD:1.1978
Å |
 |  |  |  |  |
| WNK1_PRMT8_ENST00000340908_ENST00000382622_971436_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4416
Å |
| | | |  |
| WNK1_PRMT8_ENST00000530271_ENST00000382622_971436_3649771 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8519
Å |
 |  |  |  |  |
| WNK1_PRMT8_ENST00000530271_ENST00000382622_971436_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4049
Å |
| | | |  |
| WNK1_PRMT8_ENST00000535572_ENST00000382622_971436_3649771 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.9008
Å |
 |  |  |  |  |
| WNK1_PRMT8_ENST00000535572_ENST00000382622_971436_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4367
Å |
| | | |  |
| WNK1_PRMT8_ENST00000537687_ENST00000452611_971436_3649771 superimposed PDB: 5WE8 of partner (WNK1). RMSD:0.8854
Å |
 |  |  |  |  |
| WNK1_PRMT8_ENST00000537687_ENST00000452611_971436_3649771 superimposed PDB: 4X41 of partner (PRMT8). RMSD:0.4145
Å |
| | | |  |
| WNK2_FAM120A_ENST00000297954_ENST00000277165_96021896_96259752 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.5826
Å |
 |  |  |  |  |
| WNK2_FAM120A_ENST00000427277_ENST00000277165_96021896_96259752 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.8202
Å |
 |  |  |  |  |
| WNK2_FAM120A_ENST00000427277_ENST00000333936_96021896_96259752 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.5345
Å |
 |  |  |  |  |
| WNK2_FAM120A_ENST00000427277_ENST00000340893_96021896_96259752 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.5163
Å |
 |  |  |  |  |
| WNK2_FAM120A_ENST00000427277_ENST00000375389_96021896_96259752 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.5349
Å |
 |  |  |  |  |
| WNK2_SUSD3_ENST00000427277_ENST00000375469_96031028_95838065 superimposed PDB: 6ELM of partner (WNK2). RMSD:0.547
Å |
 |  |  |  |  |
| WNK3_MKRN3_ENST00000354646_ENST00000568252_54264774_23855770 superimposed PDB: 5O2C of partner (WNK3). RMSD:1.3784
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000333781_ENST00000288319_40752412_39817544 superimposed PDB: 8CR1 of partner (WRB). RMSD:1.8842
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000333781_ENST00000288319_40752412_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4311
Å |
| | | |  |
| WRB_ERG_ENST00000333781_ENST00000398905_40752412_39817544 superimposed PDB: 8CR1 of partner (WRB). RMSD:1.6385
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000333781_ENST00000398905_40752412_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.429
Å |
| | | |  |
| WRB_ERG_ENST00000541890_ENST00000288319_40752412_39817544 superimposed PDB: 8CR1 of partner (WRB). RMSD:2.8248
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000541890_ENST00000288319_40752412_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4576
Å |
| | | |  |
| WRB_ERG_ENST00000541890_ENST00000398905_40752412_39817544 superimposed PDB: 8CR1 of partner (WRB). RMSD:2.4908
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000541890_ENST00000398905_40752412_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4716
Å |
| | | |  |
| WRB_ERG_ENST00000541890_ENST00000398907_40752412_39817544 superimposed PDB: 8CR1 of partner (WRB). RMSD:2.9459
Å |
 |  |  |  |  |
| WRB_ERG_ENST00000541890_ENST00000398907_40752412_39817544 superimposed PDB: 4IRH of partner (ERG). RMSD:0.4256
Å |
| | | |  |
| WRN_ADAM9_ENST00000298139_ENST00000466936_30982516_38871483 superimposed PDB: 9HZG of partner (WRN). RMSD:0.6732
Å |
 |  |  |  |  |
| WRN_ADAM9_ENST00000298139_ENST00000487273_30982516_38871483 superimposed PDB: 9HZG of partner (WRN). RMSD:0.7096
Å |
 |  |  |  |  |
| WRN_GSR_ENST00000298139_ENST00000414019_31024746_30569605 superimposed PDB: 9HZG of partner (WRN). RMSD:0.7424
Å |
 |  |  |  |  |
| WRN_GSR_ENST00000298139_ENST00000414019_31024746_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.6297
Å |
| | | |  |
| WRN_GSR_ENST00000298139_ENST00000537535_31024746_30569605 superimposed PDB: 9HZG of partner (WRN). RMSD:0.6717
Å |
 |  |  |  |  |
| WRN_GSR_ENST00000298139_ENST00000537535_31024746_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.8364
Å |
| | | |  |
| WRN_GSR_ENST00000298139_ENST00000541648_31024746_30569605 superimposed PDB: 9HZG of partner (WRN). RMSD:0.6915
Å |
 |  |  |  |  |
| WRN_GSR_ENST00000298139_ENST00000541648_31024746_30569605 superimposed PDB: 2AAQ of partner (GSR). RMSD:0.7977
Å |
| | | |  |
| WSB1_MED1_ENST00000262394_ENST00000300651_25621461_37571592 superimposed PDB: 7EMF of partner (MED1). RMSD:0.5157
Å |
 |  |  |  |  |
| WSB1_MED1_ENST00000579733_ENST00000394287_25621461_37571592 superimposed PDB: 7EMF of partner (MED1). RMSD:0.4826
Å |
 |  |  |  |  |
| WWOX_C15orf41_ENST00000406884_ENST00000566621_78198186_37100524 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.0438
Å |
 |  |  |  |  |
| WWOX_C15orf41_ENST00000566780_ENST00000437989_78198186_37100524 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.24
Å |
 |  |  |  |  |
| WWOX_C15orf41_ENST00000566780_ENST00000562877_78198186_37100524 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.0455
Å |
 |  |  |  |  |
| WWOX_CA5A_ENST00000406884_ENST00000309893_78149051_87938510 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.091
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000406884_ENST00000564085_78149051_77775478 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.4097
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000408984_ENST00000268533_78458952_77775478 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.2213
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000408984_ENST00000564085_78458952_77759327 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.8907
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000408984_ENST00000564085_78458952_77759327 superimposed PDB: 5T3P of partner (NUDT7). RMSD:0.8589
Å |
| | | |  |
| WWOX_NUDT7_ENST00000566780_ENST00000268533_78458952_77759327 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.2388
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000566780_ENST00000268533_78458952_77759327 superimposed PDB: 5T3P of partner (NUDT7). RMSD:1.1626
Å |
| | | |  |
| WWOX_NUDT7_ENST00000566780_ENST00000437314_78458952_77759327 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.1364
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000566780_ENST00000437314_78458952_77759327 superimposed PDB: 5T3P of partner (NUDT7). RMSD:1.0487
Å |
| | | |  |
| WWOX_NUDT7_ENST00000566780_ENST00000568787_78458952_77759327 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.7603
Å |
 |  |  |  |  |
| WWOX_NUDT7_ENST00000566780_ENST00000568787_78458952_77759327 superimposed PDB: 5T3P of partner (NUDT7). RMSD:0.464
Å |
| | | |  |
| WWOX_SRBD1_ENST00000566780_ENST00000535761_78149051_45616738 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.1538
Å |
 |  |  |  |  |
| WWOX_VAT1L_ENST00000406884_ENST00000302536_78143732_77850817 superimposed PDB: 4A27 of partner (VAT1L). RMSD:0.5047
Å |
 |  |  |  |  |
| WWOX_VAT1L_ENST00000406884_ENST00000302536_78198186_77896644 superimposed PDB: 1WMV of partner (WWOX). RMSD:0.9879
Å |
 |  |  |  |  |
| WWOX_VAT1L_ENST00000406884_ENST00000302536_78198186_77896644 superimposed PDB: 4A27 of partner (VAT1L). RMSD:1.9388
Å |
| | | |  |
| WWOX_VAT1L_ENST00000406884_ENST00000302536_78198186_78005746 superimposed PDB: 1WMV of partner (WWOX). RMSD:1.0741
Å |
 |  |  |  |  |
| WWOX_VAT1L_ENST00000408984_ENST00000302536_78420845_77850817 superimposed PDB: 1WMV of partner (WWOX). RMSD:0.8373
Å |
 |  |  |  |  |
| WWOX_VAT1L_ENST00000408984_ENST00000302536_78420845_77850817 superimposed PDB: 4A27 of partner (VAT1L). RMSD:0.4621
Å |
| | | |  |
| WWP1_CPB2_ENST00000265428_ENST00000181383_87474075_46661955 superimposed PDB: 6J1X of partner (WWP1). RMSD:1.2824
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000265428_ENST00000181383_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.8601
Å |
| | | |  |
| WWP1_CPB2_ENST00000341922_ENST00000181383_87474075_46661955 superimposed PDB: 6J1X of partner (WWP1). RMSD:3.5166
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000341922_ENST00000181383_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.7269
Å |
| | | |  |
| WWP1_CPB2_ENST00000341922_ENST00000439329_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.5657
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000349423_ENST00000181383_87474075_46661955 superimposed PDB: 6J1X of partner (WWP1). RMSD:2.5574
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000349423_ENST00000181383_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.7868
Å |
| | | |  |
| WWP1_CPB2_ENST00000349423_ENST00000439329_87474075_46661955 superimposed PDB: 6J1X of partner (WWP1). RMSD:1.5219
