| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:HNRNPUL1-CNN1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: HNRNPUL1-CNN1 | FusionPDB ID: 37308 | FusionGDB2.0 ID: 37308 | Hgene | Tgene | Gene symbol | HNRNPUL1 | CNN1 | Gene ID | 11100 | 1264 |
| Gene name | heterogeneous nuclear ribonucleoprotein U like 1 | calponin 1 | |
| Synonyms | E1B-AP5|E1BAP5|HNRPUL1 | HEL-S-14|SMCC|Sm-Calp | |
| Cytomap | 19q13.2 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | heterogeneous nuclear ribonucleoprotein U-like protein 1E1B 55kDa associated protein 5E1B-55 kDa-associated protein 5adenovirus early region 1B-associated protein 5 | calponin-1basic calponincalponin 1, basic, smooth musclecalponin H1, smooth musclecalponins, basicepididymis secretory protein Li 14 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | Q9BUJ2 | P51911 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000263367, ENST00000352456, ENST00000378215, ENST00000392006, ENST00000593587, ENST00000595018, ENST00000602130, ENST00000594207, | ENST00000544952, ENST00000588468, ENST00000535659, ENST00000592923, ENST00000252456, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 18 X 14 X 12=3024 | 4 X 3 X 3=36 |
| # samples | 20 | 5 | |
| ** MAII score | log2(20/3024*10)=-3.91838623444635 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/36*10)=0.473931188332412 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: HNRNPUL1 [Title/Abstract] AND CNN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | HNRNPUL1(41800591)-CNN1(11651891), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | HNRNPUL1-CNN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. HNRNPUL1-CNN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. HNRNPUL1-CNN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. HNRNPUL1-CNN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across HNRNPUL1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CNN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-XF-AAMT-01A | HNRNPUL1 | chr19 | 41800591 | - | CNN1 | chr19 | 11651891 | + |
| ChimerDB4 | BLCA | TCGA-XF-AAMT-01A | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + |
| ChimerDB4 | BLCA | TCGA-XF-AAMT | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + |
| ChimerDB4 | BLCA | TCGA-XF-AAMT | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000352456 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2669 | 1310 | 11 | 2140 | 709 |
| ENST00000595018 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2646 | 1287 | 45 | 2117 | 690 |
| ENST00000392006 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3050 | 1691 | 44 | 2521 | 825 |
| ENST00000378215 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2667 | 1308 | 3 | 2138 | 711 |
| ENST00000602130 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2930 | 1571 | 53 | 2401 | 782 |
| ENST00000593587 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2671 | 1312 | 94 | 2142 | 682 |
| ENST00000263367 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 2804 | 1445 | 161 | 2275 | 704 |
| ENST00000352456 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2669 | 1310 | 11 | 2140 | 709 |
| ENST00000595018 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2646 | 1287 | 45 | 2117 | 690 |
| ENST00000392006 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 3050 | 1691 | 44 | 2521 | 825 |
| ENST00000378215 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2667 | 1308 | 3 | 2138 | 711 |
| ENST00000602130 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2930 | 1571 | 53 | 2401 | 782 |
| ENST00000593587 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2671 | 1312 | 94 | 2142 | 682 |
| ENST00000263367 | HNRNPUL1 | chr19 | 41800591 | + | ENST00000252456 | CNN1 | chr19 | 11651890 | + | 2804 | 1445 | 161 | 2275 | 704 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000352456 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.014277008 | 0.98572296 |
| ENST00000595018 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.014554928 | 0.9854451 |
| ENST00000392006 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.02540182 | 0.97459817 |
| ENST00000378215 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.023482606 | 0.97651744 |
| ENST00000602130 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.024475053 | 0.9755249 |
| ENST00000593587 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.015291635 | 0.9847083 |
| ENST00000263367 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651891 | + | 0.01274726 | 0.9872528 |
| ENST00000352456 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.014277008 | 0.98572296 |
| ENST00000595018 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.014554928 | 0.9854451 |
| ENST00000392006 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.02540182 | 0.97459817 |
| ENST00000378215 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.023482606 | 0.97651744 |
| ENST00000602130 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.024475053 | 0.9755249 |
| ENST00000593587 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.015291635 | 0.9847083 |
| ENST00000263367 | ENST00000252456 | HNRNPUL1 | chr19 | 41800591 | + | CNN1 | chr19 | 11651890 | + | 0.01274726 | 0.9872528 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >37308_37308_1_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000263367_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=704AA_BP=427 MRKEDPGICRWMRSWAFSYLDAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQF QSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVC FEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKN GKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWA IKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTG RRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKT KGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPG -------------------------------------------------------------- >37308_37308_2_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000263367_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=704AA_BP=427 MRKEDPGICRWMRSWAFSYLDAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQF QSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVC FEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKN GKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWA IKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTG RRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKT KGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPG -------------------------------------------------------------- >37308_37308_3_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000352456_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=709AA_BP=432 MGGERERGSRTWARGGVSGLEPLGPHAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKP DRQQFQSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVR RGRVCFEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVEL SFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAG KTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWI EGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALA SMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAG -------------------------------------------------------------- >37308_37308_4_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000352456_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=709AA_BP=432 MGGERERGSRTWARGGVSGLEPLGPHAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKP DRQQFQSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVR RGRVCFEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVEL SFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAG KTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWI EGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALA SMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAG -------------------------------------------------------------- >37308_37308_5_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000378215_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=711AA_BP=434 MSRCRHWSGPPPFPPSPPDRKGLRGTEPWEAGPGSGATPGARAMDVRRLKVNELREELQRRGLDTRGLKAELAERLQPPPPGLQPHAEPG GYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRG RGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKDFECGNDV ELSFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPA AGKTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELRE WIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLA LASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQ -------------------------------------------------------------- >37308_37308_6_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000378215_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=711AA_BP=434 MSRCRHWSGPPPFPPSPPDRKGLRGTEPWEAGPGSGATPGARAMDVRRLKVNELREELQRRGLDTRGLKAELAERLQPPPPGLQPHAEPG GYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRG RGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKDFECGNDV ELSFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPA AGKTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELRE WIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLA LASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQ -------------------------------------------------------------- >37308_37308_7_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000392006_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=825AA_BP=548 MSRCRHWSGPPPFPPSPPDRKGLRGTEPWEAGPGSGATPGARAMDVRRLKVNELREELQRRGLDTRGLKAELAERLQAALEAEEPDDERE LDADDEPGRPGHINEEVETEGGSELEGTAQPPPPGLQPHAEPGGYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAY RPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARD RSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFE NYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSE RIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAAR KKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKP HDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPK LGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELG -------------------------------------------------------------- >37308_37308_8_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000392006_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=825AA_BP=548 MSRCRHWSGPPPFPPSPPDRKGLRGTEPWEAGPGSGATPGARAMDVRRLKVNELREELQRRGLDTRGLKAELAERLQAALEAEEPDDERE LDADDEPGRPGHINEEVETEGGSELEGTAQPPPPGLQPHAEPGGYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAY RPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARD RSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFE NYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSE RIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAAR KKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKP HDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPK LGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELG -------------------------------------------------------------- >37308_37308_9_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000593587_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=682AA_BP=405 MDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRGYFEHREDR RGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHLPSTEPDPH VVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEALGGQALYP HVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNILGTNAIMD KMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFIN KLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPG KLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSL -------------------------------------------------------------- >37308_37308_10_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000593587_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=682AA_BP=405 MDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRGYFEHREDR RGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHLPSTEPDPH VVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEALGGQALYP HVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNILGTNAIMD KMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFIN KLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPG KLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSL -------------------------------------------------------------- >37308_37308_11_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000595018_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=690AA_BP=413 MEPLGPHAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRG YFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHL PSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEA LGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNI LGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDG IILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEK QERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEH -------------------------------------------------------------- >37308_37308_12_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000595018_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=690AA_BP=413 MEPLGPHAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRG YFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHL PSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEA LGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNI LGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDG IILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEK QERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEH -------------------------------------------------------------- >37308_37308_13_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000602130_CNN1_chr19_11651890_ENST00000252456_length(amino acids)=782AA_BP=505 MDVRRLKVNELREELQRRGLDTRGLKAELAERLQAALEAEEPDDERELDADDEPGRPGHINEEVETEGGSELEGTAQPPPPGLQPHAEPG GYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRG RGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVK HLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQK EALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKY NILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLK DGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYA EKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGM -------------------------------------------------------------- >37308_37308_14_HNRNPUL1-CNN1_HNRNPUL1_chr19_41800591_ENST00000602130_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=782AA_BP=505 MDVRRLKVNELREELQRRGLDTRGLKAELAERLQAALEAEEPDDERELDADDEPGRPGHINEEVETEGGSELEGTAQPPPPGLQPHAEPG GYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAYRPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRG RGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARDRSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVK HLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFENYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQK EALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSERIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKY NILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAARKKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLK DGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYA EKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGM -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:41800591/chr19:11651891) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| HNRNPUL1 | CNN1 |
| FUNCTION: Acts as a basic transcriptional regulator. Represses basic transcription driven by several virus and cellular promoters. When associated with BRD7, activates transcription of glucocorticoid-responsive promoter in the absence of ligand-stimulation. Plays also a role in mRNA processing and transport. Binds avidly to poly(G) and poly(C) RNA homopolymers in vitro. {ECO:0000269|PubMed:12489984, ECO:0000269|PubMed:9733834}. | FUNCTION: Thin filament-associated protein that is implicated in the regulation and modulation of smooth muscle contraction. It is capable of binding to actin, calmodulin and tropomyosin. The interaction of calponin with actin inhibits the actomyosin Mg-ATPase activity (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 191_388 | 392.0 | 753.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 3_37 | 392.0 | 753.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 191_388 | 506.0 | 857.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 3_37 | 506.0 | 857.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 191_388 | 406.0 | 757.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 3_37 | 406.0 | 757.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 191_388 | 406.0 | 757.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 3_37 | 406.0 | 757.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 191_388 | 506.0 | 805.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 3_37 | 506.0 | 805.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 191_388 | 392.0 | 753.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 3_37 | 392.0 | 753.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 191_388 | 506.0 | 857.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 3_37 | 506.0 | 857.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 191_388 | 406.0 | 757.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 3_37 | 406.0 | 757.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 191_388 | 406.0 | 757.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 3_37 | 406.0 | 757.0 | Domain | SAP |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 191_388 | 506.0 | 805.0 | Domain | B30.2/SPRY |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 3_37 | 506.0 | 805.0 | Domain | SAP |
| Tgene | CNN1 | chr19:41800591 | chr19:11651890 | ENST00000252456 | 0 | 7 | 28_131 | 21.0 | 298.0 | Domain | Calponin-homology (CH) | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651891 | ENST00000252456 | 0 | 7 | 28_131 | 21.0 | 298.0 | Domain | Calponin-homology (CH) | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651890 | ENST00000252456 | 0 | 7 | 164_189 | 21.0 | 298.0 | Repeat | Note=Calponin-like 1 | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651890 | ENST00000252456 | 0 | 7 | 204_229 | 21.0 | 298.0 | Repeat | Note=Calponin-like 2 | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651890 | ENST00000252456 | 0 | 7 | 243_268 | 21.0 | 298.0 | Repeat | Note=Calponin-like 3 | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651891 | ENST00000252456 | 0 | 7 | 164_189 | 21.0 | 298.0 | Repeat | Note=Calponin-like 1 | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651891 | ENST00000252456 | 0 | 7 | 204_229 | 21.0 | 298.0 | Repeat | Note=Calponin-like 2 | |
| Tgene | CNN1 | chr19:41800591 | chr19:11651891 | ENST00000252456 | 0 | 7 | 243_268 | 21.0 | 298.0 | Repeat | Note=Calponin-like 3 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 613_666 | 392.0 | 753.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 670_689 | 392.0 | 753.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 692_811 | 392.0 | 753.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 757_845 | 392.0 | 753.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 806_832 | 392.0 | 753.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 613_666 | 506.0 | 857.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 670_689 | 506.0 | 857.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 692_811 | 506.0 | 857.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 757_845 | 506.0 | 857.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 806_832 | 506.0 | 857.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 613_666 | 406.0 | 757.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 670_689 | 406.0 | 757.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 692_811 | 406.0 | 757.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 757_845 | 406.0 | 757.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 806_832 | 406.0 | 757.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 613_666 | 406.0 | 757.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 670_689 | 406.0 | 757.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 692_811 | 406.0 | 757.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 757_845 | 406.0 | 757.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 806_832 | 406.0 | 757.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 613_666 | 506.0 | 805.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 670_689 | 506.0 | 805.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 692_811 | 506.0 | 805.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 757_845 | 506.0 | 805.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 806_832 | 506.0 | 805.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 613_666 | 392.0 | 753.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 670_689 | 392.0 | 753.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 692_811 | 392.0 | 753.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 757_845 | 392.0 | 753.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 806_832 | 392.0 | 753.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 613_666 | 506.0 | 857.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 670_689 | 506.0 | 857.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 692_811 | 506.0 | 857.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 757_845 | 506.0 | 857.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 806_832 | 506.0 | 857.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 613_666 | 406.0 | 757.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 670_689 | 406.0 | 757.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 692_811 | 406.0 | 757.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 757_845 | 406.0 | 757.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 806_832 | 406.0 | 757.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 613_666 | 406.0 | 757.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 670_689 | 406.0 | 757.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 692_811 | 406.0 | 757.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 757_845 | 406.0 | 757.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 806_832 | 406.0 | 757.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 613_666 | 506.0 | 805.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 670_689 | 506.0 | 805.0 | Compositional bias | Note=Asn-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 692_811 | 506.0 | 805.0 | Compositional bias | Note=Pro-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 757_845 | 506.0 | 805.0 | Compositional bias | Note=Tyr-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 806_832 | 506.0 | 805.0 | Compositional bias | Note=Gln-rich |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 612_658 | 392.0 | 753.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 612_658 | 506.0 | 857.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 612_658 | 406.0 | 757.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 612_658 | 406.0 | 757.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 612_658 | 506.0 | 805.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 612_658 | 392.0 | 753.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 612_658 | 506.0 | 857.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 612_658 | 406.0 | 757.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 612_658 | 406.0 | 757.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 612_658 | 506.0 | 805.0 | Region | Note=Necessary for transcription repression |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 612_614 | 392.0 | 753.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 620_622 | 392.0 | 753.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 639_641 | 392.0 | 753.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 645_647 | 392.0 | 753.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000378215 | + | 9 | 14 | 656_658 | 392.0 | 753.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 612_614 | 506.0 | 857.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 620_622 | 506.0 | 857.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 639_641 | 506.0 | 857.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 645_647 | 506.0 | 857.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000392006 | + | 10 | 15 | 656_658 | 506.0 | 857.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 612_614 | 406.0 | 757.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 620_622 | 406.0 | 757.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 639_641 | 406.0 | 757.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 645_647 | 406.0 | 757.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000593587 | + | 10 | 15 | 656_658 | 406.0 | 757.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 612_614 | 406.0 | 757.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 620_622 | 406.0 | 757.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 639_641 | 406.0 | 757.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 645_647 | 406.0 | 757.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000595018 | + | 10 | 15 | 656_658 | 406.0 | 757.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 612_614 | 506.0 | 805.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 620_622 | 506.0 | 805.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 639_641 | 506.0 | 805.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 645_647 | 506.0 | 805.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651890 | ENST00000602130 | + | 10 | 15 | 656_658 | 506.0 | 805.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 612_614 | 392.0 | 753.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 620_622 | 392.0 | 753.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 639_641 | 392.0 | 753.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 645_647 | 392.0 | 753.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000378215 | + | 9 | 14 | 656_658 | 392.0 | 753.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 612_614 | 506.0 | 857.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 620_622 | 506.0 | 857.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 639_641 | 506.0 | 857.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 645_647 | 506.0 | 857.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000392006 | + | 10 | 15 | 656_658 | 506.0 | 857.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 612_614 | 406.0 | 757.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 620_622 | 406.0 | 757.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 639_641 | 406.0 | 757.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 645_647 | 406.0 | 757.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000593587 | + | 10 | 15 | 656_658 | 406.0 | 757.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 612_614 | 406.0 | 757.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 620_622 | 406.0 | 757.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 639_641 | 406.0 | 757.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 645_647 | 406.0 | 757.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000595018 | + | 10 | 15 | 656_658 | 406.0 | 757.0 | Repeat | Note=1-5 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 612_614 | 506.0 | 805.0 | Repeat | Note=1-1 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 620_622 | 506.0 | 805.0 | Repeat | Note=1-2 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 639_641 | 506.0 | 805.0 | Repeat | Note=1-3 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 645_647 | 506.0 | 805.0 | Repeat | Note=1-4 |
| Hgene | HNRNPUL1 | chr19:41800591 | chr19:11651891 | ENST00000602130 | + | 10 | 15 | 656_658 | 506.0 | 805.0 | Repeat | Note=1-5 |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>1607_HNRNPUL1_41800591_CNN1_11651891_ranked_0.pdb | HNRNPUL1 | 41800591 | 41800591 | ENST00000252456 | CNN1 | chr19 | 11651891 | + | MSRCRHWSGPPPFPPSPPDRKGLRGTEPWEAGPGSGATPGARAMDVRRLKVNELREELQRRGLDTRGLKAELAERLQAALEAEEPDDERE LDADDEPGRPGHINEEVETEGGSELEGTAQPPPPGLQPHAEPGGYSGPDGHYAMDNITRQNQFYDTQVIKQENESGYERRPLEMEQQQAY RPEMKTEMKQGAPTSFLPPEASQLKPDRQQFQSRKRPYEENRGRGYFEHREDRRGRSPQPPAEEDEDDFDDTLVAIDTYNCDLHFKVARD RSSGYPLTIEGFAYLWSGARASYGVRRGRVCFEMKINEEISVKHLPSTEPDPHVVRIGWSLDSCSTQLGEEPFSYGYGGTGKKSTNSRFE NYGDKFAENDVIGCFADFECGNDVELSFTKNGKWMGIAFRIQKEALGGQALYPHVLVKNCAVEFNFGQRAEPYCSVLPGFTFIQHLPLSE RIRGTVGPKSKAECEILMMVGLPAAGKTTWAIKHAASNPSKKYNILGTNAIMDKMRVMGLRRQRNYAGRWDVLIQQATQCLNRLIQIAAR KKRNYILDQLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKP HDIFEANDLFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPK LGTDQPLDQATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELG | 825 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
HNRNPUL1_pLDDT.png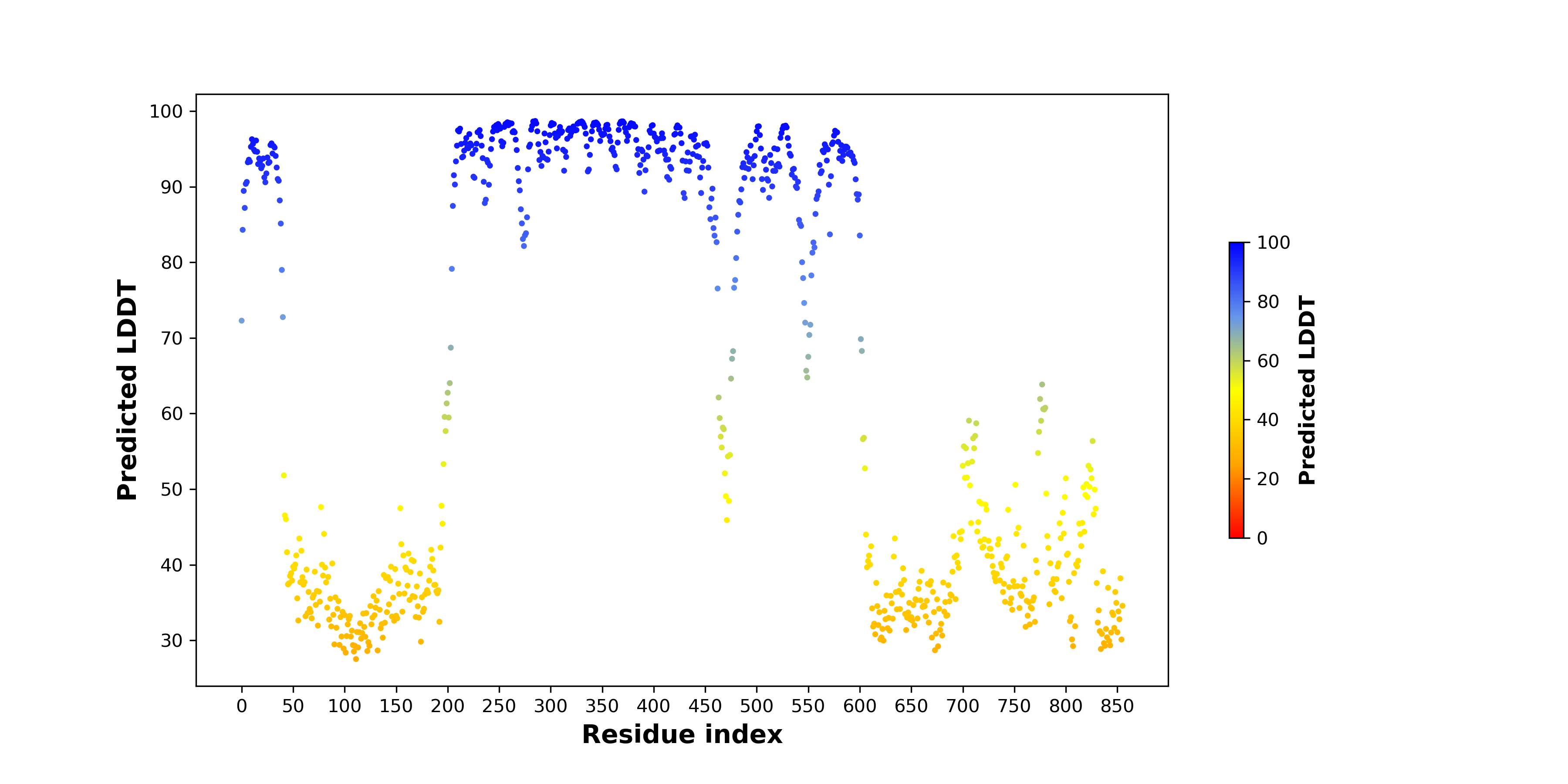  |
CNN1_pLDDT.png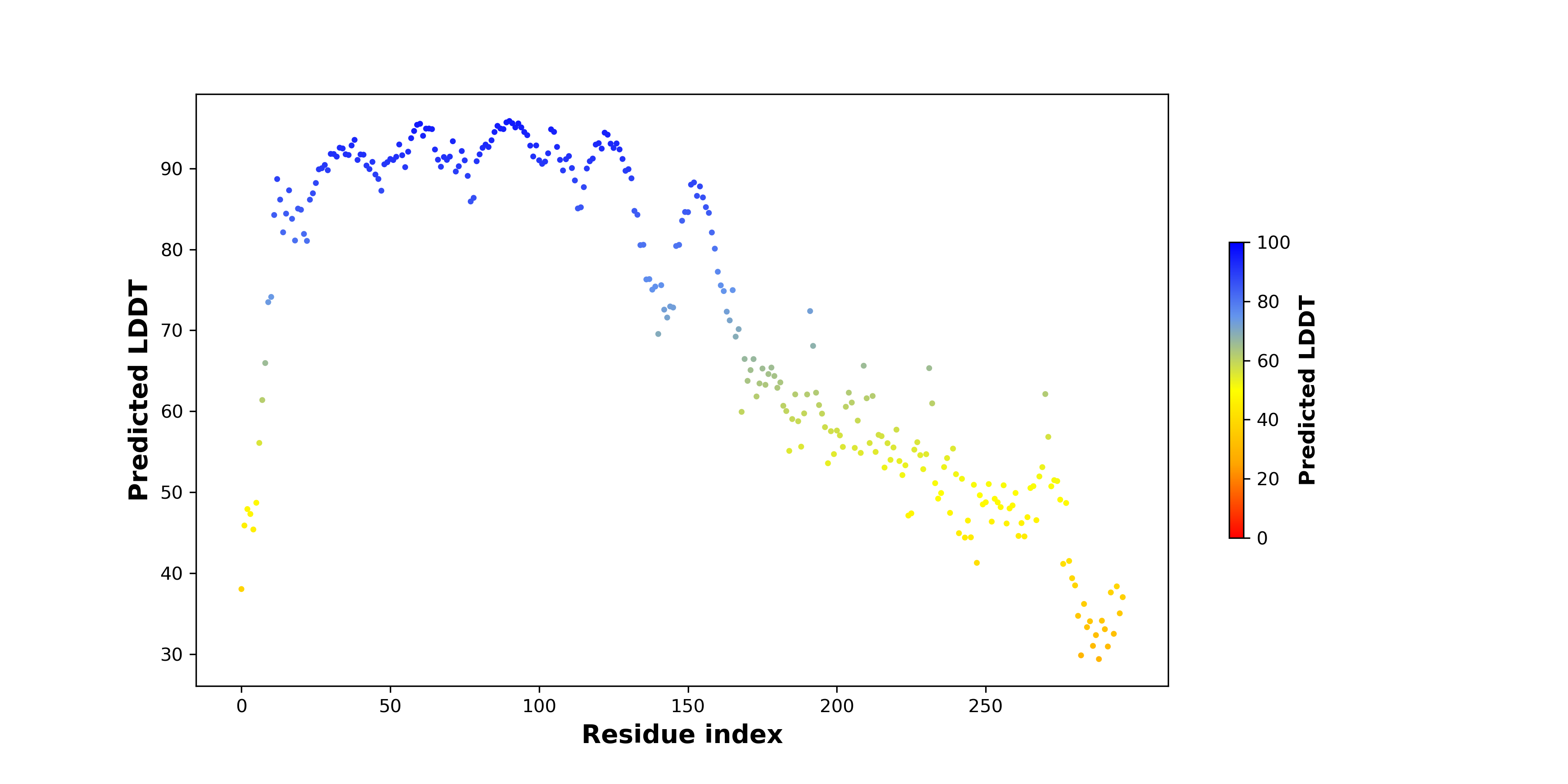  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| HNRNPUL1 | |
| CNN1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to HNRNPUL1-CNN1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to HNRNPUL1-CNN1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies