| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:AP2A2-PSMD13 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: AP2A2-PSMD13 | FusionPDB ID: 5230 | FusionGDB2.0 ID: 5230 | Hgene | Tgene | Gene symbol | AP2A2 | PSMD13 | Gene ID | 161 | 5719 |
| Gene name | adaptor related protein complex 2 subunit alpha 2 | proteasome 26S subunit, non-ATPase 13 | |
| Synonyms | ADTAB|CLAPA2|HIP-9|HIP9|HYPJ | HSPC027|Rpn9|S11|p40.5 | |
| Cytomap | 11p15.5 | 11p15.5 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-2 complex subunit alpha-2100 kDa coated vesicle protein Cadapter-related protein complex 2 subunit alpha-2adaptin, alpha Badaptor related protein complex 2 alpha 2 subunitalpha-adaptin C; Huntingtin interacting protein Jalpha2-adaptinclathrin as | 26S proteasome non-ATPase regulatory subunit 1326S proteasome regulatory subunit RPN926S proteasome regulatory subunit S1126S proteasome regulatory subunit p40.526S proteasome subunit p40.5proteasome (prosome, macropain) 26S subunit, non-ATPase, 13 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O94973 | . | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000332231, ENST00000448903, ENST00000534328, ENST00000525891, | ENST00000532025, ENST00000352303, ENST00000532097, ENST00000431206, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 13 X 10 X 12=1560 | 8 X 11 X 5=440 |
| # samples | 22 | 9 | |
| ** MAII score | log2(22/1560*10)=-2.82597060022495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/440*10)=-2.28950661719499 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: AP2A2 [Title/Abstract] AND PSMD13 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | AP2A2(977224)-PSMD13(252505), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | AP2A2-PSMD13 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. AP2A2-PSMD13 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AP2A2 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Fusion gene breakpoints across AP2A2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PSMD13 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
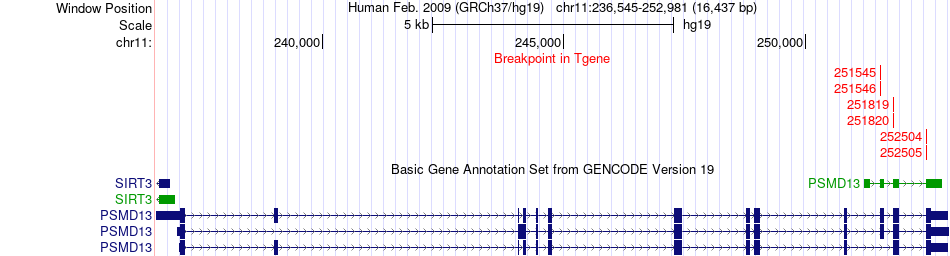 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-66-2758-01A | AP2A2 | chr11 | 977224 | - | PSMD13 | chr11 | 252505 | + |
| ChimerDB4 | LUSC | TCGA-66-2758-01A | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252505 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252504 | + |
| ChimerDB4 | LUSC | TCGA-66-2758 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252505 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252505 | + | 1222 | 745 | 142 | 840 | 232 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252505 | + | 1221 | 744 | 141 | 839 | 232 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252505 | + | 1221 | 744 | 141 | 839 | 232 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251545 | + | 1395 | 745 | 142 | 1038 | 298 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251545 | + | 1420 | 745 | 142 | 1038 | 298 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251545 | + | 1394 | 744 | 141 | 1037 | 298 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251545 | + | 1419 | 744 | 141 | 1037 | 298 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251545 | + | 1394 | 744 | 141 | 1037 | 298 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251545 | + | 1419 | 744 | 141 | 1037 | 298 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252504 | + | 1222 | 745 | 142 | 840 | 232 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252504 | + | 1221 | 744 | 141 | 839 | 232 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 252504 | + | 1221 | 744 | 141 | 839 | 232 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251819 | + | 1314 | 745 | 142 | 957 | 271 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251819 | + | 1339 | 745 | 142 | 957 | 271 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251819 | + | 1311 | 745 | 142 | 957 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251819 | + | 1313 | 744 | 141 | 956 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251819 | + | 1338 | 744 | 141 | 956 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251819 | + | 1310 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251819 | + | 1313 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251819 | + | 1338 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251819 | + | 1310 | 744 | 141 | 956 | 271 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251546 | + | 1395 | 745 | 142 | 1038 | 298 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251546 | + | 1420 | 745 | 142 | 1038 | 298 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251546 | + | 1394 | 744 | 141 | 1037 | 298 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251546 | + | 1419 | 744 | 141 | 1037 | 298 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251546 | + | 1394 | 744 | 141 | 1037 | 298 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251546 | + | 1419 | 744 | 141 | 1037 | 298 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251820 | + | 1314 | 745 | 142 | 957 | 271 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251820 | + | 1339 | 745 | 142 | 957 | 271 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251820 | + | 1311 | 745 | 142 | 957 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251820 | + | 1313 | 744 | 141 | 956 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251820 | + | 1338 | 744 | 141 | 956 | 271 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251820 | + | 1310 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000532097 | PSMD13 | chr11 | 251820 | + | 1313 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000431206 | PSMD13 | chr11 | 251820 | + | 1338 | 744 | 141 | 956 | 271 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000352303 | PSMD13 | chr11 | 251820 | + | 1310 | 744 | 141 | 956 | 271 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252505 | + | 0.001607491 | 0.9983925 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252505 | + | 0.0015431 | 0.99845695 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252505 | + | 0.0015431 | 0.99845695 |
| ENST00000534328 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.001854562 | 0.99814546 |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.002008324 | 0.9979917 |
| ENST00000332231 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.001790426 | 0.9982096 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.001936942 | 0.998063 |
| ENST00000448903 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.001790426 | 0.9982096 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251545 | + | 0.001936942 | 0.998063 |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252504 | + | 0.001607491 | 0.9983925 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252504 | + | 0.0015431 | 0.99845695 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 252504 | + | 0.0015431 | 0.99845695 |
| ENST00000534328 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001837605 | 0.99816245 |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001945461 | 0.9980545 |
| ENST00000534328 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001829407 | 0.9981706 |
| ENST00000332231 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001739069 | 0.9982609 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001844619 | 0.9981554 |
| ENST00000332231 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001731493 | 0.9982685 |
| ENST00000448903 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001739069 | 0.9982609 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001844619 | 0.9981554 |
| ENST00000448903 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251819 | + | 0.001731493 | 0.9982685 |
| ENST00000534328 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.001854562 | 0.99814546 |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.002008324 | 0.9979917 |
| ENST00000332231 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.001790426 | 0.9982096 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.001936942 | 0.998063 |
| ENST00000448903 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.001790426 | 0.9982096 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251546 | + | 0.001936942 | 0.998063 |
| ENST00000534328 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001837605 | 0.99816245 |
| ENST00000534328 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001945461 | 0.9980545 |
| ENST00000534328 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001829407 | 0.9981706 |
| ENST00000332231 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001739069 | 0.9982609 |
| ENST00000332231 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001844619 | 0.9981554 |
| ENST00000332231 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001731493 | 0.9982685 |
| ENST00000448903 | ENST00000532097 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001739069 | 0.9982609 |
| ENST00000448903 | ENST00000431206 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001844619 | 0.9981554 |
| ENST00000448903 | ENST00000352303 | AP2A2 | chr11 | 977224 | + | PSMD13 | chr11 | 251820 | + | 0.001731493 | 0.9982685 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >5230_5230_1_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251545_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_2_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251545_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_3_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251546_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_4_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251546_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_5_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251819_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_6_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251819_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_7_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251819_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_8_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251820_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_9_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251820_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_10_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_251820_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_11_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_252504_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- >5230_5230_12_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000332231_PSMD13_chr11_252505_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- >5230_5230_13_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251545_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_14_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251545_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_15_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251546_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_16_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251546_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_17_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251819_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_18_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251819_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_19_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251819_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_20_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251820_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_21_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251820_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_22_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_251820_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_23_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_252504_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- >5230_5230_24_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000448903_PSMD13_chr11_252505_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- >5230_5230_25_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251545_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_26_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251545_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_27_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251546_ENST00000431206_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_28_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251546_ENST00000532097_length(amino acids)=298AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLMTFTRPANHRQLTFEEIAKSAKITVNEVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKG -------------------------------------------------------------- >5230_5230_29_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251819_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_30_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251819_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_31_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251819_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_32_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251820_ENST00000352303_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_33_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251820_ENST00000431206_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_34_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_251820_ENST00000532097_length(amino acids)=271AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVELLVMKALSVGLVKGSIDEVDKRVHMTWVQPRVLDLQQIKGMKDRLEFWCTDVKSMEMLVEHQAHDIL -------------------------------------------------------------- >5230_5230_35_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_252504_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- >5230_5230_36_AP2A2-PSMD13_AP2A2_chr11_977224_ENST00000534328_PSMD13_chr11_252505_ENST00000431206_length(amino acids)=232AA_BP=169 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:977224/chr11:252505) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AP2A2 | . |
| FUNCTION: Component of the adaptor protein complex 2 (AP-2). Adaptor protein complexes function in protein transport via transport vesicles in different membrane traffic pathways. Adaptor protein complexes are vesicle coat components and appear to be involved in cargo selection and vesicle formation. AP-2 is involved in clathrin-dependent endocytosis in which cargo proteins are incorporated into vesicles surrounded by clathrin (clathrin-coated vesicles, CCVs) which are destined for fusion with the early endosome. The clathrin lattice serves as a mechanical scaffold but is itself unable to bind directly to membrane components. Clathrin-associated adaptor protein (AP) complexes which can bind directly to both the clathrin lattice and to the lipid and protein components of membranes are considered to be the major clathrin adaptors contributing the CCV formation. AP-2 also serves as a cargo receptor to selectively sort the membrane proteins involved in receptor-mediated endocytosis. AP-2 seems to play a role in the recycling of synaptic vesicle membranes from the presynaptic surface. AP-2 recognizes Y-X-X-[FILMV] (Y-X-X-Phi) and [ED]-X-X-X-L-[LI] endocytosis signal motifs within the cytosolic tails of transmembrane cargo molecules. AP-2 may also play a role in maintaining normal post-endocytic trafficking through the ARF6-regulated, non-clathrin pathway. During long-term potentiation in hippocampal neurons, AP-2 is responsible for the endocytosis of ADAM10 (PubMed:23676497). The AP-2 alpha subunit binds polyphosphoinositide-containing lipids, positioning AP-2 on the membrane. The AP-2 alpha subunit acts via its C-terminal appendage domain as a scaffolding platform for endocytic accessory proteins. The AP-2 alpha and AP-2 sigma subunits are thought to contribute to the recognition of the [ED]-X-X-X-L-[LI] motif (By similarity). {ECO:0000250, ECO:0000269|PubMed:12960147, ECO:0000269|PubMed:14745134, ECO:0000269|PubMed:15473838, ECO:0000269|PubMed:19033387, ECO:0000269|PubMed:23676497}. | FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251545 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251546 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251819 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:251820 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252504 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000332231 | + | 5 | 22 | 11_12 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000332231 | + | 5 | 22 | 57_61 | 201.0 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000332231 | + | 5 | 22 | 5_80 | 201.0 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000448903 | + | 5 | 22 | 11_12 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000448903 | + | 5 | 22 | 57_61 | 201.0 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:252505 | ENST00000448903 | + | 5 | 22 | 5_80 | 201.0 | 940.0 | Region | Note=Lipid-binding |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PSMD13 | chr11:977224 | chr11:251545 | ENST00000431206 | 7 | 11 | 171_338 | 281.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251545 | ENST00000532097 | 9 | 13 | 171_338 | 279.0 | 377.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251546 | ENST00000431206 | 7 | 11 | 171_338 | 281.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251546 | ENST00000532097 | 9 | 13 | 171_338 | 279.0 | 377.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251819 | ENST00000431206 | 8 | 11 | 171_338 | 308.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251819 | ENST00000532097 | 10 | 13 | 171_338 | 306.0 | 377.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251820 | ENST00000431206 | 8 | 11 | 171_338 | 308.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:251820 | ENST00000532097 | 10 | 13 | 171_338 | 306.0 | 377.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:252504 | ENST00000431206 | 9 | 11 | 171_338 | 347.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:252504 | ENST00000532097 | 11 | 13 | 171_338 | 345.0 | 377.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:252505 | ENST00000431206 | 9 | 11 | 171_338 | 347.0 | 379.0 | Domain | PCI | |
| Tgene | PSMD13 | chr11:977224 | chr11:252505 | ENST00000532097 | 11 | 13 | 171_338 | 345.0 | 377.0 | Domain | PCI |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>356_AP2A2_977224_PSMD13_252505_ranked_0.pdb | AP2A2 | 977224 | 977224 | ENST00000352303 | PSMD13 | chr11 | 252505 | + | MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP | 232 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
AP2A2_pLDDT.png  |
PSMD13_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
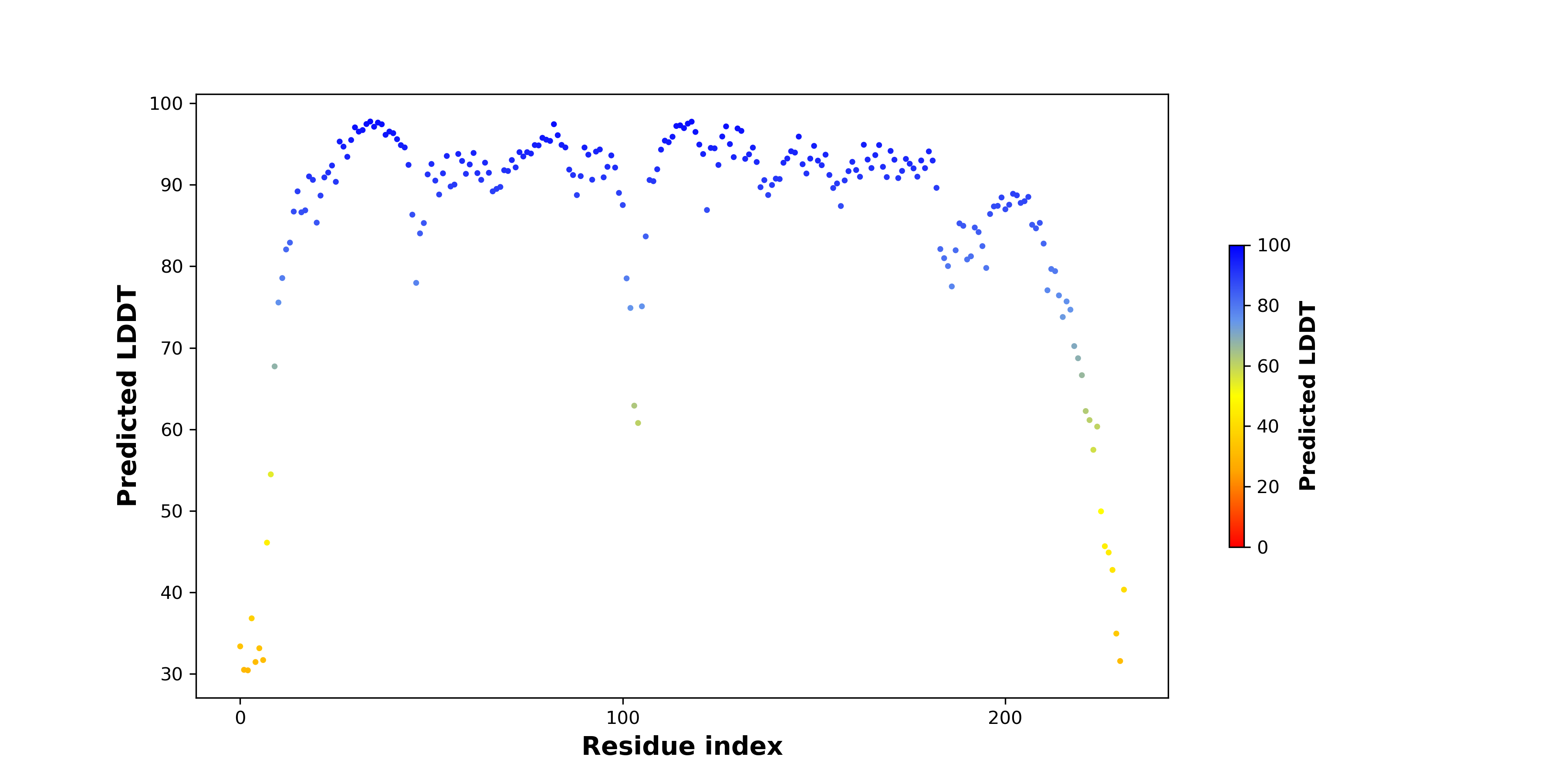 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| AP2A2 | |
| PSMD13 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to AP2A2-PSMD13 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to AP2A2-PSMD13 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies