| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:FN1-ALK |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: FN1-ALK | FusionPDB ID: 30790 | FusionGDB2.0 ID: 30790 | Hgene | Tgene | Gene symbol | FN1 | ALK | Gene ID | 2335 | 238 |
| Gene name | fibronectin 1 | ALK receptor tyrosine kinase | |
| Synonyms | CIG|ED-B|FINC|FN|FNZ|GFND|GFND2|LETS|MSF|SMDCF | CD246|NBLST3 | |
| Cytomap | 2q35 | 2p23.2-p23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | fibronectincold-insoluble globulinepididymis secretory sperm binding proteinmigration-stimulating factor | ALK tyrosine kinase receptorCD246 antigenanaplastic lymphoma receptor tyrosine kinasemutant anaplastic lymphoma kinase | |
| Modification date | 20200329 | 20200329 | |
| UniProtAcc | P02751 | Q96BT7 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000323926, ENST00000336916, ENST00000345488, ENST00000346544, ENST00000354785, ENST00000356005, ENST00000357009, ENST00000357867, ENST00000359671, ENST00000421182, ENST00000432072, ENST00000443816, ENST00000446046, ENST00000426059, ENST00000490833, | ENST00000431873, ENST00000498037, ENST00000389048, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 47 X 49 X 13=29939 | 56 X 74 X 20=82880 |
| # samples | 48 | 57 | |
| ** MAII score | log2(48/29939*10)=-5.96284781832542 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(57/82880*10)=-7.18391827352181 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: FN1 [Title/Abstract] AND ALK [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | |||
| Anticipated loss of major functional domain due to fusion event. | FN1-ALK seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. FN1-ALK seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. FN1-ALK seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | FN1 | GO:0001932 | regulation of protein phosphorylation | 11792823 |
| Hgene | FN1 | GO:0008284 | positive regulation of cell proliferation | 25834989 |
| Hgene | FN1 | GO:0010628 | positive regulation of gene expression | 25834989 |
| Hgene | FN1 | GO:0018149 | peptide cross-linking | 3997886 |
| Hgene | FN1 | GO:0034446 | substrate adhesion-dependent cell spreading | 16236823 |
| Hgene | FN1 | GO:0035987 | endodermal cell differentiation | 23154389 |
| Hgene | FN1 | GO:0048146 | positive regulation of fibroblast proliferation | 25834989 |
| Hgene | FN1 | GO:0051702 | interaction with symbiont | 12167537|12421310|19429745 |
| Hgene | FN1 | GO:0070372 | regulation of ERK1 and ERK2 cascade | 11792823 |
| Hgene | FN1 | GO:1901166 | neural crest cell migration involved in autonomic nervous system development | 26571399 |
| Hgene | FN1 | GO:1904237 | positive regulation of substrate-dependent cell migration, cell attachment to substrate | 25834989 |
| Hgene | FN1 | GO:2001202 | negative regulation of transforming growth factor-beta secretion | 25834989 |
| Tgene | ALK | GO:0016310 | phosphorylation | 9174053 |
| Tgene | ALK | GO:0046777 | protein autophosphorylation | 9174053 |
| Fusion gene breakpoints across FN1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
| Fusion gene breakpoints across ALK (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerKB3 | . | . | FN1 | chr2 | 216261859 | - | ALK | chr2 | 29448431 | - |
| ChimerKB3 | . | . | FN1 | chr2 | 216263979 | - | ALK | chr2 | 29446394 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000421182 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6115 | 3869 | 10 | 5664 | 1884 |