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000349423_ENST00000439329_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.5171
Å |
| | | |  |
| WWP1_CPB2_ENST00000517970_ENST00000439329_87474075_46661955 superimposed PDB: 6J1X of partner (WWP1). RMSD:1.8775
Å |
 |  |  |  |  |
| WWP1_CPB2_ENST00000517970_ENST00000439329_87474075_46661955 superimposed PDB: 4P10 of partner (CPB2). RMSD:0.4782
Å |
| | | |  |
| WWTR1_LCORL_ENST00000467467_ENST00000326877_149374662_17847524 superimposed PDB: 6RHC of partner (WWTR1). RMSD:2.5182
Å |
 |  |  |  |  |
| XBP1_MTERFD1_ENST00000216037_ENST00000524341_29196285_97258159 superimposed PDB: 3M66 of partner (MTERFD1). RMSD:0.4449
Å |
 |  |  |  |  |
| XBP1_MTERFD1_ENST00000403532_ENST00000287025_29196285_97258159 superimposed PDB: 3M66 of partner (MTERFD1). RMSD:0.4933
Å |
 |  |  |  |  |
| XBP1_MTERFD1_ENST00000403532_ENST00000522822_29196285_97258159 superimposed PDB: 3M66 of partner (MTERFD1). RMSD:0.5618
Å |
 |  |  |  |  |
| XPC_RCOR1_ENST00000285021_ENST00000570597_14209756_103177271 superimposed PDB: 6TUY of partner (RCOR1). RMSD:3.3478
Å |
 |  |  |  |  |
| XPC_RCOR1_ENST00000449060_ENST00000570597_14209756_103177271 superimposed PDB: 6TUY of partner (RCOR1). RMSD:2.9652
Å |
 |  |  |  |  |
| XPNPEP1_PLXDC2_ENST00000369680_ENST00000377252_111635285_20453396 superimposed PDB: 3CTZ of partner (XPNPEP1). RMSD:1.3803
Å |
 |  |  |  |  |
| XPNPEP3_RTCB_ENST00000357137_ENST00000216038_41282519_32784086 superimposed PDB: 5X49 of partner (XPNPEP3). RMSD:0.4285
Å |
 |  |  |  |  |
| XPNPEP3_RTCB_ENST00000414396_ENST00000216038_41282519_32784086 superimposed PDB: 5X49 of partner (XPNPEP3). RMSD:0.426
Å |
 |  |  |  |  |
| XPO5_MRPS18A_ENST00000265351_ENST00000372116_43526237_43648857 superimposed PDB: 3A6P of partner (XPO5). RMSD:1.1003
Å |
 |  |  |  |  |
| XPO5_MRPS18A_ENST00000265351_ENST00000372116_43526237_43648857 superimposed PDB: 7OF0 of partner (MRPS18A). RMSD:1.4938
Å |
| | | |  |
| XPO5_SCAP_ENST00000265351_ENST00000265565_43501643_47464026 superimposed PDB: 3A6P of partner (XPO5). RMSD:2.1975
Å |
 |  |  |  |  |
| XPO5_SCAP_ENST00000265351_ENST00000441517_43501643_47464026 superimposed PDB: 3A6P of partner (XPO5). RMSD:2.2388
Å |
 |  |  |  |  |
| XPO7_ASAH1_ENST00000434536_ENST00000381733_21777299_17933096 superimposed PDB: 5U7Z of partner (ASAH1). RMSD:0.326
Å |
 |  |  |  |  |
| XRCC4_AP3B1_ENST00000282268_ENST00000519295_82407022_77461496 superimposed PDB: 9CQ3 of partner (XRCC4). RMSD:0.8405
Å |
 |  |  |  |  |
| XRCC4_AP3B1_ENST00000282268_ENST00000519295_82407022_77461496 superimposed PDB: 9C5A of partner (AP3B1). RMSD:0.887
Å |
| | | |  |
| XRCC5_ABCB4_ENST00000392132_ENST00000265723_216997110_87031618 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:3.1335
Å |
 |  |  |  |  |
| XRCC5_ABCB4_ENST00000392133_ENST00000265723_216997110_87031618 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.8805
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392132_ENST00000430676_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.9012
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392132_ENST00000519966_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.706
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392132_ENST00000523911_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.706
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392133_ENST00000430676_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.7616
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392133_ENST00000519966_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.6779
Å |
 |  |  |  |  |
| XRCC5_RMDN1_ENST00000392133_ENST00000523911_216997110_87489553 superimposed PDB: 8AG4 of partner (XRCC5). RMSD:2.5511
Å |
 |  |  |  |  |
| XRCC6_ARSB_ENST00000360079_ENST00000396151_42024234_78265015 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.3817
Å |
 |  |  |  |  |
| XRCC6_ARSB_ENST00000360079_ENST00000565165_42024234_78265015 superimposed PDB: 1FSU of partner (ARSB). RMSD:0.4567
Å |
 |  |  |  |  |
| XRCC6_GPX5_ENST00000405506_ENST00000469384_42018090_28497227 superimposed PDB: 2I3Y of partner (GPX5). RMSD:0.4219
Å |
 |  |  |  |  |
| XRN1_PIP4K2A_ENST00000392981_ENST00000376573_142166711_22898646 superimposed PDB: 9L5Q of partner (PIP4K2A). RMSD:0.5425
Å |
 |  |  |  |  |
| XYLB_GOLGA4_ENST00000542835_ENST00000361924_38418482_37402733 superimposed PDB: 4BC3 of partner (XYLB). RMSD:0.4612
Å |
 |  |  |  |  |
| XYLB_GOLGA4_ENST00000542835_ENST00000361924_38418482_37402733 superimposed PDB: 1UPT of partner (GOLGA4). RMSD:0.4195
Å |
| | | |  |
| XYLB_OXSR1_ENST00000207870_ENST00000311806_38437054_38287565 superimposed PDB: 4BC3 of partner (XYLB). RMSD:0.7903
Å |
 |  |  |  |  |
| XYLB_OXSR1_ENST00000207870_ENST00000446845_38437054_38287565 superimposed PDB: 4BC3 of partner (XYLB). RMSD:0.8969
Å |
 |  |  |  |  |
| XYLB_OXSR1_ENST00000542835_ENST00000311806_38437054_38287565 superimposed PDB: 4BC3 of partner (XYLB). RMSD:0.5511
Å |
 |  |  |  |  |
| XYLB_OXSR1_ENST00000542835_ENST00000446845_38437054_38287565 superimposed PDB: 4BC3 of partner (XYLB). RMSD:0.7997
Å |
 |  |  |  |  |
| YAP1_HMGCLL1_ENST00000282441_ENST00000274901_101981900_55406938 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.958
Å |
 |  |  |  |  |
| YAP1_HMGCLL1_ENST00000526343_ENST00000398661_101981900_55406938 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.761
Å |
 |  |  |  |  |
| YAP1_MAML2_ENST00000282441_ENST00000524717_102076805_95826681 superimposed PDB: 4RE1 of partner (YAP1). RMSD:3.0855
Å |
 |  |  |  |  |
| YAP1_MAML2_ENST00000345877_ENST00000524717_102076817_95826681 superimposed PDB: 4RE1 of partner (YAP1). RMSD:3.2913
Å |
 |  |  |  |  |
| YAP1_MAML2_ENST00000531439_ENST00000524717_102076805_95826681 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.9071
Å |
 |  |  |  |  |
| YAP1_SS18_ENST00000526343_ENST00000542420_101981900_23667541 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.19
Å |
 |  |  |  |  |
| YAP1_SS18_ENST00000526343_ENST00000542420_101981900_23667541 superimposed PDB: 7VRB of partner (SS18). RMSD:2.5563
Å |
| | | |  |
| YAP1_STIM1_ENST00000282441_ENST00000527651_102080295_4045102 superimposed PDB: 2K60 of partner (STIM1). RMSD:1.9518
Å |
 |  |  |  |  |
| YAP1_STIM1_ENST00000524575_ENST00000300737_102080295_4045102 superimposed PDB: 4RE1 of partner (YAP1). RMSD:2.9816
Å |
 |  |  |  |  |
| YAP1_STIM1_ENST00000524575_ENST00000300737_102080295_4045102 superimposed PDB: 2K60 of partner (STIM1). RMSD:1.9158
Å |
| | | |  |
| YAP1_STIM1_ENST00000524575_ENST00000527651_102080295_4045102 superimposed PDB: 2K60 of partner (STIM1). RMSD:1.9246
Å |
 |  |  |  |  |
| YARS_RNF19B_ENST00000373477_ENST00000235150_33276191_33415375 superimposed PDB: 1N3L of partner (YARS). RMSD:0.8387
Å |
 |  |  |  |  |
| YARS_RNF19B_ENST00000373477_ENST00000356990_33276191_33415375 superimposed PDB: 1N3L of partner (YARS). RMSD:0.7713
Å |
 |  |  |  |  |
| YARS_TRIM62_ENST00000373477_ENST00000543586_33244982_33631167 superimposed PDB: 1N3L of partner (YARS). RMSD:1.2963
Å |
 |  |  |  |  |
| YBX3_RPS6KA3_ENST00000228251_ENST00000379565_10865809_20252932 superimposed PDB: 4D9T of partner (RPS6KA3). RMSD:0.7705
Å |
 |  |  |  |  |
| YEATS4_AGAP2_ENST00000247843_ENST00000547588_69759664_58127956 superimposed PDB: 2RLO of partner (AGAP2). RMSD:1.4976
Å |
 |  |  |  |  |
| YEATS4_CCT2_ENST00000247843_ENST00000543146_69756687_69981284 superimposed PDB: 7NVL of partner (CCT2). RMSD:0.9684
Å |
 |  |  |  |  |
| YEATS4_CCT2_ENST00000247843_ENST00000544368_69756687_69981284 superimposed PDB: 7NVL of partner (CCT2). RMSD:1.7364
Å |
 |  |  |  |  |
| YEATS4_CTDSP2_ENST00000247843_ENST00000548823_69764755_58223379 superimposed PDB: 2Q5E of partner (CTDSP2). RMSD:0.3485
Å |
 |  |  |  |  |
| YEATS4_CTDSP2_ENST00000548020_ENST00000548823_69764755_58223379 superimposed PDB: 2Q5E of partner (CTDSP2). RMSD:0.3574
Å |
 |  |  |  |  |
| YEATS4_GRIP1_ENST00000247843_ENST00000286445_69764755_66859202 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.6015
Å |
 |  |  |  |  |
| YEATS4_GRIP1_ENST00000247843_ENST00000359742_69764755_66859202 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.6135
Å |
 |  |  |  |  |
| YEATS4_GRIP1_ENST00000548020_ENST00000286445_69764755_66859202 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.61
Å |
 |  |  |  |  |
| YEATS4_GRIP1_ENST00000548020_ENST00000359742_69764755_66859202 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.6528
Å |
 |  |  |  |  |
| YEATS4_GRIP1_ENST00000548020_ENST00000398016_69764755_66859202 superimposed PDB: 2JIL of partner (GRIP1). RMSD:0.5881
Å |
 |  |  |  |  |
| YEATS4_USP15_ENST00000247843_ENST00000280377_69756687_62719652 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5104
Å |
 |  |  |  |  |
| YEATS4_USP15_ENST00000247843_ENST00000393654_69756687_62719652 superimposed PDB: 6GH9 of partner (USP15). RMSD:0.5297
Å |
 |  |  |  |  |
| YTHDC1_GAK_ENST00000344157_ENST00000511163_69215443_891946 superimposed PDB: 4Y8D of partner (GAK). RMSD:0.5627
Å |
 |  |  |  |  |
| YWHAB_CAPN8_ENST00000372839_ENST00000366872_43530474_223718212 superimposed PDB: 5N10 of partner (YWHAB). RMSD:3.1255
Å |
 |  |  |  |  |
| YWHAE_MYO1C_ENST00000264335_ENST00000575158_1264385_1369046 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.4936
Å |
 |  |  |  |  |
| YWHAE_MYO1C_ENST00000571732_ENST00000361007_1264385_1369046 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.3741
Å |
 |  |  |  |  |
| YWHAE_RIPK2_ENST00000571732_ENST00000540020_1268152_90792302 superimposed PDB: 8AZA of partner (RIPK2). RMSD:2.7213
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000301335_1257504_1489345 superimposed PDB: 8DGP of partner (YWHAE). RMSD:1.6084
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000382147_1303340_1496573 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.5825
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000382147_1303340_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.4348
Å |
| | | |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000412517_1303340_1496573 superimposed PDB: 8DGP of partner (YWHAE). RMSD:2.1881
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000412517_1303340_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.5521
Å |
| | | |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000571650_1257504_1489345 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.4787
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000571650_1257504_1489345 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:1.1196
Å |
| | | |  |
| YWHAE_SLC43A2_ENST00000264335_ENST00000571650_1303340_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.3683
Å |
 |  |  |  |  |
| YWHAE_SLC43A2_ENST00000573026_ENST00000301335_1303340_1496573 superimposed PDB: 9JBS of partner (SLC43A2). RMSD:2.3396
Å |
 |  |  |  |  |
| YWHAE_SPNS3_ENST00000571732_ENST00000333476_1264385_4381866 superimposed PDB: 8DGP of partner (YWHAE). RMSD:0.4269
Å |
 |  |  |  |  |
| YWHAZ_RPS27A_ENST00000353245_ENST00000272317_101936182_55461966 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.4876
Å |
 |  |  |  |  |
| YWHAZ_RPS27A_ENST00000395956_ENST00000272317_101936182_55461966 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.4967
Å |
 |  |  |  |  |
| YWHAZ_RPS27A_ENST00000395956_ENST00000402285_101936182_55461966 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:3.1426
Å |
 |  |  |  |  |
| YWHAZ_RPS27A_ENST00000521309_ENST00000272317_101936182_55461966 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3716
Å |
 |  |  |  |  |
| YWHAZ_RPS27A_ENST00000522542_ENST00000272317_101936182_55461966 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.4309
Å |
 |  |  |  |  |
| YWHAZ_YWHAQ_ENST00000353245_ENST00000238081_101936362_9727638 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.4451
Å |
 |  |  |  |  |
| YWHAZ_YWHAQ_ENST00000353245_ENST00000238081_101936362_9727638 superimposed PDB: 6BCR of partner (YWHAQ). RMSD:0.7852
Å |
| | | |  |
| YWHAZ_YWHAQ_ENST00000395956_ENST00000238081_101936362_9727638 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.4615
Å |
 |  |  |  |  |
| YWHAZ_YWHAQ_ENST00000395956_ENST00000238081_101936362_9727638 superimposed PDB: 6BCR of partner (YWHAQ). RMSD:0.7547
Å |
| | | |  |
| YWHAZ_YWHAQ_ENST00000521309_ENST00000238081_101936362_9727638 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.2706
Å |
 |  |  |  |  |
| YWHAZ_YWHAQ_ENST00000521309_ENST00000238081_101936362_9727638 superimposed PDB: 6BCR of partner (YWHAQ). RMSD:0.281
Å |
| | | |  |
| YWHAZ_YWHAQ_ENST00000522542_ENST00000238081_101936362_9727638 superimposed PDB: 1QJA of partner (YWHAZ). RMSD:0.3327
Å |
 |  |  |  |  |
| YWHAZ_YWHAQ_ENST00000522542_ENST00000238081_101936362_9727638 superimposed PDB: 6BCR of partner (YWHAQ). RMSD:0.3484
Å |
| | | |  |
| YY1_EWSR1_ENST00000262238_ENST00000397938_100706260_29688125 superimposed PDB: 1UBD of partner (YY1). RMSD:2.74
Å |
 |  |  |  |  |
| YY1_EWSR1_ENST00000262238_ENST00000397938_100706260_29688125 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7091
Å |
| | | |  |
| YY1_MAPK1_ENST00000262238_ENST00000544786_100728803_22162135 superimposed PDB: 8AOJ of partner (MAPK1). RMSD:0.5542
Å |
 |  |  |  |  |
| ZBTB17_FAM131C_ENST00000537142_ENST00000375662_16271431_16386546 superimposed PDB: 7T58 of partner (ZBTB17). RMSD:0.3619
Å |
 |  |  |  |  |
| ZBTB17_MTOR_ENST00000537142_ENST00000361445_16269558_11227574 superimposed PDB: 9T94 of partner (MTOR). RMSD:2.6721
Å |
 |  |  |  |  |
| ZBTB1_DTX2_ENST00000358738_ENST00000324432_64990120_76121469 superimposed PDB: 6Y2X of partner (DTX2). RMSD:1.5168
Å |
 |  |  |  |  |
| ZBTB1_DTX2_ENST00000358738_ENST00000446600_64990120_76121469 superimposed PDB: 6Y2X of partner (DTX2). RMSD:1.4791
Å |
 |  |  |  |  |
| ZBTB20_CMSS1_ENST00000462705_ENST00000421999_114069120_99865816 superimposed PDB: 9JZT of partner (ZBTB20). RMSD:0.3137
Å |
 |  |  |  |  |
| ZBTB20_CMSS1_ENST00000481632_ENST00000421999_114069120_99865816 superimposed PDB: 9JZT of partner (ZBTB20). RMSD:0.5415
Å |
 |  |  |  |  |
| ZC3H7A_CD99_ENST00000355758_ENST00000381192_11868091_2582462 superimposed PDB: 2D9M of partner (ZC3H7A). RMSD:1.67
Å |
 |  |  |  |  |
| ZC3H7A_GSPT1_ENST00000355758_ENST00000434724_11857333_11967028 superimposed PDB: 2D9M of partner (ZC3H7A). RMSD:1.6162
Å |
 |  |  |  |  |
| ZC3H7A_GSPT1_ENST00000396516_ENST00000439887_11856526_11976952 superimposed PDB: 2D9M of partner (ZC3H7A). RMSD:1.6144
Å |
 |  |  |  |  |
| ZC3H7B_L3MBTL2_ENST00000351589_ENST00000216237_41723368_41605699 superimposed PDB: 3F70 of partner (L3MBTL2). RMSD:0.7072
Å |
 |  |  |  |  |
| ZCCHC7_MLLT3_ENST00000322831_ENST00000380338_37126939_20456784 superimposed PDB: 8PJ7 of partner (MLLT3). RMSD:0.8087
Å |
 |  |  |  |  |
| ZCCHC7_TEK_ENST00000336755_ENST00000380036_37126939_27197312 superimposed PDB: 4K0V of partner (TEK). RMSD:2.9604
Å |
 |  |  |  |  |
| ZDHHC17_OARD1_ENST00000334822_ENST00000463088_77158109_41039015 superimposed PDB: 2LGR of partner (OARD1). RMSD:0.8226
Å |
 |  |  |  |  |
| ZDHHC17_OARD1_ENST00000426126_ENST00000479950_77158109_41039015 superimposed PDB: 2LGR of partner (OARD1). RMSD:0.9824
Å |
 |  |  |  |  |
| ZEB1_GLUD1_ENST00000361642_ENST00000277865_31608221_88836413 superimposed PDB: 8SK8 of partner (GLUD1). RMSD:1.2758
Å |
 |  |  |  |  |
| ZEB1_TAOK3_ENST00000320985_ENST00000392533_31608221_118651915 superimposed PDB: 6BDN of partner (TAOK3). RMSD:1.0104
Å |
 |  |  |  |  |
| ZFAND3_ATG12_ENST00000373391_ENST00000509910_37897775_115173461 superimposed PDB: 4NAW of partner (ATG12). RMSD:0.3772
Å |
 |  |  |  |  |
| ZFAND3_CMTR1_ENST00000373391_ENST00000373451_37787792_37438796 superimposed PDB: 8P4E of partner (CMTR1). RMSD:0.1884
Å |
 |  |  |  |  |
| ZFAND3_MDGA1_ENST00000287218_ENST00000434837_38084515_37631882 superimposed PDB: 1X4W of partner (ZFAND3). RMSD:1.7382
Å |
 |  |  |  |  |
| ZFAND3_MDGA1_ENST00000287218_ENST00000434837_38084515_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:2.0704
Å |
| | | |  |
| ZFAND3_MDGA1_ENST00000287218_ENST00000505425_38084515_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.8039
Å |
 |  |  |  |  |
| ZFAND3_MDGA1_ENST00000373391_ENST00000297153_38084515_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.5146
Å |
 |  |  |  |  |
| ZFAND3_MDGA1_ENST00000373391_ENST00000434837_38084515_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.9124
Å |
 |  |  |  |  |
| ZFAND3_MDGA1_ENST00000373391_ENST00000505425_38084515_37631882 superimposed PDB: 5XEQ of partner (MDGA1). RMSD:1.6976
Å |
 |  |  |  |  |
| ZFAND3_MRPL23_ENST00000287218_ENST00000381514_37787792_1972128 superimposed PDB: 7OF0 of partner (MRPL23). RMSD:2.4329
Å |
 |  |  |  |  |
| ZFAND3_MRPL23_ENST00000287218_ENST00000397294_37787792_1972128 superimposed PDB: 7OF0 of partner (MRPL23). RMSD:2.7517
Å |
 |  |  |  |  |
| ZFAND3_MRPL23_ENST00000287218_ENST00000397294_37897775_1974011 superimposed PDB: 7OF0 of partner (MRPL23). RMSD:3.0073
Å |
 |  |  |  |  |
| ZFAND3_MRPL23_ENST00000373391_ENST00000381514_37787792_1972128 superimposed PDB: 7OF0 of partner (MRPL23). RMSD:1.1875
Å |
 |  |  |  |  |
| ZFAND3_MRPL23_ENST00000373391_ENST00000397294_37787792_1972128 superimposed PDB: 7OF0 of partner (MRPL23). RMSD:2.5168
Å |
 |  |  |  |  |
| ZFP28_SLC9A8_ENST00000301318_ENST00000361573_57061974_48456077 superimposed PDB: 2EPX of partner (ZFP28). RMSD:2.2512
Å |
 |  |  |  |  |
| ZFP90_CBFB_ENST00000398253_ENST00000561924_68573728_67116115 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.6368
Å |
 |  |  |  |  |
| ZFP90_CBFB_ENST00000563169_ENST00000561924_68573728_67116115 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.5867
Å |
 |  |  |  |  |
| ZFP90_CBFB_ENST00000564323_ENST00000290858_68573728_67116115 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.5984
Å |
 |  |  |  |  |
| ZFP90_CBFB_ENST00000570495_ENST00000290858_68573728_67116115 superimposed PDB: 8CX0 of partner (CBFB). RMSD:2.5646
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000398253_ENST00000264012_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1413
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000398253_ENST00000429102_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1713
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000563169_ENST00000264012_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1645
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000563169_ENST00000429102_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1837
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000564323_ENST00000264012_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1231
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000564323_ENST00000429102_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.2335
Å |
 |  |  |  |  |
| ZFP90_CDH3_ENST00000570495_ENST00000429102_68592471_68710287 superimposed PDB: 4ZMN of partner (CDH3). RMSD:1.1128
Å |
 |  |  |  |  |
| ZFP91_CLPB_ENST00000316059_ENST00000538039_58352357_72040848 superimposed PDB: 7XBK of partner (CLPB). RMSD:1.28
Å |
 |  |  |  |  |
| ZFPM2_RRAS2_ENST00000407775_ENST00000414023_106573709_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5257
Å |
 |  |  |  |  |
| ZFPM2_RRAS2_ENST00000517361_ENST00000414023_106573709_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5939
Å |
 |  |  |  |  |
| ZFPM2_RRAS2_ENST00000520492_ENST00000414023_106573709_14317401 superimposed PDB: 9B4S of partner (RRAS2). RMSD:0.5118
Å |
 |  |  |  |  |
| ZFYVE9_USP33_ENST00000287727_ENST00000370794_52698948_78178966 superimposed PDB: 4BKW of partner (ZFYVE9). RMSD:2.7809
Å |
 |  |  |  |  |
| ZGPAT_CNBD2_ENST00000355969_ENST00000349339_62340516_34575316 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:3.1801
Å |
 |  |  |  |  |
| ZGPAT_CNBD2_ENST00000448100_ENST00000349339_62340516_34575316 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:3.0419
Å |
 |  |  |  |  |
| ZGPAT_CNBD2_ENST00000448100_ENST00000538900_62340516_34575316 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:2.9147
Å |
 |  |  |  |  |
| ZGPAT_HELZ2_ENST00000355969_ENST00000467148_62340516_62190723 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:1.6983
Å |
 |  |  |  |  |
| ZGPAT_HELZ2_ENST00000357119_ENST00000467148_62340516_62190723 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:1.7044
Å |
 |  |  |  |  |
| ZGPAT_TPD52L2_ENST00000355969_ENST00000217121_62340516_62514071 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:2.836
Å |
 |  |  |  |  |
| ZGPAT_TPD52L2_ENST00000355969_ENST00000358548_62340516_62514071 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:1.4582
Å |
 |  |  |  |  |
| ZGPAT_TPD52L2_ENST00000448100_ENST00000217121_62340516_62514071 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:2.6559
Å |
 |  |  |  |  |
| ZGPAT_TPD52L2_ENST00000448100_ENST00000346249_62340516_62514071 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:3.0794
Å |
 |  |  |  |  |
| ZGPAT_TPD52L2_ENST00000448100_ENST00000358548_62340516_62514071 superimposed PDB: 4II1 of partner (ZGPAT). RMSD:1.3399
Å |
 |  |  |  |  |
| ZHX3_CHD6_ENST00000432768_ENST00000373233_39830696_40034129 superimposed PDB: 2DA5 of partner (ZHX3). RMSD:1.0225
Å |
 |  |  |  |  |
| ZMAT5_HIRA_ENST00000397781_ENST00000340170_30134318_19319079 superimposed PDB: 9GCL of partner (ZMAT5). RMSD:1.4539
Å |
 |  |  |  |  |
| ZMIZ1_NSMCE4A_ENST00000334512_ENST00000369023_80976031_123730584 superimposed PDB: 5AIZ of partner (ZMIZ1). RMSD:0.2976
Å |
 |  |  |  |  |
| ZMPSTE24_CAP1_ENST00000372759_ENST00000372797_40737707_40535361 superimposed PDB: 9Q7O of partner (CAP1). RMSD:2.9715
Å |
 |  |  |  |  |
| ZMPSTE24_CAP1_ENST00000372759_ENST00000372802_40737707_40535361 superimposed PDB: 4AW6 of partner (ZMPSTE24). RMSD:0.6911
Å |
 |  |  |  |  |
| ZMYM2_FGFR1_ENST00000382869_ENST00000397091_20633702_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.6821
Å |
 |  |  |  |  |
| ZMYM2_FGFR1_ENST00000382874_ENST00000397091_20633702_38275891 superimposed PDB: 8JQI of partner (FGFR1). RMSD:0.7271
Å |
 |  |  |  |  |
| ZMYM2_PRIM2_ENST00000382871_ENST00000607273_20580726_57244698 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.3395
Å |
 |  |  |  |  |
| ZMYM2_PRIM2_ENST00000382874_ENST00000607273_20580726_57244698 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.378
Å |
 |  |  |  |  |
| ZMYM2_PRIM2_ENST00000382881_ENST00000607273_20580726_57244698 superimposed PDB: 4RR2 of partner (PRIM2). RMSD:2.2828
Å |
 |  |  |  |  |
| ZMYM4_ACACA_ENST00000373297_ENST00000360679_35734686_35538297 superimposed PDB: 8XL1 of partner (ACACA). RMSD:0.8603
Å |
 |  |  |  |  |
| ZMYM4_SMYD3_ENST00000314607_ENST00000541742_35827390_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8887
Å |
 |  |  |  |  |
| ZMYM4_SMYD3_ENST00000373297_ENST00000490107_35827390_246093239 superimposed PDB: 6P7Z of partner (SMYD3). RMSD:0.8359
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000381602_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.4059
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000381602_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.5916
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000381604_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.4532
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000381604_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6406
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000381607_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.4592
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000381607_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6444
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000397959_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:1.0188
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000397959_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.5937
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000402736_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.6052
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000402736_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6542
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000403354_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:3.0417
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000403354_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6441
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000509513_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.4275
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000509513_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6009
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000535374_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:0.4843
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000535374_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6472
Å |
| | | |  |
| ZMYND11_SORBS2_ENST00000545619_ENST00000431808_293406_186515089 superimposed PDB: 4NS5 of partner (ZMYND11). RMSD:2.8322
Å |
 |  |  |  |  |
| ZMYND11_SORBS2_ENST00000545619_ENST00000431808_293406_186515089 superimposed PDB: 5VEI of partner (SORBS2). RMSD:0.6043
Å |
| | | |  |
| ZMYND8_CELF5_ENST00000360911_ENST00000292672_45976599_3250982 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4225
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000360911_ENST00000541430_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9859
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000396281_ENST00000541430_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9372
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000458360_ENST00000292672_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:1.0442
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000536340_ENST00000292672_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9548
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000536340_ENST00000541430_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.9289
Å |
 |  |  |  |  |
| ZMYND8_CELF5_ENST00000540497_ENST00000292672_45976599_3250982 superimposed PDB: 2DNH of partner (CELF5). RMSD:0.8922
Å |
 |  |  |  |  |
| ZMYND8_CEP250_ENST00000262975_ENST00000342580_45852969_34079037 superimposed PDB: 6OQA of partner (CEP250). RMSD:2.6113
Å |
 |  |  |  |  |
| ZMYND8_CEP250_ENST00000446994_ENST00000397527_45852969_34078462 superimposed PDB: 6OQA of partner (CEP250). RMSD:2.9322
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000352431_ENST00000555685_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6196
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000360911_ENST00000354280_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6842
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000396281_ENST00000354280_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6626
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000458360_ENST00000555685_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7141
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000471951_ENST00000354280_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6944
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000536340_ENST00000354280_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6503
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000536340_ENST00000555685_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7222
Å |
 |  |  |  |  |
| ZMYND8_EPPIN_ENST00000540497_ENST00000555685_45905057_44171506 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.641
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000352431_ENST00000357410_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6885
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000352431_ENST00000357410_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.4433
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000360911_ENST00000327619_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6733
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000360911_ENST00000327619_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.5972
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000396281_ENST00000327619_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.686
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000396281_ENST00000327619_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.8407
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000458360_ENST00000357410_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6585
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000458360_ENST00000357410_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.4628
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000461685_ENST00000357410_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.8058
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000461685_ENST00000357410_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.4734
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000471951_ENST00000327619_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6959
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000471951_ENST00000327619_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:3.112
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000536340_ENST00000327619_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.62
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000536340_ENST00000327619_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.4988
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000536340_ENST00000357410_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.698
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000536340_ENST00000357410_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.421
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000540497_ENST00000327619_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.716
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000540497_ENST00000327619_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:2.9284
Å |
| | | |  |
| ZMYND8_EYA2_ENST00000540497_ENST00000357410_45874751_45717877 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6513
Å |
 |  |  |  |  |
| ZMYND8_EYA2_ENST00000540497_ENST00000357410_45874751_45717877 superimposed PDB: 4EGC of partner (EYA2). RMSD:0.418
Å |
| | | |  |
| ZMYND8_GNAI3_ENST00000458360_ENST00000369851_45976599_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:0.9761
Å |
 |  |  |  |  |
| ZMYND8_GNAI3_ENST00000536340_ENST00000369851_45976599_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:0.9911
Å |
 |  |  |  |  |
| ZMYND8_GNAI3_ENST00000540497_ENST00000369851_45976599_110116358 superimposed PDB: 7T10 of partner (GNAI3). RMSD:0.982
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000352431_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6122
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000396281_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7108
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000458360_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7037
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000461685_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6541
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000471951_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6724
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000536340_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6089
Å |
 |  |  |  |  |
| ZMYND8_GTPBP1_ENST00000540497_ENST00000216044_45848908_39111911 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6507
Å |
 |  |  |  |  |
| ZMYND8_ORC5_ENST00000262975_ENST00000545943_45976599_103835702 superimposed PDB: 7JPO of partner (ORC5). RMSD:3.6385
Å |
 |  |  |  |  |
| ZMYND8_ORC5_ENST00000446994_ENST00000297431_45976599_103835702 superimposed PDB: 7JPO of partner (ORC5). RMSD:0.835
Å |
 |  |  |  |  |
| ZMYND8_ORC5_ENST00000458360_ENST00000297431_45976599_103828829 superimposed PDB: 7JPO of partner (ORC5). RMSD:0.7784
Å |
 |  |  |  |  |
| ZMYND8_ORC5_ENST00000536340_ENST00000297431_45976599_103828829 superimposed PDB: 7JPO of partner (ORC5). RMSD:0.6966
Å |
 |  |  |  |  |
| ZMYND8_ORC5_ENST00000540497_ENST00000297431_45976599_103828829 superimposed PDB: 7JPO of partner (ORC5). RMSD:0.7369
Å |
 |  |  |  |  |
| ZMYND8_RHPN2_ENST00000355972_ENST00000254260_45874751_33535270 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7999
Å |
 |  |  |  |  |
| ZMYND8_RHPN2_ENST00000355972_ENST00000254260_45874751_33535270 superimposed PDB: 2VSV of partner (RHPN2). RMSD:2.879
Å |
| | | |  |
| ZMYND8_RHPN2_ENST00000446994_ENST00000254260_45874751_33535270 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6411
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000311275_ENST00000359930_45865069_46295232 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5609
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000311275_ENST00000484875_45865069_46295232 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6114
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000352431_ENST00000359930_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5007
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000352431_ENST00000359930_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5209
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000352431_ENST00000478766_45912314_46365687 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4852
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000360911_ENST00000467815_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5088
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000360911_ENST00000467815_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.721
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000360911_ENST00000484875_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5498
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000360911_ENST00000484875_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.7008
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000396281_ENST00000467815_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4834
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000396281_ENST00000467815_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6774
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000396281_ENST00000484875_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5449
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000396281_ENST00000484875_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6652
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000458360_ENST00000359930_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4915
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000458360_ENST00000359930_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6375
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000458360_ENST00000478766_45912314_46365687 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5214
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000471951_ENST00000467815_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4553
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000471951_ENST00000467815_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5437
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000471951_ENST00000484875_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4946
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000471951_ENST00000484875_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5218
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000359930_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4981
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000359930_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5981
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000467815_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5021
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000467815_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5651
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000478766_45912314_46365687 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5144
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000484875_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4976
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000536340_ENST00000484875_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5795
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000540497_ENST00000359930_45915972_46319039 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5145
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000540497_ENST00000359930_45918930_46331414 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.4941
Å |
 |  |  |  |  |
| ZMYND8_SULF2_ENST00000540497_ENST00000478766_45912314_46365687 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.5183
Å |
 |  |  |  |  |
| ZMYND8_TFE3_ENST00000355972_ENST00000315869_45849964_48896935 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.8865
Å |
 |  |  |  |  |
| ZMYND8_TFE3_ENST00000446994_ENST00000315869_45849964_48896935 superimposed PDB: 5B73 of partner (ZMYND8). RMSD:0.6673
Å |
 |  |  |  |  |
| ZNF136_NFIC_ENST00000343979_ENST00000341919_12274021_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5485
Å |
 |  |  |  |  |
| ZNF136_NFIC_ENST00000343979_ENST00000346156_12274021_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5319
Å |
 |  |  |  |  |
| ZNF136_NFIC_ENST00000343979_ENST00000395111_12274021_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5863
Å |
 |  |  |  |  |
| ZNF136_NFIC_ENST00000343979_ENST00000586919_12274021_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.6106
Å |
 |  |  |  |  |
| ZNF136_NFIC_ENST00000343979_ENST00000590282_12274021_3381709 superimposed PDB: 9XVD of partner (NFIC). RMSD:0.5471
Å |
 |  |  |  |  |
| ZNF136_NFIX_ENST00000343979_ENST00000587760_12274021_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5327
Å |
 |  |  |  |  |
| ZNF136_NFIX_ENST00000343979_ENST00000592199_12274021_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4161
Å |
 |  |  |  |  |
| ZNF14_STAT5A_ENST00000344099_ENST00000588868_19843764_40447636 superimposed PDB: 7UBT of partner (STAT5A). RMSD:0.8492
Å |
 |  |  |  |  |
| ZNF14_STAT5A_ENST00000344099_ENST00000590949_19843764_40447636 superimposed PDB: 7UBT of partner (STAT5A). RMSD:0.872
Å |
 |  |  |  |  |
| ZNF154_KIR2DL1_ENST00000426889_ENST00000291633_58216220_55284784 superimposed PDB: 1IM9 of partner (KIR2DL1). RMSD:0.763
Å |
 |  |  |  |  |
| ZNF169_SET_ENST00000395395_ENST00000409104_97055351_131453448 superimposed PDB: 2E50 of partner (SET). RMSD:1.1351
Å |
 |  |  |  |  |
| ZNF181_PEPD_ENST00000392232_ENST00000397032_35225951_33984243 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.3548
Å |
 |  |  |  |  |
| ZNF181_PEPD_ENST00000392232_ENST00000436370_35225951_33984243 superimposed PDB: 6QSC of partner (PEPD). RMSD:0.4252
Å |
 |  |  |  |  |
| ZNF195_FAM160A2_ENST00000354599_ENST00000449352_3400267_6240280 superimposed PDB: 8QAT of partner (FAM160A2). RMSD:0.6223
Å |
 |  |  |  |  |
| ZNF200_COLEC12_ENST00000396871_ENST00000400256_3282420_480757 superimposed PDB: 2OX8 of partner (COLEC12). RMSD:0.5516
Å |
 |  |  |  |  |
| ZNF207_SSU72_ENST00000321233_ENST00000291386_30677345_1480382 superimposed PDB: 4H3K of partner (SSU72). RMSD:0.8657
Å |
 |  |  |  |  |
| ZNF20_NFIX_ENST00000334213_ENST00000397661_12250994_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.4857
Å |
 |  |  |  |  |
| ZNF20_NFIX_ENST00000600335_ENST00000587760_12250994_13135834 superimposed PDB: 9WA7 of partner (NFIX). RMSD:0.5234
Å |
 |  |  |  |  |
| ZNF212_PDE3B_ENST00000335870_ENST00000455098_148947898_14839728 superimposed PDB: 8SYC of partner (PDE3B). RMSD:0.4824
Å |
 |  |  |  |  |
| ZNF226_DDX19B_ENST00000413984_ENST00000563392_44677105_70366870 superimposed PDB: 3FMP of partner (DDX19B). RMSD:2.4791
Å |
 |  |  |  |  |
| ZNF236_PIEZO2_ENST00000320610_ENST00000503781_74534618_10979658 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:2.7889
Å |
 |  |  |  |  |
| ZNF236_PIEZO2_ENST00000320610_ENST00000580640_74534618_10979658 superimposed PDB: 9VEE of partner (PIEZO2). RMSD:1.9163
Å |
 |  |  |  |  |
| ZNF264_TRAP1_ENST00000600531_ENST00000246957_57703314_3727659 superimposed PDB: 7KLV of partner (TRAP1). RMSD:1.8818
Å |
 |  |  |  |  |
| ZNF274_UBA7_ENST00000326804_ENST00000333486_58695365_49846592 superimposed PDB: 8SE9 of partner (UBA7). RMSD:2.8206
Å |
 |  |  |  |  |
| ZNF292_AKIRIN2_ENST00000339907_ENST00000257787_87928449_88391481 superimposed PDB: 7NHT of partner (AKIRIN2). RMSD:1.087
Å |
 |  |  |  |  |
| ZNF292_B3GAT2_ENST00000339907_ENST00000230053_87865477_71603975 superimposed PDB: 2D0J of partner (B3GAT2). RMSD:2.1747
Å |
 |  |  |  |  |
| ZNF292_FIG4_ENST00000339907_ENST00000441478_87865477_110113784 superimposed PDB: 1X3C of partner (ZNF292). RMSD:0.5484
Å |
 |  |  |  |  |
| ZNF292_RNGTT_ENST00000369577_ENST00000265607_87865477_89324114 superimposed PDB: 8P4B of partner (RNGTT). RMSD:2.0123
Å |
 |  |  |  |  |
| ZNF292_SYNCRIP_ENST00000339907_ENST00000355238_87865477_86328657 superimposed PDB: 6KOR of partner (SYNCRIP). RMSD:1.2912
Å |
 |  |  |  |  |
| ZNF292_SYNCRIP_ENST00000369577_ENST00000369622_87865477_86328657 superimposed PDB: 6KOR of partner (SYNCRIP). RMSD:1.5207
Å |
 |  |  |  |  |
| ZNF302_ANKRD27_ENST00000457781_ENST00000306065_35169718_33098738 superimposed PDB: 4B93 of partner (ANKRD27). RMSD:0.4335
Å |
 |  |  |  |  |
| ZNF318_PDE3A_ENST00000361428_ENST00000359062_43310413_20709593 superimposed PDB: 7LRC of partner (PDE3A). RMSD:0.4462
Å |
 |  |  |  |  |
| ZNF318_XPO5_ENST00000361428_ENST00000265351_43333029_43501744 superimposed PDB: 3A6P of partner (XPO5). RMSD:1.6683
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000346874_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9761
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000350537_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9465
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000374788_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9731
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000374789_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9832
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000374790_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9837
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000374794_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9817
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000351773_ENST00000545693_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9787
Å |
 |  |  |  |  |
| ZNF37A_PARD3_ENST00000361085_ENST00000545260_38385560_34985347 superimposed PDB: 2KOM of partner (PARD3). RMSD:0.9497
Å |
 |  |  |  |  |
| ZNF383_ELMO1_ENST00000589413_ENST00000341056_37721364_36934622 superimposed PDB: 7DPA of partner (ELMO1). RMSD:1.6477
Å |
 |  |  |  |  |
| ZNF407_ZADH2_ENST00000309902_ENST00000322342_72353078_72914295 superimposed PDB: 2X7H of partner (ZADH2). RMSD:0.3926
Å |
 |  |  |  |  |
| ZNF415_SMG9_ENST00000243643_ENST00000601170_53619565_44244370 superimposed PDB: 7PW8 of partner (SMG9). RMSD:0.9949
Å |
 |  |  |  |  |
| ZNF415_SMG9_ENST00000455735_ENST00000270066_53619565_44244370 superimposed PDB: 7PW8 of partner (SMG9). RMSD:1.0588
Å |
 |  |  |  |  |
| ZNF416_ACTN4_ENST00000196489_ENST00000424234_58089424_39191239 superimposed PDB: 6OA6 of partner (ACTN4). RMSD:0.417
Å |
 |  |  |  |  |
| ZNF417_BAX_ENST00000595559_ENST00000539787_58423427_49464066 superimposed PDB: 5W60 of partner (BAX). RMSD:2.8085
Å |
 |  |  |  |  |
| ZNF418_MYO9B_ENST00000600989_ENST00000397274_58439344_17320394 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.5794
Å |
 |  |  |  |  |
| ZNF443_MYO9B_ENST00000301547_ENST00000397274_12551725_17303554 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.3676
Å |
 |  |  |  |  |
| ZNF443_MYO9B_ENST00000301547_ENST00000594824_12551725_17303554 superimposed PDB: 5C5S of partner (MYO9B). RMSD:0.3564
Å |
 |  |  |  |  |
| ZNF461_CLIP3_ENST00000588268_ENST00000593074_37147349_36510208 superimposed PDB: 2CP0 of partner (CLIP3). RMSD:1.4587
Å |
 |  |  |  |  |
| ZNF480_CKM_ENST00000335090_ENST00000221476_52819215_45815178 superimposed PDB: 1I0E of partner (CKM). RMSD:0.7505
Å |
 |  |  |  |  |
| ZNF480_ELL_ENST00000335090_ENST00000596124_52819215_18572662 superimposed PDB: 2DOA of partner (ELL). RMSD:0.7064
Å |
 |  |  |  |  |
| ZNF480_ELL_ENST00000595962_ENST00000262809_52819215_18572662 superimposed PDB: 2DOA of partner (ELL). RMSD:2.8633
Å |
 |  |  |  |  |
| ZNF480_ELL_ENST00000595962_ENST00000596124_52819215_18572662 superimposed PDB: 2DOA of partner (ELL). RMSD:0.6904
Å |
 |  |  |  |  |
| ZNF490_FARSA_ENST00000311437_ENST00000314606_12719971_13041563 superimposed PDB: 3L4G of partner (FARSA). RMSD:0.5408
Å |
 |  |  |  |  |
| ZNF490_FARSA_ENST00000311437_ENST00000423140_12719971_13041563 superimposed PDB: 3L4G of partner (FARSA). RMSD:0.5301
Å |
 |  |  |  |  |
| ZNF493_OGT_ENST00000596302_ENST00000373701_21580069_70767756 superimposed PDB: 7YEA of partner (OGT). RMSD:2.2604
Å |
 |  |  |  |  |
| ZNF519_VAPA_ENST00000589498_ENST00000340541_14124348_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.6807
Å |
 |  |  |  |  |
| ZNF519_VAPA_ENST00000590202_ENST00000400000_14124348_9931806 superimposed PDB: 6TQR of partner (VAPA). RMSD:0.6982
Å |
 |  |  |  |  |
| ZNF532_GMPR_ENST00000591083_ENST00000259727_56621031_16247072 superimposed PDB: 2BLE of partner (GMPR). RMSD:0.3728
Å |
 |  |  |  |  |
| ZNF544_CCDC61_ENST00000333581_ENST00000263284_58758160_46506263 superimposed PDB: 6HXT of partner (CCDC61). RMSD:0.3365
Å |
 |  |  |  |  |
| ZNF568_GPATCH1_ENST00000333987_ENST00000170564_37428144_33602629 superimposed PDB: 7W5Q of partner (ZNF568). RMSD:2.9391
Å |
 |  |  |  |  |
| ZNF568_GPATCH1_ENST00000427117_ENST00000170564_37428144_33602629 superimposed PDB: 7W5Q of partner (ZNF568). RMSD:2.3864
Å |
 |  |  |  |  |
| ZNF571_SPINT2_ENST00000451802_ENST00000301244_38074871_38774266 superimposed PDB: 4U32 of partner (SPINT2). RMSD:0.2433
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000527838_ENST00000360761_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8026
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000527838_ENST00000515411_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9908
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000352832_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7421
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000354983_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9071
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000358244_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.719
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000359106_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8396
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000416767_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7558
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000429973_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9473
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000442258_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.827
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000502264_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.1284
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000503485_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7646
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000505165_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.2656
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000507336_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7743
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000507510_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9368
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000507609_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.9383
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000507896_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8724
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000510115_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8777
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000510366_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.1618
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000512389_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7521
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000513689_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.7328
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000513964_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.102
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000514079_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.8293
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000514181_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.934
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000514717_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5222
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000515165_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:2.0976
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000515411_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.956
Å |
 |  |  |  |  |
| ZNF585B_CACNA1G_ENST00000532828_ENST00000515765_37697941_48652903 superimposed PDB: 6KZO of partner (CACNA1G). RMSD:1.5345
Å |
 |  |  |  |  |
| ZNF586_AP2S1_ENST00000599802_ENST00000599990_58331307_47342835 superimposed PDB: 6URI of partner (AP2S1). RMSD:0.6981
Å |
 |  |  |  |  |
| ZNF586_SRC_ENST00000391702_ENST00000373578_58288037_36028517 superimposed PDB: 8JN8 of partner (SRC). RMSD:0.6098
Å |
 |  |  |  |  |
| ZNF586_SRC_ENST00000396154_ENST00000373578_58288037_36028517 superimposed PDB: 8JN8 of partner (SRC). RMSD:0.6443
Å |
 |  |  |  |  |
| ZNF586_SRC_ENST00000598885_ENST00000373578_58301768_36028517 superimposed PDB: 8JN8 of partner (SRC). RMSD:0.6879
Å |
 |  |  |  |  |
| ZNF587B_LHFPL4_ENST00000442832_ENST00000287585_58350517_9547887 superimposed PDB: 9FAJ of partner (LHFPL4). RMSD:1.2318
Å |
 |  |  |  |  |
| ZNF587B_LHFPL4_ENST00000594901_ENST00000287585_58350517_9547887 superimposed PDB: 9FAJ of partner (LHFPL4). RMSD:1.4501
Å |
 |  |  |  |  |
| ZNF587B_NEK9_ENST00000442832_ENST00000238616_58350517_75573405 superimposed PDB: 3ZKE of partner (NEK9). RMSD:2.2645
Å |
 |  |  |  |  |
| ZNF587B_NEK9_ENST00000594901_ENST00000238616_58350517_75573405 superimposed PDB: 3ZKE of partner (NEK9). RMSD:1.2039
Å |
 |  |  |  |  |
| ZNF587_BAX_ENST00000419854_ENST00000539787_58367601_49464066 superimposed PDB: 5W60 of partner (BAX). RMSD:2.7799
Å |
 |  |  |  |  |
| ZNF587_BAX_ENST00000423137_ENST00000539787_58367601_49464066 superimposed PDB: 5W60 of partner (BAX). RMSD:2.6745
Å |
 |  |  |  |  |
| ZNF599_SCN1B_ENST00000329285_ENST00000415950_35258220_35523431 superimposed PDB: 7W9K of partner (SCN1B). RMSD:3.0365
Å |
 |  |  |  |  |
| ZNF599_SCN1B_ENST00000587354_ENST00000262631_35258220_35523431 superimposed PDB: 7W9K of partner (SCN1B). RMSD:0.5555
Å |
 |  |  |  |  |
| ZNF609_DPP8_ENST00000326648_ENST00000300141_64792365_65759561 superimposed PDB: 6EOP of partner (DPP8). RMSD:2.1419
Å |
 |  |  |  |  |
| ZNF609_DPP8_ENST00000326648_ENST00000321118_64792365_65759561 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.9599
Å |
 |  |  |  |  |
| ZNF609_DPP8_ENST00000326648_ENST00000339244_64792365_65759561 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.9642
Å |
 |  |  |  |  |
| ZNF609_DPP8_ENST00000326648_ENST00000358939_64792365_65759561 superimposed PDB: 6EOP of partner (DPP8). RMSD:0.7154
Å |
 |  |  |  |  |
| ZNF618_MTAP_ENST00000374126_ENST00000380172_116638693_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3347
Å |
 |  |  |  |  |
| ZNF618_MTAP_ENST00000374126_ENST00000460874_116638693_21815431 superimposed PDB: 5TC6 of partner (MTAP). RMSD:0.3306
Å |
 |  |  |  |  |
| ZNF638_TRIM55_ENST00000355812_ENST00000350034_71635377_67086705 superimposed PDB: 6SXW of partner (ZNF638). RMSD:0.7119
Å |
 |  |  |  |  |
| ZNF644_ORC4_ENST00000347275_ENST00000392858_91447866_148716435 superimposed PDB: 7JPO of partner (ORC4). RMSD:2.3432
Å |
 |  |  |  |  |
| ZNF655_R3HDM1_ENST00000320583_ENST00000329971_99158318_136432901 superimposed PDB: 8PK6 of partner (ZNF655). RMSD:0.4164
Å |
 |  |  |  |  |
| ZNF66_B2M_ENST00000344519_ENST00000559916_20976684_45007620 superimposed PDB: 6AT5 of partner (B2M). RMSD:0.4293
Å |
 |  |  |  |  |
| ZNF66_B2M_ENST00000425625_ENST00000559916_20976684_45007620 superimposed PDB: 6AT5 of partner (B2M). RMSD:0.4418
Å |
 |  |  |  |  |
| ZNF66_B2M_ENST00000594534_ENST00000559916_20976684_45007620 superimposed PDB: 6AT5 of partner (B2M). RMSD:0.4602
Å |
 |  |  |  |  |
| ZNF696_MED16_ENST00000330143_ENST00000269814_144375235_880148 superimposed PDB: 8TRH of partner (MED16). RMSD:2.101
Å |
 |  |  |  |  |
| ZNF696_MED16_ENST00000330143_ENST00000312090_144375235_880148 superimposed PDB: 8TRH of partner (MED16). RMSD:2.0559
Å |
 |  |  |  |  |
| ZNF696_MED16_ENST00000330143_ENST00000325464_144375235_880148 superimposed PDB: 8TRH of partner (MED16). RMSD:2.4827
Å |
 |  |  |  |  |
| ZNF696_MED16_ENST00000330143_ENST00000589119_144375235_880148 superimposed PDB: 8TRH of partner (MED16). RMSD:2.1654
Å |
 |  |  |  |  |
| ZNF699_SIRT6_ENST00000308650_ENST00000337491_9415747_4180906 superimposed PDB: 7CL0 of partner (SIRT6). RMSD:0.4288
Å |
 |  |  |  |  |
| ZNF700_TEX101_ENST00000254321_ENST00000253435_12036088_43920032 superimposed PDB: 7BPR of partner (TEX101). RMSD:0.7051
Å |
 |  |  |  |  |
| ZNF709_POLN_ENST00000397732_ENST00000511885_12595468_2176478 superimposed PDB: 4XVK of partner (POLN). RMSD:0.9326
Å |
 |  |  |  |  |
| ZNF709_POLN_ENST00000397732_ENST00000511885_12595468_2178061 superimposed PDB: 4XVK of partner (POLN). RMSD:0.9661
Å |
 |  |  |  |  |
| ZNF773_PPP2R1A_ENST00000598770_ENST00000322088_58011481_52705196 superimposed PDB: 2IE4 of partner (PPP2R1A). RMSD:1.3055
Å |
 |  |  |  |  |
| ZNF791_ETHE1_ENST00000343325_ENST00000292147_12721896_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.3409
Å |
 |  |  |  |  |
| ZNF791_ETHE1_ENST00000446165_ENST00000600651_12721896_44015718 superimposed PDB: 4CHL of partner (ETHE1). RMSD:0.4415
Å |
 |  |  |  |  |
| ZNF823_LMNB2_ENST00000341191_ENST00000582871_11849631_2444538 superimposed PDB: 2LLL of partner (LMNB2). RMSD:1.1139
Å |
 |  |  |  |  |
| ZNF823_VAV1_ENST00000341191_ENST00000539284_11849631_6820712 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.1956
Å |
 |  |  |  |  |
| ZNF823_VAV1_ENST00000341191_ENST00000596764_11849631_6820712 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.3095
Å |
 |  |  |  |  |
| ZNF823_VAV1_ENST00000341191_ENST00000602142_11849631_6820712 superimposed PDB: 3KY9 of partner (VAV1). RMSD:2.2894
Å |
 |  |  |  |  |
| ZNF823_VAV1_ENST00000440527_ENST00000304076_11849631_6820712 superimposed PDB: 3KY9 of partner (VAV1). RMSD:1.9263
Å |
 |  |  |  |  |
| ZNF91_ASF1B_ENST00000300619_ENST00000263382_23578126_14232520 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.7454
Å |
 |  |  |  |  |
| ZNF91_ASF1B_ENST00000397082_ENST00000263382_23578126_14232520 superimposed PDB: 5BNX of partner (ASF1B). RMSD:0.7333
Å |
 |  |  |  |  |
| ZNF91_CCDC88A_ENST00000300619_ENST00000263630_23556543_55523659 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:0.5191
Å |
 |  |  |  |  |
| ZNF91_CCDC88A_ENST00000300619_ENST00000422883_23556543_55523659 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:0.4857
Å |
 |  |  |  |  |
| ZNF91_CCDC88A_ENST00000599743_ENST00000263630_23556543_55523659 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:0.7675
Å |
 |  |  |  |  |
| ZNF91_CCDC88A_ENST00000599743_ENST00000422883_23556543_55523659 superimposed PDB: 6MHF of partner (CCDC88A). RMSD:0.3964
Å |
 |  |  |  |  |
| ZNRF1_HPN_ENST00000320619_ENST00000392226_75033993_35550576 superimposed PDB: 1Z8G of partner (HPN). RMSD:0.572
Å |
 |  |  |  |  |
| ZNRF1_HPN_ENST00000335325_ENST00000262626_75033993_35550576 superimposed PDB: 1Z8G of partner (HPN). RMSD:0.6835
Å |
 |  |  |  |  |
| ZNRF1_HPN_ENST00000335325_ENST00000262626_75033993_35556153 superimposed PDB: 1Z8G of partner (HPN). RMSD:0.6855
Å |
 |  |  |  |  |
| ZNRF3_AIFM3_ENST00000332811_ENST00000335375_29383189_21327595 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.7931
Å |
 |  |  |  |  |
| ZNRF3_AIFM3_ENST00000402174_ENST00000335375_29383189_21327595 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.7308
Å |
 |  |  |  |  |
| ZNRF3_ASCC2_ENST00000544604_ENST00000307790_29280054_30221769 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.2876
Å |
 |  |  |  |  |
| ZNRF3_ASCC2_ENST00000544604_ENST00000307790_29280054_30221769 superimposed PDB: 6YXQ of partner (ASCC2). RMSD:0.6835
Å |
| | | |  |
| ZNRF3_ASCC2_ENST00000544604_ENST00000397771_29280054_30221246 superimposed PDB: 6YXQ of partner (ASCC2). RMSD:0.534
Å |
 |  |  |  |  |
| ZNRF3_ASCC2_ENST00000544604_ENST00000397771_29280054_30221769 superimposed PDB: 6YXQ of partner (ASCC2). RMSD:0.6503
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000331029_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7462
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000332035_29383189_29669729 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.4169
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000332050_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7327
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000333395_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.733
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000397938_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7158
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000406548_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7485
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000332811_ENST00000414183_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7437
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000331029_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7368
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000332050_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7414
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000333395_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.6676
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000397938_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.6867
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000406548_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7294
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000402174_ENST00000414183_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7035
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000406323_ENST00000332050_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7264
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000331029_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7169
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000332035_29383189_29669729 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.3268
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000333395_29383189_29669729 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.0625
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000333395_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.743
Å |
| | | |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000397938_29383189_29669729 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.7672
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000397938_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7376
Å |
| | | |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000406548_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7327
Å |
 |  |  |  |  |
| ZNRF3_EWSR1_ENST00000544604_ENST00000414183_29383189_29669729 superimposed PDB: 2CPE of partner (EWSR1). RMSD:0.7237
Å |
 |  |  |  |  |
| ZNRF3_PI4KA_ENST00000332811_ENST00000255882_29383189_21193019 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.5458
Å |
 |  |  |  |  |
| ZNRF3_PI4KA_ENST00000402174_ENST00000255882_29383189_21193019 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.5109
Å |
 |  |  |  |  |
| ZNRF3_PI4KA_ENST00000406323_ENST00000255882_29383189_21193019 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:2.8525
Å |
 |  |  |  |  |
| ZNRF3_PI4KA_ENST00000406323_ENST00000255882_29383189_21193019 superimposed PDB: 9B9G of partner (PI4KA). RMSD:2.5386
Å |
| | | |  |
| ZNRF3_PREPL_ENST00000544604_ENST00000409411_29280054_44556251 superimposed PDB: 7OBM of partner (PREPL). RMSD:0.6191
Å |
 |  |  |  |  |
| ZNRF3_TTC28_ENST00000544604_ENST00000397906_29280054_28702631 superimposed PDB: 8XFP of partner (ZNRF3). RMSD:3.444
Å |
 |  |  |  |  |
| ZSWIM4_RFX1_ENST00000254323_ENST00000254325_13923978_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.358
Å |
 |  |  |  |  |
| ZSWIM4_RFX1_ENST00000440752_ENST00000254325_13920034_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.393
Å |
 |  |  |  |  |
| ZSWIM4_RFX1_ENST00000440752_ENST00000254325_13923978_14094407 superimposed PDB: 1DP7 of partner (RFX1). RMSD:0.3921
Å |
 |  |  |  |  |


 Fusion gene summary
Fusion gene summary


















































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