| ENST00000357867 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000323926 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000336916 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000354785 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6220 | 3974 | 115 | 5769 | 1884 |
| ENST00000357009 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000346544 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000345488 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000359671 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000446046 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000443816 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6121 | 3875 | 16 | 5670 | 1884 |
| ENST00000432072 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6115 | 3869 | 10 | 5664 | 1884 |
| ENST00000356005 | FN1 | chr2 | 216261859 | - | ENST00000389048 | ALK | chr2 | 29448431 | - | 6116 | 3870 | 11 | 5665 | 1884 |
| ENST00000357009 | FN1 | chr2 | 216263979 | - | ENST00000389048 | ALK | chr2 | 29446394 | - | 5755 | 3614 | 11 | 3682 | 1223 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >30790_30790_1_FN1-ALK_FN1_chr2_216261859_ENST00000323926_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_2_FN1-ALK_FN1_chr2_216261859_ENST00000336916_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_3_FN1-ALK_FN1_chr2_216261859_ENST00000345488_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_4_FN1-ALK_FN1_chr2_216261859_ENST00000346544_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_5_FN1-ALK_FN1_chr2_216261859_ENST00000354785_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_6_FN1-ALK_FN1_chr2_216261859_ENST00000356005_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_7_FN1-ALK_FN1_chr2_216261859_ENST00000357009_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_8_FN1-ALK_FN1_chr2_216261859_ENST00000357867_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_9_FN1-ALK_FN1_chr2_216261859_ENST00000359671_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_10_FN1-ALK_FN1_chr2_216261859_ENST00000421182_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_11_FN1-ALK_FN1_chr2_216261859_ENST00000432072_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_12_FN1-ALK_FN1_chr2_216261859_ENST00000443816_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_13_FN1-ALK_FN1_chr2_216261859_ENST00000446046_ALK_chr2_29448431_ENST00000389048_length(amino acids)=1884AA_BP=1285 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL QPGSSIPPYNTEVTETTIVITWTPAPRIGFKLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAPIVNKVVTPLS PPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLILSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVSGMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNH QNIVRCIGVSLQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACGCQYLEENHFIHRDIAARNCLLTCPGPGRVA KIGDFGMARDIYRASYYRKGGCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQEVLEFVTSGGRMDPPKNCPG PVYRIMTQCWQHQPEDRPNFAIILERIEYCTQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEERSPAAPPPLPT TSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPPSELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE -------------------------------------------------------------- >30790_30790_14_FN1-ALK_FN1_chr2_216263979_ENST00000357009_ALK_chr2_29446394_ENST00000389048_length(amino acids)=1223AA_BP=1201 MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQPPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGP GPGLLLLAVQCLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQWERTYLGNALVCTCYGGSRGFNCESKPEAEE TCFDKYTGNTYRVGDTYERPKDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYMLECVCLGNGKGEWTCKPIAEK CFDHAAGTSYVVGETWEKPYQGWMMVDCTCLGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGRGEWKCERHTS VQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVVYSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNSNGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDAD QKFGFCPMAAHEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLRDQCIVDDITYNVNDTFHKRHEEGHMLNCTC FGQGRGRWKCDPVDQCQDSETGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVFITETPSQPNSHPIQWNAPQP SHISKYILRWRPKNSVGRWKEATIPGHLNSYTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGETTPFSPLVATS ESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQYLDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSVTLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSD TVPSPRDLQFVEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVTGLSPGVTYYFKVFAVSHGRESKPLTAQQTT KLDAPTNLQFVNETDSTVLVRWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVSLVAIKGNQESPKATGVFTTL -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:/chr2:) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| FN1 | ALK |
| FUNCTION: Fibronectins bind cell surfaces and various compounds including collagen, fibrin, heparin, DNA, and actin (PubMed:3024962, PubMed:3900070, PubMed:3593230, PubMed:7989369). Fibronectins are involved in cell adhesion, cell motility, opsonization, wound healing, and maintenance of cell shape (PubMed:3024962, PubMed:3900070, PubMed:3593230, PubMed:7989369). Involved in osteoblast compaction through the fibronectin fibrillogenesis cell-mediated matrix assembly process, essential for osteoblast mineralization (By similarity). Participates in the regulation of type I collagen deposition by osteoblasts (By similarity). Acts as a ligand for the LILRB4 receptor, inhibiting FCGR1A/CD64-mediated monocyte activation (PubMed:34089617). {ECO:0000250|UniProtKB:P11276, ECO:0000269|PubMed:3024962, ECO:0000269|PubMed:34089617, ECO:0000269|PubMed:3593230, ECO:0000269|PubMed:3900070, ECO:0000269|PubMed:7989369}.; FUNCTION: [Anastellin]: Binds fibronectin and induces fibril formation. This fibronectin polymer, named superfibronectin, exhibits enhanced adhesive properties. Both anastellin and superfibronectin inhibit tumor growth, angiogenesis and metastasis. Anastellin activates p38 MAPK and inhibits lysophospholipid signaling. {ECO:0000269|PubMed:11209058, ECO:0000269|PubMed:15665290, ECO:0000269|PubMed:19379667, ECO:0000269|PubMed:8114919}. | FUNCTION: Catalyzes the methylation of 5-carboxymethyl uridine to 5-methylcarboxymethyl uridine at the wobble position of the anticodon loop in tRNA via its methyltransferase domain (PubMed:20123966, PubMed:20308323, PubMed:31079898). Catalyzes the last step in the formation of 5-methylcarboxymethyl uridine at the wobble position of the anticodon loop in target tRNA (PubMed:20123966, PubMed:20308323). Has a preference for tRNA(Arg) and tRNA(Glu), and does not bind tRNA(Lys)(PubMed:20308323). Binds tRNA and catalyzes the iron and alpha-ketoglutarate dependent hydroxylation of 5-methylcarboxymethyl uridine at the wobble position of the anticodon loop in tRNA via its dioxygenase domain, giving rise to 5-(S)-methoxycarbonylhydroxymethyluridine; has a preference for tRNA(Gly) (PubMed:21285950). Required for normal survival after DNA damage (PubMed:20308323). May inhibit apoptosis and promote cell survival and angiogenesis (PubMed:19293182). {ECO:0000269|PubMed:19293182, ECO:0000269|PubMed:20123966, ECO:0000269|PubMed:20308323, ECO:0000269|PubMed:21285950, ECO:0000269|PubMed:31079898}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (862) >>>862.pdbFusion protein BP residue: 1201 CIF file (862) >>>862.cif | FN1 | chr2 | 216263979 | - | ALK | chr2 | 29446394 | - | MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQ PPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGPGPGLLLLAVQ CLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQW ERTYLGNALVCTCYGGSRGFNCESKPEAEETCFDKYTGNTYRVGDTYERP KDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYML ECVCLGNGKGEWTCKPIAEKCFDHAAGTSYVVGETWEKPYQGWMMVDCTC LGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGR GEWKCERHTSVQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVV YSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNS NGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDADQKFGFCPMAA HEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLR DQCIVDDITYNVNDTFHKRHEEGHMLNCTCFGQGRGRWKCDPVDQCQDSE TGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVF ITETPSQPNSHPIQWNAPQPSHISKYILRWRPKNSVGRWKEATIPGHLNS YTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGET TPFSPLVATSESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQY LDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSV TLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSDTVPSPRDLQF VEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVT GLSPGVTYYFKVFAVSHGRESKPLTAQQTTKLDAPTNLQFVNETDSTVLV RWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVS LVAIKGNQESPKATGVFTTLQPGSSIPPYNTEVTETTIVITWTPAPRIGF | 1223 |
| 3D view using mol* of 862 (AA BP:1201) | ||||||||||
 | ||||||||||
| PDB file (1050)CIF file (1050) >>>1050.cif | FN1 | chr2 | 216261859 | - | ALK | chr2 | 29448431 | - | MCCTGGGEGTPGASGKRGPAATTSLVLCIPSVPPPVPFPTLWPPPSWRRQ PPGGIRRDFSRRLRREANLVATCLPVRASLPHRLNMLRGPGPGLLLLAVQ CLGTAVPSTGASKSKRQAQQMVQPQSPVAVSQSKPGCYDNGKHYQINQQW ERTYLGNALVCTCYGGSRGFNCESKPEAEETCFDKYTGNTYRVGDTYERP KDSMIWDCTCIGAGRGRISCTIANRCHEGGQSYKIGDTWRRPHETGGYML ECVCLGNGKGEWTCKPIAEKCFDHAAGTSYVVGETWEKPYQGWMMVDCTC LGEGSGRITCTSRNRCNDQDTRTSYRIGDTWSKKDNRGNLLQCICTGNGR GEWKCERHTSVQTTSSGSGPFTDVRAAVYQPQPHPQPPPYGHCVTDSGVV YSVGMQWLKTQGNKQMLCTCLGNGVSCQETAVTQTYGGNSNGEPCVLPFT YNGRTFYSCTTEGRQDGHLWCSTTSNYEQDQKYSFCTDHTVLVQTRGGNS NGALCHFPFLYNNHNYTDCTSEGRRDNMKWCGTTQNYDADQKFGFCPMAA HEEICTTNEGVMYRIGDQWDKQHDMGHMMRCTCVGNGRGEWTCIAYSQLR DQCIVDDITYNVNDTFHKRHEEGHMLNCTCFGQGRGRWKCDPVDQCQDSE TGTFYQIGDSWEKYVHGVRYQCYCYGRGIGEWHCQPLQTYPSSSGPVEVF ITETPSQPNSHPIQWNAPQPSHISKYILRWRPKNSVGRWKEATIPGHLNS YTIKGLKPGVVYEGQLISIQQYGHQEVTRFDFTTTSTSTPVTSNTVTGET TPFSPLVATSESVTEITASSFVVSWVSASDTVSGFRVEYELSEEGDEPQY LDLPSTATSVNIPDLLPGRKYIVNVYQISEDGEQSLILSTSQTTAPDAPP DTTVDQVDDTSIVVRWSRPQAPITGYRIVYSPSVEGSSTELNLPETANSV TLSDLQPGVQYNITIYAVEENQESTPVVIQQETTGTPRSDTVPSPRDLQF VEVTDVKVTIMWTPPESAVTGYRVDVIPVNLPGEHGQRLPISRNTFAEVT GLSPGVTYYFKVFAVSHGRESKPLTAQQTTKLDAPTNLQFVNETDSTVLV RWTPPRAQITGYRLTVGLTRRGQPRQYNVGPSVSKYPLRNLQPASEYTVS LVAIKGNQESPKATGVFTTLQPGSSIPPYNTEVTETTIVITWTPAPRIGF KLGVRPSQGGEAPREVTSDSGSIVVSGLTPGVEYVYTIQVLRDGQERDAP IVNKVVTPLSPPTNLHLEANPDTGVLTVSWERSTTPVSPTPEPHLPLSLI LSVVTSALVAALVLAFSGIMIVYRRKHQELQAMQMELQSPEYKLSKLRTS TIMTDYNPNYCFAGKTSSISDLKEVPRKNITLIRGLGHGAFGEVYEGQVS GMPNDPSPLQVAVKTLPEVCSEQDELDFLMEALIISKFNHQNIVRCIGVS LQSLPRFILLELMAGGDLKSFLRETRPRPSQPSSLAMLDLLHVARDIACG CQYLEENHFIHRDIAARNCLLTCPGPGRVAKIGDFGMARDIYRASYYRKG GCAMLPVKWMPPEAFMEGIFTSKTDTWSFGVLLWEIFSLGYMPYPSKSNQ EVLEFVTSGGRMDPPKNCPGPVYRIMTQCWQHQPEDRPNFAIILERIEYC TQDPDVINTALPIEYGPLVEEEEKVPVRPKDPEGVPPLLVSQQAKREEER SPAAPPPLPTTSSGKAAKKPTAAEISVRVPRGPAVEGGHVNMAFSQSNPP SELHKVHGSRNKPTSLWNPTYGSWFTEKPTKKNNPIAKKEPHDRGNLGLE GSCTVPPNVATGRLPGASLLLEPSSLTANMKEVPLFRLRHFPCGNVNYGY | 1884 |
| 3D view using mol* of 1050 (AA BP:) | ||||||||||
| ||||||||||
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
FN1_pLDDT.png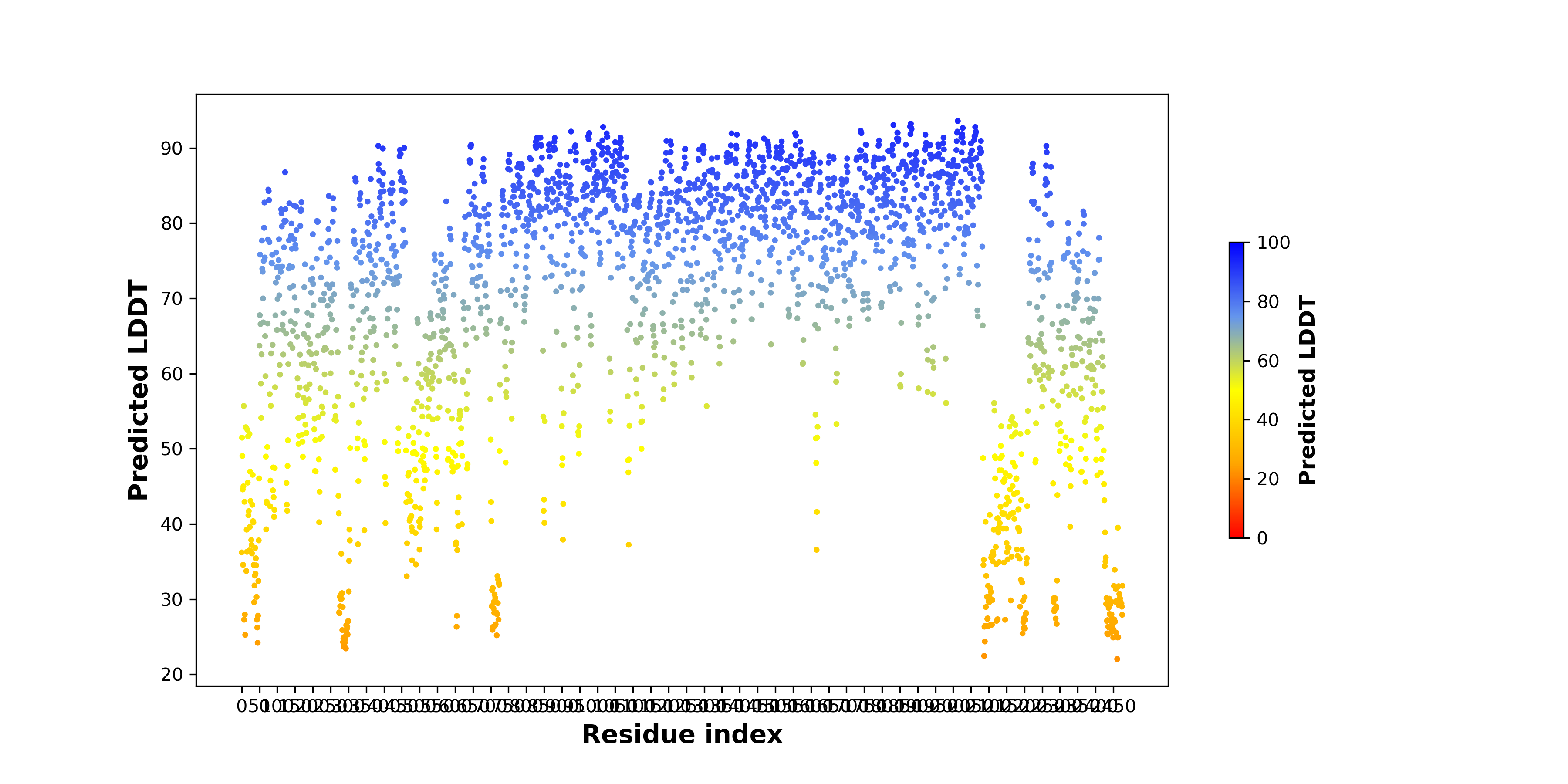  |
ALK_pLDDT.png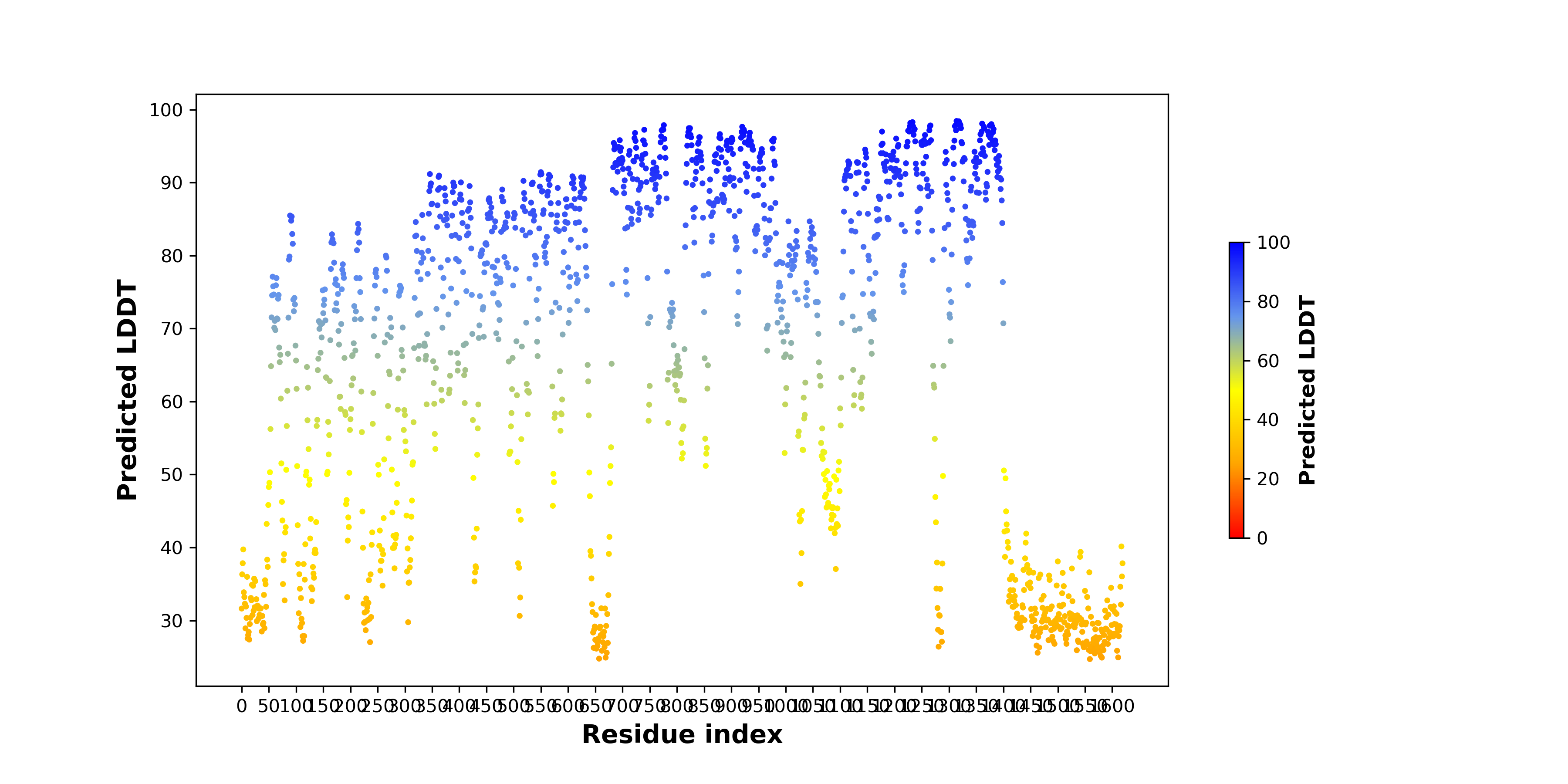  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
FN1_ALK_862_pLDDT.png (AA BP:1201)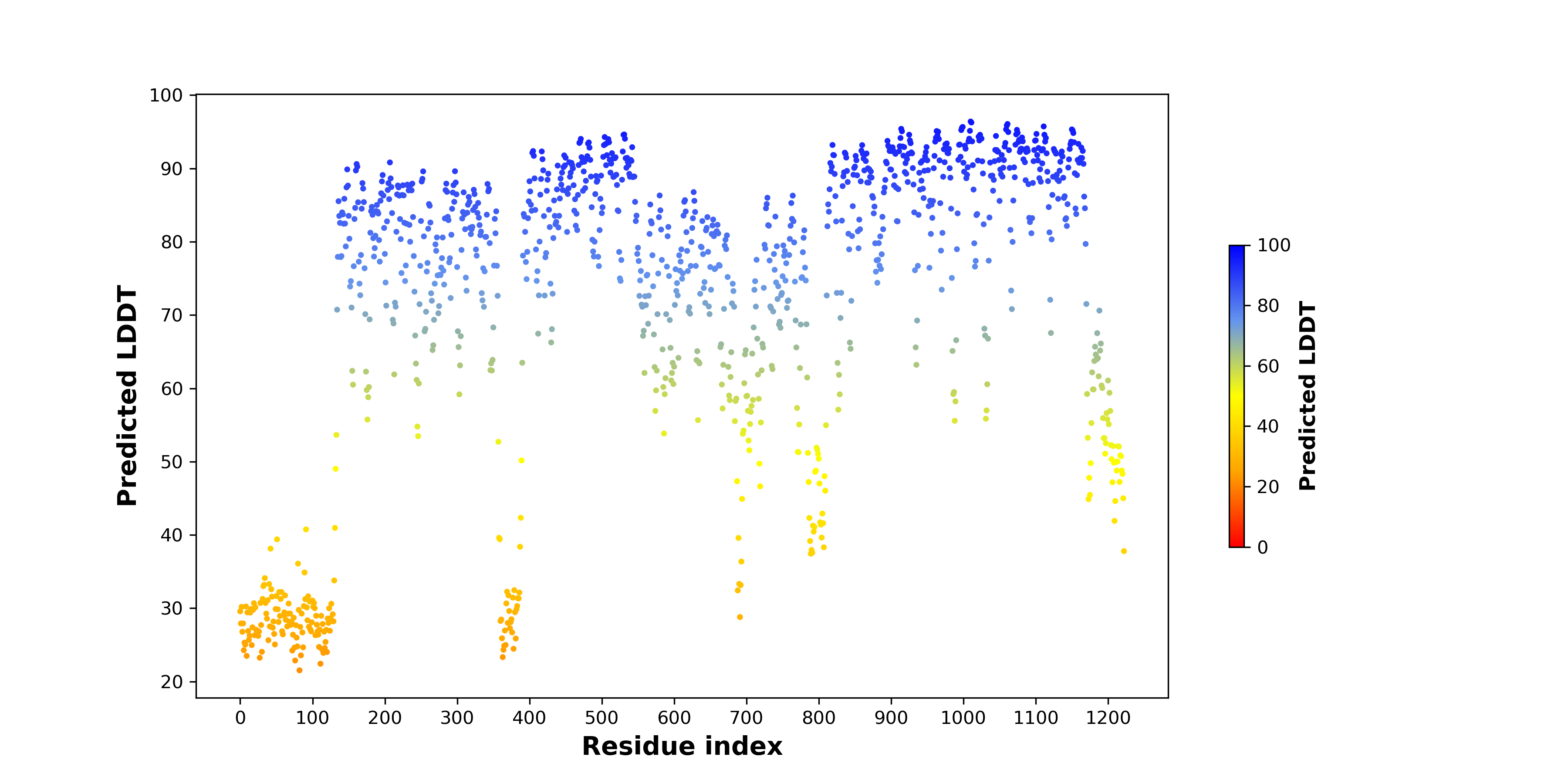 |
FN1_ALK_862_pLDDT_and_active_sites.png (AA BP:1201) |
FN1_ALK_862_violinplot.png (AA BP:1201) |
FN1_ALK_1050_pLDDT_and_active_sites.png (AA BP:) |
FN1_ALK_1050_violinplot.png (AA BP:) |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
| FN1_ALK_862.png |
 |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 862 | 0.974 | 117 | 0.944 | 318.647 | 0.603 | 0.66 | 0.934 | 0.231 | 1.203 | 0.192 | 1.02 | Chain A: 699,700,701,702,703,704,705,707,708,710,7 11,712,781,782,783,784,785,786,787,788,789,790,791 ,792,793,794,795,796 |
| 1050 | 1.076 | 120 | 1.125 | 302.183 | 0.551 | 0.739 | 0.9 | 0.794 | 0.793 | 1.002 | 2.087 | Chain A: 259,1384,1386,1388,1389,1394,1412,1414,14 44,1460,1461,1462,1463,1464,1465,1466,1467,1470,14 71,1474,1517,1518,1520,1524,1533,1534 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| FN1 | NOV, COL7A1, FASLG, TGFBI, CXCL12, PKD1, LACRT, IGFBP3, MIA, AMBP, TNC, VHL, LPA, GSN, HSPG2, C1QA, ITGB6, ITGA5, TGM2, CD44, MYOC, CRP, APCS, F13A1, MEP1A, MEP1B, ITGB7, REG3A, SDC2, TSHR, FBLN1, FBLN2, PLG, PLAT, TRIB3, EGFR, env, ATXN7, GRB2, SIRT7, ATXN10, APOA1, ALB, MYC, ITGB1, TLN1, PXN, ITGA4, UBE2N, EPN1, ATP5C1, PRMT5, RPN1, STIP1, RCC1, RPL13A, MRPS23, ILF3, PSMA6, NUP205, RAC1, NAA15, SNRNP70, NHP2L1, RAB5C, LGALS1, PSMB2, MCM6, RPL36, DIMT1, HIP1R, VDAC2, STMN1, PPIL1, UPF1, LYPLA1, PLEC, DRG1, DDX39B, MIF, RPL22, HIST1H4F, HIST2H4B, HIST1H4L, HIST1H4I, HIST1H4A, HIST1H4J, HIST1H4K, HIST1H4D, HIST1H4E, HIST1H4C, HIST1H4H, HIST1H4B, HIST2H4A, FBL, DDX21, KRT9, RPS18, PPIH, TRIM28, PDCD6, SRM, RPS19, HSPE1, RPL17, RPS8, ZW10, NDUFA9, NHP2, PELP1, ERLIN2, POLR2C, LRBA, SLC3A2, RPA2, PSMG1, TKT, PSMG2, FLOT2, GLUD1, PSMC6, MRPS34, FDFT1, RNH1, C1QBP, PSMD13, DDX18, ARF6, RSU1, SAR1A, ILK, HMGA1, COPG1, PFKL, SEPT9, NUP210, CPNE1, BAG2, CLIC2, PSMA2, COMT, EIF3K, SEC61B, TTC9C, SPTBN1, EIF4H, NDUFV2, KARS, RBBP4, PRPF19, NDUFA2, TPR, QARS, G6PD, UBE2L3, ACACA, RAE1, IPO4, PAICS, RPL6, NARS, VPS28, RPLP2, MDN1, GSTK1, RPL15, EMG1, CLIC5, PTGES3, NAT10, STX4, PPID, PAFAH1B2, LASP1, PDCD5, NDUFA5, PRKCB, SNRPE, CAP1, U2AF1, SNRPB, VPS35, DLD, KRT31, NECAP2, PSMD5, CELF2, RPA1, HMGB1, SLC5A3, SUB1, RPL29, FLOT1, DNAJB1, AP2A2, SRP14, AHNAK, STXBP3, IDI1, PRPS2, RAB7A, PRPF4, HADHA, LCP1, ITGAV, RTCB, RPL31, PGAM5, AIMP2, DHX30, SLC25A1, POLR1C, DAB2, CPSF6, NOP58, KIDINS220, MRPL13, PDLIM5, COPE, ACLY, KRT5, FAU, IGF2BP3, EIF2S3, ACOT13, ST13, CLTB, SUPT5H, CKAP5, ARHGEF1, BAG6, APOBEC3C, APOBEC3D, CLNS1A, LSM12, CNN2, TK1, NAPG, APOLD1, DDX47, ABCF1, GDI2, VPS26A, BROX, GSTO1, PGK1, PDAP1, PSMB5, RPL28, RBM12, SNAP23, RPS15, FEN1, GNAI3, COX2, PRMT1, EIF3F, ALDH1B1, SNRPA, KANK2, CNOT1, NCBP1, PFKP, ARL2, SNX15, GAR1, USP15, RPS23, SEC22B, OLA1, SEC23B, SRSF1, SF3B1, SET, SMCHD1, TTLL12, BZW2, GALE, NUP155, HNRNPDL, ARPC4, TFAM, HMGB2, SSBP1, COPB1, NACA, ATP6V1B2, PHGDH, MAP4, PUF60, AKR1C1, YES1, EPB41, DBN1, ESYT2, PDHB, RPS26, SEC24C, YWHAG, RCC2, CBX3, TUBB6, RAB11A, EIF5B, RAB35, SSB, HNRNPH2, EZR, USP39, SIPA1, KIAA0368, MRPS28, PCNA, SF3A3, SNRPD3, SEPT2, HIST1H2AA, PKM, YWHAH, IMPDH2, KRT81, CAND1, C14orf166, CSNK2A1, MPP1, H2AFV, ACTR3, LRRC59, CORO1B, PTPRCAP, PSMB3, EIF5, IGF2R, SRSF3, HDAC1, YWHAQ, BMP2K, TRAP1, RAB10, QKI, PDIA6, TPM3, MRTO4, PPP2CA, MCM2, RAP1B, AARS, ALDOA, HIST1H2BJ, RPL8, ENO1, KPNA2, MYL1, STON2, KRT18, IQGAP1, MACF1, IPO5, FLNB, VASP, HNRNPF, TARS, VCL, ANP32B, PPP2R1A, MYH9, FARSB, XPO1, ATP5A1, ATP5B, ESYT1, NCL, CCAR2, YBX1, HSD17B10, PPA1, MATR3, RPL23A, RPL23AP42, PA2G4, HSPA5, GART, UBE2M, GSTP1, RPL7, EFTUD2, SF1, LDHA, KRT2, DIAPH1, ANXA1, SYNCRIP, SRSF9, EEF2, PPP1CA, YWHAE, XRCC5, SND1, HNRNPK, DDX1, CCT2, PRDX6, YWHAZ, TOMM34, RANBP1, FUS, CCT4, XRCC6, SMAP2, TUBB4B, ACP1, RPS13, RPSA, TAGLN2, HNRNPA3, TCP1, CCT8, EIF3E, VIM, GAPDH, HNRNPH1, RPS9, TARDBP, HNRNPU, CLIC1, DDAH2, TUBA1B, KRT8, HSPD1, PI4KA, SCRIB, PSMB1, RUVBL2, PSMD11, EPS15, RPL27A, PSMA5, TIA1, ARPC3, EIF3B, MLLT4, CORO1C, RPS25, NDUFS3, RALY, MYH10, RAP2B, DHX15, PRDX3, YWHAB, RPL35, MYL4, KRT10, GTPBP4, GMPS, LY6G5B, CSNK2B, GLRX3, PDCD10, CAPZA1, DDX6, RPL21, LDHB, MYL6, MSN, RPS24, CACYBP, CPSF7, EEF1B2, NAPA, RPL10A, SF3B6, YTHDF2, ALYREF, SRI, RPS7, ANXA2, MAPRE1, RPS17, FSCN1, HIST1H1B, MDH2, MCM3, ZYX, AP2M1, NPM1, FERMT3, AP2B1, CAPZB, RPL18, RPL14, RPL5, DYNC1H1, RPS2, RPS16, HSPA1B, HSPA1A, ILF2, RPL24, PSMA7, RPS3A, GCN1L1, PFN1, RPL23, RPLP0, TUFM, RPS11, CCT3, PRDX1, VAPA, RPL4, EIF4A1, TFRC, CCT5, ACTN4, PICALM, KPNB1, KRT1, CFL1, XPO5, CCT6A, EEF1D, TOP2A, RBMX, CCT7, HSP90AA1, RPS10, CLTC, ELAVL1, RPL12, HIST1H2BK, PHB, STOM, AP2A1, FLNC, FLNA, AKR7A2, KRT16, IGF2BP2, PCMT1, IST1, RPS21, EIF4G1, CAPN1, KHSRP, CDK1, VARS, HBZ, HBA2, HBA1, EIF3L, SNRNP200, DDOST, NQO1, RSL1D1, RBM3, RFC4, CIRBP, SDHA, EIF4G2, DECR1, MBNL1, DNM2, UBAP2L, RPS20, MARS, CSE1L, RBM14, SNRPF, SLC25A5, ESD, KIF2C, PABPC4, IGF2BP1, SARNP, H2AFY, TCERG1, HNRNPAB, RAVER1, CLTA, RPS27, PHB2, PABPC1, LMNB1, FUBP3, EWSR1, HSPB1, MCM5, BUB3, MCM7, GNB2L1, HNRNPM, RPS15A, PRPF8, RPL9, RPS4X, IARS, HIST1H1D, PRKDC, RPL26, TIAL1, RPS12, HNRNPA0, RPL10, EEF1A1, NTPCR, NUDT21, ACTB, RPL7A, RPS3, HSP90AB1, ACTR2, PRDX2, FUBP1, EIF4A3, HNRNPH3, HNRNPA2B1, APRT, FASN, PARP1, ATAD3A, EPRS, RPL30, RPS14, LMNA, RAN, RPL11, YARS, KRT19, SFPQ, HNRNPC, HIST1H2AD, HSPA8, RPS27A, UBB, UBC, CAPNS1, SNRPD1, DARS, NONO, VAMP8, TUBB, RPL3, RPS5, EIF3D, DHX9, DAZAP1, VCP, LARS, PTBP1, EIF2S1, RPL13, DDX3X, RPS6, LRPPRC, HNRNPA1, RPS28, DDX17, RBM4, HIST2H3A, HIST2H3C, SNRPD2, PCBP2, DDX5, G3BP1, HNRNPR, PCBP1, HSPA9, EIF3A, HNRNPD, EEF1G, HNRNPL, PPIA, PPIAP22, ACTG1, SERPINA1, TF, IGKV3-20, FGA, ITIH2, IGLL5, C1QC, SERPINF2, SERPINA6, CPB2, SERPINA7, SERPINA4, C9, C4BPA, C4A, C3, C1S, FGG, ITIH1, F2, FGB, ITIH4, CFB, C6, CASP14, C1QB, TAB1, RBL1, FAM86B3P, CDKN2A, HRG, SMAD4, RARA, STAT5A, NR0B2, RPS6KA5, DUSP10, TAB2, PELI2, UBQLN1, LGALS3, CER1, LGALS8, LGALS9, TEAD4, COL8A2, HIF1A, SYMPK, CTR9, HGF, KLK3, COLQ, MMP2, ZKSCAN4, MMP9, MEPE, LGALS3BP, ERP44, FKBP9, PRSS2, FAM19A4, MTNR1A, ITGA2B, ITGB3, CLEC14A, KAL1, TIMD4, ITGB5, RNF123, VEGFA, MB21D1, KIAA1429, METTL14, WTAP, DISC1, MTDH, AGRN, DYRK1A, SQSTM1, FANCD2, nsp6, ITGA3, SGCA, SH3GLB1, TTN, LTBP1, Apc2, WDR76, INSIG1, AR, HOXA1, WDR5, ECM1, CGA, CSTL1, TCF7, PPP2R2B, FBXO2, SCGB2A2, GNG8, LAIR2, NPTXR, TMED5, EGFL7, C1QTNF1, LGALS7, SEC23A, CCR1, MAT2B, RDH11, PHC1, KLK10, RHBDD1, UBE2U, AGPAT1, THBS1, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| FN1 |  |
| ALK |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to FN1-ALK |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
| FN1 | ALK | Alk Inhibitor Lorlatinib | PubMed | 33007314 |
Top |
Related Diseases to FN1-ALK |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| FN1 | ALK | Inflammatory Myofibroblastic Tumors | PubMed | 33007314 |
| FN1 | ALK | Lung Adenocarcinoma | MyCancerGenome | |
| FN1 | ALK | Acute Myeloid Leukemia | MyCancerGenome | |
| FN1 | ALK | Cancer Of Unknown Primary | MyCancerGenome | |
| FN1 | ALK | Diffuse Large B-Cell Lymphoma | MyCancerGenome | |
| FN1 | ALK | MyCancerGenome |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | FN1 | C0020538 | Hypertensive disease | 2 | CTD_human |
| Hgene | FN1 | C0432221 | Spondylometaphyseal dysplasia, 'corner fracture' type | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | FN1 | C0000786 | Spontaneous abortion | 1 | CTD_human |
| Hgene | FN1 | C0000822 | Abortion, Tubal | 1 | CTD_human |
| Hgene | FN1 | C0003504 | Aortic Valve Insufficiency | 1 | CTD_human |
| Hgene | FN1 | C0006142 | Malignant neoplasm of breast | 1 | CTD_human;UNIPROT |
| Hgene | FN1 | C0007097 | Carcinoma | 1 | CTD_human |
| Hgene | FN1 | C0007621 | Neoplastic Cell Transformation | 1 | CTD_human |
| Hgene | FN1 | C0010346 | Crohn Disease | 1 | CTD_human |
| Hgene | FN1 | C0011849 | Diabetes Mellitus | 1 | CTD_human |
| Hgene | FN1 | C0011881 | Diabetic Nephropathy | 1 | CTD_human |
| Hgene | FN1 | C0017636 | Glioblastoma | 1 | CTD_human |
| Hgene | FN1 | C0017667 | Nodular glomerulosclerosis | 1 | CTD_human |
| Hgene | FN1 | C0017668 | Focal glomerulosclerosis | 1 | CTD_human |
| Hgene | FN1 | C0024667 | Animal Mammary Neoplasms | 1 | CTD_human |
| Hgene | FN1 | C0024668 | Mammary Neoplasms, Experimental | 1 | CTD_human |
| Hgene | FN1 | C0027626 | Neoplasm Invasiveness | 1 | CTD_human |
| Hgene | FN1 | C0034069 | Pulmonary Fibrosis | 1 | CTD_human |
| Hgene | FN1 | C0041956 | Ureteral obstruction | 1 | CTD_human |
| Hgene | FN1 | C0085762 | Alcohol abuse | 1 | PSYGENET |
| Hgene | FN1 | C0086432 | Hyalinosis, Segmental Glomerular | 1 | CTD_human |
| Hgene | FN1 | C0149721 | Left Ventricular Hypertrophy | 1 | CTD_human |
| Hgene | FN1 | C0156147 | Crohn's disease of large bowel | 1 | CTD_human |
| Hgene | FN1 | C0205696 | Anaplastic carcinoma | 1 | CTD_human |
| Hgene | FN1 | C0205697 | Carcinoma, Spindle-Cell | 1 | CTD_human |
| Hgene | FN1 | C0205698 | Undifferentiated carcinoma | 1 | CTD_human |
| Hgene | FN1 | C0205699 | Carcinomatosis | 1 | CTD_human |
| Hgene | FN1 | C0267380 | Crohn's disease of the ileum | 1 | CTD_human |
| Hgene | FN1 | C0334588 | Giant Cell Glioblastoma | 1 | CTD_human |
| Hgene | FN1 | C0345967 | Malignant mesothelioma | 1 | CTD_human |
| Hgene | FN1 | C0678202 | Regional enteritis | 1 | CTD_human |
| Hgene | FN1 | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Hgene | FN1 | C0949272 | IIeocolitis | 1 | CTD_human |
| Hgene | FN1 | C1257925 | Mammary Carcinoma, Animal | 1 | CTD_human |
| Hgene | FN1 | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Hgene | FN1 | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Hgene | FN1 | C1621958 | Glioblastoma Multiforme | 1 | CTD_human |
| Hgene | FN1 | C1866075 | GLOMERULOPATHY WITH FIBRONECTIN DEPOSITS 2 (disorder) | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | FN1 | C3830362 | Early Pregnancy Loss | 1 | CTD_human |
| Hgene | FN1 | C3888104 | Glomerulopathy with fibronectin deposits | 1 | CTD_human;ORPHANET |
| Hgene | FN1 | C4552766 | Miscarriage | 1 | CTD_human |
| Hgene | FN1 | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
| Hgene | FN1 | C4721507 | Alveolitis, Fibrosing | 1 | CTD_human |
| Tgene | ALK | C0007131 | Non-Small Cell Lung Carcinoma | 28 | CGI;CTD_human |
| Tgene | ALK | C0027819 | Neuroblastoma | 13 | CGI;CTD_human;ORPHANET |
| Tgene | ALK | C0152013 | Adenocarcinoma of lung (disorder) | 8 | CGI;CTD_human |
| Tgene | ALK | C2751681 | NEUROBLASTOMA, SUSCEPTIBILITY TO, 3 | 8 | CLINGEN;UNIPROT |
| Tgene | ALK | C0206180 | Ki-1+ Anaplastic Large Cell Lymphoma | 6 | CGI;CTD_human |
| Tgene | ALK | C0334121 | Inflammatory Myofibroblastic Tumor | 4 | CGI;CTD_human;ORPHANET |
| Tgene | ALK | C0018199 | Granuloma, Plasma Cell | 3 | CTD_human |
| Tgene | ALK | C0007621 | Neoplastic Cell Transformation | 2 | CTD_human |
| Tgene | ALK | C0027627 | Neoplasm Metastasis | 2 | CTD_human |
| Tgene | ALK | C0238463 | Papillary thyroid carcinoma | 2 | ORPHANET |
| Tgene | ALK | C0001973 | Alcoholic Intoxication, Chronic | 1 | PSYGENET |
| Tgene | ALK | C0006118 | Brain Neoplasms | 1 | CGI;CTD_human |
| Tgene | ALK | C0006142 | Malignant neoplasm of breast | 1 | CTD_human |
| Tgene | ALK | C0007134 | Renal Cell Carcinoma | 1 | CTD_human |
| Tgene | ALK | C0011570 | Mental Depression | 1 | PSYGENET |
| Tgene | ALK | C0011581 | Depressive disorder | 1 | PSYGENET |
| Tgene | ALK | C0027643 | Neoplasm Recurrence, Local | 1 | CTD_human |
| Tgene | ALK | C0036341 | Schizophrenia | 1 | PSYGENET |
| Tgene | ALK | C0079744 | Diffuse Large B-Cell Lymphoma | 1 | CTD_human |
| Tgene | ALK | C0085269 | Plasma Cell Granuloma, Pulmonary | 1 | CTD_human |
| Tgene | ALK | C0153633 | Malignant neoplasm of brain | 1 | CGI;CTD_human |
| Tgene | ALK | C0278601 | Inflammatory Breast Carcinoma | 1 | CTD_human |
| Tgene | ALK | C0279702 | Conventional (Clear Cell) Renal Cell Carcinoma | 1 | CTD_human |
| Tgene | ALK | C0496899 | Benign neoplasm of brain, unspecified | 1 | CTD_human |
| Tgene | ALK | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Tgene | ALK | C0750974 | Brain Tumor, Primary | 1 | CTD_human |
| Tgene | ALK | C0750977 | Recurrent Brain Neoplasm | 1 | CTD_human |
| Tgene | ALK | C0750979 | Primary malignant neoplasm of brain | 1 | CTD_human |
| Tgene | ALK | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Tgene | ALK | C1266042 | Chromophobe Renal Cell Carcinoma | 1 | CTD_human |
| Tgene | ALK | C1266043 | Sarcomatoid Renal Cell Carcinoma | 1 | CTD_human |
| Tgene | ALK | C1266044 | Collecting Duct Carcinoma of the Kidney | 1 | CTD_human |
| Tgene | ALK | C1306837 | Papillary Renal Cell Carcinoma | 1 | CTD_human |
| Tgene | ALK | C1332079 | Anaplastic Large Cell Lymphoma, ALK-Positive | 1 | ORPHANET |
| Tgene | ALK | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Tgene | ALK | C1527390 | Neoplasms, Intracranial | 1 | CTD_human |
| Tgene | ALK | C2931189 | Neural crest tumor | 1 | ORPHANET |
| Tgene | ALK | C3899155 | hereditary neuroblastoma | 1 | GENOMICS_ENGLAND |
| Tgene | ALK | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies